Embed Size (px)
Citation preview

1
Ricerca semantica: annotazioni manuali e automatiche per l'Archivio storico de La Stampa
Andrea Bolioli 27 ottobre 2014, Bolzano – Bozen
Convegno:
I giornali storici nell'era digitale. Dal file immagine al full text. Un incontro tra esperti. Historische Zeitungen im digitalen Zeitalter. Von der Bilddatei zum Volltext. Ein
Expertenaustausch

Ovvero, dalle pagine alle infografiche
Come si costruisce un motore di ricerca semantico per un archivio storico digitale ?
Trasformando i contenuti testualiin dati analizzabili.
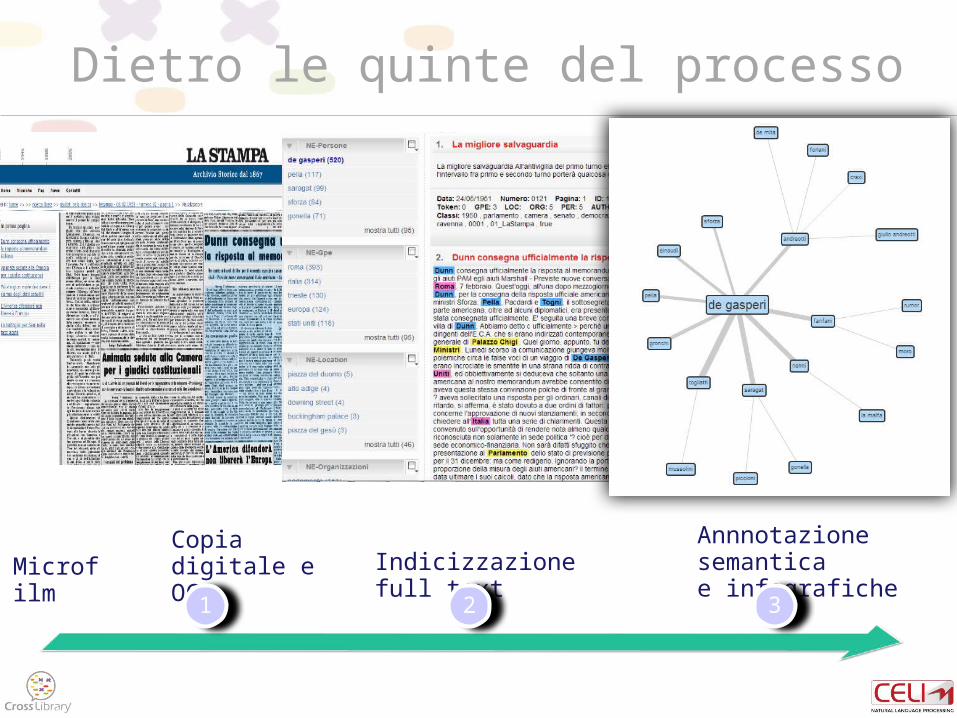
Dietro le quinte del processo
MicrofilmCopia digitale e OCR Indicizzazione full text
Annnotazione semantica e infografiche
1 2 3

Cosa abbiamo ottenuto ? Alcuni numeri
4.800.000 Articoli annotati automaticamente dal 1910 al 2005
113.000 Nomi di persona riconosciuti (PER con freq > 10)
10.200 Nomi di entità geopolitiche (GPE con freq > 10)
6.500 Nomi di organizzazioni (ORG con freq > 10)
1.020 Autori degli articoli (Author con freq > 10)
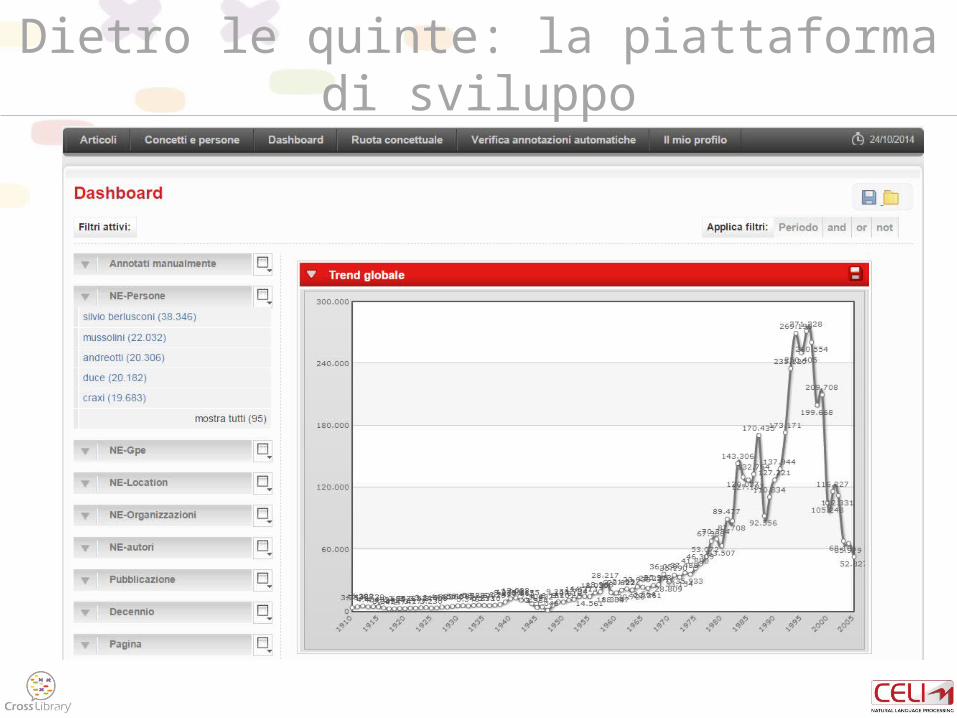
Dietro le quinte: la piattaforma di sviluppo
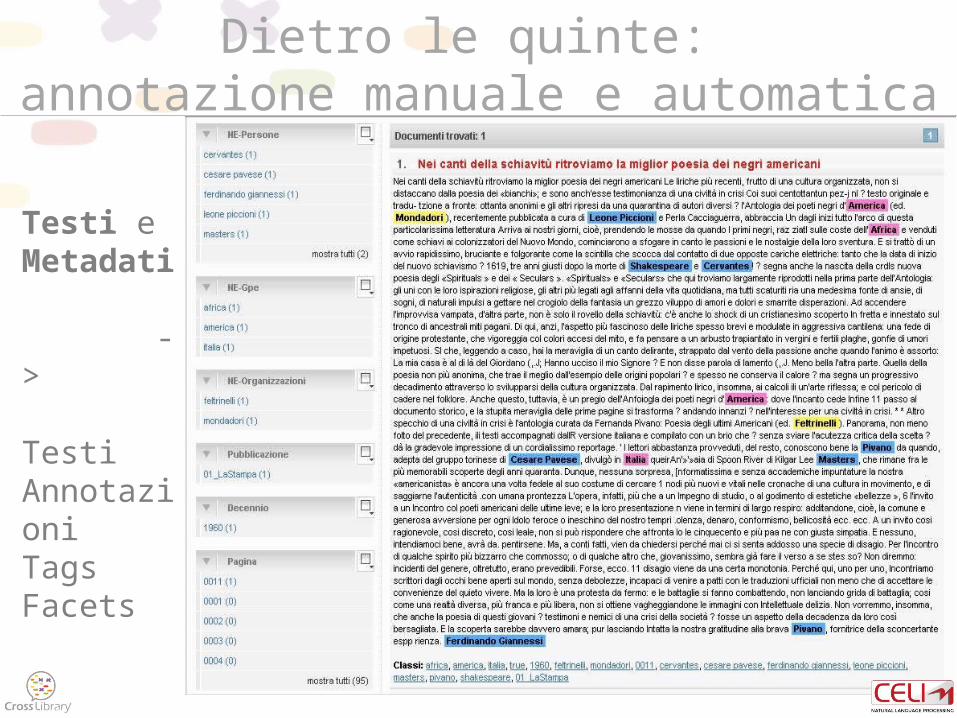
Dietro le quinte: annotazione manuale e automatica
Testi eMetadati
->
TestiAnnotazioniTagsFacets
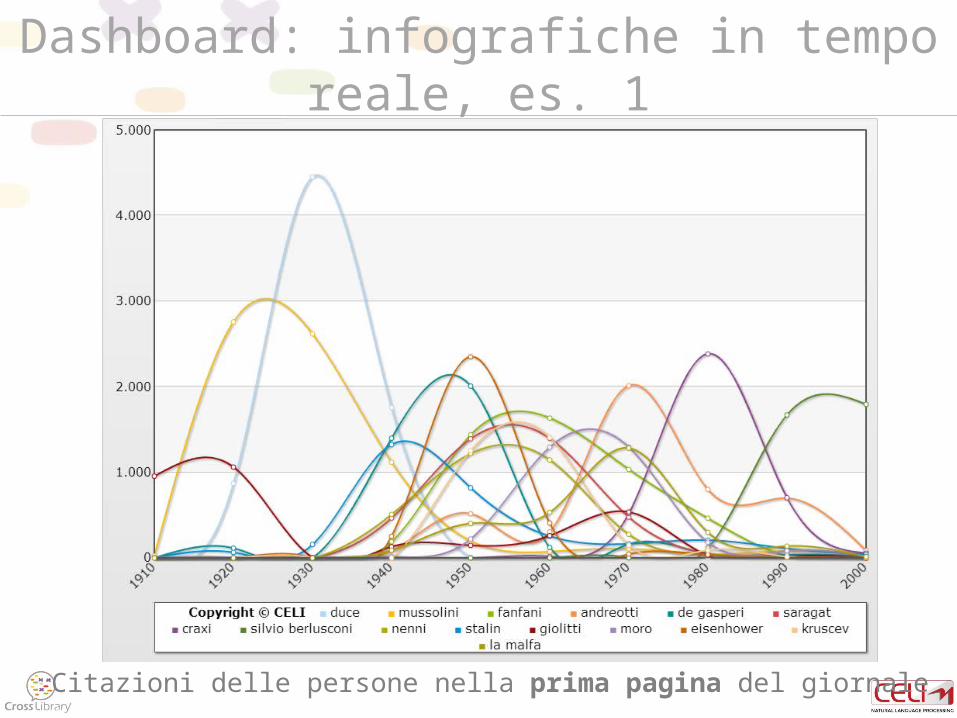
Dashboard: infografiche in tempo reale, es. 1
Citazioni delle persone nella prima pagina del giornale
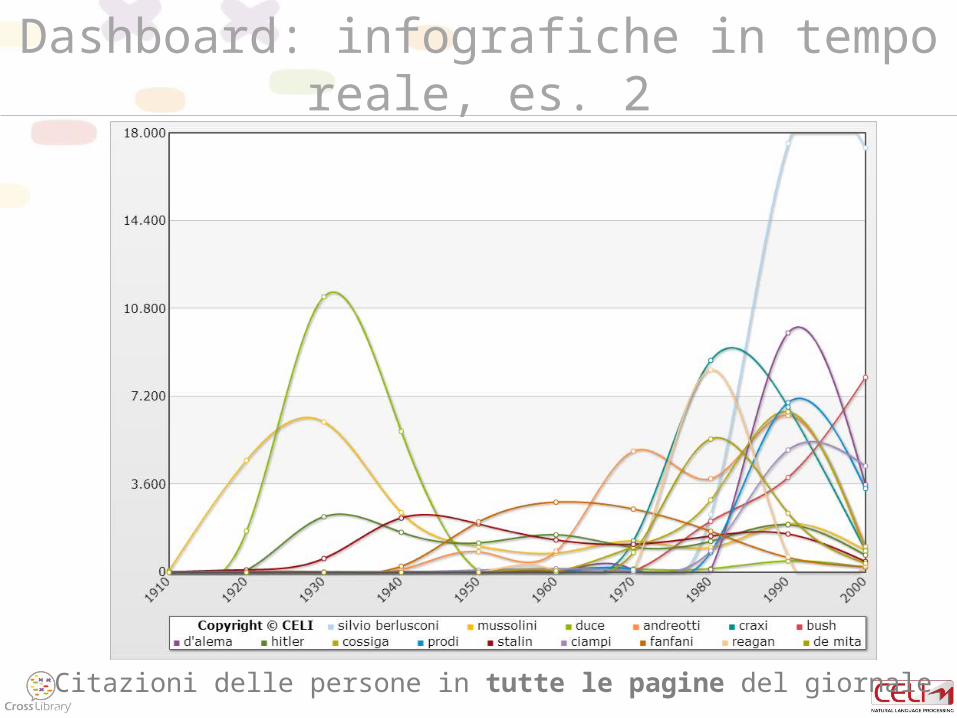
Citazioni delle persone in tutte le pagine del giornale
Dashboard: infografiche in tempo reale, es. 2

Come abbiamo fatto ?
Selezione dei corpora di training e test: un campione significativo partendo da 12 milioni di articoli dal 1867 al 2005
Connettore con i dati dell'archivio storico in standard XML METS ALTO (Analyzed Layout and Text Object)
Annotazione manuale dei corpora: interfaccia web collaborativa per annotare velocemente
Analisi degli errori di OCR: report e statistiche
Annotazione automatica: pipeline NLP con classificatori automatici SVM (Support Vector Machine) e basati su regole linguistiche
Verifiche di accuratezza dei risultati e correzioni
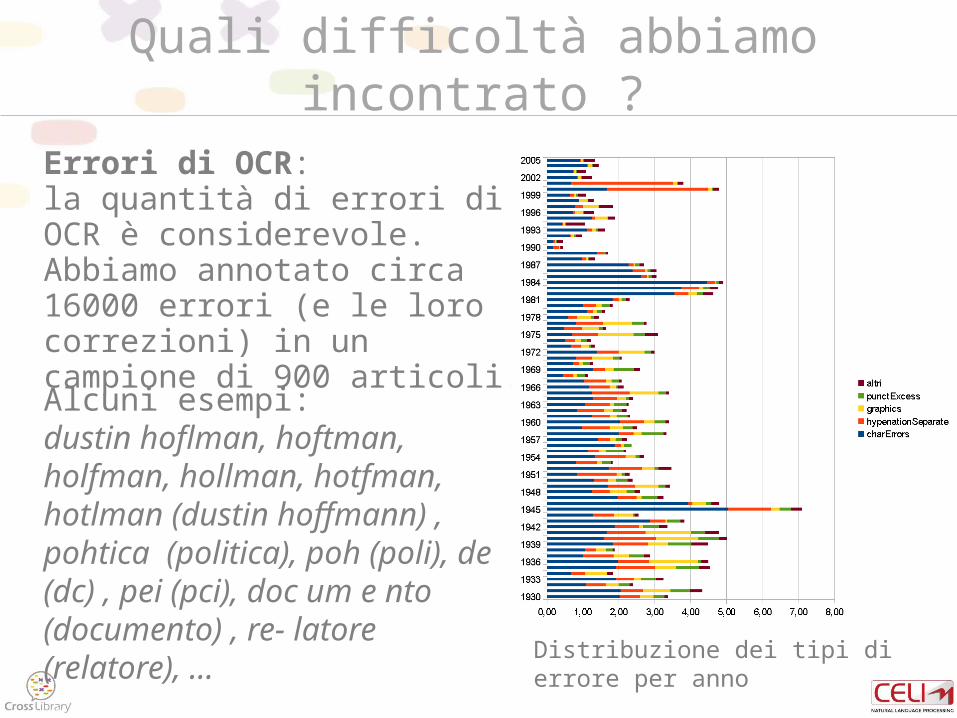
Quali difficoltà abbiamo incontrato ?
Errori di OCR: la quantità di errori di OCR è considerevole. Abbiamo annotato circa 16000 errori (e le loro correzioni) in un campione di 900 articoli.
Alcuni esempi: dustin hoflman, hoftman, holfman, hollman, hotfman, hotlman (dustin hoffmann) , pohtica (politica), poh (poli), de (dc) , pei (pci), doc um e nto (documento) , re- latore (relatore), …
Distribuzione dei tipi di errore per anno
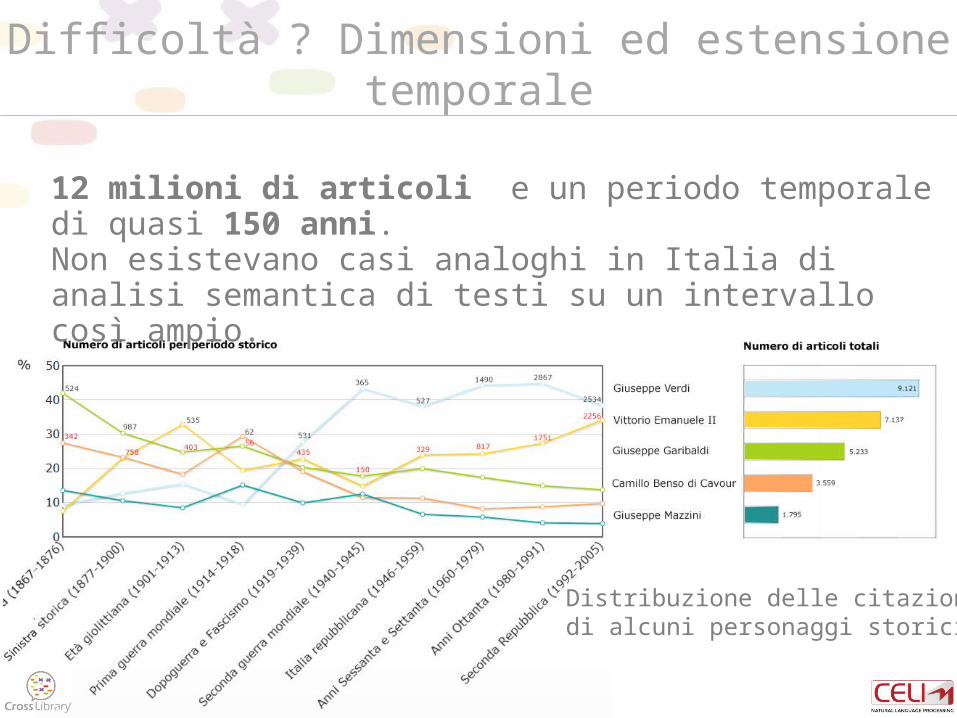
Difficoltà ? Dimensioni ed estensione temporale
12 milioni di articoli e un periodo temporale di quasi 150 anni.Non esistevano casi analoghi in Italia di analisi semantica di testi su un intervallo così ampio.
Distribuzione delle citazioni di alcuni personaggi storici

Che cosa può essere utile per gli archivi e le biblioteche digitali ?
Studiare la user experience per realizzare interfacce usabili, accessibili, semplici.
Annotazione automatica, validazione degli esperti, annotazione manuale in crowdsourcing (per correggere gli errori di OCR e annotare e correggere le entità rilevanti).
Esplorazione visuale e infografiche (grafi, grafici, timelines)
Integrazione di thesauri e ontologie (entità, concetti, sinonimi, altre relazioni semantiche); espansione delle queries (ad es. scuola media <-> scuola secondaria di primo grado; edifici religiosi del 700 -> Basilica di Superga); ricerca multilingue e cross-lingue.

Archeologia del sapere
"L'archivio è anche ciò che fa sì che tutte queste cose dette non si accumulino all'infinito in una moltitudine amorfa, non si iscrivano in una linearità senza fratture, e non scompaiano solo per casuali accidentualità esterne; ma che si raggruppino in figure distinte, si compongano le une con le altre secondo molteplici rapporti, si conservino o si attenuino secondo regolarità specifiche."
Michel Foucault (1969) L'archeologia del sapere /Die Archäologie des Wissens
"Aber das Archiv ist auch das, was bewirkt, daß all diese gesagtenDinge sich nicht bis ins Unendliche in einer amorphen Vielzahl anhäufen, auch nicht allein schon bei zufälligen äußeren Umständen verschwinden.[…]"

Grazie per
l'attenzione !
Per maggiori informazioni:
Andrea Bolioli
[email protected] [email protected]
@CrossLib @CELI_NLP
14





























