Embed Size (px)
Citation preview

Statistische Verfahren in der Computerlinguistik
Einführung in die ComputerlinguistikSommersemester 2009
Peter Kolb

Übersicht
Statistische vs. symbolische Verfahren in der CL
Statistik
beschreibende Statistik uni- und multivariate Deskription von Daten
schließende Statistik Wahrscheinlichkeitsrechnung bedingte Wahrscheinlichkeit Bayes'sche Statistik
Markov-Modelle

Statistische vs. symbolische CL
● anfänglich vor allem statistische Ansätze:
– maschinelle Übersetzung als Anwendung kryptoanalytischer und statistischer Methoden (Locke u. Booth 1955)
– Informationstheorie (Shannon u. Weaver 1949): Übersetzung = Übertragung über gestörten Kanal
● bald Aufspaltung in statistische und symbolische Ansätze
● symbolische Ansätze dominierten CL bis 1990

Statistische vs. symbolische CL
● Gründe für die Dominanz symbolischer Ansätze:
– mangelnde Leistungsfähigkeit der Hardware
– Chomsky 1957: prinzipiell ist kein statistischer Ansatz fähig, Unterschied zwischen den Sätzen (1) Colorless green ideas sleep furiously. (2) Furiously sleep ideas green colorless. zu erfassen, da keiner je in einem engl. Korpus vorkommen wird.
– Kompetenz/Performanz: in Korpora können nur Performanzdaten beobachtet werden, Linguisten aber an Kompetenz interessiert

Statistische vs. symbolische CL
● Wiederentdeckung statistischer Verfahren:
– Baker CMU 1975, Jelinek IBM 1976: erste Implementierung von Hidden-Markov-Modellen
– prakt. Anwendung: Rabiner 1989 Spracherkennung
– PoS-Tagging (DeRose 1988)
– statistische maschinelle Übersetzung (Brown et al. 1990)
● in den 90er Jahren wird die CL von statistischen Verfahren „überrollt“
● heute eher hybride Ansätze

beschreibende vs. schließende Statistik
beschreibende (deskriptive, explorative) Statistik
graphische Darstellung von Daten Ermittlung von Kenngrößen (z.B. Mittelwert) verwendet keine stochastischen Methoden
schließende Statistik
versucht über erhobene Daten hinaus Schlussfolgerungen zu ziehen
verwendet stochastische Methoden Stochastik: Wahrscheinlichkeitstheorie und
Informationstheorie

Grundbegriffe der Statistik
Daten werden an statistischen Einheiten erhoben
Grundgesamtheit (Population)
z.B. Phoneme – Phoneminventar einer Sprache
untersucht wird meist nur eine Teilmenge der Grundgesamtheit, die Stichprobe
an statistischen Einheiten in Stichprobe werden interessierende Größen beobachtet, die Merkmale oder Variablen
statistische Einheiten heißen auch Merkmalsträger
Merkmale besitzen Werte oder Ausprägungen

Grundbegriffe der Statistik
Beispiele:
Merkmal Ausprägungen Merkmalsträger
Wortlänge in Silben 1,2,3,... Wort
Satz grammatisch? ja, nein Satz
Lautdauer von
Phonemen 0 – ∞ sek. Phonem
Affixart Präfix, Suffix, ... Affix
Wortart Verb, Nomen,... Wort

Grundbegriffe der Statistik
interessierende Variable = Zielgröße
wird beeinflusst von
beobachtbaren Variablen: Einflussgrößen, Faktoren
nicht beobachtbaren Variablen: Störgrößen, latente Faktoren

Grundbegriffe der Statistik
Beispiel:
statistische Einheiten: Sätze Grundgesamtheit: Sätze der deutschen
Schriftsprache Stichprobe: NEGRA-Korpus Zielgröße: Anteil von Sätzen mit Verbzweitstellung Einflussgrößen: Textsorte, Autor Störgrößen: Annotierungsfehler

Univariate Deskription von Daten
univariate (= eindimensionale) Daten bestehen aus Beobachtungen eines einzelnen Merkmals
Stichprobe vom Umfang n: an n stat. Einheiten werden die Werte x1, x2, ..., xn eines Merkmals X beobachtet
Beispiel: Merkmal „Wortart“. An den ersten n = 20 Wörtern eines Korpus werden die folgenden Ausprägungen beobachtet (x1, ..., x20):
Konj, Pron, Det, N, V, Konj, Pron, Präp, Adj, N, Präp, N, Konj, N, V, Adv, V, Pron, Adv, Präp
Rohdaten, Urliste

Univariate Deskription von Daten
Urliste → Liste der vorkommenden Merkmalsausprägungen:
a1 Konj 3a2 Pron 3a3 Det 1a4 N 4a5 V 3a6 Präp 3a7 Adj 1a8 Adv 2

Univariate Deskription von Daten
Urliste → Liste der vorkommenden Merkmalsausprägungen:
a1 Konj 3a2 Pron 3a3 Det 1a4 N 4a5 V 3a6 Präp 3a7 Adj 1a8 Adv 2 ← absolute Häufigkeit von a8

Univariate Deskription von Daten
Anzahl Vorkommen einer Ausprägung aj in Urliste = absolute Häufigkeit von aj: h(aj) = hj, z.B. h(Konj) = 3.
Summe aller Häufigkeiten h(a1) + h(a2) + ... + h(ak) gleich Stichprobenumfang n.
relative Häufigkeit von aj = Anteil von aj-Werten in Urliste: f(aj) = hj / n.
z.B.: f(Konj) = h(Konj) / n = 3 / 20 = 0,15 = 15%.
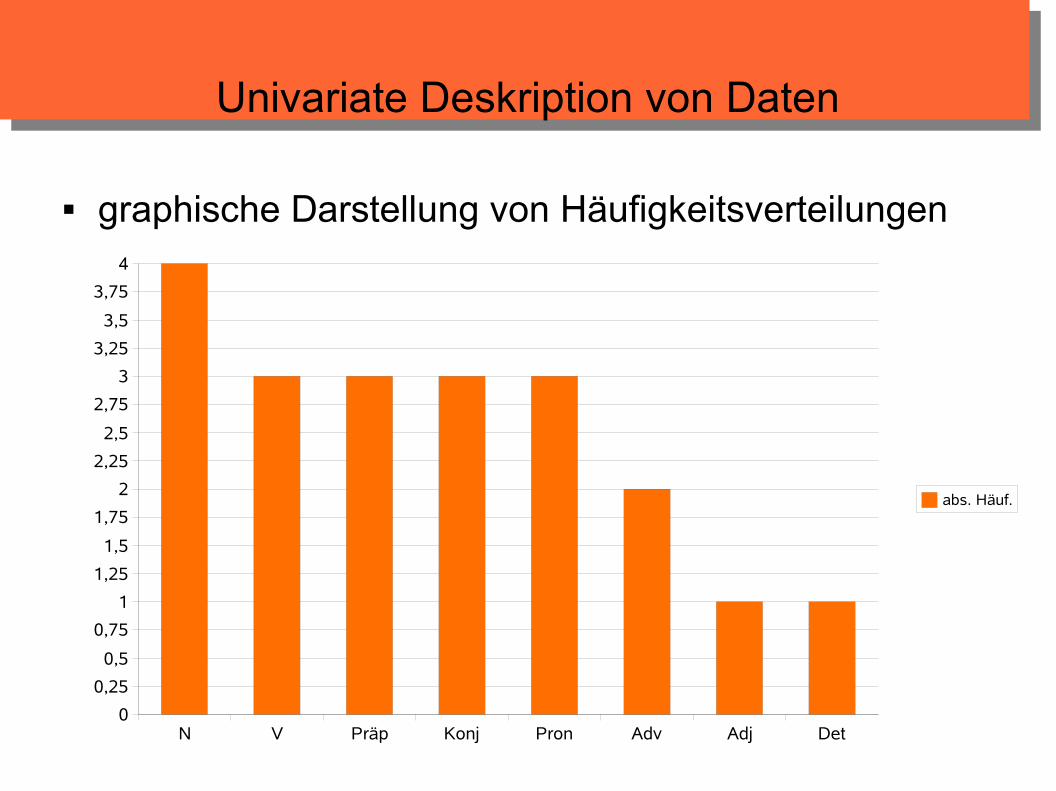
Univariate Deskription von Daten
graphische Darstellung von Häufigkeitsverteilungen
N V Präp Konj Pron Adv Adj Det0
0,25
0,5
0,75
1
1,25
1,5
1,75
2
2,25
2,5
2,75
3
3,25
3,5
3,75
4
abs. Häuf.

Univariate Deskription von Daten
Beschreibung von Verteilungen
Lagemaße und Kenngrößen erlauben den Vergleich von Häufigkeitsverteilungen
arithmetisches Mittel: xam = (x1+x2+...+xn) / n (in Excel/OpenOffice Funktion „MITTELW“)
Median xmed: Wert in Datenmitte
Modus xmod: häufigster Wert
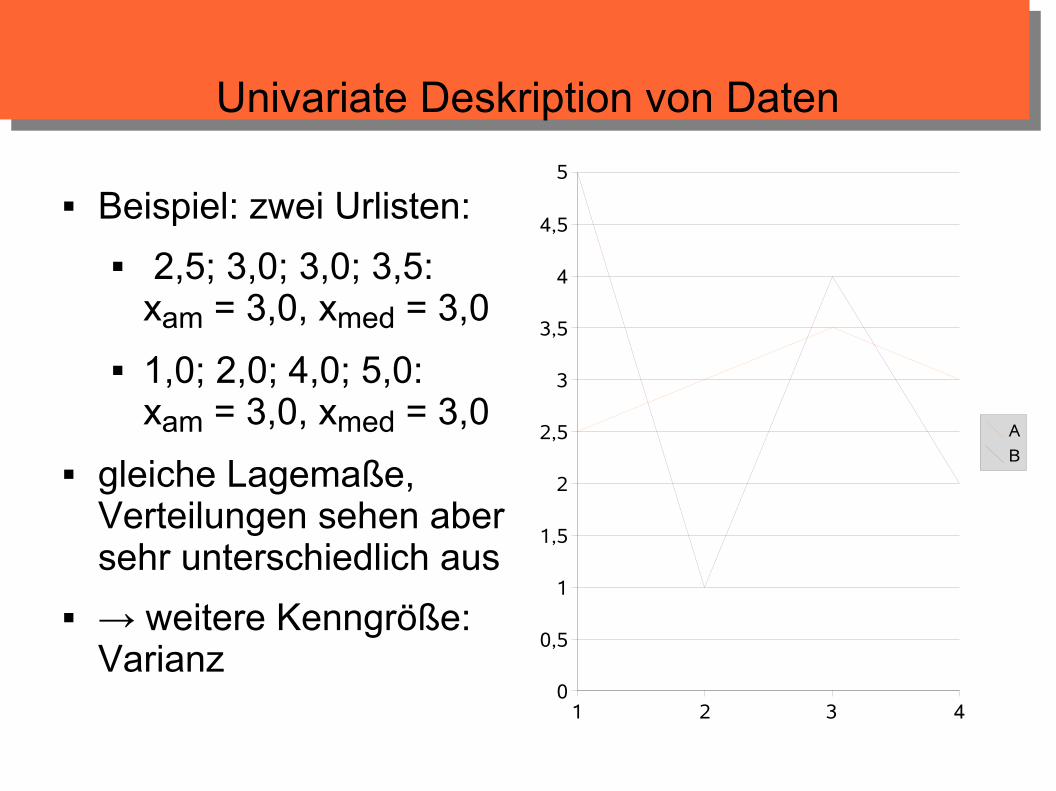
Univariate Deskription von Daten
Beispiel: zwei Urlisten:
2,5; 3,0; 3,0; 3,5: xam = 3,0, xmed = 3,0
1,0; 2,0; 4,0; 5,0: xam = 3,0, xmed = 3,0
gleiche Lagemaße, Verteilungen sehen aber sehr unterschiedlich aus
→ weitere Kenngröße: Varianz
1 2 3 40
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
A
B

Univariate Deskription von Daten
Varianz: Maß für Streuung einer Verteilung um ihren Mittelwert
s² = (x1 – xam)² + ... + (xn – xam) / n
Excel: Funktion VARIANZEN
Beispiel:
2,5; 3,0; 3,0; 3,5: xam = 3,0, xmed = 3,0, s² = 0,125
1,0; 2,0; 4,0; 5,0: xam = 3,0, xmed = 3,0, s² = 2,5
Standardabweichung = Wurzel aus Varianz
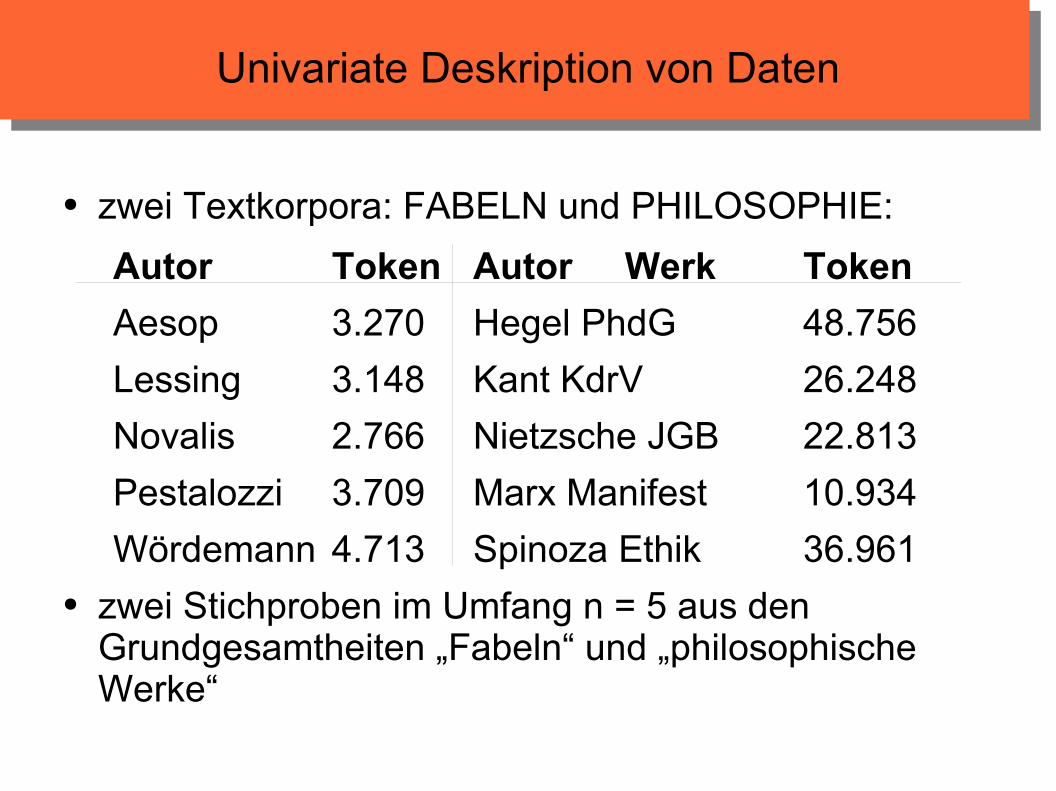
Univariate Deskription von Daten
● zwei Textkorpora: FABELN und PHILOSOPHIE:
Autor Token Autor Werk Token
Aesop 3.270 Hegel PhdG 48.756
Lessing 3.148 Kant KdrV 26.248
Novalis 2.766 Nietzsche JGB 22.813
Pestalozzi 3.709 Marx Manifest 10.934
Wördemann 4.713 Spinoza Ethik 36.961● zwei Stichproben im Umfang n = 5 aus den
Grundgesamtheiten „Fabeln“ und „philosophische Werke“
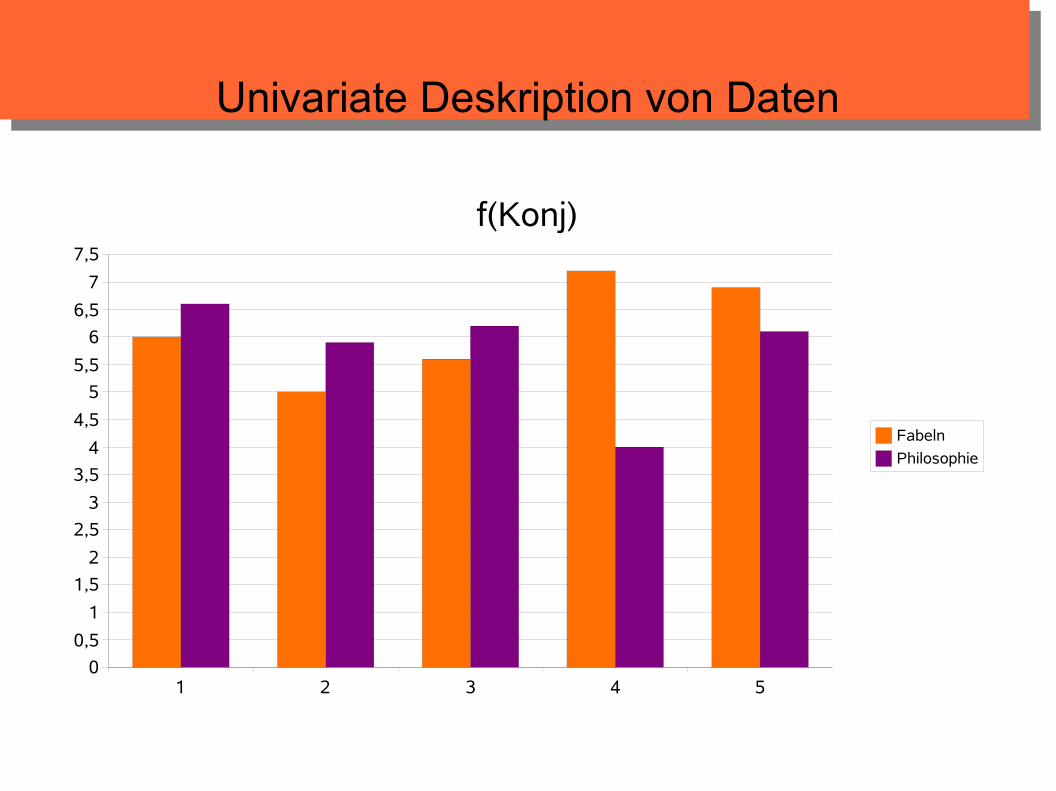
Univariate Deskription von Daten
1 2 3 4 50
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
5,5
6
6,5
7
7,5
f(Konj)
Fabeln
Philosophie
Univariate Deskription von Daten
1 2 3 4 50
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
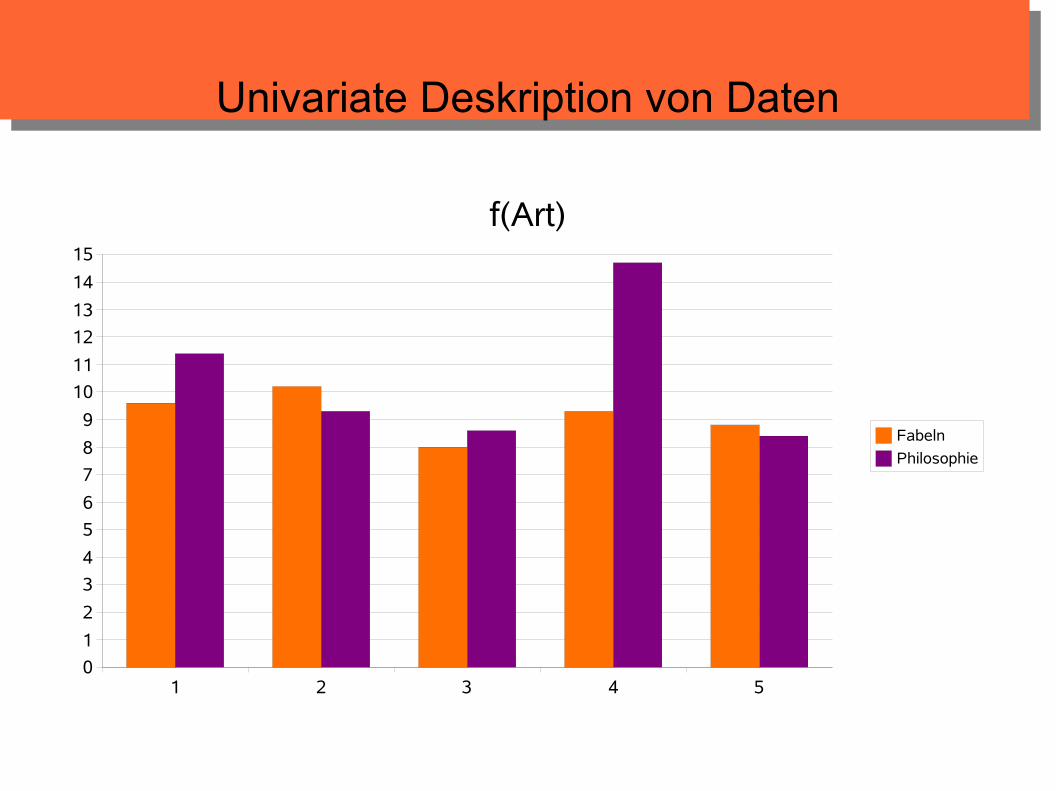
f(Art)
Fabeln
Philosophie
Univariate Deskription von Daten
1 2 3 4 50
2,5
5
7,5
10
12,5
15
17,5
20
22,5
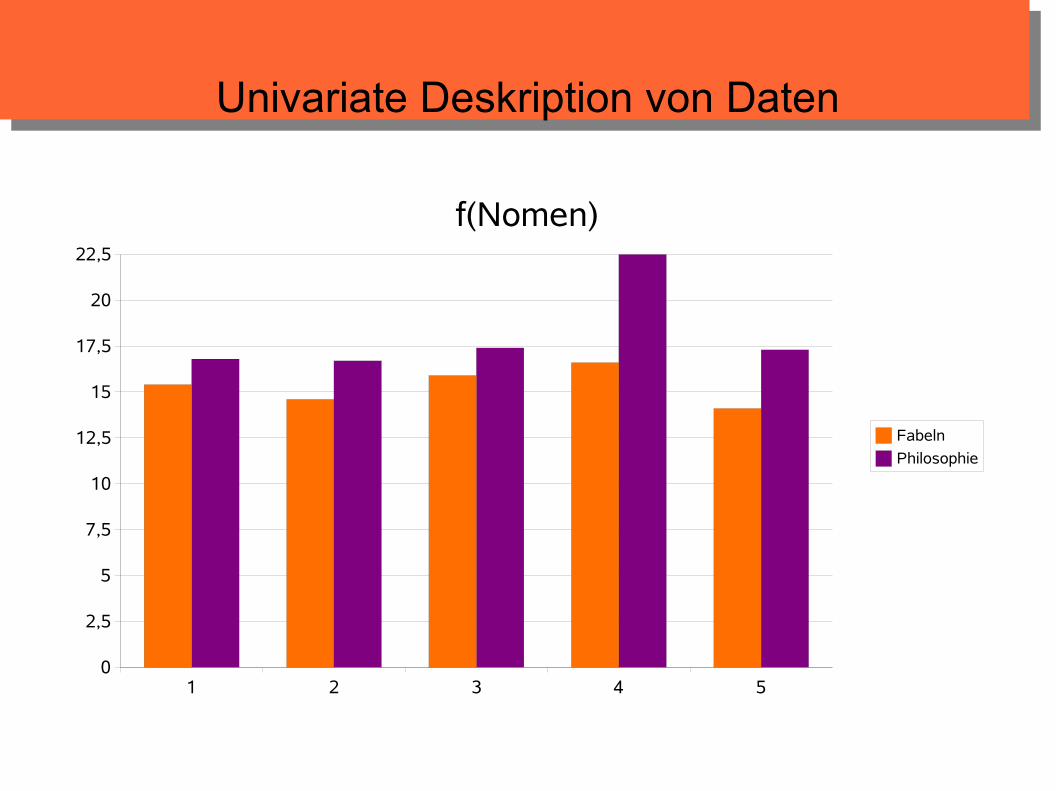
f(Nomen)
Fabeln
Philosophie
Univariate Deskription von Daten
1 2 3 4 50
1
2
3
4
5
6
7
8
9
10
11
12
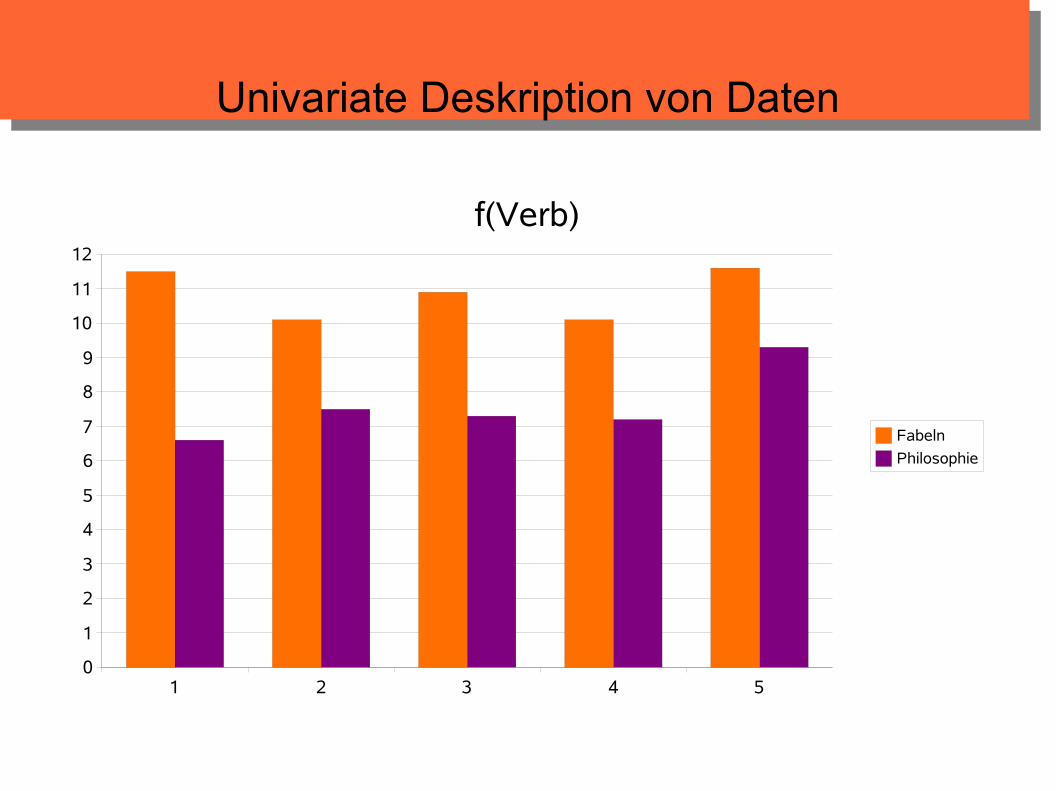
f(Verb)
Fabeln
Philosophie

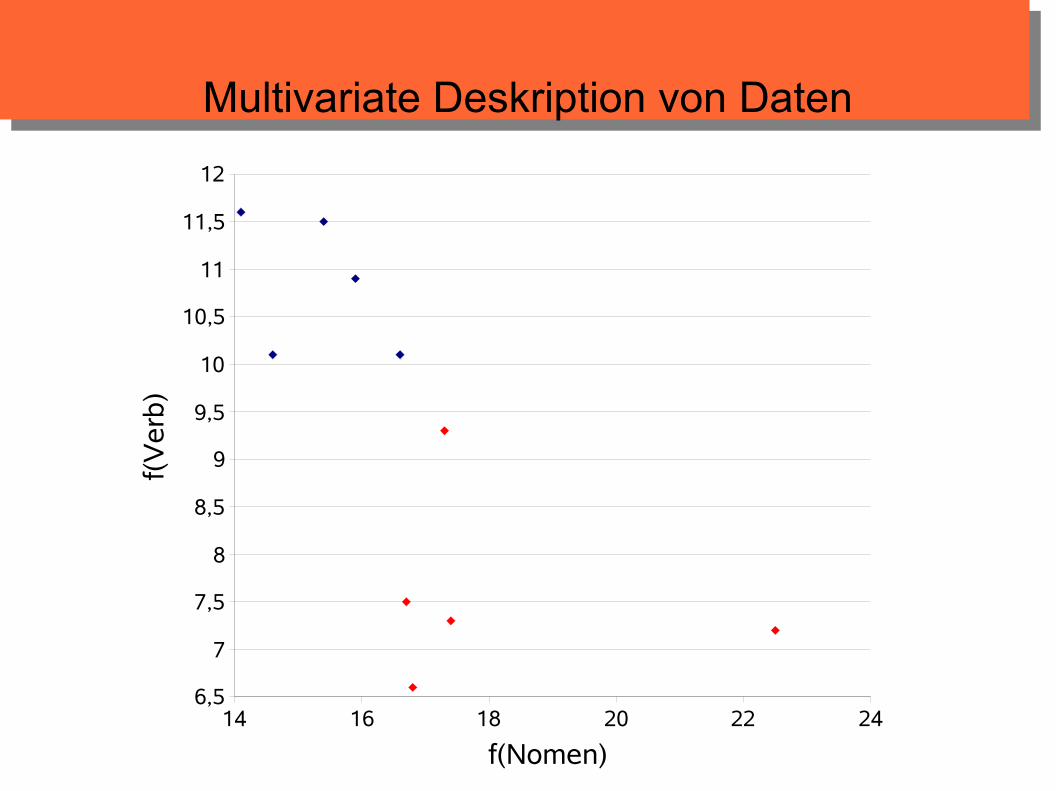
Multivariate Deskription von Daten
Vergleiche bisher eindimensional – jedes Merkmal einzeln betrachtet
multivariater Vergleich: mehrere Merkmale zugleich beobachten
Streudiagramm erlaubt gleichzeitigen Vergleich von zwei Merkmalen
ein Merkmal wird auf x-Achse aufgetragen, das andere auf der y-Achse
jedes Element der Stichprobe ein Punkt im Diagramm
Multivariate Deskription von Daten
14 16 18 20 22 246,5
7
7,5
8
8,5
9
9,5
10
10,5
11
11,5
12
f(Nomen)
f(V
erb
)

Multivariate Deskription von Daten
Bei geeigneter Wahl der Merkmale bilden sich im Streudiagramm distinkte Gruppen, sogenannte Cluster
dadurch kann festgestellt werden, welche Merkmale und Werte für Klassifizierungen nutzbar sind
Streudiagramm veranschaulicht auch Zusammenhang, den zwei Merkmale aufeinander ausüben
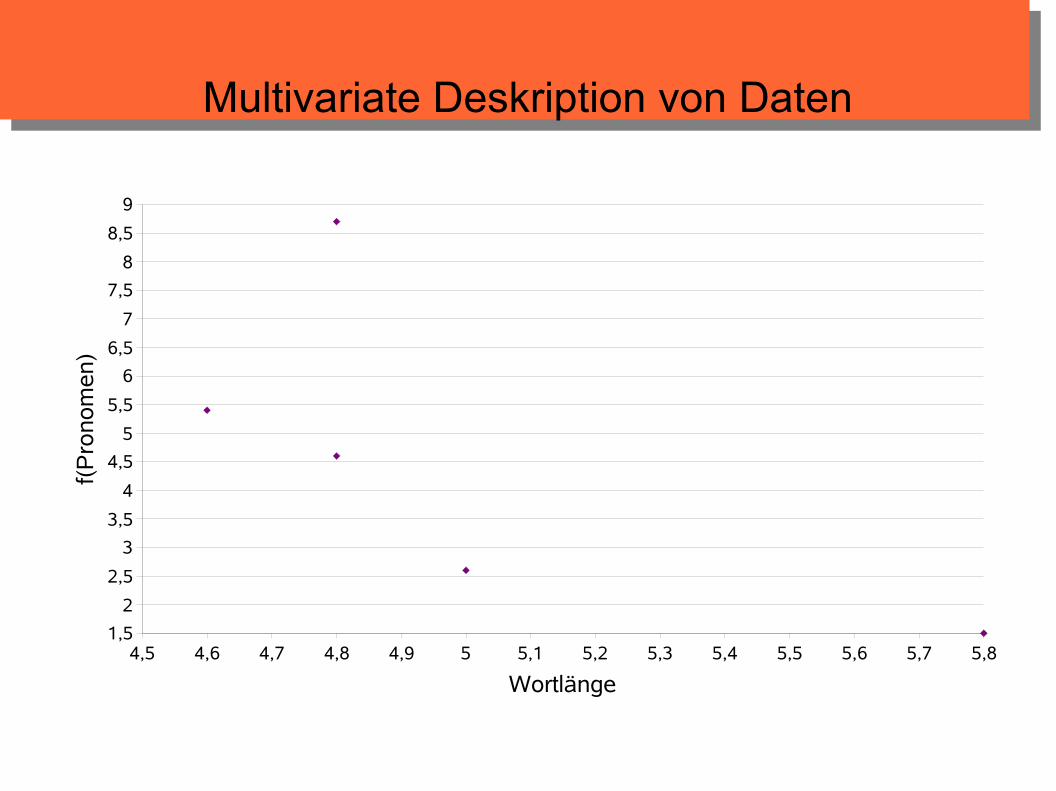
Multivariate Deskription von Daten
4,5 4,6 4,7 4,8 4,9 5 5,1 5,2 5,3 5,4 5,5 5,6 5,7 5,81,5
2
2,5
3
3,5
4
4,5
5
5,5
6
6,5
7
7,5
8
8,5
9
Wortlänge
f(P
rono
men
)
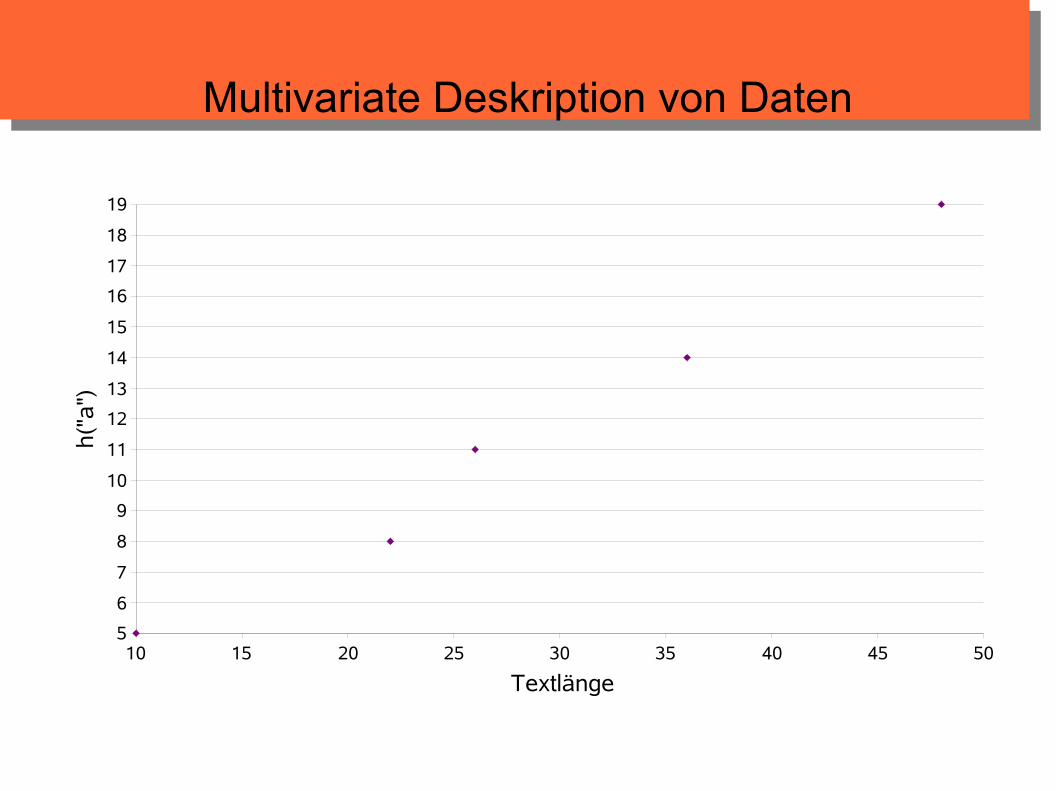
Multivariate Deskription von Daten
10 15 20 25 30 35 40 45 505
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Textlänge
h("a
")

Multivariate Deskription von Daten
Streudiagramm zeigt Korrelation der beiden Merkmale
wenn die Punkte im Diagramm nahe einer gedachten Geraden liegen, korrelieren die Merkmale
positive Korrelation: je größer die x-Werte, desto größer die zugehörigen y-Werte
negative Korrelation: je größer die x-Werte, desto kleiner die zugehörigen y-Werte
Korrelationsmaße geben Stärke des Zusammenhangs an: z.B. Korrelationskoeffizient nach Bravais-Pearson (Excel-Funktion PEARSON)

Multivariate Deskription von Daten
statistisch gefundene Korrelation zwischen zwei Merkmalen begründet keinen kausalen Zusammenhang!
Beispiel (aus [4]): hohe Korrelation für Merkmale „Orangenimport in Tonnen“ und „Anzahl Krebserkrankungen“, trotzdem besteht offensichtlich kein Zusammenhang (Scheinkorrelation)
verdeckte Korrelation: Merkmale korrelieren mit einer unberücksichtigten dritten Variable
Richtung der Beeinflussung

Wahrscheinlichkeitsrechnung
„Wahrscheinlich regnet es morgen“ → Sprecher weiß nicht, ob Ereignis eintritt oder nicht
Ziel der Wahrscheinlichkeitsrechnung: Grad der Unsicherheit auf quantitatives Maß zurückführen und damit rechnen
Z.B. Wurf eines Würfels: Zufallsvorgang mit mehreren, sich auschließenden Ergebnissen
Zufallsexperiment: mögliche Ausgänge bekannt: 1,2,3,4,5,6. Heißen Elementarereignisse. Ereignisraum R = {1,2,3,4,5,6}

Wahrscheinlichkeitsrechnung
Beispiel: Wurf zweier Münzen. Mögliche Ausgänge sind die vier Elementarereignisse Kopf&Kopf, Kopf&Zahl, Zahl&Kopf, Zahl&Zahl. Sie bilden den Ereignisraum R.
Ereignis = Teilmenge des Ereignisraums. Ereignis kann Elementarereignis oder Zusammenfassung mehrerer Elementarereignisse sein.
z.B. Würfel: Ereignis „Augenzahl ungerade“ besteht aus Elementarereignissen {1,3,5}.
ist Teilmenge für Ereignis = R: sichere Ereignis
ist Ereignismenge ∩ R = Ø: unmögliche Ereignis

Wahrscheinlichkeitsrechnung
Ereignisraum R bestehe aus N gleichmöglichen Elementarereignissen
Teilmenge von R, die Ereignis A entspricht, bestehe aus NA Elementarereignissen
Wahrscheinlichkeit für Eintreten des Ereignisses A: p = NA / N.
z.B. Wahrscheinlichkeit ungerade Zahl zu würfeln: p = NA / N = |{1,3,5}| / |{1,2,3,4,5,6}| = 3 / 6 = 0,5.

Wahrscheinlichkeitsrechnung
Wahrscheinlichkeiten immer größer oder gleich Null
unmögliches Ereignis hat Wahrscheinlichkeit Null
sicheres Ereignis hat Wahrscheinlichkeit 1
Additionssatz: wenn A ∩ B = Ø dann P(A U B) = P(A) + P(B)
z.B. R = {Kopf, Zahl}, A = {Kopf}, B = {Zahl}, „entweder Kopf oder Zahl“: P(A U B) = 0,5 + 0,5 = 1.
wenn A ∩ B ≠ Ø dann P(A U B) = P(A) + P(B) – P(A ∩ B)
z.B. Würfel: A = {1,3,5}, B = {1,6}: P(A U B) = 3/6 + 2/6 – 1/6 = 4/6

Wahrscheinlichkeitsrechnung
Wahrscheinlichkeit von Verbundereignissen
gleichzeitiges Auftreten zweier Ereignisse A und B
Multiplikationssatz: P(A ∩ B) = P(A) · P(B)
gilt für statistisch unabhängige Ereignisse
Urnenmodell: Ziehen mit Zurücklegen

Wahrscheinlichkeitsrechnung
Ziehen ohne Zurücklegen
Ausgang des ersten Zugs beeinflusst Wahrscheinlichkeit im zweiten Zug
Multiplikationssatz: P(A ∩ B) = P(A) · P(B|A)
gilt für statistisch abhängige Ereignisse
bedingte Wahrscheinlichkeit: P(B|A): Wahrscheinlichkeit von B, wenn A bereits eingetreten ist (a posteriori-Wahrscheinlichkeit von B)

Literatur
[1] Chris Manning und Hinrich Schütze: Foundations of Statistical Natural Language Processing. MIT Press, 1999.
[2] Michael P. Oakes: Statistics for Corpus Linguists. Edinburgh University Press, 1998.
[3] Gabriel Altmann: Statistik für Linguisten. Wissenschaftlicher Verlag Trier, 1995.
[4] Hans Kellerer: Statistik im modernen Wirtschafts- und Sozialleben. Rowohlt, 1960.
[5] Walter Krämer: So lügt man mit Statistik. Piper, 2000.





























