Embed Size (px)
Citation preview

Universität LeipzigInstitut für InformatikAbteilung Datenbanken
Seminararbeit
MapReduce - Konzept
Autor: Thomas König (Mat.-Nr. 1740853)Studiengang: Master Informatik (3. Semester)
Betreuer: Lars KolbGutachter: Lars Kolb
Eingereicht am: 31.03.2010

MapReduce - Konzept
Inhaltsverzeichnis1 Einleitung..................................................................................................................3
1.1 Motivation.............................................................................................................31.2 Zielstellung der Arbeit..........................................................................................41.3 Aufbau der Arbeit.................................................................................................4
2 MapReduce-Konzept................................................................................................52.1 Allgemein.............................................................................................................52.2 Funktionsweise....................................................................................................52.3 Beispiel.................................................................................................................8
2.3.1 Schritt 1: unstrukturierte Wetterdaten einlesen.............................................82.3.2 Schritt 2: Zuordnung von Datei-Inhalt zu Position........................................82.3.3 Schritt 3: Erzeugen von Zwischenschlüssel-/-wertepaaren..........................92.3.4 Schritt 4: Erzeugen von gruppierten Schlüssel-/Wertepaaren...................102.3.5 Schritt 5: Reduce-Task zur Berechnung der Endergebnisse.....................102.3.6 Schritt 6: Ausgabe der Daten......................................................................11
3 MapReduce im Vergleich.......................................................................................123.1 Vergleich mit relationalen Datenbanken............................................................123.2 Vergleich mit parallelen Datenbanken...............................................................133.3 Vergleich mit Grid Computing............................................................................163.4 Vergleich mit Volunteer-Computing...................................................................17
4 Praktische Anwendungen.....................................................................................194.1 Hadoop..............................................................................................................194.2 Google's Rechenzentren...................................................................................19
5 Zusammenfassung.................................................................................................21
6 Literaturverzeichnis...............................................................................................226.1 Web....................................................................................................................226.2 Bücher................................................................................................................236.3 Artikel.................................................................................................................23
7 Abbildungsverzeichnis..........................................................................................24
8 Tabellenverzeichnis...............................................................................................25
Seite 2

MapReduce - Konzept
1 Einleitung
1.1 Motivation
Cloud Computing beschreibt die Verwendung einer Technologie, bei der
abzuarbeitende Berechnungen nicht auf einem einzigen Computer ausgeführt
werden, sondern auf mehrere Computer in einem Netzwerk aufgeteilt werden. Dabei
werden verschiedene Kapazitäten, wie zum Beispiel Rechenkapazität, dynamisch
über das Netzwerk zur Verfügung gestellt. Die Anwendungen und Daten befinden
sich in der Cloud und werden zum Beispiel über einen Webbrowser gestartet und
verwaltet. [URL 005, URL 006]
Bei der Verwendung von Cloud Computing-Anwendungen kann eine hohe
Rechenkapazität erreicht werden, die die Zeitdauer von Berechnungen je nach
Anzahl der beteiligten Computer bzw. Server beeinflusst. Doch um auch große
Datenmengen verarbeiten zu können, reicht die CPU-Leistung allein nicht aus. Das
Einlesen der Daten hängt vielmehr von den verwendeten Festplatten ab. Zwar sind in
den letzten Jahren die Kapazitäten der Festplatten stark gestiegen, sodass die
Datenmenge an sich kein Problem mehr darstellt, die Zugriffs- und Transferzeiten
haben sich im Vergleich jedoch wenig verbessert. Zum Beispiel benötigt eine 40 GB-
Festplatte aus dem Jahr 2000 insgesamt 21 Minuten für das Lesen der kompletten
Festplatte (bei 32 MB/s), während eine 1.000 GB-Festplatte von 2009 schon 136
Minuten benötigt (bei 125 MB/s). [WHITE 09, Seite 24] [URL 007]
Da die zu verarbeitenden Daten tendenziell immer größer werden, ist eine Lösung
nötig, die neben der CPU-Leistung auch für eine Beschleunigung der
Datenoperationen vorsieht. Die Voraussetzung ist auch hier das Verbinden von
mehreren Computern zu einem Cluster. Das MapReduce-Konzept sorgt für eine
verteilte Speicherung der Daten auf den unterschiedlichen Computern im Cluster und
parallelisiert zudem Datenoperationen, indem nicht nur eine Recheneinheit alle
Daten einliest, sondern jede Recheneinheit liest jeweils unterschiedliche Daten ein.
Dadurch entsteht eine deutliche Zeitreduzierung bei Zugriffsoperationen, was
besonders bei sehr großen und un- bzw. semistrukturierten Datenmengen von Vorteil
ist. [WHITE 09]
Seite 3

MapReduce - Konzept
1.2 Zielstellung der Arbeit
Zielstellung dieser Arbeit ist es, die Funktionen des MapReduce-Verfahrens zu
betrachten und deren Arbeitsweise zu klären. Weiterhin wird kurz auf das Open-
Source-Java-Framework Hadoop als Referenzimplementierung eingegangen, sowie
deren Einsatz an einem eigenem Beispiel untersucht.
1.3 Aufbau der Arbeit
Diese Seminararbeit gliedert sich in zwei Bereiche auf, den theoretischen und den
praktischen Teil.
Der theoretische Teil wird das MapReduce-Konzept untersucht und einen kurzen
Blick auf das Hadoop-Framework werfen. Eine detaillierte Betrachtung von Hadoop
erfolgt in einer separaten Seminararbeit. Weiterhin soll ein Praxis-Beispiel mit der
Verwendung von Hadoop vorgestellt und somit die Anwendung des MapReduce-
Konzepts demonstriert werden.
Die Seminararbeit endet mit einer Zusammenfassung des untersuchten Themas.
Seite 4

MapReduce - Konzept
2 MapReduce-Konzept
2.1 Allgemein
Bei MapReduce handelt es sich um ein Programmiermodell, welches speziell zur
Verarbeitung von großen Datensätzen eingesetzt wird. Damit eine große Menge an
gesammelten Daten verarbeitet werden kann, muss der Aufwand der dafür benötigen
Berechnungen auf mehrere Recheneinheiten verteilt werden. Mit Hilfe des
MapReduce-Frameworks können solche Berechnungen auf vielen Rechnern parallel
ausgeführt werden. Außerdem ist MapReduce auch dafür zuständig, die Ergebnisse
im Anschluss wieder zu aggregieren. Die eigentliche Aufgabe von MapReduce liegt
hierbei in der Bereitstellung und dem Management der Berechnungsinfrastruktur. Ein
Entwickler, der eine verteilte Anwendung implementiert, muss sich also nicht mit der
Parallelisierung beschäftigen und kann für diese Zwecke ohne viel Aufwand auf die
Mechanismen des MapReduce-Frameworks zurückgreifen. Auf Basis dessen können
verteilte Anwendungen problemlos auch auf eine hohe Anzahl an Clients
hochskalieren, ohne dass Codeänderungen nötig werden. Ein großer Vorteil des
MapReduce-Ansatzes ist die Möglichkeit, handelsübliche Standard-Hardware statt
kostenintensiven High-End-Servern zu verwenden. Ein Cluster kann somit auch ohne
spezielle Server aufgebaut und betrieben werden. [OSDI 04]
2.2 Funktionsweise
Die MapReduce-Konzept beruht auf zwei separaten Abläufen: Map und Reduce. Die
Map-Vorgänge starten mit dem Einlesen der Daten. Es erfolgt eine Transformation
der Eingabedaten, die ungeordnet vorliegen, in Schlüssel-/Werte-Paare. Das
Auslesen der Daten wird in mehreren Map-Tasks auf mehreren Recheneinheiten
ausgeführt, was bedeutet, dass die Daten parallel eingelesen werden, wobei jede
Recheneinheit in der Regel unterschiedliche Blöcke der Dateien einliest. Nach dem
ersten Schritt, dem Extrahieren der benötigten Informationen aus dem unsortierten
Datenstrom, erhält man als Ergebnis Schlüssel-/Wertepaare mit dem Byte-Offset des
Seite 5

MapReduce - Konzept
Datenstroms (als Schlüssel) sowie die zugehörige Datenzeile (als Wert), was mit der
Signatur der Map-Funkion ausgedrückt werden kann:
map: k1, v1 → list(k2, v2)
Im Anschluss daran verarbeitet der Map-Task jeden Eintrag dieses
Schlüssel-/Wertepaares und extrahiert die benötigten Informationen. Es wird ein
neues Zwischenschlüssel-/-wertepaar erzeugt und einem Schlüssel ein Wert
zugeordnet. Nach einer Gruppierung dieser Paare liegen zu jedem Schlüssel
mehrere Werte vor, wobei jeder Schlüssel genau ein Mal existiert.
[k2, list(v2)]
Jeder ablaufende Reduce-Task verarbeitet nun eine oder mehrere gruppierte
Schlüssel-/Wertepaare und ordnet einem Schlüssel die benötigte Eigenschaft zu,
etwa die Summe der Werteliste oder das Maximum aller gesammelten Werte einer
Gruppe. Es entstehen Schlüssel-/Wertepaare, bei denen jedem Schlüssel nur ein
Wert zugeordnet wird.
reduce: k2, list(v2) → list(k3, v3)
Für die Aufteilung der Reduce-Tasks ist die Partitionierungsfunktion zuständig, die
auf Basis der intermediaten Schlüssel-/Wertepaare arbeitet und den
Partitionierungsindex an die Reducer übergibt, wobei die festgelegte Anzahl an
Reducern als Parameter an die Funktion übergeben wird. Als Partitionierungsindex
dient der Schlüssel, zugehörige Werte werden ignoriert.
partition: (k2, v2) → integer
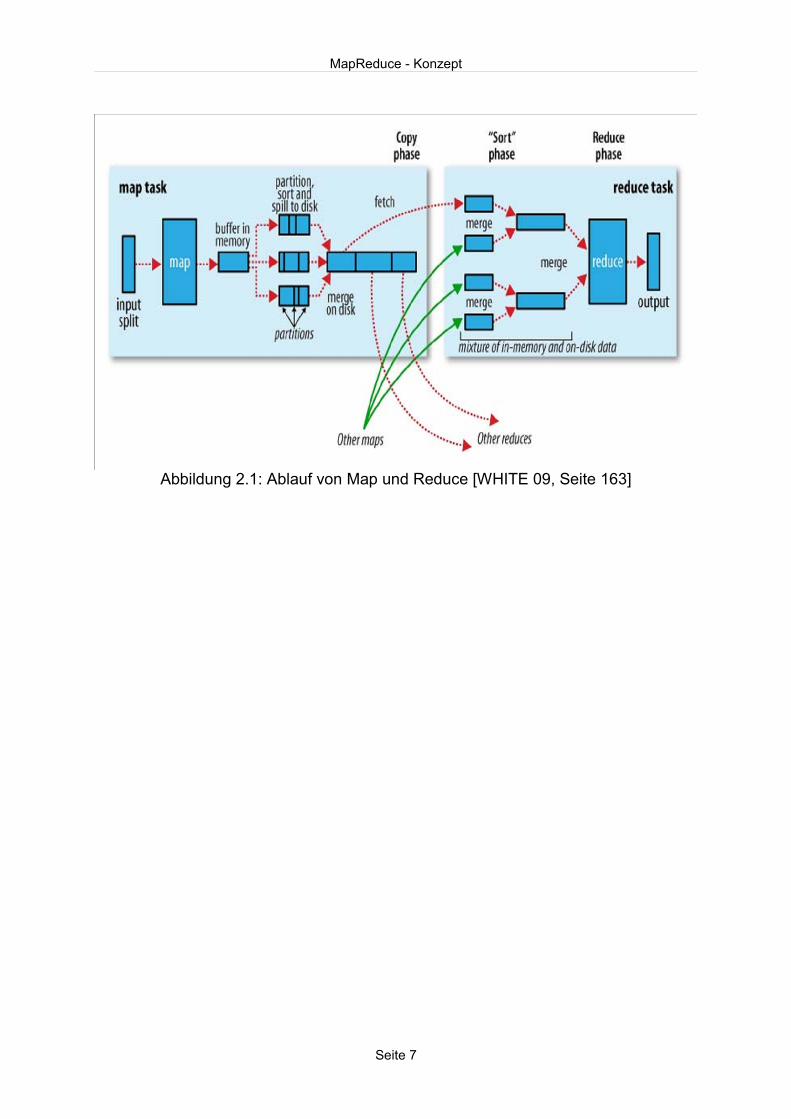
Die nachstehende Grafik verdeutlicht den Ablauf noch einmal.
Kapitel nach [WHITE 09, OSDI 04, URL 001]
Seite 6
MapReduce - Konzept
Seite 7
Abbildung 2.1: Ablauf von Map und Reduce [WHITE 09, Seite 163]

MapReduce - Konzept
2.3 Beispiel
Im folgenden Beispiel sollen Temperaturdaten aus einem unstrukturierten
Datenstrom im Form von Textdateien gelesen werden. Es ist bekannt, wie lang ein
Datensatz ist und an welchen String-Positionen sich die benötigten Daten befinden.
Ziel des Beispiels ist die Ermittlung der maximalen Temperatur eines Jahres. Die
einzelnen Schritte lassen sich anhand der nachstehenden Grafik überblicken.
2.3.1 Schritt 1: unstrukturierte Wetterdaten einlesen
Ein Datensatz, der in den Textdateien durch eine einzige Zeile repräsentiert wird, hat
die folgende Struktur:
0029029070999991901010113004+64333+023450FM-12+000599999V02029
01N008219999999N0000001N9-00721+99999102001ADDGF10499199999999
9999999999
In einem Datensatz sind unter anderem das Datum und die Uhrzeit der Erstellung
sowie die Temperatur zu diesem Zeitpunkt hinterlegt. Der Beispiel-Datensatz wurde
am 01. Januar 1901 um 13:00 Uhr aufgezeichnet, die Temperatur betrug -7,2 °C (s.
rote Markierung).
Im ersten Schritt werden sämtliche Daten parallel eingelesen.
2.3.2 Schritt 2: Zuordnung von Datei-Inhalt zu Position
Da bekannt ist, wie lang ein Datensatz ist, kann aus der unstrukturierten
Datenmenge eine Liste von Schlüssel-/Wertepaaren erzeugt werden, wobei als
Seite 8
Abbildung 2.2: Beispielablauf für die Verarbeitung von Wetterdaten

MapReduce - Konzept
Schlüssel der Byte-Offset des Zeilenanfangs dient und als Wert die Zeile, also der
Datensatz, selbst.
Die Erzeugung der Schlüssel-/Wertepaare kann mit (k1, v1) = (long, String) gleichgesetzt werden.
Byte-Offset Datensatz0 0029029070999991901010113004+6...106 0029029070999991901010114004+6...212 0029029070999991901010115004+6...318 0029029070999991902010104004+6...424 0029029070999991903081223004+6...
Tabelle 2.1: Ausgangslage: ungeordnete Schlüssel-/Wertepaare
2.3.3 Schritt 3: Erzeugen von Zwischenschlüssel-/-wertepaaren
Nach dem Zuordnen der Datensätze zu Byte-Offsets werden im dritten Schritt die
benötigten Daten aus jedem Datensatz extrahiert, was als Map-Task geschieht.
Ergebnis der Extraktion sind Zwischenschlüssel-/Wertepaare. Als Zwischenschlüssel
dient in diesem Beispiel die Jahreszahl, der zugeordnete Wert ist die Temperatur des
zugehörigen Datensatzes multipliziert mit 10. Es entstehen zahlreiche Key/Value-
Paare mit identischen Schlüsseln, die in der Form k1, v1, k2, v2 = int vorliegen.
Jahr Temperatur1950 01950 221950 -111949 1111949 78
Tabelle 2.2: Zwischenschlüssel-/Wertepaare
Seite 9

MapReduce - Konzept
2.3.4 Schritt 4: Erzeugen von gruppierten Schlüssel-/Wertepaaren
Im weiteren Verlauf des Map-Vorgangs erfolgt eine Gruppierung der Key/Value-
Paare. Dazu werden zunächst alle vorhandenen Schlüssel sortiert und im Anschluss
daran zu jedem Schlüssel alle vorhandenen Werte gesucht und diesem zugeordnet,
sodass am Ende des Map-Vorgangs ein Bestand aus gruppierten
Zwischenschlüssel-/Wertepaaren vorliegt. Jeder Zwischenschlüssel existiert nun
genau ein Mal und enthält einen oder mehrere Werte, die ihm während des Map-
Vorgangs zugeordnet wurden. Die entstandenen Schlüssel und Werte liegen hier
ebenfalls als integer-Wert vor.
Jahr Temperatur1949 111
781950 0
22-11
Tabelle 2.3: Ergebnis des Map-Vorgangs
Da mehrere Map-Tasks parallel auf mehreren Recheneinheiten ausgeführt werden,
ist es nötig, dass jeder Mapper seinen sortierten Output ins Dateisystem schreibt. Die
Partitionierungsfunktion erstellt auf Basis der intermediaten Schlüssel die
Partitionierungsindizes und ermöglicht so ein Zuordnen der Schlüssel zu einer zuvor
bestimmten Anzahl an Reducern.
2.3.5 Schritt 5: Reduce-Task zur Berechnung der Endergebnisse
Nach dem erfolgreichen Abarbeiten des Map-Vorgangs erfolgt der Ablauf der
Reduce-Funktion, die als Eingabedaten die zuvor gruppierten Zwischenschlüssel-/
Wertepaare erhält. In diesem Beispiel wird pro Jahr ein eigener Reducer auf einem
Rechner im Cluster gestartet. Dabei holen sich die Reducer die ihnen zugeordneten
Partitionen von den einzelnen Mappern ab, führen den sortierten Eingabestrom
zusammen (merge) und übergeben die nun erzeugten list(k2, list(v2)) an die
Reduce-Funktion.
Seite 10

MapReduce - Konzept
Je nach gewünschtem Ergebnis werden nun die Werte in jeder Gruppe
weiterverarbeitet. Pro Jahr soll die Maximaltemperatur ermittelt werden, sodass nach
dem Reduce-Schritt eine neue Liste von Schlüssel-/Wertepaaren vorhanden ist,
wobei jedem (einzigartigem) Schlüssel nur noch ein Wert zugeordnet wird. Diese
Schlüssel und Werte werden, wie zuvor auch, als integer-Werte zurückgegeben.
Jahr Temperatur1949 1111950 22
Tabelle 2.4: Endergebnis nach dem Reduce-Vorgang
2.3.6 Schritt 6: Ausgabe der Daten
Der letzte Schritt besteht nur noch in der Ausgabe der Key/Value-Paare in eine
Datei, in der zum Beispiel die Schlüssel und Werte durch ein Komma getrennt
eingetragen werden und jedes Paar durch einen Zeilenumbruch getrennt wird.
Kapitel nach [WHITE 09, OSDI 04, URL 001]
Seite 11

MapReduce - Konzept
3 MapReduce im Vergleich
3.1 Vergleich mit relationalen Datenbanken
Bei der Verwendung von MapReduce stellt sich die Frage, ob es nicht doch einfacher
wäre, sämtliche zu verarbeitende Daten in einer relationalen Datenbank zu speichern
und von dort auszulesen anstatt ein MapReduce-Framework zu verwenden. Um
darauf eine Antwort geben zu können, muss man die Ziele und Anwendungs-
möglichkeiten der jeweiligen Techniken näher betrachten.
Liegen strukturierte Daten vor und ist darüber hinaus auch das Schema bekannt, so
liegt der Vorteil bei den relationalen Datenbanken. Das gezielte Abfragen von be-
stimmten Spalten einer Tabelle eignet sich besonders bei „wenigen“ abzufragenden
Datensätzen aufgrund des bekannten Schemas und der verfügbaren Indexe. Somit
kann ein effizienter Zugriff auf einzelne Datensätze und Attribute gewährleistet wer-
den. Änderungsmöglichkeiten der Daten sind bei relationalen Datenbanken ebenfalls
vorhanden und leicht durchführbar, im Gegensatz zu den unstrukturierten Daten, die
beim MapReduce-Framework zum Einsatz kommen. Hier kommt das Zugriffsmuster
„Write once, read many times“ zum Einsatz, was bedeutet, dass effiziente Lese- und
Schreibzugriffe nicht möglich sind. Für das MapReduce und dessen unstrukturierte
Datenmengen spricht jedoch die enorme Datenmenge an sich und die Skalierbarkeit.
Mehrere Recheneinheiten im Cluster lesen parallel ein und können somit ein
Vielfaches der Datenmenge im Vergleich zu relationalen Datenbanken handhaben.
Je mehr Recheneinheiten, umso schneller kann das Einlesen erfolgen.
Während MapReduce also für das sequentielle (parallele) Einlesen von großen
Datenmengen geeignet ist, spielen die relationalen Datenbanksysteme ihre Stärken
bei bekannten Strukturen, Punktanfragen und Änderungsoperationen aus.
Seite 12

MapReduce - Konzept
Traditional RDMBS MapReduceData size Gigabytes PetabytesAccess Interactive and Batch BatchUpdates Read and write many times Write once read many timesStructure Static schema Dynamic schemaIntegrity High LowScaling Nonlinear Linear
Tabelle 3.1: Vergleich von RDBMS und MapReduce [WHITE 09, Seite 5]
3.2 Vergleich mit parallelen Datenbanken
Bei parallelen Datenbanken handelt es sich ebenfalls um mehrere Recheneinheiten,
die über ein Netzwerk verbunden sind.
„Unter der Bezeichnung "Mehrrechner-Datenbanksysteme" sollen sämtliche Architekturen zusammengefaßt werden, bei denen mehrere Prozessoren oder DBVS-Instanzen an der Verarbeitung von DB-Operationen beteiligt sind. Dabei ist natürlich eine Kooperation der Prozessoren bzw. DBVS bezüglich der DB-Verarbeitung bestimmter Anwendungen vorzusehen, um den Fall voneinander isoliert arbeitender DBVS oder Prozessoren auszuschließen.“ [RAHM 01]
Hierbei können insgesamt drei verschiedene Architekturen unterschieden werden.
• Shared-Everything: Alle Recheneinheiten teilen sich einen gemeinsamen
Speicher für die Lese- und Schreibvorgänge. „Die DB-Verarbeitung erfolgt
durch ein DBVS1 auf einem Multiprozessor“. [RAHM 01]
• Shared-Nothing: Sämtliche Recheneinheiten verfügen über ihren eigenen
Multiprozessor. Der gemeinsame Speicher wird unter den Recheneinheiten
partitioniert, sodass jede Recheneinheit seinen eigenen lokalen
Speicherbereich hat und nur auf diesen zugreifen kann. [RAHM 01]
• Shared-Disk: Es handelt sich um eine ähnliche Anordnung wie Shared-
Nothing, allerdings existiert hier ein gemeinsamer Speicherbereich, der nicht
aufgeteilt wird. Lese- und Schreibzugriffe erfolgen somit auf den
1 Datenverwaltungssystem
Seite 13

MapReduce - Konzept
gemeinsamen Speicherbereich, der allen Recheneinheiten zugänglich ist.
[RAHM 01]
Bei parallelen Datenbanksystemen werden, wie bei relationalen Daten-
banksystemen, Tabellen mit Zeilen und Spalten eingesetzt, die ebenfalls bei SQL
abgefragt werden können. Das Abfragen der bekannten Struktur per SQL kann
aufgrund der Parallelverarbeitung jedoch deutlich schneller geschehen als es bei re-
lationalen Datenbanken der Fall ist, da, je nach Partitionierung der Speicherbereiche,
eine Tabelle auf mehrere Recheneinheiten verteilt werden kann. Das dahinter
liegende Verfahren wird als horizontale Partitionierung bezeichnet. [STONE 10]
„The idea behind horizontal partitioning is to distribute the rows of a relational table across the nodes of the cluster so they can be processed in parallel. For example, partitioning a 10-million-row table across a cluster of 50 nodes, each with four disks, would place 50,000 rows on each of the 200 disks.“ [STONE 10]
Somit können also größere Datenmengen in der selben Zeitdauer gelesen, geändert
oder gelöscht werden, was bei (mehreren) hundert Gigabyte pro Tabelle eine
deutliche Zeitreduktion ergibt. Der Nachteil der Parallelisierung liegt in den Kosten.
Für den Betrieb von parallelen Datenbanksystemen kommen ausschließlich High-
End-Server zum Einsatz, die hohe Kosten verursachen. Darüber hinaus verursacht
auch das Datenbankverwaltungssystem hohe Kosten, sofern mehrere
Recheneinheiten im Cluster vorhanden sind. Für Single-Node-Systeme existieren
dagegen diverse Open Source-Implementierungen, die zur freien Verfügung stehen.
[STONE 10]
In der Literatur existieren einige vergleichende Aussagen bezüglich MapReduce und
parallelen Datenbanksystemen, die im Folgenden kurz vorgestellt werden sollen.
Sobald sämtliche Daten vom Speicher eingelesen wurden, haben parallele
Datenbanksysteme demnach Geschwindigkeitsvorteile beim Abfragen der benötigten
Daten, wohingegen MapReduce Geschwindigkeitsvorteile während des parallelen
Einlesens der Daten aufweisen kann, da Datenbanksysteme beim Einlesen
langsamer sind. [STONE 10]
MapReduce profitiert bei den Berechnungen und der CPU-Leistung ebenso von der
Anzahl der Recheneinheiten im Cluster wie die parallelen Datenbanksysteme, diese
Seite 14

MapReduce - Konzept
bieten jedoch zusätzlich den Vorteil der Abfragesprache SQL. [STONE 10] Für die
Open Source-Implementierung Hadoop, die das MapReduce-Konzept umsetzt,
existieren die Erweiterungen HadoopDB und Hive, die das MapReduce-Konzept um
eine SQL-ähnliche Abfragesprache erweitern (Hive) oder PostegreSQL und Hadoop
verbinden (HadoopDB). HadoopDB kann somit eine ähnliche Geschwindigkeit wie
die parallelen DBS erreichen. [URL 008, URL 009, URL 010, RASIN 09]
Die Vorteile von MapReduce liegen bei den semistrukturierten Daten, deren
Einlesezeit von der Anzahl der Recheneinheiten im Cluster bestimmt wird, was
besonders bei komplexen Datenanalysen (wie etwa Data Mining) und dem damit
verbundenen komplexen Datenfluss einen Vorteil gegenüber den parallelen DBS
ergibt, da hier keine SQL-Queries verwendet werden können. [STONE 10]
Ein weiterer Vorteil von MapReduce liegt bei der Fehlertoleranz. Da die
Eingabedaten blockweise auf den Recheneinheiten im Cluster gespeichert werden
und als Folge davon redundant vorhanden sind, kann bei einem fehlerhaften Map-
Task einfach eine andere Recheneinheit diesen einen Task wiederholen. Parallele
Datenbanksysteme müssen mit Transaktionen umgehen können, was bedeutet, dass
eine fehlgeschlagene Query komplett wiederholt werden muss. [PAVLO 09]
Weitere Vergleiche werden in [STONE 10, PAVLO 09 und RASIN 09] durchgeführt
und sollen an dieser Stelle nicht näher vertieft werden.
Parallele DBS MapReduceDatengröße Gigabytes - Petabytes PetabytesStruktur Statisches Schema Semistrukturierte DatenPartitionierung Horizontal Blöcke in DFS (Byteweise)Anfrage Deklarativ (SQL) MapReduce-ProgrammeZugriff Punkt/Bereich via Indexes BatchUpdates Read and write many times Write once read many timesScheduling Compile-time RuntimeVerarbeitung Effizienter Zugriff auf Attribute
möglich (Storage Manager)Parsen jeden Tupels zur Laufzeit
Datenfluss Push – Pipelining von Tupeln zwischen Operationen
Pull – Materialisierung von Zwischenergebnissen
Fehlertoleranz Query-Restart (z.T. Operator- Neustart des Map-/Reduce-
Seite 15

MapReduce - Konzept
Parallele DBS MapReduceRestart) Tasks
Skalierbarkeit Linear (existierende Setups) LinearUmgebung Homogen (High-End-
Hardware)Heterogen (Standard-Hardware)
Kosten Sehr teuer Open Source
Tabelle 3.2: Vergleich von parallelen DBS und MapReduce [nach Lars Kolb]
3.3 Vergleich mit Grid Computing
Neben MapReduce existiert eine weitere Anordnung, bei Recheneinheiten zu einem
Cluster verbunden werden: Grid Computing. Allerdings gibt es auch hier
Unterschiede, die sich vor allem im Anwendungszweck und in der Datenverarbeitung
äußern.
Grid Computing wird größtenteils für rechenintensive Jobs verwendet, wie zum
Beispiel bei der Pharmaforschung oder um andere wissenschaftliche Probleme zu
lösen. Dabei werden normale Computer über ein Netzwerk zu einem Supercomputer
mit enormer Rechenkraft verbunden. [URL 004] Was für die Berechnungen von
Vorteil ist, stellt sich bei den Datenzugriffen als Nachteil heraus. Benötigte Daten
müssen über das Netzwerk gestreamt werden, die Netzwerkanbindung ist hierbei der
Flaschenhals, da die einzelnen Rechner eines Grids standortunabhängig aufgebaut
werden können. Während des Datenaustauschs erfolgt eine Unterbrechung der
Berechnungen. Im Gegensatz dazu hat jeder Rechner des MapReduce-Clusters
(mindestens) eine Kopie der Daten lokal verfügbar und kann aufgrund der parallelen
Datenzugriffsoperationen schneller arbeiten. Ein fehlerhaftes Einlesen kann
problemlos wiederholt werden.
Für Grid Computing existiert eine API, die unter dem Namen „Message Passing
Interface“ (MPI) bekannt ist. Die API bietet dem Programmierer Freiheiten bei der
Gestaltung der Prozesse, verlangt im Gegenzug aber auch das eigenhändige
Implementieren der Datenoperationen auf Low Level Ebene (C Routinen und
Konstrukte, z.B. Sockets), die Berechnungen können als High Level Algorithmus
implementiert werden. MapReduce arbeitet ausschließlich auf High Level Ebene und
Seite 16

MapReduce - Konzept
übernimmt ohne Zutun des Programmierers sämtliche Dateioperationen. Die
Berechnungen können jedoch nur über Key/Value-Paare erfolgen und sind
dahingehend eingeschränkt. Es gibt eine Vielzahl von Aufgaben, die sich dennoch
mit MapReduce erledigen lassen, wie Bildanalysen oder „machine learning
algorithms“. [WHITE 09, Seite 8]
Ein weiterer Unterschied ist die Fehlerbehandlung. Der Grid-Programmierer muss
selbst für eine geeignete Implementation sorgen, was ihm zwar mehr Kontrolle gibt,
aber auch einen höheren Aufwand nach sich zieht. Fehlerbehandlungen bei
MapReduce werden vom Framework automatisch durchgeführt, fehlerhafte Map- und
Reduce-Tasks werden automatisch neu gestartet, falls ein Fehler entstanden ist.
[WHITE 09, Seite 6ff]
Grid Computing MapReduceDatengröße Gigabytes - Petabytes PetabytesDatenspeicherung Streaming der Daten über das
NetzwerkLokale Kopie auf jedem Rechner
Fehlertoleranz Muss vom Programmierer implementiert werden
Neustart des Map-/Reduce-Tasks
Skalierbarkeit Linear LinearUmgebung Heterogen (Standard-
Hardware)Heterogen (Standard-Hardware)
Anwendungsziel CPU-intensive Berechnungen Datenverarbeitung
Tabelle 3.3: Vergleich von Grid Computing und MapReduce [nach WHITE 09, S. 6ff]
3.4 Vergleich mit Volunteer-Computing
Zu Volunteer-Computing zählt beispielsweise SETI@home („Search for Extra-
Terrestrial Intelligence“). Bei diesem Projekt werden Daten von Radioteleskopen im
Bezug auf Anzeichen von intelligentem Leben im Weltall ausgewertet. Die
Berechnungen werden auf den Computern von Privatanwendern ausgeführt. Bei
wenig anliegender CPU-Last übernehmen diese die Auswertung der SETI-Daten,
wobei jeder Teilnehmer nur ein kleines Datenpaket (ca. 0,35 MB) erhält uns dieses
dann auswertet. Trotz dieser geringen Datenmenge dauert die Berechnung mehrere
Seite 17

MapReduce - Konzept
Stunden oder gar Tage. Die Anwendungsbereiche liegen beim Volunteer-Computing
also eindeutig auf der Bereitstellung von Prozessorleistung und nicht auf dem
zügigen Einlesen von riesigen Datenmengen, obwohl auch bei MapReduce die
gesamte Datenmenge in kleinere Blöcke geteilt wird. Betrugsversuche und falsche
Berechnungen werden mit bestimmten Maßnahmen automatisch abgesichert. Ein
weiterer Unterschied besteht im Aufbau der jeweiligen Cluster. MapReduce-Tasks
werden in einem Cluster ausgeführt, deren einzelne Recheneinheiten in der Regel
über ein schnelles Netzwerk verbunden sind, während beim Volunteer-Computing
der Netzwerkverkehr durch die Internetanbindung des Teilnehmers bestimmt wird.
[WHITE 09, Seite 8]
Volunteer Computing MapReduceDatengröße Kilobytes - Megabytes PetabytesDatenhaltung Streaming der Daten über das
NetzwerkLokale Kopie auf jedem Rechner
Fehlertoleranz Wird vom Projekt bzw. vom Server geregelt
Neustart des Map-/Reduce-Tasks
Umgebung Heterogen (Standard-Hardware)
Heterogen (Standard-Hardware)
Netzwerk-anbindung
Beschränkt auf die Internetverbindung der Teilnehmer
Hochgeschwindigkeits-netzwerk
Anwendungsziel CPU-intensive Berechnungen Datenverarbeitung
Tabelle 3.4: Vergleich von Volunteer Computing und MapReduce [nach WHITE 09, Seite 8]
Seite 18

MapReduce - Konzept
4 Praktische Anwendungen
4.1 Hadoop
Hadoop ist die OpenSource-Implementierung des MapReduce-Konzepts. Es handelt
sich um ein Open Source Projekt der Apache Software Foundation, das offen für
freiwillige Teilnehmer ist. Das von ihnen bereitgestellte Framework dient der
Programmierung von MapReduce-Tasks und ist, wie es das MapReduce-Konzept
vorsieht, auf große Datenmengen spezialisiert, die parallel auf mehreren Computern
abgearbeitet werden, die zu einem Cluster verbunden wurden. Das Framework steht
für Unix/Linux zum Download bereit und setzt eine installierte Java Virtual Machine
1.6 voraus, sofern man das Framework in Java-Applikationen verwenden möchte.
Sämtliche Daten, die im Cluster zur Verfügung stehen sollen, müssen zunächst von
der eigenen Festplatte auf das verteilte Dateisystem übertragen werden. Nach dem
Kopiervorgang ist das Framework in der Lage, einen MapReduce-Task durch-
zuführen. An dieser Stelle soll nicht näher auf die Ausführung eingegangen werden.
Mit Hive und HadoopDB erhält der Anwender zwei interessante Erweiterungen. Hive
erweitert das Hadoop-Framework um die auf SQL basierende Anfragesprache QL
und ermöglicht so „die Verwendung einer SQL-ähnlichen Syntax“. [URL 008] Bei
HadoopDB handelt es sich um eine Kombination aus Hadoop und der freien
Datenbank PostegreSQL. HadoopDB bietet damit die Skalierbarkeit von Hadoop und
die Geschwindigkeit von parallelen Datenbanken. [URL 008, URL 009, URL 010,
RASIN 09]
4.2 Google's Rechenzentren
Die Verwendung der Suchmaschine Google erfolgt durch das einfache Benutzen der
Weboberfläche. Welche Hardwarebasis bei einer Suchabfrage zum Einsatz kommt,
ist nicht ersichtlich. Zur Erstellung der enormen Datenmengen werden zahlreiche
Suchindexe und Page-Rank-Tabellen benötigt, die in Rechenzentren verwaltet
werden. Laut Informationen von Google soll ein Rechenzentrum aus 45 Containern
Seite 19

MapReduce - Konzept
bestehen, in denen insgesamt 45.000 Server untergebracht werden. Mit einem
solchen Cluster wird das Crawlen und Aufbereiten der Suchergebnisse durchgeführt.
Aufgrund der ständig steigenden Datenmengen setzt Google seit 2005 solche
Rechenzentren ein.
Der Energieverbrauch einer solchen Serverfarm beläuft sich auf 10 Megawatt, was
einige Kühltürme, die mit Wasser betrieben werden, sowie ein eigenes Kraftwerk
notwendig macht. Bei der Stromerzeugung sollen hocheffiziente Transformatoren
zum Einsatz kommen. [URL 002]
Der Großteil der Rechenzentren befinden sich in Nordamerika und Europa, nur
wenige Rechenzentren wurden in Südamerika und Asien errichtet.
Seite 20
Abbildung 4.1: Google Rechenzentrum
Abbildung 4.2: Standorte der Google Rechenzentren [URL 003]

MapReduce - Konzept
5 Zusammenfassung
Für die verteilte Abarbeitung von Aufgaben bietet sich ein Cluster an, das aus
mehreren Recheneinheiten besteht. Während es für CPU-intensive Aufgaben oder
das schnelle und gezielte Abfragen von Datenbanken diverse Techniken zur
Verfügung stehen, bietet sich das MapReduce-Konzept vor allem für die schnelle
Verarbeitung von riesigen Datenmengen an, die in unstrukturierter oder
semistrukturierter Form vorliegen. Der Geschwindigkeitsvorteil entsteht bei
MapReduce in Einlesevorgängen, die parallel auf den vorhandenen Recheneinheiten
durchgeführt werden. Jeder Rechner im Cluster liest einen anderen Block der Daten
ein. Je mehr Rechner im Cluster vorhanden sind, umso schneller kann das Einlesen
erfolgen. Das MapReduce-Konzept sieht außerdem vor, dass sämtliche
Fehlerbehandlungen vom Framework übernommen werden und dem Anwender
diesen Aufwand ersparen. Auch regelt das Framework selbstständig, welche
Recheneinheit welche Daten einliest und verarbeitet und wie die Aufteilung der
Berechnungen erfolgt.
Das MapReduce-Framework untergliedert die Aufgaben in Map- und Reduce-Tasks.
Grundlage der Verarbeitung sind Key/Value-Paare, die bis zur Beendigung der
Reduce-Tasks einige Zwischenschritte, wie zum Beispiel das Sortieren und
Gruppieren, erfahren.
Das von Google entwickelte MapReduce-Konzept kann als Open Source-
Implementierung Hadoop auf jedem beliebigen Rechner frei verwendet werden.
Die behandelten Vergleiche haben verdeutlicht, dass das Einsatzgebiet von
MapReduce in den parallelen Datenzugriffsoperationen von riesigen Datenmengen,
wie zum Beispiel dem Einlesen von Page-Rank-Tabellen, zu suchen ist und weniger
bei der komplexen und CPU-intensiven Berechnung von Ergebnissen. Vielmehr
sollen die eingelesenen Daten auf vergleichsweise einfache Art und Weise
weiterverarbeitet werden.
Seite 21

MapReduce - Konzept
6 Literaturverzeichnis
6.1 Web
URL 001 http://www.slideshare.net/Wombert/an-introduction-to-mapreduceaufgerufen am 26.11.2009
URL 002 http://blogoscoped.com/archive/2009-04-08-n39.htmlaufgerufen am 26.11.2009
URL 003 http://royal.pingdom.com/2008/04/11/map-of-all-google-data-center-locations/aufgerufen am 26.11.2009
URL 004 http://de.wikipedia.org/wiki/Grid-Computingaufgerufen 10.02.2010
URL 005 http://en.wikipedia.org/wiki/Cloud_computingaufgerufen 27.02.2010
URL 006 http://de.wikipedia.org/wiki/Cloud_Computingaufgerufen 27.02.2010
URL 007 http://de.wikipedia.org/wiki/Festplatteaufgerufen 27.02.2010
URL 008 http://de.wikipedia.org/wiki/Hadoopaufgerufen 28.02.2010
URL 009 http://www.heise.de/newsticker/meldung/HadoopDB-versoehnt-SQL-mit-Map-Reduce-6689.htmlaufgerufen 28.02.2010
URL 010 http://www.golem.de/0907/68643.htmlaufgerufen 28.02.2010
Seite 22

MapReduce - Konzept
6.2 Bücher
WHITE 09 Tom White:Hadoop – The Definite GuideO'Reilly Media, 2009
RAHM 01 Erhard Rahm:Mehrrechner-DatenbanksystemeSpringer, 2001
6.3 Artikel
OSDI 04 Jeffrey Dean and Sanjay GhemawatMapReduce: Simplifed Data Processing on Large Clusters
STONE 10 Michael Stonebraker, Daniel Abadi, David J. Dewitt, Sam Madden, Erik Paulson, Andrew Pavlo, Alexander Rasin:MapReduce and Parallel DBMSs: Friends or Foes?Communications of the ACM, Januar 2010
RASIN 09 Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel Abadi, Avi Silberschatz, Alexander Rasin:HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads2009
PAVLO 09 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt, Samuel Madden, Michael Stonebraker:A Comparison of Approaches to Large-Scale Data Analysis2009
Seite 23

MapReduce - Konzept
7 Abbildungsverzeichnis
Abbildung 2.1: Ablauf von Map und Reduce [WHITE 09, Seite 163]............................7
Abbildung 2.2: Beispielablauf für die Verarbeitung von Wetterdaten...........................8
Abbildung 4.1: Google Rechenzentrum......................................................................20
Abbildung 4.2: Standorte der Google Rechenzentren [URL 003]...............................20
Seite 24

MapReduce - Konzept
8 Tabellenverzeichnis
Tabelle 2.1: Ausgangslage: ungeordnete Schlüssel-/Wertepaare................................9
Tabelle 2.2: Zwischenschlüssel-/Wertepaare...............................................................9
Tabelle 2.3: Ergebnis des Map-Vorgangs...................................................................10
Tabelle 2.4: Endergebnis nach dem Reduce-Vorgang...............................................11
Tabelle 3.1: Vergleich von RDBMS und MapReduce [WHITE 09, Seite 5]................13
Tabelle 3.2: Vergleich von parallelen DBS und MapReduce [nach Lars Kolb]...........16
Tabelle 3.3: Vergleich von Grid Computing und MapReduce [nach WHITE 09, S. 6ff]
.....................................................................................................................................17
Tabelle 3.4: Vergleich von Volunteer Computing und MapReduce [nach WHITE 09,
Seite 8].........................................................................................................................18
Seite 25





























