Embed Size (px)
Citation preview

Mathematik fur Studierende
der Ingenieurwissenschaften II
Wolfgang Mackens & Heinrich Voß
Arbeitsbereich Mathematik
der Technischen Universitat Hamburg–Harburg
1998

Inhaltsverzeichnis
1 Grundlagen 1
1.1 Aussagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Mengen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Abbildungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4 Die reellen Zahlen IR . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.4.1 Algebraische Eigenschaften . . . . . . . . . . . . . . . . . . . 18
1.4.2 Ordnungseigenschaften . . . . . . . . . . . . . . . . . . . . . 19
1.4.3 Betrage, Vollstandigkeit . . . . . . . . . . . . . . . . . . . . 20
1.5 Die naturlichen Zahlen IN . . . . . . . . . . . . . . . . . . . . . . . 21
1.6 Komplexe Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1.6.1 Rechnen mit komplexen Zahlen . . . . . . . . . . . . . . . . 29
1.6.2 Zahlenebene . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1.6.3 Polardarstellung . . . . . . . . . . . . . . . . . . . . . . . . . 32
1.6.4 Wurzeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2 Vektorrechnung 38
2.1 Vektoren im 2- und 3-dim. Anschauungsraum . . . . . . . . . . . . 38
2.2 Allgemeine Vektorraume . . . . . . . . . . . . . . . . . . . . . . . . 64
2.2.1 Definition und Beispiele . . . . . . . . . . . . . . . . . . . . 66
2.2.2 Teilraume . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
2

INHALTSVERZEICHNIS 3
2.2.3 Basis, Dimension . . . . . . . . . . . . . . . . . . . . . . . . 72
2.2.4 Isomorphie von Vektorraumen . . . . . . . . . . . . . . . . . 80
2.2.5 Euklidische Vektorraume . . . . . . . . . . . . . . . . . . . . 82
2.2.6 Normierte Vektorraume . . . . . . . . . . . . . . . . . . . . 91
2.2.7 Lineare Mannigfaltigkeiten . . . . . . . . . . . . . . . . . . . 94
2.2.8 Komplexe Vektorraume . . . . . . . . . . . . . . . . . . . . . 96
4 Matrizen 121
4.1 Lineare Abbildungen . . . . . . . . . . . . . . . . . . . . . . . . . . 123
4.2 Das Matrizenprodukt . . . . . . . . . . . . . . . . . . . . . . . . . . 134
4.3 Lineare Gleichungssysteme und Inverse . . . . . . . . . . . . . . . . 141
4.4 Kongruenztransformationen . . . . . . . . . . . . . . . . . . . . . . 150
4.5 LR-Zerlegung regularer Matrizen . . . . . . . . . . . . . . . . . . . 155
4.6 Block-Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
6 Lineare Abbildungen 190
6.1 Der Basiswechsel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
6.2 Die orthogonale Projektion . . . . . . . . . . . . . . . . . . . . . . . 203
6.3 Orthogonale Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . 210
6.4 Householder Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . 215
7 Lineare Ausgleichsprobleme 220
7.1 Die QR-Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
7.2 Die Normalgleichungen . . . . . . . . . . . . . . . . . . . . . . . . . 231
7.3 Lineare diskrete Approximation . . . . . . . . . . . . . . . . . . . . 234

4 INHALTSVERZEICHNIS
8 Eigenwertaufgaben 241
8.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
8.2 Diagonalisierbarkeit von Matrizen . . . . . . . . . . . . . . . . . . . 250
8.3 Normale Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
8.4 Symmetrische und Hermitesche Matrizen . . . . . . . . . . . . . . . 257
8.5 Die Jordansche Normalform . . . . . . . . . . . . . . . . . . . . . . 273
8.6 Lokalisierung von Eigenwerten . . . . . . . . . . . . . . . . . . . . . 278
8.7 Die Hauptachsentransformation . . . . . . . . . . . . . . . . . . . . 292
8.8 Verallgemeinerte Eigenwertaufgaben . . . . . . . . . . . . . . . . . . 307
10 Folgen und Reihen 1
10.1 Einfuhrende Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . 1
10.2 Konvergenz von Folgen . . . . . . . . . . . . . . . . . . . . . . . . . 13
10.3 Reelle Zahlenfolgen . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
10.4 Cauchysches Konvergenzkriterium . . . . . . . . . . . . . . . . . . . 33
10.5 Folgen in Vektorraumen . . . . . . . . . . . . . . . . . . . . . . . . 36
10.6 Konvergenzkriterien fur Reihen . . . . . . . . . . . . . . . . . . . . 43
11 Stetige Funktionen 59
11.1 Motivation und Definition . . . . . . . . . . . . . . . . . . . . . . . 59
11.2 Eigenschaften stetiger (reeller) Funktionen . . . . . . . . . . . . . . 70
11.3 Gleichmaßige Stetigkeit . . . . . . . . . . . . . . . . . . . . . . . . . 76
11.4 Grenzwerte von Funktionen . . . . . . . . . . . . . . . . . . . . . . 78

INHALTSVERZEICHNIS 5
12 Elementare Funktionen 84
12.1 Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
12.2 Konvergenz in Funktionenraumen . . . . . . . . . . . . . . . . . . . 96
12.3 Potenzreihen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
12.4 Exponentialfunktion, Logarithmusfunktion . . . . . . . . . . . . . . 111
12.5 Trigonometrische Funktionen . . . . . . . . . . . . . . . . . . . . . 116
12.6 Hyperbelfunktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
13 Differenzierbare reelle Funktionen 126
13.1 Motivation und Definition . . . . . . . . . . . . . . . . . . . . . . . 126
13.2 Rechenregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
13.3 Hohere Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
14 Anwendungen der Differentialrechnung 152
14.1 Mittelwertsatze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
14.2 Regeln von de l’Hopital . . . . . . . . . . . . . . . . . . . . . . . . . 160
14.3 Der Satz von Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . 166
14.4 Kurvendiskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
14.5 Der Fehler der Polynominterpolation . . . . . . . . . . . . . . . . . 195
15 Numerische Losung von Gleichungen 201
15.1 Bisektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
15.2 Fixpunktsatz fur kontrahierende Abbildungen . . . . . . . . . . . . 205
15.3 Newton Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
15.4 Iterative Methoden fur lineare Systeme . . . . . . . . . . . . . . . . 221
15.5 Berechnung von Eigenwerten . . . . . . . . . . . . . . . . . . . . . . 224

6 INHALTSVERZEICHNIS
16 Das bestimmte Riemannsche Integral 229
16.1 Definition des Riemann Integrals . . . . . . . . . . . . . . . . . . . 229
16.2 Integrierbarkeitskriterien . . . . . . . . . . . . . . . . . . . . . . . . 233
16.3 Klassen integrierbarer Funktionen . . . . . . . . . . . . . . . . . . . 236
16.4 Rechenregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
17 Das unbestimmte Integral 244
17.1 Fundamentalsatz der Infinitesimalrechnung . . . . . . . . . . . . . . 244
17.2 Partielle Integration . . . . . . . . . . . . . . . . . . . . . . . . . . 248
17.3 Substitutionsregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
17.4 Partialbruchzerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . 257
17.5 Vertauschen von Grenzwerten . . . . . . . . . . . . . . . . . . . . . 262
18 Uneigentliche Integrale 267
18.1 Unbeschrankte Integrationsintervalle . . . . . . . . . . . . . . . . . 267
18.2 Unbeschrankte Integranden . . . . . . . . . . . . . . . . . . . . . . 273
19 Numerische Integration 278
19.1 Einfuhrende Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . 278
19.2 Konstruktion von Quadraturformeln . . . . . . . . . . . . . . . . . 281
19.3 Fehler von Quadraturformeln . . . . . . . . . . . . . . . . . . . . . 282
19.4 Quadraturformeln von Gauß . . . . . . . . . . . . . . . . . . . . . . 287
19.5 Adaptive Quadratur . . . . . . . . . . . . . . . . . . . . . . . . . . 290
19.6 Nicht glatte Integranden . . . . . . . . . . . . . . . . . . . . . . . . 297

20 Anwendungen der Integralrechnung 302
20.1 Volumen von Rotationskorpern . . . . . . . . . . . . . . . . . . . . 302
20.2 Kurven, Bogenlangen . . . . . . . . . . . . . . . . . . . . . . . . . . 305
20.3 Krummung einer Kurve . . . . . . . . . . . . . . . . . . . . . . . . 314
20.4 Von einer Kurve umschlossene Flache . . . . . . . . . . . . . . . . . 321
20.5 Mantelflachen von Rotationskorpern . . . . . . . . . . . . . . . . . 323
20.6 Kurvenintegrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
21 Periodische Funktionen 328
21.1 Einleitende Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . 328
21.2 Fourierentwicklung periodischer Funktionen . . . . . . . . . . . . . 330
21.3 Approximation im quadratischen Mittel . . . . . . . . . . . . . . . . 336
21.4 Gleichmaßige Konvergenz von Fourierreihen . . . . . . . . . . . . . 338
21.5 Asymptotisches Verhalten der Fourierkoeffizienten . . . . . . . . . . 343
21.6 Andere Formen der Fourierreihe . . . . . . . . . . . . . . . . . . . . 345
21.7 Numerische Fourieranalyse und -synthese . . . . . . . . . . . . . . . 347
Literaturverzeichnis 353

Kapitel 10
Folgen und Reihen
In diesem Kapitel beginnen wir die Behandlung der Infinitesimalrechnung1, in der
man sich mit Grenzprozessen und deren Anwendungen befasst. Mit Hilfe von Grenz-
prozessen werden komplizierte Objekte durch einfachere Objekte approximiert. Hau-
fig werden dabei Objekte der Mathematik sogar erst vermittels dieser Grenzprozesse
definiert. Beide Aspekte bereiten Anfangern in der Regel erhebliche Verstandnis-
schwierigkeiten. Wir fuhren deshalb im ersten Unterabschnitt in die Problematik
mit einer Reihe von Beispielen ein, wobei wir einige (moglicherweise schon aus der
Schule bekannte) Sprechweisen uber Folgen in intuitiver Weise benutzen. Die exakte
Definition und deren genauer Gebrauch wird erst in den nachfolgenden Unterab-
schnitten dargestellt werden. Wenn Sie daher im ersten Unterabschnitt den Eindruck
gewinnen, Sachverhalte nicht genau zu verstehen, so brauchen Sie nicht beunruhigt
zu sein, da Sie sie ohne genaue Vereinbarung ja tatsachlich noch gar nicht verstehen
konnen. Sie sollten in diesem Unterabschnitt nur grobe motivierende Vorstellun-
gen von den nachfolgenden Fragestellungen gewinnen. Wir hoffen, dass diese beim
Verstandnis der genauen Untersuchungen hilfreich sein werden.
10.1 Einfuhrende Beispiele
Jede rationale Zahl r lasst sich bekanntlich durch endlich viele Ziffern eindeutig
beschreiben. Dies kann durch die Angabe des Zahlers und Nenners eines Bruches aus
ganzen Zahlen geschehen oder mit Hilfe eines Dezimalbruchs. Dieser hat entweder
1finit=endlich, infinit=unendlich

2 KAPITEL 10. FOLGEN UND REIHEN
die Form
±0.Z−1Z−2 . . . Z−m · 10E := ±10E ·m∑
k=1
Z−k · 10−k,
mit Zj ∈ {0, 1, . . . , 9}, Z−1 6= 0 fur r 6= 0, E ∈ ZZ, oder der Dezimalbruch wird
(eventuell nach einigen Vorlaufziffern) periodisch
±0.Z−1Z−2 . . . Z−mZ−m−1 . . . Z−m−p · 10E,
wobei hier der Strich uber den letzten p Ziffern bedeutet, dass diese periodisch
wiederholt werden.
Irrationale Zahlen wie√
2 (vgl. Satz 1.8) oder π konnen weder durch einen endlichen
noch durch einen periodischen Dezimalbruch dargestellt werden. Die exakte Angabe
des Dezimalbruchs einer irrationalen Zahl erfordert die Spezifikation von abzahlbar
unendlich vielen Ziffern. Diesen Wert kann deshalb niemand exakt angeben.
Tatsachlich wird der exakte Zahlenwert einer reellen Große eigentlich niemals wirk-
lich benotigt. Wer wollte diesen etwa auf einem Potentiometer einstellen, und wel-
chen Sinn macht es, fur die Lange eines zu erzeugenden Werkstuckes die genaue
Lange von 1 m zu fordern? Dass”Exaktheit“ in der Praxis ein veranderlicher, zeit-
und anwendungsabhangiger Begriff ist, zeigt sich z.B. darin, dass die ursprungliche
Definition des Meters durch die Hinterlegung eines Urmeters in Paris fur gewisse
Anwendungen zu ungenau wurde, was eine verfeinerte Definition nach sich zog.
Was wir in den allermeisten Situationen brauchen, ist eine Approximation der ex-
akten Zahl mit einem durch die spezifische Anwendung vorbestimmten maximal
erlaubten Fehler. Die Große der Fehlerschranke ist dabei durch die im Anwendungs-
bereich zum jeweiligen Anwendungszeitpunkt tolerierte Fehlergroße bestimmt.
Wenn mit einer fehlerbehafteten Große noch gerechnet werden muss, so wird auch
zu berucksichtigen sein, wie der Fehler bei der weiteren Rechnung das gewunschte
Endresultat verfalscht, wie er sich”fortpflanzt“. In einem solchen Fall wird die er-
laubte Große des Fehlers im Endresultat ausschlaggebend fur den erlaubten Fehler
der aktuellen Approximation sein, so dass also auch die Art der zu erwartenden
Fehlerfortpflanzung Einfluss auf die tolerierbare Fehlergroße hat.
Um allen Situationen des Einsatzes von Naherungen einer reellen Zahl r gewachsen
zu sein, benotigt man letztendlich fur diese Zahl”nur“ einen Algorithmus, der zu
jeder vorgegebenen positiven Schranke ε > 0 eine Naherung rε ∈ Q liefert mit
|r − rε| ≤ ε.

10.1. EINFUHRENDE BEISPIELE 3
Tabelle 10.1: Intervallhalbierungsmethode
n untere Schranke obere Schranke
0 1.0000000 2.00000001 1.0000000 1.50000002 1.2500000 1.50000003 1.3750000 1.50000004 1.3750000 1.43750005 1.4062500 1.43750006 1.4062500 1.42187507 1.4140625 1.42187508 1.4140625 1.41796889 1.4140625 1.416015610 1.4140625 1.4150391
n untere Schranke obere Schranke
11 1.4140625 1.414550812 1.4140625 1.414306613 1.4141846 1.414306614 1.4141846 1.414245615 1.4141846 1.414215116 1.4141998 1.414215117 1.4142075 1.414215118 1.4142113 1.414215119 1.4142132 1.414215120 1.4142132 1.4142141
Dabei wird eine großere Genauigkeit normalerweise mit einem großeren Arbeits-
aufwand verbunden sein, weshalb man versuchen wird, mit der gerade erforderli-
chen Genauigkeit auszukommen. Der Algorithmus sollte deshalb im Idealfall nicht
nur Approximationen liefern, sondern zugleich auch Schranken fur die Betrage der
entsprechenden Fehler, so dass man die Rechnung zu einem geeigneten Zeitpunkt
abbrechen kann.
Ein einfaches Beispiel fur einen solchen Algorithmus ist die kontrollierte Approxi-
mation der Zahl√
2 mit dem Bisektions- oder Intervallhalbierungsverfahren:
Beispiel 10.1. (Approximation von√
2; Intervallhalbierung)
Fur die Startwerte a0 := 1 und b0 := 2 gilt a20 < 2 < b2
0, und damit a0 <√
2 < b0.
Sind an, bn bereits bestimmt mit a2n < 2 ≤ b2
n ( d.h. an <√
2 ≤ bn), so setzen wir
cn := 0.5(an + bn) und definieren induktiv
an+1 :=
an falls c2n ≥ 2
cn sonst, bn+1 :=
cn falls c2n ≥ 2
bn sonst.
Es folgt dann an <√
2 ≤ bn fur alle n ∈ IN, und wegen bn − an = 2−n kann man
auf diese Weise Naherungen an bzw. bn von√
2 von jeder gewunschten Genauigkeit
erzeugen.
Das angegebene Verfahren heißt Intervallhalbierungsmethode . Mit ihm erhalt
man die oberen und unteren Schranken fur√
2 in Tabelle 10.1. 2
Algorithmen zur Approximation reeller Zahlen laufen auch in Ihren Taschenrech-
nern ab, etwa zur Berechnung von√
a, a ∈ IR+, oder von cos(a), a ∈ IR. Wir haben
eben ausdrucklich nicht nur von irrationalen Zahlen gesprochen, weil selbst die mei-
sten rationalen Zahlen durch Ihren Rechner nur approximativ dargestellt werden.

4 KAPITEL 10. FOLGEN UND REIHEN
Tabelle 10.2: Newton-Verfahren fur√
2
n xn xn −√
2
0 2.00000000000000000 0.585786437626904951 1.50000000000000000 0.085786437626904952 1.41666666666666667 0.002453104293571623 1.41421568627450980 0.000002123901414764 1.41421356237468991 0.000000000001594865 1.41421356237309505 0.00000000000000000
Wollen sie z.B. die rationale Zahl 1/3 auf Ihrem Rechner darstellen, so mussen Sie
mit einer Approximation der Form 0.333333333...3 zufrieden sein. Allgemein ist bei
diesen”Rechnerapproximationen“ die Approximationsgenauigkeit ε durch die Dar-
stellungsmethode des jeweiligen Rechners bestimmt.
Da Sie erwarten, dass Ihr Taschenrechner Ihnen elementare Approximationen so-
fort liefert, sollten die verwendeten Approximationsalgorithmen nicht zu langsam
sein. Einen Algorithmus, der√
2 schneller als die Intervallhalbierungsmethode ap-
proximiert, gibt das folgende Beispiel eines Algorithmus zur Berechnung von√
a,
a ∈ IR+:
Beispiel 10.2. (Approximation von√
a, a > 0; Newton Verfahren)
Es sei x0 > 0 fest gewahlt, und fur n ≥ 0 werde xn+1 rekursiv definiert durch
xn+1 :=1
2(xn +
a
xn
). (10.1)
Wir werden schon im nachsten Unterabschnitt zeigen konnen, dass die gelieferte Ap-
proximationsfolge x0, x1, x2, . . . (von x1 an) dem gewunschten Wert in jedem Schritt
naher kommt und dass die Anzahl der in einem Schritt gewonnenen exakten Dezi-
malstellen von Schritt zu Schritt großer wird.
Fur a = x0 = 2 erhalt man die Approximationen aus Tabelle 10.2, wobei in der
zweiten Spalte die ersten siebzehn Nachkommastellen des Fehlers dargestellt sind.
Das Verfahren war schon den Babyloniern ca. 2000 vor Christi Geburt bekannt und
wird haufig nach Heron von Alexandria2 benannt. Wir werden weiter unten sehen,
dass es ein Spezialfall des sogenannten Newton3-Verfahrens zur Approximation
von Nullstellen reeller, differenzierbarer Funktionen ist (hier der positiven Nullstelle
von f(x) := x2 − a). 2
2Heron von Alexandria, ca. 65 - ca. 125, griechischer Mathematiker
3Sir Isaac Newton, 1643 - 1727, englischer Mathematiker

10.1. EINFUHRENDE BEISPIELE 5
Bemerkung 10.3. Beachten Sie, dass das Newton-Verfahren aus dem letzten Bei-
spiel nur eine einzige Sequenz von Approximationen liefert, so dass hier zunachst
keine Fehlerkontrolle moglich ist. Man kann aber im vorliegenden Anwendungsfall
aus den”Zutaten der rechten Seite“ der Formel (10.1) Folgen unterer und obe-
rer Schranken fur√
a konstruieren, wobei die oberen Schranken die berechneten
Newton-Approximationen sind (vgl. Beispiel 10.6.). 2
Wir hatten oben ausgefuhrt, dass die gewonnenen Approximationen ublicherweise
in weiteren Rechnungen verwendet werden und dass die von ihnen geforderte Appro-
ximationsgute auch bestimmt wird durch die Auswirkungen ihrer Fehler in diesen
Nachfolgerechnungen. Das folgende Beispiel zeigt einen Algorithmus zur Approxi-
mation von π, in dem Werte der Wurzelfunktion benotigt werden. Der dem Algorith-
mus zugrundeliegende geometrische Hintergrund lasst vermuten, dass die Sequenz
der darin induktiv definierten Zahlen fn monoton steigend π naherkommt. Dass dies
im Rahmen der Rechnergenauigkeit tatsachlich der Fall ist, setzt allerdings voraus,
dass die Approximationen fur die dort definierten Zahlen cn hinreichend genau sind:
Beispiel 10.4. (Approximation von π)
Wir approximieren den Flacheninhalt π
eines Kreises mit dem Radius 1 durch
die Flacheninhalte fn der eingeschriebe-
nen regelmaßigen 3n-Ecke. Mit wachsen-
dem n schopfen die 3n-Ecke den Einheits-
kreis immer weiter aus, und daher sind die
fn immer bessere Naherungen fur π.
Die nebenstehende Skizze zeigt die einge-
schriebenen regelmaßigen 3-, 6-, 12-, 24-
und 48-Ecke.
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Abbildung 10.1
Elementargeometrische Uberlegungen zeigen, dass mit cn := cosπ
3ngilt
f2n :=fn
cn
, c2n :=
√
1
2(1 + cn), f1 :=
3
4
√3, c1 :=
1
2.
Berechnet man hierin die Wurzeln auf Rechnergenauigkeit, so erhalt man bis f16777216
die Naherungen in Tabelle 10.3.
Werden die Wurzeln nur jeweils auf drei Stellen nach dem Komma genau berechnet,

6 KAPITEL 10. FOLGEN UND REIHEN
Tabelle 10.3: Approximation von π
n fn π − fn
1 1.29903810567665797 1.842554547913135272 2.59807621135331594 0.543516442236477304 3.00000000000000000 0.141592653589793248 3.10582854123024915 0.03576411235954409
16 3.13262861328123820 0.0089640403085550432 3.13935020304686721 0.0022424505429260364 3.14103195089050964 0.00056070269928360
128 3.14145247228546208 0.00014018130433116256 3.14155760791185765 0.00003504567793559512 3.14158389214831841 0.00000876144147483
1024 3.14159046322805010 0.000002190361743142048 3.14159210599927155 0.000000547590521694096 3.14159251669215745 0.000000136897635798192 3.14159261936538395 0.00000003422440928
16384 3.14159264503369090 0.0000000085561023432768 3.14159265145076765 0.0000000021390255965536 3.14159265305503684 0.00000000053475640
131072 3.14159265345610414 0.00000000013368910262144 3.14159265355637096 0.00000000003342228524288 3.14159265358143767 0.00000000000835557
1048576 3.14159265358770435 0.000000000002088892097152 3.14159265358927101 0.000000000000522224194304 3.14159265358966268 0.000000000000130568388608 3.14159265358976060 0.00000000000003264
16777216 3.14159265358978508 0.00000000000000816
so wird ein solcher Fehler auch zu einem Fehler im Endergebnis fuhren. Der vorlie-
gende Algorithmus ist allerdings hinsichtlich der Fehlerfortpflanzung des c-Fehlers
sehr gutmutig. Es tritt im Endergebnis nur ein Fehler von der Großenordnung des
Rundungsfehlers auf. Ein nicht so gutmutiges Verhalten demonstriert das nachste
Beispiel. 2
Beispiel 10.5. (Noch eine Approximation von π)
Eine andere π approximierende Folge kann man durch die Aufstellung einer Re-
kursion fur die Seitenlangen der dem Einheitskreis eingeschriebenen regelmaßigen
6 · 2n-Ecke erhalten. Es ergibt sich hierfur (vgl. Aufgabenband) der folgende For-
melsatz:
sn+1 :=
√
6 · 2n+1
(
6 · 2n −√
(6 · 2n)2 − s2n
)
, n ≥ 0, s0 = 3.
Berechnet man die ersten Glieder dieser Folge mit voller Genauigkeit von MATLAB
(15–16 Stellen), so ergeben sich die Zahlen der Tabelle 10.4, worin die dritte Spalte
den relativen Fehler angibt. Nach 10 Schritten stimmen schon die ersten 7 Stellen.
Rechnet man nun aber auf einem Rechner mit sieben Stellen, so erhalt man nicht
etwa ein ahnliches Ergebnis. Vielmehr schaukelt sich der Rundungsfehler hier auf

10.1. EINFUHRENDE BEISPIELE 7
Tabelle 10.4: Approximation von π
n sn (π − sn)/π
1 3.10582854123025 1.14e − 022 3.13262861328124 2.85e − 033 3.13935020304685 7.14e − 044 3.14103195089048 1.78e − 045 3.14145247228556 4.46e − 056 3.14155760791206 1.12e − 057 3.14158389214894 2.79e − 068 3.14159046322287 6.97e − 079 3.14159210604305 1.74e − 07
10 3.14159251681049 4.35e − 06
Tabelle 10.5: Approximation von π
n sn (π − sn)/π
1 3.10582935783665 1.14e − 022 3.13262828947196 2.85e − 033 3.13932476816274 7.22e − 044 3.14100620820780 1.87e − 045 3.14146462657153 4.08e − 056 3.14146462657153 4.08e − 057 3.14757049166519 −1.90e − 038 3.15974682529131 −5.77e − 039 3.03578655372575 3.36e − 02
10 3.50542436799162 −1.16e − 0111 3.50542436839014 −1.16e − 0112 0 1.00e + 00
und macht das Ergebnis unbrauchbar. Bei der zur Tabelle 10.5 fuhrenden Rech-
nung wurde die siebenstellige Genauigkeit durch Rundung der inneren Wurzel der
Rekursionsformel auf die fuhrenden sieben Ziffern simuliert.
Die Grunde fur das instabile Verhalten und Moglichkeiten dieses zu vermeiden wer-
den im Aufgabenband genauer diskutiert. 2
In den bisherigen (vernunftigen) Beispielen wurden die zu approximierenden Zahlen
durchweg monoton von einer Seite angenahert. Diese Eigenschaft ist in der Tat
haufig zu beobachten, und wie wir schon bald sehen werden, ist sie fur die Analyse
des Approximationsprozesses auch recht nutzlich. Das nachste Beispiel zeigt, dass
monotone Approximation nicht immer vorliegt.
Beispiel 10.6. (Noch eine Approximation von√
2)
Die Rechenvorschrift
x0 := 2; x2n+1 :=2
x2n
, x2n+2 :=1
2(x2n + x2n+1), n ≥ 0

8 KAPITEL 10. FOLGEN UND REIHEN
Tabelle 10.6: Alternierende Approximation von√
2
n xn xn −√
2
0 2.00000000000000 +5.8579e − 011 1.00000000000000 −4.1421e − 012 1.50000000000000 +8.5786e − 023 1.33333333333333 −8.0880e − 024 1.41666666666667 +2.4531e − 035 1.41176470588235 −2.4489e − 036 1.41421568627451 +2.1239e − 067 1.41421143847487 −2.1239e − 068 1.41421356237469 +1.5947e − 129 1.41421356237150 −1.5949e − 12
fuhrt zu den Approximationen von√
2 der Tabelle 10.6. Wie man sieht, nahern
sich die Werte alternierend dem gewunschten Wert. Durch Vergleich mit dem Bei-
spiel 10.2. und mit der Beobachtung, dass die geradzahlig indizierten Werte gerade
die der Newton-Iteration sind, sieht man leicht den Grund. 2
Die alternierende Approximation ist kein unangenehmes Verhalten, da man durch
jeweils zwei aufeinander folgende Approximationen xn und xn+1 die zu approximie-
rende Zahl x einschließen kann. Fur das Mittel cn := 0.5(xn +xn+1) findet man dann
die sichere Fehlerabschatzung
|x − cn| ≤ 0.5|xn − xn+1|.
Aus der Monotonie bzw. dem Alternieren der bislang angefuhrten Approximati-
onssequenzen darf nicht geschlossen werden, dass ausschließlich diese Verhaltens-
varianten auftreten konnen. Wir hatten auch Beispiele wesentlich unregelmaßigerer
Sequenzen konstruieren konnen, die aber dennoch letztlich einen bestimmten Wert
”approximieren“. Sequenzen, die von Naherungsverfahren berechnet werden, sind
aber tatsachlich haufig monoton oder alternierend, da diese Eigenschaften nutzlich
sind und daher beim Verfahrensentwurf schon angestrebt werden.
Bis hierhin waren die Folgen in den Beispielen auf die Approximation vorher defi-
nierter Großen ausgerichtet. Im nachsten Beispiel soll es nun um die Definition einer
Zahl als Grenzwert einer Folge gehen.
Beispiel 10.7. (Radioaktiver Zerfall)
In einer Probe seien zum Zeitpunkt t = 0 N radioaktive Teilchen vorhanden;
wieviele sind zum Zeitpunkt t = T noch nicht zerfallen?
Wir machen die Annahme (die sich durch Experimente bestatigen lasst), dass fur
kleine h > 0 in einem Zeitintervall t0 < t ≤ t0 + h der Lange h etwa αhK Teilchen

10.1. EINFUHRENDE BEISPIELE 9
zerfallen, wobei K die Anzahl der zum Zeitpunkt t = t0 vorhandenen radioaktiven
Teilchen bezeichnet und α > 0 eine Materialkonstante ist.
Wir zerlegen das Intervall (0, T ] in n gleich lange Intervalle ((j−1)τ, jτ ], j = 1, . . . , n,
wobei τ := T/n die Lange der Teilintervalle bezeichnet. Wir wenden auf jedes der
Intervalle die obige Annahme an. Dann sind zum Zeitpunkt t = τ noch N(1 − ατ),
zum Zeitpunkt t = 2τ noch N(1 − ατ)2, . . . , und zum Zeitpunkt t = T noch
an = N(1 − ατ)n Teilchen vorhanden. Experimente zeigen, dass diese Zahl um so
besser die Realitat beschreibt, je großer n gewahlt ist.
Genauso werden Wachstumsprozesse (z.B. Wachstum einer Bakterienkultur) nahe-
rungsweise beschrieben durch bn = N(1 + βτ)n, wobei N die Zahl der Individuen
zum Zeitpunkt t = 0, bn die Zahl der Individuen zum Zeitpunkt t = T und β > 0
die Wachstumsrate ist.
Wir werden spater zeigen, dass mit wachsendem n die Zahlen an bzw. bn jeweils eine
feste reelle Zahlen approximieren, namlich Ne−αT bzw. NeβT . Dabei wird die Zahl e
selbst als das durch die Zahlen bn fur βT = 1 und N = 1 Approximierte definiert und
der Umstand, dass es Sinn macht, die Zahlen e−αT bzw. eβT als Potenzen von e zu
interpretieren, wird ebenfalls durch Approximationsbetrachtungen erklart werden.
2
Die Approximation durch Folgen wird uns nicht nur — wie in allen obigen Bei-
spielen — in Anwendungen begegnen, wo der Grenzwert nicht exakt angebbar ist.
Es kann durchaus sinnvoll sein, Approximationen fur rationale Zahlen, ja selbst fur
Maschinenzahlen zu verwenden.
Beispiel 10.8. (Iterative Losung linearer Gleichungssysteme)
In vielen praktischen Problemen treten so große lineare Gleichungssysteme Ax = b
auf, dass das Gaußsche Eliminationsverfahren aus Speicherplatz- und Rechenzeit-
grunden nicht mehr angewendet werden kann. Schreibt man das Gleichungssystem
um in
x = (E − A)x + b
so kann man versuchen, eine Anfangsnaherung x0 der Losung sukzessive uber
xm+1 := (E − A)xm + b.
zu verbessern. Das so definierte Verfahren heißt Richardson4–Iteration und ist
eine der strukturell einfachsten Varianten der großen Klasse iterativer Loser fur
4Lewis Fry Richardson, 1881 - 1953, englischer Mathematiker

10 KAPITEL 10. FOLGEN UND REIHEN
lineare Systeme. Wir werden in Kapitel 15 untersuchen, unter welchen Bedingungen
die so definierte Folge {xm} beliebig gute Naherungen fur die Losung von Ax = b
liefert.
Solche Iterationsverfahren haben fur (große) Ingenieuranwendungen oftmals viele
Vorteile. So kann man die Iteration bei Erreichen einer gewunschten Genauigkeit
abbrechen, so dass nur fur die benotigte Genauigkeit mit Rechenzeit bezahlt wer-
den muss. Außerdem kann man (u.a.) mit dem Startvektor x0 schon Vorwissen in
die Iteration einbringen, welches die Iterations- und damit die Arbeitsdauer weiter
reduzieren kann. 2
Beispiel 10.9. (von Mises Verfahren)
Wir haben bereits bemerkt, dass Eigenwerte (und dann auch Eigenvektoren) i.a. nicht
mit endlich vielen Operationen berechnet werden konnen, sondern dass hierfur Nahe-
rungsmethoden verwendet werden mussen. Ein einfaches Verfahren hierfur ist die
von Mises5-Iteration oder die Potenzmethode
xm+1 :=Axm
‖Axm‖ (x0 ∈ IRn gegeben),
die unter sehr allgemeinen Bedingungen Vektorapproximationen liefert, die einen Ei-
genvektor zum betragsmaximalen Eigenwert von A annahern. Auch dieses Verfahren
werden wir in Kapitel 15 untersuchen. 2
Beispiel 10.10. Aus der Schule ist wahrscheinlich schon bekannt, dass die in die-
sem Kurs bislang nur geometrisch definierte Funktion f(x) = cos(x) fur kleine Bo-
genlangenwerte |x| gut approximiert werden kann durch (siehe Abbildung 10.2)
p0(x) ≡ 1,
p2(x) = 1 − x2
2,
p4(x) = 1 − x2
2+
x4
24,
p6(x) = 1 − x2
2+
x4
24− x6
720,
p8(x) = 1 − x2
2+
x4
24− x6
720+
x8
40320, . . .
und dass die Funktion f(x) letztendlich als”Grenzwert einer Funktionenfolge“ de-
finiert ist, deren erste Glieder p0, . . . , p8 sind. 2.
5Richard von Mises, 1883 - 1953, deutscher Mathematiker
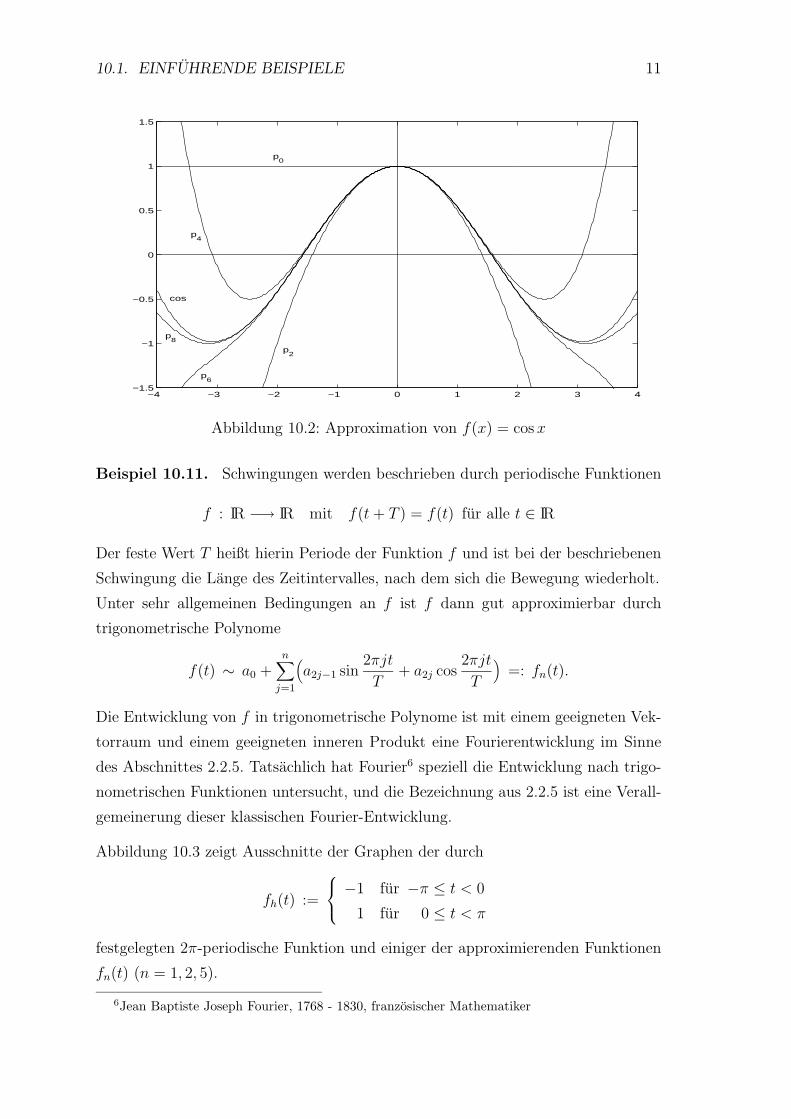
10.1. EINFUHRENDE BEISPIELE 11
−4 −3 −2 −1 0 1 2 3 4−1.5
−1
−0.5
0
0.5
1
1.5
cos
p0
p2
p4
p6
p8
Abbildung 10.2: Approximation von f(x) = cos x
Beispiel 10.11. Schwingungen werden beschrieben durch periodische Funktionen
f : IR −→ IR mit f(t + T ) = f(t) fur alle t ∈ IR
Der feste Wert T heißt hierin Periode der Funktion f und ist bei der beschriebenen
Schwingung die Lange des Zeitintervalles, nach dem sich die Bewegung wiederholt.
Unter sehr allgemeinen Bedingungen an f ist f dann gut approximierbar durch
trigonometrische Polynome
f(t) ∼ a0 +n∑
j=1
(
a2j−1 sin2πjt
T+ a2j cos
2πjt
T
)
=: fn(t).
Die Entwicklung von f in trigonometrische Polynome ist mit einem geeigneten Vek-
torraum und einem geeigneten inneren Produkt eine Fourierentwicklung im Sinne
des Abschnittes 2.2.5. Tatsachlich hat Fourier6 speziell die Entwicklung nach trigo-
nometrischen Funktionen untersucht, und die Bezeichnung aus 2.2.5 ist eine Verall-
gemeinerung dieser klassischen Fourier-Entwicklung.
Abbildung 10.3 zeigt Ausschnitte der Graphen der durch
fh(t) :=
−1 fur −π ≤ t < 0
1 fur 0 ≤ t < π
festgelegten 2π-periodische Funktion und einiger der approximierenden Funktionen
fn(t) (n = 1, 2, 5).
6Jean Baptiste Joseph Fourier, 1768 - 1830, franzosischer Mathematiker
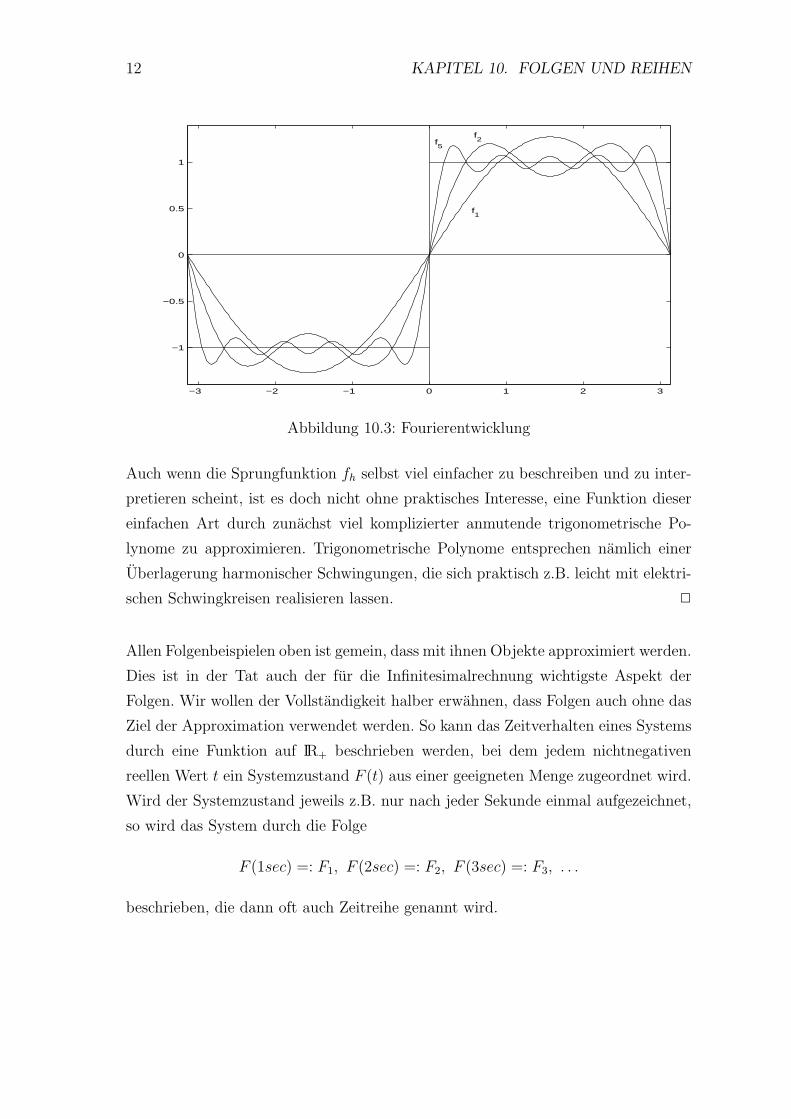
12 KAPITEL 10. FOLGEN UND REIHEN
−3 −2 −1 0 1 2 3
−1
−0.5
0
0.5
1
f1
f2f
5
Abbildung 10.3: Fourierentwicklung
Auch wenn die Sprungfunktion fh selbst viel einfacher zu beschreiben und zu inter-
pretieren scheint, ist es doch nicht ohne praktisches Interesse, eine Funktion dieser
einfachen Art durch zunachst viel komplizierter anmutende trigonometrische Po-
lynome zu approximieren. Trigonometrische Polynome entsprechen namlich einer
Uberlagerung harmonischer Schwingungen, die sich praktisch z.B. leicht mit elektri-
schen Schwingkreisen realisieren lassen. 2
Allen Folgenbeispielen oben ist gemein, dass mit ihnen Objekte approximiert werden.
Dies ist in der Tat auch der fur die Infinitesimalrechnung wichtigste Aspekt der
Folgen. Wir wollen der Vollstandigkeit halber erwahnen, dass Folgen auch ohne das
Ziel der Approximation verwendet werden. So kann das Zeitverhalten eines Systems
durch eine Funktion auf IR+ beschrieben werden, bei dem jedem nichtnegativen
reellen Wert t ein Systemzustand F (t) aus einer geeigneten Menge zugeordnet wird.
Wird der Systemzustand jeweils z.B. nur nach jeder Sekunde einmal aufgezeichnet,
so wird das System durch die Folge
F (1sec) =: F1, F (2sec) =: F2, F (3sec) =: F3, . . .
beschrieben, die dann oft auch Zeitreihe genannt wird.

10.2. KONVERGENZ VON FOLGEN 13
10.2 Konvergenz von Folgen
Im weiteren interessiert uns wesentlich die Approximationskraft von Folgen. Deren
Beschreibung durch Definition 10.13. macht erfahrungsgemaß zunachst erhebliche
Probleme. Studenten aus den Anwendungsfachern (und nicht nur diese) neigen dann
dazu, diese Definition fur unpraktischen Formalismus zu halten.
Es ist deshalb angebracht, an dieser Stelle darauf hinzuweisen, dass diese formale
Definition nicht nur von theoretischem Interesse ist, sondern extrem nutzlich und
praktisch, da in ihr der Begriff der Konvergenz in eine kurze, einpragsame Formu-
lierung gefasst wird und dem mathematischen Kalkul zuganglich gemacht wird. Es
lohnt sich daher, die anfanglich nicht ganz einfachen Aussagen dieses Abschnitts, in
dem wir jetzt wieder mathematisch prazise werden, sehr genau zu bearbeiten.
Definition 10.12. Eine Folge a : IN → M in einer Menge M ist eine Abbildung
der naturlichen Zahlen IN in M .
Ist M = IR oder M = C, so sprechen wir von einer Zahlenfolge (Beispiele 10.1.,
10.2., 10.4., 10.7.). Daneben treten aber auch Vektorfolgen (Beispiele 10.8., 10.9.)
oder Folgen von Funktionen (Beispiele 10.10., 10.11.) auf oder Folgen aus anderen
Mengen, wenn es denn sinnvoll ist, Elemente solcher Mengen durchzunumerieren.
Der n ∈ IN zugeordnete Funktionswert a(n) ∈ M wird ublicherweise mit an bezeich-
net und heißt n-tes Glied der Folge.
Wir bezeichnen Folgen mit {an}n∈ IN oder {an}n≥1 oder kurz mit {an}. Manchmal ist
es bequemer, die Folge mit einem anderen Index als 1 zu beginnen (Beispiele 10.1.,
10.9.); wir schreiben dann z.B. {an}n≥0. Dies macht mathematisch keine Probleme,
weil Mengen {m ∈ ZZ : k ≤ m} fur eine ganze Zahl k bijektiv auf IN abgebildet
werden konnen.
Dass der Urbildbereich der Folgen immer IN ist (oder mit IN identifiziert werden
kann), wird bei der rekursiven Definition von Folgen ausgenutzt. Wenn nach expli-
ziter Definition erster Elemente a1, a2, . . . , ap weiter an+1 fur n ≥ p in Abhangigkeit
von an (und moglicherweise von an−1, . . . , a1) definiert wird (Beispiele 10.2., 10.8.,
10.9.), so sagt das Induktionsprinzip, dass an damit fur alle n ∈ IN erklart ist.
Nach der exakten Definition von”Folge“ wenden wir uns nun der fur Anfanger un-
gleich schwierigeren Prazisierung der Ausdrucke”Naherungen von jeder gewunschten
Genauigkeit“,”immer bessere Approximationen“ zu. Um Approximation und Nahe

14 KAPITEL 10. FOLGEN UND REIHEN
messen zu konnen, benotigen wir auf M als erstes einen Abstandsbegriff. Die im
Rahmen unserer Kenntnisse allgemeinste Annahme ware dazu, dass die Menge M
einem metrischen Raum angehort. Fur unsere Zwecke reicht allerdings etwas weniger
Allgemeinheit, und wir setzen deshalb von nun an voraus, dass M ein normierter
Vektorraum ist. Wir werden sagen, dass die Folge {an} ⊂ M ein Element a ∈ M
beliebig gut approximiert oder gegen a konvergiert, wenn fur jede vorgegebene re-
elle Toleranz ε > 0 der Abstand des n-ten Folgengliedes an von a fur alle genugend
großen n kleiner als ε ist.
Ein Approximationsverfahren, das wie in unseren einleitenden Beispielen eine Zahl
a beliebig gut annahert, erzeugt also in dieser Sprechweise eine gegen a konvergente
Zahlenfolge {an}.
Prazise und dem mathematischen Kalkul zuganglich lauten die relevanten Verein-
barungen wie folgt:
Definition 10.13. Eine Folge {an} in einem normierten Vektorraum M heißt
(i) konvergent gegen den Grenzwert a ∈ M , wenn fur jedes ε > 0 ein N =
N(ε) existiert, so dass fur alle n ≥ N gilt
‖an − a‖ < ε,
(ii) konvergent, wenn ein Grenzwert a ∈ M existiert, gegen den sie konvergiert,
(iii) divergent, wenn sie nicht konvergent ist.
Bemerkung 10.14. Mit der Schreibweise N = N(ε) wird in der letzten Definition
darauf hingewiesen, dass der Index N , von dem an alle Folgenglieder an von a einen
Abstand kleiner als ε haben, i.a. von ε abhangt. Einfache Falle solcher Abhangig-
keiten zeigen die nachsten beiden Beispiele. 2
Beispiel 10.15. Die Folge { 1
n} konvergiert mit dem Grenzwert 0, denn fur ε > 0
gilt∣∣∣∣
1
n− 0
∣∣∣∣ =
1
n< ε fur alle n ≥
⌊1
ε
⌋
+ 1 =: N.
Dabei bezeichnet fur eine reelle Zahl x der Ausdruck ⌊x⌋ die großte ganze Zahl, die
kleiner oder gleich x ist. 2

10.2. KONVERGENZ VON FOLGEN 15
Beispiel 10.16. Die Folge {n−k}, k ∈ IN, konvergiert mit dem Grenzwert 0, denn
|n−k − 0| = n−k < ε fur alle n ≥ ⌊1/ k√
ε⌋+1 =: N. 2
Beispiel 10.17. Die Folge {an} := {(−1)n} ist divergent, denn konvergierte sie
gegen a ∈ IR, so ware wegen
|an − a| < 0.1 fur alle n ≥ N(0.1)
die Zahl a sowohl von 1 = a2m fur alle m ∈ IN als auch von −1 = a2m+1 fur alle
m ∈ IN weniger als 0.1 entfernt, was offenbar nicht moglich ist. 2
Bemerkung 10.18. In den Beispielen 10.15. und 10.16. haben wir ausgenutzt,
dass es zu jeder reellen Zahl x eine naturliche Zahl gibt, die x an Große ubert-
rifft. Diese intuitiv einleuchtende Eigenschaft folgt nicht aus den fur IR in Kapitel 1
betrachteten Korperaxiomen und Ordnungsaxiomen, sondern muss bei einer axio-
matischen Einfuhrung von IR zusatzlich gefordert werden. Das Postulat
Fur alle x ∈ IR existiert n = n(x) ∈ IN mit n(x) ≥ x
heißt das Archimedische Axiom. 2
Wenn Teilmengen normierter Raume wie die naturlichen Zahlen zu jeder reellen Zahl
C ein Element enthalten, dessen Norm großer als C ist, heißen sie unbeschrankt.
Ist dies nicht der Fall, gibt es also eine nichtnegative Zahl C, welche großer als die
Normen aller Mengenelemente ist, so heißt die Menge beschrankt. Folgen nennt
man beschrankt, wenn die Menge ihrer Folgenglieder beschrankt ist.
Definition 10.19. Eine Folge {an} heißt beschrankt, wenn es ein C ≥ 0 gibt
mit
‖an‖ ≤ C fur alle n ∈ IN.
Satz 10.20. Jede konvergente Folge ist beschrankt.
Beweis: Sei a (ein) Grenzwert der Folge. Dann existiert zu ε > 0 ein N mit
‖an − a‖ < ε. Daher ist
‖an‖ ≤ ‖an − a‖ + ‖a‖ ≤ ε + ‖a‖ fur alle n ≥ N,
und fur C := max{‖a1‖, . . . , ‖aN−1‖, ‖a‖ + ε} folgt ‖an‖ ≤ C fur alle n ∈ IN.

16 KAPITEL 10. FOLGEN UND REIHEN
Bemerkung 10.21. Mit dem letzten Satz uberzeugt man sich oft leicht von der
Divergenz einer Folge. So ist die Folge {(−1)n n2}n∈ IN offenbar divergent, da alle
Elemente aus IN Folgenglieder sind, so dass die Folge unbeschrankt ist. 2
Bemerkung 10.22. Die Umkehrung von Satz 10.20. gilt nicht, denn die Folge
{an} mit an := (−1)n ist sicher beschrankt, aber nicht konvergent. 2
Der Sachverhalt
‖an − a‖ < ε fur alle n ≥ N(ε)
besagt, dass zu jedem (noch so kleinen) vorgegeben positiven ε hochstens endlich
viele Folgenglieder einen Abstand von a haben, der großer oder gleich ε ist.
Hiermit ist der Beweis des nachsten Satzes, wonach eine konvergente Folge nur
einen Grenzwert hat, eigentlich sogleich klar. Hatte sie namlich zwei verschiedene
Grenzwerte, so wahlten wir ε etwa gleich einem Viertel von deren Abstand. Dann
hatten die beiden Kugeln um die beiden Grenzwerte mit den Radien ε keinen Schnitt.
Nach der obigen Formulierung der Konvergenz mussten zugleich aber in jeder der
Kugeln bis auf jeweils endlich viele alle Folgenelemente enthalten sein, was offenbar
nicht moglich ist.
Sicherheitshalber beweisen wir die Aussage auch noch einmal ganz formell.
Satz 10.23. Der Grenzwert einer konvergenten Folge ist eindeutig bestimmt.
Beweis: (indirekt): Es konvergiere {an} mit den Grenzwerten a und b, a 6= b. Es
sei ε ∈ (0, 12‖b − a‖). Dann gibt es ein N1 ∈ IN mit ‖an − a‖ < ε fur alle n ≥ N1 und
ein N2 ∈ IN mit ‖an − b‖ < ε fur alle n ≥ N2. Daher gilt fur alle n ≥ max(N1, N2)
‖a − b‖ ≤ ‖a − an‖ + ‖an − b‖ < 2ε
im Widerspruch zur Wahl von ε.
Bemerkung 10.24. Da der Grenzwert einer konvergenten Folge eindeutig be-
stimmt ist, sind folgende Schreibweisen fur”{an} konvergiert gegen a“ sinnvoll:
limn→∞
an = a
oder
an → a fur n → ∞ oder kurz an → a. 2

10.2. KONVERGENZ VON FOLGEN 17
Definition 10.25. Eine Folge, die gegen 0 konvergiert, heißt eine Nullfolge.
Nullfolgen haben schon aus rechentechnischen Grunden eine Sonderrolle: Will man
namlich zeigen, dass eine Folge {an} gegen a konvergiert, so zeigt man meist statt-
dessen die aquivalente Aussage, dass die durch bn := an − a fur alle n definierte
Folge {bn} eine Nullfolge ist. Dass dies erlaubt ist, ergibt sich aus dem folgenden
allgemein sehr nutzlichen Satz.
Satz 10.26. (Rechenregeln fur konvergente Folgen)(i) Es seien {an}, {bn} konvergente Folgen mit lim
n→∞ an = a, limn→∞ bn = b. Dann ist
auch {an + bn} konvergent und es gilt
limn→∞(an + bn) = a + b.
(ii) Es sei {an} eine konvergente Folge mit limn→∞ an = a und λ ∈ IR (bzw. ∈ C).
Dann ist auch {λan} konvergent und
limn→∞(λan) = λa.
Beweis: Es sei ε > 0 fest gewahlt.
(i): Zu ε2
> 0 gibt es N1 ∈ IN mit ‖an − a‖ < ε2
fur alle n ≥ N1 und N2 ∈ IN mit
‖bn − b‖ < ε2
fur alle n ≥ N2, und daher folgt fur n ≥ max(N1, N2) =: N
‖(an + bn) − (a + b)‖ ≤ ‖an − a‖ + ‖bn − b‖ <ε
2+
ε
2= ε.
(ii): Fur λ = 0 ist die Behauptung trivial. Fur λ 6= 0 gibt es ein N ∈ IN mit
‖an − a‖ < ε|λ| fur alle n ≥ N , und daher fur alle n ≥ N
‖(λan) − (λa)‖ = |λ| · ‖an − a‖ < ε.
Bemerkung 10.27. Mit Hilfe des letzten Satzes kann man oft die Konvergenz
komplizierterer Folgen mit wenig Aufwand auf die Konvergenz einfacherer schon
bekannter Folgen zuruckfuhren. Gleichzeitig ergibt sich dabei der Grenzwert der
neuen Folge aus denen der eingehenden Folgen. Fur reelle Folgen werden wir weiter
unten die Reihe von Rechenregeln noch erweitern konnen. 2
Beispiel 10.28. Die Folge
{an} :=
{(n + 1
n
)2}
konvergiert wegen
an =(
n + 1
n
)2
=n2 + 2n + 1
n2= 1 +
2
n+
1
n2
gegen 1, da sie die Summe der konstanten Folge {1} und zweier Nullfolgen ist. 2

18 KAPITEL 10. FOLGEN UND REIHEN
10.3 Reelle Zahlenfolgen
In diesem Abschnitt betrachten wir nur reelle Folgen {an}, {bn}, . . .. Eine ganz
wesentliche Eigenschaft der reellen Zahlen ist ihre Ordnung, und so schopfen wir
auch hier aus dieser Struktur sehr nutzliche Resultate. In den Beispielen des ersten
Unterabschnittes haben wir den Nutzen von Ordnung schon in der monotonen bzw.
alternierenden Approximation gesehen.
Um diese Eigenschaft nutzen zu konnen, werden wir einige Vorarbeit leisten mussen.
Zunachst vereinbaren wir weiteres mathematisches Vokabular, welches fur die Be-
schreibung von Folgen in der geordneten Menge IR gebrauchlich ist.
Definition 10.29. (i) Eine Zahlenfolge {an} ⊂ IR heißt monoton wachsend
, falls an ≤ an+1 fur alle n ∈ IN, und streng monoton wachsend , falls
an < an+1 fur alle n ∈ IN. Sie heißt monoton fallend , falls an ≥ an+1 fur
alle n ∈ IN, und streng monoton fallend , falls an > an+1 fur alle n ∈ IN.
(ii) Die Zahlenfolge {an} heißt nach oben beschrankt , falls ein Co ∈ IR existiert
mit an ≤ Co fur alle n ∈ IN, und nach unten beschrankt , falls ein Cu ∈ IR
existiert mit an ≥ Cu fur alle n ∈ IN. Ist sie nach unten und nach oben
beschrankt, existiert also ein C ∈ IR mit |an| ≤ C fur alle n ∈ IN, so heißt sie
beschrankt.
(iii) Die Zahlenfolge {an} ⊂ IR heißt uneigentlich konvergent gegen ∞ (bzw. ge-
gen −∞), wenn fur alle C ∈ IR ein N ∈ IN existiert mit an ≥ C (bzw. an ≤ C)
fur alle n ≥ N .
Durch (iii) wird das”uber-alle-Grenzen-Wachsen“ und
”unter-alle-Grenzen-Fallen“
einer Folge {an} erfasst. Man schreibt in diesem Fall
limn→∞ an = ∞ bzw. lim
n→∞ an = −∞
und nennt die Folge {an} auch bestimmt divergent gegen ∞ bzw. gegen −∞.
Beispiel 10.30. Die durch an := 1n, n ∈ IN definierte Folge ist nach oben be-
schrankt (z.B. durch Co = 3.1415), nach unten beschrankt (z.B. durch Cu = −1997),
also beschrankt (z.B. |an| ≤ C := max(|Cu|, |Co|) = 1997), und streng monoton fal-
lend. 2

10.3. REELLE ZAHLENFOLGEN 19
Bemerkung 10.31. Die Schranken Co und Cu sind nicht optimal. Obwohl die op-
timalen Schranken Copto = 1 und Copt
u = 0 hier auch von Anfangern leicht eingesehen
werden, wurden Sie im Beispiel nicht gewahlt, um zu verdeutlichen, dass Schranken
nicht notwendig optimal sein mussen. 2
Beispiel 10.32. Die Folge {n}n∈ IN ist nach unten beschrankt, nach oben nicht
beschrankt und nach dem Archimedischen Axiom bestimmt divergent gegen ∞.
Ist h 6= 0, so ist die Folge {nh}n≥1 auch bestimmt divergent, und zwar fur h > 0
gegen ∞ und fur h < 0 gegen −∞. Zu gegebenem C > 0 ist im Falle h > 0
(bzw. h < 0) die Bedingung nh > C (bzw. nh < C) aquivalent mit n > C/h
(bzw. n > −C/h), was nach dem Archimedischen Axiom von einer naturlichen Zahl
erreicht wird und dann fur deren Nachfolger naturlich erhalten bleibt. 2
Beispiel 10.33. Ist {bn} eine Folge mit bn ≥ h > 0 fur alle n ∈ IN und ein h > 0
und gilt fur die Folge {an} mit einem M ∈ IN
an ≥ bn · n fur alle n ≥ M,
so ist {an} bestimmt divergent gegen ∞. Ist namlich C > 0 gegeben, so ist
an ≥ bn · n ≥ h · n fur alle n ≥ M,
und hieraus erhalt man an ≥ C fur alle n ≥ N := max{M,C/h}. 2
Beispiel 10.34. Wir haben gesehen, dass fur die bestimmt divergente Folge {n}n∈ IN
die Folge {n−1}n∈ IN der Kehrwerte eine Nullfolge ist.
Allgemeiner gilt: Ist {an}n∈ IN eine beliebige bestimmt divergente Folge, so gibt es
ein N ∈ IN mit an 6= 0 fur n ≥ N , und die Folge {a−1n }n≥N der Kehrwerte ist eine
Nullfolge.
Denn zunachst konvergiert die Folge {|an|}n∈ IN uneigentlich gegen ∞, und daher
gibt es fur jedes feste C > 0 ein N(C) ∈ IN mit |an| ≥ C fur alle n ≥ N(C). Wahlt
man insbesondere N = N(1), so ist an 6= 0 fur n ≥ N , und die Folge der Kehrwerte
ist definiert.
{a−1n } ist eine Nullfolge, denn ist ε > 0 gegeben, so gilt fur n ≥ max(N(1), N(2/ε))
an 6= 0 und |an| ≥2
ε, d.h. |a−1
n − 0| = |a−1n | ≤ ε
2< ε. 2

20 KAPITEL 10. FOLGEN UND REIHEN
Beispiel 10.35. Die Folge
an :=
(−1)n/n, falls n durch 3 teilbar,
−n, sonst,
(an = −1,−2,−13,−4,−5, +1
6,−7, . . .) ist nicht monoton. Sie ist nach oben be-
schrankt (z.B. durch C = 16). Sie ist aber nicht nach unten beschrankt, denn be-
trachtet man die durch
bn := a3n+1 = −(3n + 1)
definierte Folge, so ist diese sicher gegen −∞ bestimmt divergent. Mit {an} ware
nun aber auch {bn} nach unten beschrankt, was nicht der Fall ist. 2
Definition 10.36. Es sei {an} eine Folge auf einer allgemeinen Menge M . Dann
heißt eine Folge {anj}j∈ IN mit {nj} ⊂ IN eine Teilfolge von {an}, falls die Folge
{nj}j∈ IN streng monoton wachsend ist, d.h.
n1 < n2 < n3 < . . .
Bemerkung 10.37. Die Folge
an :=
(−1)n/n, falls n durch 3 teilbar,
−n, sonst,
des letzten Beispiels zeigte einerseits, dass eine Folge viele Teilfolgen mit angenehmen
Eigenschaften haben kann, ohne dass die Folge selbst sie haben musste. So sind die
durch b[k]n := a3kn+1, c[k]
n := a3kn+2 fur k ∈ IN definierten Teilfolgen {b[k]n }n∈ IN und
{c[k]n }n∈ IN uneigentlich konvergent gegen −∞ und die durch d[k]
n := a3kn fur k ∈ IN
definierten Teilfolgen {d[k]n }n∈ IN sind allesamt Nullfolgen, ohne dass die Originalfolge
diese Eigenschaften hatte.
Man sieht aber auch andererseits, dass man mit Hilfe der Eigenschaften von Teilfol-
gen gewisse Eigenschaften der Gesamtfolge leicht ausschließen kann. Ist eine Teilfolge
einer reellen Folge namlich z.B. bestimmt divergent, so wird die Originalfolge weder
beschrankt noch (eigentlich) konvergent sein konnen, und gibt es umgekehrt eine
beschrankte Teilfolge, so kann die Folge nicht bestimmt divergent sein.
Wahrend also Eigenschaften der Teilfolgen sich nicht auf die Gesamtfolge ubertragen
lassen, vererben sich umgekehrt gewisse Eigenschaften der Gesamtfolge auf alle ihre
Teilfolgen sehr wohl. Man uberlegt sich recht leicht, dass zu diesen vererbbaren
Eigenschaften reeller Folgen gehoren: Monotones und streng monotones Wachsen

10.3. REELLE ZAHLENFOLGEN 21
und Fallen, Beschranktheit nach oben oder nach unten und bestimmte Divergenz.
Dass auch Konvergenz (allgemein im normierten Raum) zu diesen Eigenschaften
gehort, zeigt der folgende Satz. 2
Satz 10.38. Es sei {an} eine Folge in einem normierten Raum V . Konvergiert
{an} gegen a ∈ V , so konvergiert auch jede Teilfolge von {an} gegen a.
Beweis: Sei ε > 0 vorgegeben, und sei fur N = N(ε)
‖an − a‖ < ε fur alle n ≥ N.
Ist {anj} eine Teilfolge von {an} und ist J die erste naturliche Zahl, fur die nJ ≥ N(ε)
ist, so ist
N(ε) ≤ nJ < nJ+1 < nJ+2 < . . . ,
so dass
‖anj− a‖ < ε fur alle j ≥ J
gilt.
Ein bei Konvergenzuntersuchungen fur Zahlenfolgen haufig verwendetes Hilfsmittel
ist die Bernoullische Ungleichung:
Lemma 10.39. (Bernoullische Ungleichung)
Fur alle h > −1 und alle n ∈ IN gilt
(1 + h)n ≥ 1 + nh.
Beweis: (durch Induktion uber n)
Fur n = 1 ist die Behauptung offenbar erfullt. Ist sie schon fur ein n ∈ IN richtig,
so folgt
(1 + h)n+1 = (1 + h) (1 + h)n ≥ (1 + h) (1 + nh)
= 1 + (n + 1)h + nh2 ≥ 1 + (n + 1)h.
Mit der Bernoullischen Ungleichung konnen wir das Konvergenzverhalten der sehr
wichtigen sogenannten Geometrischen Folge im nachsten Beispiel diskutieren. Die
geometrische Folge ist selbst wieder eine der wichtigsten Vergleichsfolgen bei Kon-
vergenzuntersuchungen.

22 KAPITEL 10. FOLGEN UND REIHEN
Beispiel 10.40. (Geometrische Folge)
Es sei die Folge an := qn, q ∈ IR, vorgegeben. Wir unterscheiden sieben Falle.
(i) q > 1: Dann ist qn streng monoton wachsend, nach oben nicht beschrankt und
bestimmt divergent gegen ∞. Da namlich nach
qn =(
1 + (q − 1))n ≥ 1 + n (q − 1)
︸ ︷︷ ︸
>0
die Elemente immer mindestens so groß sind, wie die der bestimmt divergenten
Folge {n(q − 1)}, ist limn→∞ qn = ∞.
(ii) q = 1: Dann gilt qn = 1 fur alle n, also limn→∞ qn = 1.
(iii) 0 < q < 1: Dann ist qn streng monoton fallend, und analog zu (i) zeigt man
0 < qn =1
(1/q)n≤ 1
1 + n(1/q − 1)
Da die Elemente von {qn} also stets kleiner als die Kehrwerte der entsprechen-
den Elemente einer uneigentlich gegen ∞ konvergierenden Folge sind, ist die
geometrische Folge in diesem Falle eine Nullfolge, d.h. limn→∞ qn = 0.
(iv) q = 0: Dann gilt qn = 0 fur alle n, also limn→∞ qn = 0.
(v) −1 < q < 0: Dann hat qn alternierendes Vorzeichen, ist also nicht monoton.
Wegen |qn| = |q|n −→ 0 nach (iii) gilt limn→∞ qn = 0.
(vi) q = −1: Dann ist qn = (−1)n beschrankt, aber nicht konvergent.
(vii) q < −1: Dann hat qn alternierendes Vorzeichen, ist unbeschrankt, also diver-
gent, aber nicht uneigentlich konvergent. 2
Wir zeigen nun die Konvergenz des Newton Verfahrens zur Bestimmung von√
2
durch Vergleich mit einer konvergenten geometrischen Folge.
Beispiel 10.41. (Newton Verfahren zur Berechnung von√
2)
Die Rekursion des Newton-Verfahrens aus Beispiel 10.2.
xn+1 :=1
2
(
xn +2
xn
)
, x0 > 0, (10.2)
ergibt durch Subtraktion von√
2 auf beiden Seiten
xn+1−√
2 =1
2
(
xn−2√
2+2
xn
)
=1
2xn
(x2n−2
√2 xn +2) =
1
2xn
(xn−√
2)2. (10.3)

10.3. REELLE ZAHLENFOLGEN 23
Hieraus liest man sofort ab: Ist x0 > 0, so gilt xn ≥√
2 fur alle n ∈ IN. Ferner hat
man fur n ≥ 1
xn+1 −√
2 =xn −
√2
xn︸ ︷︷ ︸
0< · <1
· 1
2(xn −
√2) ≤ 1
2(xn −
√2).
Der Abstand von xn zu√
2 wird daher in jedem Schritt wenigstens halbiert, und
durch Induktion folgt
0 < xn −√
2 ≤(
1
2
)n−1
(x1 −√
2) fur alle n ≥ 1.
Auf der rechten Seite steht hier (bis auf einen festen Faktor) die geometrische Null-
folge {2−n}. Daher ist auch {xn −√
2} Nullfolge und also limn→∞
xn =√
2.
Genauso sieht man, dass fur a > 0 die Folge
yn+1 :=1
2(yn +
a
yn
), y0 > 0,
gegen√
a konvergiert, und dass fur den Fehler gilt:
yn+1 −√
a =1
2yn
(yn −√
a)2. 2
Bemerkung 10.42. Die Feststellung, dass der Fehler des Newton-Verfahrens zur
Approximation von√
2 in jedem Schritt um den Faktor 0.5 fallt, unterschatzt die
Konvergenzgeschwindigkeit erheblich (vgl. Tabelle 10.2 auf Seite 4). Ware dies rea-
listisch, so brauchte das Verfahren zum Gewinn von drei Dezimalstellen wegen
210 = 1024 ≈ 103 etwa 10 Iterationen (und zwar unabhangig von der schon er-
reichten Genauigkeit). Formel (10.3) besagt dagegen, dass der Fehler (bis auf eine
multiplikative Konstante, die wir zur Vereinfachung der Argumentation vernachlassi-
gen) in jedem Schritt quadriert wird (man nennt dies quadratische Konvergenz)
. Ist der Fehler also schon 10−1, so hat er nach einem Schritt die Großenordnung
10−2, nach zwei Schritten die Großenordnung 10−4 und nach drei Schritten schon die
Großenordnung 10−8, so dass man zur Verkleinerung des Fehlers um den Faktor 10−3
ausgehend vom Fehler 0.1 zwei Schritte, ausgehend vom Fehler 10−3 gerade einen
Schritt und fur alle kleineren Fehler nur einen”Bruchteil eines Schrittes“ benotigt.
2
Eine weitere wichtige Folge behandelt das nachste Beispiel.

24 KAPITEL 10. FOLGEN UND REIHEN
Beispiel 10.43. Wir zeigen
an =xn
n!→ 0 fur jedes feste x ∈ IR.
Man fasst diese Aussage gewohnlich in die Worte, dass”n! schneller wachst als xn
fur jedes x“.
Zum Beweis teilt man|xn|n!
=|x|1
· |x|2
· . . . · |x|n
auf in die Quotienten, die kleiner als 1 sind, und diejenigen, die dies nicht sind.
Damit es uberhaupt welche gibt, die kleiner als 1 sind, betrachten wir nur Werte
n ≥ n0, wobei n0 selbst eine Zahl großer als |x| sei. Es ist damit
|an − 0| =|x|nn!
=|x|n0
n0!· |x|n0 + 1︸ ︷︷ ︸
<1
· . . . · |x|n − 1︸ ︷︷ ︸
<1
· |x|n
.
Aus der letzten Abschatzung konnen wir nun auf mehrere Weisen auf die Konvergenz
gegen Null schließen. Lasst man einerseits die als < 1 gekennzeichneten Faktoren
einfach weg, so erhalt man
|an − 0| ≤ |x|n0
n0!· |x|
n,
schatzt also die Abweichung von Null durch ein konstantes Vielfaches der Nullfolge
{n−1} ab.
Schatzt man andererseits alle Terme ab dem Quotienten q := |x|/(n0 + 1) durch q
ab, so erhalt man die Abschatzung
|an − 0| ≤ |x|n0
n0!· qn−n0 ,
die die Konvergenz gegen Null zeigt, da {qn−n0}n≥n0 geometrische Nullfolge ist. 2
Bisher wurden nur Folgen betrachtet, deren Grenzwert man erraten konnte. Die
Konvergenz der Folge an := (1 + 1n)n aus Beispiel 10.7. ist nicht so leicht beweisbar,
da der Grenzwert nicht bekannt ist. Sie ist aber monoton wachsend und nach oben
beschrankt. Hinsichtlich der Monotonie hat man namlich
an+1
an
=(1 + 1
n+1)n+1
(1 + 1n)n
= (1 +1
n + 1)
(1 + 1
n+1
1 + 1n
)n
= (1 +1
n + 1) (1 − 1
(n + 1)2)n,
und aus der Bernoullischen Ungleichung (Lemma 10.39.) folgt
an+1
an
≥ (1 +1
n + 1) (1 − n
(n + 1)2) =
n + 2
n + 1· n2 + n + 1
n2 + 2n + 1=
n3 + 3n2 + 3n + 2
n3 + 3n2 + 3n + 1> 1.

10.3. REELLE ZAHLENFOLGEN 25
Weiter ist {an} nach oben beschrankt, denn es ist
an = (1 +1
n)n ≤ (1 +
1
2n)2n = (1 − 1
2n + 1)−2n,
und mit der Bernoullischen Ungleichung erhalt man
an ≤ (1 − n
2n + 1)−2 =
(2n + 1
n + 1
)2 ≤(2n + 2
n + 1
)2= 4.
Zu einer monoton wachsenden und nach oben beschrankten Folge sagt uns unsere
Anschauung, dass eine solche Folge konvergieren muss. Wogegen konvergiert die-
se Folge aber? Tatsachlich ist der Grenzwert eine irrationale Zahl, die wir mit e
bezeichnen werden.
Naturlich stellt sich wieder die Frage, ob diese Zahl denn uberhaupt existiert. Da wir
fur e (zumindest zum gegenwartigen Zeitpunkt) anders als fur π noch keine andere
(z.B. geometrische) Definition haben, mag die Relevanz der Frage nach der Existenz
von e schon einleuchtender sein als bei π.
Ein Weg, e zu definieren, ist nun der, auf der Konvergenz der monoton wachsen-
den und nach oben beschrankten Folge zu beharren und zu postulieren, dass der
Grenzwert zu den reellen Zahlen gehort. Man definiert damit gewissermaßen die re-
elle Zahl durch ihre approximierende Folge. Die Menge der reellen Zahlen ließe sich
so als Gesamtheit aller Grenzwerte von konvergenten Folgen aus rationalen Zahlen
definieren.
Indem man die Konvergenz von Folgen mit Hilfe eines grenzwertunabhangigen Kri-
teriums (siehe Cauchy-Kriterium, unten) charakterisiert, wird diese Vorgehensweise
ubrigens allgemein eingesetzt, um normierte Raume, welche so unvollstandig sind wie
die rationalen Zahlen (also gewissermaßen auch noch”irrationale Locher“ haben),
zu”vervollstandigen“. Die Elemente des Raumes werden erganzt um die Grenzwerte
konvergenter Folgen, die sich aus Elementen des Raumes bilden lassen.
Obwohl diese Methode eigentlich sehr konstruktiv ist und wir sie spater auch in
abstrakterem Rahmen wieder gebrauchen werden, wollen wir hier einen anderen
Weg gehen, die rationalen Zahlen Q zu den reellen Zahlen IR zu erweitern. Wir
brauchen hierzu allerdings auch noch einige weitere elementare Begriffe. U.a. gehort
dazu der Begriff der Beschranktheit einer Menge in IR. Dieser Begriff ist uns fur den
Spezialfall (der Bildmenge) einer Folge schon bekannt.
Definition 10.44. Es sei M ⊂ IR. Existiert K ∈ IR mit x ≤ K fur alle x ∈ M
(bzw. x ≥ K fur alle x ∈ M), so heißt M nach oben beschrankt (bzw. nach

26 KAPITEL 10. FOLGEN UND REIHEN
unten beschrankt) und K heißt eine obere Schranke (bzw. untere Schranke) von
M . Ist M nach oben und nach unten beschrankt, so heißt M beschrankt .
Ist K0 eine obere (untere) Schranke fur M und gilt K0 ≤ K (K0 ≥ K) fur jede obere
(untere) Schranke K von M , so heißt K0 k leinste obere Schranke (großte untere
Schranke) oder auch Supremum ( Infimum) von M .
Wir verwenden hierfur die Schreibweise
K0 = sup M (bzw. K0 = inf M).
Bemerkung 10.45. Wie im Falle der Folgen ist eine Menge M ⊂ IR genau dann
beschrankt, wenn es ein K ≥ 0 gibt mit |x| ≤ K fur alle x ∈ M . In dieser Fassung
ergibt die Definition auch fur Teilmengen von C oder von IRn einen Sinn, wenn man
|x| als komplexen Betrag liest oder durch ‖x‖ ersetzt. 2
Beispiel 10.46. Die Menge IN ist nicht nach oben beschrankt. Dies besagt gerade
das Archimedische Axiom. 2
Beispiel 10.47. M := {x ∈ IR : x > 0, x2 < 2} ist nach oben beschrankt, denn
x ≥ 2 impliziert x2 ≥ 4, also x /∈ M , und daher ist 2 obere Schranke von M . Als
kleinste obere Schranke vermutet man hier schnell√
2. Uberlegen Sie einmal allein,
weshalb dies richtig ist. 2
Beim Nachweis, dass√
2 die kleinste obere Schranke der Menge M ist, haben Sie
vermutlich stillschweigend angenommen, dass√
2 auch eine reelle Zahl ist. Dass dies
der Fall ist, postuliert das sogenannte
Vollstandigkeitsaxiom
Jede nach oben beschrankte Teilmenge M von IR besitzt eine kleinste
obere Schranke.
Bemerkung 10.48. Durch das Vollstandigkeitsaxiom wird die Menge Q der ra-
tionalen Zahlen zur Menge IR der reellen Zahlen vervollstandigt. Damit man mit
den reellen Zahlen auch rechnen kann, mussen die Addition und Multiplikation von
Q auf IR fortgesetzt werden. Dies geschieht fur die Addition a + b, indem man fur
beide Summanden Folgen {an} ⊂ Q und {bn} ⊂ Q wahlt mit limn→∞ an = a und

10.3. REELLE ZAHLENFOLGEN 27
limn→∞ bn = b und a+b definiert durch a+b = limn→∞(an +bn). Fur die Multiplika-
tion verfahrt man genauso. Naturlich muss man noch zeigen, dass die so definierten
Summen und Produkte unabhangig von den gewahlten Folgen sind. Wir verzichten
darauf und halten nur fest, dass hiermit die reellen Zahlen alle in Abschnitt 1.4
genannten algebraischen Eigenschaften und Ordnungseigenschaften der rationalen
Zahlen erben. 2
Beispiel 10.49. Die Intervalle [0, 1) und [0, 1] haben beide den Wert 1 zum Su-
premum. Suprema konnen also zur Menge gehoren, mussen es aber nicht. 2
Bemerkung 10.50. Aus dem Vollstandigkeitsaxiom folgt naturlich, dass jede nach
unten beschrankte Teilmenge von IR ein Infimum besitzt. Betrachtet man namlich
M := {x ∈ IR : −x ∈ M}, dann gilt inf M = − sup M . 2
Fur die zu Beginn der Diskussion uber die Erweiterung von Q betrachtete Folge{
(1 + 1n)n
}
n∈ INhat die nach oben beschrankte Menge
{
(1 + 1n)n : n ∈ IN
}
nach
dem Vollstandigkeitsaxiom eine kleinste obere Schranke. Die Idee, dass die monoton
wachsende Folge gegen ihr Supremum konvergiert, ist nun naheliegend und wird
sogleich bewiesen werden. Hierzu zeigen wir zunachst eine Charakterisierung des
Supremums, der beim Umgang mit Folgen zweckmaßiger ist als unsere Definition.
Satz 10.51. Es sei M ⊂ IR nach oben beschrankt. Dann ist K0 genau dann das
Supremum von M , wenn gilt
(i) K0 ist obere Schranke,
(ii) fur alle ε > 0 existiert m ∈ M mit m > K0 − ε.
Beweis: (indirekt)
Ist K0 Supremum von M und ist die Bedingung (ii) verletzt, so existiert ein ε > 0,
so dass m ≤ K0 − ε fur alle m ∈ M gilt. Damit ist K0 − ε eine obere Schranke von
M und K0 − ε < K0 im Widerspruch zur Minimalitat von K0.
Gilt umgekehrt (i) und (ii) und K0 6= sup M , so ist K0 > sup M und mit ε :=
0.5(K0 − sup M) gilt fur alle m ∈ M
m ≤ sup M < sup M + ε = K0 − ε
im Widerspruch zu (ii).
Nun sind wir endlich in der Lage, die Konvergenz monotoner beschrankter Folgen
zu zeigen.

28 KAPITEL 10. FOLGEN UND REIHEN
Satz 10.52. Jede monoton wachsende, nach oben beschrankte (bzw. monoton fal-
lende, nach unten beschrankte) Zahlenfolge ist konvergent.
Beweis: Es sei M := {an : n ∈ IN} und a := sup M . Dann gibt es nach Satz 10.51.
fur alle ε > 0 ein aN ∈ M mit aN > a− ε, und wegen der Monotonie von {an} folgt
a − ε < an ≤ a fur alle n ≥ N , d.h. an → a.
Beispiel 10.53. Wir haben schon gesehen, dass die Folge mit den Elementen
an :=(
1 +1
n
)n
monoton wachsend und nach oben beschrankt ist. Nach Satz 10.52. ist sie also
konvergent. Ihr Grenzwert
e := limn→∞(1 +
1
n)n
heißt Eulersche7 Zahl und spielt bei allen Wachstums- oder Zerfallsprozessen eine
Rolle. Die ersten Ziffern des unendlichen (nichtperiodischen) Dezimalbruches von e
sind
e = 2.71828182845904523536028747135266249775724709... 2
Beispiel 10.54. Auf Seite 3 haben wir in Beispiel 10.1. zur Berechnung von√
2
zwei Folgen {an} und {bn} konstruiert mit den Eigenschaften
(i) {an} ist monoton wachsend,
(ii) {bn} ist monoton fallend,
(iii) an ≤ bn fur alle n ∈ IN.
Zwei Folgen mit diesen Eigenschaften definieren eine Intervallschachtelung (fur
die Intervalle [an, bn] gilt ja [a1, b1] ⊃ [a2, b2] ⊃ . . .). Nach Satz 10.52. sind beide
Folgen konvergent. Gilt zusatzlich bn − an → 0, so folgt limn→∞
an = limn→∞
bn. 2
Wir haben in Satz 10.26. schon Rechenregeln fur Folgen im allgemeinen Vektorraum
aufgestellt. Wir erweitern diese nun um Regeln fur reelle Zahlenfolgen.
7Leonhard Euler, 1707 - 1783, schweizer Mathematiker

10.3. REELLE ZAHLENFOLGEN 29
Satz 10.55. (Rechenregeln fur konvergente Zahlenfolgen)
Es seien {an}, {bn} ⊂ IR konvergent mit a := limn→∞ an, b := lim
n→∞ bn. Dann gilt
(i) Aus an ≤ bn fur alle n ∈ IN folgt a ≤ b.
(ii) {an ·bn} ist konvergent und limn→∞ anbn = ab. Insbesondere gilt also lim
n→∞ amn = am
fur alle m ∈ IN.
(iii) Gilt b 6= 0 und bn 6= 0 fur alle n, so ist{an
bn
}
konvergent und limn→∞
an
bn
=a
b.
Beweis: (i): Wegen Satz 10.26. genugt es zu zeigen, dass an ≥ 0 fur alle n ∈ IN
a ≥ 0 impliziert. Angenommen a < 0; dann gilt |an − a| < −a2
fur genugend große
n, d.h. an < a2
< 0, und dies ist ein Widerspruch.
(ii): Zu δ > 0 existieren N1, N2 ∈ IN mit |an−a| < δ fur alle n ≥ N1 und |bn− b| < δ
fur alle n ≥ N2, und nach Satz 10.20. gibt es ein C ≥ 0 mit |an| ≤ C fur alle n.
Daher gilt
|ab − anbn| = |ab − anb + anb − anbn| = |(a − an)b + an(b − bn)|≤ |a − an| · |b| + |an| · |b − bn| < δ(|b| + C) ≤ ε
fur δ ≤ ε/(|b| + C) und alle n ≥ max(N1, N2). Mit bn := an erhalt man speziell
limn→∞ a2
n = a2 und durch Induktion limn→∞ am
n = am fur alle m ∈ IN.
(iii): Wegen (ii) genugt es, limn→∞
1bn
= 1b
zu zeigen.
Zu |b|2
> 0 existiert N mit |b− bn| < |b|2
fur alle n ≥ N , d.h. |bn| ≥ |b| − |bn − b| > |b|2,
und daher folgt
|bn| ≥ min{|b1|, . . . , |bN−1|,|b|2} =: L > 0
fur alle n ∈ IN. Hiermit gilt
∣∣∣∣
1
bn
− 1
b
∣∣∣∣ =
|b − bn||bn| · |b|
≤ 1
L |b| |bn − b| −→ 0 fur n → ∞.
Bemerkung 10.56. Die Aussagen (ii) und (iii) gelten mit demselben Beweis auch
fur komplexe Folgen. 2

30 KAPITEL 10. FOLGEN UND REIHEN
Bemerkung 10.57. Wir haben bei der Konstruktion der m komplexen Wurzeln
aus einer komplexen Zahl in Mathematik I die Existenz der m-ten Wurzel einer
positiven rellen Zahl vorausgesetzt. Erst jetzt konnen wir uns davon uberzeugen,
daß es zu jeder positiven reellen Zahl a eine positive reelle Zahl m√
a gibt, deren m-te
Potenz gleich a ist.
Um dies zu sehen, betrachten wir ahnlich wie in Beispiel 10.2. die Folge
an+1 := an − amn − a
m am−1n
, a0 > 0 mit am0 > a,
und zeigen, daß diese Folge gegen eine reelle Zahl α konvergiert mit αm = a. Die
Folge selbst ergibt sich wieder aus dem sogenannten Newton-Verfahren zur Appro-
ximation der positiven Nullstelle von f(x) = xm−a, das wir selbst erst etwas spater
erklaren konnen.
Wegen
an+1 = an
(
1 +a − am
n
m amn
)
erhalt man aus am0 > a zunachst a1 < a0, und mit der Bernoullischen Ungleichung
(Lemma 10.39.)
am1 = am
0
(
1 +a − am
0
m am0
)m
≥ am0
(
1 +a − am
0
am0
)
= a.
Durch vollstandige Induktion folgt genauso
an > an+1, amn > a fur alle n ∈ IN.
Die Folge {an} ist damit monoton fallend, und da sie weiter wegen
an+1 =(m − 1) am
n + a
m am−1n
> 0
nach unten beschrankt ist, konvergiert sie. Wir nennen den Grenzwert α.
Wegen des Fallens von {an} kann man die letzte Abschatzung sogar verbessern zu
der Aussage, daß die Folgenelemente von Null weg beschrankt bleiben:
an+1 =(m − 1) am
n + a
m am−1n
≥ a
mam−10
=: β > 0
Da mit an ≥ β > 0 fur alle n nach der ersten Aussage von Satz 10.55. auch α =
limn→∞ an ≥ β > 0 gilt, kann man mit Satz 10.26. und Satz 10.55. den Schluß ziehen,
daß
α = limn→∞ an+1 = lim
n→∞
(
an − amn − a
m am−1n
)
= α − αm − a
m αm−1.
Das heißt aber, daß αm = a gilt, womit die Existenz einer m-ten Wurzel aus a
gezeigt ist. 2

10.3. REELLE ZAHLENFOLGEN 31
Fur die m-te Wurzel gilt die weitere Rechenregel
Satz 10.58. Gilt an ≥ 0 fur alle n, so ist { m√
an } fur alle m ∈ IN konvergent, und
es gilt limn→∞
m√
an = m√
a.
Beweis: Aus Satz 10.55. (i) folgt a ≥ 0.
Sei zunachst a = 0. Dann gibt es zu jedem δ > 0 ein N ∈ IN mit an < δ fur alle
n ≥ N , und mit δ := εm erhalt man m√
an < ε fur n ≥ N , d.h. limn→∞
m√
an = 0.
Fur a > 0 verwenden wir, dass fur alle c, d ∈ IR
(c − d)m−1∑
j=0
cm−1−jdj =m−1∑
j=0
cm−jdj −m−1∑
j=0
cm−1−jdj+1
=m−1∑
j=0
cm−jdj −m∑
j=1
cm−jdj = cm − dm
gilt. Mit c := m√
an und d := m√
a erhalten wir daraus
| m√
an − m√
a| = |an − a|/(
( m√
an)m−1
︸ ︷︷ ︸
≥0
+ · · ·︸︷︷︸
≥0
+( m√
a)m−1)
≤ |an − a|/
( m√
a)m−1 −→ 0 fur n → ∞.
Beispiel 10.59. Fur an :=√
n2 + 3n + 4 − n gilt
limn→∞ an = lim
n→∞(n2 + 3n + 4) − n2
√n2 + 3n + 4 + n
= limn→∞
3n + 4√n2 + 3n + 4 + n
= limn→∞
3 + 4/n√
1 + 3/n + 4/n2 + 1=
limn→∞ 3 + lim
n→∞ 4/n√
limn→∞ 1 + lim
n→∞ 3/n +(
limn→∞ 2/n
)2
+ 1
=3
22
Beispiel 10.60. Fur an := n√
a, a > 0, gilt limn→∞
an = 1.
Im Falle a ≥ 1 folgt namlich aus der Bernoullischen Ungleichung
a = (1 + ( n√
a − 1))n ≥ 1 + n ( n√
a − 1),
und daher
| n√
a − 1| = n√
a − 1 ≤ a − 1
n−→ 0 fur n → ∞.
Fur 0 < a < 1 folgt die Behauptung mit b := 1a
> 1 aus
limn→∞
n√
a = limn→∞
1n√
b=
1
limn→∞
n√
b= 1. 2

32 KAPITEL 10. FOLGEN UND REIHEN
In Satz 10.38. haben wir gesehen, dass alle Teilfolgen einer konvergenten Folge kon-
vergieren, und Beispiel 10.35. zeigt, dass die Umkehrung i.a. nicht richtig ist. Fur
monotone reelle Folgen reicht jedoch aus, dass eine beliebige Teilfolge konvergiert,
um die Konvergenz der gesamten Folge zu sichern.
Satz 10.61. Besitzt die monotone Zahlenfolge {an} ⊂ IR eine konvergente Teilfol-
ge {anj}, so konvergiert auch die gesamte Folge, und es gilt
a := limj→∞
anj= lim
n→∞ an.
Beweis: Ohne Beschrankung der Allgemeinheit sei die Folge {an} monoton wach-
send. Dann gilt a ≥ an fur alle n ∈ IN.
Es sei ε > 0 gegeben. Dann gibt es ein J ∈ IN mit
|anj− a| < ε fur alle j ≥ J,
und daher gilt fur alle n ≥ N := nJ wegen an ≥ anJ
|a − an| = a − an ≤ a − anJ< ε.
Beispiel 10.62. Wir betrachten als Verallgemeinerung der die Eulersche Zahl de-
finierenden Folge {(1 + 1n)n} die Folge {an} mit
an :=(
1 +λ
n
)n, λ ∈ Q.
Fur λ = 1 gilt limn→∞(1 + 1
n)n = e, und nach Satz 10.38. folgt
limk→∞
(
1 +1
kq
)kq= e fur jedes feste q ∈ IN.
Sei nun zunachst λ > 0, so daß mit naturlichen Zahlen p und q gilt λ = pq
> 0. Dann
ist fur k ∈ IN
akp =(
1 +p
qkp
)kp=
(
1 +1
kq
)kp=
(
(1 +1
kq)kq
) p
q ,
und nach Satz 10.55. konvergiert die Teilfolge {akp}k∈ IN mit
limk→∞
(
1 +p
qkp
)kp=
(
limk→∞
(1 +1
kq)kq
) p
q = eλ.

10.4. CAUCHYSCHES KONVERGENZKRITERIUM 33
Da die Folge {an} monoton wachst (dies zeigt man fast wortlich wie fur die Folge
{(1 + 1n)n}), konvergiert nach Satz 10.61. auch die gesamte Folge, und es gilt
limn→∞
(
1 +λ
n
)n= eλ.
Fur λ < 0 gilt nach der Bernoullischen Ungleichung (Lemma 10.39.) fur alle n > |λ|
(
1 +λ
n
)n (
1 − λ
n
)n=
(
1 − λ2
n2
)n ≥ 1 − λ2
n,
d.h.
1 − λ2
n≤
(
1 +λ
n
)n (
1 − λ
n
)n ≤ 1,
und daher1 − λ2
n
(1 − λn)n
≤(
1 +λ
n
)n ≤ 1
(1 − λn)n
.
Nach Satz 10.55. konvergieren die linke und rechte Seite beide nach dem ersten Teil
des Beweises gegen 1e−λ (beachte −λ > 0), und daher gilt
limn→∞
(
1 +λ
n
)n=
1
e−λ= eλ,
auch fur λ < 0. 2
10.4 Cauchysches Konvergenzkriterium
Wir beweisen als erstes das Cauchysche8 Konvergenzkriterium, das wie Satz 10.52.
nicht die Kenntnis des Grenzwertes voraussetzt. Es nutzt nicht die Ordnungsstruktur
von IR aus und kann auf normierte Raume (oder noch allgemeiner metrische Raume)
erweitert werden. Wenn wir ein solches Kriterium haben, konnen wir die Frage nach
der Vollstandigkeit auch solcher Raume stellen, wobei man bei der Frage nach”der
Vollstandigkeit“ immer die Vollstandigkeit bezuglich der Grenzwertbildung meint.
Satz 10.63. (Cauchysches Konvergenzkriterium)
Eine Folge {an} ⊂ IR ist genau dann konvergent, wenn es zu jedem ε > 0 ein (von
ε abhangiges) N ∈ IN gibt mit
|an − am| < ε fur alle n,m ≥ N. (10.4)
8Augustin Louis Cauchy, 1789 - 1857, franzosischer Mathematiker

34 KAPITEL 10. FOLGEN UND REIHEN
Beweis: Ist {an} konvergent mit limn→∞
an = a, so existiert zu ε2
> 0 ein N ∈ IN mit
|ap − a| < ε2
fur alle p ≥ N , und daher gilt fur n,m ≥ N
|an − am| ≤ |an − a| + |am − a| <ε
2+
ε
2= ε.
Ist umgekehrt die Bedingung von Satz 10.63. erfullt, so ist {an} beschrankt, denn
fur n ≥ N gilt |an| ≤ |aN | + |an − aN | ≤ |aN | + ε, und daher
|an| ≤ max{|aN | + ε, |a1|, . . . , |aN−1|} =: K fur alle n ∈ IN.
Es sei nun bn := inf{ak : k ≥ n}. Dann ist bn = min{an, bn+1} ≤ bn+1 monoton
wachsend und wegen bn ≤ an ≤ K nach oben beschrankt, also konvergent.
Sei a := limn→∞ bn und ε > 0 vorgegeben. Dann existiert ein n0 ≥ N mit a ≥ bn0 ≥ a−ε
und ein n1 ≥ n0 mit |bn0 − an1| < ε, und daher gilt fur n ≥ N
|a − an| ≤ |a − bn0 | + |bn0 − an1| + |an1 − an| < 3ε,
d.h. limn→∞
an = a.
Bemerkung 10.64. Die Eigenschaft (10.4) aus Satz 10.63. ist auch fur Folgen in
normierten Raumen (ja sogar metrischen Raumen) sinnvoll, wenn man den Betrag
durch die Norm (bzw. |an − am| durch d(an, am)) ersetzt. Folgen mit dieser Eigen-
schaft heißen Cauchy Folgen.
Der erste Teil des Beweises von Satz 10.63. kann wortlich auf den allgemeinen Fall
von Folgen in normierten Raumen ubertragen werden. Konvergente Folgen in nor-
mierten Raumen sind also stets Cauchy Folgen. Die Umkehrung ist aber im allge-
meinen falsch. Genau wie es in den rationalen Zahlen Q Cauchy-Folgen gibt, die
nicht gegen rationale Zahlen konvergieren, gibt es normierte Raume, in denen nicht
jede Cauchy-Folge einen Grenzwert hat. 2
Bemerkung 10.65. Ein normierter Raum, in dem jede Cauchy Folge konvergent
ist, heißt vollstandiger normierter Raum oder Banachraum9. Wird die Norm
des Banach-Raumes M durch ein inneres Produkt induziert, so nennt man ihn einen
vollstandigen Euklidischen Vektorraum oder Hilbertraum10. 2
9Stefan Banach, 1892 - 1945, polnischer Mathematiker
10David Hilbert, 1862 - 1943, deutscher Mathematiker

10.4. CAUCHYSCHES KONVERGENZKRITERIUM 35
Wir haben gesehen, dass jede konvergente Folge beschrankt ist, aber nicht jede
beschrankte Folge konvergiert. Es wird sich zeigen, daß es oft schon nutzlich ist zu
wissen, daß es eine konvergente Teilfolge gibt. Der folgende Satz von Bolzano11 und
Weierstraß12 zeigt, dass dies schon die Beschranktheit der Folge liefert.
Satz 10.66. (Bolzano, Weierstraß)
Jede beschrankte reelle Zahlenfolge {an} besitzt eine konvergente Teilfolge.
Beweis: Es sei [A,B] ein Intervall, das alle an enthalt. Durch Intervallhalbierung
konstruieren wir eine Intervallschachtelung, so dass jedes Intervall unendlich viele
Folgenglieder enthalt:
Sei A0 := A, B0 := B und A ≤ An ≤ Bn ≤ B schon konstruiert, so dass unendlich
viele der ak in [An, Bn] liegen.
Sei Cn+1 := 12(An + Bn) und An+1 := An, Bn+1 := Cn+1, falls {k : ak ∈ [An, Cn+1]}
eine unendliche Menge ist, und An+1 := Cn+1, Bn+1 := Bn sonst. Dann gilt An ≤An+1 ≤ Bn+1 ≤ Bn und Bn −An = 2−n (B−A), und daher lim
n→∞An = α = limn→∞Bn.
Wir definieren nun die konvergente Teilfolge {ani} von {an}: Sei n0 = 1. Ist nk schon
bestimmt, so wahlen wir nk+1, so dass nk+1 > nk und ank+1∈ [Ak+1, Bk+1]. Dann
gilt wegen α ← Ak ≤ ank≤ Bk → α auch limk→∞ ank
= α.
Definition 10.67. Die Grenzwerte konvergenter Teilfolgen von {an} heißen die
Haufungspunkte von {an}.
Mit diesem Begriff formuliert man Satz 10.66. gewohnlich wie folgt:
Satz 10.68. (Bolzano, Weierstraß, 2. Fassung)
Jede beschrankte reelle Zahlenfolge {an} besitzt einen Haufungspunkt.
Bemerkung 10.69. Ist {an} eine konvergente Folge und a ihr Grenzwert, so ist
a naturlich ein Haufungspunkt von {an}, und es ist klar, dass es keine weiteren
Haufungspunkte von {an} geben kann.
Wahrend wir fur den Grenzwert a einer konvergenten Folge {an} sagen konnen, daß
fur jedes ε > 0 fast alle (d.h. alle bis auf endlich viele) Folgenelement eine Abstand
11Bernhard Placidus Johann Nepomuk Bolzano, 1781 - 1848, bohmischer Mathematiker
12Karl Theodor Wilhelm Weierstraß, 1815 - 1897, deutscher Mathematiker

36 KAPITEL 10. FOLGEN UND REIHEN
kleiner als ε von a haben, kann man fur einen Haufungspunkt h nur sagen, daß fur
jedes ε > 0 unendlich viele Folgenelemente einen Abstand von h haben, der kleiner
als ε ist. 2
Da auch die Haufungspunkte von Haufungspunkten wieder Haufungspunkte sind
(vgl. Aufgabenband), besitzt jede beschrankte reelle Zahlenfolge einen maximalen
und einen minimalen Haufungspunkt. Diese heißen limes superior ( lim supn→∞ an)
und limes inferior ( lim infn→∞ an). Ist {an} nach oben (bzw. nach unten) unbe-
schrankt, so schreiben wir lim supn→∞ an = ∞ (bzw. lim infn→∞ an = −∞).
Ist a = lim supn→∞ an, so ist dadurch zweierlei sicher gestellt: Fur alle α > a gibt
es hochstens endlich viele Folgenglieder an mit an ≥ α, und fur alle β < a gibt es
unendlich viele Folgenglieder an mit β < an.
Beispiel 10.70.
an :=
(−1)k fur n = 3k, k ∈ IN,
5 − 1n
fur n = 3k + 1, k ∈ IN,
−n fur n = 3k + 2, k ∈ IN.
Dann besitzt {an} die Haufungspunkte −1, 1, 5. Es gilt
lim sup an = 5 und lim inf an = −∞. 2
10.5 Folgen in Vektorraumen
Wir kehren nun zu der allgemeinen Situation einer Folge in einem Vektorraum M
mit einer Norm ‖ · ‖ zuruck. Eine Folge {an} heißt dann konvergent gegen a, wenn
es zu jedem ε > 0 ein N ∈ IN gibt mit ‖an − a‖ < ε fur alle n ∈ IN.
Bekanntlich kann ein und derselbe Vektorraum mit verschiedenen Normen versehen
werden. In der Definition der Konvergenz tritt nun eine bestimmte Norm auf. Es ist
deshalb von vornherein nicht auszuschließen, dass die Konvergenz einer Folge von
der jeweils betrachteten Norm abhangt. Dies hieße, daß eine Folge, die bezuglich
der einen Norm gegen ein Grenzelement konvergiert, bezuglich einer anderen Norm
divergent sein konnte.
Tatsachlich konnen solche Komplikationen in unendlichdimensionalen Raumen auf-
treten, wie das nachste Beispiel zeigt.

10.5. FOLGEN IN VEKTORRAUMEN 37
Beispiel 10.71. Es sei
M := {f : [0, 1] → IR stetig}.
Wir betrachten die Folge {fn} der Monome fn(x) := xn.
In Mathematik I haben wir gesehen, daß auf M durch
〈f, g〉 :=
1∫
0
f(x) g(x) dx
ein inneres Produkt definiert ist. Wir betrachten das Verhalten der Folge {fn}bezuglich der durch dieses innere Produkt induzierten Norm ‖f‖2 :=
√
〈f, f〉 und
bezuglich der weiteren sogenannten Maximum-Norm
‖f‖∞ = max{|f(x)| : x ∈ [0, 1]}.
Wegen
‖fn‖2 =
√√√√√
1∫
0
x2n dx =1√
2n + 1→ 0
konvergiert die Folge bezuglich der ‖ · ‖2-Norm gegen die Null-Funktion.
Fur die Maximum-Norm dagegen findet man ‖fn‖∞ = 1 fur alle n ∈ IN, so daß {fn}nicht gegen die Funktion f(x) ≡ 0 konvergiert. 2
Daßdie Konvergenz einer Folge von der gewahlten Norm abhangt, kann nur in un-
endlich dimensionalen Raumen auftreten. Wir werden die wichtigsten Konvergenz-
begriffe fur Folgen stetiger Funktionen in Abschnitt 12.2 diskutieren. In endlich
dimensionalen Raumen folgt aus der Konvergenz bezuglich einer Norm die Konver-
genz bezuglich jeder anderen Norm. Um dies einzusehen benotigen wir den folgenden
Begriff.
Definition 10.72. Es sei V ein Vektorraum (endlicher oder unendlicher Dimensi-
on), und es seien ‖·‖ und ‖·‖ zwei Normen auf V . Diese Normen heißen aquivalent,
wenn es Konstanten C1 > 0 und C2 > 0 gibt, so dass
C1 ‖v‖ ≤ ‖v‖′ ≤ C2 ‖v‖ fur alle v ∈ V (10.5)
gilt.
Bezuglich aquivalenter Normen stimmen die Konvergenzbegriffe uberein.

38 KAPITEL 10. FOLGEN UND REIHEN
Satz 10.73. Es sei V ein Vektorraum, und seien ‖ · ‖ und ‖ · ‖′ zwei aquivalente
Normen auf V . Eine Folge {an} konvergiert genau dann bzgl. der Norm ‖ · ‖, wenn
sie bzgl. der Norm ‖ · ‖′ konvergiert.
Beweis: Konvergiert die Folge {an} bzgl. der Norm ‖ · ‖, so gibt es ein a ∈ V , so
dass ‖an − a‖ → 0 fur n → ∞, und aus
0 ≤ ‖an − a‖′ ≤ C2‖an − a‖
folgt dann auch ‖an − a‖′ → 0 fur n → ∞. Gilt umgekehrt ‖an − a‖′ → 0, so folgt
aus
0 ≤ ‖an − a‖ ≤ 1
C1
‖an − a‖′
auch die Konvergenz bzgl. der Norm ‖ · ‖.
Bemerkung 10.74. Beispiel 10.71. zeigt, dass die Normen
‖f‖2 :=
√√√√√
1∫
0
|f(t)| dt und ‖f‖∞ := max1≤t≤1
|f(t)|
auf dem Raum der stetigen, reellenwertigen Funktion auf dem Intervall [0, 1] nicht
aquivalent sind. 2
Satz 10.75. (Normaquivalenzsatz)
Je zwei Normen auf dem Raum IRn sind aquivalent.
Beweis: Es genugt zu zeigen, dass jede Norm auf IRn der Maximumnorm
‖x‖∞ := maxi=1,...,n
|xi|
aquivalent ist. Sind namlich ‖ · ‖ und ‖ · ‖′ zwei Normen auf IRn und gilt fur alle
x ∈ IRn
C1‖x‖∞ ≤ ‖x‖ ≤ C2‖x‖∞ und C ′1‖x‖∞ ≤ ‖x‖′ ≤ C ′
2‖x‖∞
fur positive Konstante C1, C2, C′1, C
′2 > 0, so folgt
C ′1
C2
‖x‖ ≤ C ′1‖x‖∞ ≤ ‖x‖′ ≤ C ′
2‖x‖∞ ≤ C ′2
C1
‖x‖.
Zunachst gilt
‖x‖ = ‖n∑
j=1
xjej‖ ≤
n∑
j=1
|xj| · ‖ej‖ ≤ maxj=1,...,n
|xj| ·n∑
j=1
‖ej‖ =: c2‖x‖∞.

10.5. FOLGEN IN VEKTORRAUMEN 39
Um auch die zweite Ungleichung zu zeigen, setzen wir
C1 := inf{‖x‖ : ‖x‖∞ = 1}.
Ist C1 > 0, so sind wir fertig, denn dann gilt
∥∥∥∥∥
x
‖x‖∞
∥∥∥∥∥
=1
‖x‖∞‖x‖ ≥ C1 fur alle x 6= 0,
und daher
C1‖x‖∞ ≤ ‖x‖ fur alle x ∈ IRn.
Wir fuhren also die Annahme C1 = 0 zum Widerspruch. Im Falle C1 = 0 gibt es
eine Folge {am} ⊂ IRn mit
‖am‖∞ = 1 und ‖am‖ → 0 fur m → ∞.
Aus dieser Folge wahlen wir eine bzgl. ‖ · ‖∞ konvergente Teilfolge aus. Wegen
‖am‖∞ = maxj=1,...,n
|am,j| = 1
gilt fur die Folge der ersten Komponenten −1 ≤ am,1 ≤ 1. Sie ist also beschrankt,
und daher besitzt sie nach dem Satz von Bolzano und Weierstraß (Satz 10.66.) eine
konvergente Teilfolge {amj, 1}.
Wir betrachten nun die Teilfolge {amj} der Ausgangsfolge, deren erste Komponenten
die eben ausgewahlte konvergente reelle Teilfolge der ersten Komponenten bilden.
Mit der gesamten Folge {am} ist auch die Teilfolge {amj} in der Maximumnorm be-
schrankt, und daher gilt dann auch fur die zweiten Komponenten −1 ≤ amj ,2 ≤ 1.
Nach Satz 10.66. konnen wir also hieraus wieder eine konvergente Teilfolge {amjk,2}
auswahlen. Fur die entsprechende Teifolge {amjk} der Vektorfolge konvergieren dann
schon die ersten beiden Komponentenfolgen. Indem wir so fortfahren, sind wir nach
insgesamt n-maligem Auswahlen bei einer Teilfolge {am′} angelangt, fur die alle
Komponenten konvergieren, und die damit in der Maximumnorm gegen ein a kon-
vergiert.
Es gilt also
‖am′‖∞ = 1, ‖am′ − a‖∞ → 0, ‖am′‖ → 0.
Hieraus folgt einerseits
‖a‖ ≤ ‖a − am′‖ + ‖am′‖ ≤ C2‖a − am′‖∞ + ‖am′‖ → 0 fur m′ → ∞.

40 KAPITEL 10. FOLGEN UND REIHEN
Da die linke Seite unabhangig von m′ ist, gilt ‖a‖ = 0, d.h. a = 0. Andererseits hat
man
‖a‖∞ ≥ ‖am′‖∞ − ‖a − am′‖∞ → 1,
und daher a 6= 0. Damit ist der Widerspruch erreicht und die Aquivalenz von ‖ · ‖und ‖ · ‖∞ nachgewiesen.
Beispiel 10.76. Man kann sich uberlegen, dass die Aquivalenz der Normen geo-
metrisch bedeutet, dass fur je zwei Normen die Einheitskugel bezuglich der einen
Norm durch ein positives Vielfaches der Einheitskugel bezuglich der anderen Norm
umfasst werden kann. Wie der dabei zu wahlende Faktor mit den Konstanten C1 und
C2 aus der Ungleichung (10.5) zusammenhangt, behandeln wir im Aufgabenband.
Als haufig verwendete Normen des IRn
sind schon aus der Mathematik I be-
kannt
‖x‖1 :=n∑
i=1
|xi|
‖x‖2 :=
√√√√
n∑
i=1
x2i
‖x‖∞ := maxi=1,...,n
|xi|.
Die Abbildung 10.4 enthalt fur den Fall
n = 2 die zugehorigen Einheitskugeln.−1 0 1
−1
0
1
||.||1
||.||2
||.||∞
Abbildung 10.4
Fur die eben angegebenen Normen lauten die Normaquivalenzungleichungen (mit
optimalen Konstanten) gerade
‖x‖2 ≤ ‖x‖1 ≤ √n ‖x‖2 fur alle x ∈ IRn,
‖x‖∞ ≤ ‖x‖2 ≤ √n ‖x‖∞ fur alle x ∈ IRn. 2
Aus Satz 10.73. und Satz 10.75. folgt, dass die Konvergenz einer Folge {am} in IRn
nicht von der gewahlten Norm abhangt. Wahlt man bei der Konvergenzuntersuchung
speziell die Maximumnorm, so erhalt man das folgende Kriterium.
Korollar 10.77. Eine Folge {ak} ⊂ IRn konvergiert genau dann, wenn jede ihrer
Komponentenfolgen konvergiert. Der Grenzwert kann komponentenweise berechnet
werden.

10.5. FOLGEN IN VEKTORRAUMEN 41
Beweis: Es seien am := (ak1, . . . , amn)T , a := (α1, . . . , αn)T ∈ IRn mit am → a.
Dann gilt
ak → a ⇐⇒ ‖ak − a‖∞ → 0
⇐⇒ max1≤i≤n
|aki − αi| → 0
⇐⇒ |aki − αi| → 0 fur i = 1, . . . , n.
Die Normunabhangigkeit der Konvergenz gilt allgemeiner als oben gezeigt in allen
endlichdimensionalen normierten Raumen. In Mathematik I wurde gezeigt, dass
jeder endlichdimensionale Vektorraum V (mit Skalaren aus IR) der Dimension n
dem IRn isomorph ist. Ist namlich v1, . . . ,vn eine Basis von V , so kann uber die
Darstellung v =∑n
i=1 xi(v)vi jeder Vektor v ∈ V mit seinem Koordinatenvektor
x(v) = (x1(v), . . . , xn(v))T ∈ IRn identifiziert werden. Ist in V eine Norm ‖ · ‖V
gegeben, so ist durch
‖x(v)‖ := ‖n∑
i=1
xivi‖V = ‖v‖V (10.6)
eine Norm des Koordinatenvektors x(v) ∈ IRn bestimmt. Damit sieht man nun leicht
die Aquivalenz zweier Normen ‖ · ‖ und ‖ · ‖′ in V : Fur die zugehorigen Normen
‖ · ‖ und ‖ · ‖′ der Koordinatenvektoren in IRn gibt es nach Satz 10.75. Konstanten
C1, C2 > 0 mit
C1‖x‖ ≤ ‖x‖′ ≤ ‖x‖ fur alle x ∈ IRn,
und daher gilt dann fur alle v ∈ V
C1‖v‖ = C1‖x(v)‖ ≤ ‖x(v)‖′ = ‖v‖′ = ‖x(v)‖′ ≤ C2‖x(v)‖ = C2‖v‖.
Es gilt also die Verallgemeinrung von Satz 10.75.
Satz 10.78. Ist V ein endlichdimensionaler Vektorraum, so sind je zwei Normen
auf V aquivalent. Damit ist die Konvergenz einer Folge {am} (und ihr Grenzwert)
unabhangig von der gewahlten Norm.
Mit Korollar 10.77. und Satz 10.78. kann man nun alle Resultate aus Abschnitt 10.1
und Abschnitt 10.4 auf Folgen von Vektoren ubertragen. Es gilt z.B. das Cauchysche
Konvergenzkriterium.
Satz 10.79. (Cauchysches Konvergenzkriterium)
Es sei V ein endlichdimensionaler Vektorraum und ‖ · ‖ eine Norm auf V . Eine

42 KAPITEL 10. FOLGEN UND REIHEN
Folge {am} ⊂ V ist genau dann konvergent, wenn sie Cauchy-Folge ist, d.h. wenn
es zu jedem ε > 0 ein N = N(ε) ∈ IN gibt mit
‖ak − am‖ < ε fur alle k,m ≥ N.
Jeder endlichdimensionale normierte Vektorraum ist also ein Banachraum.
Beweis: Wir wissen schon, daß jede konvergente Folge Cauchy-Folge ist und brau-
chen daher nur noch die andere Richtung der Aquivalenz zu zeigen.
Es sei {am} ⊂ V eine Cauchy-Folge. Durch Ubergang zur Folge der Koordinaten-
vektoren unter Benutzung der induzierten Norm aus (10.6) konnen wir ohne Be-
schrankung der Allgemeinheit annehmen, dass {am} eine Cauchy-Folge im IRn ist,
und wegen der Aquivalenz der Normen ist sie dann auch bzgl. der Maximumnorm
eine Cauchy-Folge.
Zu jedem ε > 0 gibt es also ein N ∈ IN, so daß mit den Bezeichnungen des letzten
Beweises
|aki − ami| < ε fur alle k,m ≥ N und fur alle i = 1, . . . , n.
Alle Komponentenfolgen sind also reelle Cauchy-Folgen, und da IR vollstandig ist,
sind die Komponentenfolgen mithin konvergent. Nach Korollar 10.77. folgt hieraus
dann auch die Konvergenz der ganzen Folge.
Ebenso laßt sich der Satz von Bolzano-Weierstraß verallgemeinern:
Korollar 10.80. (Bolzano–Weierstraß, allgemeine Version)
Jede beschrankte Folge in einem endlich dimensionalen normierten Raum hat eine
konvergente Teilfolge.
Beweis: Wir beschranken uns wieder auf den Fall des Raumes IRn. Ist die Folge
{am} bezuglich irgendeiner Norm beschrankt, so ist sie auch bezuglich der Ma-
ximumnorm beschrankt, und daher sind auch alle Folgen der Vektorkomponenten
beschrankt. Wie im Beweis des Normaquivalenzsatzes kann man daher nacheinan-
der Teilfolgen auswahlen, so dass schließlich alle Komponentenfolgen und damit die
ausgewahlte Vektorfolge konvergiert.

10.6. KONVERGENZKRITERIEN FUR REIHEN 43
Beispiel 10.81. Mit der komplexen Zahl z := r eiφ definieren wir die komplexe
Folge zn = rn einφ = rn(cos nϕ + i sin nϕ), die wir mit der Folge
an := (rn cos nϕ, rn sin nϕ)T
in IR2 identifizieren.
Fur |z| < 1 ist die Folge dann beschrankt. Es ist klar, daß sie eine konvergente
Teilfolge besitzt, denn die gesamte Folge ist wegen ‖an‖2 = |z|n = rn → 0 fur
n → ∞ eine Nullfolge.
Fur |z| > 1 ist die Folge {an} unbeschrankt und also divergent. Sie besitzt auch keine
Haufungspunkte, denn die Folge {‖an‖} wachst streng monoton uber alle Grenzen.
Fur |z| = 1 schließlich ist {an} beschrankt, aber Konvergenz kann (außer fur z = 1)
nicht festgestellt werden. Die Folge hat aber (mindestens) eine konvergente Teilfol-
ge, so daß es stets (mindestens) einen Haufungspunkt der Folge auf dem komplexen
Einheitskreis gibt. Tatsachlich konnen sowohl endlich viele als auch unendlich vie-
le Haufungspunkte auftreten. Mit Mitteln, die sehr weit außerhalb des aktuellen
Kenntnisstandes liegen, kann man ubrigens zeigen, daß es (sehr viele) Falle gibt, bei
denen alle Punkte des Einheitskreises Haufungspunkte sind. 2
10.6 Konvergenzkriterien fur Reihen
Eine besonders wichtige Klasse unendlicher Folgen sind die Reihen.
Definition 10.82. Es sei {an} ⊂ V eine gegebene Folge in dem vollstandigen
normierten Vektorraum V . Dann heißt die hiermit definierte Folge
sn :=n∑
j=1
aj
eine (unendliche) Reihe. Die aj heißen die Glieder der Reihe, die sn heißen die
Partialsummen der Reihe.
Die Reihe heißt genau dann konvergent (divergent), wenn die Folge {sn} kon-
vergiert (divergiert). Wir bezeichnen die Reihe und — im Falle der Konvergenz —
auch ihren Grenzwert mit∞∑
j=1aj.

44 KAPITEL 10. FOLGEN UND REIHEN
Wir hatten oben festgestellt, dass Folgen haufig nicht direkt verfugbare Objekte ap-
proximieren. Bei solchen Approximationen ist die Verwendung von Reihen naturlich.
Der Approximationsprozess
sn −→ s
fur ein Objekt s durch eine Folge {sn} verlauft namlich oft so, dass man im (n+1)-
ten Schritt fur die Approximation sn mit geeigneten Mitteln eine Schatzung an+1
des Fehlers
an+1 ≈ s − sn
ermittelt und hiermit die Approximation durch
sn+1 := sn + an+1,
verbessert. Die sn sind offenbar die Partialsummen der Reihe mit den Gliedern an.
Beispiel 10.83. (Iterative Losung linearer Systeme)
Wir betrachten das lineare Gleichungssystem
Ax = b,
wobei die nichtsingulare Matrix A ∈ IR(n,n) und der Vektor b ∈ IRn gegeben sind.
Wir nehmen an, dass die Dimension n des Systems so groß ist, dass wir nicht das
Gaußsche Eliminationsverfahren anwenden konnen.
Es sei x0 eine Naherung der Losung x∗ = A−1b. Um diese zu verbessern, schatzen
wir den den Fehler x0 − x∗ durch das sogenannte Residuum
r0 := b − Ax0.
Wegen
A(x∗ − x0) = b − Ax0 = r0
kann man aus r0 eine Naherung φ0 des Fehlers x0 − x∗ berechnen, wenn man nur
eine regulare Matrix A ∈ IR(n,n) hat, die A gut approximiert und fur die man lineare
Gleichungssysteme Ay = c, c ∈ IRn, leicht losen kann.
Setzt man namlich
φ0 := A−1
r0 = A−1
A(x∗ − x0),
so wird φ0 eine umso bessere Naherung des Fehlers sein und
x1 := x0 + φ0 = x0 + A−1
A(x∗ − x0) = (E − A−1
A)x0 + A−1
Ax∗

10.6. KONVERGENZKRITERIEN FUR REIHEN 45
eine umso bessere Naherung von x∗ je naher A bei A liegt.
Wiederholt man das Verfahren, so ergibt sich
xn+1 := xn − A−1
(Axn − b).
Mit G := E − A−1
A und g := A−1
b schreibt sich dies einfacher als
xn+1 := Gxn + g,
woraus man nach den ersten Iterationen
x1 = Gx0 + g,
x2 = Gx1 + g = G2x0 + Gg + g,
x3 = Gx2 + g = G3x0 + G2g + Gg + g
induktiv schnell
xn = Gnx0 +n−1∑
i=0
Gig, n ∈ IN (10.7)
schließt. 2
Beispiel 10.84. (Geometrische Reihe)
Die wohl wichtigste Reihe ist die geometrische Reihe
∞∑
j=0
qj mit vorgegebenem q ∈ C.
Sie spielt in der Finanzmathematik eine zentrale Rolle. Wir benotigen sie vor allem,
um andere Reihen durch Vergleich mit geometrischen Reihen auf Konvergenz zu
untersuchen.
Nach Abschnitt 1.5 gilt fur die Partialsummen
sn =n∑
j=0
qj =
1 − qn+1
1 − qfur q 6= 1,
n + 1 fur q = 1.
Daher konvergiert die geometrische Reihe genau dann, wenn die Folge {qn} konver-
giert und q 6= 1 gilt, d.h. wenn |q| < 1. Fur den Grenzwert gilt in diesem Fall
∞∑
j=0
qj =1
1 − q. 2

46 KAPITEL 10. FOLGEN UND REIHEN
Beispiel 10.85. (Harmonische Reihe)
Die harmonische Reihe∞∑
j=1
1
jdivergiert, denn sicher ist die Folge der Partialsummen
sn :=n∑
j=1
1
jmonoton wachsend, und wegen
s1 = 1, s2 − s1 =1
2, s4 − s2 =
1
3+
1
4≥ 1
2, . . . ,
s2n − sn =1
n + 1+
1
n + 2+ · · · + 1
2n≥ n · 1
2n=
1
2
gilt
s2n = s1 + (s2 − s1) + (s4 − s2) + · · · + (s2n − s2n−1)
≥ 1 +1
2+
1
2+ · · · + 1
2= 1 +
n
2.
Die Folge sn ist also unbeschrankt. 2
Beispiel 10.86. Mit fast der gleichen Technik wie in Beispiel 10.85., mit der man
dort die Divergenz der harmonischen Reihe zeigte, kann man andererseits die Kon-
vergenz der Reihe∞∑
j=1
1
jafur jedes a > 1 zeigen. Die harmonische Reihe konvergiert
also”nur ganz knapp nicht“.
Sowohl schon beim Aufschreiben dieser Aussage als auch bei ihrem gleich anzuge-
henden Beweis verwenden wir schon die”allgemeine Potenz“ xα fur positive reelle
Werte von x und α, ohne dass diese fur nichtnaturliche Werte von α definiert und
untersucht worden ware. Wir erlauben uns aber einmal diesen Vorgriff, da sich die
Behandlung der angegebenen Reihe an dieser Stelle anbietet, um dem Eindruck
entgegenzuwirken, dass die harmonische Reihe etwa”ganz heftig divergiere“.
Wir benotigen hier im Vorgriff die Aussagen, dass bei dieser Verallgemeinerung der
Potenz die bekannten Potenzregeln erhalten bleiben und dass 2α > 1 fur alle α > 0
gilt. Damit konnen wir nun in die Analyse der Reihe einsteigen.
Die Folge der Partialsummen
sn :=n∑
j=1
1
ja
ist monoton wachsend. Wir haben daher nur die Beschranktheit der Folge {sn} zu
zeigen.
Es ist
s2n−1 − s2n−1−1 =1
(2n−1)a+ · · · + 1
(2n − 1)a≤ 2n−1 · 1
(2n−1)a=
(1
2a−1
)n−1
,

10.6. KONVERGENZKRITERIEN FUR REIHEN 47
und daher (mit s0 := 0 und q := 1/2a−1 < 1)
s2n−1 =n∑
j=1
(s2j−1 − s2j−1−1) ≤n∑
j=1
(1
2a−1
)j−1
=n−1∑
j=0
qj ≤ 1
1 − q,
woraus wegen der Monotonie von {sn} die Beschranktheit von {sn} folgt, also die
Konvergenz. 2
Da die Konvergenz von Reihen auf die der Partialsummen zuruckgefuhrt wird, sind
die folgenden beiden Satze 10.87. und 10.88. sofort auf entsprechende Satze fur
Folgen zuruckfuhrbar:
Satz 10.87. (Rechenregeln fur Reihen)
Konvergieren die Reihen∞∑
j=1aj und
∞∑
j=1bj und ist α ∈ IR (bzw. α ∈ C), so konver-
gieren auch die Reihen∞∑
j=1(aj + bj) und
∞∑
j=1(α aj), und es gilt
∞∑
j=1
(aj + bj) =∞∑
j=1
aj +∞∑
j=1
bj,
∞∑
j=1
(α aj) = α∞∑
j=1
aj.
Satz 10.88. (Cauchysches Konvergenzkriterium)
Es sei V ein vollstandiger normierter Vektorraum. Die Reihe∞∑
j=1aj in V konvergiert
genau dann, wenn fur alle ε > 0 ein N = N(ε) ∈ IN existiert mit
∥∥∥∥
m∑
j=n
aj
∥∥∥∥ < ε fur alle n,m ≥ N.
Bemerkung 10.89. Aus Satz 10.88. liest man unmittelbar ab, dass das Konver-
genzverhalten unverandert bleibt, wenn man endlich viele Glieder abandert; anders
als bei den Folgen wird hierdurch aber naturlich der Grenzwert geandert. 2
Setzt man im Cauchy Kriterium (Satz 10.88.) m = n, so folgt aus der Konvergenz
der Reihe∞∑
j=1aj, dass es zu jedem ε > 0 ein N ∈ IN gibt mit ‖an‖ < ε fur alle
n ≥ N . Es gilt also
Satz 10.90. (Notwendige Konvergenz-Bedingung fur Reihen)
Ist∞∑
j=1aj konvergent, so ist {an} eine Nullfolge.

48 KAPITEL 10. FOLGEN UND REIHEN
Dass die Umkehrung nicht gilt, zeigt das Beispiel 10.85. der harmonischen Reihe.
Besitzt die Reihe reelle Glieder, so kann man die Ordnungsstruktur von IR ausnutzen,
um die Konvergenz zu zeigen.
Definition 10.91. Eine reelle Reihe∞∑
j=1aj heißt alternierend , wenn die Glieder
aj wechselndes Vorzeichen haben, d.h. wenn
aj · aj+1 < 0 fur alle j ∈ IN.
gilt.
Fur alternierende Reihen gilt das folgende Leibniz13 Kriterium.
Satz 10.92. (Leibniz Kriterium)
Es sei {an} eine monoton fallende reelle Nullfolge. Dann konvergiert die alternie-
rende Reihe∑∞
j=0(−1)jaj, und fur den Grenzwert s :=∑∞
j=0(−1)jaj gilt
−a2n+1 ≤ s − s2n ≤ 0 ≤ s − s2n−1 ≤ a2n, (10.8)
also insbesondere die Einschließung
s2n−1 ≤ s ≤ s2n fur alle n ∈ IN.
Beweis: Es seien
bn :=2n−1∑
j=0
(−1)jaj und cn :=2n∑
j=0
(−1)jaj.
Dann gilt fur alle n ∈ IN
bn+1 = bn + (a2n − a2n+1) ≥ bn,
cn+1 = cn + (a2n+2 − a2n+1) ≤ cn,
cn = bn + a2n ≥ bn.
Die Folgen {bn}, {cn} bilden also eine Intervallschachtelung, und wegen cn − bn =
a2n → 0 gilt limn→∞ bn = lim
n→∞ cn. Damit existiert auch∞∑
j=0(−1)jaj, und es gilt die
Einschließung (10.8).
13Gottfried von Leibniz, 1646 - 1716, deutscher Mathematiker

10.6. KONVERGENZKRITERIEN FUR REIHEN 49
Beispiel 10.93. Die alternierende harmonische Reihe
−∞∑
j=1
(−1)j · 1
j= 1 − 1
2+
1
3− 1
4+
1
5− + · · ·
konvergiert. Fur ihre Partialsummen sn = −n∑
j=1
(−1)j · 1
jgilt
∣∣∣∣sn +
∞∑
j=1
(−1)j · 1
j
∣∣∣∣ ≤
1
n + 1.
Wir werden noch sehen, dass gilt
−∞∑
j=1
(−1)j · 1
j= ln 2. 2
Beispiel 10.94. Auf die Voraussetzung, dass die Folge {an} monoton fallt, kann
man nicht verzichten. Es sei namlich
a2n−1 :=1
nund a2n =
1
2n.
Dann divergiert die alternierende Reihe
∞∑
n=1
(−1)n+1an = 1 − 1
2+
1
2− 1
4+
1
3− 1
6+
1
4− 1
8+ −,
denn diese hat offenbar die Partialsummen
s2n =1
2
n∑
j=1
1
j. 2
Man kann den Wert einer Reihe als die Summe von unendlich vielen Elementen
auffassen. Wir fragen, ob man wie bei endlich Summen die Reihenfolge der Sum-
manden andern kann, ohne den Wert der Reihe zu verandern. Es ist klar, dass bei
Vertauschung von endlich vielen Elementen an der Konvergenz oder Divergenz der
Reihe sich nichts andert und dass der Grenzwert erhalten bleibt. Es wird sich jedoch
zeigen, dass man die Reihenfolge der Glieder einer konvergenten Reihe i.a. nicht
andern darf. Dies ist nur fur eine eingeschrankte Klasse von Reihen moglich, die
absolut konvergenten Reihen. Da die meisten Konvergenzkriterien auch gleich ab-
solute Konvergenz liefern, ist absolute Konvergenzin der Regel als der naturliche
Konvergenzbegriff anzusehen.
Definition 10.95. Die Reihe∞∑
j=1aj heißt absolut konvergent , falls die Reihe
der Normen ihrer Glieder konvergiert, d.h. falls∞∑
j=1‖aj‖ konvergent ist. Eine kon-
vergente Reihe, die nicht absolut konvergiert, heißt bedingt konvergent.

50 KAPITEL 10. FOLGEN UND REIHEN
Aus dem Cauchy Kriterium (Satz 10.88.) folgt unmittelbar
Satz 10.96. Jede absolut konvergente Reihe in einem vollstandigen normierten
Vektorraum ist konvergent.
Beweis: Ist∞∑
j=1aj absolut konvergent, so erfullt
∞∑
j=1‖aj‖ das Cauchysche Konver-
genzkriterium, und wegen
∥∥∥
m∑
j=n
aj∥∥∥ ≤
m∑
j=n
‖aj‖ fur alle n,m ∈ IN.
erfullt dann auch∞∑
j=1aj das Cauchy Kriterium. Nach Satz 10.88. ist daher
∞∑
j=1aj
konvergent.
Die Umkehrung von Satz 10.96. gilt jedoch nicht, wie die harmonische und die
alternierende harmonische Reihe zeigen.
Satz 10.97. (Kriterien fur absolute Konvergenz)
(i) Die Reihe∞∑
n=0aj ist genau dann absolut konvergent, wenn die Folge
{ n∑
j=1
‖aj‖}
n∈ IN
beschrankt ist.
(ii) Majorantenkriterium: Die Reihe∞∑
j=1bj sei konvergent, und es gelte ‖aj‖ ≤
bj fur alle j ∈ IN. Dann ist die Reihe∞∑
j=1aj absolut konvergent.
Beweis: (i): Die Folge∑n
j ‖aj‖ ist monoton wachsend und daher genau dann kon-
vergent, wenn sie beschrankt ist.
(ii): Wegen bj ≥ ‖aj‖ ≥ 0 fur j ∈ IN sind alle Glieder der Folge {bj} nichtnegativ,
und daher ist∞∑
j=1bj absolut konvergent. Nach Teil (i) ist
n∑
j=1bj beschrankt. Daher ist
auchn∑
j=1‖aj‖ ≤
n∑
j=1bj beschrankt, und nach (i) ist
∞∑
j=1aj absolut konvergent.
Bemerkung 10.98. Da die Anderung von endlich vielen Gliedern nichts an der
Konvergenz oder Divergenz an einer Reihe andert, genugt es, dass im Majoranten-
kriterium ‖aj‖ ≤ bj nur fur alle j ≥ N mit einem geeigneten N ∈ IN gilt. 2

10.6. KONVERGENZKRITERIEN FUR REIHEN 51
Beispiel 10.99. Die Reihe
∞∑
n=1
an :=∞∑
n=1
3 − 7 sin(n3)√
4√
n + n3
konvergiert absolut, denn es gilt
|an| =∣∣∣3 − 7 sin(n3)√
4√
n + n3
∣∣∣ ≤ 3 + 7| sin(n3)|
n3/2≤ 10
n3/2,
und da nach Beispiel 10.86. die Reihe
∞∑
n=1
10
n3/2
konvergiert, liefert das Majorantenkriterium die absolute Konvergenz der Ausgangs-
reihe. 2
Eine Folgerung aus dem Majorantenkriterium, die haufig leichter uberpruft werden
kann, ist das Wurzelkriterium:
Korollar 10.100. (Wurzelkriterium)
Es sei
R := lim supn→∞
n
√
‖an‖.
Dann gilt
(i) Die Reihe∞∑
n=0an konvergiert absolut, falls R < 1 gilt.
(ii) Die Reihe∞∑
n=0an divergiert, falls R > 1 gilt.
(iii) Ist R = 1, so ist keine Aussage uber die Konvergenz von∞∑
n=0an moglich.
Beweis: (i) Ist R < 1, so wahlen wir q ∈ (R, 1). Dann existiert ein N ∈ IN mit
n
√
‖an‖ ≤ q, d.h. ‖an‖ ≤ qn fur alle n ≥ N,
und da die geometrische Reihe∞∑
n=0qn konvergiert, erhalt man aus dem Majoranten-
kriterium die absolute Konvergenz der Reihe∞∑
n=0an.
(ii) Ist R > 1, so gilt ‖an‖ ≥ 1 fur unendlich viele n. Daher ist {an} keine Nullfolge,
und nach Satz 10.90. ist die Reihe∞∑
n=0an nicht konvergent.

52 KAPITEL 10. FOLGEN UND REIHEN
(iii) Wegen limn→∞
n√
n = 1 gilt
limn→∞
n
√
1
n= 1 und lim
n→∞n
√
1
n2= 1,
wobei die harmonische Reihe∞∑
n=0
1n
divergiert und die Reihe∞∑
n=0
1n2 konvergiert.
Beispiel 10.101. Die Reihe∞∑
n=0
an :=∞∑
n=0
( n
1 + n
)n2
konvergiert nach dem Wurzelkriterium, denn es gilt
limn→∞
n
√
|an| = limn→∞
( n
1 + n
)n= lim
n→∞
((
1 +1
n
)n)−1=
1
e< 1. 2
Beispiel 10.102. Wir betrachten die Reihe∞∑
n=0an mit
an :=
0.5n , falls n gerade
5 · 0.5n , falls n ungerade.
Dann gilt
n
√
|an| =
0.5 , falls n geraden√
5 · 0.5 , falls n ungerade,
und wegen limn→∞
n√
5 = 1 folgt
limn→∞
n
√
|an| = 0.5 < 1.
Das Wurzelkriterium liefert also die (absolute) Konvergenz der Reihe. 2
Noch leichter anzuwenden als das Wurzelkriterium ist haufig das nun folgende Quo-
tientenkriterium.
Korollar 10.103. (Quotientenkriterium)
Es gelte an 6= 0 fur alle n ∈ IN, und es seien
r := lim infn→∞
‖an+1‖‖an‖ und R := lim sup
n→∞
‖an+1‖‖an‖ .
Dann gilt
(i) Die Reihe∞∑
n=0an konvergiert absolut, falls R < 1 gilt.
(ii) Die Reihe∞∑
n=0an divergiert, falls r > 1 gilt.
(iii) Ist r ≤ 1 ≤ R, so ist keine Aussage uber die Konvergenz von∞∑
n=0an moglich.

10.6. KONVERGENZKRITERIEN FUR REIHEN 53
Beweis: (i) Ist R < 1, so wahlen wir q ∈ (R, 1). Dann existiert ein N ∈ IN mit
‖an+1‖‖an‖ ≤ q, d.h. ‖an+1‖ ≤ q‖an‖ fur alle n ≥ N.
Durch Induktion erhalt man
‖an‖ ≤ qn−N‖aN‖ =: Cqn,
und der Vergleich mit der geometrischen Reihe liefert die absolute Konvergenz der
Reihe∞∑
n=0an.
(ii) Ist r > 1, so gibt es ein N ∈ IN mit ‖an+1‖ ≥ ‖an‖ fur alle n ≥ N . Die Folge
{an} ist also sicher keine Nullfolge, und daher konvergiert die Reihe∞∑
n=0an nicht.
(iii) Um zu zeigen, dass im Falle r ≤ 1 ≤ R keine Entscheidung uber die Konver-
genz moglich ist, betrachten wir wieder die harmonische Reihe∞∑
n=0
1n
und die Reihe
∞∑
n=0
1n2 . Fur beide gilt r = R = 1, und die eine Reihe divergiert, wahrend die andere
konvergiert.
Beispiel 10.104. Fur jedes feste x ∈ C konvergiert die Reihe∞∑
j=0
xj
j!absolut, denn
mit aj :=xj
j!gilt
limj→∞
∣∣∣aj+1
aj
∣∣∣ = lim
j→∞
∣∣∣∣
xj+1
(j + 1)!· j!
xj
∣∣∣∣ = lim
j→∞
|x|j + 1
= 0 < 1.
Das Quotientenkriterium ist daher anwendbar.
Dieses Beispiel zeigt ubrigens erneut, dass{
xn
n!
}
eine Nullfolge ist. Wir werden
spater noch sehen, dass∞∑
j=0
xj
j!= ex
ist. Dort wird auch klar werden, daß diese Reihe wesentlich schneller konvergiert als
die Folge(
1 +x
n
)n
. 2
Beispiel 10.105.∞∑
j=1
j!
jjkonvergiert (absolut), denn mit aj :=
j!
jjgilt
∣∣∣aj+1
aj
∣∣∣ =
(j + 1)!
(j + 1)j+1· jj
j!=
jj
(j + 1)j=
1
(1 + 1j)j
−→ 1
e< 1. 2

54 KAPITEL 10. FOLGEN UND REIHEN
Beispiel 10.106.∞∑
j=1
(−1)j+1 xj
jkonvergiert fur jedes x ∈ C mit |x| < 1 absolut,
denn mit aj := (−1)j+1xj
jgilt
limj→∞
∣∣∣aj+1
aj
∣∣∣ = lim
j→∞
∣∣∣xj+1
j + 1· j
xj
∣∣∣ = |x| lim
j→∞
j
j + 1= |x| < 1.
Fur x = 1 hat man bedingte Konvergenz, fur x = −1 keine Konvergenz. Was fur
|x| = 1 aber x 6∈ {−1, 1} geschieht, konnen wir noch nicht beurteilen. 2
Bemerkung 10.107. Das Quotientenkriterium ist schwacher als das Wurzelkri-
terium in dem folgenden Sinne: Wenn das Quotientenkriterium anwendbar ist und
fur eine Reihe Konvergenz oder Divergenz liefert, so erhalt man dieses Ergebnis
auch aus dem Wurzelkriterium. Es gibt aber Reihen, bei denen das Wurzelkriterium
die Konvergenz liefert und das Quotientenkriterium versagt. Wir behandeln diese
Fragen im Aufgabenband. Hier geben wir nur ein Beispiel. 2
Beispiel 10.108. Wir betrachten erneut die Reihe∞∑
n=0an mit
an :=
0.5n , falls n gerade
5 · 0.5n , falls n ungerade
aus Beispiel 10.102. Dann gilt
an+1
an
=
5 · 0.5 , falls n gerade15· 0.5 , falls n ungerade
.
Mit den Bezeichnungen aus Korollar 10.103. gilt also
r =1
10< 1 <
5
2= R,
und das Quotientenkriterium ist nicht anwendbar, um zu entscheiden, ob die vorge-
legte Reihe konvergiert oder divergiert. In Beispiel 10.102. haben wir die Konvergenz
mit dem Wurzelkriterium erhalten. 2
Wir kommen nun auf die einleitenden Worte zur absoluten Konvergenz zuruck und
fragen nach der Sensitivitat von Reihen gegen eine Umordnung der Summationsrei-
henfolge.
Als Beispiel betrachten wir die nur bedingt konvergente alternierende harmonische
Reihe
s = 1 − 1
2+
1
3− 1
4+
1
5− 1
6+
1
7− 1
8+
1
9− 1
10+
1
11− 1
12+
1
13− + · · ·

10.6. KONVERGENZKRITERIEN FUR REIHEN 55
Dann gilt nach dem 2. Teil von Satz 10.87. die Aussage
1
2s =
1
2− 1
4+
1
6− 1
8+
1
10− 1
12+
1
14− + · · ·
und damit sicher auch
1
2s = 0 +
1
2+ 0 − 1
4+ 0 +
1
6+ 0 − 1
8+ 0 +
1
10+ 0 − 1
12+ 0 + · · · .
Durch elementweise Addition der alternierenden harmonischen Reihe zu der letzten
Reihe ergibt sich mit dem ersten Teil von Satz 10.87. das Resultat
3
2s = 1 + (
1
3− 1
2+
1
5) + (
1
7− 1
4+
1
9) + (
1
11− 1
6+
1
13) +
1
15− + · · ·
= 1 +∞∑
j=1
( 1
4j − 1− 1
2j+
1
4j + 1
)
.
Erstaunlicherweise stehen rechts wieder die Glieder der alternierenden harmonischen
Reihe, allerdings in anderer Reihenfolge. Hieraus kann man nur schließen, daß durch
Umordnung der Glieder der Reihe der Grenzwert geandert wird.
Wir untersuchen die Umordnung von Reihen, d.h. die Anderung der Reihenfolge der
Glieder einer Reihe genauer.
Definition 10.109. Ist f : IN → IN bijektiv, so heißt die Reihe∑∞
n=1 bn mit
bn := af(n) ein Umordnung der Reihe∑∞
n=1 an.
Satz 10.110. Ist die Reihe∑∞
n=1 an absolut konvergent mit dem Grenzwert s, so
konvergiert jede Umordnung∑∞
n=1 bn, bn := af(n), ebenfalls absolut gegen s.
Beweis: Wegen der absoluten Konvergenz der Reihe∞∑
n=0an gibt es zu ε > 0 ein
N ∈ IN mitm∑
j=n
‖aj‖ < ε fur alle n,m ≥ N. (10.9)
Es sei
M := max{f−1(j) : 1 ≤ j ≤ N} + 1.
Dann gilt f(j) > N fur alle j ≥ M , und daher folgt aus (10.9)
m∑
j=n
‖af(j)‖ < ε fur alle n,m ≥ M.
Damit ist die gleichmaßige Konvergenz der umgeordneten Reihe gezeigt.

56 KAPITEL 10. FOLGEN UND REIHEN
Wir zeigen nun, dass durch Umordnung der Grenzwert nicht geandert wird. Es seien
sn :=n∑
j=1
aj und tn :=n∑
j=1
af(j)
die Partialsummen der Originalreihe und der umgeordneten Reihe. Dann gilt nach
der Dreiecksungleichung
‖s − tn‖ ≤ ‖s − sn‖ + ‖sn − tn‖,
und wegen ‖s − sn‖ → 0 fur n → ∞ bleibt nur noch ‖sn − tn‖ → 0 fur n → ∞ zu
zeigen.
Es sei m(n) := min{j : j 6∈ {f(1), . . . , f(n)}} der kleinste Index, der in der Differenz
sn − tn =n∑
j=1
aj −n∑
j=1
af(j)
der endlich Summen sn und tn auftritt. Dann gilt m(n) ≥ N fur n ≥ M (wobei N
und M wie im ersten Teil bestimmt sind), und daher folgt
‖sn−tn‖ =∥∥∥
n∑
j=1
aj−n∑
j=1
af(j)∥∥∥ ≤
max f(j)∑
j=m(n)
‖aj‖ < ε fur n ≥ M.
Fur bedingt konvergente Reihen mit reellen Gliedern gilt das folgende Resultat, das
wir ohne Beweis angeben und das zeigt, dass fur diese Reihen genau die absolut
konvergenten Reihen beliebig umgeordnet werden konnen, ohne die Konvergenz zu
storen und ohne den Grenzwert zu andern.
Satz 10.111. (Riemann) Es sei∑∞
n=1 an eine bedingt konvergente Reihe mit re-
ellen Gliedern, und es seien x, y ∈ IR ∪ {∞,−∞} gegeben mit x ≤ y.
Dann gibt es eine Umordnung∑∞
n=1 bn der Reihe∑∞
n=1 an mit folgender Eigenschaft:
Bezeichnet tn :=∑n
j=1 bj die n–te Partialsumme von∑∞
n=1 bn, so gilt
lim infn→∞ tn = x, lim sup
n→∞tn = y.
Insbesondere kann diese Reihe also so umgeordnet werden, dass sie jeden gewunsch-
ten Grenzwert annimmt.

10.6. KONVERGENZKRITERIEN FUR REIHEN 57
Beweis: s. Gaskill—Narayanaswami [7, p. 357].
Wir wenden uns nun der Multiplikation unendlicher Reihen mit reellen oder kom-
plexen Gliedern zu. Fur das Produkt endlicher Summen gilt( n∑
i=0
ai
)
·( m∑
j=0
bj
)
=n∑
i=0
m∑
j=0
aibj.
Diese Formel lasst sich auf unendliche Reihen ubertragen, falls beide Faktoren ab-
solut konvergieren:
Satz 10.112. Sind∞∑
i=0
ai und∞∑
j=0
bj absolut konvergente Reihen mit reellen oder
komplexen Gliedern, so gilt( ∞∑
i=0
ai
)
·( ∞∑
j=0
bj
)
=∞∑
i=0,j=0
aibj, (10.10)
wobei die Indizes in der rechten Summe alle Paare
(0, 0) (0, 1) (0, 2) (0, 3) · · ·(1, 0) (1, 1) (1, 2) (1, 3) · · ·(2, 0) (2, 1) (2, 2) (2, 3) · · ·. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
in irgendeiner Reihenfolge durchlaufen.
Beweis: Ist sn =:n∑
k=1pk die n-te Partialsumme der rechten Seite von (10.10) (bei
fest gewahlter Indexfolge) und m das Maximum der in der endlichen Summe sn
auftretenden Indizes i und j (m := max{i, j : ai · bj = pk, k = 1, . . . , n}), so gilt
|sn| ≤n∑
j=1
|pj| ≤m∑
i=0
m∑
j=0
|aibj| =( m∑
i=0
|ai|) ( m∑
j=0
|bj|)
≤( ∞∑
i=0
|ai|) ( ∞∑
j=0
|bj|)
.
Es ist alson∑
j=0|pj| beschrankt, nach Satz 10.97.(i) ist sn absolut konvergent, und
nach Satz 10.110. konvergiert die rechte Seite von (10.10) fur jede Anordnung der
Indizes, wobei der Grenzwert s unabhangig von der Anordnung der Indizes ist.
Es sei nun∞∑
k=1qk =
∞∑
i,j=0aibj, wobei die Indexfolge so gewahlt ist:
1 2 5 10...
4 3 6 11...
9 8 7 12...
16 15 14 13...
. . . . . . . . . . . . . . . .. . .

58 KAPITEL 10. FOLGEN UND REIHEN
Dann gilt
q1 + q2 + · · · + q(n+1)2 = (a0 + · · · + an) (b0 + · · · + bn)
→( ∞∑
i=0
ai
) ( ∞∑
j=0
bj
)
,
und nach dem ersten Teil∞∑
k=1qk = s, zusammen also (10.10).
Haufig ist es bequem, die Indizes langs der Diagonalen anzuordnen:
1 3 6 10
2 5 9. . .
4 8. . .
7. . .
Definition 10.113. Die entstehende Summe
∞∑
i=0
( i∑
j=0
aj bi−j
)
heißt Cauchy-Produkt der Reihen∑∞
j=0 aj und∑∞
j=0 bj.
Aus Satz 10.112. folgt
Korollar 10.114. Es seien∞∑
i=0ai und
∞∑
j=0bj absolut konvergente Reihen mit reellen
oder komplexen Gliedern. Dann konvergiert auch das Cauchy-Produkt
( ∞∑
i=0
ai
) ( ∞∑
j=0
bj
)
=∞∑
i=0
( i∑
j=0
aj bi−j
)
.
Beispiel 10.115. Es sei ai =xi
i!, bj =
yj
j!mit x, y ∈ C. Dann gilt nach dem
binomischen Satz (Satz 1.19.)
( ∞∑
i=0
xi
i!
) ( ∞∑
j=0
yj
j!
)
=∞∑
i=0
( i∑
j=0
xj
j!· yi−j
(i − j)!
)
=∞∑
i=0
(1
i!
i∑
j=0
(ij
)
xj yi−j)
=∞∑
i=0
(x + y)i
i!;
bezeichnet also f : C → C die Funktion f(x) :=∞∑
i=0
xi
i!, so gilt fur alle x, y ∈ C
f(x + y) = f(x) · f(y). (10.11)
2

Kapitel 11
Stetige Funktionen
11.1 Motivation und Definition
Wir betrachten in diesem Abschnitt stetige Funktionen. In der Schule arbeitet man
haufig mit der”Charakterisierung“, daß man den Graphen einer stetigen Funktion
(IR → IR) skizzieren kann, ohne dabei den Stift abzusetzen.
Diese Vorstellung ist nicht schlecht und ganz nutzlich, wenn es z.B. darum geht
einzusehen, daß eine zwischen x1 und x2 stetige Funktion f mit einem positiven
Funktionswert f(x1) > 0 und einem negativen Funktionswert f(x2) < 0 zwischen x1
und x2 eine Nullstelle besitzt. Der Stift, der (ohne Absetzen) vom Punkt (x1, f(x1))
mit positivem Funktionswert zum Punkt (x2, f(x2)) mit negativem Funktionswert
fahrt, wird namlich (mindestens einmal) die x-Achse kreuzen mussen.
Leider konnen wir uns diese anschauliche Beschreibung von Stetigkeit aus minde-
stens drei Grunden nicht als Definition zu eigen machen: Erstens betrachten wir
nicht nur Funktionen von reellen Intervallen in die reellen Zahlen, zweitens ist die
obige geometrische Veranschaulichung dem Kalkul unzuganglich, und drittens ist
Stetigkeit eine lokale Eigenschaft, die Funktionen an einzelnen Punkten zukommt,
wahrend die Veranschaulichung sich immer auf den Graphen der Funktion uber
einem Intervall bezieht.
Es gibt mehrere aquivalente analytische Definitionen der Stetigkeit von Funktionen.
Jede fuhrt zu einer eigenen Sicht von Stetigkeit, die jeweils in bestimmten Situatio-
nen besonders hilfreich ist. Zwei von ihnen werden wir hier behandeln.

60 KAPITEL 11. STETIGE FUNKTIONEN
Definition 11.1. Es seien V und W normierte Vektorraume und f : D → W ,
D ⊂ V , eine Abbildung.
(i) f heißt stetig in x0 ∈ D, wenn fur jede Folge {xn} ⊂ D mit limn→∞xn = x0 gilt
limn→∞
f(xn) = f(x0).
(ii) f heißt stetig in D, wenn f stetig in jedem Punkt x0 ∈ D ist.
(iii) f heißt unstetig in x0 ∈ D, wenn f in x0 nicht stetig ist.
Bemerkung 11.2. Beachten Sie, daß in der Definition der Stetigkeit nicht fur
nur eine Folge {xn} mit limn→∞xn = x0 die Konvergenz der Bildfolge {f(xn)} gegen
den Funktionswert f(x0) gefordert wird, sondern daß dies fur jede Folge {xn} mit
limn→∞xn = x0 gelten soll. 2
Bemerkung 11.3. Die Fortsetzung der Addition und der Multiplikation von der
Menge der rationalen Zahlen auf die Menge der reellen Zahlen (vgl. Bemerkung 10.48.)
wird gerade so durchgefuhrt, dass die Abbildungen
+
IR × IR → IR
(a, b) 7→ a + b, ·
IR × IR → IR
(a, b) 7→ a · b
stetig sind.
Eine beliebige Funktion f : IR → IR konnen wir genau dann an einer Stelle x0 mit
Hilfe einer approximierenden Folge {xn}, limn→∞xn = x0, durch f(x0) = lim
n→∞ f(xn)
auswerten, wenn f an der Stelle x0 stetig ist. 2
Beispiel 11.4. Wir betrachten die Dirichletsche1 Sprungfunktion
χQ(x) :=
0 falls x irrational ist,
1 falls x rational ist,
die manches Vorurteil uber Funktionen widerlegen hilft.
— Erstens mussen sich Funktionen nicht grundsatzlich durch geschlossene Aus-
drucke wie f(x) = 3x2 + sin(x) beschreiben lassen. Fur die Praxis wichtig ist
z.B. die stuckweise Definition, bei der eine Funktion auf verschiedenen Teilen
des Definitionsbereichs durch verschiedene Ausdrucke definiert ist. Bei einem
Werkstuck aus mehreren Materialien finden Sie an den Materialgrenzen ganz
naturliche Wechsel der Beschreibungen solch praxisrelevanter Funktionen wie
z.B. der Dichte oder der elektrischen Leitfahigkeit.
1Johan Peter Gustav Lejeune Dirichlet, 1805 - 1859, deutscher Mathematiker

11.1. MOTIVATION UND DEFINITION 61
— Zweitens ist es moglich, dass limn→∞ f(xn) = f(x0) fur manche Folgen {xn} ⊂D mit limn→∞ xn = x0 gilt und fur andere nicht. Betrachtet man namlich etwa
x0 = 0 mit χQ(x0) = 1 und die durch xn = n−1 definierte gegen x0 konvergente
Folge, so ist
limn→∞χQ(xn) = lim
n→∞ 1 = 1 = χQ(x0).
Fur die ebenfalls gegen Null konvergente Folge mit Elementen yn = n−1π hat
man allerdings
limn→∞χQ(yn) = lim
n→∞ 0 = 0 6= χQ(x0).
Dies zeigt die Wichtigkeit von Bemerkung 11.2..
— Drittens konnen Funktionen an beliebig vielen Stellen unstetig sein. Die Funk-
tion χQ ist sogar in keinem Punkt x ∈ IR stetig, denn die Unstetigkeit in 0
haben wir schon gezeigt, und fur alle anderen x kann man analog argumentie-
ren. 2
Beispiel 11.5. Die Funktion f : IR → IR, f(x) := 19.97 ist sicher stetig in allen
Punkten. Da Sie uberall den konstanten Wert 19.97 hat, wird der Funktionswert
f(x0) eines jeden Punktes auch durch die Funktionswertefolge {f(xk)} zu jeder x0
approximierenden Folge {xk} richtig vorausgesagt. 2
Beispiel 11.6. f : IR → IR, f(x) := x, ist sicher stetig in allen Punkten x0 ∈ IR,
denn ist {xn} irgendeine Folge mit limn→∞xn = x0, so gilt
limn→∞ f(xn) = lim
n→∞xn = x0 = f(x0). 2
Beispiel 11.7. Die stuckweise definierte Heaviside2-Funktion
h(x) :=
0 fur x < 0,
1 fur x ≥ 0,
(vgl. Abbildung 11.1, links) ist stetig fur alle reellen Punkte x 6= 0 und unstetig in
x = 0.
Fur x0 > 0 sind namlich alle bis auf endlich viele Elemente einer x0 approximie-
renden Folge {xn} auch positiv, so daß sie mit x0 den Funktionswert 1 erhalten
und die Bildfolge {h(xn)} somit gegen h(x0) konvergiert. Fur negatives x0 schließt
man analog. Fur x0 = 0 ist der Funktionswert dagegen h(0) = 1, wobei aber
limn→∞h(−n−1) = 0 6= 1 = h(x0) ist. 2
2Oliver Heaviside, 1850 - 1925, englischer Elektroingenieur
62 KAPITEL 11. STETIGE FUNKTIONEN
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1−0.2
0
0.2
0.4
0.6
0.8
1
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2
0
1
2
3
4
5
6
7
8
9
10
Abbildung 11.1: Bei 0 unstetige Funktionen
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Abbildung 11.2: Graph von f(x) = sin 1x
Beispiel 11.8. Die durch
p(x) :=
x−2 fur x 6= 0,
0.9876 fur x = 0,
definierte Funktion (vgl. Abbildung 11.1, rechts) ist in Null nicht stetig, denn fur
jede gegen Null konvergente Folge {xn} konvergiert {p(xn)} uneigentlich gegen +∞.
Die Stetigkeit von p(x) in allen von Null verschiedenen Werten werden wir etwas
weiter unten ganz leicht sehen konnen. 2
Beispiel 11.9.
f : IR → IR, f(x) :=
sin 1x
fur x 6= 0,
0 fur x = 0,

11.1. MOTIVATION UND DEFINITION 63
(vgl. Abbildung 11.2) ist nicht stetig in x0 = 0. Es gilt zwar fur die durch xn = 1nπ
definierte Nullfolge
limn→∞ f(xn) = lim
n→∞ sin(nπ) = 0 = f(0),
aber andererseits hat man fur die Folge xn := ((2n + 12)π)−1 das Ergebnis
f(xn) = sin(2n +1
2)π = sin
π
2= 1 6→ f(0) = 0.
Die Stetigkeit der Funktion konnen wir in (den meisten) anderen Punkten erst ana-
lysieren, wenn wir eine analytische Beschreibung von sin(x) zur Verfugung gestellt
haben. 2
Nach diesen einfachen Beispielen wollen wir jetzt verdeutlichen, daß die getroffene
Definition der Stetigkeit auch geeignet ist, die Vorstellung “Skizzierbarkeit ohne
Absetzen“ fur reelle Funktionen zu ersetzen, wenn dort die Existenz einer Nullstelle
aus einem Vorzeichenwechsel geschlossen wird:
Satz 11.10. Es sei f : IR ⊃ [a, b] → IR stetig. Gilt f(a) · f(b) < 0, so gibt es ein
ξ ∈ (a, b) mit f(ξ) = 0.
Beweis: Aus a0 := a und b0 := b mit f(a0) · f(b0) < 0 konstruiert man mit dem
Bisektionsverfahren induktiv eine Intervallschachtelung
an ≤ an+1 ≤ bn+1 ≤ bn mit bn − an = 2−n(b0 − a0) (11.1)
und f(an) · f(bn) ≤ 0 sowie
f(a0) · f(an) ≥ 0 und f(a0) · f(bn) ≤ 0 (11.2)
fur alle naturlichen n. Analog Beispiel 10.1. geht man dazu wie folgt vor:
Sind bereits an, bn ∈ [a, b] mit f(an)·f(bn) ≤ 0 bekannt, so setze man cn :=1
2(an+bn)
und
an+1 :=
an
cn
, bn+1 :=
cn falls f(an) · f(cn) ≤ 0,
bn sonst.
Aus (11.1) folgt, daß die Folgen {an} und {bn} gegen einen gemeinsamem Grenzwert
ξ ∈ [a, b] konvergieren. Da f in [a, b] und damit auch in ξ stetig ist, konvergieren die
Folgen der Funktionswerte {f(an)} und {f(bn)} beide gegen f(ξ). Aus (11.2) folgt
dann
f(ξ) · f(a0) = limn→∞ f(bn) · f(a0) ≤ 0 ≤ lim
n→∞ f(an) · f(a0) = f(ξ) · f(a0).

64 KAPITEL 11. STETIGE FUNKTIONEN
Wegen f(a0) 6= 0 hat dies f(ξ) = 0 zur Folge, und wegen f(a) 6= 0 6= f(b) gilt
ξ ∈ (a, b).
Fur den Konvergenznachweis zusammengesetzter Folgen haben wir Rechenregeln
(Satz 10.26. und Satz 10.55.) gefunden. Die Anwendung dieser Regeln auf die bei
der Stetigkeitsdefinition zu betrachtenden Folgen liefert entsprechende Regeln fur
den Stetigkeitsnachweis zusammengesetzter Funktionen.
Satz 11.11. (i) Es seien f, g : D → W stetig in x0 ∈ D (in D) und λ ∈ IR
oder λ ∈ C. Dann sind auch f + g und λ · f stetig in x0 (in D).
(ii) Es sei f : V ⊃ D → W stetig in x0 ∈ D (in D) und g : W ⊃ D → Z
stetig in f(x0) ∈ D ⊃ f(D) (in D). Dann ist die Hintereinanderausfuhrung
g ◦ f : D → Z stetig in x0 (in D).
(iii) Es sei W = IR oder W = C und seien f, g : D → W stetig in x0 ∈ D (in
D). Dann ist auch f · g stetig in x0 (in D). Gilt f(x0) 6= 0 (f(x) 6= 0 fur alle
x ∈ D), so ist auch1
fstetig in x0 (in D).
Beweis: Die erste und letzte Aussage sind direkte Folgerungen aus Satz 10.26.
und Satz 10.55. Fur den Beweis der zweiten Aussage sei {xk} ⊂ D eine gegen x0
konvergente Folge. Wegen der Stetigkeit von f in x0 ist dann f(x0) Grenzwert der
Folge {f(xk)}, die wegen der Voraussetzung von f(D) ⊂ D im Definitionsbereich
von g liegt.
Wegen der Stetigkeit von g in f(x0) folgt aus f(xk) → f(x0), daß die Folge {g(f(xk))}gegen g(f(x0)) konvergiert. Damit gilt
(g ◦ f)(xk) → (g ◦ f)(x0) fur alle Folgen xk → x0,
was die Stetigkeit von g ◦ f in x0 bedeutet.
Beispiel 11.12. Da f : C → C, f(x) ≡ 1, und g : C → C, g(x) = x, offensicht-
lich stetig sind, folgert man mit der dritten Aussage des letzten Satzes induktiv, daß
alle Potenzfunktionen pj(x) := xj in C stetig sind. Nach dem ersten Teil des Satzes
sind damit auch die Summanden eines jeden Polynoms
p(x) :=n∑
j=0
ajxj, aj ∈ C,
stetig und damit schließlich (wiederum induktiv) auch das gesamte Polynom als
Summe solcher stetigen Funktionen . 2

11.1. MOTIVATION UND DEFINITION 65
Beispiel 11.13. Jede rationale Funktion
f(x) :=
∑nj=0 ajx
j
∑mj=0 bjxj
ist in jedem Punkt x0 stetig, in dem der Nenner von Null verschieden ist, denn sie
ist der Quotient zweier dort stetiger Funktionen. Nach dem dritten Teil des letzten
Satzes ist dieser Quotient stetig, wo der Nenner von Null verschieden ist.
Insbesondere ist die Funktion
p(x) :=
x−2 fur x 6= 0,
0.9876 fur x = 0,
aus Beispiel 11.8. in allen Punkten x 6= 0 stetig. 2
Beispiel 11.14. Nach Satz 10.58. ist jede Wurzelfunktion f : IR+ → IR+, f(x) :=m√
x, stetig in IR+. Wegen Satz 11.11.(ii) ist dann die rationale Potenz-Funktion
x 7→ xq fur alle q ∈ Q stetig auf IR+. 2
Beispiel 11.15. Polynome in mehreren Variablen
f(x1, . . . , xn) =m1∑
i1=0
m2∑
i2=0
· . . . ·mn∑
in=0
ai1,...,inxi11 · . . . · xin
n
sind stetig in IRn (oder Cn).
Diese lassen sich namlich mit den Rechenregeln des letzten Satzes aus den einfachen
Funktionen n(x1, . . . , xn) ≡ 1 und wi(x1, . . . , xn) := xi, i = 1, . . . , n kombinieren,
welche wiederum sehr leicht als stetig in ganz IRn (bzw. Cn) erkannt werden. 2
Beispiel 11.16. Sind fi(x) = fi(x1, x2, . . . , xn), i = 1, . . . ,m, stetige Funktionen
auf einer Menge D ⊂ IRn, so ist durch
f(x) :=
f1(x1, . . . , xn)...
fm(x1, . . . , xn)
eine stetige Abbildung von D nach IRm bestimmt. Die Funktionen fi, i = 1, . . . ,m,
nennt man auch die Komponentenfunktionen von f .
Die Vektorfunktion f ist mit ihren Komponentenfunktionen stetig, weil aus xk →x0 wegen der Stetigkeit der Komponentenfunktionen fi(x
k) → fi(x0) fur alle i =
1, . . . ,m folgt und dies gerade f(xk) → f(x0) bedeutet.
Insbesondere sind affin lineare Abbildungen f : IRn → IRm, f(x) := Ax + b mit
A ∈ IR(m,n) und b ∈ IRm stetig auf IRn. 2

66 KAPITEL 11. STETIGE FUNKTIONEN
Typische Unstetigkeitsstellen reeller Funktionen sind Sprungstellen (wie z.B. der
Punkt Null bei der Heaviside Funktion im linken Graphen von Abbildung 11.1 auf
Seite 62), Polstellen (rechter Graph von Abbildung 11.1) oder Oszillationsstellen
wie bei sin1
x(siehe Abbildung 11.2).
Sehr haufig sind in den Natur- und Ingenieurwissenschaften auftretende Funktionen
sogar uberall stetig. Falls allerdings doch Unstetigkeiten auftreten, so sind diese fur
die Funktion und den dadurch beschriebenen Sachverhalt meist sehr wichtig und
strukturbestimmend.
Beispiel 11.17. Gerat bei der Echoloterfassung der Hohe des Meeresgrundes ein
Fischschwarm in den Erfassungsstrahl, so springt die ermittelte Hohe am Anfang des
Schwarmes um die Schwimmhohe des Schwarmes uber Meeresgrund und fallt ebenso
plotzlich am Ende des Schwarmes wieder ab. Die beiden Sprungstellen markieren
damit Grenzen einer interessanten Einheit. Die Begrenzung von Einheiten durch
niedrigdimensionale Mengen, bei deren Uberquerung charakteristische Funktionen
springen, findet man sehr haufig.
In der Mathematik definiert man als charakteristische Funktion einer Menge
M ⊂ IRn die Funktion
χM(x) :=
0 falls x 6∈ M
1 falls x ∈ M2

11.1. MOTIVATION UND DEFINITION 67
Beispiel 11.18. (von Mises Stabwerk)Belastet man das von Mises Stabwerk
in der Abbildung 11.3 mit wachsender
Last P , so verandert sich die Lage des
Punktes A zunachst stetig. Bei der kri-
tischen Last P1 schlagt das Stabwerk
jedoch durch, und die Funktion, die je-
der Last P die Hohe von A zuordnet,
hat in P1 eine Sprungstelle. Abbildung 11.3
Beachten Sie, daß die Zuordnung
Last −→ Lage A
von der”Geschichte des Stabwerks
abhangt“. Entlastet man namlich das
Stabwerk bis zur Null-Last und erhoht
danach die Last in umgekehrter Rich-
tung, so erhalt man eine zweite Sprung-
stelle bei einer anderen kritischen Last
P2 und also auch einen anderen Verlauf
des Graphen.
−0.5 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5
−1
−0.5
0
0.5
1
y
PP1
P2
Abbildung 11.4
Zwischen den Lasten P1 und P2 ist die Zuordnung somit nicht eindeutig definiert
und deshalb eigentlich gar keine Funktion. Nur unter zusatzlicher Kenntnis des Ge-
schichte kann die Zuordnung durch eine Funktion dargestellt werden.
Es ist klar, daß der Anwender ganz besonders an den Sprungstellen interessiert ist,
weil diese plotzliche Anderungen des Systems signalisieren. In komplexeren Syste-
men konnen Unstetigkeiten Ereignisse anzeigen wie etwa das Zusammenbrechen von
Brucken oder anderen Bauwerken bei Uberschreiten von Grenzlasten, die Explosion
von Reaktoren bei Uberschreiten kritischer Betriebstemperaturen, das Heraussprin-
gen von Eisenbahnradern aus den Schienen bei Uberschreiten einer Grenzgeschwin-
digkeit, das plotzliche Kentern eines Schiffes bei Erreichen einer kritischen Krangung,
usw. 2
Der folgende Satz 11.19. enthalt eine weitere Charakterisierung der Stetigkeit, die
haufig als Definition verwendet wird und dann meist als ε-δ-Definition bezeichnet
wird.

68 KAPITEL 11. STETIGE FUNKTIONEN
Satz 11.19. f : D → W ist genau dann stetig in x0 ∈ D, wenn gilt:
Fur alle ε > 0 gibt es ein δ > 0, so dass
‖f(x) − f(x0)‖ < ε fur alle x ∈ D mit ‖x − x0‖ < δ.
}
(11.3)
Bemerkung 11.20.Ist x eine gemessene Große und wird
hieraus die Ausgangsgroße y = f(x)
berechnet, so besagt die Stetigkeit von
f in x0 gerade, dass es zu jeder To-
leranz ε > 0 fur die Ausgangsgroße
y0 = f(x0) eine Messgenauigkeit δ > 0
gibt, so dass ein Fehler von hochstens δ
bei der Messung x von x0 zu einem Feh-
ler ‖f(x) − f(x0)‖ der Ausgangsgroße
fuhrt, der hochstens ε ist.
δ δ
εε
Abbildung 11.5
Wahrend die erste Definition der Stetigkeit auf die Voraussagbarkeit des Funkti-
onswertes an der Stetigkeitsstelle durch die Funktionswerte auf approximierenden
Folgen zielte, hat die alternative Definition durch (11.3) die Kontrollierbarkeit des
Ausgabe-Fehlers (Output) durch den Eingabe-Fehler (Input) im Auge.
Naturlich sind beide Definitionen aquivalent (das sagt ja gerade der Satz), aber jede
der Versionen hat fur bestimmte Ziele ihre jeweiligen Vor- oder Nachteile. 2
Beweis: (von Satz 11.19.)
Es gelte (11.3) und es sei {xn} ⊂ D eine Folge mit limn→∞
xn = x0. Wir haben zu zeigen,
daß dann auch limn→∞ f(xn) = f(x0) ist. Fur das letztere haben wir zu vorgegebenem
ε > 0 die Existenz eines Index N ∈ IN nachzuweisen mit ‖f(xn) − f(x0)‖ < ε fur
alle n ≥ N .
Nach (11.3) gibt es aber zu dem vorgegebenem ε ein δ > 0, so daß die gewunschte
Ungleichung ‖f(xn) − f(x0)‖ < ε fur alle xn gilt, die ‖xn − x0‖ < δ erfullen. Da
die Folge {xn} gegen x0 konvergiert, gibt es aber sicher einen Index M , so daß
‖xn − x0‖ < δ fur alle n > M ist. Wahlen wir nun N := M so haben wir unser Ziel
erreicht.
Die Umkehrung zeigen wir indirekt: Es sei f stetig in x0, und es gelte nicht die
Eigenschaft (11.3). Dann gibt es ein ε > 0, so dass fur alle δ > 0 ein x(δ) ∈ D
existiert mit ‖x(δ) − x0‖ < δ aber ‖f(x(δ)) − f(x0)‖ ≥ε.

11.1. MOTIVATION UND DEFINITION 69
Wir wahlen nun eine Folge von δ-Werten δn := 1n, n ∈ IN, und zu jedem n ∈ IN das
Folgenelement xn := x(δn) ∈ D. Dann gilt
‖xn − x0‖ < 1n
und ‖f(xn) − f(x0)‖ ≥ ε, d.h.
limn→∞xn = x0 und lim
n→∞ f(xn) 6= f(x0)
im Widerspruch zur Stetigkeit von f in x0.
Beispiel 11.21. Wir verwenden die ε-δ-Charakterisierung, um die Stetigkeit der
reellen Funktion q(x) := x2 in jedem Punkt x0 ∈ IR nachzuweisen. Es ist dafur zu
zeigen, daß zu jedem vorgegebenen ε > 0 ein δ > 0 existiert, so daß aus |x− x0| < δ
die Ungleichung |q(x) − q(x0)| < ε folgt. Dies soll hier einmal ganz langsam und
ausfuhrlich geschehen.
Wegen
|q(x) − q(x0)| = |x + x0| · |x − x0| ≤ |x + x0| · δ (11.4)
fur |x−x0| < δ erreichen wir sicher unser Ziel, wenn fur |x−x0| < δ die rechte Seite
von (11.4) kleiner ε wird. Sicher konnen wir
|x + x0|δ < ε
erreichen, wenn δ abhangig von ε hinreichend klein gewahlt und wenn der Vorfaktor
|x + x0| dabei nicht groß wird. Diesen konnen wir im Falle |x − x0| < δ durch
|x + x0| ≤ |x − x0 + 2x0| ≤ |x − x0| + 2|x0| < δ + 2|x0|
abschatzen. Um uns nicht weiter mit dem δ in diesem Ausdruck herumargern zu
mussen, nehmen wir nun einfach an, daß δ auf keinen Fall großer als 1 gewahlt wird.
Dann gilt
|x + x0|δ < (2|x0| + 1)δ
und wir erreichen |x + x0|δ < ε offenbar fur
δ ≤ min
{
1,ε
2|x0| + 1
}
,
wobei die Minimumbildung der zwischenzeitlich benotigten Annahme Rechnung
tragt, daß δ ≤ 1 sein soll. 2
Beispiel 11.22. Die in Beispiel 11.7. schon behandelte Heaviside Funktion
h(x) :=
0 fur x < 0,
1 fur x ≥ 0,

70 KAPITEL 11. STETIGE FUNKTIONEN
ist nicht stetig in 0, denn wie klein man auch immer δ > 0 wahlt, immer gibt es eine
Zahl xδ mit |0−xδ| < δ ( namlich z.B. xδ := −δ/2), fur die |h(0)−h(xδ)| = |1−0| = 1
gilt. Wahlt man also ε ∈ (0, 1), so kann man hierzu kein positives δ finden, so dass
|h(x) − h(0)| < ε fur alle x mit |x − 0| < δ
gilt. Der Ausgangsfehler kann daher nicht durch Verkleinerung des Eingangsfehlers
beliebig klein gemacht werden. 2
11.2 Eigenschaften stetiger (reeller) Funktionen
In diesem Abschnitt leiten wir globale Eigenschaften von Funktionen her, welche
aus der Stetigkeit der Funktion in ihrem Definitionsbereich resultieren.
Der kontinuierliche Zusammenhang des Graphen einer stetigen reellen Funktion,
welchen wir anfangs als Veranschaulichung der Stetigkeit aus der Schulmathematik
zitierten, ist eine solche globale Eigenschaft. Mathematisch formuliert man diesen
Zusammenhang als den folgenden Zwischenwertsatz.
Satz 11.23. (Zwischenwertsatz)
Es sei f : [a, b] → IR stetig. Gilt
f(a) < c < f(b) oder f(b) < c < f(a),
so gibt es ein ξ ∈ (a, b) mit f(ξ) = c.
Eine stetige Funktion nimmt also jeden
Wert zwischen f(a) und f(b) an.
Beweis: Der Beweis folgt unmittel-
bar aus Satz 11.10., wonach die stetige
Funktion g(x) := f(x)− c in (a, b) eine
Nullstelle hat.
ξ ξ ξ
Abbildung 11.6
Wir fragen nun nach der Stetigkeit der Umkehrfunktion einer stetigen Funktion. An-
schaulich ist diese klar, wenn wir uns auf das Schulwissen berufen, daß der Graph der
Umkehrfunktion durch Spiegelung an der Winkelhalbierenden (d.h. dem Graphen
von f(x) = x) entsteht.
Um dieses Ergebnis prazise fassen zu konnen, brauchen wir noch eine Definition.

11.2. EIGENSCHAFTEN STETIGER (REELLER) FUNKTIONEN 71
Definition 11.24. Sei D ⊂ IR. Dann heißt f : D → IR monoton wachsend,
wenn fur alle x1, x2 ∈ D die Implikation
x1 < x2 ⇒ f(x1) ≤ f(x2)
gilt. Steht dabei zwischen f(x1) und f(x2) das echte <-Zeichen, so heißt f streng
monoton wachsend.
Analog heißt f monoton fallend bzw. streng monoton fallend , wenn an dieser
Stelle das ≥- bzw. >-Zeichen steht.
Bemerkung 11.25. Eine streng monoton wachsende oder streng monoton fallen-
de Funktion f : IR ⊃ D → IR ist sicher injektiv, da in beiden Fallen verschiedene
Argumente nicht auf gleiche Funktionswerte abgebildet werden konnen. Ihre Um-
kehrfunktionen f−1 existiert dann auf dem Bild f(D).
Man beachte aber, daß das Wort streng hier nicht vergessen werden darf. Die kon-
stante Funktion f : IR → 1 ist sowohl monoton wachsend als auch monoton fallend,
sie ist aber sicher nicht injektiv. 2
Satz 11.26. Sei I ⊂ IR ein Intervall. Ist f : I → IR stetig und streng monoton
wachsend (oder fallend), so ist f(I) ein Intervall, und f−1 : f(I) → IR ist stetig
und streng monoton wachsend (fallend).
Beweis: Wir betrachten nur den Fall des monotonen Wachsens. Die Injektivitat
von f und die Existenz der inversen Funktion auf f(I) ist uns aus der letzten Be-
merkung bekannt.
Wegen des Zwischenwertsatzes ist f(I) ein Intervall. Die strenge Monotonie von f−1
zeigen wir durch indirekten Beweis. Gabe es namlich y1, y2 ∈ f(I) mit y1 < y2 und
f−1(y1) ≥ f−1(y2), so folgte durch Anwendung von f auf die letzte Ungleichung der
Widerspruch y2 = f(f−1(y2)) ≤ f(f−1(y1)) = y1.
Zu zeigen bleibt die Stetigkeit von f−1. Wir konnen o.B.d.A. annehmen, dass I
offen ist, denn anderenfalls konnen wir f stetig und streng monoton auf ein offenes
Intervall I ⊃ I fortsetzen. Ist z.B. b := sup I ∈ I, so setzen wir etwa f(x) :=
x − b + f(b) fur x > b.
Es sei y0 = f(x0) ∈ f(I) und ε > 0 vorgegeben, wobei wir wegen der Offenheit von I
fur hinreichend kleines ε die Inklusion [x0 − ε, x0 + ε] ⊂ I annehmen konnen. Wegen

72 KAPITEL 11. STETIGE FUNKTIONEN
der Monotonie ist dann f(x) ∈ [f(x0 − ε), f(x0 + ε)] fur alle x mit |x− x0| ≤ ε und
wegen der strengen Monotonie ist δ := min(|y0 − f(x0 − ε)|, |f(x0 + ε)− y0|) großer
als Null.
Dann gibt es fur alle y ∈ f(I) mit |y − y0| < δ ein x ∈ (x0 − ε, x0 + ε) mit f(x) = y,
und daher gilt
|f−1(y) − f−1(y0)| = |x − x0| < ε.
Bemerkung 11.27. Aus Satz 11.26. folgt (erneut) die Stetigkeit der Wurzelfunk-
tion x 7→ m√
x fur jedes m ∈ IN, da x 7→ xm auf IR+ streng monoton wachsend und
stetig ist. 2
Bemerkung 11.28. Der Satz 11.26. ist nur richtig, wenn der Definitionsbereich
von f ein Intervall ist. Die Funktion f : [0, 1] ∪ (2, 3] → IR,
f(x) :=
x falls 0 ≤ x ≤ 1,
x − 1 falls 2 < x ≤ 3,
ist stetig und streng monoton, aber die inverse Funktion f−1 : [0, 2] → IR,
f−1(x) :=
x falls 0 ≤ x ≤ 1,
x + 1 falls 1 < x ≤ 2,
besitzt in x0 = 1 eine Sprungstelle, ist also nicht stetig. 2
Daß die Bestimmung von Argumentwerten, an denen eine gegebene reellwertige
Funktion einen minimalen (oder auch einen maximalen) Wert annimmt, eine wich-
tige Aufgabe der Analysis ist, haben Sie die Kurvendiskussionen des Mathematik-
unterrichtes an der Schule gelehrt. In der Praxis ist das dort meist Optimierung ge-
nannte Minimieren oder Maximieren von Funktionswerten mindestens ebenso wich-
tig. Optimiert wird uberall: Fahrzeuge sollen moglichst wenig Kraftstoff verbrau-
chen, dabei aber moglichst schnell fahren, trotzdem wenig umweltschadlich sein und
gleichzeitig bei Unfallen die Passagiere moglichst gut schutzen, mit dem Verkauf der
Fahrzeuge will die Firma moglichst viel Profit machen, usw.
Bei solch einer Maximierung ist es sicher von Bedeutung, ob die Menge der Funk-
tionswerte uberhaupt nach oben beschrankt ist, und ob es einen Punkt gibt, an
dem die Funktion maximal wird. Beides muß nicht der Fall sein. Bevor wir dazu ein
Beispiel angeben, fuhren wir einige Bezeichnungen ein.

11.2. EIGENSCHAFTEN STETIGER (REELLER) FUNKTIONEN 73
Definition 11.29. (i) Eine Funktion f von einer Menge M in die reellen Zahlen
heißt nach oben beschrankt (unten beschrankt) , wenn die Menge f(M) ⊂IR nach oben (unten) beschrankt ist.
(ii) Ist die Funktion f nach oben (unten) beschrankt, so heißt die Zahl sup f(M)
(inf f(M)) das Supremum (Infimum) von f auf M . Man schreibt auch
supx∈M
f(x) := sup f(M) und infx∈M
f(x) := inf f(M).
(iii) Ist f nach oben (unten) unbeschrankt, so schreibt man sup f(M) = +∞(inf f(M) = −∞).
(iv) Gibt es einen Punkt x ∈ M (x ∈ M), fur den f(x) = sup f(M) (f(x) =
inf f(M)) ist, so sagt man, dass f in M sein Supremum (Infimum) annimmt.
In diesem Fall nennt man f(x) das Maximum (f(x) das Minimum) von f
auf M und schreibt
f(x) =: maxx∈M
f(x) bzw. f(x) =: minx∈M
f(x).
Bemerkung 11.30. Nimmt die Funktion f auf M ihr Supremum (Infimum) an,
so sagt man auch, dass f ihr Maximum (Minimum) in M annimmt. Diese Formulie-
rung ist nicht besonders glucklich, denn ein Maximum, das nicht angenommen wird,
existiert nicht. 2
Bemerkung 11.31. Ist f : M → IR nach unten unbeschrankt, so gibt es eine
Folge {xn} ⊂ M , so daß {f(xn)} bestimmt divergent gegen −∞ ist. Im Sinne der
uneigentlichen Konvergenz gilt limn→∞ f(xn) = −∞.
In jedem Fall (ob f nun nach unten beschrankt ist oder nicht) gibt es also eine Folge
{xn} aus M mit limn→∞
f(xn) = inf f(M).
Ebenso gibt es stets eine Folge {zn} in M mit limn→∞
f(zn) = sup f(M). 2
Beispiel 11.32. Fur die Funktion
f :
(0, 1) −→ IR,
x 7−→ 1x

74 KAPITEL 11. STETIGE FUNKTIONEN
und die Folgen xn = n−1, n ∈ IN, und zn := 1 − n−1, n ∈ IN, gelten die Aussagen:
(i) limn→∞ f(xn) = supx∈(0,1) f(x) = +∞,
(ii) limn→∞ f(zn) = infx∈(0,1) f(x) = 1,
(iii) f nimmt auf (0, 1) weder sein Infimum noch sein Supremum an. 2
Satz 11.33. (Annahme von Minimum und Maximum)
Ist die Funktion f : [a, b] → IR stetig auf dem abgeschlossenen Intervall [a, b], so
nimmt sie in [a, b] ihr Minimum und Maximum an. Es existieren also x, x ∈ [a, b]
mit
f(x) = inf{f(x) : a ≤ x ≤ b}, f(x) = sup{f(x) : a ≤ x ≤ b}.
Beweis: Wir fuhren den Beweis nur fur das Maximum. Es sei s := sup{f(x) :
x ∈ [a, b]}, wobei zunachst auch s = ∞ zugelassen ist. Dann existiert eine Folge
{xn} ⊂ [a, b] mit f(xn) → s.
Nach dem Satz von Bolzano und Weierstraß (Satz 10.66.) gibt es eine konvergente
Teilfolge {xnj} von {xn}, und wegen der Abgeschlossenheit von [a, b] existiert ein
x ∈ [a, b] mit limn→∞xnj
= x.
Die Stetigkeit von f liefert nun f(x) = limj→∞
f(xnj) = s. Das Supremum von f wird
also in x angenommen und ist endlich.
Bemerkung 11.34. Die Beschranktheit des Intervalls [a, b] ist wesentlich fur das
letzte Ergebnis. Die Funktion f1 : IR → IR, f1(x) := x, ist stetig auf IR aber sicher
unbeschrankt.
Die Abgeschlossenheit des Intervalls [a, b] ist ebenfalls wesentlich, da sonst nicht
sicher ist, dass x bzw. x im Definitionsbereich von f liegt. Die Funktion f2 : (0, 1] →IR, f2(x) :=
1
x, ist nach oben unbeschrankt, die Funktion f3 : (0, 1) → IR, f3(x) :=
x, ist zwar beschrankt, aber sup{f3(x) : x ∈ (0, 1)} = 1 und inf{f3(x) : x ∈(0, 1)} = 0 werden in (0, 1) nicht angenommen. 2
Satz 11.33. kann sofort (mit demselben Beweis) auf allgemeinere stetige Funktionen
f : D → IR ubertragen werden, wenn die Teilmenge D eines normierten Vektorrau-
mes die Eigenschaft hat, dass aus der Folge {xk} mit limk→∞ f(xk) = sup f(D) eine
konvergente Teilfolge ausgewahlt werden kann, deren Grenzelement in D liegt. Dies
ist sicher richtig, wenn die Menge D die folgende Eigenschaft hat.

11.2. EIGENSCHAFTEN STETIGER (REELLER) FUNKTIONEN 75
Definition 11.35. Eine Teilmenge D eines normierten Vektorraumes V heißt
kompakt, wenn jede Folge {xn} ⊂ D eine konvergente Teilfolge {xnj} besitzt, deren
Grenzelement x Element von D ist.
Satz 11.36. Ist D ⊂ V kompakt und f : D → IR stetig, so nimmt f Minimum
und Maximum in D an.
In Bemerkung 11.34. hatten wir festgestellt, daß wesentliche Teileigenschaften der
kompakten Menge [a, b] aus IR ihre Beschranktheit und ihre Abgeschlossenheit wa-
ren. Wie wir gleich feststellen werden, charakterisieren diese beiden Eigenschaften
die Kompaktheit allgemein im IRn. Allerdings mussen wir dazu erst einmal eine ge-
eignete Definition von Abgeschlossenheit einer allgemeinen Menge im IRn festlegen.
Definition 11.37. Eine Teilmenge D eines normierten Vektorraumes V heißt ab-
geschlossen, wenn das Grenzelement x jeder konvergenten Folge {xn} aus D zu D
gehort.
Abgeschlossen heißt hier also”abgeschlossen gegenuber Grenzwertbildung.“ Kon-
vergente Folgen konnen auch im Grenzwert die Menge nicht verlassen.
Lemma 11.38. Die kompakten Mengen K des IRn sind genau die beschrankten
und abgeschlossenen Mengen.
Beweis: Ist K nicht beschrankt, so gibt es eine Folge {xk} ⊂ K mit
limk→∞
‖xk‖ = ∞.
Diese Folge hat keine konvergente Teilfolge, so daß K nicht kompakt ist. Die Be-
schranktheit ist damit notwendig fur Kompaktheit.
Ist K nicht abgeschlossen, so gibt es eine konvergente Folge in K, deren Grenzele-
ment x nicht in K liegt. Jede Teilfolge davon konvergiert ebenfalls gegen x, so daß
es keine in K konvergente Teilfolge gibt.
Sei nun K beschrankt und abgeschlossen und sei {xk} eine Folge in K. Wegen der
Aquivalenz der Normen ist K auch in der Maximum-Norm beschrankt und daher in
einem n-dimensionalen Wurfel
W := {x ∈ IRn : −a ≤ xi ≤ a, i = 1, . . . , n}

76 KAPITEL 11. STETIGE FUNKTIONEN
enthalten. Mit {xk} ⊂ K ⊂ W ist die Folge aus K naturlich auch Folge aus W .
Mit xk = (xk1, . . . , x
kn)T konnen wir wegen {xk
1} ⊂ [−a, a] mit dem Satz von Bolzano
und Weierstraß eine Teilfolge der Vektorfolge {xk} auswahlen, so daß die Folge der
ersten Komponenten dieser Teilfolge konvergiert. Indem wir uns nun sukzessiv in
derselben Weise mit dem Satz von Bolzano und Weierstraß der weiteren Kompo-
nenten annehmen, konnen wir durch weitere n−1 Auswahlen einer Teilfolge aus der
jeweils zuletzt gebildeten Teilfolge eine abschließende Teilfolge {xnj} konstruieren,
deren samtlichen Komponentenfolgen konvergieren, die also im IRn konvergiert. Da
{xnj} ⊂ K und K abgeschlossen ist, gehort das Grenzelement zu K. Damit haben
wir eine in K konvergente Teilfolge konstruiert. K ist also kompakt.
Beispiel 11.39. Der letzte Beweis zeigt auch, daß der dort verwendete Wurfel W
kompakt ist. Allgemeiner ist jedes verallgemeinerte abgeschlossene Intervall
I := {x ∈ IRn : ai ≤ xi ≤ bi, i = 1, . . . , n}
kompakt. 2
11.3 Gleichmaßige Stetigkeit
Die Funktion f : D → W , D ⊂ V (V , W normierte Raume) ist stetig in D, wenn
es zu jedem x0 ∈ D und jedem ε > 0 ein δ > 0 gibt, so dass
‖f(x) − f(x0)‖ < ε fur alle x ∈ D mit ‖x − x0‖ < δ
gilt. Dabei wird δ i.a. sowohl von ε als auch von dem betrachteten Punkt x0 ab-
hangen (ein Beispiel geben wir noch an).
Wir werden spater (z.B. beim Nachweis der Integrierbarkeit stetiger Funktionen)
die starkere Eigenschaft benotigen, dass (fur gewisse Mengen D) δ unabhangig von
x0 gewahlt werden kann.
Definition 11.40. Die Funktion f : D → W , D ⊂ V , heißt gleichmaßig stetig
auf D, wenn fur alle ε > 0 ein δ > 0 existiert, so dass ‖f(x) − f(y)‖ < ε fur alle
x, y ∈ D mit ‖x − y‖ < δ gilt.
Gleichmaßige Stetigkeit wird im allgemeinen schwieriger nachzuweisen sein als”ein-
fache“ Stetigkeit. Glucklicherweise ergibt sich jedoch die globale Eigenschaft der

11.3. GLEICHMASSIGE STETIGKEIT 77
gleichmaßigen Stetigkeit im Fall eines kompakten Urbildbereiches sofort aus der lo-
kalen Eigenschaft der Stetigkeit in den einzelnen Punkten. Wir zeigen dieses Ergebnis
ausfuhrlich nur fur den Spezialfall eines kompakten Intervalls:
Satz 11.41. Es sei f : [a, b] → IR stetig. Dann ist f sogar gleichmaßig stetig.
Beweis: (indirekt)
Wir nehmen an, f sei nicht gleichmaßig stetig. Dann gibt es ein ε > 0, so dass fur
jedes δ > 0 zwei Punkte x, y ∈ [a, b] existieren mit
|x − y| < δ, aber |f(x) − f(y)| ≥ ε.
Speziell fur δn =1
ngibt es also xn, yn ∈ [a, b] mit
|xn − yn| <1
nund |f(xn) − f(yn)| ≥ ε.
Nach dem Satz 10.66. von Bolzano und Weierstraß gibt es eine konvergente Teilfolge
{xnj} von {xn} mit lim
j→∞xnj
= x ∈ [a, b], und wegen |xnj− ynj
| <1
nj
gilt dann auch
limj→∞
ynj= x. Die Stetigkeit von f in x liefert nun
limj→∞
f(xnj) = f(x) = lim
j→∞f(ynj
)
im Widerspruch zu |f(xnj) − f(ynj
)| ≥ ε fur alle j.
Der Beweis verlauft fur den allgemeineren Fall einer kompakten Definitionsmenge
ganz analog, wobei die Auswahlbarkeit einer konvergenten Teilfolge mit der Voraus-
setzung der Kompaktheit an Stelle des Satzes von Bolzano und Weierstraß gesichert
wird.
Satz 11.42. Ist D ⊂ IRn kompakt und f : D → IR stetig, so ist f gleichmaßig
stetig.
Beispiel 11.43. Die stetige Funktion f : (0, 1] → IR, f(x) :=1
x, ist nicht gleich-
maßig stetig, denn ist ε = 1 und δ ∈ (0, 1], so gilt fur x = δ und y =δ
2
|x − y| =δ
2< δ und |f(x) − f(y)| =
2
δ− 1
δ=
1
δ≥ ε.
2

78 KAPITEL 11. STETIGE FUNKTIONEN
11.4 Grenzwerte von Funktionen
In diesem Abschnitt befassen wir uns mit der Frage, wie man eine stetige Funktion
in Lucken oder Rander des Definitionsbereichs fortsetzt, damit die Fortsetzung die
Stetigkeit erbt.
Beispiel 11.44. Die rationale Funktion
f(x) :=x3 − 4x2 + 3x
1 − x
ist in IR \ {1} stetig. Der Graph von f
macht den Eindruck, als konne man f
durch die Festsetzung f(1) := 2 zu einer
stetigen Funktion erganzen. Tatsachlich
gilt f(x) = 3x − x2 fur alle x 6= 1, und
die Unstetigkeit von f in x0 = 1 beruht
allein auf der Art der Definition der Ab-
bildungsvorschrift. 2
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
0
0.5
1
1.5
2
2.5
x
f
Abbildung 11.7
Ist allgemeiner f : I \ {x0} → IR (I ⊂ IR ein Intervall, x0 ∈ I) eine stetige
Abbildung, so kann f genau dann zu einer stetigen Funktion f : I → IR fortgesetzt
werden, wenn es ein α ∈ IR gibt, so dass fur jede Folge {xn} → x0, xn 6= x0 fur alle
n ∈ IN, die Bildfolge {f(xn)} gegen α ∈ IR konvergiert. Man hat nur
f(x) =
f(x) fur x ∈ I \ {x0},α fur x = x0,
zu setzen.
In der obigen Situation sagt man, dass f in x0 den Grenzwert α besitzt, und
schreibt
limx→x0
f(x) = α.
Aus der ε-δ-Charakterisierung folgt
Satz 11.45. Die Funktion f : I \ {x0} → IR besitzt genau dann den Grenzwert
α in x0, wenn fur alle ε > 0 ein δ > 0 existiert, so dass |f(x) − α| < ε fur alle
x ∈ I \ {x0} mit |x − x0| < δ gilt.

11.4. GRENZWERTE VON FUNKTIONEN 79
Beispiel 11.46. Die Funktion f : IR \ {0} → IR, f(x) := x · sin1
xbesitzt den
Grenzwert α = 0 in x0 = 0, denn mit δ := ε gilt
|f(x)−0| = |x·sin 1
x| ≤ |x| < ε fur alle x 6= 0 mit |x| < δ. 2
Der Grenzwertbegriff fur reelle Funktionen kann sofort auf die Falle α = ±∞und/oder x0 = ±∞ verallgemeinert werden:
Definition 11.47. f : I \ {x0} → IR besitzt in x0 den uneigentlichen Grenz-
wert
limx→x0
f(x) = ∞, (bzw. −∞)
falls fur jede Folge {xn} ⊂ I mit xn → x0 und xn 6= x0 fur alle n die Folge {f(xn)}uneigentlich gegen ∞ (bzw. −∞) konvergiert.
Ist f stetig in I \{x0} und besitzt |f(x)| den uneigentlichen Grenzwert limx→x0
|f(x)| =
∞, so heißt x0 Pol von f .
Beispiel 11.48. Ist f(x) =p(x)
q(x)eine rationale Funktion mit p(x0) 6= 0 und
q(x0) = 0, so besitzt f einen Pol in x0.
Es gibt namlich zunachst zu ε := 12|p(x0)| > 0 ein δ > 0 mit
|p(x)| = |p(x0) + (p(x) − p(x0))| ≥ |p(x0)| − |p(x) − p(x0)|
≥ |p(x0)| −1
2|p(x0)| =
1
2|p(x0)| fur alle x mit |x − x0| < δ.
Ferner gibt es zu jedem M > 0 ein η > 0 mit |q(x)| <|p(x0)|2M
fur alle x mit
|x − x0| < η.
Daher folgt fur alle x mit |x − x0| < min(δ, η)
|f(x)| =|p(x)||q(x)| ≥
1
2|p(x0)|
1
|q(x)| > M,
und somit haben wir
limx→x0
|f(x)| = ∞
bewiesen. 2
Beispiel 11.49. Die Funktion g : IR \ {0} → IR, g(x) =1
xsin(
1
x) hat bei x0 = 0
keinen Pol, denn fur die Folge {xn}, xn :=1
nπ, gilt lim xn = 0 und g(xn) = 0 fur
alle n ∈ IN, also sicher nicht limx→x0 |g(x)| = ∞. 2
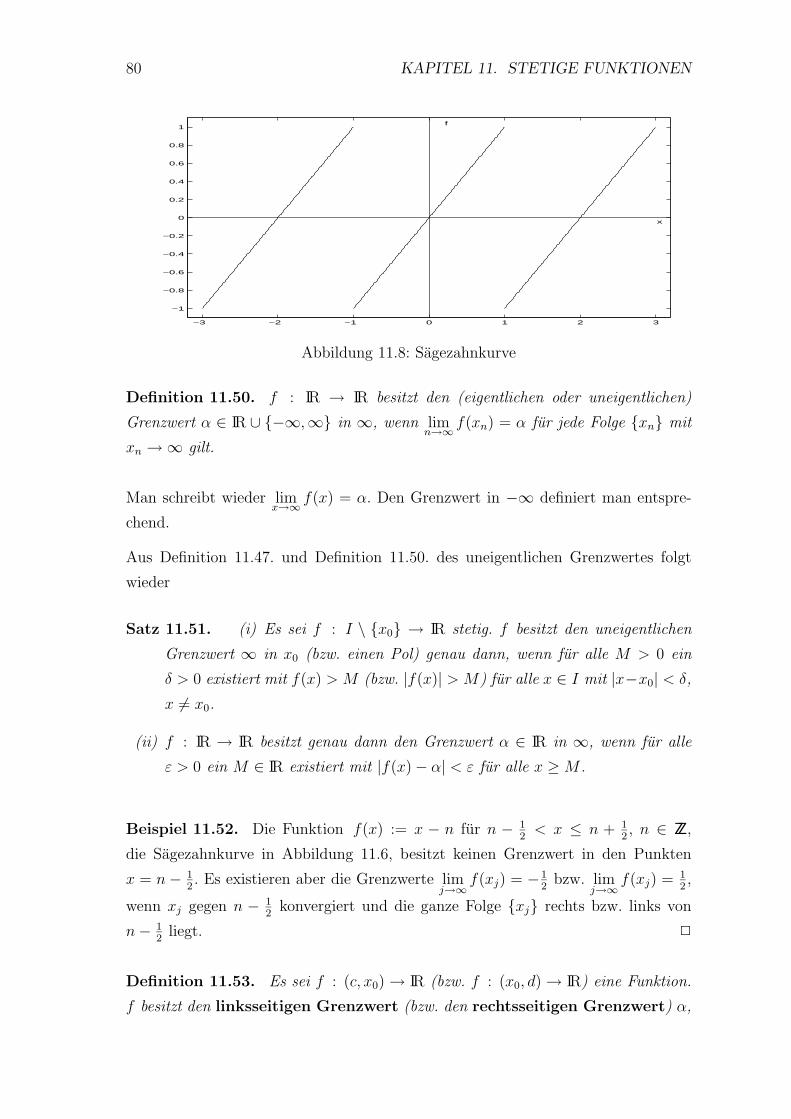
80 KAPITEL 11. STETIGE FUNKTIONEN
−3 −2 −1 0 1 2 3
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1f
x
Abbildung 11.8: Sagezahnkurve
Definition 11.50. f : IR → IR besitzt den (eigentlichen oder uneigentlichen)
Grenzwert α ∈ IR ∪ {−∞,∞} in ∞, wenn limn→∞ f(xn) = α fur jede Folge {xn} mit
xn → ∞ gilt.
Man schreibt wieder limx→∞ f(x) = α. Den Grenzwert in −∞ definiert man entspre-
chend.
Aus Definition 11.47. und Definition 11.50. des uneigentlichen Grenzwertes folgt
wieder
Satz 11.51. (i) Es sei f : I \ {x0} → IR stetig. f besitzt den uneigentlichen
Grenzwert ∞ in x0 (bzw. einen Pol) genau dann, wenn fur alle M > 0 ein
δ > 0 existiert mit f(x) > M (bzw. |f(x)| > M) fur alle x ∈ I mit |x−x0| < δ,
x 6= x0.
(ii) f : IR → IR besitzt genau dann den Grenzwert α ∈ IR in ∞, wenn fur alle
ε > 0 ein M ∈ IR existiert mit |f(x) − α| < ε fur alle x ≥ M .
Beispiel 11.52. Die Funktion f(x) := x − n fur n − 12
< x ≤ n + 12, n ∈ ZZ,
die Sagezahnkurve in Abbildung 11.6, besitzt keinen Grenzwert in den Punkten
x = n − 12. Es existieren aber die Grenzwerte lim
j→∞f(xj) = −1
2bzw. lim
j→∞f(xj) = 1
2,
wenn xj gegen n − 12
konvergiert und die ganze Folge {xj} rechts bzw. links von
n − 12
liegt. 2
Definition 11.53. Es sei f : (c, x0) → IR (bzw. f : (x0, d) → IR) eine Funktion.
f besitzt den linksseitigen Grenzwert (bzw. den rechtsseitigen Grenzwert) α,

11.4. GRENZWERTE VON FUNKTIONEN 83
wenn fur jede Folge {xn} ⊂ (c, x0) (bzw. {xn} ⊂ (x0, d)) mit limn→∞
xn = x0 gilt
limn→∞
f(xn) = α.
Wir schreiben dann
limx → x0
x < x0
f(x) := limx→x0−0
f(x) := f(x0 − 0) := α
bzw.
limx → x0
x > x0
f(x) := limx→x0+0
f(x) := f(x0 + 0) := α.
Definition 11.54. f : (c, d) → IR heißt linksseitig stetig (bzw. rechtsseitig
stetig ) in x0 ∈ (c, d), wenn f in x0 einen linksseitigen (rechtsseitigen) Grenzwert
besitzt und f(x0) = f(x0 − 0) (bzw. f(x0) = f(x0 + 0)) gilt.
Beispiel 11.55. Die Sagezahnkurve von Beispiel 11.52. besitzt den linksseitigen
Grenzwert f(n − 12− 0) = 1
2und den rechtsseitigen Grenzwert f(n − 1
2+ 0) = −1
2
und ist linksseitig aber nicht rechtsseitig stetig in n − 12, n ∈ ZZ. 2
Bemerkung 11.56. Es ist klar, dass eine Funktion f : I → IR genau dann stetig
in x0 ∈ I ist, wenn f sowohl links- als auch rechtsseitig stetig in x0 ist. 2

Kapitel 12
Elementare Funktionen
12.1 Polynome
Eine besonders wichtige Klasse von Funktionen sind die Polynome oder ganzen
rationalen Funktionen
pn(z) :=n∑
j=0
ajzj, z ∈ C (bzw. z ∈ IR),
wobei a0, . . . , an ∈ C (bzw. ∈ IR), an 6= 0, gegeben sind. Sie sind sehr leicht auswert-
bar, da nur Additionen und Multiplikationen verwendet werden. Ferner werden wir
sehen, dass man jede stetige, reellwertige Funktion auf einem beschrankten Intervall
durch ein Polynom genugend hohen Grades beliebig gut approximieren kann.
Die Zahl n heißt der Grad des Polynoms pn. Die Menge aller Polynome vom
Hochstgrade n bezeichnen wir mit Πn.
Die Auswertung eines Polynoms an einer Stelle z0 wird besonders einfach, wenn man
in folgender Weise ausklammert:
pn(z) = (. . . ((anz + an−1) · z + an−2) · z + . . . + a1) · z + a0.
Dann beginnt man die Auswertung durch Berechnung von an · z als Schritt S1 und
fahrt mit den Schritten S2, S3, usw. gemaß
pn(z) = ( (anz︸︷︷︸
S1
+an−1
︸ ︷︷ ︸
S2
) · z
︸ ︷︷ ︸
S3
+an−2
︸ ︷︷ ︸
...
) · z + . . . + a1) · z + a0
︸ ︷︷ ︸
S2n

12.1. POLYNOME 85
fort, bis man nach Schritt S2n den Polynomwert erhalt.
Programmieren laßt sich das ganz einfach. In PASCAL sieht es etwa so aus:
p := a[n];
FOR i:=n-1 DOWNTO 0 DO
p := p * z0 + a[i];
Ein Schema fur die Handrechnung ist
an an−1 . . . a1 a0
+ ↓ 0 a′n−1z0 . . . a′
1z0 a′0z0
·z0 ր a′n−1 := an a′
n−2 := an−1 + a′n−1z0 . . . a′
0 := a1 + a′1z0 pn(z0).
Dieses letzte Berechnungsschema heißt Horner Schema1. Die Rechenmethode an
sich wird oft als Horner Algorithmus bezeichnet oder ebenfalls als Horner Schema.
Mit ihr benotigt man n Multiplikationen und n Additionen fur die Auswertung
eines Polynoms vom Grad n, wahrend die naive Auswertung (Berechne z2, . . . , zn,
multipliziere zj mit aj, j = 1, . . . , n, und addiere) 2n − 1 Multiplikationen und n
Additionen erfordert. Man kann zeigen, daß unter allen Auswertungsmethoden fur
allgemeine Polynome das Horner Schema am effizientesten ist.
Beispiel 12.1. Seien p(z) = z4 + 2z3 − z2 + 1 und z0 = −2 gegeben. Dann findet
man mit dem Horner Schema
1 2 −1 0 1
[z0 = −2] 0 −2 0 2 −4
1 0 −1 2 −3 = p(−2).
Achtung: Man darf nicht vergessen, die Koeffizienten ai, die 0 sind, im Schema zu
berucksichtigen. 2
Unter den Zahlen der letzten Zeile des Horner Schemas ist die letzte der Wert des
Polynoms an der Auswertungsstelle. Aber auch die davor stehenden Werte haben
eine praktische Bedeutung. Bildet man mit ihnen entsprechend der ersten Zeile
des Horner Schemas ein Polynom (vom Grad n − 1), so ist dies gerade dasjenige
Polynom, das man bei der Polynomdivision des gegebenen Polynoms durch das
lineare Polynom (z − z0) mit Rest p(z0) erhalt.
1William George Horner, 1786 - 1837, englischer Mathematiker

86 KAPITEL 12. ELEMENTARE FUNKTIONEN
Beispiel 12.2. Im letzten Beispiel lautet dieses Polynom
p3(z) = 1 · z3 + 0 · z2 − 1 · z + 2.
Durch Ausmultiplizieren der linken Seite bestatigt man
(z3 − z + 2)(z − (−2)) + (−3) = z4 + 2z3 − z2 + 1.
Daher ist hier
p(z) = p3(z)(z−z0)+p(z0). 2
Um dies allgemein einzusehen, definieren wir mit den Werten a′n−1, . . . , a
′0 der letzten
Zeile des Schemas das Polynom
pn−1(z) :=n−1∑
j=0
a′jz
j.
Da fur die a′i nach Konstruktion
a′n−1 = an fur j = n,
a′j−1 − a′
jz0 = aj fur j = 1, . . . , n − 1,
pn(z0) − a′0z0 = a0 fur j = 0
gelten, erhalt man leicht
(z − z0) pn−1(z) + pn(z0) =n−1∑
j=0
a′jz
j(z − z0) + pn(z0)
=n−1∑
j=0
a′jz
j+1 −n−1∑
j=0
a′jz
jz0 + pn(z0)
= a′n−1z
n +n−1∑
j=1
(a′j−1 − a′
jz0)zj − a′
0z0 + pn(z0)
= pn(z).
Die Zusammenfassung dieser Uberlegungen ist der
Satz 12.3. Ist pn(z) =n∑
j=0ajz
j ein Polynom vom Grade n ≥ 1, so liefert das
Horner Schema den Wert pn(z0) und die Koeffizienten eines Polynoms
pn−1(z) =n−1∑
j=0
a′jz
j,
fur das gilt
pn(z) = (z − z0) pn−1(z) + pn(z0) fur alle z ∈ C. (12.1)

12.1. POLYNOME 87
Ist speziell z0 ∈ C eine Nullstelle von pn, so ist pn(z0) = 0. Dann sagt (12.1), dass
das Polynom pn durch den Linearfaktor (z − z0) teilbar ist:
pn(z) = (z − z0) pn−1(z).
Hieraus sieht man, daß alle Nullstellen von pn (moglicherweise mit Ausnahme von
z0) auch Nullstellen von pn−1 sind.
Eine Nullstelle von pn−1 kann man nun ganz analog mit dem Horner Schema in
Gestalt eines Linearfaktors von pn−1 abspalten, wobei der Grad des Restpolynoms
wieder um den Wert 1 fallt.
Um mit dieser Vorgehensweise die vollstandige Zerlegbarkeit eines Polynoms in Line-
arfaktoren (z−ζi) mit den Nullstellen ζi von pn zeigen zu konnen, braucht man daher
nur noch zu wissen, daß jedes Polynom vom Grad ≥ 1 mindestens eine Nullstelle
hat.
Dies besagt gerade der Fundamentalsatz der Algebra, den wir bereits in Kapitel 8
angesprochen hatten. Wir werden ihn in Mathematik IV beweisen.
Satz 12.4. (Fundamentalsatz der Algebra)
Jedes Polynom vom Grade n ≥ 1 besitzt in C wenigstens eine Nullstelle.
Bemerkung 12.5. Satz 12.4. ist nur richtig in C. Auch wenn pn nur reelle Ko-
effizienten hat (aj ∈ IR, j = 0, . . . , n), ist die Existenz einer Nullstelle von pn nur
in C gesichert. p(x) = x2 + 1 hat z.B. nur die Nullstellen ±i /∈ IR. Wir hatten die
komplexen Zahlen gerade mit dem Ziel eingefuhrt, die Unlosbarkeit von x2 + 1 = 0
in IR zu beseitigen. 2
Die oben schon angedeutete Zerlegbarkeit jedes Polynoms in Linearfaktoren formu-
lieren und beweisen wir nun noch einmal induktiv.
Korollar 12.6. Jedes Polynom pn ∈ Πn vom Grade n ≥ 1 lasst sich (uber C) in
Linearfaktoren zerlegen:
pn(z) = an · (z − ζ1) · (z − ζ2) · . . . · (z − ζn). (12.2)
Dabei sind ζ1, . . . , ζn ∈ C die (nicht notwendig verschiedenen) Nullstellen von pn.

88 KAPITEL 12. ELEMENTARE FUNKTIONEN
Beweis: Ein lineares Polynom p1 = a1z + a0 ∈ Π1 laßt sich offenbar in der
gewunschten Form
p1(z) = a1
(
z +a0
a1
)
darstellen.
Es lasse sich nun jedes Polynom vom Grade n − 1 ≥ 1 in Linearfaktoren zerlegen.
Ist pn ∈ Πn, so hat pn nach Satz 12.4. eine Nullstelle ζn ∈ C, nach Satz 12.3.
gibt es also ein Polynom pn−1 ∈ Πn−1 mit pn(z) = (z − ζn) pn−1(z), und nach
Induktionsvoraussetzung folgt
pn(z) = (z − ζn) · a′n−1
n−1∏
j=1
(z − ζj) = an
n∏
j=1
(z − ζj).
Tritt eine Nullstelle ζj in der Darstellung (12.2) genau k-mal auf, so heißt ζj eine
k-fache Nullstelle von pn. Berucksichtigt man die Vielfachheiten der Nullstellen,
so kann man Korollar 12.6. so ausdrucken:
Jedes Polynom vom Grade n hat genau n entsprechend ihrer Vielfachheit
gezahlte Nullstellen in C.
In dieser Form hatten wir den Fundamentalsatz der Algebra in Mathematik I zitiert.
Beispiel 12.7.
p5(z) = z5 + z3 = z3 (z + i) (z − i)
besitzt die einfachen Nullstellen +i und −i und die dreifache Nullstelle 0. 2
Besitzt pn(z) =n∑
j=0ajz
j nur reelle Koeffizienten aj ∈ IR, j = 0, . . . , n, und ist ein
ζ ∈ C\IR Nullstelle des Polynoms, so gilt wegen z1 · z2 = z1 ·z2 und z1 + z2 = z1 +z2
auch
pn(ζ) =n∑
j=0
aj
(
ζ)j
=n∑
j=0
ajζj = pn(ζ) = 0.
Es ist somit auch ζ Nullstelle des Polynoms. Nicht reelle Nullstellen treten deshalb
stets als konjugiert komplexe Paare auf.
Sind nun z1 und z1 Nullstellen von pn, so ist pn teilbar durch
(z − z1) (z − z1) = z2 − 2 Re (z1) · z + |z1|2.

12.1. POLYNOME 89
Die rechte Seite ist hierbei ein reelles Polynom, welches als Nullstellen gerade das
konjugiert komplexe Paar z1, z1 hat.
Will man ein reelles Polynom in moglichst einfache Faktoren zerlegen, aus denen die
Nullstellen sofort zu ersehen sind, und soll diese Zerlegung selbst auch reell sein, so
bietet es sich an, jeweils zu konjugiert komplexen Nullstellenpaaren gehorige Line-
arfaktoren wie eben demonstriert zu quadratischen Polynomen zusammenzufassen.
Fur die spatere Benutzung halten wir fest:
Satz 12.8. Die Koeffizienten aj, j = 0, . . . , n, von pn(z) =n∑
j=0ajz
j seien reell.
Dann gilt
(i) pn(ζ) = 0 ⇐⇒ pn(ζ) = 0.
(ii) Die Anzahl der nichtreellen Nullstellen von pn ist gerade.
(iii) Ist n ungerade, so hat pn mindestens eine reelle Nullstelle.
(iv) pn lasst sich als Produkt von reellen Linearfaktoren und quadratischen Poly-
nomen mit reellen Koeffizienten schreiben, wobei die quadratischen Faktoren
keine reellen Nullstellen besitzen.
Wir wenden uns nun dem Problem zu, eine reelle oder komplexe Funktion durch ein
Polynom zu approximieren. Hierzu muß man sicher Information uber die Funktion
in das Polynom integrieren. Naheliegende Informationen uber eine Funktion sind
Funktionswerte. Wenn eine Approximation mit einer Funktion vollstandig uberein-
stimmt, hat sie uberall dieselben Funktionswerte. Von daher liegt die Idee nicht fern,
bei Kenntnis einiger Funktionswerte einer Funktion ein Polynom erzeugen zu wollen,
welches dieselben Funktionswerte hat. Wieweit dies auch zu einer guten Annaherung
der Funktion außerhalb der Datenpunkte selbst fuhrt, werden wir erst beantworten
konnen, wenn (hohere) Ableitungen von Funktionen definiert sind.
Dies fuhrt uns zu dem
Interpolationsproblem:
Gegeben seien n+1 Wertepaare (zj, wj) ∈ C2, j = 0, . . . , n, zj paarweise
verschieden.
Bestimme p ∈ Πn mit p(zj) = wj, j = 0, . . . , n.

90 KAPITEL 12. ELEMENTARE FUNKTIONEN
Mit Methoden der linearen Algebra haben wir bereits in Kapitel 7 gesehen, daß das
Interpolationsproblem stets eindeutig losbar ist.
Die Eindeutigkeit kann man auch mit dem Fundamentalsatz der Algebra leicht se-
hen: Wenn p ∈ Πn und q ∈ Πn beide das Interpolationsproblem losen, so gilt fur
r := p − q ∈ Πn
r(zj) = p(zj) − q(zj) = wj − wj = 0, j = 0, . . . , n.
Das Polynom r ∈ Πn hat also n + 1 Nullstellen. Dies ist aber nur moglich, wenn
r ≡ 0 ist. Also stimmen p und q uberein.
Die Existenz kann man konstruktiv sichern: Fur j = 0, . . . , n ist
ℓj(z) :=n∏
i=0i 6=j
(z − zi)
/n∏
i=0i 6=j
(zj − zi)
offenbar das eindeutige Polynom vom Grade n, fur das gilt:
ℓj(zi) = δij, i, j = 0, 1, . . . , n. (12.3)
Damit hat man
Satz 12.9. (Lagrangesche Interpolationsformel)
Es seien (zj, wj) ∈ C2, j = 0, . . . , n, zj paarweise verschieden. Dann ist das zu-
gehorige Interpolationsproblem eindeutig losbar, und die Losung ist
p(z) =n∑
j=0
wjℓj(z) (12.4)
mit den in (12.3) gegebenen Polynomen ℓj.
Die Lagrangesche2 Interpolationsformel ist sehr ubersichtlich und nutzlich fur theo-
retische Zwecke.
Da die Polynome ℓj durch die Stutzstellen zk eindeutig festgelegt sind und un-
abhangig von den Werten wk sind, ist klar, dass das Interpolationspolynom (bei
festgehaltenen Stutzstellen) linear von den vorgegebenen Werten wk abhangt: Inter-
poliert p ∈ Πn die Daten (zj, wj) ∈ C2, j = 0, . . . , n, und q ∈ Πn die Daten (zj, vj),
j = 0, . . . , n, so ist p + q das Interpolationspolynom zu (zj, vj + wj), j = 0, . . . , n,
und fur α ∈ C interpoliert αp ∈ Πn die Daten (zj, αwj), j = 0, . . . , n.
2Joseph-Louis Lagrange, franzosischer Mathematiker, 1736 - 1813

12.1. POLYNOME 91
Man kann ferner die Veranderung des Interpolationspolynoms bei Variation einzelner
Werte sofort angeben: Interpoliert p die Daten (zj, wj), j = 0, . . . , n, und q die Daten
(zj, wj), j = 0, . . . , n − 1, und (zn, wn + δ), so gilt
q(z) − p(z) = δℓn(z) = δn−1∏
i=0
z − zi
zn − zi
.
Nachteilig ist jedoch, dass die Anderung des Interpolationspolynoms bei Hinzunah-
me eines weiteren Wertepaares in der Lagrangeschen Form sehr unubersichtlich ist,
da sich alle Basisfunktionen ℓj andern. Eine solche Interpolation mit wachsender Zahl
von Stutzstellen tritt z.B. bei der numerischen Berechnung von Integralen durch Ex-
trapolation oder der numerischen Behandlung von Differentialgleichungen auf. Sie
lasst sich ubersichtlicher mit der Newtonschen Interpolationsformel durchfuhren, die
wir nun herleiten wollen.
Das Polynom pn(z) ∈ Πn interpoliere die Daten (zj, wj) ∈ C2, j = 0, . . . , n. Wir
nehmen ein weiteres Zahlenpaar (zn+1, wn+1) ∈ C2, zn+1 6= zj, j = 0, . . . , n, hinzu
und fragen, ob und wie man das Interpolationspolynom pn+1(z) ∈ Πn+1 zu den
Daten (zj, wj), j = 0, . . . , n + 1 als
pn+1(z) = pn(z) + f(z)
mit einer leicht berechenbaren Funktion f(z) schreiben kann.
Wegen pn(z) ∈ Πn, pn+1(z) ∈ Πn+1 gilt f(z) = pn(z) − pn+1(z) ∈ Πn+1, und wegen
wj = pn+1(zj) = pn(zj)+f(zj) = wj+f(zj), j = 0, . . . , n, gilt f(zj) = 0, j = 0, . . . , n.
Daher hat f(z) mit einem a ∈ C die Gestalt
f(z) = an∏
j=0
(z − zj).
Da zn+1 von allen vorangehenden zj verschieden ist, ist∏n
j=0(zn+1 − zj) von Null
verschieden. Daher kann man a aus der Interpolationsbedingung
wn+1 = pn+1(zn+1) = pn(zn+1) + an∏
j=0
(zn+1 − zj)
ermitteln:
a =wn+1 − pn(zn+1)
(zn+1 − z0) · . . . · (zn+1 − zn).
Man verwendet diese Formel aber nicht, da es einen weniger aufwendigen Weg gibt.
Dieser benutzt die Beobachtung, daß a der fuhrende Koeffizient (Koeffizient der
(n + 1)-ten z-Potenz des Interpolationspolynoms aus Πn+1) ist und leitet fur diese

92 KAPITEL 12. ELEMENTARE FUNKTIONEN
fuhrenden Koeffizienten eine Rekursion her. Grundlage dafur ist das Lemma von
Aitken3:
Satz 12.10. (Aitken Lemma)
Es sei zu (zj, wj) ∈ C2, j = 0, . . . , n, zi 6= zj fur i 6= j, das Interpolationspolynom
p(z) gesucht.
Seien p[0], p[n] ∈ Πn−1 festgelegt durch die Interpolationsbedingungen p[0](zj) = wj,
j = 0, . . . , n − 1, und p[n](zj) = wj, j = 1, . . . , n. Dann gilt
p(z) =p[0](z)(z − zn) − p[n](z)(z − z0)
z0 − zn
.
Beweis: Durch Verifikation von p(zj) = wj, j = 0, . . . , n.
Fur 0 ≤ i ≤ j ≤ n bezeichnen wir nun mit pij ∈ Πj−i das Interpolationspolynom,
das pij(zk) = wk, k = i, . . . , j, erfullt. Dann folgt aus dem Aitken Lemma, dass die
pij rekursiv berechnet werden konnen durch
pij(z) =pi,j−1(z)(z − zj) − pi+1,j(z)(z − zi)
zi − zj
. (12.5)
Insbesondere ist pii ein Polynom vom Grade 0, das die Interpolationbedingung
pii(zi) = wi, i = 0, . . . , n, erfullt, d.h.
pii(z) ≡ wi, i = 0, . . . , n. (12.6)
Um diese Anfangsbedingungen ist die Rekursion (12.5) zu erganzen.
Aus (12.5) und (12.6) liest man unmittelbar eine Rekursionsformel fur die fuhrenden
Koeffizienten der Polynome pij ab, die wir mit [zi, . . . , zj] bezeichnen:
[zi] := wi, i = 0, . . . , n, (12.7)
[zi, . . . , zj] :=[zi, . . . , zj−1] − [zi+1, . . . , zj]
zi − zj
, 0 ≤ i < j ≤ n. (12.8)
Definition 12.11. Wegen der hier gefundenen Form der Rekursion, heißen die
Koeffizienten [zi, . . . , zj] aus (12.8) mit den Anfangsbedingungen (12.7) dividierte
Differenzen.
3Alexander Craig Aitken, 1895 - 1967, britischer Mathematiker

12.1. POLYNOME 93
Offenbar kann man alle dividierten Differenzen [zi, . . . , zj], 0 ≤ i ≤ j ≤ n, von links
nach rechts rekursiv mit dem folgenden Schema und Formel (12.8) berechnen:
[z0] ց[z0, z1]ր ց
[z1] [z0, z1, z2]ց ր ց...ց... . . . [z0, . . . , zn]ր...
ր ց ր[zn−1] [zn−2, zn−1, zn]
ց ր[zn−1, zn]
ր[zn]
Die angekundigte Newtonsche Interpolationsformel findet man, indem man die jetzt
gefundene Rekursion
pn+1(z) = pn(z) + [z0, . . . , zn+1]n∏
j=0
(z − zj)
wiederholt anwendet:
Satz 12.12. (Newtonsche Interpolationsformel)
Das Interpolationspolynom p ∈ Πn aus (12.4) hat die Gestalt
p(z) =n∑
j=0
[z0, . . . , zj]j−1∏
k=0
(z − zk), (12.9)
wobei die dividierten Differenzen [z0, . . . , zj] rekursiv berechnet werden aus
[zj] := wj,
[zk, . . . , zj] :=[zk, . . . , zj−1] − [zk+1, . . . , zj]
zk − zj
, j > k ≥ 0.
Die Berechnung der dividierten Differenzen cj := [z0, . . . , zj] kann man mit folgen-
dem PASCAL-Algorithmus aus den Wertepaaren (zj, wj) berechnen:
FOR k:=0 TO n DO
BEGIN
t[k] := w[k];
IF k>0 THEN
FOR i:=k-1 DOWNTO 0 DO
t[i] := (t[i+1]-t[i]) / (z[k]-z[i]);
c[k] := t[0]
END;

94 KAPITEL 12. ELEMENTARE FUNKTIONEN
Nach dem Schritt k ist t[i] = [zi, . . . , zk] fur i = 0, 1, . . . , k.
Das Newtonsche Interpolationspolynom kann wieder an jeder gewunschten Stelle
z∗ mit einem Horner-ahnlichen Schema ausgewertet werden. Indem man in (12.9)
wieder weitmoglichst ausklammert
p(z) =(
· · ·(
[z0, . . . , zn](z−zn−1)+[z0, . . . , zn−1])
(z−zn−2)+· · ·+[z0, z1])
(z−z0)+[z0],
gelangt man zu folgendem Algorithmus (Wert fur die Auswertung im Speicher z):
p := c[n];
FOR i:=n-1 DOWNTO 0 DO
p := p * (z - z[i]) + c[i];
Man benotigt 32n (n + 1) Operationen zur Berechnung aller cj, zur Berechnung des
Funktionswertes an einer Stelle zusatzlich 3n Operationen. Zu den 2n Operationen
eines Horner Schemas kommen hier noch n Differenzenbildungen z − zj.
Beispiel 12.13. Bestimme p ∈ Π5 mit
p(0) = 1, p(1) = 0, p(2) = 0, p(3) = −1, p(4) = 0.
Wegen p(1) = p(2) = p(4) = 0 benotigt man fur die Lagrangesche Interpolations-
formel nur
ℓ0(z) =(z − 1) (z − 2) (z − 3) (z − 4)
(0 − 1) (0 − 2) (0 − 3) (0 − 4)=
1
24(z − 1) (z − 2) (z − 3) (z − 4),
ℓ3(z) =(z − 0) (z − 1) (z − 2) (z − 4)
(3 − 0) (3 − 1) (3 − 2) (3 − 4)= −1
6z (z − 1) (z − 2) (z − 4),
und erhalt
p(z) =1
24(z − 1) (z − 2) (z − 3) (z − 4) + (−1) · (−1
6) z (z − 1) (z − 2) (z − 4)
=1
24(z − 1) (z − 2) (z − 4) (5z − 3).
Der Algorithmus auf Seite 93 liefert fur das Newtonsche Interpolationspolynom die
Koeffizienten
i zi wi = [zi] [zi, zi+1] [zi, . . . , zi+2] [zi, . . . , zi+3] [zi, . . . , zi+4]
0 0 1 = c0 −1 = c112
= c2 −13
= c3524
= c4
1 1 0 0 −12
12
2 2 0 −1 1
3 3 −1 1
4 4 0

12.1. POLYNOME 95
Es ist daher
p(z) = 1 − z +1
2z (z − 1) − 1
3z (z − 1) (z − 2) +
5
24z (z − 1) (z − 2) (z − 3)
oder — nach Ausklammern —
p(z) =((( 5
24(z − 3) − 1
3
)
(z − 2) +1
2
)
(z − 1) − 1)
(z − 0) + 1.
Wegen der vielen Nullen in den Interpolationsdaten ist hier die Lagrangesche Dar-
stellung auch recht gunstig; bei allgemeinen Daten ist die Newtonsche Darstellung
vorteilhafter. 2
Die Rekursionsformel (12.5) fur die Polynome pij kann man verwenden, um das
Interpolationspolynom p an einer festen Stelle z auszuwerten, ohne zunachst das
Interpolationspolynom in der Lagrangeschen oder Newtonschen Form bestimmen.
Nach (12.5) gilt
pij(z) =pi,j−1(z)(z − zj) − pi+1,j(z)(z − zi)
zi − zj
= pi+1,j(z) + (pi,j−1(z) − pi+1,j(z))z − zj
zi − zj
.
Hiermit erhalt man entsprechend dem Algorithmus zur Berechnung der dividierten
Differenzen:
Korollar 12.14. (Algorithmus von Neville und Aitken)
Es seien die Daten (zj, wj), j = 0, . . . , n, in den Variablen z[j], w[j], j=0,..,n,
gespeichert und die Variable z enthalte die Auswertungsstelle. Dann liefert der fol-
gende Programmabschnitt (in PASCAL) am Ende den Wert des Interpolationspoly-
noms der Daten im Speicher der Variable p :
FOR j:=0 TO n DO
BEGIN
t[j] := w[j];
zj:=z-z[j];
IF j>0 THEN
FOR i:=j-1 DOWNTO 0 DO
t[i] := t[i+1]+(t[i]-t[i+1])*zj / (z[i]-z[j])
END;
p:=t[0];
Nach dem Schritt j gilt t[i] = pij(z) fur i = 0, . . . , j.

96 KAPITEL 12. ELEMENTARE FUNKTIONEN
Bemerkung 12.15. Beachten Sie, daß man den Neville-Aitken-Algorithmus nur
verwendet, um mit einem Zahlenwert fur z den Funktionswert von p an dieser Stelle
zu berechnen. Es macht keine Freude, den Algorithmus mit variablem z zu verwen-
den, um eine Formel fur das Interpolationspolynom zu erzeugen. 2
12.2 Konvergenz in Funktionenraumen
Wir haben am Anfang dieses Abschnitts gesagt, dass die Polynome u.a. deswegen so
wichtig sind, weil sie sich elementar auswerten lassen und weil man durch Polynome
alle stetigen Funktionen beliebig gut approximieren kann. Wir wollen die zweite
dieser Bemerkungen nun prazisieren.
Wir haben in Abschnitt 10.5 bereits angemerkt, dass nur in endlich dimensiona-
len Vektorraumen die Konvergenz oder Divergenz einer Folge unabhangig von der
gewahlten Norm ist, dass dies aber in unendlichdimensionalen Raumen i.a. nicht
der Fall ist. Beispiel 10.71. gab ein Beispiel einer Folge von Funktionen, die bzgl.
der ‖ · ‖2-Norm konvergierte, bzgl. der ‖ · ‖∞-Norm aber divergierte. Wir wollen
in diesem Abschnitt drei Konvergenzbegriffe fur Folgen von Funktionen diskutie-
ren. Es gibt weitere fur die Anwendungen wichtige Konvergenzbegriffe, die andere
Struktureigenschaften der betrachteten Funktionen ausnutzen.
Definition 12.16. Es seien V und W normierte Vektorraume Wir betrachten die
Folge von Funktionen fn : V ⊃ D → W mit dem gemeinsamen Definitionsbereich
D.
(i) Die Folge {fn} heißt punktweise konvergent in D gegen die Funktion
f : D → W , wenn
limn→∞ fn(x) = f(x) fur alle x ∈ D.
(ii) Die Folge {fn} heißt gleichmaßig konvergent in D gegen die Funktion
f : D → W , wenn fur alle ε > 0 ein N ∈ IN existiert, so dass
‖fn(x) − f(x)‖W < ε fur alle n ≥ N und alle x ∈ D. (12.10)
Bemerkung 12.17. Eine Folge von Funktionen {fn} konvergiert also genau dann
in D punktweise gegen f , wenn es zu jedem x ∈ D und zu jedem ε > 0 ein N =
N(ε,x) gibt mit
‖fn(x) − f(x)‖W < ε fur alle n ≥ N(ε,x).

12.2. KONVERGENZ IN FUNKTIONENRAUMEN 97
Im Falle der gleichmaßigen Konvergenz ist diese Bedingung naturlich ebenfalls er-
fullt. Es gilt aber zusatzlich, dass bei gegebenem ε > 0 die Zahl N unabhangig von
x gewahlt werden kann, also gleichmaßig in D. Gleichmaßige Konvergenz impliziert
somit punktweise Konvergenz. 2
Beispiel 12.18. In Beispiel 10.71. haben wir die Folge von Funktionen
fn : [0, 1] → IR, fn(x) := xn,
betrachtet. Diese konvergiert offenbar punktweise gegen die Funktion
f : [0, 1] → IR, f(x) :=
0 fur 0 ≤ x < 1
1 fur x = 1.
Dass die Folge nicht gleichmaßig konvergieren kann, werden wir noch sehen. 2
Der Begriff der punktweisen Konvergenz ist konzeptionell sehr einfach und scheint
sehr naturlich zu sein, Beispiel 12.18. zeigt aber, dass er zu schwach fur die Zwecke
der Infinitesimalrechnung ist, denn die Stetigkeit aller Glieder einer punktweise
konvergenten Folge {fn} vererbt sich nicht notwendig auf den punktweisen Grenz-
wert. Der Begriff der gleichmaßigen Konvergenz weist diesen Mangel nicht auf. Fur
gleichmaßig konvergente Folgen gilt
Satz 12.19. Es seien fn : V ⊃ D → W stetige Funktionen. Konvergiert die Folge
{fn} gleichmaßig in D gegen eine Funktion f : D → W , so ist auch f stetig in D.
Beweis: Es sei ε > 0 gegeben. Dann gibt es ein N ∈ IN, so dass gilt
‖f(x) − fn(x)‖W < ε fur alle n ≥ N und alle x ∈ D.
Es sei x0 ∈ D beliebig gewahlt. Dann gilt mit jedem (festgehaltenen) n ≥ N
‖f(x) − f(x0)‖W ≤ ‖f(x) − fn(x)‖W + ‖fn(x) − fn(x0)‖W + ‖fn(x0) − f(x0)‖W
≤ 2ε + ‖fn(x) − fn(x0)‖W .
Wegen der Stetigkeit von fn gibt es ein δ > 0 mit
‖fn(x) − fn(x0)‖W < ε fur alle x ∈ D mit ‖x − x0‖V < δ,
und es folgt
‖f(x) − f(x0)‖W < 3ε fur alle x ∈ D mit ‖x − x0‖V < δ.
Dies ist gerade die Stetigkeit von f in x0.

98 KAPITEL 12. ELEMENTARE FUNKTIONEN
Beispiel 12.20. (Fortsetzung von Beispiel 12.18.)
Die durch fn(x) = xn definierte Folge aus Beispiel 12.18. konvergiert auf jedem
Teilintervall [a, b] von [0, 1] mit 0 ≤ a < b < 1 gleichmaßig gegen die Nullfunktion.
Wegen b ∈ [0, 1) ist namlich {bn} eine reelle Nullfolge, und daher gibt es zu jedem ε
ein N ∈ IN mit bn < ε fur alle n > N . Mit diesem N ist dann auch
|fn(x) − 0| = |x|n ≤ bn < ε fur alle n > N und fur alle x ∈ [a, b]. (12.11)
Konform mit der Aussage des letzten Satzes ist die Nullfunktion auch stetig in einem
solchen Intervall [a, b].
Im Falle b = 1 ist die Grenzfunktion unstetig, da in allen Punkten x < 1 der Wert
Null und in 1 naturlich der Wert 1 angenommen wird. Die Konvergenz ist auch nicht
gleichmaßig. Zu ε = 12
und jedem Index n gibt es namlich immer ein xn ∈ [a, 1), fur
das |fn(xn) − 0| > ε = 12
ist. Jedes xn ∈ ((12)1/n, 1) ∩ [a, 1) eignet sich z.B. dafur.
Es sei noch bemerkt, daß die punktweise Grenzfunktion einer Folge stetiger Funk-
tionen naturlich stetig sein kann, obwohl die Konvergenz nicht gleichmaßig ist.
Schranken wir die eben betrachtete Funktionenfolge {fn} etwa auf das Intervall
[0, 1) ein, so ist die punktweise Grenzfunktion dort die stetige Nullfunktion. Aber
naturlich liegt keine gleichmaßige Konvergenz vor. 2
Die Definition der punktweisen Konvergenz und der gleichmaßigen Konvergenz von
Folgen von Funktionen in Definition 12.16. weicht von unserem allgemeinen Konzept
der Konvergenz von Folgen in Abschnitt 10.1 ab. Dort hatten wir eine Folge {an}in einem normierten Vektorraum X konvergent gegen a ∈ X genannt, wenn es zu
jedem ε > 0 ein N ∈ IN gibt mit ‖an − a‖X < ε fur alle n ≥ N , wobei ‖ · ‖X die
Norm auf X bezeichnet.
Man kann zeigen, dass die punktweise Konvergenz nicht durch eine Norm induziert
wird. Die gleichmaßige Konvergenz kann man diesem Konzept jedoch auf folgende
Weise unterordnen.
Es sei
B(D) := {f : D → W : es existiert M ≥ 0 mit ‖f(x)‖W ≤ M fur alle x ∈ D}
der Vektorraum der beschrankten Funktionen auf D mit der Supremumnorm
‖f‖∞ := supx∈D
‖f(x)‖W . (12.12)

12.2. KONVERGENZ IN FUNKTIONENRAUMEN 99
Dann konvergiert eine Folge {fn} ⊂ B(D) genau dann gegen eine Funktion f ∈B(D), wenn es zu jedem ε > 0 ein N ∈ IN gibt mit
‖fn − f‖∞ = supx∈D
‖fn(x) − f(x)‖W < ε fur alle n ≥ N,
und dies ist offenbar genau dann der Fall, wenn fur alle x ∈ D
‖fn(x) − f(x)‖W < ε fur alle n ≥ N
gilt. Da N nicht von x ∈ D abhangt, konvergiert {fn} genau dann im Sinne der
Norm ‖ · ‖∞ gegen f , wenn {fn} gleichmaßig in D gegen f konvergiert.
Es sei nun noch spezieller D ⊂ V eine kompakte Menge. Dann bezeichnen wir mit
C(D) den Vektorraum der stetigen und reellwertigen Funktionen auf D, wobei das
C an das englische Wort”continuous“ fur stetig erinnert. Nach Satz 11.36. ist jede
Funktion aus C(D) beschrankt, und das Supremum wird angenommen. Wir konnen
daher in diesem Fall in Gleichung (12.12)
‖f‖∞ = maxx∈D
‖f(x)‖W
schreiben. In diesem Fall sprechen wir von der Maximumnorm oder auch Tsche-
byscheff Norm4 .
Nach Satz 12.19. ist der gleichmaßige Grenzwert stetiger Funktion wieder stetig.
Hieraus erhalt man
Satz 12.21. Es sei V ein normierter Raum und W ein Banachraum, und es sei
D ⊂ V eine kompakte Menge. Dann ist der Vektorraum C(D) der stetigen Funktio-
nen f : D → W bzgl. der Maximumnorm vollstandig.
Beweis: Es sei {fn} eine Cauchy Folge in C(D) bzgl. der Maximumnorm. Dann
existiert zu jedem ε > 0 ein N ∈ IN, so dass
‖fn(x) − fm(x)‖W < ε fur alle n,m ≥ N und alle x ∈ D. (12.13)
Damit ist fur jedes feste x ∈ D die Folge {fn(x)} eine Cauchy Folge in W , und
wegen der Vollstandigkeit von W gibt es ein f(x) ∈ D mit limn→∞ fn(x) = f(x).
Damit ist die Existenz einer Funktion f : D → W gesichert, gegen die die Folge
{fn} punktweise konvergiert.
4Pafnuty Lvovich Tschebyscheff, 1821 - 1894, russischer Mathematiker; in der englischen Lite-
ratur: Chebyshev

100 KAPITEL 12. ELEMENTARE FUNKTIONEN
{fn} konvergiert auch gleichmaßig gegen f , denn aus (12.13) folgt fur jedes x ∈ D
limm→∞ ‖fn(x) − fm(x)‖W = ‖fn(x) − f(x)‖W < ε fur jedes n ≥ N.
Da nach Satz 12.19. f : D → W stetig ist, besitzt die Cauchy Folge {fn} einen
Grenzwert f ∈ C(D), und daher ist C(D) vollstandig.
Ahnlich wie bei der absoluten Konvergenz von Reihen mit konstanten Gliedern
erhalt man die gleichmaßige Konvergenz von Reihen von Funktionen durch Majo-
risierung durch eine konstante Reihe. Dabei ist die punktweise und gleichmaßige
Konvergenz von Reihen von Funktionen naturlich wieder durch die entsprechende
Konvergenz der Folge der Partialsummen erklart.
Satz 12.22. Fur n ∈ IN seien fn Abbildungen einer Teilmenge D eines normier-
ten Vektorraumes V in einen Banachraum W . Die Reihe∞∑
n=0fn(x) konvergiert
gleichmaßig auf der Menge D gegen eine Abbildung s : D → W , wenn es eine
konvergente Reihe∞∑
n=0an mit reellen konstanten Gliedern an ≥ 0 gibt, so dass
‖fn(x)‖W ≤ an fur alle n ∈ IN0 und alle x ∈ D.
Beweis: Fur sm(x) :=m∑
n=0fn(x) und tm :=
m∑
n=0an gilt
‖sm(x) − sk(x)‖W = ‖m∑
n=k+1fn(x)‖
W
≤m∑
n=k+1
‖fn(x)‖W ≤m∑
n=k+1
an = tm − tk.
Da man die rechte Seite (unabhangig von x ∈ D) durch genugend große Wahl von
m und k beliebig klein machen kann, ist die Folge der Partialsummen fur jedes x
eine Cauchy Folge in W , also gegen ein Element in W konvergent, welches s(x)
definiert. Durch Ubergang m → ∞ in der letzten Abschatzung erhalt man
‖s(x) − sk(x)‖W ≤∞∑
n=k+1
an fur alle x ∈ D.
Daher ist auch die gleichmaßige Konvergenz klar.
Neben der Maximumnorm haben wir in Abschnitt 10.5 auf C[a, b], dem Vektorraum
der stetigen, reellwertigen Funktionen auf dem Intervall [a, b], die Norm
‖f‖2 :=
√√√√√
b∫
a
|f(x)|2 dx
betrachtet. Die Konvergenz bzgl. dieser Norm ist angemessen bei der Behandlung
von Fourier Reihen.

12.2. KONVERGENZ IN FUNKTIONENRAUMEN 101
Definition 12.23. Eine Folge {fn} ⊂ C[a, b] stetiger, reellwertiger Funktionen
auf dem Intervall [a, b] heißt konvergent im quadratischen Mittel gegen eine
Funktion f : [a, b] → IR, wenn fur alle ε > 0 ein N ∈ IN existiert mit√√√√√
b∫
a
(fn(x) − f(x))2 dx < ε fur alle n ≥ N.
Konvergenz im quadratischen Mittel ist ein schwacherer Konvergenzbegriff als gleich-
maßige Konvergenz in dem folgenden Sinne:
Satz 12.24. Es sei {fn} ⊂ C[a, b] eine Folge stetiger Funktionen, die gleichmaßig
gegen f : [a, b] → IR konvergiert. Dann konvergiert sie auch im quadratischen Mittel
gegen f .
Beweis: Wir greifen hier wieder vor und benutzen die Tatsache, dass das Integral
uber eine stetige, nichtnegative Funktion nach oben abgeschatzt werden kann durch
das Produkt der Intervallange mit dem Maximum des Integranden. Hiermit gilt die
Abschatzung
‖f − fn‖2 =(
b∫
a
(f(x) − fn(x))2 dx)1/2 ≤
√b − a‖f − fn‖∞,
aus der unmittelbar die Behauptung folgt.
Mit der ‖ · ‖2-Norm ist der Vektorraum C[a, b] nicht vollstandig. Das zeigt das
folgende Beispiel.
Beispiel 12.25. Wir betrachten in C[−1, 1] die Folge {gn}n≥2, die definiert sei
durch
gn(x) :=
−1 fur x ∈ [−1,−n−1),
nx fur x ∈ [−n−1, n−1],
1 fur x ∈ (n−1, 1].
{gn} konvergiert im quadratischen Mittel gegen die Funktion
g(x) :=
−1 fur x ∈ [−1, 0),
0 fur x = 0,
1 fur x ∈ (0, 1]
denn es gilt
‖gn − g‖22 =
∫ 1
−1(gn(x) − g(x))2 dx =
∫ n−1
−n−1(gn(x) − g(x))2 dx =
2
3n.

102 KAPITEL 12. ELEMENTARE FUNKTIONEN
Wie in Satz 10.63. erhalt man hieraus, dass {gn} in der ‖ · ‖2-Norm eine Cauchy-
Folge ist, und wie in dem Eindeutigkeitssatz fur Grenzwerte (Satz 10.23.) sieht man,
dass die Folge {gn} keinen anderen Grenzwert als g haben kann. Da g offenbar nicht
stetig ist, besitzt die Cauchy-Folge {gn} keinen Grenzwert in C[−1, 1], und daher
ist der Raum C[−1, 1] mit der ‖ · ‖2-Norm nicht vollstandig.
Daß die Folge bezuglich der Maximum-Norm nicht gegen die Funktion g konvergiert,
ist leicht zu sehen. Man kann auch leicht feststellen, daß {gn} bezuglich dieser Norm
keine Cauchy-Folge ist. Daher ist die Folge auch nicht konvergent. 2
Wir zeigen nun, dass jede stetige Funktion auf einem abgeschlossenen Intervall be-
liebig gut gleichmaßig durch ein Polynom approximiert werden kann.
Satz 12.26. (Approximationssatz von Weierstraß)
Es sei f : [a, b] → IR stetig. Dann gibt es zu jedem ε > 0 ein Polynom p mit
‖f − p‖∞ < ε.
Der Beweis des Weierstraßschen Approximationssatzes ergibt sich konstruktiv durch
Transformation des Intervalls [a, b] auf das Intervall [0, 1] und die Verwendung des
nachsten Satzes. Dieser stellt eine konstruktive Variante des Approximationssatzes
dar und benutzt die sogenannten Bernstein5 Polynome zu einer Funktion, die wir
zunachst definieren:
Definition 12.27. Zu f : [0, 1] → IR heißt
Bf,n(x) :=n∑
k=0
(
n
k
)
xk(1 − x)n−kf(k
n)
das zu f gehorende Bernstein Polynom vom Grade n.
Satz 12.28. (Bernstein)
Ist f : [0, 1] → IR stetig, so gibt es zu jedem ε > 0 ein N ∈ IN, so dass
|f(x) − Bf,n(x)| < ε fur alle x ∈ [0, 1] und alle n ≥ N
gilt.
5Sergi Natanovich Bernstein, 1880 - 1968, ukrainischer Mathematiker

12.2. KONVERGENZ IN FUNKTIONENRAUMEN 103
Bemerkung 12.29. Es gilt
Bf,n(0) = f(0), Bf,n(1) = f(1), aber i.a. Bf,n(k
n) 6= f(
k
n).
Das zu f gehorende Bernstein Polynom ist also kein Interpolationspolynom von f
zu den Knotenk
n. 2
Beweis: (von Satz 12.26.)
Satz 12.28. liefert sofort die Aussage des Satzes von Weierstraß, wenn das Intervall
[a, b] dort gleich [0, 1] ist. Ist dies nicht der Fall, so betrachtet man zu f : [a, b] → IR
die stetige Abbildung
g :
[0, 1] → IR,
x 7→ f(a + (b − a)x)
mit der
g( t − a
b − a
)
= f(t), t ∈ [a, b],
ist. Nach dem letzten Satz gibt es dann zu ε > 0 einen Index N , so daß fur alle
n ≥ N gilt
maxx∈[0,1]
|g(x) − Bg,n(x)| < ε fur alle x ∈ [0, 1],
und durch Rucktransformation folgt
maxt∈[a,b]
∣∣∣f(t) − Bg,n
( t − a
b − a
)∣∣∣ = max
t∈[a,b]
∣∣∣g
( t − a
b − a
)
− Bg,n
( t − a
b − a
)∣∣∣ < ε
fur dieselben Indizes, und da Bg,n
( t − a
b − a
)
ein Polynom in t vom selben Grad wie
Bg,n(x) in x ist, ist der Satz von Weierstraß somit auch fur allgemeine Intervalle
klar.
Den Beweis von Satz 12.28. fuhren wir der Vollstandigkeit halber im letzten Teil
dieses Unterabschnittes aus. Er ist ganz elementar, kann aber — da er keine fur
die Ziele dieser Vorlesung relevanten Techniken vermittelt — beim ersten Lesen
ubergangen werden.
Zunachst benotigen wir einige elementare Aussagen uber Bernstein-Summen:
Lemma 12.30. Es gilt fur alle n ∈ IN
n∑
k=0
(
n
k
)
xk(1 − x)n−k = 1 (12.14)

104 KAPITEL 12. ELEMENTARE FUNKTIONEN
n∑
j=0
j
n
(
n
j
)
xj(1 − x)n−j = x (12.15)
n∑
k=0
k(k − 1)
(
n
k
)
xk(1 − x)n−k = n(n − 1)x2 (12.16)
n∑
k=0
k2
n2
(
n
k
)
xk(1 − x)n−k = (1 − 1
n)x2 +
1
nx (12.17)
n∑
k=0
(x − k
n)2
(
n
k
)
xk(1 − x)n−k =1
nx(1 − x) (12.18)
Beweis: Nach dem binomischen Satz gilt
n∑
k=0
(
n
k
)
xk(1 − x)n−k = (x + (1 − x))n ≡ 1,
und dies beweist (12.14)
Aus (12.14) folgt
x =n−1∑
k=0
(
n − 1
k
)
xk+1(1 − x)n−1−k =n−1∑
k=0
k + 1
n
(
n
k + 1
)
xk+1(1 − x)n−1−k
=n∑
j=1
j
n
(
n
j
)
xj(1 − x)n−j =n∑
j=0
j
n
(
n
j
)
xj(1 − x)n−j,
d.h. (12.15)
Ebenfalls aus (12.14) folgt
n(n − 1)x2 = n(n − 1)x2n−2∑
j=0
(
n − 2
j
)
xj(1 − x)n−2−j
=n−2∑
j=0
n(n − 1)
(
n − 2
j
)
xj+2(1 − x)n−2−j
=n∑
k=2
n(n − 1)
(
n − 2
k − 2
)
xk(1 − x)n−k
=n∑
k=2
n(n − 1)(n − 2)!
(k − 2)!(n − 2 − (k − 2))!xk(1 − x)n−k
=n∑
k=2
k(k − 1)n!
k!(n − k)!xk(1 − x)n−k
=n∑
k=0
k(k − 1)
(
n
k
)
xk(1 − x)n−k,
d.h. (12.16).

12.2. KONVERGENZ IN FUNKTIONENRAUMEN 105
Aus (12.15) und (12.16) folgt
(1 − 1
n)x2 +
1
nx =
1
n2
(
n(n − 1)x2 + nx)
=1
n2
( n∑
k=0
k(k − 1)
(
n
k
)
xk(1 − x)n−k +n∑
k=0
k
(
n
k
)
xk(1 − x)n−k)
=n∑
k=0
k2
n2
(
n
k
)
xk(1 − x)n−k,
also (12.17)
Schließlich ist
1
nx(1 − x) = x2 − 2x2 + (1 − 1
n)x2 +
1
nx
= x2n∑
k=0
(
n
k
)
xk(1 − x)n−k − 2xn∑
k=0
k
n
(
n
k
)
xk(1 − x)n−k
+n∑
k=0
k2
n2
(
n
k
)
xk(1 − x)n−k
=n∑
k=0
(
x2 − 2xk
n+
k2
n2
)(
n
k
)
xk(1 − x)n−k
=n∑
k=0
(
x − k
n
)2(
n
k
)
xk(1 − x)n−k.
Beweis: (von Satz 12.28.)
Da f stetig auf dem abgeschlossenen Intervall [0, 1] ist, ist f beschrankt auf [0, 1].
Es gibt also ein K ≥ 0 mit
|f(x)| ≤ K fur alle x ∈ [0, 1].
Ferner ist f auf [0, 1] gleichmaßig stetig, d.h. zu ε > 0 gibt es ein δ > 0 mit
|f(x) − f(y)| <ε
2fur alle x, y ∈ [0, 1] mit |x − y| < δ.
Es sei nun x ∈ [0, 1] fest gewahlt. Dann gilt
|f(x) − Bf,n(x)| = |f(x) · 1 − Bf,n(x)|
=∣∣∣
n∑
k=0
(
n
k
)
xk(1 − x)n−k(f(x) − f(k
n))
∣∣∣
≤n∑
k=0
(
n
k
)
xk(1 − x)n−k|f(x) − f(k
n)|.
Wir zerlegen die Summe nun in zwei Anteile: Σ1 enthalte alle Terme, fur die |x −k/n| < δ gilt, und Σ2 enthalte die ubrigen Summanden. Wir zeigen, dass beide

106 KAPITEL 12. ELEMENTARE FUNKTIONEN
Anteile sich fur n ≥ N fur genugend großes N (das nicht von x abhangt) durch ε/2
abschatzen lassen.
Es gilt
Σ1 =∑
k : |x−k/n|<δ
(
n
k
)
xk(1 − x)n−k|f(x) − f(k
n)|
≤∑
k : |x−k/n|<δ
(
n
k
)
xk(1 − x)n−k ε
2
≤n∑
k=0
(
n
k
)
xk(1 − x)n−k ε
2=
ε
2.
Aus (12.18) folgt
n∑
k=0
(
n
k
)
xk(1 − x)n−k(x − k
n)2 =
1
nx(1 − x) ≤ 1
4n.
Wir wahlen N ≥ K/(εδ2) (unabhangig von x). Dann gilt fur alle n ≥ N
Σ2 =∑
k : |x−k/n|≥δ
(x − k
n)2
(
n
k
)
xk(1 − x)n−k |f(x) − f( kn)|
(x − kn)2
≤∑
k : |x−k/n|≥δ
(x − k
n)2
(
n
k
)
xk(1 − x)n−k |f(x)| + |f( kn)|
(x − kn)2
≤∑
k : |x−k/n|≥δ
(x − k
n)2
(
n
k
)
xk(1 − x)n−k 2K
δ2
≤ 2K
δ2
n∑
k=0
(x − k
n)2
(
n
k
)
xk(1 − x)n−k
≤ 1
4n· 2K
δ2<
ε
2.
Zusammengenommen gilt also
∣∣∣f(x)−Bf,n(x)
∣∣∣ ≤ Σ1+Σ2 <
ε
2+
ε
2= ε.
Beispiel 12.31. Abbildung 12.1 enthalt die Bernstein Polynome vom Grad n =
2, 4, 8, 16, . . . , 1024 fur die Funktion
f(x) :=
2x , 0 ≤ x ≤ 0.5
2 − 2x , 0.5 ≤ x ≤ 1. 2
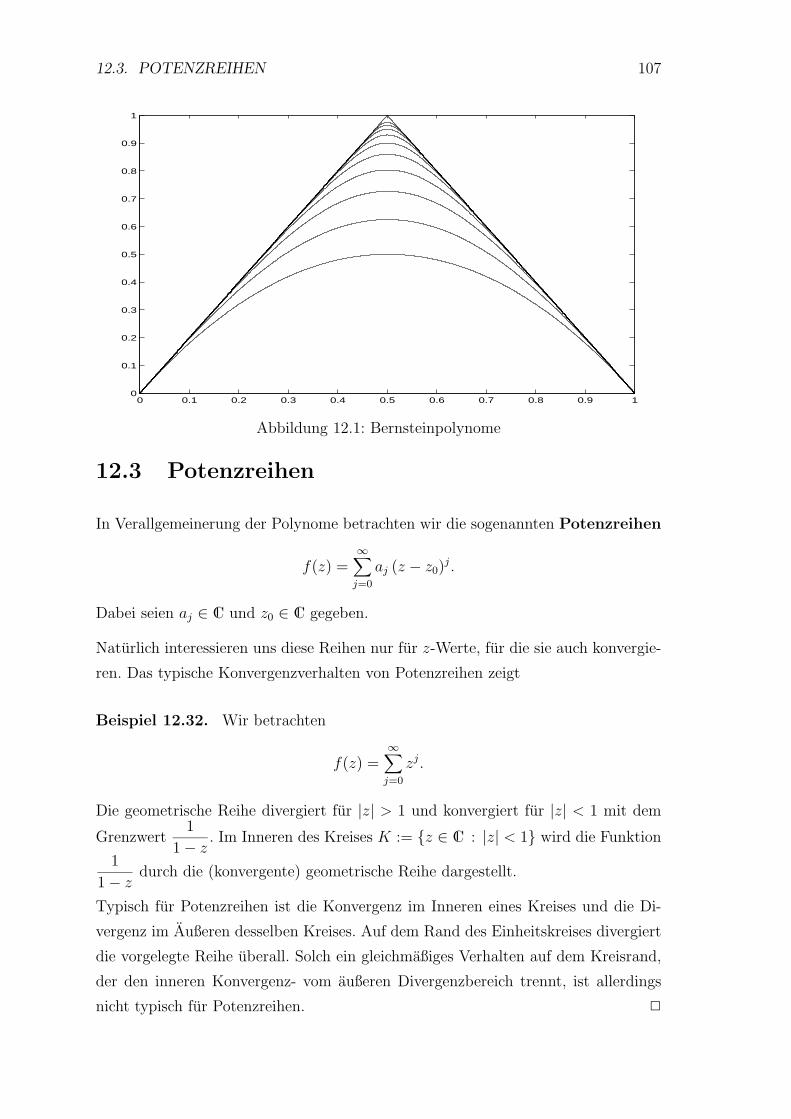
12.3. POTENZREIHEN 107
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Abbildung 12.1: Bernsteinpolynome
12.3 Potenzreihen
In Verallgemeinerung der Polynome betrachten wir die sogenannten Potenzreihen
f(z) =∞∑
j=0
aj (z − z0)j.
Dabei seien aj ∈ C und z0 ∈ C gegeben.
Naturlich interessieren uns diese Reihen nur fur z-Werte, fur die sie auch konvergie-
ren. Das typische Konvergenzverhalten von Potenzreihen zeigt
Beispiel 12.32. Wir betrachten
f(z) =∞∑
j=0
zj.
Die geometrische Reihe divergiert fur |z| > 1 und konvergiert fur |z| < 1 mit dem
Grenzwert1
1 − z. Im Inneren des Kreises K := {z ∈ C : |z| < 1} wird die Funktion
1
1 − zdurch die (konvergente) geometrische Reihe dargestellt.
Typisch fur Potenzreihen ist die Konvergenz im Inneren eines Kreises und die Di-
vergenz im Außeren desselben Kreises. Auf dem Rand des Einheitskreises divergiert
die vorgelegte Reihe uberall. Solch ein gleichmaßiges Verhalten auf dem Kreisrand,
der den inneren Konvergenz- vom außeren Divergenzbereich trennt, ist allerdings
nicht typisch fur Potenzreihen. 2

108 KAPITEL 12. ELEMENTARE FUNKTIONEN
Das Konvergenzverhalten von Potenzreihen wird durch die Formel von Cauchy und
Hadamard6 beschrieben.
Satz 12.33. Zu jeder Potenzreihe∞∑
j=0aj (z−z0)
j gibt es eine Zahl r mit 0 ≤ r ≤ ∞,
so dass die Reihe fur |z − z0| < r absolut konvergiert und fur |z − z0| > r divergiert.
Fur |z − z0| = r ist keine allgemeine Aussage moglich.
Die Zahl r kann berechnet werden mit der Formel von Cauchy und Hadamard
1
r= lim sup
n→∞n
√
|an|, (12.19)
wobei hier ausnahmsweise die Rechnungen (1r
= 0 ⇔ r = ∞) und (1r
= ∞ ⇔ r =
0) erlaubt sind. r = ∞ soll besagen, dass die Reihe fur alle z ∈ C konvergiert.
Definition 12.34. r heißt Konvergenzradius und {z ∈ C : |z − z0| < r} heißt
Konvergenzkreis der Reihe. Ist r = ∞, so heißt die durch
z 7−→∞∑
j=0
aj (z − z0)j
definierte Funktion eine ganze Funktion.
Beweis: (von Satz 12.33.)
Es sei r nach Formel (12.19) berechnet. Wir betrachten zunachst den Fall 0 < r ≤ ∞.
Es gilt
lim supn→∞
n
√
|an(z − z0)n| = |z − z0| lim supn→∞
n
√
|an| =|z − z0|
r,
und nach dem Wurzelkriterium (Korollar 10.100.) konvergiert die Potenzreihe fur
|z − z0| < r und divergiert fur |z − z0| > r, wahrend fur |z − z0| = r keine Aussage
moglich ist.
Im Falle r = 0 gilt lim supn→∞
n
√
|an| = ∞. Fur jedes z 6= z0 ist die Folge { n
√
|an|·|z−z0|}
also unbeschrankt und damit auch die Folge {|an (z−z0)n|}. Somit ist
∞∑
n=0an (z−z0)
n
divergent.
Um die Ausdrucke abzukurzen, betrachten wir von nun an den Spezialfall z0 = 0.
Dies entspricht der Transformation ζ := z − z0 von z0 in den Nullpunkt.
Die Formel (12.19) von Cauchy und Hadamard wird vor allem fur theoretische Uber-
legungen benotigt. Eine haufig einfache Art, den Konvergenzradius zu berechnen,
enthalt der folgende Satz 12.35.
6Jacques Salomon Hadamard, 1865 - 1963, franzosischer Mathematiker

12.3. POTENZREIHEN 109
Satz 12.35. Es sei an 6= 0 fur alle n ≥ N . Existiert
limn→∞
∣∣∣∣
an
an+1
∣∣∣∣ = r > 0,
so ist r der Konvergenzradius der Potenzreihe∞∑
n=0anz
n.
Beweis: Nach dem Quotientenkriterium konvergiert die Reihe∞∑
n=0anz
n absolut fur
alle z ∈ C mit
limn→∞
∣∣∣∣
an+1 zn+1
an zn
∣∣∣∣ = lim
n→∞
∣∣∣∣
an+1
an
∣∣∣∣ |z| =
|z|r
< 1,
d.h. fur |z| < r. Fur|z|r
> 1 divergiert sie, da dann nicht einmal die Glieder der
Reihe anzn gegen 0 konvergieren.
Beispiel 12.36.
f(z) :=∞∑
n=1
(−1)n+1 zn
n
hat den Konvergenzradius
r = limn→∞
∣∣∣∣
an
an+1
∣∣∣∣ = lim
n→∞
∣∣∣n + 1
n
∣∣∣ = 1.
In diesem Fall ist das Konvergenzverhalten auf dem Rand des Einheitskreises nicht
einheitlich. In z = 1 konvergiert die Reihe (alternierende harmonische Reihe) und
in z = −1 nicht (harmonische Reihe). 2
Aus den Rechenregeln (Satz 10.87. und Korollar 10.114.) fur absolut konvergente
Reihen folgt Satz 12.37.
Satz 12.37. Sind f(z) =∞∑
n=0anz
n und g(z) =∞∑
n=0bnzn Potenzreihen mit den Kon-
vergenzradien rf und rg, so gilt
(i) f(z) + g(z) =∞∑
n=0(an + bn) zn fur alle z ∈ C mit |z| < min(rf , rg),
(ii) αf(z) =∞∑
n=0(αan) zn fur alle z ∈ C mit |z| < rf ,
(iii) f(z) · g(z) =∞∑
n=0
( n∑
j=0ajbn−j
)
zn fur alle z ∈ C mit |z| < min(rf , rg).

110 KAPITEL 12. ELEMENTARE FUNKTIONEN
Bemerkung 12.38. Nur in Teil (ii) ist mit rf der Konvergenzradius exakt an-
gegeben (sofern α 6= 0 gilt). In den Teilen (i) und (iii) ist min(rf , rg) nur jeweils
der Radius eines Kreises, in dem die Konvergenz der Potenzreihen garantiert ist. In
beiden Fallen kann der Konvergenzradius sehr wohl großer sein.
Fur Teil (i) ist dies trivial. Wir wahlen namlich z.B. f aus Beispiel 12.36. mit dem
Konvergenzradius rf = 1 und g := −f . Dann ist∞∑
n=0
(an + bn)zn ≡ 0
eine ganze Funktion, der Konvergenzradius also großer als min(rf , rg) = 1. Fur das
Cauchy Produkt behandeln wir ein Beispiel in dem Aufgabenband. 2
Wir zeigen nun, dass die Potenzreihe in ihrem Konvergenzkreis eine stetige Funktion
definiert.
Satz 12.39. Besitzt die Potenzreihe∞∑
n=0anz
n den Konvergenzradius r > 0, so kon-
vergiert sie fur jedes ρ < r gleichmaßig in dem abgeschlossenen Kreis Kρ := {z ∈C : |z| ≤ ρ}.
Jede Potenzreihe definiert in ihrem Konvergenzkreis eine stetige Funktion.
Beweis: Es sei ρ < r. Die Reihe konvergiert fur z ∈ C mit |z| = ρ absolut, also
ist∞∑
n=0|an| ρn fur |z| ≤ ρ eine von z unabhangige konvergente Majorante, und nach
Satz 12.22. konvergiert∑∞
n=0 anzn gleichmaßig in Kρ gegen eine Funktion f .
Da die Funktionen z 7→ anzn fur n ∈ IN0 stetig sind, ist die Grenzfunktion f nach
Satz 12.21. stetig in Kρ, und da ρ beliebig nahe an r gewahlt werden kann, ist die
durch∑∞
n=0 anzn definierte Funktion fur alle z mit |z| < r stetig.
Bemerkung 12.40. Die in Satz 12.39. beschriebene Konvergenz von Potenzreihen
wird durch die in Abschnitt 12.2 betrachteten Arten der Konvergenz von Folgen von
Funktionen nicht hinreichend erfasst. Ist Kr := {z : |z| < r} der Konvergenzkreis
einer Potenzreihe, so konvergiert diese sicher punktweise in Kr. Sie konvergiert dort
aber nicht gleichmaßig, sondern nur in jedem abgeschlossenen Kreis Kρ, der in Kr
enhalten ist.
Ist M eine kompakte Teilmenge des Konvergenzkreises Kr, so ist M insbesondere
abgeschlossen, und daher gibt es ein ρ < r mit M ⊂ Kρ. Damit konvergiert die Po-
tenzreihe auch in M gleichmaßig. Diese Art der Konvergenz (punktweise konvergent
in der Menge und gleichmaßig konvergent in jeder kompakten Teilmenge) wird auch
kompakte Konvergenz genannt. 2

12.4. EXPONENTIALFUNKTION, LOGARITHMUSFUNKTION 111
12.4 Exponentialfunktion, Logarithmusfunktion
Definition 12.41. Die Funktion
exp(z) := ez :=∞∑
n=0
zn
n!(12.20)
heißt Exponentialfunktion oder kurz e-Funktion.
Wir haben bereits gesehen (Beispiel 10.104.), dass der Konvergenzradius der Po-
tenzreihe in (12.20) r = ∞ ist. Daher ist die Exponentialfunktion nach Satz 12.39.
stetig in C. Ferner gilt nach Beispiel 10.115. die Funktionalgleichung
exp(x + y) = exp(x) · exp(y) fur alle x, y ∈ C (12.21)
der Exponentialfunktion.
An Stelle der Schreibweise exp(z) findet man haufig fur die Exponentialfunktion den
Ausdruck ez. Inwiefern es sich bei ez um eine”echte Potenz“ handelt, wollen wir
nun untersuchen. Wir zeigen zunachst
Lemma 12.42. exp(1) = e.
Beweis: Es sei
an := (1 +1
n)n und sn :=
n∑
j=0
1
j!.
Dann gilt
limn→∞
an = e und limn→∞
sn = exp(1).
Nach dem binomischen Satz gilt
an = (1 +1
n)n =
n∑
j=0
(
n
j
)
1
nj= 1 +
n∑
j=1
1
j!· n!
(n − j)! nj
= 1 +n∑
j=1
1
j!(1 − 1
n) (1 − 2
n) · . . . · (1 − j − 1
n)
≤ 1 +n∑
j=1
1
j!= sn,
und daher folgt
e = limn→∞ an ≤ lim
n→∞ sn = exp(1). (12.22)
112 KAPITEL 12. ELEMENTARE FUNKTIONEN
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5 3
0
2
4
6
8
10
12
14
16
18
20exp
x
Abbildung 12.2: f(x) = exp(x)
Sei nun n ∈ IN fest gewahlt und N ≥ n. Dann gilt wie oben
aN = (1 +1
N)N = 1 +
N∑
j=1
1
j!(1 − 1
N) · . . . · (1 − j − 1
N)
≥ 1 +n∑
j=1
1
j!(1 − 1
N) · . . . · (1 − j − 1
N),
und daher
e = limN→∞
aN ≥ 1 +n∑
j=1
1
j!lim
N→∞
[
(1 − 1
N) · . . . · (1 − j − 1
N)]
= sn,
d.h.
e ≥ limn→∞ sn = exp(1).
Zusammen mit (12.22) gilt also e = exp(1).
Bemerkung 12.43. Lemma 12.42. zeigte e1 = exp(1).
Durch Induktion erhalten wir dann aus (12.21) fur n ∈ IN
exp(n) = [exp(1)]n = en.
Wegen
1 = exp(0) = exp(p) · exp(−p)
gilt exp(p) = ep fur alle p ∈ ZZ, und fur p ∈ ZZ und q ∈ IN ist
ep = exp(p) = exp(q · p
q) = [exp(
p
q)]q.
Daher ist
er = exp(r) fur alle r ∈ Q.

12.4. EXPONENTIALFUNKTION, LOGARITHMUSFUNKTION 113
Fur irrationale Werte x wird man nun ex so festlegen, daß die Funktionswerte fur
irrationale Argumente mit den Funktionsgrenzwerten entlang rationaler approximie-
render Argumentfolgen ubereinstimmen. Da die Exponentialfunktion stetig ist, hat
man hiermit nur noch die Moglichkeit,
ex := exp(x) fur irrationale x ∈ IR
zu definieren.
Daruber hinaus ist es naheliegend, dann auch noch
ez := exp(z) fur z ∈ C \ IR
zu setzen. 2
Satz 12.44. (Eigenschaften der reellen Exponentialfunktion)
(i) ex > 0 fur alle x ∈ IR,
(ii) x 7→ ex ist streng monoton wachsend in IR,
(iii) limx→∞
xn
ex= 0 fur jedes n ∈ IN, d.h. ex wachst fur x → ∞ schneller als jede
Potenz von x. Speziell gilt
limx→∞
ex = ∞, limx→−∞
ex = 0.
Beweis: (i): Fur x > 0 sind alle Glieder der Potenzreihe (12.20) positiv. Daher
gilt ex ≥ e0 = 1 fur alle x ≥ 0, und aus (12.21) folgt fur x < 0 auch ex = 1e−x > 0.
(ii): Fur x < y folgt aus ey−x > 1
ey = ey−x+x = ey−x · ex > ex.
(iii): Fur x > 0 folgt aus der Potenzreihe ex >xn+1
(n + 1)!, und daher
0 < xne−x <1
x(n + 1)! −→ 0 fur x → ∞.
Wegen (ii) und (iii) bildet die Exponentialfunktion die Menge IR streng monoton
auf die Menge IR+ := (0,∞) der positiven reellen Zahlen ab. Sie besitzt also eine
inverse Funktion
ln : IR+ → IR,
114 KAPITEL 12. ELEMENTARE FUNKTIONEN
0 0.5 1 1.5 2 2.5 3−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5ln
x
Abbildung 12.3: f(x) = ln(x)
den naturlichen Logarithmus (siehe Abbildung 12.3).
In der mathematischen Literatur wird an Stelle von ln meistens log verwendet.
Aus den Eigenschaften der Exponentialfunktion ergeben sich die folgenden Aussagen
fur den naturlichen Logarithmus:
Satz 12.45. (Eigenschaften des naturlichen Logarithmus)
(i) ln(x · y) = ln(x) + ln(y) fur alle x, y ∈ IR+,
(ii) ln ist stetig und streng monoton wachsend in IR+ mit
ln(1) = 0, ln(e) = 1, limx→0+0
ln(x) = −∞, limx→∞ ln(x) = ∞.
(iii) ln wachst schwacher als jede Potenz von x, d.h.
limx→∞(x−n · ln(x)) = 0 fur alle n ∈ IN, (12.23)
limx→0+0
(xn · ln(x)) = 0 fur alle n ∈ IN. (12.24)
Beweis: (i): folgt unmittelbar aus (12.21).
(ii): folgt aus Satz 11.26. und Satz 12.44.(iii).
(iii): Mit y := ln x gilt
x−n ln x =y
eny−→ 0 fur y → ∞, d.h. (12.23),
xn ln x = eny · y −→ 0 fur y → −∞, d.h. (12.24).
Mit exp und ln kann man nun die allgemeine Potenz und den allgemeinen Logarith-
mus definieren:

12.4. EXPONENTIALFUNKTION, LOGARITHMUSFUNKTION 115
Definition 12.46. Fur festes a ∈ IR+, a 6= 1, sei aexp : IR → IR+ definiert durch
aexp x := ax := ex·ln a.
Die Umkehrfunktion (die Existenz folgt aus dem folgenden Lemma 12.47. fur a 6= 1)
heißt Logarithmus zur Basis a
alog : IR+ → IR.
Die Funktionen aexp und alog haben die folgenden Eigenschaften, die unmittelbar
aus denen der Exponentialfunktion und des naturlichen Logarithmus folgen.
Lemma 12.47.
(i) aexp und alog sind fur 0 < a < 1 streng monoton fallend und fur a > 1 streng
monoton wachsend.
(ii) ax+y = ax · ay fur alle x, y ∈ IR und alog(x · y) = alog x + alog y fur alle
x, y ∈ IR+.
(iii) Fur a > 1 gilt
limx→∞
aexp x = ∞, limx→−∞
aexp x = 0,
limx→∞
alog x = ∞, limx→0+0
alog x = −∞.
Fur 0 < a < 1 mussen die Grenzwerte jeweils vertauscht werden.
(iv) (ax)y = ax·y fur alle x, y ∈ IR und alog(xy) = y · alog x fur alle x, y ∈ IR+.
Bemerkung 12.48. Auf Taschenrechnern sind haufig verschiedene Logarithmen
implementiert: ln, 10log, 2log,. . . . Tatsachlich genugt es, dass nur eine dieser Funk-
tionen aufrufbar ist, denn fur a > 0 und x > 0 folgt aus
x = aalog x =
(
eln a) alog x
= eln a· alog x
durch Logarithmieren
ln x = ln a · alog x, d.h. alog x =ln x
ln a. 2

116 KAPITEL 12. ELEMENTARE FUNKTIONEN
12.5 Trigonometrische Funktionen
Die Funktion
sin : C → C, sin z :=∞∑
n=0
(−1)n
(2n + 1)!z2n+1,
heißt Sinusfunktion, und die Funktion
cos : C → C, cos z :=∞∑
n=0
(−1)n
(2n)!z2n,
heißt Kosinusfunktion. Daß es sich bei den Restriktionen dieser beiden Funktionen
auf IR um die bisher geometrisch definierten Funktionen gleichen Namens handelt,
werden wir bald sehen.
Zunachst folgt mit dem Quotientenkriterium, dass beide Potenzreihen den Konver-
genzradius r = ∞ haben, so daß sin und cos ganze Funktionen sind und damit stetig
in ganz C sind.
Offenbar gilt
sin(−z) = − sin z und cos(−z) = cos z fur alle z ∈ C. (12.25)
Die Sinusfunktion ist also eine ungerade Funktion , und die Kosinusfunktion ist
eine gerade Funktion.
Satz 12.49. (i) Fur alle z ∈ C gilt
eiz = cos z + i · sin z,
sin z =1
2i(eiz − e−iz),
cos z =1
2(eiz + e−iz).
(ii) Fur alle z ∈ C und alle n ∈ IN gilt die Formel von Moivre7
(cos z + i sin z)n = cos(nz) + i sin(nz).
(iii) Fur alle z ∈ C und ζ ∈ C gilt
sin2 z + cos2 z = 1,
sin(z + ζ) = sin z · cos ζ + cos z · sin ζ,
cos(z + ζ) = cos z · cos ζ − sin z · sin ζ.
7Abraham de Moivre, 1667 - 1754, franzosischer Mathematiker

12.5. TRIGONOMETRISCHE FUNKTIONEN 117
Bemerkung 12.50. Man kann zeigen, daß die Funktionalgleichungen in (iii) zu-
sammen mit der Stetigkeit und den Normierungsbedingungen cos 0 = 1 und
limx→0
sin x
x= 1 die Sinus- und Kosinusfunktion auf IR eindeutig festlegen. Da die
fruher geometrisch eingefuhrten Sinus- und Kosinusfunktion diesen charakterisie-
renden Gleichungen auch genugen (Fur die geometrische Bestatigung der Grenz-
wertbedingung an den Quotienten sin(x)/x konsultiere man den Aufgabenband),
handelt es sich bei den jetzt analytisch definierten Funktionen auf IR tatsachlich um
die alten Bekannten aus Mathematik I. 2
Beweis: (von Satz 12.49.)
(i): Da die Reihe eiz =∞∑
n=0
(iz)n
n!absolut konvergiert, kann man sie umordnen und
erhalt wegen i2n = (−1)n
eiz =∞∑
n=0
(iz)n
n!=
∞∑
n=0
(−1)n
(2n)!z2n + i
∞∑
n=0
(−1)n
(2n + 1)!z2n+1 = cos z + i sin z.
Hiermit sieht man weiter
1
2(eiz + e−iz) =
1
2(cos z + i sin z + cos z − i sin z) = cos z,
und genauso erhalt man sin z =1
2i(eiz − e−iz).
(ii): (cos z + i sin z)n = (eiz)n = ei·nz = cos(nz) + i sin(nz).
(iii): Es ist fur alle z ∈ C
1 = eiz · e−iz = (cos z + i sin z) (cos z − i sin z) = cos2 z + sin2 z.
Ferner gilt
cos(z + ζ) + i sin(z + ζ) = ei(z+ζ) = eiz · eiζ
= (cos z + i sin z) · (cos ζ + i sin ζ)
= (cos z cos ζ − sin z sin ζ) + i (sin z cos ζ + cos z sin ζ) ,
und unter Benutzung von (12.25) erhalt man genauso
cos(z + ζ) − i sin(z + ζ) = cos(−(z + ζ)) + i sin(−(z + ζ))
= e−(z+ζ)i = . . . = (cos z cos ζ − sin z sin ζ) − i(sin z cos ζ + cos z sin ζ).
Subtrahiert bzw. addiert man die letzten beiden Gleichungen, so erhalt man die
Additionstheoreme.
Wir untersuchen nun die analytischen Eigenschaften der Sinus- und Kosinusfunktion
als Funktion auf der reellen Achse.
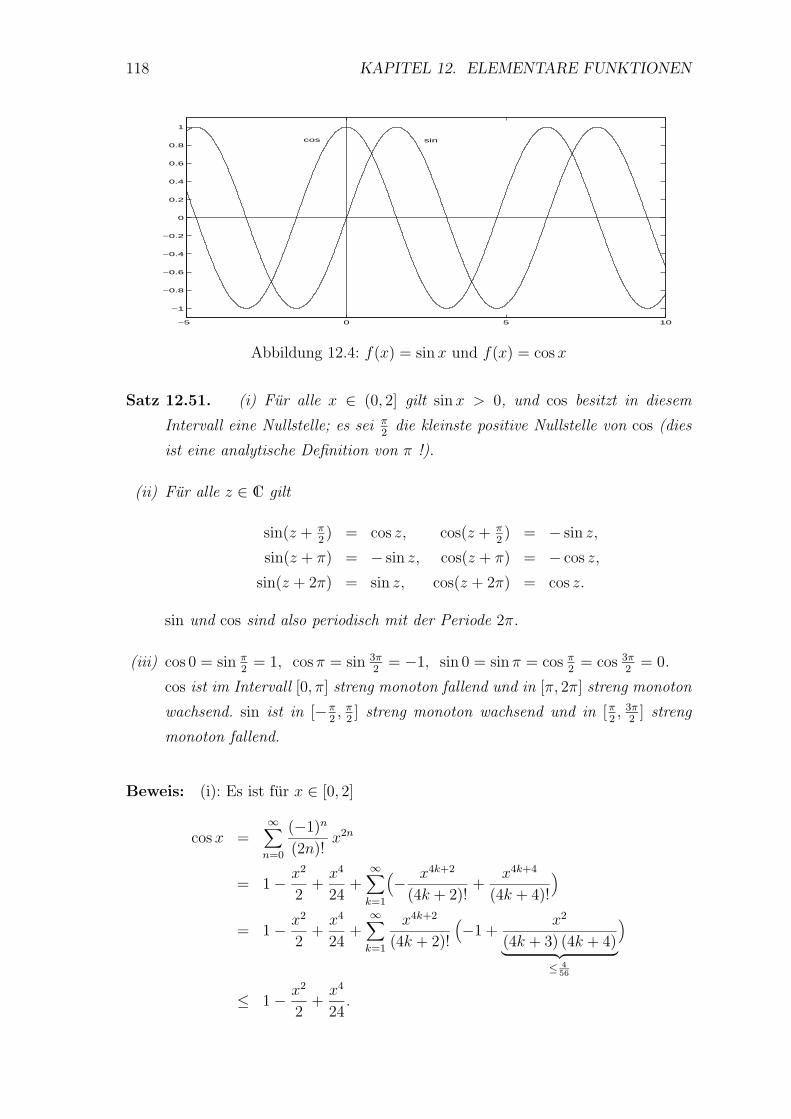
118 KAPITEL 12. ELEMENTARE FUNKTIONEN
−5 0 5 10
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
sincos
Abbildung 12.4: f(x) = sin x und f(x) = cos x
Satz 12.51. (i) Fur alle x ∈ (0, 2] gilt sin x > 0, und cos besitzt in diesem
Intervall eine Nullstelle; es sei π2
die kleinste positive Nullstelle von cos (dies
ist eine analytische Definition von π !).
(ii) Fur alle z ∈ C gilt
sin(z + π2) = cos z, cos(z + π
2) = − sin z,
sin(z + π) = − sin z, cos(z + π) = − cos z,
sin(z + 2π) = sin z, cos(z + 2π) = cos z.
sin und cos sind also periodisch mit der Periode 2π.
(iii) cos 0 = sin π2
= 1, cos π = sin 3π2
= −1, sin 0 = sin π = cos π2
= cos 3π2
= 0.
cos ist im Intervall [0, π] streng monoton fallend und in [π, 2π] streng monoton
wachsend. sin ist in [−π2, π
2] streng monoton wachsend und in [π
2, 3π
2] streng
monoton fallend.
Beweis: (i): Es ist fur x ∈ [0, 2]
cos x =∞∑
n=0
(−1)n
(2n)!x2n
= 1 − x2
2+
x4
24+
∞∑
k=1
(
− x4k+2
(4k + 2)!+
x4k+4
(4k + 4)!
)
= 1 − x2
2+
x4
24+
∞∑
k=1
x4k+2
(4k + 2)!
(
−1 +x2
(4k + 3) (4k + 4)︸ ︷︷ ︸
≤ 456
)
≤ 1 − x2
2+
x4
24.

12.5. TRIGONOMETRISCHE FUNKTIONEN 119
Daher ist cos 2 ≤ 1 − 42
+ 1624
= −13
< 0. Da cos 0 = 1 > 0 schon bekannt ist, liefert
der Zwischenwertsatz die Existenz einer Nullstelle des cos in (0, 2).
Genauso ist fur x ∈ (0, 2]
sin x =∞∑
n=0
(−1)n
(2n + 1)!x2n+1
= x(
1 − x2
6+
∞∑
k=1
( x4k
(4k + 1)!− x4k+2
(4k + 3)!
))
= x(
1 − x2
6+
∞∑
k=1
x4k
(4k + 1)!
(
1 − x2
(4k + 2) (4k + 3)︸ ︷︷ ︸
≤ 442
))
≥ x(
1 − x2
6
)
> 0.
(ii): Nach Satz 12.49.(iii) gilt sin π2
= 1 und damit
sin(z +π
2) = sin z · cos
π
2+ cos z · sin π
2= cos z,
cos(z +π
2) = cos z · cos
π
2− sin z · sin π
2= − sin z,
sin(z + π) = sin((z +π
2) +
π
2) = cos(z +
π
2) = − sin z,
und die weiteren Aussagen erhalt man genauso.
(iii): Die angegebenen Funktionswerte erhalt man mit (ii) aus cos 0 = 1 und sin 0 = 0.
Die Monotonieaussagen erhalt man so: Es seien x, y ∈ [0, π2] mit x < y und t := y−x.
Wegen t ∈ (0, π2] sind dann sin t > 0 und 0 ≤ cos t < 1. Da sin x > 0 ist, erhalt man
cos y = cos(x + t) = cos x cos t − sin x sin t < cos x.
Der Kosinus ist also streng monoton fallend in [0, π2].
Wegen sin x =√
1 − cos2 x ist der Sinus dann streng monoton wachsend in [0, π2].
Die Beziehung cos(x + π2) = − sin x liefert, dass der Kosinus streng monoton fallt in
[π2, π], so daß der Kosinus in ganz [0, π] streng monoton fallt. Die ubrigen Aussagen
erhalt man aus (ii).
Die Bestimmung von Winkeln zwischen Vektoren aus inneren Produkten stellt ei-
ne Beispielaufgabe dar, bei der die Bestimmung von Bogenmaßen aus zugehorigen
Sinus- und/oder Kosinus-Werten von Interesse war. Wie wir schon in Mathematik I
diskutierten, sind diese Funktionen aber nicht global invertierbar. Die Winkel sind
z.B. aus Sinuswerten nur bis auf additive Vielfache von 2π sowie das Vorzeichen
bestimmt. Analytisch zieht man zur Definition lokaler Umkehrfunktionen den Satz
uber die Umkehrbarkeit stetiger streng monotoner Funktionen heran:
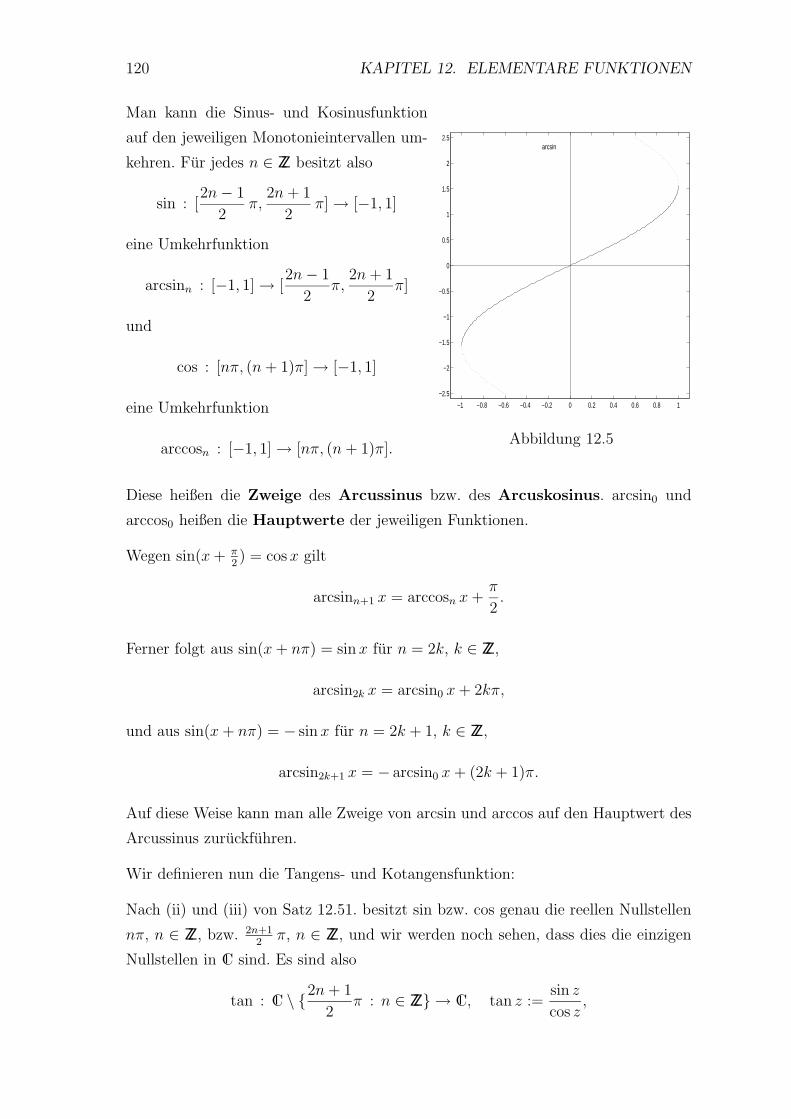
120 KAPITEL 12. ELEMENTARE FUNKTIONEN
Man kann die Sinus- und Kosinusfunktion
auf den jeweiligen Monotonieintervallen um-
kehren. Fur jedes n ∈ ZZ besitzt also
sin : [2n − 1
2π,
2n + 1
2π] → [−1, 1]
eine Umkehrfunktion
arcsinn : [−1, 1] → [2n − 1
2π,
2n + 1
2π]
und
cos : [nπ, (n + 1)π] → [−1, 1]
eine Umkehrfunktion
arccosn : [−1, 1] → [nπ, (n + 1)π].
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5arcsin
Abbildung 12.5
Diese heißen die Zweige des Arcussinus bzw. des Arcuskosinus. arcsin0 und
arccos0 heißen die Hauptwerte der jeweiligen Funktionen.
Wegen sin(x + π2) = cos x gilt
arcsinn+1 x = arccosn x +π
2.
Ferner folgt aus sin(x + nπ) = sin x fur n = 2k, k ∈ ZZ,
arcsin2k x = arcsin0 x + 2kπ,
und aus sin(x + nπ) = − sin x fur n = 2k + 1, k ∈ ZZ,
arcsin2k+1 x = − arcsin0 x + (2k + 1)π.
Auf diese Weise kann man alle Zweige von arcsin und arccos auf den Hauptwert des
Arcussinus zuruckfuhren.
Wir definieren nun die Tangens- und Kotangensfunktion:
Nach (ii) und (iii) von Satz 12.51. besitzt sin bzw. cos genau die reellen Nullstellen
nπ, n ∈ ZZ, bzw. 2n+12
π, n ∈ ZZ, und wir werden noch sehen, dass dies die einzigen
Nullstellen in C sind. Es sind also
tan : C \ {2n + 1
2π : n ∈ ZZ} → C, tan z :=
sin z
cos z,
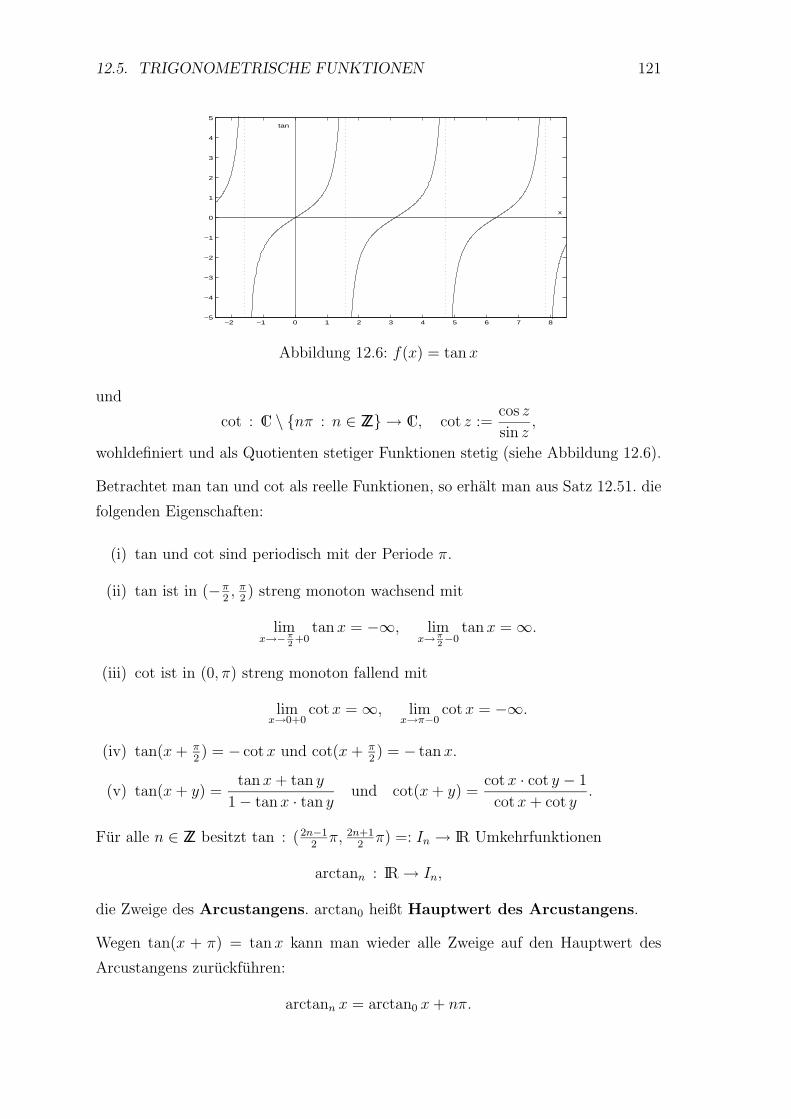
12.5. TRIGONOMETRISCHE FUNKTIONEN 121
−2 −1 0 1 2 3 4 5 6 7 8−5
−4
−3
−2
−1
0
1
2
3
4
5tan
x
Abbildung 12.6: f(x) = tan x
und
cot : C \ {nπ : n ∈ ZZ} → C, cot z :=cos z
sin z,
wohldefiniert und als Quotienten stetiger Funktionen stetig (siehe Abbildung 12.6).
Betrachtet man tan und cot als reelle Funktionen, so erhalt man aus Satz 12.51. die
folgenden Eigenschaften:
(i) tan und cot sind periodisch mit der Periode π.
(ii) tan ist in (−π2, π
2) streng monoton wachsend mit
limx→−π
2+0
tan x = −∞, limx→π
2−0
tan x = ∞.
(iii) cot ist in (0, π) streng monoton fallend mit
limx→0+0
cot x = ∞, limx→π−0
cot x = −∞.
(iv) tan(x + π2) = − cot x und cot(x + π
2) = − tan x.
(v) tan(x + y) =tan x + tan y
1 − tan x · tan yund cot(x + y) =
cot x · cot y − 1
cot x + cot y.
Fur alle n ∈ ZZ besitzt tan : (2n−12
π, 2n+12
π) =: In → IR Umkehrfunktionen
arctann : IR → In,
die Zweige des Arcustangens. arctan0 heißt Hauptwert des Arcustangens.
Wegen tan(x + π) = tan x kann man wieder alle Zweige auf den Hauptwert des
Arcustangens zuruckfuhren:
arctann x = arctan0 x + nπ.
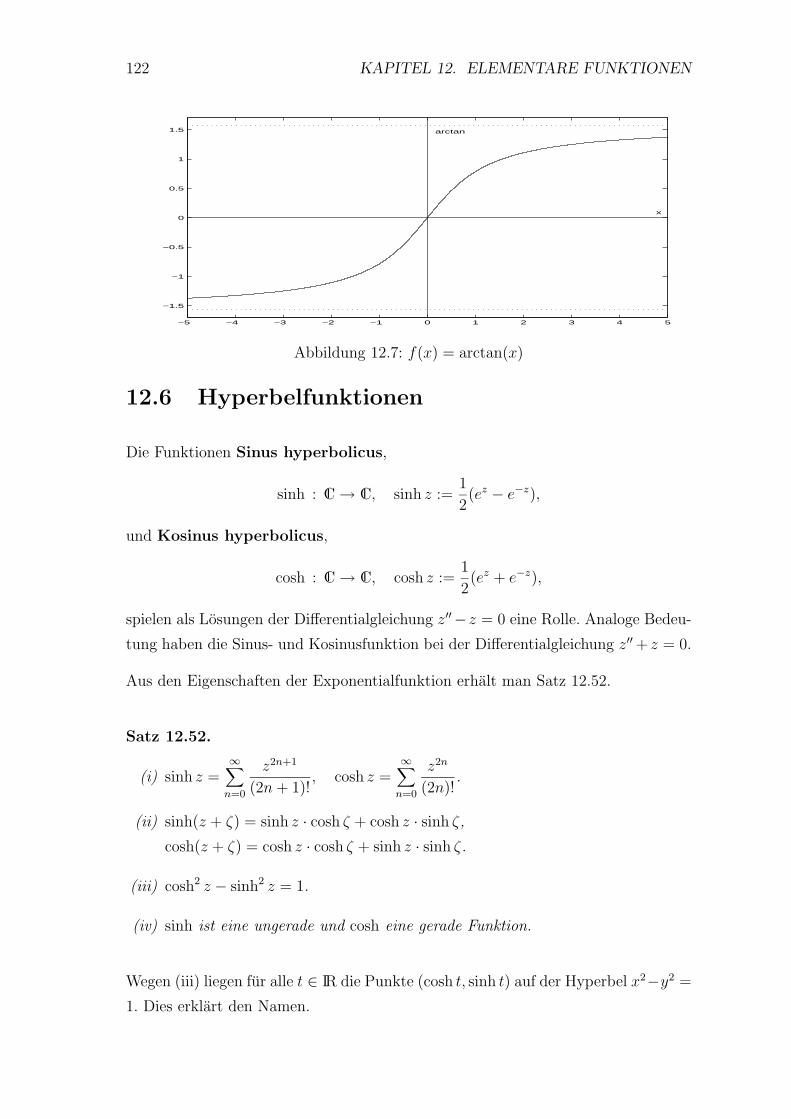
122 KAPITEL 12. ELEMENTARE FUNKTIONEN
−5 −4 −3 −2 −1 0 1 2 3 4 5
−1.5
−1
−0.5
0
0.5
1
1.5 arctan
x
Abbildung 12.7: f(x) = arctan(x)
12.6 Hyperbelfunktionen
Die Funktionen Sinus hyperbolicus,
sinh : C → C, sinh z :=1
2(ez − e−z),
und Kosinus hyperbolicus,
cosh : C → C, cosh z :=1
2(ez + e−z),
spielen als Losungen der Differentialgleichung z′′−z = 0 eine Rolle. Analoge Bedeu-
tung haben die Sinus- und Kosinusfunktion bei der Differentialgleichung z′′ + z = 0.
Aus den Eigenschaften der Exponentialfunktion erhalt man Satz 12.52.
Satz 12.52.
(i) sinh z =∞∑
n=0
z2n+1
(2n + 1)!, cosh z =
∞∑
n=0
z2n
(2n)!.
(ii) sinh(z + ζ) = sinh z · cosh ζ + cosh z · sinh ζ,
cosh(z + ζ) = cosh z · cosh ζ + sinh z · sinh ζ.
(iii) cosh2 z − sinh2 z = 1.
(iv) sinh ist eine ungerade und cosh eine gerade Funktion.
Wegen (iii) liegen fur alle t ∈ IR die Punkte (cosh t, sinh t) auf der Hyperbel x2−y2 =
1. Dies erklart den Namen.
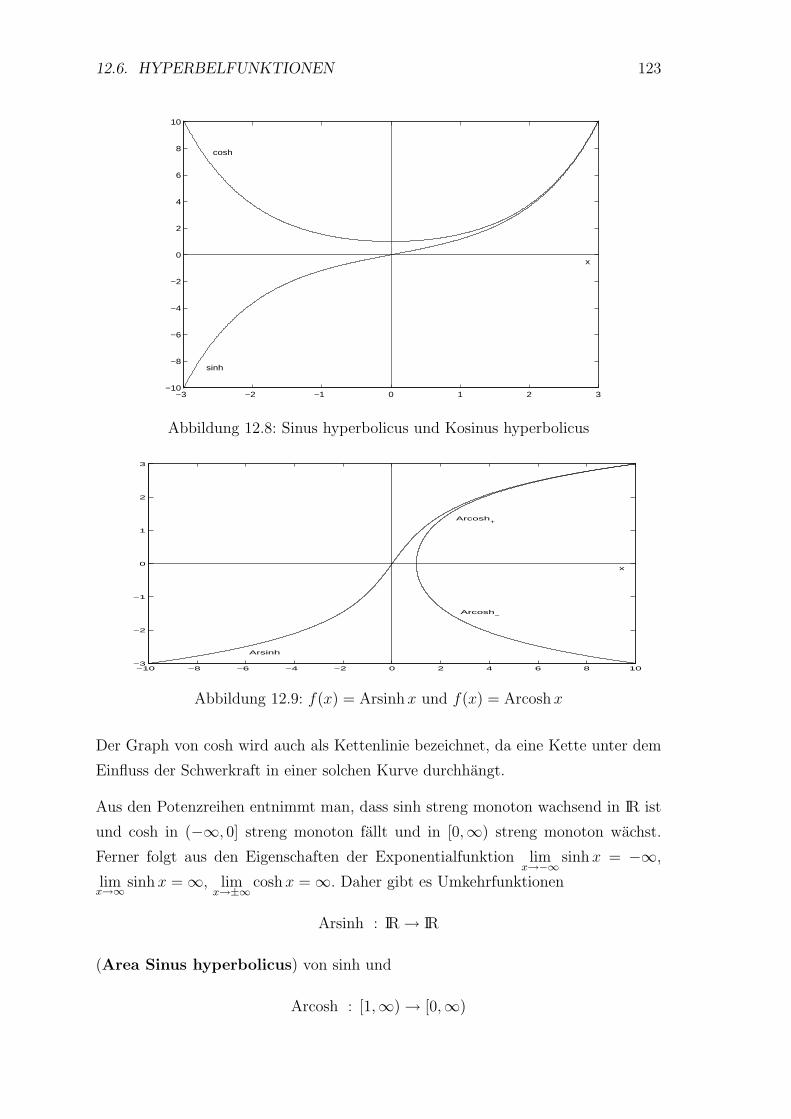
12.6. HYPERBELFUNKTIONEN 123
−3 −2 −1 0 1 2 3−10
−8
−6
−4
−2
0
2
4
6
8
10
sinh
cosh
x
Abbildung 12.8: Sinus hyperbolicus und Kosinus hyperbolicus
−10 −8 −6 −4 −2 0 2 4 6 8 10−3
−2
−1
0
1
2
3
Arsinh
Arcosh+
Arcosh−
x
Abbildung 12.9: f(x) = Arsinh x und f(x) = Arcosh x
Der Graph von cosh wird auch als Kettenlinie bezeichnet, da eine Kette unter dem
Einfluss der Schwerkraft in einer solchen Kurve durchhangt.
Aus den Potenzreihen entnimmt man, dass sinh streng monoton wachsend in IR ist
und cosh in (−∞, 0] streng monoton fallt und in [0,∞) streng monoton wachst.
Ferner folgt aus den Eigenschaften der Exponentialfunktion limx→−∞
sinh x = −∞,
limx→∞ sinh x = ∞, lim
x→±∞cosh x = ∞. Daher gibt es Umkehrfunktionen
Arsinh : IR → IR
(Area Sinus hyperbolicus) von sinh und
Arcosh : [1,∞) → [0,∞)

124 KAPITEL 12. ELEMENTARE FUNKTIONEN
(Area Kosinus hyperbolicus) und
Arcosh : [1,∞) → (−∞, 0]
von cosh (Diese beiden Zweige unterscheiden sich nur im Vorzeichen).
Die Umkehrfunktionen der Hyperbelfunktionen kann man durch die Logarithmus-
funktion ausdrucken. Zur Bestimmung von Arsinh y haben wir die Gleichung y =
sinh x = 12(ex − e−x) nach x aufzulosen. Durch Multiplikation mit ex erhalt man die
in ex quadratische Gleichung
e2x − 2exy − 1 = 0
mit den Losungen
ex = y ±√
y2 + 1.
Im Falle”−“ wird die rechte Seite negativ, wahrend ex > 0 gilt. Daher muss
ex = y +√
y2 + 1
gelten, und es folgt
x = ln(y +√
y2 + 1) = Arsinh y.
Genauso erhalt man die beiden Zweige
Arcosh y = ± ln(y +√
y2 − 1), y ≥ 1,
der Umkehrfunktion von cosh.
Zwischen den Hyperbelfunktionen und den trigonometrischen Funktionen besteht
der folgende Zusammenhang fur alle z ∈ C:
cosh(iz) = 12(eiz + e−iz) = cos z,
sinh(iz) = 12(eiz − e−iz) = i sin z,
und daher fur x + iy ∈ C, x, y ∈ IR,
sin(x + iy) = sin x cos(iy) + cos x sin(iy)
= sin x cosh y + i cos x sinh y
(wegen sin(iy) = −i sinh(i2y) = i sinh y, cos(iy) = cosh(−y) = cosh y),
cos(x + iy) = cos x cos(iy) − sin x sin(iy)
= cos x cosh y − i sin x sinh y.
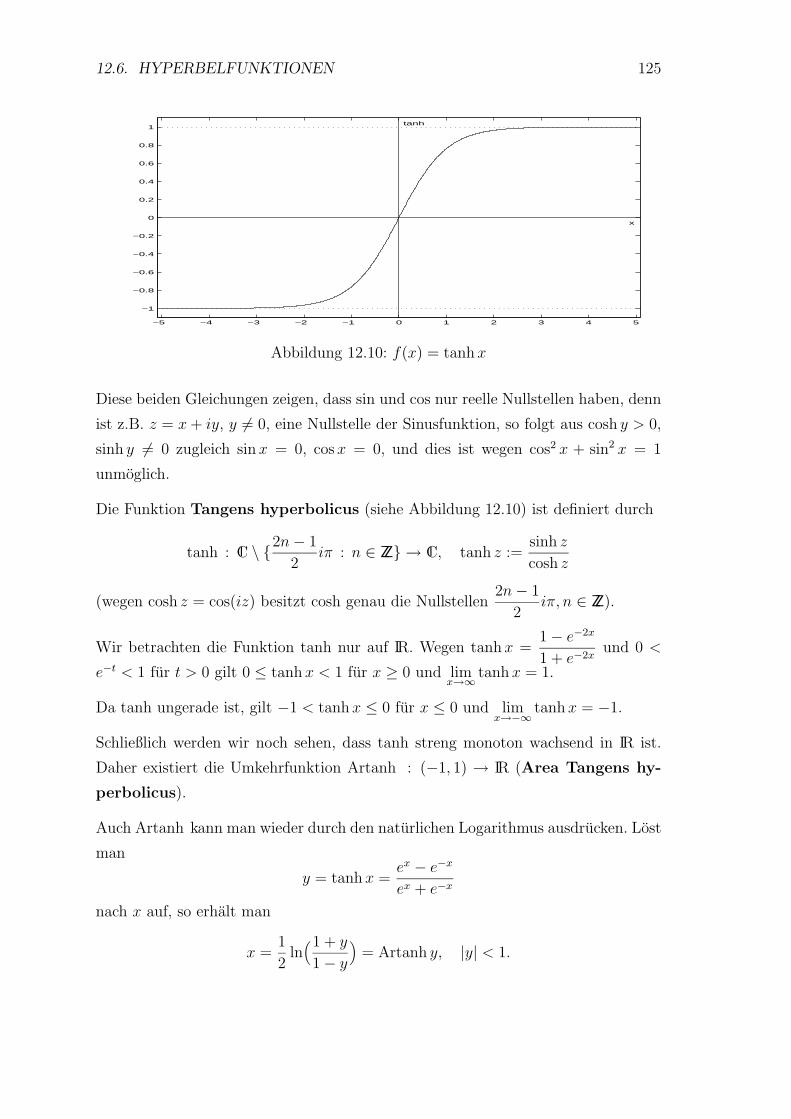
12.6. HYPERBELFUNKTIONEN 125
−5 −4 −3 −2 −1 0 1 2 3 4 5
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1tanh
x
Abbildung 12.10: f(x) = tanhx
Diese beiden Gleichungen zeigen, dass sin und cos nur reelle Nullstellen haben, denn
ist z.B. z = x + iy, y 6= 0, eine Nullstelle der Sinusfunktion, so folgt aus cosh y > 0,
sinh y 6= 0 zugleich sin x = 0, cos x = 0, und dies ist wegen cos2 x + sin2 x = 1
unmoglich.
Die Funktion Tangens hyperbolicus (siehe Abbildung 12.10) ist definiert durch
tanh : C \ {2n − 1
2iπ : n ∈ ZZ} → C, tanh z :=
sinh z
cosh z
(wegen cosh z = cos(iz) besitzt cosh genau die Nullstellen2n − 1
2iπ, n ∈ ZZ).
Wir betrachten die Funktion tanh nur auf IR. Wegen tanhx =1 − e−2x
1 + e−2xund 0 <
e−t < 1 fur t > 0 gilt 0 ≤ tanh x < 1 fur x ≥ 0 und limx→∞
tanh x = 1.
Da tanh ungerade ist, gilt −1 < tanh x ≤ 0 fur x ≤ 0 und limx→−∞
tanh x = −1.
Schließlich werden wir noch sehen, dass tanh streng monoton wachsend in IR ist.
Daher existiert die Umkehrfunktion Artanh : (−1, 1) → IR (Area Tangens hy-
perbolicus).
Auch Artanh kann man wieder durch den naturlichen Logarithmus ausdrucken. Lost
man
y = tanh x =ex − e−x
ex + e−x
nach x auf, so erhalt man
x =1
2ln
(1 + y
1 − y
)
= Artanh y, |y| < 1.

Kapitel 13
Differenzierbare reelle Funktionen
13.1 Motivation und Definition
Zum Begriff der Ableitung einer Funktion gibt es mindestens drei Zugange:
Physikalischer Zugang: Ein Punkt bewege sich auf der Zahlengerade. Jeder Zeit
t ∈ IR werde der Ort s(t) ∈ IR zugeordnet. Fur zwei verschiedene Zeiten τ, t heißt
dann
v(τ, t) :=s(τ) − s(t)
τ − t
die mittlere Geschwindigkeit. Existiert zur Zeit t der Limes v(t) := limτ→t
v(τ, t), so
ordnen wir dem Zeitpunkt t die momentane Geschwindigkeit v(t) zu, die dann Ab-
leitung von s bei t heißt.
Andert sich die Bewegung nicht zu schnell, so kann die Ortsanderung ∆s fur kleine
Zeitanderungen ∆t durch den linearen Zusammenhang ∆s ≈ ∆t · v(t) gut voraus-
gesagt werden. Die Funktion s(t), welche die Zeitabhangigkeit des Ortes beschreibt,
wird dabei selbst in der Nahe eines Zeitpunktes t0 durch die affin lineare Funktion
ℓ(t) := s(t0) + v(t0)(t − t0) ersetzt.
Analytisch-numerischer Zugang (siehe Abbildung 13.1): Gegeben sei f : IR ⊃I → IR. Bei diesem Zugang geht es direkt um eine in der Nahe von x0 ∈ I
”moglichst
gute“ Approximation der Funktion durch eine affin lineare Funktion g(x) = c1+c2x.
Zunachst wahlt man sicher die ci so, dass f(x0) = g(x0) gilt. Dies ist genau fur die
Geraden der Gestalt g(x) = a · (x − x0) + f(x0) der Fall.
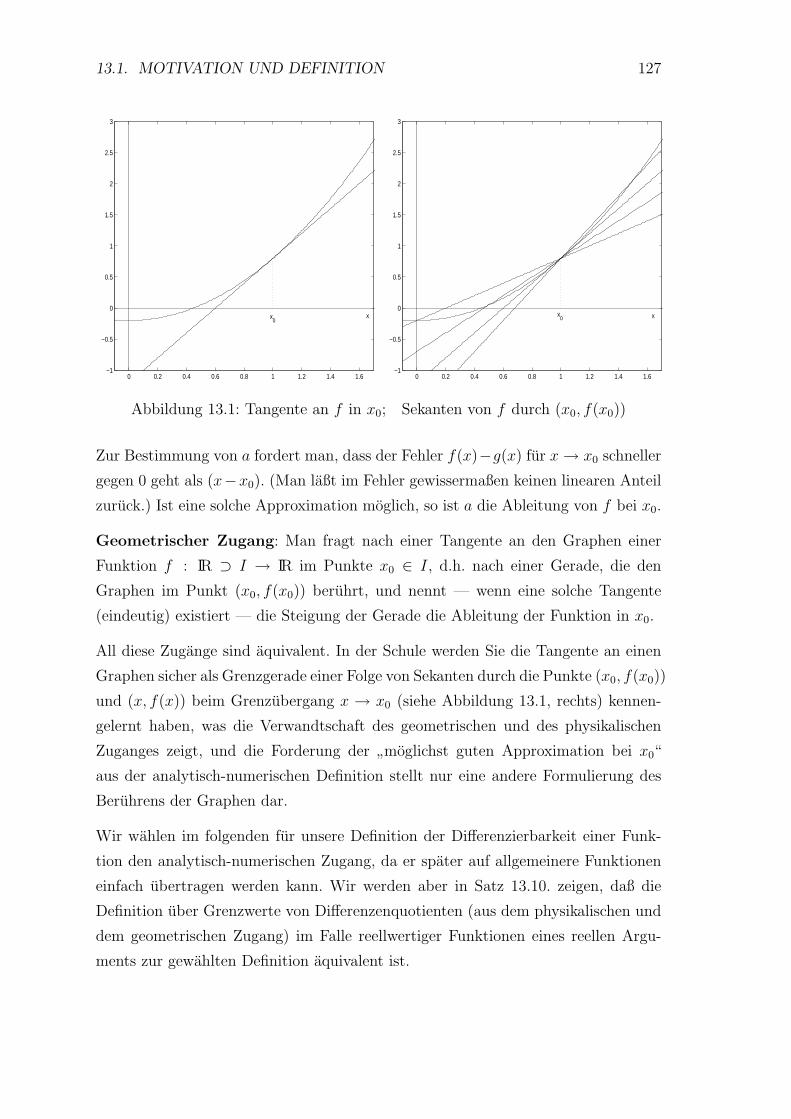
13.1. MOTIVATION UND DEFINITION 127
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6−1
−0.5
0
0.5
1
1.5
2
2.5
3
xx0
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6−1
−0.5
0
0.5
1
1.5
2
2.5
3
xx0
Abbildung 13.1: Tangente an f in x0; Sekanten von f durch (x0, f(x0))
Zur Bestimmung von a fordert man, dass der Fehler f(x)−g(x) fur x → x0 schneller
gegen 0 geht als (x−x0). (Man laßt im Fehler gewissermaßen keinen linearen Anteil
zuruck.) Ist eine solche Approximation moglich, so ist a die Ableitung von f bei x0.
Geometrischer Zugang: Man fragt nach einer Tangente an den Graphen einer
Funktion f : IR ⊃ I → IR im Punkte x0 ∈ I, d.h. nach einer Gerade, die den
Graphen im Punkt (x0, f(x0)) beruhrt, und nennt — wenn eine solche Tangente
(eindeutig) existiert — die Steigung der Gerade die Ableitung der Funktion in x0.
All diese Zugange sind aquivalent. In der Schule werden Sie die Tangente an einen
Graphen sicher als Grenzgerade einer Folge von Sekanten durch die Punkte (x0, f(x0))
und (x, f(x)) beim Grenzubergang x → x0 (siehe Abbildung 13.1, rechts) kennen-
gelernt haben, was die Verwandtschaft des geometrischen und des physikalischen
Zuganges zeigt, und die Forderung der”moglichst guten Approximation bei x0“
aus der analytisch-numerischen Definition stellt nur eine andere Formulierung des
Beruhrens der Graphen dar.
Wir wahlen im folgenden fur unsere Definition der Differenzierbarkeit einer Funk-
tion den analytisch-numerischen Zugang, da er spater auf allgemeinere Funktionen
einfach ubertragen werden kann. Wir werden aber in Satz 13.10. zeigen, daß die
Definition uber Grenzwerte von Differenzenquotienten (aus dem physikalischen und
dem geometrischen Zugang) im Falle reellwertiger Funktionen eines reellen Argu-
ments zur gewahlten Definition aquivalent ist.

128 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Definition 13.1. Sei I ⊂ IR ein offenes Intervall.
f : I → IR heißt differenzierbar in x0 ∈ I, wenn es ein a ∈ IR gibt mit
(i) f(x) = f(x0) + a · (x − x0) + r(x, x0),
(ii) limx→x0
r(x, x0)
x − x0
= 0.
a heißt Ableitung oder Differentialquotient von f in x0 und wird mit
a = f ′(x0) =df
dx(x0)
bezeichnet.
Die affin lineare, approximierende Funktion
ℓ : IR → IR, ℓ(x) := f(x0) + f ′(x0)(x − x0) (13.1)
heißt Linearisierung von f in x0.
Die durch (x, ℓ(x)) gegebene Gerade heißt Tangente an den Graphen von f in x0.
Bemerkung 13.2. In der Literatur wird die affin lineare Funktion ℓ aus (13.1)
haufig verkurzt linear genannt, obwohl ℓ : IR → IR keine lineare Abbildung im
Sinne von Kapitel 4 definiert. Wir werden uns dieser Sprachregelung anschließen. 2
Bemerkung 13.3. Es sei an dieser Stelle deutlich darauf hingewiesen, daß wir die
Differenzierbarkeit der Funktion f nur in einem inneren Punkt des Definitions-
bereiches der Funktion definieren, d.h. einem Punkt, der in einem offenen Intervall
liegt, das ganz im Definitionsbereich enthalten ist.
Wenn wir daher unten voraussetzen, daß eine Funktion in einem Punkt x0 differen-
zierbar sei, so bedeutet dies automatisch, daß die Funktion in einem offenen Intervall
erklart ist, welches den Punkt x0 umgibt. Eine solche Menge heißt in der Mathematik
auch Umgebung des Punktes x0. 2
Beispiel 13.4. Sei f : IR → IR, f(x) := mx + b, und sei x0 ∈ IR beliebig. Dann
ist f differenzierbar in x0 mit der Ableitung f ′(x0) = m. Da namlich
f(x) = mx + b = mx0 + b + m(x − x0) + 0 = f(x0) + m(x − x0) + r(x, x0)
ist, ist mit r(x, x0) ≡ 0 sicher limx→x0 r(x, x0)/(x − x0) = 0.
Nach dem numerisch-analytischen Zugang ist das klar: Die beste Approximation ei-
ner linearen Funktion aus der Menge der linearen Funktionen ist wohl unubertreffbar
sie selbst. 2

13.1. MOTIVATION UND DEFINITION 129
Beispiel 13.5. Sei g(x) = x2 und x0 ∈ IR beliebig. Dann gilt
g(x) = x2 = x20 + 2x0(x − x0) + (x − x0)
2 =: g(x0) + a (x − x0) + r(x, x0),
und wegen
limx→x0
r(x, x0)
x − x0
= limx→x0
(x − x0) = 0
ist g differenzierbar in x0 mit der Ableitung g′(x0) = 2x0. 2
Beispiel 13.6. Betrachte h(x) = |x| in x0 = 0. Aus dem Ansatz
h(x) = h(x0) + a (x − x0) + r(x, x0)
mit unbekanntem a erhalt man
r(x, x0)
x − x0
=1
x
(
h(x) − h(x0) − a (x − x0))
=1
x(|x| − ax) =
−1 − a fur x < 0,
1 − a fur x > 0.
Danach existiert limx→x0
r(x, x0)
x − x0
fur kein a ∈ IR, und h ist somit nicht differenzierbar
in x0 = 0.
h ist sehr wohl differenzierbar in jedem Punkt x0 6= 0. Ist z.B. x0 > 0, so gibt es
stets ein offenes Intervall (a, b), welches x0 enthalt und ganz aus positiven Werten
besteht. Auf diesem Intervall ist h(x) = x, so daß nach Beispiel 13.4. dort h′(x0) = 1
ist. Analog ist h in allen x0 < 0 differenzierbar mit h′(x0) = −1. 2
Beispiel 13.7. Es sei k(x) :=√
|x|. Dann gilt fur x0 > 0 und x > 0
√x =
√x0 +
1
2√
x0
(x − x0) +(√
x −√x0 −
1
2√
x0
(x − x0))
=√
x0 +1
2√
x0
(x − x0) +1
2√
x0
(
2√
x√
x0 − 2x0 − x + x0
)
=√
x0 +1
2√
x0
(x − x0) −1
2√
x0
(√x −√
x0
)2
=:√
x0 +1
2√
x0
(x − x0) + r(x, x0)
und
limx→x0
r(x, x0)
x − x0
= − 1
2√
x0
limx→x0
(√
x −√x0)
2
(√
x −√x0)(
√x +
√x0)
= − 1
2√
x0
√x −√
x0√x +
√x0
= 0.

130 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
k ist also fur alle x0 > 0 differenzierbar in x0 mit der Ableitung
k′(x0) =1
2√
x0
.
Genauso zeigt man, dass k fur alle x0 < 0 differenzierbar ist und dass
k′(x0) = − 1√
|x0|
gilt. In x0 = 0 ist k nicht differenzierbar, denn sonst wurde ein a ∈ IR existieren mit
limx→0
k(x) − k(0) − a · xx
= limx→0
(
√
|x|x
− a)
= 0.
Dies ist aber fur kein a ∈ IR erfullbar.
Die Kenntnis der Ableitung von k kann man nutzen, um z.B.√
401 naherungsweise
zu berechnen. Es ist bekannt, dass√
400 = 20 gilt, und daher liefert die Linearisie-
rung der Wurzelfunktion in x0 = 20
√401 ≈
√400 +
1
2√
400(401 − 400) = 20.025.
Tatsachlich gilt√
401 = 20.024984 . . .. 2
Definition 13.8. Ist eine in dem Intervall I := (a, b) definierte Funktion in allen
Punkten x0 ∈ I differenzierbar, so heißt f differenzierbar in I.
Ist f in I differenzierbar, so definiert die Zuordnung x0 7→ f ′(x0) eine reellwertige
Funktion auf I. Diese wird mit f ′ bezeichnet und heißt die Ableitung von f in I.
Ist die Funktion f ′ eine in x0 ∈ I stetige Funktion, so heißt f in x0 stetig diffe-
renzierbar. Die Menge der in I stetig differenzierbaren Funktionen bezeichnet man
mit C1(a, b).
Der spater wichtige Raum C1[a, b] (nun mit abgeschlossenen Intervall), ist der Raum
der auf [a, b] stetigen und in (a, b) differenzierbaren Funktionen f , deren Ableitung
f ′ : (a, b) → IR in (a, b) stetig ist und in die Randpunkte a und b stetig fortgesetzt
werden kann.
Den Raum der auf einem Intervall I (offen oder abgeschlossen) stetigen Funktionen
bezeichnet man mit C(I).
In allen hier gegebenen Definitionen ist es sinnvoll, auch verallgemeinerte Intervalle
(z.B. (a,∞), (−∞, b] oder IR) fur I zuzulassen.

13.1. MOTIVATION UND DEFINITION 131
Beispiel 13.9. Fur die Abbildungen f(x) := mx+b aus Beispiel 13.4. und g(x) :=
x2 aus Beispiel 13.5. gilt offenbar f ∈ C1(IR) und g ∈ C1(IR), und die Ableitungen
sind f ′(x) ≡ m und g′(x) = 2x.
Fur die Abbildung h(x) := |x| aus Beispiel 13.6. gilt h 6∈ C1(IR), da h nicht in
x0 = 0 differenzierbar ist. Es sind jedoch die Restriktionen von h auf die Intervalle
(−∞, 0) und (0,∞) stetig differenzierbar. Wir schreiben dafur h ∈ C1(−∞, 0) und
h ∈ C1(0,∞). Fur die Ableitung gilt
h′(x) =
−1 fur x < 0
1 fur x > 0.
Da h′ : (−∞, 0) → IR, h′(x) = −1 offenbar stetig auf x0 = 0 durch h′(0) = −1 stetig
fortgesetzt werden kann, gilt sogar h ∈ C1(−∞, 0]. Genauso gilt auch h ∈ C1[0,∞).
Man beachte aber, dass man hieraus nicht f ∈ C1((−∞, 0] ∪ [0,∞)) = C1(IR)
schließen kann.
Die Funktion k aus Beispiel 13.7. ist in (−∞, 0) und in (0,∞) stetig differenzierbar.
Es gilt aber k 6∈ C1(−∞, 0] und k 6∈ C1[0,∞), denn die Grenzwerte
limx→0−0
k′(x) = limx→0−0
1
2√−x
und limx→0+0
k′(x) = limx→0+0
1
2√
x
existieren nicht. 2
Satz 13.10. (i) f ist genau dann differenzierbar in x0, wenn
limx→x0
f(x) − f(x0)
x − x0
existiert. Es gilt dann
f ′(x0) = limx→x0
f(x) − f(x0)
x − x0
. (13.2)
(ii) Ist f differenzierbar in x0, so ist f stetig in x0.
(iii) Ist f differenzierbar in x0, so ist die Ableitung f ′(x0) eindeutig bestimmt.
Beweis: (i): f ist genau dann in x0 differenzierbar, wenn a ∈ IR existiert, so daß
fur r(x, x0) aus
f(x) = f(x0) + a(x − x0) + r(x, x0) (13.3)
folgt limx→x0
r(x, x0)/(x − x0) = 0. Indem wir (13.3) nach r(x, x0) auflosen
r(x, x0) = f(x) − f(x0) − a(x − x0)

132 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
und durch (x− x0) teilen, sehen wir, daß f genau dann differenzierbar ist, wenn ein
a ∈ IR existiert mit limx→x0
(f(x) − f(x0)
x − x0
− a)
= 0. Letzteres ist genau dann der Fall,
wenn der Grenzwert in (13.2) existiert und gleich a ist.
(iii): Die Aussage folgt aus den Rechenregeln fur Grenzwerte.
(ii): Es ist
limx→x0
(f(x)−f(x0)) = limx→x0
(x−x0)f(x) − f(x0)
x − x0
= limx→x0
(x−x0) f ′(x0) = 0.
Bemerkung 13.11. Beispiel 13.6. zeigt, dass die Umkehrung von Satz 13.10. (ii)
nicht gilt. Die Funktion f(x) = |x| ist in x0 = 0 stetig, aber nicht differenzierbar. 2
Wir haben die Ableitung einer Funktion f in einem Punkt x0 dadurch motiviert,
dass wir f in einer Umgebung von x0 linearisieren wollten. Naturlich macht es auch
Sinn, eine auf einem abgeschlossenen Intervall [a, b] definierte Funktion in der Nahe
des Randpunktes linearisieren zu wollen, d.h. durch eine lineare Funktion zu ap-
proximieren. In diesem Fall hat man aber auf die Richtung zu achten, in der die
Approximation gelten soll.
Fur die Differentiation in einem Intervallrandpunkt wahlt man zur Definition die
sogenannte einseitige Ableitung, die auch in inneren Punkten des Definitionsbe-
reichs Sinn macht.
Definition 13.12. Die Funktion f : [c, d] → IR besitze in x0 ∈ (c, d] einen links-
seitigen Grenzwert f(x0−0) = limx→x0−0
f(x). f heißt linksseitig differenzierbar in
x0, falls
f(x) = f(x0 − 0) + a (x − x0) + r(x, x0), limx→x0−0
r(x, x0)
x − x0
= 0. (13.4)
f ′−(x0) := a heißt dann linksseitige Ableitung von f in x0.
Entsprechend heißt f rechtsseitig differenzierbar in x0 ∈ [c, d), wenn f einen
rechtsseitigen Grenzwert f(x0 + 0) besitzt und
f(x) = f(x0 + 0) + a (x − x0) + r(x, x0), limx→x0+0
r(x, x0)
x − x0
= 0. (13.5)
f ′+(x0) := a heißt dann rechtsseitige Ableitung von f in x0.
Die linearen Anteile der rechten Seiten der ableitungsdefinierenden Gleichungen
(13.4) bzw. (13.5) nennt man links- bzw. rechtsseitige Linearisierung der Funkti-
on.

13.1. MOTIVATION UND DEFINITION 133
Bemerkung 13.13. Entsprechend Satz 13.10. (i) ist f in x0 genau dann linksseitig
bzw. rechtsseitig differenzierbar, wenn der einseitige Grenzwert des Differenzenqou-
tienten
limx→x0−0
f(x) − f(x0 − 0)
x − x0
bzw. limx→x0+0
f(x) − f(x0 + 0)
x − x0
existiert. Es gilt dann entsprechend (13.2)
f ′−(x0) = lim
x→x0−0
f(x) − f(x0 − 0)
x − x0
bzw. f ′+(x0) = lim
x→x0+0
f(x) − f(x0 + 0)
x − x0
2
Bemerkung 13.14. Die Definition der einseitigen Ableitungen in x0 ist unabhan-
gig vom Wert f(x0). Sie gibt an, mit welcher Steigung die Funktion sich ihrem
einseitigen Grenzwert von der jeweiligen Seite nahert.
Wenn f(x) nahe c in [c, d) (inklusive c) durch die Linearisierung f(c+0)+f ′+(c)(x−c)
ersetzt werden soll, ist diese bei c selbst sicher nur dann eine gute Approximation,
wenn f in c stetig ist, so daß dann f(c+0) = f(c) ware. Man nennt in diesem Fall die
rechtsseitige Ableitung f ′+(c) im Randpunkt c auch etwas unsauber die Ableitung
von f im Randpunkt c. 2
Beispiel 13.15. Die Funktion h aus Beispiel 13.6. ist nicht in x0 = 0 differenzier-
bar. Sie ist aber offenbar linksseitig differenzierbar in x0 = 0 mit h′−(0) = −1 und
rechtsseitig differenzierbar in x0 = 0 mit h′+(0) = 1. 2
Beispiel 13.16. Die Funktion
f(x) :=
1 , x ≥ 0
0 , x < 0
ist nicht differenzierbar in x0 = 0, da sie in x0 nicht einmal stetig ist.
f ist linksseitig differenzierbar in x0 mit f ′−(0) = 0, denn es existiert limx→0−0 f(x) =
0 und
limx→0−0
f(x) − f(0 − 0) − 0 · xx − 0
= 0.
Beachten Sie, daß f nicht linksseitig stetig in x0 = 0 ist.
Im Gegensatz dazu ist f rechtsseitig stetig. Die Tatsache, daß f auch rechtsseitig
differenzierbar in x0 = 0 ist mit f ′+(0) = 0, hangt allerdings nicht von der rechts-
seitigen Stetigkeit ab. Ware f(0) nicht durch den Wert 1, sondern etwa den Wert
f(0) = 19.98 definiert, so ware f in Null weder links- noch rechtsseitig stetig, aber
immer noch links- und rechtsseitig differenzierbar. Die linksseitigen und die rechts-
seitigen Linearisierungen von f stimmen ubrigens links bzw. rechts von x0 = 0 mit
der Funktion uberein. 2

134 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Satz 13.17. f ist genau dann differenzierbar in x0, wenn f stetig in x0 ist, links-
seitig und rechtsseitig differenzierbar in x0 ist und wenn f ′−(x0) = f ′
+(x0) gilt.
Beweis: Ist f differenzierbar in x0, so ist f nach Satz 13.10. stetig in x0. Zudem
erfullt die Linearisierung f(x0) + f ′(x0)(x− x0) sowohl die Bedingung (13.4) fur die
linksseitige Linearisierung f(x0 − 0) + f ′−(x0)(x− x0) als auch die Bedingung (13.5)
fur die rechtsseitige Linearisierung f(x0 + 0) + f ′+(x0)(x − x0).
Ist umgekehrt f stetig in x0, dort links- und rechtsseitig differenzierbar und stimmen
die einseitigen Ableitungen uberein, so stimmen wegen f(x0 + 0) = f(x0 − 0) =
f(x0) und f ′−(x0) = f ′
+(x0) die links- und rechtseitigen Linearisierungen uberein
und erfullen die Bedingungen an die Linearisierung f(x0) + f ′(x0)(x − x0).
In Beispiel 13.6. und Beispiel 13.16. ist die Differenzierbarkeit jeweils in nur einem
Punkt verletzt. Man kann leicht Beispiele angeben, die in endlich vielen Punkten,
oder abzahlbar vielen Punkten nicht differenzierbar sind. Von Weierstraß wurde
ein Beispiel einer Funktion konstruiert, die auf ganz IR stetig ist, aber nirgends
differenzierbar.
Beispiel 13.18. Ist 0 < α < 1 und ist b ∈ IN eine gerade Zahl mit αb > 1 + 32π,
so ist die Funktion
f : IR → IR, f(x) :=∞∑
n=1
αn sin(bnπx) (13.6)
stetig auf IR, aber nirgends differenzierbar.
Fur alle n ∈ IN und alle x ∈ IR gilt
|αn sin(bnπx)| ≤ αn,
und∑∞
n=1 αn konvergiert. Daher konvergiert die Reihe in (13.6) gleichmaßig, und da
alle Glieder stetig in IR sind, ist f stetig in IR.
Dass f in keinem Punkt x ∈ IR differenzierbar ist, findet man in Mangold und
Knopp [12], Band 2, Seite 280 ff.
Abbildung 13.2 und Abbildung 13.3 enthalten die ersten Partialsummen
fn(x) =n∑
j=1
1
2jcos(12jπx)
von f . 2
13.1. MOTIVATION UND DEFINITION 135
−0.05 −0.04 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05
−0.5
0
0.5
1
n=1
−0.05 −0.04 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05
−0.5
0
0.5
1
n=2
Abbildung 13.2: Partialsummen fn(x) =n∑
j=1
1
2jcos(12jπx), n = 1, n = 2
−0.05 −0.04 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05
−0.5
0
0.5
1
n=3
−0.05 −0.04 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05
−0.5
0
0.5
1
n=4
Abbildung 13.2: Partialsummen fn(x) =n∑
j=1
1
2jcos(12jπx), n = 3, n = 4

136 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Die in Satz 13.10. (i) bewiesene Charakterisierung der Differenzierbarkeit uber eine
Grenzwertbildung des Differenzenquotienten ist vermutlich in der Schule zur De-
finition herangezogen worden. Der hier gewahlte Zugang zur Ableitung uber die
lokale lineare Approximation von f(x) − f(x0) hat den Vorteil, leicht auf Funk-
tionen ubertragbar zu sein, deren Definitionsbereich und/oder Bildbereich hohere
Dimension haben.
Ist namlich f : D → IRn, D ⊂ IRm und x0 ein innerer Punkt von D (das ist hier
ein Punkt, zu dem eine ganze Kugel um x0 auch noch zu D gehort), so wird — wie
vorher im eindimensionalen Fall f(x) − f(x0) durch a(x − x0) linear approximiert
wurde — jetzt die Funktion f(x)−f(x0) von IRm nach IRn linear approximiert. Wie
aus Mathematik I bekannt, werden die linearen Abbildungen von IRm nach IRn durch
die (n,m)-Matrizen vermittelt. Man zielt daher bei der Definition der Ableitung auf
eine lineare Approximation
f(x) − f(x0) ≈ A(x − x0),
wobei die (1, 1)-Matrix a =: f ′(x0) nun allgemeiner zur Matrix A ∈ IR(n,m) wird.
Vollig analog zur eindimensionale Definition vereinbart man deshalb:
Definition 13.19. f : D → IRn, D ⊂ IRm, ist im inneren Punkt x0 von D
differenzierbar mit der Ableitung f ′(x0) = A ∈ IR(n,m), wenn fur
r(x,x0) := f(x) − f(x0) − A(x − x0)
gilt
limx→x0
‖r(x,x0)‖‖x − x0‖ = 0.
Bemerkung 13.20. Wegen der Aquivalenz der Normen in endlichdimensionalen
Raumen ist diese Definition unabhangig von der Wahl der dabei verwendeten Nor-
men. Wir konnten uns daher in der Definition die Laxheit erlauben, nicht gleich dar-
auf hinzuweisen, daß im Urbildraum (fur die Normierung der x-Differenz ‖x−x0‖)und im Bildraum (fur die Normierung des Approximationsfehlers ‖r(x,x0)‖ =
‖f(x) − f(x0) − A(x − x0)‖) im Falle m 6= n auf jeden Fall verschiedene Nor-
men verwendet werden mussen.
Im Falle m = 1 und n ≥ 1 beliebig konnen wir in der Definition der Differenzierbar-
keit von f : I → IRn, I ⊂ IR, f(x) :=
f1(x)...
fn(x)
in einem inneren Punkt x0 ∈ I, im

13.2. RECHENREGELN 137
Bildraum die Maximum-Norm ‖ · ‖∞ auf IRn verwenden und fur den Urbildraum IR
als Norm einfach den Betrag. Dann ist A =
a1...
an
∈ IR(n,1) genau dann Ableitung
von f im Punkt x0, wenn
limx→x0
1
|x − x0|max
i=1,...,n|fi(x) − fi(x0) − ai (x − x0)| = 0.
Das ist aber genau dann der Fall, wenn jede Komponentenfunktion fi in x0 differen-
zierbar ist mit der Ableitung ai. Die Ableitung von f ist damit also gegeben durch
den Vektor der Ableitungen der Komponentenfunktionen
f ′(x0) =
f ′1(x0)
...f ′
n(x0)
. 2
Wir beschranken uns in diesem Kapitel 13 im weiteren allerdings auf den eindimen-
sionalen Fall n = m = 1.
13.2 Rechenregeln
Genau wie bei der Stetigkeitsanalyse von Funktionen nutzen wir bei der Differentia-
tion aus, daß viele Funktionen mit Hilfe weniger Grundoperationen aus einfacheren
Funktionen erzeugt werden konnen. Unter der Annahme der Kenntnis der Ableitun-
gen der Bausteine kann man dann die Ableitungen zusammengesetzter Funktionen
leicht finden, wenn man Regeln fur das Verhalten der Verbindungsoperationen unter
der Operation der Differentiation kennt.
Um die Herleitung solcher Rechenregeln der Differentiation sowie ihre exemplarische
Anwendung geht es in diesem Unterabschnitt.
Satz 13.21. (Differentiationsregeln)
Sind f , g differenzierbar in x0, so auch f ± g, α · f (fur alle α ∈ IR) und f · g, und
es gilt
(i) (f ± g)′(x0) = f ′(x0) ± g′(x0),
(ii) (αf)′(x0) = α · f ′(x0),
(iii) (f · g)′(x0) = f(x0) · g′(x0) + f ′(x0) · g(x0) (Produktregel).

138 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Beweis: (i) und (ii) folgen sofort aus den Rechenregeln fur konvergente Folgen.
Die Aussage (iii) folgt so:
(f · g)′(x0) = limx→x0
f(x) · g(x) − f(x0) · g(x0)
x − x0
= limx→x0
f(x) (g(x) − g(x0)) + g(x0) (f(x) − f(x0))
x − x0
= limx→x0
f(x) · limx→x0
g(x) − g(x0)
x − x0
+ g(x0) · limx→x0
f(x) − f(x0)
x − x0
= f(x0) · g′(x0) + g(x0) · f ′(x0).
Bemerkung 13.22. (und Definition) An Stelle der Schreibweise f ′(x) benutzt
man auch die Schreibweised
dxf(x). Diese ist z.B. dann oft bequemer und deutlicher,
wenn man zeigen will, daß ein langerer Ausdruck differenziert werden soll oder wenn
z.B. eine durch eine algebraische Formel gegebenen Funktion direkt differenziert
werden soll. So schreibt man z.B. besser
d
dx
(
5x3 + 3x2 − x + 21)
statt(
5x3 + 3x2 − x + 21)′
.
Fur die durch Ableitung aus f entstehende Funktion schreibt mand
dxf oder auch
df
dx. Fur f ′(x0) schreibt man
df
dx(x0). 2
Bemerkung 13.23. An der Formdf
dxfur die Ableitung
d
dxf = f ′ kann man noch
die Entstehung der Schreibweise erkennen. Bezeichnet man mit ∆x := x − x0 ei-
ne Argumentdifferenz und mit ∆f := f(x) − f(x0) die zugehorige Differenz der
Funktionswerte, so ist die Ableitung
df
dx(x0) = lim
x→x0
∆f
∆x.
der Grenzwert der Differenzenquotienten ∆f/∆x bei x → x0. Unter df und dx stellte
man sich bei der Entwicklung der Infinitesimalrechnung im siebzehnten Jahrhundert
”die unendlich (infinitesimal) kleinen Achsenabschnitte“ vor (die man Differentiale
nannte), gegen die ∆f bzw. ∆x sich bei x → x0 bewegten und deren”Differential-
quotient“df
dxdie Ableitung war.
Es sei vorsichtshalber gesagt, daß man bei der Verwendung dieser Vorstellung der
Quotientenbildung von”beliebig kleinen Großen“ auch beliebig viele und und belie-
big große Fehler machen kann. Zwar gibt es inzwischen eine mathematische Theorie

13.2. RECHENREGELN 139
der Differentiale, in der dieser Differential-Kalkul sauber durchfuhrbar ist, doch ist
diese Theorie nicht einfach, und es sind die Differentiale dabei etwas ganz anderes
als”infinitesimal kleine Großen“. Ohne eine genaue Kenntnis dieser Theorie sollte
man es deshalb unterlassen, mit Differentialen zu rechnen und lieber sicher mit der
Definition der Ableitung arbeiten. 2
Bemerkung 13.24. Die Schreibweised
dxfur die Operation der Ableitung hat
einen weiteren Vorteil. Mit ihr wird der Tatsache Rechnung getragen, daß das Ablei-
ten einer (uberall) differenzierbaren Funktion eine Abbildung von einem Funktionen-
raum in den Raum der abgeleiteten Funktionen darstellt. Fur Abbildungen, welche
Funktionen auf Funktionen abbilden, benutzt man ubrigens gern die Bezeichnung
Operator.
Die Teile (i) und (ii) von Satz 13.21. sagen in dieser Sichtweise, daß der Ableitungs-
operatord
dxein linearer Operator ist (vgl. hierzu auch Mathematik I), da
d
dx(αf + βg) = α
d
dxf + β
d
dxg
fur alle differenzierbaren Funktionen und alle reellen Zahlen α und β ist.
Beachten Sie in diesem Zusammenhang, daß
d
dx: C1(a, b) −→ C(a, b)
undd
dx: C1[a, b] −→ C[a, b]
gelten. 2
Satz 13.25. Jedes Polynom p(x) =n∑
j=0ajx
j ist differenzierbar in IR, und es ist
p′(x) =n∑
j=1
j aj xj−1,
so daßd
dx: Πn −→ Πn−1
fur n ≥ 0, wenn man unter Π−1 den”nulldimensionalen Raum“ {0} versteht.
Beweis: Wegen (i) und (ii) aus Satz 13.21. haben wir nur zu zeigen, dass jedes
Monom xn differenzierbar ist mitd
dx(xn) = nxn−1.

140 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Fur n = 0, 1 ist dies nach Beispiel 13.4. richtig, und aus der Richtigkeit fur ein
n ∈ IN folgt nach Satz 13.21.(iii)
d
dx(xn+1) =
d
dx(x · xn) = x · d
dx(xn) +
d
dx(x) · xn
= x · n · xn−1 + xn = (n + 1) xn.
Beispiel 13.26. Fur das durch p(x) = x5 + x3 − 3x2 + 4x − 5 definierte Polynom
gilt
p′(x) = 5x4 + 3x2 − 6x + 4. 2
Satz 13.27. (Quotientenregel)
Sind f und g differenzierbar in x0 und ist g(x0) 6= 0, so istf
gin x0 differenzierbar
und es gilt(
f
g
)′(x0) =
g(x0) · f ′(x0) − g′(x0) · f(x0)
(g(x0))2.
Beweis: Es gilt
(1
g
)′(x0) = lim
x→x0
1g(x)
− 1g(x0)
x − x0
= limx→x0
−g(x)−g(x0)x−x0
g(x) · g(x0)=
−g′(x0)
(g(x0))2,
und daher folgt aus der Produktregel
(f
g
)′(x0) = (f · 1
g)′(x0) = f(x0) ·
(1
g
)′(x0) + f ′(x0) ·
(1
g
)
(x0)
= f(x0)−g′(x0)
g2(x0)+
f ′(x0)
g(x0)=
g(x0) · f ′(x0) − g′(x0) · f(x0)
g2(x0)
Aus Satz 13.27. folgt insbesondere, dass jede rationale Funktion in allen Punkten
differenzierbar ist, in denen sie definiert ist (der Nenner von Null verschieden ist).
Beispiel 13.28. Die rationale Funktion f(x) =x2 + 1
x2 − 1ist fur alle x ∈ IR \ {1,−1}
differenzierbar und es gilt dort
f ′(x) =2x(x2 − 1) − 2x(x2 + 1)
(x2 − 1)2=
−4x
(x2 − 1)2. 2

13.2. RECHENREGELN 141
Die Differenzierbarkeit der in Kapitel 12 durch Potenzreihen eingefuhrten elemen-
taren Funktionen ergibt sich aus dem folgenden Satz.
Satz 13.29. (Differentiation von Potenzreihen)
Die Potenzreihe f(x) =∞∑
n=0anx
n habe den Konvergenzradius r > 0. Dann ist f in
(−r, r) differenzierbar, und die Ableitung erhalt man durch gliedweises Differenzie-
ren:
f ′(x) =∞∑
n=1
n anxn−1.
Die abgeleitete Reihe hat wieder den Konvergenzradius r.
Bemerkung 13.30. Die gliedweise Differentiation lasst sich nicht auf beliebige
Reihen von Funktionen (auch nicht auf gleichmaßig konvergente Reihen) ubertragen.
Die Reihe∞∑
n=1
sin nx
n2
ist nach Satz 12.19. gleichmaßig konvergent. Die gliedweise differenzierte Reihe
∞∑
n=1
cos nx
n
konvergiert jedoch nicht fur alle x. Wir kommen auf das gliedweise Differenzieren
von Reihen in Kapitel 17 zuruck. 2
Beweis: (von Satz 13.29.)
Wir zeigen zunachst, dass die Konvergenzradien der angegebenen Reihen uberein-
stimmen. Sei z ∈ C mit |z| < r. Wir wahlen ζ ∈ C mit |z| < |ζ| < r. Wegen der
Konvergenz der Reihe∞∑
n=0anζ
n gibt es ein M ≥ 0 mit |anζn| ≤ M fur alle n ∈ IN.
Daher folgt
|n anzn−1| =|anζ
n||z| n
∣∣∣z
ζ
∣∣∣
n ≤ M
|z| · n ·∣∣∣z
ζ
∣∣∣
n.
Wegen∣∣∣z
ζ
∣∣∣ < 1 konvergiert die Reihe
∞∑
n=1
M
|z| · n ·∣∣∣z
ζ
∣∣∣
nnach dem Quotientenkrite-
rium, und nach dem Majorantenkriterium konvergiert die Reihe∞∑
n=1n anzn−1. Der
Konvergenzradius r′ dieser Reihe ist also nicht kleiner als r.
Ist umgekehrt |z| < r′, so folgt aus |anzn| ≤ |z| · |n anzn−1| und dem Majoranten-
kriterium die Konvergenz von∞∑
n=0anz
n, d.h. r′ ≤ r, zusammen mit dem ersten Teil
also r = r′.

142 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Es seien x, x0 ∈ (−ρ, ρ) mit ρ < r. Dann gilt
xn − xn0 = (x − x0)
n−1∑
j=0
xj0x
n−1−j
= nxn−10 (x − x0) + (x − x0)
n−1∑
j=1
(xn−jxj−10 − xn−1
0 )
= nxn−10 (x − x0) + (x − x0)
2n−1∑
j=1
xj−10
n−j−1∑
k=0
xn−j−1−kxk0
=: nxn−10 (x − x0) + (x − x0)
2sn(x, x0).
Indem man jedes x0 und jedes x in sn(x, x0) betragsmaßig einfach durch ρ abschatzt
und berucksichtigt, daß es sich genau um 12n(n − 1) Summanden handelt, fin-
det man |sn(x, x0)| ≤ 12n(n − 1) ρn−2. Wie im ersten Teil zeigt man nun, daß
∞∑
n=2n(n − 1) anρn−2 konvergiert. Daraus ergibt sich, daß die Reihe
∞∑
n=2ansn(x, x0)
absolut konvergiert, und man hat
f(x) = f(x0) + (x − x0)∞∑
n=1
n anxn−10 + (x − x0)
2∞∑
n=2
ansn(x, x0).
Dies bedeutet aber gerade, dass f ′(x0) =∞∑
n=1n anx
n−10 ist.
Beispiel 13.31. Die Exponentialfunktion f(x) := ex ist differenzierbar in IR und
es ist
d
dxex =
d
dx
( ∞∑
n=0
xn
n!
)
=∞∑
n=1
n1
n!xn−1 =
∞∑
n=0
xn
n!= ex. 2
Beispiel 13.32. Die trigonometrischen Funktionen x 7→ sin x und x 7→ cos x sind
differenzierbar in IR, und es gelten
d
dxsin x =
d
dx
( ∞∑
n=0
(−1)n x2n+1
(2n + 1)!
)
=∞∑
n=0
(−1)n x2n
(2n)!= cos x,
d
dxcos x =
d
dx
( ∞∑
n=0
(−1)n x2n
(2n)!
)
=∞∑
n=1
(−1)n x2n−1
(2n − 1)!
= −∞∑
n=0
(−1)n x2n+1
(2n + 1)!= − sin x. 2
Beispiel 13.33. x 7→ tan x ist differenzierbar in IR \ {2n−12
π : n ∈ ZZ} mit
d
dxtan x =
d
dx
( sin x
cos x
)
=cos x · d
dxsin x − sin x · d
dxcos x
cos2 x
=cos2 x + sin2 x
cos2 x=
1
cos2 x. 2

13.2. RECHENREGELN 143
Beispiel 13.34. Die Hyperbelfunktionen x 7→ sinh x, x 7→ cosh x und x 7→ tanh x
sind differenzierbar in IR, und man hat die Regeln
d
dxsinh x =
d
dx
( ∞∑
n=0
x2n+1
(2n + 1)!
)
=∞∑
n=0
x2n
(2n)!= cosh x,
d
dxcosh x =
d
dx
( ∞∑
n=0
x2n
(2n)!
)
=∞∑
n=1
x2n−1
(2n − 1)!= sinh x,
d
dxtanh x =
d
dx
( sinh x
cosh x
)
=cosh2 x − sinh2 x
cosh2 x=
1
cosh2 x. 2
Wir haben nun die Ableitungen der meisten der in Kapitel 12 vorgestellten Funk-
tionen bestimmt. Die restlichen Abbildungen waren als Umkehrfunktionen definiert.
Diese behandeln wir mit Hilfe des nun folgenden Satzes.
Satz 13.35. (Differentiation der inversen Funktion)
Ist f streng monoton in I, differenzierbar in x0 ∈ I und f ′(x0) 6= 0, so ist f−1
differenzierbar in y0 := f(x0), und es gilt
d
dy(f−1)(y0) =
1ddx
f(x0).
Beweis: Nach Satz 11.26. ist die inverse Funktion f−1 stetig und streng monoton.
Daher gilt fur jede Folge {yn} ⊂ f(I) mit yn → y0, yn 6= y0, mit xn := f−1(yn) auch
xn 6= x0, xn → x0. Hiermit folgt
limn→∞
f−1(yn) − f−1(y0)
yn − y0
= limn→∞
xn − x0
f(xn) − f(x0)= lim
n→∞1
f(xn)−f(x0)xn−x0
=1
f ′(x0).
Beispiel 13.36. f(y) := ln y ist differenzierbar in IR+, und nach Satz 13.35. gilt
mit x = ln y
d
dyln y =
1ddx
ex=
1
ex=
1
eln y=
1
y. 2
Beispiel 13.37. f(y) := arcsinn y ist differenzierbar in (−1, 1), und mit x =
arcsinn y gilt
d
dyarcsinn y =
1ddx
sin x=
1
cos(arcsinn y)= ± 1
√
1 − sin2(arcsinn y)= ± 1√
1 − y2,
wobei das richtige Vorzeichen noch bestimmt werden muss.

144 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Nach Definition liegen die Werte von arcsinn y in [(n − 12)π, (n + 1
2)π]. Dort hat cos
das Vorzeichen (−1)n, und daher gilt
d
dyarcsinn y =
(−1)n
√1 − y2
. 2
Beispiel 13.38. f(y) := arctann y ist differenzierbar in IR mit
d
dyarctann y =
1ddx
tan x=
1
1/ cos2 x= cos2 x
=1
1 + tan2 x=
1
1 + tan2(arctann y)=
1
1 + y2. 2
Beispiel 13.39. Entsprechend dem Vorgehen in Beispiel 13.37. und Beispiel 13.38.
erhalt man
d
dxArsinh x =
1√x2 + 1
, x ∈ IR,
d
dxArcosh x = ± 1√
x2 − 1, x > 1,
d
dxArtanh x =
1
1 − x2, |x| < 1. 2
Die folgende Regel erleichtert das Differenzieren verketteter Funktionen:
Satz 13.40. (Kettenregel)
Ist f differenzierbar in x0 und g differenzierbar in y0 := f(x0), so ist h := g ◦ f
differenzierbar in x0, und es gilt
(g ◦ f)′(x0) = g′(f(x0)) · f ′(x0).
Beweis: Es sei
G(y) :=
g(y) − g(y0)
y − y0
fur y 6= y0,
g′(y0) fur y = y0.
Dann ist G stetig in y0 und g(y) − g(y0) = (y − y0) · G(y) fur alle y, d.h.
g(f(x)) − g(f(x0)) = (f(x) − f(x0)) · G(f(x)).
Daher folgt
limx→x0
g(f(x)) − g(f(x0))
x − x0
= limx→x0
f(x) − f(x0)
x − x0
· limx→x0
G(f(x))
= f ′(x0) · g′(f(x0)).

13.2. RECHENREGELN 145
Beispiel 13.41. h(x) := xa, a ∈ IR fest, ist differenzierbar in IR+, denn sei f(x) =
a · ln x, g(y) = exp(y). Dann gilt
(g ◦ f)(x) = exp(a · ln x) = exp(ln(xa)) = xa,
und nach Satz 13.40.
h′(x) = g′(f(x)) · f ′(x) = exp(a · ln(x)) · a
x= axa−1.
Die fur n ∈ IN nachgewiesene Formel (xn)′ = nxn−1 gilt also fur alle reellen Expo-
nenten. 2
Beispiel 13.42. Auch mehrfach verschachtelte Funktionen kann man leicht diffe-
renzieren, indem man von innen nach außen die Kettenregel mehrfach anwendet.
f(x) = exp(sin(cos(ln x)))
ist differenzierbar in IR+ und
f ′(x) = exp(sin(cos(ln x))) · (sin(cos(ln x)))′
= f(x) · cos(cos(ln x)) · (cos(ln x))′
= −f(x) · cos(cos(ln x)) · sin(ln x) · (ln x)′
= −f(x) · cos(cos(ln x)) · sin(ln x) · 1
x. 2
Eine Funktion des Typs
f(x) =n∏
j=1
fj(x)/ m∏
k=1
gk(x)
mit in x0 differenzierbaren fj, gk und o.B.d.A. fj(x0) > 0, j = 1, . . . , n, und gk(x0) >
0, k = 1, . . . ,m, kann man im Prinzip durch mehrfache Anwendung der Produkt-
und Quotientenregel differenzieren.
Einfacher ist haufig die sogenannte logarithmische Differentiation : Man loga-
rithmiere die f(x) definierende Gleichung und differenziere die entstehende Glei-
chung
ln f(x) =n∑
j=1
ln fj(x) −m∑
k=1
ln gk(x)
unter Beachtung vond
dx(ln h(x)) =
1
h(x)· h′(x). Dann folgt
f ′(x0)
f(x0)=
n∑
j=1
f ′j(x0)
fj(x0)−
n∑
k=1
g′k(x0)
gk(x0),

146 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
woraus sich
f ′(x0) = f(x0)
(n∑
j=1
f ′j(x0)
fj(x0)−
m∑
k=1
g′k(x0)
gk(x0)
)
ergibt.
Beispiel 13.43.
f(x) =e3x
x6 cosh x.
Dann gilt ln f(x) = ln(e3x) − ln(x6) − ln(cosh x), und daher
f ′(x) = f(x)(
3e3x
e3x− 6x5
x6− sinh x
cosh x
)
=e3x
x6 cosh x(3− 6
x−tanh x). 2
Wir haben die Differentiationsregeln fur reelle Funktionen hergeleitet. Da die Ab-
leitungen einer vektorwertigen Funktion (einer reellen Variablen) der Vektor der
Ableitungen der Komponentenfunktionen ist, konnen wir sofort alle Regeln kompo-
nentenweise ubertragen.
Fur die Anwendungen wichtige Kombinationen vektorwertiger Funktionen sind de-
ren inneres sowie deren Kreuzprodukt. Fur diese gelten die Regeln von Satz 13.44.
Satz 13.44. (i) Sind f , g : I → IRn differenzierbar in x0, so ist auch das innere
Produkt 〈f , g〉 : I → IR differenzierbar in x0 und
d
dx〈f(x), g(x)〉
∣∣∣x=x0
= 〈f ′(x0), g(x0)〉 + 〈f(x0), g′(x0)〉.
(ii) Sind f , g : I → IR3 differenzierbar in x0, so auch f × g : I → IR3 und
d
dx(f(x) × g(x))
∣∣∣x=x0
= f ′(x0) × g(x0) + f(x0) × g′(x0).
Beweis: (i):
d
dx〈f(x), g(x)〉|x=x0
=d
dx
( n∑
i=1
fi(x)gi(x))∣∣∣∣∣x=x0
=n∑
i=1
d
dx(fi(x)gi(x))
∣∣∣∣∣x=x0
=n∑
i=1
(f ′i(x0)gi(x0) + fi(x0)g
′i(x0))
= 〈f ′(x0), g(x0)〉 + 〈f(x0), g′(x0)〉.

13.3. HOHERE ABLEITUNGEN 147
(ii): Die erste Komponente von f ×g lautet det(f2 f3
g2 g3
)
= f2g3 −f3g2. Hierfur gilt
d
dx(f2(x)g3(x) − f3(x)g2(x))|x=x0
= f ′2(x0)g3(x0) + f2(x0)g
′3(x0) − f ′
3(x0)g2(x0) − f3(x0)g′2(x0)
=(
det(f ′
2(x) f ′3(x)
g2(x) g3(x)
)
+ det(f2(x) f3(x)g′2(x) g′
3(x)
))∣∣∣∣x=x0
,
und dies ist die erste Komponente von f ′(x0) × g(x0) + f(x0) × g′(x0). Die beiden
anderen Komponenten erhalt man genauso.
Beispiel 13.45. Ein Teilchen bewege sich auf einer Kreisbahn (Ortsvektor r =
r(t)) mit der Geschwindigkeit v = v(t). Bezeichnet ω = ω(t) den Vektor der Win-
kelgeschwindigkeit, so gilt
v = ω × r.
Fur die Beschleunigung gilt nach Satz 13.44.
v =d
dt(ω×r) = ω×r+ω×r = ω×r+ω×v.
Da die Winkelbeschleunigung ω dieselbe
Richtung wie ω (senkrecht auf der Ebene der
Kreisbahn) hat, hat ω × r die Richtung von
v.
ω × r heißt Tangentialbeschleunigung.
ω × v = ω × (ω × r) = −|ω|2r heißt Zen-
tripetalbeschleunigung. 2
Abbildung 13.4
13.3 Hohere Ableitungen
Ist f : (a, b) → IR in (a, b) differenzierbar, so wird durch g : x 7→ f ′(x) eine reelle
Funktion auf (a, b) definiert, die erste Ableitung von f . Ist g differenzierbar in (a, b)
(in x0 ∈ (a, b)), so heißt f zweimal differenzierbar in (a, b) (in x0 ∈ (a, b)) und
f ′′(x) := g′(x) heißt die zweite Ableitung von f in x.
Allgemein definieren wir fur n ∈ IN, n ≥ 2, rekursiv

148 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
Definition 13.46. Es sei n ∈ IN, n ≥ 2, und f : (a, b) → IR (n − 1)-mal
differenzierbar in (a, b) mit der (n − 1)-ten Ableitung f (n−1) : (a, b) → IR. f
heißt n-mal differenzierbar in (a, b), wenn f (n−1) differenzierbar in (a, b) ist.
f (n)(x) :=d
dxf (n−1)(x) heißt dann die n-te Ableitung von f in x.
f : (a, b) → IR heißt n-mal differenzierbar in x0 ∈ (a, b), wenn f in einer
Umgebung U ⊂ (a, b) von x0 (n − 1)-mal differenzierbar ist und f (n−1) : U → IR in
x0 differenzierbar ist.
Beispiel 13.47. Es sei f(x) = ex. Dann ist f ′(x) = ex differenzierbar in IR, und
es ist f ′′(x) = ex. Ein trivialer Induktionsbeweis zeigt, dass ex in IR beliebig oft
differenzierbar ist und dass f (n)(x) = ex fur alle n ∈ IN und alle x ∈ IR gilt. 2
Beispiel 13.48.
f(x) := |x|3 =
x3 fur x ≥ 0,
−x3 fur x ≤ 0,
ist differenzierbar in IR mit
f ′(x) =
3x2 fur x ≥ 0,
−3x2 fur x ≤ 0.
Wegen der Differenzierbarkeit von f ′ ist f zweimal differenzierbar in IR mit
f ′′(x) =
6x fur x ≥ 0,
−6x fur x ≤ 0.
= 6 |x|.
Da f ′′′(0) nicht existiert, ist f genau zweimal differenzierbar in x0 = 0. In jedem
anderen Punkt ist f beliebig oft differenzierbar. 2
Beispiel 13.49. Sei f(x) :=∞∑
n=0an(x − x0)
n eine Potenzreihe mit dem Konver-
genzradius r > 0. Dann ist nach Satz 13.29. f in (x0 − r, x0 + r) differenzierbar
mit der Ableitung f ′(x) =∞∑
n=1n an(x − x0)
n−1 und auch diese Potenzreihe hat den
Konvergenzradius r. Erneute Anwendung von Satz 13.29. liefert, dass f zweimal
differenzierbar ist mit f ′′(x) =∞∑
n=2n (n − 1) an(x − x0)
n−2, und durch Induktion
erhalt man, dass jede durch eine Potenzreihe definierte Funktion beliebig oft in ih-
rem Konvergenzintervall differenzierbar ist. Die Reihe darf gliedweise differenziert
werden
f (m)(x) =∞∑
n=m
m!
(
n
m
)
an(x − x0)n−m,
und die differenzierte Reihe besitzt den Konvergenzradius r.

13.3. HOHERE ABLEITUNGEN 149
Insbesondere erhalt man
f (m)(x0) = m! am.
Wir haben in Abschnitt 13.1 schon den Raum der auf einem offenen Intervall stetig
differenzierbaren Funktionen C1(a, b) eingefuhrt. Weiter hatten wir C1[a, b] als den
Raum der Funktionen f ∈ C1(a, b) definiert, deren Funktionen und Ableitungen sich
aus (a, b) stetig auf den Rand fortsetzen ließen. Analog definieren wir fur naturliche
Zahlen n ≥ 2:
Definition 13.50. Es sei n ∈ IN, n ≥ 2. Dann bezeichnet Cn(a, b) den Raum
der auf (a, b) n-mal stetig differenzierbaren Funktionen, und Cn[a, b] ist die Menge
der Funktionen aus Cn−1[a, b] ∩ Cn(a, b), deren n-te Ableitung sich stetig in die
Randpunkte fortsetzen laßt.
C∞(a, b) bezeichnet die Menge der beliebig oft stetig differenzierbaren Funktionen
auf (a, b) und C∞[a, b] die Menge der Funktionen aus C∞(a, b), deren Ableitungen
alle in beide Randpunkte stetig fortgesetzt werden konnen.
Bemerkung 13.51. Die Bezeichnung Cn−1[a, b]∩Cn(a, b) ist zunachst nicht sinn-
voll, denn Cn−1[a, b] und Cn(a, b) sind Mengen von Funktionen, die auf verschiede-
nen Definitionsbereichen erklart sind. Man interpretiert diesen Durchschnitt als die
Menge aller Funktionen, die auf dem großeren der Definitionsbereiche erklart sind
und die angegebenen Eigenschaften besitzen. Cn−1[a, b] ∩ Cn(a, b) besteht also aus
allen Funktionen f : [a, b] → IR, die auf dem offenen Intervall (a, b) n-mal differen-
zierbar sind und deren Ableitungen bis zur Ordnung n− 1 stetig in die Randpunkte
fortgesetzt werden konnen. 2
Bemerkung 13.52. Wir werden im nachsten Kapitel sehen, dass die Funktionen
f ∈ Cn[a, b] in den Randpunkten a und b einseitige Ableitungen
f(j)+ (a) = lim
x→a+0
f (j−1)(x) − f(j−1)+ (a)
x − a, j = 1, . . . , n,
und
f(j)− (b) = lim
x→b−0
f (j−1)(x) − f(j−1)− (b)
x − b, j = 1, . . . , n,
besitzen. Man findet daher in der Literatur auch die Definition, dass Cn[a, b] aus al-
len Funktionen besteht, die auf [a, b] n-mal stetig differenzierbar sind. Dabei sind in

150 KAPITEL 13. DIFFERENZIERBARE REELLE FUNKTIONEN
den Randpunkten die jeweiligen einseitigen Ableitungen bis zur Ordnung n gemeint.
Wir haben diesen Weg der Definition vorgezogen, da er sofort auf den Fall ubert-
ragen werden kann, dass f nicht auf einem Intervall, sondern auf einer geeigneten
Teilmenge des IRn, n ≥ 2, erklart ist. 2
Fur hohere Ableitungen gilt die folgende Verallgemeinerung der Produktregel.
Satz 13.53. (Leibnizsche Regel) Sind f, g : [a, b] → IR in einer Umgebung von
x0 n mal differenzierbar, so gilt
(f · g)(n)(x0) =n∑
k=0
(nk
)
f (k)(x0)g(n−k)(x0) ,
wobei f (0)(x) := f(x) und g(0)(x) := g(x) gesetzt ist.
Beweis: Fur n = 1 ist die Leibnizsche Regel gerade die Produktregel. Ist sie schon
fur ein n ∈ IN bewiesen, so folgt
(f · g)(n+1)(x0) =d
dx
(
(f · g)(n))
(x0)
=d
dx
n∑
k=0
(nk
)
f (k)(x0)g(n−k)(x0)
=n∑
k=0
(nk
)
f (k+1)(x0)g(n−k)(x0) +
n∑
k=0
(nk
)
f (k)(x0)g(n+1−k)(x0)
= f (n+1)(x0)g(x0) +n−1∑
k=0
(nk
)
f (k+1)(x0)g(n−k)(x0)
+n∑
k=1
(nk
)
f (k)(x0)g(n+1−k)(x0) + f(x0)g
(n+1)(x0)
= f (n+1)(x0)g(x0) +n∑
k=1
(n
k−1
)
f (k)(x0)g(n+1−k)(x0)
+n∑
k=1
(nk
)
f (k)(x0)g(n+1−k)(x0) + f(x0)g
(n+1)(x0)
= f (n+1)(x0)g(x0) +n∑
k=1
((n
k−1
)
+(
nk
))
f (k)(x0)g(n+1−k)(x0) + f(x0)g
(n+1)(x0)
=n+1∑
k=0
(n+1
k
)
f (k)(x0)g(n+1−k)(x0) .
Beispiel 13.54. Es sei
h(x) := x5 · ln 7 + x2
1 + x.

13.3. HOHERE ABLEITUNGEN 151
Wir bestimmen die Ableitung h(5)(0).
Mit
f(x) := x5 und g(x) := ln7 + x2
1 + x
gilt h(x) = f(x) · g(x). Wegen f (j)(0) = 0 fur j = 0, 1, 2, 3, 4 und f (5)(0) = 5! folgt
aus der Leibnizschen Regel
h(5)(0) = f (5)(0) · g(0) = 5! ln 7 . 2

Kapitel 14
Anwendungen der
Differentialrechnung
14.1 Mittelwertsatze
Der Mittelwertsatz der Differentialrechnung stellt eine Beziehung her zwischen der
Wertedifferenz einer Funktion an den Randern eines Intervalls und einem Ablei-
tungswert im Innern dieses Intervalls. Man kann ihn verwenden, um mit Hilfe der
Ableitung den Fehler abzuschatzen, den man macht, wenn man einen Funktionswert
durch einen benachbarten Funktionswert ersetzt. Tatsachlich wird man in der Praxis
versuchen, bessere Approximationen zu erreichen, indem man bei der Interpolation
Funktionswerte an mehreren benachbarten Stellen hinzuzieht (Abschnitt 12.1) oder
in der Taylorapproximation an einer benachbarten Stelle sowohl den Funktionswert
als auch Ableitungswerte berucksichtigt (Abschnitt 14.3). Die entsprechenden Feh-
lerabschatzungen lassen sich als Verallgemeinerungen des Mittelwertsatzes deuten.
Gleichzeitig benotigen wir den Mittelwertsatz als beweistechnisches Hilfsmittel. Er
ist also ein wichtiges Werkzeug zur Weiterentwicklung der Differentialrechnung.
Wir beweisen zunachst den Satz von Rolle1, der einerseits ein Spezialfall des Mittel-
wertsatzes ist, andererseits aber beim Beweis des Mittelwertsatzes verwendet wird.
Satz 14.1. (Satz von Rolle)
Es sei f : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b) mit f(a) = f(b) = 0.
Dann existiert ein ξ ∈ (a, b) mit f ′(ξ) = 0.
1Michel Rolle, 1652 - 1719, franzosischer Mathematiker

14.1. MITTELWERTSATZE 153
Beweis: Ist f(x) = 0 fur alle x ∈ [a, b], so gilt f ′(x) = 0 fur alle x ∈ (a, b), und es
ist nichts zu zeigen. Anderenfalls nimmt f ein positives Maximum oder ein negatives
Minimum ξ ∈ (a, b) an. Es gelte o.B.d.A. f(ξ) ≥ f(x) fur alle x ∈ (a, b) (betrachte
sonst −f an Stelle von f). Dann gilt
f(x) − f(ξ)
x − ξ
≥ 0 fur x < ξ,
≤ 0 fur x > ξ,
und daher
0 ≤ limx→ξ−0
f(x) − f(ξ)
x − ξ= f ′(ξ) = lim
x→ξ+0
f(x) − f(ξ)
x − ξ≤ 0,
d.h. f ′(ξ) = 0.
Bemerkung 14.2. Geometrisch besagt der Satz von Rolle, dass eine differenzier-
bare Funktion zwischen je zwei Nullstellen eine waagerechte Tangente besitzt.
Physikalisch kann man den Satz z.B. so interpretieren, daß ein Korper, der sich (dif-
ferenzierbar) entlang der reellen Achse bewegt und sich zu Beginn t = a und am
Ende t = b eines Zeitintervalles [a, b] jeweils am selben Ort befindet, zu (mindestens)
einem (Umkehr-) Zeitpunkt t = ξ ∈ (a, b) die Geschwindigkeit Null haben muß.
Wendet man Satz 14.1. gleich auf die Geschwindigkeit an, so ist eine andere Interpre-
tation die folgende: Ein Korper, der sich geradlinig bewegt und zu den Zeitpunkten
t = a und t = b in Ruhe ist, muß zu einem Zeitpunkt t = ξ ∈ (a, b) die Beschleuni-
gung 0 haben. 2
Bemerkung 14.3. Wie das Beispiel [a, b] := [−1, 1] mit f(x) := |x|−1 zeigt, kann
in Satz 14.1. auf die Differenzierbarkeit in ganz (a, b) nicht verzichtet werden. 2
Eine Verallgemeinerung von Satz 14.1. ist
Satz 14.4. (Mittelwertsatz der Differentialrechnung)
Sei f : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b). Dann gibt es ein
ξ ∈ (a, b) mit
f(b) − f(a) = f ′(ξ) · (b − a).
Beweis: Die Funktion
g(x) := f(x) − f(a) − x − a
b − a(f(b) − f(a))

154 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
ξξ
x
f
ξξ
Abbildung 14.1: Satz von Rolle, Mittelwertsatz
erfullt die Voraussetzungen von Satz 14.1. (Satz von Rolle). Daher existiert ein
ξ ∈ (a, b) mit
0 = g′(ξ) = f ′(ξ)− 1
b − a(f(b)− f(a)).
Bemerkung 14.5. Geometrisch besagt der Mittelwertsatz, dass die Tangente in
einem Punkt ξ ∈ (a, b) parallel zur Sehne durch die Punkte (a, f(a)) und (b, f(b))
ist. Als physikalische Anwendung von Satz 14.4. kann man z.B. die folgende Aussage
notieren: Durchlauft ein Mensch 100m in 10.0 Sekunden, so ist seine Durchschnitts-
geschwindigkeit 36km/h, und er muss wahrend seines Laufes zu einem Zeitpunkt die
Momentangeschwindigkeit 36km/h haben. 2
Bemerkung 14.6. Fur die numerische Rechentechnik stellt der Mittelwertsatz ein
probates Mittel der Abschatzung von Funktionswertdifferenzen durch Argument-
wertdifferenzen (und umgekehrt) dar.
Nehmen wir fur ein erstes Anwendungsbeispiel einmal an, daß man eine Funktion f
in π auswerten will, daß man dies aber nicht kann (weil f z.B. nicht einfach eine kon-
stante Funktion ist und man π ja bekanntlich numerisch nie genau angeben kann).
Wie oben besprochen, wird man f dann in einer rationalen Approximation aπ von
π auswerten wollen, und naturlich wird man sich fragen, ob man den unbekannten
Approximationsfehler f(aπ)−f(π) mit Hilfe einer — meist angebbaren — Schranke
fur den Fehler der Argumentapproximation
|aπ − π| ≤ S

14.1. MITTELWERTSATZE 155
in den Griff bekommen kann. Ist unter diesen Gegebenheiten f differenzierbar in
einem offenen Intervall I, welches π und seine Approximation aπ enthalt, so liefert
der Mittelwertsatz mit einem ξ in (aπ, π) bzw. in (π, aπ) (je nachdem, ob aπ < π
oder ob π < aπ) die Beziehung
f(aπ) − f(π) = f ′(ξ)(aπ − π).
Kennt man nun noch eine Schranke L fur die Ableitung f ′ auf diesem Intervall,
|f ′(x)| ≤ L fur alle x ∈ I,
so gilt naturlich auch |f ′(ξ)| ≤ L in der letzten Beziehung, und man hat die
Abschatzung
|f(aπ) − f(π)| ≤ L|aπ − π| ≤ LS
des unbekannten Funktionsfehlers |f(aπ)−f(π)| durch die verfugbaren Werte L und
S. 2
Bemerkung 14.7. Um zu zeigen, daß es auch Sinn macht, den Mittelwertsatz
heranzuziehen, um von bekannten Funktionswertdifferenzen auf zugehorige Argu-
mentwertdifferenzen zu schließen, betrachten wir das Problem, eine Nullstelle x∗
einer Funktion f : IR −→ IR zu berechnen. Dies geschieht meistens iterativ, indem
eine gegebene Naherung xk sukzessive durch eine f involvierende Rechenvorschrift
zu einer neuen Naherung xk+1 (hoffentlich) verbessert wird. Weiter oben haben Sie
fur den Fall eines quadratischen Polynoms f(x) = x2 − a (bzw. eines Polynoms
xm − a) schon das Newton-Verfahren kennengelernt. Um zu wissen, daß mit diesem
Verfahren√
a beliebig genau approximiert werden kann, haben wir gezeigt, daß die
generierte Folge gegen die gewunschte Zahl konvergiert (und damit√
a eigentlich
erst definiert). Fur den praktischen Einsatz der Iteration haben wir auf der ande-
ren Seite konkrete Fehlerabschatzungen fur die Naherungen hergeleitet, mit denen
sich dann die Iteration gezielt abbrechen ließ, wenn eine vorgegebene Genauigkeit
erreicht wurde.
Leider waren die oben gefundenen Fehlerabschatzungen nur fur die betrachteten
Verfahren und speziellen Funktionen (xm − a) gultig. Allgemein wird man bei Ite-
rationsverfahren aus der Große |f(xk)| des Funktionswertes (der ja an der Losung
Null werden soll) auf die Gute von xk schließen wollen. Je kleiner |f(xk)| ist, desto
mehr wird man geneigt sein zu hoffen, daß xk nahe bei einer Losung x∗ liegt.
Mit Hilfe des Mittelwertsatzes kann man diese Hoffnung quantifizieren, wenn man
weiß, daß die Funktion f differenzierbar ist, und wenn man eine untere Abschatzung

156 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
|f ′(x)| ≥ C > 0 in einem hinreichend großen Intervall um xk hat. Wir nehmen zur
Vereinfachung der Argumentation einmal an, daß f ′(x) ≥ C > 0 fur alle x ∈ IR
ist. Außerdem sei f(xk) < 0. Dann ergibt sich fur x-Werte großer als xk nach dem
Mittelwertsatz
f(x) − f(xk) = f ′(ξ)(x − xk) ≥ C(x − xk).
Insbesondere ist fur
x > xk +1
C|f(xk)|
bestimmt
f(x) ≥ f(xk) + C(x − xk) > f(xk) + |f(xk)| = 0,
so daß f nach dem Zwischenwertsatz auf jedem Fall eine Nullstelle x∗ hat. Wegen
f(x∗) = 0 erhalt man fur diese nun weiter
|f(xk)| = |f(xk) − f(x∗)| = |f ′(ζ)| · |xk − x∗| ≥ C · |xk − x∗|.
Indem man dies nach der Differenz |xk − x∗| auflost, erhalt man die Abschatzung
des Argumentfehlers
|xk − x∗| ≤ C−1|f(xk)|
durch den bekannten Wert von f bei xk. 2
Bemerkung 14.8. Wir haben in Abschnitt 13.3 darauf hingewiesen, dass fur f ∈Cn[a, b] die (n− 1)-te Ableitung f (n−1) in den Intervallenden einseitige Ableitungen
besitzt. Dies konnen wir nun mit dem Mittelwertsatz leicht einsehen. Danach gibt
es fur alle x ∈ (a, b) ein ξ(x) ∈ (a, x) mit
f (n−1)(x) − f (n−1)(a + 0) = f (n)(ξ(x))(x − a),
und daher folgt
limx→a+0
f (n−1)(x) − f (n−1)(a + 0)
x − a= lim
x→a+0f (n)(ξ(x)).
Da der rechtsseitige Grenzwert von f (n) in a existiert, ist f (n−1) in a rechtsseitig
differenzierbar. Genauso zeigt man die linksseitige Differenzierbarkeit von f (n−1) in
dem rechten Intervallende b.
Die Umkehrung der obigen Aussage gilt ubrigens nicht. Die Funktion
f(x) :=
x2 sin 1x
fur 0 < x ≤ 1
0 fur x = 0

14.1. MITTELWERTSATZE 157
ist offenbar in (0, 1) differenzierbar mit der Ableitung
f ′(x) = 2x sin1
x− cos
1
x.
Diese kann nicht von rechts in den Punkt x = 0 stetig fortgesetzt werden, denn die
Folge
f( 1
πn
)
=2
πnsin(πn) − cos(πn) = (−1)n
konvergiert nicht. Damit gilt f 6∈ C1[0, 1]. Wegen
limx→0+0
f(x) − f(0 + 0)
x − 0= lim
x→0+0x sin
1
x= 0
ist f aber rechtsseitig differenzierbar in x = 0 mit f ′+(0) = 0. 2
In der Beispielrechnung von Bemerkung 14.6. hatten wir bei der Formulierung der
Anwendung des Mittelwertsatzes abhangig von der Anordnung der Werte π und aπ
die Fallunterscheidung ξ ∈ (aπ, π) bzw. ξ ∈ (π, aπ) zu machen. Eine andere Form
des Mittelwertsatzes, die haufig handlicher ist als die Formulierung in Satz 14.4. und
mit der man auf die genannte Fallunterscheidung verzichten kann, ist Satz 14.9.
Satz 14.9. (Mittelwertsatz, 2. Fassung)
Sei f differenzierbar in einer Umgebung U von x0 (d.h. in einem offenen Intervall,
das x0 enthalt). Dann existiert fur alle h ∈ IR mit x0 + h ∈ U ein θ = θ(h) ∈ (0, 1)
mit
f(x0 + h) = f(x0) + f ′(x0 + θh) · h.
Beweis: Wahle a := x0 und b := x0 +h im Falle h > 0 und a := x0 +h und b := x0
im Falle h < 0 und θ := (ξ − x0)/h mit ξ nach Satz 14.4.
Bemerkung 14.10. Beachten Sie, daß die Darstellung des Punktes x0 + θh, an
dem die Ableitung im Mittelwertsatz auszuwerten ist, diesen Punkt stets zwischen
die Punkte x0 und x0 + h legt, unabhangig von der Anordnung dieser Punkte in IR.
2
Es folgen nun einige weitere nutzliche Anwendungsbeispiele des Mittelwertsatzes.
Fur die konstante Funktion f(·) ≡ c gilt f ′(·) ≡ 0. Mit dem Mittelwertsatz kann
man auch die Umkehrung zeigen:
Korollar 14.11. Sei f : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b) mit
f ′(x) = 0 fur alle x ∈ (a, b). Dann ist f konstant in [a, b].

158 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Beweis: Zu jedem x ∈ (a, b] existiert ein ξ ∈ (a, x) mit f(x)−f(a) = f ′(ξ)(x−a) =
0, d.h. f(x) = f(a).
Korollar 14.12. Sind f, g : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b)
mit f ′(x) = g′(x) fur alle x ∈ (a, b), so gibt es ein c ∈ IR mit f(x) = g(x) + c fur
alle x ∈ [a, b].
Beweis: d(x) := f(x) − g(x) erfullt die Voraussetzungen von Korollar 14.11., ist
also konstant.
Korollar 14.13. Es sei f : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b),
und es gelte mit einem λ ∈ IR
f ′(x) = λ f(x) fur alle x ∈ (a, b).
Dann gilt fur jedes feste c ∈ (a, b) mit A := f(c)
f(x) = A exp(λ(x − c)) fur alle x ∈ [a, b].
Beweis: Es sei g(x) := f(x) · exp(−λx). Dann gilt nach der Produktregel fur die
Ableitung
g′(x) = f ′(x) exp(−λx) − λ · f(x) · exp(−λx) = 0
fur alle x ∈ (a, b), und daher ist g konstant auf [a, b].
Fur x = c gilt g(c) = f(c) exp(−λc) und daher
f(x) = g(c) exp(λx) = f(c) exp(λ(x − c)).
Bemerkung 14.14. Speziell erhalt man aus Korollar 14.13., dass exp : IR → IR
die einzige differenzierbare Funktion f : IR → IR ist mit f ′ = f und f ′(0) = 1.
Auch hierdurch hatte man die Exponentialfunktion definieren konnen. 2
Als weitere Folgerung aus dem Mittelwertsatz zeigen wir einen Zusammenhang zwi-
schen der Monotonie einer Funktion und dem Vorzeichen ihrer Ableitung:

14.1. MITTELWERTSATZE 159
Korollar 14.15. Sei f : [a, b] → IR stetig in [a, b] und differenzierbar in (a, b).
Dann gilt
(i) f ist genau dann monoton wachsend (fallend) in [a, b], wenn f ′(x) ≥ 0 (≤ 0)
fur alle x ∈ (a, b) gilt.
(ii) Gilt f ′(x) > 0 (< 0) fur alle x ∈ (a, b), so ist f streng monoton wachsend
(fallend) in [a, b].
Beweis: Ist f monoton wachsend in [a, b], so giltf(x) − f(y)
x − y≥ 0 fur alle x 6= y.
Der Grenzubergang y → x zeigt daher f ′(x) ≥ 0 in (a, b).
Die umgekehrte Implikation von (i) sowie die Aussage (ii) sieht man wie folgt:
Zu x, y ∈ [a, b] mit x < y existiert ein ξ ∈ (a, b) mit f(y)− f(x) = f ′(ξ) (y−x), und
hieraus folgt fur f ′(ξ) ≥ 0 die Monotonie und aus f ′(ξ) > 0 die strenge Monotonie
von f in [a, b].
Bemerkung 14.16. Die Aussage (ii) kann man nicht umkehren, denn f : IR →IR, f(x) = x3, ist streng monoton wachsend, aber es gilt f ′(0) = 0. 2
Bemerkung 14.17. Mit Hilfe von Korollar 14.15. ist nun leicht zu sehen, dass die
Funktionen f(x) = tan x in jedem Intervall(
(n − 12) π, (n + 1
2) π
)
, g(x) := sinh x in
IR und h(x) := tanhx in IR streng monoton wachsend sind. Fur x in den jeweils
angegebenen Bereichen der reellen Achse gelten namlich die Ungleichungen
f ′(x) =1
cos2 x> 0, g′(x) = cosh x > 0, h′(x) =
1
cosh2 x> 0.
Daher existieren die in Kapitel 12 besprochenen inversen Abbildungen von f , g und
h. 2
Satz 14.18. (Erweiterter Mittelwertsatz)
Es seien f und g stetig in [a, b], differenzierbar in (a, b), und es gelte g′(x) 6= 0 fur
alle x ∈ (a, b). Dann gilt g(b) 6= g(a), und es gibt ein ξ ∈ (a, b) mit
f(b) − f(a)
g(b) − g(a)=
f ′(ξ)
g′(ξ).
Bemerkung 14.19. Fur g(x) := x erhalt man den Mittelwertsatz (Satz 14.4.). 2

160 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Beweis: (von Satz 14.18.)
g(b) 6= g(a) folgt aus g′(x) 6= 0 und dem Mittelwertsatz. Es sei
h(x) := f(x) − f(a) − f(b) − f(a)
g(b) − g(a)(g(x) − g(a)).
Dann genugt h den Voraussetzungen des Satzes von Rolle (Satz 14.1.). Daher exi-
stiert ein ξ ∈ (a, b) mit
0 = h′(ξ) = f ′(ξ) − f(b) − f(a)
g(b) − g(a)g′(ξ),
und hieraus folgt die Behauptung.
14.2 Regeln von de l’Hopital
Der erweiterte Mittelwertsatz ist das Hauptmittel bei der Herleitung der sogenann-
ten Regeln von de l’Hopital2. Diese Regeln ermoglichen die Berechnung von Grenz-
werten des Typs
limx→a
f(x)
g(x),
wenn Zahler und Nenner (jeder fur sich) keine der bei Bruchen ublichen Grenzwerte
(Zahler endlich, Nenner endlich und von Null verschieden) haben, dies aber sehr wohl
fur ihren Quotienten gilt. Ein offensichtliches Beispiel ergibt sich mit f(x) = g(x) =
x und a = 0. In diesem Fall wird der Nenner im Grenzpunkt Null, der Quotient
f(x)/g(x) ≡ 1 hat aber offenbar bei Null einen Grenzwert. Sicher brauchen wir zur
Ermittlung dieses Grenzwertes keine raffinierten Regeln, aber schon die Berechnung
des Grenzwertes limx→0
sin x
x, bei dem Zahler und Nenner wieder beide gegen Null
streben (Wir wollen dies den”Grenzfall 0
0“ nennen), erscheint weniger trivial.
Der folgende Satz gibt fur den Grenzfall 00
eine hinreichende Bedingung dafur, dass
der Grenzwert existiert, und eine Moglichkeit zu seiner Berechnung.
Satz 14.20. (Regel von de l’Hopital; Fall 00)
Es seien f, g : [a, b] → IR differenzierbar in (a, b) und x0 ∈ (a, b) mit f(x0) =
g(x0) = 0, und es gelte g′(x) 6= 0 fur x 6= x0.
Existiert der (uneigentliche) Grenzwert limx→x0
f ′(x)
g′(x), so besitzt auch
f(x)
g(x)fur x → x0
einen (uneigentlichen) Grenzwert, und es gilt
limx→x0
f(x)
g(x)= lim
x→x0
f ′(x)
g′(x).
2Guillaume Francois Antoine Marquis de l’Hopital, 1661 - 1704, franzosischer Mathematiker

14.2. REGELN VON DE L’HOPITAL 161
Beweis: Fur alle x 6= x0 gibt es nach Satz 14.18. ein θx ∈ (0, 1) mit
f(x)
g(x)=
f(x) − f(x0)
g(x) − g(x0)=
f ′(x0 + θx(x − x0))
g′(x0 + θx(x − x0)),
und hieraus folgt die Behauptung, da fur jede Folge {xn} mit limn→∞xn = x0 wegen
θxn∈ (0, 1) auch lim
n→∞(x0 + θxn(xn − x0)) = x0 gilt.
Bemerkung 14.21. Der Beweis von Satz 14.20. zeigt, dass die Behauptung auch
fur einseitige Grenzwerte der Form limx→x0+0
f(x)
g(x)(bzw. lim
x→x0−0
f(x)
g(x)) gilt, wenn f fur
ein h > 0 in [x0, x0+h] (bzw. [x0−h, x0]) stetig und in (x0, x0+h) (bzw. (x0−h, x0))
differenzierbar ist. 2
Beispiel 14.22.
limx→0
sin x
x= lim
x→0
cos x
1= 1.
Diese Gleichung muss man richtig interpretieren. Zunachst gilt das linke Gleichheits-
zeichen nicht. Insbesondere folgt nach Satz 14.20. aus der Existenz des Grenzwertes
limx→0 sin x/x nicht die Existenz des mittleren Grenzwertes limx→0 cos x/1. Nach-
dem aber eingesehen wurde, dass limx→0 cos x/1 existiert (und den Wert 1 hat) liefert
Satz 14.20., dass auch limx→0 sin x/x existiert (und ebenfalls den Wert 1 hat), so
dass die gesamte Gleichung richtig ist.
Auch in den folgenden Beispielen muss man die auftretenden Gleichungen immer von
rechts nach links lesen. Wahrend der Rechnung stehen alle Gleichheitszeichen unter
dem Vorbehalt, dass am Ende die Existenz eines (eigentlichen oder uneigentlichen)
Grenzwerts eingesehen wird. Danach erhalt man dann nach Satz 14.20. die Existenz
der vorhergehenden Grenzwerte und die Richtigkeit der Gleichheitszeichen. 2
Beispiel 14.23. Wir bestimmen den Grenzwert
limx→0
x2 sin 1x
sin x.
Es gilt
limx→0
x2 sin 1x
sin x= lim
x→0
(
x sin1
x
)
· limx→0
x
sin x.
Wegen der Beschranktheit der Sinusfunktion konvergiert der erste Grenzwert der
rechten Seite gegen 0 und der zweite ist nach der Regel von de l’Hopital 1. Daher
gilt
limx→0
x2 sin 1x
sin x= 0.

162 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Dieses Beispiel verdeutlicht noch einmal die Aussage von Satz 14.20.: Der Grenzwert
limx→0
x2 sin 1x
sin x
existiert, aber der Quotient der Ableitungen
ddx
(x2 sin 1x)
ddx
sin x=
2x sin 1x− cos 1
x
cos x
besitzt keinen Grenzwert fur x → 0.
Das Beispiel zeigt, dass im Falle f(0) = g(0) = 0 die Existenz von
limx→0
f ′(x)
g′(x)
hinreichend fur die Existenz von
limx→0
f(x)
g(x)
ist, nicht aber notwendig. Mehr wurde in Satz 14.20. auch nicht behauptet. 2
Beispiel 14.24. Man kann die de l’Hopitalsche Regel gegebenenfalls auch mehr-
fach anwenden, wenn nach einmaliger Differentiation der Grenzwert noch nicht klar
ist.
Sind z.B. f(x) = 2x3 + x4 und g(x) = x3 − x5, so findet man aus der Existenz von
limx→0
f (3)(x)
g(3)(x)= lim
x→0
12 + 24x
6 − 60x2= 2
und der Tatsache, daß f (k)(0) = g(k)(0) = 0 fur k = 0, 1, 2 gilt, daß
limx→0
f(x)
g(x)= lim
x→0
f ′(x)
g′(x)= lim
x→0
f (2)(x)
g(2)(x)= lim
x→0
f (3)(x)
g(3)(x)= 2.
Naturlich konnten Sie den Grenzwert auch schon vorher ohne die neue Regel bewei-
sen, das Beispiel soll aber verdeutlichen, daß man mit der de l’Hopitalschen Regel
von Zahler und Nenner gewissermaßen Nullstellen abspaltet, um diese gegeneinan-
der zu kurzen.
Daß dies nicht immer so einfach auch ohne die gewonnene Regel gemacht werden
kann, zeigt das folgende Beispiel. 2
Beispiel 14.25.
limx→0
x (1 − (1 − x)4/3)
(1 − x2)1/3 − 1=: lim
x→0
f(x)
g(x).

14.2. REGELN VON DE L’HOPITAL 163
Es ist
f ′(x) = 1 − (1 − x)4/3 +4
3x (1 − x)1/3, g′(x) = −2
3x (1 − x2)−2/3,
also f ′(0) = g′(0) = 0, und die l’Hopitalsche Regel liefert noch nicht den Grenzwert.
Wir wenden Satz 14.20. erneut an auf F (x)G(x)
mit
F (x) := f ′(x), G(x) := g′(x),
F ′(x) =8
3(1 − x)1/3 − 4
9x (1 − x)−2/3,
G′(x) = −2
3(1 − x2)−2/3 − 8
9x2(1 − x2)−5/3.
Dann gilt
limx→0
f(x)
g(x)= lim
x→0
f ′(x)
g′(x)= lim
x→0
F ′(x)
G′(x)=
8/3
−2/3= −4. 2
Bemerkung 14.26. Die Aussage von Satz 14.20. bleibt richtig, wenn in der Grenz-
wertbildung x0 = ±∞ ist. In diesem Fall substituieren wir y := 1x.
Sei o.B.d.A. x0 = +∞. Dann gilt mit f(y) := f(x) = f( 1y), g(y) := g(x) = g( 1
y)
limx→∞
f(x)
g(x)= lim
y→0+0
f(y)
g(y)= lim
y→0+0
f ′(y)
g′(y)= lim
y→0+0
f ′( 1y) ·
(
− 1y2
)
g′( 1y) ·
(
− 1y2
)
= limy→0+0
f ′( 1y)
g′( 1y)
= limx→∞
f ′(x)
g′(x). 2
Beispiel 14.27. Die de l’Hopitalsche Regel ist manchmal auch geeignet, Grenz-
werte des Typs ∞−∞ zu berechnen:
limx→0
( 1
ln(1 + x)− 1
x
)
= limx→0
x − ln(1 + x)
x · ln(1 + x)
= limx→0
1 − 11+x
ln(1 + x) + x1+x
= limx→0
x
(1 + x) ln(1 + x) + x,
und die erneute Anwendung von Satz 14.20. liefert
limx→0
( 1
ln(1 + x)− 1
x
)
= limx→0
1
ln(1 + x) + 1 + 1=
1
2. 2
Satz 14.28. (Regel von de l’Hopital; Fall ∞∞)
Seien f, g : (a, b) → IR differenzierbar, mit
limx→a+0
1
f(x)= lim
x→a+0
1
g(x)= 0, (14.1)

164 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
und es sei g′(x) 6= 0 fur x ∈ (a, b).
Besitztf ′(x)
g′(x)fur x → a + 0 den (eigentlichen oder uneigentlichen) Grenzwert c, so
auchf(x)
g(x).
Beweis: Wir betrachten zunachst den Fall eines eigentlichen Grenzwerts c ∈ IR.
Zu ε ∈ (0, 12) (ε < 1
2wird spater benotigt) gibt es ein x ∈ (a, b) mit
∣∣∣∣
f ′(ξ)
g′(ξ)− c
∣∣∣∣ < ε
fur alle ξ ∈ (a, x).
Wegen1
f(x)→ 0,
1
g(x)→ 0 fur x → a+0 existiert δ > 0 mit
∣∣∣∣
f(x)
f(x)
∣∣∣∣ < ε,
∣∣∣∣
g(x)
g(x)
∣∣∣∣ < ε
fur alle x ∈ (a, a + δ).
Fur diese x gilt nach dem erweiterten Mittelwertsatz (Satz 14.18.)
f(x)
g(x)=
f(x)
f(x) − f(x)· g(x) − g(x)
g(x)· f(x) − f(x)
g(x) − g(x)=
1 − g(x)/g(x)
1 − f(x)/f(x)· f ′(ξ)
g′(ξ),
und daher
f(x)
g(x)− c =
f ′(ξ)
g′(ξ)− c +
f(x)/f(x) − g(x)/g(x)
1 − f(x)/f(x)· f ′(ξ)
g′(ξ),
das heißt
∣∣∣f(x)
g(x)− c
∣∣∣ ≤
∣∣∣f ′(ξ)
g′(ξ)− c
∣∣∣ +
(∣∣∣f(x)
f(x)
∣∣∣ +
∣∣∣g(x)
g(x)
∣∣∣
)
·∣∣∣f ′(ξ)
g′(ξ)
∣∣∣ · 1
1 − |f(x)f(x)
|
≤ ε + (ε + ε) (|c| + ε) · 1
1 − ε.
Benutzen wir nun zur Abschatzung der zuletzt gewonnenen Schranke die am Anfang
des Beweises angenommene Beschrankung 0 < ε < 12, so ergibt sich schließlich
∣∣∣∣∣
f(x)
g(x)− c
∣∣∣∣∣≤ (4 |c| + 3) ε.
Es sei nun c ∈ {−∞,∞}. Dann existiert eine rechtsseitige Umgebung (a, a + η) von
a auf der f ′ von Null verschieden ist, denn sonst wurde eine Folge {xn} in (a, b)
existieren mit limn→∞ xn = a und f ′(xn) = 0 fur alle n ∈ IN. Damit wurde man mit
g′(xn) 6= 0 den Widerspruch
limn→∞
f ′(xn)
g′(xn)= 0 6= lim
x→a+0
f ′(x)
g′(x)= c ∈ {−∞,∞}
erhalten. Wir konnen also die Rollen von f und g vertauschen, und nach dem ersten
Teil des Beweises folgt
limx→a+0
g(x)
f(x)= lim
x→a+0
g′(x)
f ′(x)= 0. (14.2)

14.2. REGELN VON DE L’HOPITAL 165
Da g′ und f ′ in einer rechtsseitigen Umgebung von a ihr Vorzeichen nicht wechseln,
sind f und g in dieser Umgebung streng monoton wachsend oder fallend, und es
folgt aus (14.2)
limx→a+0
f(x)
g(x)= lim
x→a+0
f ′(x)
g′(x).
Bemerkung 14.29. Auch Satz 14.28. lasst sich naturlich auf linksseitige Grenz-
werte und auf den Fall limx→∞ sofort ubertragen. 2
In den folgenden Beispielen seien α und β positive reelle Zahlen.
Beispiel 14.30.
limx→∞
eαx
x= lim
x→∞αeαx
1= ∞. 2
Beispiel 14.31.
limx→∞
eαx
xβ= lim
x→∞
(eαx/β
x
)β
=(
limx→∞
eαx/β
x
)β
= ∞,
fur x → ∞ wachst also jede Exponentialfunktion exp(αx) schneller als jede Potenz
xβ von x. 2
Beispiel 14.32.
limx→∞
ln x
xβ= lim
x→∞1/x
βxβ−1= lim
x→∞1
βxβ= 0,
der Logarithmus ln x geht also fur x → ∞ langsamer gegen ∞ als jede Potenz xβ
von x. 2
Beispiel 14.33.
limx→0+0
xβ ln x = limx→0+0
ln x
x−β= lim
x→0+0
1/x
−βx−β−1= lim
x→0+0
xβ
−β= 0. 2
Beispiel 14.34.
limx→0+0
xx = limx→0+0
ex ln x = exp( limx→0+0
(x·ln x)) = e0 = 1. 2

166 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
14.3 Der Satz von Taylor
Die Differentiation wurde motiviert durch Aufgabenstellung, eine Funktion lokal
durch eine (affin) lineare Funktion, also ein Polynom vom Grade 1, moglichst gut
zu approximieren. Wir verallgemeinern diese Problemstellung nun und fragen nach
einer lokal moglichst guten Approximation einer Funktion f in einer Umgebung eines
Punktes x0 durch ein Polynom p.”Moglichst gut in der Nahe von x0“ prazisieren
wir dabei durch die Forderung, dass
limx→x0
f(x) − p(x)
(x − x0)m= 0
fur moglichst großes m ∈ IN gelten moge.
Bei in x0 differenzierbarem f und bei linearem Polynom p hatten wir gefunden, daß
das Gutemaß m = 1 moglich ist. Als Verallgemeinerung dieses Ergebnisses werden
wir im Satz von Taylor3 erhalten, daß im Falle einer n-mal stetig differenzierbaren
Funktion mit einem Polynom vom Maximalgrad n eine Approximation moglich ist,
welche das Gutemaß m = n erlaubt.
Satz 14.35. (Taylorscher Satz)
Sei f ∈ Cn(a, b). Dann gibt es zu jedem x0 ∈ (a, b) genau ein Polynom Tn(x; x0)
vom Hochstgrad n mit
limx→x0
f(x) − Tn(x; x0)
(x − x0)n= 0.
Tn, das n-te Taylorpolynom von f in x0, ist gegeben durch
Tn(x; x0) =n∑
k=0
f (k)(x0)
k!(x − x0)
k, (14.3)
wobei f (0)(x) := f(x) die Funktion f bezeichnet.
Gilt sogar f ∈ Cn+1(a, b), so hat das Restglied
Rn(x) := f(x) − Tn(x; x0)
fur x ∈ (a, b) die folgende Darstellung: Fur alle p ∈ {1, . . . , n + 1} gibt es ein
ξ = x0 + θ(x − x0), θ ∈ (0, 1), mit
Rn(x) =f (n+1)(ξ)
p · n!(x − x0)
n+1(1 − θ)n+1−p. (14.4)
3Brook Taylor, 1685 - 1731, englischer Mathematiker
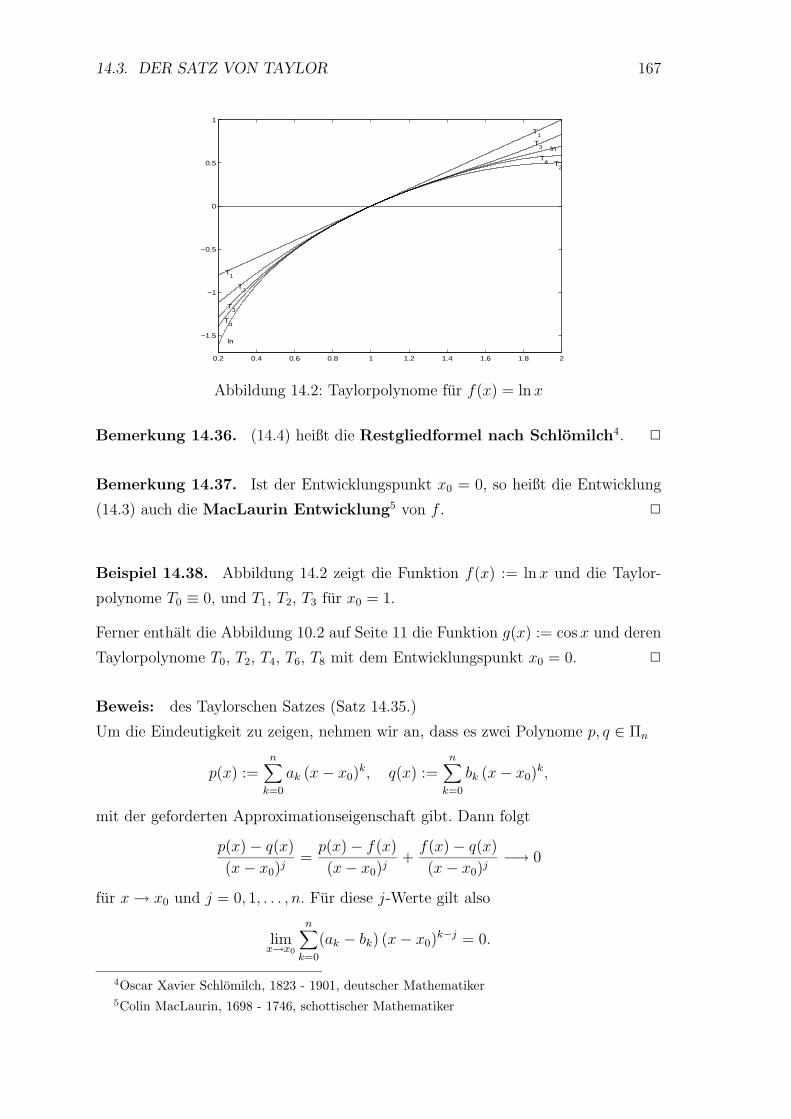
14.3. DER SATZ VON TAYLOR 167
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
−1.5
−1
−0.5
0
0.5
1
ln
T1
T3
T2
T4
T1
T2
T3
T4
ln
Abbildung 14.2: Taylorpolynome fur f(x) = ln x
Bemerkung 14.36. (14.4) heißt die Restgliedformel nach Schlomilch4. 2
Bemerkung 14.37. Ist der Entwicklungspunkt x0 = 0, so heißt die Entwicklung
(14.3) auch die MacLaurin Entwicklung5 von f . 2
Beispiel 14.38. Abbildung 14.2 zeigt die Funktion f(x) := ln x und die Taylor-
polynome T0 ≡ 0, und T1, T2, T3 fur x0 = 1.
Ferner enthalt die Abbildung 10.2 auf Seite 11 die Funktion g(x) := cos x und deren
Taylorpolynome T0, T2, T4, T6, T8 mit dem Entwicklungspunkt x0 = 0. 2
Beweis: des Taylorschen Satzes (Satz 14.35.)
Um die Eindeutigkeit zu zeigen, nehmen wir an, dass es zwei Polynome p, q ∈ Πn
p(x) :=n∑
k=0
ak (x − x0)k, q(x) :=
n∑
k=0
bk (x − x0)k,
mit der geforderten Approximationseigenschaft gibt. Dann folgt
p(x) − q(x)
(x − x0)j=
p(x) − f(x)
(x − x0)j+
f(x) − q(x)
(x − x0)j−→ 0
fur x → x0 und j = 0, 1, . . . , n. Fur diese j-Werte gilt also
limx→x0
n∑
k=0
(ak − bk) (x − x0)k−j = 0.
4Oscar Xavier Schlomilch, 1823 - 1901, deutscher Mathematiker
5Colin MacLaurin, 1698 - 1746, schottischer Mathematiker

168 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Setzt man hierin nacheinander j = 0, 1, . . . , n ein, so folgt sukzessiv bj = aj, j =
0, . . . , n, und daher ist p = q.
Um zu sehen, dass das in (14.3) angegebene Tn(x, x0) die geforderte Approximati-
onseigenschaft hat, definieren wir fur festes x 6= x0 die folgenden Hilfsfunktionen:
g(t) := f(x) −n−1∑
k=0
f (k)(t)
k!(x − t)k, a < t < b,
h(t) := g(t) − g(x0)(
x − t
x − x0
)n
, a < t < b.
Dann sind g und h stetig differenzierbar, und
g′(t) = −n−1∑
k=0
f (k+1)(t)
k!(x − t)k +
n−1∑
k=1
f (k)(t)
(k − 1)!(x − t)k−1
= − f (n)(t)
(n − 1)!(x − t)n−1, a < t < b.
Wegen h(x) = g(x) = 0, h(x0) = g(x0) − g(x0) · 1 = 0 folgt aus dem Satz von Rolle
die Existenz eines ξ := x0 + θ (x − x0), θ ∈ (0, 1), mit h′(ξ) = 0. Setzen wir die
Definition von h(t) hier ein, ergibt sich
0 = g′(ξ) + n g(x0)(x − ξ)n−1
(x − x0)n
= − f (n)(ξ)
(n − 1)!(x − ξ)n−1 + n g(x0)
(x − ξ)n−1
(x − x0)n.
Indem man den von Null verschiedenen Faktor (x − ξ)n−1 kurzt, erhalt man
0 = − f (n)(ξ)
(n − 1)!+
n g(x0)
(x − x0)n,
d.h.
g(x0) =f (n)(ξ)
n!(x − x0)
n.
Einsetzen der Definition von g liefert schließlich
f(x) =n−1∑
k=0
f (k)(x0)
k!(x − x0)
k +f (n)(ξ)
n!(x − x0)
n. (14.5)
Damit erhalt man
f(x) − Tn(x; x0) =1
n!
(
f (n)(ξ) − f (n)(x0))
(x − x0)n,
und da mit x → x0 auch ξ → x0 gilt, folgt aus der Stetigkeit von f (n)
limx→x0
f(x) − Tn(x; x0)
(x − x0)n=
1
n!lim
x→x0
(
f (n)(ξ) − f (n)(x0))
= 0.

14.3. DER SATZ VON TAYLOR 169
Damit ist die Approximationseigenschaft von Tn gezeigt.
Fur die Herleitung der Schlomilchschen Restglieddarstellung benotigen wir nun die
Differenzierbarkeit von f (n) in (a, b). Diese ist durch die Voraussetzung von f ∈Cn+1(a, b) im Satz sicher gewahrleistet (Wir haben es vorgezogen, im Satz etwas zu
viel zu fordern, da sich diese Forderung flinker formulieren und einfacher behalten
laßt). Wir betrachten dann fur x ∈ (a, b), x 6= x0 und mit der ganzen Zahl p ∈{1, . . . , n + 1} die Funktion
φ(t) := f(x) −n∑
j=0
f (j)(t)
j!(x − t)j − α
( x − t
x − x0
)p.
Dabei sei α ∈ IR die durch die Forderung φ(x0) = 0 eindeutig bestimmte Zahl.
φ ist stetig in [a, b] und differenzierbar in (a, b) mit φ(x0) = 0 und φ(x) = 0. Daher
gibt es nach dem Satz von Rolle ein ξ = x0 + θ(x − x0), θ ∈ (0, 1), mit φ′(ξ) = 0.
Nun ist
φ′(t) = −n∑
j=0
f (j+1)(t)
j!(x − t)j +
n∑
j=1
f (j)(t)
(j − 1)!(x − t)j−1 +
pα
(x − x0)p(x − t)p−1
= −f (n+1)(t)
n!(x − t)n +
pα
(x − x0)p(x − t)p−1,
und φ′(ξ) = 0 liefert
α =1
p · n!f (n+1)(ξ)(x − x0)
p(x − ξ)n+1−p
=1
p · n!f (n+1)(ξ)(x − x0)
p(x − x0 − θ(x − x0))n+1−p
=1
p · n!f (n+1)(ξ)(1 − θ)n+1−p(x − x0)
n+1.
Hiermit erhalt man wegen φ(x0) = 0
f(x) =n∑
j=0
f (j)(x0)
j!(x−x0)
j +f (n+1)(ξ)
p · n!(x−x0)
n+1(1−θ)n+1−p.
Bemerkung 14.39. Eine der 2. Fassung des Mittelwertsatzes entsprechende Fas-
sung des Taylorpolynoms (14.3) mit seinem Restterm (14.4) ist
f(x0 + h) =n∑
k=0
f (k)(x0)
k!hk +
f (n+1)(x0 + θh)
p · n!hn+1(1 − θ)n+1−p
fur ein θ ∈ (0, 1). Der Mittelwertsatz ist mit n = 0 und p = 1 hierin als Spezialfall
enthalten. 2

170 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Fur das Restglied der Taylorformel sind weitere Darstellungen gebrauchlich:
Korollar 14.40. Es sei f ∈ Cn+1(a, b) und x0 ∈ (a, b). Dann hat das Restglied
Rn(x) in
f(x) =n∑
j=0
f (j)(x0)
j!(x − x0)
j + Rn(x)
fur x = x0 + h ∈ (a, b) die Darstellungen
Rn(x) =f (n+1)(ξ)
(n + 1)!hn+1, ξ = x0 + θh, fur ein θ ∈ (0, 1), (14.6)
Rn(x) =f (n+1)(ξ)
n!hn+1(1 − θ)n, ξ = x0 + θh, fur ein θ ∈ (0, 1), (14.7)
Rn(x) =1
n!
x∫
x0
(x − t)n f (n+1)(t) dt. (14.8)
(14.6) heißt die Restgliedformel von Lagrange, (14.7) heißt Restgliedformel
von Cauchy und (14.8) heißt die Integraldarstellung des Restgliedes oder die
Restgliedformel von Taylor.
Beweis: Die Restgliedformel (14.6) von Lagrange ist mit p = n + 1 in der Formel
von Schlomilch enthalten und die Restgliedformel (14.7) von Cauchy erhalt man als
Spezialfall von (14.4) mit p = 1. Die Gultigkeit der Integraldarstellung werden wir
in Satz 17.14. beweisen.
Bemerkung 14.41. Man kann den Taylorschen Satz auch fur Cn-Funktionen
(bzw. seine Restgliedformeln fur Cn+1-Funktionen) auf abgeschlossenen Interval-
len [a, b] beweisen, wobei dann auch fur den Entwicklungspunkt x0 die Randpunkte
zulassig sind. Man hat dann nur uberall Ck(a, b) durch Ck[a, b] zu ersetzen. 2
Der Taylorsche Satz 14.35. ist fur die Anwendungen außerordentlich wichtig. Er
liefert das Standardverfahren zur lokalen Approximation einer gegebenen Funktion
durch ein Polynom einschließlich einer Fehlerabschatzung.
Beispiel 14.42. Einen typischen Anwendungsfall des Taylorschen Satzes liefert die
Aufgabe, eine Approximation fur die Zahl e1.5 mit einer vorgegebenen Fehlerschranke
etwa von 10−4 zu bestimmen.

14.3. DER SATZ VON TAYLOR 171
Die Funktion f(x) = ex ist beliebig oft differenzierbar, und daher existiert das
Taylorpolynom jeden Grades n. Wegen f (k)(x) = ex fur alle k ∈ IN gilt f (k)(0) = 1,
und daher ist
Tn(x; 0) =n∑
k=0
1
k!xk.
(Das Taylorpolynom ist also gerade die n-te Partialsumme der Potenzreihe, die die
Exponentialfunktion definiert). Das Lagrangesche Restglied ist
Rn(x) =eξ
(n + 1)!xn+1
mit ξ = θ x fur ein θ ∈ (0, 1).
Speziell fur x = 1.5 ist
0 < Rn(x) =eξ
(n + 1)!xn+1 <
31.5
(n + 1)!1.5n+1,
und man kann |Rn(x)| ≤ 10−4 garantieren, falls
1.5n+1
(n + 1)!≤ 1
3√
3· 10−4.
Dies ist fur n ≥ 9 der Fall.
Es ist T9(1.5; 0) = 4.481671, und mit jedem guten Taschenrechner, der eine Approxi-
mation fur exp(1.5) verwenden sollte, welche die angezeigten Stellen korrekt liefert,
uberzeugt man sich nun davon, daß der tatsachliche Fehler | exp(1.5) − T9(1.5; 0)|die Großenordnung 1.9 · 10−5 hat und damit wie gewunscht kleiner als 10−4 ist. 2
Bemerkung 14.43. Dass im Beispiel 14.42. das n-te Taylorpolynom Tn(x; 0) ge-
rade die n-te Partialsumme der exp(x) definierenden Potenzreihe ist, ist kein Zufall.
Besitzt
f(x) :=∞∑
n=0
an (x − x0)n
namlich einen positiven Konvergenzradius r, so ist f in (x0 − r, x0 + r) beliebig oft
differenzierbar mit f (m)(x0) = m! am (vgl. Beispiel 13.49.), und das n-te Taylorpo-
lynom ist
Tn(x; x0) =n∑
k=0
ak (x − x0)k. 2
Definition 14.44. Ist f : (a, b) → IR eine C∞-Funktion, so existieren fur jedes
x0 ∈ (a, b) alle Ableitungen f (n)(x0), n ∈ IN. Dann heißt die Reihe
Tf (x) :=∞∑
n=0
f (n)(x0)
n!(x − x0)
n
die Taylorreihe von f mit Entwicklungspunkt x0.

172 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Zur Taylorreihe sind zwei wichtige Bemerkungen angebracht:
Bemerkung 14.45. Der Konvergenzradius einer Taylorreihe ist nicht notwendig
positiv. 2
Bemerkung 14.46. Falls die Taylorreihe von f konvergiert, so konvergiert sie
nicht notwendig gegen f . 2
Bemerkung 14.47. Die Taylorreihe konvergiert genau fur diejenigen x ∈ [a, b]
gegen f(x), fur die die Folge der Restglieder der Taylorpolynome aus Satz 14.35. bei
steigendem Grad gegen 0 konvergiert. 2
Bemerkung 14.48. Eine C∞-Funktion f : (a, b) → IR, die in jedem Punkt x0 ∈(a, b) in eine Taylorreihe entwickelt werden kann, die in einer Umgebung (x0−ε, x0+
ε) von x0 gegen f konvergiert, heißt reell-analytisch . Dabei muß f nicht in eine
in ganz (a, b) konvergente Potenzreihe entwickelbar sein, wie das folgende Beispiel
der in ganz IR+ analytischen Funktion f(x) =1
xzeigt. 2
Beispiel 14.49. Fur
f : IR+ → IR, f(x) :=1
x,
gilt
f (n)(x) = (−1)n n!x−n−1,
und daher ist die Taylorreihe von f mit dem Entwicklungspunkt x0 ∈ IR+
Tf (x; x0) =∞∑
n=0
(−1)nx−n−10 (x − x0)
n =1
x0
∞∑
n=0
(x0 − x
x0
)n
mit dem Konvergenzradius r = x0.
Bei |x − x0| < r = x0 gilt fur das Restglied
|Rn(x; x0)| =∣∣∣1
x− 1
x0
n∑
j=0
(x0 − x
x0
)j∣∣∣ =
∣∣∣1
x− 1
x0
·1 −
(x0−x
x0
)n+1
1 − x0−xx0
∣∣∣
=∣∣∣1
x−
1 −(
x0−xx0
)n+1
x
∣∣∣ =
1
x
∣∣∣x0 − x
x0
∣∣∣
n+1 → 0 fur n → ∞.
Tf (x; x0) konvergiert also fur |x−x0| < x0 gegen f(x), und daher ist f reell-analytisch
in IR+. Es gibt aber keine Potenzreihenentwicklung von f , die in ganz IR+ konver-
giert. 2
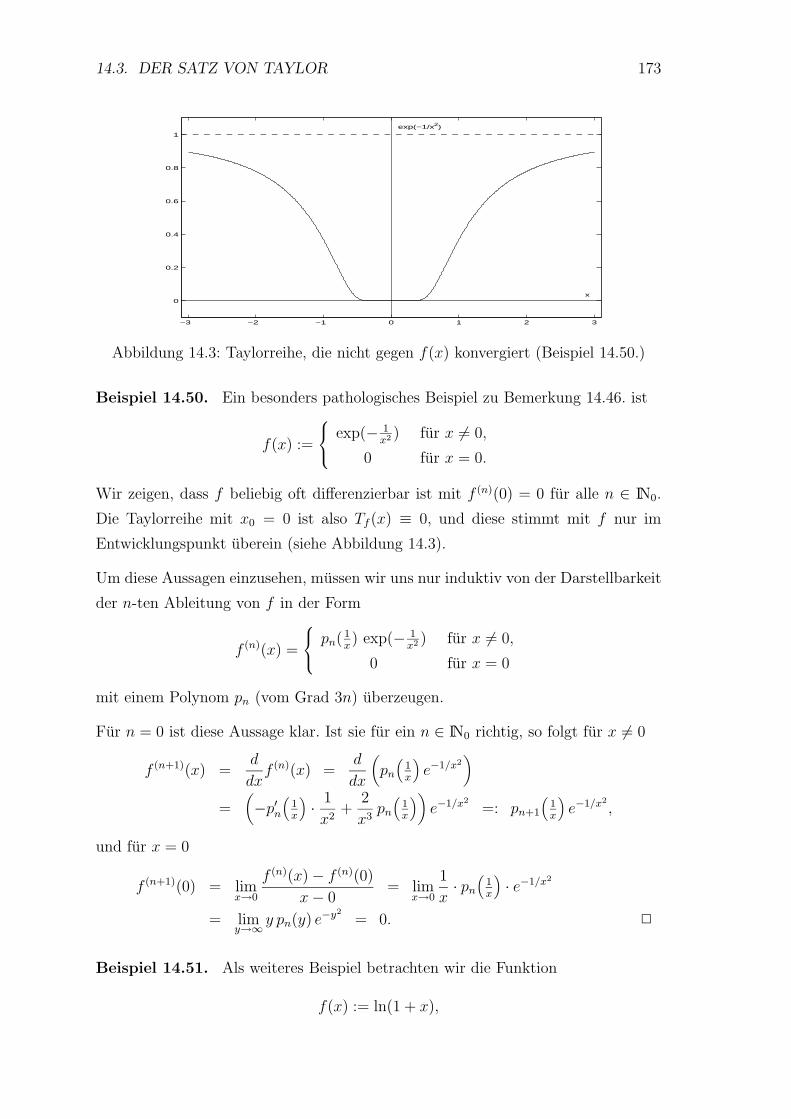
14.3. DER SATZ VON TAYLOR 173
−3 −2 −1 0 1 2 3
0
0.2
0.4
0.6
0.8
1
x
exp(−1/x2)
Abbildung 14.3: Taylorreihe, die nicht gegen f(x) konvergiert (Beispiel 14.50.)
Beispiel 14.50. Ein besonders pathologisches Beispiel zu Bemerkung 14.46. ist
f(x) :=
exp(− 1x2 ) fur x 6= 0,
0 fur x = 0.
Wir zeigen, dass f beliebig oft differenzierbar ist mit f (n)(0) = 0 fur alle n ∈ IN0.
Die Taylorreihe mit x0 = 0 ist also Tf (x) ≡ 0, und diese stimmt mit f nur im
Entwicklungspunkt uberein (siehe Abbildung 14.3).
Um diese Aussagen einzusehen, mussen wir uns nur induktiv von der Darstellbarkeit
der n-ten Ableitung von f in der Form
f (n)(x) =
pn( 1x) exp(− 1
x2 ) fur x 6= 0,
0 fur x = 0
mit einem Polynom pn (vom Grad 3n) uberzeugen.
Fur n = 0 ist diese Aussage klar. Ist sie fur ein n ∈ IN0 richtig, so folgt fur x 6= 0
f (n+1)(x) =d
dxf (n)(x) =
d
dx
(
pn
(1x
)
e−1/x2)
=(
−p′n(
1x
)
· 1
x2+
2
x3pn
(1x
))
e−1/x2
=: pn+1
(1x
)
e−1/x2
,
und fur x = 0
f (n+1)(0) = limx→0
f (n)(x) − f (n)(0)
x − 0= lim
x→0
1
x· pn
(1x
)
· e−1/x2
= limy→∞ y pn(y) e−y2
= 0. 2
Beispiel 14.51. Als weiteres Beispiel betrachten wir die Funktion
f(x) := ln(1 + x),

174 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
die fur x > −1 beliebig oft differenzierbar ist, also z.B. in dem Entwicklungspunkt
x0 = 0 in eine Taylorreihe entwickelt werden kann.
Es gilt f ′(x) = (1 + x)−1, f ′′(x) = −(1 + x)−2, f ′′′(x) = 2 (1 + x)−3 und (durch
Induktion)
f (n)(x) = (−1)n−1 (n − 1)! (1 + x)−n.
Fur x0 = 0 ist also f(0) = 0, f (n)(0) = (−1)n−1 (n − 1)!, n ≥ 1, und daher ist die
Taylorreihe gegeben durch
Tf (x) =∞∑
n=1
(−1)n−1 xn
n.
Tf hat den Konvergenzradius 1 (die Reihe konvergiert fur x = 1 und divergiert fur
x = −1).
Wir zeigen, dass durch Tf im Intervall (−1, 1) die Funktion f dargestellt wird:
Es gilt fur |x| < 1
d
dxTf (x) =
∞∑
n=1
(−1)n−1xn−1 =∞∑
n=0
(−x)n =1
1 − (−x)=
1
1 + x= f ′(x),
und nach Korollar 14.12. gibt es eine Konstante c ∈ IR mit
f(x) = Tf (x) + c fur alle x ∈ (−1, 1).
Fur x = 0 gilt f(0) = ln 1 = 0 = Tf (0), d.h. c = 0, und daher f(x) = Tf (x) fur alle
x ∈ (−1, 1).
Fur x = 1 ist Tf (1) =∞∑
n=1(−1)n−1 · 1
ndie alternierende harmonische Reihe. Um die
Konvergenz gegen f(1) = ln(2) einzusehen, betrachten wir das Restglied
Rn(1) =f (n+1)(ξ)
(n + 1)!· 1n+1 = (−1)n n! (1 + ξ)−(n+1)
(n + 1)!=
(−1)n
(n + 1) (1 + ξ)n+1.
Wegen ξ > 0 gilt (1 + ξ)−(n+1) < 1, und daher |Rn(1)| <1
n + 1→ 0 fur n → ∞. 2
Damit ist gezeigt
Satz 14.52. Fur −1 < x ≤ 1 gilt
ln(1 + x) =∞∑
n=1
(−1)n−1 · xn
n.

14.3. DER SATZ VON TAYLOR 175
Beispiel 14.53. Wir betrachten nun die Funktion
f(x) := (1 + x)α, α ∈ IR, x > −1.
Dann gilt f ′(x) = α (1 + x)α−1, f ′′(x) = α (α− 1) (1 + x)α−2 und (durch Induktion)
f (n)(x) = α (α − 1) · . . . · (α − n + 1) (1 + x)α−n.
Als Taylorreihe erhalt man also
Tf (x) =∞∑
n=0
(
α
n
)
xn,
wobei die Verallgemeinerung der Binomialkoeffizienten(
α
n
)
:=α (α − 1) · . . . · (α − n + 1)
n!fur n ≥ 1 und
(
α
0
)
:= 1, (14.9)
verwendet wird, die diese auf den Fall reeller nicht naturlicher α-Werte erweitert.
Wie man leicht bestatigt, ergibt die obige Definition (14.9) fur naturliche α-Werte
die ublichen Binomialkoeffizienten.
Ist insbesondere α = m ∈ IN, und ist m < n, so gilt(
mn
)
= 0. Daher erhalt man als
Spezialfall
Tf (x) =m∑
n=0
(
m
n
)
xn,
wobei — wegen Rn =(
mn+1
)
ξn+1 = 0 fur alle n ≥ m — die letzte endliche Reihe die
Funktion (1 + x)m exakt darstellt. Hieraus resultiert noch einmal die aus Kapitel 1
bekannte binomische Formel
(1 + x)m =m∑
n=0
(
m
n
)
xn,
die sich somit als besonders einfacher Sonderfall eines viel allgemeineren Sachver-
haltes entpuppt. Allgemein gilt 2
Satz 14.54. (Binomische Reihe)
Fur alle α ∈ IR und alle x ∈ (−1, 1) gilt
(1 + x)α =∞∑
n=0
(
α
n
)
xn.
Beweis: Zunachst besitzt die Reihe g(x) :=∞∑
n=0
(αn
)
xn wegen
limn→∞
∣∣∣∣∣
(α
n+1
)
xn+1
(αn
)
xn
∣∣∣∣∣= lim
n→∞
∣∣∣α − n
n + 1x
∣∣∣ = |x|

176 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
nach dem Quotientenkriterium den Konvergenzradius r = 1.
Fur |x| < 1 erhalt man durch gliedweise Differentiation
g′(x) =∞∑
n=1
(αn
)
nxn−1 =∞∑
n=1
(α
n−1
)
(α − n + 1) xn−1
= α∞∑
n=0
(αn
)
xn − x∞∑
n=0
n(
αn
)
xn−1 = α g(x) − x g′(x),
d.h. (1 + x) g′(x) = α g(x).
Fur h(x) := (1 + x)−α g(x) folgt daher
h′(x) = −α (1 + x)−α−1 g(x) + (1 + x)−α g′(x)
= (1 + x)−α−1(
−α g(x) + (1 + x) g′(x))
= 0,
und damit h(x) ≡ h(0) = g(0) =(
α0
)
= 1, d.h. g(x) = (1 + x)α.
Beispiel 14.55. Mit der binomischen Reihe kann man nun leicht die Potenzreihe
der Funktion
f(x) := arcsin0 x
ermitteln. f ist fur |x| < 1 beliebig oft differenzierbar, besitzt also eine Taylorreihe
Tf (x) =∞∑
n=0
an xn.
Durch gliedweises Differenzieren erhalt man
d
dxTf (x) =
∞∑
n=1
n an xn−1 =∞∑
n=0
(n + 1) an+1 xn.
Andererseits erhalt man aus Satz 14.54. fur |x| < 1
f ′(x) =1√
1 − x2=
∞∑
k=0
(
−1/2
k
)
(−x2)k =∞∑
k=0
(−1)k
(
−1/2
k
)
x2k,
und diese Reihen stimmen genau dann uberein, wenn
a2k = 0, a2k+1 =(−1)k
2k + 1
(
−1/2
k
)
, k ∈ IN0.
Die Reihe
g(x) :=∞∑
k=0
(−1)k
2k + 1
(
−1/2
k
)
x2k+1
konvergiert nach dem Quotientenkriterium fur |x| < 1. Durch gliedweises Differen-
zieren erhalt man nach Wahl der ak
d
dx
(
arcsin0 x − g(x)) = 0 fur |x| < 1,

14.3. DER SATZ VON TAYLOR 177
und nach Korollar 14.11. gibt es daher ein c ∈ IR mit
arcsin0 x = c + g(x) fur |x| < 1.
Hieraus folgt schließlich wegen arcsin0 0 = 0 fur |x| < 1
arcsin0 x =∞∑
k=0
(−1)k
2k + 1
(
−1/2
k
)
x2k+1 = x +1
2· x3
3+
1 · 32 · 4 · x5
5+
1 · 3 · 52 · 4 · 6 · x7
7+ . . . 2
Beispiel 14.56. Vollig analog kann man (mit Hilfe der geometrischen Reihe) die
Taylorreihe der Funktion x 7→ arctan0 x ermitteln. Man erhalt fur |x| < 1
arctan0 x =∞∑
k=0
(−1)k x2k+1
2k + 1= x− x3
3+
x5
5− x7
7+ . . . 2
Eine weitere Anwendung des Taylorschen Satzes ist die Umordnung von Polynomen.
Es sei p ∈ Πn,
p(x) =n∑
j=0
ajxj. (14.10)
Dann gilt nach dem Taylorschen Satz fur jedes x0 ∈ IR
p(x) =n∑
j=0
p(j)(x0)
j!(x − x0)
j + Rn(x; x0)
und wegen
Rn(x; x0) =p(n+1)(ξ)
(n + 1)!(x − x0)
n+1 = 0
erhalt man das umgeordnete Polynom
p(x) =n∑
j=0
p(j)(x0)
j!(x − x0)
j. (14.11)
Der Ubergang von der Taylorentwicklung (14.10) des Polynoms im Entwicklungs-
punkt Null zur Taylorentwicklung (14.11) im Punkte x0 ist im Sinne der linearen
Algebra nichts anderes als ein Basiswechsel im Raum der Polynome Πn.
Die neuen Koeffizienten bj :=1
j!p(j)(x0) fur die Entwicklung nach der neuen Basis
{(x− x0)0, (x− x0)
1, . . . , (x− x0)n} erhalt man mit dem sogenannten erweiterten
Horner Schema:
Wendet man auf pn := p das Horner Schema an, so erhalt man nach Satz 12.3. den
Wert pn(x0) und ein Polynom pn−1(x) =n−1∑
j=0a′
j xj mit
pn(x) = (x − x0) pn−1(x) + pn(x0).

178 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Wendet man das Horner Schema auf pn−1 an, so erhalt man
pn−1(x0) und pn−2(x) =n−2∑
j=0
a′′j xj
mit
pn−1(x) = (x − x0) pn−2(x) + pn−1(x0),
d.h.
pn(x) = (x − x0)2 pn−2(x) + (x − x0) pn−1(x0) + pn(x0).
Fahrt man so fort, so erhalt man schließlich
pn(x) =n∑
j=0
bj (x − x0)j,
wobei
an an−1 an−2 · · · a2 a1 a0
x = x0 a′n−1x0 a′
n−2x0 · · · a′2x0 a′
1x0 a′0x0
a′n−1 a′
n−2 a′n−3 · · · a′
1 a′0 b0 = p(x0)
x = x0 a′′n−2x0 a′′
n−3x0 · · · a′′1x0 a′′
0x0
a′′n−2 a′′
n−3 a′′n−4 · · · a′′
0 b1 =1
1!p′(x0)
x = x0 a′′′n−3x0 a′′′
n−4x0 · · · a′′′0 x0
a′′′n−3 a′′′
n−4 a′′′n−5 · · · b2 =
1
2!p′′(x0)
......
x = x0
bn =1
n!p(n)(x0)
wobei naturlich die Striche bei den ak im Gegensatz zu denen bei p keine Ableitungen
bezeichnen.

14.4. KURVENDISKUSSION 179
Beispiel 14.57. p(x) := x4 + 2x3 − x2 + 1 soll nach Potenzen von x− 1 entwickelt
werden:
1 2 −1 0 1
x = 1 1 3 2 2
1 3 2 2 3 = p(1)
x = 1 1 4 6
1 4 6 8 = p′(1)
x = 1 1 5
1 5 11 =1
2p′′(1)
x = 1 1
1 6 =1
6p′′′(1)
x = 1
1 =1
24p(4)(1) ,
d.h.
p(x) = (x − 1)4 + 6 (x − 1)3 + 11 (x − 1)2 + 8 (x − 1) + 3
und
p(1) = 3, p′(1) = 8, p′′(1) = 22, p′′′(1) = 36, p(4)(1) = 24. 2
14.4 Kurvendiskussion
Ziel einer Kurvendiskussion ist es, wesentliche Merkmale einer reellen Funktion
festzustellen, die durch eine Zuordnungsvorschrift x 7→ f(x) gegeben ist.
Ein solches Vorhaben wird ublicherweise von Anwendern der Mathematik nicht zum
mathematischen Zeitvertreib vorgenommen, sondern soll z.B. nutzliche Aussagen
uber den durch die Funktion modellierten Sachverhalt enthullen oder umgekehrt
klaren, ob ein Satz von Formeln zur Modellierung eines untersuchten Stuckes der
Realitat geeignet ist.
Fur die Kurvendiskussion hat es sich als zweckmaßig erwiesen, die durch die folgende
Schlagwortliste angedeuteten Untersuchungsschritte abzuarbeiten:
Definitionsbereich, Symmetrien, Grenzwerte und Pole, Asymptoten,
Nullstellen, Monotonie-Verhalten, Extrema, Konvexitat, Konkavitat,
Wendepunkte.

180 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Wir diskutieren im Rest dieses Abschnittes genauer, was unter den dadurch an-
gesprochenen Analyseschritten genauer zu verstehen ist und welche Aussagen und
Hilfsmittel zu ihrer Bewaltigung u.a. zur Verfugung stehen.
Es sei vorher aber noch einmal ausdrucklich betont, daß die Analyseschritte und
ihre Reihenfolge nur ein Vorschlag zur Untersuchung reeller Funktionen sind. Was
im konkreten Fall der Praxis getan werden muß, wird durch die aus der Praxis an
die Funktion herangetragenen Fragen bestimmt. Allerdings werden Sie im folgenden
Abschnitt sicher auch ein wenig an Fahigkeit gewinnen, geeignete praxisrelevante
Fragen an Funktionen zu stellen.
Es ist auf jeden Fall gut, wenn Sie sich bei der nun folgenden Abarbeitung der Li-
ste von Analyseschritten immer bemuhen, Anwendungsbeispiele fur die betreffende
Fragestellung zu bedenken.
Definitionsbereich: Bestimme die Menge Df aller x ∈ IR, fur die die Zuordnungs-
vorschrift sinnvoll ist, so daß sie auf Df eine Funktion definiert.
Beispiel 14.58. Die Rechenvorschrift
f(x) :=x4 − 5x2 + 4
x3
ist ausfuhrbar fur alle von Null verschiedenen x-Werte. Daher ist der Definitionsbe-
reich Df := IR \ {0}. 2
Bemerkung 14.59. Die Tatsache, daß ein mathematischer Formelausdruck fur
einen bestimmten Wert x0 eine ausfuhrbare Rechenvorschrift darstellt, laßt zu, daß
durch ihn eine Funktion erklart wird, die x0 zu ihrem Definitionsbereich zahlt. Es
heißt aber im Anwendungsfall noch lange nicht, daß der Punkt x0 auch im Definiti-
onsbereich einer durch die Rechenvorschrift darzustellenden ingenieurwissenschaft-
lichen Modellfunktion liegen mußte. Daruber entscheidet die modellierende Person.
Einer Formel fur die optimale Reisegeschwindigkeit eines Raumfahrzeuges wird man
z.B. auch bei noch so schoner Auswertbarkeit mit Skepsis begegnen, wenn sie Ge-
schwindigkeiten jenseits der Lichtgeschwindigkeit vorschlagt. 2
Symmetrien: Eine Symmetrie der Funktion (besser eine Symmetrie ihres Graphen)
liegt dann vor, wenn der Graph unter einer (einfachen) Bijektion des ihn enthalten-
den IR2 auf sich selbst invariant bleibt. Dann kann man meistens die Analyse auf
einen bestimmten Teilbereich des IR2 reduzieren.
Eine Standardsymmetrie ist etwa die Invarianz des Graphen unter der Spiegelung

14.4. KURVENDISKUSSION 181
an der y-Achse. Dann ist der Graph durch seinen Teilgraphen im Bereich x ≥ 0
bestimmt, und man kann die Untersuchung hierauf beschranken. Die Funktion ist
in solch einem Fall eine gerade Funktion (d.h. f(−x) = f(x) fur alle x ∈ Df ), was
sich am Formelsatz meist leicht prufen laßt.
Ebenso leicht pruft man, ob ein Formelsatz eine ungerade Funktion beschreibt.
Dann ist f(−x) = −f(x) fur alle x ∈ Df , der Graph ist invariant unter einer Dre-
hung des IR2 um π, und man kann sich wieder auf die Analyse fur x ≥ 0 beschranken.
Ein anderer Symmetrietyp, den man vielleicht bislang nicht unter diesem Begriff ein-
geordnet hatte, ist die normalerweise Periodizitat genannte Verschiebungssymmetrie
der trigonometrischen Funktionen. Der Graph wird bei der reellen Sinusfunktion
z.B. durch Verschiebung in x-Richtung um 2π auf sich abgebildet, und es reicht ja
bekanntlich auch, die Sinusfunktion in einem beliebigen Intervall der Lange 2π zu
diskutieren, um sie vollstandig zu kennen.
Daß die Sinusfunktion gleichzeitig noch einige weitere Symmetrien aufweist (sie ist
u.a. auch ungerade), kann man ausnutzen, um das benotigte Untersuchungsgebiet
ihres Graphen noch weiter zu reduzieren.
Wenn Symmetrien zu einem fruhen Zeitpunkt der Kurvendiskussion gesehen wer-
den, kann dies erheblich Arbeit sparen.
Abgesehen von Periodizitat, Geradheit oder Ungeradheit oder auch einer dieser Ei-
genschaften nach einer einfachen Urbild- und/oder Bildtransformation (ξ := x − x0
und η := y−y0) der Rechenvorschrift f(x) zu g(ξ) := f(ξ+x0)−y0 sind Symmetrien
aber nicht immer leicht zu entdecken. (Ein einfacher Fall ist Beispiel 14.58. Dort ist
f offensichtlich ungerade.)
Erkennt man Symmetrien nicht rasch, so stellt man die Behandlung dieses Punk-
tes zunachst zuruck. Da Symmetrien sehr viel Aufschluß uber die Funktion geben
konnen, ist es aber sinnvoll, die Frage nach Symmetrien zu einem spateren Zeitpunkt
mit mehr vorliegender Information noch einmal zu stellen.
Grenzwerte, Pole: Ist x0 ein Haufungspunkt des Definitionsbereichs mit x0 /∈ Df ,
so bestimme man die Grenzwerte limx→x0−0
f(x), limx→x0+0
f(x), falls diese existieren, und
entscheide, ob in x0 die Funktion stetig erganzt werden kann oder ob in x0 ein Pol
vorliegt. Man bestimme an diesen Stellen und an isolierten Stellen, an denen f nicht
differenzierbar ist, einseitige Grenzwerte von f ′, falls diese existieren.
In Beispiel 14.58. gilt
limx→0−0
f(x) = limx→0−0
(x − 5x−1 + 4x−3) = −∞, limx→0+0
f(x) = ∞,

182 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
d.h. f hat in x0 = 0 einen Pol. Damit ist auch das Verhalten von f ′ in der Nahe von
x0 klar, so dass man sich um Grenzwerte von f ′ nicht weiter zu kummern braucht.
Asymptoten: Man untersuche das Verhalten von f(x) fur x → ±∞, d.h., ob
limx→∞ f(x) und/oder lim
x→−∞f(x) existiert, oder allgemeiner, ob eine einfache Funktion
g(x) (etwa ein Polynom niedrigen Grades) existiert mit
f(x) − g(x) −→ 0 fur x → ∞ oder x → −∞.
Ein solches g heißt Asymptote von f in ∞ bzw. −∞.
In Beispiel 14.58. ist g(x) := x in ∞ und −∞ eine Asymptote, denn
limx→±∞
(f(x) − g(x)) = limx→±∞
−5x2 + 4
x3= 0.
Ermitteln kann man diese Asymptote hier z.B. einfach durch Ablesen aus der Form
f(x) = x − 5x−1 + 4x−3.
Nullstellen: Bestimme die Nullstellen von f .
In Beispiel 14.58. ist f(x) genau dann 0, wenn x4 − 5x2 + 4 = 0, d.h.
x2 =5
2±
√
25
4− 4 =
1
4.
Somit hat f die vier Nullstellen
x1 = −2, x2 = −1, x3 = 1, x4 = 2.
Die Ermittlung von Nullstellen ist von der Anwendungsseite her gesehen nur dann in-
teressant, wenn der Null im Bildbereich eine besondere Rolle zukommt. Sonst konnte
man genausogut (π − 1.27)-Stellen ermitteln. Wie das Beispiel der Ertragsfunkti-
on eines Betriebes zeigt, kommt der Nullinie allerdings sehr haufig eine wichtige
Trennfunktion zu.
Monotonieverhalten: Bestimme die Bereiche, in denen f monoton ist. Dabei wird
man (moglichst) die Ergebnisse aus Korollar 14.15. verwenden, wonach f streng
monoton wachsend ist, falls f ′(x) > 0 gilt, und streng monoton fallend, falls f ′(x) <
0 gilt.
In Beispiel 14.58. ist
f ′(x) =x4 + 5x2 − 12
x4

14.4. KURVENDISKUSSION 183
mit den Nullstellen x5,6 = ±√
12(−5 +
√73).
Wegen f ′(1) < 0 fallt f streng monoton in (0, x5) und wegen f ′(2) > 0 und 2 > x5
ist f streng monoton wachsend in (x5,∞).
Da f ungerade ist, ist f streng monoton wachsend in (−∞, x6) und streng monoton
fallend in (x6, 0).
Extrema: In diesem Arbeitsschritt bestimmt man moglichst alle Extrema der Funk-
tion, d.h. alle Minima und Maxima, wobei wir — weil diese Worte in allgemeinerer
Weise benutzt werden sollen als bislang schon — erst noch genauer (in einer gleich
zu gebenden Definition) deren Bedeutung erlautern werden.
Im Zusammenhang mit dem Nachweis der Annahme des Supremums und des Infi-
mums durch stetige Funktionen auf kompakten Mengen im Satz 10.52. hatten wir
bereits ausgefuhrt, daß das Erstreben von Extremen treibende Kraft vieler Akti-
vitaten ist. Man kann sich deshalb leicht vorstellen, daß der Wunsch, Extrema von
Funktionen zu charakterisieren, um sie mit Hilfe ihrer Charakterisierung anschlie-
ßend zu berechnen, ein Hauptantrieb der Wissenschaftler des 17. Jahrhunderts bei
der Konzeption der Grundlagen der Analysis war. Die Beobachtung, daß der Graph
von Funktionen in Extrem-Punkten (oft) eine waagerechte Tangente hatte, war u.a.
Motivation fur die Entwicklung eines Kalkuls zur Berechnung der Tangente, und das
heißt der grundlegenden Technik des Differenzierens.
Nun sind bei der Kurvendiskussion die Extrema nicht allein wegen der extremalen
Große der Funktionswerte interessant. Wichtig ist auch die Aussage, daß sich beim
Durchlaufen von Argumentwerten mit extremalen Funktionswerten das Verhalten
der Funktion meist grundlegend andert. Eine solche Verhaltensanderung ist sicher
in vielen Anwendungen von fundamentaler Bedeutung. Ob es sich nun um die Borse,
die Staatsverschuldung, die eigene Karriere oder nur einen Wanderweg handelt: Es
ist stets wesentlich, ob es bergab oder bergauf geht.
Solche Wechsel des Monotonietyps liegen nicht nur in den bislang als Maxima (bzw.
Minima) bezeichneten Punkten vor, welche den global (d.h. im Vergleich zu allen
konkurrierenden Funktionswerten) maximalen bzw. minimalen Funktionswert reali-
sierten. Auch in Punkten, die nur im Vergleich zu ihren direkten Nachbarn (in einem
umgebenden offenen Intervall) extremal sind, andern Funktionen ihr Monotoniever-
halten, weshalb wir lokale Extrema definieren werden.
Die folgende Definition erfaßt die Grundformen extremalen Verhaltens.
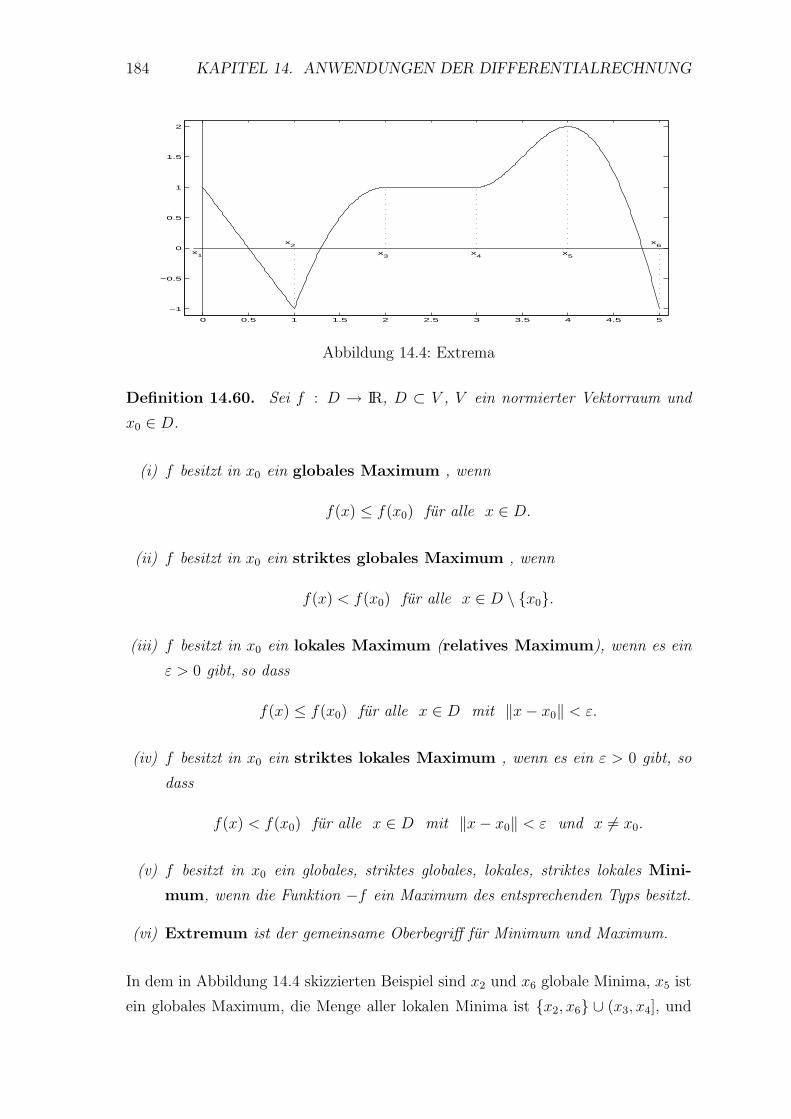
184 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
−1
−0.5
0
0.5
1
1.5
2
x1
x2
x3
x4
x5
x6
Abbildung 14.4: Extrema
Definition 14.60. Sei f : D → IR, D ⊂ V , V ein normierter Vektorraum und
x0 ∈ D.
(i) f besitzt in x0 ein globales Maximum , wenn
f(x) ≤ f(x0) fur alle x ∈ D.
(ii) f besitzt in x0 ein striktes globales Maximum , wenn
f(x) < f(x0) fur alle x ∈ D \ {x0}.
(iii) f besitzt in x0 ein lokales Maximum (relatives Maximum), wenn es ein
ε > 0 gibt, so dass
f(x) ≤ f(x0) fur alle x ∈ D mit ‖x − x0‖ < ε.
(iv) f besitzt in x0 ein striktes lokales Maximum , wenn es ein ε > 0 gibt, so
dass
f(x) < f(x0) fur alle x ∈ D mit ‖x − x0‖ < ε und x 6= x0.
(v) f besitzt in x0 ein globales, striktes globales, lokales, striktes lokales Mini-
mum, wenn die Funktion −f ein Maximum des entsprechenden Typs besitzt.
(vi) Extremum ist der gemeinsame Oberbegriff fur Minimum und Maximum.
In dem in Abbildung 14.4 skizzierten Beispiel sind x2 und x6 globale Minima, x5 ist
ein globales Maximum, die Menge aller lokalen Minima ist {x2, x6} ∪ (x3, x4], und
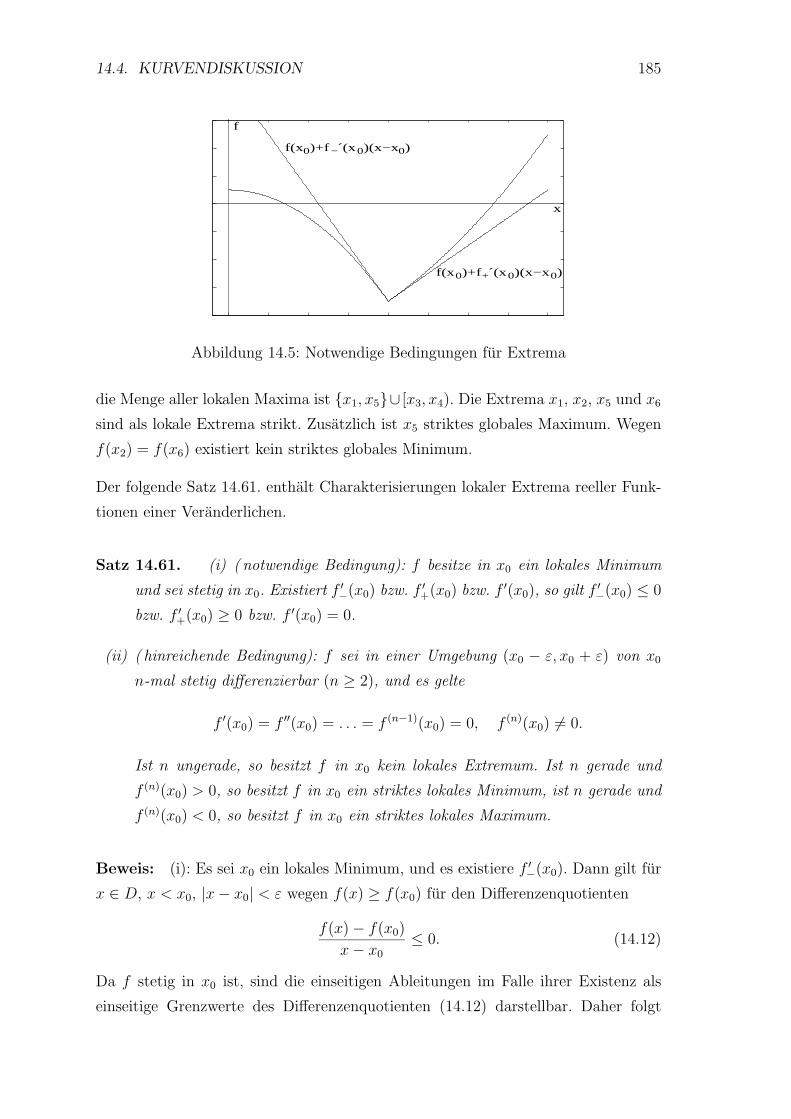
14.4. KURVENDISKUSSION 185
f(x0)+f+´(x0)(x−x0)
f(x0)+f −´(x0)(x−x0)
x
f
Abbildung 14.5: Notwendige Bedingungen fur Extrema
die Menge aller lokalen Maxima ist {x1, x5}∪ [x3, x4). Die Extrema x1, x2, x5 und x6
sind als lokale Extrema strikt. Zusatzlich ist x5 striktes globales Maximum. Wegen
f(x2) = f(x6) existiert kein striktes globales Minimum.
Der folgende Satz 14.61. enthalt Charakterisierungen lokaler Extrema reeller Funk-
tionen einer Veranderlichen.
Satz 14.61. (i) ( notwendige Bedingung): f besitze in x0 ein lokales Minimum
und sei stetig in x0. Existiert f ′−(x0) bzw. f ′
+(x0) bzw. f ′(x0), so gilt f ′−(x0) ≤ 0
bzw. f ′+(x0) ≥ 0 bzw. f ′(x0) = 0.
(ii) ( hinreichende Bedingung): f sei in einer Umgebung (x0 − ε, x0 + ε) von x0
n-mal stetig differenzierbar (n ≥ 2), und es gelte
f ′(x0) = f ′′(x0) = . . . = f (n−1)(x0) = 0, f (n)(x0) 6= 0.
Ist n ungerade, so besitzt f in x0 kein lokales Extremum. Ist n gerade und
f (n)(x0) > 0, so besitzt f in x0 ein striktes lokales Minimum, ist n gerade und
f (n)(x0) < 0, so besitzt f in x0 ein striktes lokales Maximum.
Beweis: (i): Es sei x0 ein lokales Minimum, und es existiere f ′−(x0). Dann gilt fur
x ∈ D, x < x0, |x − x0| < ε wegen f(x) ≥ f(x0) fur den Differenzenquotienten
f(x) − f(x0)
x − x0
≤ 0. (14.12)
Da f stetig in x0 ist, sind die einseitigen Ableitungen im Falle ihrer Existenz als
einseitige Grenzwerte des Differenzenquotienten (14.12) darstellbar. Daher folgt

186 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
f ′−(x0) ≤ 0 bzw. f ′
+(x0) ≥ 0, falls f ′−(x0) bzw. f ′
+(x0) existiert. Ist f differenzierbar
in x0, so ist
f ′(x0) = f ′+(x0) ≥ 0 ≥ f ′
−(x0) = f ′(x0),
so daß dann f ′(x0) = 0 ist.
(ii): Nach dem Taylorschen Satz (Satz 14.35.) gilt mit einem ξ = x0 + θ (x − x0),
θ ∈ (0, 1), die Darstellung
f(x) =n−1∑
j=0
f (j)(x0)
j!(x − x0)
j +f (n)(ξ)
n!(x − x0)
n
= f(x0) +f (n)(ξ)
n!(x − x0)
n.
Liegt x 6= x0 genugend nahe bei x0, so besitzen f (n)(x0) und f (n)(ξ) wegen der
Stetigkeit von f (n) in x0 gleiches Vorzeichen. Daher gilt fur gerades n und solche
x-Werte:
f(x) − f(x0) =1
n!f (n)(ξ) (x − x0)
n
> 0 fur f (n)(x0) > 0,
< 0 fur f (n)(x0) < 0.
Im ersten Fall liegt damit ein striktes lokales Minimum vor, im zweiten Fall ein
striktes lokales Maximum.
Fur ungerades n und f (n)(x0) > 0 gilt
f(x) − f(x0) =1
n!f (n)(ξ) (x − x0)
n
> 0 fur x > x0,
< 0 fur x < x0.
Fur f (n)(x0) < 0 kehren sich die Ungleichheitszeichen um.
Beispiel 14.62. Im Beispiel 14.58. auf Seite 180 gilt
f ′(x) =x4 + 5x2 − 12
x4
mit den Nullstellen x5,6 = ±√
(−5 +√
73)/2 und
f ′′(x) =−10x2 + 48
x5
mit f ′′(x5) > 0 und f ′′(x6) < 0.
f besitzt also in x5 ein striktes lokales Minimum und in x6 ein striktes lokales
Maximum. Dies war auch schon nach den Monotonieuberlegungen klar. 2

14.4. KURVENDISKUSSION 187
Beispiel 14.63. Die Aufgabe aus dem Beispiel 14.58., die wir fortgesetzt als De-
monstrationsbeispiel verwenden, ist dazu geeignet, die vermutlich auch schon in
der Schule eingepragte Idee zu verfestigen, daß man bei der Kurvendiskussion einer
Funktion ihre Nullstellen, ihre Extrema und vielleicht auch noch ihre (hier noch zu
besprechenden) Wendepunkte immer einfach ausrechnen konnte. Das ist in konstru-
ierten Aufgaben des Mathematikunterrichtes oft der Fall. Es trifft aber in Aufgaben
der Praxis eher selten zu. Dort muß man stattdessen mit numerischen Approxi-
mationen der dabei jeweils zu bestimmenden Nullstellen der Funktion oder ihrer
Ableitungen zufrieden sein.
Wie das folgende Beispiel zeigt, kann man mit den Bedingungen fur Extrema durch-
aus nutzliche Information herleiten, ohne daß man eine einzige Nullstelle exakt be-
stimmt haben mußte.
Als Anwendung von Satz 14.61. leiten wir das
Reflexionsgesetz her: Ein von dem Punkt
A = (0, a2) ausgehender Lichtstrahl wer-
de im Punkt P = (x1, 0) an einer Geraden
(x-Achse) reflektiert und erreiche dann den
Punkt B = (b1, b2). Gesucht ist x1.
Nach dem Fermatschen Prinzip wahlt das
Licht denjenigen Weg, fur den die benotig-
te Zeit minimal ist, d.h. P ist dadurch be-
stimmt, dass die Summe der Entfernungen
PA + PB minimal ist.
x
y
A
P
B
Abbildung 14.6
Wir machen den Ansatz P = (x, 0) und erhalten die Entfernungssumme
f(x) =√
x2 + a22 +
√
(x − b1)2 + b22.
Die Ableitungen
f ′(x) =x
√
x2 + a22
+x − b1
√
(x − b1)2 + b22
,
f ′′(x) =a2
2√
x2 + a22
3 +b22
√
(x − b1)2 + b22
3
sind nicht schwer zu bilden.
Da die zweite Ableitung nur aus Quadraten besteht, ist sie offenbar uberall positiv.

188 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
x yλ x+(1−λ)y
f(λ x+(1−λ)y)
λ f(x)+(1−λ )f(y)
Abbildung 14.7: Konvexe Funktion
Daher ist f ′ uberall streng monoton wachsend. In den Endpunkten des interessie-
renden Intervalls ist
f ′(0) = − b1√
b21 + b2
2
< 0, f ′(b1) =b1
√
b21 + a2
2
> 0.
Nach dem Zwischenwertsatz besitzt f ′ daher im Inneren dieses Intervalls eine Null-
stelle x1, und wegen der strengen Monotonie ist diese eindeutig. Da f ′′ uberall großer
als Null ist, gilt dies auch fur die Stelle x1, die nach dem hinreichenden Kriterium
fur Extrema damit ein striktes lokales Minimum ist. Da keine weiteren Extrema
existieren, ist x1 sogar globales Minimum.
Man kann sich nun naturlich bemuhen, aus f ′(x1) = 0, also
x1√
x21 + a2
2
=b1 − x1
√
(x1 − b1)2 + b22
eine Formel fur x1 herzuleiten. Einpragsamer wird das Ergebnis aber, wenn man
die letzte Gleichung genauer ansieht. Dann findet man, daß diese Gleichung fur den
Einfallswinkel α und den Ausfallswinkel β nichts anderes besagt als cos α = cos β.
Da α und β spitze Winkel sind und ihre Vorzeichen aus der Geometrie auch klar
sind, ist dies gerade das Reflexionsgesetz”Einfallswinkel = Ausfallswinkel“. 2
Wendepunkte: In einem Fahrzeug wird das Fahrgefuhl neben der Fahrtrichtung
wesentlich dadurch bestimmt, ob das Fahrzeug beschleunigt oder ob es bremst. Fahrt
man mit einem Fahrrad bergauf oder bergab, findet man es informativ zu wissen,
ob dabei die Steigung zunimmt oder abnimmt. Folgt man einer Kurve in einer Ebe-
ne (bei Zeichnen auf dem Papier oder per Fahrzeug auf der Erdoberflache) ist es
nutzlich zu wissen, ob die Kurve nach links oder nach rechts gekrummt ist.

14.4. KURVENDISKUSSION 189
In all diesen Fallen bezieht sich die benotigte Information auf die Art der Anderung
der ersten Ableitung, und diese wird (im Falle der Differenzierbarkeit der Ablei-
tungsfunktion) durch das Vorzeichen der zweiten Ableitung bestimmt. Wenn man
die genannten Anwendungsfalle einmal durchgeht, wird man feststellen, daß wir
meist fur Anderungen hoherer Art (Verstarkung der Beschleunigung, Zunahme der
Steigungsvergroßerung, Verstarkung der Linkskrummung) weniger empfindlich zu
sein scheinen. Diese naturliche Wahrnehmungsschranke fur Anderungen hoherer als
zweiter Ordnung schlagt sich auch in der Kurvendiskussion nieder, indem hier zwar
noch Umschlagspunkte dieser Anderungen zweiter Ordnung (Vorzeichenwechsel der
zweiten Ableitung) in die Diskussion einbezogen, aber nur selten Anderungen hoher-
er Ableitungen diskutiert werden.
Da Krummungsarten von Graphen auch ohne die Differenzierbarkeit der Funktionen
beschrieben werden konnen, und durch solche Beschreibungen erstens mehr Funktio-
nen erfaßt werden und zweitens auch im mehrfach differenzierbaren Fall interessante
und nutzliche Informationen uber die Funktionen und verschiedene lineare Appro-
ximationen (Sekanten und Tangenten) resultieren, beginnen wir den Abschnitt uber
Krummungen und Wendepunkte (in denen die Art der Krummung sich andert) et-
was allgemeiner als vielleicht erwartet.
Definition 14.64. Sei I ⊂ IR ein Intervall. f : I → IR heißt konvex in I, wenn
fur alle x, y ∈ I, x 6= y, und alle λ ∈ (0, 1) gilt
f(λx + (1 − λ)y) ≤ λ f(x) + (1 − λ) f(y).
Gilt diese Ungleichung mit”<“, so heißt f strikt konvex in I.
f heißt (strikt) konkav, falls −f (strikt) konvex ist.
Bemerkung 14.65. In Worten bedeutet Konvexitat (Konkavitat) von f in I, dass
zu je zwei Punkten x, y ∈ I der Graph von f zwischen x und y nicht oberhalb (un-
terhalb) der Sehne durch (x, f(x)), (y, f(y)) liegen kann.
Wir werden Konvexitat im Falle der Differenzierbarkeit mit einem Zuwachs der Ab-
leitung in Verbindung bringen. Denkt man sich den Hohenverlauf einer Straße durch
den Graphen einer Funktion modelliert, so ist der Zusammenhang von Zunahme der
Ableitung und Konvexitat schon jetzt klar. Nimmt die Steigung zu, so ist der Ge-
genverkehr erkennbar. Der Sehstrahl lauft oberhalb des Graphen von f . Nimmt die
Steigung dagegen ab (etwa vor einer Bergkuppe), so mußte der direkte Sehstrahl
zum Gegenverkehr die Kuppe durchdringen.

190 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
Als Folgerung aus Satz 14.71. werden wir ubrigens erhalten, daß Tangenten an die
eben genannten konvexen bzw. konkaven Funktionen gerade stets auf der anderen
Seite liegen wie die Sekanten. Bekannt ist dies aus dem praktischen Wissen, daß
man gemeinhin aus Linkskurven nach rechts und aus Rechtskurven nach links her-
ausgetragen wird (wenn man nicht achtgibt, und der Tangente folgt). 2
Bemerkung 14.66. Sind f , g konvexe Funktionen, so sind offenbar auch f + g
und h(x) := max(f(x), g(x)) konvex. Es ist aber nicht f · g konvex, denn f(x) := x2
und g(x) := −1 sind konvex, aber nicht (f · g)(x) = −x2. Auch wenn f und g strikt
konvex sind, ist f ·g i.a. nicht konvex, denn f(x) := (x−1)2 und g(x) := (x+1)2 sind
strikt konvex, aber (f · g)(x) = (x2 − 1)2 ist in (− 1√3, 1√
3) strikt konkav. Letzteres
zeigt man mit dem folgenden Satz 14.67. 2
Satz 14.67. Sei f : [a, b] → IR stetig in [a, b] und zweimal stetig differenzierbar
in (a, b). Dann gilt
(i) f ist genau dann konvex (konkav) in [a, b], wenn f ′′(x) ≥ 0 (f ′′(x) ≤ 0) fur
alle x ∈ (a, b) gilt.
(ii) Gilt f ′′(x) > 0 (f ′′(x) < 0) fur alle x ∈ (a, b), so ist f strikt konvex (konkav)
in [a, b].
Bemerkung 14.68. Die Aussage (ii) kann man nicht umkehren, denn es ist z.B.
f(x) = x4 strikt konvex, aber f ′′(0) = 0. 2
Beweis: (von Satz 14.67.)
Es sei f ′′(x) ≥ 0 fur alle x ∈ (a, b) und x, y ∈ [a, b] mit x < y. Zu zeigen ist, dass fur
alle t ∈ (x, y), d.h. t := λx + (1 − λ)y mit λ ∈ (0, 1), gilt
λ f(x) + (1 − λ) f(y) − f(t) ≥ 0.
Nach dem Mittelwertsatz gibt es
ξ ∈ (x, t) mit f(x) − f(t) = f ′(ξ) (x − t),
η ∈ (t, y) mit f(y) − f(t) = f ′(η) (y − t)
und
ζ ∈ (ξ, η) mit f ′(η) − f ′(ξ) = f ′′(ζ) (η − ξ).

14.4. KURVENDISKUSSION 191
Daher gilt
λ f(x) + (1 − λ) f(y) − f(t)
= λ (f(x) − f(t)) + (1 − λ) (f(y) − f(t))
= λ (x − t) f ′(ξ) + (1 − λ) (y − t) f ′(η)
= λ (1 − λ) (x − y) f ′(ξ) + (1 − λ) λ (y − x) f ′(η)
= λ (1 − λ) (y − x) (η − ξ) f ′′(ζ) ≥ 0,
d.h. f ist konvex.
Ist f ′′(x) > 0 fur alle x ∈ (a, b), so erhalt man genauso die strikte Konvexitat von
f .
Es sei nun umgekehrt f konvex, x, y ∈ (a, b) mit x < y fest gewahlt und t ∈ (x, y).
Dann gilt fur die Gerade
g(t) := f(x) +f(y) − f(x)
y − x(t − x) =: f(x) + m (t − x)
f(t) ≤ g(t), d.h.f(t) − f(x)
t − x≤ g(t) − g(x)
t − x= m,
und mit t → x folgt f ′(x) ≤ m.
Genauso erhalt man aus f(t) ≤ g(t) zunachst
f(t) − f(y)
t − y≥ g(t) − g(y)
t − y= m,
und mit t → y dann f ′(y) ≥ m.
Zusammen folgt f ′(x) ≤ f ′(y), d.h. f ′ ist monoton wachsend in (a, b), und daher
erhalt man f ′′(x) ≥ 0 fur alle x ∈ (a, b).
Beispiel 14.69. f(x) := ex, g(x) := x2, h(x) := cosh x sind strikt konvex in IR,
k(x) := sin x ist konkav in [0, π]. 2
Wir haben in Satz 14.67. eine Charakterisierung von Konvexitat unter der globalen
Voraussetzung der zweimaligen stetigen Differenzierbarkeit diskutiert. Tatsachlich
hat die Konvexitat einer Funktion selbst schon eine erhebliche Glattheit zur Folge.
Dies sagt z.B. die folgende Aussage aus R.T. Rockafellar: Convex Analysis,
deren Beweis uns hier allerdings zuviel Raum kosten wurde und die wir daher einfach
zitieren.
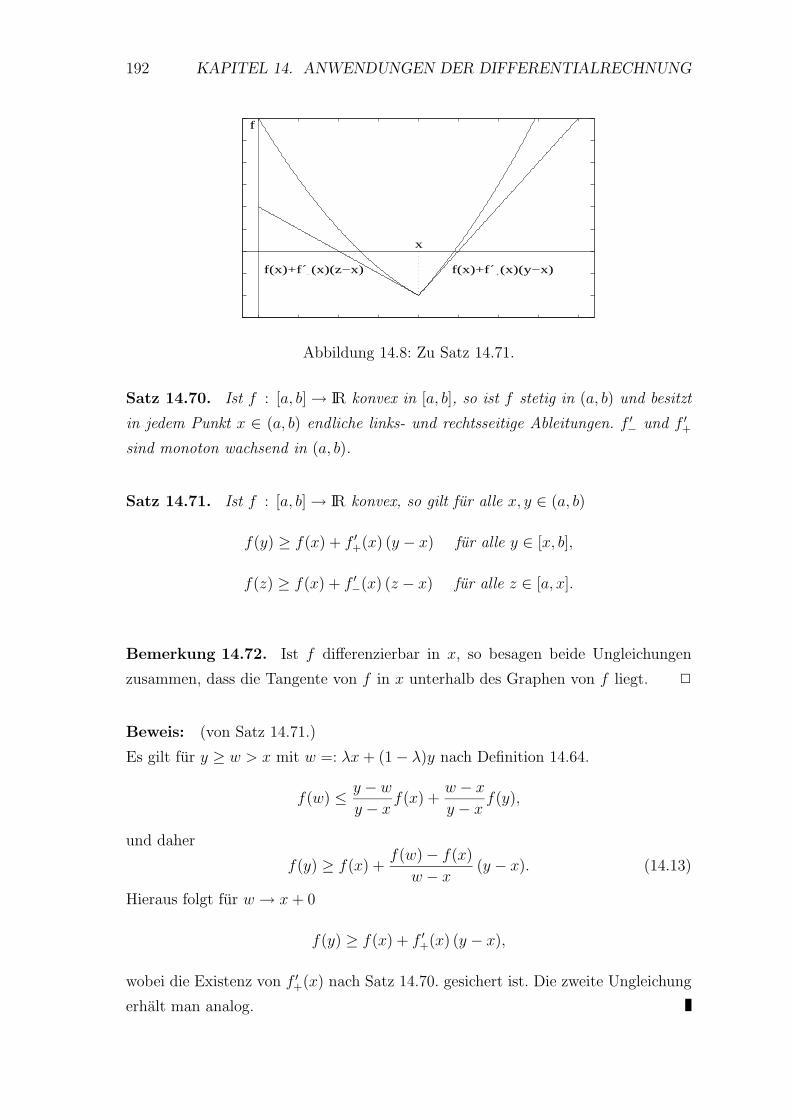
192 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
x
f(x)+f´+(x)(y−x)f(x)+f´
−(x)(z−x)
f
Abbildung 14.8: Zu Satz 14.71.
Satz 14.70. Ist f : [a, b] → IR konvex in [a, b], so ist f stetig in (a, b) und besitzt
in jedem Punkt x ∈ (a, b) endliche links- und rechtsseitige Ableitungen. f ′− und f ′
+
sind monoton wachsend in (a, b).
Satz 14.71. Ist f : [a, b] → IR konvex, so gilt fur alle x, y ∈ (a, b)
f(y) ≥ f(x) + f ′+(x) (y − x) fur alle y ∈ [x, b],
f(z) ≥ f(x) + f ′−(x) (z − x) fur alle z ∈ [a, x].
Bemerkung 14.72. Ist f differenzierbar in x, so besagen beide Ungleichungen
zusammen, dass die Tangente von f in x unterhalb des Graphen von f liegt. 2
Beweis: (von Satz 14.71.)
Es gilt fur y ≥ w > x mit w =: λx + (1 − λ)y nach Definition 14.64.
f(w) ≤ y − w
y − xf(x) +
w − x
y − xf(y),
und daher
f(y) ≥ f(x) +f(w) − f(x)
w − x(y − x). (14.13)
Hieraus folgt fur w → x + 0
f(y) ≥ f(x) + f ′+(x) (y − x),
wobei die Existenz von f ′+(x) nach Satz 14.70. gesichert ist. Die zweite Ungleichung
erhalt man analog.

14.4. KURVENDISKUSSION 193
Bemerkung 14.73. Unser Wissen, daß Sehnen bei konvexen Funktionen stets
oberhalb des Graphen verlaufen und Tangenten stets unterhalb, konnen wir z.B.
verwenden, um stuckweise lineare Funktionen zu finden, die eine Funktion uberall
einschließen und die damit berechenbare Approximationen mit Fehlerschranken lie-
fern. Bei konkaven Funktionen ist es gerade umgekehrt. Hier liefern die Sehnen die
unteren und die Tangenten die oberen Schranken. Will man eine allgemeine Funktion
einschließen, so benotigt man Informationen, wo eine Funktion den Krummungstyp
wechselt. Solche Punkte heißen Wendepunkte. 2
Definition 14.74. Sei f : [a, b] → IR stetig in x0 ∈ (a, b). Der Punkt x0 heißt
Wendepunkt von f , wenn f in einem Intervall (x0 − ε, x0) konvex und in einem
Intervall (x0, x0 + η) konkav ist oder umgekehrt.
Ist f zweimal stetig differenzierbar in einer Umgebung von x0, so gilt also nach
Satz 14.67. f ′′(x) ≥ 0 fur x ∈ (x0 − ε, x0) und f ′′(x) ≤ 0 fur x ∈ (x0, x0 + η), wegen
der Stetigkeit von f ′′ folgt f ′′(x0) = 0.
Dies ist eine notwendige Bedingung fur einen Wendepunkt. Sie ist aber nicht hin-
reichend, wie das Beispiel f(x) = x4 zeigt. f ist konvex in IR, aber es ist f ′′(0) = 0.
Eine hinreichende Bedingung erhalt man ahnlich wie in Satz 14.61. wieder unter
Benutzung hoherer Ableitungen.
Satz 14.75. (i) (notwendige Bedingung): Sei f zweimal stetig differenzierbar in
einer Umgebung des Wendepunktes x0. Dann gilt f ′′(x0) = 0.
(ii) (hinreichende Bedingung): Es sei n ≥ 3. Die Funktion f sei n-mal stetig dif-
ferenzierbar in einer Umgebung von x0, und es gelte
f (j)(x0) = 0, j = 2, . . . , n − 1, f (n)(x0) 6= 0.
Ist n ungerade, so besitzt f in x0 einen Wendepunkt. Ist n gerade, so ist f im
Falle f (n)(x0) > 0 konvex in einer Umgebung von x0 und im Falle f (n)(x0) < 0
konkav in einer Umgebung von x0.
Beweis: Die notwendige Bedingung haben wir schon gezeigt. Um die hinreichende
Bedingung Teil zu beweisen, wenden wir auf die Funktion g := f ′′ den Taylorschen
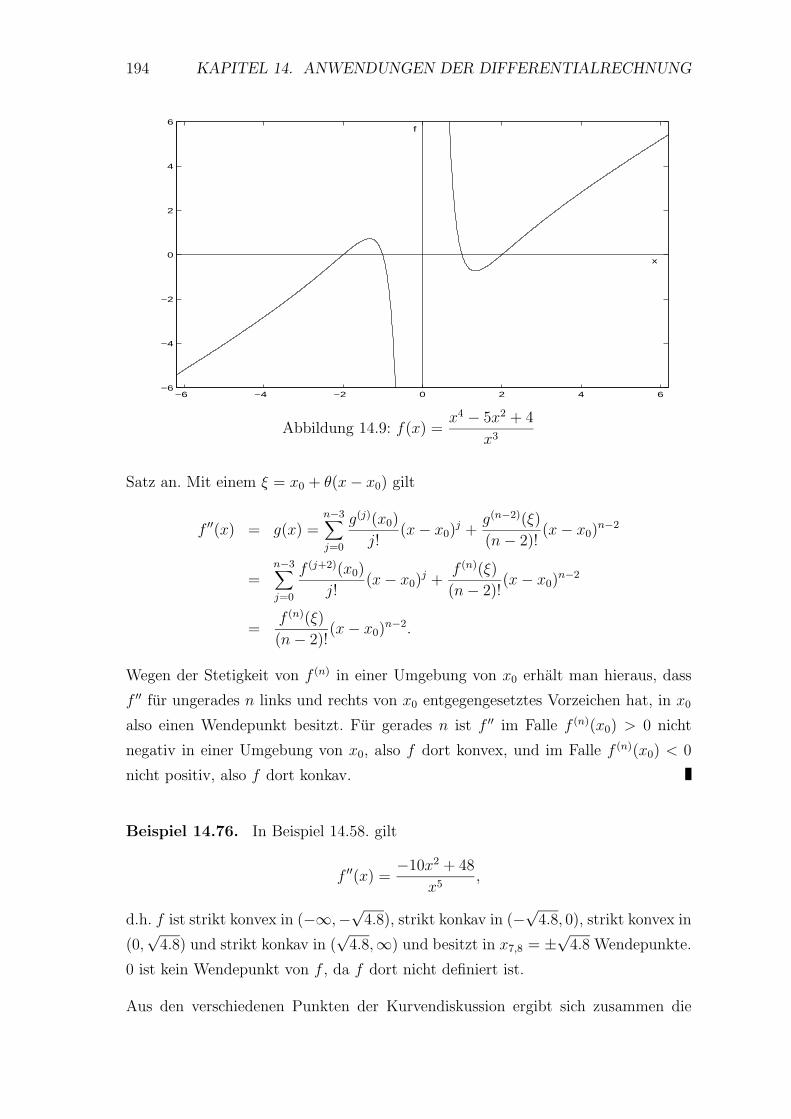
194 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
−6 −4 −2 0 2 4 6−6
−4
−2
0
2
4
6
x
f
Abbildung 14.9: f(x) =x4 − 5x2 + 4
x3
Satz an. Mit einem ξ = x0 + θ(x − x0) gilt
f ′′(x) = g(x) =n−3∑
j=0
g(j)(x0)
j!(x − x0)
j +g(n−2)(ξ)
(n − 2)!(x − x0)
n−2
=n−3∑
j=0
f (j+2)(x0)
j!(x − x0)
j +f (n)(ξ)
(n − 2)!(x − x0)
n−2
=f (n)(ξ)
(n − 2)!(x − x0)
n−2.
Wegen der Stetigkeit von f (n) in einer Umgebung von x0 erhalt man hieraus, dass
f ′′ fur ungerades n links und rechts von x0 entgegengesetztes Vorzeichen hat, in x0
also einen Wendepunkt besitzt. Fur gerades n ist f ′′ im Falle f (n)(x0) > 0 nicht
negativ in einer Umgebung von x0, also f dort konvex, und im Falle f (n)(x0) < 0
nicht positiv, also f dort konkav.
Beispiel 14.76. In Beispiel 14.58. gilt
f ′′(x) =−10x2 + 48
x5,
d.h. f ist strikt konvex in (−∞,−√
4.8), strikt konkav in (−√
4.8, 0), strikt konvex in
(0,√
4.8) und strikt konkav in (√
4.8,∞) und besitzt in x7,8 = ±√
4.8 Wendepunkte.
0 ist kein Wendepunkt von f , da f dort nicht definiert ist.
Aus den verschiedenen Punkten der Kurvendiskussion ergibt sich zusammen die

14.5. DER FEHLER DER POLYNOMINTERPOLATION 195
Abbildung 14.9 des Graphen der Funktion
f(x) =x4 − 5x2 + 4
x3. 2
14.5 Der Fehler der Polynominterpolation
Wir haben in Abschnitt 12.1 das Interpolationsproblem mit Polynomen be-
handelt:
Gegeben seien n + 1 Wertepaare (xj, yj) ∈ C2, j = 0, 1, . . . , n, xj paar-
weise verschieden. Bestimme p ∈ Πn mit p(xj) = yj, j = 0, . . . , n.
Dieses Problem ist fur alle Daten eindeutig losbar. Fur die Losung gibt es verschie-
dene Darstellungs- und Berechnungsformen: Wir hatten die Lagrangesche und die
Newtonsche Interpolationsformel behandelt sowie das Verfahren von Neville und
Aitken.
Fruher mußte die Interpolation oft verwendet werden, um aus Tabellenwerten von
Funktionen Naherungswerte fur Funktionen an Argumentstellen zu berechnen, die
nicht in den Tabellen enthalten waren. Wahlt man dazu im Interpolationsproblem
xj-Werte, an denen die Funktion bekannt (tabelliert) ist, und benutzt dann als
yj-Werte die zugehorigen Funktionswerte, so ergibt sich sofort die Frage, wie gut
ein Interpolationspolynom die interpolierte Funktion in von den dann Interpo-
lationsstutzstellen oder Interpolationsknoten genannten xj verschiedenen x-
Werten darzustellen vermag. Das Argument, daß man so etwas nicht mehr brauche,
da die Funktionen ja heute per Rechner verfugbar seien, greift etwas kurz, denn oft
sind die Funktionen (oder jedenfalls erste noch zu verfeinernde Approximationen
davon) auf dem Rechner als Tabellen mit geeigneten Interpolationen implementiert.
Beispiel 14.77. Gegeben sei auf dem Intervall I = [−1, 1] die Funktion
f(x) = sin(πx)
und p8(x) ∈ Π8, das Interpolationspolynom zu den Knoten xi = −1 + i/4 fur
i = 0, . . . , 8. Dann erhalt man die Fehlerkurve in Abbildung 14.10.
Plottet man die Funktion und ihre Interpolation, so kann man den Fehler kaum
sehen. Der auftretende absolute Fehler von der Großenordnung 0.0012 ist schon fur
die meisten Zwecke klein genug. 2
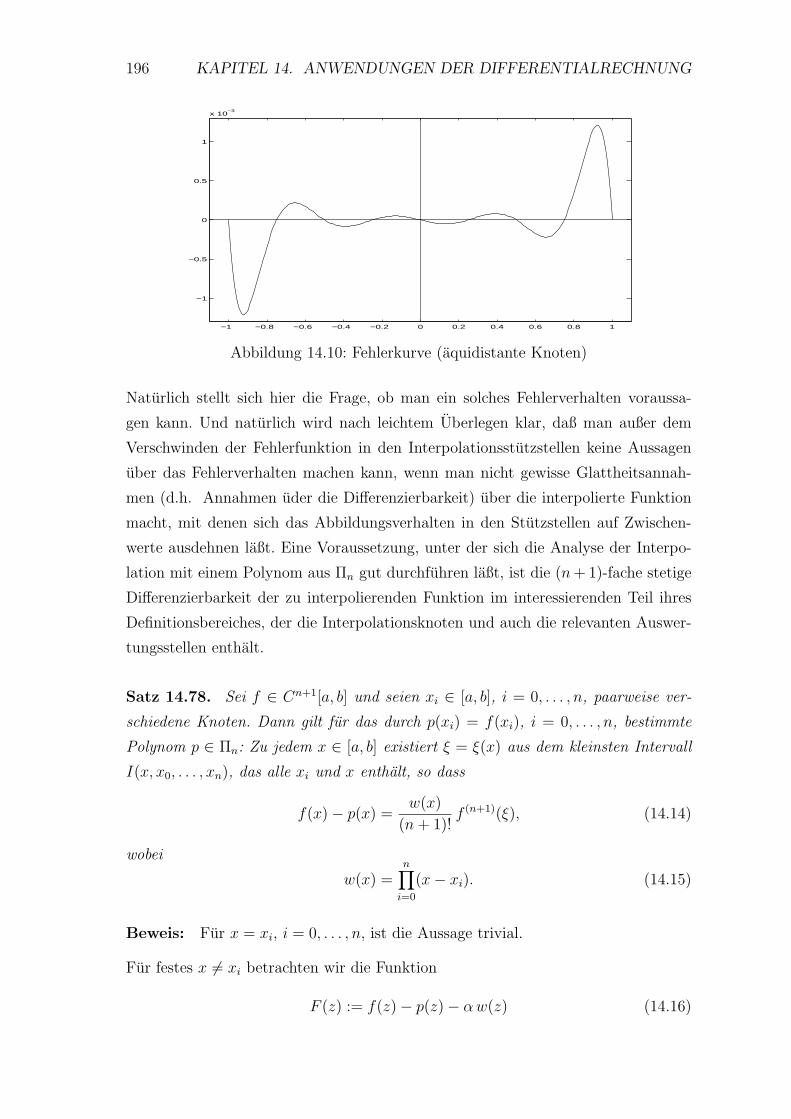
196 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−1
−0.5
0
0.5
1
x 10−3
Abbildung 14.10: Fehlerkurve (aquidistante Knoten)
Naturlich stellt sich hier die Frage, ob man ein solches Fehlerverhalten voraussa-
gen kann. Und naturlich wird nach leichtem Uberlegen klar, daß man außer dem
Verschwinden der Fehlerfunktion in den Interpolationsstutzstellen keine Aussagen
uber das Fehlerverhalten machen kann, wenn man nicht gewisse Glattheitsannah-
men (d.h. Annahmen uder die Differenzierbarkeit) uber die interpolierte Funktion
macht, mit denen sich das Abbildungsverhalten in den Stutzstellen auf Zwischen-
werte ausdehnen laßt. Eine Voraussetzung, unter der sich die Analyse der Interpo-
lation mit einem Polynom aus Πn gut durchfuhren laßt, ist die (n + 1)-fache stetige
Differenzierbarkeit der zu interpolierenden Funktion im interessierenden Teil ihres
Definitionsbereiches, der die Interpolationsknoten und auch die relevanten Auswer-
tungsstellen enthalt.
Satz 14.78. Sei f ∈ Cn+1[a, b] und seien xi ∈ [a, b], i = 0, . . . , n, paarweise ver-
schiedene Knoten. Dann gilt fur das durch p(xi) = f(xi), i = 0, . . . , n, bestimmte
Polynom p ∈ Πn: Zu jedem x ∈ [a, b] existiert ξ = ξ(x) aus dem kleinsten Intervall
I(x, x0, . . . , xn), das alle xi und x enthalt, so dass
f(x) − p(x) =w(x)
(n + 1)!f (n+1)(ξ), (14.14)
wobei
w(x) =n∏
i=0
(x − xi). (14.15)
Beweis: Fur x = xi, i = 0, . . . , n, ist die Aussage trivial.
Fur festes x 6= xi betrachten wir die Funktion
F (z) := f(z) − p(z) − α w(z) (14.16)

14.5. DER FEHLER DER POLYNOMINTERPOLATION 197
und bestimmen α so, dass F (x) = 0 gilt.
Dann besitzt F in I(x, x0, . . . , xn) wenigstens n + 2 Nullstellen. Nach dem Satz von
Rolle (Satz 14.1.) besitzt F ′ dort wenigstens n+1 Nullstellen, F ′′ wenigstens n Null-
stellen, usw. Schließlich hat F (n+1) mindestens eine Nullstelle ξ ∈ I(x, x0, . . . , xn).
Wegen p ∈ Πn erhalt man aus (14.16)
F (n+1)(ξ) = f (n+1)(ξ) − 0 − α · (n + 1)! = 0.
Hiermit folgt wegen F (x) = 0 aus (14.16) die Behauptung.
Bemerkung 14.79. Fur den Fall der Interpolation mit einer Stutzstelle x0 durch
die konstante Funktion p(x) = f(x0) war das Ergebnis des letzten Satzes als Mittel-
wertsatz
f(x) − f(x0) = f ′(ξ)(x − x0)
schon bekannt. 2
Bemerkung 14.80. Laßt man im Falle der linearen Interpolation
f(x) −(
f(x0) +f(x1) − f(x0)
x1 − x0
(x − x0)
)
=f ′′(ξ)
2!(x − x0)(x − x1)
den Punkt x1 gegen x0 gehen, so geht die Sekante gegen die Tangente in x0 und der
Fehlerterm geht gegen den Fehlerterm dieses Taylorpolynoms erster Ordnung
f(x) − (f(x0) + f ′(x0)(x − x0)) =f ′′(ξ)
2!(x − x0)
2.
Man kann allgemeiner zeigen, daß beim Zusammenlaufen aller n + 1 Punkte des
Interpolationspolynoms aus Satz 14.78. analog das Interpolationspolynom zum n-
ten Taylorpolynom aus Πn wird und das Restglied zum Lagrangeschen Restglied der
Taylorapproximation.
Bei dieser Sicht ist es vielleicht auch einsichtig, weshalb man fur die Fehleranlyse
des Interpolationspolynoms mit n + 1 Stutzstellen gerade f ∈ Cn+1 annimmt. Der
Satz von Taylor sagt dann ja, daß f dann wenigstens lokal gut durch Polynome aus
Πn approximierbar ist. 2
Aus der Fehlerdarstellung von Satz 14.78. erhalt man eine gleichmaßige Abschatzung
fur die Gute der Approximation durch das Interpolationspolynom auf dem ganzen
Intervall [a,b]
‖f − p‖∞ := maxx∈[a,b]
|f(x) − p(x)| ≤ ‖f (n+1)‖∞(n + 1)!
‖w‖∞, (14.17)

198 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
worin die Einflusse der Funktion und der Lage der Interpolationsknoten getrennt
sind.
Am Faktor ‖f (n+1)‖∞ ist normalerweise nicht zu rutteln, da dieser durch die zu
interpolierende Funktion festgelegt ist. In
‖w‖∞ = maxx∈[a,b]
|(x − x0)(x − x1) · · · (x − xn)|
sind aber noch die xi variabel, und die Frage ist naheliegend, wie man sie wahlen
sollte, so daß ‖w‖∞ moglichst klein wird.
Man kann beobachten, daß bei aquidistanten Knoten
xi := a + ib − a
n, i = 0, . . . , n, (14.18)
w stets einen Verlauf wie in Abbildung 14.10 zeigt. w ist im Inneren des Intervalls
relativ klein und neigt am Rand des Intervalls zu großen Ausschlagen, die mit großer
werdendem Interpolationsgrad n immer großer werden. Dies legt die Idee nahe, die
Knoten am Rande des Intervalls dichter zu legen. Als sehr gute Wahl erweisen sich
die sogenannten Tschebyscheff Knoten
xi :=b − a
2· cos
(2i + 1
2n + 2π
)
+a + b
2, i = 0, . . . , n. (14.19)
Zur naheren Untersuchung nehmen wir a = −1 und b = 1 an und betrachten die
Funktionen
Tn(x) := cos(n arccos(x)), −1 ≤ x ≤ 1, n ∈ IN0. (14.20)
Tn ist ein Polynom vom Grade n, das n-te Tschebyscheff Polynom, denn aus
cos((n + 1) z) = 2 · cos z · cos(nz) − cos((n − 1) z)
und aus (14.20) liest man sofort ab, dass gilt
T0(x) ≡ 1, T1(x) = x, Tn+1(x) = 2 · x · Tn(x) − Tn−1(x). (14.21)
Aus dieser Rekursion folgt, dass der Koeffizient bei xn+1 in Tn+1 gleich 2n ist.
Aus (14.20) liest man ab, dass Tn+1 in [−1, 1] genau die Nullstellen xi = cos(
2i+12n+2
π)
,
i = 0, . . . , n, besitzt. Es gilt also mit diesen xi
w(x) =n∏
i=0
(x − xi) = 2−n Tn+1(x)
und
‖w‖∞ = 2−n.
Ferner zeigt (14.20), dass Tn+1 in [−1, 1] genau (n + 2) Extrema besitzt, in denen
abwechselnd die Werte +1 und −1 angenommen werden.
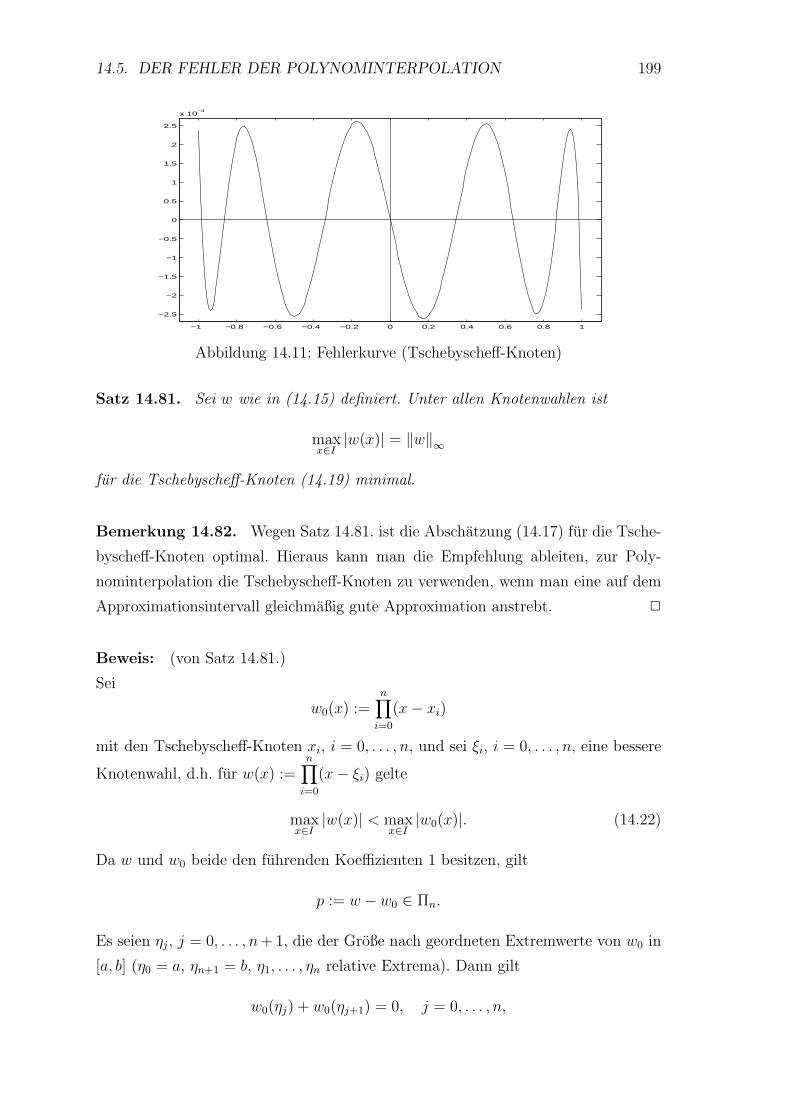
14.5. DER FEHLER DER POLYNOMINTERPOLATION 199
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
x 10−4
Abbildung 14.11: Fehlerkurve (Tschebyscheff-Knoten)
Satz 14.81. Sei w wie in (14.15) definiert. Unter allen Knotenwahlen ist
maxx∈I
|w(x)| = ‖w‖∞
fur die Tschebyscheff-Knoten (14.19) minimal.
Bemerkung 14.82. Wegen Satz 14.81. ist die Abschatzung (14.17) fur die Tsche-
byscheff-Knoten optimal. Hieraus kann man die Empfehlung ableiten, zur Poly-
nominterpolation die Tschebyscheff-Knoten zu verwenden, wenn man eine auf dem
Approximationsintervall gleichmaßig gute Approximation anstrebt. 2
Beweis: (von Satz 14.81.)
Sei
w0(x) :=n∏
i=0
(x − xi)
mit den Tschebyscheff-Knoten xi, i = 0, . . . , n, und sei ξi, i = 0, . . . , n, eine bessere
Knotenwahl, d.h. fur w(x) :=n∏
i=0
(x − ξi) gelte
maxx∈I
|w(x)| < maxx∈I
|w0(x)|. (14.22)
Da w und w0 beide den fuhrenden Koeffizienten 1 besitzen, gilt
p := w − w0 ∈ Πn.
Es seien ηj, j = 0, . . . , n + 1, die der Große nach geordneten Extremwerte von w0 in
[a, b] (η0 = a, ηn+1 = b, η1, . . . , ηn relative Extrema). Dann gilt
w0(ηj) + w0(ηj+1) = 0, j = 0, . . . , n,

200 KAPITEL 14. ANWENDUNGEN DER DIFFERENTIALRECHNUNG
und
|w0(ηj)| = ‖w0‖∞, j = 0, . . . , n + 1.
Wegen (14.22) hat p in den ηj wechselndes Vorzeichen, und daher liegt zwischen ηj
und ηj+1, j = 0, . . . , n, nach dem Zwischenwertsatz eine Nullstelle von p, d.h. p ∈ Πn
hat n + 1 Nullstellen im Widerspruch zu p 6≡ 0.
Beispiel 14.83. Fur Tschebyscheff-Knoten hat die Fehlerkurve in Beispiel 14.77.
die Gestalt in Abbildung 14.11. 2

Kapitel 15
Numerische Losung von
Gleichungen
Wir betrachten in diesem Kapitel 15 das Problem
f(x) = 0 (15.1)
mit einer reellen Funktion f : [a, b] → IR.
Viele praktische Probleme wie z.B. die Bestimmung der Extrema einer differenzier-
baren Funktion oder die Berechnung von Eigenwerten einer Matrix konnen auf das
Nullstellenproblem zuruckgefuhrt werden.
Es ist nur selten moglich, die Losungen von (15.1) in geschlossener Form anzugeben,
sondern man ist meistens auf numerische Verfahren angewiesen.
15.1 Bisektion
Eine sichere (wenn auch langsame) Methode zur Nullstellenbestimmung, die Inter-
vallhalbierungsmethode oder Bisektionsmethode, ist uns schon bekannt (vgl.
Kapitel 11):
Ist f : [a, b] → IR stetig mit f(a) · f(b) < 0, so setze man a0 := a,
b0 := b. Ist [an, bn] ⊂ [a, b] mit f(an) · f(bn) ≤ 0 schon bekannt, so setze
man γ := (an + bn)/2 sowie
[an+1, bn+1] :=
[an, γ], falls f(an) · f(γ) ≤ 0,
[γ, bn], sonst.
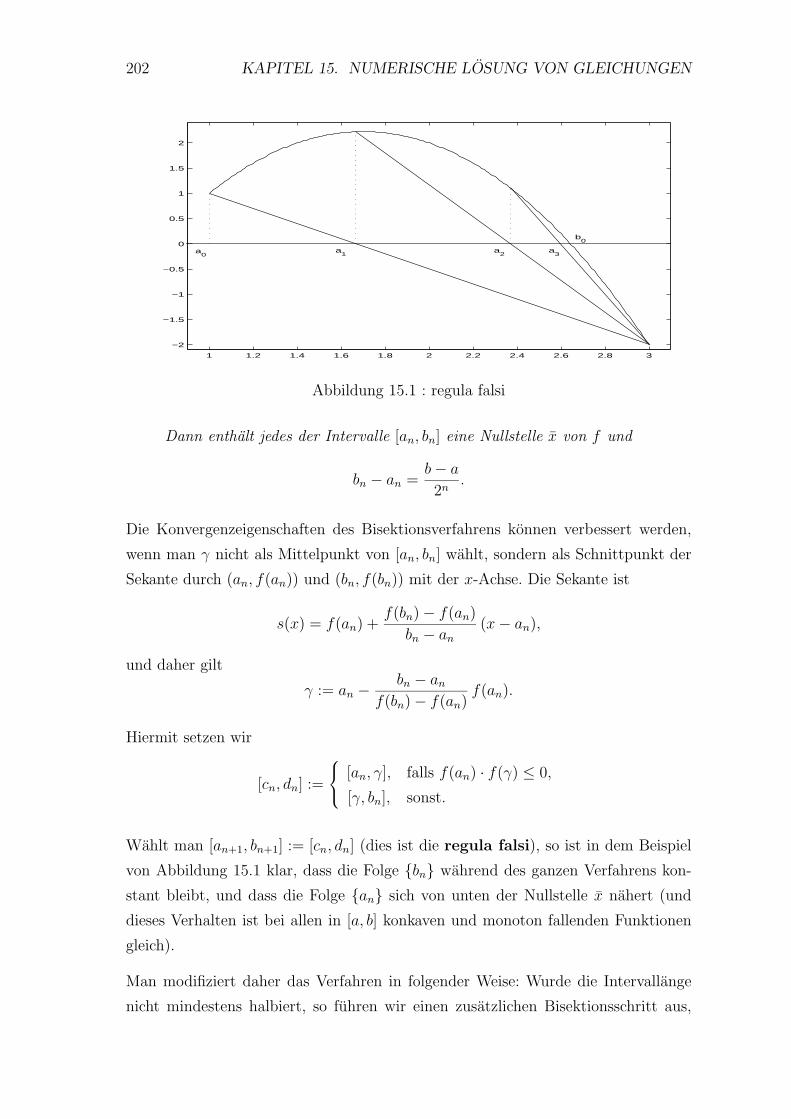
202 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 2.8 3
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
a0
a1
a2
a3
b0
Abbildung 15.1 : regula falsi
Dann enthalt jedes der Intervalle [an, bn] eine Nullstelle x von f und
bn − an =b − a
2n.
Die Konvergenzeigenschaften des Bisektionsverfahrens konnen verbessert werden,
wenn man γ nicht als Mittelpunkt von [an, bn] wahlt, sondern als Schnittpunkt der
Sekante durch (an, f(an)) und (bn, f(bn)) mit der x-Achse. Die Sekante ist
s(x) = f(an) +f(bn) − f(an)
bn − an
(x − an),
und daher gilt
γ := an − bn − an
f(bn) − f(an)f(an).
Hiermit setzen wir
[cn, dn] :=
[an, γ], falls f(an) · f(γ) ≤ 0,
[γ, bn], sonst.
Wahlt man [an+1, bn+1] := [cn, dn] (dies ist die regula falsi), so ist in dem Beispiel
von Abbildung 15.1 klar, dass die Folge {bn} wahrend des ganzen Verfahrens kon-
stant bleibt, und dass die Folge {an} sich von unten der Nullstelle x nahert (und
dieses Verhalten ist bei allen in [a, b] konkaven und monoton fallenden Funktionen
gleich).
Man modifiziert daher das Verfahren in folgender Weise: Wurde die Intervallange
nicht mindestens halbiert, so fuhren wir einen zusatzlichen Bisektionsschritt aus,

15.1. BISEKTION 203
Tabelle 15.1: Einschließung mit der modifizierten regula falsi
an bn
0.000000000 1.0000000000.390101359 0.7802027170.518660169 0.6472189790.569922327 0.6211844850.594532026 0.6191417260.606797436 0.6190628460.612929369 0.6190613020.615995328 0.6190612870.617528307 0.6190612870.618294797 0.6190612870.619061287 0.619061287
an bn
1.000000000 2.0000000001.168615340 1.5843076701.460003711 1.5843076701.506712626 1.5455101481.511875695 1.5286929211.512128340 1.5204106311.512134476 1.5162725531.512134551 1.5142035521.512134552 1.5131690521.512134552 1.5126518021.512134552 1.5123931771.512134552 1.5122638641.512134552 1.5121992081.512134552 1.5121668801.512134552 1.5121507161.512134552 1.512142634
d.h. wir setzen γ := (cn + dn)/2 und hiermit
[an+1, bn+1] :=
[cn, γ], falls f(cn) · f(γ) ≤ 0,
[γ, cn], sonst,
und, falls dn − cn ≤ bn − an
2,
[an+1, bn+1] := [cn, dn].
Das beschriebene Verfahren heißt modifizierte regula falsi . Wie beim Bisekti-
onsverfahren liegt in jedem Intervall [an, bn] eine Nullstelle x von f .
Beispiel 15.1.
f(x) := ex − 3x.
Dann gilt
f(0) = 1 > 0 > f(1) = e − 3,
f(1) = e − 3 < 0 < f(2) = e2 − 6,
und daher besitzt f wenigstens zwei Nullstellen x1 ∈ [0, 1] und x2 ∈ [1, 2].
Dies sind auch alle Nullstellen von f , denn wenn f 3 Nullstellen besaße, so hatte
f ′ nach dem Satz von Rolle zwei Nullstellen und f ′′ eine Nullstelle. Es ist aber
f ′′(x) = ex > 0.
Mit der modifizierten regula falsi

204 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
REPEAT
c := a - h * fa / (fb-fa);
fc := f(c);
IF fb*fc<=0 THEN BEGIN a := c; fa := fc END
ELSE BEGIN b := c; fb := fc END;
IF b-a>h/2 THEN
BEGIN
c := (b+a) / 2;
fc := f(c);
IF fb*fc<=0 THEN BEGIN a := c; fa := fc END
ELSE BEGIN b := c; fb := fc END
END;
WRITELN (a:12:9, b:12:9);
h := b - a
UNTIL h<1E-5;
erhalt man die Einschließungen in Tabelle 15.1. 2
Die beiden betrachteten Verfahren ha-
ben den Vorteil, dass sie eine Fehler-
abschatzung (in Form einer Einschlie-
ßung) mitliefern. Nachteil ist, dass sie
nicht geeignet sind, Nullstellen zu erfas-
sen, in denen die Funktion f nicht das Vor-
zeichen wechselt. (siehe Abbildung 15.2).
Zudem lassen sie sich nicht auf Nullstellen
von Funktionen f : D → IRn, D ⊂ IRn,
ubertragen.
−0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6−0.2
0
0.2
0.4
0.6
0.8
1
1.2
Abbildung 15.2
Definition 15.2. Eine Nullstelle x einer stetigen Funktion f heißt m-fache Null-
stelle (m ∈ IN) oder Nullstelle der Vielfachheit m, falls f geschrieben werden kann
in der Form
f(x) = (x − x)m g(x)
mit einer stetigen Funktion g, fur die g(x) 6= 0 gilt.
Ist f m-mal stetig differenzierbar in einer Umgebung von x, so ist x genau dann
eine m-fache Nullstelle von f , wenn f (j)(x) = 0, j = 0, . . . ,m − 1, und f (m)(x) 6= 0

15.2. FIXPUNKTSATZ FUR KONTRAHIERENDE ABBILDUNGEN 205
gilt, denn nach dem Taylorschen Satz ist
f(x) =m−1∑
j=0
f (j)(x)
j!(x − x)j +
f (m)(ζ)
m!(x − x)m =
f (m)(ζ)
m!(x − x)m,
ζ = x + θx (x− x), und wegen der Stetigkeit von f (m) gilt f (m)(ζ) 6= 0 fur genugend
nahe bei x liegende x.
Fur Nullstellen x gerader Vielfachheit wechselt f bei x nicht das Vorzeichen. Sie
sind also nicht mit der Bisektion oder der regula falsi berechenbar.
15.2 Fixpunktsatz fur kontrahierende
Abbildungen
Eine andere Moglichkeit der Berechnung einer Nullstelle von f ist, die Gleichung
f(x) = 0 in ein Fixpunktproblem
x = φ(x)
zu transformieren und zu iterieren gemaß
xn+1 := φ(xn) (15.2)
mit einem geeigneten Startwert x0.
Konvergiert die so erzeugte Folge {xn} gegen ein x und ist φ stetig in x, so gilt
x = limn→∞xn = lim
n→∞φ(xn−1) = φ(x),
d.h. x ist ein Fixpunkt von φ.
Beispiel 15.3.
f(x) = ex − 3x = 0
kann man auf verschiedene Weisen in ein Fixpunktprobleproblem umformen:
f(x) = 0 ⇐⇒ x =ex
3=: φ1(x),
x > 0 : f(x) = 0 ⇐⇒ x = ln(3x) =: φ2(x),
wobei dies nur die naheliegenden Moglichkeiten sind.

206 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.2: konvergente Iterationen
n x(n)
0 0.5000000000000001 0.5495737569000432 0.5775047960523803 0.5938624853204424 0.6036565893924835 0.6095979123272266 0.6132305109196917 0.6154621821393288 0.6168372251292349 0.617685986239335
10 0.61821047663474820 0.61905426105631530 0.61906122865671840 0.61906128625581750 0.619061286731976
n x(n)
0 1.5000000000000001 1.5040773967762742 1.5067919734942283 1.5085951586342344 1.5097911479224635 1.5105836172947386 1.5111083663421647 1.5114556876810328 1.5116855066917729 1.511837546571094
10 1.51193811790908020 1.51213140830089830 1.51213450136680040 1.51213455085323150 1.512134551644969
Tabelle 15.3: nicht konvergente Iterationen
n x(n)
0 1.5130000000000001 1.5134437924571152 1.5141155964562223 1.5151331271213494 1.5166756061667215 1.5190168517047536 1.5225774095747037 1.5280082973104688 1.5363293136331909 1.549166469953075
10 1.56918155562442911 1.60090527634201712 1.65250610588344013 1.74001514500658514 1.89914323654301715 2.22672288847077216 3.08981308813270617 7.32432352765116518 505.582504596351894
n x(n)
0 0.6190000000000001 0.6189622823705692 0.6189013473485893 0.6188028954342344 0.6186438074854975 0.6183866845738806 0.6179709746670187 0.6172984994824768 0.6162097083076809 0.614444350848870
10 0.61157537454059411 0.60689521893515812 0.59921316465058013 0.58647441202577414 0.56498604856821315 0.52765804772791816 0.45930544670593717 0.32057245965835218 −0.039034656328867
Mit der Iteration (15.2) erhalt man die Werte in Tabelle 15.2 fur φ1 (linke Spalte)
bzw. φ2 (rechte Spalte). Startet man die Iteration (15.2) fur φ1 mit dem Startwert
x0 = 1.513 bzw. fur φ2 mit x0 = 0.619, so erhalt man Tabelle 15.3.
Dasselbe ereignet sich (wenn auch nach einer langeren Anlaufphase), wenn man als
Startwert x0 = x2+ε, ε > 0 bzw. x0 = x1−ε, ε > 0, wahlt. Startet man die Iteration
fur φ1 mit x0 = x2 − ε, ε > 0 klein, so erhalt man Konvergenz gegen x1, und fur φ2
mit x0 = x1 + ε, ε > 0 klein, so erhalt man Konvergenz gegen x2. Man kann also
nicht jeden Fixpunkt von φ mit der Iteration (15.2) approximieren. 2
Zur Untersuchung der Eigenschaften der Iteration (15.2) benotigen wir die folgenden
Begriffe, die wir gleich fur allgemeinere Falle definieren.

15.2. FIXPUNKTSATZ FUR KONTRAHIERENDE ABBILDUNGEN 207
Definition 15.4. Sei V ein normierter Raum. φ : D → V , D ⊂ V , heißt
Lipschitz-stetig auf D, wenn es eine Konstante L, die Lipschitz-Konstante
von φ, gibt mit
‖φ(x) − φ(y)‖ ≤ L ‖x − y‖
fur alle x,y ∈ D.
Ist φ Lipschitz-stetig mit einer Lipschitz-Konstanten L < 1, so heißt φ kontrahie-
rend auf D, und L heißt die Kontraktionskonstante.
Bemerkung 15.5. Offenbar ist jede Lipschitz-stetige Funktion φ auch gleichmaßig
stetig auf D, denn fur ε > 0 gilt mit δ := ε/L fur alle x,y ∈ D mit ‖x − y‖ < δ
‖φ(x) − φ(y)‖ ≤ L ‖x − y‖ < Lδ = ε.
2
Bemerkung 15.6. Die Kontraktionsbedingung besagt, dass unter der Abbildung
φ Abstande von Punkten aus D gleichmaßig wenigstens um den Faktor L verkurzt
werden. 2
Bemerkung 15.7. Fur den Fall V = IRn folgt aus der Aquivalenz der Normen,
dass der Begriff “Lipschitz-stetig” unabhangig von der gewahlten Norm ist. Fur
den Begriff “kontrahierend” gilt dies nicht. Es gibt z.B. Funktionen, die bzgl. ‖ · ‖1
kontrahierend sind und bzgl. ‖ · ‖∞ nicht. Wir kommen darauf in Abschnitt 24.1
zuruck. 2
Bemerkung 15.8. Ist V = IR, D ein Intervall und φ differenzierbar in D, so gilt
nach dem Mittelwertsatz φ(x)−φ(y) = φ′(ξ) (x−y)fur ein ξ zwischen x und y. Ist also
φ′ beschrankt auf D, so ist φ Lipschitz-stetig auf D mit der Lipschitz-Konstanten
L := sup{|φ′(x)| : x ∈ D}.
2
Bemerkung 15.9. Ist A ∈ IR(n,n), b ∈ IRn und φ(x) := Ax+ b, so gilt fur alle x,
y ∈ IRn
‖φ(x) − φ(y)‖ = ‖Ax + b − Ay − b‖ ≤ ‖A‖ · ‖x − y‖.
φ ist also Lipschitz-stetig mit der Lipschitz-Konstanten L = ‖A‖ fur jede Vektor-
norm ‖·‖ und zugehorige Matrixnorm ‖A‖. 2

208 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Satz 15.10. (Fixpunktsatz fur kontrahierende Abbildungen)
Es sei I := [a, b] ein abgeschlossenes Intervall, φ eine kontrahierende Abbildung auf
I mit der Lipschitz-Konstanten q ∈ [0, 1) und φ(I) ⊂ I.
Dann gilt
(i) φ hat genau einen Fixpunkt x ∈ I.
(ii) Fur jeden Startwert x0 ∈ I konvergiert die durch xn+1 := φ(xn) definierte
Folge gegen x.
(iii) Es gelten die Fehlerabschatzungen
|x − xn| ≤ qn
1−q|x1 − x0| (a priori),
|x − xn| ≤ q1−q
|xn − xn−1| (a posteriori),
Beweis: Die Existenz eines Fixpunktes zeigen wir konstruktiv:
Sei x0 ∈ I beliebig gewahlt. Wegen φ(I) ⊂ I ist dann die Folge {xn}, xn+1 := φ(xn),
definiert und {xn} ⊂ I.
Aus
|xn+1 − xn| = |φ(xn) − φ(xn−1)| ≤ q |xn − xn−1|
erhalt man durch Induktion fur alle k ∈ IN
|xn+k − xn+k−1| ≤ qk |xn − xn−1|,
und daher
|xn+m − xn| = |m∑
k=1
(xn+k − xn+k−1)|
≤m∑
k=1
|xn+k − xn+k−1| ≤m∑
k=1
qk |xn − xn−1|
≤ q |xn − xn−1|m−1∑
k=0
qk ≤ q
1 − q|xn − xn−1|
≤ qn
1 − q|x1 − x0| −→ 0. (15.3)
Nach dem Cauchyschen Konvergenzkriterium ist {xn} konvergent gegen ein x, da I
abgeschlossen ist, gilt x ∈ I, und wegen der Stetigkeit von φ ist x ein Fixpunkt von
φ.

15.2. FIXPUNKTSATZ FUR KONTRAHIERENDE ABBILDUNGEN 209
x ist der einzige Fixpunkt von φ in I, denn ist x ein beliebiger Fixpunkt von φ in I,
so gilt
|x − x| = |φ(x) − φ(x)| ≤ q |x − x|,
d.h. 0 ≤ (1 − q) |x − x| ≤ 0, und wegen q < 1 folgt x = x.
Die Fehlerabschatzungen (iii) erhalt man unmittelbar aus (15.3) mit m → ∞.
Bemerkung 15.11. Der Fixpunktsatz bleibt auch fur Abbildungen φ : D → D,
(D ⊂ V , V ein normierter Vektorraum) richtig, falls
(i) V ein Banachraum ist, d.h. jede Cauchy-Folge einen Grenzwert besitzt (also
z.B. fur V = IRn) und
(ii) fur jede konvergente Folge {xm} ⊂ D auch der Grenzwert x = limm→∞ xm in
D liegt. Eine Menge mit dieser Eigenschaft heißt abgeschlossen (in IRn sind
z.B. verallgemeinerte Intervalle des Typs
[a, b] := {x ∈ IRn : ai ≤ xi ≤ bi, i = 1, . . . , n}
oder Kugeln des Typs
K := {x ∈ IRn : ‖x − x‖ ≤ r}
aber auch der ganze Raum IRn abgeschlossen). 2
Bemerkung 15.12. Die Ungleichung (15.3) zeigt, dass die a posteriori Abschat-
zung bessere Fehlerschranken liefert als die a priori Abschatzung. Die a priori Ab-
schatzung wird vor allem dazu benutzt, nach nur einer Iteration eine obere Schranke
fur die Anzahl der Iterationen zu bestimmen, die benotigt werden, um einen Fix-
punkt x von φ mit einer vorgegebenen Genauigkeit ε > 0 zu berechnen.
Es gilt ja
|x − xn| ≤qn
1 − q|x1 − x0| ≤ ε, falls n ≥
ln(
ε (1−q)|x1−x0|
)
ln q.
Die a posteriori Abschatzung kann benutzt werden, um wahrend der Rechnung die
Gute der Naherung zu kontrollieren. 2

210 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.4: Fixpunktiteration mit Abschatzung
n x(n) a priori a posteriori Fehler
0 0.5000000000000001 0.877582561890373 2.00E + 00 2.00E + 00 1.38E − 012 0.639012494165259 1.69E + 00 1.27E + 00 1.00E − 013 0.802685100682335 1.42E + 00 8.69E − 01 6.36E − 024 0.694778026788006 1.19E + 00 5.73E − 01 4.43E − 025 0.768195831282016 1.00E + 00 3.90E − 01 2.91E − 026 0.719165445942419 8.46E − 01 2.60E − 01 1.99E − 027 0.752355759421527 7.12E − 01 1.76E − 01 1.33E − 028 0.730081063137823 5.99E − 01 1.18E − 01 9.00E − 039 0.745120341351440 5.04E − 01 7.98E − 02 6.04E − 03
10 0.735006309014843 4.24E − 01 5.37E − 02 4.08E − 0320 0.739006779780813 7.55E − 02 1.03E − 03 7.84E − 0530 0.739083626103480 1.34E − 02 1.99E − 05 1.51E − 0640 0.739085104225471 2.39E − 03 3.82E − 07 2.90E − 0842 0.739085120060997 2.01E − 03 1.73E − 07 1.31E − 0843 0.739085142075963 1.69E − 03 1.17E − 07 8.86E − 0949 0.739085134042973 5.06E − 04 1.09E − 08 8.28E − 1050 0.739085132657536 4.25E − 04 7.35E − 09 5.58E − 10
Beispiel 15.13. φ(x) := cos x, I := [0, 1].
Da φ monoton fallend in [0, 1] ist, folgt aus φ(0) = 1 ∈ I und φ(1) = 0.54 ∈ I, dass
φ(I) ⊂ I gilt.
φ ist kontrahierend auf I mit der Kontraktionskonstanten q = 0.85, denn
maxx∈I
|φ′(x)| = maxx∈I
| sin x| = sin 1 ≤ 0.85 =: q.
Wir setzen uns das Ziel, den Fixpunkt x von φ mit einem absoluten Fehler von
hochstens 10−8 zu bestimmen. Mit der a priori Schranke erhalten wir (vgl. Bemer-
kung 15.12.) wegen
ln(
10−8·(1−q)|x1−x0|
)
ln q≈ 119.03,
dass nach 120 Iterationen dieses Ziel sicher erreicht ist.
Tabelle 15.4 enthalt die Iterierten, die a priori und a posteriori Schranken des Fehlers
und den tatsachlichen Fehler. Dieser ist bereits nach 43 Schritten kleiner als 10−8.
Die a posteriori Schranken garantieren dies nach 50 Schritten und liefern damit einen
wesentlich realistischeren Wert als die a priori Schranken. 2
Bemerkung 15.14. Satz 15.10. bleibt nicht richtig, wenn man die Kontraktions-
bedingung abschwacht zu |φ(x) − φ(y)| < |x − y| fur alle x, y ∈ I, x 6= y, denn fur
die abgeschlossene Menge I := [0,∞) und φ(x) := x + e−x gilt φ(I) ⊂ I und
|φ(x) − φ(y)| = |φ′(ξ) (x − y)| = |(1 − e−ξ) (x − y)| < |x − y|,

15.2. FIXPUNKTSATZ FUR KONTRAHIERENDE ABBILDUNGEN 211
aber φ besitzt keinen Fixpunkt in I. Man benotigt also, dass Abstande von Punkten
unter der Abbildung φ gleichmaßig verkurzt werden. 2
Es ist haufig schwierig, insbesondere bei der Anwendung auf Funktionen von mehre-
ren Veranderlichen, eine geeignete Menge D zu finden, die durch φ in sich abgebildet
wird. Hilfreich hierbei ist Satz 15.15.
Satz 15.15. Es gebe eine Kugel
K := {x ∈ IRn : ‖y − x‖ ≤ r}
auf der φ kontrahierend ist mit der Konstanten q, und es gelte
‖φ(y) − y‖ ≤ (1 − q) r.
Dann besitzt φ genau einen Fixpunkt x ∈ K, die durch xn+1 := φ(xn) definierte Fol-
ge konvergiert fur jeden Startwert x0 ∈ K gegen x, und es gilt die Fehlerabschatzung
‖xn − x‖ ≤ q
1 − q‖xn − xn−1‖ ≤ qn
1 − q‖x1 − x0‖.
Beweis: Wir haben nur zu zeigen, dass φ(K) ⊂ K gilt. Fur x ∈ K ist
‖φ(x) − y‖ ≤ ‖φ(x) − φ(y)‖ + ‖φ(y) − y‖≤ q ‖x − y‖ + r (1 − q) ≤ r q + r (1 − q) = r,
d.h. φ(K) = K.
Wir haben bereits gesehen, dass man nicht jeden Fixpunkt x von φ mit der Iteration
xn+1 := φ(xn) erreichen kann.
Definition 15.16. Ein Fixpunkt x von φ : D → V , D ⊂ V , heißt anziehend,
wenn die Fixpunktiteration fur jeden genugend nahe bei x liegenden Startwert x0
gegen x konvergiert (d.h. es gibt ein ε > 0, so dass ‖x0 − x‖ ≤ ε, xn+1 := φ(xn),
zur Folge hat limn→∞xn = x); er heißt abstoßend, wenn es eine Kugel gibt mit
dem Mittelpunkt x, so dass fur jeden Startwert x0 6= x aus dieser Kugel die Fix-
punktiteration aus der Kugel herausfuhrt (d.h. es gibt ein ε > 0, so dass zu jedem
x0 ∈ V mit ‖x0 − x‖ < ε, x0 6= x, ein m ∈ IN existiert mit ‖xm − x‖ ≥ ε, wobei
xn+1 := φ(xn)).
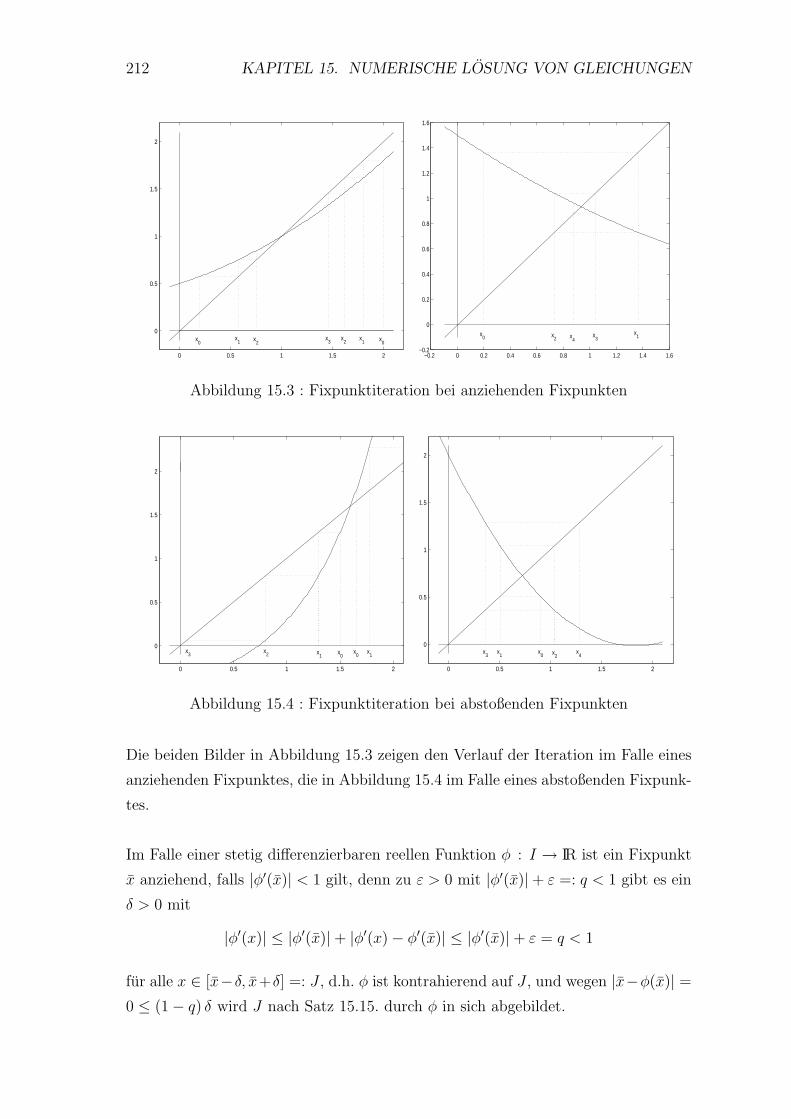
212 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
0 0.5 1 1.5 2
0
0.5
1
1.5
2
x0
x0
x1
x1x
2x
2x
3
−0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
x0
x1x
2x
3x4
Abbildung 15.3 : Fixpunktiteration bei anziehenden Fixpunkten
0 0.5 1 1.5 2
0
0.5
1
1.5
2
x0x
0x
1x1
x2
x3
0 0.5 1 1.5 2
0
0.5
1
1.5
2
x0
x1 x
2x
3x
4
Abbildung 15.4 : Fixpunktiteration bei abstoßenden Fixpunkten
Die beiden Bilder in Abbildung 15.3 zeigen den Verlauf der Iteration im Falle eines
anziehenden Fixpunktes, die in Abbildung 15.4 im Falle eines abstoßenden Fixpunk-
tes.
Im Falle einer stetig differenzierbaren reellen Funktion φ : I → IR ist ein Fixpunkt
x anziehend, falls |φ′(x)| < 1 gilt, denn zu ε > 0 mit |φ′(x)| + ε =: q < 1 gibt es ein
δ > 0 mit
|φ′(x)| ≤ |φ′(x)| + |φ′(x) − φ′(x)| ≤ |φ′(x)| + ε = q < 1
fur alle x ∈ [x−δ, x+δ] =: J , d.h. φ ist kontrahierend auf J , und wegen |x−φ(x)| =
0 ≤ (1 − q) δ wird J nach Satz 15.15. durch φ in sich abgebildet.

15.2. FIXPUNKTSATZ FUR KONTRAHIERENDE ABBILDUNGEN 213
Ist |φ′(x)| > 1, so gibt es ein Intervall J := [x − r, x + r] mit
|φ′(x)| ≥ |φ′(x)| − |φ′(x) − φ′(x)| ≥ L > 1
fur alle x ∈ J , und daher gilt fur x ∈ J mit einem ξ = x + θ (x − x)
|x − φ(x)| = |φ(x) − φ(x)| = |φ′(ξ)| · |x − x| ≥ L |x − x|,
und es folgt, dass x abstoßend ist.
Ist |φ′(x)| = 1, so kann x anziehend oder abstoßend oder keines von beiden sein.
Dies zeigen die folgenden Beispiele:
Beispiel 15.17.
φ(x) := x − x3
besitzt den Fixpunkt x = 0 mit φ′(x) = 1. x ist anziehend, denn fur xk ∈ (−1, 0)
gilt
xk+1 = φ(xk) = xk(1 − x2k) ∈ (xk, 0).
Die Folge {xk} ist fur x0 ∈ (−1, 0) also monoton wachsend und nach oben be-
schrankt, und daher konvergent. Wegen der Stetigkeit von φ ist der Grenzwert
x ∈ (x0, 1] ein Fixpunkt von φ, und daher gilt x = x = 0.
Genauso ist fur x0 ∈ (0, 1) die Folge {xk} ⊂ (0, x0) monoton fallend und nach unten
beschrankt, woraus wieder limk→∞ φ(xk) = 0 folgt. Damit ist x ein anziehender
Fixpunkt. 2
Beispiel 15.18.
φ(x) := x + x3
besitzt den abstoßenden Fixpunkt x = 0 mit φ′(x) = 1, denn fur xk ∈ (−∞, 0) gilt
xk+1 = φ(xk) = xk(1 + x2k) < xk,
und fur xk > 0 ist xk+1 = xk(1+x2k) > xk. In jedem Fall entfernen sich die Iterierten
also vom Fixpunkt x = 0. 2
Beispiel 15.19. Der Fixpunkt x = 0 von
φ(x) := x + x2
mit φ′(x) = 1 ist weder anziehend noch abstoßend, denn fur x0 ∈ (−1, 0) konvergiert
die Folge {xk} wie in Beispiel 15.17. monoton gegen x, und fur x0 > 0 wachst die
Folge {xk} uber alle Grenzen. 2

214 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.5: Newton Verfahren, f(x) = cos(x)
n x(n)
0 1.5000000000000001 1.5709148443026522 1.5707963267943423 1.5707963267948974 1.570796326794897
15.3 Newton Verfahren
Wir kehren nun zum Nullstellenproblem
(15.1)
f(x) = 0
mit einer differenzierbaren Funktion f :
[a, b] → IR zuruck.
Es sei x0 eine Naherung fur eine Nullstelle x
von f . Wir ersetzen dann die Funktion durch
ihre lineare Approximation in x0:
f(x) = f(x0) + f ′(x0) (x − x0).
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
0
0.5
1
1.5
2
x0x
1x
2
Abbildung 15.5
Gilt f ′(x0) 6= 0, so besitzt die Ersatzfunktion f genau eine Nullstelle
x1 = x0 −f(x0)
f ′(x0),
die wir als neue Naherung fur x auffassen.
Wiederholt man diesen Schritt iterativ mit xn an Stelle von x0, so erhalt man das
Newton Verfahren
xn+1 := xn − f(xn)
f ′(xn). (15.4)
Bemerkung 15.20. Ist f ein Polynom vom Grade m, so kann man f und f ′ mit
dem erweiterten Horner Schema berechnen. Man benotigt also in jedem Schritt des
Newton Verfahrens 2m Multiplikationen. 2
Beispiel 15.21. Berechneπ
2als kleinste Nullstelle von f(x) = cos x mit dem New-
ton Verfahren (siehe Tabelle 15.5)
xn+1 := xn +cos xn
sin xn
.
2
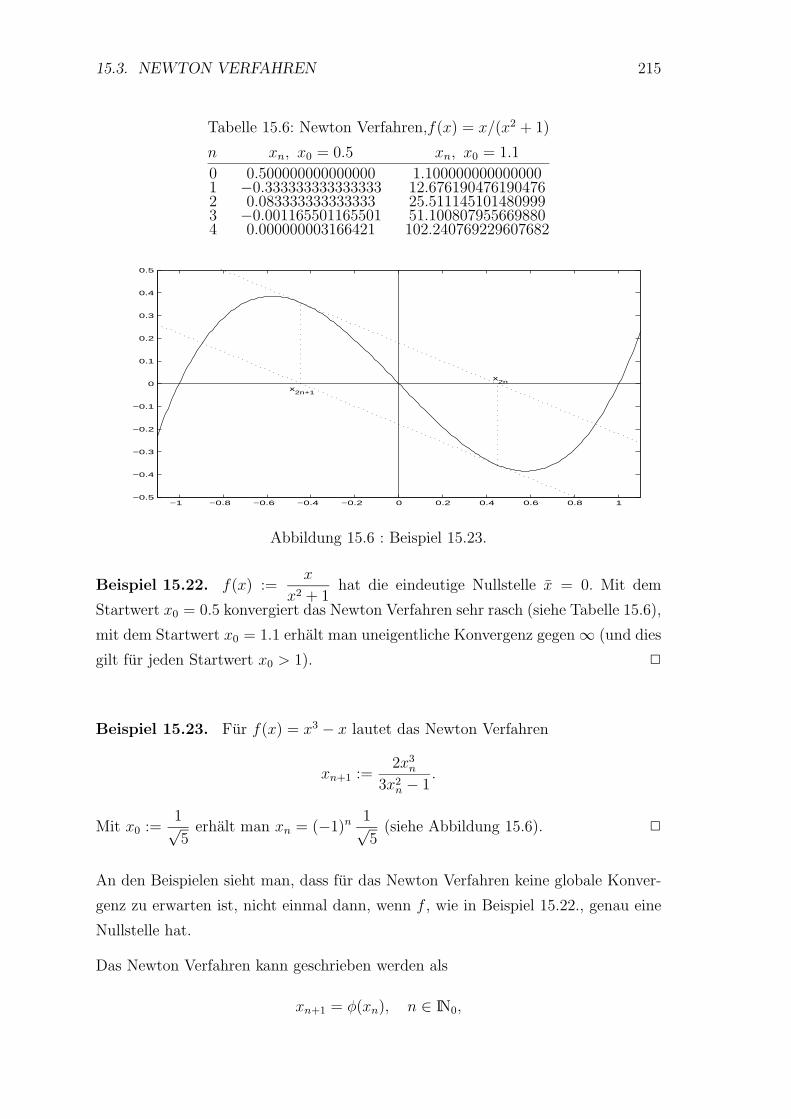
15.3. NEWTON VERFAHREN 215
Tabelle 15.6: Newton Verfahren,f(x) = x/(x2 + 1)
n xn, x0 = 0.5 xn, x0 = 1.1
0 0.500000000000000 1.1000000000000001 −0.333333333333333 12.6761904761904762 0.083333333333333 25.5111451014809993 −0.001165501165501 51.1008079556698804 0.000000003166421 102.240769229607682
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1−0.5
−0.4
−0.3
−0.2
−0.1
0
0.1
0.2
0.3
0.4
0.5
x2n
x2n+1
Abbildung 15.6 : Beispiel 15.23.
Beispiel 15.22. f(x) :=x
x2 + 1hat die eindeutige Nullstelle x = 0. Mit dem
Startwert x0 = 0.5 konvergiert das Newton Verfahren sehr rasch (siehe Tabelle 15.6),
mit dem Startwert x0 = 1.1 erhalt man uneigentliche Konvergenz gegen ∞ (und dies
gilt fur jeden Startwert x0 > 1). 2
Beispiel 15.23. Fur f(x) = x3 − x lautet das Newton Verfahren
xn+1 :=2x3
n
3x2n − 1
.
Mit x0 :=1√5
erhalt man xn = (−1)n 1√5
(siehe Abbildung 15.6). 2
An den Beispielen sieht man, dass fur das Newton Verfahren keine globale Konver-
genz zu erwarten ist, nicht einmal dann, wenn f , wie in Beispiel 15.22., genau eine
Nullstelle hat.
Das Newton Verfahren kann geschrieben werden als
xn+1 = φ(xn), n ∈ IN0,

216 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
wenn man
φ(x) := x − f(x)
f ′(x)
setzt.
φ ist auf D := {x ∈ [a, b] : f ′(x) 6= 0} definiert, und die Nullstellen von f in D sind
genau die Fixpunkte von φ in D.
Wendet man den Fixpunktsatz fur kontrahierende Abbildungen (Satz 15.10.) auf
dieses φ an, so erhalt man Satz 15.24.
Satz 15.24. Es sei f : I → IR zweimal stetig differenzierbar und x eine einfache
Nullstelle von f . Dann gibt es ein r > 0, so dass das Newton Verfahren fur alle
Startwerte x0 ∈ I mit |x − x0| ≤ r gegen x konvergiert.
Beweis: x ist Fixpunkt von φ(x) := x− f(x)
f ′(x). Wegen f ′(x) 6= 0 gilt f ′(x) 6= 0 fur
alle x ∈ J := [x − ρ, x + ρ] mit einem geeigneten ρ > 0 (f ′ ist stetig!). Daher ist φ
in J definiert und stetig differenzierbar mit
φ′(x) =f(x) f ′′(x)
(f ′(x))2,
d.h. φ′(x) = 0, und x ist anziehender Fixpunkt von φ.
Satz 15.24. ist ein typischer lokaler Konvergenzsatz: Wenn der Startwert x0 nur
genugend nahe an der Losung liegt (|x − x0| ≤ r), so konvergiert das Verfahren.
Uber die Große von r wird nichts ausgesagt.
Aus den Abschatzungen von Satz 15.10. folgt, dass der Fehler beim Newton Verfah-
ren wie eine geometrische Folge gegen 0 geht. Tatsachlich gilt nach dem Taylorschen
Satz
|xn+1 − x| =∣∣∣∣xn − f(xn)
f ′(xn)− x
∣∣∣∣ = |f(x) − f(xn) − f ′(xn) (x − xn)
f ′(xn)
∣∣∣∣
=1
2
∣∣∣∣
f ′′(ξn)
f ′(xn)(x − xn)2
∣∣∣∣, ξn = x + θn (x − xn), θn ∈ (0, 1).
Da fur ε > 0 ein genugend kleines r > 0 existiert, so daß
|f ′(x)| ≥ 1
2|f ′(x)|, |f ′′(x)| ≤ ε + |f ′′(x)|
fur alle x mit |x − x| ≤ r gilt, erhalt man
|xn+1 − x| ≤ |f ′′(x)| + ε
|f ′(x)| |x − xn|2 =: C |x − xn|2.

15.3. NEWTON VERFAHREN 217
Bis auf die multiplikative Konstante C wird also der Fehler beim Newton Verfahren
von Schritt zu Schritt quadriert, was die rasche Konvergenz des Verfahrens erklart.
Um die Konvergenzgeschwindigkeit von Folgen zu vergleichen, fuhren wir den fol-
genden Begriff ein:
Definition 15.25. Sei {xn} eine Folge in dem normierten Raum V mit limn→∞xn =
x. Die Folge {xn} konvergiert von wenigstens der Ordnung p ∈ [1,∞), wenn es eine
Konstante C > 0 gibt mit
‖x − xn+1‖ ≤ C · ‖x − xn‖p fur alle n.
Ist p = 1, so fordern wir zusatzlich C < 1.
Das maximale p mit dieser Eigenschaft heißt die Konvergenzordnung der Folge.
Ein Iterationsverfahren hat die Konvergenzordnung p, wenn jede mit ihm erzeugte,
konvergente Folge die Konvergenzordnung p hat.
Eine Folge konvergiert linear, falls p = 1 ist, superlinear , falls p > 1 gilt, und
quadratisch im Falle p = 2.
Die durch Satz 15.10. erfassten Verfahren konvergieren wenigstens linear, das New-
ton Verfahren konvergiert lokal quadratisch gegen einfache Nullstellen von f .
Ist x eine mehrfache Nullstelle von f , so konvergiert das Newton Verfahren immer
noch lokal, aber nur linear, also wie vom Fixpunktsatz fur kontrahierende Abbil-
dungen (Satz 15.10.) vorhergesagt. Genauer gilt Satz 15.26.
Satz 15.26. Ist f : [a, b] → IR (k + 3)-mal stetig differenzierbar, und besitzt f
eine Nullstelle x der Vielfachheit k ≥ 2, so konvergiert das Verfahren
xn+1 := xn − αf(xn)
f ′(xn)(15.5)
fur alle α ∈ (0, 2k) lokal linear gegen x. Fur α = k ist die Konvergenz sogar qua-
dratisch.
Beweis: Es ist f(x) = (x − x)k g(x), wobei g(x) 6= 0 gilt und g dreimal stetig
differenzierbar ist. Hiermit kann man die Iterationsvorschrift (15.5) schreiben als
xn+1 = φ(xn),
φ(x) = x − α(x − x) g(x)
k g(x) + (x − x) g′(x).

218 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.7: Newton Verfahren
n Newton fur f (15.5) mit α = 3 Newton fur g
0 1.000000000000000 1.000000000000000 1.0000000000000001 0.655145072042431 −0.034564783872708 0.0647933188462812 0.433590368363493 0.000001376571625 0.0000181320674813 0.288148400892501 −0.000000000000233 0.000000000000034
φ ist sicher in einer Umgebung von x definiert und differenzierbar, und es gilt mit
h(x) := k g(x) + (x − x) g′(x)
φ′(x) = 1 − αh(x)
(
g(x) + (x − x) g′(x))
− (x − x) g(x) h′(x)
(h(x))2,
d.h.
φ′(x) = 1 − αh(x) g(x)
(h(x))2= 1 − α
k.
Fur α ∈ (0, 2k) gilt |φ′(x)| < 1, und x ist ein anziehender Fixpunkt von φ.
Im Falle α = k gilt φ′(x) = 0, und die quadratische Konvergenz folgt aus dem
Taylorschen Satz
|xn+1 − x| = |φ(xn) − φ(x)| = |12
φ′′(ξn) (xn − x)2|.
Im allgemeinen ist die Vielfachheit einer Nullstelle nicht bekannt. Ist x eine k-fache
Nullstelle von f , so ist x eine (k − 1)-fache Nullstelle von f ′, und daher hat
g(x) :=f(x)
f ′(x)
die einfache Nullstelle x. Das Newton Verfahren fur g konvergiert quadratisch.
Beispiel 15.27. Fur die dreifache Nullstelle x = 0 von
f(x) = sin x − x
erhalt man Tabelle 15.7. 2
Da die Berechnung der Ableitung f ′(x) oft aufwendig ist, ersetzt man im Newton
Verfahren f ′(xn) durch f ′(x0) (berechnet also die Ableitung nur im Startwert x0).
Man erhalt dann das vereinfachte Newton Verfahren
xn+1 := xn − f(xn)
f ′(x0). (15.6)
Hierfur gilt der folgende Konvergenzsatz
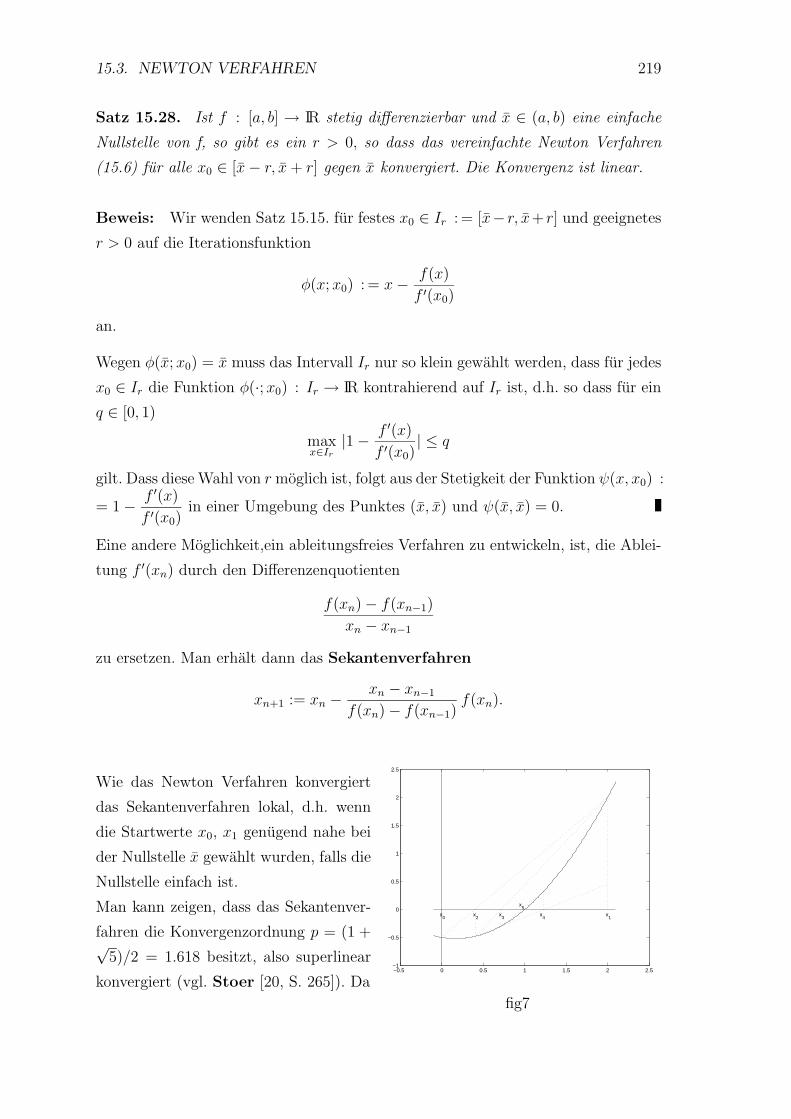
15.3. NEWTON VERFAHREN 219
Satz 15.28. Ist f : [a, b] → IR stetig differenzierbar und x ∈ (a, b) eine einfache
Nullstelle von f, so gibt es ein r > 0, so dass das vereinfachte Newton Verfahren
(15.6) fur alle x0 ∈ [x − r, x + r] gegen x konvergiert. Die Konvergenz ist linear.
Beweis: Wir wenden Satz 15.15. fur festes x0 ∈ Ir : = [x− r, x+ r] und geeignetes
r > 0 auf die Iterationsfunktion
φ(x; x0) : = x − f(x)
f ′(x0)
an.
Wegen φ(x; x0) = x muss das Intervall Ir nur so klein gewahlt werden, dass fur jedes
x0 ∈ Ir die Funktion φ(·; x0) : Ir → IR kontrahierend auf Ir ist, d.h. so dass fur ein
q ∈ [0, 1)
maxx∈Ir
|1 − f ′(x)
f ′(x0)| ≤ q
gilt. Dass diese Wahl von r moglich ist, folgt aus der Stetigkeit der Funktion ψ(x, x0) :
= 1 − f ′(x)
f ′(x0)in einer Umgebung des Punktes (x, x) und ψ(x, x) = 0.
Eine andere Moglichkeit,ein ableitungsfreies Verfahren zu entwickeln, ist, die Ablei-
tung f ′(xn) durch den Differenzenquotienten
f(xn) − f(xn−1)
xn − xn−1
zu ersetzen. Man erhalt dann das Sekantenverfahren
xn+1 := xn − xn − xn−1
f(xn) − f(xn−1)f(xn).
Wie das Newton Verfahren konvergiert
das Sekantenverfahren lokal, d.h. wenn
die Startwerte x0, x1 genugend nahe bei
der Nullstelle x gewahlt wurden, falls die
Nullstelle einfach ist.
Man kann zeigen, dass das Sekantenver-
fahren die Konvergenzordnung p = (1 +√5)/2 = 1.618 besitzt, also superlinear
konvergiert (vgl. Stoer [20, S. 265]). Da−0.5 0 0.5 1 1.5 2 2.5−1
−0.5
0
0.5
1
1.5
2
2.5
x0
x1
x2
x3
x4
x5
fig7

220 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
das Sekantenverfahren nur eine Funktionsauswertung in jedem Schritt benotigt (aus
dem vorhergehenden Schritt ist f(xn−1) ja bekannt) und keine Auswertung der Ab-
leitung, ist es effizienter als das Newton Verfahren. Vergleicht man namlich |xn+2−x|mit |xn−x| (der Aufwand beim Ubergang von xn zu xn+2 mit dem Sekantenverfahren
entspricht dem Aufwand eines Newton-Schrittes), so erhalt man
|xn+2 − x| ≤ C |xn+1 − x|p ≤ Cp+1 |xn − x|p2
,
also ein Verfahren der Ordnung p2 = (3 +√
5)/2 = 2.618.
Wir fragen nun nach Abbruchkriterien fur die behandelten Verfahren. Im Falle der
Bisektion, der regula falsi und der Fixpunktiteration (mit bekannter Kontraktions-
konstante) kann man den Fehler in jedem Iterationsschritt leicht berechnen. Beim
Newton Verfahren oder Sekantenverfahren ist dies nicht der Fall.
Naheliegend ist, die Iteration abzubre-
chen, wenn der Zuwachs |xn − xn−1| un-
terhalb einer vorgegebenen Toleranz tolx
liegt. Die nebenstehende Skizze zeigt, dass
auch bei kleinem tolx der Funktionswert
f(xn) in der letzten Naherung xn noch
sehr weit von 0 entfernt sein kann, wenn
|xn − xn−1| < tolx gilt. Dies ist fur das
Newton Verfahren z.B. dann der Fall,
wenn |f ′(xn)| wesentlich großer als |f(xn)|ist.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Abbildung 15.8
Eine andere Moglichkeit ist, die Iteration abzubrechen, wenn |f(xn)| < tolf bei
gegebener Toleranz tolf > 0 gilt. Die letzte Skizze zeigt, dass auch in diesem Fall
beim Abbruch der Fehler |xn − x| noch sehr groß sein kann.
Zu empfehlen ist, die beiden Kriterien zu kombinieren, d.h. zu iterieren gemaß
ff := f (x);
REPEAT
h := ff / fx (x);
x := x - h;
ff := f (x)
UNTIL (ABS (h) < tolx) AND (ABS (ff) < tolf);

15.4. ITERATIVE METHODEN FUR LINEARE SYSTEME 221
Aber auch hierzu kann man Beispiele konstruieren, bei denen der Fehler beim Ab-
bruch noch sehr groß ist.
15.4 Iterative Methoden fur lineare Systeme
Abschließend in diesem Kapitel 15 betrachten wir noch einmal das lineare Glei-
chungssystem
Ax = b (15.7)
mit regularem A ∈ IR(m,m) und b ∈ IRm.
Zur numerischen Behandlung haben wir bereits das Gaußsche Eliminationsverfahren
(LR-Zerlegung) und die QR-Zerlegung sowie fur symmetrisches, positiv definites A
die Cholesky Zerlegung kennengelernt, die einen Aufwand von 13m3 bzw. 2
3m3 bzw.
16m3 Operationen und m2 Speicherplatzen erfordern.
In den Anwendungen (z.B. bei elektrischen Netzwerken oder bei Berechnungen mit
Finiten Elementen in der Festigkeitslehre) treten Gleichungssysteme mit mehreren
tausend Variablen auf. Auch wenn die Koeffizientenmatrizen in diesen Fallen oft
dunn besetzt sind (d.h. sehr viele Nullen enthalten) und die oben genannten direkten
Verfahren so modifiziert werden konnen, dass die spezielle Struktur genutzt wird,
bleibt der Aufwand und der Speicherplatzbedarf viel zu hoch.
In dieser Situation werden iterative Verfahren verwendet:
Es sei A ∈ IR(m,m) eine Approximation der Matrix A. Dann ist die
Gleichung (15.7) aquivalent zu
Ax = (A − A)x + b,
d.h.
x = A−1
(A − A)x + A−1
b =: Mx + g =: φ(x). (15.8)
Wir haben bereits gesehen, dass die Abbildung φ auf IRm kontrahierend ist bzgl. einer
Vektornorm ‖·‖, wenn fur die zugehorige Matrixnorm ‖M‖ < 1 gilt. In diesem Fall
konvergiert fur jeden Startwert x0 ∈ IRm die Iteration
xn+1 = Mxn + g

222 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
gegen den einzigen Fixpunkt x von φ, d.h. die eindeutige Losung x von (15.7), und
es gilt die Fehlerabschatzung
‖x − xn‖ ≤ ‖M‖1 − ‖M‖ ‖xn − xn−1‖. (15.9)
Zur Durchfuhrung der Iteration wird man naturlich nicht M = A−1
(A − A) be-
rechnen, also A−1
bestimmen (diese Matrix ist ubrigens auch bei dunnbesetzem A
haufig voll besetzt), sondern man wird in jedem Schritt das lineare Gleichungssystem
A xn+1 = (A − A) xn + b, n = 0, 1, 2, . . .
losen. Man wird daher bei der Konstruktion von Iterationsverfahren nur Approxima-
tionen A fur A verwenden, fur die das lineare Gleichungssystem Ay = c, c ∈ IRm
gegeben, leicht losbar ist.
Es sei
L = (lij)i,j, lij :=
aij, fur i > j,
0, fur i ≤ j,
R = (rij)i,j, rij :=
0, fur i ≥ j,
ai,j, fur i < j,
D := A − L − R = diag (a11, . . . , amm).
Dann wird A haufig auf folgende Art gewahlt:
(i): A = D: Gesamtschrittverfahren, Jacobi Iteration:
In diesem Fall lautet die Iterationsvorschrift
xn+1 = −D−1(L + R)xn + D−1b,
oder komponentenweise
xn+1i =
1
aii
(bi −m∑
j =1
j 6= i
aijxnj ), i = 1, . . . ,m.
Fur die Berechnung der neuen Naherungen xn+1i von xi benotigt man also so viele
Multiplikationen wie von Null verschiedene Elemente in der i-ten Zeile von A stehen.
Sind im Mittel k Elemente in den Zeilen von A besetzt, so benotigt man fur einen
Schritt der Jacobi Iteration m k Multiplikationen. Typisch fur diskrete Versionen
von Randwertaufgaben zweiter Ordnung ist k = 5.

15.4. ITERATIVE METHODEN FUR LINEARE SYSTEME 223
Das Gesamtschrittverfahren konvergiert, falls das starke Zeilensummenkriteri-
um erfullt ist:m∑
j =1
j 6= i
|aij| < |aii|, i = 1, . . . ,m.
In dem Fall gilt namlich fur die Zeilensummennorm der Iterationsmatrix M =
D−1(D − A)
‖M‖∞ = maxi=1,...,m
m∑
j=1
|mij| = maxi=1,...,m
m∑
j =1
j 6= i
| − aij
aii
| < 1,
und man kann die Fehlerabschatzung (15.9) mit der Maximumnorm verwenden.
Man kann zeigen, dass das Gesamtschrittverfahren ebenfalls konvergiert, wenn das
starke Spaltensummenkriterium
m∑
i=1i 6=j
|aij| < |ajj|, j = 1, . . . ,m
erfullt ist.
(ii): A = L + D: Einzelschrittverfahren , Gauß-Seidel Verfahren .
Die Iterationsvorschrift
xn+1 = −(D + L)−1Rxn + (D + L)−1b
lautet komponentenweise
xn+1i =
1
aii
(
−i−1∑
j=1
aijxn+1j −
m∑
j=i+1
aijxnj + bi
)
= xni +
1
aii
(
bi −i−1∑
j=1
aijxn+1j −
m∑
j=i
aijxnj
)
.
Im Unterschied zum Gesamtschrittverfahren werden also die bereits berechneten
verbesserten Naherungen xn+11 , . . . , xn+1
i−1 bei der Bestimmung von xn+1i schon ver-
wendet.
Der Aufwand fur jeden Iterationsschritt ist wie beim Gesamtschrittverfahren k m
Multiplikationen.
Die Konvergenzuntersuchungen sind schwieriger als beim Gesamtschrittverfahren.
Man kann zeigen (vgl. Stoer, Bulirsch [21, p. 233]), dass das Einzelschrittverfahren
konvergiert, falls das starke Zeilensummenkriterium erfullt ist. Es gilt die Faustregel,

224 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
dass das Einzelschrittverfahren schneller konvergiert als das Gesamtschrittverfahren.
Diese lasst sich fur symmetrische, positiv definite Matrizen A auch beweisen, ist aber
i.a. falsch.
(iii): A = 1ωD + L: Relaxationsverfahren (SOR Verfahren)
Die Iterationsvorschrift
xn+1 =( 1
ωD + L
)−1(
1
ω
(
(1 − ω)D − ωR)
xn + b
)
lautet komponentenweise
xn+1i = xn
i +ω
aii
(
bi −i−1∑
j=1
aij xn+1j −
m∑
j=i
aij xnj
)
, i = 1, . . . ,m,
es wird also der Zuwachs xn+1i − xn
i des Einzelschrittverfahrens mit der reellen Zahl
ω multipliziert.
Man kann zeigen, dass das Relaxationsverfahren fur symmetrisches, positiv definites
A fur alle ω ∈ (0, 2) konvergiert. Durch geeignete Wahl von ω kann die Konvergenz
gegenuber dem Einzelschrittverfahren (ω = 1) erheblich beschleunigt werden.
15.5 Berechnung von Eigenwerten
Wir kommen nun zu einem einfachen Verfahren zur Bestimmung des betragsmaxi-
malen Eigenwerts einer Matrix.
Es sei A ∈ IR(n,n) diagonalisierbar, d.h. es gebe n linear unabhangigige Eigenvektoren
u1, . . . ,un mit zugehorigen Eigenwerten λ1, . . . , λn.
Wir ordnen die λi dem Betrage nach an und nehmen an, dass A einen betragsma-
ximalen Eigenwert besitzt:
|λ1| > |λ2| ≥ . . . ≥ |λn|.
Ist x0 ∈ IRn \ {0} gegeben, x0 =n∑
i=1αiu
i, so gilt
x1 := Ax0 =n∑
i=1
αiAui =n∑
i=1
αiλiui.
Definiert man die Folge {xm}, m = 0, 1, . . ., rekursiv durch xm+1 := Axm, so erhalt
man genauso
xm =n∑
i=1
αiλmi ui = λm
1
(
α1u1 +
n∑
i=2
αi
( λi
λ1
)mui
)
.

15.5. BERECHNUNG VON EIGENWERTEN 225
Tabelle 15.8: von Mises Verfahren
m xm1 xm
2 xm3 xm
4 R(xm)
1 0.7071 0.0000 0.0000 0.7071 2.00002 0.6325 −0.3162 −0.3162 0.6325 2.60003 0.6063 −0.3638 −0.3638 0.6063 2.61764 0.6022 −0.3706 −0.3706 0.6022 2.61802575 0.6016 −0.3716 −0.3716 0.6016 2.61803386 0.6015 −0.3717 −0.3717 0.6015 2.6180339857 0.6015 −0.3717 −0.3717 0.6015 2.618033988
Wegen∣∣∣λi
λ1
∣∣∣ < 1, i = 2, . . . , n, konvergiert die Summe
n∑
i=2
αi
( λi
λ1
)mui gegen 0.
Ist α1 6= 0, hat also der Startvektor x0 eine Komponente in Richtung von u1, so
”konvergiert“ die erzeugte Folge {xm} gegen einen Eigenvektor von A zum betrags-
maximalen Eigenwert λ1.
Gilt |λ1| 6= 1, so erhalt man fur große m Exponentenuber- oder -unterlauf. Man wird
also die Folge {xm} noch normieren und erhalt die Potenzmethode oder das von
Mises Verfahren :
Sei x0 ∈ IRn; bestimme fur m = 0, 1, 2, . . . Vektoren xm+1 :=Axm
‖Axm‖ .
Als Naherung fur einen Eigenwert wahlt man, wenn A symmetrisch ist, den Rayleigh
Quotienten R(xm); im allgemeinen Fall nimmt man den Quotienten(Axm)j
xmj
fur ein
j ∈ {1, . . . , n}, das u1j 6= 0 erfullt.
Beispiel 15.29.
A =
2 −1 0 0−1 2 −1 00 −1 2 −10 0 −1 2
.
Mit dem Startvektor x0 := (1, 1, 1, 1)T erhalt man die Naherungen der Tabelle 15.8
Startet man mit x0 = (0.154, 0.515, 0.681, 0.401)T (dieser Startwert wurde mit einem
Zufallszahlengenerator erzeugt), so erhalt man die Naherungen in Tabelle 15.9
Tatsachlich ist der maximale Eigenwert von A
λ1 = 2 (1 + cosπ
5) = 3.61803398874989.
Fur den ersten Startwert x0 = (1, 1, 1, 1)T gilt in der Entwicklung x0 =4∑
i=1αiu
i:
α1 = 0, und daher konvergiert xm gegen den Eigenvektor zum zweiten Eigenwert
λ2 = 2 (1 + cos2π
5) = 2.61803398874989.

226 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.9: von Mises Verfahren
m xm1 xm
2 xm3 xm
4 R(xm)
1 0.2422 0.7799 0.4000 −0.4161 1.33122 −0.1819 0.5649 0.2686 −0.7587 2.30963 −0.3899 0.4379 0.3069 −0.7497 2.5328. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10 −0.3462 0.0368 0.6146 −0.7079 2.850420 0.3279 −0.5734 0.6265 −0.4137 3.612930 0.3701 −0.6005 0.6026 −0.3734 3.61802640 0.3717 −0.6015 0.6015 −0.3718 3.618033976
Tabelle 15.10: von Mises Verfahren
m R(xm)
80 2.6180339887501390 2.61803398890
100 2.61803408110 2.618096120 2.6569130 3.5811140 3.6179150 3.618033896160 3.618033988607170 3.61803398874967
Auf dem Rechner wird durch Rundungsfehler eine Komponente in Richtung von u1
erzeugt. Setzt man die erste Iteration fort, so erhalt man
R(x30) = R(x40) = R(x50) = R(x60) = R(x70) = 2.61803398874989
(dies ist der Eigenvektor λ2 im Rahmen der Rechengenauigkeit unter Turbo Pas-
cal 6.0). Danach liefert das von Mises Verfahren weiter die Naherungen aus Ta-
belle 15.10 also doch noch Konvergenz gegen den Eigenvektor zum maximalen
Eigenwert. 2
Hat man (z.B. mit der Potenzmethode) einen Eigenvektor u1 bestimmt, so kann
man u1 zu einer orthogonalen Matrix U = (u1,v2, . . . ,vn) erganzen. Dann besitzt
B := U−1AU = UT AU
die Gestalt B =
(
λ1 bT
0 C
)
, wobei C ∈ IR(n−1,n−1) die Eigenwerte λ2, . . . , λn besitzt.
Auf C kann man wieder die Potenzmethode anwenden.
Diesen Prozess (Deflation) kann man wiederholen, um weitere Eigenvektoren und
Eigenwerte zu bestimmen.
Die Potenzmethode konvergiert linear, d.h.
‖xm+1 − u1‖ ≤ q‖xm − u1‖ mit q =∣∣∣λ2
λ1
∣∣∣;

15.5. BERECHNUNG VON EIGENWERTEN 227
Tabelle 15.11: Inverse Iteration
m xm1 xm
2 xm3 xm
4 R(xm)
1 −0.0067 −0.1477 −0.2367 −0.0914 0.66442 −0.0205 0.0698 0.3869 −0.0377 1.86253 −0.2568 0.5730 −0.1066 0.5806 3.47454 0.7989 −1.4099 1.6015 −1.0133 3.61065 −0.9338 1.5471 −1.5950 1.0007 3.6157246 0.9631 −1.5684 1.5808 −0.9821 3.617995917 −0.9705 1.5731 −1.5764 0.9758 3.618031098 0.9725 −1.5743 1.5752 −0.9740 3.61803376789 −0.9730 1.5746 −1.5749 0.9735 3.6180339718
10 0.9732 −1.5747 1.5748 −0.9733 3.618033987460
liegen also λ1 und λ2 dem Betrage nach sehr nahe beieinander, so ist die Konvergenz
sehr langsam.
Die Konvergenz kann wesentlich verbessert werden, wenn man die inverse Itera-
tion verwendet, d.h. xm+1 bestimmt aus dem linearen Gleichungssystem
(A − λ(m)E) xm+1 = xm,
wobei λ(m) eine Naherung fur einen Eigenwert von A ist. Dies entspricht (bei festem
λ(m)) der Potenzmethode fur die Matrix (A − λ(m)E)−1, die dieselben Eigenvek-
toren wie A hat und die Eigenwerte1
λi − λ(m). Ist λ(m) eine gute Naherung fur
z.B. λ1, so ist1
λ1 − λ(m)betragsmaximaler Eigenwert von (A − λ(m)E)−1, und die
Konvergenzrate der Potenzmethode ist
maxi=2,...,m
∣∣∣λ1 − λ(m)
λi − λ(m)
∣∣∣,
und diese kann sehr klein sein.
Wahlt man in Beispiel 15.29. den Startvektor x0 := (0.154 , 0.515 , 0.681 , 0.401)T
und λ(m) = 4 (dies ist nach dem Satz von Gerschgorin eine obere Schranke fur den
maximalen Eigenwert λ1, so dass man garantierte Konvergenz gegen λ1 erhalt), so
erhalt man mit der inversen Iteration die Naherungen der Tabelle 15.11
Man beachte, dass man bei der obigen Variante in den Schritten lineare Gleichungs-
systeme zu losen hat, deren Koeffizientenmatrizen A−λ(m)E identisch sind, wahrend
die rechten Seiten im vorhergehenden Schritt erzeugt. Man kann also hier mit Ge-
winn die LR-Zerlegung einsetzen.
Iteriert man λ(m) mit, so kann man sogar ein quadratisch oder bei symmetrischen
Matrizen ein kubisch konvergentes Verfahren erhalten. Der Preis ist, dass man in je-
dem Schritt ein lineares Gleichungssystem losen muss, wobei die Koeffizientenmatrix
sich von Schritt zu Schritt verandert.

228 KAPITEL 15. NUMERISCHE LOSUNG VON GLEICHUNGEN
Tabelle 15.12: Inverse Iteration; variabler Shift
m xm1 xm
2 xm3 xm
4 R(xm)
4 −2.6597 4.1098 −3.8196 2.3022 3.61555 −14.4140 23.3269 −23.3308 14.4207 3.61803397266 3.618033988749895
Wechselt man in der letzten Iteration nach dem dritten Schritt zu der inversen
Iteration mit λ(m) = R(xm−1), so erhalt man die Naherungen der Tabelle 15.12
Der wohl gebrauchlichste Algorithmus zur Berechnung von Eigenwerten von Matri-
zen ist der QR Algorithmus (Francis, Kublanovskaja 1961/62), dessen Grundform
auf der folgenden Iteration basiert:
Es sei A0 := A. Im k-ten Schritt des Algorithmus fuhre man eine QR
Zerlegung von Ak−1 durch, d.h. man bestimme wie in Kapitel 7 eine
orthogonale Matrix Qk−1 und eine obere Dreiecksmatrix Rk−1 mit
Ak−1 = Qk−1Rk−1,
und setze dann
Ak = Rk−1Qk−1.
Wegen Rk−1 = QTk−1Ak−1 gilt dann Ak = QT
k−1Ak−1Qk−1 und durch Induktion
Ak = (Q1 · · ·Qk−1)T A (Q1 · · ·Qk−1),
d.h. alle auftretenden Matrizen sind der Ausgangsmatrix A ahnlich und haben daher
dieselben Eigenwerte wie A.
Man kann zeigen, dass unter sehr allgemeinen Bedingungen an A die Diagonalele-
mente von Ak gegen die Eigenwerte von A konvergieren.
In der Praxis wird der QR Algorithmus nicht auf A angewendet, sondern es wird
zunachst A durch eine orthogonale Ahnlichkeitstransformation auf obere Hessen-
berg Gestalt gebracht, d.h. B = QT AQ (Q orthogonal, B so, dass bij = 0 fur
i ≥ j − 2). Diese Gestalt bleibt wahrend des QR Algorithmus erhalten. Ferner
wird der Algorithmus durch eine Shift Strategie (vgl. inverse Iteration) erheblich
beschleunigt.

Kapitel 16
Das bestimmte Riemannsche
Integral
16.1 Definition des Riemann Integrals
Wir betrachten in diesem Kapitel 16 das Problem der Berechnung von Flachenin-
halten. Dabei beschranken wir uns auf Flachen des Typs
F := {(x, y) : a ≤ x ≤ b, 0 ≤ y ≤ f(x)},
die links und rechts durch Parallelen zur y-Achse und oben und unten durch den
Graphen einer beschrankten, nichtnegativen Funktion f : [a, b] → IR und die x-
Achse begrenzt werden. Kompliziertere Flachen kann man haufig aus Flachen dieses
Typs zusammensetzen.
Zur Definition des Flacheninhalts zerlegen wir die Flache in schmale Streifen, erset-
zen in jedem Streifen die Flache durch ein approximierendes Rechteck und berech-
nen die Rechteckflachen elementargeometrisch als”Lange mal Breite“ (siehe Abbil-
dung 16.1). Existiert bei Verfeinerung der Zerlegung in Rechtecke der Grenzwert und
ist der Grenzwert unabhangig von der speziell gewahlten Folge von Zerlegungen, so
definieren wir den Flacheninhalt als diesen Grenzwert.
Definition 16.1. Eine endliche Teilmenge Z := {xi : i = 0, . . . , n} ⊂ [a, b] heißt
Zerlegung von [a, b], wenn gilt
a = x0 < x1 < . . . < xn−1 < xn = b.
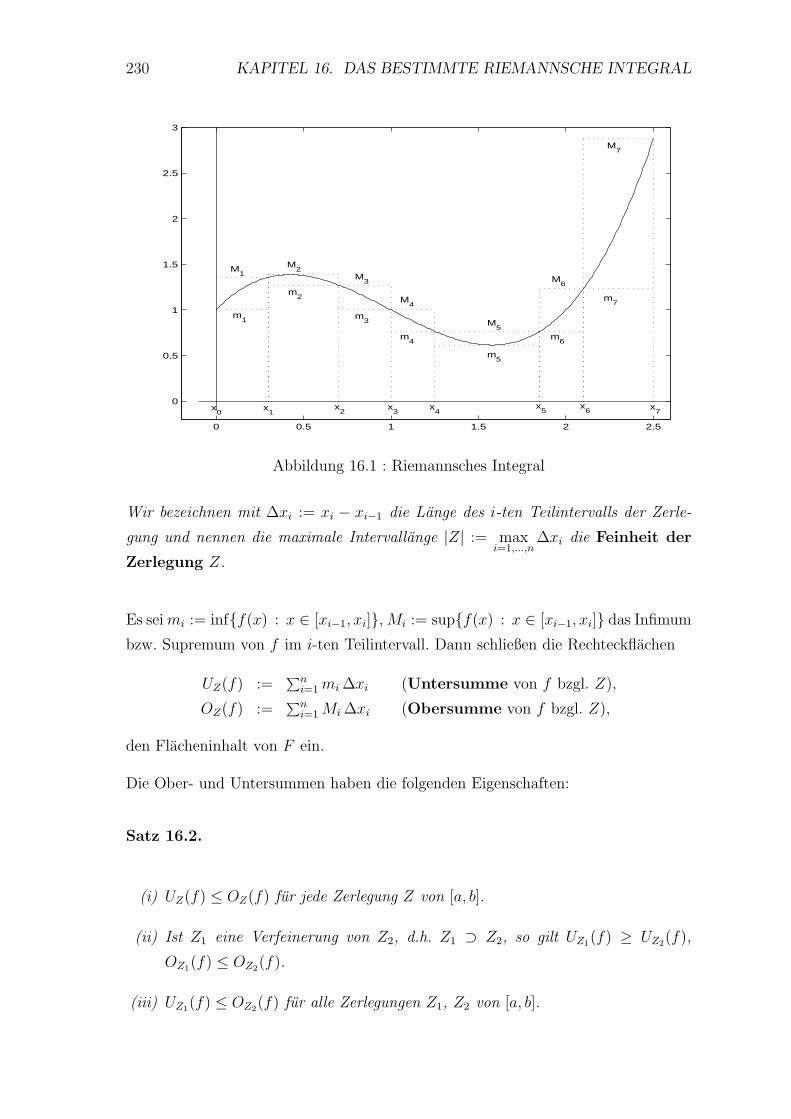
230 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
0 0.5 1 1.5 2 2.5
0
0.5
1
1.5
2
2.5
3
x1
x0
x2
x3
x4
x5
x6 x
7
m1
m2
m3
m4
m5
m6
m7
M1
M2
M3
M4
M5
M6
M7
Abbildung 16.1 : Riemannsches Integral
Wir bezeichnen mit ∆xi := xi − xi−1 die Lange des i-ten Teilintervalls der Zerle-
gung und nennen die maximale Intervallange |Z| := maxi=1,...,n
∆xi die Feinheit der
Zerlegung Z.
Es sei mi := inf{f(x) : x ∈ [xi−1, xi]}, Mi := sup{f(x) : x ∈ [xi−1, xi]} das Infimum
bzw. Supremum von f im i-ten Teilintervall. Dann schließen die Rechteckflachen
UZ(f) :=∑n
i=1 mi ∆xi (Untersumme von f bzgl. Z),
OZ(f) :=∑n
i=1 Mi ∆xi (Obersumme von f bzgl. Z),
den Flacheninhalt von F ein.
Die Ober- und Untersummen haben die folgenden Eigenschaften:
Satz 16.2.
(i) UZ(f) ≤ OZ(f) fur jede Zerlegung Z von [a, b].
(ii) Ist Z1 eine Verfeinerung von Z2, d.h. Z1 ⊃ Z2, so gilt UZ1(f) ≥ UZ2(f),
OZ1(f) ≤ OZ2(f).
(iii) UZ1(f) ≤ OZ2(f) fur alle Zerlegungen Z1, Z2 von [a, b].
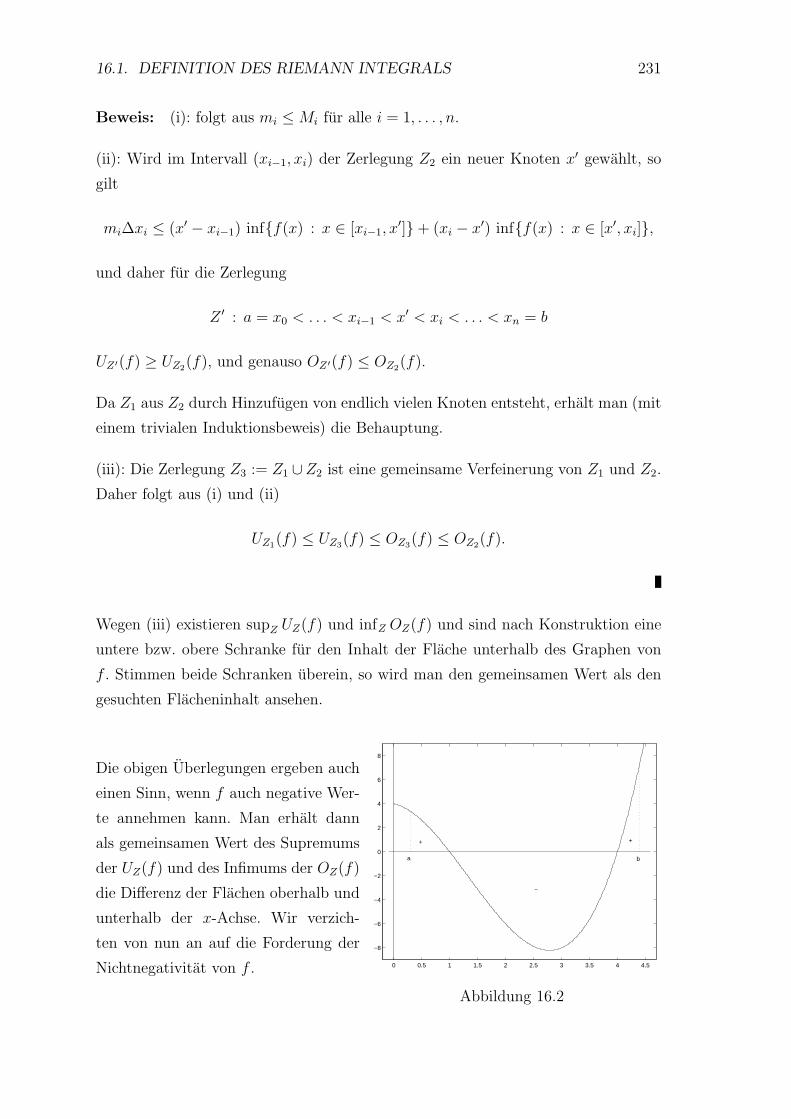
16.1. DEFINITION DES RIEMANN INTEGRALS 231
Beweis: (i): folgt aus mi ≤ Mi fur alle i = 1, . . . , n.
(ii): Wird im Intervall (xi−1, xi) der Zerlegung Z2 ein neuer Knoten x′ gewahlt, so
gilt
mi∆xi ≤ (x′ − xi−1) inf{f(x) : x ∈ [xi−1, x′]} + (xi − x′) inf{f(x) : x ∈ [x′, xi]},
und daher fur die Zerlegung
Z ′ : a = x0 < . . . < xi−1 < x′ < xi < . . . < xn = b
UZ′(f) ≥ UZ2(f), und genauso OZ′(f) ≤ OZ2(f).
Da Z1 aus Z2 durch Hinzufugen von endlich vielen Knoten entsteht, erhalt man (mit
einem trivialen Induktionsbeweis) die Behauptung.
(iii): Die Zerlegung Z3 := Z1 ∪Z2 ist eine gemeinsame Verfeinerung von Z1 und Z2.
Daher folgt aus (i) und (ii)
UZ1(f) ≤ UZ3(f) ≤ OZ3(f) ≤ OZ2(f).
Wegen (iii) existieren supZ UZ(f) und infZ OZ(f) und sind nach Konstruktion eine
untere bzw. obere Schranke fur den Inhalt der Flache unterhalb des Graphen von
f . Stimmen beide Schranken uberein, so wird man den gemeinsamen Wert als den
gesuchten Flacheninhalt ansehen.
Die obigen Uberlegungen ergeben auch
einen Sinn, wenn f auch negative Wer-
te annehmen kann. Man erhalt dann
als gemeinsamen Wert des Supremums
der UZ(f) und des Infimums der OZ(f)
die Differenz der Flachen oberhalb und
unterhalb der x-Achse. Wir verzich-
ten von nun an auf die Forderung der
Nichtnegativitat von f . 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5
−8
−6
−4
−2
0
2
4
6
8
a b
+ +
−
Abbildung 16.2

232 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
Definition 16.3. Es sei f : [a, b] → IR eine beschrankte Funktion.
(i)b∫
a∗f(x) dx := sup{UZ(f) : Z ist Zerlegung von [a, b]} heißt Unterintergral
von f uber [a, b].
(ii)b∫
a
∗f(x) dx := inf{OZ(f) : Z ist Zerlegung von [a, b]} heißt Oberintegral von
f uber [a, b].
(iii) Stimmen das Ober- und Unterintegral von f uber [a, b] uberein, so heißt f
integrierbar uber [a, b], und der gemeinsame Wert
b∫
a
f(x) dx :=
b∫
a∗f(x) dx =
b∫
a
∗f(x) dx
heißt das Integral von f uber [a, b].
Bemerkung 16.4. Das hier eingefuhrte Integral heißt Riemann Integral . Es
gibt allgemeinere Integralbegriffe wie das Lebesgue Integral, das schonere Eigen-
schaften besitzt, fur dessen Einfuhrung aber ein wesentlich großerer Begriffsapparat
erforderlich ist. 2
Beispiel 16.5. f : [0, 1] → IR,
f(x) :=
1, falls x rational,
0, falls x irrational.
Ist Z eine beliebige Zerlegung von [0, 1], so liegen in jedem Intervall [xi−1, xi] sowohl
rationale als auch irrationale Zahlen, und daher gilt mi = 0 und Mi = 1, d.h.
OZ(f) = 1 und UZ(f) = 0. Es gilt also
1∫
0∗f(x) dx = 0,
1∫
0
∗f(x) dx = 1,
und f ist nicht integrierbar. 2
Beispiel 16.6. f : [0, 1] → IR, f(x) := x2.
Wegen der Monotonie von f gilt fur jede Zerlegung Z von [0, 1]
UZ(f) =n∑
i=1
x2i−1 (xi − xi−1), OZ(f) =
n∑
i=1
x2i (xi − xi−1),

16.2. INTEGRIERBARKEITSKRITERIEN 233
und daher
OZ(f) − UZ(f) =n∑
i=1
(x2i − x2
i−1) (xi − xi−1) =n∑
i=1
(xi−1 + xi) (∆xi)2
≤ 2 ·n∑
i=1
(∆xi)2 ≤ 2 |Z|
n∑
i=1
∆xi = 2 |Z|.
Ist also {Zn} eine Folge von Zerlegungen mit limn→∞ |Zn| = 0, so folgt
0 ≤1∫
0
∗f(x) dx −
1∫
0∗f(x) dx ≤ OZn
(f) − UZn(f) ≤ 2 |Zn| → 0,
und f ist integrierbar.
Ferner gilt1∫
0f(x) dx = lim
n→∞OZn(f) fur jede Folge {Zn} mit lim
n→∞ |Zn| = 0. Wahlt
man speziell die aquidistanten Zerlegungen Zn mit den Zerlegungspunkten
x(n)i =
i
n, i = 0, . . . , n,
so erhalt man
OZn=
n∑
i=1
( i
n
)2 · 1
n=
1
n3
n∑
i=1
i2 =n (n + 1) (2n + 1)
6n3→ 1
3,
d.h.
1∫
0
x2 dx =1
3. 2
16.2 Integrierbarkeitskriterien
Die Definition der Integrierbarkeit ist etwas unhandlich. Wir leiten in diesem Ab-
schnitt Charakterisierungen der integrierbaren Funktionen her, die fur die folgenden
Untersuchungen geeigneter sind.
Satz 16.7. (Riemannsches Integrabilitatskriterium)
Sei f : [a, b] → IR eine beschrankte Funktion.
f ist genau dann integrierbar uber [a, b], wenn es fur jedes ε > 0 eine Zerlegung Z
des Intervalls [a, b] gibt, so dass
OZ(f) − UZ(f) < ε.

234 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
Beweis: Ist f integrierbar uber [a, b], so gibt es zu jedem ε > 0 Zerlegungen Z1
und Z2 von [a, b] mit
0 ≤b∫
a
f(x) dx − UZ1(f) =
b∫
a∗f(x) dx − UZ1(f) <
ε
2,
0 ≤ OZ2(f) −b∫
a
f(x) dx = OZ2(f) −b∫
a
∗f(x) dx <
ε
2,
und durch Addition erhalt man
0 ≤ OZ2(f) − UZ1(f) < ε.
Ist Z eine gemeinsame Verfeinerung von Z1 und Z2, so folgt
0 ≤ OZ(f) − UZ(f) ≤ OZ2(f) − UZ1(f) < ε.
Die Umkehrung folgt unmittelbar aus der Definition des Supremums und des Infi-
mums.
Die folgende Charakterisierung der Integrierbarkeit ist insbesondere bei der Ubertra-
gung von Begriffen, die fur diskrete Systeme erklart sind, auf kontinuierliche Systeme
von Bedeutung. Beispiele behandeln wir in Kapitel 20.
Definition 16.8. Es sei f : [a, b] → IR beschrankt, Z : = {xj : j = 0, . . . , n} eine
Zerlegung und ξj ∈ [xj−1, xj] fest gewahlt. Dann heißt
RZ(f) : =n∑
j=1
f(ξj)(xj − xj−1)
eine Riemann Summe von f zur Zerlegung Z.
Satz 16.9. (Riemann Summen)
Es sei f : [a, b] → IR eine beschrankte Funktion.
f ist genau dann integrierbar uber [a, b], wenn fur jede Folge von Zerlegungen Zk :
= {x(k)j : j = 0, . . . , nk} von [a, b] mit |Zk| → 0 fur k → ∞ und jede Auswahl von
Zwischenpunkten ξ(k)j ∈ [x
(k)j−1, x
(k)j ], j = 1, . . . , nk, die Folge der Riemann Summen
RZk(f) : =
nk∑
j=1
f(ξ(k)j )(x
(k)j − x
(k)j−1)
konvergiert. Ist f integrierbar uber [a, b], so konvergiert jede dieser Folgen gegen das
Integral
I(f) : =
b∫
a
f(x) dx.

16.2. INTEGRIERBARKEITSKRITERIEN 235
Beweis: Es sei f integrierbar uber [a, b], Zk eine Folge von Zerlegungen von [a, b]
mit |Zk| → 0 fur k → ∞ und {RZk(f)} eine zugehorige Folge von Riemann Summen.
Es sei ε > 0 vorgegeben. Dann gibt es nach dem Riemannschen Integrabilitats-
kriterium (Satz 16.7. ) eine Zerlegung Z : = {xi : i = 1, . . . , n} von [a, b] mit
OZ(f) − I(f) < ε.
Wir zerlegen die Riemann Summen in RZk= : R′
k + R′′k, wobei R′
k diejenigen Sum-
manden f(ξ(k)j )(x
(k)j − x
(k)j−1) aus RZk
(f) enthalt, fur die das Intervall [x(k)j−1, x
(k)j ] in
einem der Intervalle [xi−1, xi] der Zerlegung Z enthalten ist, und R′′k die ubrigen
Summanden, fur die die Endpunkte des Intervalls [x(k)j−1, x
(k)j ] in zwei verschiedenen
Intervallen der Zerlegung Z liegen.
Dann gilt sicher R′k ≤ OZ(f) und, da R′′
k hochstens n Summanden enthalt, |R′′k| ≤
n|Zk|supx∈[a,b]|f(x)| → 0 fur k → ∞.
Man kann also k0 so groß wahlen, dass
RZk(f) − I(f) = R′′
k + R′k − OZ(f) + OZ(f) − I(f) < 2ε
fur alle k > k0 gilt. Da man mit Hilfe einer geeigneten Untersumme UZ(f) genauso
RZk(f) − I(f) > 2ε erhalt, ist die Konvergenz der RZk
(f) gegen I(f) gezeigt.
Wir nehmen nun an, dass fur jede Zerlegungsfolge Zk von [a, b] mit |Zk| → 0 fur
k → ∞ und jede Auswahl von Zwischenpunkten die Folge der Riemann Sum-
men konvergiert. Dann haben alle Folgen dieses Typs denselben Grenzwert R (sind
namlich Rk(f) und Sk(f) Folgen von Riemann Summen mit verschiedenen Grenz-
werten, so konvergiert die Folge Tk(f), T2k(f) := Rk(f), T2k+1(f) := Sk(f), nicht).
Es sei Zk eine Folge von Zerlegungen von [a, b] mit |Zk| → 0 fur k → ∞. Dann gibt
es zu jedem k ∈ IN Punkte ξ(k)j ∈ [x
(k)j−1, x
(k)j ], j = 1, . . . , nk, so dass fur die zugehorige
Riemann Summe RZk(f) die Ungleichung OZk
(f)−RZk(f) < 1
kgilt (man muss nur
ξ(k)j so wahlen, dass f(ξ
(k)j ) genugend nahe bei sup{f(x) : x ∈ [x
(k)j−1, x
(k)j ]} liegt).
Mit dieser Wahl erhalt man
limk→∞
OZk(f) = lim
k→∞RZk
(f) = R.
Genauso kann man limk→∞ UZk(f) = R zeigen, und daher ist f integrierbar uber
[a, b] undb∫
af(x) dx = R.

236 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
16.3 Klassen integrierbarer Funktionen
Satz 16.10. Jede auf [a, b] stetige Funktion f ist integrierbar uber [a, b].
Beweis: Als stetige Funktion auf dem abgeschlossenen Intervall [a, b] ist f nach
Satz 11.41. sogar gleichmaßig stetig, d.h. fur alle η > 0 existiert ein δ > 0, so dass
fur alle x, y ∈ [a, b] mit |x − y| < δ
|f(x) − f(y)| < η.
Es sei η := ε/(b − a), δ wie oben gewahlt und
Z : a = x0 < x1 < . . . < xn = b
eine Zerlegung mit |Z| < δ.
Wegen der Stetigkeit von f gibt es ξi, ζi ∈ [xi−1, xi] mit mi = f(ξi) und Mi = f(ζi),
und es folgt
OZ(f) − UZ(f) =n∑
i=1
(Mi − mi) ∆xi =n∑
i=1
(
f(ζi) − f(ξi))
∆xi
≤ ηn∑
i=1
∆xi = η (b − a) = ε,
und nach dem Riemannschen Kriterium ist f integrierbar.
Aus Satz 16.10. folgt, dass alle Polynome, sin, cos und exp uber jedes endliche
Intervall integrierbar sind und dass rationale Funktionen und die in Kapitel 12 be-
trachteten elementaren Funktionen uber jedes abgeschlossene Intervall in ihrem De-
finitionsbereich integrierbar sind.
Wir kommen nun zu einer weiteren Klasse integrierbarer Funktionen:
Definition 16.11. Die beschrankte Funktion f : [a, b] → IR heißt von beschrank-
ter Variation (Schwankung), wenn es eine Konstante K ≥ 0 gibt, so dass fur alle
Zerlegungen Z von [a, b] gilt
V (f ; Z) :=n∑
i=1
(Mi − mi) ≤ K.
Mi − mi = sup{f(x) : xi−1 ≤ x ≤ xi} − inf{f(x) : xi−1 ≤ x ≤ xi} misst die
Schwankung von f in dem Teilintervall [xi−1, xi],
V (f) := sup{V (f ; Z) : Z ist Zerlegung von [a, b]}
ist also die Gesamtschwankung von f in [a, b].

16.3. KLASSEN INTEGRIERBARER FUNKTIONEN 237
Bemerkung 16.12. Ist f : [a, b] → IR monoton und beschrankt, so ist f von
beschrankter Variation, denn ist f z.B. monoton wachsend, so gilt fur jede Zerlegung
Z
Mi−1 ≤ mi, i = 1, . . . , n,
und daher
V (f ; Z) =n∑
i=1
(Mi − mi) ≤ Mn − m1 = f(b) − f(a) = V (f).
2
Bemerkung 16.13. Nicht jede auf [a, b] stetige Funktion ist von beschrankter
Variation, denn wahlt man fur die auf [0, 2π] stetige Funktion
f(x) := x sin1
x, x ∈ (0,
2
π], f(0) := 0,
die Zerlegung Zn mit den Teilpunkten 0,2
πund
2
(2i − 1) π, i = 1, . . . , n, so gilt
V (f ; Z) ≥n−1∑
i=1
∣∣∣∣
2
(2i − 1) πsin(
2i − 1
2π) − 2
(2i + 1) πsin(
2i + 1
2π)
∣∣∣∣
=n−1∑
i=1
( 2
(2i − 1) π+
2
(2i + 1) π
)
=2
π
n−1∑
i=1
( 1
2i − 1+
1
2i + 1
)
→ ∞
fur n → ∞. 2
Bemerkung 16.14. Ist f : [a, b] → IR differenzierbar und f ′ beschrankt, so ist f
von beschrankter Variation, denn sei |f ′(x)| ≤ M fur alle x ∈ [a, b]. Dann gilt fur
jede Zerlegung Z von [a, b] mit ξi und ζi wie im Beweis von Satz 16.10.
V (f ; Z) =n∑
i=1
(
f(ζi) − f(ξi))
=n∑
i=1
|f ′(ζi + θi (ξi − ζi))| (xi − xi−1)
≤ Mn∑
i=1
(xi − xi−1) = M (b − a).
2
Satz 16.15. Ist f : [a, b] → IR von beschrankter Variation, so ist f integrierbar
uber [a, b]. Insbesondere ist jede auf [a, b] monotone Funktion integrierbar uber [a, b].
Beweis: Es sei Zn die aquidistante Zerlegung von [a, b] mit den Teilpunkten xi =
a + ib − a
n, i = 0, . . . , n. Dann gilt fur die zugehorigen Ober- und Untersummen
OZn(f) − UZn
(f) =n∑
i=1
(Mi − mi)b − a
n≤ V (f) · b − a
n→ 0
fur n → ∞, und aus Satz 16.7. folgt die Integrierbarkeit von f .

238 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
16.4 Rechenregeln
Satz 16.16. Es seien f, g : [a, b] → IR integrierbar, und es sei λ ∈ IR. Dann sind
auch f + g und λ · f und f · g integrierbar, und es gilt
(i)b∫
a(f(x) + g(x)) dx =
b∫
af(x) dx +
b∫
ag(x) dx.
(ii)b∫
a(λ f)(x) dx = λ
b∫
af(x) dx.
(iii) Gilt f(x) ≤ g(x) fur alle x ∈ [a, b], so folgt
b∫
a
f(x) dx ≤b∫
a
g(x) dx.
Bemerkung 16.17. Satz 16.16. besagt, dass die Menge I aller uber [a, b] integrier-
baren Funktionen ein Vektorraum ist und dass durch
b∫
a
: I → IR
eine lineare Abbildung definiert wird, die wegen (iii) monoton ist. 2
Beweis: (von Satz 16.16.)
(i): Da f und g integrierbar sind, gibt es zu ε > 0 Zerlegungen Z1 und Z2 mit
OZ1(f) − UZ1(f) <ε
2, OZ2(g) − UZ2(g) <
ε
2.
Ist Z eine gemeinsame Verfeinerung der Zerlegungen Z1 und Z2 mit den Zerlegungs-
punkten a = x0 < x1 < . . . < xn = b, so gilt wegen
Mi(f + g) ≤ Mi(f) + Mi(g),
mi(f + g) ≥ mi(f) + mi(g) :(16.1)
OZ(f + g) − UZ(f + g) =n∑
i=1
(
Mi(f + g) − mi(f + g))
∆xi
≤n∑
i=1
(
Mi(f) + Mi(g) − mi(f) − mi(g))
∆xi
=n∑
i=1
(
Mi(f) − mi(f))
∆xi +n∑
i=1
(
Mi(g) − mi(g))
∆xi
= OZ(f) − UZ(f) + OZ(g) − UZ(g)
≤ OZ1(f) − UZ1(f) + OZ2(g) − UZ2(g) < ε,

16.4. RECHENREGELN 239
und nach Satz 16.7. ist f + g integrierbar.
Fur jede Zerlegung Z von [a, b] gilt nach Definition
UZ(f) + UZ(g) ≤b∫
a
f(x) dx +
b∫
a
g(x) dx ≤ OZ(f) + OZ(g),
und nach (16.1)
UZ(f) + UZ(g) ≤b∫
a
(f(x) + g(x)) dx ≤ OZ(f) + OZ(g),
und da die Differenz OZ(f)+OZ(g)−UZ(f)−UZ(g) beliebig klein gemacht werden
kann, folgtb∫
a
f(x) dx +
b∫
a
g(x) dx =
b∫
a
(f(x) + g(x)) dx.
(ii): Fur λ ≥ 0 gilt
mi(λf) = λmi(f), Mi(λf) = λMi(f),
und fur λ < 0
mi(λf) = λMi(f), Mi(λf) = λmi(f).
In jedem Fall ist also fur jede Zerlegung Z
OZ(λf) − UZ(λf) = |λ| · (OZ(f) − UZ(f)),
und daher ist mit f auch λ f integrierbar, und es gilt
b∫
a
(λf)(x) dx = λ
b∫
a
f(x) dx.
(iii): folgt unmittelbar aus mi(f) ≤ mi(g), Mi(f) ≤ Mi(g), d.h. UZ(f) ≤ UZ(g),
OZ(f) ≤ OZ(g) und der Integrierbarkeit von f und g.
Zu zeigen bleibt, dass f · g integrierbar ist. Es gilt
Mi(fg) − mi(fg) = sup{|f(x) g(x) − f(y) g(y)| : x, y ∈ [xi−1, xi]}= sup{|f(x) · (g(x) − g(y)) + g(y) · (f(x) − f(y))| : x, y ∈ [xi−1, xi]}≤ sup{|f(x)| · |g(x) − g(y)| + |g(y)| · |f(x) − f(y)| : x, y ∈ [xi−1, xi]}≤ ‖f‖∞ (Mi(g) − mi(g)) + ‖g‖∞ (Mi(f) − mi(f)),

240 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
wobei ‖f‖∞ := sup{|f(x)| : x ∈ [a, b]} gesetzt ist.
Daher folgt
OZ(f · g) − UZ(f · g) ≤ ‖f‖∞ (OZ(g) − UZ(g)) + ‖g‖∞ (OZ(f) − UZ(f)),
und hieraus erhalt man wie im Falle f + g die Integrierbarkeit von f · g.
Satz 16.18.
(i) Ist f uber [a, b] und uber [b, c] integrierbar, so ist f auch uber [a, c] integrierbar,
und es giltb∫
a
f(x) dx +
c∫
b
f(x) dx =
c∫
a
f(x) dx.
(ii) Ist f uber [a, b] integrierbar, so ist f auch uber jedes Teilintervall [c, d] ⊂ [a, b]
integrierbar.
Beweis: (i): Ist Z bzw. Z ′ eine Zerlegung von [a, b] bzw. [b, c], so ist Z := Z ∪ Z ′
eine Zerlegung von [a, c], und es gilt
c∫
a∗f(x) dx ≥ UZ(f) + UZ′(f),
c∫
a
∗f(x) dx ≤ OZ(f) + OZ′(f).
Daher folgt aus der Integrierbarkeit von f uber [a, b] und [b, c]
b∫
a
f(x) dx +
c∫
b
f(x) dx =
b∫
a∗f(x) dx +
c∫
b∗f(x) dx ≤
c∫
a∗f(x) dx
≤c∫
a
∗f(x) dx ≤
b∫
a
∗f(x) dx +
c∫
b
∗f(x) dx =
b∫
a
f(x) dx +
c∫
b
f(x) dx,
und dies ist nur moglich, wenn uberall das Gleichheitszeichen steht.
(ii): Fur alle ε > 0 existiert eine Zerlegung Z von [a, b] mit OZ(f)−UZ(f) < ε. Nimmt
man als Teilpunkte c und d hinzu (falls diese nicht schon in Z liegen), so gilt fur die
neue Zerlegung Z ′ wegen OZ(f) ≥ OZ′(f), UZ(f) ≤ UZ′(f) auch OZ′(f)−UZ′(f) <
ε, und dann erst recht fur die Restriktion Z := {xi ∈ Z ′ : xi ∈ [c, d]} von Z ′ auf
[c, d]
OZ(f) − UZ(f) < ε,
d.h. f ist integrierbar uber [c, d].

16.4. RECHENREGELN 241
Aus Satz 16.18. folgt zusammen mit Satz 16.10., dass jede stuckweise stetige Funkti-
on in [a, b] (d.h. stetig mit Ausnahme von hochstens endlich vielen Sprungstellen) in-
tegrierbar uber [a, b] ist. Ist namlich f stetig in [ai−1, ai], a = a0 < a1 < . . . < am = b,
wobei f(ai−1) := f(ai−1 + 0), f(ai) := f(ai − 0) gesetzt ist, so ist f nach Satz 16.10.
uber jedes Intervall [ai−1, ai] integrierbar und nach Satz 16.18.(i), ist f dann auch
uber die endliche Vereinigung dieser Intervalle
m⋃
i=1
[ai−1, ai] = [a, b]
integrierbar.
Satz 16.19. Ist f integrierbar uber [a, b], so ist auch |f | integrierbar, und es gilt
b∫
a
f(x) dx ≤b∫
a
|f(x)| dx. (16.2)
Beweis: Ist Z eine beliebige Zerlegung von [a, b], so gilt fur x, y ∈ [xi−1, xi]
|f(x)| − |f(y)| ≤ |f(x) − f(y)| ≤ Mi(f) − mi(f).
Daher folgt Mi(|f |) − mi(|f |) ≤ Mi(f) − mi(f), d.h. OZ(|f |) − UZ(|f |) ≤ OZ(f) −UZ(f), und |f | ist integrierbar.
Wegen f(x) ≤ |f(x)| fur alle x ∈ [a, b] folgt aus Satz 16.16.(iii)
b∫
a
f(x) dx ≤b∫
a
|f(x)| dx.
Bezeichnet f+(x) := max{f(x), 0} den Positivteil und f−(x) := max{−f(x), 0}den Negativteil der integrierbaren Funktion f , so gilt
f+(x) =|f(x)| + f(x)
2und f−(x) =
|f(x)| − f(x)
2,
und nach Satz 16.19. und Satz 16.16. sind auch f+ und f− integrierbar uber [a, b].
Wir haben bisher b > a vorausgesetzt. Sonst war der Ausdruckb∫
af(x) dx nicht
definiert. Wir erweitern diese Definition nun durch
a∫
a
f(x) dx := 0

242 KAPITEL 16. DAS BESTIMMTE RIEMANNSCHE INTEGRAL
fur jede in a definierte Funktion und
a∫
b
f(x) dx := −b∫
a
f(x) dx,
falls b > a und f integrierbar uber [a, b] ist.
Diese Erweiterung der Definition ist sinnvoll, da alle bisher nachgewiesenen Eigen-
schaften des Integrals richtig bleiben. Wir haben lediglich die Ungleichung (16.2) zu
ersetzen durch∣∣∣∣
b∫
a
f(x) dx∣∣∣∣ ≤
∣∣∣∣
b∫
a
|f(x)| dx∣∣∣∣. (16.3)
Allgemeiner gilt
Satz 16.20. Es sei f : [a, b] → IRn (komponentenweise) integrierbar und es sei
‖ · ‖ eine beliebige Norm auf IRn.
Dann ist die Abbildung φ : [a, b] → IR, φ(x) : = ‖f(x)‖, integrierbar, und es gilt
‖b∫
af(x) dx‖ ≤
b∫
a
‖f(x)‖ dx. (16.4)
Beweis: Wegen des Normaquivalenzsatzes (Satz 10.75.) gibt es ein C > 0 mit
‖y‖ ≤ C · ‖y‖∞ fur alle y ∈ IRn.
Es sei Z : = {xi : i = 0, . . . ,m} eine Zerlegung von [a, b], und
Mi(g) : = supx∈[xi−1,xi]
g(x), mi(g) : = infx∈[xi−1,xi]
g(x)
fur jede reelle Funktion g : [a, b] → IR.
Dann gilt fur alle x, y ∈ [xi−1, xi] nach der Dreiecksungleichung
|φ(x) − φ(y)| =∣∣∣‖f(x)‖ − ‖f(y)‖
∣∣∣ ≤ ‖f(x) − f(y)‖
≤ C‖f(x) − f(y)‖∞ ≤ C maxj=1,...,n
|Mi(fj) − mi(fj)|.
Hieraus folgt fur alle i = 1, . . . ,m
Mi(φ) − mi(φ) ≤ C maxj=1,...,n
(Mi(fj) − mi(fj))
und daher
OZ(φ) − UZ(φ) ≤ C maxj=1,...,n
(OZ(fj) − UZ(fj)),

16.4. RECHENREGELN 243
und aus der Integrierbarkeit aller fj folgt die Integrierbarkeit von φ.
Die Ungleichung (16.4) erhalt man aus Satz 16.9., da fur jede Zerlegung Z : {xi :
i = 0, . . . ,m} von [a, b] und jede Riemann Summe
‖( m∑
i=1fj(ξi)(xi − xi−1)
)
j=1,...,n‖ ≤
m∑
i=1
‖f(ξi)‖(xi − xi−1)
gilt.
Satz 16.21. (Mittelwertsatz der Integralrechnung)
Es sei f stetig aus [a, b], g integrierbar uber [a, b] und g(x) ≥ 0 fur alle x ∈ [a, b]
(oder g(x) ≤ 0 in [a, b]).
Dann existiert ein ξ ∈ (a, b) mit
b∫
a
f(x) g(x) dx = f(ξ)
b∫
a
g(x) dx.
Insbesondere gilt (mit g(x) ≡ 1)
b∫
a
f(x) dx = f(ξ) (b − a). (16.5)
Beweis: Nach Satz 16.7. und Satz 16.16. ist f · g integrierbar uber [a, b]. Sei m :=
min{f(x) : x ∈ [a, b]}, M := max{f(x) : x ∈ [a, b]}. Dann gilt wegen g(x) ≥ 0 in
[a, b]
m g(x) ≤ f(x) g(x) ≤ M g(x)
fur alle x ∈ [a, b], und aus Satz 16.16. folgt
m
b∫
a
g(x) dx ≤b∫
a
f(x) g(x) dx ≤ M
b∫
a
g(x) dx.
Es existiert also ein µ ∈ [m,M ] mit
b∫
a
f(x) g(x) dx = µ
b∫
a
g(x) dx,
und da f stetig ist, folgt aus dem Zwischenwertsatz, dass es ein ξ ∈ (a, b) gibt mit
f(ξ) = µ.
Geometrisch sagt (16.5), dass die Flache unterhalb des Graphen von f gleich der
Flache eines Rechtecks ist mit den Seitenlangen b − a und f(ξ) fur ein ξ ∈ (a, b).

Kapitel 17
Das unbestimmte Integral
17.1 Der Fundamentalsatz der
Infinitesimalrechnung
Wir haben in Kapitel 16 das Integral in Anlehnung an seine anschauliche Bedeutung
als Flacheninhalt definiert. Wir zeigen nun, dass die Integration die Umkehrung der
Differentiation ist. Hierdurch erhalten wir eine handliche Moglichkeit zur Berech-
nung von Integralen.
Ist f : [a, b] → IR integrierbar uber [a, b], so ist f auch uber [a, x] integrierbar fur
jedes x ∈ [a, b]. Daher ist durch
G(x) :=
x∫
a
f(t) dt (17.1)
eine Funktion G : [a, b] → IR definiert.
Andert man die untere Grenze, so erhalt man fur festes c ∈ [a, b]
H(x) :=
x∫
c
f(t) dt =
a∫
c
f(t) dt +
x∫
a
f(t) dt =: C + G(x).
Etwas allgemeiner definieren wir:
Definition 17.1. Eine Funktion F : [a, b] → IR heißt Stammfunktion von f ,
wenn es eine Konstante C ∈ IR gibt mit
F (x) = C +
x∫
a
f(t) dt fur alle x ∈ [a, b].

17.1. FUNDAMENTALSATZ DER INFINITESIMALRECHNUNG 245
Wird bei einer solchen Stammfunktion der Wert der Konstanten noch offen gelassen,
so spricht man von dem unbestimmten Integral von f und schreibt∫
f(x) dx.
Man beachte, dass das Symbol∫
f(x) dx eine ganze Familie von Funktionen be-
schreibt, dass also die Schlussweise: “Aus F (x) =∫
f(x) dx und G(x) =∫
f(x) dx
folgt F (x) = G(x)” im allgemeinen falsch ist und dass nur folgt, dass es eine Kon-
stante C ∈ IR gibt mit
F (x) = C + G(x).
Beispiel 17.2. Es sei f(x) = x3. Dann ist f integrierbar, und es gilt mit der
aquidistanten Zerlegung x(n)i := i x
n, i = 0, . . . , n, n ∈ IN von [0, x]
x∫
0
f(t) dt = limn→∞
n∑
i=1
(
ix
n
)3 · x
n= x4 lim
n→∞1
n4
n∑
i=1
i3
= x4 limn→∞
1
n4· 1
4n2 (n + 1)2 =
1
4x4.
Das unbestimmte Integral ist also∫
x3 dx =1
4x4 + C, C ∈ IR.
2
Ist eine Stammfunktion F von f bekannt, so kann man offenbar das bestimmte
Integral von f durch Auswerten von F an den Integralgrenzen berechnen. Es gilt
Satz 17.3. Sei f : [a, b] → IR integrierbar und F eine Stammfunktion von f auf
[a, b]. Dann giltb∫
a
f(x) dx = F (b) − F (a).
Wir schreiben hierfur auch
b∫
a
f(x) dx = F (b) − F (a) = : [F (x)]ba.
Wir fragen nun, wie man Stammfunktionen ermitteln kann. Im Beispiel 17.2. giltd
dx
(∫
x3 dx)
= x3, d.h. die Differentiation der Stammfunktion fuhrt zur Ausgangs-
funktion zuruck. Dies ist allgemein richtig:

246 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Satz 17.4. (Fundamentalsatz der Infinitesimalrechnung)
Es sei f : [a, b] → IR eine stetige Funktion. F : [a, b] → IR ist genau dann
Stammfunktion von f , wenn F stetig differenzierbar ist und F ′(x) = f(x) fur alle
x ∈ [a, b] gilt.
Beweis: Es sei F (x) :=
x∫
a
f(t) dt + C eine Stammfunktion von f . Dann gilt nach
dem Mittelwertsatz der Integralrechnung (Satz 16.21.) fur alle x, x + h ∈ [a, b]
F (x + h) − F (x)
h=
1
h
( x+h∫
a
f(t) dt −x∫
a
f(t) dt)
=1
h
x+h∫
x
f(t) dt = f(x + θ(x, h) h),
θ(x, h) ∈ (0, 1).
Fur h → 0 gilt x + θ(x, h) h → x, und die Stetigkeit von f liefert
limh→0
f(x + θ(x, h) h) = f(x).
Also ist F differenzierbar in x und F ′(x) = f(x).
Ist umgekehrt F ′(x) = f(x) eine stetige Funktion, so existiert das Integral G(x) :=x∫
a
F ′(t) dt. Nach dem ersten Teil ist G differenzierbar und G′(x) = F ′(x) fur alle
x ∈ (a, b), und daher gibt es eine Konstante C ∈ IR mit
F (x) = C + G(x) = C +
x∫
a
f(t) dt,
d.h. F ist Stammfunktion von f .
Eine große Anzahl von Stammfunktionen und Regeln zur Ermittlung von unbe-
stimmten Integralen erhalten wir, indem wir die Differentiation umkehren (vgl.
Satz 17.4.). Die Aufstellung in Tabelle 17.1 enthalt die unbestimmten Integrale ei-
niger elementarer Funktionen.
Fur jedes Polynom p(x) =n∑
j=0ajx
j gilt
∫
p(x) dx =n∑
j=0
1
j + 1aj xj+1 + C.
Diese Regel bleibt auch fur Potenzreihen im Inneren ihres Konvergenzintervalls rich-
tig:

17.1. FUNDAMENTALSATZ DER INFINITESIMALRECHNUNG 247
Tabelle 17.1: Einige unbestimmte Integrale von elementaren Funktionen
1.∫
xα dx =1
α + 1xα+1 + C, α 6= −1,
2.∫ 1
xdx = ln |x| + C,
3.∫
ex dx = ex + C,
4.∫
sin x dx = − cos x + C,∫
cos x dx = sin x + C,∫ 1
cos2 xdx = tan x + C,
5.∫
sinh x dx = cosh x + C,∫
cosh x dx = sinh x + C,
6.∫ 1√
1 − x2dx = arcsin x + C, |x| < 1,
∫ 1
1 + x2dx = arctan x + C,
7.∫ 1√
x2 + 1dx = Arsinh x + C,
∫ 1√x2 − 1
dx = Arcosh x + C, x > 1,∫ 1
1 − x2dx = Artanh x + C, |x| < 1.
Satz 17.5. Die Potenzreihe f(x) =∞∑
n=0anx
n habe den Konvergenzradius r > 0.
Dann gilt∫ ∞∑
n=0
anxn dx =
∞∑
n=0
1
n + 1an xn+1 + C =: F (x),
und die Potenzreihe F hat ebenfalls den Konvergenzradius r.
Beweis: Dass die Konvergenzradien der ursprunglichen und der gliedweise inte-
grierten Potenzreihe ubereinstimmen, folgt wie im Beweis von Satz 13.29. Ferner
sagt Satz 13.29., dass man die Potenzreihe F (x) in (−r, r) gliedweise differenzieren
darf.
Beispiel 17.6. Fur das Gaußsche Fehlerintegral
φ(x) :=2√π
x∫
0
e−t2 dt,
das in der Wahrscheinlichkeitstheorie und der Statistik eine große Rolle spielt, gilt

248 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
nach Satz 17.5.
φ(x) =2√π
x∫
0
e−t2 dt =2√π
∞∑
n=0
(−1)n x2n+1
(2n + 1) · n!.
2
17.2 Partielle Integration
Das Integrieren, d.h. das Bestimmen des unbestimmten Integrals einer gegebenen
Funktion, ist technisch wesentlich schwieriger als das Differenzieren, bei dem man
durch Anwendung fester Regeln (Kettenregel, Produktregel, Quotientenregel) im Be-
reich der elementaren Funktionen stets zum Ziel kommt. Beim Integrieren benotigt
man eine große Erfahrung (oder Gluck). Es gibt eine große Zahl von elementaren
Funktionen, die keine elementaren Stammfunktionen besitzen. Das Gaußsche Feh-
lerintegral aus Beispiel 17.6.,
φ(x) :=2√π
x∫
0
exp(−ξ2) dξ,
kann z.B. nicht geschlossen ausgewertet werden.
Kehrt man die Produktregel der Differentiation um so erhalt man
Satz 17.7. (Partielle Integration)
Es seien f , g : [a, b] → IR stetig differenzierbar. Dann gilt in [a, b]
∫
f ′(x) g(x) dx = f(x) g(x) −∫
f(x) g′(x) dx. (17.2)
Fur das bestimmte Integral erhalt man hieraus
b∫
a
f ′(x) g(x) dx = [f(x) g(x)]ba −b∫
a
f(x) g′(x) dx.
Beweis: Die Produktregel besagt
(
f(x) g(x))′
= f ′(x) g(x) + f(x) g′(x),
und durch Integration dieser Gleichung erhalt man (17.2).

17.2. PARTIELLE INTEGRATION 249
Beispiel 17.8.
∫
ln x dx =∫
1 · ln x dx = x · ln x −∫
x · 1
xdx = x · ln x − x + C.
2
Beispiel 17.9.
∫
arcsin x dx =∫
1 · arcsin x dx = x · arcsin x −∫ x√
1 − x2dx
= x · arcsin x +√
1 − x2 + C.
2
Beispiel 17.10.∫
sin(nx) · cos(mx) dx mit n,m ∈ IN.
Wir wahlen f ′(x) = sin(nx), d.h.
f(x) = − 1
ncos(nx), g(x) = cos(mx).
Dann gilt
∫
sin(nx) cos(mx) dx = − 1
ncos(nx) cos(mx) − m
n
∫
cos(nx) sin(mx) dx,
und durch erneute Anwendung von Satz 17.7. mit f ′(x) = cos(nx), g(x) = sin(mx)
erhalt man
∫
sin(nx) cos(mx) dx = − 1
ncos(nx) cos(mx) − m
n2sin(nx) sin(mx)
+m2
n2
∫
sin(nx) cos(mx) dx.
Man beachte, dass hieraus im Falle m = n = 1 nicht der Widerspruch
0 = − cos2 x − sin2 x = −1
folgt, da die unbestimmten Integrale links und rechts vom Gleichheitszeichen sich
um eine additive Konstante (hier 1) unterscheiden konnen.
Fur n 6= m erhalt man
∫
sin(nx) cos(mx) dx
=n2
n2 − m2
(
− 1
ncos(nx) cos(mx) − m
n2sin(nx) sin(mx)
)
+ C
=1
m2 − n2(n cos(nx) cos(mx) + m sin(nx) sin(mx)) + C

250 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
und wegen der 2π-Periodizitat der beteiligten Funktionen
2π∫
0
sin(nx) cos(mx) dx = 0. (17.3)
Fur n = m gilt
∫
sin(nx) cos(nx) dx =1
2
∫
sin(2nx) dx = − 1
4ncos(2nx) + C,
also gilt (17.3) fur alle m,n ∈ IN.
Ebenfalls durch partielle Integration erhalt man fur m 6= n
∫
sin(nx) sin(mx) dx =1
n2 − m2(−n cos(nx) sin(mx) + m sin(nx) cos(mx)) + C,
∫
cos(nx) cos(mx) dx =1
n2 − m2(n sin(nx) cos(mx) − m cos(nx) sin(mx)) + C,
d.h.2π∫
0
sin(nx) sin(mx) dx =
2π∫
0
cos(nx) cos(mx) dx = 0, (17.4)
und fur m = n mit f ′(x) = g(x) = sin(nx)
∫
sin2(nx) dx = − 1
ncos(nx) sin(nx) +
∫
cos2(nx) dx
= − 1
ncos(nx) sin(nx) +
∫
(1 − sin2(nx)) dx
= x − 1
ncos(nx) sin(nx) −
∫
sin2(nx) dx,
d.h.∫
sin2(nx) dx =x
2− 1
2ncos(nx) sin(nx) + C
und genauso∫
cos2(nx) dx =x
2+
1
2nsin(nx) cos(nx) + C.
Fur die bestimmten Integrale gilt also fur alle n ∈ IN
2π∫
0
sin2(nx) dx =
2π∫
0
cos2(nx) dx = π. (17.5)
Schließlich folgt aus∫
sin(nx) dx = − 1n
cos(nx) + C,∫
cos(nx) dx = 1n
sin(nx) + C
2π∫
0
sin(nx) dx =
2π∫
0
cos(nx) dx = 0. (17.6)
2

17.2. PARTIELLE INTEGRATION 251
Die Gleichungen (17.3), (17.4), (17.5) und (17.6) konnen wir zusammenfassen zu
Satz 17.11. Die Funktionen
φ0(x) :≡ 1√2, φ2n−1(x) := sin(nx), φ2n(x) := cos(nx), n ∈ IN,
bilden im Raum der 2π-periodischen Funktionen bezuglich des inneren Produktes
〈f, g〉 :=1
π
2π∫
0
f(x) g(x) dx
ein Orthonormalsystem, d.h.
〈φi, φj〉 = δij, i, j ∈ IN0.
Bemerkung 17.12. Wir wissen bereits, dass in einem endlich dimensionalen nor-
mierten Raum eine Menge genau dann kompakt ist, wenn sie abgeschlossen und
beschrankt ist. Ein Standardbeispiel hierfur ist die Einheitskugel {x : ‖x‖ = 1}.
Satz 17.11. zeigt, dass diese Aussage in unendlich dimensionalen Raumen nicht zu er-
warten ist. In dem Raum C2π der 2π-periodischen Funktionen mit dem in Satz 17.11.
gegebenen inneren Produkt gilt namlich fur alle n,m ∈ IN0, n 6= m,
‖φn − φm‖2 = 〈φn − φm, φn − φm〉 = 〈φn, φn〉 − 2〈φn, φm〉 + 〈φm, φm〉= ‖φn‖2 + ‖φm‖2 = 2,
und daher kann man sicher aus der Folge
{φn} ⊂ {f ∈ C2π : ‖f‖ = 1}
keine konvergente Teilfolge auswahlen. 2
Satz 17.13. Die Integrale
In(x) :=∫ dx
(1 + x2)n
erfullen die Rekursionsformel
In(x) =1
2(n − 1)
(x
(1 + x2)n−1+ (2n − 3) In−1(x)
)
, n ≥ 2, (17.7)
I1(x) = arctan x + C. (17.8)

252 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Beweis: (17.8) ist bereits bekannt. Fur n ≥ 2 erhalt man durch partielle Integra-
tion
In−1(x) =∫
1 · 1
(1 + x2)n−1dx =
x
(1 + x2)n−1−
∫
x ·(
1
(1 + x2)n−1
)′dx
=x
(1 + x2)n−1+ 2 (n − 1)
∫ x2
(1 + x2)ndx
=x
(1 + x2)n−1+ 2 (n − 1)
∫ (1
(1 + x2)n−1− 1
(1 + x2)n
)
dx
=x
(1 + x2)n−1+ 2 (n − 1) In−1(x) − 2 (n − 1) In(x),
und hieraus folgt (17.7).
Als weitere Anwendung der partiellen Integration beweisen wir noch einmal den Satz
von Taylor, wobei wir nun aber die Integraldarstellung des Restgliedes erhalten:
Satz 17.14. (Satz von Taylor)
Sei f : [a, b] → IR eine n+1-mal stetig differenzierbare Funktion und sei x0 ∈ [a, b].
Dann gilt
f(x) =n∑
j=0
f (j)(x0)
j!(x − x0)
j +1
n!
∫ x
x0
(x − t)n f (n+1)(t) dt. (17.9)
Beweis: Wir zeigen durch Induktion, dass die Formel (17.9) mit k an Stelle von
n fur k = 0, 1, . . . , n gilt.
Fur k = 0 besagt (17.9)
f(x) = f(x0) +∫ x
x0
f ′(t) dt,
und dies ist nach dem Fundamentalsatz (Satz 17.4.) richtig.
Ist (17.9) fur ein k ∈ {0, . . . , n − 1} richtig, so folgt durch partielle Integration
f(x) =k∑
j=0
f (j)(x0)
j!(x − x0)
j +1
k!
x∫
x0
(x − t)k f (k+1)(t) dt
=k∑
j=0
f (j)(x0)
j!(x − x0)
j
+1
k!
([
− 1
k + 1(x − t)k+1 f (k+1)(t)
]x
x0
+1
k + 1
x∫
x0
(x − t)k+1 f (k+2)(t) dt
)
=k+1∑
j=0
f (j)(x0)
j!(x − x0)
j +1
(k + 1)!
x∫
x0
(x − t)k+1 f (k+2)(t) dt,

17.3. SUBSTITUTIONSREGEL 253
d.h. (17.9) fur k + 1.
Da (x − t)n in [x0, x] bzw. [x, x0] das Vorzeichen nicht wechselt, folgt aus dem Mit-
telwertsatz Satz 16.21.x∫
x0
(x − t)n f (n+1)(t) dt = f (n+1)(ξ)
x∫
x0
(x − t)n dt
=1
n + 1(x − x0)
n+1 f (n+1)(ξ)
fur ein ξ zwischen x und x0. Die Lagrangesche Restgliedformel folgt aus der Inte-
gralformel fur das Restglied.
17.3 Substitutionsregel
Wir haben die partielle Integration als Umkehrung der Produktregel fur die Ablei-
tung hergeleitet. Ein entsprechendes Vorgehen fur die Kettenregel liefert Satz 17.15.
Satz 17.15. (Substitutionsregel)
Es sei f : I → IR eine stetige Funktion und φ : [a, b] → IR eine stetig differenzier-
bare Funktion mit φ([a, b]) ⊂ I. Dann gilt∫
f(φ(t)) · φ′(t) dt =∫
f(x) dx∣∣∣∣x=φ(t)
, (17.10)
und fur das bestimmte Integral
b∫
a
f(φ(t)) · φ′(t) dt =
φ(b)∫
φ(a)
f(x) dx. (17.11)
Beweis: Ist F : I → IR eine Stammfunktion von f , so gilt fur die Funktion
F ◦ φ : [a, b] → IR nach der Kettenregel
(F ◦ φ)′(t) = F ′(φ(t)) · φ′(t) = f(φ(t)) · φ′(t)
und durch Integration (mit x : = φ(t))∫
f(x) dx = F (x) = F (φ(t)) =∫
f(φ(t)) · φ′(t) dt
bzw. durch Integration von a bis b
b∫
a
f(φ(t)) · φ′(t) dt = [F ◦ φ]ba = F (φ(b)) − F (φ(a)) =
φ(b)∫
φ(a)
f(x) dx.

254 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Bemerkung 17.16. Mit der auf Leibniz zuruckgehenden Schreibweise
dx
dt= φ′(t)
erhalt Gleichung (17.10) die folgende Gestalt, die man sich besonders gut merken
kann:∫
f(x) dx =∫
f(φ(t))dx
dtdt, x = φ(t).
Formal (aber auch nur formal; die tatsachliche Begrundung liefert der Beweis von
Satz 17.15.) wird das Symbol dt aus der rechten Seite der Gleichung herausgekurzt
und x fur φ(t) eingesetzt. 2
Beispiel 17.17. Haufig haben Integranden die Gestaltφ′(t)
φ(t), d.h. mit f(x) =
1
xhat man die linke Seite der Gleichung (17.10). Daher gilt
∫ φ′(t)
φ(t)dt =
∫ 1
xdx = ln |x| + C = ln |φ(t)| + C.
Ein Beispiel dieses Typs ist
∫
tan t dt = −∫ − sin t
cos tdt = − ln | cos t| + C.
2
Beispiel 17.18. Fur Integranden des Typs φ(t) · φ′(t) erhalt man mit f(x) = x
analog∫
φ(t) · φ′(t) dt =∫
x dx =1
2x2 + C =
1
2(φ(t))2 + C.
2
Beispiel 17.19.
F = 2b
a
π/2∫
−π/2
√
a2 − a2 sin2 t · a · cos t dt = 2ab
π/2∫
−π/2
cos2 t dt
= 2ab[t
2+
1
2sin t cos t
]π/2
−π/2= abπ.
Insbesondere gilt fur die Flache des Kreises mit dem Radius r: F = πr2. 2

17.3. SUBSTITUTIONSREGEL 255
Die Flache der Ellipse
E = {(x, y) :x2
a2+
y2
b2= 1}
ist gegeben durch
F = 2b
a
a∫
−a
√a2 − x2 dx.
Mit der Substitution x = φ(t) := a sin t
gilt wegen φ′(t) = a cos t und ±a =
φ(
±π2
)
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−1.5
−1
−0.5
0
0.5
1
1.5
a
b
x
y
Abbildung 17.1
Fur den Fall, dass φ′(t) 6= 0 gilt, also die Funktion φ eine Inverse ψ := φ−1 besitzt,
geben wir der Gleichung (17.10) eine handlichere Gestalt. Es sei g(t) := f(φ(t));
t ∈ [a, b], d.h. f(x) = g(ψ(x)). Dann besagt (17.10)
∫
g(ψ(x)) dx =∫
f(x) dx =∫
f(φ(t)) · φ′(t) dt
=∫
g(t) · φ′(t) dt,
und wegen φ′(t) = 1 /ψ′(φ(t)) (vgl. Satz 13.35.) folgt
∫
g(ψ(x)) dx =∫
g(t) · 1
ψ′(φ(t))dt, t = ψ(x), (17.10’)
und fur das bestimmte Integral
β∫
α
g(ψ(x)) dx =
ψ(β)∫
ψ(α)
g(t)1
ψ′(φ(t))dt. (17.11’)
Beispiel 17.20.
I :=∫ x3
1 +√
x4 + 1dx.
Mit ψ(x) =√
x4 + 1 = t gilt ψ′(x) =2x3
√x4 + 1
= 2x3
t, und nach (17.10’)
∫ x3
1 +√
x4 + 1dx =
∫ x3
1 + t· t
2x3dt =
1
2
∫ t
1 + tdt
=1
2
(∫
dt −∫ 1
1 + tdt
)
=1
2(t − ln |1 + t|) + C
=1
2(√
x4 + 1 − ln |1 +√
x4 + 1|) + C.
2

256 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Beispiel 17.21.
I :=∫ dx
1 + cos x.
Mit ψ(x) := tan x2
= t gilt
ψ′(x) =1
2 cos2 x2
=1 + tan2 x
2
2=
1 + t2
2,
und wegen
cos x = cos2 x
2− sin2 x
2=
1 − tan2 x2
1 + tan2 x2
=1 − t2
1 + t2
folgt
I =∫ 1
1 + 1−t2
1+t2
· 2
1 + t2dt =
∫
dt = t + C = tanx
2+ C.
2
Beispiel 17.22.
I :=∫ 1√
x2 + bx + cdx.
Es ist x2 + bx + c = (x + b2)2 + c − b2
4=: (x + b
2)2 + γ.
Daher folgt mit ψ(x) := (x + b2)/
√
|γ| = t wegen ψ′(x) = 1/√
|γ|
I =∫
(
|γ| ·(( 1
√
|γ|(x +
b
2))2
+ sign γ))−1/2
dx
=1
√
|γ|
∫
(t2 + sign γ)−1/2√
|γ| dt =∫
(t2 + sign γ)−1/2 dt
=
Arsinh t + C = Arsinh
(
1√
c − b2/4
(
x +b
2
))
+ C, falls c >b2
4,
Arcosh t + C = Arcosh
(
1√
b2/4 − c
(
x +b
2
))
+ C, falls c <b2
4.
2
Als Anwendung der Substitutionsregel leiten wir in Satz 17.23. eine Formel fur
unbestimmte Integrale inverser Funktionen her.
Satz 17.23. Es sei f : [a, b] → IR differenzierbar mit f ′(x) 6= 0. Dann gilt
∫
f−1(y) dy = y f−1(y) −∫
f(x) dx, x = f−1(y).

17.4. PARTIALBRUCHZERLEGUNG 257
Beweis: Wegen (partielle Integration)
∫
x f ′(x) dx = x f(x) −∫
f(x) dx
gilt mit x = f−1(y)
∫
f−1(y) dy =∫
f−1(f(x)) f ′(x) dx∣∣∣∣x=f−1(y)
=∫
x f ′(x) dx∣∣∣∣x=f−1(y)
= x f(x) −∫
f(x) dx∣∣∣∣x=f−1(y)
= f−1(y) · y −∫
f(x) dx
∣∣∣∣x=f−1(y)
Beispiel 17.24.
∫
arcsin(y) dy = y · arcsin(y) −∫
sin x dx∣∣∣∣x=arcsin(y)
= y arcsin y + cos(arcsin y) + C
= y arcsin y +√
1 − y2 + C.
2
17.4 Partialbruchzerlegung
Wir betrachten nun die Integration rationaler Funktionen
R(x) =P (x)
q(x)
mit Polynomen P und q.
Ist der Grad von P nicht kleiner als der Grad von q, so kann man durch Polynom-
division erreichen, dass
R(x) = r(x) +p(x)
q(x),
wobei r, p, q Polynome sind und Grad(p) < Grad(q) gilt.
Beispiel 17.25.
R(x) =x5 − x4 − x2 + 5x − 1
x4 − x2 − 2x + 2.

258 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
(x5 − x4 − x3 + 5x − 1) : (x4 − x2 − 2x + 2) = x − 1
− (x5 − x3 − 2x2 + 2x
− x4 + 2x2 + 3x − 1
− (− x4 + x2 + 2x − 2)
x2 + x + 1
Daher gilt (p(x) = x2 + x + 1, r(x) = x − 1)
R(x) = x − 1 +x2 + x + 1
x4 − x2 − 2x + 2
2
Da das Integral des Polynoms r bekannt ist, mussen wir nur∫ p(x)
q(x)dx, Grad(p) <
Grad(q), untersuchen. Dazu schreiben wir den Quotientenp(x)
q(x)in einer Form, die
leicht integriert werden kann.
Es seien x1, . . . , xk ∈ IR die verschiedenen reellen Nullstellen von q, und es sei ρi
die Vielfachheit der Nullstelle xi, i = 1, . . . , k. Da q reelle Koeffizienten hat, ist mit
zi ∈ C \ IR auch zi eine Nullstelle von q und beide besitzen dieselbe Vielfachheit
(dies erkennt man, indem man q durch das quadratische Polynom (z − zi) (z −zi) mit reellen Koeffizienten dividiert). Es seien z1, . . . , zℓ, z1, . . . , zℓ ∈ C \ IR die
verschiedenen nicht reellen Nullstellen von q, und es sei σi die Vielfachheit von zi
und zi, i = 1, . . . , ℓ.
Mit diesen Bezeichnungen hat q die Darstellung
q(x) = γk∏
j=1
(x − xj)ρj ·
ℓ∏
i=1
(
(x − zi) (x − zi))σi
, γ ∈ IR \ {0},
wobei die quadratischen Polynome
(x − zi) (x − zi) = x2 − 2 Re (zi) x + |zi|2
= (x − Re zi)2 + (|zi|2 − (Re zi)
2) =: (x − αi)2 + β2
i
keine reellen Nullstellen besitzen.
Hiermit gilt

17.4. PARTIALBRUCHZERLEGUNG 259
Satz 17.26. Jede rationale Funktion φ(x) :=p(x)
q(x)mit Grad(p) < Grad(q) besitzt
eine eindeutige Darstellung
φ(x) =k∑
j=1
ρj∑
i=1
aij
(x − xj)i+
ℓ∑
j=1
σj∑
i=1
bij x + cij
((x − αj)2 + β2j )
i=: ψ(x), (17.12)
wobei xj, ρj, αj, βj, σj wie oben gewahlt sind und die Bestimmmung der aij, bij,
cij ∈ IR im Beweis dieses Satzes beschrieben wird.
Die Zerlegung (17.12) heißt Partialbruchzerlegung.
Beweis: Wir multiplizieren den Ansatz ψ(x) =p(x)
q(x)mit q(x) und erhalten die
Polynomgleichung ψ(x) · q(x) = p(x), die aus Stetigkeitsgrunden in ganz C gilt:
p(x) = γk∑
j=1
ρj∑
i=1
aij (x − xj)ρj−i
k∏
n=1n 6=j
(x − xn)ρn
ℓ∏
m=1
(
(x − αm)2 + β2m
)σm
+ q(x)ℓ∑
j=1
σj∑
i=1
bij x + cij(
(x − αj)2 + β2j
)i . (17.13)
Setzt man hier x = xµ, µ ∈ {1, . . . , k} ein, so folgt
p(xµ) = γ aρµµ
k∏
n=1n 6=µ
(xµ − xn)ρn
ℓ∏
m=1
(
(xµ − αm)2 + β2m
)σm
,
und man erhalt auf eindeutige Weise aρµµ.
Differenziert man die Gleichung (17.13) (ρµ − 1)-mal und setzt jeweils xµ ein, so
erhalt man genauso nacheinander aρµ−1,µ, . . . , a1µ, µ = 1, . . . , k.
Setzt man fur ν = 1, . . . , ℓ in (17.13) (und die Ableitungen bis zur (σν − 1)-ten
Ordnung) x = zν und x = zν ein, so erhalt man analog dem obigen Vorgehen in jedem
Fall ein lineares Gleichungssystem (mit komplexen Koeffizienten) zur eindeutigen
Bestimmung von (bσνν , cσνν), . . . , (b1ν , c1ν).
Beispiel 17.27. (Fortsetzung von Beispiel 17.25.)
φ(x) =p(x)
q(x)=
x2 + x + 1
x4 − x2 − 2x + 2.
Es gilt q(x) = (x−1)2 (x+1−i) (x+1+i) = (x−1)2 ((x+1)2+1). Das Nennerpolynom
q hat also die doppelte, reelle Nullstelle x1 = 1 und die beiden einfachen, nicht reellen
Nullstellen z1 = −1 + i und z1 = −1 − i.

260 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Aus dem Ansatz
ψ(x) =a1
x − 1+
a2
(x − 1)2+
bx + c
x2 + 2x + 2=
p(x)
q(x)
erhalt man durch Multiplikation mit q
(
a1 (x − 1) + a2
) (
x2 + 2x + 2)
+ (bx + c) (x − 1)2 = x2 + x + 1 = p(x).
Hieraus folgt
p(1) = 3 = a2 (x2 + 2x + 2)|x=1 = 5a2, d.h. a2 = 35,
p′(1) = 3 = a1 (x2 + 2x + 2) + a2 (2x + 2)|x=1 = 5a1 + 4a2, d.h. a1 = 325
,
p(z1) = (b z1 + c) (z1 − 1)2,
p(z1) = (b z1 + c) (z1 − 1)2,
mit der Losung b = − 3
25, c = 1
25. 2
Die komplexe Arithmetik kann vermieden werden, wenn man in (17.13) die linke
Seite ausmultipliziert und einen Koeffizientenvergleich durchfuhrt, oder wenn man
in die Gleichung (17.13)k∑
j=1
ρj + 2ℓ∑
j=1
σj =: κ
verschiedene reelle Werte einsetzt. In beiden Fallen erhalt man ein (eindeutig losba-
res) lineares Gleichungssystem von κ Gleichungen in κ Unbekannten.
In Beispiel 17.27. ist die Gleichung ψ(x) · q(x) = p(x) aquivalent
(a1 + b) x3 + (a1 + a2 − 2b + c) x2 + (2a2 + b − 2c) x − 2a1 + 2a2 + c = x2 + x + 1,
und der Koeffizientenvergleich liefert das lineare Gleichungssystem
a1 + b = 0,
a1 + a2 − 2b + c = 1,
2a2 + b − 2c = 1,
−2a1 + 2a2 + c = 1,
mit der bereits angegebenen Losung.
Setzt man in ψ(x) · q(x) = p(x) die Werte x = 0, x = 1, x = 2 und x = 3 ein, so
erhalt man das lineare Gleichungssystem
−2a1 + 2a2 + c = 1,
5a2 = 3,
10a1 + 10a2 + 2b + c = 7,
34a1 + 17a2 + 12b + 4c = 13,

17.4. PARTIALBRUCHZERLEGUNG 261
mit der bereits angegebenen Losung.
Hat man die Partialbruchzerlegung der rationalen Funktion φ(x) =p(x)
q(x)gefunden
(dies ist keine Kleinigkeit, denn man hat alle Nullstellen von q zu bestimmen),
so kann man φ integrieren, wenn man nur die folgenden beiden Grundtypen von
Integralen berechnen kann:∫ dx
(x − α)k, k ≥ 1,
∫ γx + δ(
(x − α)2 + β2)k dx, k ≥ 1, β 6= 0.
Der erste Typ ist bereits bekannt:
∫ dx
(x − α)k=
ln |x − α| + C fur k = 1,1
1−k(x − α)1−k + C fur k > 1.
Fur den zweiten Typ gilt
∫ γx + δ(
(x − α)2 + β2)k dx =
γ
2
∫ 2 (x − α)(
(x − α)2 + β2)k dx + (δ + αγ)
∫ dx(
(x − α)2 + β2)k .
Mit der Substitution ψ(x) := (x − α)2 + β2 =: t gilt
∫ 2 (x − α)(
(x − α)2 + β2)k dx =
∫ 1
tkdt =
ln((x − α)2 + β2) + C fur k = 1,
− 1k−1
(
(x − α)2 + β2)1−k
+ C fur k > 1.
Schließlich erhalt man mit der Substitution ψ(x) = 1β
(x − α) =: t
∫ dx(
(x − α)2 + β2)k =
∫ β dt
(β2 t2 + β2)k= β1−2k
∫ dt
(1 + t2)k=: β1−2k Ik(x),
und fur die Integrale Ik wurde in Satz 17.13. eine Rekursionsformel bereitgestellt.
Fur Beispiel 17.25. auf Seite 257 erhalt man insgesamt
∫ x5 − x4 − x3 + 5x − 1
x4 − x2 − 2x + 2dx =
∫ (
x − 1 +x2 + x + 1
x4 − x2 − 2x + 2
)
dx
=∫
(x − 1) dx +3
25
∫ dx
x − 1+
3
5
∫ dx
(x − 1)2+
1
25
∫ −3x + 1
(x + 1)2 + 1dx
=1
2x2 − x +
3
25ln |x − 1| − 3
5
1
x − 1
+1
25
(
−3
2
∫ 2 (x + 1)
(x + 1)2 + 1dx + 4
∫ dx
(x + 1)2 + 1
)
=1
2x2 − x +
3
25ln |x − 1| − 3
5
1
x − 1
− 3
50ln(x2 + 2x + 2) +
4
25arctan(x + 1) + C.

262 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
17.5 Vertauschen von Grenzwerten
Wir haben bereits gesehen, dass man Potenzreihen in ihrem Konvergenzintervall
gliedweise differenzieren und integrieren kann, dass man also den Grenzprozess der
Summation einer Reihe mit dem Grenzprozess bei der Integration und der Diffe-
rentiation miteinander vertauschen kann. Wir zeigen nun, dass dies bereits aus der
gleichmaßigen Konvergenz der Potenzreihen folgt. Allgemeiner gilt
Satz 17.28. Ist jede der Funktionen fn : [a, b] → IR, n ∈ IN, integrierbar uber
[a, b] und konvergiert die Folge {fn} gleichmaßig auf [a, b] gegen die Funktion f , so
ist f integrierbar uber [a, b], und es gilt
b∫
a
f(x) dx =
b∫
a
limn→∞ fn(x) dx = lim
n→∞
b∫
a
fn(x) dx.
Beweis: Wir wenden das Riemannsche Integrabilitatskriterium an, um die Inte-
grierbarkeit von f nachzuweisen. Sei ε > 0 gegeben. Da die Folge {fn} gleichmaßig
gegen f konvergiert, gibt es ein N ∈ IN mit
|fn(x) − f(x)| <ε
3(b − a)fur alle n ≥ N und alle x ∈ [a, b].
Hieraus folgt schon die Beschranktheit von f , denn fN ist als integrierbare Funktion
beschrankt, und daher gilt fur alle x ∈ [a, b]
|f(x)| ≤ |fN(x)| + |f(x) − fN(x)| ≤ supa≤x≤b
|fN(x)| + ε.
Ferner gibt es nach dem Riemannschen Integrabilitatskriterium eine Zerlegung
Z : a = x0 < x1 < . . . < xm = b von [a, b]
mit
OZ(fN) − UZ(fN) <ε
3.
Es seien
mj := inf{f(x) : xj−1 ≤ x ≤ xj}, µj := inf{fN(x) : xj−1 ≤ x ≤ xj}.
Dann gilt
µj − mj ≤ε
3(b − a).

17.5. VERTAUSCHEN VON GRENZWERTEN 263
Es folgt
UZ(fN) − UZ(f) =m∑
j=1
µj(xj − xj−1) −m∑
j=1
mj(xj − xj−1)
=m∑
j=1
(µj − mj)(xj − xj−1) ≤ε
3(b − a)
m∑
j=1
(xj − xj−1) =ε
3,
und daher gilt
UZ(fn) ≤ UZ(f) +ε
3.
Auf ahnliche Weise erhalt man fur die Obersummen
OZ(f) ≤ OZ(fN) +ε
3,
und damit folgt
OZ(f)−UZ(f) = (OZ(f)−OZ(fN)) + (OZ(fN)−UZ(fN)) + (UZ(fN)−UZ(f)) < ε,
und aus Satz 16.7. folgt die Integrierbarkeit von f .
Dass die Integration mit der Grenzwertbildung vertauscht werden kann, sieht man
so:
∣∣∣
b∫
a
f(x) dx −b∫
a
fN(x) dx∣∣∣ ≤
b∫
a
|f(x) − fN(x)| dx <ε
3(b − a)(b − a) =
ε
3.
Beispiel 17.29. Auf die Gleichmaßigkeit der Konvergenz kann man in Satz 17.28.
nicht verzichten. Die Funktionenfolge fn : [0, 1] → IR,
fn(x) :=
n3x , 0 ≤ x ≤ 1n
2n2 − n3x , 1n≤ x ≤ 2
n
0 , 2n≤ x ≤ 1
konvergiert punktweise gegen die Nullfunktion (aber nicht gleichmaßig), und es gilt
1∫
0
fn(x) dx = 2
1/n∫
0
n3x dx = n 6→ 0.
2
Wendet man Satz 17.28. auf die Folge der Partialsummen an, so erhalt man so-
fort den folgenden Satz uber die gliedweise Integrierbarkeit von Reihen, in dem als
Spezialfall Satz 17.5. uber die gliedweise Integration von Potenzreihen enthalten ist.

264 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Korollar 17.30. Sind die fn : [a, b] → IR integrierbar uber [a, b] und konvergiert
die Reihe
f(x) :=∞∑
n=0
fn(x)
gleichmaßig auf [a, b], so ist f integrierbar uber [a, b], und es gilt
b∫
a
∞∑
n=0
fn(x) dx =∞∑
n=0
b∫
a
fn(x) dx.
Wir sind nun auch in der Lage, die Vertauschbarkeit der Differentiation mit der
Grenzwertbildung zu untersuchen.
Satz 17.31. Es sei fn : [a, b] → IR eine Folge auf [a, b] stetig differenzierbarer
Funktionen. Konvergiert die Folge {f ′n} gleichmaßig auf [a, b] und existiert ein x0 ∈
[a, b], so dass die Folge {fn(x0)} konvergiert, so konvergiert die Funktionenfolge {fn}gleichmaßig auf dem Intervall [a, b] gegen eine stetig differenzierbare Funktion f , und
es gilt
limn→∞
f ′n(x) = f ′(x) fur alle x ∈ (a, b).
Beweis: Wir zeigen, dass {fn} eine Cauchy Folge ist.
Es sei ε > 0 gegeben. Da die Folge {f ′n} gleichmaßig auf [a, b] konvergiert, gibt es
ein N ∈ IN, so dass
|f ′n(x) − f ′
m(x)| <ε
2(b − a)fur alle x ∈ [a, b] und alle m,n ≥ N
gilt. Ferner folgt aus der Konvergenz der Folge {fn(x0)}, dass
|fn(x0) − fm(x0)| <ε
2fur alle m,n ≥ N
gilt, wobei moglicherweise N vergroßert werden mußte.
Nach dem Fundamentalsatz der Infinitesimalrechnung gilt
fn(x) = fn(x0) +
x∫
x0
f ′n(t) dt.
Hieraus folgt
fn(x) − fm(x) = fn(x0) − fm(x0) +
x∫
x0
(f ′n(t) − f ′
m(t)) dt,

17.5. VERTAUSCHEN VON GRENZWERTEN 265
und daher erhalt man fur alle x ∈ [a, b] und alle n,m ≥ N
|fn(x) − fm(x)| ≤ |x∫
x0
(f ′n(t) − f ′
m(t)) dt| + |fn(x0) − fm(x0)|
<ε
2(b − a)(b − a) +
ε
2= ε.
Daher ist die Folge {fn(x)} fur jedes x ∈ [a, b] eine Cauchy Folge. Sie konvergiert also
gegen ein f(x) ∈ IR, und da N in den vorhergehenden Uberlegungen unabhangig
von x gewahlt werden konnte, ist die Konvergenz gleichmaßig in [a, b].
Die Vertauschbarkeit der Differentiation mit der Grenzwertbildung folgt nun so: Es
sei
g(x) := limn→∞ f ′
n(x).
Nach dem Fundamentalsatz der Infinitesimalrechnung gilt
fn(x) − fn(a) =
x∫
a
f ′n(t) dt.
Da {f ′n} gleichmaßig gegen g konvergiert, folgt aus Satz 17.28.
f(x) − f(a) =
x∫
a
g(t) dt.
Da g als gleichmaßiger Grenzwert stetiger Funktionen stetig ist, ist f stetig diffe-
renzierbar in (a, b), und es gilt
f ′(x) = g(x) = limn→∞ f ′
n(x).
Als Folgerung erhalt man wieder das folgende Resultat uber die gliedweise Differen-
zierbarkeit von Reihen, das als Spezialfall Satz 13.29. uber die Differentiation von
Potenzreihen enthalt:
Korollar 17.32. Es seien fn : [a, b] → IR stetig differenzierbar, es konvergiere fur
ein x0 ∈ [a, b] die Reihe∞∑
n=0
fn(x0),
und es konvergiere die Reihe
∞∑
n=0
f ′n(x) gleichmaßig in [a, b].

266 KAPITEL 17. DAS UNBESTIMMTE INTEGRAL
Dann konvergiert fur alle x ∈ [a, b] die Reihe
f(x) :=∞∑
n=0
fn(x),
die Funktion f ist stetig differenzierbar in (a, b), und es gilt
f ′(x) =d
dx
∞∑
n=0
fn(x) =∞∑
n=0
f ′n(x).
Beispiel 17.33. Die Funktion
f(x) :=∞∑
n=1
1
nsin
x
n, 0 ≤ x ≤ 1,
ist stetig in [0, 1] und stetig differenzierbar in (0, 1), denn die gliedweise differenzierte
Reihe
−∞∑
n=1
1
n2cos
x
n
konvergiert gleichmaßig auf [0, 1] und f(0) konvergiert offensichtlich. 2
Beispiel 17.34. Eine gleichmaßig konvergente Reihe von differenzierbaren Funk-
tionen ist i.a. nicht differenzierbar, denn
f(x) :=∞∑
n=1
1
n2sin nx
konvergiert nach dem Majorantenkriterium in IR. f ist nicht gliedweise differenzier-
bar, denn∞∑
n=1
1
ncos nx
konvergiert nicht. Fur x = 0 erhalt man z.B. die harmonische Reihe. 2

Kapitel 18
Uneigentliche Integrale
Wir haben bisher vorausgesetzt, dass das Integrationsintervall endlich ist, und dass
der Integrand beschrankt ist. In diesem Kapitel 18 wollen wir den Integralbegriff auf
unendliche Integrationsintervalle und/oder unbeschrankte Funktionen erweitern.
Definition 18.1. Es sei I ⊂ IR ein (nicht notwendig beschranktes, nicht notwendig
abgeschlossenes) Intervall und f : I → IR. f heißt lokal integrierbar in I, wenn
f uber jedes abgeschlossene Teilintervall [a, b] von I integrierbar ist.
Beispiel 18.2. f(x) = xλ, λ ∈ IR, ist lokal integrierbar in (0,∞), da f in [a, b]
stetig ist fur jedes [a, b] ⊂ (0,∞). Fur λ < 0 ist f nicht integrierbar uber [0, 1], da
f unbeschrankt auf [0, 1] ist. 2
18.1 Unbeschrankte Integrationsintervalle
Wir betrachten zunachst unbeschrankte Integrationsintervalle.
Definition 18.3. Es sei f : [a,∞) → IR lokal integrierbar. Existiert der Grenz-
wert limα→∞
α∫
a
f(x) dx, so heißt f uneigentlich integrierbar uber [a,∞) und
∞∫
a
f(x) dx := limα→∞
α∫
a
f(x) dx (18.1)
heißt das uneigentliche Integral von f uber [a,∞).

268 KAPITEL 18. UNEIGENTLICHE INTEGRALE
Man sagt auch (in Analogie zur Terminologie bei den Reihen), dass das uneigentliche
Integral
∞∫
a
f(x) dx konvergiert.
Entsprechend definiert man das uneigentliche Integral der lokal integrierbaren Funk-
tion f : (−∞, b] → IR durch
b∫
−∞f(x) dx = lim
β→−∞
b∫
β
f(x) dx,
falls dieser Grenzwert existiert.
Die lokal integrierbare Funktion f : IR → IR heißt uneigentlich integrierbar uber IR,
wenn fur ein c ∈ IR die uneigentlichen Integrale
c∫
−∞f(x) dx und
∞∫
c
f(x) dx existieren.
In diesem Fall setzt man∞∫
−∞f(x) dx :=
c∫
−∞f(x) dx +
∞∫
c
f(x) dx. (18.2)
Bemerkung 18.4. Die Definition in (18.2) ist unabhangig von der Wahl von c.
Existieren
∞∫
c
f(x) dx und
c∫
−∞f(x) dx, so existieren offenbar auch
∞∫
d
f(x) dx und
d∫
−∞f(x) dx fur alle d ∈ IR, und es gilt
c∫
−∞f(x) dx +
∞∫
c
f(x) dx =
d∫
−∞f(x) dx +
∞∫
d
f(x) dx.
2
Bemerkung 18.5. In (18.2) mussen die beiden Grenzwerte auf der rechten Sei-
te getrennt gebildet werden. Es genugt nicht, die Existenz von limα→∞
α∫
−α
f(x) dx zu
untersuchen. Betrachtet man z.B. die Funktion f(x) = x, so gilt
limα→∞
α∫
0
f(x) dx = limα→∞
1
2α2 = ∞,
das uneigentliche Integral
∞∫
−∞f(x) dx existiert also nicht. Es gilt jedoch
limα→∞
α∫
−α
f(x) dx = limα→∞
[1
2x2
]α
−α= 0.
2

18.1. UNBESCHRANKTE INTEGRATIONSINTERVALLE 269
Beispiel 18.6. Es sei λ ∈ IR und f(x) = xλ, x ≥ 1. Dann ist f stetig auf [1,∞),
also lokal integrierbar, und es gilt
α∫
1
xλ dx =
[ 1λ+1
xλ+1]α1 = 1λ+1
(αλ+1 − 1), falls λ 6= −1,
[ln x]α1 = ln α, falls λ = −1.
Daher existiert
∞∫
1
xλ dx genau dann, wenn λ < −1, und es gilt in diesem Fall
∞∫
1
xλ dx = − 1
λ + 1. 2
Beispiel 18.7. f(x) = |x| e−x2ist als stetige Funktion lokal integrierbar in IR. Es
giltα∫
0
f(x) dx =
α∫
0
x e−x2
dx = [−1
2e−x2
]α0 = −1
2e−α2
+1
2
und genauso
0∫
β
f(x) dx = −0∫
β
x e−x2
dx = [1
2e−x2
]0β =1
2− 1
2e−β2
.
Daher existiert∞∫
−∞|x| e−x2
dx = 1. 2
Die folgenden Resultate konnen sofort auf Integrale uber das Intervall (−∞, b] und
dann auf Integrale uber IR ubertragen werden. Wir formulieren sie nur fur den Fall
[α,∞).
Ahnlich wie fur Reihen gilt
Satz 18.8. (Cauchy Kriterium)
Es sei f : [a,∞) → IR lokal integrierbar. Das uneigentliche Integral
∞∫
a
f(x) dx
existiert genau dann, wenn fur alle ε > 0 ein c ∈ [a,∞) existiert, so dass gilt
∣∣∣∣
η∫
ξ
f(x) dx
∣∣∣∣ < ε fur alle ξ, η ≥ c. (18.3)
Beweis: Es gelte (18.3), und es sei F (α) :=
α∫
a
f(x) dx. Fur jede Folge {αn},
αn → ∞, ist dann {F (αn)} eine Cauchy Folge, also konvergent. Der Grenzwert

270 KAPITEL 18. UNEIGENTLICHE INTEGRALE
ist unabhangig von der gewahlten Folge {αn}, den wenn zwei Folgen {αn}, {βn} mit
αn → ∞, βn → ∞ und limn→∞F (αn) 6= lim
n→∞F (βn) existieren, so konvergiert fur die
Folge {γn}, γ2n := αn, γ2n+1 := βn, die Folge {F (γn)} nicht. Also ist f uneigentlich
integrierbar uber [a,∞).
Existiert umgekehrt
∞∫
a
f(x) dx =: I, so gibt es zu jedem ε > 0 ein c ≥ a mit
|F (α) − I| < ε2
fur alle α ≥ c. Fur ξ, η ≥ c gilt daher
∣∣∣
η∫
ξ
f(x) dx∣∣∣ = |F (η) − F (ξ)| ≤ |F (η) − I| + |I − F (ξ)| < ε.
Beispiel 18.9.
∞∫
0
sin x
xdx existiert, denn
sin x
xist stetig fortsetzbar auf [0,∞),
also lokal integrierbar, und
∣∣∣∣
η∫
ξ
sin x
xdx
∣∣∣∣ =
∣∣∣∣
[
−cos x
x
]η
ξ−
η∫
ξ
cos x
x2dx
∣∣∣∣
=∣∣∣∣
cos ξ
ξ− cos η
η−
η∫
ξ
cos x
x2dx
∣∣∣∣
≤ | cos ξ|ξ
+| cos η|
η+
η∫
ξ
| cos x|x2
dx
≤ 1
ξ+
1
η+
η∫
ξ
dx
x2=
2
ξ< ε, falls η, ξ > 2
ε.
2
Bemerkung 18.10. Die Funktion
Si(x) :=
x∫
0
sin t
tdt,
der Integralsinus, wird in der Nachrichtentechnik benotigt, um die Sprungantwort
des idealen Tiefpassfilters zu beschreiben (vgl. Sauer [17, Seite 275]). Der Endwert
Si(∞), das Dirichletsche Integral , wird benotigt, um die Einschwingzeit des
idealen Tiefpassfilters zu bestimmen. 2
Bemerkung 18.11. Wie im Beweis von Satz 18.8. treten bei der Untersuchung
uneigentlicher Integrale sehr ahnliche Techniken auf wie bei den Reihen, und es
gelten sehr ahnliche Aussagen. Das folgende Beispiel 18.12. zeigt die Grenzen der
Analogie. 2

18.1. UNBESCHRANKTE INTEGRATIONSINTERVALLE 271
Beispiel 18.12. Aus der Existenz von
∞∫
a
f(x) dx folgt nicht limx→∞ f(x) = 0, denn
fur f(x) = sin(x2) gilt mit der Variablentransformation t = x2 (ahnlich wie oben)
∣∣∣
η∫
ξ
sin(x2) dx∣∣∣ =
1
2
∣∣∣
η2∫
ξ2
sin t√t
dt∣∣∣
=1
2
∣∣∣[−cos t√
t]η
2
ξ2 −1
2
η2∫
ξ2
cos t
t3/2dt
∣∣∣∣ <
1
2(1
ξ+
1
η+
1
ξ− 1
η) ≤ 1
ξ,
d.h.
∞∫
0
sin(x2) dx existiert, aber sin(x2) konvergiert nicht gegen 0 fur x gegen ∞. 2
Dagegen gilt nach Satz 18.8. fur jedes feste h > 0
limα→∞
α+h∫
α
f(x) dx = 0,
und dies entspricht der Aussage limn→∞ an = 0 fur jede konvergente Reihe
∞∑
n=0an.
Der folgende Satz 18.13. entspricht Satz 10.97.(i) fur Reihen und ist unmittelbar
klar:
Satz 18.13. (Monotoniekriterium)
Es sei f : [a,∞) → IR lokal integrierbar und nicht negativ. Das uneigentliche
Integral
∞∫
a
f(x) dx existiert, wenn es eine Konstante K gibt mit
F (α) :=
α∫
a
f(x) dx ≤ K fur alle α > a.
Definition 18.14. Das uneigentliche Integral
∞∫
a
f(x) dx heißt absolut konver-
gent, wenn
∞∫
a
|f(x)| dx existiert.
Der Beweis des nun folgenden Satzes 18.15. verlauft vollig analog dem der entspre-
chenden Aussagen fur Reihen und wird daher fortgelassen.

272 KAPITEL 18. UNEIGENTLICHE INTEGRALE
Satz 18.15. Es seien f , g : [a,∞) → IR lokal integrierbar. Dann gilt
(i) Existiert
∞∫
a
|f(x)| dx, so ist f uneigentlich integrierbar, und es gilt
∣∣∣
∞∫
a
f(x) dx∣∣∣ ≤
∞∫
a
|f(x)| dx.
(ii) (Majorantenkriterium)
Existiert
∞∫
a
g(x) dx und gilt |f(x)| ≤ g(x) fur x ∈ [a,∞), so konvergiert
∞∫
a
f(x) dx absolut.
(iii) (Minorantenkriterium)
Divergiert
∞∫
a
g(x) dx und gilt 0 ≤ g(x) ≤ f(x) fur x ∈ [a,∞), so ist f nicht
uneigentlich integrierbar.
Beispiel 18.16.
∞∫
0
sin x
xdx existiert, aber ist nicht absolut konvergent, denn aus
∞∫
0
∣∣∣sin x
x
∣∣∣ dx < ∞ folgt
∞∫
0
∣∣∣sin x
x
∣∣∣ dx =
∞∑
n=1
n π∫
(n−1) π
∣∣∣sin x
x
∣∣∣ dx ≥
∞∑
n=1
1
nπ
n π∫
(n−1) π
| sin x| dx
=1
π
π∫
0
sin x dx∞∑
n=1
1
n
im Widerspruch zur Divergenz der harmonischen Reihe. 2
Beispiel 18.17. Das Exponentialintegral
Ei(x) :=
x∫
−∞
et
tdt
ist fur alle x < 0 absolut konvergent, denn wegen limt→−∞
t et = 0 existiert zu x < 0
ein M > 0 mit |t et| ≤ M fur alle t ∈ (−∞, x]. Daher gilt fur diese t∣∣∣∣
et
t
∣∣∣∣ =
∣∣∣∣
t et
t2
∣∣∣∣ ≤
M
t2,
und aus der Konvergenz von
x∫
−∞
1
t2dt und dem Majorantenkriterium folgt die Be-
hauptung. 2
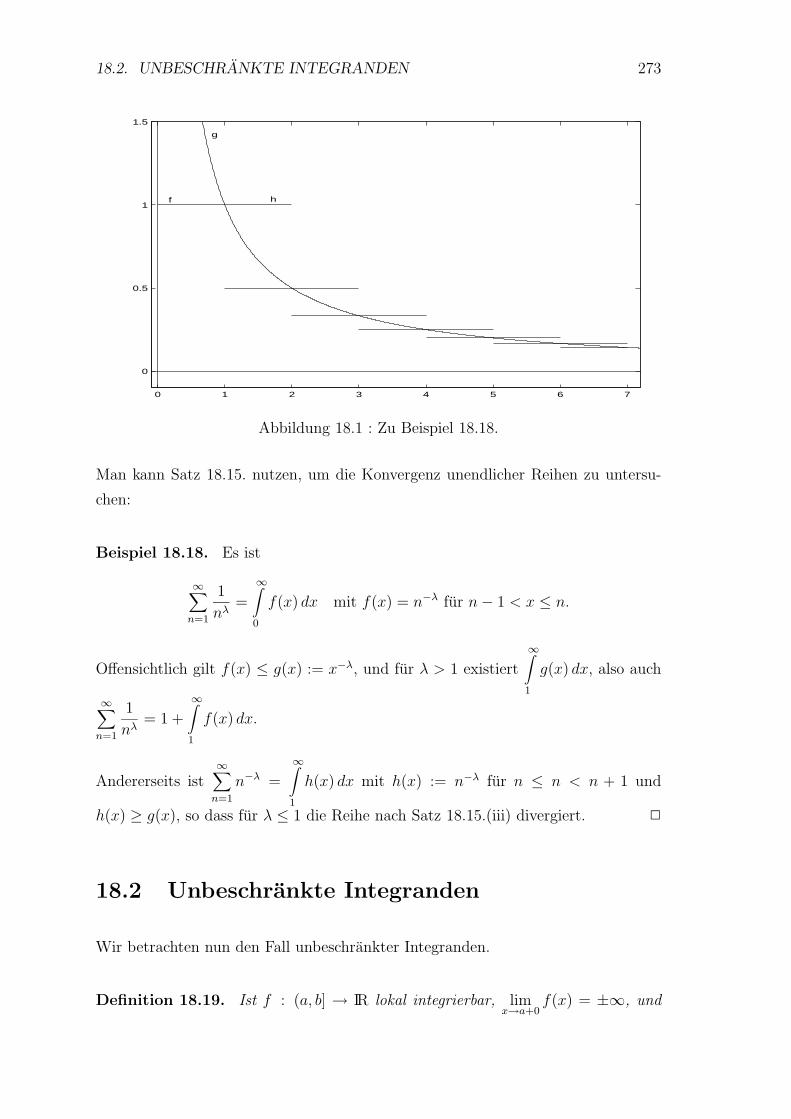
18.2. UNBESCHRANKTE INTEGRANDEN 273
0 1 2 3 4 5 6 7
0
0.5
1
1.5
f h
g
Abbildung 18.1 : Zu Beispiel 18.18.
Man kann Satz 18.15. nutzen, um die Konvergenz unendlicher Reihen zu untersu-
chen:
Beispiel 18.18. Es ist
∞∑
n=1
1
nλ=
∞∫
0
f(x) dx mit f(x) = n−λ fur n − 1 < x ≤ n.
Offensichtlich gilt f(x) ≤ g(x) := x−λ, und fur λ > 1 existiert
∞∫
1
g(x) dx, also auch
∞∑
n=1
1
nλ= 1 +
∞∫
1
f(x) dx.
Andererseits ist∞∑
n=1
n−λ =
∞∫
1
h(x) dx mit h(x) := n−λ fur n ≤ n < n + 1 und
h(x) ≥ g(x), so dass fur λ ≤ 1 die Reihe nach Satz 18.15.(iii) divergiert. 2
18.2 Unbeschrankte Integranden
Wir betrachten nun den Fall unbeschrankter Integranden.
Definition 18.19. Ist f : (a, b] → IR lokal integrierbar, limx→a+0
f(x) = ±∞, und

274 KAPITEL 18. UNEIGENTLICHE INTEGRALE
existiert limα→a+0
b∫
αf(x) dx, so heißt f uneigentlich integrierbar uber (a, b] und
b∫
a
f(x) dx := limα→a+0
b∫
α
f(x) dx
heißt das uneigentliche Integral von f uber (a, b].
Analog definiert man das uneigentliche Integral einer lokal integrierbaren Funktion
f : [a, b) → IR mit limx→b−0
f(x) = ±∞ uber [a, b) durch
b∫
a
f(x) dx := limβ→b−0
β∫
a
f(x) dx.
Ist f : (a, b) → IR an beiden Intervallenden a und b unbeschrankt, so heißt f unei-
gentlich integrierbar uber (a, b), wenn fur ein c ∈ (a, b) die uneigentlichen Integralec∫
a
f(x) dx und
b∫
c
f(x) dx existierten. Man setzt dann
b∫
a
f(x) dx := limα→a+0
c∫
α
f(x) dx + limβ→b−0
β∫
c
f(x) dx.
Schließlich kann man aus den beiden betrachteten Begriffen des uneigentlichen Inte-
grals auf offensichtliche Weise das uneigentliche Integral einer unbeschrankten Funk-
tion uber einen unbeschrankten Bereich erklaren (vgl. Definition der Gammafunk-
tion im nachfolgenden Beispiel 18.22.).
Wie im Fall des unbeschrankten Integrationsintervalls gilt fur uneigentliche Inte-
grale einer unbeschrankten Funktion das Cauchysche Kriterium, das Monotonie-,
Majoranten- und Minorantenkriterium. Da die Ubertragungen offensichtlich sind,
verzichten wir auf ihre Formulierungen.
Beispiel 18.20. Sei f(x) := xλ, x ∈ (0, 1]. Dann gilt
1∫
α
xλ dx =
[ 1λ+1
xλ+1]1α = 1λ+1
(1 − αλ+1) fur λ 6= −1,
[ln x]1α = − ln α fur λ = −1,
daher existiert das (uneigentliche) Integral genau fur λ > −1, und es gilt
1∫
0
xλ dx =1
λ + 1.
2

18.2. UNBESCHRANKTE INTEGRANDEN 275
Beispiel 18.21. Sei f(x) = ln x, x ∈ (0, 1]. Dann gilt
limα→0+0
1∫
α
ln x dx = limα→0+0
[x ln x − x]1α = limα→0+0
(−1 − α ln α + α) = −1.
2
Beispiel 18.22.
Γ(x) :=
∞∫
0
e−t tx−1 dt, x > 0. (18.4)
Fur x ∈ (0, 1) ist der Integrand f(t; x) := e−t tx−1 in einer Umgebung von t = 0
unbeschrankt. Wir zerlegen daher das uneigentliche Integral Γ(x) in
Γ(x) =
1∫
0
e−t tx−1 dt +
∞∫
1
e−t tx−1 dt =: I1(x) + I2(x).
Es gilt fur jedes x > 0
|e−t tx−1| ≤ tx−1 fur alle t ∈ (0, 1],
und wegen x−1 > −1 existiert nach dem Majorantenkriterium I1(x). I2(x) existiert
ebenfalls nach dem Majorantenkriterium, denn sicher ist e−t tx+1 fur t ∈ [1,∞)
beschrankt, etwa |e−t tx+1| ≤ M , und daher gilt
|e−t tx−1| ≤ M
t2,
und
∞∫
1
M
t2dt existiert.
Die durch (18.4) definierte Funktion Γ : IR+ → IR heißt Eulersche Gammafunk-
tion oder kurz Gammafunktion. Sie spielt in vielen Gebieten der angewandten
Mathematik (Mathematische Physik, Stochastik) eine große Rolle.
Durch partielle Integration erhalt man fur x > 0
Γ(x + 1) =
∞∫
0
e−t tx dt = [−e−t tx]∞0 + x
∞∫
0
e−t tx−1 dt = x Γ(x),
und hieraus wegen
Γ(1) =
∞∫
0
e−t dt = [−e−t]∞0 = 1
durch vollstandige Induktion
Γ(n + 1) = n! fur alle n ∈ IN0.
Die Gammafunktion ist also eine Fortsetzung der Fakultat von IN auf IR+. 2

276 KAPITEL 18. UNEIGENTLICHE INTEGRALE
Wir haben bisher das uneigentliche Integral fur den Fall definiert, bei dem der In-
tegrand in Umgebungen der Randpunkte des Intervalls unbeschrankt sein konnte.
Wir betrachten nun eine lokal integrierende Funktion f : [a, b]\{c} → IR, c ∈ (a, b).
Um die Gebietsadditivitatβ∫
α=
γ∫
α+
β∫
γfur Integrale zu erhalten, nennen wir f un-
eigentlich integrierbar uber [a, b], wenn die uneigentlichen Integrale
c∫
a
f(x) dx und
b∫
c
f(x) dx existieren. Man setz dann
b∫
a
f(x) dx := limα→c−0
α∫
a
f(x) dx + limβ→c+0
b∫
β
f(x) dx. (18.5)
Auch in (18.5) mussen die Grenzubergange getrennt ausgefuhrt werden. Die Funk-
tion f(x) =1
x, x ∈ [−1, 1] \ {0}, ist also nicht uneigentlich integrierbar, da das
uneigentliche Integral
1∫
0
1
xdx nicht existiert.
Existiert der Grenzwert
limε→0+0
( c−ε∫
a
f(x) dx +
b∫
c+ε
f(x) dx)
,
so spricht man vom Cauchyschen Hauptwert des Integrals und schreibt
C
b∫
a
f(x) dx = limε→0+0
( c−ε∫
a
f(x) dx +
b∫
c+ε
f(x) dx)
.
Fur f(x) =1
x, x ∈ [−1, 1] \ {0} gilt
C
1∫
−1
f(x) dx = limε→0+0
( −ε∫
−1
1
xdx +
1∫
ε
1
xdx
)
= limε→0+0
(
[ln |x|]−ε−1 + [ln |x|]1ε
)
= limε→0+0
(ln ε − ln ε) = 0,
der Cauchysche Hauptwert existiert also.
Das Exponentialintegral
Ei(x) =
x∫
−∞
et
tdt

18.2. UNBESCHRANKTE INTEGRANDEN 277
ist fur x < 0 definiert. Fur x = 0 existiert das Integral nicht, denn
et
t=
1
t+
∞∑
n=0
tn
(n + 1)!,
d.h. der Integrand ist Summe einer glatten Funktion∞∑
n=0
tn
(n+1)!und der nicht unei-
gentlich integrierbaren Funktion1
t. Fur x > 0 existiert dann
x∫
−∞
et
tdt als uneigentli-
ches Integral auch nicht, aber als Cauchyscher Hauptwert. Das Exponentialintegral
wird fortgesetzt durch
Ei(x) = C
x∫
−∞
et
tdt.

Kapitel 19
Numerische Integration
Bestimmte Integrale konnen in vielen Fallen nicht elementar (d.h. mit Hilfe einer
Stammfunktion) ausgewertet werden, in anderen Fallen ist die exakte Auswertung
zu muhsam. Man verwendet dann numerische Quadraturverfahren. Diese gewinnt
man dadurch, dass man den Integranden durch eine Funktion ersetzt, die leicht
integriert werden kann.
19.1 Einfuhrende Beispiele
Wir betrachten das Integral
I =
b∫
a
f(x) dx. (19.1)
Wir zerlegen das Intervall [a, b] aquidistant in n Teilintervalle
a = x0 < x1 < . . . < xn = b, xi = a + i h, h :=b − a
n,
und ersetzen f im i-ten Teilintervall [xi−1, xi] durch die konstante Funktion f(xi −h/2). Die Integration dieser stuckweise konstanten Funktion liefert die Naherung
R(f) = hn∑
i=1
f(xi − h/2) (19.2)
fur das bestimmte Integral (19.1). Die Quadraturformel (19.2) heißt summierte Mit-
telpunktregel oder Rechteckregel (siehe Abbildung 19.1).
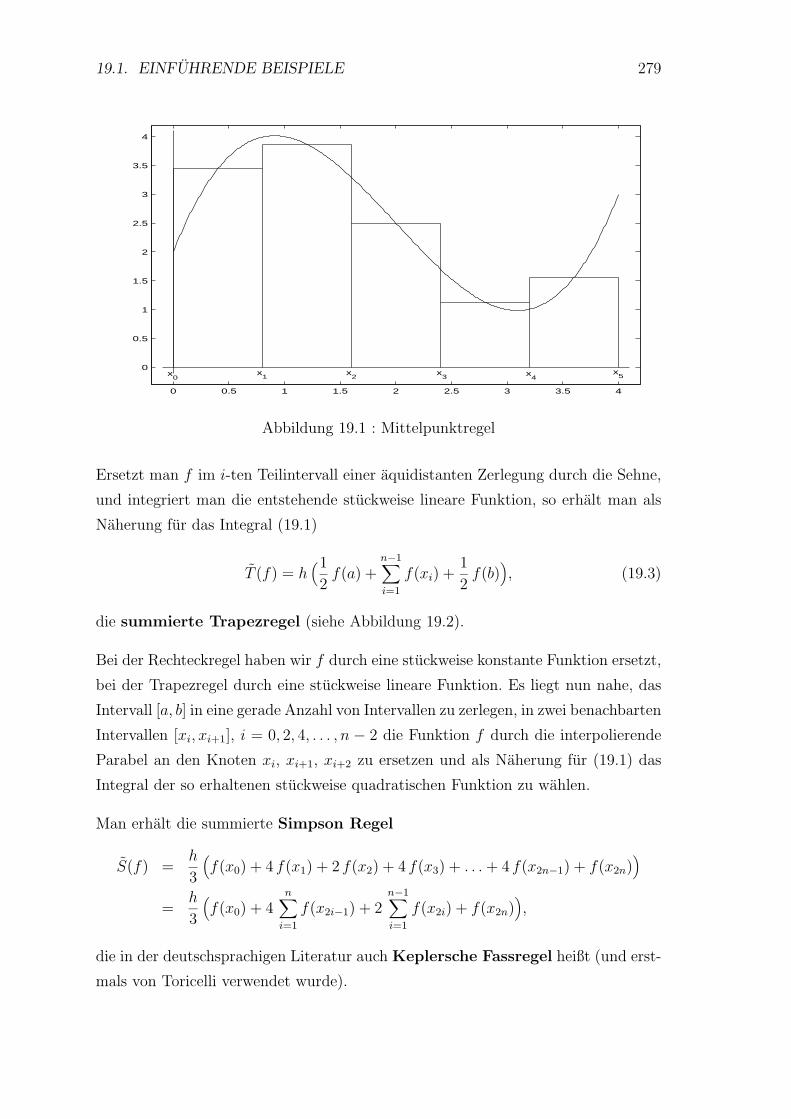
19.1. EINFUHRENDE BEISPIELE 279
0 0.5 1 1.5 2 2.5 3 3.5 4
0
0.5
1
1.5
2
2.5
3
3.5
4
x0
x1
x2
x3 x
4x
5
Abbildung 19.1 : Mittelpunktregel
Ersetzt man f im i-ten Teilintervall einer aquidistanten Zerlegung durch die Sehne,
und integriert man die entstehende stuckweise lineare Funktion, so erhalt man als
Naherung fur das Integral (19.1)
T (f) = h(1
2f(a) +
n−1∑
i=1
f(xi) +1
2f(b)
)
, (19.3)
die summierte Trapezregel (siehe Abbildung 19.2).
Bei der Rechteckregel haben wir f durch eine stuckweise konstante Funktion ersetzt,
bei der Trapezregel durch eine stuckweise lineare Funktion. Es liegt nun nahe, das
Intervall [a, b] in eine gerade Anzahl von Intervallen zu zerlegen, in zwei benachbarten
Intervallen [xi, xi+1], i = 0, 2, 4, . . . , n − 2 die Funktion f durch die interpolierende
Parabel an den Knoten xi, xi+1, xi+2 zu ersetzen und als Naherung fur (19.1) das
Integral der so erhaltenen stuckweise quadratischen Funktion zu wahlen.
Man erhalt die summierte Simpson Regel
S(f) =h
3
(
f(x0) + 4 f(x1) + 2 f(x2) + 4 f(x3) + . . . + 4 f(x2n−1) + f(x2n))
=h
3
(
f(x0) + 4n∑
i=1
f(x2i−1) + 2n−1∑
i=1
f(x2i) + f(x2n))
,
die in der deutschsprachigen Literatur auch Keplersche Fassregel heißt (und erst-
mals von Toricelli verwendet wurde).
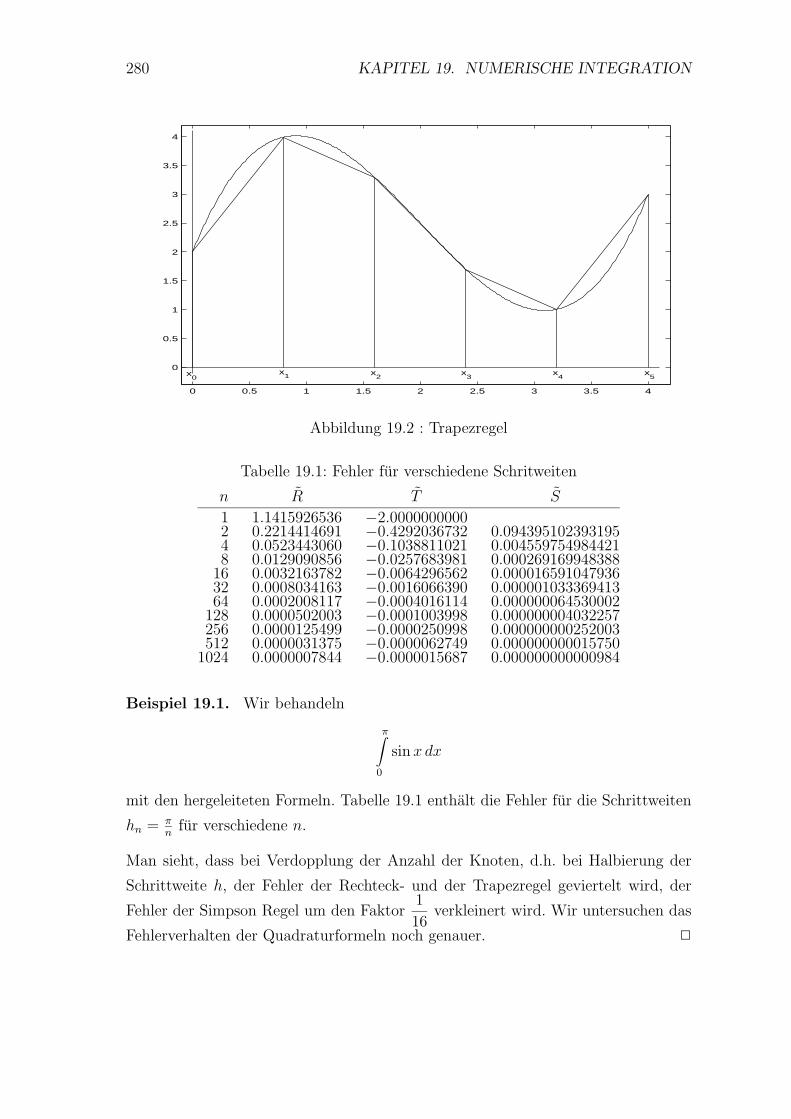
280 KAPITEL 19. NUMERISCHE INTEGRATION
0 0.5 1 1.5 2 2.5 3 3.5 4
0
0.5
1
1.5
2
2.5
3
3.5
4
x0
x1 x
2x
3x
4x
5
Abbildung 19.2 : Trapezregel
Tabelle 19.1: Fehler fur verschiedene Schritweiten
n R T S
1 1.1415926536 −2.00000000002 0.2214414691 −0.4292036732 0.0943951023931954 0.0523443060 −0.1038811021 0.0045597549844218 0.0129090856 −0.0257683981 0.000269169948388
16 0.0032163782 −0.0064296562 0.00001659104793632 0.0008034163 −0.0016066390 0.00000103336941364 0.0002008117 −0.0004016114 0.000000064530002
128 0.0000502003 −0.0001003998 0.000000004032257256 0.0000125499 −0.0000250998 0.000000000252003512 0.0000031375 −0.0000062749 0.000000000015750
1024 0.0000007844 −0.0000015687 0.000000000000984
Beispiel 19.1. Wir behandeln
π∫
0
sin x dx
mit den hergeleiteten Formeln. Tabelle 19.1 enthalt die Fehler fur die Schrittweiten
hn = πn
fur verschiedene n.
Man sieht, dass bei Verdopplung der Anzahl der Knoten, d.h. bei Halbierung der
Schrittweite h, der Fehler der Rechteck- und der Trapezregel geviertelt wird, der
Fehler der Simpson Regel um den Faktor1
16verkleinert wird. Wir untersuchen das
Fehlerverhalten der Quadraturformeln noch genauer. 2

19.2. KONSTRUKTION VON QUADRATURFORMELN 281
19.2 Konstruktion von Quadraturformeln
Wir kommen nun zur Konstruktion von numerischen Integrationsmethoden. Die
Grundidee dabei ist, den Integranden f bei gegebenen Knoten x0, . . . , xn ∈ [a, b]
durch das interpolierende Polynom p ∈ Πn mit p(xi) = f(xi), i = 0, . . . , n, zu erset-
zen und als Naherung fur
b∫
a
f(x) dx das elementar auswertbare Integral
b∫
a
p(x) dx
zu wahlen.
Die nachstliegende und historisch alteste Knotenwahl ist die aquidistante
xi = a + ib − a
n, i = 0, . . . , n.
Dann gilt nach der Lagrangeschen Interpolationsformel
p(x) =n∑
i=0
f(xi) ℓi(x), ℓi(x) =n∏
j =0
j 6= i
(x − xj
xi − xj
)
,
und man erhalt als Naherung fur (19.1) die Newton-Cotes-Formeln
In(f) =
b∫
a
p(x) dx =n∑
i=0
f(xi)
b∫
a
n∏
j =0
j 6= i
(x − xj
xi − xj
)
dx. (19.4)
Mit der Variablentransformation
x =: a + tb − a
n, 0 ≤ t ≤ n,
erhalt man
b∫
a
n∏
j =0
j 6= i
(x − xj
xi − xj
)
dx =b − a
n
n∫
0
n∏
j =0
j 6= i
(t − j
i − j
)
dt =: (b − a) αin,
wobei die Gewichte
αin :=1
n
n∫
0
n∏
j =0
j 6= i
(t − j
i − j
)
dt, i = 0, 1, . . . , n,
unabhangig von f und vom speziellen Intervall [a, b] sind. Hiermit lauten die Newton-
Cotes Formeln
In(f) = (b − a)n∑
i=0
αin f(xi).
Tabelle 19.2 enthalt die wichtigsten Newton-Cotes-Formeln.

282 KAPITEL 19. NUMERISCHE INTEGRATION
Tabelle 19.2: Newton-Cotes Formeln
n αin Name
1 1/2 1/2 Trapezregel
2 1/6 4/6 1/6 Simpson Regel
3 1/8 3/8 3/8 1/8 3/8-Regel
4 7/90 32/90 12/90 32/90 7/90 Milne Regel
Tabelle 19.3: Clenshaw-Curtis Formeln
n αin
1 1/2 1/22 1/6 4/6 1/63 1/18 8/18 8/18 1/184 1/30 8/30 12/30 8/30 1/30
Die Gewichte der Newton-Cotes Formeln bis n = 10 sind in Braß: Quadraturver-
fahren, S. 122, tabelliert. Sie wachsen rasch an und haben fur n ≥ 8 wechselndes
Vorzeichen, sind also rundungsfehleranfallig. Man benutzt die daher nur fur kleine
n auf Teilintervallen von[a, b] und summiert auf (summierte Trapez und Simpson
Regel).
In Abschnitt 14.5 haben wir gesehen, dass der Fehler des Interpolationspolynoms bei
aquidistanten Knoten am Rande des Intervalls stark wachst und dass das Fehlerver-
halten wesentlich gunstiger ist, wenn man an den Tschebyscheffknoten interpoliert.
Nimmt man die Endpunkte des Intervalls hinzu, und wahlt man als Knoten
xi =a + b
2− b − a
2cos(
i
nπ), i = 0, 1, . . . , n,
so erhalt man die Clenshaw-Curtis Formeln.
Die Gewichte der ersten Clenshaw-Curtis Formeln
CCn(f) = (b − a)n∑
i=0
αin f(xi)
enthalt Tabelle 19.3.
19.3 Fehler von Quadraturformeln
Wir untersuchen nun den Fehler von Quadraturformeln. Da man jedes Intervall [α, β]
durch die lineare Substitution x =: α+β2
+β−α2
t auf das Intervall [−1, 1] transformieren

19.3. FEHLER VON QUADRATURFORMELN 283
kann, genugt es, das Integral
I :=
1∫
−1
f(x) dx
und eine zugehorige Quadraturformel
Q(f) :=n∑
i=0
wi f(xi)
fur das Referenzintervall [−1, 1] zu betrachten.
Definition 19.2. Die Quadraturformel Q(f) hat die Fehlerordnung m, wenn
fur den Fehler
E(f) :=
1∫
−1
f(x) dx −n∑
i=0
wi f(xi)
E(f) = 0 fur alle Polynome f ∈ Πm−1 gilt und E(f) 6= 0 fur ein f ∈ Πm ist.
Wegen der Linearitat des Fehlers ist klar, dass Q genau die Fehlerordnung m hat,
wenn E(xj) = 0, j = 0, . . . ,m − 1, und E(xm) 6= 0 gilt.
Die Konstruktion liefert, dass die Newton-Cotes und die Clenshaw-Curtis Formeln
wenigstens die Fehlerordnung n + 1 haben. Fur die Trapezregel ist dies die genaue
Fehlerornung, denn
T (x2) = 2 6=1∫
−1
x2 dx =2
3.
Fur die Simpson Regel gilt
S(x3) =1
3(−1 + 4 · 0 + 1) = 0 =
1∫
−1
x3 dx, S(x4) =2
36=
1∫
−1
x4 dx =2
5,
so dass die Simpson Regel sogar die Ordnung 4 hat.
Satz 19.3. Es sei Q die Quadraturformel der Fehlerordnung m ≥ 1. Dann gibt es
eine Funktion K, den Peano Kern, so dass gilt
E(f) =
1∫
−1
f(x) dx − Q(f) =
1∫
−1
K(x) f (m)(x) dx (19.5)
fur alle f ∈ Cm[−1, 1].

284 KAPITEL 19. NUMERISCHE INTEGRATION
Beweis: Nach dem Taylorschen Satz gilt
f(x) =m−1∑
k=0
f (k)(−1)
k!(x + 1)k +
1
(m − 1)!
x∫
−1
f (m)(t) (x − t)m−1 dt,
=: p(x) + r(x)
und daher mit der Funktion
(t)k+ :=
tk, falls t ≥ 0,
0, falls t < 0,k ∈ IN0,
E(f) = E(p) + E(r) = E(r)
=1
(m − 1)!
{ 1∫
−1
x∫
−1
f (m)(t) (x − t)m−1 dt dx −n∑
i=0
wi
xi∫
−1
f (m)(t) (xi − t)m−1 dt}
=1
(m − 1)!
{ 1∫
−1
1∫
t
f (m)(t) (x − t)m−1 dx dt −n∑
i=0
wi
1∫
−1
f (m)(t) (xi − t)m−1+ dt
}
=1
(m − 1)!
{ 1∫
−1
( 1
m(1 − t)m −
n∑
i=0
wi (xi − t)m−1+
)
f (m)(t) dt}
,
d.h. (19.5) mit dem Peano Kern
K(t) =1
(m − 1)!
(1
m(1 − t)m −
n∑
i=0
wi (xi − t)m−1+
)
.
Dabei muss die Vertauschung der Integrationsreihenfolge (in Mathematik III) noch
gerechtfertigt werden.
Beispiel 19.4. Fur die Trapezregel gilt x0 = −1, x1 = 1, w0 = w1 = 1, m = 2,
und daher gilt
KT (t) =1
2(1 − t)2 − (1 − t) = −1
2(1 − t2).
2
Beispiel 19.5. Fur die Simpson Regel gilt x0 = −1, x1 = 0, x2 = 1, w0 = w2 = 13,
w1 = 43
und m = 4, und daher
KS(t) =1
3!
(1
4(1 − t)4 − 1
3(1 − t)3 − 4
3(−t)3
+
)
.
2

19.3. FEHLER VON QUADRATURFORMELN 285
Aus Satz 19.3. erhalt man die folgende Abschatzung fur den Fehler
|E(f)| ≤ max−1≤x≤1
|f (m)(x)|1∫
−1
|K(x)| dx
=: 2m+1 cm max−1≤x≤1
|f (m)(x)|. (19.6)
In vielen Fallen wechselt der Peano Kern K(x) das Vorzeichen auf [−1, 1] nicht.
Dann folgt aus (19.5) mit dem Mittelwertsatz der Integralrechnung (Satz 16.21.)
mit einem ξ ∈ (−1, 1)
E(f) = f (m)(ξ)
1∫
−1
K(x) dx =: 2m+1 cm f (m)(ξ) (19.7)
fur eine Quadraturformel der Ordnung m (Die Bedeutung des Faktors 2m+1 — auch
in Formel (19.6) — wird spater klar). cm heißt die Fehlerkonstante des Verfahrens.
Fur die Trapezregel gilt KT (x) = −(1 − x2)/2 ≤ 0 fur alle x ∈ [−1, 1]. Da T die
Ordnung 2 hat, gilt
ET (f) = −1
2f ′′(ξ)
1∫
−1
(1 − x2) dx = −2
3f ′′(ξ) = −23 f ′′(ξ)
12,
und die Fehlerkonstante ist c2 = − 1
12.
Eine elementare Rechnung zeigt, dass auch fur die Simpson Regel
KS(x) =1
3!
(1
4(1 − x)4 − 1
3(1 − x)3 − 4
3(−x)3
+
)
≤ 0
fur alle x ∈ [−1, 1] gilt. Durch Integration von K von −1 bis 1 erhalt man fur den
Fehler wegen m = 4
ES(f) = − 1
90f (4)(ξ) = −25 f (4)(ξ)
2880
fur ein ξ ∈ (−1, 1), d.h. c4 = − 1
2880.
Man kann die Fehlerkonstante der Simpson Regel und auch anderer Formeln ohne
Integration (sogar ohne Kenntnis) des Peano Kerns bestimmen. Ist bekannt, dass der
Peano Kern einer Formel der Ordnung m sein Vorzeichen in [−1, 1] nicht wechselt,
der Fehler also eine Darstellung (19.7) hat, so hat man nur E(xm) zu berechnen.
Es ist namlichdm
dxm(xm) = m! und daher
E(xm) = 2m+1 · m! · cm,

286 KAPITEL 19. NUMERISCHE INTEGRATION
und hieraus erhalt man cm.
Im Fall der Simpson Regel ist
E(x4) =
1∫
−1
x4 dx − 1
3
(
(−1)4 + 4 · 04 + 14)
=2
5− 2
3= − 4
15,
und daher gilt
c4 = 2−5 · 1
4!·(
− 4
15
)
= − 1
2880.
WIr betrachten nun das Integral von f uber ein Intervall der Lange h:
α+h∫
α
f(x) dx.
Mit der Variablentransformation x =: α +h
2(t + 1) geht dieses uber in
h
2
1∫
−1
g(t) dt, g(t) := f(
α +h
2(t + 1)
)
= f(x),
das wir mit mit der Quadraturformel
Q(g) =n∑
i=0
wig(xi)
behandeln, d.h.
Q[α,α+h](f) :=h
2
n∑
i=0
wi f(
α +h
2(xi + 1)
)
.
Fur den Fehler gilt
E[α,α+h](f) :=
α+h∫
α
f(x) dx − Q[α,α+h](f)
=h
2
( 1∫
−1
g(t) dt − Q(g))
=h
2E(g).
Besitzt der Fehler E(g) eine Darstellung (19.6), so folgt wegen
dmg
dtm=
dmf
dxm·(
dx
dt
)m
=(
h
2
)m dmf
dxm
|E[α,α+h](f)| ≤ h
2·(
h
2
)m
· 2m+1 · cm · maxα≤x≤α+h
|f (m)(x)|
= hm+1 · cm · maxα≤x≤α+h
|f (m)(x)|; (19.8)
gilt eine Darstellung (19.7), so erhalt man genauso
E[α,α+h](f) = hm+1 · cm · f (m)(η), η ∈ [α, α + h]. (19.9)

19.4. QUADRATURFORMELN VON GAUSS 287
Wir haben bereits erwahnt, dass die Genauigkeit einer Naherung fur ein Integral
nicht durch die Erhohung der Ordnung der benutzten Quadraturformel verbessert
wird, sondern dass das Intervall [a, b] in n Teilintervalle der Lange h zerlegt wird,
und dass in jedem Teilintervall eine Quadraturformel kleiner Qrdnung verwendet
wird. Fur die summierte Quadraturformel
Qh(f) :=n∑
i=1
Q[a+(i−1) h,a+i h](f)
erhalt man aus (19.8)
∣∣∣
b∫
a
f(x) dx − Qh(f)∣∣∣ =
∣∣∣∣
n∑
i=1
a+i h∫
a+(i−1) h
f(x) dx − Q[a+(i−1) h,a+i h](f)∣∣∣∣
≤n∑
i=1
|E[a+(i−1) h,a+i h](f)|
≤n∑
i=1
hm+1 · cm · max{|f (m)(x)| : a + (i − 1) h ≤ x ≤ a + i h}
≤ nh · hm · cm · maxa≤x≤b
|f (m)(x)|
≤ hm (b − a) cm maxa≤x≤b
|f (m)(x)|.
Man verliert also fur die summierte Formel eine Potenz in h.
19.4 Quadraturformeln von Gauß
Wir haben bisher die Knoten der Quadraturformeln (aquidistant oder als Nullstellen
der Tschebyscheff Polynome) vorgegeben. Die Fehlerordnung war dann (wenigstens)
gleich der Anzahl der Knoten (im Falle der Simpson Regel bei 3 Knoten 4). Wir
fragen nun, wie weit wir durch Wahl der Knoten und der Gewichte die Fehlerordnung
erhohen konnen.
Beispiel 19.6. Wir betrachten die Quadraturformel G1(f) := w1 f(x1) mit einem
Knoten x1 fur das Integral
1∫
−1
f(x) dx und bestimmen x1 ∈ [−1, 1] und w1 ∈ IR so,
dass Polynome moglichst hohen Grades exakt integriert werden:
1∫
−1x0 dx = 2 = w1 x0
1 = w1 ⇒ w1 = 2,
1∫
−1x1 dx = 0 = w1 x1
1 = 2x1 ⇒ x1 = 0.

288 KAPITEL 19. NUMERISCHE INTEGRATION
Durch diese beiden Gleichungen ist also die Quadraturformel G1(f) = 2 f(0) bereits
festgelegt; man erhalt die Mittelpunktregel. Wegen
1∫
−1
x2 dx =2
36= 2 · 02 hat sie die
Fehlerordnung 2. 2
Beispiel 19.7. Fur die Quadraturformel
G2(f) = w1 f(x1) + w2 f(x2)
mit zwei Knoten x1, x2 ∈ [−1, 1] erhalt man die Bestimmungsgleichungen
1∫
−1
x0 dx = 2 = w1 + w2,
1∫
−1
x1 dx = 0 = w1 x1 + w2 x2,
1∫
−1
x2 dx =2
3= w1 x2
1 + w2 x22,
1∫
−1
x3 dx = 0 = w1 x31 + w2 x3
2,
mit der eindeutigen Losung
w1 = w2 = 1, x1 = − 1√3, x2 =
1√3.
Wegen1∫
−1
x4 dx =2
56= 1 ·
(
− 1√3
)4+ 1 ·
( 1√3
)4=
2
9
hat die gefundene Quadraturformel
G2(f) = f(
− 1√3
)
+ f( 1√
3
)
die Fehlerordnung 4. 2
Man kann zeigen (vgl. Stoer [20, S. 122]), dass es zu jedem n ∈ IN eine eindeutige
Quadraturformel der Ordnung 2n gibt, die sog. Gaußsche Quadraturformel,
Gn(f) =n∑
i=1
wi f(xi),
und dass keine hohere Ordnung durch Wahl der Knoten und Gewichte erreichbar
ist.

19.4. QUADRATURFORMELN VON GAUSS 289
Die Knoten und Gewichte werden nicht wie in Beispiel 19.6. und Beispiel 19.7. fur
n = 1 und n = 2 aus einem nichtlinearen Gleichungssystem bestimmt, sondern man
kann zeigen, dass die Knoten von Gn die Nullstellen des n-ten Legendre Polynoms
pn(x) =1
2n · n!
dn
dxn
(
(x2 − 1)n)
sind, und dass die Gewichte aus einem linearen Gleichungssytem berechnet werden
konnen. Eine Aufstellung fur
n = 1, . . . , 12, 16, 20, 24, 32, 40, 48, 64, 80, 96
findet man in Abramowitz, Stegun [1]. Wir geben nur noch G3 an
G3(f) =5
9f(−
√0.6) +
8
9f(0) +
5
9f(√
0.6).
Anders als bei den Newton-Cotes Formeln sind die Gewichte der Gaußformeln
stets positiv. Es treten also bei ihnen auch fur große n keine Instabilitaten durch
Ausloschung auf. Man benutzt sie dennoch vornehmlich in summierten Quadratur-
formeln mit kleiner Ordnung.
Bemerkung 19.8. Bei einigen Anwendungen (insbesondere der Diskretisierung
von Integralgleichungen) ist es erforderlich, dass ein Randpunkt (bzw. beide Rand-
punkte) zu den Knoten gehort. Man setzt also xn = 1 (bzw. x1 = −1, xn = 1) und
bestimmt die ubrigen Knoten x1, . . . , xn−1 (bzw. x2, . . . , xn−1) und die Gewichte wi,
i = 1, . . . , n, so, dass die Ordnung der Quadraturformel maximal wird.
Im ersten Fall erhalt man die Radau Formel (ihre Ordnung ist bei n Knoten
2n − 1, die Knoten x1, . . . , xn−1 sind die Nullstellen des Polynoms pn − pn−1 mit
den Legendre Polynomen pν), im zweiten Fall die Lobatto Formel (ihre Ordnung
ist bei n Knoten 2n − 2, die Knoten x2, . . . , xn−1 sind die Nullstellen des Polynoms
pn − pn−2).
Als Beispiel geben wir nur die Lobatto Formel der Ordnung 6 an:
Q(f) =1
6
(
f(−1) + 5 f(
− 1√5
)
+ 5 f( 1√
5
)
+ f(1))
.
2
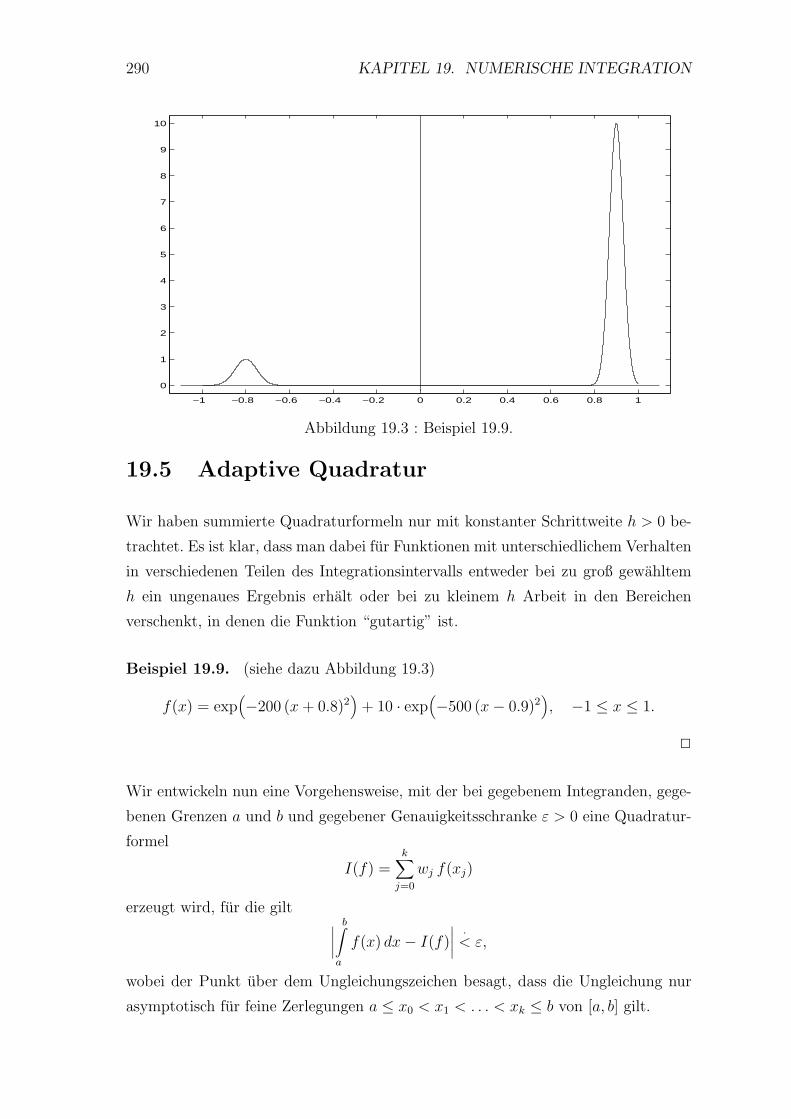
290 KAPITEL 19. NUMERISCHE INTEGRATION
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
0
1
2
3
4
5
6
7
8
9
10
Abbildung 19.3 : Beispiel 19.9.
19.5 Adaptive Quadratur
Wir haben summierte Quadraturformeln nur mit konstanter Schrittweite h > 0 be-
trachtet. Es ist klar, dass man dabei fur Funktionen mit unterschiedlichem Verhalten
in verschiedenen Teilen des Integrationsintervalls entweder bei zu groß gewahltem
h ein ungenaues Ergebnis erhalt oder bei zu kleinem h Arbeit in den Bereichen
verschenkt, in denen die Funktion “gutartig” ist.
Beispiel 19.9. (siehe dazu Abbildung 19.3)
f(x) = exp(
−200 (x + 0.8)2)
+ 10 · exp(
−500 (x − 0.9)2)
, −1 ≤ x ≤ 1.
2
Wir entwickeln nun eine Vorgehensweise, mit der bei gegebenem Integranden, gege-
benen Grenzen a und b und gegebener Genauigkeitsschranke ε > 0 eine Quadratur-
formel
I(f) =k∑
j=0
wj f(xj)
erzeugt wird, fur die gilt∣∣∣∣
b∫
a
f(x) dx − I(f)∣∣∣∣
·< ε,
wobei der Punkt uber dem Ungleichungszeichen besagt, dass die Ungleichung nur
asymptotisch fur feine Zerlegungen a ≤ x0 < x1 < . . . < xk ≤ b von [a, b] gilt.

19.5. ADAPTIVE QUADRATUR 291
Die Knoten xj und Gewichte wj werden adaptiv durch das Verfahren in Abhangigkeit
von f und ε erzeugt.
Es sei Q(f) =n∑
i=1wi f(ti) eine Quadraturformel der Ordnung m fur das Referenzin-
tervall [−1, 1].
Es sei das Integral bis zum Punkt xj ∈ [a, b) schon naherungsweise bestimmt, und
es sei xj+1 ∈ (xj, b] gegeben. Dann berechnen wir die zwei Naherungen
Q[xj ,xj+1](f) =xj+1 − xj
2
n∑
i=1
wi f(
xj+1 + xj
2+ ti
xj+1 − xj
2
)
und
Q[xj ,xj+1](f) :=xj+ 1
2− xj
2
n∑
i=1
wi f(xj+ 1
2+ xj
2+ ti
xj+ 12− xj
2
)
+xj+1 − xj+ 1
2
2
n∑
i=1
wi f(xj+1 + xj+ 1
2
2+ ti
xj+1 − xj+ 12
2
)
fur
xj+1∫
xj
f(x) dx, wobei xj+ 12
:=xj + xj+1
2gesetzt ist, und hiermit
Q[xj ,xj+1] :=1
2m − 1
(
2m · Q[xj ,xj+1](f) − Q[xj ,xj+1](f))
.
Dann ist mit Q und Q auch Q eine Quadraturformel von mindestens der Ordnung
m, und man kann leicht mit Hilfe der Fehlerdarstellung aus Satz 19.3. zeigen, dass
durch Q sogar Polynome vom Grade m exakt integriert werden, Q also wenigstens
die Ordnung m + 1 hat.
Wir benutzen nun Q, um den Fehler von Q (der genaueren der beiden Ausgangsfor-
meln) zu schatzen.
Es gilt mit h := xj+1 − xj
E[xj ,xj+1](f) :=
xj+1∫
xj
f(x) dx − Q[xj ,xj+1](f)
= Q[xj ,xj+1](f) − Q[xj ,xj+1](f) + Cm+1 hm+1
=1
2m − 1
(
2m Q[xj ,xj+1](f) − Q[xj ,xj+1](f))
− Q[xj ,xj+1](f) + Cm+1 hm+1
=1
2m − 1
(
Q[xj ,xj+1](f) − Q[xj ,xj+1](f))
+ Cm+1 hm+1.

292 KAPITEL 19. NUMERISCHE INTEGRATION
Da andererseits E[xj ,xj+1](f) = Cm hm gilt, konnen wir fur kleine h den Summanden
Cm+1 hm+1 vernachlassigen und erhalten die Fehlerabschatzung
E[xj ,xj+1](f) ≈ 1
2m − 1
(
Q[xj ,xj+1](f) − Q[xj ,xj+1](f))
. (19.10)
Wir benutzen (19.10), um das Intervall [a, b] durch Bisektion zu zerlegen in a =
x0 < x1 < . . . < xk = b, so dass fur j = 1, . . . , k gilt∣∣∣∣Q[xj−1,xj ](f) − Q[xj−1,xj ](f)
∣∣∣∣ ≤ 2m − 1
b − a(xj − xj−1) ε.
Dann folgt fur die summierte Quadraturformel
Q(f) :=k∑
j=1
Q[xj−1,xj ](f)
aus (19.10)
E(f) =
b∫
a
f(x) dx − Q(f) =k∑
j=1
E[xj−1,xj ](f)
·≤ 1
2m − 1
k∑
j=1
∣∣∣Q[xj−1,xj ](f) − Q[xj−1,xj ](f)
∣∣∣
≤ 1
b − a
k∑
j=1
(xj − xj−1) ε = ε.
Das folgende PASCAL Programm ist eine Realisierung des adaptiven Verfahrens
unter Benutzung der Gauß Formel der Ordnung m = 6.
FUNCTION Adaptive_Gauss (a, b, eps: REAL) : REAL;
{ Adaptive_Gauss berechnet das Integral der Funktion f in den
Grenzen von a bis b mit der relativen Genauigkeit eps.
f muss als FUNCTION bereitgestellt werden. }
VAR l, kn : REAL;
FUNCTION Gauss_3 (a, b: REAL) : REAL;
VAR mp : REAL;
BEGIN
mp := (a+b) / 2;
Gauss_3 := (b-a)/2 *
(5 * f(mp-kn*(b-a)/2) + 5 * f(mp+kn*(b-a)/2) + 8 * f(mp)) / 9
END; { OF GAUSS_3 }

19.5. ADAPTIVE QUADRATUR 293
Tabelle 19.4: Adaptive Gauß Quadratur
x(i − 1) x(i) x(i) − x(i − 1)
−1.00000 −0.75000 0.25000−0.75000 −0.50000 0.25000−0.50000 0.00000 0.500000.00000 0.50000 0.500000.50000 0.75000 0.250000.75000 0.87500 0.125000.87500 0.93750 0.062500.93750 1.00000 0.06250
FUNCTION Adapt (a, b, p: REAL) : REAL;
VAR c, h, ac_int, cb_int, q : REAL;
BEGIN
c := (a+b) / 2;
h := b - a;
ac_int := Gauss_3 (a, c);
cb_int := Gauss_3 (c, b);
q := ac_int + cb_int;
IF ABS(q-p) > h*l THEN
Adapt := Adapt (a, c, ac_int) + Adapt (c, b, cb_int)
ELSE
Adapt := q + (q-p) / 63 {+}
END; { OF ADAPT }
BEGIN
l := 63 * eps / (b-a);
kn := SQRT (0.6);
Adaptive_Gauss := Adapt (a, b, Gauss_3 (a, b))
END; { OF ADAPTIVE_GAUSS }
Wir haben die Fehlerschatzung fur die Quadraturformel Q durchgefuhrt. Da uns die
Formel Q hoherer Ordnung zur Verfugung steht, haben wir im Programm Q zur
Berechnung einer Naherung fur
xj+1∫
xj
f(x) dx verwendet (Anweisung {+}).
Fur das Beispiel 19.9.
f(x) = exp(
−200 (x + 0.8)2)
+ 10 · exp(
−500 (x − 0.9)2)
, −1 ≤ x ≤ 1,
erhalt man hiermit mit der Genauigkeitsschranke ε = 1E − 3 die Knotenverteilung
in Tabelle 19.4 und mit 93 Funktionsauswertungen den Naherungswert 0.917542.
Der tatsachliche Fehler ist hierfur 1.7E − 4.
Verwendet man wie oben in einem adaptiven Verfahren dieselbe Gauß Formel fur Q
und Q, so kann man die an den Knoten von Q berechneten Funktionswerte bei der

294 KAPITEL 19. NUMERISCHE INTEGRATION
Auswertung von Q nicht wiederverwenden. Von Kronrod wurde 1965 die folgende
Vorgehensweise vorgeschlagen, die diesen Nachteil nicht hat:
Wir gehen aus von einer Gauß Formel
Gn(f) =n∑
i=1
wi f(xi)
der Ordnung 2n mit den Knoten x1, . . . , xn ∈ (−1, 1), und bestimmen
n + 1 weitere Knoten y0, . . . , yn ∈ (−1, 1) und Gewichte αi, βi, so dass
die Quadraturformel
Kn(f) :=n∑
i=1
αi f(xi) +n∑
i=0
βi f(yi)
moglichst hohe Ordnung besitzt. Kn heißt die zu Gn gehorige Kronrod
Formel.
Beispiel 19.10. Ausgehend von
G2(f) = f(
− 1√3
)
+ f( 1√
3
)
machen wir fur K2 den Ansatz
K2(f) = α1 f(
− 1√3
)
+ α2 f( 1√
3
)
+ β0 f(y0) + β1 f(y1) + β2 f(y2)
und bestimmen die 8 Unbekannten α1, α2, β0, β1, β2, y0, y1, y2 so, dass die Funktio-
nen xj, j = 0, 1, 2, . . . ,m, fur moglichst großes m durch K2 exakt integriert werden.
Man kann zeigen, dass die Kronrod Formeln symmetrisch sind (hier: α1 = α2, β0 =
β2, y0 = −y2, y1 = 0). Unter Ausnutzung dieser Symmetrie folgt
K2(x2j+1) = 0 =
1∫
−1
x2j+1 dx fur alle j = 0, 1, 2, . . .
Fur die geraden Potenzen ergibt sich das nichtlineare Gleichungssystem
x0 : 2 α1 + 2 β0 + β1 = 2,
x2 : 23α1 + 2 β0 y2
0 = 23,
x4 : 29α1 + 2 β0 y4
0 = 25,
x6 : 227
α1 + 2 β0 y60 = 2
7,
mit der eindeutigen Losung
y0 =
√
6
7, α1 =
243
495, β0 =
98
495, β1 =
308
495,

19.5. ADAPTIVE QUADRATUR 295
d.h.
K2(f) =243
495G2(f) +
1
495
(
98(
f(
−√
6
7
)
+ f(√
6
7
))
+ 308 f(0)
)
.
Nach Konstruktion hat diese Formel midestens die Ordnung 8, und durch Berech-
nung von E(x8) sieht man, dass die Ordnung genau 8 ist. 2
Man kann zeigen, dass zu einer n-Punkt Gauß Formel Gn stets die (2n + 1)-Punkt
Kronrod Formel konstruiert werden kann, und dass ihre Ordnung 3n + 2 ist, falls n
gerade ist, und 3n + 3, falls n ungerade ist.
Die Kronrod Formel Kn kann man nun auf folgende Weise nutzen, um den Fehler
En der zugehorigen Gauß Formel zu schatzen. Es gilt fur [xj, xj+1] ⊂ [−1, 1]
xj+1∫
xj
f(x) dx = Kn(f) + h3n+2 · c3n+2 · f (3n+2)(η),
h := xj+1 − xj, und daher folgt
En :=
xj+1∫
xj
f(x) dx − Gn(f)
= Kn(f) − Gn(f) + h3n+2 · c3n+2 · f (3n+2)(η).
Da En proportional zu h2n ist, konnen wir fur kleine h den letzten Summanden
vernachlassigen und erhalten
En ≈ Kn(f) − Gn(f).
In dem folgenden Algorithmus schatzen wir hiermit den Fehler der Gauß Formel,
verwenden aber als Naherung fur das Integral
xj+1∫
xj
f(x) dx den mit der Kronrod
Formel ermittelten Wert. Dies fuhrt dazu, dass der Fehler wesentlich unterhalb der
geforderten Toleranz liegt.
FUNCTION Kronrod_Gauss (a, b, eps: REAL) : REAL;
{ Kronrod_Gauss berechnet das Integral der Funktion f in den
Grenzen von a bis b mit der asymptotischen Genauigkeit eps.
f muss als FUNCTION bereitgestellt werden. }
VAR k1, k2, Tol : REAL;

296 KAPITEL 19. NUMERISCHE INTEGRATION
Tabelle 19.5: Kronrod Gauß Quadratur
x(i − 1) x(i) x(i) − x(i − 1)
−1.00000 −0.87500 0.12500−0.87500 −0.75000 0.12500−0.75000 −0.50000 0.25000−0.50000 0.00000 0.500000.00000 0.50000 0.500000.50000 0.75000 0.250000.75000 0.87500 0.125000.87500 0.93750 0.062500.93750 1.00000 0.06250
PROCEDURE Integral (a, b: REAL; VAR Kronrod, Gauss : REAL);
VAR mp, h, x : REAL;
BEGIN
mp := (a+b) / 2;
h := (b-a) / 2;
x := f(mp-h*k1) + f(mp+h*k1);
Gauss := h * x;
Kronrod := h * (98 * (f(mp-h*k2) + f(mp+h*k2))
+ 243*x + 308*f(mp)) / 495
END; { OF INTEGRAL }
FUNCTION Adaption (a, b: REAL) : REAL;
VAR mp, p, q, h : REAL;
BEGIN
mp := (a+b) / 2;
h := b - a;
Integral (a, b, q, p);
IF ABS(q-p) > Tol THEN
Adaption := Adaption (a, mp) + Adaption (mp, b)
ELSE
Adaption := q
END; { OF ADAPTION }
BEGIN
Tol := eps / (b-a);
k1 := 1 / SQRT (3);
k2 := SQRT (6/7);
Kronrod_Gauss := Adaption (a, b)
END; { OF KRONROD_GAUSS }
Mit ε = 1E − 2 erhalt man fur Beispiel 19.9. die Knotenverteilung in Tabelle 19.5
und mit 85 Funktionsauswertungen die Naherung 0.917405. Der tatsachliche Fehler
ist 3.3E − 5, also wesentlich kleiner als das vorgegebene ε.

19.6. NICHT GLATTE INTEGRANDEN 297
Tabelle 19.6: Integrand nicht differenzierbar (Beispiel 19.11.)
n nicht unterteilt unterteilt
1 −1.01E − 02 1.11E − 012 −1.72E − 01 1.53E − 033 4.35E − 02 8.12E − 064 1.78E − 02 2.28E − 085 −2.54E − 02 3.96E − 116 4.98E − 03 4.66E − 147 9.29E − 03 4.44E − 16
19.6 Nicht glatte Integranden
Wir kommen nun zu einigen speziellen Tricks bei der numerischen Integration. Alle
Konvergenzuberlegungen setzen voraus, dass der Integrand glatt ist, d.h. wir benoti-
gen f ∈ Cm[a, b], um die Fehlerordnung m zu erreichen. Fur weniger glatte Funk-
tionen konvergieren die Verfahren immer noch, aber die Konvergenz ist sehr viel
langsamer.
Beispiel 19.11.
I :=
2∫
0
| cos x| dx. (19.11)
Der Integrand ist stetig, aber nicht differenzierbar in [0, 2]. Man kann hier einfach
die Schwierigkeit beheben, indem man den Integrationsbereich zerlegt und setzt:
I =
π/2∫
0
cos x dx −2∫
π/2
cos x dx. (19.12)
Tabelle 19.6 enthalt die Fehler fur die Gauß Formeln Gn, n = 1, . . . , 7, fur die
Integrale (19.11) und (19.12). 2
Man kann haufig die Schwierigkeiten durch eine Substitution beseitigen:
Beispiel 19.12.
I :=
2∫
0
3√
x sin x dx.
Auch dieser Integrand ist nur einmal stetig differenzierbar. Mit der Variablentrans-
formation t := 3√
x geht das Integral uber in
I = 3
3√2∫
0
t3 sin(t3) dt.

298 KAPITEL 19. NUMERISCHE INTEGRATION
Tabelle 19.7: Integrand nur einmal differenzierbar (Beispiel 19.12.)
n nicht transformiert transformiert
1 −5.80E − 05 −2.80E − 052 −1.15E − 05 6.76E − 083 −4.47E − 06 9.00E − 104 −2.29E − 06 2.75E − 115 −1.36E − 06 1.65E − 12
Der Integrand ist nun analytisch und man erhalt mit der (aquidistant) summierten
Gauß Formel G6 die Fehler in Tabelle 19.7 (n = Anzahl der Teilintervalle). 2
Dieses Vorgehen kann man verallgemeinern: Ist γ ∈ IR, γ > 0, und f : [0, b] → IR
stetig, so erhalt man mit der Substitution t := xγ und β := bγ
b∫
0
xγ f(x) dx =1
γ
β∫
0
t1/γ f(t1/γ) dt.
Ist 1γ∈ IN, so ist der neue Integrand (wenigstens) so glatt wie die Funktion f .
Eine weitere Moglichkeit besteht darin, in einer Umgebung der Singularitat den
Integranden in eine Reihe zu entwickeln, die Reihe gliedweise zu integrieren, und fur
das Restintervall eine Quadraturformel zu verwenden.
Fur das Beispiel 19.12. erhalt man
2∫
0
3√
x sin x dx =
1∫
0
∞∑
n=0
(−1)n x2n+4/3
(2n + 1)!dx +
2∫
1
3√
x sin x dx
=∞∑
n=0
(−1)n
(2n + 1)! (2n + 7/3)+
2∫
1
3√
x sin x dx.
Berucksichtigt man die ersten 5 Terme der Reihe und wertet man das Integral mit
der Gauß Formel G4 aus, so erhalt man den Fehler 3.9E − 10.
Reihenentwicklung ist auch bei uneigentlichen Integralen
b∫
a
f(x) dx mit limx→a+0
|f(x)| = ∞ oder limx→a−0
|f(x)| = ∞
anwendbar.
Daneben benutzt man hierfur gewichtete Quadraturformeln. Dabei schreibt man das
Integral in der Gestaltb∫
a
w(x) f(x) dx,

19.6. NICHT GLATTE INTEGRANDEN 299
wobei die Gewichtsfunktion w (mit w(x) > 0 fur alle x ∈ (a, b)) die Singularitat
enthalt und f eine (moglichst) glatte Funktion ist. Hierbei verwendet man eine
Quadraturformel der Gestalt
b∫
a
w(x) f(x) dx =n∑
i=1
wi f(xi) + Fehler, (19.13)
wobei die Gewichte wi und die Knoten so bestimmt werden, dass die Quadraturfor-
mel fur Polynome f(x) moglichst hohen Grades exakt ist.
Man kann zeigen, dass es zu jeder nichtnegativen Gewichtsfunktion w, fur die die
Integrale
b∫
a
w(x) xj dx fur j = 0, 1, . . . , 2n − 1 (im eigentlichen oder uneigentlichen
Sinne) existieren, eindeutig bestimmte Knoten x1, . . . , xn und positive Gewichte
w1, . . . , wn gibt, so dass die Quadraturformel (19.13) exakt ist fur Polynome f(x)
vom Hochstgrad 2n − 1, und dass dies der maximal erreichbare Polynomgrad ist
(vgl. Stoer [20, S. 122]).
Fur w(x) ≡ 1 sind dies gerade die betrachteten Gauß Formeln. Auch im allgemeinen
Fall spricht man von Quadraturformeln von Gauß.
Fur die Gewichtsfunktion
w(x) =1√
1 − x2, x ∈ [−1, 1],
sind die Knoten gerade die Tschebyscheff Knoten
xi = cos(
2i − 1
2nπ
)
, i = 1, . . . , n,
und die Gewichte stimmen uberein:
wi =π
n, i = 1, . . . n.
Die Aussage bleibt auch richtig fur unbeschrankte Intervalle (a = −∞ und/oder
b = ∞). Die wichtigsten Quadraturformeln fur unbeschrankte Integrationsintervalle
sind die Gauß-Laguerre Formeln ([a, b) = [0,∞), w(x) = e−x) und die Gauß-
Hermite Formeln ((a, b) = IR, w(x) = e−x2). Die Knoten und Gewichte hierzu
sind in Abramowitz, Stegun [1] tabelliert.
Beispiel 19.13.∞∫
0
x
1 + exp(x)dx.

19.6. NICHT GLATTE INTEGRANDEN 301
Schreibt man dieses Integral um in
∞∫
0
x
1 + exp(x)dx =
∞∫
0
exp(−x)x · exp(x)
1 + exp(x)dx,
so ist die Gauß-Laguerre Formel anwendbar mit
f(x) =x · exp(x)
1 + exp(x).
Fur n = 2 lauten die Knoten x1 = 2 −√
2, x2 = 2 +√
2 und die Gewichte w1 =
(2 +√
2)/4, w2 = (2 −√
2)/4 (Man erhalt sie ahnlich wie die Kronrod Knoten und
Gewichte auf Seite 294).
Hiermit erhalt man ∞∫
0
x
1 + exp(x)dx ≈ 0.805.
Der tatsachliche Wert istπ2
12= 0.822.
2

Kapitel 20
Anwendungen der
Integralrechnung
20.1 Volumen von Rotationskorpern
Zur Volumenberechnung eines Korpers K approximieren wir diesen durch eine Ver-
einigung von zylindrischen Scheiben parallel zur (y, z)-Ebene.
Das Volumen des Ersatzkorpers ist dann
V (Z) =n∑
i=1
q(xi) (xi − xi−1), (20.1)
wobei q(x) der Flacheninhalt des zur (y, z)-Ebene parallelen Querschnitts Q(x) :=
{(y, z) : (x, y, z) ∈ K} von K an der Stelle x ist und Z eine Zerlegung eines
Intervalls [a, b] ist, das die Projektion von K auf die x-Achse enthalt.
Betrachtet man eine Folge von Zerlegungen {Zm} von [a, b] mit |Zm| → 0, so kon-
vergiert V (Zm) gegen das Volumen von K und die rechte Seite von (20.1) gegen
V :=
b∫
a
q(x) dx (falls q integrierbar uber [a, b] ist).
Aus dieser Konstruktion liest man unmittelbar Satz 20.1. ab.
Satz 20.1. (Prinzip von Cavalieri)
Gegeben seien zwei Korper und eine feste Ebene E. Besitzen fur alle zu E parallelen
Ebenen die Querschnittsflachen mit beiden Korpern gleichen Flacheninhalt, so haben
beide Korper gleiches Volumen.
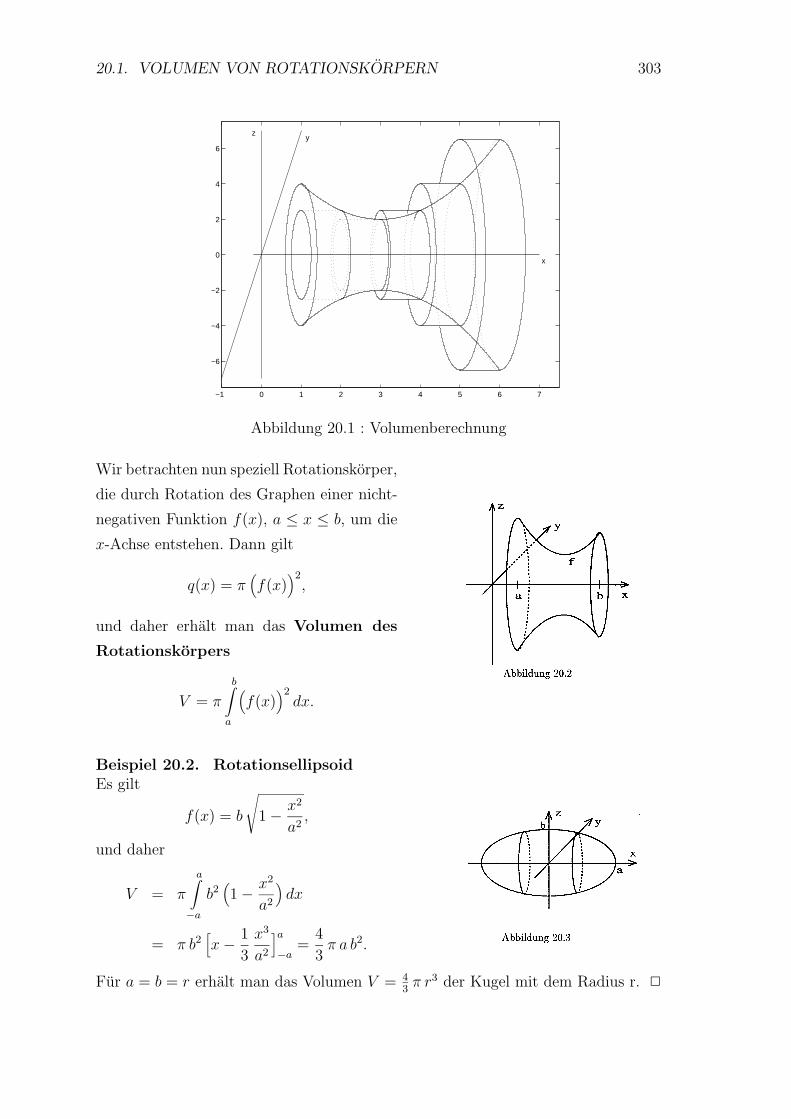
20.1. VOLUMEN VON ROTATIONSKORPERN 303
−1 0 1 2 3 4 5 6 7
−6
−4
−2
0
2
4
6
x
yz
Abbildung 20.1 : Volumenberechnung
Wir betrachten nun speziell Rotationskorper,
die durch Rotation des Graphen einer nicht-
negativen Funktion f(x), a ≤ x ≤ b, um die
x-Achse entstehen. Dann gilt
q(x) = π(
f(x))2
,
und daher erhalt man das Volumen des
Rotationskorpers
V = π
b∫
a
(
f(x))2
dx.
Beispiel 20.2. RotationsellipsoidEs gilt
f(x) = b
√
1 − x2
a2,
und daher
V = π
a∫
−a
b2(
1 − x2
a2
)
dx
= π b2[
x − 1
3
x3
a2
]a
−a=
4
3π a b2.
Fur a = b = r erhalt man das Volumen V = 43π r3 der Kugel mit dem Radius r. 2

304 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Beispiel 20.3. KegelstumpfMit der Variablentransformation
ξ := 1h
(R − r) x + r erhalt man
V = π
h∫
0
(1
h(R − r) x + r
)2dx
= π
R∫
r
ξ2 h
R − rdξ
=hπ
3· R3 − r3
R − r
=hπ
3(R2 + rR + r2).
Fur r = 0 erhalt man das Volumen des Kegels V = π3h R2. 2
Wir betrachten nun den Fall des Rotationskorpers, den man durch Rotation der
Flache unterhalb des Graphen einer nichtnegativen Funktion f(x), a ≤ x ≤ b, um
die y-Achse erhalt.
Ahnlich wie oben approximieren wir
das Volumen durch die Summen der
Volumina von Hohlzylindern der Hohe
f(xi) mit de Auß enradius xi und dem
Innenradius xi−1 bei gegebener Zerle-
gung Z : a = x0 < x1 < . . . < xn = b
von [a, b], d.h. durch
V (Z) = πn∑
i=1
f(xi) (xi + xi−1) (xi − xi−1),
und durch Verfeinerung der Zerlegung erhalt man das Volumen
V = 2π
b∫
a
x f(x) dx.
Beispiel 20.4. Das Volumen des Korpers, den man durch Rotation von
{(x, y) : 1 ≤ x ≤ 3, 0 ≤ y ≤ ex}
um die y-Achse erhalt, ist
V = 2 π
3∫
1
x ex dx = 2 π [(x − 1) ex]31 = 4 π e3.
2

20.2. KURVEN, BOGENLANGEN 305
20.2 Kurven, Bogenlangen
Um die Bahn eines Teilchens (z.B. Satelliten) zu beschreiben, muss man zu jedem
Zeitpunkt t seinen Ort x(t) angeben.
Definition 20.5. Eine stetige Funktion x : [a, b] → IRn heiß t Kurve im IRn .
x(a) heiß t der Anfangspunkt, x(b) der Endpunkt der Kurve. Eine Kurve heiß
t geschlossen, falls x(a) = x(b).
x : [a, b] → IRn heiß t C1-Kurve, falls die Komponentenfunktionen xi : [a, b] → IR,
i = 1, . . . , n, stetig differenzierbar sind. x heiß t stuckweise C1-Kurve, falls es
eine Zerlegung a = t0 < t1 < . . . < tm = b gibt, so dass x auf jedem Teilintervall
[ti−1, ti] eine C1-Kurve ist (insbesondere mussen alle einseitigen Ableitungen x′−(tj)
und x′+(tj) existieren).
Eine C1-Kurve heiß t glatt, falls x(t) := dxdt
(t) 6= 0 fur alle t ∈ [a, b] gilt.
Beispiel 20.6.
x(t) :=
r cos tr sin t
ht/(2π)
, t ∈ [0, 2πn],
beschreibt eine Schraubenlinie mit
dem Radius r und der Ganghohe h mit
n Windungen.
Wegen
x(t) =
−r sin tr cos th/(2π)
6=
000
fur alle t ∈ [0, 2πn] ist die Kurve glatt. −1
−0.5
0
0.5
1
−1
−0.5
0
0.5
10
0.1
0.2
0.3
0.4
0.5
Abbildung 20.6
2
Beispiel 20.7.
x(t) :=
(
t3
t2
)
, t ∈ [−1, 1],
beschreibt eine Kuspe (siehe Abbildung 20.7).
Die Kurve ist wegen x(t) =
(
3t2
2t
)
und x(0) = 0 nicht glatt. 2

306 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Abbildung 20.7 : Kuspe
Beispiel 20.8.
x(t) :=(cos tsin t
)
, t ∈ [0, 2π],
beschreibt einen Kreis. x ist eine glatte Kurve, denn x(t) =(− sin t
cos t
)
6=(00
)
fur
alle t ∈ [0, 2π]. 2
Beispiel 20.9.
x(t) :=(cos(ln t)sin(ln t)
)
, t ∈ [1, e2π],
beschreibt wieder den Kreis aus Beispiel 20.8. 2
Beispiel 20.10.
x(t) :=(cos(−t)sin(−t)
)
, t ∈ [0, 2π],
beschreibt erneut den Kreis aus Beispiel 20.8., der in entgegengesetzte Richtung
durchlaufen wird. 2
Beispiel 20.11.
x(t) :=(cos tsin t
)
, t ∈ [0, 2nπ],
beschreibt einen n-mal durchlaufenen Kreis. 2
Die Wertebereiche {x(t) : t ∈ [a, b]} (man sagt auch Spuren der Kurven) sind
in den letzten vier Beispielen gleich. Interpretiert man den Parameter t als Zeit, so
unterscheiden sich Beispiel 20.8. und Beispiel 20.9. nur in der Geschwindigkeit, in
der der Kreis durchlaufen wird, bei gleicher Orientierung. In Beispiel 20.10. wird
der Kreis in umgekehrte Richtung durchlaufen, in Beispiel 20.11. wird er n-mal

20.2. KURVEN, BOGENLANGEN 307
durchlaufen. In den ersten beiden Fallen werden die beiden Kurven miteinander
identifiziert und als gleich angesehen. Die Kurven in den anderen beiden Fallen sind
jedoch hiervon (und voneinander) verschieden.
Allgemeiner sei x : [a, b] → IRn eine Kurve und h : [α, β] → [a, b] bijektiv und
streng monoton wachsend. Dann ist τ 7→ x(h(τ)), τ ∈ [α, β], eine Kurve, die densel-
ben Wertebereich und dieselbe Orientierung wie die Kurve x : [a, b] → IRn besitzt.
Eine Abbildung h mit diesen Eigenschaften heiß t daher Parameterwechsel .
Definition 20.12. Zwei Kurven x : [a, b] → IRn und x : [α, β] → IRn heiß en
gleich, wenn es einen Parameterwechsel h : [α, β] → [a, b] gibt mit x ◦ h = x.
Ist x eine glatte Kurve, so betrachten wir nur stetig differenzierbare Parameterwech-
sel mit h′(τ) > 0 fur alle τ ∈ [α, β].
Wir fragen nun nach der Lange einer Kurve x : [a, b] → IRn. Wir approximieren
die Kurve durch einen Polygonzug, d.h. wir wahlen Punkte P i := x(ti), Z : a =
t0 < t1 < . . . < tm = b, und ersetzen die Kurve durch die Vereinigung der Strecken
P i−1 P i, i = 1, . . . ,m. Dann ist die Lange des Polygonzugs zur Zerlegung Z
ℓ(Z) =m∑
i=1
‖x(ti) − x(ti−1)‖2.
Es ist klar, dass ℓ(Z) fur jede Zerlegung Z von [a, b] eine untere Schranke der Lange
ℓ(x) der Kurve x ist (die kurzeste Verbindung zwischen zwei Punkten ist die Gera-
de), und dass fur |Z| → 0 die Langen ℓ(Z) gegen ℓ(x) konvergieren.

308 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Definition 20.13. Die Kurve x : [a, b] → IRn heiß t rektifizierbar, wenn {ℓ(Z) :
Z ist Zerlegung von [a, b]} nach oben beschrankt ist. In diesem Fall heiß t
ℓ(x) := supZ
ℓ(Z)
die Lange der Kurve x. Eine rektifizierbare Kurve heiß t auch Weg .
Satz 20.14.
(i) Jede C1-Kurve x : [a, b] → IRn ist rektifizierbar, und es gilt
ℓ(x) =
b∫
a
‖x(t)‖2 dt.
(ii) Die Langen von C1-Kurven sind parameterinvariant.
Beweis: (i): Fur jede Zerlegung Z gilt nach dem Mittelwertsatz der Differential-
rechnung (Satz 14.4.)
ℓ(Z) =m∑
i=1
√√√√
n∑
k=1
(
xk(ti) − xk(ti−1))2
=m∑
i=1
√√√√
n∑
k=1
(
xk(τki))2
(ti − ti−1),
wobei τki ∈ (ti−1, ti), i = 1, . . . ,m, k = 1, . . . , n.
Wir vergleichen ℓ(Z) mit einer Riemannschen Summe
S(Z) :=m∑
i=1
√√√√
n∑
k=1
(
xk(σi))2
(ti − ti−1), σi ∈ [ti−1, ti].
Da die xk : [a, b] → IR gleichmaß ig stetig sind, gibt es zu ε > 0 ein δ > 0, so dass
fur alle k = 1, . . . , n gilt
|xk(t) − xk(τ)| < ε fur alle t, τ ∈ [a, b] mit |t − τ | < δ.
Ist Z eine Zerlegung von [a, b] mit |Z| < δ, so folgt aus der Dreiecksungleichung
|ℓ(Z) − S(Z)| =
∣∣∣∣∣
m∑
i=1
(
‖(
xk(τki))
k=1,...,n‖
2− ‖x(σi)‖2
)
(ti − ti−1)
∣∣∣∣∣
≤m∑
i=1
‖(
xk(τki) − xk(σi))
k=1,...,n‖
2(ti − ti−1)
< ε√
nn∑
i=1
(ti − ti−1) = ε√
n (b − a),

20.2. KURVEN, BOGENLANGEN 309
und da S(Z) mit ε → 0 gegenb∫
a‖x(t)‖2 dt konvergiert, gilt auch
ℓ(Z) =
b∫
a
‖x(t)‖2 dt.
(ii): Ist h : [α, β] → [a, b] ein Parameterwechsel und x := x ◦ h, so gilt nach der
Substitutionsregel
ℓ(x) =
β∫
α
‖ ddτ
x(h(τ))‖2dτ =
β∫
α
‖x(h(τ)) h′(τ)‖2 dτ
=
β∫
α
‖x(h(τ))‖2 h′(τ) dτ =
b∫
a
‖x(t)‖2 dt = ℓ(x).
Bemerkung 20.15. Die Aussagen aus Satz 20.14. bleiben offensichtlich auch fur
stuckweise stetig differenzierbare Kurven richtig. 2
Beispiel 20.16. Die Kurve
x(t) :=(r cos tr sin t
)
, t ∈ [0, α],
beschreibt einen Kreisbogen vom Radius r > 0 mit dem Offnungswinkel α. Fur die
Bogenlange gilt
ℓ =
α∫
0
√
r2 sin2 t + r2 cos2 t dt = r
α∫
0
dt = r α.
Insbesondere erhalt man U = 2 π r als Umfang des Kreises mit dem Radius r. 2
Beispiel 20.17. Die geschlossene Kurve
x(t) :=
(
r cos3 tr sin3 t
)
, t ∈ [0, 2π],
heißt Astroide. Fur den Umfang gilt
U = 3r
2π∫
0
√
(− cos2 t sin t)2 + (sin2 t cos t)2 dt
= 3r
2π∫
0
√
cos2 t sin2 t (cos2 t + sin2 t) dt
= 3r
2π∫
0
| sin t cos t| dt = 12r
π/2∫
0
sin t cos t dt
= 12r[1
2sin2 t
]π/2
0= 6 r. −1 −0.5 0 0.5 1
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
2

310 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Beispiel 20.18. Die Ellipse mit den Halbachsen a > 0 und b > 0 (und dem
Mittelpunkt (0, 0)) kann beschrieben werden durch
x(t) :=(a cos tb sin t
)
, t ∈ [0, 2π].
Fur den Umfang gilt (unter Beachtung der Symmetrie zur x1-Achse)
U = 2
π∫
0
√
(−a sin t)2 + (b cos t)2 dt
= 2
π∫
0
√
a2 − (a2 − b2) cos2 t dt
= 2a
π∫
0
√
1 −(
1 − b2
a2
)
cos2 t dt. (20.2)
Dieses Integral laß t sich nur im Falle a = b (Kreis) elementar losen. Fur a 6= b ist
man auf numerische Verfahren angewiesen.
Eine andere Parametrisierung der Ellipse ist
x(t) :=1√
a2 cos2 t + b2 sin2 t
(
a2 cos tb2 sin t
)
, t ∈ [0, 2π],
die wegend
dtx(t) =
1
(a2 cos2 t + b2 sin2 t)3/2
(
−a2 b2 sin ta2 b2 cos t
)
auf den Umfang der Ellipse
U = 2 a2 b2
π∫
0
dt
(a2 cos2 t + b2 sin2 t)3/2(20.3)
fuhrt. Auch dieses Integral, das naturlich mit dem Integral in (20.2) ubereinstimmt,
ist nicht elementar berechenbar. 2
Beispiel 20.19. Die Bogenlange der Schraubenlinie aus Beispiel 20.6.
x(t) :=
r cos tr sin t
ht/(2π)
, t ∈ [0, 2πn],
ist
ℓ(x) =
2πn∫
0
√
r2 sin2 t + r2 cos2 t + h2/(2π)2 dt
= 2 π n√
r2 + h2/(2π)2.
2
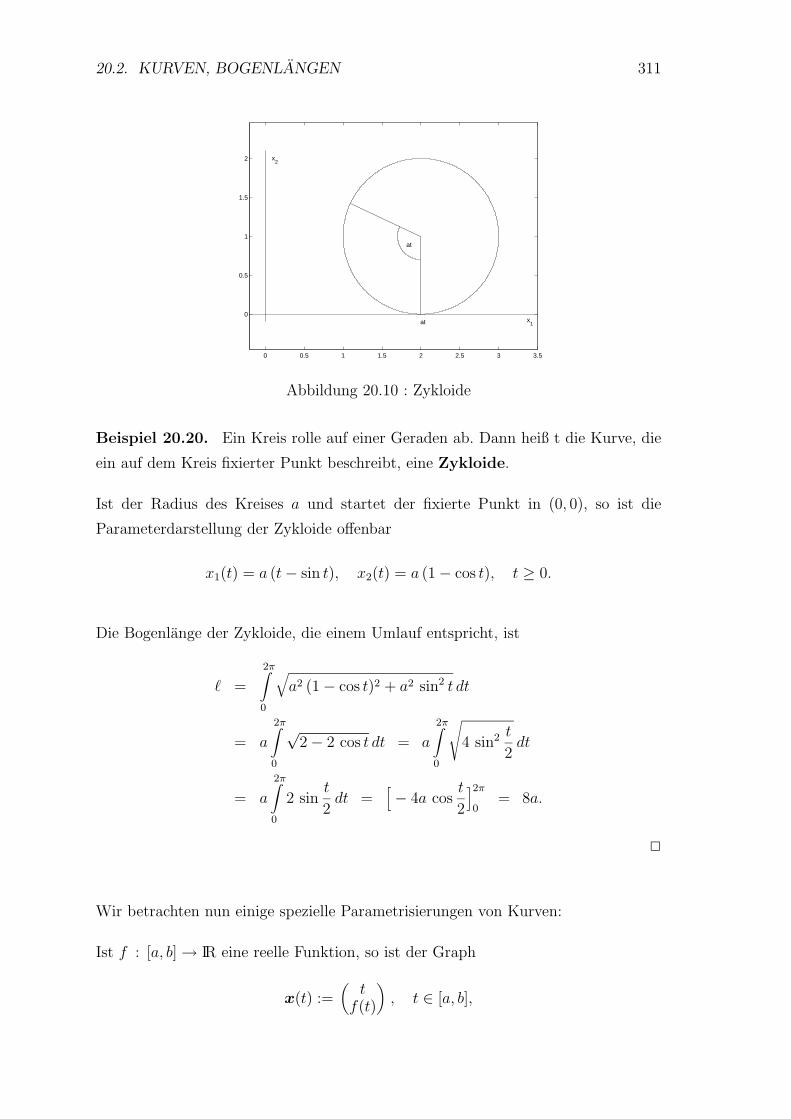
20.2. KURVEN, BOGENLANGEN 311
0 0.5 1 1.5 2 2.5 3 3.5
0
0.5
1
1.5
2
x1
x2
at
at
Abbildung 20.10 : Zykloide
Beispiel 20.20. Ein Kreis rolle auf einer Geraden ab. Dann heiß t die Kurve, die
ein auf dem Kreis fixierter Punkt beschreibt, eine Zykloide.
Ist der Radius des Kreises a und startet der fixierte Punkt in (0, 0), so ist die
Parameterdarstellung der Zykloide offenbar
x1(t) = a (t − sin t), x2(t) = a (1 − cos t), t ≥ 0.
Die Bogenlange der Zykloide, die einem Umlauf entspricht, ist
ℓ =
2π∫
0
√
a2 (1 − cos t)2 + a2 sin2 t dt
= a
2π∫
0
√2 − 2 cos t dt = a
2π∫
0
√
4 sin2 t
2dt
= a
2π∫
0
2 sint
2dt =
[
− 4a cost
2
]2π
0= 8a.
2
Wir betrachten nun einige spezielle Parametrisierungen von Kurven:
Ist f : [a, b] → IR eine reelle Funktion, so ist der Graph
x(t) :=(
tf(t)
)
, t ∈ [a, b],

312 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
eine Kurve in IR2. Ist f differenzierbar in [a, b], so erhalt man fur die Lange des
Graphen von f wegen x(t) =(
1f ′(t)
)
ℓ(x) =
b∫
a
√
1 +(
f ′(t))2
dt.
Entsprechend erhalt man fur eine Kurve im IR3, die sich parametrisieren laß t durch
x(t) =
tf(t)g(t)
, t ∈ [a, b],
die Lange
ℓ(x) =
b∫
a
√
1 +(
f ′(t))2
+(
g′(t))2
dt.
Ist die ebene Kurve
x(t) := r(t)(cos φ(t)sin φ(t)
)
, t ∈ [a, b],
in Polarkoordinaten gegeben, so gilt
x(t) = r(t)(cos φ(t)sin φ(t)
)
+ r(t) φ(t)(− sin φ(t)
cos φ(t)
)
,
und da die Vektoren(cos φ(t)sin φ(t)
)
und(− sin φ(t)
cos φ(t)
)
orthonormal sind, folgt
ℓ(x) =
b∫
a
√(
r(t))2
+(
r(t))2 (
φ(t))2
dt.
Ist die ebene Kurve noch spezieller gegeben durch
x(φ) = r(φ)(cos φsin φ
)
, φ ∈ [α, β],
so gilt fur die Lange
ℓ(x) =
β∫
α
√(
r′(φ))2
+(
r(φ))2
dφ.
Beispiel 20.21. Die Archimedische Spirale (Abbildung 20.11) ist gegeben durch
x(φ) := a φ(cos φsin φ
)
, φ ∈ [α, β].

20.2. KURVEN, BOGENLANGEN 313
−8 −6 −4 −2 0 2 4 6 8
−4
−2
0
2
4
6
8
Abbildung 20.11 : Archimedische Spirale
Fur den Umfang der inneren Windung gilt
U(x) =
π/2∫
−π/2
√
a2 + a2 φ2 dφ = a
π/2∫
−π/2
√
1 + φ2 dφ
=a
2
[
φ√
1 + φ2 + ln(
φ +√
1 + φ2)]π/2
−π/2
=a
2
(
ln
√
1 + (π/2)2 + π/2√
1 + (π/2)2 − π/2+ π
√
1 + (π/2)2
)
≈ 4.16 a.
2
Beispiel 20.22. Die Kurve
x : [0, 1] → IR, x(t) :=
t cos πt
, t > 0
0 , t = 0
ist nicht rektifizierbar, denn fur die Zerlegung
tk :=1
k, k = 1, . . . ,m − 1, tm := 0
gilt
x(tk) =(−1)k
k,
und daher folgt
ℓ(x) ≥m−1∑
k=1
|x(tk) − x(tk+1)| =m−1∑
k=1
∣∣∣(−1)k
k− (−1)k+1
k + 1(1 − δk,m−1)
∣∣∣
≥m−1∑
k=1
1
k→ ∞ fur m → ∞.
2

314 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Ist x : [a, b] → IRn eine glatte Kurve, so ist die Bogenlange s : [a, b] → [0, ℓ(x)],
s(t) :=
t∫
a
‖x(σ)‖2dσ,
eine streng monoton wachsende C1-Funktion. Sie besitzt daher eine stetig differen-
zierbare Unkehrfunktion s−1. Die Parametrisierung
x(σ) := x(
s−1(σ))
, 0 ≤ σ ≤ ℓ(x),
heiß t Parametrisierung nach der Bogenlange .
Fur die Ableitung gilt
d
dσx(σ) = x
(
s−1(σ))
· d
dσs−1(σ)
=x
(
s−1(σ))
ddτ
s(τ)∣∣∣τ=s−1(σ)
=x
(
s−1(σ))
‖x(
s−1(σ))
‖2
,
d.h.
‖ ddσ
x(σ)‖2
= 1 fur alle σ ∈ [0, ℓ(x)].
Die Parametrisierung nach der Bogenlange ist also derart, dass die Kurve mit der
gleichformigen Geschwindigkeit 1 durchlaufen wird. Der Vektor ddσ
x(σ) ist der Tan-
genteneinheitsvektor der Kurve im Punkt x(σ).
20.3 Krummung einer Kurve
Wir betrachten eine Kurve x : [0, ℓ(x)] → IR2, die bzgl. der Bogenlange σ parame-
trisiert sei.
Es sei
T (σ) =d
dσx(σ)
der Tangenteneinheitsvektor der Kurve im Punkt x(σ). Dann miß t
∆T
∆σ=
T (σ + ∆σ) − T (σ)
∆σ
die mittlere Krummung der Kurve x in dem Intervall [σ, σ + ∆σ]. Die folgende
Definition ist also sinnvoll

20.3. KRUMMUNG EINER KURVE 315
Definition 20.23. Es sei x : [0, ℓ(x)] → IR2 eine C2–Kurve, die bzgl. der Bo-
genlange parametrisiert sei. Dann heiß t
κ(σ) :=∥∥∥
d
dσT (σ)
∥∥∥2
=∥∥∥
d2
dσ2x(σ)
∥∥∥2
die Krummung der Kurve x im Punkt x(σ).
Beispiel 20.24. Wir berechnen die Krummung eines Kreises mit dem Radius r.
Dieser ist gegeben durch
x(σ) = r(
cosσ
r, sin
σ
r
)T, 0 ≤ σ ≤ 2π.
Der Tangenteneinheitsvektor ist dann
T (σ) =d
dσx(σ) =
(
− sinσ
r, cos
σ
r
)T
und die Krummung ist
κ(σ) =∥∥∥
d2
dσ2x(σ)
∥∥∥2
=∥∥∥
(
− 1
rcos
σ
r, −1
rsin
σ
r
)T ∥∥∥2
=1
r.
Der Kreis mit dem Radius r hat also die konstante Krummung1
r. 2
Definition 20.25. Die C2–Kurve x : [0, ℓ(x)] → IR2 besitze die Krummung
κ(σ) > 0 im Punkte x(σ). Dann heiß t
ρ(σ) :=1
κ(σ)
der Krummungsradius der Kurve x im Punkte x(σ).
Der Krummungsradius gibt den Radius desjenigen Kreises an, der dieselbe Krum-
mung wie die Kurve x im Punkt x(σ) hat, den man also im Punkt x(σ) an die
Kurve anschmiegen kann.
Satz 20.26. Es sei x : [a, b] → IR2 eine C2–Kurve. Dann ist die Krummung von
x im Punkt x(t) gegeben durch
κ =|x1(t)x2(t) − x2(t)x1(t)|
√
x1(t)2 + x2(t)23 =
√
‖x(t)‖22‖x(t)‖2
2 − 〈x(t), x(t)〉2
‖x(t)‖32
.

316 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Beweis: Wegendσ
dt= ‖x(t)‖2 und T (t) =
x(t)
‖x(t)‖2
gilt
κ(σ) =∥∥∥dT
dσ
∥∥∥2
=‖dT /dt‖2
dσ/dt=
1
‖x(t)‖2
·∥∥∥
d
dt
( x(t)
‖x(t)‖2
)∥∥∥2
=1
‖x(t)‖32
·∥∥∥x(t)‖x(t)‖2 − x(t)
d
dt‖x(t)‖2
∥∥∥2.
Mit
φ(t) :=d
dt‖x(t)‖2 =
d
dt
√
x1(t)2 + x2(t)2 =〈x(t), x(t)〉‖x(t)‖2
erhalt man
κ(σ) =1
‖x(t)‖32
√
〈‖x(t)‖x(t) − φ(t)x(t), ‖x(t)‖2x(t) − φ(t)x(t)〉
=1
‖x(t)‖32
√
‖x(t)‖22‖x(t)‖2
2 − 2φ(t)‖x(t)‖2〈x(t), x(t)〉 + φ(t)2‖x(t)‖22
=1
‖x(t)‖32
√
‖x(t)‖22‖x(t)‖2
2 − 〈x(t), x(t)〉2.
Nun gilt
‖x(t)‖22‖x(t)‖2
2 − 〈x(t), x(t)〉 = (x21 + x2
2)(x21 + x2
2) − (x1x1 + x2x2)
= x21x
21 + x2
1x22 + x2
2x21 + x2
2x22 − (x2
1x21 + 2x1x1x2x2 + x2
2x22)
= (x1x2)2 − 2(x1x2)(x1x2) + (x2x1)
2
= (x1x2 − x2x1)2.
Daher erhalten wir
κ(t) =1
‖x(t)‖32
|x1(t)x2(t) − x2(t)x1(t)|.
Beispiel 20.27. Fur die Krummung der Ellipse
x(t) =(a cos tb sin t
)
gilt
κ(t) =|x1(t)x2(t) − x2(t)x1(t)|
(x1(t)2 + x2(t)2)3/2=
ab
(a2 sin2 t + b2 cos2 t)3/2.
2

20.3. KRUMMUNG EINER KURVE 317
Beispiel 20.28. Fur die Archimedische Spirale
x(t) :=(at cos tat sin t
)
, t ∈ IR
gilt
x(t) =(a cos t − at sin ta sin t + at cos t
)
= a(cos tsin t
)
+ at(− sin t
cos t
)
x(t) =(−2a sin t − at cos t
2a cos t − at sin t
)
= −2a(
sin t− cos t
)
− at(cos tsin t
)
.
Daher ist
‖x(t)‖22 = a2 + a2t2, ‖x(t)‖2
2 = 4a2 + a2t2, 〈x(t), x(t)〉 = a2t,
und damit
κ(t) =
√√√√
(a2 + a2t2)(4a2 + a2t2) − a4t2
(a2 + a2t2)3=
t2 + 2
a√
1 + t23 .
2
Bemerkung 20.29. Erganzt man den Vektor x um eine dritte Komponente 0, so
gilt offensichtlich
x(t) × x(t) = (0 , 0 , x1(t)x2(t) − x1(t)x2(t))T ,
und man kann die Krummung auch schreiben als
κ(t) =‖x(t) × x(t)‖2
‖x(t)‖32
.
2
Bemerkung 20.30. Den Graphen einer C2–Funktion f : [a, b] → IR kann man
als Kurve
x(t) := (t , f(t))T , t ∈ [a, b],
auffassen. Wegen x1(t) = 1 und x1(t) = 0 ist die Krummung
κ(t) =|f ′′(t)|
√
1 + f ′(t)23 .
2

318 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Bemerkung 20.31. Ist T (σ) der Tangenteneinheitsvektor der Kurve x(σ), die
bzgl. der Bogenlange σ parametrisiert ist, so gilt
1 = ‖T (σ)‖22 = 〈T (σ),T (σ)〉,
und durch Differenzieren dieser Gleichung folgt
0 = 2〈T (σ), ddσ
T (σ)〉.
der Vektord
dσT (σ) steht also senkrecht auf dem Tangenvektor. Gilt κ(σ) 6= 0, so
heiß t
n(σ) :=ddσ
T (σ)
‖ ddσ
T (σ)‖2
der Einheitsnormalenvektor der Kurve x. Offensichtlich gilt
d
dσT (σ) = κ(σ)n(σ).
2
Die Definition der Krummung ist sofort ubertragbarauf Kurven x : [0, ℓ(x)] → IR3.
Definition 20.32. Es sei x : [0, ℓ(x)] → IR3 eine Raumkurve. Dann heiß t
κ(σ) :=∥∥∥
d
dσT (σ)
∥∥∥2
die Krummung der Kurve x im Punkte x(σ).
Bemerkung 20.33. Die Darstellung
κ(t) =‖x(t) × x(t)‖2
‖x(t)‖32
der Krummung bei beliebiger Parametrisierung aus Bemerkung 20.29. bleibt auch
fur Raumkurven richtig, denn wegen
〈T (σ), ddσ
T (σ)〉 = 0
gilt zunachst
‖T (σ) × ddσ
T (σ)‖2
= ‖T (σ)‖2 · ‖ ddσ
T (σ)‖2
= ‖ ddσ
T (σ)‖2
= κ(σ),
und ausd
dσT (σ) =
dT /dt
dσ/dt=
‖x(t)‖22x(t) − 〈x(t), x(t)〉x(t)
‖x(t)‖42
folgt
κ(t) =∥∥∥
x(t)
‖x(t)‖2
× ‖x(t)‖22x(t) − 〈x(t), x(t)〉x(t)
‖x(t)‖42
∥∥∥2
=‖x(t) × x(t)‖2
‖x(t)‖32
.
2

20.3. KRUMMUNG EINER KURVE 319
Wie fur ebene Kurven ist auch hier
n(σ) =1
κ(σ)
dT (σ)
dσ
ein Normalenvektor der Kurve x (der Lange 1). Die Normalenrichtung der Kur-
ve ist aber hier nicht mehr eindeutig bestimmt, sondern der Orthogonalraum zum
Tangenvektor ist zweidimensional. Ein weiterer Vektor in dieser Ebene ist sicher
B := T × n.
Definition 20.34. Es sei x : [0, ℓ(x)] → IR3 eine C2–Kurve, die bzgl. der Bo-
genlange parametrisiert sei. Dann heiß t
n(σ) =1
κ(σ)
d
dσT (σ)
die Hauptnormale der Kurve x und
B(σ) := T (σ) × n(σ)
die Binormale der Kurve x im Punkt x(σ).
Bemerkung 20.35. Durch (T (σ) , n(σ) , B(σ)) wird zu jedem Punkt x(σ) der
Kurve x ein Rechtssystem von rechtwinkligen Koordinatenrichtungen definiert, wo-
bei T (σ) in die Tangentenrichtung der Kurve weist, n(σ) einen dazu orthogonalen
Vektor bezeichnet, der dadurch charakterisiert ist, dass die Kurve lokal in der von T
und n aufgespannten Ebene verlauft (d.h. nimmt man zu x(σ) zwei weitere vonein-
ander verschiedene Punkte x(σ1) und x(σ2) hinzu, so geht die durch x(σ1) − x(σ)
und x(σ2)−x(σ) aufgespannte Ebene fur σ1 → σ und σ2 → σ gegen die von T und
n aufgespannte Ebene). 2
Differenziert man die Gleichung 〈B(σ),T (σ)〉 ≡ 0, so folgt
0 = 〈 d
dσB(σ),T (σ)〉 + 〈B(σ),
d
dσT (σ)〉
= 〈 d
dσB(σ),T (σ)〉 + κ(σ)〈B(σ),n(σ)〉 = 〈 d
dσB(σ),T (σ)〉.
Ist ddσ
B(σ) 6= 0, so ist ddσ
B(σ) orthogonal zu T (σ) und (entsprechend der Orthogo-
nalitat von T und n) orthogonal zu B(σ). Daher gibt es ein τ ∈ IR mit
d
dσB(σ) = −τ(σ)n(σ). (20.4)
τ(σ) heiß t die Torsion der Kurve x im Punkt x(σ). Fur sie gilt (man bilde in der
definierenden Gleichung (20.4) auf beiden Seiten das innere Produkt mit n)
τ(σ) = τ(σ)〈n(σ),n(σ)〉 = −〈 d
dσB(σ),n(σ)〉.

320 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Satz 20.36. Eine C2–Kurve x : [0, ℓ(x)] → IR3 mit κ(σ) 6= 0 ist genau dann eine
ebene Kurve, wenn ihre Binormale konstant ist. In diesem Fall steht B ≡ B(σ)
senkrecht auf der Ebene, in der die Kurve verlauft.
Beweis: Verlauft die Kurve x ganz in der Ebene E = x(0) + V mit einem zwei-
dimensionalen Teilraum V des IR3, so gilt T (σ),n(σ) ∈ V . Daher ist B(σ) =
T (σ) × n(σ) fur alle σ ein Normaleneinheitsvektor von V , und da B(σ) stetig ist,
kann B(σ) nicht seine Richtung umkehren, und muss daher konstant sein.
Ist umgekehrt B := B(σ) konstant, so folgt aus 〈B,T (σ)〉 = 0, d.h. 〈B, ddσ
x(σ)〉 =
0, durch Integration 〈B,x(σ)〉 = c fur ein c ∈ IR, und damit liegt die Kurve ganz
in der Ebene 〈B,y〉 = 0.
Man kann also die Lange vond
dσB(σ) als Maß fur die Abweichung der Kurve x von
einem ebenen Verlauf ansehen. Dies rechtfertigt den Namen Torsion fur τ .
Beispiel 20.37. Wir betrachten die Schraubenlinie
x(t) :=(
r cos t , r sin t ,ht
2π
)T, t ≥ 0.
Dann gilt
dσ
dt= ‖x(t)‖2 =
√
r2 sin2 t + r2 cos2 t +h2
4π2=
√
r2 +h2
4π2=: γ.
Der Tangenteneinheitsvektor ist dann
T (t) =dx
dσ=
dx/dt
dσ/dt=
1
γ
(
− r sin t , r cos t ,h
2π
)T.
WegendT
dσ=
dT /dt
dσ/dt=
1
γ2(−r cos t , −r sin t , 0)T
ist die Hauptnormale
n(t) =1
κ(t)
dT
dσ= (− cos t , − sin t , 0)T .
Fur die Binormale erhalt man
B(t) = T (t) × n(t) =1
γ
( h
2πsin t , − h
2πcos t , r
)T=
h
2πγ
(
sin t , − cos t ,2πr
h
)T.
Schließ lich ist wegen
dB
dσ=
dB/dt
dσ/dt=
h
2πγ2(cos t , sin t , 0)T = − h
2πγ2n(t)
die Torsion
τ(t) =h
2π(r2 + h2
4π2 )=
2πh
4π2r2 + h2.
2

20.4. VON EINER KURVE UMSCHLOSSENE FLACHE 321
Abbildung 20.12 : mathematisch positiver/negativer Sinn
20.4 Von einer Kurve umschlossene Flache
Wir fragen zunachst nach der vom Ortsvek-
tor einer Kurve uberstrichenen Flache.
Ist
Z : a = t0 < t1 < . . . < tm = b
eine Zerlegung des Parameterintervalls, so
gilt fur die Flache des Dreiecks Fi
Fi =1
2
(
x(ti−1) × x(ti))
3=
1
2
(
x1(ti−1) x2(ti) − x1(ti) x2(ti−1))
,
und daher
F (Z) =m∑
i=1
Fi =1
2
m∑
i=1
(
x1(ti−1) x2(ti) − x1(ti) x2(ti−1))
=1
2
m∑
i=1
x1(ti−1) x2(ti) − x1(ti) x2(ti−1)
ti − ti−1
∆ti
=1
2
m∑
i=1
(
x1(ti−1)x2(ti) − x2(ti−1)
ti − ti−1
− x2(ti−1)x1(ti) − x1(ti−1)
ti − ti−1
)
∆ti
→ 1
2
b∫
a
(
x1(t) x2(t) − x1(t) x2(t))
dt fur |Z| → 0,
und dies ist der insgesamt uberstrichene Flacheninhalt
F (x) =1
2
b∫
a
(
x1(t) x2(t) − x1(t) x2(t))
dt.

322 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Dabei hat F (x) positives Vorzeichen,
falls x(t) im mathematisch positiven
Sinn (gegen den Uhrzeigersinn bzgl. 0)
durchlaufen wird, und negatives Vorzei-
chen, falls x(t) im mathematisch nega-
tiven Sinn durchlaufen wird (siehe Ab-
bildung 20.12).
Bei einer geschlossenen Kurve erhalt
man durch F (x) offenbar den Inhalt
der von x umschlossenen Flache.
Beispiel 20.38. Fur die Flache der Ellipse mit den Halbachsen a und b gilt wegen
x(t) =(a cos tb sin t
)
, x(t) =(−a sin t
b cos t
)
F =1
2
2π∫
0
(
x1(t) x2(t) − x1(t) x2(t))
dt
=1
2
2π∫
0
(ab cos2 t + ab sin2 t) dt = a b π.
2
Beispiel 20.39. Wir berechnen die von der Archimedischen Spirale eingeschlosse-
ne innere Flache. Es gilt
x(t) = r(t)(cos φ(t)sin φ(t)
)
,
x(t) = r(t)(cos φ(t)sin φ(t)
)
+ r(t) φ(t)(− sin φ(t)
cos φ(t)
)
,
und daher
x1 x2 − x2 x1 = r cos φ (r sin φ + r φ cos φ) − r sin φ (r cos φ − r φ sin φ)
= r2 φ (cos2 φ + sin2 φ) = r2 φ,
d.h.
F =1
2
π/2∫
−π/2
r2 φ dt =1
2
π/2∫
−π/2
r2 dφ =1
2a2
π/2∫
−π/2
φ2 dφ
=[1
6a2 φ3
]π/2
−π/2=
1
24a2 π3 ≈ 1.29 a2.
2

20.5. MANTELFLACHEN VON ROTATIONSKORPERN 323
20.5 Mantelflachen von Rotationskorpern
Wir approximieren die Mantelflache eines
Rotationskorpers aus Abschnitt 20.1 durch
Summen von Mantelflachen von Kegelstump-
fen.
Zunachst gilt fur den Mantel eines Kegels we-
genM
π ℓ2=
2 π r
2 π ℓ=
r
ℓ
M = π r ℓ.
Abbildung 20.16
Fur den Kegelstumpf (Abbildung 20.16) gilt nach dem Strahlensatz
ℓ1
ℓ=
r1
r1 − r2
,ℓ2
ℓ=
r2
r1 − r2
,
und daher folgt fur den Mantel
M = π r1 ℓ1 − π r2 ℓ2 = π ·(
r21
r1 − r2
− r22
r1 − r2
)
· ℓ = π ℓ (r1 + r2),
d.h.
∆F = π (2f + ∆f) ∆s = π (2f + ∆f)∆s
∆x∆x.
Ist also F (x) die gesuchte Mantelflache zwischen a und x, so gilt (∆x → 0)
F ′(x) = 2π f(x)ds
dx= 2π f(x)
√
1 +(
f ′(x))2
,

324 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
und daher
F = F (b) = 2π
b∫
a
f(x)
√
1 +(
f ′(x))2
dx.
Beispiel 20.40. Eine Kugel erhalt man durch Rotation des Kreises x2 + y2 = r2
um die x-Achse. Daher gilt fur die Oberflache der Kugel
F = 2π
r∫
−r
√r2 − x2 ·
√
1 +x2
r2 − x2dx
= 2π
r∫
−r
r dx = 4 π r2.
2
Ist die rotierende Kurve in parametrischer Form(x(t)y(t)
)
, t ∈ [a, b], gegeben, so gilt
ds
dt=
√
(x(t))2 + (y(t))2,
und man erhalt wie oben fur die Mantelflache
F = 2π
b∫
a
y(t)√
(x(t))2 + (y(t))2 dt.
Beispiel 20.41. Laß t man eine Zykloide um die x-Achse rotieren, so gilt fur die
Oberflache des Rotationskorpers (vgl. Beispiel 20.20. auf Seite 311)
F = 2π
2π∫
0
a (1 − cos t) (2a sint
2) dt
= 8π a2
2π∫
0
(sin2 t
2) sin
t
2dt
= 8π a2
2π∫
0
(1 − cos2 t
2) sin
t
2dt
= 8π a2[
− 2 cost
2+
2
3cos3 t
2
]2π
0=
64
3π a2.
2

20.6. KURVENINTEGRALE 325
20.6 Kurvenintegrale
Definition 20.42. Ist f : D → IR, D ⊂ IRn, eine Abbildung und C eine Kurve
in D, die durch die Parameterdarstellung x : [a, b] → IRn gegeben ist, so ist das
Kurvenintegral von f uber C definiert durch
∫
C
f(x) ds :=
b∫
a
f(x(t)) ‖x(t)‖2 dt.
Das Kurvenintegral existiert, falls das rechts stehende Integral im eigentlichen oder
uneigentlichen Sinne existiert.
Der Begriff des Kurvenintegrals kann folgen-
dermaß en motiviert werden: Die Gesamt-
masse eines inhomogenen Drahtes der Dichte
ρ (= Masse / Lange) ist
m ≈k∑
j=1
ρ(x(tj)) ‖x(tj) − x(tj−1)‖2
≈k∑
j=1
ρ(x(tj)) ‖x(tj)‖2 (tj − tj−1)
→b∫
a
ρ(x(t)) ‖x(t)‖2 dt =∫
C
ρ(x) ds.
Satz 20.43. Das Kurvenintegral ist unabhangig von der Parametrisierung von C.
Beweis: Sei x : [a, b] → IRn eine Parametrisierung von C und h : [α, β] → [a, b]
ein Parameterwechsel. Dann gilt fur y = x ◦ h : [α, β] → IRn wegen h′(τ) > 0
β∫
α
f(
y(τ))
‖ ddτ
y(τ)‖2dτ =
β∫
α
f(
x(
h(τ)))
‖x(
h(τ))
· h′(τ)‖2dτ
=
β∫
α
f(
x(
h(τ)))
‖x(
h(τ))
‖2· h′(τ) dτ
=
b∫
a
f(
x(t))
‖x(t)‖2 dt.
Wir betrachten nun weitere Bereiche, in denen Kurvenintegrale auftreten.

326 KAPITEL 20. ANWENDUNGEN DER INTEGRALRECHNUNG
Fur n Massenpunkte mi mit den Ortsvektoren xi, i = 1, . . . , n, ist der Schwerpunkt
xS :=n∑
i=1
mi xi
/ n∑
i=1
mi.
Entsprechend definiert man den Schwerpunkt eines massebelegten Drahtes
xS ≈
n∑
i=1ρ(x(ti)) ‖x(ti) − x(ti−1)‖2 x(ti)
n∑
i=1ρ(x(ti)) ‖x(ti) − x(ti−1)‖2
→b∫
a
ρ(x(t)) ‖x(t)‖2 x(t) dt/ b∫
a
ρ(x(t)) ‖x(t)‖2 dt,
d.h.
xS =∫
C
ρ(x) x ds/ ∫
C
ρ(x) ds.
Dabei ist das Kurvenintegral uber die Vektorfunktion t 7→ ρ(x(t)) ‖x(t)‖2 x(t) kom-
ponentenweise auszuwerten.
Beispiel 20.44. Eine homogene Schraubenfeder der Dichte ρ mit n Windungen
hat die Masse (vgl. Beispiel 20.6. auf Seite 305)
m =
2π n∫
0
ρ ‖x(t)‖2 dt = ρ · 2π n√
r2 + h2/(2π)2,
und wegen
2π n∫
0
ρ ‖x(t)‖2 x(t) dt = ρ√
r2 + h2/(2π)2
2π n∫
0
r cos tr sin t
ht/(2π)
dt
= ρ√
r2 + h2/(2π)2 ·
00
h2π
· 12(2π n)2
ist der Schwerpunkt
xS =
00
12nh
.
2
Rotiert ein Massenpunkt m im Abstand r um eine Achse A mit der Winkelgeschwin-
digkeit ω, so gilt fur die kinetische Energie
E =1
2m v2 =
1
2m r2 ω2 =:
1
2θA ω2.

20.6. KURVENINTEGRALE 327
θA heiß t das Tragheitsmoment von m bzgl. A.
Entsprechend ist fur ein System von n Massenpunkten mi mit den Radien ri das
Tragheitsmoment
θA =n∑
i=1
mi r2i ,
und in Verallgemeinerung hiervon das Tragheitsmoment eines massebelegten Drah-
tes
θA =∫
C
ρ(x) r2(x) ds,
wobei r(x) den Abstand von x ∈ C von der Achse A bezeichnet.
Beispiel 20.45. Ein homogener dunner Stab der Lange ℓ rotiere um ein Ende mit
der Winkelgeschwindigkeit ω. Damit ist das Tragheitsmoment
θ = ρ
ℓ∫
0
s2 ds =1
3ρ ℓ3.
2
Beispiel 20.46.
Ein kreisformiger homogener Draht mit Radius a
rotiere um eine senkrechte Achse durch einen sei-
ner Punkte.
Mit der Parametrisierung
x(t) := a
1 + cos tsin t0
, t ∈ [0, 2π],
des Drahtes gilt wegen (r(x(t)))2 = 2a2 (1 + cos t)
und ‖x(t)‖2 = a
θA = ρ
2π∫
0
2a3 (1 + cos t) dt = 4π ρ a3. 2

Kapitel 21
Periodische Funktionen
21.1 Einleitende Beispiele
Periodische Vorgange spielen in den Anwendungen eine große Rolle (mechanische
oder elektrische Schwingungen, Wellen, Drehbewegungen). Sie werden durch Funk-
tionen beschrieben, die dieses Verhalten widerspiegeln.
Definition 21.1. Eine Funktion f : IR → C heißt periodisch, wenn es ein T > 0
gibt mit f(x + T ) = f(x) fur alle x ∈ IR. T heißt dann die Periode von f , jedes
Intervall [a, a + T ], a ∈ IR, der Lange T heißt ein Periodenintervall.
Beispiel 21.2. cos(kx), sin(kx), k ∈ IN, sind 2π-periodische Funktionen (genauer
sogar 2π/k-periodisch). 2
Beispiel 21.3. ei kx = cos(kx) + i sin(kx) ist 2π-periodisch fur jedes k ∈ ZZ. 2
Beispiel 21.4. Jedes trigonometrische Polynom
f(x) =1
2a0 +
n∑
j=1
(
aj cos(jx) + bj sin(jx))
, aj, bj ∈ IR,
ist 2π-periodisch. 2
Beispiel 21.5. Jedes trigonometrische Polynom in komplexer Schreibweise
f(x) =n∑
j=−n
cj ei jx, cj ∈ C,
ist 2π-periodisch. 2
21.1. EINLEITENDE BEISPIELE 329
0 2 4 6 8 10 12 14 16−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
3
Abbildung 21.1 : Periodische Funktion
−2 0 2 4 6 8 10 12
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
−2 0 2 4 6 8 10 12 14
−3
−2
−1
0
1
2
3
Abbildung 21.2 : Rechteckschwingung / Sagezahnschwingung
Beispiel 21.6. Die Rechteckschwingung (Abbildung 21.2, links)
f(x) =
−1, (2k − 1) π < x < 2kπ,
1, 2kπ < x < (2k + 1) π,
ist 2π-periodisch. 2
Beispiel 21.7. Die Sagezahnschwingung (Abbildung 21.2, rechts)
f(x) = x − 2k π, (2k − 1) π ≤ x < (2k + 1) π,
ist 2π-periodisch. 2
Das folgende Lemma 21.8. gibt Auskunft uber die Menge der Perioden einer peri-
odischen Funktion.

330 KAPITEL 21. PERIODISCHE FUNKTIONEN
Lemma 21.8. Sei f : IR → C periodisch, M die Menge aller positiven Perioden
von f und T := inf M . Dann gilt
(i) Ist T > 0, so gilt M = {n · T : n ∈ IN}.
(ii) Ist T = 0 und f stetig, so ist f konstant.
Beweis: (i): Mit T1, T2 ∈ M , T1 > T2, gilt auch T1 − T2 ∈ M , denn
f(x + (T1 − T2)) = f(x + (T1 − T2) + T2) = f(x + T1) = f(x).
Wegen T > 0 ist also T nicht Haufungspunkt von M , und daher gilt T ∈ M .
Ist T eine weitere Periode von f , so wahlen wir n ∈ IN0 mit nT ≤ T < (n + 1) T .
Dann ist T − nT eine Periode von f , und wegen 0 ≤ T − nT < T und T = inf M
folgt T = nT .
(ii): Ist T = 0, so gibt es zu jedem ε > 0 eine Periode T von f mit 0 < T < ε.
Fur beliebiges x0 ∈ IR liegt daher in jedem Intervall [x0, x0 + ε] ein ganzzahliges
Vielfaches nT von T , und hierfur gilt f(nT ) = f(0). Wegen der Stetigkeit von f ist
dies nur moglich fur f(x0) = f(0), d.h. f ist konstant.
Ist f periodisch mit der Periode T , so ist g : IR → C, g(x) := f(x T2π
) periodisch mit
der Periode 2π. Wir konnen uns daher von nun an auf 2π-periodische Funktionen
beschranken.
21.2 Fourierentwicklung periodischer Funktionen
Zur Approximation von 2π-periodischen Funktionen verwenden wir trigonometrische
Polynome (Beispiel 21.4.) bzw. trigonometrische Reihen
a0
2+
∞∑
n=1
(an cos(nx) + bn sin(nx)).
Um bei gegebener 2π-periodischer Funktion f die Wahl der an, bn zu begrunden und
um die Konvergenz einer solchen Reihe zu untersuchen, benotigen wir
Satz 21.9. Ist fn : [a, b] → IR eine gleichmaßig konvergente Folge integrierbarer
Funktionen, so ist auch f(x) := limn→∞ fn(x) integrierbar, und es gilt
limn→∞
b∫
a
fn(x) dx =
b∫
a
f(x) dx. (21.1)

21.2. FOURIERENTWICKLUNG PERIODISCHER FUNKTIONEN 331
Bemerkung 21.10. Der Spezialfall von Satz 21.9. einer Potenzreihe f und ihrer
Partialsummen fn wurde schon in Satz 17.5. gezeigt. 2
Beweis: (von Satz 21.9.)
Es sei Z eine Zerlegung von [a, b]. Dann gilt fur n ∈ IN (OZ bzw. UZ bezeichnet die
Ober- bzw. Untersumme zur Zerlegung Z)
OZ(f) − UZ(f) ≤ OZ(f − fn) + OZ(fn) −(
UZ(f − fn) + UZ(fn))
≤ 2 supa≤x≤b
|f(x) − fn(x)| (b − a) + (OZ(fn) − UZ(fn)).
Ist nun ε > 0 vorgegeben, so konnen wir zunachst n so groß wahlen, dass
2 supa≤x≤b
|f(x) − fn(x)| (b − a) <ε
2
gilt, und danach die Zerlegung Z so fein, dass
OZ(fn) − UZ(fn) <ε
2.
Dann ist OZ(f) − UZ(f) < ε, und f ist integrierbar.
Die Gleichung (21.1) erhalt man aus
∣∣∣∣
b∫
a
fn(x) dx −b∫
a
f(x) dx∣∣∣∣ =
∣∣∣∣
b∫
a
(fn(x) − f(x)) dx∣∣∣∣
≤ supa≤x≤b
|fn(x) − f(x)| |b − a| → 0
fur n → ∞.
Satz 21.11. Die Reihe
f(x) :=a0
2+
∞∑
n=1
(an cos(nx) + bn sin(nx))
sei gleichmaßig konvergent in [0, 2π]. Dann gilt
an =1
π
2π∫
0
f(x) cos(nx) dx, n ∈ IN0,
bn =1
π
2π∫
0
f(x) sin(nx) dx, n ∈ IN.

332 KAPITEL 21. PERIODISCHE FUNKTIONEN
Beweis: Zum Beweis benutzen wir, dass die Funktionen 1/√
2, sin(kx) und cos(kx),
k ∈ IN, orthonormal sind bzgl. des inneren Produktes
〈f, g〉 :=1
π
2π∫
0
f(x) g(x) dx (21.2)
(vgl. Satz 17.11.).
Da die Reihen f(x), f(x) sin(mx), f(x) cos(mx) gleichmaßig konvergieren, kann
man gliedweise integrieren:
1
π
2π∫
0
f(x) sin(mx) dx =a0
2π
2π∫
0
sin(mx) dx
+∞∑
n=1
(
an1
π
2π∫
0
cos(nx) sin(mx) dx + bn1
π
2π∫
0
sin(nx) sin(mx) dx)
= bm.
Genauso erhalt man
am =1
π
2π∫
0
f(x) cos(mx) dx.
Allgemeiner definieren wir fur jede Funktion f , fur die die Zahlen an und bn aus
Satz 21.11. erklart sind:
Definition 21.12. Es sei f : IR → IR eine 2π-periodische, uber [0, 2π] integrier-
bare Funktion.
Dann heißen die Zahlen
an :=1
π
2π∫
0
f(x) cos(nx) dx, n ∈ IN0,
bn :=1
π
2π∫
0
f(x) sin(nx) dx, n ∈ IN,
die Fourierkoeffizienten von f und
a0
2+
∞∑
n=1
(an cos(nx) + bn sin(nx))
heißt die Fourierreihe von f .
Bemerkung 21.13. Da mit f(x) auch f(x) ·sin(nx) und f(x) ·cos(nx) uber [0, 2π]
integrierbar sind, sind die Fourierkoeffizienten definiert. 2
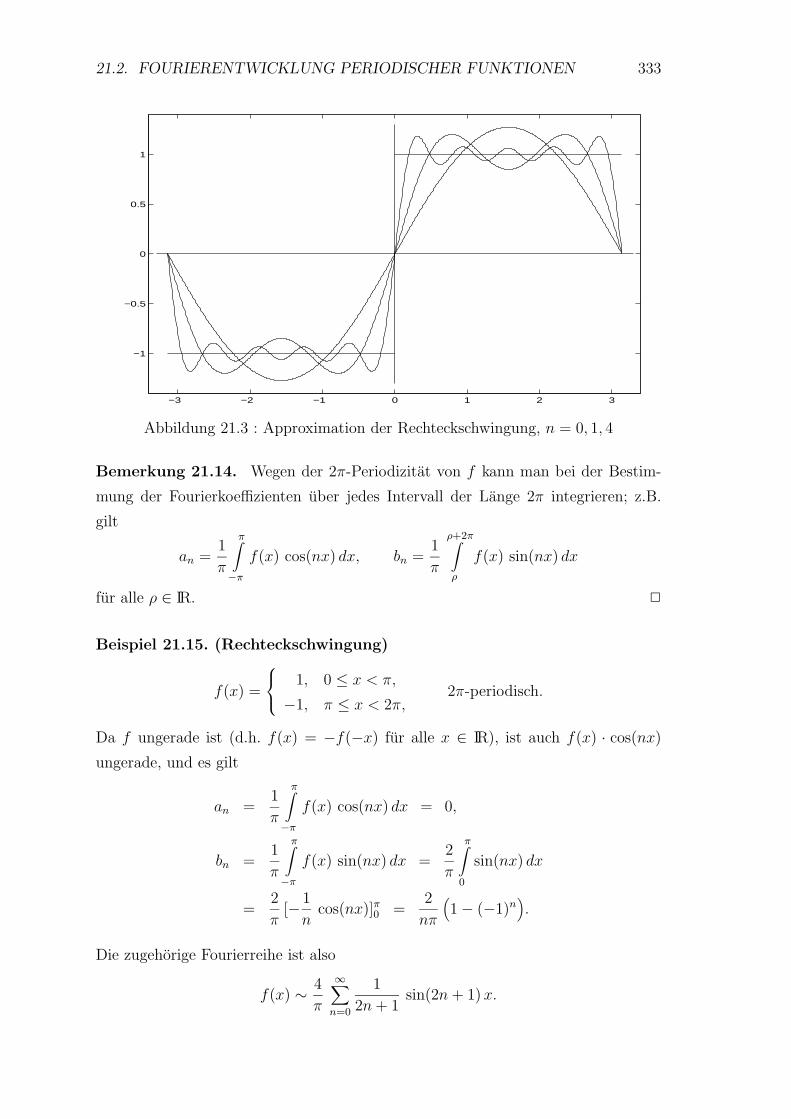
21.2. FOURIERENTWICKLUNG PERIODISCHER FUNKTIONEN 333
−3 −2 −1 0 1 2 3
−1
−0.5
0
0.5
1
Abbildung 21.3 : Approximation der Rechteckschwingung, n = 0, 1, 4
Bemerkung 21.14. Wegen der 2π-Periodizitat von f kann man bei der Bestim-
mung der Fourierkoeffizienten uber jedes Intervall der Lange 2π integrieren; z.B.
gilt
an =1
π
π∫
−π
f(x) cos(nx) dx, bn =1
π
ρ+2π∫
ρ
f(x) sin(nx) dx
fur alle ρ ∈ IR. 2
Beispiel 21.15. (Rechteckschwingung)
f(x) =
1, 0 ≤ x < π,
−1, π ≤ x < 2π,2π-periodisch.
Da f ungerade ist (d.h. f(x) = −f(−x) fur alle x ∈ IR), ist auch f(x) · cos(nx)
ungerade, und es gilt
an =1
π
π∫
−π
f(x) cos(nx) dx = 0,
bn =1
π
π∫
−π
f(x) sin(nx) dx =2
π
π∫
0
sin(nx) dx
=2
π[− 1
ncos(nx)]π0 =
2
nπ
(
1 − (−1)n)
.
Die zugehorige Fourierreihe ist also
f(x) ∼ 4
π
∞∑
n=0
1
2n + 1sin(2n + 1) x.

334 KAPITEL 21. PERIODISCHE FUNKTIONEN
Abbildung 21.3 enthalt die Funktion f und
fn(x) =4
π
n∑
j=0
1
2j + 1sin(2j + 1) x fur n = 0, 1, 4.
2
Wir haben gesehen, dass fur eine ungerade Funktion die Fourierkoeffizienten an
verschwinden. Allgemeiner gilt der Satz 21.16.
Satz 21.16. f : IR → IR sei 2π-periodisch und integrierbar uber [0, 2π]. Dann gilt
(i) Ist f eine gerade Funktion, so gilt bn = 0 fur alle n ∈ IN, d.h. f ist in eine
reine Kosinusreihe entwickelbar
f(x) ∼ a0
2+
∞∑
n=1
an cos(nx),
wobei
an =1
π
∫ π
−πf(x) cos nx dx =
2
π
∫ π
0f(x) cos nx dx.
(ii) Ist f eine ungerade Funktion, so gilt an = 0 fur alle n ∈ IN0, d.h. f ist in eine
reine Sinusreihe entwickelbar
f(x) ∼∞∑
n=1
bn sin(nx)
mit
bn =2
π
∫ π
0f(x) sin nx dx.
Beispiel 21.17. (Sagezahnkurve) Sei f(x) = x, −π ≤ x < π, 2π-periodisch.
Da f eine ungerade Funktion ist, laßt sich f in eine reine Sinusreihe entwickeln. Es
gilt
bn =1
π
π∫
−π
x sin(nx) dx =2
n(−1)n+1,
und die Fourierreihe ist
f(x) ∼ 2∞∑
n=1
(−1)n+1 1
nsin(nx).
2
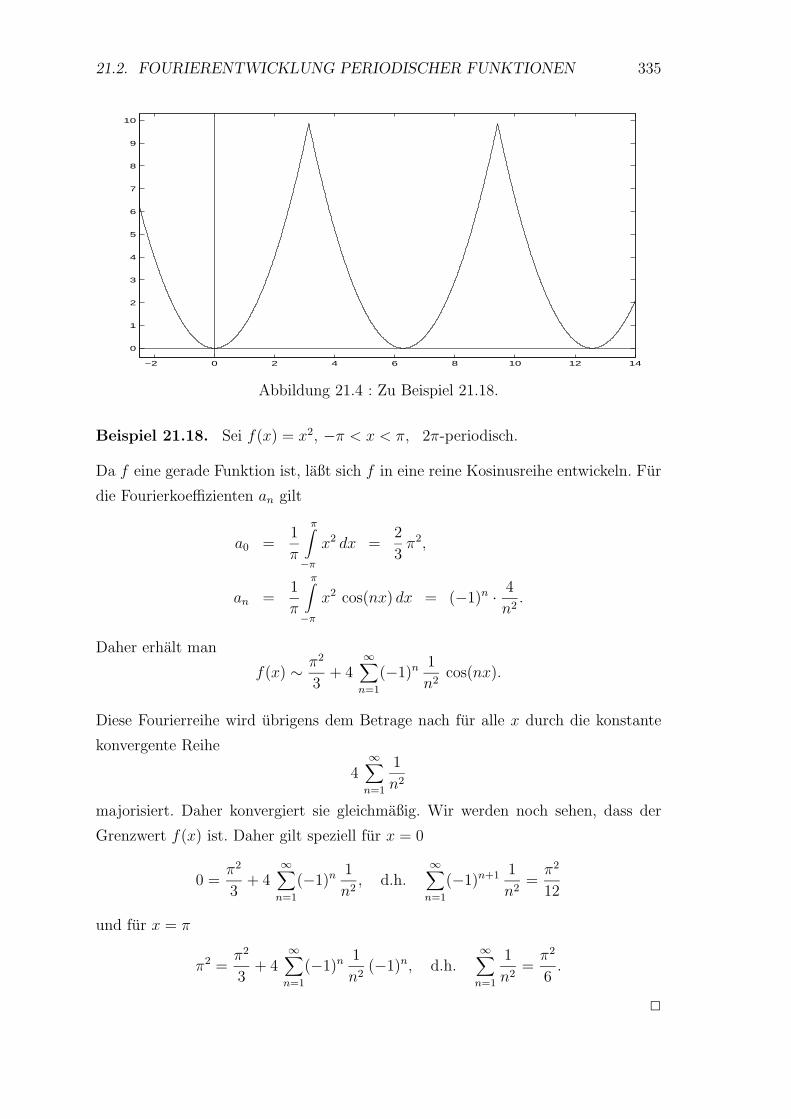
21.2. FOURIERENTWICKLUNG PERIODISCHER FUNKTIONEN 335
−2 0 2 4 6 8 10 12 14
0
1
2
3
4
5
6
7
8
9
10
Abbildung 21.4 : Zu Beispiel 21.18.
Beispiel 21.18. Sei f(x) = x2, −π < x < π, 2π-periodisch.
Da f eine gerade Funktion ist, laßt sich f in eine reine Kosinusreihe entwickeln. Fur
die Fourierkoeffizienten an gilt
a0 =1
π
π∫
−π
x2 dx =2
3π2,
an =1
π
π∫
−π
x2 cos(nx) dx = (−1)n · 4
n2.
Daher erhalt man
f(x) ∼ π2
3+ 4
∞∑
n=1
(−1)n 1
n2cos(nx).
Diese Fourierreihe wird ubrigens dem Betrage nach fur alle x durch die konstante
konvergente Reihe
4∞∑
n=1
1
n2
majorisiert. Daher konvergiert sie gleichmaßig. Wir werden noch sehen, dass der
Grenzwert f(x) ist. Daher gilt speziell fur x = 0
0 =π2
3+ 4
∞∑
n=1
(−1)n 1
n2, d.h.
∞∑
n=1
(−1)n+1 1
n2=
π2
12
und fur x = π
π2 =π2
3+ 4
∞∑
n=1
(−1)n 1
n2(−1)n, d.h.
∞∑
n=1
1
n2=
π2
6.
2

336 KAPITEL 21. PERIODISCHE FUNKTIONEN
21.3 Approximation im quadratischen Mittel
Wir geben nun eine andere Motivation fur die Definition der Fourierreihe.
Es sei
Tn :={α0
2+
n∑
j=1
(αj cos(jx) + βj sin(jx)) : αj, βj ∈ IR}
die Menge aller trigonometrischen Polynome vom Grade n und
‖g‖ :=
√√√√√
1
π
2π∫
0
(g(x))2 dx (21.3)
die durch das innere Produkt (21.2) induzierte Norm.
Satz 21.19. Es sei f : IR → IR 2π-periodisch und integrierbar uber [0, 2π], und
es sei
fn(x) :=a0
2+
n∑
j=1
(aj cos(jx) + bj sin(jx))
die abgeschnittene Fourierreihe von f . Dann gilt
(i) ‖f − fn‖ < ‖f − g‖ fur alle g ∈ Tn, g 6= fn, fn ist also die eindeutig bestimmte
beste Approximation fur f durch ein trigonometrisches Polynom vom Grade
n.
(ii) Es gilt die Besselsche Ungleichung
1
2a2
0 +n∑
j=1
(a2j + b2
j) ≤1
π
2π∫
0
(f(x))2 dx.
Beweis: (i): Nach dem Approximationssatz Satz 6.16. ist die Projektion P (f) von
f auf Tn die beste Approximation fur f in Tn, und diese ist charakterisiert durch
〈f − P (f), φj〉 = 0 fur alle Elemente φj einer Basis von Tn.
Wir wahlen als Basis von Tn
{1/√
2, cos(jx), sin(jx) : j = 1, . . . , n}.
Dann folgt die Behauptung aus der Orthogonalitat der Basiselemente und der De-
finition der Fourierkoeffizienten.

21.3. APPROXIMATION IM QUADRATISCHEN MITTEL 337
(ii): Es gilt
0 ≤ ‖f − fn‖2 =1
π
2π∫
0
(f(x))2 dx − 2
π
2π∫
0
f(x) fn(x) dx +1
π
2π∫
0
(fn(x))2 dx,
wobei
2π∫
0
f(x) fn(x) dx
=a0
2
2π∫
0
f(x) dx +n∑
j=1
(
aj
2π∫
0
f(x) cos(jx) dx + bj
2π∫
0
f(x) sin(jx) dx)
= π ·(
a20
2+
n∑
j=1
(a2j + b2
j))
,
und wegen der Orthonormalitat
2π∫
0
(fn(x))2 dx =
2π∫
0
(a0
2+
n∑
j=1
(
aj cos(jx) + bj sin(jx)))2
dx
= π ·(
a20
2+
n∑
j=1
(a2j + b2
j))
.
Damit folgt
0 ≤ 1
π
2π∫
0
(f(x))2 dx −(a2
0
2+
n∑
j=1
(a2j + b2
j))
.
Fur n → ∞ folgt aus der Besselschen Ungleichung
a20
2+
∞∑
j=1
(a2j + b2
j) ≤1
π
2π∫
0
(f(x))2 dx.
Die Reihe links ist also konvergent, und daher folgt fur die Fourierkoeffizienten jeder
integrierbaren Funktion
limn→∞ an = lim
n→∞ bn = 0.
Ferner konvergieren die Fourierpolynome genau dann im quadratischen Mittel gegen
f (d.h. in der Norm (21.3)), wenn die Parsevalsche Gleichung gilt:
a20
2+
∞∑
n=1
(a2n + b2
n) =1
π
2π∫
0
(f(x))2 dx.
Dies ist (ohne Beweis) fur alle uber [0, 2π] integrierbaren Funktionen (sogar fur
die wesentlich großere Klasse der im Lebesgueschen Sinne uber [0, 2π] quadratisch
integrierbaren Funktionen) der Fall.

338 KAPITEL 21. PERIODISCHE FUNKTIONEN
Die Approximation im quadratischen Mittel laßt zu, dass in einzelnen Punkten (z.B.
Unstetigkeitsstellen von f) durchaus große Abweichungen des approximierenden tri-
gonometrischen Polynoms auftreten konnen.
21.4 Gleichmaßige Konvergenz von
Fourierreihen
Es sei f eine stetige, 2π-periodische Funktion, die mit Ausnahme von endlich vielen
Stellen in [0, 2π] eine stetige Ableitung f ′ habe, wobei die Unstetigkeitsstellen von
f ′ Sprungstellen seien. Dann existieren die Fourierkoeffizienten von f ′
a′n =
1
π
ρ+2π∫
ρ
f ′(x) cos(nx) dx, b′n =1
π
ρ+2π∫
ρ
f ′(x) sin(nx) dx,
wobei ρ so gewahlt sei, dass f ′ in ρ stetig ist.
Durch partielle Integration erhalt man
a′n =
1
π[f(x) cos(nx)]ρ+2π
ρ +n
π
ρ+2π∫
ρ
f(x) sin(nx) dx = n bn
und genauso b′n = −n an, wobei an, bn die Fourierkoeffizienten von f sind.
Um die gleichmaßige Konvergenz der Fourierreihe von f zu zeigen, untersuchen wir
die Reihe der absoluten Betrage:
n∑
j=1
|aj cos(jx) + bj sin(jx)| =n∑
j=1
1
j|a′
j sin(jx) − b′j cos(jx)|.
Nach der Cauchy-Schwarzschen Ungleichung (Satz 2.50.) gilt
( n∑
j=1
|aj cos(jx) + bj sin(jx)|)2
=( n∑
j=1
1
j
∣∣∣ − b′j cos(jx) + a′
j sin(jx)∣∣∣
)2
≤( n∑
j=1
1
j2
)
·( n∑
j=1
(
a′j sin(jx) − b′j cos(jx)
)2)
.
Wegen
(a′j sin(jx) − b′j cos(jx))2 = a′
j2 + b′j
2 − (a′j cos(jx) + b′j sin(jx))2
≤ a′j2 + b′j
2

21.4. GLEICHMASSIGE KONVERGENZ VON FOURIERREIHEN 339
gilt weiter
( n∑
j=1
|aj cos(jx) + bj sin(jx)|)2
≤( n∑
j=1
1
j2
) n∑
j=1
(a′j2 + b′j
2),
und die Besselsche Ungleichung liefert
n∑
j=1
|aj cos(jx) + bj sin(jx)| ≤√√√√
n∑
j=1
1
j2·
√√√√√
1
π
2π∫
0
(f ′(x))2 dx
=: C
√√√√
n∑
j=1
1
j2.
Da die majorisierende Folge C
√n∑
j=1
1j2 konvergiert, konvergiert die Fourierreihe von
f gleichmaßig, und da alle Summanden aj cos(jx) + bj sin(jx) stetig sind, ist die
Grenzfunktion
F (x) :=a0
2+
n∑
j=1
(aj cos(jx) + bj sin(jx))
stetig in IR.
Um zu zeigen, dass F (x) = f(x) fur alle x ∈ IR gilt, betrachten wir die stetige
Funktion g(x) := F (x)−f(x). Da F (x) nach Satz 21.11. die Fourierkoeffizienten aj,
bj besitzt, sind alle Fourierkoeffizienten von g Null. Wir zeigen, dass daraus g(x) ≡ 0
folgt.
Lemma 21.20. Es sei g : IR → IR stetig und 2π-periodisch, und es seien alle
Fourierkoeffizienten von g Null. Dann gilt
g(x) = 0 fur alle x ∈ IR.
Beweis: (indirekt)
Angenommen g(x) 6≡ 0. Dann existiert wegen der Stetigkeit von g ein Intervall
[a, b] ⊂ [0, 2π] und o.B.d.A. ein m > 0 mit g(x) ≥ m fur alle x ∈ [a, b].
Wir wahlen ein trigonometrisches Polynom P1(x) := α + β · cos(x + φ), wobei α,
β, φ so gewahlt sind, dass P1(x) > 1 fur alle x ∈ (a, b) und |P1(x)| < 1 fur alle
x ∈ [0, a) ∪ (b, 2π] gilt.
Dann ist Pn(x) := (P1(x))n ein trigonometrisches Polynom vom Grade n, und daher
gilt2π∫
0
g(x) Pn(x) dx = 0.
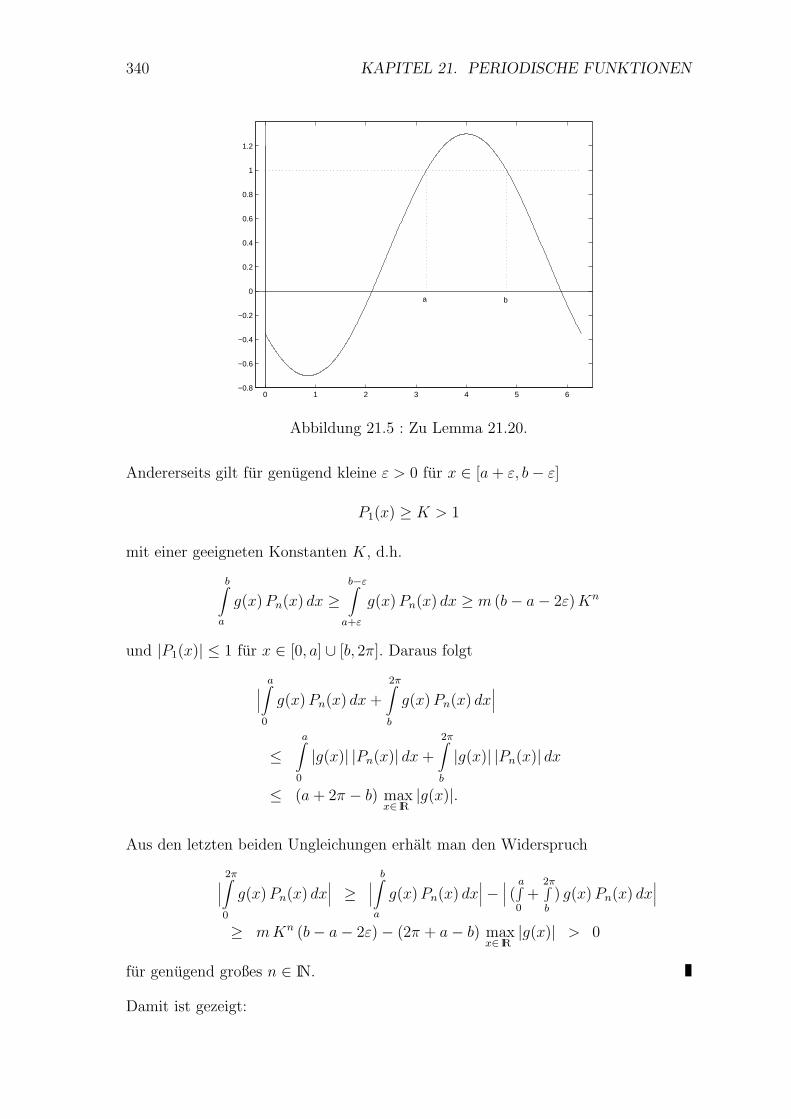
340 KAPITEL 21. PERIODISCHE FUNKTIONEN
0 1 2 3 4 5 6−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
a b
Abbildung 21.5 : Zu Lemma 21.20.
Andererseits gilt fur genugend kleine ε > 0 fur x ∈ [a + ε, b − ε]
P1(x) ≥ K > 1
mit einer geeigneten Konstanten K, d.h.
b∫
a
g(x) Pn(x) dx ≥b−ε∫
a+ε
g(x) Pn(x) dx ≥ m (b − a − 2ε) Kn
und |P1(x)| ≤ 1 fur x ∈ [0, a] ∪ [b, 2π]. Daraus folgt
∣∣∣
a∫
0
g(x) Pn(x) dx +
2π∫
b
g(x) Pn(x) dx∣∣∣
≤a∫
0
|g(x)| |Pn(x)| dx +
2π∫
b
|g(x)| |Pn(x)| dx
≤ (a + 2π − b) maxx∈ IR
|g(x)|.
Aus den letzten beiden Ungleichungen erhalt man den Widerspruch
∣∣∣
2π∫
0
g(x) Pn(x) dx∣∣∣ ≥
∣∣∣
b∫
a
g(x) Pn(x) dx∣∣∣ −
∣∣∣ (
a∫
0+
2π∫
b) g(x) Pn(x) dx
∣∣∣
≥ m Kn (b − a − 2ε) − (2π + a − b) maxx∈ IR
|g(x)| > 0
fur genugend großes n ∈ IN.
Damit ist gezeigt:

21.4. GLEICHMASSIGE KONVERGENZ VON FOURIERREIHEN 341
Satz 21.21. Es sei f : IR → IR stetig, 2π-periodisch und in [0, 2π] mit Ausnahme
von endlich vielen Stellen stetig differenzierbar, wobei f ′ in den Unstetigkeitsstellen
Sprungstellen besitze. Dann konvergiert die Fourierreihe von f gleichmaßig gegen f .
Bemerkung 21.22. Es genugt nicht, f als stetig vorauszusetzen. Es gibt sogar
stetige Funktionen, deren Fourierreihe nicht einmal punktweise gegen f konvergiert.
2
Wir lassen nun Sprungstellen fur die Funktion f zu. Als Vorbereitung untersuchen
wir zunachst die Konvergenz der Fourierreihe der Sagezahnschwingung (vgl. Bei-
spiel 21.17.).
Lemma 21.23. Es sei f(x) := x, −π < x < π, 2π–periodisch. Dann konvergiert
die Fourierreihe
2∞∑
n=1
(−1)n+1 1
nsin nx
gleichmaßig in jedem Intervall [−π + ε, π − ε], ε ∈ (0, π) gegen f .
Beweis: Fur die Partialsumme
fn(x) := 2n∑
j=1
(−1)j+1 1
jsin jx
gilt
f ′n(x) = 2
n∑
j=1
(−1)j+1 cos jx = 2Re( n∑
j=1
(−1)j+1eijx)
= 2Re(
1 −n∑
j=0
( − eix)j)
= 2Re(
1 − 1 − (−eix)n+1
1 + eix
)
= 2Re(eix + (−eix)n+1
1 + eix
)
= Ree−0.5ix(eix + (−eix)n+1)
0.5(e−0.5ix + e0.5ix)
=1
cos 0.5xRe
(
e0.5ix + (−1)n+1ei(n+0.5)x)
=1
cos 0.5x
(
cos 0.5x + (−1)n+1 cos(n + 0.5)x)
= 1 + (−1)n+1 cos(n + 0.5)x
cos 0.5x.
Es sei
gn(x) := fn(x) − (−1)n+1 1
n + 0.5· sin(n + 0.5)x
cos 0.5x.

342 KAPITEL 21. PERIODISCHE FUNKTIONEN
Dann folgt
g′n(x) = f ′
n(x)
−(−1)n+1 · 1
n + 0.5· (n + 0.5) cos 0.5x cos(n + 0.5)x + 0.5 sin 0.5x sin(n + 0.5)x
(cos 0.5x)2
= 1 − (−1)n+1 1
2n + 1· sin 0.5x sin(n + 0.5)x
(cos 0.5x)2.
Fur x ∈ [−π + ε, π − ε] ist cos 0.5x ≥ cos(0.5(π − ε)) > 0 von 0 wegbeschrankt.
Daher gilt
limn→∞
g′n(x) = 1 gleichmaßig in [−π + ε, π − ε],
und es folgt
limn→∞
x∫
0
g′n(t) dt =
x∫
0
(
limn→∞ g′
n(t))
dt = x gleichmaßig in [−π + ε, π − ε].
Hiermit erhalten wir schließlich
limn→∞ fn(x) = lim
n→∞
(
gn(x) + (−1)n+1 1
n + 0.5· sin(n + 0.5)x
cos 0.5x
)
= limn→∞
(x∫
0
g′n(t) dt + (−1)n+1 1
n + 0.5· sin(n + 0.5)x
cos 0.5x
)
= x gleichmaßig in [−π + ε, π − ε].
Es sei nun f(x) eine 2π-periodische Funktion, die uberall stetig ist mit Ausnahme
der Punkte (2k + 1) π, k ∈ ZZ, wo sie einen Sprung der Hohe 2π habe:
f((2k + 1) π + 0) − f((2k + 1) π − 0) = 2π,
und die eine Ableitung besitze, die der Voraussetzung von Satz 21.21. genugt. Dann
erfullt mit F (x) := x, −π < x < π, 2π-periodisch, die Funktion g(x) := f(x) +
F (x) die Voraussetzungen von Satz 21.21., besitzt also eine gleichmaßig konvergente
Fourierreihe
g(x) =a0
2+
∞∑
j=1
(aj cos(jx) + bj sin(jx)).
Wegen f(x) = g(x) − F (x) ist dann
f(x) ∼ a0
2+
∞∑
j=1
(
aj cos(jx) + (bj + (−1)j 2
j) sin(jx)
)
.
die Fourierreihe von f , und diese konvergiert nach Lemma 21.23. gleichmaßig in
jedem Intervall, das keine Sprungstelle (2k + 1) π von f enthalt, gegen f(x).

21.5. ASYMPTOTISCHES VERHALTEN DER FOURIERKOEFFIZIENTEN343
Wegen∞∑
j=1
(−1)j 2
jsin(jx)
∣∣∣∣∣x=(2k+1) π
= 0
konvergiert die Fourierreihe von f fur x0 = (2k + 1) π gegen
g(x0) =f(x0 + 0) + f(x0 − 0)
2,
den Mittelwert der Grenzwerte von links und rechts.
Besitzt f an irgend einer Stelle x0 ∈ (−π, π) eine Sprungstelle der Hohe f(x0 +0)−f(x0 − 0) =: s, so kann man diese genauso behandeln durch den Ubergang zu
g(x) := f(x) +s
2πF (x − π − x0).
Schließlich kann man auch endlich viele Sprunge von f auf diese Weise kompensieren
und erhalt
Satz 21.24. Sei f : IR → IR 2π-periodisch, stuckweise stetig und stuckweise
stetig differenzierbar. Dann konvergiert die Fourierreihe von f in jedem Stetigkeits-
punkt x von f gegen f(x) und in jeder Sprungstelle x von f gegen den Mittelwert
(f(x+0)+f(x−0))/2. Die Konvergenz ist gleichmaßig in jedem Intervall, das keine
Sprungstellen von f enthalt.
21.5 Asymptotisches Verhalten der
Fourierkoeffizienten
Wir untersuchen nun das asymptotische Verhalten der Fourierkoeffizienten einer
Funktion f fur n → ∞. Erfullt f die Voraussetzungen von Satz 21.21., so gilt fur
die Fourierkoeffizienten an, bn von f
an = − 1
nb′n, bn =
1
na′
n,
wobei a′n, b′n die Fourierkoeffizienten von f ′ sind. Da nach der Besselschen Unglei-
chung a′n → 0, b′n → 0 fur n → ∞ gilt, folgt
limn→∞n an = lim
n→∞n bn = 0.
Man schreibt hierfur auch
an = o(1
n), bn = o(
1
n) fur n → ∞.
(gesprochen: an ist ein klein o von 1 durch n; o heißt Landau Symbol)

344 KAPITEL 21. PERIODISCHE FUNKTIONEN
Beispiel 21.25. f(x) = x2, −π ≤ x ≤ π, 2π-periodisch, ist stetig und f ′ besitzt
Sprunge in (2k + 1) π, k ∈ ZZ. Die Fourierkoeffizienten an = (−1)n · 4/n2, bn = 0
erfullen
limn→∞
n an = 0, limn→∞
n bn = 0.
2
Ist f 2π-periodisch, k-mal stetig differenzierbar und erfullt die k-te Ableitung die
Voraussetzungen von Satz 21.21., so erhalt man entsprechend den Formeln an =
−b′n/n, bn = a′n/n durch (k + 1)-malige partielle Integration
an = (−1)ℓ 1
nk+1a(k+1)
n , bn = (−1)ℓ 1
nk+1b(k+1)n
fur k = 2ℓ − 1, und
an = (−1)ℓ+1 1
nk+1b(k+1)n , bn = (−1)ℓ 1
nk+1a(k+1)
n
fur k = 2ℓ, wobei a(k+1)n und b(k+1)
n die Fourierkoeffizienten von f (k+1) sind.
In jedem Fall gilt also wegen limn→∞ a(k+1)
n = limn→∞ b(k+1)
n = 0
limn→∞(nk+1 an) = lim
n→∞(nk+1 bn) = 0,
d.h.
an = o( 1
nk+1
)
, bn = o( 1
nk+1
)
.
Erfullt f die Voraussetzungen von Satz 21.24., so kann man f als Summe einer
Funktion g, die die Voraussetzungen von Satz 21.21. erfullt, und von Sagezahnkurven
h(x) = s F (x − x0) schreiben. h(x) besitzt die Fourierreihe
h(x) ∼ 2s∞∑
n=1
(−1)n+1 1
nsin(n (x − x0))
= 2s∞∑
n=1
(−1)n+1 1
n(cos(nx0) sin(nx) − sin(nx0) cos(nx)),
also gilt fur die Fourierkoeffizienten an und bn: |an|, |bn| ≤ C/n.
Da die Fourierkoeffizienten an, bn von g sogar limn→∞n an = lim
n→∞n bn = 0 erfullen,
also erst recht |an|, |bn| ≤ C/n, gibt es also eine Konstante C > 0, so dass fur die
Fourierkoeffizienten von f gilt
|an| ≤C
n, |bn| ≤
C
n.

21.6. ANDERE FORMEN DER FOURIERREIHE 345
0 0.5 1 1.5 2
0
0.5
1
|an|
|bn||A
n|
αn
δn
Abbildung 21.6
Ist f schließlich (k− 1)-mal stetig differenzierbar und besitzt f eine k-te Ableitung,
die den Voraussetzungen von Satz 21.24. genugt, so erhalt man wieder durch k-
malige partielle Integration
|an|, |bn| ≤1
nkmax(|a(k)
n |, |b(k)n |)
und wie oben |a(k)n |, |b(k)
n | ≤ C/n, insgesamt also
|an|, |bn| ≤C
nk+1.
Man schreibt hierfur
an = O( 1
nk+1
)
, bn = O( 1
nk+1
)
und liest an ist ein groß O von 1/nk+1. Auch O heißt Landau Symbol.
Beispiel 21.26. f(x) = x2, −π ≤ x ≤ π, 2π-periodisch, ist 0-mal stetig differen-
zierbar und f ′(x) erfullt die Voraussetzungen von Satz 21.24.. Fur die Fourierkoef-
fizienten gilt
|an| =4
n2, |bn| = 0 ≤ 4
n2.
2
21.6 Andere Formen der Fourierreihe
Wir betrachten nun andere Formen der Fourierreihe: Die 2π-periodische Funktion
f : IR → IR besitze die Fourierreihe
f(x) =a0
2+
∞∑
n=1
(
an cos(nx) + bn sin(nx))
.

346 KAPITEL 21. PERIODISCHE FUNKTIONEN
Wir definieren Winkel αn, δn wie in dem Dreieck der Abbildung 21.6 und A0 := a0/2,
An :=√
a2n + b2
n. Dann gilt
f(x) = A0 +∞∑
n=1
An cos(nx − αn)
und
f(x) = A0 +∞∑
n=1
An sin(nx + δn).
In beiden Fallen ist An die Amplitude der Komponente der Frequenz n (die Ampli-
tude des n-ten harmonischen Mittels von f).
Wegen
cos(nx) =einx + e−inx
2, sin(nx) =
einx − e−inx
2i
gilt
f(x) =a0
2+
∞∑
n=1
(an
2(einx + e−inx) − bn i
2(einx − e−inx)
)
=∞∑
n=−∞cn einx,
wobei
c0 :=a0
2, cn =
an − i bn
2, c−n =
an + i bn
2, n > 0.
Die komplexen Fourierkoeffizienten cn kann man auch direkt ausrechnen:
cn =1
2π
2π∫
0
f(x) (cos(nx) − i sin(nx)) dx =1
2π
2π∫
0
f(x) e−inx dx,
c−n =1
2π
2π∫
0
f(x) (cos(nx) + i sin(nx)) dx =1
2π
2π∫
0
f(x) einx dx,
c0 =a0
2=
1
2π
2π∫
0
f(x) dx =1
2π
2π∫
0
f(x) ei0x dx ;
in jedem Fall gilt also
ck =1
2π
2π∫
0
f(x) e−ikx dx, k ∈ ZZ.
Bemerkung 21.27. Die ck lassen sich als Integrale komplexwertiger Funktionen
φ : [a, b] → C berechnen. Ein solches φ ist genau dann integrierbar, wenn die reellen

21.7. NUMERISCHE FOURIERANALYSE UND -SYNTHESE 347
Funktionen Re φ, Im φ : [a, b] → IR integrierbar sind. Das Integral ist dann definiert
durchb∫
a
φ(x) dx =
b∫
a
Re φ(x) dx + i
b∫
a
Im φ(x) dx.
2
Wegen cn · c−n = (a2n + b2
n)/4 erhalt man die Amplitude des n-ten harmonischen
Mittels aus den komplexen Fourierkoeffizienten durch
An = 2√
cn · c−n.
Beispiel 21.28. f(x) = e−x, −π ≤ x < π, 2π-periodisch. Dann gilt
cn =1
2π
π∫
−π
e−x e−inx dx =1
2π[e−(1+i n) x
−(1 + i n)]π−π =
e(1+i n) π − e−(1+i n) π
2π (1 + i n),
und wegen ei nπ = cos nπ + i sin nπ = (−1)n
cn =(−1)n (1 − i n)
(1 + n2) πsinh(π).
Wegen
an = cn + c−n =(−1)n · 2 sinh(π)
(1 + n2) π, bn = i (cn − c−n) =
(−1)n · 2n sinh(π)
(1 + n2) π
erhalt man hieraus die reelle Fourierreihe. 2
21.7 Numerische Fourieranalyse und -synthese
Die Integrale, die die Fourierkoeffizienten an und bn bzw. cn festlegen, konnen nur in
seltenen Fallen exakt ausgewertet werden und mussen numerisch bestimmt werden.
Hierzu verwendet man stets die Trapezregel, die fur eine 2π-periodische Funktion f
wegen f(0) = f(2π) die Gestalt hat
2π∫
0
f(x) dx ≈ 2π
m
m∑
j=1
f(j2π
m) =: Tm(f). (21.4)
Aufgrund der Uberlegungen in Kapitel 19 ist der Fehler von (21.4) ein O(1/m2).
Tatsachlich gilt fur f ∈ C2k[0, 2π] in diesem speziellen Fall einer periodischen Funk-
tion (vgl. Stoer [20, S. 105])
2π∫
0
f(x) dx − Tm(f) = O( 1
m2k
)
,

348 KAPITEL 21. PERIODISCHE FUNKTIONEN
und eine hohere Konvergenzordnung ist nicht erreichbar.
Es ist auch anschaulich klar, dass fur periodische Funktionen die Trapezregel optimal
ist, denn wegen2π∫
0
f(x) dx =
a+2π∫
a
f(x) dx fur alle a ∈ IR
ist es nicht sinnvoll, gewisse Knoten starker zu gewichten als andere oder die Knoten
in einem Teil des Integrationsintervalls dichter zu wahlen als in einem anderen.
Als Naherungen fur die Fourierkoeffizienten erhalt man aus (21.4) mit h = 2π/m
ak =1
π
2π∫
0
f(x) cos(kx) dx ≈ 2
m
m∑
j=1
f(j h) cos(kjh) =: Ak, (21.5)
bk ≈ 2
m
m∑
j=1
f(j h) sin(kjh) =: Bk, (21.6)
ck ≈ 1
m
m∑
j=1
f(j h) e−i kjh =: Ck. (21.7)
Diese Naherungsformeln sind nicht fur beliebig große k brauchbar, denn wegen der
Periodizitat der Sinus- und Kosinusfunktion gilt Ak+ℓm = Ak, Bk+ℓm = Bk, Ck+ℓm =
Ck, wahrend limk→∞
ak = limk→∞
bk = limk→±∞
ck = 0 gilt. Man akzeptiert daher Ak und Bk
nur fur k < m2
und Ck nur fur |k| < m2
als Naherungen fur ak, bk und ck.
Die Naherungen in (21.5), (21.6) und (21.7) fur die Fourierkoeffizienten konnen
auch auf andere Weise begrundet werden. Wir betrachten das Problem der trigo-
nometrischen Interpolation (auch diskrete Fourieranalyse):
Bestimme ein trigonometrisches Polynom f , das eine gegebene 2π-perio-
dische Funktion f an den aquidistanten Stellen xj := j h := j 2πm
inter-
poliert: f(xj) = f(xj), j = 1, . . . ,m.
Dieses Problem ist stets eindeutig losbar; die Losung wird im folgenden Satz 21.29.
beschrieben.
Satz 21.29. Es sei eine 2π-periodische Funktion f an den aquidistanten Knoten
xj := j h, j = 1, . . . ,m, h := 2π/m, gegeben.
Dann erfullen die trigonometrischen Polynome
f(x) =m−1∑
k=0
ck ei kx

21.7. NUMERISCHE FOURIERANALYSE UND -SYNTHESE 349
und
f(x) =a0
2+
µ−1∑
k=1
(ak cos(kx) + bk sin(kx)) +θ
2aµ cos(µx) (21.8)
mit θ = 0, µ = (m− 1)/2 fur ungerades m und θ = 1, µ = m/2 fur grades m, wobei
ck =1
m
m∑
j=1
f(j h) e−i jkh, (21.9)
ak =2
m
m∑
j=1
f(j h) cos(jkh), (21.10)
bk =2
m
m∑
j=1
f(j h) sin(jkh) (21.11)
gilt, die Interpolationsbedingung f(xj) = f(xj) bzw. f(xj) = f(xj), j = 1, . . . ,m.
Zum Beweis benotigen wir eine Satz 17.11. entsprechende diskrete Orthogonalitats-
relation. Wir formulieren diese nur fur die Funktionen eikx und fuhren die Rechnung
(der Bequemlichkeit halber) im Komplexen durch.
Wir betrachten das Skalarprodukt
(f, g)m := hm∑
ℓ=1
f(xℓ) g(xℓ)
und die zugehorige Norm
‖f‖m :=√
(f, f)m.
Man beachte, dass dies kein Skalarprodukt und keine Norm auf einem Funktionen-
raum sind, sondern auf dem Raum der diskreten Werte (f(x1), . . . , f(xm))T , also
auf dem Cm.
Satz 21.30. (diskrete Orthogonalitat) Fur φk(x) := eikx, k ∈ ZZ, gilt
(φk, φl)m =
2π, fallsk − ℓ
m∈ ZZ,
0, sonst.
Beweis: Mit q := exp(i k−ℓm
2π) gilt wegen exp(ix) = exp(−ix)
(φk, φℓ)m = hm∑
j=1
exp(i kjh) exp(−i ℓjh)
= hm∑
j=1
exp(i (k − ℓ) jh) = hm∑
j=1
qj.

350 KAPITEL 21. PERIODISCHE FUNKTIONEN
Ist (k − ℓ)/m ganzzahlig, so gilt q = 1, und daher
(φk, φℓ)m = m h = 2π.
Ist (k − ℓ)/m nicht ganzzahlig, so folgt q 6= 1 und qm = 1, und daher
(φk, φℓ)m = h qm−1∑
j=0
qj = h q1 − qm
1 − q= 0.
Beweis: (von Satz 21.29.)
Die Interpolationsbedingungen lauten
f(xj) = f(xj) =m−1∑
k=0
ck φk(xj), j = 1, . . . ,m. (21.12)
Dieses lineare Gleichungssystem zur Bestimmung der ck kann man mit Hilfe von
Satz 21.30. leicht losen:
(f, φℓ)m = hm∑
j=1
f(xj) φℓ(xj) = hm∑
j=1
m−1∑
k=0
ck φk(xj) φℓ(xj)
=m−1∑
k=0
ck hm∑
j=1
φk(xj) φℓ(xj) =m−1∑
k=0
ck (φk, φℓ)m = 2π cℓ,
d.h.
cℓ =1
2π(f, φℓ)m =
1
m
m∑
j=1
f(jh) ei jℓh.
Das Gleichungssystem (21.12) ist also stets losbar, und da man wie oben fur das
homogene Problem (f(xj) = 0, j = 1, . . . ,m) als eindeutige Losung die triviale
erhalt, ist (21.12) eindeutig losbar.
Es sei nun m ungerade und µ := (m− 1)/2. Dann sieht man wie eben ein, dass das
Interpolationsproblem
Bestimme dk, k = −µ, . . . , µ, mit f(xj) =µ∑
k=−µdk φk(xj), j = 1, . . . ,m,
eindeutig losbar ist, und dass die Losung wieder gegeben ist durch
dk =1
2π(f, φk)m =
1
m
m∑
j=1
f(jh) e−i jkh.

21.7. NUMERISCHE FOURIERANALYSE UND -SYNTHESE 351
Hiermit erhalt man
f(x) =µ
∑
k=−µ
dk φk(x) =1
m
µ∑
k=−µ
m∑
j=1
f(xj) e−i jkh ei kx
=1
m
µ∑
k=−µ
m∑
j=1
f(xj)(
cos(k(x − xj)) + i sin(k(x − xj)))
=1
m
µ∑
k=−µ
m∑
j=1
f(xj) cos(k(x − xj)) +i
m
m∑
j=1
f(xj)µ
∑
k=−µ
sin(k(x − xj)).
Da sin ungerade ist, ist der rechte Summand 0, und wegen der Geradheit von cos
folgt
f(x) =1
m
m∑
j=1
f(xj) +2
m
µ∑
k=1
m∑
j=1
f(xj) cos(k(x − xj))
=1
2a0 +
2
m
µ∑
k=1
m∑
j=1
f(xj) (cos(kx) cos(kxj) + sin(kx) sin(kxj)),
d.h. (21.8) mit (21.10) und (21.11) fur ungerades m.
Die Rechnung fur gerades m verlauft genauso.
Die interpolierenden Funktionen sind i.a. verschieden:
Fur m = 2, f(π) = 1, f(2π) = 0 gilt
c0 =f(π) e0 + f(2π) e0
2=
1
2, c1 =
f(π) e−π i + f(2π) e−2π i
2= −1
2,
d.h. f(x) = (1 − eix)/2 = (1 − cos x − i sin x)/2 und a0 = 1, a1 = −1, d.h.
f(x) =1 − cos x
2.
Ist dk wie im Beweis zu Satz 21.29. definiert, so gilt fur 0 < k < µ
d−k =1
m
m∑
j=1
f(jh) ei jkh e−i jmh =1
m
m∑
j=1
f(jh) e−i j (m−k) h = cm−k.
Ferner gilt wie fur die (diskreten) Fourierkoeffizienten
ak = dk + d−k = ck + cm−k, bk = −i (dk − d−k) = −i (ck − cm−k).
Ist f eine reelle Funktion, so gilt cm−j = d−j = dj = cj, und man erhalt noch
spezieller
ak = 2 Re ck, bk = −2 Im ck, k = 0, . . . ,m
2.

352 KAPITEL 21. PERIODISCHE FUNKTIONEN
In jedem Fall genugt es also, die komplexen (diskreten) Fourierkoeffizienten
cℓ :=1
m
m∑
j=1
f(xj) e−i ℓxj
zu berechnen. Wir geben hierfur im folgenden die Ideen fur einen sehr schnellen
Algorithmus, die schnelle Fouriertransformation (fast Fouriertransform, FFT),
an, die Cooley und Tuckey (1965) zugeschrieben wird, aber erstmals von Good (1958
und 1960) veroffentlicht wurde.
Wir betrachten nur den Fall m = 2p, p ∈ IN, da hierfur der Algorithmus am besten
arbeitet und am leichtesten zu durchschauen ist.
Zur Abkurzung setzen wir
fj :=1
mf(xj), j = 0, 1, . . . ,m,
w := e−i h = e−(2π/m) i.
Dann gilt f0 = fm und wm = 1, und wir haben
cℓ =m∑
j=1
fj wjℓ, ℓ = 0, 1, . . . ,m − 1, (21.13)
zu berechnen.
Die Summe (21.13) kann man aufteilen in
cℓ =m/2∑
ι=1
f2ι w2ιℓ +
m/2∑
ι=1
f2ι−1 w(2ι−1) ℓ
=m/2∑
ι=1
f2ι (w2)ιℓ + w−ℓ
m/2∑
ι=1
f2ι−1 (w2)ιℓ, ℓ = 0, . . . ,m − 1.
Da wm = 1 gilt, ist wr = wr+ℓ m fur alle ℓ ∈ ZZ. Schreiben wir also fur das in (21.13)
auftretende ℓ
ℓ = αm
2+ λ
mit α = 0 fur ℓ = 0, . . . , m2− 1 und α = 1 fur ℓ = m
2, . . . ,m − 1, so gilt
(w2)ιℓ = (w2)ι (α m2
+λ) = (wm)αι (w2)ιλ = (w2)ιλ,
und daher
cℓ =m/2∑
ι=1
f2ι (w2)ιλ + w−ℓ
m/2∑
ι=1
f2ι−1 (w2)ιλ, ℓ = 0, . . . ,m − 1,
=: dλ + w−ℓ eλ. (21.14)

21.7. NUMERISCHE FOURIERANALYSE UND -SYNTHESE 353
Die Summen dλ und eλ haben wieder dieselbe Struktur wie die Summe cℓ (Beachte:
mit m1 := m/2 = 2p−1 und w1 := w2 gilt wm11 = 1). Wir konnen also die Fourier-
analyse in (21.13) durch zwei Fourieranalysen mit der halben Knotenzahl ersetzen.
Wendet man dieselbe Idee an, um dλ und eλ zu berechnen, so muss man 4 = 22
Fourieranalysen mit je m2 := m1/2 = 2p−2 Summanden berechnen. Fahrt man mit
der Zerlegung so fort, so hat man schließlich 2p Fourieranalysen mit jeweils mp = 2p−p
Summanden auszufuhren, die wegen wp = w2p−1 = w4
p−2 = . . . = wm = 1 trivial sind.
Ihre Werte sind gerade f1, . . . , fm.
Beim Algorithmus geht man umgekehrt vor. Man beginnt mit vorgegebenen Werten
f1, f2, . . . , fm, berechnet hiermit m/2 Fouriersummen mit 2 Summanden aus, hieraus
m/4 Fouriersummen mit 22 = 4 Summanden, usw.
Die tatsachliche Implementierung dieses Algorithmus ist technisch nicht ganz ein-
fach.
Wir ermitteln nun den Aufwand zur Bestimmung aller Fourierkoeffizienten. Verwen-
det man hierzu Formel (21.13) naiv, so benotigt man m2 komplexe Multiplikationen.
Wir bezeichnen mit FTk eine Fouriertransformation der Ordnung k, d.h. einen Satz
von k Parametern wie z.B. die cℓ oder dλ oder eλ oder . . .
Wegen (21.14) erhalt man alle cj durch 2p Multiplikationen aus den beiden FT2p−1
(dλ) und (eλ), die zwei FT2p−1 erhalt man im zweiten Reduktionsschritt mit 2 · 2p−1
Multiplikationen aus vier FT2p−2 . Allgemein erhalt man im s-ten Reduktionsschritt
2s FT2p−s mit 2s · 2p−s = 2p Multiplikationen aus 2s+1 FT2p−(s+1) .
Da nach p Redunktionsschritten die Daten f0, . . . , fm−1 erreicht sind und fur jeden
Reduktionsschritt 2p komplexe Multiplikationen benotigt werden, ist der gesamte
Aufwand zur Bestimmung aller 2p Fourierkoeffizienten p · 2p Multiplikationen.
Bemerkung 21.31. Sind die Daten fj reell, so gilt cm−j = cj, k = 0, . . . , m2− 1,
und der Aufwand zur Bestimmung der cj kann noch einmal halbiert werden zup
22p.
2
Bemerkung 21.32. Soll ein gegebenes trigonometrisches Polynom
f(x) =m−1∑
j=0
cj ei jx
an den aquidistanten Punkten xk = k h, k = 0, . . . ,m, ausgewertet werden (Fourier-
synthese), so kann diese ebenfalls mit der FFT ausgefuhrt werden. 2

Literaturverzeichnis
[1] M. Abramowitz, I. A. Stegun (Eds.): Handbook of Mathematical Functions .
Dover, New York 1964
[2] F. Ayres Jr.: Schaum’s Outline of Theory and Problems of Differential and
Integral Calculus . McGraw-Hill, New York 1962
[3] A. Blickensdrfer-Ehlers, W. G. Eschmann, H. Neunzert, K. Schelkes: Ana-
lysis 1 und 2 . Springer, Berlin 1980
[4] I.N. Bronstein, K.A. Semendjajew, G. Musiol, H. Mhlig: Taschenbuch der
Mathematik . Verlag Harri Deutsch, Thun 1993
[5] K. Burg, H. Haf, F. Wille: Hhere Mathematik fr Ingenieure (Band I–IV).
Teubner, Stuttgart 1985
[6] O. Forster: Analysis (Band 1–3). Vieweg, Braunschweig 1976
[7] H.S. Gaskill, P.P. Narayanaswami: Foundations of Analysis. The Theory of
Limits . Harper & Row, New York 1989
[8] K. Habetha: Hhere Mathematik fr Ingenieure und Physiker (Band 1–3). Klett,
Stuttgart 1976
[9] H. Heuser: Lehrbuch der Analysis (Band 1 und 2). Teubner, Stuttgart 1984
[10] W. Mackens, H. Voß: Mathematik I fr Studierende der Ingenieurwissenschaf-
ten. HECO-Verlag, Ahlsdorf 1993
[11] W. Mackens, H. Voß: Aufgaben und Lsung zu Mathematik I fr Studierende
der Ingenieurwissenschaften. HECO-Verlag, Ahlsdorf 1994
[12] H. von Mangoldt, K. Knopp: Einfhrung in die Hhere Mathematik . Band I –
III, Hirzel Verlag, Stuttgart 1958
354

LITERATURVERZEICHNIS 355
[13] J. Marsden, A. Weinstein: Calculus . Benjamin/Cummings, Menlo Park 1980
[14] E. Martensen: Analysis (Band 1–3). Bibliographisches Institut, Mannheim
1977
[15] K. Meyberg, P. Vachenauer: Hhere Mathematik (Band 1 – 2) Springer, Berlin
1991
[16] K. Niederenk, H. Yserentant: Funktionen einer Vernderlichen. Vieweg,
Braunschweig 1987
[17] R. Sauer, I. Szabo (Eds.): Mathematische Hilfsmittel des Ingenieurs (Teil I–
IV). Springer, Berlin 1967
[18] H. R. Schwarz: Numerische Mathematik . Teubner, Stuttgart 1988
[19] R. S. L. Srivastava: Engineering Mathematics (vol. 1–2). Tata McGraw-Hill,
New Delhi 1980
[20] J. Stoer: Einfhrung in die Numerische Mathematik I . Springer, Berlin 1976
[21] J. Stoer, R. Bulirsch: Einfhrung in die Numerische Mathematik II . Springer,
Berlin 1973
[22] K. A. Stroud: Engineering Mathematics . Programmes and Problems. Mac-
Millan, London 1982
[23] G.B. Thomas, Jr., R.L. Finney: Calculus and Analytic Geometry . 8th ed.,
Addison–Wesley, Reading 1992

Index
m-fache Nullstelle, 204
- . Bisektionsmethode, 201
- . Fixpunktproblem, 205
- . Francis, 228
- . Gauß-Seidel-Verfahren, 223
- . Intervallhalbierungsmethode, 201
- . Jacobi Iteration, 222
- . Konvergenzrate, 227
- . Kublanovskaja, 228
- . Potenzmethode, 226, 227
- . QR-Algorithmus, 228
- . QR-Zerlegung, 228
- . Rayleigh Quotienten, 225
- . SOR-Verfahren, 224
- . Ahnlichkeitstransformation, 228
- . ahnlich, 228
- . betragsmaximalen Eigenwerts, 224
- . dunn besetzt, 221
- . diagonalisierbar, 224
- . inverse Iteration, 228
- . k, 27
- . lineare Gleichungssystem, 221
- Fixpunktsatz fur kontrahierende Abbil-
dungen, 207
- Lipschitz-Konstante, 206
- Shift-Strategie, 228
- abgeschlossen, 209
- obere Hessenberg Gestalt, 228
aquivalente Normen, 38
abgeschlossene Menge, 76
Ableitung, 128, 130
hohere, 148
absolut konvergent, 50, 271
abstoßend, 211
Aitken Lemma, 92
Algorithmus von Neville und Aitken, 95
alternierende harmonische Reihe, 49
alternierende Reihe, 48
anziehend, 211
Approximationssatz von Weierstraß, 102
Archimedische Spirale, 313
Archimedisches Axiom, 16
Arcuskosinus, 120
Arcussinus, 120
Arcustangens, 121
Area Kosinus hyperbolicus, 124
Area Sinus hyperbolicus, 123
Area Tangens hyperbolicus, 125
Astroide, 309
Asymptote, 182
Banachraum, 35
bedingt konvergent, 50
Bernoullische Ungleichung, 22
Bernstein Polynome, 102
beschrankte Folge, 19
beschrankte Menge, 16, 26
Besselsche Ungleichung, 336
bestimmt divergent, 19
binomische Formel, 175
binomische Reihe, 175
356

INDEX 357
Binormale, 319
Bogenlange
Parametrisierung nach der, 314
Bolzano und Weierstraß, Satz von, 36, 43
C1–Kurve, 305
Cauchy Folge, 35
Cauchy Kriterium, 269
Cauchy und Hadamard, Formel von, 108
Cauchy-Produkt von Reihen, 59
Cauchyscher Hauptwert, 276
Cauchysches Konvergenzkriterium, 34, 42,
48
Cavalieri
Prinzip von, 302
charakteristische Funktion, 67
Clenshaw-Curtis Formeln, 282
Deflation, 226
Differentialquotient, 128
Differentiation
der inversen Funktion, 143
logarithmische, 145
von Potenzreihen, 141
differenzierbar, 128
Dirichletsche Sprungfunktion, 61
Dirichletsches Integral, 270
diskrete Fourieranalyse, 348
diskrete Orthogonalitat, 349
divergent, 15, 44
dividierte Differenz, 92
e-Funktion, 110
einseitige Ableitung, 132
Einzelschrittverfahren, 223
erweiterter Mittelwertsatz, 159
erweitertes Horner Schema, 177
Eulersche Zahl, 29
Exponentialfunktion, 110
Exponentialintegral, 272
Extremum, 183, 184
fast Fouriertransform, 352
Fehlerintegral, 247
Fehlerkonstante, 285
Fehlerordnung einer Quadraturformel, 283
Feinheit einer Zerlegung, 230
Fermatsches Prinzip, 187
FFT, 352
Folge, 14
beschrankte, 19
bestimmt divergent, 19
geometrische, 23
Haufungspunkt einer, 36
limes inferior einer, 37
limes superior einer, 36
monoton fallende, 19
monoton wachsende, 19
nach oben beschrankte, 19
nach unten beschrankte, 19
streng monoton fallende, 19
streng monoton wachsende, 19
uneigentlich konvergente, 19
Formel von Cauchy und Hadamard, 108
Formel von Moivre, 116
Fourierkoeffizient, 332
Fourierreihe, 332
Fouriersynthese, 353
Fundamentalsatz der Algebra, 87
Fundamentalsatz der Infinitesimalrechnung,
246
Funktion
differenzierbare, 128
gerade, 116, 181
gleichmaßig stetige, 77

358 INDEX
Grenzwert einer, 79
konkave, 189
konvexe, 189
linksseitig stetige, 83
monoton fallende, 72
monoton wachsende, 72
nach oben beschrankte, 74
nach unten beschrankte, 74
rechtsseitig stetige, 83
reell–analytische, 172
streng monoton fallende, 72
streng monoton wachsende, 72
strikt konvexe, 189
uneigentlicher Grenzwert, 80
ungerade, 116, 181
Gammafunktion, 275
ganze Funktion, 108
ganze rationale Funktion, 84
Gauß-Hermite Formeln, 299
Gauß-Laguerre Formeln, 299
Gaußsche Quadraturformel, 288
Gaußsches Fehlerintegral, 247
geometrische Folge, 23
geometrische Reihe, 46
gerade Funktion, 116, 181
Gesamtschrittverfahren, 222
geschlossene Kurve, 305
glatte Kurve, 305
Gleichheit von Kurven, 307
gleichmaßig konvergent, 96
gleichmaßig stetig, 77
Gleichungssystem
iterative Losung, 10
Glied einer Reihe, 44
globales Maximum, 184
großte obere Schranke, 27
Grad eines Polynoms, 84
Grenzwert, 15, 79
Haufungspunkt einer Folge, 36
harmonische Reihe, 46
Hauptnormale, 319
Hauptwert, 120
Heaviside Funktion, 62
Hilbertraum, 35
Horner Schema, 85
erweitertes, 177
Infimum, 27, 74
innerer Punkt, 128
Integrabilitatskriterium, 233
Integral, 232
Dirichletsches, 270
unbestimmtes, 245
uneigentliches, 267
Integralsinus, 270
Integration
partielle, 248
integrierbar, 232
lokal, 267
uneigentlich, 267
Interpolation, 89, 195
trigonometrische, 348
Interpolationsformel
von Lagrange, 90
Interpolationsknoten, 195
Intervallhalbierungsmethode, 4
Intervallschachtelung, 29
inverse Iteration, 227
iterative Losung linearer Gleichungssyste-
me, 10
iterative Losung linearer Systeme, 45
Kegelstumpf, 304

INDEX 359
Keplersche Faßregel, 279
Kettenregel, 144
kleinste obere Schranke, 27
kompakt, 76
kompakte Konvergenz, 110
Komponentenfunktion, 66
kontrahierend, 206
konkav, 189
Kontraktionskonstante, 206
konvergent, 15, 44
gleichmaßig, 96
im quadratischen Mittel, 101
kompakt, 110
punktweise, 96
quadratisch, 24
Konvergenzkreis, 108
Konvergenzkriterium
von Cauchy, 48
Konvergenzkriterium von Cauchy, 42
Konvergenzordnung der Folge, 217
Konvergenzradius, 108
konvergiert linear, 217
konvex, 189
Kosinus hyperbolicus, 122
Kosinusfunktion, 115
Krummung, 315, 318
Krummungsradius, 315
Kriterien fur absolute Konvergenz, 51
Kronrod Formel, 294
Kurve, 305
geschlossene, 305
glatte, 305
Spur einer, 306
Kurvendiskussion, 179
Kurvenintegral, 325
Kuspe, 305
Lange einer Kurve, 308
Lagrangesche Interpolationsformel, 90
Landau Symbol, 343, 345
Lebesgue Integral, 232
Legendre Polynom, 289
Leibniz Kriterium, 49
Leibnizsche Regel, 151
Lemma
von Aitken, 92
limes inferior, 37
limes superior, 36
lineares System
iterative Losung, 45
Linearisierung, 128
linksseitig differenzierbar, 132
linksseitig stetig, 83
linksseitige Ableitung, 132
linksseitiger Grenzwert, 81
Lipschitz-stetig, 206
Lobatto Formel, 289
logarithmische Differentiation, 145
Logarithmus, 113
lokal integrierbar, 267
lokales Maximum, 184
MacLaurin Entwicklung, 167
Majorantenkriterium, 51, 272
Maximum, 74
globales, 184
lokales, 184
striktes globales, 184
striktes lokales, 184
Maximumnorm, 99
Menge
beschrankte, 26
nach oben beschrankte, 26
Minimum, 74, 184

360 INDEX
Minorantenkriterium, 272
Mittelpunktregel, 278
Mittelwertsatz
erweiterter, 159
Mittelwertsatz der Differentialrechnung,
153
Mittelwertsatz der Integralrechnung, 243
modifizierte regula falsi, 203
Moivre, Formel von, 116
monoton fallend, 72
monoton fallende Folge, 19
monoton wachsend, 72
monoton wachsende Folge, 19
Monotoniekriterium, 271
nach oben beschrankt, 74
nach oben beschrankte Folge, 19
nach oben beschrankte Menge, 26
nach unten beschrankt, 74
nach unten beschrankte Folge, 19
naturlicher Logarithmus, 113
Negativteil einer Funktion, 241
Neville–Aitken Algorithmus, 95
Newton-Cotes-Formeln, 281
Newton-Verfahren, 214
Normaquivalenzsatz, 39
Normalenvektor, 318
Nullfolge, 18
Nullstelle
Vielfachheit, 88
obere Schranke, 26
Oberintegral, 232
Obersumme, 230
Operator, 139
Oszillationsstelle, 67
Parameterwechsel, 307
Parametrisierung nach der Bogenlange,
314
Parsevalsche Gleichung, 337
Partialbruchzerlegung, 259
Partialsumme, 44
partielle Integration, 248
Peano Kern, 283
Periode, 328
periodisch, 328
Polstelle, 67, 80
Polygonzug, 307
Polynom, 84
Legendre, 289
trigonometrisches, 328
Umordnung, 177
Positivteil einer Funktion, 241
Potenzmethode, 11, 225
Potenzreihe, 106
Differentiation, 141
Formel von Cauchy und Hadamard,
108
Prinzip von Cavalieri, 302
Produktregel, 137
punktweise konvergent, 96
QR-Algorithmus, 228
quadratisch, 217
quadratisch konvergent, 24
Quadraturformel
Fehlerordnung, 283
Quotientenkriterium, 53
Quotientenregel, 140
Radau Formel, 289
radioaktiver Zerfall, 9
Rechenregeln fur Reihen, 48
Rechteckregel, 278

INDEX 361
rechtsseitig differenzierbar, 132
rechtsseitig stetig, 83
rechtsseitige Ableitung, 132
rechtsseitiger Grenzwert, 81
reell–analytische Funktion, 172
Reflexionsgesetz, 187
regula falsi, 202
Reihe, 44
absolut konvergente, 50
alternierende, 48
bedingt konvergente, 50
Cauchy-Produkt, 59
geometrische, 46
harmonische, 46
Leibniz Kriterium, 49
Majorantenkriterium, 51
Partialsumme einer, 44
Quotientenkriterium, 53
Rechenregeln, 48
Wurzelkriterium, 52
rektifizierbar, 308
relatives Maximum, 184
Relaxationsverfahren, 224
Residuum, 45
Restgliedformel
nach Schlomilch, 167
von Cauchy, 170
von Lagrange, 170
von Taylor, 170
Richardson Iteration, 10
Riemann Integral, 232
Riemann Summe, 234
Riemann, Satz von, 57
Riemannsches Integrabilitatskriterium, 233
Rolle, Satz von, 152
Rotationsellipsoid, 303
Rotationskorpers
Volumen, 303
Satz
von Bolzano und Weierstraß, 36, 43
von Rolle, 152
von Taylor, 166, 252
Zwischenwertsatz, 71
Satz von Riemann, 57
schnelle Fouriertransformation, 352
Schraubenlinie, 305
Sekantenverfahren, 219
Simpson Regel, 279
Sinus hyperbolicus, 122
Sinusfunktion, 115
Sprungstelle, 67
Spur einer Kurve, 306
stuckweise C1-Kurve, 305
Stammfunktion, 244
starke Spaltensummenkriterium, 223
starke Zeilensummenkriterium, 223
stetig, 61
stetig differenzierbar, 130
streng monoton fallend, 72
streng monoton fallende Folge, 19
streng monoton wachsend, 72
streng monoton wachsende Folge, 19
strikt konvex, 189
striktes globales Maximum, 184
striktes lokales Maximum, 184
Supremumnorm, 98
Substitutionsregel, 253
summierte Trapezregel, 279
superlinear, 217
Supremum, 27, 74
Tangens hyperbolicus, 125

362 INDEX
Tangente, 128
Tangentialbeschleunigung, 147
Taylorpolynom, 166
Taylorreihe, 171
Taylorscher Satz, 166, 252
Teilfolge, 21
Torsion, 319
Trapezregel
summierte, 279
trigonometrische Interpolation, 348
trigonometrisches Polynom, 328
Tschebyscheff Knoten, 198
Tschebyscheff Norm, 99
Tschebyscheff Polynom, 198
Umgebung, 128
Umordnung eines Polynoms, 177
Umordnung von Reihen, 56
unbeschrankte Menge, 16
unbestimmtes Integral, 245
uneigentlich integrierbar, 267
uneigentlich konvergent, 19
uneigentlicher Grenzwert, 80
uneigentliches Integral, 267
ungerade Funktion, 116, 181
Ungleichung
Bernoullische, 22
Besselsche, 336
untere Schranke, 26
Unterintergral, 232
Untersumme, 230
Variation
von beschrankter, 236
vereinfachte Newton Verfahren, 218
Vielfachheit m, 204
Vielfachheit einer Nullstelle, 88
vollstandigen Euklidischen Vektorraum,
35
vollstandiger normierter Raum, 35
Vollstandigkeitsaxiom, 27
von Mises Stabwerk, 68
von Mises Verfahren, 11, 225
Weg, 308
Weierstraß
Approximationssatz von, 102
Wendepunkt, 188, 193
Wurzelkriterium, 52
Zahlenfolge, 14
Zentripetalbeschleunigung, 147
Zerlegung, 229
Zwischenwertsatz, 71
Zykloide, 311





























