Embed Size (px)
Citation preview

Kalman Filter
Ortsbezogene Anwendungen und Dienste
Stephan Meyer
Zusammenfassung: Der Kalman Filter stellt ein mathematisches Regelwerk zur Ver-
fügung, welches Werteschätzung in linearen dynamischen Systemen erlaubt. Er wird
hauptsächlich für die Korrektur von fehlerbehafteten Messwerten verwendet. Die im
Folgenden beschriebenen Eigenschaften prädestinieren den Kalman Filter besonders
für den Einsatz in der Satellitennavigation. Die vorliegende Studienarbeit beschreibt
einerseits die Funktionsweise als auch Anwendungsbeispiele. Nicht behandelt werden
die mathematischen Hintergründe des Kalman-Filters und dessen Herleitung.
1 Grundlagen
Da der Kalman Filter ein Vorwissen über sehr verschiedene Teilbereiche der Mathematik
erfordert, wird an dieser Stelle kurz auf die benötigten Grundlagen eingegangen. Da dies
den Rahmen der Studienarbeit sprengen könnte, wird jedoch nicht jedes Detail behan-
delt. Alle im Folgenden beschriebenen Grundlagen stützen sich auf das von Peter Stingl
herausgegebene Buch �Mathematik für Fachhochschulen � (siehe [Stingl04]).
1.1 Matrizen
Matrix nennt man ein rechteckiges Zahlenschema der Form:
A43 =
a11 a12 a13
a21 a22 a23
a31 a32 a33
a41 a42 a43
Üblicherweise werden Matrizen mit Groÿbuchstaben bezeichnet, die Zahlen im Index ste-
hen für Zeile und Spalte. Es gelten folgende Rechengesetze und Regeln:
Addition:
A22 + B22 =
(a11 a12
a21 a22
)+
(b11 b12
b21 b22
)=
(a11 + b11 a12 + b12
a21 + b21 a22 + b22
)

Multiplikation:
A32 ·B22 =
a11 a12
a21 a22
a31 a32
·
(b11 b12
b21 b22
)=
a11 · b11 + a12 · b21 a11 · b12 + a12 · b22
a21 · b11 + a22 · b21 a21 · b12 + a22 · b22
a31 · b11 + a32 · b21 a31 · b12 + a32 · b22
Transponierung: �Spiegeln� der Matrix an der Hauptdiagonalen.
A33 =
a11 a12 a13
a21 a22 a23
a31 a32 a33
, AT33 =
a11 a21 a31
a12 a22 a32
a13 a23 a33
Invertierung: Berechnung einer Matrix A−1 für die gilt:
A · A−1 = E
wobei E die Einheitsmatrix darstellt, eine Matrix mit Einsen auf der Hauptdiago-
nalen und Nullen auf allen anderen Positionen. Auf die Berechnung der inversen
Matrix wird an dieser Stelle nicht eingegangen, ein praktikables Verfahren ist der
Gauÿ-Jordan-Algorithmus (siehe [Stingl04], S. 210).
1.2 Zufallsvariablen
Werden die Versuchsausgänge eines Zufallsexperiments auf reelle Zahlen abgebildet, so
nennt man diese Zufallsvariablen. Man unterscheidet zwischen stetigen Zufallsvariablen,
welche nur bestimmte Werte annehmen können wie z.B. die Augensumme bei mehrma-
ligem Würfeln, sowie den diskreten Zufallsvariablen, welche alle Werte eines Spektrums
annehmen können. Für die Verteilung der Werte von Zufallsvariablen gibt es zwei Richt-
werte, den Erwartungswert µ, der einen ungefähren höchstwahrscheinlichen Wert angibt,
den die Zufallsvariable annehmen kann, sowie die Varianz σ2 die ein Maÿ für die Abwei-
chung von dem Erwartungswert darstellt.
1.3 Gauÿ- bzw. Normalverteilung
Wichtig für die Beschreibung einer Zufallsvariablen ist auÿerdem noch die Art der Vertei-
lung. Da der Kalman Filter alle Messwerte als gauÿverteilt ansieht, wird hier nur auf diese
spezielle Verteilungsart eingegangen. Die Gauÿverteilung beschreibt die Verteilung nach
einer Dichtefunktion, welche den in Abbildung 1 dargestellten Graphen erzeugt. Die Wahr-
scheinlichkeit, dass der Wert der Zufallsvariablen im Bereich zwischen zwei x-Werten liegt,
erhält man, indem man eine Integration durchführt, also die Fläche berechnet, welche der
Graph und beide Werte einschlieÿen. Dass eine Gauÿverteilung mit einem bestimmten
Abbildung 1: Gauÿsche Glockenkurve
Erwartungswert µ und einer Varianz σ2 vorliegt, beschreibt man mit der Formel
p(X) = N(µ, σ2) (1)
Ein Spezialfall der Gauÿverteilung ist die so genannte Normalverteilung, hier ist der Er-
wartungswert gleich Null und die Varianz Eins.
p(X) = N(0, 1) (2)
1.4 Kovarianz und Kovarianz-Matrizen
Die Kovarianz stellt ein Maÿ für die Abhängigkeit von zwei Zufallsvariablen untereinander
dar. Besteht kein Zusammenhang, nimmt sie den Wert Null an, ansonsten entweder positi-
ve oder negative Werte, die entweder einen linearen oder indirekt linearen Zusammenhang
beschreiben. Je höher der Betrag der Kovarianz, desto höher ist auch die Abhängigkeit.
Berechnet wird die Kovarianz mit folgenden Formeln:
Cov(X, Y ) := µ((X − µ(X))(Y − µ(X))) (3)
Cov(X, X) := σ2(X) (4)
Stellt man mehrere Zufallsvariablen in einem Vektor x dar, so kann man die zugehörige
Kovarianzmatrix Cov(x) angeben:
x =
X
Y
Z
, Cov(x) =
Cov(X, X) Cov(X, Y ) Cov(X, Z)
Cov(Y,X) Cov(Y, Y ) Cov(Y, Z)
Cov(Z,X) Cov(Z, Y ) Cov(Z,Z)
(5)

2 Der Kalman Filter
Der Kalman Filter wurde 1960 von dem ungarisch-amerikanischem Mathematiker Rudolf
Emil Kalman in dem Dokument �A New Approach to Linear Filtering and Prediction
Problems� (siehe [Kalman60]) vorgestellt. Zu den Vorteilen des Kalman Filters zählen
unter anderem die rekursive Implementierung und der geringe Rechenaufwand, was ihn
heute besonders für die Positionsbestimmung in mobilen Geräten attraktiv macht. Re-
kursiv bedeutet hier, dass der Filter immer nur sein zuletzt berechnetes Ergebnis benötigt
und nicht weitere Werte speichern muss, wodurch auch der Speicherbedarf gering gehalten
wird.
2.1 Modell
Der Kalman Filter ist ein rekursives Verfahren, das in jedem Rechenschritt basierend auf
einer fehlerbehafteten Messung des Systemszustands und auf der vorherigen Schätzung
eine Abschätzung für den aktuellen Zustand des Systems abgibt. Der aktuelle Zustand
des zu schätzenden Prozesses wird mit einem Zustandsvektor xk angegeben, wobei k für
die Nummer des Schrittes steht. xk−1 gibt somit den vorherigen Zustand an. Es wird eine
Matrix A benötigt, die den vorherigen Zustand in den aktuellen Zustand umrechnet, z.B.
wenn xk−1 Werte für Position und Geschwindigkeit enthält, rechnet A anhand der dieser
Werte eine neue Position für xk aus. Weiterhin kann der Systemzustand von auÿen z.B.
durch menschlichen Eingri� beein�usst werden. Diesen Ein�uss kann man mit der Gröÿe
uk und der Transformationsmatrix B in das Verfahren mit einrechnen. Schlieÿlich kann
noch der Prozessfehler zu einer Verfälschung der Schätzung führen, weshalb dies mit dem
gauÿverteilten Faktor wk−1 berücksichtigt werden kann. Aus diesen Angaben kann man
nun die Formel für xk angeben:
xk = A · xk−1 + B · uk + wk−1 (6)
Die aktuelle fehlerbehaftete Messung des Zustandes wird mit zk angegeben. Die nachfol-
gende Formel zeigt die Modellvorstellung für zk:
zk = H · xk + vk (7)
Zu beachten ist hier, dass sich die Elemente des Vektors zk durchaus von den Elementen
von xk unterscheiden dürfen. Beispielsweise könnte xk Werte für Position oder Geschwin-
digkeit enthalten, zk jedoch nur Positionsdaten. Die über�üssigen Geschwindigkeitsdaten
können mit der Transformationsmatrix H herausgenommen werden. Da Hxk den eigentli-
chen Systemzustand darstellt, muss der Fehler der Messung mit dem Vektor vk hinzugefügt
werden.

2.2 Fehlervektoren
Der Kalman Filter unterscheidet zwischen zwei Arten von Fehlern, welche auf das System
Ein�uss nehmen können. Der Messfehler, welchen man alsMeasurement Noise bezeichnet,
sowie das Prozessrauschen, das Process Noise genannt wird. Die Kovarianzmatrizen, wel-
che beide Fehler beschreiben, werden als konstant angenommen, was eine Vereinfachung
darstellt, jedoch in der Realität eher selten der Fall ist. Beispielsweise schwankt bei GPS
die Genauigkeit ständig mit der Sichtbarkeit der Satelliten.
2.2.1 Measurement Noise
Der eigentliche Fehler der Messung zk, ausgedrückt mit dem Vektor vk, wird als Measure-
ment Noise bezeichnet. Dieser Messfehler wird als gauÿverteilt mit dem Erwartungswert 0
und der Kovarianzmatrix R angenommen. Der Erwartungswert ist deshalb 0, weil vk nur
die Abweichung von zk vom realen Systemzustand beschreibt. R beschreibt die Kovarianz
zwischen den einzelnen Elementen von vk. Sollten die Messfehler sich nicht untereinander
beein�ussen, so ist bei R lediglich die Hauptdiagonale mit den Varianzen der Messwerte
belegt und die restlichen Werte 0. Die Formel für die Verteilung lautet:
p(v) = N(0, R) (8)
2.2.2 Process Noise
Der Begri� des Prozessrauschens ist etwas schwieriger zu de�nieren. Es beschreibt die
Abweichung des Modell-Systems vom eigentlichen realen Systemzustand. Hintergrund ist,
dass zwischen zwei Schritten k und k − 1 normalerweise eine gewisse Zeitspanne vergeht,
in der das System seinen Zustand auch ändern kann. Die Transformation von xk−1 nach
xk rechnet jedoch über die gesamte Zeitspanne mit den Werten von xk−1.
Beispiel: Enthält der Zustandsvektor Informationen über Position und Geschwindigkeit,
so kann mit der Transformation mit der Matrix A anhand der vorherigen Position und Ge-
schwindigkeit die aktuelle Position berechnet werden. Dies ist aber nur dann genau, wenn
sich die Geschwindigkeit zwischen den beiden Schritten konstant bleibt, was nicht immer
der Fall sein muss. Zum Beispiel kann bei Navigationssystemen im Auto die Schwankung
zwischen zwei Schritten stark variieren, wenn man sich im Stadtverkehr bewegt.
Der Vektor wk rechnet diesen Fehler in xk ein. wk ist gauÿverteilt nach
p(w) = N(0, Q) (9)
wobei Q die Kovarianzmatrix des Fehlers ist.
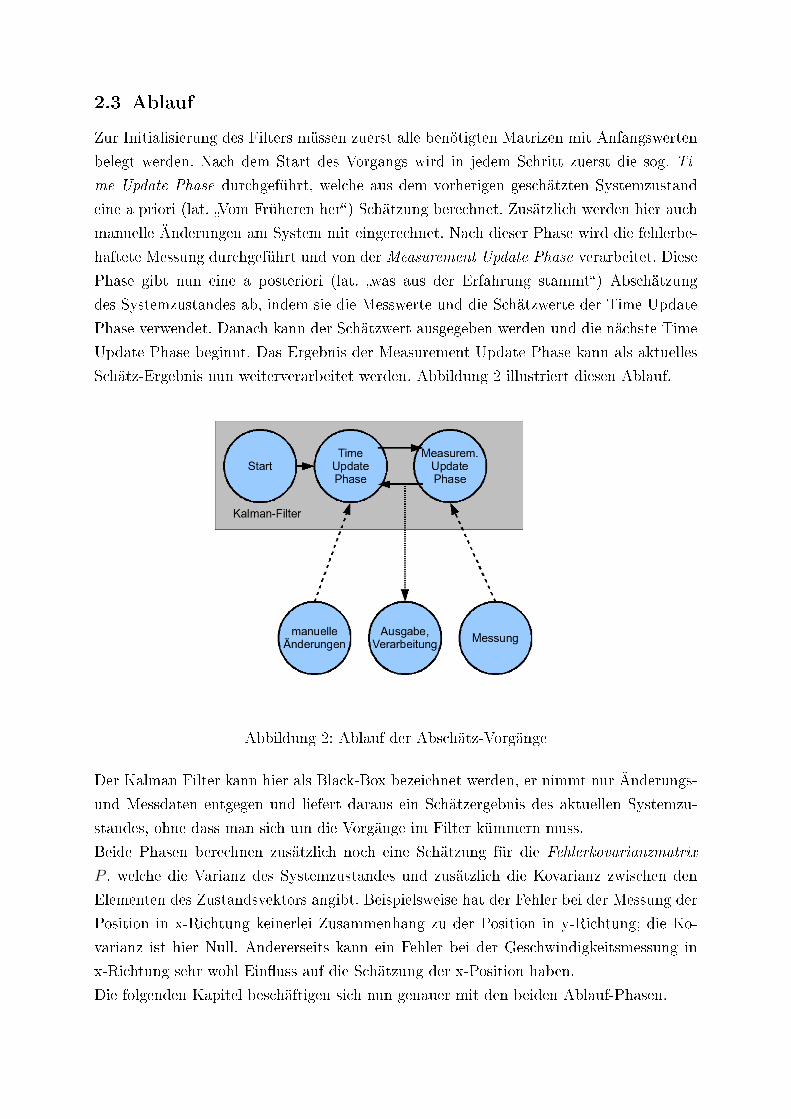
2.3 Ablauf
Zur Initialisierung des Filters müssen zuerst alle benötigten Matrizen mit Anfangswerten
belegt werden. Nach dem Start des Vorgangs wird in jedem Schritt zuerst die sog. Ti-
me Update Phase durchgeführt, welche aus dem vorherigen geschätzten Systemzustand
eine a priori (lat. �Vom Früheren her�) Schätzung berechnet. Zusätzlich werden hier auch
manuelle Änderungen am System mit eingerechnet. Nach dieser Phase wird die fehlerbe-
haftete Messung durchgeführt und von der Measurement Update Phase verarbeitet. Diese
Phase gibt nun eine a posteriori (lat. �was aus der Erfahrung stammt�) Abschätzung
des Systemzustandes ab, indem sie die Messwerte und die Schätzwerte der Time Update
Phase verwendet. Danach kann der Schätzwert ausgegeben werden und die nächste Time
Update Phase beginnt. Das Ergebnis der Measurement Update Phase kann als aktuelles
Schätz-Ergebnis nun weiterverarbeitet werden. Abbildung 2 illustriert diesen Ablauf.
Abbildung 2: Ablauf der Abschätz-Vorgänge
Der Kalman Filter kann hier als Black-Box bezeichnet werden, er nimmt nur Änderungs-
und Messdaten entgegen und liefert daraus ein Schätzergebnis des aktuellen Systemzu-
standes, ohne dass man sich um die Vorgänge im Filter kümmern muss.
Beide Phasen berechnen zusätzlich noch eine Schätzung für die Fehlerkovarianzmatrix
P , welche die Varianz des Systemzustandes und zusätzlich die Kovarianz zwischen den
Elementen des Zustandsvektors angibt. Beispielsweise hat der Fehler bei der Messung der
Position in x-Richtung keinerlei Zusammenhang zu der Position in y-Richtung; die Ko-
varianz ist hier Null. Andererseits kann ein Fehler bei der Geschwindigkeitsmessung in
x-Richtung sehr wohl Ein�uss auf die Schätzung der x-Position haben.
Die folgenden Kapitel beschäftigen sich nun genauer mit den beiden Ablauf-Phasen.

2.3.1 Time Update
Die Time Update Phase liefert die a priori Schätzwerte für xk und Pk:
x̂k,pri = A · x̂k−1,pos + B · uk (10)
Pk,pri = A · Pk−1,pos · AT + Q (11)
Formel 10 eine gewisse Ähnlichkeit zu dem Modell für xk (siehe Formel 6). Hier wird wie
in 6 einerseits die Transformation von x̂k−1 zu x̂k mittels der Matrix A durchgeführt und
zusätzlich noch mittels uk und B die manuellen Änderungen am System eingerechnet.
Die a priori Schätzung für die Fehlerkovarianzmatrix entsteht aus der Transformation der
vorherigen a posteriori Fehlerkovarianzmatrix mit A sowie dem Addieren der Kovarianz-
matrix des Prozessrauschens Q. Tabelle 1 gibt noch einmal einen kurzen Überblick über
die verwendeten Elemente, sofern nicht schon weiter oben erklärt.
Symbol Bedeutung
x̂k,pri a priori Schätzwert des Vektors zum Zeitpunkt kx̂k,pos a posteriori Schätzwert des Vektors zum Zeitpunkt kPk,pri a priori Fehler-Kovarianzmatrix zum Zeitpunkt kPk,pos a posteriori Fehler-Kovarianzmatrix zum Zeitpunkt k
Tabelle 1: Symbole und ihre Bedeutungen
2.3.2 Measurement Update
Das Measurement Update nimmt die a priori Schätzungen der Time Update Phase und
die Messung zk entgegen und liefert daraus den a posteriori Schätzwert. Zuerst wird je-
doch das so genannte Kalman Gain Kk ermittelt (siehe Formel 12), ein Zwischenwert,
welcher für die Berechnung von xk,pos und Pk,pos benötigt wird. Wichtige Elemente, die
in die Berechnung von Kk ein�ieÿen, sind die a priori Fehlerkovarianzmatrix sowie die
Kovarianzmatrix des Messfehlers. Formel 13 liefert die a posteriori Abschätzung für xk
was das Filterergebnis darstellt. Ebenfalls neu berechnet wird die a posteriori Fehlerko-
varianzmatrix (Formel 14).
Kk = Pk,pri ·HT · (H · Pk,pri ·HT + R)−1 (12)
x̂k,pos = x̂k,pri + Kk · (zk −H · x̂k,pri) (13)
Pk,pos = (E −Kk ·H) · Pk,pri (14)
Der Ausdruck (zk−H ·x̂k,pri) in Formel 13 liefert nach Formel 7 eine geschätzte Abweichung
von zk zu x̂k, also in etwa den Messfehlervektor vk.

2.4 Einschränkung
Die wichtigste Annahme im Modell des Kalman Filters ist, dass alle Messwerte gauÿver-
teilt seien. Deshalb kann man den Kalman Filter nicht auf Systeme anwenden, in denen
die Messwerte anderweitig verteilt sind.
2.5 Beispiel
Um die Funktionsweise des Kalman Filters darzustellen, soll nun folgendes Beispiel eines
einfachen Systems für die Positionsbestimmung via Satellit dienen:
Der Systemzustands-Vektor x enthält Werte für Position und Geschwindigkeit in einem
als zweidimensional angenommenen Gelände. Der Empfänger des Systems kann jedoch
nur Positionsdaten messen, weshalb der Vektor des Messergebnisses z nur Positionsdaten
enthält. Die Schätzung der Geschwindigkeit ist somit rein Aufgabe des Kalman Filters.
Für die Modellvorstellung, dass sich z aus x und v zusammensetzt, muss x noch auf
Form von z gebracht werden, wozu die Matrix H verwendet wird. Die Matrix A ist
für die Transformation zuständig, ihre Multiplikation mit x erzeugt die physikalischen
Formeln für die Position nach der Geschwindigkeit (x = x0 + v · 4t). 4t stellt hier die
Zeitdi�erenz zwischen zwei Schritten dar. Da nur der Filter die Geschwindigkeit schätzt,
kann es bei Schwankungen der Geschwindigkeit zu groÿen Abweichungen im Filterergebnis
kommen. Hierzu ist es noch möglich, dem Filter mit dem Vektor u Änderungen an der
Geschwindigkeit mitzuteilen. u muss mit der Matrix B auf die richtige Form gebracht
werden. Die Varianz des Messfehlers soll in x-Richtung 10 Meter und in Y-Richtung 12
Meter betragen. Beide Varianzen sind in der Matrix R zu �nden. Da das Prozessrauschen
schwierig zu de�nieren ist, wird es in diesem einfachen Beispiel nicht betrachtet und
somit die Matrix Q mit Nullen belegt. Die untenstehenden Formeln zeigen noch einmal
die Belegungen der Werte, mit denen nun der Kalman Filter gestartet werden könnte.
x =
x
y
vx
vy
A =
1 0 4t 0
0 1 0 4t
0 0 1 0
0 0 0 1
u =
(vx
vy
)B =
0 0
0 0
1 0
0 1
z =
(x
y
)H =
(1 0 0 0
0 1 0 0
)v =
(4x
4y
)
R =
(10 0
0 12
)Q =
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0

3 Anwendungsbeispiele
Während der Kalman Filter für die Positionsbestimmung zu einem elementaren Werkzeug
geworden ist, gibt es jedoch auch noch einige andere Anwendungsfälle, in denen ebenfalls
eine Glättung von Messwerten erreicht werden muss.
3.1 GPS-/INS-Navigation
Die Kombination aus einem GPS-Empfänger und einem INS (Inertial Navigation Sys-
tem) wird vor allem im militärischen Bereich eingesetzt. Ein INS bestimmt die aktuelle
Position aufgrund von gemessener Geschwindigkeit und Beschleunigung, die von einem
bekanntem Punkt aus auf das Gerät wirkten. Diese Art der Positionsbestimmung wird
jedoch mit zunehmender Dauer des Vorgangs immer ungenauer, weshalb zusätzlich ein
GPS-Empfänger eingesetzt wird, dessen Messdaten mit einem Kalman-Filter geglättet
und zur Korrektur des INS eingesetzt werden. Korrektur bedeutet hier, dass bei zu groÿen
Divergenz zwischen GPS- und INS-Messung das INS neu initialisiert wird. Abbildung 3
zeigt schematisch diesen Ablauf.
Abbildung 3: Navigationssystem mit INS-/GPS-Kombination
3.2 Navigation von Raumkapseln
Eine der ersten Anwendungen des Kalman Filters war die Entwicklung der Apollo-Raum-
kapseln der NASA. Der Kalman Filter sollte hier bei der Navigation und Steuerung im
Weltraum eingesetzt werden. Die seit 1959 betriebene Entwicklung führte unter Einbe-
ziehung von Rudolf Kalman zu der Entwicklung des Extended Kalman Filters, welcher
auch auf nicht-lineare Systeme angewandt werden konnte, jedoch unter ungünstigen Rah-
menbedingungen aufgrund von Divergenz keine vernünftigen Ergebnisse lieferte. Der da-

nach entworfene Schmidt-Kalman Filter, benannt nach dem NASA-Ingenieur Stanley F.
Schmidt, wandelt den Extended Kalman Filter dementsprechend, dass auf diese Fehlerzu-
stände zufriedenstellend reagiert werden kann. Weitere Informationen bietet [McGSch85].
3.3 Satellitengestützte Messungen in der Erd-Atmosphäre
Messungen von Gasen wie z.B. Ozon in der Erd-Atmosphäre werden ebenfalls als gauÿ-
verteilt angenommen, was die Filterung der Messwerte durch den Kalman Filter erlaubt.
In [Bittner03] wird der Kalman Filter mit anderen Verfahren verglichen.
3.4 Seismographen
Die Messungen hochemp�ndlicher Seismographen werden oft durch ein Rauschen gestört,
welches durch die normalen Erschütterungen aus der Umgebung auftreten. Ein Kalman
Filter kann hier helfen, die Messwerte zu glätten und somit Erdstöÿe wie gewünscht zu
erkennen.
3.5 Mustererkennung
Hier wird der Kalman Filter eingesetzt, um aus verschiedenen Mustern wesentliche Be-
standteile herauszu�ltern. Zum Beispiel bei der Erkennung von Personen bei der Video-
überwachung.
4 Fazit
Trotz der Tatsache, dass die Entwicklung des Kalman Filters schon fast ein halbes Jahr-
hundert zurückliegt, erfreute er sich besonders in den letzten Jahren einer gewissen Auf-
merksamkeit. Seine Stärken liegen einerseits im geringen Rechenaufwand, der ihn beson-
ders für die Positionsbestimmung auf mobilen Geräten wie Handys oder PDAs attraktiv
macht, als auch in seiner Flexibilität. Die vielen Varianten des Kalman Filters erlau-
ben eine Behandlung von diversen Problemstellungen aus der Technik und Wissenschaft.
Jedoch bleibt bei dem Kalman Filter die Einschränkung, dass er sich nur für Systeme eig-
net, deren Fehlerbetrachtung gauÿverteilt ist und so anderweitig verteilte Systeme nicht
analysiert werden können.

Literatur
[Bittner03] M. Bittner (2003)
�Das Verfahren des Kalman-Filters zur Interpolation von satellitenge-
stützten Ozonmessungen�
The World Data Center for Remote Sensing of the Atmosphere, Deut-
sches Zentrum für Luft- und Raumfahrt
http://wdc.dlr.de/news_features/docs/kalman_filter.pdf
[BiWe06] Gary Bishop, Greg Welch (2006)
�An Introduction to the Kalman Filter�
Technical Report TR 95-041, University of North Carolina, Department
of Computer Science
[Kalman60] Robert E. Kalman (1960)
�A New Approach to Linear Filtering and Prediction Problems�
Transactions of the ASME � Journal of Basic Engineering, Vol. 82, Series
D, pp. 35-35
[McGSch85] Leonard A. McGee, Stanley F. Schmidt (1985)
�Discovery of the Kalman Filter as a Practical Tool for Aerospace and
Industry�
NASA Technical Memorandum 86847
[Stingl04] Peter Stingl
�Mathematik für Fachhochschulen - Technik und Informatik�
7. Au�age 2004
Carl Hanser Verlag München Wien
ISBN 3-446-22702-4





























