Embed Size (px)
Citation preview

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 1
Rechnerarchitekturen I Pipelining
Dr. Michael Wahl

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 2

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 3
• Der Datenpfad erzeugt einen Fluss in der Aktivität der einzelnen HW-Einheiten – In jedem Takt einer Instruktionsausführung ist nur ein Teil der
verfügbaren Hardware beschäftigt • Ziel: Optimierung der Ressourcenausnutzung
– Aktivierung möglichst vieler der vorhandenen Ressourcen zu jedem Zeitpunkt
– Parallele Bearbeitung mehrerer Instruktionen in Form einer Fließbandverarbeitung
⇒ Pipelining
Ist unsere Hardware gut ausgelastet?

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 4
• Beispiel: Waschsalon – Anna, Bernhard, Corinna und David
haben jeweils eine Ladung Wäsche zu waschen, zu trocknen und zu falten.
– Die Waschmaschine braucht 30 Minuten.
– Der Trockner braucht 40 Minuten
– Das Falten dauert 20 Minuten
Pipelining ist was ganz Normales!
A B C D

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 5
30 20 40
A
30 40 20
B
30 40 20
C
30 40 20
D
18.00 19.00 20.00 21.00 22.00 23.00 0.00
• Der sequentielle Waschsalon braucht 6 Stunden für die 4 Wäscheladungen • Wie lange würde es mit Pipelining dauern?
Beispiel: Sequentieller Waschsalon

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 6
• Der Pipeline-Waschsalon braucht nur 3,5 Stunden für dieselbe Aufgabe
Pipeline-Waschsalon: So früh wie möglich starten
30 40 40
A
40 40 20
B
C
D
18.00 19.00 20.00 21.00 22.00 23.00 0.00

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 7
• Pipelining ändert nichts an der Ausführungszeit für eine Aufgabe, es erhöht den Durchsatz wenn mehrere Aufgaben anliegen.
• Mehrere Aufgaben werden gleich-zeitig unter Nutzung verschiede-ner Ressourcen ausgeführt.
• Maximale Beschleunigung = Anzahl Pipelinestufen
• Die Geschwindigkeit wird durch die langsamste Stufe bestimmt.
• Ungleiche Länge von Pipelinestufen reduziert den Durchsatz.
Was lernen wir aus diesem Beispiel?
A
30 40 40 40 40 20
D
B
C

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 8
• Die Zeit zum Befüllen und Entleeren der Pipeline reduziert den Durchsatz.
• Bei Abhängigkeiten zwischen den einzelnen Pipelinestufen kann es zu Problemen kommen, deren Lösung den maximal erreichbaren Durchsatz herabsetzt.
Was lernen wir aus diesem Beispiel?
A
30 40 40 40 40 20
D
B
C

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 9
Pipelines für Rechnerarchitekturen • Da die Ausführung komplexer Programme heute in der Regel das
Ausführen von Milliarden von Instruktionen bedeutet, ist Durchsatzmaximierung eines der wesentlichen Entwurfsprobleme.
• Für einen MIPS-Datenpfad mit Pipelining sollten folgende Voraussetzungen erfüllt sein: – alle Instruktionen sollten etwa gleich lang sein, – Registerreferenzen sollten in allen Instruktionen an derselben Stelle
platziert sein, – Speicherzugriuffe sollten nur in Lade- und Speicherbefehlen
vorkommen. – Die Einhaltung dieser Voraussetzungen ist durch den früheren Entwurf
des MIPS-Datenpfades bereits sichergestellt.

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 10
• IF: Lade Instruktion aus dem Instruktionsspeicher • ID: Lade Register und decodiere Instruktion • EX: Berechne die Speicheradresse • MEM: Lies die Daten aus dem Datenspeicher • WB: Schreibe die Daten ins Zielregister
Noch einmal: Die Instruktionszyklen am Beispiel des load-Befehls
Zyklus 1 Zyklus 2 Zyklus 3 Zyklus 4 Zyklus 5
IF ID EX MEM WB Load
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 11
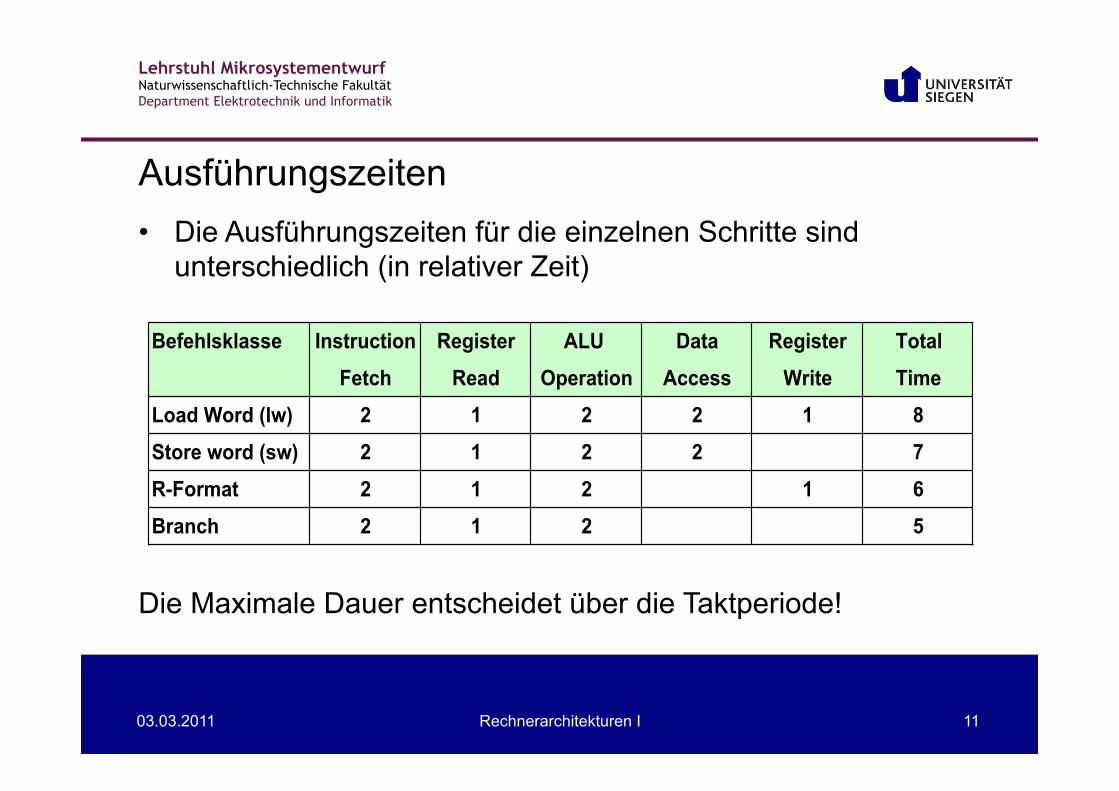
• Die Ausführungszeiten für die einzelnen Schritte sind unterschiedlich (in relativer Zeit)
Die Maximale Dauer entscheidet über die Taktperiode!
Ausführungszeiten
Befehlsklasse Instruction Register ALU Data Register Total
Fetch Read Operation Access Write Time
Load Word (lw) 2 1 2 2 1 8
Store word (sw) 2 1 2 2 7
R-Format 2 1 2 1 6
Branch 2 1 2 5

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 12
Erhöhung des Durchsatzes
Optimaler Steigerungsfaktor: Anzahl Pipeline-Stufen

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 13
• Entwurf des Befehlssatzes – Befehle mit im Idealfall gleicher Länge – Wenige Befehlsformate – Speicheroperationen nur mit Load und Store – Ausgerichtete Daten: Nur ein Speicherzugriff pro Leseoperation
• Mögliche Probleme – Befehle mit variabler Länge
möglicherweise mehrfache Zugriffe für einen Befehl – Nicht ausgerichtete Daten
möglicherweise mehrfache Zugriffe für ein Datum
Vorbedingungen
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 14
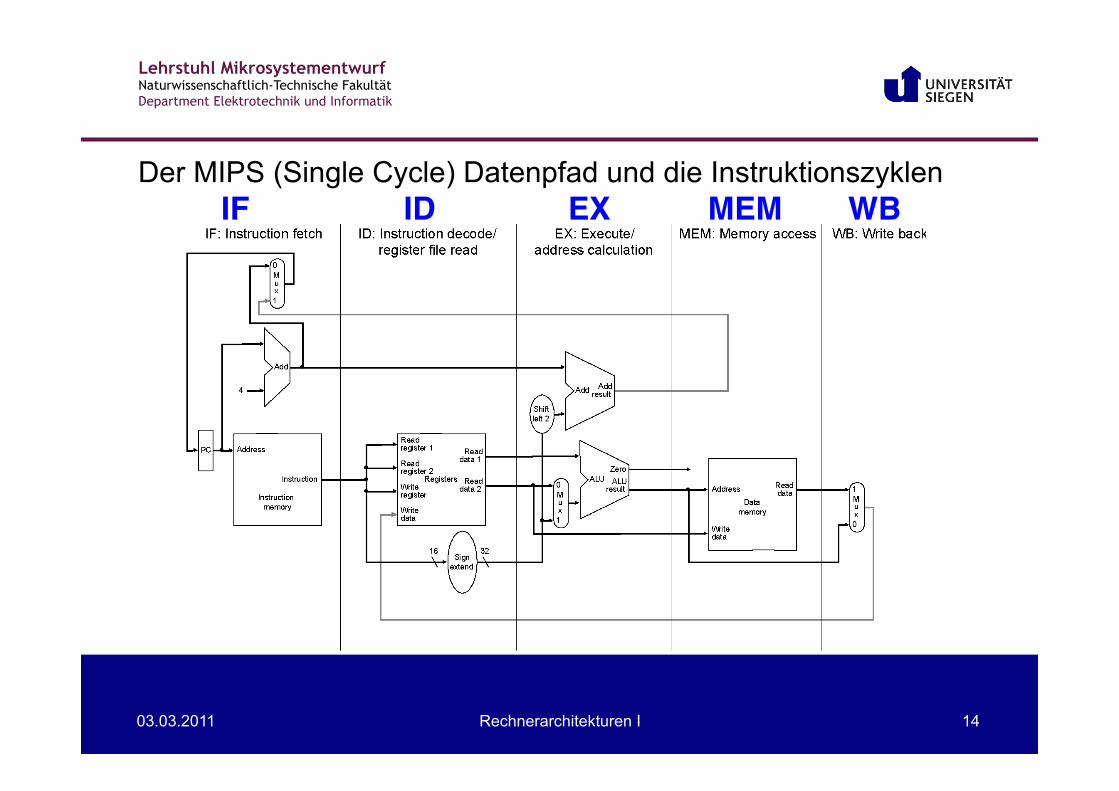
Der MIPS (Single Cycle) Datenpfad und die Instruktionszyklen IF! ID! EX! MEM! WB!
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 15
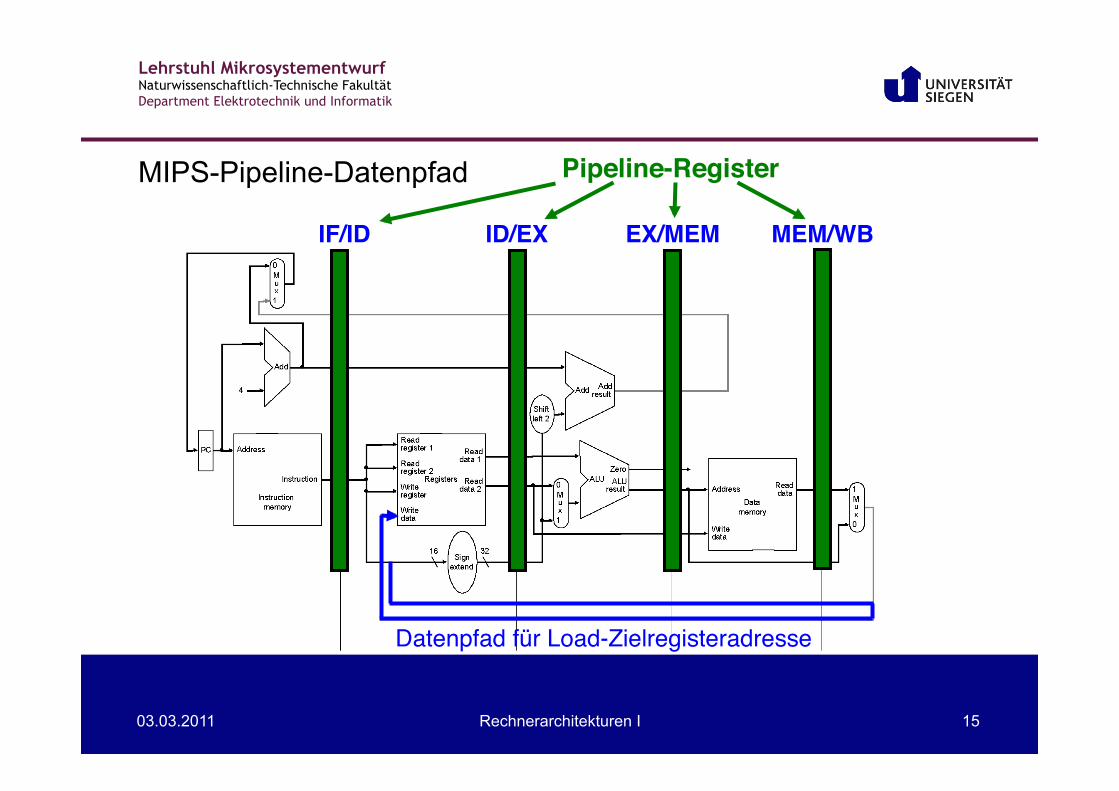
MIPS-Pipeline-Datenpfad
IF/ID! ID/EX! EX/MEM! MEM/WB!
Pipeline-Register!
Datenpfad für Load-Zielregisteradresse"

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 16
• Pipeline mit 5 Stufen • Optimale Nutzung
5 Befehle gleichzeitig aktiv • Anfangsphase:
Füllen der Pipeline • Betriebsphase:
Gleichzeitige Bearbeitung der Befehle • Endphase:
Leeren der Pipeline • Beispiele: lw, sub
Mehrere Befehle gleichzeitig
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 17
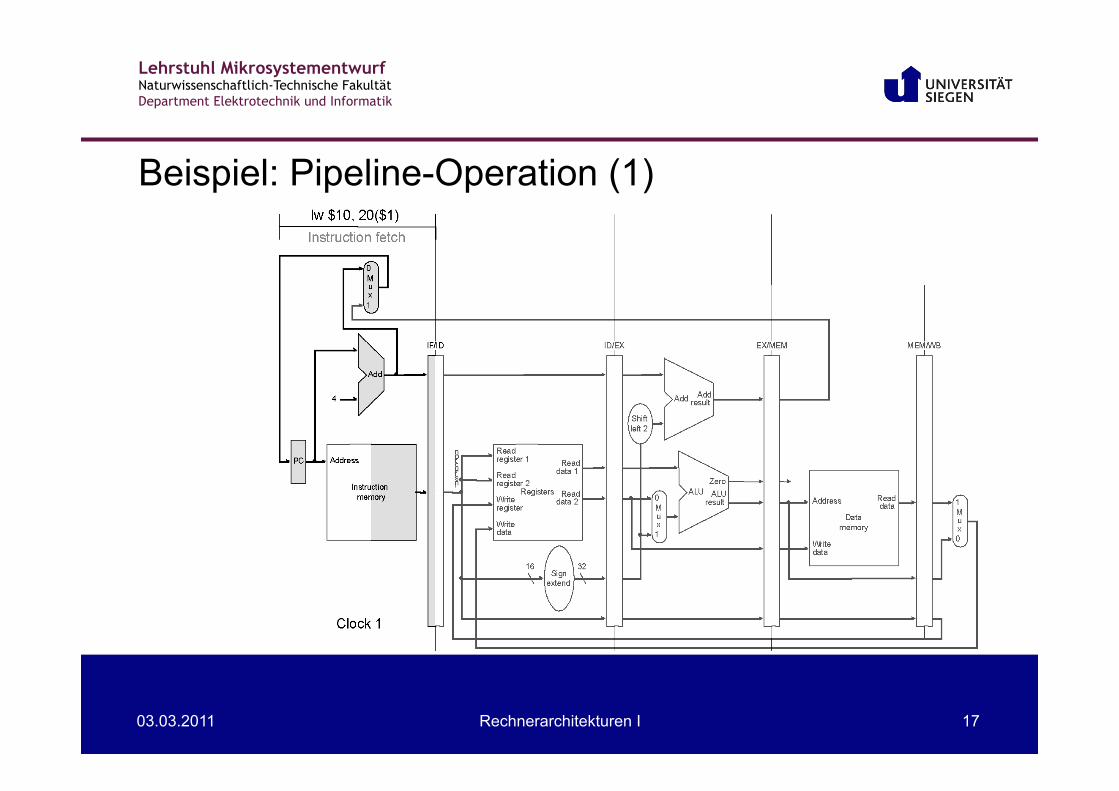
Beispiel: Pipeline-Operation (1)
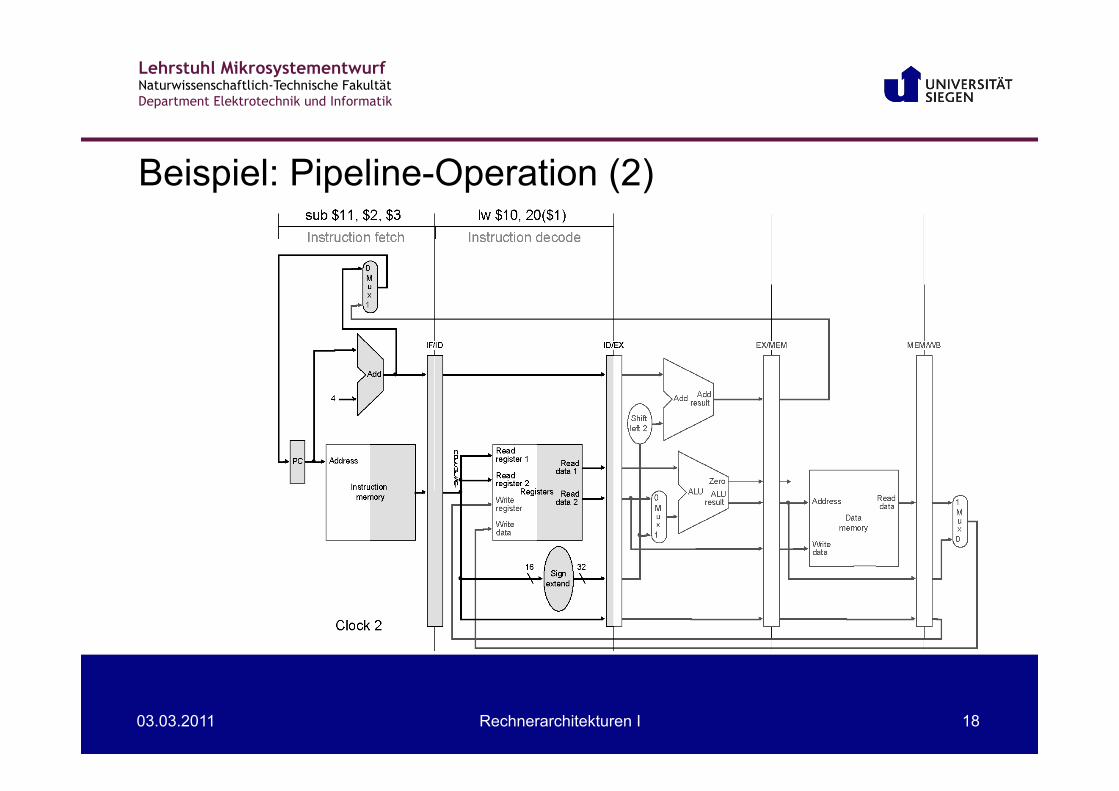
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 18
Beispiel: Pipeline-Operation (2)
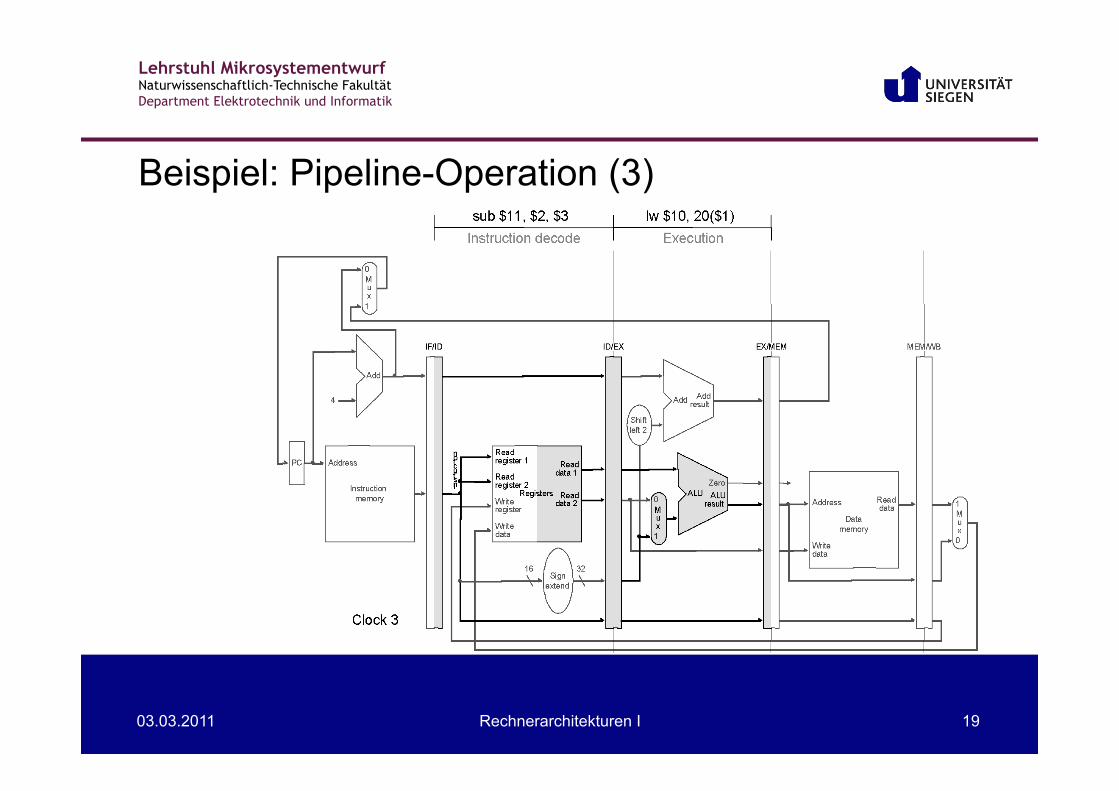
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 19
Beispiel: Pipeline-Operation (3)
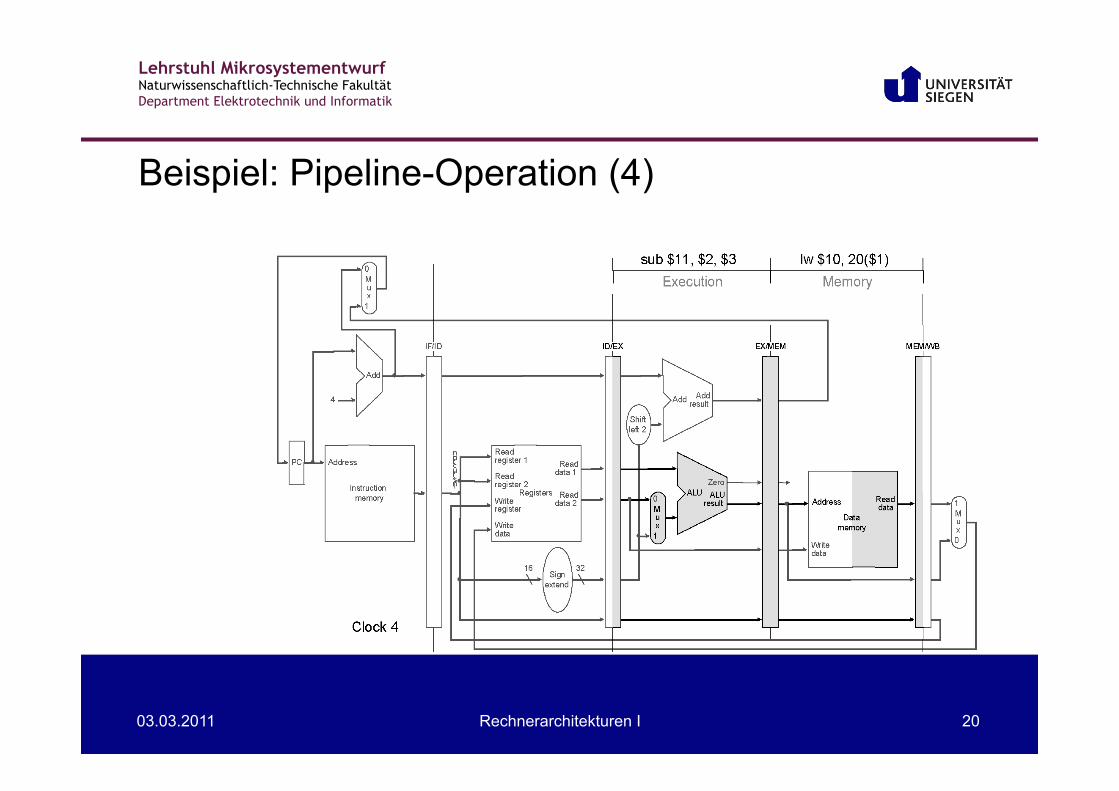
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 20
Beispiel: Pipeline-Operation (4)
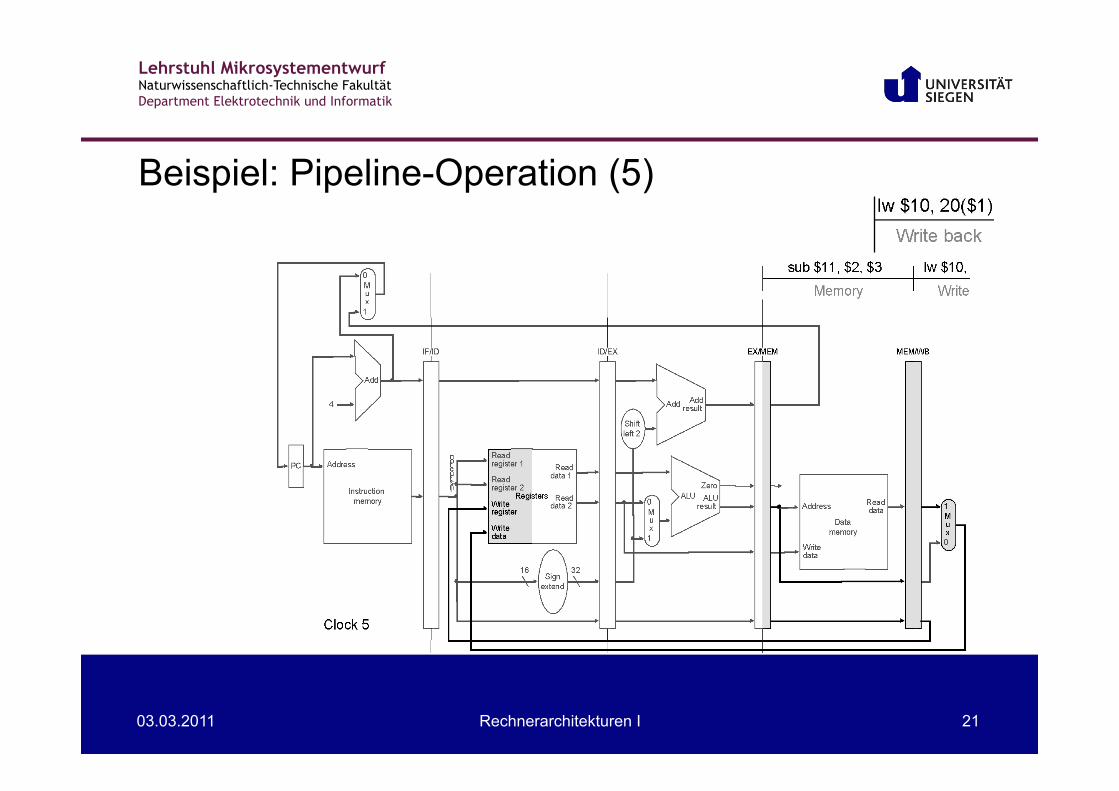
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 21
Beispiel: Pipeline-Operation (5)
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 22
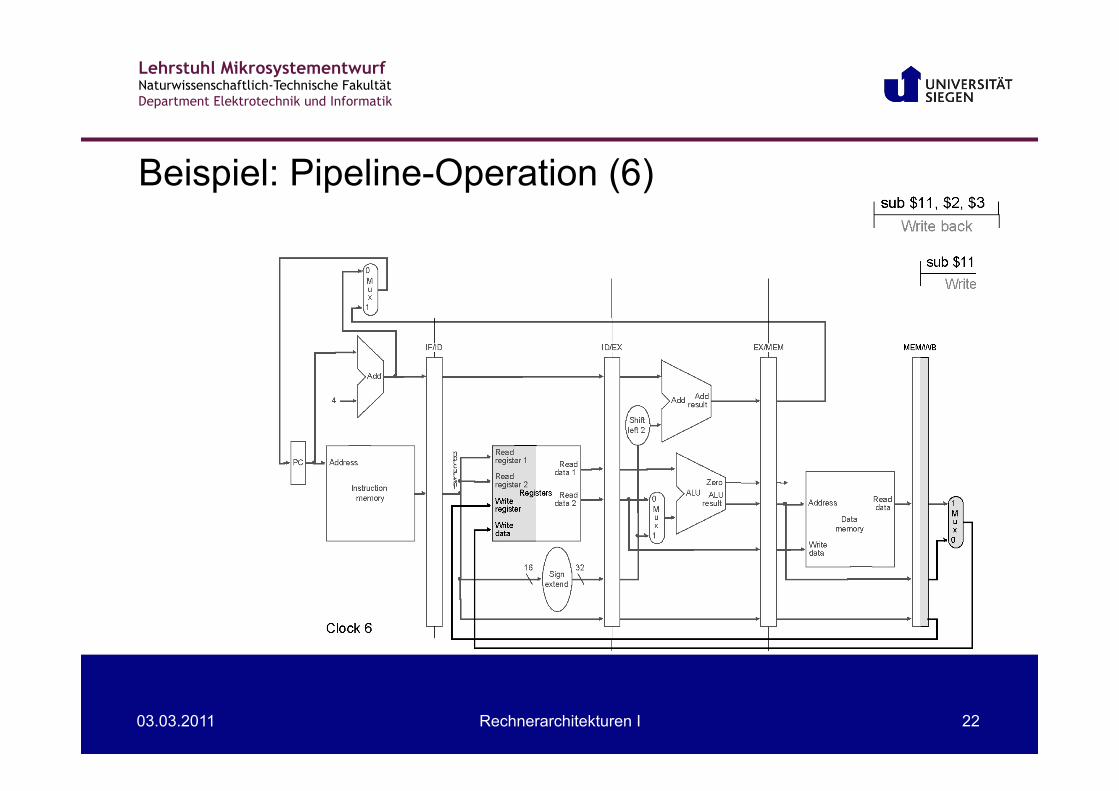
Beispiel: Pipeline-Operation (6)

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 23
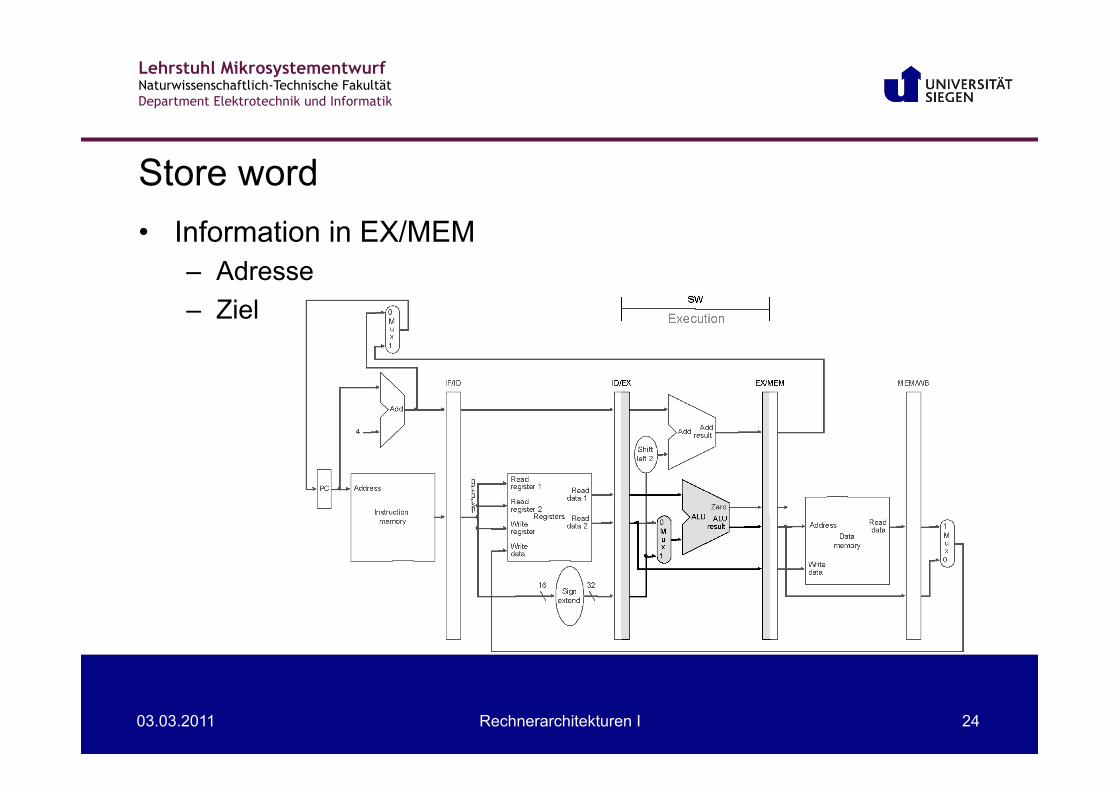
Store word • Instruction fetch:
wie vorher • Instruction decode and register file read:
wie vorher • Execute:
wie bisher, ggf. Forwarding der Registerinhalte in das EX/MEM Pipeline-Register
• Memory Daten und Adresse an den Speicher
• Letzter Schritt Nichts passiert
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 24
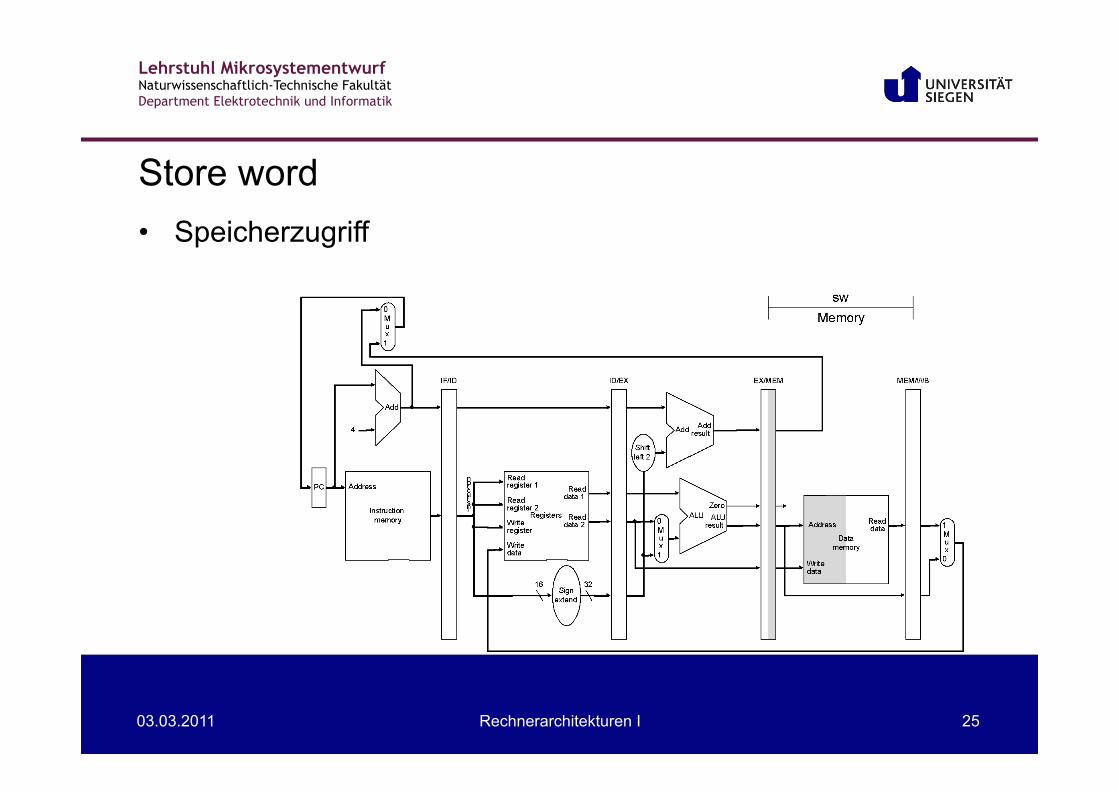
Store word • Information in EX/MEM
– Adresse – Ziel
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 25
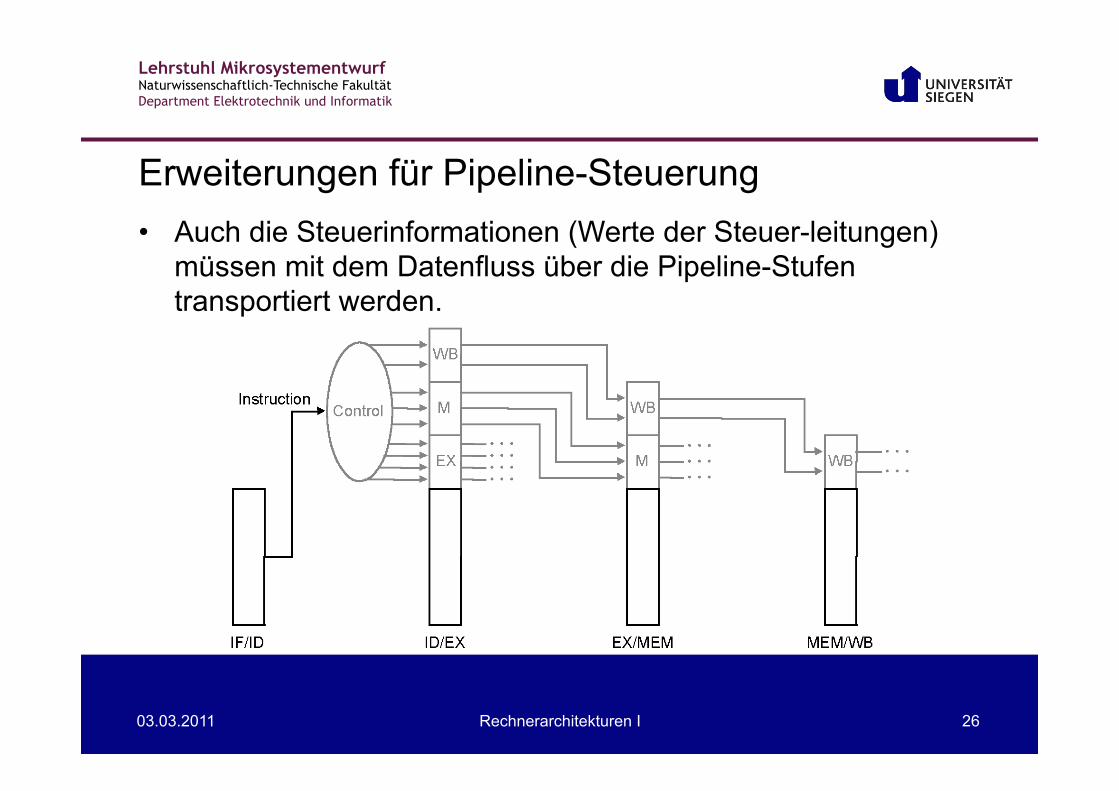
Store word • Speicherzugriff
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 26
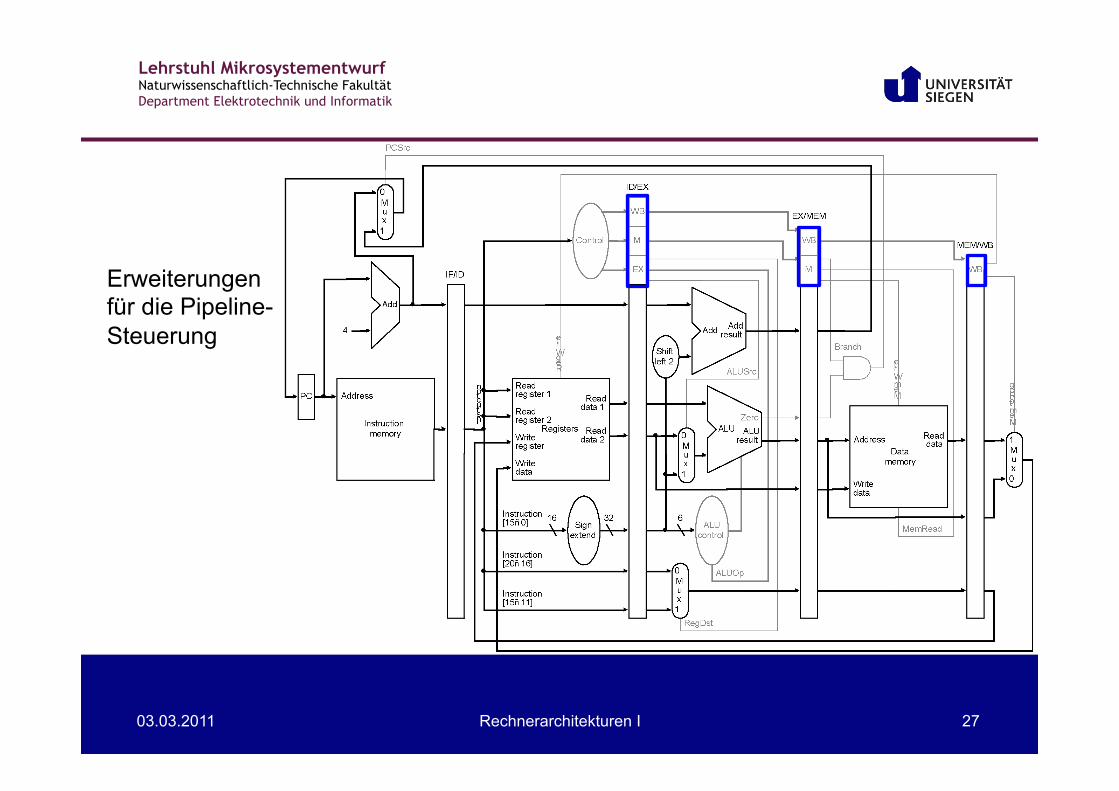
• Auch die Steuerinformationen (Werte der Steuer-leitungen) müssen mit dem Datenfluss über die Pipeline-Stufen transportiert werden.
Erweiterungen für Pipeline-Steuerung
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 27
Erweiterungen für die Pipeline-Steuerung
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 28
ALU
ALU
RegRegIM DM
RegIM DM
Time (in Clock Cycles)
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7
Prog
ram
Exe
cutio
n O
rder
(in
Inst
ruct
ions
)
Reg
RegIM DM RegALU
RegIM DM RegALU
RegIM DM RegALU
I n s t r. F o l g e
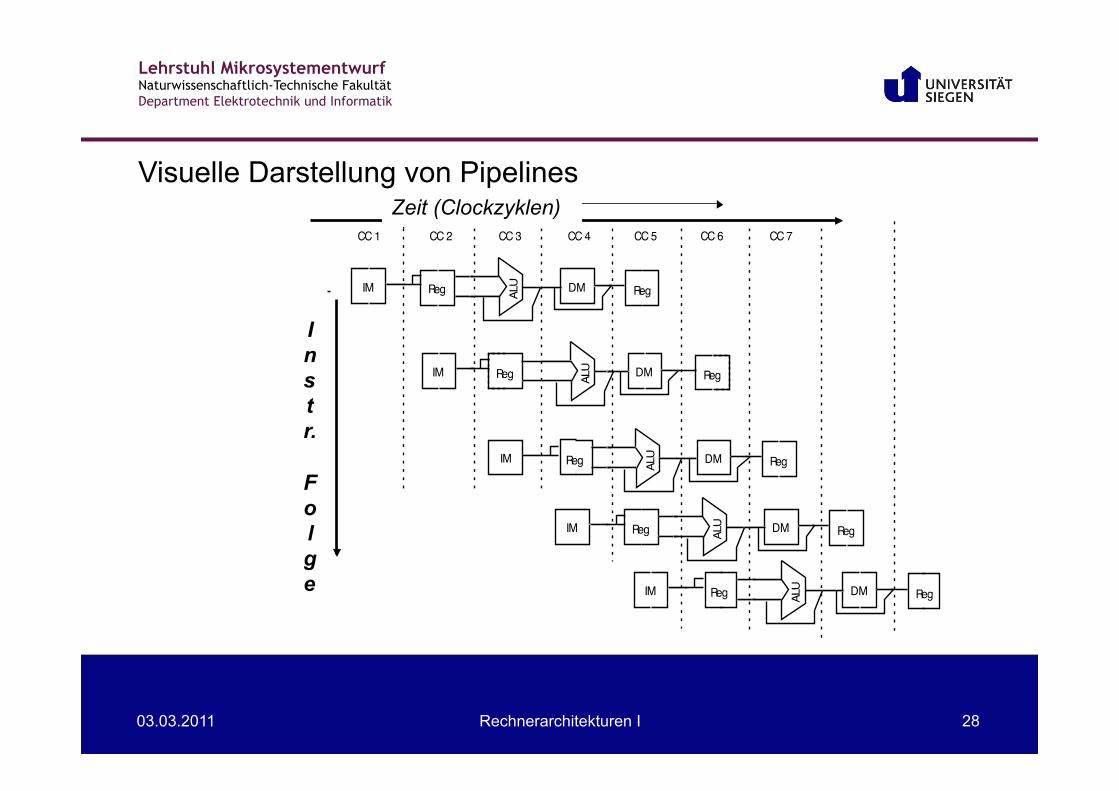
Zeit (Clockzyklen) Visuelle Darstellung von Pipelines
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 29
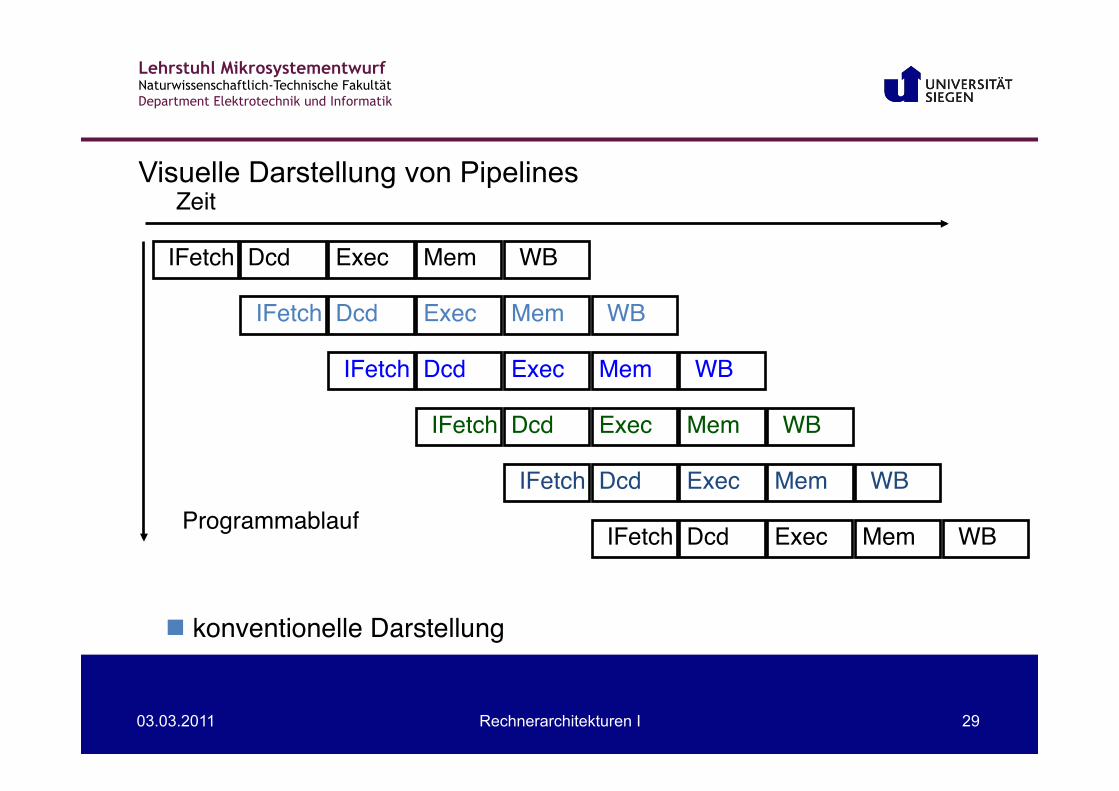
Visuelle Darstellung von Pipelines
IFetch" Dcd" Exec" Mem" WB"
IFetch" Dcd" Exec" Mem" WB"
IFetch" Dcd" Exec" Mem" WB"
IFetch" Dcd" Exec" Mem" WB"
IFetch" Dcd" Exec" Mem" WB"
IFetch" Dcd" Exec" Mem" WB"Programmablauf"
Zeit"
n konventionelle Darstellung"

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 30
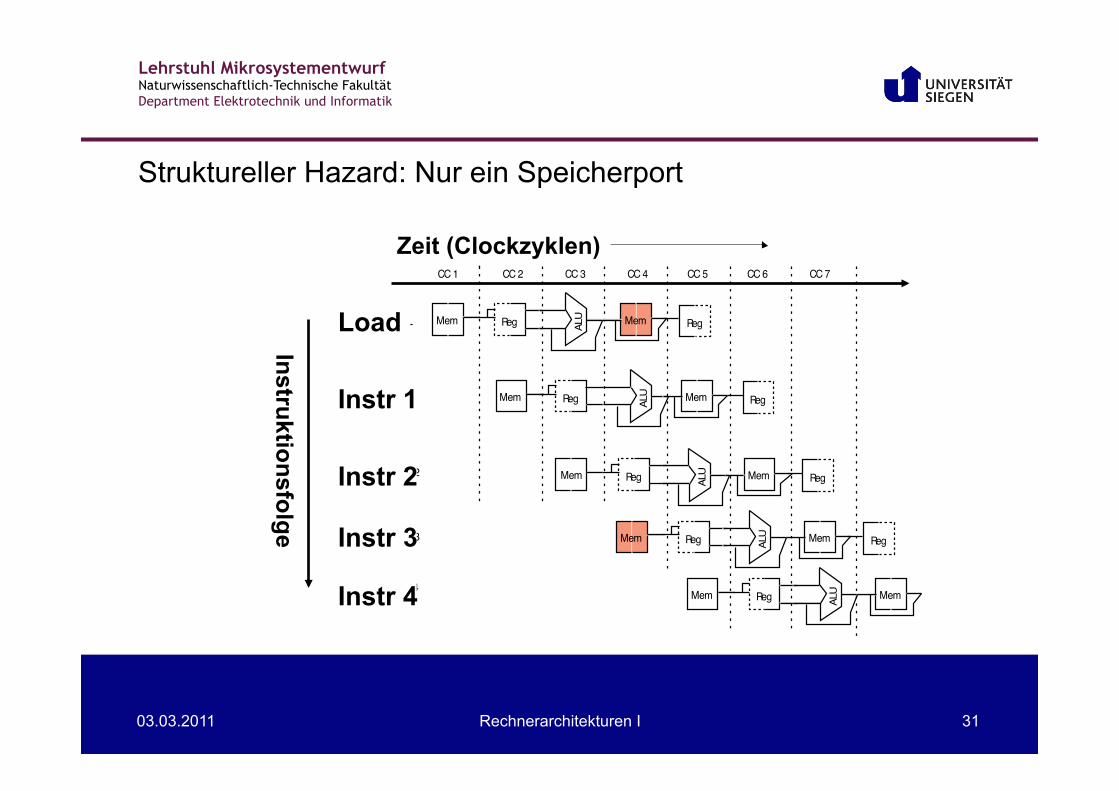
• Grenzen des Pipelining: Hazards (Konflikte) verhindern, dass die nächste Instruktion während des ihr eigentlich zustehenden Taktzyklus ausgeführt werden kann: – Strukturelle Hazards: HW kann die gewünschte Kombination
von Instruktionen nicht unterstützen. – Datenhazards: Instruktion ist von den Ergebnissen einer früher
in der Pipeline stehenden Instruktion abhängig. – Steuerungshazards: Die Folgeinstruktion in der Pipeline ist
nicht die, die wirklich als nächste ausgeführt werden soll: Tritt bei bedingten Sprungbefehlen auf.
Leider geht das Alles nicht so einfach!
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 31
Struktureller Hazard: Nur ein Speicherport
ALU
ALU
RegRegMem Mem
RegMem Mem
Time (in Clock Cycles)
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7
Reg
RegMem Mem RegALU
RegMem Mem RegALU
RegMem MemALU
Load
Instruction 1
Instruction 2
Instruction 3
Instruction 4
Zeit (Clockzyklen)
Load
Instr 1
Instr 2
Instr 3
Instr 4
Instruktionsfolge
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 32
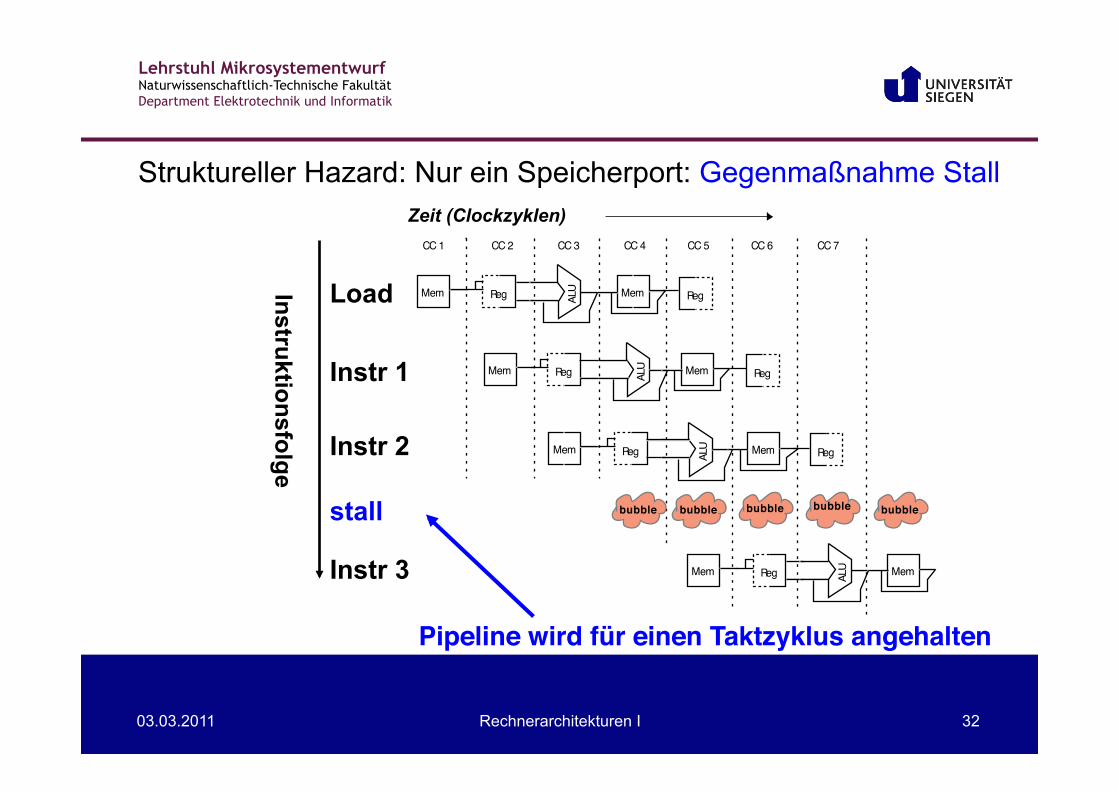
Struktureller Hazard: Nur ein Speicherport: Gegenmaßnahme Stall
ALU
ALU
RegRegMem Mem
RegMem Mem
Time (in Clock Cycles)
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7
Reg
RegMem Mem RegALU
RegMem MemALU
Load
Instruction 1
Instruction 2
Instruction 3
stall bubble bubble bubble bubble bubble
Load
Instr 1
Instr 2
stall
Instr 3
Zeit (Clockzyklen)
Pipeline wird für einen Taktzyklus angehalten!
Instruktionsfolge
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 33
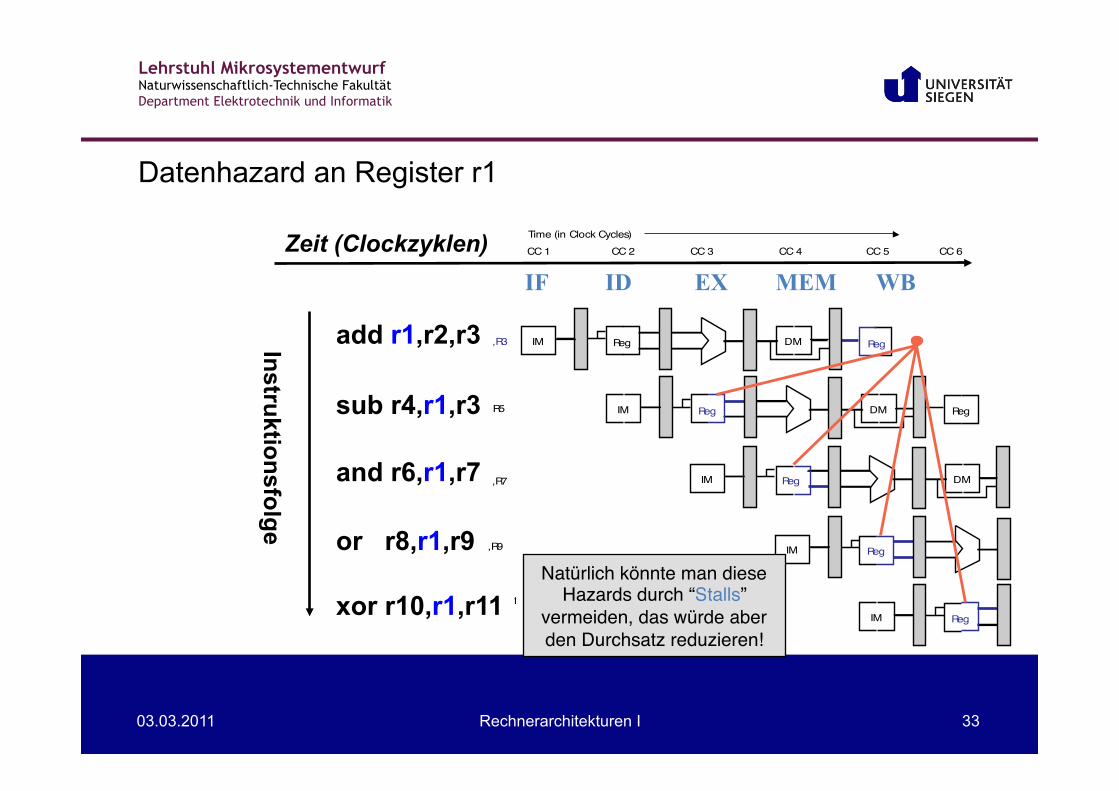
Datenhazard an Register r1
Reg
Reg
IM DM
RegIM DM
RegIM DM
RegIM
RegIM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6Time (in Clock Cycles)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
XORR10,R1,R11
Prog
ram
Exec
ution
Ord
er (in
Instr
uctio
ns) Reg
Zeit (Clockzyklen)
add r1,r2,r3 sub r4,r1,r3 and r6,r1,r7 or r8,r1,r9 xor r10,r1,r11
IF ID EX MEM WB
Natürlich könnte man diese"Hazards durch “Stalls”"
vermeiden, das würde aber"den Durchsatz reduzieren!"
Instruktionsfolge
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 34
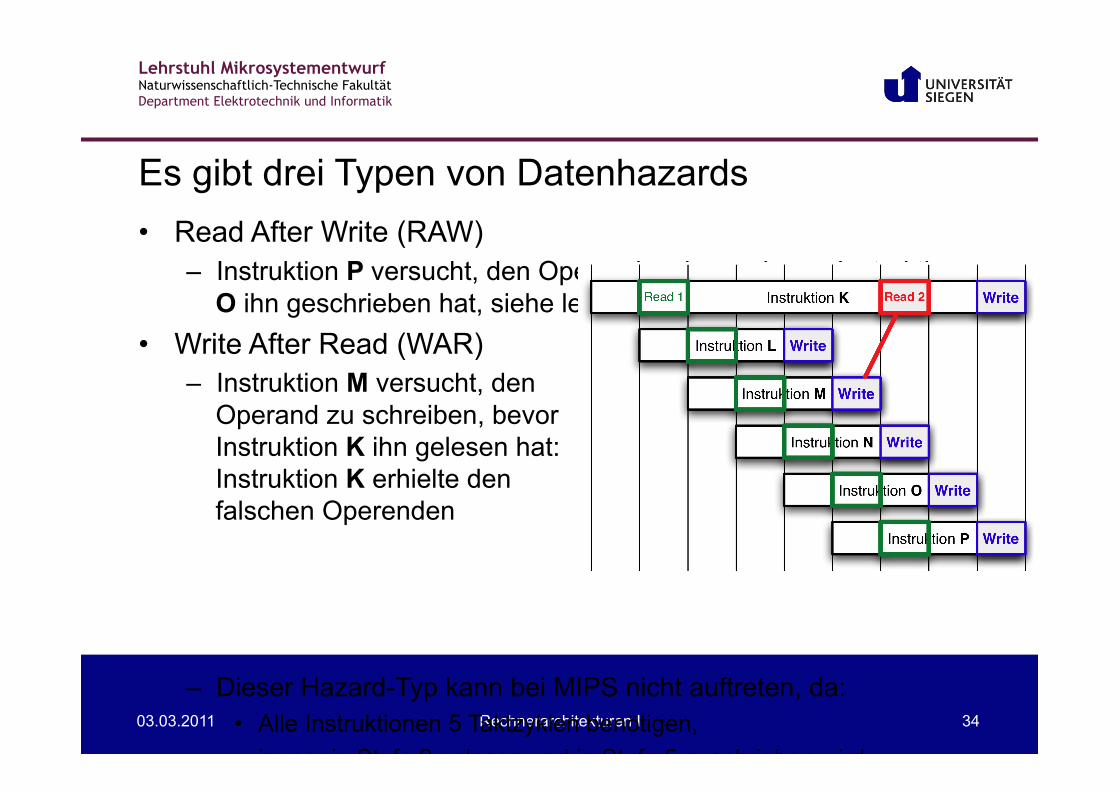
• Read After Write (RAW) – Instruktion P versucht, den Operand zu lesen, bevor Instruktion
O ihn geschrieben hat, siehe letzte Folie. • Write After Read (WAR)
– Instruktion M versucht, den Operand zu schreiben, bevor Instruktion K ihn gelesen hat: Instruktion K erhielte den falschen Operenden
– Dieser Hazard-Typ kann bei MIPS nicht auftreten, da: • Alle Instruktionen 5 Taktzyklen benötigen, • immer in Stufe 2 gelesen und in Stufe 5 geschrieben wird
Es gibt drei Typen von Datenhazards
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 35
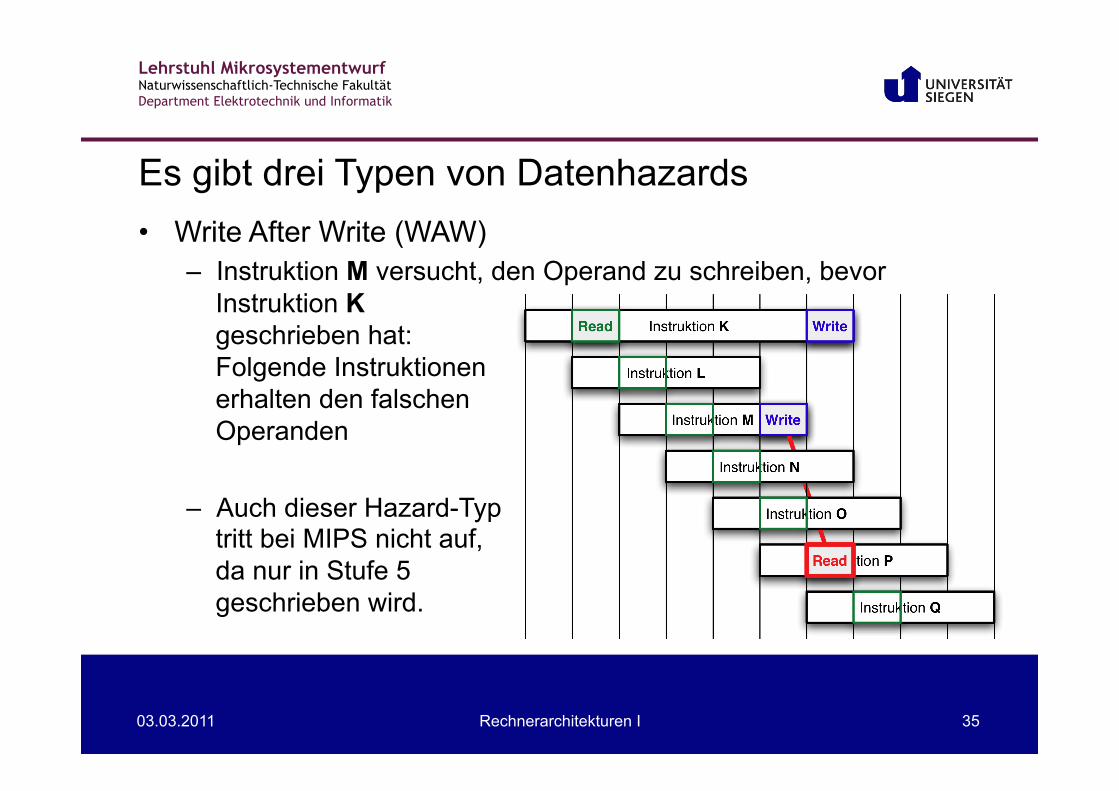
• Write After Write (WAW) – Instruktion M versucht, den Operand zu schreiben, bevor
Instruktion K geschrieben hat: Folgende Instruktionen erhalten den falschen Operanden
– Auch dieser Hazard-Typ
tritt bei MIPS nicht auf, da nur in Stufe 5 geschrieben wird.
Es gibt drei Typen von Datenhazards

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 36
Datenhazard an Register r1: Gegenmaßnahme: Forwarding
Reg
Reg
IM DM
RegIM DM
RegIM DM
RegIM
RegIM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6Time (in Clock Cycles)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
XORR10,R1,R11
Prog
ram
Exe
cutio
n O
rder
(in
Instr
uctio
ns)
Reg
Zeit (Clockzyklen)
add r1,r2,r3 sub r4,r1,r3
and r6,r1,r7
or r8,r1,r9 xor r10,r1,r11
Instruktionsfolge
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 37
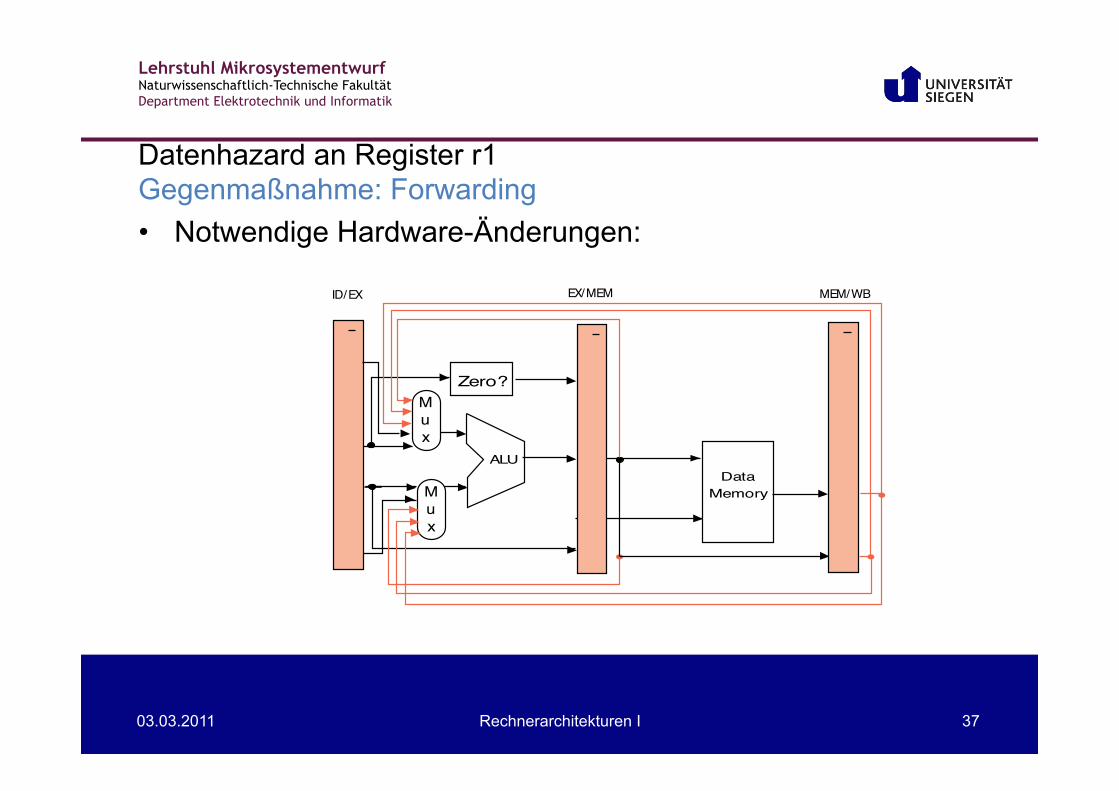
• Notwendige Hardware-Änderungen:
Datenhazard an Register r1 Gegenmaßnahme: Forwarding
Mux
DataALU
Memory
Mux
Zero?
ID/EX EX/MEM MEM/WB
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 38
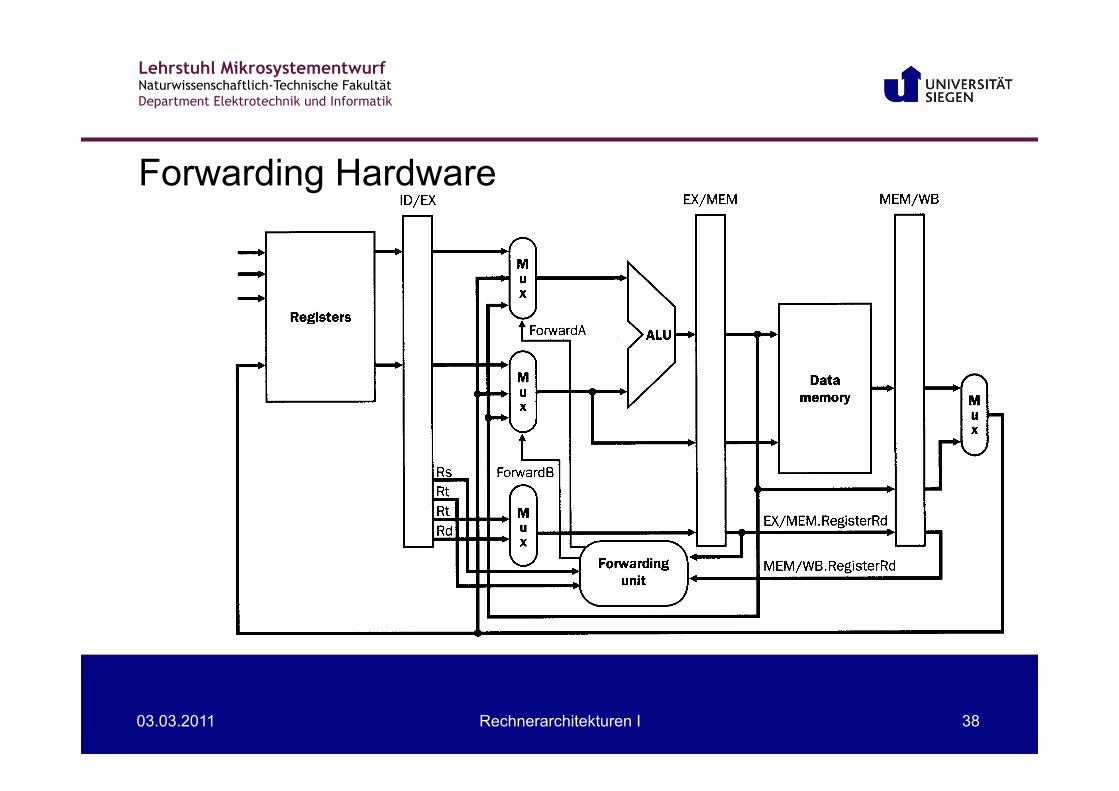
Forwarding Hardware
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 39
RegIM DM
RegIM DM
RegIM
RegIM
CC 1 CC 2 CC 3 CC 4 CC 5Time (in Clock Cycles)
LW R1,0(R1)
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
Prog
ram
Exe
cutio
n O
rder
(in
Inst
ruct
ions
) Reg
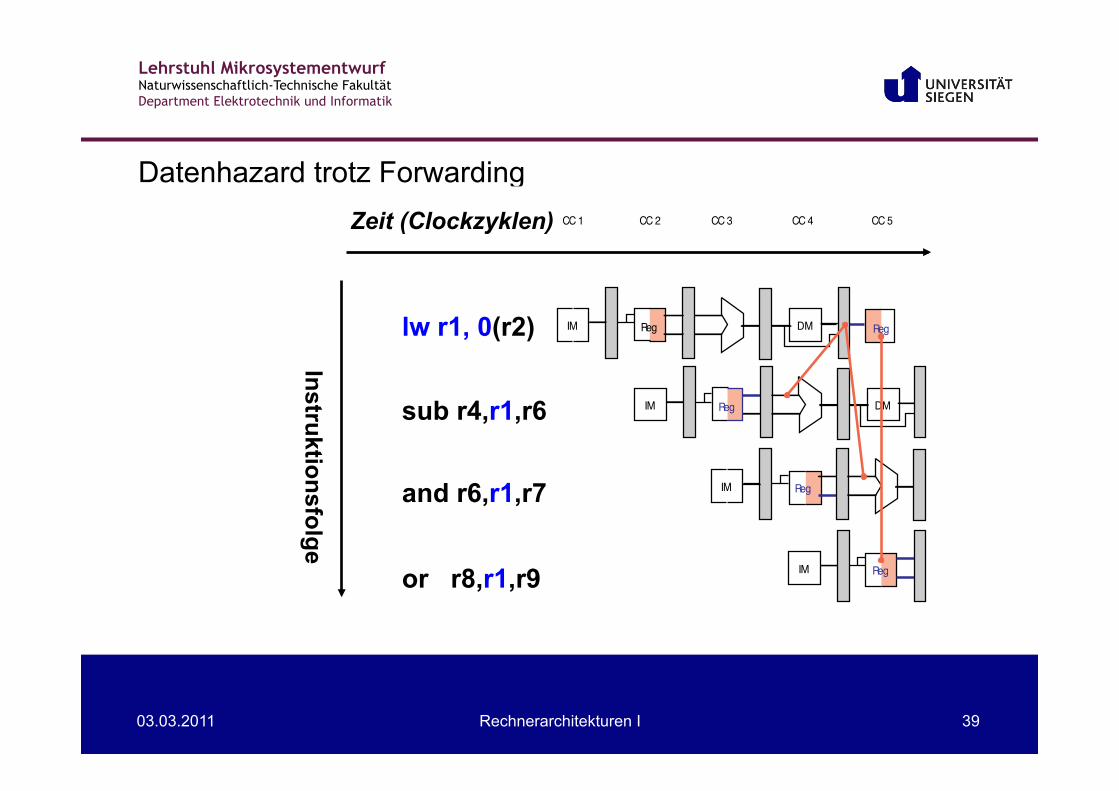
Datenhazard trotz Forwarding
lw r1, 0(r2)
sub r4,r1,r6
and r6,r1,r7
or r8,r1,r9
Zeit (Clockzyklen)
Instruktionsfolge
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 40
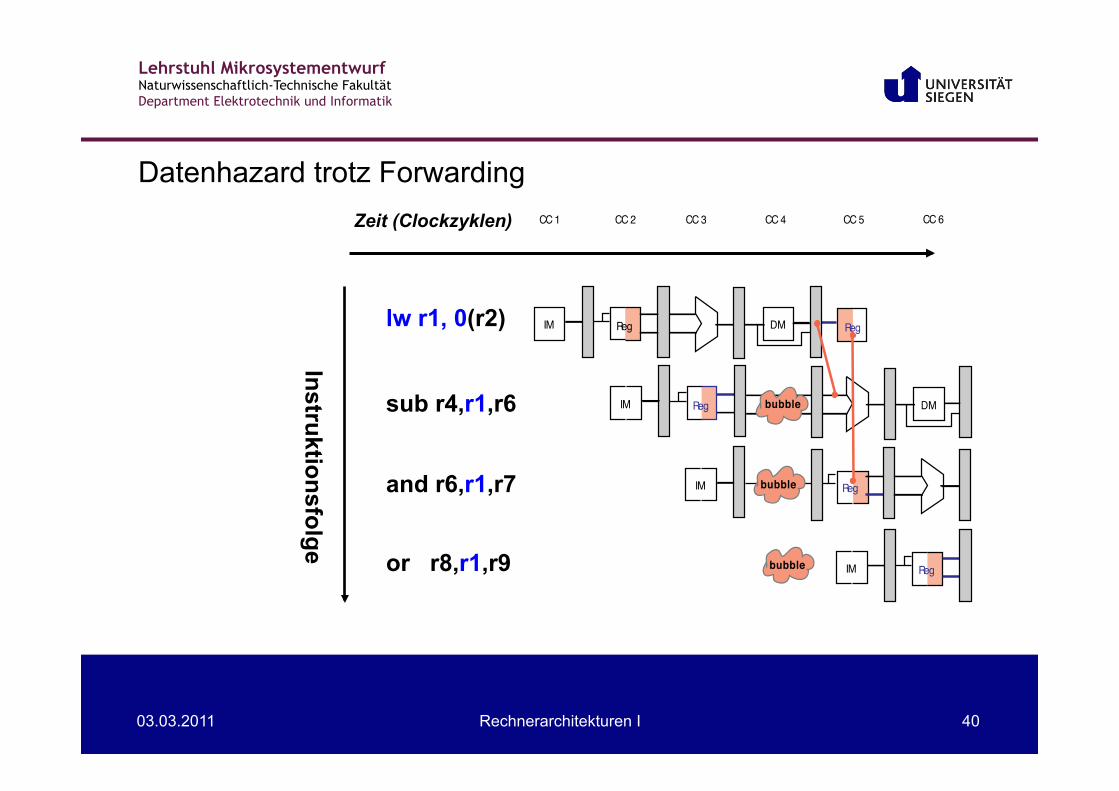
Datenhazard trotz Forwarding
RegIM DM
RegIM DM
RegIM
RegIM
CC 1 CC 2 CC 3 CC 4 CC 5Time (in Clock Cycles)
LW R1,0(R1)
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
Prog
ram
Exe
cutio
n O
rder
(in
Inst
ruct
ions
) Reg
bubble
bubble
CC 6
bubble
Zeit (Clockzyklen)
lw r1, 0(r2) sub r4,r1,r6 and r6,r1,r7 or r8,r1,r9
Instruktionsfolge
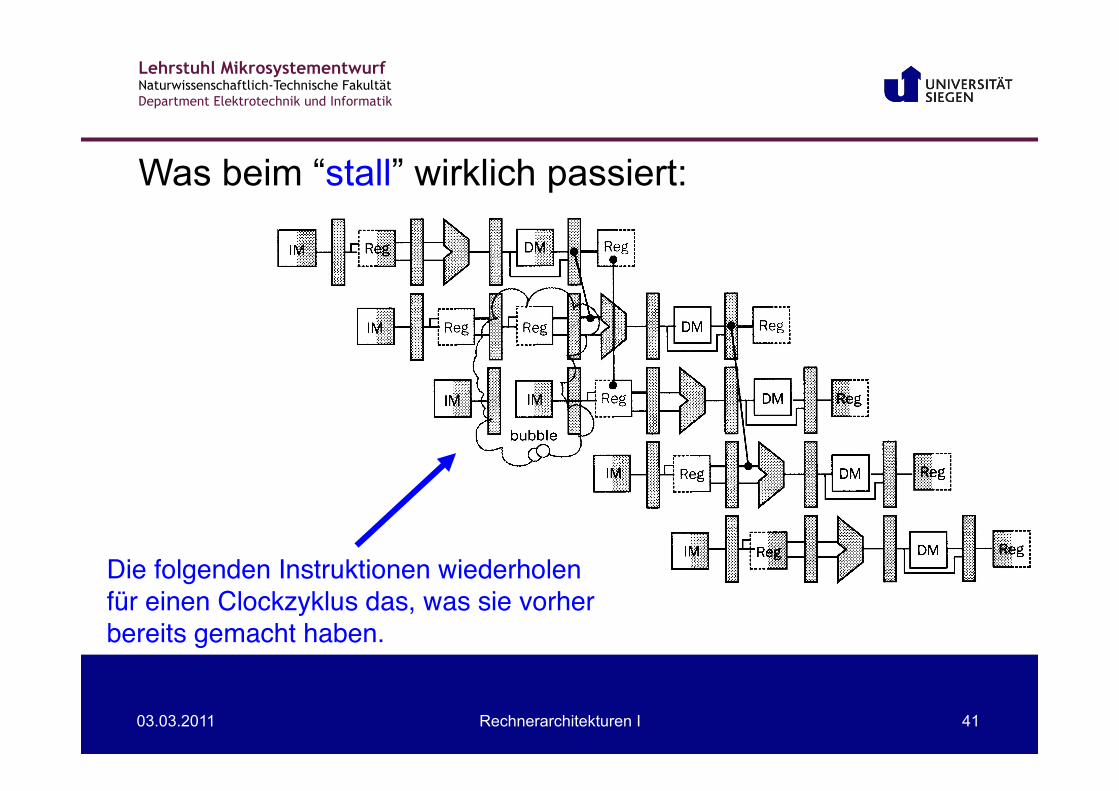
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 41
Was beim “stall” wirklich passiert:
Die folgenden Instruktionen wiederholen"für einen Clockzyklus das, was sie vorher"bereits gemacht haben."
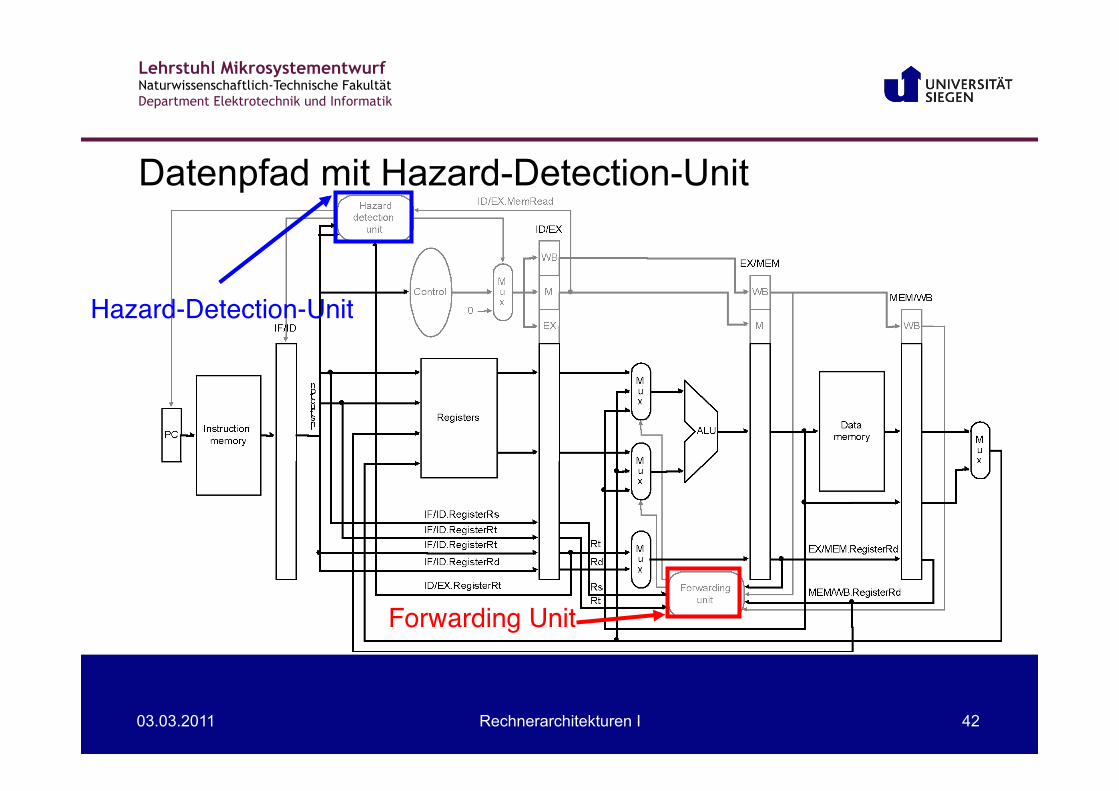
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 42
Datenpfad mit Hazard-Detection-Unit
Hazard-Detection-Unit"
Forwarding Unit"
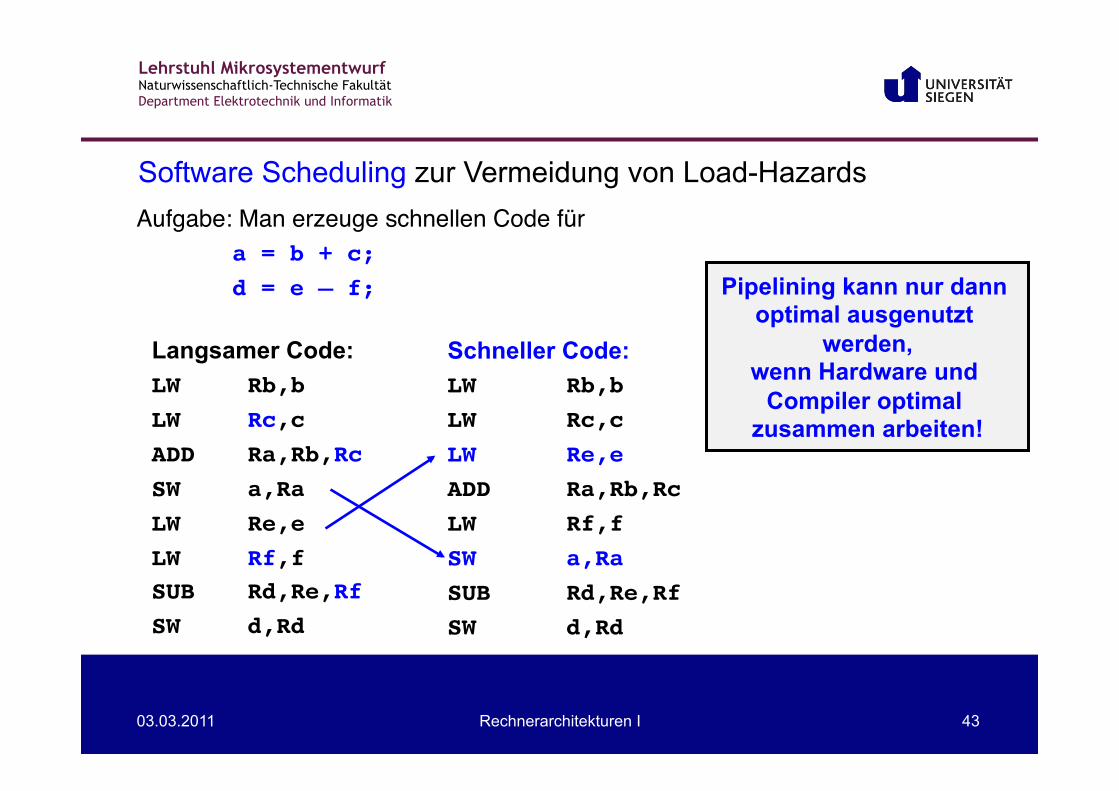
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 43
Langsamer Code: LW !Rb,b!LW !Rc,c!ADD !Ra,Rb,Rc!SW !a,Ra !LW !Re,e !LW !Rf,f!SUB !Rd,Re,Rf!SW! !d,Rd!
Schneller Code: LW !Rb,b!LW !Rc,c!LW !Re,e !ADD !Ra,Rb,Rc!LW !Rf,f!SW !a,Ra !SUB !Rd,Re,Rf!SW! !d,Rd!
Software Scheduling zur Vermeidung von Load-Hazards
Pipelining kann nur dann optimal ausgenutzt
werden, wenn Hardware und
Compiler optimal zusammen arbeiten!
Aufgabe: Man erzeuge schnellen Code für!! !a = b + c;!! !d = e – f;!
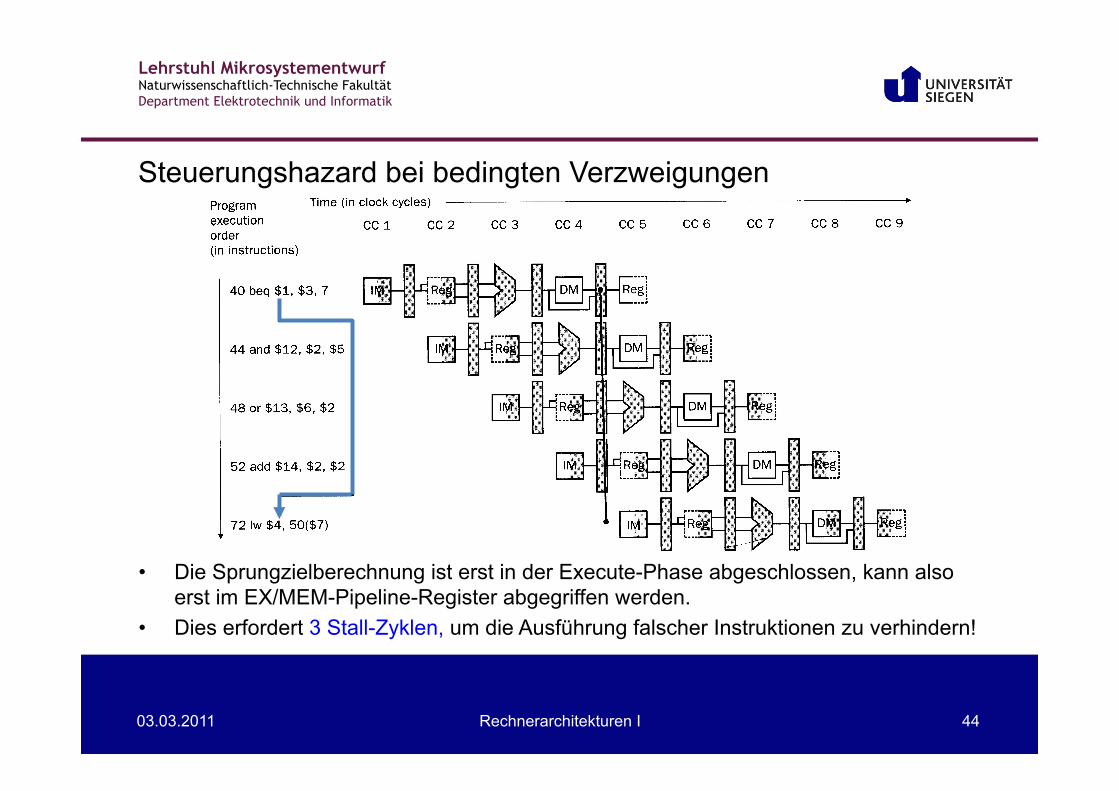
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 44
• Die Sprungzielberechnung ist erst in der Execute-Phase abgeschlossen, kann also erst im EX/MEM-Pipeline-Register abgegriffen werden.
• Dies erfordert 3 Stall-Zyklen, um die Ausführung falscher Instruktionen zu verhindern!
Steuerungshazard bei bedingten Verzweigungen

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 45
• Zusätzliche Hardware – Berechnung des Verzweigungsziels kann in der ID-Phase beginnen.
• Es sind die zu vergleichenden Register bekannt. Der Vergleich kann durch Spezialhardware (EXOR und NAND) sehr schnell erfolgen.
• Der korrekte Ziel-PC-Wert kann durch einen zusätzlichen Addierer bereits in der ID-Phase berechnet werden.
• Somit ist nur noch ein Stall-Schritt erforderlich. – Steuerungsfunktionen für den Stall-Schritt
• Es darf kein neuer Befehl im Anschluss an einen Verzweigungsbefehl gelesen werden.
• Dazu ist ein Schreiben des PC zu verhindern und ebenso ein Weiterleiten der Informationen im IF/ID-Register.
• Die entsprechenden Steuersingale sind auf “0” zu setzen.
Reduzieren der Anzahl an Branch-Stall-Zyklen

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 46
Datenpfad für Pipelines mit nur einem Brach-Stall-Zyklus
Branch Hardware-Modifikation

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 47
• Stall-Zyklen, warten bis zur Entscheidung. • Vorhersagen
– Statische Vorhersage - einfach, aber inneffektiv und daher veraltet • Predict Branch Not Taken
– Die unmittelbar folgende Instruktion wird ausgeführt. – Wird verzweigt, müssen die begonnenen Instruktionen annulliert werden.
• Predict Branch Taken – Beginnen der Ausführung der Instruktionen, die am Sprungziel stehen. – Beim IF muss bekannt sein, dass ein Branch vorliegt und welches die Zieladresse ist
– Dynamische Vorhersage mit Branch History Table » Adresse des Branch-Befehls, » Zieladresse für den Sprung » Geschichte der letzten Entscheidungen an dieser Branch-Instruktion (1-2 Bits)
Varianten zur Behandlung von Branch-Hazards

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 48
• Delayed Branch – Die Verzweigung wird in jedem Fall nach einer festgelegten Zahl
weiterer Zyklen ausgeführt – In die Zwischenzyklen (Delay-Slots) werden Instruktionen eingebracht
• die von der Verzweigung unabhängig sind, also • In jedem Fall ausgeführt werden müssen.
– In der Praxis wurde häufig 1 Delay-Slot verwendet.
Varianten zur Behandlung von Branch-Hazards
ADD !Ra,Rb,Rc!SUB !Rf,Rf,Rb !SW !a,Ra !LW !Re,e !IF !Rf = 0 then...!ADD !Ra,Rb,Rc!...!
ADD !Ra,Rb,Rc!SUB !Rf,Rf,Rb !SW !a,Ra!IF !Rf = 0 then...!LW !Re,e !ADD !Ra,Rb,Rc!...!

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 49
• Code Movement – Umordnen von Instruktionen, so dass datenabhängige Instruktionen so
weit voneinander entfernt stehen, dass keine Stalls auftreten. • Loop Unrolling (“Schleifen aufrollen”)
– Hazards treten häufig im Zusammenhang mit Schleifen auf. – Sie lassen sich manchmal reduzieren, wenn man den Schleifencode
mehrfach hintereinander kopiert und die Instruktionen dann durch Code Movement geschickt anordnet.
– Außerdem wird dadurch die Anzahl Verzweigungen (und damit mgl. Branch-Hazards) reduziert.
Software-Maßnahmen zur Reduzierung von Hazards

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 50
Beispiel: Loop-Unrolling Loop: !LD !F0,0(R1) !! ! !ADDD !F4,F0,F2 !! ! !SD !0(R1),F4 !! ! !SUBI !R1,R1,8 !! ! !BNEZ !R1,Loop !! ! !NOP !!! ! ;delayed branch !! ! ;slot!
Kompakte Schleife
Loop: !LD !F0,0(R1)!!ADDD !F4,F0,F2!!SD !0(R1),F4 !!LD !F6,-8(R1)!!ADDD !F8,F6,F2!!SD !- 8(R1),F8 !!LD !F10,-16(R1)!!ADDD !F12,F10,F2!!SD !-16(R1),F12 !!LD !F14,-24(R1)!!ADDD !F16,F14,F2!!SD !-24(R1),F16!!SUBI !R1,R1,#32!!BNEZ !R1,LOOP NOP
Schleife 4 mal aufgerollt

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 51
• Vorgehen – Bei Auftreten einer Exception muss die aktuelle Verarbeitung sofort
unterbrochen und zu einer Ausnahmebehandlung verzweigt werden. – Dies bedeutet:
• Alle vorher begonnenen Instruktionen beenden, wenn möglich • Alle Folgeinstruktionen annullieren
– Problem • Es ist manchmal schwierig, die exakte Adresse der Instruktion zu ermitteln,
die den Interrupt verursacht hat. • Weil zusätzliche Instruktionen bereits begonnen worden sind, besitzt der PC
gewöhnlich bereits einen anderen Wert – imprecise exception: Man gibt sich mit dem falschen PC zufrieden – precise exception: Man ermittelt den korrekten PC
Pipelining und Exceptions
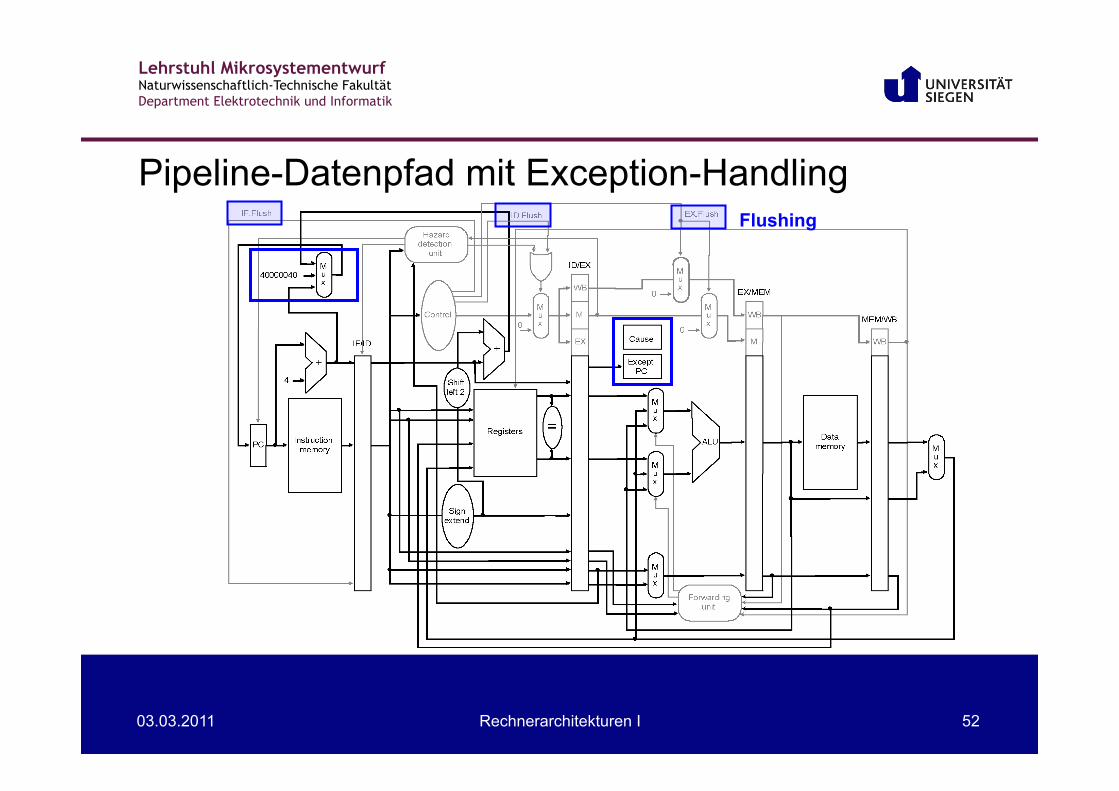
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 52
Flushing
Pipeline-Datenpfad mit Exception-Handling

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 53
• Superskalar-Prozessoren – In jedem Taktzyklus wird nicht nur eine einzelne, sondern mehrere
Instruktionen gestartet. – In der Praxis liegt die Anzahl zwischen 2 und 6. – Ein Maß dafür ist die Anzahl Instruktionen pro Clockzyklus (Instructions
per clock cycle, IPC). • Voraussetzungen für Superskalar-Prozessoren
– Es müssen zusätzliche Hardware-Einheiten vorgesehen werden, um strukturelle Hazards zu vermeiden (Wenn zwei ALU-Operationen gleichzeitig gestartet werden, müssen auch zwei ALUs vorhanden sein!).
– Es muss eine umfassende Compiler-Unterstützung geben, die eine sinnvolle Verteilung der Operationen vornimmt (scheduling).
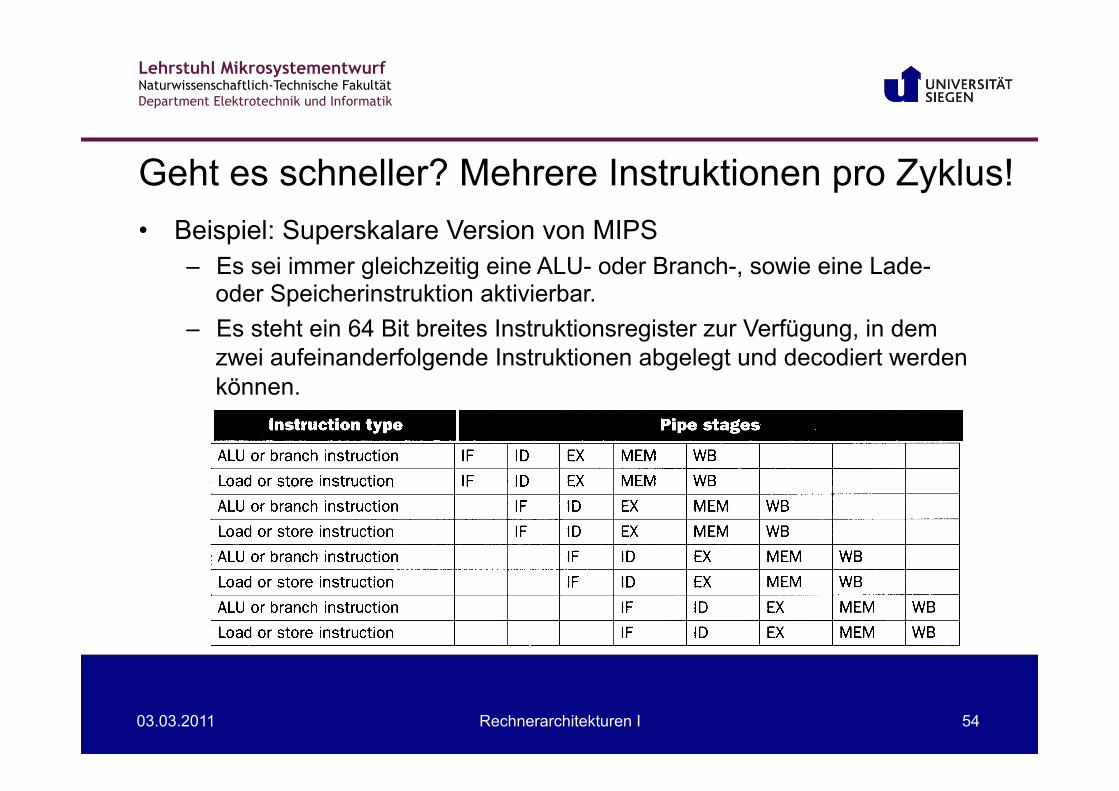
Geht es schneller? Mehrere Instruktionen pro Zyklus!
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 54
• Beispiel: Superskalare Version von MIPS – Es sei immer gleichzeitig eine ALU- oder Branch-, sowie eine Lade-
oder Speicherinstruktion aktivierbar. – Es steht ein 64 Bit breites Instruktionsregister zur Verfügung, in dem
zwei aufeinanderfolgende Instruktionen abgelegt und decodiert werden können.
Geht es schneller? Mehrere Instruktionen pro Zyklus!
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 55
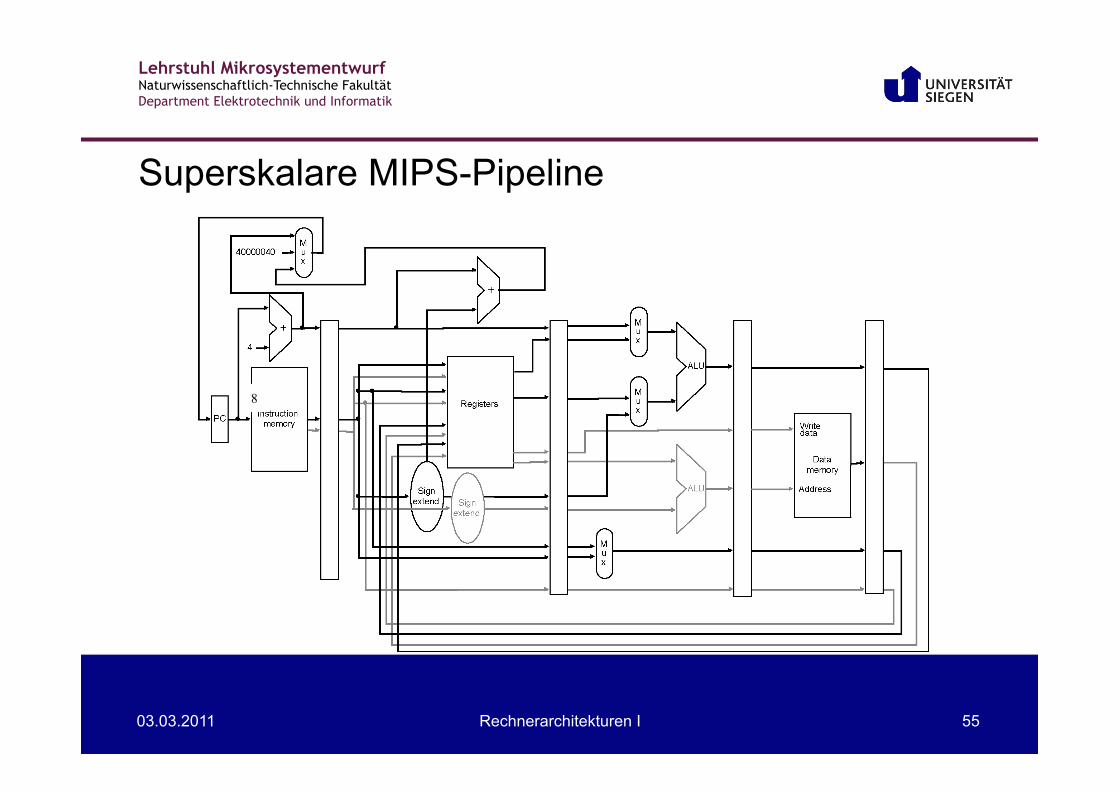
Superskalare MIPS-Pipeline
8
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 56
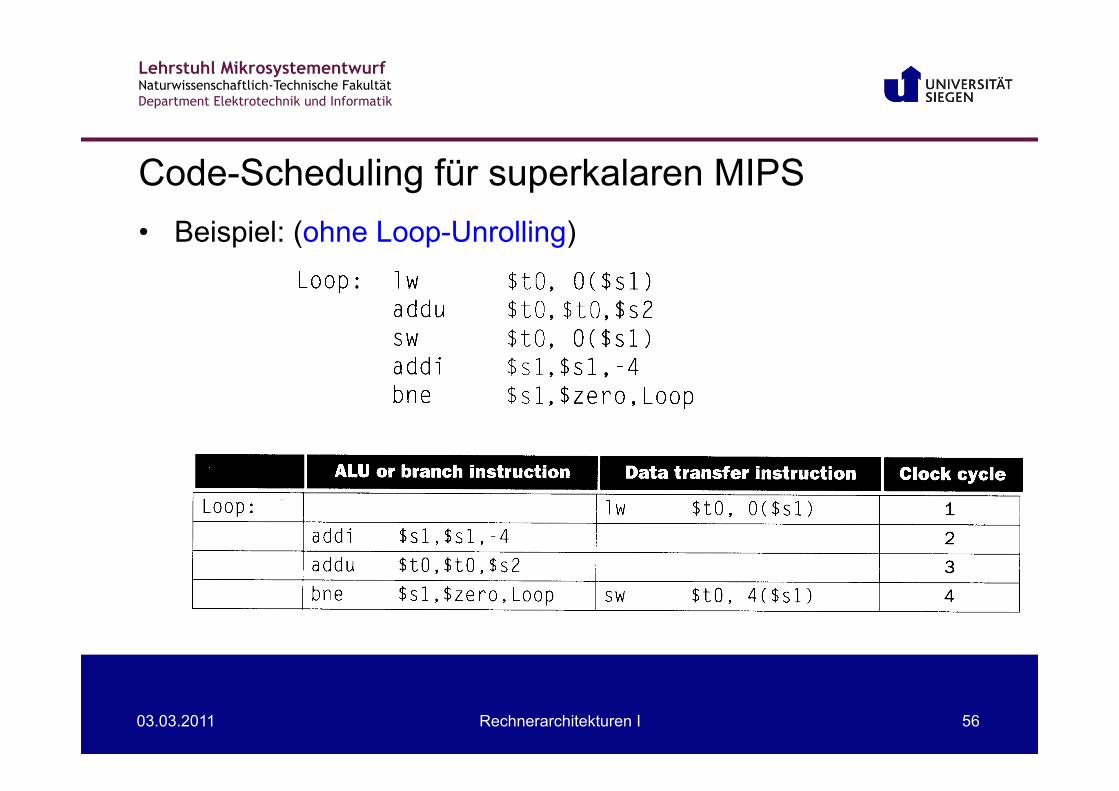
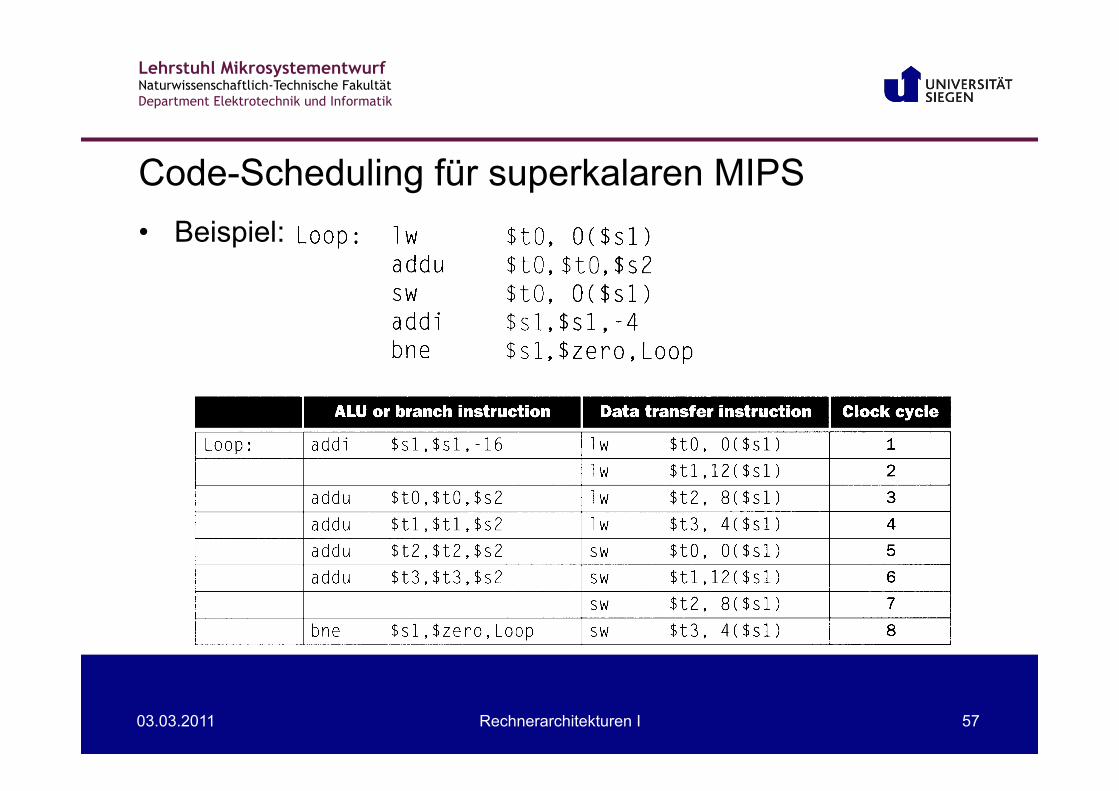
• Beispiel: (ohne Loop-Unrolling)
Code-Scheduling für superkalaren MIPS
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 57
• Beispiel: (mit Loop-Unrolling)
Code-Scheduling für superkalaren MIPS

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 58
Noch mehr Durchsatz? • VLIW-Prozessoren (Very Long Instruction Word)
– Mehrere Instruktionen werden hintereinander in einem langen Instruktionswort gespeichert (5 oder mehr Instruktionen)
– Sie werden gleichzeitig gestartet und decodiert. – Es müssen genügend HW-Einheiten vorhanden sein, um alle
Instruktionen ohne strukturelle Hazards bearbeiten zu können. – Die Verteilung der Instruktionen in die Instruktionsworte wird vom
Compiler vorgenommen – Es ist häufig schwierig, eine geeignet große Menge
unabhängiger Instruktionen zu finden, um VLIW-Pipelines sinnvoll auszunutzen.
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 59
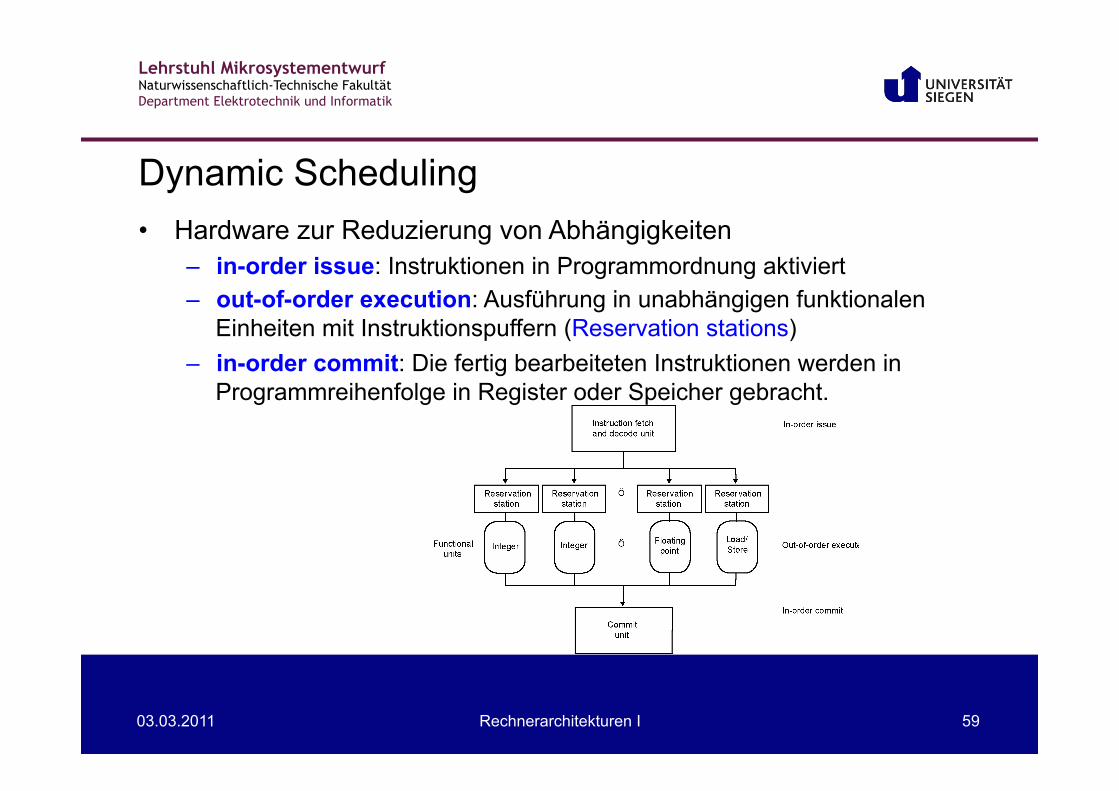
Dynamic Scheduling • Hardware zur Reduzierung von Abhängigkeiten
– in-order issue: Instruktionen in Programmordnung aktiviert – out-of-order execution: Ausführung in unabhängigen funktionalen
Einheiten mit Instruktionspuffern (Reservation stations) – in-order commit: Die fertig bearbeiteten Instruktionen werden in
Programmreihenfolge in Register oder Speicher gebracht.

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 60
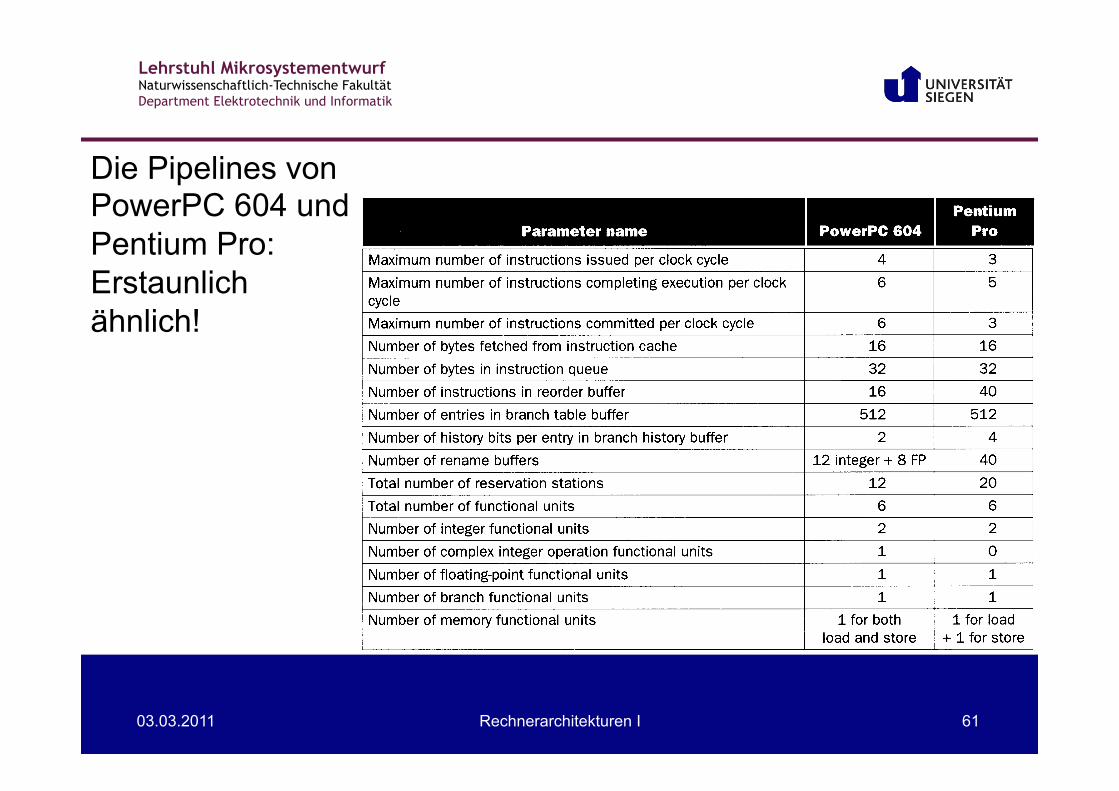
Pipelines von PowerPC 604 & Pentium Pro
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 61
Die Pipelines von PowerPC 604 und Pentium Pro: Erstaunlich ähnlich!
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 62
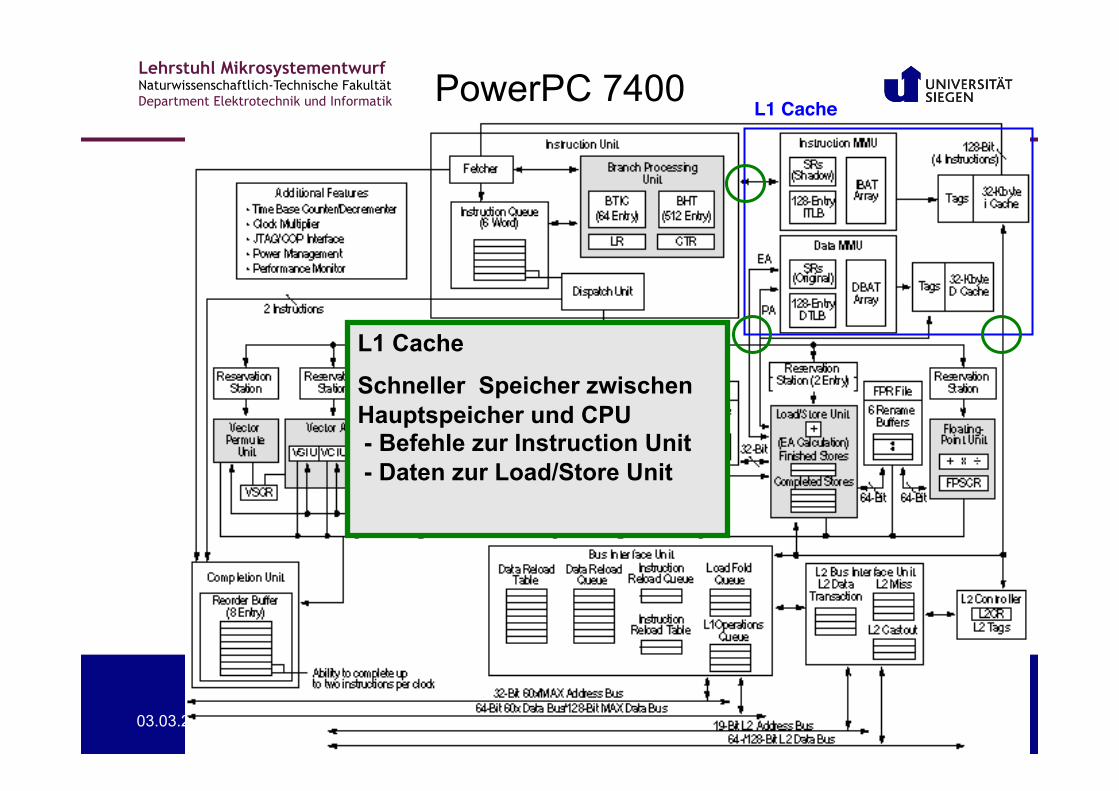
PowerPC 7400 L1 Cache!
L1 Cache
Schneller Speicher zwischen Hauptspeicher und CPU - Befehle zur Instruction Unit - Daten zur Load/Store Unit
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 63
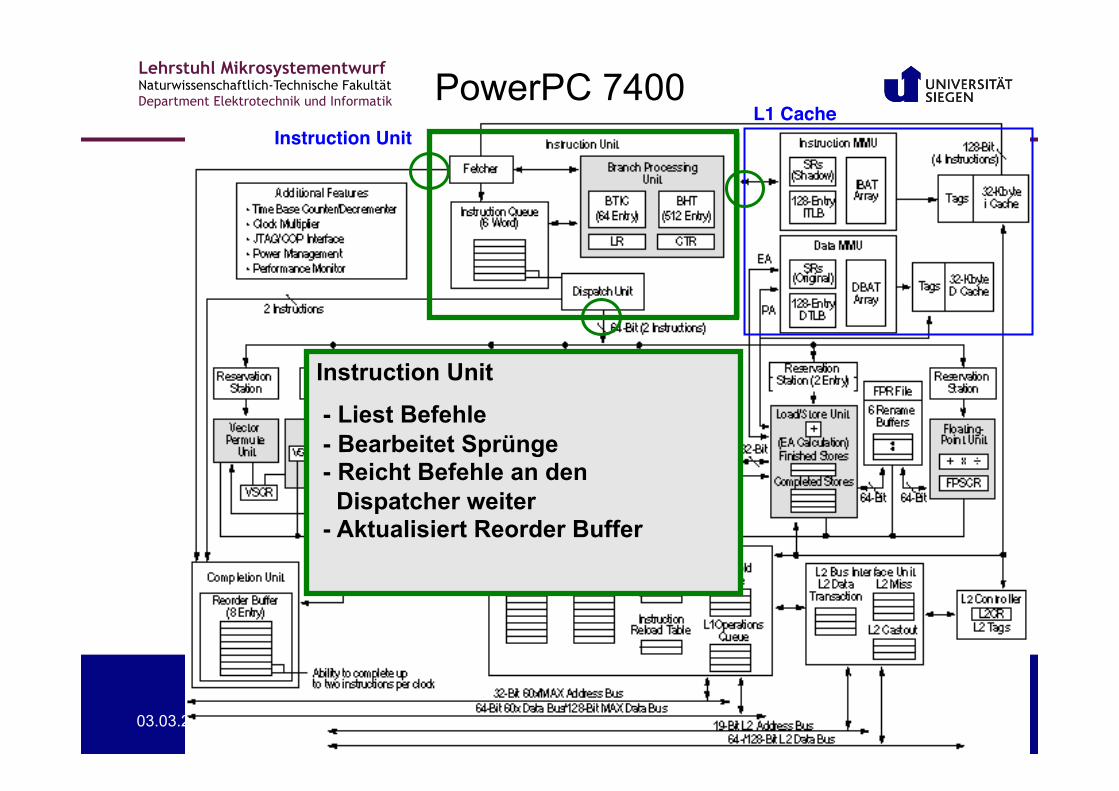
PowerPC 7400 Instruction Unit!
L1 Cache!
Instruction Unit
- Liest Befehle - Bearbeitet Sprünge - Reicht Befehle an den Dispatcher weiter - Aktualisiert Reorder Buffer
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 64
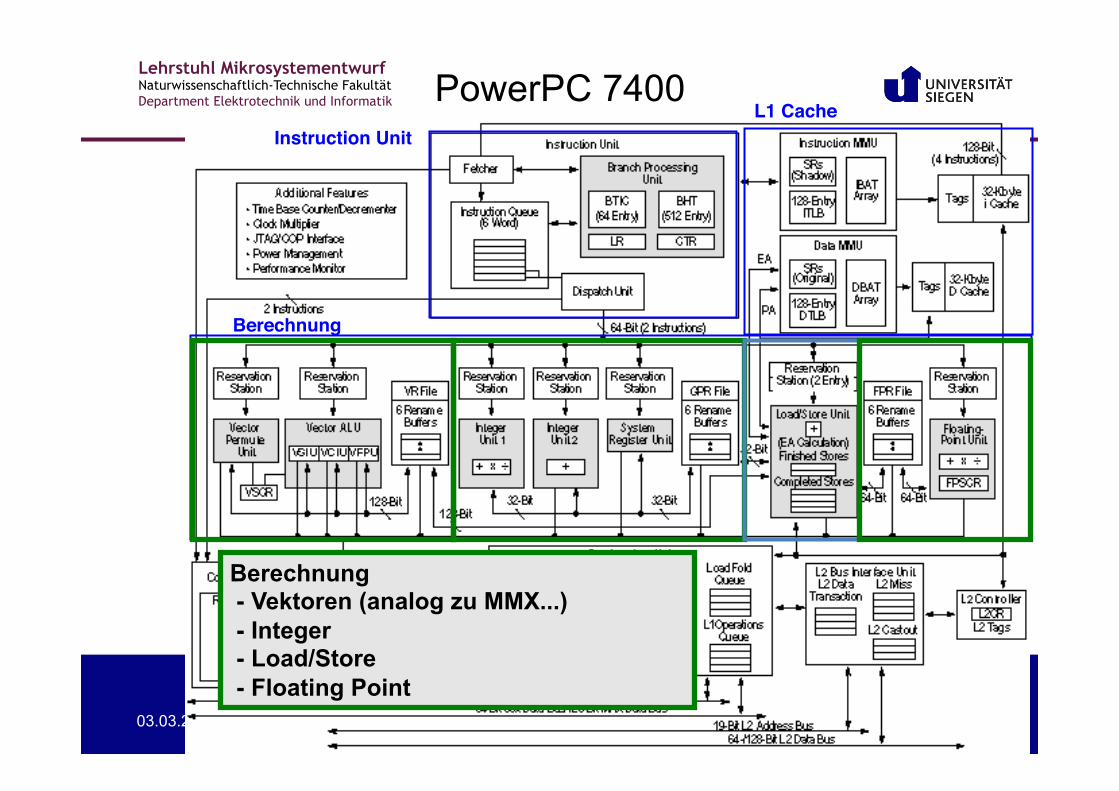
PowerPC 7400 Instruction Unit!
L1 Cache!
Berechnung!
Berechnung - Vektoren (analog zu MMX...) - Integer - Load/Store - Floating Point
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 65
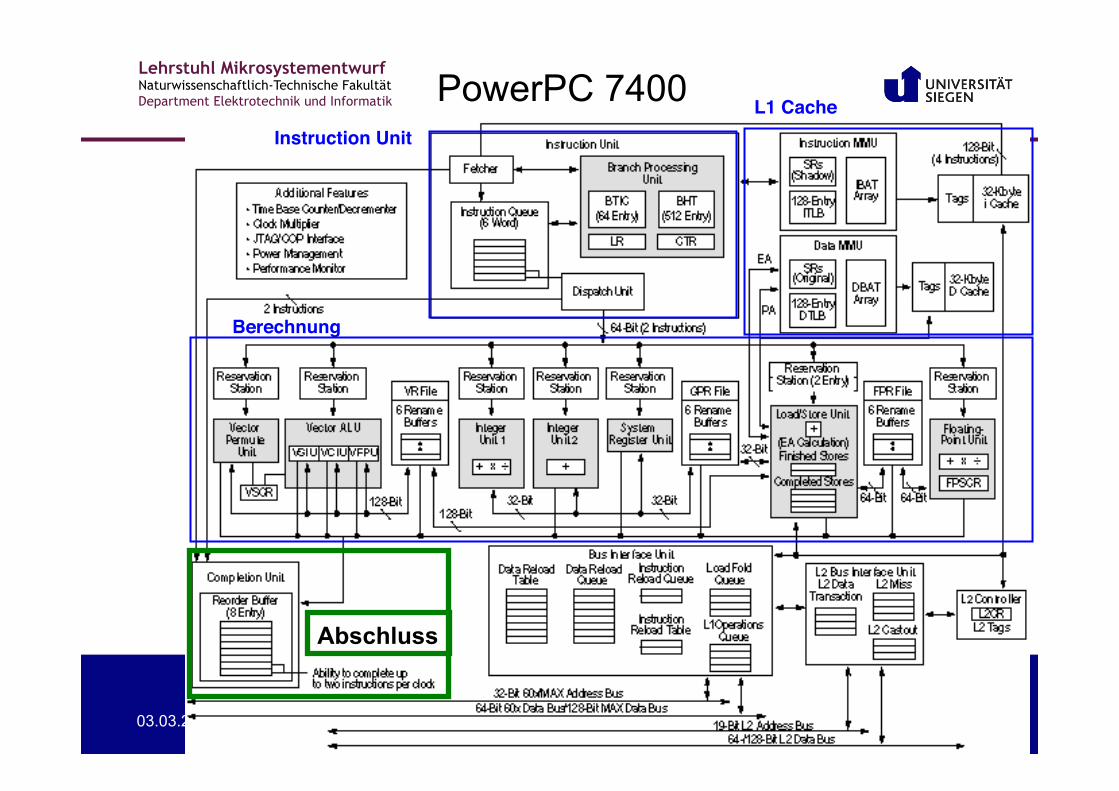
PowerPC 7400 Instruction Unit!
L1 Cache!
Berechnung!
Abschluss
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 66
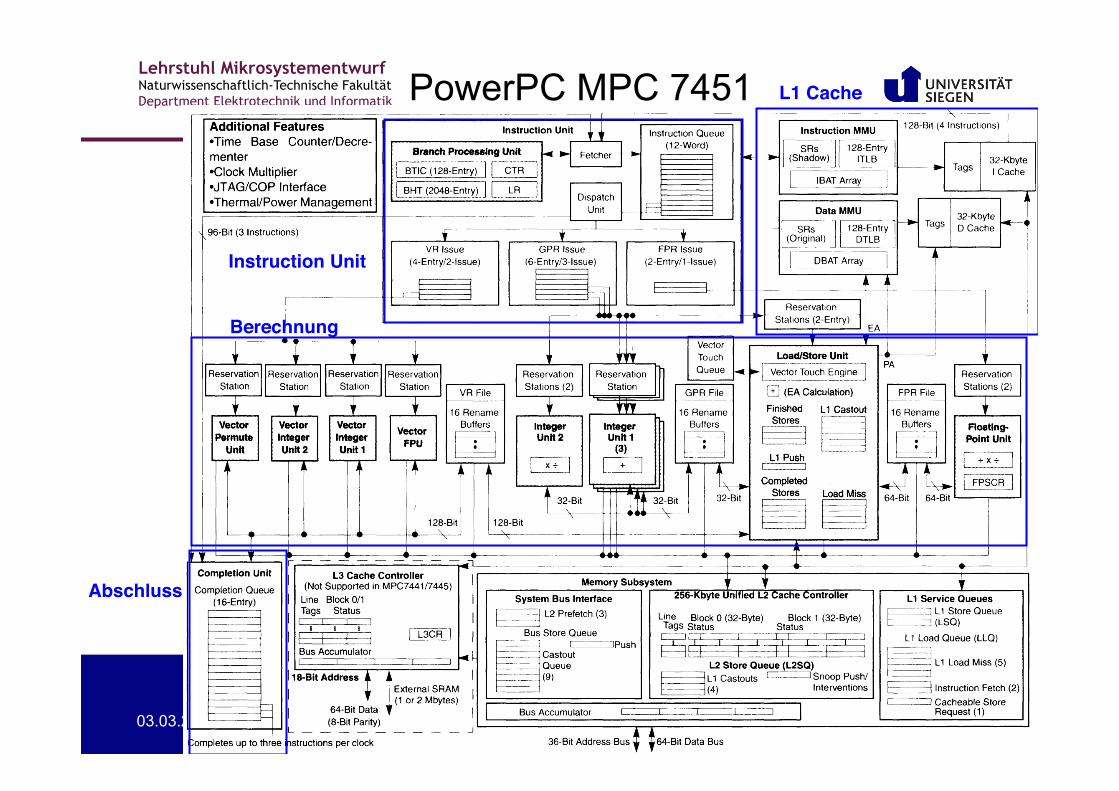
PowerPC MPC 7451
Instruction Unit!
L1 Cache!
Berechnung!
Abschluss!

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 67
• Eigenschaften – Bis zu vier Befehle in einem Zyklus aus dem Instruction-Cache – Bis zu drei Befehle können gleichzeitig an die
Bearbeitungseinheiten geschickt werden – Bis zu zwölf Befehle können in der Befehls-Queue sein – Bis zu 16 Befehle können gleichzeitig ausgeführt werden – Die meisten Befehle werden in einem Zyklus beendet – Für die meisten Befehle gilt: Ein Zyklus / Befehl – Pipeline mit sieben Stufen
• Aber dies ist nicht mehr Stand der Technik (2001)!
PowerPC MPC 7451

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 68
1. L2 Cache, 512 kB 2. L1 Cache:
64 KB Instruktionen & 32 KB Data 3. Fetch and Decode:
bis 8 Befehle/Zyklus, Aufteilung in kleinere Suboperationen
4. Dispatch 1. Ordnung der Suboperationen in Gruppen zu je
fünf 2. Bis zu 20 Gruppen im Core 3. Mehr als hundert Befehle in anderen Stufen
5. Queue 6. Optimierte Velocity Engine
1. 128 Bit Register 2. SIMD Verarbeitung
Power PC G5

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 69
7. Zwei Double-Precision Fließpunkteinheiten
8. Zwei Integer-Einheiten, 64 Bit Durchsatz FP & Integer: 1 Operation / Zyklus
9. Load/Store 10. Condition Register
Fasst die gesamte Statusinformation zusammen
11. Branch Prediction Spekulative Ausführung Genauigkeit der Vorhersage: 95%
12. Complete Zusammenfassen der Gruppierungen und Abschluss
Power PC G5
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 70
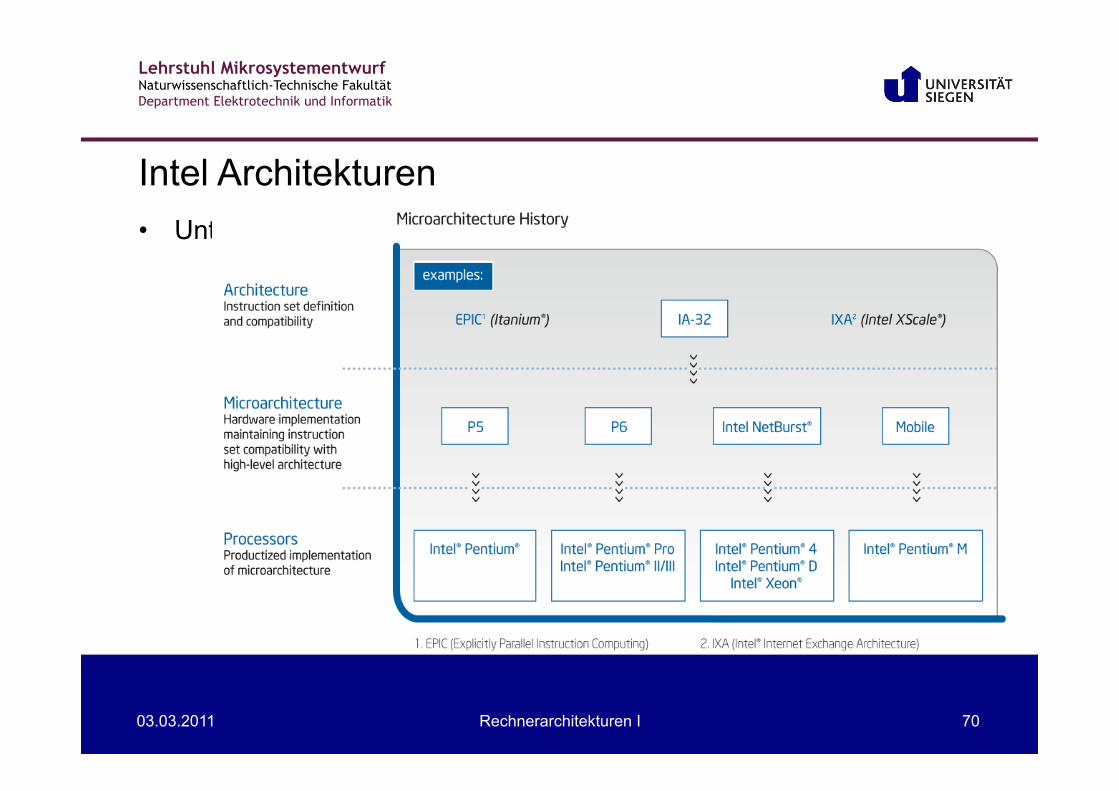
• Unterschiedliche Architekturen für gleichen Befehlssatz
Intel Architekturen
Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 71
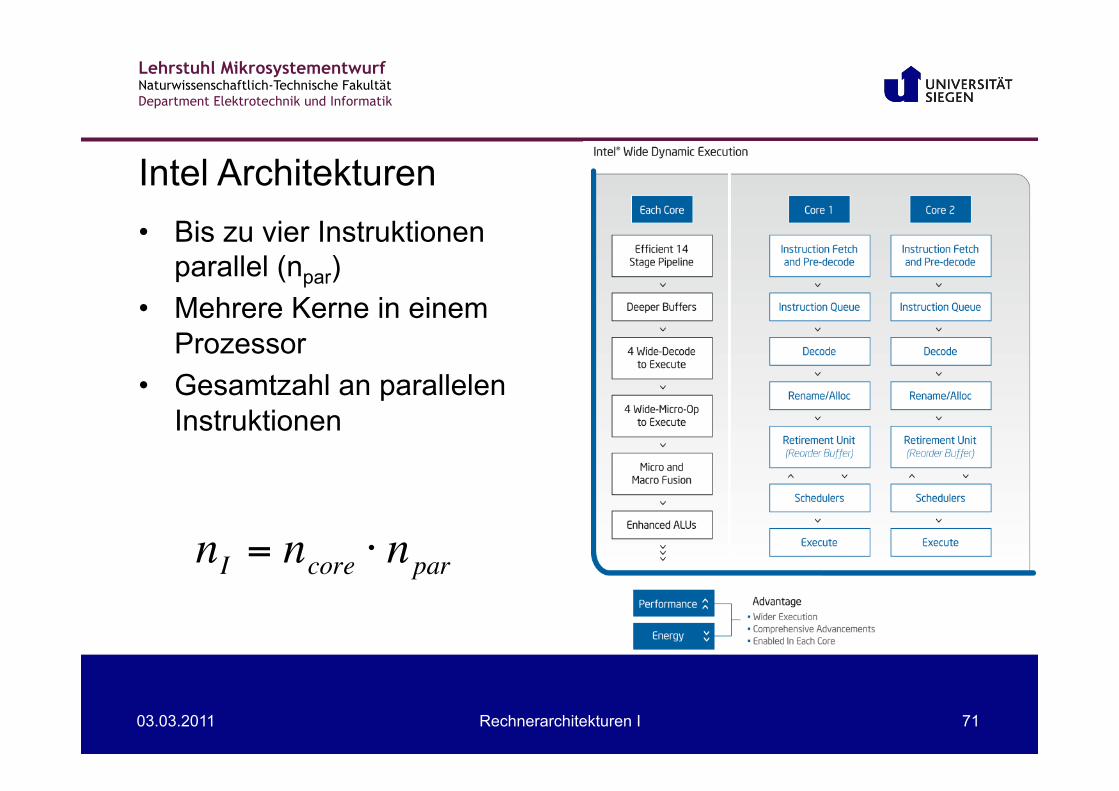
• Bis zu vier Instruktionen parallel (npar)
• Mehrere Kerne in einem Prozessor
• Gesamtzahl an parallelen Instruktionen
Intel Architekturen
!
nI = ncore " npar

Lehrstuhl Mikrosystementwurf Naturwissenschaftlich-Technische Fakultät Department Elektrotechnik und Informatik
03.03.2011 Rechnerarchitekturen I 72
Zusammenfassung • Pipelining ist eine logische Weiterentwicklung der Single- und der
Multicycle-CPU • Pipelining erhöht die Performance im Idealfall um den Faktor der
Pipelinestufen • Pipelining erzeugt Konflikte (Hazards)
– Daten-Hazards – Steuerungs-Hazards – Strukturelle Hazards
• Konfliktreduzierung durch Compileroptimierung und spezielle Branch-Hardware
• Konfliktlösung durch – Forwarding – Stalls – Komplexe Verfahren bei parallelen Verarbeitungseinheiten





























