Embed Size (px)
Citation preview

<Insert Picture Here>
SQL oder NoSQL: Das ist die Frage!
Oracle NoSQL Database
Carsten Czarski
Oracle Deutschland B.V. & Co KG

Agenda
• NoSQL: Was ist das und wozu ist das gut?Anwendungsbereiche für NoSQL-Technologien, "prominente Nutzer",
• NoSQL und SQL im ZusammenspielWas eignet sich für was? Schließt das Eine das andere aus?
Wie sieht eine Architektur aus?
• Oracle NoSQL DatenbankDatenhaltungsstrategien: Key-Value, Columnar, Document, Graph;
Architektur und Konzepte, Zugriffe, Replikation, Hochverfügbarkeit
• NoSQL Datenbank im Ganzen:Weiterführende Technologien: MapReduce, Hadoop, Oracle Loader
for Hadoop
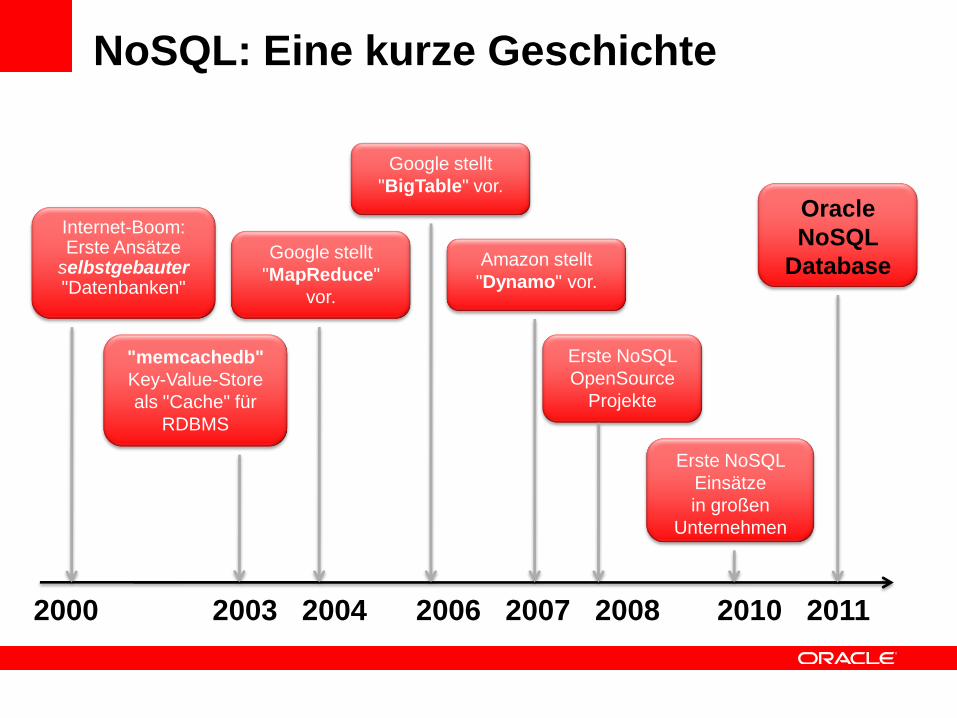
NoSQL: Eine kurze Geschichte
"memcachedb"
Key-Value-Store
als "Cache" für
RDBMS
Internet-Boom: Erste Ansätze
selbstgebauter"Datenbanken"
Google stellt
"MapReduce"
vor.
Google stellt
"BigTable" vor.
Amazon stellt
"Dynamo" vor.
Erste NoSQL
OpenSource
Projekte
Erste NoSQL
Einsätze
in großen
Unternehmen
Oracle
NoSQL
Database
2000 2003 2004 2006 2007 2008 2010 2011

NoSQL: Was ist das?
• Not-only-SQL (2009)
• Sammelbegriff für nichtrelationale Datenbanken, die …
• massiv parallelisierbar sind
• weitgehend ohne Datenmodell arbeiten
• die Datenkonsistenz nicht zwingend durchsetzen
• sehr entwicklerspezifisch sind
• Derzeit noch keine Standardisierung vorhanden
• Keine Abfragesprache (eben "NoSQL")
• Massive Produktvielfalt (über 122 auf nosql-database.org)
• Produkte nur schwer vergleichbar

NoSQL Technologie im Einsatz
• Soziale Netzwerke LinkedIn, Facebook, Xing, Google+, Twitter
• Personalisierung Amazon, Ebay, Yahoo, …
• Internetzentrische DiensteBeispiele: TinyURL, bit.ly
• Sensordaten

SQL oder NoSQL: Das ist die Frage!
SQL: RDBMS NoSQL
Konsistenz und Integrität ist höchstes
Gut: Jeder einzelne Satz ist wichtig.
Verfügbarkeit ist höchstes Gut:
Einzelne Datensätze dürfen auch
verloren gehen.
Datenmodell als Schema Kein Datenmodell
Abfragesprache: SQL Keine Abfragesprache; direkte API-
Zugriffe
Abfrageausführung durch Optimizer Know-How in der Anwendung
Generische Datenbank für viele
Anwendungen
Datenhaltung wird speziell auf eine
Anwendung zugeschnitten

SQL und NoSQL im Zusammenspiel
NoSQL DB
Hadoop
RDBMS
• Extrem dynamisch und flexibel
• Massiv parallelisierbar
• Massiv parallele Batchverarbeitung
• Größte Datenmengen
• Analyse "veredelter" Daten und BI
• Reporting / Real Time
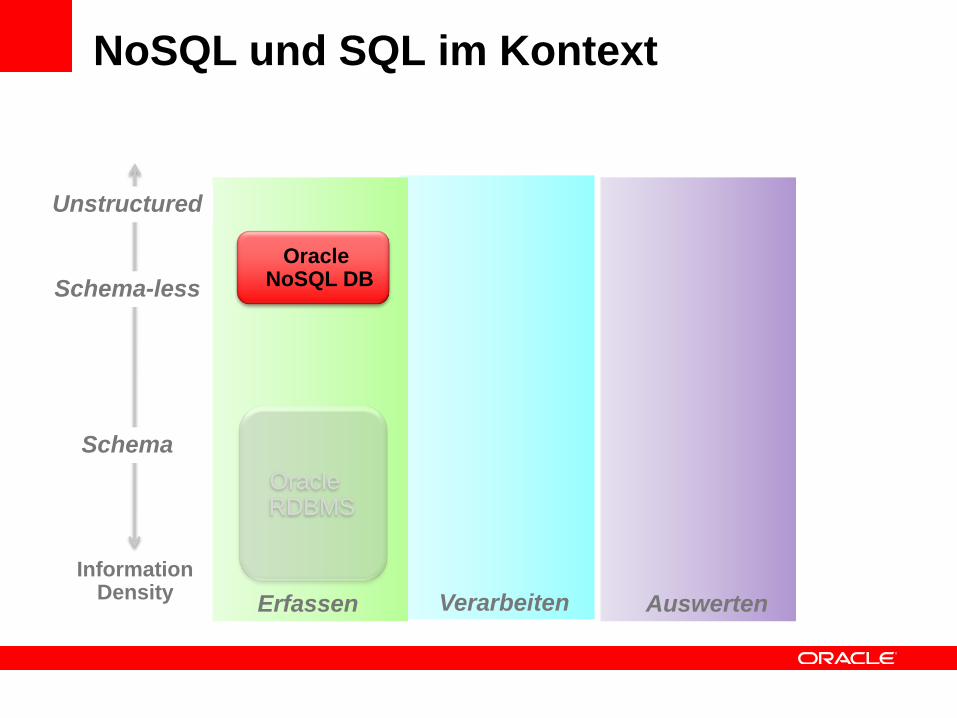
NoSQL und SQL im Kontext
Erfassen AuswertenVerarbeiten
Schema-less
Unstructured
Schema
InformationDensity
OracleRDBMS
Oracle NoSQL DB
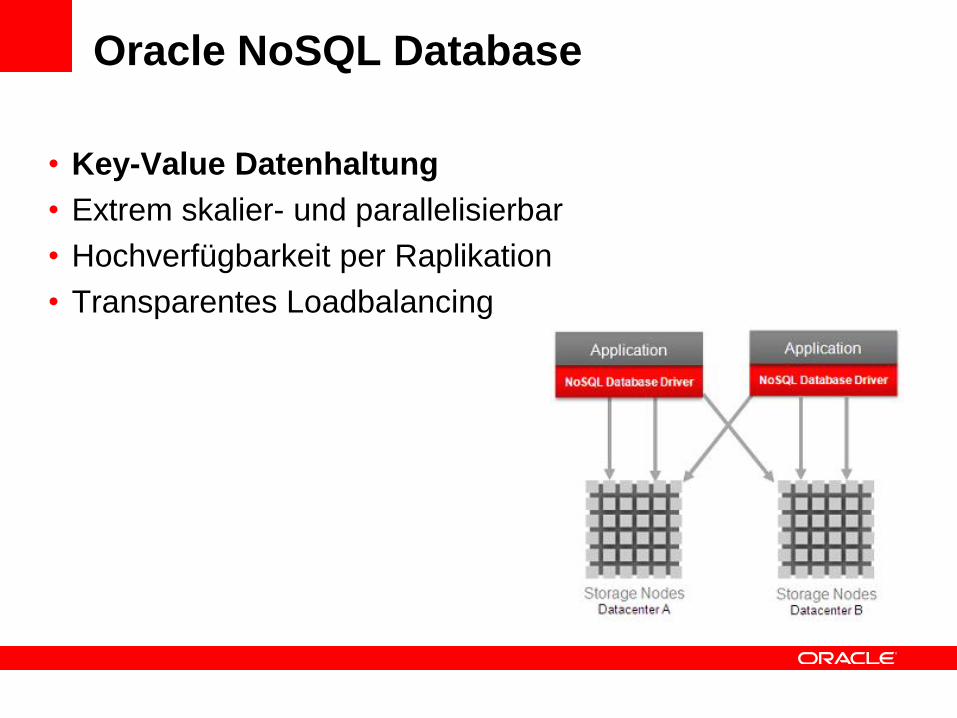
Oracle NoSQL Database
• Key-Value Datenhaltung
• Extrem skalier- und parallelisierbar
• Hochverfügbarkeit per Raplikation
• Transparentes Loadbalancing

Was ist ein "Key-Value-Store"?
• Im wesentlichen eine zweispaltige Tabelle – "KEY" und "VALUE"
• VALUE kann auch ein komplexes Objekt sein
• Die Anwendung kennt die Datenstrukturen – nicht selbstbeschreibend
• Joins zu anderen Key-Value Stores allein durch die Anwendung
• Einfache Zugriffe: GET, PUT, DELETE
• Einfach parallelisierbar
Key Value
010101010 … … … … …
010101011 … … … … …
… … … … … …
Datenstrukturen sind nicht selbstbeschreibend
Zeilen
Key-Value Store CUSTOMERSKey = Index

Oracle NoSQL DatabaseZugriffe per API (Java)

Oracle NoSQL DatabaseEin Codebeispiel: Java
:config = new KVStoreConfig("carstenstore", "sccloud032:5000");store = KVStoreFactory.getStore(config);
store.put(Key.createKey("EMP_7839_ENAME"), Value.createValue("KING".getBytes())
);store.put(Key.fromByteArray(new String("EMP_7839_SAL").getBytes()), Value.createValue("5000".getBytes())
);
store.close();:

Oracle NoSQL DatabaseEin Codebeispiel: Java
:config = new KVStoreConfig("carstenstore", "sccloud032:5000");store = KVStoreFactory.getStore(config);
new String(store.get(Key.createKey("EMP_7839_ENAME")).getValue().getValue()
)
new String(store.get(Key.fromByteArray(new String("EMP_7839_SAL").getBytes())
).getValue().getValue()))
store.close();:
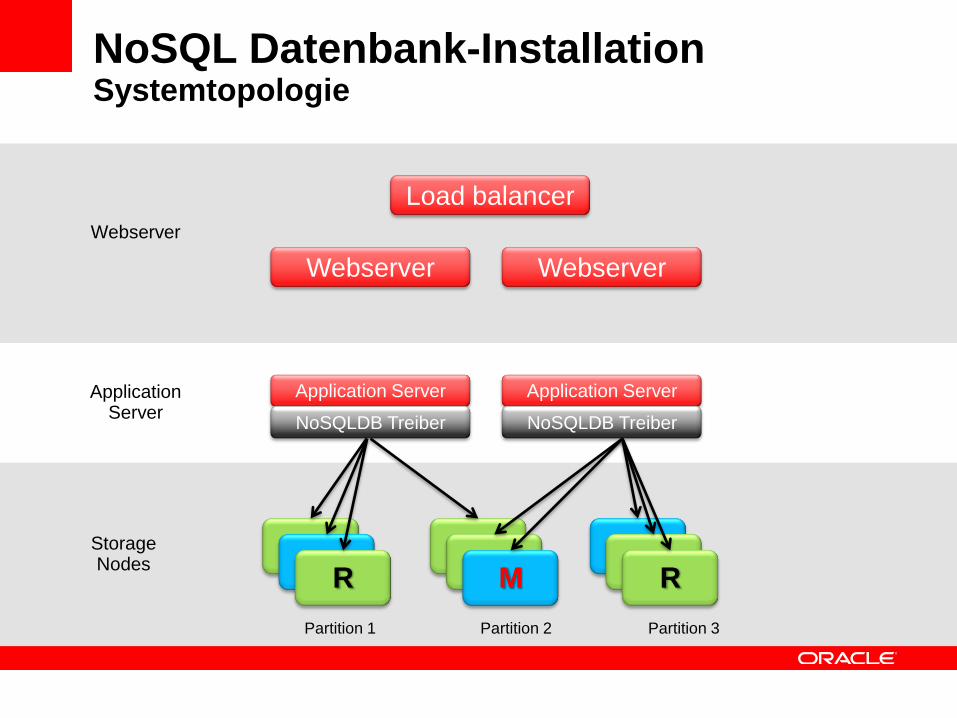
NoSQL Datenbank-InstallationSystemtopologie
Partition 1 Partition 2 Partition 3
StorageNodes
Load balancer
Webserver Webserver
Application Server
NoSQLDB Treiber
Application Server
NoSQLDB Treiber
R M R
ApplicationServer
Webserver
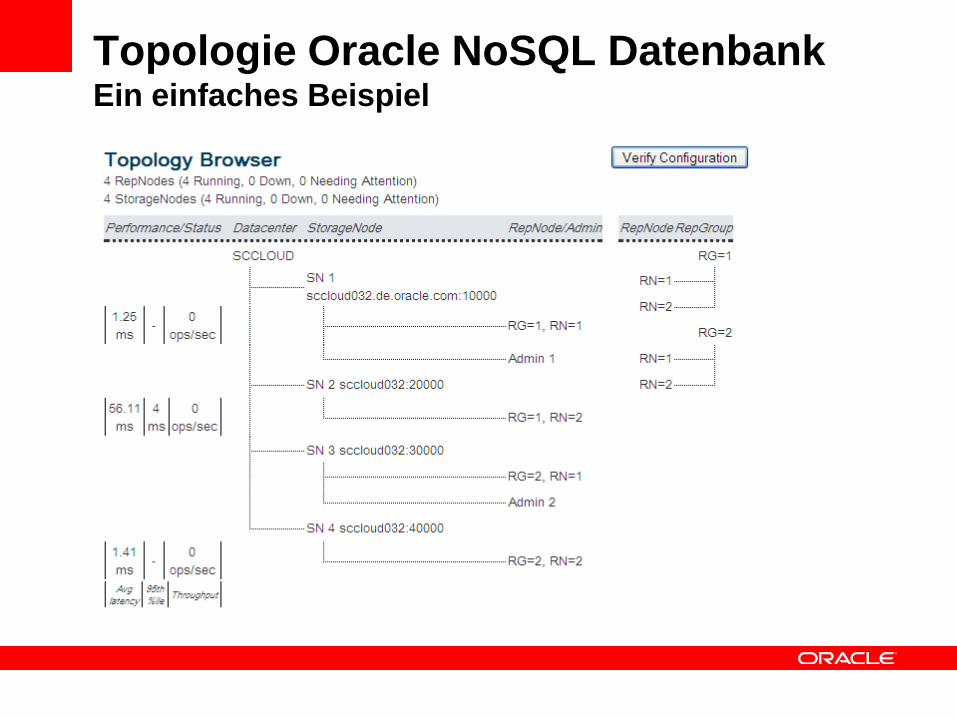
Topologie Oracle NoSQL Datenbank Ein einfaches Beispiel
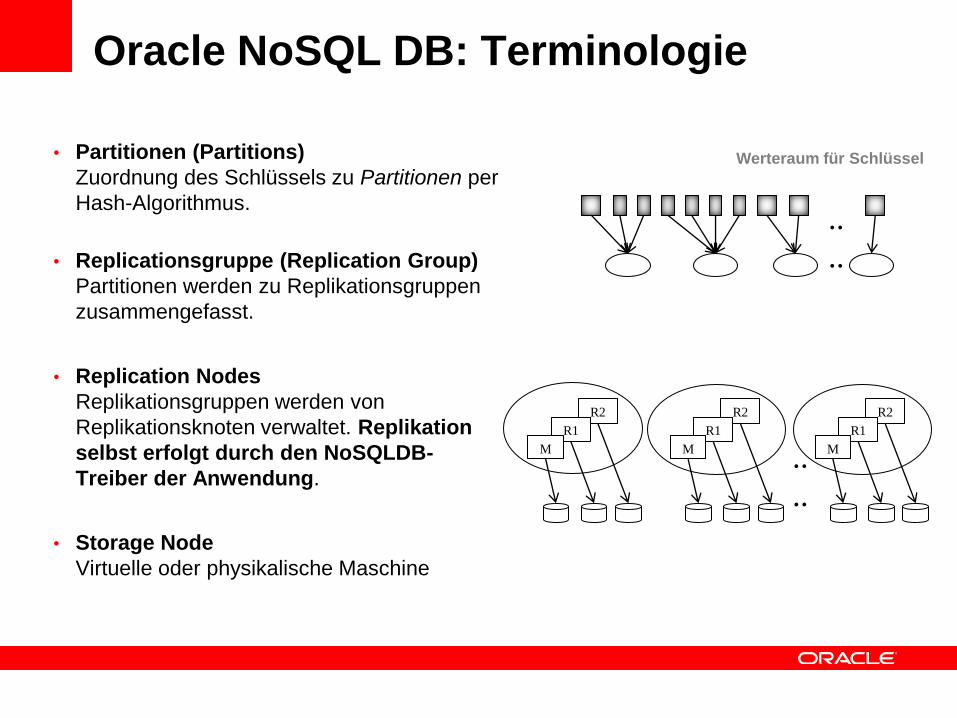
R2
Werteraum für Schlüssel
..
..
Oracle NoSQL DB: Terminologie
• Partitionen (Partitions)
Zuordnung des Schlüssels zu Partitionen per
Hash-Algorithmus.
• Replicationsgruppe (Replication Group)
Partitionen werden zu Replikationsgruppen
zusammengefasst.
• Replication Nodes
Replikationsgruppen werden von
Replikationsknoten verwaltet. Replikation
selbst erfolgt durch den NoSQLDB-
Treiber der Anwendung.
• Storage Node
Virtuelle oder physikalische Maschine
R1
M
R2
R1
M
R2
R1
M..
..

Replikationskonzept
• Master und Replica
• Master bedient WRITE Requests
• Replica bedienen WRITE und READ Requests
• Wichtig: Replikationsfaktor
• Replikationsfaktor = Master + Anzahl_Replika
• Anzahl_Nodes = Partitionen * Replikationsfaktor
• Empfohlen: Replikationsfaktor mindestens 3
• Bei Ausfall eines Master kann eine Replica neuer Master werden
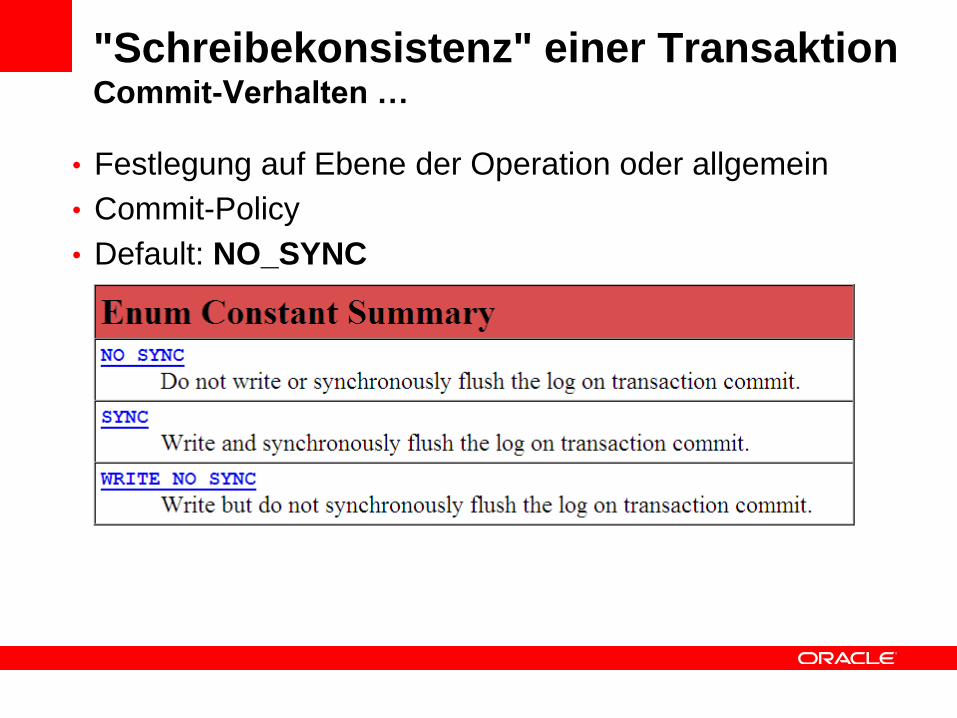
"Schreibekonsistenz" einer TransaktionCommit-Verhalten …
• Festlegung auf Ebene der Operation oder allgemein
• Commit-Policy
• Default: NO_SYNC

"Schreibekonsistenz" einer TransaktionCommit-Verhalten …
• Festlegung auf Ebene der Operation oder allgemein
• Replikations-Policy
• Default: SIMPLE_MAJORITY

Schreibkonsistenz festlegen ...Beispiel: Default setzen
• Aufgabe des Entwicklers: Java-Code :Durability d = new Durability(
Durability.SyncPolicy.SYNC, // Commit-Policy MASTERDurability.SyncPolicy.SYNC, // Commit-Policy REPLICADurability.ReplicaAckPolicy.NONE // Replikations-Policy
);
<KVStoreConfig>config.setDurability(d);:

Lesekonsistenz einer Transaktion
• Festlegung auf Ebene der Operation – Defaults sind möglich
• Mögliche Einstellungen zur Lesekonsistenz
• Absolute
Lese nur vom Master
• Time-based
Lese auch von einer Replica, die aber maximal ein bestimmtes
Zeitintervall huinter dem Master liegt
• Version
Lese auch von einer Replica, die mindestens ein bestimmtes Transaction
Token erreicht hat
• None
Lese vom Master oder von irgendeiner Replica
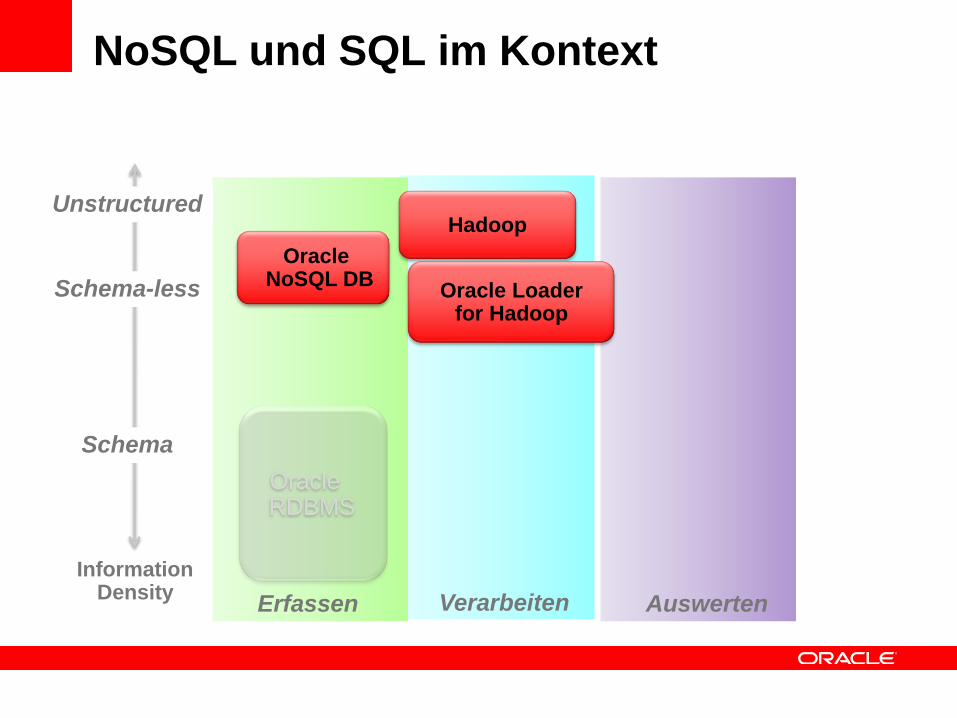
NoSQL und SQL im Kontext
Erfassen AuswertenVerarbeiten
Schema-less
Unstructured
Schema
InformationDensity
OracleRDBMS
Oracle NoSQL DB
Hadoop
Oracle Loaderfor Hadoop

Hadoop: Was ist das?
• "Shared Nothing" Compute Architecture• Open Source – Im Gegensatz zur Google-Implementierung
• Batchorientiert
• API gesteuert – Definition und Aufteilung der Teilaufgaben ist Sache des Entwicklers
• Massive Parallelisierung in extrem großen Clustern
• Automatische Behandlung eines Knoten-Ausfalls

Hadoop: Terminologie
• Hadoop ClientSchnittstelle zum Cluster; startet die Verarbeitung, tut selbst aber nichts
• NameNodeVerwaltet Informationen (wo sind die Daten) und Zugriffskontrolle; als einzelner Knoten oder doppelt auslegbar
• JobTracker ordnet die Teilaufgaben auf die einzelnen Knoten zu (query coordinator)
• Data Nodes Diese enthalten Daten und führen die Aufgaben aus.
• Hadoop Distributed File System (HDFS) Gemeinsames Filesystem für Daten
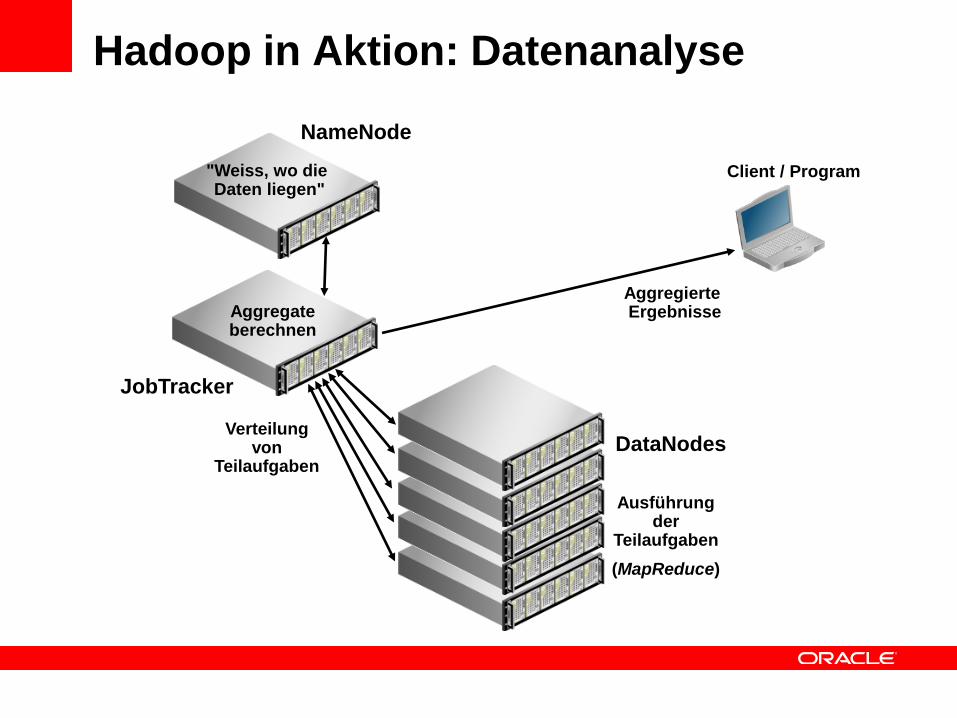
Hadoop in Aktion: Datenanalyse
DataNodes
NameNode
Aggregierte Ergebnisse
Client / Program
JobTracker
Aggregateberechnen
Ausführungder
Teilaufgaben
(MapReduce)
Verteilungvon
Teilaufgaben
"Weiss, wo die Daten liegen"

MapReduce: Was ist das?
• Ein Hadoop-Cluster führt MapReduce-Programme aus
• Ein Reducer erhält Daten von einem Mapper
• Mapper und Reducer arbeiten massiv parallel
• Nahezu alle Programmiersprachen denkbar – meist aber Java im Einsatz
MapReduce is a software framework introduced by Google to support distributed computing on large
data sets on clusters of computers.[

Oracle Loader für Hadoop
• Aufbereitung von Daten für das RDBMS Oracle:
Partitionieren, sortieren, transformieren
• Direkt aus dem Hadoop Cluster in die Oracle-Datenbank
laden
• Online mode: Lade per JDBC oder OCI
• Offline mode: Erzeuge externe Tabellen (Data Pump Format)
• Unterstützte Versionen: 10.2.0.5 oder 11.2.0.3
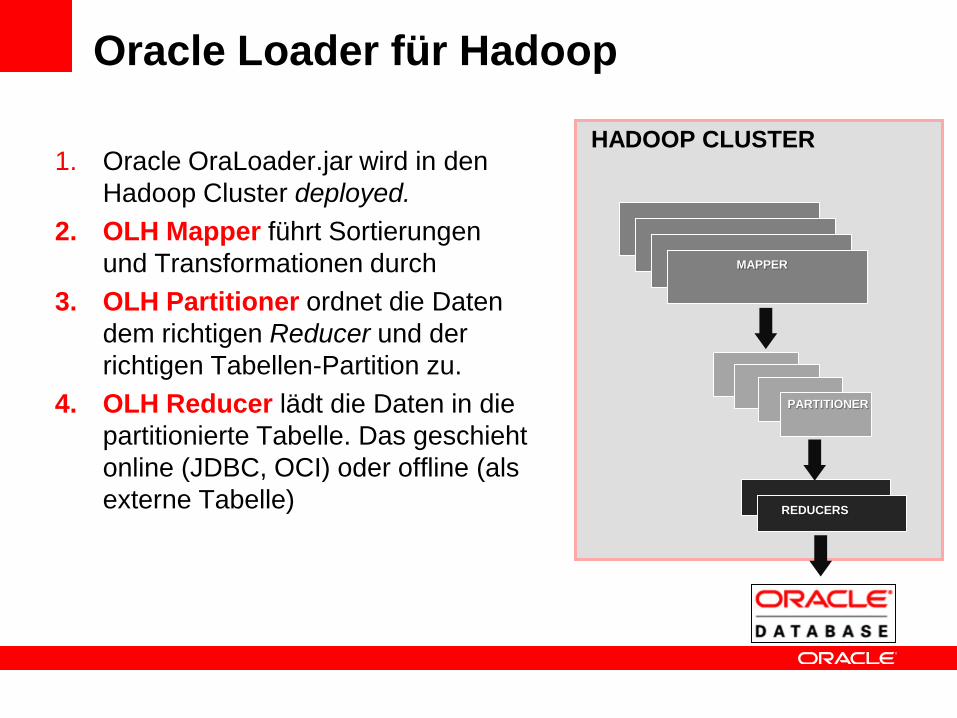
Oracle Loader für Hadoop
1. Oracle OraLoader.jar wird in den
Hadoop Cluster deployed.
2. OLH Mapper führt Sortierungen
und Transformationen durch
3. OLH Partitioner ordnet die Daten
dem richtigen Reducer und der
richtigen Tabellen-Partition zu.
4. OLH Reducer lädt die Daten in die
partitionierte Tabelle. Das geschieht
online (JDBC, OCI) oder offline (als
externe Tabelle)
MAPPER
PARTITIONER
REDUCERS
HADOOP CLUSTER
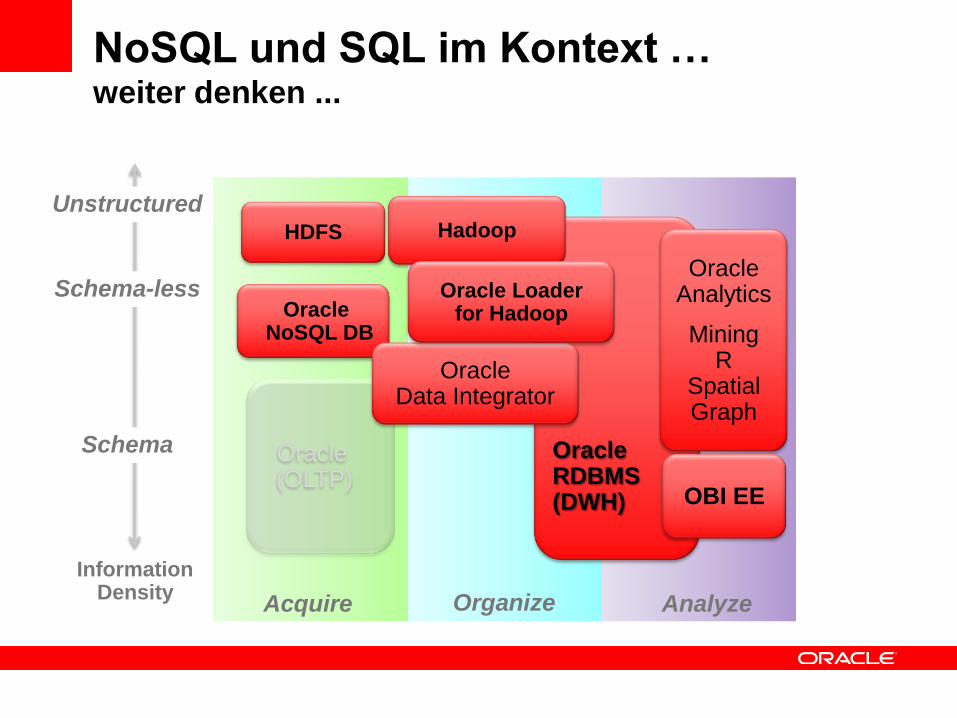
NoSQL und SQL im Kontext …weiter denken ...
Acquire AnalyzeOrganize
OracleRDBMS(DWH)
Oracle (OLTP)
Schema-less
Unstructured
Schema
InformationDensity
HadoopHDFS
Oracle NoSQL DB
OracleAnalytics
MiningR
SpatialGraph
OBI EE
OracleData Integrator
Oracle Loaderfor Hadoop

Oracle Big Data Appliance
http://www.oracle.com/us/corporate/features/feature-obda-498724.html
Weitere Informationen
• OTN: http://www.oracle.com/technetwork/database/nosqldb/overview/index.html

http://tinyurl.com/apexcommunity
http://sql-plsql-de.blogspot.comhttp://oracle-text-de.blogspot.comhttp://oracle-spatial.blogspot.com
http://plsqlexecoscomm.sourceforge.nethttp://plsqlmailclient.sourceforge.net
Twitter: @cczarski @oraclebudb