Embed Size (px)
Citation preview

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.
更快更强更轻松—Amazon EMR 为 Hive 和 Spark开挂
Derek TanAWS大数据首席架构师亚太区
李俊欣 ( Jason )AWS大数据平台业务拓展经理大中华区

• 给Hive和Spark优化有什么用?
• Amazon EMR是什么?
• Amazon EMR如何优化Hive和Spark?
• 迁移到Amazon EMR容易吗?
内容提要

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Hive和Spark的优化方向
Hive• 查询速度
• 高可用
• 动态调整计算与存储
• 降低成本
• 与数据湖的结合
Spark• 运算速度
• 集群扩展
• 数据更新
• 数据探索
• 与数据湖的结合

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
2019 年第一季度 Forrest Wave 报告
*AWS 被评为
Hadoop/Spark 云服务
领导者
*来源: Forrester Wave: Cloud Hadoop/Spark Platforms, Q1 2019

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
托管式集群,可运行 Hadoop, Spark, Presto, 以及许多其他Apache大数据生态的应用
Amazon EMR

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR的特性• 企业级特性
• 容易部署与管理
• 多主节点
• 内核完全兼容开源
• 数据安全
• 速度与成本优化
• 自动扩缩集群
• 存储与计算分离
• 调用竞价实例进行计算
• 无状态运行
• Amazon EMR Notebook
• 迁移使用简单
企业级 便捷 低成本

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR自动扩缩
Metric
AlarmRule

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR自动扩缩

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
自动扩缩
• 动态扩缩计算节点
• 动态扩缩存储(HDFS和Amazon Elastic Block Storage(EBS))
• Amazon EMR在YARN任务完成时缩容
• 有选择地移除没有任务运行的节点
• 默认超时为1小时• yarn.resourcemanager.decommissioning.timeout

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
存储与计算分离

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR: EMRFS 一致视图 (CV)
List 操作一致性
更快的 listing 操作
对象数目 无一致性视图 有一致性视图
1,000,000 147.72s 29.70s
100,000 12.70s 3.69s
*使用一个单节点集群测试,实例类型为m3.xlarge
Amazon S3
Bucket
Amazon
DynamoDB
Table
Amazon
EMR
Cluster

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价实例

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon Elastic Compute(EC2) 购买选项

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价型实例进行扩展
假设普通的按需实例每小时需要$1,10节点集群,运行14个小时成本 = 1.0 * 10 * 14 = $140
任务实例组

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价型实例进行扩展
则添加10个竞价实例
任务实例组

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价型实例进行扩展
如果每个竞价实例每小时需要$0.5,20个节点集群,运行7小时成本 = 1.0 * 10 * 7 = $70
= 0.5 * 10 * 7 = $35
总计 $105
任务实例组

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价型实例进行扩展
运行时间节省50% ( 14 7)
成本节省25% (140 105)
任务实例组

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用竞价型实例进行扩展
最坏的情况,使用按需实例
使用竞价实例以节省成本
任务实例组

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
竞价实例队列
根据容量“单位”请求容量默认为vCPU
使您的实例类型多样化
使用竞价实例EMR会找到合适的AZ

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
无状态运行

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
使用 AWS Glue 作为通用元数据存储
• 支持 Spark, Hive, Presto, Amazon
Athena和Amazon Redshift
Spectrum
• 自动生成schema与partitions
• 托管的表更新
• 对数据库与表精细化的访问控制
• 跨账号的数据catalog访问

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
无状态运行
• 在集群外维护元数据
• 更快的启动时间,更少的成本
AWS Glue
Data Catalog

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
持久集群

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
高效且可扩展的云架构
临时集群
• 大规模转换
• ETL到其它数据仓库或数据湖
• 建立机器学习作业
持久集群
• Ad-hoc作业和交互式查询
• 流 & 持续转换

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
计算:选择合适的实例
分析类型 工作负载类型
批处理 通用 M3, M4, M5, M5a, M5d
机器学期 CPU C3, C4, C5, C5d, C5n
交互式 内存 R3, R4, R5, R5d, Z1d
大型HDFS 磁盘/IO D2, H1, I3, I3en
GPU 图计算/并行计算 P2, P3, G2, G3

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Hive的优化例子
• 高可用性
通过多个主节点支持高可用性。一旦主节点发生故障,或者资源管理器或命名节点等关键进程出现崩溃,Amazon EMR 将自动检测问题并故障转移至备用主节点。Amazon EMR 还将利用新节点替换发生硬件故障的原有节点。
• 动态Auto Scaling
Autoscaling 可根据不断变化的工作负载需求自动对按需或者竞价实例进行规模伸缩;如果数据存储在 Amazon S3 内,则规模伸缩无需进行任何数据移动。提供高弹性与低成本体验,用户只需要为实际使用的资源量付费。

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Hive的优化例子
• 成本效益
将计算(Amazon EMR)与存储(Amazon S3)分离开来,确保计算与存储资源可各自独立扩展。
• 高性能
S3 Select 与 Hive 相结合以提高性能水平。S3 Select 允许应用程序仅检索对象内的特定数据子集,从而减少 Amazon EMR 集群与 Amazon S3 之间的数据传输量。
• 丰富的元存储选项
在 Amazon RDS、Amazon Aurora 以及 AWS Glue Data Catalog 之上支持多种本地与外部元存储选项。

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR Runtime for Apache Spark

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
EMRFS S3 优化的提交程序

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
弹性: 扩展Spark的弹性
平滑地处理节点丢失并尽早开始恢复
取消注册所有缓存数据和shuffle块以加快恢复过程
扩展Spark黑名单机制以防止调度新任务
https://aws.amazon.com/blogs/big-data/spark-enhancements-for-elasticity-and-resiliency-on-
amazon-emr/

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Fully Managed Notebooks
• Amazon EMR Notebooks 基于当前高人气开源 Apache Jupyter
Notebooks
• Notebook可以与Spark集群协同工作。我们提供免费的、全托管的notebook来让用户可以通过熟悉的Jupyter界面来进行实验和工作。

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
全托管 Notebooks
• 多名用户可接入同一集群(利用 Auto-scaling来进行自动扩缩!)• 各用户之间以相互完全隔离的方式安装自己的自定义库• 将 Git 库与 Notebooks 加以关联,将您的 Notebooks 保存在版本受控环境当中
• 将 Notebooks 保存在 S3 中• 基于标签的权限机制

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
全托管 Spark History Server
• 将 Spark History Server UI 直接接入 EMR Console
• 通过查看 Spark 执行历史与访问相关日志文件,快速实现对活跃作业与作业历史的分析与故障排查
• 即使集群已经关闭,仍要访问 Spark 作业记录

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
支持 Apache Hudi
• 此前,若需利用 Amazon S3 存储服务对记录内容进行插入、更新或删除,
用户必须创建自定义数据管理与提取解决方案,借以跟踪单一记录变更,同时手动管理数据集的重新创建过程(特别是那些为了合并少量变更,而经常导致大规模数据集重写的操作)。在 Hive 中,用户往往需要使用INSERT OVERWRITE 完成这项工作。
• 利用 Apache Hudi,用户可以通过事务更新插入实现变更的应用与管理,从而简化新记录创建与旧记录更新等操作。在整合了 Apache Spark、Hive
以及 Presto 之后,用户现在无需自定义解决方案即可实现变更应用。.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
弹性: 扩展Spark的弹性
平滑地处理节点丢失并尽早开始恢复
取消注册所有缓存数据和shuffle块以加快恢复过程
扩展Spark黑名单机制以防止调度新任务
https://aws.amazon.com/blogs/big-data/spark-enhancements-for-elasticity-and-resiliency-on-
amazon-emr/

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
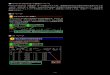
基于SAML的身份验证和细粒度访问控制(1/2)
对于使用Amazon EMR Notebook或Zeppelin的客户• 使用基于SAML的身份提供商(IdP) 启用身份验证,例如Active
Directory联合身份验证服务(ADFS)• 强制对数据库,表和列进行细粒度访问控制。
通过其向Amazon EMR授权与表和列关联的Amazon S3前缀和访问策略的临时安全凭证。

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
基于SAML的身份验证和细粒度访问控制(2/2)

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
选择Amazon EMR版本
• Amazon EMR 在 EMR 各版本当中捆绑有开源应用程序的多个版本。如果您选择使用应用程序的较新版本,请参阅各版本间的变更,并确定实际使用中可能出现的兼容性问题。
应用 版本说明 问题列表
Spark https://spark.apache.
org/releases/
https://issues.apache.org/jira/
projects /SPARK/issues
Hive https://hive.apache.or
g/downloads.html
https://issues.apache.org/jira/
projects/HIVE/issues
Presto https://prestodb.gith
ub.io/docs/current
/release.html
https://github.com/prestodb/p
resto/issues
HBase https://hbase.apache.
org/downloads. html
https://issues.apache.org/jira/
projects /HBASE/issues

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
性能: 选择实例类型 –主节点
需要大量本地存储?
大量网络I/O?
计算密集型?大内存需求?
D2或者I3系列
YES
NO
C5系列或 R5 并启用增强网络
YES
M5.xlarge 或更大机型
NO
当集群中有超过 100 个节点时,主节点可能会因为网络 I/O 而堵塞,所以最好选一个大型节点类型。

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
如何迁移到Amazon EMR上(TODO)
利用 Amazon S3 替代 HDFS
将数据移动到Amazon S3
• 利用Amazon EMR提供的S3DistCp之类的工具将数据从本地HDFS拉到Amazon S3
• 或利用诸如WANDisco Fusion或Cloudera BDR之类的商业解决方案
对数据进行分区
• 分区是一种用于组织数据集的重要技术,以便高效地实现查询。
• 例如,您可以按日期对Amazon S3中的应用程序日志进行分区,并按年,月和日进行细分。然后,将某一天的数据相对应的日志文件放在一个前缀下,例如s3://my_bucket/logs/year=2018/month=01/day=23.
• 诸如Amazon EMR,Amazon Athena,Amazon Redshift Spectrum和AWS Glue之类的服务可以使用此布局按分区值过滤数据,而不必从Amazon S3读取所有基础数据。

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
总拥有成本比较

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EMR 支持大多数云 Hadoop 与 Spark 项目

© 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
Enterprise applicationsAnalytics
Benefits of Amazon S3

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
分区: Apache Spark
文件数据源:spark.read.loadDiscovers partitions,并将Hive-style的分区路径映射到列
如果大于 spark.sql.sources.parallelPartitionDiscovery.threshold (32),使用 Spark job
从文件中infer schema – 触发Spark job 做并行
对查询计划的基本统计信息(文件大小,分区等)
使用 basePath 选项加载特定分区
表数据源: spark.read.table分区信息持久化在 Hive Metastore/Glue Data Catalog 中
不需要infer schema,统计数据,以及discover partitions

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
优化 Spark 性能
动态分区减枝 - 通过更精确地在表中选择需要被读取的特定分区,提升作业性能
扁平化标量子查询 – 查询优化器尽可能扁平化聚合使用了同样关系的标量子查询

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
表: Hive 管理 vs DataSource
Hive 管理使用“STORED AS” 或 ”USING HIVE“创建的
原生 reader 性能
spark.sql.hive.convertMetastore(Parquet|ORC) = true
不支持
EMRFS Optimized Connector with Partitioning
DataSource使用“USING FORMAT”创建的
支持Bucketing,Sorting 和 Partitioning

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
并行
不可切分 可切分 多个文件
对于多个文件,具有类似文件大小的任务的乘数
选用更少的大文件,而不是更多的小文件
小文件 – 并行过多,高开销
Task
TaskGZIP
File
Task
TaskBZ2
File
Task
Task File
File

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
管理小文件
Apache Spark – 在 output stage 中,一个task写一个文件
Repartition(N) – 数据full shuffle,并创建同等大小分区后的数据。
Coalesce(N) - 合并已存在的分区,避免一个full shuffle
df.write.option(“maxRecordsPerFile”, N)
Compaction – 使用离线作业将多个小文件合并为更大的文件

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
存储:列格式Column pruning 以及基于Min/Max的过滤
支持Schema以及嵌套数据类型
使用块级别压缩
在列格式中避免写小文件(< XX MBs)Executor
Executor
Executor列格式数据文件
列格式数据文件
列格式数据文件

© 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved.
如何迁移到EMR上(TODO)
Choose the instance types to be used in your clusters.
• Most Amazon EMR clusters can run on general-purpose EC2 instance types/families (that is, M5.large and M5.xlarge).
• Compute-intensive clusters may benefit from running on high performance computing (HPC) instances, such as the compute-optimized instance family (that is, C5).
• Database and memory-caching applications may benefit from running on high memory instances, such as the memory-optimized instance family (that is, R5).
• The master node does not have large computational requirements. For most clusters of 50 or fewer nodes, you can use a general-purpose instance type such as m5.large (Note: for clusters of more than 50 nodes, consider using a larger instance type, such as m5.xlarge).
• EMR clusters are configured using defaults that depend on the instance types chosen. These defaults run for most workloads but some jobs may require you to override the defaults. For example, EMR clusters by default use the capacity schedule as the Apache Hadoop resource scheduler. Validate that this scheduler fits the use case that you are migrating.


















![フラメンコキューピー NO.1 [更新済み]...Title フラメンコキューピー NO.1 [更新済み] Created Date 10/20/2010 6:18:29 PM](https://img.pdfslide.org/doc/110x75/5ebe2d38493d1e18af0c2066/ffffffff-no1-title-ffffffff.jpg)




![SGT-表30.1 [更新済み]...Title SGT-表30.1 [更新済み] Created Date 5/17/2018 2:45:54 PM](https://img.pdfslide.org/doc/110x75/5f2172062655c900b87c4b2c/sgt-e301-title-sgt-e301-created-date-5172018.jpg)




