Embed Size (px)
Citation preview

Testen vonHypothesen

Fällen von Entscheidungen
Statistische Auswertung von Daten bisher (Parameterschätzung, Konfidenzregionen):
➢ Bestimmung von Parametern und deren Fehler bei einer gegebenen Wahrscheinlichkeitsverteilung
Häufig soll aus Daten eine weitere Information gewonnen werden:
➢ Fällen einer Entscheidung, z.B.:
● Ist das nachgewiesene Teilchen ein Pion oder ein Kaon?● Ist die gemessene Zerfallszeitverteilung einer radioaktiven
Substanz eine Exponentialverteilung?● Existiert das Higgs-Boson oder nicht?
➔ Formulierung in Form von Hypothesen Hi
(Wahrscheinlichkeitsdichten für die Daten: f(x|Hi ))

Hypothesen
Arten von Hypothesen:
● Einfach = unabhängig von Parametern
● Zusammengesetzt = parameterabhängig: f(x|H,a)
Bezeichnung von Hypothesen:
● Zu testende Hypothese: Null-Hypothese H0
● Alle anderen Hypothesen: Alternativhypothese(n): H1, H
2, …
Reduktion der Dimensionalität durch Teststatistik
x → t, f(x|H) → g(t|H)
➔ Definition von Entscheidungskriterien anhand der Teststatistik

Wahl zwischen zwei Hypothesen
Konfidenzlevel von H0 für t > t
c : Signifikanz
➔ Verwerfen der richtigen Hypothese: Fehler erster Art
Konfidenzlevel von H1 für t < t
c : , Mächtigkeit (power) 1 –
➔ Akzeptieren der falschen Hypothese: Fehler zweiter Art
➢ Geeignete Wahl der Teststatistik für möglichst signifikanten und mächtigen Test → Klassifizierung

Klassifizierungsmethoden
Fisher-Diskriminante
● Lineare Transformation, t = const definiert Hyperebenen
➔ Optimal bei Gaußverteilungen
Neuronale Netze
➔ Optimal bei hinreichender Anzahl Knoten
Likelihood-Ratio
● r = f(x|H0) / f(x|H
1) > r
c
➢ Neyman-Pearson-Lemma
➔ Optimal (für einfache Hypothesen)

Test einer Hypothese
➢ Sind Daten statistisch verträglich mit Hypothese H0 ?
Statistische Methoden können eine Hypothese nicht (direkt) beweisen, sondern höchstens widerlegen!
➔ Beweis über Ausschluss von Alternativhypothesen
● Wahl der gewünschten Signifikanz
● Bestimmung einer Konfidenzregion (nicht eindeutig, z.B. ein-/zweiseitig)
➢ Verwerfen der Hypothese, falls Daten außerhalb der Konfidenzregion
Oft statt vorheriger Wahl von → Angabe von p-Wert
➔ Wahrscheinlichkeit statistische Fluktuation wie in den beobachteten Daten oder „größer“ zu erhalten unter Annahme von H
0 (→ „beobachtete Signifikanz“)
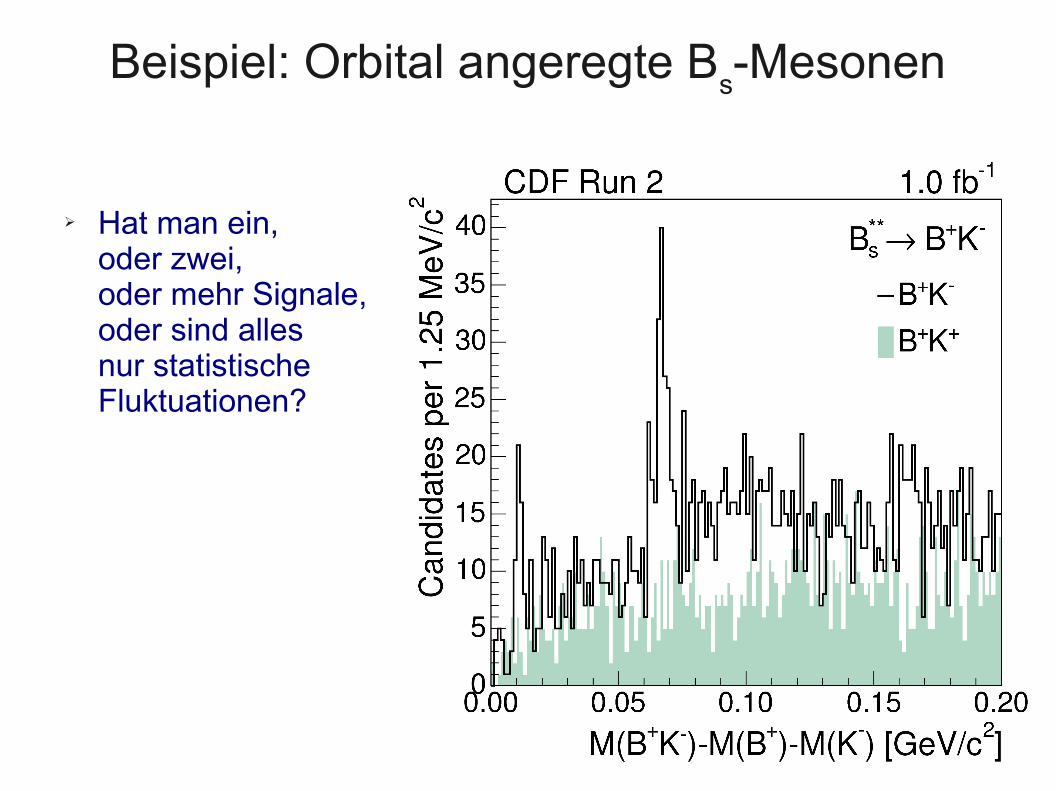
Beispiel: Orbital angeregte Bs-Mesonen
➢ Hat man ein, oder zwei, oder mehr Signale, oder sind alles nur statistische Fluktuationen?

Gefahr von Verzerrungen
Beispiel:
● 20 Physiker führen (unabhängig voneinander) jeweils eine Messung durch
● Einer sieht eine Abweichung von der Erwartung um 2(Ausschluss der Null-Hypothese mit 5% Signifikanz)
● Der eine publiziert sein Ergebnis, die anderen nicht
➔ Bias der veröffentlichten Ergebnisse!
Publikation sollte nicht vom Ausgang des Tests abhängen
➢ Auch „negative“ Resultate publizieren
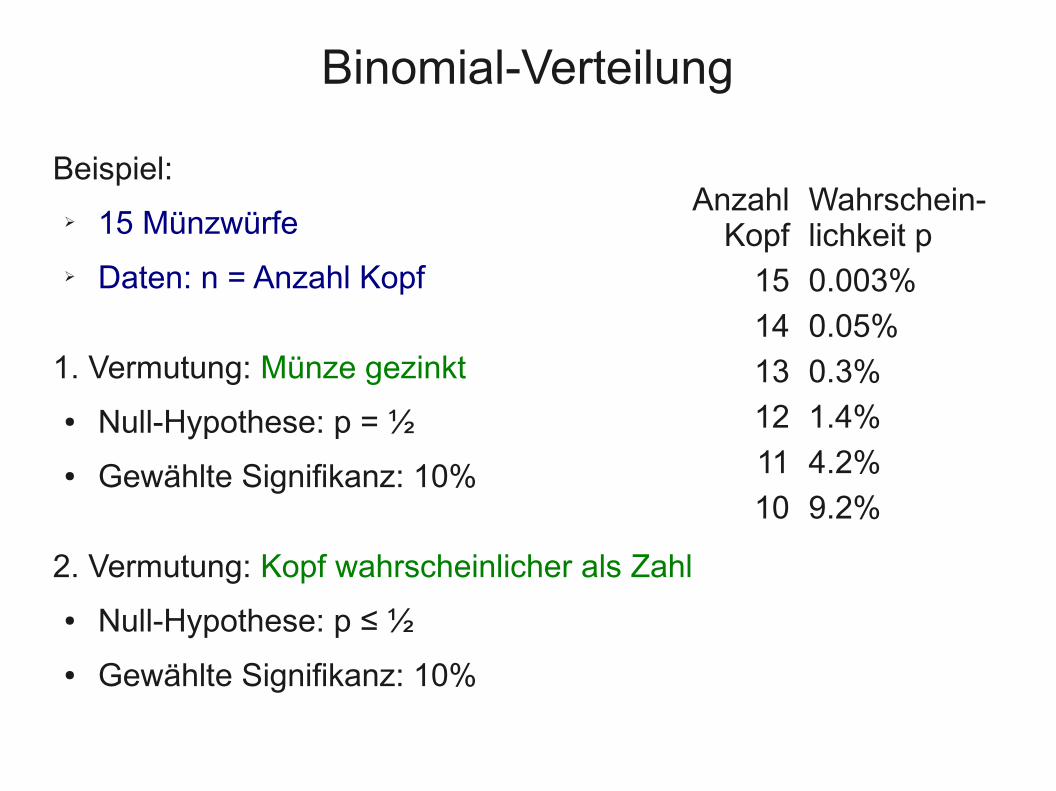
Binomial-Verteilung
AnzahlKopf
Wahrschein-lichkeit p
15 0.003%
14 0.05%
13 0.3%
12 1.4%
11 4.2%
10 9.2%
Beispiel:
➢ 15 Münzwürfe
➢ Daten: n = Anzahl Kopf
1. Vermutung: Münze gezinkt
● Null-Hypothese: p = ½
● Gewählte Signifikanz: 10%
2. Vermutung: Kopf wahrscheinlicher als Zahl
● Null-Hypothese: p ≤ ½
● Gewählte Signifikanz: 10%

Poisson-Verteilung
Häufige Frage: Signifikanz eines Signals
Beispiel:
● Daten: n = 5, Untergrund-Erwartung b = 0.5
➔ p(n >= 5 | b = 0.5) = 1.7 x 10- 4
➢ Problem: Unsicherheit der Untergrund-Erwartungz.B. für
b = 0.8: p = 1.4 x 10- 3
➔ Angabe eines Bereichs von p-Werten
Falls n groß → Gauß'sche Näherung
f(n|H0) = Gauß( =
b , = √(
b +
b2 ))
● Für b = 0: Signifikanzniveau S / √B, S = n -
b, B =
b

Signale in Verteilungen
Beispiel:
➔ Poisson-Verteilung: p = 5.0 x 10-4
➢ Nur richtig, falls schon vor der Messung dort ein Signal vermutet wird und die Bins ausgewählt wurden
Signifikanz der Abweichung geringer, falls Sie irgendwo in der Verteilung auftreten kann Man mehrere Verteilungen anschaut Die Selektionskriterien (bewusst oder unbewusst) gewählt
wurden, so dass ein Peak entsteht➔ Bilde Analyse:
Wahl der Selektionskriterien, bevor man die Daten anschaut
Mehr Ereignisse in beiden mittleren Bins als erwartet:n = 11,
b = 3.2

Pearson's 2-Test
t = ∑i = 1..N
(yi – f(x
i ))2 /
i2
folgt 2-Verteilung für N Freiheitsgrade (ndf), falls yi Gauß-verteilt
● Ndf = N – m, falls m Parameter aus den Daten bestimmt
➢ Histogramm-Binning: N klein → Empfindlichkeit, Gauß-sche NäherungN groß → Auflösung von Strukturen
Beispiel von voriger Seite mit i = √y
i :
2 = 29.8, ndf = 20 → p = 7.3%Toys: p = 11%

Run-Test
Beispiel: 2 = 12 für 12 Bins → 2-Test ok
✗ Aber Daten offensichtlich nicht linear
Struktur der Abweichungen:
AAABBBBBBAAA für A = above, B = below
➔ Nur 3 Runs
Mögliche Anzahl Anordnungen für NA A- und N
B B-Werte:
C(NA, N
B) = N! / (N
A! N
B!), N = N
A + N
B
Wahrscheinlichkeit für r Runs: r gerade: p(r) = 2 C(N
A – 1, r/2 – 1) C(N
B – 1, r/2 – 1) / C(N, N
A)
r ungerade: p(r) = [C(NA – 1, (r-3)/2) C(N
B – 1, (r-1)/2) + C(N
A – 1, (r-1)/2) C(N
B – 1, (r-3)/2)] / C(N, N
A)
➔ E[r] = 1 + 2NAN
B / N, E[V(r)] = 2N
AN
B(2N
AN
B – N) / [N2(N-1)]
Beispiel: E[r] = 7, (r) = 1.65 → r = 2.4, p(einseitig) = 1%

Kolmogorov-Smirnov-Test
● Daten der Größe nach sortieren
● Kumulierte Verteilung, normiert mit 1/N, auftragen
Y(x) = (Anzahl Werte < x) / N
● Vergleich mit kumulierter Wahrscheinlichkeitsverteilung
F(x) = ∫–∞
x f(x') dx'
➔ Testgröße definiert durch maximale Abweichung:
t = √N max|Y(x) – F(X)|
Z.B. p = 1% für t = 1.63, p = 10% für t = 1.22
● Gilt nur, wenn f(x) nicht an die Daten angepasst wurde(kein Analogon zu ndf beim 2-Test)

Vergleich von Mittelwerten und Varianzen
Test auf gleichen Mittelwerten zweier Datensätze bei unbekannter Varianz
● Schätzung der Varianz aus den Daten: s2 = 1/[N(N-1)] ∑i = 1..N
(xi - )2
● Testgröße: t = (1 –
2) / √(s
12 + s
22)
➔ folgt Studentscher t-Verteilung
Test auf gleiche Varianz zweier Datensätze
● Testgröße: F = V1 / V
2
➔ Folgt F-Verteilung
Für große Anzahlen ist Z = ½ log F Gauß-verteilt mit Mittelwert ½ (1/f
2 – 1/f
1) und Varianz ½ (1/f
2 + 1/f
1)
für f1 = N
1 – 1 und f
2 = N
2 – 1
^
^ ^
^ ^

Likelihood-Ratio als Testgröße
Häufiger Fall:
Test auf bestimmte Werte von Parametern eines allgemeinen Modells
➔ Testgröße: T = f(x|a1(H
0), ..., a
m(H
0), â
m+1, ...â
n) / f(x|â')
Satz von Wilks:
➢ Wird eine Grundgesamtheit durch eine Wahrscheinlichkeits-dichte f(x|a) beschrieben (die vernünftigen Anforderungen an ihre Stetigkeit genügt), und werden m der n Parameter festgelegt, so folgt
-2 ln T
einer 2-Verteilung mit m Freiheitsgraden für (sehr) große N
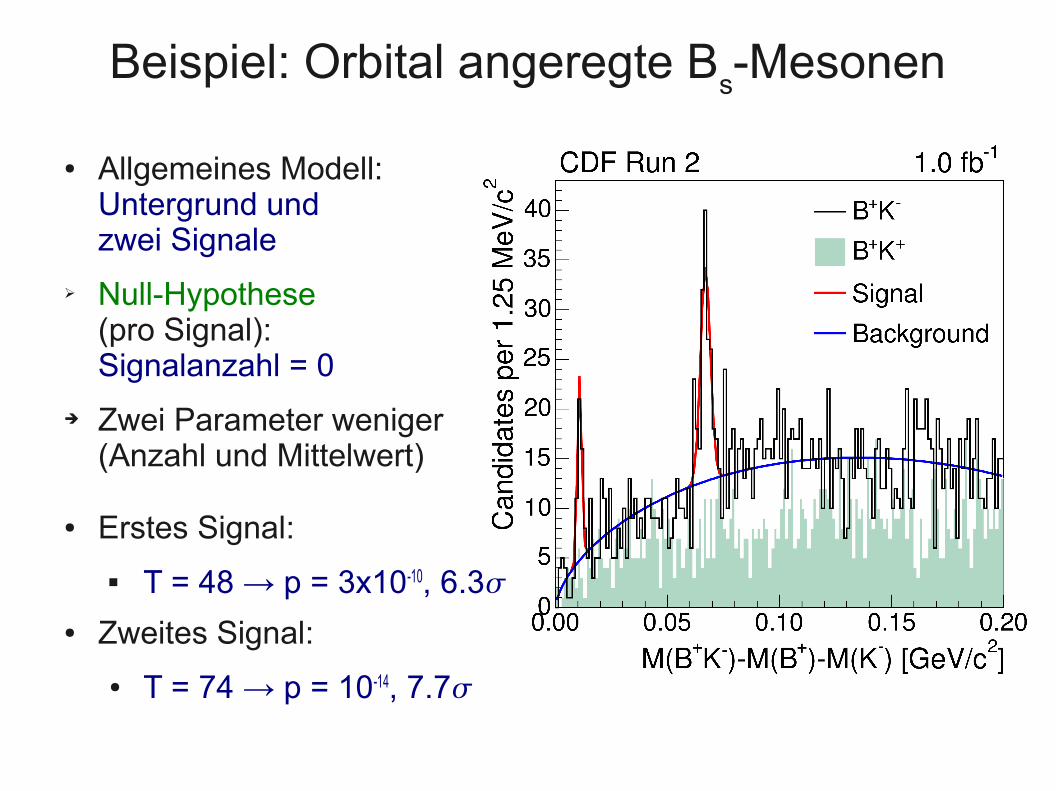
Beispiel: Orbital angeregte Bs-Mesonen
● Allgemeines Modell:Untergrund undzwei Signale
➢ Null-Hypothese (pro Signal): Signalanzahl = 0
➔ Zwei Parameter weniger (Anzahl und Mittelwert)
● Erstes Signal:
T = 48 → p = 3x10-10, 6.3● Zweites Signal:
● T = 74 → p = 10-14, 7.7
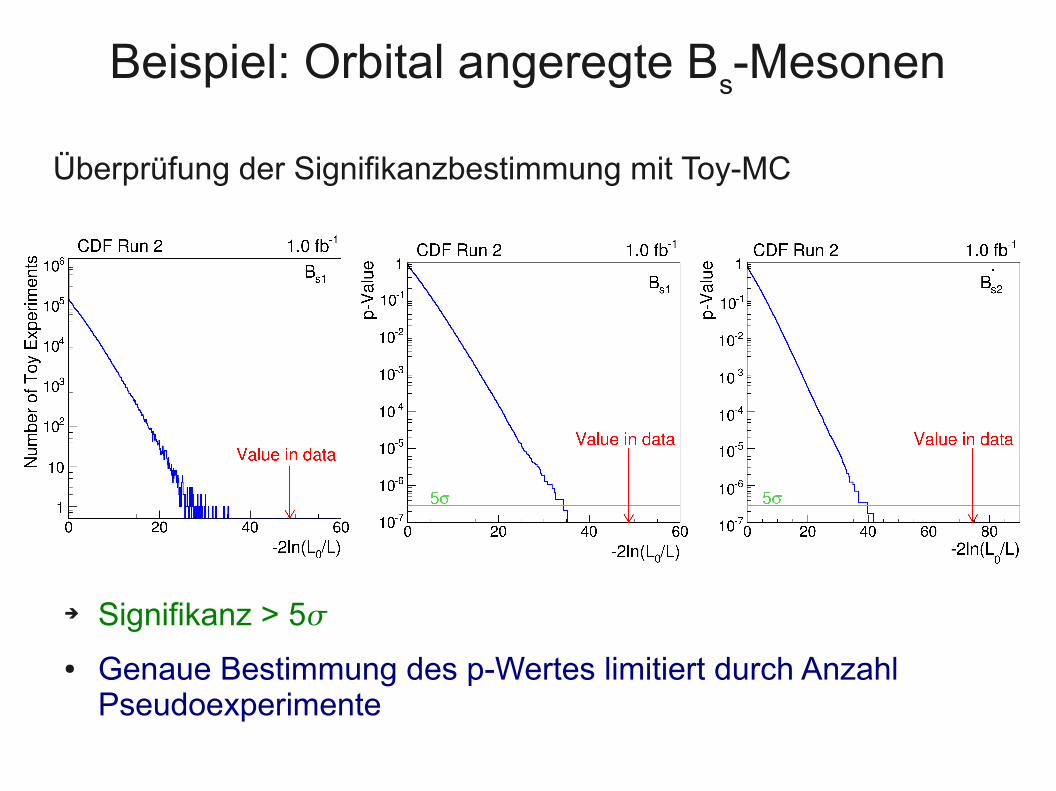
Beispiel: Orbital angeregte Bs-Mesonen
Überprüfung der Signifikanzbestimmung mit Toy-MC
➔ Signifikanz > 5
● Genaue Bestimmung des p-Wertes limitiert durch Anzahl Pseudoexperimente
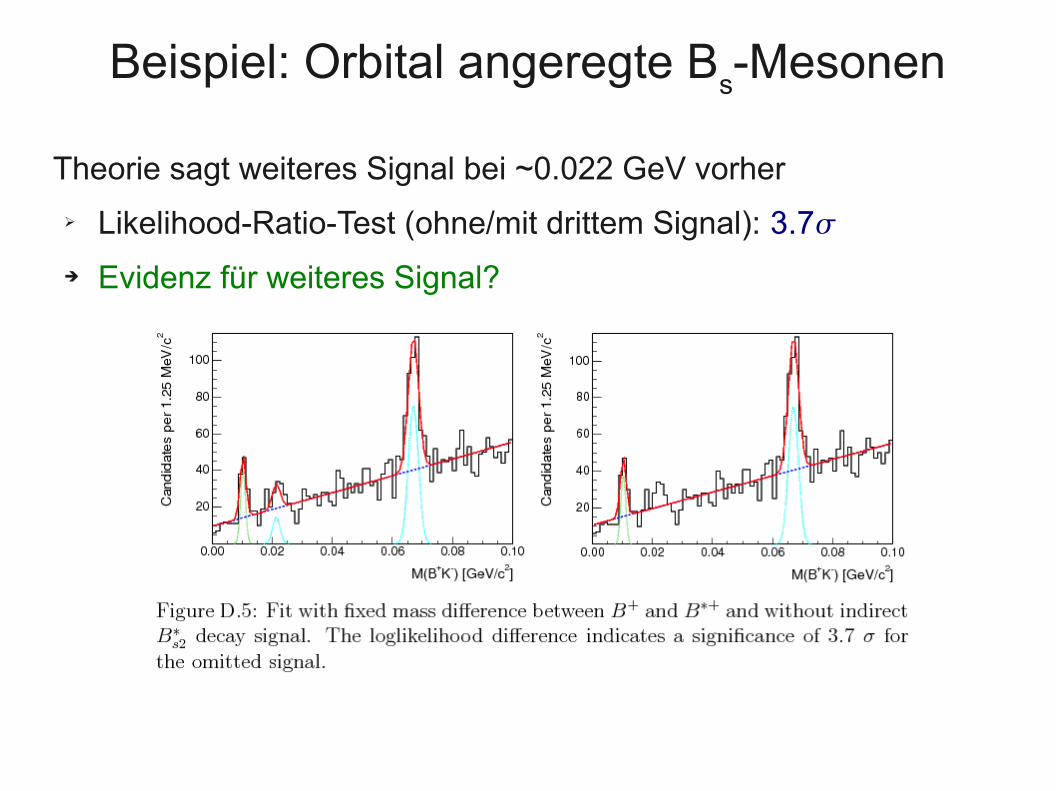
Beispiel: Orbital angeregte Bs-Mesonen
Theorie sagt weiteres Signal bei ~0.022 GeV vorher
➢ Likelihood-Ratio-Test (ohne/mit drittem Signal): 3.7
➔ Evidenz für weiteres Signal?
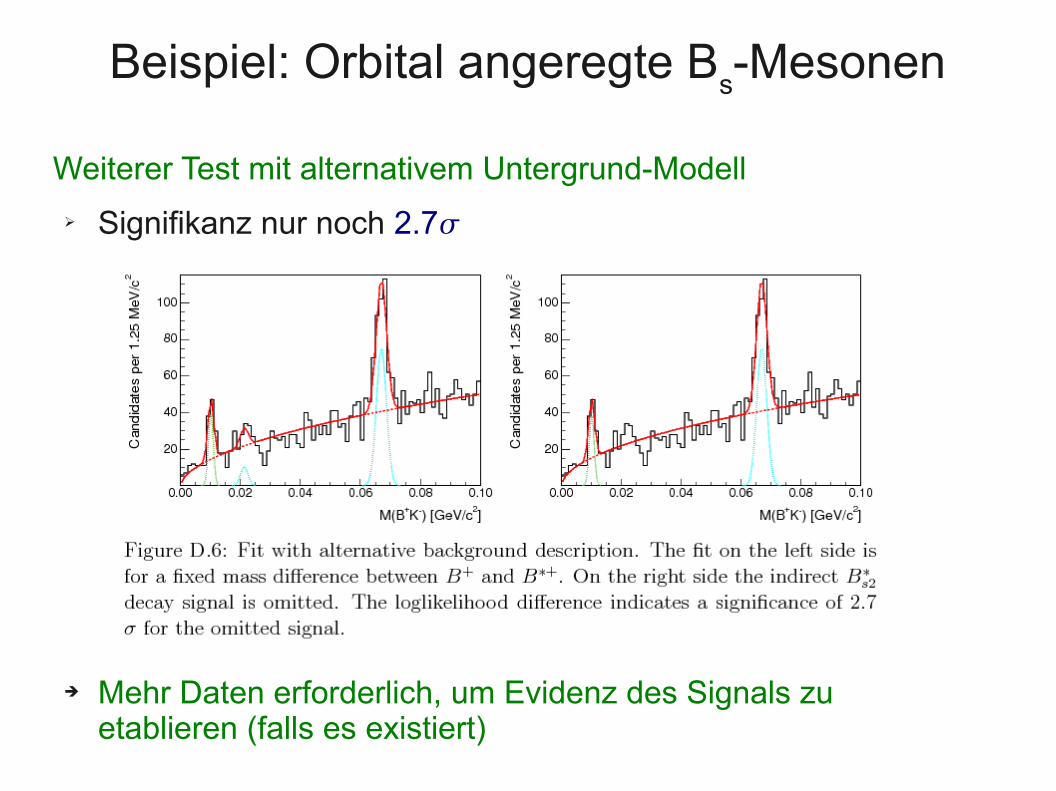
Beispiel: Orbital angeregte Bs-Mesonen
Weiterer Test mit alternativem Untergrund-Modell
➢ Signifikanz nur noch 2.7
➔ Mehr Daten erforderlich, um Evidenz des Signals zu etablieren (falls es existiert)
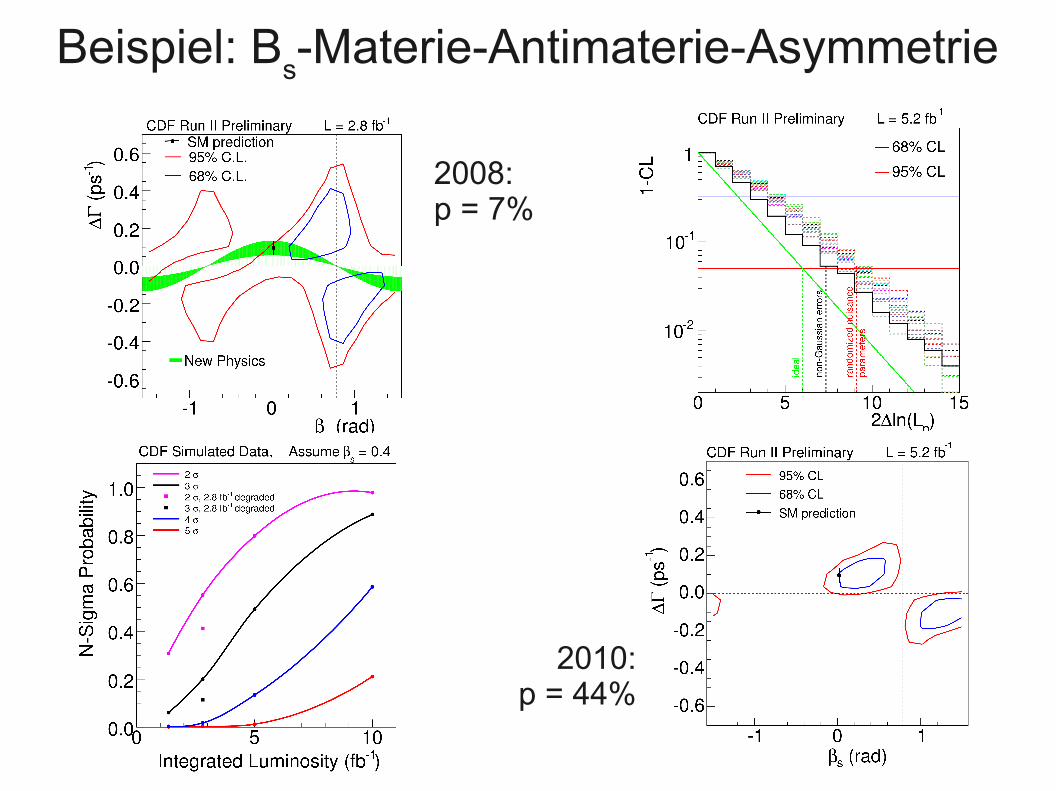
Beispiel: Bs-Materie-Antimaterie-Asymmetrie
2008:p = 7%
2010:p = 44%

Empfehlungen
➢ Legen Sie den Test und die gewünschte Signifikanz fest,bevor Sie die Messung durchführen
➢ Vermeiden Sie Verzerrungen → Blinde Analyse
➢ Prüfen Sie die Robustheit des Resultats(Binning, Selektion, Fit-Modell)
➢ Überprüfen Sie die Signifikanzbestimmung, falls angebracht, durch Pseudoexperimente
➢ Visualisieren Sie die Daten und achten Sie auf Abweichungen, die nicht vom Test erfasst werden
➢ Publizieren Sie Ihr Resultat, auch wenn kein signifikanter Effekt beobachtet wird





























