Embed Size (px)
Citation preview

CUDA by ExampleParalleles Rechnen auf der Grafikkarte
Leipzig, 31.03.2017
Paul Jähne
SethosII
1
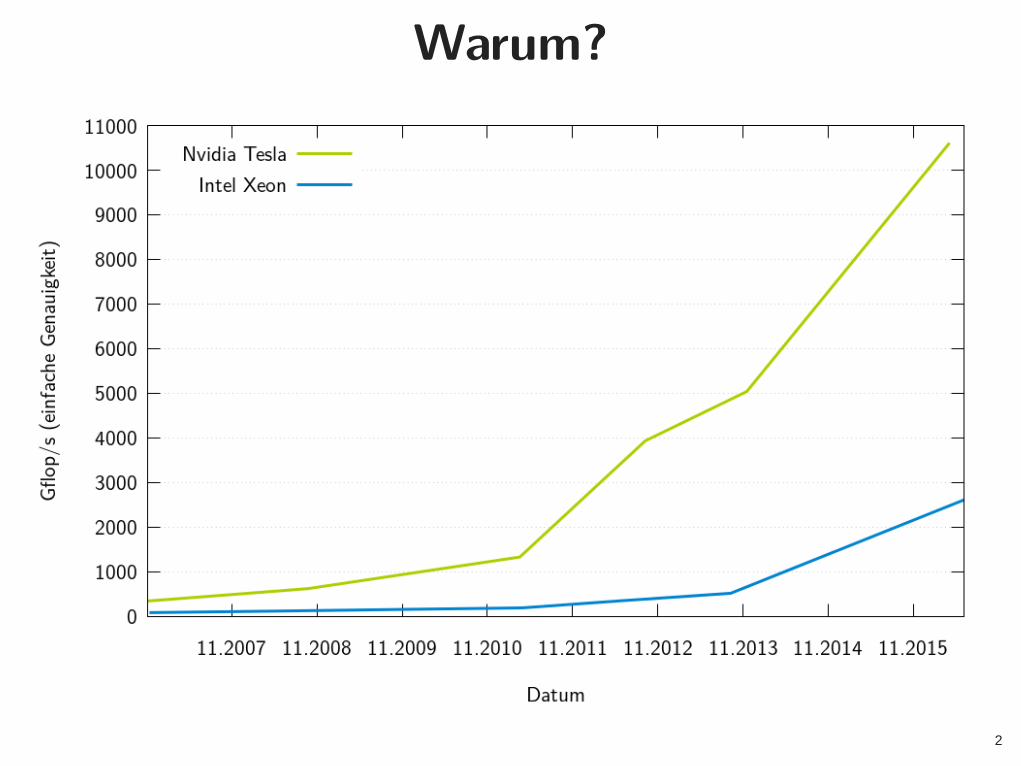
Warum?
2
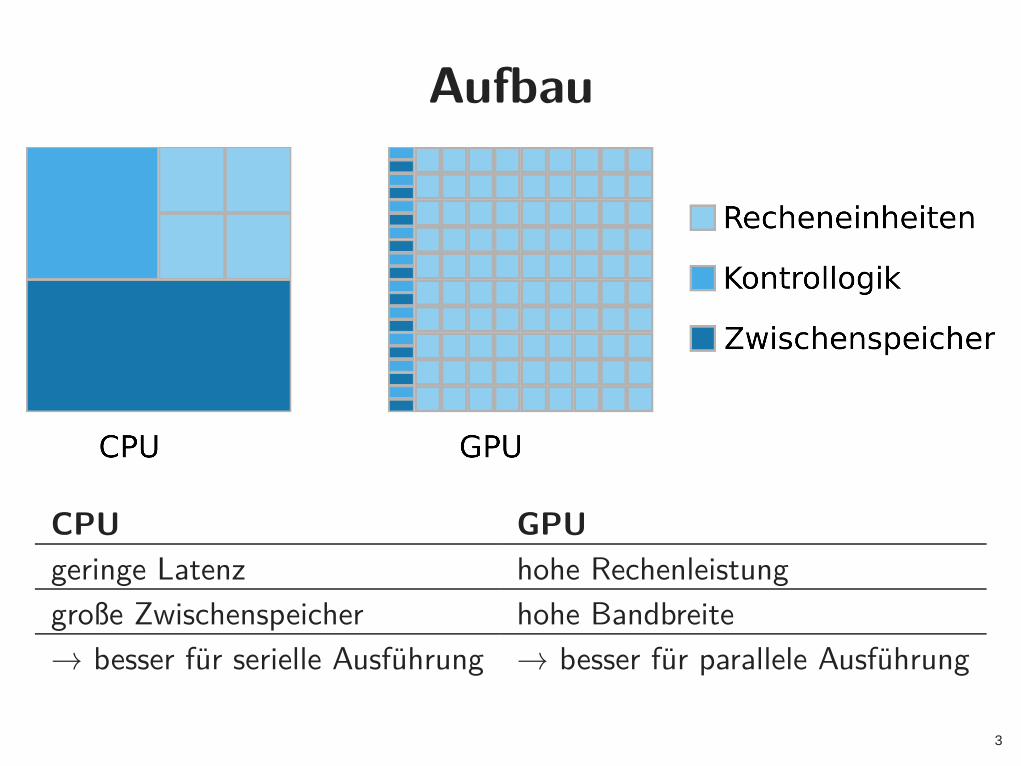
Aufbau
CPU GPU
geringe Latenz hohe Rechenleistung
große Zwischenspeicher hohe Bandbreite
→ besser für serielle Ausführung → besser für parallele Ausführung
3

Was ist CUDA?
Compute Unified Device Architecture
API zur Programmierung von Nvidia GPUs
C/C++
zum Einstieg:
http://docs.nvidia.com/cuda/index.html
https://developer.nvidia.com/cuda-downloads
4

Hello World
Kompilierung: nvcc hello_world.cu -o hello_world
#include <stdio.h> __global__ void greet() { printf("Hello World!\n"); } int main(){ greet<<<1, 1>>>(); cudaDeviceReset(); return 0; }
5
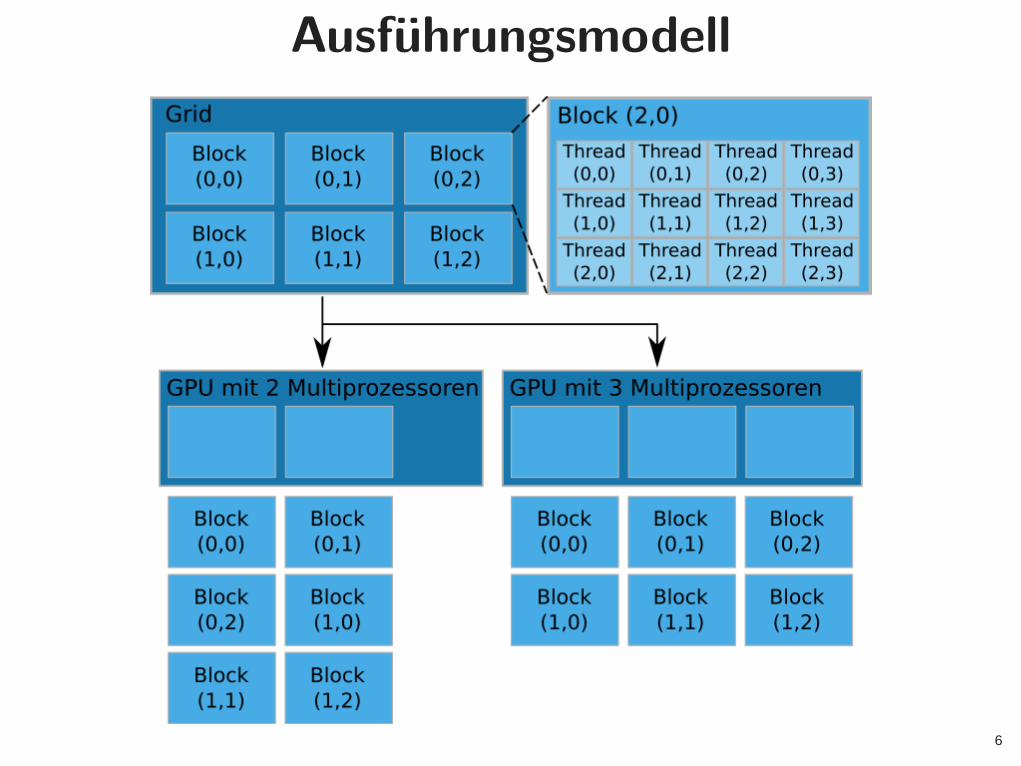
Ausführungsmodell
6

Paralleles Hello World#include <stdio.h> __global__ void greet() { printf("Thread %d von %d\n", blockIdx.x * blockDim.x + threadIdx.x + 1, blockDim.x * gridDim.x); } int main(){ greet<<<2, 2>>>(); cudaDeviceReset(); return 0; }
7
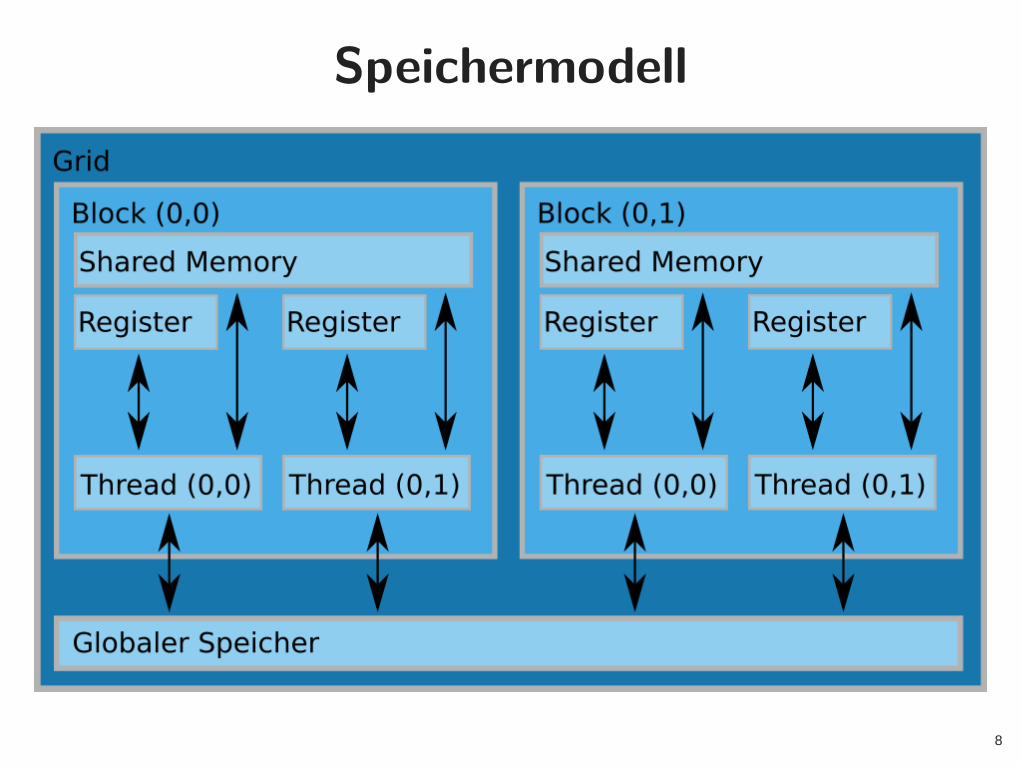
Speichermodell
8

Genereller Programmablauf1. Ressourcen anfordern2. Daten zur GPU kopieren3. Kernel aufrufen/Berechnungen ausführen4. Ergebnisse zurückkopieren5. Ressourcen freigeben
CUDA ≥ 6.0 Unified Memory
9

Beispielcode CUDA ≥ 6.0int main() { // declare pointer int* a; // allocate memory on GPU and CPU cudaManagedMalloc((void**) &a, SIZE); // fill a with data on host ... // kernel invocation kernel<<<NBLOCKS, NTHREADS>>>(a); // do somethng with a on host ... // clean up cudaFree(a); return 0: }
10
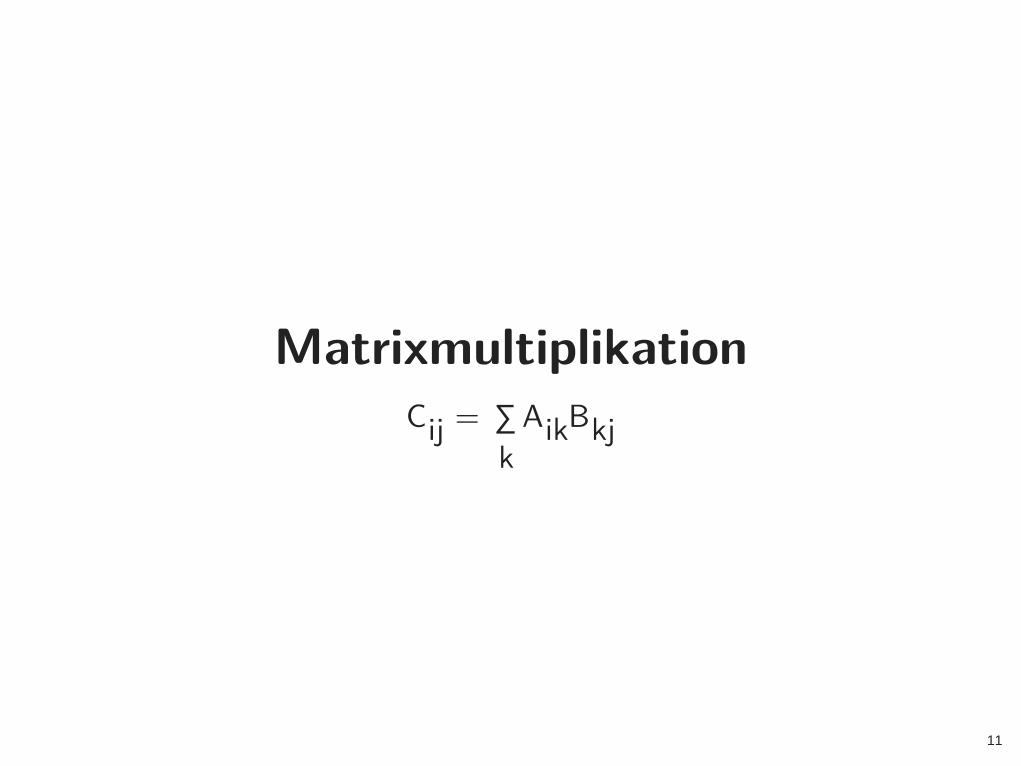
Matrixmultiplikation
Cij = ∑k
AikBkj
11

Ablauf
12

CPU-Codevoid matmul(double *a, double *b, double *c, int dim) { for (int i = 0; i < dim; i++) { for (int j = 0; j < dim; j++) { double sum = 0; for (int k = 0; k < dimension; k++) { sum += a[i * dim + k] * b[k * dim + j]; } c[i * dim + j] = sum } } }
13

GPU-Hostcode// allocate memory on GPU cudaMalloc((void**) &d_a, dim * dim * sizeof(double)); cudaMalloc((void**) &d_b, dim * dim * sizeof(double)); cudaMalloc((void**) &d_c, dim * dim * sizeof(double)); // copy data to the GPU cudaMemcpy(d_a, a, dim * dim * sizeof(double), cudaMemcpyHostToDevice); cudaMemcpy(d_b, b, dim * dim * sizeof(double), cudaMemcpyHostToDevice); // kernel invocation kernel<<<NBLOCKS, NTHREADS>>>(d_a, d_b, d_c, dim); // copy result back to the CPU cudaMemcpy(c, d_c, cx * cy * sizeof(double), cudaMemcpyDeviceToHost); // clean up cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
14

GPU-Devicecode__global__ void kernel( double *d_a, double *d_b, double *d_c, int dim) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; if (x < dim && y < dim) { double sum = 0; for (int i = 0; i < dim; i++) { sum += d_a[x * dim + i] * d_b[i * dim + y]; } d_c[x * dim + y] = sum; } }
15

ZeitmessungcudaEvent_t custart, custop; cudaEventCreate(&custart); cudaEventCreate(&custop); cudaEventRecord(custart, 0); // code to measure cudaEventRecord(custop, 0); cudaEventSynchronize(custop); cudaEventElapsedTime(&cuelapsedTime, custart,custop); cudaEventDestroy(custart); cudaEventDestroy(custop);
16

Messergebnis
Tesla K20, doppelte Genauigkeit
erwartet: 1,2 Tflop/s
gemessen: 8 Gflop/s
:(
17

Alles nur Marketing?
1, 2 ∗ 1012 flop/s → dafür werden die Daten benötigthier fused-multiply-add (FMA): c + = a ∗ bdreimal laden, einmal schreiben für zwei Rechenoperationen4 ∗ 8 Byte = 32 Byte für zwei Rechenoperation
1, 2 ∗ 1012 ∗ 16 Byte = 19, 2 TB/s Speicherbandbreite benötigt145 GB/s Speicherbandbreite verfügbar
18

Speicherbandbreite ist die Beschränkung
Optimierungen: caching, loop unrolling, ...notwendig für performanten Codeverschlechtern die Lesbarkeit des Programmcodes
Was bringt Shared Memory?
19
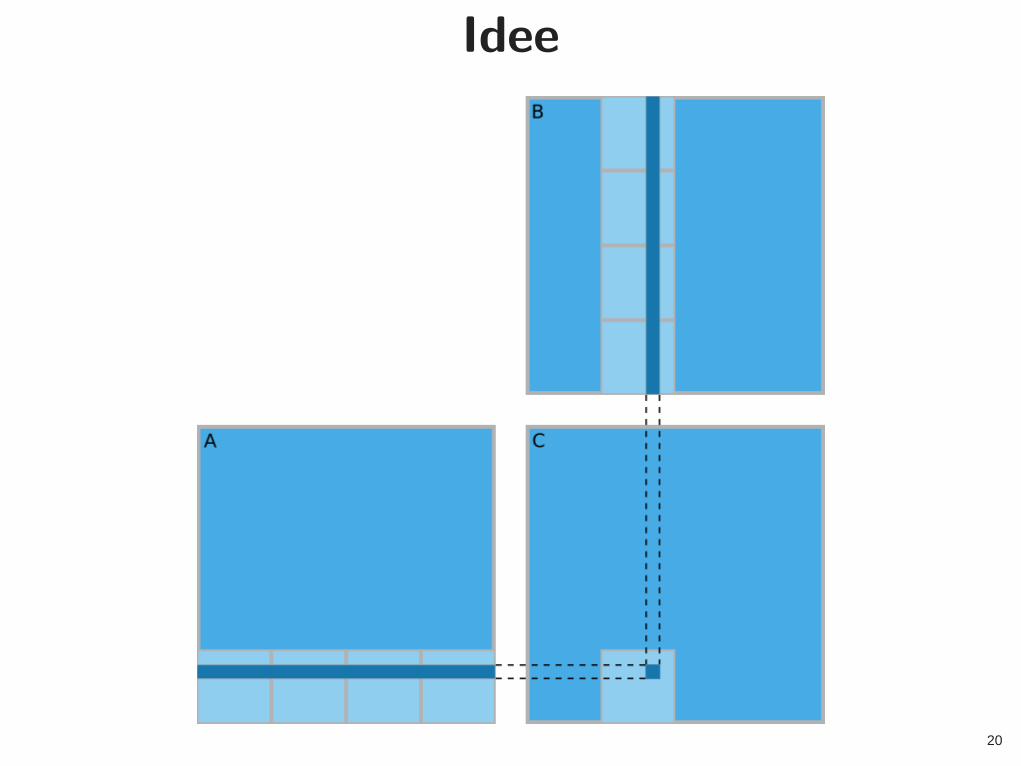
Idee
20

GPU-Devicecode__global__ void kernelShared(double *a, double *b, double *c, int dim) { __shared__ double as[32][32]; __shared__ double bs[32][32]; int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; int xdim = x * dim; int blocks = dim / 32; double sum = 0; for (int m = 0; m < blocks; m++) { int m32 = m * 32; as[threadIdx.x][threadIdx.y] = a[xdim + (m32 + threadIdx.y)]; bs[threadIdx.x][threadIdx.y] = b[(m32 +threadIdx.x) * dim + y]; __syncthreads(); for (int i = 0; i < 32; i++) { sum += as[threadIdx.x][i] * bs[i][threadIdx.y]; } __syncthreads(); } c[xdim + y] = sum; }
21

Messergebnis
Tesla K20, doppelte Genauigkeit
erwartet: 1,2 Tflop/s
gemessen: 160 Gflop/s
:|
22
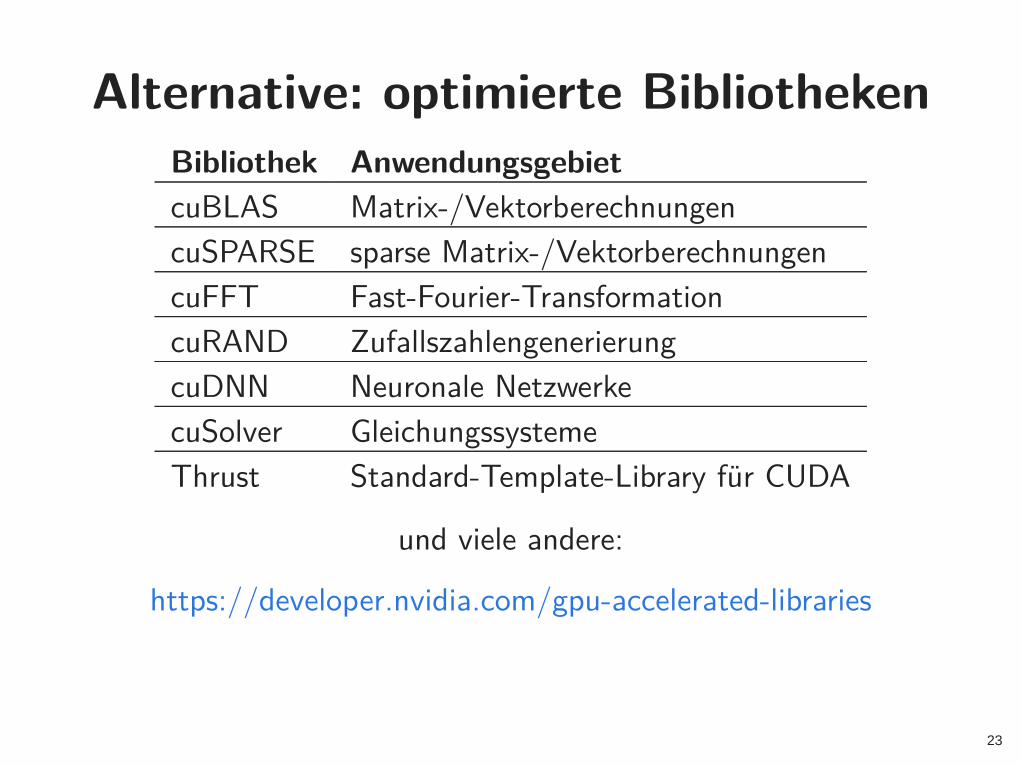
Alternative: optimierte Bibliotheken
Bibliothek Anwendungsgebiet
cuBLAS Matrix-/Vektorberechnungen
cuSPARSE sparse Matrix-/Vektorberechnungen
cuFFT Fast-Fourier-Transformation
cuRAND Zufallszahlengenerierung
cuDNN Neuronale Netzwerke
cuSolver Gleichungssysteme
Thrust Standard-Template-Library für CUDA
und viele andere:
https://developer.nvidia.com/gpu-accelerated-libraries
23

Matrixmultiplikation mit cuBLAS
cuBLAS berechnet: C = α ∗ op(A) ∗ op(B) + β ∗ C
// allocate memory on GPU ... // copy data to the GPU ... // initialize cuBLAS cublasHandle_t cublasHandle; cublasCreate(&cublasHandle); // call the library function cublasDgemm(cublasHandle, CUBLAS_OP_N, CUBLAS_OP_N, dim, dim, dim, 1, d_a, dim, d_b, dim, 0, d_c, dim); // copy result back to the CPU ... // clean up cublasDestroy(cublasHandle); ...
24

Messergebnis
Tesla K20, doppelte Genauigkeit
erwartet: 1,2 Tflop/s
gemessen: 1 Tflop/s
:)
25

Anmerkungen zum BeispielAuslastung der GPU ab Matrixdimension > 1000gut parallelisierbares Beispielsehr einfaches Beispiel
→ niemand multipliziert den ganzen Tag Matrizen
26

Was eignet sich für GPGPU?Datenparallelitätwenig Verzweigunggroße Problemgrößenhochgradig parallele Problemeje mehr arithmetische Operationen, desto besserEinschränkung durch GPU-Speichergröße
27

Quellen
CUDA by example (2010)
The CUDA handbook (2013)
http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
28

Anwendungen
Hashkollisionen
29

1. Charlie soll ein Gutachten K verfassen und an Bob senden.2. Alice soll K durch digitale Unterschrift beglaubigen.3. Alice unterschreibt mit EA(M(K)) und sendet das Ergebnis an Bob.
4. In Wirklichkeit sendet Charlie zwei verschiedene Gutachten K und K′,wobei M(K) = M(K′).
5. Bob glaubt, dass Alice K′ unterschrieben hat, Alice hat aber Kunterschrieben
Umsetzung in CUDA mit 32-Bit Streufunktion basierend auf SHA-256
30

AblaufK berechnen
K′ berechnen
K und K′ auf Kollision prüfen
31

Umsetzung
1. 216 Threads2. ∀t ∈ Threads
1. t berechnet ein k ∈ K und schreibt in gemeinsamen Speicher2. globale Synchronisation
3. t berechnet ein k′ ∈ K′4. ∀Block ∈ K
1. Threadgruppe lädt Block von K2. lokale Synchonisation
3. Thread vergleicht Block mit seinem k′
4. bei Kollision werden k und k′ gemerkt5. lokale Synchonisation
3. zum Schluss Ausgabe aller Texte zu den gefundenen Kollisionen
https://github.com/SethosII/birthday-attack
32

Ergebnis
This birthday attack took 165.8 ms.
Collisions found: 2
33

Good plaintext:
Linux is awesome! It is build on
top of reliable Software like X11.
Also there are several projects
within the Linux community
which have mostly the same
objective like Wayland and Mir -
and that's great. Why shouldn't
you? Duplicate work is no
problem. And with different
approaches you will propably find
better solutions. Thanks to the
many projects you can choose
what suits you best. The next
point are the codenames. They
Bad plaintext:
Linux sucks! It is build on top of
very old Software like X11 which
makes them hard to maintain.
Also there are several projects
within the Linux community
which have mostly identical aim
like Wayland and Mir. Therefore
there is duplicate work. This
shows how divided the
community is. The next point
are the codenames. They suck.
What should Trusty Thar stand
for? Also the whole development
process sucks. They have
Collision with good text #17470 and bad text #21144
Hash value of both is: 640cb7c734

Good plaintext:
Linux is awesome! It is build on
top of reliable Software like X11.
Also there are several projects
within the Linux community
which have mostly identical aim
like Wayland and Mir - and
that's great. Why shouldn't you?
Duplicate work is no problem.
And with more approaches you
will propably find better
solutions. Because of the many
projects you can choose what fits
you best. The next point are the
code names. They rule. How
Bad plaintext:
Linux sucks! It is build on top of
very old Software like X11 which
makes them difficult to maintain.
Also there are several projects
within the Linux community
which have mostly identical aim
like Wayland and Mir. Because
of such things there is a
duplication of effort. This shows
how divided the community is.
The next point are the code
names. They suck. What should
Trusty Thar stand for? Also the
whole development process
Collision with good text #51660 and bad text #26306
Hash value of both is: 91ada02935


















