Embed Size (px)
Citation preview

Universität Konstanz,FB Informatik und Informationswissenschaft,Masterstudiengang Information Engineering
Exploration komplexer OLAP-Datenin einem Pivot-Tabellen-Interface
— Masterarbeit —
zur Erlangung des akademischen Grades eines Master of Science (M.Sc.)
von
Marion HerbMatrikel-Nr.: 01/459988
Erstgutachter: Prof. Marc H. SchollZweitgutachter: Prof. Oliver DeussenBetreuerin: Svetlana MansmannEinreichung: 22. Dezember 2006


Zusammenfassung
Im Rahmen des Projektes UniVis Explorer wird ein visuelles Data Warehouse, basie-rend auf einer OLAP-Architektur und einem multidimensionalen Datenmodell, fürdeutsche Hochschulverwaltungen entwickelt und implementiert. Durch geeignete Vi-sualisierungstechniken werden die Benutzer des Systems, die Mitarbeiter in Verwal-tung und Lehre, bei der Exploration und Analyse der universitären Daten unterstützt.
Um korrekte Analyse-Ergebnisse zu gewährleisten, müssen die verwendeten DatenOLAP-konform sein. Die Institutionen an einer Hochschule sind jedoch oftmals hier-archisch aufgebaut und besitzen strukturelle Abhängigkeiten. In dieser Arbeit werdendie Unregelmässigkeiten in den Daten beschrieben, die der Implementation vorausge-hend konzeptionell modelliert und in ein normalisiertes Schema transformiert werdenmussten. Die Aufgabenstellung besteht in der Implementation einer Pivot-Tabellen-basierten Datenexploration und deren Integration in das Data Warehouse-FrontendUniVis Explorer. Die Umsetzung der Benutzerinteraktion in eine Datenbanksprachesowie die Aufbereitung der Datenbank-Ergebnisse in eine für eine Pivot-Tabellen--Darstellung geeignete Form, waren weitere Herausforderungen.
Organisatorisch verflochtene Daten müssen mit großer Sorgfalt modelliert werden.Durch adäquate Transformationen der „unförmigen“ Basisdaten in ein regelmässiges,für OLAP-Anwendungen problemlos zu verarbeitendes, Schema und die Integrati-on der Visualisierungstechnik Pivot-Tabelle, konnte eine für den Hochschul-Einsatzgeeignete Anwendung implementiert werden.
Abstract
Within the scope of the UniVis Explorer project a visual data warehouse for academicmanagement is designed and implemented. The system is built based on OLAP ar-chitecture and its underlying multidimensional data model. Both the administrativedepartment of the university as well as lecturers are supported when visually explo-ring and analyzing the data with appropriate visualization techniques.
Applied data needs to be OLAP-conform in order to assure correct analyses results.However, academic organizations are often based on hierarchies and hold structuraldependencies. This study describes existing irregularities within the data which needsto be modelled conceptually and transformed into a normalized scheme before imple-menting the pivot table. The main scope of this thesis lies within the implementationof a pivot-table-based data exploration and its integration into the data warehousefront-end UniVis Explorer. Transforming user interactions into a database languageand formatting the emerging database results into a format convenient for pivot tablepresentation are additional challenges dealt with in this study.
Organizationally merged and structured data needs to be modelled carefully. Withthe help of adequate transformation techniques, the „bulky“ micro data needs to bepushed into a regular scheme so that OLAP applications may smoothly handle thedata. The visualization technique pivot table can then be integrated into the visualdata warehouse.
3


Inhaltsverzeichnis
Inhaltsverzeichnis 5
Abbildungsverzeichnis 8
Tabellenverzeichnis 10
Einleitung 13
1 Grundlagen und Fallstudie UniVis Explorer 17
1.1 Data Warehouse und OLAP . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.2 Kooperationspartner SuperX . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.2.1 Aufbau von SuperX . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.2.2 Testdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.3 Das multidimensionale Datenmodell . . . . . . . . . . . . . . . . . . . . . 20
1.3.1 Grundidee . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.3.2 Fakten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.3.3 Kennzahl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3.4 Dimensionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3.5 Würfel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
1.4 Operationen auf multidimensionalen Daten . . . . . . . . . . . . . . . . . 25
1.4.1 Projektionen im Würfel . . . . . . . . . . . . . . . . . . . . . . . . 25
1.4.2 Funktionen des OLAP . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.5 Modellieren der multidimensionalen Daten . . . . . . . . . . . . . . . . . 28
1.5.1 Das konzeptionelle Schema . . . . . . . . . . . . . . . . . . . . . . 28
1.5.2 Schemaformen MOLAP und ROLAP . . . . . . . . . . . . . . . . 30
1.5.3 Das relationale Schema . . . . . . . . . . . . . . . . . . . . . . . . 31
2 Das erweiterte multidimensionale Datenmodell 34
2.1 Dimensionshierarchien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.1.1 Klassifikation der Dimensionshierarchien . . . . . . . . . . . . . . 34
2.1.2 Homogene vs. heterogene Dimensionen . . . . . . . . . . . . . . . 36
2.2 Modellierungsanforderungen . . . . . . . . . . . . . . . . . . . . . . . . . 37
5

INHALTSVERZEICHNIS
2.2.1 Modellierungsfallen . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.2.2 Bedingungen für Summierbarkeit . . . . . . . . . . . . . . . . . . 40
2.2.3 Typverträglichkeit von Fakt und Aggregationsfunktion . . . . . . 41
2.3 SuperX-Schema- und Datentransformation . . . . . . . . . . . . . . . . . 42
2.3.1 Schritt: Vom Pseudo-Sternschema zum Schneeflockenschema . . 43
2.3.2 Schritt: Trennen von Kennzahlen und Dimensionen . . . . . . . . 43
2.3.3 Schritt: Transformation von Dimensionshierarchien . . . . . . . . 44
2.3.4 Schritt: Datennormalisierung . . . . . . . . . . . . . . . . . . . . . 45
3 Hierarchische Visualisierung mit Pivot-Tabellen 49
3.1 Front End-Werkzeuge für ein Data Warehouse . . . . . . . . . . . . . . . 49
3.1.1 Hierarchische Visualisierungstechniken . . . . . . . . . . . . . . . 50
3.2 Aufbau und Funktionsweise einer Pivot-Tabelle . . . . . . . . . . . . . . 51
3.2.1 Tabelle vs. Kreuztabelle vs. Pivot-Tabelle . . . . . . . . . . . . . . 51
3.2.2 Struktureller Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.2.3 Manipulation von Pivot-Tabellen . . . . . . . . . . . . . . . . . . . 54
3.2.4 Darstellung der Zwischenaggregate . . . . . . . . . . . . . . . . . 54
3.3 Marktübersicht der Pivot-Tabellen-Interfaces . . . . . . . . . . . . . . . . 56
3.3.1 Joolap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3.2 CEUS-HB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.3.3 Tableau Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.3.4 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4 Framework 64
4.1 Multifunktionswerkzeug Schemabrowser . . . . . . . . . . . . . . . . . . 64
4.1.1 Datenbrowser vs. Schemabrowser . . . . . . . . . . . . . . . . . . 64
4.1.2 Schemabrowser UniVis Explorer . . . . . . . . . . . . . . . . . . . 65
4.1.3 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.2 Benutzeroberfläche UniVis Explorer . . . . . . . . . . . . . . . . . . . . . 66
4.3 Interaktion mit der Pivot-Tabelle . . . . . . . . . . . . . . . . . . . . . . . 67
4.3.1 Zuordnung der Dimensionen . . . . . . . . . . . . . . . . . . . . . 68
4.3.2 Navigation in hierarchischen Dimensionen . . . . . . . . . . . . . 68
4.3.3 Aggregieren entlang verschiedener Dimensionen . . . . . . . . . 68
4.3.4 Weitere Manipulationen . . . . . . . . . . . . . . . . . . . . . . . . 69
4.4 Visualisierung verschiedener Hierarchien . . . . . . . . . . . . . . . . . . 69
4.4.1 Im Schemabrowser . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.4.2 In der Pivot-Tabelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.5.1 SQL und OLAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6

INHALTSVERZEICHNIS
4.5.2 Technische Details der Implementation . . . . . . . . . . . . . . . 73
4.5.3 Übersetzung der Benutzeraktionen in SQL . . . . . . . . . . . . . 73
4.6 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
4.6.1 Verhindern von Interpretationsfehlern . . . . . . . . . . . . . . . . 79
4.6.2 Erweiterung der Funktionalität des Schemabrowsers . . . . . . . 80
4.6.3 Anzeige von Pivot-Tabelle und weiterer Visualisierung . . . . . . 80
Anhang 82
.1 Beispiel: SQL-Abfrage einer Pivot-Tabellen-Darstellung . . . . . . . . . . 82
Literaturverzeichnis 85
7

Abbildungsverzeichnis
I Aufbau SuperX und Integration UniVis Explorer . . . . . . . . . . . . 18
II Datenwürfel mit Studierendenzahlen . . . . . . . . . . . . . . . . . . . 21
III Dimensionshierarchie und -knoten sowie Hierarchieebenen . . . . . . 23
IV Klassifikationspfade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
V Projektionen im dreidimensionalen Datenwürfel . . . . . . . . . . . . 26
VI Universitäts-Data Warehouse-Schema in ME/R-Notation . . . . . . . 30
VII SuperX-Würfel Studierendenstatistik in Pseudo-Sternschema . . . . . 32
VIII Würfel Studierendenstatistik als Schneeflockenschema . . . . . . . . . 33
IX Verschiedene (nicht) hierarchische Dimensionen . . . . . . . . . . . . 35
X Verschiedene hierarchische Dimensionen . . . . . . . . . . . . . . . . . 35
XI Multiple Hierarchien in der Dimension Land . . . . . . . . . . . . . . 44
XII Unregelm. Datenbaum der zentralwissenschaftlichen Einrichtung . . 45
XIII Schemastruktur der transformierten Institutionen-Hierarchie . . . . . 46
XIV Regelmässiger Datenbaum der zentralwissenschaftlichen Einrichtung 46
XV Unregelmässiger Datenbaum der organisatorischen Einheiten . . . . 47
XVI Regelmässiger Datenbaum der organisatorischen Einheiten . . . . . . 48
XVII Festplatten-Visualisierung über eine Treemap . . . . . . . . . . . . . . 50
XVIII Cone Tree einer hierarchischen Organisation . . . . . . . . . . . . . . . 51
XIX Zeilen-, Spalten-, Seiten- und Datenfeld einer Pivot-Tabelle . . . . . . 52
XX Studierendenzahlen abhängig von Zeilen- bzw. Spaltenvariable . . . 55
XXI Studierendenzahlen abhängig von Zeilen- und Spaltenvariable . . . . 55
XXII Geschachtelte Pivot-Tabelle . . . . . . . . . . . . . . . . . . . . . . . . . 56
XXIII Pivot-Tabellen-Interface von Joolap . . . . . . . . . . . . . . . . . . . . 57
XXIV Joolap-Operation Schachtelung . . . . . . . . . . . . . . . . . . . . . . 59
XXV Pivot-Tabellen-Interface von CEUS-HB . . . . . . . . . . . . . . . . . . 60
XXVI Pivot-Tabellen-Interface von Tableau Software . . . . . . . . . . . . . . 62
XXVII Navigationsbrowser über Daten- und Schemastruktur . . . . . . . . . 64
XXVIII Schemabrowser UniVis Explorer . . . . . . . . . . . . . . . . . . . . . . 65
8

ABBILDUNGSVERZEICHNIS
XXIX Schematische Aufteilung des UniVis Explorer . . . . . . . . . . . . . . 66
XXX UniVis Explorer mit Pivot-Tabellen-Visualisierung . . . . . . . . . . . 67
XXXI Geschachtelte Pivot-Tabelle für das Zeilenfeld . . . . . . . . . . . . . . 69
XXXII Visualisierung versch. Hierarchien im Schemabrowser . . . . . . . . . 70
XXXIII Visualisierung versch. Hierarchien in einer Pivot-Tabelle . . . . . . . 71
XXXIV Parallele Exploration in Decomposition Tree und Pivot-Tabelle . . . . 81
9

Tabellenverzeichnis
I Ausschnitt der Tabelle mit Studierendenzahlen . . . . . . . . . . . . . . . 21
II Ausschnitt einer denormalisierten Dimensionstabelle Nationalität . . . . 31
III Summierte und durchschnittliche Haushaltskosten in Tausend-Euro fürein akademisches Jahr über mehrere Institute . . . . . . . . . . . . . . . . 38
IV Studierendenzahlen pro Fakultät und akademischem Jahr (Studium mitRegelstudienzeit drei Jahre, Beginn 1999/2000) . . . . . . . . . . . . . . . 38
V Studierendenzahlen pro Studienfach und Akademischem Jahr (Dreijäh-riges Studium, mehrfache Fachbelegung möglich) . . . . . . . . . . . . . 39
VI Haushaltskosten pro Institut und Lehreinheit in Tausend-Euro (für zweiakademische Jahre, Lehreinheiten sind Institute und Fächer) . . . . . . . 39
VII Summierbarkeit abhängig von Aggregationsfunktion und Faktentyp . . 42
VIII Ergebnistupel dreier Anfragen über die Zeitdimension . . . . . . . . . . 72
IX Ergebnistupel der Unteranfrage nach Länder, Abschluss und Allgemei-ner Hochschulreife . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
X Ergebnistupel der Unteranfrage nach Länder, Abschlußtyp, Allgemei-ner Hochschulreife und Fachhochschulreife . . . . . . . . . . . . . . . . . 78
10



Einleitung
Motivation und Zielsetzung
Vor dem Hintergrund aktueller Diskussionen um Hochschulrankings und Elite-Uni-versitäten sowie der leistungsorientierten Mittelverteilung, ist der Wunsch auch anHochschulen eine visuelle Exploration und Analyse der universitären Daten zu betrei-ben, um konkurrenzfähig zu sein, nachvollziehbar. Immer häufiger werden also auchan Hochschulen für die Entscheidungsunterstüzung typischerweise Data Warehouse-Systeme und -Front-Ends eingesetzt.
Dem schnellen Vorgehen bei der Einführung dieser Systeme steht die Komplexitätder zu analysierenden Daten gegenüber. So sind Organisationsstrukturen einer Hoch-schule hierarchisch und besitzen kein regelmässiges Datenschema. Man denke bei-spielsweise an Institutionen wie Verwaltungseinheiten, Lehrstühle, Institute und Ab-teilungen, die organisatorisch miteinander verflochten sind. Ausserdem sind dieseStrukturen ständiger Veränderung unterworfen, ausgelöst durch interne Reorganisa-tionen und das dynamische Wachsen der Strukturen.
Der schnelle, intuitive und flexible Zugriff auf Daten über Data Warehouse-Interfacesist ein kritisches Element. Davon hängt der Nutzen, den die Organisation aus demEinsatz eines solchen Systems zieht, ganz entscheidend ab. Damit die Benutzer effek-tiv auf die akademischen Daten im Universitäts-Data Warehouse zugreifen können,wird ihnen ein benutzerfreundliches Front-End bereitgestellt.
Für Mitarbeiter in der Verwaltung sind Pivot-Tabelle ein bekanntes und intuitiv zu be-dienendes Standardwerkzeug. Ausserdem ist die Visualisierungstechnik Pivot-Tabelle,aufgrund der typischen geschachtelten Darstellungsweise der Daten, besonders gutfür die Exploration hierarchischer Daten geeignet. Sie erlaubt seinen Benutzern spezi-ell auf hierarchische Strukturen ausgelegte Operationen auszuführen. Aufgrund die-ser Vorzüge wurde sie als eine Visualisierungstechnik in die Anwendung integriert.
Anhand eines universitären Fallbeispiels wird der Bogen gespannt von der Transfor-mation des Schemas und der Daten in eine regelmässige Struktur, bis zur Implementa-tion des Pivot-Tabellen-Interfaces. Die Umsetzung von Benutzerinteraktionen in eineDatenbanksprache, die die Ergebnisse in einer auf die Pivot-Tabelle angepassten Formzurückliefert, sind die Herausforderungen, die in dieser Arbeit beschrieben werden.
13

TABELLENVERZEICHNIS
Projektgruppe UniVis
Der UniVis Explorer1 ist ein Projekt der Arbeitsgruppe Datenbanken und Informa-tionssysteme2 der Universität Konstanz und wird gefördert vom Graduiertenkolleg„Explorative Analysis and Visualization of Large Information Spaces“3.
In der Projektgruppe UniVis wird das visuelle Data Warehouse für deutsche Hoch-schulverwaltungen als Java-Applikation, bestehend aus mehreren Komponenten, ent-wickelt und implementiert. Über einen Schemabrowser kann der Benutzer die hierar-chischen Datenstrukturen mithilfe einer Decomposition-Tree- und der Pivot-Tabellen-Darstellung analysieren.
Weitere Teammitglieder im Projekt UniVis Explorer sind Svetlana Mansmann, RomanRaedle und Andreas Weiler. Svetlana Mansmann betreute meine Arbeit und stand je-derzeit, auch am Wochenende, für meine Fragen zur Verfügung. Roman Raedle undAndreas Weiler implementierten im Rahmen ihres Projektpraktikums und ihrer Ba-chelorarbeit die Decomposition-Tree-Visualisierung. Von der von den beiden Studie-renden aus dem Decomposition-Tree und der Pivot-Tabelle zusammengeführten Ap-plikation stammen die Screenshots (siehe Kapitel 4 Framework).
Gliederung der Arbeit
Die Arbeit gliedert sich in folgende Teile:
In Kapitel 1 werden grundlegende Begriffe aus dem Bereich Data Warehouse undKonzepte des multidimensionalen Datenmodells, anhand universitärer Testdaten desProjektes UniVis Explorers, vorgestellt.
Darauf aufbauend wird in Kapitel 2 eine Erweiterung des multidimensionalen Da-tenmodells beschrieben. Diese Erweiterung soll den komplexen Strukturen, gegebendurch heterogene und gemischt-granulare Aggregationshierarchien gerecht werden.Bedingungen für korrekte Aggregation und daraus resultierende Modellierungsan-forderungen des Datenschemas werden gezeigt.
Kapitel 3 widmet sich dem Aufbau und den Manipulationsmöglichkeiten einer Pivot-Tabelle. Einige auf dem Markt vorhandene Visualisierungswerkzeuge mit Interfacesin Pivot-Tabellen-Manier werden getestet und die „Evaluationsergebnisse“ skizziert.
Im Framework-Kapitel 4 steht die Umsetzung des Pivot-Tabellen-Darstellung im Vor-dergrund. Benutzerinteraktionen werden in die Datenbanksprache SQL übersetzt undeine Visualisierung mit der Pivot-Tabelle erzeugt. Die Abbildung von heterogenenund multipel granularen Hierarchien im Schemabrowser und der Pivot-Tabelle wirddokumentiert und mit Screenshots versehen.
1Projekt-Website: http://www.inf.uni-konstanz.de/univis/ (Abgerufen 16.10.2006)2Database & Information Systems Group http://www.inf.uni-konstanz.de/dbis/ (Abgeru-
fen 16.10.2006)3Graduiertenkolleg / PhD Graduate Program http://www.inf.uni-konstanz.de/gk/ (Abge-
rufen 16.10.2006)
14



Kapitel 1
Grundlagen und Fallstudie UniVisExplorer
Data Warehouse-Konzepte und -Anwendungen zur visuellen Exploration werden aneinem Fallbeispiel mit Daten einer Hochschule vorgestellt. Die Vermittlung der Grund-lagen erfolgt anhand der speziellen Strukturen der universitären Testdaten. Die Um-setzung in ein geeignetes konzeptuelles und relationales Datenmodell steht dabei imVordergrund.
1.1 Data Warehouse und OLAP
In einem Data Warehouse werden Daten für statistische Auswertungen und Analysengetrennt von den operational betrieblichen Anwendungsdaten gespeichert [35, S.671].Daten aus unterschiedlichen Quellen werden zyklisch geladen und dienen als zentra-le Datensammlung für anspruchsvolle Entscheidungsprozesse in Unternehmen. EinData Warehouse ist im Allgemeinen themenbezogen, integriert, zeitveränderlich undnicht-flüchtig [35, 671]. Anwendungen des OLAP (On-Line Analytical Processing)greifen auf die Daten in einem Data Warehouse zu.
OLAP wird zur Informationsaufbereitung großer Mengen operativer und historischerDaten und als Analyse- und Planungswerkzeug in vielen Branchen wie dem Banken-wesen, dem Handel, der Industrie sowie im Dienstleistungssektor eingesetzt [4]. Esstellt eine Applikation einschließlich ihrer Front-End-Werkzeuge dar und ermöglichtden Benutzern die Daten interaktiv abzufragen, zu explorieren und zu analysieren.Die meisten OLAP-Systeme besitzen die folgenden Funktionen [19, S. 317]:
• Multidimensionale Repräsentation von Geschäftsdaten
• Verdichtung multidimensionaler Daten
• Navigation in Hierarchien zur Bildung von Detaildaten
• Unterstützung von Anfragen entlang der Zeitdimension
• Unterstützung der Generierung von Analysen- und Szenarien
• Konstante Antwortzeiten unabhängig der Anfragekomplexität
17

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
1.2 Kooperationspartner SuperX
SuperX ist ein Hauptvertreter für visuelle akademische Data Warehouses in Deutsch-land. Die baden-württembergische Landesregierung unterstützt die Einführung vonSuperX an den Hochschulen. Das universelle Hochschulinformationssystem SuperXist für eine Anwendergruppe aus Rektoratsmitarbeitern, Fakultätsdekanen, Professo-ren und Mitarbeitern der Universitätsverwaltung konzipiert und soll an deutschenHochschulen zum Wissensmanagement, zum Controlling und zur Hochschulsteue-rung eingesetzt werden. Verschiedene Benutzergruppen machen ein Berechtigungs-konzept notwendig, um einzelnen Anwendern oder Anwendergruppen Zugriffsrech-te auf bestimmte Sachbereiche zu geben.
Entstanden ist SuperX aus einem Projekt der Universität Karlsruhe in den 90er Jah-ren als Berichtssystem für Hochschulen. Die Abkürzung SuperX ging ursprünglichauf System zur Unterstützung von Planung und Entscheidung des Rektorats durchInformation, Controlling und Simulation zurück. Es wurde sukzessive zu einem Da-ta Warehouse-System für Hochschulen weiterentwickelt, und Die Weiterentwicklungdes Open Source Produkts sowie die Beratung der Hochschulen bei der Einführungund der Pflege des Systems übernimmt die Firma MemText1.
1.2.1 Aufbau von SuperX
SuperX besteht aus einem Datenbank-Server und mehreren Anwendungen. Abbil-dung I zeigt am Beispiel SuperX die typische Gliederung eines Data Warehouse Sy-stems in Datenquellen, Data Warehouse und Front-Ends [17, S. 18ff].
Abbildung I: Aufbau SuperX und Integration UniVis Explorer
Datenquellen
Daten aus unterschiedlichen Quellen des Hochschulbereichs werden gebündelt wo-bei das Hochschul-Informations-System HIS2 mit den Verwaltungssystemen SOS undCOB als Datenquelle dient. Das Modul SOS ist für die Daten-Laderoutine aus demoperativen Informationssystem HISSOS zuständig und ermöglicht u.a. die zentraleErfassung der Studierenden- und Absolventendaten, die von Stellen innerhalb und
1Website: http://www.memtext.de/ (Abgerufen 16.10.2006)2Website: http://www.his.de (Abgerufen 16.10.2006)
18

Kooperationspartner SuperX 1.2
außerhalb der Hochschule benötigt werden. Des Weiteren können damit Vorgängewie Einschreibung, Rückmeldung und Studienfachwechsel abgewickelt werden.
Das Modul COB extrahiert Daten aus HISCOB und beinhaltet die Kosten- und Er-lösanalyse für die Kostenstellen und -träger. Weiterhin bildet es die innerhochschuli-schen Leistungsverflechtungen ab. Auf Lehreinheiten- und Studiengangsebene kanndie Hochschulplanung unterstützt werden, wenn z.B. eine Reorganisation geplant ist.Konkret können mit den Daten die Kosten einer Hochschule nach Personal- und Sach-kosten, Miete und Abschreibung analysiert werden.
Weitere Module für spätere Integration sind Statistiken zu Stellen und Personal (dasModul SVA verwaltet z.B. das wissenschaftliche Personal pro Fachbereich), zur Finanz-und Sachmittelverwaltung (Modul FSV z.B. Drittmittelausgaben pro Institution), zuGebäude- und Flächennutzung (Modul BAU z.B. Raumausstattung), zur Zulassungs-verwaltung (Modul ZUL) oder Kombinationen von Modulen um übergreifende Aus-sagen zu treffen (z.B. Auswertungen Lehrbeauftragte pro Studierende). Ferner könnenDatenquellen integriert werden, die nicht von HIS stammen.
Data Warehouse
In einer Datenbank werden die zu analysierenden Daten und das Schema des multi-dimensionalen Datenmodells gespeichert. Im festgelegten Rhythmus, z.B. nach einemHochschulsemester, werden die in der Regel historisierten Daten [10, S. 13] geladen.SuperX enthält eine relationale Datenbank, worauf das OLAP-Front-End Joolap (mehrin Abschnitt 3) basiert. Die Daten der Joolap-Datenbank, die SuperX zur Verfügungstellte, werden nach der Transformation als Basis für den UniVis Explorer verwendet.Dazu später mehr.
Front-Ends
Für die Analyse und Auswertung der Daten existieren verschiedene Benutzeroberflä-chen, die folgenden bietet SuperX an:
• vordefinierte Ergebnistabellen für das allgemeine Berichtswesen in einem App-let
• Aufbereitung komplexer Berichte aus mehreren Ergebnistabellen in einem XML-Front-End
• Joolap für multidimensionale OLAP-Analysen
Im Wesentlichen sprach die Plattformunabhängigkeit für eine Kooperation mit Su-perX. Existierende kommerzielle Lösungen im Business Intelligence Bereich von Bran-chenriesen wie Oracle3 oder SAP4 sind zudem für öffentliche Institutionen wie Uni-versitäten nicht finanzierbar.
3Oracle Corporation, Website: http://www.oracle.com (Abgerufen 16.10.2006)4Anwendung Business Information Warehouse der SAP AG, Website http://www.sap.de (Abge-
rufen 16.10.2006)
19

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
1.2.2 Testdaten
Die Installation von SuperX auf dem Projektserver umfasst das Data Warehouse Sy-stem sowie das Datenbanksystem PostgreSQL5.
Die hier verwendeten Testdaten bilden die universitäre Struktur von Verwaltung undLehre ab und enthalten Statistiken zu Studierendenzahlen und Haushaltskosten überein akademisches Jahr der Gerhard-Mercator-Universität Duisburg. An anderen Hoch-schulen weicht daher die Struktur der Administration und der Lehreinheiten vomvorgestellten Schema ab.
SuperX stellte Testdaten zur Verfügung, da es keine „eigenen“ Zahlen der UniversitätKonstanz gibt bzw. diese nicht verfügbar gemacht werden konnten. Die Testdaten sindzum einen Studierendenzahlen aus dem Modul Studierenden-Statistik SOS und zumanderen fiktive Bestellungen der organisatorischen Einheit aus dem Modul Kosten-und Leistungsrechnung COB. Dabei wurden die Studierendenzahlen nicht personen-genau erfasst. Es existieren also nur verdichtete Studierendenzahlen für Gruppen, diedieselben Eigenschaften besitzen (Fachsemester, Nationalität etc.).
Der Faktenwürfel Studierendenstatistik beinhaltet ca. 26.000 und der FaktenwürfelHaushaltskosten 18.000 Transaktionen. Die Würfel sind jeweils 2,3 bzw. 1,7 Megabytesund das komplette Data Warehouse inklusive aller Dimensionstabellen 14,6 Megaby-tes groß.
1.3 Das multidimensionale Datenmodell
Die Hochschule verwaltet also Studierendenstatistiken sowie ihre Haushaltskosten,um zum einen Einschreibungszahlen und zum anderen die Ausgaben z.B. je institu-tionelle Einheit oder pro Projekt zu analysieren. In diesem Kapitel werden am Fallbei-spiel die Grundbegriffe von multidimensionalen Datenmodellen eingeführt.
1.3.1 Grundidee
Das multidimensionale Datenmodell, das dem Data Warehouse zugrunde liegt, wirdüber Fakten, Kennzahlen, Dimensionen sowie einen Würfel als visuelle Metapher charak-terisiert.
Die Fakten sind die zu analysierenden Transaktionen und werden durch Dimensio-nen wie Zeit und Organisation beschrieben. Die Dimensionen besitzen eine Struktur,gebildet durch das Schema, und Instanzen. Das Schema ist ein zyklusfreier gerich-teter Graph mit unterschiedlichen Granularitäten für jede Stufe. Eine Instanz besitztfür jede Stufe ein Set an Elementen, die Dimensionsknoten. Die Elemente einer Stufekönnen durch Roll-Up-Funktionen auf die nächsthöhere Dimensionsebene abgebildetwerden [12, S. 1], wodurch sich verschiedene Kennzahlen für die Aggregationsstufenergeben. Analysiert werden die Daten durch Operationen auf dem Würfel wie durchVerringern oder Erhöhen der Dimensionen oder durch Selektion von Teilen des Wür-fels.
In Abbildung II wird ein Ausschnitt des Data Warehouse, beruhend auf den Datenaus Tabelle I, abgebildet. Dargestellt sind Studierendenzahlen mit den Eigenschaften
5 Objektrelationales Datenbankverwaltungssystem, Website: http://www.postgresql.org/ (Ab-gerufen 16.10.2006)
20

Das multidimensionale Datenmodell 1.3
FachsemesterHerkunftsland Abschlußart 1 2 3 4 5D FH 3 - 5 1 2
I 2 3 7 3 -II - 1 5 2 -Sek I 6 - 2 2 1Primarstufe - - 1 4 -
AT FH - 5 2 - -. . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . .
Tabelle I: Ausschnitt der Tabelle mit Studierendenzahlen
Abschlußart, Fachsemester und Herkunftsland. Die dunkel markierte Zelle stellt dieAnzahl der Studierenden, hier beispielsweise fünf, die das Diplom II anstreben, ausDeutschland stammen und sich im 3. Fachsemester befinden dar.6
Abbildung II: Datenwürfel mit Studierendenzahlen
1.3.2 Fakten
Im universitären Kontext können Fakten Prüfungen, Kursteilnahmen oder Bestellun-gen sein. Fakten sind die tiefste Informationsebene und werden durch eine Kombi-nation von Dimensionen definiert. Dabei besitzen sie quantifizierende und qualifizie-rende Eigenschaften: der numerische Aspekt ist die Kennzahl7 als Ergebnis einer Ag-
6Der universitäre Abschluß Diplom wird in mehrere Unterklassen gegliedert, wobei FH für den Fach-hochschulabschluss steht und sich der Diplom I- vom Diplom II-Studiengang durch seine Regelstudi-enzeit unterscheidet. Des Weiteren wird das Lehramt-Studium unterteilt in Studium des Lehramts anSchulen für die Sekundarstufe I, II bzw. Sekundarstufe I/II und Primarstufe.
7auch Kenngröße, Maßzahl, Faktattribut, Measure
21

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
gregatfunktion8. Die Zuordnung vielfältiger Dimensionen bildet den qualifizierendenAspekt.
Zurück zum Fallbeispiel: ein Studierender zeichnet sich aufgrund mehrerer Eigen-schaften aus. Die Eigenschaften „persönlicher“ Natur sind Herkunftsland und Ge-schlecht. Die studiumsbezogenen Daten sind das Fachsemester, der angestrebte Ab-schluss und die Lehreinheit, der er aufgrund seines Studienfaches zugeordnet ist. DieLehreinheit ist einer Abteilung und die wiederum einer Fakultät zugeordnet. Die letz-te „Eigenschaft“ ist die Zeitangabe, wobei die feinste Auflösung das Semester dar-stellt.
Für die drei Dimensionen der Abbildung II kann die dunkel markierte Zelle in Funk-tionsschreibweise ausgedrückt werden: Studierendenkopfstatistik(D, II, 3) = 5. Dajede Dimension auf der tiefsten Granularitätsstufe jeweils fünf Instanzen enthält, istdie Anzahl der Fakten: 5× 5× 5 = 125.
1.3.3 Kennzahl
Eine Kennzahl ist der numerische Aspekt der zu analysierenden Fakten. Im Fallbei-spiel der Universität werden Studierendenzahlen in Köpfen oder Fällen, Kosten fürPersonal in Beträgen, oder Prüfungsleistungen in Form von Noten oder Punkten.
Eine Formel aggregiert mehrere Werte zu einer Kennzahl wobei verschiedene Aggre-gationsfunktionen wie Summenbildung, Durchschnitt, Minimum oder Maximum, etc.benutzt werden. Nicht jede Aggregationsfunktionen kann dabei auf alle Kennzahlenangewendet werden (mehr in Kapitel 2). Wird die Dimension oder Formel geändert,ändert sich auch die Kennzahl.
Die speziellen Kennzahlen Köpfe und Fälle in Studierendenstatistiken ergeben sichaus zwei unterschiedlichen Zählweisen. Die Kopfstatistik zählt alle Studierenden ge-nau einmal, d.h. die Summe aller Studierenden über ein Semester bildet die Gesamt-zahl der Studierenden der Universität in diesem Semester. Fall-Zahlen sind Belegungs-statistiken, da sie jeden Studierenden abhängig vom Studienfach enthalten. So wird inder Fallstatistik ein Studierender, der zwei Fächer studiert, also z.B. im Haupt- undNebenfach, „doppelt“ gezählt.
1.3.4 Dimensionen
Die Dimensionen stellen das besondere Konzept des multidimensionalen Datenmo-dells dar und sorgen für den Fakten-Kontext. Es gibt vielfältige Eigenschaften derTransaktion, im Fallbeispiel des Haushaltskostenwürfels Institutionen, Fachsemesterim Studierendenwürfel bzw. akademische Zeitabschnitte und Projektgruppen.
Sachlogische Merkmale werden in einer Dimension zusammengefasst (Land, Subkon-tinent und Kontinent gehören bspw. zu einer geografischen Dimension) und tragen sozur Strukturierung bei. Durch diese Designregel bleiben die Dimensionen unabhängigvoneinander. Dabei entsteht eine Struktur durch:
8Synonyme Bezeichnung der Begriffe: die Hierarchieebene wird auch Aggregations- oder Verdich-tungsebene, die Dimensionshierarchie kurz Hierarchie oder Verdichtungspfad, die Verdichtung wirdGruppierung oder Aggregation und die Aggregationsfunktion auch Verdichtungs- oder Gruppierungs-funktion genannt.
22

Das multidimensionale Datenmodell 1.3
• ein Schema
– (Land, Region, Kontinent) bzw.
– (Tag, Monat, Semester, Akademisches Jahr)
und
• seine Werte
– (Afghanistan, Ägypten, . . . , Zypern)
– (Australien, Mittelamerika, . . . , Zentralasien)
– (Afrika, Amerika, . . . , Europa) bzw.
– (1, 2, . . . , 31)
– (1, 2, . . . , 52)
– (WS 2001/2002, SS 2002, . . . , SS 2004)
– (2001/2002, 2002/2003, 2003/2004)
Im Schema- und Datenbaum (siehe Abbildung III) vereint der künstliche Knoten Talle Werte. Durch diesen übergeordneten Wurzelknoten und die verschiedenen Stufenentsteht eine Baumstruktur. In diesem Fall besteht die hierarchische Dimension ausvier Stufen: T, Kontinent, Region, Land.
Die Elemente (oder Instanzen) einer Stufe sind die Knoten des Datenbaums. Sie kön-nen geordnet (Dimensionshierarchie Zeit) oder ungeordnet (Dimensionshierarchie Her-kunftsland) sein. Jede Dimension besteht aus mehreren Hierarchieebenen, die jeweilseine eigene semantische Detailierungsstufe besitzen. Die Eltern-Kind-Beziehungen dervier Stufen sind die Basis für Aggregationen innerhalb der Dimension [28, S. 2].
Abbildung III: Dimensionshierarchie und -knoten sowie Hierarchieebenen
Granularität
Die Granularität ist der Verdichtungsgrad und beschreibt die „Feinheit“, in der dieFakten über die Kennzahlen beschrieben werden [10, S. 21].
Das Beispiel aus Abbildung II wird um die Dimension Zeit erweitert. Daraus entste-hen mehrere Granularitäten, zwei davon sind im Folgenden aufgeführt.
G1 besitzt eine höhere Granularität.
23

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
G1: (Zeit.Semester, Herkunftsland.Land, Abschlussart.Abschlusstyp,Studiengangsdauer.Fachsemester)
G2: (Zeit.Akademisches_Jahr, Herkunftsland.Kontinent, Abschlussart.T,Studiengangsdauer.Fachsemester)
Klassifikationspfade
Multiple Hierarchien erhöhen die Flexibilität der Analyse. Sie ermöglichen auf ver-schiedenen Pfaden durch eine Dimension zu navigieren, was einen Blick auf die Datenaus verschiedenen Aspekten erlaubt.
Abbildung IV: Klassifikationspfade
Ein Klassifikationspfad ist eine Menge von Klassifikationsstufen und enthält stets dasgrößte Element T. Eine Verdichtung ist nur entlang dieses Klassifikationspfades sinn-voll. Der Level der Klassifikationstufe ist nur eindeutig an seinem Pfad. Das granu-larste Element besitzt Level 1 und das größte Element T folglich ein variables Level(siehe Abbildung IV).
Ein typisches Beispiel ist die Zeitdimension mit den „ungranularsten“ Elementen Ka-lenderjahr und akademisches Jahr9. Das granularste Element der multiplen Hierar-chie ist der Tag. Es entstehen drei Pfade P1 bis P3 mit den folgenden Stufen über dieder Tag verdichtet wird (siehe Abbildung IV (b)):
• P1: T← Kalenderjahr←Woche← Tag
• P2: T← Akademisches Jahr← Semester←Monat← Tag
• P3: T← Kalenderjahr← Halbjahr← Quartal←Monat← Tag
9Ein akademisches Jahr fasst jeweils zwei Hochschulsemester bestehend aus Wintersemester undSommersemester zusammen. Es erstreckt sich statt von Januar bis Dezember von Oktober bis Septemberdes Folgejahres.
24

Operationen auf multidimensionalen Daten 1.4
Kanten
Ein Klassifikationspfad in einer Hierarchie wird durch funktionale Abhängigkeitenbestimmt, aber legt nicht die Bedeutung der Kanten fest. Es können diverse Abhän-gigkeiten bestimmt werden wie
• Part-Of-Beziehung: bspw. gehört das Projekt zu einer Projektgruppe
• Topologische Beziehung: ein Land bspw. Frankreich wird aufgrund seiner geogra-fischen Lage zum Subkontinent Westeuropa gerechnet
• Is-A-Beziehung: das Dezernat ist eine administrative Einheit
1.3.5 Würfel
Das Konzept des multidimensionalen Datenmodells wird typischerweise über einenDatenwürfel10 visualisiert. Die Achsen des Koordinatensystems werden von den Di-mensionen aufgespannt, die Fakten ab sind die Punkte bzw. Zellen im multidimen-sionalen Raum.
Trotz der 3D-Metapher besitzt ein Datenmodell oftmals mehr als drei Dimensionen.Die Anzahl der Dimensionen im Würfel ist nach oben offen, laut Pedersen [21, S. 41]sind Würfel zwischen vier- und zwölf-dimensional. Eine größere Anzahl führt zu Pro-blemen der Performanz.
1.4 Operationen auf multidimensionalen Daten
Die Analyse der Daten erfolgt durch Operationen auf dem Würfel. Das multidimen-sionale Datenmodell eignet sich dabei gut für Erhöhen oder Verringern von Dimen-sionen oder Auswahl von Subwürfeln.
1.4.1 Projektionen im Würfel
In einem Würfel sind Aggregationen Projektionen auf die Achsen. Eine Aggregationgeht mit der Reduktion von Dimensionen einher, dadurch verringert sich die Dimen-sionalität, aber nicht die Granularität. In Abbildung V (die Achsen entsprechen derZuordnung von Abbildung II mit nicht-hierarchischen Dimensionen) sind folgendeProjektionen dargestellt11:
1. Projektion auf XZ-Ebene→ Studierendenzahl abhängig von Abschlussart und Herkunftsland über alleFachsemester
2. Projektion auf YZ-Ebene→ Studierendenzahl abhängig von Abschlussart und Fachsemester über alleLänder
10Synonym bezeichnet mit Würfel, Data Cube, Cube, bei Dimensionalität größer drei Hypercube.11Vergleich „Data Cube and Sub-Space Aggregates“ von Gray [9]
25

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
Abbildung V: Projektionen im dreidimensionalen Datenwürfel
3. Projektion auf XY-Ebene→ Studierendenzahl abhängig von Fachsemester und Herkunftsland über alleAbschlußarten
4. Projektion auf X-Achse→ Studierendenzahl abhängig von Herkunftsland über alle Abschlußarten undFachsemester
5. Projektion auf Y-Achse→ Studierendenzahl abhängig von Fachsemester über alle Herkunftsländer undAbschlußarten
6. Projektion auf Z-Achse→ Studierendenzahl abhängig von Abschlussart über alle Herkunftsländer undFachsemester
7. Projektion auf alle Achsen→ Studierendenzahl ohne Einschränkung
Im n-dimensionalen Würfel gibt es also 2n Projektionen um Daten zu verdichten. Da-zu gehören die sieben dargestellten Projektionen, siehe Abbildung V, sowie das Ag-gregat der einzelnen Zelle. So erhält man 23 = 8 Verdichtungen im dreidimensionalenWürfel [35, S. 684f].
1.4.2 Funktionen des OLAP
Im Folgenden werden einige konkrete OLAP-Operationen aufgeführt. Nach Horner[11, S. 83] sind typische OLAP-Funktionen Roll-up, Drill-down, Slice und Dice und Pi-voting. In der Literatur finden sich noch weitere Operationen, nämlich Schachtelung,Ranking und Sorting, Multi-Cube-Join. Sie werden der Vervollständigkeit halber, undda sie in einer Pivot-Tabelle typische Visualisierungen darstellen, wie im Falle derSchachtelung, ebenfalls erläutert.
Roll-Up
Ein Roll-Up aggregiert detaillierte Daten zur Bildung von Summen entlang eines Klas-sifikationspfades, wodurch sich die Granularität verringert. „Hochkrempeln“ (engl.
26

Operationen auf multidimensionalen Daten 1.4
to roll up) der Elemente einer Stufe zu den Elementen einer weiteren ist nur sinn-voll wenn dies entlang der Dimensionshierarchie geschieht. Ein Roll-Up benutzt dieStruktur der Daten in Form von Dimensionshierarchien und der Kennzahl.
Als Beispiel wird in Abbildung III ein Roll-Up von Land zu Subkontinent durchge-führt. Eine Analyseanfrage berechnet die Studierendenzahlen bspw. mit der Summen-funktion der Herkunftsländer Finnland, Schweden und Island und die Summe fürNordeuropa.
Drill-Down
Drill-Down steht für eine Verfeinerung der Daten und ist somit die inverse Operationzu Roll-Up. Ein Drill-Down macht den Zugriff auf die Basisdaten unumgänglich, dazu granulareren Elementen der Dimensionshierarchie navigiert wird.
In SQL12 bedeutet ein Drill-Down also das Hinzufügen eines oder mehrerer Attributein die Group-by -Klausel.
Slicing und Dicing
Diese Operationen führen eine Selektion zur Bildung von horizontalen oder vertika-len Ebenen (Slice=Scheibe) und Subwürfeln bzw. einzelnen Zellen (Dice=Würfel) amWürfel durch. Die Operationen können mit Roll-Up und Drill-Down kombiniert wer-den.
Durch Auswahl von Dimensionsattributen werden Zellen betrachtet, die speziellenKriterien genügen. Z.B. eine Selektion auf Studierende aus Spanien lässt den Wür-fel zu einer Ebene „schrumpfen“. Die Auswahl kann durch ein weiteres Kriteriumeingeschränkt werden. Es werden weiterhin nur Zellen betrachtet, bei denen sich dieStudierenden im 3. Fachsemester befinden. Im dreidimensionalen Würfel wird nuneine einzelne „Spalte“ selektiert. Mit Einschränkung auf eine Ausprägung der drittenDimension, z.B. Abschlußtyp FH-Diplom ist eine einzelne Zelle selektiert.
Es können mehrere Dimensionsknoten betrachtet werden, z.B. Studierende aus Spa-nien im 2. und 3. Fachsemester mit FH-Abschluß. Dies formt einen Subwürfel undverändert dabei die Dimensionalität des Würfels nicht. Die Selektion z.B. einer Schei-be führt hingegen zur Verringerung der Dimensionalität.
Für Slice- und Dice-Operationen werden Attribute in die Where-Klausel(n) der SQL-Anfrage hinzugefügt.
Pivoting (Drill-Across)
Pivoting beschreibt das Ändern der Dimensionsauswahl eines Würfels. Dimensionenwerden hinzufügt oder auf eine andere Achse verschoben. Visuell werden die Ebe-nen des Würfels, zur Bildung einer alternativen Sicht auf die Daten, „gekippt“. Ei-ne Rotation des Würfels aus Abbildung II bildet statt der Studierendenzahlen nachAbschlussart und Herkunftsland die Studierendenzahlen nach Fachsemester und Ab-schlussart ab.
12SQL als die „Structured Query Language“ ist eine deklarative Datenbanksprache für relationale Da-tenbanken.
27

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
Nesting (Schachtelung)
Diese Operation bildet einen mehrdimensionalen Würfel auf eine zweidimensiona-le Fläche ab, bspw. für eine Präsentation am Bildschirm. In Pivot-Tabellen-Interfaceswerden Dimensionen auf den Achsen ineinander geschachtelt.
Ranking und Sorting
Nach Ausführung der Anfrage und Bildung einer Rangfolge werden die ersten bzw.letzten (Top bzw. Bottom n) Ergebnisse oder eine Prozentzahl daraus ermittelt. Z.B.können durch diese Anfragen die drei größten Institute, aufgrund der zugeordnetenStudierenden, ermittelt werden.
Multi-Cube-Join (Drill-Through)
Zwei oder mehr Würfel, die mindestens eine gemeinsame Dimension haben, könnenparallel abgefragt werden. Diese Verlinkung der Würfel ist wünschenswert, da durchdie parallele Exploration deutlich komplexere Analyseanfragen möglich werden. Beidieser Art von Operation werden nicht die Achsen, sondern die Inhalte in den Zellenverändert. So können vergleichende Aussagen über Lehrpersonal gegenüber Studie-rendenzahlen gezogen werden. Die Verlinkung ermöglicht auch, die Definition neuerKennzahlen um bspw. die Kosten pro Studierenden zu berechnen.
1.5 Modellieren der multidimensionalen Daten
Die im letzten Abschnitt 1.4 beschriebenen Operationen auf OLAP-Daten können aufspeziellen Datenbankschemen besonders effektiv ausgeführt werden. Auf relationa-ler Ebene werden die mehrdimensionalen Eigenschaften nachgebildet und besonderszwischen Fakt und Dimension unterschieden.
1.5.1 Das konzeptionelle Schema
Durch das ME/R-Modell soll der konzeptionelle Entwurf der beiden Würfel gezeigtwerden. Einige Zusammenhänge in den universitären Daten werden einleitend be-schrieben.
Strukturen und Besonderheiten der universitären Daten
Eine administrative oder eine Lehr-und-Forschungs-Einheit agieren als Besteller, dieim Haushalt der Universität Kosten verursachen. Eine administrative Einheit kanneine Kostenstelle, die Bibliothek oder auch ein Dezernat der Zentralverwaltung sein.Der zweite Typ, die Lehre-Einheiten, sind die Fakultäten, Abteilungen, Institute, Fä-cher und Lehreinheiten. Das granularste Element in der Datenhierarchie sind die Per-sonen, die einen Lehrstuhl repräsentieren können. Alle diese organisatorischen Ein-heiten können die Rolle des Bestellers innehaben.
Ein Studierender ist aufgrund seines Studienfaches einer Lehreinheit zugeteilt. DieLehreinheit wird einer Abteilung und diese der entsprechenden Fakultät unterstellt.
28

Modellieren der multidimensionalen Daten 1.5
Die Besteller werden in zwei weitere Klassen, die Administration und Lehre Einhei-ten unterteilt. Einheiten beider Institutionen können also Bestellungen aufgeben. Auf-grund der Datenstruktur wird die Administration in zwei weitere Subbäume unter-teilt, zum einen Einheiten der Verwaltung und zum anderen Sonstige. In beiden Ver-waltungsdimensionen ergeben sich Hierarchien.
Zu Umstrukturierungen innerhalb der Verwaltung und der Lehreinheiten einer Uni-versität gehören das Auflösen von Instituten oder Hinzufügen einer weiteren Einheitwie Fächer. Dieser Tatsache muss im Würfel Rechnung getragen werden, denn hiersind Strukturen und Hierarchien so abgebildet, wie sie der Realität entsprechen. Soist in Abbildung VI das unregelmässige Datenschema etwa daran zu erkennen, dasses Institute auf unterschiedlichen Hierarchiestufen gibt. Gleichnamige Instanzen aufmehreren Ebenen sollten also entweder nicht gleich bezeichnet oder nur auf derselbenHierarchiestufe verwendet werden.
ME/R-Modell
Eine grafische Modellierung des multidimensionalen Datenkonzepts erfolgt z.B. mit-tels des ME/R (Multi Entity-Relationship)-Modells [24]. Das traditionelle E/R-Modell[3] wird erweitert [24, S. 6], da es für Modellierung komplexer Datenstrukturen nichtausreichend ist. Spezielle Konzepte, wie die Klassifikationsstufe, die Halbordnungzwischen den Klassifikationsstufen (rolls-up-to Beziehung) und der Würfel werdennicht repräsentiert und wurden ergänzt.
Der Studierendenwürfel referenziert per Faktbeziehung u.a. die Dimension Herkunfts-land. In der Hierarchie existieren Roll-Up-Beziehungen von Land zu Subkontinent undzu Kontinent. Ausserdem teilen sich die Würfel mehrere Dimensionen wie Semesterund Lehreinheit.
Klassifikationsstufen und zugehörige Werte bspw. der Verwaltung sind die folgenden:
Dienst (Telefonzentrale, Hausdienst, Prüfungssekretariat, Poststelle. . . )
↓Sachgruppe (Personalentwicklung/Fortbildung. . . )
↓Dezernat (alle Dezernate, Kanzler. . . )
↓Kostenstelle (Zentralverwaltung. . . )
↓Verwaltung
Auch die Lehre Einheiten bilden eine Hierarchie:
Person
↓Fach/Institut (Angewandte Materialtechnik, Physik. . . )
↓Lehreinheit (Elektrotechnik, Maschinenbau. . . )
↓Abteilung/Institut (Abteilung für Maschinenbau, Institut für Kulturwissenschaften. . . )
29

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
Abbildung VI: Universitäts-Data Warehouse-Schema in ME/R-Notation
↓Fakultät (Geisteswissenschaften, Wirtschaftwissenschaft. . . )
1.5.2 Schemaformen MOLAP und ROLAP
Für OLAP-Datenmodelle existieren unterschiedliche Ansätze zur Speicherung. Zu denwichtigen Modellierungsverfahren gehören MOLAP und ROLAP.
MOLAP
Multidimensionale OLAP- (kurz MOLAP) Systeme basieren logisch auf der Multipli-kation aller zu betrachtenden Dimensionen und bieten direkten Zugriff auf die mehr-dimensionalen Arraystrukturen [2]. Physisch sind alle Aggregationen in einem OLAP-
30

Modellieren der multidimensionalen Daten 1.5
Würfel abgebildet.
Der Vorteil ist die Verfügbarkeit aller Dimensions-Kombinationen, was eine hohe Fle-xibilität bezüglich Operationen wie Drill-Down und Roll-Up mit sich bringt. Von Nach-teil wirkt sich die begrenzte Speicherkapazität und somit die begrenzte Größe der Di-mensionen aus [18, S.377 f].
ROLAP
Das zweite Modellierungsverfahren ist das relationale OLAP (kurz ROLAP). Die zuanalysierenden Daten werden in relationalen Datenbanken gespeichert. Eine Norma-lisierung der Daten führt zu nahezu unbegrenzter Speicherkapazität. Dies bedeutetandererseits einen Nachteil durch Einbußen bei der Performanz, da normalisierte Ta-bellen viele Joins zwischen Tabellen verlangen.
Fazit
Beide Lösungen bieten Vor- und Nachteile: MOLAP berechnet Aggregationen schnel-ler, dafür skaliert ROLAP besser. Im Rahmen des Projektes wird ROLAP bevorzugt,da die Testdaten in relationaler Form vorliegen. Zudem ist das Know-How bezüglichrelationaler Datenbanken vorhanden.
1.5.3 Das relationale Schema
Um die Mehrdimensionalität in einem relationalen System nachzubilden werden spe-zielle Datenbankschemen eingesetzt. Fakten und Dimensionen werden dabei striktunterschieden und entsprechend in Fakten- und Dimensionstabellen getrennt. Die Da-ten werden in Stern-, Schneeflocken- oder im Fact Constellation Schemen modelliert.Diese spezielle Techniken werden in den nächsten Abschnitten erläutert.
Sternschema
Das Sternschema (oder Starschema) unterscheidet zwischen zwei Arten von Tabellen[18, S. 160]. Im Mittelpunkt steht die Faktentabelle (enthält Bewegungsdaten) mit Spal-ten für jede Kennzahl sowie für die Fremdschlüssel zu jeder Dimension. Die Dimensi-onstabellen (mit Stammdaten) enthalten beschreibende Informationen zu den Fakten.Die Schlüssel der zur Faktentabelle beitragenden Dimensionenen sind die Verbindungzwischen Fakten- und Dimensionstabellen [35, S. 688].
Dabei sind die Dimensionstabellen zumeist denormalisiert, da das Sternschema keineAttributhierarchien unterstützt [35, S. 689]. Dies spiegelt sich im Falle von hierarchi-schen Dimensionen in redundanten Einträgen wider (siehe Tabelle II).
LandID LandName SubkontinentName KontinentName1 Schweden Nordeuropa Europa2 Norwegen Nordeuropa Europa3 Dänemark Nordeuropa Europa. . . . . . . . . . . .
Tabelle II: Ausschnitt einer denormalisierten Dimensionstabelle Nationalität
31

KAPITEL 1. GRUNDLAGEN UND FALLSTUDIE UNIVIS EXPLORER
Die Faktentabelle wird also von den Dimensionstabellen umringt und das sich erge-bende sternförmige Gebilde gibt dem Schema seinen Namen.
Quasi-Sternschema von SuperX
Das Schema in dem SuperX die Daten modellierte ähnelt einem Sternschema, aberverfügt nicht über typische denormalisierte Dimensionstabellen. Es wird deshalb hierals Pseudo-Sternschema bezeichnet.
Die Faktentabelle in Abbildung VII besitzt eine Kennzahl value die die Studieren-denzahl darstellt. Die Attributhierarchien in den Dimensionstabellen werden als in-härente Fremdschlüsselbeziehung abgebildet. Die Hierarchie wird über den Primär-schlüssel key gebildet, den das Attribut parent referenziert.
Über die Tabelle bluep_koepfe_faelle wird die Zuordnung zu Köpfe oder Fälledefiniert. Die Dimensionshierarchien sind implizit dargestellt und infolgedessen nuraus den Inhalten der Tabellen ersichtlich.
Abbildung VII: SuperX-Würfel Studierendenstatistik in Pseudo-Sternschema
Schneeflockenschema
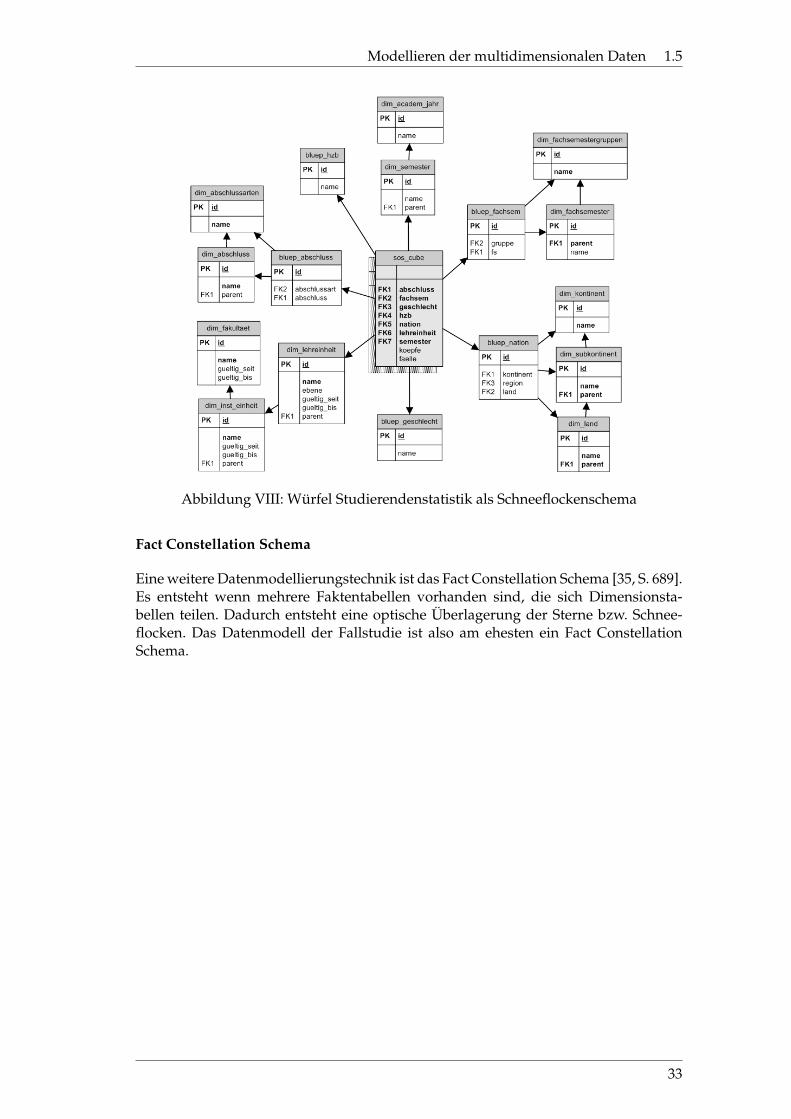
Die Normalisierung der Dimensionstabellen, bzw. im SuperX-Pseudo-Sternschemadie Auflösung der inhärenten Hierarchien, stellt den Übergang zu einem Schneeflok-kenschema (Snowflake-Schema) dar und macht die Bildung von Attributhierarchienmöglich.
Die Schneeflocken-Metapher entsteht durch die Faktentabelle in der Mitte, die vonden referenzierten Dimensionstabellen umringt wird (siehe Abbildung VIII). Der Wür-fel des Fallbeispiels besitzt sieben Dimensionen. Ist eine Dimension hierarchisch, wer-den aus Performanzgründen „prejointen“ Tabellen der Dimensionshierarchie vorge-schaltet. Sie nimmt alle Primärschlüssel der zur Hierarchie gehörenden Dimensions-tabellen auf. Jeder Eintrag erhält einen eindeutigen Schlüssel, auf den aus der Fakten-tabelle verwiesen wird. Jetzt sind Hierarchien explizit zu erkennen, da sie hierarchischin separate Tabellen ausgelagert wurden.
32
Modellieren der multidimensionalen Daten 1.5
Abbildung VIII: Würfel Studierendenstatistik als Schneeflockenschema
Fact Constellation Schema
Eine weitere Datenmodellierungstechnik ist das Fact Constellation Schema [35, S. 689].Es entsteht wenn mehrere Faktentabellen vorhanden sind, die sich Dimensionsta-bellen teilen. Dadurch entsteht eine optische Überlagerung der Sterne bzw. Schnee-flocken. Das Datenmodell der Fallstudie ist also am ehesten ein Fact ConstellationSchema.
33

Kapitel 2
Das erweiterte multidimensionaleDatenmodell
Werden OLAP-Operationen auf einem multidimensionalen Datenmodell ausgeführterwarten sie eine spezielle Modellstruktur. Sind diese Bedingungen nicht gegeben ver-sorgen traditionelle Modelle die Applikationen nicht mit korrekten Daten. In diesemKapitel werden verschiedene reguläre und irreguläre Dimensionshierarchien einge-führt, die zu Problemen bei der Aggregationsbildung führen. Die Anforderungen andas Datenmodell um Summierbarkeit zu gewährleisten werden beschrieben sowie aneinem konkreten Beispiel Modellierungstechniken zur Überführung des Schemas undder Daten in eine regelmässige Hierarchie aufgezeigt.
2.1 Dimensionshierarchien
Die Klassifikation der Hierarchien ist bezüglich der Summierbarkeit von besonderemBelang, da die Operationen Roll-Up und Drill-Down entlang dieser vordefiniertenHierarchien stattfinden. In Data Warehouses existieren aus Gründen der Performanzmaterialisierte Sichten (materialized views). Diese Sichten dienen der Vorberechnungund Speicherung aggregierter Daten und werden ebenfalls entlang dieser Hierarchi-en aufgebaut [11, S. 84].
Für die Klassifikation der Hierarchien wird zwischen Daten- und Schemahierarchieunterschieden [34, S. 4] [32]. Die Datenhierarchie stellt die Dimensionsknoten und dieSchemahierarchie die Klassifikationsstufen dar.
2.1.1 Klassifikation der Dimensionshierarchien
Nicht hierarchisch
Besitzt eine Dimension lediglich eine Klassifikationsstufe ist sie einfach (simple). Sie istnicht hierarchisch da es nur eine Granularität und folglich keine Roll-Up-Beziehunggibt.
Beispiele sind die Dimensionen Hochschulzugangsberechtigung und Geschlecht (sie-he Abbildung IX (a)).
34

Dimensionshierarchien 2.1
Abbildung IX: Nicht hierarchische (a), streng hierarchische (b) und nicht-streng hier-archische (c) Dimensionen in Schema- und Datenhierarchie
Streng hierarchisch
In einer streng hierarchischen Dimension gibt es in der Schemahierarchie je Hierar-chieebene eine ausgehende Roll-Up-Beziehung, z.B. Fachsemester→ Fachsemester-gruppe. Also bedeutet dies für die Dimensionsknoten dass sie über genau einen Vor-fahr auf einer höheren Aggregationsebene verfügen.
Die Instanzen einer streng-hierarchischen Dimension ergeben durch die n:1-Beziehungeinen ausgeglichenen Baum (siehe Abbildung IX (b)).
Nicht-streng hierarchisch
Die nicht-streng hierarchische Dimension erlaubt eine m:n-Beziehung zwischen denStufen in der Hierarchie. Aus nicht-strengen Hierarchien können sich multiple undalternative Hierarchiepfade ergeben.
Folglich kann eine Instanz zu verschiedenen Instanzen der darüberliegenden Stufe ag-gregiert werden. Im Fallbeispiel kann ein Projekt an mehreren Projektgruppen beteiligtsein. In ME/R-Notation wird die many-to-many- als belongs-to-Beziehung dargestellt.Abbildung IX (c) zeigt eine nicht-streng hierarchische Dimension.
Abbildung X: Nicht-deckend (a), nicht-ausgeglichen (b), heterogen (c) und gemischt-granular hierarchische (d) Dimensionen in Schema- und Datenhierarchie
35

KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
Nicht-deckend hierarchisch
Ist eine Hierarchie streng hierarchisch und Instanzen im Datenbaum überspringeneine oder mehrere Aggregationsstufen dann ist die Hierarchie nicht-deckend hierar-chisch (non-covering). Beispielsweise wird Kostenklasse zu einer bestimmten Kosten-gruppe oder direkt zu einer Kostenkategorie zugeordnet (siehe Abbildung X (a)).
Nicht-ausgeglichen hierarchisch
Ein Datenbaum ist nicht ausgeglichen (non-onto) wenn es innere Knoten gibt, die keineNachfahren haben.
Im Fallbeispiel können die Abteilung und die Fakultät als Besteller auftreten. Sie be-sitzen also keine Nachfolgerknoten und befinden sich nicht auf der untersten Hierar-chiestufe sondern sind selbst Blattknoten (siehe Abbildung X (b)).
Der Vorteil multipler Hierarchien ist das auf unterschiedlichen Pfaden durch die Da-ten navigiert werden kann. Analysen können durch multiple Hierarchien viel weit-räumiger gestaltet werden.
Multipel hierarchisch
Eine Stufe kann Roll-Up-Beziehungen zu beliebig vielen Klassifikationsstufen besit-zen. Die sich so aus einer einzelnen Dimension ergebende Hierarchie ist multipel. DieZeitdimension ist ein gerne benutztes Beispiel für eine multiple Hierarchie da intuitivmehrere Aggregationspfade (vgl. Abbildung IV) gefunden werden.
Trennen sich zwei Pfade an einer Stufe und treffen an einer höheren Stufe wiederaufeinander sind sie alternativ.
Heterogen hierarchisch
Eine heterogene Hierarchie ist eine Komposition mehrerer Dimensionshierarchien miteigenen Aggregationsstufen und Attributen. Eine Oberklasse besitzt mehrere Unter-klassen, die wieder Oberklassen weiterer Dimensionshierarchien oder Unterklassensein können. Jede Unterklasse bildet in der Datenhierarchie einen eigenen Teilbaum(siehe Abbildung IX (c)).
Gemischt-granular hierarchisch
Die gemischt-granularen Hierarchien (mixed granularity hierarchy) stellen einen Spe-zialfall der heterogenen Hierarchien dar. Die Subklasse einer abstrakten Oberklassekann Endinstanz der Hierarchie sein oder eine eigene Aggregationsstufe bilden.
Im Fallbeispiel: entweder tritt die Abteilung selbst als Besteller auf oder die Person alsBesteller aggregiert u.a. über die Aggregationsstufe Abteilung. In Abbildung IX (d) isteiner von vielen Datenbäumen dargestellt.
2.1.2 Homogene vs. heterogene Dimensionen
Werden für zwei Stufen s1 und s2, von s1 zu s2 existiert ein Roll-Up, alle im Schemavorhandenen Instanzen der Stufe s1 auf eine Instanz der darüberliegenden Stufe s2
36

Modellierungsanforderungen 2.2
zugeordnet, sind die beiden Hierarchiestufen homogen [12, S. 2]. Ist ein Dimensions-schema homogen und es existiert auf der untersten Stufe der Schemahierarchie nurein Hierarchieelement ist es streng-homogen (siehe Abbildung IX (b)).
Für alle anderen Fälle ist das Dimensionsschema, bzw. die Klassifikationsstufen fürdie die Beziehung zutrifft, heterogen (siehe bspw. Abbildung X (c)). Heterogene Hier-archiestrukturen besitzen partielle Roll-Up-Funktionen ohne einheitliche Aggregati-onsebenen in den Baumlevels [12, S. 2].
Ob ein Schema streng-homogen, homogen oder heterogen modelliert wird hängt vondiversen Faktoren ab. Es stellt sich die Frage ob gemeinsame Attribute der Stufenbenutzt und wie die Instanzen in Dimensionsstufen gruppiert werden sollen.
Heterogene Hierarchien sind flexibler da Stufen zusammengefügt werden können,die dieselbe Granularität besitzen. Dies reduziert die Komplexität des Schemas undder Anfragegenerierung. Dieser Vorteil wirkt sich nicht nur auf der logischen sondernauch auf der Speicherebene aus.
2.2 Modellierungsanforderungen
Die Verdichtung von Daten entlang des Klassifikationspfades ist das Ziel des mul-tidimensionalen Datenmodells. Unter gewissen Bedingungen berechnen bestimmteOperationen falsche Ergebnisse, die zu fehlerhaften Analysen und daraus resultierendzu falschen Entscheidungen führen [15, S. 1]. Was eine Kennzahl um bezüglich einesKlassifikationspfades korrekte Aggregationen zu erzeugen, erfüllen muss, wird Sum-mierbarkeit (Summarizability) oder allgemein Aggregierbarkeit [10, S. 22] genannt.
Das Datenvolumen von Data Warehouses kann beträchtlich sein. So gibt Herden [10,S. 14] die Größe von operativen Datenbanken im Bereich von Megabytes zu Gigabytesgegenüber Gigabytes zu Terabytes bei Data Warehouses an. So werden Aggregate ausPerformanzgründen aus nächstkleineren Aggregationsstufen und nicht aus den Ba-sisdaten gebildet. Möchte man bspw. die Summe aller Studierender aus Nordamerikaberechnen ist es sinnvoll, lediglich über die Studierenden aus Ländern die in Nord-amerika liegen, zu summieren, anstatt über alle Studierenden.
2.2.1 Modellierungsfallen
Anhand einiger Modellierungsfallen [15, S. 3ff] werden verschiedene Konstellationenan Kennzahlen und Fakten ersichtlich, die Summierbarkeit erlauben oder nicht.
Beispiel: Art der Aggregationsfunktion. . .
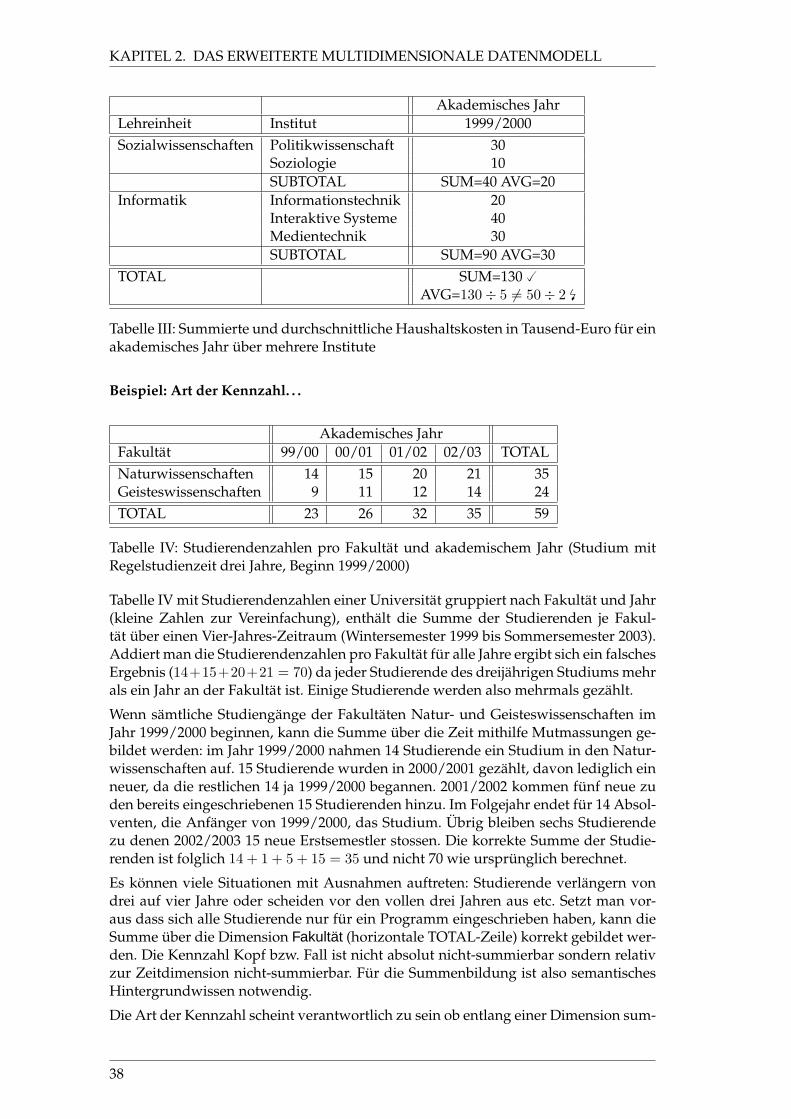
Die summierten und durchschnittlichen Haushaltskosten zweier Lehreinheiten undihrer Institute werden im Zahlenbeispiel aus Tabelle III abgebildet. Die Summenbil-dung ist für die Zwischen- sowie Endergebnis-Zeile eindeutig. Allerdings ergebensich verschiedene Ergebnisse für den Durchschnitt auf Stufe der Institute ((30 + 10 +20 + 40 + 30) ÷ 5 = 130 ÷ 5 = 26) im Vergleich zum Durchschnitt auf Basis der Zwi-schenergebnisse der Lehreinheiten ((20 + 30) ÷ 2 = 50 ÷ 2 = 25). Anhand diesesBeispieles wird deutlich, daß manche Aggregationsfunktionen hierarchisch benutztwerden können und andere hingegen nicht.
37
KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
Akademisches JahrLehreinheit Institut 1999/2000Sozialwissenschaften Politikwissenschaft 30
Soziologie 10SUBTOTAL SUM=40 AVG=20
Informatik Informationstechnik 20Interaktive Systeme 40Medientechnik 30SUBTOTAL SUM=90 AVG=30
TOTAL SUM=130 �AVG=130÷ 5 6= 50÷ 2 �
Tabelle III: Summierte und durchschnittliche Haushaltskosten in Tausend-Euro für einakademisches Jahr über mehrere Institute
Beispiel: Art der Kennzahl. . .
Akademisches JahrFakultät 99/00 00/01 01/02 02/03 TOTALNaturwissenschaften 14 15 20 21 35Geisteswissenschaften 9 11 12 14 24TOTAL 23 26 32 35 59
Tabelle IV: Studierendenzahlen pro Fakultät und akademischem Jahr (Studium mitRegelstudienzeit drei Jahre, Beginn 1999/2000)
Tabelle IV mit Studierendenzahlen einer Universität gruppiert nach Fakultät und Jahr(kleine Zahlen zur Vereinfachung), enthält die Summe der Studierenden je Fakul-tät über einen Vier-Jahres-Zeitraum (Wintersemester 1999 bis Sommersemester 2003).Addiert man die Studierendenzahlen pro Fakultät für alle Jahre ergibt sich ein falschesErgebnis (14+15+20+21 = 70) da jeder Studierende des dreijährigen Studiums mehrals ein Jahr an der Fakultät ist. Einige Studierende werden also mehrmals gezählt.
Wenn sämtliche Studiengänge der Fakultäten Natur- und Geisteswissenschaften imJahr 1999/2000 beginnen, kann die Summe über die Zeit mithilfe Mutmassungen ge-bildet werden: im Jahr 1999/2000 nahmen 14 Studierende ein Studium in den Natur-wissenschaften auf. 15 Studierende wurden in 2000/2001 gezählt, davon lediglich einneuer, da die restlichen 14 ja 1999/2000 begannen. 2001/2002 kommen fünf neue zuden bereits eingeschriebenen 15 Studierenden hinzu. Im Folgejahr endet für 14 Absol-venten, die Anfänger von 1999/2000, das Studium. Übrig bleiben sechs Studierendezu denen 2002/2003 15 neue Erstsemestler stossen. Die korrekte Summe der Studie-renden ist folglich 14 + 1 + 5 + 15 = 35 und nicht 70 wie ursprünglich berechnet.
Es können viele Situationen mit Ausnahmen auftreten: Studierende verlängern vondrei auf vier Jahre oder scheiden vor den vollen drei Jahren aus etc. Setzt man vor-aus dass sich alle Studierende nur für ein Programm eingeschrieben haben, kann dieSumme über die Dimension Fakultät (horizontale TOTAL-Zeile) korrekt gebildet wer-den. Die Kennzahl Kopf bzw. Fall ist nicht absolut nicht-summierbar sondern relativzur Zeitdimension nicht-summierbar. Für die Summenbildung ist also semantischesHintergrundwissen notwendig.
Die Art der Kennzahl scheint verantwortlich zu sein ob entlang einer Dimension sum-
38
Modellierungsanforderungen 2.2
miert werden kann oder nicht.
Beispiel: Disjunkte Faktenmengen. . .
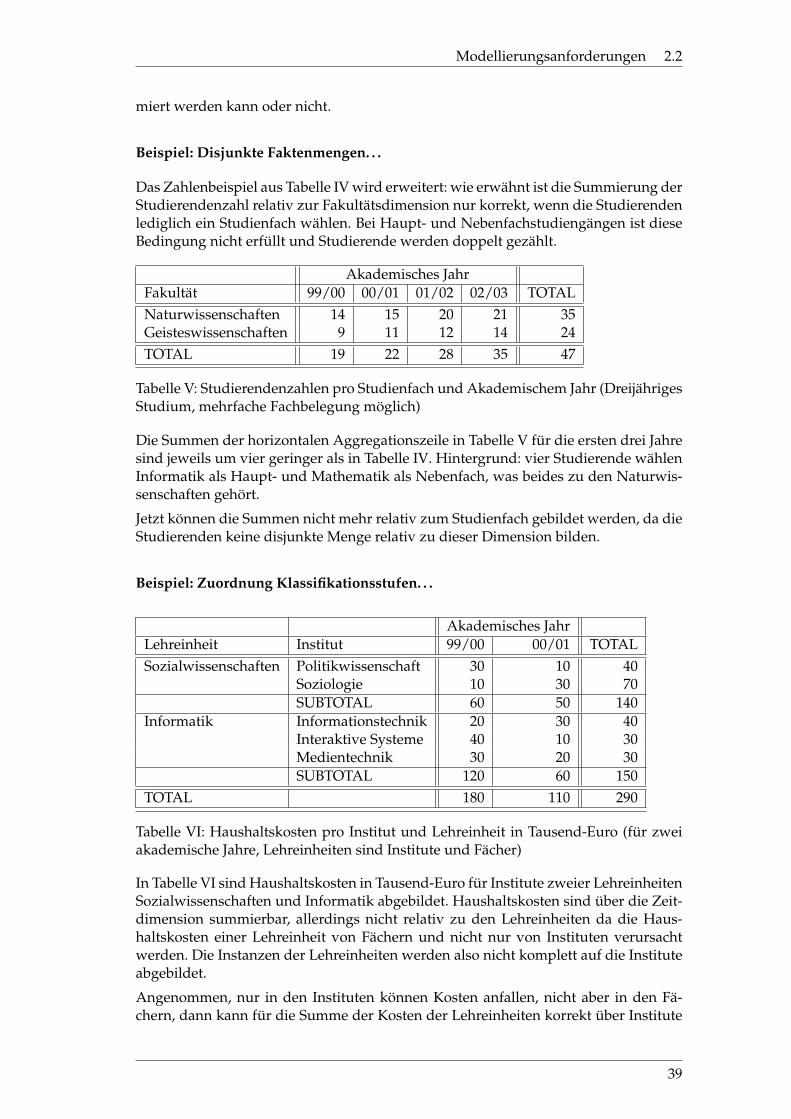
Das Zahlenbeispiel aus Tabelle IV wird erweitert: wie erwähnt ist die Summierung derStudierendenzahl relativ zur Fakultätsdimension nur korrekt, wenn die Studierendenlediglich ein Studienfach wählen. Bei Haupt- und Nebenfachstudiengängen ist dieseBedingung nicht erfüllt und Studierende werden doppelt gezählt.
Akademisches JahrFakultät 99/00 00/01 01/02 02/03 TOTALNaturwissenschaften 14 15 20 21 35Geisteswissenschaften 9 11 12 14 24TOTAL 19 22 28 35 47
Tabelle V: Studierendenzahlen pro Studienfach und Akademischem Jahr (DreijährigesStudium, mehrfache Fachbelegung möglich)
Die Summen der horizontalen Aggregationszeile in Tabelle V für die ersten drei Jahresind jeweils um vier geringer als in Tabelle IV. Hintergrund: vier Studierende wählenInformatik als Haupt- und Mathematik als Nebenfach, was beides zu den Naturwis-senschaften gehört.
Jetzt können die Summen nicht mehr relativ zum Studienfach gebildet werden, da dieStudierenden keine disjunkte Menge relativ zu dieser Dimension bilden.
Beispiel: Zuordnung Klassifikationsstufen. . .
Akademisches JahrLehreinheit Institut 99/00 00/01 TOTALSozialwissenschaften Politikwissenschaft 30 10 40
Soziologie 10 30 70SUBTOTAL 60 50 140
Informatik Informationstechnik 20 30 40Interaktive Systeme 40 10 30Medientechnik 30 20 30SUBTOTAL 120 60 150
TOTAL 180 110 290
Tabelle VI: Haushaltskosten pro Institut und Lehreinheit in Tausend-Euro (für zweiakademische Jahre, Lehreinheiten sind Institute und Fächer)
In Tabelle VI sind Haushaltskosten in Tausend-Euro für Institute zweier LehreinheitenSozialwissenschaften und Informatik abgebildet. Haushaltskosten sind über die Zeit-dimension summierbar, allerdings nicht relativ zu den Lehreinheiten da die Haus-haltskosten einer Lehreinheit von Fächern und nicht nur von Instituten verursachtwerden. Die Instanzen der Lehreinheiten werden also nicht komplett auf die Instituteabgebildet.
Angenommen, nur in den Instituten können Kosten anfallen, nicht aber in den Fä-chern, dann kann für die Summe der Kosten der Lehreinheiten korrekt über Institute
39

KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
summiert werden.
2.2.2 Bedingungen für Summierbarkeit
Sind komplexe multidimensionale Daten nicht summierbar (summarizable) kann nichtvon Aggregaten, basierend auf Aggregationsstufen mit geringerem Level, abgeleitetwerden. Um die Daten ein regelmässiges Schema zu verpassen, was viele Datenmo-delle verlangen, müssen folgende drei Bedingungen eingehalten werden [15].
Überlappungsfreiheit
Eine Klassifikationshierarchie ist überlappungsfrei (strict) wenn jeder Klassifikations-knoten der Stufe s höchstens mit einem Klassifikationsknoten der Stufe s + 1 ver-bunden ist. Zusätzlich darf jeder Datenpunkt als direkten Vorfahr höchstens einenKlassifikationsknoten mit Stufe 0 besitzen.
Überschneidungen in Teilbäumen können auftreten, wenn Studierende mehreren Stu-dienfächern zugeordnet sind. Im anderen Fall bilden die Studienfächer disjunkte Sub-mengen aus ihren Studierenden.
⇒ Kein Dimensionsknoten hat mehr als einen direkten Vorfahr.
Vollständigkeit
Ist die Klassifikationshierarchie überlappungsfrei, dann wird als nächstes die Grup-pierung der Elemente auf Vollständigkeit (covering) überprüft. Jeder Klassifikations-knoten der Stufe s muss mindestens mit einem Klassifikationsknoten der Stufe s + 1verbunden sein.
Bei der Modellierung ist also zu beachten, daß keine „Löcher“ in den Klassifikations-hierarchien entstehen. Das Beispiel der Zuordnung von Städten zu Distrikten bzw.Länder und anschliessend zu Staaten ist ein typisches Beispiel. Manche Städte sindeigenständig und sind nicht einem Land zugeordnet, wie beispielsweise Bremen. ImDatenschema ergibt sich nun ein Sprung von diesen „länderlosen“ Städten zum je-weiligen Staat.
⇒Kein Pfad überspringt eine oder mehrere Stufen von einem Dimensionsknoten zumnächsthöheren.
Ausgeglichene Baumstruktur
Die meisten Datenmodelle verlangen, daß die Instanzen der Dimensionshierarchieeinen ausgeglichenen Baum bilden. Dies bedeutet, daß der Pfad vom Wurzelknotenzu den Blättern stets gleich lang ist.
In Abbildung X (b) ist der Baum nicht ausgeglichen da nicht alle Teilbäume diesel-be Tiefe besitzen. Beispielsweise würde die Aggregationsfunktion Summe angewandtauf die Lehreinheiten und abgeleitet von der Summe der Aggregate der Abteilungenein falsches Ergebnis liefern, da manche Abteilungen keine Kinderknoten besitzen.
⇒ Das Datenschema bildet eine ausgeglichene Baumstruktur.
40

Modellierungsanforderungen 2.2
Fazit
Referenzieren alle Fakten Knoten der niedrigsten Stufe des Datenbaumes, und besit-zen diese Referenz nur auf einen und nicht auf mehrere Knoten, und der Datenbaumist balanciert [21, S. 44], dann sind alle Bedingungen für korrekte Summierbarkeit ge-geben und keine Knoten werden zu viel oder zu wenig aggregiert.
2.2.3 Typverträglichkeit von Fakt und Aggregationsfunktion
Es ergeben sich weitere Bedingungen für eine korrekte Aggregierung, definiert vonLenz [15] und illustriert durch die Beispiele 2.2.1. Im Folgenden werden die verschie-denen Typen von Fakten erläutert und anschliessend begründet, welche Kombinationan Fakten und Aggregationsfunktionen sinnvoll ist.
Verschiedenartige Fakten. . .
Im Data Warehouse gibt es in der Regel folgende numerische Faktentypen ([21, S. 42f],[15, S. 9]):
• Flow-Fakten stellen Ereignisse dar wie Umsätze, Verkäufe, Klicks auf eine Web-seite, diplomierte Studierende oder monatliche Geburtenrate. Sie beziehen sichjeweils auf eine bestimmte Zeitperiode und werden am Ende dieser aufgenom-men.
• Stock-Fakten sind sogenannte Snapshots des Zustands zu einem bestimmten Zeit-punkt wie der Lagerbestand, die Besucher einer Webseite oder Einwohnerzahleneiner Stadt o.ä.
• Value-per-Unit-Fakten beschreiben eine Eigenschaft zu einem bestimmten Zeit-punkt wie Stückpreise, Kosten der Herstellung pro Einheit oder Währungskur-se. Die Einheiten werden z.B. in Euro pro Stück angegeben.
. . . und unterschiedliche Kennzahlen
Kennzahlen können sich bezüglich ihrer Summierbarkeit unterschiedlich verhaltenund so können hier die folgenden Typen identifiziert werden ([21, S. 43], [11, S. 84]):
• Voll-additive Kennzahlen können entlang jeder Dimension sinnvoll aggregiert wer-den, da sich die Dimensionen in Realität nicht überschneiden. Dies tritt auf beiSnapshot-Daten die dasselbe Objekt zu verschiedenen Zeitpunkten abbilden.
• Semi-additive Kennzahlen können nicht entlang jeder Dimension summiert wer-den. Beispiel 2.2.1 verdeutlicht die Unterschiede da die Studierendenzahlen ent-lang der Fakultäts- aber nicht der Zeit-Dimension summierbar sind.
• Nicht-additive Kennzahlen können entlang keiner Dimension aggregiert werdenda dies z.B. durch die Aggregationsfunktion nicht erlaubt ist.
41

KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
Weitere nicht-additive Fakten Nur über numerische Fakten kann aggreggiert wer-den. Werden den Fakten kategorische Kennzahlen zugeordnet ist eine Summierungnatürlich nicht möglich, denn arithmetische Regeln werden verletzt. Fehler könnenleicht unterlaufen bei nicht-additiven Textfeldern, feststehende Nummern (Tempera-turen, Postleitzahlen, ISBN-Nummern) oder auch Angaben der geografischen Lage(„37 Grad nördliche Breite, 122 Grad westliche Länge“) [11, S. 86]. Kategorische Kenn-zahlen sollten stets als Dimensionen definiert werden.
Fazit
Flow-Daten können über eine Zeitachse summiert werden (z.B. Summe der jährlichenHaushaltskosten aus den monatlichen). Für die Entscheidung ob es sinnvoll ist Stock-und Value-per-Unit-Fakten zeitlich zu aggregieren, muss die statistische Aggregati-onsfunktion betrachtet werden. Bei Warenbeständen eines Lagers oder Studierenden-zahlen ist eine Aufsummierung über die Monate zu den Beständen bzw. Zahlen desQuartals nicht möglich.
Für die definierten Faktentypen und häufige Aggregationsfunktionen sind in TabelleVII die erlaubten (�) sowie nicht erlaubten (�) Kombinationen dargestellt.
Flow Stock Value-per-unit
MIN � � �MAX � � �SUM � � Zeit: � �AVG � � �RANGE � � �
Tabelle VII: Summierbarkeit abhängig von Aggregationsfunktion und Faktentyp
Sind komplexe Aggregationsfunktionen nicht summierbar, bspw. die Standardabwei-chung oder der Durchschnitt, können sie trotzdem summiert werden, wenn die Sum-mierbarkeitsbedingung für die Teil-Aggregationen, aus denen die Funktion zusam-mengesetzt wird, zutrifft [15, S. 4]. Die Summe (SUM) und die Anzahl (COUNT) be-rechnen bspw. den Durchschnitt (AVG).
Die Summenfunktion erfüllt laut Tabelle VII in Kombination mit Stock-Fakten dieSummierbarkeitsbedingung nicht. Trotz dieser nicht-summierbaren Komponente istdie aus SUM und COUNT zusammengesetzte AVG-Funktion summierbar. Dies liegtan der Bedeutung der Durchschnittsfunktion.
2.3 SuperX-Schema- und Datentransformation
Der folgende Abschnitt beschreibt die Überführung der von SuperX im Pseudo-Stern-schema (siehe Abbildung VII) modellierten Würfel in das Schneeflockenschema (sieheAbbildung VIII). Des Weiteren wird eine Datentransformation der unregelmässigenInstitute-Dimension durchgeführt.
42

SuperX-Schema- und Datentransformation 2.3
2.3.1 Schritt: Vom Pseudo-Sternschema zum Schneeflockenschema
In den „flachen“ Dimensionstabellen des originalen SuperX-Würfels gibt es funktio-nale Abhängigkeiten wenn, wie im Fallbeispiel (Abbildung VII zeigt die Fakten- undDimensionstabellen), das Land, der Subkontinent sowie der Kontinent in einer Tabellegespeichert werden. Das parent -Attribut referenziert als Fremdschlüssel das key -Attribut derselben Relation. Der erste Schritt ist also die Entfernung der hierarchi-schen Beziehungen innerhalb der Tabellen. Dadurch entstehen in den Dimensionsta-bellen multiple Granularitäten.
Zuerst werden alle Einträge, die hierarchische Strukturen besitzen, entsprechend ih-rer Granularität aufgeteilt. Die Elemente einer Granularitätsstufe werden jeweils ineine eigene Tabelle kopiert. Die Primärschlüssel der einzelnen Einträge in den Ta-bellen referenzieren nun jeweils den Schlüssel der nächsthöheren Aggregationsstufe(z.B. dim_land.parent → dim_subkontinent.id ). Das entsprechende Attributder Studierenden-Faktentabelle sos_cube stellt die Verbindung zum granularstenElement der Hierarchie dar (sos_cube .land → dim_land .id ).
Aus Performanzgründen wurde dann pro Dimensionshierarchie eine Tabelle, die einenPrejoin der Schlüsselattribute aller vorhandenen Dimensionen durchführt, angelegt.Für die Prejoin-Relation bluep_land ergeben sich folgende Attribute:
bluep_land.id , dim_land.id , dim_subkontinent.id , dim_kontinent.id
Nun wird die Verbindung zwischen den Attributen der Faktentabelle und der zugehö-rigen Dimension durch den Fremdschlüssel auf die Prejoin-Tabelle sos_cube.land→ bluep_land.id hergestellt. Statt einer Tabelle als Zwischenstufe ist ein Viewdenkbar bzw. sogar sinnvoller, weil sonst nach einer Veränderung im Würfel (Faktenwerden neu eingeführt, Dimensionen werden angepasst etc.), die Dimensionstabellenund auch die Prejoin-Tabellen überprüft werden müßen.
Die Prejoin-Tabellen bedeuten performantere Anfragen, denn jede Tabelle der Dimen-sionshierarchie ist direkt über die Prejoin-Tabelle mit der Faktentabelle verbunden.Dies verhindert mehrfaches Joinen entlang des Hierarchiepfades.
2.3.2 Schritt: Trennen von Kennzahlen und Dimensionen
In dem Studierendenwürfel gibt es, wie erwähnt, die Kennzahlen Köpfe und Fälle.SuperX unterscheidet in ihrem Modell zwischen den Kennzahlen mittels einer wei-teren Dimension. Diese Dimension bluep_koepfe_faelle wird entfernt und dieZuordnung der Kennzahl als Kopf- oder Fallstatistik in die Faktentabelle integriert.Zur Unterscheidung der beiden Kennzahlen werden nun zwei Attribute koepfe bzw.faelle in der Faktentabelle benutzt. Dieser Schritt verringert die Anzahl der Tupelauf die Hälfte und schafft eine explizite Trennung zwischen Dimension und Kennzahl.
Ein weiterer Designfehler von SuperX ist die Studierenden nicht einzeln zu identi-fizieren. Stattdessen sind alle Instanzen mit denselben Eigenschaften zusammenge-fasst. Durch diese Verdichtung gehen viele Analysemöglichkeiten verloren, denn ausden Daten ist die „Bewegung“ des einzelnen Studierenden nicht nachzuvollziehen.Dies wäre bei Summenbildung über eine Zeitachse von Vorteil, da aus den Basisdatenersichtlich wäre, welcher Studierende in welchem Semester eingeschrieben ist. DesWeiteren klärt dies auch die Fachbelegung. Der Datenschutz-Einwand wird entkräf-tet, wenn man einen künstlichen Schlüssel zur Identifizierung benutzt.
43

KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
2.3.3 Schritt: Transformation von Dimensionshierarchien
Hierarchische Dimension Land
Insgesamt entsprach die Datenmodellierung von SuperX nicht den angestrebten De-signkriterien. Vorhandene Hierarchien z.B. in der Herkunfts-Dimension wurden nichtauf adäquate Aggregationsstufen abgebildet. So sind in der geografischen Dimensionunterschiedliche Granularitäten in einer Aggregationsstufe abgebildet. Die Dimensi-on Nationalität besitzt nämlich auf einer Aggregationsstufe die Instanzen Deutschland,Ausland (vereint alle Länder exklusive Deutschland) und Sonstige (nicht-zuordenbareStudierende). Dies macht vergleichende Anfragen zwischen deutschen und ausländi-schen Studierenden möglich, aber erlauben keine der geografischen Dimension ange-passten typischen hierarchischen Anfrage.
Für unsere Anwendung wurden diese und andere Dimensionen in Hierarchien trans-formiert, die Länder jeweils ihrer Region und wiederum ihrem Kontinent zuordnen.Um weiterhin beide Aggregationspfade anzubieten wird die multiple hierarchischeDimension vorgeschlagen, siehe Abbildung XI. Der zusätzliche Knoten Deutschlandvs. Nicht-Deutschland läßt nun auch vergleichende Anfragen zwischen ausländischenund deutschen Studierenden zu (wie bei SuperX intendiert).
Abbildung XI: Multiple Hierarchien in der Dimension Land
Heterogene Dimension Organisatorische Einheiten
Aufgrund des Pseudo-Sternschemas von SuperX befinden sich alle organisatorischeEinheiten in einer Dimensionstabelle. Gerade diese Dimension erfordert aufgrund sei-ner heterogenen und gemischt-granularen Hierarchien eine Modellierung aus der dieStruktur ersichtlicher wird.
Das Attribut lehre der ursprünglichen SuperX-Tabelle bluep_org_einheiten teiltden gesamten Datenbaum der organisatorischen Einheiten, ungefähr 460 Einträge, inzwei Unterklassen. Diese beiden Klassen, Einheiten der Lehre und Forschung und Ein-heiten der Administration, stellen komplett unterschiedliche Objekte dar. Sie sind orga-nisatorische Einheiten aber besitzen unterschiedliche Attribute, was es nicht sinnvollmacht, sie in einer gemeinsamen Dimension abzubilden.
Sowohl Einheiten der Lehre und Forschung als auch Einheiten der Administration bil-den gemischt-granulare Hierarchien. Alle Instanzen der Aggregationsstufen Fakultät,
44

SuperX-Schema- und Datentransformation 2.3
Abteilung, Lehreinheit, Institut und Person sind Endinstanzen (also selbst Besteller)oder stellen Aggegationsstufen der Lehre-Einheiten-Dimension dar. Dasselbe gilt fürdie Einheiten der Administration.
All diese eigenständigen Objekte, die Aggregationsstufen darstellen, werden grup-piert und in eigene Dimensionstabellen ausgelagert. Alle Dimensionen sind durchPrejoin-Tabellen mit der Faktentabelle verbunden, um so alle Einträge aus beiden Un-terklassen zusammenzuführen.
2.3.4 Schritt: Datennormalisierung
Der bisherige Schritt bildet die Daten der organisatorischen Einheiten noch nicht alsausgeglichenen Baum ab. Die Unregelmäßigkeit wird in Abbildung XII an einem Aus-schnitt deutlich, die den Datenbaum der Zentralwissenschaftlichen Einrichtung (diezentralwissenschaftliche Einrichtung ist an dieser Universität den Einheiten der Ad-ministration zugeordnet) darstellt. Erkennbar sind Faktoren, die die Summierbarkeitverletzen. Dazu gehört beispielsweise dass Blattknoten innere Knoten darstellen. DasZiel ist die Modellierung eines balancierten Baumes mit einer einheitlichen Aggrega-tionsebene je Stufe.
Abbildung XII: Unregelmässiger Datenbaum der Zentralwissenschaftlichen Einrich-tung
Eine vollständige Visualisierung der Daten der beiden Teilbäume, Einheiten der Lehresowie Einheiten der Administration, offenbaren Muster und Zusammenhänge. Mithilfedes Graphen-Layout-Werkzeuges Yed werden alle Instanzen der Institutionen-Tabelleals Knoten visualisiert. Um die Hierarchie darzustellen, werden anschließend die Ver-bindungen zwischen den Knoten als Kanten eingetragen. Durch einheitliche Einfär-bung der Knoten desselben Typs können Regelmäßigkeiten und Muster erkannt wer-den.
Abbildung XV zeigt die Struktur der Verwaltung. Dieser Teilbaum läßt sich in mehre-re Teilbäume splitten. Dies schafft einheitliche Aggregationsebenen auf diesen Aus-schnitten, was aufgrund der verschiedenen Institutionen in einer Universität nichtglobal, also für den gesamten Baum, möglich ist.
Die Teilbäume sind, wie bereits erwähnt, auf oberster Ebene die Einheiten der Lehreund die Einheiten der Administration. Diese können unterteilt werden in Verwaltung(siehe in Abbildung XV oberes Cluster) und Sonstige (das untere Cluster). Das Ziel istdie verlustfreie Umstrukturierung der Daten in ein regelmäßiges Modell.
Pedersen beschreibt in [20, S. 668ff] eine Daten-Transformationstechnik um Summier-barkeit zu erreichen. Anhand dieser intuitiven Regeln wurden die Daten in ein regel-mäßiges Schema überführt. Der dreistufige Prozeß umfasst die folgenden Schritte:
1. Einfügen von Dummy-Knoten um Sprünge in der Hierarchie zu entfernen→ Covering-Anforderung
2. Einfügen von Dummy-Knoten um innere Blattknoten zu entfernen→ Onto-Anforderung
45

KAPITEL 2. DAS ERWEITERTE MULTIDIMENSIONALE DATENMODELL
3. Auflösen von Knoten-Verbindungen zu mehreren Vorfahren→ Strict-Anforderung
im Fallbeispiel werden zuerst für alle Teilbäume gemeinsame Aggregationsstufen ge-schaffen. Der daraus entstandene Schemabaum der organisatorischen Einheiten zeigtAbbildung XIII. Alle Knoten desselben Typs werden auf der gemeinsamen Stufe imBaum arrangiert. Enthalten die Verbindungen zu Vorgängerknoten nun Sprünge, wer-den diese Lücken mit Dummy-Knoten aufgefüllt. Diese erben den Schlüssel des dar-überliegenden vorhandenen Knotens, um die korrekte Verknüpfung der beiden In-stanzen zu gewährleisten. Dies ermöglicht ein vereinfachtes und automatisches „Joi-nen“ der Knoten über verschiedene Aggregationsstufen. Die Bezeichnung des neuenKnotens wird ebenfalls von seinem Vorgängerknoten bestimmt. An diesen wird einbenutzerfreundlicher Vermerk (bspw. „Sonstige“, „Alle“) angehängt. Nun ist die An-forderung des ersten Schritts erfüllt, da der Baum der covering-Anforderung genügt.
Abbildung XIII: Schemastruktur der transformierten Institutionen-Hierarchie
Der nächste Schritt ist der onto-Schritt: Knoten wie Institut für Verkehr und Logistik(siehe Abbildung XII) besitzen keine nachfolgenden Knoten auf der Blattebene. Umdas zu ändern werden auch hier Platzhalter-Dummy-Knoten eingefügt. Sie erben wiejeweils im ersten Schritt den Schlüssel und die Bezeichnung ihres Vorgängerknotens.
Die Instanzen Lehreinheit Ostasienwissenschaft und Institut für Ostasienwissenschaftaus Abbildung XII entsprechen nicht dem Muster, befinden sich also auf der „falschen“Ebene. Dieses Knotenpaar wird dann einfach bezüglich ihres Baumlevels getauscht.Dies darf nur unter einer Bedingung geschehen: der höherstufige Knoten darf nichtmehr als diesen einen Nachfolgerknoten, mit dem getauscht werden soll, besitzen.Das Tauschen bewirkt dass der nun niedrigstufigere Knoten mehrere Vorgänger be-sitzt. Dies widerspricht der dritten Forderung, den Baum strict zu halten. Das einKnoten mehrere Vorgänger besitzt, tritt im Fallbeispiel nicht auf. Alle Institutionensind genau einer anderen Institution zugeordnet.
Abbildung XIV: Regelmässiger Datenbaum der zentralwissenschaftlichen Einrichtung
Abbildung XII stellt den Zustand der Hierarchie der Zentralwissenschaftlichen Ein-richtung vor der Transformation, Abbildung XIV den Zustand danach, dar. Abbil-dung XV und XVI zeigen einen größeren Ausschnitt des ganzen Baumes jeweils vorund nach der Transformation. Entstanden ist nun eine heterogene Hierarchiestrukturmit unterschiedlichen Granularitäten. Die Ausgeglichenheit und Regelmässigkeit derStruktur nach allen Transformationsschritten ist in Abbildung XVI deutlich zu erkenn-nen.
46
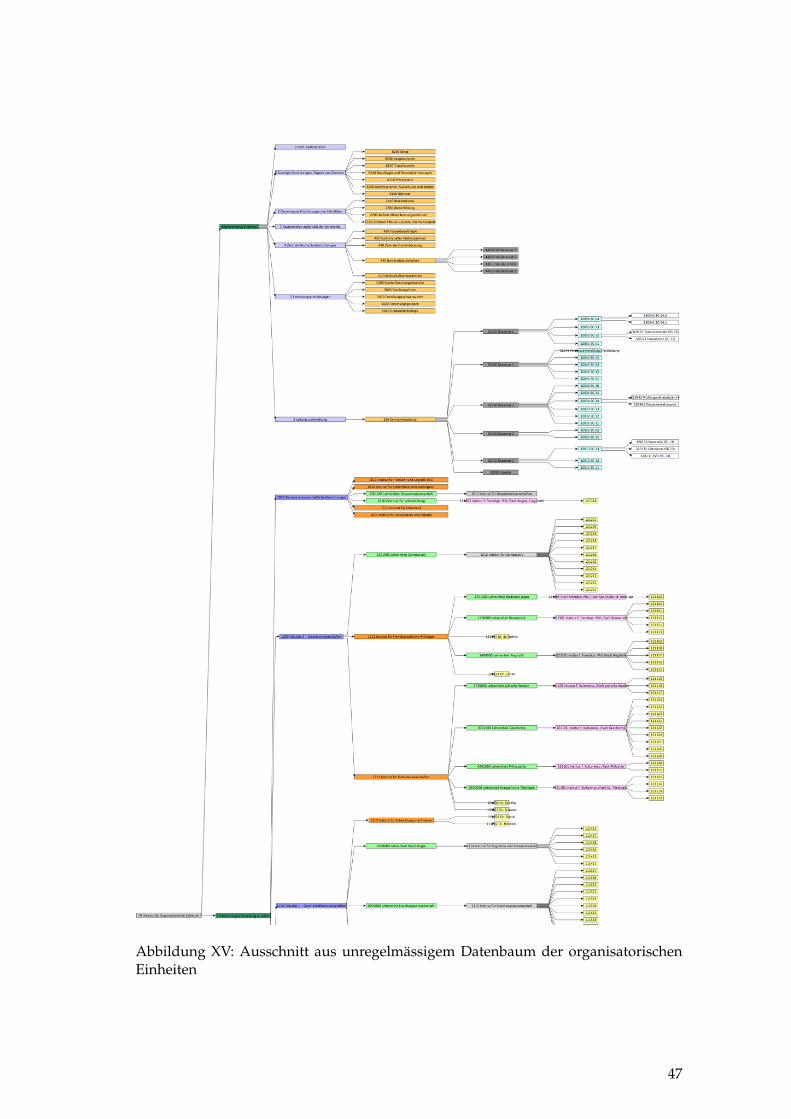
Abbildung XV: Ausschnitt aus unregelmässigem Datenbaum der organisatorischenEinheiten
47
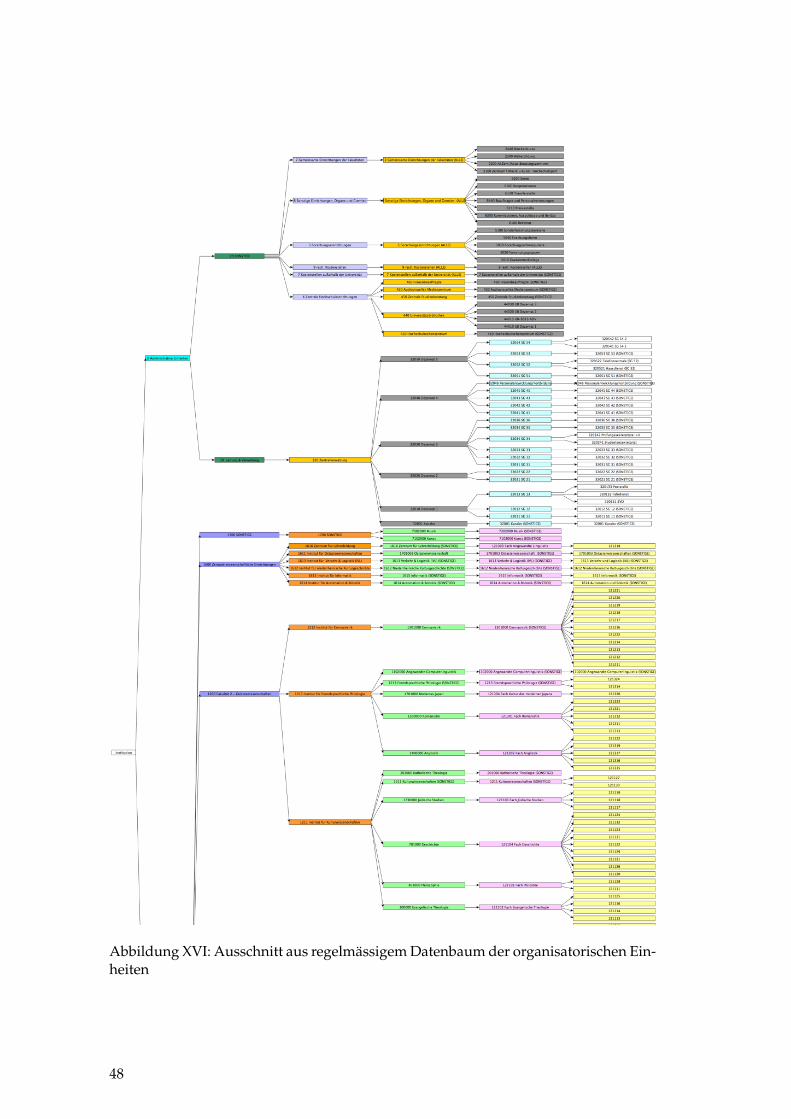
Abbildung XVI: Ausschnitt aus regelmässigem Datenbaum der organisatorischen Ein-heiten
48

Kapitel 3
Hierarchische Visualisierung mitPivot-Tabellen
In diesem Kapitel wird der Aufbau, die typische Visualisierung und die Manipula-tionsmöglichkeiten des OLAP-Standard-Werkzeugs Pivot-Tabelle beschrieben. DreiInterfaces, teilweise für die Domäne der universitären Hochschulverwaltung, wer-den vorgestellt. Die kleine Übersicht dient zur Präsentation der „Konkurrenz“-Sys-teme auf dem Markt. Des Weiteren werden wichtige Funktionalitäten festgestellt, mitSchwerpunkt auf der Navigation in den hierarchischen Datenstrukturen.
3.1 Front End-Werkzeuge für ein Data Warehouse
Kaum ein OLAP-Werkzeug verfügt heute nicht über ein Pivot-Tabellen-Interface [5,S. 608]. Oft wird darauf hingewiesen, dass das Handhaben und Verstehen von Pivot-Tabellen vergleichsweise schwer sei [5, S. 607]. Pivot-Tabellen sind limitiert, da siezum einen zweidimensionale Tabellen sind und zum anderen oft logische und physi-kalische Aspekte mit denen der Präsentation vermischt werden [8, S. 348]. Trotzdemstellt die Pivot-Tabelle einen natürlichen Startpunkt einer Analyse dar [8, S. 348] undist die Standard-Benutzerschnittstelle, um einen OLAP-Datenwürfel zu verstehen undzu manipulieren [6, S. 62].
Für den effizienten Zugriff auf ein Data Warehouse, ohne Benutzung einer Datenbank-sprache, gibt es Front End-Werkzeuge. Diese Benutzerschnittstellen teilt Herden [10,S. 15] in drei Klassen:
• Berichts- und Abfragewerkzeuge liefern vordefinierte und parametrisierte Auswer-tungen in Form von Berichten oder Diagrammen
• Data Mining-Werkzeuge decken unbekannte Zusammenhänge und Trends in denDaten auf
• OLAP-Werkzeuge erlauben dem Benutzer interaktiv den Datenbestand zu analy-sieren. Sie sind in vielfältiger Form verfügbar:
– als Client auf dem Arbeitsplatzrechner
– als Erweiterung zur Tabellenanwendung (z.B. Pivot-Tabellen Add-In fürMicrosoft Excel, siehe Abbildung XIX)
– als Webbrowser-Client, basierend auf HTML
49

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
3.1.1 Hierarchische Visualisierungstechniken
Weshalb kann eine Pivot-Tabelle als hierarchisches Visualisierungswerkzeug bezeich-net werden? Der Benutzer kann über Manipulationsmöglichkeiten, wie das Expandie-ren von Dimensionen, die hierarchische Struktur in den OLAP-Daten explorieren. DasNavigieren in den Hierarchien geschieht entweder direkt in der Pivot-Tabelle durchAuf- und Zuklappen (Expand und Collapse) der Zeilen und Spalten, oder in der Navi-gationsleiste durch Auf- und Zuklappen der Einträge, zumeist in Form von Ordnern,eines Schemabrowsers. Im ersten Fall wird die hierarchische Datenstruktur und imzweiten die hierarchische Schemastruktur exploriert (mehr zum Schemabrowser inAbschnitt 4.1).
Um hierarchische Strukturen visuell zu explorieren gibt es einige innovative Entwick-lungen. Zwei davon sind die Treemaps von Johnson/Shneiderman [14] und die ConeTrees von Robertson/Mackinlay/Card [23]. Die Intention ist jeweils große Datenmen-gen durch effiziente Raumnutzung navigierbar und darstellbar zu machen. Die Vi-sualisierung sollte verständlich sein, so dass der Benutzer sie intuitiv verstehen undbedienen kann.
Treemaps
Die Baumstruktur vernachlässigend werden die Elemente einer Hierarchie auf eineflache Karte gezeichnet. Dem einzelnen Element des Baumes werden entsprechendseiner Eigenschaft Gewichte verliehen (z.B. Grösse einer Festplatte und der sich dar-auf befindlichen Dateien und Verzeichnisse) und so deren Fläche festgelegt. Der Platz,der jedem Element zur Verfügung steht, wird je nach Gewicht auf seine Kinder ver-teilt.
Abbildung XVII: Festplatten-Visualisierung über eine Treemap
Abbildung XVII zeigt einen Treemap der über die Fläche die Dateigröße und über dieFarbe den Dateityp abbildet (Grafik aus [25]).
50
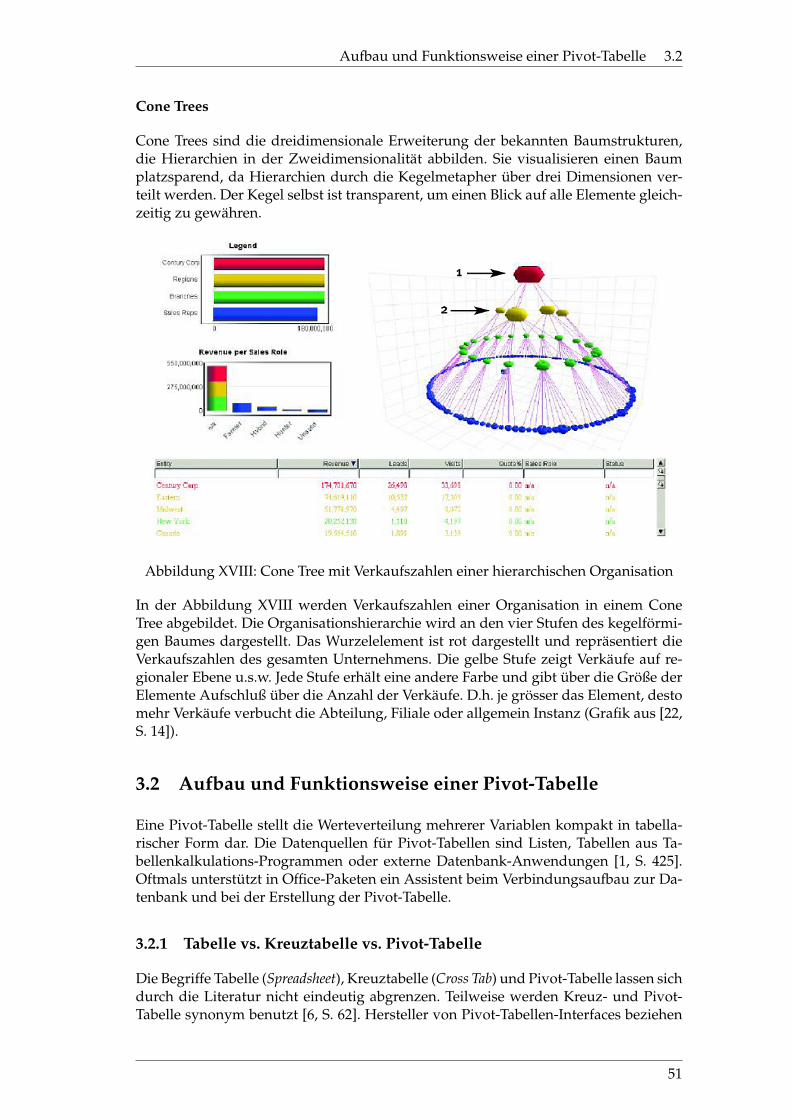
Aufbau und Funktionsweise einer Pivot-Tabelle 3.2
Cone Trees
Cone Trees sind die dreidimensionale Erweiterung der bekannten Baumstrukturen,die Hierarchien in der Zweidimensionalität abbilden. Sie visualisieren einen Baumplatzsparend, da Hierarchien durch die Kegelmetapher über drei Dimensionen ver-teilt werden. Der Kegel selbst ist transparent, um einen Blick auf alle Elemente gleich-zeitig zu gewähren.
Abbildung XVIII: Cone Tree mit Verkaufszahlen einer hierarchischen Organisation
In der Abbildung XVIII werden Verkaufszahlen einer Organisation in einem ConeTree abgebildet. Die Organisationshierarchie wird an den vier Stufen des kegelförmi-gen Baumes dargestellt. Das Wurzelelement ist rot dargestellt und repräsentiert dieVerkaufszahlen des gesamten Unternehmens. Die gelbe Stufe zeigt Verkäufe auf re-gionaler Ebene u.s.w. Jede Stufe erhält eine andere Farbe und gibt über die Größe derElemente Aufschluß über die Anzahl der Verkäufe. D.h. je grösser das Element, destomehr Verkäufe verbucht die Abteilung, Filiale oder allgemein Instanz (Grafik aus [22,S. 14]).
3.2 Aufbau und Funktionsweise einer Pivot-Tabelle
Eine Pivot-Tabelle stellt die Werteverteilung mehrerer Variablen kompakt in tabella-rischer Form dar. Die Datenquellen für Pivot-Tabellen sind Listen, Tabellen aus Ta-bellenkalkulations-Programmen oder externe Datenbank-Anwendungen [1, S. 425].Oftmals unterstützt in Office-Paketen ein Assistent beim Verbindungsaufbau zur Da-tenbank und bei der Erstellung der Pivot-Tabelle.
3.2.1 Tabelle vs. Kreuztabelle vs. Pivot-Tabelle
Die Begriffe Tabelle (Spreadsheet), Kreuztabelle (Cross Tab) und Pivot-Tabelle lassen sichdurch die Literatur nicht eindeutig abgrenzen. Teilweise werden Kreuz- und Pivot-Tabelle synonym benutzt [6, S. 62]. Hersteller von Pivot-Tabellen-Interfaces beziehen
51

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
sich bezüglich des Begriffes auf das Add-In von Microsoft, die ihre Pivot-Table zu-erst in Microsoft Excel einführten. Mmittlerweile, genauer seit der Version WindowsXP, nennt Microsoft dasselbe Produkt Pivot-Table-Bericht. In der Literatur finden sichweitere Synonyme, wie Matrixbericht [27, S. 39]. Andere Hersteller wie z.B. TableauSoftware (siehe Abschnitt 3.3.3) nennen ihr Produkt, obgleich pivot-tabellen-ähnlich,explizit anders, hier Text Table. Verkäufer grenzen ihr Pivot-Tabellen-Produkt durchAussagen wie „being like a spreadsheet on steroids“ [5, S. 608] von „einfachen“ Tabel-len ab.
Werden die Begriffe Kreuztabelle und Pivot-Tabelle nicht synonym benutzt, wird derUnterschied über die niedrigere Dimensionalität der Kreuz- gegenüber der Pivot-Tabelle erklärt. Die traditionelle Tabelle wird an manchen Stellen als die statische unddie Pivot-Tabelle als die dynamische Tabelle bezeichnet. Wie auch immer, die Gemein-samkeit ist zumindest ihre Grundstruktur, gegeben durch ein Gitter aus Zeilen undSpalten.
3.2.2 Struktureller Aufbau
Die beispielhafte (Excel-) Pivot-Tabelle aus Abbildung XIX beruht auf einer Verkaufs-statistik mit mehrjährigen Umsatzzahlen. Ein international operierendes Unterneh-men speichert zu jedem Verkauf seines Produktes das Absatzland, das Geschlecht desKäufers, das Verkaufsdatum und natürlich die Höhe des Einkaufs. Im Folgenden wer-den typische Elemente einer Pivot-Tabelle am Beispiel in Abbildung XIX erläutert [1,S. 427ff].
Abbildung XIX: Zeilen-, Spalten-, Seiten- und Datenfeld einer Microsoft Excel Pivot-Tabelle
Im Kontext von Pivot- bzw. Kreuztabellen ist von Variablen und Variablenwerten an-statt, wie bisher im Kontext des multidimensionalen Datenmodells, von Aggregati-onsstufen und Instanzen der Aggregationsstufen die Rede.
Zeilenfeld
Das Zeilenfeld nimmt eine Variable auf deren Werte auf der Y-Achse abgetragen wer-den. Die Beschriftung über der ersten Spalte repräsentiert das Land, in dem der Um-satz erwirtschaftet wurde und überschreibt alle seine Ausprägungen (Argentinien, . . . ,Venezuela). Die Anzahl der Zeilen einer Pivot-Tabelle entspricht also der Anzahl derdisjunkten Einträge in der entsprechenden Tabelle des Zeilenfeldes. Gibt es für ei-ne Zelle keinen zugehörigen Wert, beispielsweise in Mexiko kaufte keine männlichenKunden das Produkt, bleibt die Zelle leer.
52

Aufbau und Funktionsweise einer Pivot-Tabelle 3.2
Spaltenfeld
Das Spaltenfeld trägt die Beschriftung Geschlecht und listet in der Zeile darunter,jeweils einmal, sämtliche Ausprägungen der entsprechenden Tabelle aus der Daten-quelle. Auch hier gilt, dass es so viele Spaltenüberschriften unter dem Spaltenfeld gibt,wie Einträge für das Spaltenfeld in der zugehörigen Tabelle existieren.
Mindestens eine Dimension muss auf einer der beiden zur Verfügung stehenden Ach-sen, also über das Zeilen- oder Spaltenfeld, abgebildet werden, damit die Tabelle nichtleer ist. Jede Achse kann theoretisch zwischen 0 und n Variablen aufnehmen, die danndurch Schachtelung auf den Achsen abgebildet werden.
Die Achsen stellen die Variablenwerte des Spaltenfeldes neben- und die des Zeilenfel-des übereinander als eine Art Überschrift dar.
Seitenfeld
Das Seitenfeld wirkt als Filter auf die Pivot-Tabelle. Über ein Auswahlfeld kann aussämtlichen Ausprägungen des Seitenfeldes gewählt werden. Im Beispiel ist das Sei-tenfeld Zeit und der Variablenwert 2000 der im Datenbereich für die Anzeige einzigder Umsätze aus dem Jahr 2000 sorgt. Durch Blättern gelangt der Benutzer zu dengefilterten Seiten.
Der oberste Eintrag im Auswahlfeld dieser auch als Paging bekannten Funktion ist dasAggregat aller Ausprägungen (oftmals „Alle“ bezeichnet). Wird dieses Aggregat se-lektiert, findet keine Filterung über das Seitenfeld statt. Können mehrere Seitenfelderbenutzt werden, so wird nach mehreren Variablen gefiltert, und die Filterung durchlogisches „und“ verbunden.
Datenfeld
Jede Pivot-Tabelle benötigt mindestens eine Kennzahl, die im Datenbereich angezeigtwird. Ausserdem muss die Art der Aggregation definiert sein. Im Beispiel trägt dasDatenfeld die Beschriftung „Summe - Umsatz“, also findet eine Summierung des Um-satzes statt.
Zusammenfassung
Den multidimensionalen OLAP-Aspekt unterstützt die Pivot-Tabelle durch Visuali-sierung mehrerer Dimensionen über das Zeilen-, Spalten- oder Seitenfeld. Dabei kanneine Pivot-Tabelle mehr als ein Element in den verschiedenen Feldern aufnehmen.Dadurch ändert sich das Layout entsprechend: die Variablenwerte werden auf denAchsen geschachtelt, oder es findet eine Mehrfachfilterung statt, oder in den Zel-len werden mehrere Aggregate angezeigt. Diese Kombination von Zeilen-, Spalten-,Seiten- und Datenfeldern kann beliebige Sichten auf die Daten erzeugen und bestimmtals mehrdimensionaler Filter die Werte in der Pivot-Tabelle. Im Datenbereich werdenschliesslich die Schnittmengen der selektierten Elemente angezeigt.
Verändert der Benutzer einen Faktor der Pivot-Tabelle, durch Definieren einer ande-ren Dimension im Zeilen-, Spalten- oder Seitenfeld, durch Entfernen einer Dimensi-on oder durch Wählen eines Filters etc., wird der Datenwürfel bildlich gesprochen„gedreht“. Für jede Zelle ergeben sich neue Schnittmengen. Dieses Drehen gibt der
53

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
Pivot-Tabelle ihren Namen: „pivoter“ ist französisch und bedeutet „drehen“.
Die Interaktivität einer Pivot-Tabelle entsteht also durch Einfügen oder Entfernen vonDimensionen, denn dadurch kann der Einfluss durch die Veränderung auf die Datenbeobachtet werden.
3.2.3 Manipulation von Pivot-Tabellen
Zum Umfang einer Pivot-Tabelle gehört, oftmals ein interaktives, Interface mit Mög-lichkeiten zur Kontrolle der zu analysierenden Daten. Folgende Manipulationen erge-ben sich für Standard-Pivot-Tabellen-Interfaces nach Eick [6, S. 62]:
• Zuordnung von Dimensionen zum Zeilen-, Spalten- und Seitenfeld z.B. durch „Dragand Drop“ in entsprechenden Platzhalter
• Navigation in den hierarchischen Strukturen durch Auf- und Zuklappen der Hier-archien
• Verdichtung der Daten entlang den Dimensionen mit verschiedenen Aggregati-onsfunktionen
Weitere Operationen, um die Daten der Pivot-Tabelle für die aktuelle Fragestellungzu optimieren, sind Filtern und Pivoting. Das bedeutet eine Änderung der Dimen-sionen, z.B. durch Tauschen der Spalten- und Zeilenfelder oder das Einbringen neuerDimensionen. Jede Interaktion mit der Pivot-Tabelle bedeutet eine Auffrischung derDarstellung.
Alle Manipulationen haben gemein, dass die darunter liegenden Daten nicht verän-dert werden. Die Eingriffe des Benutzers passen die dargestellten Daten an, schreibenaber keine Änderungen in die Basisdaten der Datenbank zurück.
3.2.4 Darstellung der Zwischenaggregate
Weitere relevante Elemente einer Pivot-Tabelle sind die Zeilen und Spalten mit Zwi-schenaggregaten. Sie bilden eine oder mehrere Verdichtungsstufen ab und erlaubendem Benutzer so Aggregate mehrerer Aggregationsstufen gleichzeitig zu betrachten.Ausserdem ist das Einfügen von Zwischenaggregatszeilen und -spalten auch gestalte-risch von Vorteil, da sie die einzelnen Gruppierungen optisch voneinander abtrennen.
Die Begriffe “(Zwischen-) Summe“ bzw. „(Sub-) Total“ sind zwar umgangssprachlichgebräuchlich, aber irreführend, da die Summenbildung (mittels Sum) nicht die an-gewandte Aggregationsfunktion sein muss. Auch in der englischen Sprache scheintes diese missverständliche Interpretation zu geben, da „Total“ ebenfalls Summe be-deutet. Korrekt ist die Beschriftung bei Verwendung anderer Aggregationsfunktionenentsprechend zu ändern, z.B. „Alle“ für die Aggregationsfunktion Count .
Eine Variable als Zeilen- oder Spaltenfeld
Die zu analysierenden Kennzahlen sind in einem Gitter dargestellt. Eine vertikale undhorizontale Achse mit Ursprung in der linken oberen Ecke der Tabelle beinhalten dieÜberschriften der Zeilen bzw. Spalten, also ihre Variablenwerte. Die symmetrischen
54
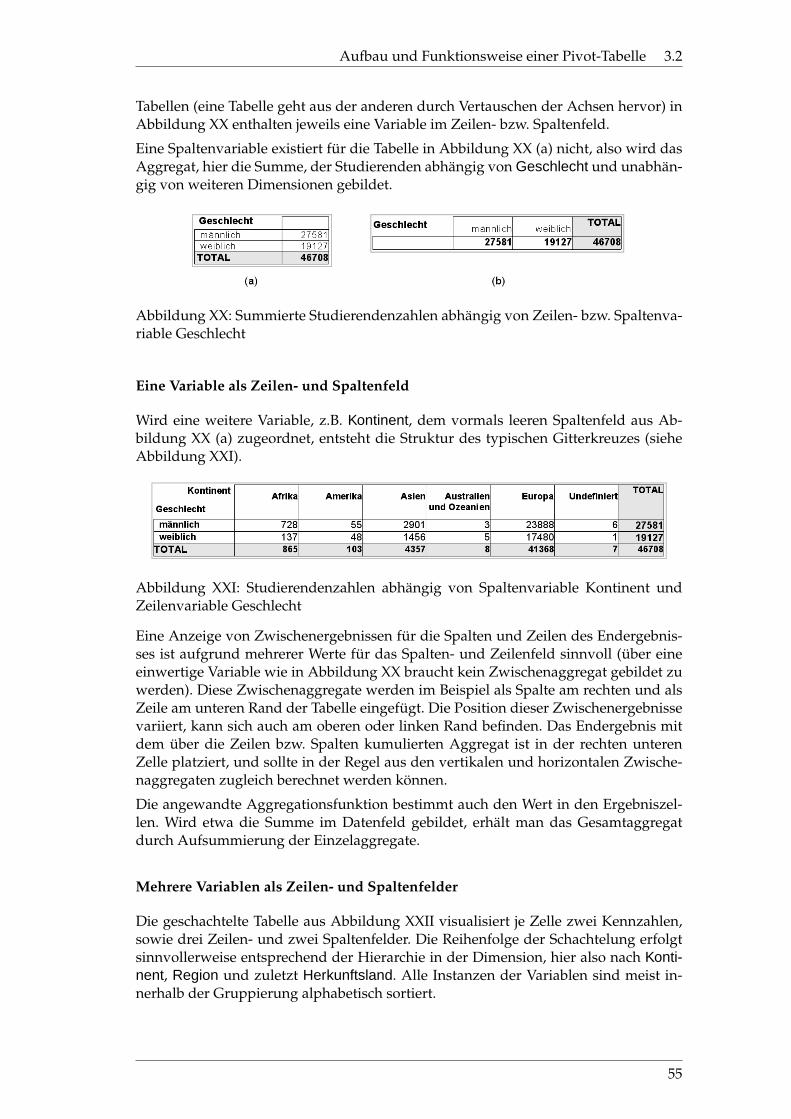
Aufbau und Funktionsweise einer Pivot-Tabelle 3.2
Tabellen (eine Tabelle geht aus der anderen durch Vertauschen der Achsen hervor) inAbbildung XX enthalten jeweils eine Variable im Zeilen- bzw. Spaltenfeld.
Eine Spaltenvariable existiert für die Tabelle in Abbildung XX (a) nicht, also wird dasAggregat, hier die Summe, der Studierenden abhängig von Geschlecht und unabhän-gig von weiteren Dimensionen gebildet.
Abbildung XX: Summierte Studierendenzahlen abhängig von Zeilen- bzw. Spaltenva-riable Geschlecht
Eine Variable als Zeilen- und Spaltenfeld
Wird eine weitere Variable, z.B. Kontinent, dem vormals leeren Spaltenfeld aus Ab-bildung XX (a) zugeordnet, entsteht die Struktur des typischen Gitterkreuzes (sieheAbbildung XXI).
Abbildung XXI: Studierendenzahlen abhängig von Spaltenvariable Kontinent undZeilenvariable Geschlecht
Eine Anzeige von Zwischenergebnissen für die Spalten und Zeilen des Endergebnis-ses ist aufgrund mehrerer Werte für das Spalten- und Zeilenfeld sinnvoll (über eineeinwertige Variable wie in Abbildung XX braucht kein Zwischenaggregat gebildet zuwerden). Diese Zwischenaggregate werden im Beispiel als Spalte am rechten und alsZeile am unteren Rand der Tabelle eingefügt. Die Position dieser Zwischenergebnissevariiert, kann sich auch am oberen oder linken Rand befinden. Das Endergebnis mitdem über die Zeilen bzw. Spalten kumulierten Aggregat ist in der rechten unterenZelle platziert, und sollte in der Regel aus den vertikalen und horizontalen Zwische-naggregaten zugleich berechnet werden können.
Die angewandte Aggregationsfunktion bestimmt auch den Wert in den Ergebniszel-len. Wird etwa die Summe im Datenfeld gebildet, erhält man das Gesamtaggregatdurch Aufsummierung der Einzelaggregate.
Mehrere Variablen als Zeilen- und Spaltenfelder
Die geschachtelte Tabelle aus Abbildung XXII visualisiert je Zelle zwei Kennzahlen,sowie drei Zeilen- und zwei Spaltenfelder. Die Reihenfolge der Schachtelung erfolgtsinnvollerweise entsprechend der Hierarchie in der Dimension, hier also nach Konti-nent, Region und zuletzt Herkunftsland. Alle Instanzen der Variablen sind meist in-nerhalb der Gruppierung alphabetisch sortiert.
55

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
Abbildung XXII: Geschachtelte Tabelle mit Studierendenzahlen abhängig von Spal-tenvariablen Fachsemestergruppe, Fachsemester und Zeilenvariablen Kontinent, Sub-kontinent, Land, aggregiert über Kennzahlen Kopf und Fall
Jede Gruppierung, z.B. Herkunftsregion Nordeuropa für das 1. bis 4. Fachsemester,schließt mit einem Zwischenergebnis ab und wird als zusätzliche Spalte bzw. Zeile andie entsprechende Position, hinter bzw. unter den letzten Variablenwerten, eingefügt.
Die Zellen mit den Zwischen- und Endaggregaten werden optisch, z.B. hier über ei-ne andere Hintergrundfarbe, von Aggregaten anderer Granularität abgegrenzt. DieZwischenaggregate werden auch zwischengeblendet, wenn die Gruppierung nur auseiner Instanz besteht (z.B. Neuseeland).
Wird eine Variable für ein Seitenfeld definiert, beziehen sich alle Zwischenergebnissenur auf den Filter. Denkbar ist eine zusätzliche Zeile bzw. Spalte einzublenden, dieunabhängig vom Wert des Seitenfelds ein globales Gesamtaggregat bildet.
3.3 Marktübersicht der Pivot-Tabellen-Interfaces
Es gibt einige Data Warehouse-Lösungen und OLAP-Front Ends im internationalenuniversitären Umfeld. Das sind neben den beiden deutschen Vertretern Joolap und
56

Marktübersicht der Pivot-Tabellen-Interfaces 3.3
CEUS-HB: HigherEd Analytics1, ASU DW2 und SKOPUS-University3.
Die Pivot-Tabellen-Interfaces von Joolap und CEUS-HB werden hier betrachtet, daes zwei der größten akademischen Data Warehouse-Initiativen in Deutschland sind.Ausserdem ist SuperX der Kooperationspartner des UniVis Explorer-Projektes undverwendet dieselben OLAP-Würfel. CEUS-HB, auch ein Projekt an einer deutschenHochschule, ist ebenso für den Einsatz an deutschen Hochschulen konzipiert. Aus-serdem ist der Zugriff auf eine Online-Demoversion möglich. Tableau Software fälltaus dem Rahmen, ist es doch keine Lösung für Hochschulen, dafür enthält das Pivot-Tabellen-Interface umfassende Möglichkeiten zur Manipulation.
Die Beschreibung konzentriert sich auf die Visualisierung und Funktionalität der Pivot-Tabellen-Interfaces und orientiert sich dabei an den von Eick [6, S. 62] definierten Stan-dard-Manipulationen (siehe Abschnitt 3.2.3).
3.3.1 Joolap
Joolap ist ein Pivot-Tabellen-Interface für Hochschulverwaltungen. Das Java-Appletwird als Client auf einem Arbeitsplatzrechner installiert. Eine Demoversion, die dieserUntersuchung zugrunde liegt, wird auf der Webseite von Memtext4 angeboten.
Abbildung XXIII: Pivot-Tabellen-Interface von Joolap
1Data Warehouse für analytisches Reporting an amerikanischen Hochschulen, Website: http://www.istrategyconsulting.com/sol_HEA_1.shtml (Abgerufen 09.10.2006)
2Data Warehouse zur Entscheidungsunterstützung an der Arizona State University in denUSA, Website: http://www.asu.edu/data_admin/data_warehouse-overview.html (Abgeru-fen 09.10.2006)
3Data Warehouse mit Modulen für die Generierung vordefinierter Reports und Analysen an ame-rikanischen Hochschulen, Website: http://www.merkurium.com/skopusuni_en.htm (Abgerufen09.10.2006)
4Download der Joolap-Demoversion unter http://www.studio-fuer-textdesign.de/superx/dist/JoolapDemoSetup.exe (Abgerufen 17.05.2006)
57

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
Visualisierung
Die Demoversion enthält eine Daten-Visualisierung über ein Balkendiagramm sowieüber eine Pivot-Tabelle. Zugrunde liegen zwei OLAP-Würfel, die Studierende- undHaushaltskosten-Daten beinhalten.
Die zu analysierenden Daten sind in einem Visualisierungsbereich optisch abgetrennt(siehe Pivot-Tabelle mit dunklem Rahmen in Abbildung XXIII). An der unteren Leistewird zu den Kennzahlen ein erläuternder Text ausgegeben, z.B. „Haupthörer ohneBeurlaubte“.
Die Pivot-Tabelle wird in Explorer-Manier dargestellt: die Werte des Zeilenfeldes sindals Ordner visualisiert. Diese sind zu expandieren wenn sie weitere Ordner oder Blatt-knoten enthalten. Blattknoten besitzen jeweils eigene Symbole bzw. Icons. Enthält einOrdner weitere Knoten wird dies mit „+“, dem Ordner-Symbol vorangestellt, gekenn-zeichnet.
Für alle im Würfel vorhandenen Dimensionen kann ein Filter angelegt werden, sofernsie nicht als Zeilen- oder Spaltenfeld verwendet werden. Sie sind dann im Einschrän-kungsbereich (siehe Abbildung XXIII rechts neben dem Visualisierungsbereich) alsButtons hinterlegt. Nach einem Klick darauf stehen in einem Popup-Fenster die Varia-blenwerte aller Hierarchiestufen zur (Mehrfach-) Selektion bereit (siehe Popupfensterin Abbildung XXIII).
Manipulation
Zuordnung der Dimensionen Zur Selektion der Dimension dient das Pulldownfeldausserhalb (für das Spaltenfeld) und das Pulldownfeld innerhalb der Visualisierung(für das Zeilenfeld). Nach der Auswahl passt sich die Visualisierung dynamisch an.In Abbildung XXIII handelt es sich bei den Spalten- bzw. Zeilenfeldern um die Mittel-herkunft bzw. die Kostenart.
Navigation in hierarchischen Dimensionen In den Werten des Zeilenfeldes kannhierarchisch navigiert werden, indem die Ordner expandiert werden. Dies entsprichteinem Drill-Down und Roll-Up entlang des Klassifikationspfades der hierarchischenDimension.
Diese Möglichkeiten bieten sich auch für die Werte des Spaltenfeldes: das Kontext-menü, über die rechte Maustaste, auf der entsprechenden Spaltenüberschrift (siehe inAbbildung XXIII „Alle“), zu erreichen, erlaubt hier die Navigation in der Hierarchie.Diese Operationen werden mit Drill-Down und „Drill-Up“ bezeichnet.
Die Werte werden nicht optisch geschachtelt, sondern auf derselben Ebene hinter dieSpalte, auf der der Drill-Downs beruht, eingefügt. Ein Drill-Down z.B. auf Alle aus derDimension Mittelherkunft fügt Titelgruppe 98, Titelgruppe 99 etc. als weitere Spaltenhinzu.
Aggregieren entlang verschiedener Dimensionen Über das Kontextmenü des Zei-lenfeldes kann der Benutzer einen zu analysierenden Dimensionsknoten wählen unddiesen nach weiteren Dimensionen trennen. „Trennen nach“ entspricht der OLAP-Operation Schachtelung. Die Instanzen dieser weiteren Dimension werden als weitereZeilen an die Elemente im aufgeklappten Baum angehängt und farblich markiert (in
58

Marktübersicht der Pivot-Tabellen-Interfaces 3.3
Abbildung XXIV: Joolap-Operation Schachtelung der Abschlüße innerhalb 10.-14.Fachsemester
Abbildung XXIV wird Abschluß in 10.-14. FS geschachtelt). Mehrfache Schachtelungsowie Drill-Down in Spalten- und Zeilenfelder gleichzeitig ist möglich.
Durch die Operation „Trennen nach“ werden nicht nur die Instanzen der weiterenDimension (Schachtelung) sondern zusätzlich die eigenen Dimensionsknoten (ent-spricht Drill-Down) sichtbar.
Zusammenfassung
Die Auswahl von Dimensionen und Würfel sind über die Anwendung verteilt, was zueiner gewissen Unübersichtlichkeit führt. Eine Dimension kann nur gefiltert werden,wenn sie nicht zur Anzeige auf einer der Achsen benutzt wird. Wie schon erwähntwerden die Kennzahlen als Dimensionen behandelt und sind konsequenterweise inder Einschränkungsauswahl wiederzufinden (siehe Abbildung XXIV).
Es existieren ausser der Summenbildung keine weiteren Aggregationsfunktionen. DieZwischenaggregate werden nicht optisch von den anderen Aggregaten in den Zel-len abgehoben. Wie in Abbildung XXIII zu sehen werden die Zwischenaggregate desZeilenfeldes gar nicht angezeigt.
Da über die Datenhierarchie eingeschränkt wird, muss der Benutzer die Daten ken-nen, um zum gewünschten Eintrag zu gelangen.
3.3.2 CEUS-HB
CEUS-HB ist ein computerbasiertes Entscheidungsunterstützungssystem für Hoch-schulen in Bayern. Es wird an der Universität Bamberg entwickelt.
CEUS-HB wird über einen Webbrowser mit Dynamic HTML5 angezeigt. Auf Fakul-tätsebene werden anonymisierte und konsolidierte Daten aus den Bereichen Studie-rende, Personalmanagement und Mittelbewirtschaftung zur Verfügung gestellt. Dabeikönnen die Statistiken mehrerer Hochschulen verglichen werden.
5Online-Demoversion: http://ceusdemo.wiai.uni-bamberg.de/MicroStrategy/Asp/ ,Login und Passwort ceus (Abgerufen 15.10.2006)
59
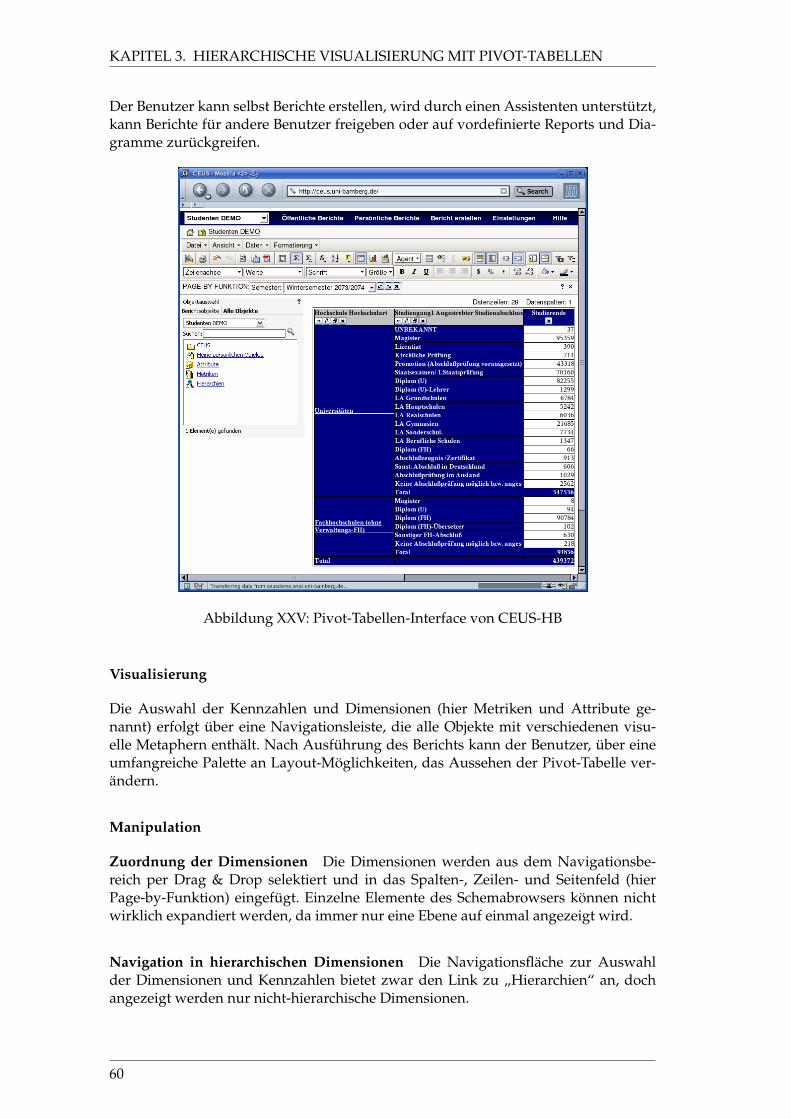
KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
Der Benutzer kann selbst Berichte erstellen, wird durch einen Assistenten unterstützt,kann Berichte für andere Benutzer freigeben oder auf vordefinierte Reports und Dia-gramme zurückgreifen.
Abbildung XXV: Pivot-Tabellen-Interface von CEUS-HB
Visualisierung
Die Auswahl der Kennzahlen und Dimensionen (hier Metriken und Attribute ge-nannt) erfolgt über eine Navigationsleiste, die alle Objekte mit verschiedenen visu-elle Metaphern enthält. Nach Ausführung des Berichts kann der Benutzer, über eineumfangreiche Palette an Layout-Möglichkeiten, das Aussehen der Pivot-Tabelle ver-ändern.
Manipulation
Zuordnung der Dimensionen Die Dimensionen werden aus dem Navigationsbe-reich per Drag & Drop selektiert und in das Spalten-, Zeilen- und Seitenfeld (hierPage-by-Funktion) eingefügt. Einzelne Elemente des Schemabrowsers können nichtwirklich expandiert werden, da immer nur eine Ebene auf einmal angezeigt wird.
Navigation in hierarchischen Dimensionen Die Navigationsfläche zur Auswahlder Dimensionen und Kennzahlen bietet zwar den Link zu „Hierarchien“ an, dochangezeigt werden nur nicht-hierarchische Dimensionen.
60

Marktübersicht der Pivot-Tabellen-Interfaces 3.3
Drill-Down und Roll-Up in hierarchischen Dimensionen, die im Visualisierungsbe-reich über die Pivot-Tabelle angezeigt werden, ist möglich, sowohl für die Spalten- alsauch die Zeilenfelder.
Aggregieren entlang verschiedener Dimensionen Alle Dimensionen, die als Zeilen-, Spalten- oder Seitenfelder benutzt werden, können in der Visualisierungsebene aneine andere Stelle geschoben werden. So wird das Seitenfeld durch einen entsprechen-den Mausklick zum Spalten- oder Zeilenfeld. Des Weiteren ist die Schachtelung allerauswählbarer Dimensionen für das Zeilenfeld möglich.
Zusammenfassung
Das Explorieren der Variablenwerte sowohl im Navigations- wie auch im Visualisie-rungsbereich ist unkomfortabel. Dies wird zusätzlich unterstützt durch die wohl in-stallationsabhängigen langen Antwortzeiten.
Dafür zeichnete sich CEUS-HB durch umfangreiche Manipulationsmöglichkeiten, diesich auf die Darstellung auswirken, aus. Des Weiteren können verschiedene Aggrega-tionsfunktionen, wie Rang oder Prozent im Verhältnis zum Gesamtwert etc., gewähltwerden.
3.3.3 Tableau Software
Tableau Software ist ein visuelles Werkzeug für allgemeine Analysen also nicht fürspezifische Anwendungsdomänen konzipiert. Es wird als Client auf einem Arbeits-platzrechner installiert und greift auf gängige Datenbankensysteme6 und Tabellenkal-kulationen zu. Um die aktuelle Demoversion zu testen, muß eine Anfrage7 an TableauSoftware gestellt werden.
Visualisierung
Die Benutzeroberfläche ist in einen Auswahl- und Visualisierungsbereich gegliedert.Die Auswahlfläche (siehe linker Bereich in Abbildung XXVI) bildet alle Felder derzugrunde liegenden Tabellen ab und ist unter anderem unterteilt in Dimensionenund Kennzahlen. Im Visualisierungsbereich sind Platzhalter für die Zeilen-, Spalten-,Daten- und Seitenfelder vorhanden.
Manipulation
Zuordnung der Dimensionen Per Drag & Drop werden die Dimensionen und Kenn-zahlen in die Zeilen- und Spaltenfelder oder direkt in die entsprechenden Bereiche derTabelle bewegt. Die Anzeige erfolgt dynamisch. In diesen Feldern stehen die Elementez.B. zur Filterung oder Dimensionsänderung zur Verfügung.
6Die OLAP-Daten des Projektes UniVis Explorer liegen in einem PostgreSQL-Datenbanksystem. Lei-der gehört PostgreSQL nicht zu den unterstützten Datenbankensysteme. So konnte Tableau Softwarenicht einfach mit den eigenen multidimensionalen Daten getestet werden.
7Registration um die auf 14 Tage begrenzte „Free Trial“-Version zu erhalten unter http://www.tableausoftware.com/trial.htm (Abgerufen 10.10.2006)
61

KAPITEL 3. HIERARCHISCHE VISUALISIERUNG MIT PIVOT-TABELLEN
Abbildung XXVI: Pivot-Tabellen-Interface von Tableau Software
Navigation in hierarchischen Dimensionen Die Datenquelle der untersuchten Test-version ist eine Tabelle aus einer Tabellenkalkulation. Die Dimensionen sind nichthierarchisch. Z.B. scheinen Product Category 1 und Product Category 2 Aggregati-onsstufen einer Dimensionshierarchie zu sein, können aber nicht als solche qualifiziertwerden was Operationen wie Roll-Up bzw. Drill-Down folglich verhindert.
Aggregieren entlang verschiedener Dimensionen Dimensionen können entlang derAchsen geschachtelt werden. Die Zwischenaggregate in den Zeilen und Spalten sindnach Veränderungen an der Pivot-Tabelle standardmässig nicht sichtbar, können abermanuell eingeblendet werden.
Zusammenfassung
Dem Benutzer bieten sich umfangreiche Interaktionsmöglichkeiten. Neben des Pivot-Tabellen-Interfaces existieren Visualisierungstechniken wie Heat Maps, Histogramme,Balkendiagramme, Scatterplots u.v.w.
Tableau Software umfasst eine Historyfunktion um zwischen den Visualisierungenund Selektionsauswahlen hin und her zu blättern. Mit Copy & Paste können selektier-te Datenzellen in Tabellenkalkulationen wie Microsoft Excel, bzw. Visualisierungen inMicrosoft Powerpoint übernommen werden.
Das Produkt besitzt umfangreiche Manipulationsoptionen. Dazu gehört, dass die Zei-len- und Spalten-Überschriften der Pivot-Tabelle fixiert werden, wenn der Benutzerscrollt und der Bildschirmbereich zu klein ist. Insgesamt ist das Interface optisch an-sprechend umgesetzt.
62

Marktübersicht der Pivot-Tabellen-Interfaces 3.3
3.3.4 Fazit
Den untersuchten Pivot-Tabellen-Interfaces mangelt es teilweise an Übersichtlichkeit,Benutzerfreundlichkeit und der Auswahl von Manipulationsmöglichkeiten. Oftmalskönnen hierarchische Strukturen in den Daten nicht korrekt oder überhaupt nicht ab-gebildet werden.
63

Kapitel 4
Framework
Der Hauptaspekt des letzten Kapitels ist die Implementation des Visualisierungswerk-zeuges Pivot-Tabelle. Neben der Generierung der Datenbankanfrage wird die Darstel-lung der heterogenen und gemischt-granularen Hierarchien im NavigationswerkzeugSchemabrowser und in der Pivot-Tabelle beschrieben. Abgeschlossen wird die Arbeitmit einem Ausblick über Weiterentwicklungen des UniVis Explorers.
4.1 Multifunktionswerkzeug Schemabrowser
4.1.1 Datenbrowser vs. Schemabrowser
Abbildung XXVII vergleicht einen Daten- (a) und Schemabrowser (b). Der Datenbrow-ser erlaubt die Navigation über die Datenstruktur, der Schemabrowser über die Sche-mahierarchie.
Abbildung XXVII: Navigationsbrowser über die Daten- (a) und Schemastruktur (b)(Abbildung aus [32, S. 8])
So kann der Benutzer des Datenbrowsers direkt in den Dimensionswerten (beispiels-weise America, North America, Mexico) navigieren, indem er die Instanzen der Hier-archiestufen, abgebildet über die Metapher Ordner, auf- oder zuklappt. Allerdingswerden die Hierarchien nicht deutlich, da kein Hinweis bezüglich der Hierarchiestufevorhanden ist. Es fehlen die Information, daß es sich bei der in Abbildung XXVII(a)abgebildeten Hierarchie um Kontinent, Region, Land handelt.
64

Multifunktionswerkzeug Schemabrowser 4.1
In erweiterten OLAP-Systemen wird Schema- mit Datennavigation kombiniert (sieheAbbildung XXVII (b)). Die kompaktere Darstellung visualisiert eindeutig die Hierar-chiestufen. Die Instanzen jeder Aggregationsstufe können „on-demand“, das heisstauf explizite Benutzeranfrage, in einem Popup-Fenster zur Vorschau angezeigt wer-den. Die Trennung der Dimensionsstruktur und der Instanzen wird deutlich.
4.1.2 Schemabrowser UniVis Explorer
Der im Projekt UniVis Explorer umgesetzte Schemabrowser (siehe Abbildung XXIX)ist wie folgt aufgebaut: die aus dem Data Warehouse an die Applikation eingebunde-nen Würfel sind die Ordner der obersten Stufe. Sie werden durch ein Würfelsymbolgekennzeichnet.
Abbildung XXVIII: Schemabrowser UniVis Explorer
Die Dimensionen werden entsprechend ihrer hierarchischen Strukturen abgebildet.Dies sorgt für die Verschachtelung. Der Startknoten einer Dimension trägt die Bezeich-nung der Dimension, bspw. Nationalität oder Lehreinheit. Die granularsten Elementeder Dimensionshierachie sind die Blattknoten, die nicht weiter zu expandieren sind.Sie besitzen zur besseren optischen Unterscheidung ein unterschiedliches Symbol. Al-le Ordner zwischen Startknoten und Blattknoten sind die Stufen der Aggregations-hierarchie.
Die Würfel sind jeweils farblich markiert, umgesetzt über einen der Dimensionsbe-schriftung vorangestellten farbigen Quader. Die Würfel geben die Farbe an ihre zuge-hörigen Dimensionen weiter. Dimensionen mehrerer Würfel werden mit der farbigenMarkierung dieser Würfel versehen (siehe in Abbildung XXVIII: die Lehreinheit be-sitzt eine rote und eine blaue Markierung).
Im Schemabrowser des UniVis Explorers werden nicht nur Dimensionen, sondernauch die Kennzahlen und Aggregationsfunktionen angezeigt. Die Check-Boxen ma-chen Mehrfach-Selektion möglich.
Um die Navigation transparent zu halten werden vom Benutzer bereits als Dimen-
65

KAPITEL 4. FRAMEWORK
sionen für die Visualisierung ausgewählte Knoten deaktiviert und ausgegraut darge-stellt. Ebenfalls werden alle weniger granularen Hierarchiestufen von weiterer Selek-tion über Drag & Drops ausgeschlossen.
4.1.3 Fazit
Ein Schemabrowser erreicht bessere Antwortzeiten aufgrund der geringeren Knoten-menge die abgebildet werden muß. Ein Performanzvorteil ist, daß die Instanzen nurangefragt werden, wenn explizit eine Vorschau durch den Benutzer gefordert wird.
Eine zur Definition der Schemastruktur geeignete Metatabelle sieht für das Beispieldes Knotens Subkontinent wie folgt aus: Attribute sind der künstliche Startknoten(Nationality bzw. jeweils die ID), zur Einordnung in die Baumstruktur der direkteVorfahr Kontinente sowie der Tabellenamen in der Datenbank (bspw. dim_konti-nent ) [32, S. 6].
Die Trennung zwischen Struktur einer Dimension und dem Inhalt bedeutet für denBenutzer, daß er sich nicht mehr in den Daten auskennen muß um effizient zu einemEintrag zu gelangen. Sucht er etwa ein bestimmtes Land mithilfe eines Datenbrow-sers, muss er wissen in welchem Ordner, das bedeutet in welchen Kontinent bzw.Subkontinent, sich der Eintrag befindet.
Der wesentlich kompaktere Schemabrowser bietet als Navigations- und Filterwerk-zeug erweiterte Manipulationsmöglichkeiten.
4.2 Benutzeroberfläche UniVis Explorer
Abbildung XXIX: Schematische Aufteilung des UniVis Explorer mit DecompositionTree-Visualisierung
Entsprechend bewährter Richtlinien anderer OLAP-Werkzeuge besitzt der UniVis Ex-plorer drei Hauptkomponenten auf der Benutzeroberfläche (siehe Abbildung XXIX):
66

Interaktion mit der Pivot-Tabelle 4.3
eine horizontale Menüleiste, einen Navigationsbereich (siehe Absatz 4.1.2) auf der lin-ken und den Visualisierungsbereich auf der rechten Seite.
Die Oberfläche enthält verschiedene Manipulationsmöglichkeiten, die dem Benutzererlauben, Lösungen zu seiner Fragestellung zu finden. Die Anfragen erfolgen mani-pulativ, ein reiner Sprachmodus zur Exploration der Daten ist nicht vorgesehen. DerBenutzer benötigt keine Datenbanksprachkenntnisse.
Die Buttons der Menüleiste dienen der allgemeinen Funktionsauswahl. Dazu gehörteine Historyfunktion, die das Blättern zwischen den einzelnen Darstellungsschrittenermöglicht. Über die Menüleiste erfolgt die Wahl der Visualisierungstechnik. Des Wei-teren kann die Visualisierungsfläche gelöscht oder skaliert werden.
Der UniVis Explorer besitzt momentan zwei Haupt-Visualisierungstechniken: der De-composition Tree1 (siehe Abbildung XXIX) spaltet die Daten entlang von Dimensio-nen. Die Dekomposition erfolgt mithilfe Standardvisualisierungen wie Balken- undTortendiagrammen. Die zweite Art der Visualisierung ist die Pivot-Tabelle.
Abbildung XXX: UniVis Explorer mit Pivot-Tabellen-Visualisierung
In den Abbildungen XXIX und XXX werden dieselben Daten bzw. Dimensionen ver-gleichend als Decomposition Tree und als Pivot-Tabelle visualisiert.
4.3 Interaktion mit der Pivot-Tabelle
Fast alle Interaktionsmöglichkeiten des UniVis Explorers befinden sich zentral an ei-ner Stelle: dem Schemabrowser. Die Möglichkeiten zur Interaktion ergeben sich intui-tiv durch:
• Drag & Drop (Auswahl der Dimensionen),
• ein Kontextmenü durch Klicken auf das entsprechende Symbol hinter dem Kno-ten (Filterung),
1Für Details sei auf die Bachelorarbeiten von Roman Rädle und Andreas Weiler verwiesen.
67

KAPITEL 4. FRAMEWORK
• Markieren eines Eintrages (zur Auswahl der Kennzahl und Aggregationsfunk-tion)
• Tool-Tipps (spezifische Hinweise und Erläuterungen auf Spaltenüberschriften,sowie den Spalten- und Zeilenfeldern der Pivot-Tabelle)
4.3.1 Zuordnung der Dimensionen
Der Benutzer befördert per Drag & Drop einen Knoten aus dem Schemabrowser indas entsprechende Feld im Visualisierungsbereich der Pivot-Tabelle. Zwei Felder re-präsentieren das Spalten- bzw. Zeilenfeld, siehe Abbildung XXX.
Hat der Benutzer mindestens eine Kennzahl und eine Aggregationsfunktion gewählt,werden die Dimensionen entsprechend ihrer Zuordnung zum Spalten- bzw. Zeilen-feld dynamisch angezeigt. Werden weitere Dimensionen hinzugefügt, erfolgt eine au-tomatische Aktualisierung der Pivot-Tabelle.
Die Variablenwerte der Spalten- und Zeilenfelder werden an der enstprechenden Ach-se aufgetragen. Wird mehr als eine Dimension für ein Feld selektiert, entsteht diePivot-Tabellen-typische Schachtelung. Rückgängig gemacht werden kann die Zuord-nung schrittweise oder vollständig. Beide Aktionen erfolgen über Buttons in der Menü-leiste.
4.3.2 Navigation in hierarchischen Dimensionen
Neben der Navigation in den Hierarchien (Aufklappen der Ordner) und dem Explo-rieren der Instanzen (Vorschau-Fenster) über den Schemabrowser bietet natürlich diePivot-Tabelle Navigationsmöglichkeiten in diesen Srukturen. Durch Hinzufügen einergranulareren Aggregationsstufe auf dieselbe Achse wird ein Drill-Down ausgeführt.Dies ist in der aktuellen Anwendung bisher nur für das Zeilenfeld realisiert, aber auchfür das Spaltenfeld denkbar. Es stellt sich die Frage ob mehrfache Schachtelung aufbeiden Achsen intuitiv verständlich ist.
Roll-Up ist momentan nicht möglich. Um es umzusetzen wird diese Funktion in einKontextmenü auf die Spalten bzw. Zeilen der Pivot-Tabelle gelegt. Wählt der Benut-zer diese Operation, werden die entsprechenden Instanzen der Hierarchiestufe ausder Verschachtelung entfernt. Parallel wird der Knoten im Schemabrowser wieder ak-tiviert.
4.3.3 Aggregieren entlang verschiedener Dimensionen
Die Vorgehensweise bezüglich der Zuordnung der Dimensionen ist identisch der Zu-ordnung der Dimensionen in hierarchischen Dimensionen. Ein Beispiel zur Aggrega-tion entlang verschiedener Dimensionen stellt Abbildung XXXI dar. Zeilenfelder sindNationalität und Abschlußtyp, das Spaltenfeld ist die Hochschulzugangsberechtigung.
Man erkennt das benutzerfreundliche und fehlerverhindernde Deaktivieren der be-reits selektierten Hierarchiestufen. „Fehlerverhindernd“ da die Schachtelung der Pivot-Tabelle reihenfolglich der Zuordnung der Dimensionen geschieht. Die Schachtelungentlang einer hierarchischen Dimension entspricht einem Drill-Down und ein Drill-Down in die „falsche Richtung“ ergibt keinen Sinn.
68

Visualisierung verschiedener Hierarchien 4.4
Abbildung XXXI: Geschachtelte Pivot-Tabelle für das Zeilenfeld
4.3.4 Weitere Manipulationen
Ein Seitenfeld kann nicht explizit, doch in Form eines Filters benutzt werden. Über dieSelektionsauswahl im Vorschau-Fenster des Schemabrowsers wird ein Filter gewählt,der auf die gesamte Darstellung wirkt.
Des Weiteren kann der Benutzer Spalten verschieben um Daten besser vergleichen zukönnen. Das Verschieben der Spalten ändert nicht die Gruppierung und Schachtelungder Dimensionen.
4.4 Visualisierung verschiedener Hierarchien
Im Folgenden wird die Darstellung von heterogenen und gemischt-granularen Hier-archien im Schemabrowser und in der Pivot-Tabelle beschrieben.
4.4.1 Im Schemabrowser
In Abbildung XXXII ist ein Ausschnitt des Schemabrowsers des Haushaltskostenwür-fels dargestellt. Die Knoten Administration vs. Lehre oder Verwaltung vs. Sonstige bil-den die Ober- und Unterklassen-Beziehung zur abstrakten Klasse Institutionen ab. Siebesitzen, wie bereits erwähnt, eigene Subbäume aber keine gemeinsamen Aggrega-tionsstufen auf den Baumstufen. Die beiden Unterklassen können auf der oberstenStufe gegenübergestellt und verglichen werden. Dieser Tatsache wird durch zusätzli-che Knoten, benannt mit „X vs. Y“, gerecht [32, S. 4].
Die zweifache Rolle der Dimension der gemischt-granularen Hierarchie, als Blattkno-
69

KAPITEL 4. FRAMEWORK
Abbildung XXXII: Visualisierung heterogener und gemischt-granularer Hierarchienim Schemabrowser
ten und als Aggregationsstufe, wird am Schemabrowser offensichtlich. Eine gemischt-granulare Dimension besitzt einen zusätzlichen abstrakten Kindknoten [34, S. 11]. Die-ser der gemischt-granularen Dimension gleichbenannte Knoten (bspw. Nur Fakultät)stellt als Blattknoten eine nicht-hierarchische Dimension dar [32, S. 4].
4.4.2 In der Pivot-Tabelle
Jetzt wird das eben im Kontext des Schemabrowsers eingeführte Beispiel anhand derPivot-Tabellen-Visualisierung, siehe Abbildung XXXIII, weitergeführt. Die Nummern1 bis 4 in beiden Abbildungen beziehen sich auf die nachfolgenden Fälle. Für alle Bei-spiele werden zur Vereinfachung keine Spaltenfelder und kleine, fiktive Zahlenwertezur Vereinfachung benutzt.
Fall 1
Als erstes Zeilenfeld der Pivot-Tabelle wird der Knoten Administration vs. Lehre ge-wählt. Alle Bestellungen der Administration werden allen Bestellungen der Lehre ge-genübergestellt. In der Pivot-Tabelle, markiert mit 1, betragen alle Ausgaben der Ad-ministration, unabhängig von Projekten oder Kostenkategorien und über die gesamteZeitperiode, 21.484.735 Euro, bzw. der Lehre 89.310.287 Euro.
Fall 2
Die weitere Auswahl des Knotens nach Fakultät bewirkt ein Drill-Down entlang derHierarchie Lehre Einheiten. Nun werden die Zwischenaggregate für alle Fakultäteninklusive ihrer zugeordneten Institutionen berechnet und eingefügt.
Wie in Abbildung XXXIII (2) zu erkennen, betrifft die Operation Drill-Down nur die
70
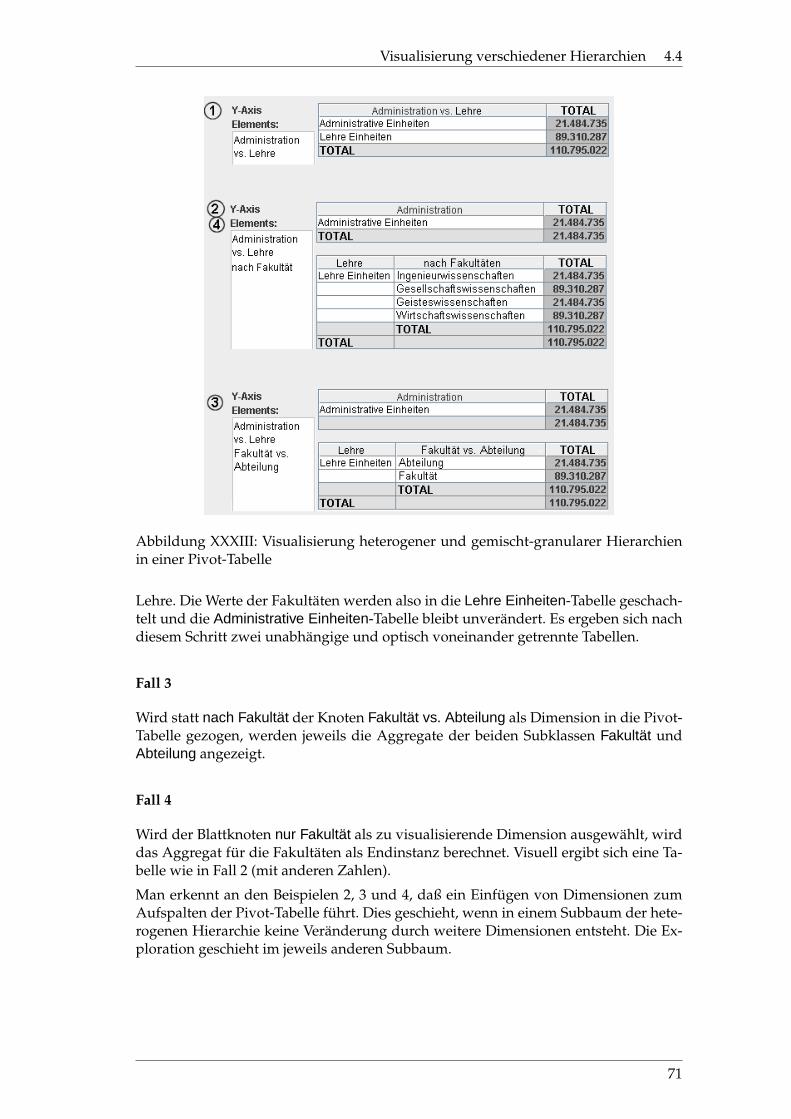
Visualisierung verschiedener Hierarchien 4.4
Abbildung XXXIII: Visualisierung heterogener und gemischt-granularer Hierarchienin einer Pivot-Tabelle
Lehre. Die Werte der Fakultäten werden also in die Lehre Einheiten-Tabelle geschach-telt und die Administrative Einheiten-Tabelle bleibt unverändert. Es ergeben sich nachdiesem Schritt zwei unabhängige und optisch voneinander getrennte Tabellen.
Fall 3
Wird statt nach Fakultät der Knoten Fakultät vs. Abteilung als Dimension in die Pivot-Tabelle gezogen, werden jeweils die Aggregate der beiden Subklassen Fakultät undAbteilung angezeigt.
Fall 4
Wird der Blattknoten nur Fakultät als zu visualisierende Dimension ausgewählt, wirddas Aggregat für die Fakultäten als Endinstanz berechnet. Visuell ergibt sich eine Ta-belle wie in Fall 2 (mit anderen Zahlen).
Man erkennt an den Beispielen 2, 3 und 4, daß ein Einfügen von Dimensionen zumAufspalten der Pivot-Tabelle führt. Dies geschieht, wenn in einem Subbaum der hete-rogenen Hierarchie keine Veränderung durch weitere Dimensionen entsteht. Die Ex-ploration geschieht im jeweils anderen Subbaum.
71

KAPITEL 4. FRAMEWORK
4.5 Implementation
Einige Implementationsdetails der Java-Programmierung leiten über zu einem Schwer-punkt des Kapitels, der Generierung der Datenbankabfragen in SQL.
4.5.1 SQL und OLAP
Um SQL-Anfragen zu stellen müssen die multidimensionalen Daten in relationalerForm vorliegen. Operationen wie Slicing und Dicing und Drill-Down, realisiert mitJoins und Group-by können dann ausgeführt werden. Schwieriger ist die Umset-zung von hierarchischen und multidimensionalen Aggregationen in SQL.
Eine Anfrage aus dem SQL-Standard-Funktionsumfang, ohne OLAP-Erweiterungen,benötigt pro Klassifikationsstufe eine Subanfrage. Bei einer geschachtelten Pivot-Ta-belle wird pro Zeilenfeld eine Subanfrage nötig.
Sind beispielsweise die Haushaltskosten der Lehreinheit Geographie für alle Mona-te, Semester und akademische Jahre gesucht, sieht eine typische SQL-Anfrage, auchSelect -Anweisung oder „SFW-Block“ (für Select , From und Where ) genannt, fürdie Monate wie folgt aus:
1 SELECT m.name, sum(c.betrag)2 FROM COB_CUBE c, dim_lehreinheit l, dim_monat m3 WHERE l.name = ’Geographie’4 AND l.ID = c.lehre_ID5 AND m.ID = c.monat_ID6 GROUP BY m.ID;
Die Anfrage wird für die drei Klassifikationsstufen der Zeitdimension ausgeführt. DieTabelle dim_monat (Zeile 2) sowie die Joinbedingung (Zeile 5) werden jeweils ange-passt.
Monat GeographieJanuar 2.290 EuroFebruar 2.540 EuroMärz 5.321 Euro. . . . . .Semester GeographieSS 2001 29.210 EuroWS 2002 32.530 Euro. . . . . .Akademisches Jahr Geographie2001/2002 61.740 Euro2002/2003 52.190 Euro
Tabelle VIII: Ergebnistupel dreier Anfragen über die Zeitdimension
Die Ergebnistupel der drei Anfragen sind durch die sukzessive Ausführung in einemeher unpraktischen Schema (siehe Tabelle VIII). Übersichtlicher ist eine Ergebnisfor-matierung wie in verschachtelten Pivot-Tabellen wo die Aggregate dann jeweils ander richtigen Stelle eingebunden sind. Beispielsweise schließt das Tupel (2001/2002,61.740 Euro) die beiden Einträge (SS 2001, 29.210 Euro) und (WS 2002, 32.530 Euro) alsZwischenaggregat ab.
72

Implementation 4.5
Bei k Stufen in der hierarchischen Dimension sind somit Unions von k Anfragennötig. Weiterhin bedeutet dies k Durchgänge durch die Faktentabelle [16, S. 29].
Operationen Cube und Rollup
OLAP-Funktionen wie Cube und Rollup unterstützen multidimensionale Anfragenund eignen sich nach Vossen [35, S. 687] besonders für das Rolap-Datenmodell. Cu-be bildet für sämtliche Kombinationen der Klassifikationsstufen Summen, allerdingswerden Hierarchien nicht beachtet. Hingegen berechnet die Funktion Rollup hierar-chische Aggregationen mit Zwischensummen.
Durch diese Erweiterungen der SQL-Standardfunktionen und eine Kombination vonRollup und Cube werden die multidimensionalen Daten exakt auf das Layout derPivot-Tabelle abgebildet [16, S. 32]. Das im Rahmen des Projektes UniVis Explorer zurVerfügung stehende Datenbanksystem PostgreSQL besitzt keine OLAP-Funktionalität.Deswegen wird auf traditionelle SQL-Operationen zurückgegriffen.
4.5.2 Technische Details der Implementation
Die Programmiersprache für die Implementation der Pivot-Tabelle ist Java Version1.5.0_07.
Das Datenbankverwaltungssystem bzw. die Datenbanksprache PostgreSQL Version8.0.8. ist deklarativ, objektrelational und implementiert Teile des SQL-Sprachstandards.
Für typische Pivot-Tabellen-Funktionalitäten wie die Berechnung der Zwischenag-gregate, eine typabhängige Formatierung der Zellen sowie die optische Gruppierungder verdichteten Elemente wurde nach einer geeigneten Java-Bibliothek gesucht. Einediese Aufgaben erfüllende Bibliothek wurde gefunden: der JTree, der java-intern diePivot-Tabelle darstellt, benutzt die Funktionalität des EnvelopeTableModels2.
4.5.3 Übersetzung der Benutzeraktionen in SQL
Die folgenden Erläuterungen beruhen auf der Visualisierung der Pivot-Tabelle in Ab-bildung XXXI und der zugehörigen SQL-Anfrage, die sich vollständig in Anhang .1der Arbeit befindet. Dabei sind die Dimensionen Herkunftsland und Abschlußtyp dieZeilenfelder und Hochschulzugangsberechtigung das Spaltenfeld. Hierarchische Ag-gregationsstufen als Zeilenfelder wirken sich auf die im Folgenden beschriebene Vor-gehensweise der Datenbankanfrage nicht grundsätzlich unterschiedlich aus.
Beruhend auf der Benutzerselektion von Spalten- und Zeilenfelder sowie etwaigenFiltern wird ein komplexes SQL generiert. Die Anfrage liefert die Ergebnisse in ex-akt der gewünschten Darstellung, sodaß die Java-Applikation keine weiteren Um-sortierungen vornehmen braucht. Die Versorgung der Daten für die Pivot-Tabellen-Darstellung erfolgt also komplett auf Datenbankseite. Im Vergleich zur Lösung diedas Umsortieren der Ergebnistupel auf Java-Seite beinhaltet, wird so zum einen dieNetzbelastung verringert und zum anderen auch die Antwortzeit verbessert.
Wählt der Benutzer Dimensionen, eine Aggregationsfunktion oder eine Kennzahl,werden diese Informationen in dynamischen Speicherstrukturen gehalten. Nach je-
2Das EnvelopeTableModel ist erhältlich unter der BSD-Lizenz für Freie Software, Webseite mit Down-load http://www.zaval.org/products/swing/ (Abgerufen 13.03.2006).
73

KAPITEL 4. FRAMEWORK
dem zulässigen Drag & Drop erfolgt eine Datenbankanfrage und ein erneuter Aufbauder Pivot-Tabelle.
Überschriften der Pivot-Tabelle
Java implementiert einen JTree, der zwei Eingabeparameter benötigt: eine eindimen-sionale Speicherstruktur für die horizontalen Überschriften und eine zweidimensio-nale Speicherstruktur für die Dateninhalte der Tabelle.
Die Methode getPivottableHeader() ermittelt die Überschriften der Pivot-Tabel-le, nämlich nach Ländern, nach Abschlußtyp, Allgemeine Hochschulreife, Fachhoch-schulreife und Hochschulreife im Ausland (die letzten drei Zeichenfolgen sind die Va-riablen des Spaltenfeldes Hochschulzugangsberechtigung):
1 public Vector<String> getPivottableHeader(2 Vector<VDimension> xAxisDimensions,3 Vector<VDimension> yAxisDimensions) {45 int size = yAxisDimensions.size();6 if (xAxisDimensions.size() > 0) {7 size += getAmountOfTableRows(xAxisDimensions.get(0));8 }9
10 Vector<String> columnNames = new Vector<String>();1112 for (VDimension dimension : yAxisDimensions) {13 columnNames.addElement(dimension.toString());14 }1516 myPSQL.execute("select name from "17 + (xAxisDimensions.get(0)).getTableName() + ";");1819 for (int i = yAxisDimensions.size(); i < size; i++) {20 columnNames.addElement(myPSQL.next()[0]);21 }2223 return columnNames;24 }
Der Funktion getPivottableHeader() werden die Parameter xAxisDimensionssowie yAxisDimensions , in denen sich die vom Benutzer gewählten Knoten bzw.Dimensionen für die Zeilen- und Spaltenfelder befinden, übergeben (Zeile 1-3).
Um die Anzahl der Schleifendurchgänge zu bestimmen, wird die Spaltenanzahl er-mittelt. Diese setzt sich aus der Anzahl der in der Y-Achse befindlichen Felder (Zeile5) und der Anzahl der Instanzen der Tabelle, die auf die X-Achse abgebildet (Zeile 6-8)wird, zusammen.
In den eindimensionale Vektor columnNames (Zeile 10) werden die Bezeichnungender Zeilenfelder (Zeile 12-14) direkt übernommen, hier also nach Ländern und nachAbschlußtyp. Anschließend wird eine PSQL-Anweisung ausgeführt, die aus der ent-sprechenden Tabelle, hier bluep_hzb , alle Ausprägungen der Hochschulzugangs-berechtigung selektiert (Zeile 16-17). Dabei werden drei Tupel zurückgeliefert, Allge-meine Hochschulreife, Fachhochschulreife und Hochschulreife im Ausland, die in derFor -Schleife (Zeile 19-21) an den Vektor angehängt werden.
74

Implementation 4.5
An die aufrufende Funktion wird im letzten Schritt (Zeile 23) der Vektor mit den Ta-bellenüberschriften zurückgegeben, die anschliessend die Inhalte der Pivot-Tabelle er-mittelt.
Datenbereich der Pivot-Tabelle
Die Programmieraufwand in Java, um die Inhalte der Pivot-Tabelle zu erhalten, sindkomplexer. Interessant ist hier letztendlich aber der Aufbau der DatenbankanfrageSQL, welche sich in mehrere Unteranfragen gliedert. Durch mehrere Joins werdendie Daten, die als Übergabeparameter für die Pivot-Tabelle bzw. das EnvelopeTableM-odel dienen, zusammengesetzt. Die Gliederung der folgenden Abschnitte orientiertsich am SFW-Block, wobei die Where-Klausel in den jeweiligen Unterabfragen steckt.Die SQL-Anfrage enthält abschliessend eine Order-by -Klausel.
Select-Klausel In der Auswahlliste der Select-Klausel, die bestimmt, welche Spal-ten der Quelle auszugeben sind, werden die benötigten nicht-leeren Variablenwertedes Zeilenfeldes (Zeile 2-11) sowie alle Aggregate aus dem Datenbereich (Zeile 12-17)selektiert.
1 SELECT2 CASE3 WHEN not subselect0.spalte0 isnull THEN subselect0.spalte04 WHEN not subselect1.spalte0 isnull THEN subselect1.spalte05 WHEN not subselect2.spalte0 isnull THEN subselect2.spalte06 END AS spalte0,7 CASE8 WHEN not subselect0.spalte1 isnull THEN subselect0.spalte19 WHEN not subselect1.spalte1 isnull THEN subselect1.spalte1
10 WHEN not subselect2.spalte1 isnull THEN subselect2.spalte111 END AS spalte1,12 CASE13 WHEN "aggr2" isnull THEN 0 ELSE "aggr2" END,14 CASE15 WHEN "aggr3" isnull THEN 0 ELSE "aggr3" END,16 CASE17 WHEN "aggr4" isnull THEN 0 ELSE "aggr4" END18 ...
From-Klausel Für jede Ausprägung auf der X-Achse, also für jeden Variablenwertdes Spaltenfeldes, wird eine Unteranfrage generiert. Diese Unteranfrage selektiert dieVariablenwerte des Zeilenfeldes (sozusagen die Überschriften der Zeilen, also bei-spielsweise Japan, Zertifikat / Zusatzstudium) sowie das Aggregat des jeweiligen Spal-tenfeldes.
Diese eindeutige Kennzeichnung der Zeile durch seine Überschriften wird benötigtum anschließend die Unteranfragen sukzessive zusammenzuführen. Im Folgendenwird dies an zwei Unteranfragen, die die Spalten Allgemeine Hochschulreife bzw.Fachhochschulreife selektieren, demonstriert.
Unteranfragen der From-Klausel Die dargestellte Unteranfrage liefert die Ergebni-stupel aus der Tabelle IX. Ein Platzhalter, hier beispielsweise „*NULL*“, wird benutzt
75

KAPITEL 4. FRAMEWORK
damit nicht zugeordnete Kennzahlen nicht verloren gehen, sondern für Benutzer zurweiteren Nachforschung verfügbar sind.
1 SELECT2 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’3 ELSE dim_land.name END AS spalte0,4 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’5 ELSE dim_abschlussarten.name END AS spalte1,6 SUM(sos_cube.koepfe) AS "aggr0"78 FROM sos_cube9 FULL JOIN bluep_hzb
10 ON ( bluep_hzb.id = sos_cube.hzb )11 FULL JOIN bluep_nation12 ON ( bluep_nation.id = sos_cube.nation )13 FULL JOIN dim_land14 ON ( dim_land.id = bluep_nation.land )15 FULL JOIN bluep_abschluss16 ON ( bluep_abschluss.id = sos_cube.abschluss )17 FULL JOIN dim_abschlussarten18 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )1920 WHERE bluep_hzb.name = ’Allg. Hochschulreife’21 GROUP BY dim_land.name, dim_abschlussarten.name;
spalte0 spalte1 aggr2Deutschland Diplom 19746Serbien u. Montenegro Diplom 51Spanien Diplom 19Japan Diplom 10Turkmenien Diplom 3Deutschland Bachelor 1189. . . . . . . . .
Tabelle IX: Ergebnistupel der Unteranfrage nach Länder, Abschluss und AllgemeinerHochschulreife
Diverse Joins (Zeile 9-18) verbinden die Faktentabelle mit den Dimensionstabellen.Die Where-Klausel der Unteranfrage schränkt auf den Variablenwert ein, hier in Zeile20 auf „Allg. Hochschulreife“.
Durch die Group-by -Klausel (Zeile 21) werden die Ergebnistupel für die gewünschteFormatierung zusammengefaßt.
Verbinden der Unteranfragen durch Joins Für alle weiteren Unteranfragen ist dasVorgehen entsprechend, die Ergebnistupel, also die Ausprägung des Spaltenfeldes,die Aggregate sowie die Anzahl der Ergebnistupel, variieren natürlich. Um sicherzu-stellen dass alle Tupel in das Gesamtergebnis eingeschlossen sind, erfolgt die Verbin-dung der Ergebnistupel der Unteranfragen über den Full Join .
1 SELECT *23 FROM4
76

Implementation 4.5
5 ( SELECT6 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’7 ELSE dim_land.name END AS spalte0,8 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’9 ELSE dim_abschlussarten.name END AS spalte1,
10 SUM(sos_cube.koepfe) AS "aggr0"1112 FROM sos_cube13 FULL JOIN bluep_hzb14 ON ( bluep_hzb.id = sos_cube.hzb )15 FULL JOIN bluep_nation16 ON ( bluep_nation.id = sos_cube.nation )17 FULL JOIN dim_land18 ON ( dim_land.id = bluep_nation.land )19 FULL JOIN bluep_abschluss20 ON ( bluep_abschluss.id = sos_cube.abschluss )21 FULL JOIN dim_abschlussarten22 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )2324 WHERE bluep_hzb.name = ’Allg. Hochschulreife’25 GROUP BY dim_land.name, dim_abschlussarten.name26 ) AS subselect02728 FULL JOIN2930 ( SELECT31 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’32 ELSE dim_land.name END AS spalte0,33 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’34 ELSE dim_abschlussarten.name END AS spalte1,35 SUM(sos_cube.koepfe) AS "aggr1"3637 FROM sos_cube38 FULL JOIN bluep_hzb39 ON ( bluep_hzb.id = sos_cube.hzb )40 FULL JOIN bluep_nation41 ON ( bluep_nation.id = sos_cube.nation )42 FULL JOIN dim_land43 ON ( dim_land.id = bluep_nation.land )44 FULL JOIN bluep_abschluss45 ON ( bluep_abschluss.id = sos_cube.abschluss )46 FULL JOIN dim_abschlussarten47 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )4849 WHERE bluep_hzb.name = ’Fachhochschulreife’50 GROUP BY dim_land.name, dim_abschlussarten.name51 ) AS subselect15253 ON (54 CASE55 WHEN not subselect0.spalte0 isnull THEN subselect0.spalte056 END = subselect1.spalte057 AND58 CASE59 WHEN not subselect0.spalte1 isnull THEN subselect0.spalte160 END = subselect1.spalte161 );
77

KAPITEL 4. FRAMEWORK
Die Join-Bedingung muß für alle Zeilenfelder erfüllt sein, deswegen erfolgt der Joinüber nach Länder und Abschlußtyp (Zeile 53-61).
spalte0 spalte1 aggr0 spalte0 spalte1 aggr1. . . . . . . . . . . . . . . . . .Dänemark Diplom 3 NULL NULL NULLDeutschland Diplom 19746 Deutschland Diplom 8677NULL NULL NULL Frankreich Diplom 3NULL NULL NULL Ghana Diplom 5. . . . . . . . . . . . . . . . . .
Tabelle X: Ergebnistupel der Unteranfrage nach Länder, Abschlußtyp, AllgemeinerHochschulreife (Spalte aggr0) und Fachhochschulreife (Spalte aggr1)
Die Tabelle X stellt ausschnittsweise die Ergebnistupel der beiden Unteranfragen dar,bevor sie durch einen Full Join vereinigt werden. NULL-Zellen weisen darauf hin,daß keine Werte für die Selektionsbedingung gefunden wurden.
Order-by-Klausel Sortierungsattribute werden in der Order-by-Klausel definiert.Standardmässig, ohne Angabe von ASC (ascending, dt. aufsteigend) bzw. DESC (de-scending, dt. absteigend), wird eine aufsteigende Sortierung durchgeführt. Zuerst er-folgt die Sortierung nach Ländern (spalte0) und dann nach Abschlußtyp (spalte1).
1 ...2 ORDER BY spalte0, spalte1;
Filterung Werden im Schemabrowser Werte selektiert auf die gefiltert werden soll,reagiert das SQL wie folgt.
Filterung auf Spaltenvariable Werden wie im Fallbeispiel die Hochschulzugangs-berechtigungen auf der Spaltenzeile angezeigt, und auf diesem Feld ein Filter defi-niert, werden lediglich die entsprechenden Unteranfragen ausgeführt. Beispielsweiseentfällt die Unteranfrage für Allgemeine Hochschulreife wenn darauf ein ausschlie-ßender Filter gesetzt wurde. Die Unteranfragen ermitteln lediglich die Aggregate fürdie restlichen Spaltenfelder.
Filterung auf Zeilenvariable Wirkt sich der Filter auf die Zeilenvariable aus, wirdeine zusätzliche Where-Bedingung in jede Unteranfrage angefügt. Das folgende Co-debeispiel demonstriert dies an einer Unteranfrage, wobei auf die Länder Dänemarkund Frankreich (Zeile 21) gefiltert wird.
1 SELECT2 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’3 ELSE dim_land.name END AS spalte0,4 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’5 ELSE dim_abschlussarten.name END AS spalte1,6 SUM(sos_cube.koepfe) AS "aggr2"78 FROM sos_cube9 FULL JOIN bluep_hzb
10 ON ( bluep_hzb.id = sos_cube.hzb )
78

Ausblick 4.6
11 FULL JOIN bluep_nation12 ON ( bluep_nation.id = sos_cube.nation )13 FULL JOIN dim_land14 ON ( dim_land.id = bluep_nation.land )15 FULL JOIN bluep_abschluss16 ON ( bluep_abschluss.id = sos_cube.abschluss )17 FULL JOIN dim_abschlussarten18 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )1920 WHERE bluep_hzb.name = ’Allg. Hochschulreife’21 AND dim_land.name IN (’Dänemark’, ’Frankreich’)22 GROUP BY dim_land.name, dim_abschlussarten.name;
Dasselbe Vorgehen tritt ein für zu filternde Dimensionen, die sich nicht als Variable imZeilen- oder Spaltenfeld befinden. Hier erfolgt zusätzlich ein Join auf die zu filterndeDimension.
Fazit
Optimierungspotential besteht an der Stelle an der der Stringvergleich stattfindet.Mit einem fortlaufenden Primärschlüssel in den Subdimensionstabellen kann stattdes teuren Stringvergleichs ein schnellerer Vergleich über die ID-Spalte erfolgen. DieWhere-Klausel des letzten Codebeispiel lautet dann beispielsweise:
WHERE bluep_hzb.id = 1
anstatt
WHERE bluep_hzb.name = ’Allg. Hochschulreife’
Dem höheren Aufwand auf Java-Seite um das SQL zu generieren, steht der Vorteilgegenüber, daß dieses Vorgehen exakt die Pivot-Tabellen-Formatierung schafft. DasEnvelopeTableModel, welches den JTRee übergeben bekommt, sorgt für die Bildungder Zwischenaggregat- und Aggregatzeilen bzw. -spalten. Fehlerhafte Aggregate auf-grund unzulässiger Faktentyp- und Kennzahlkombination werden nicht beachtet. Ei-nige Lösungsvorschläge dazu finden sich im Anschluß.
4.6 Ausblick
In diesem Abschnitt werden einige Ideen für Erweiterungen des Interfaces vorgeschla-gen.
4.6.1 Verhindern von Interpretationsfehlern
Wie bereits erwähnt sind manche Kombinationen von Kennzahlentypen und Aggre-gationsfunktionen für fehlerhafte Aggregate verantwortlich. Um diese Gefahrenquel-le zu verhindern sind im UniVis Explorer folgende Lösungsstrategien denkbar.
79

KAPITEL 4. FRAMEWORK
Möglichkeit 1
Um falsche Aggregate bezüglich der Zeitdimension zu vermeiden, kann die Auswahleines Semesters im Falle des Studierendenwürfels obligatorisch gemacht werden. Die-se Einschränkung auf die granularste Hierarchiestufe ermöglicht die fehlerfreie Ana-lyse aller Kennzahlen, auch der Kopfstatistik.
Möglichkeit 2
Durch dynamisches Anpassen der Auswahlmöglichkeit für Kennzahlen, Funktionenoder Dimensionen werden nur zulässige Kombinationen ermöglicht. In einer Metata-belle werden die erlaubten Kombinationen hinterlegt. Wählt der Benutzer beispiels-weise eine Zeitdimension als Spalten- oder Zeilenfeld, werden alle unzulässigen Ag-gregationsfunktionen für die Selektion deaktiviert.
Möglichkeit 3
Weniger restriktiv ist der folgende Vorschlag: durch visuelle Hervorhebung von Ag-gregaten, die auf kritischen Kennzahl-Fakten-Kombinationen beruhen, wird der Be-nutzer vor fehlerhaften Rückschlüssen gewarnt. Auch hier bildet eine Metatabelle dieBasis.
4.6.2 Erweiterung der Funktionalität des Schemabrowsers
Der abstrakte Startknoten jeder Dimensionshierarchie im Schemabrowser erhält eineweitere Funktion. In der aktuellen Implementation besitzt er nur abstrakte Bedeutungals Platzhalter und Beschriftung der darunterliegenden Dimension. Der Versuch denStartknoten per Drop & Drop in den Visualisierungsbereich zu bewegen bleibt bisherfür den Benutzer erfolglos.
Denkbar ist nun, daß die Benutzeraktion, die den Knoten in die Visualisierungsflächebewegt, als Auswahl aller Aggregationsstufen der Dimension verstanden wird. Be-wegt der Benutzer beispielsweise den abstrakten Startknoten Nationalität in ein Feldder Pivot-Tabelle, werden dessen Hierarchiestufen Kontinent, Region und Land ange-zeigt.
4.6.3 Anzeige von Pivot-Tabelle und weiterer Visualisierung
Um die Vorteile verschiedener Visualisierungstechniken zu kombinieren, ist eine pa-rallele Anzeige mehrerer Visualisierungen denkbar, siehe Abbildung XXXIV.
Beispielsweise kann ein Decomposition Tree im selben Panel wie die Pivot-Tabelle dar-gestellt werden. Interaktionen des Benutzers wirken sich auf beide Darstellungen aus.Eine grafische Visualisierung wird kombiniert mit der Darstellung konkreter Daten.Dies ist sinnvoll da bei Visualisierungen wie den Decomposition Trees die Beschriftun-gen der einzelnen Elemente verschwinden können wenn zu viele Werte gleichzeitigangezeigt werden. Diese Information bekommt der Benutzer dann über die Pivot-Tabelle hinzu.
80
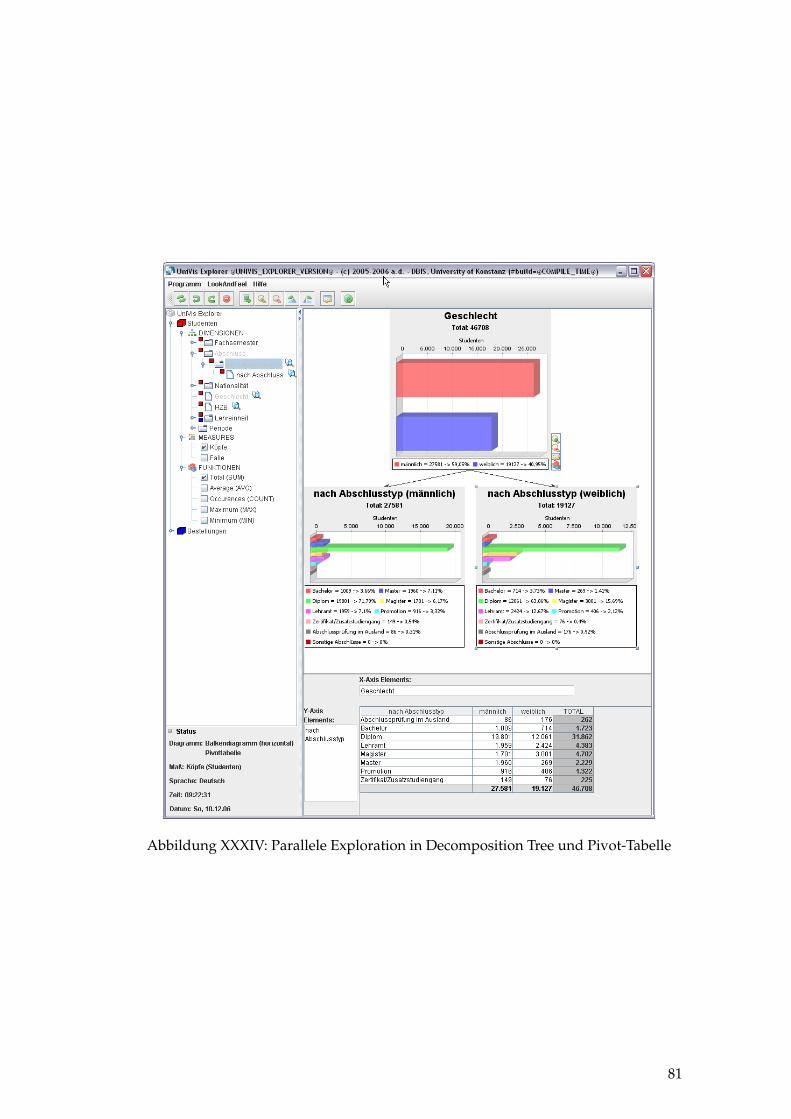
Abbildung XXXIV: Parallele Exploration in Decomposition Tree und Pivot-Tabelle
81

Appendix
.1 Beispiel: SQL-Abfrage einer Pivot-Tabellen-Darstellung
Die folgende SQL-Anfrage wird in der Pivot-Tabelle aus Abbildung XXXI visualisiert.Dabei werden zwei Variablen im Zeilenfeld (Herkunftsland, Abschlußtyp) und eineVariable im Spaltenfeld (Hochschulzugangsberechtigung mit drei Variablenwerte All-gemeine Hochschulreife, FH und Hochschulreife im Ausland) abgebildet.
1 SELECT2 CASE3 WHEN not subselect0.spalte0 isnull THEN subselect0.spalte04 WHEN not subselect1.spalte0 isnull THEN subselect1.spalte05 WHEN not subselect2.spalte0 isnull THEN subselect2.spalte06 END AS spalte0,7 CASE8 WHEN not subselect0.spalte1 isnull THEN subselect0.spalte19 WHEN not subselect1.spalte1 isnull THEN subselect1.spalte1
10 WHEN not subselect2.spalte1 isnull THEN subselect2.spalte111 END AS spalte1,12 CASE13 WHEN "aggregat_spalte2" isnull THEN 014 ELSE "aggregat_spalte2" END,15 CASE16 WHEN "aggregat_spalte3" isnull THEN 017 ELSE "aggregat_spalte3" END,18 CASE19 WHEN "aggregat_spalte4" isnull THEN 020 ELSE "aggregat_spalte4" END2122 FROM2324 ( SELECT25 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’26 ELSE dim_land.name END AS spalte0,27 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’28 ELSE dim_abschlussarten.name END AS spalte1,29 SUM(sos_cube.koepfe) AS "aggregat_spalte2"3031 FROM sos_cube32 FULL JOIN bluep_hzb33 ON ( bluep_hzb.id = sos_cube.hzb )34 FULL JOIN bluep_nation35 ON ( bluep_nation.id = sos_cube.nation )36 FULL JOIN dim_land37 ON ( dim_land.id = bluep_nation.land )38 FULL JOIN bluep_abschluss
82

Beispiel: SQL-Abfrage einer Pivot-Tabellen-Darstellung .1
39 ON ( bluep_abschluss.id = sos_cube.abschluss )40 FULL JOIN dim_abschlussarten41 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )4243 WHERE bluep_hzb.name = ’Allg. Hochschulreife’44 GROUP BY dim_land.name, dim_abschlussarten.name45 ) AS subselect04647 FULL JOIN4849 ( SELECT50 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’51 ELSE dim_land.name END AS spalte0,52 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’53 ELSE dim_abschlussarten.name END AS spalte1,54 SUM(sos_cube.koepfe) AS "aggregat_spalte3"5556 FROM sos_cube57 FULL JOIN bluep_hzb58 ON ( bluep_hzb.id = sos_cube.hzb )59 FULL JOIN bluep_nation60 ON ( bluep_nation.id = sos_cube.nation )61 FULL JOIN dim_land62 ON ( dim_land.id = bluep_nation.land )63 FULL JOIN bluep_abschluss64 ON ( bluep_abschluss.id = sos_cube.abschluss )65 FULL JOIN dim_abschlussarten66 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )6768 WHERE bluep_hzb.name = ’Fachhochschulreife’69 GROUP BY dim_land.name, dim_abschlussarten.name70 ) AS subselect17172 ON (73 CASE74 WHEN not subselect0.spalte0 isnull THEN subselect0.spalte075 END = subselect1.spalte076 AND77 CASE78 WHEN not subselect0.spalte1 isnull THEN subselect0.spalte179 END = subselect1.spalte180 )8182 FULL JOIN8384 ( SELECT85 CASE WHEN dim_land.name isnull THEN ’ * NULL* ’86 ELSE dim_land.name END AS spalte0,87 CASE WHEN dim_abschlussarten.name isnull THEN ’ * NULL* ’88 ELSE dim_abschlussarten.name END AS spalte1,89 SUM(sos_cube.koepfe) AS "aggregat_spalte4"9091 FROM sos_cube92 FULL JOIN bluep_hzb93 ON ( bluep_hzb.id = sos_cube.hzb )94 FULL JOIN bluep_nation95 ON ( bluep_nation.id = sos_cube.nation )96 FULL JOIN dim_land
83

KAPITEL 4. FRAMEWORK
97 ON ( dim_land.id = bluep_nation.land )98 FULL JOIN bluep_abschluss99 ON ( bluep_abschluss.id = sos_cube.abschluss )
100 FULL JOIN dim_abschlussarten101 ON ( dim_abschlussarten.id = bluep_abschluss.abschlussart )102103 WHERE bluep_hzb.name = ’Hochschulreife im Ausland’104 GROUP BY dim_land.name, dim_abschlussarten.name105 ) AS subselect2106107 ON (108 CASE109 WHEN not subselect0.spalte0 isnull THEN subselect0.spalte0110 WHEN not subselect1.spalte0 isnull THEN subselect1.spalte0111 END = subselect2.spalte0112 AND113 CASE114 WHEN not subselect0.spalte1 isnull THEN subselect0.spalte1115 WHEN not subselect1.spalte1 isnull THEN subselect1.spalte1116 END = subselect2.spalte1117 )118119 ORDER BY spalte0, spalte1;
84

Literaturverzeichnis
[1] Gerhard Brosius Excel 7 für Windows 95 professionell. Tabellenkalkulation mit Win-dows 95, Addison Wesley Verlag, Bonn, 1996.
[2] Surajit Chaudhuri, Umeshwar Dayal Data Warehousing and OLAP for Decision Sup-port. In Proceedings of the 1997 ACM SIGMOD international conference on Manage-ment of data, S. 507 - 508, Tucson, Arizona, USA, 1997.
[3] Peter Pin-Shan Chen The Entity Relationship Model - Towards a Unified View of Data.In ACM TODS (Volume 1, Issue 1), 1976.
[4] Nils Clausen OLAP — Multidimensionale Datenbanken. Produkte, Markt, Funktions-weisen und Implementierung. Addison Wesley Verlag, Bonn, Deutschland, 1998.
[5] Peter O’Donnell, Nick Draper An Experimental Evaluation of an Alternative to thePivot Table for Ad Hoc Access to OLAP Data. In Proceedings of the 1997 ACM SIG-MOD international conference on Management of data, S. 348 - 356, Tucson, Arizona,USA, 1997.
[6] Stephen G. Eick Visualizing multi-dimensional data. In ACM SIGGRAPH ComputerGraphics (Volume 34, Issue 1), S. 61 - 67, New York, NY, USA, 2000.
[7] Ramez Elmasri, Sham Navathe Fundamentals of database systems. Addison WesleyVerlag, Reading, Mass., USA, 2000.
[8] Michael Gebhardt, Matthias Jarke, Stephan Jacobs A Toolkit for Negotiation Sup-port Interfaces to Multi-Dimensional Data. In Proceedings of the 1997 ACM SIGMODinternational conference on Management of data, S. 348 - 356, Tucson, Arizona, USA,1997.
[9] J. Gray, A. Bosworth, A. Layman, and H. Pirahesh Data Cube: A Relational Ag-gregation Operator Generalizing GroupBy, Cross-Tab, and Sub-Total. In ICDE, S. 152 -159, IEEE Computer Society, 1996.
[10] Olaf Herden Eine Entwurfsmethodik für Data Warehouses. Dissertation, Carl vonOssietzky Universität Oldenburg, Deutschland, 2001.http://docserver.bis.uni-oldenburg.de/publikationen/dissertation/2002/herent01/pdf/herent01.pdf (Abgerufen16.08.2006)
[11] John Horner, Il-Yeol Song, Peter P. Chen An Analysis of Additivity in OLAP Systems.In Proceedings of the 7th ACM international workshop on Data warehousing and OLAP,S. 83 - 91, New York, NY, USA, 2004.
85

LITERATURVERZEICHNIS
[12] Carlos A. Hurtado, Alberto O. Mendelzon Reasoning about Summarizability in He-terogeneous Multidimensional Schemas. In Database Theory - ICDT 2001, 8th Interna-tional Conference, S. 375 - 389, London, Großbritannien, 2001.
[13] Carlos A. Hurtado, Alberto O. Mendelzon OLAP dimension constraints. In PODS’02: Proceedings of 21st ACM SIGMOD-SIGACT-SIGART Symposium on Principlesof Database Systems, S. 169 - 179, ACM Press, Madison, Wisconsin, USA, 2002.
[14] B Johnson, Ben Shneiderman Tree-maps: A Space Filling Approach to the Visuali-zation of Hierarchical Information Structures. In Proceedings of IEEE Visualization’91Conference, S. 284 - 291, San Diego, CA, USA, 1991.
[15] Hans-Joachim Lenz and Arie Shoshani Summarizability in OLAP and StatisticalData Bases. In Proceedings of 9th International Conference on Scientific and StatisticalDatabase Management, S. 132 - 143, IEEE Computer Society, 1997.
[16] Ulf Leser Data Warehousing — Operationen im multidimensionalen Datenmodell– Graphische MDDM – Summierbarkeit. Vorlesungsfolien Data Warehousing,Sommersemester 2004, Humboldt-Universität zu Berlin, Deutschland.http://www2.informatik.hu-berlin.de/Forschung_Lehre/wbi/teaching/sose04/dwh/06_zugriff_mddm.pdf (Abgerufen 26.07.2006)
[17] Christoph Litz Einsatz des Data Warehouse SuperX und Realisierung mobiler Sze-narien für die Universität Freiburg. Diplomarbeit, Albert-Ludwigs-UniversitätFreiburg, Deutschland, 2004.http://www.studio-fuer-textdesign.de/superx/bw/diplomarbeit_litz.pdf (Abgerufen 02.08.2006)
[18] Wolfgang Martin (Hrsg.) Data Warehousing - Data Mining — OLAP. InternationalThomson Publishing GmbH, Bonn, Deutschland, 1998.
[19] Object Management Group, Inc. (OMG) Common Warehouse Metamodel (CWM)Specification. Version 1.0, Februar 2001.http://www.omg.org/docs/ad/01-02-01.pdf (Abgerufen 14.10.2006)
[20] Torben Bach Pedersen, Christian S. Jensen, Curtis E. Dyreson Extending PracticalPre-Aggregation in On-Line Analytical Processing. In The VLDB Journal, S. 663 - 674,1999.citeseer.ist.psu.edu/bachpedersen99extending.html (Abgerufen16.10.2006)
[21] Torben Bach Pedersen, Christian S. Jensen Multidimensional Database Technology.In Computer (Volume 34, Issue 12), S. 40 - 46, Los Alamitos, CA, USA, 2001.
[22] Kevin R. Quinn Data Visualization: Gaining Perspective. A White Paper, Informati-on Builders, New York, NY, USA, September 2006.
[23] George G. Robertson, Jock D. Mackinlay , Stuart K. Card Cone Trees: animated 3Dvisualizations of hierarchical information. In Proceedings of the SIGCHI conference onHuman factors in computing systems: Reaching through technology, S. 189 - 194, NewOrleans, Louisiana, USA, 1991.
[24] Carsten Sapia, Markus Blaschka, Gabriele Höfling, Barbara Dinter Extending theE/R Model for the Multidimensional Paradigm. In ER ’98, Proceedings of the Workshopson Data Warehousing and Data Mining, 1998, S. 105 - 116, Springer-Verlag.
86

LITERATURVERZEICHNIS
[25] Ben Shneiderman Using Treemap Visualizations for Decision Support.http://dssresources.com/papers/features/shneiderman/shneiderman06232006.html (Abgerufen 09.12.2006)
[26] Marc H. Scholl Data Warehousing. Vorlesungsfolien Informationssysteme, Win-tersemester 2005/2006, Universität Konstanz, Deutschland, 2005.http://www.inf.uni-konstanz.de/dbis/teaching/ws0506/information-systems/K8.pdf (Abgerufen 03.08.2006)
[27] Martin B. Schultz, Jörg Knuth, und Volker PruSS Microsoft SQL Server 2005 Re-porting Services - Das Praxisbuch. Unternehmensweites Berichtswesen leicht gemacht.Microsoft Press Deutschland, Unterschleißheim, Deutschland, Juni 2006.
[28] Chris Stolte, Diane Tang and Pat Hanrahan Query, Analysis, and Visualizationof Hierarchically Structured Data using Polaris. In Proceedings of the Eighth ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, Juli2002.http://graphics.stanford.edu/papers/polaris_olap/paper.pdf(Abgerufen 16.10.2006)
[29] Erik Thomsen Olap Solutions: Building Multidimensional Information Systems. JohnWiley & Sons, Inc., New York, NY, USA, 2002.
[30] Svetlana Vinnik UniVis Explorer - ein Visuelles Data-Warehouse für Deutsche Hoch-schulen.http://www.inf.uni-konstanz.de/dbis/univis/UniVisExplorer.pdf (Abgerufen 24.07.2006).
[31] Svetlana Vinnik UniVis Explorer - Data Warehouse Frontend for Visual Exploration ofAcademic Data. Präsentationsfolien Graduiertenkolleg Sommerschule, September2005.
[32] Svetlana Vinnik, Florian Mansmann From Analysis to Interactive Exploration: Buil-ding Enhanced Visual Hierarchies from OLAP Cubes. In Proceedings of the 8th Interna-tional Conference on Data Warehousing and Knowledge Discovery (DaWaK’06), Kra-kau, Polen, September 2006.
[33] Svetlana Vinnik, Marc H. Scholl Decision Support System for Managing EducationalCapacity Utilization in Universities. In Proc. of the International Conference on Engi-neering and Computer Education (ICECE’05), Madrid, Spanien, März 2005.
[34] Svetlana Vinnik, Marc H. Scholl Extending Visual OLAP for Handling Irregular Di-mensional Hierarchies. In Proceedings of the 8th International Conference on Data Ware-housing and Knowledge Discovery (DaWaK’06), September 2006.
[35] Gottfried Vossen Datenmodelle, Datenbanksprachen und Datenbankmanagement-Systeme. Oldenbourg R. Verlag GmbH, München, Deutschland, 2000.
87





![Πολυδιάστατη Ανάλυση ((OLAP)OLAP) · Microsoft PowerPoint - 06_DST_OLAP.ppt [Compatibility Mode] Author: admin Created Date: 10/8/2009 11:35:18 PM](https://img.pdfslide.org/doc/110x75/5f46b0c323e85f71e60f3638/f-f-olapolap-microsoft-powerpoint-06dstolapppt.jpg)























