Embed Size (px)
Citation preview
Finite Elemente I 122
4 Die Losung der diskreten Poisson-Gleichung
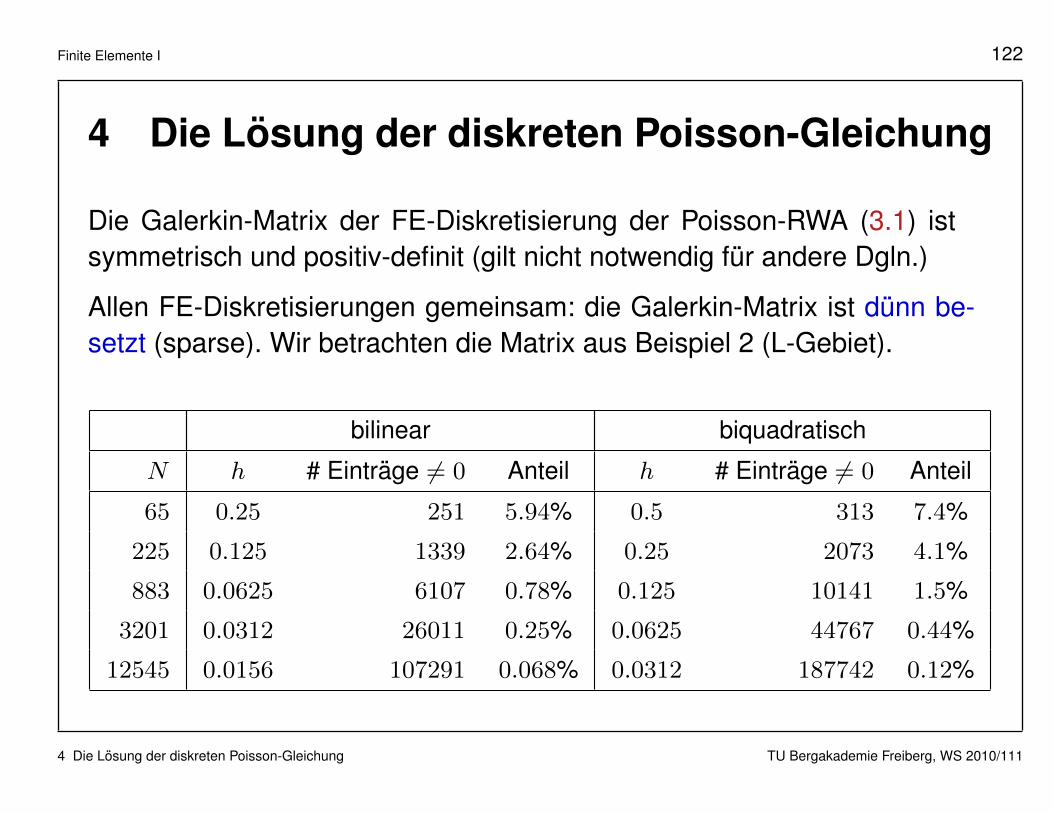
Die Galerkin-Matrix der FE-Diskretisierung der Poisson-RWA (3.1) istsymmetrisch und positiv-definit (gilt nicht notwendig fur andere Dgln.)
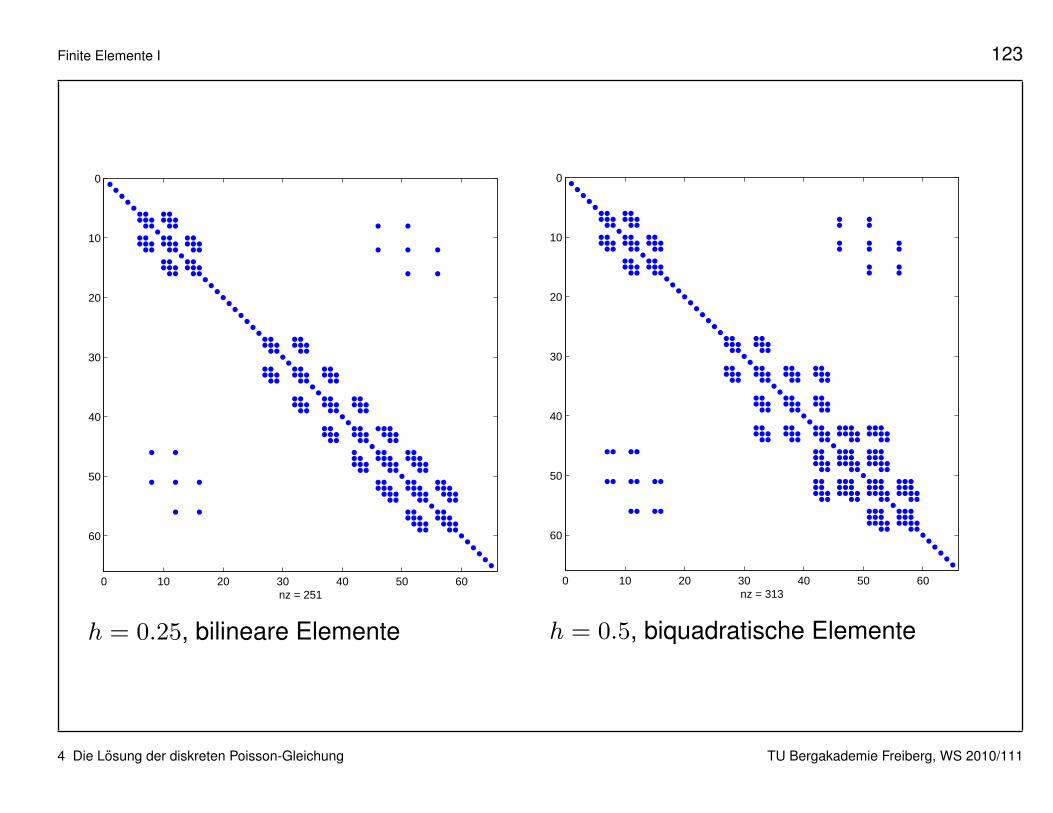
Allen FE-Diskretisierungen gemeinsam: die Galerkin-Matrix ist dunn be-setzt (sparse). Wir betrachten die Matrix aus Beispiel 2 (L-Gebiet).
bilinear biquadratisch
N h # Eintrage 6= 0 Anteil h # Eintrage 6= 0 Anteil
65 0.25 251 5.94% 0.5 313 7.4%
225 0.125 1339 2.64% 0.25 2073 4.1%
883 0.0625 6107 0.78% 0.125 10141 1.5%
3201 0.0312 26011 0.25% 0.0625 44767 0.44%
12545 0.0156 107291 0.068% 0.0312 187742 0.12%
4 Die Losung der diskreten Poisson-Gleichung TU Bergakademie Freiberg, WS 2010/111
Finite Elemente I 123
0 10 20 30 40 50 60
0
10
20
30
40
50
60
nz = 251
h = 0.25, bilineare Elemente
0 10 20 30 40 50 60
0
10
20
30
40
50
60
nz = 313
h = 0.5, biquadratische Elemente
4 Die Losung der diskreten Poisson-Gleichung TU Bergakademie Freiberg, WS 2010/111
Finite Elemente I 124
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1Q1 finite element subdivision
h = 0.25, bilineare Elemente−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1Q2 finite element subdivision
h = 0.5, biquadratische Elemente
4 Die Losung der diskreten Poisson-Gleichung TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 125
Direkte oder iterative Verfahren ?
• In der FE-Praxis wurde lange Zeit mit direkten Verfahren, also Variantender Gauß-Elimination, gearbeitet.
• Stark verbreitet: frontal solvers. Hier wird die Faktorisierung der Matrixso fruh wie moglich wahrend der Assemblierung vorgenommen.
• Weiterentwicklungen auch heute noch relevant, auch als eigenstandigeEliminationsverfahren, z.B. UMFPACK.
• Faustregel: in 2D reichen ausgereifte direkte, auf dunn-besetzte Ma-trizen spezialisierte Loser aus. Fur 3D-Diskretisierungen muss aufIterationsverahren zuruckgegriffen werden.
• Vorteil direkter Verfahren: typischerweise als ”black box“ einsetzbar.Bei Iterationsverfahren ist deutlich mehr Expertise des Anwenderserforderlich.
4 Die Losung der diskreten Poisson-Gleichung TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 126
4.1 Erste Iterationsverfahren
Zunachst sei allgemein gegeben
Ax = b, A ∈ Cn×n invertierbar, b ∈ Cn. (4.1)
Grundidee:
Startnaherung x0 ≈ A−1b,
Erzeuge rekursiv Folge xmm∈N mit limm→∞
xm = A−1b.
Bezeichnungen:
rm := b −Axm Residuum, Defekt,
x ? := A−1b (exakte) Losung,
em := x ? − xm Fehler.
4.1 Erste Iterationsverfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 127
Die ersten Iterationsverfahren (Handrechnung!) beruhen auf Umstellungeinzelner Gleichungen, Auflosen nach den entsprechenden Unbekanntenund Wiedereinsetzen (Relaxation).
• Carl-Friedrich Gauß (∼ 1832), Normalgleichungen aus Astronomie,Landesvermessung, 20–40 Unbekannte
”Ich empfehle Ihnen diesen Modus zur Nachahmung. Schwerlich wer-den Sie je wieder direkt eliminieren, wenigstens nicht, wenn Sie mehrals 2 Unbekannte haben. Das indirekte Verfahren lasst sich halb imSchlafe ausfuhren, oder man kann wahrend desselben an andere Dingedenken.“ Brief von Gauß an Gerling, 1823
• Carl Gustav Jacobi (∼ 1846)
• Ludwig Seidel (∼ 1862)
• Christian August Nagel (Sachsische Triangulation, 1867-1886) 159Unbekannte
4.1 Erste Iterationsverfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 128
Formale Beschreibung von Relaxationsverfahren durch Zerlegungen (split-tings):
A = M −N , M invertierbar, (4.2a)
uberfuhrt (4.1) in Fixpunktform Mx = Nx +b, zugehorige Fixpunktiteration
xm+1 = Txm + c, T = M−1N , c = M−1b. (4.2b)
Typische algorithmische Umsetzung: (beachte: Txm + c = xm + M−1rm)
Algorithmus 1: Relaxationsverfahren.Gegeben : A invertierbar, b, Startnaherung x0
1 for m = 0, 1, 2 . . . bis Abbruchkriterium erfullt do2 rm ← b −Axm
3 Lose Mh = rm
4 xm+1 ← xm + h
4.1 Erste Iterationsverfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 129
Klassische Zerlegungen
• M = I
Richardson-Verfahren
• M = D := diag(A)
Jacobi-Verfahren, Einzelschrittverfahren
• M = D − L, L = − tril(A)a
Gauß-Seidel-Verfahren, Einzelschrittverfahren, Liebmann-Verfahren
• M = D − ωL, ω ∈ RSOR-Verfahren (successive-overrelaxation)
• M = ω2−ω ( 1
ωD − L)D−1( 1ωD −U ), U := − triu(A), ω ∈ R
SSOR-Verfahren (symmetric SOR)
aMit tril(A) bzw. triu(A) sei, abweichend von der MATLAB-Semantik, der echte unterebzw. obere Dreieckanteil von A bezeichnet.
4.1 Erste Iterationsverfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 130
Fur den Fehler der m-ten Iterierten aus (4.2b) gilt
em+1 = x ? − xm+1 = (I −M−1A)(x ? − xm) = Tem = · · · = Tme0.
Lemma 4.1 Fur eine beliebige Matrix T ∈ Cn×n gilt
limm→∞
Tm = O ⇔ ρ(T ) < 1.
Satz 4.2 Das durch die Zerlegung (4.2a) definierte Relaxationsverfahren(4.2b) konvergiert genau dann fur alle Startnaherungen x0, wenn fur dieIterationsmatrix T = M−1N gilt ρ(T ) < 1.
4.1 Erste Iterationsverfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 131
4.2 M -Matrizen und regulare Zerlegungen
Definition 4.3 Eine Matrix A ∈ Cn×n heißt reduzibel (zerlegbar), falls eseine Permutationsmatrix P gibt sodass
PAP> =
[A1,1 A1,2
O A2,2
]
mit quadratischen Matrizen A1,1, A2,2. Eine Matrix heißt irreduzibel, fallssie nicht reduzibel ist.
Lemma 4.4 Eine Matrix A ∈ Cn×n ist genau dann irreduzibel, wenn esfur jede Zerlegung I = I1 ∪ I2 der Indexmenge I = 1, 2, . . . , n mitI1 6= ∅, I2 6= ∅, I1 ∩I2 = ∅ stets ein Element ai,j von A gibt mit i ∈ I1,j ∈ I2 und ai,j 6= 0.
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 132
Definition 4.5 Eine Matrix A ∈ Rm×n heißt nichtnegativ (positiv), falls
ai,j ≥ 0 (> 0) 1 ≤ i ≤ m, 1 ≤ j ≤ n.
Entsprechend bedeutet A ≥ B (A > B), dass A−B ≥ O (> O).
Satz 4.6 (Satz von Perron und Frobenius) Sei A ≥ 0 irreduzibel.Dann gelten:
(a) Der Spektralradius ρ(A) ist einfacher Eigenwert von A (der sog.Perron-Eigenwert von A) und positiv.
(b) Zum Perron-Eigenwert gehort ein positiver Perron-Eigenvektor x > 0 .
(c) Jeder nichtnegative Eigenvektor von A ist Eigenvektor zum Perron-Eigenwert ρ(A) (und damit positiv).
(d) Ist O ≤ B ≤ A, so folgt ρ(B) ≤ ρ(A). Ist zusatzlich A 6= B , so giltρ(B) < ρ(A).
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 133
Definition 4.7 Eine nichtsingulare Matrix A ∈ Cn×n heißt M-Matrixa, falls
ai,j ≤ 0 fur i 6= j und A−1 ≥ O .
Eine Hermitesche M-Matrix heißt Stieltjes-Matrix.
Satz 4.8 Fur B ∈ Cn×n mit ρ(B) < 1 ist I −B nichtsingular. Es gilt
(I −B)−1 =
∞∑j=0
Bj .
Diese Reihe wird Neumannsche Reihe genannt. Konvergiert umgekehrtdie Neumannsche Reihe, so ist ρ(B) < 1.
Satz 4.9 Es sei B ∈ Rn×n und B ≥ O . Die Relation ρ(B) < 1 gilt genaudann, wenn die Inverse (I −B)−1 existiert und (I −B)−1 ≥ O .
aDie Bezeichnung wurde 1937 durch Alexander Ostrowski eingefuhrt, zu Ehren von Her-mann Minkowski.
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 134
Satz 4.10 Eine Matrix A ∈ Cn×n mit ai,j ≤ 0 fur i 6= j ist genau dann eineM-Matrix, wenn D := diag(A) > O (insbesondere sind M -Matrizen stetsreell) und wenn fur die Matrix B := I −D−1A gilt ρ(B) < 1.
Definition 4.11 Die Zerlegung A = M − N der Matrix A ∈ Rn×nheißtregulare Zerlegung von A, wenn M−1 ≥ O und N ≥ O gelten.
Satz 4.12 Ist A = M−N eine regulare Zerlegung von A und ist A−1 ≥ O ,so gilt
ρ(M−1N ) =ρ(A−1N )
1 + ρ(A−1N )< 1,
d.h. jede regulare Zerlegung einer Matrix mit nichtnegativer Inversen fuhrtzu einem konvergenten Iterationsverfahren. Diese Aussage gilt insbeson-dere fur M-Matrizen.
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 135
Satz 4.13 Fur A ∈ Rn×n mit A−1 > O seien A = M1 −N1 = M2 −N2
zwei regulare Zerlegungen. Falls N2 ≥ N1 ≥ O und N2 6= N1 ist, so gilt
0 < ρ(M−11 N1) < ρ(M−1
2 N2) < 1,
d.h. das aus der ersten Zerlegung resultierende Verfahren konvergiertschneller als das aus der zweiten.
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 136
Satz 4.14 (Starkes Zeilensummenkriterium) Gilt fur A = D − L −U ∈Cn×n
‖D−1(L + U )‖∞ < 1,
so konvergieren Gauß-Seidel und Jacobi-Verfahren.
Satz 4.15 (Schwaches Zeilensummenkriterium) Ist A ∈ Cn×n irreduzi-bel und gilt ∑
j 6=i
|aij | ≤ |aii|, i = 1, . . . , n,
wobei fur mindestens einen Index i echte Ungleichheit gilt, so konvergierendas Jacobi- und sowie das Gauß-Seidel-Verfahren.
Satz 4.16 Ist A eine M-Matrix, dann konvergiert sowohl das Jacobi- alsauch das Gauß-Seidel-Verfahren.Ist A zusatzlich irreduzibel, so konvergiert das Gauß-Seidel-Verfahrenschneller als das Jacobi-Verfahren.
4.2 M -Matrizen und regulare Zerlegungen TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 137
4.3 Das CG-Verfahren
Satz 4.17 Die Iterierten, Residuen und Fehler des durch die Zerlegung(4.2a) definierten Relaxationsverfahrens (4.2b) sind gegeben durch
xm = x0 +m−1∑j=0
(I −M−1A)jM−1r0,
M−1rm = (I −M−1A)mM−1r0,
em = (I −M−1A)me0 m = 1, 2, . . .
also durch
xm = x0 + qm−1(T )M−1r0, M−1rm = pm(T )M−1r0, em = pm(T )e0
mit Polynomen
qm−1(λ) = 1 + λ+ · · ·+ λm−1 ∈Pm−1 bzw. pm(λ) = λm ∈Pm .
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 138
Das CG-Verfahren (conjugate gradients), oder allgemein polynomialeBeschleunigungsverfahren, auch Krylov-Unterraumverfahren genannt,konnen als Iterationsverfahren interpretiert werden, bei denen die Iteriertenbzw. Residuen die Form
xm = x0 + qm−1(A)r0, rm = pm(A)r0,
mitqm−1 ∈Pm−1, pm(λ) = 1− λqm−1(λ) ∈Pm
besitzen, wobei versucht wird, diese Polynome in jedem Schritt moglichstgunstig zu wahlen.
Entscheidend: in jedem Schritt der Iteration ist nur eine Matrix-Vektor-Multiplikation mit der Koeffizientenmatrix A (bzw. der Iterationsmatrix T )erforderlich.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 139
4.3.1 Herleitung des CG-Verfahrens
Gegeben: A ∈ Rn×n spd, b ∈ Rn (komplexer Fall analog).
Gesucht: Losung x ? des LGS
Ax = b. (4.3)
Sei (·, ·) ein gegebenes Innenprodukt auf Rn (mit zugehoriger Norm ‖ · ‖).
Wichtige Beobachtung: da A spda ist durch
(u , v)A := (Au , v), u , v ∈ Rn,
ebenfalls ein Innenprodukt gegeben, das A-Innenprodukt oder auchEnergie-Innenprodukt (mit zugehoriger Norm ‖ · ‖A).
Da mit A auch A−1 spd, gilt dasselbe auch fur (·, ·)A−1 .
aeigentlich: A selbstadjungiert bez. (·, ·)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 140
Ausgangspunkt dieser Herleitung des CG-Verfahrens (vgl. Numerik-Vorlesung, Abschnitt uber Variationsrechnung):
x ∗ lost (4.3) ⇐⇒ x ∗ minimiert J(x ) = 12 (x ,x )A − (b,x ) uber Rn.
Minimierung auf Unterraumen: Anstatt auf ganz Rn minimieren wir J aufeiner Folge geschachtelter affiner Unterraume der Gestalt
Sm = x0 + Vm, Vm = spanp1,p2, . . . ,pm.
Hierbei bilden p1, . . . ,pm eine Folge linear unabhangiger Richtungsvekto-ren.
Als Naherungen xm ≈ x ∗ erhalten wir die Losungen der Unterraumaufga-ben
Bestimme xm ∈ Sm mit J(xm) = minx∈Sm
J(x ).
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 141
Wegen
J(x ) = 12
(‖b −Ax‖2A−1 − ‖b‖2A−1
)= 1
2‖x? − x‖2A + J(x ?)
ist die Minimierung von J aquivalent zur Minimierung von ‖b − Ax‖A−1 ,d.h. gesucht ist ein x ∈ Sm welches den Ausdruck
‖b −Ax‖A−1 = ‖b −Ax0 −Ap‖A−1 = ‖r0 −Ap‖A−1
minimiert mit einem p ∈ Vm.
Aquivalent: bestimme Bestapproximation bez. ‖ · ‖A−1 an r0 aus demUnterraum AVm.
Aquivalent: A−1-orthogonale Projektion von r0 nach AVm
Charakterisierung:
r0 −Ap ⊥A−1 Apj , j = 1, 2, . . . ,m,
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 142
oder(p,pj)A = (r0,pj), j = 1, 2, . . . ,m,
oderrm := b −Axm ⊥ Vm.
Besitzt p die Koordinatendarstellung
p = y1p1 + · · ·+ ympm,
so erfullt der Koordinatenvektor y = [y1, y2, . . . , ym]> ∈ Rm das LGS
[(pj ,pi)A]mi,j=1y = [(r0,pi)]mi=1. (4.4)
Bemerkung: Wegen ‖b −Ax‖A−1 = ‖A−1b − x‖A besitzt die Bestappro-ximation p ∈ Vm auch die Eigenschaft, dass die zugehorige Approximationxm = x0 + p den Fehler A−1b − xm bezuglich der A-Norm minimiert.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 143
Konjugierte Suchrichtungen
Sind die Richtungsvektoren pj A-konjugiert (ein Synonym fur A-orthogonal),so vereinfacht sich das LGS (4.4) fur die Koordinaten:
• Die Koeffizientenmatrix wird diagonal,
• die Gleichungen sind entkoppelt, d.h. beim Ubergang von Vm nachVm+1 bleiben die Koeffizienten y1, . . . , ym unverandert,
• es gilt
yi =(r0,pi)
(pi,pi)A, i = 1, 2, . . . ,m.
Wir erhalten so folgenden Algorithmus:
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 144
Algorithmus 2: Verfahren der konjugierten Richtungen (CD-Verf.)Gegeben : A spd, b
1 Bestimme Startnaherung x0, berechne r0 ← b −Ax0, m← 0
2 while nicht konvergiert do3 m← m+ 1
4 Bestimme nachsten, zu p1, . . . ,pm−1 konjugierten Richtungsvektor pm
5 αm ← (rm−1,pm)
(pm,pm)A
6 xm ← xm−1 + αmpm
7 rm ← rm−1 − αmApm
Bemerkung: Eine Folge A-orthogonaler Suchrichtungen kann man erzeu-gen aus einer beliebigen Folge (linear unabhangiger) Vektoren p1, p2, . . .
mit Hilfe des Gram-Schmidtschen Orthogonalisierungsverfahrens:
pm = pm −m−1∑j=1
(pm,pj)A(pj ,pj)A
pj , m = 1, 2 . . . . (4.5)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 145
Lemma 4.18 Im m-ten Schritt des CD-Verfahrens gilt:
pm ⊥A p1,p2, . . . ,pm−1, (4.6)
rm ⊥ p1,p2, . . . ,pm, (4.7)
(pm, rm−1) = (pm, rm−2) = · · · = (pm, r0). (4.8)
Lemma 4.19 Das CD-Verfahren berechnet die Losung x ∗ von (4.3) nacheiner endlichen Anzahl L ≤ n Schritten.
Bemerkungen:
1. Die endliche Abbrucheigenschaft geht i.A. verloren bei rundungsbe-hafteter Rechnung.
2. Obwohl der Fehler die interessierende Große, ist oft nur das Residuumverfugbar. Der nachste Satz gibt prinzipielle Beziehungen zwischendiesen an.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 146
Satz 4.20 Sei x eine Approximation an A−1b. Dann gelten fur den Fehlere := A−1b − x und das zugehorige Residuum r = b −Ax
‖r‖‖r‖A
≤ ‖e‖A‖r‖
≤ ‖e‖‖e‖A
, (4.9)
‖r‖2
‖r‖2A≤ ‖e‖‖r‖
≤ ‖e‖2
‖e‖2A. (4.10)
Lemma 4.21 Im m-ten Schritt des CD-Verfahrens wird der Abstand in derA-Norm zur Losung reduziert gemaß
‖em−1‖2A − ‖em‖2A =(rm−1,pm)2
(pm,pm)A.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 147
Konjugierte Gradienten
A-orthogonale Suchrichtungen machen einen Iterationsschritt zwar effizi-ent, mussen aber per se nicht zu schneller Konvergenz fuhren. (Warum?)
Idee: Wahle in (4.5) den neuen Vektor pm+1 als Richtung starkster Abnah-me von J an der Stelle xm:
pm+1 = −∇J |x=xm = b −Axm = rm, m > 1,
p1 = p1 = r0.
Danach A-Orthogonalisierung gegen p1, . . . ,pm.Vorteil: Liefert solange neue Suchrichtungen bis Losung gefunden.(Warum?)
Aus dieser Wahl folgt sofort
spanr0, r1, . . . , rm−1 = spanp1,p2, . . . ,pm, m = 1, 2, . . . , L. (4.11)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 148
Wir erhalten so den
Algorithmus 3: CG-Verfahren (vorlaufige Version).Gegeben : A spd, b
1 Bestimme Startnaherung x0, berechne r0 ← b −Ax0
2 Setze m← 0, p1 ← r0
3 while nicht konvergiert do4 m← m+ 1
5 αm ← (rm−1,pm)
(pm,pm)A
6 xm ← xm−1 + αmpm
7 rm ← rm−1 − αmApm
8 pm+1 ← rm −∑m
j=1
(rm,pj)A(pj ,pj)A
pj
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 149
Vereinfachungen:
(1) Solangem < L ist αm 6= 0 und aus rm = rm−1−αmApm folgt zunachstApm ∈ spanrm−1, rm und allgemein
spanAp1,Ap2, . . . ,Apm−1 ⊂ spanr0, r1, . . . , rm−1(4.11)= spanp1,p2, . . . ,pm.
Da aber rm ⊥ spanp1, . . . ,pm nach (4.7) folgt hieraus rm ⊥Aspanp1, . . . ,pm−1 sodass Zeile 8 sich vereinfacht zu
pm+1 ← rm −(rm,pm)A(pm,pm)A
pm =: rm + βm+1pm. (4.12)
(2) Aus pm = rm−1 + βmpm−1 folgt wegen rm−1 ⊥ pm−1 fur Zeile 5
αm =(rm−1,pm)
(pm,pm)A=
(rm−1, rm−1)
(pm,pm)A. (4.13)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 150
(3) Aus rm = rm−1 − αmApm folgt
(rm, rm) = −αm(rm,Apm) = −αm(rm,pm)A
und daher wegen (4.13) fur (4.12)
βm+1 = − (rm,pm)A(pm,pm)A
=(rm, rm)
αm(pm,pm)A=
(rm, rm)
(rm−1, rm−1).
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 151
Mit diesen Vereinfachungen erhalten wir die endgultige Formulierung desCG-Verfahrens:
Algorithmus 4: CG-Verfahren.Gegeben : A spd, b
1 Bestimme Startnaherung x0, berechne r0 ← b −Ax0
2 Setze m← 0, p1 ← r0
3 while nicht konvergiert do4 m← m+ 1
5 αm ← (rm−1,rm−1)
(pm,pm)A
6 xm ← xm−1 + αmpm
7 rm ← rm−1 − αmApm
8 βm+1 ← (rm,rm)(rm−1,rm−1)
9 pm+1 ← rm + βm+1pm
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 152
4.3.2 Eigenschaften des CG-Verfahrens
Aufwand: Operationen pro Schritt: 1 Matrix-Vektor Produkt,2 Innenprodukte,3 Vektoraufdatierungen.
Speicher: 4 Vektoren.
Lemma 4.22 Fur die Suchrichtungen des CG-Verfahrens gilt
pm = ‖rm−1‖2m−1∑j=0
rj‖rj‖2
, m = 1, 2, . . . , L. (4.14)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 153
Satz 4.23 Beim CG-Verfahren gelten die Beziehungen
(rm,pj) = 0, 1 ≤ j ≤ m, 1 ≤ m ≤ L− 1, (4.15)
(rm, rj) = 0, m 6= j, 0 ≤ m, j ≤ L− 1, (4.16)
(rm,pj) = ‖rj−1‖2, m+ 1 ≤ j ≤ L, 0 ≤ m ≤ L− 1, (4.17)
(pm,pj)A = 0, m 6= j, 1 ≤ m, j ≤ L, (4.18)
(pm, rm−1)A = ‖pm‖2A, 1 ≤ m ≤ L, (4.19)
(pm, rj)A = 0, m+ 1 ≤ j ≤ L− 1, m = 1, 2 . . . , L, (4.20)
Lemma 4.24 Fur die Residuen und Richtungsvektoren des CG-Verfahrens gelten
(pm,pj) =‖rj−1‖2‖pm‖2
‖rm−1‖2, j ≥ m, (4.21)
‖pm‖2 = ‖rm−1‖2 + β2m‖pm−1‖2 = ‖rm−1‖4
m−1∑j=0
1
‖rj‖2. (4.22)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 154
Lemma 4.25 Im m-ten Schritt des CG-Verfahrens gilt
‖em−1‖2A − ‖em‖2A = αm‖rm−1‖2 =‖pm‖2A‖pm‖2
‖xm − xm−1‖2. (4.23)
Fur j < m gilt
‖ej‖2A − ‖em‖2A = αj+1‖rj‖2 + · · ·+ αm‖rm−1‖2. (4.24)
Die m-te Iterierte besitzt die Darstellung
xm = x0 +m∑j=1
αjpj = x0 +m∑j=1
‖ej‖2A − ‖em‖2A‖rj−1‖2
rj−1. (4.25)
Satz 4.26 Im m-ten Schritt des CG-Verfahrens gilt
‖em−1‖2 − ‖em‖2 =‖pm‖2
‖pm‖2A
[‖em‖2A + ‖em−1‖2A
]. (4.26)
Insbesondere ist der CG-Fehler auch bezuglich der Norm ‖ · ‖ monotonfallend.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 155
CG als Krylov-Unterraumverfahren
Fur A ∈ Rn×n und v ∈ Rn heißt der Unterraum
Km(A, v) := spanv ,Av , . . . ,Am−1v ⊂ Rn
der m-te Krylov-Unterraum von A und v .
Es istKm(A, v) = p(A)v : p ∈Pm−1.
Proposition 4.27
(a) Die m-te CG-Iterierte liegt im affinen Unterraum x0 + Km(A, r0).
(b) Fur den Abbruchindex L des CG-Verfahrens gilt
L = minm : Km(A, r0) = Km+1(A, r0)
= min
deg q : q monisch und q(A)r0 = 0
.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 156
4.3.3 Konvergenz des CG-Verfahrens
Die Rolle der Konditionszahl
• Bei einer n × n-Matrix A liefert das CG -Verfahren die Losung vonAx = b nach L ≤ n Schritten (in exakter Arithmetik). In diesem Sinne
”konvergiert“ das CG-Verfahren immer gegen x ? = A−1b. Gesuchtsind hier obere Schranken fur den Fehler x ? − xm (m < L).
• Von entscheidender Bedeutung ist die Optimalitatseigenschaft
‖x ? − xm‖A = minp∈Pm, p(0)=1
‖p(A)(x ? − x0)‖A.
• Sei Ω ⊂ (0,∞) eine kompakte Menge, welche die Eigenwerte von A
enthalt. Fur jedes pm ∈Pm mit pm(0) = 1 gilt dann
‖x ? − xm‖A‖x ? − x0‖A
≤ ‖pm‖∞,Ω := maxλ∈Ω
|pm(λ)|.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 157
• Alle echten Fehlerschranken fur das CG-Verfahren basieren auf obiger(trivialer) Beobachtung: ausgehend von einer kompakten ObermengeΩ ⊃ Λ(A) (typischerweise Ω = [λmin(A), λmax(A)]) versuchen wir,Polynome pm zu konstruieren mit pm(0) = 1, die auf Ω ein moglichstkleines Maximum haben. Dies fuhrt auf naturliche Weise zu einerAufgabe der polynomialen Bestapproximation:Bestimme pm ∈Pm, pm(0) = 1, sodass
‖pm‖∞,Ω = minp∈Pm,p(0)=1
‖p‖∞,Ω.
• Fur Ω = Λ(A) ist die Abschatzung
‖x ? − xm‖A‖x ? − x0‖A
≤ minp∈Pm,p(0)=1
maxλ∈Λ(A)
|p(λ)|
in folgendem Sinne scharf: Fur jedes m existiert ein Startvektor x0 =
x0(m), sodass im m-ten Schritt Gleichheit gilt.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 158
• Die Aufgabe, pm ∈Pm, pm(0) = 1, so zu bestimmen, dass
‖pm‖∞,Ω = minp∈Pm,p(0)=1
‖p‖∞,Ω
ist losbar fur jedes m ∈ N0 und jede kompakte Teilmenge Ω derkomplexen Ebene. Die Losung ist eindeutig, sofern Ω aus mindestensm Punkten besteht. Eine geschlossene Darstellung dieser Losungexistiert jedoch nur in Spezialfallen, etwa wenn Ω ein Intervall ist.
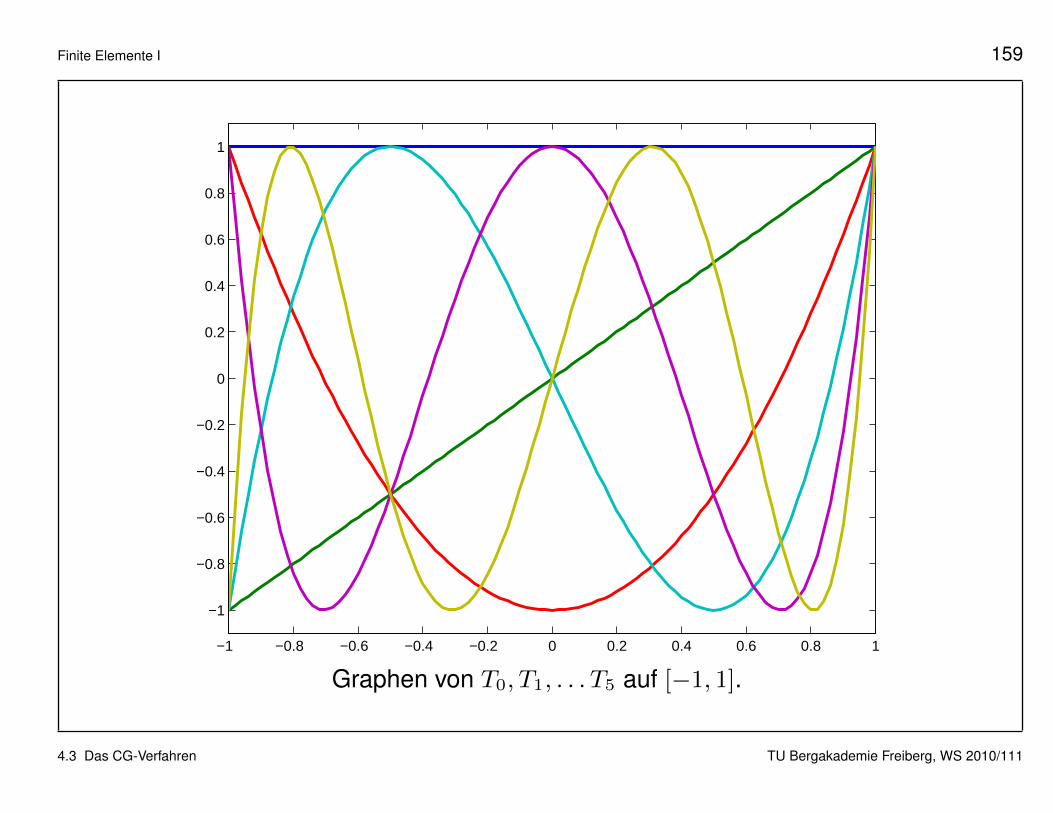
• Die Chebyshev-Polynome sind definiert durch
Tm(ξ) := cos(m arccos ξ) ∈Pm (ξ ∈ [−1, 1] , m = 0, 1, . . .) (4.27)
• Sie genugen der dreistufigen Rekursion
Tm(ξ) = 2ξ Tm−1(ξ)− Tm−2(ξ) (m = 2, 3, . . .)
mit T0(ξ) = 1 and T1(ξ) = ξ. Hieran erkennt man, dass Tm tatsachlichein Polynom vom Grad (exakt) m ist.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
Finite Elemente I 159
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Graphen von T0, T1, . . . T5 auf [−1, 1].
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 160
• Tm besitzt die m einfachen Nullstellen, ξ(m)k = cos((2k + 1)π/(2m)),
k = 0, . . . ,m− 1, welche samtlich in (−1, 1) liegen.
• Es ist |Tm(ξ)| ≤ 1 fur alle ξ ∈ [−1, 1]. Gleichheit gilt fur η(m)k :=
cos(kπ/m), k = 0, . . . ,m, genauer gesagt: Tm(η(m)k ) = (−1)k.
• Als nachstes transformieren wir die Polynome Tm auf ein beliebigesreelles Intervall [δ − γ, δ + γ] ⊂ (0,+∞), d.h., 0 < γ < δ.λ 7→ `(λ) := (λ− δ)/γ ist eine Bijektion von [δ − γ, δ + γ] auf [−1, 1].Die Umkehrabbildung ist ξ 7→ `−1(ξ) = δ + ξγ.Wegen −δ/γ < −1 gilt Tm(−δ/γ) 6= 0 und
pm(λ) :=Tm(`(λ))
Tm(`(0))=Tm((λ− δ)/γ)
Tm(−δ/γ)(m = 0, 1, . . .) (4.28)
ist somit eine Folge von Residualpolynomen, d.h., pm(0) = 1.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
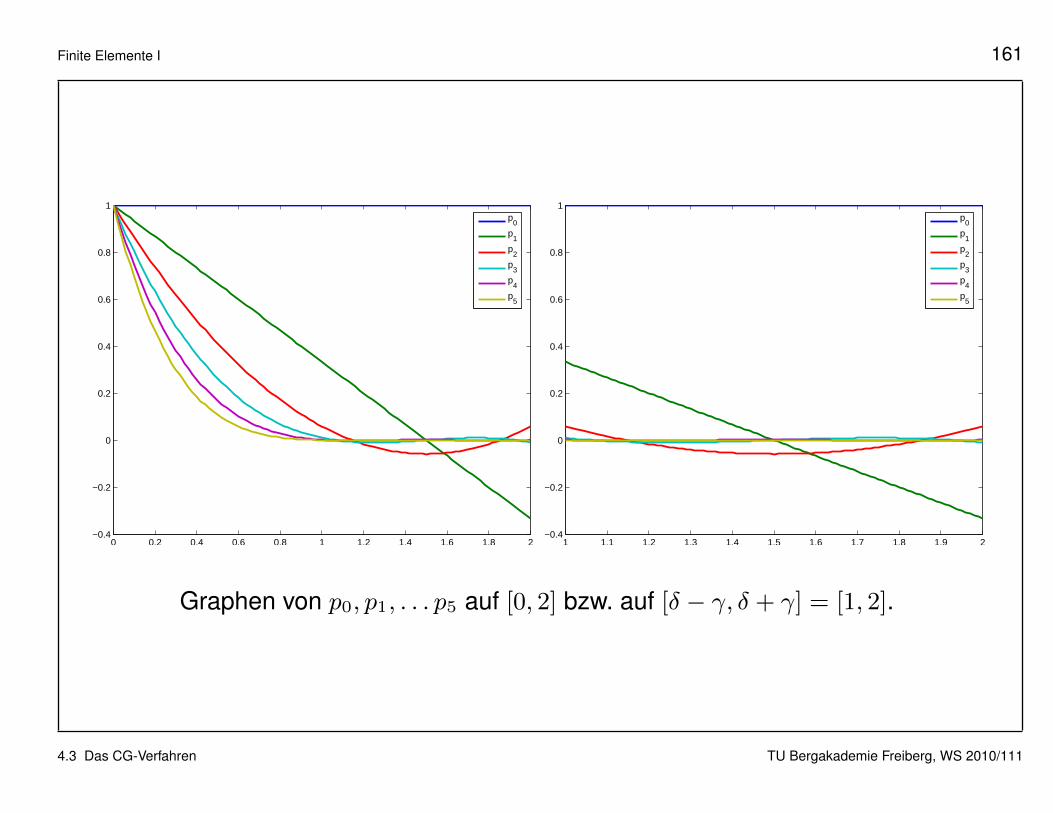
Finite Elemente I 161
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2−0.4
−0.2
0
0.2
0.4
0.6
0.8
1p
0
p1
p2
p3
p4
p5
1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2−0.4
−0.2
0
0.2
0.4
0.6
0.8
1p
0
p1
p2
p3
p4
p5
Graphen von p0, p1, . . . p5 auf [0, 2] bzw. auf [δ − γ, δ + γ] = [1, 2].
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 162
Lemma 4.28 Sei Ω := [δ − γ, δ + γ] ⊂ (0,∞). Fur die Polynome pm aus(4.28) gilt
‖pm‖∞,Ω = minp∈Pm,p(0)=1
‖p‖∞,Ω.
• Es verbleibt die Bestimmung von Tm(−δ/γ). Hierzu setzen wir
θ :=δ −
√δ2 − γ2
γ.
• Es ist 0 < θ < 1 und
maxλ∈Ω|pm(λ)| = 1
Tm(−δ/γ)=
2 θm
1 + θ2m≤ 2 θm (m = 0, 1, . . .).
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 163
Satz 4.29 (Fehlerschranke fur CG) Fur die Naherungen des CG-Verfahrensgilt die Fehlerabschatzung
‖x ? − xm‖A‖x ? − x0‖A
≤ 1
Tm
(κ+1κ−1
) =2(√
κ−1√κ+1
)m1 +
(√κ−1√κ+1
)2m ≤ 2
(√κ− 1√κ+ 1
)m.
Hierbei bezeichnet κ = cond2(A) = λmax(A)/λmin(A) die Konditionszahlvon A bezuglich der Euklid-Norm.
Diese Schranke ist (nahezu) scharf in folgendem Sinne: es gibt lineareGleichungssysteme Ax = b (mit A ∈ Rn×n) sowie cond2(A) = κ undStartnaherungen x0 sodass
‖x ? − xn−1‖A‖x ? − x0‖A
=1
Tn−1((κ+ 1)/(κ− 1))
(Setze A = diag(η1, . . . , ηn) mit ηj die Extremalstellen des transformiertenChebyshev-Polynoms pn−1.)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 164
Abbruchbedingung
Typische Abbruchbedingung: iteriere bis ‖em‖A/‖e0‖A ≤ ε mit vorgegebe-ner Toleranz ε > 0. Ausgehend von Satz 4.29 ist dies spatestens der Fall,wenn
ε ≥ 2
(√κ− 1√κ+ 1
)m= 2
(1− 2/
√κ
1 + 1/√κ
)m.
Logarithmieren und die Approximation log(1 + x) ≈ x fur x klein fuhrt aufdie Bedingung
m ≥ 1
2
∣∣∣logε
2
∣∣∣√κ .Beispiel: Poisson-Gleichung, uniformes Gitter, bilineare FE. Hier giltκ(A) = O(h−2). Dies bedeutet: bei Halbierung der Gitterweite verdop-pelt sich die Anzahl Iterationen.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
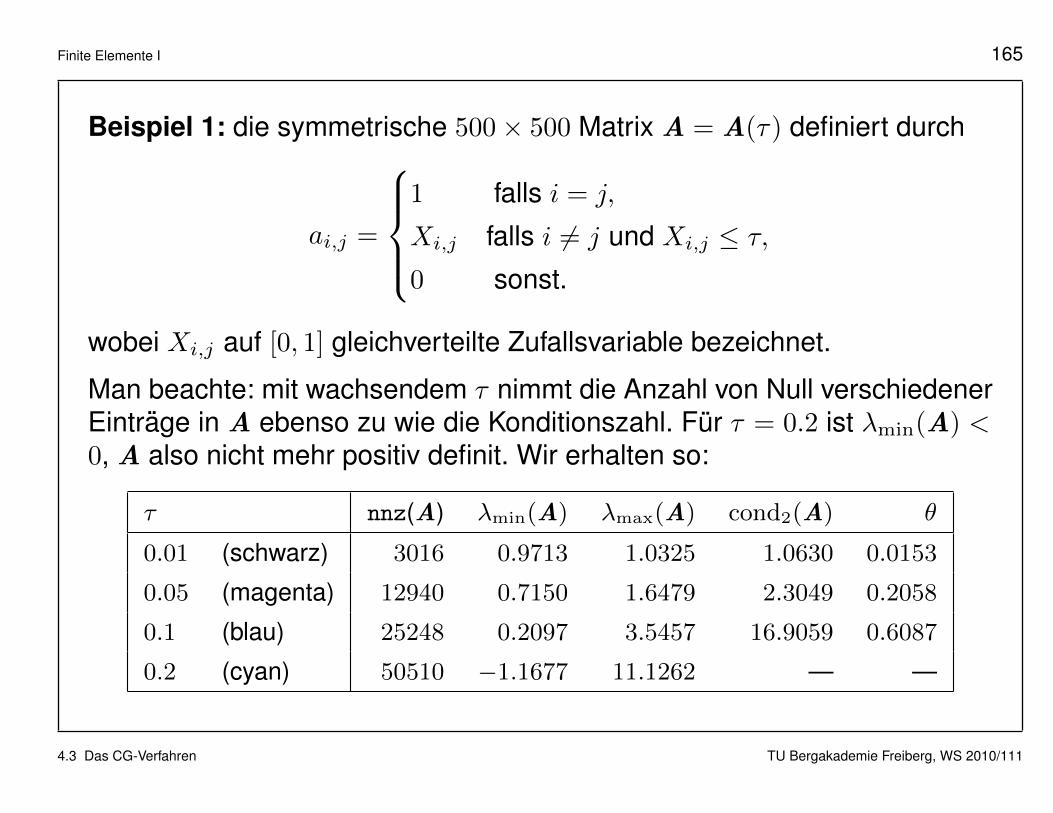
Finite Elemente I 165
Beispiel 1: die symmetrische 500× 500 Matrix A = A(τ) definiert durch
ai,j =
1 falls i = j,
Xi,j falls i 6= j und Xi,j ≤ τ,0 sonst.
wobei Xi,j auf [0, 1] gleichverteilte Zufallsvariable bezeichnet.
Man beachte: mit wachsendem τ nimmt die Anzahl von Null verschiedenerEintrage in A ebenso zu wie die Konditionszahl. Fur τ = 0.2 ist λmin(A) <0, A also nicht mehr positiv definit. Wir erhalten so:
τ nnz(A) λmin(A) λmax(A) cond2(A) θ
0.01 (schwarz) 3016 0.9713 1.0325 1.0630 0.0153
0.05 (magenta) 12940 0.7150 1.6479 2.3049 0.2058
0.1 (blau) 25248 0.2097 3.5457 16.9059 0.6087
0.2 (cyan) 50510 −1.1677 11.1262 — —
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
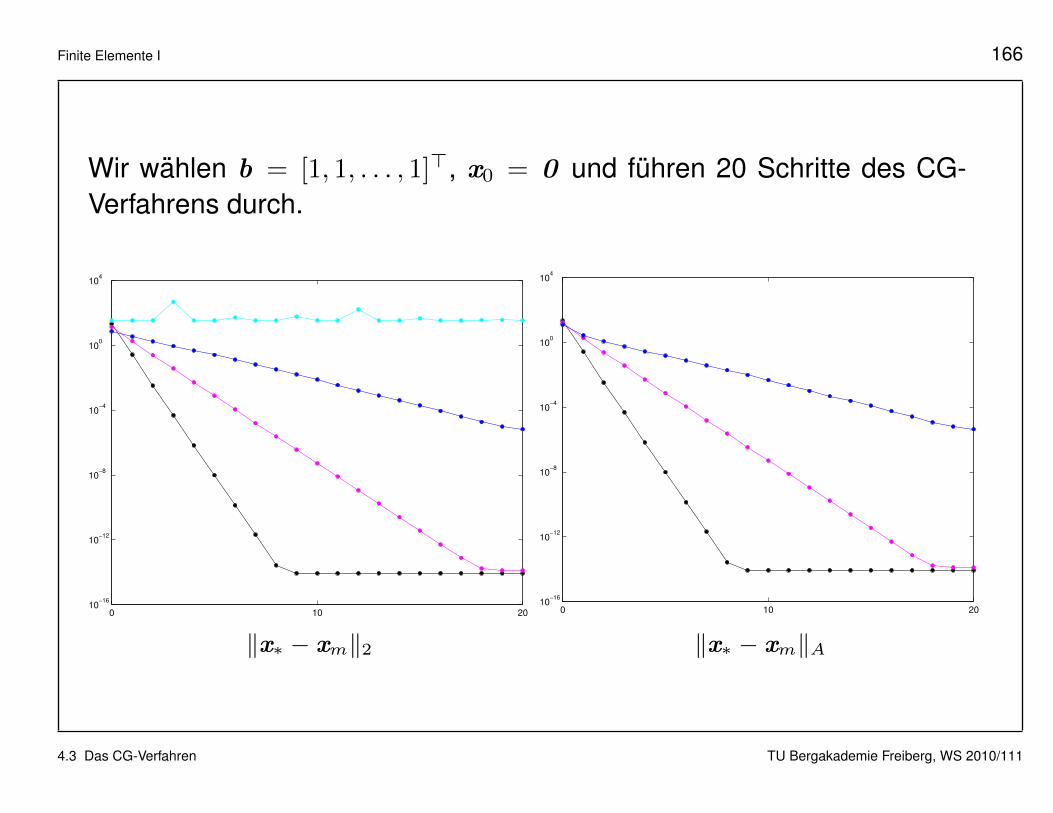
Finite Elemente I 166
Wir wahlen b = [1, 1, . . . , 1]>, x0 = 0 und fuhren 20 Schritte des CG-Verfahrens durch.
0 10 2010−16
10−12
10−8
10−4
100
104
‖x∗ − xm‖20 10 20
10−16
10−12
10−8
10−4
100
104
‖x∗ − xm‖A
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 167
Beobachtungen:
• Divergenz im Fall τ = 0.2.
• Im Fall τ = 0.1 wird der Fehler nach 20 Schritten nur auf 10−5 reduziert,bei den ubrigen Beispielen mit kleineren Konditionszahlen beobachtenwir rasche Konvergenz.
• Fur τ = 0.01 erreicht der Fehler nach 9 Schritten den Bereich derMaschinengenauigkeit. In diesem Fall lost das CG-Verfahren Ax = b
in etwa 6× 104 Flops und ist damit um den Faktor 700 schneller als dieCholesky-Zerlegung.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
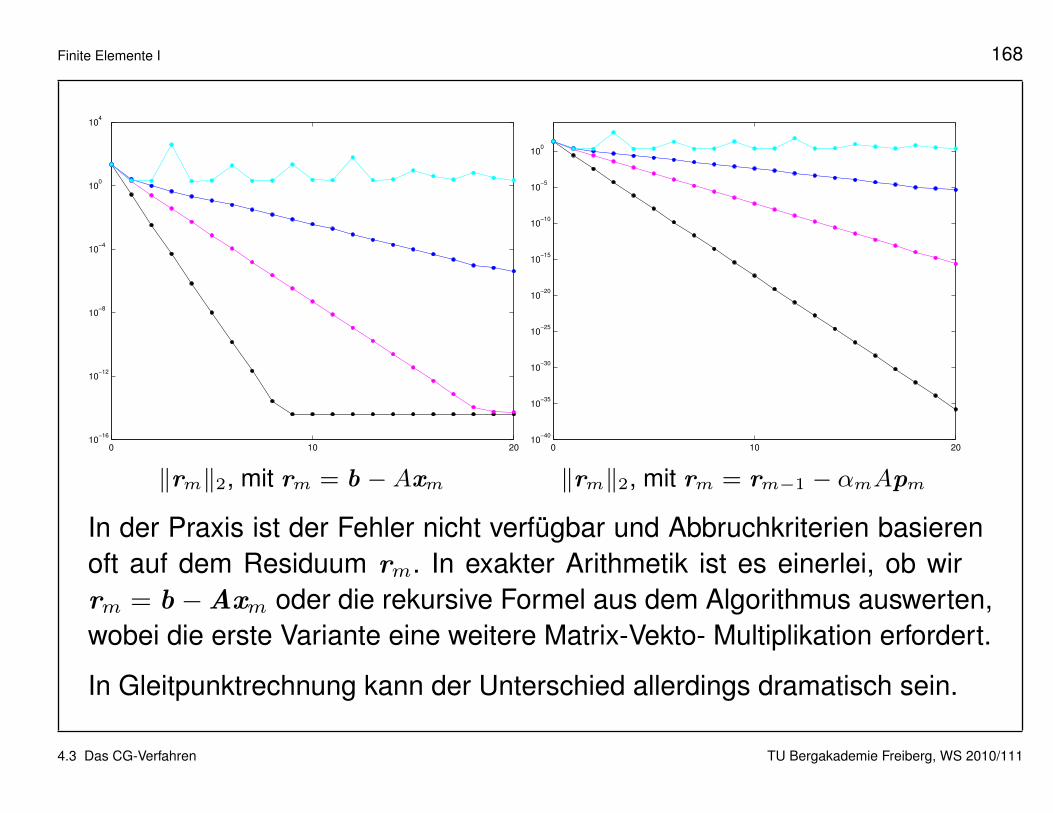
Finite Elemente I 168
0 10 2010−16
10−12
10−8
10−4
100
104
‖rm‖2, mit rm = b −Axm
0 10 2010−40
10−35
10−30
10−25
10−20
10−15
10−10
10−5
100
‖rm‖2, mit rm = rm−1 − αmApm
In der Praxis ist der Fehler nicht verfugbar und Abbruchkriterien basierenoft auf dem Residuum rm. In exakter Arithmetik ist es einerlei, ob wirrm = b −Axm oder die rekursive Formel aus dem Algorithmus auswerten,wobei die erste Variante eine weitere Matrix-Vekto- Multiplikation erfordert.
In Gleitpunktrechnung kann der Unterschied allerdings dramatisch sein.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 169
Die obere Schranke aus Satz 4.29 ist in vielerlei Hinsicht unbefriedigend:
• Sie spiegelt nicht den Einfluß von r0 (also b und x0) wider.
• Sie hangt nur von den Extremaleigenwerten ab; die Verteilung der Ei-genwerte innerhalb des Intervalls [λmin(A), λmax(A)] bleibt unberuck-sichtigt.
• In vielen fur die Praxis relevanten Fallen ist die schranke aus Satz 4.29viel zu pessimistisch.
In vielen Fallen wird bei CG ein ”superlineares“ Konvergenzverhaltenbeobachtet. Dies ist erst vor kurzem nathematisch zufriedenstellend erklartworden.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 170
Beispiel 2: Wir betrachten die FE-Diskretisierung des ersten Referenzbei-spiels aus Abschnitt 3.2 (Poisson-Gleichung auf Einheitsquadrat, homo-gene Dirichlet-Randbedingung, Quellterm ≡ 1) mit linearen und quadrati-schen Dreieckelementen.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
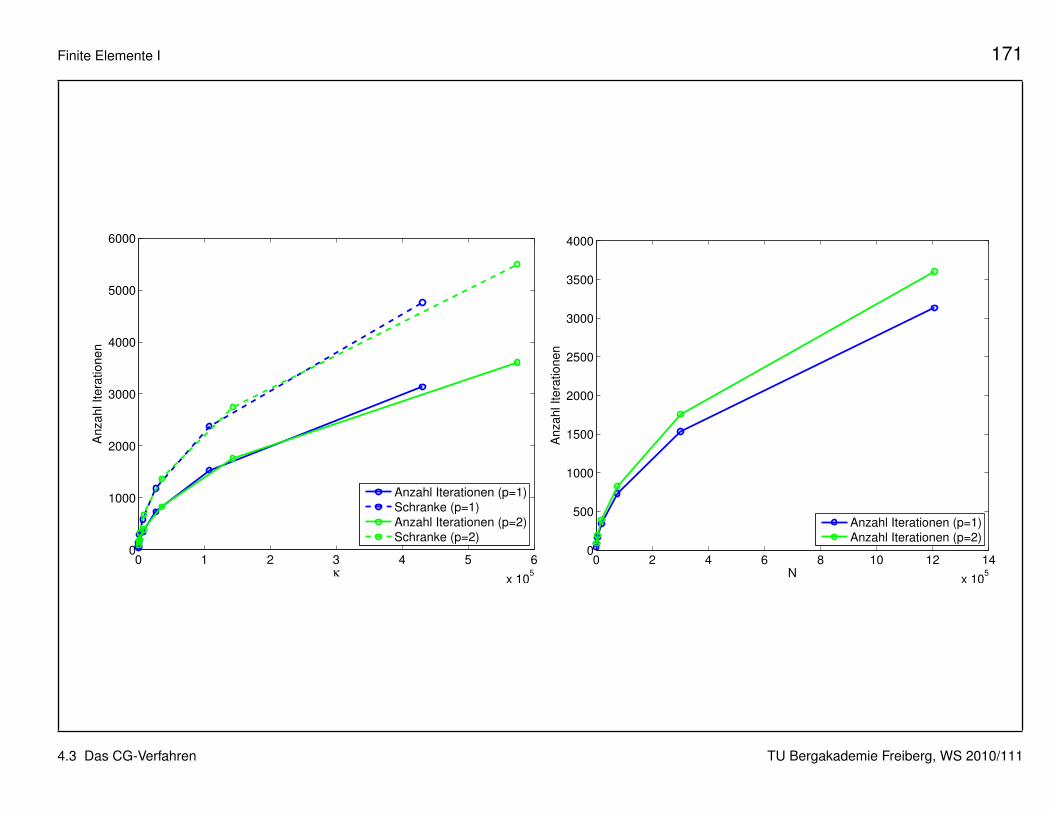
Finite Elemente I 171
0 1 2 3 4 5 6
x 105
0
1000
2000
3000
4000
5000
6000
κ
An
za
hl It
era
tio
ne
n
Anzahl Iterationen (p=1)
Schranke (p=1)
Anzahl Iterationen (p=2)
Schranke (p=2)
0 2 4 6 8 10 12 14
x 105
0
500
1000
1500
2000
2500
3000
3500
4000
N
An
za
hl It
era
tio
ne
n
Anzahl Iterationen (p=1)
Anzahl Iterationen (p=2)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 172
4.3.4 Vorkonditionierung
Idee: Falls CG fur gegebenes LGS zu langsam konvergiert, lose stattdes-sen ein aquivalentes, fur das CG schneller konvergiert.
Ein solches ist gegeben durch
M−1Ax = M−1b, M geeignete spd Matrix.
Die resultierenden Modifikationen des Algorithmus erhohen den Aufwandum
• Die Losung eines LGS mit der Matrix M in jedem Schritt,
• Die Speicherung eines weiteren Vektors zm, des ”vorkonditioniertenResiduums“.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 173
Algorithmus 5: Vorkonditioniertes CG-Verfahren.Gegeben : A spd, b, M spd
1 Bestimme Startnaherung x0, berechne r0 ← b −Ax0
2 Lose Mz0 = r0
3 Setze m← 0, p1 ← z0
4 while nicht konvergiert do5 m← m+ 1
6 αm ← (rm−1,zm−1)
(pm,pm)A
7 xm ← xm−1 + αmpm
8 rm ← rm−1 − αmApm
9 Lose Mzm = rm
10 βm+1 ← (rm,zm)(rm−1,zm−1)
11 pm+1 ← zm + βm+1pm
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111

Finite Elemente I 174
Obwohl unverzichtbar in der Praxis andert die Berucksichtigung von Vor-konditionierung wenig fur die Konvergenzanalyse: es mussen lediglichfolgende Ersetzungen vorgenommen werden:
A←M−1A,
b ←M−1b,
(x ,y)← (x ,y)M := (Mx ,y).
Beachte: die M−1A-Norm bezuglich (·, ·)M ist nichts als die A-Normbezuglich (·, ·). Das vorkonditionierte CG-Verfahren minimiert also weiterhindie A-Norm der Fehlers.
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111
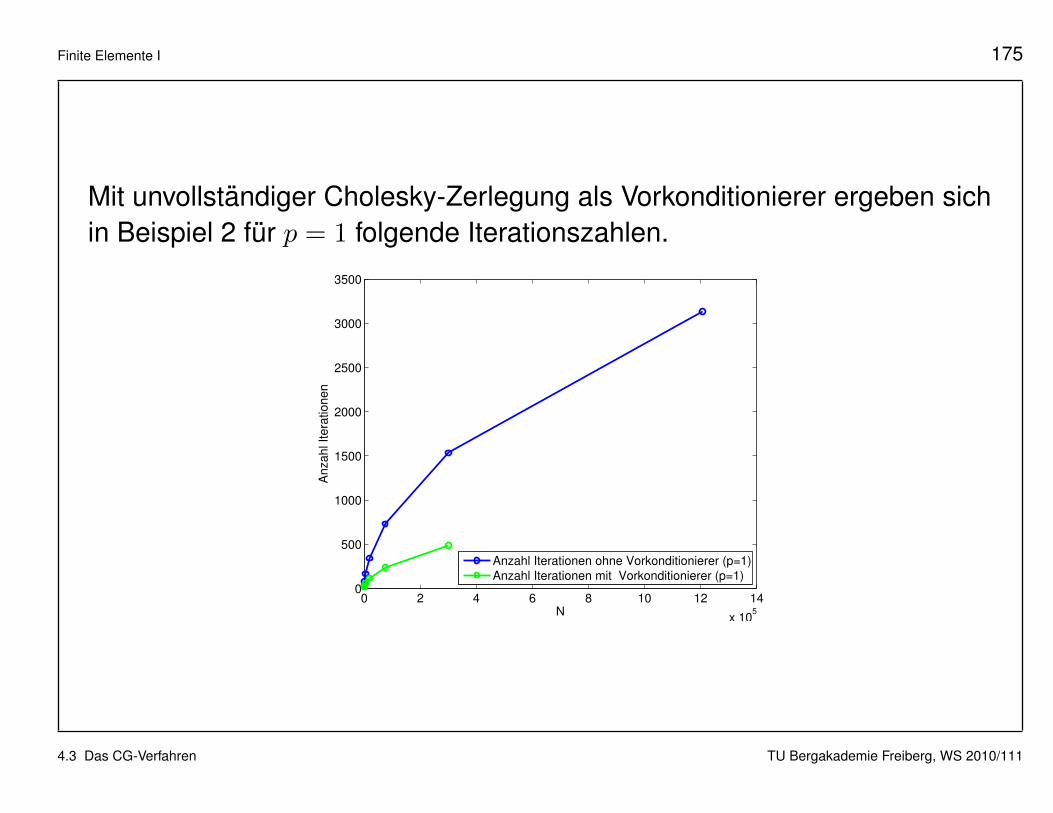
Finite Elemente I 175
Mit unvollstandiger Cholesky-Zerlegung als Vorkonditionierer ergeben sichin Beispiel 2 fur p = 1 folgende Iterationszahlen.
0 2 4 6 8 10 12 14
x 105
0
500
1000
1500
2000
2500
3000
3500
N
An
za
hl It
era
tio
ne
n
Anzahl Iterationen ohne Vorkonditionierer (p=1)
Anzahl Iterationen mit Vorkonditionierer (p=1)
4.3 Das CG-Verfahren TU Bergakademie Freiberg, WS 2010/111





























