Embed Size (px)
Citation preview

Sprachen, die nach MapReduce kompiliertwerden
Hauptseminar: Multicore-Programmierung
Franz Pius Hübl
10. November 2011

Zusammenfassung
Ziel dieser Arbeit ist es, einen Einblick in die Arbeitsweise verschiede-ner Sprachen, die nach MapReduce kompiliert werden, zu geben. Hierfürwurden zwei Beispielsprachen ausgewählt: Pig und Hive. Anhand einesgemeinsamen Beispiels wird die unterschiedliche Verwendung, sowie Vor-und Nachteile der Sprachen betrachtet.
ii

Inhaltsverzeichnis1 Einleitung 1
1.1 Was ist MapReduce? . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Apache Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Apache Pig 22.1 Pig Latin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Apache Hive 83.1 Hive Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2 HiveQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.4 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 Zusammenfassung und Ausblick 12
A Wörter zählen mit Apache Hadoop 14
iii

1 EinleitungIn dieser Ausarbeitung werden Sprachen betrachtet, die nach MapReduce kom-piliert werden. Das sind Sprachen, die zunächst keine Ähnlichkeit zu MapReduceProgrammen haben und dann mit einem Compiler in eine Folge von MapRe-duce Programmen überführt werden. Dadurch abstrahiert man von den Folgenvon MapReduce Aufgaben und der Nutzer muss nur noch ein semantisches Pro-gramm definieren, ohne die Reihenfolge der MapReduce Schritte beachten zumüssen. Dadurch können auch technisch weniger versierte Mitarbeiter Abfragenerstellen, die sonst mit komplexen MapReduce Programmen realisiert werdenmüssten. Hierfür gibt es viele Sprachen, von denen zwei, Pig und Hive, in denfolgenden Kapiteln näher betrachtet werden.
1.1 Was ist MapReduce?Seit der Erfolgsgeschichte von Google existiert ein Verfahren, das von vielen Per-sonen als das parallele Verfahren für die Verarbeitung großer Datenmengen be-trachtet wird, MapReduce (Vgl. [DG08]). MapReduce stammt ursprünglich ausder funktionalen Programmierung und bezeichnet zwei Funktionen, die nach-einander abgearbeitet werden. Zunächst wird mittels einer Map Funktion ausden Eingabedaten „Key-Value“ Paare erzeugt. Diese Paare werden dann nachdem Key sortiert und mit der Reduce Funktion kombiniert.
1.2 Apache HadoopHadoop ist ein freies in Java geschriebenes Framework. Es verfügt über eineigenes verteiltes Dateisystem, HDFS. Hadoop ist dafür gedacht, große Daten-mengen auf Computerclustern zu bearbeiten und Berechnungen mit diesen Da-ten durchzuführen. Seit 2008 wird Hadoop als Apache Top-Level Projekt ge-führt. Hadoop enthält eine Implementierung des MapReduce Algorithmus (Vgl.[HAD]).
2008 und 2009 gewann das Hadoop Projekt den Terabyte Sort BenchmarkPreis als erstes Open-Source Programm. Die Programmiersprachen Pig und Hivenutzen jeweils Hadoop als Plattform und lassen ihre kompilierten MapReduce-Programme auf der Hadoop Plattform ausführen. In den folgenden Kapitelnwird zur Verdeutlichung das Beispiel „Wörter zählen“ verwendet. Um einen Ver-gleich mit einem in Hadoop implementierten Programm zu haben, wurde imAnhang A das Beispiel als Hadoop Programm implementiert.
1

2 Apache PigApache Pig ist eine Plattform, die dem Nutzer eine Highlevel Sprache (Pig La-tin) zur Verfügung stellt, um mit einfachen Anweisungen ein Programm fürApache Hadoop zu schreiben. Pig ist dafür gedacht, große Datensätze zu ana-lysieren. Hierfür nutzt Pig einen Compiler, der aus den PigLatin KommandosFolgen von MapReduce Programmen erzeugt. Diese können dann in dem bereitsvorgestellten Framework Apache Hadoop berechnet werden. Für die Entwicklervon Pig stehen drei Schlüsselmerkmale im Vordergrund (Vgl. [PIG]):
• Einfache ProgrammierungDas Programm sollte möglichst einfach zu entwickeln sein. Damit wirdvon dem zugrundeliegenden Map Reduce System abstrahiert.
• OptimierungsmöglichkeitenNicht die Optimierungsmöglichkeiten, sondern die Semantik des Programmsstehen im Vordergrund. Die Optimierung wird dann vom System selbstdurchgeführt.
• ErweiterbarkeitDer Nutzer soll mit sogenannten User Defined Functions (UDF) das Pro-gramm erweitern können. Dadurch können einfache PigSkripte komplexeOperationen aufrufen, die beispielsweise als Java Funktion bereits imple-mentiert wurden.
Pig ist als eine Datenflusssprache konzipiert und stellt standardmäßig Opera-tionen bereit um Daten zu analysieren und zu verändern. Im nächsten Kapitelwird hierauf genauer eingegangen. Zwar wurde Pig für Apache Hadoop entwor-fen, doch könnte es mit einem geeigneten Compiler auch für andere MapReduceFrameworks verwendet werden. Im Jahr 2006 wurde Pig von Yahoo entwickelt.Damals war es für Entwickler eine einfache Möglichkeit, schnell Abfragen aufgroßen Datensätzen zu programmieren, ohne eine MapReducestruktur neu im-plementieren zu müssen. 2007 wurde das Projekt der Apache Software Founda-tion unterstellt und seit September 2010 wird Pig als Apache Top-Level Projektgeführt.
2.1 Pig LatinPig kann über eine interaktive Shell, eingebettet in einer Host-Sprache (bei-spielsweise Java), oder über ScriptFiles verwendet werden. In all diesen Fällenbenötigt man die Pig eigene Sprache Pig Latin. Diese wird im folgenden Ab-schnitt näher beschrieben (Vgl. [ORS+08]).
Am Anfang jedes Pig Skriptes steht meist ein Lade Operation. Diese wirdmit dem Schlüsselwort LOAD eingeleitet. Anschließend wird die zu ladendeDatei mit dem Dateipfad angegeben. Diese Datei befindet sich typischerweiseinnerhalb des HDFS Dateisystems von Hadoop. Besteht die Datei aus mittelsTabulator separierten Feldern und aus einem Eintrag pro Zeile, so kann mannun ein Schema angeben. Dadurch ist es möglich, den einzelnen Spalten Namenzu geben und Datentypen dafür festzulegen. Im folgenden Beispiel soll die Datei”file.txt” eingelesen werden und anschließend in File gespeichert werden. Analogzum Befehl LOAD existiert auch der Befehl STORE, der Daten speichern kann.
2

file.txt:Hallo 1Welt! 2
Pig Skript:File = LOAD ’file.txt’ AS (word:chararray, line:int);
Pig kennt viele Schlüsselworte, die meistens schon von anderen Sprachen be-kannt sind und deshalb in ihrer Bedeutung leicht erschlossen werden können.Beispielsweise wird JOIN, semantisch wie ein Join in einer SQL Sprache, undFOREACH, semantisch wie eine Foreach-Schleife in Java, verwendet. Durch die-se Übertragungen sind viele Kommandos von Pig leicht zu verstehen und bisauf kleine Syntaxabweichungen leicht zu benutzen. Daher fällt dem Program-mierer ein Umstieg auf Pig Latin leicht und man gewöhnt sich sehr schnell andie Syntax.
A = FOREACH File GENERATE COUNT(word) as count;C = JOIN A BY count FULL, B BY line;
Pig Latin arbeitet mit verschiedenen Datentypen. Darunter sind „simple Da-tentypen“ wie Integer, Long Integer, Float, Double, Chararray (ein CharacterArray in Unicode UTF-8 Kodierung) und Bytearray. Aus dieses simplen Da-tentypen können nach Belieben komplexere Datentypen erzeugt werden. Pigverwendet bei komplexen Datentypen Tupel, Bags (eine Liste von Tupeln) undMaps (Key-Value Listen).
Tupel:(1, 2, hallo)
Bag:{(1,2),(1,3),(2,3)}oder(1,2)(1,3)(2,3)
Map:[word#Hallo,line#1][word#Welt!,line#2]
Hinzu kommen zahlreiche Operatoren, die auf den verschiedenen Daten-objekten verwendet werden können, wie beispielsweise boolesche Operatoren(==, <,>, ! =, <=, >=), arithmetische Operatoren (+,−, ∗, /,% ) oder Aggre-gatfunktionen ( SUM, AVG, MIN, MAX, COUNT). Zusätzlich kann man dieeinzelnen Datenobjekte mit einem FILTER auswählen. Im folgenden Beispielenthält die Relation Y drei Spalten f1, f2 und f3, die jeweils vom Typ Integersind. Die Relation X enthält nach dieser Zeile alle Datenobjekte, die die gesuchteBedingung erfüllen. Anschließend werden in der Relation X alle Elemente nachdem Wert von f1 gruppiert und in Z gespeichert.
3

X = FILTER Y BY (f1==8) OR (NOT (f2+f3 > f1));Z = GROUP X BY f1;
Reichen die vielen integrierten Funktionen nicht aus, so kann man ganz ein-fach selbst eine Funktion schreiben und diese dann von Pig aufrufen. Dazu musszunächst die JAR-Datei mit dem Schlüsselwort REGISTER Pig mitgeteilt wer-den. Anschließend kann man die Funktionen der JAR-Datei einfach in dem PigSkript aufrufen.
REGISTER myudfs.jar;A = LOAD ’student_data’ AS (name: chararray, age: int, gpa: float);B = FOREACH A GENERATE myudfs.UPPER(name);
In der JAR-Datei existiert nun die unten angegebene Klasse UPPER. DieMethode exec() in dieser Klasse implementiert dann die gewünschte Funktion.Im Beispiel oben konvertiert UPPER jeden String in Großschreibung und gibtdiesen dann zurück.
1 package myudfs ;2 import java . i o . IOException ;3 import org . apache . p ig . EvalFunc ;4 import org . apache . p ig . data . Tuple ;5
6 pub l i c c l a s s UPPER extends EvalFunc<Str ing >{7 pub l i c S t r ing exec ( Tuple input ) throws IOException {8 i f ( input == nu l l | | input . s i z e ( ) == 0) {9 re turn nu l l ;
10 } e l s e {11 t ry {12 St r ing s t r = ( St r ing ) input . get (0 ) ;13 re turn s t r . toUpperCase ( ) ;14 } catch ( Exception e ) {15 throw new IOException ( "Caught except ion p ro c e s s i ng
input row " , e ) ;16 }17 }18 }19 }
Die Klasse UPPER (Quelle:[STL])
So ist es möglich, komplizierte Berechnung in eine Java Klasse auszulagernoder von bereits vorhandenen Bibliotheken zu profitieren. Dadurch verringertsich die Entwicklungszeit mit Pig enorm. Zusätzlich stehen in der Bibliothek vonPig zahlreiche Interfaces und Klassen zur Verfügung, die bei der Entwicklungvon benutzerdefinierten Funktionen behilflich sind.
Weiterhin ist es möglich einen Mapreduce Job direkt mit Pig aufzurufen.Gibt es also bereits fertige MapReduce Jobs, die mit Java und Apache Hadoopimplementiert wurden, so kann dieser Job in Pig direkt aufgerufen und mitDaten versorgt werden. Hierbei kann jede JAR-Datei verwendet werden, dieauch mit hadoop jar mymr.jar params lauffähig ist. Hierzu verwendet mandas Schlüsselwort MAPREDUCE mit dem gewünschten MapReduce.jar undzusätzlichen Eingabeparametern. Das Laden und Speichern kann von Pig oder
4

dem MapReduce Job selbst übernommen werden. Im folgenden Beispiel wirdein MapReduceJob namens WordCount aufgerufen und mit dem Text aus Abefüllt.
A = LOAD ’WordcountInput.txt’;B = MAPREDUCE ’wordcount.jar’ STORE A INTO ’inputDir’ LOAD ’outputDir’
AS (word:chararray, count: int)’org.myorg.WordCount inputDir outputDir’;
In der Dokumentation von Pig sind noch viele weitere nützliche Sprachkon-strukte beschrieben, die Pig dem Nutzer bereitstellt (Vgl. [PIG]). Diese aberalle aufzuzählen, würde den Rahmen dieser Arbeit eindeutig übersteigen. Dievorgestellten Konstrukte und Mechanismen genügen jedoch, um ein einfachesBeispiel mit Pig auf einem Hadoop-Cluster auszuprobieren und zu untersuchen.
2.2 BeispielUm nun die Leistungsfähigkeit im Vergleich mit Apache Hadoop zu untersuchen,wird ein einfaches Beispiel (Wörter zählen) genutzt. Die Arbeitsweise von Pig isthierbei gut zu erkennen und die Vorteile gegenüber MapReduce mit Hadoop tre-ten deutlich hervor. Der benötigte Java Programmcode für dieses Beispiel findetsich im Anhang A. Insgesamt benötigt dieses Hadoop MapReduce Programmcirca 60 Zeilen Programmcode. Der Teil mit der eigentlichen Programmlogikbenötigt allerdings nur elf Zeilen. Die restlichen Zeilen sind allein Verwaltungs-aufgaben ohne wirkliche Funktionalität, so genannter „glue code“. Im Vergleichdazu wirkt der Programmcode eines Pig Skriptes ziemlich kurz.
1 A = load ’ input / f i l e . txt ’ ;2 B = foreach A generate f l a t t e n (TOKENIZE( ( chararray ) $0 ) ) as
word ;3 C = f i l t e r B by word matches ’\\w+ ’;4 D = group C by word ;5 E = foreach D generate COUNT(C) as count , group as word ;6 F = order E by count desc ;7 s t o r e F in to ’ output / ’ ;
Wörter zählen als Pig Skript (Quelle:[WCP])
Trotzdem kann man bei erster Betrachtung leicht erkennen, was genau in welcherZeile gemacht wird. Die Eingabedatei enthält folgenden Text:
Hallo WeltHallo Nutzer
So soll zunächst die Datei eingelesen werden (Zeile 1) und in A gespeichertwerden.
(Hallo Welt)(Hallo Nutzer)
Anschließend wird pro Zeile eine Liste von Wörtern generiert. Diese Zeile wirdnun aufgespalten, so dass schließlich in C pro Zeile genau ein Wort steht.
5

(Hallo)(Welt)(Hallo)(Nutzer)
Damit ist der Einlesevorgang beendet. In Zeile 4 werden alle vorkommendenWörter gruppiert. Ausgabe von D ist ein Tupel, bestehend aus dem Wort undeiner Liste des Wortes.
(Hallo, {(Hallo),(Hallo)}(Welt,{(Welt)})(Nutzer,{(Nutzer)})
Die Länge der Listen werden dann in Zeile 5 gezählt und dem Wort zu geordnet.Die Sortierung im Schritt von E nach F dient nur als Schönheitskorrektur.
(2,Hallo)(1,Welt)(1,Nutzer)
Abschließend wird das Ergebnis in einer Ausgabedatei gespeichert.
2.3 BewertungIn dem vorherigen Beispiel ist der Datenfluss von der Eingabe, über die Verar-beitung und Aggregation hin zur Ausgabe sehr gut zu erkennen. Hier wird derVorteil, eine möglichst einfache Programmierung, von Pig ganz besonders deut-lich. Zusätzlich zeigt sich eine Abstraktion von MapReduce. Der Nutzer musssich in diesem Beispiel keine Gedanken um MapReduce selbst machen. Dieswird vom Pig Compiler komplett übernommen. Der Pig Compiler zerlegt dabeidas Skript in einzelne MapReduce Jobs, die dann in der richtigen Reihenfolgeausgeführt das gewünschte Ergebnis liefern. Dies ist ein weiterer Vorteil gegen-über Programmen, die direkt für das Apache Hadoop System entwickelt wurden.Während man bei diesen nur einen einzelnen MapReduce Schritt pro Programmhat und nur umständlich eine Folge von mehreren MapReduce Schritten nach-einander schalten kann, wird dies von Apache Pig ganz automatisch erledigt.
Aus dem obigen Beispiel wird so ein Folge von drei MapReduce Schritten.Der Hauptteil der Arbeit (Zeile 1-5) wird dabei in einem einzelnen Job erledigt.Das Sortieren und Speichern auf dem Dateisystem wird zu zwei weiteren Jobskompiliert. Die genaue Aufteilung der Jobs wird aus Abbildung 1 ersichtlich.
Dies verlangsamt zwar den Ablauf eines Pig Programms, doch wie Abbildung2 zeigt, sind Pig Programme nur etwa 1,5x so langsam wie selbst geschriebeneHadoop MapReduce Jobs. Demgegenüber stehen die geringe Größe des Quell-codes und die geringe Dauer an Entwicklungszeit (siehe Abbildung 3). Beidesspricht eher für eine Verwendung von Pig. Das ist wahrscheinlich einer der Grün-de, warum bereits 2009 mehr als 50% der Hadoop Jobs, die bei Yahoo ausgeführtwurden, Pig verwendeten.
6
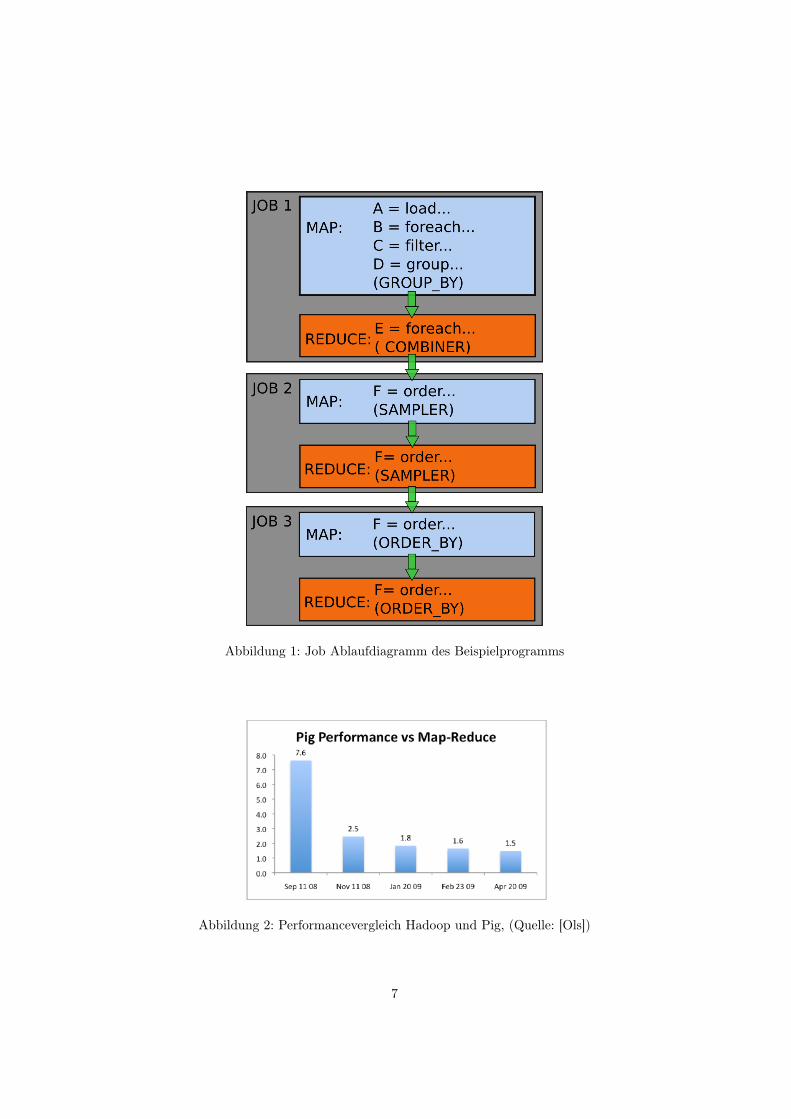
Abbildung 1: Job Ablaufdiagramm des Beispielprogramms
Abbildung 2: Performancevergleich Hadoop und Pig, (Quelle: [Ols])
7

Abbildung 3: Vergleich Hadoop und Pig in Lines-of-Code und Entwicklungszeit,(Quelle: [Ols])
3 Apache HiveEinen Schritt weiter als Yahoo gingen die Entwickler von Facebook, als sie 2008ihre Entwicklung einer Anfragesprache an ein Hadoop Cluster vorstellten. Ih-re Anfragesprache, HiveQL, war nicht mehr als eine reine Datenfluss Sprachekonzipiert, sondern ist kompatibel zum SQL-92 Standard. Dadurch wird in ei-nem weit größerem Maße von der zugrundeliegenden Datenhaltung abstrahiert.Musste bisher der Nutzer von Hadoop oder auch Pig noch genau wissen, wie dieDaten aussahen und wo welche Datei liegt, so ist dies bei Hive nur noch in ge-ringem Maße nötig. In Hive spielen vor allem Tabellen eine wichtige Rolle. Diesist begründet durch die Entwicklungsgeschichte von Hive. Ursprünglich wurdenbei Facebook berechnungsintensive Analysen über Nutzungsverhalten und vieleandere Statistiken hauptsächlich nachts durchgeführt. Dadurch sollte eine hoheBelastung der Server vermieden werden.
Mit der wachsenden Nutzerzahl und vor allem der stetig größer werdendenDatenmenge wurde es immer schwieriger, bestimmte Analysen im laufenden Be-trieb durchzuführen, ohne die Servicequalität von Facebook zu beeinträchtigen.Deshalb wurde nach einem System gesucht, das auf einer tabellarisch geordne-ten Datenmenge basiert. Ziel war es, an das System gestellte Anfragen schnellerbeantworten zu können. Mit Hadoop wurde zunächst ein System gefunden, mitdem große Datenmengen verteilt gespeichert werden können. Anschließend wur-de Hive mit der Anfragesprache HiveQL entwickelt.
Wie oben erwähnt ist diese Anfragesprache zum SQL-92 Standard kompa-tibel. Das hatte zur Folge, dass alle bisherigen Anfragen, die zur Statistik undAnalyse auf den Datenbankserver entwickelt wurden nun bei gleicher Daten-haltung auch im Hadoop Cluster mit Hive wiederverwendet werden konnten.Außerdem musste nicht für jede Analyse ein eigenes MapReduce Programm inJava für Hadoop implementiert werden, sondern konnte weiterhin von den Da-tenanalytikern selbst erledigt werden (Vgl. [TSJ+10]). Zu diesem Zweck könnenDaten aus dem laufenden Betrieb heraus in das Hive System importiert werden.Dadurch werden die Analysen unabhängig vom laufenden Betrieb durchführbarund können auch längere Zeit in Anspruch nehmen als nächtliche CronJobs. UmHive nun genauer verstehen zu können, wird im folgenden Kapitel der Aufbauvon Hive näher betrachtet.
8

3.1 Hive Architektur
Abbildung 4: Die Hive Architektur (Quelle: [DZ])
Wie in Abbildung 4 deutlich wird, fungiert HiveQL als zentrale Schnittstel-le zwischen der Anfrageschicht, bei der man mittels Webinterface oder JDB-C/ODBC Anfrage stellen kann, und der Hadoop Schicht. Diese kann man auf-teilen in eine MapReduce und die HDFS Schicht, welche die Daten verteiltspeichert.
HiveQL besitzt einen Parser, Planer, Optimierer und eine Ausführungs-komponente, um Anfragen an Hive zu bearbeiten. Zusätzlich hat Hive mehrerePlugIn Schnittstellen, um den Funktionsumfang von Hive zu erweitern. So kön-nen beispielsweise mit Hive auch eigene MapReduce Skripte ausgeführt werden,ohne dass diese zuerst in Hive neu geschrieben werden müssen. Außerdem ist esmöglich, eigene definierte Funktionen beziehungsweise Aggregationsfunktionenzu schreiben und diese dann in Hive zu verwenden.
Als eine Art Proxy fungiert die SerDe Komponente, eine Kurzform von „se-realization“ und „deserealization“, mit der man auf verschiedene Dateiformatezugreifen kann. Dadurch wird es unwichtig, ob die Datei in CSV Form oder inTabellenform vorliegt. Außerdem kann man auch eigene Speicherformate im-plementieren, um Hive im eigenen Kontext zu verwenden. Aufgrund von SerDesind in Hive alle Daten in Tabellenform verfügbar und können über HiveQLabgefragt werden.
3.2 HiveQLWie bereits erwähnt ist HiveQL zum Standard von SQL aus dem Jahr 1992 kom-patibel. Dadurch können Datenanalytiker sehr leicht mit Hive arbeiten, wennsie bereits Erfahrung mit SQL haben. Hierzu gehören die Standardanfragen, dieim folgenden Abschnitt näher erläutert werden1. Anschließend wird mit einem
1Eine ausführliche Beschreibung der Hivesyntax findet sich unter [HIV]
9

kleinen Beispiel die Arbeitsweise von Hive näher betrachtet. Bevor man Datenmit Hive analysieren kann, benötigt man Tabellen mit Daten. Das Erzeugeneiner neuen Tabelle funktioniert mit dem Kommando CREATE:
CREATE TABLE pokes (foo INT, bar STRING);
Damit kennt das System eine Tabelle „pokes“ und deren Spaltendefinition. Diegenaue Speicherung, den Speicherort und die Partitionierung kann man hierebenfalls angeben, um bei größeren Tabellen das System effizient zu halten.
Um diese Tabelle mit Daten zu füllen, hat man mehrere Möglichkeiten. Fallsdie Daten bereits in einer anderen Tabelle vorliegen oder aus den anderen Ta-bellen generiert werden können, so arbeitet man mit SELECT und INSERT.Zusätzlich kann man Textdateien, die bereits tabellarisch formatiert sind, mitdem Befehl LOAD DATA vom System in eine Tabelle laden.
LOAD DATA LOCAL INPATH ’./examples/files/kv3.txt’OVERWRITE INTO TABLE pokes;
Anschließend kann man mit den gewohnten SELECT Statements auf dieTabellen zugreifen. Hierbei ist es möglich, einzelne Spalten zu selektieren, Be-dingungen anzugeben, Filter zu verwenden und die Daten zu Gruppieren.
SELECT a.bar, count(*) FROM invites a WHERE a.foo > 0 GROUP BY a.bar;
Besonders hilfreich ist die in SQL Anfragesprache übliche Funktion des Joins.Während dies bei Hadoop schwer zu realisieren ist, benötigt man hierfür mitHive nur eine Select Anfrage.
SELECT pv.pageid, u.age_bktFROM page_view pJOIN user u ON (pv.uhash = u.uhash)JOIN newuser x on (u.uhash = x.uhash);
Dadurch gewinnt man bei Hive eine sehr große Abstraktion vom eigentlichenMap Reduce. Dies führt zu einer nützlichen Erweiterung. Im folgenden Beispielwird das bereits bekannte Wörterzählen-Beispiel wieder aufgegriffen.
3.3 BeispielZur Verdeutlichung wurde erneut das Beispiel „Wörter zählen“ verwendet. Hier-bei ergibt sich jedoch gleich ein Problem. Wie bringt man den Text in einetabellarische Form, so dass man Hive verwenden kann?
Text der Eingabedatei:Hallo WeltHallo Nutzer
Eine Lösung ist eine Vorverarbeitung mit einer anderen Programmiersprache,also beispielsweise mittels Java oder Pig. Anschließend lädt man den Text ineine vorher erzeugte Hive Tabelle.
Text nach Vorverarbeitung:HalloWelt
10

HalloNutzer
Befehl zum erzeugen der Tabelle:CREATE TABLE words (word String) STORED AS TEXTFILE;
Befehl zum Laden des Textes:LOAD DATA LOCAL INPATH ’words.txt’ INTO TABLE words;
Nun hat man die gewünschten Daten in der Tabelle. Das eigentliche HiveQLStatement zum Zählen der Wörter ist nun nur noch ein einfaches Select State-ment mit Gruppierung nach dem Wort und einer Count Aggregationsfunktion.Selbstverständlich kann man das Ergebnis nun auch noch absteigend nach derAnzahl der Wörter sortieren.
SELECT word , COUNT(word) AS countFROM wordsGROUP BY wordORDER BY count DESC;
Dadurch erhält man das gewünschte Ergebnis, welches in dem obigen Beispielnur auf der Konsole zurückgegeben wird. Um das Ergebnis zu speichern kannman es mit INSERT auch in eine Ergebnistabelle einfügen. Die Abarbeitung die-ser Query teilt Hive in zwei aufeinanderfolgende MapReduce Jobs auf. Der ersteJob erzeugt aus der Eingabetabelle eine Tabelle mit gruppierten Wörtern undder Anzahl des Wortes. Im darauffolgenden MapReduce Job wird das Ergebnisnach der Anzahl geordnet. Die Erzeugung der MapReduce Jobs übernimmt Hivekomplett.
3.4 BewertungDas Beispiel zeigt sehr deutlich die einfache Nutzung von Hive auf, aber auch sei-ne Schwächen sind gut erkennbar. Wenn die Daten nicht in tabellarischer Formgegeben sind, muss man diese zunächst über Drittprogramme einlesen. DieserNachteil ist jedoch zu vernachlässigen, wenn man bedenkt, in welchem UmfeldHive entwickelt wurde und eingesetzt wird. Hive soll rechen- und zeitintensiveDatenbankaufgaben von der Datenbank in ein Hadoop Cluster verlagern, ohnealles neu programmieren zu müssen. Dadurch sind die Daten meist in tabellari-scher Form gegeben.
Demgegenüber steht die einfache Nutzung aufgrund der verwendeten SQLAnfragesprache. Zusätzlich stellt man dem Benutzer mit Join ein vielseitig ein-setzbares Hilfmittel zur Verfügung, welches in Hadoop nicht so einfach verwend-bar ist.
Hive ist außerdem sehr leicht durch eigene Funktionen erweiterbar. Sogareigene MapReduce Jobs und flexible Speicherung der Dateien sind möglich. Fürviele Probleme wird Hive dadurch zu einem leicht einsetzbaren und flexiblenSystem.
11

4 Zusammenfassung und AusblickIn den vorangegangenen Kapiteln wurden die Programmiersprachen Pig undHive individuell beleuchtet. In diesem Abschnitt soll nun ein Vergleich von bei-den gezogen werden. Dieser Sachverhalt ist aufgrund der gemeinsamen Ent-wicklungsgeschichte interessant. Facebook hat Hive entwickelt, weil Pig zumdamaligen Zeitpunkt große Performanceverluste bei der Nutzung hatte.
Ein weiteres Problem von Pig bestand im Trainingsaufwand der Entwicklerfür den Einsatz einer neuen Programmiersprache. Mit der Entscheidung eineProgrammiersprache zu entwickeln, deren Syntax auf SQL basiert, konnte maneine „steile Lernkurve“, wie man dies von anderen Programmiersprachen kennt,vermeiden. Dieses Problem haben auch die Entwickler bei Hadoop und insbe-sondere auch bei Pig erkannt. Deshalb soll es in Zukunft auch eine SQL APIfür Pig geben. Fraglich bleibt, warum die Ingenieure von Pig sich nicht von An-fang an für eine SQL Anfragemöglichkeit entschieden haben. Andererseits hatman mit Pig eine viel größere Kontrolle wie und in welcher Reihenfolge die Da-ten verarbeitet werden. Dadurch wird Pig für manchen Nutzer möglicherweiseeinfacher zu bedienen sein. Pipeline-Verarbeitungen kann man in Pig leichterprogrammieren, was sich in Hive eher schwierig gestaltet.
Beim Typsystem geht Hive einen restriktiveren Weg als Pig, denn bei Pigmuss der Datentyp nicht unbedingt angegeben werden. Dadurch ist in manchenSituationen der Import von Fremddaten einfacher als bei Hive. Liegen die Datenjedoch bereits in Tabellenform vor, so sind die Daten schon strukturiert undhaben auch einen Typ. Dadurch wiegt dieser Nachteil von Hive gegenüber Pignicht so schwer.
Sowohl Pig als auch Hive unterstützen einen Aufruf von externen Biblio-theken. Dadurch ist es möglich die Funktionen, zu erweitern und neue Funk-tionalitäten bereitzustellen. Auch lassen sich fertige MapReduce Jobs aufrufen.Somit ist eine gewisse Rückwärtskompatibilität garantiert, da alle alten HadoopMapReduce Programme wiederverwendet werden können.
Ein weiterer Vorteil von Hive gegenüber Pig ist die Exportschnittstelle überJDBC/ODBC. Dadurch ist es sehr leicht, die Anfragen an das Hadoop Clustervon einer anderen Programmiersprache zu stellen. Bei Pig muss man hierfüreinen Umweg über das Dateisystem gehen, was zu einer Verschlechterung derPerformanz führt.
Betrachtet man die Performanz der beiden Systeme, so scheint es, dass Hiveschneller ist als Pig. Doch dies ist nur eine Tendenz. Tatsächlich ist es wohl eherein gemischtes Ergebnis. So ist bei manchen Anfragen Hive schneller und beianderen Pig. In der Tabelle 1 wurde versucht mit einer Gegenüberstellung diewichtigsten Gemeinsamkeiten und Unterschiede darzustellen.
Abschließend muss man grundsätzlich je nach Anwendung entscheiden, wel-che Technik beziehungsweise welches System man einsetzt. Gerade bei großenDatenmengen und komplizierten Systemen gibt es keinen optimalen Lösungs-weg. In dieser Arbeit wurde der Fokus vor allem auf die beiden Sprachen Pigund Hive gelegt, weil sie zusammen in den weltweit größten Clustern eingesetztwerden. So betreibt Facebook ein Cluster mit etwa 800 Knoten und Yahoo einCluster mit circa 1000 Knoten. Beide Firmen wollen ihre Cluster stark vergrö-ßern und nebenbei auch beweisen, dass ihre Anfragesprache besser als die derKonkurrenten ist. Es bleibt also abzuwarten, wie sich dieser Konkurrenzkampfin Zukunft entwickelt.
12
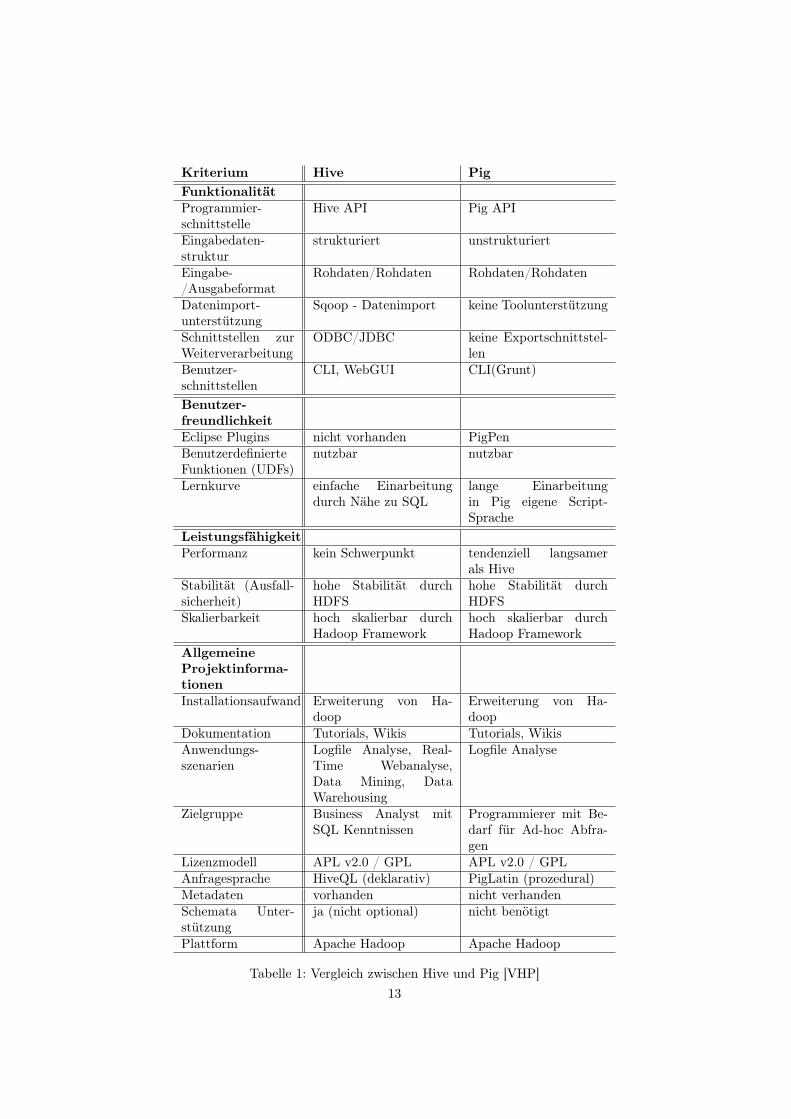
Kriterium Hive PigFunktionalitätProgrammier-schnittstelle
Hive API Pig API
Eingabedaten-struktur
strukturiert unstrukturiert
Eingabe-/Ausgabeformat
Rohdaten/Rohdaten Rohdaten/Rohdaten
Datenimport-unterstützung
Sqoop - Datenimport keine Toolunterstützung
Schnittstellen zurWeiterverarbeitung
ODBC/JDBC keine Exportschnittstel-len
Benutzer-schnittstellen
CLI, WebGUI CLI(Grunt)
Benutzer-freundlichkeitEclipse Plugins nicht vorhanden PigPenBenutzerdefinierteFunktionen (UDFs)
nutzbar nutzbar
Lernkurve einfache Einarbeitungdurch Nähe zu SQL
lange Einarbeitungin Pig eigene Script-Sprache
LeistungsfähigkeitPerformanz kein Schwerpunkt tendenziell langsamer
als HiveStabilität (Ausfall-sicherheit)
hohe Stabilität durchHDFS
hohe Stabilität durchHDFS
Skalierbarkeit hoch skalierbar durchHadoop Framework
hoch skalierbar durchHadoop Framework
AllgemeineProjektinforma-tionenInstallationsaufwand Erweiterung von Ha-
doopErweiterung von Ha-doop
Dokumentation Tutorials, Wikis Tutorials, WikisAnwendungs-szenarien
Logfile Analyse, Real-Time Webanalyse,Data Mining, DataWarehousing
Logfile Analyse
Zielgruppe Business Analyst mitSQL Kenntnissen
Programmierer mit Be-darf für Ad-hoc Abfra-gen
Lizenzmodell APL v2.0 / GPL APL v2.0 / GPLAnfragesprache HiveQL (deklarativ) PigLatin (prozedural)Metadaten vorhanden nicht verhandenSchemata Unter-stützung
ja (nicht optional) nicht benötigt
Plattform Apache Hadoop Apache Hadoop
Tabelle 1: Vergleich zwischen Hive und Pig [VHP]13

A Wörter zählen mit Apache Hadoop
1 package org . myorg ;2
3 import java . i o . IOException ;4 import java . u t i l . ∗ ;5
6 import org . apache . hadoop . f s . Path ;7 import org . apache . hadoop . conf . ∗ ;8 import org . apache . hadoop . i o . ∗ ;9 import org . apache . hadoop . mapreduce . ∗ ;
10 import org . apache . hadoop . mapreduce . l i b . input . Fi leInputFormat ;11 import org . apache . hadoop . mapreduce . l i b . input . TextInputFormat ;12 import
org . apache . hadoop . mapreduce . l i b . output . FileOutputFormat ;13 import
org . apache . hadoop . mapreduce . l i b . output . TextOutputFormat ;14
15 pub l i c c l a s s WordCount {16
17 pub l i c s t a t i c c l a s s Map extends Mapper<LongWritable , Text ,Text , IntWritable> {
18 pr i va t e f i n a l s t a t i c IntWritab le one = new IntWritab le (1 ) ;19 pr i va t e Text word = new Text ( ) ;20
21 pub l i c void map( LongWritable key , Text value , Contextcontext ) throws IOException , Inter ruptedExcept ion {
22 St r ing l i n e = value . t oS t r i ng ( ) ;23 Str ingToken ize r t ok en i z e r = new Str ingToken ize r ( l i n e ) ;24 whi le ( t ok en i z e r . hasMoreTokens ( ) ) {25 word . s e t ( t ok en i z e r . nextToken ( ) ) ;26 context . wr i t e (word , one ) ;27 }28 }29 }30
31 pub l i c s t a t i c c l a s s Reduce extends Reducer<Text ,IntWritable , Text , IntWritable> {
32
33 pub l i c void reduce ( Text key , I t e r ab l e <IntWritable>values , Context context )
34 throws IOException , Inter ruptedExcept ion {35 i n t sum = 0 ;36 f o r ( IntWritab le va l : va lue s ) {37 sum += val . get ( ) ;38 }39 context . wr i t e ( key , new IntWritab le (sum) ) ;40 }41 }42
43 pub l i c s t a t i c void main ( St r ing [ ] a rgs ) throws Exception {44 Conf igurat ion conf = new Conf igurat ion ( ) ;45
46 Job job = new Job ( conf , "wordcount" ) ;
14

47
48 job . setOutputKeyClass ( Text . c l a s s ) ;49 job . setOutputValueClass ( IntWritab le . c l a s s ) ;50
51 job . setMapperClass (Map. c l a s s ) ;52 job . setReducerClass (Reduce . c l a s s ) ;53
54 job . setInputFormatClass ( TextInputFormat . c l a s s ) ;55 job . setOutputFormatClass (TextOutputFormat . c l a s s ) ;56
57 FileInputFormat . addInputPath ( job , new Path ( args [ 0 ] ) ) ;58 FileOutputFormat . setOutputPath ( job , new Path ( args [ 1 ] ) ) ;59
60 job . waitForCompletion ( t rue ) ;61 }62
63 }
Die Klasse WordCount für einen Apache Hadoop MapReduce Job(Quelle:[CLO])
15

Literatur[CLO] Website von Cloudera. http://www.cloudera.com/
[DG08] Dean, Jeffrey ; Ghemawat, Sanjay: MapReduce: simplified dataprocessing on large clusters. In: Commun. ACM 51 (2008), January,107–113. http://dx.doi.org/10.1145/1327452.1327492. – DOI10.1145/1327452.1327492. – ISSN 0001–0782
[DZ] Dhruba, Borthakur ; Zheng, Shao: Hadoop and Hive Developmentat Facebook
[HAD] Website von Apache Hadoop. http://hadoop.apache.org/
[HIV] Website von Apache Hive. http://hive.apache.org/
[Ols] Olston, Christopher: Pig - web-scale data processing
[ORS+08] Olston, Christopher ; Reed, Benjamin ; Srivastava, Utkarsh ; Ku-mar, Ravi ; Tomkins, Andrew: Pig latin: a not-so-foreign languagefor data processing. In: Proceedings of the 2008 ACM SIGMOD in-ternational conference on Management of data. New York, NY, USA: ACM, 2008 (SIGMOD ’08). – ISBN 978–1–60558–102–6, 1099–1110
[PIG] Website von Apache Pig. http://pig.apache.org/
[STL] Stewart, R.J. ; Trinder, P.W. ; Loidl, H.W.: Comparing HighLevel MR Query Languages
[TSJ+10] Thusoo, A. ; Sarma, J.S. ; Jain, N. ; Shao, Zheng ; Chakka, P.; Zhang, Ning ; Antony, S. ; Liu, Hao ; Murthy, R.: Hive - apetabyte scale data warehouse using Hadoop. In: Data Engineering(ICDE), 2010 IEEE 26th International Conference on, 2010, S. 996–1005
[VHP] Vergleich von Hive und Pig. http://wiki.fh-stralsund.de/
[WCP] Pig Beispiel. http://en.wikipedia.org/wiki/Pig_(programming_language)
16





























