Embed Size (px)
Citation preview

Effizient suchen leicht gemacht Ein Lehrmittel für den IKT-Unterricht
von Giancarlo Gareiss

2
EFFIZIENT SUCHEN
LEICHT GEMACHT

3
Inhaltsverzeichnis
Vorwort zum Gebrauch 4
1. Bedeutung von Suchmaschinen 5
2. Die Entwicklung des Internets 6
3. Wie funktionieren Suchmaschinen 11
4. Effizientes Suchen 18
5. Gefahren im Umgang mit Google 25
6. Anhang A 30
a. Glossar 30
b. Nützliche Links 34
c. Quellenangabe 36
7. Anhang B 43
a. Lösungen 43

4
Vorwort zum Gebrauch
Was ist das Ziel des vorliegenden Lehrmittels?
Das Lehrmittel „Effizient Suchen leicht gemacht“ soll dir einen
Einblick in verschiedene Aspekte von Suchmaschinen und insbe-
sondere Google verleihen. Es bringt dir einerseits die Funktions-
weise von Suchmaschinen näher, andererseits lernst du Techniken
für ein gezielteres Suchen im Internet und wirst auf die Gefahren
im Umgang mit Google aufmerksam gemacht. Die Entstehungsge-
schichte des Internets und die Bedeutung von Google und Co. run-
den das Lehrmittel ab und setzen Suchprogramme in einen grösse-
ren Zusammenhang. Für die Bearbeitung brauchst du keinerlei
Vorkenntnisse. Dein Wissen vom täglichen googeln reicht voll-
ständig aus.
Wie ist es aufgebaut?
Das Lehrmittel ist in fünf Kapitel unterteilt, die jeweils verschie-
dene Aspekte von Suchmaschinen abhandeln. Zu Beginn jedes
Kapitels steht eine Einführungsseite in grün, die einerseits dein
Vorwissen aktivieren soll und andererseits eine Heranführung an
die Thematik des Kapitels darstellt. Der blaugefärbte Hauptteil
eines jeden Kapitels ist in eine linke und rechte Spalte unterteilt.
Die linke soll dir Informationen zum Thema beschaffen und ent-
hält auch Theorieteile, die rechte dient der Vertiefung mittels Auf-
gaben und der Auflockerung. Zum Schluss jedes Kapitels folgt
eine rote Abschlussseite, die einerseits mit einer Zusammenfas-
sung der wichtigsten Punkte, andererseits mit Repetitionsaufgaben
dienen soll. Im Anhang finden sich die Lösungen sämtlicher Auf-
gaben, ein Glossar, welcher die unterstrichenen Begriffe erklärt
und dazu noch einige nützliche Internetseiten für den Schulalltag.
Tipps zur Bearbeitung
Bearbeite das Lehrmittel in der vorgegebenen Reihenfolge
der Kapitel und Unterkapitel.
Lies vor den Aufgaben immer den Theorieteil genau
durch.
Versuche die Aufgaben, sofern nicht anders vermerkt,
selbständig zu lösen und notiere die Lösungen auf ein se-
parates Blatt Papier.
Die Lösungen im Anhang müssen nicht immer mit deinen
übereinstimmen.
Löse auch die Einstiegs- und Repetitionsaufgaben. Sie
dienen der Aktivierung deines Vorwissens bzw. der Festi-
gung des Erlernten.

5
Die Entstehung des Internet
1958
Als Reaktion auf den russischen Satelliten Sputnik (1957) ruft das
Verteidigungsministerium der USA die ARPA (Advanced Re-
search Projects Agency) ins Leben. Das erklärte Ziel der Behörde
ist, im Bereich der Technik nie mehr überraschend geschlagen zu
werden.
1964
Paul Baran entwickelt als erster die Idee zur Paketvermittlung in
einem verteilten Netz. Sie stellt ein alternatives Verfahren zur
Durchschaltevermittlung dar.[1]
1969
Die Rechner der Universität von Kalifornien, der Universität von
Kalifornien in Santa Barbara, der Universität von Utah und des
Stanford Research Institute werden miteinander verbunden und
bilden zusammen das ARPANET. Finanziert und geleitet wird das
Projekt von der ARPA. Das Ziel ist, eine Möglichkeit für die Zu-
sammenarbeit und den Datenaustausch der Universitäten zu schaf-
fen.[2]
1970
Das ARPANET wächst praktisch jeden Monat um einen Rech-
ner.[3]
1971
Das Netzwerk umfasst mittlerweile 15 Knoten,[4]
wird aber weiter-
hin nur von einigen Wenigen genutzt. Meistens Informatiker und
Studenten an Universitäten und Forschungseinrichtungen. Die
breite Öffentlichkeit weiss praktisch nichts von der Existenz des
Netzwerks.[5]
1973
Vint Cerf und Robert Kahn legen den Grundstein für das Zusam-
menschliessen von verschiedenen Netzwerken:
Sie entwickeln die Protokolle TCP/IP[6]
und das Konzept der Ga-
teways (Netzkoppler), mit deren Hilfe Netzwerke mit unterschied-
lichen Protokollen und Geschwindigkeiten miteinander kommuni-
zieren können. Jetzt konnte mit einem Router, der als Gateway
fungierte, und dem TCP/IP-Protokoll jedes beliebige Netzwerk mit
einem anderen in Verbindung treten.[7]
Als erster nicht amerikani-
scher Rechner wird ein Rechner des NORSAR (Norwegian Seis-
mic Array) mit dem ARPANET verbunden.[8]
1. Bedeutung von Suchmaschinen
Menschen stellten schon immer Fragen. Es liegt wohl einfach in
der Natur des Menschen neugierig zu sein und alles wissen zu
wollen. Denn wir suchen für alles Gründe und wollen nichts als
gegeben hinnehmen. Früher vor mehr als zweitausend Jahren stell-
ten die Griechen ihre Fragen einem Orakel.
Aber in dem unaufhaltsamen Prozess der technischen Weiterent-
wicklung, in dem sich die Menschheit seit dem Anbeginn ihrer
Existenz befindet, war es nur eine Frage der Zeit, bis auch das
Beantworten von Fragen automatisiert und zu neuer Perfektion
vorangetrieben werden sollte.
Heutzutage sind sie in aller Munde. Die Rede ist von Suchmaschi-
nen. Allen voran von einer. Von Google, dem Informationsliefe-
ranten schlechthin. Wenn man Leute fragt, einem eine Suchma-
schine zu nennen, werden sie einem die Antwort in einem Wort
geben: Google. Google ist omnipräsent. Keine andere Suchma-
schine ist so oft in den Medien, wie der Suchgigant aus Kaliforni-
en. Google stellt andere wie Yahoo! oder Microsofts Bing in den
Schatten. Doch was steckt wirklich hinter dem Weltkonzern und
welche Bedeutung kommt der Suchmaschine zu?
Dank Google finden wir heute auf viele Fragen eine Antwort.
Nicht nach fragen über den Sinn des Lebens oder der Zukunft
(noch nicht), aber z.B. nach Zugverbindungen. Vor ein paar Jahren
wäre das noch unmöglich gewesen. Suchmaschinen vollbringen
rein technisch gesehen eine grossartige Leistung. Und wir müssen
noch nicht einmal lange auf die Antworten warten. Denn das ganze
passiert in Sekundenbruchteilen. Fast schon schneller als wir den-
ken können, bekommen wir die Resultate. Menschen fragen Goog-
le für praktisch alles. Die Suchmaschine kontrolliert die Informati-
onen, wie niemand jemals zuvor in der Geschichte der Menschheit.
Google bestimmt was wir finden. Und somit auch was wir wissen.
Was wir für ein Weltbild haben. Mehr als Zeitungen oder das
Fernsehen dies tun.
Deshalb ist es wichtig, dass wir uns bewusst werden, wie gross
Googles Einfluss ist und wir andere Möglichkeiten kennen, an
Informationen zu kommen. Denn was wir nicht finden – oder auf
den Ergebnisseiten weit hinten steht –, existiert für viele auch
nicht. Gerade auch deshalb ist es so wichtig, dass wir lernen im
Internet gezielt nach den Informationen zu suchen und diese auch
kritisch zu bewerten.
Suchmaschinen vollbringen eine
grossartige technische Leistung.
Wenn wir etwas mit einer Such-
maschine nicht finden, heisst das
nicht, dass es die Sache nicht gibt.
Suchmaschinen beeinflussen unser
Weltbild.

6
Wusstest du, dass…
Im Jahr 1972 das erste Mal gechat-
tet wurde?
das Verb „googeln“ im Duden
steht?
der Absender des ersten Spam-
Mails Ärger mit dem amerikani-
schen Verteidigungsministerium
bekam?
2. Die Entwicklung des Internets
Was weiss ich schon?
Diskutiere mit deinen Kollegen, was ihr über folgende Stichworte
schon wisst? Haltet eure Gedanken schriftlich fest.
ARPANET
Internet
WWW
Nach diesem Kapitel weiss ich…
wie sich das Internet entwickelte.
was man unter Paketvermittlung versteht.
was ein verteiltes Netzwerk ist und welche Vorteile es be-
sitzt.
dass das Internet und WWW nicht dasselbe sind.
was die Aufgaben der Protokolle TCP und IP sind.
wann es die ersten Suchmaschinen gab.
einige Fakten über Google.
Eine Entwicklung, die unser Leben veränderte…
Das Internet, wie wir es heute kennen (mit Suchergebnissen in
Sekundenbruchteilen, mit sozialen Netzen und Plattformen für
Musikdownloads) entwickelte sich nicht von heute auf morgen.
Ebenso wenig wurde es von einem einzelnen entwickelt. Nicht
einmal die ARPA (eine Forschungsbehörde), die als Begründer des
Internets gilt, kann die Entdeckung des Internets als ihre alleinige
Erfindung beanspruchen. Vielmehr waren es unzählige Erfindun-
gen über Jahre hin weg, die immer wieder Teilprobleme lösten.
Aufgabe:
Studiere die Zeitlinie auf den nächsten Seiten und bearbeite an-
schliessend die Seite mit der Zusammenfassung. Die Bemerkungen
in der rechten Spalte dienen dir, wie immer, mit zusätzlichen In-
formationen und witzigem Zusatzmaterial.

7
Oft glauben die Leute, das
ARPANET wurde erstellt, um nach
einem atomaren Anschlag auf die
USA die Kommunikation aufrecht zu
erhalten. Dies war nicht das Ziel des
Netzwerkes. Vielmehr wollte man
eine Möglichkeit finden die knappen
Rechnerkapazitäten der Universitäten
miteinander zu verbinden und so den
Datenaustausch untereinander zu
fördern. Natürlich wurde das Netz-
werk auch auf Ausfallsicherheit und
Stabilität getestet, was aber eher auf
die sowieso - auch ohne nukleare
Angriffe - schon sensiblen Netzwerk-
verbindungen zurückzuführen ist.[9]
NICE TO KNOW:
Die ersten Daten, die über das ARPA-
NET verschickt wurden, waren 1969
ein „LOG“ – ein verunglücktes „LOG-
IN“. Die Universität von Kalifornien
versuchte sich in den Rechner der Uni-
versität Stanford einzuwählen.[10]
Aufgabe 2.1
Schau auf der folgenden Seite die
verschiedenen Karten an und infor-
miere dich darüber, wie sich das AR-
PANET im Laufe der Zeit verändert
hat:
http://som.csudh.edu/fac/lpress/
history/arpamaps/
Löse mit Hilfe der Karten folgende
Aufgaben:
1. In welchem Jahr wurde das Penta-
gon an das ARPANET angeschlos-
sen?
2. Warum sind gerade in Boston und
um Kalifornien herum so viele
Rechner ans Netzwerk angeschlos-
sen?
Die Entstehung des Internet
1958
Als Reaktion auf den russischen Satelliten Sputnik (1957) ruft das
Verteidigungsministerium der USA die ARPA (Advanced Re-
search Projects Agency) ins Leben. Das erklärte Ziel der Behörde
ist, im Bereich der Technik nie mehr überraschend geschlagen zu
werden.
1964
Paul Baran entwickelt als erster die Idee zur Paketvermittlung in
einem verteilten Netz. Sie stellt ein alternatives Verfahren zur
Durchschaltevermittlung dar.[1]
1969
Die Rechner der Universität von Kalifornien, der Universität von
Kalifornien in Santa Barbara, der Universität von Utah und des
Stanford Research Institute werden miteinander verbunden und
bilden zusammen das ARPANET. Finanziert und geleitet wird das
Projekt von der ARPA. Das Ziel ist, eine Möglichkeit für die Zu-
sammenarbeit und den Datenaustausch der Universitäten zu schaf-
fen.[2]
1970
Das ARPANET wächst praktisch jeden Monat um einen Rech-
ner.[3]
1971
Das Netzwerk umfasst mittlerweile 15 Knoten,[4]
wird aber weiter-
hin nur von einigen Wenigen genutzt. Meistens Informatiker und
Studenten an Universitäten und Forschungseinrichtungen. Die
breite Öffentlichkeit weiss praktisch nichts von der Existenz des
Netzwerks.[5]
1973
Vint Cerf und Robert Kahn legen den Grundstein für das Zusam-
menschliessen von verschiedenen Netzwerken:
Sie entwickeln die Protokolle TCP/IP[6]
und das Konzept der Ga-
teways (Netzkoppler), mit deren Hilfe Netzwerke mit unterschied-
lichen Protokollen und Geschwindigkeiten miteinander kommuni-
zieren können. Jetzt konnte mit einem Router, der als Gateway
fungierte, und dem TCP/IP-Protokoll jedes beliebige Netzwerk mit
einem anderen in Verbindung treten.[7]
Als erster nicht amerikani-
scher Rechner wird ein Rechner des NORSAR (Norwegian Seis-
mic Array) mit dem ARPANET verbunden.[8]

8
1982
Mit EUnet entsteht eines der ersten Netzwerke in Europa. Es ver-
bindet Rechner in Grossbritannien, Holland, Dänemark und
Schweden.[11]
1983
Ein Anschluss an das ARPANET ist teuer. So bilden die vielen
amerikanischen Informatikfakultäten, die sich das nicht leisten
können, ihr eigenes Netzwerk. Dank den TCP/IP-Protokolle konn-
ten diese völlig verschiedenen Netzwerke über das ARPANET
vereint werden und wachsen so mit der Zeit zu einem grossen Netz
zusammen. Langsam kommt der Begriff Internet auf.[12]
1988
Zwischen den USA, Frankreich und England wird das erste trans-
atlantische Glasfaserkabel verlegt.[13]
1989
Das ARPANET wird stillgelegt. Die Netzwerke des ARPANET
werden an das NSFNET angeschlossen, welches jetzt zum zentra-
len Backbone des Internet wird.[14]
1990
Archie, die erste eigentliche Suchmaschine, mit deren Hilfe Archi-
ve durchsucht werden können, geht online.[15]
Folgende Länder
haben ein eigenes Netz an das NSFNET angeschlossen und somit
Zugang zum Internet: Argentinien, Belgien, Brasilien, Chile,
Griechenland, Indien, Irland, Österreich, die Schweiz, Spanien und
Südkorea.[16]
1991
Das von Tim Berners-Lee am CERN entwickelte World Wide
Web wird für die Öffentlichkeit zugänglich gemacht. Mit dem
WWW lassen sich verschiedene Webseiten zu einem sogenannten
Hypertextsystem verlinken.[17]
1994
Erstmals in der Geschichte des Internets gibt es mehr kommerziel-
le als wissenschaftliche Seiten.[18]
Mit der Gründung von Amazon
erfolgt ein Meilenstein im Onlinehandel. Ein Jahr später wird Ebay
gegründet. Das heute grösste Internetauktionshaus macht den On-
line-Einkauf günstig und bequem.[19]
1995
Die beiden bedeutendsten Suchmaschinen der 90er-Jahre werden
gegründet: Altavista[20]
und Yahoo[21]
. Altavistas Babel Fish war
der erste Internet-Übersetzungsdienst.
Wann wurde das erste Mal gechattet?
1972 fand ein Chat zwischen zwei
Kommunikationsprogrammen statt, das
eine lief auf einem Rechner am SRI,
das andere bei BBN. PARRY spielte
einen Psychotiker mit Verfolgungs-
wahn und „Der Doktor“ imitierte einen
Psychiater. Die Programme gaben da-
bei vorgefertigte Antworten und wenn
sie etwas nicht verstanden eine neutrale
Aussage zum Besten.[22]
NICE TO KNOW:
1978 wurde von Gary Thuerk das erste
Spam-Mail verschickt. Dieser wollte so
für den Computerhersteller DEC wer-
ben, bekam aber prompt Ärger mit dem
Verteidigungsministerium, dem Betrei-
ber des ARPANET.[23]
Für weitere Informationen: Google
selbst!
NICE TO KNOW:
Vielfach wird „googeln“ synonym für
die Internetrecherche verwendet. 2004
wurde das Verb „googeln“ sogar in den
Duden aufgenommen.[24]

9
1998
Netscapes Internetbrowser Netscape Navigator verliert den Brow-
serkrieg gegen Microsofts Internet Explorer und wird eingestellt.
Der Internet Explorer ist somit lange Zeit ohne ernsthafte Konkur-
renz.[25]
Mit Napster entsteht die erste Musiktauschbörse im Inter-
net und darüber hinaus eine unglaublich schnell wachsende Com-
munity.[26]
Völlig neuartig ist das dabei verwendete Peer-to-Peer-
Verfahren (P2P).[27]
2001
Jimmy Wales gründet Wikipedia, eine Enzyklopädie, bei der jeder
und jede zum Autor werden kann.[28]
2003
Der Begriff Web 2.0 wird erstmals öffentlich verwendet. Inbegriff
des neuen Internet Zeitalters sind Plattformen wie Facebook,
MySpace, YouTube, Wikipedia oder auch Twitter. Der Nutzer
erstellt und verteilt Inhalte selber.[29]
2007
Weltweit werden 97 Milliarden Mails verschickt - täglich. 40 Mil-
liarden sind Spam-Mails.[30]
2009
Im Jahr 2009 werden ungefähr 176 Exabyte Daten über das Inter-
net transportiert. Dies entspricht der 424‘000-fachen Datenmenge
aller Bücher der Welt.[31]
2010
Die Spam-Quote bei E-Mails ist auf 97% angestiegen.[32]
Google ist ein Wortspiel mit dem Beg-
riff Googol. Dieser steht für eine 1
gefolgt von 100 Nullen. Die grosse
Zahl versinnbildlicht das Bestreben
der Firma die schier unendlich grosse
Menge aller vorhandenen Informatio-
nen zu ordnen.[36]
Google: Der Weg zum Imperium[33]
1996
Larry Page und Sergey Brin arbeiten
an der Universität Stanford gemein-
sam an einer Suchmaschine.
1998
Google wird als Firma eingetragen
und das Suchprogramm öffentlich
zugänglich.
Mai 2000
AdWords startet mit 350 Kunden.
Juni 2000
Mit einer Milliarde indizierten Seiten
ist Google die grösste Suchmaschine
der Welt.
2006
Google übernimmt für 1.65 Milliarden
Dollar YouTube.
2007
Google ist erstmals die am meisten
aufgerufene Website des Internets.
2008
Google hat im Internet eine Billion
Seiten gefunden.
2009
99% der gesamten Einnahmen gene-
riert Google aus dem Anzeigensystem
AdWords.[34]
2010
Google ist die wertvollste Marke und
hat einen weltweiten Marktanteil von
85%.[35]
Google: Der Weg zum Imperium[33]
1996
Larry Page und Sergey Brin arbeiten
an der Universität Stanford gemein-
sam an einer Suchmaschine.
1998
Google wird als Firma eingetragen
und das Suchprogramm öffentlich
zugänglich.
Mai 2000
AdWords startet mit 350 Kunden.
Juni 2000
Mit einer Milliarde indizierten Seiten
ist Google die grösste Suchmaschine
der Welt.
2006
Google übernimmt für 1.65 Milliar-
den Dollar YouTube.
2007
Google ist erstmals die am meisten
aufgerufene Website des Internets.
2008
Google hat im Internet eine Billion
Seiten gefunden.
2009
99% der gesamten Einnahmen gene-
riert Google aus dem Anzeigensystem
AdWords.[34]
2010
Google ist die wertvollste Marke und
hat einen weltweiten Marktanteil von
85%.[35]
Google ist ein Wortspiel mit dem
Begriff Googol. Dieser steht für eine
1 gefolgt von 100 Nullen. Die grosse
Zahl versinnbildlicht das Bestreben
der Firma die schier unendlich grosse
Menge aller vorhandenen Informatio-
nen zu ordnen.[36]

10
Zusammenfassung
Paketvermittlung
Um das Prinzip der Paketvermittlung und des verteilten Netzwer-
kes besser zu verstehen, soll hier ein Vergleich mit einem Umzug
herangezogen werden:
Bei einem Umzug finden unmöglich alle Möbel in einem Auto
platz. Also verteilen du und deine Freunde, die dir beim Zügeln
helfen, das Mobiliar auf mehrere Fahrzeuge. Um den Überblick
nicht zu verlieren, schreibt ihr die Zügelkisten an. Genauso funkti-
oniert das Verschicken von Informationen durch ein Netzwerk:
Die Information wird in kleine Stücke (Pakete) aufgeteilt, welche
alle beschriftet werden. Dann fahren sie los: Zuerst geht’s von der
Einfahrt auf die Quartierstrasse, danach auf die Hauptstrasse, von
dort auf die Schnellstrasse und schliesslich auf die Autobahn. In
einem Netzwerk gehen die Nachrichten vom PC zuerst in ein loka-
les Netzwerk (LAN), dann in ein MAN, von dort in ein WAN und
schliesslich laufen sie über ein Backbone. Es spielt jedoch keine
Rolle, welches Auto welche Route wählt oder welches wann an-
kommt. Entscheidend ist einzig und allein, dass alle am Zielort
eintreffen. Das Auto welches als erstes losgefahren ist, kann also
durchaus auch als letztes ankommen (macht nichts: Die Zügelkis-
ten sind ja angeschrieben und müssen nicht in der richtigen Rei-
henfolge ankommen.). Deine Freunde, welche die Autobahn nicht
kennen, benutzen dafür ein GPS und werden so automatisch zum
richtigen Ort geführt. Die Datenpakete werden durch das Internet
Protocol zum Zielort geführt. Am Ziel wird kurz kontrolliert, ob
alle eingetroffen sind, dann geht’s ans Auspacken. Die Kisten sind
angeschrieben und können so effizient in die neuen Zimmer ge-
bracht werden. Ein grosses Büchergestell, das wegen seiner Grösse
in mehreren Kisten transportiert werden musste, kann nun wieder
zusammengesetzt werden. Das TCP (Transmission Control Proto-
col) sorgt dafür, dass die Information am Zielort wieder in der
richtigen Reihenfolge zusammengesetzt wird. Zusätzlich kontrol-
liert es, ob auch alle Pakete angekommen sind und fragt fehlende
einzeln noch einmal an.
Unterscheidung Internet – WWW
Das Internet und das World Wide Web sind nicht dasselbe. Das
Internet ist die Hardware (die Infrastruktur, welche die verschiede-
nen Rechner miteinander verbindet). Das WWW hingegen ist die
Software (also das Programm, das verwendet wird um Seiten, die
auf den Rechnern liegen, miteinander zu einem „weltweiten Netz
an Webseiten“ zu verknüpfen). Die Seiten des WWW sind durch
Links miteinander verknüpft.[37]
Aufgabe 2.2
Diskutiert in Gruppen was die Vortei-
le eines verteilten Netzes (Bild unten,
rechte Graphik) gegenüber einem
zentralen Netz sind! Ihr könnt euch
dabei auch am Beispiel mit „dem
Zügeln“ orientieren. (Weshalb ist es
bei einer Fahrt von A nach B besser,
wenn nicht alle Autobahnen über
einen Knoten laufen?)
Wusstest du, dass…
die Google-Gründer am Anfang für
ihre Suchmaschine einfache Com-
puter verwendet haben?
heute hingegen ein Google Rechen-
zentrum eigene Kühltürme für die
Rechner hat und den Strom einer
Kleinstadt verbraucht?
„Am Anfang schuf die ARPA das
ARPANET.
Und das ARPANET war wüst und leer.
Und es war finster in der Tiefe.
Und der Geist der ARPA schwebte über
dem Netzwerk, und die ARPA sprach:
„Es werde ein Protokoll.“ Und es ward
ein Protokoll.
Und die ARPA sah, dass es gut war.
Und die ARPA sagte:“Es seien mehr
Protokolle.“ Und es geschah so. Und
die ARPA sah, dass es gut war. Und die
ARPA sagte:“Es seien mehr Netzwer-
ke.“
Und so geschah es.“ [38]
Aufgabe 2.3
Beschreibe das Verfahren der Direkt-
vermittlung anhand des Beispiels
links mit der Paketvermittlung.
Abbildung 1:
Zentrales, dezentrales und verteiltes
Knotennetz (v.l.n.r.).

11
3. Wie funktionieren Suchmaschinen?
Was weiss ich schon?
Diskutiere mit deinen Kollegen, was ihr über folgende Stichworte
schon wisst? Haltet eure Gedanken schriftlich fest.
Archiv
Web-Suchmaschinen
Meta-Suchmaschine
Index
Nach diesem Kapitel weiss ich…
den Unterschied zwischen einem Verzeichnisdienst und
einer Suchmaschine.
wie eine Suchmaschine den Index erstellt.
was bei einer Suchanfrage passiert.
einige Kriterien, mit denen die Relevanz der Suchergeb-
nisse bewertet wird.
was der PageRank bedeutet und was nicht.
Als alles unübersichtlich wurde…
Vor noch gar nicht so langer Zeit gab es keine Suchmaschinen.
Jetzt wirst du dich wahrscheinlich fragen warum? Ganz einfach:
Man brauchte keine. Zu klein war die Zahl der existierenden Web-
seiten. Doch dann, als in den Neunzigerjahren die Anzahl an Sei-
ten im Internet immer grösser und das gesamte Netz unübersicht-
lich wurde,[39]
musste eine Lösung auf den Tisch um schneller an
Informationen zu kommen. Irgendwie musste die unüberblickbare
Flut an Informationen in vernünftiger Zeit durchsucht werden kön-
nen.
Aufgabe:
Überlege dir, wie du ausserhalb des Internets nach Infor-
mationen suchst. Versuche dabei vor allem auf die zwei
folgenden Fragen einzugehen:
- Wo suchst du?
- Wie findest du dich in diesen Medien zurecht?
Wusstest du, dass…
die Google-Gründer am Anfang
für ihre Suchmaschine einfache
Computer verwendet haben?
heute hingegen ein Google Re-
chenzentrum eigene Kühltürme für
die Rechner hat und den Strom ei-
ner Kleinstadt verbraucht?

12
Aufgabe 3.1
Diskutiert die Vor- und Nachteile von
Katalog-Diensten im Gegensatz zu
Websuchmaschinen und erstellt da-
von eine Tabelle. Beachtet folgende
Punkte:
Effektivität, Subjektivität, Aktualität,
Vollständigkeit, Kosten.
Suchmaschinen für…
- Websites: http://www.google.ch/
- Dokumente: http://docmazy.com/
- Bilder:
http://www.google.ch/imghp
- Musik: http://www.playlist.com/
- Videos: http://www.youtube.com/
- Kataloge:
Excite, All One Search.
- Websuchmaschinen:
Google, Yahoo!, Bing, Alta Vista.
- Metasuchmaschine:
Ixquick, Meta Crawler.
- Vertikale Suchmaschine:
Tucows, Medivista.
Definition einer Suchmaschine:
Eine Suchmaschine ist in erster Linie ein Programm das nach In-
formationen sucht. Diese Suche kann einerseits auf nur einem
Rechner stattfinden oder sich über ein ganzes Netzwerk, wie z.B.
das Internet, erstrecken. Unter dem Begriff Informationen werden
Webseiten, Dokumente, Bilder, Musik- und Filmdateien zusam-
mengefasst. Mit Suchmaschinen sucht (und findet) man also In-
formationen in den unüberschaubaren Tiefen des Internets.
Suchmaschine ist nicht gleich Suchmaschine…
Wie du sicher schon erahnen wirst, gibt es für diese verschiedenen
Anforderungen auch unterschiedliche Arten von Suchmaschinen.
Und wie du auch schnell sehen wirst, verdient nicht einmal jede
den Namen Suchmaschine.
Es gibt verschiedene Arten von Suchmaschinen…
Man kann Suchmaschinen anhand von verschiedenen Kriterien
unterscheiden. Ein erstes bezieht sich auf die Daten, welche das
Programm sucht (Websites, Dokumente, Bilder, Musik, Vi-
deos).[40]
Beispiele dazu findest du rechts (oberes blaues Textfeld).
Ein weiteres Kriterium untersucht den Ursprung der Informati-
on:[41]
Beispiele zu den unterschiedlichen Arten von Suchmaschi-
nen findest du wieder rechts (im unteren blauen Textfeld).
Bei Katalogen (auch Verzeichnis genannt) tragen Men-
schen von Hand eine Zusammenstellung von verschiede-
nen Seiten nach Themen sortiert zusammen. Meist nur zu
einzelnen Themenbereichen, manchmal jedoch auch the-
menübergreifend.[42]
Websuchmaschinen durchsuchen grosse Teile des WWW
nach allen möglichen Themen. Im Vergleich zu Katalogen
werden hier die Seiten jedoch nicht von Hand in den Index
übertragen, sondern von Programmen. Diese Pragramme
(Crawler) durchsuchen das Web vollautomatisch nach
neuen Seiten.[43]
Metasuchmaschinen durchsuchen den Index von mehreren
Suchmaschinen und können so deutlich grössere Bereiche
des WWW abdecken.[44]
Vertikale Websuchmaschinen indexieren nur Seiten zu ei-
nem bestimmten Thema und erfassen daher nur einen
Teilbereich des WWW.[45]
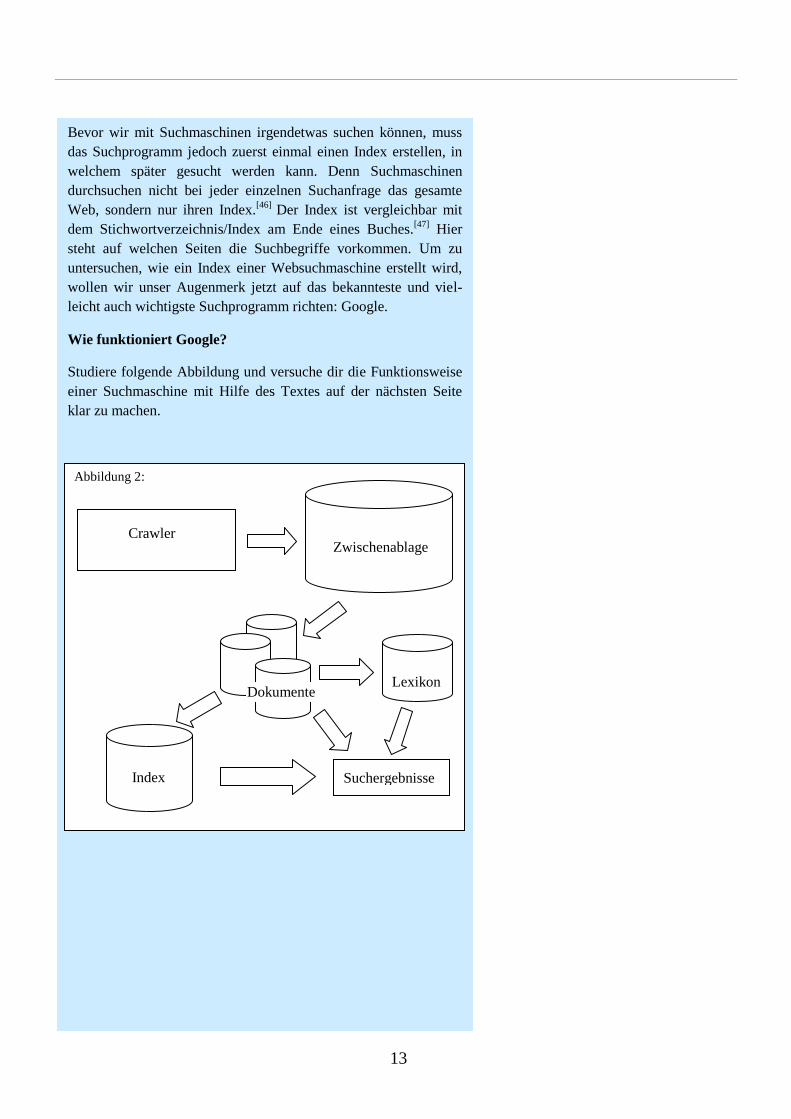
13
Bevor wir mit Suchmaschinen irgendetwas suchen können, muss
das Suchprogramm jedoch zuerst einmal einen Index erstellen, in
welchem später gesucht werden kann. Denn Suchmaschinen
durchsuchen nicht bei jeder einzelnen Suchanfrage das gesamte
Web, sondern nur ihren Index.[46]
Der Index ist vergleichbar mit
dem Stichwortverzeichnis/Index am Ende eines Buches.[47]
Hier
steht auf welchen Seiten die Suchbegriffe vorkommen. Um zu
untersuchen, wie ein Index einer Websuchmaschine erstellt wird,
wollen wir unser Augenmerk jetzt auf das bekannteste und viel-
leicht auch wichtigste Suchprogramm richten: Google.
Wie funktioniert Google?
Studiere folgende Abbildung und versuche dir die Funktionsweise
einer Suchmaschine mit Hilfe des Textes auf der nächsten Seite
klar zu machen.
Abbildung 2:
Abbildung 3:
Zwischenablage
Dokumente
Crawler
Lexikon
Index Suchergebnisse

14
Aufgabe 3.2
Auf dem Pausenhof geht ein neues
Gerücht um. Diskutiert in Gruppen,
was Kriterien sind diesem Glauben zu
schenken?
Abbildung 5:
Google Rechenzentrum in Oregon
(USA) in der Grösse eines Footballfel-
des.
Abbildung 4:
Die Rechner der Google-Gründer an
der Stanford University. Auf diesen
einfachen Computern lief die Suchma-
schine in den Anfangszeiten.
Wir betrachten nun den Aufbau einer typischen Websuchmaschine
am Beispiel von Google (Siehe Graphik Seite 13):
Mithilfe der Crawler durchsucht Google das Web. Ein Crawler ist
ein Programm, das nichts anderes macht, als bei einer beliebigen
Seite zu starten und dann von da aus den Links zu folgen. Die
besuchten Seiten werden vollständig heruntergeladen und in der
Zwischenablage gespeichert. Die heruntergeladenen Seiten werden
sortiert und auf den Rechnern nach Stichworten abgelegt. Welches
Dokument wo abgelegt wurde, steht im Index. Zusätzlich werden
alle neuen Begriffe in einem Lexikon gespeichert.[48]
Der Ablauf einer Suchanfrage an Google:
Eine Suchanfrage wird über eine Eingabe von Keywords in die
Suchmaske der Seite von google.ch (Query) an den Google Web
Server gestellt. Dieser leitet die Anfrage weiter an den Index
Server, der Seiten sucht, welche die Keywords enthalten. Danach
reicht der Index Server die Abfrage an die Doc Servers weiter.
Diese enthalten die indexierten Seiten. Aus allen Seiten, welche zu
den Stichwörtern passen, werden mit Hilfe von Bewertungs-
kriterien die Ergebnissseiten (Snippets) zusammengestellt. Die
Snippets werden an den Rechner des Benutzers geschickt. Was
zurückkommt ist die Ergebnisseite, mit den einzelnen Treffern.
Der ganze Prozess dauert selten länger als eine halbe Sekunde.[49]
Abbildung 3

15
Zusammenfassung
Suchmaschinen
Es gibt mehrere Arten von Suchmaschinen, nicht nur Websuchma-
schinen. Aber selbst bei diesen gibt es unzählige und nicht nur
Google. Eine Liste mit verschiedenen Suchmaschinen findest du
im Anhang (unter Nützliche Links). Es lohnt sich auch hier einmal
etwas anderes auszuprobieren.
Suchmaschinen durchforsten nicht erst bei einer Suchanfrage das
gesamte Web und finden dann die richtige Seite. Vielmehr wird
vorher ein Index erstellt und laufend aktualisiert, welcher dann bei
einer Suchanfrage nach den passenden Seiten durchsucht wird.[60]
Zur Relevanzbewertung werden unterschiedliche Kriterien heran-
gezogen.[61]
Nicht nur der PageRank, sondern auch der Abstand
zwischen zwei Suchbegriffen, die Position der Suchbegriffe inner-
halb des Dokuments, der Standort, von wo aus die Suchanfrage
gestellt wird, das Dateiformat, die Aktualität und bei Google neu-
erdings auch die Ladegeschwindigkeit einer Seite.[62]
PageRank
Das Wichtigste am PageRank ist nicht die Berechnung zu kennen,
sondern seine Bedeutung:
Er sagt nichts über die Qualität einer Seite aus, sondern einzig und
allein etwas über ihre Wichtigkeit. Dies solltest du für das Kapitel
fünf im Hinterkopf behalten. Beim Erstellen von Suchstrategien
gilt es dies zu beachten.
Aufgabe 3.3
Vergleiche den PageRank von folgen-
den Seiten miteinander und ziehe dar-
aus Schlüsse über den Zusammenhang
zwischen Qualität und dem von
Google erstellten Ranking:
www.ethz.ch
www.ksrychenberg.ch
www.sf.tv
www.blick.ch
www.nytimes.com
www.nzz.ch
www.google.com
www.google.ch
www.yahoo.com
Den PageRank jeder Seite kannst du
hier herausfinden:
http://www.database-
search.com/sys/pre-check.php
Gib dazu im Feld „Prüfe URL“ die
Internetadresse ein, gib den auf der
Seite angezeigten Code ein und klicke
anschliessend auf „Prüfung starten“.
Die Bewertung wird mit einer Zahl
zwischen 1 und 10 ausgedrückt. Dabei
bedeutet 10 hervorragend und 1
schlecht.
Der PageRank sagt nichts über die
Qualität einer Seite aus.
Sondern nur über die Wichtigkeit.
Unbekanntere Seiten werden durch
den PageRank benachteiligt.
Bewertung der Relevanz
Was ist Relevanz?
Im Zusammenhang mit Suchmaschinen taucht immer wieder der
Begriff Relevanz auf. Vielfach wird von relevanten Seiten gespro-
chen. Aber was bedeutet das überhaupt? Um relevant zu sein, muss
eine Seite oder ein Dokument denjenigen Teil einer Information
enthalten, der zur Aufklärung der Fragestellung dient. Im Klartext
heisst das, eine Seite ist dann relevant, wenn sie die Frage, die
hinter deiner Suchanfrage steckt, beantworten kann.
Wie bewerten Suchmaschinen die Relevanz einer Seite?
Um aus den vielen Seiten, die zum gestellten Suchbegriff passen,
die relevantesten zu finden, gibt es für Suchmaschinen verschiede-
ne Möglichkeiten, welche meistens alle miteinander angewandt
werden. So kann z.B. der Abstand von zwei Suchbegriffen in ei-
nem Dokument relativ mit dem Abstand in anderen Dokumenten
verglichen werden.[50]
Da sich dieses Kriterium auf den Text einer
Seite bezieht, nennt man es auch textbezogenes Relevanzkriterium.
Mehr dazu in Kapitel vier. Es gibt jedoch noch unzählige weitere
Kriterien zur Berechnung der Relevanz. So benutzt Google insge-
samt über 200 verschiedene (meistens geheime) Kriterien.[51]
Das
sicher bekannteste davon ist der PageRank.
PageRank
Beim PageRank Verfahren wird eine Seite aufgrund von den Sei-
ten, die auf sie verweisen, bewertet. Je mehr sogenannte Links
(oder Backlinks genannt) eine Seite bekommt, desto höher ist ihr
Wert. Natürlich spielt es eine nicht unwesentliche Rolle was für
Seiten auf sie verweisen: Je höher der Wert der verweisenden Sei-
te, desto grösser der Anstieg bei der anderen Seite. Der PageRank
wird also vererbt.[52]
Der PageRank sagt jedoch rein gar nichts über die Qualität einer
Seite aus, sondern nur etwas darüber wie beliebt oder bekannt eine
Seite ist.[53]
So gesehen sagt der PageRank auch etwas über die
Wichtigkeit einer Seite aus. Aber Achtung: Dadurch werden unbe-
kannte Seiten benachteiligt und somit eher nicht gefunden.
Löse nun Aufgabe 3.3 bevor du weiterliest.
Aufgabe 3.3
Vergleiche den PageRank von fol-
genden Seiten miteinander und ziehe
daraus Schlüsse über den Zusammen-
hang zwischen Qualität und dem von
Google erstellten Ranking:
www.ethz.ch
www.ksrychenberg.ch
www.sf.tv
www.blick.ch
www.nytimes.com
www.nzz.ch
www.google.com
www.google.ch
www.yahoo.com
Den PageRank jeder Seite kannst du
hier herausfinden:
http://www.database-
search.com/sys/pre-check.php
Gib dazu im Feld „Prüfe URL“ die
Internetadresse ein, gib den auf der
Seite angezeigten Code ein und klicke
anschliessend auf „Prüfung starten“.
Die Bewertung wird mit einer Zahl
zwischen 1 und 10 ausgedrückt. Da-
bei bedeutet 10 hervorragend und 1
schlecht.
Der PageRank sagt nichts über die
Qualität einer Seite aus.
Sondern nur über die Wichtigkeit.
Unbekanntere Seiten werden durch
den PageRank benachteiligt.

16
Angenommen wir haben zwei Seiten (Seiten B und C), welche
auf eine dritte Seite (Seite A) verweisen. N steht für die Anzahl
der gesamten Links, welche auf der jeweiligen Seite gesetzt
sind. PR ist der PageRank der Seiten. Die Folgende vereinfach-
te Formel besagt zur Berechnung des PageRanks also:
Der PRA ist definiert durch den PageRank der darauf verwei-
senden Seiten dividiert durch ihre gesamte Anzahl ausgehender
Links (N).
d = Dämpfungsfaktor, definiert zwischen 0 und 1.
Gewöhnlich auf 0.85 gesetzt.[55]
N = Anzahl der ausgehenden Links.[56]
Die folgende Seite ist freiwillig. Sie ist entweder für etwas
schnellere oder für besonders interessierte Schüler gedacht.
Wenn du sie nicht bearbeiten willst, kannst du sie überspringen
und direkt zur Zusammenfassung auf Seite 15 übergehen.
NICE TO KNOW:
Der PageRank hat seinen Namen nicht
etwa von den Seiten, die er bewertet,
sondern von seinem Erfinder Larry
Page.[59]
Berechnung des PageRanks
Der PageRank drückt im Grunde nichts anderes aus, als die Wahr-
scheinlichkeit, dass eine Seite besucht wird.
Angenommen jemand der im Internet „surft“ startet willkürlich auf
irgendeiner Seite und folgt dann immer den Links, so drückt der
PageRank der nächsten Seite aus, wie gross die Wahrscheinlichkeit
war auf dieser und nicht auf einer anderen Seite zu landen.[54]
Nur
rechnet man diese Wahrscheinlichkeit nicht wie in unserem Bei-
spiel von nur einer Seite (Startseite des „Surfers“) sondern von
allen Seiten, die einen Link zu dieser Seite gesetzt haben.
Diese Berechnung ist natürlich stark vereinfacht. In Wirklichkeit
setzt sich die Formel zur Berechnung des PageRanks aus über 500
Millionen Variablen und zwei Milliarden Ausdrücken zusam-
men.[57]
Die folgende Seite ist freiwillig. Sie ist entweder für etwas
schnellere oder für besonders interessierte Schüler gedacht.
Wenn du sie nicht bearbeiten willst, kannst du sie überspringen
und direkt zur Zusammenfassung auf Seite 15 übergehen.
Angenommen wir haben zwei Seiten (Seiten B und C), welche
auf eine dritte Seite (Seite A) verweisen. N steht für die Anzahl
der gesamten Links, welche auf der jeweiligen Seite gesetzt
sind. PR ist der PageRank der Seiten. Die Folgende vereinfach-
te Formel besagt zur Berechnung des PageRanks also:
Der PRA ist definiert durch den PageRank der darauf verwei-
senden Seiten dividiert durch ihre gesamte Anzahl ausgehender
Links (N).
d = Dämpfungsfaktor, definiert zwischen 0 und 1.
Gewöhnlich auf 0.85 gesetzt.[55]
N = Anzahl der ausgehenden Links.[56]
Aufgabe 3.4[58]
Berechne den PageRank für die Seite
A. Jeder Pfeil stellt einen Link dar.
Die Seiten B, C und D haben einen
PageRank von 1. Der Dämpfungsfak-
tor wird auf 0.85 gesetzt:
Abbildung 6
D
A
C
B
NICE TO KNOW:
Der PageRank hat seinen Namen nicht
etwa von den Seiten, die er bewertet,
sondern von seinem Erfinder Larry
Page.[59]

17
Aufgabe 3.5
Suche je ein Verzeichnisdienst, eine
Schweizer Websuchmaschine, eine
internationale Suchmaschine (nicht
Google, Yahoo! oder Bing), eine Me-
ta-Suchmaschine und eine vertikale
Suchmaschine.
Aufgabe 3.6
Vergleiche die Grösse des Index von
Google, Ixquick und Lycos mit den
Suchanfragen „Taio Cruz“ und „the“.
Aufgabe 3.7
Suche in den Suchmaschinen Google,
Yahoo! und Ixquick nach dem Begriff
„facebook“ und stelle Unterschiede
bei den Top Ten-Platzierungen fest.
Zusammenfassung
Suchmaschinen
Es gibt mehrere Arten von Suchmaschinen, nicht nur Websuchma-
schinen. Aber selbst bei diesen gibt es unzählige und nicht nur
Google. Eine Liste mit verschiedenen Suchmaschinen findest du
im Anhang (unter Nützliche Links). Es lohnt sich auch hier einmal
etwas anderes auszuprobieren.
Suchmaschinen durchforsten nicht erst bei einer Suchanfrage das
gesamte Web und finden dann die richtige Seite. Vielmehr wird
vorher ein Index erstellt und laufend aktualisiert, welcher dann bei
einer Suchanfrage nach den passenden Seiten durchsucht wird.[60]
Zur Relevanzbewertung werden unterschiedliche Kriterien heran-
gezogen.[61]
Nicht nur der PageRank, sondern auch der Abstand
zwischen zwei Suchbegriffen, die Position der Suchbegriffe inner-
halb des Dokuments, der Standort, von wo aus die Suchanfrage
gestellt wird, das Dateiformat, die Aktualität und bei Google neu-
erdings auch die Ladegeschwindigkeit einer Seite.[62]
PageRank
Das Wichtigste am PageRank ist nicht die Berechnung zu kennen,
sondern seine Bedeutung:
Er sagt nichts über die Qualität einer Seite aus, sondern einzig und
allein etwas über ihre Wichtigkeit. Dies solltest du für das Kapitel
fünf im Hinterkopf behalten. Beim Erstellen von Suchstrategien
gilt es dies zu beachten.

18
4. Effizientes Suchen.
Was weiss ich schon?
Diskutiere mit deinen Kollegen, was ihr über folgende Stichworte
schon wisst? Haltet eure Gedanken schriftlich fest.
Rangierung
Katalog vs. Suchmaschine
Wie suche ich im Internet nach Informationen?
Suchstrategie
Nach diesem Kapitel weiss ich…
wie sich die Relevanzkriterien konkret auf meine Suchre-
sultate auswirken.
wann ich einen Katalog und wann ich eine Suchmaschine
verwenden soll.
zwei Suchstrategien, die bei jeder Suchanfrage effizient
zum Ziel führen.
wie man mit einfachen Operatoren umgeht.
wie man die erweiterte Suche einsetzt und wie ich in kur-
zer Zeit komplizierte Suchanfragen formulieren kann und
so schneller zur gesuchten Information komme.
dass auch das Suchen etwas Übung braucht.
Die Internetrecherche schneller und besser machen…
Im Internet findet man alles! Ok, zugegeben, alles ist ein bisschen
übertrieben. Aber sehr, sehr vieles lässt sich im Internet finden.
Deutlich mehr als du dir vorstellen kannst. Das einzige Problem
dabei? Viele Leute wissen nicht, wie sie suchen müssen, um an
dieser Unmenge an Informationen teilzuhaben. Wenn man nämlich
wüsste wie, würde man innert kürzester Zeit genau das finden, was
man wissen will. Damit du diesem Ziel zumindest etwas näher
kommst, werden wir im folgenden Kapitel zwei Suchstrategien
anschauen, die gepaart mit dem Wissen, wie man Anfragen richtig
formuliert, in vielen Fällen zum Ziel führen.
Aufgabe:
Überlege dir wie lange du im Internet suchst, wenn du etwas
wissen willst? Eine Suchanfrage lang? Zehn Minuten? Oder gar
bis du es gefunden hast?
Hast du bei der Internetrecherche eine feste Strategie oder
suchst du einfach mal drauf los?
Wusstest du, dass…
Googles Index mehr als 25 Milliar-
den Seiten umfasst?
die Seltenheit, dass man bei einer
Suchanfrage nur ein einziges Resul-
tat zurück bekommt, einen eigenen
Namen trägt?
Wusstest du, dass…
Googles Index mehr als 25 Milli-
arden Seiten umfasst?
die Seltenheit, dass man bei einer
Suchanfrage nur ein einziges Re-
sultat zurück bekommt, einen ei-
genen Namen trägt?

19
Rangierungsprinzipien
Um zu wissen wie man effizient sucht, müssen wir zuerst die Ran-
gierungsprinzipien von Suchmaschinen etwas genauer unter die
Lupe nehmen. Im Unterkapitel Relevanz hast du schon einiges
über die Relevanzbewertung, die ein Suchprogramm durchführt,
erfahren.
Ein weiteres wichtiges Kriterium ist das Vorkommen von soge-
nannten Schlüsselwörtern im Text einer Seite.[63]
Doch nicht nur
dort, sondern bereits auf der Ergebnisseite sieht man in den kurzen
Ausschnitten der Websites, dass die Suchbegriffe fett markiert
sind. Du wirst dir die sechs wichtigsten Rangierungsprinzipien in
den Aufgaben 4.1 bis 4.6 selbständig erarbeiten. In den Lösungen
findest du anschliessend die korrekten Kriterien. Im obersten Text-
feld siehst du jeweils die gestellte Suchanfrage mit den Stichwor-
ten. Danach folgen zwei weitere Textfelder, mit den Stichworten
fett markiert. Du must nun entscheiden, weshalb das obere Text-
feld besser zur gestellten Suchanfrage passt. Daraus formulierst du
dann ein Rangierungsprinzip. Jede Aufgabe behandelt ein Rangie-
rungsprinzip. Halte deine Ergebnisse wie immer schriftlich fest.
Neben diesen sechs Kriterien die den Inhalt betreffen, gibt es auch
noch solche, die vom Inhalt unabhängig sind. Das können Ran-
king-Verfahren, wie etwa der PageRank sein. Aber auch solche
wie die Anzahl der Zugriffe auf die Seite. Seiten, welche häufiger
angeklickt werden, sind auf der Ergebnisseite sicher weiter oben
zu finden als andere. Somit ergibt sich ein ewiger Kreislauf, denn
Seiten die auf der Ergebnisseite weiter oben angezeigt werden,
werden wiederum häufiger angeklickt.
Aufgabe 4.1[64]
Eingabe:
Taio Cruz Break Your Heart Lyrics
1. Treffer:
Original Lyrics. Break Your Heart.
2. Treffer:
Download Taio Cruz Pop, R&B, Hip
Hop music singles.
Aufgabe 4.3
Eingabe:
Nati WM Vorbereitung Feusisberg
1. Treffer:
Die Schweizer Nati hat in Feusisberg mit
der Vorbereitung auf das…
2. Treffer:
Die Schweizer Fussball-Nati testet im
Rahmen der WM-Vorbereitung gegen
Uruguay.
Aufgabe 4.2
Eingabe:
Roger Federer
1. Treffer:
Roger Federer hat zum 5. Mal die ATP-
Finals gewonnen. Mit diesem Sieg hat
Roger Federer…
2. Treffer:
Roger Federer ist ein Schweizer Tennis-
spieler.
Löse nun die Aufgaben 4.1 bis 4.6 bevor du hier weiterliest.

20
Alles eine Frage der richtigen Suchstrategie
Die eben neu gelernten Rangierungsprinzipien, welche bei den
meisten Suchmaschinen verwendet werden, helfen uns, sich in die
Funktionsweise eines Suchprogramms einzudenken und so für jede
Suchanfrage die optimale Strategie zu entwickeln.
Jedoch gleich vorneweg: Es gibt nicht eine richtige Suchstrategie,
vielmehr erfordert jede Recherche eine etwas anders ausgelegte
Suche. Wir werden uns jetzt zusammen zwei verschiedene Strate-
gien erarbeiten, die beide zum Ziel führen. Anschliessend wirst du
die wichtigsten Operatoren kennen lernen, die von Google unter-
stützt werden, um die Suchstrategien auch umsetzen zu können.
Zum Abschluss werde ich dir noch die Erweiterte Suche vorstel-
len. Versuche dich jedoch nicht gleich dort, sondern arbeite dich
Schritt für Schritt durch, denn das Suchen erfordert vor allem eins
– Übung. Du wirst später auch die „Anfänger-Tipps“ gebrauchen.
Strategie 1: Synonyme
1. Überlege dir als erstes, was du genau suchst. Mach dir Notizen,
was du wissen willst. Mit etwas Übung wird dir dieser Teil
leichter fallen und du kannst ihn im Kopf erledigen. Schreibe
dir zu Beginn diesen Schritt präzise auf. Eine Suchmaschine
kann keine Gedanken lesen, du musst also ganz genau um-
schreiben was du suchst. Dafür musst du dir zuerst selbst dar-
über im Klaren sein.
2. Denke dich in das Dokument, das du finden willst, ein. Was für
Stichwörter werden darin vorkommen? Wähle den Begriff der
dir am wahrscheinlichsten erscheint. Versuche jetzt dein Vor-
wissen zu aktivieren. Suche Synonyme zu diesem Begriff. Du
brauchst, wie schon gesagt, ein paar Wörter, die charakteris-
tisch sind für das Dokument oder die Seite die du suchst,
gleichzeitig aber auf möglichst wenigen anderen Seiten vor-
kommen.
3. Jetzt kommen die Rangierungsprinzipien ins Spiel. Beachte vor
allem die Kriterien eins bis drei. Versuche möglichst viele Wör-
ter zu finden, welche im Zieldokument vorkommen könnten.
Achte darauf, dass sie im Text häufig vertreten sind und versu-
che sehr spezifische, nicht allgemein verwendete zu finden, die
auf anderen Seiten sehr wahrscheinlich nicht vorhanden sind.
4. Jetzt erst gibst du deine Suchbegriffe in die Suchmaske von
Google ein. Die Reihenfolge der Wörter ist egal.
5. Überfliege die Suchresultate (Titel, Zusammenfassung, Inter-
netadresse).
Aufgabe 4.6
Eingabe:
Xherdan Shaqiri
1. Treffer:
Xherdan Shaqiri (* 10. Oktober 1991 in
Gjilan) ist ein Schweizer Fussballspieler
kosovarischer Herkunft.
2. Treffer:
Er ist einer der grössten Talente im
Schweizer Fussball: Der 18-jährige FCB-
Spieler Xherdan Shaqiri.
Aufgabe 4.5
Eingabe:
Usain Bolt
1. Treffer:
Usain Bolt (* 21. August 1986 im Tre-
lawny Parish) ist ein jamaikanischer
Sprinter.
2. Treffer:
Usain Bolt wird in diesem Jahr keine
Rennen mehr absolvieren. Der herausra-
gende Leichtahlet bricht seine Saison
wegen Rückenbeschwerden vorzeitig ab.
Der Jamaicaner hätte noch an den Mee-
tings in Zürich und Brüssel teilnehmen
sollen.
Aufgabe 4.4
Eingabe:
Champions League
1. Treffer:
Wetten zur UEFA Champions League.
2. Treffer:
Perhaps one of the oddest champions in
the League of Legends is the yordle
known as Amumu.

21
6. Ist keines dabei, das dir die relevanten Informationen liefert, so
gehe zurück zu Schritt 2.
Suchstrategie 2: Verfeinern
1. Als erstes machst du dir wieder darüber Gedanken, was du ge-
nau wissen willst. Notiere es wieder auf einem Blatt Papier.
2. Überlege dir ein Stichwort, welches möglichst charakteristisch
ist für die Seite die du suchst.
3. Dann geht’s schon ab ins Netz. Gib den Suchbegriff in die
Suchmaske der Suchmaschine ein.
4. Überfliege wieder die Suchresultate (Titel, Textausschnitt, In-
ternetadresse).
5. Wenn du mit dem Ergebnis nicht zufrieden bist, was sehr wahr-
scheinlich ist, versuchst du ein Stichwort hinzuzufügen. So dass
deine Suche eingeschränkt wird. Das siehst du ja anhand der
Anzahl der Treffer, die das Suchprogramm anzeigt. Wie genau
man Suchbegriffe hinzufügt, wird im Abschnitt Einfache Ope-
ratoren erklärt.
6. Verfeinere deine Anfrage solange, bis du zur gewünschten In-
formation kommst.
Du fragst dich wahrscheinlich, warum du bei dieser Methode nicht
gleich von Anfang an mit mehreren Suchbegriffen arbeiten kannst.
Das wirst du mit der Zeit können. Für den Beginn ist es jedoch
ganz gut, wenn du siehst, wie die Suchmaschine auf veränderte
Suchanfragen reagiert.
Merke:
Du siehst, man kann beide Suchtechniken verwenden, um ans Ziel
zu kommen. Es ist auch etwas eine „Geschmackssache“, welche du
lieber verwendest. Du kannst natürlich auch deine eigene Suchstra-
tegie entwickeln.
Im nächsten Unterkapitel werden wir die Operatoren behandeln.
Mit der Hilfe von Operatoren können wir noch genauere Abfragen
formulieren.
TIPP:
Wenn du in einem Themengebiet
suchst, über welches du kein eigenes
Vorwissen besitzt, so kann Wikipedia
eine gute Hilfestellung leisten. Gib
einfach das Hauptstichwort (siehe
Schritt 2) in Wikipedia ein und über-
fliege die Seite nach weiteren Schlüs-
selwörtern.
TIPP:
Es ist sehr wahrscheinlich – vor allem
am Anfang, dass du mehrere Suchan-
fragen starten musst um zum Ziel zu
kommen. Habe also etwas Geduld und
nimm dir die nötige Zeit.
Aufgabe 4.7
Im Jahresbericht der KS Rychenberg
sind Klassenlisten aufgeführt. Suche
die Liste deiner Klasse (über die
Suchmaske in Google und nicht über
die Homepage der Schule).
Aufgabe 4.8:
Suche mit Hilfe von Suchstrategie 2
eine Seite die Kino- und Fernsehpro-
gramme aus der Schweiz publiziert.
Aufgabe 4.9
Katalog oder Suchmaschine?
1. Petrologie
2. Schauspieler, der in der Fernsehse-
rie „Two and a Half Men“ den
Jungen „Jake“ spielt.
3. Du möchtest dich über alle
Schweizer Universitäten erkundi-
gen.
4. Liste aller Schweizer Olympiasie-
ger

22
Einfache Operatoren[65]
Logische Operatoren sind eigentlich nichts anderes, als „mathema-
tische Rechenarten“. Sie werden auch Boolsche Operatoren ge-
nannt, nach George Boole.[66]
Sie verknüpfen die verschiedenen
Suchbegriffe miteinander. Die gängigsten Google-Operatoren sind:
AND (kann in Google durch Leerschlag ersetzt werden.)
Der Operator AND verbindet zwei Suchbegriffe miteinander.
So wird ein Dokument gesucht, in welchem die beiden Begriffe
vorkommen.
NOT
Der Operator NOT (bei Google geht auch einfach ein Minus-
zeichen) schliesst einen Begriff aus. So wird nach dem ersten
Begriff gesucht, nicht aber nach dem Begriff, der nach dem
Operator steht.
OR
Mit dem Operator OR wird entweder nach dem einen, oder
nach dem anderen Begriff gesucht.
Erweiterte Suche[67]
Abbildung 7
Mit der erweiterten Google-Suche können wir gezielter und
schneller Suchen. Die erweiterte Suche findest du unter:
http://www.google.ch/advanced_search?hl=de.
Auf der nächsten Seite erfährst du im Detail was dir für verschie-
dene Möglichkeiten zur Verfügung stehen mit der erweiterten Su-
che. Wir wollen uns im Folgenden auf die nützlichsten Möglich-
keiten beschränken: Die Suche nach Sprache, Region, Dateiformat,
Datum, Position, Domains.
Klein schreiben
Du kannst die Stichwörter in der
Google-Suche alle klein schreiben.
Grossgeschriebene Wörter werden au-
tomatisch als klein interpretiert.
Aufgabe 4.10
Suche mit Hilfe der Operatoren nach
Ballsportarten, nicht aber nach Fuss-
ball.
Aufgabe 4.11
Suche einen Preisvergleichsbericht
über die Produkte aus der Migros und
dem Coop.
Aufgabe 4.12
Welches der sechs Rangierungs-
prinzipien könnte man missbrauchen,
so dass eine Suchmaschine eine Web-
site als relevanter einstuft?
Aufgabe 4.13
Suche das weltberühmte Foto, auf
dem Bauarbeiter auf einem Stahlträ-
ger des Rockefeller Centers Mittags-
pause machen.
Abbildung 8:
Bauarbeiter auf Stahlträger.

23
All diese Optionen kannst du miteinander mischen. Du musst dafür
im hellblau gefärbten Bereich der Googlesuche als erstes die
Suchbegriffe eingeben. Diese funktionieren genau gleich wie die
einfachen Operatoren:
mit allen Wörtern: Funktioniert genau gleich wie die Suche
mit AND. Liefert Treffer mit allen Stichwörtern. Bsp.: „Fuss-
ball, Ballsportarten“. So zeigt Google Seiten an, welche die
Stichworte Fussball und Ballsportarten enthalten.
mit der genauen Wortgruppe: Sucht nach den Stichworten in
der genauen Reihenfolge. Bsp.: „Übung macht den Meister“.
Diese Anfrage liefert Treffer, welche diese Wörter in derselben
Reihenfolge beinhalten. Alternativ kann die Wortgruppe auch
in der normalen Suchmaske mit Anführungs- und Schlusszei-
chen gesetzt werden.
mit irgendeinem der Wörter: Liefert entweder den einen oder
den anderen Suchbegriff. Bsp.: „Fussball, Ballsportarten“ lie-
fert Seiten, welche entweder mit Fussball oder mit Ballsportar-
ten zu tun haben. Funktioniert genau gleich wie „OR“.
ohne die Wörter: Liefert Suchergebnisse ohne die erwähnten
Wörter. Bsp.: „Fussball“ liefert Seiten auf denen Fussball nicht
vorkommt. Funktioniert genau wie „NOT“. Achtung: Geht nur
wenn du in einem der oberen drei Felder etwas eingibst.
Jetzt hast du die Suchbegriffe eingegeben, nach denen du suchen
möchtest. Nun kannst du deine Suchergebnisse mit den folgenden
Möglichkeiten einschränken:
Sprache: Hier kannst du deine Treffer auf eine Sprache be-
schränken. Zum Beispiel auf Deutsch.
Region: Hier kannst du deine Suchergebnisse auf ein Land be-
schränken. Zum Beispiel nur Schweizer Treffer.
Dateiformat: Um nach einem gewissen Format zu suchen. Zum
Beispiel nur nach Word-Dokumenten: Einfach „Microsoft
Word (.doc)“ auswählen.
Datum: Wenn du nach Seiten suchst, die z.B. im letzten Monat
in den Index aufgenommen wurden, einfach „im letzten Monat“
auswählen.
Position: Mit dieser Funktion kannst du den Ort auf der Seite
bestimmen, an dem dein Suchbegriff gefunden werden sollte.
Z.B. in der Internetadresse. Dafür einfach „in der URL der Sei-
te“ wählen.
Domains: Hier kannst du z.B. nach Seiten suchen, welche die
Domain „.com“ haben. Einfach „.com“ eingeben.
Aufgabe 4.14
Wie findest du heraus wer beim 3:3
zwischen dem FC Liverpool und der
AC Milan im Champions League
Final 2005 das 3:2 schoss?
Aufgabe 4.15
Suche alle PDF Dokumente, die
Google in den letzten 24 Stunden
indiziert hat.
Googlewhack[68]
Einen Googlewhack schafft man wohl
sehr selten. Wenn nach der Eingabe
eines oder zweier Wörter (ohne Anfüh-
rungszeichen!) als Suchergebnis nur ein
einziger Treffer zurück kommt, spricht
man von einem Googlewhack. Jeman-
den, der nach solchen Google-whacks
Ausschau hält, nennt man Googlewha-
cker. Eine Auflistung aktueller
Googlwhacks findet man unter folgen-
dem Link:
http://www.googlewhack.com/tally.pl
Google ignoriert dich
Deine Google-Suchanfrage darf übri-
gens höchstens 32 Stichwörter beinhal-
ten. Alles was darüber geht wird von
Google nicht beachtet.
Indexgrösse
Auch wenn Google zur tatsächlichen
Grösse seines Indexes schweigt, so
kann man doch erahnen in welchen
Dimensionen sich dieser bewegt. Die
Suche nach „the*“ liefert fast 25.5 Mil-
liarden Treffer. Das Sternchen steht
dabei für ein beliebiges anderes Stich-
wort.

24
Zusammenfassung
Rangierungsprinzipien
Es gibt unzählige Rangierungsprinzipien, die von Suchmaschinen
verwendet werden. Teilweise sind diese auch von Suchmaschine
zu Suchmaschine etwas anders. Vor allem die textunabhängigen
Kriterien (z.B.: wie oft eine Seite angeklickt wird) sind für uns
meist unsichtbar. Diejenigen, die jedoch vom Text abhängig sind,
sind für uns direkt wahrnehmbar und auch umso wichtiger für
unsere Suchstrategie. Deshalb beachten wir bei jeder Suchanfrage,
die wir stellen die oben gelernten Rangierungsprinzipien.
Suchstrategien
Es gibt unzählige Suchstrategien und nicht falsche oder richtige.
Wähle deine Strategie der Situation angepasst und nach deinen
Vorlieben.
Katalog versus Suchmaschine
Suchmaschinen – allen voran Google – stellen mittlerweile ein
sehr mächtiges und auch effizientes Suchinstrument dar. Deshalb
ist es vernünftig, in den meisten Fällen auch auf sie zurückzugrei-
fen. In einigen wenigen Fällen jedoch ist es besser, wenn man ei-
nen Katalog bemüht. Vor allem, wenn man einen Überblick über
den Inhalt eines Gebietes gewinnen möchte.
Einfache Operatoren
Mit den einfachen Operatoren (-, +) können wir unsere Suchanfra-
gen differenzierter gestalten.
Erweiterte Suche
Mit den erweiterten Suchoptionen eröffnen sich uns ganz neue
Suchmöglichkeiten. Mit der Profisuche schöpfen wir das riesige
Potential, das in Google steckt, noch einen Schritt besser aus, als
mit den einfachen Operatoren. Die Suchmaske der erweiterten
Suche ist ausserdem sehr einfach zu bedienen.
Aufgabe 4.16
Finde einen Plan mit den verschiede-
nen Buslinien von Winterthur.
Aufgabe 4.17
Wo suchst du um alle Verfilmungen
von „Wall Street“ zu finden?
„Mancher suchet, um zu finden; und
mancher findet, um nicht weiter suchen
zu müssen“[69]

25
5. Gefahren im Umgang mit Google.
Was weiss ich schon?
Diskutiere mit deinen Kollegen, was ihr über folgende Stichworte
schon wisst? Haltet eure Gedanken schriftlich fest.
Cookies, IP-Adresse
Umgang mit persönlichen Daten, Persönlichkeitsprofile
Google Street View
sichere Browser-Einstellungen
Meinungsfreiheit
Zensur im Internet
Was für verschiedene Suchmaschinen kennst du?
Nach diesem Kapitel weiss ich…
wie und warum Google Daten über seine Benutzer sam-
melt.
wie ich mich davor schützen kann.
wie ein Cookie funktioniert.
welche Möglichkeiten es gibt im Web anonym zu bleiben.
wo und warum im Internet zensiert wird.
was die Gefahren der Monopolstellung von Google sind.
Google kennt dich besser als du denkst…
Google sammelt Daten – schon seit Jahren. Und erstellt damit Nut-
zerprofile um die Suchergebnisse zu verbessern. Gefährlich wird
dies vor allem, wenn die Daten der verschiedenen Dienste verbun-
den würden. Denn dann hätte Google keine Nutzerprofile mehr,
sondern Persönlichkeitsprofile von Millionen von Menschen. So
oder so, Google hat so viele Informationen angehäuft wie niemand
zuvor.
Aufgabe:
Überlege dir wie du dich schützt, wenn du im Internet unterwegs
bist und bearbeite anschliessend das Kapitel.
Wusstest du, dass…
Google all deine Suchanfragen
speichert?
Suchergebnisse auch in der
Schweiz zensiert werden?

26
Datenschutz
Personalisierte Suche
Wie du in Kapitel zwei gesehen hast, ist es Googles Vision einer-
seits alle verfügbaren Informationen dieser Welt zusammenzutra-
gen und zu organisieren, andererseits haben die Google-Gründer
den Anspruch ihre Suchmaschine so weit zu perfektionieren, dass
sie alle Fragen beantworten kann.[71]
Das Ziel, so Googles Vision,
soll ein Instrument sein, das nicht nur für die Beantwortung einfa-
cher Fragen wie die nach den aktuellen Zugverbindungen, sondern
auch auf Fragen wie: „Welches Auto soll ich kaufen?“ irgendwann
einmal eine Antwort bereit halten soll. Nicht nächstes Jahr, sehr
wahrscheinlich auch nicht in nächster, aber vielleicht in ferner
Zukunft. Was eine Suchmaschine für eine sogenannte personali-
sierte Suche benötigt, sind Informationen. Informationen über den
Benutzer. Und zwar nicht einmal eine Menge davon. Um obige
Suchanfrage zu beantworten, müsste eine Suchmaschine nur einige
Vorlieben des Benutzers kennen: Sportwagen oder Geländewagen.
Seine Lieblingsfarbe, Lieblingsmarke. Diese drei einfachen Infor-
mationen reichen vollständig aus, um dem Benutzer Werbung mit
perfekt auf seine Wünsche zugeschnittenen Angeboten vorzu-
schlagen. Was ein Autohersteller, der den perfekten Wagen für den
oben erwähnten Benutzer hat, für diese drei einfachen Informatio-
nen zahlen würde – unvorstellbar.
Googles Datenerhebung
Personalisierte Suche ist schon längst Realität. Nicht im grossen
Stil, wie oben beschrieben, aber (bisher) im Kleinen. Was für
Suchresultate angezeigt werden, ist schon jetzt von Person zu Per-
son unterschiedlich. Ein spezielles Cookie (für Erklärung siehe S.
27) mit einer Lebensdauer von 180 Tagen speichert alle Seiten die
du anklickst, alle Stichwörter die du in Google eingibst und wann
du das tust. Darauf basierend sehen die Suchergebnisse bei jedem,
ganz auf seine Vorlieben abgestützt, wieder etwas anders aus.[72]
Aber nebst diesem Cookie sammelt Google noch viel mehr: Zu-
sätzlich zu den gespeicherten Daten für die personalisierte Suche,
speichert der Suchriese Suchanfragen für 18 Monate inklusive IP-
Adresse, Google-Domain, Zeitpunkt der Suchabfrage, Stichwörter
der Suche und Informationen über den Browser. Da ist es auch ein
schwacher Trost, dass die Lebensdauer der Cookies auf 18 Monate
heruntergesetzt wurde. Zuvor setzte Google Cookies, die bis ins
Jahr 2038 lebten. Denn bei jeder erneuten Suchanfrage beginnen
die 18 Monate von neuem. Wer bei einem Google-Dienst
Unter dem folgenden Link kannst du
deine Facebook-
Sicherheitseinstellungen testen:
http://www.reclaimprivacy.org/
„Die perfekte Suchmaschine würde
genau erkennen, was der Nutzer meint
und genau die gewünschten Ergebnisse
anzeigen.“[70]
Larry Page, Mitbegründer von Google.
Abbildung 9: Ein „Choco-Cookie“

27
angemeldet ist, der kann über Google Web History all seine Such-
anfragen, die jemals gestellt worden waren, nachschlagen. Diese
Daten hat somit auch Google. Wer ein GMail Konto besitzt liefert
dem Unternehmen zu seinen Daten den Namen. Beim E-Mail
Dienst werden alle Nachrichten mitgelesen. Google scannt die
Nachrichten mit einer Analyse-Software auf Stichwörter um in den
Mails Werbung platzieren zu können. Passend zum Inhalt. Wenn
du in einer Nachricht einem Freund von deinen geplanten Ferien
erzählst, ist die Wahrscheinlichkeit hoch, dass darin Werbung von
einem Reisebüro platziert wird. Besonders gefährlich werden diese
Daten, wenn sie miteinander verbunden würden. So liessen sich
ganze Persönlichkeitsprofile erstellen.
Schutzmassnahmen
Du bist der Sammelwut des kalifornischen Suchgiganten aber nicht
schutzlos ausgeliefert. Es gibt durchaus ein paar Sicherheitsvor-
kehrungen, die du treffen kannst, um im Internet Fremden nicht
alles preiszugeben und nicht auf Googles hervorragende Suchma-
schine verzichten zu müssen.
Als erstes solltest du die Cookies in den Griff bekommen. Coo-
kies sind nichts anderes als Informationen in Form von Textda-
teien, die von bestimmten Webseiten erstellt werden, um In-
formationen, wie persönliche Einstellungen auf der entspre-
chenden Webseite zu protokollieren. Diese werden dann auf
dem Browser abgelegt. Das nächste Mal, wenn die Seite aufge-
rufen wird, kann das Cookies die Informationen an den Server
des Webseitenbetreibers übergeben. Bei einem erneuten Abru-
fen der Webseite, kann das Cookie zudem den Besucher identi-
fizieren. Dadurch kann man sich zum Beispiel automatisch auf
einer Seite anmelden. Dies kann unter Umständen sehr nützlich
sein. So kann man heutzutage eine Vielzahl an Webseiten nur
noch besuchen, wenn man in den Browsereinstellungen Coo-
kies akzeptiert. So praktisch sie auch sein können, teilweise
stellen sie auch eine Gefahr dar. Vor allem mit langlebigen
Cookies kann der Serverbetreiber der Webseite von den Benut-
zern ein Nutzerprofil erstellen, die ihm seine Surfgewohnheiten
verraten. Denn beim auswerten der „Kekse“ sieht man was für
Seiten abgefragt worden sind. Auch die E-Mail-Adresse ist, auf
der Webseite einmal eingetragen, im Cookie gespeichert. Dies
kann der Betreiber der Webseite zusammen mit seinem Wissen
über die Vorlieben des Benutzers ausnutzen und gezielte Spam-
Mails an ihn verschicken.[73]
Die Cookies, die von Webseiten ge-
setzt wurden, kannst du in der Regel
auch wieder löschen. Dies kannst du
in deinem Webbrowser tun. Und zwar
unter Tools, Options, Privacy, Coo-
kies. Klicke auf „Show Cookies“.
Jetzt werden alle Cookies angezeigt,
die auf deinen Browser angesetzt
worden sind. Um sie zu löschen,
kannst du einfach „Remove all Coo-
kies“ drücken. Wenn du nach einer
Weile wieder nachschaust, siehst du,
wie schnell welche gesetzt werden.
Unter den Sicherheitseinstellungen
deines Browsers kannst du einstellen,
wie strikt du mit Cookies umgehen
möchtest. Aber Achtung, wenn du sie
ganz aussperrst, können gewisse
Webseiten nicht angezeigt werden. Es
gilt also einen Kompromiss zu finden
zwischen Sicherheit und Bequemlich-
keit.
Aufgabe 5.1
Versuche dich daran zu erinnern, was
du gestern gegoogelt hast? In der
letzten Woche? Im letzten Monat? Im
letzten Jahr? Die letzten 18 Monate?
Wenn du jetzt eine Liste machst mit
all diesen Stichwörtern, weisst du was
Google über dich weiss!
Natürlich kann Google damit keinen
Namen, sondern nur eine Nummer in
Verbindung bringen – sofern du kein
GMail-Konto hast.

28
Google kriegt neben deinen Suchbegriffen auch noch deine IP-
Adresse. Dadurch kann er deine Aktivitäten im Netz dir zuord-
nen. Aber auch dagegen kann etwas getan werden. Mit soge-
nannten Proxy-Servern. Wenn du mit einem Proxy-Server im
Web unterwegs bist, bleibt deine eigene IP-Adresse geheim. Du
„surfst“ dann sozusagen mit derjenigen des Proxy-Servers.[74]
Benutze, wenn du nicht anonym im Netz bist, Google (und
auch andere Suchmaschinenanbieter) mit Bedacht. Suchma-
schinen sind, auch wenn sie auf den ersten Blick anonym wir-
ken, kein Ort an dem man vertrauenswürdige Sachen deponie-
ren sollte. Gib nicht alles in eine Suchmaschine ein. Eigentlich
solltest du nichts in Google eingeben, was du nicht auch einem
Fremden erzählen würdest.
Zensur
Zensiert wird im Internet nicht nur in Staaten wie China, Burma,
Iran, Saudi-Arabien, Syrien, Kuba, Ägypten, Nord Korea oder dem
Vietnam.[75]
Nein, auch in Europa wird zensiert. Zugegeben nicht
in demselben Mass wie in diesen teilweise totalitären Staaten und
auch nicht aus demselben Grund, aber es wird zensiert. Während
in China oder anderswo aus politischen Gründen zensiert wird, so
werden in der westlichen Welt Seiten mit pornographischem In-
halt, Seiten der Kinderpornographie oder rechtsradikale, neosozia-
listische Seiten zensiert.[76]
Sogar die Schweizer Regierung stellt
immer wieder Anfragen gewisse Inhalte entfernen zu lassen. Sie
fordert aber auch immer wieder die Herausgabe von sensiblen
personenbezogenen Daten.[77]
In China wird alles zensiert, was der
Regierung nicht genehm ist. Begriffe wie „Free Tibet“ oder „Ti-
an’anmen Massacre“ werden in China von einer Firewall der Zen-
surbehörde systematisch geblockt. Du fragst dich jetzt sicher, was
das ganze mit Suchmaschinen zu tun haben soll. Eine ganze Men-
ge. Denn in einer Zeit, in der fast in allen Staaten dieser Welt die
Suchergebnisse „geschönt“ werden, wird der Druck auf die Such-
maschinen, allen voran auf Google, immer grösser. Sie werden von
den Regierungen teilweise gezwungen Seiten aus dem Index zu
löschen oder Daten herauszugeben. Suchergebnisse sind also auch
beeinflussbar.
Monopolstellung?
Benutze auch einmal eine andere Suchmaschine als Google. Es
gibt unzählige Alternativen. So kannst du etwas vergleichen. Wenn
du danach zum Schluss kommst, Google ist doch die Beste, kannst
du ja immer noch zurückwechseln. Wie sagt man so schön: Ab-
wechslung macht das Leben süss.
Schau auf der folgenden Seite mit und
ohne Proxy nach, was für Informatio-
nen du im Web preisgibst:
http://www.whatsmyip.de/
Hier findest du eine Seite mit einigen
Proxy-Servern:
http://www.onionproxy.com/
Auch in der Schweiz wurde und wird
teilweise politisch motivierte Zensur
betrieben. So wurde die Seite
www.appel-au-peuple.org mit einem
richterlichen Beschluss wegen ehrver-
letzenden Verschwörungstheorien
über die Schweizer Justiz gesperrt.
Mit einem ausländischen Proxy-
Server kann jedoch weiterhin darauf
zugegriffen werden.[78]
Mit dem China Channel Firefox Add-
on kann man die chinesische Zensur
nachempfinden.
http://chinachannel.hk/
Aufgabe 5.2:
Erkundige dich nach Alternativen zu
Google und probiere sie aus. Im An-
hang steht eine Liste mit unzähligen
anderen Suchprogrammen.

29
Zusammenfassung
Datenschutz
Google sammelt Daten, Daten und nochmal Daten. Doch dagegen
kann (und soll) man sich schützen.
Dazu gibt es unterschiedliche Methoden, die natürlich auch kom-
biniert angewandt werden können:
Alte Cookies löschen und die Einstellungen des Internet-
browsers optimieren.
Sich anonym im Netz bewegen. Entweder durch ein Pro-
xy-Server oder durch einen Anonymizer.
Sich überlegen, was man in die Google Suchmaske ein-
tippt. Denn: Die Google Datenbanken vergessen niemals!
Zensur
In China und anderen totalitären Ländern wird Zensur betrieben.
Gegen alle politischen Feinde. Aber auch in den USA und Europa
wird zensiert. Vorrangig Kinderpornographie, andere pornographi-
sche Inhalte, rechtsradikale und andere „populistisch gefährliche“
Seiten. Aber nicht nur. Auch hier werden manchmal Seiten aus den
Suchergebnissen gelöscht, die politisch „nicht korrekt“ sind. Aber
Zensur kann, sofern man von der Seite schon die Internet-Adresse
kennt, umgangen werden. Mit einem Proxy-Server. Der muss
jedoch (in den meisten Fällen) eine ausländische Domain haben,
da Internetprovider – auf Druck von Regierungen – Seiten meis-
tens für eine gewisse Domain sperren (z.B. für alle Computer mit
einer Schweizer IP-Adresse).
Monopolstellung Google
Über Google laufen vier von fünf Suchanfragen – weltweit![79]
Das
bedeutet, dass Google für jeden zweiten Menschen mit einem In-
ternetanschluss die Informationen organisiert.[80]
Vorderhand ma-
chen so viele Menschen Gebrauch von Google, weil die Suchma-
schine den mit Abstand grössten Index hat, am schnellsten ist, die
relevantesten Suchergebnisse liefert, die Startseite und das Layout
allgemein schlicht und einfach ist und Google cool, hip und beliebt
ist. Vielfach kennen die Benutzer jedoch auch gar keine andere
Suchmaschine. Google wurde zum Inbegriff des Suchens. Zurück
zum Thema: Wenn eine Firma den Informationsfluss von beinahe
einer Milliarde Menschen regelt, ist Vorsicht geboten. Denn für die
meisten ist Google die einzige Informationsquelle.
Abbildung 10: Googeln in China.
Abbildung 11

30
Anhang A:
a. Glossar:
A:
AdWords
AdWords ist Googles Anzeigensystem mit dem es sein Geld ver-
dient. Mit Adwords kann man zu gewissen Stichwörtern Anzeige-
plätze ersteigern, an denen dann die eigene Werbung steht. Die
Werbung ist immer von den Suchergebnissen getrennt in der rech-
ten Spalte platziert.
Archiv
Ein Archiv ist eine Art Katalogdienst, auf den online zugegriffen
werden kann.
B:
Backbone
Das Backbone ist die Autobahn des Internetverkehrs. Ein Backbo-
ne kann mit einem riesigen Kabel verglichen werden, durch das die
ganzen Daten laufen.
Bit
Ein Bit ist eine Grösse aus der elektronischen Datenspeicherung.
Daten speichert man durch zwei verschiedene Zustände. Entweder
fliesst Strom oder es fliesst kein Strom durch die Schalter der
Harddisk (Hauptspeicher). Diese beiden Zustände werden mathe-
matisch durch eine 1 oder eine 0 dargestellt. Die Information ob
Strom fliesst oder nicht nennt man ein Bit. Acht Bits ergeben ein
Byte. Um bei grossen Datenmengen besser rechnen zu können, hat
man Bytes weiter zusammengefasst: 1024 Bytes sind ein Kilobyte
(KB), 1024 KB sind ein Megabyte (MB), 1024 MB sind ein Giga-
byte (GB), 1024 GB sind ein Terabyte (TB), 1024 TB sind ein
Petabyte (PB) und 1024 PB sind ein Exabyte (EB).
Browser
Ein Browser ist ein Programm für die Darstellung von Webseiten.
Mit ihm navigiert man durch das Web. Beispiele sind: Internet
Explorer, Firefox, Opera oder Safari.
D:
Domain
Als Domain wird ein im Web zusammenhängender Teil bezeich-
net. Anhand der Top-Level-Domain sieht man in welchem Land
der Rechner steht.

31
Durchschaltevermittlung
Die Durchschaltevermittlung ist eine Möglichkeit, wie man die
Daten über ein Netzwerk vermitteln kann. Bei der Durchschalte-
vermittlung wird immer eine Leitung für die Datenvermittlung
oder ein Telefongespräch (die Durchschaltevermittlung kommt aus
der Telekommunikation) freigeschaltet. Dabei kann die Leitung
jeweils nur für einen Datentransfer auf einmal genutzt werden.
Dies änderte sich mit der Paketvermittlung. Bei der die Nachrich-
ten in kleine Pakete aufgeteilt werden und unabhängig zu welchem
Gespräch sie gehören durch die Leitung gehen und am Zielort
wieder zusammengesetzt werden. So kann eine Leitung für mehre-
re Datentransfers auf einmal genutzt werden.
E:
Exabyte
siehe Bit.
G:
Gateways
Unter einem Gateway versteht man ein Protokollübersetzer. So
können Netzwerke mit unterschiedlichen Protokollen miteinander
kommunizieren.
Glasfaserkabel
Kabel aus Glasfäden mit denen sehr hohe Datenraten übertragen
werden können.
H:
History
In der History sind alle Suchbegriffe gespeichert, die früher einmal
eingegeben worden sind.
Hypertextsystem
Ein Hypertextsystem verbindet verschiedene Seiten durch Links.
So kann man durch das Anklicken von Links auf eine andere Seite
gelangen.
I:
Internetbrowser
siehe Browser.
K:
Knoten
Ein Rechner der über ein Netzwerk mit anderen Rechnern verbun-
den ist.

32
L:
LAN
LAN steht für Local Area Network. Ein LAN ist ein lokales Netz-
werk über das man mit Rechnern Daten austauschen kann. Dies
kann entweder (wie heute üblich) über Wireless-LAN oder über
ein normales LAN mit Netzwerkkabeln sein.
M:
MAN
Ein MAN ist ein Netzwerk, das sich über eine ganze Region er-
streckt (Metropolitan Area Network).
P:
Paketvermittlung
siehe Durchschaltevermittlung.
Peer-To-Peer
Ein Peer-To-Peer-Netzwerk steht im Gegensatz zu einem traditio-
nellen Client-Server basierten Netzwerk, bei dem der Server den
Dienst anbietet und der Client ihn nutzt. In einem P2P-Netzwerk
hingegen sind alle Rechner gleichberechtigt. Sie sind vor allem
typisch für Dienste wie Musiktauschbörsen, bei denen alle die
Musik über viele verschieden Rechner gleichzeitig heruntergela-
den wird und nicht wie sonst von nur einem Server.
Protokoll
Protokolle sind für die Kommunikation zwischen den verschiede-
nen Rechnern im Web zuständig. Sie legen fest, wie und in wel-
cher Reihenfolge der Datenaustausch erfolgt.
S:
Spam-Mail
Eine Spam-Mail ist eine Werbemail, welche in der Regel ohne
Zustimmung des Empfängers zugestellt wird.
T:
TCP/IP
Die Protokolle „Transmission Control Protocol“ und „Internet
Protocol“ sind für die Paketvermittlung in Netzwerken zuständig.
Das Internet Protocol schaut, dass die Daten am richtigen Ort an-
kommen. Das Transmission Control Protocol unterteilt die Nach-
richt in kleine Pakete, setzt sie am Zielort wieder zusammen und
kontrolliert ob alle Pakete angekommen sind.

33
W:
WAN
Ein Wide Area Network erstreckt sich im Gegensatz zu einem
LAN oder MAN über ein grosses Gebiet. Manchmal sogar über
ganze Regionen oder Länder.
WWW
Unter dem World Wide Web (auch WWW oder einfach Netz ge-
nannt) versteht man die Software, welche verwendet wird um die
einzelnen Webseiten miteinander zu verknüpfen. Somit wird das
WWW auch als Hypertextsystem bezeichnet. Die einzelnen Seiten
sind durch sogenannte Hyperlinks (Links) miteinander verbunden.
Wichtig ist die Unterscheidung zwischen dem WWW und dem
Internet. Das Internet ist lediglich die Hardware. Also die Infra-
struktur, welche die verschiedenen Rechner, auf welchen die Sei-
ten liegen, mit einander verbindet.

34
b. Nützliche Links
Internationale Suchdienste
Google http://www.google.com/
Yahoo! http://www.yahoo.com/
Bing (Microsoft) http://www.bing.com/
All The Web http://www.alltheweb.com/
AltaVista http://www.altavista.com/
Northern Light Search http://www.nlsearch.com/
Ask http://www.ask.com/
EntireWeb http://www.entireweb.com/
Schweizer Suchdienste
The Swiss Search Engine http://www.swisspage.ch/
Google Schweiz http://www.google.ch/
Yahoo Schweiz http://ch.search.yahoo.com/
AltaVista http://ch.altavista.com/
Schweizer Homepage Directory http://www.swisspage.ch/
Die Schweizer Suchmaschine http://www.yoodle.ch/
Meta-Suchmaschinen
Ixquick http://www.ixquick.com/
Web Crawler http://www.webcrawler.com/
Meta Crawler http://www.metacrawler.com/
Apollo 7 http://www.apollo7.de/
Highway 61 http://www.highway61.com/
MetaGer http://www.metager.de/
Internationale Verzeichnisdienste
Yahoo! http://www.yahoo.com/
Excite http://www.excite.com/
All One Search http://www.allonesearch.com/
Alles klar http://www.allesklar.de/
Sharelook http://www.sharelook.co.uk/
Schweizer Verzeichnisdienste
Sharelook http://www.sharelook.ch/
Vertikale Suchmaschinen International
Software http://www.tucows.com/
Filme http://www.imdb.com/
Medizin und Gesundheit http://www.medivista.de/
Zeitungsartikel http://www.paperball.de/

35
Vertikale Suchmaschinen Schweiz
Firmen, Produkte, Marken http://www.swissguide.ch/
Schweizer Musikszene http://www.music.ch/
Literapedia http://literapedia.wikispaces.com
Internet-Archive
Zeitungsartikel http://www.paperball.de/
FAZ-Archiv http://fazarchiv.faz.net/FAZ.ein
NZZ-Archiv http://nzz.gbi.de/NZZ.ein
Die Zeit http://www.zeit.de/2010/index
Der Spiegel http://www.spiegel.de/
3Sat-Mediathek http://www.3sat.de/mediathek/
GEO http://www.geo.de/
Bibliothekskataloge
Schweizer Vitueller Katalog http://www.chvk.ch/
Deutsche-Internet-Bibliothek http://www.internetbibliothek.de/
NEBIS http://opac.nebis.ch/
ETH-Bibliothek http://www.library.ethz.ch/
Schweizerisches Sozialarchiv http://www.sozialarchiv.ch/
Zentralbibliothek Zürich http://www.zb.unizh.ch/
Winterthurer Bibliotheken http://bibliotheken.winterthur.ch/
Enzyklopädien/Lexika
Wikipedia http://en.wikipedia.org/
Encyclopedia Britannica http://www.britannica.com/
Brockhaus Enzyklopädie http://www.brockhaus.de/
Meyers Lexikon Online http://www.iicm.tugraz.at/
One Look http://www.onelook.com/
Wörterbücher
LEO http://www.leo.org/
CANOO http://www.canoo.net/
Google Translate http://translate.google.com/
Babelfish http://babelfish.yahoo.com/
LENGUA http://www.lengua.com/
Computer-Wörterbuch http://foldoc.org/
Abbildung 12:
Titelseite der „Encyclopédie“ von
Diderot und D’Alembert.

36
c. Quellenangabe:
Abbildungen:
Titelbild: Rechenzentrum: http://farm4.static.flickr.com/3380/3419237278_d5da5f22bb_o.jpg
Google-Logo aus Lebensmittelverpackungen: http://picasaweb.google.com/gblogphotos/ Googley
ArtWalls?feat=flashalbum#5509770875559110002
Abbildung 1: http://interaktiv.mlpd.de/rf0502/rfart15.htm
Abbildung 2: Graphik zur Funktionsweise von Google. Aus der Doktorarbeit der Google-Gründer übernommen
(stark vereinfacht): http://infolab.stanford.edu/~backrub/google.html
Abbildung 3: http://www.google.ch/intl/de/corporate/tech.html
Abbildung 4: http://geektechnique.org/media/google/googlehardware.html
Abbildung 5: http://communication.howstuffworks.com/google-docs5.htm
Abbildung 6: Graphik (leicht modifiziert) übernommen aus: Hübener, Markus: Suchmaschinenoptimierung kom-
pakt. Heidelberg 2009. S. 18.
Abbildung 7: http://www.suchfibel.de/2kunst/feldsuche.htm
Abbildung 8: http://lequattrostagioni.wordpress.com/2009/11/06/1931-2001-bilder-die-bewegen/
Abbildung 9: http://commons.wikimedia.org/wiki/File:Choco_chip_cookie.jpg
Abbildung 10: http://bureau.comandantina.com/archivos/2006/02/
Abbildung 11: http://marketgoodstocks.com/humor-news/google-china-changing-im-feeling-lucky-to-im-feeling-
communist/
Abbildung 12: http://en.wikipedia.org/wiki/File:ENC_1-NA5_600px.jpeg
Endnoten:
[1] Viele glauben der Brite Donald Davies hätte das Paketvermittlungsverfahren als erster entdeckt. Fakt ist
aber: Er war zwar der Namensgeber des neuartigen Verfahrens, der Amerikaner Paul Baran hatte dieses je-
doch zuerst entwickelt. Er erfuhr jedoch nicht dieselbe Unterstützung der Telefongesellschaften wie sein
englischer Konkurrent, da die amerikanische Telefongesellschaft AT&T vorerst kein Interesse an der
Technik der Paketvermittlung hatte. Siehe dazu: Wikipedia, Die freie Enzyklopädie, „Packet switching“,
Bearbeitungsstand: 14.10.2010, 18:13 UTC. http://en.wikipedia.org/wiki/Packet_switching (17.10.10).
Oder auch in: Hafner, Katie und Lyon, Matthew: ARPA KADABRA oder die Anfänge des Internet. Hei-
delberg 2008. S. 72-75.
[2] H'obbes' Zakon, Robert: Hobbes‘ Internet Timeline 10. http://www.zakon.org/robert/internet/timeline/
(17.10.10).
[3] Hafner und Lyon S. 198.

37
[4] H'obbes' Zakon, Robert: Hobbes‘ Internet Timeline 10. http://www.zakon.org/robert/internet/ timeline/
(17.10.10). Oder folgende Seite: California State University Dominguez Hills: ARPANET maps.
http://som.csudh.edu/fac/lpress/history/arpamaps/f8sep1971.jpg (17.10.10). Auf letzterer sind zwar 18
Hosts zu sehen. Drei davon scheint jedoch eine Sonderfunktion zuzukommen und sind auf der Karte mit
einem „T“ versehen. Gut möglich, dass auch die erste Seite vom selben Bericht (ARPANET Completion
Report) ausgeht, die drei speziellen Hosts jedoch nicht mitzählt.
[5] Hafner und Lyon S. 210.
Die meisten Amerikaner erfuhren zum ersten Mal überhaupt von der Existenz des ARPANET im Jahre
1975. Und zwar durch einen Skandal: Militärische Geheimdienste sammelten während der Zeit des Kalten
Krieges Informationen wie selten zuvor. Sie hatten nicht nur Daten über den kommunistischen Osten, son-
dern auch innerhalb der USA wurden die örtlichen Geschehnisse vom Pentagon aus genau mit verfolgt. Als
dies 1972 an die Öffentlichkeit kam, wurde die Löschung dieser Daten verlangt. 1975 gingen jedoch Be-
hauptungen umher, wonach die Daten gar nicht gelöscht, sondern vom Geheimdienst an einen anderen Ort
geschickt worden waren – per ARPANET. Siehe dazu Ebd. S. 274.
[6] Weiterführende Lektüre zu den Internet-Protokollen TCP/IP: Universität Karlsruhe: TCP/IP.
http://www.lehrer.uni-karlsruhe.de/~za151/netz/tcpip.html (17.10.10).
[7] Hafner und Lyon S. 264–269.
[8] Wikipedia, Die freie Enzyklopädie, „NORSAR“, Bearbeitungsstand: 14.05.2010, 12:49 UTC.
http://en.wikipedia.org/wiki/NORSAR (17.10.10).
[9] Hafner und Lyon S. 10. Entkräftet den weitverbreiteten Mythos über die Ziele des ARPANET.
Oder auch: Internet Society: A Brief History oft he Internet.
http://www.isoc.org/internet/history/brief.shtml (17.10.10)
Auch ein ehemaliger Direktor der DARPA (ehemals ARPA) konnte den Mythos, das ARPANET sei nur
als Kommunikationsmöglichkeit nach einem nuklearen Anschlag erbaut worden, als falsche Annahme er-
klären: About.com: Charles Herzfeld on ARPANET and Computers. http://inventors.about.com/library/
inventors/bl_Charles_Herzfeld.htm (17.10.10).
[10] Hafner und Lyon S. 176f.
[11] Wikipedia, Die freie Enzyklopädie, „EUnet“, Bearbeitungsstand: 05.07.2010, 11:49 UTC.
http://en.wikipedia.org/wiki/EUnet (17.10.10).
[12] Wann genau der Begriff Internet aufkam, ist schwierig zu sagen, da das Aufkommen eines Begriffes selten
dokumentiert wird und oftmals einen langsamen Prozess darstellt, der sich über Jahre hinweg ziehen kann.
Es wird jedoch vermutet, dass er Mitte der 80er-Jahre populär wurde. Zudem hatte sich eine Unterschei-
dung zwischen Gross- und Kleinschreibung entwickelt: Ein „internet“ war ein privates, kleines Netzwerk,
das TCP/IP benutzte. Das „Internet“ schafte es zum festen Begriff, wie die Grossschreibung in englischer
Sprache verrät und ist definiert als das grosse, staatliche Netzwerk. Man könnte es auch Backbone nennen.
Siehe dazu: Hafner und Lyon S. 289.
[13] Wikipedia, Die freie Enzyklopädie, „TAT-8“, Bearbeitungsstand: 26.08.2010, 19:38 UTC.
http://en.wikipedia.org/wiki/TAT-8 (28.11.10).
[14] Hafner und Lyon S. 301–303.

38
[15] Wikipedia, Die freie Enzyklopädie, „Archie“, Bearbeitungsstand: 18.05.2010, 11:29 UTC.
http://de.wikipedia.org/wiki/Archie (17.10.10).
[16] H'obbes' Zakon, Robert: Hobbes‘ Internet Timeline 10. http://www.zakon.org/robert/internet/ timeli-
ne/#1990s (17.10.10).
[17] Wikipedia, Die freie Enzyklopädie, „WWW“, Bearbeitungsstand: 25.09.2010, 22:20 UTC.
http://de.wikipedia.org/wiki/World_Wide_Web (17.10.10).
Oder auch: Hafner und Lyon S. 305f.
[18] Wikipedia, Die freie Enzyklopädie, „Chronologie des Internets“, Bearbeitungsstand: 14.09.2010, 20:55
UTC. http://de.wikipedia.org/wiki/Chronologie_des_Internets (17.10.10).
[19] Wikipedia, Die freie Enzyklopädie, „Chronologie des Internets“, Bearbeitungsstand: 14.09.2010, 20:55
UTC. http://de.wikipedia.org/wiki/Chronologie_des_Internets (17.10.10).
[20] Wikipedia, Die freie Enzyklopädie, „Alta Vista“, Bearbeitungsstand: 14.09.2010, 01:30 UTC.
http://en.wikipedia.org/wiki/AltaVista (17.10.10).
[21] Wikipedia, Die freie Enzyklopädie, „Yahoo“, Bearbeitungsstand: 14.10.2010, 22:21 UTC.
http://de.wikipedia.org/wiki/Yahoo (17.10.10).
[22] Den vollständigen Chat findet man in: Hafner und Lyon S. 218-220.
[23] Wikipedia, Die freie Enzyklopädie, „Spam“, Bearbeitungsstand: 16.10.2010, 20:25 UTC.
http://en.wikipedia.org/wiki/Spam_(electronic) (17.10.10).
[24] Neue Zürcher Zeitung: Google lässt Duden-Eintrag „googeln“ ändern. http://www.nzz.ch/2006/08/16/
vm/newzzEQXM1K6L-12.html (17.10.10).
Auf Wunsch des Unternehmens wurde der Begriff in der nächsten Auflage des Dudens mittels „mit Google
im Internet recherchieren“ genauer definiert, um eine Gattungsbegriffbildung zu verhindern, die schon
längst Tatsache geworden ist.
[25] Wikipedia, Die freie Enzyklopädie, „Browserkrieg“, Bearbeitungsstand: 09.10.2010, 19:11 UTC.
http://de.wikipedia.org/wiki/Browserkrieg (17.10.10).
[26] Wikipedia, Die freie Enzyklopädie, „Napster“, Bearbeitungsstand: 16.10.2010, 09:06 UTC.
http://de.wikipedia.org/wiki/Napster (17.10.10).
[27] Das Peer-To-Peer-Verfahren wird ausführlich erklärt auf: Wikipedia, Die freie Enzyklopädie, „Peer-to-
Peer“, Bearbeitungsstand: 12.10.2010, 12:41 UTC. http://de.wikipedia.org/wiki/Peer-to-Peer (17.10.10).
[28] Wikipedia, Die freie Enzyklopädie, „Jimbo Wales“, Bearbeitungsstand: 16.10.2010, 10:43 UTC.
http://de.wikipedia.org/wiki/Jimbo_Wales (17.10.10).
[29] Wikipedia, Die freie Enzyklopädie, „Web 2.0“, Bearbeitungsstand: 16.10.2010, 01:42 UTC.
http://de.wikipedia.org/wiki/Web_2.0 (17.10.10).
[30] Marketing Boerse: 2007 täglich 97 Milliarden E-Mails weltweit.
http://www.marketing-boerse.de/News/details/2007-t%E4glich-97-Milliarden-E-Mails-weltweit/6555
(17.10.10).

39
[31] Im Jahr 2009 wurden durchschnittlich 11‘627 Petabyte Daten pro Monat über das (öffentlich zugängliche)
Internet transportiert, was einem täglichen Datenaufkommen von mehr als 415 Petabyte entspricht (415 Pe-
tabyte entsprechen der tausendfachen Datenmenge aller Bücher, die jemals in jeder Sprache auf der Welt
geschrieben wurden). Die Tendenz ist weiter steigend: Bis zum Jahr 2014 wird sich die weltweit verschick-
te Datenmenge um ungefähr den Faktor 3.5 auf 485 Exabyte erhöhen. Ein Grossteil dieser Daten wird
durch Videos verursacht.
Siehe dazu: Wikipedia, Die freie Enzyklopädie, „Internet“, Bearbeitungsstand: 16.10.2010, 07:28 UTC.
http://de.wikipedia.org/wiki/Internet (17.10.10).
Das Telekommunikationsunternehmen Cisco Systems, welches in der Branche von Routern und Internet-
verkehr eine feste Grösse ist, spricht im Jahr 2009 von 176 Exabyte Daten. Zudem erstaunlich: Um sich das
gesamte Videomaterial, das im Jahr 2014 in einer Sekunde über das Web verschickt werden wird, anzuse-
hen, bräuchte man mehr als zwei volle Jahre: Cisco Systems: Forecast and Methodology, 2009-2014.
http://www.cisco.com/en/US/solutions/collateral/ ns341/ns525/ns537/ns705/ns827/white_paper_c11-
481360_ns827_Networking_Solutions_White_ Paper. html (17.10.10).
[32] Das Löschen von Spam-Mails raubt weltweit 100 Milliarden Stunden Arbeitszeit: Wikipedia, Die freie
Enzyklopädie, „Spam“, Bearbeitungsstand: 14.10.2010, 18:48 UTC. http://de.wikipedia.org/wiki/ Spam
(17.10.10). Spam-Mails sind jedoch nicht nur nervig und halten einem vom Wesentlichen ab, nein sie sind
auch umweltschädlich: Laut einer Studie von McAfee könnten in den USA mit dem weltweiten Energie-
verbrauch, der beim versenden, sichten, lesen und bekämpfen von Spam-Mails entsteht 2,4 Millionen Häu-
ser versorgt werden. Spam-Filter sind deshalb auch umwelttechnisch gesehen ein Vorteil: Alle Filter zu-
sammen sparen die Energie von 13 Millionen Autos pro Jahr. Für weitere Informationen:
McAfee: The Carbon Footprint of Email Spam Report.
http://newsroom.mcafee.com/images/10039/carbonfootprint2009.pdf (17.10.10).
[33] Die Fakten und Zahlen der „Google-Timeline“ stammen, sofern nicht anders vermerkt, aus: Kowalsky,
Marc: Krieg der Welten. Der Kampf zwischen Apple und Google um die Vorherrschaft in der IT-Industrie
ist voll entbrannt – mit Konzepten, die unterschiedlicher nicht sein könnten. In: BILANZ. Das Schweizer
Wirtschaftsmagazin Nr. 14. Zürich 2010. S. 28-35. Hier S. 31-33.
[34] Maass Christian et al.: Der Markt für Internet-Suchmaschinen. In: Lewandowski, Dirk (Hrsg.): Handbuch
Internet-Suchmaschinen. Nutzerorientierung in Wissenschaft und Praxis. Heidelberg 2009. S. 3-17. Hier S.
7.
Google AdWords ist ein Auktionssystem, bei dem die Anzeigen versteigert werden. Wie bei allen Aukti-
onssystemen wird auch hier der Markt voll ausgelastet. Denn der Preis kann niemals zu hoch oder zu tief
sein. Sondern pendelt sich immer auf dem Niveau ein, das der Markt bereit ist zu zahlen. Für genauere In-
formationen siehe: Brandt, Richard: Googles kleines Weissbuch. Die Managementstrategien der wertvolls-
ten Marke der Welt. München 2010. S. 86.
[35] Becker, Hendrik und Arnold, Arne: Die Akte Google. In: PC WELT Nr. 8. München 2010. S. 72-82. Hier
S. 75.
[36] In ihrer Doktorarbeit äussern sich die Google-Gründer über die Hintergründe der Namensgebung: Brin,
Sergey und Page, Lawrence: The Anatomy of a Large-Scale Hypertextual Web Search Engine.
http://infolab.stanford.edu/~backrub/google.html (16.11.10).
Zudem findet man auf Wikipedia etwas zur Herkunft des Begriffs „Googol“: Wikipedia, Die freie Enzy-
klopädie, „Googol“, Bearbeitungsstand: 16.10.2010, 12:26 UTC.
http://de.wikipedia.org/wiki/Googol (17.10.10).

40
[37] Wikipedia, Die freie Enzyklopädie, „WWW“, Bearbeitungsstand: 14.11.2010, 02:15 UTC.
http://de.wikipedia.org/wiki/World_Wide_Web (28.11.10).
[38] Zitat aus Hafner und Lyon S. 304.
1989 von Danny Cohen vorgetragen als Hommage an das ARPANET auf dem Act One Symposium an der
UCLA (University of California Los Angeles) anlässlich des 20. Geburtstags des ARPANET, leicht ange-
passt und überarbeitet von den Autoren des Buches.
[39] Wikipedia, Die freie Enzyklopädie, „Geschichte des Internets“, Bearbeitungsstand: 14.11.2010, 13:20
UTC. http://de.wikipedia.org/wiki/Geschichte_des_Internets (28.11.10).
[40] Wikipedia, Die freie Enzyklopädie, „Suchmaschine“, Bearbeitungsstand: 01.10.2010, 20:56 UTC.
http://de.wikipedia.org/wiki/Suchmaschine (18.10.10).
[41] Ebd.
[42] Wikipedia, Die freie Enzyklopädie, „Webkatalog“, Bearbeitungsstand: 25.09.2010, 08:31 UTC.
http://de.wikipedia.org/wiki/Webkatalog (18.10.10).
[43] Wikipedia, Die freie Enzyklopädie, „Suchmaschine“, Bearbeitungsstand: 01.10.2010, 20:56 UTC.
http://de.wikipedia.org/wiki/Suchmaschine (18.10.10).
[44] Wikipedia, Die freie Enzyklopädie, „Metasuchmaschine“, Bearbeitungsstand: 25.09.2010, 08:31 UTC.
http://de.wikipedia.org/wiki/Metasuchmaschine (18.10.10).
[45] Wikipedia, Die freie Enzyklopädie, „Suchmaschine“, Bearbeitungsstand: 01.10.2010, 20:56 UTC.
http://de.wikipedia.org/wiki/Suchmaschine (18.10.10).
[46] SirValUse: Wer sucht, der findet! Google liefert nach wie vor die besten Suchergebnisse.
http://www.sirvaluse.de/presse/nutzenforschung-report/09-suchen-im-internet/das-interview/index.html
(28.11.10).
[47] Google: Unternehmensbezogene Informationen. http://www.google.ch/intl/de/corporate/tech.html
(28.11.10).
[48] Brin, Sergey und Page, Lawrence: The Anatomy of a Large-Scale Hypertextual Web Search Engine.
http://infolab.stanford.edu/~backrub/google.html (16.11.10).
[49] Google: Unternehmensbezogene Informationen. http://www.google. ch/intl/de/corporate/tech.html
(28.10.10).
[50] Search Engine Optimization: Relevanzkriterien – Basis für Onpage- und Offpage-Optimierung.
http://www.seo-duesseldorf.de/suchmaschinenoptimierung/relevanzkriterien.html (18.10.10).
[51] SEO für Google: Suchmaschinenoptimierung (SEO). http://www.jugendwettbewerb.de/ (18.10.10).
[52] Brin, Sergey und Page, Lawrence: The Anatomy of a Large-Scale Hypertextual Web Search Engine.
http://infolab.stanford.edu/~backrub/google.html (16.11.10).
[53] Reischl, Gerald: Die Google Falle. Die unkontrollierte Weltmacht im Internet. Wien 2008. S. 32.
Kontrovers dazu: Brin, Sergey und Page, Lawrence: The Anatomy of a Large-Scale Hypertextual Web
Search Engine. http://infolab.stanford.edu/~backrub/google.html (16.11.10).

41
In ihrer Doktorarbeit argumentieren die beiden Google-Gründer, dass je mehr Links auf eine Seite verwei-
sen, desto höher müsse automatisch auch ihre Wichtigkeit sein. Besonders, da bei Backlinks von Seiten mit
einem hohen Ranking, sprich meistens renommierte Seiten, ein Teil deren Wert weitervererbt wird. Es gibt
also Bonuspunkte für Links von gutbewerteten Seiten.
[54] Ebd.
[55] Ebd.
[56] Das Beispiel wurde aus folgendem Buch, leicht modifiziert, übernommen: Hübener, Markus: Suchmaschi-
nenoptimierung kompakt. Heidelberg 2009. S. 18.
[57] Google: Unternehmensbezogene Informationen. http://www.google.ch/intl/de/corporate/tech.html
(18.10.10).
[58] Die Aufgabe wurde, leicht abgeändert, übernommen aus: Hübener S. 18.
[59] Wikipedia, Die freie Enzyklopädie, „PageRank“, Bearbeitungsstand: 08.09.2010, 20:25 UTC.
http://de.wikipedia.org/wiki/PageRank (18.10.10).
[60] The Official Google Blog: Our new search index: Caffeine. http://googleblog.blogspot.com/2010/06/our-
new-search-index-caffeine.html (18.10.10).
Laut dieser Quelle, wurde früher der Google Index nur alle paar Wochen aktualisiert. Mit der Einführung
des neuen Systems „Caffeine“ geschieht dies nun regelmässiger, in kleineren Portionen. So kommen jeden
Tag einige Hunderttausend Gigabyte an neuen, aktualisierten Daten hinzu.
[61] Official Google Webmaster Central Blog: Using site speed in web search ranking.
http://googlewebmastercentral.blogspot.com/2010/04/using-site-speed-in-web-search-ranking.html
(18.10.10).
[62] Ebd.
Laut dem offiziellen Google-Blog fliesst neuerdings, neben den übrigen Relevanzkriterien, auch die Lade-
geschwindigkeit einer Seite in ihr Ranking mit ein. Dieser Faktor wird jedoch erst auf der englischsprachi-
gen Seite Google.com angewandt und hat, laut Google, einen sehr geringen Einfluss. Was diese neue Me-
thode jedoch tatsächlich für Auswirkungen mit sich bringt, ist noch nicht klar. Einige befürchten, dass Bil-
der und Videos grösstenteils aus dem Web verschwinden könnten, würde sich das „Speed-Ranking“ welt-
weit durchsetzten, da diese die Ladegeschwindigkeit enorm beeinträchtigen. Siehe dazu: tagSEOBlog:
Neuer Rankingfaktor „page speed“ – Googles Bildersturm? http://www.tagseoblog.de/ neuer-
rankingfaktor-ladezeit-googles-bildersturm-im-internet (18.10.10).
[63] Hartmann, Werner et al.: Informationsbeschaffung im Internet. Grundlegende Konzepte verstehen und
umsetzen. Zürich 2000. S. 38.
[64] Die Idee für die Aufgaben zum Herleiten der Relevanzkriterien stammt von mir. Die sechs Rangierungs-
prinzipien sind jedoch dem folgenden Buch entnommen: Ebd. S. 38-43. Die tatsächlichen Beispiele wurden
von mir jedoch frei erfunden und der Text dazu der (entsprechenden) Abfrage bei Google entnommen.
Teilweise musste auch auf leicht modifizierte Ergebnisseiten gewechselt werden, um explizitere Beispiele
zu generieren.
[65] Long, Johnny: Google Hacking. Bonn 2005. S. 28-30 und S. 88-91.

42
[66] Wikipedia, Die freie Enzyklopädie, „Boolescher Operator“, Bearbeitungsstand: 01.05.2010, 09:00 UTC.
http://de.wikipedia.org/wiki/Boolescher_Operator (19.10.10).
[67] Übernommen von: Google: Erweiterte Suche. http://www.google.ch/advanced_search?hl=de (28.11.10).
[68] Der Text über „Googlewhack“ wurde von der folgenden Seite übernommen und leicht abgeändert: Reischl,
Gerald: Die Googlefalle. http://www.googlefalle.com/googlefalle/index.php/about/wussten-sie-dass/
(20.10.10).
[69] Weilenmann, Anne-Katharina: Fachspezifische Internetrecherche. München 2006. S. 9.
[70] Google: Unternehmensbezogene Informationen. http://www.google.ch/intl/de/corporate/tech.html
(20.10.10).
[71] Ebd.
[72] The Official Google Blog: Personalized Search for everyone. http://googleblog.blogspot.com/2009/12/
personalized-search-for-everyone.html (20.10.10).
[73] Glos, Michael: Sicher surfen, mailen, Daten tauschen. Poing 2004. S. 47.
[74] Ebd. S. 205.
[75] Reporters without Borders: Enemies of the Internet. http://en.rsf.org/IMG/pdf/Internet_enemies.pdf
(21.10.10).
[76] Wikipedia, Die freie Enzyklopädie, „Zensur im Internet“, Bearbeitungsstand: 07.10.2010, 08:36 UTC.
http://de.wikipedia.org/wiki/Zensur_im_Internet (21.10.10).
[77] Google: Transparency Report: Government Requests. http://www.google.com/transparencyreport/ govern-
mentrequests/ (21.10.10).
[78] Wikipedia, Die freie Enzyklopädie, „Zensur im Internet“, Bearbeitungsstand: 07.10.2010, 08:36 UTC.
http://de.wikipedia.org/wiki/Zensur_im_Internet (21.10.10).
Mit einem ausländischen Proxy-Server kann weiterhin auf die Seite zugegriffen werden. Zum Beispiel: Auf
http://youproxified.info/ einfach die Internet-Adresse: www.appel-au-peuple.org in das Feld „URL“ einge-
ben.
[79] Becker, Hendrik und Arnold, Arne S. 75.
[80] Weichert, Thilo: Datenschutz bei Suchmaschinen. In: Lewandowski, Dirk (Hrsg.): Handbuch Internet-
Suchmaschinen. Nutzerorientierung in Wissenschaft und Praxis. Heidelberg 2009. S. 285-300. Hier S. 288.

43
Anhang B:
Lösungen:
Lösungen zu 2.1
1. 1976.
2. In Kalifornien und Boston liegen besonders viele führende
amerikanische Universitäten und Forschungseinrichtungen.
Und das ursprüngliche Ziel des ARPANET war ja ein verbes-
serter Datenaustausch unter diesen.
Lösungen zu 2.2
Ein verteiltes (und in Ansätzen auch ein dezentralisiertes) Netz ist
bei einem Ausfall eines Knotens oder auch mehrerer Knoten nicht
einfach stillgelegt, sondern kann den Datenverkehr über die ver-
bleibenden Knoten abwickeln.
Lösungen zu 2.3
Bei der Durchschaltevermittlung werden alle Möbel in einem Auto
transportiert und nicht auf mehrere verteilt. Der Hauptunterschied
besteht aber darin, dass bei dieser Methode die Autobahn für den
Zügelwagen reserviert ist und zu dieser Zeit keine anderen Autos
auf der Autobahn fahren dürfen.
Lösungen zu 3.1
Kataloge sind zumindest in kleiner Grösse aktueller und zu
einem kleinen Thema auch umfassender.
Suchmaschinen sind effizienter, objektiver, aktueller, vollstän-
diger und auch vom Kosten-Nutzen-Aspekt her gesehen effek-
tiver. Hier kann im Vergleich zu einem Katalog mit einem klei-
neren finanziellen Aufwand ein grosser Index erstellt und ge-
pflegt werden.
Lösungen zu 3.2
Bei der Glaubwürdigkeit kommt es auf die Quelle an. Also wer das
Gesagte verbreitet. Ist die Person auch sonst glaubhaft, wird dem
Gerücht wohl eher Glauben geschenkt.
Lösungen zu 3.3
www.ethz.ch (9)
www.ksrychenberg.ch (5)
www.sf.tv (7)
www.blick.ch (7)

44
www.nytimes.com (9)
www.nzz.ch (8)
www.google.com (10)
www.google.ch (7)
www.yahoo.com (9)
Wie du sicher unschwer erkennen kannst, hat der PageRank also
nicht direkt mit Qualität, sondern mit Popularität zu tun. Die Seite
der ETH wird deutlich öfter zitiert, als die Seite der KSR, hat dem-
zufolge also deutlich mehr Backlinks. Die Seiten des Schweizer
Fernsehens und des Blicks sind was den PageRank betrifft gleich-
auf, was man vom Inhalt der Seiten sicher nicht behaupten kann.
Die Website der New York Times hat ein leicht besseres Ranking
als die NZZ, da die New York Times wahrscheinlich weltweit
gesehen öfter zitiert wird, da sie über die Landesgrenzen hinaus
bekannt ist. Dasselbe trifft auch auf den Vergleich zwischen den
Google-Startseiten zu. Die Schweizer Seite wird im Vergleich zur
internationalen Startseite deutlich weniger oft zitiert. Auch die
Yahoo-Startseite kann „google.com“ nicht das Wasser reichen.
Lösungen zu 3.4
Bedenke jedoch, dass diese Rechnung stark vereinfacht ist. In
Wirklichkeit setzt sich der PageRank aus einer riesigen Formel mit
unzähligen Unbekannten zusammen. Diese Formel ist jedoch ein
Firmengeheimnis.
Lösungen zu 3.5
Verzeichnisdienste: Open Directory Project, Sharelook, voodoo-it.
Schweizer Suchmaschinen: search.ch
Internationale Suchmaschinen: AltaVista, Entire Web, Ask,
Gigablast, Lycos,
Meta-Suchmaschine: Ixquick
Vertikale Suchmaschinen: Google Code Search, ingenieur.de,
Medisuch.
Lösungen zu 3.6
Mit einer Suchanfrage wie „Taio Cruz“ lässt sich gut die Aktualität
der Indizes überprüfen. Während es Lycos nur auf schwache
111‘000 Treffer bringt. Schafft Google gut 8 Millionen und
Ixquick sogar gut 15 Millionen. Beide haben also einen sehr aktu-

45
ellen Index. Bei der Grösse gilt es jedoch zu beachten, dass
Ixquick Google nur schlägt, weil es eine Meta-Suchmaschine ist
und die Indizes von Yahoo, Bing, AltaVista, Ask, EntireWeb,
Gigablast, ODP, Semager, Sharelook, Suchclip, Voodoo-it und
Wikipedia bemüht. Ein wahrlich unfairer Vergleich. Dennoch
bringt es Ixquick auf nicht mehr als doppelt so viele Treffer. Der
Index von Google ist also klar der Grösste. Bei der Eingabe von
„the“ schafft Lycos gut 2 Milliarden, Google 12 Milliarden und
Ixquick nicht mehr als gut 3,2 Milliarden Treffer.
Lösungen zu 3.7
Bei Google rangiert Wikipedia auf dem 5., bei Yahoo auf dem 7.
und bei Ixquick auf dem 1. Platz. Dies liegt wahrscheinlich daran,
dass Ixquick auch Wikipedia selbst durchsucht.
Lösungen zu 4.1
Das erste Ergebnis ist relevanter, da mehr Suchbegriffe darin vor-
kommen.
Lösungen zu 4.2
Der erste Treffer ist relevanter, da ein Stichwort häufiger vor-
kommt als im ersten.
Lösungen zu 4.3
Das erste Suchergebnis ist relevanter als das zweite, da mit
„Feusisberg“ ein seltener Begriff darin vorkommt.
Rangierungsprinzip 1
Je mehr Suchbegriffe in einem Dokument vorkommen, desto
wahrscheinlicher ist das Dokument relevant.
Rangierungsprinzip 2
Je häufiger ein Suchbegriff in einem Dokument vorkommt,
desto wahrscheinlicher ist das Dokument relevant.
Rangierungsprinzip 3
Dokumente, die seltene Suchbegriffe enthalten, sind mit einer
höheren Wahrscheinlichkeit relevant, als Dokumente, die häu-
fige Suchbegriffe enthalten.

46
Lösungen zu 4.4
Der erste Treffer ist relevanter, da die Suchbegriffe näher beiei-
nander liegen.
Lösungen zu 4.5
Der erste Treffer ist relevanter, da das Dokument kürzer ist, die
Suchbegriffe aber gleich häufig enthält.
Lösungen zu 4.6
Hier ist das erste Dokument relevanter, da die gleichen Suchbegrif-
fe früher vorkommen als im zweiten.
Lösungen zu 4.7
Dein Vorwissen, das du aktivieren kannst, sind die Namen. Gib ein
paar Nachnamen deiner Klassenkammeraden bei Google ein. Fünf
sollten genügen und du kannst die Treffer an einer Hand abzählen.
Wenn du selbiges bei Yahoo und Bing versuchst, wirst du sehen,
dass du keine brauchbaren Treffer bekommst…
Lösungen zu 4.8
Als erstes Stichwort wäre wahrscheinlich „Fernsehprogramm“ eine
gute Wahl. Da du jetzt keine Treffer mit integriertem Kinopro-
gramm dabei hast, versuchen wir es mit „Fernsehprogramm Kino“.
Mit dem geben wir uns aber nicht zufrieden und geben „Fernseh-
programm Kino Schweiz“ ein. Einer der ersten Treffer scheint
somit gleich brauchbar. „Cineman“ bietet sowohl das Kinopro-
gramm aus fast allen Schweizer Grossstädten, wie auch das Fern-
sehprogramm aller wesentlichen Sender an.
Rangierungsprinzip 4
Je näher die Suchbegriffe beieinander liegen, desto wahr-
scheinlicher ist das Dokument relevant.
Rangierungsprinzip 5
Ein kurzes Dokument ist mit einer höheren Wahrscheinlichkeit
relevant als ein langes Dokument, welches die gleichen Such-
begriffe gleich häufig enthält.
Rangierungsprinzip 6
Je früher die Suchbegriffe in einem Dokument vorkommen,
desto höher seine Relevanz.

47
Lösungen zu 4.9
1. Hier empfiehlt sich eine Suchmaschine. Gleich der erste Treffer
ist von Wikipedia. Wo du erfährst, dass Petrologie die Lehre
von der Entstehung, den Eigenschaften und der Nutzung der
Gesteine ist.
2. Am besten suchst du hier über einen Katalog. Am geeignetsten
ist wohl die „Internet Movie Database“. Gib hier einfach den
Titel der Serie „Two and a Half Men“ in das Suchfeld ein. Der
erste Treffer ist gleich der beste. Unter der Rubrik „Cast“ fin-
dest du jetzt die verschiedenen Schauspieler. So auch „Angus
T. Jones“, der in der Fernsehserie „Jake Harper“ spielt.
3. Am besten suchst du im Schweizer Katalog Sharelook.
4. Wenn wir hier kein Vorwissen aktivieren können, versuche wir
es erst einmal mit den simplen Stichwörtern „Schweizer Olym-
piasieger“. Der Auszug der ersten Seite sieht gleich interessant
aus. Denn auf der offiziellen Seite des Swissolympic Verbandes
wird „Louis Zutter, der erste Olympiasieger der Neuzeit“ er-
wähnt. Sagt uns zwar nichts. Aber egal, wir klicken drauf. Hier
finden wir eine Liste „Spotlights der Schweizer Sportgeschich-
te“. Die Seite liefert aber keine vernünftige Antwort auf unsere
Frage. Eine übersichtliche Tabelle wäre nett. Aber vielleicht
finden wir ja etwas Vorwissen auf dieser Seite. Also suchen wir
einmal die Passage, wo Louis Zutter erwähnt wurde. In Win-
dows einfach den Namen eingeben und die Stelle wird grün
markiert. Darunter finden wir eine nützliche Information: Dort
steht nämlich, dass die erste Olympiasiegerin der Neuzeit „He-
len de Pourtalès“ hiess. Gleich darunter finden wir in Verbin-
dung mit einem Olympiasieg noch den Namen „Josef Imbach“.
Wir geben also bei Google diese drei Namen ein: „Josef Im-
bach Louis Zutter Helen de Pourtalès“. Der erste Treffer ist lo-
gischerweise die gleiche Seite. Der zweite scheint jedoch sehr
interessant zu sein: Olympians from switzerland – alphabetical
listing. Wir klicken die Seite an und siehe da: Eine Liste mit al-
len Schweizer Olympiasiegern, erst noch alphabetisch geordnet.
Was haben wir genau gemacht: Wir konnten zum Thema kein
eigenes Vorwissen aktivieren. Also haben wir uns das Vorwis-
sen durch das Eingeben von umschreibenden Stichwörtern be-
schafft.

48
Lösungen zu 4.10
Stichwörter: Ballsportart –Fussball
Lösungen zu 4.11
Stichwörter: Preisvergleich Produkte Migros Coop. Auch hier
scheinen schon unter den ersten Treffern einige vernünftige darun-
ter zu sein.
Lösungen zu 4.12
Am häufigsten wird wohl das Rangierungsprinzip zwei miss-
braucht. So schreiben viele Webseiten-Betreiber gewisse Stichwör-
ter mehrere Tausend Mal auf ihre Website (Natürlich in der Farbe
des Hintergrunds, sodass die Seite trotzdem noch lesbar bleibt).
Denn das Rangierungsprinzip zwei besagt: Je häufiger ein Stich-
wort vorkommt, desto wahrscheinlicher ist das Dokument relevant.
Lösungen zu 4.13
Die Stichwörter „Rockefeller Center Bauarbeiter“ bei „Google
Bilder“ eingeben genügt schon.
Lösungen zu 4.14
Hier überlegen wir uns als erstes wieder, wie eine Seite aussieht,
die unsere Informationen bereithält. Am besten suchen wir nach
einem Matchbericht. Dort sind alle Daten und Geschehnisse der
ganzen Partei aufgelistet. Um den richtigen Matchbericht zu erwi-
schen, müssen wir nur noch den Match eindeutig beschreiben. Wir
versuchen es also mit: „Matchbericht CL Final 2005 Milan Liver-
pool“. Und siehe da. Der erste Treffer ist bereits ein Volltreffer.
Bei Wikipedia unter der Rubrik Details erfahren wir, dass der
Tscheche Vladimír Šmicer Liverpool in der 56. Minute zurück ins
Spiel gebracht hat.
Lösungen zu 4.15
Für diese Aufgabe verwenden wir die „Erweiterte Suche“. Im Feld
„Dateiformat“ wählen wir „PDF“ und im Feld „Datum“ „in den
letzten 24 Stunden“.

49
Lösungen zu 4.16
Stichwörter: „stadtbus linie plan winterthur“.
Der erste Treffer ist gleich der beste.
Lösungen zu 4.17
Internet Movie Database
Lösungen zu 5.1
Die Lösungen zu 5.1 können hier leider nicht angegeben werden:
Weil ich erstens nicht Google bin und zweitens aus Platzgründen.
Lösungen zu 5.2
Auf den Seiten 34 und 35 findest du eine Liste mit einigen anderen
Suchmaschinen.





























