Embed Size (px)
Citation preview

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
1

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
2
Inhaltsverzeichnis
1. Kurzbeschreibung der Session .................................................................. 3
2. Lernziele ....................................................................................................... 3
3. Grundstruktur von HTML-Dokumenten .................................................... 3
3.1 HTML-Elemente .................................................................................. 4
3.2 Die HTML-Dokumentstruktur ............................................................ 4
4. Optimierungsmöglichkeiten im Dokumentenkopf ................................... 8
4.1 Title: Dokumententitel ........................................................................ 8
4.2 Meta-Tags .......................................................................................... 11
5. Optimierungsmöglichkeiten im Dokumentenkörper ............................. 15
5.1 Umgang mit Keywords ..................................................................... 16
5.2 Grafiken, alt- und title-Attribute ...................................................... 19
6. Rich Snippets ............................................................................................ 20
7. Exkurs: URL-Rewriting für dynamisch generierte Webdokumente ..... 20
8. Fazit ............................................................................................................ 25
9. Glossar ...................................................................................................... 26
10. Links, Literaturtipps und Quellenangaben ........................................... 27

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
3
1. Kurzbeschreibung der Session Die durch eine Analyse gewonnenen relevanten Keywords müssen für die Suchmaschinenoptimierung im HTML-Quelltext eingebettet werden, der aus verschiedenen Tags besteht, also sogenannte Auszeichnungen zur Klassifizie-rung und Strukturierung von Textelementen. Im title-Tag (dem Titelattribut im Kopfbereich eines Webdokuments) und im body-Bereich (im Dokumentenkörper, dem Hauptteil einer Webseite) sollten die Suchbegriffe enthalten sein. Zudem kann man in den Meta-Tags verschiedene Eigenschaften einer Webseite festlegen. Die Meta-Description enthält eine Beschreibung des Inhalts einer Webseite und wird bei der Gestaltung der Suchergebnisse berücksichtigt.
2. Lernziele Ziel dieser Session ist es, die suchmaschinenrelevanten HTML-Tags in ihrer Syntax und Semantik kennenzulernen. Zudem soll ein Verständnis für die Rele-vanz von Meta-Tags entstehen. Insbesondere die Wichtigkeit des title-Tags sollte klar werden. Des Weiteren wird der Unterschied zwischen statischen HTML-Seiten und dy-namisch generierten Webseiten vermittelt und wie man diese mittels URL-Rewriting modifiziert.
Die allerwichtigsten Punkte werden am Ende kurz zusammengefasst. Freiwillige kleine Rechercheaufgaben bzw. Wiederholungsaufgaben geben Dir die Möglichkeit, das Wissen zu vertiefen und zu festigen. Diese Aufgaben dienen lediglich Deiner Beschäftigung mit dem Thema, sie werden nicht bewertet und müssen nicht schriftlich abgegeben werden. Darüber hinaus erhältst Du im letz-ten Abschnitt des Dokuments ein Glossar mit Begriffsklärungen sowie einige weiterführende Literaturtipps und nützliche Links.
3. Grundstruktur von HTML-Dokumenten
HTML steht für Hyptertext Markup Language („Hypertext-Auszeichnungs-sprache“) und dient der Strukturierung von Webdokumenten. Vereinfacht gesagt, hilft diese Sprache dem Browser zu interpretieren, wie ein-zelne Elemente einer Webseite (insbesondere Textelemente) angezeigt werden sollen. Dazu werden bestimmte HTML-Befehle genutzt. HTML dient in erster Linie der Strukturierung des Inhaltes. Um das eigentliche Design festzulegen, sollten Cascading Style Sheets (CSS) genutzt werden, die angeben, wie be-stimmte Elemente aussehen sollen.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
4
3.1 HTML-Elemente
In der HTML-Sprache wird unterschieden zwischen HTML-Elementen, Tags und Attributen.
Ein HTML-Element besteht aus sogenannten Tags (engl. für Etikett, Kennzeich-nung), also den in spitzen Klammern eingeschlossenen Kürzeln zur näheren Auszeichnung und Klassifizierung des jeweiligen Abschnitts.
Das HTML-Dokument kann zudem bestimmte Attribute enthalten, denen ihrer-seits ein Wert zugeordnet ist.
Schematisch sieht ein HTML-Element also folgendermaßen aus:
<elementname attribut="wert des attributs">Elementinhalt</elementname>
Dargestellt ist das gesamte Element, das seinerseits aus dem öffnenden Tag <elementname ...>, dem Elementinhalt (dem Abschnitt des Webdokuments, auf den sich die Angaben beziehen) und dem schließenden Tag </elementname> besteht, das durch den vorangestellten Schrägstrich gekennzeichnet ist.
In dem öffnenden Tag können ein oder mehrere Attribute enthalten sein.
Man spricht auch von sogenannten „Container-Tags“, weil diese Elemente aus einem öffnenden und einem schließenden Tag bestehen, welche den dadurch gekennzeichneten Text umschließen. Möchte man beispielsweise einen Text fett darstellen lassen, würde das folgendermaßen dargestellt werden:
<strong>fetter Text</strong>
Es gibt aber auch sogenannte „leere Elemente“ (auch „Empty Tags“ genannt), die ohne den Elementinhalt und schließende Tags auskommen.
Ein Beispiel hierfür ist das Tag <img> (von engl. image = Bild) für grafische In-halte, das allein steht und durch verschiedene Attribute näher bestimmt werden kann.
<img attribut1="wert des attributs" attribut2="wert des attributs">
3.2 Die HTML-Dokumentstruktur Der Aufbau einer Webseite folgt einem bestimmten Grundgerüst, das je nach Dokumentumfang unterschiedlich stark untergliedert sein kann.
Hier die Grundstruktur:

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
5
<!DOCTYPE html>
<html>
<head>
<title>Titel</title>
...
</head>
<body>
<h1>Überschrift Abschnitt 1</h1>
<p>Absatz mit Inhalten der Webseite</p>
...
</body>
</html>
Wie man sieht, gibt es also drei wesentliche Teilbereiche:
1. Die Dokumenttypdeklaration (DTD), auch Doctype genannt: Hiermit wird dem Browser mitgeteilt, nach welchen Standards die Seite aufgebaut wurde und damit auch, welche Elemente in diesem Dokument verwendet werden dürfen und welche nicht. Da es außer HTML auch andere Auszeichnungssprachen gibt und auch HTML in mehreren Versionen vorliegt, wird im Doctype also angege-ben, welche Auszeichnungssprache in welcher Version verwendet wird. Man kann sich die DTD als eine separate Datei vorstellen, in der alle Elemente und Attribute genau definiert sind. Sie definiert also die logische Struktur von Doku-menten und gibt an, welchen Regeln sie folgen müssen.
Eine ausführliche Liste verschiedener empfohlener DTDs findest Du hier: http://www.w3.org/QA/2002/04/valid-dtd-list.html
2. Der Dokumentenkopf: Der Head (Kopf) des Dokuments enthält Beschrei-bungen, die sich auf das gesamte Dokument beziehen. Er enthält größtenteils Informationen, die nicht im Browser angezeigt werden.
Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
6
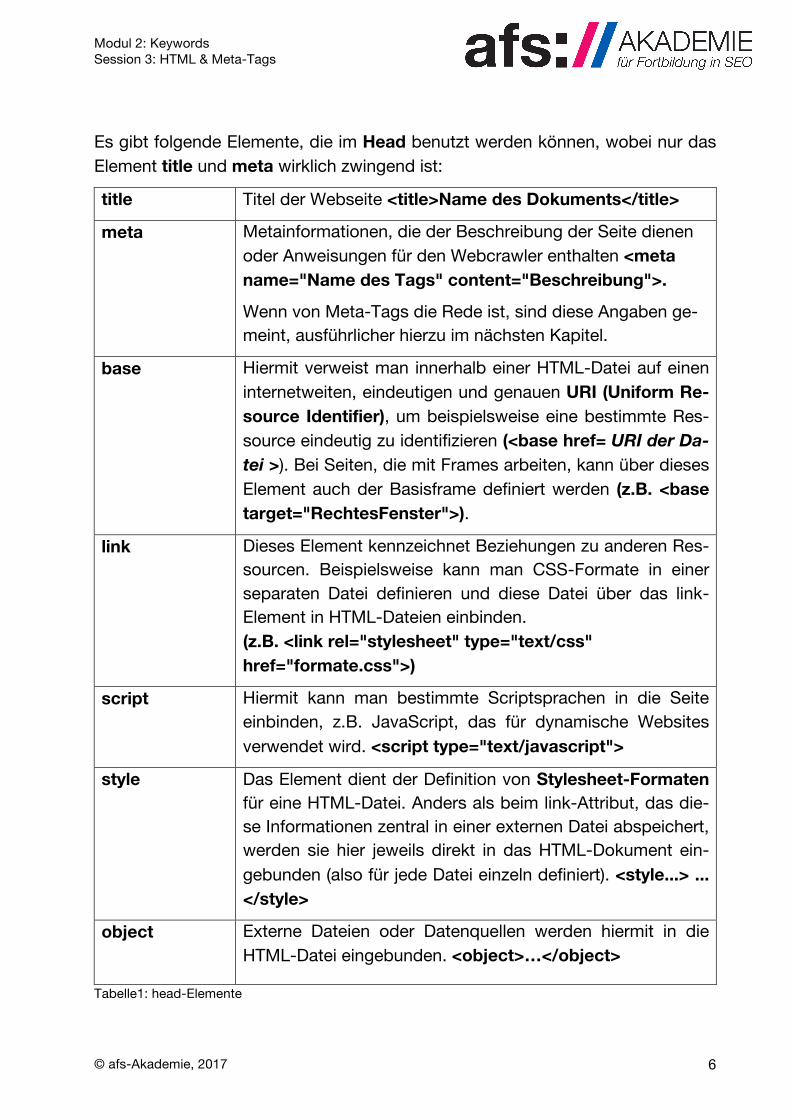
Es gibt folgende Elemente, die im Head benutzt werden können, wobei nur das Element title und meta wirklich zwingend ist:
title Titel der Webseite <title>Name des Dokuments</title>
meta
Metainformationen, die der Beschreibung der Seite dienen oder Anweisungen für den Webcrawler enthalten <meta name="Name des Tags" content="Beschreibung">.
Wenn von Meta-Tags die Rede ist, sind diese Angaben ge-meint, ausführlicher hierzu im nächsten Kapitel.
base
Hiermit verweist man innerhalb einer HTML-Datei auf einen internetweiten, eindeutigen und genauen URI (Uniform Re-source Identifier), um beispielsweise eine bestimmte Res-source eindeutig zu identifizieren (<base href= URI der Da-tei >). Bei Seiten, die mit Frames arbeiten, kann über dieses Element auch der Basisframe definiert werden (z.B. <base target="RechtesFenster">).
link
Dieses Element kennzeichnet Beziehungen zu anderen Res-sourcen. Beispielsweise kann man CSS-Formate in einer separaten Datei definieren und diese Datei über das link-Element in HTML-Dateien einbinden. (z.B. <link rel="stylesheet" type="text/css" href="formate.css">)
script
Hiermit kann man bestimmte Scriptsprachen in die Seite einbinden, z.B. JavaScript, das für dynamische Websites verwendet wird. <script type="text/javascript">
style
Das Element dient der Definition von Stylesheet-Formaten für eine HTML-Datei. Anders als beim link-Attribut, das die-se Informationen zentral in einer externen Datei abspeichert, werden sie hier jeweils direkt in das HTML-Dokument ein-gebunden (also für jede Datei einzeln definiert). <style...> ... </style>
object
Externe Dateien oder Datenquellen werden hiermit in die HTML-Datei eingebunden. <object>…</object>
Tabelle1: head-Elemente

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
7
3. Der Dokumentkörper: Der Body (Körper) eines HTML-Dokuments enthält die eigentlichen Inhalte, die im Browserfenster angezeigt werden. Für den Do-kumentkörper gibt es zahlreiche Elemente, die sich grob in Blockelemente und Inline-Elemente unterscheiden lassen. Blockelemente erzeugen einen Zeilenumbruch und dienen der Strukturierung von Texten, während Inline-Elemente keine neue Zeile erzeugen, der Text also nach dem Element einfach „weiterfließt“. Hier einige Beispiele:
Blockelemente Inline-Elemente
<h1>...</h1> <h2>...</h2> ... <h6>...</h6>
Überschriften, wobei h1 die höchste Hierarchiestufe darstellt und h2 – h6 die untergeordneten Hierarchiestu-fen (wie bei den Kapiteln und Unter-kapiteln eines Buches).
<strong>...</strong> Fettschrift
<em>...</em> Kursivschrift
<u>...</u> unterstrichen
<p>...</p>
Absätze eines Textes.
<img>
Das Image-Tag dient der Einbindung von Grafiken.
<ul> <li>...</li> <li>...</li> </ul>
Aufzählungslisten innerhalb eines Dokuments, wobei <ul>...</ul> die Liste als solche definiert und <li>...</li> die einzelnen Punkte auf der Liste.
<ol> <li>...</li> <li>...</li> </ol>
Eine nummerierte Liste, sonst ana-log zur Aufzählungsliste.
<a href="Zielseite">Ankertext</a>
Hyperlink, also Verweise auf eine an-dere Ressource z.B. eine andere Webseite oder Unterseite.
Tabelle 2: Beispiele für Block- und Inline-Elemente.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
8
Dokumentenkopf und Dokumentkörper können also sowohl die Metaangaben als auch die eigentlichen Webseiteninhalte beinhalten und werden beide von HTML-Tags umschlossen (<html>...</html>).
4. Optimierungsmöglichkeiten im Dokumentenkopf <head>...</head> Nachdem das Keywordspektrum definiert wurde, müssen die ausgewählten Keywords konsequent in den einzelnen Dokumenten vorkommen. Nachfolgend werden die Bereiche und auch die einzelnen Tags innerhalb des Dokumentes vorgestellt.
Wir beginnen mit den Angaben im Seitenkopf, also insbesondere mit dem <tit-le> und den sogenannten <meta>-Tags.
4.1 Title: Dokumententitel
Bei dem Dokumententitel <title> </title> handelt es sich um ein Element, das eine außerordentlich wichtige Bedeutung für die Suchmaschinenoptimierung hat. Es ist davon auszugehen, dass der Autor einer Webseite den Titel verwen-det, um den Inhalt des Webdokuments möglichst genau zu beschreiben. Die hohe Bedeutung des Titels resultiert vor allem aus folgenden Aspekten:
• Suchergebnisliste: Der Titel wird in Googles Suchergebnisliste angezeigt und begründet damit zu einem großen Teil die Motivation zur Verfolgung eines Hyperlinks.
• Browser: Der Titel ist für die User im Kopf des Browsers sichtbar. • Favoritenliste: Bei der Übernahme eines Dokuments in die Favoritenliste
wird der Titel als Kurzinformation übernommen.
Abbildung 1: title-Tag im Quelltext der Homepage der afs-Akademie – der Text dieses Tags wird im Browserkopf und als Titel des Tabulators angezeigt.
Erkennt der User in den Ergebnissen der Suchmaschine nicht sofort, dass er mit dem Web-Dokument sein Informationsbedürfnis befriedigen kann, klickt er in der Regel auf die Dokumente der Mitbewerber. In diesem Fall nützt auch die beste Platzierung in der Suchergebnisliste nichts.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
9
Die wichtigen Keywords sollten enthalten und der Titel muss ansprechend ge-nug gestaltet sein, um einen User zum Klick zu animieren. In diesem Zusam-menhang stellt sich die Frage, ob für den Titel ausschließlich Substantive (wie z.B. Hundezucht, Games, Weiterbildung usw.) verwendet werden sollen. Dies wird kontrovers diskutiert. Der eine empfiehlt z.B. ausschließlich Substantive zu verwenden, der andere rechtfertigt den Einsatz von Stoppwörtern der besseren Lesbarkeit wegen. Eine Möglichkeit zur Verbesserung der Optik besteht in der Verwendung von Sonderzeichen.
Nachfolgend werden Beispiele aufgeführt, die hinsichtlich der Relevanzbeurtei-lung erfahrungsgemäß eher vermieden werden sollten:
Die genannten Beispiele lassen keine automatisierte inhaltliche Bewertung der Dokumente zu.
Anstelle von wichtigen Keywords findet man im Internet oftmals allgemeine Be-griffe, die keinesfalls geeignet sind, um eine TOP‐Platzierung bei den Suchma-schinen zu erreichen.
Auch Firmennamen oder Anschriften sind im Allgemeinen für den Titel ungeeig-net. Bei sehr bekannten Marken wie beispielsweise Amazon oder eBay können die User in der Regel den Namen direkt im Browser eingeben und müssen keine Suchmaschinen benutzen. Handelt es sich dagegen um eine unbekannte Marke, bleiben die Suchanfragen nach selbiger ohnehin aus. Ganz besonders Einsteiger nutzen zur Erstellung ihrer Webseiten gerne einfach zu bedienende Editoren, welche kaum fundierte Kenntnisse im Bereich der Programmierung vorausset-zen. Hierbei wird oftmals der Dokumententitel automatisch für jedes neu ange-legte Web-Dokument vergeben. Dies führt zu Titeln wie „Neue Seite“, die eben-falls nicht geeignet sind.
Bei der Erstellung des Titels muss die Wortstellung beachtet werden. Die wich-tigsten Keywords sollten zuerst, d.h. soweit wie möglich links auftreten, da hiermit ihre Relevanz in der Regel von den Suchmaschinen höher eingestuft wird. Keywords, die in Kombination gesucht werden, sollten in genau derselben Reihenfolge im Titel auftreten. Sind die Keywords zu weit voneinander entfernt, kann die Gewichtung für die entsprechende Keyword-Kombination sinken. Betrachten wir das Ganze anhand eines Beispiels:
• „Hallo Willkommen auf unserer Website“
• „Firma Mustermann in der Musterstraße in dem Musterort“
• „Bei uns liegen Sie immer richtig“

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
10
Der Betreiber eines Diskussionsforums über die Themengebiete Fitness bzw. Sport möchte beispielsweise über die Keyword-Kombinationen Sport Forum sowie Forum Fitness ein gutes Ranking erzielen. Der bisherige Titel lautet wie folgt:
<title> Forum ‐ Diskussionen zum Thema Fitness und Sport </title>
Es ist erkennbar, dass dieser Titel nicht optimal gewählt ist, da die angestrebten Keyword‐Kombinationen nicht direkt beieinander stehen. Weitaus besser wäre folgender Titel:
<title> Sport Forum: Fitness Tipps und Tricks für jedermann</title>
Nun sind beide Keyword-Kombinationen in der korrekten Reihenfolge enthal-ten. Unabhängig vom Inhalt des Webdokuments sollte die zweite Variante ein weitaus höheres Gewicht für die Suchanfragen Sport Forum bzw. Forum Fit-ness erhalten. Der Teil Diskussionen zu dem Thema wurde entfernt, da es sich hierbei um einen überflüssigen Ballast handelt, der in der Regel selten Be-standteil einer Suchanfrage ist.
Hinsichtlich der Länge des Titels müssen einige Aspekte berücksichtigt wer-den. Obwohl Suchmaschinen bis zu ca. 250 Zeichen des Titels indexieren, sollte der Titel deutlich kürzer sein, da zu lange Titel im Snippet der Suchma-schinen gekürzt werden. Empfehlenswert sind Titellängen bis 55 – 60 Zeichen, abhängig von der Buchstabenbreite. Ein kostenloses Tool zum Prüfen ist bspw. www.seomofo.com/snippet-optimizer.html
Bei einer geringen Anzahl an Keywords sind für Suchmaschinen durchaus noch kürzere Titel empfehlenswert. Der Vorteil eines kurzen Titels ist die höhere Gewichtung der einzelnen Keywords.
Sind zu viele Keywords im Titel enthalten, dann sinkt die Bedeutsamkeit für das jeweilige Keyword. Website-Betreiber wollen oftmals möglichst viele Keywords im Titel unterbringen, da sie annehmen, dass sie dadurch eine gute Platzierung erhalten können. Nicht selten sieht man im Internet Titel wie diese:
<title> Downloads, Gedichte, Texte, Übersetzungen, Liedertexte, Songtex-te, Witze, Bilder, Sprüche, Fotos, Videos, Biografien, </title>
Dieser Titel wird zwar die einzelnen Keywords als Teil der Suchergebnisse bei Suchmaschinen anzeigen, da die Gewichtung aber gering ausfällt, wird das Do-kument sehr schwer eine Top-Platzierung zu einem der Keywords erreichen können. Außerdem wirkt diese Aneinanderreihung nicht unbedingt attraktiv für den Besucher, animiert diesen also nicht, das Ergebnis anzuklicken.
Der Titel sollte sich auf den Text im Dokument beziehen. Verwendet ein Websi-te‐Betreiber einen Titel, der keinen Bezug zum eigentlichen Inhalt hat, fällt die

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
11
Gewichtung in der Regel geringer aus. Es ist deshalb auch erforderlich, indivi-duelle Titel für jedes Dokument innerhalb einer Website zu verwenden und glo-bale Titel zwingend zu vermeiden.
4.2 Meta-Tags Vorab eine kurze Begriffsklärung: Streng genommen handelt es sich bei den Meta-Tags eher um Meta-Elemente, die im Kopfbereich einer Webseite (also im <head>...</head>) stehen und die Metaangaben enthalten, die sich auf das gesamte Dokument beziehen. Sie sind leere Elemente, die nur aus einem, in sich geschlossenem Tag bestehen, das seinerseits durch bestimmte Attribute näher bestimmt wird. Deshalb auch die Bezeichnung Meta-Tags.
Die Meta-Informationen werden innerhalb des Dokumentenkopfes platziert und sind für den User nicht sichtbar. Ziel dieser Metainformationen ist es, die Durchsuchbarkeit von Webdokumenten zu verbessern. Die Idee, dass Autoren ihre Dokumente selbst anhand der Meta-Informationen beschreiben und die Suchmaschinenbetreiber diese Daten zur Relevanzbeurteilung berücksichtigen, war zunächst sehr gut.
Aus diesem Grund verwendeten die ersten automatisierten Suchmaschinen, wie zum Beispiel AltaVista die Meta-Tags zur Bewertung des Inhaltes. Unter Website-Betreibern waren die Meta-Tags deshalb zunächst das Geheimrezept schlechthin, um das Ranking eines Webdokuments zu verbessern. Aufgrund der Kommerzialisierung des Internets wurde die Zahl der Besucher und damit die Suchmaschinenoptimierung ein immer bedeutsamerer Faktor. Dies führte dazu, dass diese Form der Inhaltserschließung von den Website-Betreibern nicht selten missbraucht wurde, indem falsche Angaben in der Suchmaschi-nen-Relevanz gemacht wurden.
So konnte beispielsweise ein Webdokument, das keinerlei Informationen über Versicherungen enthielt, dennoch bei Suchanfragen zu den entsprechenden Keywords berücksichtigt werden, wenn zum Beispiel der Meta-Tag-Bereich der Keywords mit folgenden oder ähnlichen Begriffen gefüllt wurde:
<meta name=“keywords“ content=“Versicherungen, Versicherung,
Versicherungsvergleich, Autoversicherung, Unfallversicherung,
Feuerversicherung“>
Aus diesem Grund verzichten heute Suchmaschinen im Allgemeinen auf die Auswertung der Meta-Tags für den Zweck der Relevanzbeurteilung. Im Folgen-den gehen wir auf einige dieser Elemente und ihre Bedeutung bei der Suchma-schinenoptimierung näher ein.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
12
Obwohl bei den Suchmaschinen in der Regel kein Dokument eine höhere Be-wertung aufgrund eines Meta-Tags erhält, investieren auch heute noch zahlrei-che Website-Betreiber ihre Zeit in die Erstellung entsprechender Metainforma-tionen.
<meta name=“description“ content=“Text“>
Denn ganz ohne Nutzen für die Suchmaschinenoptimierung sind einige Meta-Tags nicht. So nutzen viele Suchmaschinen die Meta-Tag-Description zur Er-stellung des Auszugs (Snippets), der in der Suchergebnisliste angezeigt wird. Ein interessanter Auszug steigert für den User den Anreiz, ein Suchergebnis an-zuklicken. Wie genau die Description genutzt wird, unterscheidet sich je nach Suchmaschine – während Lycos das Tag nicht beachtet, wird es von AltaVista in der Regel übernommen. Google indexiert zwar das description-Tag, erzeugt aber mitunter auch eigene Snippets aus dem Inhalt des Dokuments, je nachdem wie relevant Google den Inhalt des description-Tags für den Suchbegriff hält. Mit der Anweisung "noodp" im robots Tag kann man Google signalisieren, dass bevorzugt die Meta Description als Snippet verwendet werden soll.
Bei der Erstellung der Meta‐Tag-Description sollte möglichst auf folgende Punk-te geachtet werden:
• Länge: Max. 156 Zeichen, abhängig von der Buchstabenbreite. • Inhalt: Es soll eine inhaltliche Kurzangabe vorgenommen werden, in der
relevante Keywords und Keyword-Kombinationen enthalten sind. Der Text sollte möglichst interessant gestaltet sein, damit die Klickrate erhöht wer-den kann. Weiterhin muss darauf geachtet werden, dass das Keyword nicht zu häufig Verwendung findet. Am besten direkt einen Klickanreiz schaffen z.B. „Lesen Sie hier..., Kaufen Sie hier... etc.
• Individuelle Beschreibung: Jedes Webdokument sollte eine eigene Be-schreibung erhalten. Die Verwendung einer globalen Beschreibung ist nicht zu empfehlen, da sie meist schlechtere Ranking-Ergebnisse liefert als individualisierte, auf das Dokument zugeschnittene Beschreibungen.
<meta name=“robots“ content=“index | noindex | follow | nofollow, noodp“>
Neben dem Description‐Tag existiert mit robots ein Tag zur Regelung des In-dexierungsverhaltens der Suchmaschinen.
Die Werte index und follow signalisieren den Suchmaschinen, das die Seite von ihnen indexiert werden darf und der Crawler die enthaltenen Links verfolgen soll. In der Regel ist diese Angabe jedoch nicht zwingend notwendig.
Eher Verwendung findet die entgegengesetzte Anweisung, einzelne Dokumente

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
13
von der Indexierung auszuschließen:
<meta name=“robots“ content=“noindex“ />
Eine weitere Möglichkeit besteht darin, die Weiterverfolgung von Hyper-link‐Verweisen durch die Webcrawler der Suchmaschinen auszuschließen:
<meta name=“robots“ content=“nofollow“ />
Generell ist jedoch zu beachten, dass diese Anweisungen nur als Empfehlung an die Suchmaschinen anzusehen sind, ob sie tatsächlich befolgt werden, lässt sich nicht beeinflussen.
Darüber hinaus beziehen sich die Anweisungen des Tags robots nur auf das jeweilige HTML-Dokument, in dessen head sie eingefügt werden. Eine effektivere Methode, Anweisungen an die Suchmaschinenroboter einzubin-den, ist die Erstellung einer eigenen zentralen Datei, die Informationen dazu ent-hält, welche Verzeichnisse und Verzeichnisbäume ausgelesen werden dürfen und welche nicht – die sog. robots.txt.
Ausführlichere Informationen zur robots.txt findest Du auf der Website http://de.selfhtml.org/diverses/robots.htm.
Ein häufig auftretendes Problem für Website-Betreiber, insbesondere von Online Shops, ist der sogenannte Duplicate Content, also das Vorkommen gleicher In-halte auf unterschiedlichen URLs (ein häufiges Beispiel wären auch Websites, die sowohl mit als auch ohne www. erreicht werden können). Dies kann zur Ab-wertung der identischen Seiten im Index von Google und anderen Suchmaschi-nen führen, da Suchergebnisse mit übereinstimmenden Inhalten für den Su-chenden nur einen geringen Mehrwert bieten.
Da die Suchmaschinen jedoch in der Regel nicht selbst erkennen, welche Seite dabei als „Originalseite“ behandelt werden soll und welche als „Kopie“, wurde vor einigen Jahren das sogenannte Canonical Tag eingeführt. Mit dem Canoni-cal-Tag kann ein Seitenbetreiber in einem Dokument direkt angeben, dass es ein Duplikat von einem anderen Dokument ist, damit dieses Duplikat dann von Google ignoriert wird. Der PageRank des Duplikats (also die Gewichtung, die sich aus seiner Verlinkung ergibt – ausführlicher dazu Modul 4), wird dann an das Original weitergegeben. Auch wenn Seiten keine Duplikate haben, sollte ein Canonical Tag auf sie selbst verweisen.
<link rel=”canonical” href=”http://www.URL.de/”>

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
14
Hierbei ist jedoch zu beachten, dass das Canonical Tag nur ein Vorschlag an die Suchmaschine ist, keine Anweisung, die in jedem Fall befolgt wird.
In dem Google Webmaster Tools Blog hat Allan Scott auf einige der häufigsten Fehler bei der Verwendung dieses Tags hingewiesen: http://googlewebmastercentral-de.blogspot.de/2013/04/5-haeufige-rel-canonical-fehler.html
Zusammenfassend rät er dazu, die folgenden Regeln zu beachten:
Quelle: Allan Scott: 5 häufige Fehler bei der Verwendung von rel=canonical-Tags: http://googlewebmastercentral-de.blogspot.de/2013/04/5-haeufige-rel-canonical-fehler.html, Eintrag vom 10.04.2013
Weitere Meta-Tags
Es gibt zahlreiche andere Meta-Tags, auf die wir jedoch nur im Überblick einge-hen werden, da sie von Google und Co. kaum berücksichtigt werden.
<meta name=“author“ content=“Name des Autors“>
Dieses Tag gibt den Namen des Autors an.
Während es für die meisten Suchmaschinen nur geringe Bedeutung hat, kann es aus urheberrechtlicher Sicht trotzdem interessant sein, um den Verfasser einer Seite zu kennzeichnen.
<meta http-equiv="Content-Type" content="text/html; char-set=verwendeter Zeichensatz" />
Dieses Tag content-type unterscheidet sich von den anderen Meta-Tags, da es sich hier um eine Anweisung für Browser und Webcrawler handelt. Er kann ver-wendet werden, um zu definieren, welcher Zeichensatz im Dokument verwendet wird, damit beispielsweise Sonderzeichen korrekt angezeigt werden.
Um das rel=canonical effizient anzuwenden:
• Vergewissert Euch, dass der Großteil der Wörter im Duplikat der Seite auch in der kanonischen Seite auftaucht.
• Überprüft, ob das rel=canonical-Tag nur einmal (wenn überhaupt) und nur im <head> der Seite verwendet wird.
• Prüft, ob rel=canonical auf eine vorhandene URL mit guten Inhalten ver-weist (keine 404, oder sogar eine "falsche" 404-Seite).
• Vermeidet das rel=canonical-Tag von Landingpages oder Kategorien-Seiten zu Kategorien-Unterseiten oder beispielsweise Produkt-Unterseiten, da die Unterseite somit in der Ansicht der Suchergebnisse bevorzugt wird.
•

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
15
Für den westeuropäischen Zeichensatz verwendet man beispielsweise <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />, während für slawische Sprachen charset=iso-8859-2 passend wäre.
<meta http-equiv="refresh" content="15; URL"website.de/unterseite.html />
Eine ähnliche Anweisung ist das Tag refresh. Dieses Tag wird von den Such-maschinen zwar in aller Regel beachtet, dies ist jedoch nicht unbedingt von Vor-teil. Es veranlasst die Weiterleitung zu einer anderen URL, wobei die im Content angegebene Zahl definiert, nach wie vielen Sekunden diese Weiterleitung erfol-gen soll (in diesem Beispiel 15 Sekunden). Da die Seite selbst somit nur als „Brückenseite“ dient, kann sie von Suchmaschinen abgewertet werden, da da-von ausgegangen wird, dass die Seite selbst keine relevanten Informationen enthält.
<link rel=”alternate” href=”http://example.com/en‐ie” hreflang=”enie”/>
Es ist streng genommen kein Meta-Tag, sondern ein weiteres head-Element, das gezielt der Kennzeichnung logischer Verknüpfungen dient. Es soll an dieser Stelle deshalb kurz erwähnt werden, weil es in der hier angegebenen Form inte-ressant sein kann, wenn Suchmaschinen die Möglichkeit gegeben werden soll, Webseiteninhalte sprachlich anzupassen, also zwischen verschiedenen Sprach-versionen die passende Version auszuwählen.
Ausführliche Informationen zum Umgang mit mehrsprachigen Websites bietet auch die Hilfeseite der Google Webmaster Tools: http://support.google.com/webmasters/bin/answer.py?hl=de&answer=182192
Es gibt natürlich noch viele weitere Meta-Tags, die jedoch für die Suchmaschi-nenoptimierung nicht relevant sind, sodass wir darauf an dieser Stelle nicht aus-führlicher eingehen werden. Für eine genauere Auflistung der existierenden Me-ta-Elemente, nutze bitte die Informationen auf http://de.selfhtml.org/html/kopfdaten/meta.htm und http://dublincore.org/documents/dcmi-terms/.
5. Optimierungsmöglichkeiten im Dokumentenkörper
<body>...</body> Neben dem Dokumentenkopf ist vor allem der Dokumentenkörper bei der On-Page-Optimierung ein wichtiger Bereich hinsichtlich der Relevanzbeurteilung. Innerhalb des <body> ist der Fließtext enthalten. Dieser sollte, passend zum Thema des Dokuments, die entsprechenden Keywords aus der erstellten Keyword-Liste enthalten.
Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
16
5.1 Umgang mit Keywords Die Gewichtungsmodelle beachten die relative Worthäufigkeit sowie die Lage und Auszeichnung von Keywords. Wie hoch die relative Worthäufigkeit bzw. Keyword-Dichte gewählt werden soll, lässt sich nicht generell festlegen. Werden die Keywords zu häufig eingesetzt, droht eine Abstrafung aufgrund eines Keyword-Stuffings. Gemeint ist das „Vollstopfen“ einer Seite mit Keywords, vgl. dazu auch Google Webmaster Tools:
http://support.google.com/webmasters/bin/answer.py?hl=de&hlrm=en&answer=66358
Ist die Keyword-Dichte dagegen zu gering, kann es sein, dass die Suchmaschi-nen das Webdokument als nicht relevant genug für die Suche nach diesem Be-griff einstufen. Experten empfehlen als Obergrenze für eine erlaubte Keyword-Dichte zwischen 2 und maximal 4 %. Eine deutlich höhere Keyword-Dichte kann von den Suchmaschinen negativ bewertet werden.
Obwohl die Keyword-Dichte mit speziellen Tools (z.B. SISTRIX, dem Keyword-Density-Tool von Online Marketing Solutions, Searchmetrics, Keyword Density Checker von webconfs.com) sehr einfach gemessen werden kann, ist es im All-gemeinen schwierig festzustellen, ob eine Platzierung nur durch die Keyword-Dichte oder mehr durch andere Faktoren zustande gekommen ist.
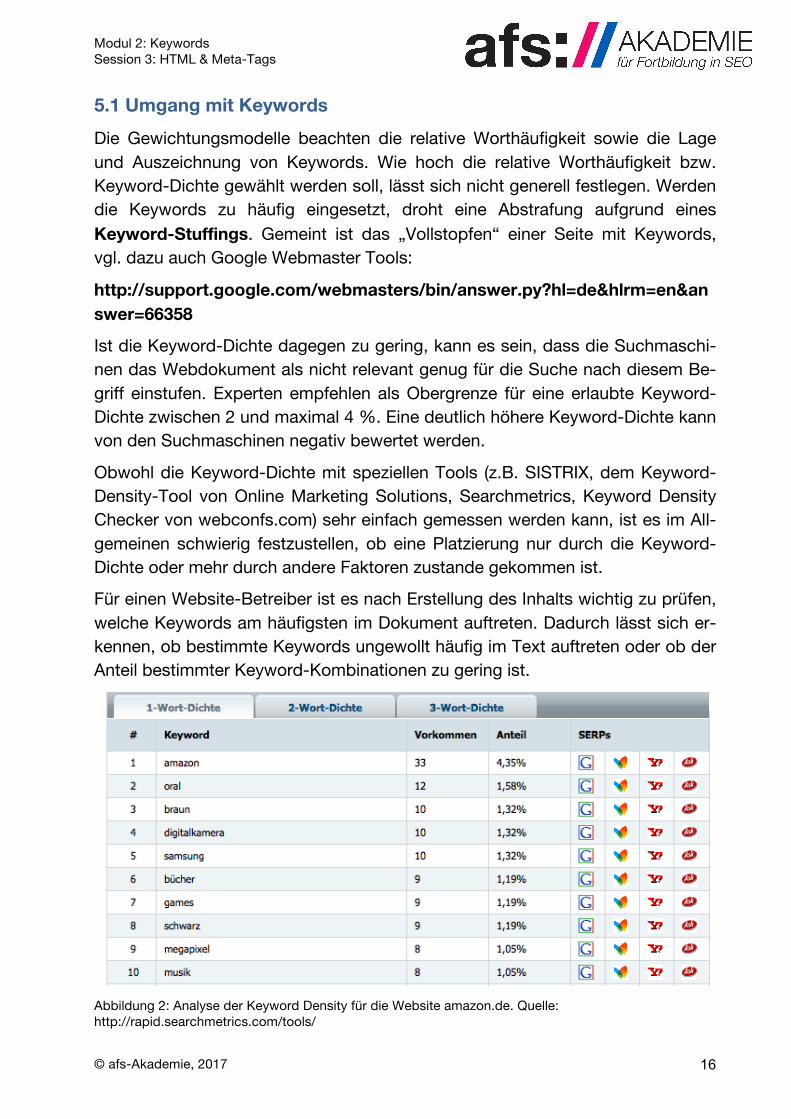
Für einen Website-Betreiber ist es nach Erstellung des Inhalts wichtig zu prüfen, welche Keywords am häufigsten im Dokument auftreten. Dadurch lässt sich er-kennen, ob bestimmte Keywords ungewollt häufig im Text auftreten oder ob der Anteil bestimmter Keyword-Kombinationen zu gering ist.
Abbildung 2: Analyse der Keyword Density für die Website amazon.de. Quelle: http://rapid.searchmetrics.com/tools/

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
17
Im Zusammenhang mit der Keyword‐Dichte steht die thematische Konsistenz. Ein Webdokument sollte sich möglichst auf ein bestimmtes Thema konzentrie-ren. Zahlreiche unterschiedliche Themen mit einer Vielzahl an Keywords können sich negativ auf die Gewichtung auswirken, da kein inhaltlicher Fokus erkennbar ist.
Neben der Keyword‐Dichte muss ebenso die Lage (also die Position im Text) und die Auszeichnung von Keywords berücksichtigt werden. Beim Schreiben des Fließtextes sollte das journalistische Grundprinzip der invertierten Pyrami-de beachtet werden. Nach diesem Prinzip sollten die bedeutendsten Informatio-nen am Anfang des Textes stehen. Die Bedeutung nimmt mit der Länge des Textes stets ab. Folglich sollten die wichtigen Keywords an prominenter Positi-on, d.h. möglichst innerhalb der ersten 1.000 Zeichen aufgeführt werden.
Für die Auszeichnung der Gewichtung von bestimmten Keywords im Satzzu-sammenhang eignen sich bestimmte HTML-Tags. Die Tags <h1> bis <h6> sind in HTML für Überschriften (engl. heading, deshalb die Abkürzung h) vorgesehen. Dabei stellt das <h1>-Tag die höchste Ebene dar. Die verschiedenen Hierarchieebenen der Header sind also vergleichbar mit den Überschriftsebenen in einem Buch. Ist ein Keyword beispielsweise in ein <h1>-Tag eingebettet, wirkt sich dies positiv auf die Relevanz des Webdokuments aus. Suchmaschinen berücksichtigen, dass eine Überschrift hervorragend dazu geeignet ist, das Thema eines Abschnittes zu beschreiben. Ein Website-Betreiber sollte auf eine einheitliche Gliederung achten. Der Idealfall ist ein aus-reichend langer Text, der in mehrere Absätze unterteilt ist und mit Überschriften strukturiert wird.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
18
Die wichtigsten Keywords sollten hierbei zu Beginn des Webdokuments im <h1>-Tag in einem Satz enthalten sein.
Ein Grund wieso Website‐Betreiber den Einsatz des <h>‐Tags oftmals vermei-den ist die vermeintliche Verunstaltung eines visuell ansprechenden Designs. Eine Lösung dieses Problems kann mit den sogenannten Cascading Style Sheets (CSS) erfolgen. Hiermit lässt sich die Darstellungsform der einzelnen Tags festlegen.
Abbildung 3: Beispiels für Style Sheets zur Hervorhebung einzelner Elemente einer Webseite am Beispiel der afs-Akademie-Seite.
Auch Keywords, die fett, unterstrichen oder kursiv ausgezeichnet sind, haben einen besonderen Stellenwert, da die Hervorhebungen sie für die Suchmaschi-nen als wichtig markieren. Allerdings sollte man vorsichtig mit unterstrichenen Keywords sein, da diese im Allgemeinen als Links verstanden werden und die Besucher enttäuscht sind, wenn es keine Weiterleitung von dem Keyword gibt.
Entscheidende Keywords sollten vor allem zu Beginn des Textes hervorgehoben werden. Es macht allerdings wenig Sinn, ganze Textabschnitte oder sämtliche Keywords aus dem definierten Spektrum hervorzuheben. Es empfiehlt sich die wichtigsten Aussagen eines Absatzes inkl. den wichtigsten Keywords hervorzu-heben und nicht nur einzelne Worte. Das können Teilsätze oder auch mal ein ganzer Satz sein. Grundsätzlich ist ein maßvoller Umgang mit den Hervorhe-bungen angebracht, um den Text lesefreundlich und übersichtlich zu halten.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
19
Die Tabelle gibt einen Überblick über die HTML‐Tags zum Hervorheben von Schlüsselwörtern:
HTML‐Tag Funktion
<h1> bis <h6> Überschriften
<strong>
Fettschriften, bold
<em> kursiv
<u>
unterstrichen
<s> durchgestrichen
<sub>
tiefergestellter Text
Tabelle 3: Überblick über HTML-Tags zur Hervorhebung von Inhalten.
5.2 Grafiken, alt- und title-Attribute Bei der Realisierung einer Website gehören Grafiken zu häufig verwendeten Elementen. Suchmaschinen sind in der Regel nicht in der Lage, Informationen aus Grafiken zu extrahieren. Aus diesem Grund sollten wichtige Texte immer im HTML-Code enthalten sein und nicht in Form einer Grafik dargestellt werden. HTML bietet mit dem alt-Attribut dennoch die Möglichkeit, den Inhalt von Grafi-ken zu beschreiben. Das alt-Attribut spielt eine wichtige Rolle bei der barriere-freien Gestaltung von Webseiten. So benutzen blinde und sehbehinderte Men-schen oft sogenannte Screenreader (also Bildschirmleseprogramme), die die Angaben des alt-Attributs vorlesen, um den Benutzern den Inhalt der dargestell-ten Grafik zu beschreiben. Alt-Texte sollten das Bild ein wenig beschreiben, so dass sich Menschen, die das Bild nicht sehen, sich dennoch einen Eindruck vom Bild machen können.
Da Suchmaschinen die alt-Attribute berücksichtigen, ist es sinnvoll, wenn in der Beschreibung ebenfalls wichtige Keywords enthalten sind. Hierbei muss sicher-gestellt werden, dass die Keywords auch mit den anderen im Text verwendeten Keywords übereinstimmen. Google kann dies sonst als unerlaubten Spam wer-ten. Weiterhin muss das Keyword-Stuffing vermieden werden.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
20
Das title-Attribut bietet eine weitere Möglichkeit, Arbeiten mit Keywords zu ver-sehen. Anders als das title-Tag im Header einer Webseite, das den Seitentitel angibt, handelt es sich bei dem Attribut gleichen Namens um ein beschreiben-des Attribut innerhalb einiger HTML-Elemente (unter anderem <img>-Tags für Grafiken und Fotos), das diese mit einem Titel versieht. Der Text des title-Attributs wird angezeigt, wenn ein User mit dem Mauscursor über eine Grafik fährt.
Folgendes Schema zeigt den Einsatz des alt-Attributs innerhalb des <img>-Tags:
<img src=“grafikname.jpg“ alt=“kurze Beschreibung der Grafik“ title “Be-zeichnung der Grafik“ />
Während das alt-Attribut bis zu zwei Sätze lang sein kann, um knackig zu be-schreiben, was man auf dem Bild sieht, kann auf das title-Attribut seit einiger Zeit auch verzichtet werden. Allerdings ist das title-Attribut eine gute Möglichkeit relevante Keywords nah beim Bild unterzubringen, ohne den Leser über zu viele Keywords im Text zu ermüden. Somit ist das title-Attribut neben dem Alt-Attribut ein sinnvolles Element zur SEO-Optimierung.
Unterschiedliche Grafiken oder Fotos sollten außerdem nicht denselben Inhalt innerhalb dieser Attribute enthalten, damit sie eindeutig identifizierbar sind. Aus-führlicher wird auf diese Thematik noch in der Session Medienoptimierung ein-gegangen.
6. Rich Snippets Snippets sind die Textauszüge, die unter jedem Suchergebnis erscheinen und Informationen darüber geben sollten, welchen Inhalt die Seite enthält. Zur Erstel-lung sogenannter Rich Snippets analysiert Google die Inhalte der Webseite. Auf der Seite "Strukturierte Daten" in den Google Webmaster-Tools kann man die strukturierten Daten finden, die Google auf der Website gefunden hat. Um Google dabei zu unterstützen, können Inhalte als strukturierte Daten markiert werden. Strukturierte Daten können bspw. Bewertungen sein. Der Vorteil liegt darin, dass die Suchergebnisse sich somit deutlicher von der Konkurrenz her-vorheben und so die Klickrate erhöht werden kann. http://support.google.com/webmasters/bin/answer.py?hl=de&answer=99170
7. Exkurs: URL-Rewriting für dynamisch generierte Webdokumente Website-Betreiber haben die Möglichkeit, sowohl statische HTML-Dateien als auch dynamisch generierte HTML-Dokumente zu verwenden. Bei der statischen

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
21
Variante ist der HTML- Code fest in HTML-Tags eingebunden. Die einzelnen Da-teien existieren daher genau in der Form, wie sie vom Webserver an Clients zu-rückgegeben werden. Im Gegensatz hierzu sind bei dynamisch generierten Do-kumenten keine endgültigen Dateien auf dem Webserver vorhanden. Vielmehr wird der Inhalt bei dieser Variante aus einer Datenbank, wie beispielsweise MySQL, ausgelesen und innerhalb von vordefinierten Templates (Schablonen) dargestellt.
Die Templates betten den Inhalt so in HTML ein, dass dynamisch generierte HTML-Dokumente problemlos von HTML-Clients interpretiert werden können.
Während die statische Variante vor allem bei relativ kleinen Websites Anwen-dung findet, kommen dynamische generierte Webdokumente häufig bei um-fangreicheren Websites, die oftmals anhand von CMS, also Content-Management-Systemen oder Shop-Systemen gepflegt werden, zum Einsatz.
Der große Vorteil bei dynamischen Lösungen ist die einfache Inhaltspflege. Der Betreiber eines Online-Shops kann beispielsweise eine Produktseite einmalig erstellen, die Daten der Produkte anschließend aus der Datenbank beziehen und über ein Datenbank-Interface pflegen. Bei statischen Dateien müsste jede Pro-duktseite separat erstellt und gepflegt werden, was bei vielen Tausend Produk-ten entsprechend aufwändig wäre. Je nach Art der Website kann die Verwen-dung dynamisch generierter Dokumente notwendig und sinnvoll sein. Aus Sicht der Suchmaschinen ergeben sich bei der Indexierung von dynamischen Webdo-kumenten jedoch folgende Nachteile:
• Die Inhalte ändern sich oftmals sehr schnell, was dazu führt, dass erfasste Dokumente bereits während der Indexierung nicht mehr mit der aktuellen Fas-sung übereinstimmen. Dies führt zu ungenauen Suchergebnissen.
• Dynamische Webdokumente unterscheiden sich oftmals nur geringfügig von-einander, weil das Template grundsätzlich dasselbe ist. Dies kann dazu füh-ren, dass sehr viele Dokumente indiziert werden, ohne nennenswerte Mehrin-formationen für den User zu bieten.
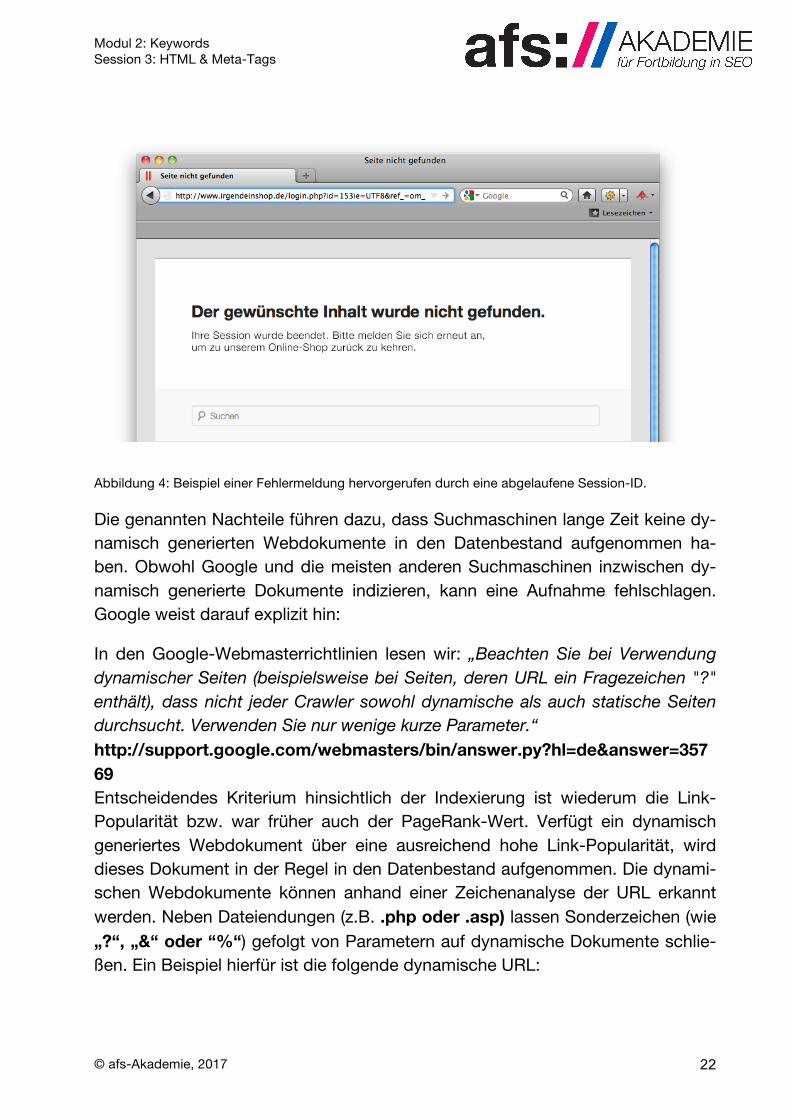
• In einigen Fällen kann sich die URL der Webdokumente ändern, was bei einer erneuten Anfrage zu keinem Ergebnis, aber zu Fehlermeldungen oder Verwei-sen auf die Startseite führen kann. Besonders bei den sogenannten Session-IDs tritt diese Problematik auf. So werden die Anfragen eines Nutzers auf eini-gen Websites (z.B. in einem Online-Shop) zu einer Sitzung (Session) zusam-mengefasst, der eine bestimmte Identifikationsnummer zugeordnet wird und diese Session-ID wird nach der Abmeldung des Nutzers wieder gelöscht.
•
Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
22
Abbildung 4: Beispiel einer Fehlermeldung hervorgerufen durch eine abgelaufene Session-ID.
Die genannten Nachteile führen dazu, dass Suchmaschinen lange Zeit keine dy-namisch generierten Webdokumente in den Datenbestand aufgenommen ha-ben. Obwohl Google und die meisten anderen Suchmaschinen inzwischen dy-namisch generierte Dokumente indizieren, kann eine Aufnahme fehlschlagen. Google weist darauf explizit hin:
In den Google-Webmasterrichtlinien lesen wir: „Beachten Sie bei Verwendung dynamischer Seiten (beispielsweise bei Seiten, deren URL ein Fragezeichen "?" enthält), dass nicht jeder Crawler sowohl dynamische als auch statische Seiten durchsucht. Verwenden Sie nur wenige kurze Parameter.“ http://support.google.com/webmasters/bin/answer.py?hl=de&answer=35769 Entscheidendes Kriterium hinsichtlich der Indexierung ist wiederum die Link-Popularität bzw. war früher auch der PageRank-Wert. Verfügt ein dynamisch generiertes Webdokument über eine ausreichend hohe Link-Popularität, wird dieses Dokument in der Regel in den Datenbestand aufgenommen. Die dynami-schen Webdokumente können anhand einer Zeichenanalyse der URL erkannt werden. Neben Dateiendungen (z.B. .php oder .asp) lassen Sonderzeichen (wie „?“, „&“ oder “%“) gefolgt von Parametern auf dynamische Dokumente schlie-ßen. Ein Beispiel hierfür ist die folgende dynamische URL:

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
23
http://www.eineseite.de/information.php?id=387
Es ist empfehlenswert, wenige und kurze Parameter zu verwenden. Dies hängt damit zusammen, dass mit einer Vielzahl an Parametern auch viele Variablen übergeben und dadurch die oben aufgeführten Nachteile verstärkt werden. Aus Sicht von Google sind URLs mit sehr vielen Parametern daher weniger für die Indexierung geeignet.
Eine Möglichkeit, die Problematik der dynamisch generierten Dokumente zu umgehen, ist das sogenannte URL-Rewriting (also das „Umschreiben“ solcher dynamischer URLs, sodass diese auch unter einer alternativen URL sichtbar sind).
Hierbei werden mithilfe einer sogenannten Rewrite-Engine Regeln definiert, dy-namische URLs so umzuschreiben, dass sowohl den Suchmaschinen als auch den Besuchern der Dokumente statische HTML-Dokumente „vorgetäuscht“ werden.
Eine gute Möglichkeit für das „Rewriting“ ist beispielsweise die Nutzung des mod_rewrite-Moduls für den Apache-Webserver. Die URL-Manipulation ge-schieht hier anhand von regulären Ausdrücken, welche in die Konfigurationsda-tei .htaccess (Hypertext Access) geschrieben werden. .htaccess-Dateien sind ein wichtiges Hilfsmittel für die Suchmaschinenoptimierung. Sie regeln den Zu-griff auf Webserver wie Apache und werden direkt im sogenannten root-Verzeichnis der Web-Präsenz abgelegt. Die Dateien sind neben dem Verzeich-nis, in das sie abgelegt werden, auch für alle Unterordner gültig. Besondere Vor-sicht ist beim Umgang mit .htaccess geboten, da sich Änderungen sofort und ohne Neustart des Webservers auswirken.
Nachfolgend soll ein Beispiel zur Umschreibung einer dynamischen URL mithilfe von mod_rewrite und .htaccess gezeigt werden:
.htaccess-Datei:
RewriteEngine On
RewriteCond %{THE_REQUEST} /dasprodukt\.php
RewriteCond %{QUERY_STRING} ^id=(.*)$
RewriteRule ^dasprodukt\.php$ http://www.irgendeinshop.de/dasprodukt_%1.html? [R=301,L]

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
24
Mit der RewriteRule wird bei Google und anderen Clients aus der dynamischen URL eine statische URL:
Vorher: http://www.irgendeinshop.de/dasprodukt.php?id=99
Nachher: http://www.irgendeinshop.de/dasprodukt‐99.html
Die statische URL wird bei einer Anfrage intern für den Webserver in die dyna-mische URL umgewandelt. URL-Rewriting führt auch zu besser lesbaren URLs. Man sagt dazu auch sprechende URLs. Der Nutzer einer Website kann sich sprechende URLs besser merken. Eine außergewöhnlich umfangreiche Doku-mentation über das Verfahren mod_rewrite und die Module sowie der regulären Ausdrücke wird von der Apache Software Foundation bereitgestellt. (siehe: http://httpd.apache.org/docs/2.2/mod/mod_rewrite.html).
An dieser Stelle sollte nur auf diese Möglichkeit hingewiesen werden.
Valides HTML
Nachdem alle Aspekte der On-Page-Optimierung berücksichtigt wurden, sollten die Dokumente, noch bevor Suchmaschinen diese indexieren können, hinsicht-lich korrekter Syntax überprüft werden. Ist der HTML-Code fehlerhaft, kann dies dazu führen, dass eine Suchmaschine die Keywords nicht nach den gewünsch-ten Vorstellungen interpretieren kann und diese hinsichtlich des gewünschten Erfolges keine Relevanzbeurteilung finden.
Insbesondere Hyperlinks sind eine häufige Fehlerquelle. Aufgrund der Bedeu-tung der Hyperlinks für die Linkpopularität und für die automatische Indexierung kann sich dies negativ auf den Erfolg einer Suchmaschinenoptimierung auswir-ken. Häufige Fehlerquellen sind fehlende spitze Klammern sowie unglücklich verwendete Anführungszeichen.
Die Vorgaben des W3C (World Wide Web Consortium) sind hierfür hilfreich. Da-zu bietet sich der vom W3C unter der URL http://validator.w3.org/ angebotene W3C Markup Validation Service an. Dieser Gültigkeitscheck kann entweder eine eingegebene URL, ein hochgeladenes Web-Dokument oder einen direkt einge-fügten HTML-Code validieren:

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
25
Abbildung 5: Eingabemaske des Markup Validation Service vom W3C. Quelle: http://validator.w3.org/
Zusammen mit den gefundenen Fehlern werden Lösungsvorschläge unterbrei-tet. Ein valider HTML-Code deutet zudem auf eine sorgfältige Arbeitsweise des Website-Betreibers hin.
8. Fazit Um den Suchmaschinen das Auffinden wichtiger Schlüsselbegriffe leicht zu ma-chen und nicht in den Weiten des Internets unterzugehen, ist es entscheidend, dass die relevanten Keywords auch im HTML-Quelltext der Website entspre-chend hervorgehoben werden.
Auch wenn die Bedeutung von Meta-Tags für die Suchmaschinenoptimierung umstritten ist, ergibt eine klare und prägnante Beschreibung einer Seite eine gu-te Struktur und erleichtert Mensch und Maschine die Orientierung im Webdo-kument.
Zusammenfassend kann man sagen, dass man die Möglichkeiten die HTML-Tags bieten bei der Optimierung einer Website nicht ungenutzt lassen sollte, da sie nicht nur wichtige Zusatzinformationen beinhalten, sondern auch den Robots der Suchmaschinen die Verarbeitung der Seiten erleichtern. Insbesondere ein sinnvoll gewählter Titel, die gezielte Platzierung der Keywords sowie ein valider HTML-Code sind über das Ranking hinaus wertvolle Bestandteile eines guten Gesamtprofils einer Seite.
Wiederholungs-Aufgaben:
1.) Wiederhole für Dich noch einmal die wichtigsten Punkte, die es im Zusammenhang mit HTML und Meta-Tags zu beachten gilt.
2.) Betrachte einen beliebigen Quellcode einer Seite mit dem http://validator.w3.org/ und schaue Dir die gefundenen Fehler an. Wie können diese behoben werden?

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
26
9. Glossar
Apache Software Foundation Die Apache Software Foundation (http://www.apache.org/) ist eine ehrenamtli-che Stiftung, deren Mitglieder freie Softwareprodukte (Apache Software) entwi-ckeln.
Apache Webserver Der Apache Webserver (http://httpd.apache.org/) ist ein freier HTTP-Server und der meistgenutzte Webserver im Internet. Er ist ein Produkt der Apache Soft-ware Foundation.
ASP
Active Server Pages nutzen eine serverseitige Programmiersprache, um dyna-mische und interaktive Websites zu erzeugen. Mittlerweile wird diese Skript-sprache nicht mehr so häufig genutzt. Interface
Ein Interface (engl. für Grenzfläche) ist die Kommunikationsschnittstelle für die Kommunikation zwischen Mensch und System. Keyword Stuffing
Keyword Stuffing (von engl. stuffing = Füllmaterial) steht für die übermäßige Verwendung von Keywords in den Meta-Tags oder im Content einer Seite. Template
Ein Template (engl. für Schablone) ist eine Vorlage z.B. für die Erstellung von Websites). URL-Rewriting
Das „Umschreiben“ dynamischer Websites, sodass diese wie statische Seiten wirken und von Suchmaschinen besser gelesen werden können. W3C
Das World Wide Web Consortium (http://www.w3.org/) ist ein Gremium mit dem Ziel, die Techniken des Internets zu standardisieren.

Modul 2: Keywords Session 3: HTML & Meta-Tags
© afs-Akademie, 2017
27
10. Links, Literaturtipps und Quellenangaben
Goldstein, Alexis / Lazaris, Louis / Weyl, Estelle: HTML5 & CSS3 in der Praxis. Haar b. München 2012.
Hogan, Brian P.: HTML5 & CSS3 : Webentwicklung mit den Standards von mor-gen. Köln 2011.
Prevezanos, Christoph: Jetzt lerne ich HTML5. Start ohne Vorwissen. München 2011.
Nützliche Links
http://de.selfhtml.org/
http://www.html-seminar.de/befehlsuebersicht.htm
http://de.selfhtml.org/html/kopfdaten/meta.htm
Google Webmaster Tools (GSC) zu Meta-Tags: http://support.google.com/webmasters/bin/answer.py?hl=de&answer=79812&topic=2371375&ctx=topic
Tutorials des World Wide Web Consortiums zu HTML, XHTML und CSS: http://www.w3.org/2002/03/tutorials.html#webdesign_htmlcss
Bitte beachten, die Nutzung der Lehrmaterialien ist nur registrierten Teilnehmern und Referenten der afs-Akademie vorbehalten. Jeder Teilnehmer / Referent ver-pflichtet sich, die ihm im Rahmen der Schulungsveranstaltung, insbesondere zur Nutzung der überlassenen Domain überreichten Unterlagen Stillschweigen zu bewahren. Diese Schweigepflicht besteht auch nach Beendigung des Vertrags-verhältnisses fort. Unterlagen, die der Teilnehmer / Referent im Rahmen der Schulungsveranstaltung erhalten hat, sind von ihm sorgfältig und gegen die Ein-sichtnahme Dritter geschützt aufzubewahren.