Embed Size (px)
Citation preview

Technische Universität MünchenFakultät für MathematikLehrstuhl M15 für Angewandte Numerische Analysis
Numerik der gewöhnlichenDifferentialgleichungen
Massimo Fornasier
4. August 2013
PDF-Version: Jan-Christian Hü[email protected]
Verbreitung nicht gestattet

Dieses Skript dient lediglich der Nachbereitung der Vorlesung und ersetzt nicht denregelmäßigen Vorlesungsbesuch. Insbesondere für die Klausur kann sich nicht auf denInhalt oder inhaltliche Fehler berufen werden. Dennoch werden Verbesserungsvorschlägeselbstverständlich gerne angenommen.
2

Inhaltsverzeichnis
0 Einführung 6
1 Polynominterpolation 81.1 Polynominterpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2 Der Interpolationsfehler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Nachteile der Polynominterpolation auf äquidistanten Knoten . . . . . . . . 10
1.4 Stabilität der Polynominterpolation . . . . . . . . . . . . . . . . . . . . . . . 11
1.5 Newtonsche Darstellung des Interpolationspolynoms . . . . . . . . . . . . . 12
1.6 Einige Eigenschaften der Newtonschen dividierten Differenzen . . . . . . . 13
1.7 Der Interpolationsfehler bei der Verwendung dividierter Differenzen . . . . 14
1.8 Stückweise Lagrange-Interpolation . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Numerische Quadratur 182.1 Quadraturformeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Quadratur vom Interpolationstyp . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Die Mittelpunkts-/Rechteckregel . . . . . . . . . . . . . . . . . . . . . 19
2.2.2 Die Trapezregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.3 Die Cavalieri-Simpson-Formel . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Newton-Cotes-Formeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4 Zusammengesetzte Newton-Cotes-Formeln . . . . . . . . . . . . . . . . . . . 27
2.5 Richardson-Extrapolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5.1 Romberg-Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6 Orthogonale Polynome und Gaußsche Integration . . . . . . . . . . . . . . . 31
2.6.1 Tschebyscheff-Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.6.2 Legendre-Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.7 Gaußsche Integration und Interpolation . . . . . . . . . . . . . . . . . . . . . 35
2.7.1 Tschebyscheffsche Integration und Interpolation . . . . . . . . . . . . 39
2.7.2 Legendre-Integration und Interpolation . . . . . . . . . . . . . . . . . 41
2.8 Gaußsche Integration über unbeschränkte Intervalle . . . . . . . . . . . . . . 42
2.8.1 Laguerresche Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.8.2 Hermitesche Polynome . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.9 Approximation von Funktionsableitungen . . . . . . . . . . . . . . . . . . . 44
3

Inhaltsverzeichnis
2.9.1 Klassische finite Differenzen . . . . . . . . . . . . . . . . . . . . . . . 44
2.9.2 Kompakte finite Differenzen . . . . . . . . . . . . . . . . . . . . . . . 46
3 Numerik gewöhnlicher Differentialgleichungen 473.1 Beispiele aus der Populationsdynamik . . . . . . . . . . . . . . . . . . . . . . 47
3.2 Das explizite Euler-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3 Das implizite Euler-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.4 Die Mittelpunktsregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5 Grundbegriffe im Detail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5.1 Anfangswertprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5.2 Lösungstheorie: Existenzsatz von Peano . . . . . . . . . . . . . . . . 51
3.5.3 Eindeutigkeitssatz von Picard-Lindelöf . . . . . . . . . . . . . . . . . 51
3.5.4 Das Lemma von Gronwall und Stabilität der Lösungen . . . . . . . . 53
3.5.5 Evolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.6 Einschrittverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.6.1 Konvergenztheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.6.1.1 Konsistenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.6.1.2 Diskretes Gronwall-Lemma . . . . . . . . . . . . . . . . . . 59
3.6.1.3 Konvergenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.6.2 Explizite Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . 64
3.6.3 Arbeitsplan zur Konstruktion eines Runge-Kutta-Verfahrens der Ord-nung p > 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
3.6.3.1 Taylor-Entwicklung des Phasenflusses Φτ . . . . . . . . . . 70
3.6.3.2 Taylorentwicklung des diskreten Flusses Ψτ . . . . . . . . . 71
3.6.3.3 Bedingungsgleichungen für p = 3 . . . . . . . . . . . . . . . 72
3.6.3.4 Lösen der Bedingungsgleichungen . . . . . . . . . . . . . . 74
3.6.3.5 Anzahl der Bedingungsgleichungen und Butcher-Schranken 75
3.6.4 Extrapolationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.7 Steife Anfangswertprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.7.1 Stabilität und Steifheit . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.7.1.1 Stabilität kontinuierlicher Flüsse . . . . . . . . . . . . . . . . 80
3.7.1.2 Stabilität linearer diskreter Flüsse . . . . . . . . . . . . . . . 83
3.7.1.2.1 Beispiele von Stabilitätsgebieten . . . . . . . . . . . 85
3.7.2 Rationale Approximationen der Exponentialfunktion . . . . . . . . . 85
3.7.3 Die charakteristische Schrittweite . . . . . . . . . . . . . . . . . . . . 86
3.7.4 Stabilitätsbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
3.8 Implizite Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . 89
3.8.1 Struktur impliziter Runge-Kutta-Verfahren . . . . . . . . . . . . . . . 89
3.8.2 Lösung des nichtlinearen Gleichungssystems . . . . . . . . . . . . . 90
3.9 Die Stabilitätsfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
3.10 Maximale Ordnung impliziter Verfahren . . . . . . . . . . . . . . . . . . . . 93
4

Inhaltsverzeichnis
3.11 Kollokationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
3.11.1 Idee . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
3.11.2 Kollokationsverfahren sind implizite Runge-Kutta-Verfahren . . . . 94
3.11.3 Kollokation und Quadratur . . . . . . . . . . . . . . . . . . . . . . . . 95
3.11.4 Globaler Approximationsfehler . . . . . . . . . . . . . . . . . . . . . . 96
3.11.5 Beispiele: Gauß- und Radau-Verfahren . . . . . . . . . . . . . . . . . 98
3.12 Mehrschrittverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
3.12.1 Lineare Mehrschrittverfahren . . . . . . . . . . . . . . . . . . . . . . . 98
3.12.2 Der Verschiebungsoperator . . . . . . . . . . . . . . . . . . . . . . . . 99
3.12.3 Konsistenz und Ordnung . . . . . . . . . . . . . . . . . . . . . . . . . 100
3.12.4 Stabilität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
3.12.5 Adams-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
3.12.6 Stabilitätsgebiete von Mehrschrittverfahren . . . . . . . . . . . . . . . 102
3.12.7 Die zweite Dahlquist-Schranke . . . . . . . . . . . . . . . . . . . . . . 104
3.12.8 BDF-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
3.12.9 Verbindung mit numerischer Differentiation . . . . . . . . . . . . . . 105
5

0 Einführung
Diese Vorlesung behandelt die numerische Approximation der Lösungen von Systemengewöhnlicher Differentialgleichungen (DG)
x′i(t) = fi(t, x1, . . . , xd), i = 1, . . . , d (0.1)
für gegebene Anfangswerte
xi(t0) = xi,0 ∈ R, i = 1, . . . , d. (0.2)
In Kurzschreibweise lautet das Anfangswertproblem bei gewöhnlichen Differentialgleichun-gen
x′(t) = f (t, x), x(t0) = x0 ∈ Rd,
wobei(t, x) ∈ Ω ⊆ Rd+1 und f : Ω→ Rd.
Da die Differentialgleichung eine Funktion x(t) indirekt über ihre Ableitung x′(t) be-schreibt, können wir den Lösungsprozess als Integration auffassen. In Zukunft sprechenwir daher von der numerischen Integration von Anfangswertproblemen.
In der Regel ist die Variable t als physikalische Zeit interpretierbar. In diesem Fallhaben die Anfangsprobleme einen halboffenen Charakter (t0 ≤ t < ∞) und heißenEvolutionsprobleme: In seltenen Fällen, zumeist bei Randwertproblemen, kann t auch eineRaumvariable darstellen. Der Vektor x charakterisiert den Zustand eines Systems undheißt deshalb oft Zustandsvektor.
Differentialgleichungen wurden erstmals im 17. Jahrhundert formuliert, nachweislichvon I. Newton 1671 und von G.W. Leibniz 1676.
Die tatsächliche Lösung solcher Gleichungen ist gleichbedeutend mit einer Zukunfts-vorhersage für das beschriebene System. In der Tat ist bei Kenntnis das Anfangswertsx0 = x(t0) der Zustand x(t) für alle Zeiten t festgelegt.
Als Prototypen deterministischer Modelle erwähnen wir
• die Newtonsche Mechanik der Himmelskörper, die uns erlaubt die Trajektorien vonSatelliten zu steuern;
• die klassische Moleküldynamik, eine Variante der Newtonschen Mechanik, die inder Biologie und Medizin Basis z.B. für den Entwurf neuer Medikamente gegenViruserkrankungen ist;
6

0 Einführung
• als Musterbeispiel deterministischer Modellierung stochastischer Prozesse die aufBoltzmann zurückgehende chemische Reaktionskinetik.
• die Simulation elektrischer Schaltkreise oder des Blutkreislaufs.
Eine gewöhnliche Differentialgleichung kann auch in der folgenden Integralform dar-gestellt werden:
x(t) = x(t0) +∫ t
t0
f (s, x(s))ds, ∀t ∈ [0, T] (0.3)
und für eine Folge t0 < t1 < . . . < tn < T können wir die Werte x(t0), . . . , x(tn) durch
x(tm+1) = x(tm−l) +∫ tm+1
tm−l
f (s, x(s))ds, m = 0, . . . , (n− 2), l = 0, . . . , m (0.4)
charakterisieren. Falls wir ein numerisches Verfahren hätten, um eine effiziente Approxi-mation des Integrals ∫ tm+1
tm−l
f (s, x(s))ds
mit einer Funktion
Ψ( f (tm−l , x(tm−l)), . . . , f (tm+1, x(tm+1)) '∫ tm+1
tm−l
f (s, x(s))ds (0.5)
zu liefern, dann könnten wir auch die Werte
x(tm+1) ' x(tm−l) + Ψ( f (tm−l , x(tm−l)), . . . , f (tm+1, x(tm+1))
approximieren. Deshalb braucht die numerische Lösung gewöhnlicher Differentialglei-chungen Methoden für die numerische Quadratur.
Die praktische Realisierung der Approximation in (0.5) geschieht durch die Interpola-tion der Funktion f auf den Knoten (tm−k, x(tm−k)) für k = 1, . . . , l durch eine einfach zuhandhabende Funktion, insbesondere Polynome, sodass
f (s) ' π(s) := a0 + a1s + . . . + amsm, s ∈ [t0, T]
und∫ T
t0
f (s)ds '∫ T
t0
π(s)ds = a0(T − t0) +a1
2(T2 − t2
0) + . . . +am
m + 1(Tm+1 − tm+1
0 ). (0.6)
Wir können die Argumentation im folgenden Schema zusammenfassen:
1 Interpolation⇒ 2 Numerische Quadratur⇒ 3 Numerik gewöhnlicher DGen,
weswegen die Vorlesung in diese drei Kapitel eingeteilt ist.
7

1 Polynominterpolation
1.1 Polynominterpolation
Betrachten wir n + 1 Paare (xi, yi) ∈ R2, i = 0, . . . , n. Das Problem besteht darin, einsogenanntes Interpolationspolynom πm ∈ Pm, zu finden, sodass
πm(xi) = amxmi + . . . + a1xi + a0 = yi, i = 0, . . . , n (1.1)
gilt. Die Punkte xi ∈ R heißen Interpolationsknoten. Falls m 6= n, so ist das Problementweder über- oder unterbestimmt und wir werden nur den Fall m = n behandeln, fürden das folgende Resultat gilt:
Theorem 1.1. Seien n+ 1 verschiedene Punkte x0, . . . , xn und n+ 1 entsprechende Werte y0, . . . , yn
gegeben. Dann existiert ein eindeutig bestimmtes Polynom πn ∈ Pn, sodass πn(xi) = yi füri = 0, . . . , n gilt.
Beweis. Um die Existenz zu zeigen, benutzen wir einen konstruktiven Ansatz, der einenAusdruck für πn liefert. Definieren wir die Polynome
li ∈ Pn, li(x) =n
∏j=0j 6=i
x− xj
xi − xj, i = 0, . . . , n, (1.2)
so gilt
li(xj) = δij =
1, i = j,
0, i 6= j,(Kronecker Delta).
Die Polynome li : i = 0, . . . , n bilden eine Basis in Pn (Übung für Mutige!). Somit gibtes ein Interpolationspolynom in der Lagrangeschen Form
πn(x) =n
∑i=0
yili(x). (1.3)
Dies erfüllt die Anforderung der Interpolation, da
πn(xj) =n
∑i=0
yili(xj) =n
∑i=0
yiδij = yj.
8

1.2 Der Interpolationsfehler
Um die Eindeutigkeit zu beweisen, nehmen wir an, dass ein weiteres Interpolationspo-lynom ψm mit m ≤ n existiert, sodass
ψm(xi) = yi, i = 0, . . . , n
gilt. πn statt πmDas Polynom πn − ψm ∈ Pn verschwindet auf n + 1 verschiedenen Punkten xi undstimmt folglich mit dem Nullpolynom überein (nach dem Fundamentalsatz der Algebra).
Jetzt definieren wir die Knotenpolynome vom Grad n + 1,
ωn+1(x) =n
∏i=0
(x− xi). (1.4)
Eine weitere Übung besteht darin zu zeigen, dass
πn(x) =n
∑i=0
yi
(ωn+1(x)
(x− xi)ω′n+1(xi)
). (1.5)
Gelten für eine gegebene Funktion f die Beziehungen yi = f (xi), i = 0, . . . , n, so wirddas zugeordnete Interpolationspolynom πn(x) durch πn f (x) bezeichnet.
1.2 Der Interpolationsfehler
Wir schätzen den Interpolationsfehler ab, der bei Ersetzung einer gegebenen Funktion fdurch ihr Interpolationspolynom πn f mit den Knoten x0, x1, . . . , xn entsteht.
Theorem 1.2. Seien x0, . . . , xn verschiedene Knoten und x ein Punkt aus dem Definitionsbereicheiner gegebenen Funktion f . Wir nehmen an, dass f ∈ C(n+1)(Ix), wobei Ix das kleinste die Knotenx0, . . . , xn und x enthaltende Intervall sei. Dann ist der Interpolationsfehler im Punkt x durch
En(x) = f (x)− πn(x) =f (n+1)(ξ)
(n + 1)!ωn+1(x) (1.6)
gegeben, wobei ξ ∈ Ix und ωn+1 das Knotenpolynom vom Grad n + 1 bezeichne.
Beweis. Das Resultat ist klar, falls x mit irgendeinem Interpolationsknoten zusammenfällt.Andernfalls definieren wir für jedes t ∈ Ix die Funktion
G(t) := En(t)−ωn+1(t)En(x)
ωn+1(x).
9

1.3 Nachteile der Polynominterpolation auf äquidistanten Knoten
Da f ∈ C(n+1)(Ix) und ωn+1 ein Polynom ist, ist G ∈ C(n+1)(Ix) und besitzt n + 2verschiedene Nullstellen in Ix, denn
G(xi) = En(xi)−ωn+1(xi)En(x)
ωn+1(x)= 0
G(x) = En(x)−ωn+1(x)En(x)
ωn+1(x)= 0.
Nach dem Mittelwertsatz besitzt G(j) n + 2 − j verschiedene Nullstellen. Folglich hatG(n+1) genau eine Nullstelle, die wir mit ξ bezeichnen wollen. Andererseits bekommenwir wegen E(n+1)
n (t) = f (n+1)(t) und ω(n+1)n+1 (t) = (n + 1)!
G(n+1)(t) = f (n+1)(t)− (n + 1)!ωn+1(x)
En(x),
was ausgewertet in t = ξ den gewünschten Ausdruck für En(x) ergibt.
1.3 Nachteile der Polynominterpolation auf äquidistantenKnoten
Wir analysieren das Verhalten des Interpolationsfehlers (1.6) für n → ∞. Dazu definierenwir für jede Funktion f ∈ C0[a, b] ihre Maximumnorm
‖ f ‖∞ = maxx∈[a,b]
| f (x)| . (1.7)
Ferner führen wir eine untere Dreiecksmatrix X endlicher Dimension – die Interpolations-matrix auf [a, b] – ein, deren Einträge xij für i ≤ j die Punkte auf [a, b] darstellen, wobeiwir annehmen, dass in jeder Zeile alle Einträge voneinander verschieden sind, d.h.
X =
x11 0 · · · 0x12 x22 · · · 0
......
. . ....
xn+1,1 xn+1,2 · · · xn+1,n+1
Somit enthält für jedes n ≥ 0 die (n + 1)-te Zeile von X n + 1 unterschiedliche Werte,die wir als Knoten identifizieren können, sodass wir für eine gegebene Funktion f einInterpolationspolynom πn f vom Grad n eindeutig in diesen Knoten bestimmen können.
Nachdem wir f und eine Interpolationsmatrix X fest vorgegeben haben, definieren wir
En,∞(X) := ‖ f − πn f ‖∞ , n = 0,1, . . .
Als nächstes bezeichnen wir mit p∗n ∈ Pn die beste polynomiale Approximation, für die
E∗n = ‖ f − p∗n‖∞ ≤ ‖ f − qn‖∞ ∀qn ∈ Pn
gilt. Es gilt das folgende Vergleichsresultat:
10

1.4 Stabilität der Polynominterpolation
Eigenschaft 1.3. Seien f ∈ C0([a, b]) und X eine Interpolationsmatrix auf [a, b]. Dann gilt
En,∞(X) ≤ E∗n(1 + Λn(X)), n = 0,1, . . . , (1.8)
wobei Λn(X) die Lebesguekonstante von X bezeichnet, die als
Λn(X) =
∥∥∥∥∥ n
∑j=0
∣∣∣l(n)j
∣∣∣∥∥∥∥∥∞
(1.9)
definiert ist (wobei l(n)j ∈ Pn das j-te Lagrangesche Polynom bezeichnet, das zur (n + 1)-ten Zeile
von X gehört, das also l(n)j (xnk) = δjk, j ≤ k genügt.
Da E∗n nicht von X abhängt, sind alle Informationen, die den Einfluss von X auf En,∞(X)
betreffen, in Λn(X) zu finden.Obwohl eine Interpolationsmatrix X∗ existiert, sodass Λn(X) minimiert wird, ist es im
Allgemeinen nicht einfach, ihre Einträge explizit zu bestimmen. Andererseits gibt es fürjede mögliche Wahl von X eine Konstante C > 0, sodass
Λn(X) >2π
log(n + 1)− C, n = 0,1, . . . .
Diese Eigenschaft zeigt, dass Λn(X) → ∞ für n → ∞. Diese Tatsache besitzt wichti-ge Folgerungen: Zu einer gegebenen Interpolationsmatrix X auf einem Intervall [a, b]existiert immer eine auf [a, b] stetige Funktion f , sodass πn f nicht gleichmäßig gegen fkonvergiert.
Beispiel 1.4 (Runges Gegenbeispiel). Angenommen, wir approximieren die Funktion
f (x) =1
1 + x2 , −5 ≤ x ≤ 5
mit Hilfe der Lagrange-Interpolation auf einem äquidistanten Gitter. Man kann zeigen, dass eseinige Punkte innerhalb des Interpolationsintervalls gibt, sodass
limn→∞| f (x)− πn f (x)| 6= 0.
Insbesondere divergiert die Lagrange-Interpolierende für |x| > 3 63 . . . Dieses Phänomen istbesonders deutlich in der Nähe der Randpunkte des Interpolationsintervalls zu beobachten undist auf die Wahl von äquidistanten Knoten zurückzuführen.
1.4 Stabilität der Polynominterpolation
Betrachten wir eine Menge von Funktionswerten f (xi), bei denen es sich um eine Stö-rung der Daten f (xi) in den Knoten xi, i = 0, . . . , n im Intervall [a, b] handele. Die Störung
11

1.5 Newtonsche Darstellung des Interpolationspolynoms
kann beispielsweise durch Rundungsfehler oder durch Fehler bei der experimentellenMessung der Daten entstanden sein. Indem wir durch πn f das Interpolationspolynomauf der Menge der Werte f (xi) bezeichnen, erhalten wir
∥∥∥πn f − πn f∥∥∥
∞= max
a≤x≤b
∣∣∣∣∣ n
∑j=0
(f (xj)− f (xj)
)lj(x)
∣∣∣∣∣≤ Λn(x) max
i=0,...,n
∣∣∣ f (xi)− f (xi)∣∣∣ .
Folglich lassen kleine Änderungen der Daten nur dann kleine Änderungen des Inter-polationspolynoms zu, wenn die Lebesguekonstante klein ist. Diese Konstante spielt dieRolle der Konditionszahl des Interpolationsproblems.
Wie zuvor bemerkt, wächst Λn mit n → ∞ und speziell im Fall der Lagrange-Interpo-lation auf äquidistanten Knoten kann
Λn(x) ' 2n+1
en log n
bewiesen werden (wobei e = 2 71 . . . die Eulersche zahl bezeichne). Dies zeigt, dass fürgroße n diese Art der Interpolation instabil werden kann.
1.5 Newtonsche Darstellung des Interpolationspolynoms
Vom praktischen Standpunkt aus ist die Lagrangesche Darstellung
πn f (x) =n
∑i=0
f (xi)li(x)
nicht die geeignetste. Wir führen eine andere Darstellung ein, die sich durch einen gerin-geren numerischen Aufwand auszeichnet:
Zu n + 1 gegebenen Paaren xi, yi, i = 0, . . . , n werden wir πn (mit πn(xi) = yi füri = 0, . . . , n) als Summe von πn−1 (mit πn−1(xi) = yi für i = 0, . . . , n − 1) und einemPolynom vom Grad n darstellen, das von xi und nur einem unbekannten Koeffizientenabhängt. Wir setzen folglich
πn(x) = πn−1(x) + qn(x), (1.10)
wobei qn ∈ Pn. Da qn(xi) = πn(xi) − πn−1(xi) = 0 für i = 0, . . . , n − 1 gilt, mussnotwendigerweise
qn(x) = an · (x− x0) · · · (x− xn−1) = anωn(x)
12

1.6 Einige Eigenschaften der Newtonschen dividierten Differenzen
gelten. Um den unbekannten Koeffizienten an zu bestimmen, nehmen wir an, dass yi =
f (xi), i = 0, . . . , n gilt. Wegen πn f (xn) = f (xn) folgt daraus, dass
an =f (xn)− πn−1 f (xn)
ωn(xn). (1.11)
Der Koeffizient an heißt die n-te Newtonsche dividierte Differenz und wird üblicherweisedurch
an = f [x0, x1, . . . , xn]
für n ≥ 1 bezeichnet. Damit kann (1.10) in der Form
πn f (x) = πn−1 f (x) + ωn(x) f [x0, . . . , xn] (1.12)
dargestellt werden. Setzen wir y0 = f (x0) = f [x0] und ω0 = 1, so erhalten wir aus (1.12)durch Rekursion in n die Formel
πn f (x) =n
∑k=0
ωk(x) f [x0, . . . , xk]. (1.13)
Die Darstellung (1.13) heißt die Newtonsche dividierte Differenzenformel des Interpolations-polynoms.
1.6 Einige Eigenschaften der Newtonschen dividiertenDifferenzen
Die n-te dividierte Differenz f [x0, . . . , xn] = an kann auch dadurch charakterisiert werden,dass sie der Koeffizient von xn in πn f ist. Selektieren wir diesen Koeffizienten aus (1.5),
πn(x) =n
∑i=0
ωn+1(x)(x− xi)ω′n+1(xi)
yi
und setzen ihn gleich dem entsprechenden Koeffizienten in der Newtonschen Darstel-lungsformel, so erhalten wir die explizite Darstellung
f [x0, . . . , xn] =n
∑i=0
f (xi)
ω′n+1(xi)(1.14)
(Übung!). Diese Formel erlaubt mehrere Folgerungen:
(i) Der von dividierten Differenzen angenommene Wert ist invariant in Bezug aufPermutationen der Knotenindizes;
(ii) Gilt f = αg + βh für α, β ∈ R, so folgt f [x0, . . . , xn] = αg[x0, . . . , xn] + βh[x0, . . . , xn];
13

1.7 Der Interpolationsfehler bei der Verwendung dividierter Differenzen
(iii) Ist f = gh, so gilt die folgende Formel (Leibniz-Formel, Übung!):
f [x0, . . . , xn] =n
∑j=0
g[x0, . . . , xj] h[xj, . . . , xn];
(iv) Eine algebraische Umformung von (1.14) liefert die Rekursionsbeziehung (Übung!)der dividierten Differenzen
− im Zählerergänzt
f [x0, . . . , xn] =f [x1, . . . , xn]− f [x0, . . . , xn−1]
xn − x0, n ≥ 1. (1.15)
1.7 Der Interpolationsfehler bei der Verwendung dividierterDifferenzen
Betrachten wir die Knoten x0, . . . , xn und sei πn f das Interpolationspolynom von f indiesen Knoten. Sei x 6= xi für i = 0, . . . , n, xn+1 = x und bezeichne πn+1 f das Interpola-tionspolynom von f in den Knoten xk, k = 0, . . . , n + 1. Unter Verwendung Newtonscherdividierter Differenzen erhalten wir
πn+1 f (t) = πn f (t) + (t− x0) · · · (t− xn) f [x0, . . . , xn, t].
Da πn+1 f (x) = f (x), gilt
En(x) = f (x)− πn f (x) = πn+1 f (x)− πn f (x)
= (x− x0) · · · (x− xn) f [x0, . . . , xn, x] x in
dividierterDifferenz
= ωn+1(x) f [x0, . . . , xn, x]. (1.16)
Die Annahme f ∈ C(n+1)(Ix) und der Vergleich mit (1.6),
En(x) = f (x)− πn f (x) =f (n+1)(ξ)
(n + 1)!ωn+1(x)
ergibt
f [x0, . . . , xn] =f (n+1)(ξ)
(n + 1)!(1.17)
für ein ξ ∈ Ix. Da (1.17) dem Restglied der Taylorentwicklung von f ähnelt, wird dieNewtonsche Formel
πn f (x) =n
∑k=0
ωk(x) f [x0, . . . , xk]
für das Interpolationspolynom oft als abgebrochene Entwicklung um x0 angesehen, vor-ausgesetzt, dass die Abstände |xk − x0| nicht zu groß sind.
14

1.8 Stückweise Lagrange-Interpolation
1.8 Stückweise Lagrange-Interpolation
Wir haben schon erwähnt, dass für äquidistante Interpolationsknoten die gleichmäßigeKonvergenz πn f → f für n → ∞ nicht gesichert ist. Andererseits sind äquidistante Kno-ten numerisch einfacher zu handhaben und die Lagrange-Interpolation niederen Gradesausreichend genau, wenn hinreichend kleine Interpolationsintervalle betrachtet werden.Daher ist es naheliegend, eine Partition Th von [a, b] in K Intervalle Ij = [xj, xj+1] derLänge hj mit h = max
hj : 0 ≤ j ≤ K− 1
einzuführen, sodass
[a, b] =K−1⋃j=0
Ij, 0 ≤ j ≤ K− 1,
gilt und die Lagrange-Interpolation auf jedem Ij unter Verwendung von k + 1 äquidistan-
ten Knoten x(i)j , 0 ≤ i ≤ k bei kleinem k anzuwenden.Für k ≥ 1 führen wir auf Th den stückweise polynomialen Raum
Xkh :=
v ∈ C0([a, b]) : v|Ij ∈ Pk(Ij) ∀Ij ∈ Th
(1.18)
als Raum der auf [a, b] stetigen Funktionen ein, deren Einschränkungen auf jedem IjPolynome vom Grad ≤ k sind. Für eine beliebige, auf [a, b] stetige Funktion f stimmtdann die stückweise polynomiale Interpolation πk
h f auf jedem Ij mit dem Interpolations-
polynom von f |Ij in den k + 1 Knoten x(i)j , 0 ≤ i ≤ k überein. Folglich erhalten wir für
f ∈ C(k+1)([a, b]) unter Verwendung von (1.6),
En(x) = f (x)− πn(x) =f (n+1)(ξ)
(n + 1)!ωn+1(x),
in jedem Teilintervall die Fehlerabschätzung∥∥∥ f − πkh f∥∥∥
∞≤ Chk+1
∥∥∥ f (k+1)∥∥∥
∞. (1.19)
Beachte, dass ein kleiner Interpolationsfehler auch für kleine k erzielt werden kann, wennnur h genügend klein ist.
Neben der Abschätzung (1.19) gibt es Konvergenzresultate in Integralnormen. Hierzuführen wir den Raum
L2(a, b) :=
f : (a, b)→ R :∫ b
a| f (x)|2 dx < +∞
(1.20)
mit
‖ f ‖L2(a,b) :=(∫ b
a| f (x)|2 dx
)1/2
(1.21)
ein. Die Formel (1.21) definiert eine Norm auf L2(a, b). Wir machen den Leser daraufaufmerksam, dass das Integral der Funktion | f |2 in (1.21) im Lebesgueschen Sinne aufzu-fassen ist.
15

1.8 Stückweise Lagrange-Interpolation
Theorem 1.5. Sei 0 ≤ m ≤ k + 1 mit k ≥ 1 und nehmen wir an, dass f (m) ∈ L2(a, b) für0 ≤ m ≤ k + 1 (z.B. f ∈ C(k+1)([a, b])). Dann gibt es eine positive Konstante C unabhängig vonh, sodass ∥∥∥( f − πk
h f )(m)∥∥∥
L2(a,b)≤ Chk+1−m
∥∥∥ f (k+1)∥∥∥
L2(a,b). (1.22)
Für k = 1 und m = 0 oder m = 1 erhalten wir insbesondere∥∥∥ f − π1h f∥∥∥
L2(a,b)≤ C1h2 ∥∥ f ′′
∥∥L2(a,b)∥∥∥( f − π1
h f )′∥∥∥
L2(a,b)≤ C2h
∥∥ f ′′∥∥
L2(a,b)
(1.23)
mit positiven Konstanten C1 und C2.
Beweis. Wir beweisen nur (1.23). Setze e := f − π1h f . Da e(xj) = 0 für alle j = 0, . . . , K,
folgt aus dem Satz von Rolle die Existenz von ξ j ∈ (xj, xj+1) für j = 0, . . . , K − 1, sodasse′(ξ j) = 0. Die Funktion π1
h f ist affin auf jedem Ij, somit erhalten wir für x inIj
e′(x) =∫ x
ξ j
e′′(s)ds =∫ x
ξ j
f ′′(s)ds,
woraus ∣∣e′(x)∣∣ ≤ ∫ xj+1
xj
∣∣ f ′′(s)∣∣ds, x ∈ [xj, xj+1], (1.24)
folgt. Wir erinnern an die Cauchy-Schwarz Ungleichung∣∣∣∣∫ β
αu(x)v(x)dx
∣∣∣∣ ≤ (∫ β
αu2(x)dx
)1/2 (∫ β
αv2(x)dx
)1/2
,
die für u, v ∈ L2(α, β) gilt. Wenden wir diese Ungleichung auf (1.24) an, bekommen wir
∣∣e′(x)∣∣ ≤ (∫ xj+1
xj
12 dx)1/2 (∫ xj+1
xj
∣∣ f ′′(s)∣∣2 ds)1/2
≤ h1/2(∫ xj+1
xj
∣∣ f ′′(s)∣∣2 ds)1/2
. (1.25)
Um eine Schranke für |e(x)| zu finden, erwähnen wir, dass
e(x) =∫ x
xj
e′(s)ds + e(xj)︸︷︷︸=0
=∫ x
xj
e′(s)ds
gilt, woraus mittels (1.25)
|e(x)| ≤∫ xj+1
xj
∣∣e′(s)∣∣ds ≤ h3/2(∫ xj+1
xj
∣∣ f ′′(s)∣∣2 ds)1/2
h3/2 statth2/2
(1.26)
16

1.8 Stückweise Lagrange-Interpolation
folgt. Weiter gilt ∫ xj+1
xj
∣∣ f ′′(s)∣∣2 ds
und (.)2 beimrechtenIntegrand
∫ xj+1
xj
|e(x)|2 dx ≤ h4∫ xj+1
xj
∣∣ f ′′(s)∣∣2 ds,
woraus wir durch Summation über den Index j von 0 bis K − 1 und durch Ziehen derQuadratwurzel auf beiden Seiten(∫ b
a
∣∣e′(x)∣∣2 dx
)1/2
≤ h(∫ b
a
∣∣ f ′′(x)∣∣2 dx
)1/2
und (∫ b
a|e(x)|2 dx
)1/2
≤ h2(∫ b
a
∣∣ f ′′(x)∣∣2 dx
)1/2
erhalten, was die gewünschte Abschätzung (1.23) ist.
Nach dieser kurzen und grundlegenden Einführung über die polynomiale Interpolationwender wir uns dem nächsten Kapitel zu, das die numerische Integration (oder auchQuadratur) behandelt.
17

2 Numerische Quadratur
2.1 Quadraturformeln
Sei f eine reelle, auf dem Intervall [a, b] integrierbare Funktion. Die explizite Berechnungdes bestimmten Integrals I( f ) =
∫ ba f (x)dx kann schwierig oder sogar unmöglich sein.
Jede explizite und berechenbare Formel, die geeignet ist, eine Näherung von I( f ) zuliefern, wird Quadraturformel oder numerische Integrationsformel genannt. Ein Beispiel erhältman, indem man f durch eine von n ≥ 0 abhängige Approximation fn ersetzt und dannI( fn) anstelle von I( f ) berechnet. Setzen wir In( f ) := I( fn), so folgt
In( f ) =∫ b
afn(x)dx, n ≥ 0. (2.1)
Die Abhängigkeit von den Randpunkten a und b wird immer stillschweigend vorausge-setzt, wir schreiben daher In( f ) anstelle von In( f ; a, b).
Ist f ∈ C0([a, b]), so genügt der Quadraturfehler En( f ) = I( f )− In( f ) der Abschätzung
|En( f )| ≤∫ b
a| f (x)− fn(x)|dx ≤ (b− a) ‖ f − fn‖∞ .
Wenn für ein gewisses n daher ‖ f − fn‖∞ ≤ ε gilt, so folgt |En( f )| ≤ ε(b− a).Die Approximation fn muss integrierbar sein, was zum Beispiel der Fall ist, wenn fn ∈
Pn. In dieser Hinsicht ist es natürlich, als Approximation fn = πn f , das interpolierendeLagrange-Polynom von f über einer Menge von n + 1 verschiedenen Knoten xi, i =
0, . . . , n, zu nehmen. Wenn wir dies tun, so folgt aus (2.1)
In( f ) =n
∑i=0
f (xi)∫ b
ali(x)dx, (2.2)
wobei li das charakteristische Lagrange-Polynom vom Grad n bezeichnet, das zum Knotenxi gehört (Formel (1.2)). Wir bemerken, dass (2.2) ein spezielles Beispiel der Quadratur-formel
In( f ) =n
∑i=0
αi f (xi) (2.3)
ist, wobei die Koeffizienten αi der Linearkombination durch∫ b
a li(x)dx gegeben sind. DiePunkte xi für i = 0, . . . , n heißen wieder Knoten der Quadraturformel, die Zahlen αi ∈ R
18

2.2 Quadratur vom Interpolationstyp
sind ihre Koeffizienten oder Gewichte. Formel (2.2) wird Lagrangesche Quadraturformelgenannt.
Wir definieren den Grad der Exaktheit einer Quadraturformel als die größte ganze Zahln ≥ 0, für die
In( f ) = I( f ), f ∈ Pn,
gilt. Jede Quadraturformel vom Interpolationstyp wie (2.2), die (n+ 1) verschiedene Kno-ten benutzt, hat mindestens den Grad der Exaktheit n. In der Tat, für f ∈ Pn haben wirπn f = f und folglich In(πn f ) = I(πn f ). Wie wir sehen werden, kann der Exaktheitsgradeiner Lagrangeschen Quadraturformel sogar 2n + 1 sein, wie es bei den sogenanntenGaußschen Quadraturformeln der Fall ist.
2.2 Quadratur vom Interpolationstyp
Wir betrachten drei bemerkenswerte Beispiele der Formel (2.2), die den Werten n = 0,1und 2 entsprechen.
2.2.1 Die Mittelpunkts-/Rechteckregel
Diese Formel erhält man, indem man f auf [a, b] durch die konstante Funktion ersetzt,die gleich dem Wert von f im Mittelpunkt des Intervalls [a, b] ist. Dies ergibt
I0( f ) = (b− a) f(
a + b2
)(2.4)
mit dem Gewicht α0 = b− a und Knoten x0 = a+b2 . Ist f ∈ C2([a, b]), so ist der Quadra-
turfehler
E0( f ) =h3
3f ′′(ξ), h =
b− a2
, (2.5)
wobei ξ im Inneren des Intervalls (a, b) liegt.Um die Formel (2.5) zu beweisen, brauchen wir den Mittelwertsatz in Integralform:
Theorem 2.1 (Mittelwertsatz). Seien G : [a, b] → R eine stetige Funktion und ϕ : [a, b] → R
eine integrierbare Funktion, die auf dem Intervall [a, b] nicht ihr Vorzeichen wechselt, d.h. es gelteentweder ϕ(x) ≥ 0 oder ϕ(x) ≤ 0 für alle x ∈ [a, b]. Dann existiert ein Punkt ξ ∈ [a, b], sodass∫ b
aG(t)ϕ(t)dt = G(ξ)
∫ b
aϕ(t)dt (2.6)
gilt.
Durch Entwicklung von f in eine Taylorreihe um c = a+b2 bis zum zweiten Glied
bekommen wir
f (x) = f (c) + f ′(c)(x− c) + f ′′(η(x))(x− c)2
2.
19

2.2 Quadratur vom Interpolationstyp
Durch Integration über (a, b) folgt∫ b
af (x)dx = (b− a) f
(a + b
2
)+ f ′
(a + b
2
) ∫ b
a
(x− a + b
2
)dx︸ ︷︷ ︸
=0
+∫ b
af ′′(η(x))
(x− c)2
2dx.
Die Verwendung des Mittelwertsatzes mit G(t) = f ′′(η(t)) und ϕ(t) = (t−c)2
2 ergibt∫ b
af ′′(η(x))
(x− c)2
2dx = f ′′(ξ)
∫ b
a
(x− c)2
2dx
= f ′′(ξ)12
[13
(x− a + b
2
)3]∣∣∣∣∣
b
a
= f ′′(ξ)16
[(b− a
2
)3
−(
a− b2
)3]=
f ′′(ξ)3
(b− a
2
)3
.
Es sollte erwähnt werden, dass der Quadraturfehler (2.5) ziemlich groß werden kann,wenn die Breite des Integrationsintervalls [a, b] nicht genügend klein ist. Nehmen wir nunan, dass wir das Integral I( f ) approximieren, indem wir f über [a, b] durch zusammenge-setzte Interpolationspolynome vom Grad 0 ersetzen, die auf m Teilintervallen der BreiteH = b−a
m für m ≥ 1 konstruiert werden. Durch Einführung der Quadraturknoten xk =
a + (2k+1)H2 für k = 0, . . . , m− 1 erhalten wir die zusammengesetzte Mittelpunktsformel
I0,m( f ) = Hm−1
∑k=0
f (xk), m ≥ 1. (2.7)
Um den Quadraturfehler der Formel (2.7) abzuschätzen, brauchen wir jetzt eine diskreteVersion des Mittelwertsatzes:
Theorem 2.2 (Diskreter Mittelwertsatz). Seien u ∈ C0([a, b]), (xj)sj=0 s + 1 Punkte in [a, b]
und (δj)sj=0 s + 1 Konstanten, die alle das gleiche Vorzeichen besitzen. Dann gibt es ein ξ ∈ [a, b],
sodasss
∑j=0
δju(xj) = u(ξ)s
∑j=0
δj. δj ergänzt
Beweis. Ohne Beschränkung der Allgemeinheit nehmen wir an, dass δj ≥ 0 für alle j =0, . . . , s gelte (der andere Fall ergibt sich analog). Seien um = minx∈[a,b] u(x) = u(x) unduM = maxx∈[a,b] u(x) = u(x), wobei x und x zwei Punkte aus [a, b] sind. Dann gilt
um
s
∑j=0
δj ≤s
∑j=0
δju(xj) ≤ uM
s
∑j=0
δj. (2.8)
20

2.2 Quadratur vom Interpolationstyp
Sei σs = ∑sj=0 δj. Dann folgt
um ≤1σs
s
∑j=0
δju(xj) ≤ uM. (2.9)
Da u stetig ist, existiert ξ ∈ [a, b], sodass u(ξ) = σ−1s ∑s
j=0 δju(xj) bzw.
s
∑j=0
δju(xj) = u(ξ)s
∑j=0
δj. Index j statt s
Der QuadraturfehlerE0,m( f ) = I( f )− I0,m( f )
kann unter der Voraussetzung f ∈ C2([a, b]) in der Form
E0,m( f ) =b− a
24H2 f ′′(ξ), H =
b− am
, (2.10)
dargestellt werden, wobei ξ ∈ (a, b). Aus (2.10) schließen wir, dass (2.7) den Exaktheits-grad 1 hat; (2.10) kann mit Hilfe von (2.5) unter Verwendung der Additivität des Integralsgezeigt werden. Für k = 0, . . . , m− 1 und ξk ∈ (a+ kH, a+(k+ 1)H) erhalten wir nämlich
E0,m( f ) =m−1
∑k=0
f ′′(ξk)
3
(H2
)3
=m−1
∑k=0
f ′′(ξk)H2
24b− a
m=
b− a24
H2 f ′′(ξ)
Die letzte Gleichheit ergibt sich aus dem diskreten Mittelwertsatz, angewandt auf den Fallu = f ′′ und δj = 1 für j = 0, . . . , m− 1. m statt k
2.2.2 Die Trapezregel
Diese Formel erhalten wir, wenn f durch π1 f , ihr Lagrangesches Interpolationspolynomvom Grad 1 in Bezug auf die Knoten x0 = a und x1 = b ersetzt wird. Die sich darausergebende Quadratur ist
I1( f ) =b− a
2[ f (a) + f (b)] , (2.11)
mit den Knoten x0 = a, x1 = b und den Gewichten α0 = α1 = (b− a)/2.
Übung. Ist f ∈ C2([a, b]), so ist der Quadraturfehler gegeben durch
E1( f ) = − h3
12f ′′(ξ), h = b− a, (2.12)
wobei ξ ein Punkt im Inneren des Integrationsintervalls ist.
21

2.2 Quadratur vom Interpolationstyp
Beweis. Aus dem Ausdruck (1.6) des Interpolationsfehlers erhalten wir
E1( f ) =∫ b
a( f (x)− π1 f (x))dx
= − 12
∫ b
af ′′(ξ(x))(x− a)(b− x)dx.
Da ω2(x) = (x− a)(x− b) < 0 in (a, b), folgt aus dem Mittelwertsatz
E1( f ) =12
f ′′(ξ)∫ b
aω2(x)dx = − f ′′(ξ)
(b− a)3
12
für ein gewisses ξ ∈ (a, b), was (2.12) zeigt.
Somit hat die Trapezregel, ebenso wie die die Mittelpunktsregel, den Exaktheitsgrad 1.
Übung. Berechne die zusammengesetzte Trapezregel und den entsprechenden Quadra-turfehler.
Lösungsskizze. Mit m ≥ 1, xk = a + kH, k = 0, . . . , m und H = (b− a)/m folgt
I1,m( f ) =H2
m−1
∑k=0
( f (xk) + f (xk+1))
= H(
12
f (x0) + f (x1) + . . . + f (xm−1) +12
f (xm)
).
Falls f ∈ C2([a, b]), so
E1,m = I( f )− I1,m( f ) = −b− a12
H2 f ′′(ξ), ξ ∈ (a, b).
Der Exaktheitsgrad ist wieder gleich 1.
2.2.3 Die Cavalieri-Simpson-Formel
Die Cavalieri-Simpson-Formel kann erhalten werden, wenn man f auf [a, b] durch seinInterpolationspolynom vom Grade 2 in den Knoten
x0 = a, x1 = (a + b)/2, x2 = b
ersetzt. Die Gewichte sind
α0 = α2 =b− a
6, α1 =
4(b− a)6
und die resultierende Formel lautet
I2( f ) =b− a
6
[f (a) + 4 f
(a + b
2
)+ f (b)
]. (2.13)
22

2.3 Newton-Cotes-Formeln
Unter der Voraussetzung f ∈ C4([a, b]) kann gezeigt werden, dass für den Quadraturfeh-ler
E2( f ) = − h5
90f (4)(ξ), h =
b− a2
, (2.14)
gilt, wobei ξ in (a, b) liegt. Aus (1.16) schließen wir, dass (2.13) den Exaktheitsgrad 3besitzt. (Übung: (2.13) und (2.14) beweisen).
Die Ersetzung von f auf [a, b] durch sein zusammengesetztes Polynom vom Grade 2ergibt die (2.13) entsprechende zusammengesetzte Formel. Führen wir die Quadraturkno-ten xk = a + kH/2 für k = 0, . . . ,2m ein und setzen H = (b− a)/m mit m ≥ 1, so erhaltenwir
I2,m( f ) =H6
[f (x0) + 2
m−1
∑r=1
f (x2r) + 4m−1
∑s=0
f (x2s+1) + f (x2m)
]. (2.15)
Der Quadraturfehler von (2.15) ist unter der Voraussetzung f ∈ C4([a, b]) durch
E2,m( f ) = −b− a180
(H2
)4
f (4)(ξ) (2.16)
gegeben, wobei ξ ∈ (a, b), und der Exaktheitsgrad der Formel ist 3. (Übung: (2.15) und(2.16) beweisen.)
2.3 Newton-Cotes-Formeln
Diese Formeln basieren auf Lagrange-Interpolation mit in [a, b] äquidistanten Knoten. Fürein festes n ≥ 0 werden die Quadraturknoten mit xk = x0 + kh, k = 0, . . . , n bezeichnet.Die Mittelpunkts-, Trapez- und Cavalieri-Simpson-Formel sind Spezialfälle der Newton-Cotes-Formeln, wenn man n = 0, n = 1 bzw. n = 2 wählt.
Im allgemeinen Fall definieren wir:
• geschlossene Formeln, bei denen x0 = a, xn = b und h = (b− a)/n für n ≥ 1;
• offene Formeln, bei denen x0 = a + h, xn = b− h, h = (b− a)/(n + 2) für n ≥ 0.
Die Newton-Cotes-Formeln besitzen die wichtige Eigenschaft, dass die Quadraturge-wichte αi explizit nur von n und h, aber nicht vom Integrationsintervall [a, b] abhängen.Um diese Eigenschaft im Fall abgeschlossener Formeln zu überprüfen, führen wir einenVariablenwechsel x = ψ(t) = x0 + th durch. Unter Berücksichtigung von ψ(0) = a,ψ(n) = b und xk = a + kh erhalten wir
ErsterSummandim Zähler astatt t
x− xk
xi − xk=
a + th− (a + kh)a + ih− (a + kh)
=t− ki− k
.
Somit gilt für n ≥ 1
li(x) =n
∏k=0,k 6=i
t− ki− k
= ϕi(t), 0 ≤ i ≤ n.
23

2.3 Newton-Cotes-Formeln
Für die Quadraturgewichte erhalten wir den Ausdruck
αi =∫ b
ali(x)dx = h
∫ n
0ϕi(t)dt,
woraus die Formel
In( f ) = hn
∑i=0
ωi f (xi), ωi =∫ n
0ϕi(t)dt
folgt. Offene Formeln können in ähnlicher Weise behandelt werden. Verwenden wir näm-lich wieder die Abbildung x = ψ(t), bekommen wir x0 = a + h, xn = b − h, xk =
a + h(k + 1), k = 1, . . . , n− 1. Seien der Kohärenz wegen x−1 statt x1x−1 = a und xn+1 = b gesetzt
und verfahren wir wie im Fall geschlossener Formeln, so ergibt sich ψi statt ϕiαi = h∫ n+1−1 ψi(t)dt
und folglich (Übung!)
In( f ) = hn
∑i=0
ωi f (xi), ωi =∫ n+1
−1ψi(t)dt.
Im Spezialfall n = 0 bekommen wir ω0 = 2 wegen l0(x) = ψ0(t) = 1.
• Die Koeffizienten ωi hängen nicht von a, b, h und f ab, sondern nur von n undkönnen somit a-priori tabelliert werden.
• Im Fall geschlossener Formeln haben die Polynome ϕi und ϕn−i für i = 0, . . . , n− 1aus Symmetriegründen das gleiche Integral, sodass die entsprechenden Gewichteωi und ωn−i, i = 0, . . . , n− 1 gleich sind.
• Im Fall offener Formeln sind die Gewichte ωi und ωn−i für i = 0, . . . , n gleich. Aberbei den offenen Formeln für n ≥ 2 können die Gewichte auch negativ sein, mitmöglichen numerischen Instabilitäten wegen Rundungsfehlern.
Neben ihrem Grad der Exaktheit kann eine Quadraturformel auch durch ihre Ordnungin Bezug auf die Integrationsschrittweite h charakterisiert werden. Diese ist definiert alsdie größte ganze Zahl p, sodass
|I( f )− In( f )| = O(hp).
Deshalb präsentieren wir das folgende Resultat, in dem die explizite Abhängigkeit desQuadraturfehlers von h gegeben wird.
Theorem 2.3. Für jede Newton-Cotes-Formel, die einer geraden Zahl n entspricht, gilt unter derVoraussetzung f ∈ Cn+2([a, b]) die Fehlerdarstellung
En( f ) =Mn
(n + 2)!hn+3 f (n+2)(ξ) (2.17)
24

2.3 Newton-Cotes-Formeln
mit ξ ∈ (a, b) und
Mn =
∫ n0 tPn+1(t)dt < 0 für geschlossene Formeln∫ n+1−1 tPn+1(t)dt > 0 für offene Formeln
(2.18)
Dabei wurde zur Abkürzung Pn+1(t) = ∏ni=0(t − i) benutzt. Aus (2.17) ergibt sich, dass der
Exaktheitsgrad n + 1 und die Ordnung n + 3 betragen.Ordnungn + 3 stattn + 1Unter der Voraussetzung f ∈ Cn+1([a, b]) gilt für ungerade Zahlen n die analoge Fehlerdar-
stellung
En( f ) =Kn
(n + 1)!hn+2 f (n+1)(η), (2.19)
mit η ∈ (a, b) und
Kn =
∫ n0 Pn+1(t)dt < 0 für geschlossene Formeln∫ n+1−1 Pn+1(t)dt > 0 für offene Formeln.
(2.20)
Der Exaktheitsgrad ist somit gleich n und die Ordnung n + 2.
Beweis. (Nur im speziellen Fall geschlossener Formeln und geraden n.) Wegen (1.16)haben wir
En( f ) = I( f )− In( f )
=∫ b
af [x0, . . . , xn, x]︸ ︷︷ ︸
dividierte Differenz
ωn+1(x)dx. (2.21)
Sei W(x) =∫ x
a ωn+1(t)dt. Dann ist W(a) = 0; darüber hinaus ist ωn+1(t) eine ungeradestatt gerade
ungeradeFunktion in Bezug auf den Mittelpunkt (a + b)/2 (Übung!), sodass W(b) = 0. PartielleIntegration von (2.21) ergibt
En( f ) =∫ b
af [x0, . . . , xn, x]W ′(x)dx
= f [x0, . . . , xn, x]W(x)|ba︸ ︷︷ ︸=0
−∫ b
a
ddx
f [x0, . . . , xn, x]W(x)dx untere Grenzea statt 1
= −∫ b
af [x0, . . . , xn, x, x]W(x)dx
= −∫ b
a
f (n+2)(ξ(x))(n + 2)!
W(x)dx,
wobei wir Gleichung (1.17) sowie ddx f [x0, . . . , xn, x] = f [x0, . . . , xn, x, x] (Übung!) verwen-
det haben. Da W(x) > 0 für a < x < b (schwierige Übung!), erhalten wir aus dem
25

2.3 Newton-Cotes-Formeln
Mittelwertsatz in Integralform
En( f ) = − f (n+2)(ξ)
(n + 2)!
∫ b
aW(x)dx
= − f (n+2)(ξ)
(n + 2)!
∫ b
a
∫ x
aωn+1(t)dt dx (2.22)
wobei ξ ∈ (a, b). Es gilt:∫ b
aW(x)dx =
∫ b
a
∫ x
aωn+1(t)dt dx =
∫ b
a
∫ x
a(t− x0) · · · (t− xn)dt dx
=∫ b
a
∫ b
aχ statt ξχ[a,x](t)(t− x0) · · · (t− xn)dt dx.
Verwenden wir jetzt die Änderung der Integrationsreihenfolge, erhalten wir∫ b
aW(x)dx =
∫ b
a
∫ b
aχ[a,x](t)(t− x0) · · · (t− xn)dx dt
=∫ b
a
[∫ b
t[(t− x0) · · · (t− xn)]dx
]dt xn statt xk
=∫ b
a[(b− t)(t− x0) · · · (t− xn)]dt.
Unter Beachtung von a = x0 und b = xn bekommen wir∫ b
aW(x)dx =
∫ b
a(t− x0) · · · (t− xn)(xn − t)dt
= −∫ b
a(t− x0) · · · (t− xn)
2 dt = −∫ xn
x0
(t− x0) · · · (t− xn)2 dt.
Mit dem Variablenwechsel t = x0 + τh schreiben wir
−∫ xn
x0
(t− x0) · · · (t− xn)(t− xn)dt
= − hn+3∫ n
0[τ(τ − 1) · · · (τ − (n− 1))(τ − n)] (τ − n)dτ.
Setzen wir schließlich s = n− τ, so erhalten wir∫ b
aW(x)dx = −hn+3
∫ n
0sPn+1(s)ds, (2.23)
was zusammen mit (2.22) die zu zeigenden Gleichungen (2.17) und (2.18) ergibt.
26

2.4 Zusammengesetzte Newton-Cotes-Formeln
2.4 Zusammengesetzte Newton-Cotes-Formeln
Das allgemeine Verfahren besteht in der Zerlegung des Integrationsintervalls [a, b] in Teil-intervalle TJ = [yJ , yJ+1], sodass yJ = a + JH mit H = (b− a)/m für J = 0, . . . , m− 1 gilt.Dann wird auf jedem Teilintervall eine Interpolationsformel mit den Knoten x(J)
k , 0 ≤k ≤ n und Gewichten α(J)
k , 0 ≤ k ≤ n verwendet. Da
I( f ) =∫ b
af (x)dx =
m−1
∑J=0
∫TJ
f (x)dx
gilt, erhält man eine zusammengesetzte Quadraturformel für I( f ),
In,m( f ) =m−1
∑J=0
n
∑k=0
α(J)k f (x(J)
k ). (2.24)
Der Quadraturfehler ist dann als En,m( f ) = I( f )− In,m( f ) definiert. Insbesondere kannman in jedem Teilintervall TJ zu einer Newton-Cotes-Formel mit n + 1 äquidistantenKnoten greifen: In diesem Fall bleiben die Gewichte α
(J)k = Hωk unabhängig von TJ .
Unter Verwendung der in Theorem 2.3 benutzten Notation gilt für die zusammengesetzteFormel das folgende Konvergenzergebnis:
Theorem 2.4. Angenommen, wir verwenden eine zusammengesetzte Newton-Cotes-Formel mitgeradem n. Dann gilt für f ∈ Cn+2([a, b])
En,m( f ) =b− a
(n + 2)!Mn
γn+3n
Hn+2 f (n+2)(ξ) (2.25)
mit ξ ∈ (a, b). Somit ist der Quadraturfehler bezüglich H von (n + 2)-ter Ordnung und dieFormel hat den Exaktheitsgrad n + 1. Für die zusammengesetzte Newton-Cotes-Formel mit unge-radem n gilt unter der Voraussetzung f ∈ Cn+1([a, b])
En,m( f ) =b− a
(n + 1)!Kn
γn+2n
Hn+1 f (n+1)(ξ) (2.26)
wobei ξ ∈ (a, b). Folglich ist der Quadraturfehler bezüglich H von (n + 1)-ter Ordnung und dieFormel hat den Exaktheitsgrad n.
In (2.25) und (2.26) ist γn = n + 2, wenn die Formel offen, und γn = n, wenn sie geschlossenist. Index n
ergänztBeweis. (Nur für den Fall einer offenen Formel und n gerade) Unter Verwendung von(2.17),
En( f ) =Mn
(n + 2)!hn+3 f (n+2)(ξ),
27

2.5 Richardson-Extrapolation
und Berücksichtigung der Tatsache, dass Mn nicht vom Integrationsintervall abhängt,erhalten wir
En,m( f ) =m−1
∑J=0
[I( f |TJ
)− In( f |TJ)]
=Mn
(n + 2)!
m−1
∑J=0
hn+3J f (n+2)(ξ J),
wobei
hJ =|TJ |
n + 2=
b− am(n + 2)
und ξ J ∈ TJ für J = 0, . . . , m− 1. Da (b− a)/m = H gilt, bekommen wir
En,m( f ) =Mn
(n + 2)!b− a
m(n + 2)n+3 Hn+2m−1
∑J=0
f (n+2)(ξ J)
=Mn
(n + 2)!b− a
m(n + 2)n+3 Hn+2 f (n+2)(ξ)m−1
∑J=0
1︸ ︷︷ ︸m
=Mn
(n + 2)!b− aγn+3
nHn+2 f (n+2)(ξ),
wobei wir in der zweiten Gleichung den diskreten Mittelwertsatz verwendet haben. Ähn-lich kann man nun auch (2.26) zeigen.
Wir bemerken, dass für feste Zahlen n der Quadraturfehler En,m( f ) gegen Null geht,wenn m→ ∞ (d.h. wenn H → 0). Diese Eigenschaft sichert die Konvergenz des numerischberechneten Integrals gegen den exakten Wert I( f ). In praktischen Berechnungen ist eszweckmäßig, zu einer lokalen Interpolation geringen Gerades (typischerweise n ≤ 2)zu greifen. Dies führt auf zusammengesetzte Quadraturformeln mit positiven Gewichtenund einer Minimierung von Rundungsfehlern.
2.5 Richardson-Extrapolation
Die Richardson-Extrapolation ist ein Verfahren, das verschiedene Approximationen einerbestimmten Größe α0 kombiniert, um eine genauere Approximation von α0 zu erhalten.
Angenommen, wir haben eine Methode, um α0 durch eine Größe A(h) zu approximie-ren, die für jeden Wert des Parameters h 6= 0 berechenbar ist. Nehmen wir darüber hinausan, dass für ein geeignetes k ≥ 0 A(h) wie folgt entwickelt werden kann:
A(h) = α0 + α1h + . . . + αkhk + Rk+1(h), (2.27)
28

2.5 Richardson-Extrapolation
wobei |Rk+1(h)| ≤ Ck+1hk+1 gelte. Die Konstante Ck+1 und die Koeffizienten αi, i =
0, . . . , k seien unabhängig von h. Dann gilt
α0 = limh→0A(h).
Schreiben wir (2.27) mit δh anstelle von h für ein δ ∈ (0,1) (üblich ist δ = 1/2), so erhaltenwir
A(δh) = α0 + α1(δh) + . . . + αk(δh)k + Rk+1(δh).
Subtrahieren wir die mit δ multiplizierte Beziehung (2.27) von diesem Ausdruck, dannergibt sich
B(h) = A(δh)− δA(h)1− δ
= α0 + α2h2 + . . . + αkhk + Rk+1(h),
wobei wir für k ≥ 2 die Notationen αi = αi(δi − δ)/(1− δ) für i = 2, . . . , k und
Rk+1(h) = [Rk+1(δh)− δRk+1(h)] /(1− δ)
verwendet haben. Beachte, dass αi 6= 0 genau dann gilt, wenn αi 6= 0. Ist insbesondereα1 6= 0, so ist A(h) eine Approximation erster Ordnung von α0, während B(h) mindestensvon zweiter Ordnung genau ist. Ist allgemeiner A(h) eine Approximation von α0 derOrdnung p, so approximiert die Größe
B(h) = A(δh)− δpA(h)1− δp
α0 (mindestens) mit der Ordnung p + 1. Fahren wir induktiv fort, wird der folgendeRichardsion-Extrapolationsalgorithmus erzeugt:
Setze n ≥ 0, h > 0, δ ∈ (0,1) und konstruiere die Folgen
Am,0 = A(δmh), m = 0, . . . , n,
Am,q+1 =Am,q − δq+1Am−1,q
1− δq+1 , q = 0, . . . , m− 1, m = q + 1, . . . , n, q geht nur
bis m− 1
(2.28)
29

2.5 Richardson-Extrapolation
die in Form des Diagramms
A0,0
A1,0 A1,1
A2,0 A2,1 A2,2
. . . . . . . . .
An,0 An,1 An,2 . . . An,n
dargestellt werden können. Die Pfeile zeigen dabei den Weg an, auf dem die bereitsberechneten Terme zur Konstruktion eines „neuen“ Terms beitragen. Man kann zeigen:
Eigenschaft 2.5. Für n ≥ 0 und δ ∈ (0,1) gilt
Am,n = α0 + O((δmh)n+1), m = 0, . . . , n.
Insbesondere ist die Konvergenz gegen α0 für die Terme in der ersten Spalte (n = 0) O((δmh)),während sie für die in der letzten O((δmh)n+1), d.h. n-mal höher ist.
2.5.1 Romberg-Integration
Die Rombergsche Integrationsmethode ist die Anwendung der Richardson-Extrapolationauf die zusammengesetzte Trapezregel. Im Folgenden werden wir ein Resultat benötigen,das als Euler-MacLaurin-Formel bekannt ist.
Eigenschaft 2.6. Sei f ∈ C2K+2([a, b]) für K ≥ 0 und α0 =∫ b
a f (x)dx durch die zusammenge-setzte Trapezregel approximiert. Dann gilt mit hm = (b− a)/m für m ≥ 1
I1,m( f ) = α0 +K
∑i=1
B2i
(2i)!h2i
m
(f (2i−1)(b)− f (2i−1)(a)
)+
B2K+2
(2K + 2)!h2K+2
m (b− a) f (2K+2)(η), (2.29)
wobei η ∈ (a, b) und B2J = (−1)J−1[∑∞
n=12
(2nπ)2J
](2J)! für J ≥ 1 die Bernoulli-Zahlen
bezeichne.
30

2.6 Orthogonale Polynome und Gaußsche Integration
Die Gleichung (2.29) ist ein Spezialfall von (2.27), in dem h = h2m und A(h) = I1,m( f ) ist;
man beachte, dass nur gerade Potenzen des Parameters hm in der Entwicklung auftreten.
Übung. Wende den Algorithmus der Richardson-Extrapolation (2.28) auf (2.29) an undberechne die Ordnung der Konvergenz mit der Verwendung von Eigenschaft 2.6.
2.6 Orthogonale Polynome und Gaußsche Integration
Sei w eine Gewichtsfunktion auf dem Intervall (−1,1), d.h. eine nicht-negative integrier-bare Funktion auf (−1,1). Wir bezeichnen mit pk : k = 0,1, . . . ein System algebraischerPolynome, wobei pk vom Gerade k für jedes k, sowie die Familie pkk orthogonal aufdem Intervall (−1,1) in Bezug auf w sei. Das bedeutet, dass∫ 1
−1pk(x)pm(x)w(x)dx = 0 für k 6= m. (2.30)
Setze ( f , g)w =∫ 1−1 f (x)g(x)w(x)dx und
‖ f ‖w = ( f , f )1/2w =
(∫ 1
−1| f (x)|2 w(x)dx
)1/2
.
(., .)w und ‖.‖w sind das Skalarprodukt und die Norm im Funktionenraum
L2w = L2
w(−1,1) =
f : (−1,1)→ R,∫ 1
−1| f (x)|2 w(x)dx < ∞
. (2.31)
Mit diesen Begriffen können wir die Beziehung (2.30) schreiben als
(pk, pm)w = 0 ∀k 6= m (2.32)
und die (pk/ ‖pk‖w)k sind auffassbar als eine orthonormale Folge in L2w oder eine Menge
von orthonormalen Vektoren in L2w.
Auf abstrakte Weise können wir L2w als einen „unendlich-dimensionalen“ euklidischen
Raum (einen sogenannten Hilbertraum) betrachten: Für jede Funktion f ∈ L2w heißen die
Reihen
S f =∞
∑k=0
(f ,
pk
‖pk‖w
)w
pk
‖pk‖w=
∞
∑k=0
fk pk (2.33)
(mit fk = ( f , pk)w/ ‖pk‖2w) verallgemeinerte Fourierreihen von f und fk k-ter Fourierkoeffizient.
Bekanntlich konvergiert S f gegen f in der Topologie des normierten Raumes L2w (wir
sagen, S f konvergiere im Mittel oder im Sinne des L2w): Dies bedeutet, dass für die durch
fn(x) =n
∑k=0
fk pk(x) (2.34)
31

2.6 Orthogonale Polynome und Gaußsche Integration
definierte Folge ( fn ∈ Pn ist der abgebrochene Teil n-ter Ordnung der verallgemeinertenFourierreihe von f ) das folgende Konvergenzergebnis gilt:
limn→∞‖ f − fn‖w = lim
n→∞
(∫ 1
−1| f (x)− fn(x)|2 w(x)dx
)1/2
= 0. (2.35)
Darüber hinaus gilt die Parsevalsche Gleichung
‖ f ‖2w =
∞
∑k=0
f 2k ‖pk‖2
w ,
und für jedes n ist
‖ f − fn‖2w =
∞
∑k=n+1
f 2k ‖pk‖2
w
das Quadrat des Rests der verallgemeinerten Fourierreihe.Wir erinnern an die Cauchy-Schwarzsche Ungleichung∣∣∣∣∫ β
αu(x)v(x)dx
∣∣∣∣ ≤ (∫ β
αu2(x)dx
)1/2 (∫ β
αv2(x)dx
)1/2
für u, v ∈ L2(α, β) = L2w(α, β), falls w ≡ 1. Im Allgemeinen haben wir für u, v ∈ L2
w(o.b.d.A. v 6= 0), dass die Funktion
z = u− (u, v)w
(v, v)wv
orthogonal zu v ist, denn
(z, v)w = (u, v)w −(u, v)w
(v, v)w(v, v)w = 0. (2.36)
Die Fourierreihe von u in Bezug auf v und z lautet
u =(u, v)w
(v, v)wv + z
und mittels der Parsevalschen Gleichung (oder expliziter Rechnung unter Verwendungvon (2.36)) ergibt sich
‖u‖2w =
∣∣∣∣ (u, v)w
(v, v)w
∣∣∣∣2 ‖v‖2w + ‖z‖2
w =|(u, v)w|2
‖v‖2w
‖v‖2w + ‖z‖2
w ≥|(u, v)w|2
‖v‖2w
und daher|(u, v)w| ≤ ‖u‖w ‖v‖w . (2.37)
32

2.6 Orthogonale Polynome und Gaußsche Integration
Wir verwenden (2.37), um eine Abschätzung von ‖ f − fn‖w zu erhalten: Für ein belie-biges Polynom q ∈ Pn gilt
‖ f − fn‖2w = ( f − fn, f − fn)w = ( f − fn, f − q)w + ( f − fn, q− fn)w
= ( f − fn, f − q)w,
weil f − fn = ∑∞k=n+1 fk pk orthogonal zu jedem Polynom p ∈ Pn ist, d.h.
( f − fn, p)w = 0 ∀p ∈ Pn,
insbesondere für p = fn − q. Es folgt, dass
‖ f − fn‖2w = ( f − fn, f − q)w ≤ ‖ f − fn‖w ‖ f − q‖w
durch Verwendung von (2.37) und
‖ f − fn‖w ≤ ‖ f − q‖w ∀q ∈ Pn
oder‖ f − fn‖w = min
q∈Pn‖ f − q‖w . (2.38)
Wir beenden diesen Abschnitt mit einer Eigenschaft, die für jede Familie normalisierterorthogonaler Polynome pk gilt, der folgenden Dreitermrekursion
pk+1(x) = (x− αk)pk(x)− βk pk−1(x), k ≥ 0,
p−1(x) = 0, p0(x) = 1,(2.39)
wobei
αk =(xpk, pk)w
(pk, pk)w, βk+1 =
(pk+1, pk+1)w
(pk, pk)w, k ≥ 0.
(Übung!)
2.6.1 Tschebyscheff-Polynome
Wir betrachten die Tschebyscheffsche Gewichtsfunktion
w(x) = (1− x2)−1/2
auf dem Intervall (−1,1) und führen gemäß (2.31) den Raum der quadrat-integrierbarenFunktionen in Bezug auf das Gewicht w ein,
L2w(−1,1) =
f : (−1,1)→ R,
∫ 1
−1| f (x)|2 (1− x2)−1/2 dx < ∞
,
33

2.6 Orthogonale Polynome und Gaußsche Integration
mit Skalarprodukt respektive Norm
( f , g)w =∫ 1
−1f (x)g(x)(1− x2)−1/2 dx,
‖ f ‖w =
(∫ 1
−1| f (x)|2 (1− x2)−1/2 dx
)1/2
.(2.40)
Die Tschebyscheff-Polynome sind nun wie folgt definiert:
Tk(x) = cos(kϑ), ϑ = arccos(x), k = 0,1, . . . (2.41)
Als Folgerung aus (2.39) können sie rekursiv durch die FormelnTk+1(x) = 2xTk(x)− Tk−1(x), k = 1,2, . . . ,
T0(x) = 1, T1(x) = x(2.42)
erzeugt werden (Übung!). Man beachte, dass für k ≥ 0 tatsächlich Tk ∈ Pk gilt, d.h. Tk(x)ist ein algebraisches Polynom vom Grad k bezüglich x.
Unter Verwendung der wohlbekannten trigonometrischen Beziehungen können wirzeigen, dass
(Tk, Tm)w = 0, k 6= m, ‖Tm‖2w =
c0 = π, m = 0,
cm = π/2, m 6= 0,
gilt, d.h. die Tschebyscheff-Polynome sind orthogonal in Bezug auf (., .)w. Wir bemerken,dass max−1≤x≤1 |Tk(x)| = 1 für jedes k ≥ 0 und die Minimax-Eigenschaft∥∥∥21−nTn
∥∥∥∞≤ min
p∈P1n
‖p‖∞ , n ≥ 1
gilt, wobei P1n =
p(x) = ∑n
k=0 akxk, an = 1
.
2.6.2 Legendre-Polynome
Die Legendre-Polynome sind orthogonale Polynome über dem Intervall (−1,1) in Bezug aufdie Gewichtsfunktion w(x) ≡ 1. Für diese Polynome ist L2
w der übliche L2(−1,1)-Raum,den wir schon eingeführt haben und (., .)w sowie ‖.‖w stimmen mit dem Skalarproduktbzw der Norm in L2(−1,1) überein, die durch
( f , g) =∫ 1
−1f (x)g(x)dx, ‖ f ‖L2(−1,1) =
(∫ 1
−1f 2(x)dx
)1/2
gegeben sind. Die Legendre-Polynome sind definiert durch
Lk(x) =12k
[k/2]
∑l=0
(−1)l(
kl
)(2k− 2l
k
)xk−2l , k = 0,1, . . . , (2.43)
34

2.7 Gaußsche Integration und Interpolation
wobei [.] die Abrundungsfunktion bezeichne, oder rekursiv durch die DreitermrekursionLk+1(x) = 2k+1
k+1 xLk(x)− kk+1 Lk−1(x)
L0(x) = 1, L1(x) = x.
Für jedes k = 0,1,2, . . . gilt Lk ∈ Pk und für k, m = 0,1,2, . . . ist (Lk, Lm) = δkm(k + 12 )−1
(Übung!). Die Legendre-Reihe nimmt für jede Funktion f ∈ L2(−1,1) die folgende Form
f = L f =∞
∑k=0
fkLk, fk =
(k +
12
) ∫ 1
−1f (x)Lk(x)dx
−1 imExponentenentfernt
an.
Bemerkung 2.7. Die zuvor eingeführten Polynome gehören der größeren Klasse derJacobi-Polynome
Jα,βk , n = 0,1, . . .
an, die orthogonal in Bezug auf das Gewicht w(x) =
(1− x)α(1 + x)β mit α, β > −1 sind. Setzen wir α = β = 0, so erhalten wir tatsächlich dieLegendre-Polynome zurück, wohingegen die Wahl α = β = −1/2 zu den Tschebyscheff-Polynomen führt.
2.7 Gaußsche Integration und Interpolation
Orthogonale Polynome spielen eine entscheidende Rolle bei der Konstruktion von Qua-draturformeln mit maximalem Exaktheitsgrad. Seien n+ 1 verschiedene Punkte x0, . . . , xn
auf dem Intervall [−1,1] gegeben. −1 statt 1Zur Approximation des gewichteten Integrals
Iw( f ) =∫ 1
−1f (x)w(x)dx, f ∈ C0([−1,1]),
betrachten wir die Quadraturformeln des Typs
In,w =n
∑i=0
αi f (xi), (2.44)
wobei αi geeignet zu bestimmende Koeffizienten sind. Offensichtlich hängen sowohl dieKnoten, als auch die Gewichte von n ab, jedoch werden wir diese Abhängigkeit still-schweigend voraussetzen.
Wir bezeichnen den Fehler zwischen dem exakten Integral und seiner Approximation(2.44) mit
En,w( f ) = Iw( f )− In,w( f ). (2.45)
Ist En,w(p) = 0 für jedes p ∈ Pr, für ein geeignetes r ∈ N, so sagen wir wiederum,dass die Formel (2.44) den Exaktheitsgrad r in Bezug auf das Gewicht w habe. Natürlichkönnen wir einen Exaktheitsgrad von (mindestens) n erhalten, wenn wir
In,w( f ) =∫ 1
−1πn f (x)w(x)dx,
35

2.7 Gaußsche Integration und Interpolation
setzen, wobei πn f ∈ Pn das in (1.3) definierte Lagrangesche Interpolationspolynom derFunktion f in den Knoten xi : i = 0, . . . , n ist. Damit hat (2.44) zumindest den Exakt-heitsgrad n, wenn wir
αi =∫ 1
−1li(x)w(x)dx, i = 0, . . . , n, (2.46)
nehmen, wobei li ∈ Pn das i-te charakteristische Lagrangesche Polynom mit li(xj) = δijfür i, j = 0, . . . , n bezeichne.
Die Frage ist nun, ob es eine geeignete Knotenwahl gibt, für die der Exaktheitsgradgrößer als n ist, sagen wir r = n + m für ein gewisses m > 0. Die Antwort wird durchfolgenden auf Jacobi zurückgehenden Satz gegeben:
Theorem 2.8. Für gegebenes m > 0 hat die Quadraturformel (2.44) genau dann den Exakt-heitgrad n + m, wenn sie vom Interpolationstyp ist und das zu den Knoten xi gehörendeKnotenpolynom ωn+1 (1.4) der folgenden Beziehung genügt:∫ 1
−1ωn+1(x)p(x)w(x)dx = 0 ∀p ∈ Pm−1 (2.47)
Beweis. Wir zeigen, dass (2.47) und der Interpolationstyp der Formel (2.44) hinreichendsind, um den Grad der Exaktheit n + m zu erreichen. Ist f ∈ Pn+m, so existieren einQuotient πm−1 ∈ Pm−1 und ein Rest qn ∈ Pn, sodass f = ωn+1πm−1 + qn. Da derExaktheitsgrad einer Interpolationsformel mit n + 1 Knoten zumindest n ist, bekommenwir
n
∑i=0
αiqn(xi) =∫ 1
−1qn(x)w(x)dx
=∫ 1
−1f (x)w(x)dx−
∫ 1
−1ωn+1(x)πm−1(x)w(x)dx.
Wegen (2.47) verschwindet das letzte Integral, sodass
i ergänzt∫ 1
−1f (x)w(x)dx =
n
∑i=0
αiqn(xi) =n
∑i=0
αi f (xi),
wegen ωn+1(xi) = 0 und f (xi) = ωn+1(xi)πm−1(xi) + qn(xi) = qn(xi). Da f beliebig war,schließen wir, dass En,w( f ) = 0 für jedes f ∈ Pn+m gilt.
Der Beweis, dass die Bedingungen auch notwendig sind, sei dem Leser als Übungüberlassen.
Korollar 2.9. Der maximale Grad der Exaktheit der Quadraturformel (2.44) ist 2n + 1.
36

2.7 Gaußsche Integration und Interpolation
Beweis. Wenn es nicht so wäre, könnte man im letzten Theorem m ≥ n + 2 wählen. Dieswürde uns folglich ermöglichen, in (2.47) p = ωn+1 zu wählen, woraus∫ 1
−1|ωn+1(x)|2 w(x)dx = 0
und damit das identische Verschwinden von ωn+1 folgen würde, was nicht zutrifft.
Setzen wir m = n + 1 (den maximal zulässigen Wert), so erhalten wir aus (2.47), dassdas Knotenpolynom ωn+1 der Beziehung∫ 1
−1ωn+1(x)p(x)w(x)dx = 0 ∀p ∈ Pn
genügt. Somit ist ωn+1 ein Polynom vom Grad n + 1, das zu allen Polynomen von gerin-gerem Grad orthogonal ist. Folglich ist ωn+1 das einzige normalisierte Polynom, das einVielfaches von pn+1 ist (es sei daran erinnert, dass pk das in Abschnitt 2.6 eingeführteSystem orthogonaler Polynome bezeichne). Insbesondere stimmen seine Wurzeln
xj
mit denen von pn+1 überein, d.h.
pn+1(xj) = 0, j = 0, . . . , n. (2.48)
Die Knoten
xj
sind die Gaußknoten, die zur Gewichtsfunktion w(x) gehören.Wir können somit schlussfolgern, dass die Quadraturformel (2.44) mit den durch (2.46)
und (2.48) gegebenen Koeffizienten bzw. Knoten den Exaktheitsgrad 2n + 1 hat. Sie heißtGaußsche Quadraturformel. Ihre Gewichte sind sämtlich positiv und die Knoten liegen imInneren das Intervalls (−1,1). Jedoch ist es oft nützlich, wenn auch die Endpunkte desIntervalls zu den Quadraturknoten gehören. Wenn man dies fordert, ist die GaußscheFormel mit dem höchsten Exaktheitsgrad jene, die als Knoten die n + 1 Nullstellen desPolynoms
ωn+1 = pn+1(x) + apn(x) + bpn−1(x) (2.49)
verwendet, wobei die Konstanten a und b derart ausgewählt werden, dass ωn+1(−1) =
ωn+1(1) = 0. Werden diese Wurzeln durch x0 = −1, x1, . . . , xn = 1 bezeichnet, könnendie Koeffizienten αi, i = 0, . . . , n aus den üblichen Formeln (2.46) erhalten werden, d.h.
li statt αiαi =∫ 1
−1li(x)w(x)dx, i = 0, . . . , n,
wobei li ∈ Pn das i-te charakteristische Lagrangesche Polynom ist, für das li(xj) = δij füri, j = 0, . . . , n gilt. Die Quadraturformel
IGLn,w( f ) =
n
∑i=0
αi f (xi) (2.50)
heißt Gauß-Lobatto-Formel mit n + 1 Knoten und hat Exaktheitsgrad 2n− 1:
37

2.7 Gaußsche Integration und Interpolation
Für jedes f ∈ P2n−1 gibt es ein Polynom πn−2 ∈ Pn−2 und einen Rest qn ∈ Pn, sodassf = ωn+1πn−2 + qn. Die Quadraturformel (2.50) besitzt zumindest den Exaktheitsgrad n,da sie vom Interpolationstyp ist, somit bekommen wir
n
∑j=0
αjqn(xj) =∫ 1
−1qn(x)w(x)dx
=∫ 1
−1f (x)w(x)dx−
∫ 1
−1ωn+1(x)πn−2(x)w(x)dx.
Aus (2.49) und der Orthogonalität von pn+1, pn und pn−1 in Bezug auf Polynome vomGrad ≤ n − 2 folgt nun, dass ωn+1 auch orthogonal zu Pn−2 ist. Daher verschwindetdas Integral
∫ 1−1 ωn+1(x)πn−2(x)w(x)dx. Darüber hinaus folgt wegen f (xj) = q(xj) für
j = 0, . . . , n, dass ∫ 1
−1f (x)w(x)dx =
n
∑i=0
αi f (xi), f ∈ P2n−1.
Indem wir durch πGLn,w f das Polynom vom Grad n bezeichnen, das f in den Knoten
xj : j = 0, . . . , n
interpoliert, erhalten wir
πGLn,w f (x) =
n
∑i=0
f (xi)li(x) (2.51)
und folglich
IGLn,w f (x) =
∫ 1
−1πGL
n,w f (x)w(x)dx.
Bemerkung 2.10. Im Spezialfall, in dem die Gauß-Lobatto-Quadratur in Bezug auf dieJacobi-Gewichte w(x) = (1 − x)α(1 + x)β mit α, β > −1, betrachtet wird, können die
inneren Knoten x1, . . . , xn+1 als die Nullstellen des Polynoms(
J(α,β)n
)′, d.h. als die Ex-
tremstellen des n-ten Jacobi-Polynoms J(α,β)n bestimmt werden.
Für die Gaußsche Integration gilt das folgende Konvergenzresultat
limn→∞
∣∣∣∣∣∫ 1
−1f (x)w(x)dx−
n
∑j=0
αj f (xj)
∣∣∣∣∣ = 0
für alle f ∈ C0([−1,1]). Ein ähnliches Ergebnis gilt auch für die Gauß-Lobatto-Integration.
Bemerkung 2.11 (Integration über ein beliebiges Intervall). Eine Quadraturformel aufdem Intervall [−1,1] mit den Knoten ξ j und Koeffizienten β j, j = 0, . . . , n, kann auf einbeliebiges Intervall [a, b] transformiert werden:
Sei ϕ : [−1,1]→ [a, b] die affine Abbildung
x = ϕ(ξ) =b− a
2ξ +
a + b2
.
38

2.7 Gaußsche Integration und Interpolation
Dann gilt ∫ b
af (x)dx =
b− a2
∫ 1
−1( f ϕ)(ξ)dξ.
Deshalb können wir auf dem Intervall [a, b] die Quadraturformel mit den Knoten xj =
ϕ(ξ j) und den Gewichten αj =b−a
2 β j verwenden.Beachte, dass diese Formel auf dem Intervall [a, b] den gleichen Exaktheitsgrad wie
die über dem Intervall [−1,1] gegebene Formel hat. Tatsächlich bekommen wir unter derAnnahme, dass ∫ 1
−1p(ξ)dξ =
n
∑j=0
p(ξ j)β j
für jedes Polynom p vom Grad r über [−1,1] gelte, für jedes Polynom q gleichen Gradesauf [a, b]
n
∑j=0
q(xj)αj =b− a
2
n
∑j=0
(q ϕ)︸ ︷︷ ︸=p∈Pr
(ξ j)β j
=b− a
2
∫ 1
−1(q ϕ)(ξ)dξ =
∫ b
aq(x)dx,
wobei wir ausgenutzt haben, dass (q ϕ)(ξ) = p(ξ) auf [−1,1] ein Polynom vom Grad rist.
2.7.1 Tschebyscheffsche Integration und Interpolation
Wenn Gaußsche Quadraturen in Bezug auf die Tschebyscheff-Gewichte w(x) = (1 −x2)−1/2 betrachtet werden, ergeben sich die Gaußknoten und Koeffizienten als
xj = − cos((2j + 1)π2(n + 1)
), αj =
π
n + 1, 0 ≤ j ≤ n, (2.52)
und die Gauß-Lobatto-Knoten und Gewichte zu
xj = − cos(
π jn
), αj =
π
djn, 0 ≤ j ≤ n, (2.53)
wobei d0 = dn = 2 und dj = 1 für j = 1, . . . , n − 1. Beachte, dass die Gauß-Knoten(2.52) für ein festes n ≥ 0 die Nullstellen des Tschebyscheff-Polynoms Tn+1 ∈ Pn+1 sind,während die inneren Knoten
xj : j = 1, . . . , n− 1
in (2.53) die Nullstellen von T′n sind.
Bezeichnen wir mit πGLn,w f das Polynom vom Grade n + 1, das f f statt 1in den Knoten (2.53)
interpoliert, so kann gezeigt werden, dass der Interpolationsfehler durch∥∥∥ f − πGLn,w f
∥∥∥w≤ C n−s ‖ f ‖s,w (2.54)
39

2.7 Gaußsche Integration und Interpolation
für s ≥ 1 abgeschätzt werden kann, wobei ‖.‖w die Norm von L2w(−1,1) ist und
‖ f ‖s,w =
(s
∑k=0
∥∥∥ f (k)∥∥∥2
w
)1/2
,
vorausgesetzt, dass für ein s ≥ 1 die Funktion f Ableitungen f (k) der Ordnung k = 0, . . . , sin L2
w besitzt.
Übung (Schwierig). Für jede Funktion f kann folgende gleichmäßige Fehlerabschätzunggezeigt werden: ∥∥∥ f − πGL
n,w f∥∥∥
∞≤ C n1/2−s ‖ f ‖s,w . (2.55)
Hinweis. Verwende die Gagliardo-Nirenberg-Ungleichung
max−1≤x≤1
| f (x)| ≤ ‖ f ‖1/2L2
∥∥ f ′∥∥1/2
L2 , ∀ f ∈ L2 mit f ′ ∈ L2.
und zeige, dass∥∥∥( f − πGLn,w f )′
∥∥∥w≤ C n1−s ‖ f ‖s,w , [QSS02, Formel (10.24)].
Somit konvergiert πGLn,w f für n → ∞ punktweise gegen f , insbesondere für jedes f ∈
C1([−1,1]). Die Ergebnisse (2.54) und (2.55) gelten in gleicher Weise, wenn πGLn,w f durch
das Polynom πGn f (Gauß-Interpolationspolynom) vom Grad n ersetzt wird. Wir haben
auch das folgende Ergebnis∥∥∥ f − πGn f∥∥∥
∞≤ (1 + Λn)E∗n( f ), Λn ≤
2ω
log(n + 1) + 1, (2.56)
wobei E∗n( f ) = infp∈Pn ‖ f − p‖∞ für alle n den Fehler der besten Approximation für f inPn ist und Λn die Lebesgue-Konstante bezeichne, die zu den Tschebyscheff-Knoten undGewichten gehört.
Was den numerischen Integrationsfehler betrifft, wollen wir als Beispiel die Gauß-Lobatto-Quadratur (2.50) mit den Knoten und Gewichten wie in (2.53) betrachten. Zu-nächst halten wir fest, dass
limn→∞
IGLn,w( f ) =
∫ 1
−1f (x)(1− x2)−1/2 dx
für jede stetige und integrierbare Funktion f gilt. Ist zusätzlich ‖ f ‖s,w für ein s ≥ 1endlich, so haben wir∣∣∣∣∫ 1
−1f (x)(1− x2)−1/2 dx− IGL
n,w( f )∣∣∣∣ ≤ C n−s ‖ f ‖s,w . (2.57)
40

2.7 Gaußsche Integration und Interpolation
Dieses Ergebnis folgt aus der allgemeineren Ungleichung
|( f , vn)w − ( f , vn)n| ≤ C n−s ‖ f ‖s,w ‖vn‖w , ∀vn ∈ Pn, (2.58)
wobei das diskrete Skalarprodukt
( f , g)n =n
∑j=0
αj f (xj)g(xj) = IGLn,w( f · g) (2.59)
eingeführt wurde. Tatsächlich folgt (2.58) aus (2.59), indem man vn ≡ 1 setzt und ‖vn‖w =(∫ 1−1(1− x2)−1/2 dx
)1/2=√
π berücksichtigt.Infolge von (2.57) können wir schließen, dass die Tschebyscheffsche Gauß-Lobatto-
Integration den Exaktheitsgrad 2n − 1 und die Genauigkeit (in Bezug auf n−1) gleich sbesitzt, vorausgesetzt, dass ‖ f ‖s,w < ∞. Vollständig analoge Betrachtungen können fürdie Gauß-Formel mit n + 1 Knoten angestellt werden.
2.7.2 Legendre-Integration und Interpolation
Wie bereits erwähnt ist das Legendre-Gewicht w(x) ≡ 1. Für n ≥ 0 sind die Gauß-Knotenund die zugehörigen Koeffizienten durch
xj Nullstellen von Ln+1(x), αj =2
(1− xj)2[L′n+1(xj)]2, j = 0, . . . , n (2.60)
gegeben, die Gauß-Lobatto-Knoten und Koeffizienten sind für n ≥ 1
x0 = −1, xn = 1, xj Nullstellen von L′n(x), j = 1, . . . , n− 1, (2.61)
αj =2
n(n + 1)1
[Ln(xj)]2, j = 0, . . . , n. (2.62)
Hierbei ist Ln das n-te Legendre-Polynom (2.43),
xn−l statt xLn(x) =12n
[n/2]
∑l=0
(−1)l(
nl
)(2n− 2l
n
)xn−l , n = 0,1,2, . . . .
Es kann gezeigt werden, dass mit einer geeigneten, von n unabhängigen Konstanten Cgilt, dass
2n(n + 1)
≤ αj ≤Cn
, j = 0, . . . , n.
Bezeichne πGLn f das Polynom vom Grad n, das f in den n+ 1 Knoten xj interpoliert. Dann
kann gezeigt werden, dass πGLn f den gleichen Fehlerabschätzungen genügt, die in (2.54)
und (2.55) im Fall der entsprechenden Tschebyscheff-Polynome angegeben wurden:∥∥∥ f − πGLn f
∥∥∥2≤ C · n−s ‖ f ‖s∥∥∥ f − πGL
n f∥∥∥
∞≤ C · n1/2−s ‖ f ‖s .
41

2.8 Gaußsche Integration über unbeschränkte Intervalle
Natürlich muss dabei die Norm ‖ . ‖w durch die Norm ‖ . ‖L2(−1,1) ersetzt werden und‖ f ‖s,w wird zu
‖ f ‖s =
(s
∑k=0
∥∥∥ f (k)∥∥∥2
L2(−1,1)
)1/2
.
Die gleichen Ergebnisse gelten auch, wenn πGLn f durch πG
n f ersetzt wird, wobei πGn f das
Interpolationspolynom von f auf den n + 1 Knoten xj ist.Die zu (2.58) äquivalente Beziehung lautet
|( f , vn)− ( f , vn)n| ≤ C · n−s ‖ f ‖s ‖vn‖2 , vn ∈ Pn, (2.63)
wobei ‖ f ‖s < ∞ vorausgesetzt ist. Setzen wir insbesondere vn ≡ 1, so bekommen wir‖vn‖2 =
√2 und aus (2.63) folgt∣∣∣∣∫ 1
−1f (x)dx− IGL
n ( f )∣∣∣∣ ≤ C · n−s ‖ f ‖s , (2.64)
was die Konvergenz der Gauß-Legendre-Lobatto-Quadratur gegen das exakte Integralvon f mit einer Genauigkeitsordnung s in Bezug auf n−1 zeigt, vorausgesetzt, dass ‖ f ‖s <
∞. Ein ähnliches Ergebnis gilt auch für die Gauß-Legendre-Quadraturformel.
2.8 Gaußsche Integration über unbeschränkte Intervalle
Wir betrachten sowohl die Integration auf der halben als auch auf der gesamten reellenAchse. In beiden Fällen verwenden wir die interpolatorischen Gaußschen Formeln, derenKnoten die Nullstellen der Laguerreschen bzw. der Hermiteschen Orthogonalpolynomesind.
2.8.1 Laguerresche Polynome
Diese Polynome sind auf dem Intervall [0, ∞) orthogonal in Bezug auf die Gewichtsfunk-tion w(x) = e−x. Sie sind durch
Ln(x) = ex dn
dxn (e−xxn), n ≥ 0 (2.65)
gegeben und erfüllen die folgende DreitermrekursionLn+1(x) = (2n + 1− x)Ln(x)− n2Ln−1(x), n ≥ 0,
L−1 ≡ 0, L0 ≡ 1.(2.66)
Für irgendeine Funktion f sei ϕ(x) = f (x) ex. Dann ist
I( f ) =∫ ∞
0f (x)dx =
∫ ∞
0e−x ϕ(x)dx,
42

2.8 Gaußsche Integration über unbeschränkte Intervalle
sodass es genügt, auf das letzte Integral die Gauß-Laguerre-Quadratur anzuwenden, umfür n ≥ 1 und f ∈ C2n([0, ∞))
Index k stattn
I( f ) =n
∑k=1
αk ϕ(xk) +(n!)2
(2n)!ϕ(2n)(ξ), 0 < ξ < ∞ (2.67)
zu bekommen, wobei die Knoten xk, k = 1, . . . , n die Nullstellen von Ln sind und dieGewichte sich aus
αk =(n!)2xk
[Ln+1(xk)]2
ergeben.Aus (2.67) schließt man, dass Gauß-Laguerre-Formeln für Funktionen des Typs ϕ e−x,
ϕ ∈ P2n−1, exakt sind. Wir können dann in einem verallgemeinerten Sinn davon sprechen,dass sie den optimalen Exaktheitsgrad 2n− 1 besitzen.
2.8.2 Hermitesche Polynome
Die Hermiteschen Polynome sind orthogonal auf der reellen Achse in Bezug auf dieGewichtsfunktion w(x) = e−x2
. Sie sind durch
Hn(x) = (−1)n ex2 dn
dxn (e−x2
), n ≥ 0 (2.68)
definiert und können rekursiv ausHn+1(x) = 2xHn(x)− 2nHn−1(x), n ≥ 0
H−1 ≡ 0, H0 ≡ 1,(2.69)
erzeugt werden. Wie im Fall zuvor, haben wir mit ϕ(x) = f (x) ex2die Darstellung
I( f ) =∫ ∞
−∞f (x)dx =
∫ ∞
−∞e−x2
ϕ(x)dx
Durch Anwendung der Gauß-Hermite-Quadratur erhalten wir für n ≥ 1 und f ∈ C2n(R)
I( f ) =∫ ∞
−∞e−x2
ϕ(x)dx =n
∑k=1
αk ϕ(xk) +(n!)√
π
2n(2n)!ϕ(2n)(ξ), (2.70)
wobei die Knoten xk, k = 1, . . . , n die Nullstellen von Hn sind und die Gewichte durchαk = 2n+1n!
√π/[Hn+1(xk)]
2 gegeben sind.Auch die Gauß-Hermite-Regeln sind für Funktionen f der Form ϕ e−x2
exakt, wobeiϕ ∈ P2n−1.
43

2.9 Approximation von Funktionsableitungen
2.9 Approximation von Funktionsableitungen
Ein oft in der numerischen Analysis anzutreffendes Problem ist die Approximation derAbleitung einer Funktion f (x) auf einem gegebenen Intervall [a, b]. Ein natürlicher Zu-gang besteht darin, in [a, b] n + 1 Knoten xk, k = 0, . . . , n einzuführen, wobei x0 =
a, xn = b, xk+1 = xk + h, k = 0, . . . , n− 1, mit h = (b− a)/n, und f ′(xi) unter Verwendungder Knotenwerte f (xk) durch
h ·m
∑k=−m
αkui−k =m′
∑k=−m′
βk f (xi−k) (2.71)
zu approximieren, wobei αk , βk ⊆ R m + m′ + 2 zu bestimmende Koeffizienten unduk die gesuchte Approximation von f ′(xk) sind.
Ein nicht vernachlässigbarer Punkt in der Wahl des Schemas (2.71) ist der numerischeAufwand. In dieser Hinsicht ist es wichtig, darauf zu verweisen, dass die Bestimmungder Werte ui im Fall m 6= 0 die Lösung eines linearen Systems erfordert.
Die Menge der Knoten, die für die Konstruktion der Ableitung von f in einem bestimm-ten Knoten involviert ist, heißt Stern. Die Bandbreite der Matrix, die mit dem System (2.71)verbunden ist, wächst, wenn der Stern größer wird.
h
α0 . . . αm 0 . . . 0
α−1 α0 . . . αm 0... 0
α−m . . . α0 . . . αm 0 . . ....
. . ....
0 . . . 0 α−m . . . α0
u0
...un
=
...
∑m′k=−m′ βk f (xi−k)
...
2.9.1 Klassische finite Differenzen
Der einfachste Weg, eine Formel wie (2.71) zu erzeugen, besteht darin, zur Definition derAbleitung zu greifen. Wenn f ′(xi) existiert, gilt
f ′(xi) = limh→0+
f (xi + h)− f (xi)
h. (2.72)
Die Ersetzung des Differentialquotienten durch den Differenzenquotient mit finitem hliefert die Approximation
uFDi =
f (xi+1)− f (xi)
h, 0 ≤ i ≤ n− 1. (2.73)
Die Beziehung (2.73) ist ein Spezialfall von (2.71), der m = 0, α0 = 1, m′ = 1, β−1 = 1,β0 = −1, β1 = 0 entspricht. −1 statt 1
44

2.9 Approximation von Funktionsableitungen
Die rechte Seite von (2.73) heißt Vorwärtsdifferenz und die verwendete Approximationentspricht der Ersetzung von f ′(xi) durch den Anstieg der Geraden, die durch die Punkte(xi, f (xi)) und (xi+1, f (xi+1)) geht.
Um den gemachten Fehler abzuschätzen, genügt es, f in eine Taylorreihe zu entwickeln.Man erhält dabei
Index ξiergänzt
f (xi+1) = f (xi) + h f ′(xi) +h2
2f ′′(ξi) mit ξi ∈ (xi, xi+1).
Wir nehmen im Folgenden an, dass f die erforderliche Regularität besitzt, sodass
f ′(xi)− uFDi = −h
2f ′′(ξi). (2.74)
Offensichtlich können wir an Stelle von (2.72) einen zentralen Differenzenquotientenverwenden, der zu der folgenden Approximation
uCDi =
f (xi+1)− f (xi−1)
2h, 1 ≤ i ≤ n− 1 (2.75)
führt. Das Schema (2.75) ist ein Spezialfall von (2.71), wenn man m = 0, α0 = 1, m′ = 1,β−1 = 1/2, β0 = 0, β1 = −1/2 setzt. Die rechte Seite von (2.75) heißt zentrale Differenzund bedeutet geometrisch die Ersetzung von f ′(xi) durch den Anstieg der Geraden, diedurch die Punkte (xi−1, f (xi−1)), (xi+1, f (xi+1)) geht. Greifen wir erneut zur Taylorreihe,bekommen wir (Übung!)
f ′(xi)− uCDi = −h2
6f ′′′(ξi). (2.76)
Die Formel (2.76) liefert folglich eine Approximation zweiter Ordnung von f ′(xi) in Bezugauf h.
Schließlich können wir auch eine Rückwärtsdifferenz herleiten, bei der
uBDi =
f (xi)− f (xi−1)
h, 1 ≤ i ≤ n, (2.77)
und für den Fehlerf ′(xi)− uBD
i =h2
f ′′(ξi) (2.78)
gilt. Die Werte der Parameter in (2.77) sind im Fall der Rückwärtsdifferenz m = 0, α0 = 1,m′ = 1 und β−1 = 0, β0 = 1, β1 = −1.
Schemata höherer Ordnung lassen sich ebenso wie finite Differenzenapproximationender höheren Ableitungen von f mittels Taylorentwicklungen höherer Ordnung herleiten.Ein erwähnenswertes Beispiel ist die Approximation von f ′′ . Ist f ∈ C4([a, b]), so bekom-men wir leicht
f ′′(xi) =f (xi+1)− 2 f (xi) + f (xi−1)
h2 − h2
24
(f (4)(xi + vih) + f (4)(xi − wih)
), (2.79)
45

2.9 Approximation von Funktionsableitungen
mit 0 < vi, wi < 1 (Übung!). Die folgende zentrale Differenz kann folglich abgeleitet werden
u′′i =f (xi+1)− 2 f (xi) + f (xi−1)
h2 , 1 ≤ i ≤ n− 1, (2.80)
die den Fehler
− ergänztf ′′(xi)− u′′i = − h2
24
(f (4)(xi + vih) + f (4)(xi − wih)
)(2.81)
besitzt. Die Formel (2.80) liefert eine Approximation zweiter Ordnung an f ′′(xi) in Bezugauf h.
2.9.2 Kompakte finite Differenzen
Genauere Approximationen werden mit folgender Formel (die wir kompakte Differenzennennen) erzielt:
αui−1 + ui + αui+1 =β
2h( fi+1 − fi−1) +
γ
4h( fi+2 − fi−2) (2.82)
für i = 2, . . . , n− 2. Zur Abkürzung haben wir fi = f (xi) gesetzt.Die Koeffizienten α, β und γ sind so zu bestimmen, dass die Beziehungen (2.82) Werte
ui liefern, die f ′(xi) von höchster Ordnung bezüglich h approximieren. Dazu werden dieKoeffizienten auf solche Weise ausgewählt, dass der Konsistenzfehler
+ statt − vor
α f (1)i+1σi(h) = α f (1)i−1 + f (1)i + α f (1)i+1 −
(β
2h( fi+1 − fi−1) +
γ
4h( fi+2 − fi−2)
), (2.83)
minimal wird, der durch die „Forderung“, dass f dem numerischen Schema (2.82) genü-ge, entsteht. Der Kürze halber haben wir f (k)i = f (k)(xi), k = 1,2, . . . , gesetzt. Nehmen wirf ∈ C5([a, b]) an und entwickeln die Funktion in eine Taylorrehe um xi, so finden wir
fi±1 = fi ± h f (1)i +h2
2f (2)i ± h3
6f (3)i +
h4
24f (4)i ± h5
120f (5)i + O(h6),
f (1)i±1 = f (1)i ± h f (2)i +h2
2f (3)i ± h3
6f (4)i +
h4
24f (5)i + O(h5).
Substitution in (2.83) ergibt
Kein /2 vor
f (3)i -Termen
σi(h) = (2α + 1) f (1)i + αh2 f (3)i + αh4
12f (5)i − (β + γ) f (1)i
− h2(
β
6+
2γ
3
)f (3)i − h4
60
(β
2+ 8γ
)f (5)i + O(h6).
Methoden zweiter Ordnung werden durch Nullsetzen des Koeffizienten vor f (1)i erhalten,d.h., wenn 2α+ 1 = β+γ gilt, während wir für Schemata 4. Ordnung zusätzlich auch denKoeffizienten von f (3)i gleich Null setzen müssen, was zu 6α = β + 4γ führt. Methoden6. Ordnung erhalten wir schließlich durch zusätzliches Nullsetzen des Koeffizienten beif (5)i , d.h. für 10α = β + 16γ (Ergebnis: α = 1
3 , β = 149 , γ = 1
9 ).
46

3 Numerik gewöhnlicherDifferentialgleichungen
3.1 Beispiele aus der Populationsdynamik
Sei x : [0, T] → R eine Funktion der Zeit, die die Größe einer Population beschreibt. Wirnehmen an, dass die Veränderung (hier das Wachstum) x(t) der Population proportionalzu ihrer Größe ist:
x(t) = ax(t), (3.1)
wobei a > 0 eine positive Konstante ist, der Fertilitätskoeffizient. Wir nehmen auch an,dass die Population eine bestimmte Größe in der Anfangszeit hat,
x(t0) = x0. (3.2)
Das gegebene x0 wird Anfangswert genannt und die Formeln (3.1) und (3.2) zusammensind ein typisches Anfangswertproblem. Die explizite Lösung des Problems (3.1) – (3.2)ist
x(t) = x0 ea(t−t0), (3.3)
womit die Größe der Population ein exponentielles Wachstum hat.Neben der Möglichkeit eines positiven Wachstums (mit stetigen Geburten) können wir
auch die Tode in der Population modellieren. Dies ist der Fall in dem klassischen Modelldes Räubers und der Beute. In diesem Modell ist das Wachstum der beiden Populationender Räuber und der Beute abhängig von der des jeweils anderen. Je größer die Populationder Räuber, desto kleiner ist die Population der Beute. Ist auf der anderen Seite die Po-pulation der Beute zu niedrig, sodass ihr Bestand nicht zum Lebensunterhalt der Räuberausreicht, so sinkt die Population der Räuber.
Wir bezeichnen mit r(t) und b(t) die Größe der Population der Räuber bzw. der Beute.Das Modell lautet
b(t) = a1b(t)− a2r(t) b(t)
r(t) = −a3r(t) + a4b(t) r(t)(3.4)
In diesem Fall steht uns eine explizite Lösung des Anfangsproblems (3.4) mit r(t0) = r0,b(t0) = b0 leider nicht zur Verfügung. Deshalb müssen wir uns numerischen Methodenzuwenden.
47

3.2 Das explizite Euler-Verfahren
0 1 2 30
2
4
6
(a) Explizites Euler-Verfahren
0 1 2 30
2
4
6
(b) Implizites Euler-Verfahren
0 1 2 30
2
4
6
(c) Mittelpunktsregel
Abbildung 3.1: Vergleich numerischer Lösungsmethoden für das Räuber-Beute-Modellmit Parametern a1 = 2, a2 = a3 = a4 = 1, x0 = (1, 1), h = 0,1
3.2 Das explizite Euler-Verfahren
Betrachten wir das Anfangswertproblem (AWP)
x = f (x), x(0) = x0 (3.5)
(im Räuber-Beute-System war x = (b, r)), wobei f : Rd → Rd ein Vektorfeld ist. DieLösung des AWPs ist eine Kurve in Rd, die (3.5) erfüllt.
Die einfachste Möglichkeit einer numerischen Methode ist die Diskretisierung der Ab-leitung x von x mit einer finiten Differenz. Für eine gegebene Schrittweite h bezeichnenwir mit x1, x2, x3, . . . die Näherungen für x(h), x(2h), x(3h), . . . Durch diese Diskretisie-rung der Lösung können wir die Rekursion
xk+1 = xk + h f (xk), k = 0,1,2, . . . (3.6)
definieren, die eine ApproximationFaktor h vorf (x(kh))entfernt
x(kh) ' x((k + 1)h)− x(kh)h
= f (x(kh))
der ursprünglichen Gleichung (3.5) ist. Die Approximation der Ableitung ist insbesonderedurch die Vorwärtsdifferenzen bestimmt.
Die Methode (3.6) ist das berühmte sogenannte explizite Euler-Verfahren. Wenn wir dasexplizite Euler-Verfahren in der numerischen Lösung des Räuber-Beute-Systems verwen-den, bekommen wir eine falsche Trajektorie, die eine offene Kurve ist, siehe Abbildung3.1(a). Um eine bessere Approximation zu erhalten, müssen wir eine sehr kleine Schritt-weite h 0,1 festsetzen.
Wir wenden uns nun einer sogenannten impliziten Methode zu, bei welcher der nächsteSchritt der Rekursion nicht mehr explizit gegeben ist.
48

3.3 Das implizite Euler-Verfahren
3.3 Das implizite Euler-Verfahren
Bei diesem Verfahren diskretisieren wir noch mal die Ableitung x mit einer Vorwärtsdif-ferenz, aber der Wert des Vektorfeldes f wird jetzt auf einen Schritt weiter in der Zukunftangewendet:
xk+1 = xk + h f (xk+1). (3.7)
Um den Wert xk+1 ausgehend von xk zu berechnen, muss man ein nichtlineares Systemlösen, weshalb diese Methode numerisch sehr teuer ist. Ist dieser numerische Aufwandsinnvoll? Leider lässt sich keine eindeutige Antwort geben, da die numerische Lösungauch in diesem Fall eine falsche Trajektorie liefern kann, sobald die Schrittweite zu weitist (siehe z.B. Abbildung 3.1(b), wo die Approximation eine sich nach innen windendeSpirale ergibt).
3.4 Die Mittelpunktsregel
Da die explizite Euler-Methode eine Abweichung nach außen und die implizite Euler-Methode eine Abweichung nach innen liefern, könnte man auf die Idee kommen, dassder Durchschnittswert eine bessere Trajektorie liefern könnte:
xk+1 = xk + h f(
xk + xk+1
2
)(3.8)
Die Rekursion ist wieder implizit, und in der Tat ist die Genauigkeit der numerischenLösung deutlich besser, auch für relativ große Schrittweiten (siehe die geschlossene Tra-jektorie in Abbildung 3.1(c) für h = 0,1)!
In den nächsten Vorlesungen wollen wir eine Erklärung der unterschiedlichen Genau-igkeit von (3.6), (3.7) und (3.8) liefern. Zuvor geben wir eine Einführung in die Theorievon Anfangswertproblemen.
3.5 Grundbegriffe im Detail
3.5.1 Anfangswertprobleme
Seien Ω eine offene Teilmenge von R × Rd und f : Ω → Rd ein Vektorfeld, das dierechte Seite der gewöhnlichen Differentialgleichung sein wird. Für gegebenes (t0, x0) ∈ Ωdefinieren wir das Anfangswertproblem durch
x = f (t, x) (Differentialgleichung),
x(t0) = x0 (Anfangswert).(3.9)
Üblicherweise ist die Variable t ∈ R die Zeit und t0 ∈ R die Anfangszeit der Evolution.Die Variable x ∈ Rd ist der Zustand des Systems, in der Physik typischerweise die
49
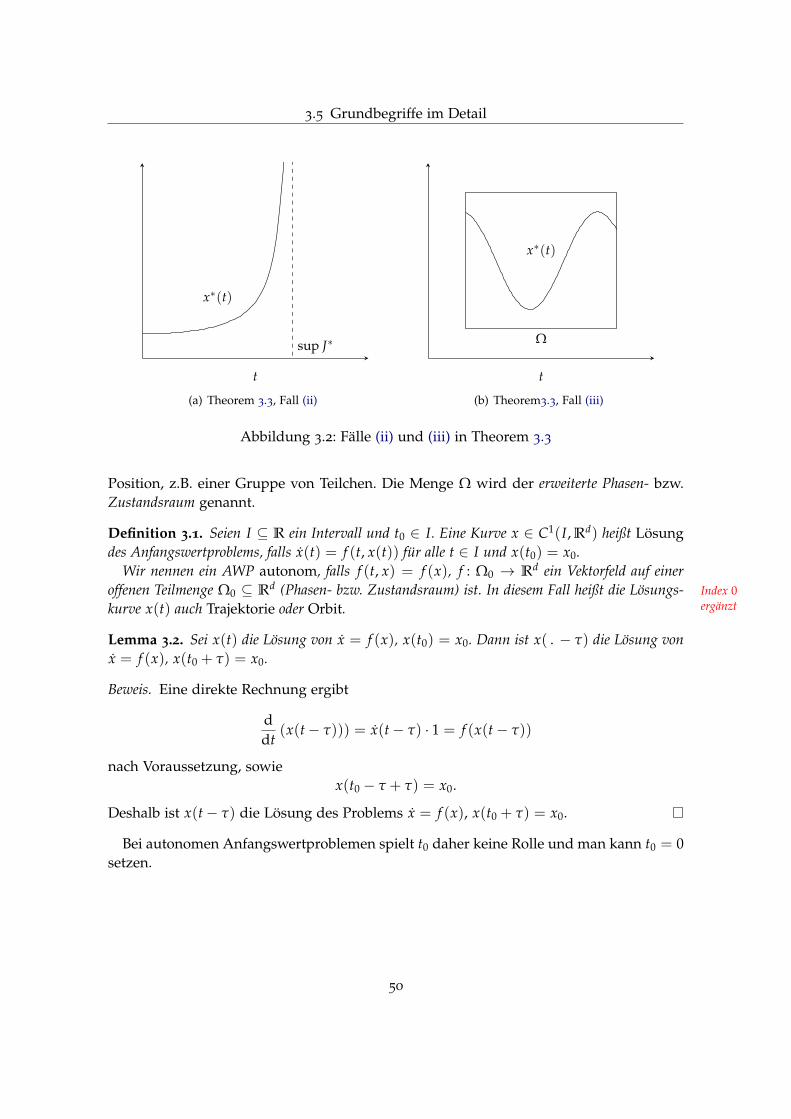
3.5 Grundbegriffe im Detail
sup J∗
x∗(t)
t
(a) Theorem 3.3, Fall (ii)
x∗(t)
Ω
t
(b) Theorem3.3, Fall (iii)
Abbildung 3.2: Fälle (ii) und (iii) in Theorem 3.3
Position, z.B. einer Gruppe von Teilchen. Die Menge Ω wird der erweiterte Phasen- bzw.Zustandsraum genannt.
Definition 3.1. Seien I ⊆ R ein Intervall und t0 ∈ I. Eine Kurve x ∈ C1(I, Rd) heißt Lösungdes Anfangswertproblems, falls x(t) = f (t, x(t)) für alle t ∈ I und x(t0) = x0.
Wir nennen ein AWP autonom, falls f (t, x) = f (x), f : Ω0 → Rd ein Vektorfeld auf eineroffenen Teilmenge Index 0
ergänztΩ0 ⊆ Rd (Phasen- bzw. Zustandsraum) ist. In diesem Fall heißt die Lösungs-
kurve x(t) auch Trajektorie oder Orbit.
Lemma 3.2. Sei x(t) die Lösung von x = f (x), x(t0) = x0. Dann ist x( . − τ) die Lösung vonx = f (x), x(t0 + τ) = x0.
Beweis. Eine direkte Rechnung ergibt
ddt
(x(t− τ))) = x(t− τ) · 1 = f (x(t− τ))
nach Voraussetzung, sowiex(t0 − τ + τ) = x0.
Deshalb ist x(t− τ) die Lösung des Problems x = f (x), x(t0 + τ) = x0.
Bei autonomen Anfangswertproblemen spielt t0 daher keine Rolle und man kann t0 = 0setzen.
50

3.5 Grundbegriffe im Detail
3.5.2 Lösungstheorie: Existenzsatz von Peano
Betrachten wir ein Anfangswertproblem
x = f (t, x), x(t0) = x0
Die Frage ist, ob (3.9) eine Lösung hat, und unter welchen Bedingungen. Eine wichtigeAntwort gibt der Satz von Peano (1890):
Theorem 3.3. Nehmen wir an, dass die rechte Seite f des AWPs (3.9) stetig ist, d.h. f ∈C(Ω, Rd) und die Anfangsdaten (t0, x0) ∈ Ω. Dann hat das AWP mindestens eine Lösung.Jede Lösung lässt sich in die Vergangenheit und in die Zukunft bis an den Rand von Ω fortsetzen.
Das bedeutet: Ist x ∈ C1(J, Rd), J Intervall in R, eine Lösung des AWPs, dann gibt eseine Lösung x∗ ∈ C1(J∗, Rd) des AWPs, sodass x∗ = x auf J, J ⊆ J∗ und entweder
(i) sup J∗ = ∞ oder
(ii) sup J∗ < ∞, aber limt→sup J∗ ‖x∗(t)‖ = ∞, oder
(iii) sup J∗ < ∞, aber limt→sup J∗ dist((t, x∗(t)), ∂Ω) = 0.
(bzw. inf statt sup für die Vergangenheit). Die Fälle (ii) und (iii) sind in Abbildung 3.2skizziert.
Was gilt für die Eindeutigkeit der Lösung? Im Allgemeinen ist die Stetigkeit der rechtenSeite f nicht hinreichend. Betrachten wir zum Beispiel die Gleichung
x =√|x|. (3.10)
Die rechte Seite der Gleichung (3.10) ist die Funktion f (t, x) = f (x) =√|x|, also stetig,
aber die Kurvenx1(t) ≡ 0,
x2(t) =14(t + x1/2
0 )2(3.11)
sind beides passende Lösungen.
3.5.3 Eindeutigkeitssatz von Picard-Lindelöf
Definition 3.4. Eine Funktion f : Ω → Rd heißt lokal Lipschitz-stetig bezüglich x, falls es zujeder kompakten Menge K ⊆ Ω eine Konstante LK gibt, sodass
‖ f (t, x)− f (t, x)‖ ≤ LK ‖x− x‖ (3.12)
für alle (t, x), (t, x) ∈ K.
Wir haben die folgende Eindeutigkeitsaussage.
51

3.5 Grundbegriffe im Detail
Theorem 3.5 (Picard 1890, Lindelöf 1894). Sei die rechte Seite f des AWPs (3.9) auf demerweiterten Phasenraum Ω mit Datum (t0, x0) ∈ Ω stetig und bezüglich der Zustandsvariablen xlokal Lipschitz-stetig. Dann besitzt das AWP eine in die Vergangenheit und in die Zukunft bis anden Rand von Ω fortsetzbare Lösung. Sie ist eindeutig bestimmt, d.h. Fortsetzung jeder weiterenLösung.
Beweis. Sei I das maximale Intervall, auf dem eine Lösung existiert. Wir wählen δ > 0und b > 0, sodass
K = I ∩ Bδ(t0)× Bb(x0) ⊆ Ω
undδ ≤ b
max(t,x)∈I×Bb(x0)| f (t, x)| . (3.13)
Setzen I0 = I ∩ Bδ(t0) und X = C(I0, Bb(x0)) und definieren den Operator
Tx(t) = x0 +∫ t
t0
f (s, x(s))ds.
Für x, z ∈ C(I0, Bb(x0)) haben wir
|Tx(t)− Tz(t)| =∣∣∣∣∫ t
t0
( f (s, x(s))− f (s, z(s)))ds∣∣∣∣
≤ Lk
∫ t
t0
|x(s)− z(s)| e−2LK |s−t0|e2LK |s−t0| ds.
Mit der Norm‖x‖X = max
t∈I0|x(t)| e−2LK |t−t0|
erhalten wir
|Tx(t)− Tz(t)| ≤ LK ‖x− z‖X
∫ t
t0
e2LK |s−t0| ds
= LK ‖x− z‖Xe2LK |t−t0|
2LK
und‖Tx− Tz‖X ≤
12‖x− z‖X . (3.14)
Außerdem, falls x ∈ C(I0, Bb(x0)),
|Tx(t)− x0| =∣∣∣∣∫ t
t0
f (s, x(s))ds∣∣∣∣
≤∫ t
t0
| f (s, x(s))|ds ≤ |t− t0|[
max(t,x)∈I0×Bb(x0)
| f (t, x)|]
≤ δ
[max
(t,x)∈I0×Bb(x0)| f (t, x)|
]≤ b. (3.15)
52

3.5 Grundbegriffe im Detail
Deshalb ist Tx(t) ∈ Bb(x0) für alle t ∈ I0 = I ∩ Bδ(t0) und der Operator T ist einekontrahierende Abbildung auf dem Banach-Raum X. Aus dem Banachschen Fixpunktsatzfolgt die Existenz einer eindeutigen Funktion x ∈ C(I0, Bb(x0)), sodass
x(t) = x0 +∫ t
t0
f (s, x(s))ds, (3.16)
mit anderen Worten x(t) = f (t, x(t)), t ∈ I0,
x(t0) = x0.
Diese auf I0 definierte eindeutige Lösung kann fortgesetzt werden, um die Eindeutigkeiteiner Lösung auf dem gesamten Intervall zu erhalten.
3.5.4 Das Lemma von Gronwall und Stabilität der Lösungen
Lemma 3.6 (Gronwall, 1919). Seien I ein Intervall und α, β und u Funktionen auf I mit reellenWerten. Nehmen wir an, dass β und u stetig sind und dass α und β positiv sind. Ist α monotonsteigend und gilt
u(t) ≤ α(t) +∫ t
t0
β(s)u(s)ds, t0, t ∈ I, (3.17)
dann gilt die Gronwallsche Ungleichung
u(t) ≤ α(t) exp(∫ t
t0
β(s)ds)
. (3.18)
Beweis. Wir setzen
v(s) = exp(−∫ s
t0
β(r)dr)·∫ s
t0
β(r)u(r)dr. (3.19)
Differentiation von v(s) ergibt
v′(s) =(
u(s)−∫ s
t0
β(r)u(r)dr)
β(s) exp(−∫ s
t0
β(r)dr)
.
Der Term in der Klammer ist wegen (3.17) von oben durch α(s) abschätzbar:(u(s)−
∫ s
t0
β(r)u(r)dr)≤ α(s).
Daher bekommen wir die Ungleichung
v′(s) ≤ α(s)β(s) exp(−∫ s
t0
β(r)dr)
,
53

3.5 Grundbegriffe im Detail
die integriert
v(t) ≤∫ t
t0
α(s)β(s) exp(−∫ s
t0
β(r)dr)
ds (3.20)
ergibt. Wegen der Definition von v(s) in (3.19) können wir∫ t
t0
β(s)u(s)ds = exp(∫ t
t0
β(r)dr)
v(t)
Integrations-
grenze t statts
≤∫ t
t0
α(s)β(s) exp(∫ t
t0
β(r)dr−∫ s
t0
β(r)dr)
ds
schreiben. Da α monoton steigend ist, gilt α(s) ≤ α(t) für alle s ≤ t und damit∫ t
t0
β(s)u(s)ds ≤ α(t)∫ t
t0
β(s) exp(∫ t
sβ(r)dr
)ds. (3.21)
Der Fundamentalsatz der Analysis ergibt
∫ t
t0
β(s) exp(∫ t
sβ(r)dr
)ds = − exp
(∫ t
sβ(r)dr
)∣∣∣∣s=t
s=t0
= exp(∫ t
t0
β(r)dr)− 1. (3.22)
Die Ungleichungen (3.21) und (3.22) ergeben das gewünschte Ergebnis:
u(t) ≤ α(t) +∫ t
t0
β(s)u(s)ds
≤ α(t) + α(t)∫ t
t0
β(s) exp(∫ t
sβ(r)dr
)ds
≤ α(t) + α(t)(
exp(∫ t
t0
β(r)dr)− 1)
= α(t) exp(∫ t
t0
β(r)dr)
.
Korollar 3.7. Sei die rechte Seite f des AWPs (3.9) auf dem erweiterten Phasenraum Ω stetigund bezüglich der Zustandsvariable x lokal Lipschitz-stetig. Seien (t0, xI
0) ∈ Ω und (t0, xI I0 ) ∈ Ω
zwei verschiedene Anfangswerte für das Problem (3.9) und xI(t) und xI I(t) die entsprechendenLösungen. Seien JxI und JxI I die maximalen Existenzintervalle von xI bzw. xI I und T > t0 so,dass [t0, T] ⊆ JxI ∩ JxI I . Dann haben wir die folgende Stabilitätsungleichung:∥∥∥xI(t)− xI I(t)
∥∥∥ ≤ ∥∥∥xI0 − xI I
0
∥∥∥ eLT(t−t0), t ∈ [t0, T], (3.23)
wobei die Konstante LT abhängig von den Anfangswerten, f und T > 0 ist.
54

3.5 Grundbegriffe im Detail
Beweis. Sei ρ > 0 hinreichend klein, sodass
[t0, T]× ⋃
t∈[0,T]
Bρ(xI(t)) ∪ Bρ(xI I(t))
= KT ⊆ Ω.
Durch Integration können wir
xI(t) = xI0 +
∫ t
t0
f (s, xI(s))ds, xI I(t) = xI I0 +
∫ t
t0
f (s, xI I(s))ds
schreiben und es gilt∥∥∥xI(t)− xI I(t)∥∥∥ =
∥∥∥∥xI0 − xI I
0 +∫ t
t0
(f (s, xI(s))− f (s, xI I(s))
)ds∥∥∥∥
≤∥∥∥xI
0 − xI I0
∥∥∥+ ∫ t
t0
∥∥∥ f (s, xI(s))− f (s, xI I(s))∥∥∥ds
≤∥∥∥xI
0 − xI I0
∥∥∥+ LT
∫ t
t0
∥∥∥xI(s)− xI I(s)∥∥∥ds, (3.24)
wobei die Konstante LT die Lipschitz-Konstante von f in Bezug auf die kompakte MengeKT ist. Aus (3.24) ergibt die Anwendung des Gronwall-Lemmas, dass∥∥∥xI(t)− xI I(t)
∥∥∥ ≤ ∥∥∥xI0 − xI I
0
∥∥∥ exp(∫ t
t0
LT ds)
=∥∥∥xI
0 − xI I0
∥∥∥ eLT(t−t0), t ∈ [0, T]
gilt.
3.5.5 Evolution
Nehmen wir die Voraussetzungen von Theorem 3.5 an. Seien (t0, x0) ∈ Ω der Anfangs-wert für das AWP (3.9) und x(t) = x(t; (t0, x0)) die eindeutige maximale Lösung auf J =Jmax(t0, x0), dem maximalen Existenzintervall der Lösung x ∈ C1(J, Rd). Wir definierendie Evolution der Differentialgleichung x = f (t, x)
Φt,t0(x0) = x(t; (t0, x0)), wenn x(t0) = x0, (3.25)
die eine zweiparametrige Familie von Abbildungen ist. Durch die Eindeutigkeit der Lö-sungen erhalten wir die folgenden Eigenschaften der Evolution:
Lemma 3.8. Es gilt für alle (t0, x0) ∈ Ω, dass
Jmax(t, Φt,t0 x0) = Jmax(t0, x0) für alle t ∈ Jmax(t0, x0). (3.26)
Die Evolution Φt,t0 erfüllt für (t0, x0) ∈ Ω die beiden Eigenschaften
55

3.5 Grundbegriffe im Detail
(i) Φt0 ,t0 x0 = x0 (Identität);
(ii) Φt,sΦs,t0 x0 = Φt,t0 x0 ∀t, s ∈ Jmax(t0, x0).
Die Eigenschaft (i) ist klar wegen der Definition des Anfangswerts. Eigenschaft (ii) isteine direkte Folge der Eindeutigkeit der Lösungen.
Der Graph der maximal fortgesetzten Lösung im erweiterten Phasenraum
Klammerγ(t0, x0) =(t, Φt,t0 x0) : t ∈ Jmax(t0, x0)
⊆ Ω
heißt Integralkurve durch (t0, x0). Die Eigenschaft (ii) der Evolution Φt,t0 besagt jetzt,dass die Integralkurven eine disjunkte Zerlegung (Faserung) des erweiterten PhaseraumsΩ darstellen,
γ(t, x) ∩ γ(s, y) 6= ∅ =⇒ γ(t, x) = γ(s, y).
Für autonome Probleme ( f (t, x) = f (x)) setzen wir die kanonische Anfangszeit t0 := 0und definieren für x0 ∈ Ω0 (Phasenraum)
Jmax(x0) = Jmax(0, x0),
und für t ∈ Jmax(x0)
Φtx0 = Φt,0x0. (3.27)
Die einparametrige Familie Φt von Transformationen in Ω0 heißt Phasenfluss der autono-men Differentialgleichung x = f (x). Die in Lemma 3.2 formulierte Translationsinvarianzin der Zeit gibt dem Phasenfluss eine Gruppenstruktur.
Lemma 3.9. Für alle x0 ∈ Ω0 gilt
Jmax(t + τ, x0) = Jmax(t, x0) + τ, t, τ ∈ R. (3.28)
Der Phasenfluss Φt ist eine einparametrige Gruppe von Transformationen in Ω0, d.h. er erfülltfür x0 ∈ Ω0 die beiden Eigenschaften
(i) Φ0x0 = x0,
(ii) ΦtΦsx0 = Φt+sx0 für alle t + s, s ∈ Jmax(x0).
Die Evolution der autonomen Differentialgleichung kann durch den Phasenfluss dargestelltwerden, für x0 ∈ Ω und t− s ∈ Jmax(x0) gilt
Φt,sx0 = Φt−sx0. (3.29)
Beweis. Die Eigenschaft (i) ist wiederum nur die Definition des Anfangswerts.Zu Eigenschaft (ii):
Φt(Φs(x0)) = Φt,0(Φs,0(x0))
= Φs+t,s(Φs,0(x0)) (Lemma 3.2)
= Φs+t,0(x0) (Lemma 3.8)
= Φt+s(x0) (Definition des Phasenflusses).
Der Beweis von (3.29) ist eine Übung.
56

3.6 Einschrittverfahren
3.6 Einschrittverfahren
In diesem Abschnitt wenden wir uns der numerischen Approximation einer Lösung x ∈C1([t0, T], Rd) eines AWPs
x = f (t, x), x(t0) = x0.
zu. Wir haben bereits drei wichtige Beispiele, nämlich das explizite Euler-Verfahren, dasimplizite Euler-Verfahren und die Mittelpunktregel in den Abschnitten 3.2, 3.3 und 3.4kennengelernt. Alle diese Verfahren basieren auf einer Zwei-Term-Rekursion und gehörenzu der allgemeinen Klasse der sogenannten Einschrittverfahren. Auf den nächsten Seitenbeschäftigen wir uns mit der Theorie der Einschrittverfahren für sogenannte nichtsteifeProbleme, für welche expliziten Methoden geeignet sind. Danach wenden wir uns steifenProblemen zu.
3.6.1 Konvergenztheorie
Wir unterteilen zunächst das Intervall [t0, T] in n + 1 ausgewählte diskrete Zeitpunkte
t0 < t1 < · · · < tn = T.
Diese diskreten Zeitpunkte bilden ein Gitter ∆ = t0, t1, . . . , tn auf [t0, T] und heißenGitterpunkte. Ferner bezeichnen wir mit
τj = tj+1 − tj, j = 0, . . . , n− 1, (3.30)
die Schrittweiten von einem Gitterpunkt zum nächsten. Die maximale Schrittweite wirdmit
τ∆ = max0≤j≤n−1
τj (3.31)
bezeichnet.Unsere weitere Aufgabe besteht nun darin, Algorithmen zur Konstruktion einer Gitter-
funktionx∆ : ∆→ Rd (3.32)
anzugeben, welche die Lösung x eines AWPs an den Gitterpunkten möglichst gut appro-ximiert,
x∆(t) ≈ x(t), t ∈ ∆. (3.33)
Solche Algorithmen zur Approximation an diskreten Stellen heißen auch Diskretisierungs-verfahren oder kurz Diskretisierungen. Außerdem soll die Gitterfunktion x∆ rekursiv be-stimmbar sein,
x∆(t0) = x0 7→ x∆(t1) 7→ . . . 7→ x∆(tn) = x∆(T),
57

3.6 Einschrittverfahren
wobei bei Einschrittverfahren der Rechenvorgang für alle Gitter ∆ einheitlich durch eineZwei-Term-Rekursion beschrieben wird:
x∆(t0) = x0, (3.34a)
x∆(tj+1) = Ψtj+1,tj x∆(tj), j = 0,1, . . . , n− 1 (3.34b)
mit einer von ∆ unabhängigen Funktion Ψ. Mit Blick auf die Evolution Φ der Differen-tialgleichung (Abschnitt 3.5.5) nennen wir Ψ eine diskrete Evolution auf dem erweiterntenPhasenraum Ω, wenn für jedes (t, x) ∈ Ω der Ausdruck Ψt+τ,tx für hinreichend kleines τ
erklärt ist.Ein Einschrittverfahren ordnet jeder Differentialgleichung, repräsentiert durch ihre rech-
te Seite f , eine diskrete Evolution Ψ zu,
f 7→ Ψ = Ψ( f ).
3.6.1.1 Konsistenz
Natürlich können wir als eine mögliche diskrete Evolution Ψt,s die Evolution der Diffe-rentialgleichung Ψt,s = Φt,s wählen, die für alle Gitter ∆ an den Gitterpunkten die exakteLösung liefert. Leider ist diese spezielle diskrete Evolution nahezu nicht auswertbar.
Wir suchen also nach möglichst elementar berechenbaren diskreten Evolutionen Ψ, diesich durch eine feste Anzahl an Operationen aus der recheten Seite f ergeben.
Von den drei charakterisierenden Eigenschaften der Evolution,
Φt,tx = x, (t, x) ∈ Ω (3.35a)d
dτΦt+τ,tx
∣∣∣∣τ=0
= f (t, x), (t, x) ∈ Ω (3.35b)
Φt,σΦσ,sx = Φt,sx, t, σ ∈ Jmax, (s, x), (t, x) ∈ Ω (3.35c)
werden im Allgemeinen nicht alle drei gleichzeitig von einer berechenbaren diskretenEvolution Ψ erfüllt werden. Eigenschaft (3.35a) ist offenbar das Mindeste, was von ei-nem sinnvollen Verfahren gefordert werden kann. Eigenschaft (3.35b) ist die einzige, dieden Bezug zur rechten Seite der Differentialgleichung herstellt. Deshalb heißen diskreteEvolutionen, welche den Eigenschaften (3.35a) und (3.35b) genügen, konsistent mit derDifferentialgleichung.
Die Konsistenz einer diskreten Evolution Ψ wird quantitativ dadurch beschrieben, wiesehr Ψ von der Evolution Φ abweicht:
Definition 3.10. Sei (t, x) ∈ Ω. Die für hinreichend kleines τ erklärte Differenz
ε(t, x, τ) = Φt+τ,tx−Ψt+τ,tx (3.36)
heißt Konsistenzfehler der diskreten Evolution Ψ.
58

3.6 Einschrittverfahren
Konsistente diskrete Evolutionen können wir in einfacher Weise durch folgendes Lem-ma charakterisieren:
Lemma 3.11. Die diskrete Evolution Ψt+τ,tx sei für festes (t, x) ∈ Ω und hinreichend kleines τ
bezüglich τ stetig differenzierbar. Dann sind folgende Eigenschaften äquivalent:
(i) Die diskrete Evolution ist konsistent;
(ii) Die diskrete Evolution besitzt die Darstellung
Ψt+τ,tx = x + τψ(t, x, τ)
ψ statt Ψψ(t, x, 0) = f (t, x)(3.37)
mit einer bezüglich τ stetigen Funktion ψ, der Inkrementfunktion;
(iii) Der Konsistenzfehler erfüllt ε(t, x, τ) = o(τ) für τ → 0.
Beweis. Wir vergleichen die Taylorentwicklungen von Φt+τ,tx und Ψt+τ,tx an der Stelleτ = 0. Die zweite Eigenschaft der Evolution ist äquivalent zur Taylorentwicklung
Φt+τ,tx = x + τ f (t, x) + o(τ), τ → 0. (3.38)
Analog ist die Konsistenz der diskreten Evolution äquivalent zu
Ψt+τ,tx = x + τ f (t, x) + o(τ), τ → 0. (3.39)
Subtraktion dieser Entwicklungen zeigt die Äquivalenz von (i) und (iii). Eine leichteUmformung zeigt die Äquivalenz der Konsistenz mit der Entwicklung
ψt+τ,tx− xτ
= f (t, x) + o(1), τ → 0.
Das Landau-o bedeutet, dass die rechte Seite eine in τ stetige Funktion ψ(t, x, τ) definiert,für welche Ψ(t, x, 0) = f (t, x) ist. ψ statt Ψ
3.6.1.2 Diskretes Gronwall-Lemma
Lemma 3.12 (Diskrete Gronwall-Ungleichung). Seien (kn)n eine nicht-negative Folge und ϕn
eine Folge mit ϕ0 ≤ g0
ϕn ≤ g0 +n−1
∑s=0
ps +n−1
∑s=0
ks ϕs, n ≥ 1.(3.40)
Sind g0 ≥ 0 und pn ≥ 0 für jedes n ≥ 0, so gilt
ϕn ≤(
g0 +n−1
∑s=0
ps
)exp
(n−1
∑s=0
ks
), n ≥ 1 (3.41)
59

3.6 Einschrittverfahren
Beweis. Wir zeigen, dass
1 +n−1
∑s=0
(s−1
∏l=0
(1 + kl)
)ks ≤
n−1
∏s=0
(1 + ks) (3.42)
gilt. Wir erhalten die Abschätzung induktiv: Für n = 1 haben wir die Beziehung
1 ≤ 1 + k0,
die gilt, da k0 ≥ 0. Nehmen wir nun an, dass
1 +n−1
∑s=0
(s−1
∏l=0
(1 + kl)
)ks ≤
n−1
∏s=0
(1 + ks) (3.43)
gilt. Wir schätzen (3.43) durch
1 +n
∑s=0
(s−1
∏l=0
(1 + kl)
)ks
= 1 +n−1
∑s=0
(s−1
∏l=0
(1 + kl)
)ks +
n−1
∏l=0
(1 + kl)kn
≤n−1
∏s=0
(1 + ks) +n−1
∏s=0
(1 + ks)kn =n
∏s=0
(1 + ks)
ab. Daher gilt (3.42) für alle n ≥ 1.Ebenfalls induktiv zeigen wir die Abschätzung
ϕn ≤(
g0 +n−1
∑s=0
ps
)︸ ︷︷ ︸
αn−1
n−1
∏s=0
(1 + ks). (3.44)
Für n = 1 gilt
ϕ1 ≤ g0 + p0 + k0ϕ0
≤ statt =≤ g0 + p0 + k0g0
≤ (g0 + p0) + k0(g0 + p0)
≤ (g0 + p0)(k0 + 1),
60

3.6 Einschrittverfahren
da (3.44) für n = 1 erfüllt ist. Nehmen wir nun (3.44) an. Dann folgt aus (3.42) und (3.44)
ϕn+1 ≤ αn +n
∑s=0
ks ϕs
≤ αn +n
∑s=0
ksαs−1
s−1
∏l=0
(1 + kl)
≤ αn + αn
n
∑s=0
ks
s−1
∏l=0
(1 + kl)
= αn
(1 +
n
∑s=0
ks
s−1
∏l=0
(1 + kl)
)
≤ αn
n
∏s=0
(1 + ks),
was die Ungleichung (3.44) für n+ 1 ergibt. Wir schließen den Beweis mit der Bemerkung,dass
1 + x ≤ ex, x ≥ 0
gilt, sodass
αn−1 statt αnϕn ≤ αn−1
n
∏s=0
(1 + ks)
≤ αn−1
n−1
∏s=0
eks = αn−1 exp
(n−1
∑s=0
ks
).
3.6.1.3 Konvergenz
Sei x ∈ C1([t0, T], Rd) die Lösung eines AWPs. Der Vektor der Approximationsfehler aufdem Gitter ∆,
ε∆ : ∆→ Rd, ε∆(t) = x(t)− x∆(t), (3.45)
nennen wir Gitterfehler und bezeichnen seine Norm
‖ε∆‖∞ = maxt∈∆|ε∆(t)| (3.46)
als Diskretisierungsfehler.
Definition 3.13. Zu jedem Gitter ∆ auf [t0, T] mit hinreichend kleinem τ∆ (siehe (3.31)) sei eineGitterfunktion x∆ gegeben. Die Familie dieser Gitterfunktionen konvergiert gegen die Abbildungx ∈ C([t0, T], Rd), wenn der Diskretisierungsfehler
‖ε∆‖∞ → 0, τ∆ → 0 (3.47)
erfüllt. Sie konvergiert mit der Ordnung p > 0, falls
‖ε∆‖∞ = O(τp∆), τ∆ → 0.
61

3.6 Einschrittverfahren
Den Rest dieses Abschnitts widmen wir der Frage, unter welchen Bedingungen einediskrete Evolution eine Familie von Gitterfunktionen definiert, die gegen die Lösung kon-vergiert. Wir werden auch die Beziehung zwischen der Konvergenz der entsprechendenFamilie und der Konsistenz der diskreten Evolution sehen.
Definition 3.14. Eine diskrete Evolution Ψ besitzt die Konsistenzordnung p, wenn der Konsis-tenzfehler die Beziehung
ε(t, x, τ) = O(τp+1), τ → 0 (3.48)
lokal gleichmäßig in Ω erfüllt.
Beispiel. Wir wollen nun die Konsistenzordnung des expliziten Euler-Verfahrens bestim-men. Dazu gelte für die rechte Seite der Differentialgleichung f ∈ C1(Ω, Rd). SeienK ⊂⊂ K ⊂⊂ Ω relativ kompakte Mengen. Nach dem Existenz- und Eindeutigkeitssatzgibt es ein τ > 0, sodass für alle (t, x) ∈ K und 0 < τ ≤ τ
(t + τ, Φt+τ,tx) ∈ K.
Für diese (t, x) und τ gilt
ε(t, x, τ) = Φt+τ,tx− (x + τ f (t, x))︸ ︷︷ ︸=Ψt+τ,tx für expliziten Euler
.
Mit den Ableitungend
dτΦt+τ,tx = f (t + τ, Φt+τ,tx)
undd2
dτ2 Φt+τ,tx = ft(t + τ, Φt+τ,tx) + fx(t + τ, Φt+τ,tx) f (t + τ, Φt+τ,tx),
erhalten wir die Taylorentwicklung
Φt+τ,tx− x = Φt+τ,tx−Φt,tx
= τ f (t, x) + τ2∫ 1
0(1− σ)
(ft(t + στ, Φt+στ,tx)
+ fx(t + στ, Φt+στ,tx) f (t + στ, Φt+στ,tx))
dσ.
Wir erhalten daher die folgende Abschätzung des Konsistenzfehlers
|ε(t, x, τ)| ≤ τ2
2max(s,z)∈K
| ft(s, z) + fx(s, z) f (s, z)| ,
für alle (t, x) ∈ K, 0 < τ ≤ τ. Also besitzt das explizite Euler-Verfahren für jede rechteSeite f ∈ C1(Ω, Rd) die Konsistenzordnung p = 1.
62

3.6 Einschrittverfahren
Wir betrachten jetzt die allgemeine diskrete Evolution des Typs
Ψt+τ,tx = x + τψ(t, x, τ)
mit einer stetigen Inkrementfunktion ψ.
Theorem 3.15 (Konsistenzordnung p =⇒ Konvergenzordnung p). Gegeben sei eine diskreteEvolution Ψ mit in den Zustandsvariablen lokal Lipschitz-stetiger Inkrementfunktion ψ. ψ statt ΨEntlangeiner Trajektorie x ∈ C1([t0, T], Rd) genüge der Konsistenzfehler der diskreten Evolution Ψ derAbschätzung
x(t + τ)−Ψt+τ,tx(t) = O(tp+1). (3.49)
Dann definiert die diskrete Evolution Ψ für alle Gitter ∆ mit hinreichend kleinem τ∆ eine Gitter-funktion x∆ zum Anfangswert x∆(t0) = x(t0). Die Familie dieser Gitterfunktionen konvergiertmit der Ordnung p gegen die Trajektorie x.
Beweis. Sei K ⊂⊂ Ω irgendeine kompakte Umgebung des Graphen der Lösung x. Esexistieren zwei Konstanten τK > 0 und ΛK > 0, sodass
|ψ(t, x, τ)− ψ(t, x, τ)| ≤ ΛK |x− x| , (3.50)
für alle (t, x), (t, x) ∈ K, 0 < τ ≤ τK. Fixieren wir jetzt 0 < τ ≤ τK. Weiter gibt es einδK > 0, sodass für t ∈ [t0, T] gilt:
|x− x(t)| ≤ δK =⇒ (t, x) ∈ K.
Betrachten wir Gitter ∆ auf [t0, T] mit τ∆ ≤ τ, sodass die durch Ψ definierte Funktion x∆
existiert und|ε∆(t)| = |x(t)− x∆(t)| ≤ δK , t ∈ ∆
erfüllt. Wir zerlegen für j = 0,1, . . . , n− 1 den Fehler im Gitterpunkt tj+1 gemäß
ε∆(tj+1) = x(tj+1)− x∆(tj+1)
= x(tj+1)−Ψtj+1 ,tj x∆(tj)
= x(tj+1)−Ψtj+1 ,tj x(tj)︸ ︷︷ ︸Konsistenzfehler
+Ψtj+1,tj x(tj)−Ψtj+1,tj x∆(tj)︸ ︷︷ ︸:=ε j
. (3.51)
Der zweite Fehleranteil kann mit Hilfe der Inkrementfunktion ψ dargestellt werden,
ε j = x(tj)− x∆(tj) + τj(ψ(tj, x(tj), τj)− ψ(tj, x∆(tj), τj)
),
sodass wir ihn wegen der Lipschitzbedingung an ψ, (3.50), durch ε∆(tj) wie folgt abschät-zen können: ∣∣ε j
∣∣ ≤ (1 + τjΛK)∣∣ε∆(tj)
∣∣ . (3.52)
Dabei haben wir von (tj, x∆(tj)) ∈ K, τj ≤ τ∆ ≤ τK Gebrauch gemacht.
63

3.6 Einschrittverfahren
Aus (3.51) und (3.52) erhalten wir die Rekursion |ε∆(t0)| = 0∣∣ε∆(tj+1)∣∣ ≤ Cτ
p+1j + (1 + τjΛK)
∣∣ε∆(tj)∣∣ , j = 1, 2, . . . , n− 1.
(3.53)
Aus dem diskreten Gronwall-Lemma 3.12 erhalten wir die diskrete Abschätzung
|ε∆(t)| ≤ Cτ
p∆
ΛK
(eΛK(t−t0) − 1
), t ∈ ∆. (3.54)
(Übung: Zeige (3.54) ohne Anwendung des Gronwall-Lemmas!) Mit (3.54) können wirτ∗ > 0 so klein wählen, dass
τp∗
CΛK
(eΛK(T−t0) − 1
)≤ δK
und τ∗ ≤ τ gilt undε∆(tj) =
∣∣x(tj)− x∆(tj)∣∣ ≤ δK .
Das erlaubt uns, immer in K zu bleiben und die lokale Lipschitz-Stetigkeit von ψ zubenutzen.
Wir erhalten abschließend
‖ε∆‖∞ ≤ τp∆
CΛK
(eΛK(T−t0) − 1
)= O(tp
∆)
für τ∆ ≤ τ∗, τ∆ → 0.
3.6.2 Explizite Runge-Kutta-Verfahren
Wir interessieren uns für eine generelle Konstruktion von Verfahren höherer Konsistenz-ordnung. Wir betrachten noch einmal das explizite Euler-Verfahren, um eine allgemeineStrategie zu finden: In diesem Fall haben wir den Konsistenzfehler folgendermaßen dar-gestellt:
ε(t, x, τ) = Φt+τ,tx−Ψt+τ,tx
= Φt+τ,tx− (x + τψ(t, x, τ)), x ergänzt
mit der Inkrementfunktion ψ. Wir haben dann den Term
Φt+τ,tx− x = τ f (t, x) + O(τ2)
in einer Taylorentwicklung geschrieben und gesehen, dass das explizite Euler-Verfahrenwegen
τψ(t, x, τ) = τ f (t, x),
64

3.6 Einschrittverfahren
gerade den in τ linearen Term eliminiert, sodass wir schließlich ε(t, x, τ) = O(τ2) erhiel-ten. Treiben wir dieses Vorgehen einen Schritt weiter, so erhalten wir mit der Entwicklung
Φt+τ,tx− x = τ f (t, x) +τ2
2( ft(t, x) + fx(t, x) f (t, x)) + O(τ3),
dass für f ∈ C2(Ω, Rd) die Inkrementfunktion
ψ∗(t, x, τ) = f (t, x) +τ
2( ft(t, x) + fx(t, x) f (t, x))
eine diskrete Evolution der Konsistenzordnung p = 2 liefert. Analog kann man für f ∈Cp(Ω, Rd) Einschrittverfahren beliebiger Konsistenzordnung p ∈ N konstruieren, indemman schlichtweg vom Ausdruck Φt+τ,tx − x das Taylorpolynom vom Grad p in t alsInkrement τψ∗ nimmt. Solche Verfahren heißen Taylor-Verfahren.
Um solche Verfahren praktisch zu benutzen, benötigt man allerdings leider eine genaueAuswertung der Ableitungen
∂
∂tf (t, x) ∈ Rd und
∂
∂xf (t, x) ∈ Rd×d bzw.
∂
∂xf (t, x) f (t, x) ∈ Rd,
(3.55)
was im Allgemeinen mit Zusatzkosten verbunden ist. Um die Ableitungen in (3.55) zuberechnen, kann man symbolische Differentiation benutzen, aber für d 1 ist das schwerdurchführbar. Ansonsten kann Numerische Differentiation eine Wahl sein, aber wir ha-ben schon erwähnt, dass solche Differentiation generell sehr instabil ist. Deshalb wirdeine kostengünstige Lösung gesucht, die uns zu den sogenannten Runge-Kutta-Verfahrenführt.
Wir erläutern die Idee von Runge-Kutta-Verfahren mit einem Beispiel für die Kon-sistenzordnung p = 2: Die Konsistenzordnung p des Taylor-Verfahrens wird nicht be-einträchtigt, wenn wir dessen Inkrementfunktion ψ∗ (die mit dem Taylor-Polynom vonΦt+τ,tx− x in τ bis zum Grad p übereinstimmt) durch eine einfachere Inkrementfunktion
ψ(t, x, τ) = ψ∗(t, x, τ) + O(τp) (3.56)
ersetzen, welche nur in p-ter Ordnung von ψ∗ abweicht. In welcher Form können wir dieseinzig mit f -Auswertungen bewerkstelligen?
Nehmen wir momentan p = 2 an. Gehen wir zur Integraldarstellung des Restglieds derTaylorentwicklung über, so gilt für p = 2
τψ∗(t, x, τ) =∫ τ
0f (t + σ, Φt+σ,tx)dσ + O(τ3).
65

3.6 Einschrittverfahren
Dieses Integral approximieren wir mit der gleichen Fehlerordnung durch die Mittel-punktsregel (siehe Abschnitt 2.2.1 und die Formeln (2.4) und (2.5)),∫ τ
0f (t + σ, Φt+σ,tx)dσ = τ f (t +
τ
2, Φt+ τ
2 ,t) + O(τ3).
Das einzige Problem ist jetzt der Ausdruck Φt+ τ2 ,tx, den wir mit dem expliziten Euler-
Verfahren approximieren:
Φt+ τ2 ,tx = x +
τ
2f (t, x) + O(τ2),
was die nötige Ordnung liefert, da dieser Term in einem mit τ multiplizierten Ausdruckauftritt (τ f (t + τ
2 , Φt+ τ2 ,tx)). Somit erhalten wir für f ∈ C2(Ω, Rd) mit
ψ(t, x, τ) = f (t +τ
2, x +
τ
2f (t, x))
ein Einschrittverfahren der Konsistenzordnung p = 2. Wir erinnern daran, dass f inBezug auf x Lipschitz-stetig ist, sodass∣∣∣ f (t + τ
2, x +
τ
2f (t, x))− f (t +
τ
2, Φt+ τ
2 ,tx)∣∣∣ ≤ L
∣∣∣Φt+ τ2 ,tx− (x +
τ
2f (t, x))
∣∣∣ = O(τ2).
Dieses Verfahren würde 1895 von Carl Runge angegeben und wir können es rekursiv wiefolgt schreiben:
k1 = f (t, x), k2 = f (t +τ
2, x + τ
k1
2), Ψt+τ,tx = x + τk2. (3.57)
diese Gestalt können wir wie Martin Kutta 1901 zu allgemeinen Schachtelungen von f -Auswertungen erweitern, den s-stufigen expliziten Runge-Kutta-Verfahren:
i) ki = f (t + ciτ, x + τi−1
∑j=1
ai,jk j) für i = 1, . . . , s
ii) Ψt+τ,tx = x + τs
∑i=1
biki.
(3.58)
Dabei heißt ki = ki(t, x, τ) die i-te stufe.Wir fassen die Koeffizienten des Verfahrens wie folgt zusammen:
b = (b1, . . . , bs)T ∈ Rs, c = (c1, . . . , cs)
T ∈ Rs, (3.59)
sowie
A =
0 . . . . . . . . . 0
a2,1 0 . . . . . . 0a3,1 a3,2 0 . . . 0
... . . . . . .. . .
...as,1 as,2 . . . as,s−1 0
(3.60)
66

3.6 Einschrittverfahren
Konkrete Verfahren werden wir verkürzt im Butcher-Schema (1963)
c AbT (3.61)
notieren und auch vom Runge-Kutta-Verfahren (b, c, A) sprechen. In dieser Schreibwei-se geben wir auch das explizite Euler-Verfahren und das Verfahren von Runge in denfolgenden Tabellen an:
Explizites Euler-Verfahren Runge-Verfahren
0 01
0 01/2 1/2 0
0 1
(3.62)
Die s + s + (s−1)s2 Verfahrensparameter b, c und A wollen wir nun so bestimmen, dass
Verfahren möglichst hoher Konsistenzordnung p entstehen. Untersuchen wir zunächstdie Frage der Konsistenz. Das Verfahren liegt in der inkrementellen Form
Ψt+τ,tx = x + τψ(t, x, τ) mit
ψ(t, x, τ) =s
∑i=1
biki(3.63)
vor. Nun erhalten wir für τ ≡ 0 gerade ki = ki(t, x, 0) = f (t, x) für alle i = 1, . . . , s, also
ψ(t, x,0) =
(s
∑i=1
bi
)f (t, x). (3.64)
Da nach Lemma 3.11 (insbesondere Formel (3.37)) die Konsistenz gleichbedeutend mitψ(t, x, 0) = f (t, x) ist, gelangen wir zu folgender Charakterisierung konsistenter Runge-Kutta-Verfahren:
Lemma 3.16. Ein explizites Runge-Kutta-Verfahren (b, c, A) ist genau dann konsistent für allef ∈ C(Ω, Rd), wenn gilt
s
∑i=1
bi = 1. (3.65)
Wir erwarten nun für höhere Konsistenzordnung p einen steigenden Aufwand, alsowachsende Stufenzahl s. Eine einfache Abschätzung in diese Richtung liefert folgendesLemma.
Lemma 3.17. Ein s-stufiges explizites Runge-Kutta-Verfahren besitze für alle f ∈ C∞(Ω, Rd)
die Konsistenzordnung p ∈N. Dann gilt
p ≤ s. (3.66)
67

3.6 Einschrittverfahren
Beweis. Wir wenden das Verfahren auf das Anfangswertproblem
x′ = x, x(0) = 1
an. So ist zum einen
Φτ,01 = eτ = 1 + τ +τ2
2!+ · · ·+ τp
p!+ O(τp+1),
zum anderen sieht man rekursiv
ki(0, 1, .) ∈ Pi−1, i = 1, . . . , s,
also dass Ψτ,01 ein Polynom in τ vom Grad ≤ s ist. Damit der Konsistenzfehler dieAbschätzung
ε(0, 1, τ) = Φτ,01−Ψτ,01 = O(τp+1)
erfüllen kann, muss s ≥ p gelten.
Bemerkung 3.18. Ohne Beschränkung der Allgemeinheit machen wir die Zeitvariabledurch Autonomisierung zu einer Zustandsvariablen, d.h. wir betrachten statt des An-fangswertproblems
x = f (t, x), x(t0) = x0,
auf dem erweiterten Phasenraum Ω das äquivalente erweiterte System[xs
]=
[f (s, x)
1
],[
x(0)s(0)
]=
[x(0)
t0
](3.67)
auf dem Phasenraum Ω0 = Ω. Bezeichnen wir die Evolution des erweiterten Systems(3.67) mit Φt,s, so wird die Äquivalenz der beiden Systeme auch durch[
Φt+τ,txt + τ
]= Φt+τ,t
[xt
](3.68)
dargestellt.
Wir sind nun an Runge-Kutta-Verfahren interessiert, die diese Äquivalenz in dem Sinneberücksichtigen, dass bei ihnen das gleiche herauskommt, wenn wir sie auf das nichtau-tonome und das autonomisierte Problem anwenden. Dazu fordern wir, dass sie invariantgegen Autonomisierung sind, also[
Ψt+τ,txt + τ
]= Ψt+τ,t
[xτ
], (3.69)
wobei Ψ die zum erweiterten System gehörige diskrete Evolution des Runge-Kutta-Verfahrensbezeichne.
68

3.6 Einschrittverfahren
Lemma 3.19. Ein explizites Runge-Kutta-Verfahren (b, c, A) ist genau dann invariant gegenAutonomisierung, wenn es konsistent ist und
ci =s
∑j=1
aij, i = 1, . . . , s (3.70)
erfüllt.
Beweis. Bezeichnen wir die Stufen von Ψ mit ki = (ki, θi)T, so gilt
Ψt+τ,t[
xt
]=
[x + τ ∑i bi kit + τ ∑i biθi
](3.71)
mit [kiθi
]=
[f (t + τ ∑j=1 aijθj, x + τ ∑j aij k j)
1
](3.72)
für i = 1, . . . , s. Bezeichnen wir die Stufen von Ψt+τ,tx mit ki, so gilt ki = ki, i = 1, . . . , s,und t + τ ∑i biθi = t + τ genau dann, wenn die Beziehung (3.70) und ∑i bi = 1 gilt, sodassdas Verfahren nach Lemma 3.17 konsistent ist.(
Mit (3.63) und (3.72):[
x + τ ∑si=1 biki
t + τ
]=
[Ψt+τ,txt + τ
]=
[x + τ ∑i bi kit + τ ∑i biθi
])
Da die Koeffizienten ci durch die Matrix A definiert werden, werden wir ein Runge-Kutta-Verfahren, das invariant gegenüber Autonomisierung ist, mit (b, A) bezeichnen.Damit genügt es im Folgenden ohne Einschränkung, stets autonome Probleme
x = f (x), x(0) = x0,
auf einem Phasenraum Ω0 ⊆ Rd zu betrachten, zusammen mit dem Phasenfluss Φt undder diskreten Evolution
Ψtx = x + τΨ(x, τ) = Ψt+τ,tx.
3.6.3 Arbeitsplan zur Konstruktion eines Runge-Kutta-Verfahrens derOrdnung p > 1
Wir sollten die folgenden Schritte befolgen, um ein Runge-Kutta-Verfahren (b, A) derKonsistenzordnung p ∈N zu bestimmen:
(i) Das Aufstellen von Bedingungen an die s(s + 1)/2 Koeffizienten (b, A) derart, dassdas Verfahren von der Konsistenzordnung p für alle f ∈ Cp(Ω, Rd) ist.
(ii) Das Lösen dieser Bedingungsgleichungen, also die Angabe konkreter Koeffizienten-sätze, welche diesen Gleichungen genügen.
69

3.6 Einschrittverfahren
Die Strategie ist die folgende:
• Taylorentwicklung von Φτx nach τ
• Taylorentwicklung von Ψτx nach τ
• Koeffizientenvergleich liefert die Bedingungen für b und A
• Bedingungsgleichungen lösen
Zur Erinnerung: Für f ergänztf ∈ Cn(Ω0, Rm) definiert man die n-te Ableitung f (n)(x) ange-wendet auf h1, . . . , hn ∈ Rd durch den Ausdruck
f (n)(x)(h1, . . . , hn) =d
∑i1 ,...,in=1
∂n f (x)∂xi1 , . . . , ∂xin
(h1,i1 , · · · hn,in),
sodass f (n)(x) : Rd × · · · ×Rd︸ ︷︷ ︸n−fach
→ Rm linear in jedem Argument hj und invariant unter
Permutationen der Vektoren h1, . . . , hn ist.
Lemma 3.20 (Multivariate Taylorformel). Sei f ∈ Cp+1(Ω0, Rm), x ∈ Ω0 und h ∈ Rd
hinreichend klein. Dann gilt
f (x + h) =p
∑n=0
1n!
f (n)(x) (h, . . . , h)︸ ︷︷ ︸n−fach
+O(|h|p+1).
Beweis. Durch Taylorformel in jeder Koordinatenrichtung.
3.6.3.1 Taylor-Entwicklung des Phasenflusses Φτ
Wir wollen exemplarisch die Fälle p = 3, 4 demonstrieren. Wir wissen bereits, dass
Φτx = x + τ f (x) +τ2
2f ′(x) · f (x) + O(τ3).
Mit Hilfe der multivariaten Taylorformel erhalten wir (indem wir benutzen, dass Φτ
das entsprechende AWP löst)
τ statt td
dτΦτx = f (Φτ) = f (x + τ f (x) +
τ2
2f ′(x) · f (x) + O(τ3))
= f + f ′ · (τ f +τ2
2f ′ · f ) +
12!
f ′′ · (τ f , τ f ) + O(τ3) (Taylor, Linearität)
= f + τ f ′ f +τ2
2!( f ′ f ′ f + f ′′( f , f )) + O(τ3) (3.73)
70

3.6 Einschrittverfahren
Aufintegration ergibt
Φτx = x +∫ τ
0f (Φsx)ds
= x + τ f +12
τ2 f ′ f +13!
τ3( f ′ f ′ f + f ′′( f , f )) + O(τ4), (3.74)
sodass wir eine weitere Ordnung der Entwicklung dazugewonnen haben. Wiederholungdieser Technik liefert:
f (Φτx) = f + τ f ′ f +τ2
2!( f ′′( f , f ) + f ′ f ′ f )
+τ3
3!(
f ′′′( f , f , f ) + 3 f ′′( f ′ · f , f ) + f ′ f ′′( f , f ) + f ′ f ′ f ′ f)+ O(τ4),
(3.75)
und daher nach Aufintegration die gesuchte Taylorentwicklung
Φτx = x + τ f +τ2
2!f ′ f +
τ3
3!( f ′′( f , f ) + f ′ f ′ f )
+τ4
4!(
f ′′′( f , f , f ) + 3 f ′′( f ′ · f , f ) + f ′ f ′′( f , f ) + f ′ f ′ f ′ f)+ O(τ5).
(3.76)
3.6.3.2 Taylorentwicklung des diskreten Flusses Ψτ
Wir betrachten
ki = f (x + τ ∑j
aijk j︸ ︷︷ ︸h
) = f (x) + O(τ) für i = 1, . . . , s
= f (x + τ ∑j
aij f (x) + O(τ2))
Überflüssige
Zeile entfernt
= f (x + τci f + O(τ2)︸ ︷︷ ︸h
) (ci = ∑j
aij)
= f (x) + f ′(x)h + O(τ2) = f + τci f ′ f + O(τ2).
Nochmaliges Einsetzen des letzten Terms in ki ergibt
ki = f (x + τ ∑j
aij( f + τcj f ′ f ) + O(τ3))
= f (x + τci f + τ2 ∑j
aijcj f ′ f + O(τ3)︸ ︷︷ ︸h
)
= f (x) + f ′(x)h +12
f ′′(x)(h, h) + O(τ3)
= f + τci f ′ f + τ2 ∑j
aijcj f ′ f ′ f +12
τ2c2i f ′′( f , f ) + O(τ3).
71

3.6 Einschrittverfahren
Zusammen erhalten wir
Ψτx = x + τs
∑i=1
biki
= x + τ
(∑
ibi f
)+
τ2
2!
(2 ∑
ibici f ′ f
)
+τ3
3!
(3 ∑
ibic2
i f ′′( f , f ) + 6 ∑i
∑j
biaijcj f ′ f ′ f
)+ O(τ4) (3.77)
Übung: Wie können wir die Ordnung O(τ5) erreichen?
3.6.3.3 Bedingungsgleichungen für p = 3
Aus (3.75) folgt
Φτx = x + τ f +τ2
2f ′ f +
τ3
3!( f ′ f ′ f + f ′′( f , f )) + O(τ4),
während wir aus (3.77)
Ψτx = x + τ
(∑
ibi f
)+
τ2
2!
(2 ∑
ibici
)f ′ f
+τ3
3!
(3 ∑
ibic2
i f ′′( f , f ) + 6 ∑i
∑j
biaijcj f ′ f ′ f
)+ O(τ4)
erhalten. Koeffizientenvergleich ergibt:
(i) ∑i bi = 1
(ii) ∑i bici =12
(iii) ∑i bic2i = 1
3
(iv) ∑i,j biaijcj =16
um Konsistenzordnung p = 3 zu erfüllen.
Jetzt lösen wir die Übungsaufgabe, die Taylorentwicklung von Ψτx bis zur OrdnungO(τ5) zu liefern. Wir setzen die Entwicklung der Stufen ki,
ki = f + τci f ′ f + τ2 ∑j
aijcj f ′ f ′ f +τ2
2c2
i f ′′( f , f ) + O(τ3)
72

3.6 Einschrittverfahren
in die Beziehung ki = f (x + τ ∑sj=1 aijk j) ein und erhalten (nach etwas Rechnung)
ki = f + τci f ′ f + τ2 ∑j
aijcj f ′ f +τ2
2c2
i f ′′( f , f ) + τ3 ∑j,k
aijajkck f ′ f ′ f ′ f
+τ3
2 ∑j
aijc2j f ′ f ′′( f , f ) + τ3 ∑
jciaijcj f ′′( f ′ · f , f ) +
τ3
6ci f ′′′( f , f , f , f ) + O(τ4).
Die Einsetzung der so berechneten Stufen ki in Ψτx = x + τ ∑i biki ergibt jetzt
Ψτx = x + τ
(∑
ibi f
)+
τ2
2!
(2 ∑
ibici f ′ f
)+
τ3
3!
(3 ∑
ibic2
i f ′′( f , f ) + 6 ∑i,j
biaijcj f ′ f ′ f
)
+τ4
4!
(4 ∑
ibic3
i f ′′′( f , f , f , f ) + 24 ∑i,j
biciaijcj f ′′( f ′ · f , f )
+ 12 ∑i,j
biaijc2j f ′ f ′′( f , f ) + 24 ∑
i,j,kbiaijajkck f ′ f ′ f ′ f
)+ O(τ5) (3.78)
Der Koeffizientenvergleich von (3.76) und (3.78) gibt uns die folgenden Bedingungen, diewir in einem Satz zusammenfassen:
Theorem 3.21. Ein Runge-Kutta-Verfahren (b, A) besitzt für jede rechte Seite f ∈ Cp(Ω0, Rd),jeden Phasenraum Ω0 ⊆ Rd und jede Dimension d ∈ N genau dann die Konsistenzordnungp = 1, wenn die Koeffizienten des Verfahrens der Bedingungsgleichung
(1) ∑i bi = 1
genügen; genau dann die Konsistenzordnung p = 2, wenn sie zusätzlich der Bedingungsgleichung
(2) ∑i bici =12
genügen; genau dann die Konsistenzordnung p = 3, wenn sie zusätzlich den zwei Bedingungs-gleichungen
(3) ∑i bic2i = 1
3
(4) ∑i,j biaijcj =16 cj ergänzt
genügen; genau dann die Konsistenzordnung p = 4, wenn sie zusätzlich den vier Bedingungs-gleichungen
(5) ∑i bic3i = 1
4
(6) ∑i,j biciaijcj =18
(7) ∑i,j biaijc2j =
112
(8) ∑i,j,k biaijajkck =1
24
73

3.6 Einschrittverfahren
genügen. Dabei erstrecken sich die Summationen jeweils von 1 bis s.
Bemerkung 3.22. Unsere bisherigen Argumente zeigen nur, dass die Bedingungsglei-chungen hinreichend sind. Notwendig sind sie nur, wenn wir zeigen können, dass sämt-liche elementaren Differentiale wie etwa f ′ f ′′( f , f ) und f ′′( f , f ) linear unabhängig sind.Dies braucht für spezielle Situationen keineswegs der Fall zu sein. So ist für d = 1 geradef ′ f ′′( f , f ) = f ′′ f ′ f 2 = f ′′( f ′, f , f ). So sind im Fall skalarer autonomer Differentialglei-chungen nur sieben statt acht Gleichungen zu erfüllen.
3.6.3.4 Lösen der Bedingungsgleichungen
Wir bemerken, dass (1), (2), (3), (5) Bedingungen an eine Quadraturformel
4
∑i=1
bi ϕ(ci) ≡≈∫ 1
0ϕ(t)dt
mit Gewichten bi und Knoten ci sind, die für Polynome 3. Grades auf [0,1] exakt ist.Wir erinnern an zwei wichtige Newton-Cotes-Formeln, die klassische Simpson-Regel
und die sogenannte Newtonsche- 38 -Regel (Abschnitt 2.2.3 und Theorem 2.3).
Grad Name Formel Fehler
2 Simpson b−a6 ( f0 + 4 f1 + f2) − (b−a)5
2880 f (4)(ξ)3 Newton- 3
8b−a
8 ( f0 + 3 f1 + 3 f2 + f3) − (b−a)5
6480 f (4)(ξ)
Mit der Newtonschen- 38 -Regel erhalten wir die Knoten und Koeffizienten
c1 = 0, c2 =13
, c3 =23
, c4 = 1
b1 =18
, b2 =38
, b3 =38
, b4 =18
.
Aus den Bedingungsgleichungen folgt jetzt: (4), (6) ergeben
a3,2 = 1 und
a4,2c2 + a4,3c3 =13
, (6”)
(8) ergibta4,3 = 1 und
(6”) ergibta4,2 = −1.
Die Bedingung ∑j aij = ci hilft auch, um die Koeffizienten
a2,1 =13
, a3,1 = −13
, a4,2 = −1
74

3.6 Einschrittverfahren
zu bestimmen. Mit dieser Rechnung haben wir die sogenannte Kuttasche- 38 -Regen be-
stimmt, die wir in folgendem Butcher-Schema zusammenfassen:
013
13
23 − 1
3 11 1 −1 1
18
38
38
18
(3.79)
Die Herleitung der klassischen Runge-Kutta-Methode ist analog zur Kutta- 38 -Regel, aber
basierend auf der Simpson-Regen, mit dem resultierenden Butcher-Schema
012
12
12 0 1
21 0 0 1
16
13
13
16
(3.80)
3.6.3.5 Anzahl der Bedingungsgleichungen und Butcher-Schranken
In der folgenden Tabelle haben wir die Anzahl der Bedingungen aufgelistet, die wirbenötigen, um ein Runge-Kutta-Verfahren der Ordnung p zu bestimmen:
Ordnung p 1 2 3 4 5 6 . . . 10 . . . 20#Bedingungsgleichungen Np 1 2 4 8 17 37 . . . 1205 . . . > 2 · 107
Aber viele dieser Gleichungen sind redundant und die Frage ist, wie groß die minimaleStufenzahl Sp eines Runge-Kutta-Verfahrens der Ordnung p ist. Die folgende Tabelleenthält einige sogenannte Butcher-Schranken (das Resultat für p = 10 stammt von E.Heirer, 1978):
p 1 2 3 4 5 6 7 8 ≥ 9 10Sp 1 2 3 4 6 7 9 11 ≥ p + 3 ≤ 17
3.6.4 Extrapolationsverfahren
Die Konstruktion von expliziten Runge-Verfahren hoher Konsistenzordnung (p > 8)ist per Hand eigentlich kaum durchführbar. Man kann allerdings Einschrittverfahrenbeliebiger Ordnung konstruieren, ohne Bedingungsgleichungen lösen zu müssen, genaudurch die Technik der Extrapolation, die wir in Abschnitt 2.5 erwähnt haben.
Wir haben schon gesehen, dass, falls eine Größe A eine Entwicklung
A(h) = α0 + α1h + · · ·+ αhk + Rk+1(h) (3.81)
75

3.6 Einschrittverfahren
besitzt, wobei |Rk+1(h)| ≤ Ck+1hk+1 gilt, die RekursionAm,0 = A(δmh)
Am,q+1 =Am,q − δq+1Am−1,q
1− δq+1 , q = 0, . . . , m− 1, m = q + 1, . . . , n(3.82)
für n ≥ 0, h > 0 und δ ∈ (0, 1) eine Approximation der Größe α0 liefert, die von hoherOrdnung ist:
Am,n = α0 + O((δmh)n+1), m = 0, . . . , n. (3.83)
Die Konstruktion der Koeffizienten Am,n folgt dem folgenden Schema von Abhängigkei-ten:
A0,0
A1,0 A1,1
A2,0 A2,1 A2,2
. . . . . . . . .
An,0 An,1 An,2 . . . An,n
(3.84)
Wir wollen jetzt zeigen, dass die Technik der Extrapolation auch für Größen, die durchein konsistentes Einschrittverfahren berechnet werden, durchführbar ist.
Angenommen, wir approximieren mit einem solchen Verfahren als Basis-Diskretisierungden Lösungswert x(T) = ΦT,t0 x0 zu sukzessive kleiner werdenden Schrittweiten τ1, τ2, . . .Dann können wir hoffen, sukzessiv bessere Approximationen xτ1(T), . . . , xτn(T), . . . zuerhalten. Einerseits besagt nun der Konvergenzsatz, Theorem 3.15, dass
limτ→0
xτ(T) = x(T). (3.85)
Andererseits wächst bei diesem Vorgehen aber auch der Aufwand sukzessive.Wir wollen jetzt zeigen, dass die asymptotische Entwicklung
xτ(T) = x(T) + e0(T)τp + e1(T)τp+ω + · · ·+ ek−1(T)τp+(k−1)ω + Rk(T; τ)τp+kω (3.86)
gilt, wobei xτ(T) von einem Einschrittverfahren der Ordnung p bestimmt ist und ω =
1 gilt. Diese Entwicklung (3.86) gibt uns die konkrete Möglichkeit, eine Richardson-Extrapolation des Typs (3.83) anzuwenden.
76

3.6 Einschrittverfahren
Lemma 3.23. Sei xτ(t) durch ein konsistentes Einschrittverfahren der Ordnung p berechnet.Dann existiert eine Folge e0, e1, e2, . . . glatter Funktionen mit Anfangswerten ek(t0) = 0, sodassfür jedes k ∈N0 die asymptotische Entwicklung
xτ(t) = x(t) + e0(t)τp + · · ·+ ek−1(t)τp+k−1 + O(τp+k) (3.87)
gleichmäßig in t ∈ ∆τ gilt.
Beweis. Wir führen den Beweis mit Hilfe einer „virtuellen“ Folge rekursiv modifizierterTrajektorien:
x0(t) = x(t)
xk(t) = xk−1(t) + ek−1(t)τp+k−1,(3.88)
wobei die Koeffizientenfunktionen e0, e1, e2, . . . so konstruiert werden, dass die diskreteEvolution Ψ der Methode entlang dieser Hilfstrajektorien eine hohe Konsistenzordnunghat:
xk(t + τ)−Ψt+τ,txk(t) = O(τ(p+1)+k). (3.89)
Das würde uns sofort durch den Konvergenzsatz, Theorem 3.15, die gewünschte asym-ptotische Entwicklung(
x(t) + e0(t)τp + · · ·+ ek−1(t)τp+k−1)− xτ(t) = xk(t)− xτ(t) = O(τp+k) (3.90)
liefern. Wir müssen daher die Trajektorie (3.88) rekursiv bestimmen durch eine induktiveKonstruktion der Koeffizientenfunktionen e0, e1, . . . , ek.
Angenommen, wir hätten die Taylorentwicklung
− statt +xk(t + τ)−Ψt+τ,txk(t) = dk(t)τp+k+1 + O(τp+k+2), (3.91)
wobei die Existenz dieser Koeffizientenfunktionen dk eine Folge der vorausgesetzten Glatt-heit ist. Wir werden nun induktiv aus einem bereits bekannten xk (beachte x0(t) = x(t))die nächste Hilfstrajektorie xk+1 bestimmen. Dazu ermitteln wir aus den Entwicklungs-koeffizienten dk die Funktion ek, sodass die Fehlerabschätzung (3.89) für xk+1 erfüllt ist.Hierdurch ist der nächste Koeffizient dk+1 gemäß (3.91) bestimmt, und die Induktion kannfortgeführt werden.
Wir brauchen das folgende Lemma:
Lemma. Für δx = O(τk) mit k ∈N gilt
Ψt+τ,t(x + δx) = Ψt+τ,tx + δx + τ fx(t, x)δx + O(τk+2).
Beweis des obigen Lemmas. Stellen wir die diskrete Evolution mit Hilfe der Inkrementfunk-tion dar, erhalten wir
Ψt+τ,t(x + δx) = x + δx + τψ(t, x + δx, τ)
= x + δx + τ(
ψ(t, x, τ) + ψx(t, x, τ)δx + O(τ2k))
(Beachte δx = O(τk))
= Ψt+τ,tx + δx + τψx(t, x,0)δx + O(τk+2)
77

3.6 Einschrittverfahren
Wegen der Konsistenz gilt ψ(t, x,0) = f (t, x), so dass die vorausgesetzte Glattheit ψx(t, x,0) =fx(t, x) impliziert. Hier haben wir die Approximation
ψx(t, x, τ)δx = ψx(t, x,0)δx + O(τ)δx
= ψx(t, x,0)δx + O(τk+2) (δx = O(τk))
benutzt.
Setzen wir nun den Ansatz xk+1(t) = xk(t) + ek(t)τp+k in die Forderung (3.89) ein,erhalten wir mit Hilfe des obigen Lemmas
O(τp+k+2) = xk+1(t + τ)− ψt+τ,txk+1(t)
= xk(t + τ) + ek(t + τ)τp+k − ψt+τ,t(xk(t) + ek(t)τp+k)
= xk(t + τ)−Ψt+τ,txk(t) + (ek(t + τ)− ek(t))τp+k
− fx(t, xk(t))ek(t)τp+k+1 + O(τp+k+2)
=[dk(t) + e′k(t)− fx(t, xk(t))ek(t)
]τp+k+1 + O(τp+k+2).
Dies ergibt sofort e′k(t) = fx(t, xk(t))ek(t)− dk(t)
ek(t0) = 0.(3.92)
Nun erhalten wir die Koeffizientenfunktionen ek als glatte Lösungen des AWPs. Dieinduktive Konstruktion kann daher wie geplant durchgeführt werden.
Eine alternative Interpretation der Extrapolation kommt aus der Interpolation der dis-kreten Trajektorien durch ein Polynom χ mit
χ(τk) = xτk(t), k = 1,2, . . . , (3.93)
um schließlich den neuen Wert einer diskreten Approximation von x(t) mit
χ(0) ' x(t)
zu berechnen.Wir erwähnen das folgende Resultat ohne Beweis und verweisen auf [DB08] für Details.
Lemma 3.24. Es seien m + 1 paarweise verschiedene positive Interpolationsknoten τ1, . . . , τm+1
gegeben. Dann gibt es zu m + 1 Vektoren η1, . . . , ηm+1 ∈ Rd genau ein Polynom
χ ∈
P ∈ Pdp+m−1 : P(τ) = α0 + α1τp + · · ·+ αmτp+m−1
, αm statt αk
das die Interpolationsaufgabe
χ(τk) = ηk, k = 1, . . . , m + 1
löst.
78
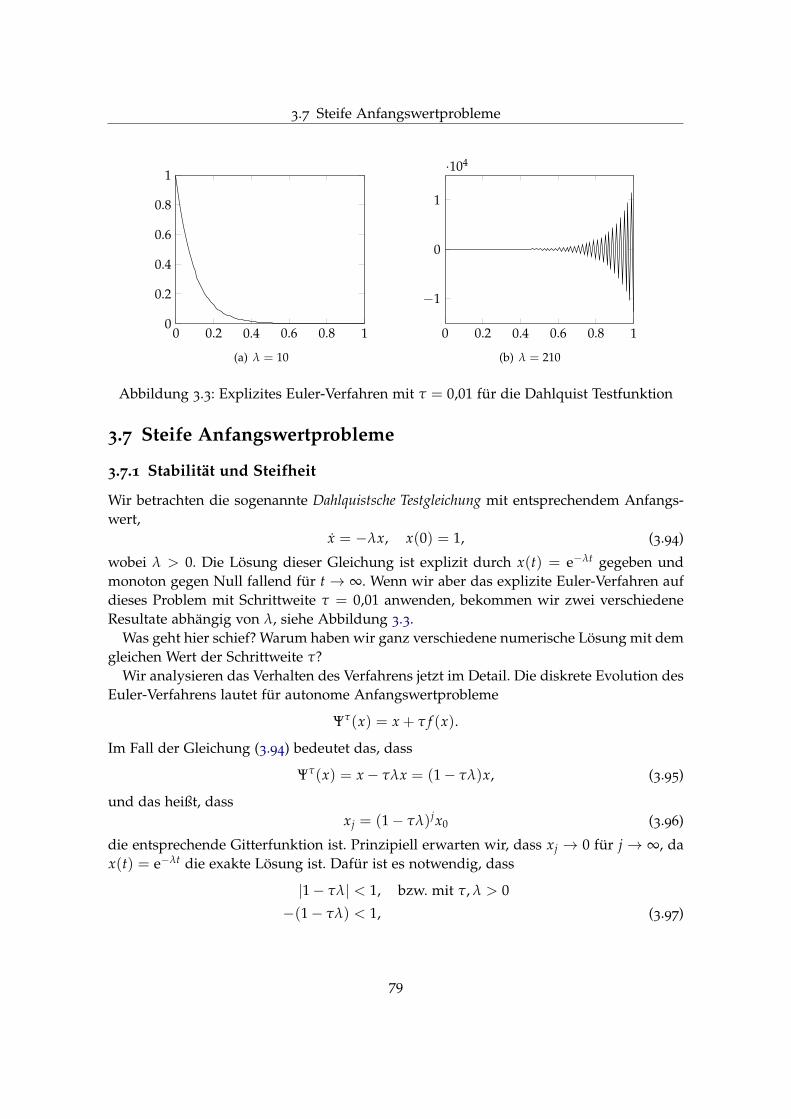
3.7 Steife Anfangswertprobleme
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
(a) λ = 10
0 0.2 0.4 0.6 0.8 1
−1
0
1
·104
(b) λ = 210
Abbildung 3.3: Explizites Euler-Verfahren mit τ = 0,01 für die Dahlquist Testfunktion
3.7 Steife Anfangswertprobleme
3.7.1 Stabilität und Steifheit
Wir betrachten die sogenannte Dahlquistsche Testgleichung mit entsprechendem Anfangs-wert,
x = −λx, x(0) = 1, (3.94)
wobei λ > 0. Die Lösung dieser Gleichung ist explizit durch x(t) = e−λt gegeben undmonoton gegen Null fallend für t → ∞. Wenn wir aber das explizite Euler-Verfahren aufdieses Problem mit Schrittweite τ = 0,01 anwenden, bekommen wir zwei verschiedeneResultate abhängig von λ, siehe Abbildung 3.3.
Was geht hier schief? Warum haben wir ganz verschiedene numerische Lösung mit demgleichen Wert der Schrittweite τ?
Wir analysieren das Verhalten des Verfahrens jetzt im Detail. Die diskrete Evolution desEuler-Verfahrens lautet für autonome Anfangswertprobleme
Ψτ(x) = x + τ f (x).
Im Fall der Gleichung (3.94) bedeutet das, dass
Ψτ(x) = x− τλx = (1− τλ)x, (3.95)
und das heißt, dassxj = (1− τλ)jx0 (3.96)
die entsprechende Gitterfunktion ist. Prinzipiell erwarten wir, dass xj → 0 für j → ∞, dax(t) = e−λt die exakte Lösung ist. Dafür ist es notwendig, dass
|1− τλ| < 1, bzw. mit τ, λ > 0
−(1− τλ) < 1, (3.97)
79

3.7 Steife Anfangswertprobleme
und diese letzte Beziehung gilt genau dann, wenn
τ <2λ
. (3.98)
Dies ist für λ = 210 und τ = 0,01 aber nicht erfüllt! Deshalb liefert das Verfahren eineinstabile numerische Lösung.
Betrachten wir jetzt das implizite Euler-Verfahren
xj+1 = xj + τ f (xj+1), j = 0,1, . . . , τ > 0.
Für die Dahlquistsche Testgleichung gilt also
xj+1 = xj − τλxj+1 bzw.
xj+1 =1
1 + τλxj, j = 0,1, . . . . (3.99)
Wir fordern wieder xj → 0 für j→ ∞ und erhalten als notwendige Bedingung, dass∣∣∣∣ 11 + τλ
∣∣∣∣ < 1 (τ, λ > 0)
⇐⇒ 1 < 1 + τλ (3.100)
⇐⇒ 0 < τλ
Das ist aber für τ, λ > 0 immer erfüllt. Wir schließen, dass das implizite Euler-Verfahrenalso unabhängig von der Schrittweite eine qualitativ korrekte Lösung liefert. Außerdemist das explizite Euler-Verfahren im Vergleich zum impliziten ineffizient.
Wir definieren grob den folgenden Begriff: Anfangswertprobleme, für die expliziteVerfahren (im Vergleich zu impliziten) ineffizient sind, heißen steif.
3.7.1.1 Stabilität kontinuierlicher Flüsse
Wir beachten die autonome Gleichung x = f (x).
Definition 3.25. Eine Lösung Φtx0 der Gleichung (mit [0, ∞) ⊆ J(x0), dem maximalen Exis-tenzintervall) heißt
(i) stabil, falls es zu jedem ε > 0 ein δ > 0 gibt, sodass
Φt(x) ∈ Bε(Φt(x0)) (3.101)
für alle t ≥ 0 und alle x ∈ Bδ(x0).(ii) asymptotisch stabil, falls es zusätzlich ein δ0 > 0 gibt, sodass
limt→∞
∥∥Φtx−Φtx0∥∥ = 0 (3.102)
für alle x ∈ Bδ0(x0).
80

3.7 Steife Anfangswertprobleme
(iii) instabil, falls sie nicht stabil ist.
Definition 3.26. Ein Punkt x ∈ Ω0 heißt Ruhepunkt oder Fixpunkt der Differentialgleichungx = f (x), falls f (x) = 0. Wir nennen x asymptotisch stabilen Ruhepunkt, wenn es ein δ0 > 0gibt, sodass
limt→∞
∥∥Φtx− x∥∥ = 0, (3.103)
für alle x ∈ Bδ0(x).
Betrachten wir nun das lineare System
x = Ax. (3.104)
In diesem Fall ist der Fluss
Φtx0 = etAx0, (siehe (3.110) für die Definition), (3.105)
das heißtΦtx−Φtx0 = Φt(x− x0) (3.106)
undsupt≥0
∥∥Φtx−Φtx0∥∥ ≤ ε (3.107)
für ‖x− x0‖ hinreichend klein genau dann, wenn
supt≥0
∥∥Φt∥∥ = supt≥0
∥∥∥etA∥∥∥ < ∞. (3.108)
Wir fassen diese Bemerkungen in dem folgenden Lemma zusammen:
Lemma 3.27. Eine Lösung des linearen Systems (3.104) ist genau dann stabil, wenn (3.108) gilt.Sie ist genau dann asymptotisch stabil, wenn
limt→∞
∥∥Φt∥∥ = 0. (3.109)
Bemerkung. Wegen (3.106) ist eine Lösung von x = Ax genau dann (asymptotisch) stabil,wenn alle Lösungen es sind.
Definition 3.28. (i) Das Spektrum σ(A) einer Matrix A ∈ Cd×d ist die Menge
σ(A) = λ ∈ C : det(λI − A) = 0
aller Eigenwerte von A.(ii) Der Index ι(λ) eines Eigenwerts λ ∈ σ(A) ist die maximale Dimension der zu λ gehörigen
Jordan-Blöcke von A.
81

3.7 Steife Anfangswertprobleme
Bemerkung (Matrix-Exponentielle). Die Funktion etA wird durch
exp(tA) := etA =∞
∑k=0
(tA)k
k!(3.110)
definiert. Diese konvergiert gleichmäßig auf kompakten Zeitintervallen [−T, T]. Die Ma-trixexponentielle besitzt die Eigenschaften:
(i) t ergänztexp(tMAM−1) = M exp(tA)M−1, M ∈ GL(d);
(ii) exp(t(A + B)) = exp(tA) exp(tB), falls AB = BA;
(iii) Für B = Blockdiag(B1, . . . , Bk) gilt
exp(tB) = Blockdiag(exp(tB1), . . . , exp(tBk)).
Der Beweis dieser Eigenschaften ist eine Übung.
Theorem 3.29. Die Lösungen von x = Ax für eine Matrix A ∈ Cd×d sind genau dann stabil,wenn Re(λ) ≤ 0 für alle Eigenwerte λ von A gilt und alle Eigenwerte mit Re(λ) = 0 den Indexι(λ) = 1 besitzen.
Die Lösungen sind genau dann asymptotisch stabil, falls Re(λ) < 0 für alle λ ∈ σ(A) gilt.
Beweis. Da Stabilität eine affine Invariante ist, können wir wegen Eigenschaft (i) derMatrixexponentiellen annehmen, dass A = J in Jordanscher Normalform ist (J = MAM−1
und x = Ax impliziert (Mx) = J(Mx)). Durch Eigenschaft (iii) können wir A zu einemeinzelnen Jordan-Block J = λI + N reduzieren, wobei
N =
0 1 0
. . .1
0 0
︸ ︷︷ ︸
k
nilpotent ist, d.h. Nk = 0. Dann gilt
‖exp(tA)‖ = |eλt| ‖exp(tN)‖
≤ eRe(λ)t(
1 + t ‖N‖+ · · ·+ tk−1
(k− 1)!‖N‖k−1
)︸ ︷︷ ︸
≤Mεeεt
,
für jedes ε > 0 und zugehöriges Mε > 0, woraus
‖exp(tA)‖ ≤ Mεe(Re(λ)+ε)t
folgt.
82

3.7 Steife Anfangswertprobleme
Ist Re(λ) < 0, dann wählen wir ε > 0 so klein, dass Re(λ) + ε < 0 und es folgt∥∥∥etA∥∥∥ ≤ Mεe(Re(λ)+ε)t → 0, t→ ∞.
Für Re(λ) = 0 gilt k = 1 und damit ‖exp(tA)‖ = 1, was heißt, dass die Lösung stabil ist.Gilt Re(λ) = 0 und k > 1, dann folgt für ek = (0, . . . ,0, 1)T ∈ Rk, dass
exp(tJ)ek = eλt(
tk−1
(k− 1)!, . . . , t, 1
)T
,
also ‖exp(tJ)‖ → ∞ für t→ ∞, die Bedingung ι(λ) = 1 ist somit für alle λ mit Re(λ) = 0notwendig. Was passiert, wenn Re(λ) > 0 ist, verbleibt als Übung.
3.7.1.2 Stabilität linearer diskreter Flüsse
Für Einschrittverfahren gibt es eine diskrete Evolution Ψτ(x) = x+ τψ(x, τ). Zum Beispielerinnern wir daran, dass für das explizite Euler-Verfahren ψ(x, τ) = f (x) für x = f (x)gilt. Beachten wir nochmal den Spezialfall der linearen Systeme
x = Ax, (3.111)
womit Ψτ ebenfalls linear ist. Allgemein interessieren wir uns nun für die allgemeinelineare Iteration
xj+1 = Mxj, j = 0,1,2, . . . (3.112)
Definition 3.30. Eine lineare Iteration wie (3.112) heißt stabil, falls
supj≥1
∥∥∥Mj∥∥∥ < ∞, (3.113)
und asymptotisch stabil, fallslimj→∞
∥∥∥Mj∥∥∥ = 0. (3.114)
Angenommen, wir haben eine stabile Differentialgleichung x = Ax mit kontinuierli-chem Fluss
Φτ(x) = exp(τA)x.
Die Funktion des diskreten Flusses für Einschrittverfahren ist es, die Matrixexponentiellezu approximieren, d.h. Ψτ(x) ' exp(τA)x. Die Frage ist nun, für welche τ > 0 diediskrete lineare Approximation stabil ist. Für explizite Verfahren, besonders für s-stufigeRunge-Kutta-Verfahren, haben wir (Übung!)
Ψτ(x) = P(τA)x,
83

3.7 Steife Anfangswertprobleme
wobei P ∈ Ps ein Polynom vom Maximalgrad s ist. Für implizite Runge-Kutta-Verfahren,die wir später einführen werden (z.B. das implizite Euler-Verfahren), gilt
Ψτ(x) = R(τA)x,
wobei R(z) = P(z)Q(z) eine rationale Funktion mit Polynomen P, Q ist (wobei wir annehmen,
dass Q(λ) 6= 0 für alle λ ∈ σ(A).
Theorem 3.31. Eine lineare Iteration, gegeben durch eine Matrix M wie in (3.112), ist genaudann stabil, wenn ρ(M) ≤ 1 und alle Eigenwerte λ mit |λ| = 1 den Index ι(λ) = 1 besitzen,wobei
ρ(M) := supλ∈σ(M)
|λ| .
Beweis. Analog zum Beweis von Theorem 3.29: Zunächst zieht man sich auf eine Matrixzurück, die nur aus einem Jordan-Block besteht. Dann ist
Jn = λn I + λn−1(
n1
)N + · · ·+ λn−k+1
(n
k− 1
)Nk−1,
‖Jn‖ ≤ |λ|n(
1 + |λ|−1(
n1
)‖N‖+ · · ·+ |λ|−(k−1)
(n
k− 1
)‖N‖k−1
)≤ Mθ(θ |λ|)n
für ein hinreichend großes Mθ abhängig von jedem θ > 1, sodass θ |λ| < 1.Die restliche Argumentation funktioniert dann wie in Theorem 3.29.
Bemerkung.Zeit-kontinuierlich Zeit-diskret
x = Ax xj+1 = exp(τA)xjexp(τσ(A)) = σ(exp(τA))
Re λ < 0 ∀λ ∈ σ(A) ⇐⇒ ρ (exp (τA)) < 1.
Mit Theorem 3.31 haben wir bereits gesehen, dass Ψτ genau dann stabil ist, wennρ(Ψτ) ≤ 1 und ι(µ) = 1 für |µ| = 1, µ ∈ σ(R(τA)). Aus [DB08, Satz 3.42] erhaltenwir, dass
σ(R(A)) = R(σ(A)) (3.115)
für alle rationalen Funktionen mit R(λ) 6= ∞ und alle λ ∈ σ(A) gilt. Daher gilt auchρ(Ψτ) = ρ(R(τA)) = maxλ∈σ(A) |R(τλ)| und wir erhalten
Ψτstabil ⇐⇒|R(τλ)| ≤ 1, für λ ∈ σ(A) und
ι(µ) = 1, für |µ| = 1.
84

3.7 Steife Anfangswertprobleme
Definition 3.32. Die Menge
S := SR := z ∈ C : |R(z)| ≤ 1 (3.116)
heißt Stabilitätsgebiet der Funktion R.
Also ist Ψτ genau dann stabil, wenn τλ ∈ SR für λ ∈ σ(A) und ι(µ) = 1 für |µ| = 1 mitµ = R(τλ), λ ∈ σ(A).
3.7.1.2.1 Beispiele von Stabilitätsgebieten Für das explizite Euler-Verfahren ist der dis-krete Fluss
Ψτ(x) = x + τ f (x)
= x + τAx
= (I + τA)x = R(τA)x,
d.h. R(z) = 1 + z. Das zugehörige Stabilitätsgebiet ist
SR = z ∈ C : |R(z)| ≤ 1= |1 + z| ≤ 1= B1(−1).
Für das implizite Euler-Verfahren ist der diskrete Fluss
Ψτx = x + τA(Ψτ(x))
= x + τAΨτ(x),
was Ψτ(x) = (I − τA)−1x = R(τA)x impliziert, also R(z) = (1− z)−1. Das Stabilitätsge-biet ist
SR = z ∈ C : |R(z)| ≤ 1
=
1
|1− z| ≤ 1
= |1− z| ≥ 1
= (B1(1))c,
das Komplement der Kreisscheibe B1(1).
3.7.2 Rationale Approximationen der Exponentialfunktion
Definition 3.33. Eine rationale Funktion R : C → C ∪ ∞ ist eine Approximation derExponentialfunktion der Konsistenzordnung p, falls p ∈N die größte Zahl ist mit
R(z) = exp (z) + O(|z|p+1), z→ 0. (3.117)
R ist eine konsistente Approximation, falls p ≥ 1.
85
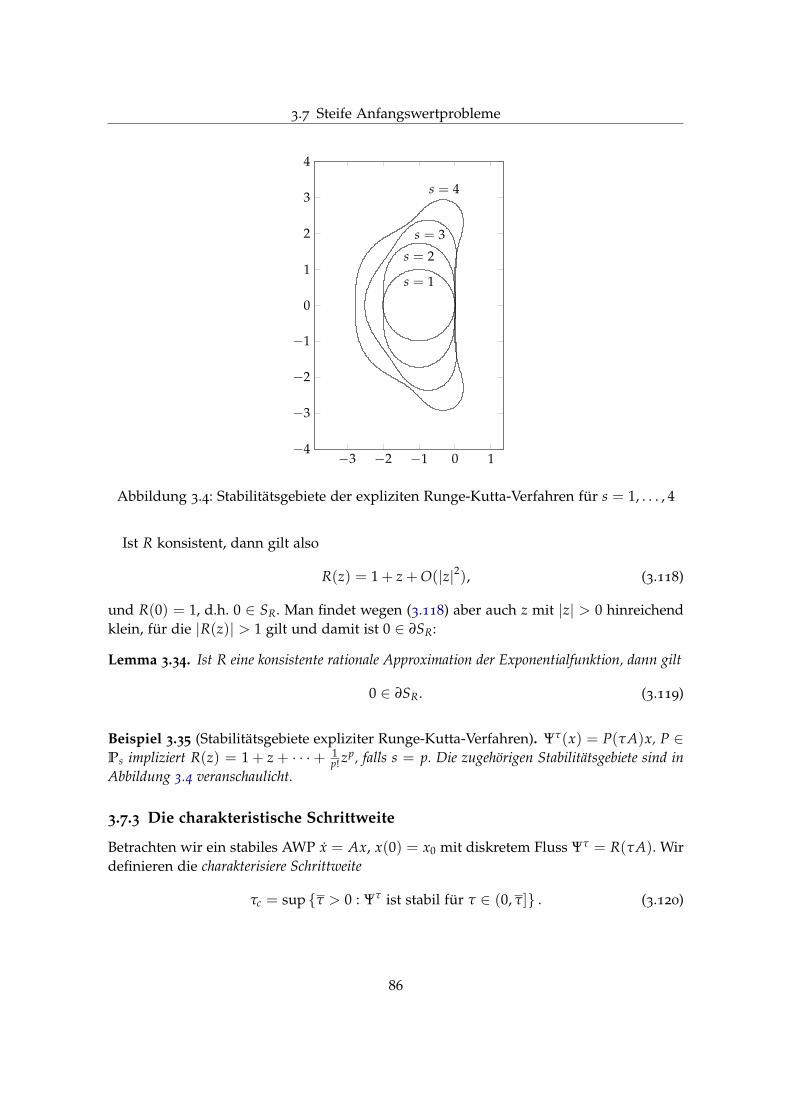
3.7 Steife Anfangswertprobleme
−3 −2 −1 0 1−4
−3
−2
−1
0
1
2
3
4
s = 1
s = 2
s = 3
s = 4
Abbildung 3.4: Stabilitätsgebiete der expliziten Runge-Kutta-Verfahren für s = 1, . . . , 4
Ist R konsistent, dann gilt also
R(z) = 1 + z + O(|z|2), (3.118)
und R(0) = 1, d.h. 0 ∈ SR. Man findet wegen (3.118) aber auch z mit |z| > 0 hinreichendklein, für die |R(z)| > 1 gilt und damit ist 0 ∈ ∂SR:
Lemma 3.34. Ist R eine konsistente rationale Approximation der Exponentialfunktion, dann gilt
0 ∈ ∂SR. (3.119)
Beispiel 3.35 (Stabilitätsgebiete expliziter Runge-Kutta-Verfahren). Ψτ(x) = P(τA)x, P ∈Ps impliziert R(z) = 1 + z + · · ·+ 1
p! zp, falls s = p. Die zugehörigen Stabilitätsgebiete sind in
Abbildung 3.4 veranschaulicht.
3.7.3 Die charakteristische Schrittweite
Betrachten wir ein stabiles AWP x = Ax, x(0) = x0 mit diskretem Fluss Ψτ = R(τA). Wirdefinieren die charakterisiere Schrittweite
τc = sup τ > 0 : Ψτ ist stabil für τ ∈ (0, τ] . (3.120)
86

3.7 Steife Anfangswertprobleme
Wie groß ist τc in Abhängigkeit vom Stabilitätsgebiet SR von R und dem Spektrum vonA? Die notwendige Bedingung ist, dass τλ ∈ SR für alle λ ∈ σ(A) und dass ι(R(τλ)) = 1für |R(τλ)| = 1.
Zu einem Stabilitätsgebiet S definieren wir
r−S (ϕ) = sup
r > 0 : reiϕ ∈ int S für r ∈ (0, r]
; (3.121)
r+S (ϕ) = sup
r > 0 : reiϕ ∈ S für r ∈ (0, r]
, (3.122)
wobei natürlich r−S (ϕ) ≤ r+s (ϕ) für alle ϕ gilt.Diese Definitionen implizieren, dass τc maximal so groß sein kann, dass
τc |λ| ≤ r+s (arg(λ)), λ ∈ σ(A). (3.123)
Lemma 3.36. Es gilt immerτ−c ≤ τc ≤ τ+
c , (3.124)
wobei
τ−c = minλ∈σ(A)
λ 6=0
r−s (arg(λ))|λ| und τ+
c = minλ∈σ(A)
λ 6=0
r+s (arg(λ))|λ| .
Darüber hinaus giltτc = τ+
c , (3.125)
falls alle λ ∈ σ(A) mit r−S (arg(λ)) < ∞ den Index 1 besitzen.
Beweis. Wir führen den Beweis in mehreren Schritten. Erst erinnern wir uns daran, dassλ ∈ σ(A) impliziert, dass µ = R(τλ) ∈ σ(Ψτ).
1. Falls λ = 0 ergibt die Stabilität von A (die wir immer voraussetzen!), dass ι(λ) = 1als Folge von Theorem 3.29.
2. Falls λ 6= 0 und τ < τ−c , dann gilt τ |λ| < r−S (arg(λ)) und τλ ∈ int SR. Die Definitiondes Stabilitätsgebiets S = SR impliziert |µ| = |R(τλ)| < 1.
3. Die beiden Bedingungen aus Schritt 1 und 2 implizieren, dass ρ(Ψτ) ≤ 1 und µ =
R(0) = 1 der einzige Eigenwart mit Betrag 1 ist. Darüber hinaus ist der Index ι(0) = 1.Aus Theorem 3.31 erhalten wir, dass Ψτ stabil ist und τc ≥ τ−c .
4. Es gilt
τ+c |λ| ≤ r+S (arg(λ)) ∀λ ∈ σ(A) \ 0
i statt λ= sup
r > 0 : rei arg(λ) ∈ S für r ∈ (0, r]
.
Wäre τ > τ+c , so wäre τ |λ| ei arg(λ) = τλ /∈ S und τc ≤ τ+
c .5. Falls τ ≤ τ+
c , dann τ |λ| ∈ r+S (arg(λ)) und τλ ∈ S, |R(τλ)| ≤ 1. Sei |µ| = |R(τλ)| =1 für ein λ ∈ σ(A), damit ist r−S (arg(λ)) < ∞, also ι(λ) = 1 und folglich ι(µ) = 1. Dasergibt die Stabilität von Ψτ. Da dies für alle τ ≤ τ+
c gilt, folgt τc = τ+c .
87

3.7 Steife Anfangswertprobleme
Insbesondere gilt 0 /∈ σ(A), falls A asymptotisch stabil ist, also |R(τλ)| < 1 für τ < τ−c ,mithin
Korollar 3.37. Falls A asymptotisch stabil ist, ist
τ−c = sup τ > 0 : Ψτ ist asymptotisch stabil .
Beispiel. Betrachten wir die Dahlquistsche Gleichung x = λx mit λ < 0 (asymptotischstabil) und arg(λ) = π. Für das explizite Euler-Verfahren ist das Stabilitätsgebiet S =
B1(−1). Es folgt, dass r−S (π) = r+S (π) = 2 und nach Lemma 3.36 gilt
τc = τ+c =
r+S (π)
|λ| =2|λ| .
Das ist exakt das Kriterium, dass wir auch von Hand hergeleitet hatten (siehe Formel(3.98)).
Eine Folge von Gleichung (3.123),
τc |λ| ≤ r+S (arg(λ)), λ ∈ σ(A),
ist die Schrittweitenbeschränkung für explizite Runge-Kutta-Verfahren. Für diese Metho-den (wie wir später beweisen werden) wird die diskrete Evolution von einem Polynombeschrieben, also
Ψτ(x) = P(τA)x, für ein P ∈ Ps.
Da |P(z)| → ∞ für |z| → ∞, gilt:
Lemma 3.38. Das Stabilitätsgebiet von Polynomen ist kompakt, es gilt
r+S (ϕ) < ∞, ϕ ∈ [0, 2π).
Es ist also auch τc < ∞.
3.7.4 Stabilitätsbegriffe
Wir schreiben C− = z ∈ C : Re z ≤ 0.Definition 3.39. Eine rationale Funktion R : C→ C mit C− ⊆ SR heißt A-stabil.
Theorem 3.40. Eine diskrete Evolution Ψτ = R(τA) ist genau dann (asymptotisch) stabil füralle τ > 0 und alle (asymptotisch) stabilen A, wenn R A-stabil ist.
Beweis. Sei Ψτ stabil für alle τ > 0 und alle stabilen A, das heißt, es gilt |R(τλ)| ≤ 1 füralle τ > 0 und alle λ ∈ C−, also insbesondere |R(λ)| ≤ 1 für alle λ ∈ C−. Daher gilt dieA-Stabilität von R.
Sei umgekehrt R A-stabil, τ > 0 und A = λ ∈ C−. Da C− ⊆ SR, gilt |R(τλ)| ≤ 1.Fall 1: Re λ < 0. Dann gilt τλ ∈ int S für alle τ > 0 und damit |R(τλ)| < 1.Fall 2: Re λ = 0. Da A stabil ist, folgt ι(λ) = 1 und damit auch ι(R(τλ)) = 1. Wir
schließen, dass Ψτ stabil ist.
88

3.8 Implizite Runge-Kutta-Verfahren
Beispiel. Beim impliziten Euler-Verfahren ist die rationale Funktion R(z) = 11−z und
SR = |1− z| ≥ 1. Hier gilt C− ⊆ SR, also ist das implizite Euler-Verfahren A-stabil.
Bemerkung. (i) Eine rationale Funktion R mit Cα ⊆ SR heißt A(α)-stabil, wobei
Cα = z ∈ C : |arg(−z)| ≤ α .
(ii) Eine A-stabile rationale Funktion R mit
limz→∞
R(z) = 0
heißt L-stabil. Ist A asymptotisch stabil, dann folgt, dass Ψτ = R(τA)→ 0 für τ → ∞.
3.8 Implizite Runge-Kutta-Verfahren
3.8.1 Struktur impliziter Runge-Kutta-Verfahren
Wir betrachten ein Anfangswertproblem
x = f (t, x), x(t0) = x0,
und die Methode, die durch die Stufen
ki = f (t + ciτ, x + τs
∑j=1
aijk j), i = 1, . . . , s (3.126)
und
Ψt+τ,t(x) = x + τs
∑j=1
bjk j (3.127)
definiert wird. Vergleicht man die Formeln (3.126) und (3.127) mit (3.58), beobachtet man,dass die Summationen in (3.126) und (3.127) bis s laufen, statt bis i− 1, i = 1, . . . , s wie in(3.58). Das zugehörige Butcher-Schema
c AbT ,
, c, b ∈ Rs, A ∈ Rs×s (3.128)
ergibt ein explizites Verfahren, falls A eine strikte untere Dreiecksmatrix ist, ansonsten istdas Verfahren implizit. Implizite Verfahren liefern immer ein nichtlineares Gleichungs-system, wobei die Stufen ki, i = 1, . . . , s die Variablen sind. Eine Frage, die sich hierbeistellt, ist die eindeutige Lösbarkeit des Systems.
Beispiel. Beim impliziten Euler-Verfahren giltk1 = f (t + τ, ξ)
ξ = x + τk1
Ψτx = ξ
(3.129)
89

3.8 Implizite Runge-Kutta-Verfahren
mit Butcher-Schema1 1
1. (3.130)
Theorem 3.41. Falls f bezüglich x Lipschitz-stetig ist, ist für hinreichend kleine Schrittweite τ
die diskrete Evolution Ψt+τ,t eindeutig bestimmt.
Beweis (Skizze). Wir machen die vereinfachende Annahme, dass f global Lipschitz-stetigbzgl. x mit Konstante L ist. Setze k = (k1, . . . , ks)T ∈ Rs×d und
Fi(k) = f (t + ciτ, x + τs
∑j=1
aijk j), i = 1, . . . s
F(k) = (F1(k), . . . , Fs(k))T .
Betrachte die Norm‖k‖ = max
1≤i≤s‖ki‖2 . (3.131)
Dann erfüllt eine Lösung k = (k1, . . . , ks)T des Runge-Kutta-Systems (3.126) die Fixpunkt-gleichnug
k = F(k). (3.132)
Nun gilt
‖F(k)− F(k)‖ ≤ Lτ max1≤i≤s
s
∑j=1
∣∣aij∣∣ ‖k j − kj‖2
≤ Lτ‖A‖∞‖k− k‖, (3.133)
falls ‖k− k‖ hinreichend klein ist. Für τ < 1L‖A‖∞
ist F also eine Kontraktion und F besitzteinen eindeutigen Fixpunkt.
3.8.2 Lösung des nichtlinearen Gleichungssystems
Wie wir gesehen haben, setzt Theorem 3.41 die Schranke τ < 1L‖A‖∞
für die Schrittweite,um das Runge-Kutta-System (3.126) zu lösen. Aber der Vorteil der impliziten Runge-Kutta-Verfahren ist ihre Stabilität auch für sehr große Schrittweiten und für steife Pro-bleme. Jedenfalls ist die Schranke nur hinreichend, aber nicht notwendig, weswegen wirhoffen können, dass die Lösbarkeit mit anderen Methoden gezeigt werden kann.
Das System (3.126) ist äquivalent zu
gi = x + τs
∑j=1
aij f (t + cjτ, gj), i = 1, . . . , s, (3.134)
Ψt+τ,tx = x + τs
∑j=1
bj f (t + cjτ, gj) (3.135)
90

3.8 Implizite Runge-Kutta-Verfahren
Wir schreiben das System jetzt in den Variablen zi = gi − x, i = 1, . . . , s, sodass
zi = τs
∑j=1
aij f (t + cjτ, x + zj), i = 1, . . . , s, (3.136)
Ψt+τ,tx = x + τs
∑j=1
bj f (t + cjτ, x + zj). (3.137)
Wir betrachten zwei verschiedene Lösungstechniken für das System (3.136)– (3.137):1. Fixpunktiteration: Für eine lineare Differentialgleichung gilt
ξ = Ψτ(x) = R(τA)x =P(τA)
Q(τA)x
genau dann, wennQ(τA)ξ = P(τA)x.
Das suggeriert die folgende Fixpunktiteration
ξk+1 = ξk −Q(τA)ξk + P(τA)x
= [I −Q(τA)] ξk + P(τA)x,(3.138)
die nur kontrahiert, wenn ρ(I−Q(τA)) < 1. Das heißt, falls τλ im Inneren des Stabilitäts-gebiets S1−Q(z) des Polynoms 1− Q(z) für alle λ ∈ σ(A) liegt . Da S1−Q(z) nach Lemma3.38 kompakt ist, erhalten wir eine Schrittweitenbeschränkung
|τmax| ≤ C oder τmax = O(
1ρ(A)
). (3.139)
Damit schließen wir, dass die Fixpunktiteration für steife Probleme ungeeignet ist!2. Newton-Verfahren: Für z = (z1, . . . , zs)T ∈ Rs×d setzen wir
z− . . . stattz + . . .
F(z) = z− τ
∑sj=1 a1j f (t + cjτ, x + zj)
...∑s
j=1 asj f (t + cjτ, x + zj)
(3.140)
und wenden die Iterationz0 = 0
∇F(zk)∆zk = − F(zk), zk+1 = zk + ∆zk (3.141)
an. Der Nachteil der Iteration (3.141) ist wie immer, dass die Jacobi-Matrix ∇F in jedemSchritt ausgewertet wird. Eine einfache Lösung ist die Ersetzung der Matrix∇F(zk) durch∇F(z0), die uns ein sogenanntes Quasi-Newton-Verfahren liefert.
91

3.9 Die Stabilitätsfunktion
3.9 Die Stabilitätsfunktion
Wir betrachten noch mal das lineare System x = Ax und ein implizites Runge-Kutta-Verfahren (b, A) mit rationaler Funktion R, die die diskrete Evolution Ψτ = R(τA)
definiert. In diesem Abschnitt nennen wir R die Stabilitätsfunktion. Endlich können wireine explizite Charakterisierung der Funktion geben:
Lemma 3.42. Die rationale Stabilitätsfunktion R hat für ein Runge-Kutta-Verfahren immer dieForm
R(z) = 1 + zbT(I − zA)−1e, e = (1, . . . , 1)T . (3.142)
Außerdem ist R(z) = P(z)Q(z) mit eindeutig bestimmten Polynomen P, Q ∈ Ps, P(0) = 1, Q(0) = 1.
Beweis. Betrachte die Dahlquistsche Gleichung x = λx, x(0) = 1. Die Anwendung derRunge-Kutta-Evolution ergibt
Ψτ(1) = R(τλ) = 1 + τs
∑j=1
bjλgj,
gi = 1 + τs
∑j=1
aijλgj.
Mit z = τλ und g = (g1, . . . , gs)T ∈ Rs erhalten wir also den Ausdruck
R(z) = 1 + zbTg (3.143)
g = e + zAg, d.h. g = (I − zA)−1e. (3.144)
Nach der Cramerschen Regel,
Ax = b =⇒ xi =det(Ai)
det(A), Ai = (a1, . . . , b
i-te Spalte, . . . , as),
gilt
gi =Pi
det(I − zA)mit Pi ∈ Ps−1, (3.145)
det(I − zA) ∈ Ps und R(z) = 1 +∑s
j=1 bjzPj
det(I − zA).
Beispiel. Wir betrachten das Verfahren
Ψt+τ,tx = ξ = x +τ
2( f (t, x) + f (t + τ, ξ)) (3.146)
mit Butcher-Schema0 0 01 1
212
12
12
.
92

3.10 Maximale Ordnung impliziter Verfahren
Die entsprechende Stabilitätsfunktion ist
R(z) = 1 + zbT(I − zA)−1e
= 1 + z[ 1
212
] ( 1 0− z
2 1− z2
)−1 [11
]= 1 + z
[ 12
12
] [ 11+ z
21− z
2
]
Faktor 12
ergänzt
= 1 +z2
(1 +
1 + z2
1− z2
)=
1 + z2
1− z2
.
3.10 Maximale Ordnung impliziter Verfahren
Wir haben schon in Lemma 3.17 gesehen, dass ein explizites Runge-Kutta-Verfahren nurOrdnung p ≤ s für allgemeines f hat. Gibt es eine Ordnungsschranke für implizite Runge-Kutta-Verfahren?
Lemma 3.43. Ist R = P/Q eine rationale Approximation der Exponentialfunktion der Ordnungp, dann gilt
p ≤ deg(P) + deg(Q). (3.147)
Beweis. [DB08, S. 233, Lemma 6.4]
Theorem 3.44. Für ein s-stufiges Runge-Kutta-Verfahren der Ordnung p gilt
p ≤ 2s. (3.148)
Beweis. Betrachte x = x, x(0) = 1. Der Konsistenzfehler ist
τ statt zΨτ(1)−Φτ(1) = R(τ)− eτ = O(τp+1).
Durch [DB08, Lemma 3.60] erhalten wir R = P/Q mit deg R, Q ≤ s. Lemma 3.43 liefertuns dann
p ≤ deg P + deg Q ≤ 2s.
3.11 Kollokationsverfahren
3.11.1 Idee
Bestimme ein Polynom u ∈ Ps so, dassu(t0) = x(t0)
u(t0 + ciτ) = f (t0 + ciτ, u(t0 + ciτ)), i = 1, . . . , s,(3.149)
93

3.11 Kollokationsverfahren
für 0 ≤ c1 < · · · < cs ≤ 1, die sogenannten relativen Stützstellen. Dann setze
Ψt0+τ,t0(x0) = u(t0 + τ). (3.150)
3.11.2 Kollokationsverfahren sind implizite Runge-Kutta-Verfahren
Sei l1, . . . , ls eine Lagrange-Basis zu den Knoten c1, . . . , cs (siehe Formel (1.2)), sodass
ci statt eilj(ci) = δij, i, j = 1, . . . , s.
Theorem 3.45. Das Kollokationsverfahren zu den Stützstellen c = (c1, . . . , cs) ist ein implizitesRunge-Kutta-Verfahren (b, c, A) mit
aij =∫ ci
0lj(θ)dθ, i, j = 1, . . . , s (3.151)
und
bi =∫ 1
0li(θ)dθ, i = 1, . . . , s. (3.152)
Beweis. Setzek j = u(t0 + cjτ), j = 1, . . . , s.
Die Lagrange-Interpolation zu den relativen Stützstellen c1, . . . , cs liefert
u(t0 + θτ) =s
∑j=1
k jlj(θ).
Integration nach θ ergibt
u(t0 + ciτ) = x0 + τ∫ ci
0u(t0 + θτ)dθ
= x0 + τ∫ ci
0
s
∑j=1
k jlj(θ)dθ
= x0 + τs
∑j=1
[∫ ci
0lj(θ)dθ
]k j
= x0 + τs
∑j=1
aijk j.
Eingesetzt in (3.149) ergibt sich
ki = f (t0 + ciτ, x0 + τs
∑j=1
aijk j) (3.153)
94

3.11 Kollokationsverfahren
und analog folgt
u(t0 + τ) = x0 + τ∫ 1
0u(t0 + θτ)dθ
= x0 + τs
∑i=1
biki.(3.154)
Wir erhalten also ein implizites Runge-Kutta-Verfahren.
3.11.3 Kollokation und Quadratur
Wie wir in der Einführung, Abschnitt 0, gesehen haben, ist die Quadratur eng verwandtmit der Lösung einer gewöhnlichen Differentialgleichung: Wir definieren
x(t0 + τ) =∫ t0+τ
t0
f (t)dt, (3.155)
sodassx(t) = f (t), x(t0) = 0. (3.156)
Die Anwendung des Kollokationsverfahrens auf (3.156) liefert uns eine Quadraturformel
x(t0 + τ) ≈ τs
∑i=1
biki
= τs
∑i=1
bi f (t0 + ciτ),(3.157)
auf den Knoten c1, . . . , cs, siehe Abschnitt 2.3 über Newton-Cotes-Formeln.
Theorem 3.46 (Butcher). Ein Kollokationsverfahren besitzt genau dann die Ordnung p für f ∈Cp(Ω, Rd), wenn die Quadraturformel (3.157) für Funktionen f ∈ Cp(R, Rd) die Ordnung pbesitzt.
Beweis. Angenommen, das Kollokationsverfahren habe die Ordnung p. Da das Quadra-turproblem mit (3.156) ein spezielles Anfangswertproblem ist, hat dann die Quadratur-formel Ordnung p.
Angenommen, die Quadraturformel (3.157) habe umgekehrt Ordnung p. Wir zeigen,dass
|x(t0 + τ)− u(t0 + τ)| = O(τp+1).
Es giltu(t) = f (t, u(t)) + [u(t)− f (t, u(t))] ,
d.h. das Kollokationspolynom u löst das gestörte Anfangswertproblem
x = f (t, x) + δ f (t), x(t0) = x0,
95

3.11 Kollokationsverfahren
wobei δ f (t) = u(t)− f (t, u(t)).Beachten wir jetzt, dass δ f (t0 + ciτ) = 0 für alle i = 1, . . . , s. Dann liefert [DB08, Satz
3.4]:
x(t0 + τ)− u(t0 + τ) =∫ t0+τ
t0
M(t0 + τ, σ)︸ ︷︷ ︸Matrixwertige Abbildung
δ f (σ)dσ
= τs
∑i=1
M(t0 + τ, t0 + ciτ) δ f (t0 + ciτ)︸ ︷︷ ︸≡0
+O(τp+1)
= O(τp+1).
Lemma 3.47. Die durch die Koeffizienten b, c eines Kollokationsverfahrens definierte Quadratur-formel
s
∑i=1
bi ϕ(ci) ≈∫ 1=τ
0=t0
ϕ(x)dx (3.158)
ist exakt für Polynome vom Grad s− 1.
Beweis. Es gilt
θk−1 =s
∑j=1
ck−1j lj(θ), k = 1, . . . , s,
(da die lj eine Basis von Ps−1 bilden). Damit folgt
s
∑j=1
bjck−1j =
s
∑j=1
∫ 1
0ck−1
j lj(θ)dθ
=∫ 1
0θk−1 dθ =
1k
, k = 1, . . . , s,
d.h. Polynome vom Grad s− 1 werden exakt integriert.
Für k = 1 erhalten wir insbesondere ∑sj=1 bj = 1, also die Konsistenz des Verfahrens aus
Lemma 3.16.
3.11.4 Globaler Approximationsfehler
Theorem 3.48. Falls f hinreichend oft differenzierbar ist, gilt∥∥∥x(k) − u(k)∥∥∥
∞= O(τs+1−k) (3.159)
auf [t0, t0 + τ] für k = 0, . . . , s und hinreichend kleines τ.
96

3.11 Kollokationsverfahren
Beweis (Idee). Wir interpolieren u, sodass
u(t0 + θτ) =s
∑j=1
f (u(t0 + cjτ)) lj(θ),
wobei wir f o.B.d.A. als autonom annehmen. Durch Integration folgt
u(t0 + θτ) = x0 +∫ θ
0τu(t0 + ητ)dη
= x0 + τs
∑j=1
f (u(t0 + cjτ))∫ θ
0lj(η)dη. u ergänzt
Analog erhalten wir für x
x(t0 + θτ) =s
∑j=1
f (x(t0 + cjτ)) lj(θ) + O(τs)
und
x(t0 + θτ) = x0 + τs
∑j=1
f (x(t0 + cjτ))∫ θ
0lj(η)dη + O(τs+1).
Zusammen ergibt das mit
δ f j = f (x(t0 + cjτ))− f (u(t0 + cjτ)),
dass
‖x(t0 + θτ)− u(t0 + θτ)‖ =∥∥∥∥∥τ
s
∑j=1
δ f j
∫ θ
0lj(η)dη + O(τs+1)
∥∥∥∥∥ O(τs+1) statt
O(τs+2)
≤ τ maxj=1,...,s
∥∥δ f j∥∥ s
∑j=1
∣∣∣∣∫ θ
0lj(η)dη
∣∣∣∣+ O(τs+1) ebenso
Da f glatt und damit auch lokal Lipschitz-stetig ist, gilt
maxj=1,...,s
∥∥δ f j∥∥ ≤ L max
j=1,...,s
∥∥u(t0 + cjτ)− x(t0 + cjτ)∥∥ . cj statt lj
Mit
Λ0 = maxθ∈[0,1]
s
∑j=1
∣∣∣∣∫ θ
0lj(η)dη
∣∣∣∣bekommen wir
‖x− u‖∞ = maxθ∈[0,1]
‖x(t0 + θτ)− u(t0 + θτ)‖
≤ τLΛ0 ‖x− u‖∞ + O(τs+1)
oder‖x− u‖∞ = O(τs+1)
für τ hinreichend klein. Der Beweis für die Ableitungen x(k) − u(k) geht analog.
97

3.12 Mehrschrittverfahren
3.11.5 Beispiele: Gauß- und Radau-Verfahren Radau stattRadon
Konstruktionsprinzip für s-stufiges implizites Runge-Kutta-Verfahren:
• Wähle Quadraturformel mit Knoten c1, . . . , cs
• Konstruiere zugehöriges Kollokationsverfahren durch
aij =∫ ci
0lj(θ)dθ, i, j = 1, . . . , s
a) Gauß-Verfahren:
• ci Nullstellen der Orthogonalpolynome zur Gewichtsfunktion w ≡ 1 (Legendre-Polynome, Abschnitt 2.6.2 und Abschnitt 2.7.2)• s-stufig mit Ordnung p = 2s• sind A-stabil• Beispiel: implizite Mittelpunktsregel
Ψτx = x + τ f(
x + Ψτx2
)b) Radau-Verfahren
• cs = 1, c1, . . . , cs−1 Nullstellen der Jacobi-Polynome (siehe die Bemerkung nachAbschnitt 2.6.2)• L-stabil (ψ(τA)→ 0 für τ → ∞ und A asymptotisch stabil)• Beispiel: implizites Euler-Verfahren
Ψτx = x + τ f (Ψτx).
3.12 Mehrschrittverfahren
3.12.1 Lineare Mehrschrittverfahren
Für ein Anfangswertproblem
x = f (t, x), x(t0) = x0,
ist die Lösung x : [t0, T] → Rd stetig differenzierbar, falls die Funktion f stetig ist. Ein-schrittverfahren berechnen eine Gitterfunktion x∆ : ∆→ Rd auf einem Gitter ∆ = t0, . . . , tn,sodass x∆ ≈ x auf ∆ durch die diskrete Evolution
x∆(tj+1) = Ψtj+1,tj(x∆(tj)), j = 0, . . . , n− 1.
Die zentrale Eigenschaft dieser Methoden ist, dass nur x∆(tj) zur Berechnung von x∆(tj+1)
verwendet wird. Der Nachteil hingegen besteht darin, dass die lokalen Informationen
98

3.12 Mehrschrittverfahren
über die rechte Seite f nicht für den nächsten Schritt weiterverwendet werden und daherneu berechnet werden müssen. Dies hat zur Folge, dass die Stufenzahl s größer als dieOrdnung p ist (allgemein gilt s ≥ p).
Die Idee der Mehrschrittverfahren liegt in der Benutzung von x∆(tj−k+1), . . . , x∆(tj) miteinem festen k > 1, um x∆(tj+1) zu berechnen. Die Hoffnung ist, damit eine hohe Ord-nung bei wenigen Auswertungen von f zu liefern.
Wir beschränken uns hier auf den Fall, dass die Schrittweite τ = tj+1− tj, j = 0, . . . , n−1 fest ist, was ein Gitter mit äquidistanten Knoten zur Folge hat.
Wir beginnen mit dem Beispiel der expliziten Mittelpunktsregel. Die Integralformulierungdes Anfangswertproblems liefert
x(t) = x(t0) +∫ t
t0
f (s, x(s))ds. (3.160)
Aus der Approximation des Integrals mit der Mittelpunktsregel (2.4) in Abschnitt 2.2.1erhalten wir
x(tj+1) = x(tj−1) +∫ tj+1
tj−1
f (s, x(s))ds
= x(tj−1) + 2τ f (tj, x(tj)) + O(τ3)
und damit ein 2-Schrittverfahren
x∆(tj+1) = x∆(tj−1) + 2τ f (tj, x∆(tj)) Index ∆ergänzt
(3.161)
der Ordnung 2.Nun betrachten wir ein allgemeines lineares k-Schrittverfahren. Mit der abgekürzten
Schreibweise xj = x∆(tj) und f∆ : ∆ → Rd, f∆(tj) = f (tj, x∆(tj)) für j = 0, . . . , n bzw.f j = f∆(tj) definieren wir
αkxj+k + · · ·+ α0xj = τ(βk f j+k + · · ·+ β0 f j), (3.162)
mit Koeffizienten α0, . . . , αk, β0, . . . , βk ∈ R. Damit erhalten wir explizite Verfahren, fallsβk = 0 ist. Allgemein ist αk 6= 0, sonst ist die Anzahl der Schritte bei einem explizitenVerfahren k− 1. Die Durchführung des Verfahren erfordert Startwerte x0, . . . , xk−1.
3.12.2 Der Verschiebungsoperator
Eine elegante und kompakte Darstellung von Mehrschrittverfahren wird durch den soge-nannten Verschiebungsoperator
(Eg)(t) = g(t + τ), τ ∈ ∆τ (3.163)
gegeben. Der Operator E ist linear und ein Mehrschrittverfahren wird zu
(αkEk + · · ·+ α0E0)x∆(t) = τ(βkEk + · · ·+ β0E0) f∆(t), t ∈ ∆τ . (3.164)
99

3.12 Mehrschrittverfahren
Mit den weiteren Abkürzungen
ρ(E) = αkEk + · · ·+ α0E0
σ(E) = βkEk + · · ·+ β0E0∈ Pk (3.165)
wird ein Mehrschrittverfahren zu
ρ(E)x∆(t) = τσ(E) f∆(t). (3.166)
Für die Mittelpunktsregel xj+2 − xj = 2τ f j+1 gilt beispielsweise
α2 = 1, α1 = 0, α0 = −1, also ρ(E) = E2 − 1 (3.167)
sowie β2 = 0, β1 = 2, β0 = 0, also σ(E) = 2E. (3.168)
3.12.3 Konsistenz und Ordnung
Wir betrachten den Differentialoperator
L(x, t, τ) = ρ(E)x(t)− τσ(E)x(t). (3.169)
Definition 3.49. Ein lineares Mehrschrittverfahren besitzt die Konsistenzordnung p, falls
L(x, t, τ) = O(τp+1) (3.170)
für alle x ∈ C∞([t0, T], Rd) und alle relevanten t, τ gilt.
Lemma 3.50. Ein Mehrschrittverfahren hat genau dann die Ordnung p, falls eine der folgendenäquivalenten Bedingungen erfüllt ist:
(i) L(Q, 0, τ) = 0 für alle Q ∈ Pp;
(ii) L(exp, 0, τ) = O(τp+1);
(iii) ∑kj=0 αj = 0 und ∑k
j=0 αj jl = l ∑kj=0 β j jl−1 für l = 1, . . . , p.
Insbesondere ist ein Mehrschrittverfahren genau dann konsistent, falls
k
∑j=0
αj = 0, d.h. ρ(1) = 0 (3.171)
undk
∑j=0
αj j =k
∑j=0
β j, d.h. ρ′(1) = σ(1). (3.172)
Beweis. [DB08, Lemma 7.8].
100

3.12 Mehrschrittverfahren
3.12.4 Stabilität
Wir betrachten das Zweischrittverfahren mit maximaler Ordnung p = 3:
xj+2 + 4xj+1 − 5xj = τ(4 f j+1 + 2 f j). (3.173)
Angewendet auf das triviale Testproblem
x = 0, x(0) = 1
erhalten wirxj+2 + 4xj+1 − 5xj = 0. (3.174)
Durch Transformation auf eine lineare Iteration wird (3.174) zu
yj =
(xj
xj+1
); yj+1 =
(xj+1
xj+2
)=
(xj+1
−4xj+1 + 5xj
)=
[0 15 −4
]︸ ︷︷ ︸
A
yj (3.175)
Aber σ(A) = 1,−5, also ρ(A) = 5 und die diskrete Iteration (3.175) ist instabil (Theo-rem 3.31).
Definition 3.51. Ein lineares Mehrschrittverfahren heißt stabil, falls die Differenzengleichung
ρ(E)x∆ = 0 (3.176)
stabil ist, d.h. falls für beliebige Startwerte x0, . . . , xk−1 eine Konstante M > 0 existiert, sodass∣∣xj∣∣ ≤ M, ∀j ≥ 0. (3.177)
Theorem 3.52 (Dahlquistsche Wurzelbedingung). Ein Mehrschrittverfahren ist genau dannstabil, wenn für alle Nullstellen λ von ρ gilt, dass |λ| ≤ 1, sowie alle Nullstellen mit |λ| = 1einfache Nullstellen sind.
Zum Beispiel liefert die explizite Mittelpunktsregel ρ(E) = E2− 1 Nullstellen 1 und −1und somit ist das Verfahren stabil.
3.12.5 Adams-Verfahren
Wir betrachten die Approximation
xj+k = xj+k−1 +∫ tj+k
tj+k−1
f (t, x(t))dt (3.178)
' xj+k−1 +∫ tj+k
tj+k−1
q(t)dt,
101

3.12 Mehrschrittverfahren
wobei q ein Polynom ist. D.h. wir wählen q ∈ Pk−1 oder q ∈ Pk so, dass q die f (tj+i) inden tj+i für i = 0, . . . , k− 1 (bzw. k) interpoliert:
q(tj+i) = f (tj+i), i = 0, . . . , k− 1(, k). (3.179)
In der Lagrange-Basis gilt also mit∫ tj+k
tj+k−1
q(t)d = τ∫ 1
0q(tj+k−1 + θτ)dθ (3.180)
die Darstellung
q(tj+k−1 + θτ) =k−1
∑i=0
f∆(tj+i) lk−1−i(θ), (3.181)
wobei li(−l) = δil für i, l = 0, . . . , k− 1. Wir erhalten also die Verfahren
xj+k = xj+k−1 + τk−1
∑i=0
βi f j+i (3.182)
mit
βi =∫ 1
0lk−1−i(θ)dθ, i = 0, . . . , k− 1,
mit maximaler Konsistenzordnung p = k.Das Verfahren (3.182) heißt Adams-Bashforth-Verfahren. Die sogenannten Adams-Moulton-
Verfahren lauten analog
τ ergänztxj+k = xj+k−1 + τk
∑i=0
βi f j+i (3.183)
mit
βi =∫ 1
0lk−i(θ)dθ, (li−k(1− l) = δil) , (3.184)
mit Ordnung p = k + 1.
3.12.6 Stabilitätsgebiete von Mehrschrittverfahren
Ist eine stabile lineare Differentialgleichung x = Ax gegeben, für welche Schrittweiten τ
ist dann die lineare Differentialgleichung
ρ(E)x∆ = τσ(E)Ax∆ (3.185)
stabil?
102

3.12 Mehrschrittverfahren
Wir reduzieren die Frage auf den skalaren Fall (der einem diagonalisierbaren E ent-spricht)
ρ(E)x∆ = τσ(E)λx∆ stabil
⇔(
ρ(E)− τλ︸︷︷︸z∈C
σ(E))
︸ ︷︷ ︸ρz(E)
x∆ = 0. x∆ ergänzt(3.186)
Wir definieren daher das Stabilitätsgebiet
S = z ∈ C : ρz(E)x∆ = 0 (3.187)
und definieren die A-Stabilität und die A(α)-Stabilität durch die Forderung C− ⊆ S bzw.Cα ⊆ S.
Nun ist ρ0(E) = ρ(E) und damit gilt
0 ∈ S⇔ Das Mehrschrittverfahren ist stabil.
Außerdem giltz ∈ ∂S =⇒ ρz(ξ) = 0 für |ξ| = 1
nach der Dahlquistschen Wurzelbedingung, bzw.
ρ(ξ)− zσ(ξ) = 0, d.h. z =ρ(ξ)
σ(ξ)=
ρ(eiϕ)
σ(eiϕ)für ein ϕ ∈ [0,2π),
mithin
∂S ⊆ C :=
ρ(eiϕ)
σ(eiϕ): ϕ ∈ [0, 2π)
, (3.188)
und C nennen wir die Wurzelkurve.
Theorem 3.53. Das Stabilitätsgebiet eines expliziten linearen Mehrschrittverfahrens ist beschränkt.
Beweis. Wir zeigen, dass z /∈ S für |z| > M und hinreichend großes M:z /∈ S für |z| > M gilt genau dann, wenn ρz eine Nullstelle ξ mit |ξ| > 1 für |z| > M
hat. Diese Äquivalenz folgt aus Theorem 3.52. Nun ist
ρz(ξ) = ρ(ξ)− zσ(ξ) = 0⇔ z =ρ(ξ)
σ(ξ).
Für ein explizites Verfahren ist deg(ρ) > deg(σ) (da βk = 0), also gilt
z(∞) =ρ(∞)
σ(∞)= ∞.
Also gibt es ein M > 0, sodass es zu jedem z mit |z| > M ein |ξ| > 1 mit
z = z(ξ) =ρ(ξ)
σ(ξ)
gibt, womit ρz(ξ) = 0.
103

3.12 Mehrschrittverfahren
3.12.7 Die zweite Dahlquist-Schranke
Für steife Probleme ist die A-Stabilität leider nicht vereinbar mit einer hohen Ordnung.
Theorem 3.54 (Dahlquist, 1968). Ein A-stabiles lineares Mehrschrittverfahren besitzt die Kon-sistenzordnung p ≤ 2.
Beweis. [DB08, Satz 7.36]
Allerdings existieren A(α)-stabile k-Schrittverfahren mit p = k für jedes α < π/2.
3.12.8 BDF-Verfahren
Wir bestimmen die Werte xj+k der Gitterfunktion durch das nichtlineare Gleichungssys-tem
q(tj+k) = f (tj+k, xj+k)
q(tj+i) = xj+i, i = 0, . . . , k.(3.189)
Durch die Lagrange-Basis erhalten wir die übliche Darstellung
q(tj+k + θτ) =k
∑i=0
xi+jlk−i(θ)
mitli(−l) = δil , i, l = 0, . . . , k.
Aus (3.189) ergibt sich unmittelbar die explizite Darstellung
αkxj+k + · · ·+ α0xj = τ f j+k (3.190)
mit αi = l′k−i(0), i = 0, . . . , k.Für k = 1 ergibt sich
xj+1 − xj = τ f j+1 (implizites Euler-Verfahren),
für k = 232
xj+2 − 2xj+1 +12
xj = τ f j+2.
Diese Methoden haben beide Die Konsistenzordnung p = k.
104

3.12 Mehrschrittverfahren
3.12.9 Verbindung mit numerischer Differentiation
Im Abschnitt 2.9 haben wir die numerische Approximation von Funktionsableitungendiskutiert. Für ein BDF-Verfahren haben wir aus (3.189)
q(tk) = f (tk, xk) = fk und q(tj) = xj, j = 0, . . . , k,
und aus (3.190)
q(tk) =αkq(tk) + · · ·+ α0q(t0)
τ.
Deshalb kann die Formel
αkx(tk) + · · ·+ α0x(t0)
τ' x(tk) x statt q(3.191)
für die numerische Differentiation einer Funktion x ∈ C1 eingesetzt werden.
105

Literaturverzeichnis
[DB08] Peter Deuflhard and Folkmar Bornemann. Numerische Mathematik 2. de GruyterLehrbuch. Walter de Gruyter & Co., Berlin, 2008.
[QSS02] A. Quarteroni, R. Sacco, and F. Saleri. Numerische Mathematik 2. Springer-Verlag,2002.
106





























