Embed Size (px)
Citation preview

Hochschule für Technik,Wirtschaft und Kultur Leipzig
Ausarbeitung zum Thema:
Mehrdimensionale Dateiorganisation und Zugriffspfade
Eingereicht von: Thomas Reinhardt, 05IN-B

Inhaltsverzeichnis
1 Einleitung 31.1 mehrdimensionale Speichertechniken . . . . . . . . . . . . . . . . . . . . . 31.2 Klassifikation von Anfragetypen . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Ein-Attribut- vs. Mehr-Attribut-Index . . . . . . . . . . . . . . . . . . . . 31.4 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 mehrdimensionale binäre Suchbäume 52.1 k-d-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 KdB-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Struktur des KdB-Baumes . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4 Komplexität/Aufwand . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 mehrdimensionales Hashing 83.1 formale Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3 Komplexität/Aufwand . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4 Grid-Files 104.1 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2 Operationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.3 Beispiel, Einfügen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.4 Beispiel, Löschen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2

1 Einleitung
1.1 mehrdimensionale Speichertechniken
Im Unterschied zu eindimensionalen Speichertechniken, wie z.B. B-Bäume, eindimensio-nales Hashing und Andere unterstützen die hier behandelten mehrdimensionalen Spei-cherechniken einen meist effizienteren Zugriff innerhalb eines mehrdimensionalen Daten-raumes. In diesem spannen k unterschiedliche Attribute einen k-dimensionalen Raumauf und können durch optimierte Zugriffspfade nun gleichberechtigt unterstützt werden.Auch eine effiziente Indexierung von Punktobjekten und räumlich ausgedehnten Objek-ten wird unterstützt.
1.2 Klassifikation von Anfragetypen
1. Exakte Anfrage ( exact-match query)
spezifiziert für jeden Schlüssel einen Wert
2. Partielle Anfrage (partial match query)
spezifiziert mindestens eins und weniger als k Attribute einen Wert
3. Bereichsanfrage (range query)
spezifiziert einen Bereich für jeden Schlüssel
4. Partielle Bereichsanfrage (partial range query)
spezifiziert für mindestens eins und weniger als k Attribute einen Bereich
1.3 Ein-Attribut- vs. Mehr-Attribut-Index
Man unterscheidet bei mehrdimensionalen, indexierten Daten zwischen dem Ein-Attribut-Index (non-composite index), bei welchem der Zugriffspfad über einem einzigen Zugriffsat-tribut realisiert ist und dem Mehr-Attribut-Index (composite index), bei welchem derZugriffspfad mehrere Attribute beinhaltet.
3

1 Einleitung
1.4 Beispiel
Vorname PLZ AdresseThomas 04277 ...Matrin 34567 ...Gunter 39138 ...
Sollen Anfragen zu Vorname und PLZ effizient durchgeführt werden, kann man entwe-der zwei Ein-Attribut-Indexe oder ein Zwei-Attribut-Index über beide Attribute nutzen.Dabei ist ein Ein-Attribut-Index immer eindimensionale Zugriffsstruktur in welcher dieZugriffsattributwerte immer eine lineare Ordnung im eindimensionalen Raum bestimmen.Im Gegensatz dazu ist ein Mehr-Attribut-Index eine eindimensionale sowie mehrdimen-sionale Zugriffsstruktur.
Eindimensionaler Fall: Kombination der verschiedenen Zugriffsattributwerde konkate-niert als einen einzigen Zugriffsattributwert betrachtet (wieder lineare Ordnung in eindi-mensionalem Raum). Im Beispiel (Vorname, PLZ) werden allerdings keine partial-matchAnfragen nach PLZ unterstützt.
Mehrdimensionaler Fall: Menge der Zugriffsattributwerde spannt mehrdimensionalenRaum auf
Dabei hat der Mehr-Attribut-Index bei exact-match-Anfragen nur einen Indexzugriff,was dadurch zu insgesamt weniger Seitenzugriffen führt. Je nach Ausführungsart könnenneben exact-match-Anfragen auch partial-match-Anfragen effizient unterstützt werden.
4

2 mehrdimensionale binäre Suchbäume
Sie sind eine Erweiterung des Binärbaumes, wobei nicht nur ein, sondern k-Schlüsselberücksichtigt werden können.
2.1 k-d-Baum
der k-d-Baum von Bentley und Friedman wurde ursprünglich für Hauptspeicheralgorith-men entwickelt und stellt eine mehrdimensionale Grundstruktur dar. Alle Datensätzewerden mit Hilfe der Baumstruktur organisiert (knotenorientiert), wobei auf jeder Ebeneein Schlüsselvergleich für einen der k Schlüssel erfolgt. Die Auswahl des jeweiligen Schlüs-sels erfolgt durch einen sogenannten Diskriminator. Eine einfache und meist genutzte Va-riante ist eine zyklische Variantion der Schlüssel. Sei beispielsweise i die Baumebene, sokann ein Schlüssel d von k Schlüsseln durch folgende einfache Formel ausgewählt werden:d = (i mod k) + 1
Der linke/rechte Nachfolger zu einem Knoten im k-d-Baum enthält alle Sätze mit klei-neren/größeren Werten für das Diskriminatorattribut
2.2 KdB-Baum
Der KdB-Baum ist eine Kombinaton aus k-d- und B*-Baum und unterstützt primär-und mehrere Sekundärschlüssel gleichzeitig, wodurch zusätzliche Sekundärindexe als Da-teiorganisationsform überflüssig sind. Der Baum beruht auf der Idee in jeder Indexseiteeinen Teilbaum (k-d-Baum) darzustellen, der nach mehreren Attributen hintereinanderverzweigt. Auf jeder Baumebene wird der k-dimensionale Datenraum sozusagen durchden (k-d-Baum) in schachtelförmige Zellen oder Regionen (bei k=2 in Rechecke) partitio-niert, wobei eine Region jeweils die Zeilen/Regionen eines Knotens der darunterliegendenEbene zusammenfaßt und repräsentiert. Alle Datensätze sind im Gegensatz zu dem k-d-Baum allerdings nun in den Blättern (Satzseiten) gespeichert.
5

2 mehrdimensionale binäre Suchbäume
2.3 Struktur des KdB-Baumes
Abbildung 2.1: Struktur eines KdB-Baumes
KdB-Baum vom Typ(b,t) besteht aus
• inneren Knoten (Bereichsseiten) die einen kd-Baum mit maximal b internen Knotenenthalten
• Blätter (Satzseiten) die bis zu t Tupel der gespeicherten Relation speichern können
Bereichsseiten
• kd-Baum enthalten mit mehreren Schnittelementen und zwei Zeigern
• Schnittelement enthält Zugriffsattribut und Zugriffsattributwert
• linker Zeiger: kleinere Zugriffsattributwerte
• rechter Zeiger: größerer Zugriffsattributwert
• Anzahl der Schnitt- und Adresselemente der Seite
• Zeiger auf Wurzel des in der Seite enthaltenen kd-Baumes
• Schnitt- und Adresselemente
Schnittelement
• Zugriffsattribut
• Zugriffsattributwert
• zwei Zeiger auf Nachfolgerknoten des kd-Baumes dieser Seite (können Schnitt- oderAdresselemente sein)
6

2 mehrdimensionale binäre Suchbäume
Adresselemente
• Adresse eines Nachfolgers der Bereichsseite im KdB-Baum (Bereichs- oder Satzsei-te)
Trennattribute
• Reihnfolge der Trennattribtue:
– Reihnfolge durch Diskriminator gegeben
– entweder zyklisch festgelegt
– oder Selektivitäten einbeziehen: Zugriffsattribut mit hoher Selektivität solltefrüher und häufiger als Schnittelement eingesetzt werden
• Trennattributwert:
– aufgrund von Informationen über die Verteilung von Attributwerten eine ge-eignete ”Mitte” eines aufzutrennenden Attributwertebereichs ermitteln (Medi-an)
2.4 Komplexität/Aufwand
• lookup, insert und delete bei exact-match Anfragen: O(log n)
• bei partial-match Anfragen besser als: O(n)
• bei t von k Attributen in der Anfrage spezifiziert: O(n1− tk )
7

3 mehrdimensionales Hashing
Das mehrdimensionale Hashing baut auf dem lineare Hashing auf, wobei die Grundlagedas Bit Interleaving bildet. Die Hash-Werte sind Bitfolgen, von denen jeweils ein An-fangsstück als aktueller Hashwert dient. Es wird pro beteiligtem Attribut je ein Bitstringberechnet und anschließend die Anfangsstücke nach dem Prinzip des Bit-Interleavingzyklisch abgearbeitet, also reihum aus den Bits der Einzelwerte zusammensetzen.
3.1 formale Beschreibung
Aus einem k-dimensionaler Wert x
x = (x1, ..., xk)εD = D1 × ...×Dk
wird eine Folge von mit i indizierten Hashfunktionen konstruiert, wobei die i-te Hash-funktion hi(x) mittels Kompositionsfunktion h̄iaus den jeweils j-ten Anfangsstücken derlokalen Hashwerte hij (xj) zusammengesetzt wird:
hi = h̄i(hi1(x1), ..., hik(xk))
Dann ergibt die lokale Hashfunktion hij jeweils einen Bitvektor der Länge zij + 1:
hij : Dj → {0, ..., zij}, jε{1, ..., k}
Abbildung 3.1: Beispiel für 2 Dimensionen
8

3 mehrdimensionales Hashing
Damit die verschiedenen Dimensionen möglichst gleichmäßig berücksichtigt werden kön-nen, sollte zijmöglichst groß sein. Schließlich setzt die Kompositionsfunktion h̄i die lokalenBitvektoren zu einem einzigen Bitvektor der Länge i zusammen:
h̄i : {0, ..., zi1} × ...× {0, ..., zik} → {0, ..., 2i+1 − 1}
Die Bestimmung der Länge von zij wird durch folgende Festlegung bestimmt, wobei dieLängen zyklisch bei jedem Erweiterungsschritt an einer Stelle erhöht werden:
zij =
{2b
ikc+1 − 1 für j − 1 ≤ (i mod k)
2bikc − 1 für j − 1 > (i mod k)
Die Kompositionsfunktion ist definiert als:
h̄i(x) =i∑
r=0
(x(r mod k)+1 mod 2b
rk+1c)−(x(r mod k)+1 mod 2b
rkc)
2brkc
3.2 Beispiel
Abbildung 3.2: Veranschaulichung des MDH
Das obige Beispiel verdeutlicht die Komposition der Hashfunktion hi für drei Dimensio-nen und den Wert i = 7. Würde man nun i = 8 setzen, dann würde das nächste Bit vonx2 verwendet werden.
3.3 Komplexität/Aufwand
• bei exact-match Anfragen: O(1)
• bei partial-match Anfragen, in denen t von k Attributen festgelegt sind: O(n1− tk )
• Spezialfälle: O(1) bei t = k, O(n) für t = 0
9

4 Grid-Files
Die Grid-Files sind eine mehrdimensionale Dateiorganisationsform, welche eine Kombi-nation von Elementen der Schlüsseltransformation (Hash-Verfahren) und Indexdateien(Baumverfahren) zugrunde legt. Die Idee basiert auf der Dimensionsverfeinerung, d.h. diegleichmäßige Aufteilung des mehrdimensionalen Raumes in der ausgewählten Dimensiondurch einen vollständigen Schnitt (Einziehen einer Hyperebene). Damit möchte man dieZerlegung des Datenraumes in n-dimensionale Quader erreichen, wobei ähnliche Objekteauf einer gleichen Seite gespeichert werden sollen, um die Nachbarschaftserhaltung zugewährleisten. Die Struktur des Grid-File passt sich dynamisch an die lokale Dichte derDaten beim Einfügen und Löschen an. Das sogenannte Prinzip der 2 Plattenzugriffe,d.h. nur ein Zugriff auf ein Indexelement (Grid-Directory), ein weiterer direkt auf denDatensatz, wird bei exact-match-Anfragen realisiert.
4.1 Aufbau
Abbildung 4.1: Aufbau eines Grid-Files
Grid: k eindimensionale Felder (Skalen), von welche jede Skala ein Attribut repräsentiert
Skalen: bestehen aus Partitionen der zugeordneten Wertebereiche in Intervalle
Grid-Directory: besteht aus Grid-Zellen, die Datenraum in Quader zerlegen
Grid-Zellen: bilden eine Grid-Region, der genau eine Datensatzseite zugeordnet ist
Grid-Region: k-dimensionales, konvexes Gebilde (paarweise disjunkt)
10

4 Grid-Files
4.2 Operationen
Im Ausgangszustand existiert nur eine einzige Grid-Region, welche auch gleichzeitig eineGrid-Zelle bzw. die eigentliche Datensatzseite darstellt. Kommt es nun beim Einfügenvon Datensätzen zu einem Seitenüberlauf, werden die jeweiligen Seiten geteilt. Falls diezu dieser Seite gehörende Grid-Region nur aus einer Zelle besteht, wird das Interval aufeiner Skala unterteilt. Anderenfalls, also wenn die Region aus mehreren Zellen besteht,wird diese Zelle in einzelne Regionen zerlegt. Bei einem Seitenunterlauf werden beim lö-schen von Datensätze zwei Regionen wieder zusammengefasst, falls es sich beim Ergebnisanschließend um eine konvexe Region handelt (n-dimensionaler Quader).
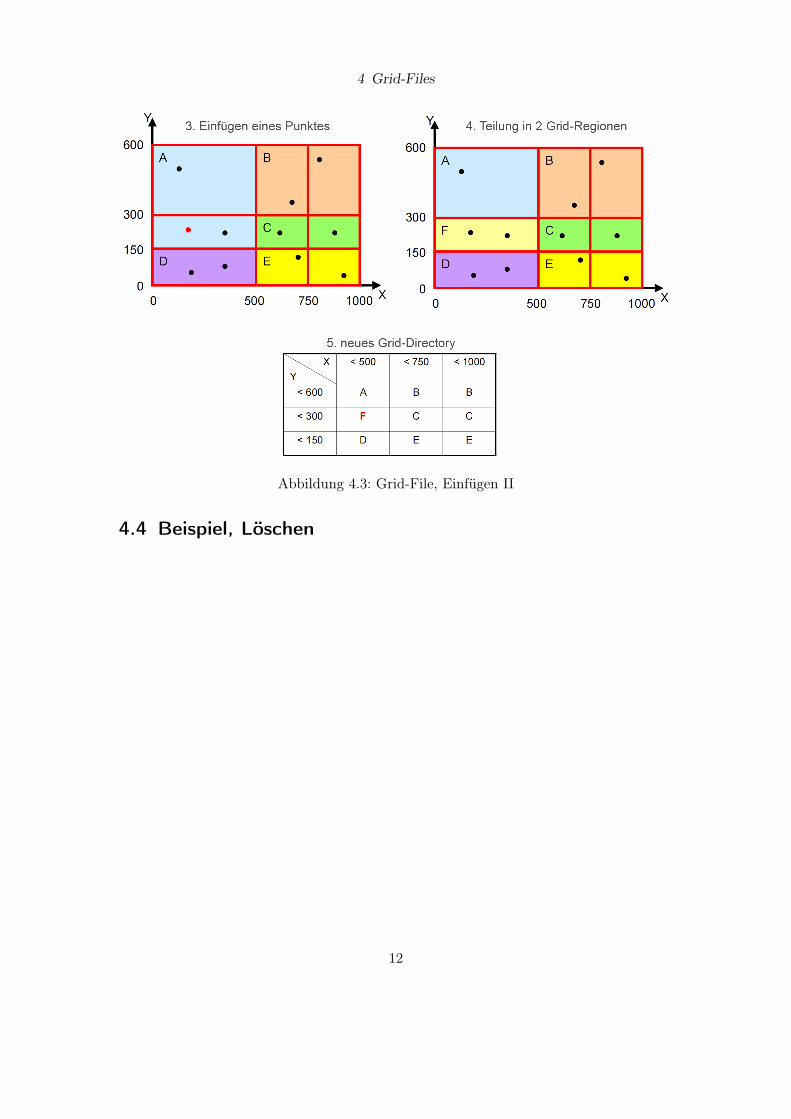
4.3 Beispiel, Einfügen
Abbildung 4.2: Grid-File, Einfügen I
11
4 Grid-Files
Abbildung 4.3: Grid-File, Einfügen II
4.4 Beispiel, Löschen
12
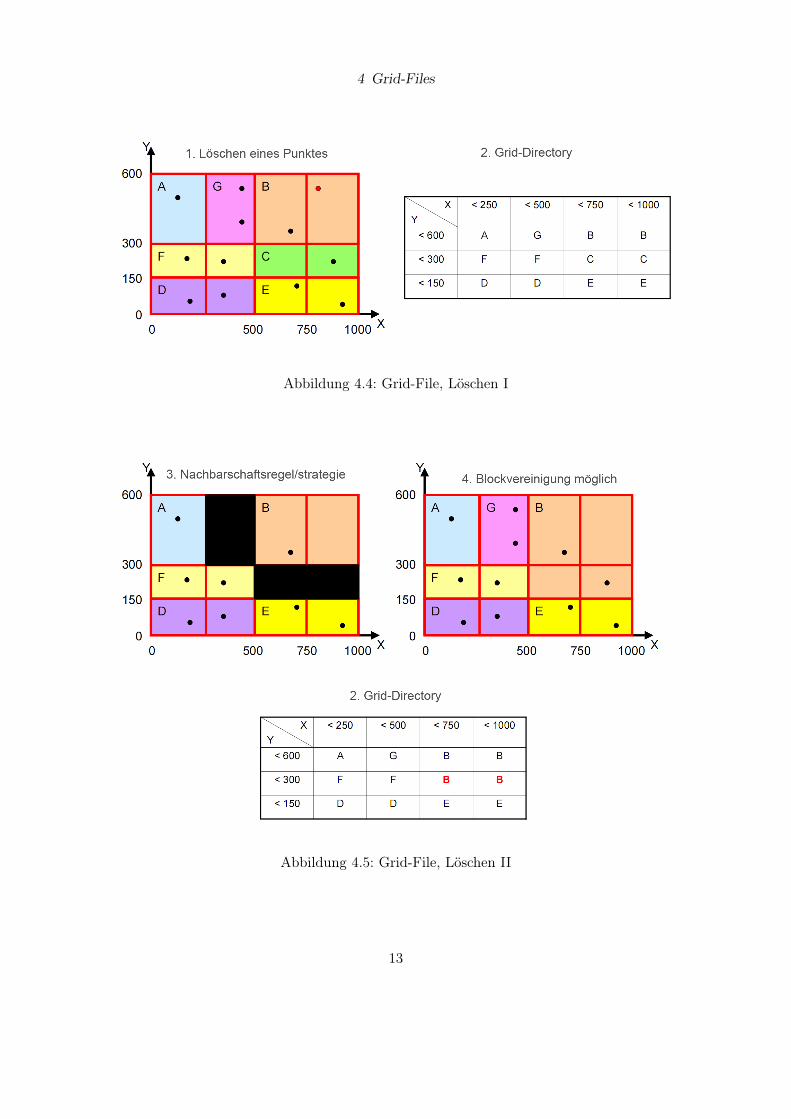
4 Grid-Files
Abbildung 4.4: Grid-File, Löschen I
Abbildung 4.5: Grid-File, Löschen II
13

Abbildungsverzeichnis
2.1 Struktur eines KdB-Baumes . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.1 Beispiel für 2 Dimensionen . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Veranschaulichung des MDH . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.1 Aufbau eines Grid-Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2 Grid-File, Einfügen I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.3 Grid-File, Einfügen II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.4 Grid-File, Löschen I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.5 Grid-File, Löschen II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
14

Literaturverzeichnis
[1] Theo Härder, Erhard RahmDatenbanksysteme: Konzepte und Techniken der Imple-mentierung
[2] T. Ottmann, P.Widmayer Algorithmen und Datenstrukturen
[3] J. Nievergelt, Hans Hinterberger, Kenneth C. SevcikThe The Grid File: An Adapta-ble, Symmetrix Multikey File Structure
15





























