Embed Size (px)
Citation preview

DWH-Modellierung mit Data Vault in Kombination mit ODI 12c - Erfahrungen aus der Praxis -
Claus Jordan Trivadis GmbH
Stuttgart
Schlüsselworte
Data Warehouse, DWH, Data Vault, ODI, Oracle Data Integrator
Einleitung
Dieser Vortrag (eine Mischung aus Projektbericht und Best Practices) beschäftigt sich im ersten Teil mit dem praktischen Einsatz der zur Zeit viel diskutierten Data Warehouse Methode Data Vault (Stichwort agiles DWH) am Beispiel eines realen Kundenprojekts. Dabei wird schrittweise der Weg vom logischen Datenmodell zur physischen Implementierung in den verschiedenen DWH-Schichten Stage, Cleanse, Core und Mart aufgezeigt. Im zweiten Teil wird die Umsetzung der ETL-Prozesse mit Hilfe der neuesten Version von Oracle Data Integrator (ODI 12c) aus Sicht eines Oracle Warehouse Builder (OWB) Entwicklers vorgestellt. Der Schwerpunkt dabei ist die Logik zum Befüllen der Tabellen im Core und die spezielle Funktionsweise der ODI-Knowledge-Module, die für die meisten OWB Kenner noch (!) unbekannt sein dürften.
Von den Anforderungen zum Data Vault Datenmodell - Systemlandschaft & Anforderungen
Das nachfolgende Schaubild zeigt die aktuelle Systemlandschaft der zentralen Abteilung HR (Human Resources) eines internationalen Konzerns.
Abb. 1: Systemlandschaft „Heute“

Unterschiedliche Empfängersysteme (z.B. DWH’s, OLAP-Cubes, Operative System) werden über eine große Zahl von Schnittstellen aus den operativen HR Systemen mit Daten versorgt. Für die Schnittstellen werden unterschiedliche Technologien eingesetzt, weshalb die Wartbarkeit zunehmend aufwändiger wird. Die Historisierung der gelieferten Daten erfolgt aktuell nicht an zentraler Stelle, sondern je nach Bedarf und Anforderung in jedem Empfängersystem in unterschiedlicher Art und Weise.
Die folgende Abbildung zeigt, wie das Unternehmen die zukünftige Systemlandschaft plant.
Abb. 2: Systemlandschaft „Morgen“
Dabei soll für den gesamten HR-Bereich ein zentrales Data Warehouse aufgebaut werden, welches dazu dient, alle relevanten Daten aus den operativen HR-Systemen zu sammeln, permanent zu speichern und vollständig zu historisieren. Alle Empfängersysteme werden ausschließlich aus dem neuen HR Data Warehouse versorgt. Ein Online-Zugriff auf Daten im HR Data Warehouse ist aktuell nicht angedacht. Technologische Basis ist Oracle RDBMS, als ETL Werkzeug wird Oracle Data Integrator 12c eingesetzt.
Da die Implementierung schrittweise erfolgen soll, war die einfache Erweiterbarkeit eine der zentralen Anforderung an das zukünftige HR Data Warehouse. Um dieser und anderen wichtigen Anforderungen gerecht zu werden, wurden in einem Vorprojekt verschiedene Architekturen und Modellierungsmethoden evaluiert. Die Entscheidung fiel auf eine mehrschichtige, typische DWH Architektur mit den Schichten Stage, Cleanse, Core und Mart (siehe Abbildung 3).

Abb. 3: Schichten einer typischen DWH Architektur
Die vierte Schicht dient dabei lediglich als Schnittstelle zu den Empfängersystemen, aus der die Daten regelmäßig (z.B. einmal pro Tag) in der jeweils gewünschten Form bereitgestellt werden. Die Datenmodellierung der zentralen Schicht Core soll mit Hilfe der Modellierungsmethode Data Vault erfolgen.
Data Vault
Nachfolgend wird die von Dan Linstedt im Zeitraum 1990 bis 2000 ins Leben gerufene Methode Data Vault in wenigen Sätzen erläutert.
Die zentrale Komponente des Data Warehouses – in unserer Architektur das Core – wird bei diesem Modellierungsansatz als Data Vault bezeichnet. Ein Data Vault besteht aus drei verschiedenen Strukturen, die als Tabellen implementiert werden:
• Hubs enthalten ausschliesslich die Business Keys der fachlichen Entitäten sowie einen künstlichen Schlüssel, der von Links und Satellites referenziert wird. Beschreibende Attribute werden nie in Hubs abgespeichert, sondern in Satellites ausgelagert.
• Links beschreiben Beziehungen zwischen Entitätstypen (Hubs) und erlauben generell die Definition von n:m - Beziehungen zwischen verschiedenen Hubs. Auf eine fachliche Abbildung der Kardinalitäten (1:1, 1:n, n:m) wie in der klassischen relationalen Datenmodellierung wird hier verzichtet.
• Satellites umfassen sämtliche beschreibenden Attribute von Entitätstypen oder Beziehungen in versionierter Form. Ein Satellite wird via Fremdschlüsselbeziehung einem Hub oder einem Link zugeordnet. Pro Hub/Link können mehrere Satellites definiert werden.
Abb. 4: Logisches Data Vault Datenmodell mit Hub-, Link- und Satellite-Tables

Von den Anforderungen zum Data Vault Datenmodell – Logisches Datenmodell
Aus den logischen Entiätstypen werden die physischen Datenbankobjekte (i.d.R. Tabellen) für die verschiedenen DWH-Schichten abgleitet. Das logische Datenmodell (ein kleiner Auszug davon!) ist nachfolgend abgebildet.
Abb. 5: Auszug des logischen Datenmodells für das HR Data Warehouse
Die zwei Entitätstypen stehen folgendermaßen in Beziehung: Einem Mitarbeiter sind eine oder mehrere Adressen zugeordnet (z.B. Privatadresse, Privatadresse des zweiten Wohnsitzes).
Im Folgenden wird aus dem logischen Datenmodell das phyische Datenmodell in den beiden Schichten Core und Cleanse abgeleitet. Die Tabellen im Stage ergeben sich aus den Quellobjekten (z.B. Dateien, Views oder Tabellen) und werden, genau wie die Tabellen in der Schicht Mart, an dieser Stelle nicht weiter beschrieben.
Core – Datenmodell
Das aus dem logischen Datenmodell abgeleitete Datenmodell im Core sieht wie folgt aus:

Abb. 6: Physisches Data Vault Datenmodell im Core
Aus zwei Entitätstypen werden mindestens 6 Tabellen. Mindestens, weil pro Hub/Link-Table mehr als eine Satellite-Table implementiert werden könnte. Schön zu sehen ist, dass alle beschreibenden Attribute in den Satellite-Tables (gelb) und die natürlichen Schlüssen in den Hub-Tables (blau) stehen. Die Beziehung zwischen den beiden Entitätstypen wird, unabhängig von der fachlichen Kardinalität im logischen Modell, immer als separate Link-Table (rot) implementiert. So muss am Datenmodell keine Änderung vorgenommen werden, wenn sich die Kardinalität ändert. Die nachträgliche Implementierung von weiteren Entitäten gestaltet sich ebenfalls ohne Änderung der bestehenden Tabellen.
Cleanse - Datenmodell
Das physische Datenmodell der Schicht Cleanse wird direkt aus den Core-Tables abgeleitet. Für jede Hub/Link-Satellite Kombination ergibt sich eine Cleanse-Table. Im Gegensatz zum Core existieren im Cleanse noch keine künstlichen Schlüssel. Die Constraints sind implementiert, in der Regel jedoch deaktiviert.
Abb. 7: Physisches Datenmodell im Cleanse
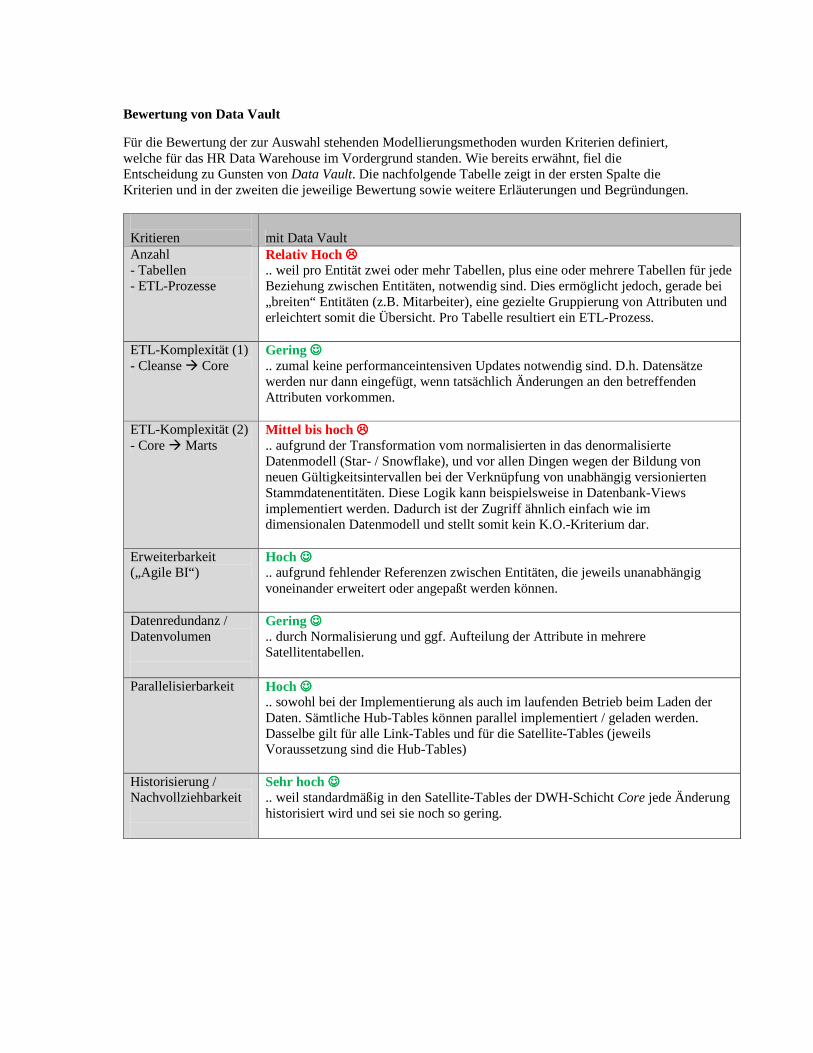
Bewertung von Data Vault
Für die Bewertung der zur Auswahl stehenden Modellierungsmethoden wurden Kriterien definiert, welche für das HR Data Warehouse im Vordergrund standen. Wie bereits erwähnt, fiel die Entscheidung zu Gunsten von Data Vault. Die nachfolgende Tabelle zeigt in der ersten Spalte die Kriterien und in der zweiten die jeweilige Bewertung sowie weitere Erläuterungen und Begründungen. Kritieren mit Data Vault Anzahl - Tabellen - ETL-Prozesse
Relativ Hoch ���� .. weil pro Entität zwei oder mehr Tabellen, plus eine oder mehrere Tabellen für jede Beziehung zwischen Entitäten, notwendig sind. Dies ermöglicht jedoch, gerade bei „breiten“ Entitäten (z.B. Mitarbeiter), eine gezielte Gruppierung von Attributen und erleichtert somit die Übersicht. Pro Tabelle resultiert ein ETL-Prozess.
ETL-Komplexität (1) - Cleanse � Core
Gering ☺☺☺☺ .. zumal keine performanceintensiven Updates notwendig sind. D.h. Datensätze werden nur dann eingefügt, wenn tatsächlich Änderungen an den betreffenden Attributen vorkommen.
ETL-Komplexität (2) - Core � Marts
Mittel bis hoch ���� .. aufgrund der Transformation vom normalisierten in das denormalisierte Datenmodell (Star- / Snowflake), und vor allen Dingen wegen der Bildung von neuen Gültigkeitsintervallen bei der Verknüpfung von unabhängig versionierten Stammdatenentitäten. Diese Logik kann beispielsweise in Datenbank-Views implementiert werden. Dadurch ist der Zugriff ähnlich einfach wie im dimensionalen Datenmodell und stellt somit kein K.O.-Kriterium dar.
Erweiterbarkeit („Agile BI“)
Hoch ☺☺☺☺ .. aufgrund fehlender Referenzen zwischen Entitäten, die jeweils unanabhängig voneinander erweitert oder angepaßt werden können.
Datenredundanz / Datenvolumen
Gering ☺☺☺☺ .. durch Normalisierung und ggf. Aufteilung der Attribute in mehrere Satellitentabellen.
Parallelisierbarkeit Hoch ☺☺☺☺ .. sowohl bei der Implementierung als auch im laufenden Betrieb beim Laden der Daten. Sämtliche Hub-Tables können parallel implementiert / geladen werden. Dasselbe gilt für alle Link-Tables und für die Satellite-Tables (jeweils Voraussetzung sind die Hub-Tables)
Historisierung / Nachvollziehbarkeit
Sehr hoch ☺☺☺☺ .. weil standardmäßig in den Satellite-Tables der DWH-Schicht Core jede Änderung historisiert wird und sei sie noch so gering.

ETL-Logik und -Prozesse mit ODI 12c
Die Definition der ETL-Logik für das HR Data Warehouse erfolgt mit Hilfe von Oracle Data Integrator (ODI), Version 12. Dabei geht es nachfolgend in erster Linie um das Laden der Hub-, Link- und Satellite-Tables der DWH Schicht Core. Entsprechend den 3 Tabellenkategorien kann in 3 Mappingtypen mit unterschiedlichen Aufgaben unterschieden werden:
Mappings für:
• Hub-Tables: .. prüfen, welche der zu ladenden Datensätze noch nicht in der Hub-Table existieren (Prüfkriterium ist der natürliche Schlüssel)? .. Neue Datensätze einfügen (Insert)
• Link-Tables: .. ermitteln der künstlichen Schlüssel der referenzierten Hub-Tables (Lookup) .. prüfen, welche der zu ladenden Beziehungen noch nicht in der Link-Table existieren .. Neue Datensätze einfügen (Insert)
• Satellite-Tables: .. ermitteln der künstlichen Schlüssel zur referenzierten Hub/Link-Table (Lookup) .. prüfen, welche der zu ladenden Datensätze noch nicht in der Satellite-Table existieren. Dabei werden nur die beschreibenden Attribute der zu ladenden Satellite-Tabelle berücksichtigt. .. Neue Datensätze einfügen (Insert) Für die 3 unterschiedlichen Kategorien von Tabellen wird in den folgenden Abschnitten jeweils anhand, bewusst sehr einfacher Beispiele, die ETL-Logik erklärt.
Hub-Tables
Das folgende Beispiel zeigt die Logik für das Laden der Hub-Tables:

Abb. 9: Beispiel für das zweimalige Laden einer Hub-Table und DML-Statement
Link-Tables
Das folgende Beispiel zeigt die Logik für das Laden der Link-Tables:
Abb. 10: Beispiel für das zweimalige Laden einer Link-Table und DML-Statement
In diesem Beispiel ändert sich die Region einer Person (offenbar ein Umzug). In diesem Fall genügt es vermutlich nicht, einen neuen Datensatz in die Link-Table einzufügen, weil sonst der Eindruck entsteht, dass die Person zwei Regionen zugeordnet ist. In diesem Fall wird eine ansonsten optionale Satellite-Table benötigt, welche ein Flag oder ein Datumsfeld enthält, das entsprechend gesetzt werden muss. Allerdings geschieht dies erst beim Laden in die zur Link-Table gehörenden Satellite-Table.

Satellite-Tables (zu Hub-Tables)
Das folgende Beispiel zeigt die Logik für das Laden einer Satellite-Table, welche einer Hub-Table zugeordnet ist:
Abb. 11: Beispiel für das dreimalige Laden einer Satellite-Table und DML-Statement

Satellite-Tables (zu Link-Tables)
Das folgende Beispiel zeigt die Logik für das Laden einer Satellite-Table, welche einer Link-Table zugeordnet ist:
Abb. 12: Beispiel für das zweimalige Laden einer Satellite-Table und DML-Statement
In diesem Beispiel ändert sich die Zuordung der Person zur Region (Umzug). Die Link-Table wurde bereits geändert (siehe weiter oben). Die alte Zuordnung soll aber explizit als ungültig markiert werden. Da diese Information nicht in der Link-Tabelle selbst gespeichert werden kann bzw. eine Löschung nicht in Frage kommt (� unwiederbringlicher Informationsverlust), ist eine Satellite-Tabelle, welche die Link-Table referenziert, notwendig. In dieser Tabelle können Information zur Beziehung gespeichert und historisiert werden. In diesem Fall ist es ein Datum, bis zu dem eine Beziehung gültig bzw. ab dem sie ungültig ist.
Knowledge-Module (Code Templates)
Ziel sollte es sein, für jeden Mapping-Typ (Hub-, Link- und Satellite-Mapping) ein eigenes ODI Knowledgemodul (KM) zu entwickeln, welches die jeweils benötigte Ladestrategie abdeckt. Eine für mich passendere Bezeichnung für KM ist der Begriff Code-Template.
Grundsätzlich gibt es in ODI verschiedene KM-Typen, welche für verschiedenen Aufgaben benutzt werden. Eine große Anzahl von KM’s werden für alle gängigen Technologien und verschiedene Anwendungsgebiet (etc. Insert, Delete, Merge, SCD2) mitgeliefert. Sie können ohne Anpassung benutzt oder aber kopiert und auf die eigenen Bedürfnisse angepaßt werden. Eine vollständige Neuentwicklung ist zwar möglich, aber meist nicht notwendig.
Für das Laden in die Data Vault Tabellen des HR Data Warehouse wurden drei so genannte IKMs (Integration KMs) entwickelt, welche den jeweiligen Mappings zugeordnet wurden. Eine nachträgliche Änderung eines KMs bewirkt, dass diese Änderung sich auf alle Mappings auswirkt, die dieses KM eingebunden haben. Diese Eigenschaft ist einer der wesentlichen Unterschiede zu Oracle Warehouse Builder (OWB). Damit kann eine Menge manuelle Arbeit und damit Fehler vermieden werden. In OWB müssten in so einem Fall ggf. hunderte von Mappings angepaßt werden.

Die folgende Abbildung zeigt die verschiedenen Tasks eines KMs:
Abb. 13: Typische Tasks eine IKM‘s
Die Tasks können sehr einfach, aber auch beliebig komplex sein. Bei der Einbindung der KMs können bestimmte Tasks ein- oder ausgeschaltet werden. So wäre auch ein komplexes KM für alle drei Tabellen-Typen denkbar.

Zusammenfasssung
Durch die mehrschichtige Architektur des HR Data Warehouse (Stage, Cleanse, Core und Mart) sind Datenströme und Transformationen sehr gut nachvollziehbar. Außerdem sind die ETL-Prozesse dadurch wenig komplex und besser wartbar.
Data Vault als Modellierungsansatz für die zentrale DWH-Schicht Core ist für den vorliegenden Anwendungsfall ideal ..
• .. weil standardmäßig eine lückenlose Historisierung der Daten gewährleistet wird. • .. weil durch die Trennung in Hub/Link-Tables und Satellite-Tables, und zusätzlich durch die
Möglichkeit mehr als eine Satellite-Table pro Hub/Link-Table zu implementieren, wenig Datenredundanz und damit hohe Datenkonsistenz erreicht wird.
• .. weil der Aufwand für das nachträgliche Hinzufügen neuer Entitäten, Attribute und Beziehungen verhältnismäßig gering ist.
• .. weil Sonderfälle, z.B. rückwirkende Änderung von Stamm- und Bewegungsdaten, relativ einfach zu implementieren sind.
Dem Effekt vieler Tabellen und ETL-Prozesse kann mit Hilfe von geeigneten Werkzeugen (Generatoren, Scripting) begegnet werden.
Mit den sehr flexibel einsetzbaren Knowledge Modulen von Oracle Data Integrator (ODI) können alle möglichen Ladestrategien und Sonderfälle effizient abgebildet werden. Die Neuentwicklung, die Durchführung von Änderungen und Fehlerkorrekturen bestehender ETL-Prozesse sind wesentlich schneller und meist einfach als mit Oracle Warehouse Builder (OWB) zu bewerkstelligen. Abgesehen davon ist ODI in Bezug auf die Zieltechnologie, im Gegensatz zu OWB, vollkommen offen.
Kontaktadresse: Claus Jordan Trivadis GmbH Industriestrasse 4 D-70565 Stuttgart Telefon: +49-162-295 96 43 E-Mail [email protected] Internet: www.trivadis.com





























