Embed Size (px)
Citation preview

Acoustics research Institute
Audio Inpainting of musical signals
M.Sc. Andrés Marafioti
Graz, 16-06-2018, Doktorandinnenforum

Acoustics research Institute
Content
● The Merlin project
● Audio inpainting
● The proposal
● The first year
● Future work

Acoustics research Institute
The MERLIN Project
● Modern methods for the restoration of lost information in digital signals (MERLIN) is a bilateral FWF-GAČR joint project.
● Concerned with the development of new, innovative methods for the automatic recovery of lost signal segments and concealment of damaged signal content.
● Is a cooperative project with other working groups at ARI, our project partner the Nonorthogonal Signal Representation group, Signal Processing Laboratory, Technical University of Brno, as well as national and international partners.
Acoustics research Institute
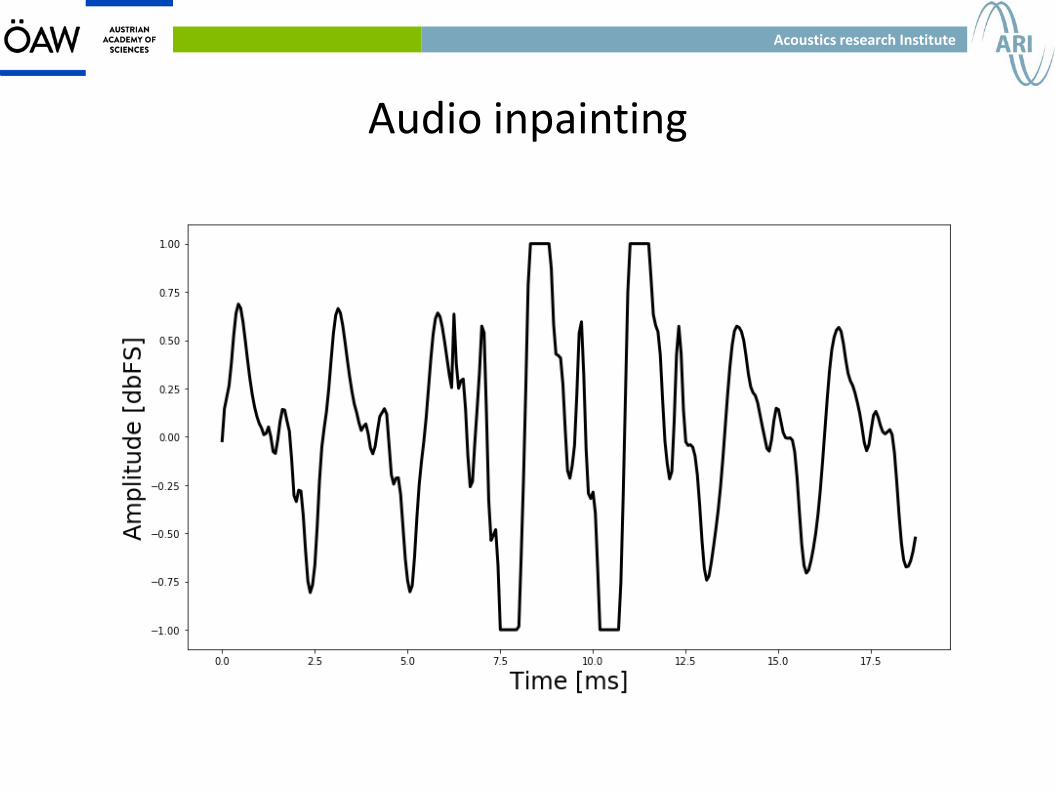
Audio inpainting

Acoustics research Institute
Audio inpainting
● Restoration/error concealment on audio signals with lost or corrupted information in large connected regions of time, frequency, or time-frequency (TF) domains.
● The results have to be perceptually pleasing.
● A good reconstruction should provide coherent and meaningful information while preventing audible artifacts so that, ideally, the listener remains unaware of any problem.
Acoustics research Institute
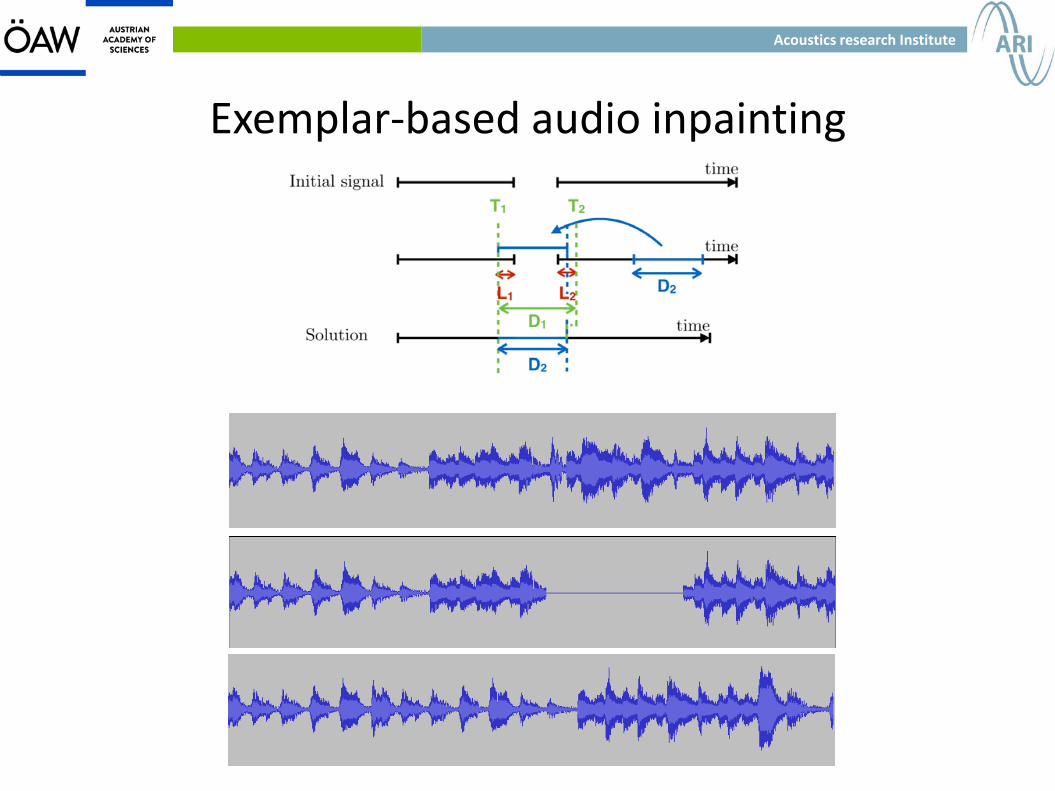
Exemplar-based audio inpainting

Acoustics research Institute
Exemplar-based audio inpainting
● There are several conditions in music that benefit the use of exemplar-based inpainting: – An exact reconstruction is not important as long as it is
perceptually pleasant.
– Very complex information can be recovered without fidelity loss.
– Music, with its structure and repetition, is often highly redundant. There is a good chance to find a signal that is perceptually similar to the missing one.
Acoustics research Institute
Motivation
● How do we improve on the state of the art?
● How do we extract structures in music?

Acoustics research Institute
The proposal
● Perform audio inpainting of music signals on long gaps by using both “exemplar-based” and “deep learning” techniques.
● Adapt deep learning techniques from the field of image processing and apply them to the Time-Frequency domain.
● Use deep learning techniques to extract information about the structure of music.

Acoustics research Institute
First year
● Raw sound generation: – Context Encoder
– Inpainting system with memory
● Study of: – deep learning tools.
– Time-Frequency representations.
● Retrieval of datasets.
● One month at the Swiss Data Science Center (SDSC).

Acoustics research Institute
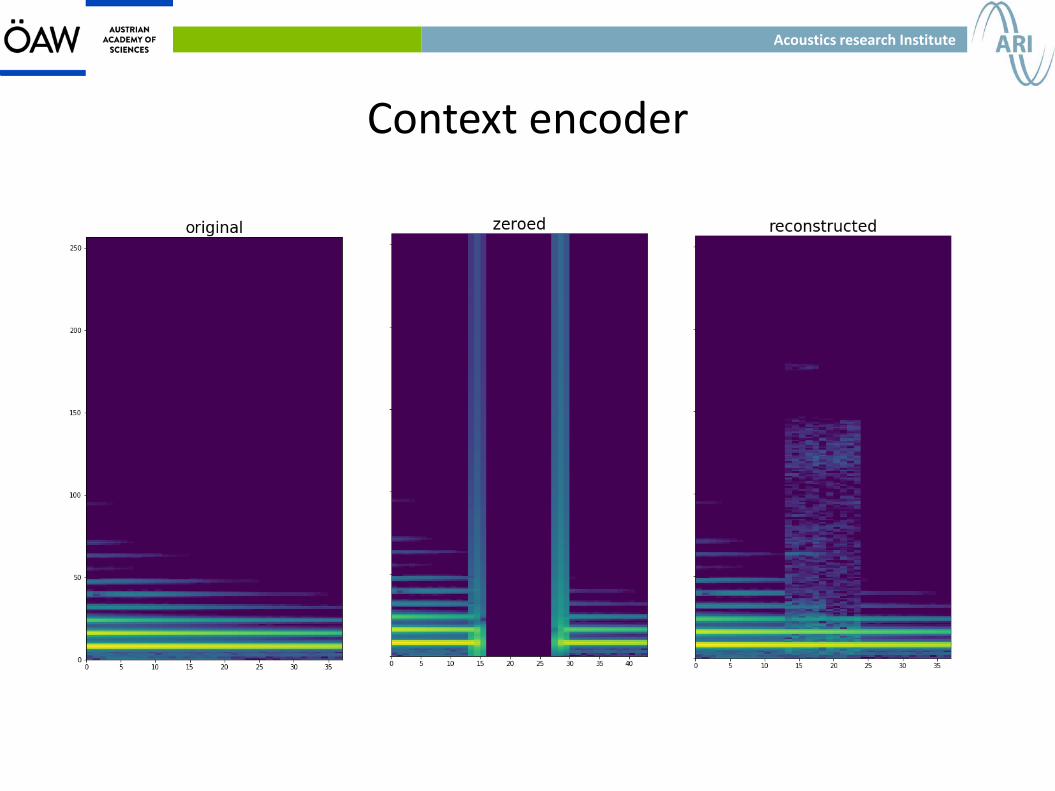
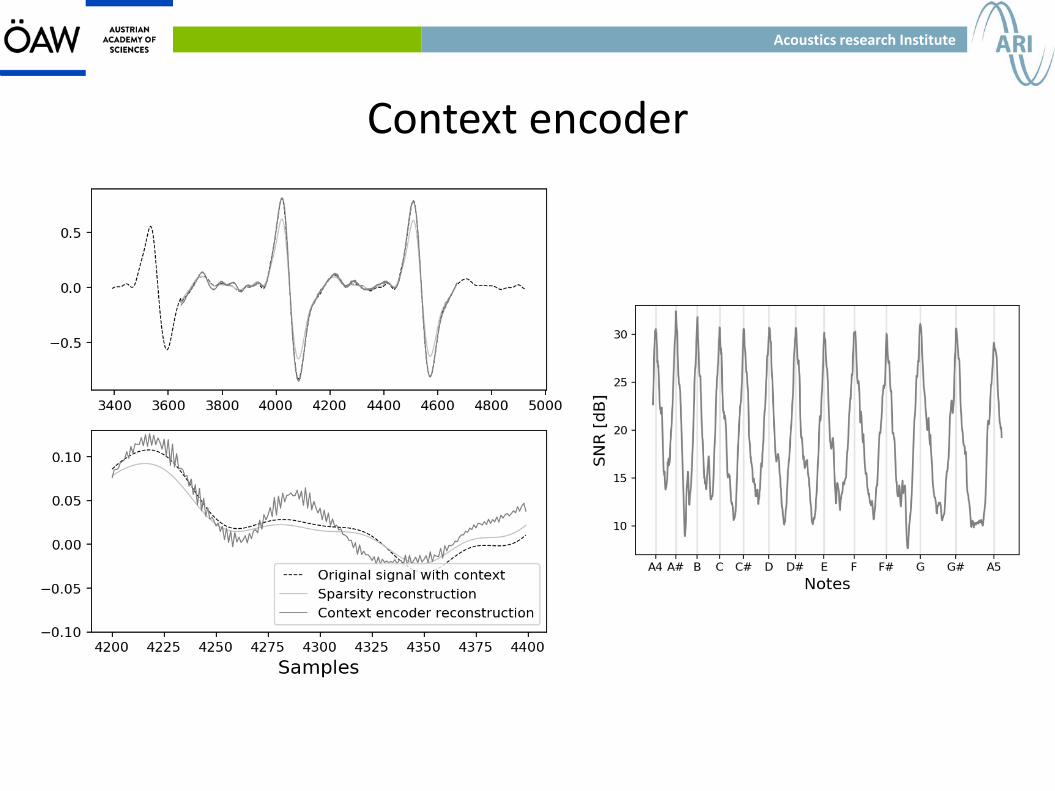
Context encoder
● The goal is to learn a function that maps the context of a signal to a hole in it.
● It was first introduced for images in 2016.
● Our implementation is the first one for audio. We inpaint 64ms gaps and wrote a paper detailing our approach.
● The system generates coherent outputs.
● The complexity grows both for longer gaps and to add more information as context, so it can not be used for longer signals.
Acoustics research Institute
Context encoder
Acoustics research Institute
Context encoder
Acoustics research Institute
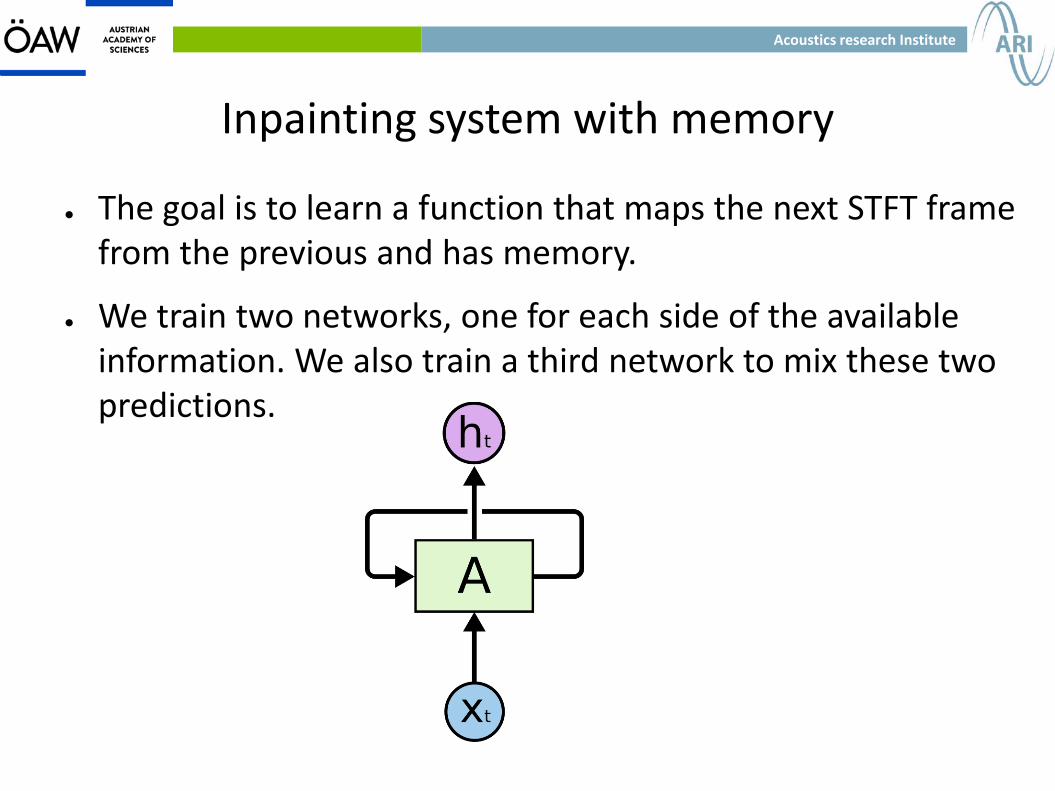
Inpainting system with memory
● The goal is to learn a function that maps the next STFT frame from the previous and has memory.
● We train two networks, one for each side of the available information. We also train a third network to mix these two predictions.
Acoustics research Institute
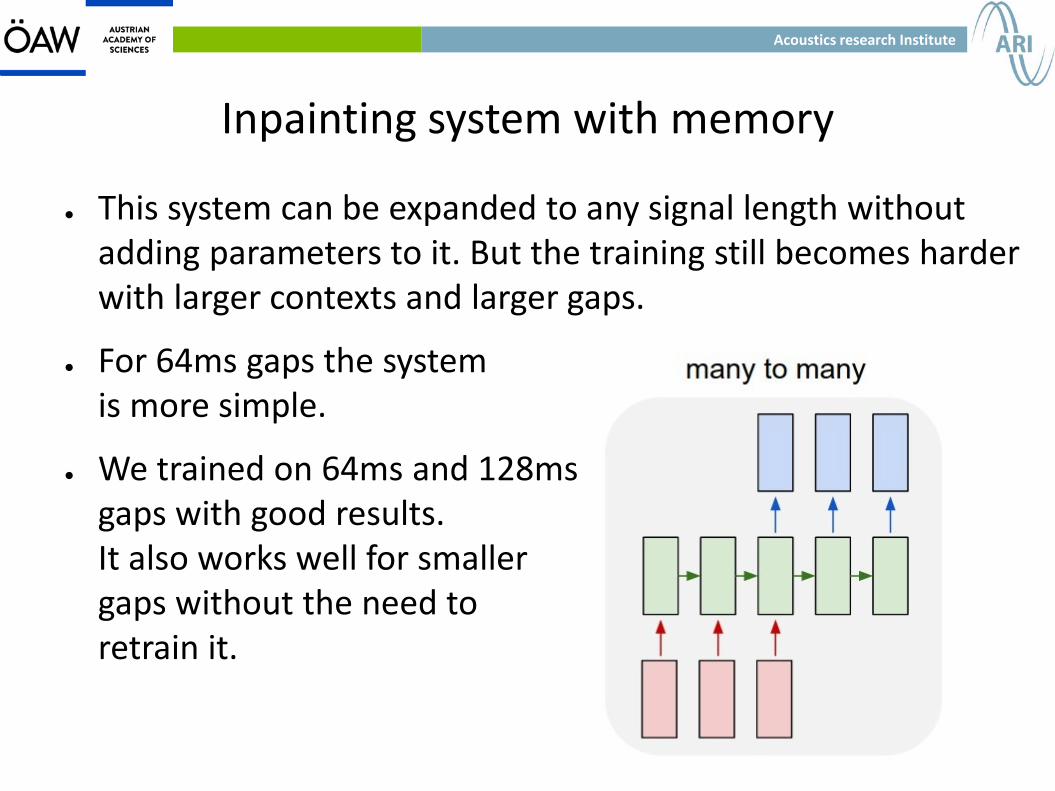
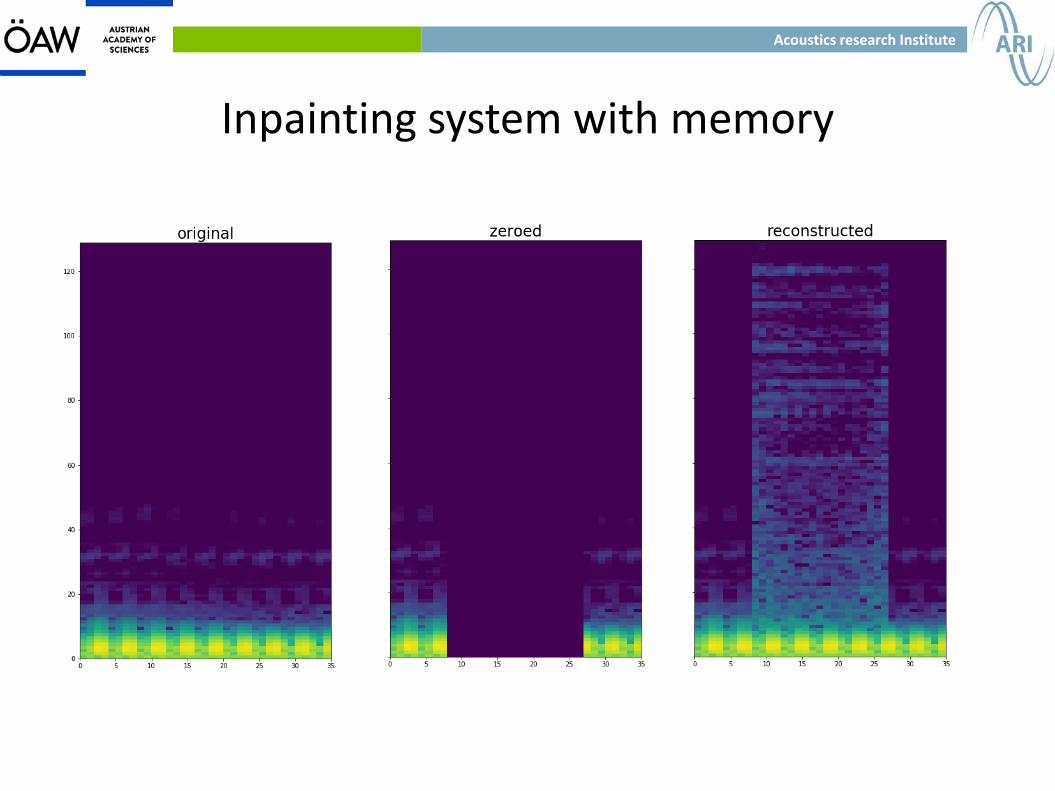
Inpainting system with memory
● This system can be expanded to any signal length without adding parameters to it. But the training still becomes harder with larger contexts and larger gaps.
● For 64ms gaps the system is more simple.
● We trained on 64ms and 128ms gaps with good results. It also works well for smaller gaps without the need to retrain it.
Acoustics research Institute
Inpainting system with memory

Acoustics research Institute
Future work
● Perform listening tests for the two developed systems.
● Write a detailed report on the inpainting system with memory.
● Work towards inpainting longer time frames.
● Try exemplar-based techniques both for short and long time frames.

Acoustics research Institute
Bibliography
● N. Perraudin, N. Holighaus, P. Majdak, and P. Balazs. Inpainting of long audio segments with similarity graphs. IEEE/ACM Transactions on Audio, Speech, and Language Processing, PP(99):1–1, 2018.
● MG. Jafari M. Elad R. Gribonval A. Adler, V. Emiya and MD. Plumbley. Audio inpainting. IEEE Transactions on Audio, Speech, and Language Processing, 20(3):922–932, mar 2012.
● J. Donahue T. Darrell D. Pathak, P. Krahenbuhl and AA. Efros. Context encoders: Feature learning by inpainting, CVPR 2016.
● S Hochreiter, J Schmidhuber. Long short-term memory - Neural computation, 1997 - MIT Press
● X Sun, R Szeto, JJ Corso, A Temporally-Aware Interpolation Network for Video Frame Inpainting, arxiv preprint, Mar 2018.
● Ruben Villegas, Jimei Yang, Seunghoon Hong, Xunyu Lin, Honglak Lee, Decomposing motion and content for natural video sequence prediction.

Acoustics research Institute
Bibliography
● A. Graves. Generating sequences with recurrent neural networks. CoRR, abs/1308.0850, 2013.
● A. Roberts S. Dieleman D. Eck K. Simonyan J. Engel, C. Resnick and M. Norouzi. Neural audio synthesis of musical notes with wavenet autoencoders, 2017.
● M. Dorfler K. Siedenburg and M. Kowalski. Audio inpainting with social sparsity. SPARS (Signal Processing with Adaptive Sparse Structured Representations), 2013.
● M. Kashino. Phonemic restoration: The brain creates missing speech sounds. Acoustical Science and Technology, 27(6):318–321, 2006.
● I. Goodfellow, Y. Bengio, and A. Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
● H. Zen K. Simonyan O. Vinyals A. Graves N Kalchbrenner AW. Senior A. van den Oord, S. Dieleman and K. Kavukcuoglu. Wavenet: A generative model for raw audio. CoRR, abs/1609.03499, 2016.

Acoustics research Institute
Audio Inpainting of musical signals
M.Sc. Andrés Marafioti
Graz, 16-06-2018, Doktorandinnenforum
Thank you!


![Neuerwerbungsliste · Web viewDer verlorene Sohn [Audio-CD] : Kinder-Mini-Musical / Dagmar Heizmann ; Klaus Heizmann. - Asslar, 1999. - 33 Min., Vortrag/Lieder + Booklet Signatur:](https://img.pdfslide.org/doc/110x75/5b9fd0fb09d3f2385c8c580f/n-web-viewder-verlorene-sohn-audio-cd-kinder-mini-musical-dagmar-heizmann.jpg)


























