Embed Size (px)
Citation preview

Seminarausarbeitung
Clustering mit MySQL 5
vonPatrick Schneider
Matrikelnummer:XXXXXX
Betreuer:Prof. Dr. P. Kneisel
FH Gießen-Friedberg
Erstellt am:09.03.2007

Seminar MySQL Cluster 09.03.2007
Inhaltsverzeichnis
1 Einleitung - warum Clustering?...........................................................................................3
2 Was ist „Hochverfügbarkeit“ und wie erreicht man sie?.....................................................4
3 Implementierung hochverfügbarer Datenbanken...............................................................63.1 SAN und verteilte Dateisysteme..................................................................................63.2 Replikation...................................................................................................................8
3.2.1 Asynchrone Replikation........................................................................................83.2.2 Synchrone Replikation.........................................................................................93.3.3 Externe Replikation..............................................................................................9
4 Clustering mit MySQL 5....................................................................................................104.1 Management-Knoten.................................................................................................104.2 SQL-Knoten...............................................................................................................114.3 Datenknoten...............................................................................................................11
5 Beispielimplementation.....................................................................................................135.1 Management-Knoten.................................................................................................135.2 Datenknoten..............................................................................................................155.3 SQL-Knoten...............................................................................................................155.4 Den Cluster testen.....................................................................................................15
6 Fazit...................................................................................................................................176.1 Vorteile des NDB-Clusters.........................................................................................176.2 Nachteile des NDB-Clusters......................................................................................176.3 Empfehlung................................................................................................................18
Quellenverzeichnis...............................................................................................................19
Patrick Schneider 2/19

Seminar MySQL Cluster 09.03.2007
1 Einleitung - warum Clustering?Kein Rechner ist absolut zuverlässig. Laut einer Studie des IDC1 machen Ausfallzeiten den größten Anteil an den Betriebskosten einer Datenbank aus, hauptsächlich verursacht durch den entstehenden Verdienstausfall. Um Ausfallzeiten zu verringern wird versucht, das Risiko eines Zwischenfalls auf mehrere Rechner zu verteilen und damit einen „Single Point of Failure“ zu vermeiden.
Kein Rechner von heute ist den Anforderungen von morgen gewachsen. Die Anforderungen an ein Datenbanksystem steigen mit Nutzerzahl und Datenmenge pro User stark an. Oftmals bietet ein einzelner, vor kurzem noch ausreichender Rechner nicht mehr genug Leistung, um alle an ihn gestellten Anfragen in einem akzeptablem Zeitrahmen zu bearbeiten.
Gerade im Internet-Bereich sind viele Unternehmen auf zuverlässige und schnelle Datenbankensysteme angewiesen, da Daten für sie der wichtigste Rohstoff sind. Ein Ausfall der Datenbank hätte für Google, Amazon oder Ebay katastrophale folgen, aber auch kleine Unternehmen und Forschungseinrichtungen benötigen „ständigen“ Zugriff auf ihre Daten.
Ein Cluster aus mehreren einfachen Rechnern kann helfen, hohe Verfügbarkeit und Leistung zu erreichen. MySQL2 bietet seit der Version 4.1 mit dem NDB3 Cluster Backend eine kostengünstige Open Source Lösung für ein hochverfügbares Datenbanksystem, das ich hier vorstellen möchte.
1 International Data Corporation: „Maximizing the Business Value of Enterprise Database Applications on a Linux Platform“
2 MySQL AB: http://www.mysql.com3 NDB: Network Database
Patrick Schneider 3/19

Seminar MySQL Cluster 09.03.2007
2 Was ist „Hochverfügbarkeit“ und wie erreicht man sie?Ein System gilt als verfügbar, wenn es in der Lage ist, an es gerichtete Anfragen zeitnah zu beantworten. Die Verfügbarkeit gibt das Verhältnis zwischen Uptime und Downtime eines Systems an:
Verfügbarkeit=Uptime
UptimeDowntime
Treten Störungen des Systems auf, muß es diese Störungen selbständig kompensieren können, bis die Ursache von einem Administrator beseitigt wurde.
„Ein System gilt als hochverfügbar, wenn eine Anwendung auch im Fehlerfall weiterhin verfügbar ist und ohne unmittelbaren menschlichen Eingriff weiter genutzt werden kann. In der Konsequenz heißt dies, dass der Anwender keine oder nur eine kurze Unterbrechung wahrnimmt. Hochverfügbarkeit (abgekürzt auch HA, abgeleitet von engl. High Availability) bezeichnet also die Fähigkeit eines Systems, bei Ausfall einer seiner Komponenten einen uneingeschränkten Betrieb zu gewährleisten."4
4 Held, Andrea: Oracle 10g Hochverfügbarkeit, Addison-Wesley 2004
Patrick Schneider 4/19
Abbildung 1: Die 5 Neuner zur Verfügbarkeit

Seminar MySQL Cluster 09.03.2007
100%, also ständige Verfügbarkeit, ist kaum zu erreichen und auch nur selten wirtschaftlich sinnvoll umzusetzen. Um die Verfügbarkeit von Systemen anschaulich darzustellen, kann man das Schema der „5 Neuner“ verwenden (siehe Abbildung 1). Jede weitere 9 steht für ein höheres Level an Verfügbarkeit, steigert allerdings auch die Kosten um bis zu Faktor 10! Ein hochverfügbares System sollte mindestens 99,9% seiner Laufzeit tatsächlich verfügbar sein. Eine Verfügbarkeit von 99,99% bedeutet auf ein Jahr gerechnet eine Ausfallzeit von nur noch weniger als einer Stunde5 - wobei geplante Wartungsarbeiten mit eingeschlossen sind. MySQL AB sagt in seinem „Leitfaden für hochverfügbares Clustering“, daß mit einem MySQL Cluster auf NBD Basis eine Verfügbarkeit von 99,999% erreichbar ist.
Störquellen und Ausfallgründe gibt es ebenso viele, wie Möglichkeiten, sich darauf vorzubereiten. In einem verteilten System ist es bereits manuell möglich, geplante Software- und Hardware-Upgrades an einzelnen Komponenten durchzuführen, ohne die Verfügbarkeit des Gesamtsystems zu beeinträchtigen. Auch ein unzuverlässiges System kann so, wenn auftretende Fehler schnell behoben werden, eine hohe Verfügbarkeit erreichen.
Um aber plötzliche Ausfälle der Infrastruktur ohne zusätzlichen Arbeitsaufwand (und damit verbundenen Kosten) kompensieren zu können, muß das System darauf ausgelegt sein, solche Störungen selbst zu erkennen und darauf zu reagieren. Ist es dazu in der Lage, gilt es als fehlertolerant. Sind die einzelnen Komponenten des Systems für sich bereits fehlertolerant, hilft das, die Gesamtverfügbarkeit zu steigern. Gegen einzelne Stromausfälle können USVs6 eingesetzt werden, gegen interne Netzwerkausfälle helfen redundante Netzwerkverbindungen und gegen Naturkatastrophen die ein ganzes Rechenzentrum lahmlegen hilft es, das System über mehrere räumlich getrennte Rechenzentren zu verteilen.
5 Genau: 52,6 Minuten6 Unterbrechungsfreie Stromversorgung
Patrick Schneider 5/19

Seminar MySQL Cluster 09.03.2007
3 Implementierung hochverfügbarer DatenbankenAusgehend von einer einzelnen Datenbank auf einem lokalen Server existieren viele Möglichkeiten, die Verfügbarkeit und Performance des Datenbanksystems zu erhöhen. Eine Auswahl davon stelle ich hier vor. Die Zuverlässigkeit des Datenspeichers kann zunächst durch redundante Datenhaltung (RAID7, SAN) deutlich erhöht werden. Durch verteilen der Daten auf mehrere Rechner (Fragmentierung, Replikation) kann die Leistungsfähigkeit erhöht werden.
3.1 SAN und verteilte Dateisysteme
Ein Storage Area Network (SAN) kann dem Datenbanksystem performanten, hochverfügbaren Speicherplatz bieten. Ein an das SAN angeschlossene Disk Array arbeitet intern mit mindestens zwei Festplatten8 im RAID-Verbund, nach außen stellt es sich dem Datenbankserver als ein einziger virtueller Datenspeicher dar. Die einzelnen Mitglieder des SAN sind per redundanter GBit Leitung verbunden.
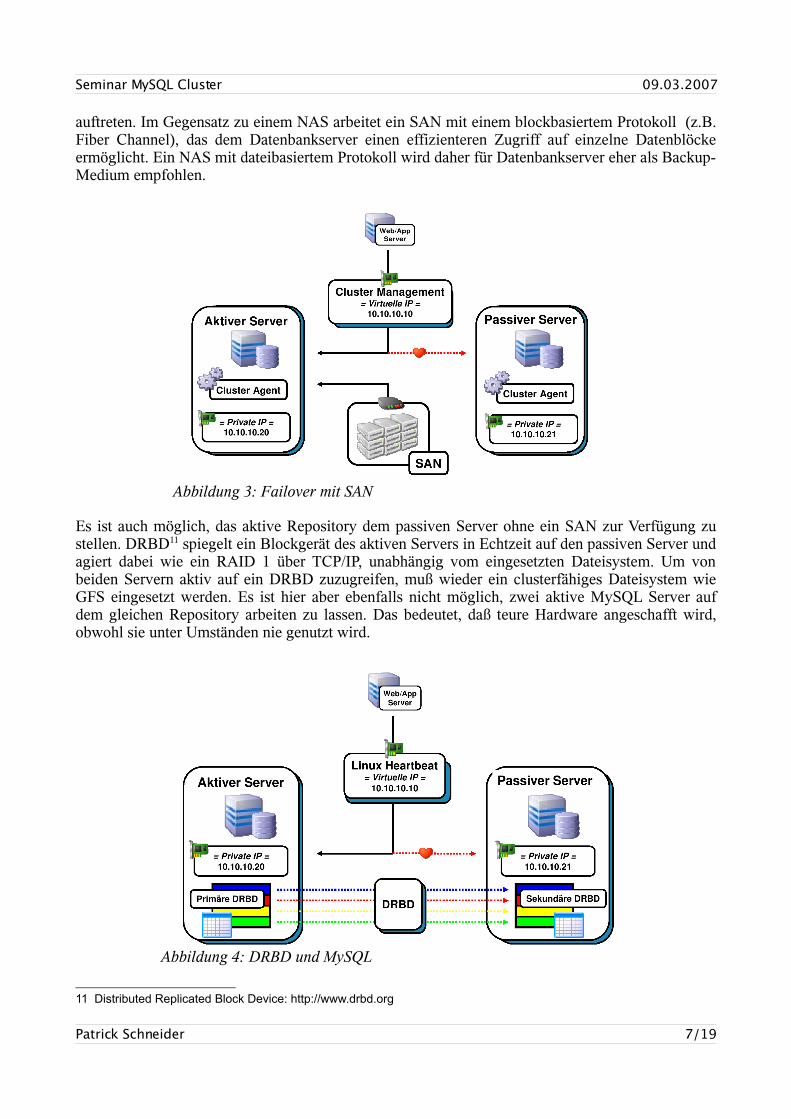
Bei Störung einer der beiden Datenleitungen ist das Gesamtsystem weiter arbeitsfähig, ebenso beim Ausfall von maximal 50% der Festplatten. Fällt der Datenbankserver wegen eines Hardwaredefekts aus, kann ein Ersatzserver (Failover) auf den Daten des ersten Servers zeitnah weiter arbeiten. Um die Ausfallzeit dabei so gering wie möglich zu halten, sollte der Ersatzserver dauerhaft passiv bereit stehen. Ein Heartbeat9 System kann den primären Server überwachen und bei Bedarf auf den sekundären Server umschalten. Leider ist es mit MySQL nicht möglich, daß zwei Server gleichzeitig aktiv auf dem gleichen Repository arbeiten, deshalb muß ein Server immer passiv bleiben.
Auch ein Network Attached Storage (NAS) bietet redundanten Speicher, der von mehreren Servern genutzt werden kann, arbeitet aber meist mit einem dateibasiertem Übertragungsprotokoll (NFS oder SMB/CIFS, für Cluster GFS10). GFS ist ein Cluster-Dateisystem, das den gleichzeitigen Zugriff mehrerer Server auf einen Datenspeicher verwalten kann, ohne daß dabei Inkonsistenzen
7 „Redundant Array of Independant Disks“8 Eher 4 oder 6 Festplatten im RAID 10 + 1-2 Platten als HotSpare9 High Availability Linux Project – Heartbeat: http://www.linux-ha.org/Heartbeat10 Global File System: http://sources.redhat.com/cluster/gfs/
Patrick Schneider 6/19
Abbildung 2: Storage Area Network
Seminar MySQL Cluster 09.03.2007
auftreten. Im Gegensatz zu einem NAS arbeitet ein SAN mit einem blockbasiertem Protokoll (z.B. Fiber Channel), das dem Datenbankserver einen effizienteren Zugriff auf einzelne Datenblöcke ermöglicht. Ein NAS mit dateibasiertem Protokoll wird daher für Datenbankserver eher als Backup-Medium empfohlen.
Es ist auch möglich, das aktive Repository dem passiven Server ohne ein SAN zur Verfügung zu stellen. DRBD11 spiegelt ein Blockgerät des aktiven Servers in Echtzeit auf den passiven Server und agiert dabei wie ein RAID 1 über TCP/IP, unabhängig vom eingesetzten Dateisystem. Um von beiden Servern aktiv auf ein DRBD zuzugreifen, muß wieder ein clusterfähiges Dateisystem wie GFS eingesetzt werden. Es ist hier aber ebenfalls nicht möglich, zwei aktive MySQL Server auf dem gleichen Repository arbeiten zu lassen. Das bedeutet, daß teure Hardware angeschafft wird, obwohl sie unter Umständen nie genutzt wird.
11 Distributed Replicated Block Device: http://www.drbd.org
Patrick Schneider 7/19
Abbildung 4: DRBD und MySQL
Abbildung 3: Failover mit SAN

Seminar MySQL Cluster 09.03.2007
3.2 Replikation
Anstatt dem Dateisystem die Aufgabe zu übertragen, die Datensicherheit zu gewährleisten - oder als zusätzliche Maßnahme - bietet der MySQL Server selbst die Möglichkeit der Datenreplikation. Dazu sollten wir uns zunächst ansehen, welche Formen der Replikation möglich sind.
3.2.1 Asynchrone Replikation
Bei asynchroner Replikation sind Original und Kopie nur zum Zeitpunkt der Synchronisierung identisch. Der Außendienstmitarbeiter, der eine Kopie der Datenbank auf seinem Laptop mit zum Kunden nimmt und diese dann bei seiner Rückkehr synchronisiert ist ein verbreitetes Beispiel für asynchrone Replikation, betrifft aber eher Desktop-Datenbanken und nicht hochverfügbare Systeme. Asynchrone Replikation kann bei einem MySQL System verwendet werden, um die Ausfallsicherheit und die Leseleistung zu erhöhen. Abbildung 5 zeigt eine besonders bei kleinen Firmen beliebte Form der asynchronen Replikation, bei der ein Slave-Server verwendet wird, um den Master-Server bei Lesezugriffen zu entlasten. Dies hat den Vorteil, daß der sekundäre Server nicht untätig auf den Ausfall des primären Servers wartet, sondern dauerhaft genutzt wird. Alle Schreibzugriffe finden weiterhin auf dem Master-Server statt, dessen Repository per Kopie der binären Log-Dateien auf den Slave übertragen wird. Dies ist ohne zusätzliche Software möglich. Der primäre Server muß nur als „Replication Master“ konfiguriert werden, beliebige sekundäre Server können dann auf ihn zugreifen und ihre Daten beziehen.
Der Nachteil dieses Setups ist, daß die zugreifende Applikation sehr viel über den Systemaufbau wissen muß. Sie darf vom Slave-Server ausschließlich lesen, es sei denn der Master-Server fällt aus. Hier ist entweder ein manuelles Failover oder ein gut angepasstes Heartbeat-System nötig. Es ist möglich, beliebig weitere Replikationsserver hinzuzufügen, um mehr Lastverteilung und
Patrick Schneider 8/19
Abbildung 5: Asynchrone Replikation Master-Slave

Seminar MySQL Cluster 09.03.2007
Ausfallsicherheit zu erreichen, aber bei jedem zusätzlichen Server müssen die Applikation und eventuell das Heartbeat-System erneut angepasst werden.
3.2.2 Synchrone Replikation
Bei synchroner Replikation werden alle Operationen parallel und damit quasi gleichzeitig auf den beteiligten Kopien der Datenbank ausgeführt. Ein Protokoll, zum Beispiel das 2-Phasen-Commit-Protokoll12 (2PC), stellt dabei sicher, daß eine Transaktion entweder auf allen, oder auf keinem der Knoten ausgeführt wird. Im Fehlerfall wird die Transaktion abgebrochen.
Vorteil der synchronen Replikation ist, daß beim Ausfall eines Teilsystems nur maximal die gerade laufenden Transaktionen verloren gehen. Im Gegenzug werden dadurch aber alle Server belastet und es entsteht mehr Netzwerkverkehr zwischen den einzelnen Servern durch das Synchronisierungsprotokoll. Der NDB-Cluster von MySQL verwendet intern synchrone Replikation.
3.3.3 Externe Replikation
Eine weitere Möglichkeit der Replikation von MySQL Datenbanken ist die Verwendung von hochverfügbarkeits Middleware wie dem Continuent m/Cluster13. Dieser bietet externe (synchrone) Replikation, indem er mehrere MySQL-Server zusammenfaßt und den Datenbankapplikationen eine einzige virtuelle Datenbank zur Verfügung stellt. Außerdem bietet er Lastverteilung über die an ihn angeschlossenen Datenbankserver.
Der Nachteil einer externen Lösung ist, daß dadurch zusätzliche Kosten entstehen können.
12 Siehe http://en.wikipedia.org/w/index.php?title=Two-phase_commit_protocol13 http://www.continuent.com
Patrick Schneider 9/19
Abbildung 6: Continuent m/Cluster (von www.continuent.com)
Seminar MySQL Cluster 09.03.2007
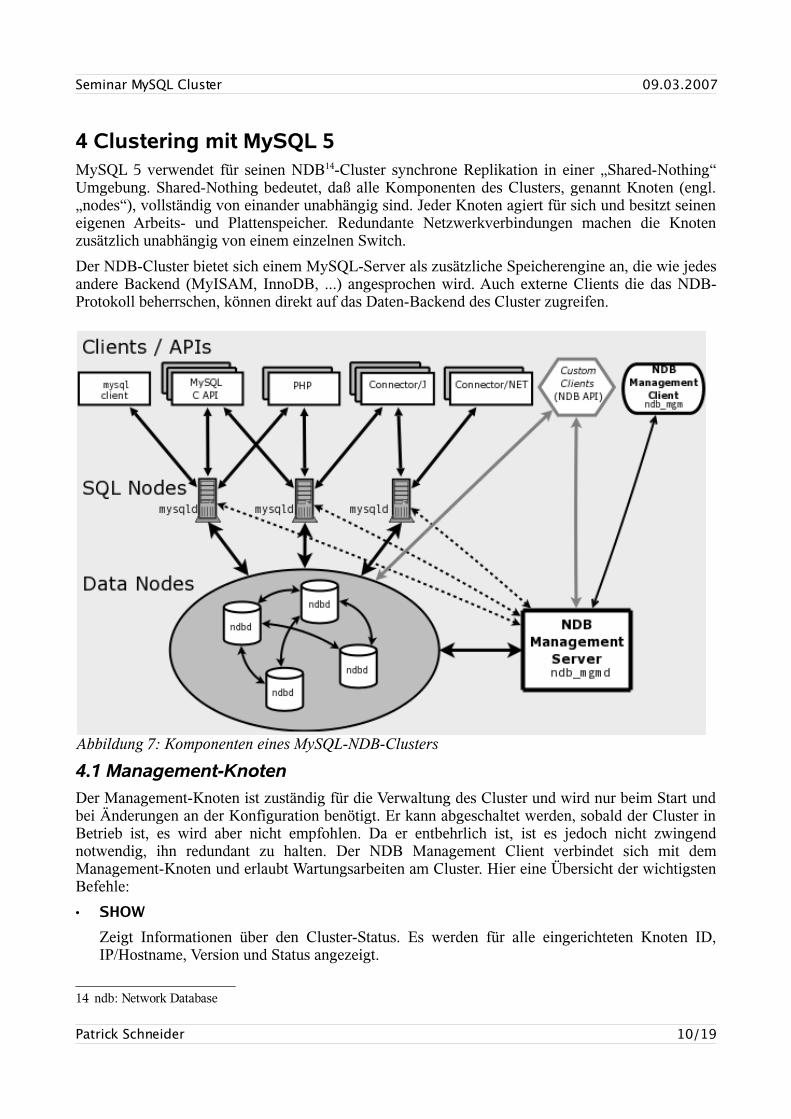
4 Clustering mit MySQL 5MySQL 5 verwendet für seinen NDB14-Cluster synchrone Replikation in einer „Shared-Nothing“ Umgebung. Shared-Nothing bedeutet, daß alle Komponenten des Clusters, genannt Knoten (engl. „nodes“), vollständig von einander unabhängig sind. Jeder Knoten agiert für sich und besitzt seinen eigenen Arbeits- und Plattenspeicher. Redundante Netzwerkverbindungen machen die Knoten zusätzlich unabhängig von einem einzelnen Switch.
Der NDB-Cluster bietet sich einem MySQL-Server als zusätzliche Speicherengine an, die wie jedes andere Backend (MyISAM, InnoDB, ...) angesprochen wird. Auch externe Clients die das NDB-Protokoll beherrschen, können direkt auf das Daten-Backend des Cluster zugreifen.
4.1 Management-Knoten
Der Management-Knoten ist zuständig für die Verwaltung des Cluster und wird nur beim Start und bei Änderungen an der Konfiguration benötigt. Er kann abgeschaltet werden, sobald der Cluster in Betrieb ist, es wird aber nicht empfohlen. Da er entbehrlich ist, ist es jedoch nicht zwingend notwendig, ihn redundant zu halten. Der NDB Management Client verbindet sich mit dem Management-Knoten und erlaubt Wartungsarbeiten am Cluster. Hier eine Übersicht der wichtigsten Befehle:
• SHOW
Zeigt Informationen über den Cluster-Status. Es werden für alle eingerichteten Knoten ID, IP/Hostname, Version und Status angezeigt.
14 ndb: Network Database
Patrick Schneider 10/19
Abbildung 7: Komponenten eines MySQL-NDB-Clusters

Seminar MySQL Cluster 09.03.2007
• START/ABORT BACKUP
Startet ein Backup der Datenbank bzw. bricht es ab. Die Backup-Daten werden auf jedem Datenknoten einzeln gespeichert, nicht auf dem Management-Knoten.
• node_id START/STOP/RESTART
Ein Datenknoten kann jederzeit gestoppt und neu gestartet werden, um Wartungsarbeiten an ihm durchzuführen. Ein Datenknoten kann sich nach einem Neustart auch angehalten mit dem Cluster verbinden und manuell gestartet werden, sobald sicher ist, daß er korrekt funktioniert.
• ENTER/EXIT SINGLE USER MODE node_id
Versetzt den Cluster in den Einzelbenutzermodus. Dies bedeutet, daß nur noch der SQL-Knoten mit der angegebenen node_id auf die Daten im Cluster zugreifen darf.
• SHUTDOWN
Stoppt zuerst alle Datenknoten und danach den Management-Knoten. Die SQL-Knoten sind davon nicht betroffen.
4.2 SQL-Knoten
SQL-Knoten sind die bekannten MySQL-Server, die den Cluster nach außen hin verfügbar machen. Damit ein MySQL-Server auf den Cluster zugreifen kann, muß man ihm nur mitteilen, daß er die NDB-Engine verwenden soll und wo er den Management-Knoten findet. Sofern er zugreifen darf, gibt dieser ihm dann genauere Informationen über den Cluster. Ein SQL-Knoten kann zu jeder Zeit gestartet und gestoppt werden, ohne daß dies Auswirkungen auf den Cluster hat. Es können sich auch jederzeit zusätzliche SQL-Knoten zur Lastverteilung mit dem Cluster verbinden.
Die NDB-Engine kann pro Tabelle genutzt werden. Eine einzelne MySQL-Datenbank kann also gleichzeitig aus MyISAM-, Memory-, NDB- und anderen Tabellen bestehen, ohne das für den Anwender oder den Anwendungsserver ein Unterschied zu erkennen ist.
4.3 Datenknoten
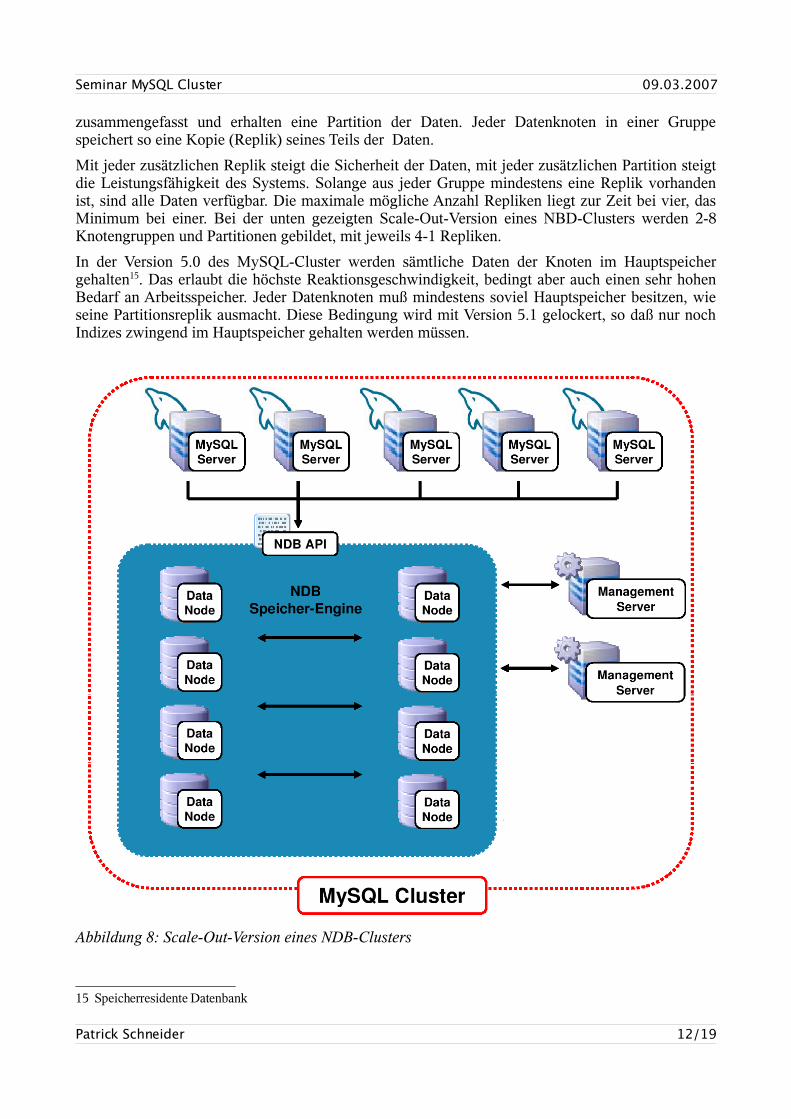
Die Datenknoten bilden das Herz des Clusters, hier werden die Daten gespeichert. Datenknoten werden zu Gruppen zusammengefasst, die zu speichernden Daten werden anhand der Gruppen Partitioniert und Repliziert, so daß jeder aktive Datenknoten einer Gruppe genau eine aktuelle Partitionsreplik enthält.
• Partition: Ein Teil der im Cluster gespeicherten Daten. Jede Knotengruppe ist für eine Cluster-Partition verantwortlich. Durch Aufteilen der Daten in mehrere Partitionen kann die Leistung des Clustersystems erhöht werden, da große Abfragen auf mehreren Rechnern gleichzeitig bearbeitet werden können.
• Replik: Eine Kopie einer Cluster-Partition. Jeder Knoten in einer Knotengruppe speichert eine Replik seiner Partition.
• Knotengruppe: Knotengruppen werden automatisch gebildet und bestehen aus einem oder mehreren Knoten. Bis MySQL 5.1 müssen alle Gruppen in einem Cluster die gleiche Anzahl Knoten besitzen.
Die Anzahl der Repliken kann vom Administrator bestimmt werden und legt gleichzeitig die Mindestanzahl an Datenknoten fest. Die Anzahl der Datenknoten sollte immer ein ganzzahliges Vielfaches der Anzahl an Repliken sein. Stehen zum Beispiel 4 Datenknoten zur Verfügung und es sollen 2 Repliken gespeichert werden, so werden jeweils 2 Knoten zu einer Gruppe
Patrick Schneider 11/19
Seminar MySQL Cluster 09.03.2007
zusammengefasst und erhalten eine Partition der Daten. Jeder Datenknoten in einer Gruppe speichert so eine Kopie (Replik) seines Teils der Daten.
Mit jeder zusätzlichen Replik steigt die Sicherheit der Daten, mit jeder zusätzlichen Partition steigt die Leistungsfähigkeit des Systems. Solange aus jeder Gruppe mindestens eine Replik vorhanden ist, sind alle Daten verfügbar. Die maximale mögliche Anzahl Repliken liegt zur Zeit bei vier, das Minimum bei einer. Bei der unten gezeigten Scale-Out-Version eines NBD-Clusters werden 2-8 Knotengruppen und Partitionen gebildet, mit jeweils 4-1 Repliken.
In der Version 5.0 des MySQL-Cluster werden sämtliche Daten der Knoten im Hauptspeicher gehalten15. Das erlaubt die höchste Reaktionsgeschwindigkeit, bedingt aber auch einen sehr hohen Bedarf an Arbeitsspeicher. Jeder Datenknoten muß mindestens soviel Hauptspeicher besitzen, wie seine Partitionsreplik ausmacht. Diese Bedingung wird mit Version 5.1 gelockert, so daß nur noch Indizes zwingend im Hauptspeicher gehalten werden müssen.
15 Speicherresidente Datenbank
Patrick Schneider 12/19
Abbildung 8: Scale-Out-Version eines NDB-Clusters
Seminar MySQL Cluster 09.03.2007
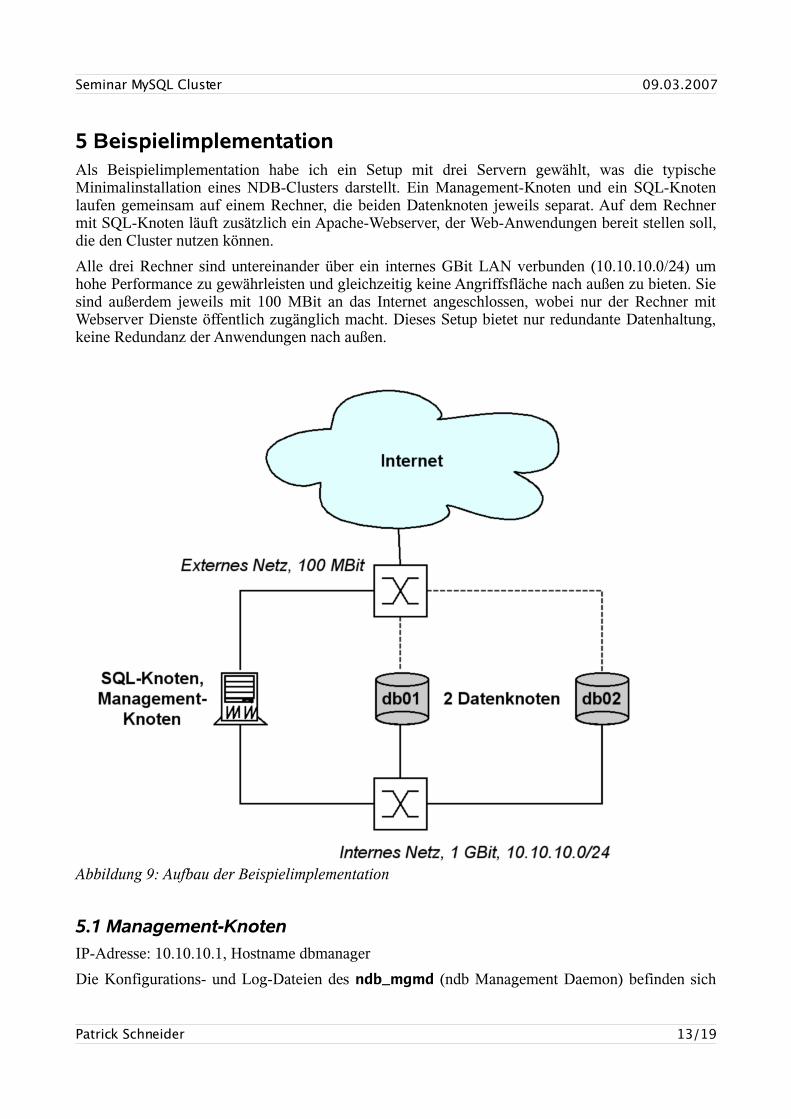
5 BeispielimplementationAls Beispielimplementation habe ich ein Setup mit drei Servern gewählt, was die typische Minimalinstallation eines NDB-Clusters darstellt. Ein Management-Knoten und ein SQL-Knoten laufen gemeinsam auf einem Rechner, die beiden Datenknoten jeweils separat. Auf dem Rechner mit SQL-Knoten läuft zusätzlich ein Apache-Webserver, der Web-Anwendungen bereit stellen soll, die den Cluster nutzen können.
Alle drei Rechner sind untereinander über ein internes GBit LAN verbunden (10.10.10.0/24) um hohe Performance zu gewährleisten und gleichzeitig keine Angriffsfläche nach außen zu bieten. Sie sind außerdem jeweils mit 100 MBit an das Internet angeschlossen, wobei nur der Rechner mit Webserver Dienste öffentlich zugänglich macht. Dieses Setup bietet nur redundante Datenhaltung, keine Redundanz der Anwendungen nach außen.
5.1 Management-Knoten
IP-Adresse: 10.10.10.1, Hostname dbmanager
Die Konfigurations- und Log-Dateien des ndb_mgmd (ndb Management Daemon) befinden sich
Patrick Schneider 13/19
Abbildung 9: Aufbau der Beispielimplementation

Seminar MySQL Cluster 09.03.2007
standardmäßig in /var/lib/mysql-cluster. In der Datei config.ini werden alle wichtigen Einstellungen für die Management- und Datenknoten vorgenommen, sie sollte auf allen beteiligten Knoten genau gleich sein. Der Management-Knoten ist hier mit seinem Hostnamen angegeben, was es erleichtert, ihn auf einen anderen Server zu verschieben.
# Optionen für den Management-Knoten:[NDB_MGMD]hostname=dbmanager # Hostname oder IP Addresse des Management-Knotensdatadir=/var/lib/mysql-cluster # Datenverzeichnis für Logfiles
# Optionen die alle ndb-Prozesse auf allen Knoten betreffen:[NDBD DEFAULT]NoOfReplicas=2 # Anzahl der ReplikenDataMemory=3000M # Speicherplatz für Daten IndexMemory=800M # Speicherplatz für Indizes
TimeBetweenLocalCheckpoints=10 # Anzahl Daten zwischen Checkpoints als 4 * 2^X, default = 20NoOfFragmentLogFiles=400 # Anzahl REDO-Log-Dateien a 64MB, default = 8
# TCP/IP options (wenn hier nichts angegeben wird, Defaultwerte übernehmen)[TCP DEFAULT]
# Jeweils ein [NDBD] Abschnitt pro Datenknoten# Optionen für ersten Datenknoten (db01):[NDBD]hostname=10.10.10.2 # Hostname oder IP Adressedatadir=/var/lib/mysql-cluster # Datenverzeichnis für Logfiles, Backups und Replay-Daten
# Optionen für zweiten Datenknoten (db02):[NDBD]hostname=10.10.10.3 # Hostname oder IP Adressedatadir=/var/lib/mysql-cluster # Datenverzeichnis für Logfiles, Backups und Replay-Daten
# Informationen über die SQL-Knoten, Einstellungen aus Sicht der ndb-Prozesse[MYSQLD][MYSQLD][MYSQLD]hostname=10.10.10.1 # IP Adresse eines SQL-Knotens hier fest angegeben/var/lib/mysql-cluster/config.ini
Dem Management-Knoten werden zwei Datenknoten (NDBD) und drei SQL-Knoten (MYSQLD) gemeldet. Die Anzahl der Datenknoten kann im laufenden Betrieb nicht geändert werden, sie können aber nach einem Ausfall ersetzt werden. SQL-Knoten hingegen können jederzeit an- und abgemeldet werden. Man sollte hier mehr Knoten vorsehen, als tatsächlich benötigt werden, um zusätzliche SQL-Knoten zur Lastverteilung anbinden zu können und um für Wartungs- und Diagnosezwecke Verbindungen frei zu haben. Ich habe einen SQL-Knoten fest mit IP angegeben, damit sich der MySQL-Daemon auf dem dafür vorgesehen Server in jedem Fall am Cluster anmelden kann.
Der Management-Knoten wird zuerst gestartet und erlaubt dann den anderen angegeben Knoten, sich zu verbinden. Die Standardinstallation von Debian bietet unter /etc/init.d/mysql-ndb-mgm ein Init-Script, das den Management-Knoten bei einem Neustart des Rechners (zum Beispiel nach einem Stromausfall) automatisch mit startet.
Patrick Schneider 14/19

Seminar MySQL Cluster 09.03.2007
5.2 Datenknoten
IP-Adressen: 10.10.10.2, 10.10.10.3
Die Datenknoten beziehen ihre Konfiguration ebenfalls aus der config.ini in /var/lib/mysql-cluster. Zum Initialisieren werden sie mit ndbd --initial gestartet, wodurch eventuell vorhandene Daten gelöscht werden. Bei späteren Neustarts genügt ein Aufruf von ndbd (zum Beispiel über /etc/init.d/mysql-ndb), der Knoten synchronisiert sich dann automatisch mit den noch aktiven Knoten.
Der zuerst am Management-Knoten angemeldete Datenknoten übernimmt die „Master“ Rolle. Bei Ausfall des Masters übernimmt sofort der zweite Knoten die Rolle des Master und behält diese auch bei, nachdem der erste Knoten wieder verfügbar ist.
5.3 SQL-Knoten
IP-Adresse: 10.10.10.1
Damit ein SQL-Knoten den NDB-Cluster nutzen kann, müssen nur die folgende Angaben in die Datei my.cnf eingetragen werden:
[mysqld]ndbcluster # NDB-Engine benutzenndb-connectstring = dbmanager # Adresse oder Hostname des Management-Knotensbind-address = 10.10.10.1 # Netzwerkunterstützung auf dem internen Device aktivieren
[MYSQL_CLUSTER]ndb-connectstring = dbmanager # Adresse oder Hostname des Management-Knotens
/etc/mysql/my.cnf
Nach einem Neustart des MySQL-Servers können beliebige Tabellen angelegt werden, die das NDB-Backend benutzen. Es können auch bestehende Tabellen in NDB-Tabellen umgewandelt werden.
5.4 Den Cluster testen
Um den neu eingerichteten Cluster zu testen, sollte man sich zunächst vergewissern, ob er auch einsatzbereit ist. ndb_mgm -e show zeigt uns den aktuellen Status des Cluster. Wenn die Ausgabe der unten gezeigten entspricht, ist der Cluster bereit.
Cluster Configuration---------------------[ndbd(NDB)] 2 node(s)id=2 @10.10.10.2 (Version: 5.0.32, Nodegroup: 0, Master)id=3 @10.10.10.3 (Version: 5.0.32, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)id=1 @10.10.10.1 (Version: 5.0.32)
[mysqld(API)] 3 node(s)id=4 (not connected, accepting connect from any host)id=5 (not connected, accepting connect from any host)id=6 @10.10.10.1 (Version: 5.0.32)
Patrick Schneider 15/19

Seminar MySQL Cluster 09.03.2007
Sind die Datenknoten nicht mit Management-Knoten verbunden, sollte man zunächst ihre Konfiguration und Netzwerkeinstellungen überprüfen (Firewall aktiv? Routing korrekt?). Bricht ein Datenknoten beim Verbinden ab, enthält er unter Umständen noch alte Daten, dann ist ein Aufruf von ndbd --initial nötig. Nach Änderungen der Konfiguration die die Anzahl der Datenknoten oder Repliken betreffen ist eine erneute Initialisierung nötig, da Knotengruppen und Partitionen neu berechnet werden und die alte Aufteilung der Daten nicht mehr gilt. Vor solchen Änderungen sollte unbedingt ein Backup erstellt werden, entweder über den Management-Knoten oder per mysqldump.16
Wie man an der Ausgabe oben sehen kann, ist bereits ein SQL-Knoten mit dem Cluster verbunden, auf dem man jetzt NDB-Tabellen anlegen kann.
mysql use test; CREATE TABLE testtabelle (a INT) ENGINE=NDBCLUSTER; INSERT INTO testtabelle (a) VALUES (1); SELECT * FROM testtabelle;
Das Select-Statement sollte eine gefundene Zeile mit Wert 1 zurückliefern. Als nächstes kann man die Failover-Fähigkeiten des Clusters prüfen, in dem man einen Knoten deaktiviert.
Hat man direkten Zugriff auf den Server, kann man einfach das Netzwerkkabel eines Knotens entfernen. Falls nicht, sucht man auf einem Datenknoten mit ps aux | grep ndbd die ProzessID des NDB-Servers und bricht ihn mit kill -9 ProzessID ab. Die Management-Konsole sollte zeigen, daß nun ein Knoten fehlt. Jetzt kann man erneut Werte in die Testtabelle eintragen, danach den ersten Knoten wieder starten und anschließen den zweiten Knoten deaktivieren. Es ist nicht nötig, einen ausgefallenen Knoten mit --initial zu starten, es sei denn seine Daten sind beschädigt. Der neu gestartete Knoten sollte innerhalb kürzester Zeit synchronisiert sein, abhängig von der Datenmenge die er von seinem lokalen Datenspeicher und den anderen Repliken lesen muß.
Um bestehende Tabellen auf den NDB-Cluster zu verschieben, genügt ein Aufruf von
ALTER TABLE `Tabellenname` ENGINE = ndbcluster;
Die zu verschiebende Tabelle sollte einen Primärschlüssel besitzen. Ist dieser nicht vorhanden, wird er im Hintergrund erzeugt.
16 Siehe MySQL Referenzhandbuch, Kapitel 8.10 „mysqldump – Programm zur Datensicherung“
Patrick Schneider 16/19

Seminar MySQL Cluster 09.03.2007
6 FazitEin NDB-Cluster benötigt im Vergleich zu einem einzelnen MySQL-Server viel Hardware zum Betrieb – sinnvoll ist ein separater Rechner pro Knoten – und zusätzlichen Aufwand beim einrichten. Im Vergleich zu anderen Replikationsmöglichkeiten bietet er aber hohe Flexibilität und viel Leistung auf Standardkomponenten bei hoher Verfügbarkeit und gleichem Hardwareeinsatz.
6.1 Vorteile des NDB-Clusters
Es ist jederzeit möglich, zusätzliche SQL-Knoten zur Lastverteilung an den Cluster anzuschließen und die einzelnen Knoten können ohne die Verfügbarkeit des Gesamtsystems zu beeinträchtigen aufgerüstet werden, falls mehr Leistung benötigt wird. Gleichzeitig ist der Cluster nach außen hin völlig transparent, was eine Anpassung der Anwendungen an die Replikationsarchitektur überflüssig macht.
Zum Betrieb eines NDB-Clusters ist weder ein SAN noch ein Cluster-Filesystem nötig, was den Verwaltungsaufwand relativ gering hält. Für die Fehlertoleranz des Backends wird auch kein Hearbeat-System benötigt, das selbst ebenfalls ausfallen könnte. Das Prinzip „kein Single Point of Failure“ wird konsequent umgesetzt.
6.2 Nachteile des NDB-Clusters
Kein im Netzwerk verteiltes System kann die Reaktionszeit eines einzelnen lokalen Zugriffs schlagen. Eine einzelne Select-Anfrage kann von einem lokalen MySQL-Datenbankserver im besten Falle sofort aus dem Hauptspeicher beantwortet werden, während ein Zugriff auf den Cluster für den MySQL-Server zunächst einen Zugriff über das Netzwerk auf den ihm zugeordneten Datenknoten bedeutet. Doch wenn es um mehrere Tausend Zugriffe pro Sekunde geht, verliert der Nachteil in der Reaktionsgeschwindigkeit an Bedeutung, da es dann auf den maximalen Datendurchsatz ankommt – und der ist bei einem Cluster-System leicht durch hinzufügen neuer Knoten erweiterbar.
Besonders bis Version 5.0 erweist sich der NDB-Cluster als ein wahrer Speicherfresser, weil die Speicherroutinen für Daten variabler Länge (varchar, text, blob) immer die maximale Länge pro Eintrag reservieren. Da alle Daten im Hauptspeicher gehalten werden, kann dieser schnell zu klein werden - und sobald auf SWAP-Speicher zurückgegriffen werden muß, bricht die Performance des Clusters stark ein.
MySQL AB stellt ein Perl-Script zur Verfügung, daß für eine gegebene Datenbank im MyISAM-Format den Speicherbedarf in einem NDB-Cluster berechnet. Abbildung 12 zeigt das Ergebnis der Berechnung für eine mir vorliegende reale Datenbank, die als SQL-Dump 1GB und im laufenden Betrieb (mit
Patrick Schneider 17/19
Abbildung 10: Datensätze variabler Länge 5.0
Abbildung 11: Datensätze variabler Länge 5.1

Seminar MySQL Cluster 09.03.2007
Indizes) ca 1,4GB belegt. Man erkennt, daß bis MySQL 5.0 die Datenbank plötzlich über 9GB an Hauptspeicher benötigt, was eine Versechsfachung des Speicherbedarfs bedeutet und die Nutzung des NDB-Backends erschwert.
Mit MySQL 5.1 wird dieser Fehler behoben und die Datenbank belegt nur noch die Hälfte an Speicherplatz. Da mit der neuen Version auch Daten, die keine Indizes betreffen auf Plattenspeicher ausgelagert werden können, kann der Bedarf an Arbeitsspeicher weitere verringert werden.
6.3 Empfehlung
Wer plant, einen Datenbankcluster auf Basis von MySQL NDB einzurichten, sollte auf die Version 5.1 warten, sofern die geplante Datenbank eine Größe von wenigen hundert Megabyte übersteigt. Die aktuellste Version ist zur Zeit 5.1.16, gilt aber immer noch als „Beta-Version“.
Patrick Schneider 18/19
Abbildung 12: Speicherverbrauch NDB-CLuster

Seminar MySQL Cluster 09.03.2007
Quellenverzeichnis• MySQL AB, Offizielle Homepage: http://www.mysql.com
• MySQL AB „MySQL 5.1 Referenzhandbuch“, Revision 403, Februar 2007
• MySQL AB „MySQL 5.0 Reference Manual“, Revision 4565, Januar 2007
• MySQL Whitepaper „Hochverfügbarkeitslösungen von MySQL“, Januar 2007
• MySQL Whitepaper „Leitfaden zur Hochverfügbarkeit von Datenbanken“, Dezember 2006
• MySQL Whitepaper „Die neuen Leitungsmerkmale von MySQL Cluster 5.1“, September 2006
• MySQL Whitepaper „Leitfaden für hochverfügbares Clustering“, Februar 2006
• Continuent, Whitepaper “Continuent™ uni/cluster for MySQL”, 2006
• Davies, Fisk: MySQL Clustering, Sams 2006
• IDC Studie „Maximizing the Business Value of Enterprise Database Applications on a Linux Platform“, August 2002
• Wikipedia, die freie Enzyklopädie: „Global File System“
URL: http://de.wikipedia.org/wiki/Global_File_System
• Wikipedia, die freie Enzyklopädie: „Storage Area Network“
URL: http://de.wikipedia.org/wiki/Storage_Area_Network
• Wikipedia, die freie Enzyklopädie: „Verfügbarkeit“
URL: http://de.wikipedia.org/wiki/Verfuegbarkeit
AbbildungsverzeichnisAbbildung 1: Die 5 Neuner zur Verfügbarkeit..................................................................... ................4Abbildung 2: Storage Area Network.......................................................................................... .........6Abbildung 3: Failover mit SAN........................................................................................... ................7Abbildung 4: DRBD und MySQL...................................................................................................... ..7Abbildung 5: Asynchrone Replikation Master-Slave................................................ ...........................8Abbildung 6: Continuent m/Cluster (von www.continuent.com).............................. ............................9Abbildung 7: Komponenten eines MySQL-NDB-Clusters.................................................... ..............10Abbildung 8: Scale-Out-Version eines NDB-Clusters............................................... ........................12Abbildung 9: Aufbau der Beispielimplementation...................................................... .......................13Abbildung 10: Datensätze variabler Länge 5.0.................................................................... .............17Abbildung 11: Datensätze variabler Länge 5.1............................................................... ..................17Abbildung 12: Speicherverbrauch NDB-CLuster................................................... ...........................18
Patrick Schneider 19/19





![5.3 Dichtebasiertes Clustering - dbs.ifi.lmu.de · 226 5.3 Dichtebasiertes Clustering SNN-Clustering Algorithmus [Ertöz, Steinbach, Kumar 03] Eingabe: k, ε, minPts 1. Berechne Ähnlichkeitsmatrix](https://img.pdfslide.org/doc/110x75/5e1a9c3f3f3b1f0b064ef719/53-dichtebasiertes-clustering-dbsifilmude-226-53-dichtebasiertes-clustering.jpg)






















