Embed Size (px)
Citation preview

Biometrisches Tutorial II
Montag 16-18 Uhr
Sitzung 2
17.06.2019
Dr. Christoph Borzikowsky

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
2

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
3

Ziel: Unterstützung (wissenschaftsinitiierter) klinischer Studien
Leistungen
1. Beratungsgespräche
• Fortbildungen + Beratungen, Biometrie
2. Planung klinischer Studien
3. Durchführung klinischer Studien
4. Abschluss klinischer Studien (Auswertungen, Berichte, Abmeldungen)
5. Fortbildungen
• GCP(Good Clinical Practice)-Kurse, Prüfarztkurse nach AMG
(Arzneimittelgesetz) und MPG (Medizinproduktegesetz), Medical
Writing, English for Investigators
Das Zentrum für klinische Studien Kiel
4

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
5
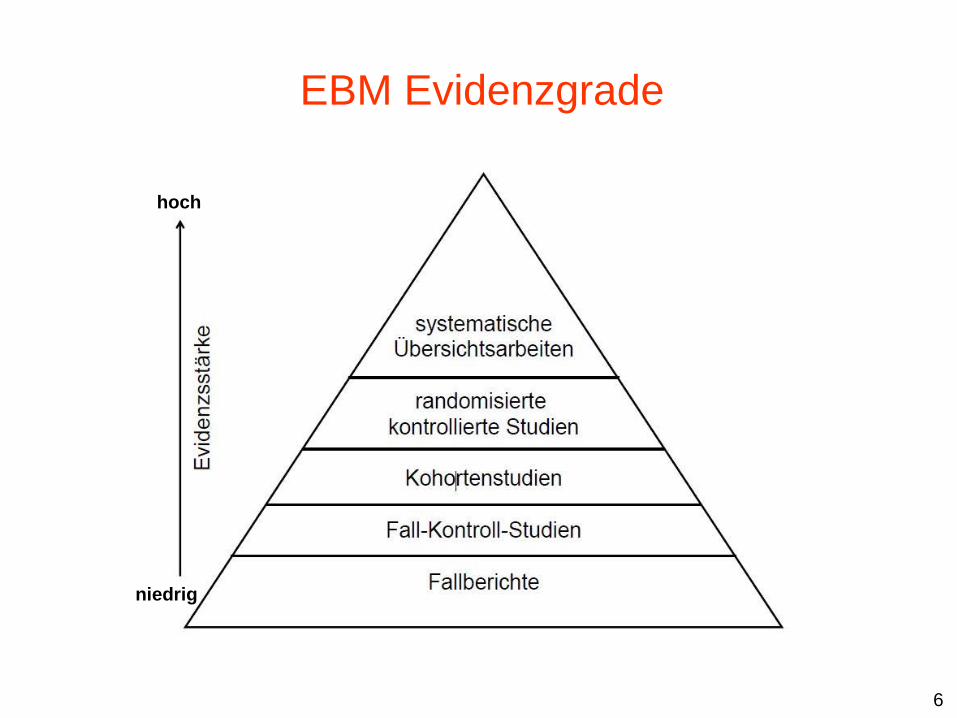
EBM Evidenzgrade
niedrig
hoch
6

Anmeldebogen zur statistischen Beratung
7
PDF für Promovierende (3 Seiten)
Infos zur
Person
Infos zur
Studie
Infos zur
Studie
Unter- schriften
+ Stempel

Dazu wird retrospektiv an Individuen mit bekanntem
Erkrankungsstatus (Fall/Kontrolle) der Expositionsstatus
erhoben (Exposition ja/nein).
Statistische Analyse Rückblick: Fall-Kontroll-Studie
Typischerweise wird in Fall-Kontroll-Studien der
Zusammenhang zwischen Exposition und Erkrankung
untersucht
8

Fragestellung:
Ist die Wahrscheinlichkeit einen Infarkt zu erleiden bei
Männern und Frauen gleich?
Stichprobe:
40 Infarktpatienten, 40 Kontrollen
Herzinfarkt und Geschlecht
9
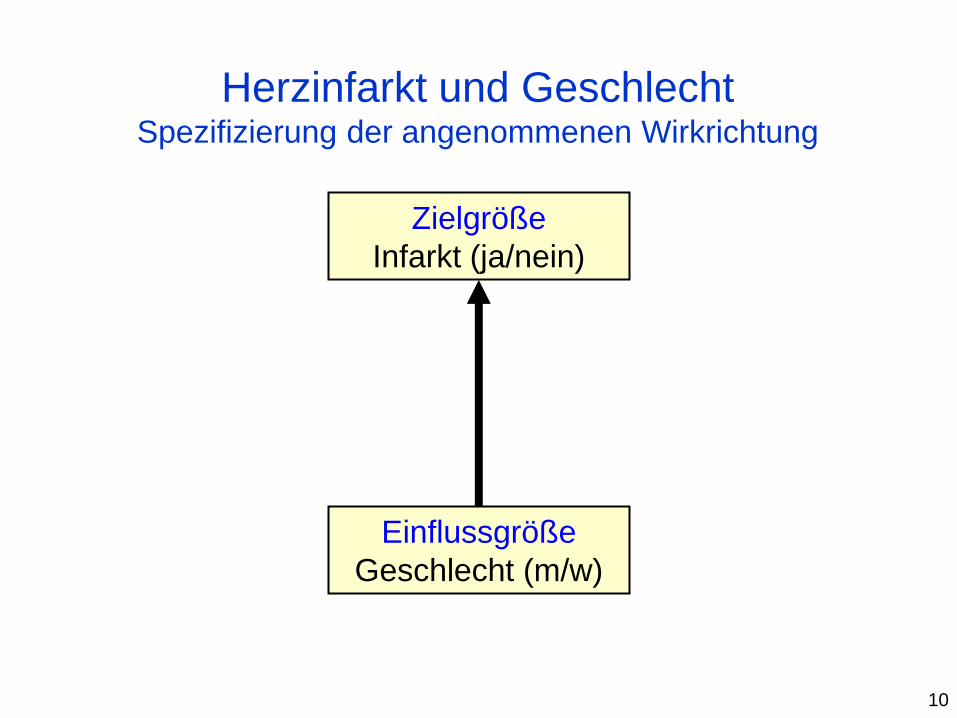
Einflussgröße
Geschlecht (m/w)
Zielgröße
Infarkt (ja/nein)
Herzinfarkt und Geschlecht Spezifizierung der angenommenen Wirkrichtung
10

40 Infarktpatienten werden mit 40 Kontrollen verglichen
Zielgröße: Infarkt (dichotom: ja/nein)
Einflussgröße: Geschlecht (dichotom: m/w)
Fragestellung: Ist die Wahrscheinlichkeit einen Infarkt zu
erleiden bei Männern und Frauen gleich?
Nullhypothese: Infarkt und Geschlecht sind unabhängig
Herzinfarkt und Geschlecht
11

Anmeldebogen zur statistischen Beratung
12
Bitte daran denken: Infos auf dem Anmeldebogen eintragen!
Infos zur
Person
Infos zur
Studie
Infos zur
Studie
Unter- schriften
+ Stempel

Statistische Test für Daten
mit nominalen Skalenniveau
13
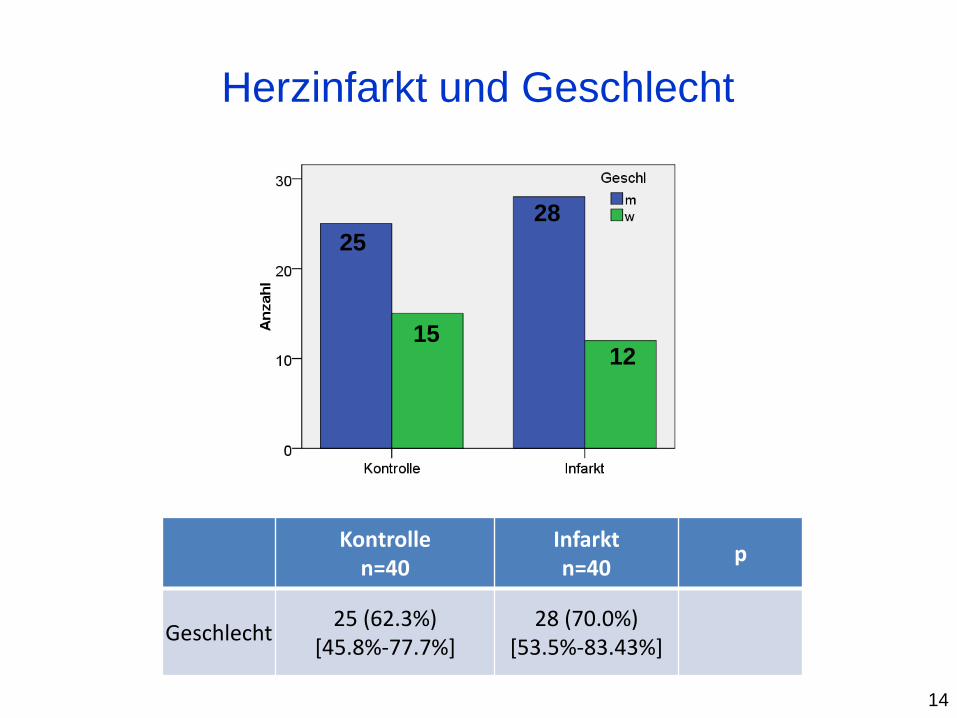
Herzinfarkt und Geschlecht
Kontrolle n=40
Infarkt n=40
p
Geschlecht 25 (62.3%)
[45.8%-77.7%] 28 (70.0%)
[53.5%-83.43%]
14
25
15
28
12

Herzinfarkt und Geschlecht
25 28
15 12
40 40
53
27
80
X 0 1 Y
m
w
N
fofofe
ji
ij
..
Nullhypothese Geschlecht und Infarkt sind unabhängig
Unter der Nullhypothese
erwartete Werte:
15
Berechnung erwartete Häufigkeiten:
feij = (Zeilensummei ∙ Spaltensummej)/N
fe = frequency expected
fo = frequency observed
N = Gesamtstichprobenumfang
0 = Kontrolle; 1 = Infarkt

Herzinfarkt und Geschlecht
25 28
15 12
40 40
53
27
80
X 0 1 Y
m
w
26.5 26.5
13.5 13.5
Nullhypothese Geschlecht und Infarkt sind unabhängig
Unter der Nullhypothese
erwartete Werte:
16
N
fofofe
ji
ij
..
fe11 = 53 * 40 / 80 = 26.5
0 = Kontrolle; 1 = Infarkt

Herzinfarkt und Geschlecht
25 28
15 12
40 40
53
27
80
X 0 1 Y
m
w
26.5 26.5
13.5 13.5
Nullhypothese Geschlecht und Infarkt sind unabhängig
Teststatistik
kritische Werte Chi-Quadrat-Verteilung c1-,
Unter der Nullhypothese
erwartete Werte:
n
i
m
jij
ijij
fe
fefo
1 1
2
2)(
17
N
fofofe
ji
ij
..
0 = Kontrolle; 1 = Infarkt

Herzinfarkt und Geschlecht
25 28
15 12
40 40
53
27
80
X 0 1 Y
m
w
26.5 26.5
13.5 13.5
Nullhypothese Geschlecht und Infarkt sind unabhängig
Teststatistik
kritische Werte c0.95,1=3.841 > 0.503 => H0 nicht ablehnen
Unter der Nullhypothese
erwartete Werte:
5.2680
4053
503.0...26.5
)26.5(25χ
2
2
N
fofofe
ji
ij
..
18
0 = Kontrolle; 1 = Infarkt

Die in den Daten einer Stichprobe enthaltene Information
wird in der empirischen Teststatistik Temp
zusammengefasst.
Der Annahmebereich des Tests enthält alle Werte von Temp,
bei denen H0 beibehalten wird.
Der Ablehnungsbereich enthält alle Werte von Temp, bei
denen H0 verworfen wird.
Annahme- und Ablehnungsbereich werden von den
kritischen Werten begrenzt.
Statistisches Testen Vorgehensweise
19
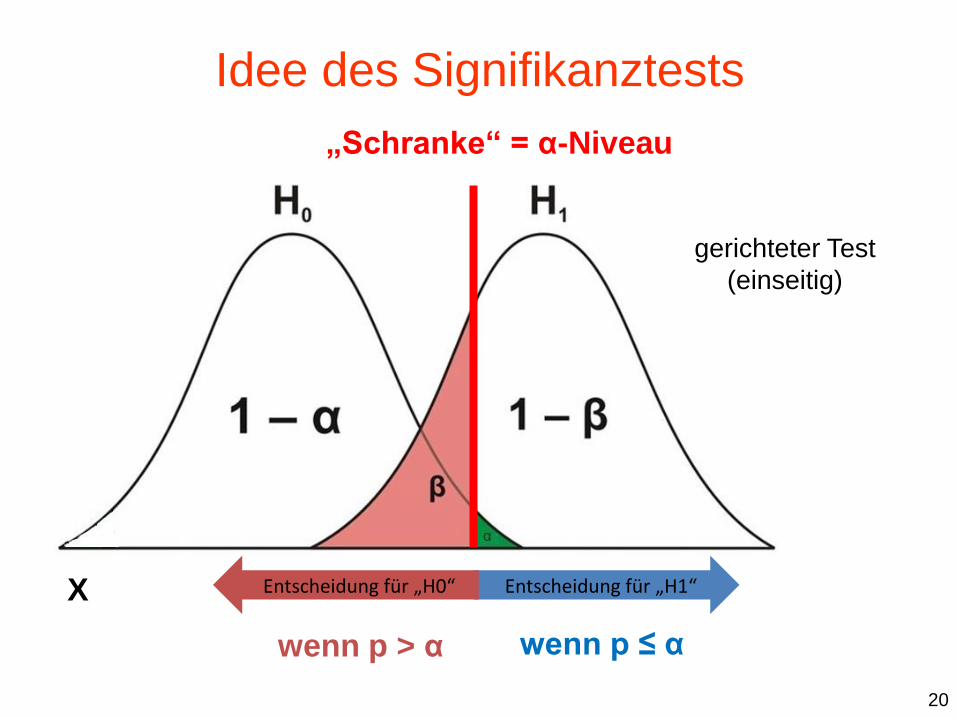
X
gerichteter Test
(einseitig)
„Schranke“ = α-Niveau
Entscheidung für „H0“
wenn p ≤ α wenn p > α
Entscheidung für „H1“
20
Idee des Signifikanztests
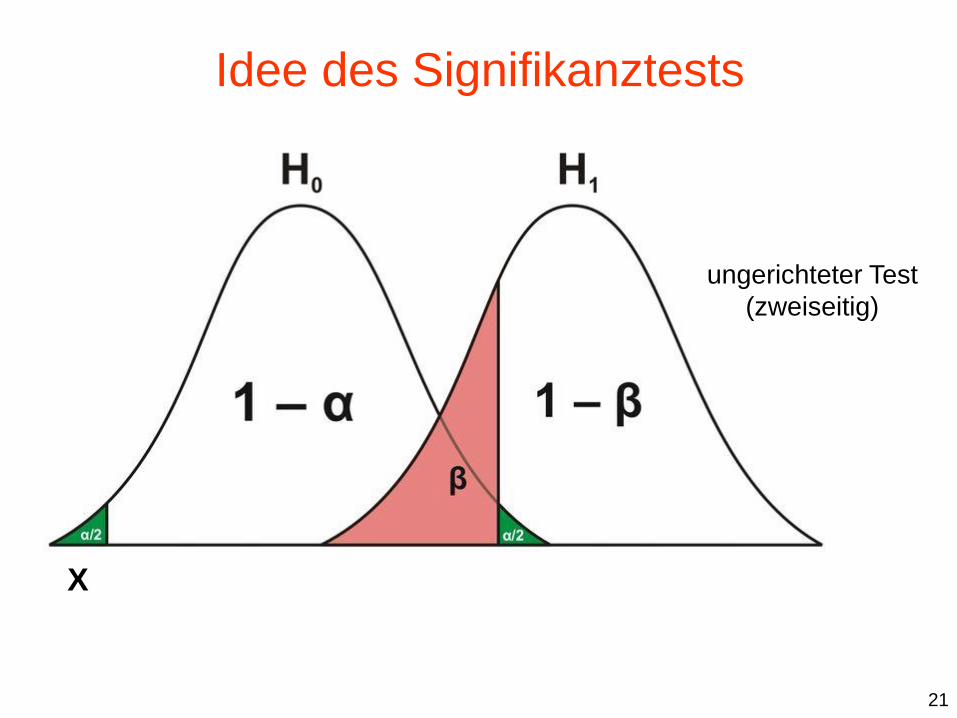
X
ungerichteter Test
(zweiseitig)
Idee des Signifikanztests
21
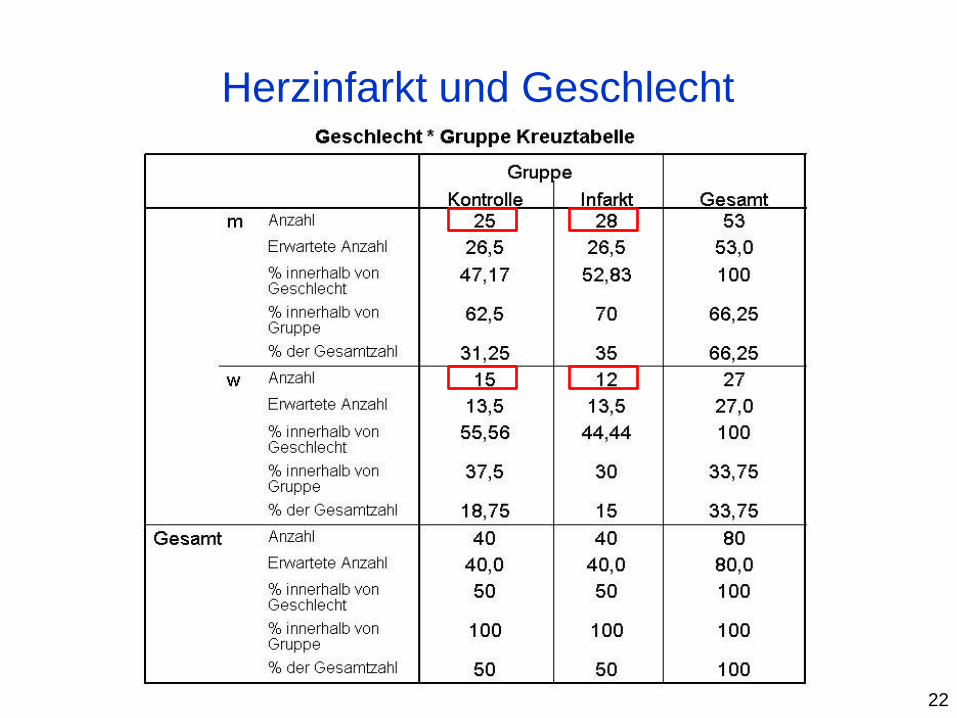
Herzinfarkt und Geschlecht
22
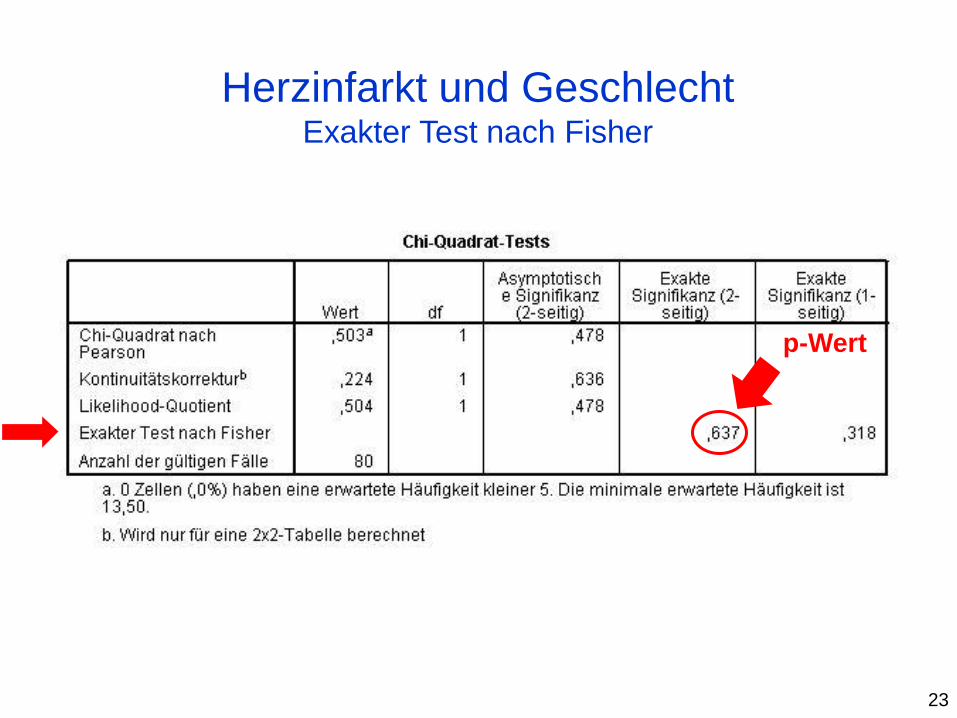
Herzinfarkt und Geschlecht Exakter Test nach Fisher
23
p-Wert
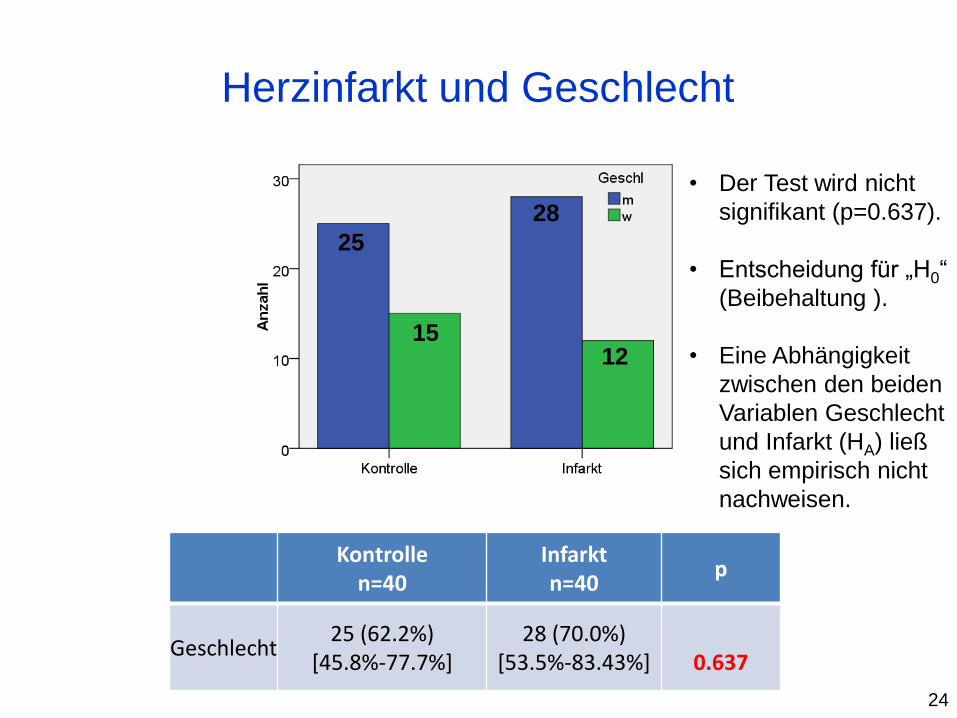
Herzinfarkt und Geschlecht
Kontrolle n=40
Infarkt n=40
p
Geschlecht 25 (62.2%)
[45.8%-77.7%] 28 (70.0%)
[53.5%-83.43%]
0.637
24
25
15
28
12
• Der Test wird nicht
signifikant (p=0.637).
• Entscheidung für „H0“
(Beibehaltung ).
• Eine Abhängigkeit
zwischen den beiden
Variablen Geschlecht
und Infarkt (HA) ließ
sich empirisch nicht
nachweisen.

Nullhypothese
Teststatistik
kritische Werte c1-, "Anzahl Freiheitsgrade" = (n-1)(m-1)
H0: X und Y sind unabhängig
o11 o1m ...
...
on1 onm ...
o.1 o.m ...
o1.
on.
N
Unter der Annahme, dass
die Zeilen und Spalten
unabhängig sind (H0),
beträgt die erwartete
Zellhäufigkeit:
2-Test
X 1 ... m
... ... ...
Y
1
...
n
25
N
fofofe
ji
ij
..
n
i
m
jij
ijij
fe
fefo
1 1
2
2)(

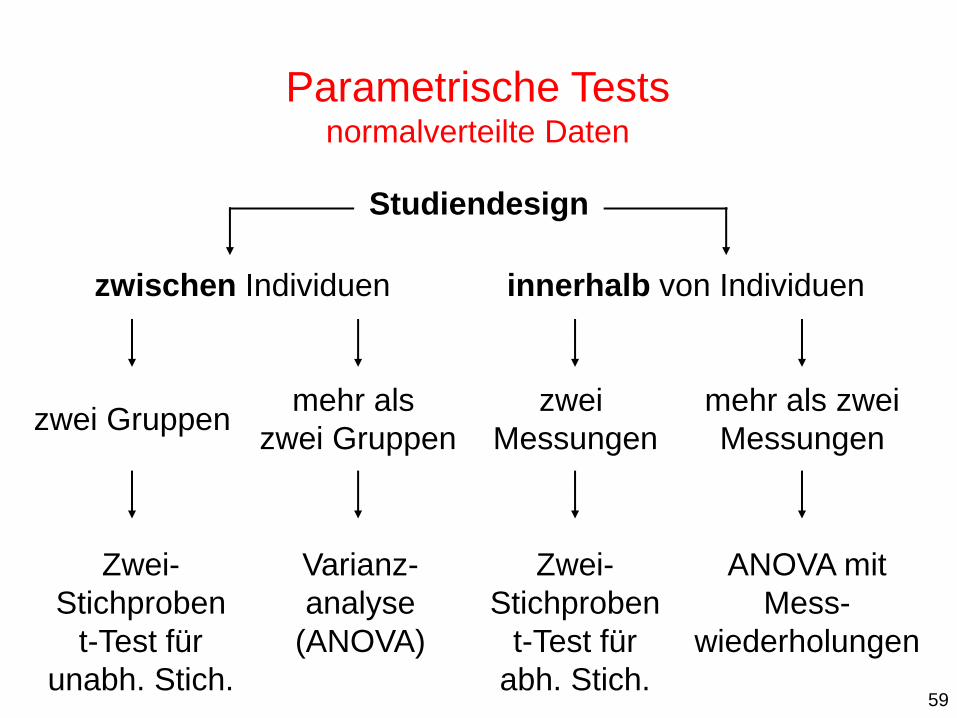
zwischen Individuen innerhalb von Individuen
zwei Messungen
mehr als zwei Messungen
zwei Gruppen mehr als
zwei Gruppen
Studiendesign
McNemar- Test
Symmetrie- Test
2-Test (Fishers exakter
Test)
Zusammenfassung Statistische Tests für nominale Daten
2-Test (Fishers exakter
Test)
26

Statistische Test für Daten
mit stetigem Skalenniveau
(normalverteilt)
27

Statistische Analyse ein stetiges, normalverteiltes Merkmal
Normalverteilung N(,2) mit = E(X) und 2 = Var(x)
2
2
2
)x(
e2
1)x(f
28
29
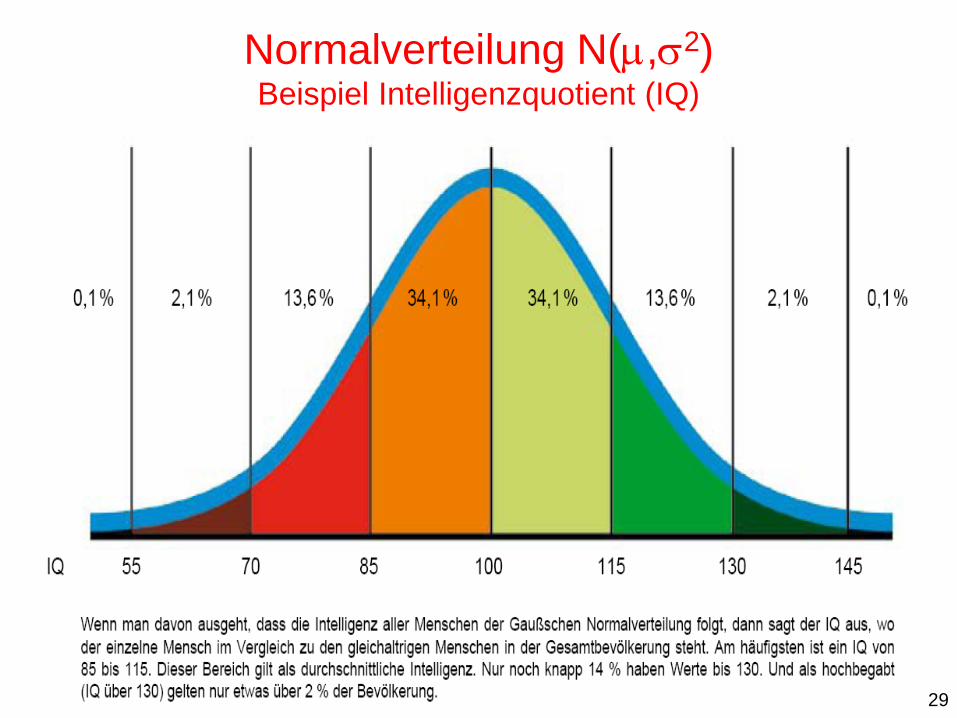
Normalverteilung N(,2) Beispiel Intelligenzquotient (IQ)
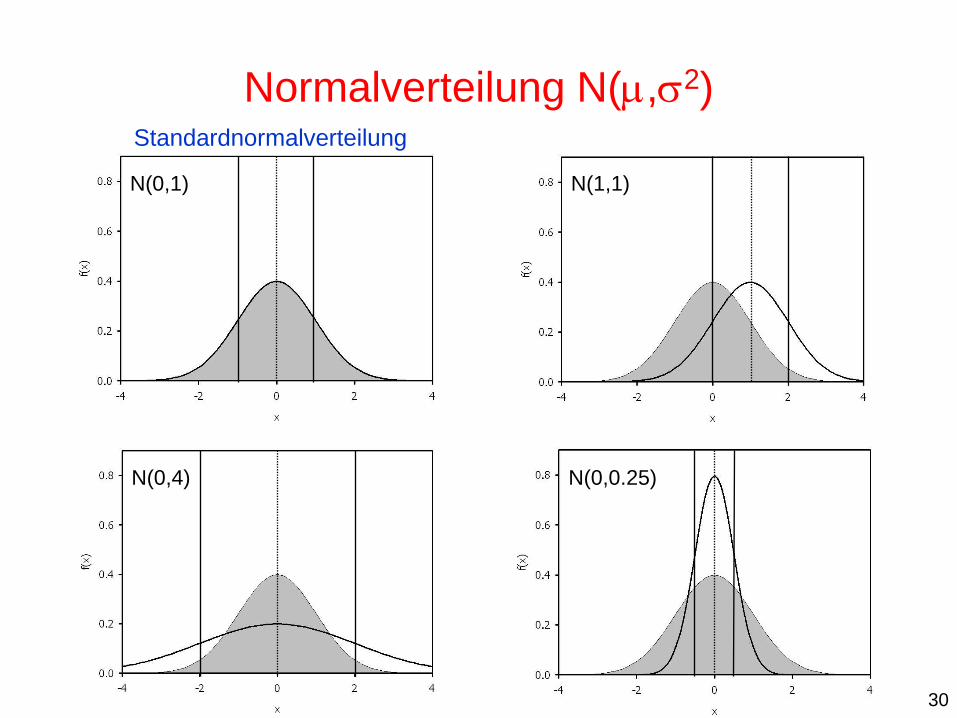
N(1,1)
N(0,0.25)
N(0,1)
N(0,4)
Normalverteilung N(,2)
30
Standardnormalverteilung
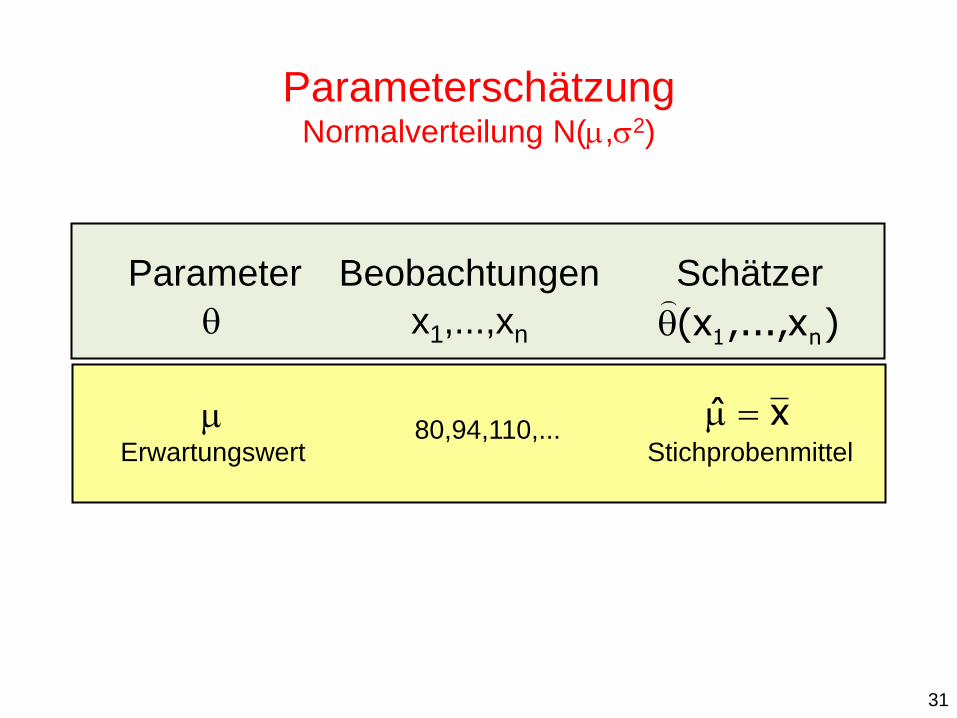
Parameter
Erwartungswert
Beobachtungen
80,94,110,...
x1,...,xn
Schätzer
Stichprobenmittel
)x,...,x( n1
xˆ
Parameterschätzung Normalverteilung N(,2)
31

a) Vergleich von einer Gruppe
mit einem Referenzwert
1-Stichproben-t-Test
32

Im Rahmen einer Fall-Kontroll-Studie soll geprüft
werden, ob sich der erwartete diastolische Blutdruck
von den Kontrollpersonen vom erwarteten Blutdruck 0 =
80 mmHg bei Normalpersonen unterscheidet.
H0: =0 HA: 0
Wie repräsentativ ist die Kontrollgruppe?
33
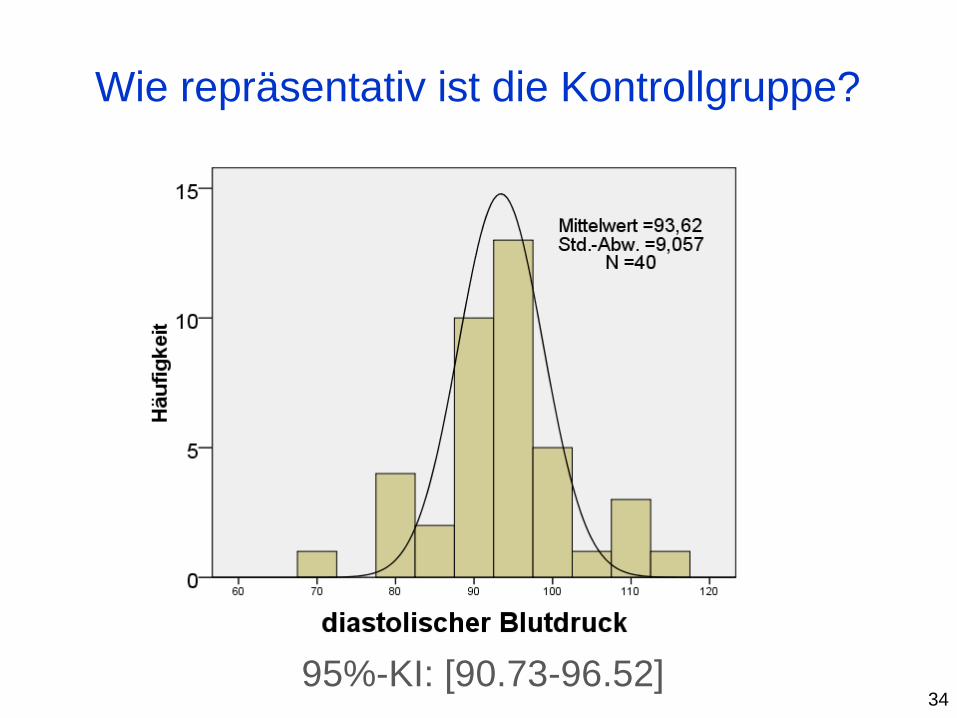
Wie repräsentativ ist die Kontrollgruppe?
95%-KI: [90.73-96.52] 34

nS
μXT 0
Teststatistik
Zufallsvariable XN(,2) beide Parameter unbekannt
Hypothesen 00 μμ :H 0A μμ :H (zweiseitig)
kritische Werte t1-/2,n-1 (zweiseitig)
0H wird abgelehnt, falls 1nα/2,1t |t|
Statistische Analyse Ein-Stichproben-t-Test
35

Statistische Analyse Ein-Stichproben-t-Test
36

Statistische Analyse Ein-Stichproben-t-Test
37
Stichprobenmittelwert M
erwartetes μ0
Differenz M - μ0 p-Wert temp
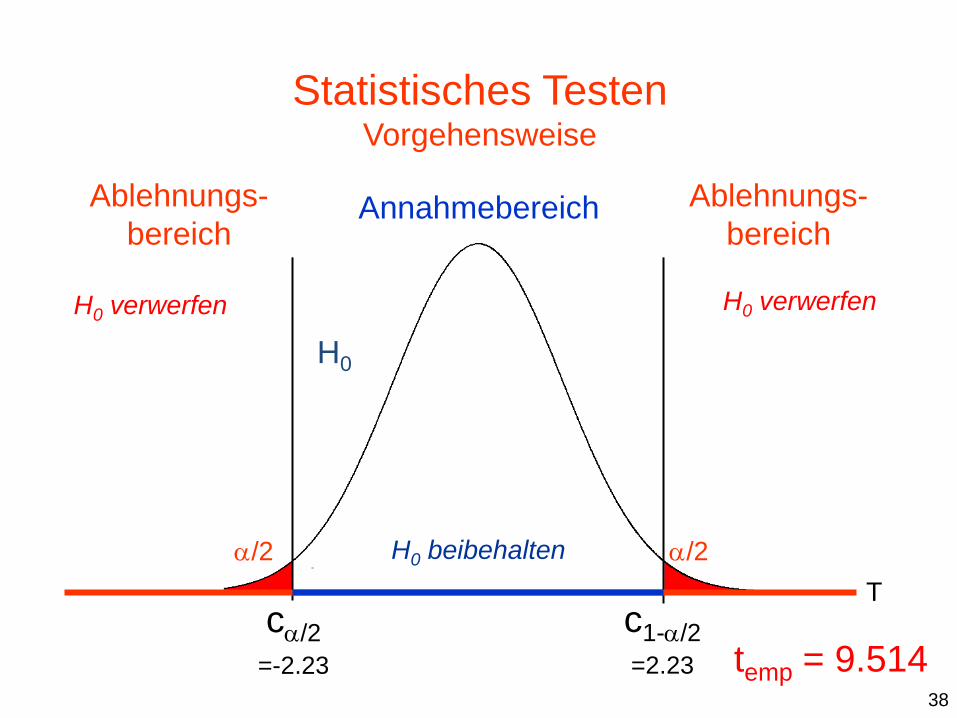
c1-/2
=2.23
c/2
=-2.23
/2 /2
T
H0
temp = 9.514
Ablehnungs-
bereich
Annahmebereich Ablehnungs-
bereich
H0 verwerfen H0 verwerfen
H0 beibehalten
Statistisches Testen Vorgehensweise
38

b) Vergleich von zwei abhängigen Gruppen
39
2-Stichproben-t-Test für
abhängige Stichproben

• eGFR = geschätzte glomeruläre Filtrationsrate [ml/min]; ein
Maß für die Nierenfunktion
• N=40 Patienten vor und nach einer OP (Messwiederholung)
Fragestellung:
Ist die Nierenfunktion nach der OP (post-OP) besser vor der
OP (prä-OP)?
Zielgröße: eGFR [ml/min] (prä-OP und post-OP)
Einflussgrößen: OP
Nierenfunktion
(prä-OP vs. post-OP)
40

0 :H D0 Hypothesen
Teststatistik
0 :H DA
Zufallsvariable X, Y verbunden, D=X-YN(D,D2)
beide Parameter unbekannt
Ablehnungs- bereich
Tt/2,n-1 oder Tt1-/2,n-1
n/S
DT
D
41
Statistische Analyse zwei normalverteilte Merkmale
Zwei-Stichproben-t-Test für abhängige Stichproben:
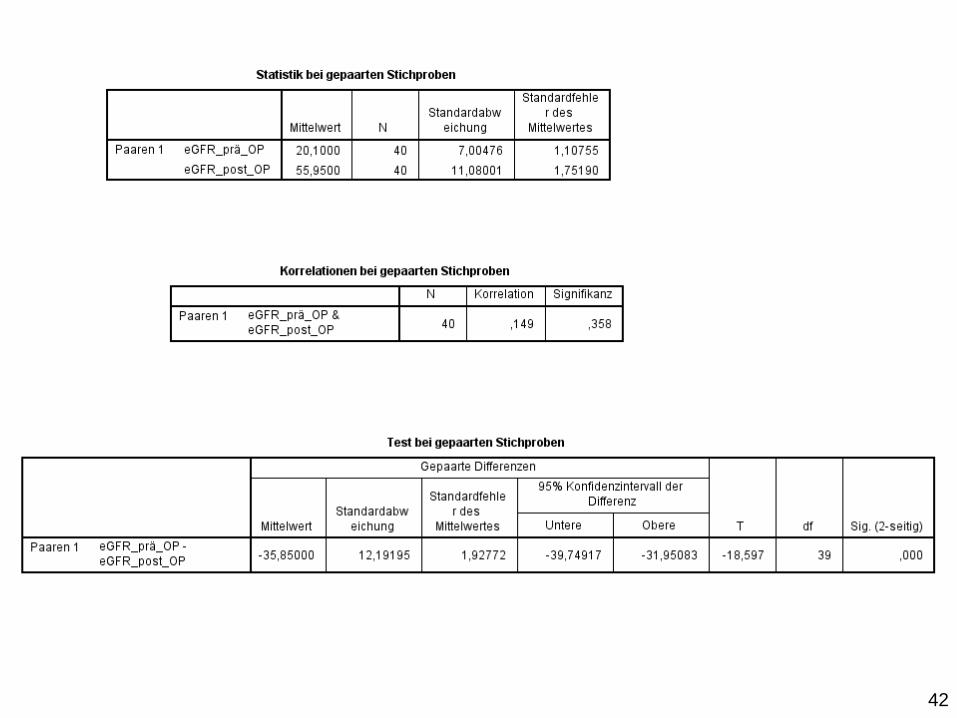
42
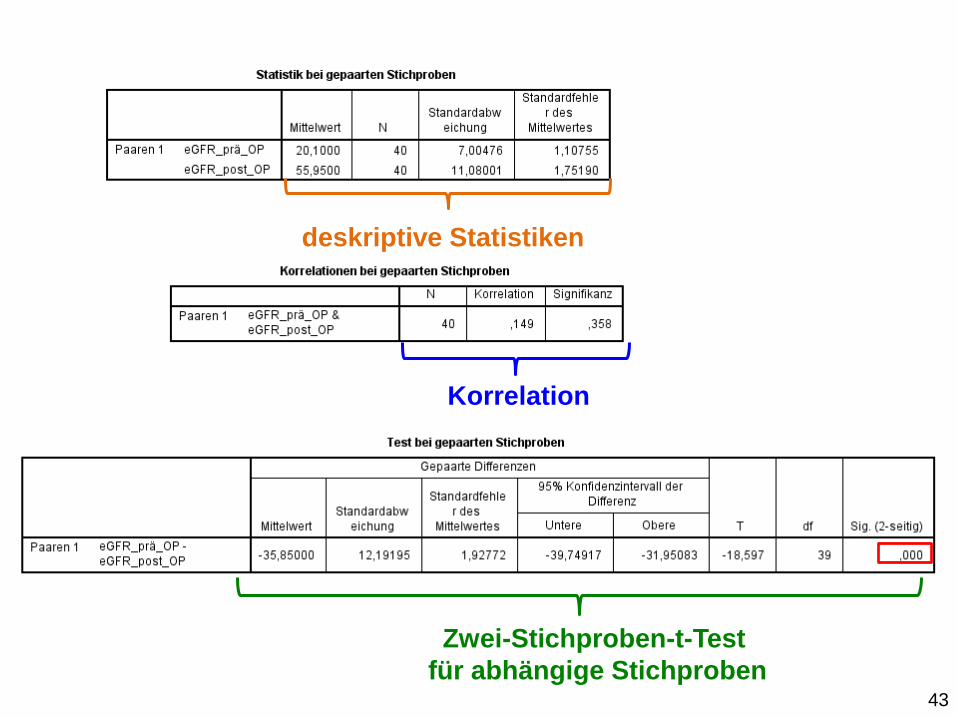
43
deskriptive Statistiken
Korrelation
Zwei-Stichproben-t-Test
für abhängige Stichproben

c) Vergleich von zwei unabhängigen Gruppen
44
2-Stichproben-t-Test für
unabhängige Stichproben

• ACE-Hemmer (Angiotensin-Converting-Enzym-Hemmer):
beeinflussen die Herstellung von körpereigenen Hormonen, die den
Blutdruck steuern.
blockieren ein bestimmtes Enzym, das an der Bildung des
blutdrucksteigernden Hormons Angiotensin beteiligt ist.
• N=80 Patienten mit Bluthochdruck
Fragestellung:
Kann die Gabe von ACE-Hemmern nachweislich den
Blutdruck senken?
Zielgröße: Blutdruck [mmHg]
Einflussgrößen: Verum (ACE-Hemmer) vs. Placebo
ACE-Hemmer und Bluthochdruck
45
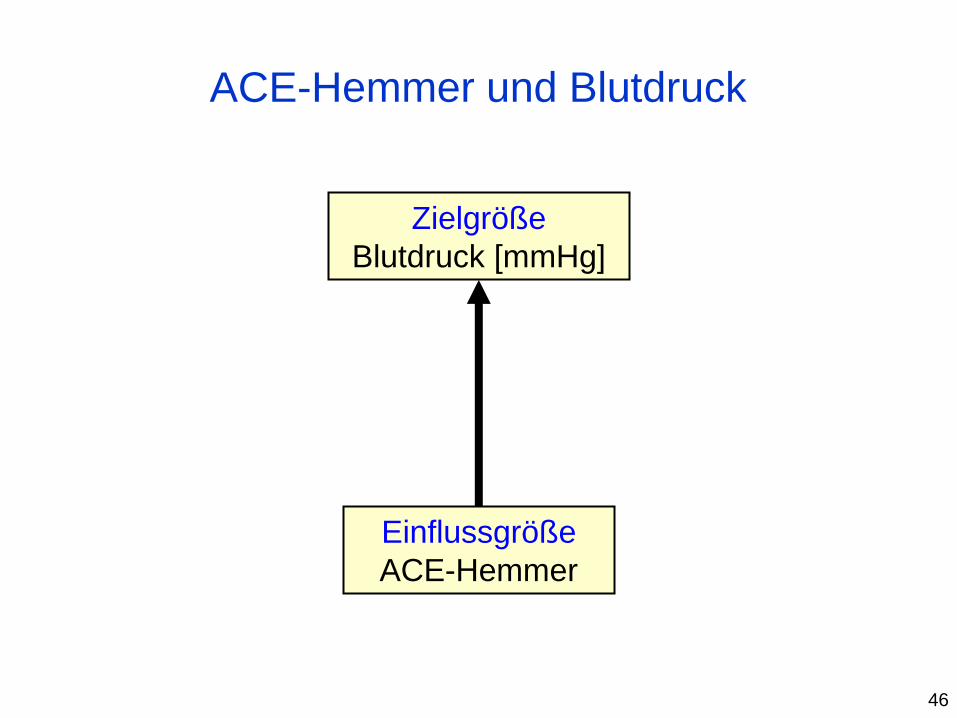
Einflussgröße
ACE-Hemmer
Zielgröße
Blutdruck [mmHg]
ACE-Hemmer und Blutdruck
46

ba
ba
pooled
ba
nn
nn
S
XXT
ba0 :H baA :H
XaN(a,2) und XbN(b,
2)
(zweiseitig)
(zweiseitig)
Hypothesen
Teststatistik
Zufallsvariable
Ablehnungs-
bereich oder 2nn,2/ ba
tT 2nn,2/1 batT
Statistische Analyse zwei normalverteilte Merkmale
47
Zwei-Stichproben-t-Test für unabhängige Stichproben:
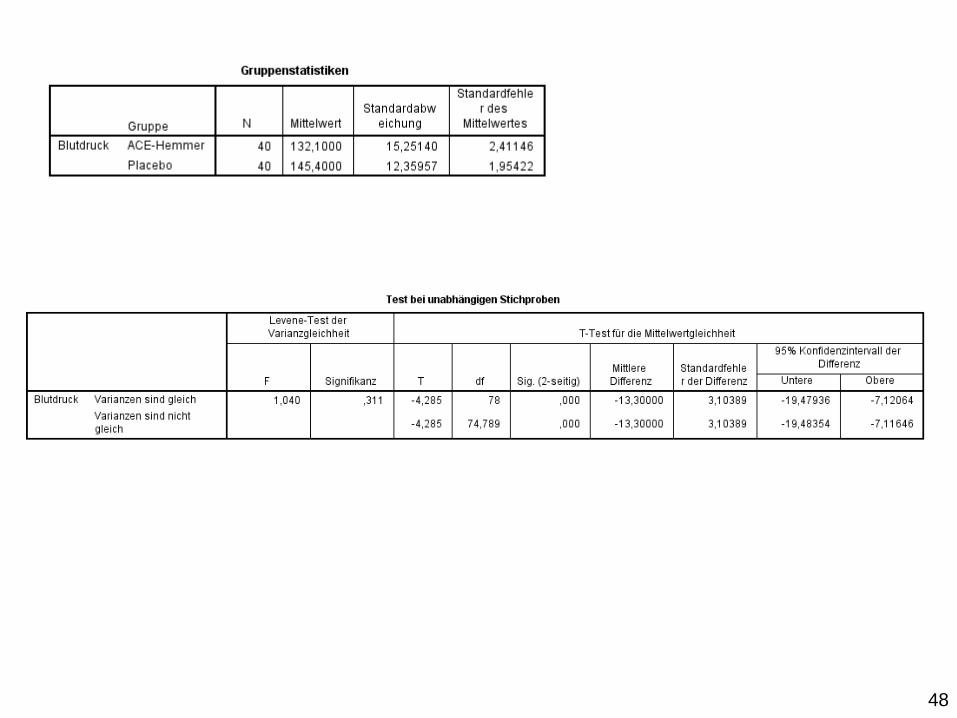
48
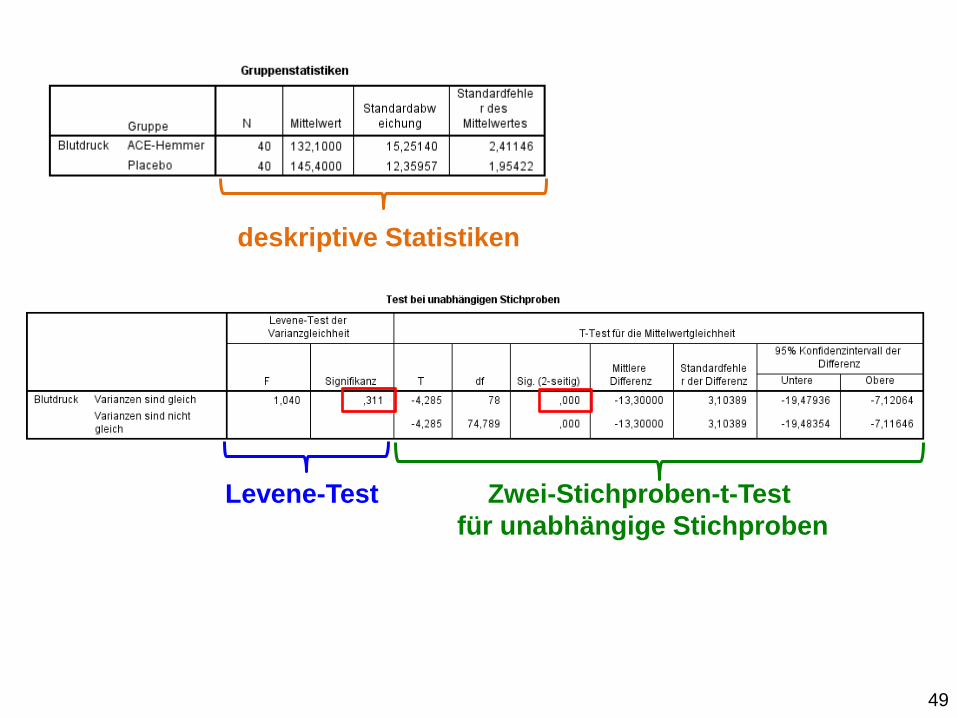
Levene-Test Zwei-Stichproben-t-Test
für unabhängige Stichproben
deskriptive Statistiken
49

Statistische Test für Daten
mit stetigem Skalenniveau
(nicht normalverteilt)
50
0
5
10
15
20
25
30
10 - 20 20 - 30 30 - 40 40 - 50 50 - 60 60 - 70 70 - 80 80 - 90
0
5
10
15
20
25
30
10 - 20 20 - 30 30 - 40 40 - 50 50 - 60 60 - 70 70 - 80 80 - 900
5
10
15
20
25
30
10 - 20 20 - 30 30 - 40 40 - 50 50 - 60 60 - 70 70 - 80 80 - 90
0
5
10
15
20
25
30
10 - 20 20 - 30 30 - 40 40 - 50 50 - 60 60 - 70 70 - 80 80 - 90
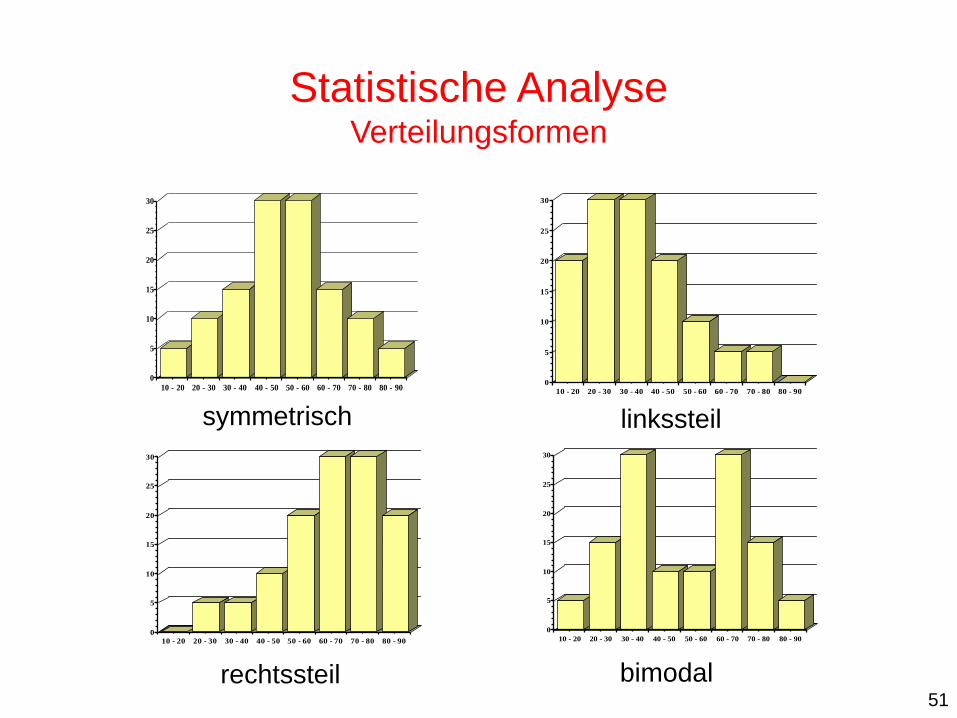
symmetrisch linkssteil
rechtssteil bimodal
Statistische Analyse Verteilungsformen
51

Vergleich von zwei Gruppen
Statistische Test für Daten
mit stetigem Skalenniveau
(nicht normalverteilt)
52

Statistische Analyse zwei stetige, nicht normalverteilte Merkmale
Teststatistik
Zufallsvariablen XF, YG F, G stetige Verteilungen
Hypothesen
kritische Werte und W/2,n
Howird abgelehnt, falls Wn>W1-/2,n oder Wn<W/2,n
n
1i
X_iR
W1-/2,n
Wn =
Ho: F(z) = G(z) HA: F(z+d) = G(z)
53
Wilcoxon-Rangsummentest

• Zur Wirksamkeitsprüfung eines neuen
Antidepressivums werden 10 klinisch depressive
Patienten zufällig einer von zwei Gruppen zugeordnet.
• Gruppe 1 bekommt für 6 Monate das neue
Medikament, Gruppe 2 bekommt ein Placebo.
• Am Ende der Studie wird der Zustand jedes
Teilnehmers von einem verblindeten Psychiater mit
einem Score bewertet.
H0: Die Verteilung des Depressionsscores ist unter Verum
die gleiche wie unter Placebo.
HA: Die Verteilung des Depressionsscores ist unter Verum
eine andere als unter Placebo.
Behandlung von Depressionen
54

X1
11
X2
15
X3
7
X4
8
X5
12
Y1
3
Y2
4
Y3
9
Y4
2
Y5
5
Patient
Score
X1
8
X2
10
X3
5
X4
6
X5
9
Y1
2
Y2
3
Y3
7
Y4
1
Y5
4
Patient
Rang
38109865)( iXR
Teststatistik (maximale Rangsumme) W=38
kritischer Wert (zweiseitig) W0.975,5=37
H0 kann zum 5% Signifikanzniveau verworfen werden.
Behandlung von Depressionen Wilcoxon-Rangsummentest
55
1774321)( iYR
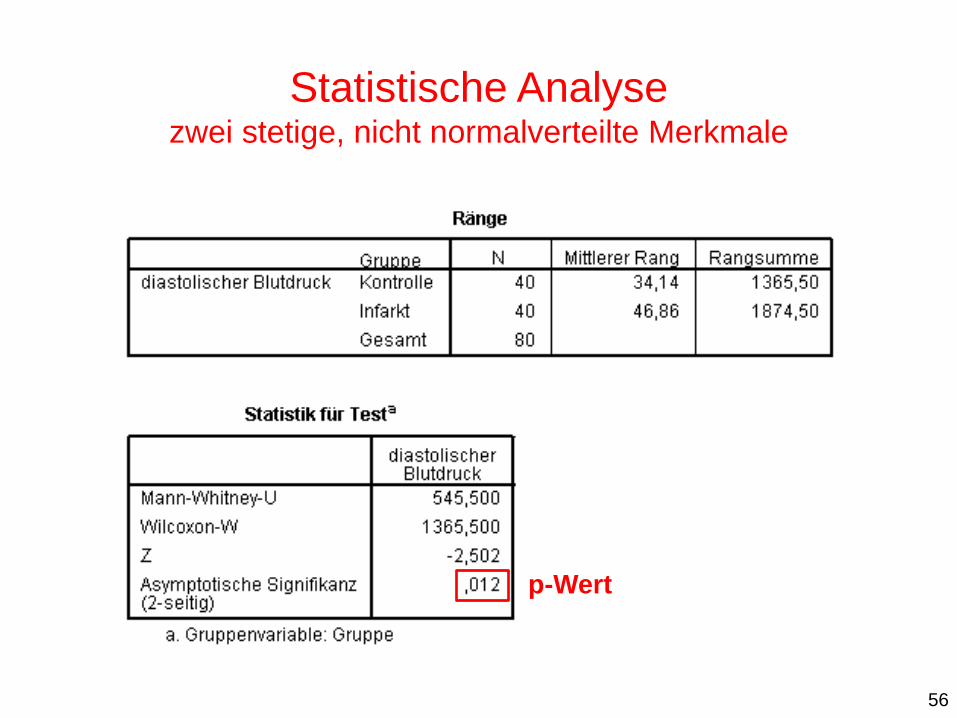
Statistische Analyse zwei stetige, nicht normalverteilte Merkmale
p-Wert
56

Viele statistische Tests machen implizite Annahmen
über die den Daten zu Grunde liegende Verteilung.
Solche Tests heißen "parametrisch".
Statistische Tests, die keine oder nur schwache
Annahmen über die den Daten zu Grunde liegende
Verteilung machen, heißen "nicht-parametrisch".
Statistische Analyse parametrische versus nicht-parametrisch
57

Werden die Verteilungsannahmen verletzt, so ist
der parametrische Test möglicherweise nicht
"valide" (d.h. das Signifikanzniveau ist falsch).
Parametrische Tests gewinnen mehr Information
aus Daten und haben daher für normalverteilte
Daten (etwas) mehr Power als nicht-
parametrische.
Im Fall der Normalität haben nicht-parametrische
Tests etwa 95% der Power des entsprechenden
parametrischen Tests.
Statistische Analyse parametrische versus nicht-parametrisch
58
Zwei-
Stichproben
t-Test für
unabh. Stich.
Varianz-
analyse
(ANOVA)
ANOVA mit
Mess-
wiederholungen
Zwei-
Stichproben
t-Test für
abh. Stich.
zwischen Individuen innerhalb von Individuen
zwei
Messungen
mehr als zwei
Messungen zwei Gruppen
mehr als
zwei Gruppen
Studiendesign
Parametrische Tests normalverteilte Daten
59

Wilcoxon-
Rangsummen-
Test
Kruskal-
Wallis-Test
Friedman-Test Wilcoxon-
Vorzeichen-
Rangtest
zwischen Individuen innerhalb von Individuen
zwei
Messungen
mehr als zwei
Messungen zwei Gruppen
mehr als
zwei Gruppen
Studiendesign
Nichtparametrische Tests nicht normalverteilte Daten
60

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
61

40 Infarktpatienten werden mit 40 Kontrollen verglichen
Zielgröße: Infarkt ja/nein
Einflussgrößen: Geschlecht, Alter, Blutdruck, Diabetiker,
Cholesterin, Triglyzerid, HBDH, GOT,
Zigaretten pro Tag
Fragestellung: Welche Faktoren beeinflussen die
Wahrscheinlichkeit für einen Herzinfarkt?
Beispiel für eine Modellbildung:
Risikofaktoren für Herzinfarkt
62
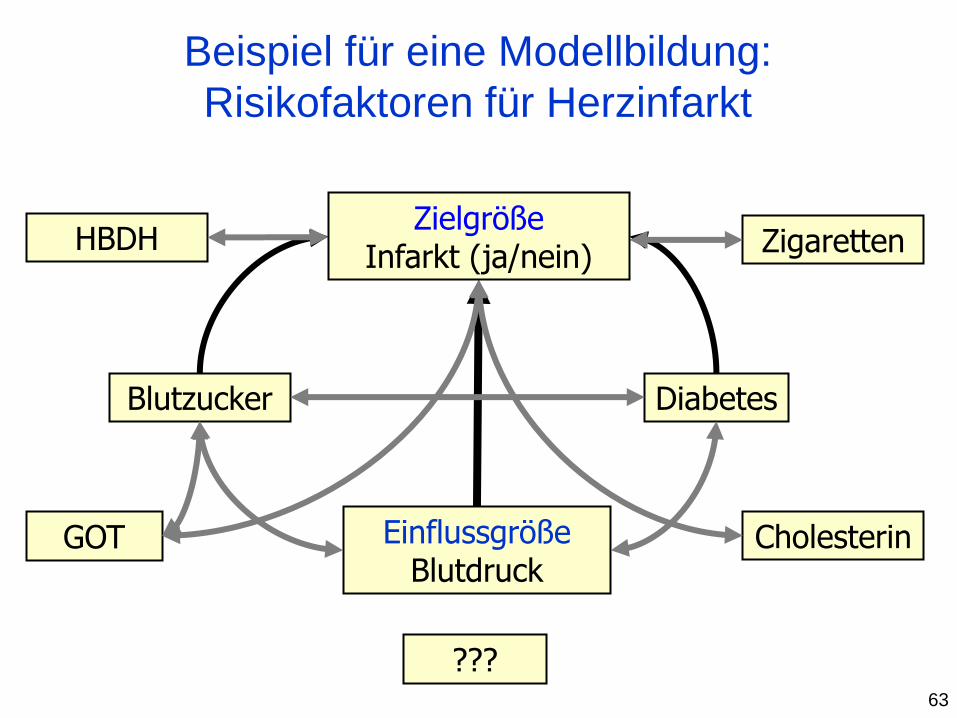
Einflussgröße Blutdruck
Blutzucker Diabetes
Zigaretten
Cholesterin GOT
HBDH
???
Zielgröße Infarkt (ja/nein)
63
Beispiel für eine Modellbildung:
Risikofaktoren für Herzinfarkt

Statistische Modellbildung
... beinhaltet die Analyse des
funktionellen Zusammenhangs zwischen
Zielgröße (abhängige Variable) und Einflussgrößen
(unabhängigen Variablen),
einschließlich der Adjustierung für
unkontrollierbare Störgrößen.
64
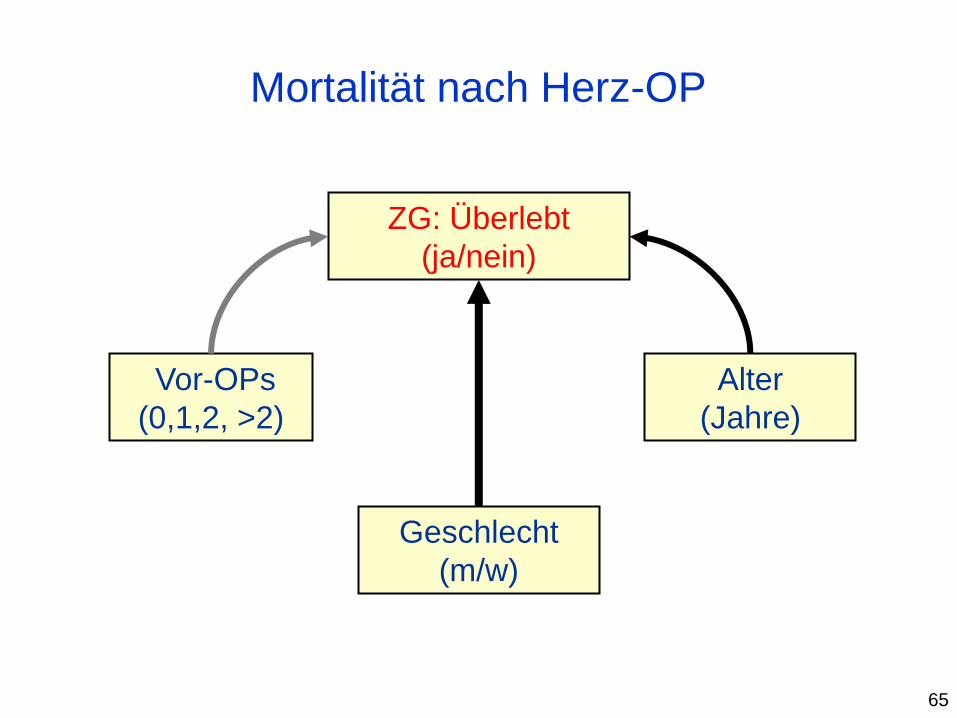
Geschlecht
(m/w)
ZG: Überlebt
(ja/nein)
Vor-OPs
(0,1,2, >2)
Alter
(Jahre)
Mortalität nach Herz-OP
65
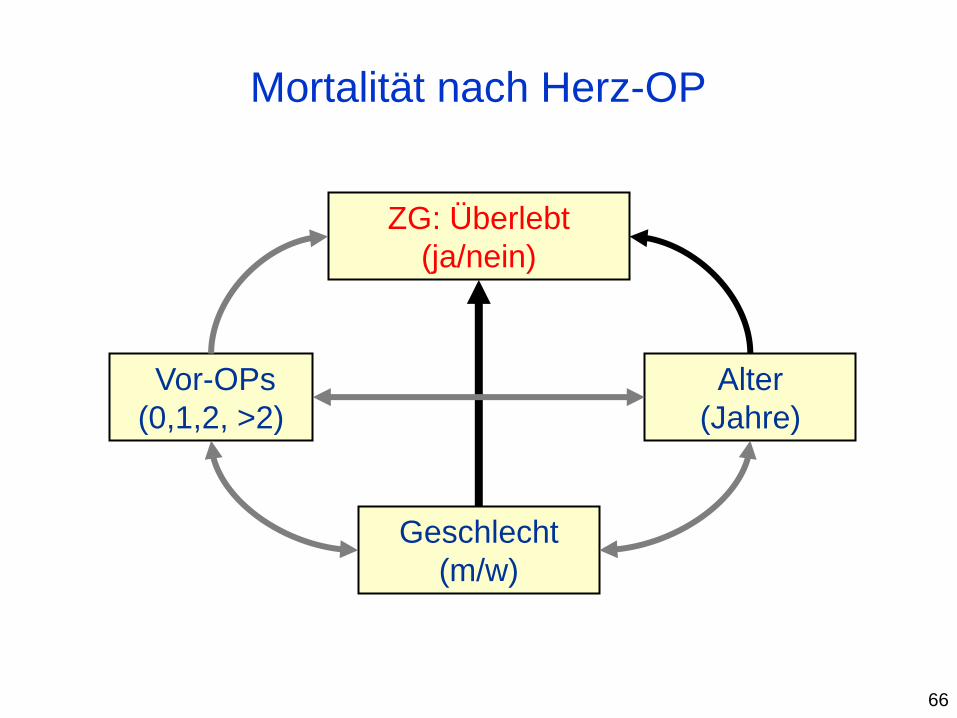
Geschlecht
(m/w)
ZG: Überlebt
(ja/nein)
Vor-OPs
(0,1,2, >2)
Alter
(Jahre)
Mortalität nach Herz-OP
66

Korrelation
67
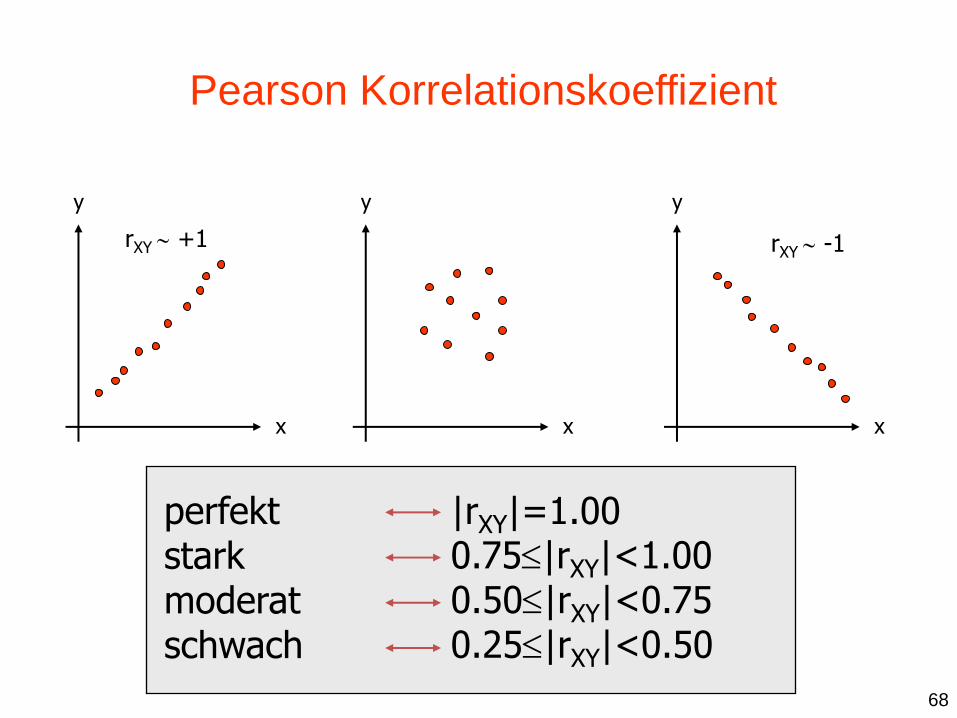
rXY misst die Stärke und Richtung des linearen Zusammenhangs zwischen X und Y.
Pearson Korrelationskoeffizient
rXY +1
rXY 0
rXY -1
x
y
x
y
x
y
perfekt stark moderat schwach
|rXY|=1.00 0.75|rXY|<1.00 0.50|rXY|<0.75 0.25|rXY|<0.50
68

Signifikanztest
2XY
XYr1
2nrT
0r :H XY0 0r :H XYA
XN(X,X2), YN(Y,Y
2), alle unbekannt
0r :H XY0 0r :H XYA
(zweiseitig)
(einseitig)
Hypothesen
Teststatistik
Zufallsvariable
Pearson Korrelationskoeffizient
(zweiseitig)
(einseitig)
Ablehnungs-
bereich
oder 2n,2/tT 2n,2/1tT
2n,1tT
69
t-Test
auf Nullkorrelation
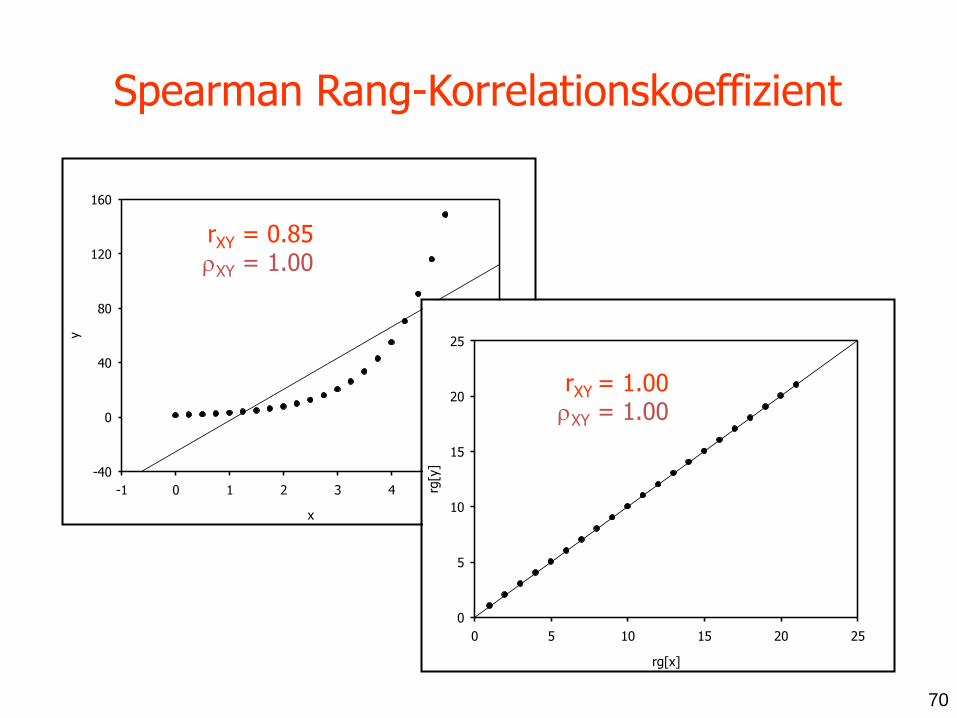
x
-1 0 1 2 3 4 5 6
y
-40
0
40
80
120
160
rXY = 0.85 XY = 1.00
rg[x]
0 5 10 15 20 25
rg[y
]
0
5
10
15
20
25
rXY = 1.00 XY = 1.00
Spearman Rang-Korrelationskoeffizient
70

Lineare Regressionen
71
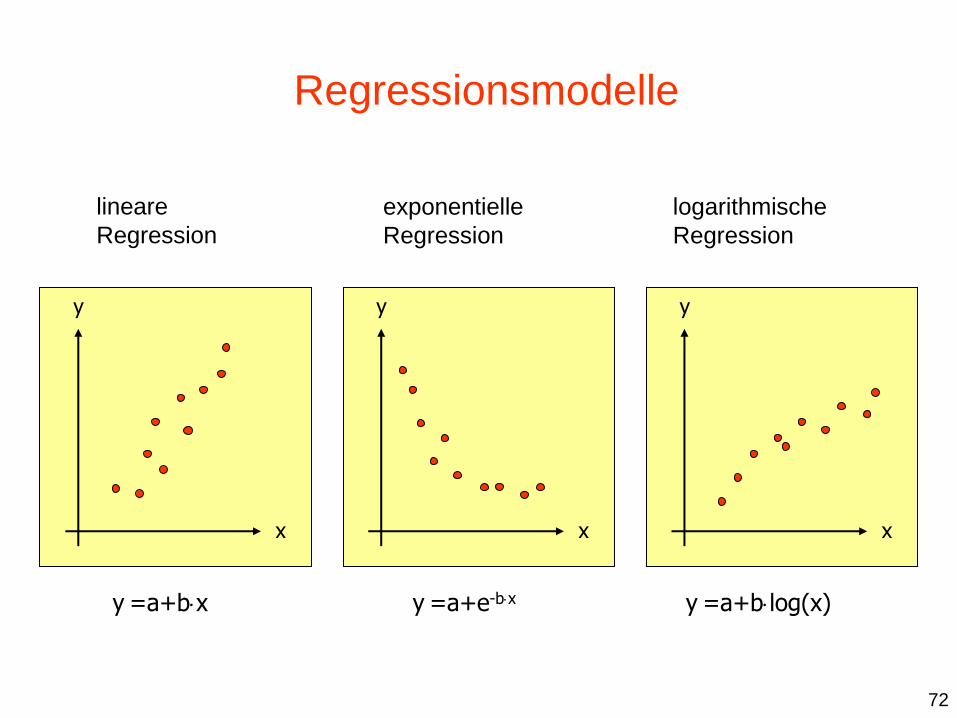
y =a+bx y =a+e-bx y =a+blog(x)
lineare
Regression
exponentielle
Regression
logarithmische
Regression
Regressionsmodelle
x
y
x
y
x
y
72

Lineare Regression
Y: stetige Zielgröße
X: stetige Einflussgröße
: Zufallsfehler
xbaY
Für wird im Allgemeinen eine N(0,2)-Verteilung
mit unbekanntem 2 unterstellt.
Diese Modellgleichung nennt man lineares
Regressionsmodell, b heißt "Regressionskoeffizient" 73
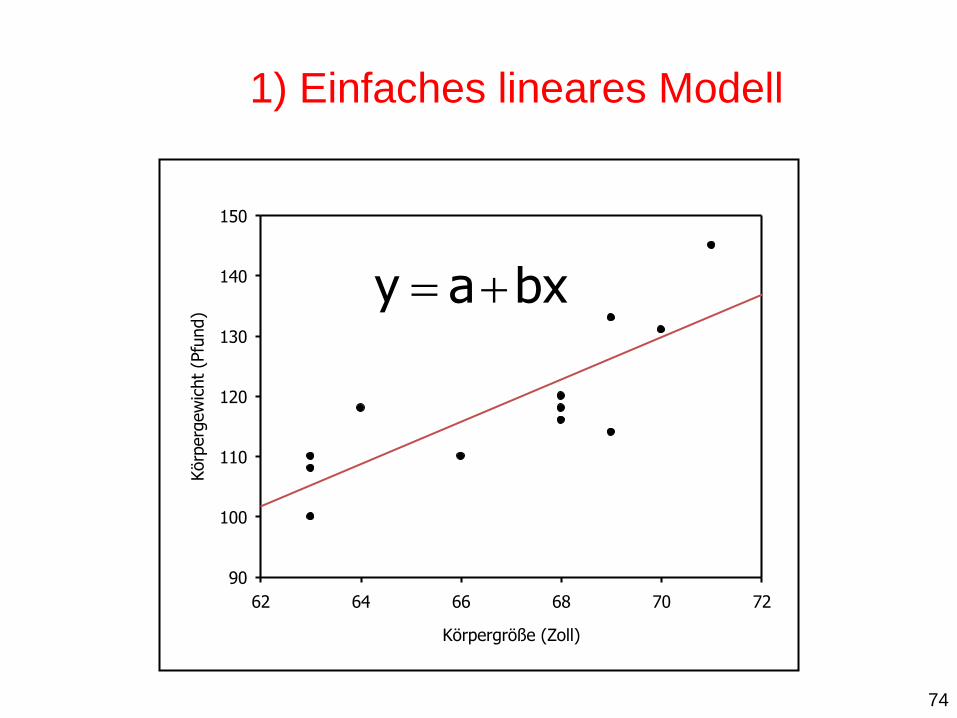
Körpergröße (Zoll)
62 64 66 68 70 72
Körp
erg
ew
icht
(Pfu
nd)
90
100
110
120
130
140
150
1) Einfaches lineares Modell
bxay
74

iii yye ˆ
Definition der Regressionsresiduen:
iii exbby 10
Regressionsmodell:
Erwartete Ausprägungen von Y in Abhängigkeit von X:
ii xbby 10ˆ
• Vorhersage und Abweichungen (Regressionsresiduen)
• Betrachtung der Abweichungen vor dem Hintergrund
erwarteter Ausprägungen von Y in Abhängigkeit der
Ausprägung von X
1) Einfaches lineares Modell
iy
75

Y: stetige Zielgröße
X1,...,Xk: Einflussgrößen
: Zufallsfehler
kk2211 xb...xbxbaY
Multiple lineare (und andere) Modelle erlauben die Schätzung der
Regressionskoeffizienten bi unter Berücksichtigung von
Störgrößen ("Adjustierung").
Für wird im Allgemeinen eine N(0,2)-Verteilung mit unbekanntem
2 unterstellt.
2) Multiples lineares Modelle
76

x
0.0 0.2 0.4 0.6 0.8 1.0
logit(x
)
-6
-4
-2
0
2
4
6
kk2211 xb...xbxba)logit(
Verallgemeinertes Lineares Modell mit "logit" als Link-Funktion
3) Logistische Regression
)x1
xln(logit(x)
77
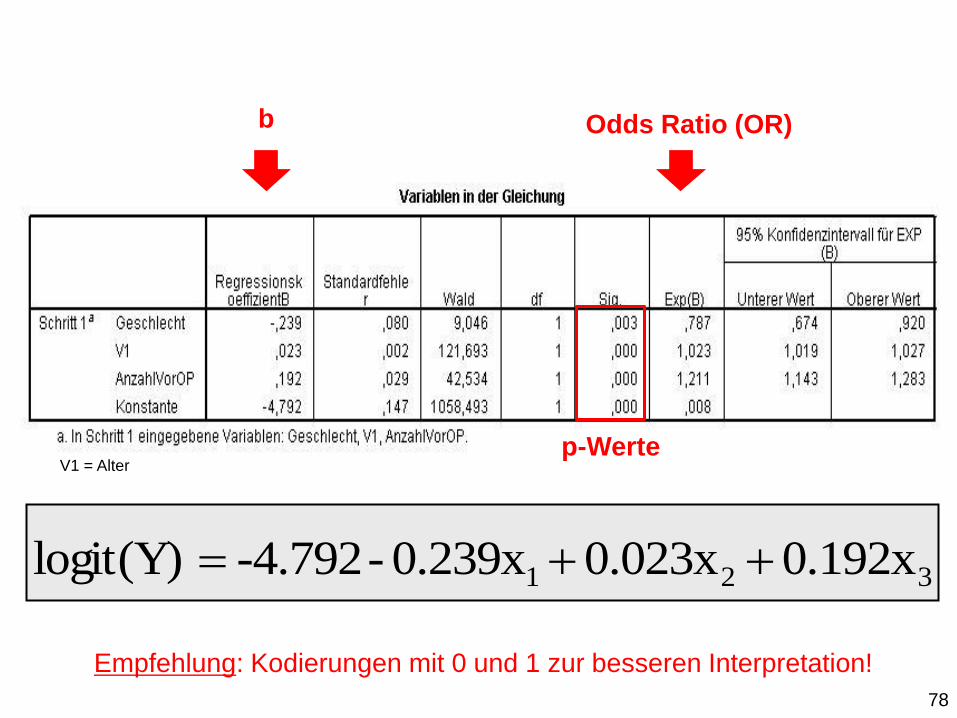
321 0.192x0.023x0.239x --4.792logit(Y)
78
p-Werte
Odds Ratio (OR) b
Empfehlung: Kodierungen mit 0 und 1 zur besseren Interpretation!
V1 = Alter
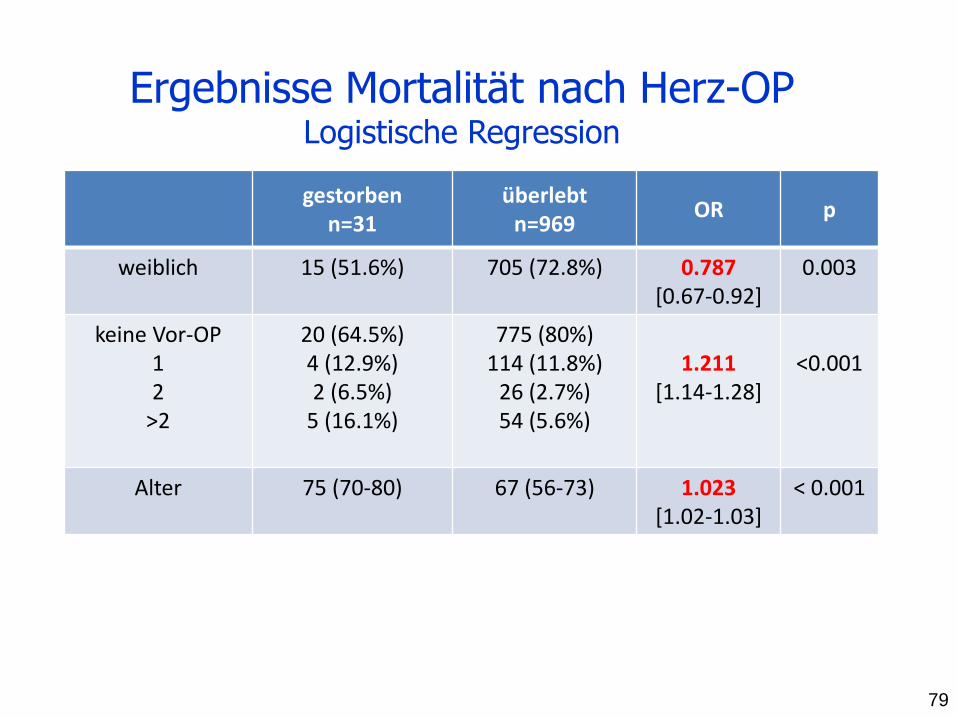
gestorben n=31
überlebt n=969
OR p
weiblich 15 (51.6%) 705 (72.8%) 0.787 [0.67-0.92]
0.003
keine Vor-OP 1 2
>2
20 (64.5%) 4 (12.9%) 2 (6.5%)
5 (16.1%)
775 (80%) 114 (11.8%)
26 (2.7%) 54 (5.6%)
1.211
[1.14-1.28]
<0.001
Alter 75 (70-80) 67 (56-73) 1.023 [1.02-1.03]
< 0.001
Ergebnisse Mortalität nach Herz-OP Logistische Regression
79
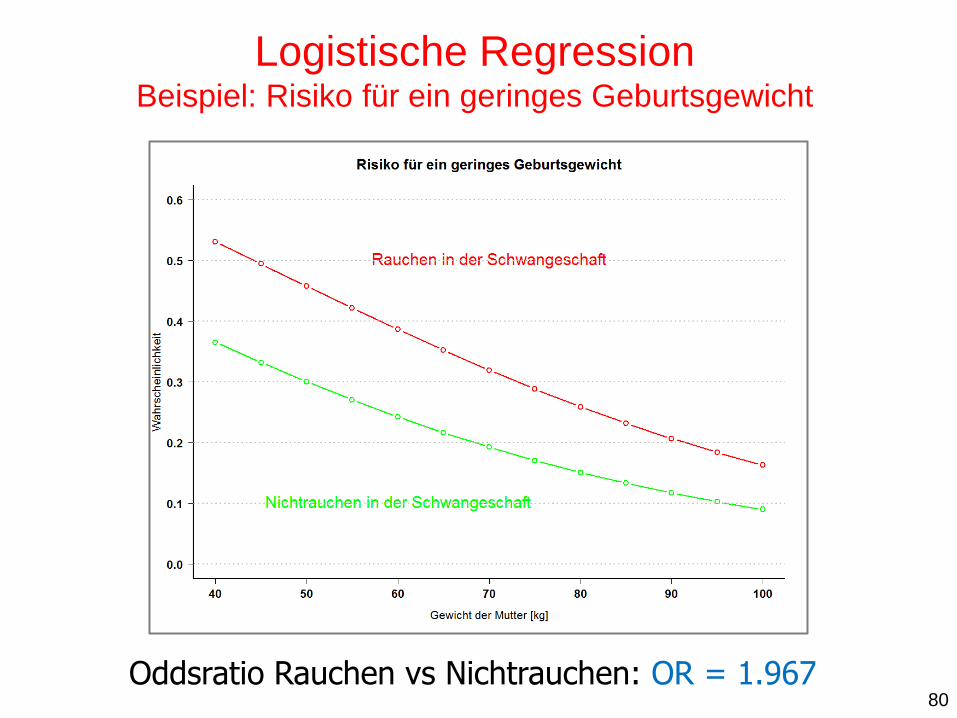
Oddsratio Rauchen vs Nichtrauchen: OR = 1.967
Logistische Regression Beispiel: Risiko für ein geringes Geburtsgewicht
80

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
81
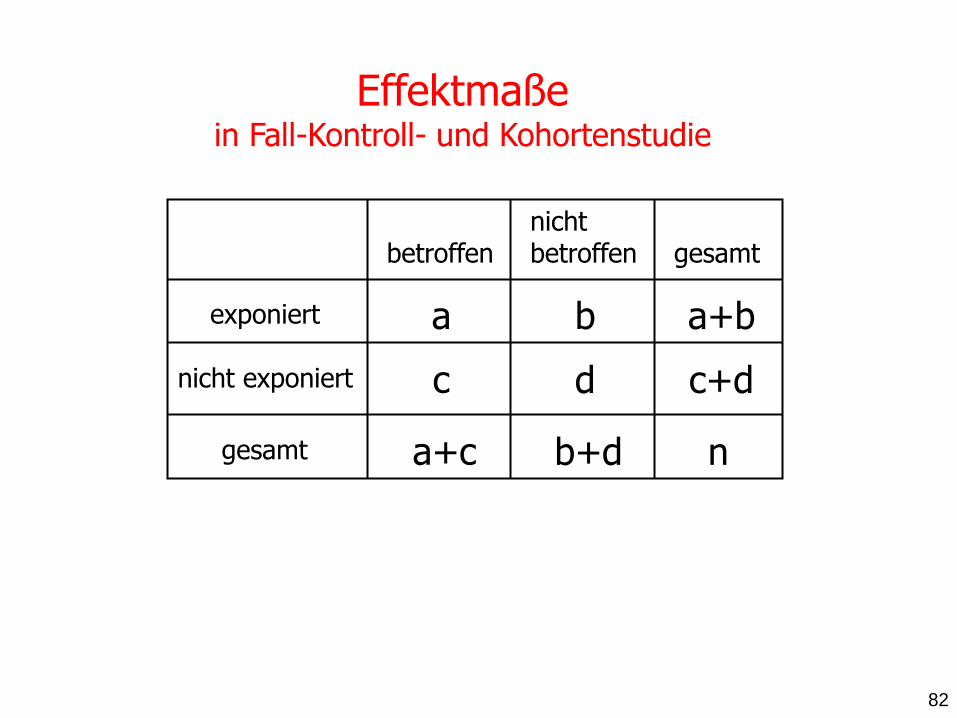
Effektmaße in Fall-Kontroll- und Kohortenstudie
exponiert
betroffen nicht betroffen
a b
nicht exponiert c d
gesamt a+c b+d
gesamt
a+b
c+d
n
82
exponiert
betroffen nicht betroffen
a b
nicht exponiert c d
gesamt a+c b+d
gesamt
a+b
c+d
n
ˆ
ˆ
ˆ
)dc/(c
)ba/(a
n
e
e
e
N
A
ba
a
n
n
N
A
dc
c
und
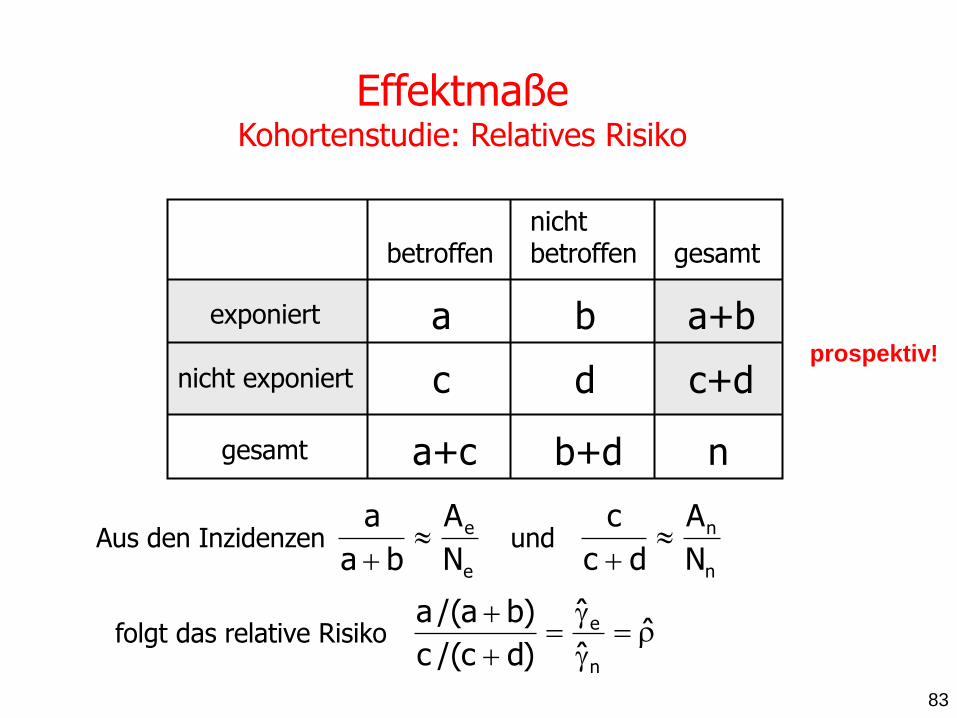
Effektmaße Kohortenstudie: Relatives Risiko
Aus den Inzidenzen
folgt das relative Risiko
83
prospektiv!
exponiert
betroffen nicht betroffen
a b
nicht exponiert c d
gesamt a+c b+d
gesamt
a+b
c+d
n
OR ) ˆ 1 /( ˆ
) ˆ 1 /( ˆ ...
) A N /( ) A N (
A / A
d / b
c / a
n n
e e
n n e e
n e
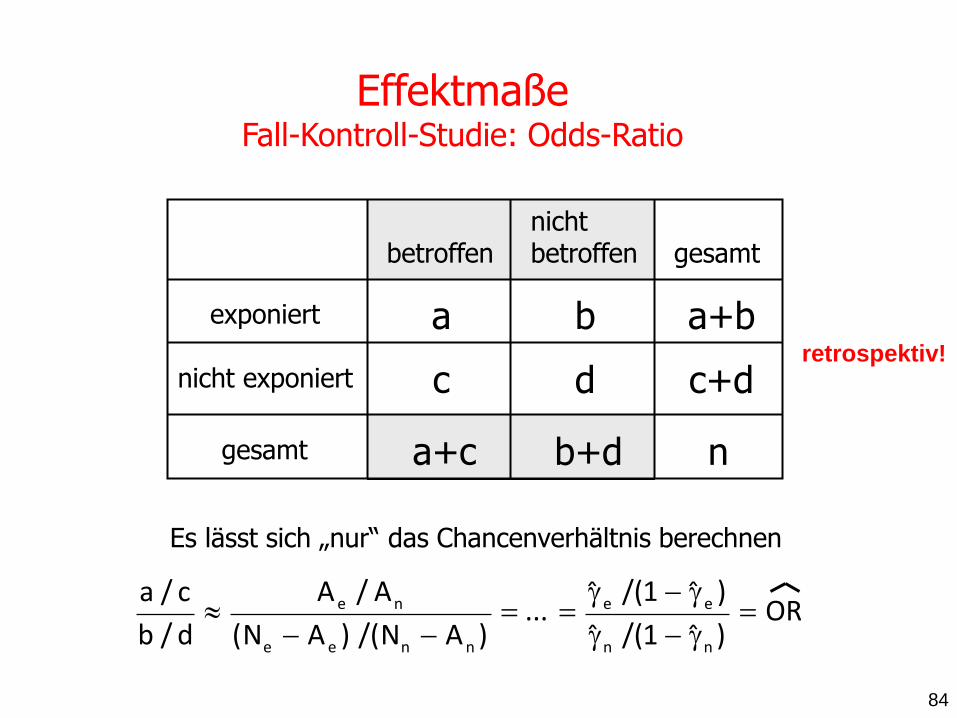
Effektmaße Fall-Kontroll-Studie: Odds-Ratio
Es lässt sich „nur“ das Chancenverhältnis berechnen
84
retrospektiv!
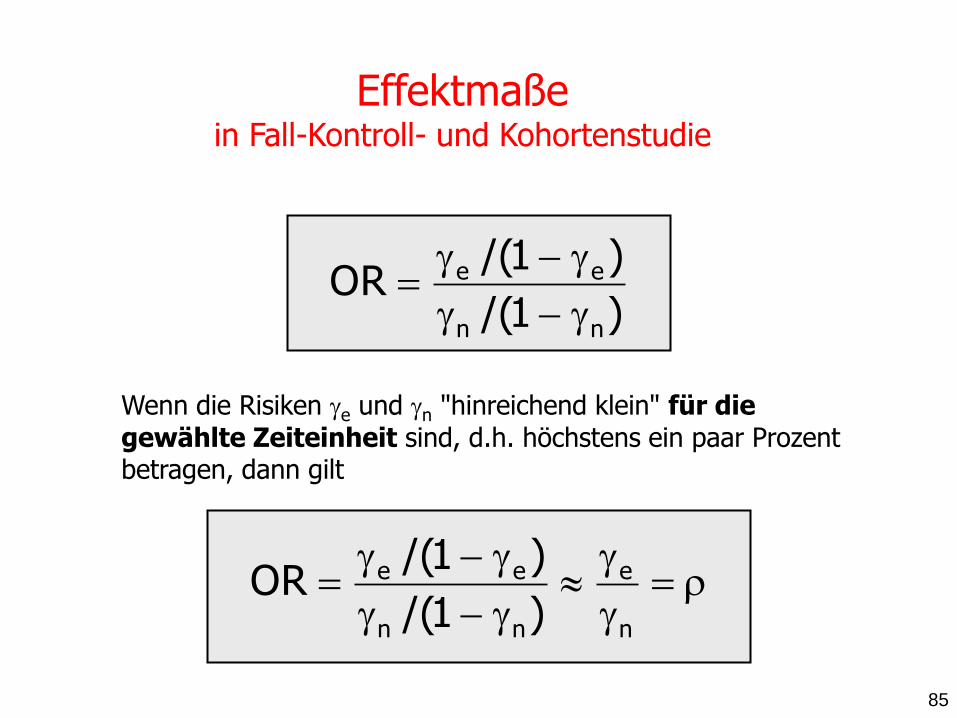
Wenn die Risiken e und n "hinreichend klein" für die gewählte Zeiteinheit sind, d.h. höchstens ein paar Prozent betragen, dann gilt
)1/(
)1/(OR
nn
ee
n
e
nn
ee
)1/(
)1/(OR
Effektmaße in Fall-Kontroll- und Kohortenstudie
85

exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
7 11
51 1651
58 1662
18
1702
1720
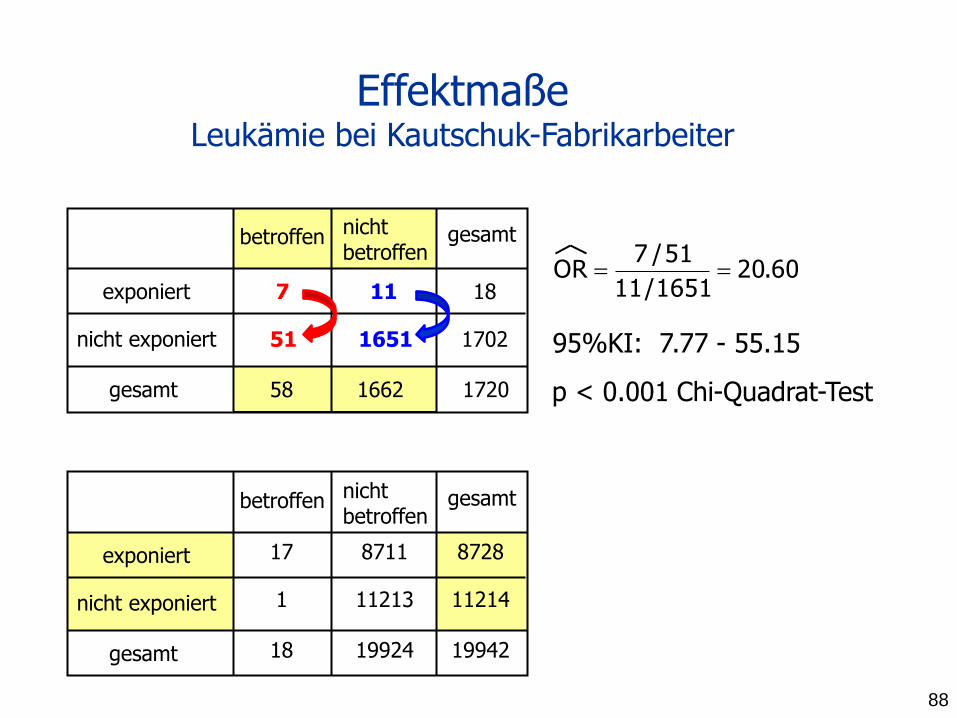
Effektmaße Leukämie bei Kautschuk-Fabrikarbeiter
86

60.201651/11
51/7OR
95%KI: 7.77 - 55.15
exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
7 11
51 1651
58 1662
18
1702
1720 p < 0.001 Chi-Quadrat-Test
Effektmaße Leukämie bei Kautschuk-Fabrikarbeiter
87
60.201651/11
51/7OR
95%KI: 7.77 - 55.15
exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
17 8711
1 11213
18 19924
8728
11214
19942
7 11
51 1651
58 1662
18
1702
1720 p < 0.001 Chi-Quadrat-Test
Effektmaße Leukämie bei Kautschuk-Fabrikarbeiter
88

60.201651/11
51/7OR
95%KI: 7.77 - 55.15
21.84=1/11214
17/8728=ρ
95%KI: 2.89 - 164.02
exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
exponiert
betroffen nicht betroffen
nicht exponiert
gesamt
gesamt
17 8711
1 11213
18 19924
8728
11214
19942
7 11
51 1651
58 1662
18
1702
1720 p < 0.001 Chi-Quadrat-Test
p < 0.001 Chi-Quadrat-Test
Effektmaße Leukämie bei Kautschuk-Fabrikarbeiter
89

1. ZKS Kiel – Zentrum für klinische Studien Kiel
2. Statistisches Testen
3. Modellbildung
4. Effektmaße
5. Multiples Testproblem
Biometrisches Tutorial II
90

Multiples Testen Problemstellung
Wenn mehrere Nullhypothesen gleichzeitig jeweils zum
Signifikanzniveau 5% getestet werden, dann kann die
Wahrscheinlichkeit, mindestens eine wahre
Nullhypothese fälschlicherweise zu verwerfen *, sehr viel
größer als 5% sein.
Beispiel: 6 Nullhypothesen (NP)
P(mindestens eine NP fälschlicherweise ablehnen)=
1-P(keine NP fälschlicherweise ablehnen)
= 1-0.956 = 0.265 > 0.05
91

Fünf Naturheilmittel wurden in randomisierten, doppelt verblindeten und placebokontrollierten Studien an jeweils 100 Patienten hinsichtlich ihrer heilenden Wirkung (ja/nein) bei Fingerwarzen untersucht.
Naturheilmittel gegen Warzen
15 Placebo 35
17 Verum 33
ja nein
Teeblätter
92

Fünf Naturheilmittel wurden in randomisierten, doppelt verblindeten und placebokontrollierten Studien an jeweils 100 Patienten hinsichtlich ihrer heilenden Wirkung (ja/nein) bei Fingerwarzen untersucht.
Naturheilmittel gegen Warzen
15 Placebo 35
17 Verum 33
ja nein
Teeblätter
93
2=0.184 (p=0.668)
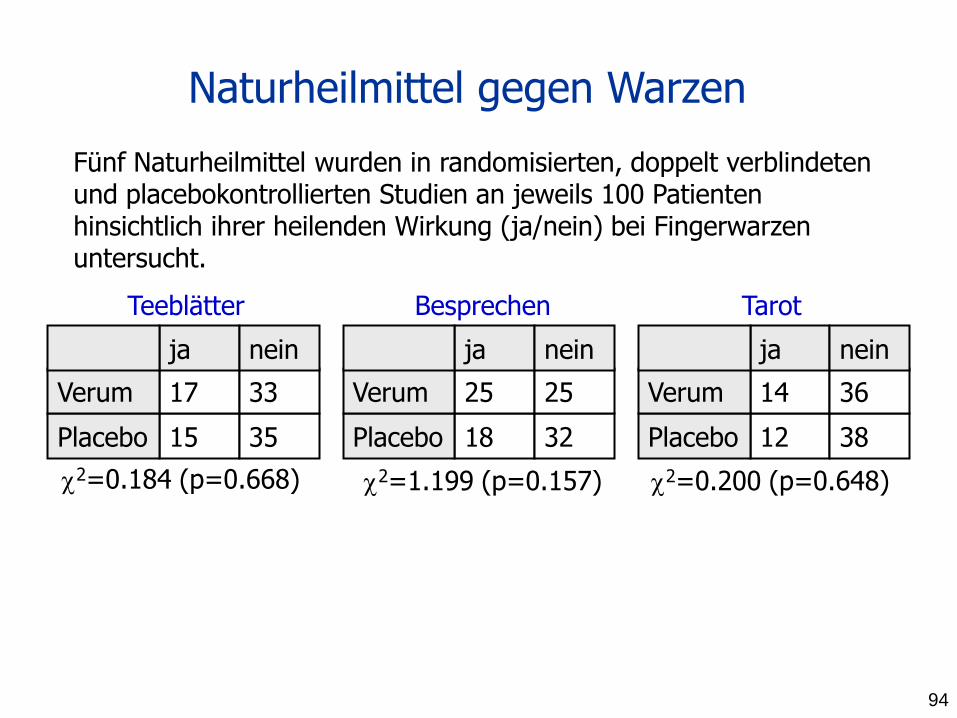
Fünf Naturheilmittel wurden in randomisierten, doppelt verblindeten und placebokontrollierten Studien an jeweils 100 Patienten hinsichtlich ihrer heilenden Wirkung (ja/nein) bei Fingerwarzen untersucht.
15 Placebo 35
17 Verum 33
ja nein
18 Placebo 32
25 Verum 25
ja nein
12 Placebo 38
14 Verum 36
ja nein
Teeblätter Besprechen Tarot
2=0.184 (p=0.668) 2=1.199 (p=0.157) 2=0.200 (p=0.648)
Naturheilmittel gegen Warzen
94
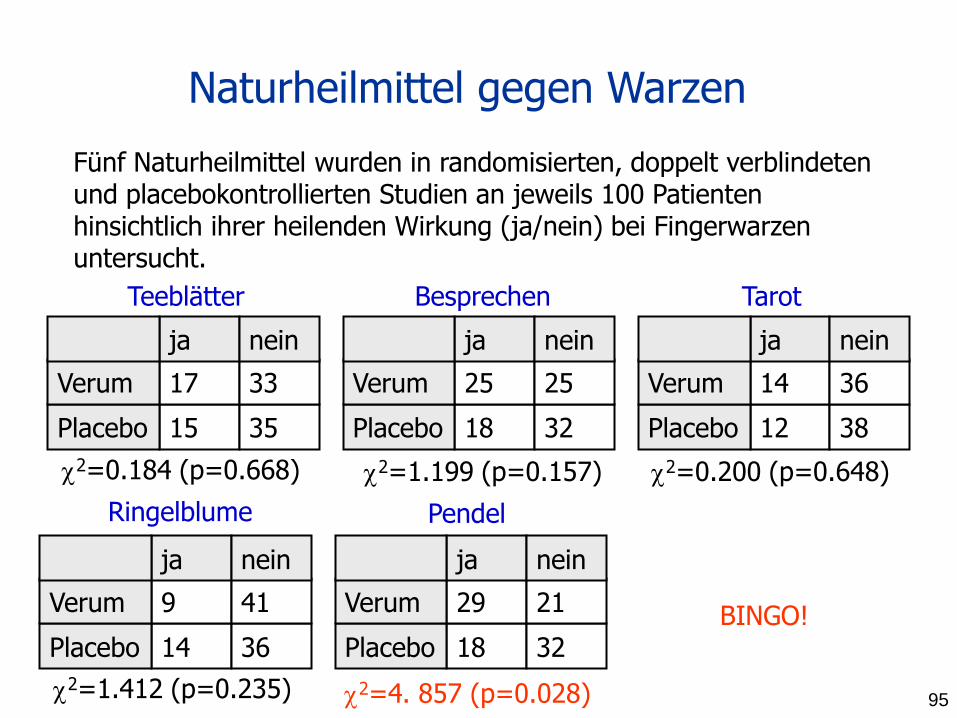
Fünf Naturheilmittel wurden in randomisierten, doppelt verblindeten und placebokontrollierten Studien an jeweils 100 Patienten hinsichtlich ihrer heilenden Wirkung (ja/nein) bei Fingerwarzen untersucht.
15 Placebo 35
17 Verum 33
ja nein
18 Placebo 32
25 Verum 25
ja nein
12 Placebo 38
14 Verum 36
ja nein
14 Placebo 36
9 Verum 41
ja nein
18 Placebo 32
29 Verum 21
ja nein
Teeblätter Besprechen Tarot
Ringelblume Pendel
2=0.184 (p=0.668) 2=1.199 (p=0.157) 2=0.200 (p=0.648)
2=1.412 (p=0.235) 2=4. 857 (p=0.028)
BINGO!
Naturheilmittel gegen Warzen
95

Carlo Bonferroni (1892-1960)
testnFWER
Werden n Nullhypothesen getestet, so gilt
Wird test=/n gewählt, so folgt daraus
n
nn test
Multiples Testen Bonferroni-Korrektur
*
*
n
96

Teeblätter
Besprechen
Tarot
Ringelblume
Pendel
2=0.184 (p=0.668)
2=1.999 (p=0.157)
2=0.200 (p=0.648)
2=1.412 (p=0.235)
2=4.857 (p=0.028)
Damit * höchstens 5% ist, muss das testspezifische Signifikanzniveau nach Bonferroni-Korrektur test=0.05/5=0.01 betragen, wozu ein kritischer Wert von 2
0.99,1=6.635 gehört.
Damit * von höchstens 5% eingehalten wird, kann keine der H0 verworfen werden.
Naturheilmittel gegen Warzen
97
Nicht mehr BINGO!

• Für eine Fallzahlplanung (Berechnung der
benötigten Stichprobengröße n) werden
allgemein benötigt:
(1) das Signifikanzniveau α
(meistens 5%)
(2) eine vorgegebene Mindestpower 1-β
(meistens 80%)
(3) eine vorgegebene Effektstärke
(meistens aus anderen Studien bekannt)
Fallzahlplanung allgemeine Überlegungen
98

1. den Umfang einer Stichprobe so lange vergrößern, bis sich ein "signifikantes" Ergebnis einstellt.
2. Daten nach auffälligen Resultaten durchsuchen und diese nachträglich für "signifikant" erklären.
3. auf Daten so lange verschiedene Tests anwenden, bis einer davon ein "signifikantes" Ergebnis liefert.
4. das Signifikanzniveau nachträglich so an das Ergebnis anpassen, dass letzteres gerade eben "signifikant" wird.
5. ein und dasselbe Experiment so lange wiederholen, bis es zu einem "signifikanten" Ergebnis führt.
6. einem statistisch signifikanten Ergebnis automatisch auch wissenschaftliche Relevanz zuschreiben.
Quelle: R. Hilgers, P. Bauer, V. Schreiber (2002) Einführung in die Medizinische Statistik
Statistisches Testen Was man nicht tun sollte!
99

Durchführung von Fallzahlplanungen Powerberechnung ANOVA Überlebenszeiten ….
Das schaffen wir nicht mehr:
100
















![Glücksburg Restaurant • Kneipe · 2017. 11. 3. · $3(5,7,) 2x]r Ä1hnwdu³ fo ¼ vhuylhuw plw hlqhp *odv (lvzdvvhu 0duwlql dxi (lv fo ¼ jhuqh dxfk plw 2olyh 6khuu\ fo ¼ gu\](https://img.pdfslide.org/doc/110x75/5fe6786daac61e30405e9c7e/glcksburg-restaurant-a-2017-11-3-357-2xr-1hnwdu-fo-vhuylhuw.jpg)












![[ij#CW]Wp d](https://img.pdfslide.org/doc/110x75/61c0139f8a4eb24e5a0963f8/ijcwwp-d.jpg)