Embed Size (px)
Citation preview

Report HepixAutumn 2017
Manuel Giffels

Netzwerk

INTERNATIONALNETWORKS
At Indiana University
13
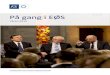
NetSage: Network measurement, analysis, and visualization
http://portal.netsage.global
13
Eventuell kann man aus diesem Projekt was für Netzwerk-Benchmarks von opportunistischen Ressourcen verwenden?
INTERNATIONALNETWORKS
At Indiana University
11
11

Network Benchmarks

Opportunistische Ressoucen

PIC

Opportunistic Resources at PIC
HEPIX Fall 2017 – KEK – J. Flix 11
Flexible use of WLCG resources in Spain
● Create a powerful, sustainable data and compute platorm by
linking the most reliable/cost-efectve sites in Spain
- PIC/IFAE(BCN) & CIEMAT(MAD) joint project for prototyping (new) ideas
● HTCondor pools being deployed (focking, CMS overfow – under test)
● Remote data reads via XRootD federatons (regional CMS XRootD redirector deployed)
● Prototypes for storage federaton under a single namespace (development needed)
● Provide an integrated/modern analysis facility in this platorm
● Integrate gateways for CPU intensive tasks towards least
expensive (or “free” resources) – Cloud / HPC

BNL

Existing Resources
• Dedicated• Custom workloads whose rigid constraints
make it difficult for others to use productively• Legacy RHIC/ATLAS clusters
• Shared• HPC clusters (IC, KNL and others)• Recently purchased RHIC/ATLAS resources• New general-purpose cluster in 2018

Enabling Resource Sharing
• Integration of cyber infrastructure• Discussions on single sign-on to integrate distinct user bases• Cross-mounting of disk storage instances• Plan to offer access to tape storage via BNLBox
• Rethink HTCondor policy to increase productivity of RHIC/ATLAS clusters. Possibilities are:
• Collapse multiple HTCondor pools into a single pool and expand usage of hierarchical group quota model deployed on ATLAS Tier 1
• Increase flocking among multiple Condor pools in existing model• HTC workloads on HPC clusters
• Direct access for HPC-adapted workloads• Mechanism to submit HTCondor jobs to Slurm at BNL
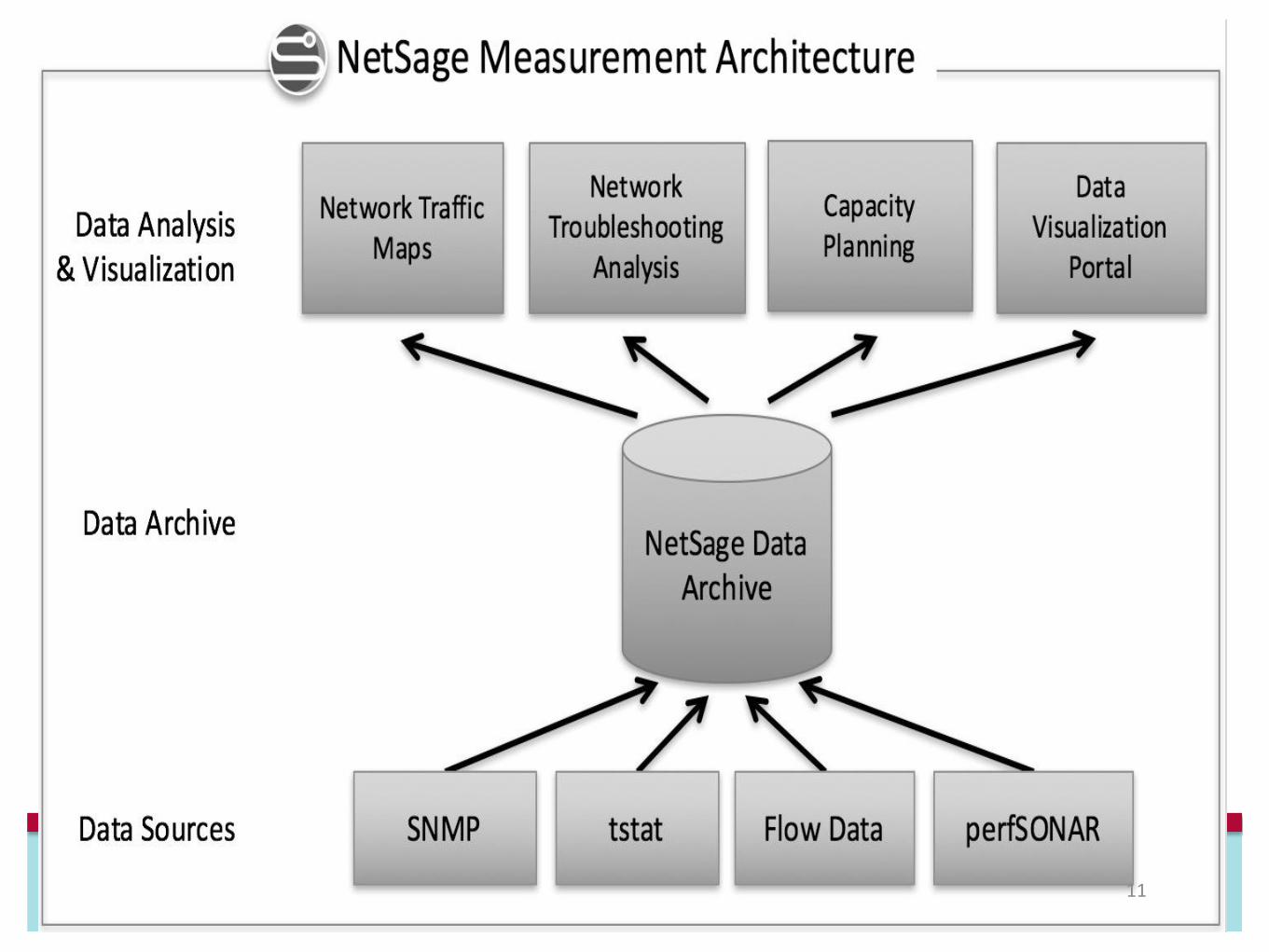
ATLAS on Titan
• Job sizes shaped to backfill opportunistically via PanDA
• Used 129M core-hours from July 2016 to June 2017
• ~2.5% of total available time on Titan• ~10% of all US-ATLAS computing
Slide kindly provided by Sergey Panitkin (BNL)

● Reasons to Use Singularity in HTC/HPC Jobs– Divorces a job's software requirements from what's actually available in
the host OS. Administrators can (almost) run whatever flavor and version of Linux they'd like on their physical nodes, as long as users create containers with all of their software dependencies inside
● Essentially gives users freedom to run their jobs wherever there's a Linux host with Singularity installed
– Administratively straightforward and lightweight to mange: install a single package (and potentially make minor configuration changes), and you're done.
● Unlike Docker, there is no daemon to start, and no need to add users to a special group in order to execute jobs in containers
● Doesn't make use of namespaces which aren't typically required by compute jobs
– By default, PID and network namespaces are the same as the host OS'
● Secure out of the box - regular users are never root in a container
– setuid permissions not required with newer distros (RHEL 7.4+)
● Built-in support in new versions of HTCondor (8.6.0+)

● Singularity at RACF/SDCC - ATLAS (Cont.)– Many of our NFS mounts under /direct contain the '+' character – I.e
/direct/usatlas+u
● Singularity didn't permit this special character in bindmount pathnames
– Submitted a patch to address this; merged in 2.3
– Singularity is available for use on our IC and KNL HPC clusters, as well as our HEP/NP HTC resources
– ATLAS is interested in making opportunistic use of these resources
● CVMFS is not available on our HPC systems
● Solution: creation of a “fat” ATLAS Singularity container image
– Contains the entire contents of /cvmfs/atlas.cern.ch
– ~600 GB in size
– Single image file, allowing it to be easily shipped
– Created by Wei Yang from SLAC
– Stored in GPFS
● Successfully ran test ATLAS jobs on KNL using this image

CSCS

Operational challenges▪ OS environment
▪ Cray Linux Environment (stripped down SUSE)▪ Diskless nodes
▪ scratch areas, job workdirs, ARC cache/sessiondirs ▪ /tmp ▪ swap
▪ Data delivery / access / retrieval ▪ network connectivity
▪ Memory management ▪ operate with .le. 2GB/core
▪ Job scheduling ▪ job prioritisation and fair-share in the global environment
▪ Software provisioning ▪ CVMFS cache performance in absence of local disk
▪ Scalability ▪ depends on all of the above
4
✓
✓✓
✓✓
✓
?Gianfranco Sciacca - University of Bern HEPiX Fall 2017 - KEK Tsukuba, 18th October 2017

Current configuration - CVMFS▪ CVMFS running natively on CNs using workspaces and tiered cache, two new features of CVMFS ▪ Was previously configured to use a XFS loopback filesystem on top of DVS as local cache ▪ Tried also Cache on DWS, but this suffered from data corruption
▪ CVMFS_WORKSPACE=$PATH allows us to store data directly on a DVS projected filesystem (no more XFS)
▪ DVS does not support `flock()`, with the workspace setting it is now possible to set all locks relative to the cache local to the node
▪ CVMFS_CACHE_hpc_TYPE=tiered with upper layer in-ram storage: this can dramatically increase performance. We have a CVMFS upper layer of 6GB in-RAM per node (shared by all VOs).
▪ Lower layer RO on GPFS: cvmfs_preload now a fast and reliable service provided by CERN for HPC sites. This syncs several times a day. If a file is not found on the local caches, the query propagates to the outside.
8
✓
Gianfranco Sciacca - University of Bern HEPiX Fall 2017 - KEK Tsukuba, 18th October 2017

University of Victoria

15
Workflow CloudScheduler
0) queues empty, no worker nodes running
– HTCondor and CloudScheduler (CS) are running at UVic
1) user submits jobs into queuing system
2) CS sees jobs in queue, and knows no (free) resources are available
3) CS boots VM on any cloud which has matching resources
– VMs could be anywhere in world
4) VMs boot and start HTCondor during their startup
– jobs will start automatically on booted VMs
5) more jobs would populate empty job slots on running VMs or new VMs are booted by CS

23
Shoal – “School of Squids”
● all squid servers we utilize register with shoal-server at UVic http://shoal.heprc.uvic.ca/
– register IP and load of squid server
● all VMs contact shoal-server to find their nearest squid - ‘nearest’ based on GeoIP DB
– some squids are ‘private’ i.e servingonly local cloud (e.g. due to private IP of VMs)
● basically it runs “curl http://shoal.heprc.uvic.ca/nearest”
– e.g. at UVic: finds squid in Vancouver
– amazon-east (Virginia): finds squid in Sherbrooke/CA
https://github.com/hep-gc/shoal

26
DynaFed
● dynamic federation of storage elements
– can federate many different SE protocols: http(s), webdav, S3, MS Azure
– presents http or webdav interface to user, hides authentication to e.g. S3 via temporary tokens
● ATLAS: test instance with own storage behind, trying to integrate into ATLAS DDM
● Belle II: also trying to integrate, but looking also at using DynaFed to store background files locally on clouds we utilize
→ more in Marcus’ Talk on Thursday

What is Dynafed● redirector for a dynamic data federation, developed by CERN-IT ([email protected])
○ for data transfers, client is redirected to a storage element with the data○ this can be done depending on geographic location
■ storage elements closer to the job are preferred
● access through http(s)/dav(s) protocols
● can federate existing sites without configuration changes at sites○ site needs to be accessible by http(s)/dav(s) (DPM, dCache, plain xrootd with plugin,...)○ world wide distributed data can be made accessible under common name space and through
a single endpoint
● X509/VOMS based authentication/access authorization can be used with dynafed○ http://HEPrc.blogspot.com for grid-mapfile based authentication/authorization
■ different posts have also links to dynafed installation instructions in our TWiki
● can also directly access S3 and Azure based storage○ no credentials visible to the client○ preauthorized URL with limited lifetime is used to access files on the storage
5

32
CloudScheduler V2
● re-write to bring software development into 21st century:
– unit tests, Jenkins, CI, ...
● overcome scaling issue at O(10^4) jobs
– could flocking help for far clouds ?
● update ‘dependencies’ of software like rabbitmq
● common interfaces with other cloud provisioning solutions to ease integration ?
● containers for software disitrbution + workload

Other Topics

Big Data Solutions in HEP
HEPIX Fall 2017 – KEK – J. Flix 13
Big Data solutons for LHC Analysis
● Work done to move a real ATLAS analysis program from
ROOT/C++ to Python and Hadoop/Spark
– ATLAS Charged Higgs analysis from IFAE researcher re-coded
– Developed by D. Beltran (summer student)
– Code initally developed at the SWAN platorm at CERN, then later
moved to PIC Hadoop test infrastructure
– The analysis C++ code was replaced with a random generator resembling
its CPU patern → the target was the data handling
● The prototype has shown that real analysis program can be easily
adapted to Hadoop/Spark (in a reasonable tme)
– Promising reducton on executon tme, due to the parallelizaton of the
data reads and the use of mapreduce calls to select the data
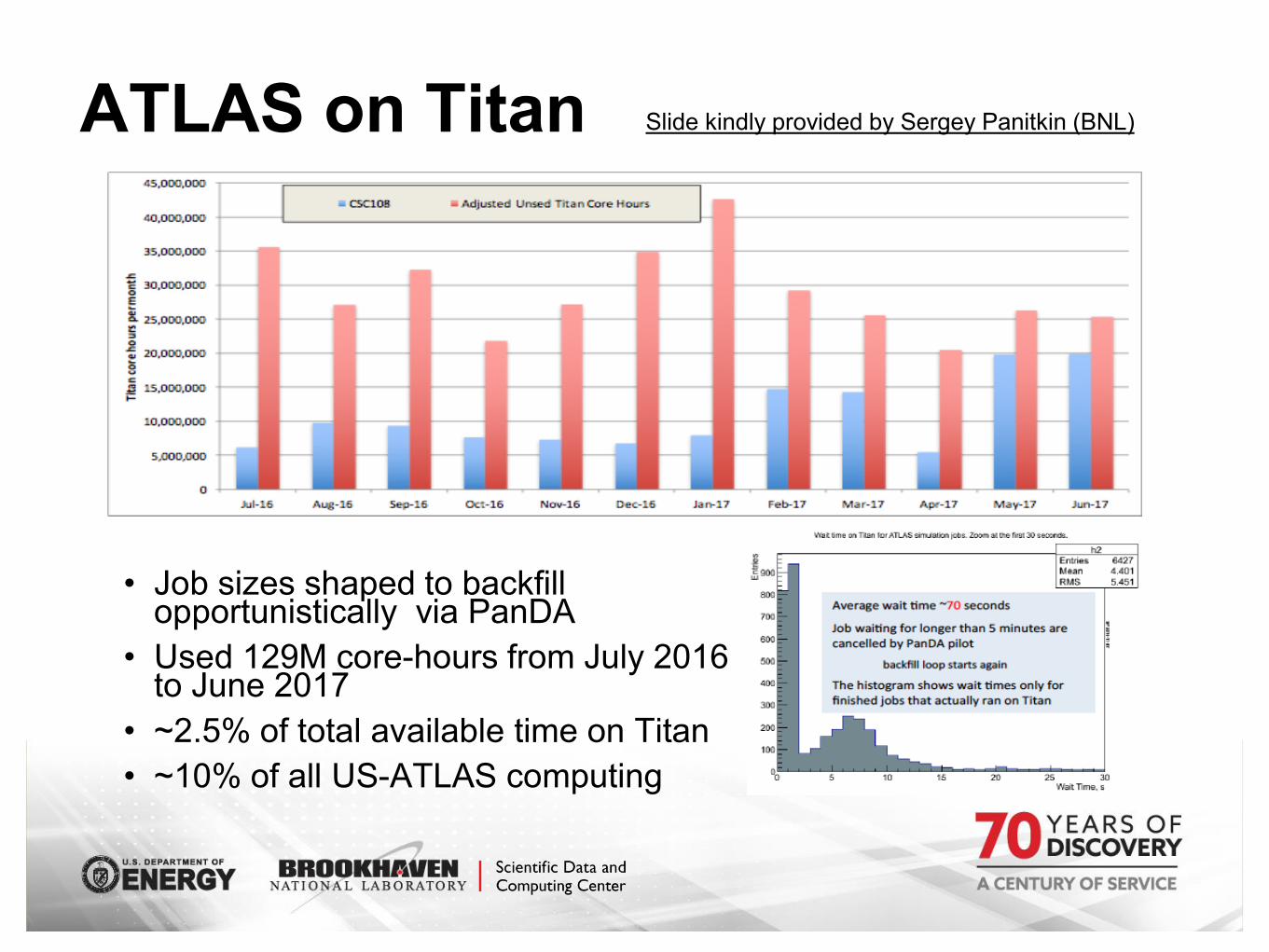
Tape@GridKA
HEPIX Fall 2017 – KEK – J. Flix 6
Storage @ PIC
● Improving disk pool performances:
– SAM tests in a dedicated dCache pool group – to help prioritze (no cheatng)
– Beter adjustment of movers limits for GridFTP and XrootD protocols
– Moving dCache metadata to system disks (SSDs)
– Introducton of tape recall-only pools (re-using old hardware)
– real-encp (Enstore) optons tuned to boost drive rates for stores/pre-stage
requests
● Good results shown during the CMS Tape stress tests (450 MB/s avg – 1.1 GB/s peak)
Tests @ PIC