Embed Size (px)
Citation preview

Eine Einführung in R:
Deskriptive Statistiken und Graphiken
Katja Nowick, Markus Kreuz(basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus)
Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE),Universität Leipzig
http://www.nowick-lab.info/?page_id=365
06. Januar 2015
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 1 / 104
I. Ergänzungen zu Übung 1
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 2 / 104

Scope [Gültigkeitsbereich]von Variablen bei Funktionen
Es können drei Arten von Variablen in einer Funktion auftauchen:
Formale Parameter:Werden beim Aufruf der Funktion angegeben
Lokale Variablen:Werden beim Abarbeiten einer Funktion erzeugt
Freie Variablen:Alle anderen
Frage: Wo sucht R nach freien Variablen?Antwort: In der Umgebung der Variable
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 3 / 104

z <- 3f <- function(x) {y <- 2*xprint(z)}
Ausgabe bei Aufruf der Funktion:
f(1) f(60)
3 3
x: Formaler Parameter
y: Lokale Variable
z: Freie Variable, die in diesem Bsp. von R auÿerhalb der Funktiongesucht wird
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 4 / 104
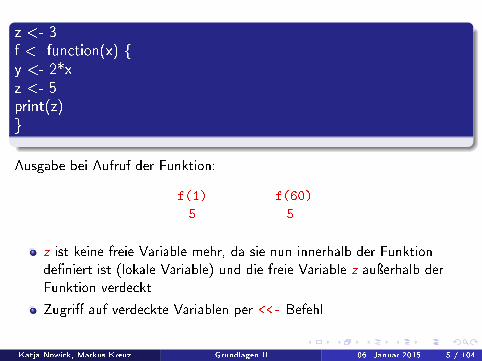
z <- 3f <- function(x) {y <- 2*xz <- 5print(z)}
Ausgabe bei Aufruf der Funktion:
f(1) f(60)
5 5
z ist keine freie Variable mehr, da sie nun innerhalb der Funktionde�niert ist (lokale Variable) und die freie Variable z auÿerhalb derFunktion verdeckt
Zugri� auf verdeckte Variablen per <<- Befehl
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 5 / 104

Ermittlung der Rechenzeit
system.time(expr)
expr: R-Befehl, dessen Rechenzeit ausgewertet werden soll
Beispiel: colMeans gegen apply
try<-matrix(1:4000000, nrow=4)
system.time(colMeans(try))
user system elapsed
0.02 0.00 0.01
system.time(apply(try, MARGIN=2, FUN=mean, na.rm=TRUE))
user system elapsed
32.16 0.00 32.20
Alternativ:
ptm <- proc.time()
exrps
proc.time()-ptmKatja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 6 / 104

Pakete und Hilfe
Download unter http://cran.r-project.org
R besteht aus einem Grundprogramm mit vielen Zusätzen densogenannten packages oder Pakete
Hilfe per ?<Name> oder help.search(suchbegriff)
Übersicht über die Hilfe help.start( )
Pakete speziell für Bioinformatik / Biostatistik:http://bioconductor.org/
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 7 / 104

Was sind Pakete?
R bietet eine Vielzahl frei verfügbarer Pakete
Ein Paket enthält unterschiedlichste, spezielle Funktionen
Beim Start von R ist nur eine Grundausstattung geladen,alle anderen Pakete müssen zusätzlich geladen werden
Jeder kann sein eigenes Paket schreiben
Derzeit gibt es 6158 Pakete (Stand Oktober 2009: 2112 Pakete)
Es besteht aber KEINE GARANTIE für richtige Funktionsweise!
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 8 / 104

Was sind Pakete?
Überblick über die geladenen Pakete sessionInfo( )
package laden require(packagename) oder library(packagename)
package installieren install.packages(packagename)
Repositories auswählen setRepositories()
Wichtige Pakete:survival: Überlebenszeitanalysen (Kaplan-Meier, Log-Rank-TestsCox-Modelle)mvtnorm: Multivariate NormalverteilungR2HTML: R Ausgabe in HTML
Mögliche Pakete:sendmailR: send email from inside RtwitteR: R based Twitter clientsudoku: Sudoku Puzzle Generator and Solver
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 9 / 104
II. Diskrete Daten: Deskriptive Statistiken und Graphiken
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 10 / 104

Was sind diskrete Variablen?
Diskrete Variablen nehmen nur eine endliche Anzahl an Werten an:
Kategorial: Es besteht keine Rangordnung der Kategorien
Ordinal: Kategorien können geordnet werden
Kategoriale oder ordinale Variablen sollten in R als Faktoren de�niertsein.
Mit einer Häu�gkeitstabelle kann man ein kategoriales Objektzusammenfassen:
table(object): Absolute Häu�gkeiten
prop.table(table(object)): Relative Häu�gkeiten
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 11 / 104

Betrachten wir einen Faktor mit 4 Ausprägungen:DNA <- rep(c(�A�, �C�, �G�, �T�), 10)
1 �A�2 �C�3 �G�3 �T�...
...
table(DNA) ergibt:
A C G T
10 10 10 10
prop.table(table(DNA)) ergibt:
A C G T
0.25 0.25 0.25 0.25
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 12 / 104
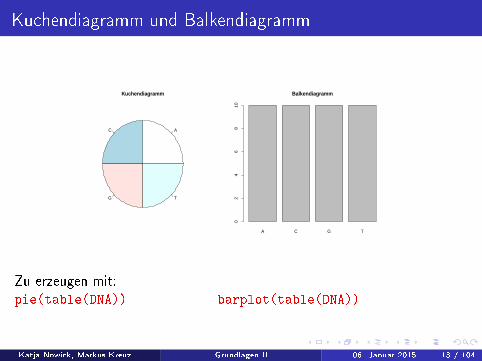
Kuchendiagramm und Balkendiagramm
AC
G T
Kuchendiagramm
A C G T
Balkendiagramm
02
46
81
0
Zu erzeugen mit:pie(table(DNA)) barplot(table(DNA))
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 13 / 104
III. Stetige Daten: Deskriptive Statistiken und Graphiken
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 14 / 104

Was sind stetige Variablen?
Stetige Variablen können (in der Theorie) eine unendliche Anzahl anWerten annehmen. Beispiele:
Gewicht
Gröÿe
Gehalt
R speichert stetige Variablen alsmetrische Objekte (numeric) ab.
Häu�gkeitstabelle sind für stetige Variablen meist nicht geeignet. Wichtigersind:
Maÿe für die Lage
Maÿe für die Streuung
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 15 / 104

Maÿe für die Lage
Die Lage (location) gibt an, in welcher Gröÿenordnung sich Datenbewegen.
(Empirische) Mittelwert
x =1n
n∑i=1
xi =1n(x1 + . . .+ xn) .
In R: mean()
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 16 / 104

Maÿe für die Lage II
x%-Quantile, trennen die Daten in zwei Teile.So liegen x% der Daten unter dem x%-Quantileund 100− x% darüber.
Median x0.5 entspricht dem 50%-QuantilIn R: median()
25%-Quantil x0.25 (das erste Quartil)In R: quantile(x,0.25)
75%-Quantil x0.75 (das dritte Quartil)In R: quantile(x,0.75)
Der Median ist robuster gegen Ausreiÿer als der Erwartungswert
Oder gleich in R: summary()
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 17 / 104

Maÿe für die Streuung
Die Streuung (scale) gibt an, wie stark die verschiedenen Wertevoneinander abweichen.
Die (empirische) Varianz
s2 =1
n − 1
n∑i=1
(xi − x)2 =1
n − 1
((x1 − x)2 + . . .+ (xn − x)2
).
Spannbreite:Di�erenz vom gröÿten zum kleinsten Wert
Interquartilsabstand:
IQR = x0.75 − x0.25
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 18 / 104

Beispiel: oecd -Daten
Betrachten wir das durchnittliche, frei verfügbare Einkommen einer Familie[ pro Kind, in tausend US-Dollar ].
Einen Überblick erhält man durch:
summary(Einkommen)
Min. 1st Qu. Median Mean 3rd Qu. Max.
5.10 16.60 21.10 19.18 22.65 34.20
Die Varianz bzw. Standardabweichung
var(Einkommen)
[1] 50.75937
sd(Einkommen) (alternativ sqrt(var(Einkommen)) )[1] 7.124561
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 19 / 104

Beispiel: oecd -Daten II
Den Interquartilsabstand erhält man durch:
IQR(Einkommen)
[1] 6.05
Die Spannweite mit
max(Einkommen)-min(Einkommen)
[1] 29.1
Bei der Variable Alkohol (Prozentsatz der 13-15 jährigen Kinder, diemindestens zweimal betrunken waren) bestehen fehlende Werte.
Mittelwertsberechnung über
mean(Alkohol,na.rm=TRUE)
[1] 15.225
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 20 / 104

Was ist ein Boxplot?
Der Boxplot ist eine Graphik zur Darstellung stetiger Variablen.Er enthält:
Minimum und Maximum
25%-Quantil und 75%-Quantil
Median
In R: boxplot(variable)
Um Variablen getrennt nach Faktorstufen zu untersuchen, bietet sichan: boxplot(variable ∼ factor)
Einschub: Ein Label für den Faktor Geofactor(Geo,levels=c(�R�,�E�),
labels=c(�Nicht-Europa�,�Europa�))
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 21 / 104
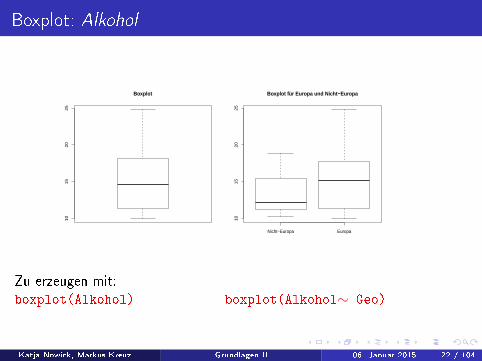
Boxplot: Alkohol
10
15
20
25
Boxplot
Nicht−Europa Europa1
01
52
02
5
Boxplot für Europa und Nicht−Europa
Zu erzeugen mit:boxplot(Alkohol) boxplot(Alkohol∼ Geo)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 22 / 104
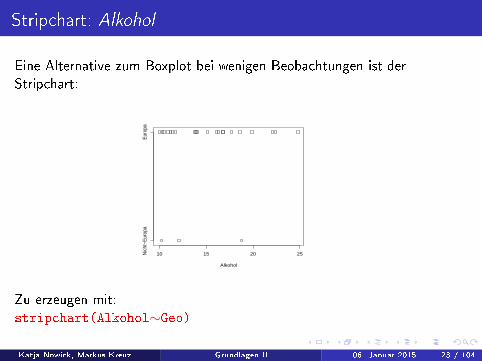
Stripchart: Alkohol
Eine Alternative zum Boxplot bei wenigen Beobachtungen ist derStripchart:
10 15 20 25Nic
ht−E
urop
aE
urop
a
Alkohol
Zu erzeugen mit:stripchart(Alkohol∼Geo)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 23 / 104

Was ist ein Histogramm?
Zur Erstellung eines Histogramms teilt man die Daten in homogeneTeilintervalle ein und plottet dann die absolute Häu�gkeit proTeilintervall
Dieses Verfahren gibt einen ersten Überblick über die Verteilung derDaten( => Ermitteln der �empirischen Dichte� möglich )
hist(x, breaks = �AnzahlBins�, freq = NULL )
x: Daten
breaks = �AnzahlBins�: Steuerung der Teilintervalle
freq=TRUE: absolute Häu�gkeiten
freq=FALSE: relative Häu�gkeiten (�empirische Dichte�)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 24 / 104
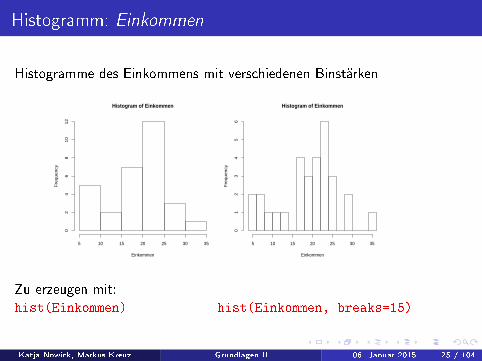
Histogramm: Einkommen
Histogramme des Einkommens mit verschiedenen Binstärken
Histogram of Einkommen
Einkommen
Fre
qu
en
cy
5 10 15 20 25 30 35
02
46
81
01
2
Histogram of Einkommen
Einkommen
Fre
qu
en
cy
5 10 15 20 25 30 35
01
23
45
6
Zu erzeugen mit:hist(Einkommen) hist(Einkommen, breaks=15)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 25 / 104
Aufgabenkomplex 1
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 26 / 104

IV. Graphiken in R: Grundaufbau und Parameter
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 27 / 104

Graphiken in R
R kennt einen Standardbefehl für einfache Graphiken (plot()), aber auchviele spezielle Befehle, wie hist() oder pie().
plot(x, y, type, main, par (...) )
x: Daten der x-Achse
y: Daten der y -Achse
type=�l�: Darstellung durch eine Linie
type=�p�: Darstellung durch Punkte
main: Überschrift der Graphik
par (...): Zusätzlich können sehr viele Parametereinstellungengeändert werden
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 28 / 104

Parameter für Graphiken in R
par(cex, col, lty, mfrow, pch, x/yaxs)
cex: Skalierung von Graphikelementen
col: Farbe (colors() zeigt die vorde�nierten Farben an)
lty: Linienart
mfrow: Anordnen von mehreren Graphiken nebeneinander
pch: Andere Punkte oder Symbole
x/yaxs: Stil der x- bzw. y -Achse
Einen Überblick über die Parameter erhält man mit ?par.par() kann entweder im plot() -Befehl gesetzt werden oder als eigeneFunktion vor einem oder mehreren plot()-Befehlen.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 29 / 104

Aufbau von Graphiken in R
1 plot(): Bildet den Grundstein einer Graphik2 Zusätzlich können weitere Elemente eingefügt werden wie:
lines(): Linienpoints(): Punktelegend(): Legendetext(): Text
3 dev.off(): schlieÿt die Graphik
Einen Überblick erhält man mit der betre�enden Hilfefunktion,z.B. ?legend.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 30 / 104

Abspeichern von Graphiken
Folgende Graphikformate können in R erzeugt werden:
pdf()
ps()
jpg()
Beispiel:pdf(file=�boxplot.pdf�, width=13, height=6)
par(mfrow=c(1,2))
boxplot(Alkohol, main=�Boxplot�)
boxplot(Alkohol∼Geo, main=�Boxplot für ...�)
par(mfrow=c(1,1))
dev.off()
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 31 / 104
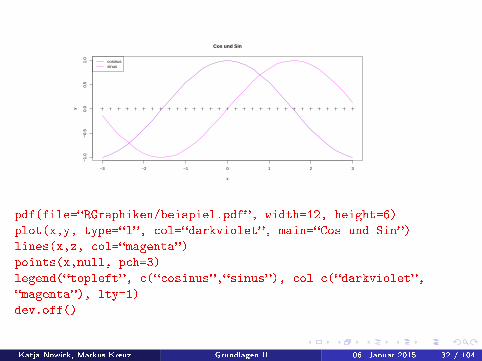
−3 −2 −1 0 1 2 3
−1.
0−
0.5
0.0
0.5
1.0
Cos und Sin
x
y
cosinussinus
pdf(file=�RGraphiken/beispiel.pdf�, width=12, height=6)
plot(x,y, type=�l�, col=�darkviolet�, main=�Cos und Sin�)
lines(x,z, col=�magenta�)
points(x,null, pch=3)
legend(�topleft�, c(�cosinus�,�sinus�), col=c(�darkviolet�,
�magenta�), lty=1)
dev.off()
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 32 / 104

V. Dichten und Verteilungsfunktionen in R
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 33 / 104

Einschub: Zufallsvariablen
Eine Variable oder Merkmal X , dessen Werte die Ergebnisseeines Zufallsvorganges sind, heiÿt Zufallsvariable.
Notation:
X : Die Zufallsvariable
x : Eine Realisierung oder Beobachtung der Zufallsvariable
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 34 / 104

Induktive (Schlieÿende) Statistik:
Mittels einer Stichprobe wird versucht Aussagen bezüglich einerGrundgesamtheit zu tre�en.
Grundgesamtheit: Menge aller für die Fragestellung relevanten Objekte
Stichprobe: Tatsächlich untersuchte Teilmenge der Grundgesamtheit
Die Aussagen beziehen sich auf Merkmale der Grundgesamtheit.
Merkmal: Die interessierende Gröÿe oder Variable
Merkmalsausprägung: Der konkret gemessene Wert an einem Objektder Stichprobe
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 35 / 104

Das Model: Theoretische Ebene
Statistische Analysen beruhen auf Modellannahmen.Ziel: Formalisierung eines reellen Sachverhaltes
Stetige Variablen mit Erwartungswert und VarianzDiskrete Variablen mit Gruppenzugehörigkeiten
Parametrischer Ansatz: Verteilungsannahmen,wie eine Zufallsvariable X ist normalverteilt mit Erwartungswert µ undVarianz σ2
Non-Parametrischer Ansatz: Ohne Verteilungsannahmen
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 36 / 104

Die beobachteten Daten: Die empirische Ebene
Erwartungswert und Varianz einer Grundgesamtheit können nicht inder Realität beobachtet werden, sondern müssen aus der Stichprobegeschätzt werden.
Beobachtet werden n Realisierungen x1, ..., xn einer ZufallsstichprobeX .Notation:
Erwartungswert µSchätzer für den Erwartungswert µ̂ = 1
n
∑ni=1
xi
Gesetz der groÿen Zahlen: �Je mehr Realisierungen einer Zufallszahlbeobachtet werden, desto besser approximiert der Mittelwert denErwartungswert�
Realisierungen einer Zufallsvariable folgen nicht exakt einerbestimmten Verteilung. Nur bei groÿer Stichprobenzahl nährt sich dieempirische Dichte der theoretischen an.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 37 / 104

Normalverteilung N(µ, σ)
Die Normal- oder Gauÿ-Verteilung ist formalisiert durch Erwartungswert µund Varianz σ2:
f (x |µ, σ) = 1
σ ·√2π
exp
(−12
(x − µσ
)2)
Diese Funktion ist in R implementiert:dnorm(x, mean=0, sd=1)
(Vorsicht: mean steht hier für den Erwartungswert)
Erzeugen von n Realisierungen x1, ..., xn:rnorm(n, mean=0, sd=1)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 38 / 104

Beispiel: Normalverteilung
Darstellung: Gesetz der groÿen Zahlenx10<-matrix(rnorm(100),nrow=10,ncol=10)
x1000<-matrix(rnorm(10000),nrow=10,ncol=1000)
apply(x10,MARGIN=1, mean)
-0.392 -0.309 0.195 -0.727 -0.150 0.327 0.142 0.020 0.069 0.594apply(x1000,MARGIN=1, mean)
-0.018 -0.011 0.007 -0.011 -0.021 -0.013 0.036 0.026 0.074 0.010
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 39 / 104
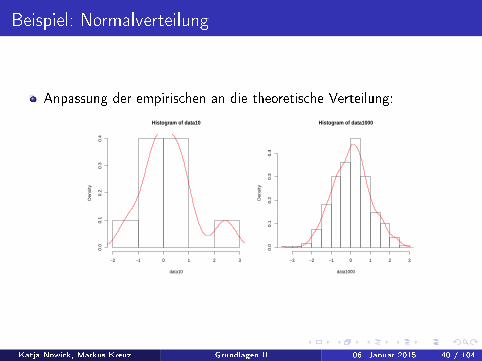
Beispiel: Normalverteilung
Anpassung der empirischen an die theoretische Verteilung:
Histogram of data10
data10
De
nsi
ty
−2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Histogram of data1000
data1000
De
nsi
ty−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 40 / 104

V.I Diskrete Daten
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 41 / 104

Eine Zufallsvariable heiÿt diskret, wenn sie endlich vieleWerte x1, ..., xk annehmen kann.
Die Wahrscheinlichkeitsfunktion f (x) einer diskreten Zufallsvariable X istfür x ∈ R de�niert durch die Wahrscheinlichkeiten pi :
f (x) =
{P(X = xi ) = pi falls x = xi ∈ {x1, ..., xk}0 sonst
Die Verteilungsfunktion F (x) einer diskreten Zufallsvariable ist gegebendurch die Summe:
F (y) = P(X ≤ y) =∑i :xi≤y
f (xi )
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 42 / 104

Eigenschaften
Für die Wahrscheinlichkeitsfunktion f (x) gilt:
0 ≤ f (x) ≤ 1∑i≥1
pi = 1
Für die Verteilungsfunktion F (x) gilt:
F (x) =
{1 x ≥ max(x)0 x ≤ min(x)
F(x) ist monoton steigend mit Wertebereich 0 bis 1.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 43 / 104

Bernoulli-Experiment
Binäre Zufallsvariable X : Tritt ein Ereignis A ein?
X =
{1 falls A eintritt0 falls A nicht eintritt
Das Ereignis A tritt mit einer bestimmten Wahrscheinlichkeit 0 < π < 1 ein
P(X = 1) = πP(X = 0) = 1− π
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 44 / 104

Binomialverteilung
Die Binomialverteilung entspricht dem n-maligen Durchführen einesBernoulli-Experimentes mit Wahrscheinlichkeit π
f (x) =
(n
x
)πx(1− π)n−x falls x = 0, 1, ..., n
0 sonst
Beispiel
Ein Schütze schieÿt n = 10 mal auf eine Torwand.Wie groÿ ist die Wahrscheinlichkeit, dass er genau fünfmal tri�t,
wenn er eine Tre�erwahrscheinlichkeit π von 25 % hat?
P(X = 5) =
(105
)0.255(1− 0.25)10−5 = 0.058
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 45 / 104

Diskrete Gleichverteilung
Die diskrete Gleichverteilung charakterisiert die Situation, dassx1, . . . , xk -verschiedene Werte mit gleicher Wahrscheinlichkeit angenommenwerden.
f (x) =
{1k falls xi mit i = 1, ..., k0 sonst
Beispiel
Würfeln, jede Zahl hat die gleiche Wahrscheinlichkeit 16
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 46 / 104
V.II Stetige Daten
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 47 / 104

Eine Zufallsvariable heiÿt stetig, wenn sie unendlich vieleWerte x1, ..., xk , ... annehmen kann, wie beispielsweise
metrische Variablen.
Die Dichte f (x) einer stetigen Zufallsvariable X ist für ein Intervall [a, b]de�niert als:
P(a ≤ X ≤ b) =
∫ b
af (x)∂x
Die Verteilungsfunktion F (y) einer stetigen Zufallsvariable ist gegebendurch das Integral:
F (y) = P(X ≤ y) =
∫ y
−∞f (x)∂x
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 48 / 104

Eigenschaften
Für die Dichte f (x) gilt: ∫ +∞
−∞f (x)∂x = 1
P(X = a) =
∫ a
af (x)∂x = 0
Für die Verteilungsfunktion F (x) gilt:
F (x) =
{1 für x ≥ max(x)0 für x ≤ min(x)
F ′(x) =∂F (X )
∂x= f (x)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 49 / 104

Normalverteilung N(µ, σ)
Eine der wichtigsten Verteilungen ist die Normal- oder Gauÿ-Verteilung mitErwartungswert µ und Varianz σ2:
f (x |µ, σ) = 1
σ ·√2π
exp
(−12
(x − µσ
)2)
Symmetrisch um µ
Nur abhängig von µ und σ
Beispiele: Klausurnoten, das (logarithmierte) Einkommen, Messfehler,Gröÿe und Gewicht
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 50 / 104

Stetige Gleichverteilung U(a, b)
Gegeben: ein Intervall, de�niert durch reelle Zahlen a und b mit a < b:
f (x) =
{ 1b−a für x ∈ [a, b]
0 sonst
Die stetige Gleichverteilung spielt eine wichtige Rolle bei statistischen Tests.
Hat man x1, . . . , xn Realisierungen einer Variablen X mitVerteilungsfunktion F , so gilt:
F (x1), . . . ,F (xn) ∼ U(0, 1)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 51 / 104
Aufgabenkomplex 2
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 52 / 104
V.III Umgang mit Zufallszahlen
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 53 / 104
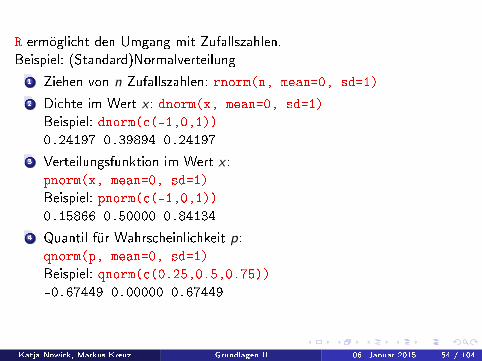
R ermöglicht den Umgang mit Zufallszahlen.Beispiel: (Standard)Normalverteilung
1 Ziehen von n Zufallszahlen: rnorm(n, mean=0, sd=1)
2 Dichte im Wert x : dnorm(x, mean=0, sd=1)
Beispiel: dnorm(c(-1,0,1))0.24197 0.39894 0.24197
3 Verteilungsfunktion im Wert x :pnorm(x, mean=0, sd=1)
Beispiel: pnorm(c(-1,0,1))0.15866 0.50000 0.84134
4 Quantil für Wahrscheinlichkeit p:qnorm(p, mean=0, sd=1)
Beispiel: qnorm(c(0.25,0.5,0.75))-0.67449 0.00000 0.67449
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 54 / 104
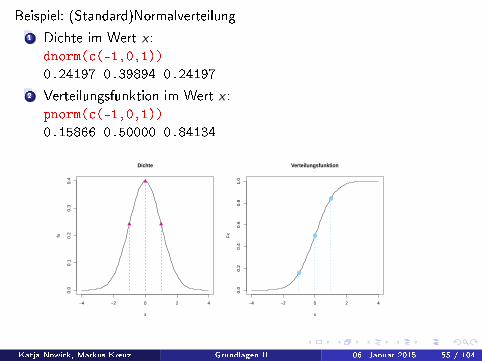
Beispiel: (Standard)Normalverteilung1 Dichte im Wert x :
dnorm(c(-1,0,1))
0.24197 0.39894 0.24197
2 Verteilungsfunktion im Wert x :pnorm(c(-1,0,1))
0.15866 0.50000 0.84134
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
Dichte
x
fx
−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
Verteilungsfunktion
x
Fx
●
●
●
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 55 / 104

R-Befehle für weitere Verteilungen
rnorm(n, mean=0, sd=1) Normalverteilung mit Mittelwert mean undStandardabweichung sd
rexp(n, rate=1) Exponentialverteilung mit Rate rate
rpois(n, lambda) Poissonverteilung mit Rate lambda
rcauchy(n, location=0, scale=1) Cauchyverteilung mitLokations- und Skalenparameter
rt(n, df)(Studen)t-verteilung mit Freiheitsgraden df
rbinom(n, size, prob) Binomialverteilung vom Umfang size undWahrscheinlichkeit prob
rgeom(n, prob) Geometrische Verteilung mit Wahrscheinlichkeitprob
rhyper(nn, m, n, k) Hypergeometrische Verteilung
runif(n, min=0, max=1) Stetige Gleichverteilung im Intervall [min,max]
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 56 / 104

Darstellung: Histogrammeund Kerndichteschätzer
1 Histogramme: Darstellung von stetigen und diskreten Verteilungen
hist(x, breaks = �AnzahlBins�, freq = NULL )
x: Datenbreaks = �AnzahlBins�: Steuerung der Teilintervallefreq=TRUE: absolute Häu�gkeitenfreq=FALSE: relative Häu�gkeiten (�empirische Dichte�)
2 Kerndichteschätzer: Darstellung von stetigen Verteilungen
plot(density(x, kernel=�gaussian�, bw))
density(x): Kerndichteschätzung der Datenkernel: Option für spezielle Kerntypenbw: Bandbreite
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 57 / 104

Darstellung: Kerndichteschätzer
Kerndichteschätzer sind aus dem Histogramm abgeleitete Verfahren zurSchätzung von stetigen Dichten
Hat man gegebene Daten x1, . . . , xn und eine konstante Bandbreiteh ∈ R so ist der Kerndichteschätzer gegeben durch:
f̂ (x) =1n
n∑i=1
1hK
(x − xi
h
)Typische Kerne sind:
Bisquare Kern: K (u) = 1516(1− u2)2 für u ∈ [−1, 1] und 0 sonst
Gauÿ Kern: K (u) = 1√2π
exp
(−1
2u2
)für u ∈ R
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 58 / 104
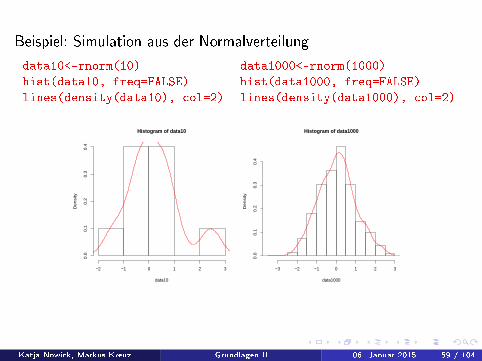
Beispiel: Simulation aus der Normalverteilung
data10<-rnorm(10) data1000<-rnorm(1000)
hist(data10, freq=FALSE) hist(data1000, freq=FALSE)
lines(density(data10), col=2) lines(density(data1000), col=2)
Histogram of data10
data10
De
nsi
ty
−2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Histogram of data1000
data1000
De
nsi
ty
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 59 / 104
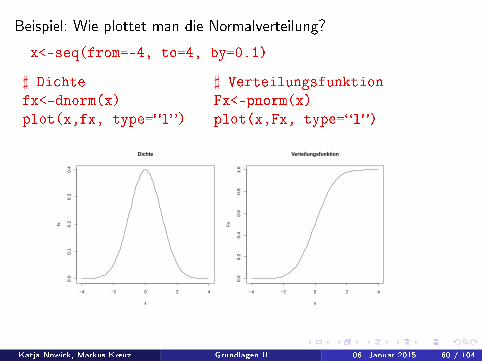
Beispiel: Wie plottet man die Normalverteilung?
x<-seq(from=-4, to=4, by=0.1)
] Dichte ] Verteilungsfunktionfx<-dnorm(x) Fx<-pnorm(x)plot(x,fx, type=�l�) plot(x,Fx, type=�l�)
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
Dichte
x
fx
−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
Verteilungsfunktion
x
Fx
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 60 / 104

Darstellung: Q-Q-Plot
Quantil-Quantil-Plots tragen die Quantile (empirisch oder theoretisch)zweier Verteilungen gegeneinander ab. Somit können Verteilungenmiteinander verglichen werden.
qqplot(x,y): Plottet die emp. Quantile von x gegen die emp.Quantile von y
qqnorm(y): Plottet die emp. Quantile von y gegen die theoretischenQuantile einer Standard-Normalverteilung
qqline(y): Fügt dem Quantilplot eine Gerade hinzu die durch daserste und dritte Quartil geht
Bsp: Vergleich von Normal- und t-Verteilung
data <- rt(400, df = 2)
qqnorm(data, main = �QQ-Plot�, xlab= �Normalverteilung�, ylab =
�t-Verteilung�)
qqline(data, col = �green�)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 61 / 104
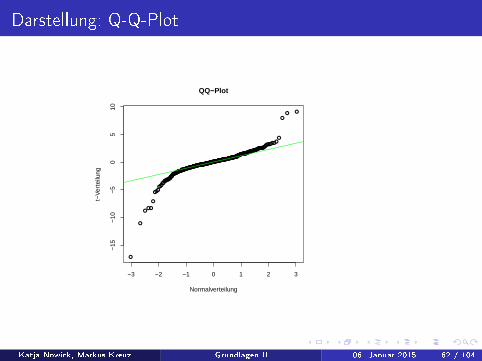
Darstellung: Q-Q-Plot
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●●
●●
●● ●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●●
●●
●
●
●
●●●
●
●
●
●●●
●●
●
●
●●
●
●●●
●
●●
●
●
●●
●●
●
●●
●
●
●●
●
●●
●
●●●
●●● ●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●●
●
●
●
●●
●
●
●
●
● ●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●●
●●●
●
●●●
●●
● ●●●
●
●
●●
●
●
●
●●
●
●
●●
●● ●●
●●
●●
●
●
●●
●●
●
●●
●
●●
●●●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●●
●
●
●●
●
●●●●
●●
●
●
●
●
●
●● ●
●
●●
●
●●
●●
●●
●●
●●
●●
●
●
●
●●
●
●●
●
●●
●●
●
●
●● ●
●●
●
●
●
●
●
●●
●
●
●
●●
●●
●
● ●
●●
● ●●
●
●
●
●●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
−3 −2 −1 0 1 2 3
−15
−10
−5
05
10
QQ−Plot
Normalverteilung
t−V
erte
ilung
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 62 / 104
VI. Statistische Tests
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 63 / 104
VI.I Einführungsbeispiel
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 64 / 104
VI.I Einführungsbeispiel
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 65 / 104

Fragestellung
Einführungsbeispiel: Trinkt die Jugend in Europa mehr Alkohol alsim Rest der Welt?
Untersucht wird die Variable Alkohol im oecd-Datensatz: Der Anteil an13-15 jährigen Jugendlichen, die mindestens zweimal betrunken waren.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 66 / 104
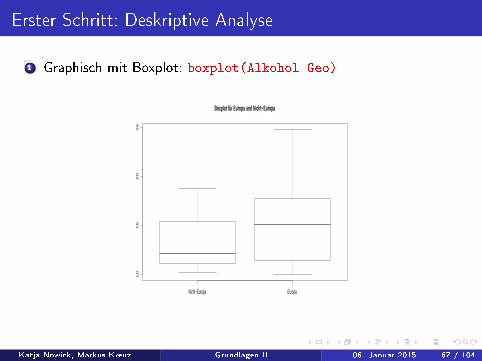
Erster Schritt: Deskriptive Analyse
1 Graphisch mit Boxplot: boxplot(Alkohol Geo)
Nicht−Europa Europa
10
15
20
25
Boxplot für Europa und Nicht−Europa
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 67 / 104

Zweiter Schritt: Kennzahlen
2 Kennzahlen:
Mittelwert:mu<-tapply(Alkohol, Geo, FUN=mean, na.rm=TRUE)
Nicht-Europa Europa
13.700 15.443Standardabweichung:sigma<-tapply(Alkohol, Geo, FUN=sd, na.rm=TRUE)
Nicht-Europa Europa
4.518 4.341
Es ist zu erkennen, dass in Europa im Mittel ein höherer Anteil anJugendlichen schon mindestens zweimal betrunken war als innicht-europäischen Staaten.
Doch dies könnte auch ein Zufall sein! Denn dieBeobachtungen beruhen auf Stichproben, sie sind
Realisierungen einer Zufallsvariable.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 68 / 104

Eigentliches Ziel:Überprüfung von Annahmen über das Verhalten des interessierendenMerkmales in der Grundgesamtheit mittels Stichproben.
Annahme: Jugendliche in Europa trinken mehr Alkohol als im Restder Welt
Merkmal: Alkoholkonsum der Jugend
Grundgesamtheit: Jugendliche in Europa und im Rest der Welt
Stichprobe: Die oecd-Daten
Für solche Fragestellungen mit gleichzeitiger Kontrolle derFehlerwahrscheinlichkeit sind statistische Tests geeignet!
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 69 / 104

Statistisches Testen I
1 Aufstellen von zwei komplementären Hypothesen:
Testhypothese (H0): Der Anteil in Europa ist kleiner dem im Rest derWelt µE ≤ µNE
Alternativhypothese (H1): Der Anteil in Europa gröÿer als der imRest der Welt µE > µNE
2 Fehlerwahrscheinlichkeit festlegen:H0 soll mit einer W'keit von weniger als 5% abgelehnt werden, wennH0 wahr ist.
Also: Wenn der Anteil in Wahrheit kleiner oder gleich ist,soll der Test nur mit einer Wahrscheilichkeit von weniger als5% zu dem (falschen) Ergebnis kommen, dass der Anteil
gröÿer ist.
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 70 / 104

Statistisches Testen II
3 Beobachtete Daten: 2 Gruppenµ̂ σ̂ n
Nicht-Europa 13.700 4.518 3Europa 15.443 4.341 21
4 (Weitere Annahmen, hier: Normalverteilung, Varianzgleichheit)5 Berechnen der Prüfgröÿe T , einer Kennzahl, die zeigt, wie starkdie Gruppenmittel voneinander abweichen:
Mittelwertsdi�erenz der beiden GruppenStandardisieren mit der entsprechenden Standardabweichung
T = (µ̂E − ˆµNE )/
√(1nE
+1
nNE)(nE − 1)σ̂2E + (nNE − 1)σ̂2NE
nE + nNE − 2
(Hypothetische Verteilung der Prüfgröÿe festlegen, hier t-Verteilungmit 3 + 21 - 2 = 22 Freiheitsgraden)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 71 / 104

Statistisches Testen III
6 Berechnung der Prüfgröÿe T in R:
Mittelwertsdi�erenz der beiden Gruppenm.diff<-mu[2]-mu[1]
Standardisieren mit der entsprechenden Standardabweichungdiff.std2 <- sqrt((1/21+1/3)*
(20*sigma[2]̂2+2*sigma[1]̂2)/(21+3-2))
Prüfgröÿe:1-pt(pg.T, df=22)
0.648
7 Wie wahrscheinlich ist es (unter der Nullhypothese), einePrüfgröÿe T zu beobachten, die gröÿer oder gleich 0.648 ist?1-pt(pg.T, df=22)
0.262
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 72 / 104
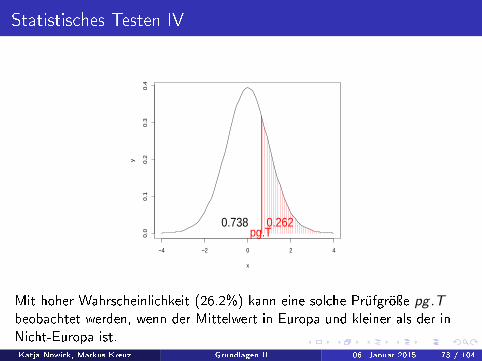
Statistisches Testen IV
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
pg.T0.2620.738
Mit hoher Wahrscheinlichkeit (26.2%) kann eine solche Prüfgröÿe pg .Tbeobachtet werden, wenn der Mittelwert in Europa und kleiner als der inNicht-Europa ist.Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 73 / 104

Statistisches Testen V
8 Entscheidung: Aus diesen Daten kann nicht geschlossen werden, dassin Europa Jugendliche mehr Alkohol trinken als im Rest der Welt.
9 Grund: Zu geringe Fallzahl!Mit nE = nNE = 101 ergibt sich
Standardisieren mit der entsprechenden Standardabweichungdiff.std <- sqrt((1/101+1/101)*
(100*sigma[2]�2+100*sigma[1]�2)/(101+101-2))
Prüfgröÿe:pg.T2 <-m.di�/di�.std22.796Vergleich mit der t-Verteilung:1-pt(pg.T2, df=200)0.003
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 74 / 104
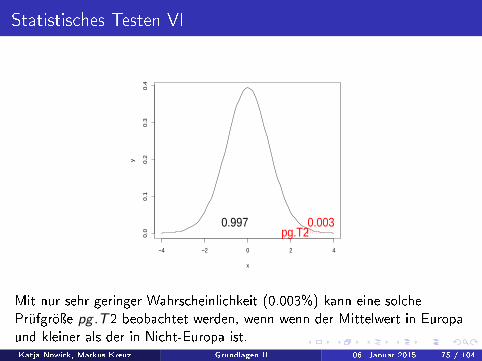
Statistisches Testen VI
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
pg.T20.0030.997
Mit nur sehr geringer Wahrscheinlichkeit (0.003%) kann eine solchePrüfgröÿe pg .T2 beobachtet werden, wenn wenn der Mittelwert in Europaund kleiner als der in Nicht-Europa ist.Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 75 / 104

Fünf Schritte zum Testergebnis
I. Hypothesen aufstellenII. Betrachtung der DatenIII. Aufstellen der PrüfgröÿeIV. Durchführen des TestsV. Testentscheidung
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 76 / 104

I. Hypothesen aufstellen
Was soll verglichen werden?
Mittelwerte von unabhängigen GruppenMittelwert gegen einen festen WertGepaarte Messungen
Einseitige oder zweiseitige Fragestellung?
Einseitige Fragestellung:H0 : µ1 ≤ µ2gegen H1 : µ1 > µ2Zweiseitige Fragestellung:H0 : µ1 = µ2gegen H1 : µ1 6= µ2
Aufstellen der eigentlich interessierenden AlternativhypotheseH1 und der Nullhypothese H0
Signi�kanzniveau α festlegen
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 77 / 104

Fehler bei statistischen Tests
Entscheidung H0 Entscheidung H1
H0 wahr richtig Fehler erster Art αH1 wahr Fehler zweiter Art (β) richtig
Fehler erster Art (α-Fehler):Obwohl H0 wahr ist, entscheidet man sich für H1
(Falsch positives Testergebnis)
Fehler zweiter Art (β-Fehler):Obwohl H1 wahr ist, entscheidet man sich für H0
(Falsch negatives Testergebnis)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 78 / 104

II. Betrachtung der Daten
Können Verteilungsannahmen getro�en werden?Ja: Parametrische TestsNein: Nicht-Parametrische Tests
Weitere Annahmen wie z.B. Varianzgleichheit in den Gruppen
Aus Schritt I. und II. folgt die Auswahl eines geeigneten Tests und alleweiteren Schritte!
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 79 / 104

III. Aufstellen der Prüfgröÿe
Aus den Hypothesen ergibt sich die Form der Prüfgröÿe, z.B. dieMittelwertsdi�erenzStandardisieren der Prüfgröÿe mit:
unter H0 gültigen Erwartungswertunter H0 gültigen Standardabweichung
Festlegen der Verteilung, die unter H0 gültig ist
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 80 / 104

IV./V. Durchführen des Tests und Testentscheidung
Hier sind zwei Werte entscheidend:
Kritischer Wert κ: Welchen Wert darf die Prüfgröÿe bei gegebenemSigni�kanzniveau α maximal/minimal annehmen, wenn H0 tatsächlichgültig ist
p-Wert: Wahrscheinlichkeit, die vorliegenden Daten zu beobachten,wenn H0 gültig ist
Entscheidung H0 ablehnen, falls:
die Prüfgröÿe gröÿer als der kritische Wert ist (bzw. kleiner als derkritische Wert bei einigen nonparametrischen Tests)
falls der p-Wert kleiner dem vorher festgelegten Signi�kanzniveau α ist
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 81 / 104
t-Test - gegen festen Wert (Einstichproben-t-Test)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 82 / 104

1. Ziel, Hypothesen und Voraussetzungen
Vergleich das emp. Populationsmittel x einer Population mit einemhypothetischen Mittelwert µ0Voraussetzung: Normalverteilung der Stichprobe
Varianz wird als unbekannt angenommen und aus den Daten geschätzt
Varianten für die Hypothesen:
1 Einseitige Fragestellung 1:H0 : x ≤ µ0 gegen H1 : x > µ0
2 Einseitige Fragestellung 2:H0 : x ≥ µ0 gegen H1 : x < µ0
3 Zweiseitige Fragestellung:H0 : x = µ0 gegen H1 : x 6= µ0
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 83 / 104

2. Teststatistik
Teststatistik
T =x − µ0
s·√n
Schätzung der Standardabweichung σ durch:
s =
[∑ni=1(x − xi )
2
n − 1
]0.5
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 84 / 104
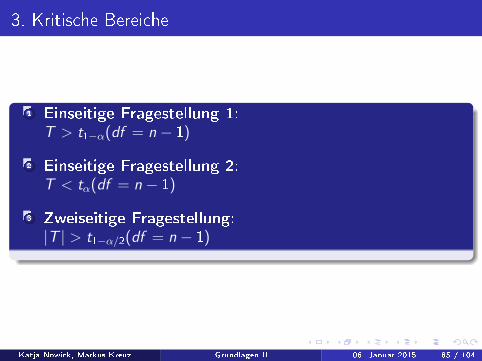
3. Kritische Bereiche
1 Einseitige Fragestellung 1:T > t1−α(df = n − 1)
2 Einseitige Fragestellung 2:T < tα(df = n − 1)
3 Zweiseitige Fragestellung:|T | > t1−α/2(df = n − 1)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 85 / 104
t-Test für unabhängige Stichproben (Zweistichproben-t-Test)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 86 / 104

1. Ziel, Hypothesen und Voraussetzungen
Vergleich das emp. Populationsmittel x1 und x2 miteinander
Voraussetzung: Normalverteilung der Stichproben
Varianz der Populationen unbekannt
2 Varianten: Varianzen der Populationen gleich oder ungleich
Varianten für die Hypothesen:
1 Einseitige Fragestellung 1:H0 : x1 ≤ x2 gegen H1 : x1 > x2
2 Einseitige Fragestellung 2:H0 : x1 ≥ x2 gegen H1 : x1 < x2
3 Zweiseitige Fragestellung:H0 : x1 = x2 gegen H1 : x1 6= x2
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 87 / 104

2. Teststatistik
Teststatistik
T =x1 − x2
s·√n
Schätzung der Standardabweichung σ durch:
s =
[(1n1
+1n2
)· (n1 − 1)s1 + (n2 − 1)s2
n1 + n2 − 1
]0.5wobei s1 und s2 die Standardvarianzschätzer für die Populationen sind
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 88 / 104
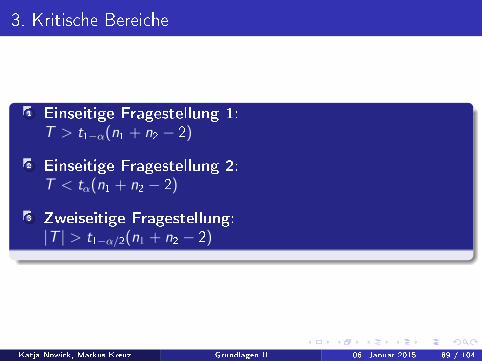
3. Kritische Bereiche
1 Einseitige Fragestellung 1:T > t1−α(n1 + n2 − 2)
2 Einseitige Fragestellung 2:T < tα(n1 + n2 − 2)
3 Zweiseitige Fragestellung:|T | > t1−α/2(n1 + n2 − 2)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 89 / 104

t-Test für Paardi�erenzen
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 90 / 104

1. Ziel, Hypothesen und Voraussetzungen
Teste die Di�erenz d =∑n
i=1 di =∑n
i=1 x1i − x2i miteinandergepaarter Stichproben (x1i , x2i )
Typisches Bsp.: Messen eines Blutwertes vor und nach einer med.Behandlung
Voraussetzung: Normalverteilung der Stichproben
Varianten für die Hypothesen:
1 Einseitige Fragestellung 1:H0 : d ≤ 0 gegen H1 : d > 0
2 Einseitige Fragestellung 2:H0 : d ≥ 0 gegen H1 : d < 0
3 Zweiseitige Fragestellung:H0 : d = 0 gegen H1 : d 6= 0
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 91 / 104

2. Teststatistik
Teststatistik
T =d
s·√n
Schätzung der Standardabweichung σ durch:
s =
[∑ni=1(d − di )
2
n − 1
]0.5
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 92 / 104
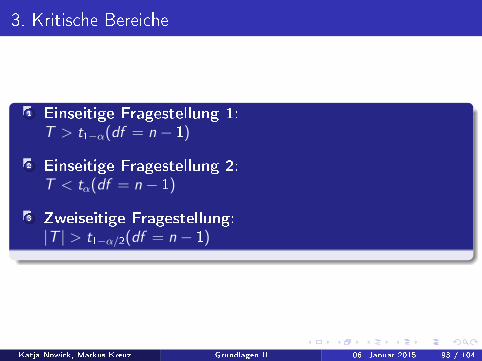
3. Kritische Bereiche
1 Einseitige Fragestellung 1:T > t1−α(df = n − 1)
2 Einseitige Fragestellung 2:T < tα(df = n − 1)
3 Zweiseitige Fragestellung:|T | > t1−α/2(df = n − 1)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 93 / 104
Der Wilcoxon-Rangsummen-Test
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 94 / 104

1. Ziel, Hypothesen und Voraussetzungen
Teste nicht-parametrisch, ob zwei Population den gleichen Medianbesitzen
Zu verwenden, wenn Vor. für den t-Test nicht erfüllt sind
Voraussetzung: Normalverteilung der Stichproben
Benötigt KEINE konkrete Verteilungsannahme
Alternative für den t-Test
Varianten für die Hypothesen:
1 Einseitige Fragestellung 1:H0 : x1,med ≤ x2,med gegen H1 : x1,med > x2,med
2 Einseitige Fragestellung 2:H0 : x1,med ≥ x2,med gegen H1 : x1,med < x2,med
3 Zweiseitige Fragestellung:H0 : x1,med = x2,med gegen H1 : x1,med 6= x2,med
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 95 / 104

2. Teststatistik
Bilde für sämtlichen Beobachtungen x11, . . . x1n1 , x21, . . . x2n2 Rängerg(x11), . . . rg(x1n1), rg(x21), . . . rg(x2n2)
Teststatistik:
R =
n1∑i=1
rg(x1i )
Wertebereich: n1(n1+1)2 < R < (n1+n2)(n1+n2+1)
2 − n1(n1+)2
Nullverteilung von R liegt tabelliert vor
Approximation durch die Normalverteilung ab einer Stichprobengröÿevon ca. 20 möglich
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 96 / 104
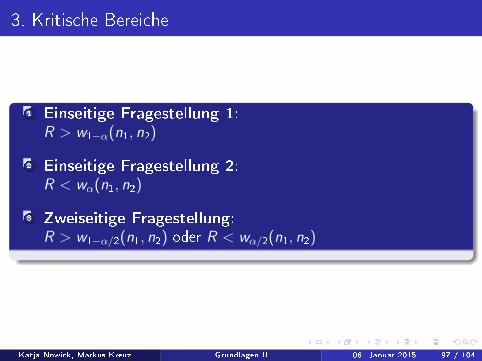
3. Kritische Bereiche
1 Einseitige Fragestellung 1:R > w1−α(n1, n2)
2 Einseitige Fragestellung 2:R < wα(n1, n2)
3 Zweiseitige Fragestellung:R > w1−α/2(n1, n2) oder R < wα/2(n1, n2)
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 97 / 104
t-Test und Wilcoxon-Rangsummen - Test in R - PraktischeDurchführung
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 98 / 104

t-Test in R
t.test(x, y, alternative, paired, var.equal)
Erklärung der Parameter:
x,y = NULL: Die Daten, beim t-Test für eine Population genügt es, xanzugeben
alternative = c(�two.sided�, �less�, �greater�):
Varianten für die Alternativhypothese
var.equal = TRUE: Gibt an, ob Varianzgleichheit bei denPopulationen vorliegt
paired: Gibt an, ob x und y als gepaarte Stichprobe anzusehen sind
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 99 / 104

Wilcoxon-Rangsummen - Test in R
wilcox.test(x, y, alternative, paired, exact)
Erklärung der Parameter:
Im wesentlichen analog zum t-Test
exact: Soll die Teststatistik exakt bestimmt werden, oder perApproximation an die Normalverteilung?
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 100 / 104

Beispiel:
Nettokaltmieten pro m2 für 1- (X) und 2-Raum (Y) Wohnungen
Gibt es einen Unterschied zwischen beiden Gruppen?
Wir untersuchen diese Frage per Wilcoxon- und t-Test
1 2 3 4 5X 8.70 11.28 13.24 8.37 12.16Y 3.36 18.35 5.19 8.35 13.10
6 7 8 9 10X 11.04 10.47 11.16 4.28 19.54Y 15.65 4.29 11.36 9.09
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 101 / 104
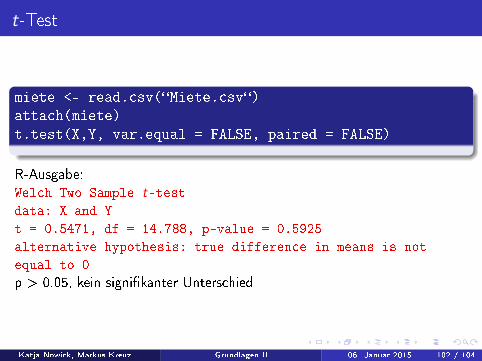
t-Test
miete <- read.csv(�Miete.csv�)attach(miete)t.test(X,Y, var.equal = FALSE, paired = FALSE)
R-Ausgabe:Welch Two Sample t-testdata: X and Y
t = 0.5471, df = 14.788, p-value = 0.5925
alternative hypothesis: true difference in means is not
equal to 0
p > 0.05, kein signi�kanter Unterschied
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 102 / 104

Wilcoxon-Rangsummen-Test
wilcox.test(X,Y, exact = TRUE)
R-Ausgabe:Wilcoxon rank sum test
data: X and Y
W = 51, p-value = 0.6607
alternative hypothesis: true location shift is not
equal to 0
p > 0.05, kein signi�kanter Unterschied
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 103 / 104
Aufgabenkomplex 3
Katja Nowick, Markus Kreuz (basierend auf Vorarbeiten von Verena Zuber und Bernd Klaus) ( Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.nowick-lab.info/?page_id=365)Grundlagen II 06. Januar 2015 104 / 104