Embed Size (px)
Citation preview
© H.-D. Wuttke 2012
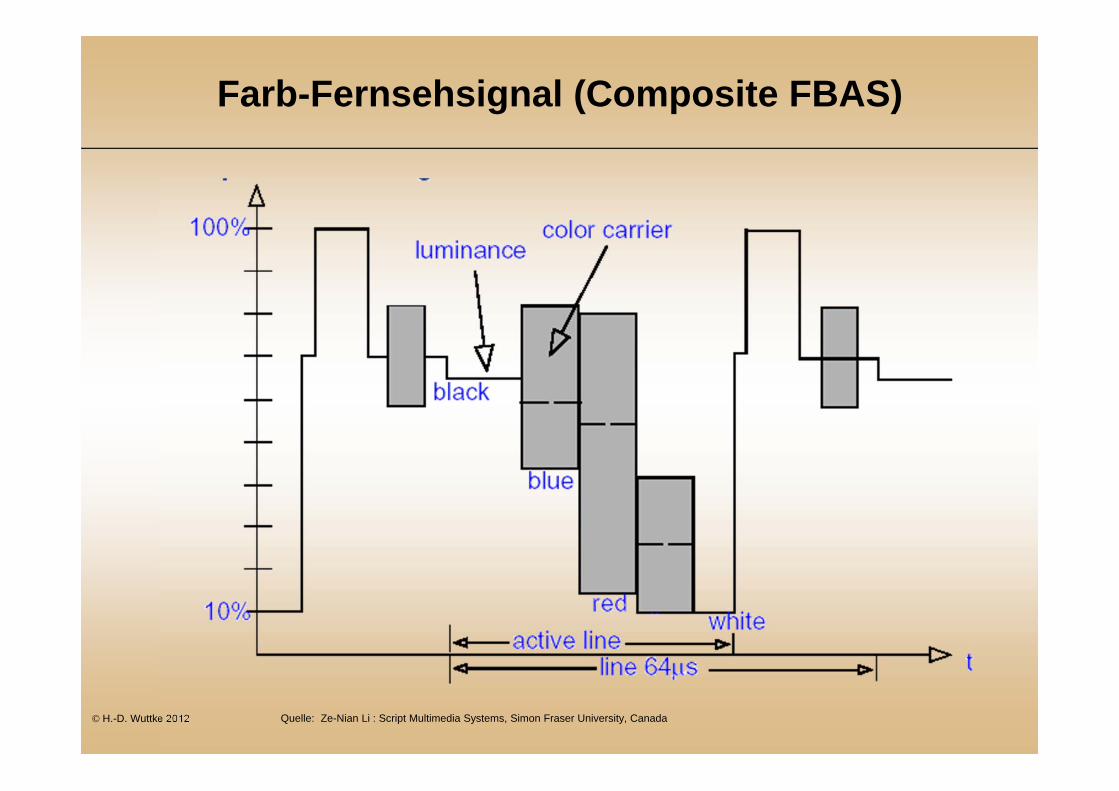
Farb-Fernsehsignal (Composite FBAS)
Quelle: Ze-Nian Li : Script Multimedia Systems, Simon Fraser University, Canada

© H.-D. Wuttke 2012
VIDEO- Digitalisierung
Gemeinsame KodierungFBAS – Farbbild- Austast- und Synchronsignal
Gleichmäßige Abtastung für Luminanz und Chrominanz
=> uneffektiv, => Komponentenkodierung

© H.-D. Wuttke 2012
Digitalisierung
Komponentenkodierung CCIR 601
Separate Erfassung von Luminanz und Chrominanz, mit unterschiedlichen Abtastraten
Luminanz höher als Chrominanz
© H.-D. Wuttke 2012
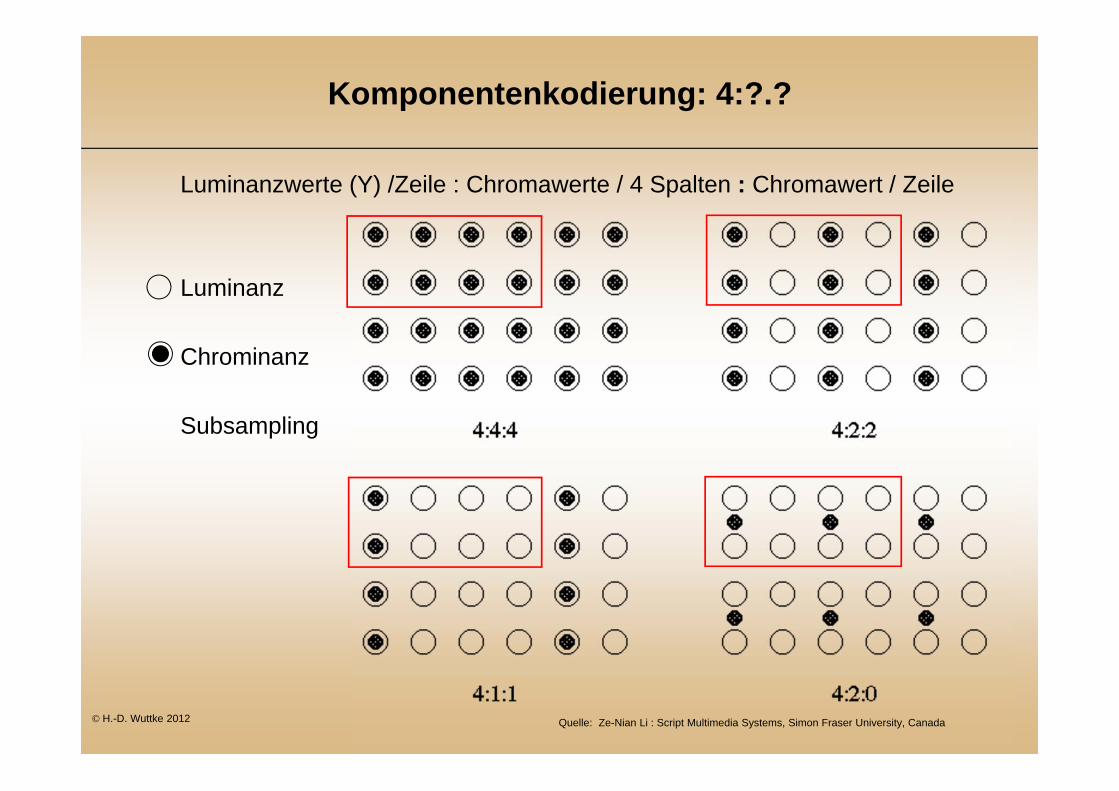
Komponentenkodierung: 4:?.?
Luminanzwerte (Y) /Zeile : Chromawerte / 4 Spalten : Chromawert / Zeile
Luminanz
Chrominanz
Subsampling
Quelle: Ze-Nian Li : Script Multimedia Systems, Simon Fraser University, Canada
© H.-D. Wuttke 2012
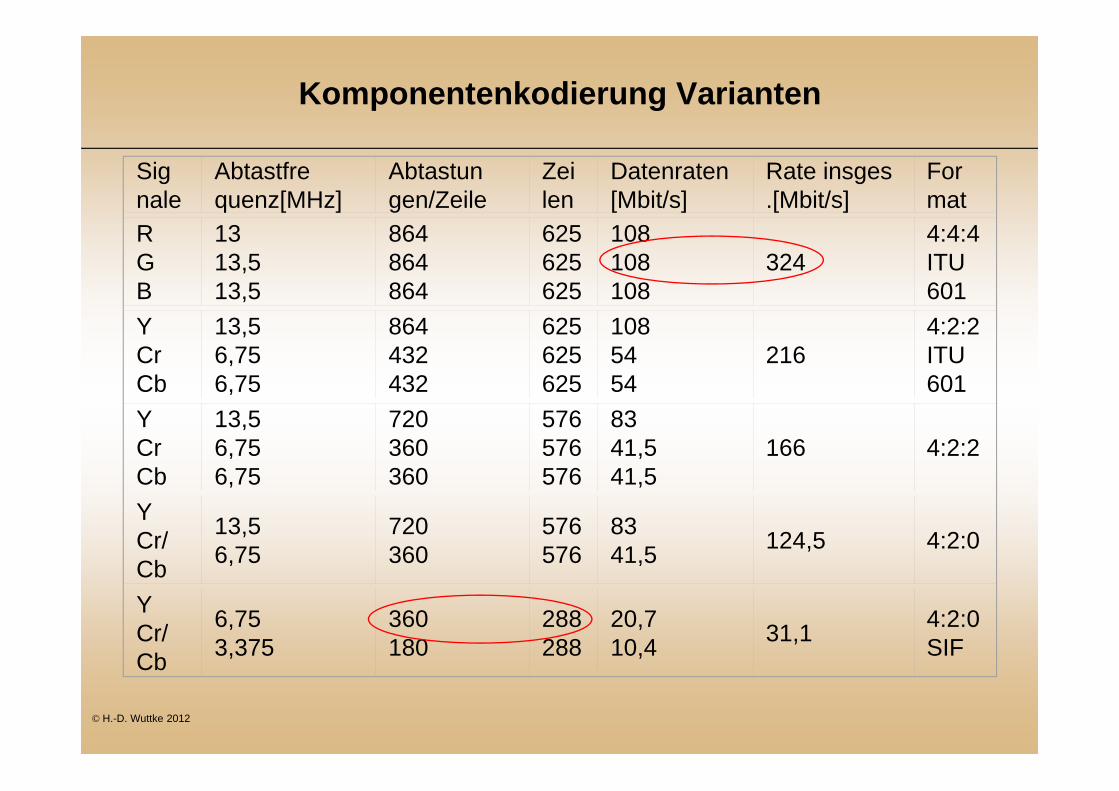
Komponentenkodierung Varianten
Sig nale
Abtastfre quenz[MHz]
Abtastun gen/Zeile
Zei len
Datenraten [Mbit/s]
Rate insges .[Mbit/s]
For mat
R G B
13 13,5 13,5
864 864 864
625 625 625
108 108 108
3244:4:4 ITU 601
Y Cr Cb
13,5 6,75 6,75
864 432 432
625 625 625
108 54 54
2164:2:2 ITU 601
Y Cr Cb
13,5 6,75 6,75
720 360 360
576 576 576
83 41,5 41,5
166 4:2:2
Y Cr/ Cb
13,5 6,75
720 360
576 576
83 41,5 124,5 4:2:0
Y Cr/ Cb
6,75 3,375
360 180
288 288
20,7 10,4 31,1 4:2:0
SIF

© H.-D. Wuttke 2012
Komponentenkodierung in Zahlen
PAL 864 Abtastungen/Zeile* 625 Zeilen/ Bild * 25 Bilder/s * 8 Bit
864 * 625 * 25 * 8 = 108 000 000 Bit/s (108 MBit/s ?)
108 / 1,024 / 1,024 ~ 103 MBit/s
SIF (Source Input Format)360 * 288 * 25 * 8 = 20 736 000 Bit/s (20,7 MBit/s)
QSIF (Quarter SIF) 180 * 144 * 25 * 8 5184000 MBits (5,18 MBit/s)

© H.-D. Wuttke 2012
Medium Video
Kompression erforderlich !

© H.-D. Wuttke 2012
Kompression
Algorithmen
JPEG
MPEG

© H.-D. Wuttke 2012
Kompressionsverfahren
Quelle: Steinmetz, Ralf: Multimedia-Technologie: Einführung und Grundlagen, Springer, Verlag

© H.-D. Wuttke 2012
Verlustlose Kompressionsalgorithmen
RLC
Huffman
Adaptive Huffman Kodierung
Arithmetische Kodierung
LZW

© H.-D. Wuttke 2012
RLC: Run Length Code
Spezielles Zeichen außerhalb des Alphabetszeigt, dass als nächstes ein Zahlenwert und dann das zu wiederholende Zeichen folgt
z.B. eaaaabaaabb 11 Zeichen
e#4abaaabb 10 Zeichen
Sinnvoll bei vielen gleichen Zeichen

© H.-D. Wuttke 2012
Entropie - Kodierung
Informationsgehalt eines Zeichens ist indirekt proportional
• zur Wahrscheinlichkeit seines Auftretens und • zu seiner Codelänge
Seltene Zeichen : weniger wahrscheinlich• höherer Informationsgehalt
(ihr Fehlen ist schwerer ausgleichbar)• längeres Codewort
(wird seltener benötigt)

© H.-D. Wuttke 2012
Entropie - Kodierung
Kodierung: Zeichen eines Alphabets werden Zeichen A oder Worten A* eines anderen Alphabets z. B. A={0,1} zugeordnet
ASCII- Code : e => 0110 0101 A*Zeichen e {a,b,c,d,…} => Worte aus {0,1}l
Bei binärer Kodierung (|A|=2) kann man mit l Bits 2l Zeichen mit gleicher Codelänge l kodieren
Bei a-närer Kodierung (|A|=a): mit l Elementen al Zeichen mit gleicher Codelänge l kodieren

© H.-D. Wuttke 2012
Entropie - Kodierung
d.h. : will man n Zeichen mit Worten aus einem Alphabet A mit a = |A| Zeichen kodieren, benötigt man bei gleichlanger Kodierung eine Codelänge l von l= loga(n)
Im Fall binärer Kodierung l= ld(n) Bits
Häufigkeit von Zeichen ist unterschiedlich =>angepasste Codelänge spart Zeichen
Idee: Häufigkeit ~ Wahrscheinlichkeit

© H.-D. Wuttke 2012
Entropie - Kodierung
Informationsgehalt Ii eines kodierten Zeichens Simit Si A* (Wort aus Alphabet A mit |A|= a)ist indirekt proportional zur Wahrscheinlichkeit pi seines Auftretens in einer Nachricht S mit n Zeichen (|S|= n)
Informationsgehalt : Ii = loga(1/pi) = - loga(pi)
Gesucht: optimale Codelänge relativ zumInformationsgehalt I und zur Nachrichtenlänge n
=> Entropie H ~ Codelänge => Algorithmus?

© H.-D. Wuttke 2012
Entropie - Kodierung
n Zeichen (binäre Worte der Länge l aus {0,1}l) für n Zeichen gleiche Codelänge : l = ld(n) Bits
Informationsgehalt Zeichen i: I = ld(1/pi)= - ld(pi)An Informationsgehalt I angepasste Codelänge:
Informationsquelle S mit Codes unterschiedlicherHäufigkeiten Hi mit Wahrscheinlichkeiten pi = Hi / n
Entropie H(S) = - i pi ld(pi)= -(i Hi ld(pi))/n
© H.-D. Wuttke 2012
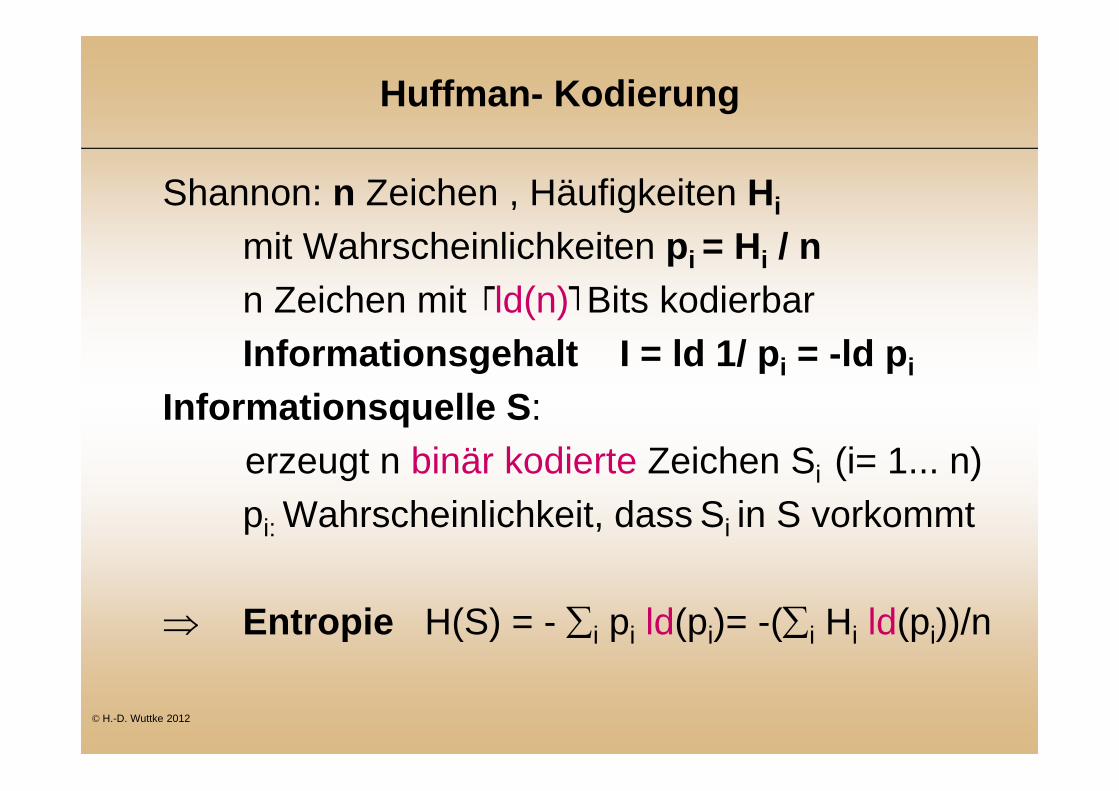
Huffman- Kodierung
Shannon: n Zeichen , Häufigkeiten Hi
mit Wahrscheinlichkeiten pi = Hi / nn Zeichen mit ld(n) Bits kodierbar Informationsgehalt I = ld 1/ pi = -ld pi
Informationsquelle S: erzeugt n binär kodierte Zeichen Si (i= 1... n)pi: Wahrscheinlichkeit, dass Si in S vorkommt
Entropie H(S) = - i pi ld(pi)= -(i Hi ld(pi))/n

© H.-D. Wuttke 2012
Huffman- Kodierung
Entropie H(S) = - i pi ld(pi) i= 1... n
z.B. Bild mit gleich verteiltem Grau-Anteil bei 8-Bit-Code: i= 1... 256 n=256 Grau-Werte, jeder Grau-Wert mit Wahrscheinlichkeit
pi= 1/256 => ld(pi) = ld(1/256) = ld(1)-ld(256) = -8
H(S) = - (1/256 * (-8) +...+1/256 *(-8) )= - 256 * 1/256 *(-8) = 8

© H.-D. Wuttke 2012
Shannon- Fano Algorithmus
Top Down S= AEABADDABADACADABADACABABABECADABCECECE
1. Sortiere nach Häufigkeit
Symbol A B C D E
Anzahl 15 7 6 6 5

© H.-D. Wuttke 2012
Shannon- Fano Algorithmus
2. Teile iterativ so, dass je 2 Mengen mit Summen etwa gleicher Häufigkeiten entstehen
22 17 1.Bit (0 |1)15 7 6 11 2.Bit (0 |1)
6 5 3.Bit (0 |1)3. Kodierung: 00 01 10 110 111
A B C D E
Symbol A B C D E
Anzahl 15 7 6 6 5
© H.-D. Wuttke 2012
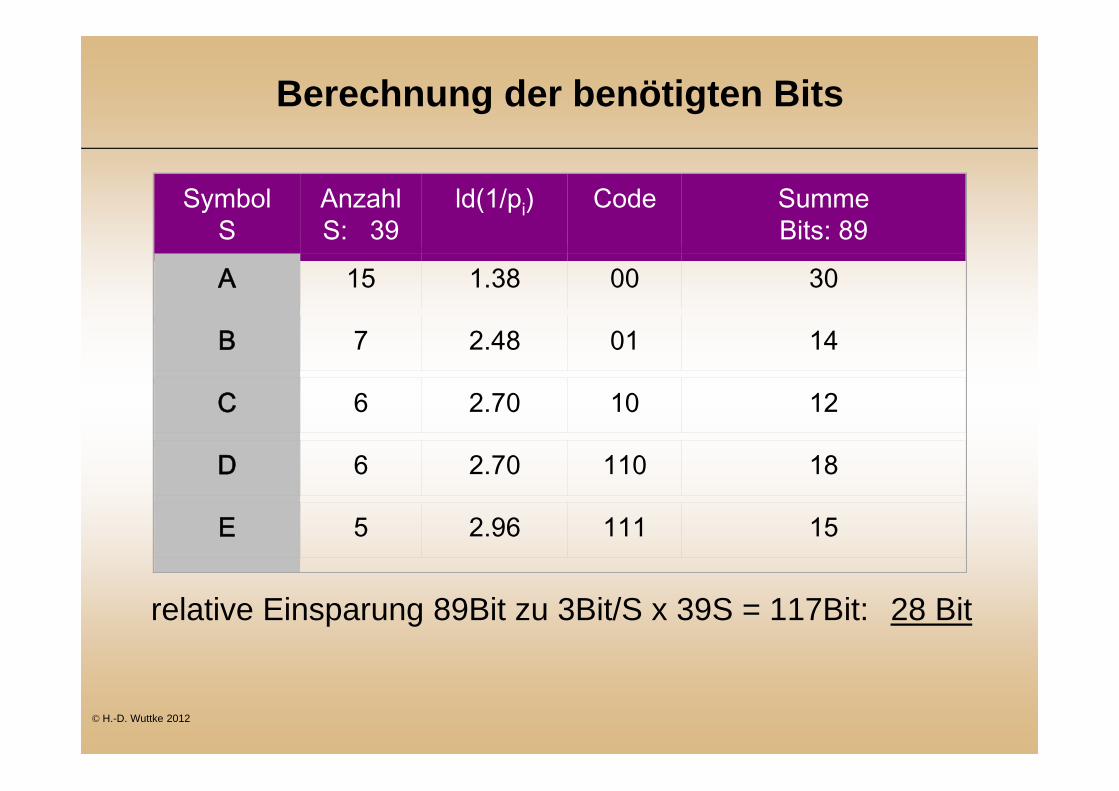
Berechnung der benötigten Bits
relative Einsparung 89Bit zu 3Bit/S x 39S = 117Bit: 28 Bit
SymbolS
AnzahlS: 39
ld(1/pi) Code SummeBits: 89
A 15 1.38 00 30
B 7 2.48 01 14
C 6 2.70 10 12
D 6 2.70 110 18
E 5 2.96 111 15
© H.-D. Wuttke 2012
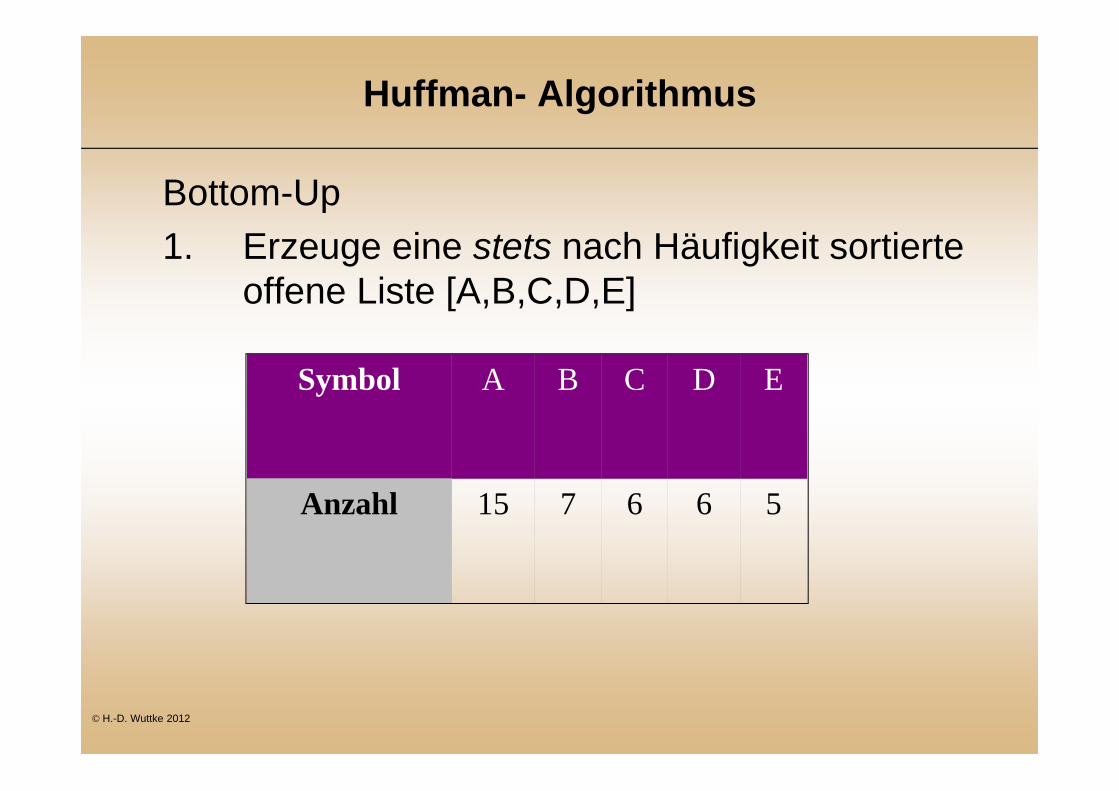
Huffman- Algorithmus
Bottom-Up 1. Erzeuge eine stets nach Häufigkeit sortierte
offene Liste [A,B,C,D,E]
Symbol A B C D E
Anzahl 15 7 6 6 5

© H.-D. Wuttke 2012
Huffman- Algorithmus
2. Entnimm jeweils zwei der Elemente mit niedrigster Häufigkeit und berechne deren Summe s, [A(15),B(7),C(6),D(6),E(5)], s =11Erzeuge dafür einen Wichtungsknoten Wi(s) (W1(11)) in der Liste: [A(15),B(7),C(6),W1(11)] und sortiere: [A(15),W1(11),B(7),C(6)]
weiter:[A(15),W1(11),B(7),C(6)][A(15),W1(11),W2(13)][A(15),W2(13),W1(11)][A(15),W3(24)] [W3(24),A(15)][W4(39)]bis nur 1 Element in Liste => binärer Baum
W1(11)
E(5) D(6)
W2(13)
W3(24) A(15)
W4(39)
C(6) B(7)
1 1
1
01
0
0
0

© H.-D. Wuttke 2012
Berechnung der benötigten Bits, Entropie
relative Einsparung 87 zu 3 x 39 = 117: 30 Bit
Symbol Anzahl39
log2(1/pi) Code Summe Bits87
A 15 1.38 0 15B 7 2.48 100 21
C 6 2.70 101 18
D 6 2.70 110 18
E 5 2.96 111 15
Applet Quelle: Steinmetz, Ralf: Multimedia-Technologie: Einführung und Grundlagen, Springer, Verlag

© H.-D. Wuttke 2012
Huffman - Kodierung
Entropie H(S) = - i pi ld(pi)= -(i Hi ld(pi))/n (pi = Hi / n)
Entropie der Zeichenkette (p(A)=15/39, p(B)=7/39...)
(15 x 1.38 + 7 x 2.48 + 6 x 2.7 + 6 x 2.7 + 5 x 2.96) / 39
= 85.26 / 39 = 2.19 (Idealwert für Kodierung)
Bits / Zeichen für die Huffman Kodierung:
87 / 39 = 2.23 ~ Informationsgehalt 2,19 !

© H.-D. Wuttke 2012
Kodierungseigenschaften
+ Optimale Kodierung (Entropie)+ Präfix eindeutig+ => kein Trennzeichen erforderlich trotz
unterschiedlicher Codelänge- Häufigkeit (Codetabelle) muss bekannt sein- => mit Nachricht übertragen, - Overhead- Bei live Video oder Audio nicht möglich
=> Adaptive Huffman Kodierung

© H.-D. Wuttke 2012
Adaptive Huffman - Kodierung
Idee: gleiche Initial-Tabellegleiche Aktualisierungsroutinebei Kodierer und Dekodierer
Aktualisierungsroutine „update model“:Zählen der HäufigkeitAktualisierung des Huffman- Baumes, fallsnotwendig (d.h. Huffman-Baum verletzt)
=> Kodierung der Zeichen wechselt!

© H.-D. Wuttke 2012
Adaptive Huffman - Kodierung
ENCODER Initialize_model(); while ((c = getc(input)) !=eof) {
encode (c, output);update_model (c);
}
DECODER Initialize_model(); while ((c = decode(input)) != eof) {
putc (c, output); update_model (c);
}
© H.-D. Wuttke 2012
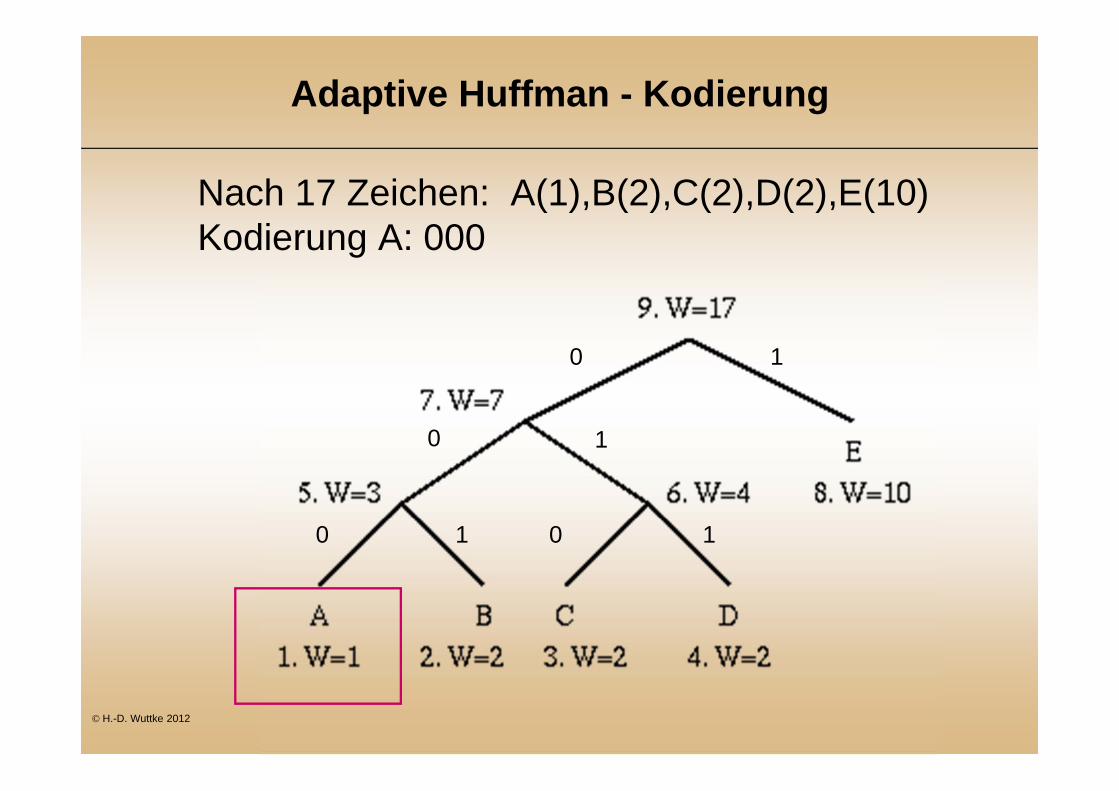
Adaptive Huffman - Kodierung
Nach 17 Zeichen: A(1),B(2),C(2),D(2),E(10) Kodierung A: 000
0
0
1
00
1
1 1
© H.-D. Wuttke 2012
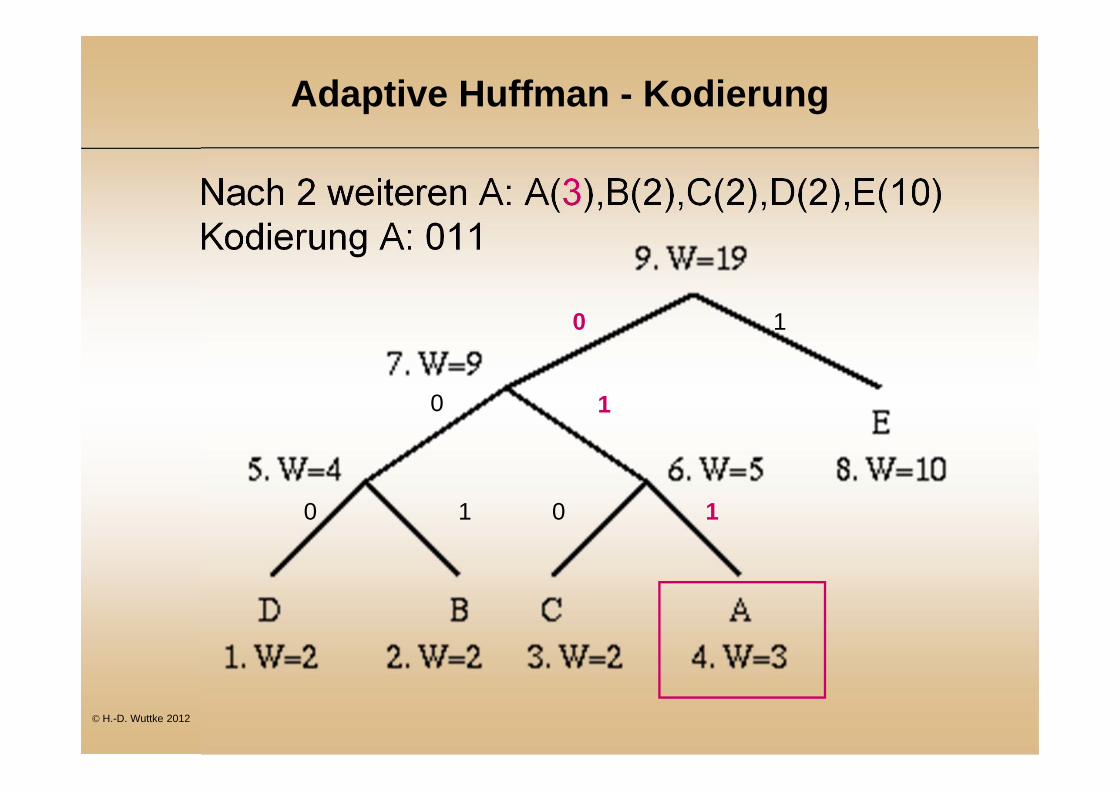
Adaptive Huffman - Kodierung
Nach 2 weiteren A: A(3),B(2),C(2),D(2),E(10) Kodierung A: 011
0
0
1
00
1
1 1
© H.-D. Wuttke 2012
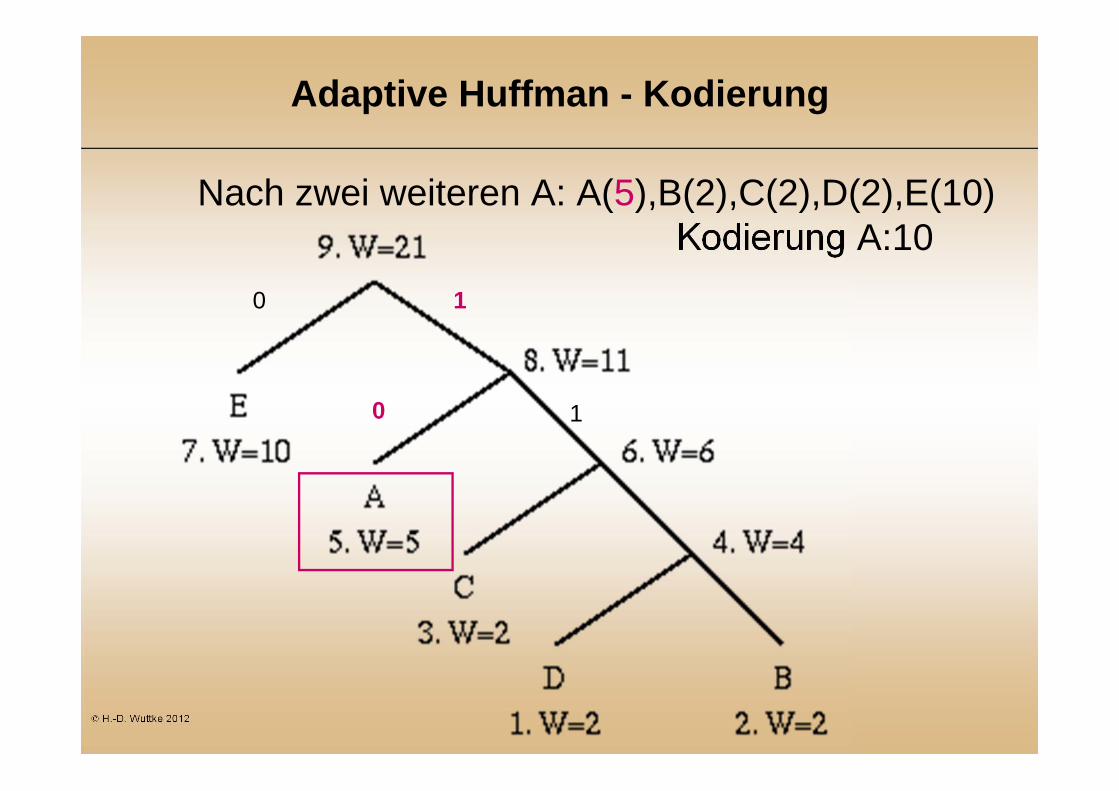
Adaptive Huffman - Kodierung
Nach zwei weiteren A: A(5),B(2),C(2),D(2),E(10) Kodierung A:10
0
0
1
1

© H.-D. Wuttke 2012
Kodierungseigenschaften
+ Optimale Kodierung (Entropie)+ Präfix eindeutig+ => kein Trennzeichen erforderlich trotz
unterschiedlicher Codelänge+ Wahrscheinlichkeit muss nicht bekannt sein
- hoher Kodierungs- / Dekodierungsaufwand- Wächst mit Zeichenzahl- exakte Synchronität erforderlich

© H.-D. Wuttke 2012
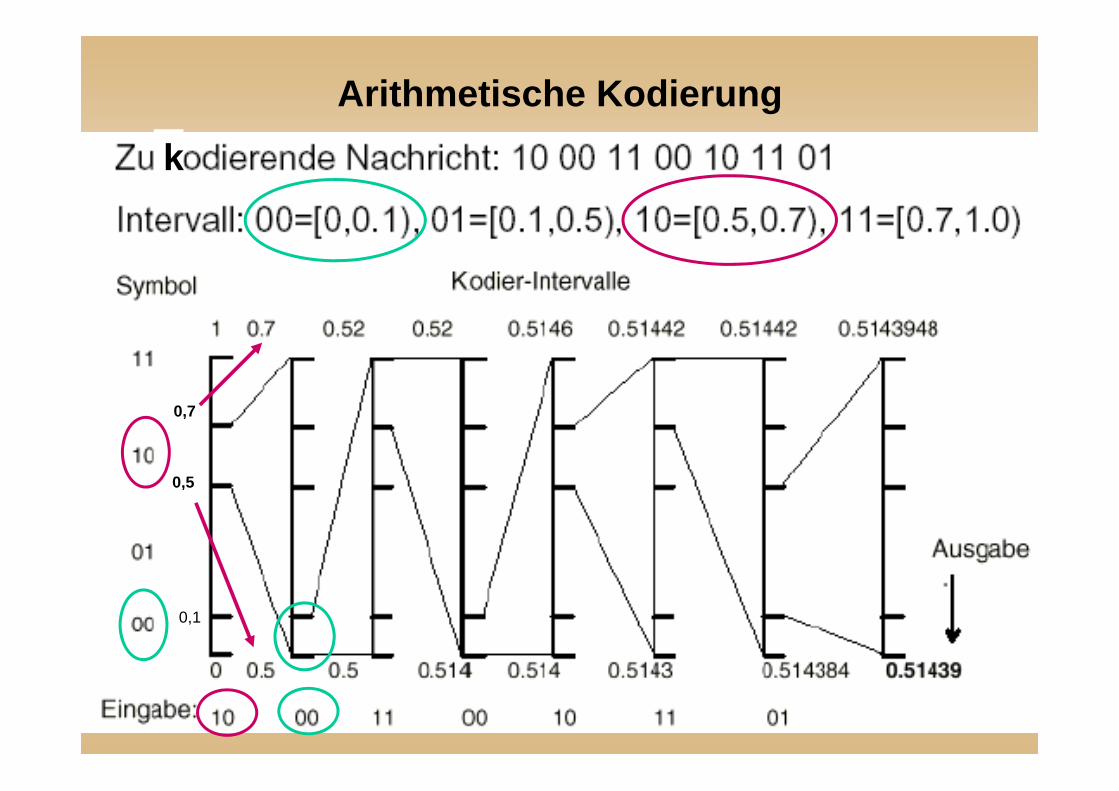
Arithmetische Kodierung
1. Häufigkeiten werden auf Intervall von 0...1 normiert
2. Erstes Zeichen der zu kodierenden Folge bestimmt 1.Intervall, dieses wird wiederum proportional zur Zeichenhäufigkeit geteilt
3. Das zweite Zeichen bestimmt die Auswahl aus diesen Intervallen u.s.w.
4. Abbruch bei Ende der Zeichenkette5. Zahl mit wenigsten Ziffern-Stellen im letzten
ermittelten Intervall ist gesuchte Kodierung

© H.-D. Wuttke 2012
Arithmetische Kodierung
© H.-D. Wuttke 2012
Arithmetische Kodierung
0,1
0,5
0,7
k
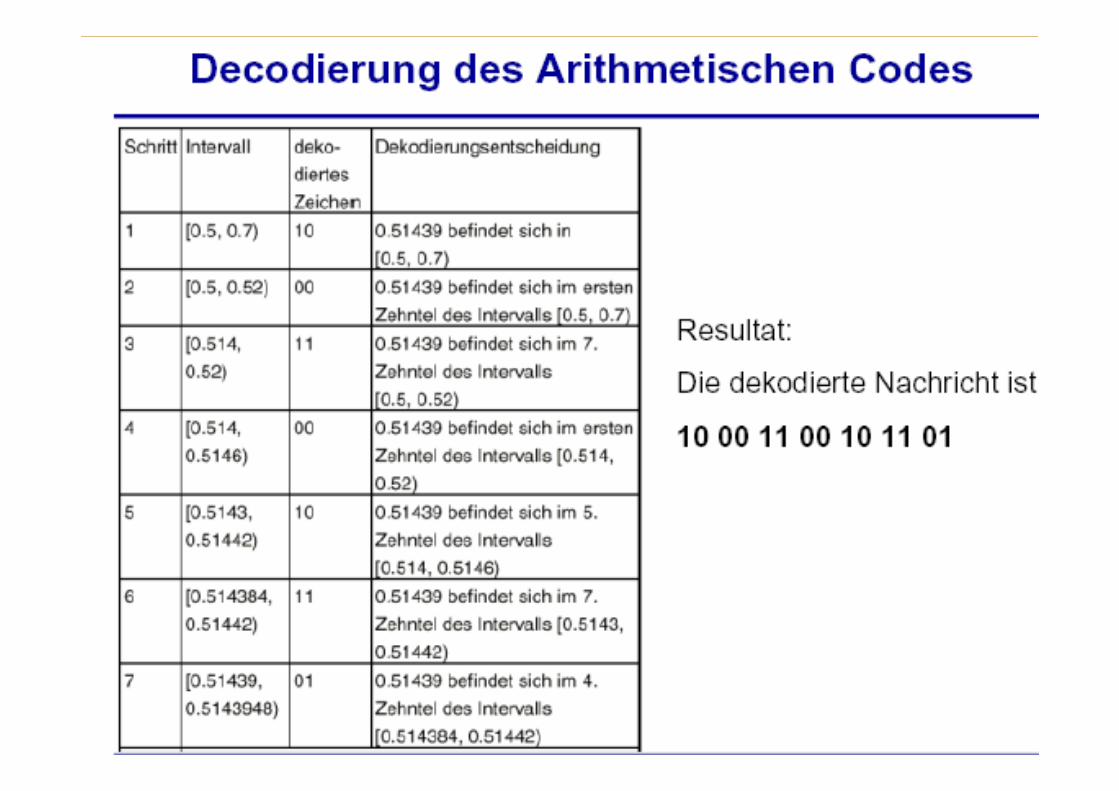
© H.-D. Wuttke 2012
Arithmetische Kodierung

© H.-D. Wuttke 2012
Kodierungseigenschaften
+ Ein Zahlenwert für gesamte Zeichenkette
- Häufigkeit muss bekannt sein- => mit Nachricht übertragen, - Overhead- Bei live Video oder Audio nicht möglich- Begrenzte Genauigkeit der Gleitkommazahlen
in Rechnern => begrenzte Länge

© H.-D. Wuttke 2012
Lempel-Ziv-Welch Algorithmus (LZW)
Ursprung: LZ77, LZ78
Terry A. Welch:"A Technique for High Performance Data Compression",IEEE Computer, Vol. 17, No. 6, 1984, pp. 8-19.
Genutzt im Compress-Befehl von Unixund Bildkomprimierungsformat TIFF
Idee: sukzessiver Aufbau eines Wörterbuches

© H.-D. Wuttke 2012
Lempel-Ziv-Welch Algorithmus (LZW)
w = aktuell bearbeitete Zeichenkette (Wort)k = aktuelles Zeichenwk = Zeichenfolge aus w und k
Iniziales Wörterbuch : 8 Bit ASCII 0...255
=> 1. freie Kodierung: 256

© H.-D. Wuttke 2012
Lempel-Ziv-Welch Algorithmus (LZW)
w = NIL;while ( read a character k )
{if wk exists in the dictionaryw = wk;
elseadd wk to the dictionary;output the code for w;w = k;
}
© H.-D. Wuttke 2012
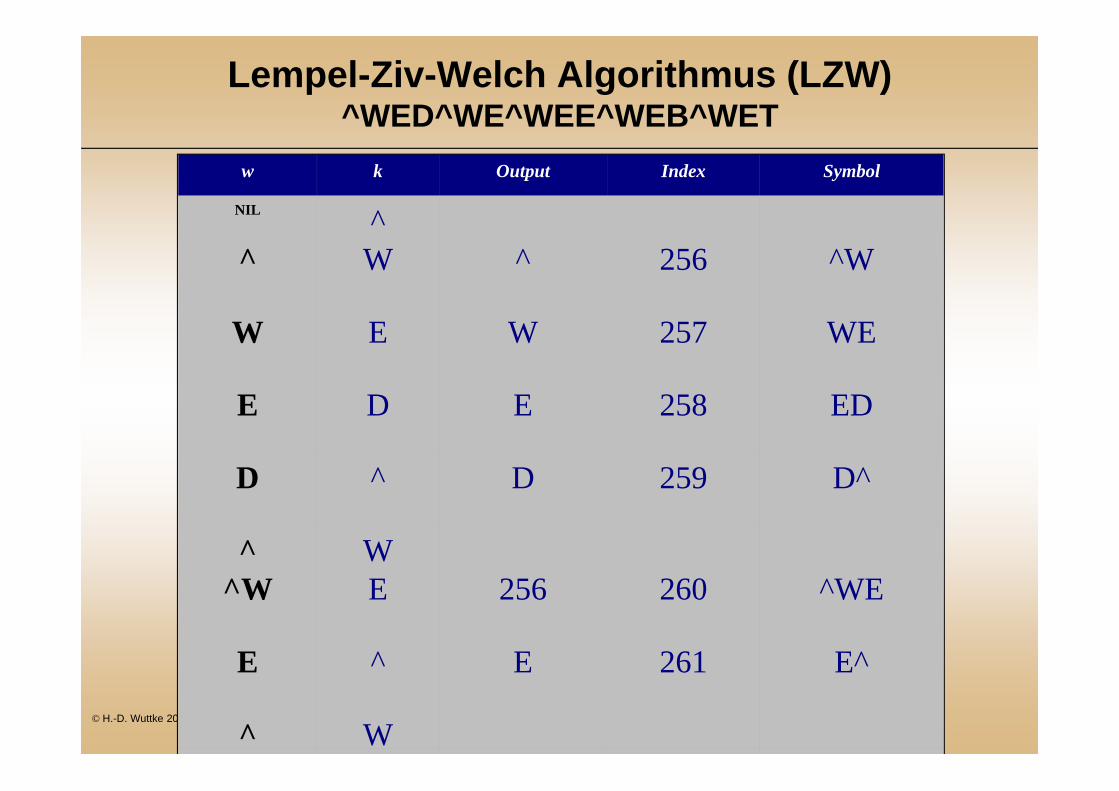
Lempel-Ziv-Welch Algorithmus (LZW)^WED^WE^WEE^WEB^WET
w k Output Index Symbol
NIL ^^ W ^ 256 ^W
W E W 257 WE
E D E 258 ED
D ^ D 259 D^
^ W^W E 256 260 ^WE
E ^ E 261 E^
^ W
© H.-D. Wuttke 2012
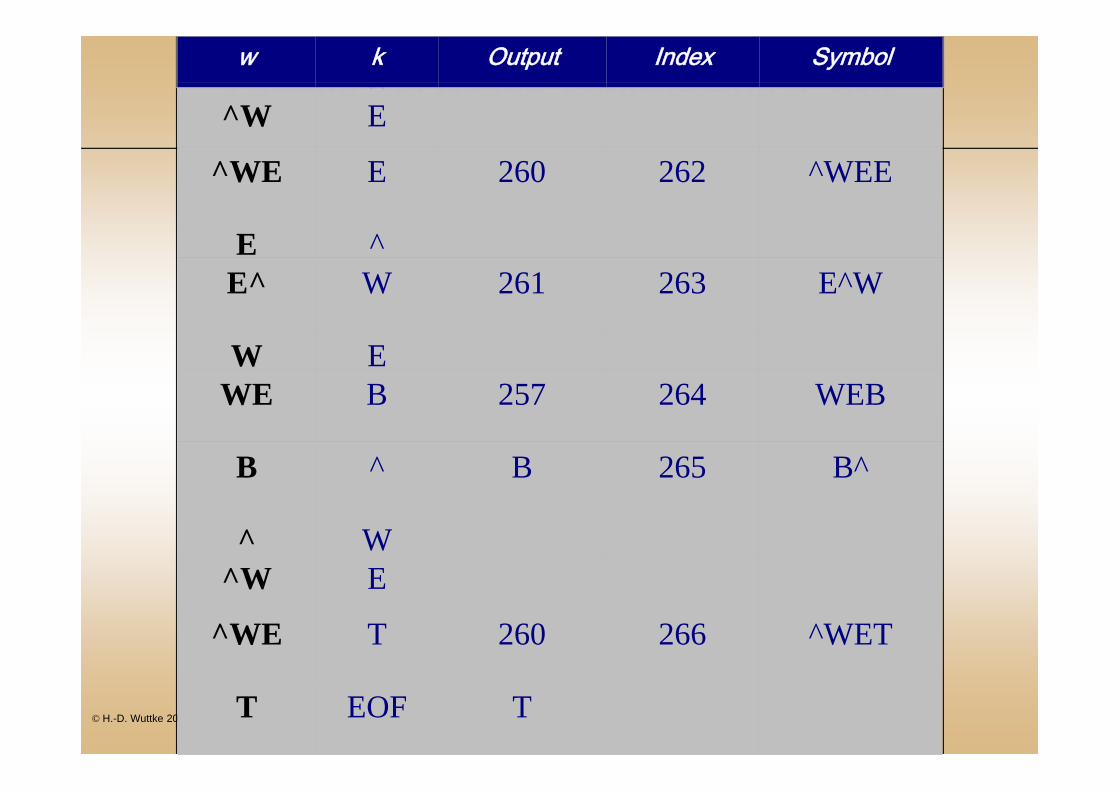
Lempel-Ziv-Welch Algorithmus (LZW)^ W^W E
^WE E 260 262 ^WEE
E ^E^ W 261 263 E^W
W EWE B 257 264 WEB
B ^ B 265 B^
^ W^W E
^WE T 260 266 ^WET
T EOF T
w k Output Index Symbol

© H.-D. Wuttke 2012
LZW Decompression Algorithm
read a character k; output k; w = k; while ( read a character k )
/* k could be a character or a code. */ { entry = dictionary entry for k;
output entry; add w + entry[0] to dictionary; w = entry;
}
© H.-D. Wuttke 2012
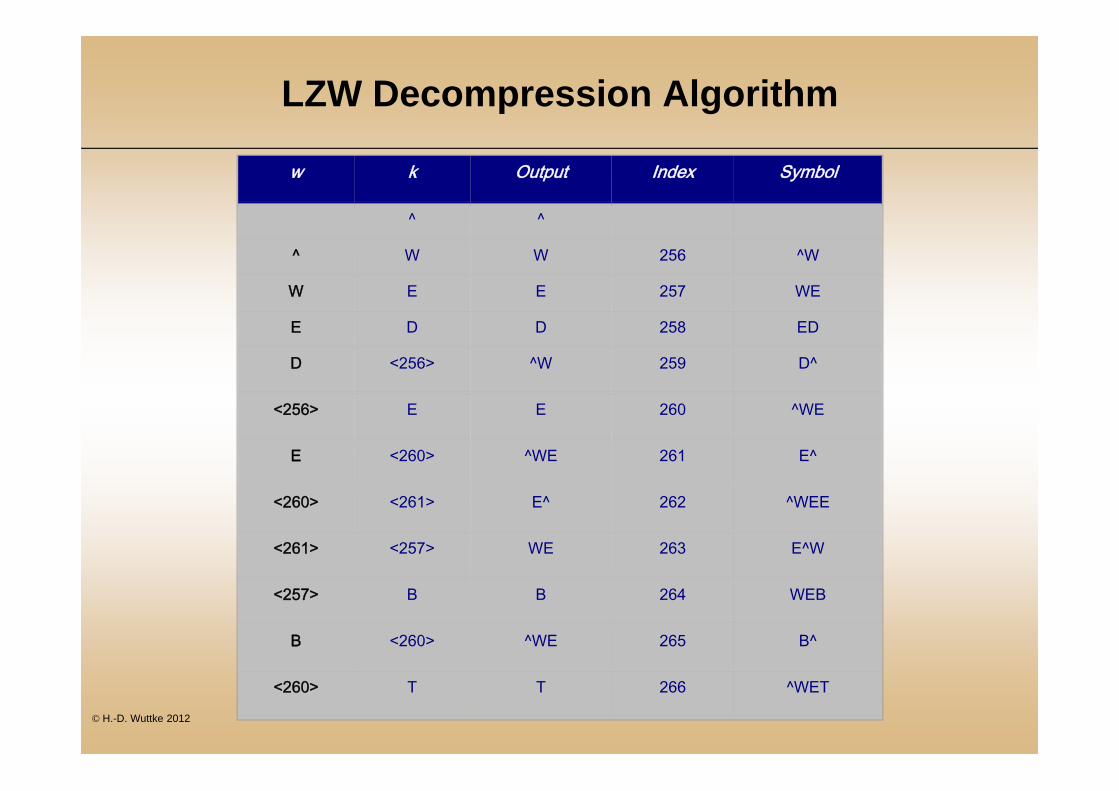
LZW Decompression Algorithm
w k Output Index Symbol
^ ^
^ W W 256 ^W
W E E 257 WE
E D D 258 ED
D <256> ^W 259 D^
<256> E E 260 ^WE
E <260> ^WE 261 E^
<260> <261> E^ 262 ^WEE
<261> <257> WE 263 E^W
<257> B B 264 WEB
B <260> ^WE 265 B^
<260> T T 266 ^WET

© H.-D. Wuttke 2012
Kompressionsverfahren
Quelle: Steinmetz, Ralf: Multimedia-Technologie: Einführung und Grundlagen, Springer, Verlag