Embed Size (px)
Citation preview

Bruce Alberts, Alexander Johnson, Julian Lewis, David Morgan, Martin Ra� , Keith Roberts und Peter Walter
Molekularbiologie der ZelleÜbersetzung herausgegeben von Ulrich Schäfer 6. Au� age
Molekularbiologie
Übersetzung herausgegeben von Ulrich Schäfer 6. Au� age
LESEPROBELESEPROBEALBERTS_U1.indd 3 07.03.2017 08:44:46

In dieser Lehrbuchinformation �nden Sie die folgenden Abschnitte:
Die Autoren Vorwort Inhaltsverzeichnis Probekapitel in Auszügen Bestellinformationen


Reemers Publishing Services GmbHO:/Wiley/Alberts_6Aufl/3d/03_fcontrib.3d from 20.02.2017 07:35:523B2 9.1.580; Page size: 210.00mm x 275.00mm
Die Autoren
Bruce Alberts promovierte an der Harvard University und ist Inhaber desChancellor’s Leadership Chair in Biochemistry and Biophysics for Science andEducation an der University of California, San Francisco. Von 2008 bis 2013 warer Editor-in-Chief von Science und für zwölf Jahre Präsident der U.S. NationalAcademy of Sciences (1993–2005).
Alexander Johnson promovierte an der Harvard University und ist Pro-fessor für Mikrobiologie und Immunologe an der University of California, SanFrancisco.
Julian Lewis (1946–2014) promovierte als D.Phil. an der University ofOxford und war Emeritus Scientist am London Research Institute of CancerResearch UK.
David Morgan promovierte an der University of California, San Francisco,und ist Professor am dortigen Institut für Physiologie sowie Direktor des Bio-chemistry, Cell Biology, Genetics, and Developmental Biology Graduate Pro-gram.
Martin Raff erwarb seinen M.D. an der McGill University und ist EmeritusProfessor of Biology am Medical Research Council Laboratory for Molecular CellBiology des University College London.
Keith Roberts promovierte an der University of Cambridge und war Stell-vertretender Direktor des John Innes Centre, Norwich.
Peter Walter promovierte an der Rockefeller University in New York undist Professor am Department of Biochemistry and Biophysics an der University ofCalifornia, San Francisco, sowie Forscher am Howard Hughes Medical Institute.
SECHSTE AUFLAGE
mit Alberts, Johnson, Lewis, Morgan, Ra�, Roberts und Walker
Innenseiten_nachbau.indd 1 07.03.2017 09:38:41

Reemers Publishing Services GmbHO:/Wiley/Alberts_6Aufl/3d/05_fpref.3d from 20.02.2017 07:36:063B2 9.1.580; Page size: 210.00mm x 275.00mm
Vorwort
Seit die letzte Auflage dieses Buchs erschienen ist, wurden über fünf Millionenwissenschaftliche Arbeiten veröffentlicht. Zusätzlich nimmt das Ausmaß derdigitalen Medien immer weiter zu: neue Daten über Genomsequenzen, Protein-Interaktionen, Molekularstrukturen und Genexpression – alle in riesigen Daten-banken gespeichert. Die Herausforderung sowohl für Wissenschaftler als auchfür Buchautoren besteht darin, diese überwältigende Masse an Information in einzugängliches und zeitgemäßes Verständnis darüber wie Zellen funktionieren,umzuwandeln.
Hilfreich ist die große Zunahme an Review-Artikeln, die versuchen, „Roh-wissen“ leichter verständlich zu machen, obwohl die große Mehrheit dieserReviews immer noch ziemlich stark fokussiert ist. Mittlerweile versucht unseine schnell wachsende Ansammlung von Online-Quellen zu überzeugen, dassdas Verständnis nur wenige Mausklicks entfernt ist. In einigen Bereichen wardiese Veränderung, wie wir auf Wissen zugreifen, sehr erfolgreich – zum Beispielbei der Entdeckung der neuesten Information über unsere eigenen medizini-schen Probleme. Aber um etwas so schönes und komplexes zu verstehen wie dasFunktionieren lebender Zellen, braucht es mehr als nur ein Wiki-Dies oder Wiki-Das. Es ist extrem schwer, die wertvollen und beständigen Juwelen aus so vielMüll herauszufinden. Viel effektiver ist eine sorgsam ausgearbeitete Schilderung,die logisch und schrittweise durch die wesentlichen Begriffe, Komponenten undExperimente führt, sodass die Leser sich selbst ein einprägsames, konzeptionellesGrundgerüst der Zellbiologie bilden können. Dieses Konzept ermöglicht ihnen,die ganze neue Wissenschaft kritisch zu beurteilen und, noch wichtiger, sie zuverstehen. Das ist es, was wir mit Molecular Biology of the Cell erreichen wollen.
Bei der Vorbereitung dieser neuen Auflage mussten wir zwangsläufig einigeschwierige Entscheidungen treffen. Um spannende, neue Entdeckungen auf-zunehmen, mussten wir, um das Buch transportabel zu halten, vieles streichen.Wir haben neue Abschnitte hinzugefügt, wie diejenigen über neue RNA-Funk-tionen, Fortschritte in der Stammzellbiologie, neue Methoden zur Untersuchungvon Proteinen und Genen und zur Abbildung von Zellen, Fortschritte in derGenetik und Behandlung von Krebs und zeitlicher Ablauf, Wachstumskontrolleund Morphogenese der Entwicklung.
Die Chemie einer Zelle ist extrem komplex und jede Liste von Zellteilen undihren Wechselbeziehungen – ganz gleich wie vollständig sie ist – wird gewaltigeLücken in unserem Verständnis hinterlassen. Wir begreifen inzwischen, dass wir,wenn wir überzeugende Erklärungen für das Verhalten einer Zelle liefern wollen,quantitative Information über Zellen benötigen. Diese Informationen sind anausgefeilte mathematische/computergestützte Ansätze gebunden, die z.T. nochgar nicht erfunden sind. Dementsprechend zeichnet es sich ab, dass es immermehr zum Ziel von Zellbiologen wird, ihre Studien weiter in Richtung quantita-tiver Beschreibungen und mathematischer Schlussfolgerungen zu verlagern.Dieses Konzept und einige seiner Methoden legen wir in einem neuen Abschnittam Ende von Kapitel 8 dar.
Konfrontiert mit der Unermesslichkeit dessen was wir über Zellbiologiegelernt haben, mag es verlockend für einen Studenten sein zu glauben, dass esnur noch wenig zu entdecken gibt. Je mehr wir jedoch über Zellen herausfinden,umso mehr neue Fragen tauchen auf. Um deutlich zu machen, wie lückenhaftunser Verständnis von der Zellbiologie ist, haben wir einige wichtige Wissens-lücken am Ende eines jeden Kapitels in dem Abschnitt Was wir nicht wissenhervorgehoben. Diese kurzen Listen enthalten nur einen winzigen Teil derheiklen, unbeantworteten Fragen und Herausforderungen für die nächste Gene-


Inhaltsverzeichnis (gekürzt)Einführung in die Zelle Teil I
1 Zellen und Genome 1.1 Die allgemeinen Merkmale von Zellen auf der Erde 1.2 Die Vielfalt der Genome und der Stammbaum des Lebens 1.3 Genetische Information bei Eukaryoten
2 Zellchemie und Bioenergetik 2.1 Die chemischen Bestandteile einer Zelle 2.2 Katalyse und Energienutzung durch Zellen 2.3 Wie Zellen Energie aus Nahrung gewinnen
3 Proteine 3.1 Form und Struktur von Proteinen 3.2 Proteinfunktion
Genetische Grundmechanismen Teil II
4 DNA, Chromosomen und Genome 4.1 Struktur und Funktion von DNA 4.2 Chromosomale DNA und ihre Verpackung in der Chromatinfaser 4.3 Die Struktur und Funktion von Chromatin 4.4 Die Gesamtstruktur der Chromosomen 4.5 Wie sich Genome entwickeln
5 Replikation, Reparatur und Rekombination von DNA 5.1 Die Erhaltung der DNA-Sequenzen 5.2 Mechanismen der DNA-Replikation 5.3 Die Initiation und Vollendung der DNA-Replikation der Chromosomen 5.5 Homologe Rekombination 5.6 Transposition und konservative ortsspezi�sche Rekombination
6 Wie Zellen das Genom ablesen: von der DNA zum Protein 6.1 Von der DNA zur RNA 6.2 Von der RNA zum Protein 6.3 Die RNA-Welt und die Ursprünge des Lebens
7 Kontrolle der Genexpression 7.1 Ein Überblick über die Genkontrolle 7.2 Transkriptionskontrolle durch sequenzspezi�sche DNA-Bindeproteine 7.3 Transkriptionsregulatoren schalten Gene an und aus 7.4 Molekulargenetische Mechanismen, die spezialisierte Zelltypen scha�en und erhalten 7.5 Mechanismen, die das Zellgedächtnis in P�anzen und Tieren verstärken 7.6 Posttranskriptionale Kontrolle 7.7 Regulation der Genexpression durch nicht codierende RNAs
Methoden für die Arbeit mit Zellen Teil III
8 Untersuchung von Zellen, Molekülen und Systemen 8.1 Isolierung von Zellen und ihre Aufzucht in Kultur 8.2 Aufreinigung von Proteinen 8.3 Proteine analysieren 8.4 DNA analysieren und manipulieren 8.5 Untersuchung der Genexpression und -funktion 8.6 Mathematische Analyse der Zellfunktionen
9 Das Abbild der Zellen 9.1 Betrachtung der Zellstrukturen unter dem Lichtmikroskop9.2 Betrachtung von Zellen und Molekülen im Elektronenmikroskop
Die innere Organisation der Zelle Teil IV
10 Der Aufbau der Membran 10.1 Die Lipid-Doppelschicht 10.2 Membranproteine
11 Membrantransport kleiner Moleküle und elektrische Eigenschaften von Membranen 11.1 Grundlagen des Transports durch Membranen 11.2 Transporter und aktiver Membrantransport 11.3 Kanäle und die elektrischen Eigenschaften von Membranen
12 Zellkompartimente und Proteinsortierung12.1 Die Kompartimentierung der Zelle 12.2 Molekültransport zwischen Zellkern und Cytosol 12.3 Proteintransport in Mitochondrien und Chloroplasten 12.4 Peroxisomen 12.5 Das Endoplasmatische Reticulum
13 Intrazellulärer Membranverkehr 13.1 Die molekularen Mechanismen des Membrantransports und die Erhaltung der Kompartimentunterschiede13.2 Transport vom ER durch den Golgi-Apparat 13.3 Transport vom trans-Golgi-Netzwerk zu den Lysosomen 13.4 Transport von der Plasmamembran ins Zellinnere: Endocytose 13.5 Transport vom trans-Golgi-Netzwerk zur Zellober�äche: Exocytose
14 Energieumwandlung: Mitochondrien und Chloroplasten 14.1 Das Mitochondrium 14.2 Die Protonenpumpen der Elektronentransportkette 14.3 ATP-Produktion in Mitochondrien 14.4 Chloroplasten und Photosynthese 14.5 Die genetischen Systeme von Mitochondrien und Chloroplasten

15 Zellsignalübertragung 15.1 Grundsätze der Zellsignalübertragung 15.2 Signalisierung über G-Protein-gekoppelte Rezeptoren 15.3 Signalisierung über Enzym-gekoppelte Rezeptoren 15.4 Alternative Signalwege bei der Genregulation 15.5 Signalisierungsvorgänge in P�anzen
16 Das Cytoskelett 16.1 Funktion und Ursprung des Cytoskeletts 16.2 Aktin und aktinbindende Proteine 16.3 Myosin und Aktin 16.4 Mikrotubuli 16.5 Intermediär�lamente und Septine 16.6 Zellpolarisierung und Zellwanderung
17 Zellzyklus 17.1 Überblick über den Zellzyklus 17.2 Das Zellzyklus-Kontrollsystem 17.3 S-Phase 17.4 Mitose 17.5 Cytokinese 17.6 Meiose 17.7 Kontrolle von Zellteilung und Zellwachstum
18 Der Zelltod18.1 Die Apoptose beseitigt unerwünschte Zellen 18.2 Die Apoptose hängt von einer intrazellulären proteolytischen Kaskade ab, die durch Caspasen vermittelt wird 18.3 Todesrezeptoren auf der Zellober�äche aktivieren den extrinsischen Apoptoseweg 18.4 Der intrinsische Weg der Apoptose hängt von Mitochondrien ab 18.5 Bcl2-Proteine regulieren den intrinsischen Weg der Apoptose 18.6 IAPs helfen bei der Kontrolle der Caspasen 18.7 Extrazelluläre Überlebensfaktoren hemmen die Apoptose auf verschiedene Weisen 18.8 Phagocyten entfernen die apoptotische Zelle 18.9 Sowohl eine überschießende als auch eine unzureichende Apoptose kann zu Krankheiten führen
Zellen in ihrem sozialen Umfeld Teil V
19 Zellverbindungen und die extrazelluläre Matrix 19.1 Zell–Zell-Verbindungen 19.2 Die extrazelluläre Matrix bei Tieren 19.3 Zell–Matrix-Verbindungen 19.4 Die P�anzenzellwand
20 Krebs 20.1 Krebs als Mikro-Evolutionsprozess 20.2 Krebskritische Gene: Wie man sie �ndet und was sie tun 20.3 Behandlung von Krebs und Krebsvorsorge: heute und in Zukunft
21 Die Entwicklung vielzelliger Organismen 21.1 Überblick über die Entwicklung 21.2 Mechanismen der Musterbildung 21.3 Zeitliche Steuerung der Entwicklung 21.4 Morphogenese 21.5 Wachstum 21.6 Neuronale Entwicklung
22 Stammzellen und Gewebeerneuerung22.1 Stammzellen und die Erneuerung von Epithelgewebe 22.2 Fibroblasten und ihre Abkömmlinge: die Familie der Bindegewebszellen 22.3 Entstehung und Neubildung der Skelettmuskulatur 22.4 Blutgefäße, Lymphgefäße und Endothelzellen 22.5 Ein hierarchisches Stammzellsystem: Bildung der Blutzellen 22.6 Erneuerung und Reparatur 22.7 Zell-Reprogrammierung und pluripotente Stammzellen
23 Krankheitserreger und Infektion 23.1 Einführung in die Krankheitserreger und die Normal�ora des Menschen 23.2 Zellbiologie der Infektion
24 Angeborene und adaptive Immunsysteme24.1 Das angeborene Immunsystem 24.2 Überblick über das adaptive Immunsystem 24.3 B-Zellen und Immunglobuline 24.4 T-Zellen und MHC-Proteine
Glossar
Register

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:40:513B2 9.1.580; Page size: 210.00mm x 275.00mm
Kontrolle derGenexpression
Die DNA eines Organismus codiert für alle RNA- und Proteinmoleküle, die zumAufbau seiner Zellen notwendig sind. Trotzdem würde es uns die Beschreibungder vollständigen DNA-Sequenz eines Organismus – gleichgültig, ob es sich umdie paar Millionen Nukleotide eines Bakteriums oder um die mehreren Milliar-den Nukleotide eines Menschen handelt – nicht ermöglichen, den Organismuszu rekonstruieren, genauso wenig, wie es möglich wäre, ein Theaterstück vonShakespeare aus einem englischen Wörterbuch abzuleiten. In beiden Fällenstehen wir vor dem gleichen Problem, nämlich: Wie werden die Elemente derDNA-Sequenz bzw. des Wörterbuches benutzt? Unter welchen Bedingungenwird jedes einzelne Genprodukt hergestellt und – wenn es hergestellt ist –welche Funktion übt es aus?
In diesem Kapitel konzentrieren wir uns auf die erste Hälfte dieses Problems:Wir werden die Regeln und Mechanismen betrachten, nach denen eine Gruppevon Genen in jeder Zelle selektiv aktiviert werden kann. Diese Mechanismenarbeiten auf vielen Ebenen, und wir werden jede Ebene der Reihe nach behan-deln. Wir beginnen mit einer Übersicht über einige der beteiligten Grundprinzi-pien.
7.1 Ein Überblick über die Genkontrolle
Die verschiedenen Zelltypen eines vielzelligen Organismus unterscheiden sichsowohl in ihrer Morphologie als auch in ihrer Funktion wesentlich voneinander.Vergleichen wir beispielsweise bei einem Säuger ein Neuron mit einer Leberzelle,sind die Unterschiede so extrem, dass es schwierig wird sich vorzustellen, dassbeide Zellen das gleiche Genom enthalten (Abb. 7–1). Aus diesem Grund, undweil die Zelldifferenzierung häufig irreversibel ist, nahmen die Biologen ur-sprünglich an, dass Gene im Verlauf der Differenzierung selektiv verloren gehen.Jetzt wissen wir jedoch, dass die Zelldifferenzierung im Allgemeinen ohneVeränderungen in der Nukleotidsequenz des Zellgenoms zustande kommt.
77.1 Ein Überblick über die
Genkontrolle
7.2 Transkriptionskontrolle durchsequenzspezifische DNA-Bindeproteine
7.3 Transkriptionsregulatorenschalten Gene an und aus
7.4 MolekulargenetischeMechanismen die spezialisierteZelltypen schaffen und erhalten
7.5 Mechanismen, die dasZellgedächtnis in Pflanzen undTieren verstärken
7.6 Posttranskriptionale Kontrolle
7.7 Regulation der Genexpressiondurch nicht codierende RNAs
25 μm
LeberzelleNeuron
Abb. 7–1 Ein Neuron und eine Leberzelleteilen das gleiche Genom. Die langen Ästedieses Neurons aus der Retina ermöglichen esihm, elektrische Signale von vielen Zellen zuempfangen und diese Signale an viele be-nachbarte Zellen weiterzuleiten. Die Leberzel-le, die im gleichen Maßstab gezeichnet ist, istan vielen Stoffwechselvorgängen beteiligt, da-runter die Verdauung und Entgiftung vonAlkohol und Arzneistoffen. Beide Zelltypenenthalten das gleiche Genom, aber sie expri-mieren unterschiedliche RNAs und Proteine.(Neuron nach S. Ramón y Cajal, Histologie duSysteme Nerveux de l’Homme et de Vertebres,1909–1911. Paris: Maloine; Nachdruck Madrid:C.S.I.C., 1972.)
Molekularbiologie der Zelle, 6. Auflage. B. Alberts, A. Johnson, J. Lewis, D. Morgan, M. Raff, K. Roberts, P. Walker© 2017 WILEY-VCH Verlag GmbH & Co. KGaA. Published 2017 by WILEY-VCH Verlag GmbH & Co. KGaA.

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:40:523B2 9.1.580; Page size: 210.00mm x 275.00mm
7.1.1 Die verschiedenen Zelltypen eines vielzelligen Organismusenthalten die gleiche DNA
Die Zelltypen eines vielzelligen Organismus entwickeln sich unterschiedlich, weilsie verschiedene RNA- und Proteinmoleküle synthetisieren und anreichern. ErsteHinweise darauf, dass sie dies ohne Änderung ihrer DNA-Sequenz tun, stammenvon klassischen Experimenten an Fröschen. Wenn der Kern einer vollständigdifferenzierten Froschzelle in ein Frosch-Ei injiziert wird, dessen Kern vorher
nicht befruchteteEizelle
Kern zerstörtdurch UV-Licht
erwachsenerFrosch
(A)
(B)
(C)
Hautzellen inKulturschale
Kern inPipette
Kern injiziertin Eizelle
normaler Embryo
Kaulquappe
Scheibe einerMöhre
proliferierendeZellmasse
getrennte Zellenin komplettem,
flüssigemMedium
Einzelzelle Klon aus sichteilenden Zellen
jungerEmbryo
jungePflanze
Möhre
Kühe
Epithelzellendes Oviducts
nichtbefruchtete
Eizelle
meiotischeSpindel
MEIOTISCHE SPINDELUND DAZUGEHÖRIGECHROMOSOMENWERDEN ENTFERNT
DONATORZELLE IN DIE NÄHE DES EIES GEBRACHT
wieder-hergestellte
Zygote
ELEKTRISCHEENTLADUNGBEWIRKT DIEFUSION DERDONATORZELLEMIT DER ENT-KERNTEN EIZELLE
ZELL-TEILUNG
Embryo implantiertin Ziehmutter
KalbEmbryo
UV
Abb. 7–2 Differenzierte Zellen enthalten alle zur Bildung eines kompletten Organismus nötigen genetischen Informationen. (A) Der in ein entkerntes Eitransplantierte Kern einer Hautzelle eines erwachsenen Froschs kann die Entwicklung einer ganzen Kaulquappe bewirken. Der unterbrochene Pfeil deutet an, dassein weiterer Transferschritt nötig ist, um dem transplantierten Genom Zeit zu geben, sich einer embryonalen Umgebung anzupassen. Dabei wird ein Kern dessich entwickelnden frühen Embryos in eine weitere entkernte Eizelle gebracht. (B) Bei vielen Pflanzenarten behalten die differenzierten Zellen die Fähigkeit zur„Entdifferenzierung“. Dadurch kann aus einer einzelnen Zelle ein Klon von Nachkommen hervorgehen, aus dem später eine vollständige Pflanze entstehen kann.(C) Ein Zellkern aus einer differenzierten Zelle von einer ausgewachsenen Kuh wurde in eine entkernte Eizelle einer anderen Kuh eingebracht, aus der ein Kalbentstehen kann. Verschiedene, aus differenzierten Zellen desselben Spenders hervorgegangene Kälber sind alle Klone dieses Spenders und somit genetischidentisch. (A, verändert nach J. B. Gurdon, Sci. Am. 219:24–35, 1968. Mit Erlaubnis von Scientific American.)
412 Kapitel 7: Kontrolle der Genexpression


Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:193B2 9.1.580; Page size: 210.00mm x 275.00mm
7.6.2 Riboswitche stellen wahrscheinlich eine alte Form derGenkontrolle dar
In Abschnitt 6.3 haben wir die Vorstellung erörtert, dass RNA sowohl dieFunktion von DNA als auch von Protein innehatte und sowohl Erbinformationspeicherte als auch chemische Reaktionen katalysierte, bevor die modernenZellen auf der Erde entstanden. Die Entdeckung der Riboswitche zeigte, dassRNA auch Kontrollvorrichtungen bilden kann. Riboswitche sind kurze RNA-Sequenzen, die bei Bindung kleiner Moleküle, wie Metaboliten, ihre Konforma-tion ändern. Jeder Riboswitch erkennt ein bestimmtes kleines Molekül, und diesich ergebende Konformationsänderung dient dazu, die Genexpression zu regu-lieren. Riboswitche sitzen oft in der Nähe des 5′-Endes der mRNAs, und siefalten sich, während die mRNA synthetisiert wird, und blockieren oder erlaubendas Voranschreiten der RNA-Polymerase, je nachdem, ob das kleine Regulator-molekül gebunden ist oder nicht (Abb. 7–55).
Riboswitche sind besonders in Bakterien üblich, in denen sie wichtige kleineMetaboliten in der Zelle wahrnehmen und die Genexpression entsprechendanpassen. Ihre vielleicht bemerkenswerteste Eigenschaft ist die hohe Spezifitätund Affinität, mit der jeder Riboswitch nur das jeweils passende kleine Molekülerkennt; in vielen Fällen wird jede chemische Eigenschaft des kleinen Molekülsdurch die RNA gelesen (Abb. 7–55C). Zudem sind die beobachteten Bindungs-affinitäten so fest wie diejenigen, die man normalerweise zwischen kleinenMolekülen und Proteinen beobachtet.
Riboswitche sind vielleicht insofern die ökonomischsten Beispiele von Gen-Kontrollvorrichtungen, als sie die Notwendigkeit für Regulatorproteine ins-gesamt umgehen. In dem in Abb. 7–55 gezeigten Beispiel kontrolliert derRiboswitch die Transkriptionselongation, aber Riboswitche regulieren auch an-dere Schritte der Genexpression, wie wir an späterer Stelle in diesem Kapitelnoch sehen werden. Offensichtlich können hoch entwickelte Gen-Kontrollvor-richtungen aus kurzen RNA-Sequenzen gebildet werden, eine Tatsache, die dieHypothese einer frühen „RNA-Welt“ unterstützt.
G
G
Guanin
Transkriptions-terminator
Gene für Purin-biosyntheseausgeschaltet
Gene für Purin-biosynthese angeschaltet
RNA-Polymerase
Riboswitch
(A) (B)
(C)
Abb. 7–55 Ein Riboswitch, der auf Guanin rea-giert. (A) In diesem Beispiel aus Bakterien kontrolliertder Riboswitch die Expression der Gene für die Pu-rinbiosynthese. Wenn die Guaninkonzentration inZellen niedrig ist, dann transkribiert eine trans-kriptverlängernde RNA-Polymerase die Gene der Pu-rinbiosynthese und deshalb werden die für die Gua-ninsynthese benötigten Enzyme exprimiert. (B) Wennreichlich Guanin vorhanden ist, bindet es den Ribos-witch und verursacht, dass dieser eine Konformati-onsänderung erfährt, die die RNA-Polymerase dazuzwingt, die Transkription einzustellen (s. Abb. 6–11).(C) An ein Riboswitch gebundenes Guanin (rot). Essind nur diejenigen Nukleotide gezeigt, die die Gua-nin-Bindungstasche bilden. Es existieren viele andereRiboswitche, dazu zählen auch jene, die S-Adenosyl-methionin, Coenzym B12, Flavinmononukleotid,Adenin, Lysin und Glycin erkennen. (Verändert nachM. Mandal und R. R. Breaker, Nat. Rev. Cell Biol. 5:451–463, 2004. Mit Erlaubnis von Macmillan PublishersLtd., und nach C. K. Vanderpool und S. Gottesman,Mol. Microbiol. 54:1076–1089, 2004. Mit Erlaubnis vonBlackwell Publishing.)
462 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:193B2 9.1.580; Page size: 210.00mm x 275.00mm
7.6.3 Durch alternatives RNA-Spleißen können verschiedeneFormen eines Proteins von ein und demselben Gen entstehen
Wie in Kapitel 6 (s. Abb. 6–26) besprochen, verkürzt das RNA-Spleißen dieTranskripte vieler eukaryotischer Gene, indem die Intronsequenzen aus derVorläufer-mRNA entfernt werden. Wir haben auch gesehen, dass eine Zelle dasRNA-Transkript auf verschiedene Weise spleißen und dadurch unterschiedlichePolypeptidketten von demselben Gen herstellen kann – ein Prozess, der alter-natives RNA-Spleißen genannt wird (Abb. 7–56). Ein wesentlicher Anteil derGene von Tieren (schätzungsweise 90 % im Menschen) führt auf diese Weise zumehreren Proteinen.
Falls es verschiedene Spleißmöglichkeiten an mehreren Stellen des Trans-kripts gibt, kann ein einzelnes Gen zu Dutzenden von Proteinen führen. Ein Genbei Drosophila kann, als allerdings außergewöhnliches Beispiel, durch alternati-ves Spleißen theoretisch zu etwa 38.000 unterschiedlichen Proteinen führen(Abb. 7–57), jedoch konnte bisher nur ein Teil dieser Formen experimentellbeobachtet werden. Bedenken wir, dass das Drosophila-Genom etwa 14.000identifizierte Gene hat, dann wird deutlich, dass die Komplexität der Proteineeines Lebewesens die Anzahl seiner Gene weit überschreiten kann. DiesesBeispiel zeigt auch die Gefahr, die Anzahl der Gene mit der Komplexität einesLebewesens gleichzusetzen. Ein Beispiel: Alternatives Spleißen ist bei einzelligenSprosshefen selten, aber sehr üblich bei Fliegen. Die Sprosshefe hat etwa6.200 Gene, von denen nur rund 300 gespleißt werden, und fast alle haben nurein einziges Intron. Zu behaupten, dass Fliegen nur zwei- bis dreimal so viele
12
Überspringen von Exons
12
Beibehalten von Introns
12
sich gegenseitig ausschließende Exons
12
alternative 5'-Spleißstelle
12
alternative 3'-Spleißstelle
Abb. 7–56 Fünf Muster des alternativen Splei-ßens. In jedem Fall wird ein einzelner Typ von RNA-Transkripten auf zwei verschiedene Arten gespleißt,wodurch zwei verschiedene mRNAs (1 und 2) entste-hen. Die dunkelblauen Kästchen markieren Exonse-quenzen, die in beiden mRNAs vertreten sind. Diehellblauen Kästchen markieren mögliche Exonse-quenzen, die nur in einer der mRNAs auftreten. DieKästchen werden mit roten Linien verbunden, umanzudeuten, wo Intronsequenzen (gelb) entferntwerden. (Verändert nach H. Keren et al., Nat. Rev.Genet. 11:345–355, 2010. Mit Erlaubnis von MacmillanPublishers Ltd.)
481 12 1 33 1 21
A-Exons B-Exons C-Exons D-Exons
A8 C16
B24 D2
Dscam-Gen
eine von 38.016 möglichen Spleißvarianten
mRNA
Abb. 7–57 Alternatives Spleißen des RNA-Transkripts des Dscam-Gens von Drosophila. DSCAM-Proteine haben mehrere verschiedene Funktionen. In Zellen des Fliegen-Immunsystems vermittelnsie die Phagocytose bakterieller Krankheitserreger. In Zellen des Nervensystems sind DSCAM-Proteine für die Verschaltung der Nervenzellen nötig. Die endgültige mRNA enthält 24 Exons, vondenen 4 (mit A, B, C und D bezeichnet) im Dscam-Gen als Gruppen alternativer Exons vorliegen. JedeRNA enthält 1 von 12 Alternativen für Exon A (rot), 1 von 48 Alternativen für Exon B (grün), 1 von33 Alternativen für Exon C (blau) und 1 von 2 Alternativen für Exon D (gelb). In der Abbildung ist nureines der vielen möglichen Spleißmuster (angedeutet durch die rote Linie und die reife mRNAdarunter) dargestellt. Jede Variante des DSCAM-Proteins würde sich in ungefähr die gleiche Gestaltfalten (vorzugsweise eine Serie extrazellulärer immunoglobulinartiger Domänen, verbunden miteiner membrandurchspannenden Region, s. Abb. 24–48, aber die Aminosäuresequenz der Domänenwürde sich abhängig vom Spleißmuster unterscheiden. Die Diversität der DSCAM-Varianten trägtebenso zur Plastizität des Immmunsystems wie zur Bildung komplexer neuronaler Schaltkreise bei;wir greifen die spezifische Rolle der DSCAM-Varianten wieder genauer auf, wenn wir die Entwicklungdes Nervensystems in Kapitel 21 beschreiben. (Verändert nach D. L. Black, Cell 103:367–370, 2000. MitErlaubnis von Elsevier.)
7.6 Posttranskriptionale Kontrolle 463

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:203B2 9.1.580; Page size: 210.00mm x 275.00mm
Gene wie Hefen haben, bedeutet, den Unterschied in der Komplexität dieser zweiGenome weit zu unterschätzen.
Es gibt Fälle, wo das alternative Spleißen deshalb auftritt, weil es eine„Intronsequenzmehrdeutigkeit“ (engl. intron sequence ambiguity) gibt: Der nor-male, in Kapitel 6 besprochene Spleißosomenmechanismus zur Entfernung vonIntrons ist nicht in der Lage, zwischen zwei oder mehreren alternativen Paa-rungen der 5′- und 3′-Spleißstellen sauber zu unterscheiden, sodass durch Zufallbei verschiedenen individuellen Transkripten eine unterschiedliche Auswahlgetroffen wird. Wo dieses konstitutive alternative Spleißen auftritt, werdenmehrere Versionen des Proteins ein und desselben Gens in allen Zellen her-gestellt, in denen dieses Gen exprimiert wird.
In vielen Fällen jedoch ist das alternative Spleißen reguliert. Im einfachstenBeispiel wird das regulierte Spleißen benutzt, um von der Synthese eines nichtfunktionsfähigen Proteins zur Synthese eines funktionierenden umzuschalten(oder umgekehrt). Die Transposase z. B., die die Transposition des P-Elementsbei Drosophila katalysiert, wird in den Keimzellen der Fliege in einer funktions-fähigen Form und in den Somazellen in einer funktionsunfähigen Form syn-thetisiert, wodurch es möglich ist, dass das P-Element sich über das Fliegen-genom verteilt, ohne dass Schäden in den Somazellen verursacht werden(s. Abb. 5–61). Der Unterschied in der Transposonaktivität konnte auf dieAnwesenheit einer Intronsequenz in der Transposase-RNA zurückgeführt wer-den, die nur in den Keimzellen entfernt wird.
Das regulierte RNA-Spleißen kann, neben der Befähigung zum Wechsel vonder Synthese eines funktionierenden Proteins zu der einer nicht funktionieren-den Form (oder umgekehrt), gemäß den Bedürfnissen der Zelle unterschiedlicheVersionen eines Proteins in unterschiedlichen Zelltypen erzeugen. Tropomyosinbeispielsweise wird in unterschiedlichen Zellen in unterschiedlichen Formenhergestellt (s. Abb. 6–26). Zelltypspezifische Formen vieler anderer Proteinewerden auf die gleiche Weise gebildet.
Das RNA-Spleißen kann entweder negativ reguliert werden, indem einKontrollmolekül den Zugang zu einer bestimmten Spleißstelle auf der RNA fürdie Spleißmaschinerie blockiert, oder positiv, indem ein Kontrollmolekül dieSpleißmaschine zu einer andernfalls ignorierten Spleißstelle lenkt (Abb. 7–58).
Aufgrund der Plastizität des RNA-Spleißens kann die Blockade einer „star-ken“ Spleißstelle eine „schwache“ Stelle freigeben und in einem anderen Spleiß-muster resultieren. Somit kann man das Spleißen eines Vorläufer-RNA-Molekülsals feines Gleichgewicht zwischen konkurrierenden Spleißstellen ansehen – einGleichgewicht, das leicht durch die Einwirkung von Regulationsproteinen auf dasSpleißen aus der Balance gebracht werden kann.
prä-mRNA-Transkript
prä-mRNA-Transkript
SPLEISSEN
KEIN SPLEISSEN
mRNA
mRNA
(A) NEGATIVE KONTROLLE
(B) POSITIVE KONTROLLE
R
Repressor
KEIN SPLEISSEN
mRNA
A
Aktivator
mRNA
SPLEISSEN
Abb. 7–58 Negative und positive Kontrolle desalternativen RNA-Spleißens. (A) Bei der negativenKontrolle bindet ein Repressorprotein an einespezifische Sequenz des prä-mRNA-Transkriptsund blockiert damit den Zugang der Spleiß-maschinerie zu einer Spleißverbindung. Dies hatoft die Verwendung einer sekundären Spleißstellezur Folge, wodurch ein verändertes Spleißmusterentsteht (s. Abb. 7–56). (B) Bei der positiven Kon-trolle ist es der Spleißmaschine ohne Unterstüt-zung durch ein Aktivatorprotein nicht möglich,eine bestimmte Intronsequenz zu entfernen. WeilRNA flexibel ist, können die Nukleotidsequenzen,die diese Aktivatoren binden, viele Nukleotidpaareentfernt von den Spleißverbindungen, die siekontrollieren, lokalisiert sein. Sie heißen oft Spleiß-Verstärker in Analogie zu den Transkriptionsver-stärkern, die an früherer Stelle in diesem Kapitelerwähnt wurden.
464 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:203B2 9.1.580; Page size: 210.00mm x 275.00mm
7.6.4 Die Definition eines Gens wurde nach der Entdeckung desalternativen RNA-Spleißens geändert
Die Entdeckung, dass Eukaryoten gewöhnlich Introns enthalten und dass ihrecodierenden Sequenzen in mehr als einer Art zusammengesetzt werden können,hat die Diskussion um die Definition des Gens neu belebt. Die erste klareDefinition eines Gens in der Terminologie der Molekularbiologie wurde in denfrühen 1940er-Jahren aus Arbeiten über die biochemische Genetik des PilzesNeurospora erhalten. Bis dahin wurde ein Gen funktionell als Abschnitt desGenoms definiert, der als Einheit der Meiose segregiert und durch den eindefinierbares Phänotypmerkmal entsteht, wie z. B. rote oder weiße Augen beiDrosophila oder glatte oder runzlige Samen bei Erbsen. Die Arbeiten an Neuro-spora zeigten, dass die meisten Gene mit solchen Abschnitten auf dem Genomzusammenfallen, die die Synthese eines einzelnen Enzyms bestimmen. Diesführte zu der Hypothese, dass ein Gen für eine Polypeptidkette codiert. DieseHypothese hat sich für die weitere Forschung als enorm fruchtbar erwiesen, undje mehr man in den 1960er-Jahren über den Mechanismus der Genexpressionlernte, desto mehr wurde ein Gen als ein Stück DNA erkannt, das in RNAtranskribiert wird, das für eine einzelne Polypeptidkette (oder eine einzelneStruktur-RNA, wie beispielsweise ein tRNA- oder ein rRNA-Molekül) codiert.Die Entdeckung der Mosaik-Gene und Introns in den späten 1970er-Jahrenkonnte noch leicht mit der ursprünglichen Definition eines Gens in Einklanggebracht werden, vorausgesetzt, dass nur eine einzige Polypeptidkette durch dieRNA spezifiziert wurde, die von irgendeiner DNA transkribiert wurde. Es ist jetztjedoch klar, dass viele DNA-Sequenzen bei Zellen höherer Eukaryoten zwei odermehrere unterscheidbare (aber verwandte) Proteine mithilfe des alternativenSpleißens hervorbringen. Wie sollen wir nun ein Gen definieren?
In jenen relativ seltenen Fällen, in denen zwei sehr verschiedene eukaryoti-sche Proteine von einer einzelnen Transkriptionseinheit hergestellt werden,nimmt man an, dass die beiden Proteine von verschiedenen Genen produziertwerden, die auf dem Chromosom überlappen. Es scheint jedoch unnötig kom-pliziert, die meisten Proteinvarianten, die durch alternatives Spleißen entstehen,als solche zu betrachten, die von überlappenden Genen abstammen. Sinnvollerist es, die ursprüngliche Definition zu modifizieren und eine DNA-Sequenz alseinzelnes proteincodierendes Gen zu werten, wenn sie als eine Einheit trans-kribiert wird und für einen Satz von nahe verwandten Polypeptidketten (Pro-teinisoformen) codiert. Diese Definition wird auch jenen DNA-Sequenzen ge-recht, die für Proteinvarianten codieren, die durch andere posttranskriptionaleProzesse als das RNA-Spleißen entstehen, wie z. B.Transkriptspaltung und RNA-Editierung (s. unten).
7.6.5 Eine Änderung der Stelle der RNA-Transkriptspaltung und derPolyadenylierung kann den carboxyterminalen Bereich einesProteins verändern
In Kapitel 6 haben wir gehört, dass das 3′-Ende des mRNA-Moleküls beiEukaryoten nicht wie in Bakterien durch den Abschluss der RNA-Synthesedurch die RNA-Polymerase gebildet wird. Stattdessen entsteht es durch eineSpaltungsreaktion an der RNA, die durch zusätzliche Faktoren katalysiert wird,während das Transkript verlängert wird (s. Abb. 6–34). Die Zelle kann die Stelledieser Spaltung kontrollieren, sodass das Carboxyende des entsprechenden Pro-teins verändert wird. Im einfachsten Fall ist eine Proteinvariante nur einegestutzte Version der anderen; in vielen Fällen liegen jedoch die alternativenSchnitt- und Polyadenylierungsstellen innerhalb von Intronsequenzen und dasSpleißmuster wird dadurch verändert. Dieser Vorgang kann zwei eng verwandte
7.6 Posttranskriptionale Kontrolle 465

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:203B2 9.1.580; Page size: 210.00mm x 275.00mm
Proteine erzeugen, die sich nur in den Aminosäuresequenzen an ihren C-terminalen Enden unterscheiden. Genaue Untersuchung von RNAs, die vomHumangenom in einer Vielzahl von Zellarten gebildet werden (s. Abb. 7–3),zeigen, dass 50 % der menschlichen proteincodierenden Gene mRNA-Artenerzeugen, die sich an ihren Polyadenylierungsstellen unterscheiden.
Ein gut untersuchtes Beispiel der regulierten Polyadenylierung ist derWechsel von der Synthese eines membrangebundenen zur Synthese eines sezer-nierten Antikörpers während der Entwicklung der B-Lymphocyten (s. Abb. 24–22). Zu Beginn der Lebensgeschichte eines B-Lymphocyten wird der von ihmproduzierte Antikörper in der Plasmamembran verankert, wo er als Rezeptor fürein Antigen wirkt. Die Stimulierung durch das Antigen veranlasst die Zelle, sichzu vermehren und mit der Sezernierung ihres Antikörpers zu beginnen. Diesezernierte Form des Antikörpers ist mit der membrangebundenen Form mitAusnahme des äußersten Carboxyendes identisch. In diesem Teil des Proteinsträgt die membrangebundene Form eine lange Kette hydrophober Aminosäuren,die die Lipid-Doppelmembran durchdringen, während die sezernierte Form hiereine viel kürzere Folge hydrophiler Aminosäuren aufweist. Der Wechsel voneinem membrangebundenen zu einem sezernierten Antikörper wird über eineÄnderung der Schnitt- und Polyadenylierungsstelle in der RNA erzeugt, wie inAbb. 7–59 skizziert.
Die Änderung wird durch einen Anstieg in der Konzentration einer Unter-einheit eines Proteins (CStF) bewirkt, das die Spaltung der RNA fördert(s. Abb. 6–34). Die erste Spalt- und poly-A-Anheftungsstelle, auf die eine trans-kribierende RNA-Polymerase stößt, ist suboptimal und wird normalerweise innicht stimulierten B-Lymphocyten übergangen, was zur Synthese der längerenRNA-Transkripte führt. Wenn der B-Lymphocyt aktiviert ist, um Antikörper zubilden, dann steigert er seine CStF-Konzentration; infolgedessen wird nun dieRNA an der suboptimalen Stelle gespalten und das kürzere Transkript wirdhergestellt. So hat die Änderung in der Konzentration eines allgemeinen RNA-Prozessierungsfaktors drastische Auswirkungen auf die Expression eines spezi-fischen Gens.
7.6.6 RNA-Editierung kann den Inhalt der RNA-Botschaft verändern
Die von den Zellen genutzten molekularen Mechanismen sind eine stetigeQuelle von Überraschungen. Ein Beispiel ist das Phänomen der RNA-Editie-rung, durch das die Nukleotidsequenz von mRNA-Transkripten verändert wird,nachdem sie synthetisiert wurden, wodurch sich die in ihnen codierte Botschaftverändert. In Kapitel 6 haben wir gesehen, dass tRNA- und rRNA-Moleküle nach
DNA
prä-mRNA prä-mRNAAAA AAA
mRNA AAA
5’3’
nicht codierende 3’-RNA
schwach stark
Polyadenylierungsstellen
DNA5’3’
schwach stark
Polyadenylierungsstellen
ruhende B-Zelle, niedrige CstF-Spiegel(A) aktivierte B-Zelle, hohe CstF-Spiegel(B)
CstFCstF
mRNA AAA
B-Zelle mit membran-gebundenen Antikörpern
B-Zelle sezerniert Antikörper
nicht codierende 3’-RNA
Abb. 7–59 Die Regulation der RNA-Spaltungs- undpoly-A-Anheftungsstelle bestimmt, ob einAntikörpermolekül sezerniert wird oder memb-rangebunden bleibt. Bei nicht stimulierten B-Lym-phocyten (links) wird ein langes RNA-Transkript ge-bildet, und die Intronsequenz (gelb) nahe seinem 3′-Ende wird durch RNA-Spleißen entfernt, um einmRNA-Molekül zu erzeugen, das für ein mem-brangebundenes Antikörpermolekül codiert. In derAbbildung ist nur ein Teil des Antikörpergens gezeigt;das tatsächliche Gen und seine mRNA würden sichnoch weiter links im Diagramms erstrecken. NachAntigenstimulierung (rechts) wird das RNA-Transkriptstromaufwärts von der 3′-Spleißstelle des Introns ge-schnitten und polyadenyliert. Als Folge davon ver-bleibt ein Teil der Intronsequenz als codierende Se-quenz in dem kurzen Transkript und spezifiziert denhydrophilen C-terminalen Anteil des sezernierten An-tikörpermoleküls (braun). (Nach D. Di Giamartino etal., Mol. Cell 43:853–866, 2011. Mit Erlaubnis vonElsevier.)
466 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:213B2 9.1.580; Page size: 210.00mm x 275.00mm
ihrer Synthese chemisch modifiziert werden: Hier konzentrieren wir uns aufÄnderungen an mRNAs.
In Tieren gibt es zwei grundsätzliche Arten von mRNA-Editierung: dieDesaminierung von Adenin, bei der Inosin entsteht (A-zu-I-Editierung), undnicht so häufig die Desaminierung von Cytosin, bei der sich Uracil bildet (C-zu-U-Editierung; s. Abb. 5–43). Weil diese chemischen Modifikationen die Paa-rungseigenschaften der Basen ändern (I paart mit C und U paart mit A), könnensie tiefgreifende Auswirkungen auf den Informationsgehalt der RNA haben.Wenn das Editieren in einer codierenden Region stattfindet, kann es die Amino-säuresequenz des Proteins verändern oder durch ein vorzeitiges Stopp-Codonein gestutztes Protein erzeugen. Editierungen, die sich außerhalb codierenderSequenzen abspielen, können das Muster der prä-mRNA-Spleißung, den Trans-port der mRNA vom Zellkern ins Cytosol, die Effizienz, mit der die RNAtranslatiert wird, oder die Basenpaarung zwischen microRNAs (miRNAs) undihren mRNA-Zielen beeinträchtigen, eine Regulationsform, die an späterer Stellein diesem Kapitel behandelt wird.
Die A-zu-I-Editierung herrscht besonders beim Menschen vor, wo es beietwa tausend Genen vorkommt. Enzyme namens ADARs (Adenosindesaminasenagierend an RNA, engl. adenosine deaminases acting on RNA) führen diesenEditiertyp durch; diese Enzyme erkennen eine doppelsträngige RNA-Struktur,die sich durch Basenpaarung zwischen der zu editierende Stelle und einerkomplementären Sequenz, die irgendwo auf dem gleichen RNA-Molekül sitzt,normalerweise in einem Intron, bildet (Abb. 7–60). Die Struktur der doppel-strängigen RNA spezifiziert, ob die mRNA editiert werden soll, und falls ja, wogenau die Editierung vorgenommen werden soll. Ein besonders wichtiges Bei-spiel der A-zu-I-Editierung findet an der Vorläufer-mRNA statt, die für einenTransmitter-kontrollierten Ionenkanal im Gehirn codiert. Ein einziger Bearbei-tungsschritt ändert ein Glutamin zu einem Arginin; die betroffene Aminosäureliegt an der inneren Wand des Kanals, und der durch das Editieren bewirkteAustausch ändert die Permeabilität des Kanals für Ca2+. Mutierte Mäuse, diediese Editierung nicht durchführen können, sind anfällig für epileptische Anfälleund sterben während oder kurz nach der Entwöhnung, was zeigt, dass dieEditierung der Ionenkanal-RNA normalerweise für eine ordentliche Gehirnent-wicklung entscheidend ist.
Die C-zu-U-Editierung, die von einem anderen Enzymsatz durchgeführtwird, ist bei Säugetieren ebenfalls sehr wichtig. In bestimmten Darmzellenbeispielsweise erfährt die mRNA für Apolipoprotein B eine C-zu-U-Editierung,die ein vorzeitiges Stopp-Codon erzeugt und deshalb eine verkürzte Form diesesProteins hervorbringt. In Zellen der Leber wird das Editier-Enzym nicht expri-miert, und das Apolipoprotein B wird in voller Länge gebildet. Die beidenProteinisoformen haben unterschiedliche Eigenschaften und jede spielt eine
A
5’ 3’Exon Intron
ADAR-Enzym
Abb. 7–60 Mechanismen der A-zu-I-RNA-Editierungbei Säugern. Typischerweise existiert eine zur Editier-Position komplementäre Sequenz in einem Intron,und die resultierende doppelsträngige RNA zieht einA-zu-I-editierendes Enzym (ADAR) an. Im gezeigtenFall wird das Editieren im Exon durchgeführt; in denmeisten Fällen jedoch geschieht dies in den nichtcodierenden Anteilen der mRNA. Das Editieren durchADAR findet im Zellkern statt, bevor die prä-mRNAvollständig prozessiert wurde. Mäuse und Menschenbesitzen zwei ADAR-Gene: ADR1 wird in vielen Ge-weben exprimiert und ist in der Leber für die korrekteEntwicklung der roten Blutkörperchen erforderlich;ADR2 wird nur im Gehirn exprimiert, wo es für dierichtige Gehirnentwicklung nötig ist.
CAA TAA
CAA UAA
5’3’DNA
Apolipoprotein-B-Gen
mRNA UAA UAAmRNA
neues Stopp-Codon
in der Leber hergestelltes Protein im Darm hergestelltes Protein
kein Editieren Editieren CAA → UAA
Protein Protein
Abb. 7–61 Die C-zu-U-RNA-Editierung erzeugt einegestutzte Form von Apolipoprotein B.
7.6 Posttranskriptionale Kontrolle 467

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:213B2 9.1.580; Page size: 210.00mm x 275.00mm
Rolle im Fettstoffwechsel, die für das Organ, das sie produziert, spezifisch ist(Abb. 7–61).
Warum die RNA-Editierung überhaupt existiert, ist ein Rätsel. Eine Vor-stellung ist, es sei im Laufe der Evolution entstanden, um „Fehler“ im Genom zukorrigieren. Eine andere ist, dass es der Zelle eine etwas schludrige Möglichkeitgibt, von einem einzigen Gen geringfügig unterschiedliche Proteine herzustellen.Eine dritte Möglichkeit ist, dass sich das RNA-Editieren ursprünglich aus einemAbwehrmechanismus gegen Retroviren und Retrotransposons entwickelte undspäter von der Zelle angepasst wurde, um die Bedeutung bestimmter mRNAs zuverändern. In der Tat spielt die RNA-Editierung in der Zellabwehr immer nocheine wichtige Rolle. Manche Retroviren, einschließlich HIV, werden ausgiebigeditiert, nachdem sie Zellen infiziert haben. Dieses Hypereditieren erzeugt vieleschädliche Mutationen im viralen RNA-Genom und verursacht auch, dass viralemRNAs im Zellkern zurückgehalten werden, wo sie schließlich abgebaut werden.Obwohl sich manche der heutigen Retroviren vor diesem Abwehrmechanismusschützen, trägt die RNA-Editierung vermutlich dazu bei, viele Viren in Schach zuhalten.
7.6.7 Der Transport der RNA aus dem Zellkern kann kontrolliertwerden
Man schätzt, dass bei Säugetieren nur etwa 5 Prozent der gesamten synthetisier-ten Menge der RNA jemals den Zellkern verlässt. In Kapitel 6 haben wir gesehen,dass die meisten RNA-Moleküle bei Säugetieren einer ausgeprägten Bearbeitungunterliegen und die „übrig gelassenen“ RNA-Fragmente (ausgeschnittene Intronsund hinter der Spalt-/poly-A-Stelle gelegene RNA-Sequenzen) im Zellkern abge-baut werden. Unvollständig prozessierte und sonstwie beschädigte RNAs werdenebenfalls im Rahmen der Qualitätskontrolle für die RNA-Produktion im Zellkernabgebaut.
Wie in Kapitel 6 beschrieben, wird der Export von RNA-Molekülen aus demZellkern verzögert, bis deren Bearbeitung abgeschlossen ist. Mechanismen, dieabsichtlich diesen Kontrollpunkt überwinden, können jedoch zur Regulation derGenexpression verwendet werden. Diese Eigenschaft bildet die Grundlage füreines der am besten verstandenen Beispiele des kontrollierten Kerntransportsvon mRNA, das bei HIV, dem AIDS auslösenden Virus, auftritt.
HIV ist, wie wir in Kapitel 5 gesehen haben, ein Retrovirus – ein RNA-Virus,das, einmal in einer Zelle angekommen, die Bildung einer doppelsträngigenDNA-Kopie seines Genoms steuert, die dann in das Genom des Wirts eingebautwird (s. Abb. 5–62). Sobald sie eingebaut ist, kann die DNA des Virus als langesRNA-Molekül durch die RNA-Polymerase II der Wirtszelle transkribiert werden.Dieses Transkript wird dann auf viele unterschiedliche Arten zu über 30 unter-schiedlichen mRNAs gespleißt, die wiederum zu einer Vielzahl unterschiedlicherProteine translatiert werden (Abb. 7–62). Um Virusnachkommen zu bilden,müssen ganze, nicht gespleißte Transkripte des Virus aus dem Zellkern in dasCytosol exportiert werden, wo sie dann in virale Capside verpackt werden und alsvirales Genom dienen. Dieses große Transkript sowie alternativ gepleißte HIV-
RRE
Tat
Env
NefVpuVif
Vpr
PolGag
Rev
5’-Spleißstellen
3’-Spleißstellen
in Wirts-genomintegriertevirale DNA
virale RNA
1.000 Nukleotidpaare
Abb. 7–62 Das kompakte Genom von HIV,dem AIDS-Virus des Menschen. Die Lage derneun HIV-Gene ist grün dargestellt. Die rote
Doppellinie stellt eine in die Wirts-DNA (grau)integrierte DNA-Kopie des Virusgenoms dar.Man beachte, dass die codierenden Regionenmehrerer Gene überlappen und die von Tat
und Rev durch Introns geteilt sind. Die blaueLinie unten in der Abbildung stellt das prä-mRNA-Transkript der viralen DNA dar, auf deralle möglichen Spleißstellen (Pfeile) markiertsind. Es gibt viele alternative Möglichkeiten,das virale Transkript zu spleißen; beispiels-weise behält die Env-mRNA das Intron, dasaus den mRNAs von Tat und Rev entferntwird. Das auf Rev reagierende Element (Revresponse element; RRE) ist als blauer Kreis mitStiel angedeutet. Es ist ein 234 Nukleotidelanges Stück RNA, das sich in eine definierteStruktur falten kann; Rev erkennt eine beson-dere Haarnadelstruktur innerhalb dieses grö-ßeren Gebildes.Das Gag-Gen codiert für ein Protein, das inmehrere kleinere Proteine gespalten wird, diedas virale Capsid bilden. Das Pol-Gen codiertfür ein Protein, das in die Reverse Transkripta-se, die RNA in DNA umschreibt, und die Inte-grase, die am Einbau des Virusgenoms (alsdoppelsträngige DNA) in das Wirtsgenom be-teiligt ist, gespalten wird. Das Env-Gen codiertfür die Hüllproteine (s. Abb. 5–62). Tat, Rev,Vif, Vpr, Vpu und Nef sind kleine Proteine mitunterschiedlichen Funktionen. So reguliertbeispielsweise Rev den Kernexport(s. Abb. 7–63) und Tat reguliert die Elongationder Transkription über das gesamte inte-grierte virale Genom (s. Abschnitt 7.6.1).
468 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:213B2 9.1.580; Page size: 210.00mm x 275.00mm
mRNAs, die das Virus für die Proteinsynthese ins Cytosol überführen muss,tragen immer noch die vollständigen Introns. Die normale Blockade des Kern-exports von ungespleißten RNAs der Wirtszelle stellt somit ein speziellesProblem für HIV dar.
Die Blockade wird auf geniale Weise bezwungen. Das Virus codiert für einmit Rev bezeichnetes Protein, das an eine spezifische, innerhalb eines viralenIntrons gelegene RNA-Sequenz (genannt „auf Rev reagierendes Element“, RRE)bindet. Das Rev-Protein interagiert mit einem Kernexportrezeptor (Crm1),worauf trotz der Gegenwart der Intronsequenzen der Transport viraler RNAsdurch die Kernporen in das Cytosol erfolgt. Wie Exportrezeptoren im Detailfunktionieren, besprechen wir in Kapitel 12.
Die Regulation des Kerntransports durch Rev hat mehrere wichtige Folgenfür das Wachstum und die Pathogenese von HIV. Es stellt nicht nur den Kern-transport bestimmter nicht gespleißter RNAs sicher, sondern teilt die Virus-infektion in eine frühe Phase, bei der Rev von einer völlig gespleißten RNAtranslatiert wird und alle intronhaltigen viralen RNAs im Kern zurückbleibenund abgebaut werden, und eine späte Phase, in der nicht gespleißte RNAs dankder Funktion von Rev exportiert werden. Diese zeitliche Abstimmung erlaubtdem Virus die Replikation, indem die Genprodukte in ungefähr der Reihenfolgebereitgestellt werden, in der sie benötigt werden (Abb. 7–63). Die Regulationdurch Rev und durch Tat, dem HIV-Protein, das der vorzeitigen Beendigungentgegenwirkt, erlaubt dem Virus, Latenz zu erlangen, ein Zustand, in dem dasHIV-Genom ins Wirtszellgenom integriert wurde, aber die Bildung viraler Pro-teine vorübergehend nachgelassen hat. Falls nach dem anfänglichen Eintritt ineine Wirtszelle die Umstände für eine Transkription und Replikation des Viruszu schlecht werden, werden Rev und Tat in zu geringen Mengen hergestellt, um
im Kern zurück-gehalten
und abgebaut
gespleißtemRNAs
Rev und anderefrühe virale Proteinewerden synthetisiert
KERN CYTOSOL
integrierte virale DNA
nicht ge-spleißte RNAs
(A) früh in der HIV-Synthese
KERN CYTOSOL
integrierte virale DNA
(B) spät in der HIV-Synthese
alle viralenProteine werdensynthetisiert
Abb. 7–63 Regelung des Exports aus dem Kerndurch das HIV-Rev-Protein. (A) Früh bei der HIV-Infektion werden nur vollständig gespleißte RNAs(die die codierenden Sequenzen für Rev, Tat und Neftragen) vom Kern exportiert und translatiert. (B) So-bald sich genug Rev-Protein angesammelt hat und inden Kern transportiert worden ist, können nicht ge-spleißte virale RNAs vom Kern exportiert werden.Viele dieser RNAs werden zu Proteinen translatiert,und die Transkripte voller Länge werden zu neuenViruspartikeln verpackt.
7.6 Posttranskriptionale Kontrolle 469
Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:223B2 9.1.580; Page size: 210.00mm x 275.00mm
die Transkription und den Export nicht gespleißter RNAs zu ermöglichen.Dieser Zustand bremst den Wachstumszyklus des Virus, bis sich die Bedingun-gen verbessern, woraufhin die Mengen an Rev und Tat ansteigen und das Virusin den Replikationszyklus eintreten kann.
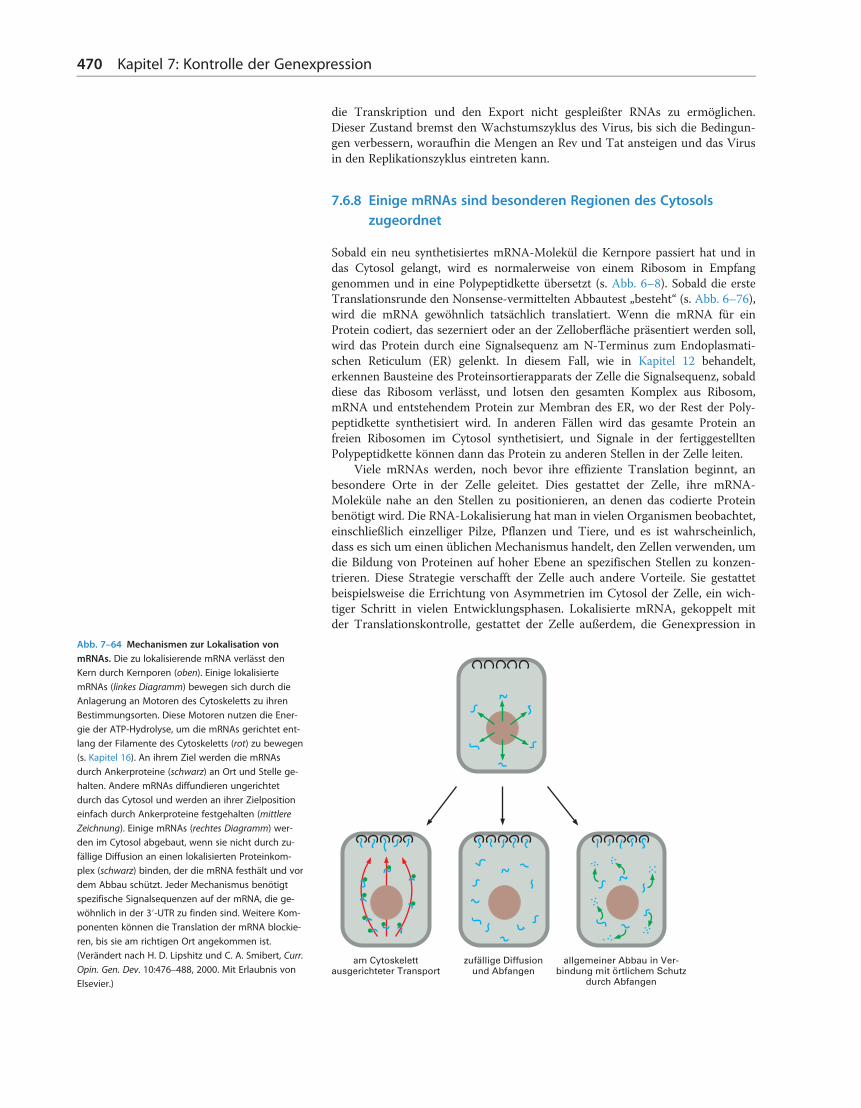
7.6.8 Einige mRNAs sind besonderen Regionen des Cytosolszugeordnet
Sobald ein neu synthetisiertes mRNA-Molekül die Kernpore passiert hat und indas Cytosol gelangt, wird es normalerweise von einem Ribosom in Empfanggenommen und in eine Polypeptidkette übersetzt (s. Abb. 6–8). Sobald die ersteTranslationsrunde den Nonsense-vermittelten Abbautest „besteht“ (s. Abb. 6–76),wird die mRNA gewöhnlich tatsächlich translatiert. Wenn die mRNA für einProtein codiert, das sezerniert oder an der Zelloberfläche präsentiert werden soll,wird das Protein durch eine Signalsequenz am N-Terminus zum Endoplasmati-schen Reticulum (ER) gelenkt. In diesem Fall, wie in Kapitel 12 behandelt,erkennen Bausteine des Proteinsortierapparats der Zelle die Signalsequenz, sobalddiese das Ribosom verlässt, und lotsen den gesamten Komplex aus Ribosom,mRNA und entstehendem Protein zur Membran des ER, wo der Rest der Poly-peptidkette synthetisiert wird. In anderen Fällen wird das gesamte Protein anfreien Ribosomen im Cytosol synthetisiert, und Signale in der fertiggestelltenPolypeptidkette können dann das Protein zu anderen Stellen in der Zelle leiten.
Viele mRNAs werden, noch bevor ihre effiziente Translation beginnt, anbesondere Orte in der Zelle geleitet. Dies gestattet der Zelle, ihre mRNA-Moleküle nahe an den Stellen zu positionieren, an denen das codierte Proteinbenötigt wird. Die RNA-Lokalisierung hat man in vielen Organismen beobachtet,einschließlich einzelliger Pilze, Pflanzen und Tiere, und es ist wahrscheinlich,dass es sich um einen üblichen Mechanismus handelt, den Zellen verwenden, umdie Bildung von Proteinen auf hoher Ebene an spezifischen Stellen zu konzen-trieren. Diese Strategie verschafft der Zelle auch andere Vorteile. Sie gestattetbeispielsweise die Errichtung von Asymmetrien im Cytosol der Zelle, ein wich-tiger Schritt in vielen Entwicklungsphasen. Lokalisierte mRNA, gekoppelt mitder Translationskontrolle, gestattet der Zelle außerdem, die Genexpression in
am Cytoskelettausgerichteter Transport
zufällige Diffusionund Abfangen
allgemeiner Abbau in Ver-bindung mit örtlichem Schutz
durch Abfangen
Abb. 7–64 Mechanismen zur Lokalisation vonmRNAs. Die zu lokalisierende mRNA verlässt denKern durch Kernporen (oben). Einige lokalisiertemRNAs (linkes Diagramm) bewegen sich durch dieAnlagerung an Motoren des Cytoskeletts zu ihrenBestimmungsorten. Diese Motoren nutzen die Ener-gie der ATP-Hydrolyse, um die mRNAs gerichtet ent-lang der Filamente des Cytoskeletts (rot) zu bewegen(s. Kapitel 16). An ihrem Ziel werden die mRNAsdurch Ankerproteine (schwarz) an Ort und Stelle ge-halten. Andere mRNAs diffundieren ungerichtetdurch das Cytosol und werden an ihrer Zielpositioneinfach durch Ankerproteine festgehalten (mittlere
Zeichnung). Einige mRNAs (rechtes Diagramm) wer-den im Cytosol abgebaut, wenn sie nicht durch zu-fällige Diffusion an einen lokalisierten Proteinkom-plex (schwarz) binden, der die mRNA festhält und vordem Abbau schützt. Jeder Mechanismus benötigtspezifische Signalsequenzen auf der mRNA, die ge-wöhnlich in der 3′-UTR zu finden sind. Weitere Kom-ponenten können die Translation der mRNA blockie-ren, bis sie am richtigen Ort angekommen ist.(Verändert nach H. D. Lipshitz und C. A. Smibert, Curr.Opin. Gen. Dev. 10:476–488, 2000. Mit Erlaubnis vonElsevier.)
470 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:223B2 9.1.580; Page size: 210.00mm x 275.00mm
ihren verschiedenen Teilen unabhängig zu regulieren. Diese Eigenschaft istbesonders wichtig in großen, stark polarisierten Zellen wie Neuronen, wo sieeine zentrale Rolle bei der Funktion der Synapsen spielt.
Man hat mehrere Mechanismen für die mRNA-Lokalisierung entdeckt(Abb. 7–64), aber sie alle benötigen spezifische Signale in der mRNA selbst.Diese Signale sind normalerweise in der 3′-untranslatierten Region (UTR) kon-zentriert, der RNA-Region, die vom Stopp-Codon, das die Proteinsynthesebeendet, bis zum Beginn des poly-A-Schwanzes reicht (Abb. 7–65). DiesemRNA-Lokalisierung ist normalerweise mit Translationskontrollen gekoppelt,um sicherzustellen, dass die mRNA ruhig bleibt, bis sie an ihren Platz gewandertist.
Ein besonders auffälliges Beispiel der mRNA-Lokalisierung kann im Ei vonDrosophila beobachtet werden, wo die für den Transkriptionsregulator Bicoidcodierende mRNA durch Anlagerung an das Cytoskelett in der anterioren Spitzedes sich entwickelnden Eies angesammelt ist. Wenn die Translation diesermRNA durch die Befruchtung ausgelöst wird, bildet sich ein Gradient desBicoid-Proteins, der bei der Steuerung der Entwicklung der Vorderhälfte desEmbryos eine wichtige Funktion erfüllt (s. Abb. 7–26). Viele mRNAs in somati-schen Zellen sind auf eine ähnliche Weise angeordnet. Beispielsweise ist diemRNA, die für Aktin codiert, bei Säugerfibroblasten durch ein 3′-UTR-Signal ander Zellrinde angelagert, die viele Aktinfilamente enthält.
Wir haben in Kapitel 6 gelesen, dass mRNA-Moleküle den Zellkern ver-lassen und zahlreiche Markierungen in Form von RNA-Modifikationen (das5′-Cap und der 3′-poly-A-Schwanz) und gebundenen Proteinen (z. B. Exon-Junction-Komplexe) tragen, die den erfolgreichen Abschluss der verschiedenenprä-mRNA-Prozessierungsschritte signalisieren. Wie wir gerade gehört haben,kann die 3′-UTR praktisch eine „Postleitzahl“ enthalten, durch die die mRNA anverschiedene Stellen der Zelle geleitet wird. Weiter unten werden wir aucherfahren, dass die mRNA außerdem Informationen trägt, die die durchschnitt-liche Lebensdauer einer jeden mRNA im Cytosol und die Effizienz, mit der jedemRNA in Protein translatiert wird, festlegt. Im weiteren Sinne gleichen die nichttranslatierten Regionen der eukaryotischen mRNA den Transkriptionskontroll-regionen der Gene: Ihre Nukleotidsequenz enthält Informationen über denrichtigen Gebrauch der RNA, und spezielle Proteine, die diese Informationinterpretieren, binden an diese Sequenz. Neben der Information über die Ami-nosäuresequenz eines Proteins enthalten also mRNA-Moleküle noch sehr vieleandere Informationen.
7.6.9 Die 5′- und 3′-untranslatierten Bereiche der mRNAskontrollieren ihre Translation
Einer der häufigsten Wege, nach der mRNA-Synthese die Menge eines Proteinszu regulieren, ist, die Translationsinitiation zu kontrollieren. Auch wenn sich dieDetails der Translationsinitiation zwischen Eukaryoten und Bakterien (wie wir inKapitel 6 gesehen haben) unterscheiden, verwenden sie alle die gleichen grund-legenden Kontrollstrategien.
In mRNAs von Bakterien wird wenige Nukleotide vor dem initiierendenAUG-Codon stets eine konservierte Sequenz von sechs Nukleotiden, die Shine–Dalgarno-Sequenz, gefunden. In Bakterien werden Translationskontrollmecha-nismen von Proteinen oder RNA-Molekülen ausgeführt und sie schließen imAllgemeinen eine Freilegung oder Blockade der Shine–Dalgarno-Sequenz ein(Abb. 7–66).
Auf mRNAs von Eukaryoten gibt es keine solche Sequenz; stattdessen wird,wie wir in Kapitel 6 besprochen haben, die Auswahl eines AUG-Codons alsTranslationsstartstelle zum Großteil durch seine Nähe zum Cap am 5′-Ende desmRNA-Moleküls bestimmt, der Stelle, an der die kleine ribosomale Untereinheit
20 µm
Abb. 7–65 Ein Experiment, das die Bedeutung der3′-UTR für den Transport von mRNA an spezifischeOrte im Cytoplasma zeigt. Für dieses Experimentwurden durch In-vitro-Transkription von DNA in Ge-genwart von fluoreszenzmarkierten Derivaten desUTP zwei unterschiedlich fluoreszenzmarkierte RNAshergestellt. Die eine RNA (markiert mit einem roten
Fluorochrom) enthält die für das Drosophila-ProteinHairy codierende Region sowie die anschließende3′-UTR (s. Abb. 6–21). Die andere RNA (grün markiert)enthält auch die für Hairy codierende Region, die3′-UTR wurde jedoch entfernt. Die beiden RNAs wur-den gemischt und in einen Drosophila-Embryo ineinem frühen Entwicklungsstadium injiziert, in demviele Kerne in einem syncytialen Cytoplasma zu fin-den sind (s. Abb. 7–26). Als die markierten RNAs nach10 Minuten sichtbar gemacht wurden, war die hairy-RNA von voller Länge (rot) auf die apikale Seite derKerne (blau) begrenzt, während das Transkript ohne3′-UTR (grün) nicht lokalisiert wurde. Hairy ist einervon vielen Transkriptionsregulatoren, die im sich ent-wickelnden Embryo von Drosophila die Informationüber die Position festlegen (wie in Kapitel 21 dis-kutiert). Die Lokalisation seiner mRNA (die, wie indiesem Experiment gezeigt, von der 3′-UTR abhängigist) ist für die richtige Entwicklung der Fliege not-wendig. (Mit freundlicher Genehmigung von SimonBullock und David Ish-Horowicz.)
7.6 Posttranskriptionale Kontrolle 471

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:223B2 9.1.580; Page size: 210.00mm x 275.00mm
an die mRNA bindet und mit der Suche nach dem initiierenden AUG-Codonbeginnt. In Eukaryoten können Translationsrepressoren an das 5′-Ende dermRNA binden und dadurch die Translationsinitiation hemmen. Andere Repres-soren erkennen Nukleotidsequenzen in der 3′-UTR bestimmter mRNAs undvermindern die Translationsinitiation durch Störung der Kommunikation zwi-schen dem 5′-Cap und dem 3′-poly-A-Schwanz – ein Schritt, der für eineerfolgreiche Translation nötig ist (s. Abb. 6–70). Eine besonders wichtige Artder Translationskontrolle der Eukaryoten stützt sich auf kleine RNAs (micro-RNAs oder miRNAs genannt), die an mRNAs binden und die hergestellteProteinmenge verringern, wie später in diesem Kapitel behandelt wird.
7.6.10 Die Phosphorylierung eines Initiationsfaktors regelt dieProteinsynthese umfassend
Eukaryotische Zellen senken die Geschwindigkeit ihrer Proteinsynthese alsReaktion auf verschiedene Bedingungen, einschließlich Mangel an Wachstums-faktoren oder Nährstoffen, Infektionen durch Viren und Hitzeschock. DieseKontrolle wird zu einem großen Teil durch die Phosphorylierung des Trans-lationsinitiationsfaktors eIF-2 durch eine spezifische Proteinkinase, die auf sichändernde Bedingungen reagiert, gesteuert.
Die normale Funktion des eIF-2 ist in Abschnitt 6.2.10 besprochen worden.Er bildet einen Komplex mit GTP und vermittelt die Bindung der Methionyl-Initiator-tRNA an die kleine Ribosomenuntereinheit, die sich dann an das5′-Ende der mRNA heftet und ihre Suche an der mRNA beginnt. Nach demErkennen eines AUG-Codons hydrolysiert das eIF-2-Protein das gebundeneGTP zu GDP, was zu einer Konformationsänderung im Protein führt, wodurches von der kleinen Ribosomenuntereinheit entlassen wird. Die große Ribosomen-untereinheit verbindet sich nun mit der kleinen, um das komplette Ribosom zubilden, das die Proteinsynthese beginnt.
STOPP STOPP
STOPP
STOPP
STOPP
STOPP
STOPP
STOPP
AUG
AUG
AU
G
AU
G
AUG AUG
AUG
H2N COOH3’ 3’
3’
5’ 5’
5’
5’ 3’
5’ 3’
3’ 5’
3’5’
Protein gebildet
Translationsrepressorprotein
kein Protein gebildet
EIN
H2N COOH
H2N COOH
H2N COOH3’
3’
5’
5’
EIN
AUS EIN
AUS
AUS
EIN
AUS
(A)
(C)
(B)
(D)
TEMPERATUR-ZUNAHME
Antisense-RNA
kleines Molekül
AUG
Abb. 7–66 Mechanismen der Translationskontrol-le. Obgleich diese Beispiele von Bakterien stammen,sind viele gleiche Prinzipien in Eukaryoten wirksam.(A) Sequenzspezifische RNA-Bindungsproteine repri-mieren die Translation spezifischer mRNAs, indem siefür Ribosomen den Zugang zur Shine–Dalgarno-Se-quenz (orange) blockieren. Beispielsweise reprimierenmanche ribosomalen Proteine die Translation ihrereigenen RNA. Dieser Mechanismus erlaubt der Zelle,die ausgewogenen Mengen der verschiedenen Kom-ponenten, die zur Bildung der Ribosomen erforder-lich sind, korrekt aufrechtzuerhalten. (B) Ein RNA-„Thermosensor“ erlaubt eine wirksame Translations-initiation nur bei erhöhten Temperaturen, bei denendie Haarnadelstruktur geschmolzen wurde. Ein Bei-spiel kommt beim Humanpathogen Listeria mono-cytogenes vor, bei dem die Translation seiner Viru-lenzgene bei 37 °C, der Temperatur des Wirts,zunimmt. (C) Die Bindung eines kleinen Moleküls aneinen Riboswitch verursacht eine große Struktur-änderung der RNA, wodurch eine andere Reihe vonStamm-Schleifen-Strukturen gebildet wird. Im ge-bundenen Zustand wird die Shine–Dalgarno-Sequenz(orange) verborgen und dadurch die Translationsini-tiation blockiert. In vielen Bakterien wirkt S-Adenosyl-methionin auf diese Weise, um die Bildung der En-zyme zu blockieren, die es synthetisieren. (D) Eine„Antisense“-RNA, die irgendwo vom Genom gebildetwurde, geht Basenpaarungen mit einer spezifischenmRNA ein und blockiert ihre Translation. Viele Bakte-rien regulieren die Expression der Eisenspeicherpro-teine auf diese Weise.
472 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:233B2 9.1.580; Page size: 210.00mm x 275.00mm
Da eIF-2 sehr fest an GDP gebunden ist, wird ein Guanin-Nukleotid-Aus-tauschfaktor (s. Abschnitt 3.2.22), als eIF-2B bezeichnet, zur Freisetzung desGDP benötigt, damit ein neues GTP binden und eIF-2 wiederverwendet werdenkann (Abb. 7–67A). Der erneute Einsatz des eIF-2 wird unterdrückt, wenn es imphosphorylierten Zustand vorliegt; das phosphorylierte eIF-2 bindet ungewöhn-lich fest an eIF-2B und inaktiviert es dadurch. In den Zellen gibt es mehr eIF-2als eIF-2B, und selbst ein Bruchteil an phosphoryliertem eIF-2 genügt, umnahezu alles verfügbare eIF-2B einzufangen. Dies verhindert die Wiederverwen-dung von nicht phosphoryliertem eIF-2 und verlangsamt die Geschwindigkeitder Proteinsynthese wesentlich (Abb. 7–67B).
Die Regulierung der Menge an aktivem eIF-2 ist in Säugerzellen besonderswichtig, da sie Teil des Mechanismus ist, der es ihnen ermöglicht, einen Ruhe-zustand (als G0 bezeichnet) einzunehmen, in dem sie sich nicht teilen und indem die gesamte Proteinsynthese auf etwa ein 1/5 der Geschwindigkeit inproliferierenden Zellen reduziert ist.
7.6.11 Initiation an AUG-Codons oberhalb des Start-Codons kanndie Translation bei Eukaryoten regulieren
Wir haben in Kapitel 6 gesehen, dass die Translation bei Eukaryoten normaler-weise am ersten AUG nach dem 5′-Ende der mRNA beginnt, dem ersten AUG,das die kleine Ribosomenuntereinheit auf ihrer Suche antrifft. Die Nukleotideunmittelbar um das AUG beeinflussen ebenfalls die Wirksamkeit der Trans-lationsinitiation. Wenn die Erkennungsstelle schwach ist, wird die Ribosomen-untereinheit auf ihrer Suche das erste AUG-Codon auf der mRNA manchmalüberlesen und stattdessen zum zweiten oder dritten AUG-Codon weiterlaufen.Dieses Phänomen, das als „durchlässige Suche“ (engl. leaky scanning) bekannt ist,ist eine oft benutzte Strategie, um von derselben mRNA zwei oder mehr naheverwandte Proteine herzustellen, die sich nur in ihrem N-Terminus unterschei-den. Eine besonders wichtige Anwendung dieses Mechanismus ist die Bildungdes gleichen Proteins mit und ohne Signalsequenz am N-Terminus. Dies ermög-licht, dass das Protein an zwei unterschiedliche Orte in der Zelle (z. B. sowohl zuMitochondrien als auch zum Cytosol) geleitet wird. Zellen können die relativen
Guaninnukleotid-Austauschfaktor,elF-2B
inaktiveseIF-2
aktiveseIF-2
(A)
eIF-2B
PROTEINKINASEPHOSPHORYLIERTelF-2
PHOSPHORYLIERTES eIF-2 FÄNGT ALLE eIF-2B-MOLEKÜLE AB UND BILDETEINEN INAKTIVENKOMPLEX
(B)
inaktiveselF-2
OHNE AKTIVES EIF-2B BLEIBT DAS ÜBRIGE UNGEBUND-ENE EIF-2 IN SEINER INAKTIVEN, GDP-BINDENDEN FORM UND DIE PROTEIN-SYNTHESE NIMMT DRASTISCH AB
GTP
GDP
GDP
GDPGDP GDP
GDP
P P
Abb. 7–67 Der eIF-2-Kreislauf. (A) Wiederver-wendung von benutztem eIF-2 durch einenGuaninnukleotid-Austauschfaktor (eIF-2B).(B) Phosphorylierung von eIF-2 kontrolliert dieGeschwindigkeit der Proteinsynthese durchBindung an eIF-2B.
7.6 Posttranskriptionale Kontrolle 473

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:233B2 9.1.580; Page size: 210.00mm x 275.00mm
Mengen der durch „durchlässige Suche“ hergestellten Proteinisoformen kontrol-lieren; beispielsweise führt ein zelltypspezifischer Anstieg in der Menge desInitiationsfaktors eIF-4F zu einer bevorzugten Nutzung des AUG, das am nächs-ten zum 5′-Ende der mRNA liegt.
Ein weiterer bei Eukaryoten gefundener Kontrolltyp nutzt einen oder meh-rere kurze offene Leseraster – kurze DNA-Abschnitte, die mit einen Start-Codon(ATG) beginnen und mit einem Stopp-Codon enden, ohne Stopp-Codonsdazwischen – die zwischen dem 5′-Ende der mRNA und dem Beginn des Gensliegen. Häufig sind die Aminosäuresequenzen, die durch diese vorangestelltenoffenen Leseraster (uORFs, engl. upstream open reading frames) codiert sind,nicht wichtig; vielmehr haben diese uORFs eine reine Kontrollfunktion. Ein aufdem mRNA-Molekül vorhandenes uORF senkt im Allgemeinen die Translationdes nachgelagerten Gens, da es einen Ribosomeninitiationskomplex auf derSuche abfängt und das Ribosom so das uORF translatiert und von der mRNAabspringt, bevor es die eigentliche proteincodierende Sequenz erreicht.
Man würde erwarten, dass, wenn die Aktivität eines allgemeinen Trans-lationsfaktors (wie des oben besprochenen eIF-2) vermindert wird, die Trans-lation aller mRNAs ebenso vermindert würde. Entgegen dieser Erwartung kannjedoch die Phosphorylierung von eIF-2 selektive Effekte zeigen und sogar dieTranslation von bestimmten mRNAs, die uORFs enthalten, erhöhen. Auf dieseWeise können sich Zellen einem Mangel an bestimmten Nährstoffen anpassen,indem sie die Synthese aller Proteine beenden, mit Ausnahme derer, die für eineSynthese der fehlenden Substrate nötig sind. In allen Einzelheiten wurde derMechanismus für eine bestimmte Hefe-mRNA aufgeklärt, die für ein mit Gcn4bezeichnetes Protein codiert, ein Transkriptionsregulator, der viele Gene akti-viert, die für Proteine codieren, die für die Aminosäuresynthese wichtig sind.
Die Gcn4-mRNA enthält vier kurze uORFs, und wenn ausreichend Amino-säuren vorhanden sind, translatieren Ribosomen die uORFs und lösen sich imAllgemeinen ab, bevor sie die codierende Region von Gcn4 erreichen. Eine durchAminosäuremangel ausgelöste allgemeine Abnahme der eIF-2-Aktivität machtes wahrscheinlicher, dass eine suchende kleine Ribosomenuntereinheit über dieuORFs hinweggeht (ohne sie zu translatieren), bis sie sich einen eIF-2 aneignet(s. Abb. 6–70). Ein solches Ribosom kann dann die Translation der tatsächlichenGcn4-Sequenz initiieren, und die gesteigerte Menge dieses resultierenden Trans-kriptionsregulators führt zur Produktion von Enzymen für die Synthese vonAminosäuren.
7.6.12 Interne Ribosomeneintrittsstellen bieten eine Möglichkeitder Translationskontrolle
Obwohl bei Eukaryoten die Translation bei etwa 90 % der mRNAs mit demersten AUG nach dem 5′-Cap beginnt, können manche AUGs, wie wir imvorigen Abschnitt gesehen haben, bei dem Suchvorgang übergangen werden.In diesem Abschnitt werden wir eine weitere Möglichkeit besprechen, durch dieZellen die Translation an Stellen fern vom 5′-Ende der mRNA beginnenkönnen. Hier wird die Translation mithilfe einer besonderen RNA-Sequenzbegonnen, die als interne Ribosomeneintrittsstelle (IRES) bezeichnet wird.In einigen Fällen liegen zwei unterschiedliche proteincodierende Sequenzen alsTandem auf derselben mRNA; die Translation der ersten Sequenz geschiehtüber den üblichen Suchmechanismus und die Translation der zweiten über eineIRES. IRES-Sequenzen sind normalerweise mehrere Hundert Nukleotide langund falten sich in bestimmte Strukturen, an die viele, aber nicht alle der Proteinebinden, die für die Initiation der normalen 5′-Cap-abhängigen Translation nötigsind (Abb. 7–68). Unterschiedliche IRESs benötigen tatsächlich unterschiedli-che Untergruppen von Initiationsfaktoren. Alle sind jedoch unabhängig von
474 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:233B2 9.1.580; Page size: 210.00mm x 275.00mm
einer 5′-Cap-Struktur und dem sie erkennenden TranslationsinitiationsfaktoreIF-4E.
Manche Viren verwenden IRESs als Teil einer Strategie, damit ihre eigenenmRNA-Moleküle translatiert werden, während die normale 5′-Cap-abhängigeTranslation der Wirts-mRNAs blockiert wird. Bei der Infektion bilden dieseViren eine im Genom des Virus codierte Protease, die den TranslationsfaktoreIF-4G der Wirtszelle spaltet und ihn dadurch unfähig macht, an eIF-4E, denCap bindenden Komplex, zu binden. Dies legt den größten Teil der Wirtszell-translation still und lenkt den Translationsapparat wirkungsvoll zu den IRES-Sequenzen um, die sich auf den viralen mRNAs befinden. (Das geschnittene eIF-4G ist noch in der Lage, die Translation an diesen internen Stellen zu initiieren.)
Die vielen Weisen, auf die Viren die Proteinsynthesemaschinerie ihrerWirtszellen zu ihrem eigenen Vorteil manipulieren, überrascht Biologen immerwieder. Die Untersuchung dieses „Wettrüstens“ zwischen Menschen und Krank-heitserregern hat zu vielen grundlegenden Einsichten in die Arbeitsweisen derZelle geführt, und wir werden diesem Thema in Kapitel 23 nochmals begegnen.
7.6.13 Eine Veränderung der mRNA-Stabilität kann dieGenexpression regulieren
Die meisten mRNAs der Bakterien sind sehr instabil und haben eine Halbwerts-zeit von weniger als ein paar Minuten. Exonukleasen, die in 3′→5′-Richtungarbeiten, sind normalerweise für den raschen Abbau der mRNAs zuständig. Dabakterielle mRNAs sowohl sehr rasch synthetisiert als auch sehr rasch wiederabgebaut werden, kann sich ein Bakterium schnell an Veränderungen seinerUmwelt anpassen.
In der Regel sind die mRNAs der eukaryotischen Zellen viel stabiler. Einige,wie z. B. die des β-Globins, haben eine Halbwertszeit von mehr als 10 Stunden.Aber die meisten haben eine beträchtlich kürzere Halbwertszeit, normalerweiseunter 30 Minuten. Die mRNAs, die für Proteine wie die Wachstumsfaktoren undTranskriptionsregulatoren codieren, deren Bildungsgeschwindigkeit sich in Zel-len rasch ändern muss, besitzen besonders kurze Halbwertszeiten.
In Kapitel 6 haben wir gesehen, dass die Zelle über mehrere Mechanismenverfügt, um nicht richtig prozessierte RNAs rasch zu zerstören; hier betrachtenwir das Schicksal der typischen „normalen“ eukaryotischen RNA. Es gibt zweiMechanismen, um jede von der Zelle gebildete mRNA schließlich abzubauen.Beide beginnen mit einer schrittweisen Verkürzung des poly-A-Schwanzes durch
IRES
andere Translationsfaktoren
kleine und große ribosomale Untereinheiten
INITIATION DER TRANSLATION INITIATION DER TRANSLATION
(A) (B)
AAAAAAAAA
eIF-4G
eIF-4GeIF-4E
3’
3’
poly-A-bindendesProtein 5’-Cap
AA
AA
AA
AA
A
Abb. 7–68 Zwei Mechanismen für die Translations-initiation. (A) Der normale Cap-abhängige Mechanis-mus braucht eine Gruppe von Initiationsfaktoren,deren Versammlung auf der mRNA durch das Vor-handensein eines 5′-Caps und eines poly-A-Schwan-zes (s. auch Abb. 6–70) stimuliert wird. (B) Der haupt-sächlich bei Viren vorkommende IRES-abhängigeMechanismus benötigt nur eine Untergruppe dernormalen Translationsinitiationsfaktoren, die sich di-rekt auf der gefalteten IRES ansammeln. (Verändertnach A. Sachs, Cell 101:243–245, 2000. Mit Erlaubnisvon Elsevier.)
7.6 Posttranskriptionale Kontrolle 475

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:243B2 9.1.580; Page size: 210.00mm x 275.00mm
eine Exonuklease, ein Vorgang, der beginnt, sobald die mRNA das Cytosolerreicht. In gewissem Sinn wirkt diese poly-A-Verkürzung als Zeitmesser, derdie Lebensdauer jeder mRNA herunterzählt. Sobald der poly-A-Schwanz auf einekritischeLänge gekürzt ist (etwa 25 Nukleotide beim Menschen), trennen sich diebeiden Wege. Auf dem einen Weg wird das 5′-Cap entfernt (ein Vorgang, denman Decappping nennt) und die „freigelegte“ mRNA wird rasch von ihrem5′-Ende her abgebaut. Auf dem anderen Weg wird die mRNA weiterhin vonihrem 3′-Ende her abgebaut, durch den poly-A-Schwanz in die codierendenSequenzen hinein (Abb. 7–69).
Nahezu alle mRNAs unterliegen den beiden Abbauarten, und die spezi-fischen Sequenzen jeder mRNA legen fest, wie schnell jeder Schritt abläuft unddamit wie lange jede mRNA in der Zelle bestehen bleibt und in der Lage ist,Protein zu bilden. Die 3′-UTR-Sequenzen sind besonders wichtig bei der Kon-trolle der mRNA-Lebensdauer, und sie tragen oft Bindungsstellen für bestimmteProteine, die die Geschwindigkeit der poly-A-Verkürzung, des Decappings oderdes 3′→5′-Abbaus steigern oder drosseln. Die Halbwertszeit einer mRNA wirdauch dadurch beeinflusst, wie effizient sie translatiert wird. Die poly-A-Verkür-zung und das Decapping konkurrieren direkt mit der Maschinerie, die die mRNAtranslatiert; deshalb wirken sich alle Faktoren, die die Translationseffizienz einermRNA beeinflussen, auf ihren Abbau gegenteilig aus (Abb. 7–70).
Obwohl die poly-A-Verkürzung die Halbwertszeit der meisten eukaryoti-schen mRNAs verkürzt, können manche mRNAs durch einen spezialisiertenMechanismus abgebaut werden, der diesen Schritt insgesamt umgeht. In diesenFällen schneiden Nukleasen die mRNA intern, sodass sie von einem Ende dasCap und vom anderen den poly-A-Schwanz entfernen, wodurch beide Hälftenschnell abgebaut werden. Die auf diese Weise zerstörten mRNAs tragen spezi-fische Nukleotidsequenzen, oft in den 3′-UTRs, die als Erkennungssequenzen fürdiese Endonukleasen dienen. Diese Strategie macht es besonders einfach, dieStabilität dieser mRNAs streng zu regulieren, indem die Endonukleasestelle alsReaktion auf äußere Signale blockiert oder exponiert wird. Die Zugabe von Eisenzu Zellen verringert beispielsweise die Stabilität der mRNA, die für das Rezep-
AAAAA~200 3’5’
codierendeSequenz
Cap 3’-UTR
5’ A~25 3’
A~25
allmähliche poly-A-Verkürzung
Entfernen der Cap-Struktur,dann rascher Abbau
von 5’ nach 3’
fortgesetzter Abbauvon 3’ nach 5’
Abb. 7–69 Zwei Mechanismen für den Abbau eukaryotischer mRNA. Eine kritischeSchwelle der Länge des poly-A-Schwanzes induziert den raschen 3′→5′-Abbau undsteht möglicherweise in Zusammenhang mit dem Verlust von poly-A-bindenden Prote-inen. Wie in Abb. 7–70 gezeigt, assoziiert die Desadenylase sowohl mit dem 3′-poly-A-Schwanz als auch mit der 5′-Cap-Struktur, und diese Verbindung kann an dem Signal zurBeseitigung der Cap-Struktur nach der poly-A-Verkürzung beteiligt sein. Obwohl der5′→3′- und der 3′→5′-Abbau hier an verschiedenen RNA-Molekülen gezeigt werden,können beide Vorgänge zusammen am selben Molekül ablaufen. (Verändert nach C. A.Beelman und R. Parker, Cell 81:179–183, 1995. Mit Erlaubnis von Elsevier.)
AAAAAAAAAAAAAAA
eIF-4G
eIF-4E
3’
poly-A-bindendesProtein
Translationsinitiation
AAAAA
mRNA-Abbau
A
AA
A
Desadenylase
5’-Cap
Abb. 7–70 Der Wettstreit zwischen mRNA-Translation und mRNA-Abbau. Die gleichenzwei Merkmale eines mRNA-Moleküls, 5′-Cap und3′-poly-A-Schwanz, werden sowohl bei derTranslationsinitiation als auch beim desadenylie-rungsabhängigen mRNA-Abbau (s. Abb. 7–69)benutzt. Die Desadenylase, die den poly-A-Schwanz von 3′ nach 5′ verkürzt, assoziiert auchmit dem 5′-Cap. Wie in Kapitel 6 (s. Abb. 6–70)beschrieben, assoziiert auch die Translationsini-tiationsmaschinerie mit dem 5′-Cap und dempoly-A-Schwanz. (Verändert nach M. Gao et al.,Mol. Cell 5:479–488, 2000. Mit Erlaubnis von Else-vier.)
476 Kapitel 7: Kontrolle der Genexpression
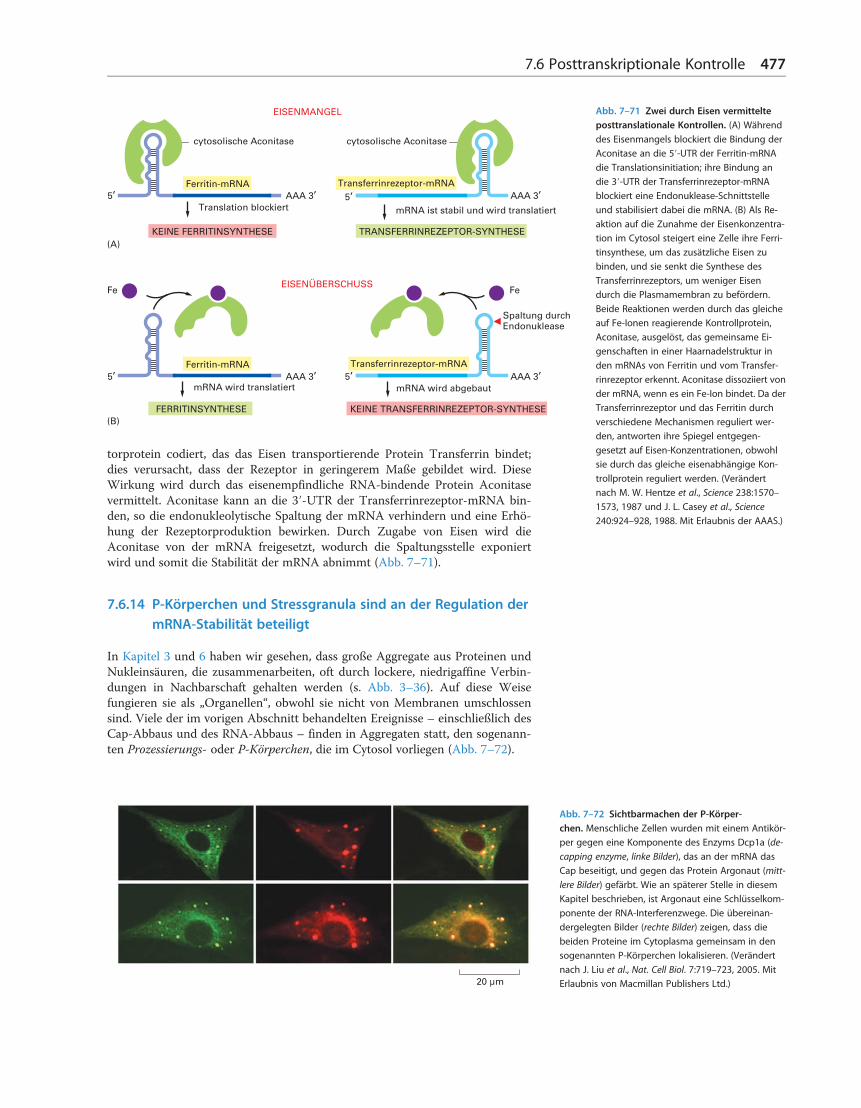
Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:243B2 9.1.580; Page size: 210.00mm x 275.00mm
torprotein codiert, das das Eisen transportierende Protein Transferrin bindet;dies verursacht, dass der Rezeptor in geringerem Maße gebildet wird. DieseWirkung wird durch das eisenempfindliche RNA-bindende Protein Aconitasevermittelt. Aconitase kann an die 3′-UTR der Transferrinrezeptor-mRNA bin-den, so die endonukleolytische Spaltung der mRNA verhindern und eine Erhö-hung der Rezeptorproduktion bewirken. Durch Zugabe von Eisen wird dieAconitase von der mRNA freigesetzt, wodurch die Spaltungsstelle exponiertwird und somit die Stabilität der mRNA abnimmt (Abb. 7–71).
7.6.14 P-Körperchen und Stressgranula sind an der Regulation dermRNA-Stabilität beteiligt
In Kapitel 3 und 6 haben wir gesehen, dass große Aggregate aus Proteinen undNukleinsäuren, die zusammenarbeiten, oft durch lockere, niedrigaffine Verbin-dungen in Nachbarschaft gehalten werden (s. Abb. 3–36). Auf diese Weisefungieren sie als „Organellen“, obwohl sie nicht von Membranen umschlossensind. Viele der im vorigen Abschnitt behandelten Ereignisse – einschließlich desCap-Abbaus und des RNA-Abbaus – finden in Aggregaten statt, den sogenann-ten Prozessierungs- oder P-Körperchen, die im Cytosol vorliegen (Abb. 7–72).
5’ AAA 3’
5’ AAA 3’
5’ AAA 3’
5’ AAA 3’
cytosolische Aconitase
Ferritin-mRNA
Translation blockiert
KEINE FERRITINSYNTHESE TRANSFERRINREZEPTOR-SYNTHESE
FERRITINSYNTHESE KEINE TRANSFERRINREZEPTOR-SYNTHESE
mRNA wird abgebaut
Fe
mRNA wird translatiert
mRNA ist stabil und wird translatiert
Transferrinrezeptor-mRNA
Ferritin-mRNA Transferrinrezeptor-mRNA
Fe
cytosolische Aconitase
EISENMANGEL
EISENÜBERSCHUSS
(A)
(B)
Spaltung durchEndonuklease
Abb. 7–71 Zwei durch Eisen vermittelteposttranslationale Kontrollen. (A) Währenddes Eisenmangels blockiert die Bindung derAconitase an die 5′-UTR der Ferritin-mRNAdie Translationsinitiation; ihre Bindung andie 3′-UTR der Transferrinrezeptor-mRNAblockiert eine Endonuklease-Schnittstelleund stabilisiert dabei die mRNA. (B) Als Re-aktion auf die Zunahme der Eisenkonzentra-tion im Cytosol steigert eine Zelle ihre Ferri-tinsynthese, um das zusätzliche Eisen zubinden, und sie senkt die Synthese desTransferrinrezeptors, um weniger Eisendurch die Plasmamembran zu befördern.Beide Reaktionen werden durch das gleicheauf Fe-Ionen reagierende Kontrollprotein,Aconitase, ausgelöst, das gemeinsame Ei-genschaften in einer Haarnadelstruktur inden mRNAs von Ferritin und vom Transfer-rinrezeptor erkennt. Aconitase dissoziiert vonder mRNA, wenn es ein Fe-Ion bindet. Da derTransferrinrezeptor und das Ferritin durchverschiedene Mechanismen reguliert wer-den, antworten ihre Spiegel entgegen-gesetzt auf Eisen-Konzentrationen, obwohlsie durch das gleiche eisenabhängige Kon-trollprotein reguliert werden. (Verändertnach M. W. Hentze et al., Science 238:1570–1573, 1987 und J. L. Casey et al., Science240:924–928, 1988. Mit Erlaubnis der AAAS.)
20 μm
Abb. 7–72 Sichtbarmachen der P-Körper-chen. Menschliche Zellen wurden mit einem Antikör-per gegen eine Komponente des Enzyms Dcp1a (de-capping enzyme, linke Bilder), das an der mRNA dasCap beseitigt, und gegen das Protein Argonaut (mitt-
lere Bilder) gefärbt. Wie an späterer Stelle in diesemKapitel beschrieben, ist Argonaut eine Schlüsselkom-ponente der RNA-Interferenzwege. Die übereinan-dergelegten Bilder (rechte Bilder) zeigen, dass diebeiden Proteine im Cytoplasma gemeinsam in densogenannten P-Körperchen lokalisieren. (Verändertnach J. Liu et al., Nat. Cell Biol. 7:719–723, 2005. MitErlaubnis von Macmillan Publishers Ltd.)
7.6 Posttranskriptionale Kontrolle 477

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:253B2 9.1.580; Page size: 210.00mm x 275.00mm
Obwohl viele mRNAs letztendlich in P-Körperchen abgebaut werden, blei-ben manche intakt und werden später wieder dem Vorrat der translatierendenmRNAs zurückgegeben. Um auf diese Weise „gerettet“ zu werden, wandern diemRNAs von den P-Körperchen zu einem anderen Aggregattyp, dem Stress-granulum, das Translationsinitiationsfaktoren, poly-A-Bindeproteine und kleineRibosomenuntereinheiten enthält. Die Translation selbst findet in den Stress-granula nicht statt, aber mRNAs können „translationsbereit“ gemacht werden,wenn die an sie in den P-Körperchen gebundenen Proteine durch diejenigen inden Stressgranula ersetzt werden. Die Wanderung der mRNAs zwischen deraktiven Translation, den P-Körperchen und den Stressgranula kann als mRNA-Kreislauf (Abb. 7–73) angesehen werden, in dem die Konkurrenz zwischenTranslation und mRNA-Abbau sorgfältig kontrolliert wird. Wenn der Start derTranslation blockiert wird (durch Hungern, Arzneistoffe oder genetische Mani-pulation), vergrößern sich die Stressgranula, da ihnen immer mehr nicht trans-latierte mRNAs zur Speicherung direkt zugeführt werden. Wenn eine Zelle diegroße Investition gemacht hat, ein ordentlich prozessiertes mRNA-Molekül zuerzeugen, kontrolliert sie offensichtlich sein nachfolgendes Schicksal sorgfältig.
Zusammenfassung
Viele Schritte auf dem Weg von der RNA zum Protein werden durch die Zellenreguliert, um die Genexpression zu kontrollieren. Außer der Kontrolle im Anfangs-stadium der Transkription werden die meisten Gene auf mehreren Ebenenreguliert. Zu den Regulationsmechanismen zählen: (1) RNA-Transkriptabschwä-chung durch vorzeitige Beendigung, (2) alternative RNA-Spleißstellenauswahl,(3) Kontrolle der 3′-Endenbildung durch Schneiden und poly-A-Anheftung,(4) RNA-Editierung, (5) Kontrolle des Transports vom Zellkern zum Cytosol,(6) Lokalisierung der mRNAs in bestimmten Zellregionen, (7) Kontrolle desTranslationsstarts und (8) regulierter mRNA-Abbau. Die meisten dieser Kontroll-vorgänge erfordern die Erkennung spezifischer Sequenzen oder Strukturen im zuregulierenden RNA-Molekül, eine Aufgabe, die entweder durch Regulationspro-teine oder regulatorische RNA-Moleküle ausgeführt wird.
7.7 Regulation der Genexpression durch nichtcodierende RNAs
Im vorigen Kapitel haben wir das zentrale Dogma eingeführt, demgemäß derFluss der genetischen Information von der DNA über die RNA zum Proteinverläuft (s. Abb. 6–1). Aber wir haben immer wieder in diesem Buch gesehen,dass RNA-Moleküle neben ihrer Übermittlerfunktion für genetische Informationviele andere entscheidende Aufgaben in der Zelle wahrnehmen. Unter diesennicht codierenden RNAs sind rRNA- und tRNA-Moleküle, die für das Lesen desgenetischen Codes und die Proteinsynthese verantwortlich sind. Das RNA-Molekül in der Telomerase dient als Matrize für die Replikation der Chromoso-menenden, snoRNAs modifizieren ribosomale RNA und snRNAs führen diewichtigsten Abläufe des RNA-Spleißens aus. Und im vorangegangenen Abschnitthaben wir gesehen, dass Xist-RNA eine wichtige Rolle bei der Inaktivierung einerKopie des X-Chromosoms in weiblichen Individuen spielt.
Eine Reihe von Entdeckungen in jüngster Zeit hat offenbart, dass nichtcodierende RNAs weit mehr vorherrschen, als man zuvor dachte. Wir wissenjetzt, dass solche RNAs weitreichende Aufgaben bei der Regulation der Gen-expression sowie dem Schutz des Genoms vor Viren und springenden Elementenwahrnehmen. Diese neu entdeckten RNAs sind Gegenstand dieses Abschnitts.
P-Körperchen Stress-granulum
Translation
ZELLKERN
CYTOSOL
mRNA AAA
Abb. 7–73 Mögliches Schicksal eines mRNA-Mole-küls. Ein aus dem Zellkern freigesetztes mRNA-Mole-kül kann aktiv translatiert (Mitte), in Stressgranulagespeichert (rechts) oder in P-Körperchen abgebaut(links) werden. Wenn sich die Bedürfnisse der Zelleändern, können mRNAs, wie durch die Pfeile ange-deutet, von einer Stelle zur nächsten verschobenwerden.
478 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:253B2 9.1.580; Page size: 210.00mm x 275.00mm
7.7.1 Kleine nicht codierende RNA-Transkripte regulieren durchRNA-Interferenz viele tierische und pflanzliche Gene
Wir beginnen unsere Besprechung mit einer Gruppe kurzer RNAs, die RNA-Interferenz oder RNAi ausführen. Hier dienen kurze einzelsträngige RNAs (20–30 Nukleotide) als Leit-RNA, die selektiv – über Basenpaarung – andere RNAs inder Zelle umgruppiert und bindet. Wenn es sich bei dem Ziel um eine reifemRNA handelt, können die kleinen nicht codierenden RNAs ihre Translationhemmen oder sogar ihre Zerstörung katalysieren. Falls das RNA-Zielmolekül sichim Transkriptionsvorgang befindet, kann die kleine nicht codierende RNA an esbinden und die Bildung bestimmter repressiver Chromatinarten auf seiner an-gehefteten DNA-Matrize steuern (Abb. 7–74). Drei Klassen kleiner nicht codie-render RNAs arbeiten auf diese Weise – microRNAs (miRNAs), kleine interferie-rende RNAs (siRNAs, engl. small interfering RNAs) und piwi-wechselwirkendeRNAs (piRNAs, engl. piwi-interacting RNAs) – und wir behandeln sie nach-einander in den folgenden Abschnitten. Obwohl sie sich hinsichtlich der Weise,wie die kurzen Stücke einzelsträngiger RNA erzeugt werden, unterscheiden, ortenalle drei Arten kurzer RNAs ihre Ziele über eine RNA–RNA-Basenpaarung undim Allgemeinen verursachen sie eine Verringerung der Genexpression.
7.7.2 miRNAs regulieren die mRNA-Translation und -Stabilität
Der Mensch exprimiert beispielsweise über 1.000 verschiedene microRNAs(miRNAs), und diese scheinen zumindest ein Drittel aller menschlichen pro-teincodierenden Gene zu regulieren. Sobald sie hergestellt sind, basenpaaren sichmiRNAs mit bestimmten mRNAs und stimmen deren Translation und Stabilitätfein ab. Die miRNA-Vorstufen werden von der RNA-Polymerase II synthetisiert,mit einem Cap versehen und polyadenyliert. Sie unterliegen dann einer speziel-len Art von Prozessierung, nach der sich die miRNA (typischerweise 23 Nukleo-tide lang) mit einer Reihe von Proteinen zu einem Komplex namens RISC (RNA-induzierter Stilllegungskomplex, engl. RNA-induced silencing complex) zusam-menlagert. Sobald sich der RISC gebildet hat, spürt er seine Ziel-mRNAs auf,indem er nach komplementären Nukleotidsequenzen sucht (Abb. 7–75). DieseSuche wird durch das Argonaut-Protein erheblich erleichtert, eine Komponentedes RISC, die die 5′-Region der miRNA festhält, sodass sie optimal für dieBasenpaarung mit einem anderen RNA-Molekül positioniert ist (Abb. 7–76). InTieren erstreckt sich die Basenpaarung normalerweise über zumindest siebenNukleotidpaare und findet zumeist in der 3′-UTR der Ziel-mRNA statt.
Sobald die mRNA von der miRNA gebunden wurde, sind mehrere Aus-wirkungen möglich. Wenn die Basenpaarung weitreichend ist (was beim Men-schen unüblich, aber bei Pflanzen üblich ist), wird die mRNA vom Argonaut-Protein gespalten, wodurch ihr poly-A-Schwanz erfolgreich entfernt und sie denExonukleasen ausgesetzt wird (s. Abb. 7–69). Auf die Spaltung der mRNA folgt
Ziel-RNA
Prozessierung
doppelsträngige RNAArgonaut- oderPiwi-Proteine
Translationsrepressionund schließlich Zerstörung
der Ziel-RNA
Bildung von Heterochromatinauf der DNA, von der
die Ziel-RNA transkribiert wird
Spaltung derZiel-RNA
interferierende RNAAbb. 7–74 RNA-Interferenz in Eukaryoten.Aus doppelsträngigen RNAs werden einzel-strängige Interferenz-RNAs gebildet. Diese or-ten Ziel-RNAs über Basenpaarung und an die-sem Punkt sind, wie gezeigt, mehrereSchicksale möglich. Wie im Text beschrieben,gibt es mehrere Arten von RNA-Interferenz; dieArt und Weise, wie die doppelsträngige RNAgebildet und bearbeitet wird, sowie das letzt-endliche Schicksal der Ziel-RNA hängen vondem jeweiligen System ab.
7.7 Regulation der Genexpression durch nicht codierende RNAs 479

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:263B2 9.1.580; Page size: 210.00mm x 275.00mm
die Freisetzung des RISC (mit der assoziierten miRNA), der nun weitere mRNAsausfindig machen kann (s. Abb. 7–75). Somit kann eine einzelne miRNAkatalytisch arbeiten und viele komplementäre mRNAs zerstören. Man kann sichsomit diese miRNAs als Leitsequenzen vorstellen, die die abbauenden Nukleasenmit spezifischen mRNAs in Kontakt bringen.
Falls die Basenpaarung zwischen der miRNA und der mRNA nicht soausgedehnt ist (wie man bei den meisten menschlichen miRNAs beobachtet),schneidet Argonaut die mRNA nicht; stattdessen wird die Translation dermRNA reprimiert und die mRNA pendelt zu den P-Körperchen (s. Abb. 7–73),wo sie sich vor den Ribosomen verborgen schließlich der Verkürzung des poly-A-Schwanzes, dem Entfernen des Caps und dem Abbau unterwirft.
Mehrere Eigenschaften machen die miRNAs zu besonders nützlichen Re-gulatoren der Genexpression. Erstens kann ein einzelnes miRNA-Molekül eineganze Reihe verschiedener mRNAs regulieren, solange die mRNAs in ihren
SPALTUNG
SPALTUNG
AAAAA
AAAAAAAAAA
AAAAA
AAAAA
ZELLKERN
CYTOSOL
„BESCHNEIDEN“
„DICING“
„SCHNEIDEN“
RISC
Argonaut undandere Proteine
mRNAmRNA
nicht so weitreichende Übereinstimmungweitreichende Übereinstimmung
RASCHE TRANSLATIONSREPRESSIONSCHLIESSLICH ABBAU DER mRNARASCHER ABBAU DER mRNA
RISC freigesetzt zur Wiederverwendung
3’ 5’
ATP
ADP
EIN STRANG WIRD ABGEBAUT
Abb. 7–75 miRNA-Prozessierung und Wirk-mechanismus. Die miRNA-Vorstufe bildet überdie Komplementarität zwischen einem Teil ihrerSequenz und einem anderen eine doppelsträn-gige Struktur. Diese RNA wird beschnitten, wäh-rend sie noch im Zellkern ist, und dann insCytosol exportiert, wo sie vom Enzym Dicer nochweiter geschnitten wird, sodass die richtigemiRNA entsteht. Argonaut, in Verbindung mitanderen Komponenten des RISC, verbindet sichzunächst mit beiden Strängen der miRNA, spaltetdann einen davon und verwirft ihn. Der andereStrang lenkt RISC durch Basenpaarung zu spezi-fischen mRNAs. Wenn die RNA–RNA-Paarungweitreichend ist, wie man es üblicherweise inPflanzen beobachtet, dann schneidet Argonautdie Ziel-mRNA und verursacht dadurch ihren ra-schen Abbau. Bei Säugern erstreckt sich diemiRNA–mRNA-Paarung oft nicht weiter als bis zueiner kurzen 7-Nukleotid-„Keim“-Region in derNähe des 5′-Endes der miRNA. Diese wenigerausgedehnte Basenpaarung führt zur Hemmungder Translation, mRNA-Destabilisierung undÜbergabe der mRNA an P-Körperchen, wo sieletztlich abgebaut wird.
microRNA
5’-Phosphat
3’-OH (RNA-Ende)
Aktives Zentrum, gezeigt sind die beidenMg2+-Atome, die für das „Schneiden“ notwendig sind
Nukleotide, die dieZiel-RNA ausfindig machen
Abb. 7–76 Menschliches Argonaut-Protein, das eine miRNA trägt. Das Protein ist in vierStrukturdomänen gefaltet, jede ist mit einer anderen Farbe kenntlich gemacht. Die miRNA istin einer ausgestreckten Form gehalten, die optimal für die Bildung der RNA–RNA-Basenpaareist. Das Aktive Zentrum von Argonaut, das eine Ziel-RNA „schneidet“, wenn sie mit einermiRNA ausgiebig Basenpaare ausgebildet hat, ist rot gezeigt. Viele Argonaut-Proteine (z. B.drei von vier der menschlichen Proteine) haben kein Katalysezentrum und binden deshalbZiel-RNAs, ohne sie zu schneiden. (Nach C. D. Kuhn und L. Joshua-Tor, Trends Biochem. Sci.38:262−271, 2003. Mit Erlaubnis von Cell Press.)
480 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:263B2 9.1.580; Page size: 210.00mm x 275.00mm
UTRs eine gemeinsame Sequenz tragen. Diese Situation ist beim Menschenüblich, wo eine einzelne miRNA Hunderte verschiedener mRNAs kontrollierenkann. Zweitens kann die Regulation durch miRNAs kombinatorisch sein. Wennes der Basenpaarung zwischen der miRNA und der mRNA misslingt, dieSpaltung einzuleiten, dann führen weitere miRNAs, die an dieselbe mRNAbinden, zu einer weiteren Verringerung ihrer Translation. Wie an früherer Stellefür Transkriptionsregulatoren besprochen, erweitert die kombinatorische Kon-trolle die für die Zelle verfügbaren Möglichkeiten enorm, indem sie die Gen-expression mit einer Kombination verschiedener Regulatoren – anstatt miteinem einzigen Regulator – verbindet. Drittens nimmt eine miRNA im Vergleichzu einem Protein relativ wenig Raum im Genom ein. Tatsächlich ist ihre kleineGröße der Grund dafür, dass die miRNAs erst vor kurzem entdeckt wurden.Obwohl wir erst jetzt beginnen, die volle Bedeutung von miRNAs zu würdigen,ist es klar, dass sie einen sehr wichtigen Teil der zellulären Ausstattung für dieRegulation der Expression der Zellgene darstellen. Wir behandeln spezielleBeispiele von miRNAs, die wichtige Funktionen in der Entwicklung haben, inKapitel 21.
7.7.3 RNA-Interferenz wird auch als zellulärer Abwehrmechanismusverwendet
Viele der Proteine, die an dem eben beschriebenen miRNA-Regulationsmecha-nismus beteiligt sind, haben auch eine weitere Funktion als Abwehrmechanis-mus: Sie koordinieren den Abbau fremder RNA-Moleküle, insbesondere jener,die in doppelsträngiger Form vorkommen. Viele springende Elemente und Virenbilden im Laufe ihres Lebenszyklus zumindest vorübergehend doppelsträngigeRNA, und RNA-Interferenz hält solche potenziell schädlichen Eindringlinge inSchach. Wie wir sehen werden, liefert diese Form von RNAi der Forschung aucheine wirkungsvolle Experimentaltechnik, um die Expression einzelner Gene einerZelle abzuschalten.
Die Anwesenheit doppelsträngiger RNA in der Zelle löst RNAi aus, indemsie einen Proteinkomplex anlockt, der Dicer enthält, die gleiche Nuklease, diemiRNAs prozessiert (s. Abb. 7–75). Dieses Protein spaltet die doppelsträngigeRNA in kleine Bruchstücke (etwa 23 Nukleotidpaare), die man siRNAs (smallinterfering RNAs, kleine interferierende RNAs Interferenz-RNAs) nennt. Diesedoppelsträngigen siRNAs werden dann von Argonaut und anderen Komponen-ten des RISC gebunden. Wie wir oben für miRNAs gesehen haben, wird einStrang des RNA-Doppelstrangs von Argonaut geschnitten und verworfen. Daseinzelsträngige siRNA-Molekül, das übrig bleibt, lenkt RISC zurück zu kom-plementären RNA-Molekülen, die vom Virus oder transponierbaren Elementengebildet werden. Weil die Paarung in der Regel exakt ist, schneidet Argonautdiese Moleküle, was zu deren rascher Zerstörung führt.
Jedes Mal, wenn RISC ein neues RNA-Molekül spaltet, wird RISC wiederfreigesetzt. Somit kann ein einzelnes RNA-Molekül – so wie wir es bei miRNAsgesehen haben – katalytisch arbeiten und viele komplementäre RNAs zerstören.Manche Organismen verwenden einen weiteren Mechanismus, der die RNAi-Antwort noch weiter verstärkt. In diesen Organismen verwenden RNA-abhän-gige RNA-Polymerasen siRNAs als Primer, um zusätzliche Kopien der doppel-strängigen RNAs zu bilden, die dann zu siRNAs geschnitten werden. DieseVermehrung gewährleistet, dass die RNA-Interferenz, sobald sie begonnen hat,sogar dann weiter wirken kann, nachdem die gesamte auslösende doppel-strängige RNA abgebaut oder ausgedünnt wurde. So können beispielsweiseTochterzellen die spezifische RNA-Interferenz weiterführen, die in der Mutter-zelle ausgelöst wurde.
In manchen Organismen kann RNA-Interferenzaktivität durch die Übertra-gung von RNA-Fragmenten von Zelle zu Zelle verbreitet werden. Dies ist
7.7 Regulation der Genexpression durch nicht codierende RNAs 481

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:263B2 9.1.580; Page size: 210.00mm x 275.00mm
besonders wichtig für Pflanzen (deren Zellen, wie wir in Kapitel 19 erfahrenwerden, durch dünne, verbindende Kanäle vernetzt sind), da es so einer ganzenPflanze möglich ist, resistent gegen ein RNA-Virus zu werden, obwohl nurwenige ihrer Zellen infiziert wurden. Im weiteren Sinn ähnelt die RNAi-Antwortbestimmten Aspekten des tierischen Immunsystems; in beiden Fällen erzeugt eineindringender Organismus eine individuelle Reaktion, und der Wirt wird –durch Vermehrung der „Angriffs“-Moleküle – systemisch geschützt.
Wir haben gesehen, dass miRNAs und siRNAs, obwohl auf leicht unter-schiedliche Weise erzeugt, auf die gleichen Proteine bauen und ihre Ziele aufgrundsätzlich ähnliche Weise suchen. Weil siRNAs in den verschiedenstenSpezies zu finden sind, glaubt man, dass sie die älteste Form der RNA-Interferenzdarstellen, mit miRNAs als spätere Verfeinerung. Diese siRNA-vermitteltenAbwehrmechanismen sind für Pflanzen, Würmer und Insekten wesentlich. InSäugetieren hat ein proteinbasiertes System (in Kapitel 24 beschrieben) größ-tenteils die Aufgabe der Virenabwehr übernommen.
7.7.4 RNA-Interferenz kann die Heterochomatinbildung steuern
Der eben beschriebene siRNA-Interferenzweg stoppt nicht zwangsläufig mit derZerstörung der Ziel-RNA-Moleküle. In manchen Fällen kann die RNA-Interfe-renzmaschinerie auch selektiv die Synthese der Ziel-RNAs abschalten. Damit diesabläuft, vereinigen sich die kurzen, vom Protein Dicer gebildeten siRNAs miteiner Gruppe von Proteinen (einschließlich Argonaut), um den RITS-Komplex(RNA-induzierter transkriptionaler Stilllegungskomplex, engl. RNA-inducedtranscriptional silencing complex) zu bilden. Mithilfe einzelsträngiger siRNA alsLeitsequenz bindet dieser Komplex komplementäre RNA-Transkripte, wenn siean einer transkribierenden RNA-Polymerase II entstehen (Abb. 7–77). Auf dieseWeise auf dem Genom positioniert, zieht der RITS-Komplex Proteine an, diebenachbarte Histone kovalent modifizieren, und bewirkt schließlich die Bildung
doppelsträngige RNA
siRNAsArgonaut und
andere RISC-ProteineArgonaut und
andere RITS-Proteine
DER WEG FOLGT JETZTEINEM DER IN ABB. 7–76 GEZEIGTEN
HISTONMETHYLIERUNGDNA-METHYLIERUNG
TRANSKRIPTIONSHEMMUNG
RISC RITS
RNA-Polymerase
Abb. 7–77 Durch siRNA gesteuerteRNA-Interferenz. In vielen Organismen kann doppelsträngige RNAsowohl die Zerstörung der komplementären mRNAs (links) als auch die Stilllegung der Transkription (rechts)ankurbeln. Die Änderung der Chromatinstruktur, die durch den gebundenen RITS- (RNA-induzierte trans-kriptionale Stilllegung, engl. RNA-induced transcriptional silencing) Komplex eingeleitet wird, ähnelt derjeni-gen in Abb. 7–45.
482 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:273B2 9.1.580; Page size: 210.00mm x 275.00mm
von Heterochromatin, um eine weitere Transkriptionsinitiation zu verhindern.In manchen Fällen werden auch eine RNA-abhängige RNA-Polymerase und einDicer-Enzym durch den RITS-Komplex rekrutiert, um fortwährend weiteresiRNAs in situ zu erzeugen. Diese positive Rückkopplungsschleife gewährleistetsogar dann die fortgesetzte Repression des Zielgens, wenn die initiierendensiRNA-Moleküle verschwunden sind.
Die RNAi-gesteuerte Heterochromatinbildung ist ein wichtiger zellulärerAbwehrmechanismus, der die Ausbreitung transponierbarer Elemente im Ge-nom beschränkt, indem er ihre DNA-Sequenzen in einer transkriptionsstummenForm hält. Der gleiche Mechanismus wird aber auch bei manchen anderenVorgängen in der Zelle verwendet. In vielen Organismen erhält beispielsweisedie RNA-Interferenzmaschinerie das um Centromere gebildete Heterochromatinaufrecht. Centromer-DNA-Sequenzen werden in beide Richtungen transkribiert,wobei komplementäre RNA-Transkripte entstehen, die über Basenpaarung einedoppelsträngige RNA bilden können. Diese doppelsträngige RNA kurbelt denRNA-Interferenzweg an und stimuliert die Bildung von Heterochromatin, dasdie Centromeren umgibt. Dieses Heterochromatin ist wiederum nötig, damit dieCentromere während der Mitose die Chromosomen exakt trennen können.
7.7.5 piRNAs schützen die Keimbahn vor springenden Elementen
Ein drittes RNA-Interferenzsystem baut auf piRNAs (piwi-wechselwirkendeRNAs, engl. piwi-interacting RNAs, benannt nach Piwi, einer mit Argonautverwandten Proteinklasse). piRNAs werden speziell in der Keimbahn gebildet,wo sie die Bewegung springender Elemente blockieren. Die Gene, die für piRNAscodieren finden sich in vielen Lebewesen, einschließlich des Menschen, und siebestehen größtenteils aus Sequenzbruchstücken springender Elemente. DieseFragment-Cluster werden transkribiert und in kurze einzelsträngige piRNAsaufgebrochen. Die Prozessierung unterscheidet sich von der bei miRNAs undsiRNAs (z. B. ist das Dicer-Enzym nicht daran beteiligt) und die daraus hervor-gehenden piRNAs sind geringfügig länger als miRNAs und siRNAs; zudem sindsie im Komplex mit Piwi- anstatt mit Argonaut-Proteinen. Sobald sie gebildetsind, suchen die piRNAs RNA-Ziele durch Basenpaarung und ganz wie siRNAsschalten sie die Transkription intakter Transposongene stumm und zerstörenjede RNA (einschließlich mRNAs), die von ihnen gebildet wird.
Viele Geheimnisse umgeben die piRNAs. Über eine Million piRNA-Artensind in den Genomen vieler Säugetiere verschlüsselt und in den Hoden expri-miert, wenngleich nur ein kleiner Anteil gegen die in diesen Genomen vorhan-denen Transposons gerichtet ist. Sind die piRNAs Überbleibsel oder ehemaligeInvasoren? Decken sie so viel „Sequenzraum“ ab, dass sie vor jeder fremden DNAweitgehend Schutz bieten können? Eine andere kuriose Eigenschaft der piRNAsist, dass viele von ihnen (insbesondere, wenn die Basenpaarung nicht perfekt seinmuss) grundsätzlich die normalen, vom Organismus gebildeten mRNAs angrei-fen müssten, dies aber nicht tun. Man hat vorgeschlagen, dass die große Anzahlvon piRNAs ein System bilden könnte, um „eigene“ RNAs von „fremden“ RNAszu unterscheiden und nur Letztere anzugreifen. Wenn das der Fall ist, muss esfür die Zelle einen speziellen Weg geben, ihre eigenen RNAs zu verschonen. EineVorstellung ist, dass RNAs, die in der vorausgegangenen Generation einesOrganismus gebildet wurden, irgendwie registriert werden und in nachfolgendenGenerationen von einem piRNA-Angriff verschont bleiben. Ob dieser Mecha-nismus tatsächlich existiert oder nicht, und falls ja, wie er dann arbeitet, sindFragen, die unser unvollständiges Verständnis der vollen Bedeutung der RNA-Interferenz zeigen.
7.7 Regulation der Genexpression durch nicht codierende RNAs 483

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:273B2 9.1.580; Page size: 210.00mm x 275.00mm
7.7.6 RNA-Interferenz wurde ein schlagkräftiges Werkzeug fürExperimente
Obwohl die RNA-Interferenz wahrscheinlich als Abwehrmechanismus gegenViren und springende Elemente entstand, wurde sie, wie wir gesehen haben,vollauf in viele Aspekte der normalen Zellbiologie integriert – von der Kontrolleder Genexpression bis zur Struktur von Chromosomen. Sie wurde auch vonWissenschaftlern zu einem leistungsfähigen experimentellen Werkzeug ent-wickelt, das die Inaktivierung nahezu jedes Gens gestattet, indem eine RNAi-Antwort gegen das Gen hervorgerufen wird. Diese Technik, die leicht in kulti-vierten Zellen und manchmal in ganzen Tieren und Pflanzen ausgeführt wird,hat neue genetische Ansätze in der Zell- und Molekularbiologie ermöglicht. Wirwerden sie im nächsten Kapitel ausführlicher behandeln, in dem wir modernegenetische Methoden besprechen, die zur Untersuchung von Zellen eingesetztwerden (s. Abschnitt 8.5.15). Die RNAi besitzt auch ein großes Potenzial bei derBehandlung menschlicher Krankheiten. Da viele Krankheiten beim Menschenvon der Fehlexpression von Genen herrühren, ist die Fähigkeit, diese Gene durchexperimentell eingeführte komplementäre siRNA-Moleküle abzuschalten, medi-zinisch vielversprechend. Obwohl der Mechanismus der RNA-Interferenz schonvor einigen Jahrzehnten entdeckt wurde, werden wir immer noch von seinenmechanistischen Details und seinen breiten biologischen Konsequenzen über-rascht.
7.7.7 Bakterien verwenden kleine nicht codierende RNAs, um sichvor Viren zu schützen
Bakterien machen die große Mehrheit der Biomasse der Erde aus und, was nichtüberrascht, Viren, die Bakterien befallen, übertreffen die Pflanzen- und Tiervirenzahlenmäßig. Diese Viren besitzen im Allgemeinen DNA-Genome. Eine neuereEntdeckung enthüllte, dass viele Bakterienarten (und nahezu alle Arten vonArchaebakterien) einen Vorrat kleiner nicht codierender RNA-Moleküle benut-zen, um die DNA eindringender Viren ausfindig zu machen und zu zerstören.Viele Eigenschaften dieses Abwehrmechanismus, als CRISPR-System bekannt,ähneln denjenigen, die wir oben für miRNAs und siRNAs gesehen haben, aber esgibt zwei entscheidende Unterschiede. Erstens, wenn Bakterien und Archaeenerstmals von einem Virus befallen werden, haben sie einen Mechanismus, derverursacht, dass kurze Bruchstücke dieser viralen DNA in ihr Genom eingebautwerden. Diese dienen insofern als „Impfstoffe“, als sie Matrizen für die Bildungkleiner nicht codierender RNAs werden, die crRNAs (CRISPR-RNAs), diedanach das Virus zerstören, sollte es die Nachkommen der ursprünglichen Zelleerneut infizieren. Dieser Aspekt des CRISPR-Systems ähnelt prinzipiell deradaptiven (erworbenen) Immunität bei Säugetieren, insofern als die Zelle eineAufzeichnung vergangener Kontakte trägt, die dazu dient, vor künftigen Exposi-tionen zu schützen. Die zweite, sich unterscheidende Eigenschaft des CRISPR-Systems ist, dass diese crRNAs dann mit speziellen Proteinen vergesellschaftetwerden, die es ihnen erlauben, anstatt einzelsträngiger RNA-Moleküle doppel-strängige DNA-Moleküle aufzuspüren und zu zerstören.
Obwohl noch viele Einzelheiten der CRISPR-vermittelten Immunität aufihre Entdeckung warten, können wir den allgemeinen Vorgang in drei Schrittenskizzieren (Abb. 7–78). Im ersten Schritt werden virale DNA-Sequenzen inspezielle Regionen des Bakteriengenoms, als CRISPR (geclusterte regulär unter-brochene kurze palindromische Wiederholung, engl. clustered regularly inters-persed short palindromic repeat)-Loci bezeichnet, eingebaut; diese sind benanntnach der eigenartigen Struktur, die zuerst die Aufmerksamkeit der Wissenschaft-ler erweckte. In seinem einfachsten Fall besteht ein CRISPR-Locus aus mehreren
484 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:273B2 9.1.580; Page size: 210.00mm x 275.00mm
Hundert Wiederholungen einer Wirts-DNA-Sequenz, die mit einer großenSequenzsammlung (typischerweise jeweils 25–70 Nukleotidpaare) durchsetztist, die von früheren Kontakten mit Viren und anderer Fremd-DNA stammt.Die neueste virale Sequenz wird immer am 5′-Ende des CRISPR-Locus einge-baut, dem Ende, das zuerst transkribiert wird. Jeder Locus trägt deshalb einezeitliche Aufzeichnung vorangegangener Infektionen. Viele Bakterien- und Ar-chaeenarten tragen mehrere große CRISPR-Loci in ihren Genomen und sinddamit gegen eine große Bandbreite von Viren immun.
Im zweiten Schritt wird der CRISPR-Locus transkribiert, um ein langesRNA-Molekül zu bilden, das dann zu viel kürzeren (etwa 30 Nukleotide) crRNAsverarbeitet wird. Im dritten Schritt spüren crRNAs im Komplex mit Cas-(CRISPR-assoziierten) Proteinen komplementäre virale DNA-Sequenzen aufund steuern deren Zerstörung durch Nukleasen. Obgleich strukturell unähnlich,entsprechen Cas-Proteine den oben besprochenen Argonaut- und Piwi-Prote-inen: Sie halten kleine einzelsträngige RNAs in einer ausgestreckten Konforma-tion, die in diesem Fall zum Aufspüren komplementärer Basenpaare mit DNAoptimiert ist.
Wir haben noch viel über die CRISPR-basierte Immunität in Bakterien undArchaebakterien zu lernen. Der Mechanismus, über den Virussequenzen zu-nächst identifiziert und ins Wirtsgenom eingebaut werden, ist kaum verstanden,ebenso die Art und Weise, wie die crRNAs ihre komplementären Sequenzen indoppelsträngiger DNA finden. Zudem werden in verschiedenen Bakterien- undArchaeenarten crRNAs auf verschiedene Weise bearbeitet, und in manchenFällen können die crRNAs sowohl virale RNAs als auch DNAs angreifen.
Im folgenden Kapitel werden wir sehen, dass bakterielle CRISPR-Systemebereits künstlich in Pflanzen und Tiere eingebracht worden sind, wo sie zu sehrleistungsfähigen experimentellen Werkzeugen zur Manipulation von Genomenwurden.
7.7.8 Lange nicht codierende RNAs haben in der Zelle verschiedeneFunktionen
In diesem und den vorausgegangenen Kapiteln haben wir gesehen, dass nichtcodierende RNA-Moleküle viele Funktionen in der Zelle haben. Dennoch bleibenwie im Fall der Proteine viele nicht codierende RNAs übrig, deren Funktionimmer noch unbekannt ist. Viele RNAs unbekannter Funktion gehören zu einerGruppe, die lange nicht codierende RNAs (lncRNAs) genannt werden. Diesewerden willkürlich als über 200 Nukleotide lange RNAs definiert, die nicht fürProteine codieren. Nachdem die Methoden zur Bestimmung der Nukleo-tidsequenzen aller von einer Zelllinie oder einem Gewebe gebildeten RNA-
CRISPR-Locus imBakteriengenom
Transkription
Prozessierung
prä-crRNA
crRNAs
Cas-Protein
CRISPR-Locus
5’ 3’5’3’
Schneiden der
viralen DNA
Einbau Wiederholungs-
sequenzen
DNA-Sequenzen ausfrüheren Infektionen
neue Virus-infektion
DNA-Virus
doppel-strängige virale DNA wird geschnitten
Bakterium
SCHRITT 1: kurze virale DNA-Sequenz wird in den CRISPR-Locus eingefügt
SCHRITT 2: RNA wird vom CRISPR-Locus transkribiert, prozessiert und an Cas-Protein gebunden
SCHRITT 3: kleine crRNA im Komplex mit Cas sucht und zerstört virale Sequenzen
Abb. 7–78 CRISPR-vermittelte Immunität inBakterien und Archaebakterien. Nach derInfektion durch ein Virus (linke Tafel) wird einkleines Stückchen des viralen Genoms in denCRISPR-Locus eingebaut. Damit dies passiert,muss ein kleiner Anteil der infizierten Zellendie anfängliche Virusinfektion überleben. Dieüberlebenden Zellen, oder allgemeiner ihreNachkommen, transkribieren den CRISPR-Lo-cus und bearbeiten das Transkript zu crRNAs(mittlere Tafel). Bei einer erneuten Infektionmit einem Virus, gegen das die Populationbereits „geimpft“ wurde, wird die eindrin-gende virale DNA durch eine komplementärecrRNA zerstört (rechte Tafel). Damit ein CRISPR-System effektiv sein kann, dürfen die crRNAsnicht den eigentlichen CRISPR-Locus zerstö-ren, auch wenn die crRNAs eine zu ihm kom-plementäre Sequenz besitzen. Damit crRNAsdas eindringende DNA-Molekül angreifen,muss es in vielen Spezies zusätzliche kurzeNukleotidsequenzen geben, die vom Zielmo-lekül getragen werden. Da diese sogenanntenPAM (Protospacer benachbartes Motiv, engl.protospacer adjacent motif)-Sequenzen außer-halb der crRNA-Sequenzen liegen, bleibt derWirts-CRISPR-Locus verschont (s. Abb. 8–55).
7.7 Regulation der Genexpression durch nicht codierende RNAs 485

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:273B2 9.1.580; Page size: 210.00mm x 275.00mm
Moleküle verbessert wurden, stellte sich die enorme Anzahl der lncRNAs (z. B.beim menschlichen Genom schätzungsweise 8.000) als eine Überraschung für dieWissenschaftler heraus. Die meisten lncRNAs werden von der RNA-Polymerase IItranskribiert und besitzen 5′-Caps und poly-A-Schwänze, und in vielen Fällenwerden sie gespleißt. Es war schwierig, lncRNAs zu beschreiben, weil, wie nunbekannt ist, von 75 % des Humangenoms RNA in niedrigen Konzentrationengebildet wird. Man denkt, dass die meisten dieser RNAs vom Hintergrund-„Rauschen“ der Transkription und der RNA-Prozessierung stammen. Gemäßdieser Vorstellung bieten solche nichtfunktionalen RNAs keine Fitnessvorteileoder -nachteile für den Organismus und sind ein toleriertes Nebenprodukt derkomplexen Genexpressionsmuster, die in Vielzellern gebildet werden müssen.Aus diesen Gründen ist es schwierig, die Anzahl der lncRNAs, die in der Zellewahrscheinlich eine Funktion haben, abzuschätzen und sie von der Hintergrund-transkription zu unterscheiden.
Wir sind bereits auf einige wenige lncRNAs gestoßen, darunter die RNA inder Telomerase (s. Abb. 5–33), die Xist-RNA (s. Abb. 7–52) und eine an derPrägung beteiligte RNA (s. Abb. 7–49). Andere lncRNAs spielen eine Rolle beider Kontrolle der Enzymaktivität von Proteinen, der Inaktivierung von Trans-kriptionsregulatoren, der Beeinflussung von Spleißmustern und der Blockierungder Translation bestimmter mRNAs.
Hinsichtlich der biologischen Funktion sollte lncRNA als Sammelbegriffbetrachtet werden, der eine große Funktionsvielfalt umfasst. Dennoch gibt eszwei verbindende Eigenschaften der lncRNAs, die der Grund für ihre vielenAufgaben in der Zelle sein können. Die erste ist, dass lncRNAs als Gerüst-RNA-Moleküle fungieren können, die Gruppen von Proteinen zusammenhalten, umderen Funktionen zu koordinieren (Abb. 7–79A). Wir haben bereits ein Beispielbei der Telomerase gesehen, wo das RNA-Molekül Proteinkomponenten zusam-menhält und organisiert. Diese RNA-basierten Gerüste entsprechen den inKapitel 3 (s. Abb. 3–78) und Kapitel 6 (s. Abb. 6–47) behandelten Proteingerüs-ten. RNA-Moleküle eignen sich gut als Gerüste: Kleine RNA-Sequenzstückchen,oft die Teile, die die Stamm-Schleifen-Strukturen bilden, können als Bindungs-stellen für Proteine dienen, und diese können aneinandergereiht sein, mit zufäl-ligen RNA-Sequenzen dazwischen. Diese Eigenschaft mag ein Grund sein,warum lncRNAs eine relativ geringe Konservierung der Primärsequenz über dieArten hinweg zeigen.
Das zweite Hauptmerkmal der lncRNAs ist ihre Fähigkeit, als Leitsequenzenzu dienen, indem sie über Basenpaarung an spezifische RNA- oder DNA-Zielmo-leküle binden. Bei diesem Vorgang bringen sie Proteine, die an sie gebunden sind,in enge Nachbarschaft zu DNA- und RNA-Sequenzen (Abb. 7–79B). DiesesVerhalten hat Ähnlichkeit mit demjenigen der snoRNAs (s. Abb. 6–41), crRNAs(s. Abb. 7–78) und miRNAs (s. Abb. 7–75), die allesamt auf diese Weise wirken,um Proteinenzyme zu spezifischen Nukleinsäuresequenzen zu lotsen.
In manchen Fällen arbeiten lncRNAs einfach über Basenpaarung, ohneEnzyme oder andere Proteine einzubeziehen. Eine Anzahl von lncRNA-Genenist beispielsweise in proteincodierende Gene eingebettet, aber sie werden in die„falsche Richtung“ transkribiert. Diese (gegensinnigen) Antisense-RNAs könnenmit der mRNA (die in die„ richtige“ Richtung transkribiert wurde) komplemen-täre Basenpaare bilden und deren Translation in das Protein blockieren(s. Abb. 7–66D). Andere Antisense-lncRNAs bilden mit prä-mRNAs Basenpaare,wenn diese synthetisiert werden, und ändern das RNA-Spleißmuster, indem sieSpleißstellensequenzen maskieren. Wieder andere wirken als „Schwämme“, in-dem sie Basenpaare mit miRNAs bilden und dabei deren Wirkungen abschwä-chen.
Schließlich ist anzumerken, dass manche lncRNAs nur in cis arbeiten, d. h.sie beeinflussen nur das Chromosom, von dem sie transkribiert wurden. Diesgeschieht leicht, wenn die transkribierte RNA noch nicht von den RNA-Poly-merasen freigesetzt wurde (Abb. 7–79C). Viele lncRNAs diffundieren jedoch weg
486 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:283B2 9.1.580; Page size: 210.00mm x 275.00mm
von ihrem Synthesort und wirken in trans. Obwohl die am besten verstandenenlncRNAs im Zellkern arbeiten, finden sich auch viele im Cytosol. Die Funktionen– falls vorhanden – der überwiegenden Mehrheit dieser cytosolischen lncRNAsist noch unentdeckt.
Zusammenfassung
RNA-Moleküle haben neben der Funktion als Informationsträger zur Spezifizie-rung der Aminosäurenreihenfolge während der Proteinsynthese viele andere Ver-wendungen. Obwohl wir in anderen Kapiteln auf nicht codierende RNAs gestoßensind (z. B. tRNAs, rRNAs, snoRNAs), hat die hohe Anzahl der von Zellengebildeten nicht codierenden RNAs die Wissenschaftler überrascht. Eine gutverstandene Anwendung nicht codierender RNAs geschieht bei der RNA-Interfe-renz, bei der sich Leit-RNAs (miRNAs, siRNAs, piRNAs) mit mRNAs basenpaaren.RNA-Interferenz kann dazu führen, dass mRNA-Moleküle entweder zerstörtwerden oder ihre Translation reprimiert wird. Sie kann auch bewirken, dassbestimmte Gene in Heterochromatin verpackt werden, um so ihre Transkriptionzu hemmen. In Bakterien und Archaebakterien dient die RNA-Interferenz als eineadaptive Immunantwort, um Viren zu zerstören, die sie befallen. Vor Kurzemwurde eine große Familie langer nicht codierender RNAs (lncRNAs) entdeckt.Obwohl die Funktion der meisten dieser RNAs unbekannt ist, dienen manche alsRNA-Gerüste, um spezifische Proteine und RNA-Moleküle zusammenzubringen,damit erforderliche Reaktionen beschleunigt werden.
Was wir nicht wissen
• Wie wird die Endgeschwindigkeit der Transkription eines Gens durch Hun-derte von Proteinen spezifiziert, die sich auf seinen Kontrollregionen auf-bauen? Werden wir je in der Lage sein, diese Geschwindigkeit aus derBetrachtung der DNA-Sequenzen der Kontrollregionen vorherzusagen?
• Wie dirigiert die Sammlung der cis-Regulationssequenzen in einem Genomdas Entwicklungsprogramm eines Vielzellers?
• Wie viel der menschlichen Genomsequenz ist funktional und warum wirdder Rest beibehalten?
• Welche der Tausende nicht untersuchter nicht codierender RNAs haben eineFunktion in der Zelle und was sind diese Funktionen?
• Waren in frühen Zellen Introns vorhanden (und gingen anschließend inmanchen Lebewesen verloren) oder sind sie zu späteren Zeiten entstanden?
(A) IncRNA
IncRNA
IncRNA
(C)(B)
RNA DNA
RNA-Polymerase
kontrolliert die Transkription von Genen auf demselben Chromosom
kontrolliert die Transkription von Genen auf anderen Chromosomen
Chromosom A
Chromosom A
Chromosom B
WIRKT IN CIS
WIRKT IN TRANS
Abb. 7–79 Funktionen der langen nicht codieren-den RNAs (lncRNAs). (A) lncRNAs können als Gerüstedienen, die Proteine zusammenbringen, die beimgleichen Vorgang mitwirken. Wie in Kapitel 6 be-schrieben, können sich RNAs zu spezifischen dreidi-mensionalen Strukturen falten, die oft von Proteinenerkannt werden. (B) Zusätzlich zu ihrer Gerüstfunk-tion können lncRNAs über die Bildung komplemen-tärer Basenpaare Proteine an spezifischen Sequenzenauf RNA- oder DNA-Molekülen lokalisieren. (C) Inmanchen Fällen wirken lncRNAs nur in cis, z. B. wenndie RNA von der RNA-Polymerase an Ort und Stellefestgehalten wird (oben). Andere lncRNAs diffundie-ren jedoch weg von ihren Syntheseorten und wirkensomit in trans.
7.7 Regulation der Genexpression durch nicht codierende RNAs 487

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:283B2 9.1.580; Page size: 210.00mm x 275.00mm
Literatur7 Allgemein
Brown, T.A. (2007) Genomes 3, Garland Science, New York; dt. (2007) Genome und Gene,3. Aufl. Heidelberg: Spektrum.
Epigenetics (2004) Cold Spring Harb. Symp. Quant. Biol. 69.Gilbert, S.F. (2013) Developmental Biology, 10th ed. Sinauer Associates, Inc., Sunderland, MA.Hartwell, L., Hood, L., Goldberg, M.L. et al. (2010) Genetics: From Genes to Genomes. 4th edn
McGraw Hill, Boston.McKnight, S.L., Yamamoto, K.R. (eds) (1993) Transcriptional Regulation. Cold Spring Harbor
Laboratory Press, Cold Spring Harbor, NY.Mechanisms of Transcription (1998) Cold Spring Harb. Symp. Quant. Biol. 63.Ptashne, M., Gann, A. (2002) Genes and Signals. Cold Spring Harbor Laboratory Press, Cold
Spring Harbor, NY.Watson, J., Baker, T., Bell, S. et al. (2013) Molecular Biology of the Gene, 7th ed. Benjamin
Cummings, Menlo Park, CA.
7.1 Ein Überblick über die Genkontrolle
Davidson, E.H. (2006) The Regulatory Genome: Gene Regulatory Networks in Developmentand Evolution. Elsevier, Burlington, MA.
Gurdon, J.B. (1992) The generation of diversity and pattern in animal development. Cell 68,185–199.
Kellis, M., Wold, B., Synder, M.P. et al. (2014) Defining functional DNA elements in thehuman genome. Proc. Natl. Acad. Sci. USA 111, 6131–6138.
7.2 Transkriptionskontrolle durch sequenzspezifische DNA-Bindeproteine
McKnight, S.L. (1991) Molecular zippers in gene regulation. Sci. Am. 264, 54–64.Pabo, C.O., Sauer, R.T. (1992) Transcription factors: structural families and principles of DNA
recognition. Annu. Rev. Biochem. 61, 1053–1095.Seeman, N.C., Rosenberg, J.M., Rich, A. (1976) Sequence-specific recognition of double helical
nucleic acids by proteins. Proc. Natl. Acad. Sci. USA 73, 804–808.Weirauch, M.T., Hughes, T.R. (2011) A catalogue of eukaryotic transcription factor types,
their evolutionary origin, and species distribution. In A Handbook of TranscriptionFactors. Springer Publishing Company, New York, NY.
7.3 Transkriptionsregulatoren schalten Gene an und aus
Beckwith, J. (1987) The operon: an historical account. In: Escherichia coli and Salmonellatyphimurium: Cellular and Molecular Biology Neidhart, F.C., Ingraham, J.L., Low, K.B.,et al. (eds.)), 2: 1439–1443. ASM Press, Washington, DC.
Gilbert, W., Müller-Hill, B. (1967) The lac operator is DNA. Proc. Natl. Acad. Sci. USA 58,2415–2421.
Jacob, F., Monod, J. (1961) Genetic regulatory mechanisms in the synthesis of proteins. J. Mol.Biol. 3, 318–356.
Levine, M., Cattoglio, C., Tjian, R. (2014) Looping back to leap forward: transcription enters anew era. Cell 157, 13–25.
Narlikar, G.J., Sundaramoorthy, R., Owen-Hughes, T. (2013) Mechanisms and functions ofATP-dependent chromatin-remodeling enzymes. Cell 154, 490–503.
Ptashne, M. (1967) Specific binding of the lambda phage repressor to lambda DNA. Nature214, 232–234.
Ptashne, M. (2004) A Genetic Switch: Phage and Lambda Revisited, 3rd edn. Cold SpringHarbor Laboratory Press, Cold Spring Harbor, NY.
St Johnston, D., Nüsslein-Volhard, C. (1992) The origin of pattern and polarity in theDrosophila embryo. Cell 68, 201–219.
Turner, B.M. (2014) Nucleosome signaling: an evolving concept. Biochim. Biophys. Acta 1839,623–626.
7.4 Molekulargenetische Mechanismen, die spezialisierte Zelltypenschaffen und erhalten
Alon, U. (2007) Network motifs: theory and experimental approaches. Nat. Rev. Genet. 8, 450–461.
488 Kapitel 7: Kontrolle der Genexpression

Reemers Publishing Services GmbHo:/Wiley/Alberts_6Aufl/3d/c07_US.3d from 16.02.2017 14:41:283B2 9.1.580; Page size: 210.00mm x 275.00mm
Buganim, Y., Faddah, D.A., Jaenisch, R. (2013) Mechanisms and models of somatic cellreprogramming. Nat. Rev. Genet. 14, 427–439.
Hobert, O. (2011) Regulation of terminal differentiation programs in the nervous system.Annu. Rev. Cell Dev. Biol.. 27, 681–696.
Lawrence, P.A. (1992) The Making of a Fly: The Genetics of Animal Design. BlackwellScientific Publications, New York.
7.5 Mechanismen, die das Zellgedächtnis in Pflanzen und Tierenverstärken
Bird, A. (2011) Putting the DNA back into DNA methylation. Nat. Genet. 43, 1050–1051.Gehring, M. (2013) Genomic imprinting: insights from plants. Annu. Rev. Genet. 47, 187–208.Lawson, H.A., Cheverud, J.M., Wolf, J.B. (2013) Genomic imprinting and parent-of-origin
effects on complex traits. Nat. Rev. Genet. 14, 609–617.Lee, J.T., Bartolomei, M.S. (2013) X-Inactivation, imprinting, and long noncoding RNAs in
health and disease. Cell 152, 1308–1323.Li, E., Zhang, Y. (2014) DNA methylation in mammals. Cold Spring Harb. Perspect. Biol. 6,
a019133.
7.6 Posttranskriptionale Kontrolle
DiGiammartino, D.C., Nishida, K., Manley, J.L. (2011) Mechanisms and consequences ofalternative polyadenylation. Mol. Cell 43, 853–866.
Gottesman, S., Storz, G. (2011) Bacterial small RNA regulators: versatile roles and rapidlyevolving variations. Cold Spring Harb. Perspect. Biol. 3, a003798.
Hershey, J.W.B., Sonenberg, N., Mathews, M.B. (2012) Principles of translational control: anoverview. Cold Spring Harb. Perspect. Biol. 4, a011528.
Hundley, H.A., Bass, B.L. (2010) ADAR editing in double-stranded UTRs and other noncodingRNA sequences. Trends Biochem. Sci. 35, 377–383.
Kalsotra, A., Cooper, T.A. (2011) Functional consequences of developmentally regulatedalternative splicing. Nat. Rev. Genet. 12, 715–729.
Kortmann, J., Narberhaus, F. (2012) Bacterial RNA thermometers: molecular zippers andswitches. Nat. Rev. Microbiol. 10, 255–265.
Parker, R. (2012) RNA degradation in Saccharomyces cerevisae. Genetics 191, 671–702.Popp, M.W., Maquat, L.E. (2013) Organizing principles of mammalian nonsense-mediated
mRNA decay. Annu. Rev. Genet. 47, 139–165.Serganov, A., Nudler, E. (2013) A decade of riboswitches. Cell 152, 17–24.Thompson, S.R. (2012) Tricks an IRES uses to enslave ribosomes. Trends Microbiol. 20, 558–
566.
7.7 Regulation der Genexpression durch nicht codierende RNAs
Bhaya, D., Davison, M., Barrangou, R. (2011) CRISPR-Cas systems in bacteria and archaea:versatile small RNAs for adaptive defense and regulation. Annu. Rev. Genet. 45, 273–297.
Cech, T.R., Steitz, J.A. (2014) The noncoding RNA revolution–trashing old rules to forge newones. Cell 157, 77–94.
Fire, A., Xu, S., Montgomery, M.K. et al. (1998) Potent and specific genetic interference bydouble-stranded RNA in Caenorhabditis elegans. Nature 391, 806–811.
Guttman, M., Rinn, J.L. (2012) Modular regulatory principles of large non-coding RNAs.Nature 482, 339–346.
Lee, H.C., Gu, W., Shirayama, M. et al. (2012) C. elegans piRNAs mediate the genome-widesurveillance of germline transcripts. Cell 150, 78–87.
Meister, G. (2013) Argonaute proteins: functional insights and emerging roles. Nat. Rev.Genet. 14, 447–459.
Rinn, J.L., Chang, H.Y. (2012) Genome regulation by long noncoding RNAs. Annu. Rev.Biochem. 81, 145–166.
tenOever, B.R. (2013) RNA viruses and the host microRNA machinery. Nat. Rev. Microbiol.11, 169–180.
Ulitsky, I., Bartel, D.P. (2013) lincRNAs: genomics, evolution, and mechanisms. Cell 154, 26–46.
Wiedenheft, B., Sternberg, S.H., Doudna, J.A. (2012) RNA-guided genetic silencing systems inbacteria and archaea. Nature 482, 331–338.
Literatur 489

www.wiley-vch.de
ISBN 978-3-527-34072-9
Aus Rezensionen zu früheren englisch- und deutschsprachigen Au�agen:„Jede Seite zeugt von der Liebe der Autoren zum exakten Detail, gleichzeitig aber von ihrer Anstrengung, Wissen aus einem schier unüberschaubaren Fachgebiet leicht erfassbar und gut lesbar aufzubereiten. … Der klare, prägnante Stil, die Fülle an informativen Diagram-men und Abbildungen setzen eindrucksvolle Maßstäbe.“
Nature
„… Molecular Biology of the Cell gelingt es ausgezeichnet, die Fortschritte [der moleku-laren Zellbiologie] darzustellen. Auch aus der kommenden Generation von Interessenten wird es niemand auch nur einen Moment bedauern, sich dieses Werk zugelegt zu haben.“
Cell
„Man spürt, wie sehr es den Autoren daran gelegen ist, ihre eigene Begeisterung für ihr Metier auf den geneigten Leser zu übertragen. … Wer hier einmal eingestiegen ist, wird nur schwerlich wieder heraus�nden, denn Biologie live macht süchtig. … Das Buch … gehört auf das Bücherregal jedes Lebenswissenschaftlers ...“
BIOspektrum
„Gleichgültig, was man gerade sucht: immer wird mehr geboten als erwartet … Beispiel-haft sind nicht nur die verständlichen, prägnanten Texte, sondern auch die großzügigen, durchwegs farbigen Illustrationen.“
Frankfurter Allgemeine Zeitung
Die Zelle – das ganze Wissen in einem Buch
„Molekularbiologie der Zelle“ ist auch international das führende Lehrbuch der Zellbiologie. Vollständig aktualisiert stellt die Neuau�age das sich rasch weiter- entwickelnde Wissen zum zentralen Gegenstand der Biologie dar – der Zelle.
Studierende in den Fächern Molekularbiologie, Genetik, Zellbiologie, Biochemie und Biotechnologie führt dieses Buch vom ersten Semester des Bachelor- bis ins Master-Studium und darüber hinaus:
• zum Lesen verführender, unverwechselbarer „Alberts“-Stil
• vermittelt neue Erkenntnisse zu intrazellulärer Organisation, Membranstruktur, Dynamik und Transport
• stellt aktuelle Themen verständlich dar, wie neu entdeckte Funktionen von RNA, Nuclear Reprogramming, pluripotente Stammzellen, Krebs und personalisierte Medizin
• vertieft den Sto� des Buchs mit über 170 englischsprachigen Animationen und mikroskopischen Aufnahmen auf einer separaten Web-Seite
• über 1400 anschauliche Farbabbildungen, größtenteils neu gestaltet
• 21 großformatige Tafeln verdeutlichen komplexe Vorgänge, klassische Experimente und aktuelle Methoden
• weiterführende Literatur mit wichtigen Originalarbeiten und Lehrbüchern
• Glossar mit mehr als 1100 grundlegenden Begri�en
Mit erstklassiger und bewährter Didaktik führt die sechste Au�age sowohl in die grundlegenden Konzepte der Zellbiologie als auch in deren faszinierende Anwendungen in Medizin, Gentechnik und Biotechnologie ein.
Web-Seite mit Zusatzmaterial: www.wiley-vch.de/home/MolBioZelle6
B. Alberts, A. Johnson, J. Lewis, D. Morgan, M. Ra�, K. Roberts, P. Walter
Molekularbiologie der ZelleÜbersetzung herausgegeben von Ulrich Schäfer
6. Au�age April 2017. 1676 Seiten, Hardcover. 1492 Abbildungen, 70 Tabellen. Lehrbuch ISBN: 978-3-527-34072-9 Preis: 139,00 €
Bruce Alberts, Alexander Johnson, Julian Lewis, David Morgan, Martin Ra� , Keith Roberts und Peter Walter
Molekularbiologie der ZelleÜbersetzung herausgegeben von Ulrich Schäfer 6. Au� age
Molekularbiologie
Übersetzung herausgegeben von Ulrich Schäfer 6. Au� age