Embed Size (px)
Citation preview

David Silver1*, Aja Huang1*, Chris J. Maddison1, Arthur Guez1, Laurent Sifre1, George van den Driessche1
Julian Schrittwieser1, Ioannis Antonoglou1, Veda Panneershelvam1, Marc Lanctot1, Sander Dieleman1, Dominik Grewe1,
John Nham2, Nal Kalchbrenner1, Ilya Sutskever2, Timothy Lillicrap1, Madeleine Leach1, Koray Kavukcuoglu1,
Thore Graepel1 & Demis Hassabis1
(1 Google DeepMind. 2 Google,)
(*These authors contributed equally to this work)
Mastering the game of Go with deep neural
networks and tree search

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
2

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
3

4
5
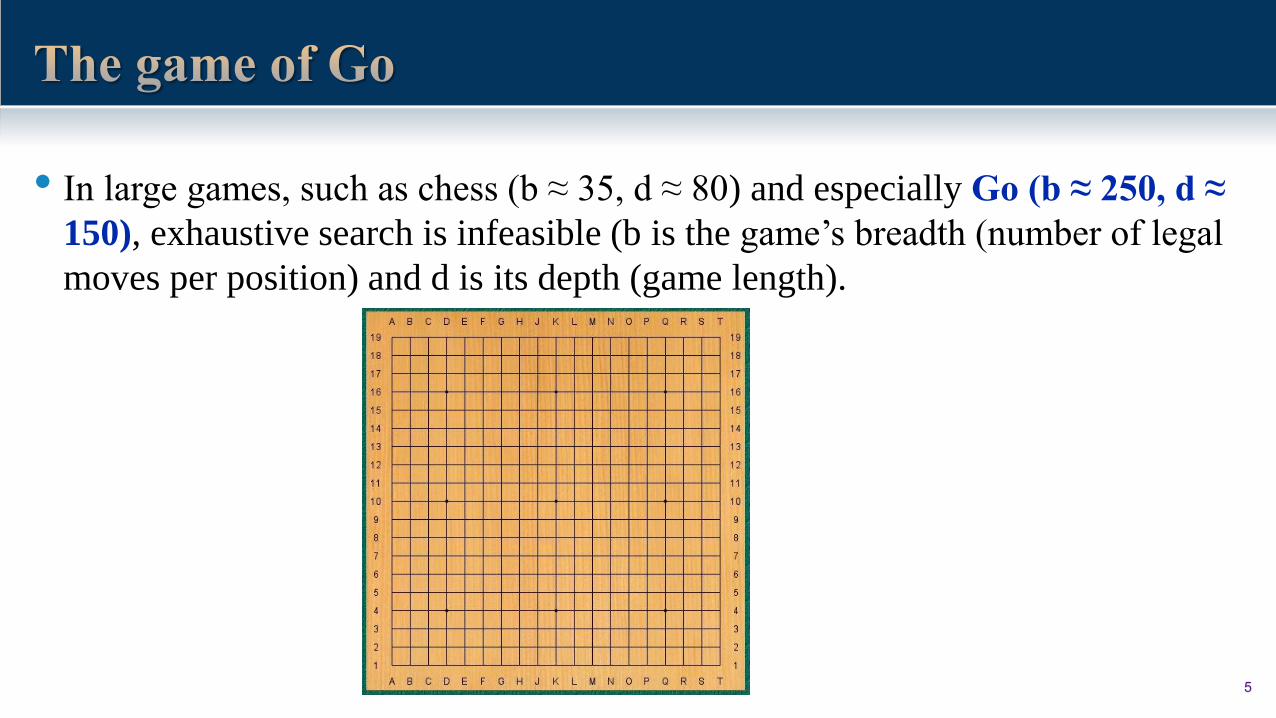
• In large games, such as chess (b ≈ 35, d ≈ 80) and especially Go (b ≈ 250, d ≈
150), exhaustive search is infeasible (b is the game’s breadth (number of legal
moves per position) and d is its depth (game length).
6
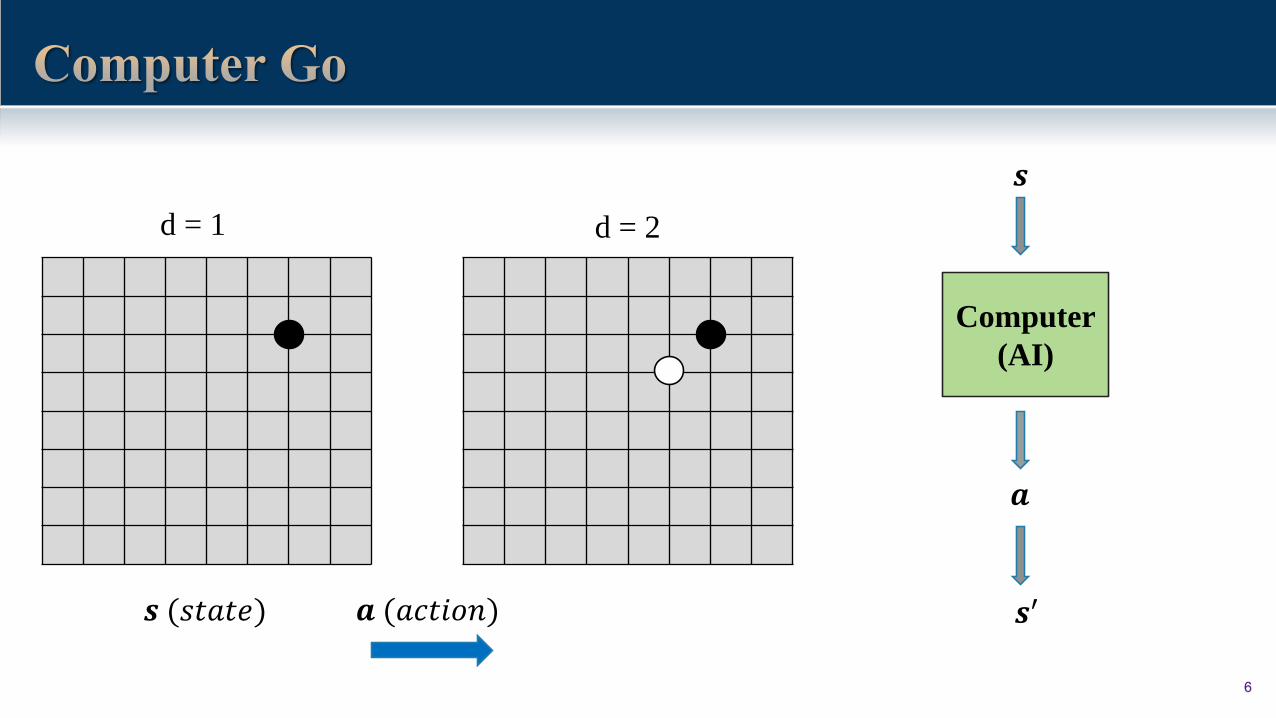
d = 1
𝒔 (𝑠𝑡𝑎𝑡𝑒)
d = 2
𝒂 (𝑎𝑐𝑡𝑖𝑜𝑛)
Computer
(AI)
𝒂
𝒔
𝒔′

7
d = 1

8
d = 1

• Reducing “action candidates” (Breadth Reduction)
9
d = 1
If there is a model that can tell you that these
moves are not common / probable (e.g. by experts, etc.) …

• Reducing “action candidates” (Breadth Reduction)
10
d = 1
Remove these from search candidates in advance
(breadth reduction)

• Position evaluation ahead of time (Depth Reduction)
11
d = 1
Instead of simulating until the maximum depth ...

• Position evaluation ahead of time (Depth Reduction)
12
d = 1
If there is a function that can measure:V(s):
“board evaluation of state s”
V=1
V=2
V=10

• 1. Reducing “action candidates” (Breadth Reduction)
• 2. Board Evaluation (Depth Reduction)
13
Police Network
Value Network

• 1. Reducing “action candidates” (Breadth Reduction)
• 2. Board Evaluation (Depth Reduction)
14
Police Network
Value Network
• 1. Reducing “action candidates” (Breadth Reduction)
• 2. Board Evaluation (Depth Reduction)
15
Police Network
Value Network
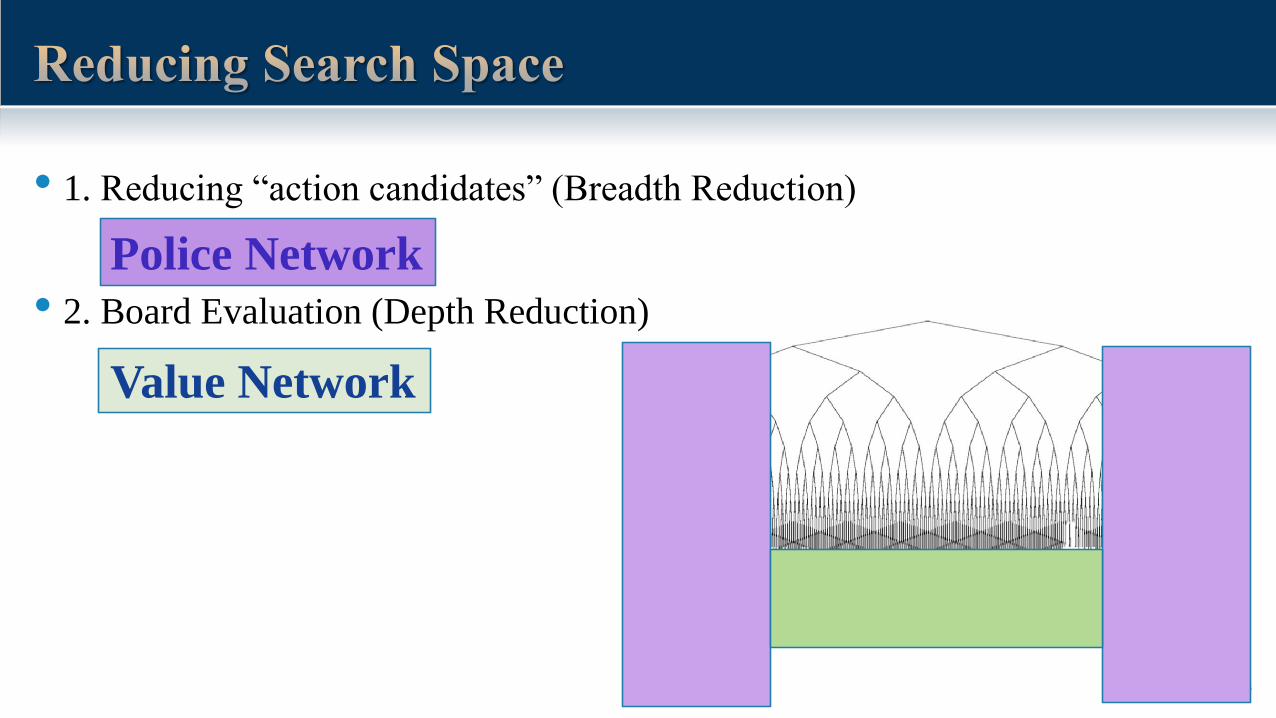
• 1. Reducing “action candidates” (Breadth Reduction)
• 2. Board Evaluation (Depth Reduction)
16
Police Network
Value Network
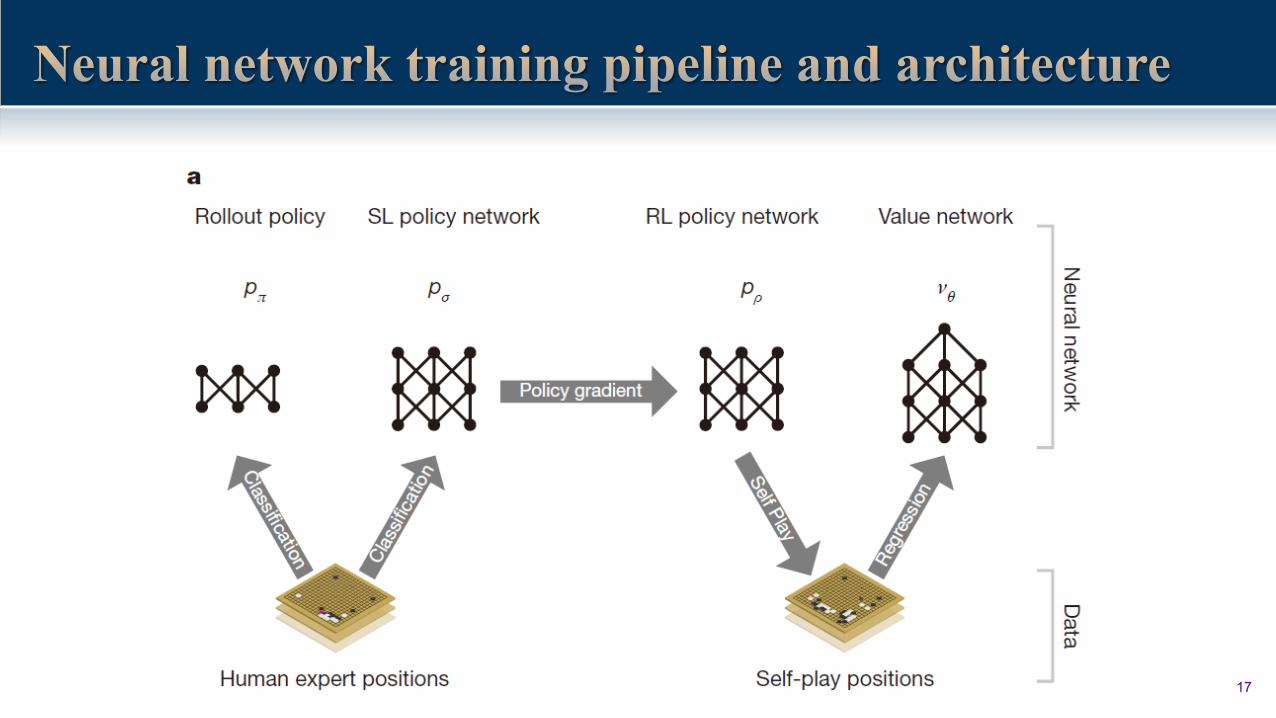
17

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
18
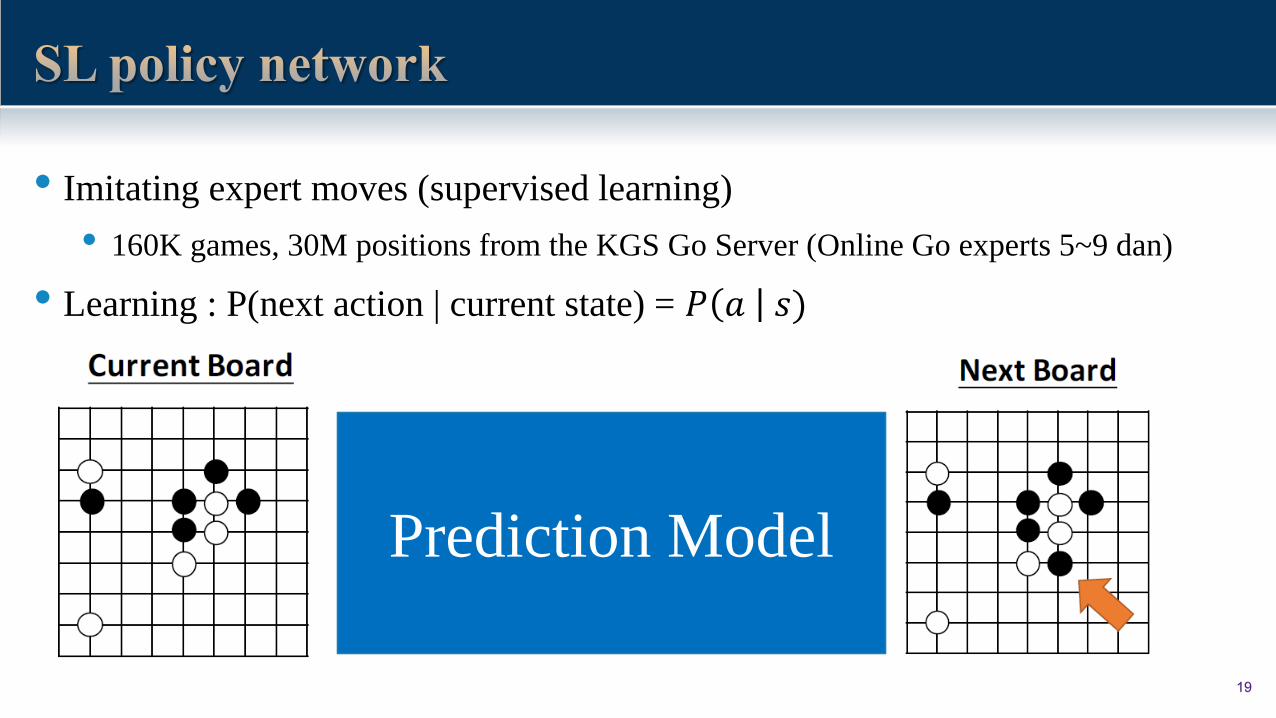
19
• Imitating expert moves (supervised learning)
• 160K games, 30M positions from the KGS Go Server (Online Go experts 5~9 dan)
• Learning : P(next action | current state) = 𝑃 𝑎 𝑠)
Prediction Model
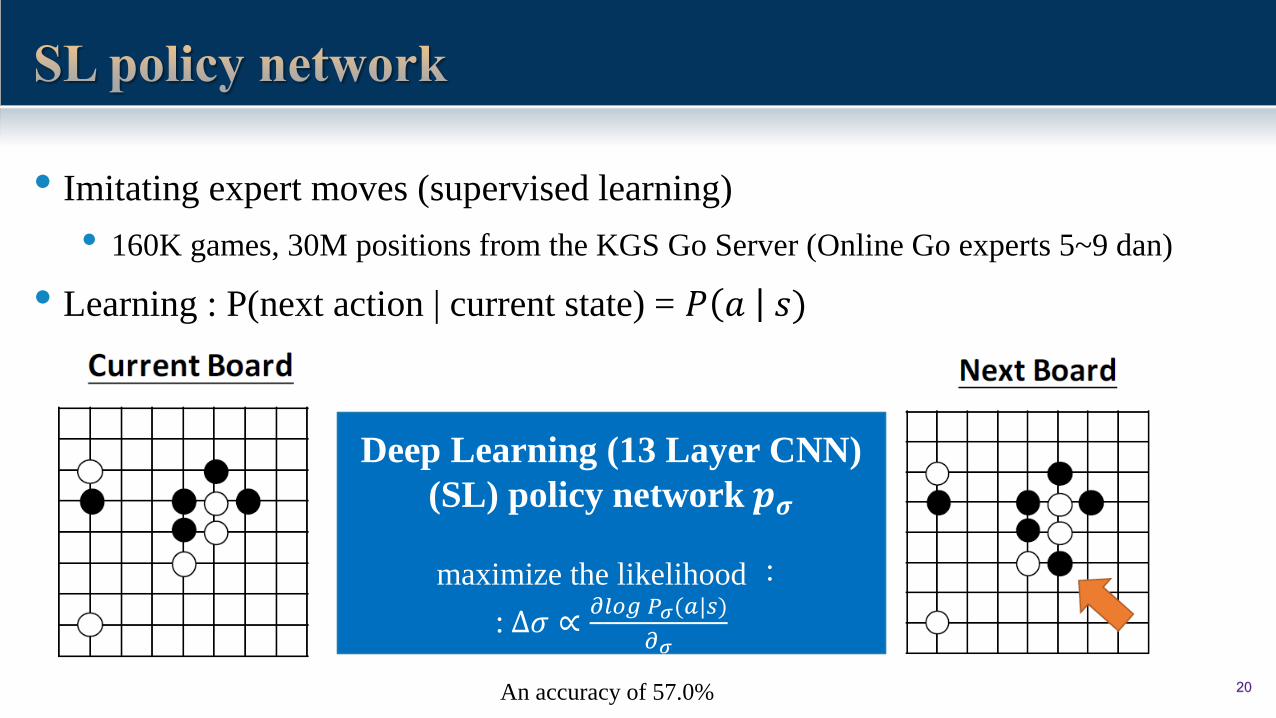
20
• Imitating expert moves (supervised learning)
• 160K games, 30M positions from the KGS Go Server (Online Go experts 5~9 dan)
• Learning : P(next action | current state) = 𝑃 𝑎 𝑠)
Deep Learning (13 Layer CNN)
(SL) policy network 𝒑𝝈
maximize the likelihood :
: ∆𝜎 ∝𝜕𝑙𝑜𝑔 𝑃𝜎(𝑎|𝑠)
𝜕𝜎
An accuracy of 57.0%
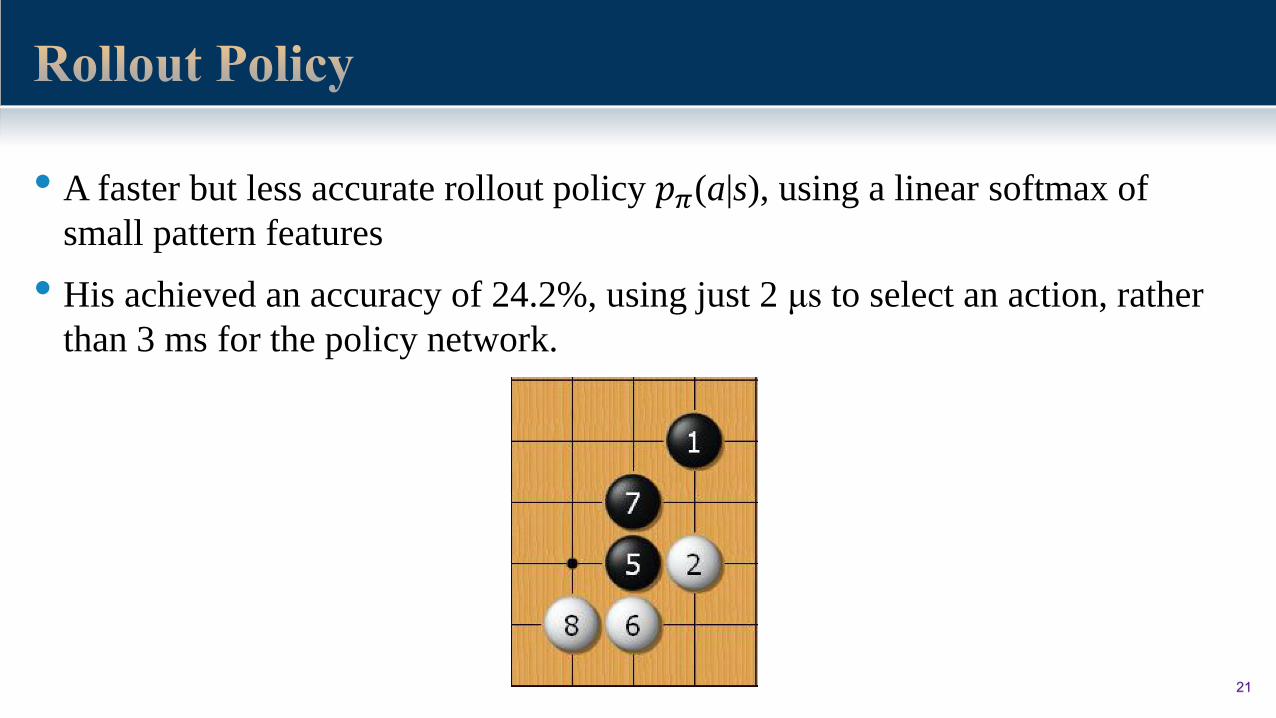
• A faster but less accurate rollout policy 𝑝𝜋(a|s), using a linear softmax of
small pattern features
• His achieved an accuracy of 24.2%, using just 2 μs to select an action, rather
than 3 ms for the policy network.
21

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
22

23
• Improving through self-‐plays (reinforcement learning)
Expert Moves Imitator Model
maximize the likelihood :
∆𝜌 ∝𝜕𝑙𝑜𝑔 𝑃𝜌(𝑎𝑡|𝑠𝑡)
𝜕𝜌𝑧𝑡

24
• Improving through self-‐plays (reinforcement learning)
Expert Moves Imitator Model
maximize the likelihood :
∆𝜌 ∝𝜕𝑙𝑜𝑔 𝑃𝜌(𝑎𝑡|𝑠𝑡)
𝜕𝜌𝑧𝑡

25
• Improving through self-‐plays (reinforcement learning)
Older models vs. Newer models
Updated
Model
Ver. 1.1
Updated
Model
Ver. 1.3
It uses the same topology as the expert moves imitator model,
and just uses the updated parameters
VS
26
• Improving through self-‐plays (reinforcement learning)
Older models vs. Newer models
Updated
Model
Ver. 2343
Updated
Model
Ver. 3455
Return: board positions, win/lose info
VS
27
• Improving through self-‐plays (reinforcement learning)
Older models vs. Newer models
Expert Moves
Imitator Model
Updated
Model
Ver. 100000
The final model wins 80% of the time when playing
against the first model
VS

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
28

• Focuses on position evaluation, estimating a value function
• In practice, we approximate the value function using a value network
𝑣𝜃 𝑠 with weights 𝜃, 𝑣𝜃 𝑠 ≅ 𝑣𝑝𝑝(𝑠) ≅ 𝑣∗(𝑠).
29
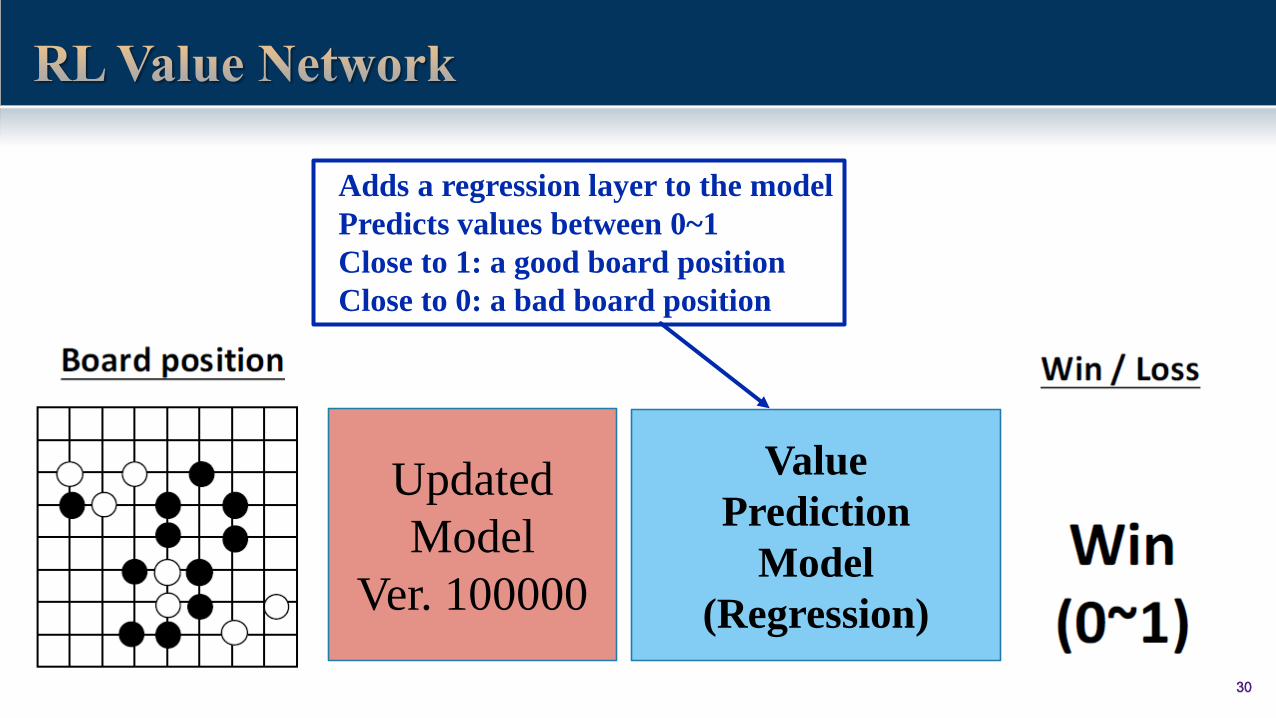
3030
Value
Prediction
Model
(Regression)
Updated
Model
Ver. 100000
Adds a regression layer to the model
Predicts values between 0~1
Close to 1: a good board position
Close to 0: a bad board position

3131
∆𝜃 ∝𝜕𝑣𝜃 𝑠
𝜕𝜃(𝑧 − 𝑣𝜃 𝑠 )
Updated
Model
Ver. 100000
minimize the mean squared error (MSE)
between the predicted value
𝒗𝜽(𝒔), and the corresponding outcome 𝒛

3232
∆𝜃 ∝𝜕𝑣𝜃 𝑠
𝜕𝜃(𝑧 − 𝑣𝜃 𝑠 )
Updated
Model
Ver. 100000
1.Randomly sampling a time step U ~ unif{1, 450},
2.Sampling the first t = 1,... U − 1 moves from the SL policy network,
3.Sampling one move uniformly at random from available moves, aU ~ unif{1, 361} (repeatedly until aU is legal);
4.Sampling the remaining sequence of moves until the game terminates, t = U + 1, ... T, from the RL policy network
5.Finally, the game is scored to determine the outcome 𝑧𝑡 = ±𝑟 𝑠𝑇 .
Only a single training example (𝑠𝑈+1, 𝑧𝑈+1) is added to the data set from each game.
This data provides unbiased samples of the value function 𝑣𝑝𝑝(𝑠𝑈+1)=𝔼[𝑧𝑈+1 | 𝑠𝑈+1,𝑎𝑈+1,...T ~ 𝑝𝑝]

• 1. Reducing “action candidates” (Breadth Reduction)
• 2. Board Evaluation (Depth Reduction)
33
Police Network
Value Network

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
34
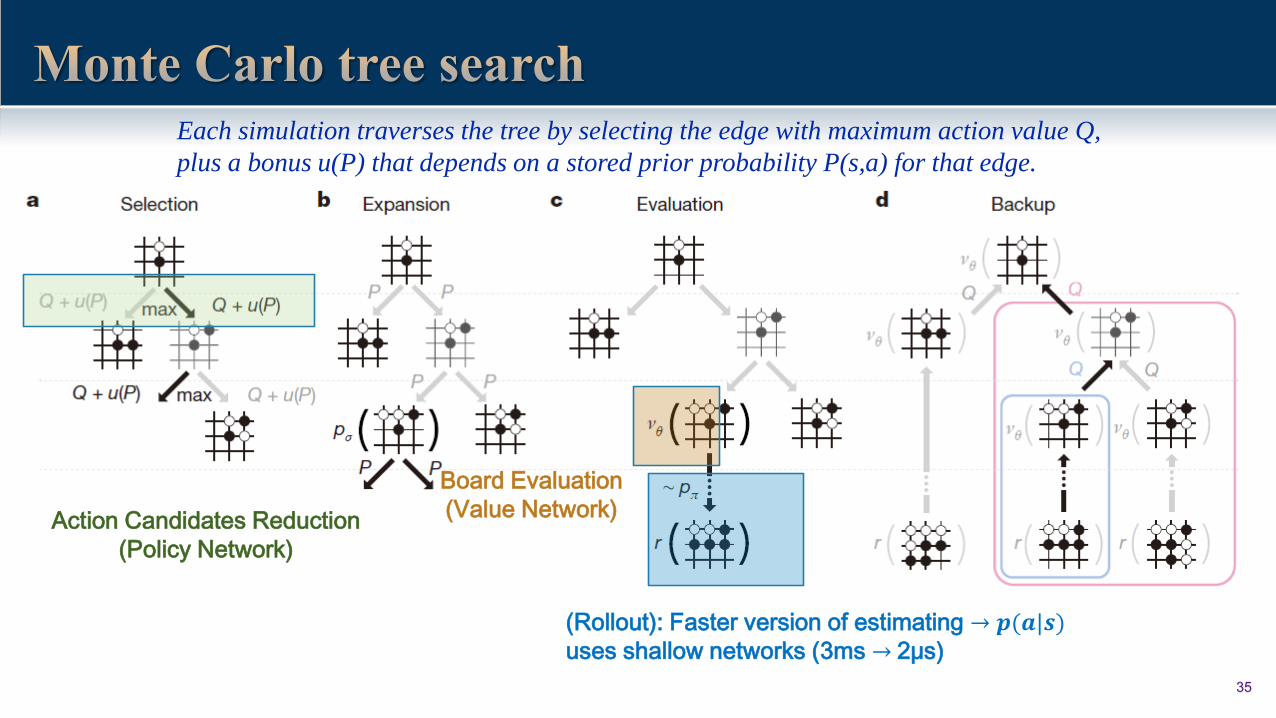
35
Action Candidates Reduction
(Policy Network)
Board Evaluation
(Value Network)
(Rollout): Faster version of estimating → 𝒑(𝒂|𝒔)uses shallow networks (3ms → 2μs)
Each simulation traverses the tree by selecting the edge with maximum action value Q,
plus a bonus u(P) that depends on a stored prior probability P(s,a) for that edge.

• At each time step t of each simulation, an action 𝑎𝑡 is selected from state 𝑠𝑡
36
a. Selection
b. Evaluation
c. Expansion
d. Backup
When the visit count exceeds a threshold,
Nr(s, a) > 𝑛𝑡ℎ𝑟,
The successor state s′ = f(s, a)
is added to the search tree.
𝜆=0.5, winning ≥95% of games
against other variant
exploit term explore term
prior probability
the leaf node from the ith simulation
visit count
leaf node 𝑠𝐿 at step L

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
•Evaluations
•Conclusions
37
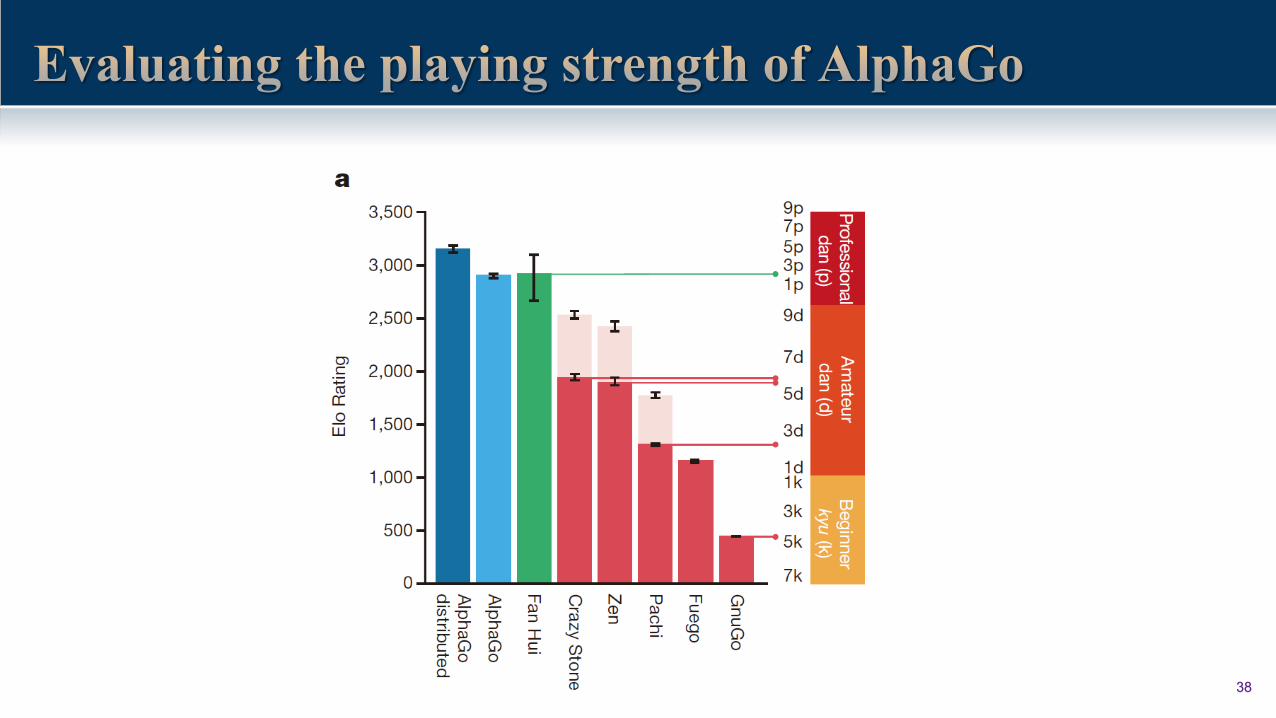
38
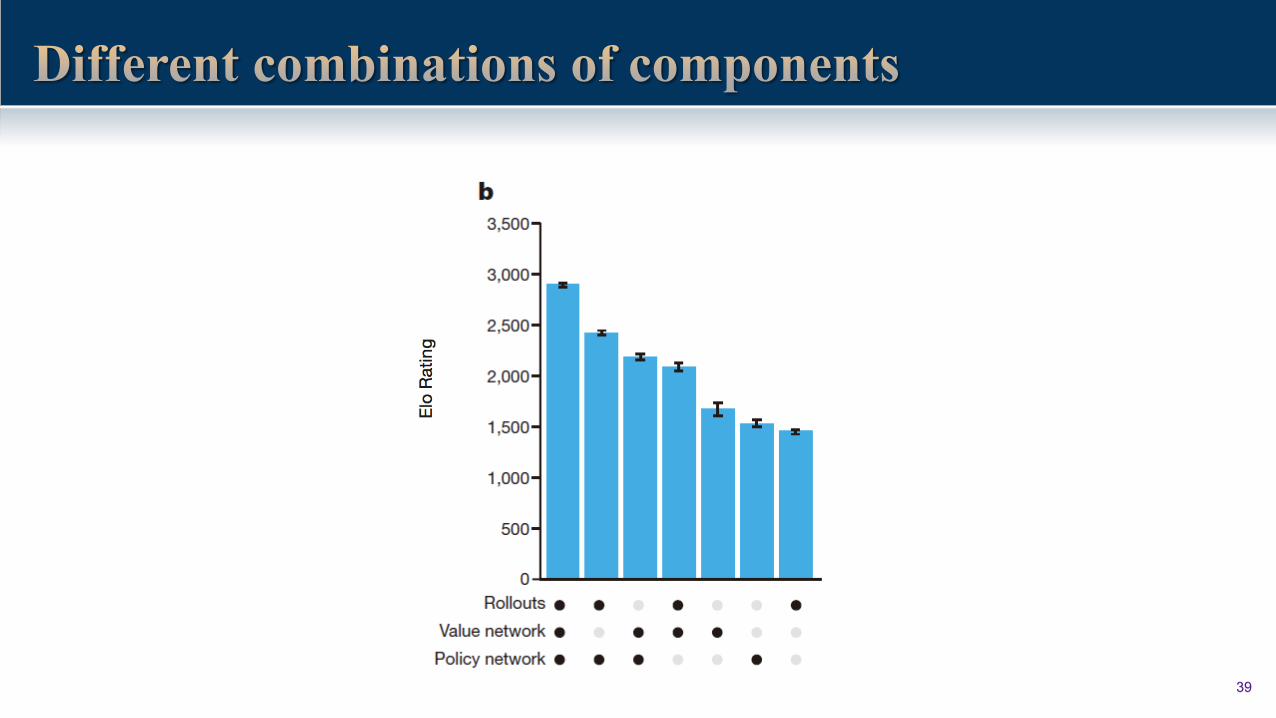
39
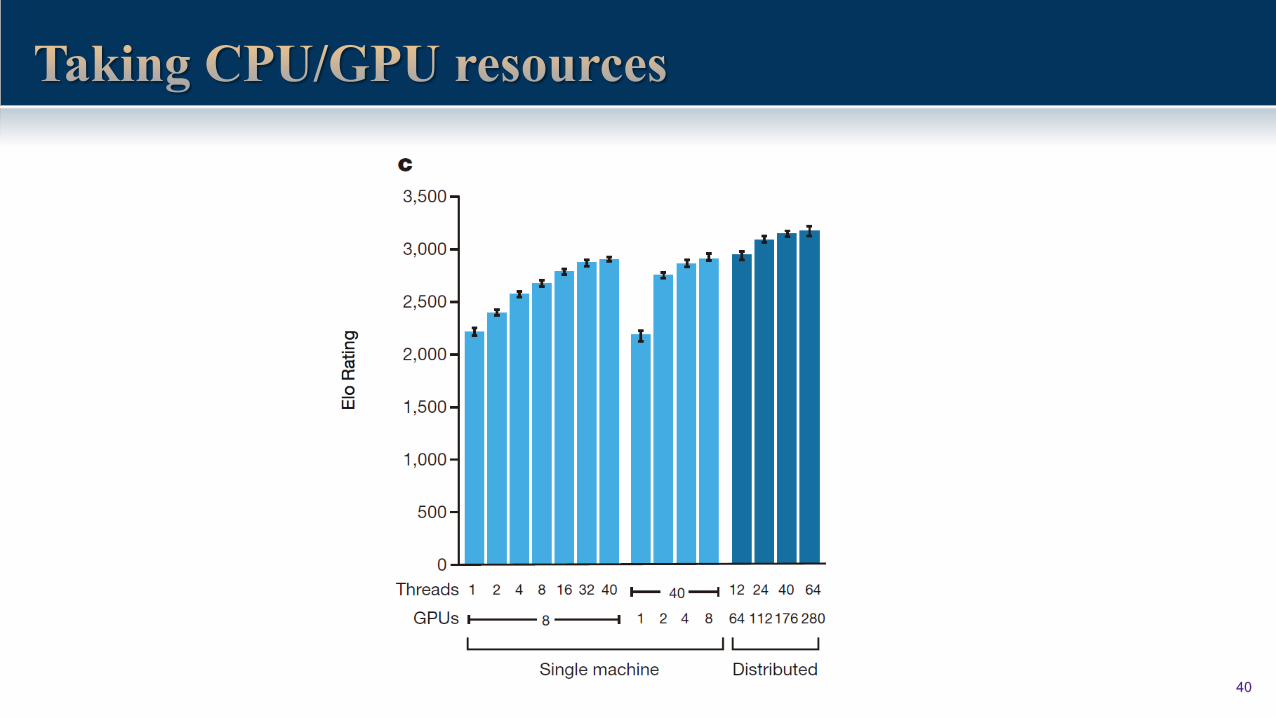
40

• The final version of AlphaGo used 40 search threads, 48 CPUs, and 8 GPUs.
Distributed version of AlphaGo that exploited multiple machines, 40
search threads, 1,202 CPUs and 176 GPUs.
• Google has promised not to use more CPU/GPUs than they used for Fan
Hui for the game with Lee Se-dol
41

42
• October 5 – 9, 2015
• <Official match> Time limit:1 hour
•

43
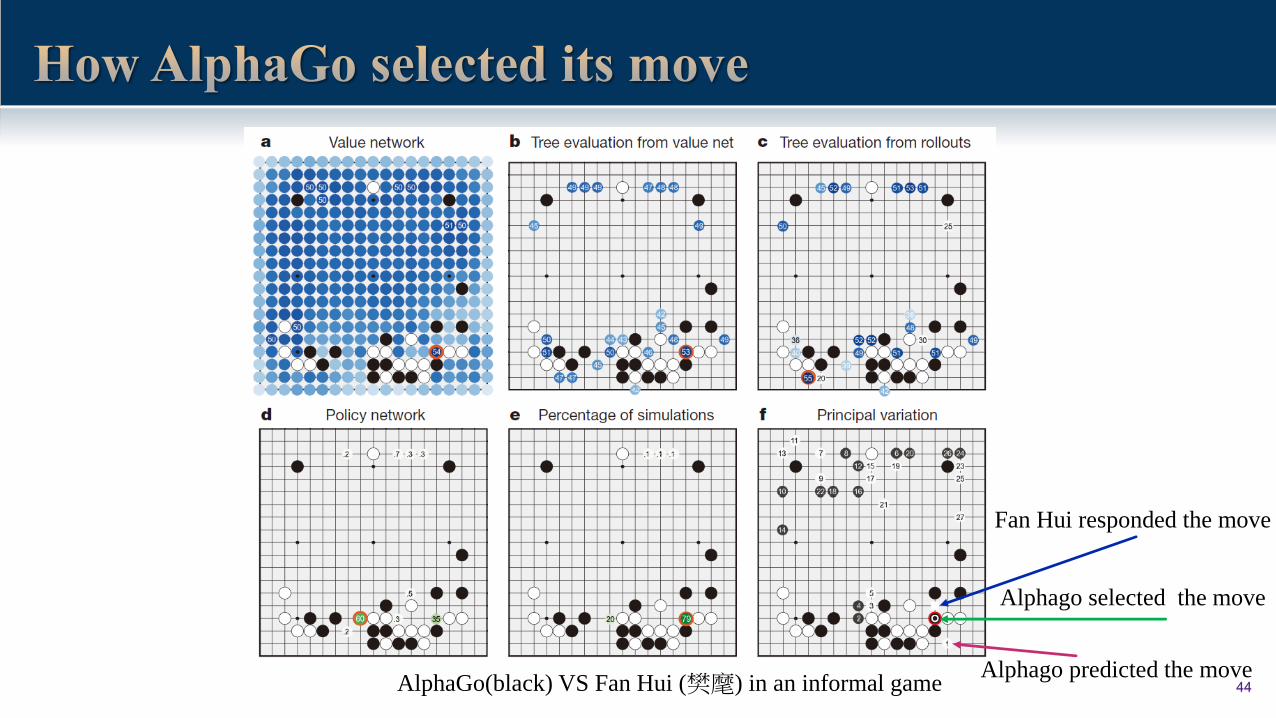
44AlphaGo(black) VS Fan Hui (樊麾) in an informal game
Fan Hui responded the move
Alphago predicted the move
Alphago selected the move

45
• March 9– 15, 2016
• <Official match> Time limit: 2 hours
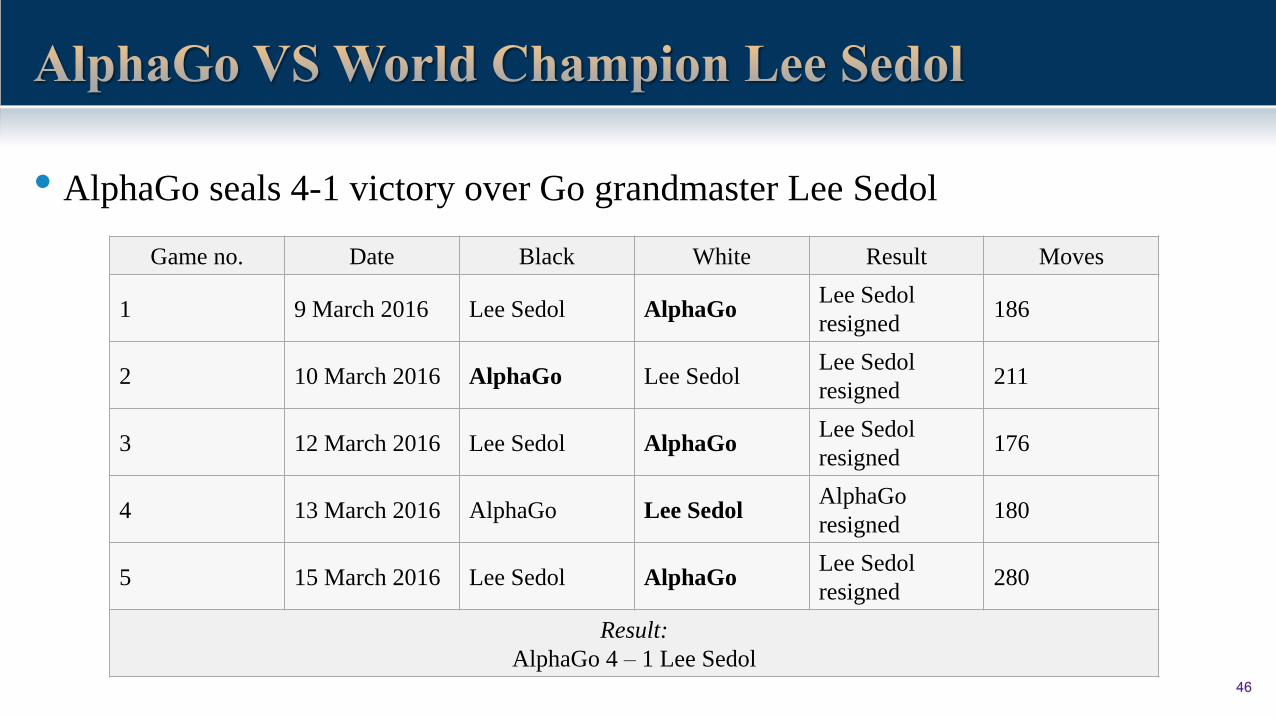
• AlphaGo seals 4-1 victory over Go grandmaster Lee Sedol
46
Game no. Date Black White Result Moves
1 9 March 2016 Lee Sedol AlphaGoLee Sedol
resigned186
2 10 March 2016 AlphaGo Lee SedolLee Sedol
resigned211
3 12 March 2016 Lee Sedol AlphaGoLee Sedol
resigned176
4 13 March 2016 AlphaGo Lee SedolAlphaGo
resigned180
5 15 March 2016 Lee Sedol AlphaGoLee Sedol
resigned280
Result:
AlphaGo 4 – 1 Lee Sedol

• Introduction
• Supervised learning of policy networks
•Reinforcement learning of policy networks
•Reinforcement learning of value networks
•Monte Carlo tree search
• Evaluations
•Conclusions
47

• In this work we have developed a Go program, based on a combination of
deep neural networks and tree search, that plays at the level of the strongest
human players, thereby achieving one of artificial intelligence’s “grand
challenges.
48