Embed Size (px)
Citation preview

RWTH Aachen SS 2002 Lehrstuhl für Informatik IV Prof. Dr. O. Spaniol
Proseminar Kommunikationsprotokolle
Domain Name System
Harald Derksen Matr.-Nr. 228724
Betreuer: Dirk Thißen

- 1 -
INHALT
1 Einleitung
1.1 Motivation 2 1.2 Historisches 2 1.3 Übersicht 3
2 Der Aufbau des DNS
2.1 Der Einsatz des DNS 4 2.2 Das Design 4 2.3 Der DNS Namensraum 6 2.4 Dienste von DNS 8 2.5 Allgemeine Arbeitsweise von DNS 9 2.6 Beispiel-Anfragen 11 2.7 Arten von Anfragen 13 2.8 DNS-Caching 15
3 Technisches Details
3.1 DNS-Records 16 3.2 DNS-Nachrichten 18
4 Schlussbemerkungen 4.1 Ausblick 20 4.2 Zusammenfassung 21
5 Literaturverzeichnis 22

- 2 -
1 Einleitung 1.1 Motivation Im Laufe der Geschichte haben sich mehrere Identifikationsmöglichkeiten für Menschen entwickelt. Ein Beispiel ist das Prinzip von Vorname-Nachname: Hans Müller, Gertrude Schmidt usw. Für Einrichtungen, die Daten von mehreren Millionen Menschen verwalten müssen, ist diese Art von Identifikation natürlich unzulässig, da es dabei viel zu schnell zu Doppelbelegungen kommt. Das Sozialamt z.B. benutzt stattdessen die Sozialversicherungs-nummer. Im zwischenmenschlichen Bereich wird aber mit Sicherheit niemand mit seiner Sozialversicherungsnummer angeredet, sondern mit seinem Namen, da dieser sich leichter merken lässt. Genauso wie es mehrere Möglichkeiten gibt, einen Menschen zu identifizieren, gibt es auch mehrere Möglichkeiten, einen Rechner in einem Netzwerk zu identifizieren. Ein Identifikator für einen Rechner ist sein „Hostname“. Der Hostname ist ein mnemonischer Identifikator für einen Rechner und wird deswegen vorrangig von Menschen benutzt. Allgemein bekannte Hostnamen sind zum Beispiel www.yahoo.com, www.microsoft.com, www.kernel.org und sogar www.rwth-aachen.de. Die meisten Hostnamen enthalten aber keine Informationen darüber, wo sich der Rechner innerhalb des Internets befindet. Das Beispiel www.rwth-aachen.de gehört zu den Ausnahmen, da man an dem „de“ ablesen kann, dass der Rechner in Deutschland stationiert ist, und da sowohl Stadt als auch Organisation im Namen vorkommen. Der Hostname besteht aus alphanumerischen Buchstaben beliebiger Länge, was ihn schwer maschinell verarbeitbar macht. Es ist also vernünftig, eine andere Art der Identifikation von Rechnern zu haben, die von diesen leichter „verstanden“ werden kann. Deswegen werden Rechner auch durch so genannte IP-Adressen identifiziert. IP-Adressen werden als 32-Bit-Zahlen kodiert und meistens in der „Dotted Quad Notation“ angegeben: z.B. 149.76.12.4 oder 137.226.136.109. Die IP-Adresse ist hierarchisch aufgebaut, da sie mithilfe der Subnetmask in zwei Bereiche aufgeteilt wird. Der vordere Teil enthält dabei die Netzwerkadresse und der hintere die Adresse des Rechners. Mehr Informationen zu IP-Adressen findet man z.B. im [nag2]. Da auf technischer Ebene IP-Adressen zur Identifizierung eines Rechners verwendet werden, auf „menschlicher“ Ebene allerdings leicht verständliche Hostnamen, braucht man einen Übersetzer von Hostname nach IP-Adresse und umgekehrt. Diesen Zweck erfüllt das Domain Name System (kurz DNS). 1.2 Historisches In den Anfangszeiten der Vernetzung wurde die Übersetzung von Hostname nach IP-Adresse vom Network Information Center (NIC) in einer Datei (hosts.txt) realisiert, die per FTP verbreitet wurde. Da immer mehr Rechner miteinander vernetzt wurden und das Internet (damals ARPANET) stetig wuchs, gestaltete sich die Verbreitung einer zentralen hosts.txt immer problematischer. Die tatsächliche Bandbreite des Master NIC Rechners konnte mit den Erfordernissen nicht Schritt halten, da die Netwerkbandbreite, die benötigt wird um eine neue Version der hosts.txt zu verteilen, proportional zum Quadrat der Anzahl der Rechner ist. Die Verteilung der hosts.txt auf mehrere FTP-Server wäre auch nicht unproblematisch, da die Datei auf diese FTP-Server ebenfalls kopiert werden muss, und bei der heutigen Größe des

- 3 -
Internet wäre die Anzahl der FTP-Server immens. Es waren aber nicht nur quantitative Gründe die gegen eine zentrale hosts.txt sprachen:
1 Der Charakter des Netzwerks änderte sich. Das ARPANET mit seinen Mehrbenutzer-Rechnern und Terminals wurde durch lokale Netzwerke von Workstations ersetzt. Diese hatten eine eigene IP-Adressen- und Hostnamen-Administration. Die Administratoren mussten aber bei Änderungen im lokalen Netz darauf warten, dass das NIC die globale hosts.txt anpasst, um die lokalen Änderungen für das globale Internet sichtbar zu machen.
2 Die Anwendungen des Internets wurden komplexer und entwickelten ein Bedürfnis
für allgemein einsetzbare Namensdienste. Diese Probleme zogen notwendigerweise eine Überarbeitung des bestehenden Konzepts nach sich. In den 80er Jahren entstanden mehrere verschiedene Vorschläge, die Namensauflösung mittels der hosts.txt zu ersetzen bzw. zu verbessern. Diese verschiedenen Vorschläge sollen hier nicht vorgestellt werden, können aber in [RFC799], [RFC819] und [RFC830] nachgelesen werden. Die Idee, eine verteilte Datenbank mit standardisierten Ressourcen zu benutzen, wurde in [RFC882] und [RFC883] beschrieben. Die Erfahrungen, die mit verschiedenen Implementierungen dieser Idee gemacht wurden, wurden in [RFC1034] und [RFC1035] zusammengefasst und führten zur Entwicklung des Domain Name System. Paul Mockapetris gilt als „Erfinder“ des heutigen DNS. 1.3 Übersicht Im zweiten Kapitel wird dem Leser das Domain Name System, im Top-Down Verfahren näher gebracht. Es werden die Grundlagen von DNS vorgestellt und Schrittweise ins Detail gegangen. Im dritten Kapitel, das mit „Technische Details“ betitelt wurde, werden die Datenstrukturen der internen Datenbank des Domain Name System und die Nachrichten, die zur Kommunikation zwischen DNS-Servern und -Clients benutzt werden, spezifiziert. Im letzten Kapitel schließlich wird anhand eines Vorschlags des „International Ad Hoc Comitees“ zur Weiterentwicklung des DNS, ein Ausblick auf das zukünftige Domain Name System gegeben. Wesentliche Teile dieses Dokuments stützen sich auf [KR01].

- 4 -
2 Der Aufbau des DNS In diesem Kapitel soll der Aufbau des Domain Name System vorgestellt werden. Zuerst wird gezeigt, wie sich das DNS aus der Sicht des Benutzers verhält. Im Anschluss daran wird die Design-Idee, ausgehend von den Problemen, die sich beim DNS ergeben, vorgestellt. Die Unterkapitel drei bis fünf widmen sich den Grundlagen und dem allgemeinen Aufbau des DNS. Um das zuvor Beschriebene zu verdeutlichen, werden im sechsten Unterkapitel beispielhaft ein paar Namenauflösungsprozesse gezeigt. In den letzten Unterkapiteln des zweiten Kapitels werden schließlich noch einige Details bezüglich der Namensauflösung erläutert. 2.1 Der Einsatz des DNS Ein Benutzer tippt die URL http://www.rwth-aachen.de in seinen Browser. Der Browser extrahiert aus der URL den benötigten Rechnernamen, in diesem Fall www.rwth-aachen.de. Um die IP-Adresse des Rechners herauszufinden, benutzt der Browser den DNS-Client auf dem Rechner des Benutzers. (1)Dieser sendet eine Anfrage an den Name Server, auf den er konfiguriert ist. Der Name Server bearbeitet diese Anfrage (wie wird später geklärt) und (2)sendet die IP-Adresse zurück. (3)Mithilfe dieser Information kann der Browser jetzt eine Verbindung zum HTTP-Port des Rechners www.rwth-aachen.de herstellen. Dieses Beispiel wird in Abbildung 1 visualisiert.
Abbildung 1: Das DNS aus der Sicht des Benutzers
Dem Benutzer stellt sich das Domain Name System also als Black Box, wie in Abbildung 1 gezeigt, dar. Es wird deutlich, dass das Übersetzen des Rechnernamens so schnell wie möglich erfolgen sollte, da der Browser ohne die Antwort des DNS nicht weiterarbeiten kann. Abgesehen davon scheint sich hinter der Black Box eine simple Funktionsweise zu verbergen, denn das Übersetzen eines Rechnernamens in eine IP-Adresse ist eine algorithmisch leicht lösbare Problemstellung. In den folgenden Kapiteln wird aber gezeigt, dass sich in der Black Box weit mehr als eine simple Übersetzung verbirgt. 2.2 Das Design Ein einfaches Design für das Domain Name System würde einen Name Server verwenden, der alle Daten, die zu einer Übersetzung eines Hostnamen in eine IP-Adresse benötigt

- 5 -
werden, enthalten würde. Hierbei würden einfach alle Clients ihre Namenauflösungs-Anfragen an diesen zentralen Rechner leiten, der dann jeden einzelnen Client bedienen würde. Dieses Design ist natürlich verlockend leicht zu implementieren, ist aber für das heutige Internet absolut nicht tauglich. Der zentrale Name Server wäre schon vor zehn Jahren ständig überlastet gewesen. Und da der technologische Fortschritt bei der Netzwerktechnologie (in Form von Erhöhung von Bandbreite und Senkung von Zugriffszeiten) bei weitem nicht mit dem Wachstum des Internets mithalten kann, ist es aussichtslos, auf neue Technologien zu hoffen, um die Idee eines zentralen Name Servers zu verwirklichen. Weitere Probleme, die mit einem zentralen Name Server auftreten würden, sind:
• Stabilität. Falls der Name Server „abstürzen“ würde, würde er das ganze Internet mitreißen.
• Antwortzeit. Ein einziger Name Server kann nicht für alle Clients gut erreichbar sein.
Wenn man den Name Server in New York platzieren würde, müssten alle Anfragen aus Australien um den halben Globus reisen und hierbei unter Umständen „langsame Leitungen“ benutzen. Signifikante Verzögerungen wären die Folge.
• Wartung. Dieser Name Server würde die Daten aller bei NIC angemeldeten Rechner
verwalten müssen. Er müsste also nicht nur über riesige Datenspeicher verfügen, sondern die Datensätze darin auch immer in einem aktuellen Zustand halten, d.h. neue Rechner hinzufügen, veraltete entfernen und Änderungen an Hostnamen sofort übernehmen.
Zusammenfassend kann man sagen, dass ein zentraler Name Server nicht skaliert und der einzige Ausweg daraus die Verteilung von DNS auf mehrere Rechner ist. Hieraus ergeben sich folgende Anforderungen an ein verteiltes Domain Name System:
• Konsistenter Namensraum. Um Probleme zu vermeiden, die bei so genannter ad hoc Namensgebung auftreten, sollen die Namen keine Adressen, Routen oder ähnliches enthalten.
• Verteilung der Daten. Die Größe und Anzahl der Aktualisierungen der Datenbank erfordern eine Realisierung einer verteilten Datenbank mit lokalen Caches, um den Datenverkehr zu minimieren und die Zugriffsgeschwindigkeit zu erhöhen. Es soll vermieden werden, eine komplette konsistente Kopie der Datenbank zusammen-zustellen, da dieses (zeitlich gesehen) teuer und (algorithmisch gesehen) schwer sein wird.
• Anwendungsunabhängigkeit. Dieses System soll unabhängig von Anwendungen
sein, um eine maximale Flexibilität zu erreichen. Es soll zum Beispiel möglich sein, Anfragen von Browsern, Mail-Clients und anderen Programmen zu bearbeiten. Die Anfragen müssen dann aber auch typ-abhängig sein, d.h. bei einer Mail-Anfrage soll nicht die „Browser-Datenbank“ mit durchsucht werden, sondern nur die „Mail-Datenbank“.
• Systemunabhängigkeit. Das Domain Name System soll sowohl von PCs als auch von
großen (UNIX) Mehrbenutzer-Systemen benutzbar sein.

- 6 -
• Namensraum-Nutzung. Weil derselbe Namensraum in unterschiedlichen Netzen und Anwendungen benutzbar sein soll, muss die Möglichkeit bereitgestellt werden, denselben Namensraum mit verschiedenen Protokoll-Familien oder Handhabungen zu benutzen. Zum Beispiel unterscheiden sich Protokolle bei der Darstellung der Adresse, obgleich alle Protokolle den Typ „address“ haben. Das DNS verbindet alle Daten sowohl mit einer Klasse als auch mit einem Typ, so dass es möglich ist, parallel unterschiedliche Formate für Daten vom Typ „address“ zu benutzen.
Das heutige DNS erfüllt all diese Anforderungen. Im folgendem wird die Realisierung beschrieben. 2.3 Der DNS Namensraum
DNS organisiert Hostnamen in einer Hierarchie von Domänen (engl. Domains). Eine Domain ist eine Sammlung von Sites, die in irgendeiner Weise zusammengehören - sei es, dass sie ein Netzwerk bilden (z. B. alle Maschinen der Universität), weil sie einer bestimmten Organisation (z. B. der Regierung) angehören, oder einfach, weil sie geographisch nah beieinander liegen. Beispielsweise werden in den USA Universitäten in der Domain edu zusammengefasst, wobei jede Universität bzw. jedes College noch mal unter einer Unterdomain (Subdomain) zusammengefasst wird. Die Groucho-Marx-Universität könnte die Domain groucho.edu bekommen, wobei dem mathematischen Institut der Name maths.groucho.edu zugewiesen würde. Bei Rechnern im Netzwerk des Instituts würde der Domainname einfach an den Hostnamen angehängt, d.h. erdos wäre als erdos.maths.groucho.edu bekannt. Solch ein Name wird als „voll qualifizierter Domain-name“ (Fully Qualified Domain Name, kurz FQDN) bezeichnet, weil er den Host weltweit eindeutig identifiziert.
Abbildung 2: Ausschnitt aus dem DNS Namensraum
Abbildung 2 zeigt einen Ausschnitt aus dem Namensraum des Domain Name System (Name Space). Der Eintrag an der Wurzel dieses Baums, der durch einen einzelnen Punkt symbolisiert wird, wird passenderweise Root Domain genannt und umfasst alle anderen Domains. Die Knoten des Baumes sind die (Sub-) Domains und die Blätter des Baumes sind

- 7 -
Hostnamen. Ein FQDN wird von unten nach oben abgelesen, wie z.B. www.microsoft.com. Um zu verdeutlichen, dass ein gegebener Hostname ein voll qualifizierter Domainname, und nicht nur ein in einem relativen Verhältnis zu irgendeiner lokalen Domain stehender Name ist, wird ihm auf technischer Ebene ein Punkt angehängt. Das verdeutlicht, dass der letzte Teil des Namens die Root-Domain adressiert. Der abschließende Punkt eines FQDN wird bei Programmen, die direkt vom User benutzt werden, weggelassen, um ihm Tipparbeit zu ersparen.
Abhängig von ihrer Position in der Namenshierarchie wird eine Domain als Top-Level, Second-Level oder Third-Level bezeichnet. Weitere Unterteilungen können zwar vorkom-men, sind aber selten. Die Top-Level Domains sind standardisiert und umfassen:
• edu. (Meist U.S.-amerikanische) Bildungseinrichtungen wie Universitäten etc.
• com. Kommerzielle Organisationen und Unternehmen.
• org. Nichtkommerzielle Organisationen. Private UUCP-Netzwerke sind häufig in dieser Domain zu finden. (UUCP steht für Unix-to-Unix-CoPy. UUCP ist ein Dienst, der nach Zeitplänen arbeitet und entwickelt wurde, um zu bestimmten Zeiten Dateien über serielle Kabel zu transferieren, oder Programme auf entfernten Rechnern zu starten. Siehe auch [nag2].)
• net. Gateways und andere administrative Hosts in einem Netzwerk.
• mil. Militärische Einrichtungen der US-Armee.
• gov. US-amerikanische Regierungsbehörden.
• uucp. Diese Domain enthält offiziell die Namen aller UUCP-Sites, die keinen
vollständigen Domainnamen haben. Sie wird aber kaum noch verwendet.
Technisch gesehen gehören die vier erstgenannten Domains zum U.S.-amerikanischen Teil des Internet. Nichtsdestotrotz kann man in diesen Domänen auch Sites aus der restlichen Welt begegnen. Dies trifft vor allem auf die net-Domain zu. Nur mil und gov werden ausschließlich in den USA benutzt.
Jedes Land besitzt eine eigene Top-Level-Domain. Genutzt wird dabei der aus zwei Buchstaben bestehende Ländercode nach ISO-3166. Finnland nutzt beispielsweise die fi-Domain; fr wird von Frankreich genutzt, de von Deutschland und au von Australien. Unterhalb dieser Domain kann das NIC des jeweiligen Landes die Hostnamen nach Gutdünken organisieren. Zum Beispiel arbeitet Australien mit einer Second-Level-Domain, die sich an den internationalen Top-Level-Domains orientiert, also com.au, edu.au und so weiter. Andere, darunter auch Deutschland, benutzen diese zusätzliche Ebene nicht, arbeiten aber mit etwas längeren Namen, die direkt auf die Organisationen hinweisen, die eine bestimmte Domain betreiben. Beispielsweise sind Hostnamen wie ftp.informatik.rwth-aachen.de nicht unüblich. Auch die USA besitzen eine Top-Level-Domain (us), diese wird aber praktisch nicht genutzt.
Allerdings deuten solche nationalen Domains nicht zwangsläufig an, dass ein Host einer Landes-Domain auch tatsächlich in diesem Land steht. Es bedeutet nur, dass der Host beim NIC dieses Landes registriert wurde. Ein schwedischer Hersteller könnte in Australien eine

- 8 -
Niederlassung betreiben, aber trotzdem alle Hosts unter der Top-Level-Domain se registrieren.
Die Organisation von Namen in einer Hierarchie von Domains löst auch das Problem der Eindeutigkeit von Namen sehr elegant. Bei DNS muss ein Hostname nur innerhalb einer Domain eindeutig sein, und schon ist sichergestellt, dass er sich von allen anderen Hosts weltweit unterscheidet. Mehr noch, voll qualifizierte Namen sind einfacher zu merken. Alle diese Argumente sind für sich genommen schon Grund genug, eine große Domain in mehrere Subdomains aufzuteilen.
Der Namensraum wird jedoch nicht nur in Domains, sondern auch in Zonen eingeteilt. Eine Zone charakterisiert den Datenbestand eines Name Servers. Zu einer Zone eines Name Servers gehören all die Hosts, dessen Hostnamen vom Name Server aufgelöst werden können. Eine Domäne und eine Zone unterscheiden sich durch ihren Umfang: Die Domäne eines Knotens umfasst alle Rechner, die von diesem Knoten aus durch beliebige Pfade erreicht werden können (beachte: ein Baum ist gerichtet). Eine Zone dagegen umfasst nur die Rechner, deren Hostnamen direkt aufgelöst werden können. Auf den unteren Ebenen des Baumes entsprechen die Zonen den Subdomains. Die Informationen die in diesen Zonen gespeichert sind, brauchen in den höheren Ebenen des Baumes nicht mehr verwaltet zu werden. Stattdessen werden dort Verweise auf die für die Subdomain zuständigen Name Server gehalten. Hierdurch entsteht eine Hierarchie von Name Servern. In Abbildung 2 wird ein Ausschnitt aus der Domain .com gezeigt und im Gegensatz dazu zwei Zonen der Domain .edu dargestellt.
2.4 Dienste von DNS
In 2.1 wurde gezeigt, dass es mindestens zwei Wege gibt, einen Rechner zu identifizieren: per Hostname, per IP-Adresse und unter Umständen noch auf andere Arten. Menschen bevorzugen den leicht zu merkenden Hostnamen, Router dagegen können nur mit den hierarchischen IP-Adressen umgehen. Die primäre Aufgabe von DNS ist es, Hostnamen in IP-Adressen umzuwandeln. Dazu besteht das Domain Name System aus (1) einer verteilten Datenbank, die von mehreren Name Servern verwaltet wird, die untereinander hierarchisch aufgebaut sind. Weiterhin besteht es aus (2) einem Anwendungsschicht-Protokoll (siehe Schichtenmodell von TCP/IP), welches es den Rechnern und den Name Servern ermöglicht, zu kommunizieren, um die vom Rechner benötigte Namensauflösung an den Name Server weiterzuleiten. Der Name Server bearbeitet diese und gibt das Ergebnis unter Benutzung des Protokolls an den Rechner zurück. Name Server sind meistens Unix-Maschinen, auf denen das Berkley Internet Name Domain (BIND) Packet installiert ist. Speziell für den Namensdienst zeichnet sich hierbei der Named (ausgesprochen Name Dee, steht für Name Daemon) aus. Das DNS Protokoll läuft über UDP und benutzt den Port 53. Im Gegensatz zu anderen Internet-Programmen für Mail, Web oder Datei Transfer interagiert der Benutzer normalerweise nicht direkt mit DNS. Stattdessen bekommt das DNS seine Anfragen meistens von Web-Browsern, Mail- oder FTP-Clients und ähnlichen Programmen. Zusätzlich zur Übersetzung von Hostnamen in IP-Adressen stellt das DNS aber auch ein paar andere Dienste bereit.

- 9 -
• Alias Hostname. Ein Rechner, auf dem mehrere Server laufen, kann verschiedene Alias-Namen zugewiesen bekommen. Zum Beispiel kann der Rechner madariaga.informatik.rwth-aachen.de die Namen ftp.rwth-aachen.de und www.rwth-aachen.de zugewiesen bekommen. Es laufen also sowohl ein Web-Server als auch ein FTP-Server auf dem Rechner, die über zwei verschiedene Namen angesprochen werden können. Um diese (hier drei) Namen unterscheiden zu können, wird der Hostname madariaga.informatik.rwth-aachen.de der kanonische Name genannt. Der Alias-Name ist typischerweise kürzer und leichter zu merken als der kanonische Name. Bei einer Namensauflösungsanfrage mit einem Alias-Namen wandelt das DNS den Alias-Namen zuerst in den kanonischen Namen und diesen dann in die IP-Adresse um.
• Alias-Hostname für Mail-Server. Die im letzten Punkt vorgestellte Möglichkeit,
Kurznamen für Rechner zu vergeben, kann man natürlich auch auf Mail-Server anwenden, denn es ist klar, dass E-Mail Adressen kurz und prägnant sein sollen. Angenommen, Hans hat einen E-Mail Account bei GMX. Seine E-Mail-Adresse kann dann beispielsweise die Form [email protected] haben, der POP3-Server könnte pop.gmx.net und der SMTP-Server könnte mail.gmx.net heißen. Wenn man davon ausgeht, dass diese beiden Server auf demselben Rechner laufen, könnte, der kanonische Hostname dieses Rechners z.B. post1.europe.gmx.net lauten. Der E-Mail-Client von Hans kann mithilfe des DNS den Alias-Namen des Mailservers der Domäne gmx.net ermitteln, den Alias-Namen in den kanonischen Hostnamen und diesen dann in die IP-Adresse umwandeln.
• Load Distribution. DNS wird auch immer mehr dazu eingesetzt, die Belastung von
Servern zu verteilen. Hoch frequentierte Web-Seiten sind über mehrere Server repliziert, wobei jeder replizierte Server auf einem anderen Endsystem läuft. Daraus folgt, dass alle diese Server unterschiedliche IP-Adressen haben. Das DNS hält deswegen für einen kanonischen Namen eines replizierten Web-Servers mehrere IP-Adressen in seiner Datenbank. Falls ein Client einen Hostnamen (oder kanonischen Namen) eines solchen Servers aufgelöst haben will, antwortet das DNS mit der kompletten Liste der IP-Adressen. Damit die HTTP-Anfragen aber auf mehrere Server verteilt werden, wird die Reihenfolge der IP-Adressen bei jeder Antwort permutiert. Da die Clients normalerweise ihre HTTP-Anfragen an die erste IP-Adresse senden, wird der Netzwerkverkehr auf die Server verteilt. Diese so genannte DNS Rotation wird auch bei Mail-Servern eingesetzt, so dass unterschiedliche Mail-Server den gleichen Alias-Namen haben können. Den Mail-Servern werden hierbei Prioritäten zugeordnet, so dass die Anfragen vom Client zuerst zum Mail-Server mit der höchsten Priorität geschickt werden. Falls dieser nicht erreichbar sein sollte, werden die Anfragen an den nächsten Mail-Server gesendet.
• Reverse Lookup. Neben der Ermittlung einer IP-Adresse eines bestimmten Hosts ist
es manchmal auch notwendig, den kanonischen Hostnamen zu bestimmen, der zu einer bestimmten IP-Adresse gehört. Dies wird als „Reverse Mapping“ bezeichnet und wird von verschiedenen Netzwerkdiensten genutzt, um die Identität eines Client zu überprüfen. Um ausführliche Suchen im DNS-Namensraum zu vermeiden, wurde eine spezielle Domain eingerichtet (in-addr.arpa), die die IP-Adressen aller Hosts in umgekehrter „Dotted Quad Notation“ enthält. Beispielsweise entspricht die IP-Adresse 149.76.12.4 dem Namen 4.12.76.149.in-addr.arpa. Wenn nun ein Host eine Auflösungs-Anfrage für den „Hostnamen“ 4.12.76.149.in-addr.arpa stellt, bekommt er den Hostnamen des Rechners mit der IP-Adresse 149.76.12.4.

- 10 -
2.5 Allgemeine Arbeitsweisen von DNS Im Folgenden wird ein grober Überblick über die Arbeitsweise von DNS gegeben, wobei primär die Abbildung von Hostname auf die IP-Adresse behandelt wird. Wenn man DNS als Black Box betrachtet, ist alles ganz einfach: Der Client sendet eine Anfrage, die den Hostnamen spezifiziert, und das DNS übersetzt diesen in eine IP-Adresse und gibt ihn zurück. Dieses System wäre wirklich so leicht, wenn das DNS nur aus einem Server bestehen würde. Dass dieses aber unzureichend ist, wurde schon in 2.3 gezeigt. Tatsächlich ist das DNS sehr komplex. Es besteht aus sehr vielen Name Servern, die auf der ganzen Welt verteilt sind und einem Anwendungsschicht-Protokoll, das festlegt, wie die Name Server untereinander und die Clients mit den Name Servern kommunizieren sollen. Kein einziger Name Server hat alle (Hostname/IP-Adresse) Zuordnungen aller Rechner im Internet. Das DNS wurde bisher sehr abstrakt betrachtet. Wenn man jetzt spezifischer wird, sieht man, dass das DNS drei Typen von Name Servern unterscheidet: Lokale Name Server, Root Name Server und Authoritative Name Server. Diese Name Server interagieren untereinander und mit den Clients wie folgt:
• Lokale Name Server. Jeder ISP (Internet Service Provider), wie z.B. AOL, T-Online oder auch die RWTH Aachen hat einen lokalen Name Server. Wenn ein Rechner aus dem Netz des ISP eine DNS-Anfrage stellt, wird diese zuerst zum lokalen Name Server geleitet. Der lokale Name Server ist meistens „nah“ am Client. Bei institutionellen ISP (bei Firmen bspw.) kann er sich im gleichen LAN befinden. Bei anderen ist er nur ein paar Router weit entfernt. Wenn ein Rechner eine Namensauflösung an seinen lokalen Name Server richtet und der Rechner, dessen IP-Adresse angefragt wird, sich beide im Netz desselben ISP befinden, dann kann der Name Server sofort antworten. Um diesen Vorgang zu verdeutlichen, folgendes Beispiel: Wenn der Rechner host1.rwth-aachen.de die IP-Adresse von host2.rwth-aachen.de herausfinden will, dann kann der lokale Name Server sofort antworten, ohne einen anderen Name Server zu kontaktieren.
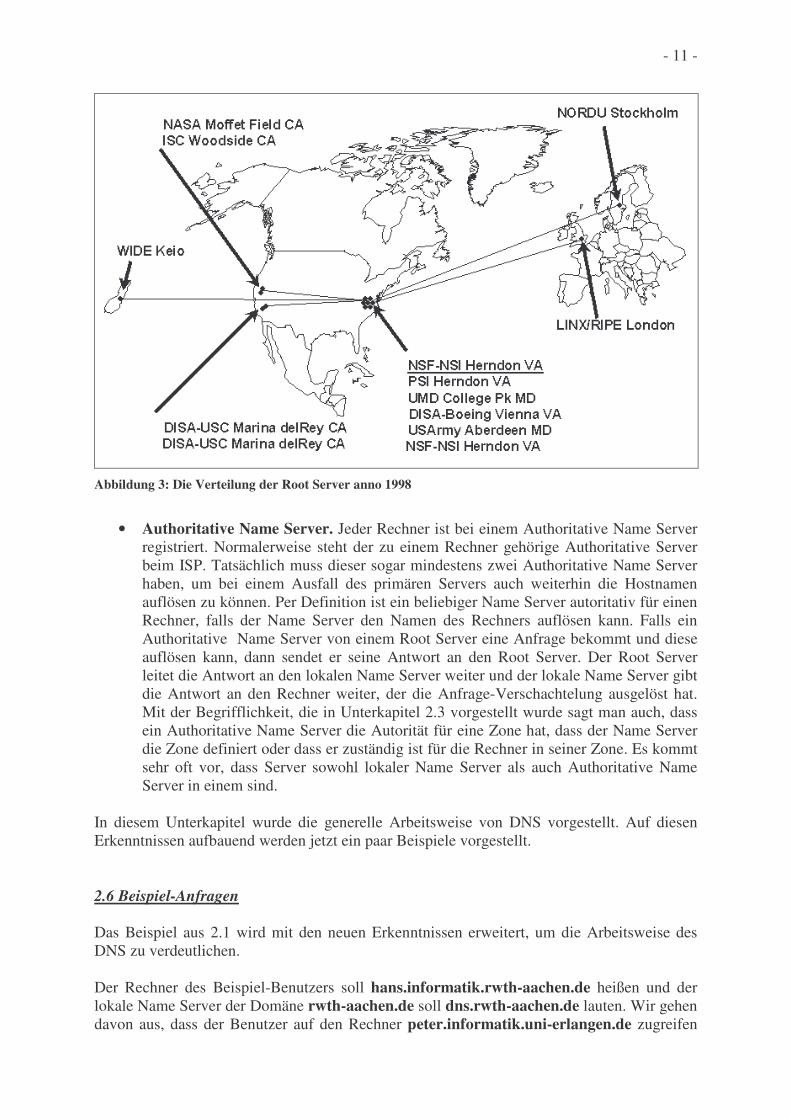
• Root Name Server. Im Internet gibt es 13 Root Name Server. Die Verteilung der Root Name Server ist durch Abbildung 3 gegeben. Die meisten befinden sich in Nord Amerika, wovon sich alleine an der Ostküste sechs Stück befinden. Dies wurde schon oft kritisiert, da es ein enormes Sicherheitsrisiko ist. Ein Angriff auf die Root Name Server der Ostküste würde zur Folge haben, dass ein großteil des Internets ausfällt. In Europa befinden sich übrigens nur zwei Root Name Server: einer in London und einer in Stockholm (Stand: 1998). Falls ein lokaler Name Server dem Client nicht sofort antworten kann, schlüpft der Name Server in die Rolle des Clients und sendet die Anfrage an einen der Root Server. Wenn der Root Name Server die Anfrage auflösen kann, sendet er seine Antwort an den lokalen Name Server und dieser leitet sie weiter an den fragenden Client. Es ist aber möglich (es ist sogar meistens so), dass der Root Name Server die benötigte Namensauflösung nicht in seiner Datenbank hat. In diesem Fall sollte der Root Name Server eine IP-Adresse eines weiteren Name Servers wissen, der die benötigte Zuordnung hat, oder zumindest weiß, in welche Domäne er die Anfrage weiterleiten soll, um eine Antwort zu bekommen. Dieser weitere Name Server wird Authoritative Name Server genannt. Die Antwort läuft dann über den Root und lokalen Name Server (und natürlich auch über all die anderen Rechner) zum Client.
- 11 -
Abbildung 3: Die Verteilung der Root Server anno 1998
• Authoritative Name Server. Jeder Rechner ist bei einem Authoritative Name Server
registriert. Normalerweise steht der zu einem Rechner gehörige Authoritative Server beim ISP. Tatsächlich muss dieser sogar mindestens zwei Authoritative Name Server haben, um bei einem Ausfall des primären Servers auch weiterhin die Hostnamen auflösen zu können. Per Definition ist ein beliebiger Name Server autoritativ für einen Rechner, falls der Name Server den Namen des Rechners auflösen kann. Falls ein Authoritative Name Server von einem Root Server eine Anfrage bekommt und diese auflösen kann, dann sendet er seine Antwort an den Root Server. Der Root Server leitet die Antwort an den lokalen Name Server weiter und der lokale Name Server gibt die Antwort an den Rechner weiter, der die Anfrage-Verschachtelung ausgelöst hat. Mit der Begrifflichkeit, die in Unterkapitel 2.3 vorgestellt wurde sagt man auch, dass ein Authoritative Name Server die Autorität für eine Zone hat, dass der Name Server die Zone definiert oder dass er zuständig ist für die Rechner in seiner Zone. Es kommt sehr oft vor, dass Server sowohl lokaler Name Server als auch Authoritative Name Server in einem sind.
In diesem Unterkapitel wurde die generelle Arbeitsweise von DNS vorgestellt. Auf diesen Erkenntnissen aufbauend werden jetzt ein paar Beispiele vorgestellt. 2.6 Beispiel-Anfragen Das Beispiel aus 2.1 wird mit den neuen Erkenntnissen erweitert, um die Arbeitsweise des DNS zu verdeutlichen. Der Rechner des Beispiel-Benutzers soll hans.informatik.rwth-aachen.de heißen und der lokale Name Server der Domäne rwth-aachen.de soll dns.rwth-aachen.de lauten. Wir gehen davon aus, dass der Benutzer auf den Rechner peter.informatik.uni-erlangen.de zugreifen

- 12 -
will. Dieser Rechner sollte einen Authoritative Name Server haben, der in diesem Beispiel dns.uni-erlangen.de heißen soll. Der Client des Benutzers sendet nun eine Namenauflösungs-Anfrage an seinen (lokalen) primären Name Server. Es ist nicht davon auszugehen, dass der Rechner dns.rwth-aachen.de die IP-Adresse des benötigten Rechners kennt. Er leitet also die Anfrage an einen Root Name Server weiter. Peters Rechner ist aber nicht in der Zone dieses Root Name Servers, deshalb kann der Root Name Server die Anfrage (noch) nicht beantworten. Der Root Name Server kennt aber einen Name Server, der die Anfrage beantworten kann, nämlich dns.uni-erlangen.de. An diesen wird jetzt die Anfrage weitergeleitet. dns.uni-erlangen.de sendet nun die Antwort über den Root Name Server und den lokalen Name Server an den Client des Rechners hans.informatik.rwth-aachen.de. Zur Übersicht siehe Abbildung 4. In diesem Beispiel werden sechs DNS-Nachrichten benötigt, um einen Hostnamen aufzulösen: Drei zum Authoritative Name Server und drei zurück. Die Anzahl der Nachrichten kann sich aber noch erhöhen, denn in diesem Beispiel wurde angenommen, dass der Root Name Server direkt einen Autoritative Name Server kennt, dieses muss nicht unbedingt sein.
Abbildung 4: Eine Beispiel Anfrage
Um eine längere Frage-Antwort-Abfolge zu illustrieren kommen wir zu einem weiteren Beispiel. Das Beispiel wird nun erweitert (Abbildung 5): Der Administrator der Domäne informatik.uni-erlangen.de hat keine Lust mehr, bei einer Änderung eines Hostnamens in seinem Netz zum Administrator des lokalen Name Servers zu gehen, deshalb richtet er in seiner Domäne einen eigenen Name Server ein und registriert ihn beim lokalen Name Server. Falls nun wieder eine Namenauflösungs-Anfrage vom Rechner hans.informarik.rwth-
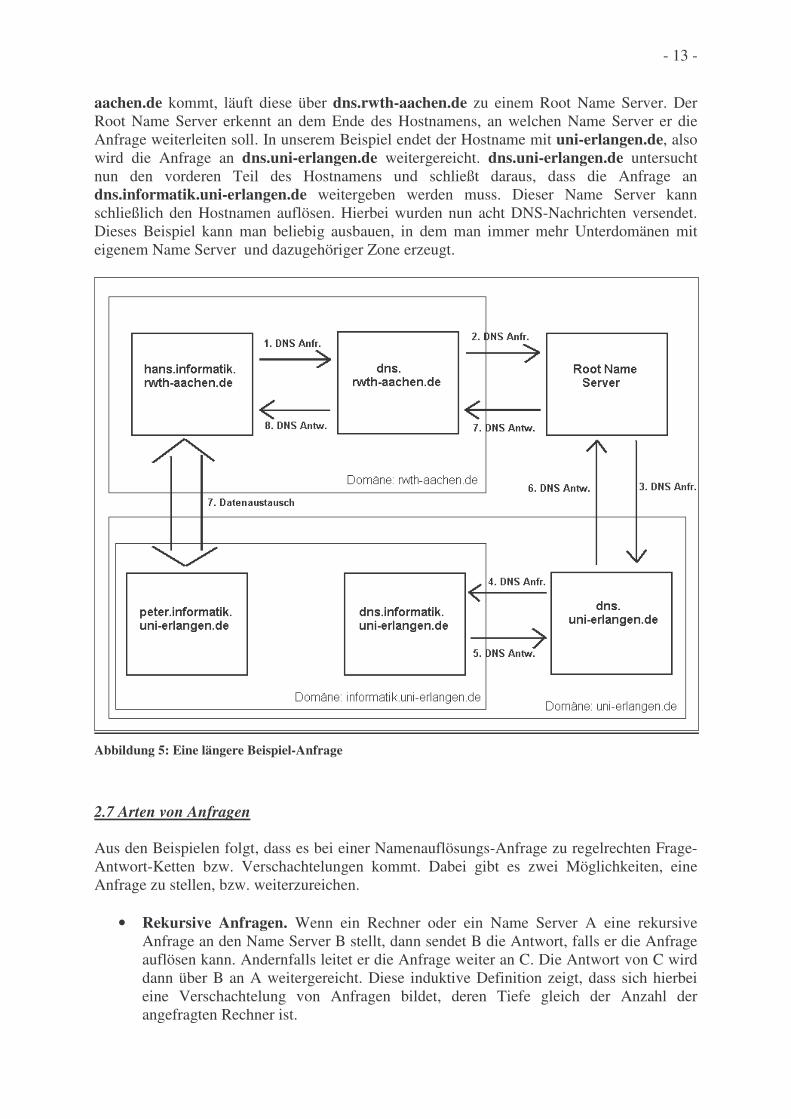
- 13 -
aachen.de kommt, läuft diese über dns.rwth-aachen.de zu einem Root Name Server. Der Root Name Server erkennt an dem Ende des Hostnamens, an welchen Name Server er die Anfrage weiterleiten soll. In unserem Beispiel endet der Hostname mit uni-erlangen.de, also wird die Anfrage an dns.uni-erlangen.de weitergereicht. dns.uni-erlangen.de untersucht nun den vorderen Teil des Hostnamens und schließt daraus, dass die Anfrage an dns.informatik.uni-erlangen.de weitergeben werden muss. Dieser Name Server kann schließlich den Hostnamen auflösen. Hierbei wurden nun acht DNS-Nachrichten versendet. Dieses Beispiel kann man beliebig ausbauen, in dem man immer mehr Unterdomänen mit eigenem Name Server und dazugehöriger Zone erzeugt.
Abbildung 5: Eine längere Beispiel-Anfrage
2.7 Arten von Anfragen Aus den Beispielen folgt, dass es bei einer Namenauflösungs-Anfrage zu regelrechten Frage-Antwort-Ketten bzw. Verschachtelungen kommt. Dabei gibt es zwei Möglichkeiten, eine Anfrage zu stellen, bzw. weiterzureichen.
• Rekursive Anfragen. Wenn ein Rechner oder ein Name Server A eine rekursive Anfrage an den Name Server B stellt, dann sendet B die Antwort, falls er die Anfrage auflösen kann. Andernfalls leitet er die Anfrage weiter an C. Die Antwort von C wird dann über B an A weitergereicht. Diese induktive Definition zeigt, dass sich hierbei eine Verschachtelung von Anfragen bildet, deren Tiefe gleich der Anzahl der angefragten Rechner ist.

- 14 -
• Iterative Anfragen. Wenn ein Rechner oder Name Server A eine iterative Anfrage an den Name Server B stellt und B diese auflösen kann, dann sendet B, genauso wie bei der rekursiven Anfrage, sofort seine Antwort an A. Falls er sie aber nicht auflösen kann, dann sendet B eine Antwort an A, die die IP-Adresse des nächsten Name Servers C enthält. A sendet dann seine Anfrage an C.
Iterative und rekursive Anfrage können beliebig kombiniert werden, aber meistens werden nur die rekursiven Anfragen benutzt. Nur die Anfragen an Root Name Server sind meistens iterativ. Da die Root Name Server riesige Mengen von Daten verwalten, möchte man sie möglichst entlasten (bei iterativen Anfrage wird die Antwort nämlich sofort abgeschickt). Um das Zusammenspiel verschiedener Arten von Anfragen zu erläutern, wird anhand eines Beispiels, in eine Abfolge von rekursiven Anfragen eine iterative eingestreut.
Abbildung 6: Iterative und rekursive Anfragen
Die Vorraussetzungen sollen sein wie im vorigen Beispiel (siehe Abbildung 6). Die (rekursive) Anfrage von Hans wird wie gehabt an den lokalen Name Server gesendet. Der lokale Name Server stellt jetzt aber eine iterative Anfrage an den Root Name Server. D.h. der Root Name Server sendet sofort eine Antwort mit der IP-Adresse eines weiteren Name Servers. In diesem Fall ist das noch nicht die Adresse des Authoritative Name Servers. Wie in Abbildung 5 wird also noch eine rekursive Anfrage gesendet. Der Rückweg verläuft dann über den Authoritative Name Server, den „vermittelnden“ Name Server und den lokalen Name Server zum Rechner vom Hans.

- 15 -
2.8 DNS-Caching Bisher wurde ein wichtiges Feature von DNS noch nicht behandelt, nämlich DNS-Caching. Das DNS nutzt das Caching sehr häufig. Es wird eingesetzt, um die Verzögerungszeit bei der Namensauflösung zu reduzieren und die Anzahl der DNS-Nachrichten zu senken. Um dies zu erreichen, werden all die aufgelösten Hostnamen, die einen Name Server erreichen, auf dem Server zwischen gespeichert, während der aufgelöste Hostname in der Name Server-Kette weiter gereicht wird. Je nachdem, wie schnell auf den Cache zugegriffen werden soll, befindet sich dieser im Hauptspeicher oder auf Festplatten. Falls nun eine Anfrage kommt, die mithilfe des Caches aufgelöst werden kann, wird die Antwort sofort gesendet, obwohl der Rechner, dessen Hostname aufgelöst werden soll sich nicht in der Zone des Name Servers befindet. Um aber Konsistenz-Probleme zu vermeiden, werden die Daten nur für eine bestimmte Zeit im Cache gehalten (ca. zwei Tage). Es ist klar, dass sich im Cache eines Name Servers vorwiegend solche Adressen finden, die populär sind (zumindest in der Domäne des lokalen Name Servers) und deshalb der Zugriff auf diese sehr schnell ist. Das Beispiel zum DNS-Caching fällt sehr kurz aus, da der Mechanismus nicht sonderlich kompliziert ist: Wenn hans.informatik.rwth-aachen.de dem Name Server dns.rwth-aachen.de eine Anfrage zur Auflösung des Hostnamen cnn.com stellt, dann wird das Ergebnis als (Hostname, IP-Adresse) Tupel im Cache des Name Servers zwischen-gespeichert. Falls nun uli.informatik.rwth-aachen.de ebenfalls auf cnn.com zugreifen will, wird nur der lokale Name Server kontaktiert, dieser sendet die Antwort direkt aus seinem Cache, ohne einen anderen Name Server zu kontaktieren.

- 16 -
3 Technische Details Das dritte Kapitel widmet sich den technischen Details des Domain Name System. Als erstes werden die DNS Resource Records, die den Datenbestand des Domain Name System bilden vorgestellt. Die Kommunikation zwischen den Name Servern in Form von DNS Nachrichten wird im zweiten Unterkapitel erläutert. 3.1 DNS-Records Die Name Server bilden zusammen eine verteilte Datenbank, die die Hostnamen IP-Adressen zuordnet. Es stellt sich die Frage, in welcher Weise diese Zuordnungen abgespeichert werden. Um die Daten zu speichern, werden so genannte Resource Records benutzt. Jede DNS-Antwort besteht aus einem oder mehreren Resource Records. Ein Resource Record ist ein Vierer-Tupel, das folgende Felder besitzt: ( Name, Value, Type, TTL ) TTL ist die „Time To Live“, zu Deutsch „Zeit Zu Leben“. Sie gibt an, wann ein Resource Record aus dem Cache gelöscht werden soll. Da das TTL-Feld bei der weiteren Betrachtung der Resource Records keine große Rolle spielt, wird es nicht mehr erwähnt. Die Felder Name und Value hängen vom Type Feld ab. Das Feld Type kann u.a. folgende Werte annehmen:
• Type=A. In diesem Fall ist Name ein Hostname und Value ist die IP-Adresse für diesen Hostnamen. Das Typ-A-Record enthält also eine Antwort mit der Hostname-zu-IP-Adresse-Auflösung. (hans.informatik.rwth-aachen.de, 134.130.226.17, A) ist z.B. ein Typ-A-Resource Record.
• Type=NS. Das Typ-NS-Resource Record kennzeichnet einen für eine Zone
zuständigen Name Server. Es wird also dazu benutzt, die DNS-Anfragen in der Anfragekette weiterzuleiten. Um dieses zu erreichen enthält das Name-Feld eine Domäne und Value ist der Hostname eines Authoritative Name Servers für diese Domäne. Z.B. ist (rwth-aachen.de, dns.rwth-aachen.de, NS) ein Typ-NS-Resource Record.
• Type=CNAME. CNAME steht für Canonical Name. Das Value-Feld enthält hierbei
den kanonischen Hostnamen für den Alias-Hostnamen, der sich im Feld Name befindet. Dieses Record wird dazu benutzt, einem anfragenden Rechner den kanonischen Hostnamen zu einem Alias-Hostnamen zu liefern. (www.rwth-aachen.de, rechner1.intern.rwth-aachen.de, CNAME) ist ein CNAME Record.
• Type=MX. MX steht für Mail eXchange. Wie der Name schon andeutet, wird dieses
Resource Record bei Mail-Servern benutzt und erlaubt Mail-Servern Alias-Namen zu haben. Dieser Resource Record-Typ ist vergleichbar mit dem Typ-CNAME-Resource Records. Value ist dabei der Hostname eines Mail-Servers, der den Alias-Hostnamen Name besitzt. (gmx.de, mail.germany.gmx.net, MX) ist ein MX Resource Record.
• Type=PTR. Dieser Record-Typ bildet eine IP-Adresse auf einen Hostnamen ab. Es
wird verwendet, um IP-Adressen auf den zugehörigen kanonischen Host-Namen abzubilden. Das Name-Feld enthält die umgedrehte IP-Adresse mit .in-addr.arpa dahinter (siehe auch 2.4). Das Value-Feld dieses Resource Records enthält den

- 17 -
kanonischen Hostnamen. (13.4.130.134.in-addr.arpa, hans.inforamtik.rwth-aachen.de, PTR) wäre ein mögliches Typ-PTR-Resource Record, falls der Rechner hans die IP-Adresse 134.130.4.13 besitzt.
• Type=SOA. SOA ist eine Abkürzung für Start Of Authority. Dieses Resource Record
definiert Werte, wie die REFRESH TIME, RETRY TIME, EXPIRE TIME und MINIMUM TTL. Die REFRESH TIME gibt die Zeit an, die vergehen sollte, bevor der Datenbestand des Servers erneuert werden wird. Die RETRY TIME gibt die Zeit an, die nach einem misslungenen Erneuern der Daten verstreichen soll, bevor ein neuer Versuch gestartet wird. EXPIRE TIME ist die Zeit, die die Lebensdauer des Datenbestandes angibt und die MINIMUM TTL legt einen Standardwert für das TTL-Feld aller Resource Records aus der zugehörigen Zone fest. Dieses Record besitzt außerdem noch die Felder MNAME, RNAME und SERIAL. MNAME gibt den Master Server an, also den Server, von dem der Datenbestand primär stammt. RNAME ist die Mailbox des Administrators der Zone. SERIAL ist die Versionsnummer des Datenbestandes. Sie wird bei jedem Update geprüft und angepasst.
Abbildung 7: Eine Anfrage im Detail
Diese Liste von Resource Record Typen ist nicht vollständig. Diejenigen, die hier nicht aufgezählt wurden, sind zum größten Teil niemals aus dem experimentellen Stadium herausgekommen. Wenn ein Name Server zuständig für einen bestimmten Rechner ist, dann enthält er ein Typ-A-Resource Record mit dem Hostnamen und der IP-Adresse des Rechners (Der Name Server muss nicht unbedingt zuständig sein, denn er könnte das Record auch im Cache gespeichert haben). Wenn der Server nicht zuständig ist, dann enthält er ein Typ-NS-Resource Record, welches den DNS-Server der angefragten Domäne oder zumindest eine Referenz auf einen Root Server enthält. Da der DNS-Server im Value-Feld ein Hostname ist, muss der Name Server auch ein Typ-A-Resource Record für den DNS-Server enthalten. Nehmen wir mal an, der Root Server ist für den Rechner hans.informatik.rwth-aachen.de nicht zuständig. Dann muss der Root Server ein Typ-NS-Resource Record enthalten, welches eine Zuordnung der Domäne vom Hostnamen zu einem Name Server enthält. Das Record könnte beispielsweise so aussehen: (rwth-aachen.de, dns.rwth-aachen.de, NS). Um jetzt die
- 18 -
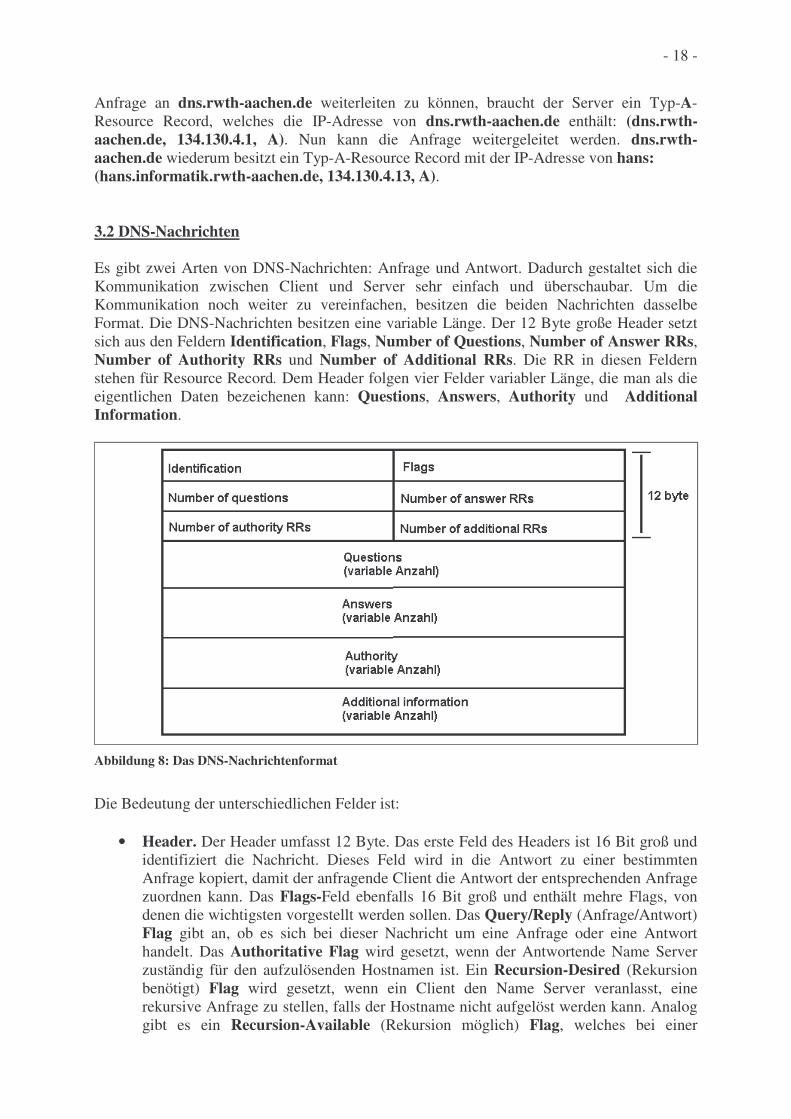
Anfrage an dns.rwth-aachen.de weiterleiten zu können, braucht der Server ein Typ-A-Resource Record, welches die IP-Adresse von dns.rwth-aachen.de enthält: (dns.rwth-aachen.de, 134.130.4.1, A). Nun kann die Anfrage weitergeleitet werden. dns.rwth-aachen.de wiederum besitzt ein Typ-A-Resource Record mit der IP-Adresse von hans: (hans.informatik.rwth-aachen.de, 134.130.4.13, A). 3.2 DNS-Nachrichten Es gibt zwei Arten von DNS-Nachrichten: Anfrage und Antwort. Dadurch gestaltet sich die Kommunikation zwischen Client und Server sehr einfach und überschaubar. Um die Kommunikation noch weiter zu vereinfachen, besitzen die beiden Nachrichten dasselbe Format. Die DNS-Nachrichten besitzen eine variable Länge. Der 12 Byte große Header setzt sich aus den Feldern Identification, Flags, Number of Questions, Number of Answer RRs, Number of Authority RRs und Number of Additional RRs. Die RR in diesen Feldern stehen für Resource Record. Dem Header folgen vier Felder variabler Länge, die man als die eigentlichen Daten bezeichenen kann: Questions, Answers, Authority und Additional Information.
Abbildung 8: Das DNS-Nachrichtenformat
Die Bedeutung der unterschiedlichen Felder ist:
• Header. Der Header umfasst 12 Byte. Das erste Feld des Headers ist 16 Bit groß und identifiziert die Nachricht. Dieses Feld wird in die Antwort zu einer bestimmten Anfrage kopiert, damit der anfragende Client die Antwort der entsprechenden Anfrage zuordnen kann. Das Flags-Feld ebenfalls 16 Bit groß und enthält mehre Flags, von denen die wichtigsten vorgestellt werden sollen. Das Query/Reply (Anfrage/Antwort) Flag gibt an, ob es sich bei dieser Nachricht um eine Anfrage oder eine Antwort handelt. Das Authoritative Flag wird gesetzt, wenn der Antwortende Name Server zuständig für den aufzulösenden Hostnamen ist. Ein Recursion-Desired (Rekursion benötigt) Flag wird gesetzt, wenn ein Client den Name Server veranlasst, eine rekursive Anfrage zu stellen, falls der Hostname nicht aufgelöst werden kann. Analog gibt es ein Recursion-Available (Rekursion möglich) Flag, welches bei einer

- 19 -
Antwort angibt, ob der Server rekursive Anfragen unterstützt. Danach folgen vier Number-of (Anzahl-von)-Felder die die Anzahl von Daten in dem Daten-Feld angeben. Jedes dieser Number-of-Felder ist 16 Bit lang.
• Questions. Die Questions (Antwort)-Sektion enthält Angaben über die Anfrage die
gemacht wird. Die Sektion besteht aus einem Name-Feld, welches den Hostnamen, der aufgelöst werden soll, enthält und einem Type-Feld, das den Typ der Frage enthält (zum Beispiel die Frage nach einer IP-Adresse zu einem Hostnamen – Typ A, oder die Frage nach einem Mail Server zu einer Domäne – Typ MX).
• Answers. Bei einer Antwort eines Name Server enthält die Answers (Antwort)-
Sektion die Resource Records für den aufzulösenden Namen. Zur Erinnerung: Das Resource Record besteht aus den Feldern Name, Value, Type und TTL. Eine Antwort kann mehrere Resource Records enthalten, da ein Hostname mehrere IP-Adressen besitzen kann (siehe auch Abschnitt 2.4: Load Distribution).
• Authority. Die Authority-Sektion enthält Resource Records zu Authoritative Name
Servern.
• Additional Information. Die Additional Information (zusätzliche Informationen)-Sektion besteht aus weiteren “hilfreichen” Informationen in Form von Resource Records. Wenn das Answers-Feld zu einer MX-Anfrage den kanonischen Hostnamen eines Mail-Servers enthält, dann enthält die zusätzliche Sektion ein Typ-A-Resource Record mit der IP-Adresse des Mail-Servers.
In diesem Kapitel wurden die DNS-Nachrichten, die das Auslesen von Informationen aus der DNS-Datenbank ermöglichen, beschrieben. Es stellt sich die Frage, wie die Daten zuvor in die Datenbank kommen. Bisher wurden die Daten meistens per Hand in eine Konfigurations- Datei geschrieben und vom jeweiligen Name Server eingelesen. Vor kurzem aber wurde das DNS-Protokoll erweitert, so dass die Datenbank sich jetzt auch dynamisch mithilfe von DNS-Nachrichten aufbauen lässt. Diese Methode wird in [RFC2136] beschrieben.

- 20 -
4 Schlussbemerkungen Die Schlussbemerkungen gliedern sich in einen Ausblick in die Zukunft des DNS und ein zusammenfassendes Schlusswort über dieses Thema. 4.1 Ausblick Das DNS gibt es in der gleichen Form bereits seit den 80ern, und einige Modifikationen sind überfällig. Probleme, die sich im Laufe der Zeit ergeben haben, sind:
1. Die Auswahl der Top-Level-Domain-Namen ist sehr eingeschränkt, wie man in 2.3
sehen konnte. Es gibt z.B. keine Kategorie für Privatpersonen. 2. Die Namensüberschneidungen von Unternehmen führten zu rechtlichen Auseinander-
setzungen um bestimmte Domain Namen. 3. Im Moment ist die DNS-Administration stark monopolisiert, was zu hohen Preisen
und zu eingeschränktem Service führt(e). Es sind aber Veränderungen im Gange. Die Anzahl der Top-Level-Domain-Namen soll erhöht werden, es soll Wettbewerb bei der Domain Name-Registration erlaubt werden und es sollen Entscheidungs-Methoden bei Namensüberschneidungen erstellt werden. Um dieses zu erreichen, wurden schon viele Vorschläge von den verschiedensten Institutionen eingereicht. Es soll hier ein Vorschlag dargestellt werden. Das „International Ad Hoc Comitee“ (IAHC; www.iahc.org) hat sieben neue Top-Level-Domain-Namen vorgeschlagen:
• Arts. Unter dieser Domain sollen Kunst, Kultur und Unterhaltung zusammengefasst werden.
• Firm. Firmen und Unternehmen fallen unter diese Kategorie.
• Info. Für Organisationen, die Informations-Dienste bereitstellen.
• Nom. Private Seiten.
• Rec. Für Organisationen, die Erholung und Unterhaltung anbieten.
• Store. Kaufmännische Organisationen.
• Web. Für Organisationen und Privatleute, die WWW-Aktivitäten betonen.
Es fallen aber auch gleich Probleme mit diesem Schema auf, z.B. kann man viele Organisationen unter mehr als einer Sparte eintragen. Aber kein Kategorisierungs-Schema kann allen zusagen, und dieses Schema hat den Vorteil, erweiterbar und einfach zu sein. Nebenbei wird es auch von vielen Schlüssel-Organisationen unterstützt. Der Vorschlag vom IAHC enthielt auch Bedingungen zur Vermittlung zwischen mehreren Organisationen, die sich um denselben Domain Namen streiten. Die World Intellectual Property Organisation (WIPO; www.wipo.org) stellt eine Kommission von internationalen Experten zusammen, die bei den soeben beschriebenen Problemen helfend eingreifen soll. Anstelle des heutigen InterNIC-Monopols sollen später ein „Council of Registrars“ mit 28 Mitgliedern entstehen. Die Mitglieder sollen durch eine geographisch festgelegte Lotterie ausgewählt werden. Aus

- 21 -
jeder der vier geographischen Regionen (die noch festgelegt werden müssen) sollen 7 Mitglieder „entsandt“ werden. Es überrascht nicht, dass das InterNIC mit einigen Punkten nicht einverstanden ist, aber die Veränderung des DNS wird das InterNIC nicht aufhalten können. 4.2 Zusammenfassung Das Domain Name System ist kein simpler „Übersetzer“-Dienst, wie er früher mal war. Durch die verschiedenen Anforderungen, die gestellt wurden, und die Problemstallungen, die aufkamen, ist das Domain Name System zu einem komplexen, anpassungsfähigen und dennoch unauffälligen Dienst im Internet geworden. Wenn man das Internet benutzt, dann benutzt man das DNS ohne es zu merken. Trotz seiner Unauffälligkeit ist es grundlegend für das Internet, denn wer würde das Internet benutzen, wenn man ständig IP-Adressen eintippen müsste. Doch auch für Administratoren hat das DNS Vorteile, in Form von freier Namens-gebung in seiner Zone, oder der angesprochenen Verteilung von Bandbreite. Doch es hat sich gezeigt, dass das DNS noch nicht allen Ansprüchen gerecht wird. Sei es durch die Knappheit der Top-Level-Domains oder andere angesprochene Probleme. Die Anpassungen des Domain Name System an heutige Gegebenheiten lassen weiterhin auf sich warten, obwohl die Probleme schon lange bekannt sind. Man kann aber zuversichtlich sein, da die meisten (einflussreichen) Unternehmen an dieser Anpassung arbeiten.

- 22 -
5 Literaturverzeichnis [nag2] Linux Network Administrator Guide, http://www.linuxdoc.org [KR01] James F. Kurose, Ross Keith, „Computer Networking: a top-down approach featuring the Internet“, Addison Wesley, 2001 [RFC799] D. L. Mills, „Internet Name Domains“, http://www.faqs.org/rfcs/rfc799.html, 1981 [RFC819] Zaw-Sing Su, Jon Postel, „The Domain Naming Convention for Internet User Applications“, http://www.faqs.org/rfcs/rfc819.html, 1982 [RFC830] Zaw-Sing Su, „A Distributed System for Internet Name Service“, http://www.faqs.org/rfcs/rfc830.html, 1982 [RFC882] P. Mockapetris, „DOMAIN NAMES - CONCEPTS and FACILITIES“, http://www.faqs.org/rfcs/rfc882.html, 1983 [RFC883] P. Mockapetris, „DOMAIN NAMES - IMPLEMENTATION and SPECIFICATION“, http://www.faqs.org/rfcs/rfc883.html, 1983 [RFC1034] P. Mockapetris, „DOMAIN NAMES - CONCEPTS AND FACILITIES“, http://www.faqs.org/rfcs/rfc1034.html, 1987 [RFC1035] P. Mockapetris, „DOMAIN NAMES - IMPLEMENTATION AND SPECIFICATION“, http://www.faqs.org/rfcs/rfc1035.html, 1987 [RFC2136] P. Vixie, S. Thomson, Y. Rekhter, J. Bound, „Dynamic Updates in the Domain Name System (DNS UPDATE)“, http://www.faqs.org/rfcs/rfc2136.html, 1997