Embed Size (px)
Citation preview

SEMINARARBEIT
zum Thema
Recommender Systems mit Assoziationsregeln
Von
Markus Braun
9951085
Wien, im Mai 2005
1

Inhaltsverzeichnis Inhaltsverzeichnis....................................................................................................................... 2
Abstract ...................................................................................................................................... 3
Einleitung ................................................................................................................................... 3
Assoziationsregeln – Aufbau und Arten .................................................................................... 4
Aufbau von Assoziationsregeln ............................................................................................. 4
Arten von Assoziationsregeln ................................................................................................ 7
Probleme bei der Verwendung von Assoziationsregeln ............................................................ 9
Ausgewählte Lösungsansätze................................................................................................. 9
Lösungsansatz von Agrawal, Imielinski und Swami ......................................................... 9
Lösungsansatz von Mobasher, Dai, Luo und Nakagawa ................................................. 10
Lösungsansatz von Lin, Alvarez und Ruiz....................................................................... 11
Verwendung von Assoziationsregeln in Recommender Systemen.......................................... 12
Anwendungsbeispiele von Assoziationsregeln ........................................................................ 15
Anwendungsbeispiel 1: SmartPad........................................................................................ 15
Anwendungsbeispiel 2: e-VZpro ........................................................................................ 18
Anwendungsbeispiel 3: PROFSET – Product Selection...................................................... 19
Anwendungsbeispiel 4: Effekte von Produktpromotionen 1 ............................................... 22
Anwendungsbeispiel 5: Effekte von Produktpromotionen 2 ............................................... 24
Conclusio.................................................................................................................................. 26
2

Abstract Die vorliegende Arbeit behandelt die Verwendung von Assoziationsregeln als konkrete Data
Mining Technik. Es soll gezeigt werden, wie die grundlegende Struktur dieser Technik
aufgebaut ist. In einem weiteren Kapitel soll ausgehend von dieser Grundstruktur auf Fehler
eingegangen werden, auf welche von einigen Autoren regelmäßig hingewiesen wird. Für
diese Probleme sollen mit 3 Lösungsvorschlägen repräsentative Alternativen präsentiert
werden. Nach der Beschreibung der Einsatzbereiche von Assoziationsregeln in Online-
Recommender Systemen wird in mehreren ausführlichen Anwendungsbeispielen gezeigt,
welches Einsatzspektrum Assoziationsregeln bieten.
--------------
This paper is going to show the usage of association rules as a specific data mining technique.
Firstly the basic structure of association rule mining is going to be explained extensively.
Continuing from this basic position, secondly, some of the most well known problems of this
mining technique are presented. In a further step, 3 possible ways of solving those problems
are shown. Finally, after explaining the most common usages of association rule mining in
online recommender systems, a few examples for ranges of applications of association mining
are going to be introduced.
Einleitung Wir leben heute in einer Periode, welche als Informationszeitalter bezeichnet wird.
Information, also die Summe aus Nachrichten, Mitteilungen, Auskünften, etc., gibt dieser
Periode ihren Namen, weil sie zu einem wichtigen Bestandteil des Alltags geworden ist.
Durch die rasante Entwicklung der Informationstechnologie ist es heute möglich auf
Information zuzugreifen, die hunderte oder tausende Kilometer vom Benutzer entfernt
aufbewahrt wird.
Besonders die Technologie des Internets hat es ermöglicht, einen Großteil der Tätigkeiten des
täglichen Lebens durchzuführen, ohne einen Schritt vor die Tür setzen zu müssen. Flüge und
Urlaubsreisen buchen, Bücher ausleihen, Arznei- oder Lebensmittel kaufen und viele andere
Tätigkeiten, all das kann mit wenigen Mausklicks bequem von zu Hause vom Bildschirm aus
erledigt werden. Doch kein Vorteil, wo nicht auch ein Nachteil. Die Menge dieser
Information nimmt sehr rasch zu und ist in vielen Bereichen bereits jetzt unüberschaubar
geworden. Die Zeit, welche benötigt wird um die relevanten Daten von weniger oder nicht
relevanten zu unterscheiden, wird immer länger. Es ist daher notwendig, diese ungeheuren
Datenmengen zu analysieren und zu filtern um die wertvollen Ressourcen von Wissen und
3

Information auch nutzen zu können. Menschliche Fähigkeiten reichen schon lange nicht mehr
aus, um der Masse an Information Herr zu werden. Deswegen bedient man sich technischer
Hilfsmittel.
Jegliche Art von Daten wird in Datenbanken gespeichert. Mit Hilfe des Data Mining wird
versucht die Menge an Daten in verwendbare Information umzuwandeln. Die vorliegende
Arbeit soll einen Einblick in einen Teil dieses Data Mining Prozesses mit Hilfe von
Empfehlungssystemen (engl. Recommender Systems) geben. Es wird im Speziellen auf die
Verwendung so genannter Assoziationsregeln (engl. Association Rules) in Recommender
Systemen eingegangen.
Was ist überhaupt Data Mining? Mittels Data Mining wird versucht, in großen
Datenbeständen versteckte Informationen zu finden. Häufig spricht man in diesem
Zusammenhang auch von knowledge mining, knowledge extraction, data/pattern analysis
[Jürg01]. Das Data Mining selbst stellt nur einen Teilschritt im gesamten
Informationserstellungsprozess dar. Data Mining hat verschiedene Funktionen. Eine von
ihnen ist Assoziation.
Assoziationsregeln – Aufbau und Arten
Aufbau von Assoziationsregeln
Bevor der Aufbau von Assoziationsregeln näher erläutert werden kann, ist es notwendig
zuerst eine Begriffsdefinition vorzunehmen. Bei dieser Form von Data Mining werden
konditionale Regeln gesucht. Das bedeutet, die Suche bezieht sich auf Verbindungen, welche
eine WENN-DANN-Beziehung erfüllen. Die Regeln lauten: Wenn ein bestimmtes Ereignis
eintritt, tritt auch automatisch ein anderes Ereignis ein. Die Suche kann sich auf alle
möglichen Ergebnisse beziehen, oder nur auf ein vom Benutzer gewähltes Ergebnis
[Oberle00].
Assoziationsregeln fanden und finden besondere Anwendung im Bereich der
Warenkorbanalyse. Das Ziel hierbei ist, Assoziationen zwischen verschiedenen gekauften
Produkten zu finden, oder Käuferverhalten über einen längeren Zeitraum zu beobachten. Eine
Regel in diesem Zusammenhang könnte lauten: In 40 Prozent aller Fälle, in denen Kaviar
gekauft wird, wird auch Champagner gekauft. Diese beiden Produkte tauchen in 2 Prozent
aller Fälle auf. [Diest01]. Eine Assoziationsregel wird dargestellt als X → Y und zeigt, dass
das Vorhandensein von X mit dem Vorhandensein von Y korreliert. X wird als Regelrumpf
oder englisch Consequent und Y als Regelkopf oder englisch Antecedent bezeichnet. Gesucht
4

werden nun alle Regeln, die eine große Konfidenz und einen großen Support haben. Die
Konfidenz gibt dabei an, wie oft die Assoziationsregel Kaviar → Champagner vorhanden ist,
dividiert durch die Anzahl des Vorkommens der Bedingung Kaviar. Die Konfidenz gibt somit
die Implikationsstärke an, drückt also aus wie stark die Assoziation ist. Der Support stellt fest,
wie oft die Assoziationsregel Kaviar → Champagner vorhanden ist, dividiert durch die
Anzahl aller Einkäufe. Er gibt somit die prozentuale Häufigkeit des gemeinsamen Auftretens
beider Elemente einer Assoziation bezogen auf alle Mengen an. Das folgende
Anwendungsbeispiel soll erklären, wie die Technik verwendet wird.
Die Datenbank eines Supermarktes umfasst vier Abrechnungen von Kundentransaktionen,
ersichtlich aus Tabelle 1
Rechnung 1 Rechnung 2 Rechnung 3 Rechnung 4
Butter Champagner Butter Champagner Baguette Baguette Champagner Kaviar Bier Kaviar Baguette Tee Kaviar Tabelle 1: Rechnungen in einer Supermarktdatenbank Es wird definiert, dass eine Transaktion die Assoziationsregeln Kaviar → Champagner enthält,
wenn man beide Produkte auf einer Rechnung findet. Rechnung 2 weist beispielhaft folgende
Paare auf:
Champagner → Baguette
Champagner → Kaviar
Baguette → Champagner
Baguette → Kaviar
Kaviar → Champagner
Kaviar → Baguette
Nun wird überprüft auf wie vielen Rechnungen Kaviar → Champagner aufscheint und stellt
fest, dass dies bei den Rechnungen 2, 3 und 4 der Fall ist. Wie bereits erwähnt gilt es, jene
Artikel zu finden, die eine hohe Konfidenz und einen hohen Support haben. Dafür muss für
beide jeweils eine Schranke definiert werden, welche eine Unterscheidung in häufig und nicht
häufig auftretende Paare zulässt. Diese Schranke bezeichnet man als Minimumkonfidenz bzw.
Minimumsupport. Für das Beispiel definieren wir sowohl die Schranke für die Konfidenz als
auch die Schranke für den Support mit 30%. Danach werden alle Artikel erst auf ihre
5

Unterstützung überprüft um danach ihre Konfidenz festzustellen. Tabelle 2 listet den Support
der einzelnen Artikel auf.
Produkt Häufigkeit Support Butter 2 50% Baguette 3 75% Bier 1 25% Champagner 3 75% Kaviar 3 75% Tee 1 25% Tabelle 2: Unterstützung der jeweiligen Artikel Da zuvor die Schranke für den Support bei 30% festgelegt wurde, können die Artikel Bier
und Tee bereits ausgeschieden werden und gehen nicht mehr in den weiteren Messvorgang
ein. Aus den verbliebenen Artikeln werden nun alle möglichen Kombinationspaare gebildet.
Tabelle 3 zeigt den Support, welcher für jedes der Paare gemessen wird.
Assoziation Häufigkeit Support {Butter, Baguette} 2 50% {Butter, Champagner} 1 25% {Butter, Kaviar} 1 25% {Baguette, Champagner} 2 50% {Baguette, Kaviar} 2 50% {Champagner, Kaviar} 3 75% Tabelle 3: Unterstützung der Artikelpaare In Anbetracht der definierten Supportschranke können nun wieder Elemente entfernt werden.
Die Paare {Butter, Champagner} und {Butter, Kaviar} haben nur 25% Support und werden
daher in weiteren Messungen nicht mehr einbezogen.
In einem weiteren Schritt werden aus den verbliebenen Paaren mögliche Assoziationen
erzeugt und die Konfidenz berechnet. Die in Werte in Tabelle 4 zeigen das Beispielergebnis.
Assoziation Häufigkeit Konfidenz Butter → Baguette 2/2 100% Baguette → Butter 2/3 66% Baguette → Champagner 2/3 66% Champagner → Baguette 2/3 66% Baguette → Kaviar 2/3 66% Kaviar → Baguette 3/3 100% Champagner → Kaviar 2/3 66% Kaviar → Champagner 3/3 100% Tabelle 4: Konfidenz der Artikelpaare
6

Aus Tabelle 4 ist abzulesen, dass die Konfidenz der Regel Kaviar → Champagner ist 100%
und ihr Support liegt bei 75%.
Nachdem Support und Konfidenz aller Paare überprüft und mit den Schranken verglichen
wurden, werden jeweils die beiden Elemente der verbliebenen Paare zu einem Element
zusammengefasst und um einen zusätzlichen Artikel erweitert. Es wird also versucht, Paare
von Produkten zu finden, die gemeinsam den Kauf eines weiteren Produktes begünstigen. In
unserem Beispiel ist dies nur bei Champagner – Baguette – Kaviar möglich.
Das eben genannte Beispiel soll der Verdeutlichung für das Auffinden von Assoziationsregeln
dienen. Daher wurde dieses Beispiel auch mit einer sehr geringen Menge an Daten
durchgeführt. Würde dieses Beispiel in einem Supermarkt durchschnittlicher Größe
angewendet werden, würden sich die Datenbestände sehr schnell erhöhen. Aufgrund dieser
möglicherweise sehr großen Menge an Daten kommt dem Algorithmus zum Auffinden
solcher Assoziationsregeln große Bedeutung zu. Denn durch die Art des Algorithmus werden
die notwendigen Ressourcen, die zur Auswertung der Daten benötigt werden, bestimmt.
Hierbei ist besonders die Ausführungsdauer zu berücksichtigen. Die Begründung dafür wird
im Kapitel „Probleme bei der Verwendung von Assoziationsregeln“ näher erläutert. Weiters
haben Autoren auch darauf hingewiesen, dass Kofidenz alleine nicht die ideale Kennzahl für
die Messung der Abhängigkeit zwischen Regelrumpf und Regelkopf darstellt. Daher wurde
ein weiterer Wert eingeführt, der mit Lift bezeichnet wird. Lift misst die statistische
Abhängigkeit zwischen Consequent and Antecedent [PSW03]. Die Verwendung des Lift wird
im Kapitel „Anwendungsbeispiele von Assoziationsregeln“ dargestellt.
Arten von Assoziationsregeln
Grundsätzlich haben Algorithmen zum Auffinden von Assoziationsregeln folgenden Aufbau
[Grobl03]:
1) Finde alle „häufig auftretenden Artikelmengen“ in einer Datenbasis
2) Generiere aus diesen Mengen die Regeln, welche die vorgegebene Konfidenz und die
notwendige Unterstützung erfüllen.
3) Filtere die Regeln nach Interesse des Benutzers
In den meisten Fällen wird eine große Anzahl an Regeln gefunden. Allerdings sind nicht alle
für den Benutzer verwendbar. Daher ist es nötig eine Filterung durchzuführen um brauchbare
7

von unbrauchbaren Ergebnissen zu trennen. Im Folgenden werden 2 unterschiedliche Arten
beschrieben die zur Bildung von Assoziationsregeln verwendet werden können.
a) Boolsche Assoziationsregeln
Werden Assoziationsregeln mittels boolscher Attributswerte gebildet, spricht man von
boolschen Assoziationsregeln. Bei dieser Form wird nur festgestellt, ob ein Artikel in der
Transaktion enthalten ist oder nicht. Ein bekannter Algorithmus im Zusammenhang mit
boolschen Attributen ist der so genannte „Apriori-Algorithmus“. Da dieser Algorithmus
jedoch auch einige Schwachstellen, besonders in Bezug auf den Hauptspeicherbedarf aufweist,
gibt es zahlreiche Erweiterungen. Diese Problematik wird im Kapitel „Probleme bei der
Verwendung von Assoziationsregeln“ näher betrachtet.
b) Generalisierte Assoziationsregeln
Diese Art ist durch komplexere Algorithmen und aufwendigere Regelsuche gekennzeichnet.
Um Regeln zu finden werden Taxanomien definiert. Unter einer Taxanomie versteht man eine
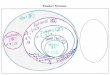
Ist-ein-Beziehung zwischen zwei Artikeln[Grobl03]. Abbildung 1 veranschaulicht das Prinzip
zum Auffinden solcher Taxanomien.
Lebensmittel
Abbildung 1: Beispiel für Taxanomien von Gütern eines Lebensmittelmarktes Anhand der Abbildung 1 wird deutlich, dass es umso schwieriger wird Assoziationsregeln zu
finden, je genauer und detaillierter die Unterteilung der einzelnen Produktgruppen wird. Es
wird vermutlich eine häufigere Unterstützung zu erkennen sein, wenn Fisch und Wein
Getränke Speisen
Fisch Fleisch alkoholisch …
Champagner
Wein
Gemüse alkoholfrei
…Cola Bier …
…
… … …Kaviar
… … … … … …… …
8

überprüft wird, als wenn Beluga-Kaviar und australischer Shiraz in der Messung analysiert
werden. Um solche Taxanomien zu erkennen verwendet man generalisierte
Assoziationsregeln. Diese prüfen nicht nur ob ein Artikel in einer Transaktion enthalten ist,
sondern auch in welcher Hierarchiestufe er vorkommt.
Probleme bei der Verwendung von Assoziationsregeln Wie bereits erwähnt wurde, kann die Menge an auszuwertenden Daten rasch sehr groß
werden. Ein Problem das unweigerlich auftaucht ist das Abwägen zwischen der benötigten
Anzahl an Durchläufen und unnötigen Messungen um die Messaufwendungen möglichst
effizient zu gestalten. In der ursprünglichen Version eines Algorithmus zum Auffinden von
Assoziationsregeln wird jedes Element in einem Durchlauf in die Messung mit einbezogen.
Das bedeutet im schlimmsten Fall 2m Zählungen, wobei m die Anzahl der Elemente aus dem
zu messenden Pool darstellt (z.B.: alle Artikel eines Supermarktes). Allerdings wird sich
herausstellen, dass ein Teil dieser 2m Kombinationen generell nicht häufig vorkommt.
Ein anderer Zugang ist nur jene Elemente in der Messung zu berücksichtigen, die aus einer
genau definierten Anzahl von Artikeln k bestehen. Im darauf folgenden Durchlauf werden
dann nur jene Elemente gemessen, die aus k+1 Artikeln bestehen. Durch diese Methode
werden alle Elemente die in einem Durchlauf als nicht häufig erkannt wurden im nächsten
Durchlauf nicht mehr überprüft.
Der größte Nachteil dieser Vorgehensweise ist die zu große Anzahl an benötigten
Durchläufen. Eine Vielzahl an Autoren hat sich bereits mit diesen Problemen beschäftigt. Im
folgenden Abschnitt sollen nun 3 unterschiedliche Lösungsvorschläge präsentiert werden, in
welchen versucht wird die eben genannten Schwierigkeiten zu beseitigen.
Ausgewählte Lösungsansätze
Lösungsansatz von Agrawal, Imielinski und Swami
Ausgehend vom Apriori-Algorithmus sowie dem k-Nearest-Neighbor-Ansatz werden nun
einige Lösungsvorschläge präsentiert, die helfen sollen die Ergebnisse der Auswertung durch
Assoziationsregeln zu verbessern. Der erste Vorschlag wurde von Rakesh Agrawal, Tomasz
Imielinski und Arun Swami ausgearbeitet [AIS93]. Sie verwenden einen Algorithmus,
welcher in mehreren Durchläufen die gespeicherten Daten der Datenbank überprüft. In jedem
Durchlauf wird die Unterstützung eines konkreten Elements gemessen. Weiters benutzen sie
zwei zusätzliche Gruppierungen um die ausgewerteten Daten einzuteilen. Diese beiden
Untergruppen definieren sie als Frontierset und als Candidateset. Dem Frontierset werden all
9

jene Elemente zugeordnet, welche in einem weiteren Durchlauf um ein zusätzliches Element
erweitert werden. Das Candidateset beinhaltet die „Kandidaten“ für die Messung. Es setzt
sich somit einerseits aus den Elementen der Datenbank und andererseits aus den Elementen
des Frontiersets zusammen. Zusätzlich beinhaltet der Algorithmus einen Zähler, der das
Aufscheinen der Elemente in den Transaktionen zählt.
Beginnt der Algorithmus seinen ersten Durchlauf, besteht das Frontierset aus einem einzigen
leeren Element. Am Ende jedes Durchlaufs wird die Unterstützung mit der definierten
Minimumunterstützung verglichen um festzustellen, ob die Beziehung häufig ist oder nicht.
Gleichzeitig wird festgelegt, ob das Elementenbündel im darauf folgenden Durchlauf zum
Frontierset hinzugefügt werden soll oder nicht. Der Algorithmus endet sobald alle Elemente
des Frontiersets abgearbeitet sind und dieses somit leer ist.
Lösungsansatz von Mobasher, Dai, Luo und Nakagawa
Die genannten Autoren gehen davon aus, dass bei der Verwendung allgemein definierter und
global gültiger Minimumunterstützungen die Messungen dahingehend ungenau werden, als in
den festgestellten Mustern nicht häufig vorkommende, aber trotzdem für die Empfehlung
wichtige Elemente nicht berücksichtigt werden [MDLN01]. Diese Tatsache ist vor allem bei
der Empfehlung von Internetseiten wichtig, da Seiten mit detailliertem Inhalt zwar sehr wohl
wesentliche Informationen für den Benutzer enthalten, aber seltener von Benutzern verwendet
werden. Daher ist es aus der Sicht von Mobasher et al. notwendig auch diese seltenen, aber
inhaltlich gewichtigen Elemente bei der Empfehlung zu berücksichtigen. Zur Behebung des
Problems wurde eine Methode entwickelt, die nicht nur eine Minimumunterstützung
verwendet, sondern mehrere Supportschranken, wodurch der Deckungsgrad an
informationsreichen Empfehlungen ansteigt ohne Einbußen der Genauigkeit. Die im
Folgenden vorgestellte Weiterentwicklung des k-Nearest-Neighbor-Ansatzes geht von der
Verwendung zur Empfehlung von Internetseiten aus.
Für die Recommendations sammelt das System alle häufigen Elementenbündel und vergleicht
diese mit der aktuellen Tätigkeit eines Users während seiner Internetsitzung. Mit Hilfe eines
sogenannten „Sliding Windows“ wird die Tiefe der Historie der Sitzung festgelegt, die bei der
Erstellung der Empfehlung berücksichtigt werden soll. Der Umfang der im Window
enthaltenen Elemente kann den gewünschten Anforderungen entsprechend selbst festgelegt
werden. Wird das Sliding Window beispielsweise auf 3 Elemente beschränkt, generiert das
System aus den letzten 3 vom User besuchten Internetseiten Kandidaten für die Erstellung
von Assoziationsregeln. Erfüllt eine besuchte Seite die Unterstützungs- und
Konfidenzanforderungen wird sie als Empfehlung an den User übermittelt.
10

Lösungsansatz von Lin, Alvarez und Ruiz
In der dritten und letzten vorzustellenden Lösungsmöglichkeit von Problemen bei
Empfehlungen mittels der grundlegenden Entwicklungen, stellen die Autoren Lin, Alvarez
und Ruiz eine Methode vor, in welcher sie Assoziationsregeln wahlweise für definierte User,
definierte Artikel oder eine Kombination aus beiden generieren [LAR00]. Der wiederum vom
Apriori-Algorithmus abgeleitete Mining-Prozess verwendet zwei Prozesskreisläufe: den
äußeren und den inneren Kreislauf. Weiters wird eine Ober- und eine Untergrenze für die
Anzahl der zu erstellenden Assoziationsregeln festgelegt. Der gesamte Prozess besteht nun
aus drei Schritten. Im ersten Schritt beginnt im äußeren Kreislauf die Messung der Anzahl der
vorkommenden Minimumunterstützungen in Abhängigkeit von einem ausgewählten Element.
Danach startet der innere Kreislauf mit der Generierung von Assoziationsregeln. Sobald
dieser Durchgang abgeschlossen ist, überprüft in einem 3. Schritt erneut der äußere Kreislauf
ob die erstellten Regeln die zu Beginn definierte Anzahl übersteigen. Ist dies der Fall wird die
Supportschranke erhöht und wiederum der innere Kreislauf gestartet. Dieser Prozess wird
solange wiederholt, bis die Anzahl der erstellten Assoziationsregeln kleiner oder gleich der
ursprünglich definierten Anzahl für die Regeln ist. Abschließend überprüft der äußere
Kreislauf, ob die Menge der gefundenen Regeln geringer ist als die anfangs festgelegte. Wenn
dies der Fall ist, wird die Supportbeschränkung solange verringert, bis die Anzahl der
gefundenen Regeln mit jener der definierten gleich ist oder diese übersteigt. Mit Hilfe der
soeben genannten Methode werden nun sowohl Assoziationen zwischen Usern, als auch
Assoziationen zwischen Artikeln generiert. Aufgrund dieser parallel erfolgenden Generierung
ist es möglich eine höhere Präzision bei der Empfehlung zu erreichen, als es beim Apriori-
Algorithmus der Fall ist. Dies geschieht indem die Empfehlung nach jener Gruppe (User oder
Artikel) vorgenommen wird, welche die größere Minimumunterstützung aufweist.
11

Verwendung von Assoziationsregeln in Recommender Systemen Besonders im immer größer werdenden elektronischen Markt ist es wichtig dem Kunden in
der Flut an Produkten Hilfestellung zu bieten, damit er einen gewissen Überblick bewahren
kann. Diese Hilfestellungen werden mittels Empfehlungssystemen, so genannten
Recommender Systemen zur Verfügung gestellt. Einerseits helfen diese Systeme dem Kunden,
Zeit beim Interneteinkauf zu sparen, andererseits kann der Betreiber durch empfohlene
Produkte zu zusätzlichen Käufen animieren und dadurch höhere Gewinne erzielen. Aber auch
die zunehmende Zahl an Online-Ressourcen und Webpages macht es dem
Gelegenheitsbenutzer immer schwieriger möglichst schnell das zu finden, was er auch
tatsächlich sucht. Durch die Verwendung von Recommender Systemen erhält der Benutzer
während seiner virtuellen Sitzung Informationen zu anderen Produkten, Internetseiten, etc.
Welche Produkt- oder Seitenhinweise er bekommt hängt von der Art des
Empfehlungssystems ab, genauer gesagt, davon wie das System benutzt und wie es diese
Daten auswertet und an den Benutzer weiter gibt. Grob können vier verschiedene
Vorgehensweisen unterschieden werden [Prei04].
• Statistische Zusammenfassungen: Aggregation von Bewertungen und Meinungen
• Attribut basierte Empfehlungstechnologien: verwenden Produkteigenschaften oder
Kundenprofile zur Generierung von Empfehlungen
• Item-to-Item Korrelation: berechnet wird die Korrelation zwischen Produkten; benutzt
werden gegenwärtige Bedürfnisse des Kunden, welche als Input dienen und auf deren
Grundlage das System ähnliche Produkte empfiehlt
• User-to-User Korrelation (Colaborative Filtering): berechnet werden Ähnlichkeiten
zwischen Kunden; empfohlen werden Produkte, die von ähnlichen Kunden gekauft
oder positiv bewertet wurden
Anhand dieser Unterscheidung wird deutlich, dass Assoziationsregeln den Item-to-Item
basierten Empfehlungssystemen zuzuordnen sind. Meistens basieren Assoziationen auf der
Grundlage von gemeinsam erworbenen Artikeln oder Präferenzen von Kunden, aber auch
andere Methoden sind möglich. Die einfachste Anwendungsform in Item-to-Item basierten
Recommender Systemen ist es einzelne Artikel zu suchen, die zueinander passen.
Beispielsweise Kleidungsstücke wie ein Paar Jeans und T-Shirts, usw. Zielführender ist es
12

allerdings ganze Artikelbündel zu suchen, die zusammenpassen. Beim Internetshopping
könnten z.B. alle Artikel im Einkaufswagen als ein Artikelbündel herangezogen werden und
danach könnten weitere Produkte empfohlen werden. Es wäre für den Betreiber des virtuellen
Geschäfts somit möglich einem Kunden, der soeben ein TV-Gerät in seinen Einkaufswagen
gelegt hat auch noch DVD-Player oder diverse Verbindungskabel für diese Geräte anzubieten.
Um von den Rohdaten zu einer übermittelbaren Empfehlung zu gelangen, ist ein mehrstufiger
Arbeitsprozess notwendig. Es soll nun überblicksmäßig der Prozessablauf bei
Empfehlungssystemen mit Assoziationsregeln erklärt werden. Grundsätzlich werden
personalisierte Empfehlungen, die während einer Online-Sitzung dem Benutzer angeboten
werden in 3 Phasen durchgeführt [MDLN01]:
1) Vorbereitung der Daten und Datentransformation
2) Erstellung von Empfehlungsmustern
3) Empfehlung
Üblicherweise erfolgen die Phasen 1 und 2 als Offline-Vorgang, während die letzte Phase
online, also während der entsprechenden Sitzung durchgeführt wird. Im Prozessschritt der
Mustererstellung werden die Assoziationsregeln erstellt, sowie Clustering von Benutzern oder
von Sitzungen und ähnliches durchgeführt. Ob die an den Benutzer übermittelten
Empfehlungen zielführend sind, wird bereits bei der Aufbereitung der Daten festgelegt. Dazu
sind eine Reihe von Aufgaben erforderlich wie beispielsweise Datenbereinigung,
Identifikation der Benutzer, Identifikation der Sitzungen, Identifikation der Zugänge zu den
Internetseiten und vieles mehr. Der letzte Schritt vor der Erstellung der Muster ist häufig die
Identifikation der Transaktionen. Dies hat den Grund, dass dadurch aus den besuchten
Webpages Untergruppen gebildet werden können, welche eine zusätzliche
Unterscheidungsmöglichkeit geben und dadurch den Auswertungsprozess vereinfachen.
Während der Online-Phase stellt der Recommendation Engine eine Verknüpfung zwischen
den erstellten Regeln und der aktuellen Sitzungshistorie her, um Recommendations anbieten
zu können. Diese Recommendations können in Form von angezeigten Links zu anderen
Webseiten oder Produkten, sowie gezielten Werbefenstern an die Präferenzen des Benutzers
bzw. des Kunden angepasst werden.
Empfehlungen könnten auch zu unterschiedlichen Zeitpunkten erfolgen. Die Auswertung der
gesammelten Datenbestände könnte eine Assoziationsregel ermitteln, dass Kunden die zum
13

Zeitpunkt X einen tragbaren MP3-Player kaufen, zum Zeitpunkt Y Kopfhörer kaufen. Durch
die mittels Assoziationsregeln gefundene Beziehung kann dem Konsumenten bei seinem
nächsten Einkauf ein weiteres Produkt empfohlen werden [Sch05]. Hierbei ist allerdings zu
berücksichtigen, dass Item-to-Item basierte Empfehlungssysteme eher für die kurzfristigen
Bedürfnisse der Konsumenten geeignet sind wie Bücherempfehlungen, etc. Weiters sind sie
nicht besonders geeignet, wenn die Datensätze zu spärlich sind, da unter solchen Umständen
nur sehr wenige Regeln gefunden werden können und die Qualität der Regeln unzureichend
wird. Andererseits ist bei zu großem Produktangebot aufgrund der benötigten Rechenleistung
des Systems, die Performance des Empfehlungssystems beeinträchtigt.
Eine Möglichkeit diese Probleme zu verringern ist die Kombination mehrerer Methoden.
Beispielsweise kann eine gemeinsame Verwendung von Item-to-Item basierten mit User-to-
User basierten Systemen die Ergebnisse verbessern. Durch die Unterteilung der Konsumenten
in unterschiedliche Gruppen mittels Clustering (User-to-User) wird die Datenbasis für die
Anwendung von Assoziationsregeln nötigenfalls verringert, wodurch Effizienzsteigerungen
zu erwarten sind.
Allerdings haben auch Assoziationsregeln Fehler aufzuweisen. Einen wesentlichen Mangel
stellt in diesem Zusammenhang das Problem der fehlerhaften Information dar. Die besuchten
Seiten eines Benutzers werden üblicher Weise in einem Logbuch in Form der „Click-Stream-
History“ aufgezeichnet. Diese ist vergleichbar mit dem Verlauf der besuchten Internetseiten,
der jedem Privatanwender bekannten sein dürfte. Wenn nun ein Benutzer seine Sitzung
beendet, werden die gespeicherten Seiten für weitere Empfehlungen herangezogen. Die
Speicherung der Clicks kann jedoch zu fehlerhaften Recommendations führen, vor allem dann,
wenn Seiten schlecht strukturiert sind oder die Benutzer ihre Sitzung bei einer vom System
nicht empfohlenen Seite beenden und diese somit fälschlicher Weise für das System
empfehlenswert zu sein scheint. Aber auch die Nachhaltigkeit kann bei der Verwendung von
auf Assoziationsregeln basierten Recommender Systemen leiden. Diese Problematik
entwickelt sich besonders dann, wenn neue Seiten zu bestehenden hinzugefügt werden. Da
diese neuen Seiten noch nicht besucht wurden, können sie auch noch nicht vom System
empfohlen werden, obwohl sie möglicher Weise für den User relevant wären. Die
Schwierigkeit besteht darin, dass die Empfehlung einer Seite mit der Häufigkeit an Besuchen
durch die Benutzer zunimmt, auch wenn sich diese danach als nicht besonders relevant
herausstellt [LiZai04].
14

Anwendungsbeispiele von Assoziationsregeln In diesem Kapitel werden Praxisbeispiele für die unterschiedlichen Möglichkeiten zur
Anwendung von Assoziationsregeln vorgestellt. Es wurde bereits erwähnt, dass die Methodik
der Assoziation vor allem in der Warenkorbanalyse eine wichtige Rolle spielt. Ausserdem
wurde gezeigt, dass auch Online-Recommender Systeme die Generierung von
Assoziationsregeln nutzen. Mit Hilfe dieser exemplarischen Darstellung soll gezeigt werden,
dass Assoziationsregeln zusätzlich auch bei Untersuchungen die zu Marketingzwecken erstellt
werden eine wichtige Funktion übernehmen.
Anwendungsbeispiel 1: SmartPad
Alle in diesem Abschnitt enthaltenen Informationen wurden aus [LAKVD01] entnommen.
Eine Gruppe von Wissenschaftern um R. D. Lawrence führte vor einigen Jahren ein
Versuchsprojekt mit einer Supermarktkette durch, um den Einfluss und die Wirksamkeit von
personalisierten Recommender Systemen auf die Konsumenten zu untersuchen. Für die
Untersuchung erhielten die Kunden des Kaufhauses Personal Digital Assistants (PDAs), mit
welchen sie ihre Einkaufsliste elektronisch aus einem persönlich zusammengestellten
Artikelangebot des Supermarktes erstellen konnten. Danach wurden diese Listen elektronisch
an das Geschäft übermittelt. Die gewünschten Produkte wurden im Kaufhaus
zusammengestellt und die Kunden mussten diese nur noch abholen, was für den Kunden eine
wesentliche Zeitersparnis brachte. Andererseits kam es jedoch, da die Konsumenten nun nicht
mehr durch die Gänge des Supermarktes gingen, zu keinen Spontankäufen der Kunden. Aus
diesem Grund entwickelten die Forscher ein Empfehlungssystem, welches den Kunden in
regelmäßigen Zeitabständen über den PDA Informationen über ausgewählte Produkte
übermittelte. Diese Empfehlungen wurden anhand des früheren, individuellen Kaufverhaltens
erstellt. Das Recommender System verwendete eine Kombination der Methoden von
Generierung von Assoziationsregeln und des Clustering. In einem ersten Schritt wurden
mittels Assoziationen Beziehungen zwischen Produktklassen und Produktsubklassen gesucht.
Da diese Beziehungen auf bereits durchgeführten Transaktionen beruhen, konnte davon
ausgegangen werden, dass zusätzliche Beziehungen gefunden werden würden, die nicht nur
aufgrund der Taxanomie der Produkte offensichtlich sind (z.B.: Konsumenten die Hundefutter
kaufen, kaufen auch Teppichreiniger). In einem zweiten Schritt wurden die Ergebnisse durch
Clustering zu Konsumentenbündeln verknüpft, die anhand bestehender Konsummuster
gebildet wurden.
15

Für die Bestellung standen drei persönliche Datenbanken zur Verfügung. Erstens ein
persönlicher Katalog, zweitens erstellte Empfehlungen und drittens Anzeigen von
Aktionartiklen. Die Erstellung der Assoziationsregeln wurde auf einem eigens geschaffenen
SmartPad-Server durchgeführt, welcher wöchentlich Empfehlungen generierte und diese mit
allen aktualisierten Daten inklusive den Werbeanzeigen für Produktaktionen an alle
Teilnehmer des Forschungsprojekts versendete. Da jeder Konsument einem spezifischen
Cluster zugeordnet war, konnte für jeden Cluster eine separate Liste der meist gekauften
Produkte erstellt werden. Die Recommendations für die Konsumenten wurden darauf folgend
aus Produkten dieser Liste erstellt. Bevor die Empfehlung jedoch tatsächlich versendet wurde,
musste sie den „Matching Engine“ durchlaufen, welcher wieder Assoziationsregeln
berechnete und mit Hilfe dieser zusätzlichen Regeln eine Reihenfolge der zu empfehlenden
Produkte erstellte. Schlussendlich wurden jeweils 10 bis 20 Produkte mit den höchsten
Werten an die Kunden als Empfehlung verschickt. Zu berücksichtigen ist, dass keine Artikel
empfohlen wurden, die von dem betroffenen Konsument zuvor bereits gekauft worden waren.
Für die Berechnung der Assoziationsregeln zwischen den 99 Produktkategorien und den 2302
Unterkategorien wurde der Apriori-Algorithmus verwendet. Die Ausgangsdaten, welche als
Input für die Analyse herangezogen wurden, wurden über einen Zeitraum von 8 Wochen, aus
den Transaktionen von 8000 Kunden mit überdurchschnittlich hohem Zahlungsverhalten,
gesammelt. Um die Assoziationen innerhalb der Produktklassen zu erhalten, wurden die
Transaktionen nach Produktkategorien zusammengefasst und danach über den
Messungszeitraum aggregiert. Zum Abschluss wurden Paare bestehend aus Kundenkennzahl
und Produktklassenkennzahl gebildet. Von diesen Paaren stellte jedes eine Produktkategorie
dar, in welcher der Konsument innerhalb des 8-wöchigen Zeitraumes Artikel eingekauft hatte.
In diesem letzten Schritt besteht auch der maßgebliche Unterschied zu einer herkömmlichen
Warenkorbanalyse, da in dem genannten Fall eine Mischung zwischen Kunden und Produkten
stattfindet, was in der Warenkorbanalyse nicht der Fall ist. Analog wurde der Vorgang auch
für die Produktsubkategorien durchgeführt.
Die Anzahl der möglichen Regeln wurde für beide Kategorieebenen auf 100 beschränkt, um
einerseits die Deutlichkeit der Ergebnisse zu erhöhen und andererseits die Komplexität der
Berechnung zu verringern. Weiters wurden Schranken für die Unterstützung, die Konfidenz
und den Lift definiert. Diese Werte wurden nach mehreren Testreihen wie folgt festgelegt:
Minimumsupport 1 bis 4 Prozent, Minimumkonfidenz 30 bis 40 Prozent und Minimumlift 2
bis 3. Die Ergebnisse eines Teils der Berechnung für Produktkategorie-Ebenen und
16

Unterkategorie-Ebenen sind in Tabelle 5 zu sehen. Daraus lässt sich erkennen, dass
beispielsweise Konsumenten, welche Babyprodukte kaufen in 41 Prozent der Fälle auch
italienische Pasta in Dosen kaufen. Das entspricht der 2,4-fachen Rate, von der man
annehmen würde, die beiden Produkte wären statistisch unabhängig.
Sup. Konf. Lift Produktklasse oder Unterklasse relevante Beziehungen 0,059 0,41 2,4 20(Baby Produkte) →41(ital. Pasta in Dosen) 0,082 0,47 2,2 66(Tafelweine) →68(Beer/Spirituosen) 0,125 0,50 2,0 90(Frischfleisch) →91(Schweinefleisch/Lammfleisch) 0,025 0,38 9,0 2010(Baby:Wegwerfwindeln) →2007(Baby:Reinigungstücher) 0,016 0,33 4,9 2010(Baby:Wegwerfwindeln) →1012(Milchprodukte:Kinderjoghurt) 0,01 0,33 4,9 2010(Baby:Wegwerfwindeln) →3115(Serviceeinrichtungen:Babysitting Center)
0,012 0,37 3,4 1020(Milchprodukte:Kinderkäse) →3115(Serviceeinrichtungen:Babysitting Center) 0,016 0,52 5,2 2306(Kekse:Kekse für Kinder) →3115(Serviceeinrichtungen:Babysitting Center) 0,022 0,30 4,9 9015(Frischfleisch:Rinderbraten) →9120(Schweinefl./Lammfl.:Schweinebraten)
Tabelle 5: Ergebnisse für Assoziationen für Produktklassen und Produktsubklassen Die Ergebnisse der Untersuchung können wie folgt zusammengefasst werden:
Für die Bewertung der Ergebnisse ist es notwendig sich daran zu erinnern, dass das
Recommender System, wie eingangs erwähnt dazu diente, um die durch Spontankäufe
verlorenen Gewinne abzudecken. Von diesem Gesichtspunkt waren die Ergebnisse nicht
besonders zufrieden stellend. Durch die Empfehlungen stieg der Gewinn um 0,3
Prozentpunkte über jenen, der ausschließlich durch die Einkäufe von der persönlichen Liste
der Konsumenten erzielt worden war. Eine interessante Beobachtung, die sich feststellen ließ
war, dass die Ausgaben der Konsumenten sich stark unterschieden, je nachdem, ob das
Produkt von der Empfehlungsliste oder von der persönlichen Einkaufsliste kam, obwohl die
auf beiden Listen verfügbaren Artikel sehr ähnlich waren. Zum Beispiel betrug der Anteil am
Gewinn, welcher aus Weinkäufen von der persönlichen Liste entstand 3,5 Prozent, während
der Anteil aus Weinkäufen aus der Empfehlungsliste 8,7 Prozent betrug. Im Gegensatz dazu
waren die Anteile von Reinigungsprodukten für den Haushalt 12,1 Prozent von der
persönlichen Einkaufsliste und nur 4,6 Prozent von den empfohlenen Artikeln. Lawrence et al.
ziehen daraus den Schluss, dass Empfehlungen bestimmter Produktkategorien eher von den
Konsumenten angenommen werden, als jene anderer. Diese Annahme wurde in einer späteren
Befragung von den Kunden bestätigt.
17

Anwendungsbeispiel 2: e-VZpro
Alle in diesem Abschnitt enthaltenen Informationen wurden aus [Demz04] entnommen.
e-VZpro ist ein auf Assoziationsregeln basierendes Recommender Tool der Firma Verizon.
Die Empfehlungen werden in 2 Phasen erstellt. Im 1. Schritt werden historische Kundendaten
mittels Assoziationsanalyse aufbereitet und Assoziationsregeln erstellt. Während der 2. Phase
durchsucht ein Algorithmus ausgehend vom Benutzerprofil des aktiven Users die erstellten
Regeln, um eine Reihenfolge für die möglichen Produktempfehlungen zu erstellen. Diese
Recommendations werden danach dem User übermittelt. Zusätzlich wird nach Assoziationen
zwischen vom Benutzer gewählten und nicht gewählten Produkten gesucht. Der wesentliche
Unterschied des hier beschriebenen Systems zu früheren ist, dass nicht versucht wird, eine
möglichst exakte Übereinstimmung zwischen dem aktiven Benutzer und den erstellten
Assoziationsregeln zu finden. Viel mehr wird versucht möglichst ähnliche, übergeordnete
Regeln mit höchster Konfidenz zu finden und diese in eine konkrete Reihenfolge zu bringen.
Diese Reihenfolge wiederum ergibt sich aus Regeln die ebenfalls nach Übereinstimmung mit
dem aktiven User und ihrer Konfidenz gereiht sind.
Bei der Suche nach Assoziationsregeln wurden 12 unterschiedliche Kombinationen von
Werten verwendet. Die Schranken für die Unterstützung betrugen 0,01, 0,05 und 0,1 Prozent.
Die Grenzwerte für die Konfidenz wurden mit 55, 60, 65 und 75 Prozentpunkten festgelegt.
Um die Genauigkeit der Ergebnisse zu erhöhen, ist es notwendig sowohl die Grenzrate für
den Support, als auch jene für die Konfidenz zu verringern. Dies ist besonders auch für die
Leistungsfähigkeit zu berücksichtigen, die bei zunehmender Anzahl an erstellten Regeln
zurückgeht. Hinter dieser Tatsache verbirgt sich auch der eindeutige Vorteil des e-VZpro
Systems, da es mit einer geringern Anzahl an Assoziationsregeln auskommt. Die Ergebnisse
von e-VZpro im Vergleich zu einem herkömmlich auf Assoziationsregeln basierendem Minig
System sind in Tabelle 6 exemplarisch dargestellt. Das Versuchsziel bestand darin, die
Vorhersagegenauigkeit der Methoden zu vergleichen. Die verwendeten Daten wurden aus
einer Kundendatenbank von Verizon entnommen.
Aus Tabelle 6 ist deutlich zu erkennen, dass die Genauigkeit von e-VZpro in jedem Fall höher
ist als bei der Verwendung anderer Mining-Methoden mit Assoziationsregeln. Die besten
Ergebnisse in Bezug auf Genauigkeit sind jeweils hervorgehoben.
18

e-Vzpro Assoc. Mining Sup. (%)
Konf. (%)
Anzahl der Regeln
ben. Zeit (Sek.)
Geauigkeit (%)
ben. Zeit (Sek.)
Geauigkeit (%)
0,01 55 394203 11915 52,99 8442 45,030,01 60 345173 10077 52,28 7221 36,500,01 65 294471 8498 51,92 6044 26,620,01 75 209445 6045 49,88 4182 14,080,05 55 63611 1848 55,61 1390 44,540,05 60 53396 1533 53,13 1152 36,000,05 65 43786 1253 50,24 945 26,040,05 75 27049 796 47,64 602 13,390,1 55 26850 741 58,87 663 44,190,1 60 22040 599 55,66 455 35,680,1 65 17758 477 53,06 364 25,770,1 75 10366 292 51,11 223 13,04
Tabelle 6: Ergebnisse des Genauigkeitsvergleichs von e-VZpro mit herkömmlichem Association Mining In späteren Versuchen wurde festgestellt, dass eine Reduzierung der Konfidenzschranke einen
größeren Effekt auf die Leistungsfähigkeit beim Erstellen von Assoziationsregeln hat, als eine
Verringerung der Supportschranke. Außerdem führt ein geringer Grenzwert der Konfidenz zu
besserer Vorhersagefähigkeit.
Anwendungsbeispiel 3: PROFSET – Product Selection
Alle in diesem Abschnitt enthaltenen Informationen wurden aus [BSVW99/2] entnommen.
Dieses Fallbeispiel soll zeigen, dass es möglich ist unter Einsatz von Assoziationsregeln
Beziehungen zwischen Produkten aufzudecken, die es ermöglichen die Auswahl für das
Produktsortiment zu verbessern. Assoziationsregeln weisen für diese Verwendung allgemein
sehr positive Eigenschaften auf, da sie häufig als eine sehr wertvolle Technik für die Lösung
von Problemen im realen Wirtschaftsleben herausgestellt haben.
Aus der Marketing-Literatur ist bekannt, dass es zwei wichtige Voraussetzungen für das
optimale Produktangebot gibt. Zum einen sollte das Sortiment qualitativ dem Image des
Geschäftes entsprechen, wobei das Image durch Design, Layout, Leistungen und natürlich die
Produkte selbst bestimmt wird. Daher muss sich der Anbieter häufig zwischen grundlegenden
Produkten und einem zusätzlichem, besonderem Angebot entscheiden. Die grundlegenden
Produkte sollten selbst bei einer Verschlechterung der Geschäftslage keinesfalls aus dem
Sortiment gestrichen werden, da sie den Kern des Geschäftes darstellen. In einem
Lebensmittelmarkt wären zum Beispiel Getränke, Nahrungsmittel und Süßwaren die von den
Kunden erwartete Grundausstattung. Die zusätzlichen Produkte wählt der Anbieter nach
eigenem Ermessen aus, um dem Geschäft eine individuelle Note zu verleihen. Jedoch sollte
bei der Auswahl des zusätzlichen Angebots Rücksicht auf das Potential für Cross-Selling
19

genommen werden. Dadurch könnte durch eine Ausweitung des Sortiments der Verkauf von
bereits im Sortiment befindlichen Produkten gesteigert werden. Beispiele für solche Produkte
können Tageszeitungen oder Feuerzeuge genannt werden.
Mit dem Begriff Cross-Selling werden Effekte verstanden, die durch Beziehungen zwischen
Produkten auftreten. Kauft sich ein Kunde einen Videorekorder, wird er mit sehr großer
Wahrscheinlichkeit auch Videokassetten kaufen. Diese und ähnliche
Komplementärbeziehungen, werden in weiterer Folge als Cross-Selling bezeichnet. Auch
Substitutsbeziehungen zählen zum Bereich des Cross-Selling, werden aber in der
vorliegenden Betrachtung nicht miteinbezogen.
Als zweite Voraussetzung für das optimale Produktangebot gilt die Wahl der Mengen unter
dem Gesichtspunkt der Profitmaximierung. Will man nun ein Modell für die richtige
Produktauswahl erstellen, gilt es die soeben erwähnten Voraussetzungen zu berücksichtigen.
Selbstverständlich wäre es möglich, sich den Gewinn jedes Produktes zu errechnen und dann
jene auszuwählen, die den höchsten Profit aufweisen. Allerdings wären durch diese
Vorgehensweise die Cross-Selling-Beziehungen nicht berücksichtigt. Trotzdem sollte der
erzielbare Profit nicht von der Berechnung ausgeschlossen werden. Weitere Daten die auf
jeden Fall in das Modell einbezogen werden müssen, sind die Produktkosten. Die Lösung für
all diese Probleme soll mit der PROFSET-Methode behoben werden. PROFSET steht als
Abkürzung für „PROFitability per frequent SET to determine the optimal selection of
products in terms of maximal total profit“. Die Methode erstellt eine Liste häufig
vorkommender Produkte, gereiht nach dem erzielbaren Gewinn.
Die Datenbasis welche für die Studie herangezogen wurde, bestand aus 27148
Verkaufstransaktionen in einem neuartigen, vollautomatischen Lebensmittelladen. Der
Beobachtungszeitraum betrug 5,5 Monate. Im Vergleich zu einem herkömmlichen Automaten
besteht der Unterschied zu diesem „Geschäft“ darin, dass das Sortiment etwa 200 Artikel
umfasst. Das Produktangebot umfasst Getränke, Lebensmittel, Süßwaren, Zigaretten,
Hygieneartikel, Tiernahrung, Obst, Batterien sowie Fotozubehör. Die Produkte werden dem
Kunden durch ein 8m2 großes Schaufenster angeboten. In dem hier beschriebenen Versuch
wurden pro Einkauf durchschnittlich 1,4 Produkte gekauft. Dies ist dadurch zu begründen,
dass in den wenigsten Fällen die Konsumenten mehr als 1 Produkt pro Einkauf beziehen. Die
Untersuchung wurde in 2 Phasen durchgeführt. Zuerst wurden anhand des Käuferverhaltens
Assoziationsregeln erstellt, die in der 2 Phase mittels der PROFSET-Methode dazu verwendet
wurden, um eine Liste der meistverkauften Produkte zu erstellen.
20

Die Untergrenze für den Support wurde mit 10 festgelegt. Dies bedeutet, dass ein Produkt erst
als häufig angesehen wird, wenn es in mindestens 10 Verkaufstransaktionen vorgekommen ist.
Mit dieser Einschränkung wurden 523 häufige Elemente definiert, die eine Unterstützung
zwischen 10 bis 2833 aufwiesen. Die Anzahl der häufig auftretenden Artikel mag ein wenig
klein erscheinen. Dies kann mit der geringen Anzahl der pro Transaktion gekauften Produkte
begründet werden.
Obwohl bei der Anwendung der PROFSET-Methode keine grundlegenden Produkte definiert
wurden, war es trotzdem möglich Cross-Selling-Eigenschaften herauszufiltern. Als Ergebnis
kann folgendes berichtet werden:
1) Unter der Verwendung von PROFSET wurden Produkte mit relativ geringem
produktspezifischem Profitanteil, aber hoher Cross-Selling-Eigenschaft zur Bestenliste
der Produkte hinzugefügt.
2) Mit Hilfe der PROFSET-Methode konnte die richtige Auswahl des Produktsortiments
verbessert werden. Als Folge daraus wurde auch die Wichtigkeit des Einflusses
solcher Entscheidungen auf die Profitabilität verdeutlicht.
Als illustratives Beispiel für die Erkenntnisse können Tabak und Zigarettenpapier genannt
werden. In der Studie war Tabak an 17. Stelle der profitabelsten Produkte. Zigarettenpapier
stand an 66. Position. Würde man die Bestenliste auf weniger als 66 Artikel begrenzen, wäre
Zigarettenpapier daher nicht mehr vertreten. Bei der ausschließlich nach
Profitgesichtspunkten vorgenommenen Auswertung, war dies auch der Fall. Im Vergleich
führte die Untersuchung mit der PROFSET-Methode selbst bei einer auf 35 Elemente
beschränkten Liste dazu, dass Zigarettenpapier trotzdem auf dieser vertreten war. Die
Erklärung dafür ist, dass Zigarettenpapier durch Cross-Selling-Effekte zu einem oder
mehreren Produkten, wesentliche Vorteile gegenüber anderen Artikeln aufweist.
Diese Tatsache kann auch bei genauerer Betrachtung der Assoziationsregeln festgestellt
werden. Die Regeln verdeutlichen, dass wenn immer ein Konsument Zigarettenpapier kaufte,
er ebenfalls Tabak gekauft hat (Konfidenz = 100%). Weiters wurde aufgezeigt, dass bei
Tabakkäufen häufig auch Zigarettenpapier gekauft wurde (Konfidenz = 82%). Um die
Abhängigkeiten zwischen Produkten noch stärker hervorzuheben, verwendeten die Forscher
die zusätzliche Variable Lift. Der Lift wird als Quotient aus beobachteter Häufigkeit und
erwarteter Häufigkeit der in der Assoziationsregel vorkommenden Produkte berechnet. Die
Liftvariable kann 3 Werte annehmen. Ist der Wert größer als 1 treten zwischen den Artikeln
21

Komplementäreffekte auf. Ist der Wert gleich 1 sind die Produkte voneinander unabhängig.
Ergibt sich jedoch für den Lift ein Wert der kleiner als 1 ist, stehen die Artikel zueinander in
einem Substitutionsverhältnis. Die Einbeziehung der Liftvariable bei Tabak und
Zigarettenpapier hat ergeben, dass zwischen den beiden Produkten eine starke
Komplementärbeziehung besteht. Die sich ergebende Folge war, dass die Produkte, wenn sie
gemeinsam angeboten wurden einen wesentlich höheren Beitrag zum Gewinn geleistet haben,
als dies durch Tabak alleine der Fall war. Insgesamt war diese Produktkombination auf Platz
10 der Bestenliste vertreten, wodurch PROFSET beide Produkte für die Liste auswählte.
Trotzdem bedeutet dies nicht, dass Produktpaare allein wegen ihres Cross-Selling-Potentials
gelistet werden, denn auch die Höhe des Gewinnbeitrags muss ausreichend sein um alle
Voraussetzungen dafür zu erfüllen. Beispielsweise haben die Artikel Zahnpaste und
Zahnbürste einen sehr großen Liftwert und werden laut den generierten Assoziationsregeln
immer gemeinsam gekauft. Hingegen ist die Unterstützung des Artikelpaares nur knapp über
der Mindestgrenze. Insofern ist die Auswirkung dieser beiden Produkte auf den Profit nicht
groß genug um sie in der Sortimentsauswahl zu berücksichtigen. Die beiden genannten
Beispiele zeigen somit klar, dass Assoziationsregeln einerseits sehr interessante statische
Eigenschaften aufzeigen können, aber andererseits sind sie auch sehr hilfreich bei der Analyse
zur Abwicklung realer wirtschaftlicher Geschäftprozesse.
Anwendungsbeispiel 4: Effekte von Produktpromotionen 1
Alle in diesem Abschnitt enthaltenen Informationen wurden aus [PSW03] entnommen.
Wie schon in den vorherigen Anwendungsbeispielen erläutert, beschäftigen sich
Geschäftsleute und Marketer bereits seit längerer Zeit mit den Einflüssen von Marketing-Mix-
Instrumenten auf das Konsumverhalten, Sortimentsentscheidungen, Preis- und
Promotionsplanung, etc. Bei der Einbindung von Komplementärbeziehungen zwischen
Produkten zur Bewertung von Marketing-Mix-Methoden stehen mehrere Alternativen zur
Verfügung. Wie ebenfalls bereits erwähnt, können bei der Sortimentsauswahl berücksichtigte
Komplementäreffekte positive Auswirkungen auf den Gewinn haben. Weiters können
gewonnene Erkenntnisse über Produktzusammenhänge von großem Nutzen bei der
Gestaltung der Anordnung der Regale im Geschäft sein. Die Anordnung könnte dahingehend
beeinflusst werden, dass Produkte die häufig gekauft werden, besonders nahe bei einander
platziert werden. Letztendlich können auch Promotionen besser geplant werden, wenn die
Beziehungen zwischen verschiedenen Produkten bekannt sind. Dies ist besonders deshalb
interessant, weil in Untersuchungen festgestellt wurde, dass 75 Prozent der Konsumenten,
22

deren ursprünglicher Beweggrund das Geschäft aufzusuchen ein Preisangebot war, ebenfalls
Produkte zum regulären Preis kauften.
Die hier dargestellte Untersuchung beleuchtet die Effekte von Produktpromotionen bei
Produkten zwischen denen es Komplementärbeziehungen gibt. Der Ablauf wird in 3 Schritte
unterteilt. Zuerst werden Cross-Selling-Effekte bei Produktpromotionen von komplementären
Produkten mittels Assoziationsregeln gesucht und analysiert. Im 2. Schritt werden die
Veränderungen der Promotionsauswirkungen. die sich aufgrund der unterschiedlichen
Produktpaare ergeben, beschrieben. Zum Abschluss werden zusätzlich die Auswirkungen auf
die Verkaufszahlen der Komplemente überprüft. Es ist darauf hinzuweisen, dass in der hier
präsentierten Studie jeweils nur das Hauptprodukt, nur das Nebenprodukt, oder beide zur
gleichen Zeit speziell angeboten wurden.
Die für die Untersuchung verwendeten Daten wurden aus der Datenbank eines
Selbstbedienungsmarktes entnommen. Der Messungszeitraum betrug 1 Jahr. Zusätzlich
wurden Informationen über Ein- und Verkaufspreise, Gewinnspannen und die
Zusammenstellung der Angebotsflugblätter eingeholt. Da der Versand der Flugblätter
regelmäßig im 2 Wochen Rhythmus erfolgte wurden auch die Daten der Transaktionen
diesem Rhythmus angepasst. Die zur Verfügung stehenden Daten beinhalteten 141383
Einkäufe und das Angebot des Supermarktes umfasste 45000 Artikel. Von diesen wurden je
Produktgruppe 100 Artikel ausgewählt, die einerseits den höchsten Gewinnbeitrag leisteten
und andererseits mindestens zwei Mal innerhalb des Kontrollzeitraumes als Aktionsangebot
angepriesen wurden. Durchschnittlich wurden diese Produkte innerhalb von zwei Wochen
256 Mal oder 20 Mal pro Tag verkauft. Diese Artikel wurden jeweils als Regelrumpf für die
Assoziationsregeln verwendet. Darauf folgend wurden Assoziationsregeln zwischen diesen
und allen anderen Artikeln im Sortiment generiert. Die Supportschranke wurde mit 250
festgelegt und statt der Konfidenz wurde der Koeffizient Lift verwendet, der, wie bereits
zuvor erwähnt, größer als 1 sein muss um Komplementärbeziehungen aufzuweisen. Unter
diesen Beschränkungen wurden 191 Produktpaare ermittelt, die alle nötigen Voraussetzungen
erfüllen.
Die Ergebnisse auf Artikelebene waren wie folgt: Aktionsangebote haben generell eine
positive Auswirkung auf die Verkaufszahlen und Gewinne der Aktionsartikel. Auch konnten
zusätzliche Verkäufe von Aktionsartikeln die in Postwurfsendungen angekündigt wurden,
festgestellt werden. Soweit zu den direkten Auswirkungen. Zwischen komplementären
Produkten wurde herausgefunden, dass das Aufscheinen von Produkten in einem
23

Aktionsflugblatt auch die Gewinne aus den Komplementen steigerte. Zugleich erfolgte
Promotionen zweier Produkte, steigerten die Häufigkeit des gleichzeitigen Kaufs beider. Eine
hohe Preisreduzierung des Hauptproduktes hat weiters einen großen Einfluss auf
komplementäre Artikel, wenn diese ebenfalls preisreduziert angeboten werden. Vor allem
Kunden die ausschließlich durch das Aktionsangebot in das Geschäft gelockt wurden, sind
auch bereit komplementäre Produkte zu kaufen, wenn diese auch in Aktion sind. Außerdem
wurde herausgefunden, dass die komplementären Effekte der Preispromotionen je nach Stärke
der komplementären Beziehung, unterschiedlich ausfallen. Denn je stärker die Beziehung ist,
desto größer ist auch der Effekt auf das komplementäre Produkt. In diesem Zusammenhang
wurde auch deutlich, dass speziell vom Aktionsangebot angelockte Konsumenten nur die
Produkte mit der stärksten Komplementärbeziehung kauften. Es wäre daher für die Händler
sinnvoller, bei gleichzeitigen Promotionen von komplementären Produkten eher die
schwächeren Komplemente anzubieten. Für die stärksten zugleich angebotenen Komplemente
konnte in der Studie sogar festgestellt werden, dass sich ein negativer Effekt auf den Gewinn
des komplementären Produktes ergibt. Allerdings haben Produktpromotionen von
Hauptprodukten keinen Einfluss auf die verkauften Mengen der komplementären Artikel.
Anwendungsbeispiel 5: Effekte von Produktpromotionen 2
Alle in diesem Abschnitt enthaltenen Informationen wurden aus [VPW04] entnommen.
Assoziationsanalyse hat wie bereits an den vorherigen Anwendungsbeispielen gezeigt, ein
sehr umfangreiches Einsatzspektrum, welches besonders für Marketingzwecke sehr hilfreich
ist. In dem nun vorliegenden Beispiel soll auch wieder auf mögliche Effekte zwischen
komplementären Produkten hingewiesen werden. Allerdings untersucht die Studie, zusätzlich
zu den im vorangegangenen Anwendungsbeispiel gezeigten Effekten, den Einfluss des so
genannten Umbrella Branding auf Komplemente, sowie das Preisniveau um auftretende
Kreuzpreiseffekte zu erläutern. Unter Umbrella Branding wird die Verwendung desselben
Markennamens bei Hauptprodukten und Komplementen verstanden. Auch in dieser
Untersuchung wurden mittels Assoziationsregeln Komplementärbeziehungen zwischen
Produkten auf Artikelebene gesucht.
Die verwendeten Daten setzten sich aus mehr als 15000 unterschiedlichen Artikeln zusammen.
Daraus ergaben sich 112492500 zu analysierende Paare. Die Daten wurden über einen
Zeitraum von etwa vier Jahren gesammelt, in welchen in Summe 194 wöchentliche
Beobachtungen durchgeführt wurden. Die Produktpaare wurden als häufig vorkommend
24

deklariert, wenn sie einen Liftwert größer als 2 und einen Supportwert über 0,0157 aufweisen.
Zusätzlich mussten die ausgewählten Produkte mindestens 1 Mal innerhalb des
Beobachtungszeitraumes in einer Produktpromotion enthalten gewesen sein. Die
Anforderungen an die Promotionen waren, dass der Aktionspreis mindestens fünf Prozent
unter dem ursprünglichen Preis liegen musste und das die Aktionsprodukte innerhalb der
nächsten acht Wochen wieder um mindestens drei Prozent im Preis ansteigen mussten. Die
Anwendung dieser Restriktionen führte im Ergebnis zu 1350 ausgewählten
Produktassoziationen. Aus dieser Anzahl an gefundenen Assoziationen wurden 1112
Komplementärbeziehungen festgestellt.
Folgende Ergebnisse konnten aus der Analyse abgleitet werden:
Bei einem Großteil der Artikel konnten bei gemeinsam durchgeführten Aktionsangeboten von
komplementären Produkten Kreuzpreiseffekte festgestellt werden, wodurch höhere
Verkaufszahlen der Aktionsprodukte erreicht wurden. Es wurden jedoch auch negative
Auswirkungen beobachtet, die sich vor allem durch so genannte Cherry Pickers ergaben. Als
Cherry Pickers werden Konsumenten bezeichnet, die Aktionsangebote in Supermärkten
gezielt nutzen, um so die für Einkäufe aufgewendeten Ausgaben zu reduzieren. Ein Geschäft
kann die Aufmerksam solcher Kunden nur dann auf sich ziehen, wenn es regelmäßig
umfangreiche Aktionsangebote anpreist. Jedoch weisen Produkte die häufig in Aktionen
angeboten werden eine geringere Kreuzpreiselastizität auf. Diese Tatsache widerlegt somit die
Strategie des Loss-Leader-Pricing. Bei dieser Methode bietet ein Händler ein Produkt zu
einem sehr günstigen Preis unterhalb der Gewinngrenze an. Dabei hofft er, dass die durch den
günstigen Preis angelockten Konsumenten durch den Kauf von Komplementärgütern ihm den
nötigen Gewinn einbringen.
Die Beobachtungen hinsichtlich der Umbrella Branding Strategie zeigten positive
Auswirkungen auf die Kreuzpreiseffekte. Durchwegs konnten stärkere Einflüsse auf die
Produkte nachgewiesen werden, wenn das Komplement denselben Markennamen wie das
Hauptprodukt trug. In Bezug auf das Preisniveau ergaben die Beobachtungen, dass
komplementäre Artikel, die einen Preis bis zu 1,93 Euro hatten positiv durch die
Kreuzpreiseffekte vom Hauptprodukt beeinflusst wurden. War der Preis jedoch höher, waren
die Auswirkungen negativ.
Abschließend kann gesagt werden, dass intensive Verkaufspromotionen keine vorteilhaften
Einflüsse für den Anbieter ergeben. Hohe Kreuzpreiseffekte für die komplementären Artikel
durch Aktionsprodukte wirken besonders, wenn die Komplemente von der Aktion
ausgenommen sind. Je häufiger Produkte in Verkaufsaktionen angeboten werden, desto mehr
25

verlieren sie die Wirkung auf komplementäre Produkte. Aus Sicht des Cross-Selling hat
Umbrella Branding eine positive Wirkung auf die Komplemente. Was die Preise der Produkte
betrifft, sind die Kreuzpreiseffekte umso größer, je höher die Preisdifferenz zwischen dem
Hauptprodukt und dem Komplement. Dies gilt jedoch nur für komplementäre Güter im
Niedrigpreissegment. Hat das Komplement jedoch einen hohen Preis, überwiegt die
ursprünglich bestehende Preisdifferenz und es kommt ein geringerer Kreuzpreiseffekt zu
tragen.
Conclusio Die rasant ansteigende Menge an Information, der die Menschen Tag für Tag ausgesetzt sind,
verlangt nach Methoden, die eine einfachere Verarbeitung der Informationsdaten ermöglichen.
Mit der Entwicklung von Recommender Systemen wurde ein grundlegendes Mittel
geschaffen, das besonders bei den zunehmenden Einkäufen und Recherchen im Internet
notwendige Hilfe leistet. Unter der Vielzahl an möglichen Techniken um Recommendations
mit Empfehlungssystemen zu erzeugen, stellt die Verwendung von Assoziationsregeln eine
wesentliche, allgemein akzeptierte Möglichkeit dar.
Grundsätzlich ist die Verwendung von Assoziationsregeln eine sehr vielfältig einsatzfähige
Methode um Daten zu analysieren. Wie die Reihe von beschriebenen Anwendungsbeispielen
zeigt, stellen Assoziationsregeln besonders in der Sortimentsplanung und bei der Analyse von
Beziehungen zwischen Produkten, ein wichtiges Instrument dar. Als wesentlicher Nachteil ist
zu erwähnen, dass bei großen Datenmengen die Leistungsfähigkeit des verwendeten Systems
beeinträchtigt wird und die aufzuwendende Zeit erheblich ansteigt. Dieser Mangel kann
jedoch durch die kombinierte Anwendung mehrerer Methoden zur Generierung von
Empfehlungen ausgeglichen werden. Im Zusammenhang mit Assoziationsregeln kommt vor
allem dem Clustering eine besondere Bedeutung zu, da es eine gute Methode darstellt um
durch Datenbündelung die Leistungsfähigkeit der Assoziationsanalyse zu steigern.
Da das Data Mining mittels Apriori-Algorithmus einige Probleme aufweist, beschäftigen sich
zahlreiche Autoren mit diesen Schwierigkeiten. Dadurch gibt es eine Vielzahl an
Lösungsansätzen, die je nach Anwendungsbereich unterschiedlich eingesetzt werden können.
Abschließend bleibt festzustellen, dass auch in Zukunft die Verwendung von
Assoziationsregeln ein wichtiges Mittel in vielen Wirtschafts- und Forschungsbereichen
darstellen wird.
26

Literaturverzeichnis [AIS93] Agrawal Rakesh, Imielinski Tomasz, Swami Arun: Mining Association Rules between Sets of Items in Large Databases, In Proceedings of the 1993 ACM SIGMOD Conference, 1993 [Scha05] Schafer J. Ben: The Application of Data-Mining to Recommender Systems, Cedar Falls 2005 [MDLN01] Mobasher Bamshad, Dai Honghua, Luo Tao, Nakagawa Miki: Effective Personalization Based on Association Rule Discovery from Web Usage Data, Atlanta 2001 [LAR00] Lin Weiyang, Alvarez Sergio A., Ruiz Carolina: Collaborative Recommendation via Adaptive Association Rule Mining, Wellesley 2000 [LAKVD01] Lawrence R. D., Almasi G. S., Kotlyar V., Viveros M. S., Duri S. S.: Personalization of Supermarket Product Recommendations, New York 2001 [Demz04] Ayhan Demiriz: Enhancing Product Recommender Systems on Sparse Binary Data, Irving 2004 [BSVW99/1] Tom Brijs, Gilbert Swinnen, Koen Vanhoof, Geert Wets: Building an Association Rules Framework to Improve Product Assortment Decisions, Diepenbeek 1999 [BSVW99/2] Tom Brijs, Gilbert Swinnen, Koen Vanhoof, Geert Wets: Using Association Rules for Product Assortment Decisions: A Case Study, Diepenbeek 1999 [VPW04] Bernd Vindevogel, Dirk Van den Poel, Geert Wets: Dynamic cross-sales effects of price promotions: Empirical generalizations, Gent 2004 [PSW03] Dirk Van den Poel, Jan De Schamphelaere, Geert Wets: Direct and Indirect Effects of Retail Promotions, Gent 2003 [Brügg03] T. Brüggemann et al.: Personalisierung internetbasierter Handelsszenarien, Carl von Ossietzky Universität, Oldenburg 2003 [Grobl03] Martin Groblschegg: Entwicklung eines Testdatengenerator für Market Basket Analysis für e-commerce Anwendungen, Wien 2003
27

[LiZai04] Jia Li, Osmar R. Zaiane: Combining Usage, Content, and Structure Data to Improve Web Site Recommendation, Alberta 2004 [Karu02] Julien Tane: Assoziationsregeln, http://www.aifb.uni-karlsruhe.de/Lehre/Winter2002-03/kdd/download/VII-3-Assoziationsregeln.pdf%20, Karlsruhe 2002 Abfrage am 21.3.05 [Busl05] Sandra Busl: Adaptive Website, Assisted Browsing, Web Caching and Prefetching, http://cgnmpegasus.informatik.uni-freiburg.de/rs-04s-wiki/attach?page=Main%2F09-busl-web-personalisierung.pdf, Freiburg 2004 Abfrage am 7.3.05 [Diest01] Lars Diestelhorst: Recommendation Engines, http://www.sts.tu-harburg.de/papers/2001/Dies01.pdf, Harburg 2001 Abfrage am 7.3.05 [Jürg01] Ralph Marcus Jürgens: Mining Techniken in unterschiedlich strukturierten Datenbeständen – eine vergleichende Bewertung, http://www.tu-dresden.de/wwwiisih/ftp/hsws0102/Seminararbeit_Juergens.pdf, Dresden 2001 Abfrage am 7.3.05 [Oberle00] Vincent Oberle: Data Mining - eine Einführung, http://www.oberle.org/data-mining.pdf, Karlsruhe 2000 Abfrage am 21.3.05 [Kern04] Gabriele Kern-Isbemer: Darstellung, Verarbeitung und Erwerb von Wissen, http://ls6-www.informatik.uni-dortmund.de/ie/teaching/lectures/04ws/Vorlesung-DVEW/folien/dvew_2005_01_06.pdf, Dortmund 2005 Abfrage am 26.4.05 [GH02] Andreas Geyer-Schulz, Michael Hahsler: Evaluation of Recommender Alorithms for an Internet Information Broker based on Simple Association Rules and on the Repeat-Buying Theory, In Proceedings WEBKDD 2002, http://wwwai.wu-wien.ac.at/~hahsler/research/recomm_webkdd2002/final/webkdd2002.pdf, Edomonton 2002 Abfrage am 17.5.05 [Prei04] Christine Preisach: Recommender Systems in E-Commerce (Präsentation), http://cgnmpegasus.informatik.uni-freiburg.de/rs-04s-wiki/attach?page=Main%2FRS_in_E-Commerce.pdf, Freiburg 2004 Abfrage am 26.4.05
28
![Abschlussvortrag Diplomarbeit Neighbor Explorer ... · Recommender Systems (2004) • [4] Pampalk, Goto: Musicsun: A new approach to artist recommendation (ISMIR 2007) • [5] Swearingen](https://img.pdfslide.org/doc/110x75/6059a2f959444b19143eb810/abschlussvortrag-diplomarbeit-neighbor-explorer-recommender-systems-2004-a.jpg)