Embed Size (px)
Citation preview

Modul Datenbanken II – Unit 4304.1
Prof. Dr. Karl Friedrich Gebhardt

c©1996 – 2017 Karl Friedrich Gebhardt
Auflage vom 5. Dezember 2018
Prof. Dr. K. F. GebhardtDuale Hochschule Baden-Wurttemberg StuttgartAngewandte Informatik
Tel: 0711-667345-11(16)(15)(12)Fax: 0711-667345-10email: [email protected]

Inhaltsverzeichnis
1 Speicherstrukturen 1
1.1 Speichermedien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Magnetplatten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.2 Speicherarrays: RAID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.3 Magnetbander . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Datenbankpufferung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Seitenersetzungsstrategien . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.2 Schattenspeicher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Dateiverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.1 Datenbank und Betriebssystem . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.2 Typen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.3 Dateiaufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3.4 Datensatze und Blocke bzw Seiten . . . . . . . . . . . . . . . . . . . . . . 8
1.3.5 Blocke einer Datei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3.6 Addressierung von Datensatzen . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3.7 Dateikopf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.8 Dateioperationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Primare Dateiorganisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.4.1 Datei mit unsortierten Datensatzen . . . . . . . . . . . . . . . . . . . . . . 11
1.4.2 Datei mit sortierten Datensatzen . . . . . . . . . . . . . . . . . . . . . . . 11
1.4.3 Hash-Dateien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.5 Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.5.1 Magnetplatte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.5.2 StudentInnenverwaltung 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
i

ii INHALTSVERZEICHNIS
1.5.3 StudentInnenverwaltung 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5.4 Teile-Verwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Zugriffsstrukturen 17
2.1 Einstufige sortierte Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Mehrstufige Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3 Dynamische mehrstufige Indexe mit Baumen . . . . . . . . . . . . . . . . . . . . 20
2.3.1 Suchbaume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.2 B-Baume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.3 B+-Baume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3.4 Andere Indextypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4 Objektballung, Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5 Indexierung mit SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.6 Bemerkungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.6.1 Index Intersection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.6.2 Geclusterte Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.6.3 Unique Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.6.4 Indexe auf berechneten Spalten . . . . . . . . . . . . . . . . . . . . . . . . 26
2.6.5 Indexierte Views . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.6.6 Covering Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.7 Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.7.1 B-Baum, B+-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.7.2 Angestellten-Verwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Mehrdimensionale Zugriffsstrukturen 31
3.1 KdB-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2 Grid-File . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.3 Raumfullende Kurven . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.4 R-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

INHALTSVERZEICHNIS iii
4 NoSQL-Datenbanken 77
4.1 Uberblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.2 Begriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3 Datenmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3.1 Aggregate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.3.2 Key-Value-Store und Document-Store . . . . . . . . . . . . . . . . . . . . 81
4.3.3 Column-Family-Store . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.3.4 Graph-Store . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
A Cassandra 83
A.1 Geschichte, Charakteristika . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
A.2 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
A.2.1 MacOS X . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
A.3 CQL – Cassandra Query Language . . . . . . . . . . . . . . . . . . . . . . . . . . 84
A.3.1 Verbindung mit der Datenbank . . . . . . . . . . . . . . . . . . . . . . . . 84
A.3.2 Erste CQL-Anweisungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
A.3.3 Weitere CQL-Anweisungen . . . . . . . . . . . . . . . . . . . . . . . . . . 85
A.4 Daten-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
A.4.1 Relationales Daten-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
A.4.2 Cassandras Daten-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
A.4.3 Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
A.4.4 Keyspace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
A.4.5 Table, Column Family . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
A.4.6 Column . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
A.5 Datentypen in CQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
A.5.1 Numerische Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
A.5.2 Textuelle Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
A.5.3 Zeit- und Identitats-Datentypen . . . . . . . . . . . . . . . . . . . . . . . 89
A.5.4 Andere einfache Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . 90
A.5.5 Collection-Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
A.5.6 Benutzer-definierte Datentypen (UDT) . . . . . . . . . . . . . . . . . . . . 91
A.6 Sekundar-Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
A.7 Daten-Modellierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92

iv INHALTSVERZEICHNIS
A.7.1 Begriffe, Design-Prinzipien, Notation . . . . . . . . . . . . . . . . . . . . . 92
A.7.2 HBS: Systembeschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
A.7.3 HBS: Relationales Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . 95
A.7.4 HBS: Definition der Queries . . . . . . . . . . . . . . . . . . . . . . . . . . 97
A.7.5 HBS: Logisches Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . . 99
A.7.6 HBS: Physisches Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . . 102
A.7.7 HBS: CQL-Implementierungs-Datenmodell . . . . . . . . . . . . . . . . . 107
A.7.8 Aufspaltung zu großer Partitionen . . . . . . . . . . . . . . . . . . . . . . 112
A.8 Beispiele in Golang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
A.8.1 Beispiel ”Gezwitscher” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
A.9 Beispiele in Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
A.9.1 Beispiel ”GettingStarted” . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
A.10 What more about Cassandra? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
A.11 Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
A.11.1 DataStax-Trivadis-Aufgaben . . . . . . . . . . . . . . . . . . . . . . . . . 117
B Transaktionsverarbeitung 119
B.1 Transaktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
B.2 Nebenlaufigkeit (Concurrency) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
B.2.1 Probleme bei Nebenlaufigkeit . . . . . . . . . . . . . . . . . . . . . . . . . 121
B.2.2 Sperren (Locking) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
B.2.3 Serialisierbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
B.2.4 Isolationsniveau (Level of Isolation) . . . . . . . . . . . . . . . . . . . . . 126
B.2.5 Sperrgranularitat (Degree of Granularity) . . . . . . . . . . . . . . . . . . 126
B.3 Transaktions-Modell der ODMG . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
B.3.1 Java Binding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
B.4 Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
B.4.1 U-Locks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
B.4.2 Serialisierbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
B.4.3 Zwei-Phasen-Sperrtheorem . . . . . . . . . . . . . . . . . . . . . . . . . . 131

INHALTSVERZEICHNIS v
C Objektorientiertes Datenbanksystem db4o 133
C.1 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
C.2 Offnen, Schließen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
C.3 Speichern von Objekten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
C.4 Finden von Objekten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
C.5 Aktualisierung von Objekten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
C.6 Loeschen von Objekten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
C.7 NQ – Native Anfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
C.8 SODA Query API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
C.9 Strukturierte Objekte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
C.10 Felder und Collections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
C.11 Vererbung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
C.12 Tiefe Graphen und Aktivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
C.12.1 Defaultverhalten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
C.12.2 Dynamische Aktivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
C.12.3 Kaskadierte Aktivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
C.12.4 Transparente Aktivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
C.12.5 Transparente Persistenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
C.13 Indexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
C.14 Transaktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
C.15 Client/Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
C.15.1 Embedded Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
C.15.2 Verteiltes System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
C.15.3 Spezialitaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
C.16 Identifikatoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
C.16.1 Interne IDs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
C.16.2 Eindeutige universelle ID (UUID) . . . . . . . . . . . . . . . . . . . . . . . 155
C.17 Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
C.17.1 Viele Objekte, Lazy Query . . . . . . . . . . . . . . . . . . . . . . . . . . 156
C.17.2 Defragmentierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
C.17.3 Maximale Datenbankgroße . . . . . . . . . . . . . . . . . . . . . . . . . . 157
Literaturverzeichnis 159

vi INHALTSVERZEICHNIS

Kapitel 1
Speicherstrukturen
Daten mussen auf einem Speichermedium (storage medium) physisch gespeichert werden.In diesem Kapitel wird die physische Organisation (Dateiverwaltung) der gespeicherten Datenbesprochen.
Man spricht von einer Speicherhierarchie:
• Primarspeicher ist ein Speichermedium, mit dem die CPU direkt arbeiten kann. Das sindim wesentlichen der Hauptspeicher (RAM (random access memory)) (Zugriffszeit etwa 100ns) und gewisse schnellere, aber kleinere Cache-Speicher (Zugriffszeit etwa 10 ns). DerPrimarspeicher bietet einen schnellen Zugriff auf Daten, hat aber eine begrenzte Großeund ist relativ teuer. Die Lebenszeit der Daten ist begrenzt (fluchtiger Speicher, volatilestorage).
• Sekundarspeicher oder Hintergrundspeicher sind magnetische und optische Plattenmit großer Kapazitat. Die Kosten fur den Speicher sind vergleichsweise gering, d.h. um ein,zwei Großenordnungen kleiner als beim Primarspeicher. Der Zugriff ist wesentlich langsa-mer (Zugriffslucke (access gap) Großenordnung 105, Zugriffszeit etwa 10 ms). Die CPUkann nicht direkt auf diesen Daten arbeiten. Die Daten mussen erst in den Primarspeicherkopiert werden. Die Lebenszeit der Daten gilt als unbegrenzt (nichtfluchtiger Speicher,non-volatile storage).
Die folgende Diskussion bezieht sich auf Magnetplatten – kurz Platten – als das zur Zeitublichste sekundare Speichermedium. Wegen ihrer hohen Zugriffsgeschwindigkeit gehorensie zu den on-line-Geraten.
• Tertiarspeicher oder Archivspeicher sind meistens Magnet-Bander, die sehr billig(Pfennige pro MB) sind und eine hohe Ausfallsicherheit bieten. Der Zugriff auf Banderist sehr langsam. Sie werden fur Back-up benutzt. Die Daten sind dann off-line gespei-chert. CDs und DVDs werden auch als Tertiarspeicher verwendet.
Man unterscheidet noch die Begriffe Nearline-Tertiarspeicher, bei dem die Speicherme-dien automatisch bereitgestellt werden, und Offline-Tertiarspeicher, bei dem die Spei-chermedien von Hand bereitgestellt werden.
1

2 KAPITEL 1. SPEICHERSTRUKTUREN
Der DBA muss physische Speichermethoden kennen, um den Prozess des physischen Da-tenbankdesigns durchfuhren zu konnen. Normalerweise bietet das DBMS dazu verschiedeneMoglichkeiten an.
Typische DB-Anwendungen benotigen nur einen kleinen Teil der DB. Dieser Teil muss auf derPlatte gefunden werden, in den Primarspeicher kopiert werden und nach der Bearbeitung wiederauf die Platte zuruckgeschrieben werden.
Die Daten auf der Platte sind in Dateien (file) von Datensatzen (record) organisiert. JederDatensatz ist eine Menge von Datenwerten, die Tatsachen uber Entitaten, ihre Attribute undBeziehungen enthalten.
Es gibt verschiedene primare Dateiorganisationen (primary file organization), nach de-nen die Datensatze in der Datei physisch auf die Platte geschrieben werden:
• Heapdatei (heap file, unordered file): Die Datensatze werden ungeordnet auf die Plattegeschrieben.
• Sortierte oder sequentielle Datei (sorted file, sequential file): Die Datensatze wer-den nach einem besonderen Feld geordnet auf die Platte geschrieben.
• Hash-Datei (hash file): Eine Hashfunktion wird benutzt, um die Datensatze in der Dateizu platzieren.
• Sonstige Strukturen wie z.B. Baume.
1.1 Speichermedien
1.1.1 Magnetplatten
Die Informationseinheit auf der Platte (disk) ist ein Bit. Durch bestimmte Magnetisierung einesFlachenstucks auf der Platte kann ein Bitwert 0 oder 1 dargestellt werden. Normalerweise werden8 Bit zu einem Byte gruppiert. Die Kapazitat der Platte ist die Anzahl Byte, die man auf seinerFlache unterbringen kann. Typische Kapazitaten sind einige Gigabyte (GB).
Eine ”Platte” besteht i.a. aus mehreren einseitigen oder doppelseitigen Platten (platter) undbildet einen Plattenstapel (diskpack). Die einzelnen Platten haben Oberflachen (surface).Die Information auf den Platten ist in konzentrischen Kreisen (Spur, track) gespeichert. Spurenmit demselben Durchmesser bilden einen Zylinder (cylinder). Wenn Daten auf demselbenZylinder gespeichert sind, konnen sie schneller geholt werden, als wenn sie auf verschiedenenZylindern liegen.
Jede Spur speichert dieselbe Menge von Information, sodass auf den inneren Spuren die Bitdichter liegen. Die Anzahl der Spuren liegt in der Großenordnung 1000.
Die Unterteilung der Spuren in Sektoren (sector) ist auf der Plattenoberflache hart kodiertund kann nicht geandert werden. Nicht alle Platten haben eine Unterteilung in Sektoren.
Die Unterteilung einer Spur in Blocke (block) oder Seiten (page) wird vom Betriebssystemwahrend der Formatierung oder Initialisierung der Platte vorgenommen. Die Blockgroße (512bis 4096 Byte) kann dynamisch nicht geandert werden. Die Blocke werden durch interblock gaps

1.1. SPEICHERMEDIEN 3
getrennt. Diese enthalten speziell kodierte Steuerinformation, die wahrend der Formatierunggeschrieben wird.
Eine Platte ist ein random access Medium. D.h. auf jeden Block kann direkt zugegriffen werden,ohne dass davorliegende Blocke gelesen werden mussen. Die Transfereinheit zwischen Platte undHauptspeicher ist der Block. Die Adresse eines Blocks setzt sich zusammen aus Blocknummer,Sektornummer, Spurnummer und Plattenseitennummer.
Bei einem Lesekommando wird ein Block in einen speziellen Hauptspeicherpuffer kopiert. Beieinem Schreibkommando wird dieser Puffer auf einen Plattenblock kopiert. Manchmal werdenmehrere hintereinanderliegende Blocke, sogenannte Cluster, als Einheit kopiert.
Der eigentliche Hardware-Mechanismus ist der auf einen mechanischen Arm montierte Lese-Schreib-Kopf des Plattenlaufwerks (disk drive). Der mechanische Arm kann radial bewegtwerden. Bei Plattenstapeln ist das ein Zugriffskamm mit entsprechend vielen Kopfen.
Um einen Block zu transferieren sind drei Arbeitsschritte notwendig. Zunachst muss der Kopf aufdie richtige Spur bewegt werden. Die benotigte Zeit ist die Suchzeit, Zugriffbewegungszeit(seek time). Danach muss gewartet werden, bis sich die Platte an die richtige Stelle gedreht hat:Latenzzeit, Umdrehungszeit, Umdrehungswartezeit (latency, rotational delay, rota-tional latency). Schließlich werden die Daten wahrend der Transferzeit, Ubertragungszeitoder Lesezeit (block transfer time) in den oder vom Hauptspeicher transferiert.
Als Großenordnung fur Suchzeit und Latenzzeit kann man 10 ms angeben, fur die Transferzeit0,01 ms. Daher wird man immer versuchen viele hintereinanderliegende Blocke zu lesen. DieseZeiten sind groß verglichen mit CPU-Verarbeitungszeiten und bilden daher immer einen Fla-schenhals. Geeignete Dateistrukturen versuchen, die Anzahl der Blocktransfers zu minimieren.
Fur das Disk-I/O ist entscheidend, ob Informationen auf der Platte ”hintereinander” liegen unddaher mit minimaler Such- und Latenzzeit zuganglich sind (sequential I/O, serial I/O, indisk order) oder ob die Information auf der Platte verstreut ist und jedesmal eine Kopfbewegungund Latenzzeit investiert werden muss (nonsequential I/O).
1.1.2 Speicherarrays: RAID
Die fur die mechanischen Arbeitsvorgange einer Festplatte benotigten Zeiten lassen sich nichtmehr wesentlich reduzieren. Die RAID-Technologie (redundant array of inexpensive – neu-erdings – independent disks) versucht dieses Problem zu losen, indem viele, relativ billigeLaufwerke benutzt werden. Der RAID-Controller sorgt dafur, dass sich die vielen Laufwer-ke nach außen transparent wie ein Laufwerk verhalten. Daher mussen wir hier nicht auf dieEinzelheiten dieser Technologie eingehen [26].
1.1.3 Magnetbander
Magnetbander sind sequential access Medien. Um auf den n-ten Block zuzugreifen, muss manerst n – 1 Blocke lesen. Normalerweise wird ein Byte quer uber das Band gespeichert. Die Bytewerden dann hintereinander gespeichert. Banddichten liegen zwischen 600 und 3000 Byte procm. Blocke sind gewohnlich großer als bei Platten um Zwischenraume einzusparen.
Zugriffszeiten sind extrem lang. Daher werden Bander nur fur Back-up verwendet.

4 KAPITEL 1. SPEICHERSTRUKTUREN
1.2 Datenbankpufferung
Die Organisationseinheit des Speichermediums ist der (physische) Block ((physical) block).Das Dateisystem des Betriebssystems oder des DBMSs fordert Seiten (page) an. Die Zuordnungzwischen Seite und Block wird mit festen Faktoren vorgenommen: 1, 2, 4 oder 8 Blocke einerSpur werden auf eine Seite abgebildet. Ohne Beschrankung der Allgemeinheit konnen wir dieZuordnung ”ein Block – eine Seite” wahlen und werden im Folgenden diese Begriffe synonymverwenden.
Wenn viele Blocke benotigt werden, dann kann man im Hauptspeicher spezielle Puffer (Daten-bankpuffer) reservieren, um den Transfer insgesamt durch parallele Bearbeitung der Daten zubeschleunigen. Außerdem ist es sinnvoll, Blocke langer als nur fur eine Operation im Haupt-speicher zu halten. Anwendungen zeigen oft eine sogenannte Lokalitat, indem sie mehrmalshintereinander auf dieselben Daten zugreifen.
Der Datenbankpuffer hat eine begrenzte Große. Daher mussen Blocke immer wieder ersetztwerden. Dabei werden verschiedene Ersetzungsstrategien verwendet, z.B. wird der am langstennicht mehr gebrauchte Block ersetzt.
Der Datenbankpuffer ist in Pufferrahmen gegliedert. Ein Pufferrahmen kann eine Seite zwi-schenspeichern. Die Pufferverwaltung hat im einzelnen folgende Bereiche:
Suchverfahren: Werden vom DBMS Seiten angefordert, dann werden diese zunachst im Puffergesucht. Es mussen also effiziente Suchverfahren zur Verfugung stehen. Wenn eine direkteSuche (Uberprufung jedes Pufferrahmens) nicht genugend effizient ist, dann mussen Zusatz-strukturen verwendet werden wie unsortierte oder (nach Seitennummer) sortierte Tabellenoder Listen oder Hash-Tabellen, in denen alle Seiten des Datenbankpuffers vermerkt sind.
Speicherzuteilung: Wenn DB-Transaktionen parallel Seiten anfordern, dann muss der Pufferunter den Transaktionen geschickt aufgeteilt werden. Dafur gibt es verschiedene Strategien:
1. Lokale Strategie: Der Puffer wird statisch oder dynamisch in disjunkte Bereicheaufgeteilt, die jeweils einer Transaktion zur Verfugung gestellt werden.
2. Globale Strategie: Bereiche fur bestimmte Transaktionen sind nicht erkennbar. Je-der Transaktion steht der gesamte Puffer zur Verfugung. Gemeinsam referenzierteSeiten konnen so besser berucksichtigt werden.
3. Seitentypbezogene Strategie: Der Puffer wird in Bereiche fur Datenseiten, Zu-griffspfadseiten, Data-Dictionary-Seiten oder weitere Seitentypen eingeteilt. Jeder Be-reich kann dann sein eigenes Seitenersetzungsverfahren haben.
Seitenersetzungsstrategie: Ist der Puffer voll, so muss entschieden werden, welche Seite ver-drangt, d.h. nach eventuellem Zuruckschreiben auf die Platte uberschrieben werden soll.Da dies die wichtigste Aufgabe der Pufferverwaltung ist, werden wir uns dies im folgendenAbschnitt genauer ansehen.
1.2.1 Seitenersetzungsstrategien
Beim Laden von Seiten von der Platte unterscheiden wir zwei Begriffe:

1.2. DATENBANKPUFFERUNG 5
• Demand-paging-Verfahren: Nur die angeforderte Seite wird in den Puffer geladen. Dasist das Standardverfahren.
• Prepaging-Verfahren (oder read-ahead processing): Neben der angeforderten Seite wer-den auch weitere Seiten in den Puffer geladen, die eventuell in nachster Zukunft benotigtwerden. Das ist insbesondere bei großen zusammenhangenden Objekten vorteilhaft.
Eine gute Seitenersetzungsstrategie ersetzt die Seiten, die am ehesten in Zukunft nicht mehrgebraucht werden. Die optimale Strategie wurde also wissen, welche Zugriffe in Zukunft an-stehen. Das ist naturlich nicht realisierbar. Realisierbare Verfahren besitzen keine Kenntnisseuber das zukunftige Referenzverhalten.
Die Effizienz einer einfachen Zufallsstrategie sollte von jedem realisierbaren Verfahren erreichtwerden. Gute realisierbare Verfahren benutzen das vergangene Referenzverhalten.
Messbar sind das Alter einer Seite im Puffer und die Anzahl der Referenzen auf eine Seiteim Puffer. Im Einzelnen ist messbar:
• AG: Alter einer Seite seit Einlagerung (globale Strategie)
• AJ: Alter einer Seite seit dem letzten Referenzzeitpunkt (Strategie des jungsten Verhaltens)
• RG: Anzahl aller Referenzen auf eine Seite (globale Strategie)
• RJ: Anzahl nur der letzten Referenzen auf eine Seite (Strategie des jungsten Verhaltens)
Im folgenden stellen wir einige konkret verwendete Strategien vor:
Zufall: Die zu ersetzende Seite wird erwurfelt. Diese Strategie ist wegen der steigende Große desDB-Puffers nicht zu verachten und wird daher insbesondere bei Betriebssystemen vermehrteingesetzt.
FIFO (AG, first-in-first-out): Die Seite (alteste Seite), die am langsten im Puffer steht, wirdersetzt. Bei einem sequentiellen Durchlauf durch eine Datei ist dieses Verfahren gunstig,sonst eher schlecht.
LFU (RG, least-frequently-used): Die Seite, die am seltensten referenziert wurde, wird ersetzt.Da dieses Verfahren vom Alter unabhangig ist, kann es sein, dass eine Seite, die vor langerSeite sehr haufig benutzt wurde, nicht mehr aus dem Puffer zu verdrangen ist.
LRU (AJ, RJ, least-recently-used): Die Seite, die am langsten nicht mehr referenziert wurde,wird ersetzt. Das Referenzverhalten in jungster Zeit wird berucksichtigt. Diese Strategie istbei Betriebssystemen sehr beliebt, bei Datenbanksystemen in dieser reinen Form allerdingsnicht optimal.
Eine self-tuning Variante ist LRU-K, wobei die Zeiten der letzten K Zugriffe auf eine Seiteberucksichtigt werden.
DGCLOCK (AG, RJ, RG, dynamic-generalized-clock) und

6 KAPITEL 1. SPEICHERSTRUKTUREN
LRD (AJ, AG, RG, least-reference-density): Die Kriterien Alter und Referenzhaufigkeit wer-den kombiniert, wobei durch Gewichtung der Referenzzahler das jungste Verhalten hoherbewertet wird.
Das Verfahren basiert auf einem globalen Referenzzahler fur den gesamten Puffer (GLOB)und auf einem lokalen Referenzzahler fur jeden Pufferrahmen j (LOKj). Diese Zahler werdenfolgendermaßen verwaltet:
1. Beim Laden einer Seite in den Pufferrahmen j findet eine Neubestimmung des lokalenReferenzzahlers statt:
LOKj = GLOB
2. Bei jeder Referenz auf eine Seite werden die Zahler aktualisiert:
GLOB = GLOB + 1LOKj = LOKj + GLOB
3. Erreicht GLOB eine festgelegte Obergrenze, wird GLOB auf einen vorgegebene Untergren-ze MINGLOB gesetzt und die lokalen Zahler werden durch Division mit einer KONSTANTEnnormiert:
GLOB = MINGLOB
LOKj = LOKj div KONSTANTE (j = 1, ... n)
4. Schließlich konnen zum Feintuning von außen Seitengewichte gesetzt oder Seiten fest-gesetzt werden.
Auf die eher marginalen Unterschiede zwischen DGCLOCK und LRD wird hier nicht ein-gegangen.
Die mangelnde Eignung des Betriebssystem-Puffers fur Datenbankoperationen soll an einer ein-fachen nested-loop-Verbundoperation zwischen zwei Tabellen A und B gezeigt werden. BeideTabellen bestehen auf dem Sekundarspeicher aus einer Folge von Seiten Ai bzw Bi. Wir ladenzunachst Seite A1 und lesen dort das erste Tupel. Damit referenzieren wird die Seite A1. Daserste Tupel wird mit allen Tupeln von B verglichen. Dazu laden wird nacheinander die Seiten B1
usw. Nach Seite B5 sei der Puffer voll. Fur die Seite B6 muss nun eine Seite verdrangt werden.
• Bei FIFO wurde A1 verdrangt werden, die aber weiterhin benotigt wird, namlich um daszweite, dritte usw. Tupel zu vergleichen.
• Bei LRU wird ebenfalls A1 verdrangt, da sie nur beim Lesen des ersten Tupels referenziertwurde. Sie wird aber fur die weiteren Tupel noch benotigt. Wenn A1 wegen des nachstenTupels wieder geladen wird, wurde ausgerechnet Seite B1 verdrangt werden, die als nachsteaber benotigt wird. Bei FIFO und LRU werden tendenziell gerade die Seiten verdrangt,die als nachste benotigt werden.
Ein DBMS muss daher weitere Moglichkeiten haben, die auf der Kenntnis der Semantik undRealisierungskonzepte von DB-Operationen beruhen. Die Moglichkeiten sind:
• Fixieren von Seiten: Ein Seite wird von der Verdrangung ausgeschlossen.
• Freigeben von Seiten: Eine Seite kann zur Verdrangung freigegeben werden.
• Zuruckschreiben einer Seite: Eine geanderte Seite kann auf die Platte zuruckgeschriebenwerden, um sie schneller verdrangbar zu machen.

1.3. DATEIVERWALTUNG 7
1.2.2 Schattenspeicher
Das Schattenspeicherkonzept (shadow page table) ist eine Modifikation des Pufferkon-zepts. Es ist ein Konzept, um im Fehlerfall den alten Datenbankzustand wiederherzustellen.Wird im Laufe einer Transaktion eine Seite auf die Platte zuruckgeschrieben, so wird sie nichtauf die Original-Seite geschrieben, sondern auf eine neue Seite. Fur die Pufferrahmen gibt eszwei Hilfsstrukturen V0 und V1. In der Version V0 sind die Adressen der Original-Seiten aufdem Sekundarspeicher vermerkt, in dem Schattenspeicher V1 werden die neuen Seiten gefuhrt.Diese Hilfsstrukturen heißen auch virtuelle Seitentabellen. Transaktionen arbeiten nun aufden Seiten im Puffer oder den uber die virtuellen Seitentabellen erreichbaren Seiten. Wird eineTransaktion abgebrochen, dann muss man nur auf die Ursprungsversion V0 zuruckgreifen undhat somit den Zustand vor Beginn der Transaktion wiederhergestellt. Wird die Transaktion er-folgreich abgeschlossen, dann wird V1 die Originalversion, und V0 wird als neuer Schattenspeicherverwendet.
1.3 Dateiverwaltung
1.3.1 Datenbank und Betriebssystem
Ein DBMS kann sich unterschiedlich stark auf das Betriebssystem abstutzen.
• Das DBMS kann jede Relation oder jeden Zugriffspfad in einer Betriebssystem-Datei spei-chern. Damit ist die Struktur der DB auch im Dateisystem des Betriebssystems sichtbar.
• Das DBMS legt relativ wenige Betriebssystem-Dateien an und verwaltet die Relationen undZugriffspfade innerhalb dieser Dateien selbst. Damit ist die Struktur der DB im Dateisystemdes Betriebssystems nicht mehr sichtbar.
• Das DBMS steuert selbst das sekundare Speichermedium als raw device an. Das DBMSrealisiert das Dateisystem selbst am Betriebssystem vorbei.
Damit wird das DBMS zwar unabhangig vom Betriebssystem, hangt aber von Gerates-pezifika ab. Das DBMS muss sich nicht bezuglich der Dateigroße (4 GB bei 32-Bit-BS)einschranken. Dateien konnen Medien-ubergreifend angelegt werden. Die Pufferverwaltungkann DB-spezifisch gestaltet werden.
1.3.2 Typen
Ein Datensatz (record) besteht aus Feldern (field). Jedes Feld hat einen Datentyp (datatype) und einen Wert (value, item). Die Datentypen der Felder ergeben den Datensatztyp(record type, record format).
Zusatzlich zu den ublichen Datentypen Integer, Long-Integer, Real, String, Boolean gibt esbei DB-Anwendungen Date, Time, BLOB (binary large object) und CLOB (character large object).Blobs sind große unstrukturierte Objekte, die Bilder, Video oder Audiostrome reprasentieren,Clobs reprasentieren Texte.

8 KAPITEL 1. SPEICHERSTRUKTUREN
1.3.3 Dateiaufbau
Eine Datei ist eine Folge von Datensatzen. Wenn jeder Datensatz dieselbe Lange hat, sprichtman von fixed-length record, sonst von variable-length record.
Bei fester Lange kann die Adresse eines Datensatzes leicht berechnet werden. Allerdings wird oftSpeicher verschwendet, da auch Datensatze mit kurzen Feldinhalten dieselbe Maximalanzahl vonBytes verbrauchen. Bei variabler Lange wird Speicher gespart, aber der Verwaltungsaufwand istgroßer. Es gibt verschiedene Moglichkeiten:
• Fullung mit einem speziellen Zeichen auf eine feste Lange.
• Verwendung von speziellen Trennzeichen zwischen Feldern.
• Speicherung der Anzahl Felder und fur jedes Feld ein (Feldlange, Feldwert)-Paar.
• Speicherung der Anzahl Felder, dann fur jedes Feld einen Zeiger auf den Wert des Feldesund schließlich fur jedes Feld den Feldwert (dort, wo der Zeiger hinzeigt).
• (bei optionalen Feldern) Speicherung von (Feldname, Feldwert)-Paaren, wobei der Feldna-me geeignet zu kodieren ist.
• (repeating field) Ein Trennzeichen wird benotigt, um die Feldwiederholung zu trennen, einweiteres Trennzeichen wird benotigt, um den Feldtyp abzuschließen.
• (bei unterschiedlichen Datensatztypen) Jeder Datensatz wird durch eine Typkennung ein-geleitet.
• Bei BLOBs (binary large object), die beliebige Byte-Folgen (Bilder, Audio- und Vi-deosequenzen) aufnehmen, und CLOBs (character large object), die ASCII-Zeichenaufnehmen, wird als Feldwert ein Zeiger auf den Beginn einer Blockliste verwaltet. Umwahlfrei in das BLOB hineingreifen zu konnen, eignet sich anstatt des Zeigers die Spei-cherung eines BLOB-Verzeichnisses, das mehrere Zeiger auf die verschiedenen Blocke desBLOBs enthalt.
1.3.4 Datensatze und Blocke bzw Seiten
Definitionen:
• bs ist die Blockgroße (block size) des Datenbanksystems in Byte.
• tsR ist die (mittlere) Große von Tupeln der Relation R.
Die Datensatze einer Datei mussen Blocken bzw Seiten auf der Platte zugeordnet werden(Blocken, record blocking). Wenn der Block großer als der Datensatz ist, dann enthalt einBlock viele Datensatze. Das abgerundete Verhaltnis
fR =bstsR
=Blockgroße
Datensatzgroße

1.3. DATEIVERWALTUNG 9
ist der Blockungsfaktor (blocking factor) einer Datei. Um den ungenutzten Platz zu verwen-den, kann ein Teil eines Datensatzes in einem Block, der Rest in einem anderen Block gespeichertwerden. Ein Zeiger am Ende des ersten Blocks enthalt die Adresse des nachsten Blocks. DieseOrganisation heißt blockubergreifend (Spannsatz, spanned). Die Blockverarbeitung wirdallerdings einfacher, wenn die Datensatze gleiche Lange haben, die Datensatze kleiner als dieBlocke sind und eine nicht-blockubergreifende (Nichtspannsatz, unspanned) Organisationgewahlt wird.
1.3.5 Blocke einer Datei
Fur die Allokierung der Blocke einer Datei auf der Platte gibt es verschiedene Standardtechniken:
• contiguous allocation: Die Blocke einer Datei liegen hintereinander. Die Datei kannschnell gelesen und geschrieben werden. Die Erweiterung einer Datei ist schwierig.
• linked allocation: Jeder Block hat am Ende einen Zeiger auf den nachsten Block, derzu dieser Datei gehort. Die Erweiterung einer Datei ist unproblematisch. Wenn auch nochder vorhergehende Block mitverwaltet wird, werden diese Zeiger und andere Informationenuber den Block in einen Kopf (header) des Blocks geschrieben.
• clusters (segments, extents): Nach Moglichkeit werden mehrere hintereinanderliegendeBlocke (cluster) verwendet. Das Ende des Clusters zeigt auf den nachsten Cluster.
• Indexierte Allokierung (indexed allocation): Ein oder mehrere Index-Blocke enthal-ten Zeiger auf die Datenblocke der Datei.
• Kombinationen der oben genannten Techniken
Wir wollen hier einfach auf den Unterschied zwischen sequentiellen (sequential, serial, indisk order) I/O-Operationen und nichtsequentiellen (nonsequential) I/O-Operationen hin-weisen. Sequentielle Operationen sind im allgemeinen wesentlich performanter.
1.3.6 Addressierung von Datensatzen
Datensatze konnen im Prinzip durch Angabe der Seiten-Nummer und eines Offsets auf der Seiteadressiert werden. Dabei sind die Datensatze aber an die Position auf einer Seite fixiert (pinned).Muss der Datensatz nach einer Aktualisierung verschoben werden, dann mussten alle Referen-zen auf diesen Datensatz nachgezogen werden, was viel zu aufwendig ist. Dieses Problem wirdmit dem in relationalen DBMS ublichen TID-Konzept gelost (Tupel-Identifikator) (recordidentifier, row-ID, RID).
Ein TID ist eine Datensatz-Adresse, die aus der Seitennummer und einem Offset besteht unddie nicht direkt auf den Datensatz selbst, sondern nur auf einen Datensatz-Zeiger zeigt. DieseDatensatz-Zeiger befinden sich am Anfang einer Seite und enthalten den Offset zum eigentlichenDatensatz.
Wenn ein Datensatz innerhalb der Seite verschoben wird, dann andert sich nur der Eintrag beiden Datensatz-Zeigern.

10 KAPITEL 1. SPEICHERSTRUKTUREN
Wenn ein Datensatz auf eine andere Seite verschoben wird, dann wird an die alte Stelle desDatensatzes der neue TID (TID2) des Datensatzes geschrieben. Dabei entstehen zweistufige undauch mehrstufige Referenzen.
Daher wird eine solche Struktur in regelmaßigen Abstanden reorganisiert.
Fur die Diskussionen in den Kapiteln uber Zugriffsstrukturen, Basisoperationen und Optimierungist nur wichtig zu wissen, dass mit dem TID der Zugriff auf ein Tupel nur ein oder wenige Disk-I/Os kostet.
1.3.7 Dateikopf
Der Dateikopf (file header, file descriptor) enthalt Informationen uber einen File. DieseInformation wird benotigt, um auf die einzelnen Datensatze zuzugreifen. Das bedeutet, der Da-teikopf enthalt Blockadressen und Dateisatzformate. Um einen Datensatz zu suchen, mussenBlocke in den Hauptspeicher kopiert werden. Wenn die Blockadresse nicht bekannt ist, mussenalle Blocke der Datei durchsucht werden (linear search). Das kann viel Zeit kosten. Ziel einerguten Dateiorganisation ist die Lokalisierung des Blocks, der den gesuchten Datensatz enthalt,mit einer minimalen Anzahl von Blockubertragungen.
1.3.8 Dateioperationen
Unabhangig vom jeweiligen DBMS und Betriebssystem wollen wir hier die wichtigsten Datei-operationen nennen.
Suchen (find, locate): Sucht nach dem ersten Datensatz, der einer gewissen Suchbedingunggenugt. Transferiert den Block in einen Hauptspeicherpuffer, wenn der Block nicht schondort ist. Der gefundene Datensatz wird der aktuelle Datensatz (current record).
Lesen (holen, read, get): Kopiert den aktuellen Datensatz aus dem Hauptspeicherpuffer ineine Programmvariable oder den Arbeitsspeicher eines Programms. Gleichzeitig wird haufigder nachste Datensatz zum aktuellen Datensatz gemacht.
Weitersuchen (find next): Sucht nach dem nachsten Datensatz, der einer Suchbedingunggenugt und verfahrt wie bei Suchen.
Loschen (delete): Loscht den aktuellen Datensatz.
Aktualisieren (modify): Verandert einige Werte im aktuellen Datensatz.
Einfugen (insert): Fugt einen neuen Datensatz in die Datei ein, wobei zunachst der Blocklokalisiert wird, in den der Datensatz eingefugt wird. Unter Umstanden muss ein neuerBlock angelegt werden.
Neben diesen record-at-a-time Operationen gibt es eventuell auch set-at-a-time Operationen,die mehrere Datensatze betreffen:
Suche alle (find all): Lokalisiert alle Datensatze, die einer Suchbedingung genugen.
Reorganisiere (reorganize): Startet den Reorganisationsprozess z.B. zur Sortierung einer Da-tei nach einem Datensatzfeld.

1.4. PRIMARE DATEIORGANISATION 11
1.4 Primare Dateiorganisation
1.4.1 Datei mit unsortierten Datensatzen
Die einfachste Dateiorganisation ist die Heap-Datei (heap file, pile file, (manchmal auch)sequential file), wo jeder neue Datensatz am Ende angefugt wird.
Dieses Anfugen geht sehr effizient: Der letzte Block der Datei wird in den Hauptspeicherpufferkopiert, der neue Datensatz dort angefugt, und der Block wird auf die Platte zuruckgeschrieben.Die Adresse des letzten Blocks wird im Dateikopf verwaltet. Aber die Suche nach einem Datensatzmit einer Suchbedingung erfordert einen linearen Durchgang durch – im Schnitt die Halfte – allerBlocke.
Zur Loschung eines Datensatzes muss der entsprechende Block gefunden und in den Hauptspei-cherpuffer kopiert werden. Dort bekommt der Datensatz eine Loschmarke (deletion marker)oder wird mit einer Defaultinformation uberschrieben. Beide Techniken lassen Speicherplatz un-genutzt. Der Block wird wieder auf die Platte zuruckgeschrieben. Eine gelegentliche Reorganisa-tion der Datei stellt den verlorenen Speicherplatz wieder zur Verfugung; oder neue Datensatzewerden an Stelle der geloschten Datensatze eingefugt.
Bei einer Datei mit Datensatzen fester Lange, nicht ubergreifend belegten, hintereinanderliegen-den Blocken kann ein Datensatz durch seine Position in der Datei direkt angesprochen werden(relative file). Das hilft zwar nicht beim Suchen, aber erleichtert die Erstellung von Zugriffs-pfaden.
1.4.2 Datei mit sortierten Datensatzen
Wenn die Datensatze einer Datei physisch nach einem Sortierfeld (ordering field) sortiertsind, dann hat man eine sortierte Datei (ordered, sequential file). Das Sortierfeld kannein Schlusselfeld (key field, ordering key) sein, d.h. den Datensatz eindeutig bestimmen(sequentielle Datei).
Bei einer sortierten Datei ist eine Binarsuche (binary search) moglich, wenn die Suchbedin-gung auf dem Sortierfeld beruht. Wenn die Datei b Blocke hat, dann werden im Schnitt
log2(b)
Blockzugriffe benotigt, um einen Datensatz zu finden.
Wenn die Suche nicht auf dem Sortierfeld beruht, dann bietet eine sortierte Datei keinen Vorteil,da in diesen Fallen auch linear gesucht werden muss. Ferner ist eine binare Suche oft praktischnicht moglich, da man ja nicht weiß, wo denn jeweils der ”mittlere” Block liegt. Daher machtdiese Organisation meistens nur Sinn, wenn zusatzlich ein Index verwendet wird.
Einfugen und Loschen von Datensatzen sind ”teure” Operationen, da im Schnitt die Halftealler Blocke bewegt werden muss. Beim Loschen kann man aber mit Loschmarken arbeiten. ZurMilderung des Einfugeproblems kann man in jedem Block Platz fur neue Datensatze reservieren.Eine weitere Technik ist die Verwendung einer zusatzlichen Transaktionsdatei (transaction,overflow file), wobei neue Datensatze dort einfach angehangt werden. Periodisch wird die ganzeTransaktionsdatei in die geordnete Hauptdatei (main, master file) eingefugt. Einfugen wird

12 KAPITEL 1. SPEICHERSTRUKTUREN
dadurch sehr effizient, aber der Suchalgorithmus ist komplizierter, da nach einer Binarsuche inder Hauptdatei noch eine lineare Suche in der Transaktionsdatei durchgefuhrt werden muss.
1.4.3 Hash-Dateien
Hash-Dateien (hash, direct file) bieten sehr schnellen Zugriff auf Datensatze, wenn die Such-bedingung ein Gleichheitsvergleich mit einem Hash-Feld (hash field) ist. Wenn das Hash-Feldauch ein Schlussel ist, dann spricht man von einem Hash-Schlussel (hash key).
Mit Hilfe der Hash-Funktion (hash function, randomizing function) kann aus dem Hash-Feld-Wert die Adresse des Blocks ermittelt werden, in dem der Datensatz gespeichert ist.
Das Speichermedium wird in Eimer (bucket) aufgeteilt. Ein Eimer ist entweder ein Blockoder ein Cluster hintereinanderliegender Blocke. Die Hash-Funktion bildet den Schlussel auf dierelative Eimernummer ab. Eine Tabelle im Dateikopf stellt die Beziehung zwischen Eimernummerund absoluter Blockadresse her.
Normalerweise passen viele Datensatze in einen Eimer, sodass relativ wenige Kollisionen auftre-ten. Wenn allerdings ein neuer Datensatz in einen vollen Eimer hineinhashed, dann kann eineVariation des Verkettungsmechanismus angewendet werden, bei dem jeder Eimer einen Zeiger aufeine Liste uberzahliger Datensatze verwaltet. Die Zeiger in der Liste sind Zeiger auf Datensatze,d.h. enthalten eine Blockadresse mit relativer Datensatzposition in diesem Block.
Fur die Hash-Funktion h gibt es verschiedenste Moglichkeiten. Auf irgendeine Art muss der Wertk des Hash-Feldes in einen Integer c verwandelt werden (Hashcode hc). Die Anzahl der Eimersei M mit den relativen Eimernummern 0 bis M − 1. Beispiele fur Hash-Funktionen sind dann:
• c = hc(k) (Hashcode)
• h(k) = c mod M (Hashfunktion)
• h(k) = irgendwelche n Stellen von c, wobei M = 10n
Z.B. sei n = 3. Wenn c = 3627485, dann werden z.B. die mittleren n Stellen von c, also274 als h(k) genommen.
Die Suche mit einer allgemeinen Suchbedingung bedeutet lineare Suche durch alle Blocke derDatei. Modifikationen von Datensatzen sind aufwendig, wenn das Hash-Feld beteiligt ist.
Fur die Datei muss ein fester Speicherplatz allokiert werden. Daher betrachten wir jetzt nochHash-Techniken, die eine dynamische Dateierweiterung erlauben. Diese Techniken beruhen dar-auf, dass das Resultat der Hash-Funktion ein nicht negativer Integer ist, den wir als Binarzahl(hash value) darstellen konnen.
Dynamisches Hashing
Beim dynamischen Hashing (dynamic hashing) ist die Anzahl der Eimer nicht fest, sondernwachst oder schrumpft nach Bedarf. Die Datei beginnt mit einem Eimer (evtl.mit Blattknoten).Wenn der Eimer voll ist, wird ein neuer Eimer angelegt, und die Datensatze werden – abhangigvom ersten (linken) Bit des Hashcodes – auf die beiden Eimer verteilt. Damit wird eine binareBaumstruktur, der Index (Verzeichnis, directory, index), aufgebaut.

1.4. PRIMARE DATEIORGANISATION 13
Der Index hat zwei Knotentypen:
• Interne Knoten (internal node) enthalten einen Links(0Bit)- und einen Rechts(1Bit)-Zeiger auf einen internen Knoten oder einen Blattknoten.
• Blattknoten (leaf node) enthalten einen Zeiger auf einen Eimer.
Wenn Eimer leer werden oder wenn benachbarte Eimer so wenige Datensatze enthalten, dass siein einen Eimer passen, dann wird der Baum zuruckgebaut.
Erweiterbares Hashing
Beim erweiterbaren Hashing (extendible hashing) wird der Index als ein Feld von 2d Ei-meradressen verwaltet, wobei d die globale Tiefe (global depth) des Index ist. Der Index, derden ersten d Bit des Hashwertes entspricht, wird als Feldindex zur Bestimmung der Eimeradres-se verwendet. Der Trick ist, dass die Eimeradressen nicht alle verschieden sein mussen, d.h. dielokale Tiefe der Eimer kann dl < d sein. Der Index muss verdoppelt werden, wenn ein Eimermit lokaler Tiefe dl = d voll ist und ein neuer Datensatz eingefugt werden soll. Der Index kannhalbiert werden, wenn alle Eimer eine lokale Tiefe < d haben. d muss ≤ b (Anzahl der Bit imHashwert) sein.
Lineares Hashing
Das lineare Hashing (linear hashing) erlaubt eine Datei zu vergroßern oder zu verkleinernohne Verwendung eines Indexes. Angenommen die Datei hat zunachst M Eimer 0 bis M − 1und verwendet die Hashfunktion h0(k) = hc(k) mod M . Overflow wegen Kollisionen wird mit(fur jeden Eimer) individuellen Overflowlisten behandelt. Wenn es aber zu irgendeiner Kollisionkommt, dann wird der erste Eimer 0 aufgeteilt in zwei Eimer: Eimer 0 und Eimer M . DieDatensatze des alten Eimers 0 werden auf die beiden Eimer verteilt mit der Hashfunktion h1(k) =hc(k) mod 2M . Eine wichtige Eigenschaft der Hashfunktionen h0 und h1 muss sein, dass, wennh0 nach dem alten Eimer 0 hashed, h1 nach den neuen Eimern 0 oder M hashed. Bei weiterenKollisionen werden in linearer Folge die Eimer 1, 2, 3 . . . verdoppelt (gesplittet). Es muss also dieNummer N (split pointer) des als nachsten zu splittenden Eimers verwaltet werden. Wenn dieDatei zu leer wird, konnen Eimer wieder koaleszieren. Wann gesplittet wird, hangt irgendwievom Fullungsgrad ab. Der als nachster gesplittete Eimer hat somit keinen Bezug zu dem Eimer,in den ein Datensatz einzufugen ist. Das ist ein Nachteil des linearen Hashings: Es werden Eimergesplittet, die gar nicht voll sind.
Diesen Nachteil vermeidet das sogenannte Spiral-Hashing, wobei die Hash-Funktion derart ma-nipuliert wird, dass der Fullgrad der Seiten an der Position des Split-Zeigers am großten ist ([34]Seite 171).

14 KAPITEL 1. SPEICHERSTRUKTUREN
1.5 Ubungen
1.5.1 Magnetplatte
Betrachten Sie eine Magnetplatte mit folgenden Eigenschaften: Blockgroße B = 512 Byte, inter-block gap G = 128 Byte, Anzahl Blocke pro Spur N = 150, Anzahl der Spuren pro OberflacheZ = 5000, Anzahl der Plattenoberflachen P = 20 (Plattenstapel mit 10 doppelseitigen Platten),Rotationsgeschwindigkeit R = 10000 UPM, mittlere Zugriffsbewegungszeit Tz = 8 ms.
1. Was ist die Gesamtkapazitat einer Spur?
2. Was ist die nutzbare Kapazitat einer Spur?
3. Was ist die Anzahl der Zylinder?
4. Was ist die nutzbare Kapazitat eines Zylinders?
5. Was ist die nutzbare Kapazitat dieser Platte?
6. Was ist die Transferrate in KB/ms?
7. Was ist die Block-Transferzeit in µs?
8. Was ist die mittlere Umdrehungswartezeit in ms?
9. Wielange dauert im Mittel das Finden und Ubertragen von 20 willkurlich verstreutenBlocken.
10. Wielange dauert im Mittel das Finden und Ubertragen von 20 hintereinander liegendenBlocken.
1.5.2 StudentInnenverwaltung 1
Eine Datei auf oben angegebener Platte hat r = 20000 STUDentInnen-Datensatze fester Lange.Jeder Datensatz hat die folgenden Felder:
NAME (30 Byte, Name),MATR (6 Byte, Matrikel),ADRE (40 Byte, Adresse),TELE (16 Byte, Telefon),GEBD (8 Byte, Geburtsdatum),GESC (1 Byte, Geschlecht),BERE (3 Byte, Bereichscode),FACH (3 Byte, Fachrichtungscode),GRUP (4 Byte, Gruppe),WAHL (6 Byte, Wahlfacherkombination)
Ferner wird ein Byte als Loschmarke verwendet.
1. Berechnen Sie die Datensatzgroße R.

1.5. UBUNGEN 15
2. Berechnen Sie den Blockungsfaktor bei einer Blockgroße von 512 Byte bei nicht blockuber-greifender Organisation.
3. Berechnen Sie die Anzahl der Blocke, die diese Datei benotigt.
4. Berechnen Sie die durchschnittliche Zeit, die fur das Aufinden eines Datensatzes benotigtwird, wenn die Datei linear durchlaufen wird. Dabei sind noch zwei Falle zu unterscheiden:
(a) Contiguous Allocation der Blocke
(b) Linked Allocation der Blocke
5. Angenommen die Datei sei nach Matrikelnummer geordnet. Wielange dauert eine Binarsu-che nach einer bestimmten Matrikelnummer?
6. Angenommen die Datei sei eine Hash-Datei, wobei die Hashfunktion MATR mod 6007 ver-wendet wird. Jeder Eimer ist ein Block. Die Hashfunktion ergibt die Blockadresse (derEinfachheit halber). Bei Kollision wird der nachste Block genommen.
(a) Wielange dauert die Suche nach einer bestimmten Matrikelnummer?
(b) Kann die Anzahl der StudentInnen ohne Umorganisation der Datei wachsen? Wennja, wie weit?
1.5.3 StudentInnenverwaltung 2
Angenommen nur 30% der STUDentInnen-Datensatze (siehe StudentInnenverwaltung 1) habeneinen Wert fur das Telefon, nur 60 % einen Wert fur die Adresse und nur 20% einen Wert fur dieWahlfacherkombination. Daher wollen wir jetzt eine Datei mit variabler Datensatzlange verwen-den. Jeder Datensatz hat aber zusatzlich ein Feldtyp-Byte fur jedes mit Werten belegte Feld undein Byte als Datensatz-Ende-Marke. Ferner benutzen wir eine Spannsatz-Organisation, wobeijeder Block einen 5-Byte-Zeiger auf den nachsten Block hat.
1. Wie groß ist die maximale Lange eines Datensatzes?
2. Wie groß ist die durchschnittliche Lange eines Datensatzes?
3. Wie groß ist die Anzahl der benotigten Blocke?
1.5.4 Teile-Verwaltung
Angenommen eine Datei hat Teile-Datensatze, die als Schlussel die Teile-Nummern T = 2369,3760, 4692, 4871, 5659, 1821, 1074, 7115, 1620, 2428, 3943, 4750, 6975, 4981, 9208 haben. DieDatei benutzt 8 Eimer mit den Nummern 0 bis 7. Jeder Eimer ist ein Plattenblock und kannhochstens zwei Datensatze aufnehmen.
1. Laden Sie diese Datensatze in der angegebenen Ordnung in die Datei unter Verwendungder Hash-Funktion h(T ) = T mod 8. Berechnen Sie die durchschnittliche Anzahl der Block-zugriffe beim Zugriff auf einen beliebigen Datensatz.

16 KAPITEL 1. SPEICHERSTRUKTUREN
2. Benutzen Sie dynamisches Hashing mit der Hash-Funktion h(T ) = mod32 und laden Siedie Teile nacheinander in die Datei. Zeigen Sie die Struktur der Datei nach jeder Einfugung.Jeder Eimer kann zwei Datensatze aufnehmen.
3. Benutzen Sie erweiterbares Hashing mit der Hash-Funktion h(T ) = mod32 und laden Siedie Teile nacheinander in die Datei. Zeigen Sie die Struktur der Datei nach jeder Einfugung.Lassen Sie die Eimer-Adressen willkurlich bei EA beginnen. Die nachsten Eimer haben danndie Adressen EB, EC usw. Jeder Eimer kann zwei Datensatze aufnehmen.
4. Benutzen Sie lineares Hashing. Jeder Eimer kann zwei Datensatze aufnehmen.

Kapitel 2
Zugriffsstrukturen
In diesem Kapitel werden Zugriffspfade oder Zugriffsstrukturen (access path, accessstructure), sogenannte Indexe (index) besprochen, die die Suche von Dateisatzen bei gewissenSuchbedingungen beschleunigen.
Mit dem Index eines Buches konnen wir Informationen in dem Buch finden ohne das ganze Buchzu lesen. Die Indexe einer DB erlauben es, Tupel zu finden ohne die ganze Tabelle zu lesen.Ein Index ist im Prinzip eine Liste von Datenwerten mit Adressen derjenigen Tupel, die diesenDatenwert enthalten.
Der Index einer Datei ist immer mindestens eine zusatzliche Datei. Ziel der Einfuhrung vonIndexen ist die Reduktion der (”teuren”) Blockzugriffe bei der Suche nach einem Datensatz.
Bei den Suchbedingungen unterscheiden wir:
• single-match query: Fur ein Attribut wird ein Wert vorgegeben (exakte Suche).
• exact-match query: Fur jedes Attribut wird ein Wert vorgegeben (exakte Suche).
• partial-match query: Fur einige Attribute wird ein Wert vorgegeben (exakte Suche).
• range query: Fur einige Attribute wird ein Wertebereich vorgegeben (Bereichsanfrage).
Der Suchschlussel oder Suchfeldwert oder Indexfeld (search key, search field value, in-dexing field) ist das, wonach gesucht wird (nicht zu verwechseln mit dem Schlussel einer Tabel-le). Suchschlussel konnen einfach (ein Attribut) oder (aus mehreren Attributen) zusammengesetztsein. Entsprechend spricht man manchmal auch von Ein-Attribut-Indexen (non-compositeindex) oder Mehr-Attribut-Indexen (composite index).
Ein Ein-Attribut-Index wird immer als eindimensionale Zugriffsstruktur realisiert. EinMehr-Attribut-Index kann als eindimensionale oder mehrdimensionale Zugriffsstrukturausgefuhrt werden.
Im eindimensionalen Fall werden die Werte der Attribute eines Mehr-Attribut-Indexes zu einemWert konkateniert, der wie der Wert eines Attributs behandelt wird. Eine exact-match-Anfrage
17

18 KAPITEL 2. ZUGRIFFSSTRUKTUREN
bezuglich des Mehr-Attribut-Indexes wird daher durch eine eindimensionale Zugriffsstruktur ef-fektiv unterstutzt. Fur eine partial-match-Anfrage werden mehrdimensionale Zugriffsstrukturenbenotigt.
Wenn aber statt eines Mehr-Attribut-Indexes ein eindimensionaler Indexe verwendet wird, kannz.B. bei einem Index auf den Spalten A, B, C effektiv nach A oder nach A+B oder nach A+B+C
gesucht werden, wobei das + eine Konkatenierung bedeutet.
Ansonsten wird eben fur jedes Attribut eines Mehr-Attribut-Indexes je ein Index angelegt. Diejeweils resultierenden TID-Listen werden dann geschnitten.
Bemerkung zur Terminologie: Es werden geclusterte (clustered) (index-organisierte Ta-belle) und ungeclusterte (non-clustered) Indexe unterschieden. Im ersten Fall sind die Tu-pel der indizierten Relation im Index untergebracht. Geclusterte Indexe bieten Vorteile beiBereichs-Anfragen. Die im Kapitel ”Speicherstrukturen” behandelten sortierten Dateien oderHash-Dateien haben demnach einen geclusterten Index auf dem Sortierfeld. (Diese ”gecluster-ten” Indexe unterscheiden sich von den im nachsten Abschnitt behandelten ”Clusterindexen”nur dadurch, dass das Indexfeld auch ein Schlussel der Tabelle sein kann, und, dass die Tabelleals zum Index gehorig betrachtet wird und keine eigene Existenz hat.)
2.1 Einstufige sortierte Indexe
Der einstufig sortierte Index (single-level ordered index) orientiert sich an der Technikdes Schlagwortverzeichnisses bei Buchern. Der Index wird verwendet, um Blockadressen nachzu-schlagen. Der Index wird nach den Werten sortiert, sodass eine Binarsuche durchgefuhrt werdenkann.
Man unterscheidet folgende Indexe:
Primarindex (primary index): Das Indexfeld (indexing field) ist Schlussel und Sor-tierfeld der Hauptdatei. Es kann nur einen Primarindex geben.
Bei einem Primarindex genugt es, fur jeden Block der Hauptdatei das Indexfeld des er-sten (oder letzten) Datensatzes im Block (Ankerdatensatz, Seitenanfuhrer, anchorrecord, block record) und die Blockadresse zu speichern. Solch ein Primarindex ist nichtdicht (dunnbesetzt, non-dense). (Ein dichter (dichtbesetzt, dense) Index speichertfur jeden Datensatz Indexfeld und Blockadresse.)
Die Kombination von Hauptdatei und Primarindexdatei wird oft als indexsequentielleDateiorganisation bezeichnet, da normalerweise solch ein Index linear durchsucht werdenmuss.
Clusterindex (clustering index): Das Indexfeld ist nur Sortierfeld der Datei, aber keinSchlussel. Es kann nur einen Clusterindex geben.
Bei einem Clusterindex wird fur jeden Wert des Indexfeldes die Adresse des ersten Blocksgespeichert, der einen Datensatz mit dem Wert des Indexfeldes enthalt. Ein Clusterin-dex ist ebenfalls nicht dicht. Er unterstutzt Bereichsanfragen sehr gut, da die Sortierungbeibehalten wird.
Sekundarindex (secondary index) (sekundare Zugriffspfade): Indexfeld kann jedes Feldeines Datensatzes sein. Mehrere Sekundarindexe sind moglich, da diese Indexe unabhangig

2.2. MEHRSTUFIGE INDEXE 19
von der physikalischen Anordnung der Datensatze auf der Platte sind. Sie bieten alternativeSuchpfade auf der Basis von Indexfeldern.
Eine Datei, die auf jedem Feld einen Sekundarindex hat, heißt vollstandig invertiert(fully inverted file). (Einen Sekundarindex nennt man auch invertierte Datei.)
Bei einem Sekundarindex auf einem Schlusselindexfeld wird fur jeden Wert des Indexfel-des die Blockadresse oder Datensatzadresse gespeichert. Der Sekundarindex ist daher eindichter Index und benotigt mehr Speicher und Suchzeit als ein Primarindex.
Wenn das Indexfeld kein Schlussel ist, dann gibt es pro Wert mehrere Blockadressen. Daskann mit folgenden Moglichkeiten (Optionen) verwaltet werden:
1. Fur jeden Datensatz wird ein Indexeintrag gemacht, wobei manche Indexfeldwerteofter vorkommen.
2. Zu jedem Indexfeldwert wird eine Liste von Blockadressen gefuhrt (etwa in einemDatensatz variabler Lange). Diese Blockadressen zeigen auf Blocke, wo mindestensein Datensatz den Indexfeldwert enthalt.
3. (Das ist die verbreitetste Methode.) Fur jeden Indexfeldwert gibt es genau einen Ein-trag mit einer Blockadresse, die auf eine Block zeigt, der Zeiger auf die Datensatzeenthalt, die diesen Indexfeldwert enthalten. Wird mehr als ein Block benotigt, wirdeine verkettete Liste von Blocken verwendet.
Beim Primar- und Clusterindex muss die Datensatz-Datei sortiert sein. Dies erfordert einengewissen Aufwand (siehe Kapitel Speicherstrukturen). Daher verwenden manche DBS nur Se-kundarindexe.
2.2 Mehrstufige Indexe
Die bisher beschriebenen Indexschemata benutzen eine sortierte Indexdatei, in der binar gesuchtwird, d.h. der Suchraum wird bei jedem Schritt nur um den Faktor 2 reduziert.
Bei mehrstufigen (multilevel) Indexen wird der Suchraum bei jedem Schritt um denBlockungsfaktor (Anzahl der Datensatze in einem Block) des Indexes reduziert(fI). In demZusammenhang heißt der Blockungsfaktor auch fan-out (fo). Wir benotigen daher etwa logfo(b)Blockzugriffe, wobei b die Anzahl der Datensatze der ersten Stufe des Indexes ist. Das kann dieAnzahl der Blocke oder die Anzahl der Datensatze der Hauptdatei oder die Anzahl der unter-schiedlichen Werte des Indexfeldes sein.
Die erste Stufe (first, base level) eines mehrstufigen Index ist eine sortierte Datei mit eindeuti-gen Indexfeldwerten (Schlusselindexfeld). Daher konnen wir fur die erste Stufe einen Primarindexanlegen. Dieser bildet die zweite Stufe (second level). Da die zweite Stufe ein Primarindex ist,genugt es, nur auf die Ankerdatensatze zu verweisen. Die dritte Stufe wird dann als Primarindexfur die zweite Stufe angelegt. Dieser Prozess wird fortgesetzt, bis die letzte Stufe (top indexlevel) in einen Block passt.
Um das Einfugen und Loschen von Datensatzen zu erleichtern wird haufig in jedem Block etwasPlatz reserviert.
Diese Methode kann auch fur Nicht-Schlussel-Indexfelder adaptiert werden. (Bezieht sich aufOption 1 des vorangehenden Abschnitts.)

20 KAPITEL 2. ZUGRIFFSSTRUKTUREN
Ein Nachteil der bisher besprochenen Methoden ist die Verwaltung von sortierten Index- undeventuell auch Hauptdateien. Dieses Problem wird im folgenden mit Suchbaumen gelost.
2.3 Dynamische mehrstufige Indexe mit Baumen
Bezeichnungen: Ein Baum (tree) besteht aus Knoten (node). Jeder Knoten außer der Wur-zel (root) hat einen Elterknoten (parent node) und mehrere (oder keinen) Kindknoten(child node). Ein Knoten ohne Kinder heißt Blatt (leaf). Ein nicht-Blatt-Knoten heißt inne-rer (internal) Knoten. Die Stufe (level) eines Knotens ist immer um Eins erhoht gegenuberdem Elterknoten. Die Wurzel hat Stufe 0. Ein Unterbaum (subtree) eines Knotens bestehtaus diesem Knoten und allen seinen Nachkommen.
Ein Baum wird implementiert, indem ein Knoten Zeiger auf alle seine Kinder hat. Manchmal hater auch noch einen Zeiger auf sein Elter. Zusatzlich zu den Zeigern enthalt ein Knoten irgendeineArt von gespeicherter Information. Wenn ein mehrstufiger Index als Baumstruktur implementiertwird, dann besteht diese Information aus Werten eines Indexfeldes zur Fuhrung der Suche nacheinem bestimmten Datensatz.
2.3.1 Suchbaume
Bei einem Suchbaum (search tree) der Ordnung (Grad) p enthalt jeder Knoten hochstensp− 1 Suchwerte (Suchschlusselwerte oder auch Zugriffsattributwerte) Ki und hochstens p ZeigerPi auf Kindknoten in der Ordnung
〈P0,K0, P1,K1 . . . Pq−1,Kq−1, Pq〉,
wobei q < p.
Die Ki sind Werte aus einer geordneten Menge von eindeutigen Suchwerten (Suchfeld (searchfield) eines Datensatzes).
Es gilt
K0 < K1 < . . . < Kq−1
und fur alle Werte X in einem Unterbaum, auf den der Zeiger Pi zeigt, gilt
Ki−1 < X < Ki fur 0 < i < qX < Ki fur i = 0Ki−1 < X fur i = q
Die Zeiger Pi zeigen auf Kindknoten oder ins Leere. Mit jedem K-Wert ist eine Blockadresseassoziiert.
Ein Problem bei solchen Suchbaumen ist, dass sie meist nicht ausgeglichen (balanced) sind.(”Ausgeglichen” heißt, dass alle Blatter moglichst auf demselben Niveau sind.)

2.3. DYNAMISCHE MEHRSTUFIGE INDEXE MIT BAUMEN 21
2.3.2 B-Baume
B-Baume (B wie balanced) sind immer ausgeglichen. Dies wird durch zusatzliche Bedingungengarantiert, die auch dafur sorgen, dass der durch Loschungen vergeudete Speicherplatz nicht zugroß wird. Die entsprechenden Algorithmen sind normalerweise einfach, werden aber kompliziert,wenn in einen vollen Knoten eingefugt werden muss, oder wenn aus einem halbvollen Knotengeloscht werden soll.
Zunachst definieren wir einen B-Baum der Ordnung p zur Verwendung als Zugriffsstruktur aufein Schlusselfeld um Datensatze in einer Datei zu suchen.
1. Jeder innere Knoten hat die Form
〈P0, 〈K0, P r0〉, P1, 〈K1, P r1〉 . . . Pq−1, 〈Kq−1, P rq−1〉, Pq〉,
wobei q < p ≥ 3. Jeder Zeiger Pi zeigt auf einen Kindknoten. Jeder Zeiger Pri ist einDatenzeiger.
2. Jedes Pri ist ein Datenzeiger, der auf den Datensatz zeigt, dessen Suchfeldwert Ki ist, oderder auf einen Block zeigt, der den Datensatz mit dem Suchfeldwert Ki enthalt, oder der –falls das Suchfeld kein Schlussel ist – auf einen Block von Datensatzzeigern zeigt, die aufDatensatze zeigen, die den Suchfeldwert Ki haben.
Im Fall eines geclusterten Indexes wird Pri direkt durch den Datensatz oder die Da-tensatze, die den Suchfeldwert enthalten, ersetzt.
3. In jedem Knoten gilt K0 < K1 < . . . < Kq−1.
4. Fur alle Suchschlusselfeldwerte X in dem Unterbaum, auf den Pi zeigt, gilt
Ki−1 < X < Ki fur 0 < i < qX < Ki fur i = 0Ki−1 < X fur i = q
5. Jeder Knoten hat hochstens p Zeiger auf Kindknoten (q < p).
6. Jeder Knoten – ausgenommen der Wurzel und der Blatter – hat mindestens p2 Zeiger auf
Kindknoten. Die Wurzel hat mindestens 2 Zeiger auf Kindknoten, wenn sie nicht der einzigeKnoten im Baum ist.
7. Ein Knoten mit q + 1 Zeigern auf Kindknoten hat q Schlusselfeldwerte und q Datenzeiger.
8. Alle Blattknoten sind auf demselben Niveau. Blattknoten haben dieselbe Struktur wieinnere Knoten, außer dass die Zeiger Pi auf Kindknoten alle NULL sind.
Ein neues Element wird grundsatzlich immer in ein Blatt eingefugt. Wenn ein Blatt voll ist, dannwird es auf demselben Niveau gespalten, wobei das mittlere Element eine Stufe hoher steigt.
Ein B-Baum beginnt mit der Wurzel, die zunachst auch ein Blatt ist. Ist die Wurzel voll, dannwerden zwei Kindknoten gebildet. Der mittlere Wert bleibt in der Wurzel, alle anderen Wertewerden auf die beiden Kinder verteilt.
Wenn ein Knoten voll wird, dann wird er aufgespalten in zwei Knoten auf demselben Niveau,wobei der mittlere Wert zusammen mit zwei Zeigern auf die neuen Knoten in den Elterknotenaufsteigt.

22 KAPITEL 2. ZUGRIFFSSTRUKTUREN
Wenn der Elterknoten voll ist, wird auch er auf demselben Niveau gespalten. Das kann sich biszur Wurzel fortsetzen, bei deren Spaltung eine neue Stufe entsteht.
Wenn durch Loschung ein Knoten weniger als halbvoll wird, wird versucht, ihn mit Nachbarkno-ten zu verschmelzen. Auch dies kann sich bis zur Wurzel fortsetzen, sodass es zu einer Vermin-derung der Stufen kommen kann.
Durch Simulation von beliebigen Einfugungen und Loschungen konnte gezeigt werden, dass dieKnoten etwa zu 69% gefullt sind. Dann sind Knotenspaltungen und Knotenrekombinationenziemlich selten, sodass Einfugungen und Loschungen normalerweise sehr schnell gehen.
B-Baume werden manchmal fur die primare Dateistruktur verwendet (index-organisierte Tabelleoder geclusterter Index). In dem Fall werden ganze Datensatze in den Knoten gespeichert. Dasgeht bei wenigen Datensatzen und/oder kleinen Datensatzen gut. Ansonsten wird die Anzahl derStufen oder die Knotengroße fur einen effizienten Zugriff zu groß.
2.3.3 B+-Baume
In einem B-Baum erscheint jeder Wert des Suchfeldes genau einmal zusammen mit seinem Da-tenzeiger. In einem B+-Baum werden Datenzeiger nur in den Blattern gespeichert. Die innnerenKnoten enthalten keine Datenzeiger (hohler Baum). Das bedeutet, dass die Blatter fur jedenSuchwert einen Eintrag zusammen mit dem Datenzeiger haben mussen.
Die Blatter sind gewohnlich durch Zeiger verknupft, sodass ein schneller Zugriff in der Reihen-folge des Suchfeldes moglich ist. Die Blatter sind ahnlich strukturiert wie die erste Stufe einesIndexes. Die inneren Knoten entsprechen den anderen Stufen eines mehrstufigen Indexes. EinigeSuchfeldwerte kommen in den inneren Knoten wieder vor.
Die Struktur des B+-Baums ist folgendermaßen:
1. Jeder innere Knoten hat die Form
〈P0,K0, P1,K1 . . . Pq−1,Kq−1, Pq〉
mit q < pKnoten. Die Pi sind dabei insgesamt q + 1 Zeiger auf Kindknoten.
2. In jedem Knoten gilt: K0 < K1 < . . . < Kq−1
3. Fur alle Suchfeldwerte X in dem Unterbaum, auf den Pi zeigt, gilt:
Ki−1 < X ≤ Ki fur 0 < i < qX ≤ Ki fur i = 0Ki−1 < X fur i = q
4. Jeder innere Knoten hat hochstens pKnoten Zeiger auf Kindknoten (q < pKnoten).
5. Jeder innere Knoten außer der Wurzel hat mindestens pKnoten
2 Zeiger. Die Wurzel hatmindestens 2 Zeiger, wenn sie kein Blatt ist.
6. Ein innerer Knoten mit q + 1 Zeigern (q < pKnoten) hat q Suchfeldwerte.
7. Jedes Blatt hat die Form
〈〈K0, P r0〉, 〈K1, P r1〉 . . . 〈Kq, P rq〉, Pnext〉,

2.3. DYNAMISCHE MEHRSTUFIGE INDEXE MIT BAUMEN 23
wobei q < pBlatt, Pri Datenzeiger sind und Pnext auf das nachste Blatt zeigt.
8. Fur jedes Blatt gilt: K0 < K1 < . . . < Kq
9. Jedes Pri ist ein Datenzeiger, der auf den Datensatz zeigt, dessen Suchfeldwert Ki ist, oderder auf einen Block zeigt, der den Datensatz mit dem Suchfeldwert Ki enthalt, oder der –falls das Suchfeld kein Schlussel ist – auf einen Block von Datensatzzeigern zeigt, die aufDatensatze zeigen, die den Suchfeldwert Ki haben.
Im Fall eines geclusterten Indexes wird Pri direkt durch den Datensatz oder die Da-tensatze, die den Suchfeldwert enthalten, ersetzt.
10. Jedes Blatt außer der Wurzel (wenn sie Blatt ist) hat mindestens pBlatt
2 Werte.
11. Alle Blatter sind auf derselben Stufe.
12. Ein Pprevious kann auch eingebaut werden.
Vorgehensweise beim Einfugen eines neuen Elements: Man versucht das neue Element in dasrichtige Blatt einzufugen. Passt es nicht mehr rein, dann wird das Blatt aufgespalten, wobei dermittlere Schlussel nach oben wandert. Das kann moglicherweise zur Spaltung des betreffendenKnotens fuhren.
Zur Implementation von Algorithmen muss eventuell noch weitere Information (Zahler, Knoten-typ usw.) verwaltet werden.
Variationen: Anstatt der Halbvoll-Forderung konnen andere Fullfaktoren angesetzt werden, etwa,dass man auch fast leere Knoten zulasst, ehe sie rekombiniert werden. Letztere Moglichkeit scheintbei zufalligen Einfugungen und Loschungen nicht allzuviel Platz zu verschwenden.
B+-Baume werden manchmal fur die primare Dateistruktur verwendet (index-organisierte Ta-belle oder geclusterter Index). In dem Fall werden ganze Datensatze in den Blattern gespeichert.Das geht bei wenigen Datensatzen und/oder kleinen Datensatzen gut. Ansonsten wird die Anzahlder Stufen oder die Blattgroße fur einen effizienten Zugriff zu groß.
Gegenuber B-Baumen haben B+-Baume folgende Vorteile:
• pKnoten kann in den inneren Knoten wesentlich großer sein als pBlatt. Dadurch hat derBaum weniger Stufen.
• Die Verkettung der Blatter erlaubt schnellen Zugriff in der Reihenfolge des Suchfeldes.
B∗-Baume und B#-Baume sind Varianten des B+-Baums, bei denen ein voller Knoten nichtsofort aufgespalten wird, sondern zunachst versucht wird, die Eintrage auf benachbarte Knotenumzuverteilen. Falls dies nicht moglich ist, wird nicht ein Knoten in zwei aufgespalten, sondernzwei Knoten in drei ([34] Seite 150).
B+-Baume werden oft zur Verwaltung von BLOBs verwendet. Dabei werden Positionen oderOffsets im BLOB als Schlusselwerte verwendet (positional B+-tree).
Tries, Patricia-Baume und Prafix-Baume sind Varianten, die bei Zeichenketten als Such-werte in den inneren Knoten Speicher- und Vergleichsvorteile haben, da in den inneren Knotennur Teile des Suchwertes gespeichert werden mussen. Wir gehen hier nicht naher darauf ein ([34]Seite 152).

24 KAPITEL 2. ZUGRIFFSSTRUKTUREN
2.3.4 Andere Indextypen
Es ist moglich Zugriffsstrukturen zu entwerfen, die auf dem Hashing beruhen. Die Indexeintrage〈K,Pr〉 oder 〈K,P 〉 konnen als eine dynamisch expandierbare Hash-Datei organisiert werden.
Bisher sind wir davon ausgegangen, dass die Indexeintrage physikalische Adressen von Plat-tenblocken (physical index) spezifizieren mit dem Nachteil, dass die Zeiger geandert werdenmussen, wenn ein Datensatz an eine andere Stelle auf der Platte bewegt wird, was bei Hash-Dateien haufig vorkommt (Aufteilung eines Eimers). Die Nachfuhrung der Zeiger ist nicht ein-fach.
Dem Problem kann mit einem logischen Index (logical index) begegnet werden, der Eintrage〈K,Kp〉 hat, wobei Kp der Wert des Feldes ist, das fur die primare Dateiorganisation verwendetwird. Mit dem sekundaren Index wird das Kp bestimmt. Dann wird unter Verwendung derprimaren Dateiorganisation die eigentliche Block- oder Datensatzadresse bestimmt.
Eine sortierte Datei mit einem mehrstufigen primaren Index auf dem Sortierschlusselfeld heißtindexierte sequentielle Datei (indexed sequential file). Einfugen wird durch eine Overflow-Datei behandelt, die periodisch eingearbeitet wird, wobei der Index neu aufgebaut wird. IBM’sindexed sequential access method (ISAM) benutzt einen zweistufigen Index mit enger Plat-tenbeziehung: Die erste Stufe ist ein Zylinderindex, der den Schlusselwert eines Ankerdatensat-zes fur jeden Plattenzylinder und einen Zeiger auf den Spurindex fur diesen Zylinder verwaltet.Der Spurindex hat den Schlusselwert eines Ankerdatensatzes fur jede Spur des Zylinders undeinen Zeiger auf die Spur. Die Spur kann dann sequentiell nach dem Block und dem Datensatzabgesucht werden.
Eine andere IBM-Methode virtual storage access method (VSAM) ist ahnlich einer B+-Baum-Zugriffsstruktur.
2.4 Objektballung, Cluster
Man versucht, Datensatze, die oft gemeinsam benutzt werden, in einem oder in benachbartenBlocken unterzubringen ([34] Seite 192).
2.5 Indexierung mit SQL
Die meisten Systeme bieten ein Kommando mit folgender Syntax an:
CREATE [UNIQUE] INDEX index-nameON base-table (column-komma-list)
Beispiel:
CREATE UNIQUE INDEX SNRINDEX ON S (SNR);
In der Tabelle S wird auf der Spalte SNR ein Index angelegt. Wenn ein Index aus mehreren Spaltenzusammengesetzt ist, heißt er zusammengesetzt (composite). Wenn UNIQUE spezifiziert ist,dann wird nach Erstellung des Indexes dafur gesorgt, dass die Zeilen bezuglich der Index-Spalten

2.6. BEMERKUNGEN 25
eindeutig bleiben. Wenn der Index fur eine Tabelle nachtraglich definiert wird, dann wird dieDefinition des Indexes im Fall von Duplikaten bezuglich der Index-Spalten zuruckgewiesen.
Manche Systeme bieten an, sogenannte geclusterte Indexe anzulegen, bei denen die Datenauch physikalisch nach dem Index sortiert werden, d.h. die ganze Tabelle wird in den Index auf-genommen. Das bedeutet naturlich, dass es pro Tabelle nur einen geclusterten Index geben kann.Ein geclusterter Index erhoht die Zugriffsgeschwindigkeit uber die Index-Spalte, verlangsamt aberAktualisierungs-Operationen. Da Many-To-Many-Beziehungen oft keine oder nur wenige Datenenthalten, eignen sie sich besonders gut fur einen geclusterten Index.
Generell erhoht ein Index die Zugriffsgeschwindigkeit bei Suchoperationen – oft drastisch – undverringert die Geschwindigkeit bei Aktualisierungen, d.h. Einfuge- und Loschoperationen, da jader Index mitverwaltet werden muss.
Folgende Regeln ergeben sich bezuglich der Erstellung von Indexen:
• Spalten, die Primarschlussel sind, sollten einen UNIQUE Index haben.
• Spalten, die regelmaßig in Joins verwendet werden, sollten einen Index haben (Fremd-schlussel- und Schlussel-Spalten).
• Eine Spalte, uber deren Werte oft zugegriffen wird, sollte einen Index haben.
• Spalten, bei denen oft Wertebereiche abgesucht werden, sollten einen Index haben. Bereichs-Anfragen sind mit geclusterten Indexen performanter. Aber es ist nur ein geclusterter Indexpro Tabelle moglich.
• Spalten, deren Wertebereich nur wenige Werte enthalt (z.B. ja/nein oder mann-lich/weiblich/unbekannt, allgemein: Attribute mit geringer Selektivitat), sollten keinen In-dex haben.
• Kleine Tabellen mit wenigen – bis zu 1000 – Zeilen profitieren nicht von einem Index, dadas System in diesen Fallen meistens einen table scan macht.
• Indexfelder sollten moglichst kompakt sein, d.h. der Suchschlussel sollte aus wenigen Spal-ten bestehen und/oder wenige Bytes lang sein.
2.6 Bemerkungen
2.6.1 Index Intersection
Manche DBS erlauben mehrere Indexe zu schneiden, um Mehr-Attribut-Anfragen effektiv durch-zufuhren. Die resultierenden TID-Mengen werden geschnitten. Der Schnitt zweier Mengen hatKomplexitat O(n2) oder, wenn die Mengen vorher sortiert werden, O(n log n).
Anfragen konnen ohne Zugriff auf die indexierte Tabelle eventuell performanter durchgefuhrtwerden. Dazu ein kurzes Beispiel:
Die Tabelle T habe einen Index IA auf Spalte A und einen Index IB auf Spalte B. Betrachtenwir nun folgende Anfrage:
SELECT * FROM T WHERE A = ’aWert’ AND B = ’bWert’

26 KAPITEL 2. ZUGRIFFSSTRUKTUREN
Jeder der beiden Indexe IA und IB liefert fur die vorgegebenen Werte eine TID-Menge. Diebeiden Mengen werden geschnitten und liefern eine resultierende TID-Menge.
2.6.2 Geclusterte Indexe
Wenn fur eine Tabelle ein geclusterter und mehrere nicht-geclusterte Indexe angelegt werdensollen, dann sollte man mit dem geclusterten Index beginnen, da in diesen ja die ganze Tabelleaufgenommen wird. (Die ursprungliche Tabelle wird dabei – wahrscheinlich – geloscht.) Danachkonnen die nicht-geclusterten Indexe angelegt werden. Bei dieser Vorgehensweise wird die Tabelleauf der Platte wahrscheinlich in der Sortierreihenfolge des geclusterten Indexes angelegt, wasdeutliche Disk-I/O-Vorteile zur Folge hat.
Zur Realisierung einer Many-to-Many-Beziehung muss ja eine zusatzliche Tabelle angelegt wer-den, die u.U. nur zwei Fremdschlussel-Spalten und keine weiteren Daten enthalt. Hier bietetsich idealerweise ein geclusterter Index an. Wenn in beiden Richtungen navigiert werden soll,dann sollte man eigentlich zwei geclusterte Indexe auf derselben Tabelle haben, was normaler-weise nicht moglich ist oder was die DBSs wohl nicht anbieten. (Dann muss man eventuell zweiTabellen (mit identischem Inhalt) fur die Beziehung anlegen, dort je einen geclusterten Indexdefinieren und selbst fur die Konsistenz dieser Tabellen sorgen.)
Nehmen wir an, dass wir zwei Tabellen A und B mit jeweils etwa 100.000 Tupeln und eine Many-to-Many-Beziehung zwischen den beiden Tabellen haben, wobei ein a ∈ A zu 100 bis 1000 b ∈ Bin Beziehung steht. Dann hatte die Beziehungstabelle großenordnungsmaßig 10 bis 100 MillionenEintrage. In solch einem Fall kann sich eine redundante Beziehungstabelle durchaus lohnen.
2.6.3 Unique Indexe
Unique Indexe werden angelegt um die Eindeutigkeit eines Attributs zu erzwingen.
2.6.4 Indexe auf berechneten Spalten
Manche DBS bieten Indexe auf berechneten Spalten (sogenannte Funktionsindexe) an, wennder Berechnungsausdruck deterministisch und prazise ist und nicht Texte oder Bilder als Re-sultat hat. Die Datums- oder Zeitfunktion ist sicher nicht deterministisch, da sie bei gleichenEingabeparametern unterschiedliche Werte liefern kann. Float-Datentypen sind nicht prazise.
2.6.5 Indexierte Views
Indexierte Views sind solche, deren Werte in der Datenbank persistent gemacht werden. DieWartung solcher Views kann bei vielen Updates der zugrunde liegenden Tabellen teuer werden.Das kann den Performanzgewinn zunichte machen.
Der erste Index auf einem View wird wahrscheinlich ein geclusterter Index sein, um die Datendes Views persistent zu machen. Danach konnen beliebig viele nicht-geclusterte Indexe angelegtwerden.

2.7. UBUNGEN 27
2.6.6 Covering Index
Wir sprechen von einem covering index fur eine spezielle Anfrage, wenn alle Attribute, diein dieser Anfrage (bei Projektion und Selektion) verwendet werden, indexiert sind. Damit kanndiese spezielle Anfrage oder dieser Anfragetyp wesentlich beschleunigt werden.
2.7 Ubungen
2.7.1 B-Baum, B+-Baum
Fugen Sie in einen B-Baum der Ordnung 3 oder einen B+-Baum der Ordnung 3 (innere Knoten),Ordnung 2 (Blatter) nacheinander die Buchstaben
A L G O R I T H M U S
ein. Zeigen Sie nach jedem Schritt den ganzen Baum.
Fugen Sie diese Buchstaben in aufsteigender Reihenfolge ein, also:
A G H I L M O R S T U
2.7.2 Angestellten-Verwaltung
Angenommen die Block- und Seitengroße sei 512 Byte. Ein Zeiger auf einen Block (Blockadresse)sei P = 6 Byte lang, ein Zeiger auf einen Datensatz (Datensatzadresse) sei Pr = 7 Byte lang.
Eine Datei hat r = 30000 ANG-Datensatze (Angestellte) fester Lange. Jeder Datensatz hat dieFelder:
NAM (30 Byte, Name),ANR (9 Byte, Angestelltennummer),ABT (9 Byte, Abteilung),ADR (40 Byte, Adresse),TEL (9 Byte, Telefon),GEB (8 Byte, Geburtsdatum),GES (1 Byte, Geschlecht),BER (4 Byte, Berufscode),GEH (4 Byte, Gehalt)
1. Berechnen Sie die Datensatzlange.
2. Berechnen Sie den Blockungsfaktor und die Anzahl der benotigten Blocke bei Nicht-Spannsatz-Organisation.
3. Angenommen die Datei sei nach dem Schlusselfeld ANR geordnet. Wir wollen einenPrimarindex auf ANR konstruieren.
(a) Berechnen Sie den Index-Blockungsfaktor fI (gleich dem index fan-out fo).

28 KAPITEL 2. ZUGRIFFSSTRUKTUREN
(b) Berechnen Sie die Anzahl der Eintrage im Primarindex und die Anzahl der benotigtenBlocke.
(c) Berechnen Sie die Anzahl der benotigten Stufen, wenn wir den Index zu einem mehr-stufigen Index machen, und die Gesamtzahl der fur den Index verwendeten Blocke.
(d) Berechnen Sie die Anzahl der Blockzugriffe, wenn ein Datensatz mit Hilfe der ANRgesucht wird.
4. Angenommen die Datei sei nicht nach ANR geordnet. Wir wollen einen Sekundar-Indexauf ANR konstruieren.
(a) Berechnen Sie den Index-Blockungsfaktor fI (gleich dem index fan-out fo).
(b) Berechnen Sie die Anzahl der Eintrage im Index erster Stufe und die Anzahl derbenotigten Blocke.
(c) Berechnen Sie die Anzahl der benotigten Stufen, wenn wir den Index zu einem mehr-stufigen Index machen, und die Gesamtzahl der fur den Index verwendeten Blocke.
(d) Berechnen Sie die Anzahl der Blockzugriffe, wenn ein Datensatz mit Hilfe der ANRgesucht wird.
5. Angenommen die Datei sei bezuglich des (Nicht-Schlussel-) Feldes ABT nicht geordnet. Wirwollen einen Sekundar-Index auf ABT konstruieren, wobei die dritte Option (ein Eintragpro Indexfeldwert, Liste von Blocken, die Datensatzzeiger enthalten) verwendet werdensoll. Angenommen es gabe 1000 unterschiedliche ABT-Nummern und die ANG-Datensatzeseien gleichmaßig uber diese Abteilungen verteilt.
(a) Berechnen Sie den Index-Blockungsfaktor und die Anzahl der auf der ersten Stufebenotigten Blocke.
(b) Berechnen Sie die Anzahl der Blocke, die benotigt werden, um die Datensatz-Zeigerzu speichern.
Blocke benotigt.
(c) Wieviele Stufen werden benotigt, wenn wir den Index mehrstufig machen?
(d) Wieviele Blocke werden insgesamt fur diesen Index benotigt?
(e) Wieviele Blockzugriffe werden im Durchschnitt benotigt, um alle zu einer bestimmtenABT gehorenden Datensatze zu lesen?
6. Angenommen die Datei sei nach dem (Nicht-Schlussel-)Feld ABT geordnet. Wir wolleneinen Cluster-Index auf ABT konstruieren, wobei Block-Anker (D.h. jeder neue Wert vonABT beginnt mit einem neuen Block.) verwendet werden. Angenommen es gabe 1000 un-terschiedliche ABT-Nummern und die ANG-Datensatze seien gleichmaßig uber diese Ab-teilungen verteilt.
(a) Berechnen Sie den Index-Blockungsfaktor und die Anzahl der auf der ersten Stufebenotigten Blocke.
(b) Wieviele Stufen werden benotigt, wenn wir den Index mehrstufig machen?
(c) Wieviele Blocke werden insgesamt fur diesen Index benotigt?
(d) Wieviele Blockzugriffe werden im Durchschnitt benotigt, um alle zu einer bestimmtenABT gehorenden Datensatze zu lesen?

2.7. UBUNGEN 29
7. Angenommen die Datei sei nicht nach dem Schlusselfeld ANR sortiert und wir wollten eineB+-Baum-Zugriffsstruktur auf ANR konstruieren.
(a) Berechne den Grad pKnoten des Baumes und pBlatt.
(b) Wieviele Blattknoten werden benotigt, wenn ein Fullungsgrad von 69% gewunschtwird?
(c) Wieviele Stufen von internen Knoten werden benotigt, wenn auch die internen Knotennur zu 69% gefullt sein sollen?
(d) Wieviele Blocke werden fur den Index insgesamt benotigt?
(e) Wieviele Blockzugriffe sind notig, um einen Datensatz zu lesen, wenn ANR gegebenist?
(f) Fuhren Sie diese Analyse fur einen geclusterten Index durch.
8. Stelle dieselben Uberlegungen fur einen B-Baum an und vergleiche die Resultate.
(a) Berechne den Grad p des Baumes.
(b) Wieviele Stufen und Knoten werden benotigt, wenn ein Fullungsgrad von 69%gewunscht wird?
(c) Wieviele Blocke werden fur den Index insgesamt benotigt?
(d) Wieviele Blockzugriffe sind notig, um einen Datensatz zu lesen, wenn ANR gegebenist?
(e) Vergleich B- und B+-Baum:

30 KAPITEL 2. ZUGRIFFSSTRUKTUREN

Kapitel 3
MehrdimensionaleZugriffsstrukturen
Mehrdimensionale Zugriffsstrukturen oder Indexe gibt es bei den gangigen kommerziellen Syste-men eher noch als Ausnahme oder Besonderheit.
Hier beschranken wir uns auf die Nennung von verschiedenen Verfahren. Einigen wird auch einAbschnitt gewidmet. Details sind bei [34] (Seite 175) und der dort genannten Literatur[18] zufinden.
• KdB-Baum
• Grid-File
• Raumfullende Kurven
• R-Baum
• Geometrische Zugriffsstrukturen
3.1 KdB-Baum
Ein KdB-Baum (k-dimensionaler B-Baum) besteht aus
• inneren Knoten (Bereichsseiten), die einen binaren kd-Baum mit maximal b Knoten(Schnittelementen) enthalten, und
• Blattern (Satzseiten), die bis zu t Tupel der gespeicherten Relation enthalten.
k ist die Anzahl der Zugriffs-Attribute. Ein Schnittelement teilt den Baum bezuglich einesZugriffs-Attributs. Die Normalstrategie ist, dass die Zugriffs-Attribute in den Schnittelementenzyklisch alteriert werden.
31

32 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Auf die komplizierten Mechanismen zur Ausgleichung des Baumes kann hier nicht eingegangenwerden.
Den Aufbau des Indexes werden wir an Hand eines Beispiels erlautern.
k = 2 (2 Dimensionen)t = 1 (Satzseiten enthalten hochsten ein Tupel.)b = 2 (Bereichsseiten enthalten hochstens 2 Schnittelemente.)Datensatze mit numerischem und alphabetischem Attribut:15 G | 45 G | 85 F | 15 D | 50 C | 15 A | 85 B | 60 H
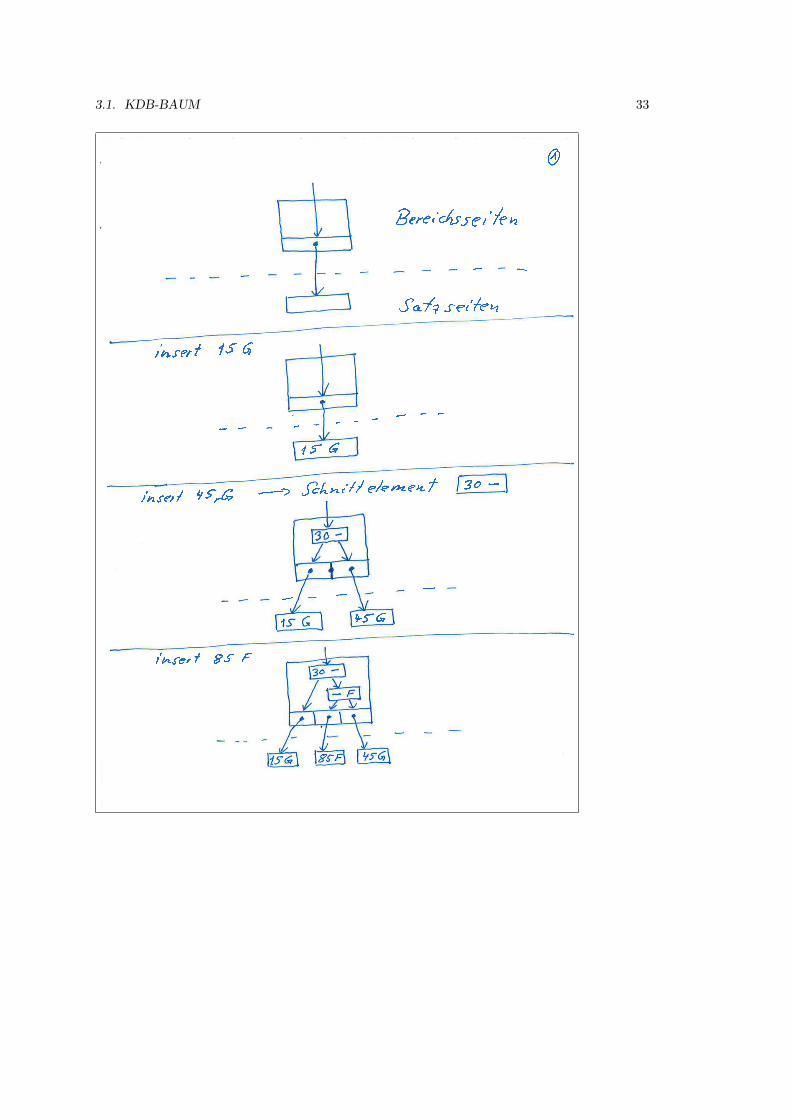
3.1. KDB-BAUM 33
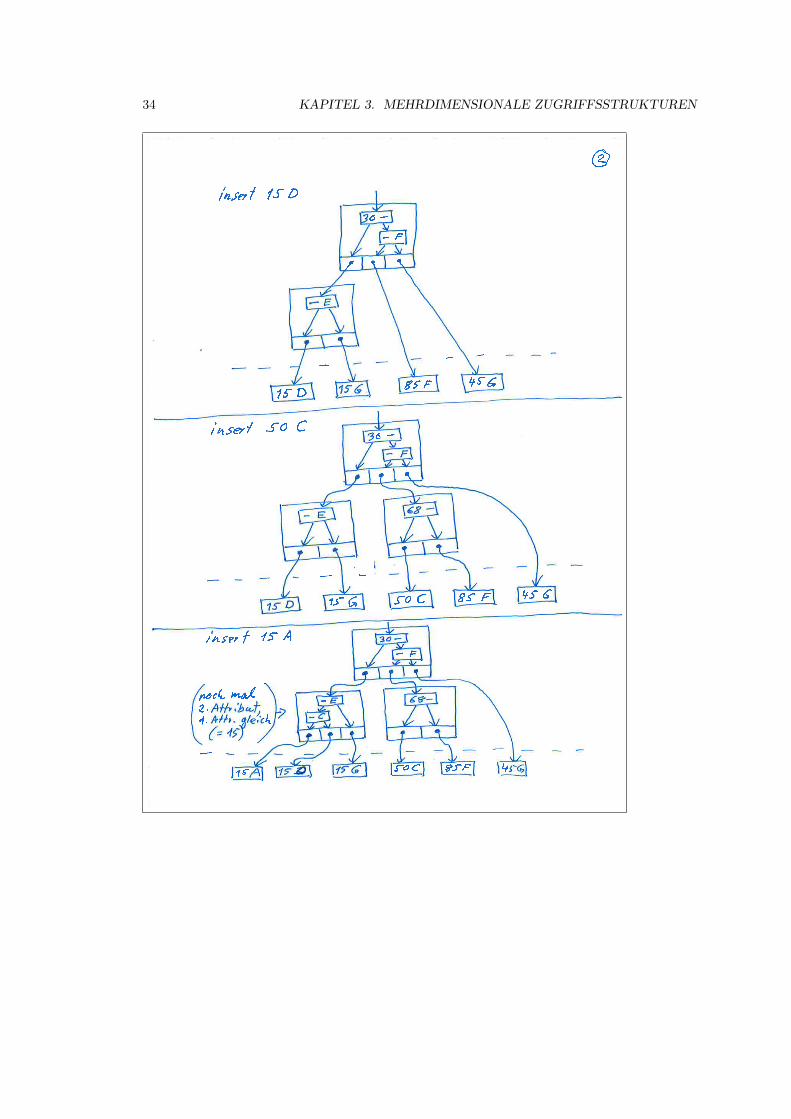
34 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
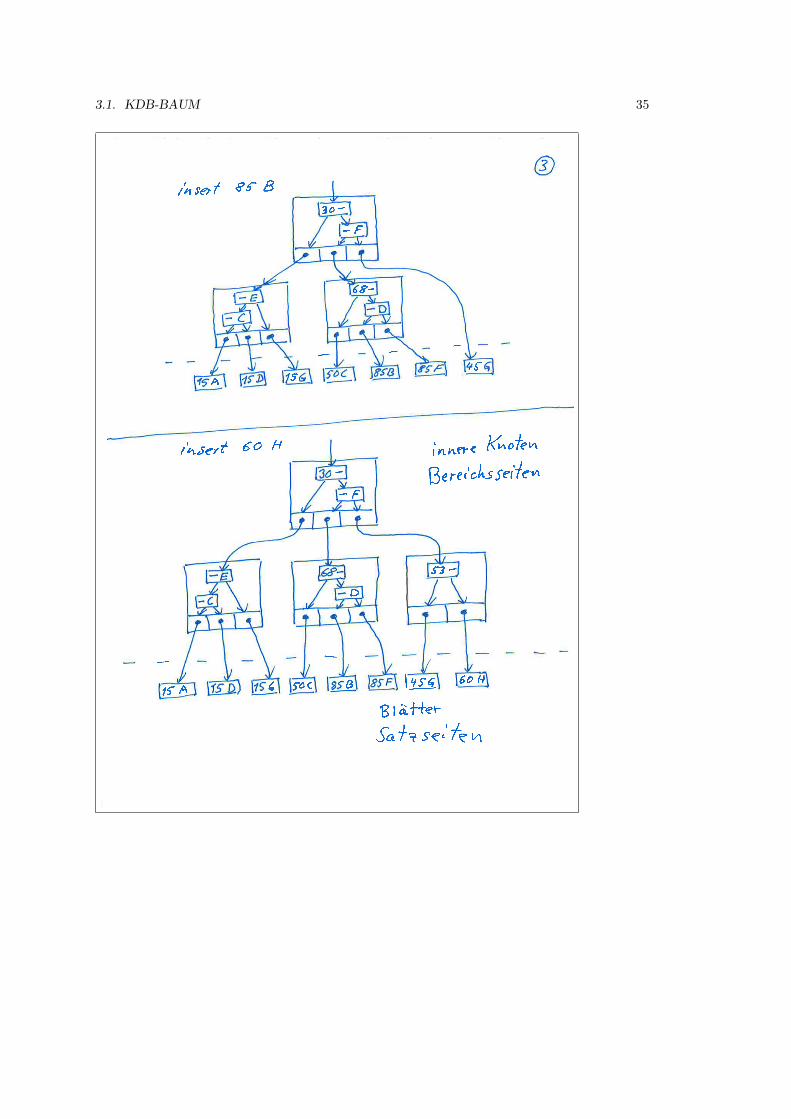
3.1. KDB-BAUM 35

36 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Eine eventuell bessere Veranschaulichung des KdB-Baums ist die ”Brickwall”-Darstellung, diewir im folgenden mit den Satzseiten-Großen ein und drei Tupel zeigen werden.
Bemerkungen:
1. Jeder Schritt des Aufbaus der Brickwall (Historie der Zellteilung) muss verwaltet werden,um Datensatze zu finden, einzufugen oder zu loschen. D.h. jede innere Brick-Wand ent-spricht einem Schnittelement.
2. Die Brickwall besteht aus Quadern sehr unterschiedlicher Große und hat daher eine un-regelmaßige Struktur, die es nicht erlaubt, Hyperebenen oder Regionen fur die Suche vonObjekten zu definieren.
Wir fullen einen zweidimensionalen KdB-Baum nacheinander mit zweidimensionalen Da-tensatzen bestehend aus einer ganzen Zahl und einem Großbuchstaben.
k = 2 (2 Dimensionen)t = 1 (Satzseiten enthalten hochsten ein Tupel.)Datensatze mit numerischem und alphabetischem Attribut:15 G | 40 G | 80 F | 10 D | 50 C | 20 A | 90 B | 60 H | 65 E | 5 C
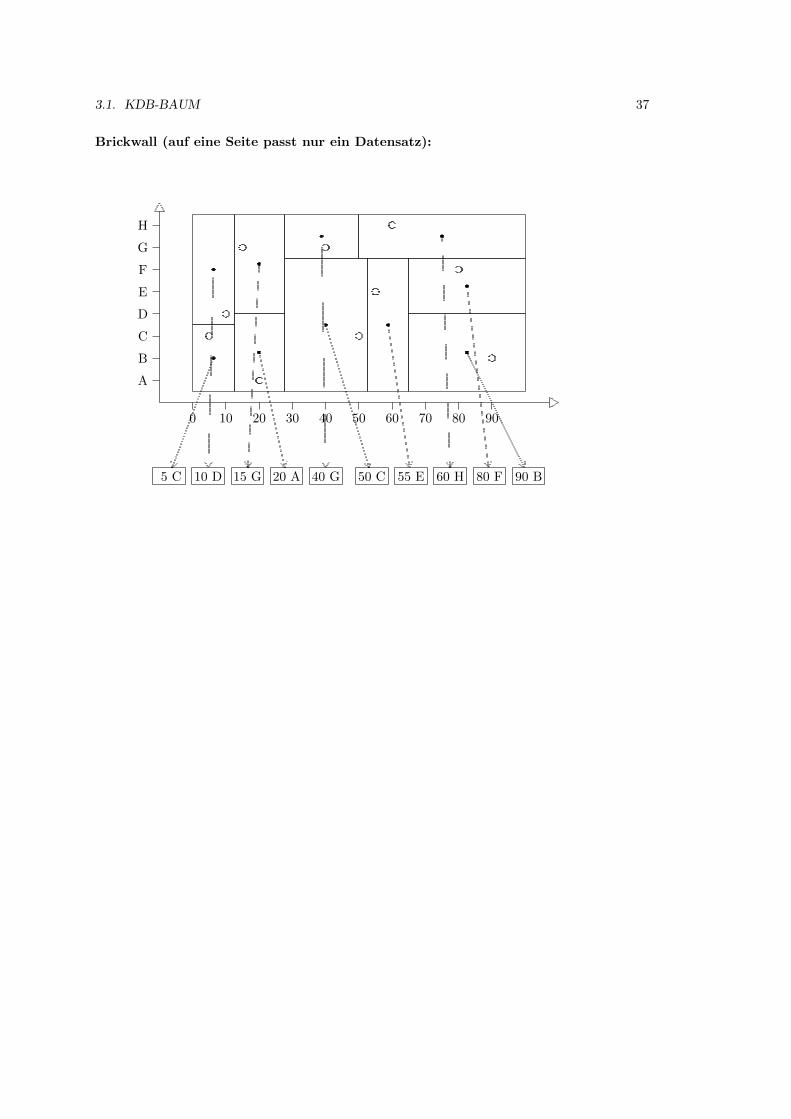
3.1. KDB-BAUM 37
Brickwall (auf eine Seite passt nur ein Datensatz):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G20 A15 G10 D5 C 50 C 55 E 60 H 80 F 90 B
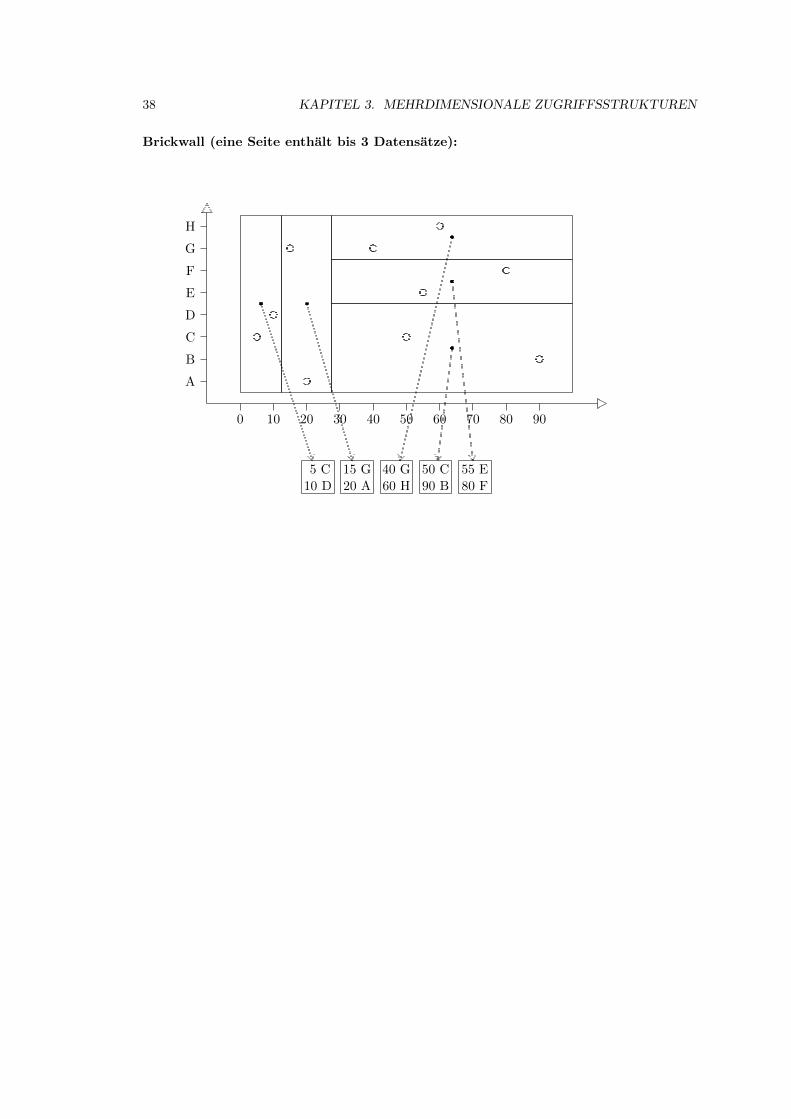
38 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Brickwall (eine Seite enthalt bis 3 Datensatze):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G
60 H
15 G
20 A
5 C
10 D
50 C
90 B
55 E
80 F

3.2. GRID-FILE 39
3.2 Grid-File
Anstatt des unregelmaßigen ”Brickwall”-Musters eines KdB-Baums wird der Datenraumgleichmaßig in Grid-Zellen eingeteilt.
• Skala: Fur jede Dimension gibt es ein Feld von Intervallen des Wertebereichs eines Zugriffs-Attributs.
• Das Grid-Directory zerlegt den Datenraum in Grid-Zellen (k-dimensionale Quader)gemaß den Intervallen der Skalen.
Das Grid-Directory ist i.a. so groß, dass es normalerweise auf dem Sekundarspeicher liegt.Allerdings genugen wenige Zugriffe, um eine Zelle zu finden. Bei einer exact-match querygenugt ein Zugriff.
• Die Grid-Region besteht aus einer oder mehreren Grid-Zellen. Jeder Grid-Region ist eineSatzseite zugeordnet. Die Grid-Region ist ein k-dimensionales konvexes Gebilde, d.h. jederDatensatz auf der Geraden zwischen zwei Datensatzen derselben Region liegt ebenfalls inder Region. Regionen sind paarweise disjunkt.
• Die Satzseiten (data bucket) enthalten die Datensatze und liegen auf dem Sekundarspei-cher.
Wir fullen einen zweidimensionalen Grid-File nacheinander mit zweidimensionalen Datensatzenbestehend aus einer ganzen Zahl und einem Großbuchstaben.
k = 2 (2 Dimensionen)t = 1 (Satzseiten enthalten hochsten ein Tupel.)Datensatze mit numerischem und alphabetischem Attribut:15 G | 40 G | 80 F | 10 D | 50 C | 20 A | 90 B | 60 H | 65 E | 5 C
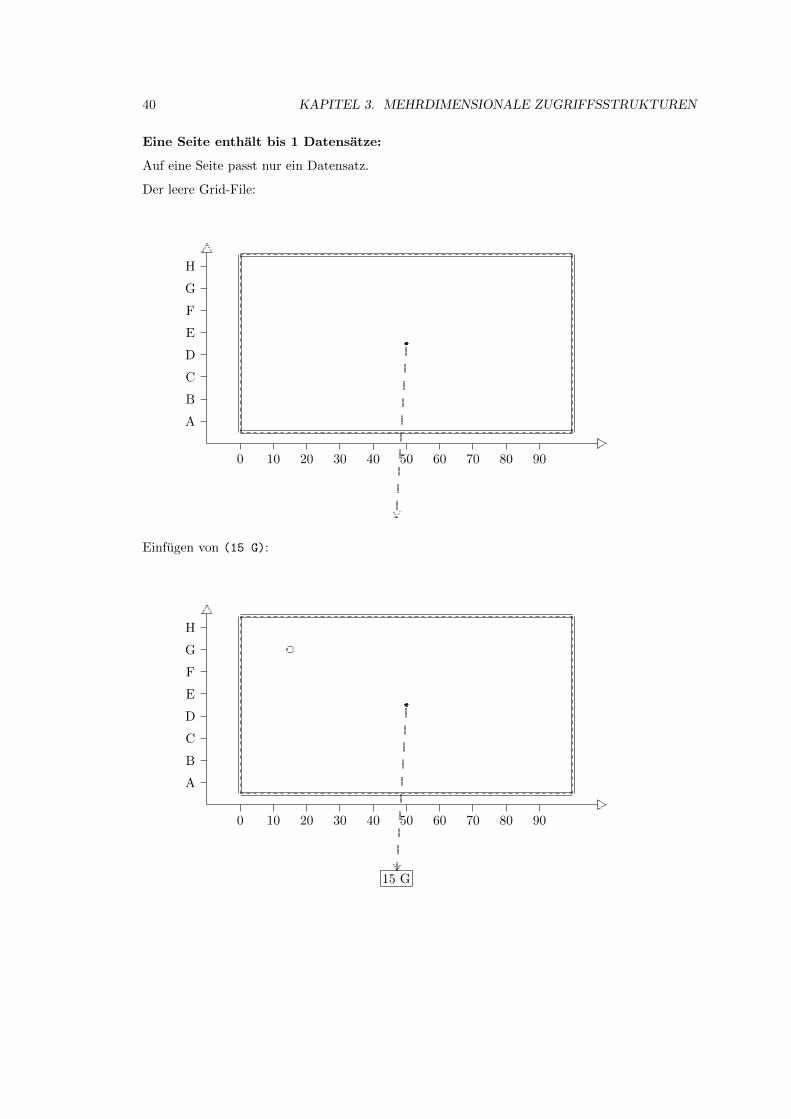
40 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Eine Seite enthalt bis 1 Datensatze:
Auf eine Seite passt nur ein Datensatz.
Der leere Grid-File:
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
Einfugen von (15 G):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G
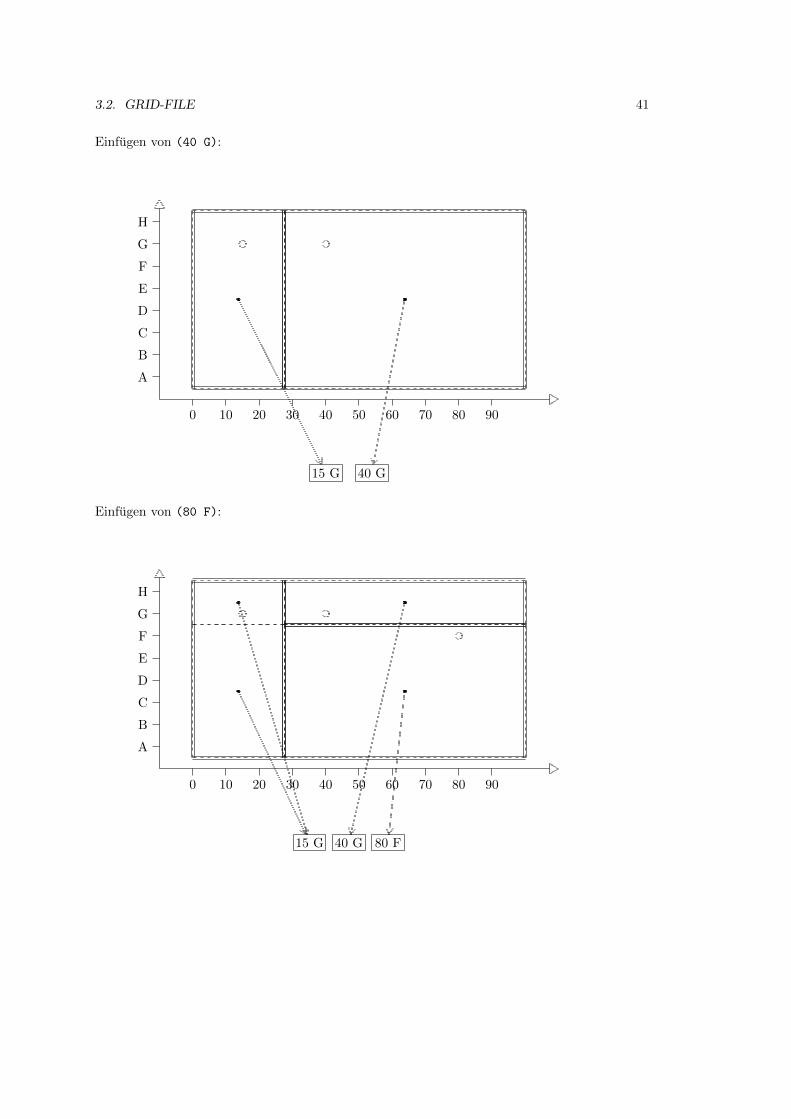
3.2. GRID-FILE 41
Einfugen von (40 G):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G 40 G
Einfugen von (80 F):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G15 G 80 F
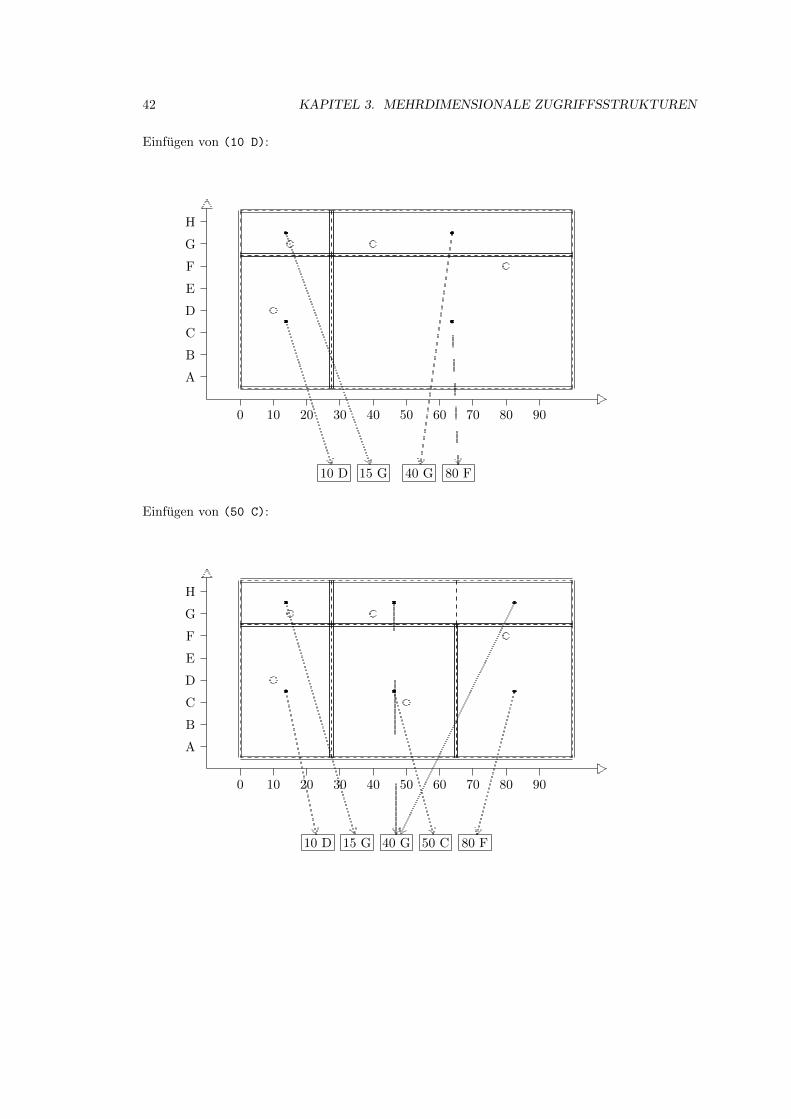
42 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Einfugen von (10 D):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G10 D 40 G 80 F
Einfugen von (50 C):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G15 G10 D 50 C 80 F
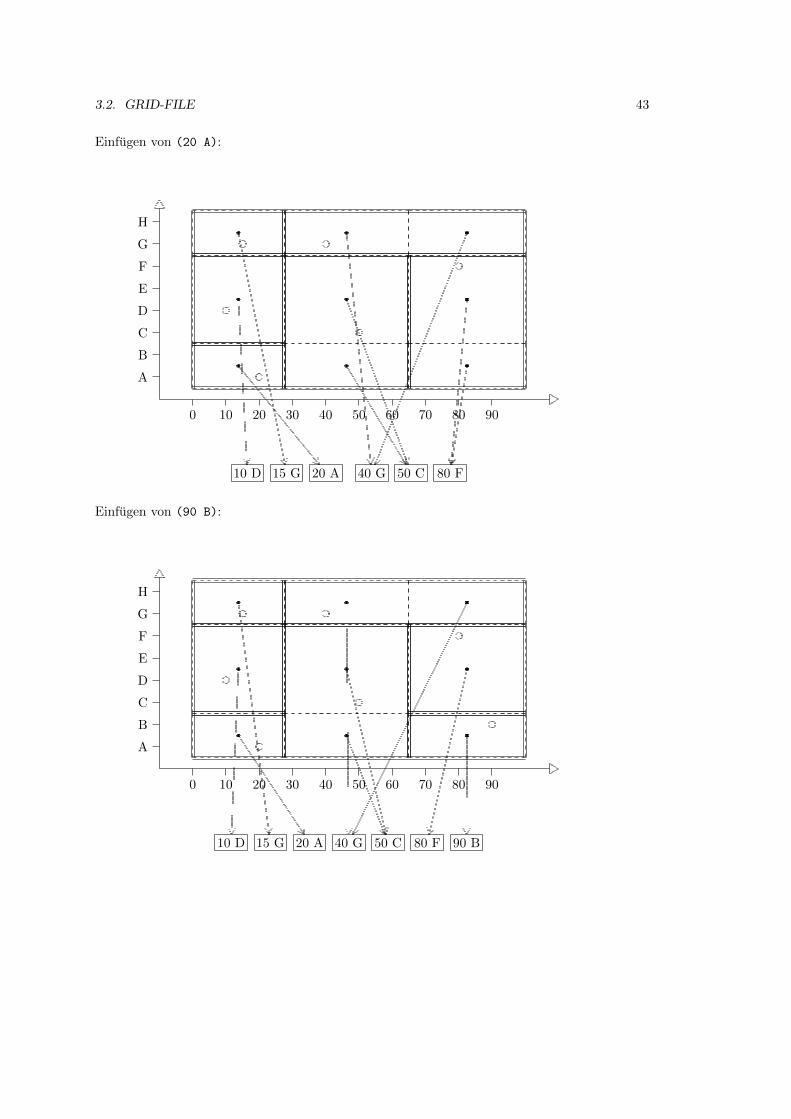
3.2. GRID-FILE 43
Einfugen von (20 A):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
20 A15 G10 D 40 G 50 C 80 F
Einfugen von (90 B):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G20 A15 G10 D 50 C 80 F 90 B
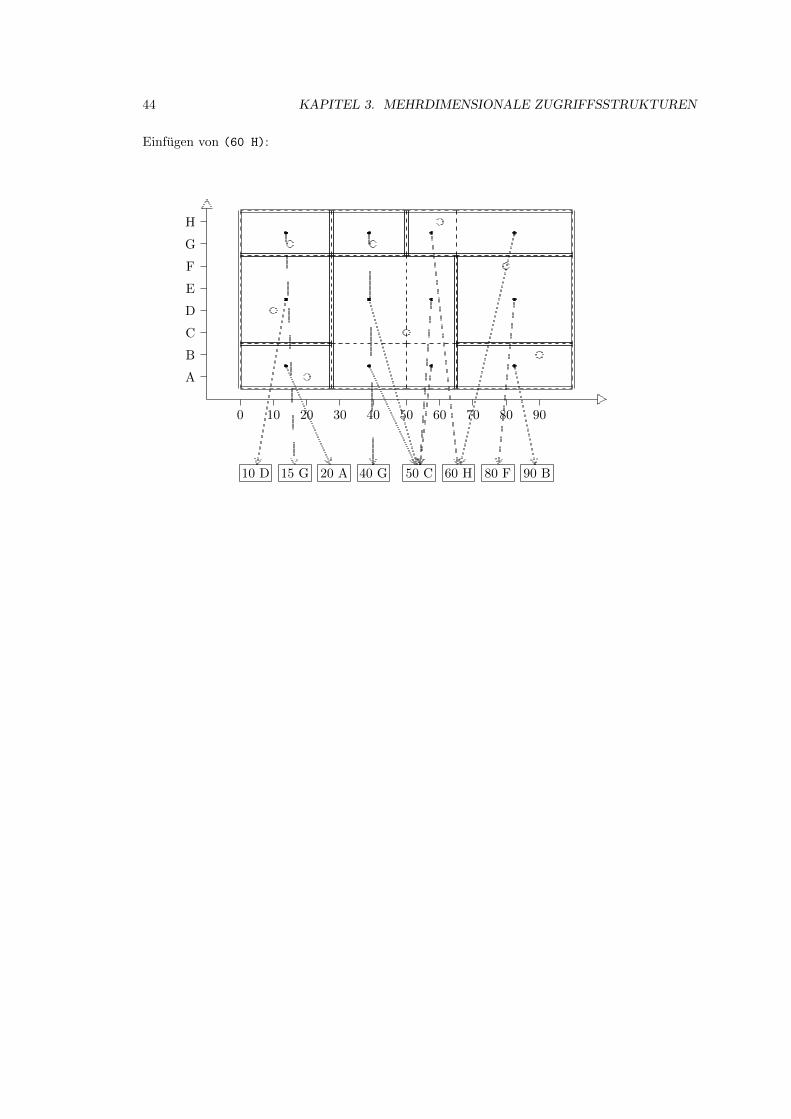
44 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Einfugen von (60 H):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G20 A15 G10 D 50 C 60 H 80 F 90 B
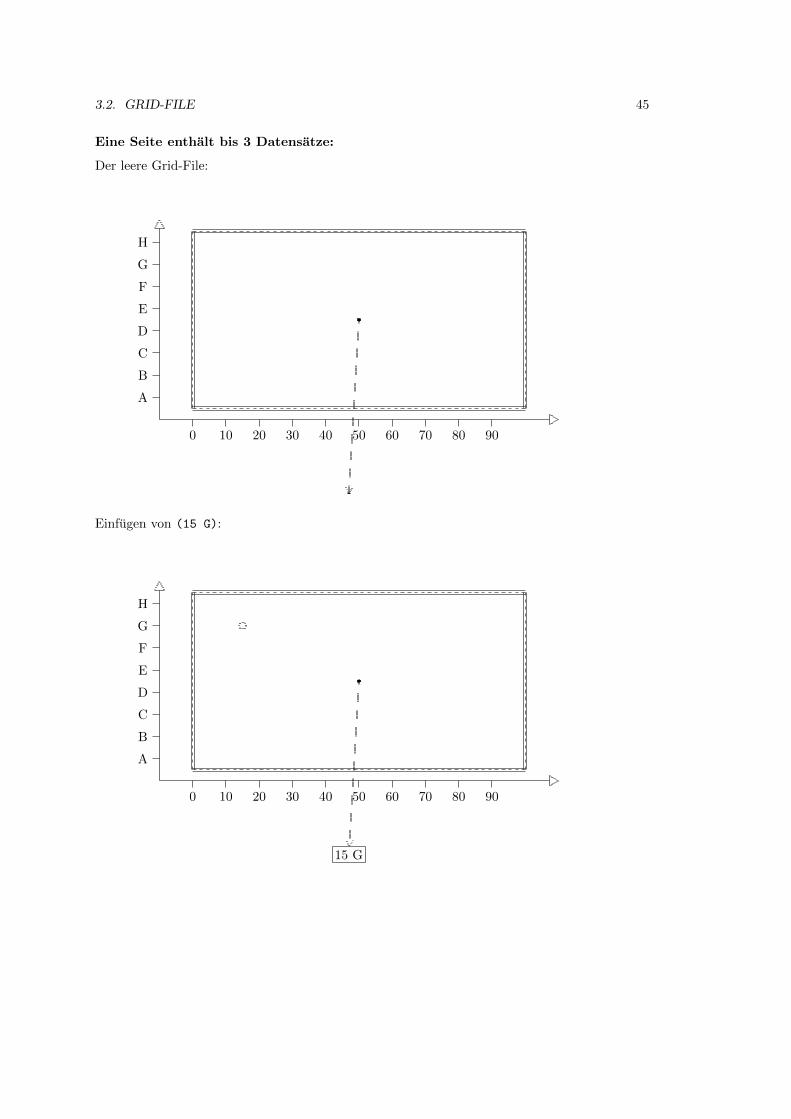
3.2. GRID-FILE 45
Eine Seite enthalt bis 3 Datensatze:
Der leere Grid-File:
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
Einfugen von (15 G):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G
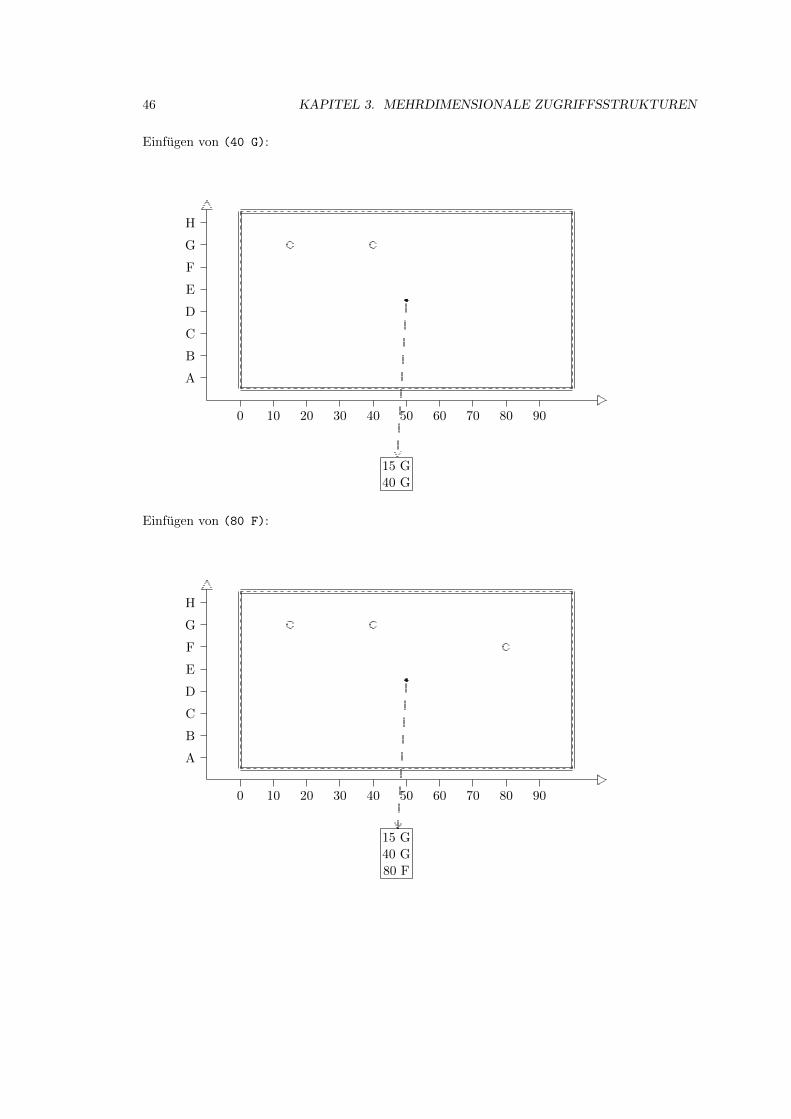
46 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Einfugen von (40 G):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G
40 G
Einfugen von (80 F):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
15 G
40 G
80 F
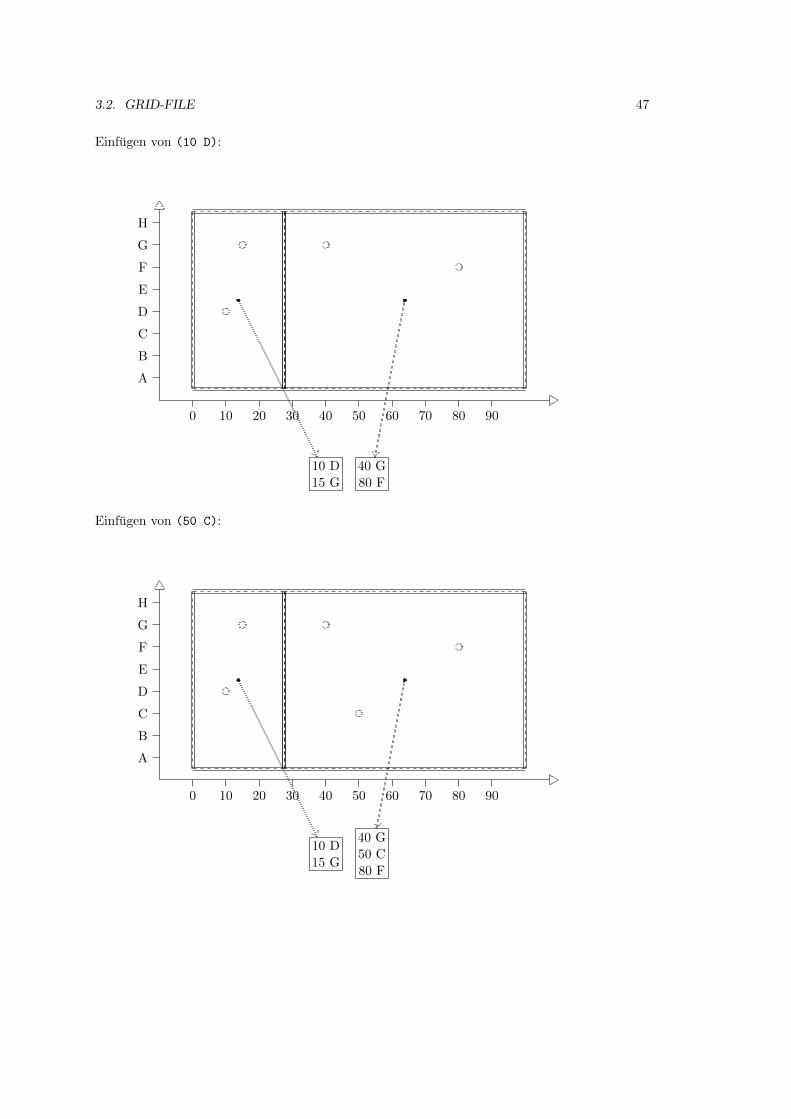
3.2. GRID-FILE 47
Einfugen von (10 D):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
10 D
15 G
40 G
80 F
Einfugen von (50 C):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
10 D
15 G
40 G
50 C
80 F
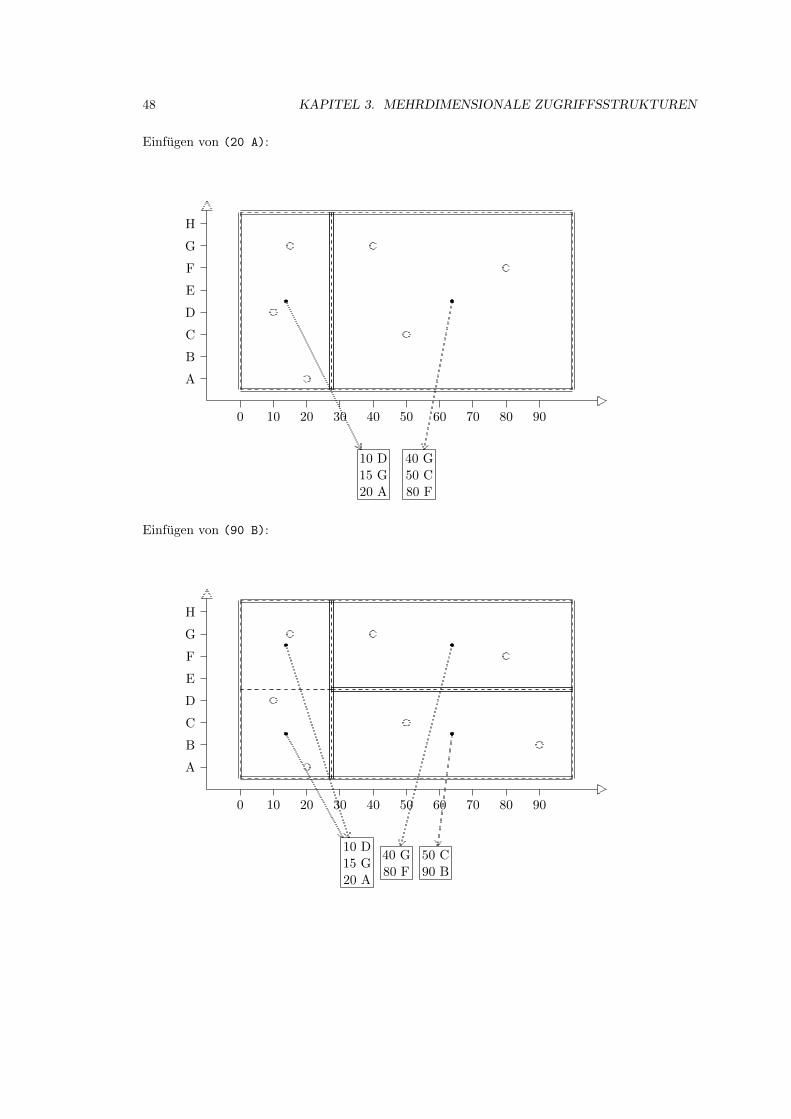
48 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Einfugen von (20 A):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
10 D
15 G
20 A
40 G
50 C
80 F
Einfugen von (90 B):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G
80 F
10 D
15 G
20 A
50 C
90 B
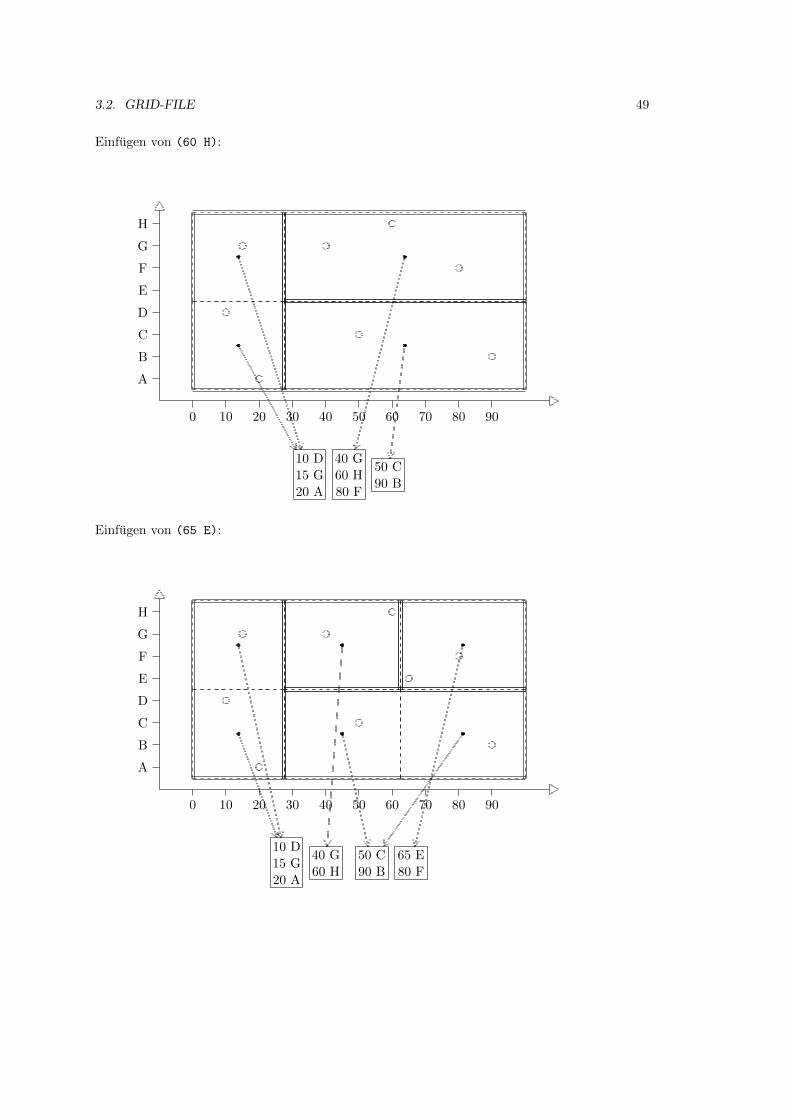
3.2. GRID-FILE 49
Einfugen von (60 H):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G
60 H
80 F
10 D
15 G
20 A
50 C
90 B
Einfugen von (65 E):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G
60 H
10 D
15 G
20 A
50 C
90 B
65 E
80 F
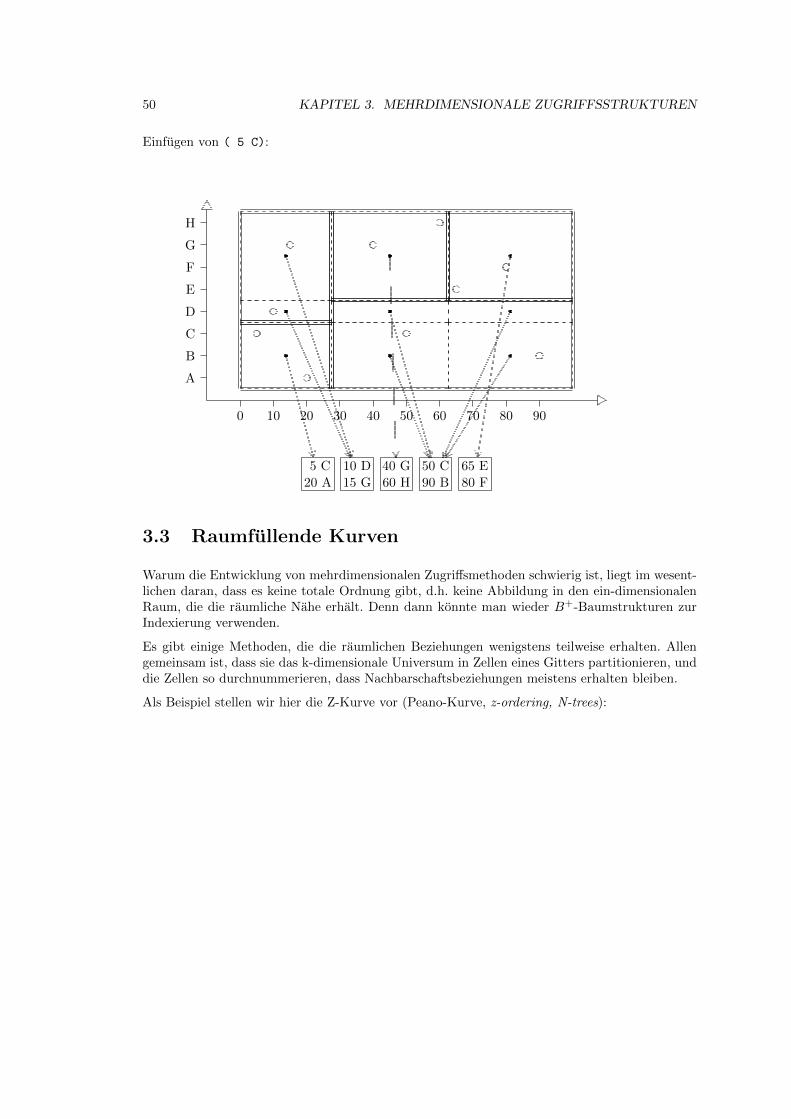
50 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
Einfugen von ( 5 C):
0 10 20 30 40 50 60 70 80 90
A
B
C
D
E
F
G
H
40 G
60 H
10 D
15 G
5 C
20 A
50 C
90 B
65 E
80 F
3.3 Raumfullende Kurven
Warum die Entwicklung von mehrdimensionalen Zugriffsmethoden schwierig ist, liegt im wesent-lichen daran, dass es keine totale Ordnung gibt, d.h. keine Abbildung in den ein-dimensionalenRaum, die die raumliche Nahe erhalt. Denn dann konnte man wieder B+-Baumstrukturen zurIndexierung verwenden.
Es gibt einige Methoden, die die raumlichen Beziehungen wenigstens teilweise erhalten. Allengemeinsam ist, dass sie das k-dimensionale Universum in Zellen eines Gitters partitionieren, unddie Zellen so durchnummerieren, dass Nachbarschaftsbeziehungen meistens erhalten bleiben.
Als Beispiel stellen wir hier die Z-Kurve vor (Peano-Kurve, z-ordering, N-trees):

3.3. RAUMFULLENDE KURVEN 51

52 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
3.4 R-Baum
Der R-Baum wurde entwickelt zur Indexierung ausgedehnter Objekte im k-dimensionalen Raum.Der Index speichert fur jedes Objekt seine MBB (minimal bounding box). Der MBB ist danndie Referenz auf das Objekt zugeordnet. Im zwei-dimensionalen Fall ware das z.B.:

3.4. R-BAUM 53
Der R-Baum eignet sich aber auch zur mehrdimensionalen Indexierung beliebiger Objekte, wennman alle Index-Attribute in numerische Werte transformiert. Das sollte meistens moglich sein.
Ein R-Baum ist eine Hierarchie von verschachtelten k-dimensionalen Intervallen Ik (Schachteln,boxes) sogenannten Regionen Rx.
Jeder Knoten ν eines R-Baums belegt maximal eine Seite (Transfer-Einheit Platte<—>Hauptspeicher).
Jeder innere Knoten enthalt maximal pKnoten Paare der Form:
Ri = (Region Iki , Adresse von Knoten νiauf der nachst tieferen Ebene (= Unterbaum))
fur i = 0 . . . q mit q < pKnoten
Die Region Iki ist die MBB aller Boxen oder Objekte des Unterbaums νi. Die Iki konnen sichuberlappen!
In der folgenden Darstellung nummerieren wir diese Paare mit R1, R2, R3 ... uber alle Knotendurch.
Jeder Blattknoten enthalt maximal pBlatt Paare der Form:
(Box Iki = MBB eines Datenobjekts, Adressen eines oder mehrerer Datenobjekte)fur i = 0 . . . q mit q < pBlatt
Die Wurzel steht oben und ist am Anfang ein Blatt, bis dieses in zwei Blatter gespalten wirdund eine neue Wurzel als innerer Knoten entsteht mit mindestens zwei Region-Adresse-PaarenR1 und R2.
Suche: Wir kennen die k-dimensionale MBB des gesuchten Objekts. (Bei einer Punkt-Sucheschrumpft diese auf einen Punkt zusammen. Wegen der schlechten Vergleichbarkeit vonRealzahlen muss eventuell eine ”Epsilon-MBB” definiert werden.)
Beginnend mit der Wurzel suchen wir die Regionen Iki , die die gesuchte MBB enthalten.
Gibt es mehr als eine Region Iki , mussen wir mehrere Suchpfade weiterverfolgen. Gibt eskeine Region, die die MBB enthalt, dann konnen wir die Suche abbrechen.
Jedenfalls fuhrt uns das zu einem oder mehreren Knoten auf der nachst tieferen Ebene. Dortsuchen wir wieder eine enthaltende (uberlappende?) Region. Gibt es das Objekt im Index,dann finden wir schließlich in einem Blatt bei einer exakten Suche genau seine MBB oderfinden mehrere Objekte, deren MBB mit unserer uberlappen. Alle diese Objekte werdenals Resultat zuruckgegeben.
Gibt es das Objekt nicht im Index, dann kann die Suche u.U. auf jeder Stufe schon beendetsein.
Einfugen: Wir suchen zunachst das Objekt mit seiner MBB. Dabei kommen wir schließlich
1. entweder zu einem inneren Knoten, bei dem es keine Region Iki mehr gibt, in die dieMBB unseres Objekts hineinpasst. Dann wird die Region Iki bestimmt, die am wenig-sten vergroßert werden muss, um die MBB des einzufugenden Objekts aufzunehmen.Sie wird vergroßert, so dass die MBB hineinpasst.
So verfahrt man dann mit allen inneren Knoten auf den folgenden Stufen, bis man einBlatt erreicht. Das Blatt wird wie folgt behandelt.

54 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
2. Oder man erreicht ein Blatt.
(a) Entweder gibt es dort die MBB, aber mit einem anderen zugeordneten Objekt.Dann wird dieser MBB auch das neu einzufugende Objekt zugeordnet.
(b) Oder die MBB gibt es nicht. Dann wird sie in das Blatt eingefugt mit der Adressedes ihr zugeordneten Datenobjekts. Ferner mussen bis zur Wurzel die jeweiligenIki der daruber liegenden Knoten angepasst, d.h. vergroßert werden.Falls das Blatt voll war, wird das Blatt in zwei Blatter aufgespalten. Fur jedes Teil-Blatt wird die MBB uber alle seine Iki bestimmt. Im daruber liegenden innerenKnoten wird die Iki und Adresse νi des ursprunglichen Blatts durch die beidenneuen MBB und die zugehorigen Blatt-Adressen ersetzt.Dadurch bekommt der innere Knoten ein zusatzliches Element. Wenn der Knotenvoll war, dann wird auch er gespalten, mit der Folge, dass der daruber liegendeKnoten wieder ein weiteres Element bekommt. Das kann sich bis zur Wurzelfortsetzen, so dass schließlich eine neue Wurzel entsteht. So wachst der Baumnach oben.Die vernunftigste Spaltung der Region ware wahrscheinlich die, bei der sich dieTeile am wenigsten uberlappen. Der entsprechende Algorithmus hatte aber Kom-plexitat O(2n) und kommt daher nicht in Frage.Fur die Spaltung einer Region in zwei Teil-Regionen hat sich offenbar folgendeHeuristik mit linearer Komplexitat O(n) bewahrt:Man wahlt die beiden extremsten Eintrage E1 und E2. Damit sind die Eintragegemeint, die in den Ecken des Raums liegen, oder eventuell auch die am weitestenvoneinander entfernt sind.Sie werden den Gruppen G1 und G2 zugewiesen. Danach wird jeder noch nichtzugewiesene Eintrag derjenigen Gruppe zugewiesen, deren MBB am wenigstenvergroßert werden muss.Wenn E1 gleich E2 ist, dann wird der besser in der Ecke liegende Eintrag einerGruppe zugewiesen. Alle anderen Eintrage werden der anderen Gruppe zugewie-sen.
Loschen: Der Baum kann wieder schrumpfen, wenn Objekte geloscht werden und zu leere Kno-ten wieder rekombiniert werden. Dabei hat sich offenbar bewahrt, zu leere Knoten ganz zuloschen und deren Elemente wieder einzufugen.
Außerdem mussen bei jeder Objekt-Loschung die Boxen bis zur Wurzel angepasst werden.
Bemerkung: Bei String-wertigen Dimensionen mussen die Strings irgendwie in numerische Werteumgewandelt werden.
Zusammenfassend kann man sagen, dass ein R-Baum ein B+-Baum ist, bei dem die SuchschlusselKi durch Regionen Iki ersetzt sind.
Beispiel: Wir fullen einen zweidimensionalen R-Baum nacheinander mit zweidimensionalen nu-merischen Datensatzen.
k = 2 (2 Dimensionen)pKnoten = 3 (Innere Knoten enthalten hochsten 3 Knoten-Referenzen.)pBlatt = 3 (Blatter enthalten hochsten 3 Tupel-Referenzen.)Die Datensatze p1 ... p10 reprasentieren punktformige Objekte.Die Datensatze m1 ... m10 reprasentieren ausgedehnte Objekte.

3.4. R-BAUM 55
Reihenfolge des Einfugens der Datensatze: p1, m1, p2, m2 ...
(Die Beispieldaten sind ahnlich denen von Gaede und Gunther [18]. Die Reihenfolgeder Einfugung konnte unterschiedlich sein.)
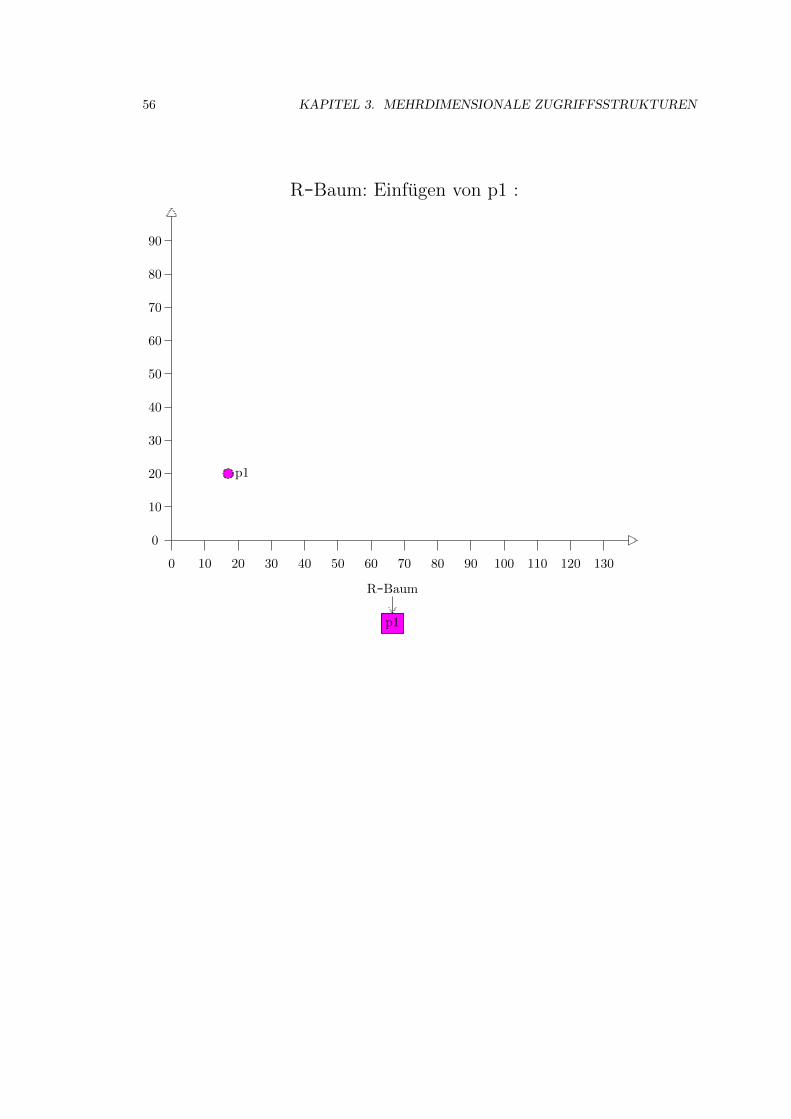
56 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p1 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
p1
R-Baum
p1p1
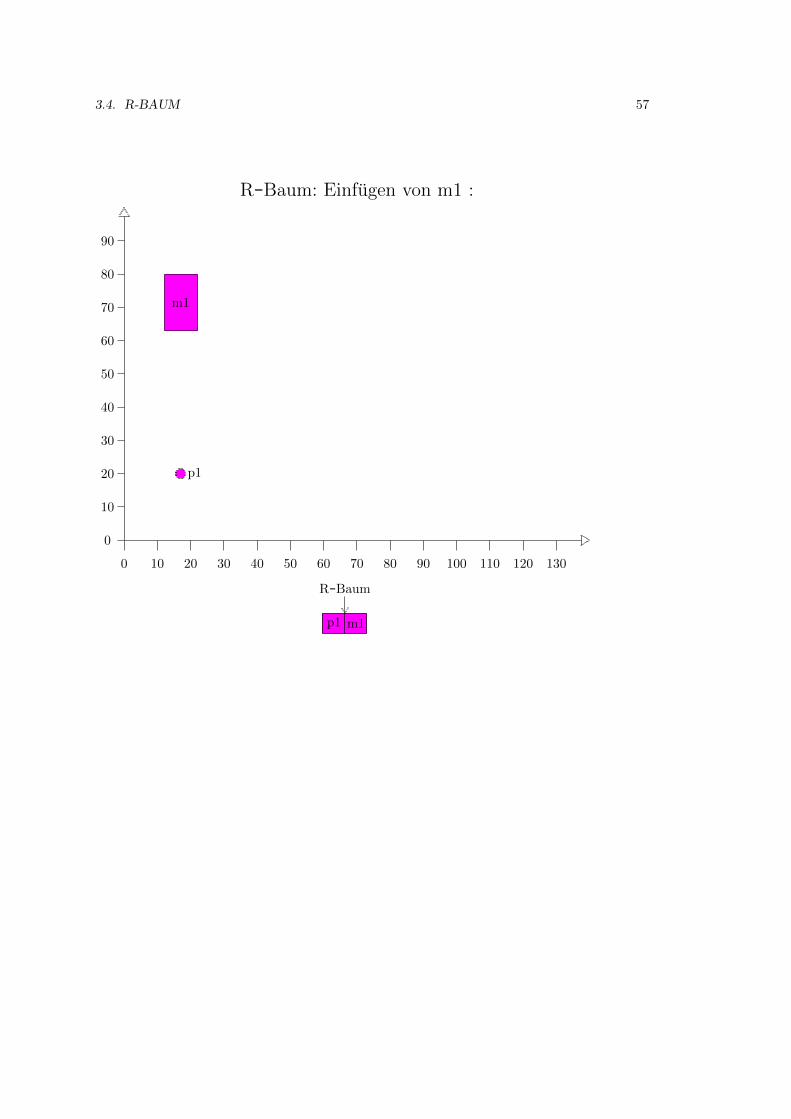
3.4. R-BAUM 57
R-Baum: Einfugen von m1 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
p1
m1
R-Baum
p1 m1p1 m1
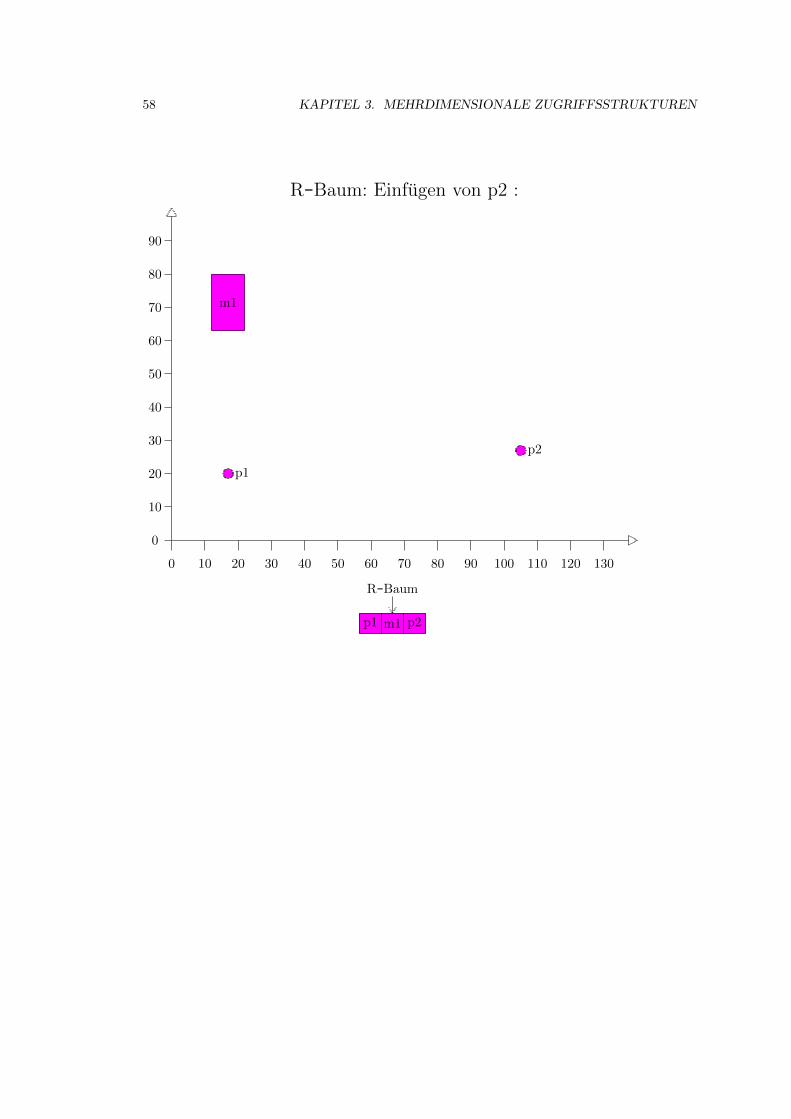
58 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p2 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
p1
m1
p2
R-Baum
p1 m1 p2p1 m1 p2
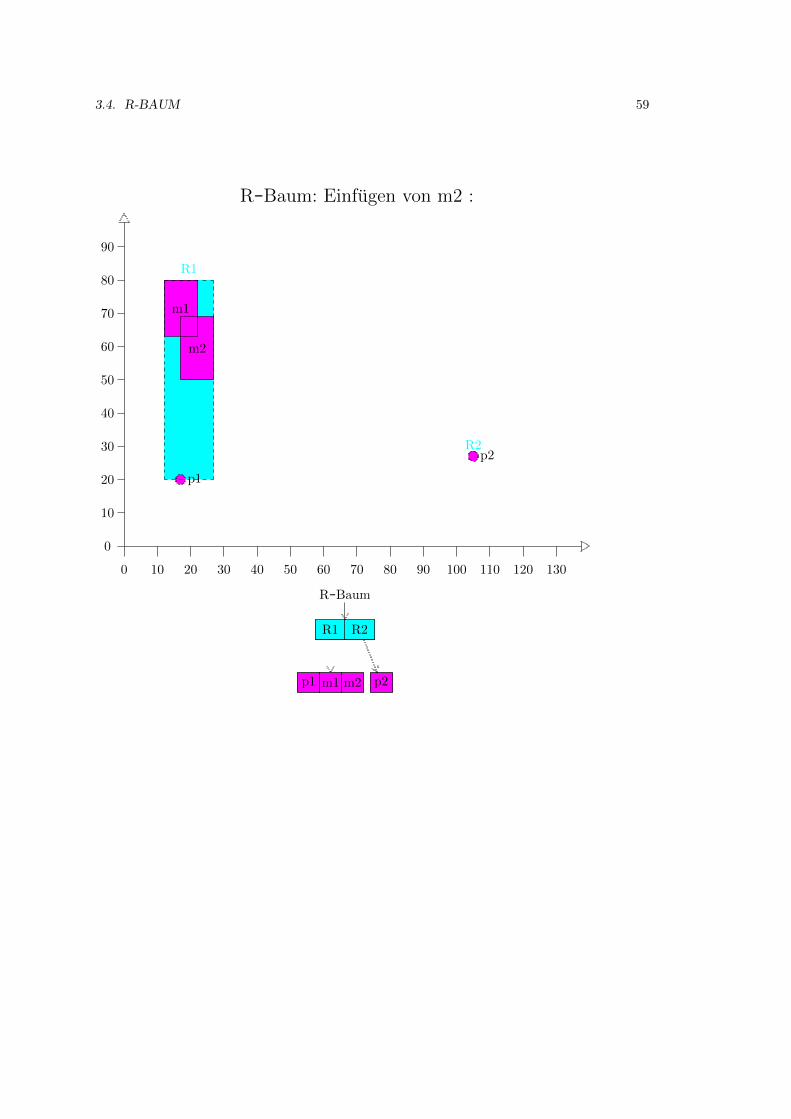
3.4. R-BAUM 59
R-Baum: Einfugen von m2 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R1
p1
m1
m2
R2p2
R-Baum
p1 m1 m2 p2
R1 R2R1
p1 m1 m2
R2
p2
R1 R2
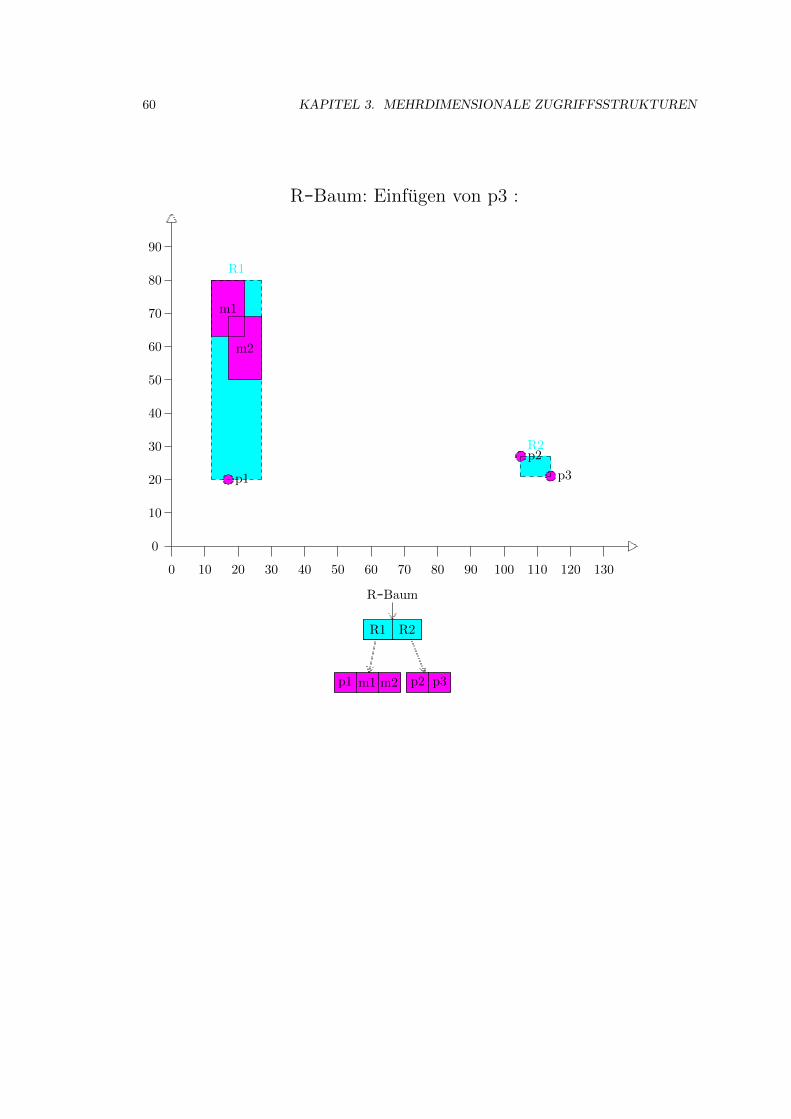
60 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p3 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R1
p1
m1
m2
R2p2
p3
R-Baum
p1 m1 m2 p2 p3
R1 R2R1
p1 m1 m2
R2
p2 p3
R1 R2
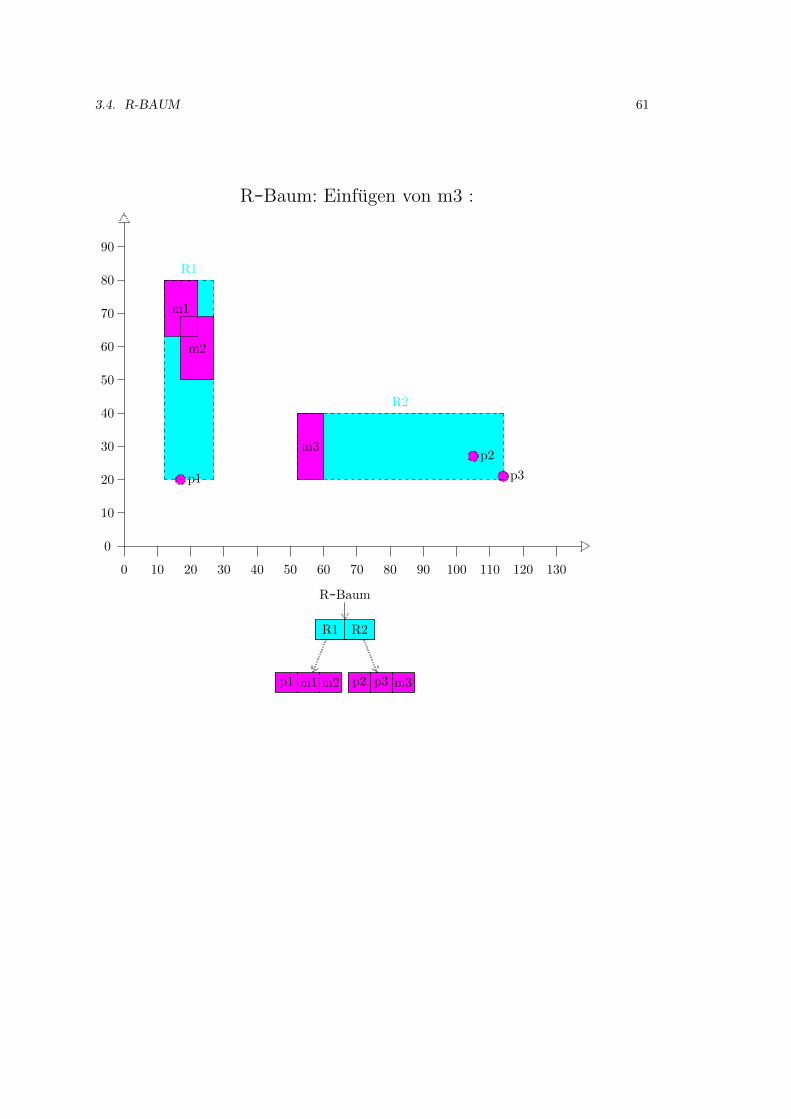
3.4. R-BAUM 61
R-Baum: Einfugen von m3 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R1
p1
m1
m2
R2
p2
p3
m3
R-Baum
p1 m1 m2 p2 p3 m3
R1 R2R1
p1 m1 m2
R2
p2 p3 m3
R1 R2
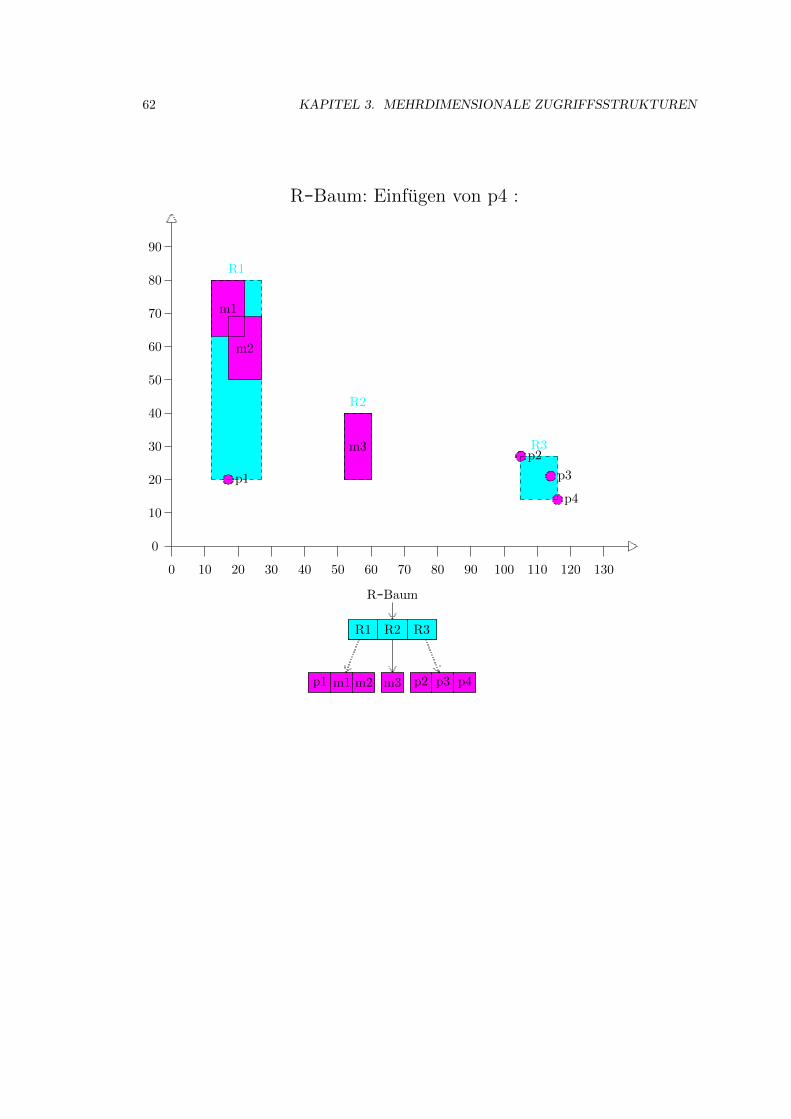
62 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p4 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R1
p1
m1
m2
R2
m3 R3p2
p3
p4
R-Baum
p1 m1 m2 m3 p2 p3 p4
R1 R2 R3R1
p1 m1 m2
R2
m3
R3
p2 p3 p4
R1 R2 R3
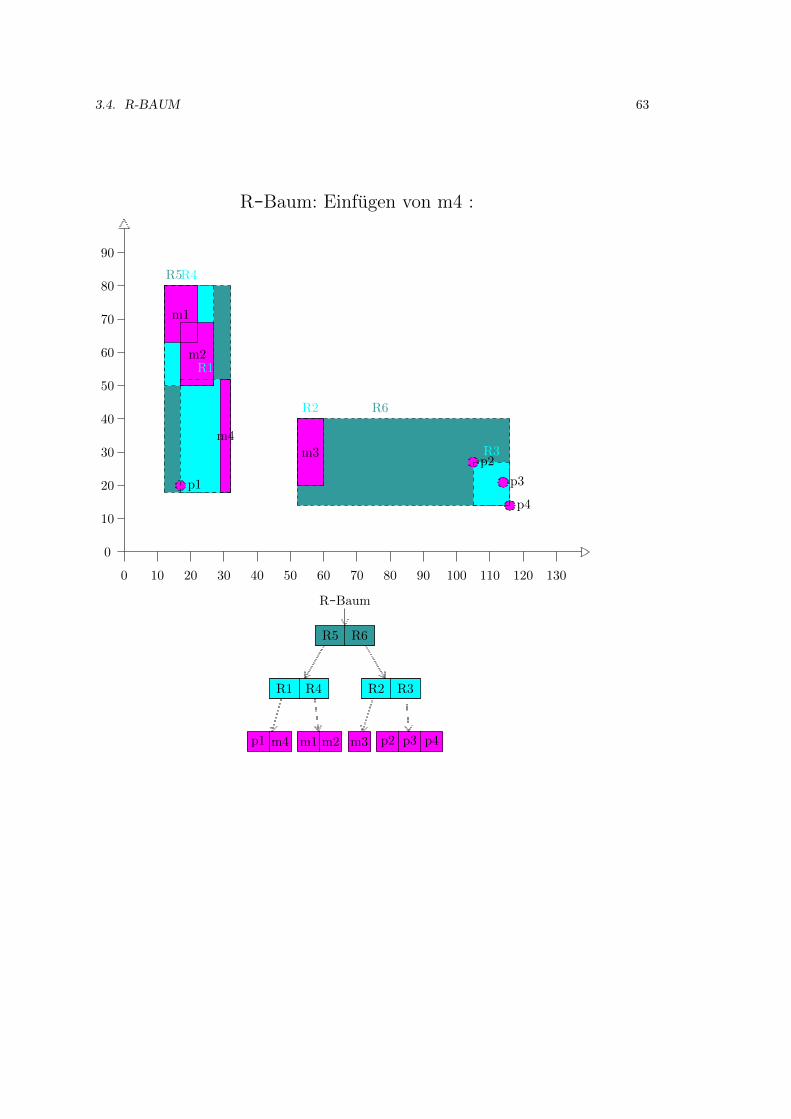
3.4. R-BAUM 63
R-Baum: Einfugen von m4 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3 R3p2
p3
p4
R-Baum
p1 m4 m1 m2 m3 p2 p3 p4
R1 R4 R2 R3
R5 R6R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3
R3
p2 p3 p4
R2 R3
R5 R6
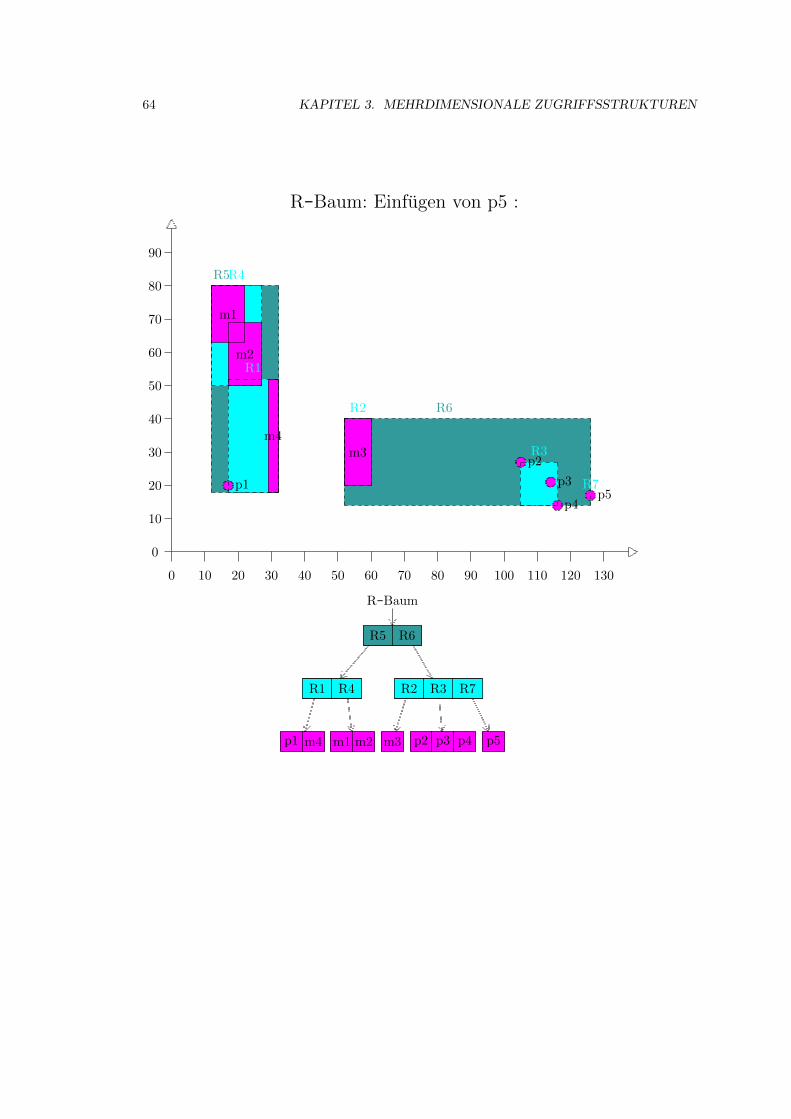
64 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p5 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3 R3p2
p3
p4
R7p5
R-Baum
p1 m4 m1 m2 m3 p2 p3 p4 p5
R1 R4 R2 R3 R7
R5 R6R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3
R3
p2 p3 p4
R7
p5
R2 R3 R7
R5 R6
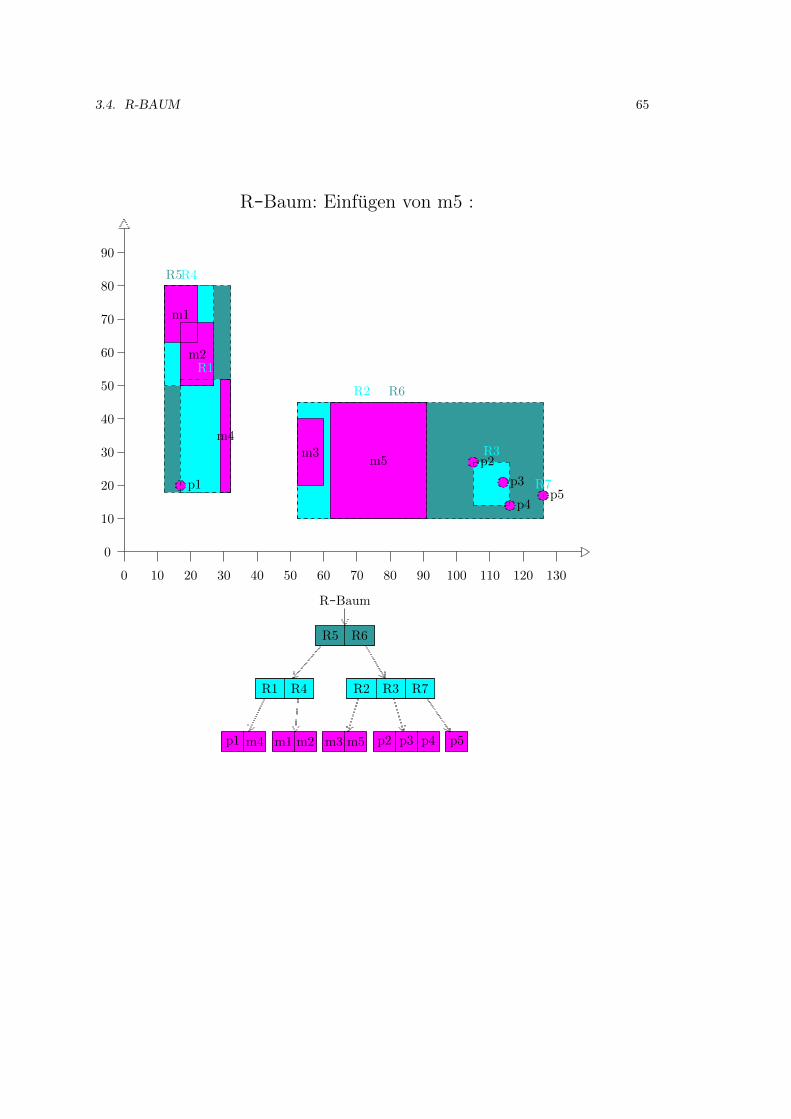
3.4. R-BAUM 65
R-Baum: Einfugen von m5 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7p5
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5
R1 R4 R2 R3 R7
R5 R6R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5
R2 R3 R7
R5 R6
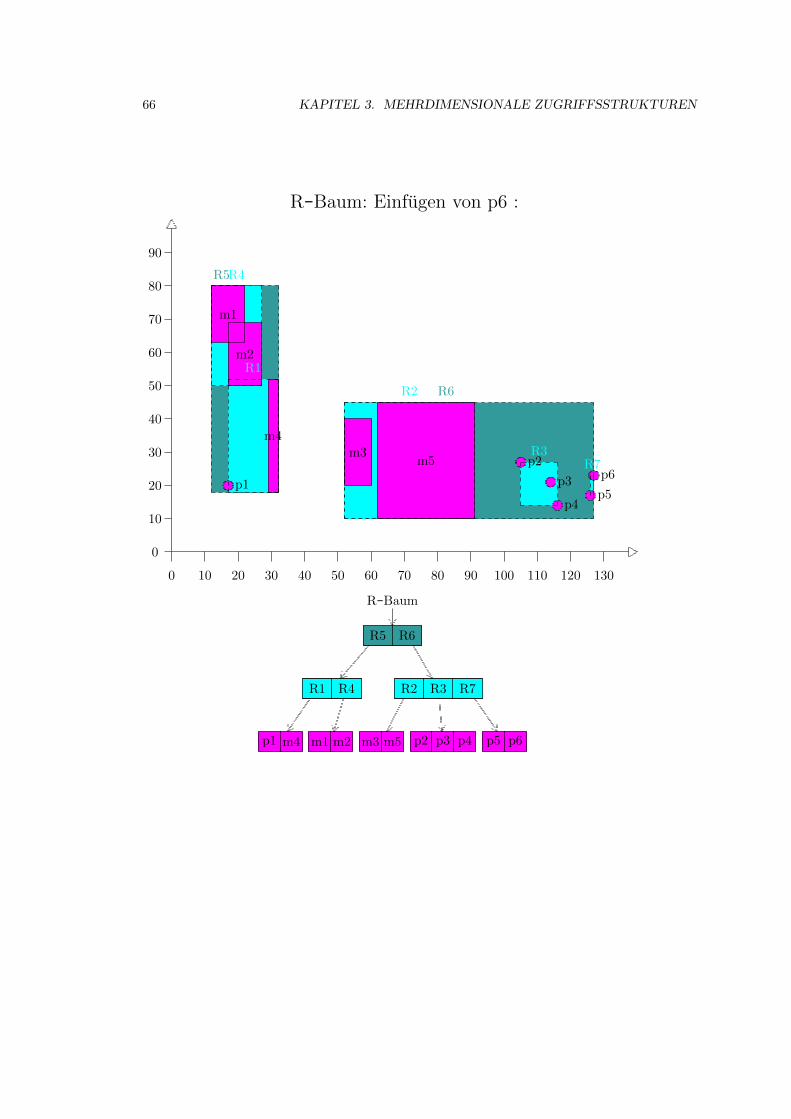
66 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p6 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6
R1 R4 R2 R3 R7
R5 R6R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6
R2 R3 R7
R5 R6
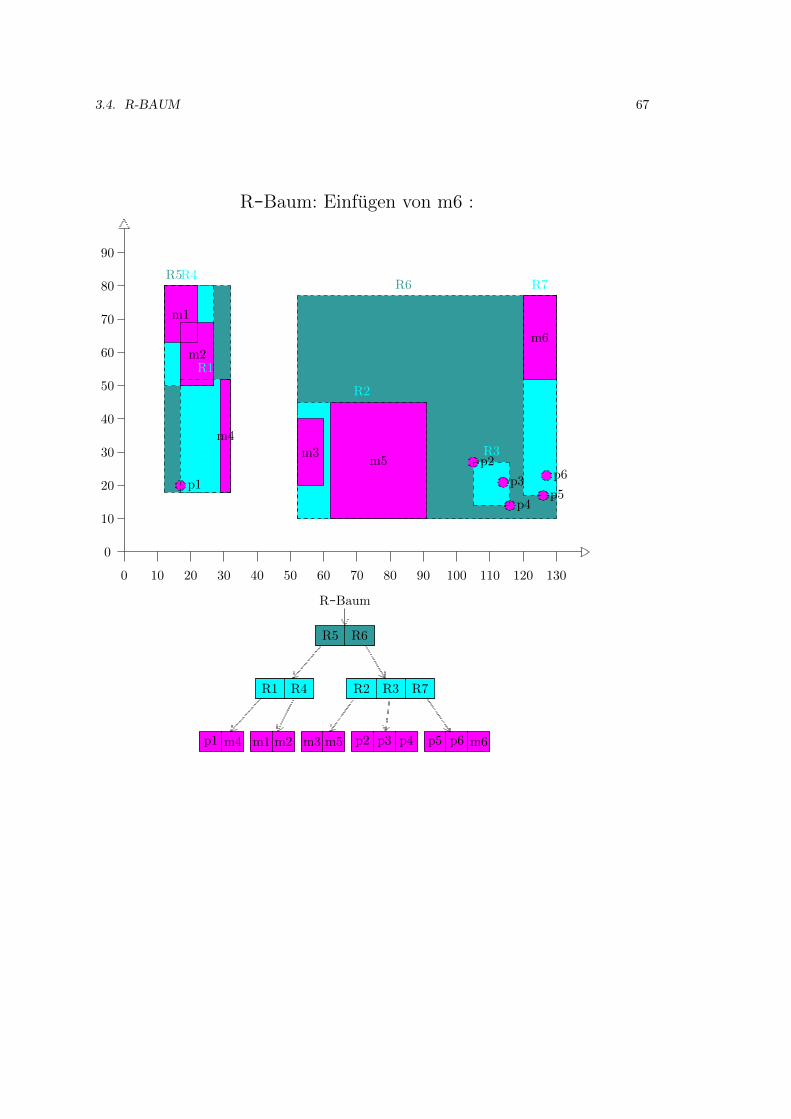
3.4. R-BAUM 67
R-Baum: Einfugen von m6 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6
R2
m3m5
R3p2
p3
p4
R7
p5
p6
m6
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6 m6
R1 R4 R2 R3 R7
R5 R6R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m6
R2 R3 R7
R5 R6
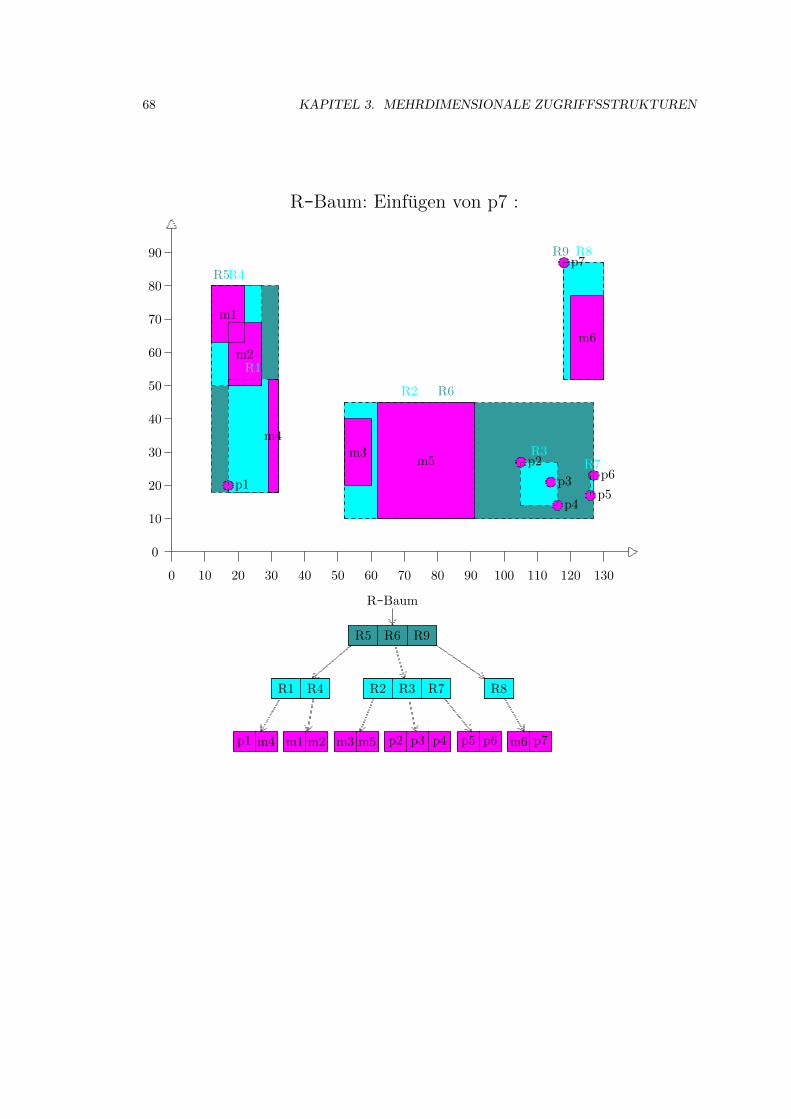
68 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p7 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
R9 R8
m6
p7
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6 m6 p7
R1 R4 R2 R3 R7 R8
R5 R6 R9R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6
R2 R3 R7
R9
R8
m6 p7
R8
R5 R6 R9
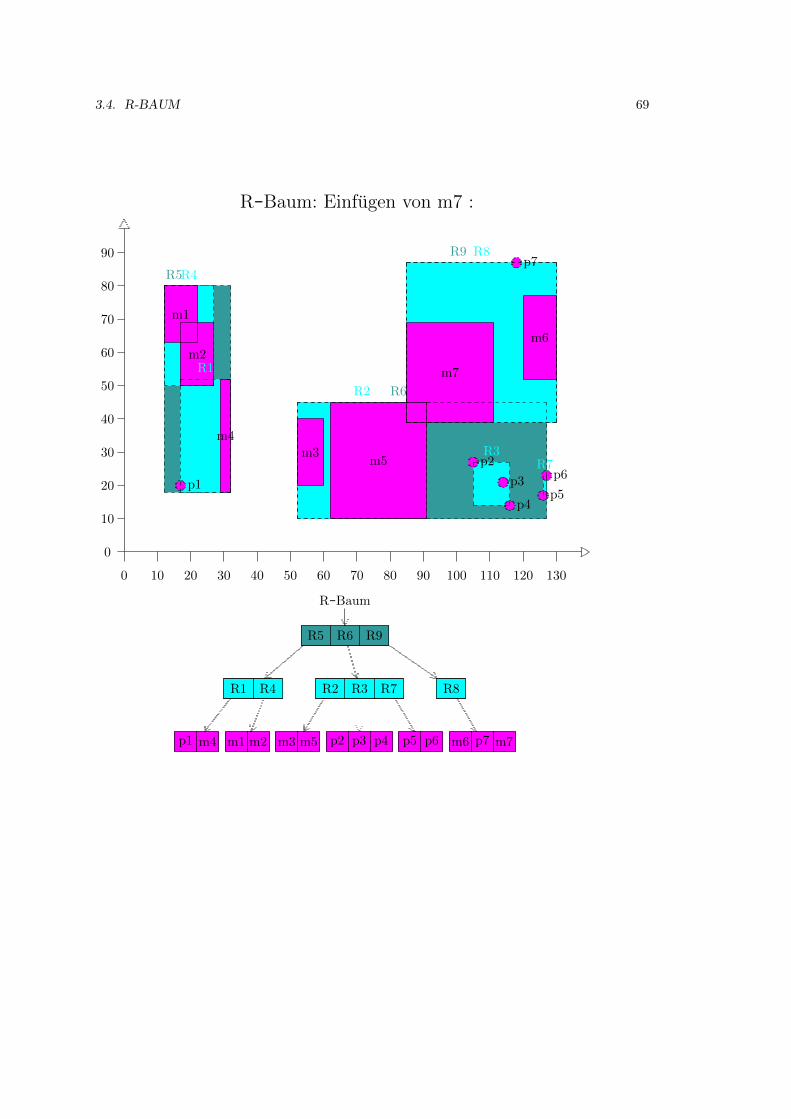
3.4. R-BAUM 69
R-Baum: Einfugen von m7 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
R9 R8
m6
p7
m7
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6 m6 p7 m7
R1 R4 R2 R3 R7 R8
R5 R6 R9R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6
R2 R3 R7
R9
R8
m6 p7 m7
R8
R5 R6 R9
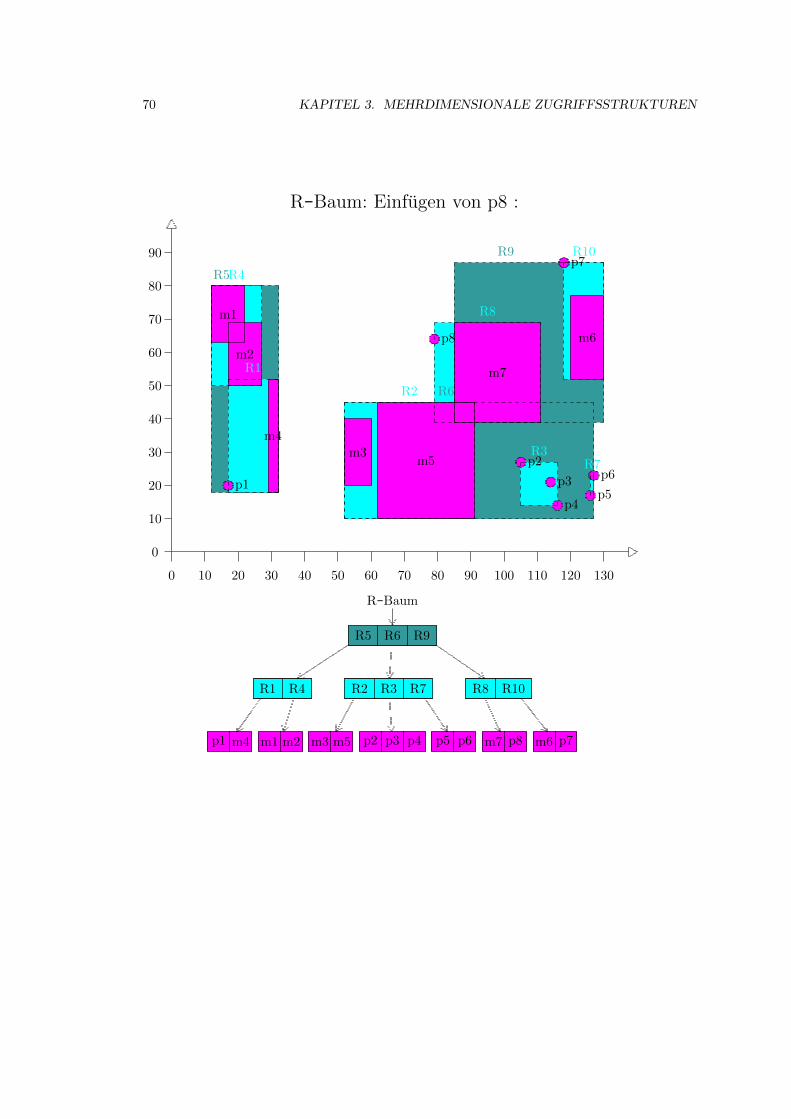
70 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p8 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
R9
R8
m7
p8
R10
m6
p7
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6 m7 p8 m6 p7
R1 R4 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6
R2 R3 R7
R9
R8
m7 p8
R10
m6 p7
R8 R10
R5 R6 R9
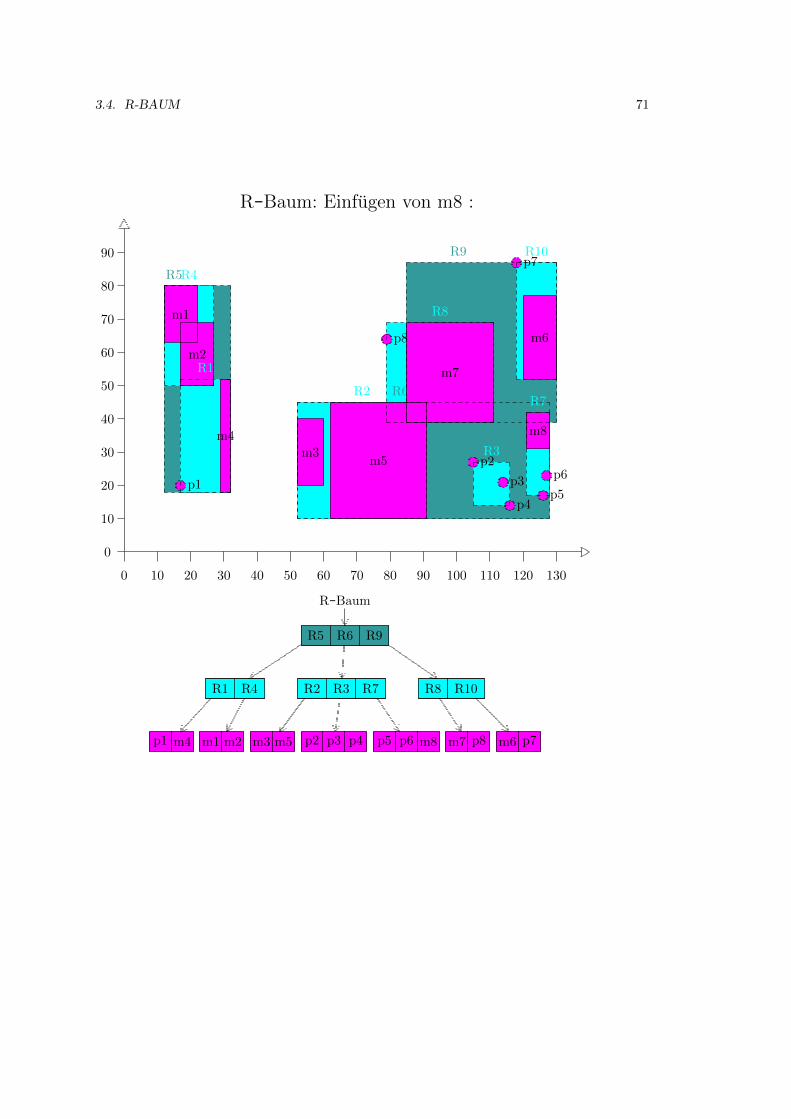
3.4. R-BAUM 71
R-Baum: Einfugen von m8 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
m8
R9
R8
m7
p8
R10
m6
p7
R-Baum
p1 m4 m1 m2 m3 m5 p2 p3 p4 p5 p6 m8 m7 p8 m6 p7
R1 R4 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m8
R2 R3 R7
R9
R8
m7 p8
R10
m6 p7
R8 R10
R5 R6 R9
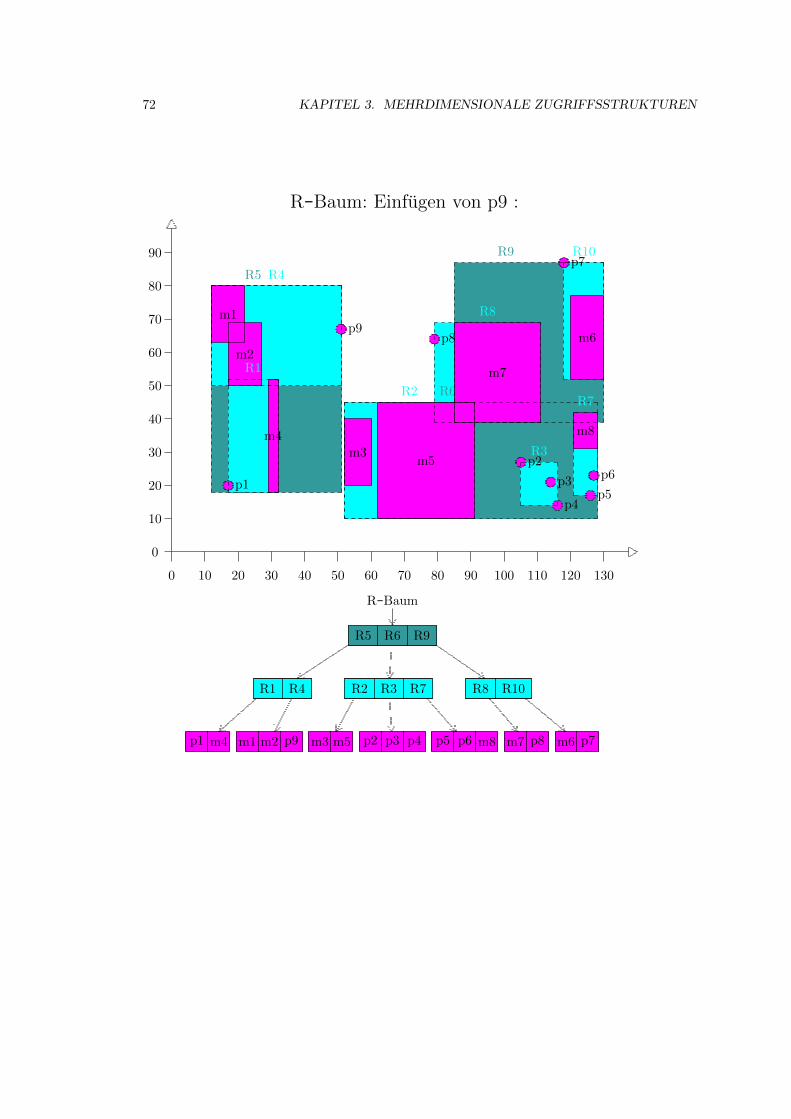
72 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p9 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
p9
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
m8
R9
R8
m7
p8
R10
m6
p7
R-Baum
p1 m4 m1 m2 p9 m3 m5 p2 p3 p4 p5 p6 m8 m7 p8 m6 p7
R1 R4 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2 p9
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m8
R2 R3 R7
R9
R8
m7 p8
R10
m6 p7
R8 R10
R5 R6 R9
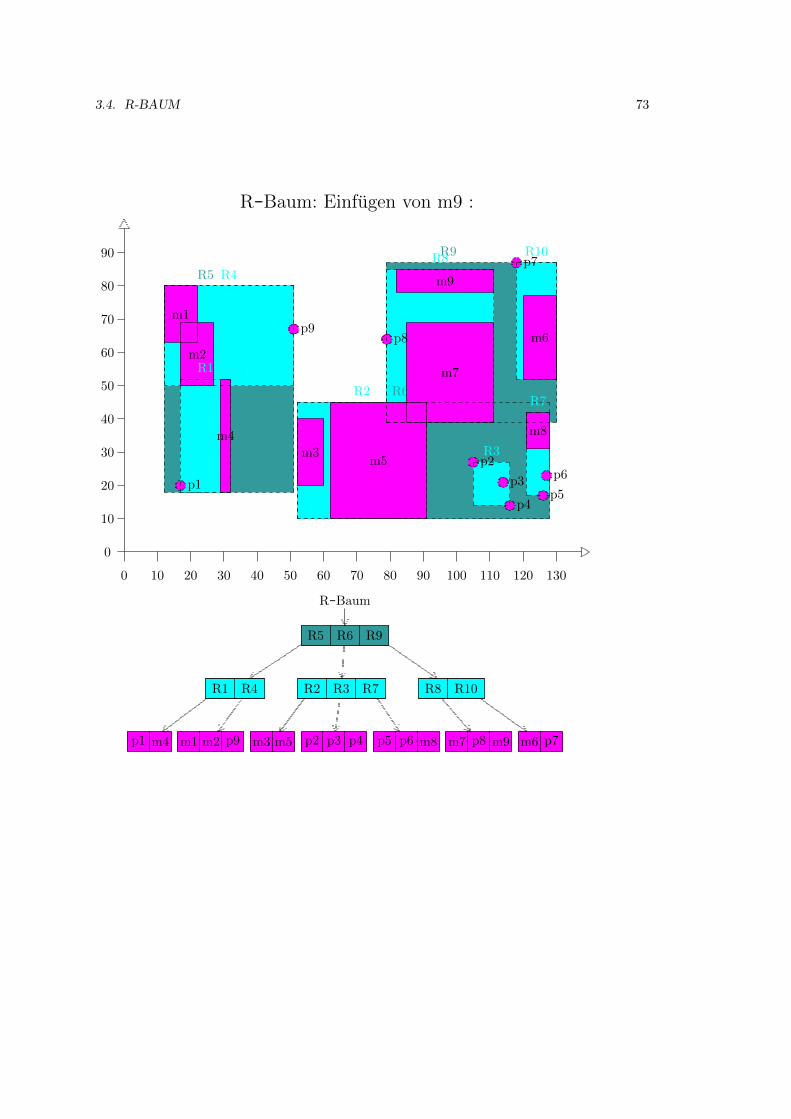
3.4. R-BAUM 73
R-Baum: Einfugen von m9 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2
p9
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
m8
R9R8
m7
p8
m9
R10
m6
p7
R-Baum
p1 m4 m1 m2 p9 m3 m5 p2 p3 p4 p5 p6 m8 m7 p8 m9 m6 p7
R1 R4 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2 p9
R1 R4
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m8
R2 R3 R7
R9
R8
m7 p8 m9
R10
m6 p7
R8 R10
R5 R6 R9
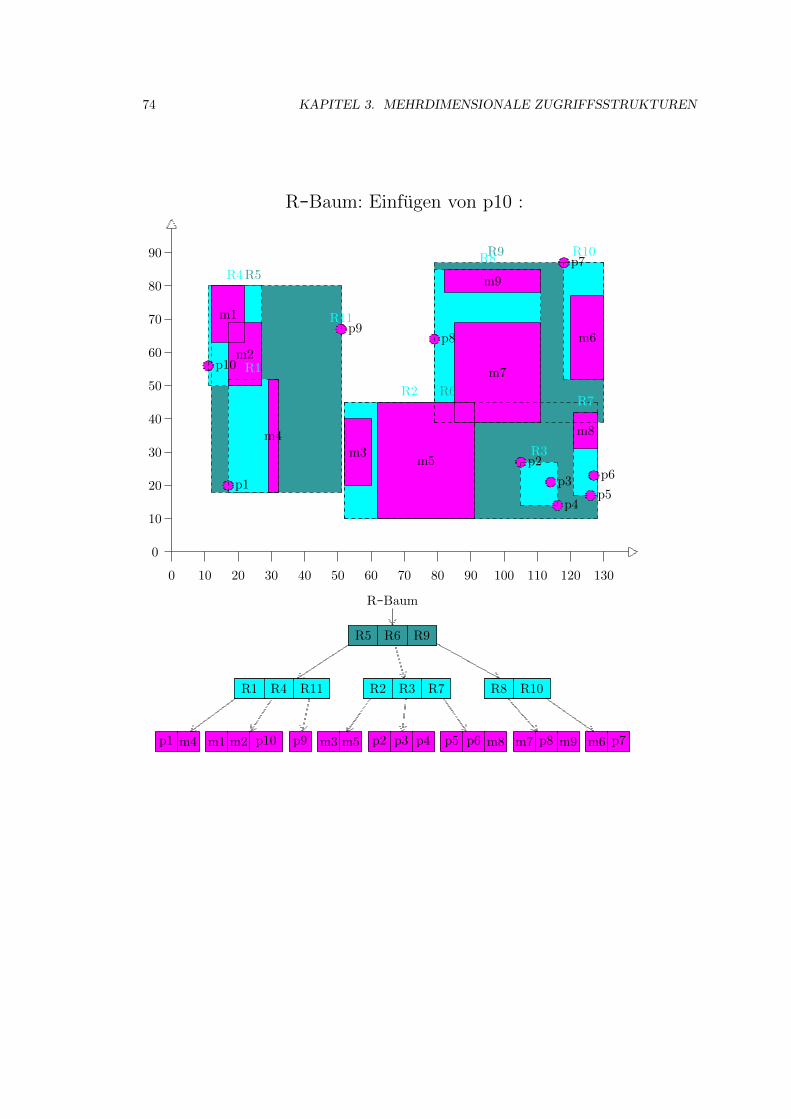
74 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN
R-Baum: Einfugen von p10 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2p10
R11p9
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
m8
R9R8
m7
p8
m9
R10
m6
p7
R-Baum
p1 m4 m1 m2 p10 p9 m3 m5 p2 p3 p4 p5 p6 m8 m7 p8 m9 m6 p7
R1 R4 R11 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2 p10
R11
p9
R1 R4 R11
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m8
R2 R3 R7
R9
R8
m7 p8 m9
R10
m6 p7
R8 R10
R5 R6 R9
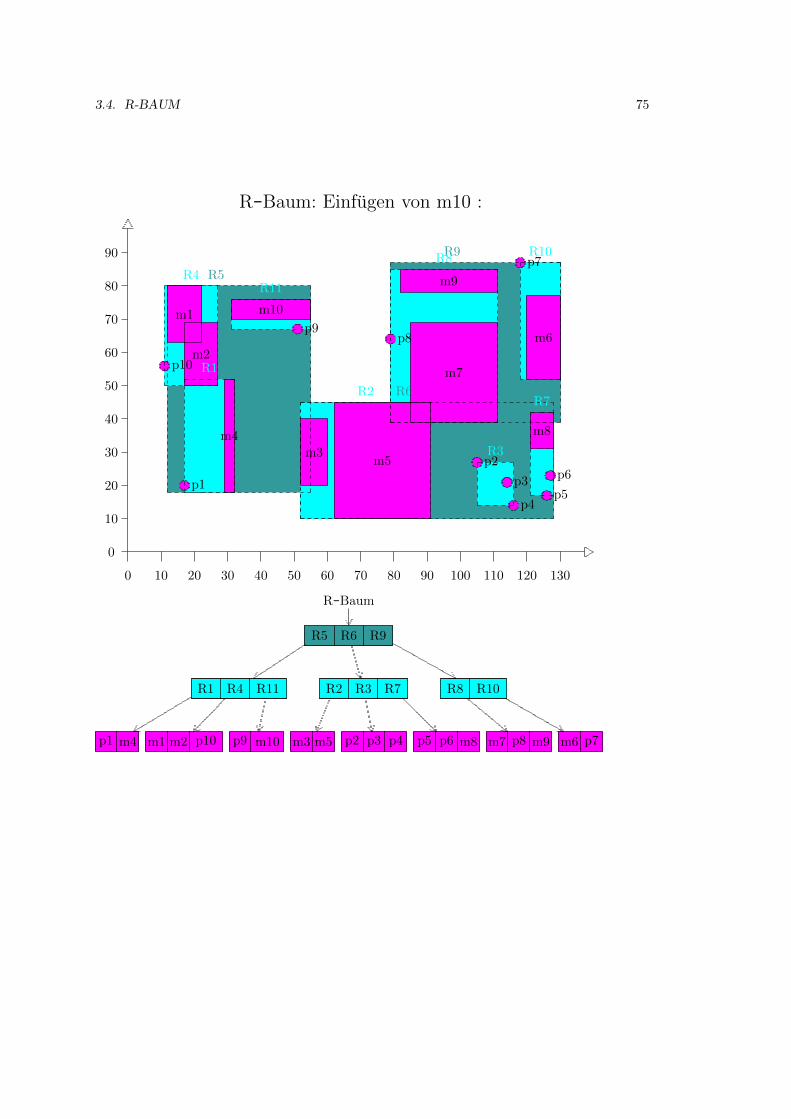
3.4. R-BAUM 75
R-Baum: Einfugen von m10 :
0 10 20 30 40 50 60 70 80 90 100 110 120 130
0
10
20
30
40
50
60
70
80
90
R5
R1
p1
m4
R4
m1
m2p10
R11
p9
m10
R6R2
m3m5
R3p2
p3
p4
R7
p5
p6
m8
R9R8
m7
p8
m9
R10
m6
p7
R-Baum
p1 m4 m1 m2 p10 p9 m10 m3 m5 p2 p3 p4 p5 p6 m8 m7 p8 m9 m6 p7
R1 R4 R11 R2 R3 R7 R8 R10
R5 R6 R9R5
R1
p1 m4
R4
m1 m2 p10
R11
p9 m10
R1 R4 R11
R6
R2
m3 m5
R3
p2 p3 p4
R7
p5 p6 m8
R2 R3 R7
R9
R8
m7 p8 m9
R10
m6 p7
R8 R10
R5 R6 R9

76 KAPITEL 3. MEHRDIMENSIONALE ZUGRIFFSSTRUKTUREN

Kapitel 4
NoSQL-Datenbanken
4.1 Uberblick
”NoSQL” (no SQL, not only SQL, non-relational) sind Datenbank-Technologien, dieversuchen das Bedurfnis nach Flexibilitat bezuglich Skalierung und Datenmodellzu befriedigen. Eine positive Definition von NoSQL ist schwierig. Meistens sind damitnicht-relationale Datenbanken gemeint.
Geschichte:
• Google (2006): BigTable reasearch (sparse, distributed multidimensional sorted maps)
• Amazon (2007): Dynamo research
Gemeinsame Charakteristika:
• Unterstutzung einer großen Anzahl von Benutzern (einige 10 000, ja Millionen)
• Schnelle Antwortzeiten fur global verteilte Benutzer (low latency)
• System ist immer online. Keine Ausfall- oder Wartungszeiten.
• Varianz der Daten:
– strukturiert
– wenig strukturiert
– unstrukturiert
• Schnelle Adaption an neue Anforderungen
• Velocity, Variety, Volume, Complexity
Skalierung: Das relationale Datenmodell ist hoch normalisiert, d.h. redundanzfrei. Anstatt Da-ten zu replizieren, werden Daten an einer einzigen Stelle (Relation, Tabelle) gehalten, aufdie dann nur noch verwiesen wird. Daher sind die zu einem Objekt gehorigen Daten oftuber viele Relationen verteilt (”striped”).
Diese Abhangigkeiten machen eine Skalierung (Speicher oder I/O-Kapazitat) durch Ver-teilung der Datenbank auf viele gleichwertige Systeme sehr schwierig (Scale-out oder ho-rizontal scaling).
77
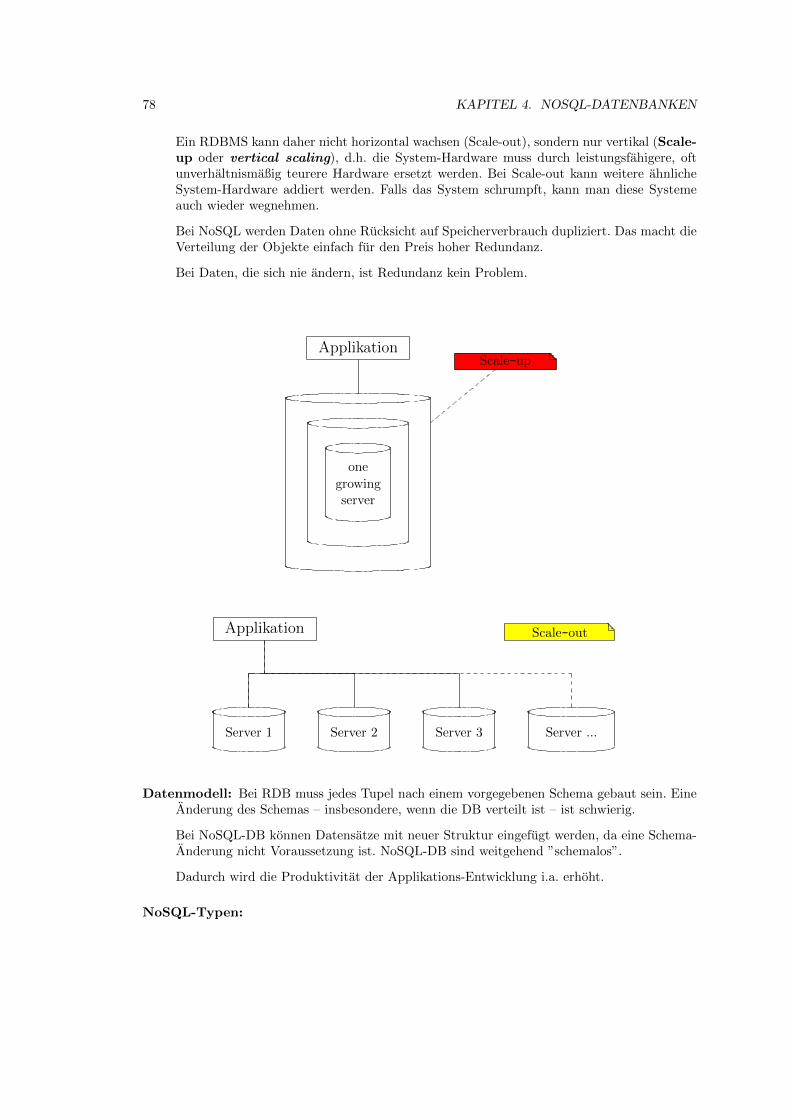
78 KAPITEL 4. NOSQL-DATENBANKEN
Ein RDBMS kann daher nicht horizontal wachsen (Scale-out), sondern nur vertikal (Scale-up oder vertical scaling), d.h. die System-Hardware muss durch leistungsfahigere, oftunverhaltnismaßig teurere Hardware ersetzt werden. Bei Scale-out kann weitere ahnlicheSystem-Hardware addiert werden. Falls das System schrumpft, kann man diese Systemeauch wieder wegnehmen.
Bei NoSQL werden Daten ohne Rucksicht auf Speicherverbrauch dupliziert. Das macht dieVerteilung der Objekte einfach fur den Preis hoher Redundanz.
Bei Daten, die sich nie andern, ist Redundanz kein Problem.
Applikation
one
growingserver
Scale-up
Applikation
Server 1 Server 2 Server 3 Server ...
Scale-out
Datenmodell: Bei RDB muss jedes Tupel nach einem vorgegebenen Schema gebaut sein. EineAnderung des Schemas – insbesondere, wenn die DB verteilt ist – ist schwierig.
Bei NoSQL-DB konnen Datensatze mit neuer Struktur eingefugt werden, da eine Schema-Anderung nicht Voraussetzung ist. NoSQL-DB sind weitgehend ”schemalos”.
Dadurch wird die Produktivitat der Applikations-Entwicklung i.a. erhoht.
NoSQL-Typen:

4.1. UBERBLICK 79
Daten-Modell Beispiel DBKey-Value-Store Riak
BerkeleyDBDynamoLevelDBMemcacheDBOrientDBOracle NoSQL DatabaseProject VoldemortRedis
Document-Store MongoDBApache CouchDBCouchbaseMarkLogicOrientDBRavenDBTerrastore
Column-Family-Store CassandraAmazon SimpleDBHBaseHypertableVertica
Graph-Store Neo4JAllegroGraphFlockDBHyperGraphDBInfinite GraphMarkLogicOrientDB
Integrations-Datenbanken:
Ein wichtiger Faktor fur den Erfolg von RDBs ist, dass unerschiedlichste Anwendungendurch die RDB integriert werden. Als Integrations-Mechanismus dient i.a. SQL.
App1
App2
Appx
Appn
RDB
SQL
SQL
SQL
SQL
Applikations-Datenbanken:
Bei einer sogenannten Applikations-Datenbank wird die Datenbank im wesentlichen nurvon einer Anwendung benutzt. Datenbank und Anwendung werden von einem Team ge-wartet, was die DB-Schema- und Anwendungs-Entwicklung wesentlich vereinfacht. Die In-tegration der verschiedenen Anwendungen erfolgt uber gemeinsame Protokolle, z.B. HTTP.

80 KAPITEL 4. NOSQL-DATENBANKEN
Die Anwendungen sind typischerweise Web-Services innerhalb einer Service-orientierten Ar-chitektur (SOA) mit dem Vorteil einer außerst flexiblen Struktur der gespeicherten Datenund Zugriff auf diese (polyglot persistence).
Anfragesprachen query languages:
4.2 Begriffe
Aggregate: Objekte von NoSQL-Datenbanken
Sharding: Partitionierung (Aufteilung) des Datenbank-Inhalts auf verschiedene Knoten. Bsp.DHBW: Kurse eignen sich als Aggregate fur das Sharding. Aber die Firmen?
Replication: Redundante Verteilung von Aggregaten
Großenordnungen: kilo (K), mega (M), giga (G), tera (T), peta (P), exa (E), zetta (Z), yotta(Y)
JSON: JavaScript Object Notation
4.3 Datenmodelle
Das relationale Datenmodell kann mit Tabellen und deren Zeilen und Spalten (Relation, Tupel,Attribut) beschrieben werden. Die Zellen sind atomare Objekte, d.h. sie sind fur die RDB ohneStruktur. Jede Datenbankoperation arbeitet auf Tabellen und liefert als Ergebnis eine Tabelle.
NoSQL-Datenmodelle werden ublicherweise mit vier verschiedenen Kategorien beschrieben, wo-bei es keine scharfen Grenzen zwischen den Kategorien gibt: key-value, document, column-familyund graph. Die ersten drei Kategorien konnen als Aggregat-orientiert beschrieben werden. DieserBegriff soll zunachst geklart werden.
4.3.1 Aggregate
NoSQL-Datenmodelle erlauben statt einer atomaren Zelle (Attribut einer Entitat) komplexereStrukturen als Objekte der DB, sogenannte Aggregate, ein Begriff, den Sadalage und Fowler[36]aus Mangel eines allgemein verwendeten Begriffs gepragt haben. Aggregate konnen beliebig kom-pliziert sein, z.B. Listen von unterschiedlich strukturierten Elementen.
Aggregate sind naturlich Einheiten fur Replication und Sharding.
Was man zu einem Aggregat zusammenfasst, d.h. wie man die Aggregat-Grenzen definiert, istsehr Kontext-abhangig, d.h. hangt sehr stark von der Anwendung ab oder wie man auf die Da-ten zugreifen mochte. Aggregation ist keine logische Dateneigenschaft! Bei Aggregat-orientiertenDatenbanken lassen sich Intra-Aggregat-Beziehungen wesentlich leichter handhaben als Inter-Aggregat-Beziehungen.
Im RDB-Modell werden Aggregate auf verschiedene Tabellen verteilt. Die Zugehorigkeit zu einemAggregat wird durch Schlussel-Fremdschlussel-Beziehungen dargestellt. Allerdings unterscheidet

4.3. DATENMODELLE 81
das RDB-Modell nicht zwischen ”Aggregat-Beziehungen” und sonstigen Beziehungen. Insofernhat das RDB-Modell und damit eine RDB keine Kenntnis von Aggregat-Strukturen.
Ein Aggregat-ignorantes Modell (z.B. RDB, Graph-Store) erlaubt verschiedenste Sichten aufdie Daten. Ein Aggregat-orientiertes Modell (die meisten NoSQL-DBs) erlauben oft nur eine,dafur aber sehr performante Sicht auf die Daten. Das wird insbesondere dann relevant, wenn dieDB auf einem Cluster lauft und fur jede Anfrage die Anzahl der betroffenen Knoten minimiertwerden muss. Eine Aggregat-orientierte Speicherung der Daten sagt der DB, welche Bytes wirals Einheit manipulieren mochten und daher auf einem Knoten liegen sollten.
Im allgemeinen werden ACID-Transaktionen unterstutzt, wenn sie sich auf ein Aggregat be-ziehen. Wenn eine Transaktion mehrere Aggregate betrifft, dann wird ACID oft nur eventuellgarantiert.
4.3.2 Key-Value-Store und Document-Store
Beide Daten-Modell-Typen sind Ansammlungen von Aggregaten, eventuell sehr unterschiedlicherStruktur. Jedes Aggregat hat einen Schlussel (key oder ID), uber den es in der DB zu finden ist.
Die beiden Modelle unterscheiden sich folgendermaßen:
Key-Value-Store: Das Aggregat ist fur die DB strukturlos. Es ist nur eine mehr oder wenigergroße, fur die DB bedeutungslose Ansammlung von Bytes.
Der Vorteil ist, dass man beliebige Daten speichern kann. Wie aber mit den Daten umge-gangen werden kann, muss dann die Anwendung wissen.
Document-Store: Fur die Aggregate kann definiert werden, welche Typen und Strukturenerlaubt sind.
Man kann zwar nicht beliebige Daten speichern. Dafur sind aber Anfragen moglich, diesich auf die Struktur der Aggregate beziehen. Man kann Teile von Aggregaten ermitteln.Indexe konnen erstellt werden, die sich auf den Inhalt der Aggregate beziehen.
In der Praxis findet man diese strenge Unterscheidung nicht. Es ist eine sehr grobe Unter-scheidung. Wenn hauptsachlich Anfragen unter Verwendung des Schlussels gestellt werden,dann spricht man von Key-Value. Wenn die Anfragen sich hauptsachlich auf Aggregat-Strukturund/oder -Inhalt beziehen, dann wird man von einem Document-Store sprechen.
4.3.3 Column-Family-Store
Das Modell Column-Family-Store wird charakterisiert durch ”sparse columns and no sche-ma”. Was heißt das?
Es ist nicht ein sogenannter ”column store” (z.B. C-Store), bei dem die Speichereinheit nichteine oder mehrere Zeilen einer Tabelle ist, sondern eine oder auch mehrere Spalten einer Tabelle.
Column-Family-Stores haben eine zweistufige Aggregat-Struktur. Uber einen ”ersten” Schlusselwird ein Aggregat (erste Stufe) angesprochen, das eine Zeile reprasentiert. Dieses Zeilen-Aggregatbesteht aus einer Abbildung (map) detailierter Werte (zweite Stufe). Uber die erste Stufe kannman direkt auf die zweite Stufe zugreifen.

82 KAPITEL 4. NOSQL-DATENBANKEN
Eine Zeile hat Spalten (columns). Das ware gegenuber RDB nichts Neues. Allerdings habenverschiedene Zeilen nicht notwendig die gleichen Spalten. Jederzeit konnen Spalten an eine Zeileangefugt werden, ohne dass andere Zeilen betroffen sind.
Die Struktur der zweiten Stufe kann sehr unterschiedlich sein. Bei Cassandra werden wide rowsund skinny rows unterschieden:
• Skinny rows haben wenige Spalten, die wahrscheinlich fur die meisten Zeilen gleich sind.Jede Zeile ist ein Datensatz (record), jede Spalte ein Datenfeld (field).
• Wide rows haben viele Spalten (vielleicht tausende), die sich von Zeile zu Zeile sehr starkunterscheiden. Hier wird eine Liste modelliert, wobei jede Spalte ein Listenelement ist.Diese Listen konnen eventuell sortiert werden.
4.3.4 Graph-Store
Key-Value-Store, Document-Store und Column-Family-Store sind Aggregat-orientiert, Graph-Store nicht.
Aggregat-orientierte Datenbanken tun sich schwer bei Inter-Aggregat-Beziehungen. Und wenn esviele solche gibt, dann ist moglicherweise die Verwendung einer RDB vernunftiger. Wenn aller-dings die Beziehungen sehr komplex werden, dann wird es auch bei einer RDB schwer handhabbar(viele Joins, sinkende Performanz).
Komplexe Beziehungen konnen oft durch ein Netz von Knoten (node) und verbindenden Kanten(edge) modelliert werden, d.h. durch einen Graphen. Graph-Stores sind spezialisiert, diese Artvon Informationen zu reprasentieren. Dabei kann Information in den Knoten und in den Kantengespeichert werden.

Anhang A
Cassandra
A.1 Geschichte, Charakteristika
• Beginn bei Facebook (Prashant Malik und Avinash Lakshman), ab 2008 Open SourceProjekt
• 2010 Top-Level-Project von Apache Software Foundation
• Elevator pitch of Nishant Neeraj: Apache Cassandra is an open source, distributed, decen-tralized, elastically scalable, highly available, fault-tolerant, tunable consistent, row-orienteddatabase that bases its distribution design on Amazons Dynamo and its data model on Goo-gles Bigtable. Created at Facebook, it is now used at some of the most popular sites on theWeb.
• Vollstandig in Java geschrieben.
• CAP-Theorem: Cassandra bietet hohe Availability und Partition Tolerance auf Kostenvon Consistency, die einstellbar (tunable) ist.
• Referenzen: Uber 1000 Firmen, Instagram, Spotify, Facebook, Netflix, Apple
A.2 Installation
A.2.1 MacOS X
1. Download apache-cassandra-......tar
Momentane Version: apache-cassandra-3.10Native Protocol v4
2. Auspacken des tar-Files:
$ tar -zxvf apache-cassandra-...tar
83

84 ANHANG A. CASSANDRA
3. Verschiebe Cassandra-Verzeichnis in ein eigenes Verzeichnis (z.B. $HOME/cassandra ).
Alle Daten einer Datenbank befinden sich im Verzeichnis:
$HOME/cassandra/data/data/<keyspace>
z.B.$HOME/cassandra/data/data/bsp
4. Erweitere Pfad in .profile um $HOME/cassandra/bin
5. • Starten des Datenbankservers im Vordergrund:$ cassandra -f
Stoppen des Datenbankservers:<ctrl> + C
im Terminal, wo der DB-Server gestartet wurde.
• Starten des Datenbankservers im Hintergrund:$ cassandra
Stoppen des im Hintergrund gestarteten Datenbankservers:$ kill <pid>
im Terminal, wo der DB-Server gestartet wurde.(Die pid kann man finden mit $ ps.)
6. Starten der Cassandra-Query-Language-Shell (CQL-Shell):
$ cqlsh <dbserver>
7. Ausfuhrung einer Datei mit CQL-Anweisungen (z.B. f1.cql) in der Betriebs-System-Shell:
$ cqlsh -f f1.cql
8. Ausfuhrung einer Datei mit CQL-Anweisungen (z.B. f1.cql) in der CQL-Shell:
cqlsh> SOURCE ’f1.cql’
9. Entwickungsumgebung:
DataStax DevCenter(https://academy.datastax.com/downloads )
Die Entwicklungsumgebung ist installiert unter $HOME/dse. Dort findet sich ein README.md.
A.3 CQL – Cassandra Query Language
A.3.1 Verbindung mit der Datenbank
Verbindung zum Datenbank-Server aufbauen:$ cqlsh localhost
(Oder mit --port und --host Optionen.) ?

A.3. CQL – CASSANDRA QUERY LANGUAGE 85
A.3.2 Erste CQL-Anweisungen
1. Erste Anfrage:cqlsh> SELECT cluster_name, listen_address FROM system.local;
2. Einige Info-Anweisungen:cqlsh> SHOW HOST;
cqlsh> SHOW VERSION;
cqlsh> DESCRIBE CLUSTER;
cqlsh> DESCRIBE KEYSPACES;
cqlsh> DESCRIBE TABLES;
3. Beenden:cqlsh> EXIT;
A.3.3 Weitere CQL-Anweisungen
Dieser Abschnitt gibt einen praktischen Uberblick uber CQL, das große Ahnlichkeit mit SQL hat.Auf viele Optionen und deren Bedeutung gehen wir nicht ein. Sie sollten der CQL-Dokumentationoder einem Lehrbuch entnommen werden[6].
Die Syntax von CQL ist uber HELP zuganglich:cqlsh> HELP;
Viele Kommandos konnen mit dem Tabulator erganzt bzw. vervollstandigt werden. Groß- undKleinschreibung spielt in CQL keine Rolle.
Zunachst muss ein Keyspace (entspricht in etwa einer Datenbank) erzeugt werden. Im einfach-sten Fall sieht das folgendermaßen aus:
cqlsh> CREATE KEYSPACE bsp WITH REPLICATION
= { ’class’ : ’SimpleStrategy’, ’replication_factor’ : 1 };
Mitcqlsh> DESCRIBE KEYSPACE bsp;
konnen wir uns den Keyspace und alle seine Tabellen (Column Families) anschauen.
Mitcqlsh> USE bsp;
begeben wir uns in den Keyspace bsp. Dadurch andert sich der Prompt zu:cqlsh:bsp>
Die Objekte des Keyspaces (z.B. Tabellen) mussen nicht mehr durch seinen Namen spezifiziertwerden.
Erzeugen einer Tabelle:cqlsh:bsp> CREATE TABLE stud(
vorname text,
nachname text,

86 ANHANG A. CASSANDRA
PRIMARY KEY(vorname));
Wichtig: Es muss ein Schlussel definiert werden!
Schauen wir uns die Tabelle naher an mit:cqlsh:bsp> DESCRIBE TABLE stud;
Dabei werden die Default-Werte samtlicher Optionen ausgegeben.
Einfugen einer Zeile in die Tabelle stud und Uberprufung:cqlsh:bsp> INSERT INTO stud(vorname, nachname) VALUES(’Oskar’, ’Mueller’);
cqlsh:bsp> INSERT INTO stud JSON ’{"vorname": "Max", "nachname": "Mayer"}’;cqlsh:bsp> SELECT COUNT(*) FROM stud;
cqlsh:bsp> SELECT * FROM stud WHERE vorname=’Oskar’;
cqlsh:bsp> SELECT * FROM stud WHERE nachname=’Mueller’;
cqlsh:bsp> SELECT * FROM stud WHERE nachname=’Mueller’ ALLOW FILTERING;
Jederzeit kann eine Spalte hinzugefugt werden:cqlsh:bsp> ALTER TABLE stud ADD beruf text;
cqlsh:bsp> INSERT INTO stud(vorname, nachname, beruf)
VALUES(’Manfred’, ’Barth’, ’Maurer’);
Und nun loschen wir unseren Eintrag ”scheibchenweise” (eine Spalte, eine Zeile, alle Zeilen undschließlich Vernichtung der ganzen Tabelle):
cqlsh:bsp> DELETE nachname FROM stud WHERE vorname=’Oskar’;
cqlsh:bsp> DELETE FROM stud WHERE vorname=’Oskar’;
cqlsh:bsp> TRUNCATE stud;
cqlsh:bsp> DROP TABLE stud;

A.4. DATEN-MODELL 87
A.4 Daten-Modell
Bevor wir naher auf Cassandras Daten-Modell (CDM) eingehen, wollen wir noch mal einen Blickauf das relationale Modell werfen, zu dem das CDM zunachst sehr große Ahnlichkeit hat.
A.4.1 Relationales Daten-Modell
Im relationalen Daten-Modell ist die Datenbank (database) die außerste Schicht. Sie ist einBehalter (container), der Tabellen (Relationen, tables, relations) enthalt. Jede Tabellebesteht aus Zeilen (Tupeln, rows, tuples) und Spalten (Attributen, columns, attribu-tes).
Daten werden als ganze Zeilen eingefugt, wobei fur jede Spalte ein Wert oder Null zu spezifizierenist.
Eine Spalte oder eine Kombination von Spalten kann als Schlussel (primary key) definiertwerden. Mit dem Schlussel oder mit irgendwelchen Suchkriterien konnen eine oder mehrere Zeilenin der Datenbank wieder gefunden werden.
Zur Vermeidung von Daten-Redundanz werden Daten in unterschiedlichen Tabellen gespeichert,die sich eventuell gegenseitig durch Schlussel-Fremdschlussel-Beziehungen (key – foreign key)referenzieren. Die Auflosung dieser – heutzutage sich oft uber viele Tabellen erstreckenden –Beziehungen durch einen sogenannten Join ist aufwandig in SQL zu formulieren und oft auch einPerformanzengpass. Das ist einer der Grunde, warum eventuell NoSQL-Daten-Modelle eingesetztwerden.
A.4.2 Cassandras Daten-Modell
In einer ”Bottom-up-Sicht” haben wir in Cassandra folgende Datenstrukturen (Es werden abjetzt hauptsachlich die englischen Begriffe als Termini technici verwendet.):
• Column: Name/Value-Pair
• Row: Container fur Columns eindeutig referenziert durch einen Primary Key (PK)
• Table (Column Family): Container fur Rows. Hat einen Keyspace-weit eindeutigen Na-men.
• Keyspace: Container fur Tables. Hat einen Cluster-weit eindeutigen Namen.
• Cluster: Container fur Keyspaces. Uberspannt einen oder mehrere Knoten.
In den folgenden Abschnitten betrachten wir diese Strukturen etwas naher, aber ”Top-down”.
A.4.3 Cluster
Zum Design van Cassandra gehort, dass die Datenbank verteilt ist uber mehrere Knoten (Clusteroder Ring), die aber fur den End-Benutzer der Datenbank als eine Maschine erscheinen. AlleKnoten sind gleichberechtigt und konzeptionell in einem Ring angeordnet.

88 ANHANG A. CASSANDRA
A.4.4 Keyspace
Ein Keyspace reprasentiert ungefahr das, was man bei relationalen Systemen unter ”Database”versteht. So wie eine relationale Datenbank aus Tabellen besteht, besteht ein Keyspace ausColumn Families = Table. Diese Parallelitat zu einem RDBS wird dadurch unterstrichen,dass TABLE und COLUMNFAMILY in CQL synonym verwendet werden konnen.
Allerdings besteht die Datenbank einer Anwendung oft aus mehreren Keyspaces.
Ein Keyspace hat Attribute, die sein Verhalten beschreiben.
A.4.5 Table, Column Family
Eine Table enthalt sortierte Rows. Sie muss einen Primary Key (PK) haben. Die Sortierungwird durch die PK-Columns bestimmt. Wenn eine neue Row angelegt wird, mussen mindestensValues fur die PK-Columns angegeben werden. Alle anderen Column-Values sind optional.
Jeder Zeit kann fur eine Tabelle eine zusatzliche Column definiert werden.
A.4.6 Column
Die Basis-Einheit einer Daten-Struktur in Cassandra ist die Column. Sie enthalt Name undValue. Wir nennen das auch eine Zelle. Der Value hat einen Type. Zwei weitere Attribute derColumn sind Timestamp und Time to live.
Timestamp
Jedesmal wenn eine Zelle (Name/Value-Pair) geschrieben oder aktualisiert wird, wird ein Time-stamp (in Millisekunden) generiert. Damit werden Schreib-Konflikte gelost. Im allgemeinen giltder letzte Timestamp.
Den Timestamp kann man sich ausgegeben lassen:
SELECT vorname, nachname, writetime(nachname) FROM stud;
Fur PRIMARY KEYs oder Teile davon ist das allerdings nicht erlaubt!
Es ist moglich den Timestamp selbst zu setzen:
UPDATE stud USING TIMESTAMP 1234567890123456
SET nachname=’Maler’ WHERE vorname=’Oskar’;
Dabei muss der Timestamp in der Zukunft liegen. Diese Moglichkeit sollte mit Vorsicht verwendetwerden.

A.5. DATENTYPEN IN CQL 89
Time to live (TTL)
Fur jede Zelle, die nicht zum Primary Key gehort, kann eine Lebenszeit in Sekunden definiertwerden. Die Default-Lebenszeit ist unendlich (TTL-Wert = 0). Diese Lebenszeit kann gesetztwerden, wenn eine Zelle eingefugt oder aktualisiert wird.
INSERT INTO stud (vorname, nachname) VALUES (’Jos’, ’Mayhof’) USING TTL 3600;
SELECT vorname, nachname, ttl(nachname) FROM stud;
UPDATE stud USING TTL 3600 SET nachname=’Mayerhofer’ WHERE vorname=’Jos’;
SELECT vorname, nachname, ttl(nachname) FROM stud;
A.5 Datentypen in CQL
A.5.1 Numerische Datentypen
int: 32-bit signed integer
bigint: 64-bit signed integer
smallint: 16-bit signed integer
tinyint: 8-bit signed integer
varint: variable precision signed integer
float: 32-bit IEEE-754 floating point
double: 64-bit IEEE-754 floating point
decimal: variable precision decimal
A.5.2 Textuelle Datentypen
text: UTF-8 character string
varchar: synonym fur text
ascii: ASCII character string
A.5.3 Zeit- und Identitats-Datentypen
timestamp:
date:
time:

90 ANHANG A. CASSANDRA
uuid: Ein UUID-Identifikator ist ein Typ-4 128-bit-Wert, der ganz von Zufallszahlen abhangt.Beispiel:
ALTER TABLE stud ADD id uuid;
UPDATE stud SET id=uuid() WHERE vorname=’Oskar’;
SELECT vorname, id FROM stud WHERE vorname=’Oskar’;
timeuuid: Dieser Identifikator ist ein Typ-1 128-bit-Wert und beruht auf der MAC-Adresse desRechners, der System-Zeit und einer laufenden Nummer. Außer der Erzeugungsfunktionnow() gibt es noch dateOf() und unixTimestampOf(), die offenbar der Grund dafur sind,dass dieser Identifikator haufig benutzt wird. Beispiel:
ALTER TABLE stud ADD tid timeuuid;
UPDATE stud SET tid=now() WHERE vorname=’Oskar’;
SELECT vorname, tid FROM stud WHERE vorname=’Oskar’;
SELECT vorname, tid, dateOf(tid), unixTimestampOf(tid)
FROM stud WHERE vorname=’Oskar’;
uuid oder timeuuid sollten fur Columns des Primary Keys verwendet werden.
Primary Keys konnen nie geandert werden! (Die Idiotie, in der Tabelle stud als Primar-Schlussel vorname genommen zu haben, kann nachtraglich nicht verbessert werden!)
A.5.4 Andere einfache Datentypen
boolean:
blob:
inet:
counter:
A.5.5 Collection-Datentypen
Die Elemente der Collections konnen einfache Typen sein, aber auch Collections und Benutzer-definierte Typen.
set: Die Elemente von set sind nicht sortiert. (Die Ausgabe erfolgt allerdings sortiert.) Beispielmehrere Email-Adressen:
ALTER TABLE stud ADD emails set<text>;
UPDATE stud SET emails={’[email protected]’} WHERE vorname=’Oskar’;
SELECT vorname, emails FROM stud WHERE vorname=’Oskar’;
UPDATE stud SET emails=emails + {’[email protected]’} WHERE vorname=’Oskar’;
SELECT vorname, emails FROM stud WHERE vorname=’Oskar’;
UPDATE stud SET emails=emails - {’[email protected]’} WHERE vorname=’Oskar’;
SELECT vorname, emails FROM stud WHERE vorname=’Oskar’;

A.5. DATENTYPEN IN CQL 91
UPDATE stud SET emails={} WHERE vorname=’Oskar’;
SELECT vorname, emails FROM stud WHERE vorname=’Oskar’;
list: Eine Liste enthalt die Elemente in der Reihenfolge, in der sie addiert werden. Beispielmehrere Telefon-Nummern:
ALTER TABLE stud ADD telefone list<text>;
UPDATE stud SET telefone=[’12345’] WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
UPDATE stud SET telefone=telefone + [’0345-672’] WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
UPDATE stud SET telefone=[’345123’] + telefone WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
UPDATE stud SET telefone=telefone - [’12345’] WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
Listen-Elemente konnen uber den Index referenziert werden:UPDATE stud SET telefone[1]=’0345-672666’ WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
DELETE telefone[0] FROM stud WHERE vorname=’Oskar’;
SELECT vorname, telefone FROM stud WHERE vorname=’Oskar’;
map: Eine Map kann Key/Value-Paare speichern. Außer counter konnen alle Datentypen alsKey oder als Value verwendet werden. Als Beispiel nehmen wir Temperaturwerte abhangigvon der Zeit:
ALTER TABLE stud ADD temperatur map<timeuuid, float>;
UPDATE stud SET temperatur={now(): 37.3, now(): 40.5} WHERE vorname=’Oskar’;
SELECT vorname, temperatur FROM stud WHERE vorname=’Oskar’;
Man kann Map-Elemente auch uber ihren Key referenzieren.
A.5.6 Benutzer-definierte Datentypen (UDT)
Man kann eigene Strukturen als Datentypen (User Defined Type, UDT) definieren. AlsBeispiel nehmen wir die Adresse:
CREATE TYPE adresse (strasse text, stadt text, plz int);
ALTER TABLE stud ADD adressen map<text, frozen<adresse>>;
Das frozen ist ein Mechanismus, der wegen Upward-Compatibility bis zu einer neueren Versionvon Cassandra noch zu verwenden ist.
Und jetzt noch eine komplexere Struktur – ein Modul mit seinen Units:CREATE TYPE unit (nummer text, titel text, note tinyint);

92 ANHANG A. CASSANDRA
CREATE TYPE modul (nummer text, titel text, units frozen<list<frozen<unit>>>);
ALTER TABLE stud ADD module map<text, frozen<modul>>;
UPDATE stud SET module = module + {’DBII’:{nummer: ’4304’, titel: ’Datenbanken II’,
units: [{nummer: ’1’, titel: ’DBIM’, note: 18},{nummer: ’2’, titel: ’DWH/DM’, note: 23}]}}
WHERE vorname=’Oskar’;
SELECT vorname, module FROM stud WHERE vorname=’Oskar’;
Die UDTs erscheinen dann in der Keyspace-Definition:DESCRIBE KEYSPACE bsp;
A.6 Sekundar-Indexe
Von relationalen DB-Systemen sind wir gewohnt, Suchbedingungen auf Nicht-Schlussel-Attributen zu formulieren. In Cassandra geht das nur mit dem Zusatz ALLOW FILTERING, wobeiman allerdings Performanzeinbußen riskiert.
Wenn wir das in Cassandra performant machen wollen, mussen wir erst einen Index auf solcheinem Nicht-Schlussel-Attribut (d.h. Nicht-Schlussel-Column) definieren. Ab Cassandra 3.4 sollteman SASI-Indexe (SSTable Attached Secondary Index) verwenden:
CREATE CUSTOM INDEX ON stud (nachname)
USING ’org.apache.cassandra.index.sasi.SASIIndex’;
Man kann dabei nur ein Attribut angeben.
MitDESCRIBE KEYSPACE bsp;
sehen wir den Index. Und nun sind Anfragen wie folgende moglich:SELECT * FROM stud WHERE nachname LIKE ’Ma%’;
A.7 Daten-Modellierung
A.7.1 Begriffe, Design-Prinzipien, Notation
Key, Schlussel: In Cassandra werden verschiedene Keys (Primary Key, Partition Key, Sim-ple Key, Composite Key, Compound Key, Clustering Key) verwendet, deren Bedeutungzunachst geklart werden soll.
• Simple Key: Der Key besteht aus einer Column.
• Composite (= Compound) Key: Der Key besteht aus mehreren Columns (Mul-tiple Column Key).
Jeder Key kann simple oder composite sein.

A.7. DATEN-MODELLIERUNG 93
• Primary Key: Identifiziert eine Row einer Tabelle eindeutig. Wird in CQL mitPRIMARY KEY
spezifiziert. Wenn der Primary Key aus mehreren Columns besteht, spielt die Reihen-folge der Columns eine Rolle (siehe Partition Key).
• Partition Key: Identifiziert die Rows einer Tabelle, die physisch auf einem Knotendes Clusters gespeichert werden sollen. Wenn der Partition Key simple ist, dann istes die erste Column der Primary-Key-Spezifikation.
Bei einem composite Partition Key werden die dazugehorigen Columns bei derPrimary-Key-Spezifikation zusatzlich geklammert, z.B.:
PRIMARY KEY ((c1, c2), c3, c4, c5)
Der Partition Key wird dann durch c1 und c2 gebildet. Alle Rows mit denselbenWerten fur (c1, c2) werden auf einem Knoten gespeichert.
• Clustering Key: Sind alle Nicht-Partition-Key-Columns des Primary Keys. Mit ih-nen kann eine Sortierung der zu einer Partition gehorigen Rows definiert werden.
Weiter Beispiele:
• PRIMARY KEY (a): Partition Key ist a.
• PRIMARY KEY (a, b): Partition Key ist a, Clustering Key ist b.
• PRIMARY KEY (a, b, c): Partition Key ist a, Composite Clustering Key ist (b, c).
• PRIMARY KEY ((a, b), c):Composite Partition Key ist (a, b), Clustering Key ist c.
• PRIMARY KEY ((a, b), c, d):Composite Partition Key ist (a, b), Composite Clustering Key ist (c, d).
Die WHERE-Klausel eines SELECTs muss mindestens den Partition Key enthalten. WeitereColumns des Primary Keys konnen nur in der definierten Reihenfolge hinzugenommen wer-den. Columns durfen dabei nicht ubersprungen werden. Z.B. mit oben definiertem PrimaryKey:
• Richtig:c1 and c2
c1 and c2 and c3
c1 and c2 and c3 and c4
• Falsch:c1 and c2 and c4
alles ohne c1 and c2
Wide Row: Es gibt wide und skinny Rows. Die skinny Row ist vergleichbar mit einer Zeileeiner Tabelle einer RDB, hat also eine eher begrenzte Anzahl Spalten.
Eine wide Row aber kann sehr viele – tausende – Columns haben, deren Anzahl undNamen von Row zu Row sehr unterschiedlich sein kann. Fur eine Row werden nur dieColumns gespeichert, die auch Werte haben. Das Resultat ist eine dunnbesetzte (sparse),multidimensionale Struktur.
Normalisierung, Joins: In CQL sind keine Joins moglich, um die Information aus normali-sierten Tabellen zusammenzufuhren.

94 ANHANG A. CASSANDRA
Entweder wird das irgendwie durch die Anwendung realisiert, oder man muss denormali-sierte Tabellen erzeugen, die Join-Resultate reprasentieren. Letztere Option ist vorzuzie-hen, wobei naturlich Daten dupliziert werden.
Referenzielle Integritat hat fur Cassandra keine Bedeutung.
Denormalisierung: In RDBs wird manchmal wegen Performanz denormalisiert. Ein zweiterGrund ist, dass man, um etwa die Historie zu dokumentieren, einen Schnappschuss vonTeilen einer Tabelle benotigt, die viele andere Tabellen referenziert.
Neben denormalisierten Tabellen bietet Cassandra auch Materialized Views. Diese Viewswerden automatisch mit den zu Grunde liegenden Tabellen synchronisiert.
Query-first Design: Bei einem RDBS liefern die Entitaten normalisierte Tabellen (Entity-first Design) und Relationships eventuell Join-Tabellen. Anfragen sind zunachst eherzweitrangig.
Wie aber kommt man in Cassandra zu Tabellen? Man startet nicht mit einem Datenmodell,sondern mit einem Anfrage- oder Query-Modell. Zuerst muss also eine Liste von Querieserstellt werden, mit der dann Tabellen definiert werden.
Optimal Storage Design: Bei RDB spielt auf Design-Ebene die Speicherstruktur fast keineRolle.
Bei Cassandra wird man versuchen, zusammengehorige Columns in einer Tabelle zu defi-nieren. Ein wichtiges Prinzip ist, die Anzahl der Partitionen, die durch eine Query betroffensind, zu minimieren, da die Partition eine Speichereinheit ist, die nicht uber mehrere Knotenverteilt wird.
Sortieren ist eine Design-Entscheidung. Die Sortierung wird bestimmt durch die Wahl derClustering-Columns.
Als Beispiel werden wir im folgenden ein Hotel-Buchungs-System (HBS) behandeln. Das Beispielorientiert sich an dem Beispiel im Buch von Carpenter und Hewitt[6], vermeidet aber verschiedeneFehler dort.
A.7.2 HBS: Systembeschreibung
Das Hotel-Buchungs-System (HBS) verwaltet Hotels, deren Zimmer von Gasten gebucht werdenkonnen.
Die Hotels befinden sich in der Nahe von Points of Interest (POI, Sehenswurdigkeit). DieHotels haben einen Namen, eine Telefonnummer und eine Adresse. Ferner haben sie mehrereZimmer zu vermieten.
Die POIs haben einen Namen und eine Beschreibung.
Jedes Zimmer hat eine Nummer, ist frei oder nicht, bietet verschiedene Annehmlichkeiten(Vorzuge) und hat einen Preis, der vom Datum abhangt.
Ein Gast mit Vor- und Nachname, Adressen und Telefonnummern kann in einem Hotel ein odermehrere Zimmer buchen. Eine Buchung hat ein Startdatum, ein Endedatum und eine Bestaeti-gungsnummer.
Die Adresse besteht aus Straße, Stadt, Region, PLZ und Land.
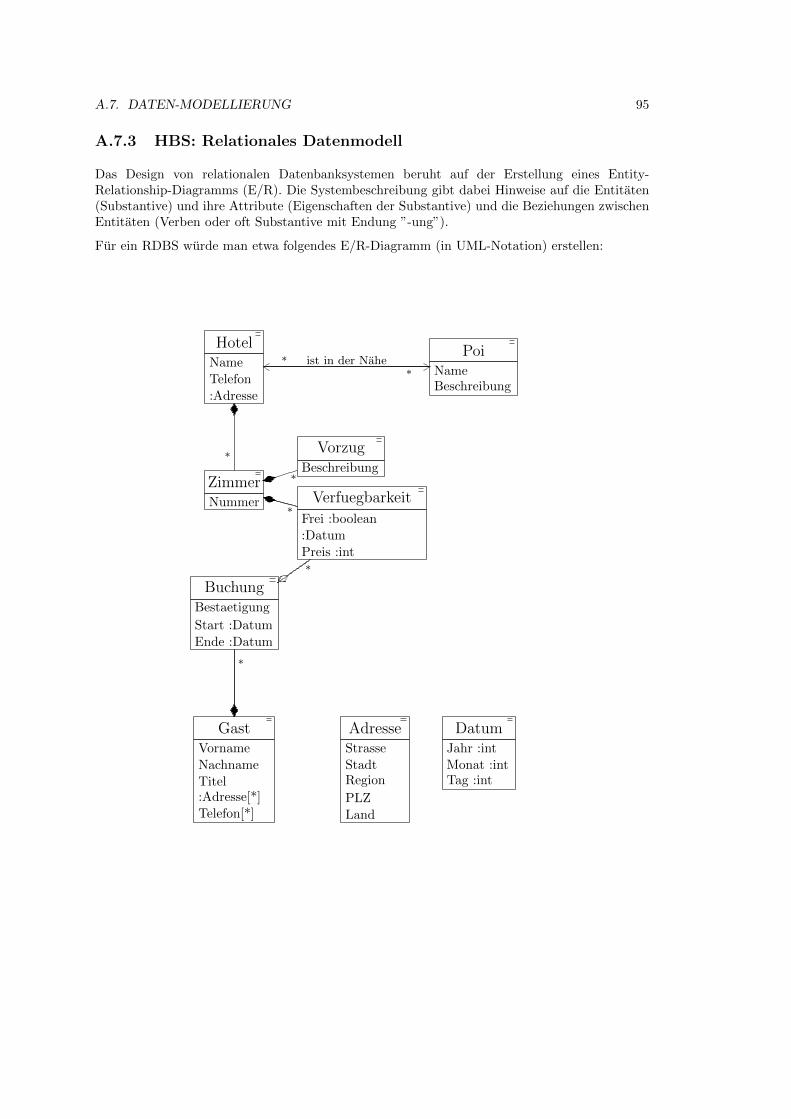
A.7. DATEN-MODELLIERUNG 95
A.7.3 HBS: Relationales Datenmodell
Das Design von relationalen Datenbanksystemen beruht auf der Erstellung eines Entity-Relationship-Diagramms (E/R). Die Systembeschreibung gibt dabei Hinweise auf die Entitaten(Substantive) und ihre Attribute (Eigenschaften der Substantive) und die Beziehungen zwischenEntitaten (Verben oder oft Substantive mit Endung ”-ung”).
Fur ein RDBS wurde man etwa folgendes E/R-Diagramm (in UML-Notation) erstellen:
HotelName
Telefon
:Adresse
*
*
PoiNameBeschreibung
*
ZimmerNummer
*
*
VorzugBeschreibung
Verfuegbarkeit
Frei :boolean:Datum
Preis :int
GastVorname
Nachname
Titel:Adresse[*]
Telefon[*]
*
BuchungBestaetigung
Start :Datum
Ende :Datum
*
AdresseStrasse
StadtRegion
PLZ
Land
DatumJahr :intMonat :intTag :int
ist in der Nahe

96 ANHANG A. CASSANDRA
Bemerkungen:
• Attribute ohne Typ-Angabe sind Strings.
• ”Verfuegbarkeit” ist eine etwas merkwurdig Bezeichnung fur den Tag, an dem ein Zimmergebucht werden kann.
• Ein Gast bucht nicht Zimmer, sondern die Verfuegbarkeiten eines Zimmers oder mehrererZimmer.
• Der Preis eines Zimmers kann sich von Tag zu Tag andern.
• Die Buchung hat die Verfuegbarkeiten als Aggregat, da eine Verfuegbarkeit zwar nur zuhochstens einer Buchung gehoren kann, aber die Buchung wechseln kann bzw. nicht mehrgebucht sein kann.
Das E/R-Modell fur dieses System war relativ problemlos zu erstellen. Die Umsetzung in Tabellenfolgt einem Automatismus. Moglicherweise ist die Formulierung von Anfragen (z.B. ob ein Hotelnoch ein Zimmer frei hat) nicht ganz trivial.
Fur ein Column-Family-Modell sind zunachst ein Query-Modell und dann insgesamt drei Daten-modelle zu erstellen: Logisches, physisches und Implementierungs-Datenmodell.

A.7. DATEN-MODELLIERUNG 97
A.7.4 HBS: Definition der Queries
Im ersten Design-Schritt muss ermittelt werden, wie die Datenbank verwendet wird (Use-Case-Driven).
Wahrscheinlich sind folgende Anfragen zu erwarten:
• A1: Finde Hotels, deren Namen und Adresse in der Nahe eines POI (Point of Interest,Sehenswurdigkeit).
• A2: Finde mehr Informationen wie Telefon und Beschreibung uber ein Hotel.
• A3: Finde POIs in der Nahe eines Hotels.
• A4: Finde freie Zimmer in einem Datumsfenster.
• A5: Finde Preis und Annehmlichkeiten (Vorzuge) eines Zimmers.
• A6: Finde eine Buchung zu einer Bestatigungsnummer.
• A7: Finde eine Buchung uber Hotel, Datum und Zimmernummer
• A8: Finde alle Buchungen eines Gastes (Nachname).
• A9: Finde Informationen uber einen Gast.
Folgendes Diagramm zeigt die Anfragen, die sich aus einem moglichen dem Workflow (Ablauf,Arbeitsfluss) der HBS-Anwendung ergeben:
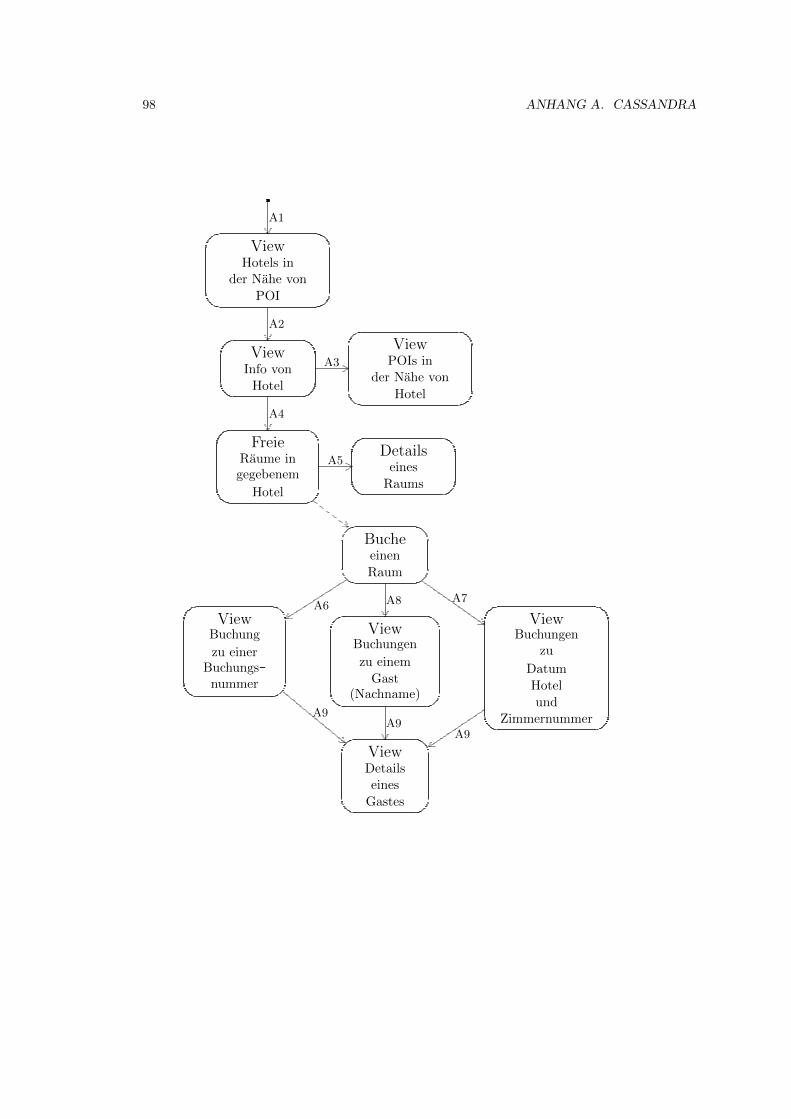
98 ANHANG A. CASSANDRA
ViewHotels in
der Nahe von
POI
A1
ViewInfo von
Hotel
A2
ViewPOIs in
der Nahe von
Hotel
A3
FreieRaume ingegebenem
Hotel
A4
Detailseines
Raums
A5
Bucheeinen
Raum
ViewBuchung
zu einerBuchungs-
nummer
A6
ViewBuchungen
zu einem
Gast(Nachname)
A8
ViewBuchungen
zu
Datum
Hotel
undZimmernummer
A7
ViewDetailseines
Gastes
A9A9
A9

A.7. DATEN-MODELLIERUNG 99
A.7.5 HBS: Logisches Datenmodell
Fur jede oben definierte Query wird eine Tabelle entworfen. Eine Query hat zwei Teile:
– Suchziel (Was wird gesucht? z.B. hotels)und– Suchkriterien (z.B. ein POI bzw. Inhalt einer WHERE-Klausel)
Eine vernunftige Art, den Namen der Query-Tabelle zu definieren, ist:
Tabellenname = suchziel_by_suchkriterium
• Das Suchkriterium definiert den Primarschlussel i.a. bestehend aus Partition und ClusteringKey Columns. Dadurch wird Eindeutigkeit garantiert und eine gewisse Sortierung definiert.
• Die ubrigen Non-Key Columns definieren das Suchziel.
• Attribute, die fur jede Instanz des Partition Keys den gleichen Wert haben, stehen in einerstatic Column.
Als Notation verwenden wir Chebotko-Diagramme (Artem Chebotko). Ein Chebotko LogicalDiagram folgende allgemeine Struktur:
Column_name_1
Column_name_2
Column_name_3
Column_name_4
Column_name_5
Column_name_6
Column_name_7
Column_name_8
K
K
K
C\
C/
C
S
Table_name_1
Q1 durch Tabelle 1 unterstutzte Query
Partition Key Column
Clustering Key Column (DESC)
Clustering Key Column (ASC)
Clustering Key Column
Static (Non-Key) Column
Andere (Non-Key) Column
... K
Table_name_2
Q2 Downstream Queries
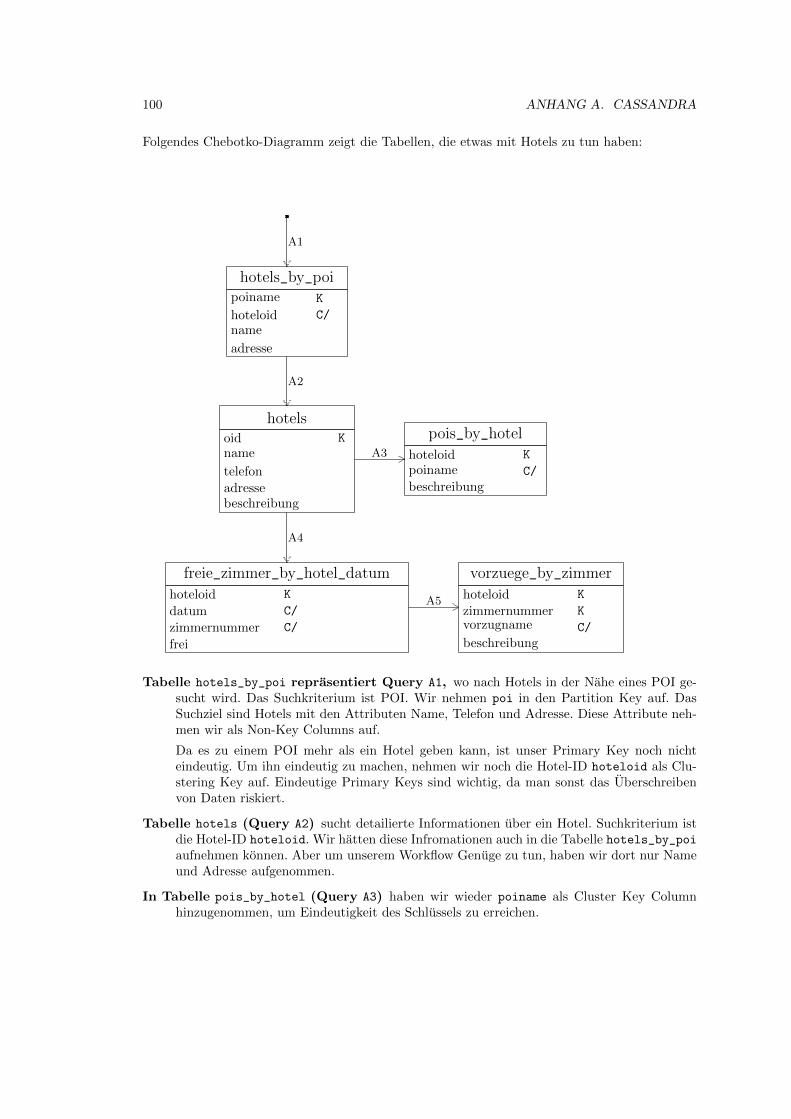
100 ANHANG A. CASSANDRA
Folgendes Chebotko-Diagramm zeigt die Tabellen, die etwas mit Hotels zu tun haben:
poiname
hoteloidname
adresse
K
C/
hotels_by_poi
A1
oidname
telefon
adressebeschreibung
K
hotels
A2
hoteloidpoiname
beschreibung
K
C/
pois_by_hotelA3
hoteloid
datumzimmernummer
frei
K
C/
C/
freie_zimmer_by_hotel_datum
A4
hoteloidzimmernummervorzugname
beschreibung
K
K
C/
vorzuege_by_zimmer
A5
Tabelle hotels_by_poi reprasentiert Query A1, wo nach Hotels in der Nahe eines POI ge-sucht wird. Das Suchkriterium ist POI. Wir nehmen poi in den Partition Key auf. DasSuchziel sind Hotels mit den Attributen Name, Telefon und Adresse. Diese Attribute neh-men wir als Non-Key Columns auf.
Da es zu einem POI mehr als ein Hotel geben kann, ist unser Primary Key noch nichteindeutig. Um ihn eindeutig zu machen, nehmen wir noch die Hotel-ID hoteloid als Clu-stering Key auf. Eindeutige Primary Keys sind wichtig, da man sonst das Uberschreibenvon Daten riskiert.
Tabelle hotels (Query A2) sucht detailierte Informationen uber ein Hotel. Suchkriterium istdie Hotel-ID hoteloid. Wir hatten diese Infromationen auch in die Tabelle hotels_by_poiaufnehmen konnen. Aber um unserem Workflow Genuge zu tun, haben wir dort nur Nameund Adresse aufgenommen.
In Tabelle pois_by_hotel (Query A3) haben wir wieder poiname als Cluster Key Columnhinzugenommen, um Eindeutigkeit des Schlussels zu erreichen.

A.7. DATEN-MODELLIERUNG 101
Mit Tabelle freie_zimmer_by_hotel_datum (Query A4) suchen wir nach freien Zimmern ineinem Datumsbereich. Deshalb definieren wir das Datum auf jeden Fall als aufsteigendsortierte (ASC) Clustering Key Column.
Tabelle vorzuege_by_zimmer (Query A5) gibt uns detailierte Informationen – nach Namenaufsteigend sortiert – uber ein Hotelzimmer.
Das folgende Chebotko-Diagramm zeigt das logische Design der Tabellen, die mit der Reservie-rung von Hotelzimmern zu tun haben:
hoteloid
startdatumzimmernummer
endedatumbestaetigung
gastoid
K
K
C/
buchungen_by_hotel_datum
A7
gastnachname
hoteloidzimmernummer
startdatum
endedatumbestaetigung
gastoid
K
C/
C/
C/
buchungen_by_gast
A8
bestaetigung
hoteloidzimmernummer
startdatum
endedatumgastoid
K
C/
buchungen_by_bestaetigung
A6
gastoidvorname
nachname
titel
telefone
adressen
K
gaesteA9
A9
A9
Tabelle buchungen_by_bestaetigung (Query A6) soll zu einer Bestatigung die Buchungsda-ten liefern. Das Suchkriterium ist also die Bestatigung. Sie wird zum Partition Key. Diehoteloid wird als aufsteigender Clustering Key dazugenommen, um den Primary Keyeindeutig zu machen.

102 ANHANG A. CASSANDRA
Tabelle buchungen_by_hotel_datum (Query A7) liefert Buchungsdaten fur ein Hotel undStartdatum. Hotel und Startdatum bilden daher den Partition Key, der sicher nicht ein-deutig ist, aber mit der Zimmernummer als Clustering Key eindeutiger Primary Key wird.
Tabelle buchungen_by_gast (Query A8) gibt zu einem Gastnamen die Buchungsdaten, ins-besondere auch die gastoid, mit der wir die Downstream-Query machen konnen.
Tabelle gaeste (Query A9) wird Downstream von A6, A7 und A8 zur Ermittlung von Gastda-ten mittels der gastoid verwendet.
A.7.6 HBS: Physisches Datenmodell
Das Physische Modell erganzt die Column-Namen um CQL-Typen. Fur mehrwertige Columnswerden passende Collections definiert.
Insbesondere werden Keyspaces definiert. Bequem ist es zwar, nur einen einzigen Keyspace zudefinieren. Die Design-Empfehlung lautet allerdings, mit Keyspaces nicht zu sparen, um verschie-dene Belange (concerns) zu trennen. Im Beispiel HBS trennen wird Hotels und Buchungen durchDefinition der beiden Keyspaces hotel und buchung.
Das physische Datenmodell kann in einem Chebotko Physical Diagram dargestellt werden,das folgende allgemeine Form hat:
<<Keyspace>>
keyspace_name
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
CQL-Type
UDT-NameCQL-Type
CQL-Type
Column_name_1
Column_name_2
Column_name_3
Column_name_4
Column_name_5
Column_name_6
Column_name_7[Column_name_8]
{Column_name_8}<Column_name_10>
*Column_name_11*(Column_name_12)
Column_name_13
K
C/
C\
C
S
IDX
++
Table_name
Partition Key Column
Clustering Key Column (ASC)
Clustering Key Column (DESC)
Clustering Key Column
Static ColumnSecondary Index Column
Counter Column
List Collection Column
Set Collection ColumnMap Collection Column
UDT ColumnTuple Column
Regular Column
Bemerkungen:
Identifikatoren: Es ist i.a. sinnvoll, uuid oder timeuuid als Identifikatoren zu verwenden.Aber es ist nicht verboten, eigene Text-IDs zu definieren, wie es hier in diesem Beispiel oft

A.7. DATEN-MODELLIERUNG 103
gemacht wird. Diese sind allerdings nicht notwendig global eindeutig, bzw. die Anwendungmuss fur Eindeutigkeit sorgen.
Typ text ist ziemlich universell einsetzbar und daher auch fur viele scheinbar numerische Co-lumns wie Telefonnummern zu empfehlen. In unserem Beispiel haben wir fur die Zimmer-nummer ein smallint verwendet, was sich sicher rachen wird.
UDT: Ein User Defined Type ist nur in einem Keyspace gultig. Wenn er in anderen Keyspacesauch verwendet wird, muss er dort auch definiert werden. In unserem Beispiel wird derUDT adresse zweimal definiert. Das ist eine lastige Redundanz.
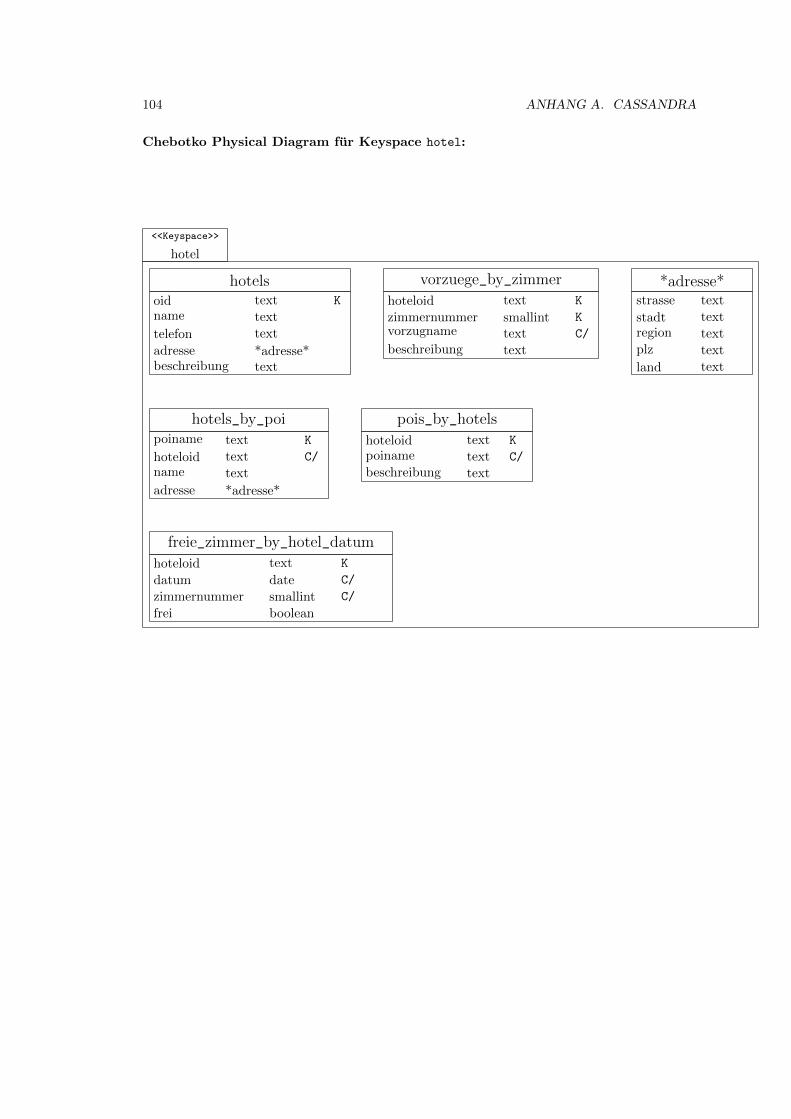
104 ANHANG A. CASSANDRA
Chebotko Physical Diagram fur Keyspace hotel:
<<Keyspace>>
hotel
text
text
text
*adresse*text
oidname
telefon
adressebeschreibung
K
hotelstext
smallinttext
text
hoteloidzimmernummervorzugname
beschreibung
K
K
C/
vorzuege_by_zimmer
text
text
text
text
text
strasse
stadtregion
plz
land
*adresse*
text
text
text
*adresse*
poiname
hoteloidname
adresse
K
C/
hotels_by_poi
text
text
text
hoteloidpoiname
beschreibung
K
C/
pois_by_hotels
text
date
smallint
boolean
hoteloid
datumzimmernummer
frei
K
C/
C/
freie_zimmer_by_hotel_datum
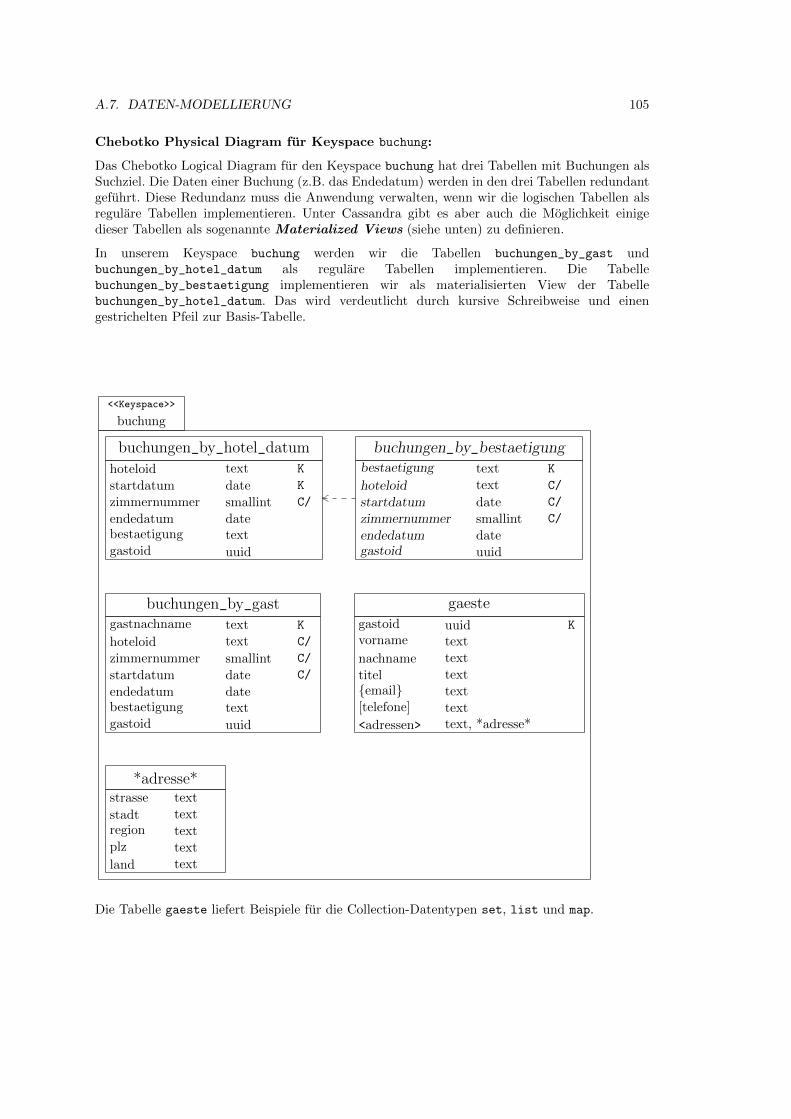
A.7. DATEN-MODELLIERUNG 105
Chebotko Physical Diagram fur Keyspace buchung:
Das Chebotko Logical Diagram fur den Keyspace buchung hat drei Tabellen mit Buchungen alsSuchziel. Die Daten einer Buchung (z.B. das Endedatum) werden in den drei Tabellen redundantgefuhrt. Diese Redundanz muss die Anwendung verwalten, wenn wir die logischen Tabellen alsregulare Tabellen implementieren. Unter Cassandra gibt es aber auch die Moglichkeit einigedieser Tabellen als sogenannte Materialized Views (siehe unten) zu definieren.
In unserem Keyspace buchung werden wir die Tabellen buchungen_by_gast undbuchungen_by_hotel_datum als regulare Tabellen implementieren. Die Tabellebuchungen_by_bestaetigung implementieren wir als materialisierten View der Tabellebuchungen_by_hotel_datum. Das wird verdeutlicht durch kursive Schreibweise und einengestrichelten Pfeil zur Basis-Tabelle.
<<Keyspace>>
buchung
text
date
smallint
datetext
uuid
hoteloid
startdatumzimmernummer
endedatumbestaetigung
gastoid
K
K
C/
buchungen_by_hotel_datum
text
text
smallint
date
datetext
uuid
gastnachname
hoteloidzimmernummer
startdatum
endedatumbestaetigung
gastoid
K
C/
C/
C/
buchungen_by_gast
text
text
date
smallint
date
uuid
bestaetigung
hoteloid
startdatumzimmernummer
endedatumgastoid
K
C/
C/
C/
buchungen_by_bestaetigung
uuidtext
text
text
text
texttext, *adresse*
gastoidvorname
nachname
titel{email}[telefone]
<adressen>
K
gaeste
text
text
text
text
text
strasse
stadtregion
plz
land
*adresse*
Die Tabelle gaeste liefert Beispiele fur die Collection-Datentypen set, list und map.

106 ANHANG A. CASSANDRA
Materialized Views
Cassandra ubernimmt die Verantwortung fur die Konsistenz der materialisierten Views zur refe-renzierten Basis-Tabelle. Die CQL-Sytax ist etwa:
CREATE MATERIALIZED VIEW <viewTable> AS
SELECT * FROM <baseTable>
WHERE <anyColumn> IS NOT NULL
AND <baseTablePrimaryKeyColumn> IS NOT NULL ...
PRIMARY KEY ((<anyColumn>), <all baseTablePrimaryKeyColumns> );
Der Primary Key des Views muss mindestens den ganzen Primary Key der Basis-Tabelle enthal-ten. Als Partition Key wird normalerweise eine zusatzliche Column (hier anyColumn) genommen.In Zukunft sind wahrscheinlich auch mehrere Columns moglich.
Anstatt SELECT * kann naturlich auch eine Auswahl an Columns getroffen werden, solange derPrimary Key der Basis-Tabelle enthalten ist.
In unserem Beispiel lohnt sich der materialisierte View insbesondere deshalb, weil die Columnbestaetigung eine hohe Kardinalitat hat.
Die Konsistenzerhaltung hat zwar Performanzkosten, die aber durch Ersparnisse in der Anwen-dung normalerweise mehr als ausgeglichen werden.

A.7. DATEN-MODELLIERUNG 107
A.7.7 HBS: CQL-Implementierungs-Datenmodell
Implementierung des Chebotko-Diagramms fur Keyspace hotel:
CQL-Datei: hotel.cql
CREATE KEYSPACE IF NOT EXISTS hotelWITH replication = {’class’: ’SimpleStrategy’, ’replication_factor’: 3};
USE hotel;
CREATE TYPE IF NOT EXISTS adresse (strasse text,stadt text,region text,plz text,land text
);
CREATE TABLE IF NOT EXISTS hotels_by_poi (poiname text,hoteloid text,name text,adresse frozen<adresse>,PRIMARY KEY ((poiname), hoteloid)
) WITH comment = ’A1: Finde alle Hotels in der Nahe eines POIs’AND CLUSTERING ORDER BY (hoteloid ASC);
CREATE TABLE IF NOT EXISTS hotels (oid text PRIMARY KEY,name text,telefon text,adresse frozen<adresse>,beschreibung text
) WITH comment = ’A2: Finde Info uber ein Hotel (? pois set<text>)’;
CREATE TABLE IF NOT EXISTS pois_by_hotel (hoteloid text,poiname text,beschreibung text,PRIMARY KEY ((hoteloid), poiname)
) WITH comment = ’A3: Finde POIs in der Nahe eines Hotels’;
CREATE TABLE IF NOT EXISTS freie_zimmer_by_hotel_datum (hoteloid text,datum date,zimmernummer smallint,frei boolean,PRIMARY KEY ((hoteloid), datum, zimmernummer)
) WITH comment = ’A4: Finde freie Zimmer eines Hotels an einem Datum’;
CREATE TABLE IF NOT EXISTS vorzuege_by_zimmer (hoteloid text,zimmernummer smallint,vorzugname text,beschreibung text,PRIMARY KEY ((hoteloid, zimmernummer), vorzugname)
) WITH comment = ’A5: Finde Vorzuge eines Zimmers in einem Hotel’;

108 ANHANG A. CASSANDRA
Implementierung des Chebotko-Diagramms fur Keyspace buchung:
CQL-Datei: buchung.cql
CREATE KEYSPACE IF NOT EXISTS buchungWITH replication = {’class’: ’SimpleStrategy’, ’replication_factor’: 3};
USE buchung;
CREATE TYPE IF NOT EXISTS adresse (strasse text,stadt text,region text,plz text,land text
);
CREATE TABLE IF NOT EXISTS buchungen_by_hotel_datum (hoteloid text,startdatum date,zimmernummer smallint,endedatum date,bestaetigung text,gastoid uuid,PRIMARY KEY ((hoteloid, startdatum), zimmernummer)
) WITH comment = ’A7: Finde Buchungen in einem Hotel an einem Start-Datum’;
CREATE MATERIALIZED VIEW IF NOT EXISTS buchungen_by_bestaetigung ASSELECT * FROM buchungen_by_hotel_datumWHERE bestaetigung IS NOT NULL AND hoteloid IS NOT NULL
AND startdatum IS NOT NULL AND zimmernummer IS NOT NULLPRIMARY KEY (bestaetigung, hoteloid, startdatum, zimmernummer);
CREATE TABLE IF NOT EXISTS buchungen_by_gast (gastnachname text,hoteloid text,zimmernummer smallint,startdatum date,endedatum date,bestaetigung text,gastoid uuid,PRIMARY KEY ((gastnachname), hoteloid, zimmernummer, startdatum)
) WITH comment = ’A8: Finde Buchungen eines Gastes mit Nachname.’;
CREATE TABLE IF NOT EXISTS gaeste (gastoid uuid PRIMARY KEY,vorname text,nachname text,titel text,emails set<text>,telefone list<text>,adressen map<text, frozen<adresse>>
) WITH comment = ’A9: Finde Gast mit OID.’;

A.7. DATEN-MODELLIERUNG 109
Abfullung von Beispiel-Daten im Keyspace hotel:
CQL-Datei: hoteldaten.cql
USE hotel;
INSERT INTO hotels (oid, name, telefon, adresse, beschreibung)VALUES (’ul1’, ’Donaublick’, ’0731-68376’,
{strasse: ’Fritz-Mayer-Str. 12’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89070’, land: ’Germany’},’Jedes Hotelzimmer bietet einen wundervollen Blick auf die Donau.’);
INSERT INTO hotels (oid, name, telefon, adresse, beschreibung)VALUES (’ul2’, ’Gasthof am Munster’, ’0731-384729’,
{strasse: ’Munsterplatz 7’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89060’, land: ’Germany’},’Jedes Hotelzimmer bietet einen wundervollen Blick auf das Munster.’);
INSERT INTO hotels (oid, name, telefon, adresse, beschreibung)VALUES (’s1’, ’Maritim’, ’0711-863835’,
{strasse: ’Augustenstr. 51’, stadt: ’Stuttgart’,region: ’Baden-Wurttemberg’, plz: ’78156’, land: ’Germany’},’Wir sind ein Luxushotel und haben nur sehr teure Zimmer.’);
INSERT INTO hotels_by_poi (poiname, hoteloid, name, adresse)VALUES (’donau’, ’ul1’, ’Donaublick’,
{strasse: ’Fritz-Mayer-Str. 12’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89070’, land: ’Germany’});
INSERT INTO hotels_by_poi (poiname, hoteloid, name, adresse)VALUES (’ulmue’, ’ul1’, ’Donaublick’,
{strasse: ’Fritz-Mayer-Str. 12’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89070’, land: ’Germany’});
INSERT INTO hotels_by_poi (poiname, hoteloid, name, adresse)VALUES (’donau’, ’ul2’, ’Gasthof am Munster’,
{strasse: ’Munsterplatz 7’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89060’, land: ’Germany’});
INSERT INTO hotels_by_poi (poiname, hoteloid, name, adresse)VALUES (’ulmue’, ’ul2’, ’Gasthof am Munster’,
{strasse: ’Munsterplatz 7’, stadt: ’Ulm’,region: ’Baden-Wurttemberg’, plz: ’89060’, land: ’Germany’});
INSERT INTO hotels_by_poi (poiname, hoteloid, name, adresse)VALUES (’sfst’, ’s1’, ’Maritim’,
{strasse: ’Augustenstr. 51’, stadt: ’Stuttgart’,region: ’Baden-Wurttemberg’, plz: ’78156’, land: ’Germany’});
INSERT INTO pois_by_hotel (hoteloid, poiname, beschreibung)VALUES (’ul1’, ’donau’,
’Die blaue Donau ist mit 2800 km der langste Fluss Europas.’);INSERT INTO pois_by_hotel (hoteloid, poiname, beschreibung)
VALUES (’ul1’, ’ulmue’,’Das Ulmer Munster ist mit 168 Metern der hochste Kirchturm Europas.’);
INSERT INTO pois_by_hotel (hoteloid, poiname, beschreibung)VALUES (’ul2’, ’donau’,
’Die blaue Donau ist mit 2800 km der langste Fluss Europas.’);INSERT INTO pois_by_hotel (hoteloid, poiname, beschreibung)
VALUES (’ul2’, ’ulmue’,’Das Ulmer Munster ist mit 168 Metern der hochste Kirchturm Europas.’);
INSERT INTO pois_by_hotel (hoteloid, poiname, beschreibung)VALUES (’s1’, ’sfst’,
’Der Stuttgarter Fernsehturm ist mit 211 Metern der hochste Turm in BW.’);
INSERT INTO vorzuege_by_zimmer (hoteloid, zimmernummer, vorzugname, beschreibung)
VALUES (’ul1’, 11, ’Mobiliar’,’Dieser Zimmer ist im Stil des Barock mobliert.’);
INSERT INTO vorzuege_by_zimmer (hoteloid, zimmernummer, vorzugname, beschreibung)
VALUES (’ul1’, 11, ’Aussicht’,’Dieser Zimmer hat einen wundervollen Blick auf den Reitstall.’);
INSERT INTO freie_zimmer_by_hotel_datum (hoteloid, datum, zimmernummer, frei)
VALUES (’ul1’, ’2016-11-09’, 11, True);INSERT INTO freie_zimmer_by_hotel_datum (
hoteloid, datum, zimmernummer, frei)

110 ANHANG A. CASSANDRA
VALUES (’ul1’, ’2016-11-10’, 11, False);INSERT INTO freie_zimmer_by_hotel_datum (
hoteloid, datum, zimmernummer, frei)VALUES (’ul1’, ’2016-11-11’, 11, False);

A.7. DATEN-MODELLIERUNG 111
Abfullung von Beispiel-Daten im Keyspace buchung:
CQL-Datei: buchungdaten.cql
USE buchung;
INSERT INTO gaeste (gastoid, vorname, nachname, titel, emails, telefone, adressen)VALUES (uuid(), ’Finn’, ’Ledford’, ’Herr Prof. Dr.’, {’fi@super’, ’fl@boston’},
[’0761-373641’, ’07071-2316’, ’0711-8729’],{’home’: {strasse: ’Bahnhof-Str. 50’, stadt: ’Freiburg’,region: ’Baden-Wurttemberg’, plz: ’78071’, land: ’Germany’},’arbeit’: {strasse: ’Immental-Str. 16’, stadt: ’Freiburg’,region: ’Baden-Wurttemberg’, plz: ’78073’, land: ’Germany’}});
INSERT INTO buchungen_by_hotel_datum (hoteloid, startdatum, zimmernummer,endedatum, bestaetigung, gastoid)
VALUES (’ul1’, ’2016-11-09’, 11, ’2016-11-15’, ’ul116-11-09’,2f0b0441-f0be-46d1-a393-be9c94bf45c1);
INSERT INTO buchungen_by_gast (gastnachname, hoteloid, zimmernummer, startdatum,endedatum, bestaetigung, gastoid)
VALUES (’Ledford’, ’ul1’, 11, ’2016-11-09’, ’2016-11-15’, ’ul116-11-09’,2f0b0441-f0be-46d1-a393-be9c94bf45c1);

112 ANHANG A. CASSANDRA
A.7.8 Aufspaltung zu großer Partitionen
Es kann relativ leicht passieren, dass eine Partition nicht mehr auf einen Knoten passt. Dannmuss sie aufgeteilt werden.
Eine Moglichkeit ist, eine Key-Column mit in den Partition Key aufzunehmen. Wenn wir z.B. inder Tabelle freie_zimmer_by_hotel_datum das Datum mit in den Partition Key aufnehmen,werden die Partitionen wesentlich kleiner sein, aber vielleicht zu klein, weil dann aufeinanderfolgende Tage wahrscheinlich auf unterschiedlichen Knoten liegen.
Eine weitere Moglichkeit ist das Bucketing, wobei eine zusatzliche, oft redundante Columneingefuhrt wird. In unserem Beispiel konnte man den Monat (redundant zum Datum) als zusatz-liche Column einfuhren und in den Partition Key aufnehmen. Das wurde die Partitionsgroßevernunftig reduzieren.

A.8. BEISPIELE IN GOLANG 113
A.8 Beispiele in Golang
Im wesentlichen werden CQL-Anweisungen der Session-Methode Query(...) ubergeben. Dabeiist der CQL-Code ein Template (in einfachen Grave-Akzenten ‘any ? cql-co?de‘). Die Frage-zeichen werden durch die weiteren Argumente von Query(...) ersetzt.
A.8.1 Beispiel ”Gezwitscher”
Installation des Go-Treibers:
go get github.com/gocql/gocql
Voraussetzung: Datenbank und cqlsh starten.
Folgende cqlsh-Kommandos sind vorher zu geben:
cqlsh> create keyspace bsp with replication= { ’class’ : ’SimpleStrategy’, ’replication_factor’ : 1 };
cqlsh> create table bsp.zwitscher(zeitlinie text, id TIMEUUID, text text, PRIMARY KEY(id));
cqlsh> create index on bsp.zwitscher(zeitlinie);
Im Programm-Code war es wichtig, die Protokoll-Version auf 4 zu setzen:
cluster.ProtoVersion = 4
Das Programm funktioniert unter:
Cassandra 3.9
gocql-Version?
Programm-Code:
// Zwitscher.go
package main
import ("fmt""log""github.com/gocql/gocql"
)
func main() {// connect to the cluster//cluster := gocql.NewCluster("192.168.1.1", "192.168.1.2", "192.168.1.3")cluster := gocql.NewCluster("127.0.0.1")cluster.Keyspace = "bsp"cluster.ProtoVersion = 4 // ! Important because default is 2 !cluster.Consistency = gocql.Quorumsession, _ := cluster.CreateSession()defer session.Close()
// insert a tweet:if err := session.Query(
‘INSERT INTO zwitscher (zeitlinie, id, text) VALUES (?, ?, ?)‘,"ich", gocql.TimeUUID(), "Guten Tag").Exec(); err != nil {
log.Fatal(err)}

114 ANHANG A. CASSANDRA
var id gocql.UUIDvar text string
/* Search for a specific set of records whose ’zeitlinie’ column matches* the value ’ich’. The secondary index that we created earlier will be* used for optimizing the search */if err := session.Query(
‘SELECT id, text FROM zwitscher WHERE zeitlinie = ? LIMIT 1‘,"ich").Consistency(gocql.One).Scan(&id, &text); err != nil {
log.Fatal(err)}fmt.Println("Gezwitscher:", id, text)
// list all tweetsiter := session.Query(
‘SELECT id, text FROM zwitscher WHERE zeitlinie = ? ‘, "ich").Iter()for iter.Scan(&id, &text) {
fmt.Println("Gezwitscher:", id, text)}if err := iter.Close(); err != nil {
log.Fatal(err)}
}
Starten des Programms:go run Zwitscher.go

A.9. BEISPIELE IN JAVA 115
A.9 Beispiele in Java
Im wesentlichen werden CQL-Anweisungen der Session-Methode execute(aQueryString) uber-geben.
A.9.1 Beispiel ”GettingStarted”
Es war langwierig den folgenden Code zum Laufen zu bringen. Das Tutorial scheint vollig veraltetzu sein.
Das Programm funktioniert unter:
Cassandra 3.9
cassandra-java-driver-3.1.0
Am bequemsten ist es den Java-Treiber in den CLASSPATH aufzunehmen, z.B. unter UNIX in.profile in der Form:CLASSPATH="...:$HOME/cassandra-java-driver/*:$HOME/cassandra-java-driver/lib/*"
Dazu muss der Inhalt eines heruntergeladenen binary tarballs in das Verzeichniscassandra-java-driver kopiert werden.
Programm-Code:
import com.datastax.driver.core.*;import java.util.UUID;
public class GettingStarted {public static void main(String[] args) {
//org.apache.log4j.BasicConfigurator.configure();
Cluster cluster;Session session;
// Connect to the cluster and keyspace "bsp"cluster = Cluster.builder().addContactPoint("127.0.0.1")
.withProtocolVersion(ProtocolVersion.V3)
.build();session = cluster.connect("bsp");
System.err.println ("1*");
// Create tablesession.execute("CREATE TABLE IF NOT EXISTS benutzer"
+ "(id uuid PRIMARY KEY, nachname text, age int, stadt text,"+ " email text, vorname text)");
System.err.println ("2*");
// Insert one record into the users tablesession.execute("INSERT INTO benutzer "
+ "(id, nachname, age, stadt, email, vorname)"+ "VALUES (uuid(), ’Hachinger’, 33, ’Munchen’,"+ " ’[email protected]’, ’Nepomuk’)");
System.err.println ("3*");
// Use select to get the user we just enteredResultSet results = session.execute(
"SELECT * FROM benutzer WHERE nachname=’Hachinger’"+ " ALLOW FILTERING");
UUID pk = null;for (Row row : results) {
System.out.format("%s %s %d\n",(pk = row.getUUID("id")).toString (),row.getString("vorname"), row.getInt("age"));
}System.err.println ("4*");

116 ANHANG A. CASSANDRA
// Update the same user with a new ageString pks = pk.toString ();//session.execute("UPDATE benutzer SET age = 34 WHERE nachname = ’Hachinger’");session.execute(
"UPDATE benutzer SET age = 34 WHERE id = " + pks);//+ " AND nachname = ’Hachinger’");
System.err.println ("41*");// Select and show the changeresults = session.execute(
"SELECT * FROM benutzer WHERE nachname=’Hachinger’"+ " ALLOW FILTERING");
for (Row row : results) {System.out.format( "%s %d\n",
row.getString("vorname"), row.getInt("age"));}System.err.println ("5*");
// Delete the user from the users table//session.execute("DELETE FROM benutzer WHERE nachname = ’Hachinger’");session.execute("DELETE FROM benutzer WHERE id = " + pks);// Show that the user is goneresults = session.execute("SELECT * FROM benutzer");for (Row row : results) {
System.out.format("%s %s %d %s %s %s\n",row.getUUID("id").toString (),row.getString("nachname"), row.getInt("age"),row.getString("stadt"), row.getString("email"),row.getString("vorname"));
}System.err.println ("6*");
// Clean up the connection by closing itcluster.close();
}}
Das Programm wird mitjavac GettingStarted.java
ubersetzt und mitjava GettingStarted
laufen gelassen.
A.10 What more about Cassandra?
A lot such as:
Cassandra-Konfiguration
Physikalische Cluster-Topologie: Data Centers – Racks – Nodes
Logische Cluster-Topologie: Rings – Nodes, Tokens
Data Distribution by Partition Key: Die Daten werden gleichmaßig uber das Cluster ver-teilt.
Konsistenz Niveaus: Schreiben und Lesen von Daten.
Replication Strategies
Speicherstrukter: Memtables, SSTables, Commit Logs, Caching

A.11. UBUNGEN 117
Monitoring
Wartung
Performance Tuning
Sicherheit
DSE Tools (DataStax Enterprise)
Graph, Gremlin (sql2gremlin.com)
https://academy.datastax.com/courses
A.11 Ubungen
A.11.1 DataStax-Trivadis-Aufgaben
Siehe Verzeichnis trivadis.
Und:
In the real world, how many tweets would you guess occur per day? As of this writing, Twittergenerates 500M tweets/day according to these guys, Internet Live Stats:
http://www.internetlivestats.com/twitter-statistics/
Let’s say we need to run a query that captures all tweets over a specified range of time. Givenour data model scenario, we simply data model a primary key value of (ch, dt) to capture alltweets in a single Cassandra row sorted in order of time, right? Easy! But, alas, the Cassandralogical limit of single row size (2B columns in C* v2.1) would fill up after about 4 days. Ack!Our primary key won’t work. What would we do to solve our query?

118 ANHANG A. CASSANDRA

Anhang B
Transaktionsverarbeitung
Das Thema der Transaktionsverarbeitung (transaction processing) ist ein riesiges The-ma [20]. Wir werden daher nur die wichtigsten Gesichtspunkte darstellen. Nach einer Klarungdes Begriffs Transaktion (transaction) gehen wir auf die beiden Aspekte Nebenlaufigkeit(concurrency) und in einem eigenen Kapitel Wiederherstellung (recovery) ein, wobei wirhaufig die englischen Begriffe verwenden werden, weil sie eingefuhrt sind.
B.1 Transaktionen
Definition: Eine Transaktion ist eine logische Arbeitseinheit, die zu einem einzelnen Vorgang odereiner elementaren Ausfuhrungseinheit in dem Unternehmen korrespondiert, das in der Datenbankabgebildet ist.
Als Beispiel nehmen wir an, dass die Teile-Relation P als zusatzliches Attribut TOTQTY habe,namlich die Menge aller gelieferten Teile eines Typs. Nun soll die neue Lieferung ”S5 liefert180 P1-Teile” in die Datenbank eingetragen werden. Dazu mussen die Relationen SP und Paktualisiert werden:
EXEC SQL INSERT
INTO SP (SNR, PNR, QTY)
VALUES (’S5’, ’P1’, 180);
EXEC SQL UPDATE P
SET TOTQTY = TOTQTY + 180
WHERE PNR = ’P1’;
Dies ist ein Beispiel fur eine Transaktion. Eine Transaktion erhalt die Konsistenz und Korrekt-heit der Datenbank, d.h. die Datenbank wird durch die Transaktion von einem konsistenten undkorrekten Zustand in einen anderen konsistenten und korrekten Zustand uberfuhrt. Zwischen-zustande (etwa nach der INSERT-Anweisung) konnen inkonsistent sein. Um die Konsistenz derDatenbank zu garantieren, darf eine Transaktion entweder nur vollstandig oder garnicht durch-gefuhrt werden, d.h. Transaktionen mussen unteilbar, atomar (atomic) sein. Es muss fur diesogenannte Ablauf- oder operationale Integritat gesorgt werden.
119

120 ANHANG B. TRANSAKTIONSVERARBEITUNG
Die Systemkomponente Transaktions-Manager (transaction manager) stellt Methoden zurVerfugung, die die Atomaritat garantieren:
begin transaction (BOT) : Mit diesem Statement beginnt eine Transaktion. Oft ergibt sichdieses Kommando implizit und wird weggelassen. Auch in SQL gibt es dafur kein explizitesStatement. In SQL beginnt eine Transaktion, wenn gerade keine Transaktion lauft und eintransaktionsinitiierendes (fast alle DDL- und DML-Statements) Statement gegebenwird.
commit transaction (EOT) : Mit diesem Statement sagt man dem Transaktions-Manager,dass die logische Arbeitseinheit erfolgreich abgeschlossen wurde und die Datenbank wiederin einem konsistenten Zustand ist. Alle durch diese Transaktion veranlassten Anderungenan der Datenbank konnen permanent gemacht werden. In SQL heißt das Statement:COMMIT;
rollback (abort) transaction (EOT) : Durch dieses Statement wird dem Transaktions-Manager gesagt, dass die Transaktion nicht erfolgreich zu Ende gebracht wurde und dassdie Datenbank moglicherweise in einem inkonsistenten Zustand ist. Alle seit Beginn derTransaktion durchgefuhrten Anderungen an der Datenbank mussen ruckgangig gemachtwerden. In SQL heißt das Statement:ROLLBACK;
In SQL wird mit COMMIT oder ROLLBACK eine Transaktion beendet.
Die oben gezeigte Transaktion hat mit diesen Mechanismen nun folgende Form:
EXEC SQL WHENEVER SQLERROR GO TO rollback;
EXEC SQL INSERT -- Beginn der Transaktion
INTO SP (SNR, PNR, QTY)
VALUES (’S5’, ’P1’, 180);
EXEC SQL UPDATE P
SET TOTQTY = TOTQTY + 180
WHERE PNR = ’P1’;
EXEC SQL COMMIT -- Ende der Transaktion;
goto ende;
rollback: EXEC SQL ROLLBACK -- Ende der Transaktion;
ende: ;
Diese Mechanismen sind normalerweise nur mit embedded SQL erlaubt, da sie interaktiv zugefahrlich sind. Manche Implementationen aber erlauben interaktive Anwendung und stellenentsprechende Mechanismen zur Verfugung.
Transaktionen sollten die sogenannten ACID-Eigenschaften haben:
• Atomicity : Atomaritat. Transaktionen sind atomar (”Alles oder Nichts”). Eine Transaktionwird entweder ganz durchgefuhrt oder hat keine Auswirkung auf die Datenbank.

B.2. NEBENLAUFIGKEIT (CONCURRENCY) 121
• Consistency : Konsistenz. Integritatserhaltung. Eine Transaktion transformiert die Daten-bank von einem konsistenten (korrekten) Zustand in einen anderen konsistenten Zustand.Wahrend einer Transaktion kann es Datenbank-Zustande geben, die nicht konsistent oderkorrekt sind.
• Isolation : Transaktionen sind voneinander isoliert. Keine Transaktion kann Zwischen-zustande einer anderen Transaktion sehen. Die Transaktion T1 kann die Anderungen vonTransaktion T2 nach deren COMMIT sehen, oder T2 kann die Anderungen von T1 nach derenCOMMIT sehen. Beides oder etwas dazwischen ist nicht moglich.
• Durability : Dauerhaftigkeit. Persistenz. Anderungen an der Datenbank sind nach einemCOMMIT permanent, auch wenn es sofort danach zu einem Systemabsturz kommt.
B.2 Nebenlaufigkeit (Concurrency)
B.2.1 Probleme bei Nebenlaufigkeit
Ursache fur Datenbank-Fehler ist der ”gleichzeitige” Zugriff von verschiedenen Transaktionenauf dasselbe Datenobjekt.
Folgende drei Probleme konnen auftreten, wenn Transaktionen (im folgenden A und B) paralleldurchgefuhrt werden. (Fur die Zeiten ti gilt ti < tj , falls i < j):
lost update (verlorene Aktualisierung) bei folgendem Szenario:
1. Transaktion A ermittelt Tupel p zur Zeit t1.
2. Transaktion B ermittelt Tupel p zur Zeit t2.
3. Transaktion A aktualisiert Tupel p zur Zeit t3 (auf der Basis von Werten, die zur Zeitt1 gesehen wurden).
4. Transaktion B aktualisiert Tupel p zur Zeit t4 (auf der Basis von Werten, die zur Zeitt2 gesehen wurden).
Zur Zeit t4 ist die Aktualisierung durch A verloren, da B sie uberschrieben hat.
uncommitted dependency (dirty read, Abhangigkeit von nicht permanenten Daten) beifolgendem Szenario:
1. Transaktion B aktualisiert Tupel p zur Zeit t1.
2. Transaktion A ermittelt (oder aktualisiert gar) Tupel p zur Zeit t2.
3. Transaktion B macht ein ROLLBACK zur Zeit t3.
A hat falsche Daten (oder hat seine Aktualisierung verloren).
inconsistent analysis (non repeatable read, Arbeit mit inkonsistenten Daten) bei folgen-dem Szenario: A soll die Summe S von drei Konten K1 = 40,K2 = 50,K3 = 60 bestimmen.B transferiert einen Betrag 10 von Konto K3 nach Konto K1.
1. Transaktion A ermittelt K1(= 40) und summiert (S = 40).
2. Transaktion A ermittelt K2(= 50) und summiert (S = 90).

122 ANHANG B. TRANSAKTIONSVERARBEITUNG
3. Transaktion B ermittelt K3(= 60).
4. Transaktion B aktualisiert K3 = K3 − 10 = 50.
5. Transaktion B ermittelt K1(= 40).
6. Transaktion B aktualisiert K1 = K1 + 10 = 50.
7. Transaktion B COMMIT.
8. Transaktion A ermittelt K3(= 50) und summiert (S = 140).
A hat einen inkonsistenten Zustand der Datenbank gesehen. Nach 6. ist das erste Lesenvon K1 nicht wiederholbar.
phantoms (repeatable read, Lesen von Phantomen) Eine zweite Transaktion fugt ein Tupelein, das der Selektionsbedingung einer ersten Transaktion genugt. Wenn die erste Transak-tion die Selektion wiederholt, dann liest sie beim zweiten Mal mehr Tupel. Entsprechendesgilt fur Tupel, die zwischendurch geloscht werden.
B.2.2 Sperren (Locking)
Parallele Transaktionen mussen geeignet synchronisiert (synchronized) werden. Die im vor-hergehenden Abschnitt angesprochenen Probleme kann man mit Sperrmechanismen (locking)losen. Uberlicherweise gibt es folgende Arten von Sperren (locks):
1. X-Lock (exclusive lock, write-Lock, write-exclusive, exclusives Schreiben, Schreibsperre):Erlaubt Schreib- und Lesezugriff auf ein Objekt nur fur die das X-Lock beantragendeTransaktion. Hat die Transaktion das X-Lock auf ein Objekt bekommen, werden Lock-Beantragungen anderer Transaktionen zuruckgewiesen, d.h. diese Transaktionen werden inWarteschlangen fur das betreffende Objekt gestellt.
2. S-Lock (shared lock, read-lock, read-sharable, gemeinsames Lesen, Lesesperre): Ein Lesezu-griff auf ein Objekt ist erlaubt. Ein Schreibzugriff ist nicht moglich. Hat eine Transaktionein S-Lock auf ein Objekt, dann konnen weitere Transaktionen ein S-Lock auf dasselbeObjekt bekommen. Versuche, ein X-Lock zu bekommen, werden zuruckgewiesen.
3. U-Lock (upgrade lock, Anderungssperre): Dieses Lock findet man bei OODBS. Bei richtigerVerwendung (siehe unten) verhindert es Verklemmungen. Nur eine Transaktion darf ein U-Lock auf ein Objekt haben. Andere Transaktionen konnen aber S-Locks fur dieses Objektbekommen. Eine Transaktion, die auf ein Objekt ein U-Lock setzt, beabsichtigt, dieses Lockim Laufe der Transaktion zu einem X-Lock zu verscharfen (upgrade).
Diese Regeln werden ublicherweise in sogenannten Kompatibilitatsmatrizen zusammenge-stellt:
S-Lock X-Lock
S-Lock ja neinX-Lock nein nein

B.2. NEBENLAUFIGKEIT (CONCURRENCY) 123
S-Lock U-Lock X-Lock
S-Lock ja ja neinU-Lock ja nein neinX-Lock nein nein nein
In SQL gibt es keine expliziten Lockingmechanismen. Normalerweise werden die entsprechendenLocks (S- bzw X-Lock) implizit von einer Retrieve- oder Update-Anweisung angefordert. DieLocks sollten bis zum Ende der Transaktion (COMMIT oder ROLLBACK) gehalten werden.
Die drei genannten Probleme werden mit Lockingmechanismen folgendermaßen gelost:
lost update :
1. Transaktion A fordert S-Lock fur Tupel p, bekommt das S-Lock und ermittelt Tupelp zur Zeit t1.
2. Transaktion B fordert S-Lock fur Tupel p, bekommt das S-Lock und ermittelt Tupelp zur Zeit t2.
3. Transaktion A fordert X-Lock fur Tupel p zur Zeit t3 und muss auf das X-Lock warten,da Transaktion B ein S-Lock auf Tupel p hat.
4. Transaktion B fordert X-Lock fur Tupel p zur Zeit t4 und muss ebenfalls auf dasX-Lock warten, da Transaktion A ein S-Lock auf Tupel p hat.
5. . . .
Verklemmung (Deadlock!)!!
uncommitted dependency :
1. Transaktion B fordert X-Lock fur Tupel p, bekommt das X-Lock und aktualisiert Tupelp zur Zeit t1.
2. Transaktion A fordert S-Lock (X-Lock) fur Tupel p zur Zeit t2 und muss warten, bisB das X-Lock freigibt.
3. Transaktion B macht ein ROLLBACK zur Zeit t3 und gibt damit alle Locks frei.
4. Transaktion A bekommt das S-Lock (X-Lock) und ermittelt (aktualisiert) Tupel p zurZeit t4.
inconsistent analysis :
1. Transaktion A fordert S-Lock fur K1, bekommt dies, ermittelt K1(= 40) und summiert(S = 40).
2. Transaktion A fordert S-Lock fur K2, bekommt dies, ermittelt K2(= 50) und summiert(S = 90).
3. Transaktion B fordert S-Lock fur K3, bekommt dies und ermittelt K3(= 60).
4. Transaktion B fordert X-Lock fur K3, bekommt dies und aktualisiert K3 = K3−10 =50.
5. Transaktion B fordert S-Lock fur K1, bekommt dies und ermittelt K1(= 40).
6. Transaktion B fordert X-Lock fur K1 und bekommt dies nicht, weil A ein S-Lockdarauf hat. Wartet.

124 ANHANG B. TRANSAKTIONSVERARBEITUNG
7. Transaktion A fordert S-Lock fur K3 und bekommt dies nicht, weil B ein X-Lockdarauf hat. Wartet.
8. . . .
Verklemmung (Deadlock)!!!
Behandlung von Verklemmung:
Voranforderungsstrategie (preclaim strategy): Jede Transaktion fordert alle ihre Sperren an,bevor sie mit der Ausfuhrung beginnt (”konservativer Scheduler”). Das verringert denGrad der Nebenlaufigkeit bei Datenbanksystemen derart, dass dies i.a. nicht akzeptabelist. Ferner ist es oft unmoglich, vor der Ausfuhrung einer Transaktion zu wissen, was zusperren ist.
Toleranzstrategie: Verklemmungen werden erlaubt und gelost (”aggressiver Scheduler”). ZurErkennung einer Verklemmung muss ein Vorranggraph (Konfliktgraph, Wait-For-Graph) aufgebaut werden, dessen Knoten die derzeit laufenden Transaktionen sind unddessen Kanten wie folgt bestimmt sind: Sofern eine Transaktion Ti eine Sperre auf einObjekt, das derzeit von Tj gesperrt ist, anfordert, dann wird eine Kante vom Knoten Tizum Knoten Tj gezogen. Die Kante wird entfernt, sobald Tj die Sperre aufhebt. Ein Zyklusim Graphen zeigt eine Verklemmung an.
Zur Auflosung einer Verklemmung wird eine der verklemmten Transaktionen zuruckgesetzt(ROLLBACK) – eventuell mit Meldung an den Benutzer – und spater wieder neu gestartet.
T1 T2
T3
T4
T5
T6
Strategie mit U-Locks: Vor Beginn fordert jede Transaktion fur alle Objekte, die gelesen wer-den sollen, ein S-Lock, und fur alle Objekte, die aktualisiert werden sollen, ein U-Lock an.Wahrend einer Transaktion werden dann vor dem Aktualisieren die entsprechenden X-Locks angefordert. Ansonsten wird das Zwei-Phasen-Sperr-Protokoll (siehe unten) befolgt.Diese Strategie vermindert die Wahrscheinlichkeit von Deadlocks – insbesondere im Fallevon einem Schreiber und mehreren konkurrierenden Lesern – und erhoht die Nebenlaufig-keit gegenuber der Voranforderungsstrategie. Auch hier gibt es die Problematik, dass vonvornherein oft unklar ist, was zu sperren ist.
B.2.3 Serialisierbarkeit
Serialisierbarkeit ist ein Kriterium, das die Korrektheit von nebenlaufigen Transaktionen be-stimmt. Das Kriterium lautet:

B.2. NEBENLAUFIGKEIT (CONCURRENCY) 125
• Eine verschachtelte Durchfuhrung (schedule) von mehreren korrekten Transaktionen istdann korrekt, wenn sie serialisierbar ist, d.h. wenn sie – fur alle erlaubten Ausgangswer-te (korrekte Datenbankzustande vor Durchfuhrung der Transaktionen) – dasselbe Resultatliefert wie mindestens eine nicht verschachtelte (serielle) Durchfuhrung der Transaktionen.
Bemerkungen:
1. Individuelle Transaktionen sind korrekt, wenn sie die Datenbank von einem konsisten-ten Zustand in einen anderen konsistenten Zustand uberfuhren. Daher ist die serielleDurchfuhrung von korrekten Transaktionen auch wieder korrekt.
2. Es mag serielle Durchfuhrungen korrekter Transaktionen geben, die unterschiedliche Resul-tate – insbesondere unterschiedlich zur verschachtelten Durchfuhrung – liefern. Es kommtdarauf an, dass eine serielle Durchfuhrung dasselbe Ergebnis liefert.
Betrachten wir die Transaktion A mit den Schritten
Lies x
Addiere 1 zu x
Schreib x
und die Transaktion B:
Lies x
Verdopple x
Schreib x
Wenn x anfanglich 10 war, dann ist x = 22 nach AB (d.h. erst A, dann B) und nach BA x
= 21. Beide Serialisierungen sind korrekt, liefern aber unterschiedliche Datenbankzustande.
3. Die Anzahl der moglichen Verschachtelungen ist ”astronomisch”. Bei zwei Transaktionenzu je 2 atomaren Anweisungen sind es 6, bei je 3 Anweisungen 20, bei je 4 Anweisungen70, bei je 5 Anweisungen 252 Verschachtelungen. Bei drei Transaktionen zu je 1 atomarenAnweisungen sind es 6, bei je 2 Anweisungen 90, bei je 3 Anweisungen 1680, bei je 4Anweisungen 34650, bei je 5 Anweisungen 756756 Verschachtelungen.
Das Zwei-Phasen-Sperrtheorem (two-phase-locking theorem) lautet:
• Wenn alle Transaktionen das Zwei-Phasen-Sperrprotokoll beachten, dann sind alle mogli-chen verschachtelten Durchfuhrungen serialisierbar, wobei das Zwei-Phasen-Sperrprotokollfolgendermaßen aussieht:
1. Bevor eine Transaktion ein Objekt benutzt, muss sie eine Sperre auf das Objekt setzen.
2. Nach der Freigabe einer Sperre darf eine Transaktion keine weiteren Sperren setzen(auch keine Upgrade-Locks).
Mit dem Abschluss einer Transaktion durch COMMIT oder ROLLBACK – und damit automatischeFreigabe aller Locks – erzwingt SQL automatisch mindestens (eigentlich mehr als) dieses Pro-tokoll. Diese starkere Forderung hat zur Folge, dass es nicht zu kaskadierenden Abbruchenkommt.
Es gibt aber Systeme, die die Befolgung dieses Protokolls freistellen.
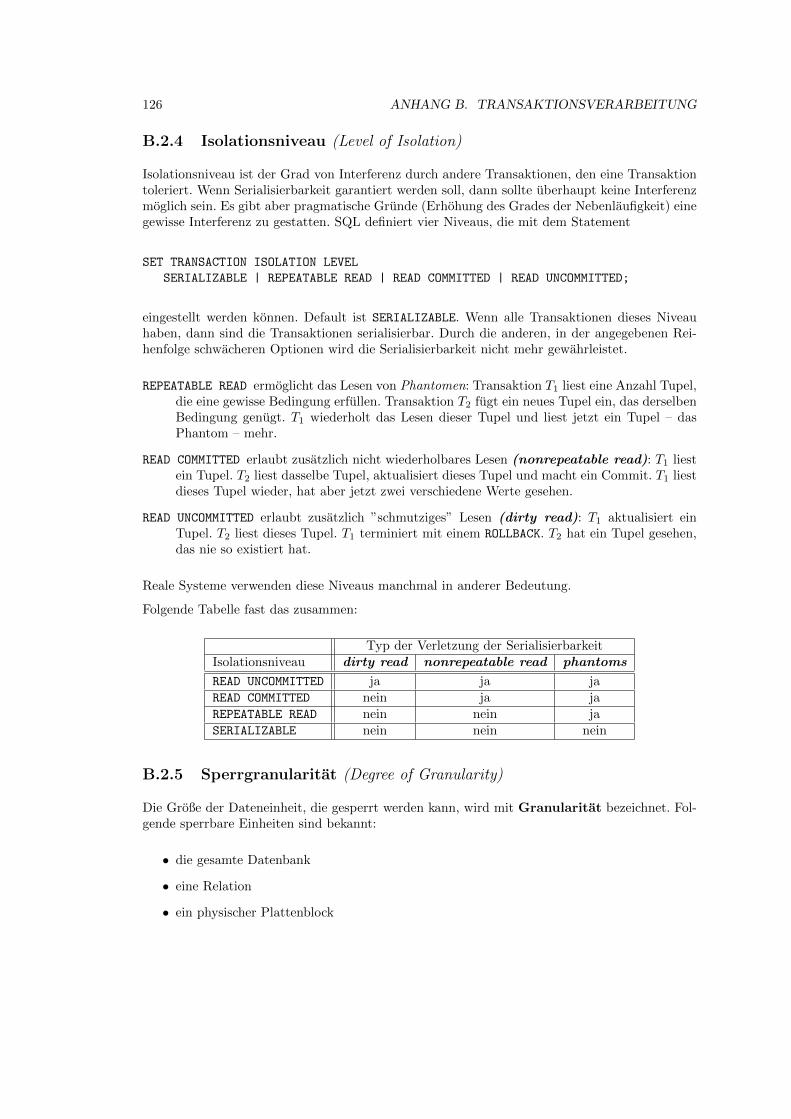
126 ANHANG B. TRANSAKTIONSVERARBEITUNG
B.2.4 Isolationsniveau (Level of Isolation)
Isolationsniveau ist der Grad von Interferenz durch andere Transaktionen, den eine Transaktiontoleriert. Wenn Serialisierbarkeit garantiert werden soll, dann sollte uberhaupt keine Interferenzmoglich sein. Es gibt aber pragmatische Grunde (Erhohung des Grades der Nebenlaufigkeit) einegewisse Interferenz zu gestatten. SQL definiert vier Niveaus, die mit dem Statement
SET TRANSACTION ISOLATION LEVEL
SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED;
eingestellt werden konnen. Default ist SERIALIZABLE. Wenn alle Transaktionen dieses Niveauhaben, dann sind die Transaktionen serialisierbar. Durch die anderen, in der angegebenen Rei-henfolge schwacheren Optionen wird die Serialisierbarkeit nicht mehr gewahrleistet.
REPEATABLE READ ermoglicht das Lesen von Phantomen: Transaktion T1 liest eine Anzahl Tupel,die eine gewisse Bedingung erfullen. Transaktion T2 fugt ein neues Tupel ein, das derselbenBedingung genugt. T1 wiederholt das Lesen dieser Tupel und liest jetzt ein Tupel – dasPhantom – mehr.
READ COMMITTED erlaubt zusatzlich nicht wiederholbares Lesen (nonrepeatable read): T1 liestein Tupel. T2 liest dasselbe Tupel, aktualisiert dieses Tupel und macht ein Commit. T1 liestdieses Tupel wieder, hat aber jetzt zwei verschiedene Werte gesehen.
READ UNCOMMITTED erlaubt zusatzlich ”schmutziges” Lesen (dirty read): T1 aktualisiert einTupel. T2 liest dieses Tupel. T1 terminiert mit einem ROLLBACK. T2 hat ein Tupel gesehen,das nie so existiert hat.
Reale Systeme verwenden diese Niveaus manchmal in anderer Bedeutung.
Folgende Tabelle fast das zusammen:
Typ der Verletzung der SerialisierbarkeitIsolationsniveau dirty read nonrepeatable read phantoms
READ UNCOMMITTED ja ja jaREAD COMMITTED nein ja jaREPEATABLE READ nein nein jaSERIALIZABLE nein nein nein
B.2.5 Sperrgranularitat (Degree of Granularity)
Die Große der Dateneinheit, die gesperrt werden kann, wird mit Granularitat bezeichnet. Fol-gende sperrbare Einheiten sind bekannt:
• die gesamte Datenbank
• eine Relation
• ein physischer Plattenblock

B.2. NEBENLAUFIGKEIT (CONCURRENCY) 127
• ein Tupel
• ein Attributwert
Sind die Einheiten groß, dann ist der Systemaufwand (Verwaltung der Sperren) fur die Ne-benlaufigkeit klein; aber auch der Grad der Nebenlaufigkeit ist klein. Bei kleinen Einheiten wirdder Systemaufwand groß; dafur wachst auch der Grad der Nebenlaufigkeit.
Durch weitere Sperrmechanismen (intent locking protocol) kann der Systemaufwand einiger-maßen beherrscht werden.
X-Locks und S-Locks haben wir schon kennengelernt. Sie konnen auf einzelne Tupel und ganzeRelationen angewendet werden. Die zusatzlichen Locks machen nur Sinn fur Relationen (R):
IS (intent shared) : Transaktion T beabsichtigt S-Locks auf einzelne Tupel von R zu setzen, umeinzelne Tupel in R zu lesen.
S (shared) : Transaktion T erlaubt konkurrierende Leser fur R. Aktualisierende Transaktionensind in R nicht erlaubt. T selbst wird keine Aktualisierungen von R vornehmen.
IX (intent exclusive) : Transaktion T beabsichtigt X-Locks auf einzelne Tupel von R zu setzen.
SIX (shared intent exclusive) : Transaktion T erlaubt fur R Leser, die beabsichtigen zu lesen.Lesende und aktualisierende Transaktionen sind in R nicht erlaubt. Aber T selbst wirdeinzelne Tupel von R aktualisieren und X-Locks auf einzelne Tupel von R setzen.
X (exclusive) : T erlaubt uberhaupt keinen konkurrierenden Zugriff auf R. T selbst wird eventuelleinzelne Tupel von R aktualisieren.
Die Kompatibiltatsmatrix hat folgende Form:
X SIX IX S IS –
X nein nein nein nein nein jaSIX nein nein nein nein ja jaIX nein nein ja nein ja jaS nein nein nein ja ja jaIS nein ja ja ja ja ja– ja ja ja ja ja ja
Formulierung des (intent) Sperrprotokolls:
• Bevor eine Transaktion ein S-Lock auf ein Tupel setzen kann, muss sie erst ein IS-Lockoder starkeres Lock auf die entsprechende Relation setzen.
• Bevor eine Transaktion ein X-Lock auf ein Tupel setzen kann, muss erst ein IX-Lock oderstarkeres Lock auf die entsprechende Relation setzen.
Da SQL diese Mechanismen nicht explizit unterstutzt, wird implizit gesperrt. D.h., wenn eineTransaktion nur liest, wird fur jede betroffene Relation ein IS-Lock implizit gesetzt. Fur eineaktualisierende Transaktion werden fur die betroffenen Relationen IX-Locks gesetzt.
Manche Systeme arbeiten mit lock escalation: Wenn der Aufwand fur das Sperren zu großwird, dann werden z.B. automatisch individuelle S-Locks auf einzelnen Tupeln ersetzt durch einS-Lock auf der ganzen Relation (Konvertierung eines IS-Locks zu einem S-Lock).

128 ANHANG B. TRANSAKTIONSVERARBEITUNG
B.3 Transaktions-Modell der ODMG
Es werden die S-, U- und X-Locks unterstutzt. Alle Locks werden bis zum Ende einer Transaktiongehalten. Die Locks werden implizit beantragt, konnen aber auch explizit uber Methoden derObjekte (lock und try_lock) beantragt werden. Das Upgrade-Lock kann nur explizit beantragtwerden.
Jeder Zugriff (Erzeugen, Loschen, Aktualisieren, Lesen) auf persistente Objekte muss innerhalbeiner Transaktion erfolgen (within the scope of a transaction).
Innerhalb eines Threads kann es nur eine lineare Folge von Transaktionen geben. D.h. ein Threadkann hochstens eine aktuelle Transaktion haben. Aber ein Thread kann eine Transaktion ver-lassen und eine andere betreten. Eine Transaktion bezieht sich auf genau eine DB, die allerdingseine verteilte DB sein kann.
Eine Transaktion kummert sich nicht um transiente Objekte. D.h. transiente Objekte werdenbeim Abbruch einer Transaktion nicht automatisch wiederhergestellt.
In der Schnittstelle Transaction sind die Methoden definiert, mit denen eine Transaktion ma-nipuliert werden kann:
interface Transaction
{void begin () raises (TransactionInProgress, DatabaseClosed);
void commit () raises (TransactionNotInProgress);
void abort () raises (TransactionNotInProgress);
void checkpoint () raises (TransactionNotInProgress);
void join () raises (TransactionNotInProgress);
void leave () raises (TransactionNotInProgress);
boolean isOpen ();
};
Transaktionen werden erzeugt mit Hilfe einer TransactionFactory, die Methoden new () undcurrent () zur Verfugung stellt.interface TransactionFactory
{Transaction new ();
Transaction current ();
};
Nach der Erzeugung einer Transaktion ist sie zunachst geschlossen. Sie muss explizit mit der Me-thode begin () geoffnet werden. Die Operation commit () sorgt dafur, dass alle in der Trans-aktion erzeugten oder modifizierten Objekte in die Datenbank geschrieben werden. Nach einemabort () wird die DB in den Zustand vor der Transaktion zuruckgesetzt. Nach einem commit ()
oder abort () werden alle Locks freigegeben. Die Transaktion wird geschlossen.
Die Operation checkpoint () ist aquivalent zu einem commit () gefolgt von einem begin (),außer dass alle Locks behalten werden. D.h. es kommt dabei zu permanenten Anderungen an derDB, die von einem spateren abort () nicht mehr ruckgangig gemacht werden konnen.

B.3. TRANSAKTIONS-MODELL DER ODMG 129
Damit eine Thread auf persistente Objekte zugreifen kann, muss sie erst mit einer Transaktionassoziiert werden. Das erfolgt entweder implizit durch das begin () oder explizit durch einjoin (). Mit join () kann eine Thread eine aktive Transaktion betreten. Ist die Thread schonmit einer Transaktion assoziiert, wird vorher automatisch ein leave () fur diese Transaktiondurchgefuhrt. Ein Thread kann hochstens mit einer Transaktion assoziiert sein. Beim Wechselvon einer Transaktion zu einer anderen wird kein commit () oder abort () gemacht.
Mehrere Threads eines Adressraums konnen mit derselben Transaktion assoziiert sein. Zwischendiesen Threads gibt es kein Lockmechanismus. Dafur muss der Programmierer sorgen.
B.3.1 Java Binding
Unter Java sind Transaktionen Objekte von Klassen, die die Schnittstelle Transaction imple-mentieren.
package kj.ovid.odmg;
public interface Transaction
{public void begin ()
throws TransactionInProgressException, DatabaseClosedException;
public void commit ()
throws TransactionNotInProgressException;
public void abort ()
throws TransactionNotInProgressException;
public void checkpoint ()
throws TransactionNotInProgressException;
public void join ()
throws TransactionNotInProgressException;
public void leave ()
throws TransactionNotInProgressException;
public boolean isOpen ();
public void lock (Object obj, int mode)
throws LockNotGrantedException;
public boolean try_lock (Object obj, int mode);
public static final int READ = 1;
public static final int UPGRADE = 2;
public static final int WRITE = 4;
}
Bevor eine Thread irgendeine Datenbankoperation macht, braucht sie ein Transaktionsobjekt,wofur sie begin () oder join () aufruft, jenachdem, ob sie das Objekt selbst erzeugt hat odernicht. Das ist dann ihre aktuelle (current) Transaktion, und nur auf der kann sie Operationenausfuhren. Sonst werden die entsprechenden Exceptions geworfen.

130 ANHANG B. TRANSAKTIONSVERARBEITUNG
Aber mehrere Threads konnen unter derselben Transaktion laufen. Allerdings muss in diesemFall der Programmierer selbst fur die Nebenlaufigkeits-Kontrolle sorgen.
Ein Transaction-Objekt wird erzeugt, indem fur das Implementation-Objekt die Methode
newTransaction ()
aufgerufen wird.
(Auf das Implementation-Objekt gehen wir hier nicht weiter ein. Es bildet den Hersteller-abhangigen Einstieg in das Java-Binding.)
Da Java selbst eine Wurzelklasse Object hat, kann dieser Name nicht mehr fur das ODMG-Object-Interface verwendet werden. Beim Java-Binding verzichtet man daher ganz auf dieseSchnittstelle und verteilt die dort definierten Operationen auf verschiedene andere Klassen. Furdie Operation copy () wird das clone () in Object verwendet. delete () taucht in der Schnitt-stelle Database als deletePersistent (Object o) auf. same_as (in Object anObject) habeich noch nicht gefunden. Die Lock-Operationen sind nun in der Schnittstelle Transaction un-tergebracht.
Transktions-Objekte konnen nicht persistent gemacht werden. ”Lange” Transaktionen sind daher(bisher) nicht moglich.
B.4 Ubungen
B.4.1 U-Locks
Zeigen Sie, dass es bei lost update und bei inconsistent analysis nicht zu einer Verklemmungkommt, wenn die Strategie mit U-Locks verwendet wird.
B.4.2 Serialisierbarkeit
Ist folgende verschachtelte Durchfuhrung V1 von zwei Transaktionen T1 und T2 serialisierbar?(Die Anfangswerte seien x = 10 und y = 5)
T1: Liest x
T2: Liest y
T2: Liest x
T1: x = x + 7
T2: if (x > 12) then x = x + y
T2: Schreibt x
T1: Schreibt x

B.4. UBUNGEN 131
B.4.3 Zwei-Phasen-Sperrtheorem
Wird von den folgenden beiden Transaktionen das Zwei-Phasen-Sperrtheorem eingehalten.
T1.Slock (x)
T1.read (x)
T1.x = x + 7
T1.Xlock (x)
T1.write (x)
T1.free (x)
T2.Slock (y)
T2.read (y)
T2.Slock (x)
T2.read (x)
T2.free (x)
T2.if (x > 12) then x = x + y
T2.Xlock (x)
T2.write (x)
T2.free (y)
T2.free (x)

132 ANHANG B. TRANSAKTIONSVERARBEITUNG

Anhang C
ObjektorientiertesDatenbanksystem db4o
Das objektorientierte Datenbanksystem db4o gibt es unter .NET und Java. Der folgende Anhangenthalt eine kurze Einfuhrung in die Verwendung der Datenbank db4o unter Java JDK 5.
Als Beispiel werden Taxen und ihre Chauffeure in der Datenbank verwaltet. Alle Beispiele werdenuber die Klasse Anwendung gestartet.
C.1 Installation
Die db4o-Datenbank-Maschine besteht aus einer einzigen .jar-Datei.
Wenn man von db4o die Java-zip-Datei fur die Datenbank heruntergeladen und entpackt hat,findet man im Verzeichnis lib eine Datei mit etwa folgendem Namen:
db4o-8.0.184.15484-all-java5.jar
Es genugt, diese Datei in den CLASSPATH fur javac und java aufzunehmen. Unter Eclipsewird die Datei in das /lib/-Verzeichnis Ihres Projekts kopiert und als Bibliothek zum Projektaddiert.
Damit ist das Datenbanksystem installiert. Die Große der jar-Datei betragt nur etwa 2,7 MByte!
C.2 Offnen, Schließen
Unter db4o ist eine Datenbank eine Datei an beliebiger Stelle mit beliebigem Namen. Es istallerdings Konvention, dass als Datei-Erweiterung .db4o verwendet wird.
Als import-Anweisung genugt zunachst:
133

134 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
import com.db4o.*;
und/oderimport com.db4o.query.*
Unsere Beispieldatenbank soll taxi.db4o heißen. Sie wird neu angelegt oder geoffnet, indem
com.db4o.ObjectContainer db
= com.db4o.Db4oEmbedded.openFile (
Db4oEmbedded.newConfiguration (),
"taxi.db4o");
aufgerufen wird.
Nach Verwendung der Datenbank, muss sie wieder geschlossen werden:
db.close ();
Um das Schließen der Datenbank zu garantieren, werden wir einen Konstrukt
try { ... } finally { db.close (); }
verwenden.
Bemerkungen:
1. Ein ObjectContainer reprasentiert im Single-User-Mode die Datenbank, im Multi-User-Mode eine Client-Verbindung zu einem db4o-Server fur eine Datenbank. Wir werdenzunachst im Single-User-Mode arbeiten.
2. Jeder ObjectContainer besitzt eine Transaktion. Jeder Datenbank-Vorgang ist transak-tional. Wenn ein ObjectContainer geoffnet wird, beginnt sofort eine Transaktion. Mitcommit () oder rollback () wird die nachste Transaktion gestartet. Die letzte Transak-tion wird durch close () beendet.
3. Jeder ObjectContainer verwaltet seine eigenen Referenzen zu gespeicherten Objekten.
4. com.db4o.ObjectContainer hat sehr wenige Methoden. Jeder ObjectContainer kannnach com.db4o.ext.ExtObjectContainer gecasted werden. Dort sind wesentlich mehrMethoden definiert.
DBTAXI :String
Anwendung
main (arg :String[*])
Verzeichnis: ../code/oeffnen/

C.3. SPEICHERN VON OBJEKTEN 135
C.3 Speichern von Objekten
Wir schreiben eine Klasse Chauffeur, deren Konstruktor den Namen und das Alter des Chauf-feurs erwartet:
ChauffeurName :String
Alter :int
Folgender Code legt einen Chauffeur neu an und speichert ihn in der Datenbank:
Chauffeur chauffeur = new Chauffeur ("Ballack", 29);
db.store (chauffeur);
Verzeichnis: ../code/speichern/
Bemerkung: Primitive Datenelemente (boolean, byte, char, int, long, float, double) undauch String- und Date-Objekte konnen nicht als eigene Objekte in der Datenbank gespeichertwerden.
C.4 Finden von Objekten
Es gibt drei Moglichkeiten Objekte durch Anfragen an die Datenbank zu ermitteln:
• QBE: Query by Example, Anfrage durch Angabe eines Beispielobjekts
• NQ: Native Query
• SODA: Query API Simple Object Database Access
Es wird empfohlen NQ zu verwenden. Aber in diesem Abschnitt behandeln wir zunachst QBE.
Wir erzeugen ein prototypisches Objekt, z.B.:
Chauffeur chauffeur = new Chauffeur (null, 29);
Damit konnen wir uns alle Chauffeure im Alter von 29 Jahren aus der Datenbank holen:
List<Chauffeur> resultat = db.queryByExample (chauffeur);
Die resultierenden Chauffeure zeigen wir uns an mit:

136 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
for (Object o : resultat)
{System.out.println (o);
}
Da wir diesen Code ofters benotigen, schreiben wir ihn in die Methode
static void zeigeResultat (List<?> aList)
der Klasse DB.
Wenn wir alle Objekte der Klasse Chauffeur benotigen, dann schreiben wir
List<Chauffeur> resultat = db.query (Chauffeur.class);
Leider funktioniert auch
List<Chauffeur> resultat = db.queryByExample (new Chauffeur (null, 0));
genauso, weil ”0” der Defaultwert eines int ist.
Wenn wir den Namen angeben, erhalten wir alle Chauffeure, die diesen Namen tragen:
List<Chauffeur> resultat = db.queryByExample (new Chauffeur ("Kahn", 0));
Wir konnen auch nach Objekten von Klassen suchen, die eine bestimmte Schnittstelle realisierenoder eine abstrakte Klasse erweitern.
Bemerkungen:
1. Wenn nichts gefunden wird, dann kann das daran liegen, dass man nach unterschiedlichenChauffeur-Klassen sucht! Die Chauffeur-Klassen konnten in unterschiedlichen Packagesliegen (bei Eclipse)!
2. Die verschiedenen Query-Methoden liefern als Resultat immer ein ObjectSet. Es wird aberempfohlen List zu verwenden, das von ObjectSet erweitert wird.
Verzeichnis: ../code/finden/
C.5 Aktualisierung von Objekten
Ballack wird ein Jahr alter:

C.6. LOESCHEN VON OBJEKTEN 137
List<Chauffeur> resultat = db.queryByExample (new Chauffeur ("Ballack", 0));
Chauffeur gefunden = resultat.get (0);
gefunden.setAlter (gefunden.getAlter () + 1);
db.store (gefunden); // Aktualisierung!
Dabei ist zu beachten, dass wir ein zu aktualisierendes Objekt erst aus der Datenbank holenmussen, bevor wir es aktualisieren konnen. Wenn man nicht aufpasst, setzt man ausversehen einneues Objekt in die Welt!
Verzeichnis: ../code/aktualisieren/
C.6 Loeschen von Objekten
Objekte werden aus der Datenbank mit der Methode delete entfernt:
List<Chauffeur> resultat
= db.queryByExample (new Chauffeur ("Ballack", 0));
Chauffeur gefunden = resultat.get (0);
db.delete (gefunden);
Mit dem Code
List<Object> resultat
= db.queryByExample (new Object ());
for (Object o : resultat))
{db.delete (o);
}
loeschen wir alle Objekte in der Datenbanken.
Verzeichnis: ../code/loeschen/
C.7 NQ – Native Anfragen
QBE-Anfragen sind sehr eingeschrankt verwendbar, insbesondere wenn nach Defaultwerten ge-sucht werden soll. NQ-Anfragen dagegen bieten weitergehende Moglichkeiten unter Beibehaltungdes Vorteils, dass sie in der Hostsprache formuliert werden konnen. Damit werden diese Anfragentypsicher, Compilezeit-prufbar und refactorierbar.

138 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
Syntax: Der ObjectContainer-Methode query (...) wird ein Objekt einer – normalerweiseanonymen – Klasse ubergeben, die die Schnittstelle Predicate<T> realisiert, indem die Methodematch (...) implementiert wird. Das sei an folgendem Beispiel verdeutlicht:
List<Chauffeur> chauffeure = db.query (new Predicate<Chauffeur> ()
{public boolean match (Chauffeur chauffeur)
{return chauffeur.getAlter () > 30;
}});
Die Anfrage wird gegen alle Objekte vom Typ T, hier im Beispiel also Chauffeur, durchgefuhrt.Die Methode match kann irgendwelchen Code enthalten, solange sie ein boolean zuruckgibt.
Bemerkung: In Eclipse kann man sich fur diesen Anfragetyp ein Template erstellen:Window -> Preferences -> Java -> Editor -> Templates -> New
(Rechts muss Java als Kontext eingestellt sein.)Als Name konnte man nq verwenden und dann folgenden Text in das Musterfeld eingeben:
List<${extent}> list = db.query (new Predicate<${extent}> ()
{public boolean match (${extent} candidate)
{return true;
}});
Der folgende Code zeigt einige Beispiele:
Verzeichnis: ../code/nqQueries/
C.8 SODA Query API
SODA (simple object database access) ist die low-level Anfrage-API. Mit SODA konnenAnfragen dynamisch generiert werden.
Mit der ObjectContainer-Methode query () wird ein Query-Objekt erzeugt, fur das Ein-schrankungen definiert werden konnen.
// Finde alle Chauffeure junger als 30 Jahre:
Query query = db.query ();
query.constrain (Chauffeur.class);
query.descend ("alter")
.constrain (new Integer (30))

C.9. STRUKTURIERTE OBJEKTE 139
.smaller ();
List resultat = query.execute ();
Ein sogenannter Query-Graph besteht aus Query-Knoten und Einschrankungen. Ein Query-Knoten ist ein Platzhalter fur ein mogliches Ergebnis-Objekt. Eine Einschrankung entscheidet,ob ein Objekt tatsachlich ins Ergebnis aufgenommen wird.
Die Syntax von SODA wird hier nicht prasentiert. Stattdessen sollen einige Beispiele grob zeigen,wie es funktioniert. Wenn man tiefer einsteigen will, muss man die (leider sparliche) Dokumenta-tion von db4o oder das Internet zu Rate ziehen. Ein gute ausfuhrliche Darstellung gibt es offenbarnoch nicht.
Der folgende Code zeigt einige Beispiele:
Verzeichnis: ../code/sodaQueries/
C.9 Strukturierte Objekte
Jetzt geben wir dem Chauffeur ein Taxi
ChauffeurName :String
Alter :int
TaxiModell :StringNummer :String
und legen ein paar Taxen und Chauffeure an:
Chauffeur chauffeur = new Chauffeur ("Ballack", 31);
db.store (chauffeur);
// Chauffeur ist jetzt schon in der Datenbank.
Taxi taxi = new Taxi ("BMW", "13", chauffeur);
db.store (taxi);
chauffeur = new Chauffeur ("Kahn", 39);
taxi = new Taxi ("VW", "1", chauffeur);
db.store (taxi);
// Chauffeur ist hiermit auch in der Datenbank.
db.store (new Taxi ("Mercedes", "32", new Chauffeur ("Gomez", 22)));
Wenn ein Objekt auf andere Objekte verweist, werden diese mit dem Objekt gespeichert, fallssie noch nicht in der Datenbank sind.
Anfragen: Wir wollen alle Taxen haben, die Gomez fahrt.
QBE:

140 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
Chauffeur prototypChauffeur = new Chauffeur ("Gomez", 0);
Taxi prototypTaxi = new Taxi (null, null, prototypChauffeur);
List<Taxi> resultat = db.queryByExample (prototypTaxi);
NQ:
List<Taxi> resultat = db.query (
new Predicate<Taxi> ()
{public boolean match (Taxi taxi)
{return taxi.getChauffeur ().getName ().equals ("Gomez");
}});
SODA:
Query query = db.query ();
query.constrain (Taxi.class);
query.descend ("aChauffeur").descend ("name").constrain ("Gomez");
List resultat = query.execute ();
Eine interessante SODA-Anfrage ist: ”Alle Chauffeure, die ein BMW-Taxi fahren.” (Interessant,weil die Chauffeure ihr Taxi nicht kennen.)
Query taxiQuery = db.query ();
taxiQuery.constrain (Taxi.class);
taxiQuery.descend ("modell").constrain ("BMW");
Query chauffeurQuery = taxiQuery.descend ("aChauffeur");
List resultat = chauffeurQuery.execute ();
Aktualisierung:
1. Ein Taxi bekommt einen anderen Chauffeur.List<Taxi> resultat = db.queryByExample (new Taxi ("BMW", null, null));
Taxi taxi = resultat.get (0);
List<Chauffeur> res = db.queryByExample (new Chauffeur ("Gomez", 0));
Chauffeur chauffeur = res.get (0);
taxi.setChauffeur (chauffeur);
db.store (taxi); // Taxi wird zuruckgespeichert.

C.10. FELDER UND COLLECTIONS 141
2. Der Name des Chauffeurs eines Taxis wird geandert.List<Taxi> resultat = db.queryByExample (new Taxi ("BMW", null, null));
Taxi taxi = resultat.get (0);
taxi.getChauffeur ().setName ("Strauss-Kahn");
db.store (taxi); // Taxi wird zuruckgespeichert.
Wenn man das mit einer zweiten Datenbank-Verbindung uberpruft, dann sieht man, dassder Name nicht geandert ist. Hier stoßen wir auf das – i.a. große –
Problem der Aktualisierungstiefe(update depth).
Bei db4o ist die Aktualisierungstiefe defaultmaßig eins, d.h. die Operation db.store (...)
aktualisiert nur primitive Datenelemente. In diesem Fall hatten wir den Chauffeur gesondertspeichern mussen.
Ahnlich verhalt sich das System beim Loschen von Objekten, das defaultmaßig nur ”flach”ausgefuhrt wird.
Man kann die Datenbank-Verbindung bezuglich Update- und Delete-Verhalten konfigurie-ren. Darauf wird in einem spateren Abschnitt eingegangen. Aber insgesamt ist das einProblem, fur das es bei vielen DBMS schließlich keine wirklich befriedigende allgemeineLosung gibt.
Verzeichnis: ../code/taxi/
C.10 Felder und Collections
Jedes Taxi verwaltet alle seine Fahrten (Klasse Fahrt). Eine Fahrt beginnt (Beginn), endet(Ende) und hat zwei Entfernungen (Hin- und Ruckfahrt), die – um ein Beispiel fur ein Feld zuhaben – in einem Feld von double gespeichert werden.
ChauffeurName :String
Alter :int
TaxiModell :StringNummer :String
erzeugeFahrt ()
FahrtBeginn :Date
Ende :DateEntfernung :double[*]
*
• Felder sind keine Objekte der Datenbank.
• Collections sind eigene Objekte der Datenbank.
Anfrage QBE: Alle Fahrten mit Klose:

142 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
Chauffeur prototypChauffeur = new Chauffeur ("Klose", 0);
Fahrt prototypFahrt = new Fahrt (null, null, null, prototypChauffeur);
List<Fahrt> resultat = db.queryByExample (prototypFahrt);
Anfrage NQ: Alle Fahrten mit Geschwindigkeit kleiner 40 oder großer 80 km/h:
List<Fahrt> resultat = db.query (new Predicate<Fahrt> ()
{public boolean match (Fahrt fahrt)
{double v = fahrt.getEntfernung ()[0]
/ ((fahrt.getEnde ().getTime () - fahrt.getBeginn ().getTime ())
/1000/60/60);
return v < 40.0 || v > 80.0;
}});
Anfrage SODA: Alle Fahrten mit Klose:
Query fahrtQuery = db.query ();
fahrtQuery.constrain (Fahrt.class);
fahrtQuery.descend ("aChauffeur")
.descend ("name")
.constrain ("Klose");
List resultat = fahrtQuery.execute ();
Verzeichnis: ../code/fctaxi/
C.11 Vererbung
Neben den normalen Taxen gibt es auch Lasttaxen (Klasse LastTaxi), die sich wie Taxen verhal-ten, allerdings fahren sie etwas langsamer und haben noch einen Preisaufschlagsfaktor (AttributAufschlag):

C.12. TIEFE GRAPHEN UND AKTIVIERUNG 143
ChauffeurName :String
Alter :int
TaxiModell :StringNummer :String
erzeugeFahrt ()
LastTaxiAufschlag :double
erzeugeFahrt ()
FahrtBeginn :Date
Ende :DateEntfernung :double[*]
*
Die Vererbung funktioniert, wie erwartet. Es ist nur noch zu erganzen, dass wir mit
db.query (X.class)
public boolean match (X x) { }
auch nach Objekten von Klassen suchen konnen, die eine bestimmte Schnittstelle X realisierenoder eine Klasse X erweitern.
Verzeichnis: ../code/lasttaxi/
C.12 Tiefe Graphen und Aktivierung
Betrachten wir folgende Objektstruktur mit einem tiefen Graphen, d.h. die Struktur ist sehr tiefund weit verzeigert.
ob0 ob1 ob2 ob3 ob4
ob5ob6ob7ob8ob9
...
Wenn wir Objekt ob0 von der Datenbank holen, sollen dann alle anderen uber den Graphen anihm hangenden Objekte auch mitgeholt werden? Nein, denn man wurde damit ja eventuell dieganze ”Welt” laden, was eventuell sehr lange dauern und unseren Speicherplatz sprengen wurde.

144 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
C.12.1 Defaultverhalten
Bei db4o heißt der Term anstatt ”Laden” ”Aktivieren”. In der Tat werden defaultmaßig nurObjekte bis zur Tiefe 5 aktiviert, also ob0 bis ob4. Der Zeiger von ob4 auf ob5 ist zwar noch eingultiger Zeiger, aber das ob5 wird mit Defaultwerten initialsiert (Standard- und Referenztypen),d.h. alle Zeiger von ob5 aus bleiben null.
Das wollen wir demonstrieren, indem wir die Fahrten eines Taxis nicht in einem ArrayList-Objekt, sondern in einer verketteten Liste verwalten, die wir selbst schreiben. Die Klasse Fahrt
bekommt einfach einen Zeiger nextFahrt auf die nachste Fahrt. Die Klasse Taxi kennt direktnur die erste Fahrt.
ChauffeurName :String
Alter :int
TaxiModell :StringNummer :String
anzFahrten :interzeugeFahrt ()
FahrtBeginn :Date
Ende :DateEntfernung :double[*]
nextFahrt :Fahrt
Der folgende Code legt einen Chauffeur und ein Taxi mit 9 Fahrten an. Wenn wir nach Neueroff-nung der Datenbank das Taxi wieder von der Datenbank holen, dann wird zwar noch die funfteFahrt aktiviert, nicht mehr aber deren Referenz auf ihren Chauffeur, obwohl der Chauffeur schonlangst wieder aktiv ist. Auch bleiben die Entfernung und die Date-Objekte null.
Verzeichnis: ../code/tiefgraph/
C.12.2 Dynamische Aktivierung
Wir konnen Objekte dynamisch aktivieren durch:
db.activate (objekt, tiefe);
Dazu muss allerdings db zur Verfugung stehen.
Im folgenden Code wurde das in der toString ()-Methode der Klasse Taxi mit
Anwendung.getDb ().activate (fahrt, 1);
gemacht:
Verzeichnis: ../code/tiefgraph2/

C.12. TIEFE GRAPHEN UND AKTIVIERUNG 145
C.12.3 Kaskadierte Aktivierung
Man kann fur einen Typ die Aktivierung kaskadieren:
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.common ().objectClass (Fahrt.class).cascadeOnActivate (true);
db = Db4oEmbedded.openFile (conf, "taxi.db4o");
(Damit wird eine geladene Fahrt auch sofort aktiviert, was das Laden der nachsten Fahrt zurFolge hat.)
Siehe dazu: Verzeichnis: ../code/tiefgraph3/
C.12.4 Transparente Aktivierung
Wir konnen allerdings auch dafur sorgen, dass alle Objekte immer aktiviert werden mit:
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.common ().add (new TransparentActivationSupport ());
db = Db4oEmbedded.openFile (conf, "taxi.db4o");
Dabei riskieren wir aber wieder, dass eventuell die ganze Datenbank geladen wird. Objektesollten eigentlich nur dann aktiviert werden, wenn wir sie brauchen. Genau das ist jetzt (beitransparenter Aktivierung) moglich fur Objekte von Klassen, die die Schnittstelle Activatable
realisieren.
com.db4o.activation.ActivationPurposeREAD
WRITE
ChauffeurName :String
Alter :int
Fahrt:Activator {transient}Beginn :Date
Ende :DateEntfernung :double[*]
<<interface>>
com.db4o.ta.Activatablebind (:Activator)
activate (:ActivationPurpose)
Die get-Methoden werden – nach Bedarf – folgendermaßen implementiert:

146 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
public Typ getX ()
{activate (ActivationPurpose.READ);
return x;
}
Im folgenden Beispiel machen wir die Klasse Fahrt aktivierbar.
Verzeichnis: ../code/tiefgraph4/
Es sei darauf hingewiesen, dass db4o noch wesentlich mehr Moglichkeiten bezuglich Aktivierunganbietet. Dennoch: Mit der Aktivierung von Objekten muss man vorsichtig sein. Offenbar kannman leicht Fehler machen, die sich meistens entweder in NullPointerExceptions oder in derPerformanz außern oder den Speicher voll laufen lassen.
C.12.5 Transparente Persistenz
Bei den strukturierten Objekten hatten wir schon uber das Problem der Aktualisierungstiefeupdate depth gesprochen. Wenn sie zu klein ist, vergessen wir eventuell aktualisierte Objektezuruckzuspeichern. Wenn sie zu groß ist, kann es zu viele unnotige Aktualisierungen geben.
Mit transparent persistence kann das Problem gelost werden. Der Mechanismus ist ganzahnlich der transparenten Aktivierung. Die Datenbank wird entsprechend konfiguriert:
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.common ().add (new TransparentPersistenceSupport ());
db = Db4oEmbedded.openFile (conf, "taxi.db4o");
Ab jetzt ist die Aktualisierungstiefe fur jede Klasse unendlich. Das kann jetzt aber wieder furjede Klasse individuell gesteuert werden, indem die Schnittstelle Activatable realisiert wird undin den set-Methoden
activate (ActivationPurpose.WRITE)
aufgerufen wird.
Verzeichnis: ../code/tiefgraph5/
C.13 Indexe
Bemerkung: Indexe wirken sich insbesondere bei QBE- und SODA-Anfragen aus, inzwischen aberauch bei NQ-Anfragen, allerdings nicht besonders drastisch. Das ist auch verstandlich, da mandem Code von match (...) i.a. nur schwer ansehen kann, welcher Index zu verwenden ware.
Bei geschlossener Datenbank kann mit den Anweisungen

C.14. TRANSAKTIONEN 147
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.common ().objectClass (Chauffeur.class)
.objectField ("name").indexed (true);
db = Db4oEmbedded.openFile (conf, "taxi.db4o");
ein Index uber dem Attribut name der Klasse Chauffeur erzeugt werden, der beim ersten Ge-brauch der Klasse Chauffeur erzeugt wird.
Wenn der Index erzeugt ist, dann genugt zur Offnung der Datenbank:
db = Db4oEmbedded.openFile (Db4oEmbedded.newConfiguration (), "taxi.db4o");
Mit
db.close ();
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.common ().objectClass (Chauffeur.class)
.objectField ("name").indexed (false);
db = Db4oEmbedded.openFile (conf, "taxi.db4o");
wird der Index wieder geloscht.
Verzeichnis: ../code/index/
Indexe konnen auch auf Referenzen angelegt werden. Bei der Suche muss man aller-dings darauf achten, dass man mit Objekten aus der Datenbank sucht! Im Beispiel
Verzeichnis: ../code/indexRef/ wird nach Chauffeuren mit einer gewissen Adresse gesucht.Die Adresse muss daher erst einmal aus der Datenbank geholt werden.
Wenn man eine neues Adress-Objekt nimmt, dann wird es – bei SODA und QBE – offenbarals Prototyp verwendet, um die Adresse in der Datenbank zu finden, die dann fur die Sucheverwendet wird. Also man findet schließlich auch die gewunschten referenzierenden Objekte.Allerdings wirkt sich der Index nicht aus.
Bei NQ wird tatsachlich mit der Hauptspeicher-Adresse des neuen Adress-Objekts verglichen,die es in der Datenbank nicht gibt. Also findet man hier keine Chauffeure.
Bemerkung: Das nachtragliche Anlegen eines Index ist insgesamt schneller, kostet aber mehr,eventuell zu viel Speicher.
C.14 Transaktionen
Schon die ganze Zeit hatten wir implizit mit einer Transaktion gearbeitet, die mit dem Off-nen (openFile) eines ObjectContainers beginnt und mit dessen Schließen (close) mit einemCommit endet.
Mit
db.commit ();

148 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
beenden wir eine Transaktion vor dem Schließen des Objektcontainers. Die nachste Transaktionbeginnt mit dem nachsten Zugriff auf den Objektcontainer.
Mit
db.rollback ();
kann die laufende Transaktion ruckgangig gemacht werden. Dabei wird zwar der Datenbankin-halt ruckgangig gemacht, nicht aber Objekte, die fur die Transaktion aus der Datenbank geholtwurden. Diese sogenannten Live-Objekte mussen wir selbst wieder aus der Datenbank holen undzwar mit:
db.ext ().refresh (objekt, Integer.MAX_VALUE);
Ein erneutes db.query... (...) nutzt hier nichts, da hierbei offenbar nur das Live-Objektgeholt wird.
Bemerkung: ext-Funktionalitat lauft zwar stabil, konnte aber noch geandert werden.
Das Isolations-Niveau einer Transaktion ist READ COMMITTED.
Wie stehts mit Locks? Es gibt offenbar alle Moglichkeiten (uber Semaphore und Callbacks).
Verzeichnis: ../code/transaction/
C.15 Client/Server
In diesem Abschnitt behandeln wir nun Transaktionen, die parallel laufen. Das kann inner-halb einer JVM oder uber mehrere JVMs verteilt stattfinden. Konzeptionell gibt es da keinenUnterschied. ”ObjectContainer” und ”Datenbankverbindung” sind unter db4o synonym. EineTransaktion bezieht sich immer auf eine(n) ObjectContainer/Datenbankverbindung.
Bei nur einer JVM wird ein Datenbank-Server unter Port 0 geoffnet. Das bedeutet, dass keinNetz verwendet wird. Diesen Fall – Embedded Server – behandeln wir zunachst.
C.15.1 Embedded Server
Bisher hatten wir einen ObjectContainer direkt durch Offnen der Datenbankdatei erhalten.Wenn wir mehrere Container (d.h. Transaktionen) gleichzeitig benotigen, dann mussen wir ubereinen Server gehen. Folgender Code zeigt die Vorgehensweise:
import com.db4o.cs.*;
// ...
ObjectServer server = Db4oClientServer.openServer (
Db4oClientServer.newServerConfiguration (), "taxi.db4o", 0); // Port 0
try

C.15. CLIENT/SERVER 149
{ObjectContainer ct1 = server.openClient ();
ObjectContainer ct2 = server.openClient ();
ObjectContainer ct3 = server.openClient ();
// tu was mit den Containern bzw. Clients
ct1.close ();
ct2.close ();
ct3.close ();
}finally
{server.close ();
}
Jeder Client-Container hat seinen eigenen Cache von schwachen Referenzen auf die ihm schonbekannten Objekte. Um alle committed Anderungen durch andere Transaktionen sichtbar zumachen, muss eine Transaktion die ihr bekannten Objekte explizit mit der Datenbank abgleichen(refresh):
container.ext ().refresh (objekt, tiefe);
Die tiefe gibt an, wie weit bei einem Objekt-Graphen gegangen werden soll.
Im folgenden Programm legt die Transaktion ct1 einen neuen Chauffeur an und gibt diesen einemexistierenden Taxi. Das aktualisierte Taxi wird wieder zuruckgespeichert. Ein zweite Transaktionct2 ”schaut dabei zu”. Was diese zweite Transaktion vor und nach einem Commit bzw. Refreshsieht, soll das oben Ausgefuhrte exemplarisch verdeutlichen.
Verzeichnis: ../code/embeddedServer/
C.15.2 Verteiltes System
Um das System uber ein TCP/IP-Netz zu verteilen, wird der Server mit einer Port-Nummergroßer Null geoffnet. Die prinzipielle Vorgehensweise zeigt folgender Code:
ObjectServer server = Db4oClientServer.openServer (
Db4oClientServer.newServerConfiguration (), "taxi.db4o", 0xdb40); // Port > 0
try
{server.grantAccess ("user1", "password1");
server.grantAccess ("user2", "password2");
ObjectContainer ct1
= Db4oClientServer.openClient ("localhost", 0xdb40, "user1", "password1");
ObjectContainer ct2
= Db4oClientServer.openClient ("localhost", 0xdb40, "user2", "password2");

150 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
// tu was mit den Containern bzw. Clients
ct1.close ();
ct2.close ();
}finally
{server.close ();
}
Verzeichnis: ../code/clientServer/
Server und Clients laufen normalerweise auf unterschiedlichen JVMs. Wir prasentieren ohneweiteren Kommentar den Code fur die verschiedenen Aktionen, die dann auf unterschiedlichenHosts durchgefuhrt werden konnen, wobei ”localhost” entsprechend zu andern ist:
Starten des Servers:Verzeichnis: ../code/startServer/
public class Anwendung{// Constructors and Operations:public static void main (String[] aString)
{new StartServer (false).runServer ();}
} // end Anwendung
import com.db4o.*;import com.db4o.cs.*;import com.db4o.messaging.*;
public class StartServerimplements MessageRecipient{private boolean stop;
// Constructors and Operations:public final boolean isStop ()
{return stop;}
private final void setStop (boolean stop){this.stop = stop;}
public StartServer (boolean stop)/*** working constructor**/{setStop (stop);}
public synchronized void runServer (){ObjectServer server = Db4oClientServer.openServer (
Db4oClientServer.newServerConfiguration (), DB.TAXI, DB.PORT);

C.15. CLIENT/SERVER 151
try{server.grantAccess ("stopUser", "stopPassword");server.grantAccess ("user1", "password1");server.grantAccess ("user2", "password2");
server.ext ().configure ().clientServer ().setMessageRecipient (this);// this.processMessage erhalt die Botschaften (insbesondere stop)
Thread.currentThread ().setName (this.getClass ().getName ());// um den Thread in einem Debugger zu identifizieren
Thread.currentThread ().setPriority (Thread.MIN_PRIORITY);// server hat eigenen Thread. Daher genugt hier ganz niedrige Prio.
try{System.out.println ("db4o-Server wurde gestartet.");while (!isStop ())
{this.wait ();
// Warte, bis du gestoppt wirst.}
}catch (InterruptedException e) { e.printStackTrace (); }
}finally
{server.close ();System.out.println ("db4o-Server wurde gestoppt.");}
}public void processMessage
(MessageContext aMessageContext,Object message){if (message instanceof StopServer)
{close ();}
}public synchronized void close ()
{setStop (true);this.notify ();}
} // end StartServer
public class StopServer{// Constructors and Operations:public StopServer ()
/*** working constructor**/{}
} // end StopServer
import com.db4o.*;import java.util.*;
public class DB{

152 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
public static final String TAXI = System.getProperty ("user.home") + "/tmp/taxi.db4o";
public static final String HOST = "localhost";
public static final int PORT = 0xdb40;
// Constructors and Operations:public static void zeigeResultat (List<?> aList)
{System.out.println ("Anzahl Objekte: " + aList.size ());for (Object o : aList)
{System.out.println (" " + o);}
}} // end DB
Stoppen des Servers:
Verzeichnis: ../code/stopServer/
import com.db4o.*;import com.db4o.cs.*;import com.db4o.messaging.*;
public class Anwendung{// Constructors and Operations:public static void main (String[] aString)
{ObjectContainer cont = null;try
{cont = Db4oClientServer.openClient (
DB.HOST, DB.PORT, "stopUser", "stopPassword");}catch (Exception e ) { e.printStackTrace (); }
if (cont != null){MessageSender sender = cont.ext ().configure ().clientServer ()
.getMessageSender ();sender.send (new StopServer ());//cont.close ();while (!cont.ext ().isClosed ());}
}} // end Anwendung
Fullen der Datenbank:Verzeichnis: ../code/fillClient/
import com.db4o.*;import com.db4o.query.*;import java.util.*;
public class Anwendung{private static ObjectContainer db;
// Constructors and Operations:public static final ObjectContainer getDb ()
{return db;}
private static final void setDb (ObjectContainer db){

C.15. CLIENT/SERVER 153
Anwendung.db = db;}
public static void erzeugeChauffeureUndTaxen (){Chauffeur chauffeur = new Chauffeur ("Ballack", 31);getDb ().store (chauffeur); // Chauffeur ist jetzt schon in der Datenbank.Taxi taxi = new Taxi ("BMW", "13", chauffeur);getDb ().store (taxi);
chauffeur = new Chauffeur ("Kahn", 39);taxi = new Taxi ("VW", "1", chauffeur);getDb ().store (taxi); // Chauffeur ist hiermit auch in der Datenbank.
getDb ().store (new Taxi ("Mercedes", "32", new Chauffeur ("Gomez", 22)));
System.out.println ("Alle Taxen in der Datenbank:");List<Taxi> resultat = getDb ().query (Taxi.class);DB.zeigeResultat (resultat);
System.out.println ();System.out.println ("und alle Objekte in der Datenbank:");resultat = getDb ().queryByExample (new Object ());DB.zeigeResultat (resultat);}
public static void alleObjekteLoeschen (){List<Object> resultat
= getDb ().queryByExample (new Object ());for (Object o : resultat)
{getDb ().delete (o);}
resultat = getDb ().queryByExample (new Object ());DB.zeigeResultat (resultat);}
public static void main (String[] arg){try
{setDb (Db4o.openClient (DB.HOST, DB.PORT, "user1", "password1"));try
{alleObjekteLoeschen ();erzeugeChauffeureUndTaxen ();}finally
{getDb ().close ();}
}catch (Exception e) { e.printStackTrace (); }
}} // end Anwendung
Zwei Clients:Verzeichnis: ../code/zweiClients/
import com.db4o.*;import com.db4o.cs.*;import com.db4o.query.*;import java.util.*;
public class Anwendung{// Constructors and Operations:public static void main (String[] arg)
{ObjectContainer ct1 = null;

154 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
ObjectContainer ct2 = null;try
{ct1 = Db4oClientServer.openClient (
DB.HOST, DB.PORT, "user1", "password1");
ct2 = Db4oClientServer.openClient (DB.HOST, DB.PORT, "user2", "password2");
// Zunachst ein paar Daten in die Datenbank:ct1.store (new Taxi ("BMW", "13", new Chauffeur ("Ballack", 31)));ct1.commit ();
System.out.println ();System.out.println ("Wir legen einen neuen Chauffeur Lahm an ");System.out.println (" und geben ihn dem Taxi, das Ballack fahrt,");System.out.println (" unter Verwendung des Clients ct1.");Chauffeur lahm = new Chauffeur ("Lahm", 27);List<Taxi> rs = ct1.queryByExample (new Taxi ("BMW", "13",
new Chauffeur ("Ballack", 31)));Taxi taxi = rs.get (0);System.out.println ("Taxi: " + taxi);System.out.println ();taxi.setChauffeur (lahm);ct1.store (taxi);System.out.println ("Datenbank-Inhalt von ct1 aus gesehen:");List<Object> rso = ct1.queryByExample (new Object ());DB.zeigeResultat (rso);System.out.println ("Datenbank-Inhalt von ct2 aus gesehen:");rso = ct2.queryByExample (new Object ());DB.zeigeResultat (rso);
System.out.println ();if (true) // Umschalten zwischen commit und rollback
{System.out.println ("ct1 macht commit!");ct1.commit ();}
else{System.out.println ("ct1 macht rollback!");ct1.rollback ();}
System.out.println ();System.out.println ("Datenbank-Inhalt von ct1 aus gesehen:");rso = ct1.queryByExample (new Object ());DB.zeigeResultat (rso);System.out.println ("Datenbank-Inhalt von ct2 aus gesehen:");rso = ct2.queryByExample (new Object ());DB.zeigeResultat (rso);System.out.println ();System.out.println ("Datenbank-Inhalt von ct1 aus gesehen"
+ " nach Refresh:");rso = ct1.queryByExample (new Object ());DB.zeigeRefreshedResultat (ct1, rso, 2);System.out.println ("Datenbank-Inhalt von ct2 aus gesehen"
+ " nach Refresh:");rso = ct2.queryByExample (new Object ());DB.zeigeRefreshedResultat (ct2, rso, 2);}catch (Exception e) { e.printStackTrace (); }finally
{ct1.close ();ct2.close ();}
}} // end Anwendung

C.16. IDENTIFIKATOREN 155
C.15.3 Spezialitaten
Ohne auf Einzelheiten einzugehen nennen wir hier Probleme und auch Moglichkeiten, die mansich gegebenenfalls mit Hilfe der db4o-Dokumentation erarbeiten sollte.
• Native Queries als anonyme innere Klassen
• Out-of-band signalling: Wird eingesetzt, um dem Server besondere Botschaften zu senden(z.B. Defragmentierung. Als ein Beispiel haben wir das Stoppen des Servers gezeigt.).
C.16 Identifikatoren
db4o verwaltet Objekt-Identifikatoren (ID) transparent. IDs sollten von der Anwendungspro-grammiererIn nie verwendet werden. Daher ist dieser Abschnitt eigentlich uberflussig. Allerdingskonnen IDs fur die Fehlersuche hilfreich sein, wenn z.B. nicht klar ist, wie oft ein und dasselbeObjekt gespeichert wurde.
IDs spielen eventuell eine Rolle in zustandslosen Anwendungen, wenn Objekt und Datenbankgetrennt wurden.
Unter db4o gibt es zwei ID-Systme.
C.16.1 Interne IDs
Die interne ID eines Objekts ob erhalt man mit:
long id = objectContainer.ext ().getID (ob);
Uber die ID ist der schnellste Zugriff auf ein Objekt moglich:
Object ob = objectContainer.ext ().getByID (id);
Vor Verwendung muss das Objekt allerdings noch aktiviert werden:
objectContainer.ext ().activate (ob, tiefe);
Die interne ID ist nur eindeutig bezuglich eines ObjectContainers.
C.16.2 Eindeutige universelle ID (UUID)
Die UUID (unique universal ID) ist die eigentliche, unveranderliche, uber Container eindeu-tige ID. Sie wird allerdings von db4o nicht automatisch generiert, da sie Platz und Performanzkostet.
Man kann die UUIDs global oder fur einzelne Klassen generieren lassen (oder auch nicht).

156 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O
Configuration conf = Db4o.newConfiguration ();
conf.generateUUIDs (ConfigScope.DISABLED);
oderconf.generateUUIDs (ConfigScope.GLOBALLY);
oderconf.generateUUIDs (ConfigScope.INDIVIDUALLY);
conf.objectClass (Taxi.class).generateUUIDs (true);
Die UUID eines Objekts ob erhalt man mit:
Db4oUUID uuid = objectContainer.ext ().getObjectInfo (ob).getUUID ();
Uber die UUID ist ein Zugriff auf ein Objekt moglich:
Object ob = objectContainer.ext ().getByUUID (uuid);
C.17 Probleme
In diesem Abschnitt nennen oder diskutieren wir Probleme, die uns bei der Arbeit mit db4oaufgefallen sind.
C.17.1 Viele Objekte, Lazy Query
Wenn man sehr viele Objekte, d.h. unter Windows etwa 1 000 000 Chauffeure, unter FreeBSDetwa 10 000 000 Chauffeure in der Datenbank speichert und dann versucht, einige dieser Objektedurch eine Anfrage wieder zu finden, dann kommt es zum Absturz, da offenbar der Java HeapSpace uberschritten wird. Dieses Problem kann man losen, indem man die Anfrage als lazyquery durchfuhrt:
conf.common ().queries ().evaluationMode (QueryEvaluationMode.LAZY);
Verzeichnis: ../code/lazy/
Im Lazy Querying Mode werden Objekte nicht ausgewertet. Stattdessen wird ein Iterator gegenden besten Index erzeugt. Damit erhalt man die ersten Anfrageresultate beinahe sofort, und eswird kaum Speicher verbraucht. Die gefundenen Objekte werden erst dann in den ObjectContai-ner geladen, wenn sie wirklich benotigt werden. Bei nebenlaufigen Transaktionen bedeutet das,dass committed Anderungen an der Datenbank durch andere Transaktionen (oder uncomitteddurch die eigene) wahrend der Anfrage Einfluss auf die ermittelten Objekte haben.

C.17. PROBLEME 157
C.17.2 Defragmentierung
Auch wenn Objekte geloscht werden, wachst die Datenbank-Datei trotzdem immer weiter. Dahermuss gelegentlich – bei geschlossener Datenbank – defragmentiert werden mit:
com.db4o.defragment.Defragment.defrag (Datenbankdateiname);
Die alte Version wird nach Datenbankdateiname.backup kopiert.
Verzeichnis: ../code/defragment/
Es gibt zahlreiche Optionen fur die Defragmentierung.
C.17.3 Maximale Datenbankgroße
Defaultmaßig ist die maximale Datenbankgroße 2GB. Das entspricht einer ”Blockgroße” (blocksize) von 1 byte. Die Blockgroße kann eingestellt werden zwischen 1 byte und 127 byte, waseiner maximalen Datenbankgroße von 254GB entspricht.
Diese Einstellung ist moglich bei der Neuanlage einer Datenbank oder beim Defragmentierenmit:
EmbeddedConfiguration conf = Db4oEmbedded.newConfiguration ();
conf.file ().blockSize (8);

158 ANHANG C. OBJEKTORIENTIERTES DATENBANKSYSTEM DB4O

Literaturverzeichnis
[1] Carlo Batini, Stefano Ceri und Shamkant B. Navathe, ”Conceptual Database Design”, TheBenjamin/Cummings Publishing Company 1992
[2] Christian Bauer und Gavin King, ”Java Persistence with Hibernate”, Manning Publications2006
[3] Grady Booch, ”Object-Oriented Analysis and Design”, The Benjamin/Cummings Publis-hing Company 1994
[4] Rainer Burkhardt, ”UML – Unified Modeling Language”, Addison-Wesley 1997
[5] Stephen Cannan und Gerard Otten, ”SQL — The Standard Handbook”, McGraw-Hill In-ternational 1993
[6] Jeff Carpenter und Eben Hewitt, ”Cassandra – The Definitive Guide”, O’Reilly
[7] Rick G. G. Cattell und Douglas K. Barry, ”The Object Data Standard: ODMG 3.0” MorganKaufmann Publishers 2000
[8] Peter Pin-Shan Chen, ”The Entity-Relationship Model: Toward a Unified View of Data”,ACM Transactions on Database Systems 1, 9-36 (1976)
[9] Peter Coad und Edward Yourdon, ”Object-Oriented Analysis”, Prentice-Hall 1991
[10] Peter Coad und Edward Yourdon, ”Object-Oriented Design”, Prentice-Hall 1991
[11] Edgar Frank Codd, ”The Relational Model for Database Management Version 2”, Addison-Wesley 1990
[12] Thomas Connolly und Carolyn Begg, ”Database Systems”, Addison-Wesley 2002
[13] C. J. Date, ”An Introduction to Database Systems”, Addison-Wesley
[14] C. J. Date und Hugh Darwen, ”A Guide to the SQL Standard”, Addison-Wesley 1993
[15] David Flanagan, Jim Farley, William Crawford und Kris Magnusson, ”Java Enterprise in aNutshell”, O’Reilly & Associates 1999
[16] Stefan Edlich, Achim Friedland, Jens Hampe, Benjamin Brauer und Markus Bruckner,”NoSQL – Einstieg in die Welt nichtrelationaler Web 2.0 Datenbanken”, Hanser
[17] Ramez Elmasri und Shamkant B. Navathe, ”Fundamentals of Database Systems”, The Ben-jamin/Cummings Publishing Company
159

160 LITERATURVERZEICHNIS
[18] Volker Gaede und Oliver Gunther, ”Multidimensional Access Methods”, ACM ComputingSurveys 30, 170-231 (1998)
[19] Hector Garcia-Molina, Jeffrey D. Ullman und Jennifer Widom, ”Database Systems TheComplete Book” Pearson Prentice Hall
[20] Jim Gray und Andreas Reuter, ”Transaction Processing: Concepts and Techniques”, MorganKaufmann (1992)
[21] Terry Halpin und Tony Morgan ”Information Modeling and Relational Databases”, MorganKaufmann 2008
[22] Andreas Heuer und Gunter Saake, ”Datenbanken: Konzepte und Sprachen” MITP 2000
[23] Uwe Hohenstein und Volkmar Pleßer, ”Oracle8 Effiziente Anwendungsentwicklung mit ob-jektrelationalen Konzepten”, dpunkt.verlag 1998
[24] John G. Hughes, ”Objektorientierte Datenbanken”, Hanser und Prentice-Hall International1992
[25] Jennifer Little in ”High Performance Web-Databases”, ed. Sanjiv Purba, Auerbach 2001
[26] Alfons Kemper und Andre Eickler, ”Datenbanksysteme”, R.Oldenbourg 1999
[27] W. Kim, ”On Optinizing an SQL-like Nested Query”, ACM Transactions on Database Sy-stems 7, 443 (1982)
[28] Michael Kofler, ”MySQL”, Addison-Wesley 2001
[29] Jochen Ludewig, ”Einfuhrung in die Informatik”, Verlag der Fachvereine Zurich 1989
[30] D. Maier, ”The Theory of Relational Databases”, Computer Science Press 1983
[31] Jim Melton und Alan R. Simon, ”Understanding The New SQL: A Complete Guide”, Mor-gan Kaufmann 1993
[32] Greg Riccardi, ”Principles of Database Systems with Internet and Java Applications”,Addison-Wesley 2001
[33] James Rumbaugh, Michael Blaha, William Premerlani, Frederick Eddy und William Loren-sen, ”Object-Oriented Modeling and Design”, Prentice Hall (Deutsch bei Hanser)
[34] Gunter Saake und Andreas Heuer, ”Datenbanken: Implementierungstechniken” MITP 2005
[35] Gunter Saake und Kai-Uwe Sattler, ”Datenbanken & Java JDBC, SQLJ und ODMG”dpunkt 2000
[36] Pramod J. Sadalage und Martin Fowler, ”NoSQL Distilled” Addison-Wesley 2013
[37] Sanjiv Purba in ”High Performance Web-Databases”, ed. Sanjiv Purba, Auerbach 2001
[38] ”Database Language SQL”, ISO/IEC 9075:1992 oder ANSI X3.135-1992
[39] Michael Stonebraker und Paul Brown, ”Object-Relational DBMSs”, Morgan Kaufmann 1999
[40] Christof Strauch, ”NoSQL Databases”http://home.aubg.bg/students/ENL100/Cloud%20Computing/Research%20Paper/nosqldbs.pdf
(24. Januar 2014)
[41] Niklaus Wirth, ”Algorithmen und Datenstrukturen” Teubner 1986





























