Embed Size (px)
Citation preview
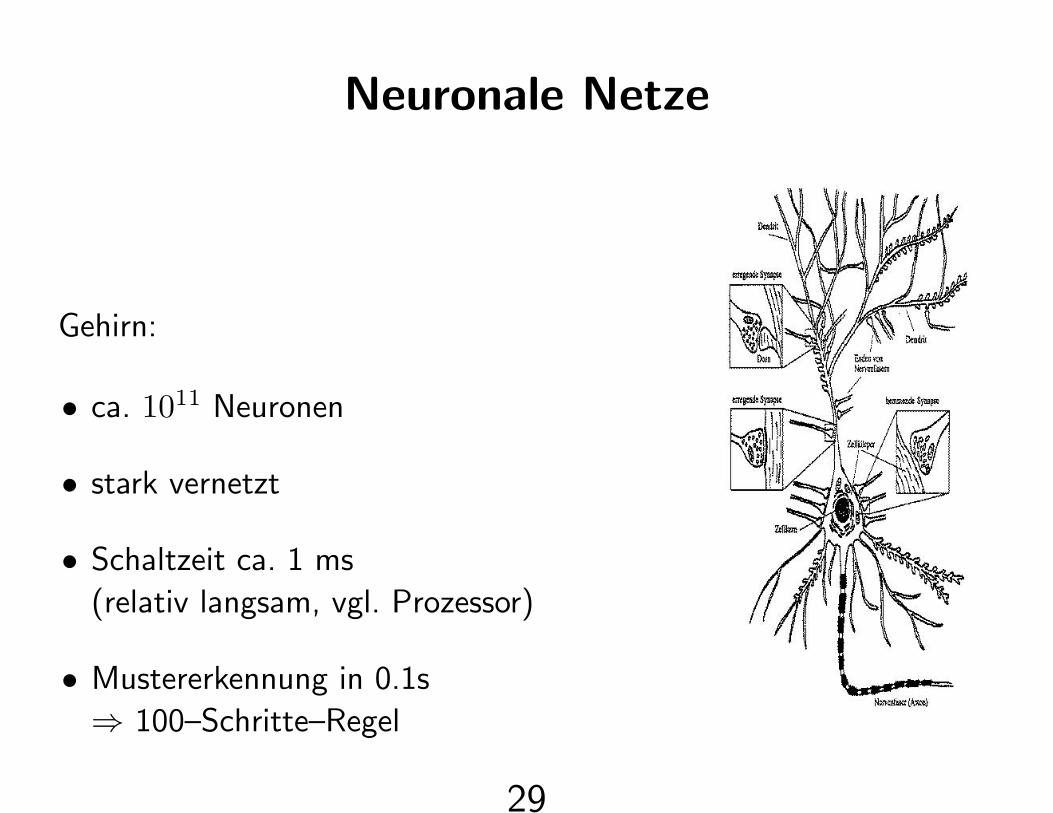
Neuronale Netze
Gehirn:
• ca. 1011 Neuronen
• stark vernetzt
• Schaltzeit ca. 1 ms
(relativ langsam, vgl. Prozessor)
• Mustererkennung in 0.1s
⇒ 100–Schritte–Regel
29

Was ist ein kunstl. neuronales Netz?
Ein (kunstliches) neuronales Netz ist ein massiv paralleler,verteilter Prozessor, bestehend aus einfachen Prozessoreinheiten.
Damit kann man Daten bzw. experimentelles Wissen sehr gut
speichern, um sie in einer Anwendung zu benutzen. Ein
neuronales Netz ahnelt dem Gehirn in zwei Aspekten:
1. Wissen wird vom Netz durch einen Lernprozess aufgenommen
2. Die Starke der Verbindungen wird benutzt, um das Wissen zu
speichern
30

Historischer Uberblick (Quelle: Zell)
• Fruhe Anfange (1942-55): McCulloch/Pitts - Neuron, Hebb -
Lernregel, Lashley - verteilte Reprasentation
• Erste Blute (1955-1969): Rosenblatt - ’Perzeptron’ (512 Potis),
Steinbuch, Widrow/Hoff - Adaline (Neurocomputing-Firma!)
• Stille Jahre (1969 - 1982/85): Minsky/Papert - Perceptrons
(1969), Kohohnen (1972) - SOMs, v.d. Malsburg, Barto/Sutton -
AHC/ACE (1983), Hopfield (1982)
31

Historischer Uberblick II
• Renaissance, Blute 1986 - 1995 : Rumelhart et. al. –
Backpropagation (1986), PDP; Barto, Sutton – Reinforcement
Learning, NDP (1989); Sejnowski - Nettalk (1986), viele
Anwendungen
• seit 1995: Realismus bzgl. Verwendung als Methode: eines von
vielen moglichen Modellen des Maschinellen Lernens
32

Grober Uberblick
1. Lineare Modelle – Perzeptrons
2. Nichtlineare Modelle – MLPs, RBFs, ...
3. Selbstorganisierende Karten (Kohonenkarten, SOMs)
4. Rekurrente Netze
• Es gibt sehr verschiedenartige Modelle mit sehr
unterschiedlichen Zielsetzungen/ Anwendungsgebieten (z.B.
Verstandnis biologischer Informationsverarbeitung, Einsatz als
maschinelles Lernverfahren, ...)
• Schwerpunkt hier: Lernen aus Daten (NNs ein Modell unter
vielen)
33
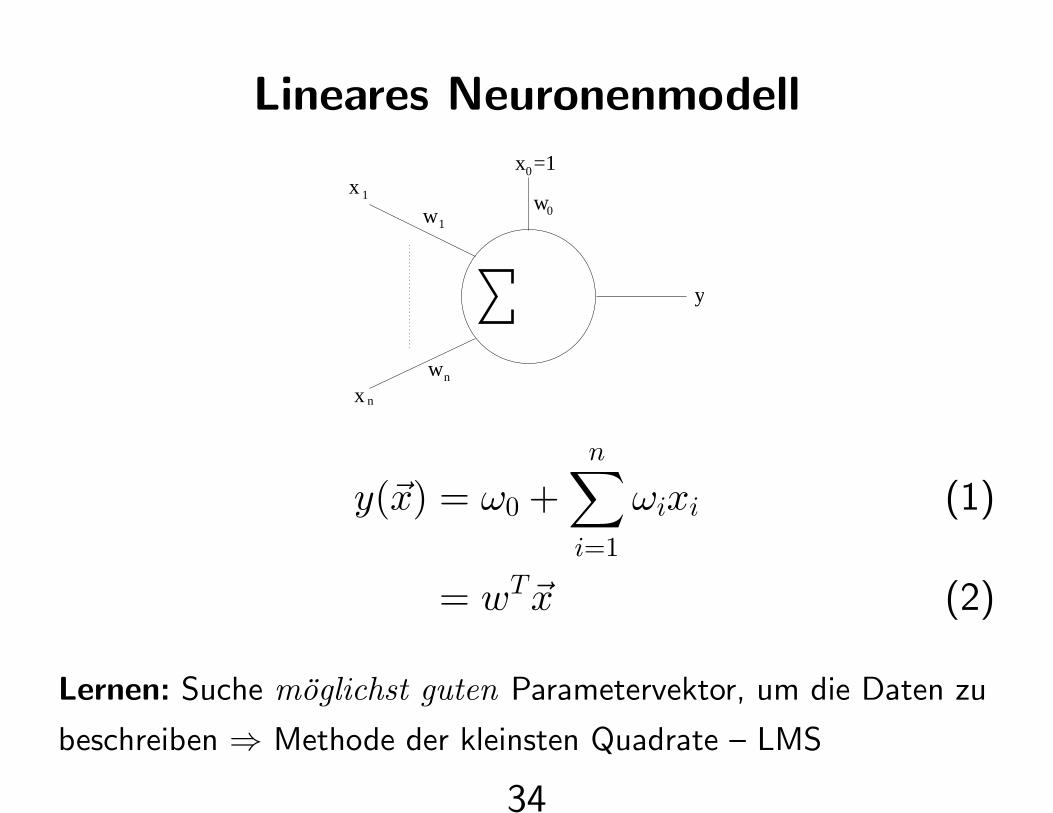
Lineares Neuronenmodell
1
wn
ww0
x0=1
y
x n
x 1
y(~x) = ω0 +n∑
i=1
ωixi (1)
= wT~x (2)
Lernen: Suche moglichst guten Parametervektor, um die Daten zu
beschreiben ⇒ Methode der kleinsten Quadrate – LMS
34

Lernen mit Least Square
Trainingsmenge:
D = {(~x1, y1soll), (~x
2, y2soll), . . . , (~x
P , yPsoll)}
Gesamtfehler uber alle Trainingsbeispiele:
E =12
P∑p=1
(ysoll − y(~xp))2
35

Lernen mit Least Square II
gesucht ~ω∗ mit
~ω∗ = arg minω
E = arg minω
12
P∑p=1
(ysoll − y(~xp))2
’Suche ~ω, welches den Abstand der Ausgabe zu den
Zielwerten minimiert.’
Lernregel uber Gradientenabstiegsverfahren:
∆~ω = −εδE
δ~ω
36
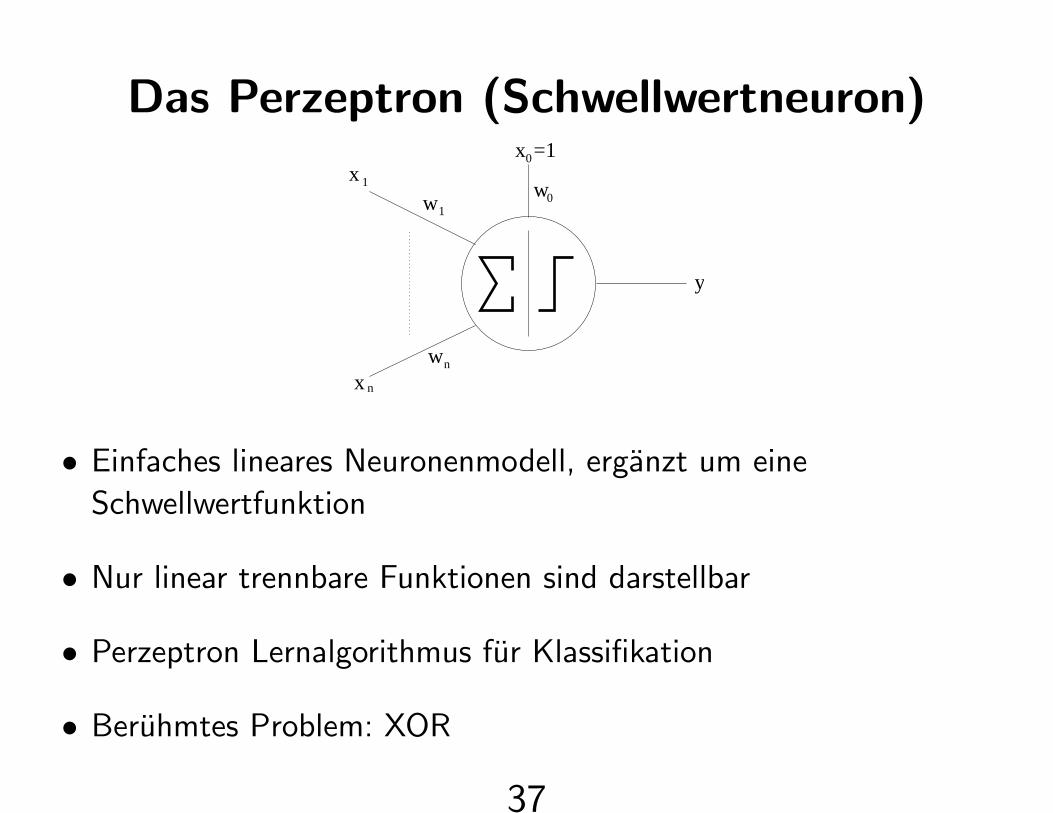
Das Perzeptron (Schwellwertneuron)
1
wn
ww0
x0=1
y
x n
x 1
• Einfaches lineares Neuronenmodell, erganzt um eine
Schwellwertfunktion
• Nur linear trennbare Funktionen sind darstellbar
• Perzeptron Lernalgorithmus fur Klassifikation
• Beruhmtes Problem: XOR
37
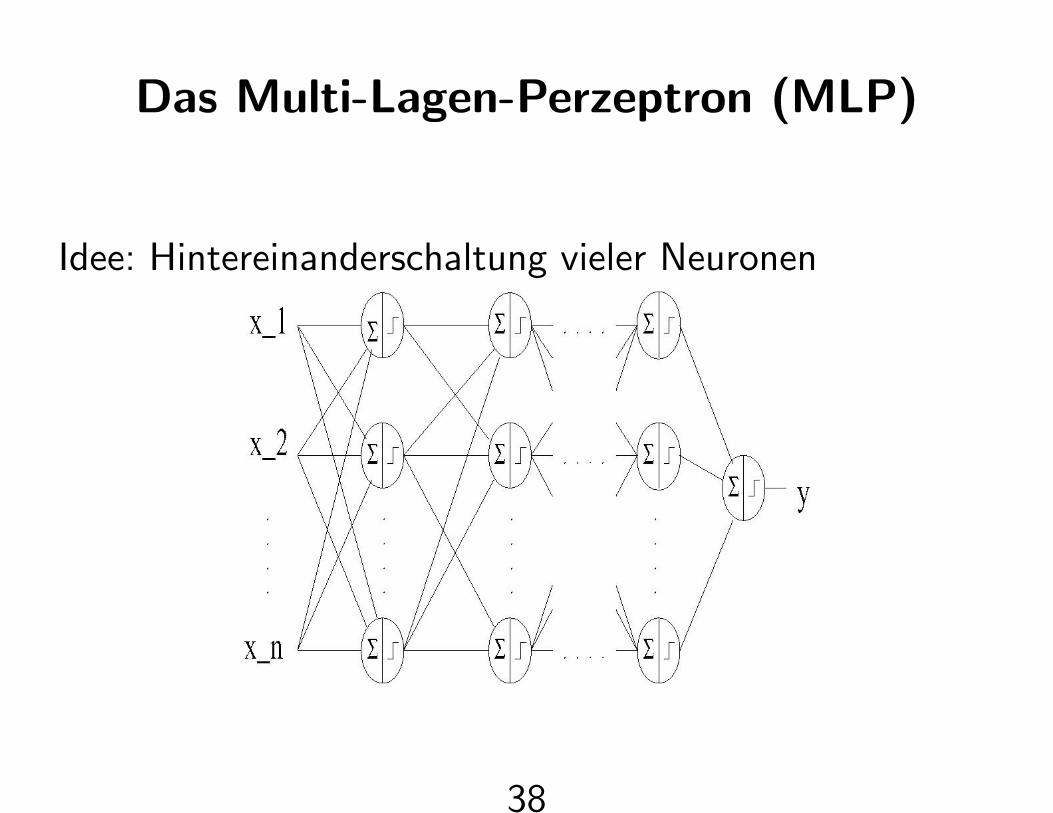
Das Multi-Lagen-Perzeptron (MLP)
Idee: Hintereinanderschaltung vieler Neuronen
38

Das Multi-Lagen-Perzeptron II
• Berechnungsrichtung (vorwarts) gerichtet, keine
Ruckkopplung
• Allgemeiner Funktionsapproximator
• Lernregel: Backpropagation (Rumelhart, McClelland,
1985)
39

Anwendungen von MLPs
• Dollar-DM-Wechselkursprognose
• Autofahren: ALVINN (CMU)
• Absatzprognose Bildzeitung
• Harmonet, Melonet (http://i11www.ira.uka.de/∼musik/)
40
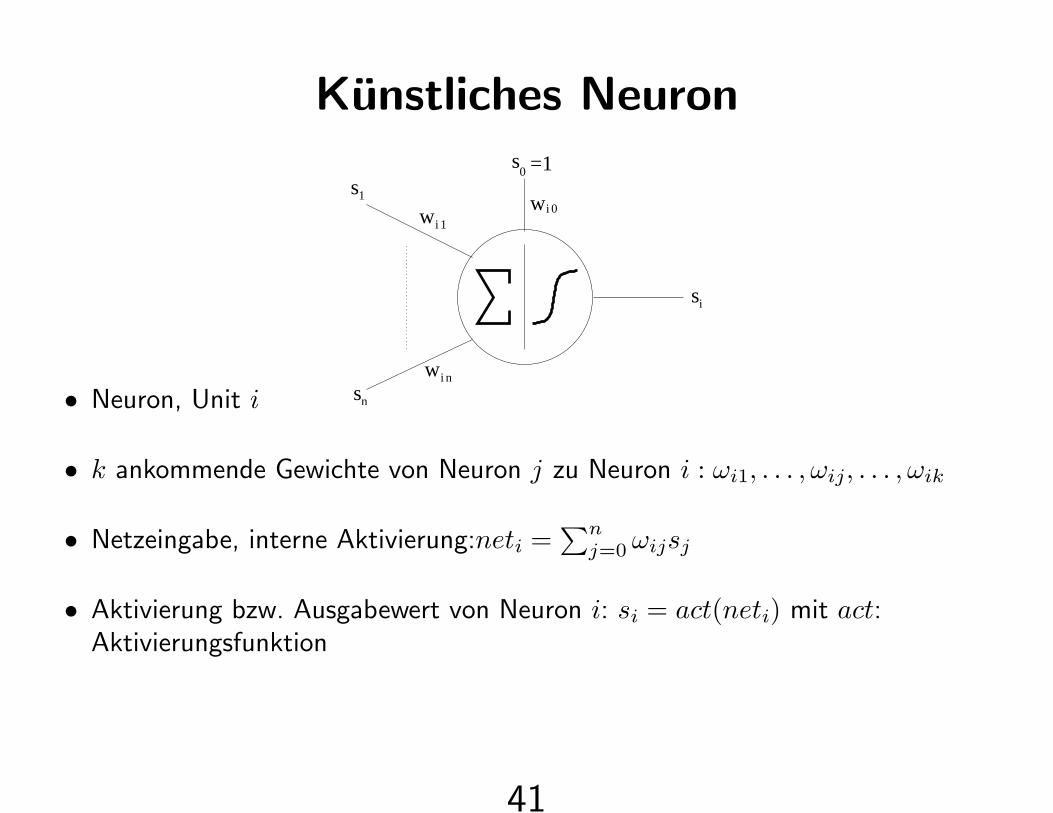
Kunstliches Neuron
w
ww
=11
i 1
i n
i 0
s
ss
sn
0
i
• Neuron, Unit i
• k ankommende Gewichte von Neuron j zu Neuron i : ωi1, . . . , ωij, . . . , ωik
• Netzeingabe, interne Aktivierung:neti =∑n
j=0 ωijsj
• Aktivierung bzw. Ausgabewert von Neuron i: si = act(neti) mit act:Aktivierungsfunktion
41

Die Aktivierungsfunktion
Motivation: Die Schwellwertfunktion, wie sie im Perzeptron
Verwendung findet, wird angenahert durch eine differenzierbare,
monoton wachsende Funktion. Hier haben sich die sogenannten
Sigmoidfunktionen durchgesetzt.
actsig(z) =1
1 + e−az
42

Die Aktivierungsfunktion II
Eigenschaften:
• differenzierbar, streng monoton wachsend, Wertebereich zwischen
0 und 1 (manchmal auch durch einfache Transformation zwischen
-1 und 1)
• fur kleines a einen fast linearen mittleren Bereich
• fur großes a nahert sich actsig einer Schwellwertfunktion an
• In der Praxis wird der Parameter a nicht explizit verwendet; man
kann zeigen, dass dieser sich durch entsprechende Wahl des
Gewichtsvektors (Parametervektors) ~ω ausdrucken lasst
43
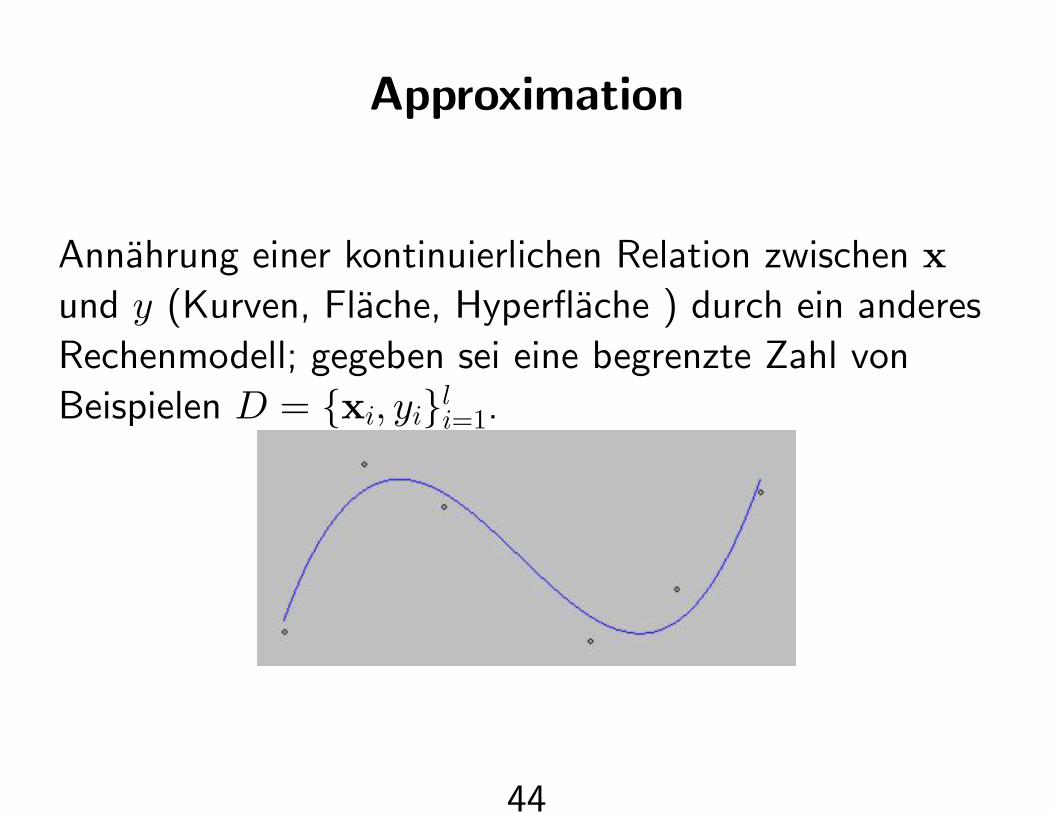
Approximation
Annahrung einer kontinuierlichen Relation zwischen xund y (Kurven, Flache, Hyperflache ) durch ein anderes
Rechenmodell; gegeben sei eine begrenzte Zahl von
Beispielen D = {xi, yi}li=1.
44
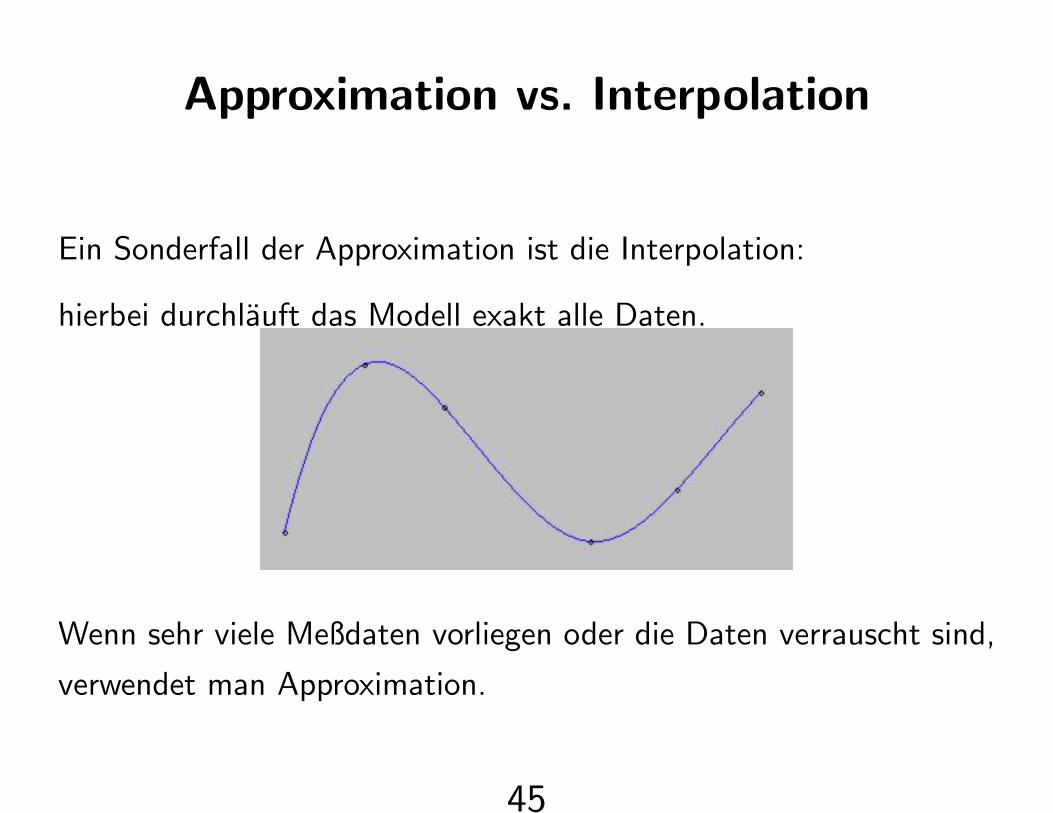
Approximation vs. Interpolation
Ein Sonderfall der Approximation ist die Interpolation:
hierbei durchlauft das Modell exakt alle Daten.
Wenn sehr viele Meßdaten vorliegen oder die Daten verrauscht sind,
verwendet man Approximation.
45
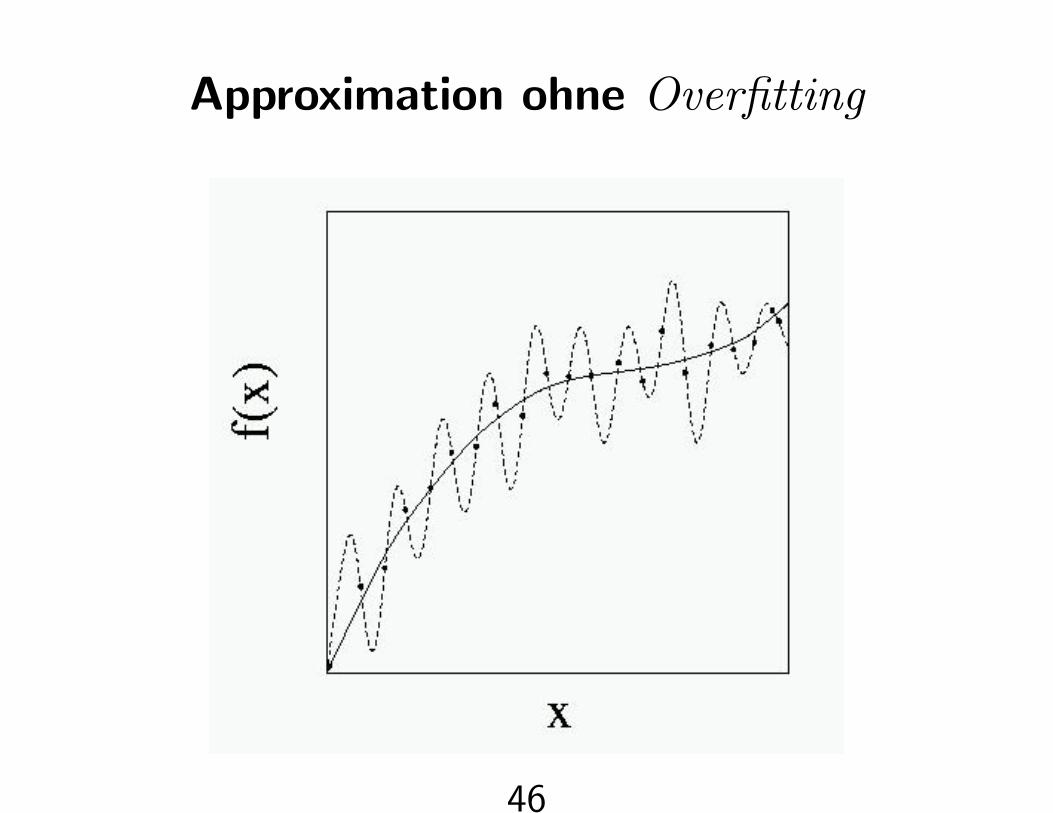
Approximation ohne Overfitting
46

Interpolation mit Polynomen
Einige Interpolationsverfahren mit Polynomen:
• Lagrange-Polynome,
• Newton-Polynome,
• Bernstein-Polynome,
• Basis-Splines.
47

Lagrangesche Interpolation
Um durch l + 1 Punkte (xi, yi) (i = 0, 1, . . . , l) ein Polynom vom
Grade l hindurchzulegen, kann man nach LAGRANGE den
folgenden Ansatz benutzen:
pl(x) =l∑
i=0
yiLi(x)
Die LAGRANGEschen Grundpolynome werden wie folgt definiert:
Li(x) =(x− x0)(x− x1) · · · (x− xi−1)(x− xi+1) · · · (x− xl)
(xi − x0)(xi − x1) · · · (xi − xi−1)(xi − xi+1) · · · (xi − xl)
={
1 wenn x = xi
0 wenn x 6= xi
48

Newtonsche Interpolation
Ein Newtonsches Polynom vom Grade l wird wie folgt konstruiert:
pl(x) = a0+a1(x−x0)+a2(x−x0)(x−x1)+· · ·+al(x−x0) · · · (x−xl−1)
Dieser Ansatz ermoglicht die einfache Berechnung der Koeffizienten.
Fur n = 2 erhalt man das folgende Gleichungssystem:p2(x0) = a0 = y0
p2(x1) = a0 + a1(x1 − x0) = y1
p2(x2) = a0 + a1(x2 − x0) + a2(x2 − x0)(x2 − x1) = y2
49
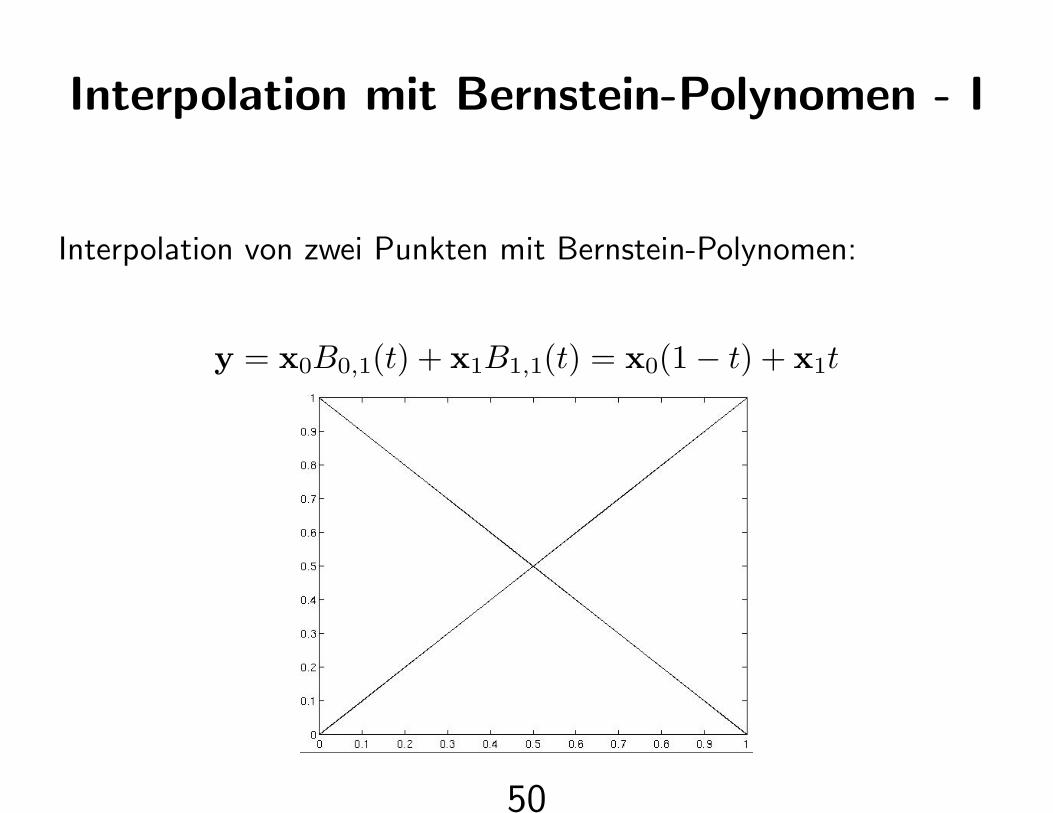
Interpolation mit Bernstein-Polynomen - I
Interpolation von zwei Punkten mit Bernstein-Polynomen:
y = x0B0,1(t) + x1B1,1(t) = x0(1− t) + x1t
50
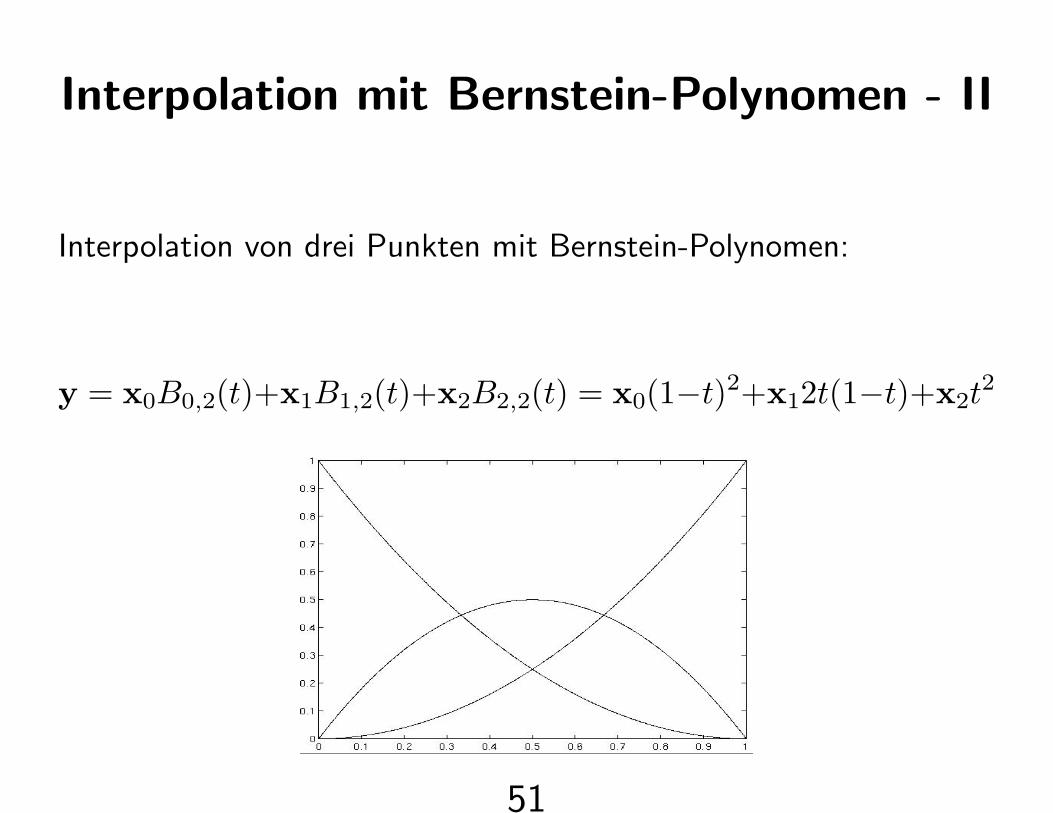
Interpolation mit Bernstein-Polynomen - II
Interpolation von drei Punkten mit Bernstein-Polynomen:
y = x0B0,2(t)+x1B1,2(t)+x2B2,2(t) = x0(1−t)2+x12t(1−t)+x2t2
51

Interpolation mit Bernstein-Polynomen -III
Interpolation von vier Punkten mit Bernstein-Polynomen:
y = x0B0,3(t) + x1B1,3(t) + x2B2,3(t)x3B3,3(t)
= x0(1− t)3 + x13t(1− t)2 + x23t2(1− t) + x3t3
52

Interpolation mit Bernstein-Polynomen -IV
Die Bernstein-Polynome der Ordnung k + 1 werden wie folgt
definiert:
Bi,k(t) =(
k
i
)(1− t)k−iti, i = 0, 1, . . . , k
Interpolation mit Bernstein-Polynomen Bi,k:
y = x0B0,k(t) + x1B1,k(t) + · · ·+ xkBk,k(t)
53

B-Splines
Als normalisierte B-Splines Ni,k der Ordnung k (vom Grad k − 1)
werden folgende Funktionen bezeichnet:
Fur k = 1,
Ni,k(t) ={
1 : fur ti ≤ t < ti+1
0 : sonst
sowie fur k > 1, eine rekursive Darstellung:
Ni,k(t) =t− ti
ti+k−1 − tiNi,k−1(t)+
ti+k − t
ti+k − ti+1Ni+1,k−1(t)
mit i = 0, . . . ,m.
54





























