Embed Size (px)
Citation preview

M-13017 SBTN-IFU-V1-2013-08 1
SBTengine®
Gebrauchsanweisung
M13017
GenDx
Telefon: +31 302 523 799
E-Mail: [email protected]
Web: www.gendx.com
Adresse: Yalelaan 48
NL-3584 CM Utrecht
The Netherlands

M-13017 SBTN-IFU-V1-2013-08 2
1 Verwendungszweck
SBTengine® ist ein Softwarepaket zur DNA-Sequenzanalyse für die hochauflösende Identifikation von Allelen des Humanen
Leukozytenantigens (HLA). Man erhält die Sequenzen durch HLA-Sequencing-Based-Typing (SBT)-Reagenzien. SBTengine® ist
für professionelle In-vitro-Diagnostik konzipiert wie sie von Gesundheitsexperten (Labortechnikern und Ärzten) betrieben
wird, die nach EFI- oder ASHI-Spezifikationen arbeiten können oder die für HLA-Typisierung und DNA-Sequenzierung in EFI-
oder ASHI-akkreditierten Diagnoselabors geschult sind.
1.1 Zeichenerklärung
Gesetzlicher Hersteller
Materialnummer
Medizinisches Gerät zur In-vitro-Diagnose
Gebrauchsanweisung konsultieren
1.2 Hinweise zur Produktbenutzung
Um eine optimale Leistung zu erzielen, setzen Sie die SBTengine®-Software nur mit Systemen ein, die die
Mindestanforderungen erfüllen (siehe hierzu auch den Abschnitt 2.1: 'Systemanforderungen').
Beachten Sie dabei, dass eine inkorrekte Verwendung der Filter und Funktionen der SBTengine®-Software die generierten
Daten verfälschen kann. Aktualisierungen der Software werden u.a. zur Verfügung gestellt, um die Referenzdatenbank auf
dem aktuellsten Stand zu halten – es wird daher dringend empfohlen, die Software durch jedes neue Release Update stets
auf dem neuesten Stand zu halten. Wenn Daten mit verschiedenen Software-Releases analysiert werden, kann es zu
abweichenden Resultaten bei der Zuweisung möglicher Genotypen kommen.
SBTengine® ist ein Medizin produkt zur In-vitro-Diagnose (IVD). Die hiermit gewonnenen Daten müssen durch qualifiziertes
Personal aus dem Gesundheitswesen (Labortechnikern und Ärzten) geprüft werden, die nach EFI oder ASHI-Spezifikationen
arbeiten können oder für HLA-Typisierung und DNA-Sequenzierung in EFI- oder ASHI-akkreditierten Diagnoselabors geschult
sind. Anhand von SBTengine® generierte Daten stellen in keiner Weise eine endgültige Schlussfolgerung oder Diagnose dar.
Eine unsachgemäße Verwendung der SBTengine® -Software, u.a. in Form ungenehmigter Änderungen an der
Referenzdatenbank, Einsatz mit falschen Lizenzen etc. kann zu stark abweichenden Änderungen führen, für die GenDx weder
Support bietet noch haftet. Solche Änderungen können u.a. zu mit Fehlern behafteten Datenanalysen, Akkreditierungs- oder
regulatorischen Problemen sowie unvollständiger Datenspeicherung führen.
1.3 Technischer Support
GenDx-Kunden
Technischen Support und weitere Informationen erhalten Sie von Ihrem örtlichen GenDx-Vertrieb (www.gendx.com) oder
unserem GenDx-Supportdesk unter [email protected] oder telefonisch unter +31 (0)30-252-3799.
Abbott-Kunden
Technischen Support und weitere Informationen erhalten Sie bei den Abbott Molecular Technical Services unter 1-800-
5537042 (USA) oder unter +49-6122-580 (außerhalb der USA) oder auf der Website von Abbott Molecular unter
http://www.abbottmolecular.com.

M-13017 SBTN-IFU-V1-2013-08 3
2 Installation der SBTengine®-Software und -Lizenz
2.1 Systemanforderungen
Mindestanforderungen
• Windows Vista, Windows 7
• 2 GB RAM
• 80 MB freier Speicherplatz
• Netzwerkverbindung für TCP-/IP-Traffic mit Port 3500
• Microsoft .NET Framework 2.0
Empfohlene Systemanforderungen
• Windows 7
• 2 GB RAM
• Internetverbindung zur Durchführung von Lizenzvalidierungen und automatischen Updates
• 250 MB freier Speicherplatz
• Microsoft .NET Framework 2.0

M-13017 SBTN-IFU-V1-2013-08 4
2.2 Hinweise zur Installation
2.2.1 Hinweise zur Installation von Software und Lizenzen
Sollten Sie eine Vorversion von SBTengine® haben, deinstallieren Sie diese zunächst. Dann entfernen Sie bitte die Datei
licence.ldf (diese Datei wurde von der Vorversion des Lizenzierungssystems verwendet). Unter Windows XP befindet sich
diese Datei unter C:\Documents and Settings\All Users\Application Data\GenDx\Shared\Licensing. Für alle anderen
Windows-Versionen befindet sich die Datei unter C:\ProgramData\GenDx\Shared\Licensing.
1. Bitte installieren Sie dann SBTengine® und verwenden Sie hierzu den Link, den Ihnen das Support-Team zur
Verfügung gestellt hat.
2. Entzippen und installieren Sie die Software mit der Datei SBTengine.zip. Befolgen Sie die Anweisungen am
Bildschirm. SBTengine® startet dann automatisch.
3. Wenn Sie SBTengine® zum ersten Mal verwenden, werden Sie aufgefordert, den Schlüssel zur Lizenzaktivierung, den
GenDx Ihnen zur Verfügung gestellt hat, einzugeben. Steht Ihnen kein solcher Aktivierungsschlüssel zur Verfügung,
wenden Sie sich an das Support-Team.
4. Bei der ersten Verwendung werden Sie zur Eingabe Ihrer persönlichen Benutzer- und Passwortangaben
aufgefordert. Dies geht nur auf Administratoren-Ebene.
Eingabe bei 'User': admin
Eingabe bei 'Password': GenDx
(Achtung: es wird nach Groß- und
Kleinschreibung unterschieden!)
5. Klick auf [Administration]:
6. Nun können Sie neue Benutzer hinzufügen, bestehende Benutzerdaten bearbeiten und Prüfungsebenen bearbeiten
und zuweisen. (eine Beschreibung der Hierarchie der Autorisierungsebenen findet sich unter 2.2.2). Nach dem
Hinzufügen aller Benutzer klicken Sie auf 'Quit' ('Schließen').
7. SBTengine® schließen.
8. Öffnen Sie die Software erneut und loggen Sie sich mit dem entsprechenden Usernamen ein.

M-13017 SBTN-IFU-V1-2013-08 5
2.2.2 Hierarchie der Autorisierungsebenen
Bei der ersten Verwendung werden Sie zur Eingabe Ihrer persönlichen Benutzer- und Passwortangaben aufgefordert. Dies
geht nur auf Administratoren-Ebene.
Eingabe bei 'User': admin
Eingabe bei 'Password': GenDx (Achtung: es wird nach Groß- und Kleinschreibung unterschieden!)
Nun können Sie neue Benutzer hinzufügen, bestehende Benutzerdaten bearbeiten und Prüfungsebenen bearbeiten und
zuweisen.
SBTengine® unterstützt 3 verschiedene Credential Levels: ‘Administrator’, ‘First Reviewer’ ('Erstprüfer') und ‘Final Reviewer’
('Abschlussprüfer').
1. Administrator (admin)
Der Administrator kann keine Daten einsehen. Er kann lediglich Benutzerkonten erstellen und die Autorisierungsebene
jedes Benutzers festlegen bzw. ändern.
2. First Reviewer (Erstprüfer)
Der Erstprüfer kann alle noch nicht genehmigten Rohdaten analysieren, bearbeiten und genehmigen. Darüber hinaus
kann der Erstprüfer alle von allen anderen Erstprüfern (einschließlich seiner eigenen Person) genehmigten Rohdaten
analysieren, bearbeiten und genehmigen.
Der Benutzer ist auf zwei Ebenen tätig:
- Im ‘Workfolder’ (Arbeitsordner) – hierbei handelt es sich vor allem um die Arbeitsliste des Tages, die Zugriff auf
sämtliche Rohdaten gestattet. Nach Bestätigung wird das Credential Level der Daten auf das des Final Reviewer
(Abschlussprüfer) hochgestuft.
- 'Approved' ('Genehmigt') ermöglicht den Zugriff auf alle Daten, die von First-Reviewer-Benutzern genehmigt
wurden. Dies ermöglicht die Prüfung und Bearbeitung der vom User und aller User desselben Credential Levels
genehmigten Daten.
3. 'Final Reviewer’ ('Abschlussprüfer')
Der Abschlussprüfer kann alle von den Erstprüfern genehmigten Rohdaten analysieren, bearbeiten und genehmigen.
Darüber hinaus kann der Abschlussprüfer alle von anderen Abschlussprüfern (einschließlich seiner eigenen Person)
genehmigten Daten analysieren, bearbeiten und genehmigen.
Der Benutzer ist auf zwei Ebenen tätig:
- Der 'Workfolder’ (Arbeitsordner) ist in erster Linie die 'Arbeitsliste des Tages', die Zugriff auf alle von den Erstprüfern
genehmigten Daten ermöglicht.
- 'Approved' ('Genehmigt') ermöglicht den Zugriff auf alle von sämtlichen Final-Reviewer-Benutzern genehmigten
Daten. Dies ermöglicht die Prüfung und Bearbeitung der vom User und aller User desselben Credential Levels
genehmigten Daten.
Dies kann in folgendem Diagramm zusammengefasst werden:
Erstprüfer Abschlussprüfer
Arbeitsliste für
Erstprüfer
Arbeitsliste für
Abschlussprüfer
Genehmigt vom
Erstprüfer
Datenfluss
Genehmigung
Datenzugriff
Genehmigt vom
Abschlussprüfer
Endgültig genehmigt Genehmigte Daten (vom Erstprüfer) Rohdaten
User Credential Level:
Administrator: Kann nur Benutzerkonten erstellen und die Autorisierungs-ebenen
festlegen/ ändern. Hat keinen Zugriff auf Sequenzdaten.
Zugriffsebene:
Daten:
M-13017 SBTN-IFU-V1-2013-08 6
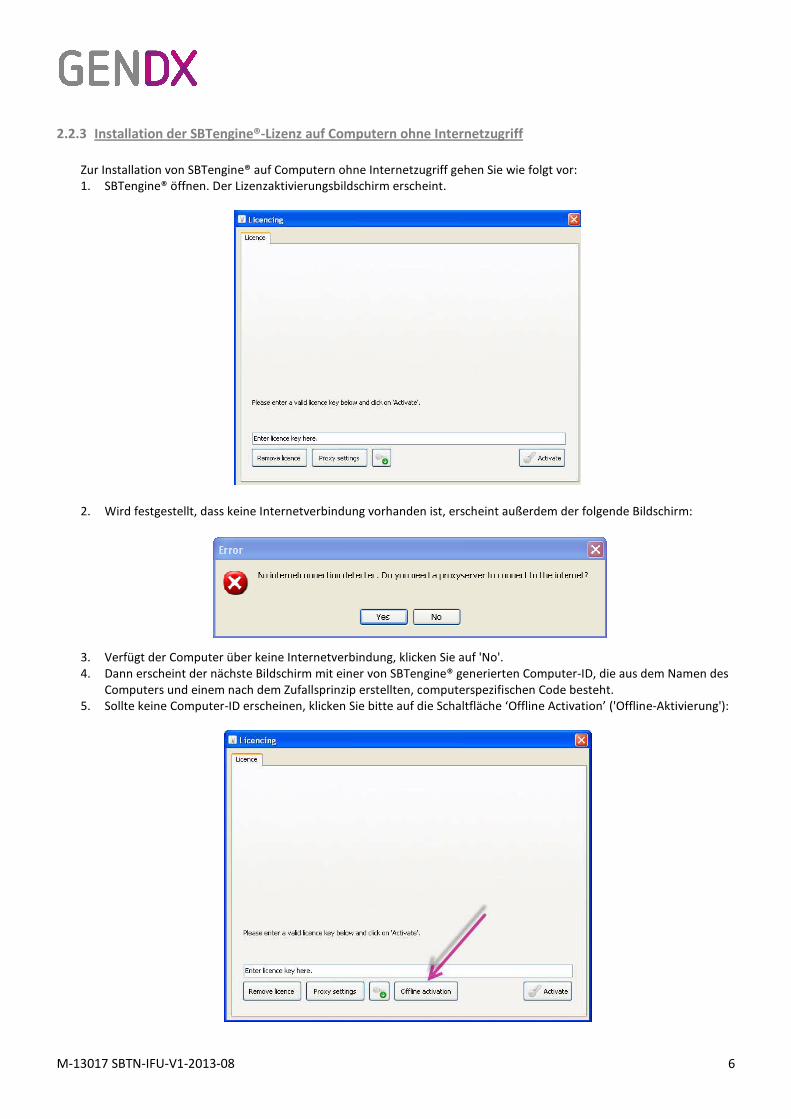
2.2.3 Installation der SBTengine®-Lizenz auf Computern ohne Internetzugriff
Zur Installation von SBTengine® auf Computern ohne Internetzugriff gehen Sie wie folgt vor:
1. SBTengine® öffnen. Der Lizenzaktivierungsbildschirm erscheint.
2. Wird festgestellt, dass keine Internetverbindung vorhanden ist, erscheint außerdem der folgende Bildschirm:
3. Verfügt der Computer über keine Internetverbindung, klicken Sie auf 'No'.
4. Dann erscheint der nächste Bildschirm mit einer von SBTengine® generierten Computer-ID, die aus dem Namen des
Computers und einem nach dem Zufallsprinzip erstellten, computerspezifischen Code besteht.
5. Sollte keine Computer-ID erscheinen, klicken Sie bitte auf die Schaltfläche ‘Offline Activation’ ('Offline-Aktivierung'):
M-13017 SBTN-IFU-V1-2013-08 7
6. Dann kopieren Sie die Computer-ID und
7. arbeiten an einem anderen Computer weiter, der über eine Internetverbindung verfügt.
8. Öffnen Sie ein Browserfenster und geben Sie folgende URL ein:
GenDx-Kunden:
https://quicklicensemanager.com/gendx/sql1/QlmAspLicenseSite/QlmWebActivation.aspx
Abbott-Kunden:
https://quicklicensemanager.com/gendx/sql2/QlmAspLicenseSite/QlmWebActivation.aspx
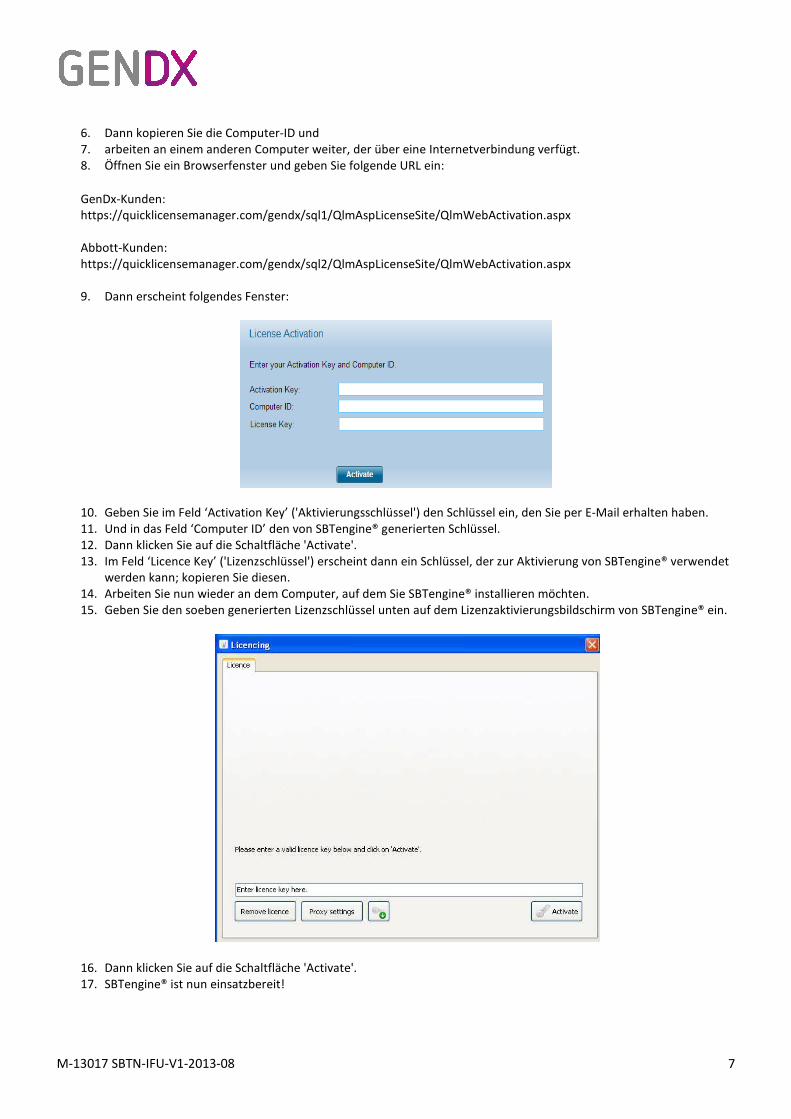
9. Dann erscheint folgendes Fenster:
10. Geben Sie im Feld ‘Activation Key’ ('Aktivierungsschlüssel') den Schlüssel ein, den Sie per E-Mail erhalten haben.
11. Und in das Feld ‘Computer ID’ den von SBTengine® generierten Schlüssel.
12. Dann klicken Sie auf die Schaltfläche 'Activate'.
13. Im Feld ‘Licence Key’ ('Lizenzschlüssel') erscheint dann ein Schlüssel, der zur Aktivierung von SBTengine® verwendet
werden kann; kopieren Sie diesen.
14. Arbeiten Sie nun wieder an dem Computer, auf dem Sie SBTengine® installieren möchten.
15. Geben Sie den soeben generierten Lizenzschlüssel unten auf dem Lizenzaktivierungsbildschirm von SBTengine® ein.
16. Dann klicken Sie auf die Schaltfläche 'Activate'.
17. SBTengine® ist nun einsatzbereit!

M-13017 SBTN-IFU-V1-2013-08 8
3 Workflow mit SBTengine®
Ein Workflow mit SBTengine® lässt sich in folgende Schritte aufteilen:
3.1 Benennung von Samples
Bevor ABI-Sequenzdateien (*.ab1) von SBTengine® analysiert werden können, muss für jede ABI-Sequenzdatei ein Sample-
und Locus-Name vergeben werden. Wir empfehlen Ihnen, bei der Benennung von Sample-Dateien nach folgendem Schema
vorzugehen: Sample-Name_Locus_Exon plus sequenzierter Strang, wobei alle Elemente durch Unterstrich getrennt sein
sollten. Mit dieser Information kann SBTengine® automatisch den Sample-Namen und Locus für jede Spur ermitteln.
Lautet der Dateiname beispielsweise DNA1_HLA-C_Ex5F_otherinformation.ab1:
Name des Samples: DNA1
Locus: HLA-C
Sequenzierter Strang: Exon 5 Vorwärtsprimer
Weitere Informationen: Abhängig von der Sequenziereinstellung (von SBTengine® für Benennungszwecke ignoriert)
Bei Einsatz von GSSP fügen Sie anstatt des sequenzierten Stranges die entsprechenden GSSP-Angaben hinzu.
Lautet der Dateiname beispielsweise DNA1_HLA-C_C16_otherinformation.ab1:
Name des Samples: DNA1
Locus: HLA-C
GSSP-Angaben: Die Spur wird per C16 GSSP ermittelt
Weitere Informationen: Abhängig von der Sequenziereinstellung (von SBTengine® für Benennungszwecke ignoriert)
SBTengine® kann die Samples dann automatisch lesen.
Es können auch andere Benennungskonventionen für Samples und Loci verwendet werden. Für mehr Informationen sehen
Sie bitte im Glossar von SBTengine® (Automatic Name/Locus Assignment oder Manual Name/Locus Assignment) nach oder
kontaktieren Sie Ihr Support-Team.
Datenanalyse
(3.3)
Schritt 1:
Lösung von Inkonsistenzen im Alignment
(3.3.1)
Schritt 2:
Lösung von Inkonsistenzen zwischen
einzelnen Spuren
(3.3.2)
Schritt 3:
Überprüfung/Änderung von
schlüsselposition
(3.3.3)
Freigabe von
Ergebnissen (3.4)
Ergebnisbericht-
erstattung (3.5)
Importieren von Sequenzierungsdateien und
Auswahl von Samples (3.2)
Benennung von Samples
(3.1)
M-13017 SBTN-IFU-V1-2013-08 9
3.2 Import von Sequenzierungsdateien in SBTengine® und Auswahl von Samples
Wir empfehlen Ihnen, die Sequenzierungsdaten in einem eigenen Analyse-Ordner in SBTengine® (z.B. SBTdata) zu speichern.
Arbeiten Sie in einem Computernetzwerk, empfehlen wir Ihnen die Speicherung der Sequenzdaten auf einem Datenserver,
auf den von jeder Workstation, auf der SBTengine® installiert ist, zugegriffen werden kann. Um versehentlichen Daten-
verlusten vorzubeugen, stellen Sie bitte sicher, dass an diesem Computer regelmäßige Datenbackups vorgenommen werden.
Hinweis: unabhängig davon, ob Sie in einer Netzwerkumgebung arbeiten oder nicht, verwenden wir in der vorliegenden
Gebrauchsanweisung zur Bezeichnung des Ordners mit den Sequenzierungsdateien die Bezeichnung 'SBTdata'-Ordner.
3.2.1 Importieren von Kernsequenzierungsdateien in SBTengine® und Auswahl von Samples
1. Nach Abschluss des Sequenzierungslaufs müssen Sie den dazugehörigen Ordner komplett vom
Sequenzierungsrechner in den SBTdata-Ordner kopieren.
2. Dazu braucht SBTengine® Angaben zum Speicherort des SBTdata-Ordners. Diese Einstellung brauchen Sie bei der
Installation von SBTengine® jedoch nur ein einziges Mal vorzunehmen. Starten Sie hierzu SBTengine®, gehen Sie auf
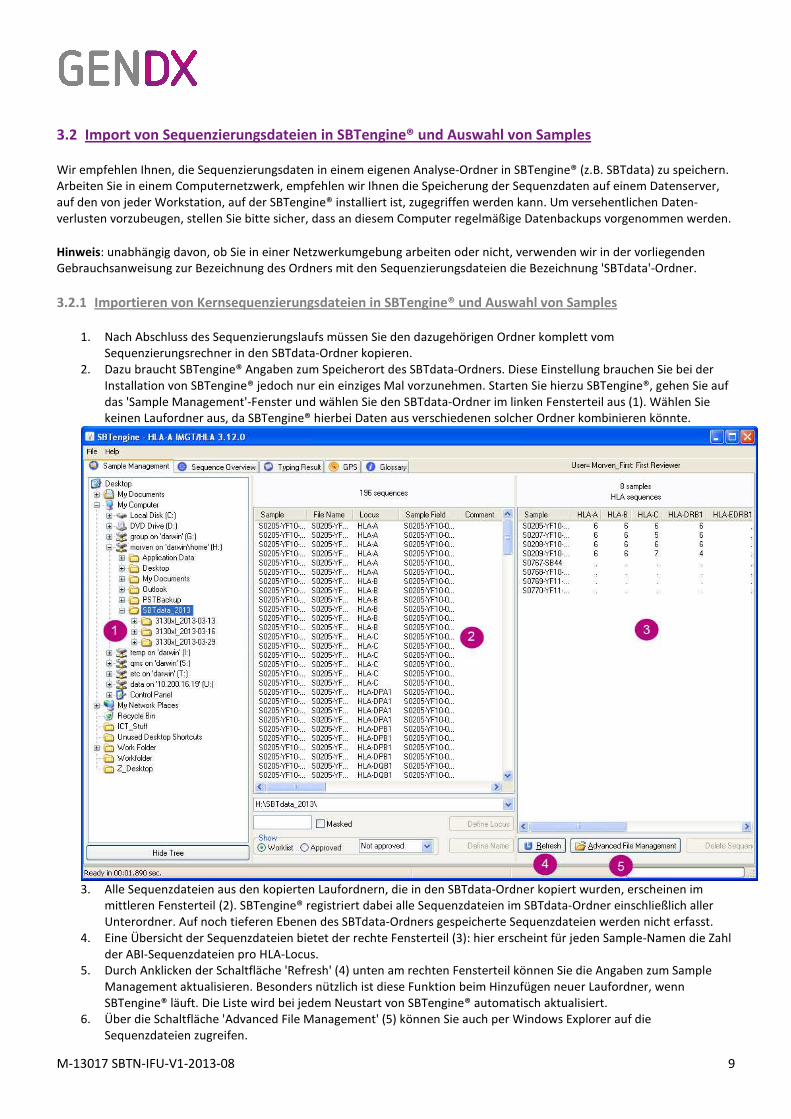
das 'Sample Management'-Fenster und wählen Sie den SBTdata-Ordner im linken Fensterteil aus (1). Wählen Sie
keinen Laufordner aus, da SBTengine® hierbei Daten aus verschiedenen solcher Ordner kombinieren könnte.
3. Alle Sequenzdateien aus den kopierten Laufordnern, die in den SBTdata-Ordner kopiert wurden, erscheinen im
mittleren Fensterteil (2). SBTengine® registriert dabei alle Sequenzdateien im SBTdata-Ordner einschließlich aller
Unterordner. Auf noch tieferen Ebenen des SBTdata-Ordners gespeicherte Sequenzdateien werden nicht erfasst.
4. Eine Übersicht der Sequenzdateien bietet der rechte Fensterteil (3): hier erscheint für jeden Sample-Namen die Zahl
der ABI-Sequenzdateien pro HLA-Locus.
5. Durch Anklicken der Schaltfläche 'Refresh' (4) unten am rechten Fensterteil können Sie die Angaben zum Sample
Management aktualisieren. Besonders nützlich ist diese Funktion beim Hinzufügen neuer Laufordner, wenn
SBTengine® läuft. Die Liste wird bei jedem Neustart von SBTengine® automatisch aktualisiert.
6. Über die Schaltfläche 'Advanced File Management' (5) können Sie auch per Windows Explorer auf die
Sequenzdateien zugreifen.
M-13017 SBTN-IFU-V1-2013-08 10
3.3 Datenanalyse in SBTengine®
Die Analyse von Sequenzdateien erfolgt über das 'Sequence Overview'-Fenster in folgenden drei Hauptschritten:
1) Lösung von Alignment-Inkonsistenzen
2) Lösung von Inkonsistenzen zwischen einzelnen Spuren
3) Überprüfung/Änderung von schlüsselposition
3.3.1 Schritt 1: Lösung von Alignment-Inkonsistenzen
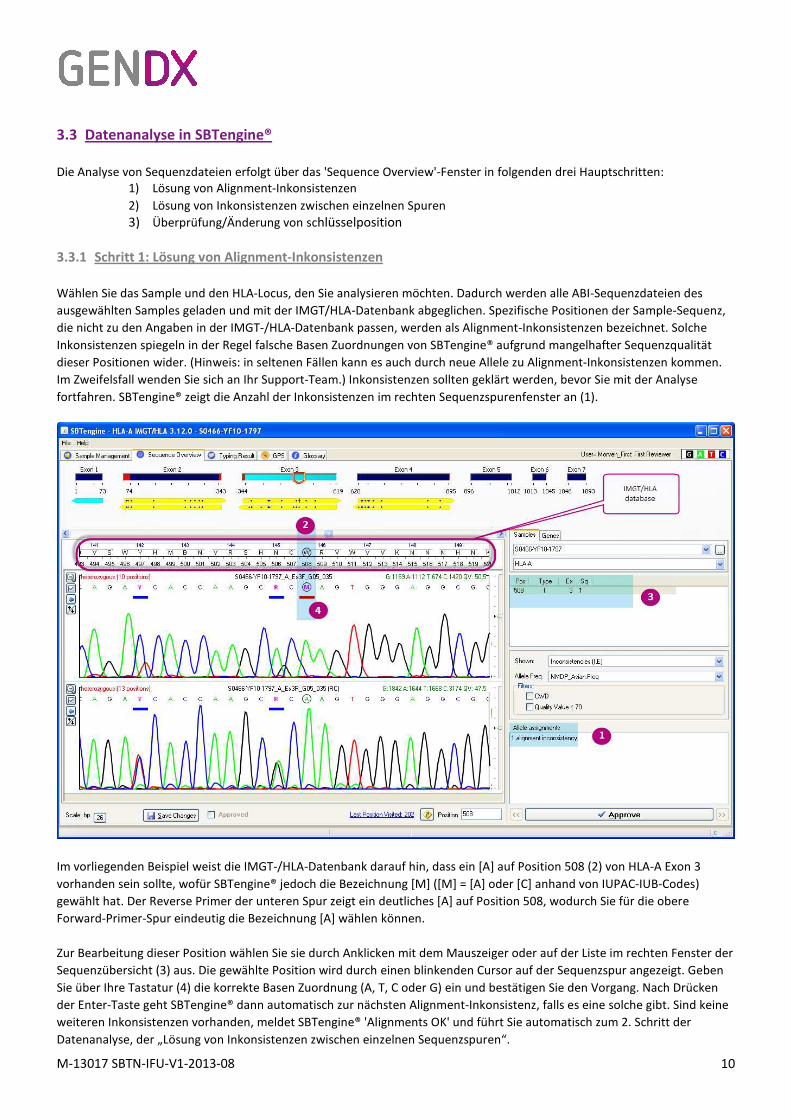
Wählen Sie das Sample und den HLA-Locus, den Sie analysieren möchten. Dadurch werden alle ABI-Sequenzdateien des
ausgewählten Samples geladen und mit der IMGT/HLA-Datenbank abgeglichen. Spezifische Positionen der Sample-Sequenz,
die nicht zu den Angaben in der IMGT-/HLA-Datenbank passen, werden als Alignment-Inkonsistenzen bezeichnet. Solche
Inkonsistenzen spiegeln in der Regel falsche Basen Zuordnungen von SBTengine® aufgrund mangelhafter Sequenzqualität
dieser Positionen wider. (Hinweis: in seltenen Fällen kann es auch durch neue Allele zu Alignment-Inkonsistenzen kommen.
Im Zweifelsfall wenden Sie sich an Ihr Support-Team.) Inkonsistenzen sollten geklärt werden, bevor Sie mit der Analyse
fortfahren. SBTengine® zeigt die Anzahl der Inkonsistenzen im rechten Sequenzspurenfenster an (1).
Im vorliegenden Beispiel weist die IMGT-/HLA-Datenbank darauf hin, dass ein [A] auf Position 508 (2) von HLA-A Exon 3
vorhanden sein sollte, wofür SBTengine® jedoch die Bezeichnung [M] ([M] = [A] oder [C] anhand von IUPAC-IUB-Codes)
gewählt hat. Der Reverse Primer der unteren Spur zeigt ein deutliches [A] auf Position 508, wodurch Sie für die obere
Forward-Primer-Spur eindeutig die Bezeichnung [A] wählen können.
Zur Bearbeitung dieser Position wählen Sie sie durch Anklicken mit dem Mauszeiger oder auf der Liste im rechten Fenster der
Sequenzübersicht (3) aus. Die gewählte Position wird durch einen blinkenden Cursor auf der Sequenzspur angezeigt. Geben
Sie über Ihre Tastatur (4) die korrekte Basen Zuordnung (A, T, C oder G) ein und bestätigen Sie den Vorgang. Nach Drücken
der Enter-Taste geht SBTengine® dann automatisch zur nächsten Alignment-Inkonsistenz, falls es eine solche gibt. Sind keine
weiteren Inkonsistenzen vorhanden, meldet SBTengine® 'Alignments OK' und führt Sie automatisch zum 2. Schritt der
Datenanalyse, der „Lösung von Inkonsistenzen zwischen einzelnen Sequenzspuren“.
M-13017 SBTN-IFU-V1-2013-08 11
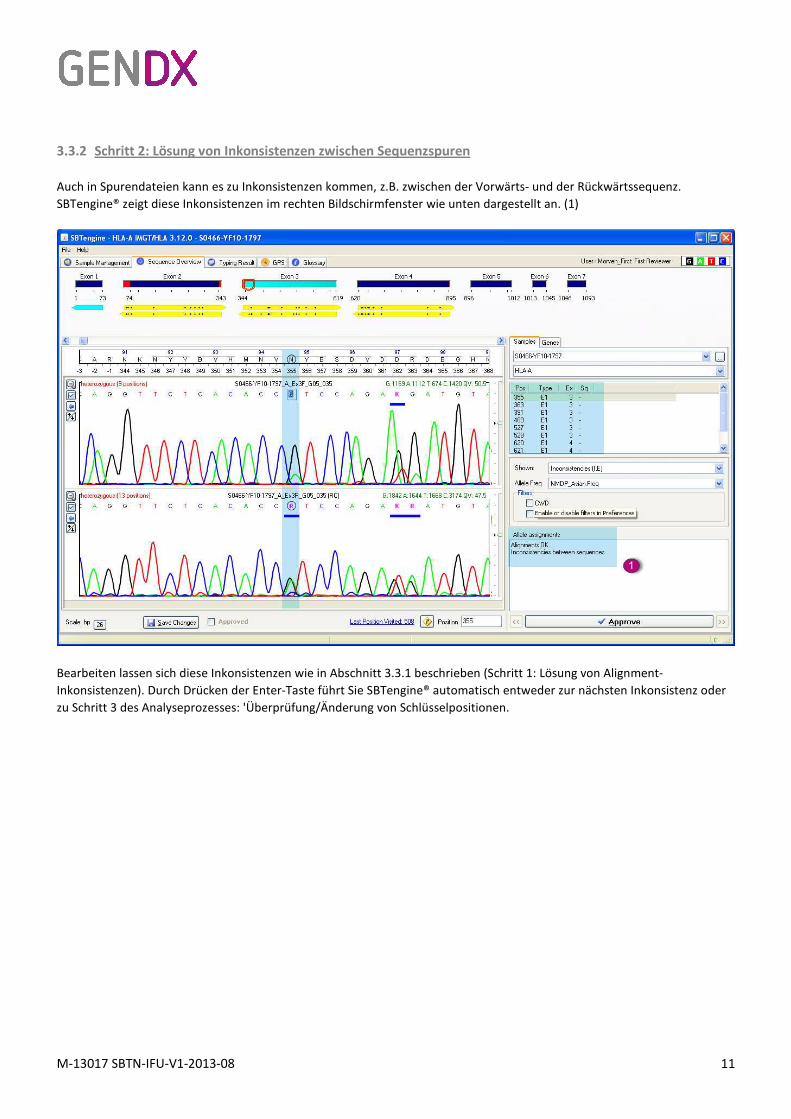
3.3.2 Schritt 2: Lösung von Inkonsistenzen zwischen Sequenzspuren
Auch in Spurendateien kann es zu Inkonsistenzen kommen, z.B. zwischen der Vorwärts- und der Rückwärtssequenz.
SBTengine® zeigt diese Inkonsistenzen im rechten Bildschirmfenster wie unten dargestellt an. (1)
Bearbeiten lassen sich diese Inkonsistenzen wie in Abschnitt 3.3.1 beschrieben (Schritt 1: Lösung von Alignment-
Inkonsistenzen). Durch Drücken der Enter-Taste führt Sie SBTengine® automatisch entweder zur nächsten Inkonsistenz oder
zu Schritt 3 des Analyseprozesses: 'Überprüfung/Änderung von Schlüsselpositionen.
M-13017 SBTN-IFU-V1-2013-08 12
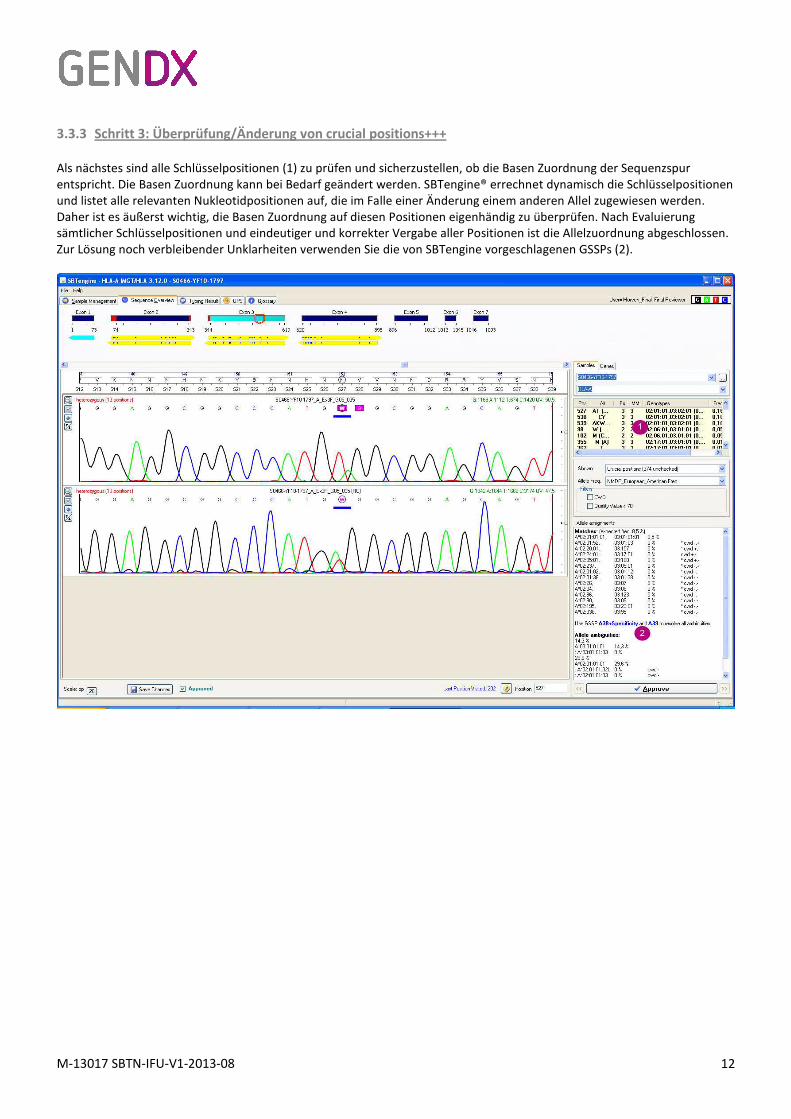
3.3.3 Schritt 3: Überprüfung/Änderung von crucial positions+++
Als nächstes sind alle Schlüsselpositionen (1) zu prüfen und sicherzustellen, ob die Basen Zuordnung der Sequenzspur
entspricht. Die Basen Zuordnung kann bei Bedarf geändert werden. SBTengine® errechnet dynamisch die Schlüsselpositionen
und listet alle relevanten Nukleotidpositionen auf, die im Falle einer Änderung einem anderen Allel zugewiesen werden.
Daher ist es äußerst wichtig, die Basen Zuordnung auf diesen Positionen eigenhändig zu überprüfen. Nach Evaluierung
sämtlicher Schlüsselpositionen und eindeutiger und korrekter Vergabe aller Positionen ist die Allelzuordnung abgeschlossen.
Zur Lösung noch verbleibender Unklarheiten verwenden Sie die von SBTengine vorgeschlagenen GSSPs (2).
M-13017 SBTN-IFU-V1-2013-08 13
Senkung des Arbeitsaufwandes
Manchmal sind über 100 Schlüsselpositionen zu überprüfen. Zur Senkung des Arbeitsaufwandes kann die Option 'Quality
Value Filter' (QV-Filter) angehakt werden. Er filtert peaks von hoher Qualität heraus, deren Qualität SBTengine® zu 100 %
vertraut.
Wie unten dargestellt, müssen bei ausgeschaltetem QV-Filter 140 Schlüsselpositionen überprüft werden. Wird der QV-Filter
angeschaltet (2), reduziert sich die Zahl der von Hand zu überprüfenden Schlüsselpositionen erheblich. Es bleiben lediglich 12
solcher Positionen übrig.
3.4 Freigabe von Ergebnissen
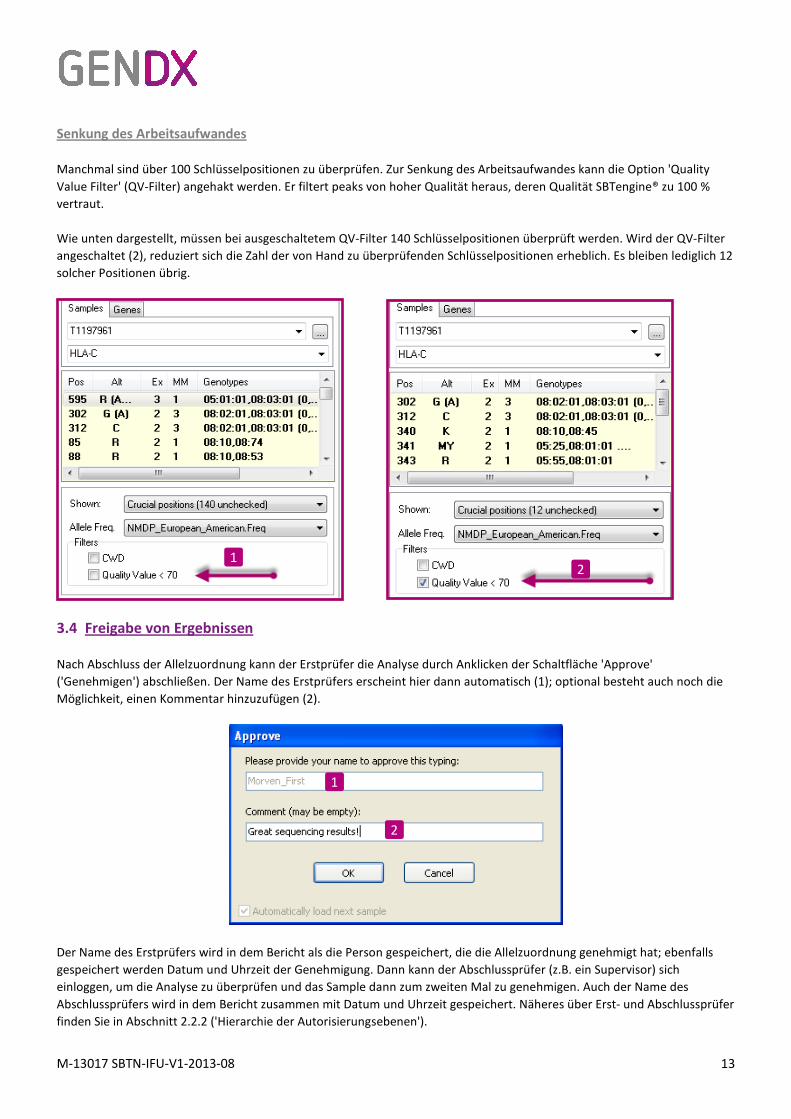
Nach Abschluss der Allelzuordnung kann der Erstprüfer die Analyse durch Anklicken der Schaltfläche 'Approve'
('Genehmigen') abschließen. Der Name des Erstprüfers erscheint hier dann automatisch (1); optional besteht auch noch die
Möglichkeit, einen Kommentar hinzuzufügen (2).
Der Name des Erstprüfers wird in dem Bericht als die Person gespeichert, die die Allelzuordnung genehmigt hat; ebenfalls
gespeichert werden Datum und Uhrzeit der Genehmigung. Dann kann der Abschlussprüfer (z.B. ein Supervisor) sich
einloggen, um die Analyse zu überprüfen und das Sample dann zum zweiten Mal zu genehmigen. Auch der Name des
Abschlussprüfers wird in dem Bericht zusammen mit Datum und Uhrzeit gespeichert. Näheres über Erst- und Abschlussprüfer
finden Sie in Abschnitt 2.2.2 ('Hierarchie der Autorisierungsebenen').
1 2
1
2
M-13017 SBTN-IFU-V1-2013-08 14
Durch Bestätigung der Allelzuordnung werden die Sequenzdateien des Samples in den Archivordner verschoben und wird ein
XML-Bericht erstellt. Ein XML-Bericht ist eine Textdatei, deren Information in getaggter Struktur abrufbar sind. Die XML-Datei
dient dem Importieren von Sample- und Allelzuordnungsdaten in eine Reihe von Softwareprogrammen (z.B. ein LIMS-
System) zur weiteren Verarbeitung.
SBTengine® erstellt einen Bericht über alle Bestätigten Loci, der unter der Reiterkarte Typing Result abrufbar ist; er lässt sich
in ein Programm Ihrer Wahl (z.B. Microsoft Word) importieren, um damit einen Arztbericht an eine Praxis zu erstellen.
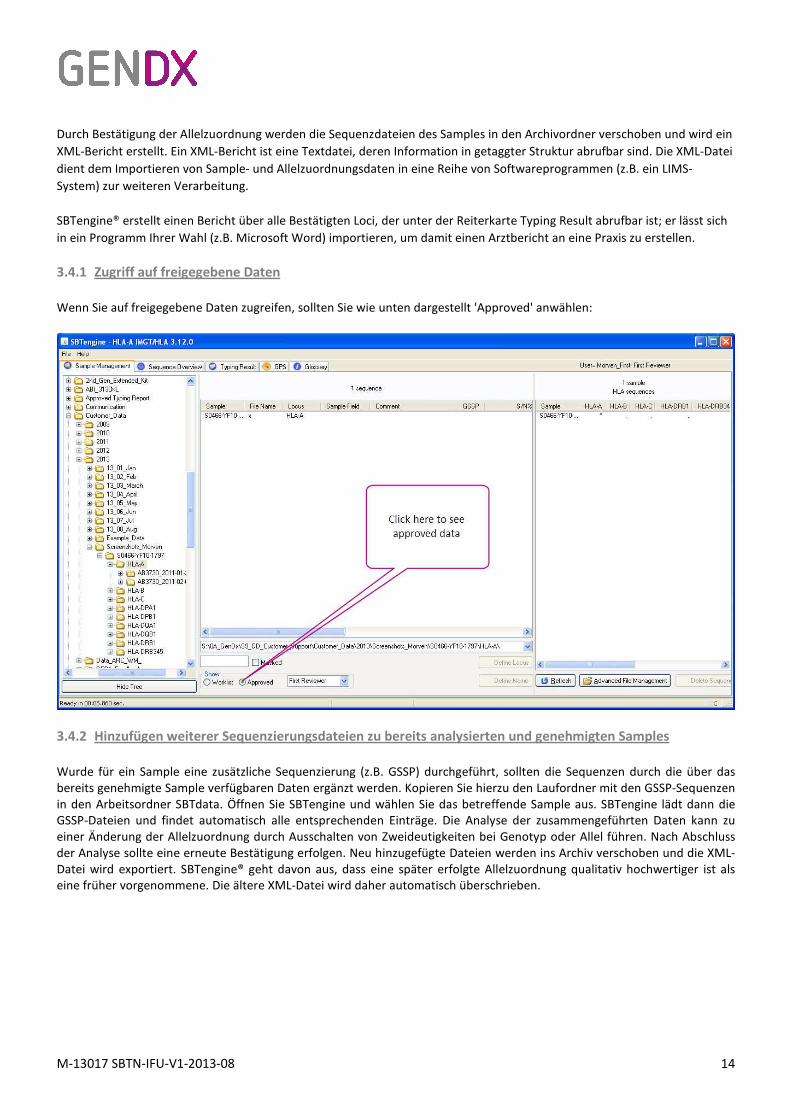
3.4.1 Zugriff auf freigegebene Daten
Wenn Sie auf freigegebene Daten zugreifen, sollten Sie wie unten dargestellt 'Approved' anwählen:
3.4.2 Hinzufügen weiterer Sequenzierungsdateien zu bereits analysierten und genehmigten Samples
Wurde für ein Sample eine zusätzliche Sequenzierung (z.B. GSSP) durchgeführt, sollten die Sequenzen durch die über das
bereits genehmigte Sample verfügbaren Daten ergänzt werden. Kopieren Sie hierzu den Laufordner mit den GSSP-Sequenzen
in den Arbeitsordner SBTdata. Öffnen Sie SBTengine und wählen Sie das betreffende Sample aus. SBTengine lädt dann die
GSSP-Dateien und findet automatisch alle entsprechenden Einträge. Die Analyse der zusammengeführten Daten kann zu
einer Änderung der Allelzuordnung durch Ausschalten von Zweideutigkeiten bei Genotyp oder Allel führen. Nach Abschluss
der Analyse sollte eine erneute Bestätigung erfolgen. Neu hinzugefügte Dateien werden ins Archiv verschoben und die XML-
Datei wird exportiert. SBTengine® geht davon aus, dass eine später erfolgte Allelzuordnung qualitativ hochwertiger ist als
eine früher vorgenommene. Die ältere XML-Datei wird daher automatisch überschrieben.
M-13017 SBTN-IFU-V1-2013-08 15
3.5 Ergebnisberichterstattung
Unter der Reiterkarte 'Typing Result' finden Sie die Tabs 'Typing result for current loci' ('Ergebnis für aktuelle Loci') und
'Approved loci' ('Genehmigte Loci'). Hier finden Sie die Informationen über die Typing-Ergebnisse. Diese Berichte können
direkt ausgedruckt oder als Rich-Text-Datei (*.rtf) gespeichert werden; klicken Sie hierzu unten am Fenster auf die
Schaltfläche 'Drucken' bzw. 'Speichern'.
Wenn Sie den Bericht als *.rtf-Datei speichern, können Sie ihn in jedem beliebigen Text-Editor öffnen (z.B. in Microsoft
Word), Ihren Briefkopf sowie Zusatztext hinzufügen und damit einen Arztbericht erstellen. Um dies zu automatisieren,
könnten Sie sogar ein entsprechendes Makro in Ihrem Textverarbeitungsprogramm erstellen. Einzelheiten zum Erstellen von
Makros entnehmen Sie bitte Ihrer jeweiligen Textverarbeitungssoftware.
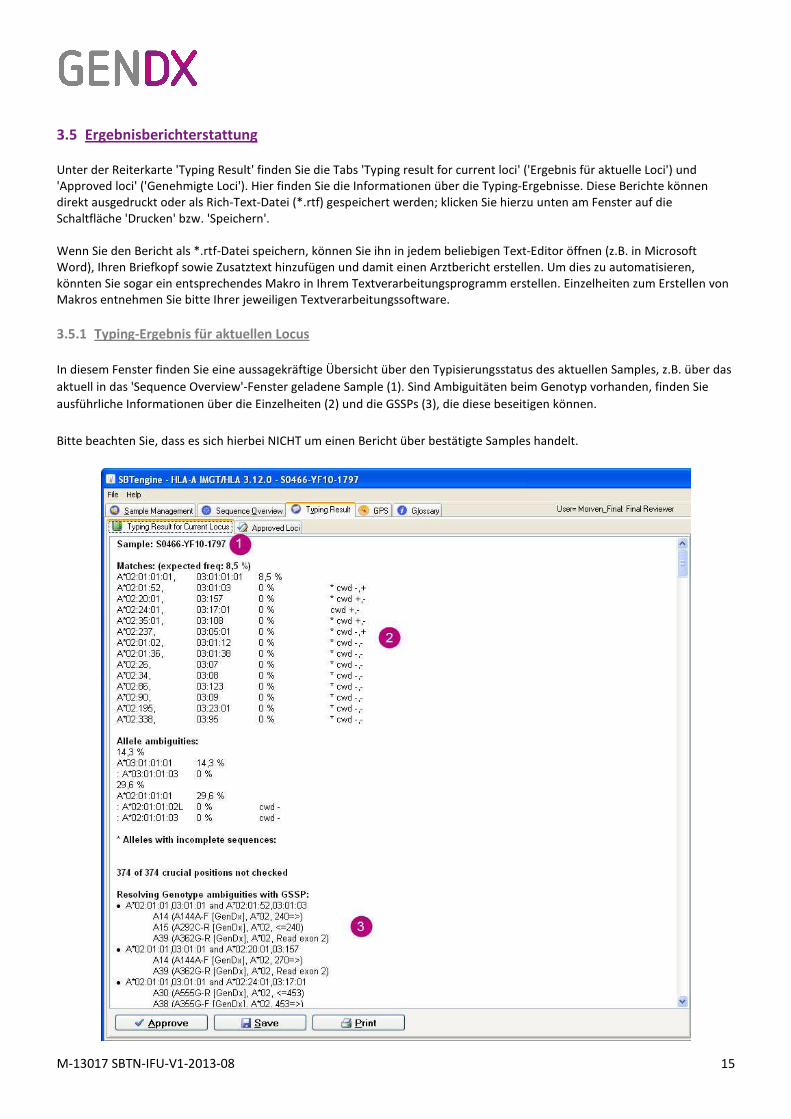
3.5.1 Typing-Ergebnis für aktuellen Locus
In diesem Fenster finden Sie eine aussagekräftige Übersicht über den Typisierungsstatus des aktuellen Samples, z.B. über das
aktuell in das 'Sequence Overview'-Fenster geladene Sample (1). Sind Ambiguitäten beim Genotyp vorhanden, finden Sie
ausführliche Informationen über die Einzelheiten (2) und die GSSPs (3), die diese beseitigen können.
Bitte beachten Sie, dass es sich hierbei NICHT um einen Bericht über bestätigte Samples handelt.
M-13017 SBTN-IFU-V1-2013-08 16
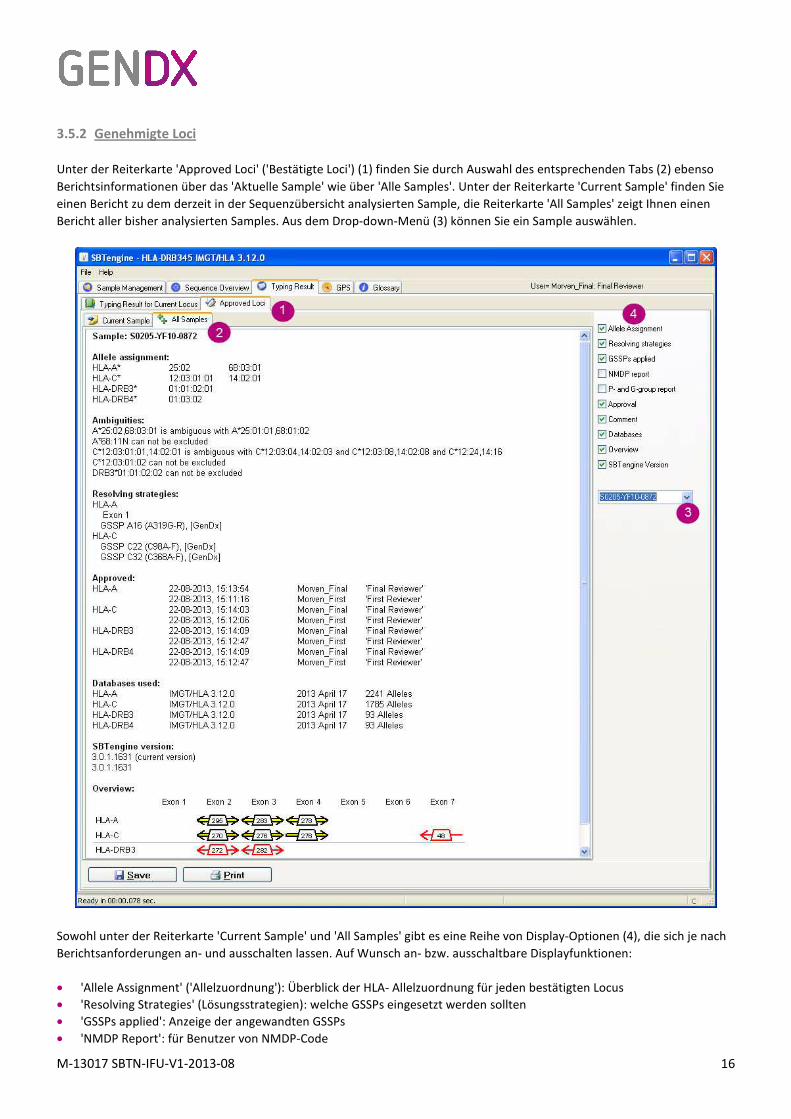
3.5.2 Genehmigte Loci
Unter der Reiterkarte 'Approved Loci' ('Bestätigte Loci') (1) finden Sie durch Auswahl des entsprechenden Tabs (2) ebenso
Berichtsinformationen über das 'Aktuelle Sample' wie über 'Alle Samples'. Unter der Reiterkarte 'Current Sample' finden Sie
einen Bericht zu dem derzeit in der Sequenzübersicht analysierten Sample, die Reiterkarte 'All Samples' zeigt Ihnen einen
Bericht aller bisher analysierten Samples. Aus dem Drop-down-Menü (3) können Sie ein Sample auswählen.
Sowohl unter der Reiterkarte 'Current Sample' und 'All Samples' gibt es eine Reihe von Display-Optionen (4), die sich je nach
Berichtsanforderungen an- und ausschalten lassen. Auf Wunsch an- bzw. ausschaltbare Displayfunktionen:
• 'Allele Assignment' ('Allelzuordnung'): Überblick der HLA- Allelzuordnung für jeden bestätigten Locus
• 'Resolving Strategies' (Lösungsstrategien): welche GSSPs eingesetzt werden sollten
• 'GSSPs applied': Anzeige der angewandten GSSPs
• 'NMDP Report': für Benutzer von NMDP-Code

M-13017 SBTN-IFU-V1-2013-08 17
• 'P and G Group Report': für Benutzer von P- und G-Gruppen (zur Vereinfachung der Berichterstattung über nicht
eindeutige Allel Typisierungen.
• 'Approval': Übersicht der Personen, die Allelzuordnungen genehmigt haben, deren Credentials sowie Angaben zu Datum
und Uhrzeit der Bestätigung. Jede Bestätigung wird gespeichert.
• Anmerkung: Anzeige aller bei der Typisierungs- Bestätigung hinzugefügten Kommentare
• 'Databases': Überblick der eingesetzten IMGT-/HLA-Datenbanken mit Angabe der Allelzahl
• 'Overview': Überblick der Sequenzdaten, die am jeweiligen Ort für die Allelzuordnung verwendet wurden. Vorwärts-
bzw. rückwärtsgerichtete Pfeile stehen für Vorwärts- bzw. Rückwärtssequenzen. Die Farbe Gelb steht für heterozygote,
Rot für homozygote Sequenzen.
Ausführliche Informationen über die Verwendung von SBTengine® finden Sie unter der Hilfefunktion im Glossar der
SBTengine®-Software.

M-13017 SBTN-IFU-V1-2013-08 18
Vertrieb
GenDx-Kunden
CE-IVD
Produktnummern und Lizenzoptionen finden Sie auf unserer Website: www.gendx.com
GenDx
Yalelaan 48
NL-3584 CM Utrecht
The Netherlands
Eine Übersicht aller lokalen GenDx-Vertriebshändler finden Sie ebenfalls auf www.gendx.com
Abbott-Kunden
CE IVD
Listennummer: 08N33-02 Listennummer: 08N33-01
Abbott
1300 East Touhy Avenue
Des Plaines, IL 60018
USA
Offizieller Vertreter in Europa
Qarad b.v.b.a.
Volmolenheide 19
B-2400 Mol, Belgium
+32 (0)14-3238-99
Version 1, 09/2013
Disclaimer
Genome Diagnostics B.V. ist bestrebt, sicherzustellen, dass diese Gebrauchsanweisung korrekt ist.
Genome Diagnostics B.V. übernimmt keine Haftung für etwaige Ungenauigkeiten oder Unterlassungen, die aufgetreten sein
können. Änderungen der Informationen in dieser Gebrauchsanweisung können ohne Vorankündigung durchgeführt werden.
Genome Diagnostics B.V. übernimmt keine Verantwortung für etwaige Ungenauigkeiten, die in dieser Gebrauchsanweisung
enthalten sein können.
Genome Diagnostics B.V. behält sich das Recht vor, Verbesserungen an dieser Gebrauchsanweisung und/oder die Produkte,
die in dieser Gebrauchsanweisung beschrieben sind, jederzeit ohne Vorankündigung vorzunehmen.
Copyright
Die Veröffentlichung, einschließlich aller Fotografien, Illustrationen, ist unter internationalen Urheberrechtgesetzen
geschützt, alle Rechte vorbehalten. Weder diese Gebrauchsanweisung noch die darin enthaltenen Materialien dürfen ohne
schriftliche Zustimmung des Autors vervielfältigt werden.
© Copyright 2013

![WATT MAS - Modulares Antriebssystem - …percentage p3 from table V1 and V2. Vedrehspiel / backlash s Übersetzung / ratio i [·] Diagramm V1 / diagram V1 Tabelle V1 / table V1 Beispiel](https://img.pdfslide.org/doc/110x75/5ec42f0037c99e4ad7465a5b/watt-mas-modulares-antriebssystem-percentage-p3-from-table-v1-and-v2-vedrehspiel.jpg)



























