Embed Size (px)
Citation preview

Grundlagen der KI
13. Maschinelles Lernen
Lernen durch Beobachtung
Michael Beetz
458
Viele Abbildungen sind dem Buch “Artificial Intelligence: A Modern Approach” entnommen. Viele Folien beruhen auf Vorlagen von Prof. Bernhard Nebel, Dr.Jana Kohler (Universitat Freiburg) und Prof. Gerhard Lakemeyer, (RWTH Aachen).
459
Inhalt
� Der lernende Agent
� Induktives Lernen
� Lernen von Entscheidungsbaumen
� Lernen von allgemeinen Hypothesen
� Warum Lernen funktioniert
460
Lernen
� Was ist lernen?Ein Agent lernt, wenn er durch Erfahrung seine Fahigkeit, eine Aufgabezu losen, verbessern kann.
� z.B. Spielprogramme� Warum lernen?
� Engineering, Philosophie, Kognitionswissenschaften
� Data Mining (Entdeckung von neuem Wissen durch Datenanalyse)
Keine Intelligenz ohne Lernen!
461
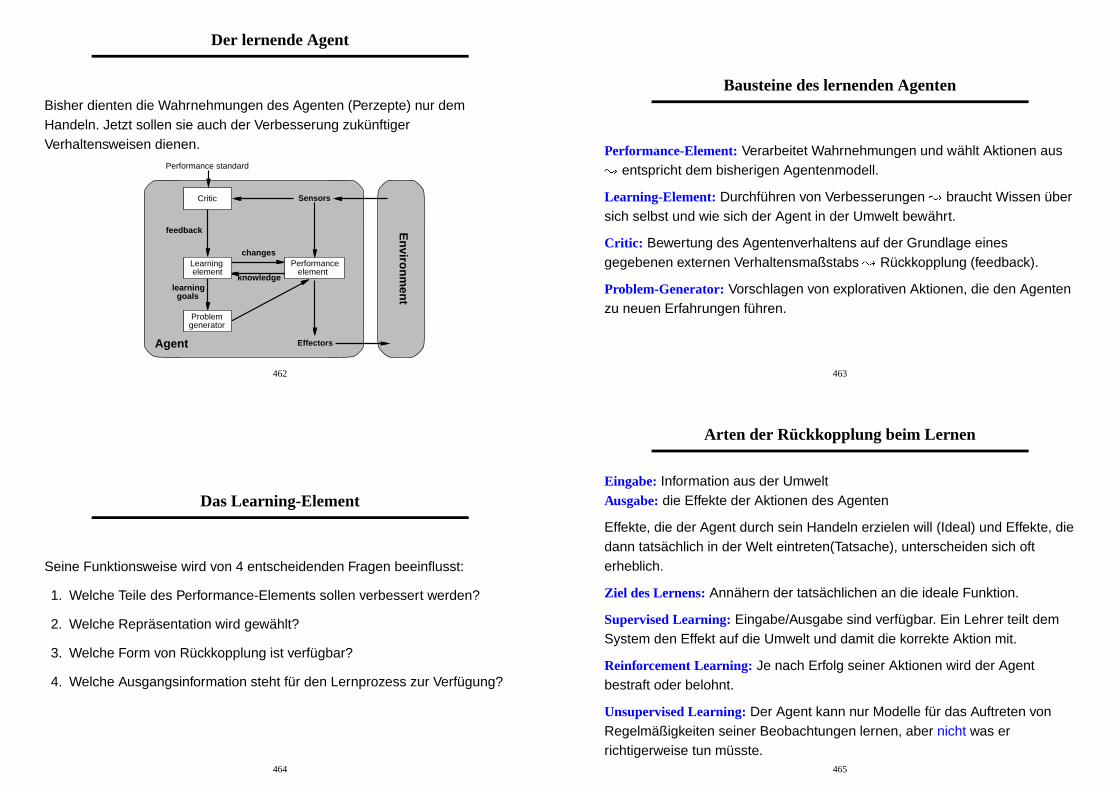
Der lernende Agent
Bisher dienten die Wahrnehmungen des Agenten (Perzepte) nur demHandeln. Jetzt sollen sie auch der Verbesserung zukunftigerVerhaltensweisen dienen.
Performance standard
Agent
En
viron
men
t
Sensors
Effectors
Performance element
changes
knowledgelearning goals
Problem generator
feedback
Learning element
Critic
462
Bausteine des lernenden Agenten
Performance-Element: Verarbeitet Wahrnehmungen und wahlt Aktionen aus
� entspricht dem bisherigen Agentenmodell.
Learning-Element: Durchfuhren von Verbesserungen � braucht Wissen ubersich selbst und wie sich der Agent in der Umwelt bewahrt.
Critic: Bewertung des Agentenverhaltens auf der Grundlage einesgegebenen externen Verhaltensmaßstabs � Ruckkopplung (feedback).
Problem-Generator: Vorschlagen von explorativen Aktionen, die den Agentenzu neuen Erfahrungen fuhren.
463
Das Learning-Element
Seine Funktionsweise wird von 4 entscheidenden Fragen beeinflusst:
1. Welche Teile des Performance-Elements sollen verbessert werden?
2. Welche Reprasentation wird gewahlt?
3. Welche Form von Ruckkopplung ist verfugbar?
4. Welche Ausgangsinformation steht fur den Lernprozess zur Verfugung?
464
Arten der Ruckkopplung beim Lernen
Eingabe: Information aus der UmweltAusgabe: die Effekte der Aktionen des Agenten
Effekte, die der Agent durch sein Handeln erzielen will (Ideal) und Effekte, diedann tatsachlich in der Welt eintreten(Tatsache), unterscheiden sich ofterheblich.
Ziel des Lernens: Annahern der tatsachlichen an die ideale Funktion.
Supervised Learning: Eingabe/Ausgabe sind verfugbar. Ein Lehrer teilt demSystem den Effekt auf die Umwelt und damit die korrekte Aktion mit.
Reinforcement Learning: Je nach Erfolg seiner Aktionen wird der Agentbestraft oder belohnt.
Unsupervised Learning: Der Agent kann nur Modelle fur das Auftreten vonRegelmaßigkeiten seiner Beobachtungen lernen, aber nicht was errichtigerweise tun musste.
465

Induktives Lernen
Jede Art von Lernen kann als das Lernen der Reprasentation einer Funktionverstanden werden.
Ein Beispiel ist ein Paar � � � � � � � � .
Induktive Inferenz: Fur eine Menge von Beispielen fur � ist eine Funktion �
(Hypothese) gesucht, die � approximiert.
oo
oo
(c)
oo
o
oo
(a)
oo
o
oo
(b)
oo
o
oo
(d)
o
Bias: Tendenz, eine bestimmte Hypothese zu bevorzugen
466
Entscheidungsbaume
Eingabe: Beschreibung einer Situation durch eine Menge von Eigenschaften(entspricht Grundliteralen in FOL).
Ausgabe: Ja/Nein Entscheidung bezuglich eines Zielpradikats.
Entscheidungsbaume stellen boolesche Funktionen dar.
Ein interner Knoten im Entscheidungsbaum reprasentiert einen Test einerEigenschaft. Zweige sind mit den moglichen Werten des Tests markiert.Jeder Blattknoten tragt den booleschen Wert, der bei Erreichen des Blatteszuruckgegeben werden soll.
Ziel des Lernprozesses: Definition eines Zielpradikates in Form einesEntscheidungsbaums
467
Restaurantbeispiel (Tests)
Patrons: wieviele Gaste sind da? (none, some, full)
WaitEstimate: Wie lange warten? (0-10, 10-30, 30-60, � 60)
Alternate: Gibt es eine Alternative? (T/F)
Hungry: Bin ich hungrig? (T/F)
Reservation: Habe ich reserviert? (T/F)
Bar: Hat das Restaurant eine Bar zum Warten? (T/F)
Fri/Sat: Ist es Freitag oder Samstag (T/F)
Raining: Regnet es draußen? (T/F)
Price: Wie teuer ist das Essen? ($, $$, $$$)
Type: Art des Restaurants? (french, italian, Thai, Burger)
468
Restaurantbeispiel (Entscheidungsbaum)
No Yes
No Yes
No Yes
No Yes
No Yes
No Yes
None Some Full
>60 30−60 10−30 0−10
No Yes
Alternate?
Hungry?
Reservation?
Bar? Raining?
Alternate?
Patrons?
Fri/Sat?
No Yes
No Yes
Yes
Yes
No Yes
YesNoYes
YesNo
WaitEstimate?
469

Reprasentation des Zielpradikats
Ein Entscheidungsbaum kann als Konjunktion von Implikationen reprasentiertwerden. Eine Implikation entspricht den Pfaden, die in einem YES Knotenenden.
� � �
Patrons(r,Full) � WaitEstimate(r,10-30) � Hungry(r,No) � WillWait(r)
�
Patrons(r,Some) � WillWait(r)
� � � � �
470
Ausdruckskraft von Entscheidungsbaumen
Theorem 1 Alle aussagenlogischen Formeln (boolesche Fakten) sind mitEntscheidungsbaumen darstellbar.
Kann ein Entscheidungsbaum eine beliebige Menge von Objekten darstellen?
� Mit traditionellen Entscheidungsbaumen nicht. Alle Tests beziehen sichimmer nur auf ein Objekt (hier: Restaurant � ) und die Sprache vontraditionellen Entscheidungsbaumen ist inharent propositional.
Zum Beispiel ist
� � Near � � � � � Price � � � � Price � � � � Cheaper � �
als Test nicht darstellbar.
Zwar konnten wir einen Test CheaperRestaurantNearby hinzufugen, aber einEntscheidungsbaum mit allen solchen Attributen wurde exponentiell wachsen.
� Erweiterungen existieren, z.B. (Blockeel und De Raedt, ArtificialIntelligence, 1998)
471
Kompakte Reprasentationen
Theoretisch kann jede Zeile einer Wahrheitswerttabelle in einen Pfad einesEntscheidungsbaums ubertragen werden. Allerdings ist die Große der Tabelleund damit des Baums exponentiell in der Anzahl der Attribute.
Funktionen, die einen Baum exponentieller Große erfordern:
Parity Funktion:
� � � ���
��
�� gerade Anzahl von Eingaben
� sonst
Majority Funktion:
� � � ���
��
�� Halfte der Eingaben ist 1
� sonst
Aber: Es gibt keine kompakte Reprasentation fur alle moglichen booleschenFunktionen.
472
Die Trainingsmenge
Klassifizierung eines Beispiels = Wert des Zielpradikats
TRUE � positives Beispiel
FALSE � negatives Beispiel
ExampleAttributes Goal
Alt Bar Fri Hun Pat Price Rain Res Type Est WillWait
X1 Yes No No Yes Some $$$ No Yes French 0–10 YesX2 Yes No No Yes Full $ No No Thai 30–60 NoX3 No Yes No No Some $ No No Burger 0–10 YesX4 Yes No Yes Yes Full $ No No Thai 10–30 YesX5 Yes No Yes No Full $$$ No Yes French >60 NoX6 No Yes No Yes Some $$ Yes Yes Italian 0–10 YesX7 No Yes No No None $ Yes No Burger 0–10 NoX8 No No No Yes Some $$ Yes Yes Thai 0–10 YesX9 No Yes Yes No Full $ Yes No Burger >60 NoX10 Yes Yes Yes Yes Full $$$ No Yes Italian 10–30 NoX11 No No No No None $ No No Thai 0–10 NoX12 Yes Yes Yes Yes Full $ No No Burger 30–60 Yes
473

Ockham’s Rasiermesser
Den trivialen Entscheidungsbaum erhalt man, indem jedes Beispiel in einemPfad reprasentiert wird.
� reprasentiert nur die Erfahrung des Agenten
� keine Extraktion eines allgemeineren Musters
� besitzt keine Vorhersagekraft
Ockham’s razor:”Die wahrscheinlichste Hypothese ist die einfachste,
die alle Beispiele umfasst.“
� Baum mit der minimalen Anzahl von Tests
Leider ist das Erzeugen des kleinsten Entscheidungsbaums nichthandhabbar.
� Heuristiken, die zu einer kleinen Menge von Tests fuhren
474
Gewichtung von Attributen
Wahle das Attribut aus, das die großtmogliche Unterscheidung der Beispiele erlaubt.
Beispiel: Patrons? ist gunstig, weil im NONE/SOME-Fall keine weiteren Tests benotigt werden.
Type? hingegen ist ungunstig.
None Some Full
Patrons?
Yes No
(a)
French Italian Thai Burger
(b)
(c)
Type?
None Some Full
Patrons?
Hungry?
NY
+: X1,X3,X4,X6,X8,X12−: X2,X5,X7,X9,X10,X11
+: −: X7,X11
+: X1,X3,X6,X8−:
+: X4,X12−: X2,X5,X9,X10
+: X1,X3,X4,X6,X8,X12−: X2,X5,X7,X9,X10,X11
+: X1−: X5
+: X6−: X10
+: X4,X8−: X2,X11
+: X3,X12−: X7,X9
+: X1,X3,X4,X6,X8,X12−: X2,X5,X7,X9,X10,X11
+: −: X7,X11
+: X1,X3,X6,X8−:
+: X4,X12−: X2,X5,X9,X10
+: X4,X12−: X2,X10
+: −: X5,X9
475
Rekursives Lernverfahren
Nach jedem Test liegt wieder ein Entscheidungsbaum-Lernproblem vor,wobei wir weniger Beispiele haben und die Anzahl der Attribute um einsreduziert ist.
Fur den rekursiven Fall mussen 4 Falle betrachtet werden:
1. Positive und Negative Beispiele: Wahle neues Attribut.
2. Nur positive (oder nur negative) Beispiele: fertig.
3. Keine Beispiele: es gab kein Beispiel mit dieser Eigenschaft. Antworte JA,wenn Mehrzahl der Beispiele des Vaterknotens positiv ist, sonst NEIN.
4. Keine Attribute mehr, aber noch Beispiele mit unterschiedlicherKlassifikation: es lagen Fehler in den Daten vor (� NOISE) oder dieAttribute sind unzureichend. Reagiere wie im vorherigen Fall.
476
Der Algorithmus
function DECISION-TREE-LEARNING(examples, attributes, default) returns a decision treeinputs: examples, set of examples
attributes, set of attributesdefault, default value for the goal predicate
if examples is empty then return defaultelse if all examples have the same classification then return the classificationelse if attributes is empty then return MAJORITY-VALUE(examples)else
best � CHOOSE-ATTRIBUTE(attributes, examples)tree � a new decision tree with root test bestfor each value vi of best do
examplesi � � elements of examples with best = vi �
subtree � DECISION-TREE-LEARNING(examplesi, attributes � best,MAJORITY-VALUE(examples))
add a branch to tree with label vi and subtree subtreeendreturn tree
477
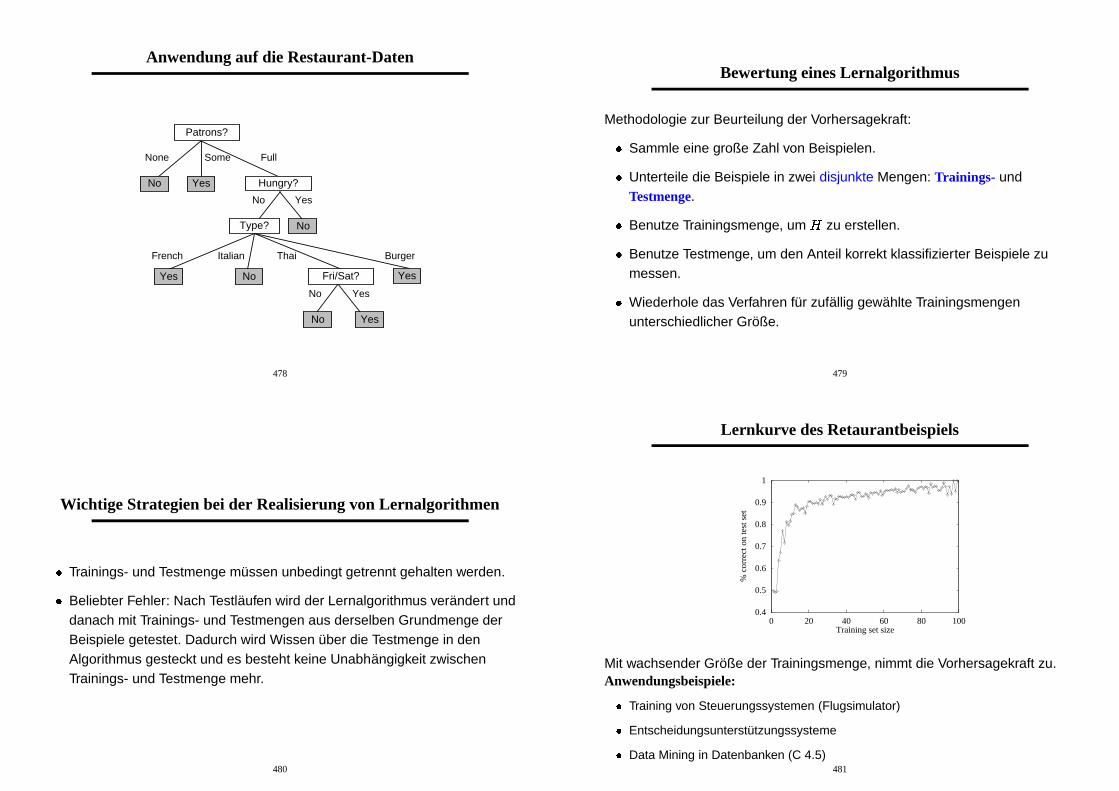
Anwendung auf die Restaurant-Daten
No Yes
Fri/Sat?
YesNo
None Some Full
Patrons?
No Yes
No Yes
Hungry?
No
Yes
Type?
French Italian Thai Burger
Yes No
478
Bewertung eines Lernalgorithmus
Methodologie zur Beurteilung der Vorhersagekraft:
� Sammle eine große Zahl von Beispielen.
� Unterteile die Beispiele in zwei disjunkte Mengen: Trainings- undTestmenge.
� Benutze Trainingsmenge, um � zu erstellen.
� Benutze Testmenge, um den Anteil korrekt klassifizierter Beispiele zumessen.
� Wiederhole das Verfahren fur zufallig gewahlte Trainingsmengenunterschiedlicher Große.
479
Wichtige Strategien bei der Realisierung von Lernalgorithmen
� Trainings- und Testmenge mussen unbedingt getrennt gehalten werden.
� Beliebter Fehler: Nach Testlaufen wird der Lernalgorithmus verandert unddanach mit Trainings- und Testmengen aus derselben Grundmenge derBeispiele getestet. Dadurch wird Wissen uber die Testmenge in denAlgorithmus gesteckt und es besteht keine Unabhangigkeit zwischenTrainings- und Testmenge mehr.
480
Lernkurve des Retaurantbeispiels
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
% c
orre
ct o
n te
st s
et
Training set size
Mit wachsender Große der Trainingsmenge, nimmt die Vorhersagekraft zu.Anwendungsbeispiele:
� Training von Steuerungssystemen (Flugsimulator)
� Entscheidungsunterstutzungssysteme
� Data Mining in Datenbanken (C 4.5)481
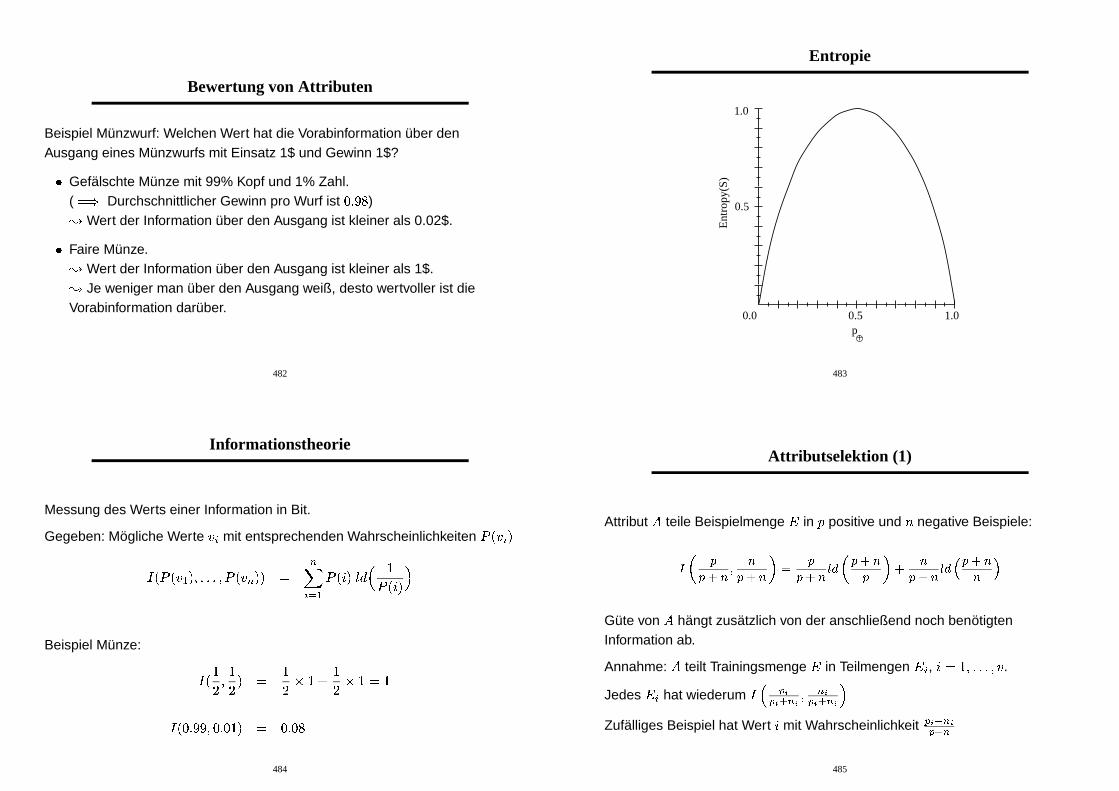
Bewertung von Attributen
Beispiel Munzwurf: Welchen Wert hat die Vorabinformation uber denAusgang eines Munzwurfs mit Einsatz 1$ und Gewinn 1$?
� Gefalschte Munze mit 99% Kopf und 1% Zahl.(� � Durchschnittlicher Gewinn pro Wurf ist �� �� )
� Wert der Information uber den Ausgang ist kleiner als 0.02$.
� Faire Munze.
� Wert der Information uber den Ausgang ist kleiner als 1$.
� Je weniger man uber den Ausgang weiß, desto wertvoller ist dieVorabinformation daruber.
482
Entropie
Ent
ropy
(S)
1.0
0.5
0.0 0.5 1.0p+
483
Informationstheorie
Messung des Werts einer Information in Bit.
Gegeben: Mogliche Werte � � mit entsprechenden Wahrscheinlichkeiten � � � � �
� � � � � � � �� � � � � � � � �
�
�� � � � � � �� � �� �� ���
Beispiel Munze:
� �� � �� � �
� � ��� � � � ��� � � �
� � �� � � � �� �� �
� �� � �
484
Attributselektion (1)
Attribut � teile Beispielmenge � in � positive und � negative Beispiele:
� � � � � � � � � � � �"!# � ��
���
� �!# $ � ��%
Gute von � hangt zusatzlich von der anschließend noch benotigtenInformation ab.
Annahme: � teilt Trainingsmenge � in Teilmengen � � ,� � � �� � � � � .Jedes � � hat wiederum � �'& (& () ( �
(& () (�
Zufalliges Beispiel hat Wert� mit Wahrscheinlichkeit& () (& )
485
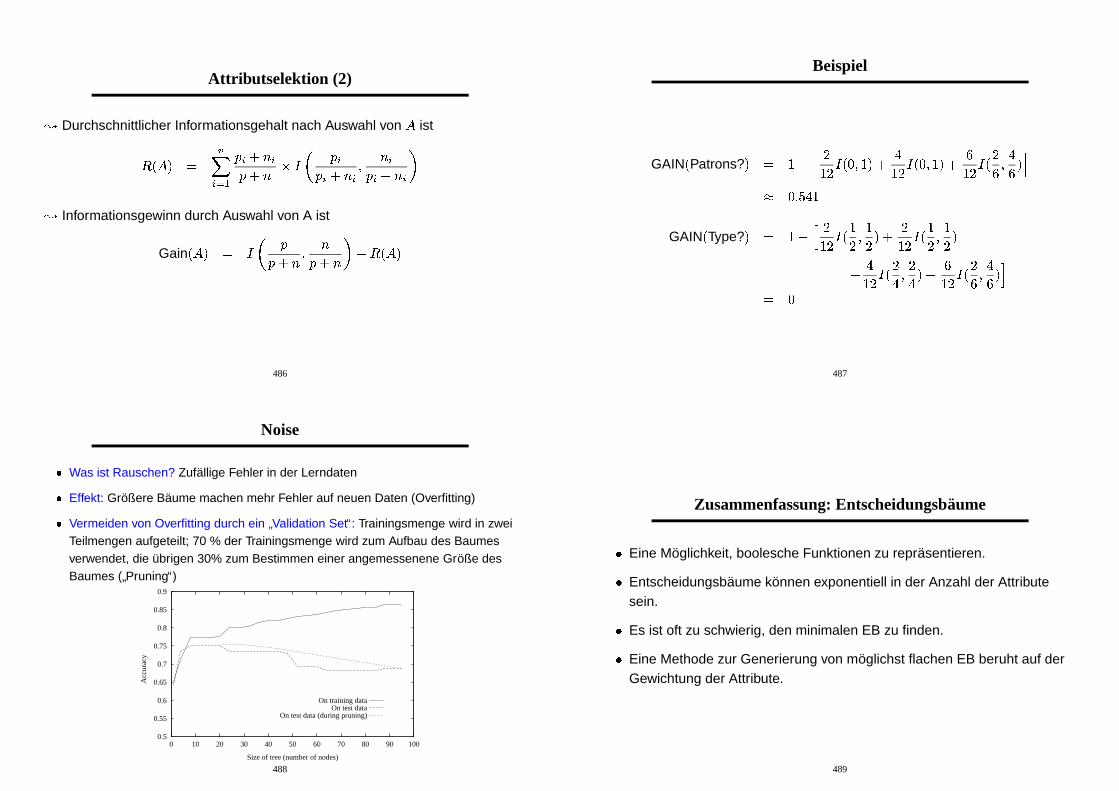
Attributselektion (2)
� Durchschnittlicher Informationsgehalt nach Auswahl von � ist� � � �
�
� �� �
� � � � �� � � � �
�
� �� � � � � �
� �� � � � � �
� Informationsgewinn durch Auswahl von A ist
Gain � � �
� ��
�� � � �
�� � � �
� � � � �
486
Beispiel
GAIN � Patrons? �
� � �
��
� � � � � �� � � �� � � � � �� � � �� � � ��
��
��
��
�� ��
GAIN � Type? �
� � �
��
� � � �� � �� � � � �� � � �� � �� � �
� �� � � ��
���
�� � �
� � � ��
��
��
��
� �
487
Noise
� Was ist Rauschen? Zufallige Fehler in der Lerndaten
� Effekt: Großere Baume machen mehr Fehler auf neuen Daten (Overfitting)
� Vermeiden von Overfitting durch ein”Validation Set“: Trainingsmenge wird in zwei
Teilmengen aufgeteilt; 70 % der Trainingsmenge wird zum Aufbau des Baumesverwendet, die ubrigen 30% zum Bestimmen einer angemessenene Große desBaumes (
”Pruning“)
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0 10 20 30 40 50 60 70 80 90 100
Acc
urac
y
Size of tree (number of nodes)
On training dataOn test data
On test data (during pruning)
488
Zusammenfassung: Entscheidungsbaume
� Eine Moglichkeit, boolesche Funktionen zu reprasentieren.
� Entscheidungsbaume konnen exponentiell in der Anzahl der Attributesein.
� Es ist oft zu schwierig, den minimalen EB zu finden.
� Eine Methode zur Generierung von moglichst flachen EB beruht auf derGewichtung der Attribute.
489

Lernen von allgemeinen Hypothesen
1-stelliges Zielpradikat � � WillWait � � �
Der Hypothesenraum H ist die Menge aller logischen Definitionen fur � . Ist
� � eine mogliche Definition, so hat jede Hypothese � � die Form
� � � � � �� � � � � �
Restaurant-Beispiel: Hypothese � �
� � WillWait � ��
Patrons � � some ��
Patrons � � �� ! ! � � Hungry � � � Type � � French ��
Patrons � � full � � Hungry � � � Type � � Thai � � Fri Sat � ��
Patrons � � �� ! ! � � Hungry � � � Type � � Burger �
Die Disjunktion der aktuellen Hypothesen � �� � � � � � ist wahr.
Extension einer Hypothese: Menge der Beispiele, die � � erfullen.490
Trainingsbeispiel und Hypothese
� � ��� � � ist Beschreibung des� -ten Beispiels� �
�!� � � �� � � �� � � � � � � �� � � � � �� � � � �� � � �� � � � � � � � � � � � �! � ! ! ! � �� �� � �
Die Klassifizierung eines positiven Beispiels� � ist � ��� � � , die eines negativenist " � � � � � .
Die vollstandige Trainingsmenge ist die Konjunktion aller Satze.
Eine Hypothese stimmt mit den Beispielen uberein gdw. sie logisch konsistentmit der Trainingsmenge ist.
Hypothesen konnen mit einzelnen Beispielen inkonsistent sein:
1. false negative: � sagt, dass� negativ sein muss, aber tatsachlich ist�
positiv.
2. false positive: � sagt, dass� positiv sein muss, aber tatsachlich ist�
negativ.491
Suchverfahren: Current-best Hypothesis
Betrachtet immer nur eine Hypothese, deren Extension bei auftretendenInkonsistenzen verandert wird.
� Generalisierung: Erweiterung bei false negative (b+c)
� Spezialisierung: Verkleinern bei false positive (d+e)
(a) (b) (c) (d) (e)
++
+
++
+ +
−−
−
−
−−
−
− −−
−
++
+
++
+ +
−−
−
−
−−
−
− −−
−
+
++
+
++
+ +
−−
−
−
−−
−
− −−
−
+
++
+
++
+ +
−−
−
−
−−
−
− −
−
+−
++
+
++
+ +
−−
−
−
−−
−
− −
−
+
− −
−
Nach jeder Veranderung muss erneut auf Konsistenz getestet werden, damitauch die bisherigen Beispiele von der modifizierten Hypothese noch korrektklassifiziert werden.
492
Der Algorithmus
function CURRENT-BEST-LEARNING(examples) returns a hypothesis
H # any hypothesis consistent with the first example in examplesfor each remaining example in examples do
if e is false positive for H thenH # choose a specialization of H consistent with examples
else if e is false negative for H thenH # choose a generalization of H consistent with examples
if no consistent specialization/generalization can be found then failendreturn H
� � ist Generalisierung von � � : � � � � � � � � � � � � �
� dropping conditions (Konjunkte streichen)
� schwachere Definition wird von mehr Beispielen erfulltSpezialisierung analog durch Hinzufugen von Konjunkten oder Streichen vonDisjunkten (sprachabhangig).
493

Beispiel (1)
ExampleAttributes Goal
Alt Bar Fri Hun Pat Price Rain Res Type Est WillWait
X1 Yes No No Yes Some $$$ No Yes French 0–10 YesX2 Yes No No Yes Full $ No No Thai 30–60 NoX3 No Yes No No Some $ No No Burger 0–10 YesX4 Yes No Yes Yes Full $ No No Thai 10–30 YesX5 Yes No Yes No Full $$$ No Yes French >60 NoX6 No Yes No Yes Some $$ Yes Yes Italian 0–10 YesX7 No Yes No No None $ Yes No Burger 0–10 NoX8 No No No Yes Some $$ Yes Yes Thai 0–10 YesX9 No Yes Yes No Full $ Yes No Burger >60 NoX10 Yes Yes Yes Yes Full $$$ No Yes Italian 10–30 NoX11 No No No No None $ No No Thai 0–10 NoX12 Yes Yes Yes Yes Full $ No No Burger 30–60 Yes
1. Beispiel� � ist positiv. � !� � � �� � � �� � � ist wahr
� �� � � WillWait � � � Alternate � � .
2. Beispiel� ist false positive:� � spezialisieren
� � � � WillWait � � � Alternate � � � Patrons � � some �
494
Beispiel (2)
3. � � ist false negative:� generalisieren
� � � � � WillWait � � � Patrons � � some �
4. � � ist false negative:� � generalisierenFallenlassen von Patrons � � some � widerspricht� . Disjunktion hinzufugen, z.B.
� � � � � WillWait � � � Patrons � � some � �
�Patrons � � full � � Fri Sat � � �
495
Nachteile von Current-best Hypothesis
� Alle vorherigen Beispiele mussen nochmals uberpruft werden.
� Es wird nicht garantiert die einfachste Hypothese gefunden.
� Gute Heuristiken fur die Suche sind schwierig zu finden.
� Suche kann leicht in eine Sackgasse fuhren, in der keine Modifizierungzu einer konsistenten Hypothese fuhrt.
Backtracking ist notwendig, da zu jedem Zeitpunkt nur eine Hypotheseaufrechterhalten wird. Der Hypothesenraum ist jedoch eine Disjunktion!
� Version Space
496
Version-Space/Candidate-Elimination Learning
function VERSION-SPACE-LEARNING(examples) returns a version spacelocal variables: V, the version space: the set of all hypotheses
V � the set of all hypothesesfor each example e in examples do
if V is not empty then V � VERSION-SPACE-UPDATE(V, e)endreturn V
function VERSION-SPACE-UPDATE(V, e) returns an updated version space
V � � h � V : h is consistent with e �
Mit jedem inkonsistenten Beispiel wird der Hypothesenraum reduziert. DasVerfahren ist inkrementell und auch ein Beispiel fur least commitment, da derHypothesenraum nur an auftretende Inkonsistenzen angepasst wird.
� kompakte Reprasentation des Hypothesenraums?
497
Boundary Set
Generalisierung/Spezialisierung definieren eine partielle Ordnung auf denHypothesen.
Der Hypothesenraum lasst sich durch die Menge der
� allgemeinsten (most general) Hypothesen G-Set und
� speziellsten (most specific) Hypothesen S-Set reprasentieren.
Theorem 2 Eine Hypothese � ist konsistent gdw. sie eine Generalisierungeines Elements von S-Set und eine Spezialisierung eines Elements vonG-Set ist.
G-Set = � �� �� �
S-Set = ��� � � �
TRUE und FALSE sind boolesche Funktionen (Konstanten).
498
Update des Boundary Sets (1)
Seien G = �� � �� � � �� � und S = �� � �� � � �� � .Sei� ein neues Beispiel.
� � ist false positive fur� � .
� � � zu allgemein: �� � � � � � �
� � ist false negative fur� � .
� � � zu spezifisch: generalisiere� � .
� � ist false positive fur� � .
� � � zu allgemein: spezialisiere� � .
� � ist false negative fur� � .
� � � zu spezifisch: � � � � � �� � �
499
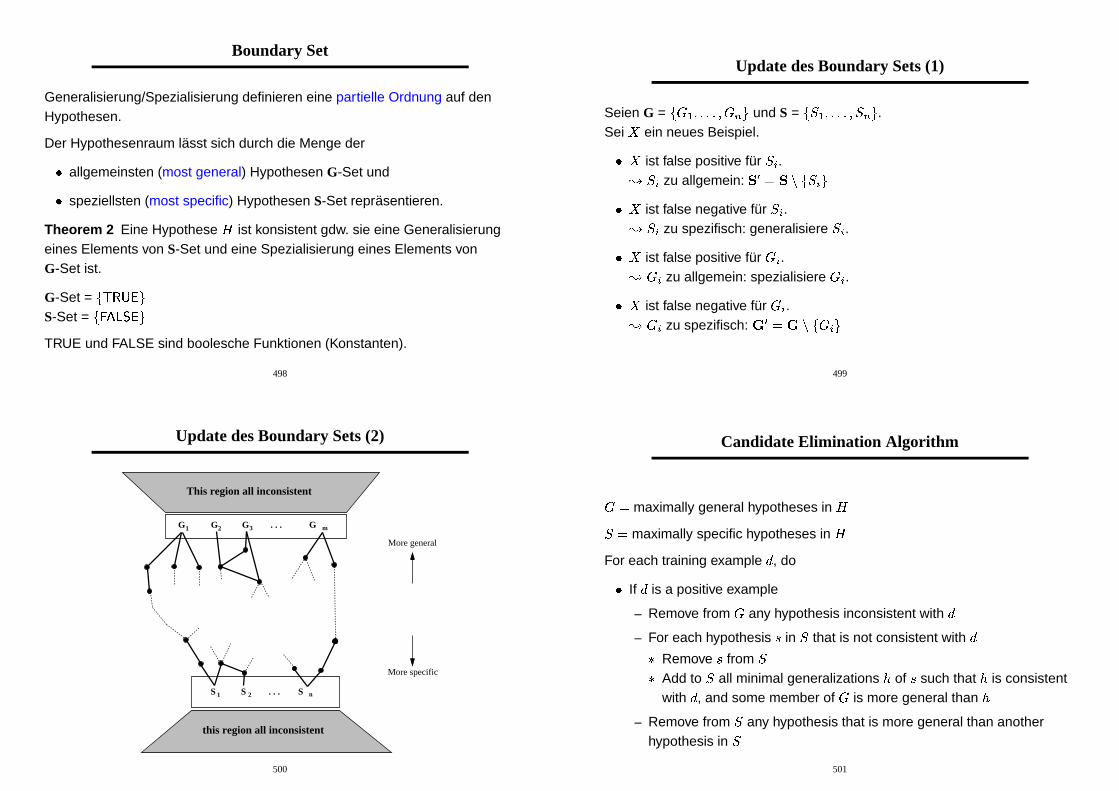
Update des Boundary Sets (2)
this region all inconsistent
This region all inconsistent
More general
More specific
S 1
G1
S 2
G2 G3 . . . G m
. . . S n
500
Candidate Elimination Algorithm
� � maximally general hypotheses in �
� � maximally specific hypotheses in �
For each training example� , do
� If� is a positive example
– Remove from� any hypothesis inconsistent with�
– For each hypothesis � in� that is not consistent with�
� Remove � from�
� Add to� all minimal generalizations � of � such that � is consistentwith� , and some member of� is more general than �
– Remove from� any hypothesis that is more general than anotherhypothesis in�
501

Candidate Elimination Algorithm (ctd.)
� If� is a negative example
– Remove from� any hypothesis inconsistent with�
– For each hypothesis � in� that is not consistent with�
� Remove � from�
� Add to� all minimal specializations � of � such that � is consistentwith� , and some member of� is more specific than �
– Remove from� any hypothesis that is less general than anotherhypothesis in�
502
Terminierung (1)
3 Moglichkeiten:
1. Genau eine Hypothese bleibt ubrig.
� Losung
2. Der Hypothesenraum kollabiert (S oder G leer).
� keine konsistente Hypothese moglich
3. Eine Menge von Hypothesen bleibt ubrig.
� Disjunktion als Ergebnis (Klassifikation eines Testbeispiels ist Mehrheitder Klassifikation der einzelnen Disjunkte.)
503
Terminierung (2)
Probleme:
� Bei Rauschen (Noise) oder ungenugender Information kollabiert derHypothesenraum immer.
� Bei Zulassen beliebiger Disjunktion enthalt S eine speziellste Hypothese(die Disjunktion der Beschreibungen aller positiven Beispiele), und G eineallgemeinste Hypothese (die Negation der Disjunktion derBeschreibungen aller negativen Beispiele).
504
Warum Lernen funktioniert
Wie kann man entscheiden, dass � dicht an � liegt, wenn � doch aberunbekannt ist?
� Probably Approximately Correct
Stationarity als Grundannahme des PAC-Learning: Trainings- und Testmengewerden mit der gleichen Wahrscheinlichkeitsverteilung aus der Populationausgewahlt.
Wieviele Beispiele braucht man?� Beispielmenge
� Population
� Hypothesenraum ( � � � )
� Anzahl der Beispiele in der Trainingsmenge
� � �� � � � ��� � � � � � � ��� � � � � � �
505

PAC Lernen
Eine Hypothese � heißt approximativ korrekt gdw. � � �� � � � � � � .
Zu zeigen: nach dem Training mit � Beispielen ist jede konsistenteHypothese mit hoher Wahrscheinlichkeit approximativ korrekt.
f
Hbad
H
∋Wie hoch ist die Wahrscheinlichkeit, daß eine falsche Hypothese � � � � �� �
konsistent mit den ersten � Beispielen ist?
506
Sample Complexity
Annahme: � � �� � � � � � � � . �
� � � � kons. mit� Beispiel � � �� � � �
� � � � kons. mit � Beispielen � � �� � � ���
� � � � � � enthalt kons. � � � � � � � � � �� � � ���
Es gilt auf jeden Fall � � �� � � � � � � und damit
� � � � �� � � ���
Forderung:
� � � �� � � �� �
wegen � �� � � � � � � gilt das, falls
� � � � � �� � � � � � �
Sample complexity: Anzahl benotigter Beispiele als Funktion uber � und .507
Sample Complexity (2)
Sample complexity realisiert ein Maß, um den Trainingsaufwandabzuschatzen.
Ist eine Hypothese mit � � � � � �� � � � � � � Beispielen konsistent, dann istFehler einer Wahrscheinlichkeit von wenigstens� � hochstens � .
Problem: Bestimmung der Große des Hypothesenraums
Beispiel: boolesche Funktionen
Anzahl boolescher Funktionen uber � Attributen ist � � � ��� .
Die Sample complexity wachst daher mit � .Weil � gerade die Anzahl moglicher Beispiele ist, gibt es keinenLernalgorithmus, der besser ist als eine Lookup-Tabelle und gleichzeitigkonsistent mit allen bekannten Beispielen ist.
508
Die Abschatzung
�� � �� � � ��� � �
! � �� � �� � � ��� � ! � �
! � �� �� � ! � � � � � � ! � �
Es gilt die Abschatzung! � ��� � � � � und mit �� � � erhalten wir! � �� � � � � � � .
! � �� � � � � � ! � �
�� ! � �� � � � � �� ! � �
�� ! � �� � � �� �� ! � �
�� $! � �� � � ! � �% � �
� Fur die booleschen Funktionen wachst � exponentiell, da� doppelt exponentiell
wachst.
Dilemma: Schrankt man den Hypothesenraum nicht ein, dann kann kein Algorithmus
richtig lernen. Schrankt man ihn ein, dann wird � eventuell eliminiert.509

Lernen von Entscheidungslisten
Im Vergleich zu Entscheidungsbaumen:
� die Gesamtstruktur ist einfacher
� der einzelne Test komplexer
>
Y
N
Y
N
Yes Yes
NoPatrons(x,Some) Patrons(x,Full) Fri/Sat(x)
Dies entspricht der Hypothese
� � � � � WillWait � � �� Patrons � � � some �� � Patrons � � � full � � Fri � Sat � � ��
Sind Tests von beliebiger Lange zugelassen, so konnen beliebige boolescheFunktionen dargestellt werden.
k-DL: Sprache mit Tests der Lange � � .
k-DT � k-DL510
Lernbarkeit von k-DL
function DECISION-LIST-LEARNING(examples) returns a decision list, No or failure
if examples is empty then return the value Not � a test that matches a nonempty subset examplest of examples
such that the members of examplest are all positive or all negativeif there is no such t then return failureif the examples in examplest are positive then o � Yeselse o � Noreturn a decision list with initial test t and outcome o
and remaining elements given by DECISION-LIST-LEARNING(examples examplest)
� k-DL(n) � � �� �� � �� �� �� � �� � � � � �� � ��� (Yes,No,kein-Test, alle Permutationen)
�� � � � � � � � � � �� �� �
! �� " (Kombination ohne Wdh. von pos/neg Attribut)
� # � � �
� k-DL(n) � � !%$ ��'& () ��'& � � (mit Eulerscher Summenformel)
� * �� $! � � �� # � � !# � � � �%
511
Zusammenfassung
Induktives Lernen als das Lernen der Reprasentation einer Funktion anhandvon Beispielen ihres Eingabe/Ausgabe-Verhaltens.
� Entscheidungsbaume/discrimination nets lernen deterministischeboolesche Funktionen.
� Current-best Hypothesis als Methode zum Lernen logischer Theorien, diezu jedem Zeitpunkt genau eine Hypothese verfolgt.
� Version Space/Candidate Elimination als Methode zum Lernen logischerTheorien, deren Grundlage eine kompakte Reprasentation desHypothesenraums ist.
� PAC Lernen beschaftigt sich mit der Komplexitat des Lernens.
� Entscheidungslisten als”einfach“ zu lernende Funktionen.
512
Grundlagen der KI
14. Reinforcement Lernen
Passives und Aktives Lernen
Michael Beetz
513

Viele Abbildungen sind dem Buch “Artificial Intelligence: A Modern Approach” entnommen. Viele Folien beruhen auf Vorlagen von Prof. Bernhard Nebel, Dr.Jana Kohler (Universitat Freiburg) und Prof. Gerhard Lakemeyer, (RWTH Aachen).
514
Inhalt
� Naives Aktualisieren
� Adaptive Dynamische Programmierung
� Zeitliche Differenz
� Exploration
� Q Lernen
� Eingabe-Generalisierung
� Einige Anwendungen
515
Grundidee des Reinforcement Lernen
Der Agent hat kein Modell der Umgebung � � � � und keine Nutzenfunktion � �� �
fur Zustande.
Der Agent bekommt mitgeteilt, ob seine Aktionsfolge erfolgreich war odernicht. Die “richtigen” oder besseren Aktionen erfahrt er jedoch nicht. �
reward/reinforcement
Beispiel: Gewinnen/Verlieren in einem Brettspiel durch zufallige Zuge
passives Lernen: Der Agent beobachtet die Welt und versucht, den Nutzenverschiedener Zustande einzuschatzen.
aktives Lernen: Der Agent fuhrt explorative Aktionen aus, um unbekannteZustande seiner Umgebung zu erkunden. Dabei wird das bereits gelernteWissen verwendet.
516
Uberblick: Was lernen wir kennen?
function PASSIVE-RL-AGENT(e) returns an actionstatic: U, a table of utility estimates
N, a table of frequencies for statesM, a table of transition probabilities from state to statepercepts, a percept sequence (initially empty)
add e to perceptsincrement N[STATE[e]]U � UPDATE(U, e, percepts, M, N)if TERMINAL?[e] then percepts � the empty sequencereturn the action Observe
3 verschiedene “Update”-Funktionen fur den passiven Agenten:
1. naives Aktualisieren (ohne Modell)
2. adaptives dynamisches Programmieren (mit Modell)
3. zeitliche Differenz (ohne Modell)
Wie lernt man ein Modell?
Wie lernt man aktiv?517

Passives Lernen einer Nutzenfunktion
Die Umwelt erzeugt Zustandsubergange, die der Agent wahrnimmt= der Agent bestimmt, was eine gegebene Strategie wert ist.
� Der Agent muss das Transitionsmodell � � � kennen.
(a)
1 2 3
1
2
3
− 1
+ 1
4
START
−1
+1
.5
.33
.5
.33 .5
.33
.5
1.0.33
.33
.33
(b)
1.0.5
.5
.5
.5
.5
.5
.5
.5
.33
.33
.33
1 2 3
1
2
3
− 1
+ 1
4
(c)
−0.0380
−0.0380
0.0886 0.2152
−0.1646
−0.2911
−0.4430
−0.5443 −0.7722
eine mogliche Trainingssequenz: � �� � ! � � � � � � ! � � � � � � � �
Ziel ist es, � �� � fur jeden Nicht-Endzustand� zu lernen
� �� � = reward-to-Go bei additiver FunktionSumme der Rewards von� zum Endzustand
518
Das Naive Aktualisierungsverfahren (NA)
Annahme: beobachteter Reward-to-Go bestimmt tatsachlichen Reward-to-Go
function LMS-UPDATE(U, e, percepts, M, N) returns an updated U
if TERMINAL?[e] then reward-to-go � 0for each ei in percepts (starting at end) do
reward-to-go � reward-to-go + REWARD[ei]U[STATE[ei]] � RUNNING-AVERAGE(U[STATE[ei]], reward-to-go, N[STATE[ei]])
end
� Lernen der Nutzenfunktion aus Beispielen (Zustand,Reward-to-Go)
� Reinforcement Lernen auf induktives Lernen reduziert
Problem:
NA Verfahren ignoriert den Einfluss der Wahrscheinlichkeit, mit der bestimmteZustandsubergange eintreten.
519
Lernkurve fur das NA Verfahren
Die Wahrscheinlichkeiten der Zustandsubergange werden ignoriert. DieLernkurve konvergiert sehr langsam (mehr als 1000 Epochen sind notig).
-1
-0.5
0
0.5
1
0 200 400 600 800 1000
Util
ity e
stim
ates
Number of epochs
(4,3)
(3,3)(2,3)
(1,1)(3,1)
(4,1)(4,2)
Der tatsachliche Nutzen eines Zustandes ist520
= gewichteter Nutzen seiner Nachfolgerzustande+ eigener Nutzen
521

Reinforcement Lernen durch Adaptives DynamischesProgrammieren
� �� �� � � � � �
�� � � � �� �
Hinweis: Aktionen spielen keine Rolle fur einen passiven Agenten
� � � Belohnung fur Erreichen des Zustands�
� � � Wahrscheinlichkeiten der Zustandsubergange
ADP ist ein Standard, mit dem andere Reinforcement Lernverfahren bewertetwerden.Nicht handhabbar fur grosse Zustandsraume: Fur Backgammon mussten
� ���� Gleichungen mit� � �� Unbekannten gelost werden.
� Temporal Difference Lernen
522
Temporal Difference Lernen
� � � ��� � �� � �� � � �� � � � �� �� � �� ��
Bei einem beobachteten Zustandsubergang von� nach� wird der Wert von�
an den Wert von� mit Lernrate� angepasst.
function TD-UPDATE(U, e, percepts, M, N) returns the utility table U
if TERMINAL?[e] thenU[STATE[e]] RUNNING-AVERAGE(U[STATE[e]], REWARD[e], N[STATE[e]])
else if percepts contains more than one element thene the penultimate element of perceptsi, j STATE[e ], STATE[e]U[i] U[i] +� (N[i])(REWARD[e ] + U[j] - U[i])
523
-1
-0.5
0
0.5
1
0 200 400 600 800 1000
Util
ity e
stim
ates
Number of epochs
(4,3)
(3,3)(2,3)
(1,1)(3,1)
(4,1)
(4,2)
524
Passives Lernen in einer unbekannten Umgebung
Bisher hatten wir angenommen, dass der Agent � � � kennt
� NA und TD verwenden nur Folgezustands/ Endzustands-Information
� ADP muss ein vermutetes Modell der Umgebung aktualisierenLernen von � � �
� durch direktes Beobachten von Zustandsubergangen
� jedes Perzept ist ein Ein-/Ausgabe Paar der TransitionsfunktionJedes induktive Lernverfahren fur stochastische Funktionen ist geeignet.Ganz einfach: Wie oft tritt ein Zustandsubergang in einem Zeitraum auf?
525

-1
-0.5
0
0.5
1
0 100 200 300 400 500
Util
ity e
stim
ates
Number of epochs
(4,3)
(3,3)(2,3)
(1,1)
(3,1)
(4,1)(4,2)
526
Aktives Lernen in einer unbekannten Umgebung
Das Transitionsmodell muss jetzt die moglichen Aktionen des Agenenberucksichtigen, d.h. wir rechnen mit � � � � .
Die ursprungliche Gleichung aus dem Werte-iterations-verfahren mussverwendet werden:
� �� �
� � �� � � �� �� �
� � � �� � �� �
Der Agent verwendet sein Performance Element, um eine mogliche Aktionauszuwahlen.
527
Performance Element
function ACTIVE-ADP-AGENT(e) returns an actionstatic: U, a table of utility estimates
M, a table of transition probabilities from state to state for each actionR, a table of rewards for statespercepts, a percept sequence (initially empty)last-action, the action just executed
add e to perceptsR[STATE[e]] � REWARD[e]M � UPDATE-ACTIVE-MODEL(M, percepts, last-action)U � VALUE-ITERATION(U, M, R)if TERMINAL?[e] then
percepts � the empty sequencelast-action � PERFORMANCE-ELEMENT(e)return last-action
528
Exploration (1)
Gibt es eine optimale Erkundungsstrategie?
Der “dumme” Agent wahlt zufallig Aktionen aus in der Hoffnung, so dieUmgebung vollstandig zu erkunden � findet eher zufallig eine Losung,optimiert seinen Nutzen nicht zielgerichtet.
Der “gierige” Agent maximiert seinen gegenwartigen Nutzen auf Basis deraktuellen Schatzungen � einmal eine Losung gefunden, wird der Agent nichtbesser.
� Agenten finden nicht immer optimale Losung
� statistische Entscheidungstheorie: Banditenprobleme
� einfache Losung: unbekannten (Zustand,Aktion) Paaren einen hoheren Nutzenzuweisen
529

Exploration (2)
��� � � expected reward-to-go
� � �� � wie oft wurde Aktion a in Zustand i ausgefuhrt
fur Werte Iteration erhalten wir
��� � �� � � �� � � �� � $ � �� �� � ��� � � � � � �� �%
� � � � � heisst Explorationsfunktion und bestimmt in welchem Verhaltnis Neugier und
Nutzenmaximierung stehen (wachst in� und fallt in � ).
530
Q Lernen
bisher: Lernen des Nutzens, in einem bestimmten Zustand zu sein � �� �
jetzt: Lernen des Nutzens, eine Aktion in einem bestimmten Zustandauszufuhren � �� � � �
� �� ��� � � �� � �� � � �
� Q Werte dienen direkt der Entscheidungsfindung
� werden direkt aus dem reward feedback gelernt
� �� � � ��� � �� � � �
� � � � �� ��� � �� �� � �
Q Lernen mit TD Ansatz:
� �� � � ��� � �� � � � �� � � �� � � �� ��� � �� �� � �
� � �� � � � �
� fur TD Ansatz kein explizites Modell � � � � notig
531
Diskussion
Was ist besser?
� Ein Model und eine Nutzenfunktion zu lernen?
� Den Wert einer Aktion ohne Model zu lernen?
Wie reprasentiert man am besten einen Agenten?
wissensbasierter Ansatz:
Die explizite Reprasentation von Agent und Umwelt in einem Modell istinsbesondere dann vorteilhaft, wenn Situationen komplexer werden.
Gegenargument:
Die Existenz erfolgreicher Lernmethoden, die ohne Modell auskommen,beweist, dass der wissensbasierte Ansatz uberflussig ist.
� die Diskussion ist unentschieden
532
Eingabe-Generalisierung (1)
Die Zustandsraume von Schach und Backgammon haben ca.� � � �� bzw.� � ��
Zustande. Es ist absurd zu verlangen, dass man all diese Zustande besuchenmuss, um spielen zu lernen.
Wir benotigen eine implizite Reprasentation der Nutzenfunktion. Zum Beispiellasst sich jede Position im Schach anhand weniger Merkmale bewerten. �
ca.� � Merkmale anstelle von� � � �� Zustanden
Generalisierung von besuchten Zustanden zu nicht-besuchten!
533

Eingabe-Generalisierung (2)
Wie lernt man eine Funktion, die die Nutzenfunktion moglichst gut approximiert?
� richtige Auswahl der Attribute (schwierig)
� Methode des steilsten Abstiegs, um die richtige Wichtung der Attribute zu
bestimmen
Das Lernen eines Modells der Umwelt ist auch moglich, aber weitausschwieriger (Generalisieren einer abstrakten Zustandsbeschreibung).
534
Erfolgreiche Anwendungen
� im Spielebereich: Checkers, TD-GammonEingabe-Generalisierung
� Invertiertes PendelBisher sind Algorithmen aus der klassischen Steuer- undRegelungstechnik besser.
x
θ
535
Zusammenfassung (1)
Je nach der Rolle des Agenten unterscheiden wir aktives (explorativesHandeln) und passives Lernen (Beobachten der Umwelt).
1. mit Model der Umwelt: Nutzenfunktion uber Zustanden wird gelernt
2. ohne Model der Umwelt: Aktionsbewertung wird gelernt
Der Nutzen eines Zustands ist die Summe der Belohnungen, die ein Agentzwischen seinem aktuellen Zustand und dem Endzustand erwartet.
536
Zusammenfassung (2)
3 Ansatze, um die Nutzenfunktion zu lernen:
1. Naives Aktualisieren
2. Adaptive Dynamische Programmierung
3. Zeitliche Differenz
Q Lernen (Lernen der Aktionsbewertung) kann durch einen ADP oder TDAnsatz realisiert werden.
537

Grundlagen der KI
15. Lernen in Neuronalen Netzen
Grundlagen, Netzwerkstrukturen, Perzeptron, Backpropagation
Michael Beetz
538
Viele Abbildungen sind dem Buch “Artificial Intelligence: A Modern Approach” entnommen. Viele Folien beruhen auf Vorlagen von Prof. Bernhard Nebel, Dr.Jana Kohler (Universitat Freiburg) und Prof. Gerhard Lakemeyer, (RWTH Aachen).
539
Inhalt
� Motivation
� Grundlegende Elemente neuronaler Netze
� Netzwerkstrukturen
� Lernen in neuronalen Netzen
� Perzeptron
� Backpropagation
� Beispielanwendungen
� Zusammenfassung & Ausblick
540
Motivation (1)
vom mathematischen Standpunkt:
Neuronale Netze als Methode, Funktionen zu reprasentieren.
� durch Netzwerke von einfachen Berechnungselementen(vergleichbar mit logischen Schaltkreisen)
� die aus Beispielen gelernt werden konnen� in dieser Vorlesung
vom biologischen Standpunkt:
Neuronale Netze als (adaquates ?) Modell des Gehirns und seinerFunktionsweise.
� Konnektionismus
� nicht in dieser Vorlesung
541

Motivation (2)
Bisher: KI von”oben“: Modellierung eines intelligenten Agenten durch
algorithmische Realisierung von bestimmten Aspekten rationalenHandelns.
Jetzt: KI von”unten“: Nachbildung der Struktur und der
Verarbeitungsmechanismen des Gehirns (grob):
Axon
Cell body or Soma
Nucleus
Dendrite
Synapses
Axonal arborization
Axon from another cell
Synapse
Viele Prozessoren (Neuronen) und Verbindungen (Synapsen), die parallelund lokal Informationen verarbeiten.
542
Konventionelle Rechner vs. Gehirn
Computer Human Brain
Computational units 1 CPU, 105 gates 1011 neuronsStorage units 109 bits RAM, 1010 bits disk 1011 neurons, 1014 synapsesCycle time 10� 8 sec 10� 3 secBandwidth 109 bits/sec 1014 bits/secNeuron updates/sec 105 1014
Beachte: Hirnschaltzeit langsam �� � � � � � , aber Updates erfolgen parallel. Dagegenbraucht die serielle Simulation auf einem Rechner mehrere hundert Zyklen fur 1
Update.
Vorteile naturlicher neuronaler Netze:
� Hohe Verarbeitungsgeschwindigkeit durch massive Parallelitat.
� Funktionstuchtig selbst bei Ausfall von Teilen des Netzes (Fehlertoleranz).
� Langsamer Funktionsabfall bei fortschreitenden Ausfallen von Neuronen.(Graceful degradation).
� Gut geeignet fur induktives Lernen.543
Forschung auf dem Gebiet neuronaler Netze
1943: McCulloch und Pitts fuhren die Idee eines kunstlichen Neurons ein.
1943-1969: Forschung an neuronalen Netzen meist Einschichten-Netze= Perzeptrons
1969: Minsky und Papert zeigen, dass Perzeptrons sehr beschrankt sind
1969-1980: Kaum noch Arbeiten auf dem Gebiet
Seit 1981: Renaissance neuronaler Netze
Heute:
� In der KI als Werkzeug benutzt zum Approximieren von Funktionen
� Insbesondere fur senso-motorische Aufgaben gut geeignet
� In der Biologie und Physiologie als Modell
544
Grundbegriffe kunstlicher neuronaler Netze
Einheiten (Units): stellen die Knoten (Neuronen) im Netz dar.
Verbindungen (Links): Kanten zwischen den Knoten des Netzes. JederKnoten hat Ein- und Ausgabekanten.
Gewichte (Weights): Jede Kante hat eine Gewichtung, in der Regel einereelle Zahl.
Ein-/Ausgabeknoten (Input and Output units): Besonders gekennzeichneteKnoten, die mit der Außenwelt verbunden sind.
Aktivierungsniveau (Activation level): Der von einem Knoten aus seinenEingabekanten zu jedem Zeitpunkt berechnete Wert. Dieser Wert wirduber Ausgabekanten an die Nachbarknoten weitergeleitet.
545

Funktionsweise einer Einheit
Eingabefunktion:
� � � berechnet die Starke der Eingabe fur Einheit� als Linearkombination vonEingabeaktivierung� � und Gewicht � �� � uber alle Knoten� � , die mit�
verbunden sind:
� � �� � � � �� �� � � � � � � �
Aktivierungsfunktion:berechnet mit Hilfe einer i.allg. nicht-linearen Funktion � dasAktivierungsniveau� � :
� � �� � � � � � ��� � � � � � � � �� � ��Output
gInput
Links
Output
Links
ini
Σ
a = g(in ) iia j Wj,i
Activation Function
Input Function
ia
546
Aktivierungsfunktionen
�� � � � �� �� �
� � if � *�� � if � � �� � � � �� �� �� � � if � *�
� � � if � � �� � � ��# � �� ��� � �
(a) Step function (b) Sign function
+1
ai
−1
ini
+1
ai
init
(c) Sigmoid function
+1
ai
ini
Beachte:� in step� stellt einen Schwellwert dar. Analogie zur Reizleitung imNervensystem.
Mathematisch ist� aquivalent zu zusatzlicher Eingabe mit Aktivierungsniveau� �� � �
und! � � �� � . Damit
� �� �� � � $� � � � �! � � � � � �% � �� � � $� � � � �! � � � � � �%
547
Was kann man mit neuronalen Netzen darstellen?
� Funktionen . . .
� insbesondere boolesche Funktionen (mit Hilfe der step � Funktion):
AND OR NOT
t = 1.5 t = 0.5 t = −0.5W = −1
W = 1
W = 1W = 1
W = 1
� . . . und durch Verschaltung vieler Einheiten beliebige boolescheFunktionen
� Schaltkreistheorie
� allerdings konnen die Netze dann sehr groß werden. Ein Ergebnis aus der
Schaltkreistheorie besagt, dass die meisten booleschen Funktionen mit # ! � � )Gattern dargestellt werden mussen.
� Aber neuronale Netze konnen noch viel mehr . . .
548
Netzwerktopologien
Rekurrent: Verbindungen konnen beliebige Topologien aufweisen.
Feed-forward: Verbindungen stellen gerichteten azyklischen Graphen dar(DAG).
549

Feed-forward-Netze
FF-Netzwerke werden normalerweise in Schichten konstruiert. Dabei keineVerbindungen zwischen Einheiten einer Schicht, immer nur zur jeweilsnachsten Schicht. Beispiel:
2I
1I
O5
w13
w14
w23
w24
w35
w45
H3
H4
Feed-forward-Netze sind am besten verstanden. Die Ausgabe ist allein eine Funktionder Eingaben und der Gewichte.
Rekurrente Netze sind oft instabil, oszillieren oder zeigen chaotisches Verhalten.Interner Zustand bildet sich durch Ruckpropagierung im Aktivierungsniveau ab –
Kurzzeitgedachtnis (Gehirn ist massiv rekurrent).550
Rekurrente Netzwerktypen: Hopfield-Netze
� Rekurrente Netze mit symmetrischen bidirektionalen Verbindungen( � �� � � � �� � ).
� Alle Einheiten fungieren als Ein- und Ausgabeeinheiten.
� Aktivierungsfunktion ist die sign Funktion, d.h. Aktivierungsniveau = � � .
� Realisieren assoziative Speicher. Nach dem Training mit Beispielen undeiner neuen Eingabe wird das
”ahnlichste“ Beispiel gefunden.
Beispiel: Trainieren mit � Fotos. Neue Eingabe = Teil eines schon gesehenen Fotos.
Netz rekonstruiert das Gesamtbild.
Beachte: Jedes Gewicht im Netz ist partielle Darstellung aller Bilder.
Satz Ein Hopfield Netz kann �� � �� � � Beispiele sicher speichern, wobei �
die Zahl der Einheiten im Netz ist.
551
Rekurrente Netzwerktypen: Boltzmann-Maschinen
� Ebenfalls symmetrische Gewichte.
� Es gibt Einheiten, die weder Ein- noch Ausgabeeinheiten sind.
� Stochastische Aktivierungsfunktion.
� Zustandsubergange ahneln Suchverfahren mit Simulated annealing:Suche nach bester Approximation der Trainingsmenge.
� Formal identisch zu einer Variante von bayesschen Netzen, die mitstochastischer Simulation bearbeitet werden.
552
Geschichtete Feed-forward-Netze (GFFs) (1)
2I
1I
O5
w13
w14
w23
w24
w35
w45
H3
H4
Eingabeeinheiten: ( � � � � � ) erhalten ihr Aktivierungsniveau von der Umwelt.
Ausgabeeinheiten: ( � � ) teilen ihr Ergebnis der Umwelt mit.
553

Geschichtete Feed-forward-Netze (GFFs) (2)
Verborgene Einheiten (hidden units): ( � � � � � ) Einheiten ohne direkteVerbindungen nach draußen, angeordnet in verborgenen Schichten(Hidden layers).
Anzahl der Schichten: wird bestimmt unter Ignorierung der Eingabeschicht.
Perzeptron: Einschichtiges FF-Netz (ohne verborgene Schicht).
554
Darstellungskraft von GFF-Netzen
� GFF-Netze mit einer verborgenen Schicht konnen beliebige stetigeFunktionen darstellen.
� GFF-Netze mit zwei verborgenen Schicht konnen daneben auchdiskontinuierliche Funktionen darstellen.
Bei fester Topologie und Aktivierungsfunktion � sind darstellbare Funktionencharakterisierbar durch parametrisierte Form (Parameter = Gewichte).
555
Beispiel
2I
1I
O5
w13
w14
w23
w24
w35
w45
H3
H4
� �� � ! � �� �� ! � �� � �� � ! � � � ! � �� �� ! �� �� ! � � � ! � �� �� ! �� � �
� Lernen= Suche nach richtigen Parameterwerten= nichtlineare Regression
556
Lernen mit neuronalen Netzen
Gegeben eine Menge von Beispielen � � � � � �� � � � � � , wobei jedes Beispielaus Eingabewerten und Ausgabewerten besteht, soll das Netzwerk dieFunktion lernen, die die Beispiele erzeugt hat – dabei ist dieNetzwerktopologie vorgegeben und die Gewichte sollen angepasst werden.
Lernen in Epochen: Normalerweise legt man dem Netz die Beispielemehrfach (in Epochen) vor.
function NEURAL-NETWORK-LEARNING(examples) returns network
network � a network with randomly assigned weightsrepeat
for each e in examples doO � NEURAL-NETWORK-OUTPUT(network, e)T � the observed output values from eupdate the weights in network based on e, O, and T
enduntil all examples correctly predicted or stopping criterion is reachedreturn network
557

Optimale Netzwerkstruktur?
Die Wahl des richtigen Netzes ist ein schwieriges Problem . . .
Außerdem kann das optimale Netz exponentiell groß werden (relativ zuEin-/Ausgabe).
� Netz zu klein: gewunschte Funktion nicht darstellbar.
� Netz zu groß: Beim Trainieren eines Netzes lernt dieses die Beispiele
”auswendig“, ohne zu generalisieren � Overfitting.
Es gibt keine gute Theorie zur Wahl des richtigen Netzes.
558
Heuristik des Optimal brain damage
Wahle Netz mit maximaler Zahl an Verbindungen. Nach 1. Training reduziereZahl der Verbindungen mit Hilfe von Informationstheorie. Iteriere diesenProzess.
Bsp.: Netz zum Erkennen von Postleitzahlen. 3/4 der anfanglichenVerbindungen wurden eingespart.
Es gibt auch Verfahren um von einem kleinen Netz zu einem besserengroßeren zu kommen.
559
Perzeptron
Einschichten-FF-Netze (Perzeptrons) wurden insbesondere in den 50erJahren studiert, da sie die einzigen GFF-Netze waren, fur die Lernverfahrenbekannt waren.
Da alle Ausgabeknoten unabhangig voneinander sind, konzentrieren wir unsauf einen einzigen Ausgabeknoten � :
Perceptron Network Single Perceptron
InputUnits Units
Output InputUnits Unit
Output
OIj Wj,i Oi Ij Wj
� � � � � �� � � � � � � �� � � � � �� � � � �
mit �� � � � fur Schwellwert
560
Was konnen Perzeptrons darstellen?
Perzeptrons konnen genau die Klasse der linear separierbaren Funktionendarstellen. Beispiele:
I 1
I 2
I 1
I 2
I 1
I 2
?
(a) (b) (c)and or xor
0 1
0
1
0
1 1
0
0 1 0 1
I 2I 1I 1 I 2I 1 I 2
(a) Separating plane (b) Weights and threshold
W = −1
t = −1.5W = −1
W = −1
I3
I2
I1
Grund: � � � � teilt den gesamten Raum gerade in zwei Teile entlang einer
Graden (2D), einer Ebene (3D), . . .561
Was konnen Perzeptrons lernen?� alle linear separierbaren Funktionen
Die meisten Lernverfahren folgen dem Ansatz der Current Best Hypothesis.
Hypothese = Netz= aktuelle Werte der Gewichte
Das Netzwerk wird mit zufallig gewahlten Gewichten, in der Regel aus
� � �� � �� � , initialisiert.
Durch Verandern der Gewichte wird die Konsistenz mit denTrainingsbeispielen hergestellt:
� Reduzieren der Differenz zwischen vorhergesagtem und tatsachlichemWert
� Perzeptron Lernregel
562
Die Perzeptron-Lernregel
Sei
� � die korrekte Ausgabe und
� � die Ausgabe des Netzes, dann ist
� � � � � � � � der Fehler.
� � � positiv � � erhohen
� � � negativ � � erniedrigen
Da jede Eingabeeinheit � � � � zu � beitragt, sollte, um � zu erhohen, beipositivem � � das Gewicht � � großer werden, und bei negativem � � dasGewicht � � kleiner werden.
� � �� � � � � � � �� � � �
wobei� eine positive Konstante ist, die Lernrate genannt wird.
Satz [Rosenblatt 1960]. Lernen mit der Perzeptron-Lernregel konvergiertimmer zu korrekten Werten bei linear separierbaren Funktionen.
563
Wieso funktioniert die Perzeptron-Lernregel?
Perzeptron-Lernen kann als Gradientenabstieg im Raum aller Gewichteaufgefasst werden, wobei der Gradient durch die Fehlerflache bestimmt wird.Jede Gewichtskonfiguration bestimmt einen Punkt auf der Flache.
� partielle Ableitung bzgl. der einzelnen Gewichte.
Err
b
a
W2
W1
Da man leicht zeigen kann, dass es bei linear separierbaren Funktionenkeine lokalen Minima gibt, folgt der Perzeptron-Konvergenzsatz.
564
Lernkurven: Perzeptron vs. Entscheidungsbaum
Majoritatsproblem
0.4
0.5
0.6
0.7
0.8
0.9
1
0 10 20 30 40 50 60 70 80 90 100
% c
orre
ct o
n te
st s
et
Training set size
PerceptronDecision tree
Restaurantproblem (nicht linear separierbar):
0.4
0.5
0.6
0.7
0.8
0.9
1
0 10 20 30 40 50 60 70 80 90 100
% c
orre
ct o
n te
st s
et
Training set size
PerceptronDecision tree
565

Mehrschichten-FF-Netze
Beispiel:
Input units
Hidden units
Output units Oi
Wj,i
a j
Wk,j
Ik
. . . geeignet zum Lernen des Restaurantproblems
� Lernalgorithmen fur FF Netze sind nicht effizient
� sie konvergieren nicht zum globalen Minimum
Aber aus dem PAC Lernen wissen wir, dass das Lernen allgemeinerFunktionen aus Beispielen im ungunstigsten Fall nicht handhabbar ist –unabhangig von der Methode!
566
Lernen in Mehrschichten-Netzen: Backpropagation
Es wird versucht, fur jedes Gewicht � �� � und � � � � seinen Anteil am Fehler zubestimmen und die Gewichte entsprechend zu andern, d.h. der Fehler wirdruckwarts durchs Netz propagiert.
� �� � �� � � � � �� � � �� � � � �� ��
�� � � �� �� �
� (�
wobei �� die Ableitung von � ist. Da � differenzierbar sein muss, wahlt man fur
� meist die sigmoid-Funktion.
Um wieviel mussen wir nun die � � � � Gewichte andern?
� Abhangig von � � und � �� � :
� � � ��
�� � � �� � � � �� �� � � �
� � � � �� � � � � � � � � �� � �
567
Der Backpropagation-Algorithmus
function BACK-PROP-UPDATE(network, examples, � ) returns a network with modified weightsinputs: network, a multilayer network
examples, a set of input/output pairs� , the learning rate
repeatfor each e in examples do/* Compute the output for this example */
O � RUN-NETWORK(network, Ie)/* Compute the error and ∆ for units in the output layer */
Erre � Te O/* Update the weights leading to the output layer */
Wj, i � Wj, i + � aj Errei g� (ini)
for each subsequent layer in network do/* Compute the error at each node */
∆j � g� (inj) � i Wj, i ∆i
/* Update the weights leading into the layer */Wk, j � Wk, j + � Ik ∆j
endend
until network has convergedreturn network
� � � = Fehler � ��� � � fur i-te Ausgabeeinheit
�� � = Fehlervektor
� � = � � �� ��� ��� � �
568
Lernkurven
. . . fur das Restaurantbeispiel mit dem Zweischichtennetz:
0.4
0.5
0.6
0.7
0.8
0.9
1
0 10 20 30 40 50 60 70 80 90 100
% c
orre
ct o
n te
st s
et
Training set size
Multilayer networkDecision tree
Fehler in Abhangigkeit von der Anzahl der Lernepochen:
0
2
4
6
8
10
12
14
0 50 100 150 200 250 300 350 400
Tot
al e
rror
on
trai
ning
set
Number of epochs
569

Backpropagation � Gradientenabstieg
Backpropagation kann wieder als Gradientenabstieg im Raum aller Gewichteaufgefasst werden, wobei der Gradient durch die Fehlerflache bestimmt wird.Allerdings treten nun nicht mehr rein konvexe Fehlerflachen auf, sondern derLernalgorithmus ist mit dem Problem lokaler Minima konfrontiert.
evaluation
currentstate
� Neustarten
� Rauschen
� Tabusuche
570
Herleitung . . .
Sei � der Gewichtsvektor und � die folgende Fehlerfunktion:
� � � � �! � � �� � � # � � � �! � � �� � � � � �! � � �� � � �
� �! � � �� � � � � �! � � � � � � ! � � � � � � � �
Partielle Ableitung von � nach � �� � :� �� � �� � .
� � ist unabhangig von � �� � . Die meisten Summanden enthalten � � � � nicht.
Abzuleiten: �� � � � � � � � � � �� �� � � �� :
� ��! � � � �
!! �� � � � � �! � � �� � � � � � � � � �! � � �� � � � � �� � �� � � # � � � � � � � � � � � �
� � � �� �
Wir gehen in Richtung entgegen der Steigung!
Fur � � � � kann man zeigen: �� & ��� � � � � �
571
Neuronale Netze . . .
� Wofur sind sie gut? Neuronale Netze eignen sich zum Lernen vonFunktionen uber Attributen, die auch kontinuierlich sein konnen.
� Große des Netzes: Bis zu � � � Einheiten, um beliebige boolescheFunktionen darzustellen, meist aber weniger.
� Effizienz des Lernens: keine brauchbaren theoretischen Ergebnisse.Außerdem Problem der lokalen Minima.
� Generalisierung: Gut, wenn man das richtige Netz gewahlt hat . . .
� Rauschen: stellt kein Problem dar.
� Transparenz: schlecht! Oft weiß man nicht, warum das Netz gutfunktioniert.
� Verwendung zusatzlichen Wissens: schlecht. Es gibt keine Theorie, wieman Vorwissen einem neuronalen Netz mitgeben kann.
572
Beispielanwendung (1): Aussprache lernen
� Das NETtalk-Programm [Sejnowski & Rosenberg 87] lernt aus einemtranskribierten englischsprachigen Text Ausspracheregeln.
� 29 Eingabeeinheiten (26 Buchstaben � Zeichensetzung), 80 verborgeneEinheiten, Ausgabeschicht steuert Merkmale des zu produzierendenLautes.
� Nach 50 Epochen auf einem Text mit 1024 Worten erreicht NETtalk 95%Korrektheit auf der Trainingsmenge.
� Auf Testmenge allerdings nur 78%!
� Das kann auch mit anderen Methoden einfach erreicht werden(z.B. Hidden Markov Modelle).
� Das System hat allerdings die Suggestion hervorgerufen, dass es denkindlichen Spracherwerb nachahmt (die Tonlage!) . . .
573

Beispielanwendung (2): Handgeschriebene Postleitzahlen erkennen
� Vorverarbeitung zur Segmentierung der einzelnen Ziffern.
� � �� � � Eingabeeinheiten, 3 verborgene Schichten mit 768, 192, bzw. 30Einheiten, und 10 Ausgabeeinheiten.
� Netzwerktopologie organisiert als Merkmalsdetektoren, deshalb nur 9760Verbindungen (statt 200000).
� Training auf 7300 Beispielen. Korrektheit auf den Testdaten, nachdem12% als mehrdeutig zuruckgewiesen wurden: 99%!
� Realisierung als VLSI-Schaltkreis.
574
Beispielanwendung (3): Auto fahren
� ALVINN [Pomerleau 93] steuert ein Fahrzeug auf einer Straße.
� Eingabe von Farbstereokamera, das zu einem � �� � � Bild fur dieEingabeeinheiten transformiert wird.
� 5 verborgene Einheiten und 30 Ausgabeeinheiten furSteuerungskommandos.
� Trainingsdaten werden durch Beobachtung eines menschlichen Fahrersgewonnen.
� Achtung: Menschliche Fahrer sind zu gut!
� Nach 5 Minuten Fahrt als Trainingsdaten kann ALVINN auf den trainiertenStraßen bis zu 70 mph schnell fahren.
� Probleme: Andere Straßentypen und andere Beleuchtungsverhaltnisse.
� MANIAC [Jochem et al 93] ist ein Metasystem, das das”richtige“ ALVINN
Netz fur die aktuelle Straße auswahlt.
575
Zusammenfassung & Ausblick
� Neuronale Netze sind ein Berechnungsmodell, das einige Aspekte desGehirns nachbildet.
� Feed-forward-Netze sind die am einfachsten zu analysierenden Netze.
� Ein Perzeptron ist ein einschichtiges FF-Netz, mit dem man aber nurlinear separierbare Funktionen reprasentieren kann. Mit Hilfe derPerzeptron-Lernregel konnen solche Funktionen erlernt werden.
� Mehrschichtige Netze konnen beliebige Funktionen darstellen.
� Backpropagation ist ein Verfahren, um Funktionen in solchen Netzen zulernen, und das auf Gradientenabstieg beruht. In der Praxis kann mandamit viele Probleme losen, allerdings gibt es keine Garantien.
� Problem: Verbindung von symbolischen und”sub-symbolischen“
Verfahren
576
Grundlagen der KI
18. Lernen mit Hintergrundwissen
EBL, RBL und ILP
Michael Beetz
577

Viele Abbildungen sind dem Buch “Artificial Intelligence: A Modern Approach” entnommen. Viele Folien beruhen auf Vorlagen von Prof. Bernhard Nebel, Dr.Jana Kohler (Universitat Freiburg) und Prof. Gerhard Lakemeyer, (RWTH Aachen).
578
Inhalt
� Erklarungsbasiertes Lernen (EBL)
� Relevanzbasiertes Lernen (RBL)
� Induktives logisches Programmieren (ILP)
579
Logische Rekonstruktion des Lernproblems
� = Konjunktion aller Beispielbeschreibungen
� = Konjunktion aller Beispielklassifikationen
Dann muss die Hypothese � die folgende Eigenschaft erfullen:
� � � �� �
Entailment Constraint, in dem � die Unbekannte ist.
Lernen � Losen des Constraints durch Bestimmen von � . Die triviale
Losung erhalt man mit � � � .
580
Lernen mit Hintergrundwissen �
Observations PredictionsHypotheses
Prior knowledge
Knowledge−basedinductive learning
EBL: Hypothese folgt aus dem Wissen
� � � �� �
� �� �
RBL: Hypothese folgt aus Wissen+Beispielen
� � � �� �
� � � � � �� �
581

ILP: Hypothesen entstehen neu
� � � � � �� �
EBL und RBL sind deduktive Formen des Lernens. Sie transformierenvorhandenes Wissen in anwendbare Form. ILP ist induktiv.
582
EBL
Durch Memoization werden vorhandene Losungen in einer Datenbankabgelegt. Bevor ein neues Problem durch Regelanwendung gelost wird, pruftman, ob die Losung nicht bereits in der Datenbank vorhanden ist.
� EBL erzeugt allgemeine Regeln fur eine ganze Problemklasse:
1. Konstruktion einer Erklarung der Beobachtung auf der Grundlage desHintergrundwissens.
2. Extraktion einer allgemeinen Regel, die auf alle Instanzen derProblemklasse zutrifft.
583
Ein Beispiel
Aufgabe:
Vereinfachen des Ausdrucks� � � � � � � zu �
Wissensbasis:
� �� � � � � ��� � � � � � � � �� � �� � � �� � � � � � �� � �� ��� �� �
� � � � � � � � � ��� � � � � � �� � �� ��� � � �
� � � � � � � � � � � � ��� � � � � � � � � � � � ��� �
� � � � � � ��� � � � � � � � � � � � ��� �
� � � � � � �� � � � � �� � � � � �
� � � � � � �� � � � � � �� � � � �
� eine Erklarung kann ein Beweisbaum des vereinfachten Ausdrucks mitHilfe der bekannten Regeln sein.
584
Beweis und Generalisierung
� Beweis der Probleminstanz
Primitive(X)
ArithmeticUnknown(X)
Primitive(z)
ArithmeticUnknown(z)
Simplify(X,w)
Yes, { }
Yes, {x / 1, v / y+z}
Simplify(y+z,w)
Rewrite(y+z,v’)
Yes, {y / 0, v’ / z}
{w / X}
Yes, { }
Yes, {v / 0+X}
Yes, {v’ / X}
Simplify(z,w)
{w / z}
Simplify(1 (0+X),w)+
Rewrite(x (y+z),v)+
Simplify(x (y+z),w)+
Rewrite(1 (0+X),v)+ Simplify(0+X,w)
Rewrite(0+X,v’)
� generalisierter Beweis
585

Extraktion von Regeln (1)
Die Regel ergibt sich aus den Blattern des generalisierten Beweisbaumsunter den entsprechenden Substitutionen.
� �� � � � � �� � � � � � � � � � � �
� � �� � � � � � � � � � � �
� � � � � � � � � � � � � � � �
� � � � �� � �� �� � � � � � � � � �
Die ersten beiden Bedingungen sind Tautologien. Also vereinfacht sich dieRegel zu
� � � � � � � � � � � � � � � � � � � �� � �� �� � � � � � � � � �
586
Extraktion von Regeln (2)
Allgemein konnen alle Bedingungen (aus der linken Seite) der Regel entferntwerden, die unter beliebiger Belegung der Variablen des Zielpradikats (aufder rechten Seite) wahr sind.
Durch Pruning des Baums konnen weitere Regeln gewonnen werden:
� � � � � � � � � � � � � � � � �� � �� �� � � � � � � � � �
587
Welche Regeln auswahlen? (1)
Regeln konnen aus beliebigen Teilbaumen gewonnen werden. MancheRegeln implizieren andere.
� nur allgemeinste Regel behalten?
� � � � � � � � � � � � � � � � � � � �� � �� �� � � � � � � � � �
�
� � � � � � � � � � � � � � � � �� � �� �� � � � � � � � � �
�
� � � �� � �� �� � � �� � � � � � �� � �� �� � �� � � � �� �
588
Welche Regeln auswahlen? (2)
Je mehr spefizische Regeln, desto grosser die Verzweigung im Suchraum (furjeden Fall eine Regel erzeugen). Zu allgemeine Regeln konnen aber wiederzu viele Falle abdecken, so dass die Berechnung der Losung sehr aufwendigbleibt (am allgemeinsten sind eben die ursprunglichen Regeln desHintergrundwissens).
� die “richtige” Mischung hangt von der Anwendung ab
� empirische Bewertung anhand der Laufzeit
589

RBL� enthalt Funktionale Abhangigkeiten
� � �
Wir sagen “ � bestimmt � ” bzw. “ � ist eine Funktion von � ”.
Beispiel:
� � � � � � � �! � �� � � � �� ! �� � � � � � � �� � � � �� ! �� � � � � �
� ! � � �� � � � � �! � � ! � � �� � � � � �! ��� � � � �� ! �� � � � � �� ! � � �� � � � � �! �
� �� � � � �� ! �� � � �� �� � � ! � � ! � � �� � � � � � � �� � �� � � � �
� � � � �� � � � �� ! �� � � � � �� � � ! � � ! � � �� � � � � � � �� � �� � � � �
� folgt logisch aus � und � . Funktionale Abhangigkeiten stellen ein
Basisvokabular fur die Formulierung von Hypothesen zur Verfugung.590
Funktionale Abhangigkeiten
Reduktion des Hypothesenraums fur Boolsche Funktionen uber � Variablenvon � � � �� � auf � � � ��� � , wenn� Pradikate in den linken Seiten der “ � ”-Regelnauftreten.
Wie lernt man “ � ”-Regeln?
� � � ist konsistent mit einer Menge von Beispielen, wenn alle Beispiele, die
� erfullen, auch � erfullen, d.h. die gleiche Klassifikation � besitzen.
Gesucht ist die kleinste (= minimale Anzahl von Pradikaten in � ) derkonsistenten Regeln.
� Grundidee
Man beginnt mit einer Eigenschaft in � und fugt weitere Eigenschaften hinzu,solange die funktionale Abhangigkeit noch nicht konsistent ist.
591
Lernen von Funktionale Abhangigkeiten
function MINIMAL-CONSISTENT-DET(E, A) returns a determinationinputs: E, a set of examples
A, a set of attributes, of size n
for i � 0, . . . , n dofor each subset Ai of A of size i do
if CONSISTENT-DET?(Ai, E) then return Ai
endend
function CONSISTENT-DET?(A, E) returns a truth-valueinputs: A, a set of attributes
E, a set of exampleslocal variables: H, a hash table
for each example e in E doif some example in H has the same values as e for the attributes A
but a different classification then return Falsestore the class of e in H, indexed by the values for attributes A of the example e
endreturn True
� dieser Algorithmus ist exponentiell in der Grosse der minimalen Regel
� � �& � (Das Problem ist NP-vollstandig.)
592
Deklarativer Bias
= Lernen der Abhangigkeiten identifiziert den Hypothesenraum, innerhalbdessen das Zielpradikat gelernt wird.
� Kombination mit dem Entscheidungsbaumlernen:
function �� � � � �� � � returns a decision tree
return DECISION-TREE-LEARNING � � MINIMAL-CONSISTENT-DET � � � �� �� �
attribute
� �
593
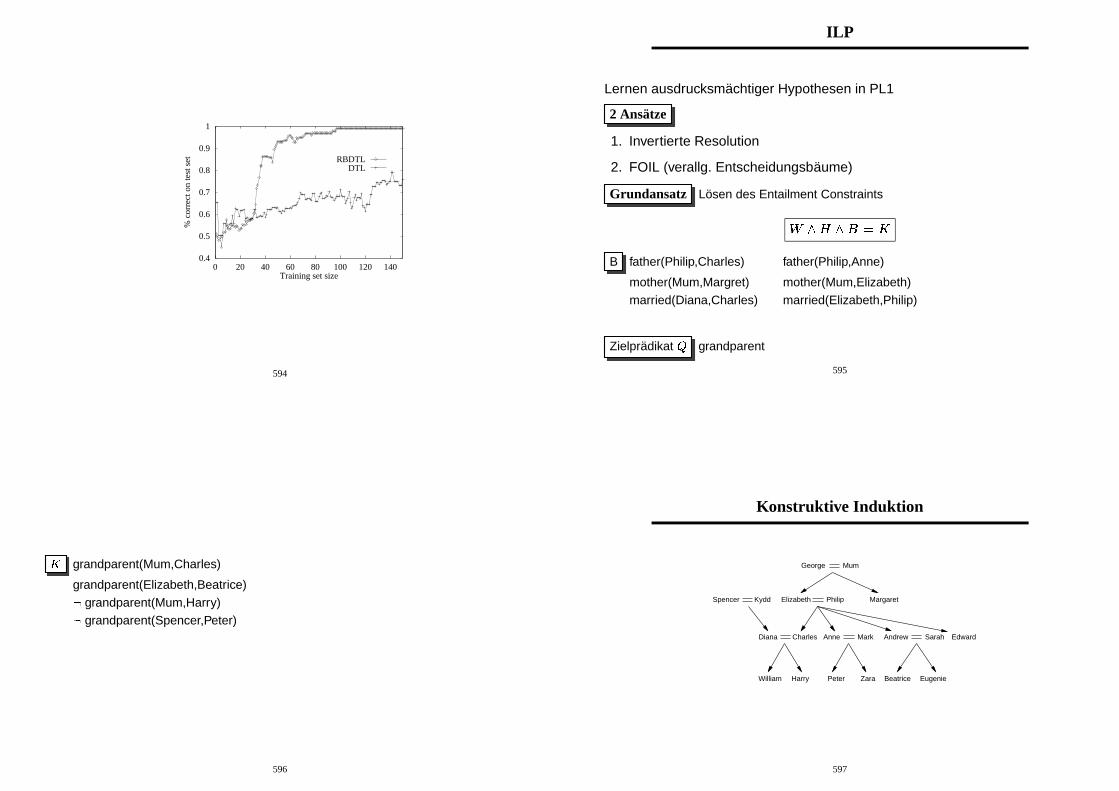
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100 120 140
% c
orre
ct o
n te
st s
et
Training set size
RBDTLDTL
594
ILP
Lernen ausdrucksmachtiger Hypothesen in PL1
2 Ansatze
1. Invertierte Resolution
2. FOIL (verallg. Entscheidungsbaume)
Grundansatz Losen des Entailment Constraints
� � � � � �� �
B father(Philip,Charles) father(Philip,Anne)
mother(Mum,Margret) mother(Mum,Elizabeth)
married(Diana,Charles) married(Elizabeth,Philip)
Zielpradikat � grandparent
595
� grandparent(Mum,Charles)
grandparent(Elizabeth,Beatrice)
grandparent(Mum,Harry)
grandparent(Spencer,Peter)
596
Konstruktive Induktion
Beatrice
Andrew
EugenieWilliam Harry
CharlesDiana
MumGeorge
PhilipElizabeth MargaretKyddSpencer
Peter
Mark
Zara
Anne Sarah Edward
597

Mit � � � erhalten wir�
� �� �# � � � �� � � � � � � � � �� � � � � � � � � � �� � � � � � � �
� � � � �� � � � � � � � � �� � � � � � � � �
� � � �� � � � � � � � � � � �� � � � � � � �
� � � �� � � � � � � � � � �� � � � � � � � �
Mit � � � � � �� � � � � � � �� � � � � � � � � �� � � � � � � � �
�
� �� �# � � � �� � � � � � � � � � � �� � � � � � � � � �� � � � �
� Das Pradikat (Konzept) Parent kann auch vom Algorithmus durchkonstruktive Induktion gelernt (“entdeckt”) werden.
598
Invertierte Resolution (1)
Wir erinnern uns an die Resolutionsregel:
� � � �� � � � � � � "� �
� � � � �
Ausgehend von der Resolvente � � � � � kann man auch nach moglichenElternklauseln suchen.
{y/Anne}
>=True Parent(Elizabeth,Anne)
>=True False
>= Grandparent(George,Anne)True >=Grandparent(George,Anne) False
Grandparent(George,y)>=Parent(Elizabeth,y)
599
Invertierte Resolution (2)
Beschrankung der Suche:
� eingeschrankte Syntax (Hornlogik)
� eingeschrankte Kalkule (lineare Resolution)
� Konsistenz von Hypothese und Beobachtungen
� Konsistenz der Hypothesen untereinander
600
Konstruktion neuer Pradikate
{x/George}
>=P(George,y) Ancestor(George,y)
>=Father(George,y) Ancestor(George,y)
>=Father(x,y) P(x,y)
Besonders einfach bei Invertierter Resolution. Das Pradikat� kann beliebiggewahlt werden.
� hier � � � �� �
� Heuristic Discovery� AM Automated Mathematician (Lenat)
entdeckt selbstandig Goldbachsche Vermutung
� Heurisko (Lenat)konnte selbstandig seine Entdeckungsregeln andern
Bemerkung: Die Ergebnisse waren nicht nachvollziehbar.
601

FOIL (1)
Ausgangspunkt ist eine sehr allgemeine Hypothese, die so lange spezialisiertwird bis die Konsistenz zu den Beobachtungen erreicht ist.
Hypothese: Hornklauseln mit positivem Zielpradikat
positive Beispiele:
� � � � � � � � � � � � � ��� � � ! � � � �� � � � �� � �� � �� � � � � �
negative Beispiele:
� � � � � � � � � ! � �� � �� � � �� � � � � �� � �� � � � �� �! � � � � � � ! � �
� � � � � � �� �� �� � � � � � � �� �
� mit dieser Regel ware jedes Beispiel positiv
� 3 mogliche Spezialisierungen
602
FOIL (2)
1. �� � � � � � � � � � � �� �# �� � � � � � � � � (pos. Bsp. falsch)2. � � � �� � � � � � � �� �# �� � � � � � � � � (neg. Bsp. falsch)
3. �� � � � � � � � � � � �� �# �� � � � � � � � � (neg. Bsp. falsch)
3. hat die wenigsten negativen Beispiele, die falsch klassifiziert sind
� �� � � � � � � � � � � � � �� � � � � � � �� �# �� � � � � � � � �
603
Der Algorithmus
function FOIL(examples,target) returns a set of Horn clausesinputs: examples, set of examples
target, a literal for the goal predicatelocal variables: clauses, set of clauses, initially empty
while examples contains positive examples doclause � NEW-CLAUSE(examples)remove examples covered by clause from examplesclauses � � clause clauses
return clauses
function NEW-CLAUSE(examples,target) returns a Horn clauselocal variables: clause, a clause with target as head and an empty body
l, a literal to be added to the clauseextended-examples, a set of examples with values for new variables
extended-examples � exampleswhile extended-examples contains negative examples do
l � CHOOSE-LITERAL(NEW-LITERALS(clause),extended-examples)append l to the body of clauseextended-examples � set of examples created by applying EXTEND-EXAMPLE
to each example in extended-examplesreturn clause
function EXTEND-EXAMPLE(example,literal) returnsif example satisfies literal
then return the set of examples created by extending example witheach possible constant value for each new variable in literal
else return the empty set
NEW-LITERALS fuhrt zu einer sehr hohen Verzweigung im Suchraum:
� beliebige Pradikate, die mindestens eine Variable aus� enthalten mussen604
� Test auf Gleichheit uber Variablen/Konstanten
� Arithmetische Vergleiche, wenn Funktionssymbole zugelassen sind
605

Zusammenfassung� EBL und RBL sind deduktive Lernverfahren die implizit vorhandenes
Wissen explizit machen und es in eine fur den Agenten leichteranwendbare Form bringen. Man spricht auch von
– Makro-operatoren (z.B. im Planen)
– Knowledge Compilation
� Mit ILP kann ein Agent allgemeine PL1 Theorien lernen und neueKonzepte entdecken. Das Verfahren ist sehr machtig, leidet aber unterder ungeheuren Verzweigung im Suchraum. Hier helfen nur OckhamsRasiermesser (zu lange Klauseln, die Spezialfalle abdecken, eliminieren)und (anwendungsspezifische) Heuristiken.
606





























