Embed Size (px)
Citation preview

3. Struktur und Funktionsweise künstlicher Neuronaler Netze
Ein Neuronales Netz ist kein statisches Gebilde, es kann als ein dynamisches System aufgefasst werden, zwecks Darstellung einer bestimmten Systemeigenschaft. Da im allgemeinen auf eine beliebige Eingabe nicht die gewünschte Ausgabe erfolgt benötigen wir Lernmechanismen (siehe oben) mit denen wir eine optimale Anpassung erreichen. 3.1 Multilayer Perceptrons Multilayer Perceptrons (MLP´s) haben, wie ihr biologisches Vorbild (menschliches Gehirn), eine geschichtete Struktur mit verschiedenen Möglichkeiten zur Vernetzung.
2
3
4
5
6
7
8
2
3
4
5
6
7
8
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
forward
bias1.0
lateral
feedback lateral feedback
direct feedback
In2
In1 Out1
Out2
shortcut
2
3
4
5
6
7
8
2
3
4
5
6
7
8
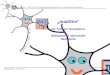
Fig.3.1: Mögliche Verbindungen in einem 2-3-2 MLP. Ein MLP hat eine Eingabe-Schicht (input layer) und eine Aus-gabe-Schicht (output layer) und eine oder mehrere Zwischen-schichten (hidden layer).
78

input pattern
desired output
neural net
output layer layer
hidden
input layer
actual output
difference vector
actual output … desired output result of the propagation: goal: difference vector ⇒ null vector ! limit … iteration procedure Fig. 3.2: Momentaufnahme eines Standard MLP´s. Da bei einer beliebigen Eingabe in ein MLP wahrscheinlich nicht die richtige Ausgabe erfolgt, müssen wir die Verbin-dungsgewichte, die Biaswerte oder die Schwellwerte an den Neuronen verändern um einen neuen Netzwerkzustand zu er-halten. Die Veränderung kann synchron für alle Neuronen oder asynchron erfolgen. Im Gehirn sind nicht alle Neuronen in ei-nem Areal aktiv. Diese Eigenschaft lässt sich berücksichtigen, indem wir zunächst eine Grundkonfiguration nach formalen Überlegungen betrachten und diese Topologie der Vernetzung mittels Optimierungsverfahren reduzieren. In der numerischen Mathematik und bei der Informationsver-arbeitung spielt die Interpolation und Approximation von Funktionen eine große Rolle. Künstliche Neuronale Netze kön-nen Messwerte gut interpolieren und sind damit fähig, einen funktionalen Zusammenhang darzustellen. Es können aber auch dynamische Prozesse dargestellt und überwacht werden.
79

Im Folgenden betrachten wir eine eingeschränkte Auswahl von Anwendungen mit MLP´s die wesentlichen Eigenschaften Neuronaler Netze darstellen sollen. a) Interpolation von Messwerten
Wir betrachten ein 1-5-1 MLP das interpolieren soll und inte-ressieren uns für die Genauigkeit und das Lernverhalten. Dem MLP wurden 10 Wertepaare der Funktion xlogy = vorgege-ben. Wie zu erkennen ist, ändert sich der relative Gesamtfehler mit der Zahl der Lernschritte in Abhängigkeit vom Lernfaktor
und Trägheitsparameter . η α
Fig. 3.3.: Fehlerverhalten bei Variation der Parameter η und α. Die Wahl geeigneter Lernparameter (η und α) können ent-scheidend das Lernverhalten beeinflussen. Aber auch bei einer optimalen oder suboptimalen Einstellung der Lernparameter ist das Lernverhalten von der Anzahl der Zwischenschicht-Neuronen abhängig.
Fig. 3.4: Fehlerverhalten bei Variation der Zwischenschicht-Neuronen.
80

Betrachten wir vorgegebene Punkte die aus einer Messung stammen könnten, so liefert ein 1-5-1 MLP mit 6.0=µ und
ein relativ gutes Ergebnis bei 60 000 Lernschritten. 9.0=α
Fig. 3.5: Funktionsapproximation bei vorgegebenen diskreten Wertepaaren. b) Elektronische Nase Zunehmende Umweltbeeinträchtigungen, z. B. durch
, die konzentrierte Lagerung großer Mengen von Gefahrenstoffen, aber auch die Optimierung von Prozessen, wie sie beispielsweise bei Verbrennungsvorgängen auftreten, verlangen selbständig arbeitende Analyseverfahren für die Grenzwertüberwachung von verschiedenen Stoffen. Dabei geht es oft um die selektive Erfassung einzelner Gase mittels preis-werter Sensoren.
,CO2
xx SO,NO
Es werden die Konzentration von Methan und Butan mit zwei identischen -Halbleiter-Sensoren bei unterschiedlichen Heizspannungen (6.0 V und 4.7 V) gemessen, für die die bei-den Sensoren unterschiedliche Sensitivität bezüglich der Gase besitzen. Die Sensorsignale werden zunächst aufbereitet, sie besitzen im oberen Konzentrationsbereich eine strukturelle gleichförmige Abhängigkeit untereinander.
2SnO
81

Signalaufbereitung
Signalaufbereitung
Rücktrans-formation
Senor 1
Senor 2
Neuronales Netz:
Muster- erkennung
Fig. 3.6: Prinzipielle Darstellung für die Mustererkennung von unbekannten Gaskonzentrationen. Zur besseren Diskriminierung des Sensorsignals führen wir eine Transformation wie folgt aus
0R/R
β+⎟⎟⎠
⎞⎜⎜⎝
⎛⋅α=⎟⎟
⎠
⎞⎜⎜⎝
⎛
0t0 RRlog
RR
und analog transformieren wir die Gas-Konzentrationswerte c
δ+⋅γ= cct , wobei gewöhnliche konstante Zahlenwerte sind (Fig.2 und 3). Die transformierten Daten werden als Input-Daten für ein MLP verwendet.
δα ,,
Architektur eines Zwei-Sensorsystems
Fig.3.7: Das aus zwei MLP´s verkoppelte MLP besitzt einen Sensor für Methan und einen Butan-Sensor.
82

Diese Netzwerk-Architektur erlaubt die Butankonzentration zu bestimmen, wenn die Methan-Konzentration bekannt ist. Das Netzwerk (Fig. 3.7) wird mit Sensordaten trainiert, nach ca. 1.5 Millionen Trainingsläufen lässt sich ein RMS-Fehler von 0.037 für das Butan-Netzwerk erreichen, dieses entspricht einem Fehler von 0.1 % bezüglich der mittleren absoluten Bu-tangas-Konzentration. Entsprechende Fehlerwerte ergeben sich auch für das Methan-Netzwerk. Nach der Trainingsphase las-sen sich aus unbekannten Sensorsignalen die zugeordneten Gaskonzentrationen bestimmen. c) Optimierte Elektronische Nase Unser Interesse konzentriert sich nun darauf, wie man eine optimale Netz-Struktur für ein solches Zweisensor-Array fin-den kann. Für das hier vorliegende Problem testen wir den Ein-satz von Genetischen Algorithmen (GA) und Evolutionären Strategien (ES) für eine Topologie-Optimierung, bei ebenfalls durch Backpropagation-Training optimierten Lernparametern. Das Ziel ist es, eine minimale Hardware-Struktur bei minima-lem RMS-Fehler für ein Neuronales Netz zu finden. c.1) Optimierung mit Genetischen Algorithmen Für diese Art der Optimierung ist eine binäre Codierung der sogenannten Individuen erforderlich. Wir wählen einen Bit-string der Länge von 37 Bits, wobei 6 Bits jeweils für die Lernparameter η und α gewählt werden und 25 Bits für die Matrix der Verbindungsgewichte.
25 η 2 α 1 24 3 Lernparameter Die Lernparameter η und α kodiert mit jeweils 6 Bits variieren im Intervall . Weiterhin benutzen wir Gray coding für die reell-wertigen Variablen. Im Gegensatz zum üblichen binary coding ist nur ein Wechsel in einer Bit-Position zwischen be-nachbarten Gray code Zahlen erforderlich. Als Start-Netzwerk versehen wir das Zwei-Sensornetzwerk noch zusätzlich mit lateralen Verbindungen und erhalten so eine Dreiecksmatrix der Verbindungsgewichte mit 25 Einträgen.
[ 2,0 ]
83

output
node 8 input 2
node 3
bias
node 1
6
7
4
5
input 1
node 2
Fig. 3.8: MLP vor der Optimierungsprozedur. Als Fitness-Funktion wird gewählt
n
n2
c
c1 m
nCRMSmn
CRMSRMSf ⋅⋅+⋅⋅+=
mit
∑=
−=N
1p
2pp ot
N1RMS .
Hierbei sind
21 C,C : Gewichtsparameter,
cn : tatsächliche Zahl von Verbindungen,
cm : maximale Zahl von Verbindungen im Netz,
nn : tatsächliche Zahl von Knoten,
nm : maximale Zahl von Knoten im Netz. Eine Population besteht aus µ Individuen, die wir mittels ver-schiedener Operatoren (genannt genetische Operatoren siehe z. B. in /Gr2/) verändern können. Erst durch Rekombination in einer nachfolgend erzeugten Population können neue Individu-en entstehen. Wir benutzen die Crossover-, Mutations- und Inversions-Operation sowie zufallserzeugte Operationen zur Veränderung. In einem ersten Experiment setzen wir 1.0C1 = und 0C2 = . In einer Population von 60 Individuen, mit 15 Eltern und 45 Nachkommen, kam das Verfahren nach 17 Generationen zum Stillstand bezüglich der erreichten Genauigkeit. Der Fitness-wert lag bei 0.036 und der RMS-Fehler betrug 0.034 für eine neue Architektur des Netzes mit nur 16 Gewichten (Fig.3.9) konnte erzeugt werden.
84

input
input
output
bias
3 1st hidden layer
5
4
6
7
2nd hidden layer
8
1
2
Fig.3.9: Genetisch erzeugte Netzwerk-Architektur. In weiteren Experimenten konnte ebenfalls eine Topologie-Reduktion festgestellt werden. Ein "schlankes" Netz ergibt sich für und , mit der gleichen Populationsgrö-ße wie vorher. Nach 37 Generationen, entstand ein Netzwerk mit 6 Gewichten, einem Fitnesswert von 0.067 und einem RMS-Fehler von 0.039 (Fig.3.10).
25.0C1 = 0.1C2 =
c2) Optimierung mit Evolutionären Strategien Evolutionäre Strategien gehen auf Arbeiten von Rechenberg (/Re/) und Schwefel (/Schw/) zurück. Jedes Individuum wird durch einen Vektor im repräsentiert. Durch Wahl eines Startvektors im und durch Hinzufügen eines gewichteten Zufallsvektors lässt sich die biologische Mutation simulieren. die Selektion erfolgt aufgrund der Bestenauslese unter Berück-sichtigung der Nebenbedingung, dass z. B. der Funktionswert sich auf ein Maximum oder Minimum hinbewegt (/Gr2/). Die Optimierungsvariablen sind in einem Vektor mit reellen Zahlen repräsentiert, hier in diesem Beispiel die 25 Verbindungsge-wichte. Zusammen mit den entsprechenden Standardabwei-chungen für eine Zufallsauswahl, besitzt der Vektor insgesamt 50 Komponenten.
nIRnIR
input output
hidden layer
1
4
5 input
3
2
input layer
Fig.3.10: Netzwerk-Architektur mit nur sechs Verbindungs-gewichten.
85

Legen wir die gleiche Fitness-Funktion (∗) zugrunde, so erhal-ten wir eine typische Strukturoptimierung wie sie in Figur 3.11 zu sehen ist 6
bias
input 1
input 2 3
5
4
7
2
1
8
output
Fig.3.11 Netzwerk-Architektur erzeugt durch eine Evolutionä-re Strategie. Die Optimierung reduziert das ursprüngliche Netz-werk auf 20 Verbindungsgewichte mit einem RMS-Fehler von 0.046. Zusammenfassung Evolutionäre Algorithmen sind für viele Optimierungsproble-me einsetzbar, insbesondere, wenn die zugrunde liegenden Funktionen nicht stetig und differenzierbar sind. Allerdings tritt ein zusätzliches Problem auf, eine geeignete Fitness-Funktion zu finden. In der Praxis ist es allerdings so, dass unterschiedli-che Größen extremalisiert und in einem Optimierungsziel zu-sammengefasst werden sollen. Diese Aussage können wir als Konstruktionsprinzip für eine Fitness-Funktion betrachten. In unseren Untersuchungen stellte sich heraus. dass Genetische Algorithmen schlankere Netzwerke generieren können gegen-über Betrachtungen mit Evolutionären Strategien und auch einer Black-Box-Optimierung der Lernparameter α und η , wie sie bei dem Training Neuronaler Netze üblich ist. Das bes-te erzeugte Netzwerk war mit einem Fehler 0.034 behaftet und damit besser bezüglich dem Original-Netzwerk mit einem Feh-ler von 0.037. Die Zahl der Verbindungsgewichte betrug 16, gegenüber dem ursprünglichen Netz mit 17 Gewichten. Lässt man einen etwas größeren Fehler zu, beispielsweise 0.038, dann kann die Anzahl der Gewichte auf 12 und auf 6 bei einem Fehler von 0.039 erniedrigt werden. Die Resultate die mit Evo-lutionären Strategien erreicht wurden lassen sich wie folgt zu-sammenfassen. Ein Fehler von 0.046 erhält man bei 20 Ver-bindungsgewichten und bei 8 Verbindungsgewichten steigt der Fehler auf 0.079 an.
86

d) Prozessüberwachung mit Multilayer Perceptrons Die Generalisierungsfähigkeit der neuronalen Netze kann zur Prozesskontrolle verwendet werden. Die Automatisierung von Fertigungsprozessen erfordert die fortlaufende Erfassung bei-spielsweise des momentanen Verschleißzustandes des Werk-zeuges. Ist der Verschleiß eines Werkzeuges so weit fortge-schritten, dass ein Qualitätsprodukt nicht mehr gefertigt werden kann, so ist zum Beispiel rechtzeitig ein Wechsel vorzuneh-men. Hinweise auf den Zustand des Werkzeuges erhalten wir aus einer Datenanalyse, indem wir daraus die relevanten Merkmale extrahieren und einem Mustererkennungsprozess unterwerfen. In anderen Worten, liegen hinreichend viele und brauchbare Daten für die Extraktion von Merkmalsvektoren vor, so lässt sich damit ein MLP trainieren. Unbekannte Daten-sätze aus diesem Problemkreis, beispielsweise Veränderungen während des Prozesses, können über eine Mustererkennung mit Hilfe von Multilayer-Perceptrons analysiert und in Qualitäts-gruppen eingeteilt werden. Dieses Verfahren erlaubt den Zu-stand eines Prozesses zu analysieren und zu kontrollieren. Technischer Prozess: Gewindefurchvorgang. Die Zugbügel von Leitungsverbinder für Schaltschränke werden in einer Stanz-biegemaschine vorgefertigt, mit einer Bohrung versehen. In das Bohrloch wird ein Gewinde spanlos durch einen Formvorgang eingebracht. Der Former verschleißt, zwei Verschleißarten des Formers sind bekannt:
• abrasive Verschleiß: Abrieb an Form- und Führungsteilen, • adhäsiver Verschleiß: Kaltaufschweißung. Über die Veränderung der Drehmomentmesskurve sollen Aus-sagen über den Verschleiß des Formers und die Güte des ge-formten Gewindes gewonnen werden. Messwertaufnahme und -übertragung: Ein Dehnungsmessstrei-fen (DMS) liefert ein elektrisches Signal proportional des Tor-sionsmomentes der Spindel. Das Signal wird verstärkt und auf eine Trägerfrequenz von 13.2 MHz moduliert und anschließend wird das Signal induktiv von einer rotierenden Ringantenne auf eine stationäre Empfangsantenne übertragen. Das analoge Sig-nal wird digitalisiert und weitergegeben zur Signalanalyse (sie-he unten).
87

-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
M/Nm
0 100 200 300 400 t/ms
I I II III IV V
Fig.3.12: Messsignal. Eventuell auftretende Messfehler, beispielsweise durch Daten-verlust, Rauschen, Störfrequenzen, Offset, etc. müssen besei-tigt werden durch eine entsprechende Vorverarbeitung:
• heuristische Fehlereliminierung • digitale Filter und Glättungen • Triggerkorrektur • Offsetkompensation
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
M/Nm
0 100 200 300 400 t/ms
Fig.3.13: Messsignal geglättet.
88

Zur Datenstruktur über die gesamte Standzeit des Formers (50000 Formvorgänge) wurden alle 5000 Formvorgänge eine Stichprobe von 100 aufeinanderfolgenden Formvorgängen auf-gezeichnet und eine Klasseneinteilung vorgenommen. Klasse 1: Formvorgänge 1 bis 100 Klasse 2: Formvorgänge 5001 bis 5100 Klasse 3: Formvorgänge 10001 bis 10100 Klasse 10: Formvorgänge 45001 bis 45100 Auswertung mit drei unterschiedlichen MLP´s
nicht praktikabel
Durchschnitt von 5 Werten
Durchschnitt von 5 Werten
gute Erkennung kleine Netze
KNN 10 Eingänge 10 Ausgänge
KNN 98 Eingänge 10 Ausgänge
490 Werte
10 Merkmale
98Werte 98Werte
490 Werte
KNN 490 Eingänge 10 Ausgänge
490 Werte
Fig. 3.14: Untersuchung mit drei unterschiedlichen MLP-Architekturen. Lernverfahren: Online-Backpropagation-Training mit Lernrate und Trägheitsterm:
)1n(wo)1n(wwE
)n(w ijjiijij
pij −∆⋅α+⋅δ⋅η=−∆⋅α+
∂
∂⋅η−=∆
Lernrate Trägheitsterm
89

Fehlerermittlung mittels:
(∑=
−=N
1i
2iip ot
21E ) , Sollausgabe tatsächlicher Ausgabe it io
und Fehlersignal
( ) ( )( )⎪⎩
⎪⎨⎧
⋅δ⋅
−⋅=δ
∑=
N
1kkiki
iii
i Neuron s verdecktei falls wnet'F
ronAusgabeneu i falls otnet'F
Verwendung der Standard-Sigmoidfunktion als Aktivie-rungsfunktion F:
sF
( ) ( )iisi netexp11netFo−+
≡=
ist ( ) ( ) ( )( ) ( )iiisisis o1onetF1netFnet'F −⋅=−⋅= und damit
( ) ( )( )⎪⎩
⎪⎨⎧
⋅δ⋅−⋅
−⋅−⋅=δ
∑=
N
1kkikii
iiii
i Neuron s verdecktei falls wo1o
ronAusgabeneu i falls oto1o
Trainingsmenge: 10 zufällig gewählte Kurven aus jeder Klas-
se (= 100), Testmenge: Gesamtheit aller 100 Kurven aus jeder Klasse
(=1000). Ergebnisse: Lernzeiten und Gesamterkennungsraten verschiedener MLP-Architekturen:
Eingabedaten Netzgröße η α Lern- schritte
relative Lernzeit
Erkennungs- rate
original 98 − 55 − 10 0.3 0.9 200000 100 % 92.6 % vorverarbeitet 85 − 50 − 10 0.3 0.8 200000 88 % 93.1 %
5 Merkmale 5 − 8 − 10 0.2 0.8 5000000 57 % 74.7 % 10 Merkmale 10 − 10 − 10 0.1 0.8 2000000 37 % 82.3 % 15 Merkmale 15 − 13 − 10 0.3 0.8 1500000 43 % 72.6 %
90

Anzahl erkannter Kurven in den einzelnen Klassen: Verschleißklasse 1 2 3 4 5 6 7 8 9 10
original 100 100 100 96 63 88 94 98 91 96 vorverarbeitet 100 100 90 98 97 73 88 99 97 89
5 Merkmale 88 84 91 85 57 66 76 61 63 76 10 Merkmale 86 76 89 90 70 84 81 80 78 89 15 Merkmale 87 87 93 79 44 48 75 88 47 78
Vor-/Nachteile neuronale Netze:
• beispielbasiert • generalisationsfähig • kein Expertenwissen integrierbar Vor-/Nachteile wissensbasierter Fuzzy-Systeme:
• Expertenwissen leicht einsetzbar • Regelbasis ist Voraussetzung • empfindlich bei Fuzzifizierungsänderung Vorteile beider Systeme:
• kein mathematisches Prozessmodell aber • erfahrungsbasierte, "intuitive" Systemerstellung nötig. Fuzzy-Clustering (FCM) möglich:
• Unscharfes Clustering in zwei Klassen: Former neuwer-tig/verschlissen.
• Auftragung des Zugehörigkeitsgrades zur Klasse verschlis-sen gegen die Einsatzzeit des Formers ergibt eine einsatz-zeitabhängige Verschleißkurve.
3.2 Rückgekoppelte Neuronale Netze Zwecks Demonstration der Eigenschaften betrachten wir rück-gekoppelte NN
• Beispiele zur Funktionsapproximation • Simulation nichtlineare Systeme zeit-invariant : Filter zeit-variant : Dynamische Systeme Architektur eines synchron aktivierten rückgekoppelten MLP´s:
91

) ( k u
f j=1
f j=2
f j
f j no=
=
=
=
( ) u k i = 1
( ) u k i
( ) u k i n u =
G
fz∑ Tw 1 1 ,
w n n o u ,
w nu1 1, +
w nu1 2, +w 2 1 ,
W
( )1ky1 +
( )1k +y
( )1kyyn +
Fig.3.15: MLP mit den Matrizen G und W für die üblichen Kopplungsstärken und die Rückkopplungswerte. Die Aktivitätszustände in den einzelnen Knoten werden syn-chron aktiviert um den neuen Aktivitätszustand des Netzes zu erhalten. In der Simulationsprozedur wird die Aktivität von allen Knoten im Zeitschritt 0n ( 1k )+ berechnet
( ) ( ) ( )kowkuw1kz in
1iin,ji
n
1ii,jj
0
u
u⋅+⋅=+ ∑∑
=+
=.
un bezeichnet die Zahl der Knoten in der Eingangsschicht.
Der Zustand eines jeden Ausgangsknoten folgt aus:
( ) ( )( )1kzf1ko jjj +=+ . Der erste Term in beschreibt die übliche Kopplung der Verbindungen in feed forward direction und der zweite Term charakterisiert die Rückkopplungen (feedback connecti-ons). Im ersten Zeitschritt existieren noch keine Aktivitäten in der Ausgabeschicht:
( 1kz j + )
( )⎟⎟
⎠
⎞
⎜⎜
⎝
⎛==
0
00ko .
92

Folglich besitzt der zweite Term in ( )1kz j + zu diesem Zeit-schritt keine Aktivität. Die Aktivität des Netzwerks in Vektor-form notiert liefert:
( ) ( ) ( )kk1k oWuGz ⋅+⋅=+ , oder durch Umordnung
( ) ( ) ( )( )⎟⎠
⎞⎜⎝⎛⋅=+ k
k1k ouWGz .
Die Komponentenschreibweise liefert
( )( )
( )
( )( )
( )( )( )
( )⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
⋅
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
+
++
ko
kokoku
kuku
ww
wwww
1kz
1kz1kz
0
u
000
n
21
n
21
n,n1,n
1,2n,12,11,1
n
21
Für die Ausgangsknoten erhalten wir
( ) ( )( )⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
=+=+
0n
1
f
fmit1k1k fzfo ,
f repräsentiert die vektor-wertige Transferfunktion und mit der Identitätsfunktion erhalten wir am Ausgang der Ausgangskno-ten die Ausgangsinformation:
( ) ( )1k1k +=+ oy . Lern-Prozedur: Die Gewichtsänderungen erfolgen durch eine ES-Strategie und die Strukturoptimierung des Netzwerkes durch GA-Methoden. Dieser hybride Lernmechanismus ermög-licht es die Fehlerfunktion des Netzwerkes zu minimalisieren. Das Konzept der GA wird benutzt für die Kodierung der Netz-werkparameter in passenden Strings und die Erzeugung von Nachkommen (offsprings) durch crossing-over an multiplen Punkten.
93

node 1: first linematrix of weights
node 2: second linematrix of weights
3 4 5 6 7 821parent1
3 4 5 6 7 821
offspring
3 4 5 6 7 821parent 2
wn
wn
wn
Fig. 3.16: Schema des Crossing-over. Die Modifikation der Gewichte in der Matrix der Kopplungs-stärken erfolgt mittels Prinzipien von ES.
offspringnew matrix of weights
P(WM/LC) )/(1 NCNMP−
P(NC)−1 P(NC)
ab c
de
P(WM/LC)−1 P(NM/NC)
))/((1 NCNMNEP− ))P(NE(NM/NC
NIoffspring
nodes inversion
NEoffspring
nodes exchange
WMoffspring
weights mutation
LC1st parent and 2st parent
linerar cross over of weights
NC1st parent and 2st parent
cross over of nodes
1st parent: weight matrix2st parent: weight matrix
ES GA
Fig.3.17: Entscheidungsbaum der Wahrscheinlichkeiten für die Erzeugung von Nachkommen.
94

Die Wahrscheinlichkeiten für die Erzeugung neuer Nachkom-men werden wie folgt gewählt: ( ) ( )( ) ( )( ) ( )( ) ( )( )( ) ( ) ( )( )( ) ( ) ( ) ( )( )( ) ( ) ( ) ( )( )( ) .04.0NCNMNEP1NCNMPNCPeP
,04.0NCNMNEPNCNMPNCPdP
,02.0NCNMP1NCPcP
,18.0LCWMP1NCP1bP
,72.0LCWMPNCP1aP
=−⋅⋅=
=⋅⋅=
=−⋅=
=−⋅−=
=⋅−=
Abkürzungen:
LC Linear Crossing NC Crossing of Nodes WM Weight Muation NI Node Inversion NE Node Exchange NM Node Mutation Mit der vorgeschlagenen Konzeption ist es möglich verschie-dene Variationen bezüglich der Netzwerk-Architektur zu erhal-ten. Im Einzelnen: (1) Anordnung der Gewichtsmatrix in Bitstring-
Anordnung. (2) Variation der Elemente von der Gewichtsmatrix. Die Veränderung der Gewichtsmatrix erfolgt über eine Variati-on der Schrittweite. Einzelheiten:
( p,,p,p 21T =p )
) alter Parametervektor.
( o,,o,o 21T =o Schrittweite.
Erzeugung neue Schrittweitenwerte mittels
( )( )∆⋅= ,0Nexpoo EN , wobei ∆ eine beliebige Konstante ist. Neuer Parametervektor
rpp += oldnew
mit . ( )N0,0N=r Um die beste Lösung, d.h. den besten Nachkommen (bestes Netzwerk) mittels Rekombination (recombination), Mutation
95

(mutation) und durch Selektion (selection) in der nächsten Ge-neration zu finden benötigen zwecks Beurteilung seine Fitness. Als Fitness-Funktion wählen wir den Root Mean Square Error (RMS) in der Form
RMSa fcf ⋅=
mit gewöhnlichen Konstanten c, a IR∈ . Für die System-Identifikation liegt folgendes Schaltschema zugrunde
( )u kT
( )( )y k T+1
( )( )y k T+1
recurrentMLP
Wdynamical
system
evolutionaryalgorithm
W
f
Fig. 3.18: Training eines MLP mittels EA für ein bestimmtes Systemverhalten. Bez.: Input Vektor im Eingangsraum zu einem
diskreten Zeitschritt kT, in Kurznotation .
( )kTu
( )ku Output Vektor des dynamischen Systems. ( )( T1k +y )
) Output Vektor des NN. ( )( T1kˆ +y 3.2.1 NN für eine Funktionsapproximation a) Beispiel Funktion in 2IR Gesucht ist die Approximation der nichtlinearen Funktion ( ) ( ) ( ) ( )( )x5,1tanh3x6tanh75,0x12tanhtanhxf ⋅−⋅−⋅−⋅−⋅−=
im Intervall [ . Bild der Funktion: ]1,1−
96

-1-0,8-0,6-0,4-0,2
00,20,40,60,8
1
-1 -0,8 -0,6 -0,4 -0,2 0 0,2 0,4 0,6 0,8 1
f(x)
x
Fig. 3.19: Analytische Darstellung der Funktion ( )xf . Approximation mit Netzwerk-Architektur: 2-4-1 MLP. Das MLP hat 7 Knoten (Neuronen):
• Eingang: ein Neuron und Bias-Knoten • vier Neuronen in der Zwischenschicht • Ausgang: ein Neuron Das Intervall [ wurde in 100 Intervalle unterteilt. Für die Population wurden hundert Individuen einschließlich zehn El-tern berücksichtigt. Approximationsergebnis:
]1,1−
1,5
0 0,5 1
0,02033 9
36387 RMS-Fehler:
Generation: 36387
RMS-error : generation :
0.02033
-0,5-1,5
-1
-0,5
0
0,5
1
1,5
-1-1 -0,5 0 0,5 1
0,16049 1
1723 RMS-Fehler:
Generation: 0.16049 1723
RMS-error : generation :
1
0,5
0
-0,5
-1
-1,5
Fig. 3.20: Approximation der Funktion. Matrix für die Verbindungsgewichte:
from 1 2 3 4 5 6 7 to Transf.fkt Bias input hidden hidden hidden hidden output 3 tanh 0,15032 1,20224 − − − − − 4 tanh 0,07469 −1,22462 −0,09102 − − − − 5 tanh −0,03218 2,06482 0,73384 −1,22145 − − − 6 tanh −0,05973 0,40487 0,52820 −0,51050 2,13619 − − 7 linear 0,03751 0,11149 −0,28751 −0,03541 2,14431 −1,08628 −
97

Bewertung: Mit Hilfe einer vergleichsweise einfachen Netz-werkstruktur lässt sich eine nichtlineare Funktion hinreichend gut approximieren. b) Konstruktion einer Fläche im 3IR bei fester Zahl von
Individuen und Eltern Wir betrachten die zwei-dimensionale Funktion:
( ) 22
21
42
4121 222, xxxxxxf −−+=
-1
0
1 -1,25
0
1,25-1,9-1,8-1,7-1,6-1,5-1,4-1,3-1,2-1,1-1-0,9-0,8-0,7-0,6-0,5-0,4-0,3-0,2-0,10
+1 25,
−1 25,
−1
+1
00x1
x2
−15,
0
f x x( , )1 2
−0 75,
Fig.3.21: Analytische Darstellung der Funktion ( )21 x,xf im Intervall und 1x1 1 +≤≤− 25,1x25,1 2 +≤≤− . Die Funktion hat die folgenden analytischen Eigenschaften:
.1x0fund0x
,2
1x0fund0x
2x1
1x2
2
1
±=⇒==
±=⇒==
( ) 00,0f:x0x 21 === .
0f,4x12f,4x24f212211 xxxx
21xx =−=−= .
Extrema: ( 0,0P1 ) ) Maximum, Sattelpunkt, ( 1,0P2 ( )1,0P3 − Sattelpunkt,
98

⎟⎠
⎞⎜⎝
⎛ 0,2
1P4 Sattelpunkt, ⎟⎠
⎞⎜⎝
⎛ 1,2
1P5 Minimum,
⎟⎠
⎞⎜⎝
⎛ −1,2
1P6 Minimum, ⎟⎠
⎞⎜⎝
⎛− 0,2
1P7 Sattelpunkt,
⎟⎠
⎞⎜⎝
⎛− 1,2
1P8 Minimum, ⎟⎠
⎞⎜⎝
⎛ −− 1,2
1P9 Minimum.
Approximation mit einem 3-7-1 MLP liefert ein brauchbares Resultat. Für die Approximation wurden einhundert Individuen einschließlich zehn Eltern berücksichtigt.
-1
0
1 -1 25
0
1,25-1,9-1,8-1,7-1,6-1,5-1,4-1,3-1,2-1,1-1-0,9-0,8-0,7-0,6-0,5-0,4-0,3-0,2-0,10
-1
0
1 -1 25
0
1,25-1,9-1,8-1,7-1,6-1,5-1,4-1,3-1,2-1,1-1-0,9-0,8-0,7-0,6-0,5-0,4-0,3-0,2-0,10
Generation: 10, RMS-error: 0.3076
Generation: 1000, RMS-error: 0.2080
-1 0
1 -1,25
0
1,25-1,9-1,8-1,7-1,6-1,5-1,4-1,3-1,2-1,1-1 -0,9-0,8-0,7-0,6-0,5-0,4-0,3-0,2-0,10
-1
0
1 -1,25
0
1,25
Generation: 50000, RMS-error: 0.0281
Generation: 1100, RMS-error: 0.1562
Fig.3.22: Approximationsfolge für die gegebene Funktion ( )21 x,xf .
99

c) Approximation im 3IR bei variabler Elternzahl Untersucht werden soll die Funktion:
( ) ( )22
2121 xxcosx,xf +=
im Bereich [ ] [ ]1,1xund1,1x 21 −=−= .
Fig.3.23: Analytische Darstellung von ( ) ( )2
22121 xxcosx,xf += .
Approximation mit einer Netzwerk-Architektur: 3-2-1 MLP: Sum of nodes Bias input nodes hidden nodes output nodes
7 1 2 2 1 In diesem Beispiel soll das günstigste Verhältnis Eltern zu Nachkommen bei einer fester Anzahl von Individuen experi-mentell ermittelt werden. Eltern 5 10 15 20 25 · · · 85 90 95 Nachkommen 95 90 85 80 75 · · · 15 10 5 Die Experimente ergeben, dass der Zeitbedarf proportional zur Anzahl der erzeugten Individuen (getestete Netze) ansteigt. Bei 95 Eltern werden in jeder Generation 5 Nachkommen erzeugt, bei 5 Eltern dagegen 95 Nachkommen. Aus dem Experiment folgte, dass der Zeitbedarf im Mittel pro Generation bei der Aufspaltung 5 Eltern und 95 Nachkommen ungefähr 19 mal
100

größer ist. Für Konvergenzgeschwindigkeitsvergleiche ist also die benötigte Anzahl an Generationen und die Anzahl der Nachkommen zu berücksichtigen. Alle Ergebnisse für die er-zeugten Individuen sind über 5 gleiche Läufe gemittelt.
Generation ↑
→ Eltern Fig.3.24: Aus der Abbildung erkennt man, dass die Ergebnis-se streuen. Die größte Konvergenzgeschwindigkeit ist bei etwa 25-30 Eltern zu erwarten (bei einer Population von 100). Eine Möglichkeit zur Beschleunigung des Verfahrens ist die Fitness abhängig vom Alter zu machen durch Einführung eines Fak-tors, der das Altern der Eltern berücksichtigt.
101

Ergebnisse der Approximation:
Fig.3.25: Evolutionsverlauf zur Approximation einer Funktion im 3IR .
102

3.2.2 Simulation nichtlinearer Systeme
Fig.3.26: Architektur eines vorwärts verschalteten Netzwerks mit externer Rückführung Im Falle eines statischen Zusammenhangs zwischen den Ein- und Ausgangsgrößen eines Systems oder Prozesses sind die betreffenden Augenblickswerte über eine, im allgemeinen nichtlineare Funktion verknüpft. Die Konfiguration eines vor-wärtsverschalteten Netzwerkes mit externer Rückführung zur Nachbildung dynamischer Systeme zeigt Fig. 3.25 in zeitdis-kreter Form. Die Rückführung zeitverzögerter Ein- und Aus-gangsgrößen des Systems auf den Eingang des Netzwerkes ist der Schlüssel für das Erlernen dynamischer Abbildungen. Es wird gewissermaßen ein Kurzzeitgedächtnis des Netzwerkes dadurch implementiert, dass außer den aktuellen Eingangsgrö-ßen auch Ein- und Ausgangsgrößen zurückliegender Zeitschrit-te benutzt werden. Die maximale Anzahl N der Vektoren eines rückgekoppelten Systems richtet sich nach der Ordnung des Systems. Die Anzahl L der verwendeten verzögerten Ein-gangsvektoren wird durch die höchste zu berücksichtigende Ableitung der Eingangsgröße (Anzahl der Nullstellen des Sys-tems, bei linearen Systemen) beeinflusst. Im allgemeinen ist
. NL ≤
103

Fig.3.27: System-Architektur für das Lernen dynamischer Ab-bildungen. Die in Fig. 3.27 dargestellte Konfiguration zum Lernen einer dynamischen Abbildung durch ein Netzwerk unterscheidet sich im prinzipiellen Aufbau nicht von der für das Lernen eines funktionalen statischen Zusammenhangs. Dem Netzwerk wird dieselbe Eingangsgröße wie dem dynamischen System als Fol-ge abgetasteter und zwischengespeicherter Werte zugeführt. Es gibt zwei unterschiedliche Lernphasen: Modus I. Die Eigenrückkopplung des Netzwerkes stellt die
Lern- und Testphase für den EA dar. Modus II. Dies ist die Anordnung die für ein Verfahren wie
Backpropagation geeignet ist. Bei dem Evolutionären Algorithmus, werden erst alle k Fehler zwischen dem Netzausgang und dem Systemausgang be-stimmt. Dann wird die Gewichtsmatrix optimiert Modus III.
104

a) Beispiel: Filter erster Ordnung Wir betrachten das zeitinvariante System
5
5s +u y
Übliche Notation:
DuCxyBuAxx
+=+=
[ ] [ ][ ] [ ]0;5
;1;5===−=
DCBA
( ) ( ) ( ) [ ] [ ]
[ ] [ ]0;5;0442.0;7788,0
dd
dd====
DCBA
( ) ( ) ( )kkkkk1k
dd
dduDxCyuBxAx
+=+=+
( ) ( ) ( )
( ) ( )kx0000,5kyku04424,0kx7788,01kx
⋅=⋅+⋅=+
Als Netzstruktur wurde ein Netz mit nur einer Schicht vorge-geben, d.h. mit einem linearen Ausgangsknoten. Nach einer Anzahl von 100 bis 300 Generationen (Populationsgröße 100 Individuen / 25 Eltern) erzeugt der Evolutionäre Algorithmus immer ein auf 6 Nachkommastellen identisches Netz wie in Fig.3.26 dargestellt ist.
105

Fig.3.28: Generiertes Netz mit Eigenschaft: Filter erster Ord-nung. Betrachtet man das von dem EA erzeugte Netzwerk, so findet man das vorgegebene System, in etwas anderer Form wieder. Bei diesem Netzwerk, ist es noch möglich das Wissen aus den Netzparametern zu extrahieren. Man sieht, dass die entstandene Struktur die Parameter der diskreten Vorgabe enthält, wobei der Faktor 5,0 und 0,04424 zum Gewicht 0,2212 zusammen gefasst sind. Der EA hat hier nur die Möglichkeit gehabt, die Gewichte in einer vorgegebenen Netzwerk-Struktur zu verän-dern. Da aber Gewichte von 0,0 (Genauigkeit kleiner 0,000001) mit nicht vorhandenen Gewichten identisch sind, erhält man auch eine Strukturoptimierung. Aus der Menge der Netze die in der Vorgabestruktur enthalten sind, sucht sich der EA das optimale Netz heraus.
Fig.3.29 Lernkurve Filter 1. Ordnung im Modus II. Bei diesem Beispiel wurde während der Lernphase der Pro-gramm Modus II benutzt. Dabei wurde in bestimmten Abstän-den getestet, wie sich das Netz verhält, wenn es den eigenen
106

Ausgang zurückgekoppelt bekommt (Modus I). Man erkennt, dass sich das Netz dann schlechter verhält. Erst wenn das Netz mit dem System identisch ist werden die richtigen Werte zu-rückgekoppelt. Bekommt das Netz beim Lernen seine eigenen anfangs fehlerhaften Ausgänge zurückgekoppelt, so dauert das Lernen länger. Bekommt es Werte des Systems, so ist sein Verhalten besser, da diese Eingangswerte ohne Fehler sind.
Fig.3.30: Lernkurve Filter 1. Ordnung im Modus I.
0 2,5 5 7,5 Zeit [s]
0,6735510
RMS-Fehler :Generation :
1
0 2,5 5 7,5 Zeit [s]
0,42198921
RMS-Fehler :Generation :
1
0 2,5 5 7,5 Zeit [s]
0,005341191
RMS-Fehler :Generation :
1
time[s]
0.421989
generation :
RMS-error :
21
0.673551
generation :
RMS-error :
0
0.005341
generation :
RMS-error :
191
time[s]
time[s]
− 1
+ 1
0
− 1
+ 1
0
− 1
+ 1
0
u
y
y
Fig. 3.31: Man sieht den Verlauf der Evolution (Lernen im Modus I, siehe Fig. 3.30) mit Rückkopplung des eigenen Aus-gangs während der Lernphase. Bereits bei 191 Generationen ist eine gute Nachbildung der Filterfunktion erreichbar.
107

b) Beispiel: Finite Impulse Response [FIR] Filter
( ) (∑=
−⋅=+M
0)
mm mkua1ky ,
mit 52.0a,12.0a,32.0a,43.0a 3210 −==−== und
22.0a4 −= als beliebig gewählte Parameter.
z−1 z−1 z−1
a1 am aMa0
∑
( )u k
( )y k +1
( )u k −1 ( )u k M−( )u k m−
Fig.3.32: FIR-Filter. Abbildung des Filterverhaltens mittels eines rückgekoppelten MLP´s
y
u
y
k
Fig.3.33: Die Darstellung veranschaulicht die guten Approxi-mationseigenschaften des MLP´s. Architektur des MLP: Coupling Nodes Bias Input Hidden Output Weights RMS-error intern 5 1 1 2 1 15 0,032670
-1,5
-1
,5
0
0,5
1
0 20 40 60 80
-0
108

Matrix der Verbindungsgewichte: Zeile:1 2 3 4 5 Spalte: 1 0 0 0 0 0 2 0 0 0 0 0 3 0.010505 -0.292458 0.085684 3.187823 -2.586260 4 -0.082518 1.222397 -0.020175 0.179104 -0.194675 5 0.006780 0.363717 0.097602 -0.222985 0.157583 oder
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−−−
−−
=
157583.0194675.0586260.200222985.0179104.0187823.300363717.0222397.1029245800006780.0082518.0010505.000
W
MLP für den FIR-Filter:
=∑=∑
=∑
=∑
0.179104
10.
( )u k
1
23
4
0.010505
-0.292458
0.0856844
3.187823
-0.082518
1.222397
-0.020175
=∑( )y k +1
5
0.157583
0.006780
0.363717
0.097602
-0.222985
-2.586260
-0.194675
Fig.3.34: Das dargestellte Neuronale Netz repräsentiert einen FIR-Filter.
109

c) Beispiel: Filter 2. Ordnung Wir untersuchen das folgende Netzwerk:
C 1 i 1
R 1 R 2
u yC 2
i 2
Fig.3.35: Darstellung eines RC-Filters. Die relevanten Gleichungen des Netzwerkes sind gegeben durch folgende Darstellung:
( )∫ =−+ to 21
111 udtii
C1iR ,
( )∫∫ =−++ to 12
1
to 2
222 0dtii
C1dti
C1iR .
Anwendung der Laplace-Transformation liefert:
( ) ( )( ) 1sCRCRCRsCCRR
ssUCsI
2221112
2121
22
++++= .
Die Ausgangsspannung ist bestimmt durch:
∫= to 2
2dti
C1y .
Das Übertragungsverhalten ist gegeben wie folgt:
( )( ) ( ) 1sCRCRCRsCCRR
1sUsY
2221112
2121 ++++= .
Mit den Abkürzungen
213222111 CRTundCRT,CRT === erhalten wir
110

( )( ) ( ) 1sTTTsTT
1sUsY
3212
21 ++++= .
Die Simulation und diskrete Darstellung des nichtlinearen Sys-tems mit dem dargestellten Übertragungsverhalten
1s3022,1s5515,11
2 ++
( )ty ( )tu wird mit Hilfe der Toolbox SIMULINK in MATLAB durchge-führt. Eine gute Approximation erhalten wir schon ab der 500. Gene-ration (Fig.3.36).
0
0,0005
0,001
0,0015
0,002
0,0025
0,003
0,0035
0,004
0,0045
0,005
0
100
200
300
400
500
600
700
800
900
1000
RMS error−
generation
Fig. 3.36: Verlauf des RMS-Fehlers bezüglich der Generation. Ergebnis: Das Ausgangssignal y des Systems kann adäquat durch den Ausgang eines MLP´s repräsentiert werden. y
111

y
u y
k -1,5
-1
-0,5
0
0,5
1
1,
0 20 40 60 80 100 120 140 160 180
Fig.3.37: Abbildung der Filtereigenschaften. Das durch EA erzeugte MLP ist von einfacher Struktur:
=∑=∑
=∑
=∑
10.
( )u k( )y k +1
1
23
4
0.000033
-0.312746
1.056390
0.719925
0.000009
0.000237
-0.019728
0.857283
Fig. 3.38: MLP das die Filtereigenschaften abbildet. Coupling Nodes Bias Input Hidden Output Gewichte RMS-error 4 1 1 1 1 8 0,000231 Gewichtsmatrix
Zeile: 1 2 3 4 Spalte: 1 0 0 0 0 2 0 0 0 0 3 0.000033 -0.312746 1.056390 0.719925 4 0.000009 0.000237 -0.019728 0.857283
112

Bem.: MLP´s sind ebenfalls in Lage komplexere Systeme wie sie bei einer Steuerung der Flugzeugdynamik (automatischer Pilot) auftreten zu simulieren.
113