Embed Size (px)
Citation preview
R.Niketta Datenaufbereitung in SPSS
Erste Datenbereinigung
I. Datenbereinigung „klassisch“
I. Schritt: Praktisch: Auf zwei PCs die Datei herunterladen. Auf dem einen PC wird die Häufigkeitsauszählung durchgeführt, auf dem anderen PC wird die Daten-korrektur vorgenommen.
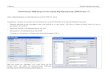
II. Schritt: PC 1: Häufigkeitsauszählung (über Analysieren -à Deskriptive Statistiken à Häufigkeiten
Alle Variablen markieren und über den Pfeil ins Variablenfenster kopieren
R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 2
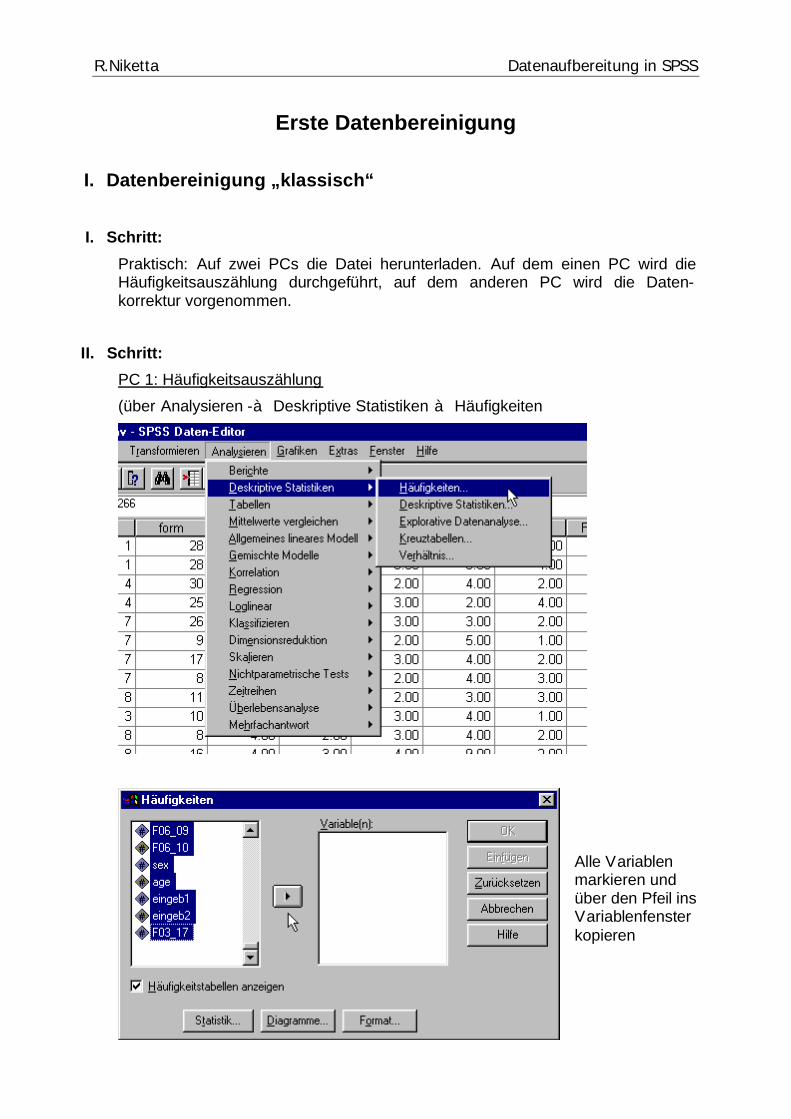
Dann auf OK klicken:
Es erscheinen die Ergebnisse im Ausgabefenster (SPSS-Viewer, diese Datei kann gespeichert werden (*.spo, ab Version 15 *.spv).
III. Schritt: Überprüfung der Werte. Durch Klicken auf die Variable im linken Übersichts-fenster wird die entsprechende Tabelle angezeigt. Sie müssen nun Tabelle auf Tabelle sorgfältig durchsehen, ob nicht erlaubte Werte auftauchen.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 3
IV. Schritt: Wenn Fehler auftreten:
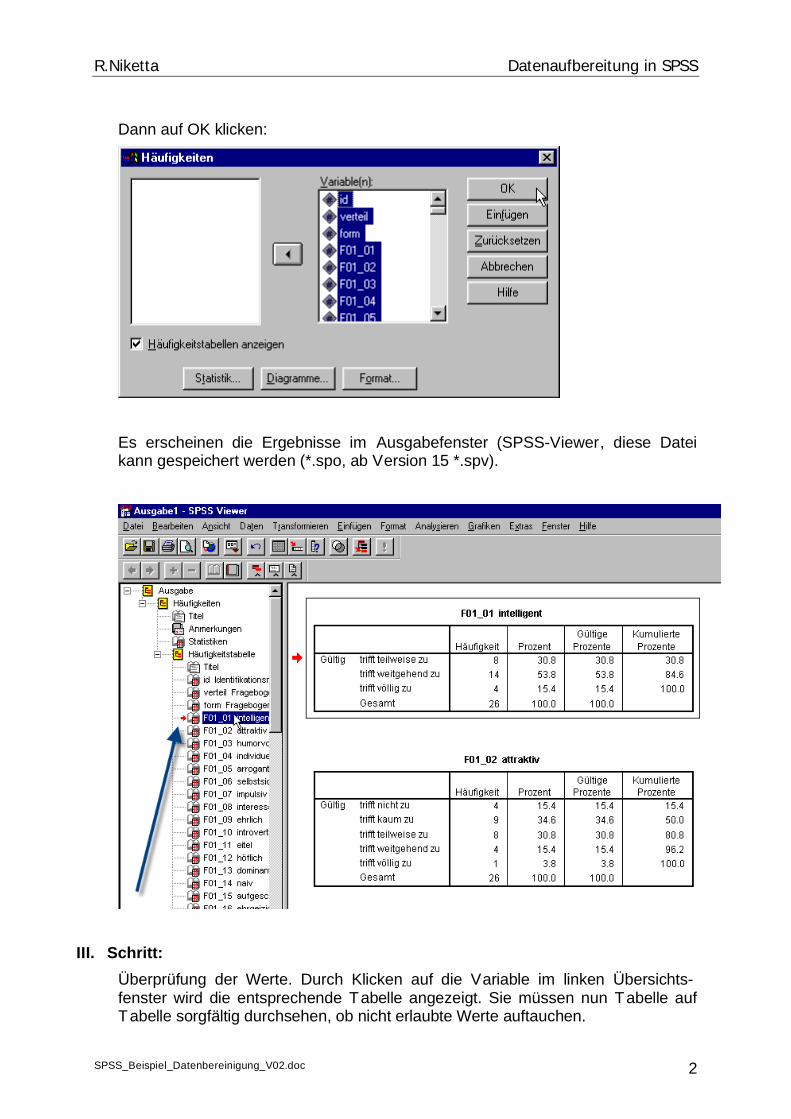
Hier ist die Zahl ‚5‘ nicht erlaubt, da nur 1, 2 und 9 erlaubt sind. Diese Zahl wurde bei einer Person falsch eingegeben, die Person muss gefunden werden, um den Wert zu berichtigen.
V. Schritt In dem Datenblatt die Variable markieren:
dann die Zahl suchen:
die 5 eingeben und auf „Weitersuchen“ klicken
R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 4
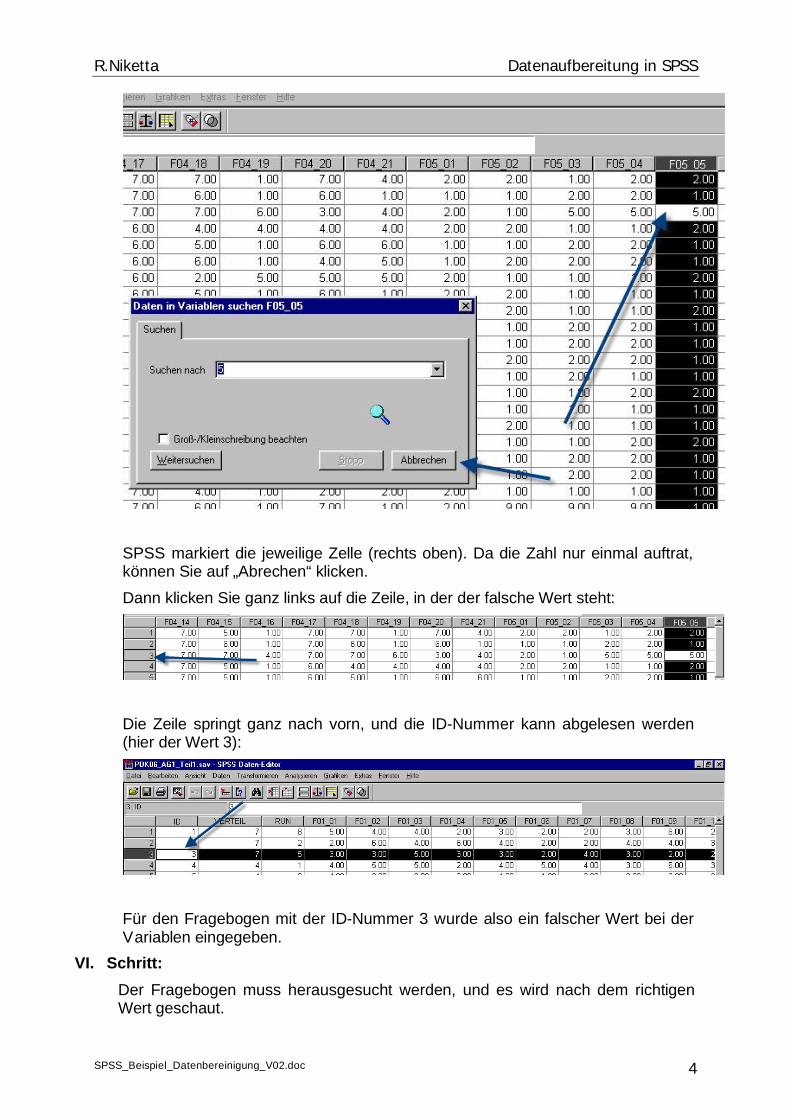
SPSS markiert die jeweilige Zelle (rechts oben). Da die Zahl nur einmal auftrat, können Sie auf „Abrechen“ klicken. Dann klicken Sie ganz links auf die Zeile, in der der falsche Wert steht:
Die Zeile springt ganz nach vorn, und die ID-Nummer kann abgelesen werden (hier der Wert 3):
Für den Fragebogen mit der ID-Nummer 3 wurde also ein falscher Wert bei der Variablen eingegeben.
VI. Schritt: Der Fragebogen muss herausgesucht werden, und es wird nach dem richtigen Wert geschaut.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 5
VII. Schritt PC 2: Hier werden jetzt die korrekten Daten eingegeben.
VIII. Schritt Die Datei mit den korrigierten Werten unter einem neuen Namen speichern und dann in stud.ip hochladen.
Mit der ENTER-Taste oder mit den Cur-sortasten wird der Wert gespeichert.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 6
II. Datenbereinigung mit „Validierung“ (ab Version 14)
1. Schritt Klicken Sie unter „Daten“ auf „Validierung“ und dann auf „Vordefinierte Regeln la-den….:
2. Schritt: SPSS hält einige vordefinierte Regeln bereit, die Sie verwenden können und nicht extra definieren müssen. Sie müssen aber diese Schritte nicht durchführen, Sie können auch mit Schritt 3 anfangen.
R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 7
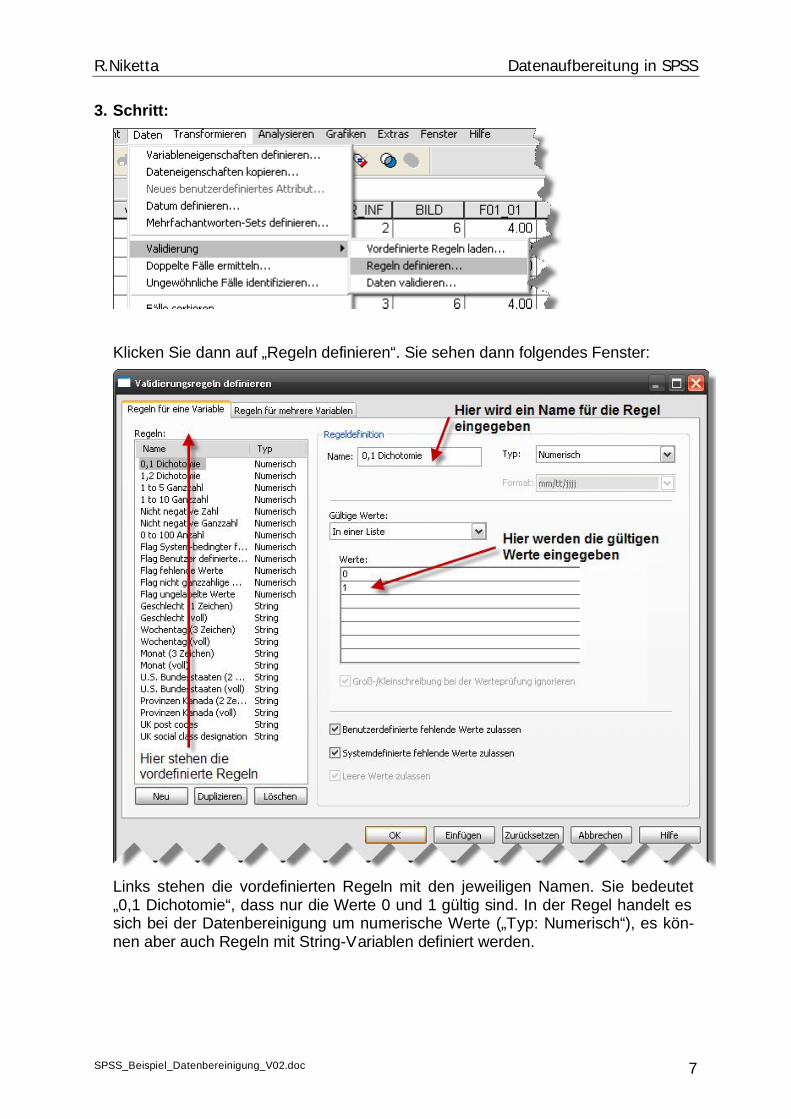
3. Schritt:
Klicken Sie dann auf „Regeln definieren“. Sie sehen dann folgendes Fenster:
Links stehen die vordefinierten Regeln mit den jeweiligen Namen. Sie bedeutet „0,1 Dichotomie“, dass nur die Werte 0 und 1 gültig sind. In der Regel handelt es sich bei der Datenbereinigung um numerische Werte („Typ: Numerisch“), es kön-nen aber auch Regeln mit String-Variablen definiert werden.
R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 8
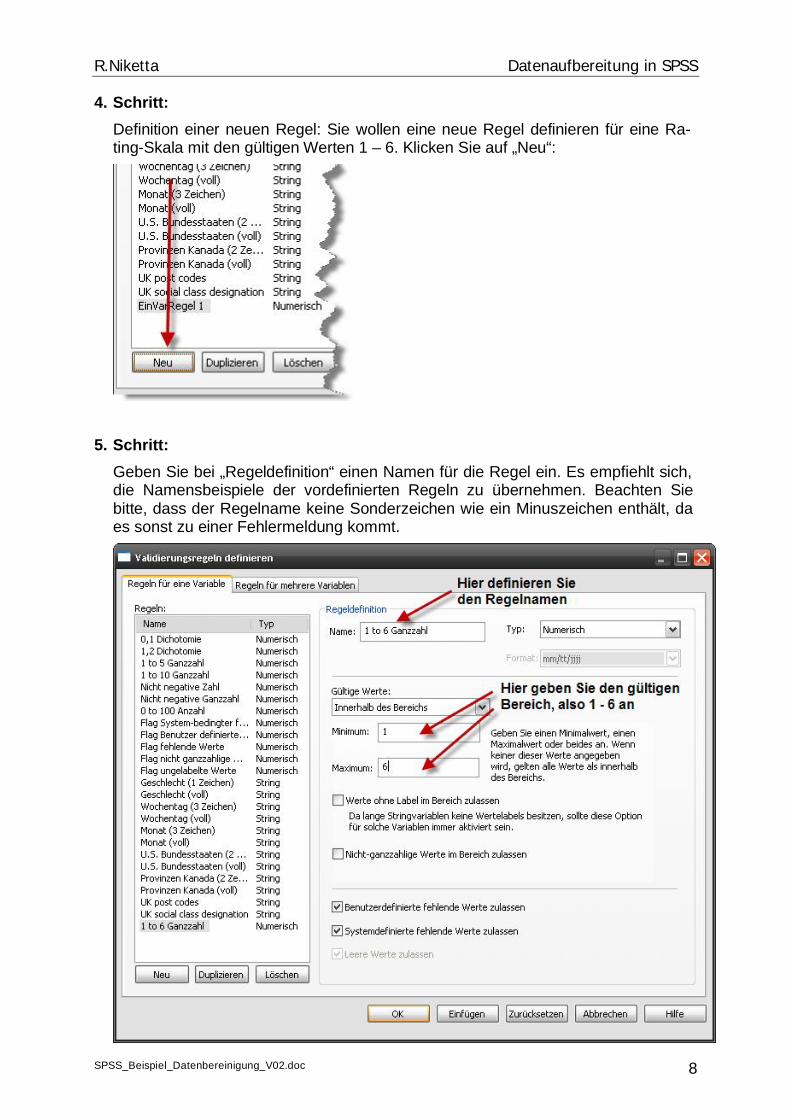
4. Schritt: Definition einer neuen Regel: Sie wollen eine neue Regel definieren für eine Ra-ting-Skala mit den gültigen Werten 1 – 6. Klicken Sie auf „Neu“:
5. Schritt: Geben Sie bei „Regeldefinition“ einen Namen für die Regel ein. Es empfiehlt sich, die Namensbeispiele der vordefinierten Regeln zu übernehmen. Beachten Sie bitte, dass der Regelname keine Sonderzeichen wie ein Minuszeichen enthält, da es sonst zu einer Fehlermeldung kommt.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 9
Bei „Gültige Werte“ können Sie zwischen „In einer Liste“ (Beispiel 0,1-Dichotomie) oder „Innerhalb des Bereichs“ wählen. Hier ist „Innerhalb des Bereichs“ günstiger, da Sie nur den minimalen und den maximalen gültigen Wert eingeben müssen. Klicken Sie abschließend auf „OK“. Das Fenster wird geschlossen. Wenn Sie das Fenster wieder öffnen, sehen Sie, dass die neue Regel aufgenommen wurde.
6. Schritt: Auf diese Weise definieren Sie alle Regeln für die Wertebereiche, die in Ihrem Fragebogen vorkommen.
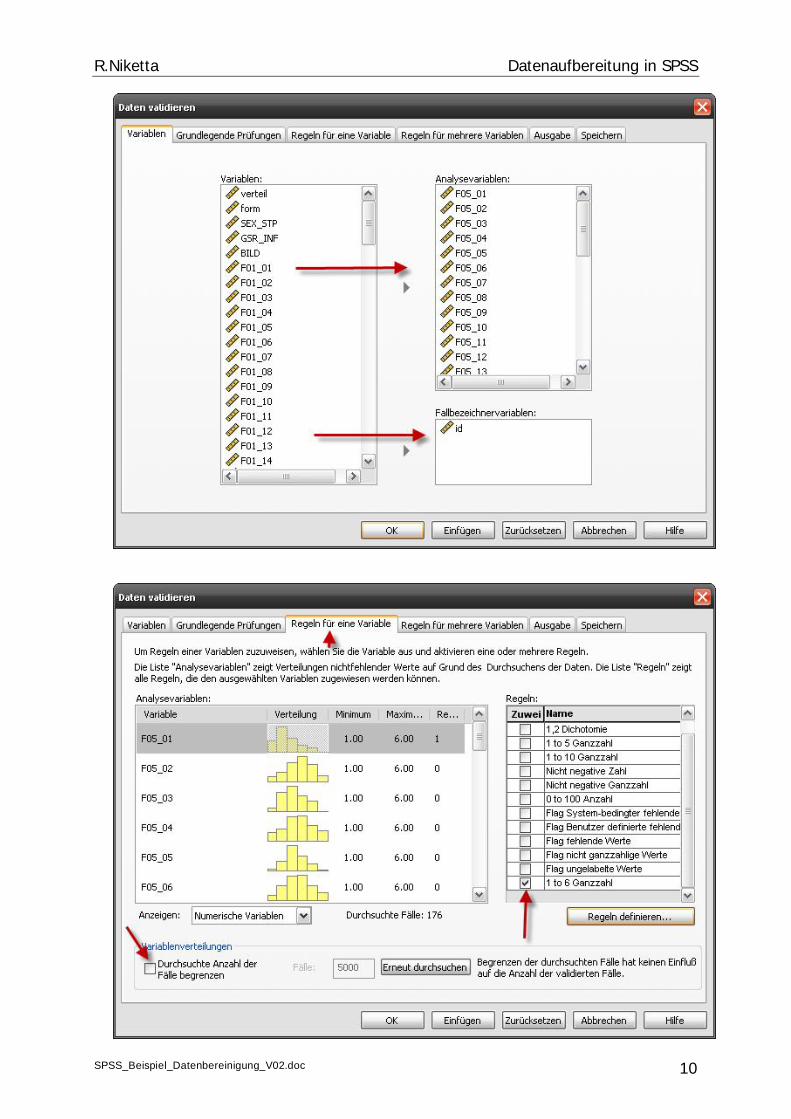
7. Schritt: Jetzt können die Daten validiert werden:
Zuerst müssen die Variablen definiert werden. In diesem Beispiel sind es die Vari-ablen F05_01 – F05_34 mit einer Ratingskala von 1 – 6. Sie sollten auch die ID (Fall)-Variablen berücksichtigen, da dann schneller der Fragebogen gefunden wird, aus dem ein falscher Wert eingegeben wurde.
R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 10

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 11
8. Schritt: Klicken Sie jetzt auf „Regeln für eine Variable“. Sie sehen auf der linken Seite die Verteilungen der Variablen sowie die niedrigsten und höchsten auftretenden Wer-te. Auch an dieser Stelle ist eine Definition von Regeln möglich.
9. Schritt: Markieren Sie alle Variablen, die Sie überprüfen wollen. Klicken Sie dann auf der rechten Seite auf die gültige Regel. Auch entfernen Sie das Kästchen, das die Zahl der zu durchsuchenden Fälle beschränkt. Klicken Sie dann auf OK. Übrigens: Wenn Sie bei Minimum und Maximum sehen, dass alle Werte im gültigen Bereich zwischen 1 und 6 sind, können Sie sich die weiteren Schritte sparen, da ja keine Fehler vorhanden sind.
Nach dem OK finden Sie im Ausgabefenster in diesem Fall die folgende Meldung:
Warnungen
Einige oder alle der angeforderten Ausgaben werden nicht gezeigt, weil alle Fälle,Variablen oder Datenwerte die angeforderten Prüfungen bestanden haben.
Bei diesen Variablen wurden also keine falschen Werte gefunden. Falls falsche Werte vorhanden sein sollten, erhalten Sie von SPSS folgende Meldungen:

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 12
Es werden die Regeln nochmals be-schrieben, die Sie angewendet haben. Sie können in einem Durchlauf mehrere Variablen mit unterschiedlichen Regeln überprüfen. Hier wurde nur diese Regel verwendet.
Es wird angezeigt, bei welcher Variablen falsche Werte („Ver-letzungen“) aufgetreten sind. In diesem Fall also eine Verletzung bei der Variablen F05_01.
In dieser Tabelle werden die interne Fallnummer und die ID-Nummer angegeben.
Der Fall 11 mit der ID-Nummer 538 hat also einen falschen Wert bei der Variablen F05_01. 10. Schritt: Zur Korrektur gehen Sie in die Datenmatrix, wählen den Fall mit der ID-Nummer 538 und geben bei der Variablen F05_01 den richtigen Wert ein. Hierzu benötigen Sie den Originalfragebogen. Sie sollten sich auch die Werte der vorangehenden Variablen anschauen, nicht selten sind die Zahlen einer Itembatterie auf einer Frage-bogenseite verschoben worden. Alternativ können Sie auch im Syntaxfenster folgende Befehle eingeben (unter der Annahme, dass 1 der richtige Wert sei): IF (ID = 538) F05_01 = 1. EXECUTE.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 13
III. Datenfehlersuche über Syntaxbefehle
Eine einfache Überprüfung der Daten kann über Befehle im Syntaxfenster vor-genommen werden. Ziel ist hierbei, nur die Daten auszugeben, die fehlerbehaftet sind. Zusätzlich sollen die ID-Nummer, die Variable und der falsche Wert aus-gegeben werden. Dies geschieht über DO IF – END IF-Schleifen und dem PRINT-Befehl. Allerdings muss diese Schleife für jede Variable getrennt vorgenommen werden. Dies bedeutet einige Schreibarbeit, die aber über das übliche „Copy & Paste“ vereinfacht werden kann. Beispiel: Für die Variable F02 sollen falsche Werte ermittelt werden. Gültige Werte auf der Ratingskala sind die Werte 1 – 5. Auch der systemfehlende Wert sollte nicht vorhanden sein. *** FRAGE 2. DO IF (F02 < 1 OR F01 > 5 OR SYSMIS(F02)). PRINT / 'ID: ' ID (F4.0,5X) 'F02: ' F02 (F2.0). END IF. EXECUTE. Es bedeuten:
In der DO IF – END IF-Schleife wird für die einzelne Variable angegeben, welche Werte keine gültigen Werte sind. Diese Werte können von Variable zu Variable je nach Skalenbreite unterschiedlich sein.

R.Niketta Datenaufbereitung in SPSS
SPSS_Beispiel_Datenbereinigung_V02.doc 14
Nach dem PRINT / - Befehle werden in Hochkomma der Text eingegeben, der im Ausdruck erscheinen soll (auf Leerzeichen achten, das macht den Ausdruck les-barer), gefolgt von dem Variablennamen. In den Klammern wird dann gemäß den FORTRAN-Konventionen die Ausgabeart wiedergegeben. ‚4.0’ bedeutet, dass die Variable aus vier Zeichen ohne Komma besteht. Enthält die Variable nur 1 Zeichen, z.B. die Zahl 2, dann erscheint die Zahl rechtsbündig, die 3 Zeichen vor der ‚2’ werden leer gelassen. ‚5X’ bedeutet, dass fünf Leerzeichen folgen, es wird also ein Abstand zu den nächsten Zeichen gelassen. Bevor Sie die Daten überprüfen, müssen Sie unter „Optionen“ das Häkchen bei „Be-fehle im Log anzeigen“ entfernen, da ansonsten die Ausgabe unübersichtlich wird. Die Ausgabe für F02 sieht dann wie folgt aus:
Beim Fragebogen mit der ID-Nummer 119 wurde bei der Variablen F02 der falsche Wert 7 eingegeben, bei der ID 123 der falsche Wert 22. In dieser Weise können dann für jede Variable DO IF - END IF-Scheifen geschrieben werden. Sie sollten die Syntaxdatei speichern, dann die Prozedur jederzeit wieder-holt werden. Das Gesamtergebnis könnte dann wie folgt aussehen:
Fazit: Die Vorarbeit ist aufwändig und ist in der Regel nicht auf Anhieb fehlerfrei. Auf der anderen Seite ist der Ausdruck übersichtlich, die falschen Werte werden über-sichtlich ausgegeben und in der Datei gefunden.








![Statistische Datenanalyse mit SPSS 8 für Windows · Statistische Datenanalyse mit SPSS 8 für Windows [= Reihe Benutzereinführung, Bd. 25] 1999. ... plattform er SPSS einsetzen](https://img.pdfslide.org/doc/110x75/603eaeb2cb2baf078000a0bb/statistische-datenanalyse-mit-spss-8-fr-windows-statistische-datenanalyse-mit.jpg)