Embed Size (px)
Citation preview

TeIe
T
ID= 1
= D
C
C
Rechnerarchitektur IInformationscodierung
Technische Universitat DresdenInstitut fur Technische Informatik
R.G. [email protected]
Dresden, 2003
RA I Rechnerarchitektur I
TeIe
T
ID= 1
= D
C
C
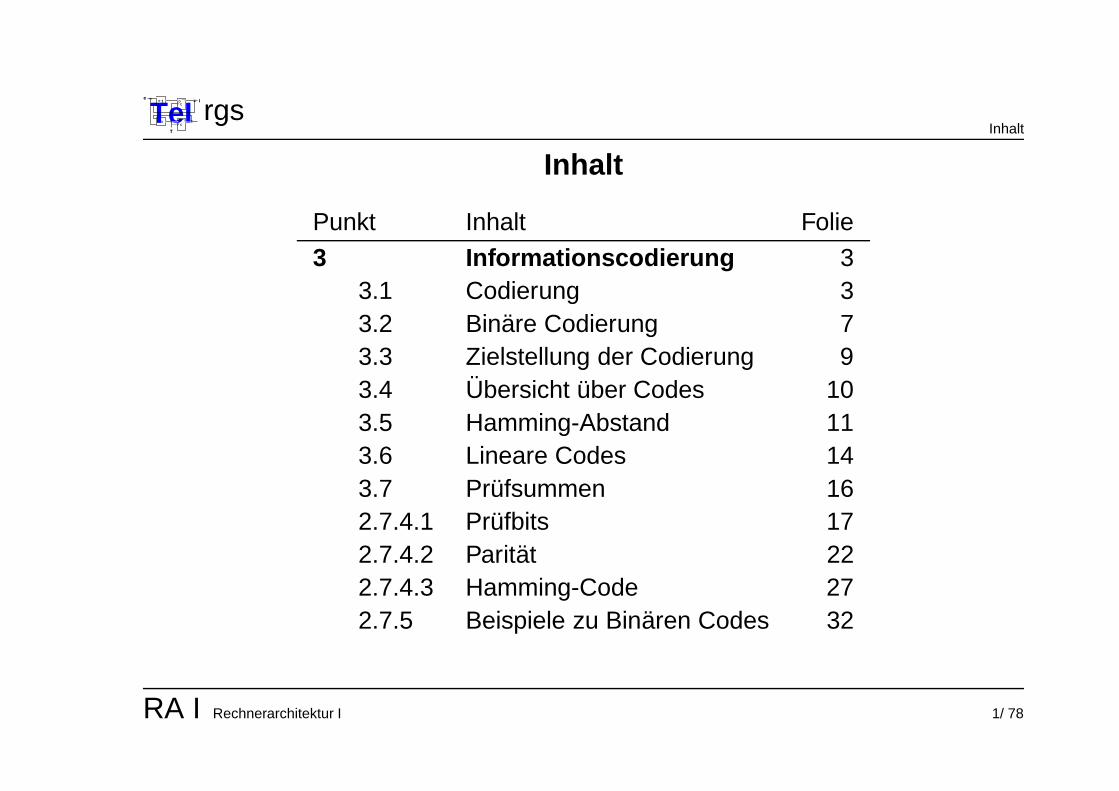
rgsInhalt
Inhalt
Punkt Inhalt Folie
3 Informationscodierung 33.1 Codierung 33.2 Binare Codierung 73.3 Zielstellung der Codierung 93.4 Ubersicht uber Codes 103.5 Hamming-Abstand 113.6 Lineare Codes 143.7 Prufsummen 162.7.4.1 Prufbits 172.7.4.2 Paritat 222.7.4.3 Hamming-Code 272.7.5 Beispiele zu Binaren Codes 32
RA I Rechnerarchitektur I 1/ 78
TeIe
T
ID= 1
= D
C
C
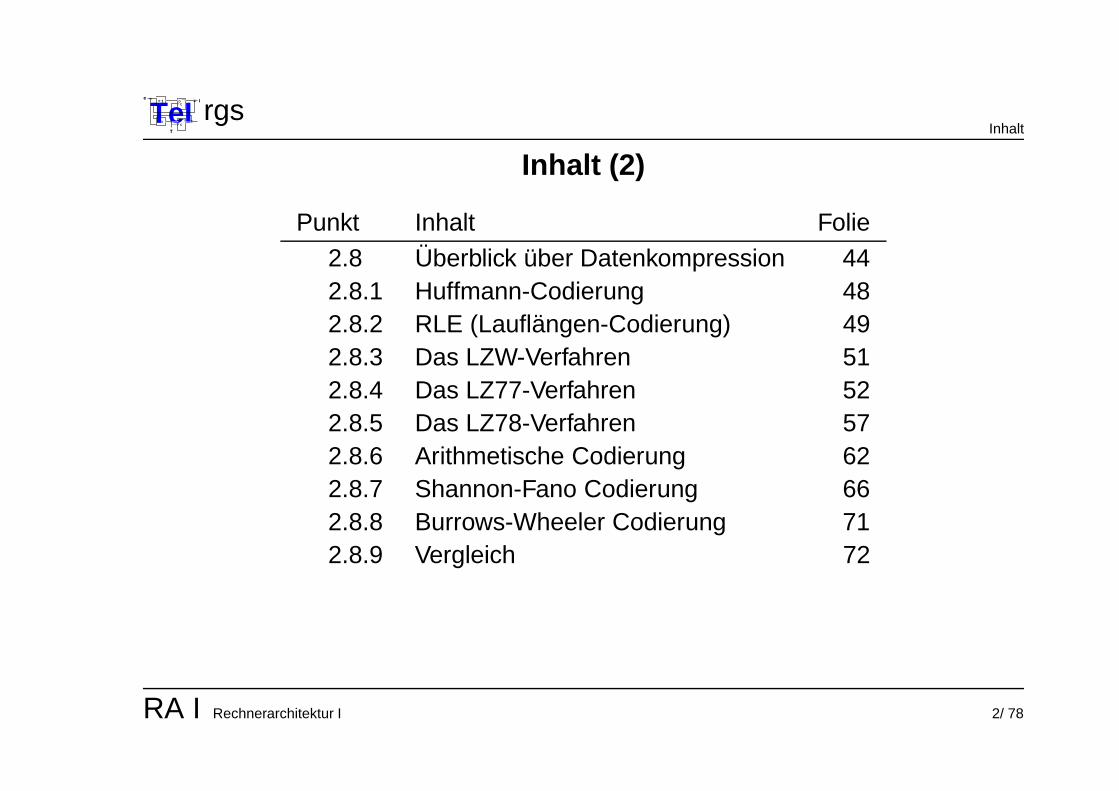
rgsInhalt
Inhalt (2)
Punkt Inhalt Folie
2.8 Uberblick uber Datenkompression 442.8.1 Huffmann-Codierung 482.8.2 RLE (Lauflangen-Codierung) 492.8.3 Das LZW-Verfahren 512.8.4 Das LZ77-Verfahren 522.8.5 Das LZ78-Verfahren 572.8.6 Arithmetische Codierung 622.8.7 Shannon-Fano Codierung 662.8.8 Burrows-Wheeler Codierung 712.8.9 Vergleich 72
RA I Rechnerarchitektur I 2/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.1 Codierung 3 Informationscodierung
3 Informationscodierung
3.1 Codierung
Informationen konnen in codierter Form auf Basis von Zeichenfolgen(Zeichenmenge Z) oder als Signalfolgen (Signalmenge S) vorliegen.
Codierung ist eine eindeutige Abbildung einer endlichen Menge von Zeicheneines Alphabetes A in eine geeignete Folge uber der unterliegendenSignalmenge Sn bzw. Zeichenmenge Zn oder aber in eine Zeichenmenge einesanderen Alphabetes B (Sn � S ��� � �
�
S � Zn � Z � � � � � Z).
Codierung ist Alphabetwandlung: κ : A � Zn bzw. κ : A � Sn oder κ : A � B
Dabei bezeichnet Sn bzw. Zn das n-fache kartesische Produckt uber der MengeS bzw. Z. Die Elemente von Sn bzw. Zn sind n-Tupel (Zeichenketten, Codeworter)mit
�
s1s2� � � sν� � � sn
�� Sn � sν� S bzw.
�
z1z2� � � zν� � � zn
�� Zn � zν
� Z .
RA I Rechnerarchitektur I 3/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.1 Codierung 3 Informationscodierung
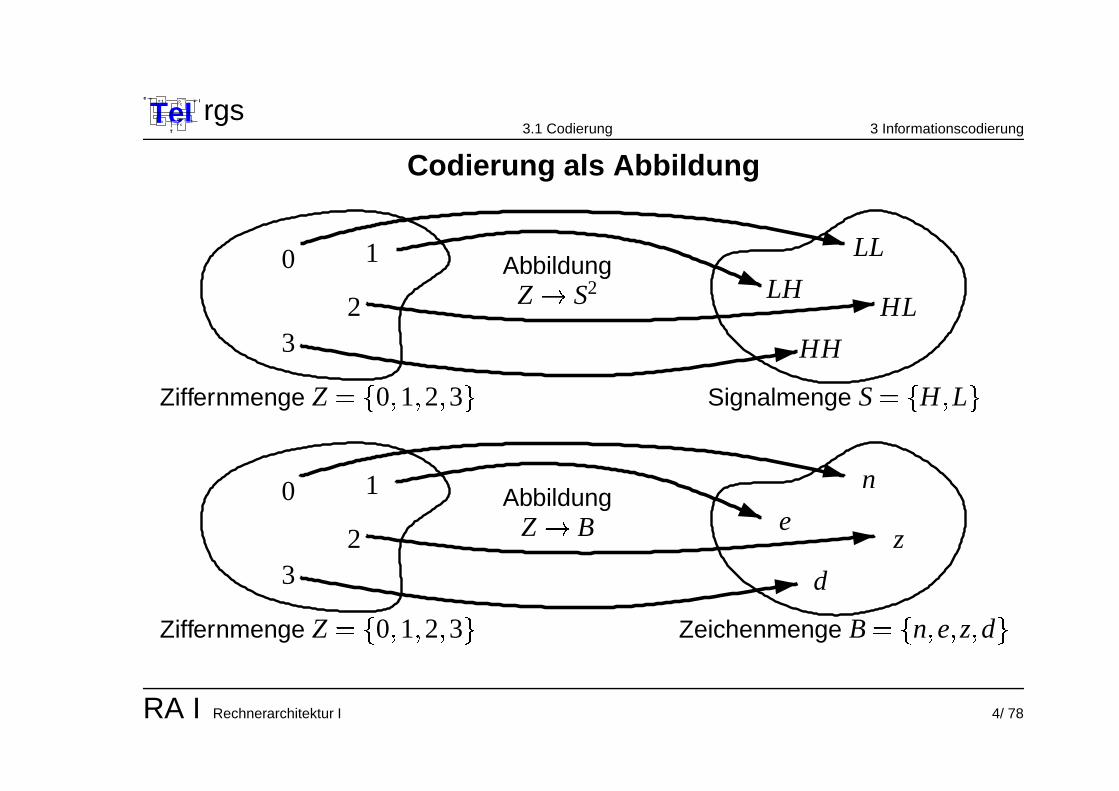
Codierung als Abbildung
LL
LHHL
HH
23
0 1
Z � S2Abbildung
Ziffernmenge Z � �
0 � 1 � 2 � 3
�
Signalmenge S � �
H � L
�
n
ez
d
23
0 1
Z � BAbbildung
Ziffernmenge Z � �
0 � 1 � 2 � 3�
Zeichenmenge B � �
n � e � z � d
�
RA I Rechnerarchitektur I 4/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.1 Codierung 3 Informationscodierung
Beispiel: Morse-Alphabet
Signalmenge:
� � ��� � ��
Codierung: µ :
�
A� � � Z � 0� � � 9
� � ��� � ��
n
A � � J � � � � S � � � 1 � � � � �
B � � � � K � � � T � 2 � � � � �
C � � � � L � � � � U � � � 3 � � � � �
D � � � M � � V � � � � 4 � � � � �
E � N � � W � � � 5 � � � � �
F � � � � O � � � X � � � � 6 � � � � �
G � � � P � � � � Y � � � � 7 � � � � �
H � � � � Q � � � � Z � � � � 8 � � � � �
I � � R � � � 0 � � � � � 9 � � � � �
Die Morse-Codierung ist nicht langenkonstant (n � 1� � � 5). Die Decodierbarkeiterfolgt durch ein Trennzeichen (Pause �) ( z.B. RGS: � � � � � � � � � � � � �).
RA I Rechnerarchitektur I 5/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.1 Codierung 3 Informationscodierung
Decodierbarkeit eines Codes
Eine Codierung ist decodierbar, wenn mindestens eine der folgendenVoraussetzungen gegeben ist:
� Alle Codeworter sind gleich lang (Blockcodeeigenschaft).
� Verwendung eines gesonderten Trennzeichens.
� Kein (kurzes) Codewort ist Anfang bzw. Ende eines anderen (langen)Codewortes (Prafixeigenschaft).
Suffix-Codeungleichmassiger Code, bei dem kein (kurzes) Codewort Ende (Suffix) einesanderen (langen) Codewortes darstellt.
Prafix-Codeungleichmassiger Code, bei dem kein (kurzes) Codewort Anfang (Prafix) einesanderen (langen) Codewortes ist (Prafixeigenschaft z.B. Huffman-Code).
RA I Rechnerarchitektur I 6/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.2 Binare Codierung 3 Informationscodierung
3.2 Binare Codierung
Binar bedeutet zweiwertig, dual, bivalent. Codierungen fur moderneelektronische Computer basieren praktisch ausschlieslich auf der MengeB � �
0 � 1
�
der binaren Zeichen 0 und 1. Fur eine Codierung mit Zeichenfolgenvon n-Zeichen aus B gilt:
Zeichenmenge : B � �
0 � 1
�
Codierung : β : A � �
0 � 1�
n
Codewortlange : n Zeichen (Zeichenfolge)Zeichenvorrat : 2n verschiedene n-Bit Codeworter
Die Codeworter werden als Zeichenketten der Binarziffern 0 � 1 dargestellt. EineBinarziffer wird Bit (binary digit) genannt.
Mit einem n-Bit Code (β : A � �0 � 1
�
n) konnen maximal 2n verschiedene n-BitCodeworter (Zeichenketten) realisiert werden ( � Blockcode).
RA I Rechnerarchitektur I 7/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.2 Binare Codierung 3 Informationscodierung
Blockcode
In der Computertechnik werden hauptsachlich Blockcode (Codeworter festerLange n) verwendet, wobei Vorzugsformate verwendet werden (Byte, Wort, . . . ).
Dichter Code:Ein dichter Blockcode liegt vor, wenn q verschiedene Codeworter fur dieAbbildung benotigt werden und n die folgende Bedingung erfullt:
2n � 1 � q
�
2n .
Voller Code:Ein Blockcode wird dann voll genannt, wenn alle Kombinationsmoglichkeiten qder verschiedenen Zeichen des Zielalphabets genutzt werden, also bei gleichbleibender Codewortlange kein weiteres Codewort mehr gefunden werden kann:
q � 2n .
RA I Rechnerarchitektur I 8/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.3 Zielstellungen der Codierung 3 Informationscodierung
3.3 Zielstellungen der Codierung
Beeinflussung der Informationsdarstellung durch gezielte Codierung:
� Lesbarkeit
� Verarbeitbarkeit
� Ubertragbarkeit
� Fehlersicherheit
� Speicherbarkeit
� Vertraulichkeit
Anwendungsgebiete fur die Codierung:
� Informationsdarstellung allgemein (Signalfolgen),
� Informationsverschlusselung (Kryptographie)
� Informationsubertragung (Kommunikationstechnik)
� Informationsverarbeitung (Computertechnik)
RA I Rechnerarchitektur I 9/ 78
TeIe
T
ID= 1
= D
C
C
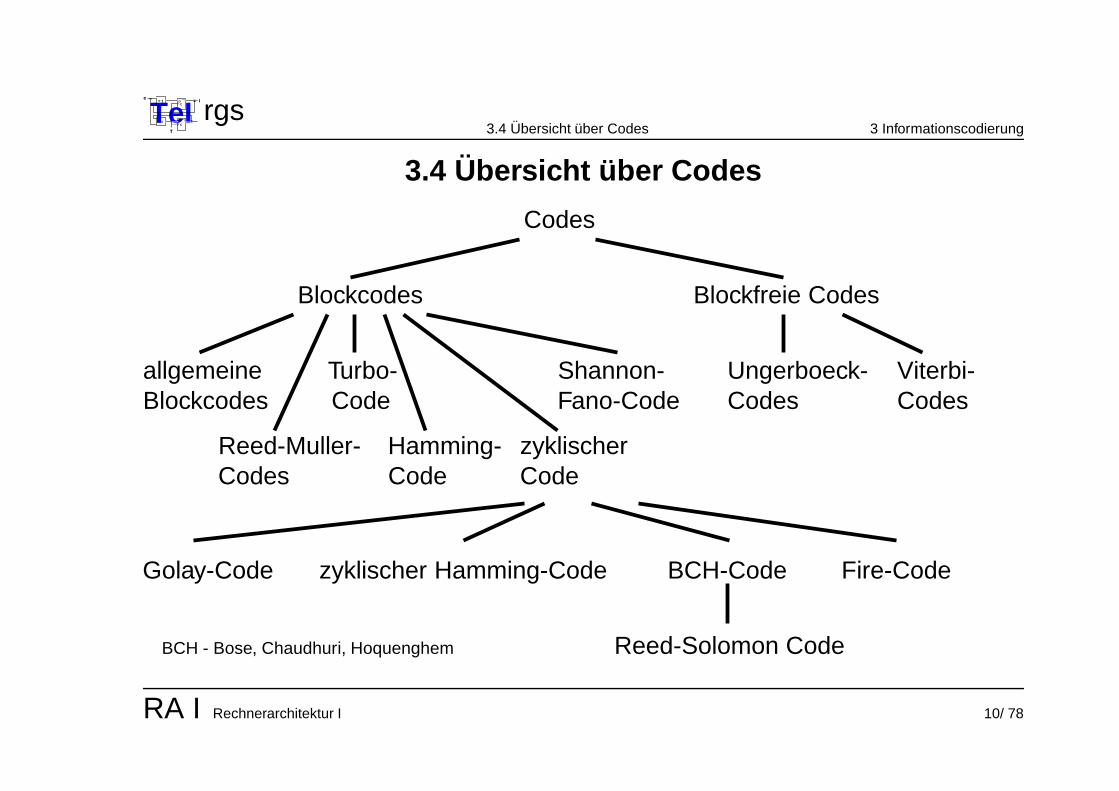
rgs3.4 Ubersicht uber Codes 3 Informationscodierung
3.4 Ubersicht uber Codes
Blockcodes
Turbo-Code
zyklischer
Blockfreie Codes
Codes
CodeCodeCodes
allgemeineBlockcodes Fano-Code
Shannon-
BCH - Bose, Chaudhuri, Hoquenghem
Codes
CodesViterbi-
Reed-Solomon Code
BCH-Code
Ungerboeck-
Reed-Muller- Hamming-
zyklischer Hamming-CodeGolay-Code Fire-Code
RA I Rechnerarchitektur I 10/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.5 Hamming-Abstand (Hamming-Distanz) 3 Informationscodierung
3.5 Hamming-Abstand (Hamming-Distanz)
Richard Hamming (1950)Zwei Bitketten (Codeworter gleicher Lange) a und b eines Codes C haben denAbstand hd
�
a � b
� � d, wenn sie sich in genau d Bit-Positionen unterscheiden.
Hamming-Abstand: min
�
hd
�
a � b
��
a � b� C � a
� � b
�Der Hamming-Abstand ist der minimale Abstand zwischen den Codewortern.
Hamming-Gewicht: hw
�
an � 1 � an � 2 � � � � � a0
� � hd� �
an � 1 � an � 2 � � � � � a0
� � �
0 � 0 �� � � � 0
� �
Eine Bitkette a hat das Gewicht hw
�
a
� � w , wenn sie in genau w Bit-Positionenungleich 0 ist (Anzahl der 1-Positionen).
Beispiel (n � 8 � hd � 3):
Codeworter: 00100110 00110011 11010011 01111011
RA I Rechnerarchitektur I 11/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.5 Hamming-Abstand (Hamming-Distanz) 3 Informationscodierung
Ein Blockcode C heißt linear, wenn die Summe zweier Codeworter wieder einCodewort ist. Der Hamming-Abstand von C gleich dem minimalenHamming-Gewicht aller von 0 verschiedenen Codewrter.
Beispiel:Der 3-Bit-Binrcode mit Parittsbit C4,3 ist ein linearer Code: 0 0 0 0 0 0 11 0 1 0 1 0 1 1 0 1 0 0 1 1 0 1 0 1 1 0 0 1 1 1 1
Die Menge T = 1 0 0 1, 0 1 0 1, 0 0 1 1 ist eine Basis von C4,3. Somit hat C4,3die Dimension 3.
Bei einem linearen Code kann man bestimmte Grundwrter aus der Menge Cherausnehmen und zu einer Generatormatrix zusammenfassen, aus der mandurch Linearkombination alle anderen Codewrter bilden (generieren, daherGeneratormatrix) kann.
Diese Regel lautet: a1c1a2c2...ancn
Dabei ist ci ein Codewort und ai GF(q).
RA I Rechnerarchitektur I 12/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.5 Hamming-Abstand (Hamming-Distanz) 3 Informationscodierung
Zum Erstellen einer Generatormatrix sucht man eine maximale Menge linearunabhngiger Codewrter, die man dann in Matrizenform aufschreibt.
RA I Rechnerarchitektur I 13/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.6 Lineare Codes 3 Informationscodierung
3.6 Lineare Codes
�
n � m � hd ��
- Code * hd - nicht immer angegebenn - Codewortlangem - Lange des Nutzcodewortes p � n � mhd - Hamming-Abstand Informationsrate : R � m
n
Definition:
Lasst sich die Codierungsvorschrift eines
�
n � k�
Codes durch eine k � n Matrix Gbeschreiben, d.h. gilt fur alle Nachrichtenblocke b und ihre dazugehorigenCodeworte c die Beziehung c � b � G, so heisst G Generatormatrix diesesCodes und der Code wird als linearer Code bezeichnet.
RA I Rechnerarchitektur I 14/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.6 Lineare Codes 3 Informationscodierung
Redundanz linearer Codes
Ein Code dessen m-stellige Codeworter um p redundante Kontrollstellenerweitert werden, bezeichnet man als (n, n - p)- Code oder (n,m)-Code.Als relative Redundanz rp wird dabei Anzahl p redundanten Stellen in einemCodewort der Lange n bezweichnet.
rp
� n � mn
� pn
n - Bit Codewort
p - Prufbits m - Bit Nutzcodewort
RA I Rechnerarchitektur I 15/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
3.7 PrufsummenAls Schutz gegen Fehler wird der Datenblock um eine Prufsumme erweitert.Auswertung der Prufsumme:
� Fehlererkennung
� Fehlerkorrektur
� Fehlerverhalten
Beispiele zu Prufsummen:
� Prufziffer (z.B. Kontonummer)
� Paritat (z.B. einfaches Paritatsbit)
� Summenbildung (z.B. Fletscher-Algorithmus)
� CRC-Verfahren (Cyclic Redundancy Check)
� Hamming-Codes
� BCH-Codes (Bose, Chaudhuri, Hoquenghem)
� Reed-Salomon-Codes
RA I Rechnerarchitektur I 16/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.7.4.1 Anzahl notwendiger Prufbits fur Erkennung undKorrektur von Einzelbitfehlern
m - Datenbits (Nutzcodewort) � 2m Nutzcodeworterp - redundanten Prufbits � n = m + p - Codewortlange (erweitert)
� Zu jedem Codewort gibt es n Codeworter mit hd=1 (Invertieren der Bitstellen).
� Bei 2m Nutzcodewortern existieren n � 2m Codeworter mi dem Abstand hd=1.
� Damit existieren (n+1) � 2m gultige bzw. mit hd=1 korrigierbare Codeworter.
� Die Gesamtanzahl der Codeworter 2n muss grosser oder hochstens gleichdieser korrekten bzw. korrigierbaren Anzahl (n+1) � 2m sein.
(n+1) � 2m �
2n
m + p + 1�
2p mit n = m + p
� Erkennung von f Einzelbitfehlern: hd = f + 1
� Korrektur von f Einzelbitfehlern: hd = 2f + 1
RA I Rechnerarchitektur I 17/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
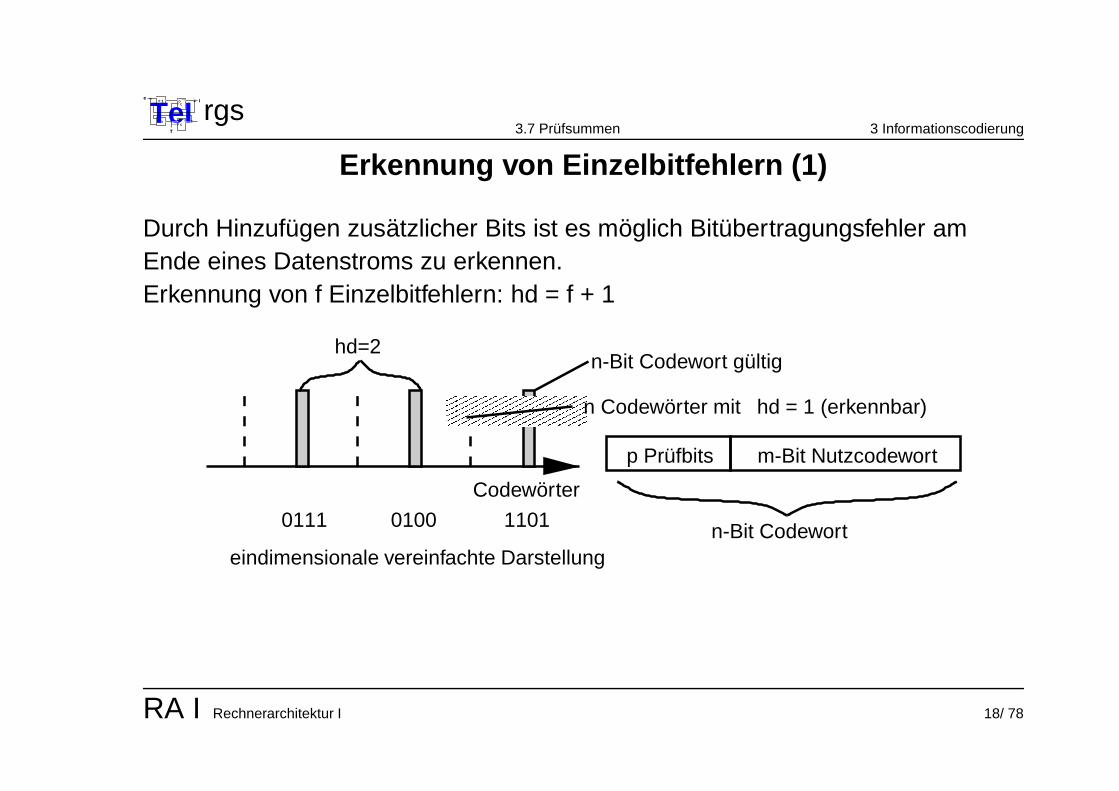
Erkennung von Einzelbitfehlern (1)
Durch Hinzufugen zusatzlicher Bits ist es moglich Bitubertragungsfehler amEnde eines Datenstroms zu erkennen.Erkennung von f Einzelbitfehlern: hd = f + 1
� � � � � � �� � � � � � �� � � � � � �
� � � � � � �� � � � � � �� � � � � � �
n-Bit Codewort gultig
n Codeworter mit
n-Bit Codewort
m-Bit Nutzcodewortp Prufbits
hd=2
hd = 1 (erkennbar)
Codeworter
110101000111
eindimensionale vereinfachte Darstellung
RA I Rechnerarchitektur I 18/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
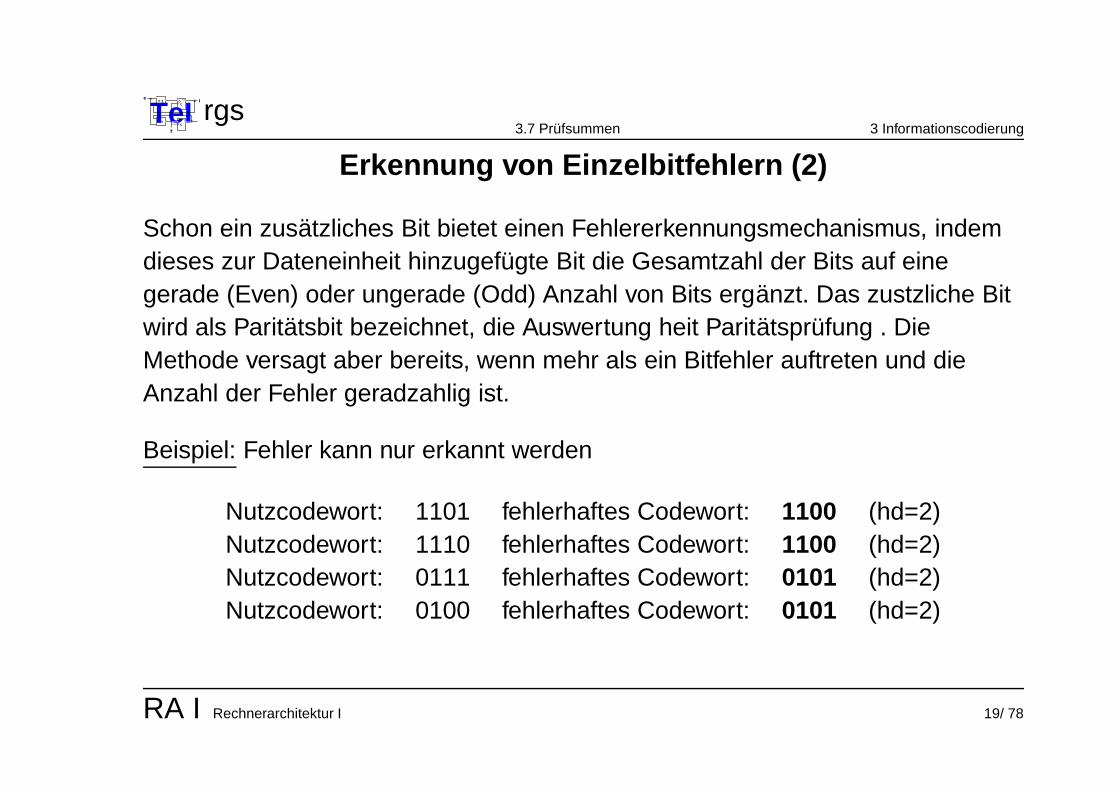
Erkennung von Einzelbitfehlern (2)
Schon ein zusatzliches Bit bietet einen Fehlererkennungsmechanismus, indemdieses zur Dateneinheit hinzugefugte Bit die Gesamtzahl der Bits auf einegerade (Even) oder ungerade (Odd) Anzahl von Bits erganzt. Das zustzliche Bitwird als Paritatsbit bezeichnet, die Auswertung heit Paritatsprufung . DieMethode versagt aber bereits, wenn mehr als ein Bitfehler auftreten und dieAnzahl der Fehler geradzahlig ist.
Beispiel: Fehler kann nur erkannt werden
Nutzcodewort: 1101 fehlerhaftes Codewort: 1100 (hd=2)Nutzcodewort: 1110 fehlerhaftes Codewort: 1100 (hd=2)Nutzcodewort: 0111 fehlerhaftes Codewort: 0101 (hd=2)Nutzcodewort: 0100 fehlerhaftes Codewort: 0101 (hd=2)
RA I Rechnerarchitektur I 19/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Korrektur von Einzelbitfehlern (hd = 3) (1)
� � � � � � �� � � � � � �
n-Bit Codewort
m-Bit Nutzcodewortp Prufbits
n-Bit Codewort gultig
n Codeworter mit
hd=1hd=3100110 110011 111010
hd = 1 (korrigierbar)
Codeworter
eindimensionale vereinfachte Darstellung
2m gultige Codeworter (Nutzcodeworter mit je p Prufbits).
(n+1) � 2m �2n
m + p + 1�
2p mit n = m + p
RA I Rechnerarchitektur I 20/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Korrektur von Einzelbitfehlern (2)
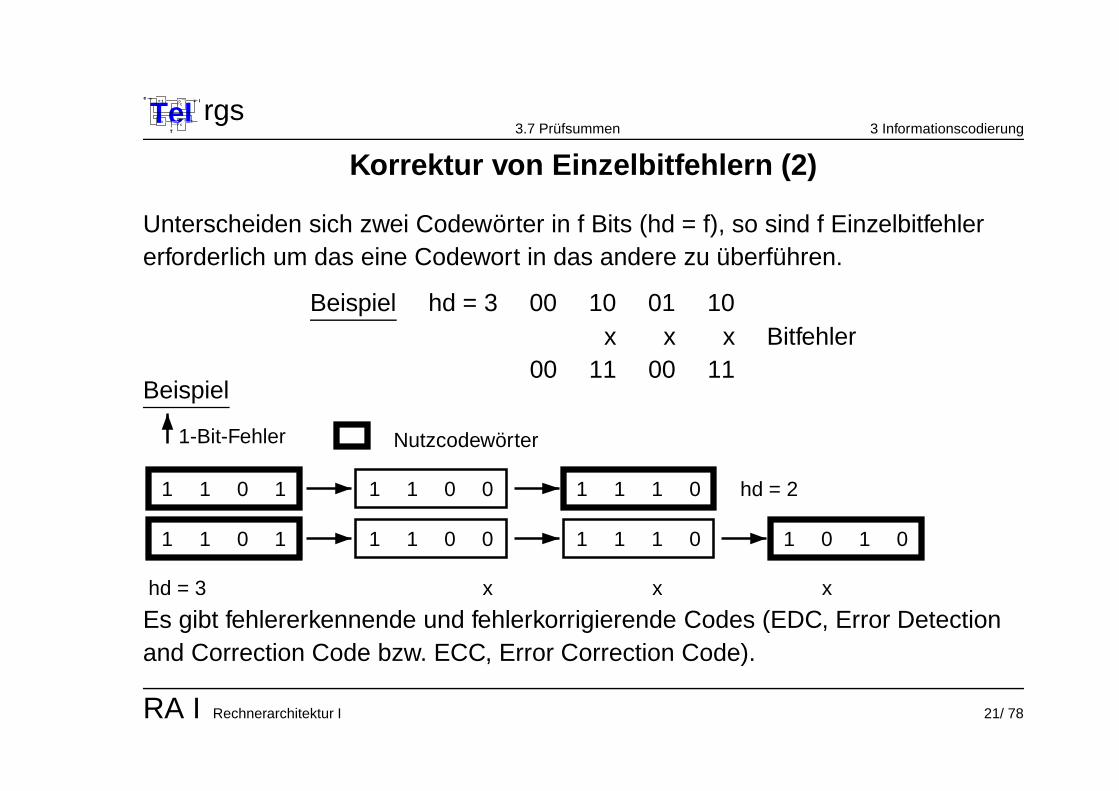
Unterscheiden sich zwei Codeworter in f Bits (hd = f), so sind f Einzelbitfehlererforderlich um das eine Codewort in das andere zu uberfuhren.
Beispiel hd = 3 00 10 01 10x x x Bitfehler
00 11 00 11Beispiel
1-Bit-Fehler Nutzcodeworter
1 1 0 1 1 1 0 0 1 1 1 0 hd = 2
1 1 0 1 1 1 0 0 1 1 1 0 1 0 1 0
hd = 3 x x x
Es gibt fehlererkennende und fehlerkorrigierende Codes (EDC, Error Detectionand Correction Code bzw. ECC, Error Correction Code).
RA I Rechnerarchitektur I 21/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.7.4.2 Paritat
Erweiterung der Codeworter um ein oder mehrere Paritatsbitsgerade Paritat:die Summe aller 1-Bits, inklusive des Paritatsbits im betrachteten Teil desCodewortes ist geradzahligungerade Paritat:die Summer aller 1-Bits, inklusive des Paritatsbits im betrachteten Teil desCodewortes ist ungeradzahligParitatscodes konnen von 1D auf 2D, 3D oder mehrdimensionale Schemataerweitert werden.Bildung der Paritat:Die Paritat wird durch XOR-Verknupfung (MODULO 2 Addition) aller betroffenenStellen gebildet.
gerade Paritat: PG
� an � 1
� an � 2 � � � � � a1
� a0 = 0PG
� an � 1
� an � 2 � � � � � a1
� a0
RA I Rechnerarchitektur I 22/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
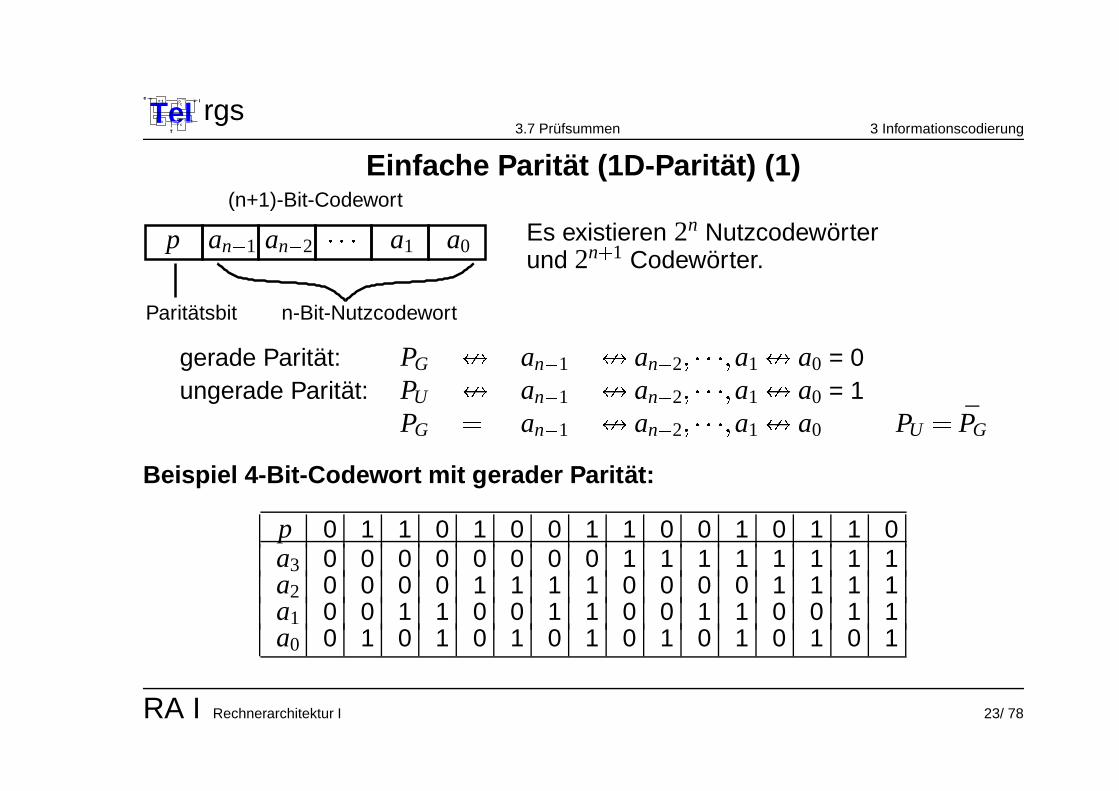
Einfache Paritat (1D-Paritat) (1)
Es existieren 2n Nutzcodeworterund 2n
�
1 Codeworter.
Paritatsbit
p an � 1 an � 2 a0
� � � a1
n-Bit-Nutzcodewort
(n+1)-Bit-Codewort
gerade Paritat: PG
� an � 1
� an � 2 � � � � � a1
� a0 = 0ungerade Paritat: PU
� an � 1
� an � 2 � � � � � a1
� a0 = 1PG
� an � 1
� an � 2 � � � � � a1
� a0 PU
� PG
Beispiel 4-Bit-Codewort mit gerader Paritat:
p 0 1 1 0 1 0 0 1 1 0 0 1 0 1 1 0a3 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1a2 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1a1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1a0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
RA I Rechnerarchitektur I 23/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
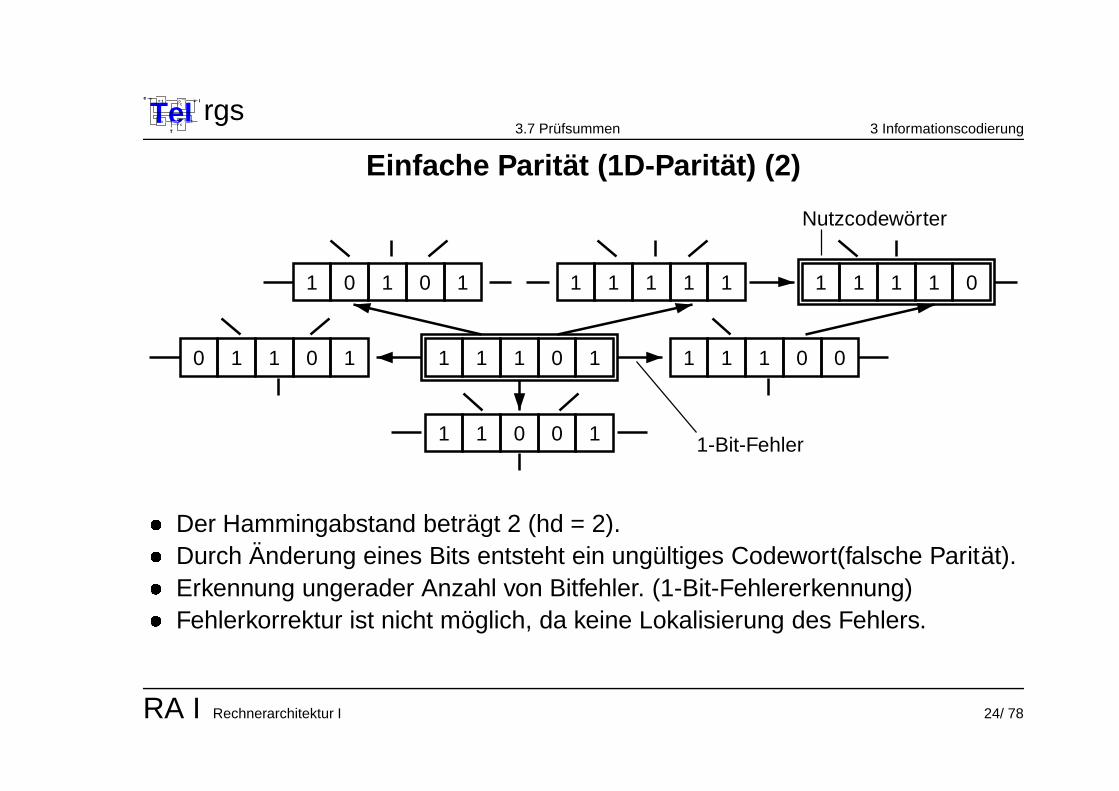
Einfache Paritat (1D-Paritat) (2)
1 1 11 0
1 1 10 0
1 1 1 11 0 1 0 1 1 1 1 1 1
0 1 1 0 1 1 1 1 0 0
0
1-Bit-Fehler
Nutzcodeworter
� Der Hammingabstand betragt 2 (hd = 2).
� Durch Anderung eines Bits entsteht ein ungultiges Codewort(falsche Paritat).
� Erkennung ungerader Anzahl von Bitfehler. (1-Bit-Fehlererkennung)
� Fehlerkorrektur ist nicht moglich, da keine Lokalisierung des Fehlers.
RA I Rechnerarchitektur I 24/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2D-Paritat (Blocksicherung) (1)
Beispiel zur Aufteilung des Codewortes in Zeilen und Spaltenparitat. Fur ein4-Bit-Codewort werden 5 Paritatsbits (2 Zeilen- und 2 Spaltenparitat und 1Paritatskontrollbit) verwendet.
Paritatsbits
p0p3
Nutzcodewort
a2 a0p2 p1 a3 a1p4p3
a3
a1
a2
a0
p2
p1
p0
p4
Fur gerade Paritat: p4
� a0
� a2
p3
� a3
� a1
p2
� p3
� p4� p1
� p0
p1
� a3� a2
p0
� a0� a1
p2 nicht unbedingt notwendig nur fur erweiterten Code.
RA I Rechnerarchitektur I 25/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
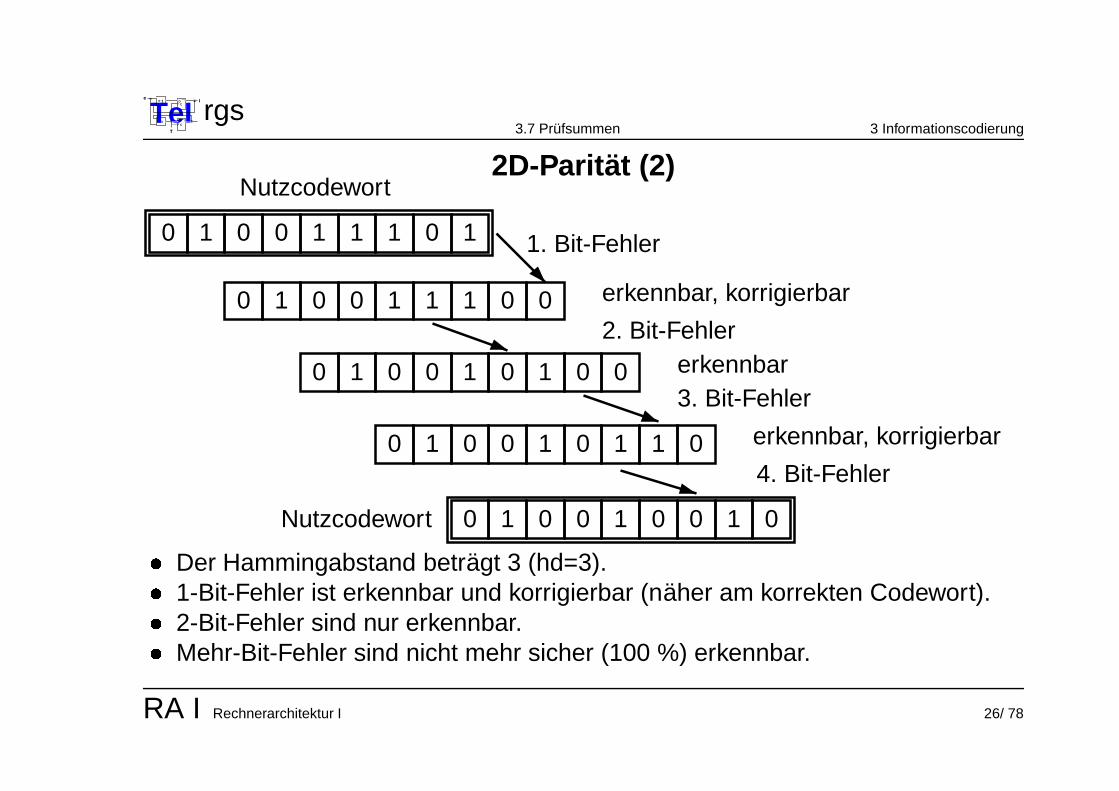
2D-Paritat (2)
0 1 0 0 1 1 1 10
Nutzcodewort
1. Bit-Fehler
0 0 0 0 01 1 1 1 erkennbar, korrigierbar
2. Bit-Fehler
0 1 0 0 1 0 1 1
0 0 0 0 0 01 1 1Nutzcodewort
erkennbar, korrigierbar0
3. Bit-Fehler
4. Bit-Fehler
10 0 0 0 0 01 1 erkennbar
� Der Hammingabstand betragt 3 (hd=3).
� 1-Bit-Fehler ist erkennbar und korrigierbar (naher am korrekten Codewort).
� 2-Bit-Fehler sind nur erkennbar.
� Mehr-Bit-Fehler sind nicht mehr sicher (100 %) erkennbar.
RA I Rechnerarchitektur I 26/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.7.4.3 Hamming-Code (Hamming Algorithmus)(1)
Bildungsvorschrift
1. Bits von links (MSB), beginnend mit 1 durchnummerieren.2. Alle Bits, deren Bitnummer eine Potenz von 2 ist, sind Paritatsbits, alle
ubrigen Datenbits.3. Ein Bit b an der Stelle n wird von denjenigen Paritatsbits gepruft, deren
Summe der Indizes die Stellennummer des Bits ergeben.4. Das Paritatsbit ist gesetzt, falls die Anzahl der gesetzten und von diesem zu
uberpfrufenden Datenbits ungerade ist.5. Die Summe der Indizes der fehlerhaften Paritatsbits ergibt die Stelle des
fehlerhaften (zu invertierenden) Datenbits.
RA I Rechnerarchitektur I 27/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Hamming-Code (2)Beispiel fur 8-Bit-Datenwort:
�
0 1 0 1 1 0 0 1
�
1. 1 2 3 4 5 6 7 8 9 10 11 122. p1 p2 d1 p4 d2 d3 d4 p8 d5 d6 d7 d8
0 1 0 1 1 0 0 13. 0 3. Bit uberpruft durch p1 und p2
1 5. Bit uberpruft durch p1 und p40 6. Bit uberpruft durch p2 und p41 7. Bit uberpruft durch p1 und p2 und p41 9. Bit uberpruft durch p1 und p80 10. Bit uberpruft durch p2 und p80 11. Bit uberpruft durch p1 und p2 und p81 12. Bit uberpruft durch p4 und p8
4. p1 uberpruft d1, d2, d4, d5 und d7 � p1 = 1p2 uberpruft d1, d3, d4, d6 und d7 � p2 = 1p4 uberpruft d2, d3, d4 und d8 � p4 = 1p8 uberpruft d5, d6, d7 und d8 � p8 = 0
Das Codewort mit Prufbits lautet:
�
1 1 0 1 1 0 1 0 1 0 0 1
�
RA I Rechnerarchitektur I 28/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Hamming-Code (3)
Beispiel:Es liegt ein Nutz-Codewort
�
1 1 0 1 1 0 1 0 1 1 0 1
�
vor.
5. Uberprufung des Codeworts durch Bildung der Prufbits.
uberpruft vorliegendp1 p1 = 1 p1 = 1p2 p2 = 0 p2 = 1p4 p4 = 1 p4 = 1p8 p8 = 1 p8 = 0
� Das 2. und das 8. Prufbit unterscheiden sich vom vorliegenden Bit.
� Daraus folgt das 10. Bit ist fehlerhaft und wird invertiert.
� Das korrigierte Nutzcodewort lautet�
1 1 0 1 1 0 1 0 1 0 0 1
�
.
RA I Rechnerarchitektur I 29/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Erweiterter Hamming-Code
� Modifizierung des Hamming-Codes durch Erhohung der Hamming-Distanz
� Hinzufugen eines weiteren Kontrollelements pk
� p0 (Prufbits) zu jedemCodewort
� in Codewortern mit geradem Gewicht ist pk = 0
� in Codewortern mit ungeradem Gewicht ist pk = 1
Beispiel:
p1 p2 d1 p4 d2 d3 d4 p8 d5 d6 d7 d81 1 0 1 1 0 1 0 1 0 0 1
p0 p1 p2 d1 p4 d2 d3 d4 p8 d5 d6 d7 d80 1 1 0 1 1 0 1 0 1 0 0 1
pk = p0, das Gewicht des Codewortes ist gerade, deshalb ist p0 = 0.
RA I Rechnerarchitektur I 30/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
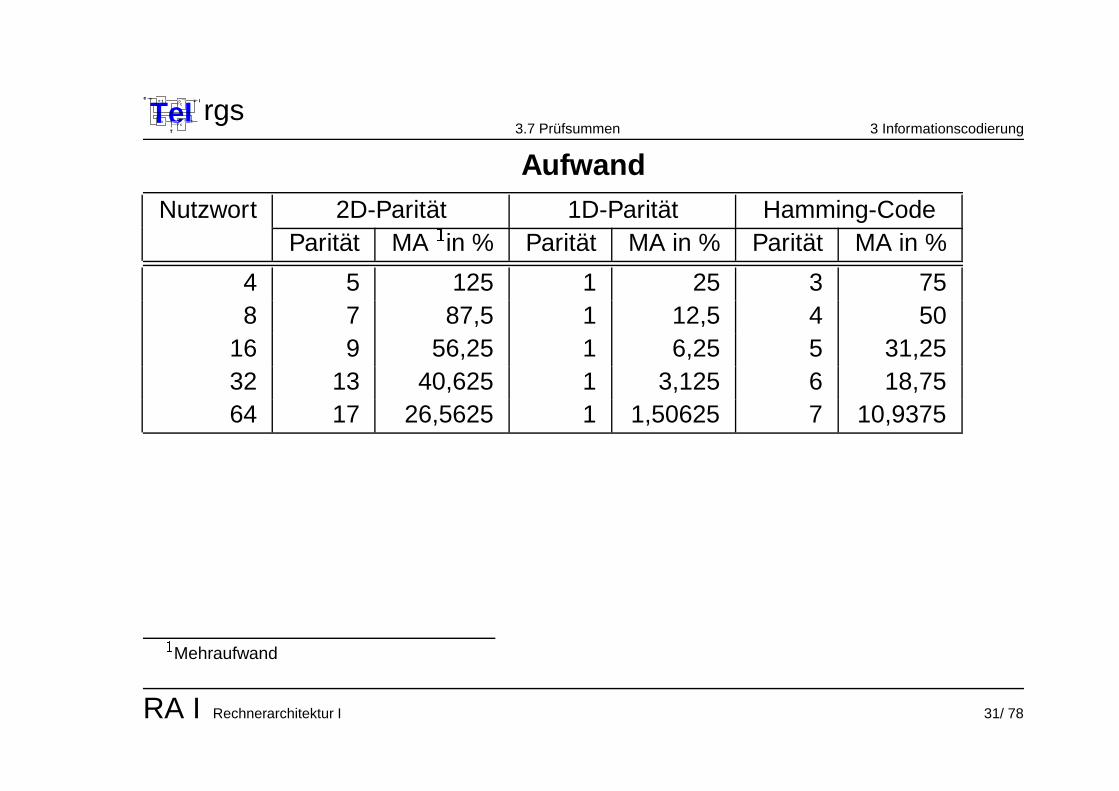
AufwandNutzwort 2D-Paritat 1D-Paritat Hamming-Code
Paritat MA
�
in % Paritat MA in % Paritat MA in %
4 5 125 1 25 3 758 7 87,5 1 12,5 4 50
16 9 56,25 1 6,25 5 31,2532 13 40,625 1 3,125 6 18,7564 17 26,5625 1 1,50625 7 10,9375
�
Mehraufwand
RA I Rechnerarchitektur I 31/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.7.5 Beispiele zu Binaren Codes
1. Binar-Code2. Gray-Code3. BCH-Code (Bose, Chaudhuri, Hoquenghem)4. M-aus-N-Code5. Huffmann-Codierung
RA I Rechnerarchitektur I 32/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
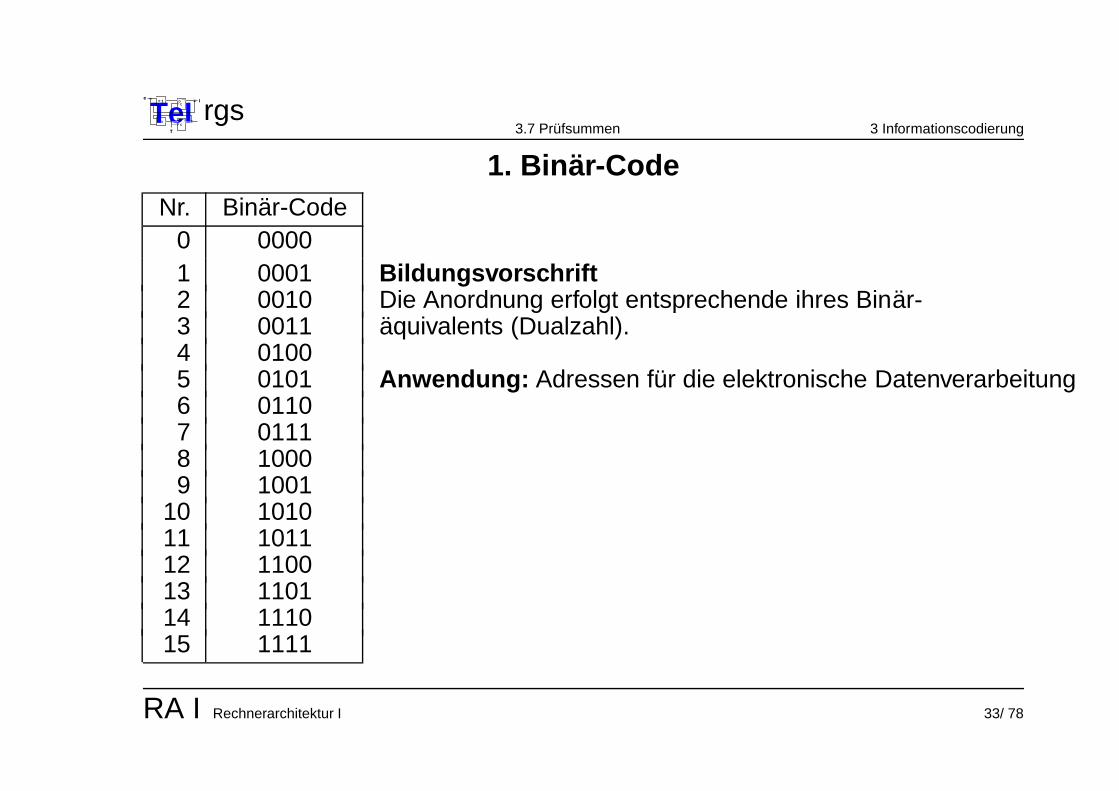
1. Binar-CodeNr. Binar-Code
0 00001 0001 Bildungsvorschrift2 0010 Die Anordnung erfolgt entsprechende ihres Binar-3 0011 aquivalents (Dualzahl).4 01005 0101 Anwendung: Adressen fur die elektronische Datenverarbeitung6 01107 01118 10009 1001
10 101011 101112 110013 110114 111015 1111
RA I Rechnerarchitektur I 33/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2. Gray-CodeNr. Gray-Code
0 0000 Benachbarte Codeworter unterscheiden sich jeweils nur in1 0001 einem Bit.2 00113 0010 Bildungsvorschrift4 0110 0 und 1 bilden den Anfang. Im folgenden wird ein 1-Bit5 0111 vor die existierenden Codeworter gesetzt und ihre Reihen-6 0101 folge gespiegelt um weitere Codeworter zu bilden. Dies7 0100 wird solange wiederholt bis die Codeworter die8 1100 gewunschte Lange erreichen. Die fehlenden Bitstellen9 1101 werden mit Nullen aufgefullt.
10 111111 1110 Anwendung:12 1010 Messtechnik, Zahler13 1011 - Erhohung der Storsicherheit14 1001 - Reduzierung der Verlustleistung15 1000
RA I Rechnerarchitektur I 34/ 78
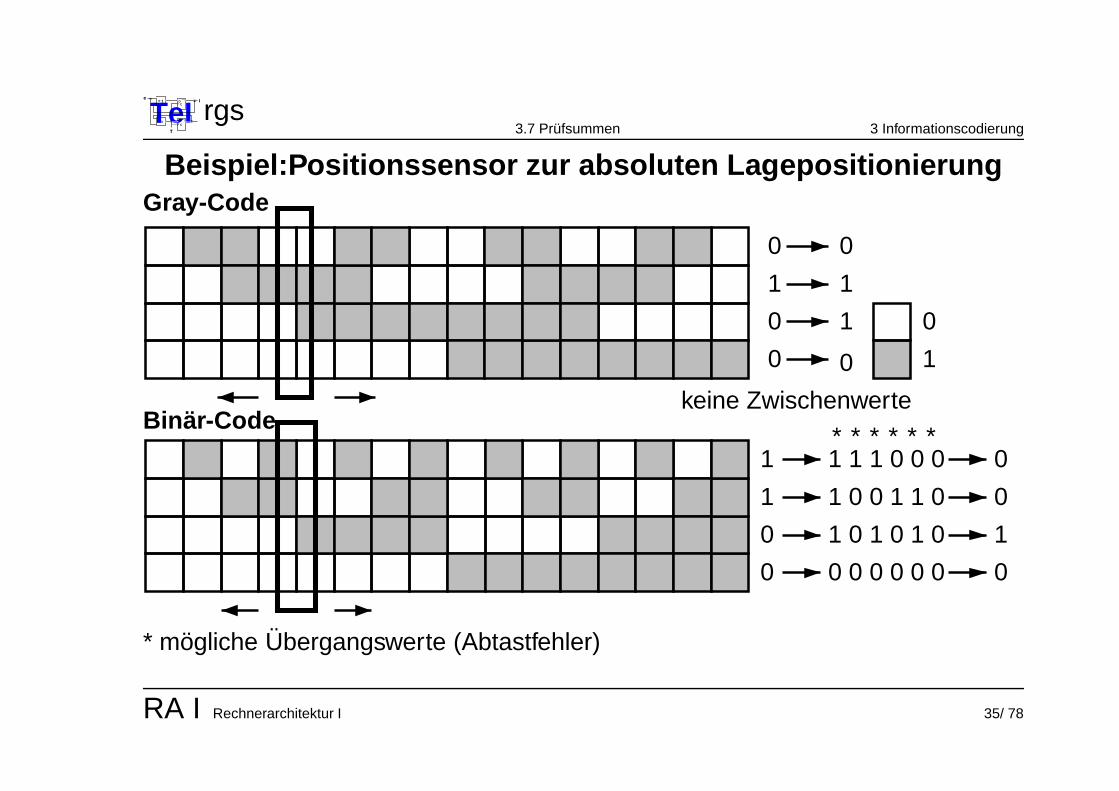
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel:Positionssensor zur absoluten LagepositionierungGray-Code
keine Zwischenwerte
0
0 1
0
1
00
0
1
1
Binar-Code
0
0
0
1
1
1
0
0
******1 1 1 0 0 0
1 0 0 1 1 0
1 0 1 0 1 0
0 0 0 0 0 0
* mogliche Ubergangswerte (Abtastfehler)
RA I Rechnerarchitektur I 35/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
4. M-aus-N-Code
Bei einem M-aus-N-Code haben alle
�
nm
�
Codeworter das gleiche Gewicht (sieheHamming-Gewicht, gleiche Anzahl 1-Stellen).Dabei gibt n die Lange der Codeworter und m die Anzahl der vorhandenen1-Stellen an.Die Anzahl der Codworter eine M-aus-N-Codes berechnet sich:
nm
� n!m!
�
n � m�
!Beispiel:2 aus 4 CodeDer 2 aus 4 Code besteht aus den Codewortern 1100, 1010, 1001, 0101, 0011,0110. Die Minimale Hamming-Distanz dieses Codes ist 2.
42
� 4!2!
�
2 � 4
�
!
� 2 � 3 � 6
RA I Rechnerarchitektur I 36/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
1-aus-N-Code
One-Hot CodeDer 1-aus-N-Code besteht aus N Codewortern wobei die Hammingdistanzzwischen den Codewortern hd = 2 betragt.1-aus-10-CodeDer 1-aus-10-Code besteht aus 10 Codewortern. Sie lauten:
1000000000, 0100000000, 0010000000, 0001000000, 0000100000,0000010000, 0000001000, 0000000100, 0000000010, 0000000001.
RA I Rechnerarchitektur I 37/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
5. Huffmann-Codierung (1)
Baumcodierung:Bei der Baumcodierung wird jedes Zeichen durch eine Bitfolge codiert. AllesCodierungen werden in einem binaren Baum dargestellt, die Blatter entsprechenjeweils einem Zeichen. Der Weg von Wurzel zum Blatt des Baumes ergibt denCode.Baumcodierungsbedingung: Die k Zeichen z1, z2 bis zk konnen genau danndurch eine Baumcodierung mit den Codelangen l1, l2 bis lk dargestellt werden,wenn
k
∑i �1
2� li �
1
gilt.Die Huffmann-Codierung ist das beste ganzzahlige Baumcodierungsverfahren.
RA I Rechnerarchitektur I 38/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Optimale Baumcodierung
Die k Zeichen z1, z2 bis zk mogen mit einer relativen Haufigkeit p1, p2 bis pk
auftreten (mit pi
�
0 � p1
�
p2
�� � � �
pk = 1). Die Codelangen sind dabei l1, l2 bislk. Dann ist die mittlere Codelange definiert als:
k∑
i � 1pili
Ein optimaler Code minimiert die mittlere Codelange unter Beachtung derBaumcodierungsbedingung:
k
∑i � 1
2 � li
�
1 mit mink
∑i � 1
pili
Dies tritt ein, wenn li
� � log2
�pi
�
ist.
RA I Rechnerarchitektur I 39/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Huffmann-Codierung (2)
Konstruktion:
1. Sortiere die Zeichen nach ihrer Haufigkeit.2. Fasse die beiden seltensten Zeichen zu einem Knoten zusammen, der
Knoten erhalt eine Haufigkeitsangabe, welche die Summe aus den beidenUrsprungszeichen ist.
3. Fasse nun fortfolgend die zwei Zeichen / Knoten mit der geringsten Haufigkeit(bei gleichen Wahrscheinlichkeiten : zufallige Auswahl) zu einem Knotenzusammen. Wiederhole den dritten Schritt, bis alle Zeichen und Knotenzusammengefasst sind und der entstandene Baum nur noch einenWurzelknoten hat.
4. Gib jeder nach links weisenden Verknupfung des Baumes den Wert 0 undjeder nach rechts weisenden Verknupfung den Wert 1.
5. Die Wegbeschreibung vom Wurzelknoten zum jeweiligen Buchstaben codiertden Buchstaben.
RA I Rechnerarchitektur I 40/ 78
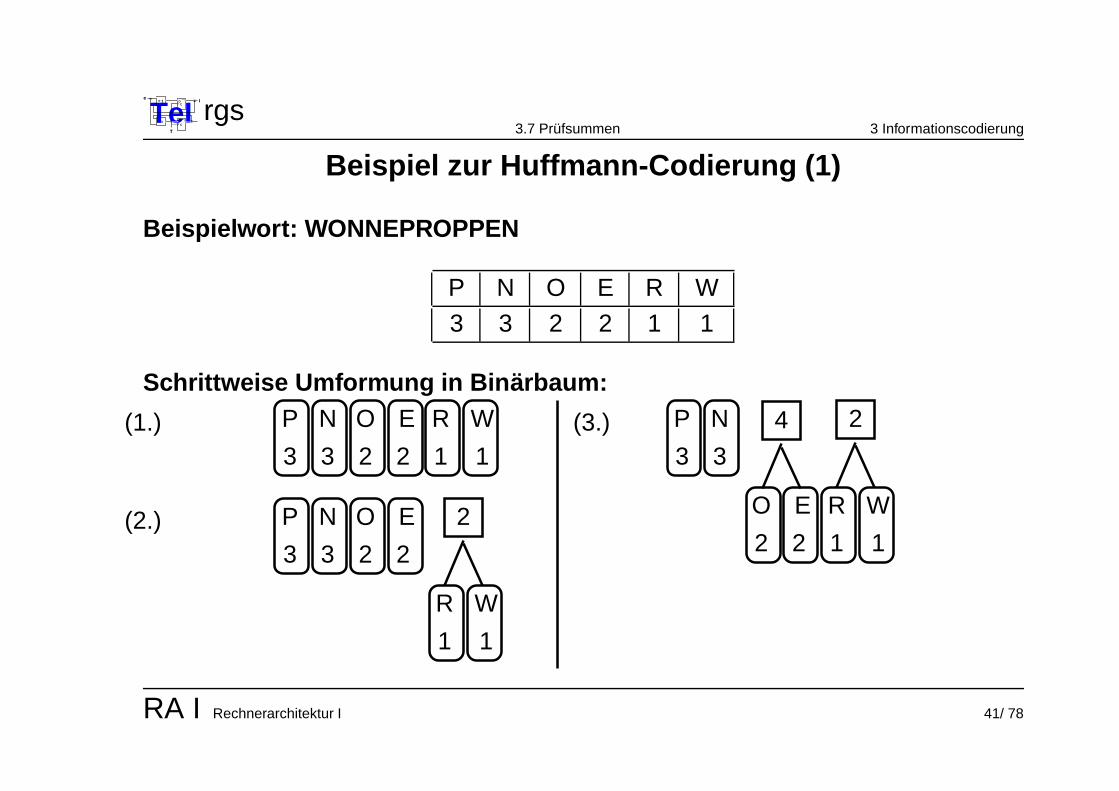
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel zur Huffmann-Codierung (1)
Beispielwort: WONNEPROPPEN
P N O E R W
3 3 2 2 1 1
Schrittweise Umformung in Binarbaum:
2 2
O E
1
R
1
W 2
2 2
O E 2
1
R
1
W
2 2
O E
1
R
1
W
4N
3 3(3.)
(2.)
NP
3 3
NP
3 3
P(1.)
RA I Rechnerarchitektur I 41/ 78
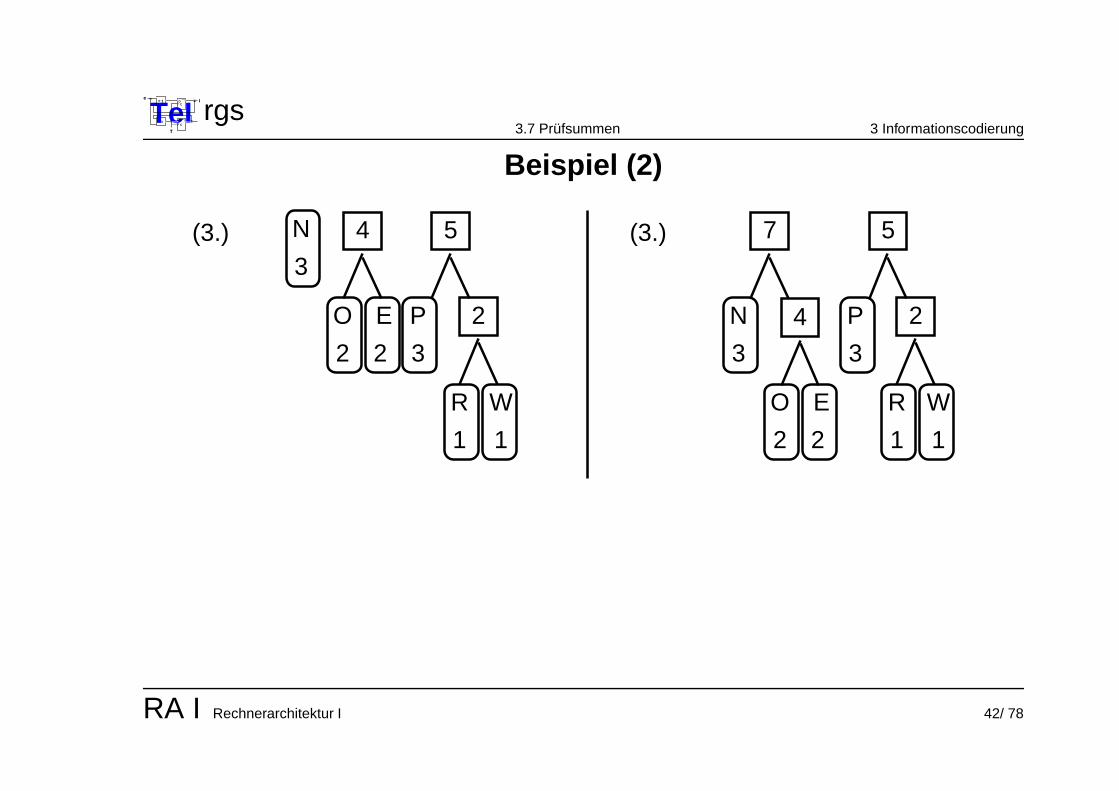
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel (2)
2
1
R
1
W
P
3
4N
3
5
2
1
R
1
W
P
3
5
4N
3
2 2
O E
7(3.)
2 2
O E
(3.)
RA I Rechnerarchitektur I 42/ 78
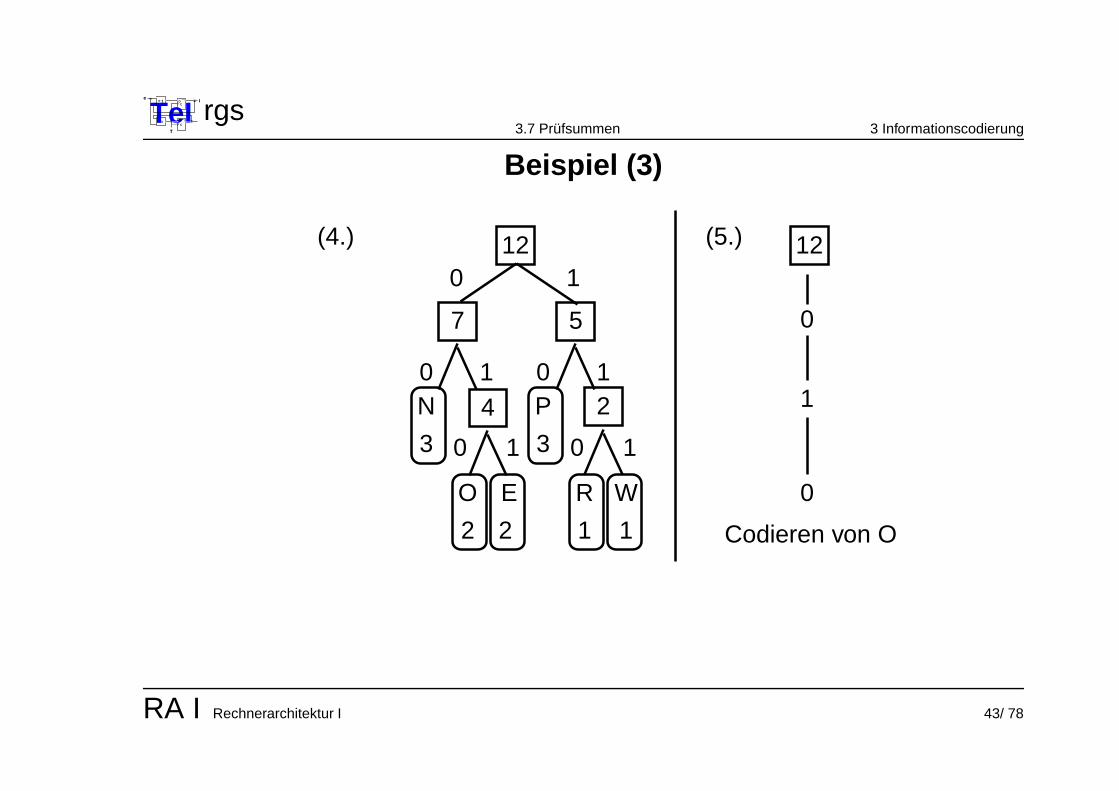
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel (3)
2
1
R
1
W
P
3
57
12 12
4
(4.) (5.)
2 2
O E
N
3
0
0
0 0
01
1
1
11
Codieren von O
0
1
0
RA I Rechnerarchitektur I 43/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Vergleich der Codelange
Die Zeichenkette ’Wonneproppen’ umfasst 12 Zeichen und wird nun wie folgtcodiert:111 010 00 00 011 10 110 010 10 10 011 00Die mittlere Codelange berechnet sich aus:
1 2 3 4 5 6
p 1/4 1/4 1/6 1/6 1/12 1/12l 2 2 3 3 3 3
k∑
i � 1pili � 30
12
� 2 � 5
Fur das Ergebnis ist ein 30 Bit-Strom erforderlich.Fur den gleichen Text in ASCII-Codierung benotigt man 12 x 8 = 96 Bit.
RA I Rechnerarchitektur I 44/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8 Uberblick uber Datenkompression
� Technisches Verfahren zur systematischen Verminderung der Menge anDaten, die notwendig ist, um einen gegebenen Inhalt in einercomputerlesbaren Form wiederzugeben.
� Orginaldaten werden mit Hilfe eines Kompressionsverfahrens untersucht undin eine komprimierte Form gepackt.
� Mit Hilfe eines zu dem gewahlten Verfahren passenden Leseverfahrens wirddie verkurzte Fassung des Textes oder der Daten wieder in die ursprunglicheentpackt.
� Es wird unterschieden zwischen verlustfreier und verlustbehafteterDatenkompression.
RA I Rechnerarchitektur I 45/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
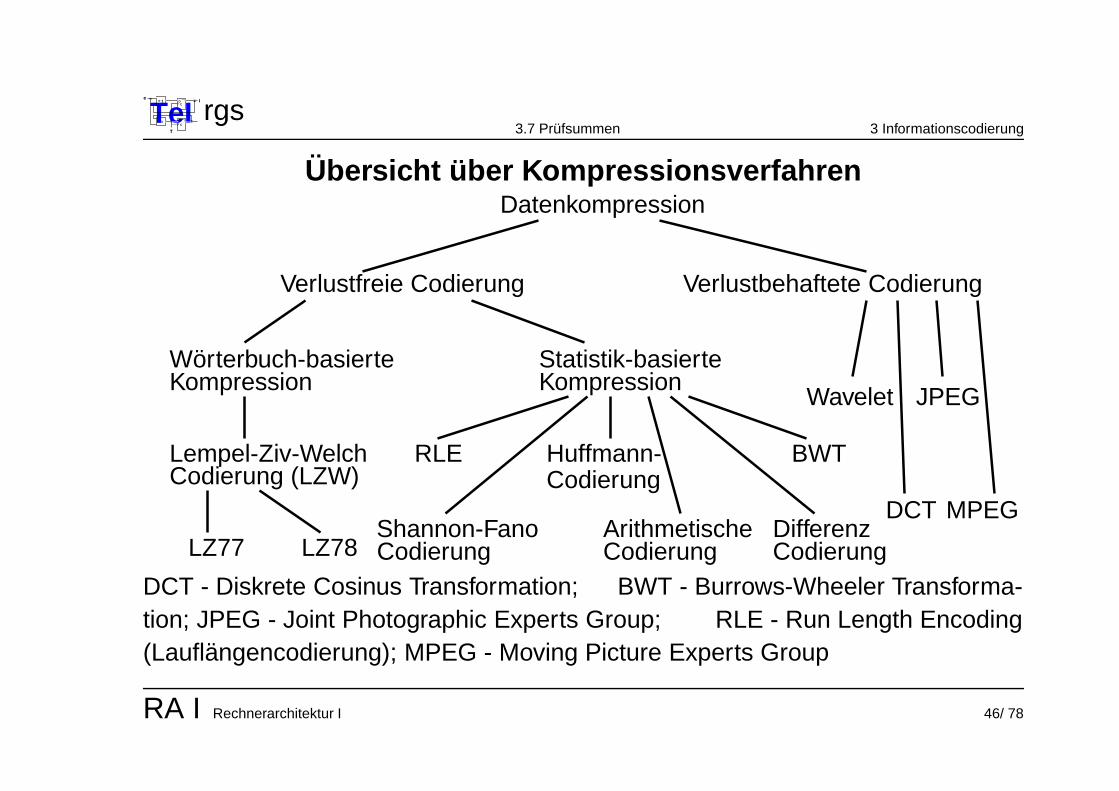
Ubersicht uber KompressionsverfahrenDatenkompression
JPEGWavelet
Verlustbehaftete CodierungVerlustfreie Codierung
Worterbuch-basierteKompression
Statistik-basierteKompression
Lempel-Ziv-WelchCodierung (LZW)
DCT MPEG
LZ77 LZ78
RLE
Codierung
BWT
DifferenzCodierungArithmetischeShannon-Fano
Codierung
Huffmann-Codierung
DCT - Diskrete Cosinus Transformation; BWT - Burrows-Wheeler Transforma-tion; JPEG - Joint Photographic Experts Group; RLE - Run Length Encoding(Lauflangencodierung); MPEG - Moving Picture Experts Group
RA I Rechnerarchitektur I 46/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Kompressionsverfahren
� verlustfrei (lossless) - keine Verringerung des Informationsgehalts– Dekompression liefert wieder Ursprungsdaten (reversibel).– Prinzipiell fur alle Arten von Daten geeignet.– Eigenschaften der Datenquelle werden ignoriert (Entropiecodierung).– Geringe Kompressionsfaktoren– Datenwiederholungen werden eleminiert.
� verlustbehaftet (lossy) - Verringerung des Informationsgehalts– Dekompression liefert nicht wieder Ursprungsdaten.– Hauptschlich Kompression von Audio-, Video- u. Grafikdaten– Eigenheiten der Datenquelle berucksichtigt (Quellencodierung)
RA I Rechnerarchitektur I 47/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.1 Huffmann-Codierung
Eigenschaften:
� 1951 von David A. Huffmann veroffentlicht.
� Erzeugt einen optimalen Prafixcode variabler Lange.
� Haufige Zeichen mit kurzen Bitfolgen codieren.
� Seltene Zeichen mit langeren (eventuell sehr langen) Bitfolgen.
� Erfordert a-priori Kenntnisse der Haufigkeiten der Zeichen.
� Sehr langsames Verfahren
� Der Baum muss standig an geanderte Haufigkeiten neu angepasst werden.
RA I Rechnerarchitektur I 48/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.2 Lauflangen-Codierung (RLE - Run Length Encoding)
Eigenschaften:
� Relativ einfaches Verfahren, richtig eingesetzt hoch effektiv.
� Lohnt nur ab Lauflange 3 (bei mehr als 3 Zeichen).
� Diverse Varianten zur Codierung des Zahlers.
� Sehr einfach, sehr schnell und nur fur bestimmte Daten geeignet.
� Z.B fur die Kompression Schwarz-Weiss-Bilder.
� Zur Codierung beliebiger Folgen von Zeichen aus einem festem Alphabetwerden nur Zeichen dieses Alphabets verwendet auch fur Anzahl und Marke
� Das i-te Zeichen das Alphabets wird benutzt um die Zahl i darzustellen
� Marke ist ein Zeichen, das selten in der Datei vorkommt, wird vor jedeSequenz aus Zahler und sich wiederholendem Zeichen gestellt
� fur die Marke selbst wird eine spezielle Sequenz implementiert
RA I Rechnerarchitektur I 49/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Codieren mit Run Length EncodingAlgorithmus:
1. Codiere die Zahl i durch das i-te Zeichen des Alphabets (fur die Anzahl derZeichen).
2. Lege die Marke fest (seltenes Zeichen)3. Ersetze drei und mehr sich wiederholende Zeichen durch
Marke+Anzahl+Zeichen
Beispiel: AAAABBBBCCEEEEEEEEE(1.) A - 1, B - 2, C - 3, ..., Z - 26(2.) Marke : Q
(3.)
Marke ZeichenAnzahl
Q D A Q B C QE C I E
Der Beispieltext ist 19 Zeichen lang. Nach der Codierung mit RLE ist der Textnur noch 11 Zeichen lang.
RA I Rechnerarchitektur I 50/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.3 Lev-Ziv-Welch-Codierung (LZW-Coding)
Eigenschaften:
� Gibt unzahlige Varianten des Verfahrens
� Das Verfahren ist universell anwendbar: fur Texte, Programme, Bilder, etc.
� Sehr gute Kompressionsraten (fur verlustfreie Algorithmen)
� Das wird Dictionary mit Einzelzeichen (z.B. 256 Bytes) initialisieren
� Unbekannte Strings werden in das Dictionary aufgenommen.
� Dabei Strings maximaler Lange versuchen
� Die nachsten Zeichen im Eingabestrom werden codiert, indem auf denbereits codierten Teil einer Datei oder Nachricht Bezug genommen wird
� Entdeckte Ubereinstimmungen werden ausnutzt
� Einsatz u.a. fur zip, gzip, gif und tiff
� Viele Kompressionsverfahren verwenden Lev-Ziv-Welch Codierung +Huffmann - Codierung (ace, arj, rar, pkzip) um die langen Positionsangabenzu komprimieren
RA I Rechnerarchitektur I 51/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.4 LZ77-Verfahren
Eigenschaften:
� Sliding Window Methode, 1977 von Lempel und Ziv veroffentlicht
� Eingabestrom wird nach links durch ein zweiteiliges Fenster geschoben
� Der linke Teil (search buffer) enthalt die zuletzt codierten Symbole
� Der rechte Teil (look ahead buffer) enthalt die Zeichen, die als nachstescodiert werden
� Zur Codierung der Zeichenkette werden der Offset (Entfernung zurTrennlinie), die Lange der Zeichenubereinstimmung und das nachste Zeichendes look ahead buffers gespeichert.
� Da der Speicherplatzbedarf fur nach LZ77 komprimierten Daten sehr hoch ist,werden sie meist noch nach einem anderen Kompressionsverfahren codiert.
RA I Rechnerarchitektur I 52/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Codieren nach LZ77Algorithmus:
1. Zu Beginn stehen alle Zeichen im Look Ahead Buffer (links), der SearchBuffer ist leer.
2. Durchsuche den Searchbuffer von der rechten Trennlinie nach links nacheiner Ubereinstimmung mit dem ersten Zeichen im look ahead Buffer.Speichere die Entfernung der langsten Zeichenubereinstimmung zwischenlook ahead und search buffer zur Trennlinie als offset.
3. Speichere als zweiten Wert die Lange der Zeichenubereinstimmung.4. Speichere als dritten Wert das nachste Zeichen des look ahead buffers, um
den Fall abzudecken, dass keine Ubereinstimmung gefunden wurde5. Gib diese drei Werte mit Komma getrennt aus.6. Verschiebe das Fenster nach rechts (den Inhalt nach links) und zwar um die
Lange der Ubereinstimmung plus eine Stelle fur das unkomprimierte Zeichen7. Ist der Look Ahead Buffer nicht leer, kehre zu Schritt 2 zuruck.
RA I Rechnerarchitektur I 53/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
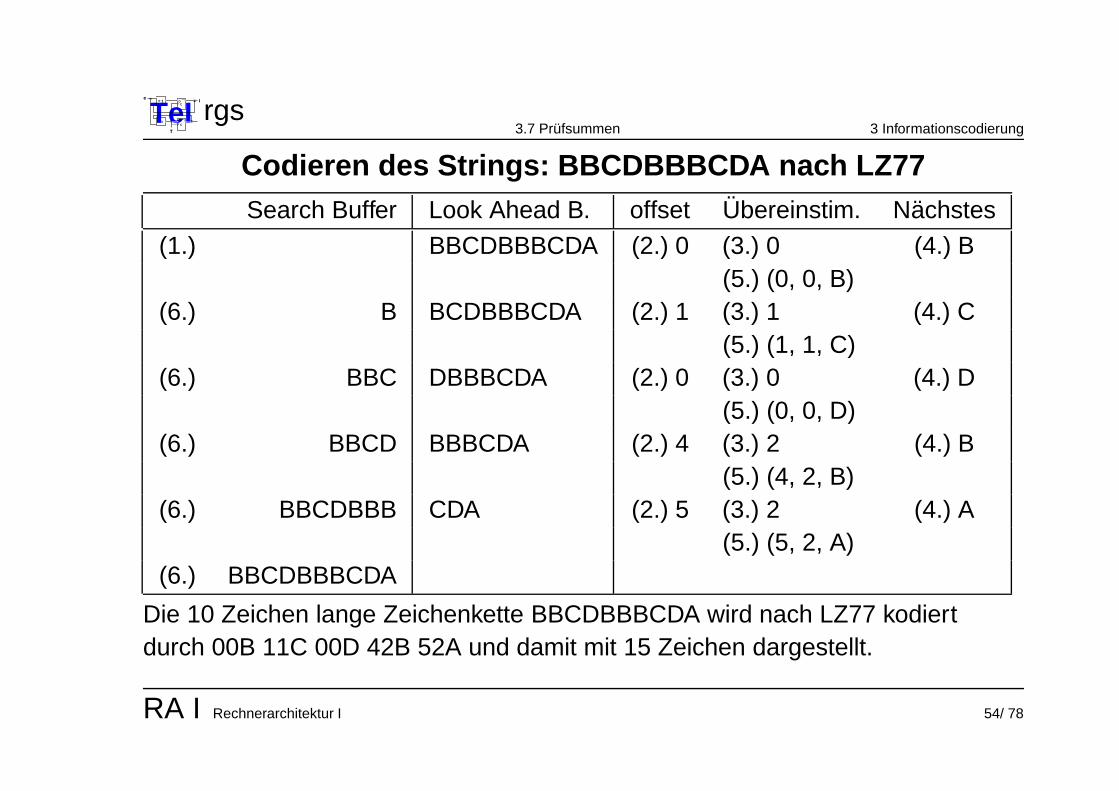
Codieren des Strings: BBCDBBBCDA nach LZ77Search Buffer Look Ahead B. offset Ubereinstim. Nachstes
(1.) BBCDBBBCDA (2.) 0 (3.) 0 (4.) B(5.) (0, 0, B)
(6.) B BCDBBBCDA (2.) 1 (3.) 1 (4.) C(5.) (1, 1, C)
(6.) BBC DBBBCDA (2.) 0 (3.) 0 (4.) D(5.) (0, 0, D)
(6.) BBCD BBBCDA (2.) 4 (3.) 2 (4.) B(5.) (4, 2, B)
(6.) BBCDBBB CDA (2.) 5 (3.) 2 (4.) A(5.) (5, 2, A)
(6.) BBCDBBBCDA
Die 10 Zeichen lange Zeichenkette BBCDBBBCDA wird nach LZ77 kodiertdurch 00B 11C 00D 42B 52A und damit mit 15 Zeichen dargestellt.
RA I Rechnerarchitektur I 54/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Decodieren nach LZ77
Algorithmus:
1. Man verwendet den Search-Buffer und die Ausgabe zum Decodieren.2. Das zu decodierende Tupel (Offset, Lange, Zeichen) kommt in die Eingabe.3. Kopiere aus dem Search-Buffer den String von der linken Trennlinie den
Offset mit der Entfernung Lange in die Ausgabe. Hange das unkomprimiertemit ubermittelte Symbol an.
4. Verschiebe den in die Ausgabe eingefugten String nach links in denSearch-Buffer.
5. Solange eine Eingabe existiert fahre mit Schritt 2 fort.
RA I Rechnerarchitektur I 55/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel zum Decodieren nach LZ77
Decodieren von (0,0,B); (1,1,C); (0,0,D); (4,2,B); (5,2,A)
Eingabe Search-Buffer Ausgabe
(2.) (0,0,B) (3.) B(2.) (1,1,C) (4.) B (3.) BC(2.) (0,0,D) (4.) BBC (3.) D(2.) (4,2,B) (4.) BBCD (3.) BBB(2.) (5,2,A) (4.) BBCDBBB (3.) CDA
(4.)BBCDBBBCDA
BBCDBBCDA wurde mit LZ77 aus 00B 11C 00D 42B 52A decodiert.
RA I Rechnerarchitektur I 56/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.5 LZ78-Verfahren
Eigenschaften:
� Das zweite von Lempel und Ziv entwickelte Kompressionsverfahren
� Worterbuch enthalt die bisher entdeckten Strings
� Worterbuch ist anfangs leer und nur durch den zur Verfugung stehendenSpeicherplatz beschrankt
� Ausgabe sind Tupeln, die sich aus einem Zeiger auf das Worterbuch undeinem Feld fur ein weiteres, unverschlusseltes Symbol zusammensetzen
RA I Rechnerarchitektur I 57/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Codieren nach LZ78
Algorithmus:
1. Worterbuch = leer, y = leer, x = leer;2. x:= nachstes Zeichen aus dem Eingabestrom3. Ist String y+x im Worterbuch? - Ja: - y = y + x
Nein: - (Zeiger auf y, x) ausgeben - Trage y + x ins Worterbuch ein - y = leer4. Ist das Ende des Eingabestroms erreicht? -Nein: Gehe zu Schritt 2
Ja: ist y leer? -Nein: den y entsprechenden Code ausgeben
RA I Rechnerarchitektur I 58/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel zum Codieren nach LZ78
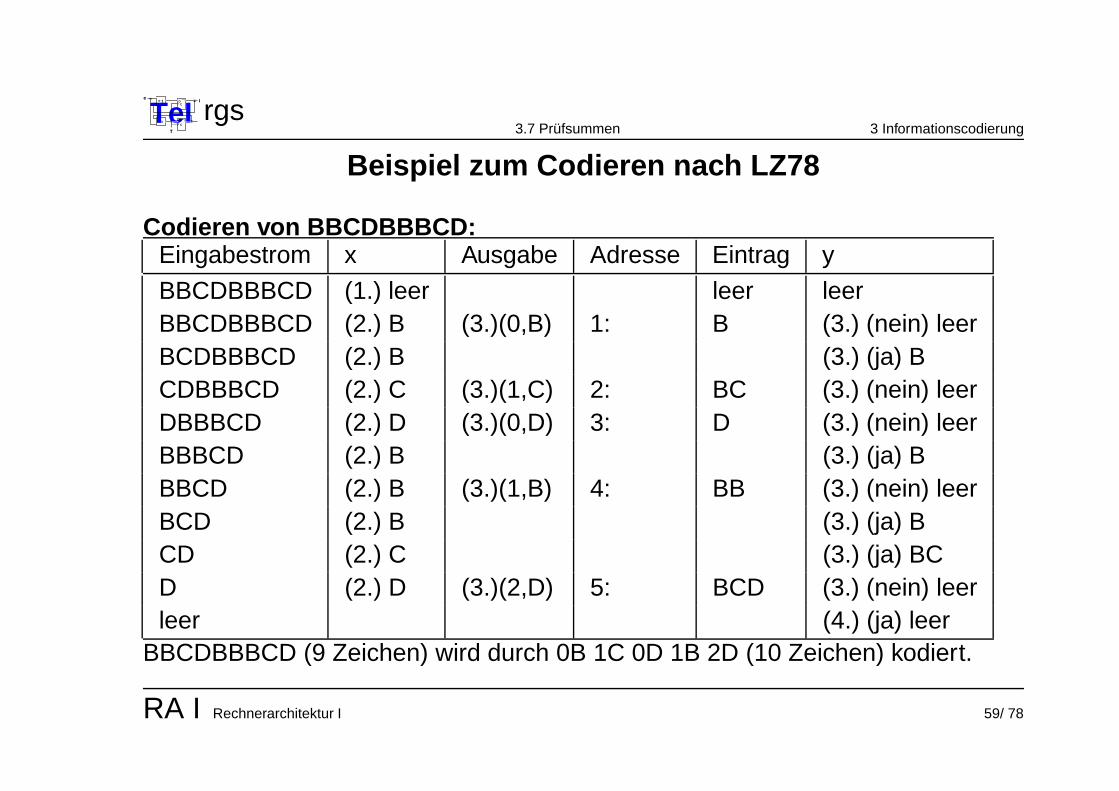
Codieren von BBCDBBBCD:Eingabestrom x Ausgabe Adresse Eintrag y
BBCDBBBCD (1.) leer leer leerBBCDBBBCD (2.) B (3.)(0,B) 1: B (3.) (nein) leerBCDBBBCD (2.) B (3.) (ja) BCDBBBCD (2.) C (3.)(1,C) 2: BC (3.) (nein) leerDBBBCD (2.) D (3.)(0,D) 3: D (3.) (nein) leerBBBCD (2.) B (3.) (ja) BBBCD (2.) B (3.)(1,B) 4: BB (3.) (nein) leerBCD (2.) B (3.) (ja) BCD (2.) C (3.) (ja) BCD (2.) D (3.)(2,D) 5: BCD (3.) (nein) leerleer (4.) (ja) leer
BBCDBBBCD (9 Zeichen) wird durch 0B 1C 0D 1B 2D (10 Zeichen) kodiert.
RA I Rechnerarchitektur I 59/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Decodieren mit LZ78
Algorithmus:
1. Das Worterbuch ist leer2. x:= Worterbuchverweis des nachsten Tupels3. z:= das unkomprimierte Zeichen des Tupels4. Gib die durch x im Worterbuch reprasentierte Zeichenfolge und anschließend
z aus5. Trage x+z ins Worterbuch ein6. Wenn das Ende des Eingabestroms noch nicht erreicht ist, zuruck zu Schritt 2
RA I Rechnerarchitektur I 60/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiel zum Decodieren mit LZ78
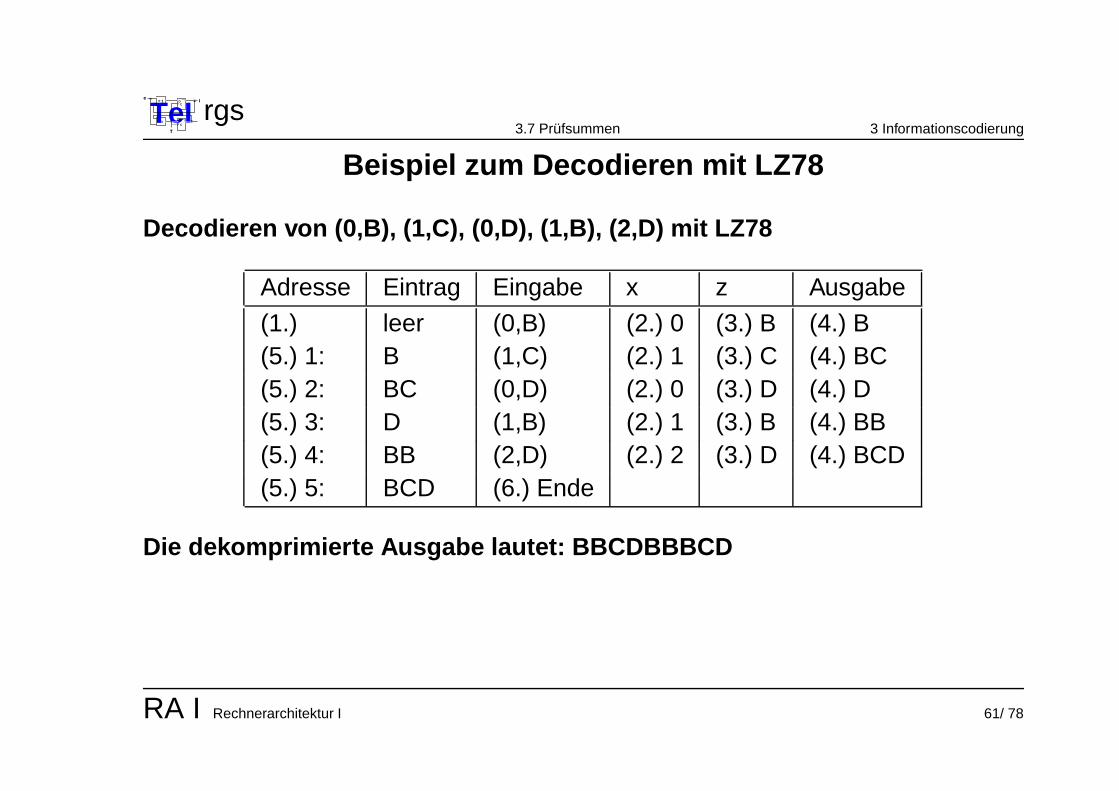
Decodieren von (0,B), (1,C), (0,D), (1,B), (2,D) mit LZ78
Adresse Eintrag Eingabe x z Ausgabe
(1.) leer (0,B) (2.) 0 (3.) B (4.) B(5.) 1: B (1,C) (2.) 1 (3.) C (4.) BC(5.) 2: BC (0,D) (2.) 0 (3.) D (4.) D(5.) 3: D (1,B) (2.) 1 (3.) B (4.) BB(5.) 4: BB (2,D) (2.) 2 (3.) D (4.) BCD(5.) 5: BCD (6.) Ende
Die dekomprimierte Ausgabe lautet: BBCDBBBCD
RA I Rechnerarchitektur I 61/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.6 Arithmetische-Codierung
Eigenschaften:
� Zuordnung der Zeichen zu arithm. Intervallen entsprechend ihrer Haufigkeit
� Fur Zeichenfolgen rekursiv angewendet
� Der Code ist eine reelle Zahl aus dem Intervall von Null bis Eins
� Die Null vor dem Komma wird beim Speichern weggelassen
Algorithmus zum Codieren mit Arithmetischer Codierung:
1. Sammle Wahrscheinlichkeitsverteilung2. UntereSchranke := 0 ; obereSchranke := 13. X := nachstes Symbol des Eingabestroms4. NeueObereSchranke = alteUntereSchranke + Range * HighRange(x)
NeueUntereSchranke = alteUntereSchranke + Range * LowRange(x)
RA I Rechnerarchitektur I 62/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
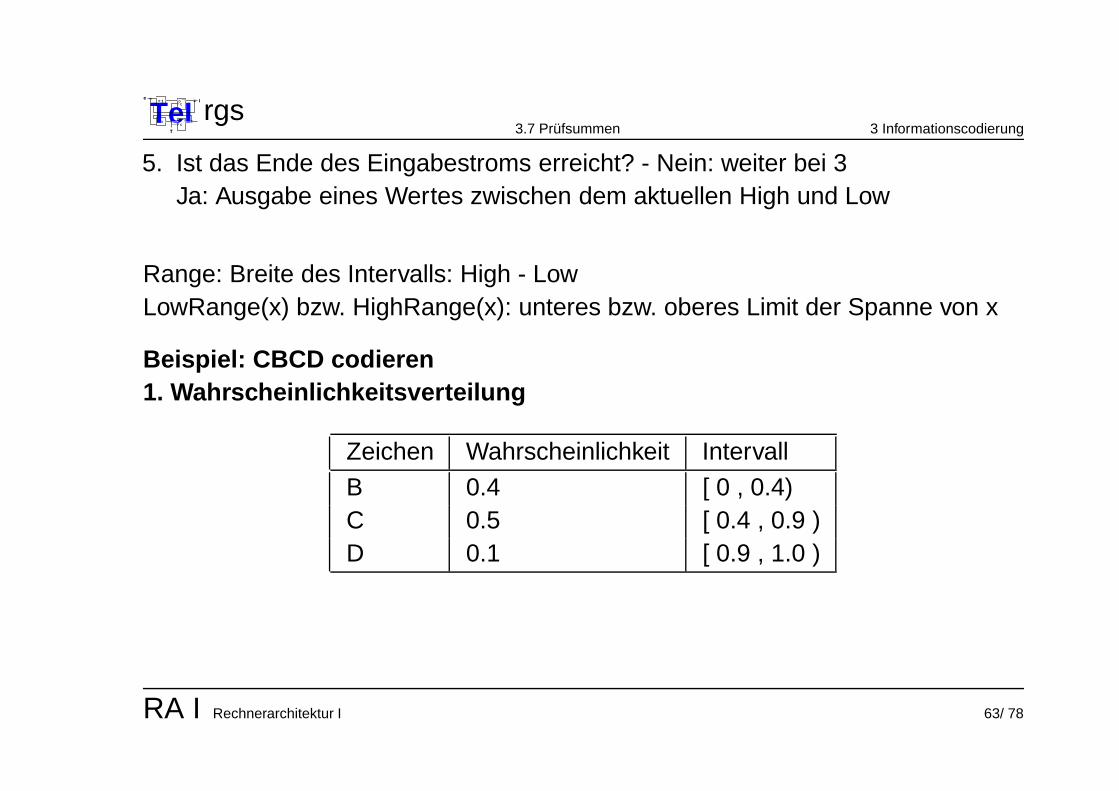
5. Ist das Ende des Eingabestroms erreicht? - Nein: weiter bei 3Ja: Ausgabe eines Wertes zwischen dem aktuellen High und Low
Range: Breite des Intervalls: High - LowLowRange(x) bzw. HighRange(x): unteres bzw. oberes Limit der Spanne von x
Beispiel: CBCD codieren1. Wahrscheinlichkeitsverteilung
Zeichen Wahrscheinlichkeit Intervall
B 0.4 [ 0 , 0.4)C 0.5 [ 0.4 , 0.9 )D 0.1 [ 0.9 , 1.0 )
RA I Rechnerarchitektur I 63/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
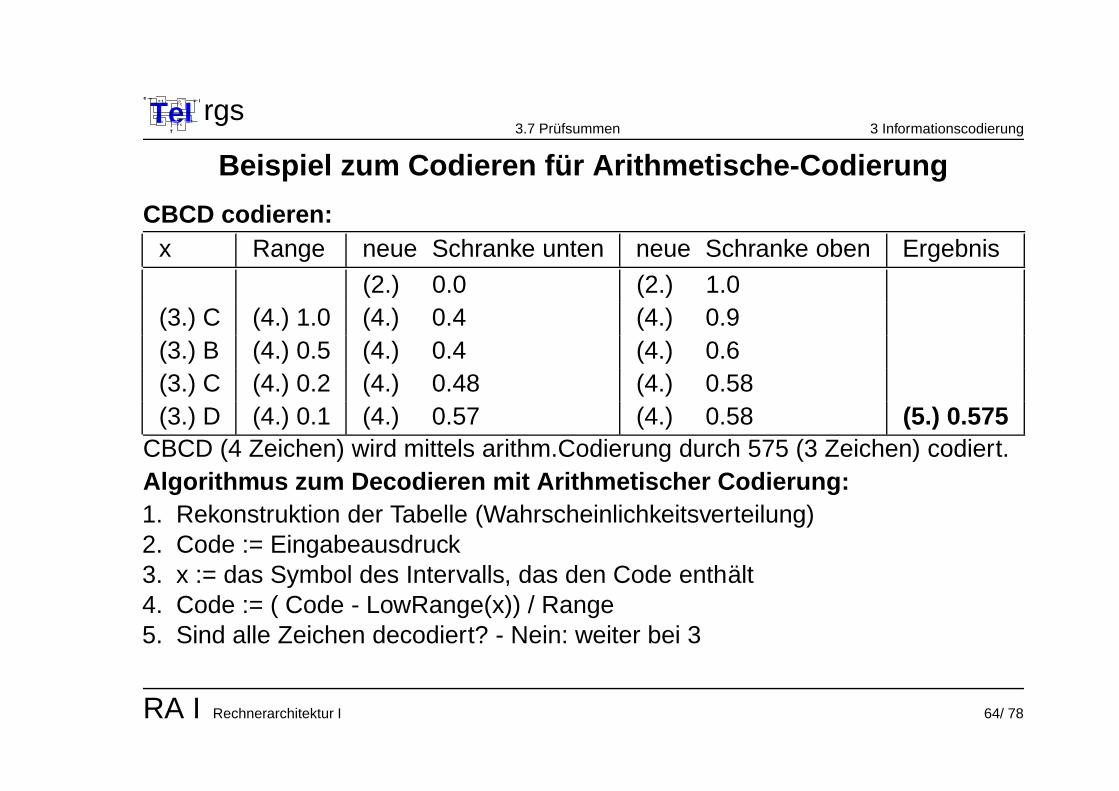
Beispiel zum Codieren fur Arithmetische-Codierung
CBCD codieren:x Range neue Schranke unten neue Schranke oben Ergebnis
(2.) 0.0 (2.) 1.0(3.) C (4.) 1.0 (4.) 0.4 (4.) 0.9(3.) B (4.) 0.5 (4.) 0.4 (4.) 0.6(3.) C (4.) 0.2 (4.) 0.48 (4.) 0.58(3.) D (4.) 0.1 (4.) 0.57 (4.) 0.58 (5.) 0.575
CBCD (4 Zeichen) wird mittels arithm.Codierung durch 575 (3 Zeichen) codiert.Algorithmus zum Decodieren mit Arithmetischer Codierung:1. Rekonstruktion der Tabelle (Wahrscheinlichkeitsverteilung)2. Code := Eingabeausdruck3. x := das Symbol des Intervalls, das den Code enthalt4. Code := ( Code - LowRange(x)) / Range5. Sind alle Zeichen decodiert? - Nein: weiter bei 3
RA I Rechnerarchitektur I 64/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
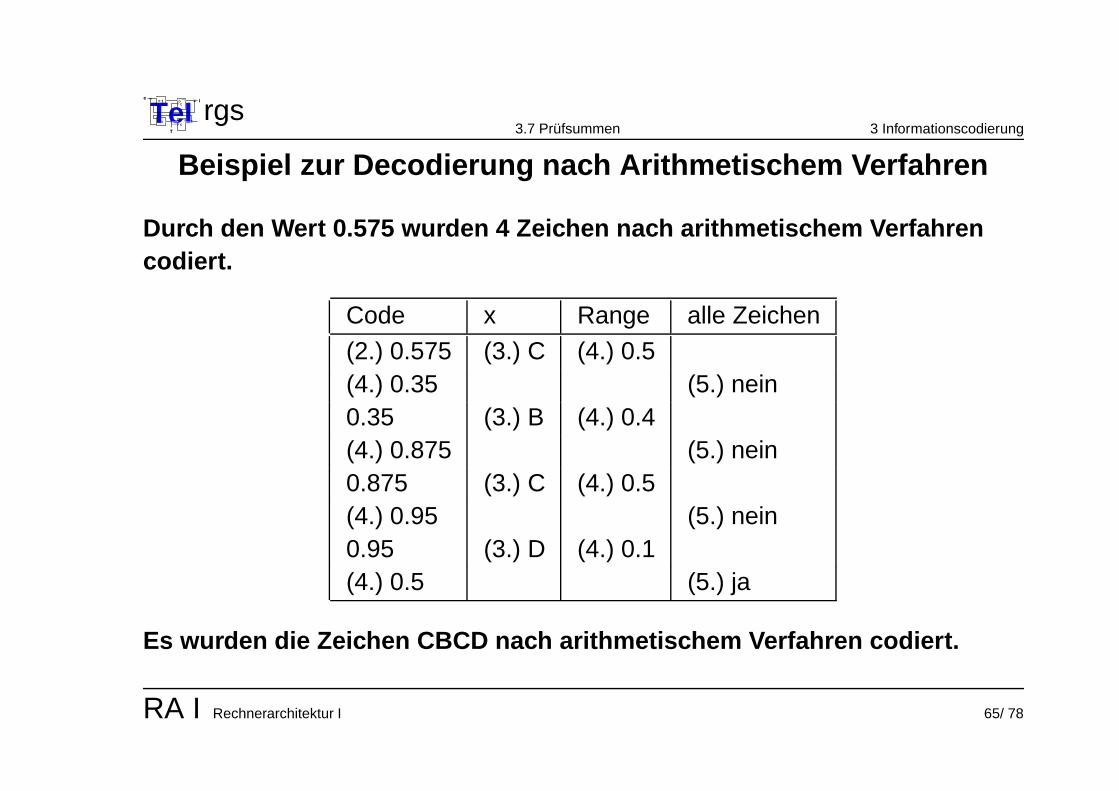
Beispiel zur Decodierung nach Arithmetischem Verfahren
Durch den Wert 0.575 wurden 4 Zeichen nach arithmetischem Verfahrencodiert.
Code x Range alle Zeichen
(2.) 0.575 (3.) C (4.) 0.5(4.) 0.35 (5.) nein0.35 (3.) B (4.) 0.4(4.) 0.875 (5.) nein0.875 (3.) C (4.) 0.5(4.) 0.95 (5.) nein0.95 (3.) D (4.) 0.1(4.) 0.5 (5.) ja
Es wurden die Zeichen CBCD nach arithmetischem Verfahren codiert.
RA I Rechnerarchitektur I 65/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.7 Shannon-Fano-Codierung
Eigenschaften:
� 1960 von Bell Labs /MIT entwickelt
� Das Verfahren ist der Huffmann-Codierung ahnlich
� Nur optimal, wenn in jedem Schritt gleichgroße Mengen verwendet werden
� Basiert auf statistischen Annahmen uber die zu komprimierenden Daten.
� Haufige Zeichen werden durch kurze, und seltene Zeichen durch langeBitfolgen codiert.
� Die Decodierung erfolgt indem aus der Haufigkeitstabelle die entsprechendenZeichen zu den Bitcodes ausgelesen werden.
RA I Rechnerarchitektur I 66/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Codieren mit Shannon-Fano-Codierung
Algorithmus:
1. Aus einem Datenstrom wird fur jedes Zeichen, in einer Tabelle die Anzahl(Haufigkeit) seines Auftretens gespeichert. Die Tabelle wird so sortiert, dassdie haufigsten Symbole am Anfang, und die seltensten Symbole am Endestehen.
2. Erstellung des Bitcodes fur jedes Zeichen: Teile die Tabelle so, dass dieSumme der Anzahl der Zeichen in beiden Teilen, gleich ist. Weise demoberen Teil als erste Bitcodestelle eine 1, und dem unteren eine 0 zu.
3. Wiederhole 2. rekursiv fur beide Teile, bis in jedem Teil nur jeweils ein Symbolliegt.
4. Zur Kompression speichere die Haufigkeitstabelle in der komprimierten Dateiund fasse die Zeichen entspreichend der ermittelten Bitcodes zusammen.
RA I Rechnerarchitektur I 67/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
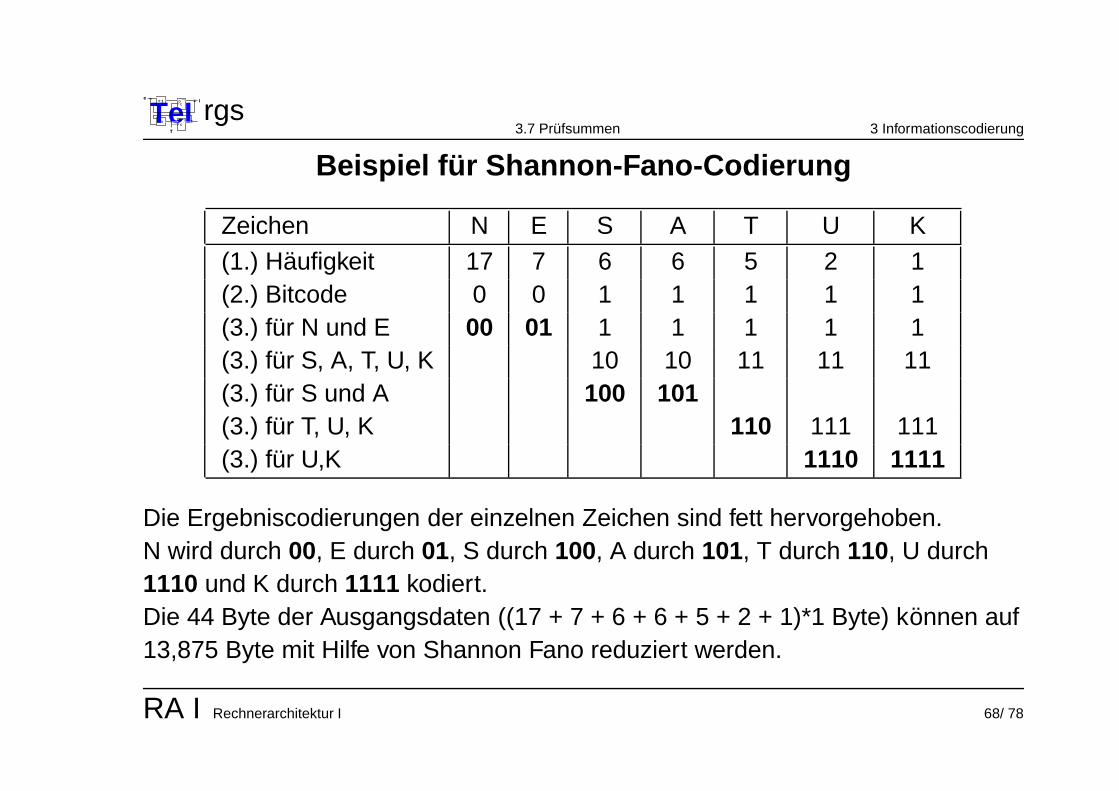
Beispiel fur Shannon-Fano-Codierung
Zeichen N E S A T U K
(1.) Haufigkeit 17 7 6 6 5 2 1(2.) Bitcode 0 0 1 1 1 1 1(3.) fur N und E 00 01 1 1 1 1 1(3.) fur S, A, T, U, K 10 10 11 11 11(3.) fur S und A 100 101(3.) fur T, U, K 110 111 111(3.) fur U,K 1110 1111
Die Ergebniscodierungen der einzelnen Zeichen sind fett hervorgehoben.N wird durch 00, E durch 01, S durch 100, A durch 101, T durch 110, U durch1110 und K durch 1111 kodiert.Die 44 Byte der Ausgangsdaten ((17 + 7 + 6 + 6 + 5 + 2 + 1)*1 Byte) konnen auf13,875 Byte mit Hilfe von Shannon Fano reduziert werden.
RA I Rechnerarchitektur I 68/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
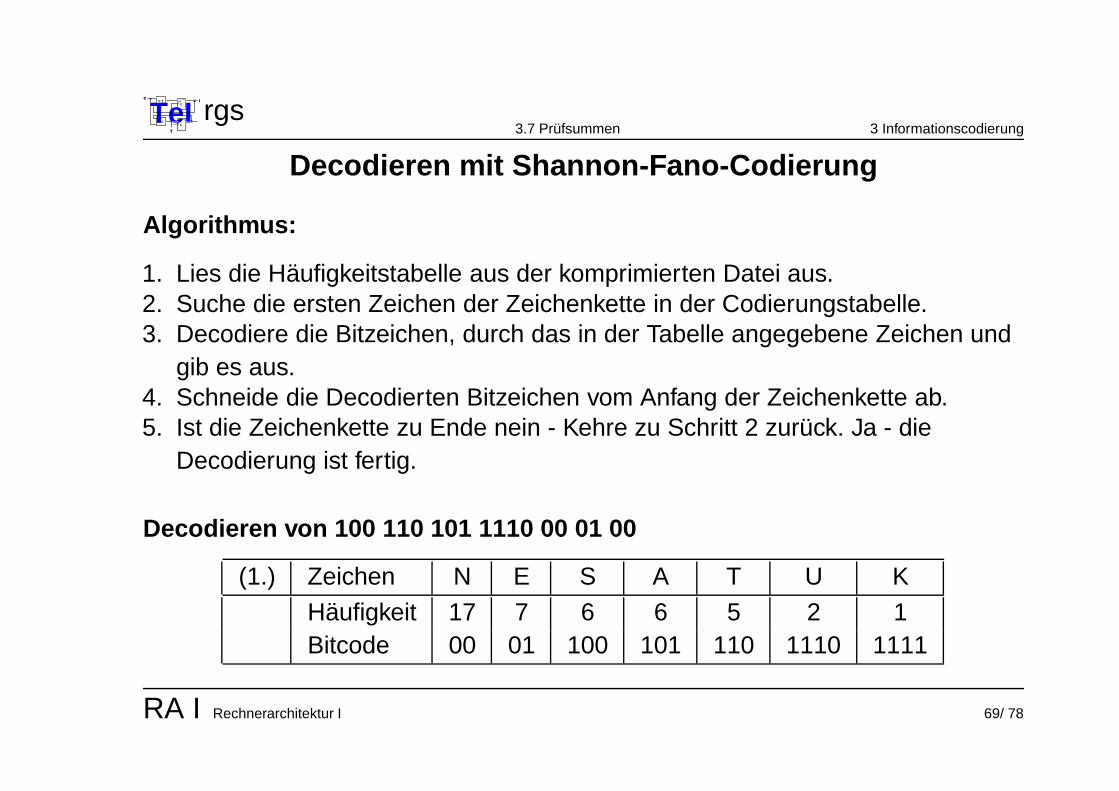
Decodieren mit Shannon-Fano-Codierung
Algorithmus:
1. Lies die Haufigkeitstabelle aus der komprimierten Datei aus.2. Suche die ersten Zeichen der Zeichenkette in der Codierungstabelle.3. Decodiere die Bitzeichen, durch das in der Tabelle angegebene Zeichen und
gib es aus.4. Schneide die Decodierten Bitzeichen vom Anfang der Zeichenkette ab.5. Ist die Zeichenkette zu Ende nein - Kehre zu Schritt 2 zuruck. Ja - die
Decodierung ist fertig.
Decodieren von 100 110 101 1110 00 01 00
(1.) Zeichen N E S A T U K
Haufigkeit 17 7 6 6 5 2 1Bitcode 00 01 100 101 110 1110 1111
RA I Rechnerarchitektur I 69/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
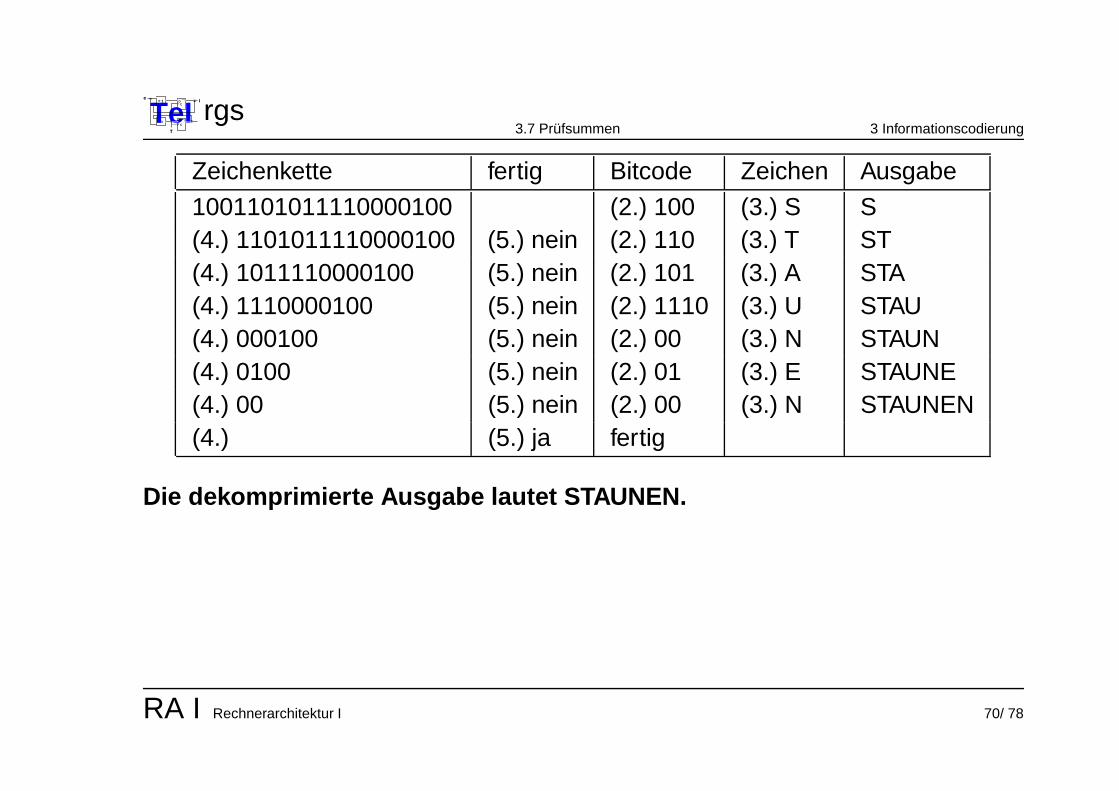
Zeichenkette fertig Bitcode Zeichen Ausgabe
1001101011110000100 (2.) 100 (3.) S S(4.) 1101011110000100 (5.) nein (2.) 110 (3.) T ST(4.) 1011110000100 (5.) nein (2.) 101 (3.) A STA(4.) 1110000100 (5.) nein (2.) 1110 (3.) U STAU(4.) 000100 (5.) nein (2.) 00 (3.) N STAUN(4.) 0100 (5.) nein (2.) 01 (3.) E STAUNE(4.) 00 (5.) nein (2.) 00 (3.) N STAUNEN(4.) (5.) ja fertig
Die dekomprimierte Ausgabe lautet STAUNEN.
RA I Rechnerarchitektur I 70/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
2.8.8 Burrows-Wheeler-Transformation (BWT)
Eigenschaften:
� 1994 von Michael Burrows und David Wheeler entwickeltes Verfahren
� Liefert eine der besten Komprimierungsergebnisse und wird fur dasProgramm BZIP2 verwendet.
� Die zu komprimierenden Daten werden umsortiert und in ein gut zukomprimierendes Format gebracht.
� Die sortierten Zieldaten sind (bis auf wenige Bytes) genauso gro wie dieursprungliche Menge.
� BWT betrachtet die Eingabe nicht als Eingabestrom sondern blockweise.
� Die Sortierung kann wieder ruckgangig gemacht werden und es fallen keinezusatzlichen Daten durch die Sortierung an.
RA I Rechnerarchitektur I 71/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
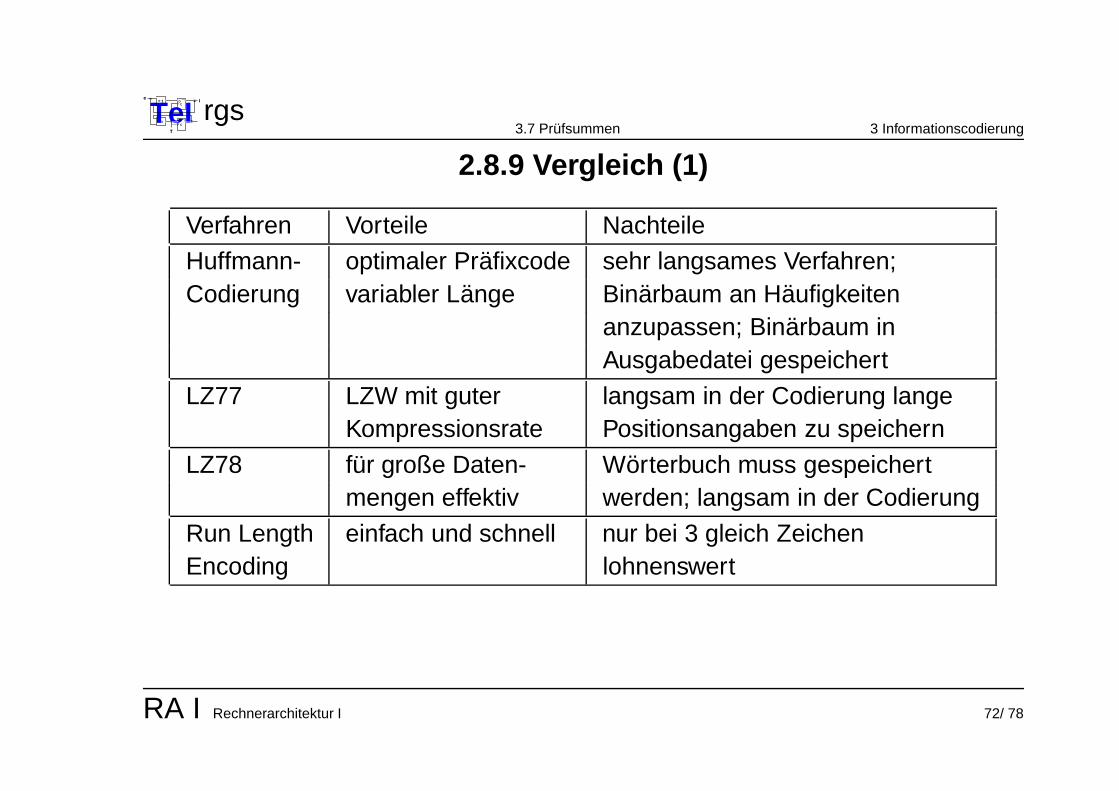
2.8.9 Vergleich (1)
Verfahren Vorteile Nachteile
Huffmann- optimaler Prafixcode sehr langsames Verfahren;Codierung variabler Lange Binarbaum an Haufigkeiten
anzupassen; Binarbaum inAusgabedatei gespeichert
LZ77 LZW mit guter langsam in der Codierung langeKompressionsrate Positionsangaben zu speichern
LZ78 fur große Daten- Worterbuch muss gespeichertmengen effektiv werden; langsam in der Codierung
Run Length einfach und schnell nur bei 3 gleich ZeichenEncoding lohnenswert
RA I Rechnerarchitektur I 72/ 78
TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
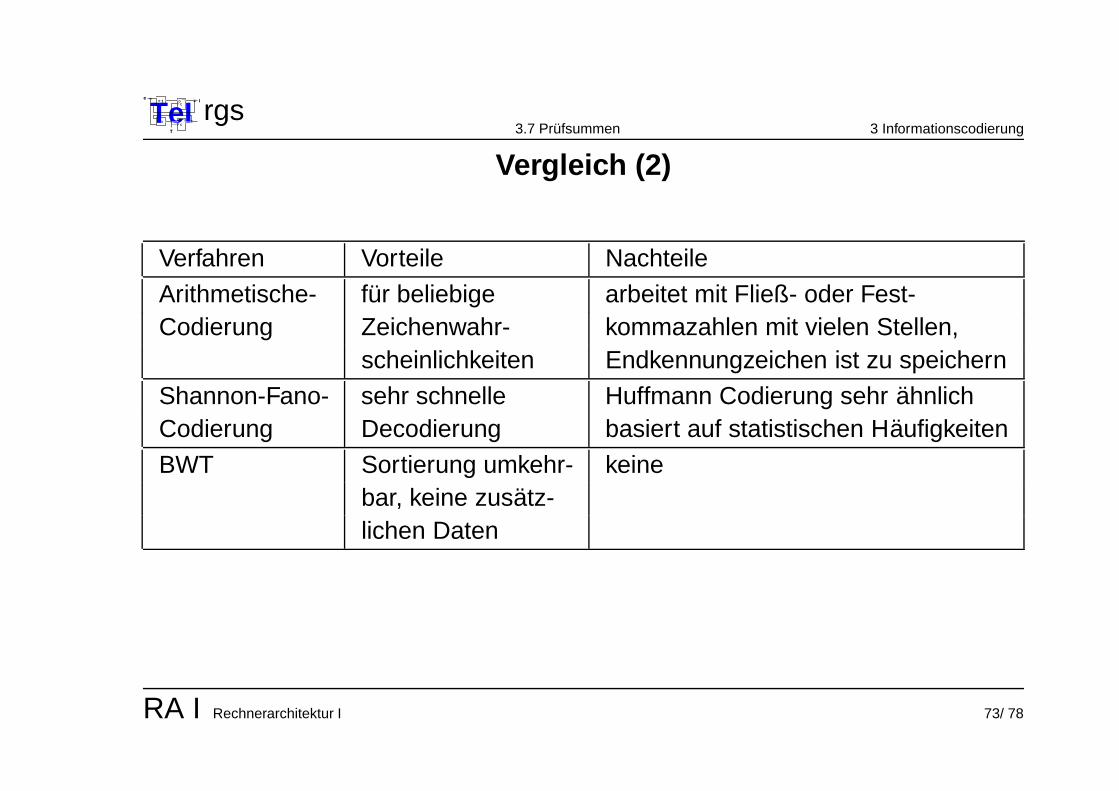
Vergleich (2)
Verfahren Vorteile Nachteile
Arithmetische- fur beliebige arbeitet mit Fließ- oder Fest-Codierung Zeichenwahr- kommazahlen mit vielen Stellen,
scheinlichkeiten Endkennungzeichen ist zu speichern
Shannon-Fano- sehr schnelle Huffmann Codierung sehr ahnlichCodierung Decodierung basiert auf statistischen Haufigkeiten
BWT Sortierung umkehr- keinebar, keine zusatz-lichen Daten
RA I Rechnerarchitektur I 73/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Vergleich (3)
Verfahren Anwendungen
Huffmann-Codierung Postprozessor fur ace, arj, rar, pkzip
LZ77 ace, arj, rar, pkzip
LZ78 zip, gzip, gif, tiff
RLE Schwarz-Weiss-Bilder
Arithmetische Cod. auf Grund etlicher Patente keine
Shannon-Fano Cod.
BWT BZIP2
RA I Rechnerarchitektur I 74/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Entropiecodierung
Entropiecodierung:Es handelt sich um eine verlustfreie Codierung, wobei die Daten als Bytecodeaufgefasst werden. Sie erfolgt unabhangig vom Medium und liefert einekompakte Darstellung, durch auf die Datenmenge zugeschnittenen Code. Zieldieser Codierung ist es, annahernd mit der Rate der Entropie zu ubertragen.Beispiele: Huffmann Codierung, Arithmetische Codierung, Lauflangencodierung
RA I Rechnerarchitektur I 75/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Quellencodierung
Quellencodierung:Diese Codierungsverfahren ist meist verlustbehaftet und bezieht die Semantikder Datenmenge in die Codierung mit ein. Fur den Menschen kaum erkennbareDetails werden nicht oder weniger aufwendig codiert.Die Quellencodierung dientzur Reduktion der zu ubertragenden Datenmenge durch Vermeidung vonRedundanz und Irrelevanz.Redundanzreduktion entspricht einer verlustlosen Quellencodierung, d.h. dieoriginale Datenmenge ist trotz einer Komprimierung des Datenstroms wiederunverfalscht herstellbar. Irrelevanzreduktion stellt eine verlustbehafteteQuellencodierung dar, wobei jedoch die Senke (der Nachrichtenverbraucher)nicht im Stande ist, die Veranderung des Nachrichtensignals wahrzunehmen.Beispiele: Huffman-Codierung, Lauflangencodierung, Lempel-Ziv-Kompression,diskrete Kosinustransformation (DCT ), Bildkompression mit JPEG,Wavelet-Bildkompression
RA I Rechnerarchitektur I 76/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Verlustbehaftete Codierung
Diese Verfahren sind auf bestimmte Datenquellen (Bilder, Sound/Musik, Videos)spezialisiert.Diese Vorgehensweise bietet Vor- und Nachteile. Unwichtige Detailswerden weggelassen, dadurch konnen sehr gute Kompressionsraten erzieltwerden. Der Kompromiss aus Qualtitat und Kompressionsrate fuhrt zuInformationsverlust. Eine exakte Reproduktion der Ursprungsdaten ist deshalbmeist nicht moglich. Selbst wenn die Qualitat so hoch gewahlt wurde, dass Augebzw. Ohr keine Unterschiede wahrnehmen konnen, existieren Abweichungen aufBitebene, die aufgrund von Rundungsfehlern auftreten.
RA I Rechnerarchitektur I 77/ 78

TeIe
T
ID= 1
= D
C
C
rgs3.7 Prufsummen 3 Informationscodierung
Beispiele fur Verlustbehaftete Codierung
Verfahren Anwendung
Diskrete Cosinus Transformation Audiosignale, Bild- und Videodatenkomprimieren (JPEG, MPEG)
Wavelet Bildkomprimierung, Rauschunterdruckung
Moving Picture Experts Group Videocodierung (MPEG-1, MPEG-2,MPEG-4, MPEG-7)
Joint Photographic Experts Group Bildkompression (JPEG, JPEG-2000)
RA I Rechnerarchitektur I 78/ 78













![Grundlagen der Rechnerarchitektur - Universität Ulm · Grundlagen der Rechnerarchitektur [CS3100.010] Wintersemester 2014/15 Heiko Falk Institut für Eingebettete Systeme/Echtzeitsysteme](https://img.pdfslide.org/doc/110x75/5e0c3136118dc0188b1d56b3/grundlagen-der-rechnerarchitektur-universitt-ulm-grundlagen-der-rechnerarchitektur.jpg)















