Embed Size (px)
DESCRIPTION
Effiziente Evaluierung von XQuery-Anfragen über XML-Strömen. Michael Schmidt, 05.11.2007 LS Datenbanken und Informationssysteme, Prof. Georg Lausen Graduiertenkolleg „Mathematische Logik und Anwendungen“. Inhalt. XQuery Auswertung auf XML-Strömen Motivation und Anforderungen - PowerPoint PPT Presentation
Citation preview

Effiziente Evaluierung von XQuery-Anfragen über
XML-Strömen
Michael Schmidt, 05.11.2007
LS Datenbanken und Informationssysteme, Prof. Georg Lausen
Graduiertenkolleg „Mathematische Logik und Anwendungen“

2
Inhalt
XQuery Auswertung auf XML-StrömenI. Motivation und AnforderungenII. Statische Analyse:
Effiziente Projektion von XML-Dokumenten
III. Kombination statischer & dynamischer Analyse:Effiziente Minimierung von Hauptspeicherressourcen
Christoph Koch, Stefanie Scherzinger, Michael SchmidtXML Prefiltering as a String Matching Problem. In Proc. ICDE 2008.
To appear.
Michael Schmidt, Stefanie Scherzinger, Christoph KochCombined Static and Dynamic Analysis for Effective Buffer
Minimization in Streaming XQuery Evaluation. In Proc. ICDE 2007.

3
Verarbeitung von XML-Strömen gewinnt immer mehr an Bedeutung
z.B. Börsendaten, Satellitendaten, Temperaturdaten …
Empfangsraten ggf. sehr hoch
Zwischenspeichern auf Festplatte oft unmöglich Herkömmliche DBMS ungeeignet, da
Daten üblicherweise phyikalisch gespeichert werden … … und Zwischenspeichern zudem oftmals überflüssig ist
Motivation
I. Motivation und Anforderungen

4
Daten müssen im Hauptspeicher verarbeitet werden
Probleme: Datenmengen können sehr groß werden Darstellung von XML-Dokumenten im Speicher als
DOM-Baum sehr platzaufwendig
Effizientes Puffermanagement wird zur Schlüsselkomponente
Streaming Techniken auch sehr gut geeignet für in-memory Engines
Motivation
I. Motivation und Anforderungen

5
Anforderungen an Pufferminimierung
(1) Puffere lediglich die Daten, die auch zur Auswertung der Anfrage benötigt werden
(2) Vermeide mehrfache Kopien der selben Daten im Hauptspeicher
(3) Puffere die Daten nicht länger als notwendig
I. Motivation und Anforderungen

6
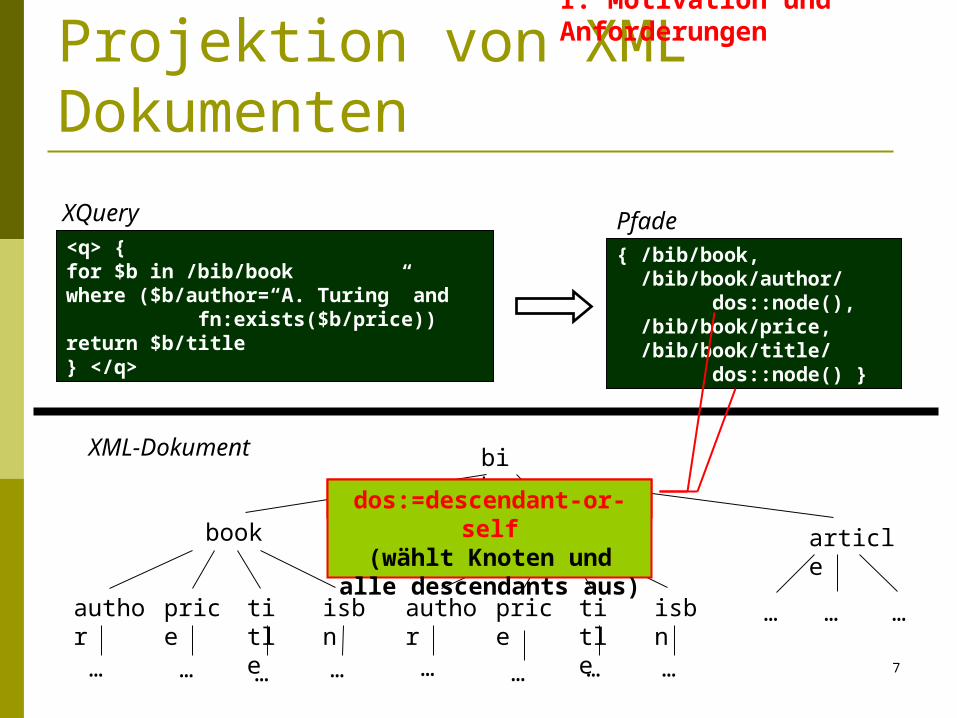
Projektion von XML Dokumenten
(1) Puffere lediglich die Daten, die auch zur Auswertung der Anfrage benötigt werden
Projektion Statische Analyse der XML-Query Identifikation von Teilen des XML-Dokuments,
die für die Anfrageauswertung relevant sind Nicht relevante Teile des XML-Dokuments
können wegprojiziert werden
A. Marian and J. SiméonProjecting XML DocumentsIn Proc. VLDB’03, pages 213–224, 2003
S. Bréssan, B. Catania, Z. Lacroix, Y. G. Li and A. Maddalena Accelerating Queries by Pruning XML DocumentsTKDE, 54(2):211–240, 2005
V. Benzaken, G. Castagna, D. Colazzo, and K. NguyenType-Based XML ProjectionIn Proc. VLDB’06, 2006
I. Motivation und Anforderungen
7
<q> {for $b in /bib/bookwhere ($b/author=“A. Turing” and fn:exists($b/price))return $b/title} </q>
XQuery
Pfade{ /bib/book, /bib/book/author/
dos::node(), /bib/book/price, /bib/book/title/
dos::node() }
bib
book
author price title
book
author price title
… … … …
article
… … …isbn
isbn
… … … …
XML-Dokument
dos:=descendant-or-selfdos:=descendant-or-self(wählt Knoten und alle
descendants aus)
Projektion von XML Dokumenten
I. Motivation und Anforderungen
8
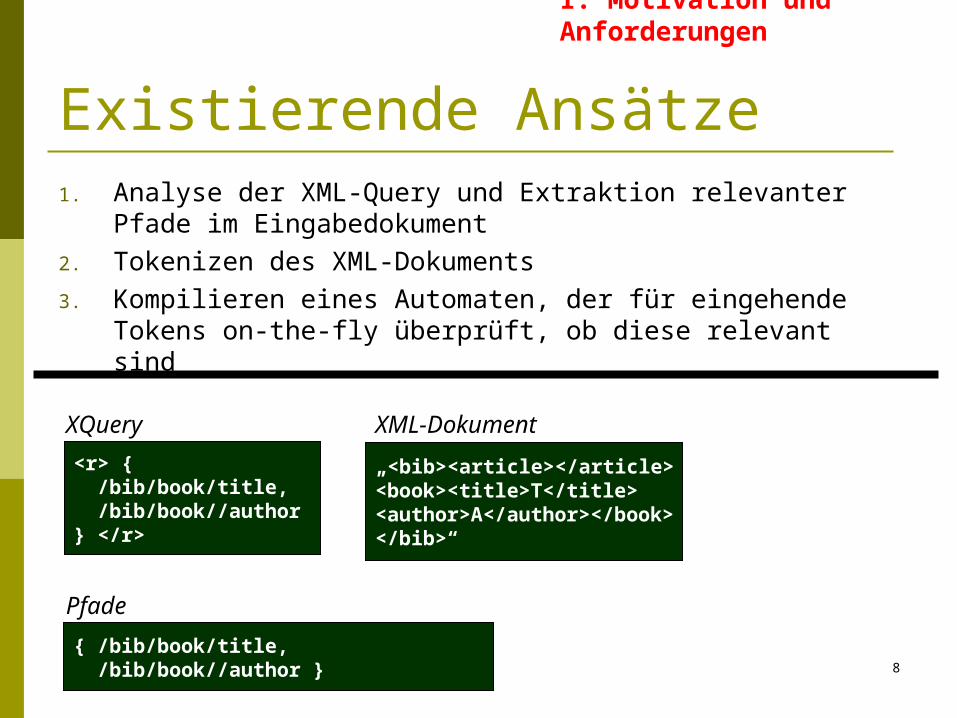
1. Analyse der XML-Query und Extraktion relevanter Pfade im Eingabedokument
2. Tokenizen des XML-Dokuments3. Kompilieren eines Automaten, der für eingehende
Tokens on-the-fly überprüft, ob diese relevant sind
<r> { /bib/book/title, /bib/book//author} </r>
XQuery
„<bib><article></article><book><title>T</title><author>A</author></book></bib>“
XML-Dokument
Pfade
{ /bib/book/title, /bib/book//author }
Existierende Ansätze
I. Motivation und Anforderungen

9
XML<bib><article></article><book><title>T</title><author>A</author></book></bib>
●/bib/book/title ●/bib/book//author
/bib●/book/title/bib●/book//author
/bib/book●//author/bib/book●/title
/bib/book●//author/bib/book/title●
/bib/book●//author/bib/book//author●
Pfade
{/bib/book/title, /bib/book//author} <bib>
<book><article>
<title> <author>
Existierende Ansätze1. Analyse der XML-Query und Extraktion relevanter Pfade
im Eingabedokument2. Tokenizen des XML-Dokuments3. Kompilieren eines Automaten, der für eingehende
Tokens on-the-fly überprüft, ob diese relevant sind
I. Motivation und Anforderungen
10
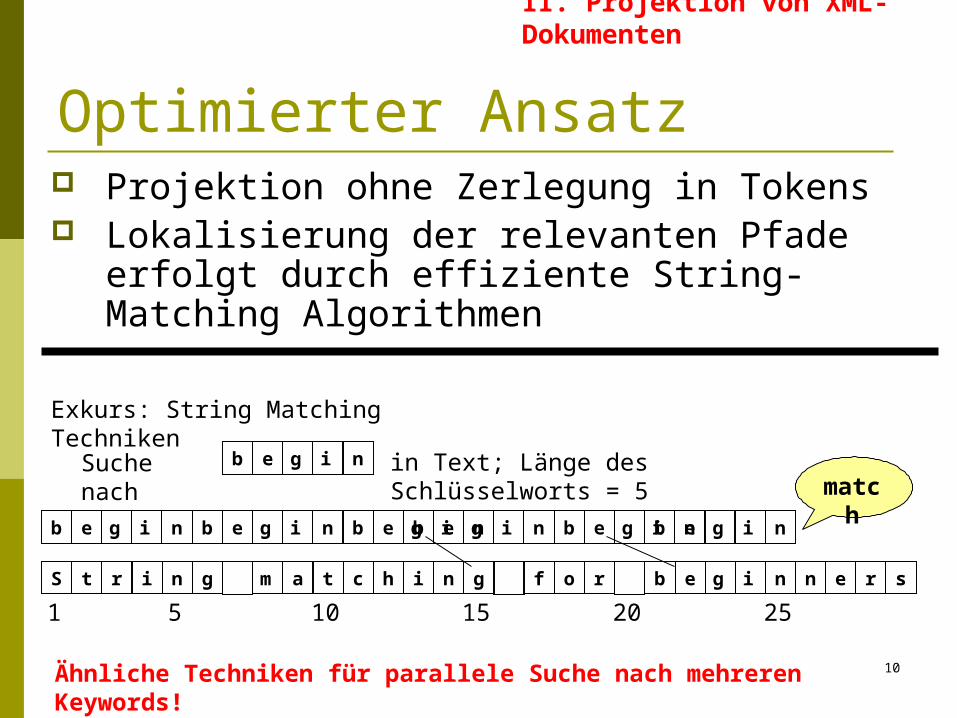
Optimierter Ansatz Projektion ohne Zerlegung in Tokens Lokalisierung der relevanten Pfade
erfolgt durch effiziente String-Matching Algorithmen
Exkurs: String Matching Techniken
S t r i n g m a t c h i n g f o r b e g i n n e
b e g i n
Suche nach
in Text; Länge des Schlüsselworts = 5
1 5 10 15 20 25
r s
Ähnliche Techniken für parallele Suche nach mehreren Keywords!
b e g i n b e g i n b e g i nb e g i n
b e g i n
b e g i n
match
II. Projektion von XML-Dokumenten
11
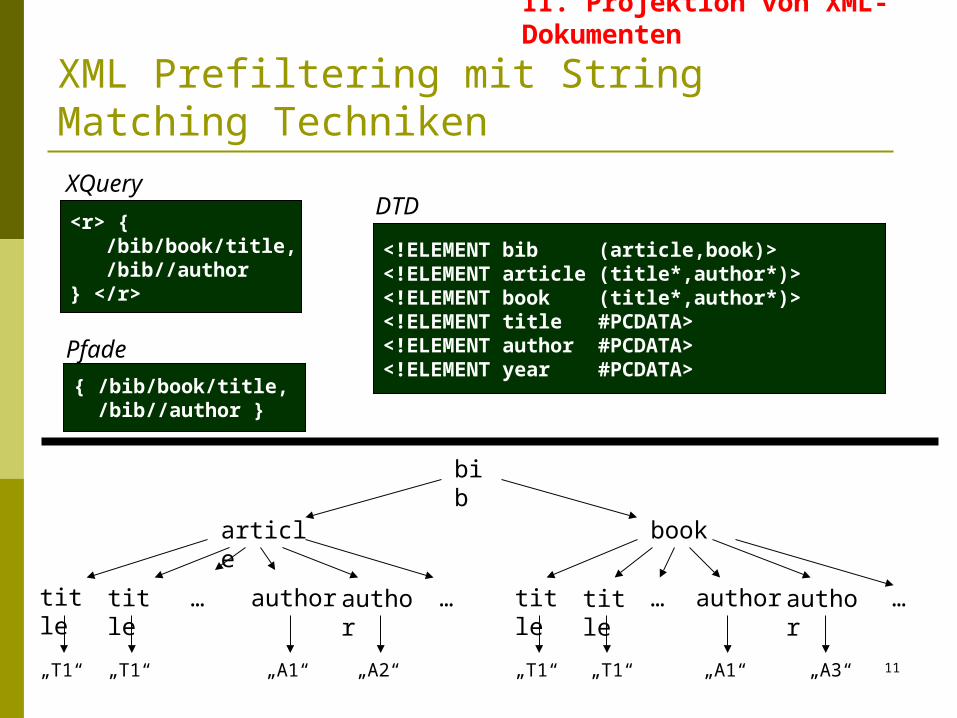
<r> { /bib/book/title, /bib//author} </r>
XQuery
Pfade
{ /bib/book/title, /bib//author }
<!ELEMENT bib (article,book)><!ELEMENT article (title*,author*)><!ELEMENT book (title*,author*)><!ELEMENT title #PCDATA><!ELEMENT author #PCDATA><!ELEMENT year #PCDATA>
DTD
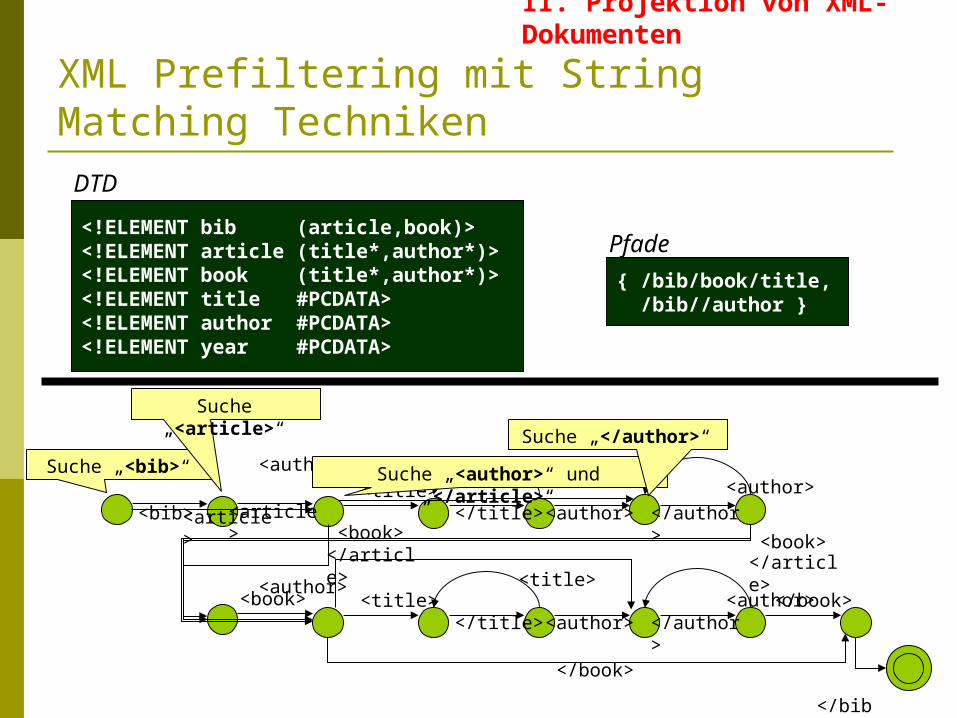
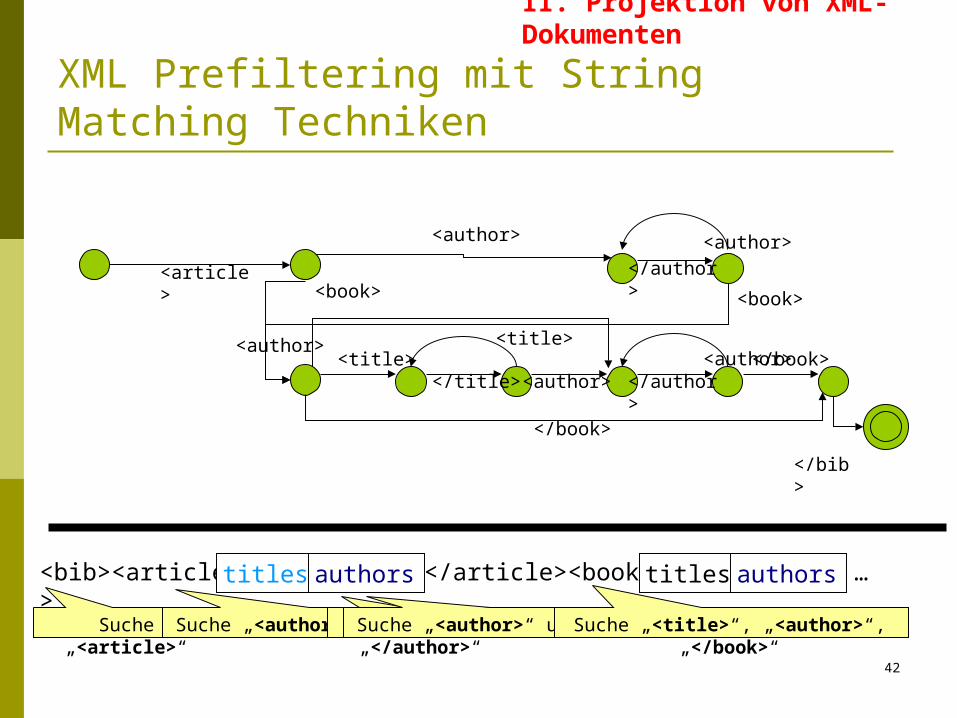
XML Prefiltering mit String Matching Techniken
II. Projektion von XML-Dokumenten
bib
article book
title title title title author authorauthor author… … … …
„T1“ „T1“ „T1“ „T1“„A1“ „A2“ „A1“ „A3“
12
<!ELEMENT bib (article,book)><!ELEMENT article (title*,author*)><!ELEMENT book (title*,author*)><!ELEMENT title #PCDATA><!ELEMENT author #PCDATA><!ELEMENT year #PCDATA>
DTD
<bib> <article> <title> </title> <author> </author> <title> <author>
<book> <title> </title> <author> </author> <title> <author>
</article>
</book>
</bib> </book>
<author>
<author>
</article> <book> <book>
<article>
Suche „<bib>“ Suche „<author>“ und „</article>“
Suche „</author>“
XML Prefiltering mit String Matching Techniken
Pfade
{ /bib/book/title, /bib//author }
Suche „<article>“
II. Projektion von XML-Dokumenten

13
Vorkompilieren der Automaten/Sprungtabellen in Lookup-Tables:
State Match State
q0 <article> q1
q1 <author> q2
q1 <book> q4
q2 </author> q3
q3 <author> q2
q3 <book> q4
… … …
DFAState
Vocabulary
q0 {<article>}
q1 {<author>, <book>}
q2 {</author>}
q3 {<author>, <book>}
… …
Vokabular
State Action
q0 no operation
q1 „<bib><article>“
q2 copy on
q3 copy off
… …
Action
Kurzer, hocheffizienter Laufzeitalgorithmus, der die vorkompilierten Lookup-Tables nutzt
XML Prefiltering using String Matching Techniques
II. Projektion von XML-Dokumenten

14
• Prototyp-Implementierung in C++• Experimente
• Setting• Core2 Duo IBMThinkPad Z61p• T2500 2.00GHz CPU mit 1GB RAM• Ubuntu Linux 6.06 LTS
• Verschiedene Daten: XMark, Medline, ProtSeq• Verschiedene Dokumentgrößen: 1MB bis 5000MB
XML Prefiltering using String Matching Techniques
II. Projektion von XML-Dokumenten
15
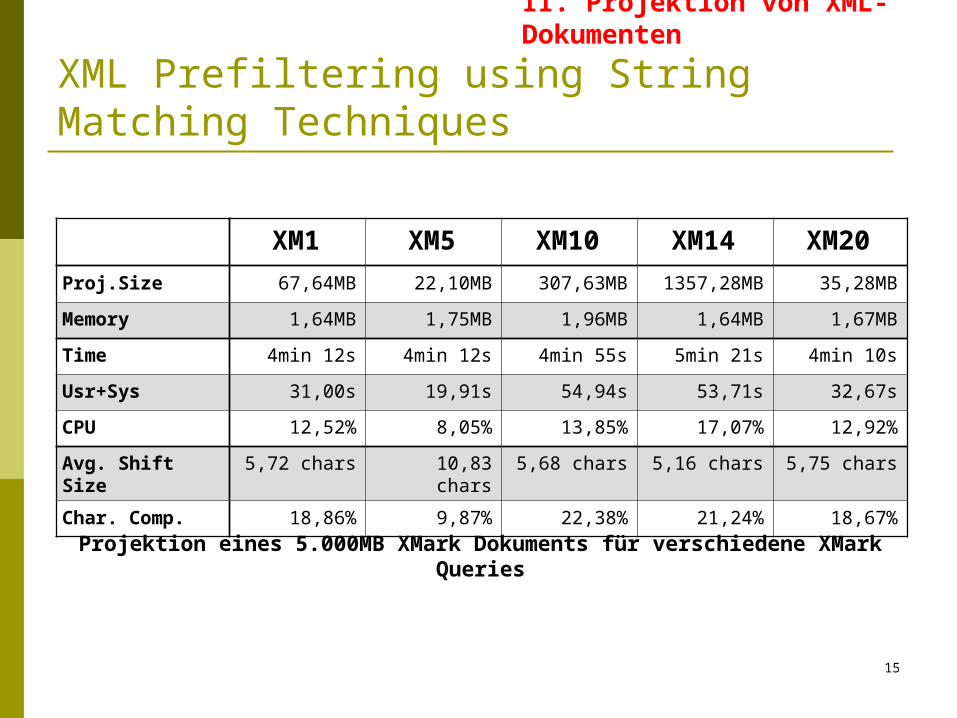
XM1 XM5 XM10 XM14 XM20
Proj.Size 67,64MB 22,10MB 307,63MB 1357,28MB 35,28MB
Memory 1,64MB 1,75MB 1,96MB 1,64MB 1,67MB
Time 4min 12s 4min 12s 4min 55s 5min 21s 4min 10s
Usr+Sys 31,00s 19,91s 54,94s 53,71s 32,67s
CPU 12,52% 8,05% 13,85% 17,07% 12,92%
Avg. Shift Size 5,72 chars 10,83 chars 5,68 chars 5,16 chars 5,75 chars
Char. Comp. 18,86% 9,87% 22,38% 21,24% 18,67%
Projektion eines 5.000MB XMark Dokuments für verschiedene XMark Queries
XML Prefiltering using String Matching Techniques
II. Projektion von XML-Dokumenten

16
QizX XQuery Engine
Erfolg TimeFail MemFail
1000MB unprojiziert
0 0 18
1000MB projiziert
18 0 0
5000MB unprojiziert
0 0 18
5000MB projiziert
15 2 1
Erfolgsquoten für 18 XMark Queries mit vs. ohne Projektion
TimeFail: >1 Stunde
MemFail: >1GBVerbesserung von XQuery Engines durch Projektion
XML Prefiltering using String Matching Techniques
II. Projektion von XML-Dokumenten

17
Durchsatzverbesserung durch Projektion für XPath Queries
Datensätze:- Medline: M1-M5
- Protein Sequence: P1-P5
- Einfache XPath-Anfragen
- Auswertung durch SPEX
XML Prefiltering using String Matching Techniques
MB/s
II. Projektion von XML-Dokumenten
18
Kombination Statischer und Dynamischer Analyse
2. Vermeide mehrfache Kopien der selben Daten im Hauptspeicher
3. Puffere die Daten nicht länger als notwendig
Behauptung: Sowohl statische als auch dynamische Analyse erforderlich, um beide Ansprüche zu erfüllen
Michael Schmidt, Stefanie Scherzinger, Christoph Koch Combined Static and Dynamic Analysis for Effective Buffer Minimization in Streaming XQuery EvaluationIn Proc. ICDE 2007, Istanbul
III. Kombination statischer und dynamischer Analyse
19
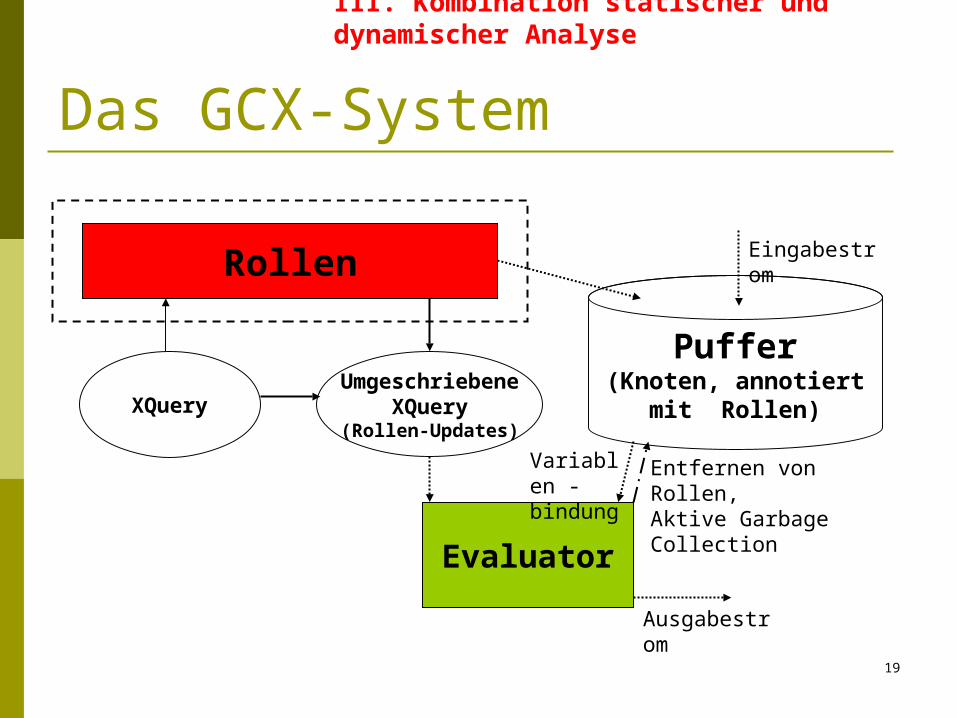
Das GCX-System
XQuery
Rollen
Puffer(Knoten, annotiert
mit Rollen)
Eingabestrom
Evaluator
Ausgabestrom
UmgeschriebeneXQuery
(Rollen-Updates)
Variablen -bindung
Entfernen von Rollen, Aktive Garbage Collection
III. Kombination statischer und dynamischer Analyse

20
<r> { for $bib in /bib return ( for $book in $bib/book for $title in $book/title return $title, for $author in $bib//author return $author )} </r>
XQuery
Pfade
{ /bib/book/title/dos::node(), /bib//author/dos::node() }
/bib
/book
/title
//author
/descendant-or-self::node()
/descendant-or-self::node()
Projektions-Baum
/bib/book/title/dos::node()
r2
r1
r3
r4
Ableiten von Rollen
/bib//author/dos::node()
III. Kombination statischer und dynamischer Analyse

21
Selektierte Dokumentknoten bekommen Rollen zugewiesen, wenn sie in den Puffer geladen werden
Unselektierte Knoten werden wegprojiziert
bib
book
authortitle
{ r1 }
{ r2 }
{ r4}{ r3 }
rr1 1 /bib /bib
rr22 /bib/book /bib/book
rr33 /bib/book/title/dos::node() /bib/book/title/dos::node()
rr44 /bib//author/dos::node() /bib//author/dos::node()
XML DokumentRollen
Verteilen von Rollen
III. Kombination statischer und dynamischer Analyse
22
rr1 1 /bib /bib
rr22 /bib/book /bib/book
rr33 /bib/book/title/dos::node() /bib/book/title/dos::node()
rr44 /bib//author/dos::node() /bib//author/dos::node()
<r> { for $bib in /bib return (for $book in $bib/book for $title in $book/title return $title, for $author in $bib//author return $author )} </r>
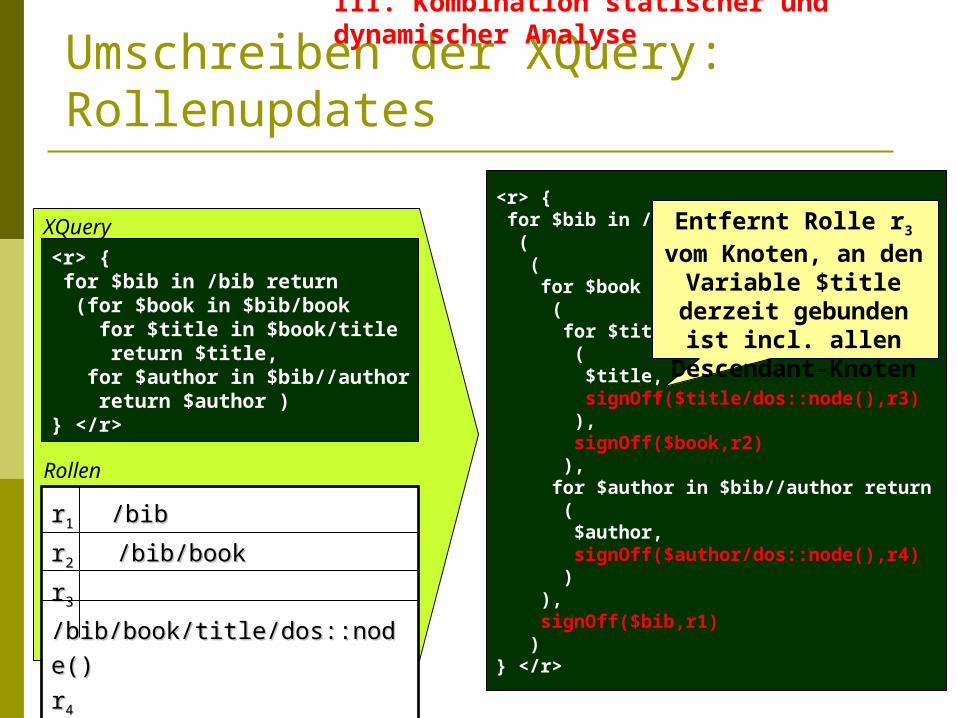
Umschreiben der XQuery: Rollenupdates
Rollen
XQuery<r> { for $bib in /bib return ( ( for $book in $bib/book ( for $title in $book/title return ( $title, signOff($title/dos::node(),r3) ), signOff($book,r2) ), for $author in $bib//author return ( $author, signOff($author/dos::node(),r4) ) ), signOff($bib,r1) )} </r>
Entfernt Rolle r3 vom Knoten, an den
Variable $title derzeit gebunden ist incl. allen
Descendant-Knoten
III. Kombination statischer und dynamischer Analyse

23
Aktives Garbage Collection
<r> { for $bib in /bib return ( ( for $book in $bib/book ( for $title in $book/title return ( $title, signOff($title/dos::node(),r3) ), signOff($book,r2) ), for $author in $bib//author return ( $author, signOff($author/dos::node(),r4) ) ), signOff($bib,r1) )} </r>
XQuery
Input Stream
Buffer
Output Stream
<book><title><bib> </title><author></author></book></bib>
<r>
bib{ r1 }
book{ r2 }
title{ r3 }
<title> </title>
{}author
{ r4 }
<author> </author>
{}
{}
{}
</r>
III. Kombination statischer und dynamischer Analyse

24
Garbage Collected XQuery Implementiert für ein mächtiges Fragment von
XQuery Verschachtelte for-loops Child und descendant Axen For–where–return expressions If-expressions mit and, or, not, Existenzchecks Aggregationen derzeit nicht unterstützt
Open Source (Berkeley Software Distribution Licence)
GCX Projektseite:http://dbis.informatik.uni-freiburg.de/index.php?project=GCX
Die GCX Engine
III. Kombination statischer und dynamischer Analyse

25
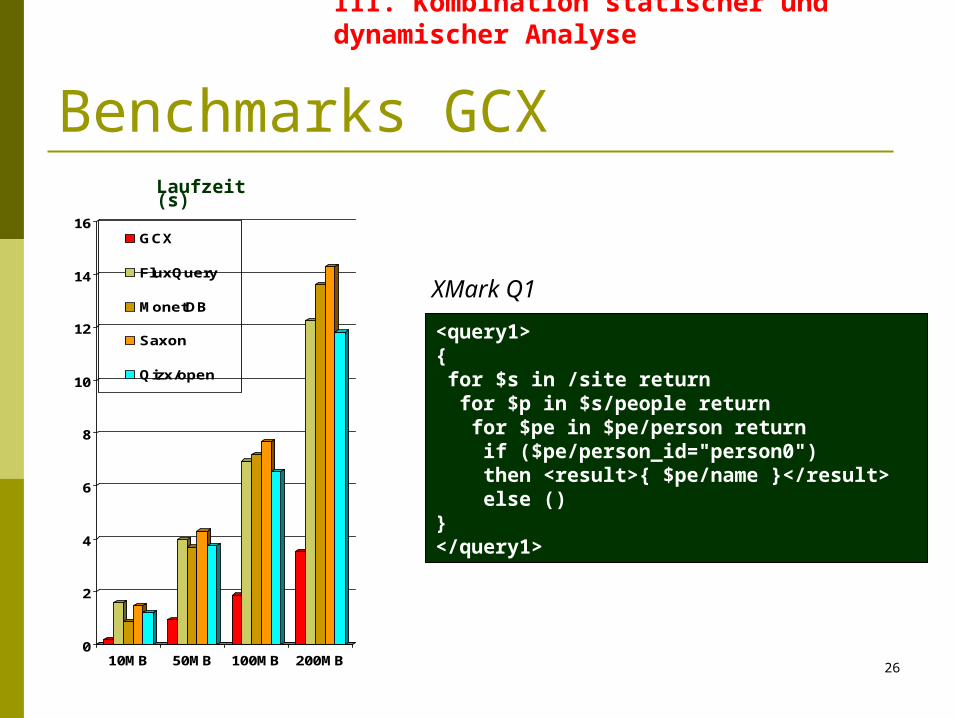
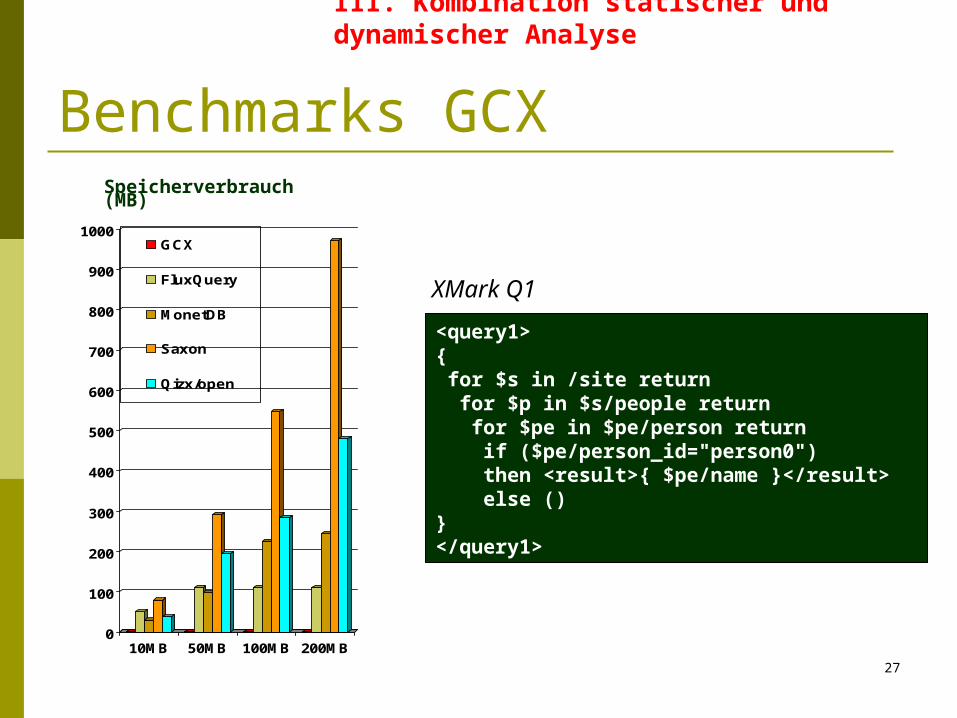
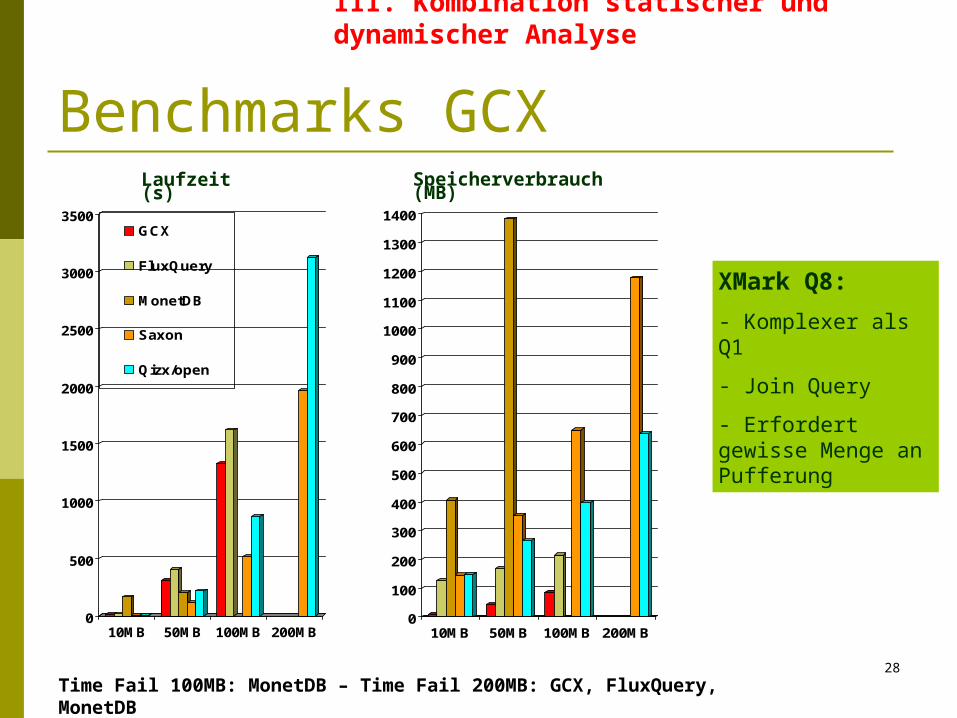
Messung von Zeit- und Speicherverbrauch Queries und Dokumente des XMark Benchmarks (angepasst) Experimentelles Setting:
3GHz CPU Intel Pentium IV mit 2GB RAM SuSe Linux 10.0 J2RE v1.4.2 für Java-basierte Systeme
1 Stunde Zeitlimit pro Query Benchmarks gegen verschiedene Systeme
FluX: In-memory Engine für Streaming XQuery Evaluation (Java) MonetDB v4.12.0/XQuery v0.12.0:
Secondary storage Engine (C++) QizX/open v1.1: Freie in-memory XQuery Engine (Java) Saxon v8.7.1: Freie in-memory XQuery Engine (Java)
Benchmarks GCX
III. Kombination statischer und dynamischer Analyse
26
<query1> { for $s in /site return for $p in $s/people return for $pe in $pe/person return if ($pe/person_id="person0") then <result>{ $pe/name }</result> else ()}</query1>
XMark Q1
0
2
4
6
8
10
12
14
16
10MB 50MB 100MB 200MB
GCX
FluxQuery
MonetDB
Saxon
Qizx/open
Laufzeit (s)
Benchmarks GCX
III. Kombination statischer und dynamischer Analyse
27
0
100
200
300
400
500
600
700
800
900
1000
10MB 50MB 100MB 200MB
GCX
FluxQuery
MonetDB
Saxon
Qizx/open
<query1> { for $s in /site return for $p in $s/people return for $pe in $pe/person return if ($pe/person_id="person0") then <result>{ $pe/name }</result> else ()}</query1>
XMark Q1
Benchmarks GCXSpeicherverbrauch (MB)
III. Kombination statischer und dynamischer Analyse
28
0
500
1000
1500
2000
2500
3000
3500
10MB 50MB 100MB 200MB
GCX
FluxQuery
MonetDB
Saxon
Qizx/open
0
100
200
300
400
500
600
700
800
900
1000
1100
1200
1300
1400
10MB 50MB 100MB 200MB
Time Fail 100MB: MonetDB – Time Fail 200MB: GCX, FluxQuery, MonetDB
Laufzeit (s)
Speicherverbrauch (MB)
XMark Q8:
- Komplexer als Q1
- Join Query
- Erfordert gewisse Menge an Pufferung
Benchmarks GCX
III. Kombination statischer und dynamischer Analyse

29
Vielen Dank für Ihre Aufmerksamkeit!

30
Additional Resources
31
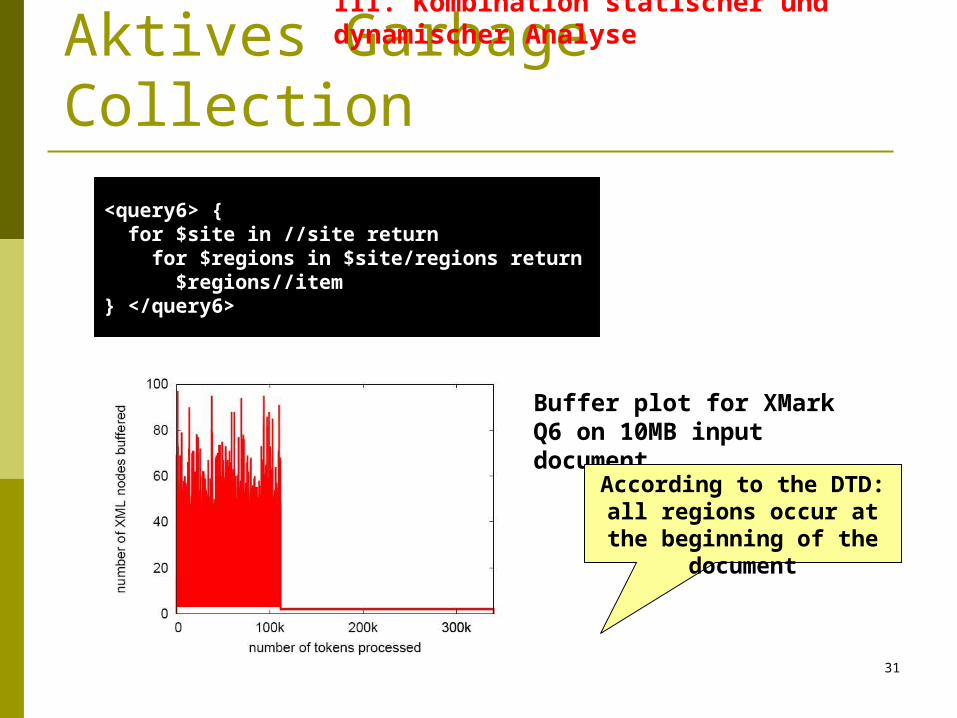
<query6> { for $site in //site return for $regions in $site/regions return $regions//item} </query6>
Buffer plot for XMark Q6 on 10MB input document
According to the DTD:all regions occur at the
beginning of the document
Aktives Garbage Collection
III. Kombination statischer und dynamischer Analyse

32
Benchmark Queries (2)
<query8> { for $root in (/) return for $site in $root/site return for $people in $site/people return for $person in $people/person return <item> { ( <person>{ $person/name }</person>, <items_bought> { for $site2 in $root/site return for $cas in $site2/closed_auctions return for $ca in $cas/closed_auction return for $buyer in $ca/buyer return if ($buyer/buyer_person=$person/person_id) then <result> { $ca } </result> else () } </items_bought> ) } </item> } </query8>
33
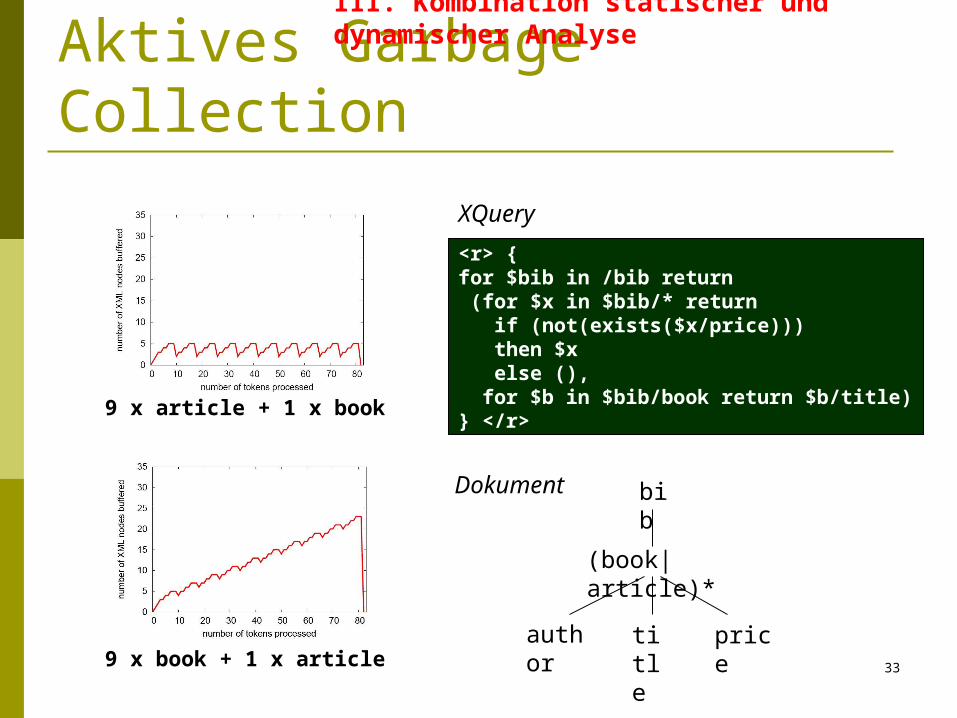
<r> {for $bib in /bib return (for $x in $bib/* return if (not(exists($x/price))) then $x else (), for $b in $bib/book return $b/title)} </r>
bib
(book|article)*
title
author
price
9 x article + 1 x book
9 x book + 1 x article
XQuery
Dokument
Aktives Garbage Collection
III. Kombination statischer und dynamischer Analyse

34
Benchmark Queries (1)
<query1> { for $s in /site return for $p in $s/people return for $pe in $pe/person return if ($pe/person_id="person0") then <result>{ $pe/name }</result> else ()}</query1>
<query6> { for $site in //site return for $regions in $site/regions return $regions//item} </query6>

35
Benchmark Queries (3)
<query13> { for $site in /site return for $regions in $site/regions return for $australia in $regions/australia return for $item in $australia/item return <item> { ( <name> { $item/name } </name>, <desc> { $item/description } </desc> ) } </item>} </query13>

36
Benchmark Queries (4)
<query20> { for $site in /site return for $people in $site/people return for $person in $people/person return if (fn:not(fn:exists($person/person_income))) then $person else ()} </query20>
37
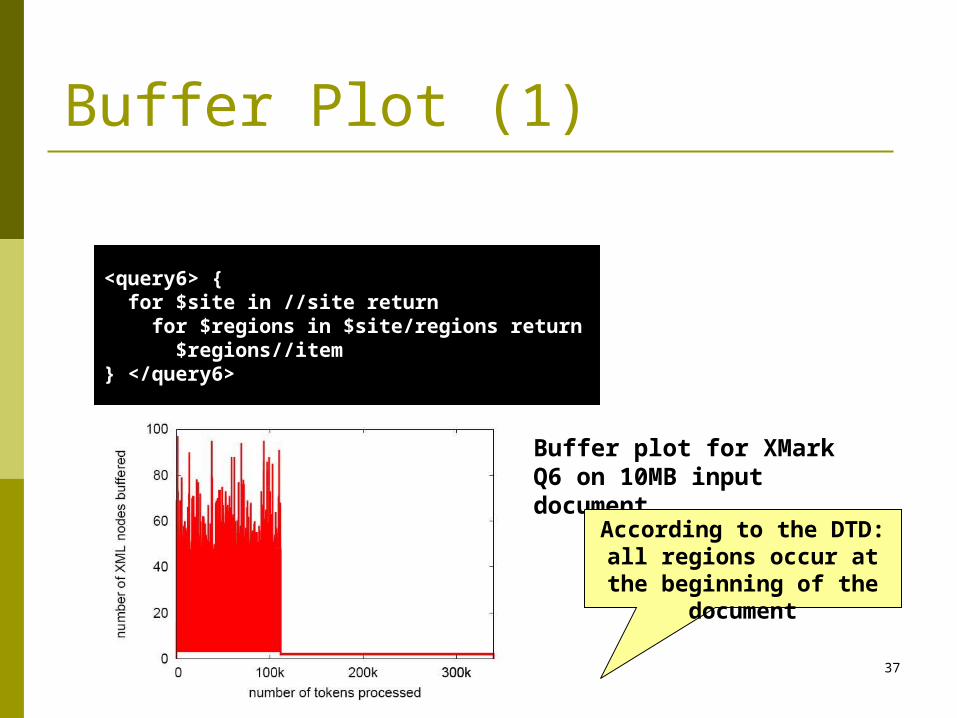
<query6> { for $site in //site return for $regions in $site/regions return $regions//item} </query6>
Buffer plot for XMark Q6 on 10MB input document
According to the DTD:all regions occur at the
beginning of the document
Buffer Plot (1)
38
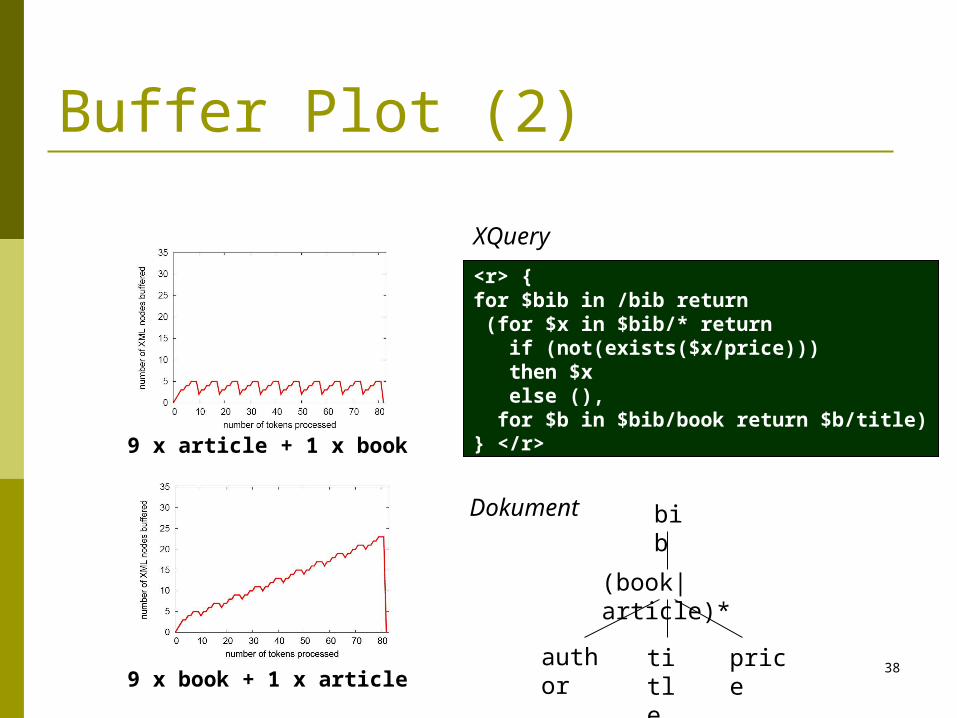
<r> {for $bib in /bib return (for $x in $bib/* return if (not(exists($x/price))) then $x else (), for $b in $bib/book return $b/title)} </r>
bib
(book|article)*
title
author
price
9 x article + 1 x book
9 x book + 1 x article
XQuery
Dokument
Buffer Plot (2)
39
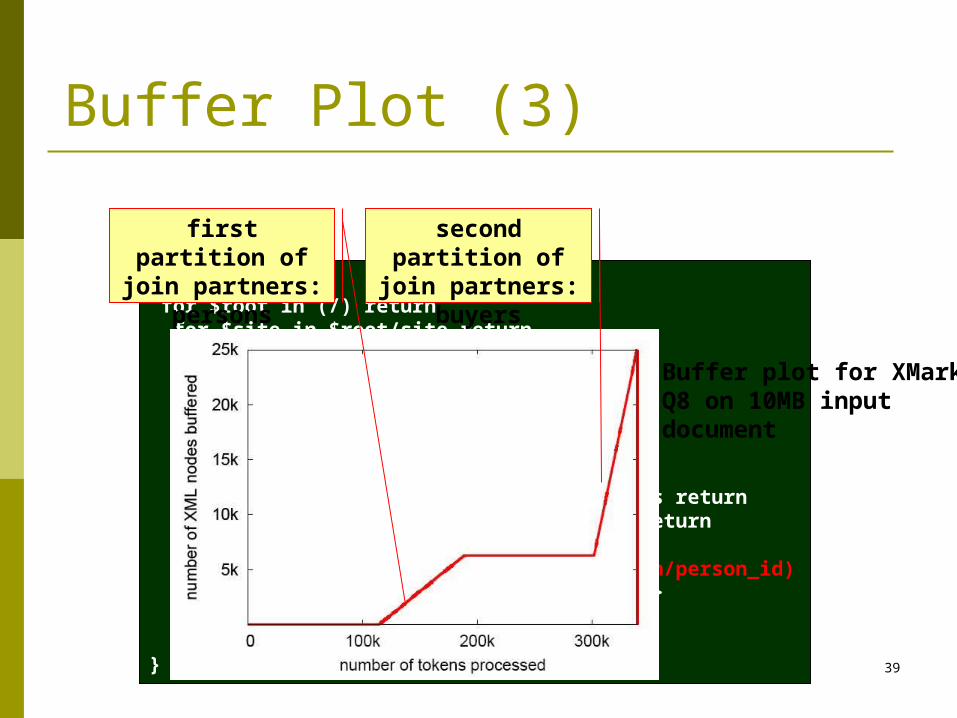
<query8> { for $root in (/) return for $site in $root/site return for $people in $site/people return for $person in $people/person return <item> { ( <person>{ $person/name }</person>, <items_bought> { for $site2 in $root/site return for $cas in $site2/closed_auctions return for $ca in $cas/closed_auction return for $buyer in $ca/buyer return if ($buyer/buyer_person=$person/person_id) then <result> { $ca } </result> else () } </items_bought> ) } </item> } </query8>
Buffer plot for XMark Q8 on 10MB input document
first partition of join partners:
persons
second partition of join partners:
buyers
Buffer Plot (3)
40
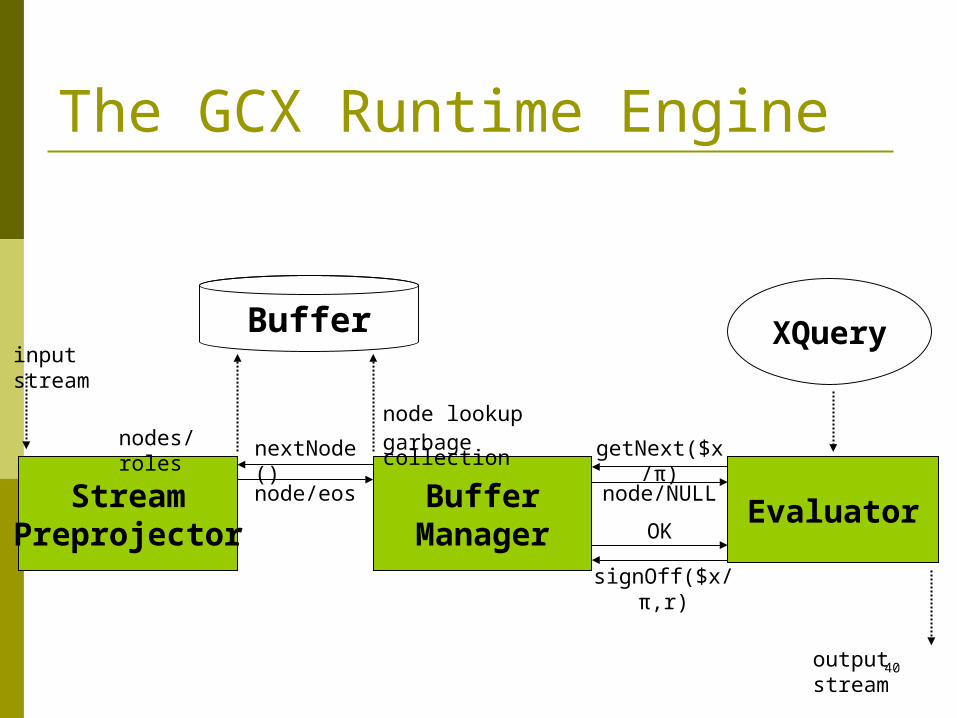
The GCX Runtime Engine
StreamPreprojector
BufferManager
Evaluator
XQueryinput stream
output stream
nodes/roles
node lookupgarbage collection
node/eos
signOff($x/π,r)
OK
node/NULL
getNext($x/π)
Buffer
nextNode()
41
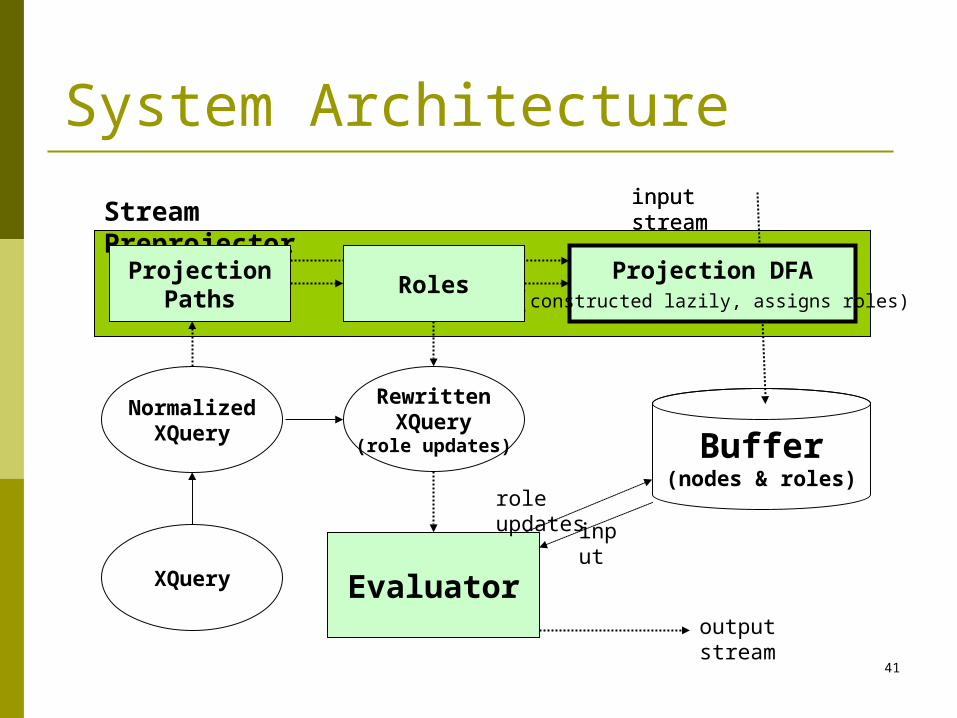
XQuery
NormalizedXQuery
Evaluator
Buffer(nodes & roles)
role updates
input
input stream
output stream
Stream Preprojector
RewrittenXQuery
(role updates)
ProjectionPaths
Projection DFA(constructed lazily, assigns roles)
Roles
input stream
System Architecture
42
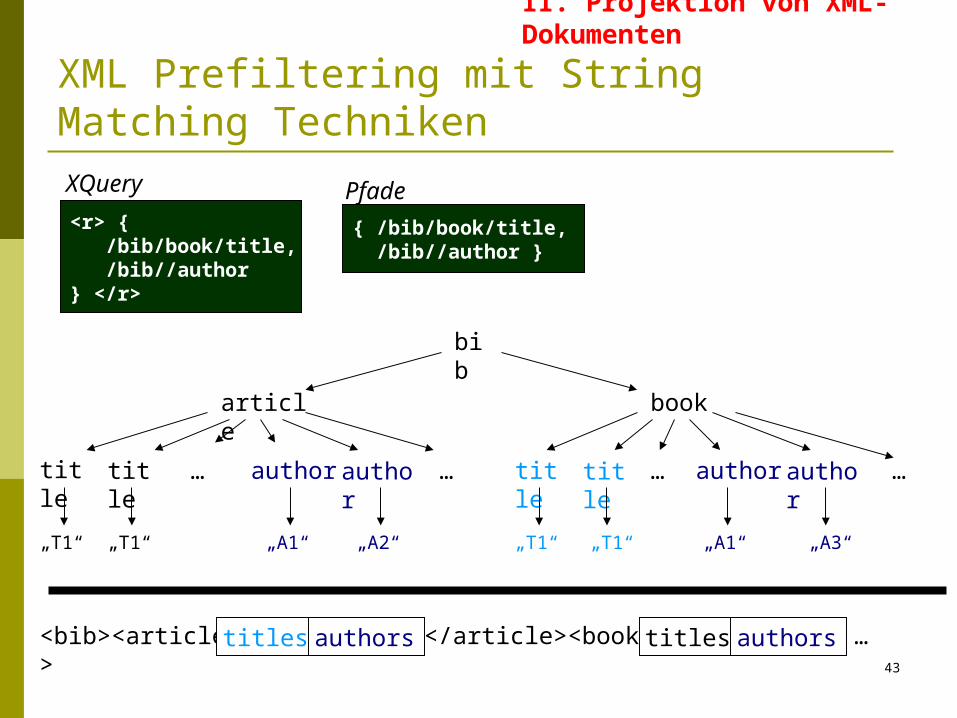
XML Prefiltering mit String Matching Techniken
II. Projektion von XML-Dokumenten
</author>
<author>
<title> </title> <author> </author> <title> <author>
</book>
</bib> </book>
<author>
<author>
<book> <book>
<article>
<bib><article> </article><book> …titles authors titles authors
Suche „<article>“Suche „<author>“ und „<book>“Suche „</author>“Suche „<author>“ und „<book>“Suche „<title>“, „<author>“, „</book>“
43
XML Prefiltering mit String Matching Techniken
II. Projektion von XML-Dokumenten
<r> { /bib/book/title, /bib//author} </r>
XQuery
Pfade
{ /bib/book/title, /bib//author }
bib
article book
title title title title author authorauthor author… … … …
„T1“ „T1“ „T1“ „T1“„A1“ „A2“ „A1“ „A3“
<bib><article> </article><book> …titles authors titles authors

44
Exkurs: XML und XQuery
<bib> <book> <title>T1</title> <author>A1</author> </book> <book> <title>T2</title> <author>A2</author> </book> <article> <author>A3</author> </article></bib>
XML-Dokument
XQuery
<q> { for $book in /bib/book where ($book/title=„T1“) return $book, for $author in /bib//author return $author} </q>
Ergebnis<q> <book> <title>T1</title> <author>A1</author> </book> <author>A1</author> <author>A2</author> <author>A3</author></q>
“/”: selektiert Kind-Knoten
“//”: selektiert Descendant-Knoten





























