Embed Size (px)
Citation preview

Ludwig Maximilians Universität München
Seminar über Philosophische Grundlagen derStatistik
WS 2010/11
Prof. Dr. Thomas Augustin
SeminararbeitAlgorithmische Modelle als neues Paradigma
Vorgelegt von: Axel Schwer
Betreuer: Prof. Dr. Thomas Augustin

Inhaltsverzeichnis
1 Neue Fragestellungen 3
1.1 Das Ozonprojekt . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Das Chlorprojekt . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Grenzen der bisherigen Modelle 6
3 Entscheidungsbäume 7
4 Gütekriterien 9
4.1 bei einer binären Zielgröße . . . . . . . . . . . . . . . . . . . . . . 9
4.2 bei einer kategorialen Zielgröße . . . . . . . . . . . . . . . . . . . 9
4.3 Beispiel I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.3.1 Splitkriterium anhand des Missqualifikationsfehlers . . . . 10
4.3.2 Vergleich Missqualifikationsfehler und Gini-Koeffizient . . 11
5 Praxistest der algorithmischen Modelle 12
6 Gefahr des Overfittings einzelner Bäume 13
6.1 Beispiel II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
7 Qualitätsvergleich der “Kulturen” 17
8 Fazit 18
ii

INHALTSVERZEICHNIS
Einleitung
Die Bezeichnung algorithmischer Modelle als neues Paradigma, einer neuenBetrachtungsweise, gar einem Vorbild, setzt gleichermaßen eine hohe Erwar-tungshaltung frei. Etwas vorsichtiger formuliert, könnte man aus dieser Aussageeine Frage machen.
Algorithmische Modelle als neues Paradigma?
Ob man letztendlich von einem neuen Paradigma sprechen kann, liegt sicherlichauch an dem Standpunkt des jeweiligen Betrachters und ist objektiv nichtabschließend zu bestimmen. Diese Seminararbeit soll daher beleuchten, von wassich die algorithmischen Modelle und deren Entwickler eigentlich abgrenzenwoll(t)en. Ist es überhaupt sinnvoll sich abzugrenzen oder nicht generell dieAufgabe der Wissenschaft kontinuierlich auf neu aufkommende Fragestellungenzu reagieren und neue Lösungsansätze zu entwickeln? Dann wiederum stelltsich die Frage, ob es sich nicht um ein neues Paradigma handelt, sondernlediglich um eine notwendige Erweiterung der bestehenden Werkzeugpalette.Neue Problemstellungen erfordern neue Herangehensweisen, ohne dass damitgleich bewährte Methoden ihren Nutzen verlieren müssen.
In Kapitel wird Leo Breiman vorgestellt. Dieser Exkurs in das Leben einesder Hauptmotoren der algorithmischen Modelle macht verständlich, aus welcherMotivation heraus eine neue Bewegung entstehen konnte. Kapitel stellt zweizentrale Projekte vor, die Breiman in vielen Veröffentlichungen als zentraleEreignisse anführt und die ihn zu der Entwicklung neuer Verfahren motivierthat.
Kapitel 4 gibt einen Überblick über Breimans Verhältnis zu den Datenmodellenund seiner Grenzen. Kapitel 2 ist eine Einführung in das Verfahren der Entschei-dungsbäume, als Beispiel für algorithmische Modelle und die Frage inwieweitdieses neue Verfahren die in Kapitel 1.2 kritisierten Punkte auffangen kann. Einkurzer Vergleich beider “Kulturen” wird in Kapitel 7 anhand eines Beispielsdemonstriert.
Ob das Fragezeichen entfernt werden kann bzw. in welchen Punkten es sichtatsächlich um ein neues Paradigma handelt wird abschließend in Kapitel 8diskutiert.
Leo Breiman
Leo Breiman wuchs als Sohn osteuropäischer Einwanderer in einem jüdischenGhetto in Los Angeles auf. Im Umfeld vieler junger aufstrebenden Leute, die ineiner guten Ausbildung ihren Weg aus dem schwierigen sozialen Milieu sahen,studierte er Physik an der Universität von Kalifornien, bevor er mit einem Zwi-schenstop in New York, in Berkeley seine Promotion abschloss. Zur damaligenZeit galt er als Statistiker als eine Art Exot im Bereich der Mathematik. EigeneStatistikfakultäten gab es zu diesem Zeitpunkt noch nicht. In dieser Zeit missfielihm die Schulbildung seiner Studenten. Auch bei seinem ehrenamtlichen Engage-ment in der Betreuung Jugendlicher konnte er sich nicht mit der etablierten Art
1

INHALTSVERZEICHNIS
der Wissensvermittlung anfreunden. Er entwickelte neue Unterrichtsmethodenauf Schul- wie auf Universitätsniveau um die unzureichenden Vorgehensweisenauszugleichen.Nachdem er genug von der starren Welt der Wissenschaft hatte, wechselte erzur UNESCO um in Liberia als statistischer Berater zu arbeiten. Auch nachseiner Rückkehr in die USA blieb er in der Praxis und arbeitet als Consultant imBereich Statistik. In dieser Zeit stieß er an die Grenzen seiner bisher bekanntenVerfahren, da die Fragestellungen zunehmend komplexer wurden.Nach seiner Rückkehr an die Universität missfiel ihm die bisherige Arbeitsweiseseiner Kollegen. Zu sehr war der Fokus auf den Modellen, die allesamt nicht dieAntworten auf die Fragestellungen lieferten, mit denen er sich in seiner Zeit alsConsultant konfrontiert sah.Der zunehmende Einsatz von Computern bot ihm die Möglichkeit an der Uni-versität von Kalifornien eine computergestützte Statistikabteilung aufzubauen.In diesen neuen Möglichkeiten sah er, besonders durch den interdisziplinärenAustausch mit anderen Fachbereichen, die große Chance, neue Lösungsmechanis-men zu entwickeln. Breiman positionierte sich fortan eher im Bereich zwischender Statistik und der Informatik und Entwickelte dort den CART-Algorithmus.Classification And Regression Trees, waren für ihn der Schlüssel, mit Metho-den, die bis dahin in der Statistik vernachlässigt wurden, die Tür für neueAnwendungsgebiete zu öffnen.Konkrete Fälle aus der PraxisDie immer beliebter werdende Anwendung algorithmische Modelle, in diesemFall die Einbeziehung moderner Computeralgorithmen, wurde erst durch dieWeiterentwicklung leistungsfähiger Computer angestoßen.Die Möglichkeit umfangreichere Berechnungen durchzuführen zeigte neue Mög-lichkeiten auf, um alte, aber auch besonders neue Problemstellungen anzugehen.Letztlich zeigten sich algorithmische Vorgehensweisen immer wieder als gewinn-bringende Alternative.Der Einsatz von Algorithmen ist dabei nicht auf die Informatik und die Ma-thematik ausschließlich beschränkt, sondern vielmehr ein für viele Bereicheinteressantes Anwendungsmittel. Der Einsatz von Computern, die stur nachVorgabe ihre Prozeduren durchrechnen mag auf die Befürworter althergebrachterMethoden auf den ersten Blick befremdlich wirken, da Entscheidungen automa-tisiert werden und damit die menschliche Kontrolle entfällt. Die kontinuierlicheWeiterentwicklung der Rechenleistung lässt dazu momentan nur vermuten, wieweit das Potential neuer Herangehensweisen bisher ausgeschöpft ist.Schlussendlich entwickelt sich eine neue Technologie am besten, wenn bishervalidiertes Wissen mit neuen Methoden kombiniert wird und diese Kombinationneue Problemstellungen angehen lässt.Im Folgenden wird konkret die Entwicklung von Entscheidungsbäumen betrachtet.Die Grundlage dazu bot Leo Breiman, der mit den damals ihm zur Verfügung
2

1 NEUE FRAGESTELLUNGEN
stehenden Mitteln keine akzeptablen Lösungen für seine Fragestellungen fandund mit algorithmischen Methoden ein neues Tool für eine neue Fragestellungschaffte.
1 Neue Fragestellungen
Leo Breiman führt in seinen Publikationen über die Entwicklung der Entschei-dungsbäume häufig zwei Beispiele an, die ihn in seiner Zeit als Consultantdazu bewegten, in der klassischen Statistik umzudenken und nach alternativenMöglichkeiten zu forschen.
1.1 Das Ozonprojekt1
Das Ozonprojekt war ein Projekt, der Environmental Protection Agency (EPA),welches Mitte der 1970er startete um die in den letzten zehn Jahren teils ge-sundheitsgefährdenden hohen Ozonwerte genauer prognostizieren zu können.Von politischer Seite wurden drei Warnstufen eingerichtet, bei der im Falle derhöchsten Stufe die Bevölkerung angewiesen wurde, das Haus möglichst nicht zuverlassen und auch nicht ihren Arbeitsplatz aufzusuchen.
Das Projekt der EPA bestand aus der möglichst präzisen Vorhersage der Ozon-werte für die folgenden 12 Stunden. Als Grundlage stellte die EPA die Daten derBeobachtungen von über 450 meteorologischen Variablen zur Verfügung, welchein den vergangenen sieben Jahren teils täglich, teils stündlich aufgenommenworden sind, sowie der Ozonwert zum jeweiligen Zeitpunkt.
f(x) = y
mit x=
x1x2...
x450
und y = OzonwerteT ag n bzw. y = OzonwerteT ag n+1
Um eine Funktion f(x) zu schätzen, wurden die Daten aufgeteilt in ein Trai-ningsdatensatz (die ersten 5 Jahre) und einem Testdatensatz (die letzten 2Jahre), auf welche die Funktion getestet werden sollte. Linearen Regressionen,Variablenselektion, der Einbeziehung quadratischer Terme und Interaktionender Variablen führten zu keinem akzeptablen Ergebnis, sodass die Fehlerquoteletztlich zu hoch war und das Projekt scheiterte.
1Vgl. Breiman et al. (1984). Classification and Regression Trees, S.2ff
3

1 NEUE FRAGESTELLUNGEN
1.2 Das Chlorprojekt2
Ebenfalls durch das EPA beauftragt, wurden tausende Gemische auf ihre toxischeWirkung untersucht. Das damals standardmäßige Vorgehen war eine Massen-spektrometeranalyse um Aufschluss über die chemische Struktur zu bekommen.
Dieses Vorgehensweise führte zu dem Problem, dass die Massenspektrometerana-lyse schnell und kostengünstig zu bewerkstelligen war, die Auswertung jedocheinen ausgebildeten und damit hohe Kosten verursachenden Chemiker benötigte.Ziel des Projektes war, zu versuchen, anhand des Ergebnisses eines Massen-spektrometers das Vorhandensein von Chlor nachzuweisen. Datengrundlage indiesem Projekt waren die bisher erfolgreich analysierten Gemische, sowie dieMassenspektrometer von 30.000 weiteren.
y = 1 : beinhaltet Chlor
y = 0 : beinhaltet kein Chlor
Ziel war es, eine Funktion f(x) zu finden, welche anhand des Inputs x unterschied-licher Größe, möglichst präzise die Zielvariable y schätzt. Der Datensatz wurdeebenfalls in einen Trainingsdatensatz (25.000) und ein Testdatensatz (5.000)aufgeteilt. Gerade bei der Handhabung der unterschiedlichen Größenordnungder Variablen spielte Breiman erstmals mit dem Gedanken Entscheidungsbäumeeinzuführen. Mit Hilfe der Entscheidungsbäume gelang es, durch eine Design mit1.500 Ja-Nein-Fragen eine Genauigkeit von 95% für y zu erreichen.
Datenmodelle
Nach Breimans Rückkehr an die Universität und den Erfahrungen in der Praxisstand das gegenwärtige wissenschaftliche Vorgehen im Bereich Statistik in derseiner Kritik . Jeder Artikel in den führenden wissenschaftlichen Zeitschriftenbegann mit der Einleitung “Assume that the data are generated by the followingmodel...”3 . Genau hier im Beginn steckt laut Breiman das Problem, dessenKonsequenzen sich durch die gesamte weiterführende Analyse ziehen. Der Fokus-wechsel von der eigentlichen Problemstellung auf das Datenmodell, setzt für dienächsten Schritten voraus, dass das gewählte Modell auch mit dem eigentlichenDatengenerierungsprozess, wie er in der Natur vorkommt, übereinstimmt. Darausfolgt jedoch auch, falls das Modell die Natur schlecht abbildet, die Schlussfolge-rungen der Analyse sehr fragwürdig sind. Diese Feststellung ist aus heutiger Sichtkeine Überraschung und auch zur damaligen Zeit gab es an der Theorie keineZweifel. Der Glaube an die grenzenlose Macht der Datenmodelle führte jedoch inder Praxis zu einer Verdrängung und geringen Beachtung dieser Problematik. 4
Die naheliegende Berechnung eines Bestimmtheitsmaßes bedingt eine weitere Be-trachtung der Daten, da ein guter Wert noch nicht zwingend eine hohe Qualität
2Vgl. Breiman (2001). Statistical Modeling: The Two Cultures. Statistical Science 16, S.203ff
3Breiman (2001), S. 2024Vgl. Breiman (2001). Statistical Modeling: The Two Cultures. Statistical Science 16. S.
202
4

1 NEUE FRAGESTELLUNGEN
des gewählten Datenmodells widerspiegelt. Vielzuviele möglichen Fehlerquellen,wie beispielsweise ein irrtümlich hohes R2 verursacht durch eine hohe Dimensi-on des Modells führen zu irrtümlichen Bewertungen. Viele dieser zusätzlichenKontrollen wurden von seinen Kollegen nicht mehr ernsthaft angewandt. Diedamals größtenteils ausschließliche Verwendung der Anpassungstest und derBetrachtung der Residuen vernachlässigt dabei jedoch die Tatsache, dass dieAnpassungstests erst dann anschlagen, wenn ausreichende Anhaltspunkte fürdie Alternativhypothese gegeben sind. Ebenso führen bei hohen Dimensionensehr gute Residuenplots zu einer Überschätzung des Modells. So ausführlichsich die wissenschaftlichen Artikel mit der Herleitung stochastischer Modellebeschäftigten, so wenig befassten sie sich mit der Überprüfung ihrer Qualität imBezug auf die Anpassung an die Daten.
Die Vorteile der Datenmodelle waren jedoch nicht von der Hand zu weisen.Neben dem Ziel einer möglichst genauen Datenanpassung, bilden sie ein klaresBild ab, auf welche Art des Zusammenspiels der Inputvariablen es zum jeweili-gen Output kommt.5 Die Erkenntnis über die Relevanz der Variablen anhandihrer Gewichtung ist in vielen Fällen ein mindestens gleichwertiges Ziel wie dieGenauigkeit der Prognosen. In der praktischen Umsetzung führt die Anwendungder Datenmodelle jedoch auch zu dem Problem, dass nicht selten unterschied-liche Modelle, mit gleichguter Anpassung eine unterschiedliche Aussage überdie Relevanz der Variablen treffen. Während McCullah und Nelder 1989 diesesPhänomen mit den Worten “Data will often point with almost equal emphasison several possible models, and it is important that the statistician recognize andaccept this.”6 beschreiben, bedient sich eines Begriffes aus der Psychologie - denRoshomon-Effekt, in Anlehnung an einen japanischen Film (Rashomon - im deut-schen fehlerhaft übersetzt mit “Das Lustwäldchen”, Japan 1950). In diesem Filmbeschreiben vier Personen jeweils eine Vergewaltigungs- und Ermordungsszene.Dabei beschreiben alle Beteiligten übereinstimmend die tatsächlichen Faktender Vorkommnisse (Input), kommen aber in der Darstellung des eigentlichenTathergangs (Modell) zu komplett unterschiedlichen Sichtweisen7.
Statistisch lässt sich das Problem an einem einfachen Beispiel demonstrieren:
Gegeben sind 30 Variablen und gesucht wird das beste lineare Modell bestehendaus den fünf wichtigsten. Aus der Aufgabenstellung heraus ergeben sich schonallein
�305
�= 142.506 mögliche Modelle. Gesetzt den Fall, man bezeichne nun
wegen des äquivalentem RSS folgende drei lineare Modelle als beste Modelle8:
Modell 1: y = 2, 1 + 3.8x3 − 0, 6x8 + 83, 2x12 − 2, 1x17 + 3, 2x27
Modell 2: y = −8, 9 + 4, 6x5 + 0, 01x6 + 12, 0x15 + 17, 5x21 + 0, 2x22
Modell 3: y = 76, 7 + 9, 3x2 + 22, 0x7 − 13, 2x8 + 3, 4x11 + 7, 2x28
5Breiman(2001), S.2036Breiman(2001), S. 2037Vgl. Breiman(2001), S. 2068Breiman(2001), S. 206
5

2 GRENZEN DER BISHERIGEN MODELLE
Da jedes Modell einen anderen “Tathergang” beschreibt, jedoch alle Modelleim Bezug auf ihre Qualität der Anpassung gleichwertig sind, stellt sich dieFrage, welches Modell als tatsächliche “Wahrheit” angesehen werden sollte,falls beispielsweise damit eine Grundlage für Handlungsempfehlung gegebenwerden muss. Ebenso lässt sich auf diesem Weg auch nicht erkennen, welche fünfVariablen tatsächlich die höchste Relevanz besitzen.
2 Grenzen der bisherigen Modelle
Die bis zum damaligen Zeitpunkt vorliegende Palette an statistischen Werkzeu-gen bot eine sinnvolle Anwendung in Fällen, in denen sicher davon ausgegangenwerden konnte, dass die Daten auch einem bestimmten Modell folgten. Mit(multiplen) linearen und logarithmischen Regressionen und Diskriminanzanaly-sen ließen sich eine Vielzahl an Problemstellungen bearbeiten. Die zunehmendwachsende Zahl an Fragestellungen, insbesondere aus den Bereichen der Physik,Chemie und Biologie, die nicht selten hoch komplexe Systeme aufwiesen konntenmit der A-priori-Annahme, dass die Daten einem bestimmten Modell folgennicht mehr ohne Weiteres gelöst werden, ohne fragwürdige Schlussfolgerungen zuziehen9. Dieses Ende der Fahnenstange vergleicht Breiman mit dem Sprichwort“If all a man has is a hammer, then every problem looks like a nail”10, jedochergänzt er mit Blick auf die heutigen Fragestellungen, dass viele Problem mitt-lerweile nicht mehr aussehen wie Nägel. Viele Datenstrukturen sind zunehmendkomplexer, sodass es auch zunehmend schwieriger wird, diese noch verlässlichin die vorhandenen Datenmodelle zu implementieren. Viele Fragestellungen imBezug auf Daten lassen die Voraussetzung vermissen, dass die Mechanismeneiner klaren Struktur folgen.
Daraus ergab sich auch die Anforderung an eine neue Herangehensweise derProbleme. Nicht ausschließlich die Daten dürfen zu einem Lösungsansatz füh-ren, sondern ein ausgewogenes Zusammenspiel von Daten und der eigentlichenProblemstellung. Nur mit einer neuen Art der Betrachtung sowie einer Erwei-terung der Palette, kann die Statistik sich auch einem breiteren Spektrum anThemengebieten öffnen. Die Statistik, wie sie sich zum damaligen Zeitpunktdarstellte, war dagegen auf einem Weg, sich selbst von einer großen Bandbreitean Fragestellungen auszuschließen11. Der Trend für die Lösungsfindung in vielenaktuellen Bereichen ging zunehmend aus statistikfremden Disziplinen hervor.
Algorithmische Modelle
Die Entwicklung algorithmischer Modelle war schon damals außerhalb der Wis-senschaft im Bereich Statistik bekannt12. Großer Beliebtheit erfreuten sich dieseModelle auch in Gebieten der Psychometrie, also dem Gebiet der Messbarkeit
9Breiman(2001), S.20510Breiman(2001), S.20411Vgl. Breiman(2001), S.204f12Breiman(2001), S.205
6

3 ENTSCHEIDUNGSBÄUME
von psychologischen Vorgängen, sowie den Sozialwissenschaften, aber auch in denMedizinbereich erhielten diese Modelle Einzug13. Während die Zahl der Statisti-ker bei der Entwicklung dieser neuen Verfahren recht überschaubar war, nahmensich vermehrt Informatiker, Physiker und Ingenieure diesen Fragestellungenan. Daraus folgte auch, dass die in den 1980er aufkommenden algorithmischenModelle wie neuronale Netze und Entscheidungsbäume außerhalb der Statistikvorangetrieben wurden. Gerade diese neuen Methoden befassten sich jedoch mitden von Breiman angesprochenen Bereichen, auf welche die Datenmodelle keineAnwendung mehr fanden, wie der Sprach-, Bild- und Handschrifterkennung oderder Analyse der komplexer werdenden Finanzmärkte. Aber auch vor statistischenThemen machten diese Modelle nicht Halt und befassten sich zunehmend mitThemengebieten, die vormals klares Anwendungsgebiete der Statistiker waren14.
Den Hauptunterschied in der Herangehensweise dieser neuen Generation vonModellen lag in der Tatsache, dass man sich im Gegensatz zu den Datenmodellengerade nicht mehr darauf konzentriert, welchem Modell die Daten folgen, sondernbewusst diesen Teil als Black Box behandelt. Die Struktur dieser Black Box istoft komplex und größtenteils nicht erfassbar, darf bzw. soll bei algorithmischenModellen aber auch so bleiben15. Als Gütekriterium des jeweils verwendetenModells galt ausschließlich, die Qualität in der Vorhersagegenauigkeit.
3 Entscheidungsbäume
Stellvertretend für eine Vielzahl an altorithmischen Modellen soll die Konstruk-tion von Entscheidungsbäumen demonstrieren, worin der Hauptunterschied zuden Datenmodellen liegt.
Ein Entscheidungsbaum besteht aus einer Wurzel (engl: root) an der Spitze, inder die Gesamtpopulation enthalten ist. Mit Hilfe eines Kriteriums, wird dieseMenge in zwei (binäre Bäume) oder mehr Knoten aufgespaltet. Diese Knoten,die nur noch eine Teilmenge des Elternknotens (engl. parent) enthalten, werdennach weiteren Kriterien in Nachkommen (engl: ancestors) aufgespaltet , sodassam Ende eine baumähnliche Struktur entsteht16.
Abbildung 1 zeigt eine Untersuchung des San Diego Medical Centers der Uni-versität von Kalifornien über Herzinfarktpatienten. Dabei wurden innerhalb derersten 24 Stunden nach einem Herzinfarkt 19 für relevant erscheinende Faktorengemessen. Dazu lag die Information vor, ob die Person innerhalb der folgenden 30Tage verstarb oder nicht. Aufgrund dieser Daten wurde ein Entscheidungsbaumerstellt, der die Patienten anhand der Variablen und ihren Ausprägungen in dieKategorie “Hohes Risiko” oder “Niedriges Risiko” einteilen sollte17.
13Vgl. Breiman(1984), S. ix14Vgl. Breiman(2001), S.20515Vgl. Breiman(2001), S. 19916Vgl. Breiman(1984), S.28117Vgl. Breiman(1984), S.174ff
7

3 ENTSCHEIDUNGSBÄUME
Abb. 1: Entscheidungsbaum einer Herzinfarktstudie. Quelle: Breiman(1984), S.2
Der Vorteil dieses Verfahrens ist die einfache Interpretationsmöglichkeit, ins-besondere auch für Nichtstatistiker. Es ist intuitiv abzulesen, dass allein einBlutdruck über 91 schon als einziges Kriterium ausreicht, um eine Person alsgefährdet einzustufen. Ein niedrigerer Blutdruck und ein Alter unter 62,5 führtdazu, der Person ein geringes Risiko, innerhalb der nächsten 30 Tage zu sterben,zu prognostizieren.
Für die Kriterien, mit der die Knoten weiter aufgespaltet werden, müssen geeigne-te Regeln definiert werden. Ein Baum, der soviel Endknoten hat, wie der Umfangder Wurzel, wäre zwar zu 100% korrekt, jedoch auch kaum mehr überschaubar,dazu zu sehr an die Daten angepasst (Overfitting). Für kleinste Änderungenoder das Hinzunehmen neuer Werte wäre der Baum stark fehleranfällig.
Damit ein Knoten erneut aufgeteilt wird, muss gewährleistet sein, dass sichder Baum insgesamt in seiner Qualität verbessert. Dazu muss die Spaltung sogewählt werden, dass die Knoten am Ende untereinander so heterogen, jedochinnerhalb so homogen wie möglich sind.
Dazu wurden Gütekriterien entwickelt, als Maß für die Qualität eines Baumes.Dabei deutet ein niedriges Maß auf gut gewählte, also heterogene Knoten hin.Auf diese Weise, lässt sich die Güte bei weiteren Verzweigungen messbar machen.
8
4 GÜTEKRITERIEN
4 Gütekriterien
4.1 bei einer binären Zielgröße
Als Basiswert für eine Berechnung eine Gütekriteriums zur Messungder Qualität wird ein Wert p berechnet, welcher den Anteil einerKlasse im Knoten angibt. nt1 steht dabei für die Menge der derElemente aus Klasse 1 im t-ten Knoten. Nt ist die Gesamtgröße dest-ten Knotens. Daraus folgt:pt1 = nt1
Ntmit nt1
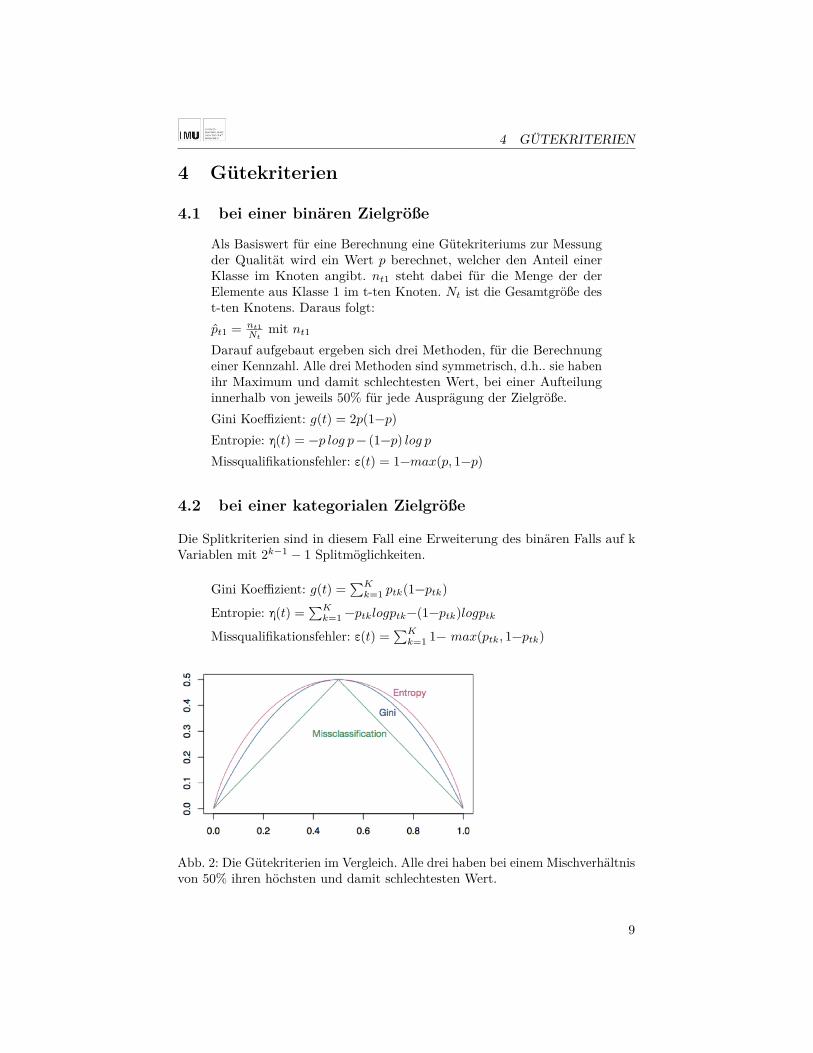
Darauf aufgebaut ergeben sich drei Methoden, für die Berechnungeiner Kennzahl. Alle drei Methoden sind symmetrisch, d.h.. sie habenihr Maximum und damit schlechtesten Wert, bei einer Aufteilunginnerhalb von jeweils 50% für jede Ausprägung der Zielgröße.Gini Koeffizient: g(t) = 2p(1−p)Entropie: η(t) = −p log p − (1−p) log p
Missqualifikationsfehler: ε(t) = 1−max(p, 1−p)
4.2 bei einer kategorialen Zielgröße
Die Splitkriterien sind in diesem Fall eine Erweiterung des binären Falls auf kVariablen mit 2k−1 − 1 Splitmöglichkeiten.
Gini Koeffizient: g(t) =�K
k=1 ptk(1−ptk)Entropie: η(t) =
�Kk=1 −ptklogptk−(1−ptk)logptk
Missqualifikationsfehler: ε(t) =�K
k=1 1− max(ptk, 1−ptk)
Abb. 2: Die Gütekriterien im Vergleich. Alle drei haben bei einem Mischverhältnisvon 50% ihren höchsten und damit schlechtesten Wert.
9

4 GÜTEKRITERIEN
4.3 Beispiel I
Berechnung eines Knotens und Vergleich der Kriterien.
4.3.1 Splitkriterium anhand des Missqualifikationsfehlers
Abb. 3: Beispiel eines Ausgangs für einen Entscheidungsbaum
Abbildung 3 zeigt eine fiktive Stichprobe einer Wohnungsbeurteilungsuntersu-chung. Der Umfang der Stichprobe ist N = 800 , mit zwei den Kategorien“Luxuswohnung” und “keine Luxuswohnung”. Gemessen wurden dabei die Varia-blen Anzahl der Bäder, die Quadratmeterzahl der Wohnung und die Miete proqm. Ziel ist es, anhand der in Abschnitt 4.1 vorgestellten Kriterien für binäreZielgrößen, die Gesamtmenge in möglichst heterogene Knoten aufzuteilen.
Abb. 4: Kriterium 1 (links) spaltet die Stichprobe in zwei Knoten à 400 auf, mitden Verhältnissen 300
100 bzw. 100300 . Kriterium 2 (rechts) spaltet die Stichprobe in
zwei Knoten à 500 bzw. 300 mit den Verhältnissen 200300 bzw. 200
100 .
Anhand des Kriteriums “Anzahl der Bäder” entstehen für den Wert Anzahl derBäder > 3 zwei Knoten, welche noch beide Kategorien beinhalten, jedoch imVerhältnis 300
100 bzw. 100300 . Der nach der Größe gewichtete Missqualifikationsfehler
für diese Ebene liegt damit bei:
eAnzBad>3(1) = 300800 ∗ 1
4 + 100800 ∗ 1
4 = 18 = 0, 125 .
10

4 GÜTEKRITERIEN
Im rechten Beispiel (blau) aus Abbildung 4 teilt das Kriterium Quadratmeterzahl> 150 die Menge in zwei andere Knoten auf. Dabei ist die Knotengröße unter-schiedlich, die absolute Anzahl aus der Kategorie “Luxuswohnung” jedoch gleich.Hier ergibt sich durch analoge Rechnung ein gewichteter Missqualifikationsfehlervon
eqm>150(1) = 200800 ∗ 2
5 + 200800 ∗ 1
3 = 1160 = 0, 1833.
Damit ist
eAnzBad>3(1) = 0, 125 < 0, 1833 = eqm>150(1)
und damit Kriterium AnzBad>3 dem Kriterium qm>150 vorzuziehen.
4.3.2 Vergleich Missqualifikationsfehler und Gini-Koeffizient
Abb. 5: Kriterium 1 (links) spaltet die Stichprobe in zwei Knoten à 400 auf, mitden Verhältnissen 300
100 bzw. 100300 . Kriterium 2 (rechts) spaltet die Stichprobe in
zwei Knoten à 600 bzw. 200 mit den Verhältnissen 200400 bzw. 200
0 .
Im Vergleich der Kriterien AnzBad>3 und Miete pro Quadratmeter (MpQ)> 20 Euro im rechten Beispiel in Abbildung 5 ergeben sich die gewichtetenMissqualifikationsfehler
eAnzBad>3(1) = 300800 ∗ 1
4 + 100800 ∗ 1
4 = 18 = 0, 125
eMpQ>20(1) = 200800 ∗ 1
2 + 0 = 18 = 0, 125
Damit ergibt sich nach dem Verfahren des Missqualifikationsfehlers keine klarePräferenz für ein Kriterium. Beide Bäume bieten bei gleicher Qualität einunterschiedliches Bild, was wiederum dem negativen Rashomon-Effekt entspricht.
Im Vergleich dazu ergeben die Koeffizienten nach Gini:
gAnzBad>3(1) = 300800 ∗ 3
8 + 100800 ∗ 3
8 = 316 = 0, 1873
gMpQ>20(1) = 200800 ∗ 4
9 + 0 = 19 = 0, 11
11

5 PRAXISTEST DER ALGORITHMISCHEN MODELLE
und damit
gAnzBad>3(1) = 0, 1873 > 0, 11 = gMpQ>20(1) .
Damit ist nach dem Gini-Koeffizienten die Trennung nach dem zweiten Krite-rium zu bevorzugen. Dies entspricht damit noch mehr den Anforderungen andie Knotenbildung, da zusätzlich zur Heterogenität zwischen den Knoten imKriterium MpQ auch noch die Homogenität innerhalb der Knoten verstärktberücksichtigt wird. Der rechte Knoten entspricht hierbei einem reinen Knoten,dem Ideal eines homogenen Knotens.
5 Praxistest der algorithmischen Modelle
In Kapitel 4.3 wird deutlich, worin der wesentliche Unterschied zu den Daten-modellen liegt. Es ist irrelevant, welcher Verteilung die Daten folgen, da esdieser Einteilung nicht mehr bedarf. Es ist nicht notwendig, sich auf ein Modellzu beschränken um darauf dann ein dafür geeignetes Verfahren anzuwenden,sondern es werden alle möglichen Splitpunkte getestet und verglichen. DiesesVerfahren ist ohne die Zuhilfenahme von rechnergestützter Leistung schon abeiner sehr geringen Variablenanzahl kaum zu bewältigen, wenngleich es nicht ander besonderen Rechenleistung im mathematischen Sinn liegt, sondern eher ander Schnelligkeit, mit der die Rechenschritte abgearbeitet werden können.Neben der Genauigkeit besteht besonders in der Informatik das Ziel Prozedurenso einfach wie möglich zu gestalten. Unter dem Begriff Ockhams Rasiermesserversteht sich das Bemühen, alle für das Verfahren nicht wirklich notwendigenSchritte zu entfernen um letztlich eine maximale Vereinfachung zu erreichen. Ausstatistischem Blickwinkel kann diese Einfachheit im Konflikt mit der eigentlichgewünschten Genauigkeit stehen.Um diesen möglichen Konflikt genauer zu betrachten ist es hilfreich zwei Punktegenauer zu fokussieren.Zum Einen die Einfachheit im Bezug auf die Interpretation der Ergebnisse. Wiein Abbildung 1 schon beschrieben ist die Interpretation der Ergebnisse sehrintuitiv und auch für Nichtstatistiker lesbar. Während Abbildung 1 einen relativkleinen Baum zeigt, können bei umfangreicheren Analysen die Bäume aucherheblich größer sein. Ein kleiner und leicht verständlicher Baum würde wiederdazu führen, dass es auf Kosten der Genauigkeit geht.Zum Anderen die Nachvollziehbarkeit der Entwicklung eines Baumes. Die theore-tische Basis, auf der die Entwicklung eines Baumes beruht ist in Einzelschrittengut nachvollziehbar. Wie in Abschnitt 4.3 erläutert, erfolgt die Entstehungdurch einen fest vorgegebenen Algorithmus. Durch die Tatsache, dass eine oftunüberschaubare Anzahl an Splitkriterien miteinander vergleichen werden, istein genaues Nachvollziehen, warum der Baum an bestimmten Punkten einenweiteren Knoten hat, ohne den Computereinsatz nicht nachvollziehbar.
12

6 GEFAHR DES OVERFITTINGS EINZELNER BÄUME
Nachdem die Einfachheit im Bezug auf die Interpretierbarkeit möglich sein kannaber nicht sein muss und sie im Bezug auf die Erstellung nicht gegeben ist,stellt sich im Anschluss die Frage, ob die Bäume im Bezug auf die Genauigkeitoffensichtliche Vorteile liefern.
Die Gefahr bei der Anwendung von einzelnen Bäumen auf größere Datensätze liegtin der Überanpassung (Overfitting) des Baumes an die Daten. Besonders dann,wenn kein künstliches Stoppkriterium eingebaut ist, wachsen die Bäume so lang,bis am Ende nur noch reine Knoten vorhanden sind. Daher ist eine Notwendigkeit,künstlich Schranken festzulegen, bis zu welchen der Baum maximal wachsendarf. Sinnvoll ist dabei die Qualitätsverbesserung anhand der Gütekriterien (vgl.4.1 und 4.2) zu betrachten und zu bewerten, inwieweit eine weitere Aufteilungauch im Bezug auf die Stabilität überhaupt noch Sinn macht. Alternativ sowieergänzend kann die Mindestgröße der Endknoten von Beginn an festgelegt werdenum ein Overfitting einzugrenzen.
Um die Baumstruktur im Bezug auf Vorhersagen neuer Daten zu stabilisieren,baut auf die Baumentwicklung die Entwicklung mehrere Bäume, sogenanntenWäldern (engl. forests) auf. Technisch bedeutet dies, anstatt sich auf einen Baumzu begrenzen, wird eine Vielzahl an unterschiedlichen Bäumen geschaffen. Dieneuen Werte, werden anschließend durch jeden Baum geführt. Im Bereich derKlassifizierung wird die Zugehörigkeit des Wertes pro Klasse gezählt und dieKlasse mit der höchsten Trefferquote bestimmt die Vorhersage der Klassenzuge-hörigkeit des jeweiligen Wertes.
6 Gefahr des Overfittings einzelner Bäume
Die reine Anwendung der Entscheidungsbäume beinhalten die Gefahr des Over-fittings. Voll ausgewachsene Bäume, das heißt ohne Stoppkriterium entwickelteBäume, mit der selben Anzahl an Endknoten wie die Größe des Datensatzes, sindideal an den Datensatz angepasst. Kleinste Änderungen am Trainingsdatensatzführen zu stark unterschiedlichen Ausprägungen der Bäume und damit zu einemgeringeren Nutzen als allgemeine Klassifizierungsmethode.
Um die Entscheidungsbäume stabiler zu gestalten wurden mehrere Verfahrenentwickelt. In den verschiedenen Ansätzen sind zwei unterschiedliche Herange-hensweisen zu erkennen.
Während bei einer Methode versucht wird, den Baum bereits erstellten zuanalysieren und ggf. zu korrigieren (Bearbeitung des Outputs), ist der andereAnsatz, den Baum (später auch mehrere Bäume) durch die Veränderung desherangezogenen Trainingsdatensatz (Training Set) eine robustere Struktur zuerreichen (Bearbeitung des Inputs).
Im ersten Fall, um einen Baum nicht zu groß werden zu lassen, kann diesermit geeigneten Kriterien (Stopkriterien) an einem weiteren Wachstum gehindertwerden. Ebenfalls in diese Richtung geht der Ansatz, voll ausgewachsene Bäume
13

6 GEFAHR DES OVERFITTINGS EINZELNER BÄUME
im Nachhinein zu beschneiden (engl. pruning). In diesem Verfahren wird dererstellte Baum nachträglich darauf hin untersucht, ob durch eine weitere Verzwei-gungen eine Verbesserung im Bezug auf die Prognose getroffen werden kann18.Falls sich zeigt, dass keine Verbesserung mehr erreicht werden kann, wird derBaum an diesem Punkt beschnitten. Im Bezug auf auf das Ockhamsche Messer(Vgl. Abschnitt 5) stellt sich an dieser Stelle die Frage, ob eine Reduzierung desBaumes, zur einer einfacheren Darstellung führen kann, ohne oder nur geringdamit auf Kosten der Genauigkeit gehen zu müssen.
Der zweite Fall wird versucht durch eine bestimmte Variation des Training Sets,mehrere Bäume, sogenannte Wälder (engl.: forests) zu entwickeln. Die Datenaus den modifizierten Training Sets werden im Anschluss an jedem einzelnender so entstandenen Bäumen getestet. Die Wahl der Kategorien wird gezähltund die Kategorie, für die sich die meisten Bäume entschieden haben, wird alsErgebnis übernommen.
Für die Erstellung der Forests wurden unterschiedliche Verfahren entwickelt,bei denen neben Leo Breiman, auch viele weitere Wissenschaftler Algorithmenentwarfen.
Das Grundverfahren zur Erstellung der Bäume ist das sogenannte Boosting.Boosting steht für das algorithmische Verfahren zur automatischen Klassifizie-rung. Der Algorithmus teilst dabei jeweils binär in Klassen auf, wie später auchdie Baumentwicklung von Breiman (im Gegensatz zu multiplen Splits).
Darauf aufgebaut wurden unterschiedliche Algorithmen zur Generierung derForests entwickelt.
Ein früher Entwurf stammt von Breiman direkt. In einem Artikel aus dem Jahre1996 beschrieb er eine Methode, in der für jeden Baum aus dem Trainingsda-tensatz eine zufällige Auswahl gezogen wurde19. Die Methode nannte BreimanBootstrap aggregating oder kurz »Bagging«.
In Abbildung 6 beschreibt Livingston grafisch den Prozess des Bootstrappings.Aus dem ursprünglichen Datensatz der Größe 2500 wird ein Training Set mitN=1000 gezogen. Im nächsten Schritt wird daraus 1000 mal mit zurücklegengezogen. Der inBag-Datensatz hat die gleiche Größe wie das Training Set, jedochmit Duplikaten. Der in-Bag Datensatz enthält nun 63.2% der im Training Setvorhandenen Daten. Das fehlende Drittel wird als Out-Of-Bag bezeichnet.
Zwei Jahre später verglich Thomas Dietterich von der Oregon State UniversityBagging, Boosting und ein randomisiertes Verfahren, in welchem nicht automa-tisch der beste Splitpunkt ausgewählt wird, sondern eine zufällige Auswahl ausden K besten Splitpunkte benutzt wird20. Im Vergleich dieser drei Verfahren
18Vgl. Breiman(1984), S.27919Vgl. Breiman, L. (1996). Bagging predictors. Machine Learning 26(2), 123–140.20Dietterich, T. (1998). An experimental comparison of three methods for constructing
ensembles of decision trees: Bagging, boosting and randomization, Machine Learning, 1–22.
14

6 GEFAHR DES OVERFITTINGS EINZELNER BÄUME
Abb. 6: Darstellung des Erstellung eines Data Sets mittels Bootstrapping. Quelle:Frederick, L., Implementation of Breiman’s Random Forests Machine LearningAlgorithm, Machine Learning Journal Paper. Fall 2005, Seite 2
stelle er fest, dass die random split selection weit bessere Ergebnisse erzielt, alsBagging21.
In einer weiterem Vergleich, stellte Breiman fest, dass diese Verfahrung nicht anden ebenfalls 1996 vorgestellten Algorithmus Adaptive Boosting, kurz AdaBoost22
mit ihrere Qualität herankommen23.
Die Gemeinsamkeit dieser Verfahren ist der Zufallsvektor Θ. Anhand diesesZufallsvektors, wird unabhängig der vorherigen Bäume ein neuer Baum generiert.Damit lassen sich die durch all diese zufälligen Verfahren generierten Bäumeunter dem Begriff Random Forest zusammenfassen.
Der k-te Baum wird überall durch ein Verfahren h() erstellt, mit Inputvektor x
und einem Zufallsvektor Θ:
h(x, Θk), k = 1, ...
21Vgl. Dietterich, T. (1998). An experimental comparison of three methods for constructingensembles of decision trees: Bagging, boosting and randomization, Machine Learning, S. 1–22.
22Vgl. Freund, Y. & Schapire, R. (1996). Experiments with a new boosting algorithm,Machine Learning: Proceedings of the Thirteenth International Conference, S. 148–156.
23Breiman L., Random forests. In Machine Learning, S. 5
15
6 GEFAHR DES OVERFITTINGS EINZELNER BÄUME
6.1 Beispiel II
Vergleich von Wäldern mit einzelnen Bäumen
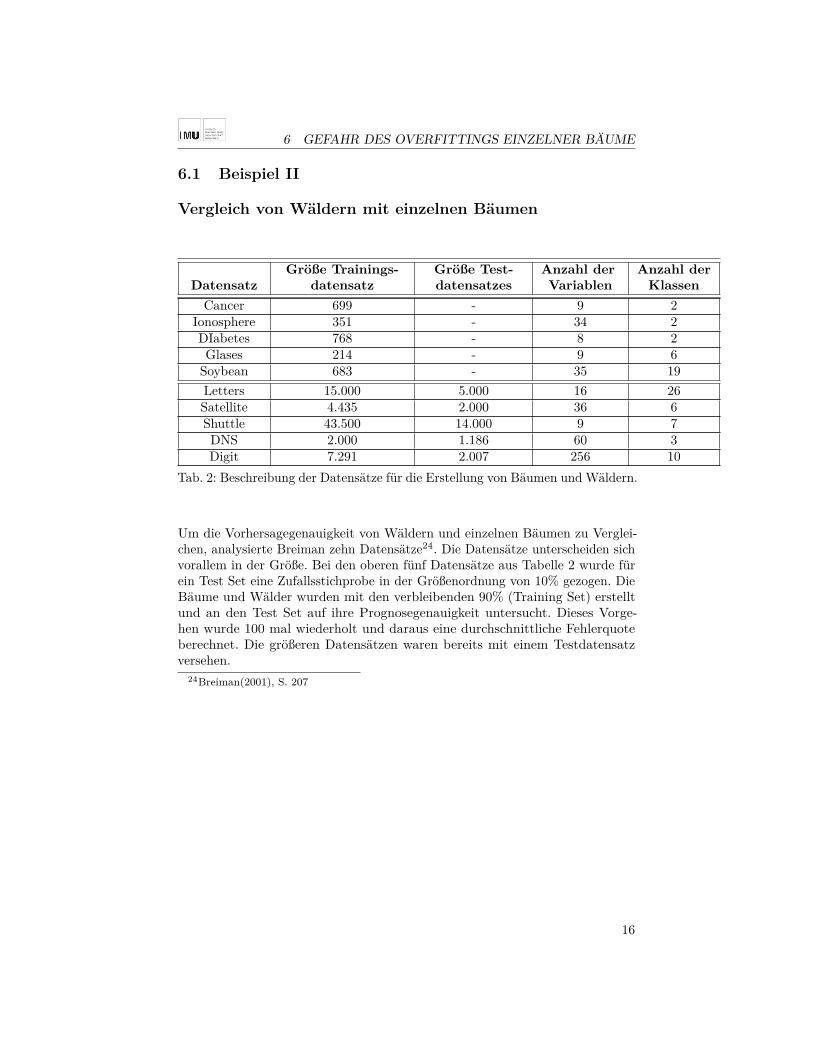
Größe Trainings- Größe Test- Anzahl der Anzahl der
Datensatz datensatz datensatzes Variablen Klassen
Cancer 699 - 9 2Ionosphere 351 - 34 2DIabetes 768 - 8 2Glases 214 - 9 6
Soybean 683 - 35 19Letters 15.000 5.000 16 26Satellite 4.435 2.000 36 6Shuttle 43.500 14.000 9 7DNS 2.000 1.186 60 3Digit 7.291 2.007 256 10
Tab. 2: Beschreibung der Datensätze für die Erstellung von Bäumen und Wäldern.
Um die Vorhersagegenauigkeit von Wäldern und einzelnen Bäumen zu Verglei-chen, analysierte Breiman zehn Datensätze24. Die Datensätze unterscheiden sichvorallem in der Größe. Bei den oberen fünf Datensätze aus Tabelle 2 wurde fürein Test Set eine Zufallsstichprobe in der Größenordnung von 10% gezogen. DieBäume und Wälder wurden mit den verbleibenden 90% (Training Set) erstelltund an den Test Set auf ihre Prognosegenauigkeit untersucht. Dieses Vorge-hen wurde 100 mal wiederholt und daraus eine durchschnittliche Fehlerquoteberechnet. Die größeren Datensätzen waren bereits mit einem Testdatensatzversehen.
24Breiman(2001), S. 207
16

7 QUALITÄTSVERGLEICH DER “KULTUREN”
Datensatz Wald Baum
Cancer 2,9 5,9Ionosphere 5,5 11,2DIabetes 24,2 25,3Glases 22,0 30,4
Soybean 5,7 8,6Letters 3,4 12,6Satellite 8,6 14,8Shuttle 7,0 62,0DNS 3,9 6,2Digit 6,2 17,1
Tab. 4: Fehlerquoten der aus Tabelle 2 erstellen Wälder im Vergleich zu einzelnenBäumen
Nach wiederholtem Durchlaufen des Testdatensatzes zeigten sich die Fehlerquotenaus Tabelle 425. Durch die Erweiterung der einzelnen Bäume auf Wälder, konntedie Fehlerquote mindestens verringert, in einigen Fällen auch gedrittelt werden.
7 Qualitätsvergleich der “Kulturen”
Eine Studie über 155 Hepatitispatienten untersuchte anhand 19 Variablen dieMortalität der Personen (Quelle: ftp.ics.uci.edu/pub/MachineLearning-Databses).Mit den verfügbaren Ausprägungen der Variablen sollte die Überlebenschanceprognostiziert werden. In zwei Analysen von Diaconis und Efron26 und Cestnik,Konenenko und Bratko27 lag die minimalste Fehlerquote bei 17%. In einerweiteren Analyse der selben Daten an der Stanford Medical School wurde eineFehlerquote von 20% gemessen und die Variablen 6, 12, 14 und 19 als die mitder höchsten Relevanz bestimmt28.
Die Analyse durch Random Forests erreicht eine minimale Fehlerquote von 12.3%und damit eine Reduzierung um fast 30% gegenüber den anderen Verfahren. DieForests wurden dabei wie in Abschnitt 6 erstellt.
Um die Bedeutung einer Variable zu messen, wurde diese in all den Fällen, diemomentan nicht zur Erstellung des Baumes genutzt wurden, zufällig verschmutzt.
25Breiman(2001), S. 20726Vgl. Diaconis, P. and Efron, B. (1983). Computer intensive methods in statistics. Scientific
American 248 116–131.27Vgl. Cestnik B, KononenkoI, Bratko I (1987). ASSISTANT 86: A knowledge elicitation
tool for sophisticated users, In: I.Bratko, N.Lavrač (eds.): ’Progress in machine learning’28Breiman(2001), S. 210
17

8 FAZIT
Diese Fälle wurden dann durch die Bäume erneut untersucht und ihre Klassifi-zierung betrachtet. Die so erhaltenen Ergebnisse wurden im Anschluss mit denursprünglichen (besseren) Fehlerquoten verglichen29.
Abb. 7: Relevanz der Variablen im Bezug auf die Mortalität im Falle von Hepatitis
Der jeweilige Zuwachs durch die Verschmutzung wird in Abbildung 730 darge-stellt. Die Verschmutzug der Variablen 12 und 17 verursacht einen Anstieg derFehlerquote um jeweils über 40%. Daraus lässt sich ableiten, dass die Qualitätder Prognosegenauigkeit stark von diesen Variablen abhängt und weist diesendamit eine hohe Relevanz zu. Dieser Vorteil der Random Forests liefert damitauch die Antwort auf den von Breiman beschriebenen Rashomon-Effekt.
Auch mit den Erkenntnissen aus den algorithmischen Modellen ließen sich imAnschluss die Datenmodelle nicht bemerkbar verbessern. Das Minimum lag wei-terhin bei 17%, was bei 32 Todesfällen der 155 Patienten nicht zufriedenstellendsein kann. Würden alle 32 Fälle als überlebend klassifiziert werden, wäre dieFehlerquote mit 20,6% nur unwesentlich höher31.
8 Fazit
Nachdem beide Kulturen vorgestellt worden sind und auch der direkte Vergleichin praktischen Beispielen vollzogen worden ist, stellt sich die Frage, ob diealgorithmischen Modelle den “Wettkampf” gewonnen haben und den Beginneines neuen Zeitalters markieren.
Zweifelsohne war es nur eine Frage der Zeit, bis rechnergestütze Verfahren auchin der Statistik eingeführt werden. Das Festhalten an bisherigen Methoden, mit
29Vgl. Breiman(2001), S.21130Breiman(2001), S.21131Vgl. Breiman(2001), S.213
18

8 FAZIT
Blick auf Computer, die heute über 2 Millionen Rechenschritte pro Sekundeausführen können, wäre es grob fahrlässig, sich neuen Anwendungsgebieten zuversperren, weil die bewährten Methoden an ihre Grenzen stoßen. Es stellt sichan diesem Punkt dann die Frage, ob die bisherigen Verfahren das Potentialhaben ausgebaut werden zu können, oder die Notwendigkeit erscheint, sich neuenHilfsmitteln zu bedienen. In Anbetracht der Produktpalette, die zur Zeit derVeröffentlichung des CART-Books verfügbare waren, kann man aus heutigerSicht die Schwächen der Datenmodelle wieder etwas relativieren. Auch in dieser“Kultur” wurde die Notwendigkeit neuer Kriterien erkannt und weitere Goodnessof fit-Tests wie AIC und BIC entwickelt.Dazu ist es gegebenenfalls auch nötig, den bisher bekannten Standpunkt zuverlassen um Problemstellungen mit einer neuen Sichtweise zu betrachten.Die algorithmischen Modelle bieten nun die Möglichkeit, besonders im endlichenFall, alle möglichen Szenarien durchzugehen und diese miteinander zu vergleichen.Ein neues Paradigma besteht damit aus dem Übergang von bisher “eleganten Lö-sungen” zu Komplettlösungen. Während die “eleganten Lösungen” es ermöglichthaben durch die A-priori-Annahme einer bestimmten Verteilung, Vorhersagenüber ähnliche Daten zu treffen bietet die Komplettlösung in vielen Fällen sehrumfangreiche, aber verlässliche Ergebnisse.Viele Fragestellungen wurden erst durch den Einsatz der Computer beantwortbar.So wurde beispielsweise die Frage nach der Minimalanzahl zur Lösung des Rubic’sCube dadurch gelöst, dass alle Szenarien durchgerechnet wurden. Auch moderneSchachcomputer bedienen sich schon lang der Methode, eine große Anzahl anMöglichkeiten durchzurechnen, was mittlerweile innerhalb weniger Sekunden zubewältigen ist.Die kontinuierliche Weiterentwicklung leistungsstarker Prozessoren zu verhältnis-mäßig günstigen Preisen verbessert auch die Grundlage, die neuen Technologienin vielen Bereichen einzusetzen.Es stellt sich also erneut die Frage, worin das neue Paradigma genau liegt. Brei-mans Ansatz liegt darin, sich von dem starren Fokus auf Modellannahmen zulösen und die Mechanismen, durch welche die Daten generiert wurden als BlackBox anzusehen. Bedingt ist diese Sichtweise vorallem durch zunehmend komple-xere Fragestellungen, die nicht mehr durch ein klassisches Modell beantwortbarsind.In seinen Erfahrungen durch das Chlorprojekt schildert Breiman, dass es finan-ziell nicht möglich war, eine Vielzahl an Chemikern für Analysen einzusetzen.Analog ist es auch in vielen Bereichen, in denen die Statistik mittlerweile Einzuggehalten hat, nicht immer finanzierbar, ausgebildete Statistiker einzusetzen. DieNotwendigkeit automatisierte Prozesse einzusetzen, die zeit- und kostensparendeingesetzt werden können ist durch den heute in vielen Bereichen vorhandenenKostendruck schon längst vorhanden.Die Frage nach einem neuen Paradigma im Sinne einer neuen Zeit, in der al-gorithmische Modelle die Datenmodelle adäquat ersetzen können muss jedoch
19

8 FAZIT
klar verneint werden. Darauf gibt Breiman schon indirekt eine Antwort, indemer anprangert, dass nicht mehr jedes Problem aussieht wie ein einfacher Nagel.Nicht jedes, aber ein Teil der Fragestellungen wird weiterhin wie ein Nagelaussehen. Gerade in der Statistik ist es das Bemühen, verbesserte Prognosentreffen zu können, indem man zusätzliche Informationen in das Verfahren miteinfließen lässt. Eine starre Betrachtung der Black Box als ein nicht durch-schaubarer Kasten, obwohl man in vielen Fällen genaue Kenntnis darüber hat,welchem Modell die Daten folgen, wäre ein bewusster Verzicht auf zusätzlicheVerbesserungsmöglichkeiten. Im Gegenzug zu Kapitel 6 gibt es auch Beispiele, indenen Datenmodelle durch das Wissen über den Inhalt der Black Box wesentlichbessere Resultate erzielen.
Breimans Festhalten an bestimmten Projekten aus seiner Beraterzeit, führte zurEntwicklung neuer Verfahren, die neue Antworten geben können. Sein Vergleichbezieht sich jedoch hauptsächlich auf die Bereiche, die auch wirklich durchalgorithmische Modelle verbessert werden konnten, wie die Verarbeitung vonsehr großen und unbekannten (Black Bock) Datensätzen. Hier kann ohne großeVorabanalyse eine gute Klassifizierung und auch eine Filterung der wichtigenVariablen bestimmt werden (Rashomon-Effekt). Andere Fragestellungen wiebeispielsweise der Bestimmung von Konfidenzintervallen bleibt er mit seinenVerfahren schuldig.
Im “Kampf der Kulturen” zwischen den Datenmodellen und den algorithmischenModellen ist ein neues Zeitalter angebrochen. Ein neues Paradigma im Sinnevon neuen Betrachtungswinkeln sowie dem Umdenken, zu welcher Disziplin sichdie Statistik am nächsten fühlt ist sicherlich vorhanden. Während die Statistiksich lange Zeit um Anerkennung in der Mathematik bemühen musste, stellt sichzunehmend die Frage, ob sie ausschließlich ein Teilgebiet dieser Wissenschaftgesehen werden muss, oder ob nicht zunehmend ein weiterer Statistikbereich ausder Richtung der Informatik kommt.
Letztlich bieten beide Seiten eine große Produktpalette an Lösungswegen undhaben zwangsläufig auch eine gewisse Schnittmenge. Im Zuge einer “statistischenGlobalisierung” ist es daher fragwürdig, ob es Sinn macht, “national” zu denkenund sich auf einen der beiden Wege festzulegen oder ob es nicht angebracht ist“global” zu denken und sich über die erweiterten Einsatzmöglichkeiten bei einerparallelen Anwendung bewusst zu sein.
20

LiteraturverzeichnisBreiman, L,. Friedmann, J., Olshen, R. ans Stone, C. (1984). Classfi-
cation and Regression Trees. Wadsworth, Belmont, CA
Breiman, L. (1996). Bagging predictors. Machine Learning 26(2),
123–140.
Breiman (2001). Statistical Modeling: The Two Cultures. Statistical
Science 16.
Breiman L.(2001). Random forests. In Machine Learning, Seiten 5-32,
Cestnik B, Kononenko I, Bratko I (1987). ASSISTANT 86: A knowled-
ge elicitation tool for sophisticated users, In: I.Bratko, N.Lavrač
(eds.): ’Progress in machine learning’, Sigma Press
Diaconis, P. and Efron, B. (1983). Computer intensive methods in
statistics. Scientific American 248 116–131.
Dietterich, T. (1998). An experimental comparison of three methods
for constructing ensembles of decision trees: Bagging, boosting
and randomization, Machine Learning, 1–22.
Frederick, L.(2005). Implementation of Breiman’s Random Forests
Machine Learning Algorithm, Machine Learning Journal Paper.
Fall 2005
Freund, Y. & Schapire, R. (1996). Experiments with a new boos-
ting algorithm, Machine Learning: Proceedings of the Thirteenth
International Conference, S. 148–156.
Olshen (2001). A Conversaton with Leo Breiman. Statistical Science
16.
i


















![Seminararbeit zu Philosophische Grundlagen der Statistikcattaneo.userweb.mwn.de/pgs-ws1011/materials/Seminararbeit 7... · 1968 beschreibt Hampel in einem Artikel [6] die Ein ussfunktion](https://img.pdfslide.org/doc/110x75/5e1b17adf1ba9e65984b159b/seminararbeit-zu-philosophische-grundlagen-der-7-1968-beschreibt-hampel-in.jpg)








