Embed Size (px)
Citation preview

Einführung in Text Mining
Prof. Dr. Brigitte Mathiak

Was ist Text Mining?
• Die Kunst aus Text etwas maschinenverwertbares zu machen
• Methodisch an der Schnittstelle zwischen Natural Language Processing und Data Mining
• Grundkenntnisse in Computerlinguistik, aber auch in KI sind hilfreich

Was kann man mit Text Mining machen?
• Klassische sind Textklassifikation (z.B. Spam) und Themenanalyse (z.B. für Verzeichnisse)
• Man kann allerdings auch andere Daten miteinbeziehen (z.B. Zeit) und dann Trendanalysen machen
• Oft sucht man nicht nach Klassen, sondern versucht besonders ähnliche oder besonders unähnliche Dokumente zu finden
• Mit Hilfe von Extrawissen, z.B. Wortdatenbanken, kann man auch spezielle Einschätzungen machen, z.B. ob jemand ein Thema positiv oder negativ sieht

Was kann man nicht mit Text Mining machen?
• Die Datenstruktur sollte idealerweise mindestens 100 Dokumente enthalten, die jeweils mindestens 100 Worte enthalten
• Die Dokumente sollte Sacheinheiten bilden. Grenzen und Regionen innerhalb von Dokumenten zu finden ist mit der Methodik schwierig (aber möglich)
• Es ist sehr schwierig zwischen sprachlichen Unterschieden und sachlichen Unterschieden zu unterscheiden
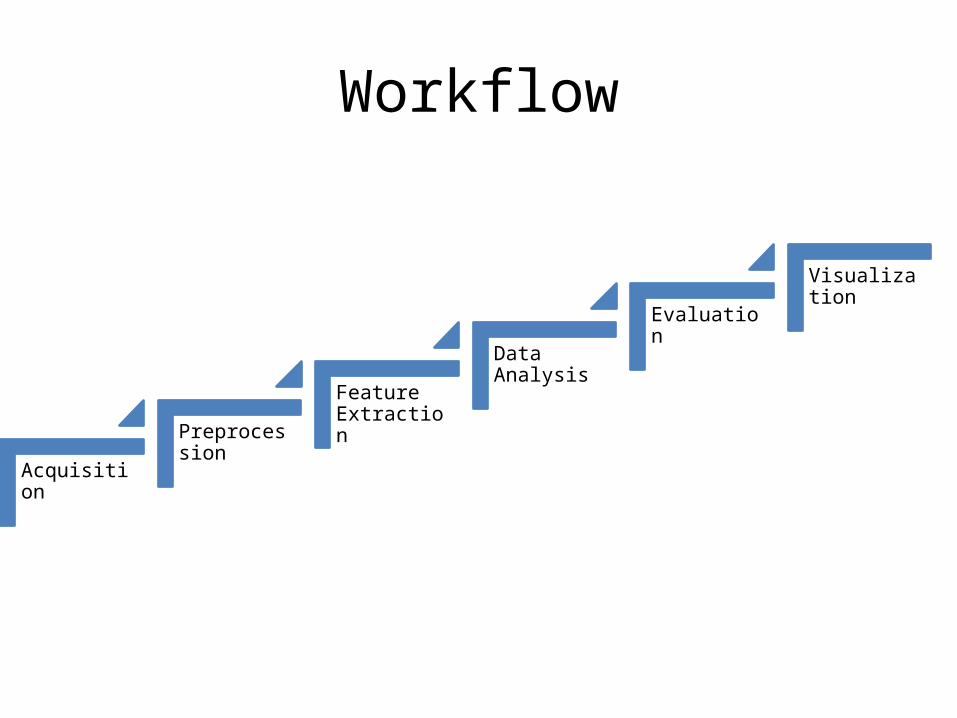
Workflow
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
Visualization
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
Visualization
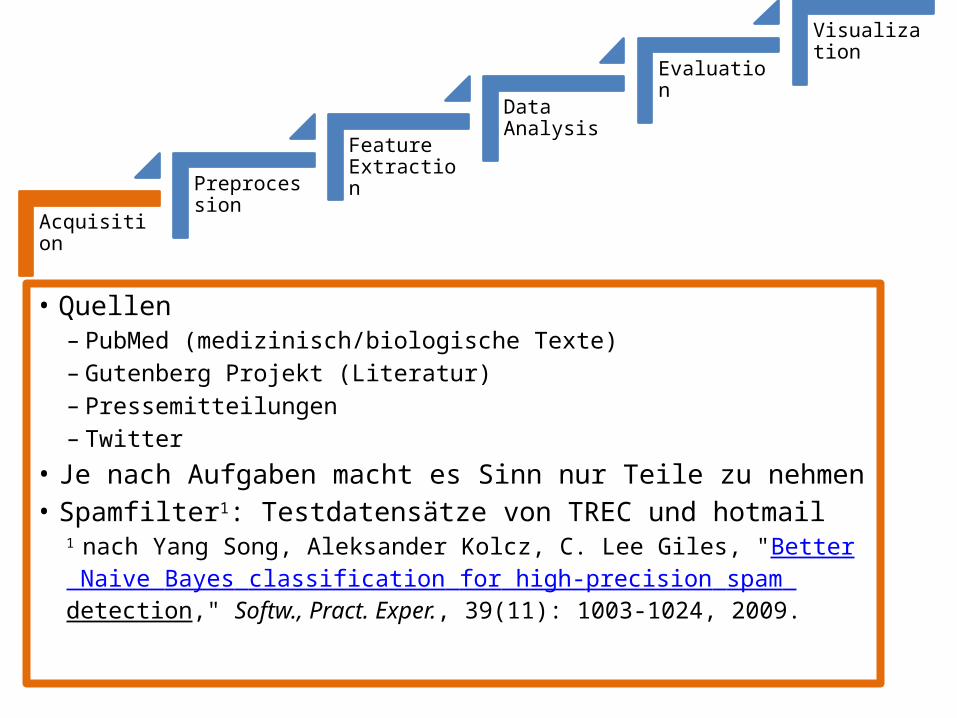
• Quellen– PubMed (medizinisch/biologische Texte)– Gutenberg Projekt (Literatur)– Pressemitteilungen– Twitter
• Je nach Aufgaben macht es Sinn nur Teile zu nehmen• Spamfilter1: Testdatensätze von TREC und hotmail
1 nach Yang Song, Aleksander Kolcz, C. Lee Giles, "Better Naive Bayes classification for high-precision spam detection," Softw., Pract. Exper., 39(11): 1003-1024, 2009.
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
Visualization
Korpus
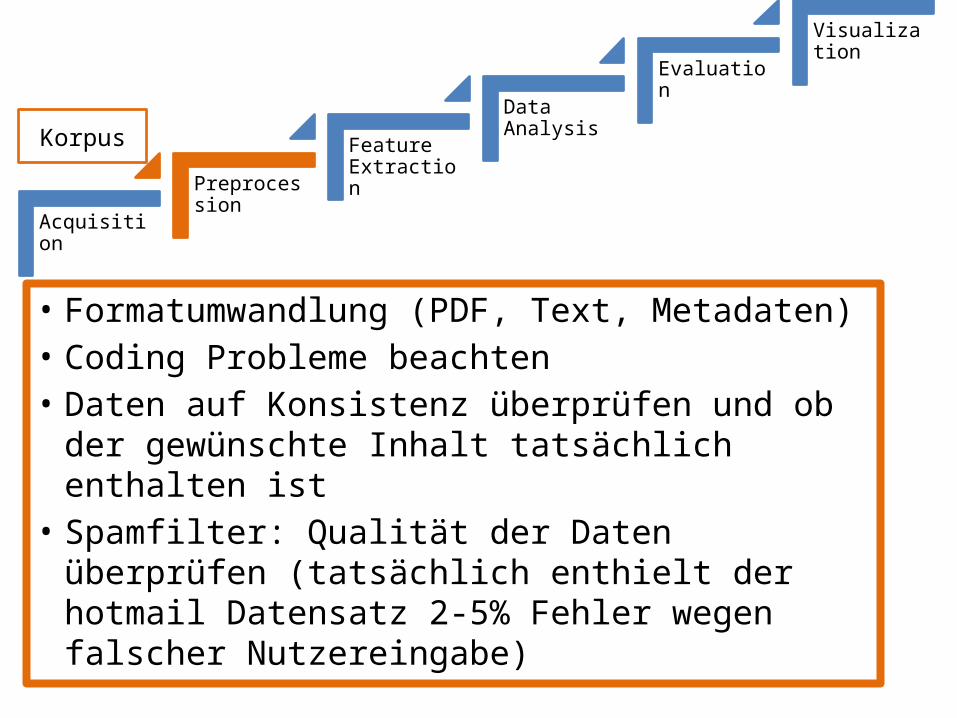
• Formatumwandlung (PDF, Text, Metadaten)• Coding Probleme beachten• Daten auf Konsistenz überprüfen und ob der
gewünschte Inhalt tatsächlich enthalten ist• Spamfilter: Qualität der Daten überprüfen
(tatsächlich enthielt der hotmail Datensatz 2-5% Fehler wegen falscher Nutzereingabe)
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
Visualization
Bearbeiteter Korpus
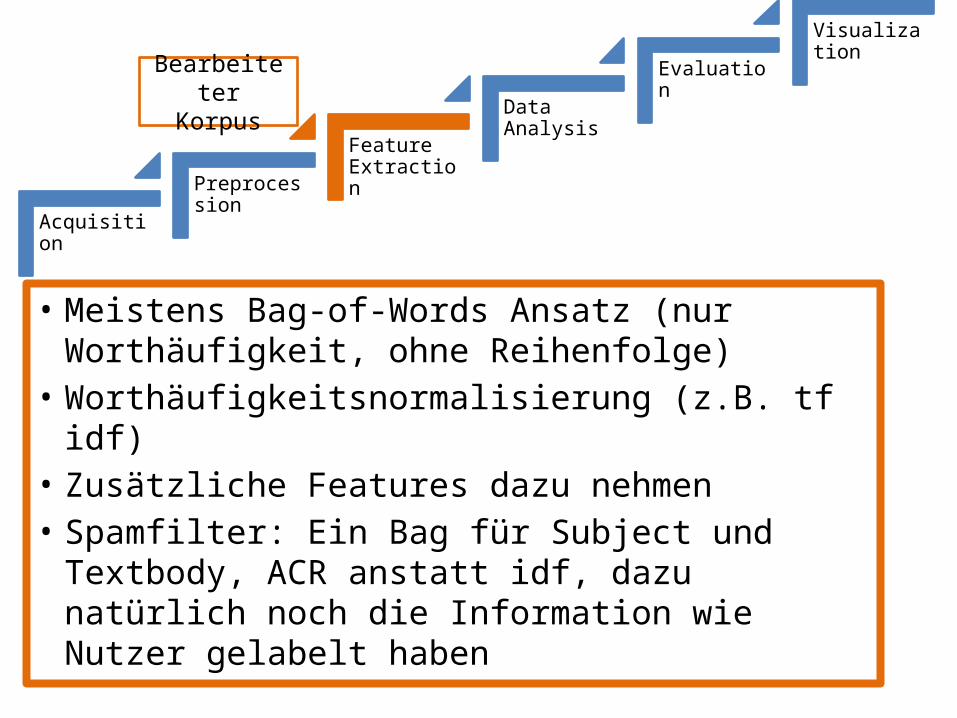
• Meistens Bag-of-Words Ansatz (nur Worthäufigkeit, ohne Reihenfolge)
• Worthäufigkeitsnormalisierung (z.B. tf idf)• Zusätzliche Features dazu nehmen• Spamfilter: Ein Bag für Subject und Textbody,
ACR anstatt idf, dazu natürlich noch die Information wie Nutzer gelabelt haben
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
VisualizationDokumentvektoren
• Klassifikation oder Clustering oder etwas exotisches
• Jeweils mit einer Menge möglicher Algorithmen
• Spamfilter: Klassifikation Spam/nicht Spam mit Hilfe von cascading Naïve Bayes und synthetic minority over-sampling (SMOTE)
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
VisualizationErgebnis
• Um Overfitting zu vermeiden muss das Ergebnis überprüft werden
• Gemessen wird die Quote der falsch erkannten (Precision) und die der nicht gefundenen (Recall)
• Spamfilter: Für Spam ist Precision sehr viel wichtiger als Recall (wenn Spam durchrutscht ist es nicht so schlimm, wie wenn eine echte Email im Spamordner landet), daher Messung von AUC für niedrige Precision (0..0,14)
Acquisition
Preprocession
Feature Extraction
Data Analysis
Evaluation
VisualizationErgebnis
• Bei Klassifikation häufig sehr einfach (z.B. unterschiedliche Farben oder Ordner)
• Bei Clustering manchmal einfach mit Tags• Netzwerke zum Teil sehr komplex• Spamfilter: Spam kommt in den Spamordner

Was muss ich wissen?
• Was ist ein Wort?• Die statistisches Eigenschaften von Sprache• Die relevanten linguistischen Eigenschaften
von Sprache• Welches Modell benutze ich für die
Repräsentation?• Welchen Algorithmus benutze ich?• Wie funktioniert die Evaluation?

Was ist ein Wort?• Normalerweise definiert als der String zwischen zwei
Leerzeichen ohne Satzzeichen• Ist ‚3.14‘ ein Wort?• Ist ‚qwerty‘ ein Wort?• Ist ‚:-)‘ ein Wort?• Ist ‚Die‘ gleich ‚die‘?• Ist ‚Erfahrung‘ gleich ‚Erfarung‘?• Wie viele Worte hat ‚das Bundesland Rheinland-Pfalz‘?• Wie viele Worte hat ‚Donaudampfschiffahrtskapitän‘?• Den Prozess der Wortextraktion nennt man Tokenization• Die obigen Fragen können nur nach Bedeutung geklärt werden
Statistische Linguistik (1/4)
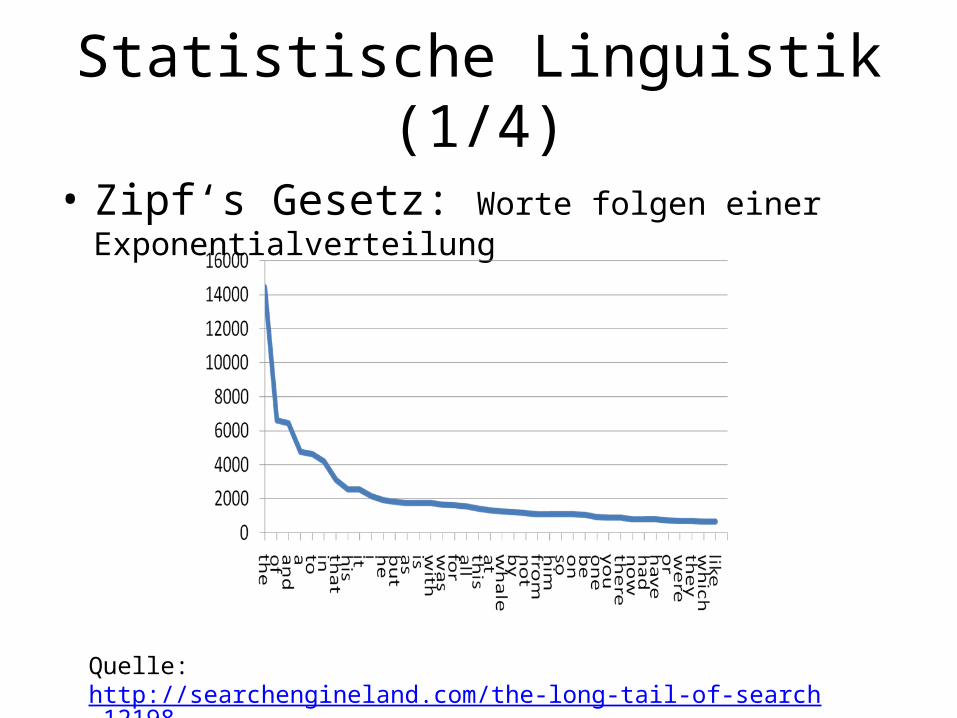
• Zipf‘s Gesetz: Worte folgen einer Exponentialverteilung
Quelle: http://searchengineland.com/the-long-tail-of-search-12198Anzahl der Worte in Moby Dick von Melville

Statistische Linguistik (2/4)
• Konsequenzen aus Zipf‘s Gesetz: – Das häufigste Wort kommt etwa zweimal so oft vor
wie das zweithäufigste, dreimal so oft wie das dritthäufigste, …
– Sehr häufige Worte wie der, und, die machen einen Großteil der Worte insgesamt aus (>50%), tragen aber nur wenig Sinn
– Es gibt sehr viele, sehr seltene Worte, wenn diese aber zu selten vorkommen (z.B. nur einmal), dann kann man da auch keinen Sinn erkennen
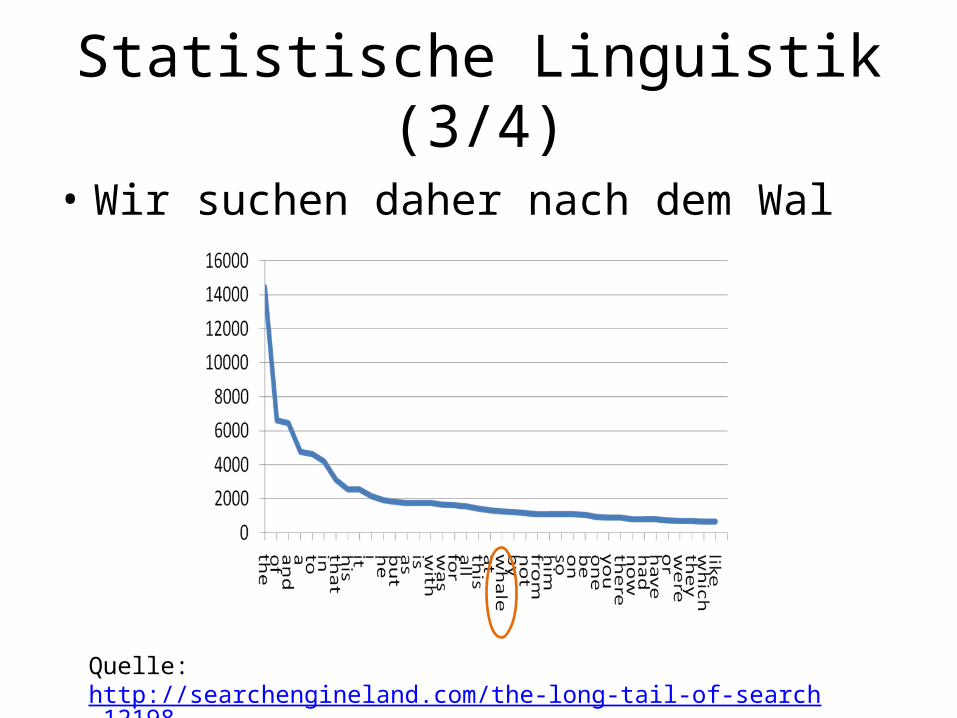
Statistische Linguistik (3/4)
• Wir suchen daher nach dem Wal
Quelle: http://searchengineland.com/the-long-tail-of-search-12198Anzahl der Worte in Moby Dick von Melville

Statistische Linguistik (4/4)
• Annahme: Signifikant für ein Dokument sind insbesondere die Worte, die in diesem Dokument überdurchschnittlich häufig vorkommen
• Mathematisch kann man dies durch das höhergewichten solcher Worte ausdrücken
• tf idf = term frequency*document frequency-1
i steht für inverse

Ausflug: Latent Semantic Indexing
• Annahme: Worte im selben Dokument sind semantisch näher aneinander als andere Worte
• Daher kann man mit Matrizenzerlegungdie Matrix auf eine kleinere Matrix reduzieren
• Diese ist dann sogar eine bessere Repräsentation des Dokuments, obwohl sie weniger Information enthält

Linguistik
• Es ist also von Vorteil zu wissen, welche Worte gleich, ähnlich und wenn ja wie ähnlich sind
• Die Linguistik hilft da z.B.:– Grammatik: Baum und Bäume ist von der Bedeutung
her fast gleich, solche grammatikalisch begründeten Endungen können also systematisch eliminiert werden (stemming)
– Wortdatenbanken, wie WordNet, enthalten Informationen über ähnliche Worte und deren Bedeutung

Wortbedeutung• Synonyme: Bereich, Gebiet • Homonyme: Bank (Geldinstitut), Bank (Sitzgelegenheit)• Fast jedes Wort hat synonymischen und homonymischen Charakter • Suche teilt sich homonymisch auf in:
– Ermittlung– Verfolgung– Untersuchung– Nachstellung
• Was wiederum Synonyme sind• Die tatsächliche Bedeutung ist (für Menschen) aus dem Kontext
erkennbar (Kontext Geld vs. Spaziergang)• Die Bedeutung bleibt aber immer unscharf, da der Kontext nie
vollständig bekannt ist (auch nicht für Menschen)
Faustregel: Statistische Verfahren werden immer besser je mehr Daten zur Verfügung stehen, wenn also nicht viele Daten da sind, dann sollte man sich linguistische Gedanken machen, bei vielen Dokumenten und hoher Datenqualität ist das nicht so relevantWenn allerdings die Ergebnisse ganz schlecht sind, dann kann einen die Linguistik im Allgemeinen auch nicht mehr retten

Modelle (1/2)
• Für die Benutzung von Data Mining Algorithmen brauchen wir Vektoren von möglichst unabhängigen Variablen
• Der klassische Weg dabei ist der Bag-of-Words Ansatz• Dabei wird die Reihenfolge der Worte bewusst
weggelassen• Trotzdem gibt es noch eine Reihe von Möglichkeiten
Dokumente und Worte miteinander mit Zahlen zu verknüpfen

Modelle (2/2)
• Binäres Modell: Wort da 1, sonst 0geeignet für kurze Texte
• tf term frequency: Wie oft kommt das Wort vor geteilt durch die Länge des Dokuments
• tf idf = term frequency*document frequency-1
• Latent semantic indexing• Topic models (kompliziert…)

Data Mining
• Klassifikation: (supervised)– Der Computer lernt verschiedene Label und kann
sie dann selbstständig zuordnen– Benötigt möglichst viele Trainingsdaten
• Clustering: (unsupervised)– Die Label werden ohne Trainingsdaten rein
aufgrund der Nähe von Dokumenten untereinander vergeben

Algorithmen• Es gibt eine Reihe von Bibliotheken für Data Mining Algorithmen:
– Weka (Java, nur Data Mining)– Mallet (Java Bibliothek speziell für Text Mining, enthält auch einiges für
Text Pre-processing)• Alle Algorithmen haben individuelle Stärken und Schwächen um
sicher zu gehen sollte man mindestens Algorithmen aus den folgenden Familien ausprobieren: – Support Vector Machine (SVM bzw. SVO)– Rule-based Learning (JRip bei Weka, es gehen auch decision trees)– Naive Bayes (nicht zu verwechseln mit Naive Bayes networks oder
cascades)– Maximum Entropy
Der Vorteil bei regelbasierten Algorithmen ist, dass man direkt
sehen kann, was passiert

Evaluation
• Die Bibliotheken machen normalerweise gleich eine Evaluation der Daten (mittels cross-validation)
• Die wichtigsten Begriffe: – Precision, Recall, F-Measure sind alles Begriffe aus
dem Information Retrieval und messen für binäre Klassifikation die Anzahl der korrekten Klassifikationen
– Accuracy ist dasselbe für mehrere Klassen– Am Besten sind in der Regel große Werte nah an 1

Dokumentähnlichkeit
• Manchmal braucht man nur die Ähnlichkeit zwischen zwei Dokumenten, Termen, Themen, …
• Bei Vektorbasierten Modellen gibt es wieder ein paar Methoden dafür: – Cosine simililarity– Tanimoto similarity– Mutual information– Google/Wikipedia distance (für Terme)– …

Sentiment Analysis
• Anhand von Wörterbüchern kann man die Meinung des Schreibers extrahieren
• Das wird z.B. für Reviews verwendet• Achtung! Das funktioniert nicht so gut, wie
man gemeinhin erwarten würde

Pattern• Beim der Suche nach bestimmten Wörtern werden Pattern
eingesetzt • „X ist mein Geburtstag“ findet Zeitangaben
(lt. Google 2xMorgen, 7xHeute, 1xbald )• Aber Achtung „X ist eine Krankheit“ -> Demütigung,
Homosexualität, Hartz-IV, Arroganz, …• Dies ist gut um einen Spezialkorpus von Wörtern
aufzubauen• Wenn man bereits Beispiele hat, dann kann man auch
umgekehrt die Pattern lernen und dann wieder anwenden um mehr solche Worte zu finden





























