Embed Size (px)
Citation preview

SkriptGRUNDLAGEN DER AUTOMATISCHENSPRACHERKENNUNG
Prof. Dr.-Ing. Dorothea KolossaInstitut für KommunikationsakustikRuhr-Universität [email protected]
Version:27. Mai 2018


Inhaltsverzeichnis
1. Einführung 11.1. Warum ist Spracherkennung schwierig? . . . . . . . . . . . . . . . . . . . . 21.2. Organisation der Lehrveranstaltung . . . . . . . . . . . . . . . . . . . . . . 7
1.2.1. Vorlesung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.2. Übung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.3. Literaturhinweise . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3. Spracherzeugung und Klassifikation . . . . . . . . . . . . . . . . . . . . . . 101.3.1. Phonetik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.3.2. Klassifikation von Lauten . . . . . . . . . . . . . . . . . . . . . . . 111.3.3. Phonologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2. Menschliche Sprachwahrnehmung 142.1. Aufbau des Gehörapparates . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2. Lautheitswahrnehmung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.3. Frequenzwahrnehmung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.1. Skala der westlichen Musik . . . . . . . . . . . . . . . . . . . . . . 192.3.2. Mel-Skala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.3. Bark-Skala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.4. Gerade wahrnehmbare Frequenzunterschiede . . . . . . . . . . . . . 212.3.5. Vergleich der Skalen . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.4. Gehörorientierte Frequenzbandanalyse . . . . . . . . . . . . . . . . . . . . 22
3. Wahrscheinlichkeitsrechnung 233.1. Diskrete Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.2. Kontinuierliche Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . 263.3. Eigenschaften von Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . 293.4. Vektorwertige Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . 313.5. Konvergenzbegriffe bei Zufallsvariablen . . . . . . . . . . . . . . . . . . . . 33
3.5.1. Konvergenz „in Distribution“ . . . . . . . . . . . . . . . . . . . . . 343.5.2. Konvergenz „in Wahrscheinlichkeit“ . . . . . . . . . . . . . . . . . 343.5.3. Konvergenz „with Probability 1“ . . . . . . . . . . . . . . . . . . . 353.5.4. Konvergenz im r-ten Mittel . . . . . . . . . . . . . . . . . . . . . . 35
4. Klassifikation 364.1. Satz von Bayes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.2. Entwurf von Klassifikatoren . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2.1. Vorüberlegungen zum Entwurf eines Klassifikators . . . . . . . . . . 39
I

Inhaltsverzeichnis
4.2.2. Der Maximum-Likelihood-Klassifikator . . . . . . . . . . . . . . . 414.2.3. Bayes’sche Klassifikation . . . . . . . . . . . . . . . . . . . . . . . 424.2.4. Entwurf optimaler Klassifikatoren . . . . . . . . . . . . . . . . . . . 42
4.3. Einsatz von Klassifikatoren zur Einzelworterkennung . . . . . . . . . . . . . 454.3.1. Wortschatzdefinition . . . . . . . . . . . . . . . . . . . . . . . . . . 454.3.2. Struktur eines einfachen Einzelworterkenners . . . . . . . . . . . . . 46
5. Schätztheorie 475.1. Wiederholung zur Klassifikation . . . . . . . . . . . . . . . . . . . . . . . . 475.2. Schätztheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.1. Aufgabe der Schätzverfahren . . . . . . . . . . . . . . . . . . . . . 475.2.2. Gütekriterien für Schätzverfahren . . . . . . . . . . . . . . . . . . . 495.2.3. Cramer-Rao Lower Bound (CRLB) . . . . . . . . . . . . . . . . . . 505.2.4. Bayes-Schätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.3. Nichtparametrische Schätzung . . . . . . . . . . . . . . . . . . . . . . . . . 58
6. Neuronale Klassifikatoren 616.1. Analogien und Unterschiede zur parametrischen, bayes’schen Klassifikation 61
6.1.1. Was zuvor geschah . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.1.2. Verwendung neuronaler Netze . . . . . . . . . . . . . . . . . . . . . 62
6.2. Struktur neuronaler Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . 636.3. Anpassung der Parameter neuronaler Netze . . . . . . . . . . . . . . . . . . 666.4. Anwendung zur Spracherkennung . . . . . . . . . . . . . . . . . . . . . . . 69
7. Feature Extraction 717.1. Gesamtstruktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
7.1.1. Abtastung und Quantisierung . . . . . . . . . . . . . . . . . . . . . 717.1.2. Voice Activity Detection . . . . . . . . . . . . . . . . . . . . . . . . 747.1.3. Preemphasefilter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
7.2. Parameterberechnung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 757.3. Zeitbereichsfeatures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
7.3.1. Framing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 767.3.2. Energie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 777.3.3. Grundfrequenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
7.4. Frequenzbereichsfeatures . . . . . . . . . . . . . . . . . . . . . . . . . . . 807.4.1. Herleitung der Diskreten Fouriertransformation . . . . . . . . . . . 807.4.2. Einfluss der Fensterfunkion . . . . . . . . . . . . . . . . . . . . . . 827.4.3. Wahrnehmungsangepasste Analyse . . . . . . . . . . . . . . . . . . 86
7.5. Cepstrale Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 917.5.1. Das Cepstrum als Raum der Verzögerungszeiten . . . . . . . . . . . 927.5.2. Verzögerungszeiten in Sprachsignalen . . . . . . . . . . . . . . . . 93
7.6. Anwendungen des Cepstrums . . . . . . . . . . . . . . . . . . . . . . . . . 947.6.1. Grundfrequenzbestimmung . . . . . . . . . . . . . . . . . . . . . . 947.6.2. Kompensation der Raumübertragungsfunktion . . . . . . . . . . . . 94
II

Inhaltsverzeichnis
7.6.3. Trennung von Quelle und Vokaltrakt . . . . . . . . . . . . . . . . . 97
8. Klassifikation von Zeitreihen 998.1. Überblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 998.2. NEUE Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1008.3. Markov-Ketten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
8.3.1. Berechnung der Wahrscheinlichkeit von Zustandssequenzen . . . . . 1028.3.2. Berechnung der durchschnittlichen Aufenthaltsdauer in einem Zustand 103
8.4. Hidden Markov Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1038.5. Hidden Markov Modelle für die Spracherkennung . . . . . . . . . . . . . . 105
8.5.1. Ausgangsverteilungsdichten für die Spracherkennung . . . . . . . . 1058.5.2. Hidden Markov Modell-Strukturen zur Spracherkennung . . . . . . 1068.5.3. Drei wichtige Probleme . . . . . . . . . . . . . . . . . . . . . . . . 1078.5.4. Lösung für die Probleme 1 und 2 . . . . . . . . . . . . . . . . . . . 111
8.6. Training von Hidden Markov Modelle für die Spracherkennung . . . . . . . 1218.6.1. Lösung für das Problem 3 . . . . . . . . . . . . . . . . . . . . . . . 1218.6.2. Verbesserung der Parameterschätzung durch Viterbi-Reestimation . . 1268.6.3. Verbesserung der Parameterschätzung durch Baum-Welch-Reestimation126
9. Gesamtstruktur von Spracherkennern 1329.1. Phonetische Sprachmodellierung . . . . . . . . . . . . . . . . . . . . . . . . 1359.2. Grammatikalische Sprachmodellierung . . . . . . . . . . . . . . . . . . . . 137
9.2.1. Generative Sprachmodelle . . . . . . . . . . . . . . . . . . . . . . . 1389.2.2. Probabilistische Sprachmodelle . . . . . . . . . . . . . . . . . . . . 139
10. Ausblick auf weitere Themen 14110.1. Effiziente Suchstrategien . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14110.2. Rechenzeit- und Speicherplatzüberlegungen . . . . . . . . . . . . . . . . . . 14110.3. Robuste Spracherkennung . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
A. Anhang 143A.1. Herleitung des Maximum-Likelihood-Klassifikators . . . . . . . . . . . . . 144A.2. Herleitung des Maximum-Likelihood-Schätzers für mehrere Beobachtungen 145A.3. Herleitung des SNR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147A.4. Verhältnis zwischen Discrete Fourier Transform (DFT) und Discrete Cosine
Transform (DCT) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148A.4.1. Definition der DCT . . . . . . . . . . . . . . . . . . . . . . . . . . 148A.4.2. Definition der erweiterten Sequenz . . . . . . . . . . . . . . . . . . 148A.4.3. DFT der symmetrischen Erweiterung . . . . . . . . . . . . . . . . . 148
A.5. Beweis zum Forward-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . 152A.5.1. Kettenregel und Marginalisierung . . . . . . . . . . . . . . . . . . . 152A.5.2. Initialisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153A.5.3. Update . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153A.5.4. Terminierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
III

Inhaltsverzeichnis
A.6. Herleitung des Vorwärtsalgorithmus . . . . . . . . . . . . . . . . . . . . . . 155A.7. Herleitung des Rückwärtsalgorithmus . . . . . . . . . . . . . . . . . . . . . 157A.8. Reestimationsgleichungen für mehrere Sequenzen . . . . . . . . . . . . . . 158A.9. Liste der Abkürzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159A.10. Liste der Symbole . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160A.11. Literaturhinweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
IV

1. Einführung
Seit langem gibt es die Wunschvorstellung, mit einem Computer zu sprechen und verstandenzu werden. Obwohl sich in den letzten Jahren eine enorme Entwicklung ergeben hat, sindaber auch die besten, heutigen Systeme noch weit von einem echten Verständnis entfernt.Zunehmend besser können sie allerdings die menschliche Sprache aus einem Audiosignal ineinen Text umsetzen - seit neuestem mit einigem Erfolg für natürliche, fließend gesprocheneSprache. Mit den Grundlagen, die für solche Anwendungen notwendig sind, soll sich dieseLehrveranstaltung in der Vorlesung und Übung beschäftigen.
Einige Beispiele für interessante Anwendungsgebiete sind:
• Diktierprogramme: Darunter sind einige zu finden, z. B. IBM ViaVoice oder DragonSystems Naturally Speaking, die mit Vokabularien von mehreren hunderttausend Wor-ten umgehen können. Generell benötigt man dafür ein Training auf den Sprecher, derdas System benutzen soll, und ein geräuscharmes Mikrofon. Letzteres wird gerne vomSoftwarehersteller mitgeliefert.
• Fernbedienung: Gerne würden viele Anbieter beispielsweise von Home-Entertainment-Systemen auch akustische Fernbedienungen anbieten, sodass der Couchtisch von den5 separaten (oder der einen programmierbaren aber nicht optimal nutzbaren) Fernbe-dienung befreit wäre. Die neuesten Spracherkennungssysteme können hierfür mit denlangen Raumimpulsantworten, Hintergrundgeräuschen und laufenden Fernsehern oderRadios umgehen.
• Fahrzeugnavigation und Telefonie: Einige größere Automobilhersteller bieten Systemean, mit denen das Telefon oder das Navigationssystem per Sprache gesteuert werden.Auch hier liegt, wie bei den Diktiersystemen, der Schwerpunkt der Arbeit auf der Ge-räuschbefreiung. Glücklicherweise sind die Raumimpulsantworten in Autos recht kurz,sodass in dieser Hinsicht keine größeren Probleme auftreten.
• Telefonauskunftsysteme: Sowohl die deutsche Bahn als auch viele Banken und andereAnbieter lassen die Benutzer mit Sprachdialogsystemen telefonieren. In einem inter-essanten Praxisversuch kann man bei der Deutschen Bahn, unter der Telefonnummer0800-15070901, die Leistung aktueller Systeme selbst ausprobieren.
• Fremdsprachensoftware: Um die Aussprache zu trainieren, bieten einige Firmen Fremd-sprachensoftware mit automatischer Spracherkennung an. Da dort die Vokabularien li-mitiert und die gewünschten Antworten von vornherein bekannt sind, ist das eines derweniger problematischen Einsatzgebiete für Spracherkennungssysteme.
1Stand 10.2016
1

1. Einführung
• Behindertenunterstützung und -kommunikation: Diktiersysteme und Sprachbedienungkönnen für motorisch eingeschränkte Menschen das Leben erleichtern. Was in dieserHinsicht noch fehlt, sind aber auch gute Ideen, wie eine Sprachbedienung so einge-setzt werden kann, dass der maximale Nutzen entsteht. An dieser Stelle liegt eine derinteressanteren, bislang wenig genutzten Schnittstellen zwischen Kommunikationswis-senschaft, Ergonomie und Softwaretechnik.
• Mobile Computer: Smartphones sollen in Zukunft mehr durch Sprache gesteuert wer-den. Hier liegt aber ein Problem darin, dass diese Geräte an völlig unterschiedlichen,verschieden lauten und unterschiedlich stark verhallten Orten genutzt werden und dassdie Verwendung eines Headsets oft inakzeptabel ist. So bleibt trotz des hohen Interessesvieler Hersteller und auch Kunden das primäre Eingabemedium zurzeit noch der Touch-screen. Trotzdem steigt das Interesse an Spracheingabe über Mobiltelefone rapide, undalle großen Hersteller bieten diese Möglichkeit an.
Auch andere Anwendungen sind gut denkbar, sodass sich die Frage stellt, warum es nichthäufiger im Alltag Spracherkennungssysteme zu sehen gibt. Zwei Aspekte sind dazu wichtig:
• Benutzbarkeit und Zuverlässigkeit: Es ist nicht offensichtlich, wie Spracherkennungs-systeme entworfen werden sollten, sodass sie dem Benutzer attraktiver erscheinen alsein Mausklick oder ein anderer Knopfdruck. Man wünscht sich, dass das Gerät, dasgesteuert werden soll, exakt und sofort, also ohne Rückfragen, die gewünschte Aktioneinleitet. Da Spracherkenner noch deutlich unter 100% Erkennungsrate liefern, mussmeistens eine besondere Situation vorliegen, wie z. B. eine Fahrt im Auto, die man sel-ber zu steuern hat, damit die Verwendung eines Spracherkenners attraktiv ist - oder derSpieltrieb, den Systeme wie Alexa und Siri ganz besonders ansprechen. Aber in sicher-heitskritischen Anwendungen wird durch die genannten Aspekte der zuverlässigen undschnellen Reaktion der Einsatz von Spracherkennern völlig unmöglich.
• Programmierbarkeit: Spracherkennung ist nicht ganz leicht. Woran das liegt, zeigt derfolgende Abschnitt.
1.1. WARUM IST SPRACHERKENNUNG SCHWIERIG?
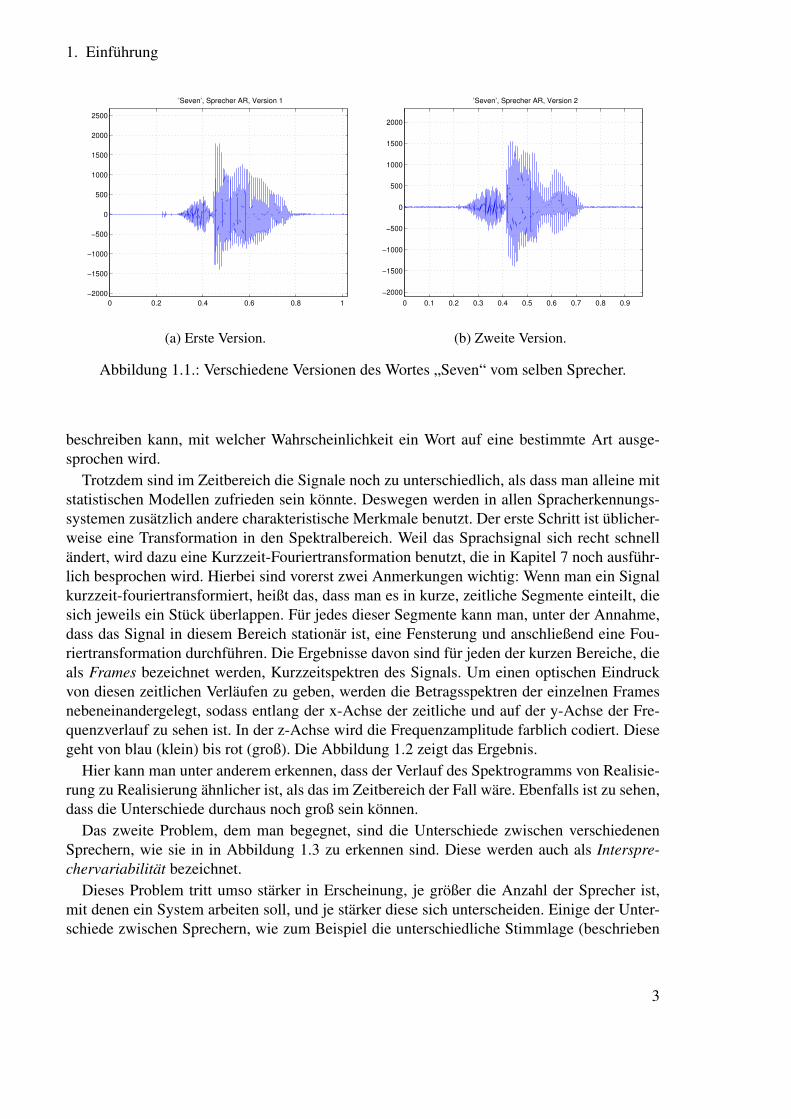
Der zeitliche Verlauf des Schalldrucks sieht sehr unterschiedlich aus, selbst wenn dasselbeWort vom selben Sprecher zweimal ähnlich ausgesprochen wird. Das zeigen zum Beispiel diefolgenden zwei Bilder in Abbildung 1.1. Dieses erste Problem, dass ein und derselbe Sprecherdasselbe Wort immer wieder anders sagt, wird auch als Intrasprechervariabilität bezeichnet.Dieses Problem besteht grundsätzlich, unabhängig davon, für welche konkrete Anwendungein Spracherkenner entwickelt werden soll.
Um mit dieser Verschiedenheit des gleichen Wortes umzugehen, arbeitet man in der Spra-cherkennung mit statistischen Methoden. Diese beruhen darauf, dass man nicht versucht, ei-ne Eins-zu-eins-Abbildung der aufgenommenen Sprache auf vorher gespeicherte Signale vonbekannten Worten zu finden. Stattdessen wird ein flexibles, statistisches Modell gelernt, das
2
1. Einführung
0 0.2 0.4 0.6 0.8 1
−2000
−1500
−1000
−500
0
500
1000
1500
2000
2500
’Seven’, Sprecher AR, Version 1
(a) Erste Version.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
−2000
−1500
−1000
−500
0
500
1000
1500
2000
’Seven’, Sprecher AR, Version 2
(b) Zweite Version.
Abbildung 1.1.: Verschiedene Versionen des Wortes „Seven“ vom selben Sprecher.
beschreiben kann, mit welcher Wahrscheinlichkeit ein Wort auf eine bestimmte Art ausge-sprochen wird.
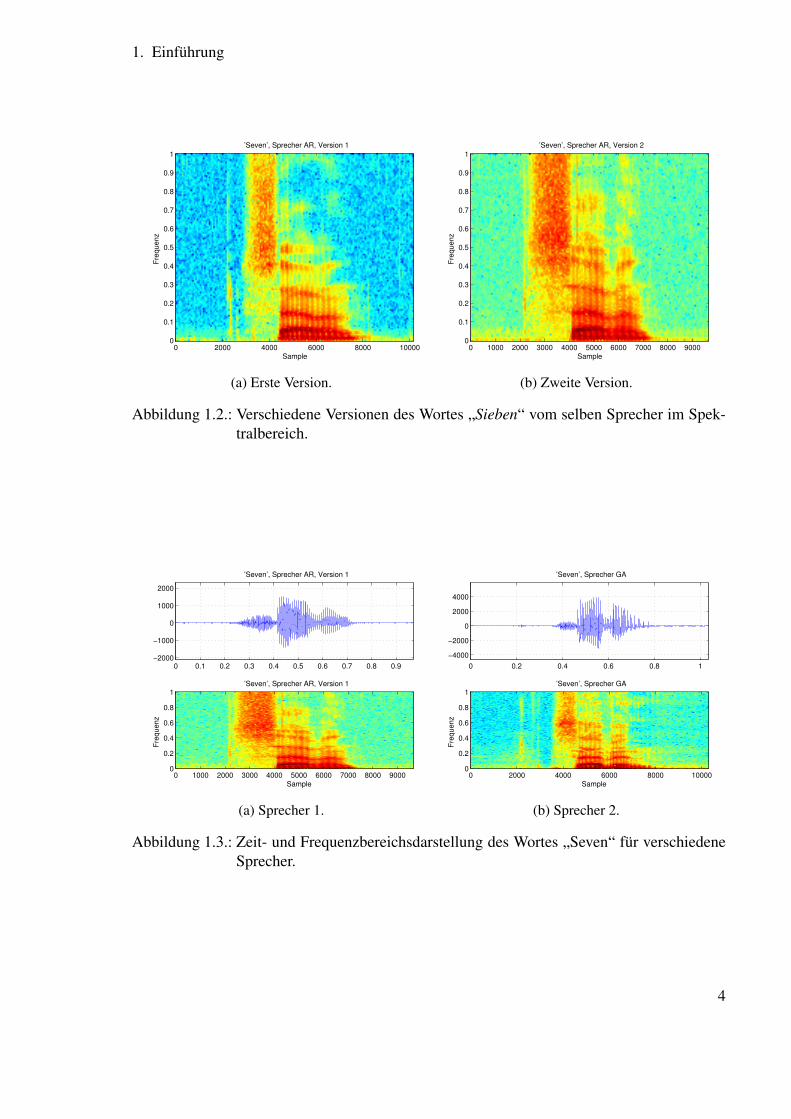
Trotzdem sind im Zeitbereich die Signale noch zu unterschiedlich, als dass man alleine mitstatistischen Modellen zufrieden sein könnte. Deswegen werden in allen Spracherkennungs-systemen zusätzlich andere charakteristische Merkmale benutzt. Der erste Schritt ist üblicher-weise eine Transformation in den Spektralbereich. Weil das Sprachsignal sich recht schnelländert, wird dazu eine Kurzzeit-Fouriertransformation benutzt, die in Kapitel 7 noch ausführ-lich besprochen wird. Hierbei sind vorerst zwei Anmerkungen wichtig: Wenn man ein Signalkurzzeit-fouriertransformiert, heißt das, dass man es in kurze, zeitliche Segmente einteilt, diesich jeweils ein Stück überlappen. Für jedes dieser Segmente kann man, unter der Annahme,dass das Signal in diesem Bereich stationär ist, eine Fensterung und anschließend eine Fou-riertransformation durchführen. Die Ergebnisse davon sind für jeden der kurzen Bereiche, dieals Frames bezeichnet werden, Kurzzeitspektren des Signals. Um einen optischen Eindruckvon diesen zeitlichen Verläufen zu geben, werden die Betragsspektren der einzelnen Framesnebeneinandergelegt, sodass entlang der x-Achse der zeitliche und auf der y-Achse der Fre-quenzverlauf zu sehen ist. In der z-Achse wird die Frequenzamplitude farblich codiert. Diesegeht von blau (klein) bis rot (groß). Die Abbildung 1.2 zeigt das Ergebnis.
Hier kann man unter anderem erkennen, dass der Verlauf des Spektrogramms von Realisie-rung zu Realisierung ähnlicher ist, als das im Zeitbereich der Fall wäre. Ebenfalls ist zu sehen,dass die Unterschiede durchaus noch groß sein können.
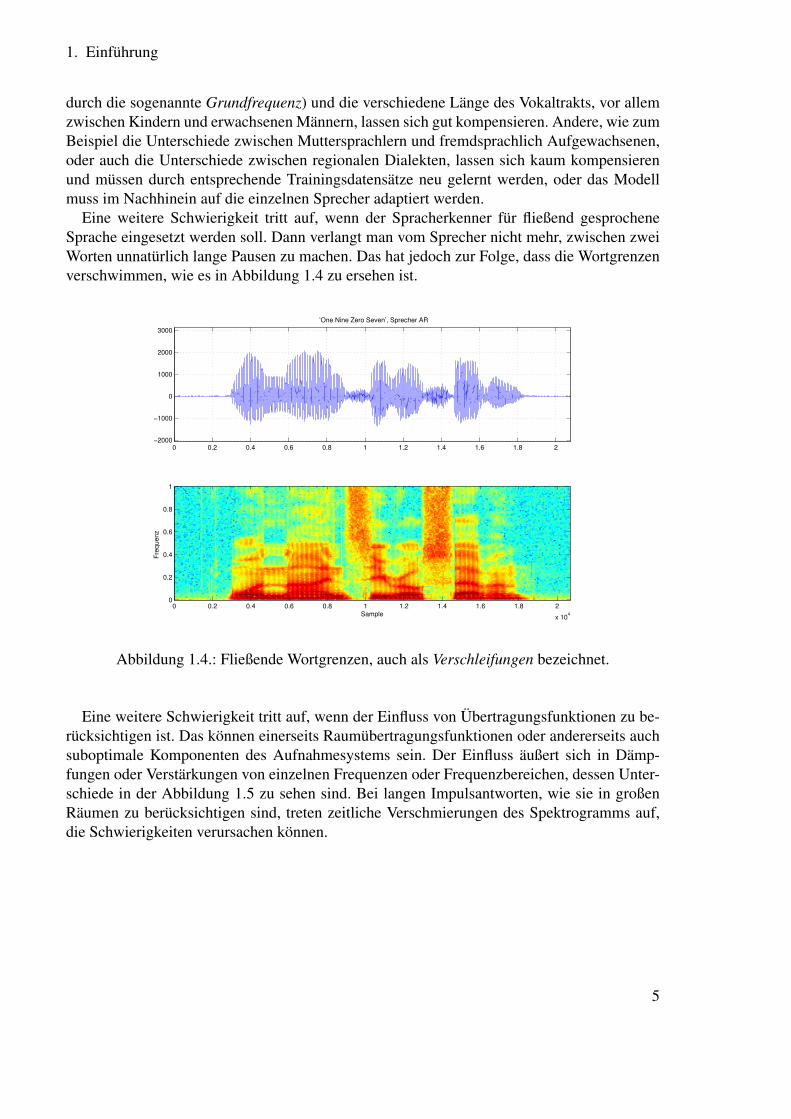
Das zweite Problem, dem man begegnet, sind die Unterschiede zwischen verschiedenenSprechern, wie sie in in Abbildung 1.3 zu erkennen sind. Diese werden auch als Interspre-chervariabilität bezeichnet.
Dieses Problem tritt umso stärker in Erscheinung, je größer die Anzahl der Sprecher ist,mit denen ein System arbeiten soll, und je stärker diese sich unterscheiden. Einige der Unter-schiede zwischen Sprechern, wie zum Beispiel die unterschiedliche Stimmlage (beschrieben
3
1. Einführung
Sample
Fre
quenz
’Seven’, Sprecher AR, Version 1
0 2000 4000 6000 8000 100000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
(a) Erste Version.
Sample
Fre
quenz
’Seven’, Sprecher AR, Version 2
0 1000 2000 3000 4000 5000 6000 7000 8000 90000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
(b) Zweite Version.
Abbildung 1.2.: Verschiedene Versionen des Wortes „Sieben“ vom selben Sprecher im Spek-tralbereich.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9−2000
−1000
0
1000
2000
’Seven’, Sprecher AR, Version 1
Sample
Fre
qu
enz
’Seven’, Sprecher AR, Version 1
0 1000 2000 3000 4000 5000 6000 7000 8000 90000
0.2
0.4
0.6
0.8
1
(a) Sprecher 1.
0 0.2 0.4 0.6 0.8 1
−4000
−2000
0
2000
4000
’Seven’, Sprecher GA
Sample
Fre
qu
enz
’Seven’, Sprecher GA
0 2000 4000 6000 8000 100000
0.2
0.4
0.6
0.8
1
(b) Sprecher 2.
Abbildung 1.3.: Zeit- und Frequenzbereichsdarstellung des Wortes „Seven“ für verschiedeneSprecher.
4
1. Einführung
durch die sogenannte Grundfrequenz) und die verschiedene Länge des Vokaltrakts, vor allemzwischen Kindern und erwachsenen Männern, lassen sich gut kompensieren. Andere, wie zumBeispiel die Unterschiede zwischen Muttersprachlern und fremdsprachlich Aufgewachsenen,oder auch die Unterschiede zwischen regionalen Dialekten, lassen sich kaum kompensierenund müssen durch entsprechende Trainingsdatensätze neu gelernt werden, oder das Modellmuss im Nachhinein auf die einzelnen Sprecher adaptiert werden.
Eine weitere Schwierigkeit tritt auf, wenn der Spracherkenner für fließend gesprocheneSprache eingesetzt werden soll. Dann verlangt man vom Sprecher nicht mehr, zwischen zweiWorten unnatürlich lange Pausen zu machen. Das hat jedoch zur Folge, dass die Wortgrenzenverschwimmen, wie es in Abbildung 1.4 zu ersehen ist.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2−2000
−1000
0
1000
2000
3000
’One Nine Zero Seven’, Sprecher AR
Sample
Fre
quenz
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
0.2
0.4
0.6
0.8
1
Abbildung 1.4.: Fließende Wortgrenzen, auch als Verschleifungen bezeichnet.
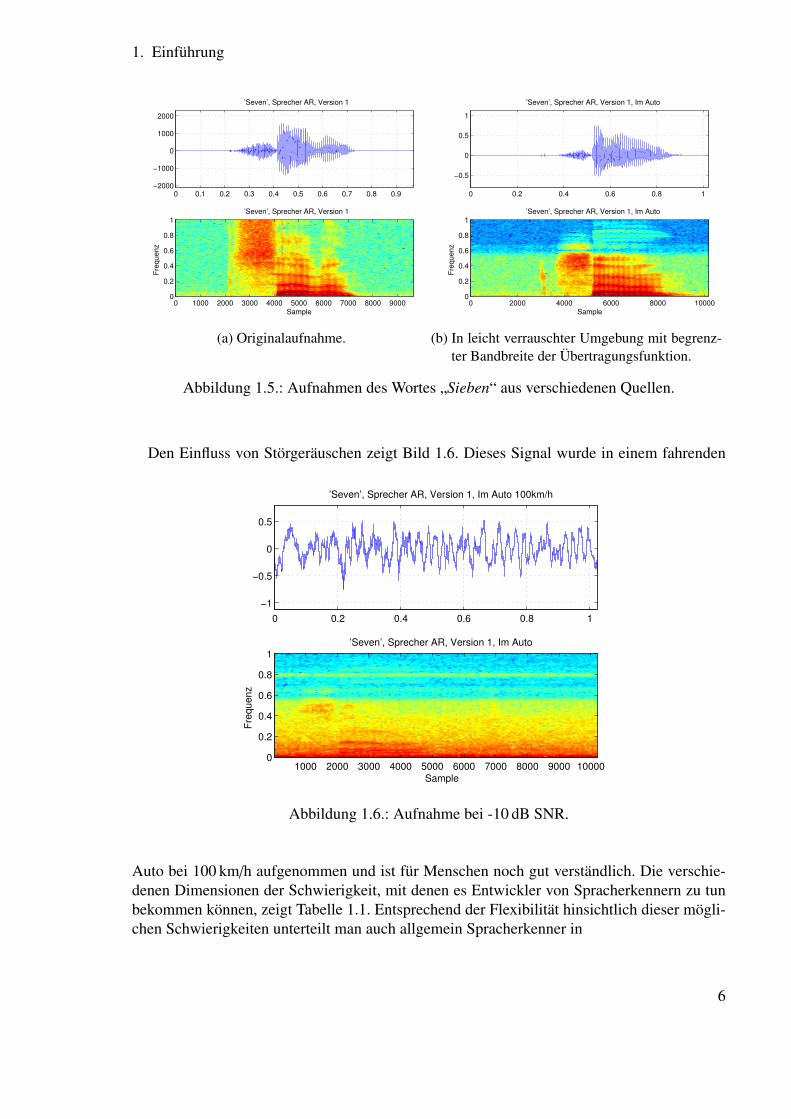
Eine weitere Schwierigkeit tritt auf, wenn der Einfluss von Übertragungsfunktionen zu be-rücksichtigen ist. Das können einerseits Raumübertragungsfunktionen oder andererseits auchsuboptimale Komponenten des Aufnahmesystems sein. Der Einfluss äußert sich in Dämp-fungen oder Verstärkungen von einzelnen Frequenzen oder Frequenzbereichen, dessen Unter-schiede in der Abbildung 1.5 zu sehen sind. Bei langen Impulsantworten, wie sie in großenRäumen zu berücksichtigen sind, treten zeitliche Verschmierungen des Spektrogramms auf,die Schwierigkeiten verursachen können.
5
1. Einführung
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9−2000
−1000
0
1000
2000
’Seven’, Sprecher AR, Version 1
Sample
Fre
que
nz
’Seven’, Sprecher AR, Version 1
0 1000 2000 3000 4000 5000 6000 7000 8000 90000
0.2
0.4
0.6
0.8
1
(a) Originalaufnahme.
0 0.2 0.4 0.6 0.8 1
−0.5
0
0.5
1
’Seven’, Sprecher AR, Version 1, Im Auto
Sample
Fre
que
nz
’Seven’, Sprecher AR, Version 1, Im Auto
0 2000 4000 6000 8000 100000
0.2
0.4
0.6
0.8
1
(b) In leicht verrauschter Umgebung mit begrenz-ter Bandbreite der Übertragungsfunktion.
Abbildung 1.5.: Aufnahmen des Wortes „Sieben“ aus verschiedenen Quellen.
Den Einfluss von Störgeräuschen zeigt Bild 1.6. Dieses Signal wurde in einem fahrenden
0 0.2 0.4 0.6 0.8 1
−1
−0.5
0
0.5
’Seven’, Sprecher AR, Version 1, Im Auto 100km/h
Sample
Fre
que
nz
’Seven’, Sprecher AR, Version 1, Im Auto
1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
0.2
0.4
0.6
0.8
1
Abbildung 1.6.: Aufnahme bei -10 dB SNR.
Auto bei 100 km/h aufgenommen und ist für Menschen noch gut verständlich. Die verschie-denen Dimensionen der Schwierigkeit, mit denen es Entwickler von Spracherkennern zu tunbekommen können, zeigt Tabelle 1.1. Entsprechend der Flexibilität hinsichtlich dieser mögli-chen Schwierigkeiten unterteilt man auch allgemein Spracherkenner in
6

1. Einführung
Problem Wichtig bei LösungsansätzeIntersprechervariabilität allen Erkennern geeignete FeaturesIntrasprechervariabilität sprecherunabhängigen Systemen geeignete Features,
SprechernormalisierungVerschleifungen Systemen für fließend Modellierung der
gesprochene Worte WortübergängeÜbertragungssysteme: mobilen Geräten, Kompensation der
Verzerrungen Hausgerätesteuerung Übertragungsfunktion,Frequenzgang Trainingsdaten in vielen
Situationen sammeln,aber große Probleme in
verhallten RäumenRauschen und mobilen Geräten, Rauschunterdrückung,Störgeräusche Hausgerätesteuerung, ICA,
in Fahrzeugen viele Trainingsdatenan verschiedenen Orten
Tabelle 1.1.: Probleme und Lösungsansätze in der Spracherkennung.
• Sprecherabhängige, sprecheradaptive und sprecherunabhängige Systeme
• mit kleinem (<100), mittlerem und großem (>1.000 Worte) Vokabular
• für getrennt oder verbunden gesprochene Sprache.
1.2. ORGANISATION DER LEHRVERANSTALTUNG
1.2.1. Vorlesung
In der Vorlesung werden wir uns mit folgenden Themen beschäftigen:
Grundlagen
• Spracherzeugung und Phonologie
• Sprachwahrnehmung
• Wahrscheinlichkeitsrechnung und Statistik
Signalverarbeitung
• Signalaufnahme
• Signalanalyse
7

1. Einführung
– Zeit/Frequenzanalyse
– Wahrnehmungsorientierte Analyse
– Cepstrum
Spracherkennung
• Sprachmodelle
– Hidden Markov Modelle
– Gauß’sche Mischungsmodelle
– Neuronale Netze (Tandem/Hybrid/End-to-End-Systeme)
• Mustererkennung
– Viterbi-Algorithmus
• Training von Spracherkennern
• Viterbi-Training & Baum-Welch-Algorithmus
• Training von DNN-basierten Systemen
• Besonderheiten bei großem Vokabular
– Grammatiken und Sprachmodelle
– Effiziente Suchverfahren
– Parameter-Tying
1.2.2. Übung
In der Übung wird als Begleitung zur Vorlesung ein einfacher Erkenner für fließend gespro-chene Ziffernketten programmiert. Dazu sind Vorkenntnisse in Matlab nützlich, aber nichtnotwendig.
8

1. Einführung
1.2.3. Literaturhinweise
Hier sind ein paar Buchtipps, die für die gesamte Veranstaltung nützlich sind:
Automatische SpracherkennungSchukat-TalamazziniVieweg 1995.www.minet.uni-jena.de/fakultaet/schukat/MYPUB/SchukatTalamazzini95:ASG.pdf
HTK-BookS. Young et. al.http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.394.5632&rep=rep1&type=pdf
Fundamentals of Speech RecognitionRabiner and JuangPrentice Hall 1993.
Spoken Language ProcessingHuang, Acero and HonPrentice Hall 2001.
Automatic Speech Recognition - A Deep Learning ApproachYu & DengSpringer 2015.
9

1. Einführung
1.3. SPRACHERZEUGUNG UND KLASSIFIKATION
1.3.1. Phonetik
Mit der menschlichen Spracherzeugung beschäftigt sich die Phonetik, genauer gesagt de-ren Teilgebiet der artikulatorischen Phonetik. Um die Spracherzeugung mathematisch zu be-schreiben, wird dabei das in Bild 1.7 gezeigte Modell häufig verwendet.
Lunge
Stimmloses
Signal
Grundton
Periodisches Signal
Vokaltrakt+
Stimmbänder
Luftperiodische
Bewegung
offen
*
1 / F0
*
Abbildung 1.7.: Grundlegendes, physiologisch motiviertes Modell der Spracherzeugung.
Hier dient die Lunge als Quelle, die den Luftstrom für alle weiteren Vorgänge zur Ver-fügung stellt. An den Stimmbändern entscheidet sich, ob der Laut stimmhaft oder stimmloswerden soll. Bei stimmlosen Lauten sind die Stimmbänder so weit auseinandergezogen, dasssie durch den vorbeigehenden Luftstrom nicht beeinflusst werden, bei stimmhaften Lautenliegen sie aneinander und werden durch den Luftstrom in regelmäßigen Abständen auseinan-derbewegt und so in Schwingungen versetzt. Die Frequenz dieser Schwingung wird auch alsGrundfrequenz bezeichnet. Dieser, je nach Stimmbandstellung periodische oder aperiodischeLuftstrom passiert anschließend den Vokaltrakt, der als Filter dient und manche Frequenzenbetont, andere dämpft. Der Vokaltrakt kann gut als Allpolfilter beschrieben werden, was zumBeispiel zur Analyse oder Synthese von Sprachsignalen von Nutzen ist. Die Abb. 1.8 zeigt denVokaltrakt genauer. Die Sprechorgane, die eine besondere Rolle in der Klangerzeugung oderFormung spielen, werden als Artikulatoren bezeichnet. Dabei unterscheidet man die, mehroder minder bewusst beeinflussten, aktiven Artikulatoren von den, nur mitbenutzten, passivenArtikulatoren.
10

1. Einführung
Zahndamm (Alveolen)Hintere Alveolen
Vordere Alveolen
Oberzähne
Oberlippe
Unterlippe
Unterzähne
Kiefer
Stimmbänder (Glottis)
Nasenhöhle
Zungenspitze
harter Gaumen (Palatum)
weicher Gaumen (Velum)
Nasengang
Zäpfchen (Uvula)
hintere Zunge
mittlere Zunge
Zungenrücken
Abbildung 1.8.: Aufbau des Vokaltraktes. Einzig Unterlippe, Zungenrücken und Zungenspitzesind aktive Artikulatoren. Alles andere gehört zu den passiven Artikulatoren.
1.3.2. Klassifikation von Lauten
Um die vielen, verschiedenen Klänge der menschlichen Sprache zu beschreiben, benötigt manzunächst eine kleinste Einheit, die als Basis für ein Beschreibungsalphabet dienen kann. Diesekleinste Einheit bezeichnet man in der Phonetik als Laut oder auch als Phon. Um zu einemSatz von allen möglichen Lauten zu gelangen, ist dann ein systematischer Klassifikationsme-chanismus nötig. Dazu gibt es einen weit anerkannten Standard, der auch die Grundlage fürdas International Phonetic Alphabet (IPA) bildet.2 Die wichtigste Unterscheidung bei diesemSystem ist die in Vokale und Konsonanten. Bei Vokalen kann die Luft, der sogenannte Phona-tionsstrom, weitgehend ungehindert ausströmen, während bei Konsonanten der Vokaltrakt anmindestens einer Stelle stark verengt ist. Dementsprechend klassifiziert man auch Konsonan-ten nach Art und Ort der Engebildung, wie es in der folgenden Übersicht gezeigt ist.
Außerdem gibt es laterale Laute und Halbvokale - also Laute, die durch frikationslose En-gebildung gekennzeichnet sind - im Deutschen das “l” als Lateral und das “j” als Halbvokal.
Im Gegensatz dazu werden die Vokale nach der Stellung der Zunge und der Lippen ein-geteilt, wobei zum einen die Weite der Öffnung und zum anderen der Ort der größten Engeentscheidend sind. Außerdem unterteilt man Vokale in gerundete und ungerundete Vokale.
2Das IPA sollte nicht verwechselt werden mit der International Phonetic Association (IPA), die das IPA ent-wickelt hat.
11

1. Einführung
ArtikulationsartOrt
bilabial labiodental alveolar palatal velar uvular glottal
Plosivep,b t,d k,g Q
Nasalem n ï
Frikativef,v s,z,S,Z ç,j x χ h
Tabelle 1.2.: Klassifikation von Konsonanten.
Zungen-Vertikallagegeschlossen halboffen offen
i: e: a
Zungen-Horizontallagevordere mittlere hintere
i:, e: @ u:, o:
Lippenrundunggerundet ungerundet
y:, φ i:, e:
Tabelle 1.3.: Klassifikation von Vokalen.
geschlossen
Vokalviereck mit deutschen
offen
hier
See
ähnlichkönnen sein
Kanne neu
Luftdünn
Wasser Bau
hinten hintenvorne vorne
Hecke
DiphtongenVokalen
Abbildung 1.9.: Vokalviereck, mit Eintragung aller deutschen Vokale und Diphtonge. Als Ko-ordinaten für eine Darstellung der möglichen Vokale dient hier die Zungen-horiznotallage und Vertikalstellung.
1.3.3. Phonologie
Die Phonologie untersucht die Rolle, die verschiedene Laute in der menschlichen Sprach-kommunikation spielen. Dazu entfernt sie sich von dem Konzept des Phons, das die Art derKlangerzeugung als Gruppierungsmerkmal für Laute verwendet, und untersucht stattdessen,
12

1. Einführung
welche Klänge in einer konkreten Sprache wichtig zur Übertragung von Informationen sind.So kommen Phonetik und Phonologie zu zwei verschiedenen Alphabeten. Die Phonetik suchtund findet die kleinsten klanglichen Einheiten und kommt dadurch zum „International Pho-netic Alphabet“, das alle Laute umfasst, die von Menschen in irgendeiner Sprache verwendetwerden (jedenfalls, so weit wie diese bekannt sind). Die Phonologie dagegen unterscheidetin ihrem Alphabet die kleinsten bedeutungsrelevanten Einheiten, die sogenannten Phoneme.Diese sind von Sprache zu Sprache unterschiedlich. So unterscheidet das Mandarin vier ver-schiedene, der kantonesische Dialekt der chinesischen Sprache sogar neun verschiedene Ton-höhen bzw. Tonhöhenvariationen, die die Bedeutung eines Wortes bestimmen. In europäischenSprachen hingegen dient die Tonhöhe nur zur Unterscheidung von Fragen und Aussagen undzur Übermittlung anderer, z. B. emotionaler, Nebeninformationen. Da also die Bedeutung inverschiedenen Sprachen anhand von verschiedenen Aspekten der Laute unterschieden wird,ist auch das Phonem-Alphabet von Sprache zu Sprache unterschiedlich, beispielsweise bildetim Japanischen das r und l ein einziges Phonem. Die einzelnen Laute, die ein Phonem umfasst,werden als Allophone bezeichnet, so hat also das Japanische Phonem /r/ die beiden Laute [r]und [l] als Allophone.3 Um den Satz von Phonemen einer Sprache zusammenzustellen, gibtes prinzipiell zwei verschiedene Ansätze:
1.3.3.1. Minimalpaaranalyse
In der Minimalpaaranalyse findet man zwei Worte, die sich nur durch einen Laut unterschei-den. Diese beiden unterschiedlichen Laute sind dann offenbar verantwortlich für die Unter-scheidung der Bedeutung und müssen so zu zwei verschiedenen Phonemklassen gehören.Beispielsweise unterscheiden sich die Worte „Fach“ und „wach“ nur im Anlaut und bildendeswegen ein Minimalpaar. So ist klar, dass die Laute „f“ bzw. „w“ zu zwei verschiedenenPhonemen gehören müssen, im deutschen zu den Phonemen /f/ und /w/.
1.3.3.2. Komplementärdistributionsanalyse
Zwei Laute stehen in komplementärer Distribution, wenn sie nie im selben lautlichen Zu-sammenhang vorkommen. Beispielsweise wird im Deutschen der Laut [x] (zweiter Laut in„ich“) am Wortanfang, nach vorderen Vokalen oder Konsonanten gesprochen, der Laut [ç] (in„Dach“) taucht dagegen nur nach hinteren Vokalen auf, sodass diese beiden Laute in kom-plementärer Distribution stehen. Diese Eigenschaft kann auch zur Konstruktion eines Pho-nemalphabets genutzt werden, wobei nur Laute in komplementärer Distribution jeweils demgleichen Phonem zugeordnet werden können. Im beschriebenen Fall beispielsweise werdensowohl [x] als auch [ç] dem Phonem /x/ zugeordnet.
3Um Phoneme und Phone in der Notation zu unterscheiden, werden Phoneme in Schrägstriche /a/, Phone da-gegen in eckige Klammern eingeschlossen [a].
13

2. Menschliche Sprachwahrnehmung
Die Wahrnehmung von Sprache erfolgt sowohl durch das Gehör als auch visuell. Das zeigtsich beispielsweise daran, dass die menschliche Erkennung von Sprache wesentlich durchdie Präsentation von Bildinformation gesteigert werden kann, was zum Beispiel die Sprach-ausgabe in Form einer Gesichtsanimation attraktiv macht. So ist auch eines der aktuellerenForschungsthemen in der automatischen Spracherkennung die Fusion von mehreren, auchoptischen, Sensoren. Trotzdem wird sich dieses Kapitel ausschließlich mit der akustischenWahrnehmung von Sprache beschäftigen, die das einfachste und verbreitetste Medium zurSpracheingabe darstellt.
Menschliches Gehör
Der Mensch kann einen Frequenzbereich von 20 bis 16.000 Hz wahrnehmen, Kinder bis zu20.000 Hz.1 Das Gehör bietet mindestens in zwei Aspekten eine erstaunliche Wahrnehmungs-fähigkeit:
• Intensität: Schalldrücke sind in der Luft auch bei von uns als laut empfundenen Ereignis-sen sehr gering. Die Einheit des Schalldruckpegels LP in dB ist definiert als 20 log p
p0.
Dabei ist der Referenzdruck mit p0 = 20 µPa so gewählt, dass er nahe an der durch-schnittlichen Ruhehörschwelle für reine 2 kHz Sinustöne liegt. Im Vergleich mit dematmosphärischen Druck ist er klein, mit einem Größenordnungsunterschied von 10−7.2
• Frequenz: Die Nerven, deren Impulse benutzt werden müssen, um akustische Informa-tionen an das Gehirn weiterzuleiten und dort zu verarbeiten, haben eine Refraktärzeitvon 2 ms.3 Damit könnte man theoretisch nur Schall mit bis zu 500 Hz exakt wiederge-ben, trotzdem sind feine Frequenzauflösungen auch im oberen Frequenzbereich mög-lich. Um das zu bewerkstelligen, ist eine aufwendige mechanische Verarbeitung derSchallimpulse notwendig.
2.1. AUFBAU DES GEHÖRAPPARATES
Das Ohr besteht prinzipiell aus drei Teilen, dem äußeren, mittleren und Innenohr. Das äußereOhr besteht seinerseits aus der Gehörmuschel, die es unter anderem durch ihre Richtcharakte-
1Im Vergleich dazu gibt es Tierarten, die auch hochfrequentere Schwingungen wahrnehmen können - beispiels-weise Hunde hören bis 35.000 Hz, Wale sogar bis 100.000 Hz.
2Ein Pascal entspricht einem Druck von einem Newton pro Quadratmeter, der atmosphärische Druck beträgtauf Meereshöhe im Mittel 1.013,2 hPa.
3Die Refraktärzeit ist die „Erholungszeit“ nach einem Aktionspotential, während derer die Nervenzellen nochnicht erneut feuern können.
14

2. Menschliche Sprachwahrnehmung
ristik erleichtert, sich auf Geräusche aus einer bestimmten Einfallsrichtung zu konzentrierenund aus dem Gehörgang, der vor allem Fremdkörper fernhält. Es wird begrenzt vom Trom-melfell, das durch Schallwellen zu Schwingungen angeregt wird. Das Mittelohr besteht auseiner etwa 1 cm3 großen, luftgefüllten Kammer, die über die eustachische Röhre belüftet wird.Im Mittelohr bewirken die drei Gehörknöchelchen Hammer, Amboß und Steigbügel eine Im-pedanzanpassung, die notwendig ist, weil der Schallwiderstand des flüssigkeitsgefüllten Inne-nohrs viel größer ist als der der Luft, sodass ohne eine entsprechende mechanische Umsetzungder Schall keine nennenswerte Wirkung auf das Innenohr haben würde. Zu dem Zweck werden
GehörknöchelchenOvales Fenster
OhrtrompeteTrommelfell
Paukenhöhle
Cochlea
Hörnerv
Rundes Fenster
GehörgangEustachische Röhre
Gehörmuschel
Abbildung 2.1.: Aufbau des Gehörs.
von den Gehörknöchelchen, die in Bild 2.1 zu sehen sind, zwei Mechanismen ausgenutzt:
• Druck = Kraft pro Fläche. Da das Trommelfell eine viel größere Fläche hat als derSteigbügel, der am ovalen Fenster die Kraft auf das Innenohr überträgt, kann hier derDruck deutlich, im Mittel etwa um den Faktor 17, gesteigert werden.
• Hebelwirkung. Durch die Hebelwirkung wird der Druck weiter etwa um den Faktor 1,3gesteigert.
Insgesamt erreicht das gesunde Mittelohr somit eine Verstärkung um etwa den Faktor 22,sodass ca. 60% der Schallenergie in das Innenohr übertragen werden können, während 40%reflektiert werden. Ohne die Wirkung der Gehörknöchelchen kann bei einem geschädigtenMittelohr nur ca. 2% der Energie übertragen werden.
Die Aufgabe des Innenohrs besteht in der Frequenzanalyse des Schalls, was teils auf me-chanischem Weg erreicht wird. Im Innenohr findet eine Frequenz-Ortsabbildung statt, dasheißt, dass Eingangssignale verschiedener Frequenz mit Hilfe des Resonanzprinzips auf ver-schiedenen Stellen des Innenohrs zu Anregungen von Neuronen führen. Diese Frequenz-Ortsabbildung wird als Tonotopie bezeichnet. Um diese Abbildung leisten zu können, be-steht das Innenohr aus einer aufgerollten, flüssigkeitsgefüllten Röhre, der sogenannten Coch-lea oder Gehörschnecke. Wie diese abgerollt prinzipiell aussieht zeigt Abbildung 2.2. Ent-lang der Cochlea ändern sich die Festigkeit des Proteingewebes und die Breite der Cochleaselbst. Am Anfang ist die Cochlea dünn und fest, zum Ende hin wird sie breiter und flexibler.
15

2. Menschliche Sprachwahrnehmung
Fenster
Helicotrema
0.1 mmhohe Resonanz-
frequenz (20000 Hz)
0.5 mm
niedrige Resonanz-
frequenz (20 Hz)
weicherhärter
Abbildung 2.2.: Abgerollte Cochlea.
Aus dem gleichen Grund, aus dem dünne, feste Gitarrensaiten über hohe Resonanzfrequen-zen verfügen, und dicke, lockere Saiten über niedrige Resonanzfrequenzen verfügen, hat auchdie Cochlea an ihrem Anfang am ovalen Fenster, wo sie dünn und fest ist, eine hohe Reso-nanzfrequenz von ca. 20 kHz, während sie an der Spitze, dem Helicotrema, ihre niedrigsteResonanzfrequenz von etwa 20 Hz besitzt. Wie aus Abbildung 2.3 zu erkennen ist, trifft derSteigbügel des Mittelohrs am Ovalen Fenster auf die Cochlea und überträgt dort die Schall-energie in die Gehörschnecke. Diese besteht aus drei flüssigkeitsgefüllten Kammern, der ScalaVestibuli, der Scala Media und der Scala Tympani. Die Grenze zwischen Scala Tympani undScala Media bildet die Basilarmembran, die durch die Schwingungen der Flüssigkeit an derStelle in Schwingungen versetzt wird, die eine mit der Schallfrequenz korrespondierende Re-sonanzfrequenz hat. Am anderen Ende der Cochlea, am runden Fenster, wird schließlich dieSchwingung der Flüssigkeit gedämpft. Die Wanderwelle, die sich über die Basilarmembran
Scala Vestibuli
Scala Media
Scala Tympani
Rundes Fenster
Ovales Fenster
Helicotrema
Basilarmembran
Reißnersche Membran
Steigbügel
Abbildung 2.3.: Prinzipieller Aufbau der Cochlea.
bewegt, hat noch in einem großen Bereich hohe Amplituden, auch wenn nur eine einzelneFrequenz im Schall vorhanden ist. Die hohe Frequenzselektivität des Gehörs wird erst da-durch erreicht, dass eine selektive Verstärkung durch die äußeren Haarzellen stattfindet. Dieseäußeren Haarzellen werden durch die Verschiebungen der Tektorialmembran gegenüber derBasilarmembran depolarisiert, was sie zu rhythmischen Kontraktionen veranlasst. Dadurchwird die Welle an der Stelle der maximalen Auslenkungen noch weiter, um den Faktor 1.000
16

2. Menschliche Sprachwahrnehmung
verstärkt, sodass sie groß genug wird, um die inneren Haarzellen anzuregen, die dann einenImpuls am Gehörnerv verursachen. Die inneren Haarzellen, von denen es beim Menschen et-wa 3.500 gibt, sind entlang der Cochlea angeordnet. Bis zu einer Anregungsfrequenz von etwa500 Hz lösen sie synchron zum Schallereignis Aktionspotentiale aus, danach ist die Feuerratenichtlinear abhängig von der Signalamplitude. Bis etwa 6.000 Hz besteht aber eine Neigungzur Synchronisation mit der Schallwelle, die auch als Phasenkopplung bezeichnet wird. Einegenauere Vorstellung vom Aufbau des Corti-Organs, in dem diese Verstärkung und Reizaus-lösung stattfindet, bietet Abbildung 2.4.
Scala Vestibuli
Scala TympaniBasilarmembran
Scala MediaReißnermembran
Tektorialmembran
HörnervfasernÄußere HaarzellenInnere Haarzellen
Abbildung 2.4.: Querschnitt durch die Cochlea.
2.2. LAUTHEITSWAHRNEHMUNG
Im Gegensatz zur Schallintensitätspegel LI und zum Schalldruckpegel LP, deren Werte fre-quenzunabhängig aus
LP = 20 logpp0
mit p0 = 20 µPa = 20 µNm2 für den Schalldruck, bzw.
10 logII0
mit I0 = 10−12 Wm2 für die Schallintensität berechnet werden, ist die Lautheit von den Signal-
charakteristika abhängig. Die empfundene Lautheit eines Tons hängt nichtlinear
• von seiner Amplitude
• seiner Frequenz und
• verschiedenen Zeit- und Frequenzmaskierungseffekten ab.
17

2. Menschliche Sprachwahrnehmung
Um diese Effekte zu beschreiben, wird die Einheit der Lautheit eingeführt, die das Lautstär-keempfinden in sone misst. Für einen Sinuston oder breitbandiges Rauschen sind nichtlineareFunktionen gemessen worden, die die Lautheit in Abhängigkeit von der Signalfrequenz unddessen Pegel angeben. Allgemein hängt aber die Lautheit nicht nur von der Frequenz son-dern vom Frequenzspektrum und nicht nur von der Schallintensität sondern auch von derenVerlauf über die Zeit ab. In DIN 45631 und ISO 532 B sind genormte Messverfahren zur Laut-heitsmessung beschrieben, die auf einer ausführlichen Modellierung dieser Effekte beruhen,wie sie dem Verfahren von Zwicker, siehe [ZF99] zugrunde liegen. Die Modellierung allerdieser Effekte ist wichtig, wenn beispielsweise eine verlustbehaftete Audiocodierung gesuchtwird, die das ästhetische Empfinden und gegebenenfalls die Verständlichkeit möglichst wenigbeeinträchtigt. Auch einige Methoden zur Feature Extraction berücksichtigen diese Maskie-rungseffekte, da das Themengebiet aber umfangreich ist, werden in dieser Veranstaltung nur anentsprechenden Stellen, soweit erforderlich, weitere Aspekte der Maskierung und Lautheits-empfindung behandelt. Schneller zu modellieren und universell in Spracherkennungssystemenverwendet ist dagegen die menschliche Frequenzwahrnehmung, die genau wie die Lautstär-keempfindung zwar nichtlinear, trotzdem aber leichter zu modellieren ist und im folgendenAbschnitt 2.3 beschrieben wird.
2.3. FREQUENZWAHRNEHMUNG
Die Abbildung der Frequenzen auf ihre Resonanzstellen in der Cochlea zeigt schematischAbbildung 2.5. Wie auch in dieser schematischen Darstellung zu sehen ist, ist die Abbildung
Ovales Fenster
Rundes Fenster
20 kHz
7 kHz 5 kHz Basilarmembran
4 kHz
Helicotrema
3 kHz
2 kHz
1,5 kHz
1 kHz800 Hz
600 Hz400 Hz
200 Hz
Abbildung 2.5.: Frequenz-Ortsabbildung in der Cochlea.
der Frequenz auf den Ort keineswegs linear, stattdessen steht ein großer Bereich der Cochlea
18

2. Menschliche Sprachwahrnehmung
für die Abbildung der niedrigen Frequenzen zur Verfügung und mit steigender Frequenz wirddie Abbildung immer gröber. Diese physiologische Gegebenheit korrespondiert auch mit dermenschlichen Wahrnehmung von Frequenzen, die sich in verschiedenen wahrnehmungsori-entierten Skalen niederschlägt.
2.3.1. Skala der westlichen Musik
In der westlichen Musik liegt die Frequenz F2 eine Oktave über F1, wenn sie doppelt so großist, also entspricht eine Oktave einer Verdopplung der Frequenz. Halbtöne werden gebildet,indem die Oktave in 12 Intervalle eingeteilt wird. Die Wahl dieser Halbtöne hängt stark vonder angestrebten harmonischen Wirkung ab. Wenn ein Instrument auf eine Tonart gestimmtwird, liegen die Halbtöne in ungleichen Verhältnissen zueinander, es ist allerdings möglich,den Halbtönen jeweils das gleiche Frequenzverhältnis zueinander zu geben. In diesem Fall,der als gleichstufig temperiert bezeichnet wird, liegt F2 um einen Halbton über F1, das heißt:F2 = F1 ·2
112 . Zumindest grob lässt sich aus dieser Darstellung erkennen, dass das menschliche
Gehör in etwa logarithmisch funktionieren muss, ein doppelt so groß empfundener Abstandvon F2 zu F1 entspricht einem doppelten log( F2
F1 ).
2.3.2. Mel-Skala
Lässt man Testhörer den wahrnehmbaren Frequenzbereich in gleich große Intervalle auftei-len, ergibt sich in Einheiten von Hertz eine ungleiche Einteilung, bei der, bis etwa 1.000 Hz,die Frequenzintervalle angenähert gleich groß sind, während sie bei weiter wachsenden Fre-quenzen größer werden. Verzerrt man die Frequenzskala so, dass gleich groß empfundeneIntervalle auch auf der Skala gleich sind, dann erhält man die Mel-Skala mit der nichtlinearenVerzerrungsfunktion
Mel( f ) = 2.595 log(1 +
f700
),
deren Parameter durch die oben beschriebenen Experimente bestimmt worden sind.4
2.3.3. Bark-Skala
Misst man die Intensität, die ein einzelner Ton bei 1 kHz haben muss, um wahrgenommen zuwerden, erhält man im Mittel +3 dB als Schwellwert. Benutzt man zwei Töne, die im Ab-stand von 20 Hz um 1 kHz liegen, muss jeder von Ihnen 0 dB als Intensität haben, um gehörtzu werden. Es bleibt also der Gesamtpegel konstant, was wenig Erstaunen hervorruft. Nimmtman zwei weitere Töne mit jeweils 20 Hz Abstand hinzu, ist der Schwellwert bei -3 dB, beiacht Tönen -6 dB. Bis dahin bleibt also der Gesamtpegel weiter konstant. Nimmt man aller-dings weitere Töne hinzu, endet bei 1.000 Hz nach 9 Tönen diese Regelmäßigkeit, stattdessen
4Diese Definition der Mel-Skala wurde von Stanley Smith Stevens eingeführt. Dabei wird dem Ton mit derFrequenz f = 1.000 Hz der Wert von 1.000 mel zugeordnet. Später wurde von Eberhard Zwicker eine Mel-Skala definiert, die den Ton mit der Frequenz f = 125 Hz auf 125 mel abbildet [ZF99]. Abgesehen von derNormierung sind die beiden Skalen äquivalent.
19
2. Menschliche Sprachwahrnehmung
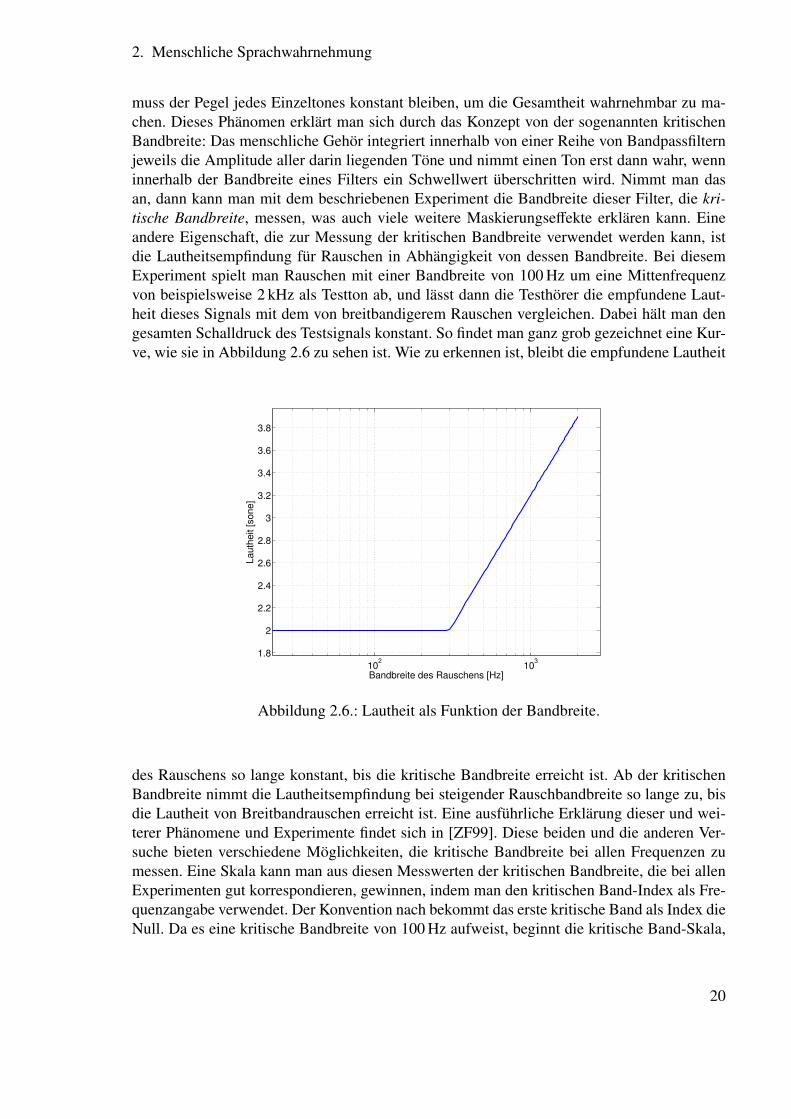
muss der Pegel jedes Einzeltones konstant bleiben, um die Gesamtheit wahrnehmbar zu ma-chen. Dieses Phänomen erklärt man sich durch das Konzept von der sogenannten kritischenBandbreite: Das menschliche Gehör integriert innerhalb von einer Reihe von Bandpassfilternjeweils die Amplitude aller darin liegenden Töne und nimmt einen Ton erst dann wahr, wenninnerhalb der Bandbreite eines Filters ein Schwellwert überschritten wird. Nimmt man dasan, dann kann man mit dem beschriebenen Experiment die Bandbreite dieser Filter, die kri-tische Bandbreite, messen, was auch viele weitere Maskierungseffekte erklären kann. Eineandere Eigenschaft, die zur Messung der kritischen Bandbreite verwendet werden kann, istdie Lautheitsempfindung für Rauschen in Abhängigkeit von dessen Bandbreite. Bei diesemExperiment spielt man Rauschen mit einer Bandbreite von 100 Hz um eine Mittenfrequenzvon beispielsweise 2 kHz als Testton ab, und lässt dann die Testhörer die empfundene Laut-heit dieses Signals mit dem von breitbandigerem Rauschen vergleichen. Dabei hält man dengesamten Schalldruck des Testsignals konstant. So findet man ganz grob gezeichnet eine Kur-ve, wie sie in Abbildung 2.6 zu sehen ist. Wie zu erkennen ist, bleibt die empfundene Lautheit
102
103
1.8
2
2.2
2.4
2.6
2.8
3
3.2
3.4
3.6
3.8
Bandbreite des Rauschens [Hz]
La
uth
eit [
so
ne
]
Abbildung 2.6.: Lautheit als Funktion der Bandbreite.
des Rauschens so lange konstant, bis die kritische Bandbreite erreicht ist. Ab der kritischenBandbreite nimmt die Lautheitsempfindung bei steigender Rauschbandbreite so lange zu, bisdie Lautheit von Breitbandrauschen erreicht ist. Eine ausführliche Erklärung dieser und wei-terer Phänomene und Experimente findet sich in [ZF99]. Diese beiden und die anderen Ver-suche bieten verschiedene Möglichkeiten, die kritische Bandbreite bei allen Frequenzen zumessen. Eine Skala kann man aus diesen Messwerten der kritischen Bandbreite, die bei allenExperimenten gut korrespondieren, gewinnen, indem man den kritischen Band-Index als Fre-quenzangabe verwendet. Der Konvention nach bekommt das erste kritische Band als Index dieNull. Da es eine kritische Bandbreite von 100 Hz aufweist, beginnt die kritische Band-Skala,
20

2. Menschliche Sprachwahrnehmung
die Bark-Skala mit
0 Hz↔ 0 Bark100 Hz↔ 1 Bark
...
Die Mittenfrequenz bekommt einen Offset von 0,5 Bark, sodass 50 Hz genau 0,5 Bark entspre-chen.
2.3.4. Gerade wahrnehmbare Frequenzunterschiede
Schließlich kann man das menschliche Frequenzempfinden noch untersuchen, indem man tes-tet, wie groß ein Unterschied zwischen zwei Frequenzen sein muss, damit er gerade ebenwahrgenommen wird. Dieser Frequenzunterschied wird in der englischen Fachliteratur alsjust audible pitch step bezeichnet, und kann auch als Maß für die Einteilung des hörbarenFrequenzbereichs verwendet werden, was dann zwischen 0 Hz und 16.000 Hz eine Skala von640 Schritten ergibt.
2.3.5. Vergleich der Skalen
Vergleicht man alle diese Skalen - die Skala der empfundenen Intervallgrößen von 0 bis2.400 mel, die Skala der kritischen Bandbreite von 0 bis 24 Bark und die Skala der geradewahrnehmbaren Frequenzunterschiede in 640 Schritten mit der Anordnung der Resonanzfre-quenzen auf der Cochlea, ergibt sich folgende Abbildung 2.7. Daraus lässt sich zumindest eine
HelicotremaOvales FensterCochlea
Länge [mm]
Anzahl der Schritte
Pitch [mel]
Kritische Bänder [Bark]
Frequenz [kHz]
0
0
0
0
0
3224168
640480320160
240018001200600
211593 2418126
84210,50,25 16
Abbildung 2.7.: Verschiedene Frequenzskalen, bezüglich der Resonanzorte auf der Cochleaweitestgehend linear, nichtlinear bezüglich der Frequenz in [Hz].
Tatsache erkennen: Weder die lineare Frequenz noch eine völlig logarithmische Skala sind gutgeeignet, um die empfundene Tonhöhe zu beschreiben. Demgegenüber bildet die abgerollteCochlea eine Skala, in Bezug auf welche sich die Mel-, die Bark- und die Just-Noticeable-Difference-Skala angenähert linear verhalten. Zwar ist dies keine exakte Beziehung, so sinddie Bark- und die Mel-Skala relativ zueinander auch leicht nichtlinear, aber die Annäherungist viel besser, als das entweder eine lineare oder eine logarithmische Skala liefern kann.
21
2. Menschliche Sprachwahrnehmung
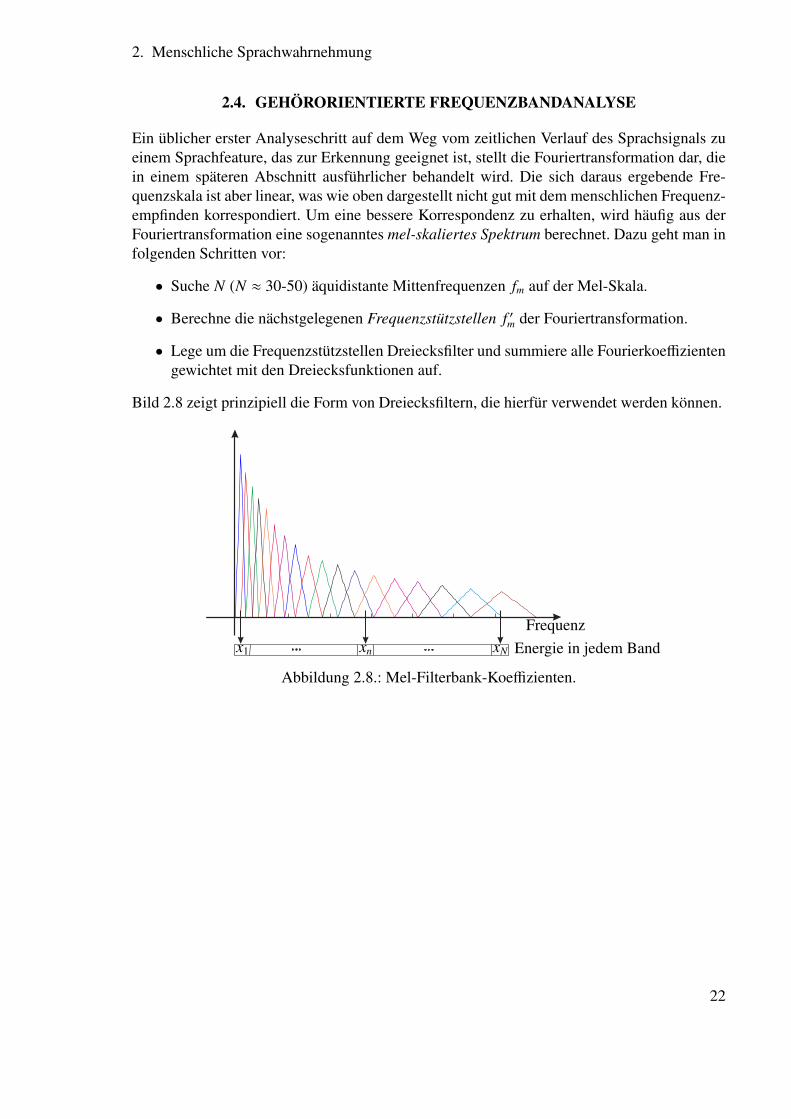
2.4. GEHÖRORIENTIERTE FREQUENZBANDANALYSE
Ein üblicher erster Analyseschritt auf dem Weg vom zeitlichen Verlauf des Sprachsignals zueinem Sprachfeature, das zur Erkennung geeignet ist, stellt die Fouriertransformation dar, diein einem späteren Abschnitt ausführlicher behandelt wird. Die sich daraus ergebende Fre-quenzskala ist aber linear, was wie oben dargestellt nicht gut mit dem menschlichen Frequenz-empfinden korrespondiert. Um eine bessere Korrespondenz zu erhalten, wird häufig aus derFouriertransformation eine sogenanntes mel-skaliertes Spektrum berechnet. Dazu geht man infolgenden Schritten vor:
• Suche N (N ≈ 30-50) äquidistante Mittenfrequenzen fm auf der Mel-Skala.
• Berechne die nächstgelegenen Frequenzstützstellen f ′m der Fouriertransformation.
• Lege um die Frequenzstützstellen Dreiecksfilter und summiere alle Fourierkoeffizientengewichtet mit den Dreiecksfunktionen auf.
Bild 2.8 zeigt prinzipiell die Form von Dreiecksfiltern, die hierfür verwendet werden können.
FrequenzEnergie in jedem Bandx1 xn xN
Abbildung 2.8.: Mel-Filterbank-Koeffizienten.
22

3. Wahrscheinlichkeitsrechnung
Die klassische Wahrscheinlichkeitsrechnung1 befasst sich mit Ergebnissen von Zufallsexperi-menten. Ein Zufallsexperiment ist ein Experiment
• zu dem der Raum aller möglichen Ergebnisse bekannt ist,
• bei dem man aber im Voraus den Ausgang eines konkreten Versuchs nicht kennt und
• das unter identischen Bedingungen wiederholt werden kann.
Den Raum aller möglichen Ergebnisse eines Zufallsexperiments bezeichnet man als den Er-eignisraum Ω.
Wenn dann bei N Versuchen ein Ereignis A ∈ Ω K-mal auftritt, bezeichnet man mit
PN(A) =KN
die relative Häufigkeit von A.Die Wahrscheinlichkeit von A ist definiert als der Grenzwert der relativen Häufigkeit:2
P(A) = limN→∞
PN(A) = limN→∞
KN.
Eine Zufallsvariable ist eine Funktion
x : Ω→ R,
die den Ereignisraum auf den Raum der reellen Zahlen abbildet, beispielsweise die Punkte
1Mehr Informationen dazu sind zum Beispiel auf der Internetseite des Instituts für Stochastik der JohannesKepler Universität Linz zu finden [JKUL].
2Man kann Wahrscheinlichkeiten auch ganz anders einführen, unter Verzicht auf relative Häufigkeiten in unend-lich vielen Experimenten. Das zeigt E.T. Jaynes in [JB03], wo Wahrscheinlichkeiten, ganz grob gesprochen,mit dem Grad der Plausibilität eines bestimmten Ereignisses gleichgesetzt werden, und wo auf interessanteWeise gezeigt wird, warum aus ganz wenigen Annahmen, die alle nur den „gesunden Menschenverstand“wiederspiegeln, alle bekannten Regeln der Wahrscheinlichkeitsrechnung folgen.
23
3. Wahrscheinlichkeitsrechnung
beim Skat:
Kartenwert → Punktex : 7 → 0
8 → 09 → 0
10 → 10B → 2D → 3K → 4
As → 11
Grundsätzlich unterscheidet man diskrete und kontinuierliche Zufallsvariablen.
3.1. DISKRETE ZUFALLSVARIABLEN
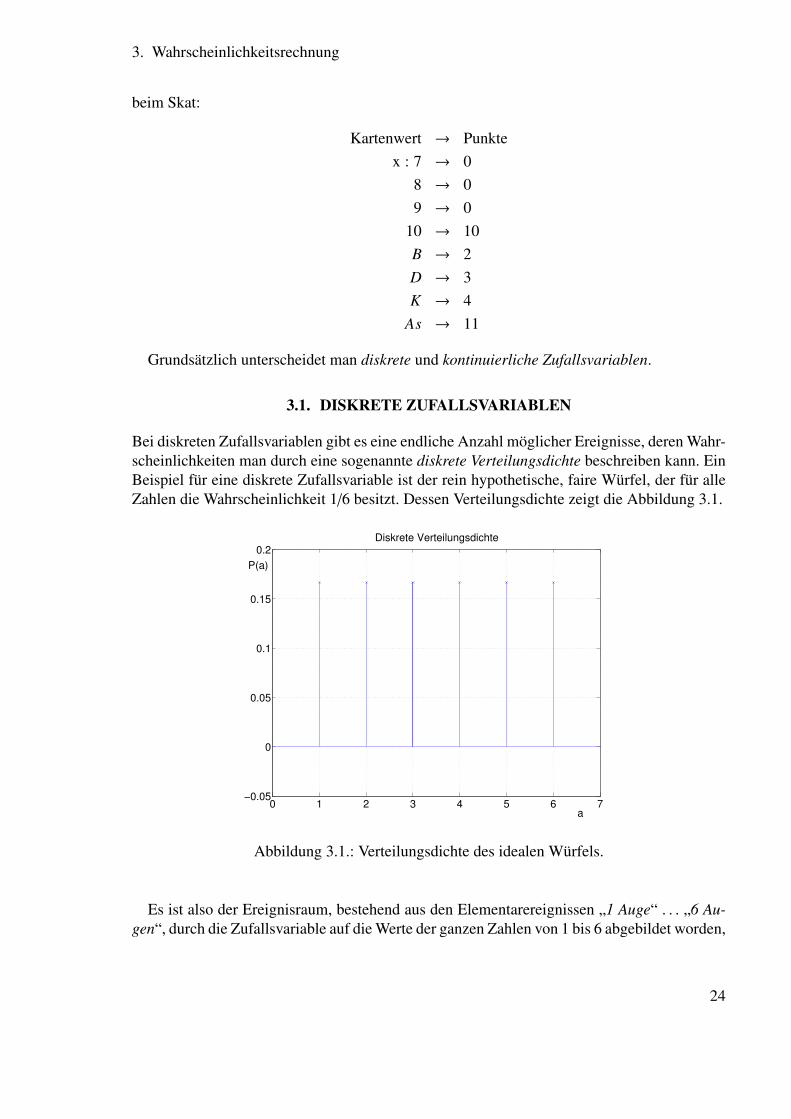
Bei diskreten Zufallsvariablen gibt es eine endliche Anzahl möglicher Ereignisse, deren Wahr-scheinlichkeiten man durch eine sogenannte diskrete Verteilungsdichte beschreiben kann. EinBeispiel für eine diskrete Zufallsvariable ist der rein hypothetische, faire Würfel, der für alleZahlen die Wahrscheinlichkeit 1/6 besitzt. Dessen Verteilungsdichte zeigt die Abbildung 3.1.
0 1 2 3 4 5 6 7−0.05
0
0.05
0.1
0.15
0.2
a
Diskrete Verteilungsdichte
P(a)
Abbildung 3.1.: Verteilungsdichte des idealen Würfels.
Es ist also der Ereignisraum, bestehend aus den Elementarereignissen „1 Auge“ . . . „6 Au-gen“, durch die Zufallsvariable auf die Werte der ganzen Zahlen von 1 bis 6 abgebildet worden,
24
3. Wahrscheinlichkeitsrechnung
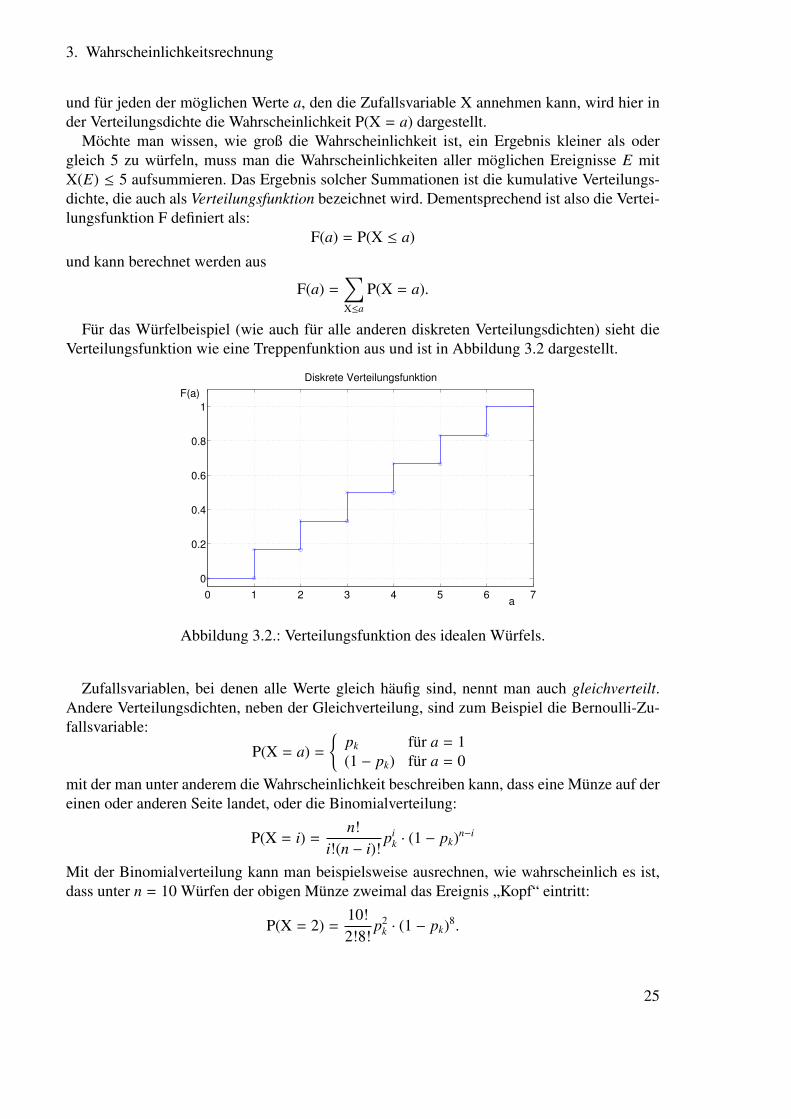
und für jeden der möglichen Werte a, den die Zufallsvariable X annehmen kann, wird hier inder Verteilungsdichte die Wahrscheinlichkeit P(X = a) dargestellt.
Möchte man wissen, wie groß die Wahrscheinlichkeit ist, ein Ergebnis kleiner als odergleich 5 zu würfeln, muss man die Wahrscheinlichkeiten aller möglichen Ereignisse E mitX(E) ≤ 5 aufsummieren. Das Ergebnis solcher Summationen ist die kumulative Verteilungs-dichte, die auch als Verteilungsfunktion bezeichnet wird. Dementsprechend ist also die Vertei-lungsfunktion F definiert als:
F(a) = P(X ≤ a)
und kann berechnet werden aus
F(a) =∑X≤a
P(X = a).
Für das Würfelbeispiel (wie auch für alle anderen diskreten Verteilungsdichten) sieht dieVerteilungsfunktion wie eine Treppenfunktion aus und ist in Abbildung 3.2 dargestellt.
0 1 2 3 4 5 6 7
0
0.2
0.4
0.6
0.8
1
Diskrete Verteilungsfunktion
F(a)
a
Abbildung 3.2.: Verteilungsfunktion des idealen Würfels.
Zufallsvariablen, bei denen alle Werte gleich häufig sind, nennt man auch gleichverteilt.Andere Verteilungsdichten, neben der Gleichverteilung, sind zum Beispiel die Bernoulli-Zu-fallsvariable:
P(X = a) =
pk für a = 1(1 − pk) für a = 0
mit der man unter anderem die Wahrscheinlichkeit beschreiben kann, dass eine Münze auf dereinen oder anderen Seite landet, oder die Binomialverteilung:
P(X = i) =n!
i!(n − i)!pi
k · (1 − pk)n−i
Mit der Binomialverteilung kann man beispielsweise ausrechnen, wie wahrscheinlich es ist,dass unter n = 10 Würfen der obigen Münze zweimal das Ereignis „Kopf“ eintritt:
P(X = 2) =10!2!8!
p2k · (1 − pk)8.
25

3. Wahrscheinlichkeitsrechnung
Dabei stellt n die Anzahl der Experimente dar, i die Anzahl der positiven Ereignisse und pk
die Wahrscheinlichkeit eines positiven Ereignisses in einem Einzelexperiment. Wie kann mansich die Binomialverteilung erklären?
3.2. KONTINUIERLICHE ZUFALLSVARIABLEN
Wenn man ein Kontinuum möglicher Ereignisse beschreiben möchte, funktionieren diskreteZufallsvariablen nur noch schlecht. Wenn beispielsweise ein Anfänger auf eine Bowlingbahngeht, und den Ball wie in Abbildung 3.3 in Richtung Kugeln rollt und dabei einen Abwurf-winkel zur Optimalrichtung von α = 9, 743457 erzielt, dann ist die Wahrscheinlichkeit diesesEreignisses p(α = 9, 743457) gleich Null, da es unendlich viele andere Winkel gibt, die ergenauso gut oder noch wahrscheinlicher hätte treffen können. Auch bei einem Profi würdees nicht einfacher werden. Selbst dann, wenn jahrzehntelanges Training garantiert, dass derWinkel nie um mehr als 1 vom Optimum abweicht, gibt es doch innerhalb der 2 Breiteunendlich viele mögliche Ergebnisse. Um solche Fälle kontinuierlicher Zufallsvariablen zu
Abbildung 3.3.: Zufallsexperiment im Bowling.
beschreiben, benutzt man das Konzept einer Verteilungsdichte f. Diese beschreibt die Ablei-tung der (kumulativen) Verteilungsfunktion F(a) = P(X ≤ a), das heißt:
f(a) =d
daP(X ≤ a).
Bild 3.4 zeigt, wie man diese Funktion benutzt: Wenn die Wahrscheinlichkeit gesucht ist,dass der Abwurfwinkel in einem bestimmten Bereich (hier zwischen -10 und +10) liegt,integriert man die Verteilungsdichtefunktion über diesen Bereich. Das heißt hier also konkret:
P(−10 ≤ α ≤ 10) =
∫ 10
−10f(α)dα.
Dabei ist es egal, ob man als Operator < oder ≤wählt, da die Wahrscheinlichkeit des einzelnenWertes wieder bei Null liegt. Im Überblick zeigt Abbildung 3.5 die wichtigsten Eigenschaftenvon diskreten und kontinuierlichen Verteilungsdichten und -funktionen.
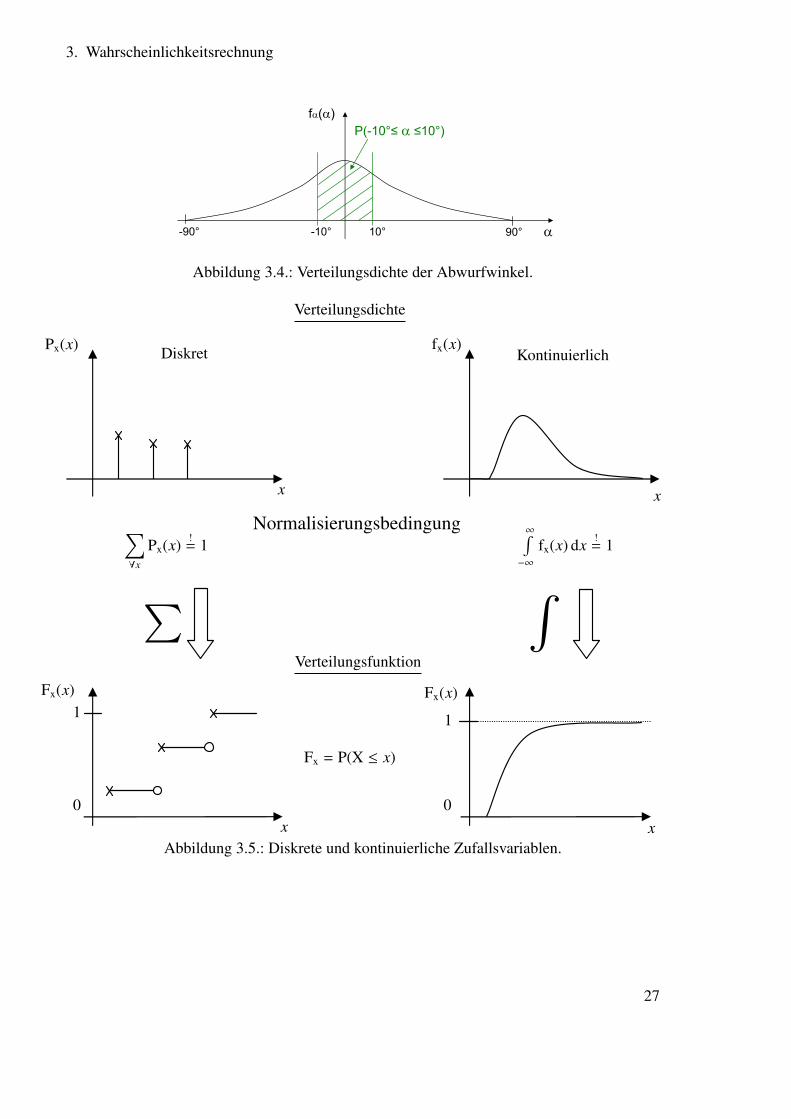
26
3. Wahrscheinlichkeitsrechnung
-10° 10°
f ( )
P(-10° 10°)
90°-90°
Abbildung 3.4.: Verteilungsdichte der Abwurfwinkel.
Px(x)
Verteilungsdichte
Normalisierungsbedingung
Verteilungsfunktion
x
x
Diskret
Fx(x)
∑∀x
Px(x) != 1
Fx = P(X ≤ x)
0
Fx(x)
fx(x)
x
x
Kontinuierlich
∞∫−∞
fx(x) dx != 1
0
11
Abbildung 3.5.: Diskrete und kontinuierliche Zufallsvariablen.
27
3. Wahrscheinlichkeitsrechnung
Wichtige kontinuierliche Verteilungsfunktionen
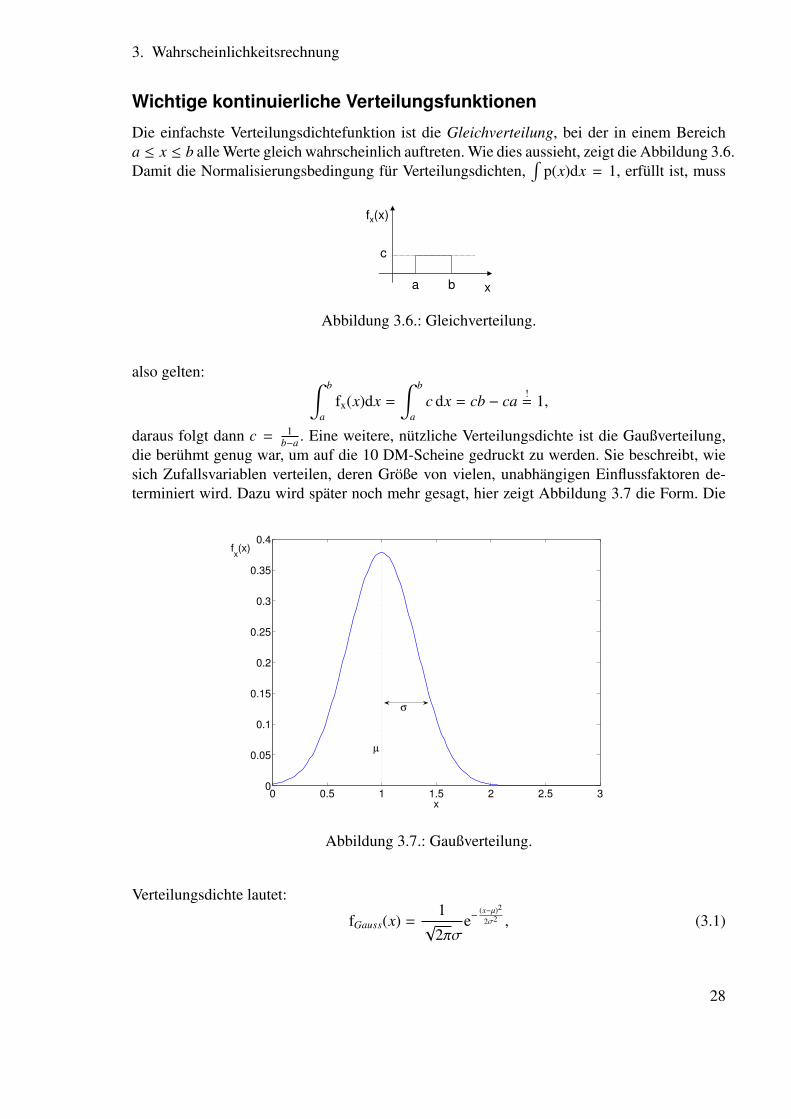
Die einfachste Verteilungsdichtefunktion ist die Gleichverteilung, bei der in einem Bereicha ≤ x ≤ b alle Werte gleich wahrscheinlich auftreten. Wie dies aussieht, zeigt die Abbildung 3.6.Damit die Normalisierungsbedingung für Verteilungsdichten,
∫p(x)dx = 1, erfüllt ist, muss
fx(x)
xa b
c
Abbildung 3.6.: Gleichverteilung.
also gelten: ∫ b
afx(x)dx =
∫ b
ac dx = cb − ca !
= 1,
daraus folgt dann c = 1b−a . Eine weitere, nützliche Verteilungsdichte ist die Gaußverteilung,
die berühmt genug war, um auf die 10 DM-Scheine gedruckt zu werden. Sie beschreibt, wiesich Zufallsvariablen verteilen, deren Größe von vielen, unabhängigen Einflussfaktoren de-terminiert wird. Dazu wird später noch mehr gesagt, hier zeigt Abbildung 3.7 die Form. Die
0 0.5 1 1.5 2 2.5 30
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
x
fx(x)
µ
σ
Abbildung 3.7.: Gaußverteilung.
Verteilungsdichte lautet:
fGauss(x) =1√
2πσe−
(x−µ)2
2σ2 , (3.1)
28

3. Wahrscheinlichkeitsrechnung
wobei µ den Mittelwert und auch den Ort des Maximums und der Symmetrieachse darstelltund σ die Standardabweichung. Zu diesen beiden Parametern gibt es mehr Informationen imAbschnitt 3.3. Die Gaußverteilung wird sehr häufig verwendet, sodass sich eine abkürzendeSchreibung durchgesetzt hat:
N(x, µ, σ2) def=
1√
2πσ2e−
(x−µ)2
2σ2 ,
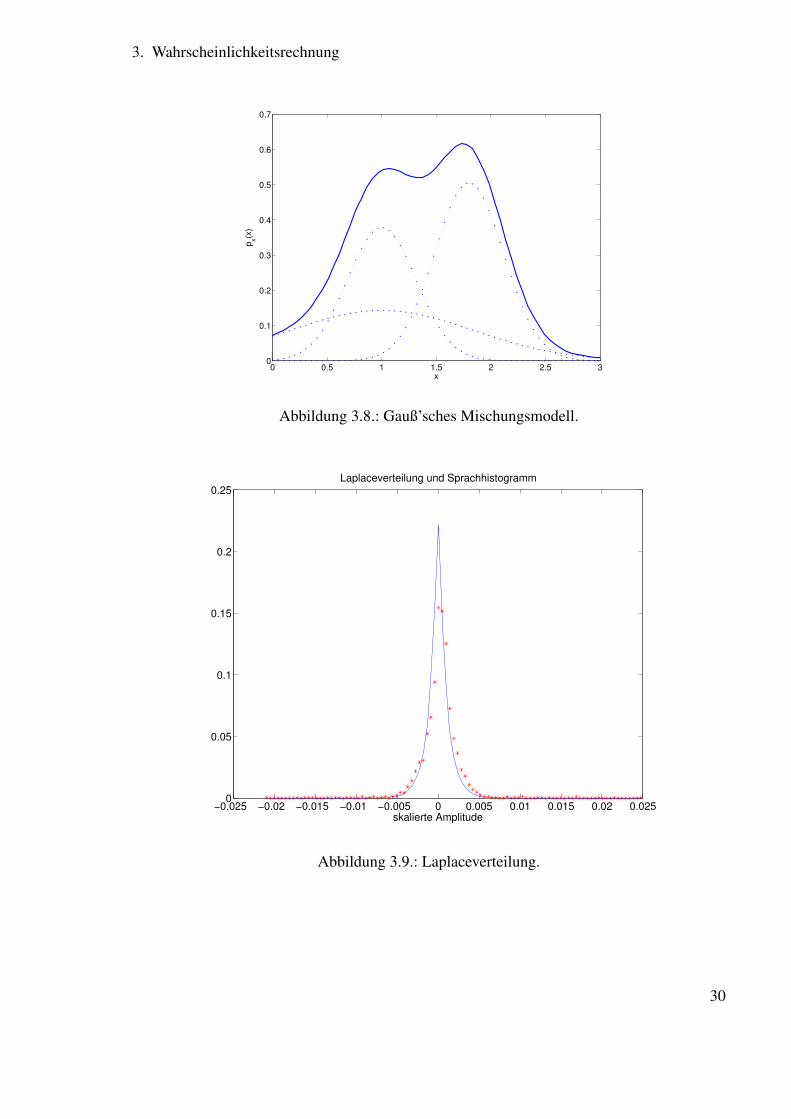
es ist also N(x, µ, σ2) die Verteilung einer gaußverteilten Zufallsvariable x mit dem Mittel-wert µ und der Standardabweichung σ. Eine nützliche Erweiterung der Gaußverteilung ist dieGauß’sche Mischverteilung (engl.: Mixture of Gaussians (MOG)). Sie ist beliebt weil
• man mit einer MOG-Verteilung beliebige Verteilungsdichten mit beliebiger Genauigkeitapproximieren kann [AS72] und weil
• es mit dem Expectation-maximization (EM)-Algorithmus ein Verfahren gibt, das zumAnpassen einer MOG-Verteilung an beliebige Datensätze geeignet ist.
Die Gauß’sche Mischverteilung ist eine gewichtete Summe von einzelnen Gaußverteilungen:
p(x) =
K∑i=1
γiN(x, µi, σi). (3.2)
Damit sie richtig normiert ist, müssen die Mischungsgewichte γ sich zu 1 addieren:
K∑i=1
γi!= 1.
Ein Beispiel einer MOG-Verteilung wird in Bild 3.8 gezeigt, dort sieht man, wie sie aussehenkann, wenn sie aus drei Komponenten (also drei überlagerten Gaußverteilungen) besteht.
Schließlich zählt noch die Laplaceverteilung zu den interessanteren Verteilungen dieser Ver-anstaltung, weil sie gut die Verteilungsdichte von Sprachsignalen annähert. Abbildung 3.9zeigt die Laplaceverteilung im Vergleich mit dem Histogramm eines Sprachausschnitts. DieVerteilungsdichte der Laplaceverteilung lautet
p(x) =1
2be−
|x−µ|b ,
wobei µ der Erwartungswert und b der Skalenparameter ist.
3.3. EIGENSCHAFTEN VON ZUFALLSVARIABLEN
Der Mittelwert mn einer Zufallsvariablen x ist der mittlere Wert, den sie in n Experimentenangenommen hat:
mn =1n
n∑i=1
x(i).
29
3. Wahrscheinlichkeitsrechnung
0 0.5 1 1.5 2 2.5 30
0.1
0.2
0.3
0.4
0.5
0.6
0.7
x
px(x
)
Abbildung 3.8.: Gauß’sches Mischungsmodell.
−0.025 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.0250
0.05
0.1
0.15
0.2
0.25Laplaceverteilung und Sprachhistogramm
skalierte Amplitude
Abbildung 3.9.: Laplaceverteilung.
30

3. Wahrscheinlichkeitsrechnung
Beschreibt man die relative Häufigkeitsverteilung nach n Experimenten mit Pn(x), dann kannman also auch folgendermaßen den Mittelwert berechnen:
mn =∑∀xk
Pn(xk) · xk.
Dabei sind die xk alle Werte, die die Zufallsvariable x annehmen kann. Der Erwartungswertist der Limes des Mittelwertes für unendlich viele Versuche:
E(x) = limn→∞
mn
= limn→∞
∑∀xk
Pn(xk) · xk
=∑∀xk
limn→∞
Pn(xk) · xk
=∑∀xk
P(xk) · xk
def= µx. (3.3)
So definiert, gibt µx also an, was wir als mittleres Ergebnis des durch x beschriebenen Zu-fallsprozesses erwarten können. Wenn man außerdem berechnen möchte, wie weit sich x imMittel von seinem Mittelwert entfernt, wie breit also die Streuung des Zufallsprozesses ist,erweist sich die Standardabweichung
σxdef=
√∑xk
(xk − µx)2 · P(xk)
als günstig. Ihr Quadrat σ2 wird auch als die Varianz von x, var(x), bezeichnet.
3.4. VEKTORWERTIGE ZUFALLSVARIABLEN
Zufallsvariablen dürfen auch in Form von Vektoren auftreten, wo sie mehrere Dimensionenhaben, die voneinander ganz oder teilweise unabhängig sein dürfen. Im Weiteren werden diesemehrdimensionalen Zufallsvariablen hier als Spaltenvektoren geschrieben, zum Beispiel so:
x =
x1
x2...
xm
.Wenn man jetzt den Erwartungswert µx genauso berechnet, wie das in (3.3) definiert wurde,also über ∑
∀xk
P(xk) · xk,
31

3. Wahrscheinlichkeitsrechnung
erhält man auch für den Erwartungswert einen Vektor, der die selbe Dimension besitzt wie dieZufallsvariable x:
µx =
µx1
µx2...µxm
.Eine Frage, die bei mehreren Zufallsvariablen (z. B. x und y) auftaucht ist die, wie stark dieVariablen miteinander korreliert sind, das heißt, wie weit sie im Mittel gleichzeitig und in diegleiche Richtung von ihren jeweiligen Mittelwerten abweichen. Um diese Frage zu beantwor-ten, muss man also folgenden Ausdruck berechnen:3
Cov(x, y) = E((x − µx)(y − µy)
).
Sind die interessanten Zufallsvariablen in einem Vektor zusammengefasst, kann man die Kor-relationen aller Komponenten von x durch eine einzige Operation berechnen, das Ergebnisbezeichnet man als Kovarianzmatrix Cx(x):
Cx(x) = E((x − µ)(x − µ)ᵀ
).
Welche Dimension hat die Kovarianzmatrix, wenn x aus 3 Elementen besteht? Welche Einträ-ge hat dann Cx(x) im Einzelnen?Neben der Kovarianzmatrix ist außerdem die Autokorrelationsmatrix Rx(x) interessant, diesich von der Kovarianzmatrix dadurch unterscheidet, dass der Mittelwert nicht subtrahiertwird:
Rx(x) = E(x xᵀ).
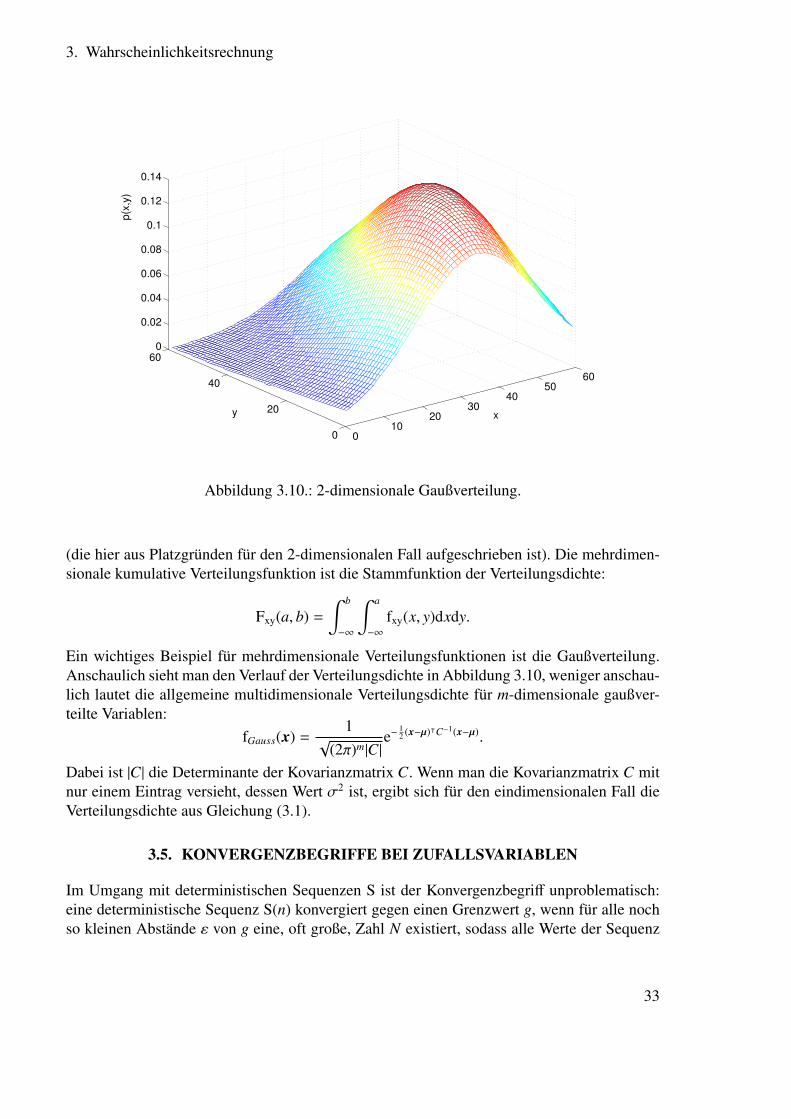
Wie sieht die Autokorrelationsmatrix einer 4-dimensionalen Zufallsvariablen aus?Die Autokorrelationsmatrix wird oft für Zufallsvektoren berechnet, die sich aus einzelnenSamples eines Zufallsprozesses zu verschiedenen Zeitpunkten zusammensetzt, wo also giltx = [x(t = 0), x(t = T s), x(t = 2T s) . . .]ᵀ.Auch für 2- und beliebige m-dimensionale Zufallsvariablen kann man das Verhalten über Ver-teilungsdichten beschreiben. Wieder gibt dann das Integral über einen Bereich der Verteilungs-dichte an, wie wahrscheinlich es ist, dass der Zufallsvektor in diesem Bereich liegt:
P(a ≤ x ≤ b, c ≤ y ≤ d) =
∫ d
c
∫ b
afxy(x, y)dxdy
Hier handelt es sich also, wie auch in Abbildung 3.10 veranschaulicht, um eine mehrdimensio-nale Verteilungsdichte und dementsprechend muss auch das Integral als Flächen-, Volumen-oder allgemein mehrdimensionales Integral ausgeführt werden. Auch hier gilt die Normie-rungsbedingung ∫ ∞
−∞
∫ ∞
−∞
fxy(x, y)dxdy != 1,
3Damit bestimmt man die Kovarianz, der Korrelationskoeffizient von zwei Variablen ist die auf den Bereich−1 ≤ Corr ≤ 1 normierte Kovarianz.
32
3. Wahrscheinlichkeitsrechnung
010
2030
4050
60
0
20
40
600
0.02
0.04
0.06
0.08
0.1
0.12
0.14
xy
p(x
,y)
Abbildung 3.10.: 2-dimensionale Gaußverteilung.
(die hier aus Platzgründen für den 2-dimensionalen Fall aufgeschrieben ist). Die mehrdimen-sionale kumulative Verteilungsfunktion ist die Stammfunktion der Verteilungsdichte:
Fxy(a, b) =
∫ b
−∞
∫ a
−∞
fxy(x, y)dxdy.
Ein wichtiges Beispiel für mehrdimensionale Verteilungsfunktionen ist die Gaußverteilung.Anschaulich sieht man den Verlauf der Verteilungsdichte in Abbildung 3.10, weniger anschau-lich lautet die allgemeine multidimensionale Verteilungsdichte für m-dimensionale gaußver-teilte Variablen:
fGauss(x) =1
√(2π)m|C|
e−12 (x−µ)ᵀC−1(x−µ).
Dabei ist |C| die Determinante der Kovarianzmatrix C. Wenn man die Kovarianzmatrix C mitnur einem Eintrag versieht, dessen Wert σ2 ist, ergibt sich für den eindimensionalen Fall dieVerteilungsdichte aus Gleichung (3.1).
3.5. KONVERGENZBEGRIFFE BEI ZUFALLSVARIABLEN
Im Umgang mit deterministischen Sequenzen S ist der Konvergenzbegriff unproblematisch:eine deterministische Sequenz S(n) konvergiert gegen einen Grenzwert g, wenn für alle nochso kleinen Abstände ε von g eine, oft große, Zahl N existiert, sodass alle Werte der Sequenz
33

3. Wahrscheinlichkeitsrechnung
für n > N einen kleineren Abstand als ε von g haben. Das Konvergenzkriterium lautet also:S(n) konvergiert gegen g genau dann wenn:
∀ ε∃N : |S(n) − g| ≤ ε ∀n > N.
Bei Zufallsvariablen ist dieser einfache Test nicht ausreichend, um die vielen möglichen Situa-tionen zu beschreiben, stattdessen werden verschiedene Konvergenzkriterien je nach Situationbenötigt. Um Konvergenz4 definieren zu können, braucht man zunächst eine Sequenz von Zu-fallsvariablen: X1 . . .XN , mit der Möglichkeit, dass N → ∞, darauf aufbauend werden dannverschiedene Formen von Konvergenz definiert.
3.5.1. Konvergenz „in Distribution“
Diese Art der Konvergenz ist auch bekannt als die schwache Konvergenz, und stellt das schwächs-te der behandelten Kriterien dar. Eine Sequenz von Zufallsvariablen X1 . . .XN konvergiertschwach („in Distribution“) gegen X, wenn die zugehörigen Verteilungsfunktionen F1 . . . FN
gegen die Verteilungsfunktion von X konvergieren, also:
XnD→ X g.d.w. lim
n→∞Fn = F.
Diese Art von Konvergenzkriterium benutzt der zentrale Grenzwertsatz: Es seien X1 . . .Xn
eine Menge von identisch verteilten, unabhängigen Zufallsvariablen mit dem Mittelwert µund der Varianz σ2. Dann konvergiert die Verteilung von ihrer normierten Summe Xsn „inDistribution“ gegen die Gaußverteilung mit Mittelwert 0 und Varianz 1. Anders geschriebenheißt das:
Xsn
def=
∑ni=1 Xi − nµσ√
nD→ N(Xs, 0, 1).
Hier soll wieder N(x, µ, σ2) eine Gaußverteilung mit Mittelwert µ und Standardabweichungσ darstellen.
3.5.2. Konvergenz „in Wahrscheinlichkeit“
Eine Folge von Zufallsvariablen X1 . . .XN konvergiert „in Wahrscheinlichkeit“ gegen X, wenndie Wahrscheinlichkeit einer beliebig kleinen, festen Abweichung mit zunehmendem n zu Nullwird:
XnPr.→ X g.d.w. ∀ε : lim
n→∞P(|Xn − X| > ε
)= 0.
Diese Art von Konvergenzkriterium benutzt das schwache Gesetz der großen Zahl. Diesesbesagt: Wenn X1 . . .Xn unkorrelierte Variablen mit dem selben Mittelwert µ und identischerVarianz σ sind, dann konvergiert der Mittelwert ihrer Summe „in Wahrscheinlichkeit“ gegenden Erwartungswert: ∑N
i=1 Xi
NPr→ µ.
Konvergenz in Wahrscheinlichkeit impliziert schwache Konvergenz.4Mehr Informationen dazu sind zum Beispiel im Skript der Vorlesung Wahrscheinlichkeitsrechnung der Uni-
versität Ulm zu finden [UU04].
34

3. Wahrscheinlichkeitsrechnung
3.5.3. Konvergenz „with Probability 1“
Dies ist ein starkes Konvergenzkriterium, aus Konvergenz „with Probability 1“ kann man aufbeide oben genannte Konvergenzformen schließen. Konvergenz with Probability 1 wird auchals fast sichere Konvergenz, als almost sure convergence und als convergence almost every-where bezeichnet. Eine Folge von Zufallsvariablen X1 . . .XN konvergiert „with probability 1“oder „almost surely“ gegen X, wenn unendlich viel mehr Sequenzen dieser Zufallsvariablenexistieren, die exakt konvergieren, als solche die es nicht tun, anders ausgedrückt
Xna.s.→ X g.d.w. P
(limn→∞
(Xn) = X)
= 1.
Das Konzept der starken Konvergenz wird vom starken Gesetz der großen Zahl benutzt. Dasstarke Gesetz der großen Zahl sagt: Wenn X1 . . .Xn identisch verteilte, unabhängige Variablenmit dem Mittelwert µ und mit begrenzter Varianz σ2 sind, dann konvergiert der Mittelwertihrer Summe fast sicher gegen den Erwartungswert:∑N
i=1 Xi
Na.s.→ µ.
3.5.4. Konvergenz im r-ten Mittel
Konvergenz im r-ten Mittel bedeutet:
limn→∞
E(|Xn − X|r
)= 0.
Die wichtigsten Sonderfälle sind r = 1, dann konvergiert Xn „im Mittel“ gegen X und r = 2,dann liegt Konvergenz im quadratischen Mittel vor. Dieser Konvergenzbegriff wird später zurÜberprüfung der Leistungsfähigkeit von Schätzverfahren benötigt.
35

4. Klassifikation
Die Klassifikationstheorie beschäftigt sich mit der Frage, wie man gegebene Objekte oderDaten optimal in verschiedene Klassen einteilen kann. Die einfachste Beispielanwendung isteine Einteilung in zwei Klassen, wie zum Beispiel in der Fertigungskontrolle in intakte und de-fekte Teile oder in der Sprachvorverarbeitung in Sprachsegmente und Nicht-Sprachsegmente.Komplexer wird die Situation, wenn beispielsweise dutzende oder auch hunderte von Pho-nemmodellen oder Hidden Markov Modell (HMM)-Zuständen unterschieden werden sollen.
Die probabilistischen Klassifikationsmethoden sind aber in allen diesen Fällen anwend-bar, und gehen in den meisten Fällen zurück auf die Verwendung von Verteilungsdichten undVerteilungsfunktionen, wobei man annimmt, dass jede Klasse durch ihre eigene Verteilungs-funktion von den anderen unterschieden werden kann. Dabei können die Verteilungsfunktio-nen (die man auch als die probabilistischen Modelle der Klassen bezeichnen könnte) ein-oder mehrdimensional und diskret oder kontinuierlich sein, wie es im Überblick auch Abbil-dung 4.1 zeigt.
4.1. SATZ VON BAYES
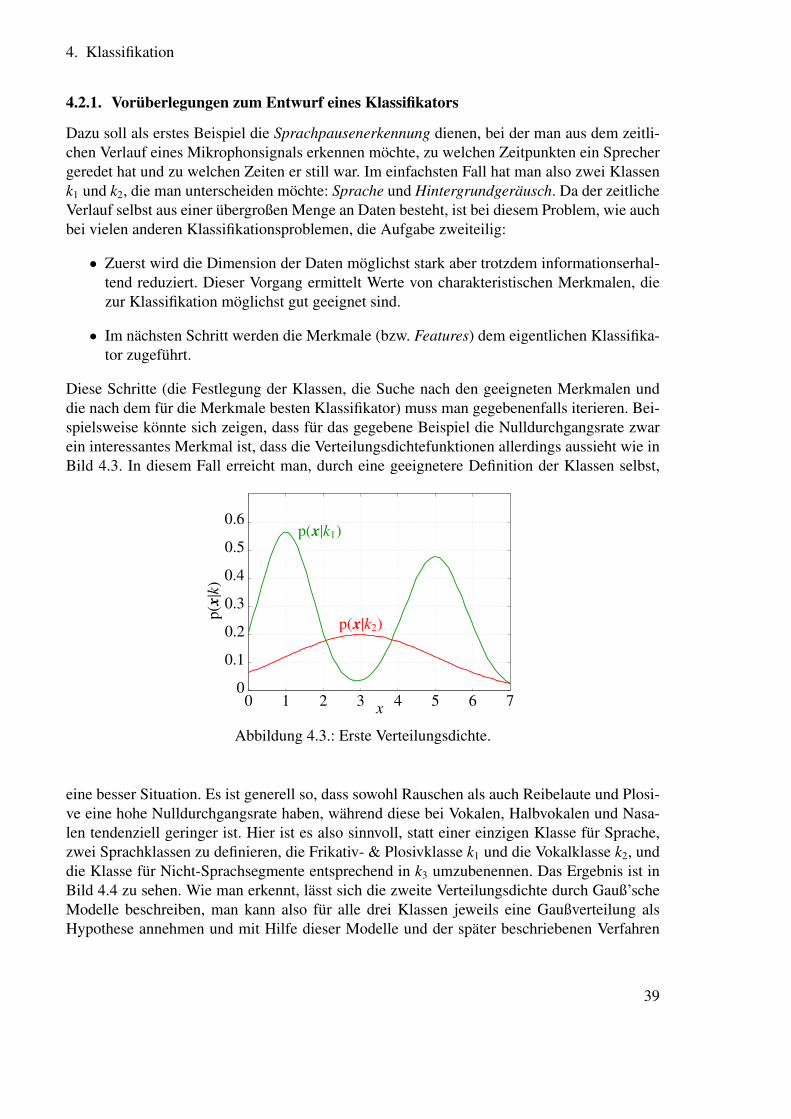
Eine wichtige Frage bei der Klassifikation ist die, wie man Vorwissen auf strukturierte Art indie Entscheidungsfindung einbeziehen kann.
Dazu zeigt Abbildung 4.2 ein Beispiel, in dem die Einbeziehung von Vorwissen recht ein-fach ist. Die Aufgabenstellung ist folgende: Es ist bekannt, mit welcher Wahrscheinlichkeites an einem beliebigen Abend regnet. Wie kann man, wenn man die zusätzliche Informationerhält, dass es am Morgen des betrachteten Tages neblig ist, diese Zusatzinformation einbe-ziehen, um das Wetter des Abends genauer vorherzusagen? In dem Beispiel hier sollen nichtnur die einzelnen Wahrscheinlichkeiten bekannt sein, sondern außerdem auch die Wahrschein-lichkeiten aller Schnittmengen von Ereignissen. Damit sind auch implizit alle Abhängigkeitender einzelnen Zufallsvariablen gegeben. Um diese festzuhalten, ist in Abbildung 4.2 ein (aus-nahmsweise eckiges) Venn-Diagramm gezeigt. Dieses veranschaulicht die Wahrscheinlichkeitdes Ereignisses A (eines nebligen Morgens) mit dem Flächenverhältnis von der Menge A zumgesamten Ereignisraum E:
P(A) =F(A)F(E)
=13
und genauso ist
P(B) =F(B)F(E)
=16.
Möchte man das Vorwissen, dass der Morgen neblig war, einbeziehen, um die Wettervorhersa-ge für den Abend zu verbessern, kann man den Ereignisraum einschränken auf die Teilmenge
36
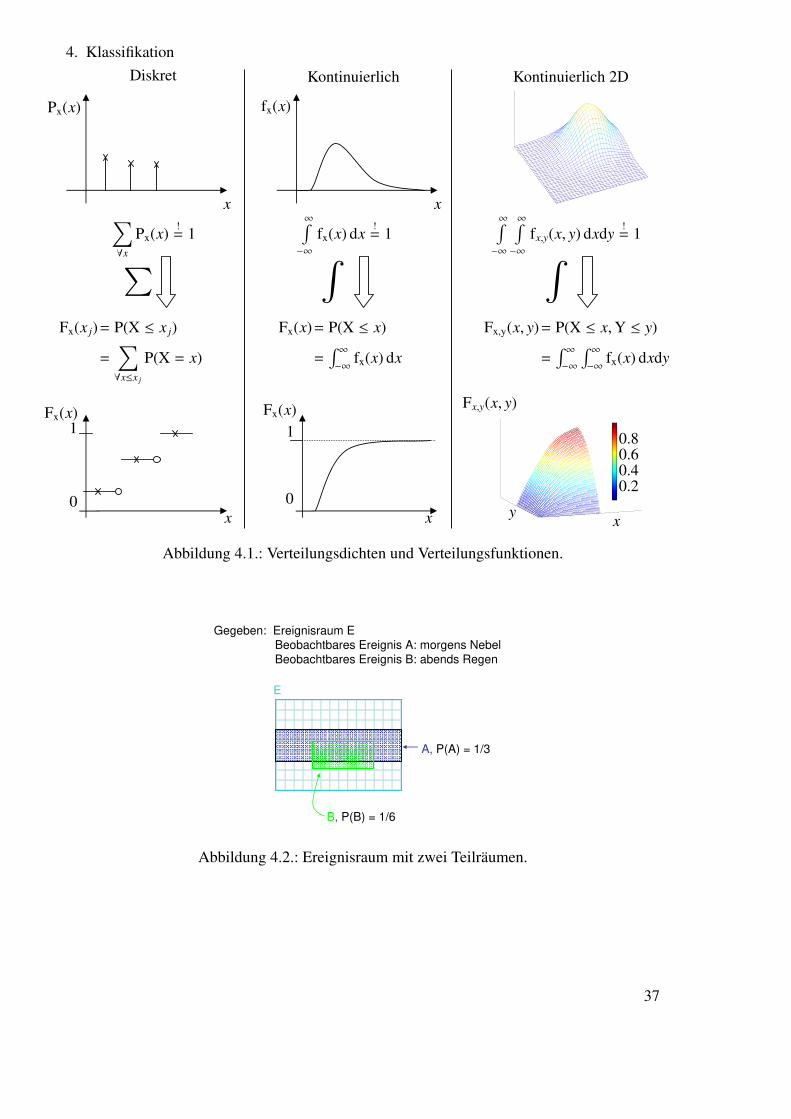
4. Klassifikation
Px(x)
x
fx(x)
xx
Diskret Kontinuierlich
Fx(x)
∑∀x
Px(x) != 1
∞∫−∞
fx(x) dx != 1
0
Fx(x)
x0
11
Fx(x j)= P(X ≤ x j)
=∑∀x≤x j
P(X = x)
Fx(x)= P(X ≤ x)
=∫ ∞−∞
fx(x) dx
Kontinuierlich 2D
Fx,y(x, y)
xy
∞∫−∞
∞∫−∞
fx,y(x, y) dxdy != 1
Fx,y(x, y)= P(X ≤ x,Y ≤ y)
=∫ ∞−∞
∫ ∞−∞
fx(x) dxdy
0.20.40.60.8
Abbildung 4.1.: Verteilungsdichten und Verteilungsfunktionen.
Gegeben: Ereignisraum E
Beobachtbares Ereignis A: morgens Nebel
Beobachtbares Ereignis B: abends Regen
E
A, P(A) = 1/3
B, P(B) = 1/6
Abbildung 4.2.: Ereignisraum mit zwei Teilräumen.
37

4. Klassifikation
des Morgennebels, also auf die Teilmenge A. Damit erhält man dann die Wahrscheinlichkeitvon B unter Einbeziehung des Vorwissens, dass A wahr ist aus den Flächenverhältnissen, aberdiesmal aus dem Teilbereich in dem A gilt:
P(B|A) =F(B ∩ A)
F(A)=
1442
=13. (4.1)
Diese Wahrscheinlichkeit nennt man bedingte Wahrscheinlichkeit und „P(B|A)“ spricht man„Wahrscheinlichkeit von B gegeben A“. Neben der Möglichkeit, Vorwissen einzubeziehen,möchte man auch Schlussketten umkehren können. Dazu hilft die Umformung von (4.1) in
P(B|A) =P(B ∩ A)
P(A)⇔ P(B ∩ A) = P(B|A)P(A).
Genauso muss auchP(A ∩ B) = P(A|B)P(B)
gelten, sodass man letztlich
P(A ∩ B) = P(B|A)P(A) = P(A|B)P(B)
⇔ P(A|B) =P(B|A)P(A)
P(B).
als Ergebnis erhält. Das ist der bekannte Satz von Bayes, der auch in einigen Variationennützlich ist. Einerseits kann man zusätzliche Informationen (zum Beispiel die Tatsache C,dass mittags die Sonne geschienen hat) jederzeit hinzunehmen, ohne dass sich etwas an derStruktur der Gleichung ändert:
P(A|B,C) =P(B|A,C)P(A|C)
P(B|C)
und andererseits kann man von bedingten Wahrscheinlichkeiten auch durch Summation auf„bedingungslose“ Wahrscheinlichkeiten, auf sogenannte Randverteilungsdichten bzw. margi-nal distributions gelangen:
P(A) =∑∀Bk
P(A|Bk)P(Bk). (4.2)
Diese Vorgehensweise wird Marginalisierung genannt und ist oft zielführend. Für kontinuier-liche Zufallsvariablen geschrieben, ergibt (4.2) den Satz von der totalen Wahrscheinlichkeit
p(a) =
∫ ∞
−∞
p(a|b)p(b)db. (4.3)
4.2. ENTWURF VON KLASSIFIKATOREN
Der Satz von Bayes ist für viele probabilistische Lernverfahren nützlich, unter anderem auchfür das Lernen von optimalen Klassifikationsregeln. Nach welchen Regeln man dabei vorge-hen kann, ist das Thema dieses Abschnitts.
38
4. Klassifikation
4.2.1. Vorüberlegungen zum Entwurf eines Klassifikators
Dazu soll als erstes Beispiel die Sprachpausenerkennung dienen, bei der man aus dem zeitli-chen Verlauf eines Mikrophonsignals erkennen möchte, zu welchen Zeitpunkten ein Sprechergeredet hat und zu welchen Zeiten er still war. Im einfachsten Fall hat man also zwei Klassenk1 und k2, die man unterscheiden möchte: Sprache und Hintergrundgeräusch. Da der zeitlicheVerlauf selbst aus einer übergroßen Menge an Daten besteht, ist bei diesem Problem, wie auchbei vielen anderen Klassifikationsproblemen, die Aufgabe zweiteilig:
• Zuerst wird die Dimension der Daten möglichst stark aber trotzdem informationserhal-tend reduziert. Dieser Vorgang ermittelt Werte von charakteristischen Merkmalen, diezur Klassifikation möglichst gut geeignet sind.
• Im nächsten Schritt werden die Merkmale (bzw. Features) dem eigentlichen Klassifika-tor zugeführt.
Diese Schritte (die Festlegung der Klassen, die Suche nach den geeigneten Merkmalen unddie nach dem für die Merkmale besten Klassifikator) muss man gegebenenfalls iterieren. Bei-spielsweise könnte sich zeigen, dass für das gegebene Beispiel die Nulldurchgangsrate zwarein interessantes Merkmal ist, dass die Verteilungsdichtefunktionen allerdings aussieht wie inBild 4.3. In diesem Fall erreicht man, durch eine geeignetere Definition der Klassen selbst,
p(x|k2)
p(x|k1)
p(x|
k)
x
0.1
0.2
0.3
0.4
0.5
0.6
00 1 2 3 4 5 6 7
Abbildung 4.3.: Erste Verteilungsdichte.
eine besser Situation. Es ist generell so, dass sowohl Rauschen als auch Reibelaute und Plosi-ve eine hohe Nulldurchgangsrate haben, während diese bei Vokalen, Halbvokalen und Nasa-len tendenziell geringer ist. Hier ist es also sinnvoll, statt einer einzigen Klasse für Sprache,zwei Sprachklassen zu definieren, die Frikativ- & Plosivklasse k1 und die Vokalklasse k2, unddie Klasse für Nicht-Sprachsegmente entsprechend in k3 umzubenennen. Das Ergebnis ist inBild 4.4 zu sehen. Wie man erkennt, lässt sich die zweite Verteilungsdichte durch Gauß’scheModelle beschreiben, man kann also für alle drei Klassen jeweils eine Gaußverteilung alsHypothese annehmen und mit Hilfe dieser Modelle und der später beschriebenen Verfahren
39
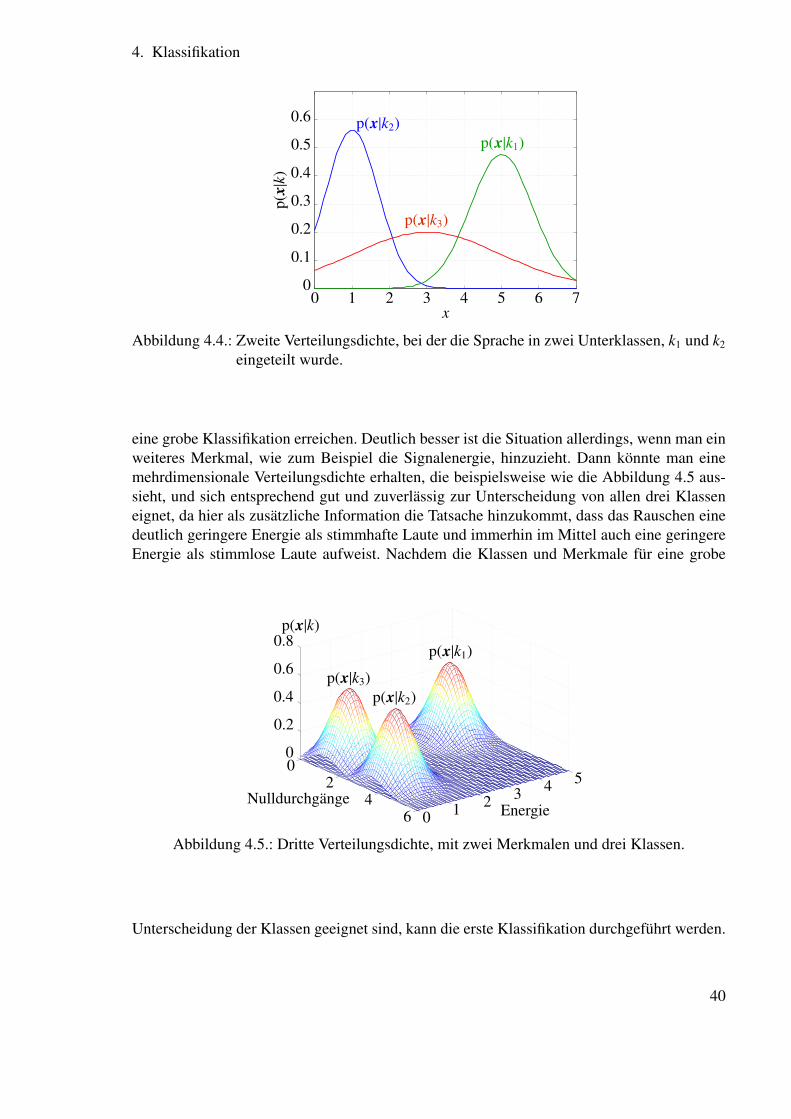
4. Klassifikation
0.1
0.2
0.3
0.4
0.5
0.6
00 1 2 3 4 5 6 7
x
p(x|
k)
p(x|k2)p(x|k1)
p(x|k3)
Abbildung 4.4.: Zweite Verteilungsdichte, bei der die Sprache in zwei Unterklassen, k1 und k2
eingeteilt wurde.
eine grobe Klassifikation erreichen. Deutlich besser ist die Situation allerdings, wenn man einweiteres Merkmal, wie zum Beispiel die Signalenergie, hinzuzieht. Dann könnte man einemehrdimensionale Verteilungsdichte erhalten, die beispielsweise wie die Abbildung 4.5 aus-sieht, und sich entsprechend gut und zuverlässig zur Unterscheidung von allen drei Klasseneignet, da hier als zusätzliche Information die Tatsache hinzukommt, dass das Rauschen einedeutlich geringere Energie als stimmhafte Laute und immerhin im Mittel auch eine geringereEnergie als stimmlose Laute aufweist. Nachdem die Klassen und Merkmale für eine grobe
p(x|k3)p(x|k2)
p(x|k1)
p(x|k)
0
0.2
0.4
0.6
0.8
NulldurchgängeEnergie
02
46 1 2 3 4 5
0
Abbildung 4.5.: Dritte Verteilungsdichte, mit zwei Merkmalen und drei Klassen.
Unterscheidung der Klassen geeignet sind, kann die erste Klassifikation durchgeführt werden.
40
4. Klassifikation
4.2.2. Der Maximum-Likelihood-Klassifikator
Die einfachste Möglichkeit zur Klassifikation eines unbekannten Datensatzes - also in diesemBeispiel eines Frames des Mikrofonsignals - besteht darin, dass man berechnet, mit welcherWahrscheinlichkeit man diesen Datensatz erhält, wenn die verschiedenen Klassen auftreten.Dann ordnet man den neuen Datensatz der Klasse zu, bei der er die höchste Wahrschein-lichkeit erhält. Da diese Wahrscheinlichkeit eines Merkmalswertes oder -vektors, gegebendie Klasse, auch Likelihood heißt, trägt der Klassifikator den Namen Maximum-Likelihood-Klassifikator. Das Bild 4.6 zeigt, wie der Raum aller möglichen Merkmale im eindimensiona-len Fall vom Maximum-Likelihood-Klassifikator eingeteilt würde. Zusammenfassend schreibt
0.1
0.2
0.3
0.4
0.5
0.6
00 1 2 3 4 5 6 7
Nulldurchgangsrate
p(x|
k)
p(x|k2)p(x|k1)
p(x|k3)
Abbildung 4.6.: Entscheidungsräume des Maximum-Likelihood-Klassifikators.
man die Klassifikationsregel auch:
k = arg maxki
p(x|ki).
Hier ist k die vom Klassifikator getroffene Klassenentscheidung, ki, i = 1 . . .N sind die Nmöglichen Klassen und p(x|ki) ist die Likelihood des Merkmalsvektors1 innerhalb der Klasseki. Eingesetzt wird der Maximum-Likelihood-Klassifikator besonders in den Fällen, wenn
• Die Klassenwahrscheinlichkeiten p(ki) für alle Klassen entweder angenähert gleich odervöllig unbekannt sind und
• eine Fehlklassifikation in jeder Richtung ähnlich hohe Kosten verursacht (anders alszum Beispiel in der Fertigungskontrolle eines Luftfahrzeugherstellers, wo defekte Teile(false positive) viel teurer sind als eine zweite Kontrolle von inadäquaten Teilen (falsenegative)).
1In diesem Beispiel ist der Merkmalsvektor eindimensional und besteht aus der Nulldurchgangsrate des be-trachteten Frames.
41

4. Klassifikation
4.2.3. Bayes’sche Klassifikation
Wenn die Wahrscheinlichkeiten der einzelnen Klassen p(ki) a-priori2 bekannt sind, kann manmit diesen das Klassifikationsergebnis im Mittel deutlich verbessern. Dazu bestimmt man bei-spielsweise statt
k = arg maxki
p(x|ki)
die wahrscheinlichste Klasse, also
k = arg maxki
p(ki|x).
Mit dem Satz von Bayes erhält man dafür den Ausdruck
k = arg maxki
p(x|ki)p(ki)p(x)
.
Da die Wahrscheinlichkeit eines Merkmalsvektors p(x) von der Klasse ki unabhängig ist, istdas äquivalent zu
k = arg maxki
p(x|ki)p(ki),
was die Klassifikationsregel des Bayes-Klassifikators darstellt. Bildlich gesehen, wichtet derBayes-Klassifikator also die Likelihood p(x|ki) noch zusätzlich mit den Klassenwahrschein-lichkeiten, sodass häufige Klassen bevorzugt erkannt werden, wie auch Bild 4.7 zeigt.
4.2.4. Entwurf optimaler Klassifikatoren
Um einen optimalen Klassifikator entwerfen zu können, muss als erstes festgelegt werden,was unter „optimal“ verstanden wird. Das kann geschehen, indem man jeder Fehlentschei-dung Kosten zuordnet, also eine Kostenfunktion definiert. Dabei kann man zum Beispiel mitdem Ausdruck ci j die Kosten beschreiben, die entstehen, wenn die Klasse i als Klasse j klas-sifiziert wird. Bei zwei Klassen, einer Klasse kd mit defekten und einer ko mit Teilen, die inOrdnung sind, würde man dann zum Beispiel aus wirtschaftlichen Erwägungen die Kosten-funktion folgendermaßen definieren:
• coo = 0
• cdd = 0
• cod = Herstellungskosten, evtl. Entsorgungskosten
• cdo = Haftung, Imageschäden.
Was man nun minimieren möchte, sind die im Mittel auftretenden Kosten, also den Erwar-tungswert der Kostenfunktion E(ci j). Um diese Kosten zu beschreiben, definiert man zunächst
2Von Vornherein, bevor ein Versuch gemacht wurde. Diese Klassenwahrscheinlichkeiten p(ki) kann man auchals a-priori-Wahrscheinlichkeiten bezeichnen.
42
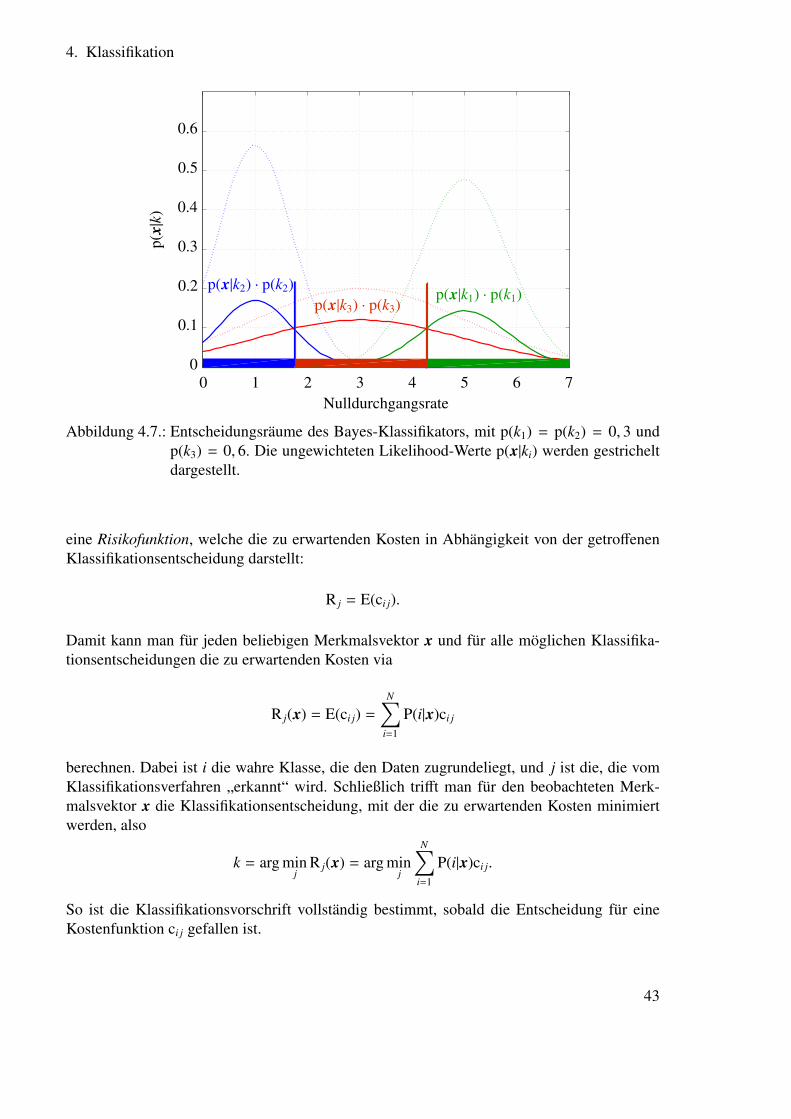
4. Klassifikation
0.1
0.2
0.3
0.4
0.5
0.6
00 1 2 3 4 5 6 7
Nulldurchgangsrate
p(x|
k)
p(x|k2) · p(k2)p(x|k3) · p(k3)
p(x|k1) · p(k1)
Abbildung 4.7.: Entscheidungsräume des Bayes-Klassifikators, mit p(k1) = p(k2) = 0, 3 undp(k3) = 0, 6. Die ungewichteten Likelihood-Werte p(x|ki) werden gestricheltdargestellt.
eine Risikofunktion, welche die zu erwartenden Kosten in Abhängigkeit von der getroffenenKlassifikationsentscheidung darstellt:
R j = E(ci j).
Damit kann man für jeden beliebigen Merkmalsvektor x und für alle möglichen Klassifika-tionsentscheidungen die zu erwartenden Kosten via
R j(x) = E(ci j) =
N∑i=1
P(i|x)ci j
berechnen. Dabei ist i die wahre Klasse, die den Daten zugrundeliegt, und j ist die, die vomKlassifikationsverfahren „erkannt“ wird. Schließlich trifft man für den beobachteten Merk-malsvektor x die Klassifikationsentscheidung, mit der die zu erwartenden Kosten minimiertwerden, also
k = arg minj
R j(x) = arg minj
N∑i=1
P(i|x)ci j.
So ist die Klassifikationsvorschrift vollständig bestimmt, sobald die Entscheidung für eineKostenfunktion ci j gefallen ist.
43

4. Klassifikation
4.2.4.1. Beispielentwurf eines optimalen Klassifikators
Wählt man die Kostenfunktion folgendermaßen:
ci j =
0 wenn i = jc sonst
,
dann werden alle Fehlentscheidungen gleich hart bestraft. Kurz könnte man die gleiche Kos-tenfunktion auch so formulieren:
ci j = c(1 − δi j).
mit der Delta-Funktion
δi j =
1 wenn i = j0 sonst
.
Die Risikofunktion R j, die die erwarteten Kosten angibt, wenn der Klassifikator sich ange-sichts des Merkmalsvektors x für Klasse j entscheidet, erhält man, wie oben beschrieben, alsErwartungswert von ci j. Dazu muss man über alle möglichen Klassen summieren:
R j(x) =
N∑i=1
ci jP(i|x)
=
N∑i=1
c(1 − δi j)P(i|x)
= cN∑
i=1,i, j
P(i|x)
= c
N∑i=1,i, j
P(i|x) + P( j|x) − P( j|x)
= c
N∑i=1,
P(i|x) − P( j|x)
= c
[1 − P( j|x)
].
Damit ist also die Risikofunktion bei konstanten Kosten:
R j(x) = c − cP( j|x).
Um diese Funktion durch Wahl der Klasse j zu minimieren, muss man also P( j|x) maximieren,das heißt
jopt = arg minj
R j(x) = arg maxj
P( j|x).
Das ist genau die Klassifikationsregel des Bayes-Klassifikators - dieser ist also immer dannoptimal, wenn
• alle Fehlklassifikation das gleiche Maß an Problemen verursachen und
44

4. Klassifikation
• wenn man P( j|x) halbwegs zuverlässig berechnen kann.
Weil die Bayes’sche Klassifikationsregel
jopt = arg maxj
P( j|x).
immer die Klasse auswählt, deren a-posteriori-Wahrscheinlichkeit3 P( j|x) maximal ist, wirder in der Literatur auch als Maximum-a-posteriori (MAP)-Klassifikator bezeichnet.
4.2.4.2. Beispielentwurf eines anderen optimalen Klassifikators
Der Maximum-Likelihood-Klassifikator aus Abschnitt 4.2.2 kann auch als optimaler Klassifi-kator hergeleitet werden, wenn man dazu die Kostenfunktion
ci j =
0 wenn i = j
1P(i) sonst
benutzt. Das heißt, dass man Fehlentscheidungen umso stärker bestraft, je unwahrscheinlicherdie falsch ausgewählte Klasse war. Die Herleitung ist nicht unbedingt für jeden spannend undverläuft nach einem ähnlichen Muster wie die des Bayes-Klassifikators, deswegen befindet siesich im Anhang A.1.
4.3. EINSATZ VON KLASSIFIKATOREN ZUR EINZELWORTERKENNUNG
4.3.1. Wortschatzdefinition
Für die Erkennung einzelner Worte muss zuerst ein Wortschatz definiert werden. Einmal an-genommen, er bestünde aus den vier Worten „up“, „down“, „left“ und „right“, dann könnteman eine erste Klassenzuordnung definieren:
k1 ↔ „up “k2 ↔ „down “k3 ↔ „left “k4 ↔ „right “
Außerdem ist es sinnvoll, ein Modell hinzuzunehmen, das beschreibt, wie alles andere klingt,also zum Beispiel andere Worte und Hintergrundgeräusche. So ein Auffangmodell wird auchgerne Garbage-Modell genannt und könnte hier die Klassendefinitionen noch um
k5 ↔ garbage
ergänzen.3A-posteriori sagt in dem Fall, dass es die Wahrscheinlichkeit der Klasse nach Beobachtung des Feature-Vektors
x ist.
45

4. Klassifikation
Sprache Analyse Merkmale „up“
„right“
„down“
„left“
garbage
xp(x|„up“) = p(x|k1)
p(x|„down“) = p(x|k2)
p(x|„left“) = p(x|k3)
p(x|„right“) = p(x|k4)
p(x|garbage) = p(x|k5)
Abbildung 4.8.: Struktur eines Einzelworterkenners.
4.3.2. Struktur eines einfachen Einzelworterkenners
Modelle für die einzelnen Worte sind komplexer, als die bisher betrachteten „Modelle“ P(x|ki),die aus Verteilungsdichtefunktionen bestehen. Als Wortmodelle für Einzelworterkenner kannman stattdessen sinnvollerweise HMMs oder auch Neuronale Modelle benutzen, wie sie spä-ter noch genauer besprochen werden. Im Moment ist nur eines zum Verständnis wichtig: EinWortmodell liefert, analog zu dem, was bei den Beispielen die Verteilungsdichtefunktionentun, die Wahrscheinlichkeit der Merkmalsvektoren. Wenn also das Wortmodell für das Wort„up“ trainiert ist, und wenn das Sprachsignal analysiert und in die Merkmalsvektoren x zer-legt worden ist, kann mit Hilfe des Wortmodells die Wahrscheinlichkeit P(x|„up“) bestimmtwerden. Parallel kann man auch alle anderen Wortmodelle benutzen, um die Wahrscheinlich-keiten der Merkmalsvektoren x bezüglich dieser anderen Modelle zu bestimmen. Insgesamtsieht das System dann also so aus, wie es die Abbildung 4.8 zeigt. So erhält man also aus demSprachsignal s(t) zuerst die Featurevektoren x und dann mit Hilfe der Wortmodelle aus denFeatures die einzelnen Likelihoods der Klassen P(x|ki). Gesucht ist dann das Wort, das unterBerücksichtigung der Featurevektoren am wahrscheinlichsten ist, also
k = arg maxki
P(ki|x)
= arg maxki
P(x|ki)P(ki)P(x)
.
Wieder ist der Term P(x) unabhängig von der Klasse, sodass mit
k = arg maxki
P(x|ki)P(ki) (4.4)
auch die optimale Klasse, also hier das optimale Wort, gefunden wird. Dieser Ausdruck, (4.4),enthält zwei Terme, die gemeinsam zu einer im Bayes’schen Sinn optimalen Erkennung füh-ren: Die P(x|ki) werden von den Wortmodellen geliefert, den zweiten Teil, P(ki), liefert wennnötig das sogenannte Sprachmodell, im einfachsten Fall in Form von Wortwahrscheinlichkei-ten.
46

5. Schätztheorie
5.1. WIEDERHOLUNG ZUR KLASSIFIKATION
Die bisher vorgestellten Klassifikationsverfahren benötigen für jede Klasse k eine dazugehöri-ge Verteilungsdichte der Features, p(x|k). Erst damit können sie die Klassifikation vornehmen.Dazu zeigt Abbildung 5.1 kurz den Überblick:
• Zuerst berechnet eine Feature-Extraction-Stufe aus den Rohdaten s (z. B. den Mikro-fonsignalen) die Features x, die zur Klassifikation verwendet werden.
• Anschließend werden die Features anhand der Verteilungsdichten der Klasse zugeord-net.
Zwei Klassifikationsmethoden sind besonders populär. Bei der Maximum-Likelihood-Klassi-fikation werden die Likelihoods p(x|ki) für alle Klassen verglichen, und letztlich wird dieKlasse ausgewählt, bei der die beobachteten Features am wahrscheinlichsten sind:
k = arg maxki
p(x|ki).
Bei der Bayes’schen Klassifikation dagegen wird auch das Vorwissen über die Klassenwahr-scheinlichkeiten einbezogen, sodass wahrscheinlichere Klassen häufiger ausgewählt werden.Dazu optimiert man die a-posteriori-Wahrscheinlichkeit der Klasse entsprechend
k = arg maxki
p(ki|x) = arg maxki
p(ki)p(x|ki).
Wie im Abschnitt 4.2.4 gezeigt wurde, kann man mit diesen beiden Klassifikationsmethodenin Bezug auf unterschiedliche Kostenfunktionen optimale Ergebnisse erhalten. In jedem Fallhängt diese Optimalität aber davon ab, dass in den Likelihood-Funktionen p(x|ki) tatsächlichdie wahren Verteilungsdichten gegeben sind.
5.2. SCHÄTZTHEORIE
5.2.1. Aufgabe der Schätzverfahren
Die Schätztheorie beschäftigt sich mit dieser Frage, wie man die Verteilungsdichten einesDatensatzes p(x|k) optimal lernen kann. Dies Problem kann man auf zwei verschiedene Ar-ten angehen, mit sogenannten parametrischen und mit nichtparametrischen Methoden. Hierwerden im folgenden nur die parametrischen Verfahren behandelt, die nichtparametrischenMethoden sind beispielsweise Grundlage von Kernel-Density-Estimation-Verfahren, die aberbisher in der Sprachverarbeitung nur sehr vereinzelt eingesetzt werden. Bei parametrischenMethoden geschieht das Schätzen von Verteilungsdichten in zwei Schritten:
47
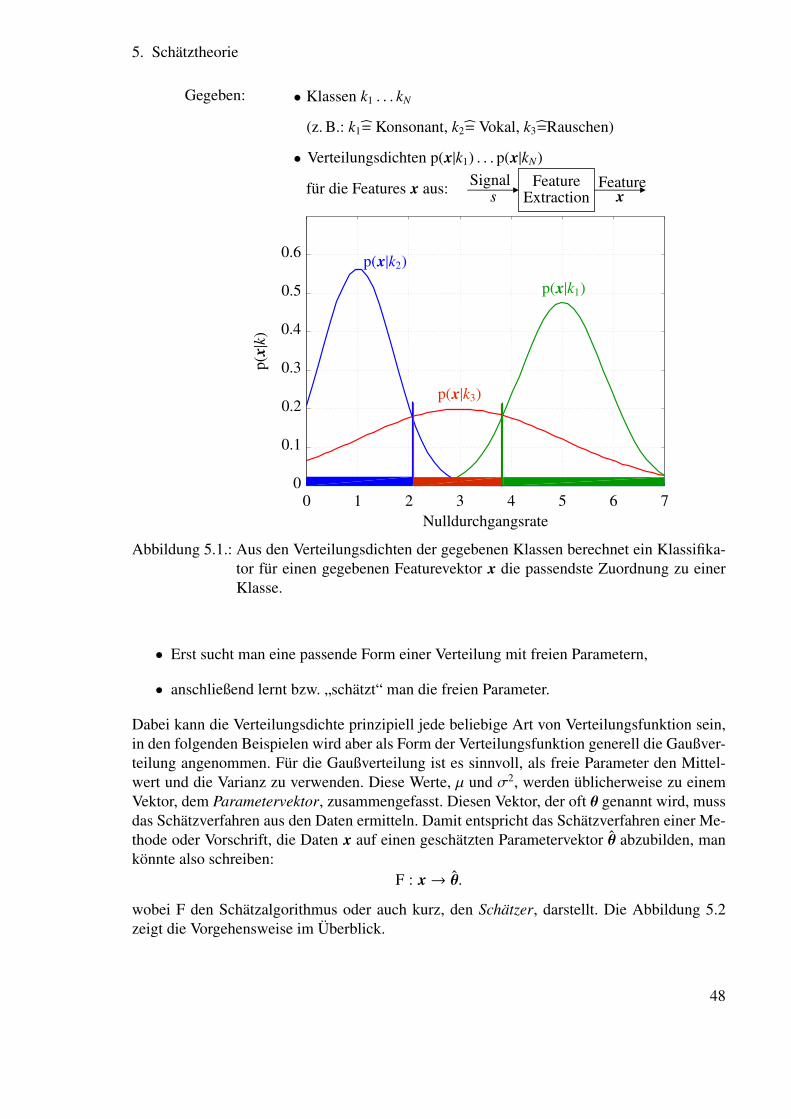
5. Schätztheorie
0.1
0.2
0.3
0.4
0.5
0.6
00 1 2 3 4 5 6 7
Nulldurchgangsrate
p(x|
k)p(x|k2)
p(x|k1)
p(x|k3)
Gegeben: •
• Verteilungsdichten p(x|k1) . . . p(x|kN)
Klassen k1 . . . kN
(z. B.: k1= Konsonant, k2= Vokal, k3=Rauschen)
für die Features x aus: Signal Featurexs
FeatureExtraction
Abbildung 5.1.: Aus den Verteilungsdichten der gegebenen Klassen berechnet ein Klassifika-tor für einen gegebenen Featurevektor x die passendste Zuordnung zu einerKlasse.
• Erst sucht man eine passende Form einer Verteilung mit freien Parametern,
• anschließend lernt bzw. „schätzt“ man die freien Parameter.
Dabei kann die Verteilungsdichte prinzipiell jede beliebige Art von Verteilungsfunktion sein,in den folgenden Beispielen wird aber als Form der Verteilungsfunktion generell die Gaußver-teilung angenommen. Für die Gaußverteilung ist es sinnvoll, als freie Parameter den Mittel-wert und die Varianz zu verwenden. Diese Werte, µ und σ2, werden üblicherweise zu einemVektor, dem Parametervektor, zusammengefasst. Diesen Vektor, der oft θ genannt wird, mussdas Schätzverfahren aus den Daten ermitteln. Damit entspricht das Schätzverfahren einer Me-thode oder Vorschrift, die Daten x auf einen geschätzten Parametervektor θ abzubilden, mankönnte also schreiben:
F : x→ θ.
wobei F den Schätzalgorithmus oder auch kurz, den Schätzer, darstellt. Die Abbildung 5.2zeigt die Vorgehensweise im Überblick.
48

5. Schätztheorie
Gesucht: p (x|k)Gegeben: Trainingsdaten der Klasse k
Merkmale x
p(x|k)
zweistufige Vorgehensweise: 1. Hypothese über die Form der Verteilungsdichtez. B. Gaußverteilung, d.h.:
p(x|k) =1
√2πσ2
e−(x−µ)2
2σ2
2. Parameter lernen oder schätzen aus den Trainingsdatenθ = (µ, σ)F : x→ θ
Abbildung 5.2.: Ablauf eines parametrischen Schätzverfahrens.
5.2.2. Gütekriterien für Schätzverfahren
Das Schätzverfahren liefert aus den Daten (N vorliegenden Featurevektoren x1 . . . xN) einengeschätzten Parameterwert θ. Um abzuschätzen, wie gut dieses Ergebnis ist, benutzt man alswichtiges Kriterium die Erwartungstreue: Ein Schätzer ist erwartungstreu, wenn der Erwar-tungswert des geschätzten Parametervektors E(θ) mit dem wahren Wert übereinstimmt, wennalso gilt
E(θ) = θ.
Eventuell ist die Erwartungstreue erst dann gegeben, wenn der Schätzer unendlich viele Da-tenpunkte in die Schätzung einbezogen hat. In diesem Fall bezeichnet man den Schätzer alsasymptotisch erwartungstreu und schreibt
limN→∞
E(θN) = θ.
Die Erwartungstreue sagt also, ob der Erwartungswert eines Schätzers gegen den wahren Para-meter konvergiert. Damit ist noch nichts über die Größe der möglichen Fehler gesagt (solangesie in beide Richtungen im Mittel gleich groß sind). Aussagen über die Größe der Fehler er-hält man, wenn man die Konsistenz eines Schätzers untersucht. Dabei gilt ein Schätzer alskonsistent, wenn die Wahrscheinlichkeit eines mehr als infinitesimal großen Fehlers gegenNull geht:
limN→∞
P(|θN − θ| > ε) = 0.
49
5. Schätztheorie
Das entspricht der Konvergenz in Wahrscheinlichkeit, man könnte also auch kürzer schreiben,dass ein Schätzer konsistent ist, wenn
θNPr.→ θ
gilt. Aber auch konsistente Schätzverfahren können, in Abhängigkeit von den Featurevekto-ren, die sie präsentiert bekommen, gelegentlich (wenn auch selten) gegen falsche Werte (odergar nicht) konvergieren. Wenn das nicht der Fall sein soll, ist starke Konsistenz gefordert. Siesagt, dass die Wahrscheinlichkeit dafür, dass der Schätzer gegen den wahren Wert konvergiert,gleich eins sein soll:
θNa.s.→ θ,
entsprechend
P(
limN→∞θN = θ
)= 1.
Aber asymptotische Fehlerfreiheit sagt nichts über das Verhalten bei endlich vielen Datenaus, was in der Praxis besonders wichtig ist. In der Abbildung 5.3 sind die Verteilungsdichte-funktionen der Ergebnisse θ von zwei Schätzverfahren für den selben Parameter gezeigt. Wieaus der Abbildung hervorgeht, sind beide Schätzer erwartungstreu. Gleichzeitig hat aber dereine Schätzer eine geringere durchschnittliche Abweichung vom wahren Parameterwert, istalso im Mittel besser. Um diesen quantitativen Unterschied zu beschreiben, vergleicht mandie Varianzen von Schätzern. Ein Schätzer ist besser, und heißt wirksamer, als ein andererSchätzer, wenn er für alle möglichen wahren Parameterwerte θ eine kleinere Varianz als derandere Schätzer hat.
θ
P(θ)
θ
E(θ)=θ
E(θ)=θ
Abbildung 5.3.: Verteilungsdichtefunktionen der Ergebnisse für zwei unterschiedlich wirksa-me, aber erwartungstreue Schätzer.
5.2.3. Cramer-Rao Lower Bound (CRLB)
Für die Varianz, die man erreichen kann, gibt es allerdings eine Untergrenze: Wie Abbil-dung 5.4 illustriert, kann kein erwartungstreuer Schätzer eine Fehlervarianz unterhalb des
50
5. Schätztheorie
Cramer-Rao Lower Bound erreichen. Dass es eine Untergrenze für die mögliche Wirksam-
Var(θ)
untere
Schranke:
CRLB
θ
Abbildung 5.4.: Der CRLB begrenzt die erreichbare Wirksamkeit der erwartungstreuen Schät-zer.
keit bzw. Genauigkeit der Schätzung gibt, liegt daran, dass in den Daten eine begrenzte Infor-mation über die Parameterwerte enthalten ist. zum Beispiel sei angenommen, dass man eineSpannung u aus einem verrauschten Messwert x bestimmen möchte. Wenn das Rauschen unddie zu messende Spannung sich addieren, ist also
x = u + n (5.1)
und das Rauschen n ist eine Zufallsvariable, die durch ihre Verteilungsdichte, z. B.
n ∼ N(0, σ2) (5.2)
beschrieben wird. Dann zeigt die Abbildung 5.5 die Verteilungsdichte, die sich daraus für dieMesswerte x ergibt. Wie man sich auch anhand dieses Bildes vorstellen kann, lässt sich ein Pa-rameter umso genauer schätzen, je mehr „Information“ über den Parameter in den gemessenenDaten vorhanden ist. Das Maß, dass sich dafür aus informationstheoretischer Sicht anbietet,ist die „Fisher-Information“, die informell gesprochen die Spitzheit der Verteilungsdichte an-gibt. Sie wird als zweite Ableitung der logarithmierten Wahrscheinlichkeit gemessen, wobeiein Erwartungswert über alle möglichen Messwerte x gebildet wird. Für skalare Parameter θ
Px(x)
u
x=u+N(0,σ1)
x=u+N(0,σ2)
x
2
2
Abbildung 5.5.: Verteilungsdichten der Messwerte.
51

5. Schätztheorie
ist die Fisher-Information I(θ) mathematisch definiert als
I(θ) = −E[δ2 ln p(x; θ)
δθ2
]und für vektorielle Parameter θ = [θ1 . . . θn] ist die Fisher-Information gegeben durch dieMatrix
[I(θ)]i j = −E[δ2 ln p(x; θ)δθiδθ j
].
Um den CRLB für eine gegebene Situation zu ermitteln, braucht man dann folgenden Satz:
Satz 5.2.1 Gegeben die Verteilungsdichte p(x; θ), die für alle θ die Bedingung
−E[δ ln p(x; θ)
δθ
]!= 0
erfüllt, ist die optimal erreichbare Schätzfehlervarianz aller erwartungstreuen Schätzer nachunten begrenzt durch
var(θopt) ≥1
I(θ)
für skalare Parameter und alsvar(θi,opt) ≥ [I(θ)−1]ii
für das i-te Element eines vektoriellen Parameters.
Dabei begrenzt der CRLB die erreichbare Wirksamkeit aller erwartungstreuen Schätzer. Es istaber nicht gesagt, ob ein Schätzer existiert, der diese minimale Varianz besitzt. Ob ein solchererwartungstreuer Schätzer existiert, der den CRLB erreicht, sagt der folgende Satz:
Satz 5.2.2 Ein erwartungstreuer Schätzer, der den CRLB erreicht, existiert nur dann, wenn esFunktionen g und I gibt, für die
δ ln p(x; θ)δθ
= I(θ)(g(x) − θ)
gilt. Dieser optimale Schätzer, der „Minimum-Variance-Unbiased-Estimator“, ist dann θopt =
g(x).
Die Verwendung des CRLB kann man sich an einem Beispiel klar machen: Wenn ein DC-Pegel in einem verrauschten Messsignal mit gaußverteiltem weißem Rauschen bestimmt wer-den soll, wenn also Gleichungen (5.1) und (5.2) gelten, dann ist der zu schätzende Parameterθ. Der DC-Pegel u und die Verteilungsdichte p(x, θ) entspricht damit
p(x; u) =1√
2πσe−
(x−u)2
2σ2 . (5.3)
52

5. Schätztheorie
Um den CRLB zu bestimmen, wird als erstes die Fisher-Information I(θ) = −E[δ2 ln p(x;θ)
δθ2
]benötigt. Diese erhält man folgendermaßen:
ln p(x; u) = ln1√
2πσ−
(x − u)2
2σ2
δ
δuln p(x; u) =
x − uσ2
δ2
δu2 ln p(x; u) = −1σ2
−E[δ2
δu2 ln p(x; u)]
=1σ2 .
Daraus ergibt sich dann der CRLB mit
var(θopt) ≥1
I(θ)= σ2.
So ist also der bestmögliche Schätzer, den man aus informationstheoretischer Sicht für eineneinzigen Messwert eines DC-Signals in Rauschen mit der Varianz σ2 bekommen kann einerwartungstreuer Schätzer der Varianz σ2. Wenn man sich als Schätzer für u den Abtastwert xnimmt, also u = x setzt, dann gilt:
u = x = u + nvar(u) = var(u + n)
= var(u) + var(n)= var(n)= σ2.
Damit hat man also den optimalen Schätzer gefunden und es lohnt sich nicht, weitere Opti-mierungsversuche zu unternehmen.
5.2.4. Bayes-Schätzung
Bei der bisherigen Beschreibung der Schätzverfahren wurde der zu schätzende Parameter θ alsunbekannt, aber fest, betrachtet. Im Gegensatz dazu behandeln Bayes’sche Verfahren auch denParameter selbst als eine Zufallsvariable. Aus dieser Idee heraus ergeben sich neue Möglich-keiten zur Bestimmung angenähert optimaler Schätzmethoden. Denn genau wie die optimalenKlassifikatoren durch Minimierung einer Risikofunktion hergeleitet werden können, kann dasauch für im Bayes’schen Sinn optimale Schätzer geschehen. Dazu wird auch hier eine Kosten-funktion C definiert, deren Wert von dem wahren Parameter θ und dem geschätzten Parameterθ′ abhängen sollte. Und genau wie bei der optimalen Klassifikation eine Risikofunktion R denErwartungswert der Kostenfunktion C angibt, soll das auch hier passieren. Man definiert sichalso ein
R(θ′) = E(C(θ, θ′)
)und versucht, diese Risikofunktion durch die bestmögliche Wahl von θ′ zu minimieren.
53

5. Schätztheorie
C(θ,θ')
θθ'
Abbildung 5.6.: Kostenfunktion für Maximum-a-posteriori (MAP)-Schätzung.
5.2.4.1. Maximum-a-posteriori-Schätzung
Definiert man die Kostenfunktion als C(θ, θ′) = 1 − δ(θ − θ′),1 erhält man einen Verlauf derKostenfunktion wie in Abbildung 5.6. Die dazugehörige Risikofunktion ist
R(θ′) = E(C(θ, θ′)
)=
∫ ∞
−∞
C(θ, θ′) p(θ|x)dθ
=
∫ ∞
−∞
(1 − δ(θ − θ′)
)p(θ|x)dθ
=
∫ ∞
−∞
p(θ|x)dθ −∫ ∞
−∞
δ(θ − θ′)p(θ|x)dθ
⇒ R(θ′) = 1 − p(θ′|x).
So kann man dann den optimalen Schätzer θ aus
θ = arg minθ′
R(θ′) = arg maxθ′
p(θ′|x) (5.4)
bestimmen.2 Dieses Schätzverfahren wird MAP-Schätzung genannt, dabei steht das MAP fürMaximum-a-posteriori. Durch Einbeziehung von Vorwissen kann man bei der MAP-Schätzungein verbessertes Ergebnis erreichen. Dazu formt man Gleichung (5.4) mit dem Satz von Bayesum in
θ = arg maxθ′
p(θ′|x)
= arg maxθ′
p(x|θ′)p(θ′)p(x)
= arg maxθ′
p(x|θ′)p(θ′).
Der erste Term, p(x|θ′) beschreibt die Likelihood der Daten, gegeben hier den Parameter θ′3
und der zweite Ausdruck, p(θ′), kann benutzt werden, um das Vorwissen über den Parameter
1Das δ-Funktional ist definiert über∫
f(t)δ(t − τ)dt = f(τ).2Das erinnert nicht wenig an den Bayes-Klassifikator kopt = arg maxk p(k|x).3Im letzten Kapitel war es „gegeben die Klasse“.
54
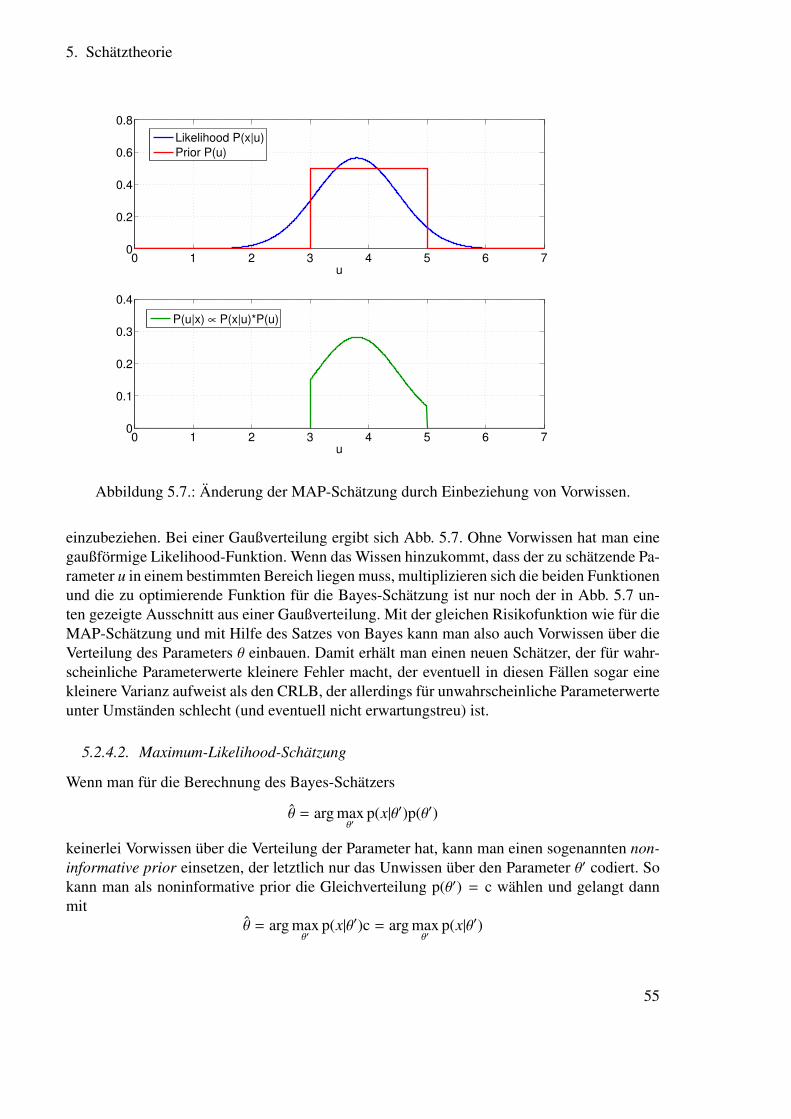
5. Schätztheorie
0 1 2 3 4 5 6 70
0.2
0.4
0.6
0.8
u
Likelihood P(x|u)
Prior P(u)
0 1 2 3 4 5 6 70
0.1
0.2
0.3
0.4
u
P(u|x) ∝ P(x|u)*P(u)
Abbildung 5.7.: Änderung der MAP-Schätzung durch Einbeziehung von Vorwissen.
einzubeziehen. Bei einer Gaußverteilung ergibt sich Abb. 5.7. Ohne Vorwissen hat man einegaußförmige Likelihood-Funktion. Wenn das Wissen hinzukommt, dass der zu schätzende Pa-rameter u in einem bestimmten Bereich liegen muss, multiplizieren sich die beiden Funktionenund die zu optimierende Funktion für die Bayes-Schätzung ist nur noch der in Abb. 5.7 un-ten gezeigte Ausschnitt aus einer Gaußverteilung. Mit der gleichen Risikofunktion wie für dieMAP-Schätzung und mit Hilfe des Satzes von Bayes kann man also auch Vorwissen über dieVerteilung des Parameters θ einbauen. Damit erhält man einen neuen Schätzer, der für wahr-scheinliche Parameterwerte kleinere Fehler macht, der eventuell in diesen Fällen sogar einekleinere Varianz aufweist als den CRLB, der allerdings für unwahrscheinliche Parameterwerteunter Umständen schlecht (und eventuell nicht erwartungstreu) ist.
5.2.4.2. Maximum-Likelihood-Schätzung
Wenn man für die Berechnung des Bayes-Schätzers
θ = arg maxθ′
p(x|θ′)p(θ′)
keinerlei Vorwissen über die Verteilung der Parameter hat, kann man einen sogenannten non-informative prior einsetzen, der letztlich nur das Unwissen über den Parameter θ′ codiert. Sokann man als noninformative prior die Gleichverteilung p(θ′) = c wählen und gelangt dannmit
θ = arg maxθ′
p(x|θ′)c = arg maxθ′
p(x|θ′)
55

5. Schätztheorie
zur Maximum-Likelihood-Schätzung. Dieses Verfahren ist aus mehreren Gründen beliebt:
• Zum einen, weil es mit der Likelihood-Funktion p(x|θ′) arbeitet, die oft leicht zu model-lieren und zu überprüfen ist,
• weil es eine Methode ist, die man ohne allzuviele Sonderüberlegungen und Spezialfälleeinfach anwenden kann,
• weil der Maximum-Likelihood-Schätzer asymptotisch erwartungstreu ist, weil alsolimN→∞ θML = θ gilt und
• weil der Maximum-Likelihood-Schätzer auch asymptotisch wirksam ist, also für unend-lich viele Daten die geringstmögliche Schätzfehlervarianz erreicht, oderlimN→∞ var(θML) = var(θopt).
Als Beispiel kann man auch hier den DC-Pegel im Gauß’schen Rauschen benutzen, es ist alsowie bei Gleichungen (5.1), (5.2) und (5.3). Daraus bekommt man
u = arg maxu′
p(x|u′)
= arg maxu′
1√
2πσe−
(x−u′)2
2σ2
und durch Ableiten und Nullsetzen
u = arg maxu′
p(u′|x) = x.
Die Herleitung des Maximum-Likelihood-Schätzers für mehrere Beobachtungen ist im An-hang A.2 zu finden.
5.2.4.3. Verfahren mit Gewichtung der Schätzfehler
Manchmal sollen größere Schätzfehler stärker gewichtet werden als kleine Fehler. Dazu kannals Kostenfunktion zum Beispiel der absolute Fehler oder der quadratische Fehler verwendetwerden. Die Kostenfunktion ist dementsprechend
CMAVE(θ, θ′) = |θ − θ′|
oderCMMSE(θ, θ′) = (θ − θ′)2
und wird in Abbildung 5.8 dargestellt. Beliebt ist vor allem der (differenzierbare) quadratischeFehler, dessen Minimierung den Minimum Mean Square Error (MMSE)-Schätzer liefert. ZurMinimierung des mittleren quadratischen Fehlers geht man dann folgendermaßen vor: Zuerststellt man die Risikofunktion auf, also
RMMSE(θ′) = E(CMMSE(θ, θ′)
)= E
((θ − θ′)2
)
56
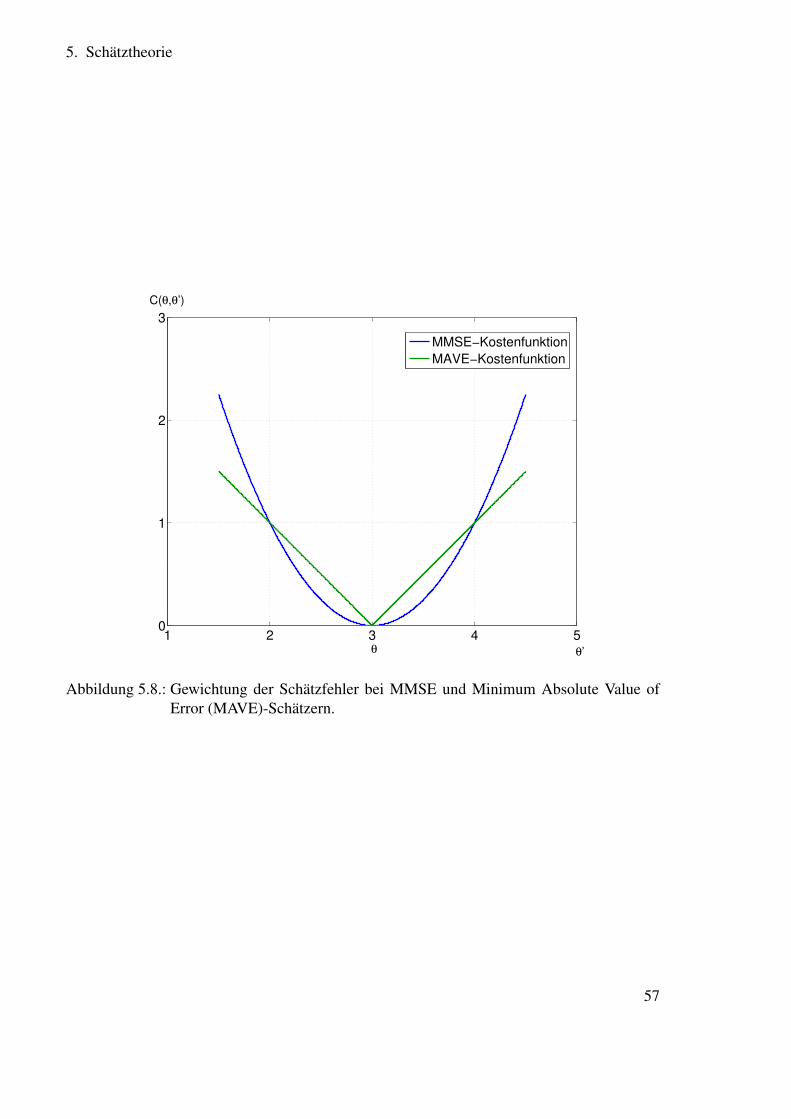
5. Schätztheorie
1 2 3 4 50
1
2
3
θ’
C(θ,θ’)
θ
MMSE−Kostenfunktion
MAVE−Kostenfunktion
Abbildung 5.8.: Gewichtung der Schätzfehler bei MMSE und Minimum Absolute Value ofError (MAVE)-Schätzern.
57

5. Schätztheorie
und minimiert diese dann, sucht also den Punkt, an dem δR(θ′)δθ′
= 0 ist. Dazu benötigt man dieAbleitung der Risikofunktion nach den Parametern, also
δR(θ′)δθ′
=δ
δθ′E
((θ − θ′)2|x
)=
δ
δθ′
∫ ∞
−∞
p(θ|x)(θ − θ′)2dθ.
Nach Einsetzen der binomischen Formel und Weglassen des von θ′ unabhängigen Ausdrucksder binomischen Summe bekommt man dann
δR(θ′)δθ′
=δ
δθ′
[∫ ∞
−∞
p(θ|x)θ′2dθ −∫ ∞
−∞
p(θ|x)2θ′θdθ]
=
∫ ∞
−∞
p(θ|x)2θ′dθ −∫ ∞
−∞
p(θ|x)2θdθ
= 2θ′∫ ∞
−∞
p(θ|x)dθ − 2∫ ∞
−∞
p(θ|x)θdθ
= 2θ′ · 1 − 2E(θ|x).
Damit die Risikofunktion Null wird, muss dieser letzte Ausdruck auch Null sein, es muss alsogelten:
θ′ = E(θ|x).
Letztlich zeigt sich also, dass der MMSE-Schätzer eines Parameters θ dem bedingten Erwar-tungswert E(θ|x) entspricht. Den kann man dann in einigen Fällen durch Lösen des IntegralesE(θ|x) =
∫ ∞−∞
p(θ|x)θdθ berechnen. Das kostet im Allgemeinen recht viel Mühe, gelegent-lich lohnt sich aber der Aufwand. Ein Ergebnis, das auf diese Weise entstanden ist, ist dasEphraim-Malah-Filter [EM84], das verrauschte Sprachsignale optimal vom Rauschen befrei-en kann (und in vielen Fällen gute Ergebnisse liefert).
5.3. NICHTPARAMETRISCHE SCHÄTZUNG
Die bisher behandelten Verfahren der Schätztheorie kann man alle auch als parametrischeVerfahren bezeichnen, weil das Konzept eines zu lernenden Paramterwertes bei ihnen allenzentral ist. Zusammenfassend besteht die bisher vorgestellte Vorgehensweise darin, dass man
1. eine parametrisierte Verteilungsdichtefunktion der Daten x, p(x|θ) postuliert, in der θ diefreien Parameter sind, und
2. die freien Parameter θk für jede der Klassen k aus den Trainingsdaten xtrain lernt.
3. Dann kann man mit einer beliebigen Klassifikationsregel, beispielsweise durchk = arg maxi p(xtest|θki), neue, unbekannte Daten xtest einer bestimmten Klasse k zuord-nen.
58

5. Schätztheorie
Diese Vorgehensweise ist insofern sinnvoll, als man oft weiß, welche Form einer Vertei-lungsfunktion (z. B. eine Gauß- oder Laplaceverteilung) die Daten gut beschreibt. Dann kannman mit parametrischen Verfahren dieses Vorwissen über die Art der Verteilung einbeziehen.Auch die Wahrscheinlichkeiten bestimmter Parameter lassen sich durch Bayes’sche Schätz-verfahren gut in den Lernprozess einbeziehen. Andererseits gibt es auch Fälle, in denen ent-weder die Form einer sinnvollen Hypothese der Verteilungsdichte unklar ist, oder in denenkeine guten Schätzverfahren für die Parameter gefunden werden können (wie beispielsweisebei hochdimensionalen Problemen). In diesen Fällen, oder auch, wenn vor allem ein leicht zuimplementierendes Klassifikationsverfahren benötigt wird, kann es sich anbieten, nichtpara-metrischen Klassifikationsverfahren den Vorzug zu geben. Diese zeichnen sich dadurch aus,dass der Umweg über eine postulierte Verteilungsfunktion ganz vermieden wird, und dassman stattdessen direkt eine Klassifikationsfunktion Q : Q(x) → k aus den Trainingsdatenlernt. Damit wird es auch möglich, bei immer mehr vorliegenden Trainingsdaten immer bes-ser zu klassifizieren, sofern die Trainingsdaten der gleichen Verteilungsdichte gehorchen wiedie Testdaten.
Nearest-Neighbor-Klassifikation
Eine geradlinige Variante der nichtparametrischen Klassifikatoren ist der Nearest-Neighbor-Klassifikator, der genau einen Trainingsdatenpunkt benutzt, nämlich den besten, um einenneuen Featurevektor xtest zu klassifizieren. Der wird dann also zu der Klasse zugeordnet, inder sich der ähnlichste Featurevektor aus den Trainingsdaten befindet. Damit lautet die Klas-sifikationsvorschrift
ki = arg mini
d(xtrain,i, xtest).
In diesem Ausdruck kann d ein beliebiges Distanzmaß sein. Diese Kostenfunktion führt dannzu Entscheidungsgeraden, wie sie in Abbildung 5.9 gezeigt sind. Das Verfahren ist damit un-
x1
x2
Test-Datenpunkte:
Abbildung 5.9.: Entscheidungsgeraden des Nearest-Neighbor-Klassifikationsverfahrens.
gewöhnlich leicht zu implementieren, ist allerdings gegenüber Ausreißern (engl. Outliers) inden Trainingsdaten nicht besonders robust, wie die Abbildung 5.10 zeigt. Wegen dieser man-
59

5. Schätztheorie
x1
x2
Test-Datenpunkte:
Abbildung 5.10.: Reaktion des Nearest-Neighbor-Klassifikationsverfahrens auf Ausreißer inden Trainingsdaten.
gelnden Robustheit sind k-Nearest-Neighbor Verfahren (häufig mit ungeraden k = 3, 5 . . .)die geeignetere Wahl. Dabei sucht man die k nächsten Nachbarn des Testfeaturevektors undwählt dann diejenige Klasse, die in den k nächsten Nachbarn am häufigsten ist. In deadlock-Situationen (z. B. drei Nachbarn aus drei Klassen) kann man zum Beispiel ein oder zwei wei-tere nächste Nachbarn suchen, und mit deren Hilfe die Entscheidung treffen. Das resultierendeVerhalten des 3-NN-Klassifikators zeigt Abb. 5.11. Insgesamt gesprochen, liegen die Vorteile
x1
x2
Test-Datenpunkte:
Abbildung 5.11.: Reaktion des 3-Nearest-Neighbor-Klassifikationsverfahrens auf Ausreißerin den Trainingsdaten.
der k-Nearest-Neighbor-Klassifikatoren in
• der leichten Implementierbarkeit und
• dem geringen Trainingsaufwand.
Allerdings verschiebt sich auf der anderen Seite der Rechenaufwand auf die Klassifikations-zeit, der Speicherbedarf ist unter Umständen recht hoch und somit bleibt einem die Chanceverwehrt, durch das Lernen der Klassifikationsfunktion selber etwas Menschenverständlichesüber die Verteilungen der Features zu lernen.
60

6. Neuronale Klassifikatoren
In den letzten Jahren hat das maschinelle Lernen mit neuronalen Netzen dramatische Fort-schritte gemacht. Erstmals wurde die menschliche Leistungsfähigkeit in einer Vielzahl vonMustererkennungsaufgaben erreicht oder überschritten - beispielsweise für die Spracherken-nung in natürlichen Konversationen [XDH+16], das Lippenlesen [ASWF16], oder die Ge-sichtserkennung [TYRW14]. Neuronale Klassifikatoren sind daher in den letzten Jahren auchzum Mittel der Wahl für die Big-Data-basierte Spracherkennung avanciert.
Die Ursprünge der neuronalen Spracherkennung gehen zurück auf zwei neuronale Topolo-gien:
• Das Multi-Layer Perzeptron mit dem Backpropagation-Lernverfahren und
• die Time-Delay Neuronalen Netze.
Das Multi-Layer-Perzeptron wurde in der Spracherkennung oft in hybriden NN/HMM-Struk-turen eingesetzt (siehe zum Beispiel [BM94]), während das Time-Delay-Neural-Network (bei-spielsweise in [ZHW93]) quasi stand-alone-fähig ist, da es auch zeitliche Verläufe gut charakte-risieren kann. Beide Arten von Klassifikatoren litten unter dem Problem von Under- und Over-fitting und viele lokale Minima der Kostenfunktion behinderten das Lernen der Parameter. Fürdiese Probleme haben sich aber, teils durch Wahl einer günstigen Kostenfunktion, teils durchgeeignete Trainingsstrategien, Lösungen finden lassen, sodass neuronale Netze heute aus denaktuellen Spracherkennungssystemen nicht mehr wegzudenken sind.
6.1. ANALOGIEN UND UNTERSCHIEDE ZUR PARAMETRISCHEN,BAYES’SCHEN KLASSIFIKATION
Im Folgenden werden die beiden Ansätze der statistischen und der neuronalen Klassifikationeinander ganz prinzipiell gegenübergestellt.
6.1.1. Was zuvor geschah
In den vergangenen Kapiteln wurden statistische Klassifikatoren betrachtet. Wie Abbildung 6.1zeigt, werden dort in einer Trainingsphase die Parameter eines statistischen Modells gelernt,um dann neue, bis dato ungesehene Testdaten mit Hilfe eines statistischen Klassifikators -beispielsweise nach dem Maximum-a-Posteriori-Prinzip - der wahrscheinlichsten (oder nacheinem anderen Kriterium am besten passenden) Klasse zuzuordnen.
Dies ist ein geradliniger Prozess. Wenn die statistischen Eigenschaften der Trainingsdatenhinlänglich gut bekannt sind, kann das statistische Modell und das Trainingsverfahren dazupassend gewählt werden. Insgesamt ergibt sich daraus in vielen konkreten Spielarten dieserVerfahren das Ergebnis deterministisch, und deswegen leicht reproduzierbar.
61
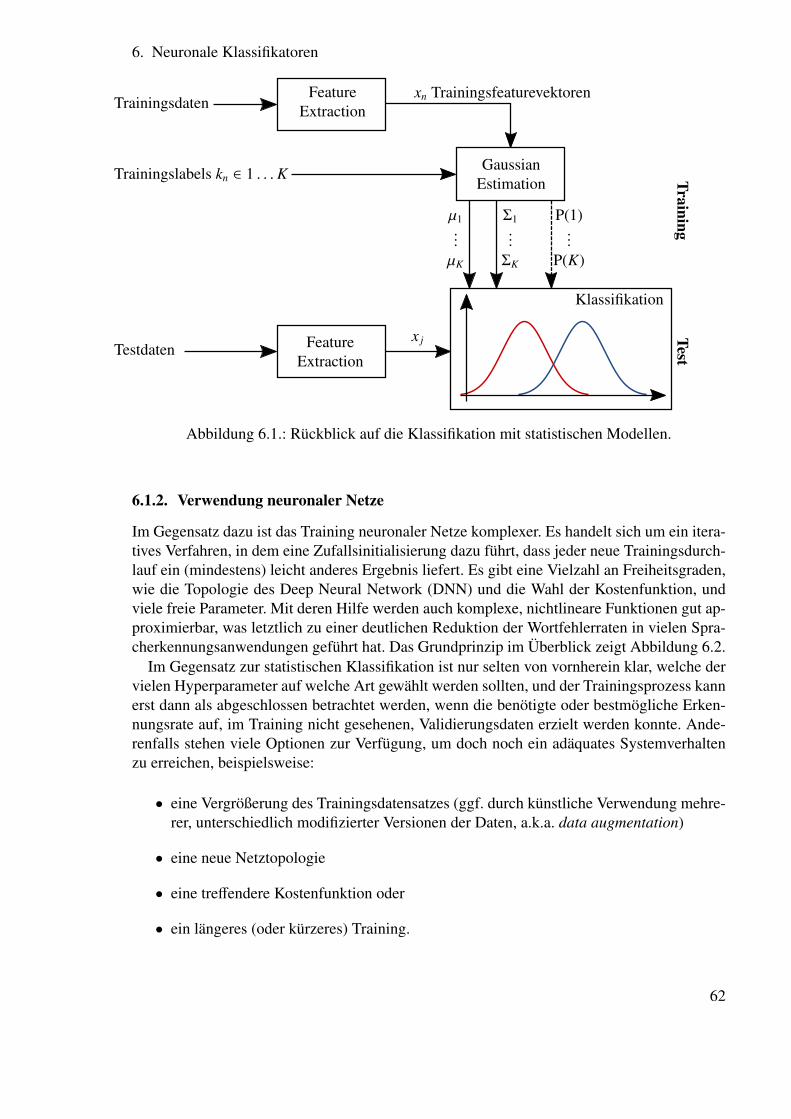
6. Neuronale Klassifikatoren
Testdatenx j
TrainingTest
Trainingsdaten
Trainingslabels kn ∈ 1 . . .K
xn Trainingsfeaturevektoren
µ1...µK
Σ1...
ΣK
P(1)...
P(K)
FeatureExtraction
FeatureExtraction
GaussianEstimation
Klassifikation
Abbildung 6.1.: Rückblick auf die Klassifikation mit statistischen Modellen.
6.1.2. Verwendung neuronaler Netze
Im Gegensatz dazu ist das Training neuronaler Netze komplexer. Es handelt sich um ein itera-tives Verfahren, in dem eine Zufallsinitialisierung dazu führt, dass jeder neue Trainingsdurch-lauf ein (mindestens) leicht anderes Ergebnis liefert. Es gibt eine Vielzahl an Freiheitsgraden,wie die Topologie des Deep Neural Network (DNN) und die Wahl der Kostenfunktion, undviele freie Parameter. Mit deren Hilfe werden auch komplexe, nichtlineare Funktionen gut ap-proximierbar, was letztlich zu einer deutlichen Reduktion der Wortfehlerraten in vielen Spra-cherkennungsanwendungen geführt hat. Das Grundprinzip im Überblick zeigt Abbildung 6.2.
Im Gegensatz zur statistischen Klassifikation ist nur selten von vornherein klar, welche dervielen Hyperparameter auf welche Art gewählt werden sollten, und der Trainingsprozess kannerst dann als abgeschlossen betrachtet werden, wenn die benötigte oder bestmögliche Erken-nungsrate auf, im Training nicht gesehenen, Validierungsdaten erzielt werden konnte. Ande-renfalls stehen viele Optionen zur Verfügung, um doch noch ein adäquates Systemverhaltenzu erreichen, beispielsweise:
• eine Vergrößerung des Trainingsdatensatzes (ggf. durch künstliche Verwendung mehre-rer, unterschiedlich modifizierter Versionen der Daten, a.k.a. data augmentation)
• eine neue Netztopologie
• eine treffendere Kostenfunktion oder
• ein längeres (oder kürzeres) Training.
62

6. Neuronale Klassifikatoren
Bewertung des neuronalen Netzes für Validierungsdaten: xv, kv∀v = 1 . . .VFalls gut genug→ AbbruchFalls nicht gut genug→ neuer Traingsdurchlauf oder neue• Netztopologie
• Kostenfunktion
• Parameteradaption
kn ∈ 1 . . .N
Trainingslabels
kn oder p(kn|xn)
Parameteradaption
∀n = 1 . . .N
Trainingsdaten
xn
∀n = 1 . . .NNeuronales
NetzBewertung
FeatureExtraction
TrainingValidierung
Kostenfunktion C
Validierung
Abbildung 6.2.: Prinzipbild der Klassifikation mit mehrschichtigen neuronalen Modellen(a.k.a. Deep Neural Networks (DNNs)).
Dadurch wird das Training neuronaler Netze zu einem gewissen Grad ein rückgekoppelterProzess und eine Erfahrungssache, und eine wissenschaftliche Aufarbeitung der damit ein-hergehenden Optimalitätsfragen - wann ist eine Topologie, eine Kostenfunktion und ein Trai-ningsprozess für eine bestimmte Aufgabe notwendigerweise optimal? - ist gleichzeitig inter-essant und offen.
6.2. STRUKTUR NEURONALER NETZE
In Bild 6.3 wird der Aufbau eines neuronalen Netzes (eines sogenannten feedforward-Netzes,also eines Netzes ohne Rückkopplungen) gezeigt.
Der Ausgang eines einzelnen Neurons wird berechnet mit
n1 = fa(b1 + w11x1 + w12x2 + . . . + w1DxD)
= fa
( [1 x1 x2 x3 . . . xD
]︸ ︷︷ ︸Eingangsvektor x′
·
b1
w11
w12...
w1D
︸︷︷︸Gewichtsvektor w1
1
).
Die Nichtlinearitäten fa sorgen dafür, dass das neuronale Netz beliebig komplexe, nicht-lineare Funktionen lernen kann. Sie sollten möglichst gut (schnell) differenzierbar sein und
63

6. Neuronale Klassifikatoren
Abbildung 6.3.: Aufbau eines neuronalen Netzes.
idealerweise einen beschränkten Wertebereich besitzen. Einige Beispiele dafür zeigt Abb. 6.4.Neben den recht weit verbreiteten Sigmoid- und Tangens-Hyperbolicus-Aktivierungsfunk-
tionen ist hier auch die sogenannte Elliot-Sigmoidfunktion gezeigt, die keine Berechnung vnExponentialfunktionen oder trigonometrischen Functionen erforderlich macht, und damit aufeinfacher Hardware schneller zu berechnen ist, die aber auch einen breiteren Anstieg zeigt alsdie anderen Aktivierungsfunktionen, und damit evtl. mehr Neuronen für die selbe Genauigkeitbenötigt.
Abbildung 6.5 zeigt darüberhinaus die sogenannte Rectified Linear Unit oder Rectified Li-near Unit (ReLU) Funktion. Diese hat zwar unbeschränkte Ausgangswerte, wird aber wegender sehr guten Differenzierbarkeit und Praktikabilität weit eingesetzt.
Im Ausgangslayer sollte eine Verteilungsdichtefunktion nachgebildet werden, sofern es sichum ein Netz zur Lösung von Klassifikationsaufgaben handelt. In diesem Fall wird also gefor-dert
NA∑i=1
nAi
!= 1
64
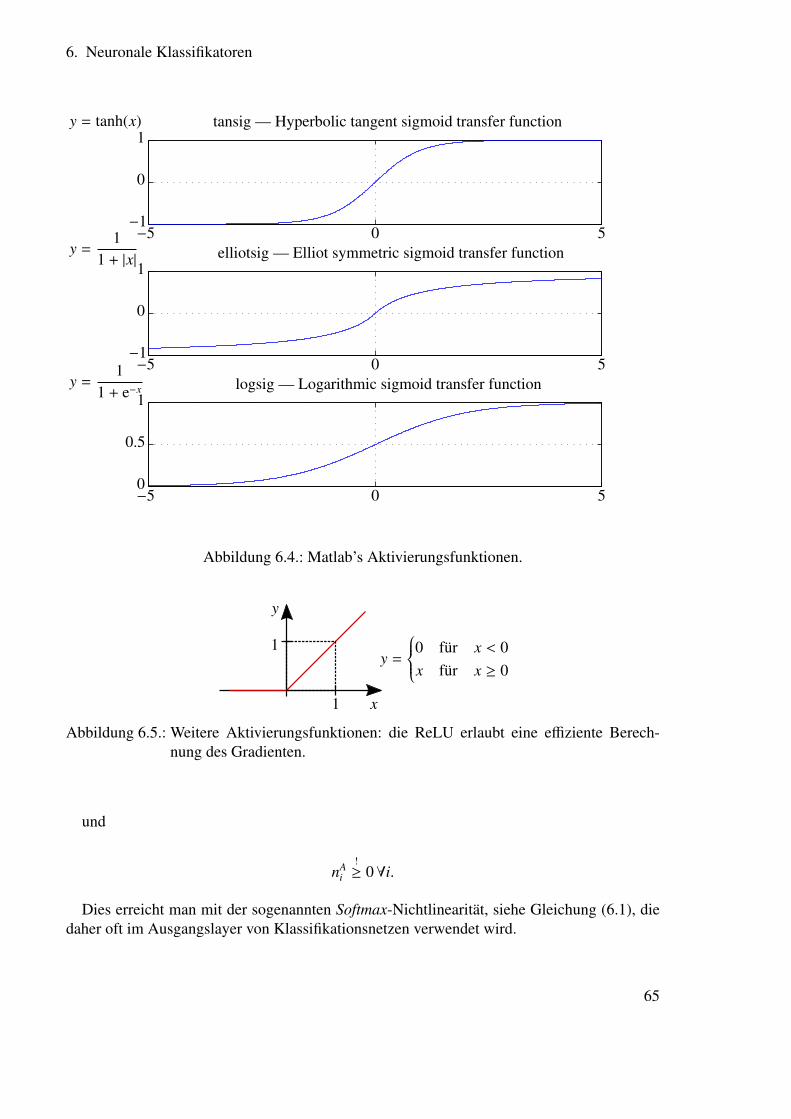
6. Neuronale Klassifikatoren
−5 0 5−1
0
1tansig — Hyperbolic tangent sigmoid transfer function
−5 0 5−1
0
1elliotsig — Elliot symmetric sigmoid transfer function
−5 0 50
0.5
1logsig — Logarithmic sigmoid transfer function
y = tanh(x)
y =1
1 + |x|
y =1
1 + e−x
Abbildung 6.4.: Matlab’s Aktivierungsfunktionen.
1
1
y
x
y =
0 für x < 0x für x ≥ 0
Abbildung 6.5.: Weitere Aktivierungsfunktionen: die ReLU erlaubt eine effiziente Berech-nung des Gradienten.
und
nAi
!≥ 0∀i.
Dies erreicht man mit der sogenannten Softmax-Nichtlinearität, siehe Gleichung (6.1), diedaher oft im Ausgangslayer von Klassifikationsnetzen verwendet wird.
65

6. Neuronale Klassifikatoren
p(k = j|nA−1) =ewᵀj ·n
A−1∑Kj=1 ewᵀj ·n
A−1
mit nA−1 =
nA−1
1
nA−12...
nA−1N
, w j =
wA
1 j
wA2 j...
wAN j
.(6.1)
6.3. ANPASSUNG DER PARAMETER NEURONALER NETZE
Das sogenannte Training der neuronalen Netze sieht dann so aus, dass die Parameter in der Artangepasst werden, dass das neuronale Netz möglichst gut funktioniert, also möglichst wenigeund möglichst kleine Fehler macht. Diese Fehler werden über alle Trainingsdaten gemittelt -das gemittelte Ergebnis bezeichnet man auch als die „Kosten“, die durch die aktuelle Wahlder Parameter entstehen, und die es dann zu minimieren gilt. Je nach Wahl der Kostenfunktionkann man auf diese Art verschiedene Eigenschaften des Netzes bei der Optimierung betrach-ten. In Abbildung 6.6 werden einige wichtige Kostenfunktionen hierfür gezeigt.
Für Klasifikationsaufgaben ist es sinnvoll, die Fehlentscheidungen möglichst direkt zu be-werten. Dabei schneidet die erste Kostenfunktion, der quadratische Fehler, schlecht ab. Er isteher nützlich für Regressionsaufgaben, die wir hier aber nicht weiter betrachten werden.
Die zweite Kostenfunktion misst zwar direkt, wie viele Fehlentscheidungen das Netz liefert,ist aber leider nicht differenzierbar. Besonders gute Ergebnisse im Bereich der Spracherken-nung sind dagegen mit der Kreuzentropie-Kostenfunktion erzielt worden, die bewertet, wiegut das neuronale Netz die Klassenwahrscheinlichkeiten schätzen kann - eine differenzierbareKostenfunktion, die einen starken Bezug zur Klassifikationsgüte besitzt. Die Kreuzentropie-Kosten sind definiert als
C =
N∑n=1
K∑k=1
−
0 für k, kn1 für k = kn︷︸︸︷
p(k) log p(k|xn)︸ ︷︷ ︸Cross-Entropy H(p,p)
(6.2)
Weil die Label-Informationen gegeben sind, gilt für jedes Trainingsbeispiel n, dassp(k = kn) = 1, sodass Gleichung (6.2) sich deutlich vereinfacht:
C =
N∑n=1
− log p(kn|xn). (6.3)
In dieser Form lässt sich die Kreuzentropie schnell aus den jeweils geschätzten Label-Wahrscheinlichkeiten der wahren Labels gewinnen.
Nachdem die Wahl der Kostenfunktion erfolgt ist, stellt sich die nächste Frage: Wie könnendiese „Kosten“ minimiert werden? Das Grundprinzip ist, wie in Abbildung 6.7 gezeigt, derGradientenabstieg.
66
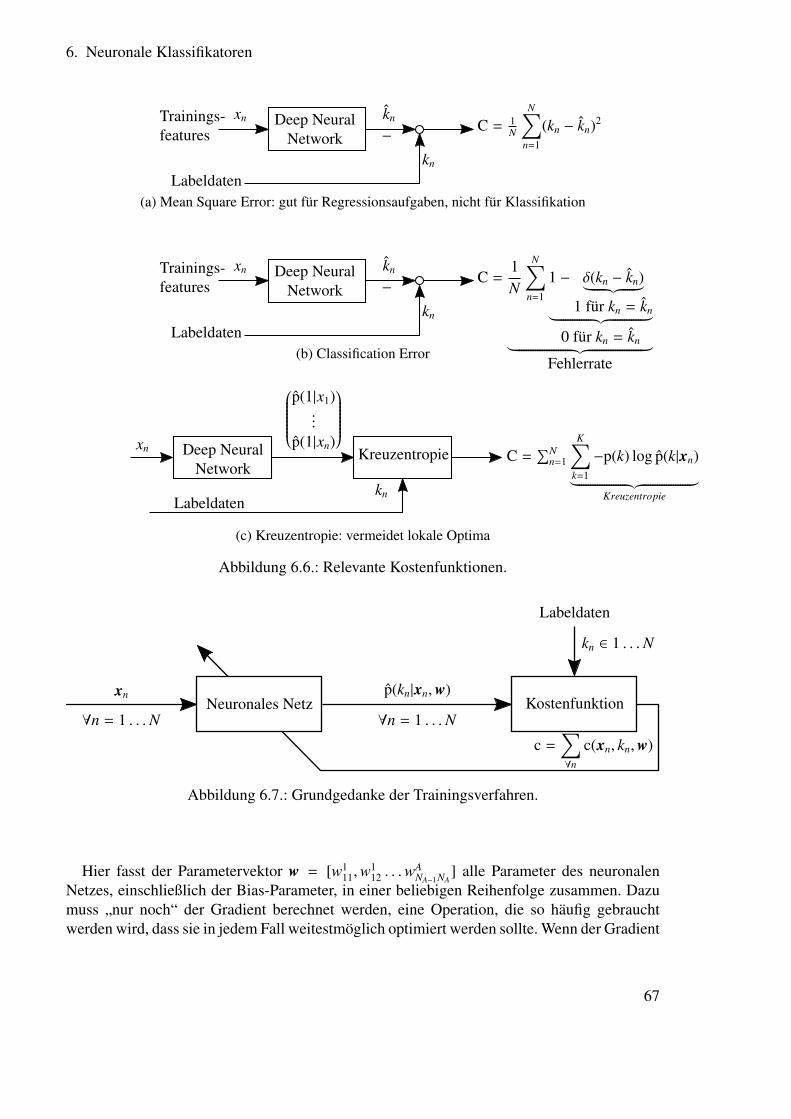
6. Neuronale Klassifikatoren
kn
kn
Labeldaten
xnTrainings-features −
Deep NeuralNetwork
C = 1N
N∑n=1
(kn − kn)2
(a) Mean Square Error: gut für Regressionsaufgaben, nicht für Klassifikation
kn
kn
Labeldaten
xnTrainings-features −
Deep NeuralNetwork
C =1N
N∑n=1
1 − δ(kn − kn)︸ ︷︷ ︸1 für kn = kn︸ ︷︷ ︸
0 für kn = kn︸ ︷︷ ︸Fehlerrate
(b) Classification Error
p(1|x1)
...p(1|xn)
kn
Labeldaten
xn C =∑N
n=1
K∑k=1
−p(k) log p(k|xn)︸ ︷︷ ︸Kreuzentropie
Deep NeuralNetwork
Kreuzentropie
(c) Kreuzentropie: vermeidet lokale Optima
Abbildung 6.6.: Relevante Kostenfunktionen.
kn ∈ 1 . . .N
Labeldaten
p(kn|xn,w)
∀n = 1 . . .N
xn
∀n = 1 . . .NNeuronales Netz
c =∑∀n
c(xn, kn,w)
Kostenfunktion
Abbildung 6.7.: Grundgedanke der Trainingsverfahren.
Hier fasst der Parametervektor w = [w111,w
112 . . .w
ANA−1NA
] alle Parameter des neuronalenNetzes, einschließlich der Bias-Parameter, in einer beliebigen Reihenfolge zusammen. Dazumuss „nur noch“ der Gradient berechnet werden, eine Operation, die so häufig gebrauchtwerden wird, dass sie in jedem Fall weitestmöglich optimiert werden sollte. Wenn der Gradient
67

6. Neuronale Klassifikatoren
∇C =
∂C∂w1
11
,∂C∂w1
12
. . .∂C
∂wANA−1NA
ᵀ de f= ∆w
bekannt ist, können die Netzparameter entgegen der Gradientenrichtung angepasst werden, umdie Kosten in jedem Optimierungsschritt für die jeweiligen Daten zu senken. Diese Parameterkönnen folgendermaßen berechnet werden:
Gehe in die Richtung des negativen Gradienten:
wNEU = w − η · ∆w, mit Eta = Lernrate
Sei i der Iterationsindex:
wi+1 = wi − η · ∆wi
Die hierfür notwendige Berechnung des Gradienten ∆w lautet:
Gesucht∂
∂wki j
C (w) =∂
∂wki j
N∑n=1
c (xn, kn,w)
=
N∑n=1
∂
∂wki j
c (xn, kn,w)
=
N∑n=1
∂
∂wki j
− log p(kn|xn,w)︸ ︷︷ ︸nA
kn
Zur Erinnerung:[f(g(z)
)]′= f′
(g(z)
)· g′(z)
f : − log(·) g : p(·) f′ : −1(·)
=
N∑n=1
−1
p(kn|xn,w)·∂
∂wki j
p(kn|xn,w)
=
N∑n=1
−1
p(kn|xn,w)·
∂
∂wki j
nAkn.︸ ︷︷ ︸
gesucht,Berechnung durch„Backpropagation“
Mit Hilfe der sogenannten Backpropagation kann die Gradientenberechnung effizient er-folgen. Dazu muss der Gradient am aktuellen Arbeitspunkt am Ausgang berechnet werden,und sukzessive erlaubt es dann die Kettenregel, auch nach weiter innen liegenden Parameternabzuleiten. Hierfür zeigt Abbildung 6.8 die Berechnungsvorschrift und Detailansicht für eineinzelnes Neuron.
Wichtig ist dabei, dass dann, wenn ein Parameter auf mehreren Pfaden auf den Gradientenwirkt, das totale Differential berücksichtigt wird, siehe Abbildung 6.9.
68

6. Neuronale Klassifikatoren
Berechnung von
Abbildung 6.8.: Berechnung des Gradienten in einem Neuron.
6.4. ANWENDUNG ZUR SPRACHERKENNUNG
In jedem Fall, statistisch oder neuronal, können die letztlich trainierten Modelle dann alsSprachmodelle für die Einzelworterkennung verwendet werden, siehe Abbildung 6.10. Auchfür die Erkennung fließender Sprache ist die gleiche Netzwerktopologie und sind die gleichenTrainingsverfahren anwendbar, mit einigen notwendigen Anpassungen, die in den letzten Ka-piteln betrachtet werden.
Beide Arten von Klassifikatoren - neuronal oder probabilistisch - werden dann zu einem Er-kennungssystem verbunden, wie es Abbildung 4.8 zeigt, oder zu einem Erkenner für fließendeSprache, wie in Kapitel 9.
69
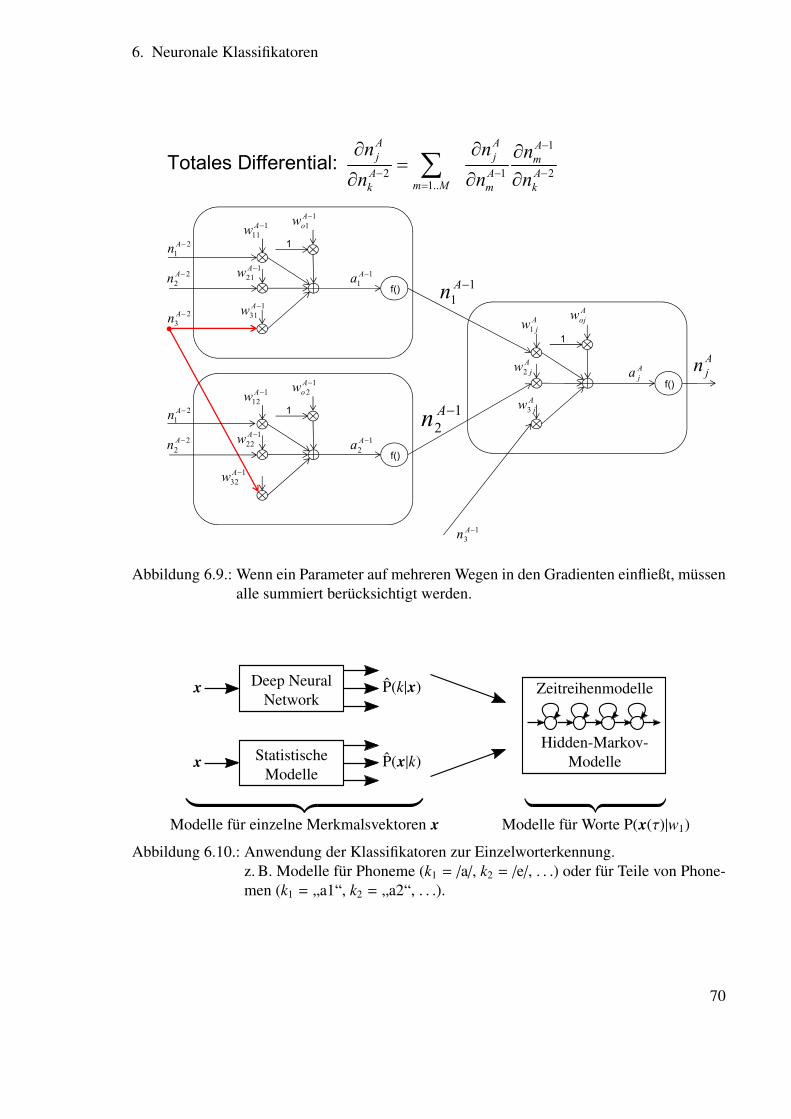
6. Neuronale Klassifikatoren
Abbildung 6.9.: Wenn ein Parameter auf mehreren Wegen in den Gradienten einfließt, müssenalle summiert berücksichtigt werden.
x P(k|x)
x P(x|k)
Deep NeuralNetwork
StatistischeModelle
Modelle für einzelne Merkmalsvektoren x Modelle für Worte P(x(τ)|w1)
Zeitreihenmodelle
Hidden-Markov-Modelle
Abbildung 6.10.: Anwendung der Klassifikatoren zur Einzelworterkennung.z. B. Modelle für Phoneme (k1 = /a/, k2 = /e/, . . .) oder für Teile von Phone-men (k1 = „a1“, k2 = „a2“, . . .).
70

7. Feature Extraction
Die Aufgabe der Merkmalsextraktion besteht darin, aus dem Sprachsignal, das eine Vielzahlan redundanter und irrelevanter Information enthält, einige relevante und möglichst kompakteMerkmale zu ermitteln.
7.1. GESAMTSTRUKTUR
Den Ablauf der typischen Vorgehensweise zur Feature Extraction zeigt Abbildung 7.1.
Abtastung
Quantisierung
Voice Activity
Detection
Preemphase
Parameter-
berechnung
Sprachsignal
s(t)
Features x( )
s(k)
Anforderung bei VAD:
Entscheidung sollte immer zugunsten des
Sprachsignals fallen.
a T
sin sout-
.Ts *
TsFs > Fmax
. 2!
1/Ts
ft
Abbildung 7.1.: Signalflussplan der Feature Extraction.
7.1.1. Abtastung und Quantisierung
Zuerst muss das Sprachsignal abgetastet und quantisiert werden. Die Abtastung sollte mitmehr als der doppelten, im Signal maximal vorkommenden Frequenz Fmax geschehen, umAliasing-Fehler zu vermeiden.
Bei der Signalquantisierung gibt es drei wichtige Entscheidungen, die zu treffen sind:
• Die Quantisierungskennlinie sq(k),
71

7. Feature Extraction
• die Anzahl von Bits B und
• die maximal zu quantisierende Amplitude smax.
Bezüglich der Quantisierungskennlinie kann man zwischen Mid-Tread und Mid-Rise Quan-tisierungskennlinien wählen, welche beide in Abbildung 7.2 gezeigt sind.1 In beiden Fällentreten zwei Arten von Fehler auf: zum einen das Quantisierungsrauschen innerhalb und zumandern die Überlastungsfehler außerhalb des Arbeitsbereiches. Dies veranschaulicht Abbil-dung 7.3. Wie man erkennen kann, wird der Einfluss des Überlastungsrauschens auf den
Mid-Rise
• symmetrisch
• auch leises Rauschen wird
übertragen
Mid-Tread
• asymmetrisch
• Signal konstant null
bei kleiner Amplitude
s(k) sq(k)
Kennlinie: sq(k)=f(s(k))
s(k)
sq(k)
smax
E
s(k)
sq(k)
s(k)
s(k)
Abbildung 7.2.: Ausschnitte aus den Kennlinien von Mid-Rise- und Mid-Tread-Quantisierern.
Gesamtfehler größer, wenn der Maximalpegel smax kleiner wird. Andererseits sinkt der Ein-fluss des Quantisierungsrauschens innerhalb des Arbeitsbereiches stetig mit sinkendem smax,sodass es einen Optimalwert für smax geben muss, bei dem der Gesamtfehler minimal wird,wie es auch in Abbildung 7.4 veranschaulicht wird. Unter einigen Annahmen, nämlich
• einer Gleichverteilung des Quantisierungsrauschens zwischen ∆/2 und −∆/2,
• der Unabhängigkeit zwischen Signal und Quantisierungsrauschen und
• der zeitlichen Unkorreliertheit des Quantisierungsrauschens1Nichtlineare Quantisierung ist für Spracherkennungszwecke unüblich, weil viele der Eigenschaften, die die
spätere Feature Extraction ausnutzt, auf einer Linearität der Eingangsstufe beruhen.
72
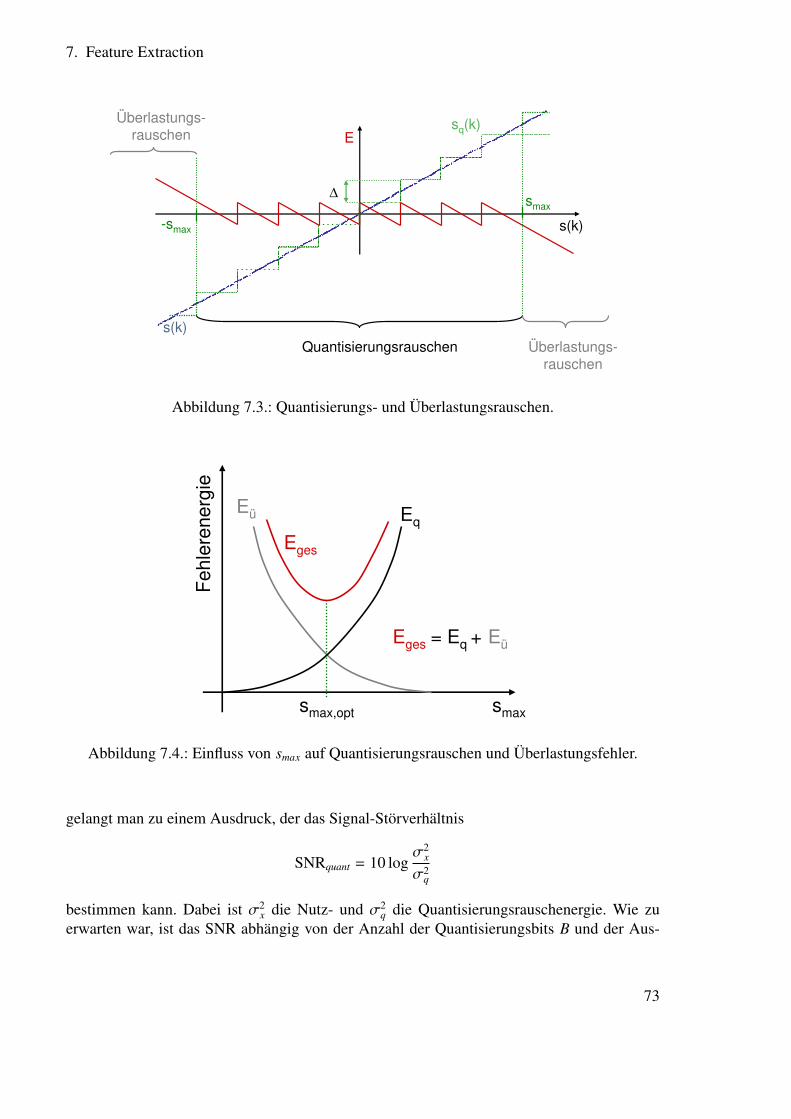
7. Feature Extraction
s(k)
sq(k)
smax
E
s(k)-smax
Quantisierungsrauschen Überlastungs-rauschen
Überlastungs-rauschen
Abbildung 7.3.: Quantisierungs- und Überlastungsrauschen.
smax
Eges
Eq
Eges = Eq +
Eü
smax,opt
Eü
Fehle
renerg
ie
Abbildung 7.4.: Einfluss von smax auf Quantisierungsrauschen und Überlastungsfehler.
gelangt man zu einem Ausdruck, der das Signal-Störverhältnis
SNRquant = 10 logσ2
x
σ2q
bestimmen kann. Dabei ist σ2x die Nutz- und σ2
q die Quantisierungsrauschenergie. Wie zuerwarten war, ist das SNR abhängig von der Anzahl der Quantisierungsbits B und der Aus-
73

7. Feature Extraction
steuerungsgrenze smax. Daraus kann mit Hilfe von
SNRquant ≈ 6, 02B + 4, 77 − 20 logsmax
σx[dB] (7.1)
das SNR berechnet werden, wobei in der Gleichung (7.1) das Überlastungsrauschen als irrele-vant betrachtet und ignoriert wird.2 Möchte man also mit Hilfe dieser Gleichung die Aussteue-rungsgrenze festlegen, sollte man durch geeignete Wahl von smax dafür sorgen, dass Überlas-tungsfehler (also Übersteuerung) möglichst selten auftreten. Ein häufig gewählter Grenzwert,der an dieser Stelle einen guten Kompromiss darzustellen scheint, ist smax = 4σx. Unter derAnnahme eines laplaceverteilten Sprachsignals kann man zeigen, dass bei dieser Wahl derAussteuerungsgrenze 0,35% der Signalsamples außerhalb des Aussteuerungsbereiches liegen,gleichzeitig trägt in Gleichung (7.1) der Term 20 log(smax/σx) 12 dB zum Signal-Störabstandbei, sodass insgesamt beispielsweise bei B = 12 Bits ein SNR von SNRquant = 65 dB erreichtwird. Da der Dynamikbereich der Sprache bei etwa 50 bis 60 dB liegt, kann man also etwabei 12 Bits von einer sinnvollen Quantisierungsgenauigkeit sprechen, während bei 8 Bits einTeil des Dynamikumfangs im Quantisierungsrauschen untergehen kann. Die Herleitung derFormel für das SNR im Anhang A.3 zu finden.
7.1.2. Voice Activity Detection
In der Voice Activity Detection werden Sprachsegmente von Intervallen des Schweigens desZielsprechers unterschieden. Dadurch kann man vermeiden, dass der Spracherkenner Hinter-grundgeräusche als Worte identifiziert. Dies erlangt eine besondere Bedeutung, wenn eineSprachbedienung zum Beispiel in lauten Umgebungen erfolgen soll, vor allem wenn mehrereStörsprecher im Aufnahmebereich der Mikrofone sind, deren Sprache nicht erkannt werdensoll. Die Unterscheidung von Ziel- und Störsprechern ist nur mit mehreren Mikrofonen mög-lich, hier soll aber die Unterscheidung von Sprachsignalen und Störungen im Vordergrundstehen.
Zu diesem Zweck gibt es eine große Anzahl von Algorithmen, welche unter anderem in[RS75] und [DPH93] zu finden sind. Die einfacheren Verfahren, die aber für viele Anwen-
dungen hinreichend sind, unterscheiden Sprache von Störungen anhand zweier Merkmale:der Nulldurchgangsrate und der Energie des Signals. Anhand von geeigneten Schwellwertenkann mit diesen beiden Features eine hinlänglich gute Unterscheidung von Sprach- und Stör-segmenten getroffen werden, wobei immer ein zentrales Kriterium sein wird, dass die VoiceActivity Detection
• so gut wie gar keine Sprachsegmente als Störsegment klassifiziert (während es durch-aus akzeptabel sein kann, einige Fehler in die andere Richtung, also False-Acceptance-Fehler, zuzulassen), und
• niemals Worte zerschneidet.
Während eine Voice Activity Detection nicht zwingend erforderlich ist, kann doch auf die-se Weise mit geringem Aufwand eine große Verbesserung der Erkennungsleistung erreicht
2Die ausführliche Herleitung ist im Anhang A.3.
74
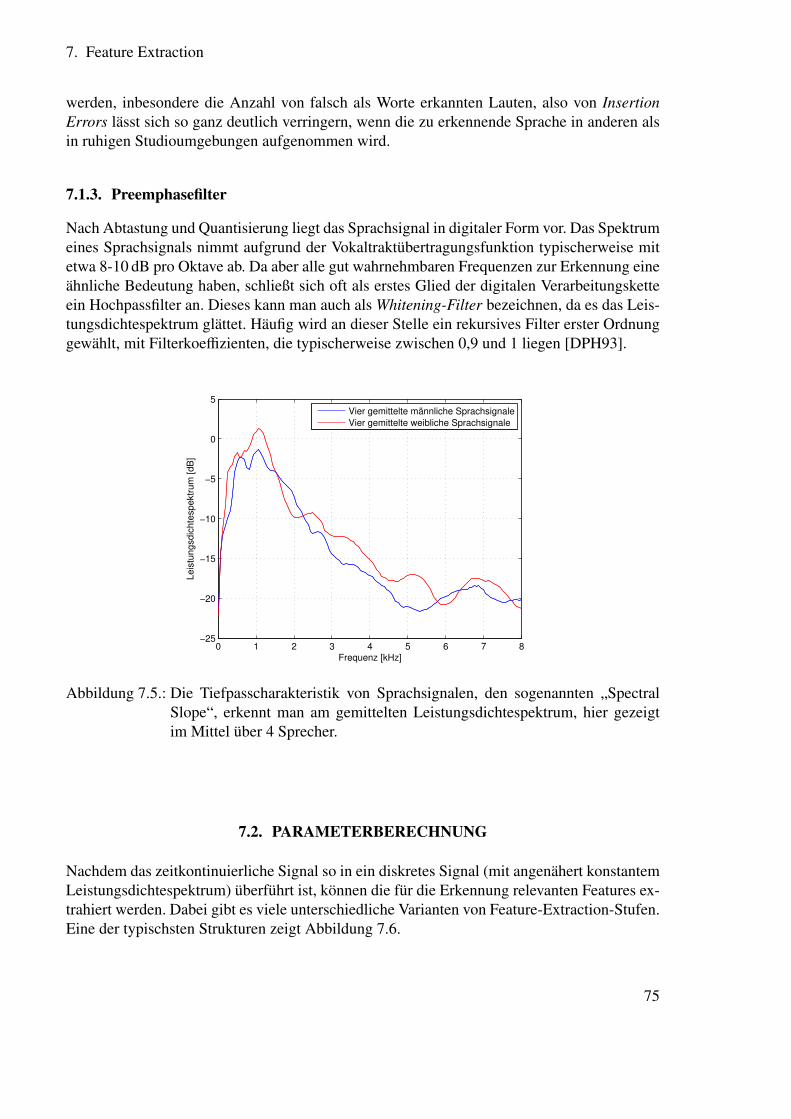
7. Feature Extraction
werden, inbesondere die Anzahl von falsch als Worte erkannten Lauten, also von InsertionErrors lässt sich so ganz deutlich verringern, wenn die zu erkennende Sprache in anderen alsin ruhigen Studioumgebungen aufgenommen wird.
7.1.3. Preemphasefilter
Nach Abtastung und Quantisierung liegt das Sprachsignal in digitaler Form vor. Das Spektrumeines Sprachsignals nimmt aufgrund der Vokaltraktübertragungsfunktion typischerweise mitetwa 8-10 dB pro Oktave ab. Da aber alle gut wahrnehmbaren Frequenzen zur Erkennung eineähnliche Bedeutung haben, schließt sich oft als erstes Glied der digitalen Verarbeitungsketteein Hochpassfilter an. Dieses kann man auch als Whitening-Filter bezeichnen, da es das Leis-tungsdichtespektrum glättet. Häufig wird an dieser Stelle ein rekursives Filter erster Ordnunggewählt, mit Filterkoeffizienten, die typischerweise zwischen 0,9 und 1 liegen [DPH93].
0 1 2 3 4 5 6 7 8−25
−20
−15
−10
−5
0
5
Frequenz [kHz]
Leis
tungsdic
hte
spektr
um
[dB
]
Vier gemittelte männliche Sprachsignale
Vier gemittelte weibliche Sprachsignale
Abbildung 7.5.: Die Tiefpasscharakteristik von Sprachsignalen, den sogenannten „SpectralSlope“, erkennt man am gemittelten Leistungsdichtespektrum, hier gezeigtim Mittel über 4 Sprecher.
7.2. PARAMETERBERECHNUNG
Nachdem das zeitkontinuierliche Signal so in ein diskretes Signal (mit angenähert konstantemLeistungsdichtespektrum) überführt ist, können die für die Erkennung relevanten Features ex-trahiert werden. Dabei gibt es viele unterschiedliche Varianten von Feature-Extraction-Stufen.Eine der typischsten Strukturen zeigt Abbildung 7.6.
75

7. Feature Extraction
ggf.Zeitbereichs-
featureanalyse
Zeit-
Frequenzanalyse
Cepstral-
analyse
Zeitbereichssignals(k)
Features x( )‘
Vektor-
quantisierung
Features x( )
xq( )
Dimensions-
reduktion
Berechnung
der
Ableitungen
S(j )
scep( )
scep( )
scep( )
Optimierungsmöglichkeit:
Abbildung 7.6.: Typisches Blockdiagramm der Feature Extraction.
7.3. ZEITBEREICHSFEATURES
Im Zeitbereich haben zwei Features eine signifikante Bedeutung für die Spracherkennung:
• Energie und
• Grundfrequenz.
Beide Features haben nicht für einzelne Samples sondern nur für größere Blöcke tatsächlicheine Bedeutung, deswegen bietet es sich hier schon an, das Signal in Blöcke einzuteilen (dassogenannte Framing) bevor diese Features berechnet werden.
7.3.1. Framing
Das Signal wird in mehrere, überlappende Segmente eingeteilt. Die Länge der Frames soll-te kurz genug sein, dass das Sprachsignal innerhalb eines Frames noch hinlänglich stationärist (d.h. seine statistischen Eigenschaften sich nicht ändern), gleichzeitig aber lang genug,dass eine sinnvolle Schätzung statistischer Parameter möglich wird. Typischerweise werden10 bis 25 ms Framelänge gewählt. Die Frames werden dann überlappend gebildet, wie esAbbildung 7.7 zeigt. Die notwendige Überlappung beträgt normalerweise 3/4 einer Framelän-ge. Damit läuft der Zeitindex für das k-te Frame von tk,min = (k − 1) · (1 − overlap) · N bis
76

7. Feature Extraction
Sprachsignal
Fensterlänge
Rahmenverschiebung
Frame k Frame k + 1
Merkmalsvektoren
Abbildung 7.7.: Einteilung des Signals in überlappende Frames.
tk,max = (k − 1) · (1 − overlap) · N + N − 1, wobei N und overlap hier für die Framelänge undden Überlappungsfaktor stehen.
7.3.2. Energie
Die Energie kann im Zeitbereich berechnet werden, dazu rechnet man zum Beispiel für dask-te Frame
E(k) =
tk,max∑n=tk,min
s(n)2.
Die Energie ist allerdings nur dann ein zuverlässiges Kriterium für die Spracherkennung, wenndie Sprachdaten an irgendeinem Punkt auf den gleichen, durchschnittlichen Energiepegel ge-bracht werden. Das kann entweder durch die Art der Aufnahme mit automatischer Ampli-tudenregelung geschehen, oder muss anderenfalls später in der Signalverarbeitungskette anirgendeiner Stelle explizit berechnet werden. Wegen dieses Aufwandes und der damit verbun-denen Unsicherheiten verzichten einige Spracherkenner auch ganz auf die Energie als Merk-mal.
77

7. Feature Extraction
7.3.3. Grundfrequenz
In der deutschen und auch in fast allen anderen europäischen Sprachen dient die Grundfre-quenz nur zur Übermittlung syntaktischer und emotionaler Nebeninformationen3 und wirddeswegen auch im Entwurf von Spracherkennern oft nicht berücksichtigt. In vielen asiati-schen Sprachen4 (wie zum Beispiel den sino-tibetischen) und einigen afrikanischen Sprachenist aber auch die Grundfrequenz bedeutungstragend. Und auch in sprachverarbeitenden Syste-men europäischer Sprachen wird die Grundfrequenzinformation benötigt, beispielsweise:
• wenn prosodisch übermittelte Information wie zum Beispiel die Intention oder die Stim-mung des Sprechers erkannt werden soll,
• zur Sprecheridentifikation oder
• für grundfrequenzsynchrone Signalanalyse.
Für die Grundfrequenzanalyse müssen Periodizitäten im Signal gefunden werden. Dazuwerden vor allem zwei wichtige Merkmale des Sprachsignals genutzt:
Erstens bietet sich das Cepstrum an, das zur Ermittlung von periodischen Anteilen in Si-gnalen gedacht ist. Starke periodische Anteile zeigen sich durch deutlich ausgeprägte Peaksim Cepstrum, die dann zur Grundfrequenzanalyse ausgewertet werden. Dazu gibt es später,im Abschnitt 7.6.1, mehr Informationen.
Zweitens ist auch die Autokorrelationsfunktion (AKF) zur Grundfrequenzanalyse geeignet.Diese ist definiert als
rss(τ) = E (s(k)s(k − τ)) .
Sie kann in der Praxis für ein Signalframe, von tmin bis tmax, zum Beispiel mit
rss(τ) =1
tmax − tmin + 1
tmax∑k=tmin+τ
s(k)s(k − τ)
geschätzt werden.5 Die AKF eines periodischen Signals mit der Periode Tp ist selbst peri-odisch, und zwar ebenfalls mit der Periode Tp, und sie hat Maxima bei den Vielfachen derPeriode, N · Tp. Wenn beispielsweise das Signal s(k) die Form
s(k) = cos(ωp · k + ϕ)
besitzt, dann ist
rss(m) = E (s(k)s(k − m))= E
[cos(ωpk + ϕ) cos
(ωp(k − m) + ϕ
)]3Sie ist ein wichtiger Teil der Satzmelodie, der sogenannten Prosodie, die neben dem Verlauf der Grundfrequenz
vor allem durch den Sprachrhytmus bestimmt wird.4Dazu gehören unter anderem Mandarin und Kantonesisch.5Für kurze Frames geht rss(τ) gegen Null, wenn τ → N. Für limN → ∞ handelt es sich hierbei aber um einen
konsistenten Schätzer [JW69].
78

7. Feature Extraction
und wegen des Additionstheorems cosα cos β = 12 cos(α − β) + 1
2 cos(α + β):
rss(m) = E[12
cos(ωpk − ωp(k − m)
)+
12
cos(ωp(2k − m) + 2ϕ
)].
Weil der Erwartungswert des zweiten Summanden gleich Null ist, gilt weiter
rss(m) = E[12
cos(ωpm)]
=12
cos(ωpm)
=12
cos(2πTp
m)
und der letzte Ausdruck, 1/2 cos(2πm/Tp
), wird maximal, wenn das Argument des Kosinus
ein Vielfaches von 2π ist, wenn also m/Tp ganzzahlig ist. Das heißt, dass die AKF ihre Maximabei den Zeitverschiebungen m hat, die ganzzahlige Vielfache der Grundperiodendauer sind.Damit kann prinzipiell die Grundperiode der Sprache ermittelt werden. Schwierig wird es
• durch den weiten Bereich, in dem die Grundfrequenz liegen kann - diese liegt fürmenschliche Sprache zwischen etwa 40 Hz bei erwachsenen Männern und 600 Hz beiKindern,
• durch subharmonische Fehler (periodische Signale mit der Periode T0 sind auch peri-odisch mit der Periode m · T0), und
• durch superharmonische Fehler, die auftreten können, wenn durch die Übertragungs-funktion des Vokaltrakts die Grundfrequenz stark gedämpft wird und gleichzeitig For-manten (die Resonanzstellen des Vokaltraktes) nahe an einem Vielfachen der Grundfre-quenz liegen.
Trotz dieser Probleme eine zuverlässige Grundfrequenzschätzung zu erhalten, ist nicht trivial.Umfangreiche Informationen zu dem Thema gibt es beispielsweise in [DPH93].
Ganz grundsätzlich gesprochen, ist es vor allem wichtig, bei der Grundfrequenzanalyse
• nur stimmhafte Segmente zu analysieren (da nur in diesen eine Grundfrequenz definiertist) und
• die Schätzung durch die Nachverfolgung der Grundfrequenz über einen längeren Zeit-raum, durch Pitch-Tracking, zuverlässiger zu gestalten.
79
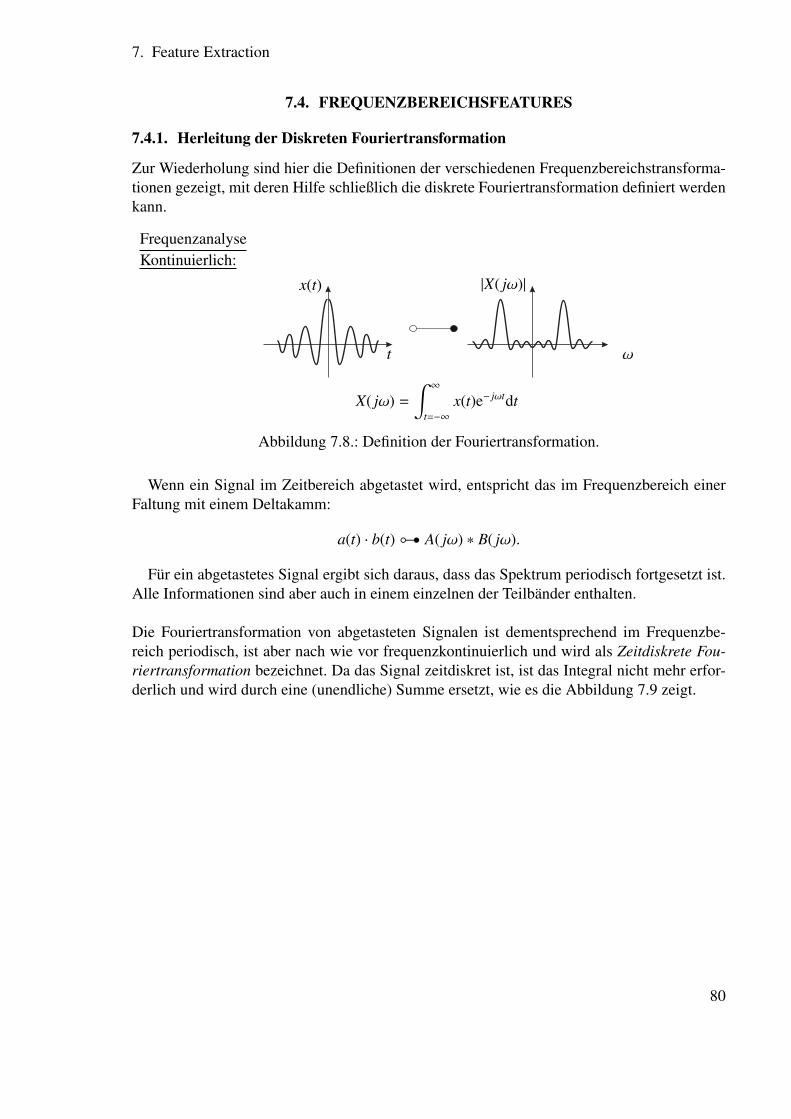
7. Feature Extraction
7.4. FREQUENZBEREICHSFEATURES
7.4.1. Herleitung der Diskreten Fouriertransformation
Zur Wiederholung sind hier die Definitionen der verschiedenen Frequenzbereichstransforma-tionen gezeigt, mit deren Hilfe schließlich die diskrete Fouriertransformation definiert werdenkann.
FrequenzanalyseKontinuierlich:
x(t) |X( jω)|
t ω
X( jω) =
∫ ∞
t=−∞x(t)e− jωtdt
Abbildung 7.8.: Definition der Fouriertransformation.
Wenn ein Signal im Zeitbereich abgetastet wird, entspricht das im Frequenzbereich einerFaltung mit einem Deltakamm:
a(t) · b(t) A( jω) ∗ B( jω).
Für ein abgetastetes Signal ergibt sich daraus, dass das Spektrum periodisch fortgesetzt ist.Alle Informationen sind aber auch in einem einzelnen der Teilbänder enthalten.
Die Fouriertransformation von abgetasteten Signalen ist dementsprechend im Frequenzbe-reich periodisch, ist aber nach wie vor frequenzkontinuierlich und wird als Zeitdiskrete Fou-riertransformation bezeichnet. Da das Signal zeitdiskret ist, ist das Integral nicht mehr erfor-derlich und wird durch eine (unendliche) Summe ersetzt, wie es die Abbildung 7.9 zeigt.
80

7. Feature Extraction
FrequenzanalyseDiskret:
tk =kFs
xzd = x(t) · δ 1Fs
d tXzd( jω)
x(k) |Xzd( jω)|
k 2πFs ω
Xzd( jω) =
∫ ∞
t=−∞x(t)δ 1
Fse− jωtdt
Xzd( jω) =
∞∑k=−∞
x(
kFs
)e− jω k
Fs
Abbildung 7.9.: Berechnung der zeitdiskreten Fouriertransformation (ZDFT).
Für die Definition der diskreten Fouriertransformation werden die Frequenzen auf den Be-reich 0 . . . 2π normiert, die normierte Frequenz Ω erhält man dazu aus
Ωdef=
2π fFs
.
Xzd( jω) =
∞∑k=−∞
xk (k) e− j 2π fFs
k
Normierte Kreisfrequenz⇒ Ω :=2π fFs
Xzd(Ω) =
∞∑k=−∞
xk (k) e− jΩk
Abbildung 7.10.: Normierung der Frequenzen für die diskrete Fouriertransformation.
Die diskrete Fouriertransformation ist nicht nur im Zeit- sondern auch im Frequenzbereichquantisiert. Die Quantisierung findet für die normierte Frequenz Ω statt, es werden N Wertebenötigt, also berechnet man die Frequenzen
Ω = 0,2πN,
2 · 2πN
. . .(N − 1)2π
N
81

7. Feature Extraction
oderΩn
def=
n · 2πN
, für n = 0 . . .N − 1.
Allerdings sind für reelle Zeitsignale nur die ersten N/2+1 Werte6 relevant, da der zweite Teildes Spektrums konjugiert symmetrisch ist. Diese Quantisierung im Frequenzbereich entsprichtim Zeitbereich einer periodischen Fortsetzung des Signals, sodass die Fouriertransformiertenur für Signale von endlicher Länge definiert ist.
Abtastung im Frequenzbereich = Periodische Fortsetzung im Zeitbereich
x(k) |Xzd( jω)|
k n
⇒ deswegen nur definiert für endliche Folgen
XDFT(n) =
N−1∑k=0
xk (k) e− jωnk =
N−1∑k=0
xk (k) e− j 2πnN k
Abbildung 7.11.: Definition der diskreten Fouriertransformation (DFT).
7.4.2. Einfluss der Fensterfunkion
Vor der Berechnung der Fouriertransformation wird das Signal im Zeitbereich in überlappendeSegmente eingeteilt, wie es in Abschnitt 7.3.1 beschrieben ist. Mathematisch betrachtet ent-spricht dieses Ausschneiden von Zeitsegmenten aus dem Gesamtsignal einer Multiplikationmit einer Rechteckfunktion. Diese Operation der Multiplikation mit einer Funktion, die alleSignalanteile, abgesehen von einem endlichen Bereich, auf Null setzt, wird auch als Fenste-rung bezeichnet. Eine Fensterfunktion muss fünf Eigenschaften besitzen, um als solche be-zeichnet zu werden:
Definition 7.4.1 Das Transformationspaar w(t) W( jω) stellt eine Fensterfunktion dargenau dann, wenn
• w(t) reell ist,
• w(t) symmetrisch ist,
• w(t) auf einem begrenzten Bereich ungleich Null ist: w(t) = 0 ∀|t| > T,
• w(0) normalisiert ist, also w(0) = 12π
∫ ∞−∞
W( jω)dω = 1 und
6Bei ungeraden N sind es die ersten (N + 1)/2 Werte.
82

7. Feature Extraction
• W( jω) schmalbandig ist.
Um den Effekt einer Fensterung analysieren zu können, schreibt man
xw(k) = x(k) · w(k),
wobei xw(k) für das gefensterte Zeitsignal steht. Diese Fensterung im Zeitbereich entsprichtim Frequenzbereich einer Faltung mit der fouriertransformierten Fensterfunktion:
Xw(Ω) = X(Ω) ∗W(Ω).
Wenn der Faltungsoperator ausgeschrieben wird, erhält man
Xw(Ω) =
∫ ∞
−∞
X(Ω′)W(Ω −Ω′)dΩ′.
Betrachtet man diesen Ausdruck konkret für eine Frequenzstützstelle Ωn, ergibt sich
Xw(Ωn) =
∫ ∞
−∞
X(Ω′)W(Ωn −Ω′)dΩ′.
Man erhält also das n-te Band der DFT, indem man das Spektrum des Ursprungssignals X(Ω)nach Multiplikation mit dem Spektrum der Fensterfunktion über alle Frequenzen integriert,nachdem das Spektrum der Fensterfunktion, W(Ω) um Ωn verschoben und außerdem gespie-gelt wurde. Der Effekt einer gefensterten DFT entspricht also dem einer Gruppe von Band-passfiltern. Die Übertragungsfunktion der Bandpässe ist die Fouriertransformierte der Fenster-funktion und die Mittenfrequenzen sind die Analysefrequenzen Ωn. Die Abbildung 7.12 zeigtdie Filterbankdarstellung der DFT im Spektralbereich. Da also das Spektrum der Fensterfunk-tion die Form der einzelnen Bandpässe der DFT ergibt, ist es wichtig, eine geeignete Fens-terfunktion auszuwählen. Je schmaler die Hauptkeule der Fensterfunktion ist, und je stärkerdie Nebenkeulen gedämpft werden, desto selektiver wird die DFT jeweils die Mittenfrequen-zen zeigen. Die Rechteckfunktion ist als Fensterfunktion insofern immerhin akzeptabel, dasie eine schmale Hauptkeule besitzt. Wegen ihrer vergleichsweise schwach gedämpften Ne-benkeulen bevorzugt man allerdings andere Fensterfunktionen, die bezüglich der Größe derNebenkeulen ein besseres Verhalten zeigen. Besonders häufig findet man die Hamming- undHann-Fensterfunktion oder das Blackman-Fenster. Bei dem Kaiser-Fenster, das in Bezug aufdas Verhältnis zwischen den Energien der Haupt- und der Nebenkeulen optimiert ist, erlaubtein zusätzlicher Parameter die Kontrolle über die Amplitude der Nebenkeulen.
Betrachtet man das Rechteck-, Hamming-, Hannfenster im Zeitbereich, zeigt sich, dass sieeine gemeinsame Form besitzen:
w(k) = ξ0 + ξ1 cos(
2πkM − 1
), 0 ≤ k ≤ M − 1.
Das Blackman-Fenster besitzt einen zweiten Kosinusterm, der den Ripple im Sperrbereichverringert. Tabelle 7.1 fasst die Parameter der genannten Fensterfunktionen zusammen undAbbildung 7.13 zeigt ihre Übertragungsfunktionen.
83
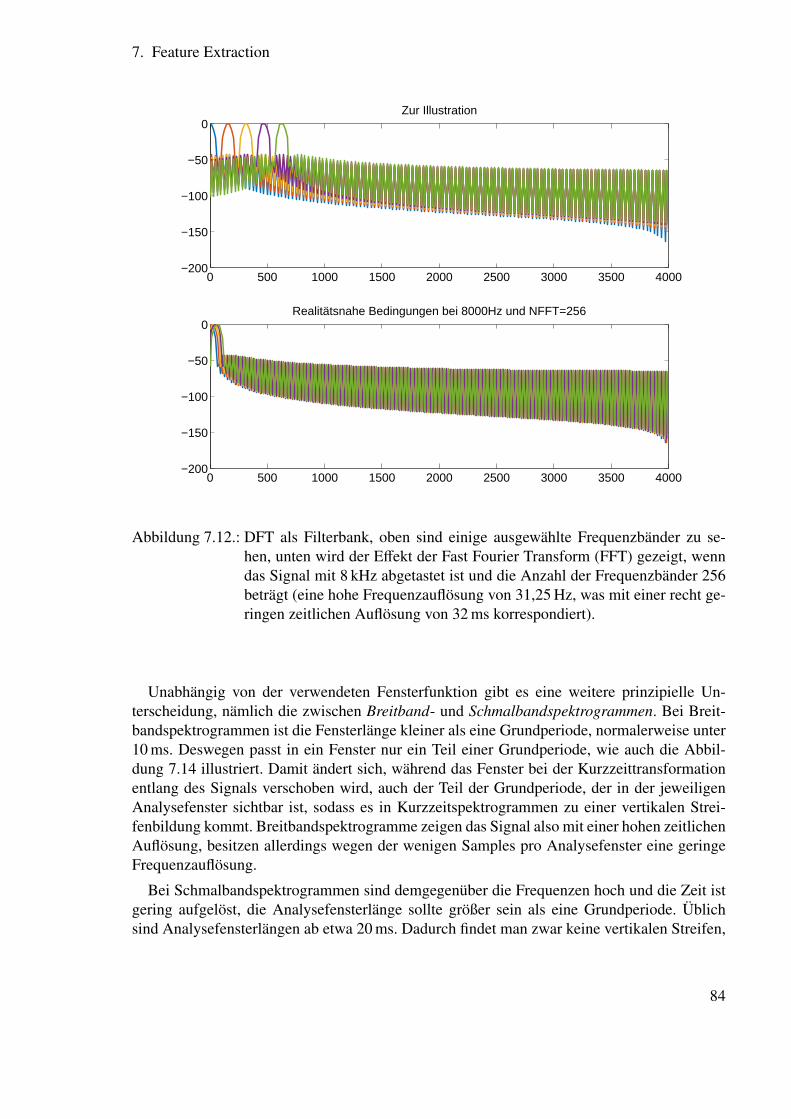
7. Feature Extraction
0 500 1000 1500 2000 2500 3000 3500 4000−200
−150
−100
−50
0Zur Illustration
0 500 1000 1500 2000 2500 3000 3500 4000−200
−150
−100
−50
0Realitätsnahe Bedingungen bei 8000Hz und NFFT=256
Abbildung 7.12.: DFT als Filterbank, oben sind einige ausgewählte Frequenzbänder zu se-hen, unten wird der Effekt der Fast Fourier Transform (FFT) gezeigt, wenndas Signal mit 8 kHz abgetastet ist und die Anzahl der Frequenzbänder 256beträgt (eine hohe Frequenzauflösung von 31,25 Hz, was mit einer recht ge-ringen zeitlichen Auflösung von 32 ms korrespondiert).
Unabhängig von der verwendeten Fensterfunktion gibt es eine weitere prinzipielle Un-terscheidung, nämlich die zwischen Breitband- und Schmalbandspektrogrammen. Bei Breit-bandspektrogrammen ist die Fensterlänge kleiner als eine Grundperiode, normalerweise unter10 ms. Deswegen passt in ein Fenster nur ein Teil einer Grundperiode, wie auch die Abbil-dung 7.14 illustriert. Damit ändert sich, während das Fenster bei der Kurzzeittransformationentlang des Signals verschoben wird, auch der Teil der Grundperiode, der in der jeweiligenAnalysefenster sichtbar ist, sodass es in Kurzzeitspektrogrammen zu einer vertikalen Strei-fenbildung kommt. Breitbandspektrogramme zeigen das Signal also mit einer hohen zeitlichenAuflösung, besitzen allerdings wegen der wenigen Samples pro Analysefenster eine geringeFrequenzauflösung.
Bei Schmalbandspektrogrammen sind demgegenüber die Frequenzen hoch und die Zeit istgering aufgelöst, die Analysefensterlänge sollte größer sein als eine Grundperiode. Üblichsind Analysefensterlängen ab etwa 20 ms. Dadurch findet man zwar keine vertikalen Streifen,
84
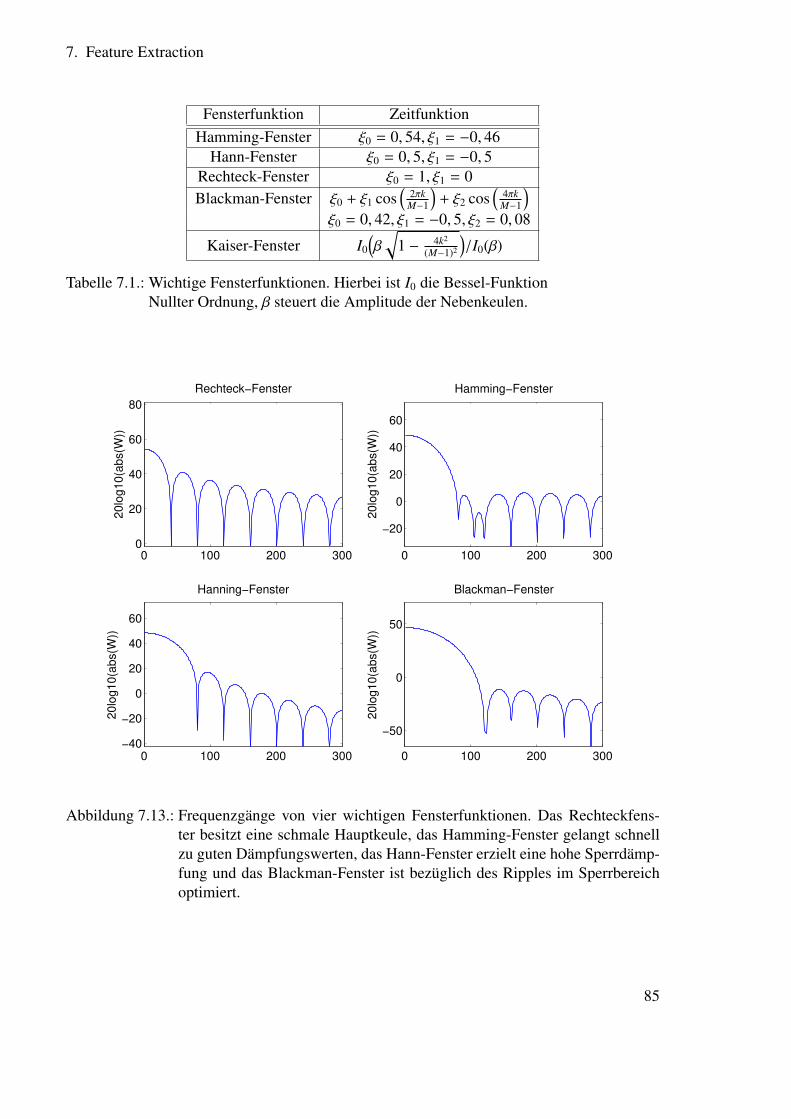
7. Feature Extraction
Fensterfunktion ZeitfunktionHamming-Fenster ξ0 = 0, 54, ξ1 = −0, 46
Hann-Fenster ξ0 = 0, 5, ξ1 = −0, 5Rechteck-Fenster ξ0 = 1, ξ1 = 0Blackman-Fenster ξ0 + ξ1 cos
(2πkM−1
)+ ξ2 cos
(4πkM−1
)ξ0 = 0, 42, ξ1 = −0, 5, ξ2 = 0, 08
Kaiser-Fenster I0
(β√
1 − 4k2
(M−1)2
)/I0(β)
Tabelle 7.1.: Wichtige Fensterfunktionen. Hierbei ist I0 die Bessel-FunktionNullter Ordnung, β steuert die Amplitude der Nebenkeulen.
0 100 200 3000
20
40
60
80
20lo
g10(a
bs(W
))
Rechteck−Fenster
0 100 200 300
−20
0
20
40
60
20lo
g10(a
bs(W
))
Hamming−Fenster
0 100 200 300−40
−20
0
20
40
60
20lo
g10(a
bs(W
))
Hanning−Fenster
0 100 200 300
−50
0
50
20lo
g10(a
bs(W
))
Blackman−Fenster
Abbildung 7.13.: Frequenzgänge von vier wichtigen Fensterfunktionen. Das Rechteckfens-ter besitzt eine schmale Hauptkeule, das Hamming-Fenster gelangt schnellzu guten Dämpfungswerten, das Hann-Fenster erzielt eine hohe Sperrdämp-fung und das Blackman-Fenster ist bezüglich des Ripples im Sperrbereichoptimiert.
85
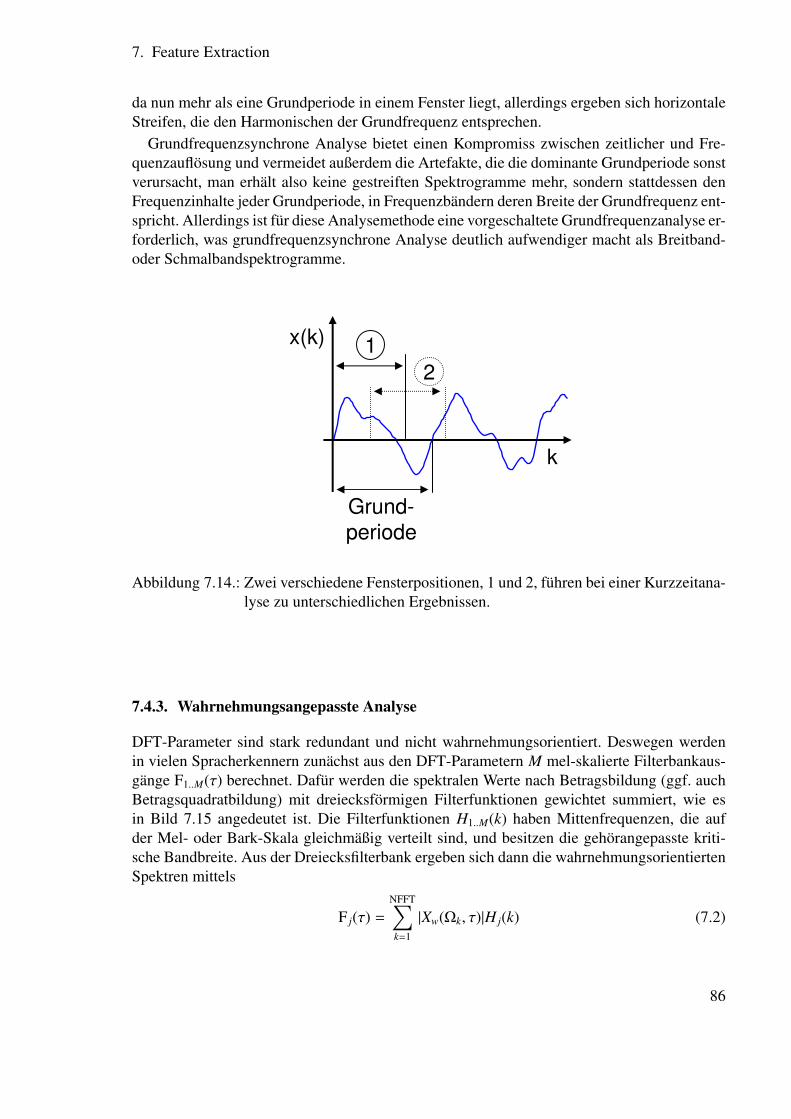
7. Feature Extraction
da nun mehr als eine Grundperiode in einem Fenster liegt, allerdings ergeben sich horizontaleStreifen, die den Harmonischen der Grundfrequenz entsprechen.
Grundfrequenzsynchrone Analyse bietet einen Kompromiss zwischen zeitlicher und Fre-quenzauflösung und vermeidet außerdem die Artefakte, die die dominante Grundperiode sonstverursacht, man erhält also keine gestreiften Spektrogramme mehr, sondern stattdessen denFrequenzinhalte jeder Grundperiode, in Frequenzbändern deren Breite der Grundfrequenz ent-spricht. Allerdings ist für diese Analysemethode eine vorgeschaltete Grundfrequenzanalyse er-forderlich, was grundfrequenzsynchrone Analyse deutlich aufwendiger macht als Breitband-oder Schmalbandspektrogramme.
Grund-
periode
x(k)
2
k
1
Abbildung 7.14.: Zwei verschiedene Fensterpositionen, 1 und 2, führen bei einer Kurzzeitana-lyse zu unterschiedlichen Ergebnissen.
7.4.3. Wahrnehmungsangepasste Analyse
DFT-Parameter sind stark redundant und nicht wahrnehmungsorientiert. Deswegen werdenin vielen Spracherkennern zunächst aus den DFT-Parametern M mel-skalierte Filterbankaus-gänge F1..M(τ) berechnet. Dafür werden die spektralen Werte nach Betragsbildung (ggf. auchBetragsquadratbildung) mit dreiecksförmigen Filterfunktionen gewichtet summiert, wie esin Bild 7.15 angedeutet ist. Die Filterfunktionen H1..M(k) haben Mittenfrequenzen, die aufder Mel- oder Bark-Skala gleichmäßig verteilt sind, und besitzen die gehörangepasste kriti-sche Bandbreite. Aus der Dreiecksfilterbank ergeben sich dann die wahrnehmungsorientiertenSpektren mittels
F j(τ) =
NFFT∑k=1
|Xw(Ωk, τ)|H j(k) (7.2)
86

7. Feature Extraction
H1(k) = Dreiecksfunktion des
ersten Filters
F1( )
FM( )
Xw( 1, )
Xw( N, )
x(t)DFT
:
:
:
:
Abbildung 7.15.: Dreiecksfilterbank.
als Summen der Einzelbandbeträge oder über
F j(τ) =
NFFT∑k=1
|Xw(Ωk, τ)|2H j(k)
als Summen der Energien über alle NFFT nichtredundanten Frequenzstützstellen. Die resul-tierende Betragsübertragungsfunktion entsprechend (7.2) erhält man aus
|H j,ges(Ω)| =NFFT∑k=1
|W(Ωk −Ω)|H j(k),
da die einzelnen Bänder |W(Ωk − Ω)| linear kombiniert werden. Das Ergebnis der betragsmä-ßigen Summation ist in Abbildung 7.16 für ein Beispiel eines Dreiecksfilters gezeigt. Statt derFilterung via DFT mit anschließender Gewichtung könnte eine Filterbank auch auf anderemWeg realisiert werden, z. B. als
• Filter im Zeitbereich (Finite Impulse Response (FIR) oder Infinite Impulse Response(IIR)) (ggf. mit anschließender Unterabtastung),
• als Filterbank in Baumstruktur,
• als im Zeitbereich entworfenes Gammaton-Filter (das sowohl die Frequenz- als auch dieZeitauflösung der gehörinternen Signalverarbeitung approximiert) oder
• über Wavelets.
• Die derzeit wichtigste Alternative zur DFT ist die linear prädiktive Codierung, die auch(u.A. im Mobilfunk) zur Sprachkompression verwendet wird.
Bei der linear prädiktiven Codierung (engl.: Linear Predictive Coding (LPC)) wird einSpracherzeugungsmodell zugrunde gelegt, in dem das Sprachsignal durch die Faltung eines
87
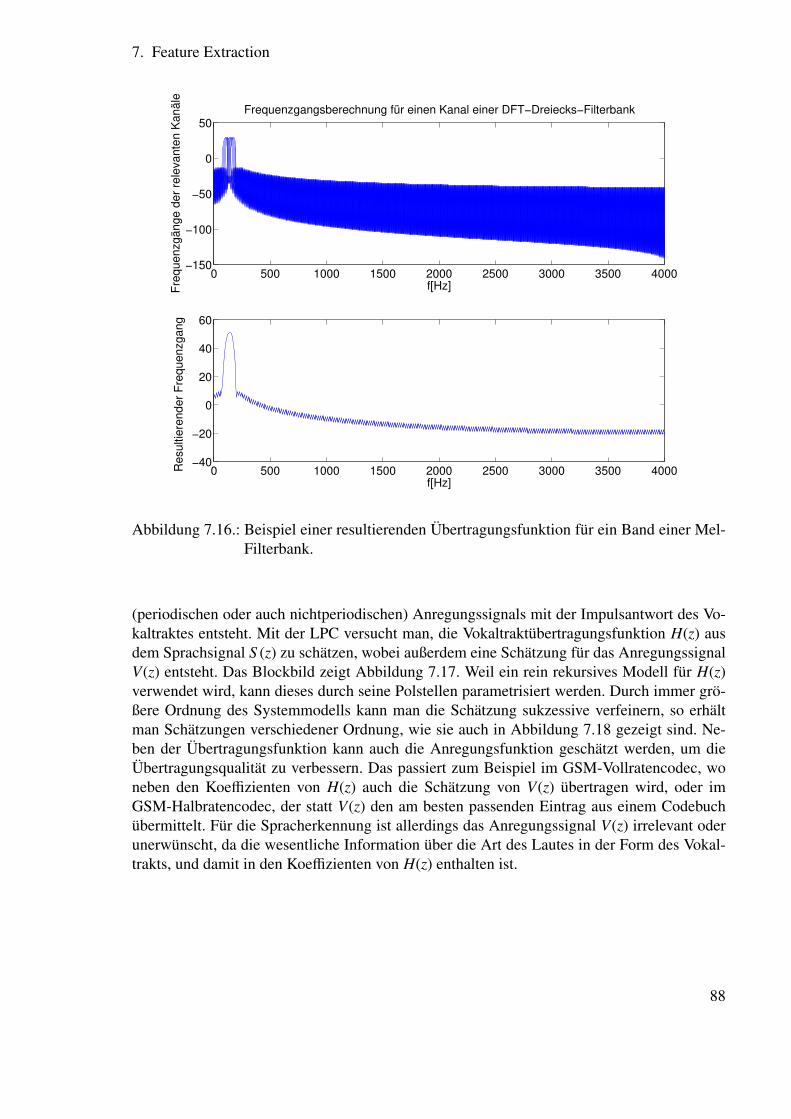
7. Feature Extraction
0 500 1000 1500 2000 2500 3000 3500 4000−40
−20
0
20
40
60
Resultie
render
Fre
quenzgang
f[Hz]
0 500 1000 1500 2000 2500 3000 3500 4000−150
−100
−50
0
50
Fre
quenzgänge d
er
rele
vante
n K
anäle
Frequenzgangsberechnung für einen Kanal einer DFT−Dreiecks−Filterbank
f[Hz]
Abbildung 7.16.: Beispiel einer resultierenden Übertragungsfunktion für ein Band einer Mel-Filterbank.
(periodischen oder auch nichtperiodischen) Anregungssignals mit der Impulsantwort des Vo-kaltraktes entsteht. Mit der LPC versucht man, die Vokaltraktübertragungsfunktion H(z) ausdem Sprachsignal S (z) zu schätzen, wobei außerdem eine Schätzung für das AnregungssignalV(z) entsteht. Das Blockbild zeigt Abbildung 7.17. Weil ein rein rekursives Modell für H(z)verwendet wird, kann dieses durch seine Polstellen parametrisiert werden. Durch immer grö-ßere Ordnung des Systemmodells kann man die Schätzung sukzessive verfeinern, so erhältman Schätzungen verschiedener Ordnung, wie sie auch in Abbildung 7.18 gezeigt sind. Ne-ben der Übertragungsfunktion kann auch die Anregungsfunktion geschätzt werden, um dieÜbertragungsqualität zu verbessern. Das passiert zum Beispiel im GSM-Vollratencodec, woneben den Koeffizienten von H(z) auch die Schätzung von V(z) übertragen wird, oder imGSM-Halbratencodec, der statt V(z) den am besten passenden Eintrag aus einem Codebuchübermittelt. Für die Spracherkennung ist allerdings das Anregungssignal V(z) irrelevant oderunerwünscht, da die wesentliche Information über die Art des Lautes in der Form des Vokal-trakts, und damit in den Koeffizienten von H(z) enthalten ist.
88
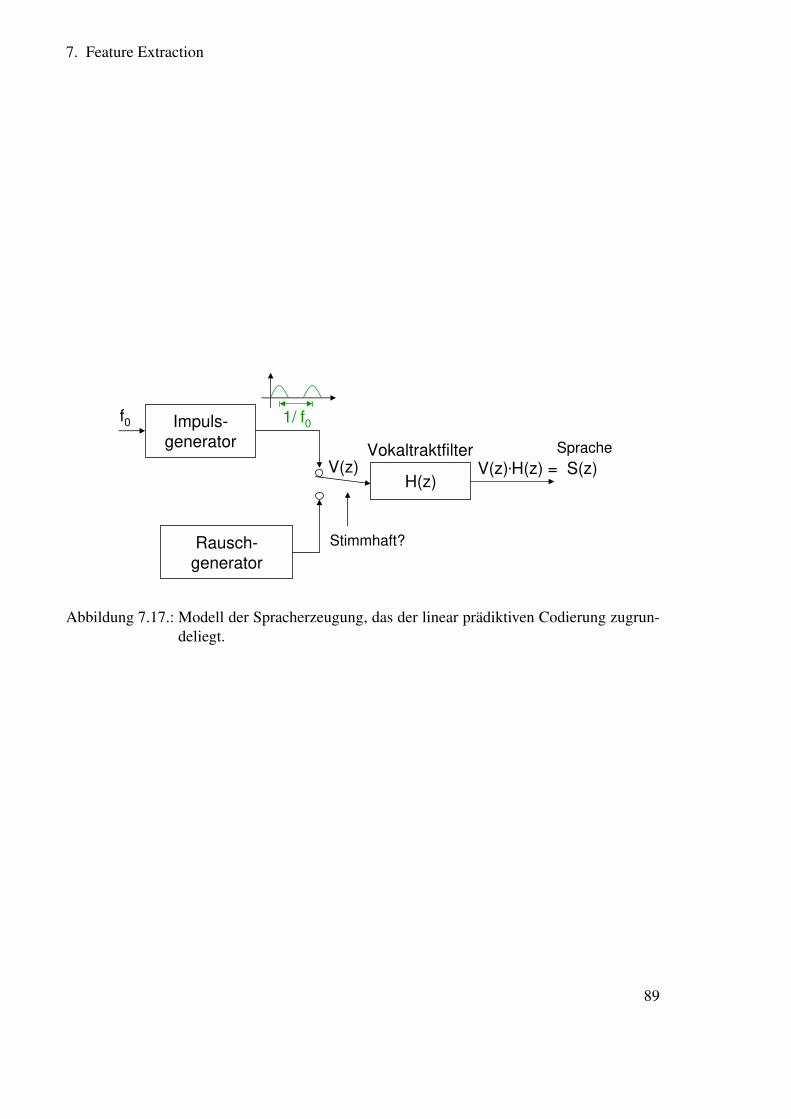
7. Feature Extraction
Impuls-
generator
Rausch-
generator
H(z)
Stimmhaft?
f0 1/ f0
VokaltraktfilterV(z) V(z).H(z) = S(z)
Sprache
Abbildung 7.17.: Modell der Spracherzeugung, das der linear prädiktiven Codierung zugrun-deliegt.
89
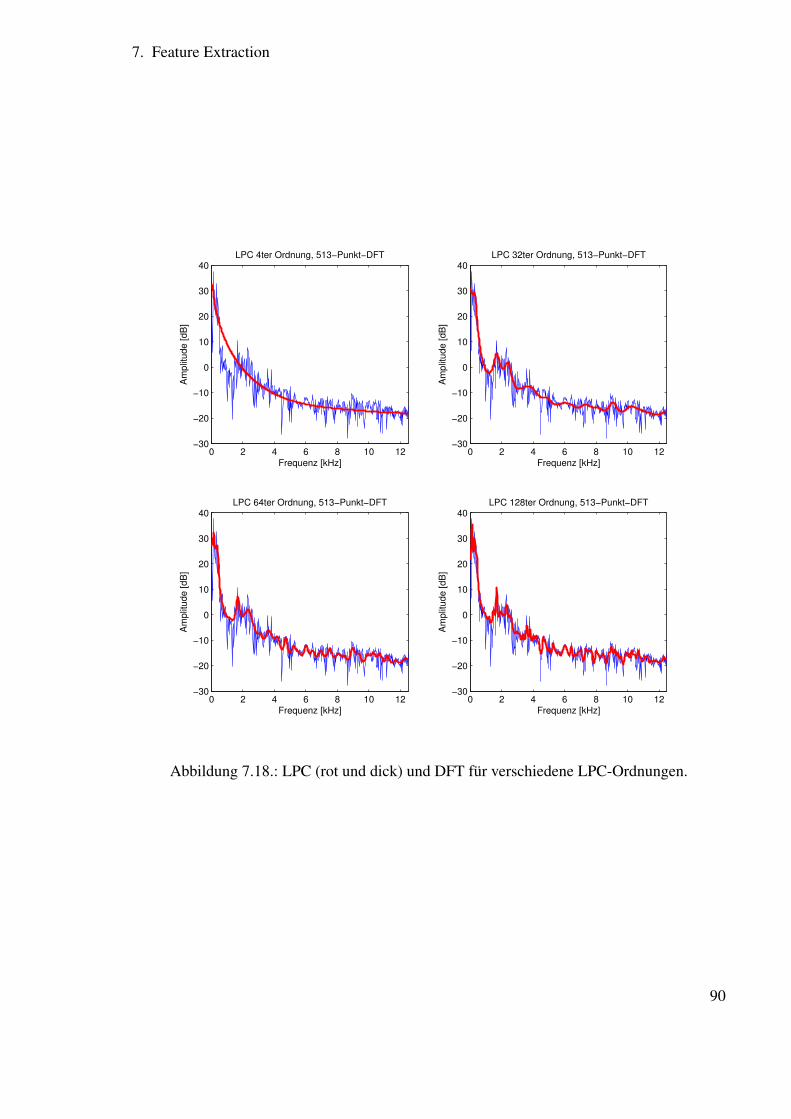
7. Feature Extraction
0 2 4 6 8 10 12−30
−20
−10
0
10
20
30
40LPC 4ter Ordnung, 513−Punkt−DFT
Frequenz [kHz]
Am
plit
ud
e [d
B]
0 2 4 6 8 10 12−30
−20
−10
0
10
20
30
40LPC 32ter Ordnung, 513−Punkt−DFT
Frequenz [kHz]
Am
plit
ud
e [d
B]
0 2 4 6 8 10 12−30
−20
−10
0
10
20
30
40LPC 64ter Ordnung, 513−Punkt−DFT
Frequenz [kHz]
Am
plit
ude [dB
]
0 2 4 6 8 10 12−30
−20
−10
0
10
20
30
40LPC 128ter Ordnung, 513−Punkt−DFT
Frequenz [kHz]
Am
plit
ude [dB
]
Abbildung 7.18.: LPC (rot und dick) und DFT für verschiedene LPC-Ordnungen.
90

7. Feature Extraction
Struktur der Parameterextraktion
Zur Wiederholung ist hier der Überblick über die Parameterextraktion aus Abschnitt 7.2 ge-zeigt:
ggf.Zeitbereichs-
featureanalyse
Zeit-
Frequenzanalyse
Cepstral-
analyse
Zeitbereichssignals(k)
Features x( )‘
Vektor-
quantisierung
Features x( )
xq( )
Dimensions-
reduktion
Berechnung
der
Ableitungen
S(j )
scep( )
scep( )
scep( )
Optimierungsmöglichkeit:
Abbildung 7.19.: Typischer Ablauf der Feature Extraction.
Wie hier zu sehen ist, werden aus Frequenzbereichsfeatures in der nächsten Stufe der Para-meterberechnung Cepstrale Features gewonnen.
7.5. CEPSTRALE FEATURES
Nach der Bestimmung des Spektrums sind die Merkmale noch stark von dem Sprecher und derUmgebung abhängig, gleichzeitig sind die einzelnen Parameter stark redundant und korreliert.Eine robustere und gleichzeitig kompaktere Repräsentation des Sprachsignals erhält man mitdem Cepstrum. Es wird derzeit beispielsweise für
• die Spracherkennungssysteme von Microsoft und Nippon Telegraph and Telephone Cor-poration (NTT),
• den HTK-Erkenner, der für eine aktuelle, internationale Robustheitsstudie7 eingesetztwurde, und
7Aurora 2/3, verwendet für Special Sessions zu Robuster Spracherkennung auf den Konferenzen Eurospeech2001, 2002 und 2003, [PHG00].
91

7. Feature Extraction
• den aktuell von dem European Telecommunications Standards Institute (ETSI) entwi-ckelten Feature-Extraction-Standard [ETS00] verwendet.
7.5.1. Das Cepstrum als Raum der Verzögerungszeiten
Gegeben ist zuerst ein Signal s(t). Wenn dieses Signal auf zwei Wegen an einem Sensor ein-trifft, einmal unverzögert und einmal um t′ verzögert und mit dem Dämpfungsfaktor α abge-schwächt, erhält man als Sensorsignal x(t):
x(t) = s(t) + αs(t − t′).
Das kann man auch schreiben als
x(t) = s(t) ∗(δ(t) + αδ(t − t′)
)sodass die Fouriertransformierte des Gesamtsignals
X( j f ) = S ( j f ) ·(1 + αe− j2π f t′
)ist. Das Energiedichtespektrum |X( j f )|2 erhält man dann aus
|X( j f )|2 = X( j f ) · X( j f )∗
= S ( j f ) · S (− j f )(1 + αe j2π f t′
) (1 + αe− j2π f t′
)= |S ( j f )|2
(1 + α2 + αe j2π f t′ + αe− j2π f t′
).
Weil e jx + e− jx = 2 cos x gilt, erhält man dann
|X( j f )|2 = |S ( j f )|2(1 + α2 + 2α cos(2π f t′)
).
Das Spektrum des Mikrofonsignals besteht aus dem ursprünglichen Signalspektrum, verstärktum den Faktor (1 + α2), und aus einer weiteren Komponente, in der das Spektrum |S ( j f )|2
zusätzlich mit einer Kosinusschwingung moduliert ist. Die „Frequenz“ dieser Schwingung istgleich der Verzögerungszeit t′ und die „Amplitude“ ist 2α. Es wäre interessant, automatisiertaus einem Signalspektrum solche periodischen Anteile zu extrahieren.
Zu diesem Zweck kann man das Mikrofonsignal im Frequenzbereich logarithmieren. DasErgebnis besteht dann aus:
log |X( j f )|2 = log |S ( j f )|2 + log(1 + α2 + 2α cos(2π f t′)
).
Hier sieht man, dass das logarithmierte Spektrum aus zwei Anteilen besteht, dem logarithmier-ten Spektrum des Quellensignals log |S ( j f )|2 und der Funktion log
(1 + α2 + 2α cos(2π f t′)
).
Es sind also der Anteil des Quellensignals und der Anteil der Übertragungsfunktion aus ei-ner Faltung (im Zeitbereich) in eine Summe (im logarithmierten Spektrum) überführt worden.Wenn man an der Verzögerungszeit t′ interessiert ist, kann man diese aus dem zweiten Teildes Spektrums, log
(1 + α2 + 2α cos(2π f t′)
), gewinnen. Dieses ist periodisch (periodisch im
Frequenzbereich) mit der „Periodendauer“ 1/t′, also mit der „Frequenz“ t′. Wenn man diese
92

7. Feature Extraction
Funktion also mit einer Fouriertransformation in ihre „spektralen“ Anteile zerlegt, erhält manzwei Teile: einen „Gleichanteil“ und einen Anteil bei der „Frequenz“ t′.
Das ist die Vorgehensweise, der man bei der Cepstral-Transformation folgt: das reelle Cep-strum ist definiert als die inverse Fouriertransformation8 des logarithmierten Betragsspektrums
sc(t′) = IDFTlog |S ( j f )|
oder, genauer:
sc(t′) =1
2π
∫ Fs/2
−Fs/2log |S ( j f )|e j2π f t′d f .
Weil Betragsspektren reell und symmetrisch sind, kann statt der IDFT die DCT der nicht-redundanten spektralen Anteile verwendet werden. Diese nimmt implizit eine symmetrischeErgänzung des Spektrums vor, die im Anhang A.4 ausführlicher beschrieben ist.
Um nach der zweiten Spektraltransformation mit den Begriffen nicht durcheinanderzukom-men, wurden die Analyseergebnisse von ihren Erfindern mit neuen Namen versehen:
• das Ergebnis der gesamten Rechnung, das „Spektrum“ des logarithmierten Betragsspek-trums, wird als Cepstrum bezeichnet,
• die „Frequenz“ einer Schwingung im logarithmierten Spektrum, äquivalent zur Verzö-gerungszeit im Zeitsignal, nennt man Quefrenz, und
• eine „Filterung“ des Cepstrums wird (vor allem in der englischen Literatur) als Lifteringbezeichnet.
7.5.2. Verzögerungszeiten in Sprachsignalen
Sprachsignale bestehen aus mehreren Gründen aus verzögerten Überlagerungen eines Ur-sprungssignals:
• mit der Grundfrequenz besitzen sie in stimmhaften Segmenten einen starken periodi-schen Anteil,
• es kommt im Vokaltrakt und
• im Raum zu Reflexionen.
Einerseits ist das von den Stimmbändern gebildete Anregungssignal periodisch, sodass man esals Faltung einer einzigen Grundperiode mit einem Deltakamm modellieren kann, andererseitswird dieses Anregungssignal sowohl mit der Impulsantwort des Vokaltrakts als auch mit derdes Raumes gefiltert, was wiederum als die Summe von verschiedenen stark gedämpften undverzögerten Varianten des Ursprungssignals dargestellt werden kann. Mit der Cepstralanalyseversucht man, alle drei Ursachen für solche „Wiederholungen“ im Signal zu finden und zutrennen - man trennt also die Periodizität des Anregungssignals von den Verzögerungszeitendes Vokaltraktes und des Raumes.
8Fouriertransformierte und inverse Fouriertransformierte eines reellen Signals unterscheiden sich darin, dasssie konjugiert komplex zueinander sind und einen anderen Skalierungsfaktor haben: F S = cF −1 S ∗.Insofern ist es sinnvoll, die inverse Fouriertransformation hier als eine Spektralanalyse zu bezeichnen.
93

7. Feature Extraction
7.5.2.1. Periodizität mit der Grundperiode
Das Sprachsignal ist in stimmhaften Segmenten angenähert periodisch mit der GrundperiodeTp. Wäre es exakt periodisch, könnte man es als Faltung einer einzelnen Grundperiode s1(t)mit einem Deltakamm δT p(t) modellieren, wie auch die Abbildung 7.20 zeigt. Ein Sprachsi-
t
s
T0
t
s0
*
t
T0
T0
s(t)=s0(t)+s0(t-T0)+s0(t-2T0)+... = s0(t) * T0(t)
Abbildung 7.20.: Periodische Signale können als Faltung der Grundperiode mit einem Delta-kamm modelliert werden.
gnal ist zwar nie exakt periodisch, aber trotz der Änderungen von Grundperiode zu Grund-periode hat es spektrale Anteile, die einen deutlichen Einfluss der Grundperiode zeigen, wieman in Abbildung 7.21 erkennen kann. Dementsprechend kann man erwarten, dass das Cep-strum einen starken Anteil bei der Verzögerungszeit Tp enthält. Abbildung 7.22 zeigt an einemBeispiel, dass das tatsächlich in stimmhaften Segmenten der Fall ist.
7.6. ANWENDUNGEN DES CEPSTRUMS
7.6.1. Grundfrequenzbestimmung
Wie in Abschnitt 7.3.3 erwähnt wurde, kann das Cepstrum eines stimmhaften Sprachsignalszur Grundfrequenzbestimmung verwendet werden, da es ausgeprägte Peaks bei den Viel-fachen der Grundperiode k · Tp besitzt. Im Cepstralbereich ist der erste Peak im, für dieGrundfrequenz relevanten, Suchbereich deutlicher von harmonischen und subharmonischenSchwingungen separiert, als das beispielsweise bei der AKF der Fall ist. Damit werden auchVorverarbeitungsmethoden wie zum Beispiel das Peak-Clipping, das für AKF-basierte Grund-frequenzbestimmung benötigt wird, unnötig. Ausführlichere Erklärungen dazu sind unter an-derem in [DPH93] und [Nol67] zu finden.
7.6.2. Kompensation der Raumübertragungsfunktion
Außerdem kann mit Hilfe des Cepstrums die Raumübertragungsfunktion berechnet und kom-pensiert werden. Dazu setzt man voraus, dass das Cepstrum des Sprachsignals variabel undim Mittel Null ist, während die Raumübertragungsfunktion sich mit der Zeit nicht ändert, so-dass der Mittelwert des Cepstrums der Raumübertragungsfunktion entsprechen sollte. Dann
94
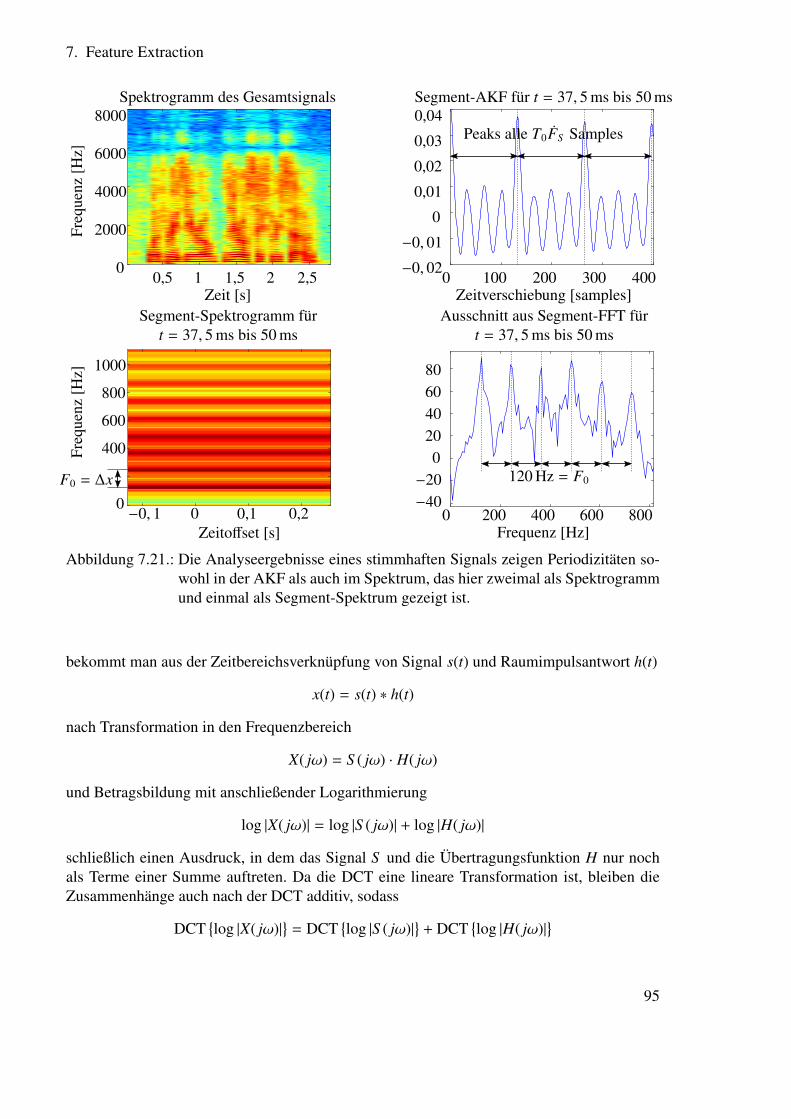
7. Feature Extraction
Spektrogramm des Gesamtsignals
0,5 1 1,5 2 2,5Zeit [s]
0
2000
4000
6000
8000
Freq
uenz
[Hz]
Ausschnitt aus Segment-FFT fürt = 37, 5 ms bis 50 ms
Segment-Spektrogramm fürt = 37, 5 ms bis 50 ms
0 200 400 600 800Frequenz [Hz]
−40−20
020406080
120 Hz = F0
−0, 1 0 0,1 0,2Zeitoffset [s]
0
400
600
800
1000
Freq
uenz
[Hz]
F0 = ∆x
0 100 200 300 400Zeitverschiebung [samples]
−0, 02
−0, 01
0
0,01
0,02
0,03
0,04Segment-AKF für t = 37, 5 ms bis 50 ms
Peaks alle T0FS Samples
Abbildung 7.21.: Die Analyseergebnisse eines stimmhaften Signals zeigen Periodizitäten so-wohl in der AKF als auch im Spektrum, das hier zweimal als Spektrogrammund einmal als Segment-Spektrum gezeigt ist.
bekommt man aus der Zeitbereichsverknüpfung von Signal s(t) und Raumimpulsantwort h(t)
x(t) = s(t) ∗ h(t)
nach Transformation in den Frequenzbereich
X( jω) = S ( jω) · H( jω)
und Betragsbildung mit anschließender Logarithmierung
log |X( jω)| = log |S ( jω)| + log |H( jω)|
schließlich einen Ausdruck, in dem das Signal S und die Übertragungsfunktion H nur nochals Terme einer Summe auftreten. Da die DCT eine lineare Transformation ist, bleiben dieZusammenhänge auch nach der DCT additiv, sodass
DCTlog |X( jω)|
= DCT
log |S ( jω)|
+ DCT
log |H( jω)|
95
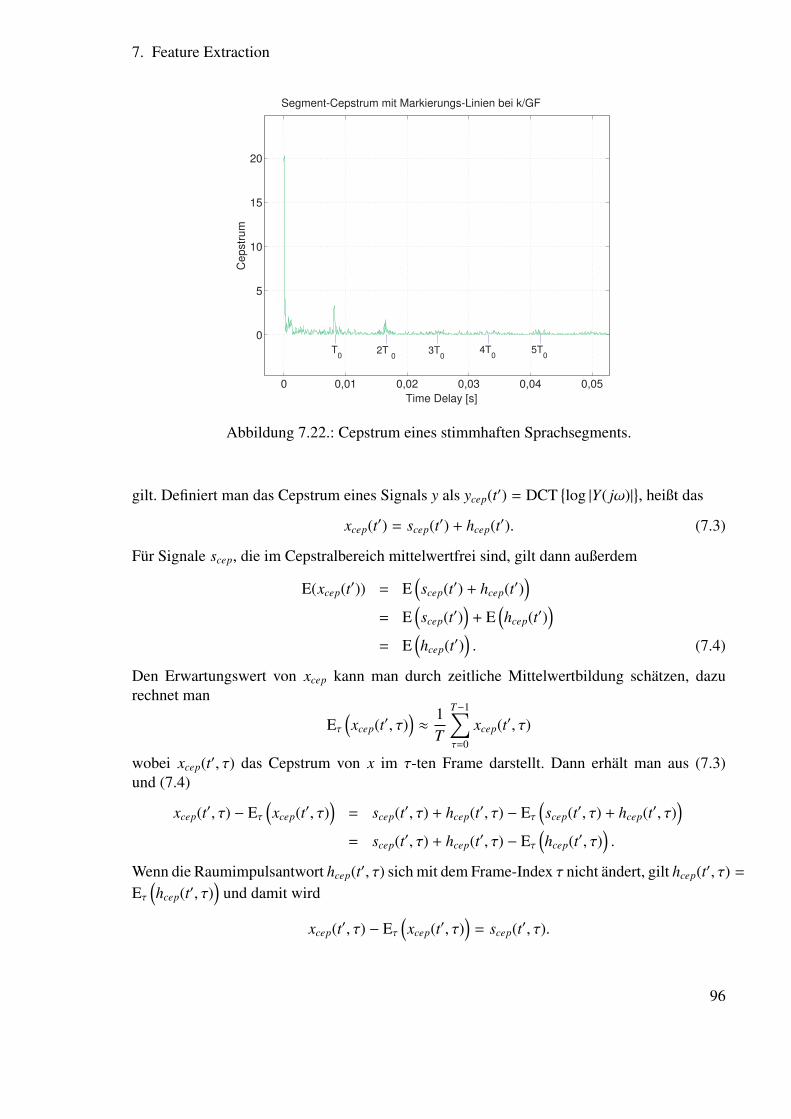
7. Feature Extraction
0 0,01 0,02 0,03 0,04 0,05
0
5
10
15
20
Segment-Cepstrum mit Markierungs-Linien bei k/GF
Time Delay [s]
Ce
pstr
um
T0
3T0
2T 0
4T0
5T0
Abbildung 7.22.: Cepstrum eines stimmhaften Sprachsegments.
gilt. Definiert man das Cepstrum eines Signals y als ycep(t′) = DCTlog |Y( jω)|
, heißt das
xcep(t′) = scep(t′) + hcep(t′). (7.3)
Für Signale scep, die im Cepstralbereich mittelwertfrei sind, gilt dann außerdem
E(xcep(t′)) = E(scep(t′) + hcep(t′)
)= E
(scep(t′)
)+ E
(hcep(t′)
)= E
(hcep(t′)
). (7.4)
Den Erwartungswert von xcep kann man durch zeitliche Mittelwertbildung schätzen, dazurechnet man
Eτ
(xcep(t′, τ)
)≈
1T
T−1∑τ=0
xcep(t′, τ)
wobei xcep(t′, τ) das Cepstrum von x im τ-ten Frame darstellt. Dann erhält man aus (7.3)und (7.4)
xcep(t′, τ) − Eτ
(xcep(t′, τ)
)= scep(t′, τ) + hcep(t′, τ) − Eτ
(scep(t′, τ) + hcep(t′, τ)
)= scep(t′, τ) + hcep(t′, τ) − Eτ
(hcep(t′, τ)
).
Wenn die Raumimpulsantwort hcep(t′, τ) sich mit dem Frame-Index τ nicht ändert, gilt hcep(t′, τ) =
Eτ
(hcep(t′, τ)
)und damit wird
xcep(t′, τ) − Eτ
(xcep(t′, τ)
)= scep(t′, τ).
96

7. Feature Extraction
Aus verständlichen Gründen nennt man diese Vorgehensweise auch Cepstral Mean Subtrac-tion (CMS). Statt den Mittelwert explizit zu berechnen und abzuziehen, kann man auch dieAbleitung des Cepstrums nach der Zeit berechnen. Für diskrete Signale kann man die Ablei-tung nach t durch eine diskrete Ableitung nach dem Frame-Index τ approximieren:
∆xcep(t′, τ) =xcep(t′, τ + δτ) − xcep(t′, τ − δτ)
2δτ.
Diese ist, bei zeitinvarianter Raumübertragungsfunktion hcep(t′, τi) = hcep(t′, τ j)∀ i, j, eben-falls unabhängig von der Raumübertragungsfunktion, und kann deswegen als Feature einge-setzt werden, das nur vom Sprachsignal selbst abhängig ist.
Das Verhältnis zwischen der DFT und der DCT im Anhang A.4 zu finden.
7.6.3. Trennung von Quelle und Vokaltrakt
Betrachtet man die Abbildung 7.17, sieht man, dass das Sprachsignal s(t) maßgeblich vonzwei Faktoren abhängt:
• Zuerst erzeugt die Quelle, die Lunge in Kombination mit den Stimmbändern, das soge-nannte Anregungssignal,
• anschließend wird dieses im Vokaltrakt gefiltert.
Das Anregungssignal ist in stimmhaften Segmenten periodisch mit recht langen Periodendau-ern > 1.5 ms.9 Die Impulsantwort des Vokaltrakts liegt hauptsächlich bei kürzeren Verzöge-rungszeiten. Deswegen kann man die oberen Teile des Cepstrums (also die hohen Verzöge-rungszeiten) dem Anregungssignal und die unteren (für kurze Verzögerungen) dem Vokaltraktzuordnen. Da die Stellung des Vokaltraktes für die Spracherkennung viel interessanter ist alsdas Stimmbandsignal selbst, werden nur die unteren cepstralen Koeffizienten verwendet, derenVerzögerungszeit unter der Grundperiodendauer liegt.10 Ein Beispiel für diese Vorgehenswei-se zeigt Abbildung 7.23.
9Die Grundfrequenz liegt in den allermeisten Fällen zwischen 40 und 600 Hz, sodass die Grundperiode zwi-schen 1,7 ms und 25 ms variieren kann.
10Diese Vorgehensweise hat eine gewisse Ähnlichkeit mit dem Entfernen spektraler Signalkomponenten, alsomit dem Filtern von Signalen, und wird deswegen als Liftering bezeichnet. Mehr Informationen dazu sindzum Beispiel im Artikel von Oppenheim zu finden [OS04].
97
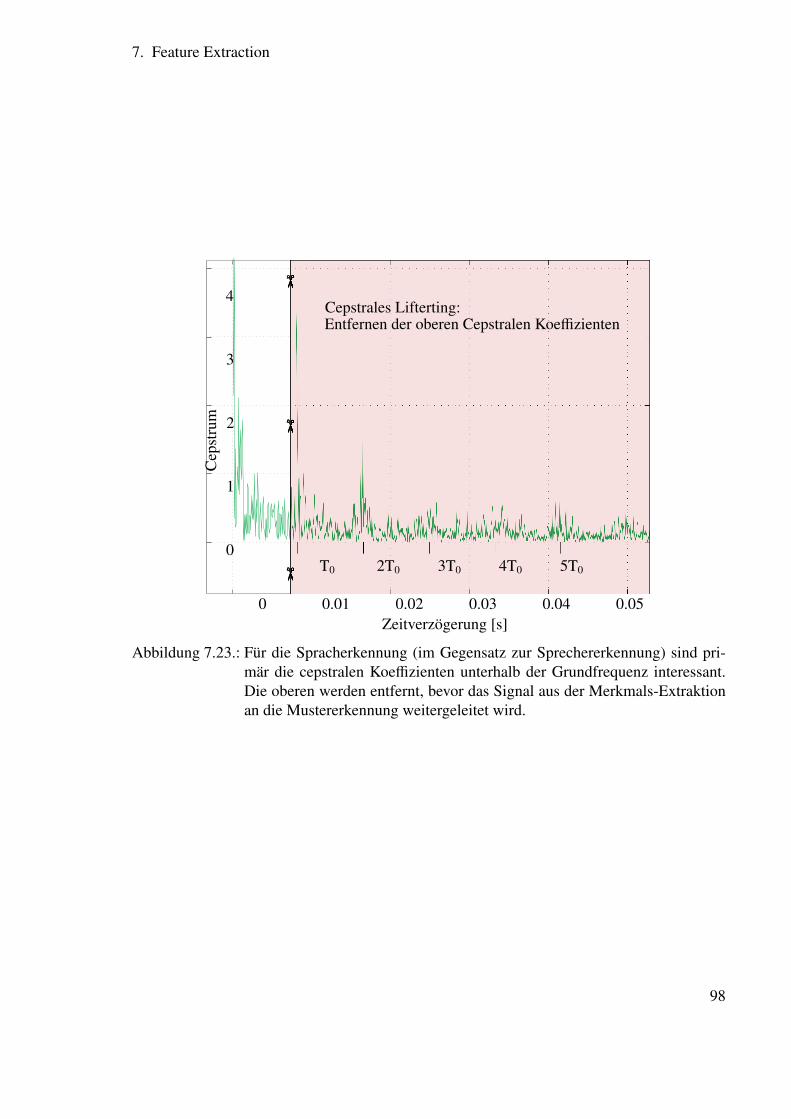
7. Feature Extraction
Cep
stru
m
4T0
Zeitverzögerung [s]
3T02T0 5T0T0
0
1
2
3
4
0 0.02 0.030.01 0.04 0.05
Entfernen der oberen Cepstralen KoeffizientenCepstrales Lifterting:
Abbildung 7.23.: Für die Spracherkennung (im Gegensatz zur Sprechererkennung) sind pri-mär die cepstralen Koeffizienten unterhalb der Grundfrequenz interessant.Die oberen werden entfernt, bevor das Signal aus der Merkmals-Extraktionan die Mustererkennung weitergeleitet wird.
98

8. Klassifikation von Zeitreihen
8.1. ÜBERBLICK
Bisher hat sich diese Veranstaltung mit zwei Aspekten der Spracherkennung beschäftigt, mitder
• Klassifikation und der
• Merkmalsextraktion.
Die bisher behandelten Methoden der Klassifikation sind allerdings nur für einzelne Merk-malsvektoren x geeignet. Die Klassifikation dieser Merkmale erfolgt dann durch Vergleichvon p(x|ki) für alle möglichen Klassen ki, zum Beispiel lautete die Entscheidungsregel desMaximum-Likelihood-Klassifikators
k = arg maxi
P(x|ki) (8.1)
und der Bayes’sche-Klassifikator entscheidet sich für diejenige Klasse, bei der
k = arg maxi
P(x|ki)P(ki) (8.2)
ist.Bei Sprachsignalen liefert die Merkmalsextraktion allerdings nicht nur einzelne Feature-
vektoren x, sondern für ein einzelnes Wort wird der Zeitverlauf in aufeinander folgende Seg-mente eingeteilt, deren Features jeweils separat extrahiert werden können. Das führt dann zueiner Zeitreihe von Featurevektoren, wie sie in Tabelle 8.1 beispielhaft für Mel-Frequenz-Cepstralkoeffizienten mit ersten und zweiten Ableitungen gezeigt ist. Daher muss für die Ver-wendung in Spracherkennern die Klassifikationsstufe so modifiziert werden, dass sie auch mitZeitreihen x(t) umgehen kann. Das kann auf verschiedene Arten geschehen, zum Beispieldurch
• Hidden Markov Modelle,
• Dynamic Time Warping oder
• Time-Delay Neural Networks.
Bei den Hidden Markov Modellen (HMMs), die wegen ihrer großen Flexibilität im Um-gang mit Wort- und Sprachmodellen und wegen ihrer effizienten Implementierbarkeit häu-fig verwendet werden, kann die Entscheidungsmethode der „klassischen“ Klassifikatoren di-rekt übernommen werden, denn HMMs erlauben es, die Wahrscheinlichkeit einer Zeitreihe
99

8. Klassifikation von Zeitreihen
scep (1)
scep (2)
· · ·
scep (τ)
∆scep (1)
∆scep (2)
· · ·
∆scep (τ)
∆∆
scep (1)
∆∆
scep (2)
· · ·
∆∆
scep (τ)
x(1) x(2) x(τ)
Tabelle 8.1.: Das Ergebnis der Feature Extraction ist eine Sequenz von Featurevektorenx(1) . . . x(τ). Für ein 500 ms langes Wort mit einem Frameshift von 10 ms er-geben sich zum Beispiel τ = 50 Featurevektoren.
P(x(t)|ki) direkt zu berechnen. Wenn diese berechnet sind, kann der Rest der Klassifikations-regel, also zum Beispiel Gleichung (8.1) oder (8.2) direkt übernommen werden.1 Für Einzel-worterkenner, bei denen die Klassen k1 . . . kN den N verschiedenen Worten entsprechen, erhältman dann zum Beispiel als Bayes’sche Entscheidungsregel:
k = arg maxi
P(x(t)|ki)P(ki).
Die Berechnung von P(x(t)|ki) wird dann mit Hilfe von HMMs erledigt, wie die nächstenAbschnitte es beschreiben.
8.2. NEUE NOTATION
In der bisher behandelten Klassifikation von Objekten anhand einzelner Merkmalsvektorenbezeichnet man die Merkmalsvektoren üblicherweise mit einem x. Bei den Hidden MarkovModellen hat sich aber das x als Bezeichnung für den Zustand des Modells durchgesetzt.Um hier konform mit der beinahe gesamten Literatur zum Thema zu bleiben, heißen ab jetztdie Featurevektoren auch Beobachtungen, und werden in Formeln mit einem kleinen o für„observation“ bezeichnet. Die Beobachtung zum Zeitpunkt t wird mit o(t) oder kurz mit ot
geschrieben.
8.3. MARKOV-KETTEN
Markov-Ketten sind eine wichtige Vorstufe der HMMs. Markov-Ketten können das zeitlicheVerhalten von Zufallsprozessen modellieren. Dazu benutzen sie einen sogenannten Zustand,der in der Zustandsvariablen x gespeichert wird.
1Zumindest ist das für Einzelworterkenner möglich, die Vorgehensweise für fließend gesprochene Worte istkomplexer und wird in einem späteren Abschnitt ausführlicher behandelt.
100

8. Klassifikation von Zeitreihen
In der Abbildung 8.1 ist ein Beispiel für solch eine Markov-Kette zu sehen.
„2“
Regen
are,re = 0.8
are,so
= 0.1
asn,sn = 0.3
„3“
Schnee
„1“
Sonne
aso,so = 0.5
0.3
asn,so
= 0.3
0.20.1
0.4
so =
0.2
sn
= 0.3
re
= 0.5
Abbildung 8.1.: Beispiel einer Markov-Kette.
Zu jedem Zeitpunkt t befindet sich dann eine Markov-Kette genau in einem Zustand X(t).Die Wahrscheinlichkeit dafür, dass es mit einem bestimmten Zustand i anfängt, ist mit derinitialen Wahrscheinlichkeit πi gegeben, man könnte also auch sagen
p(X(1) = i) = πi.
Zu jedem Zeitpunkt findet dann in der Markov-Kette zufällig ein Zustandsübergang statt.Mit welcher Wahrscheinlichkeit welcher Nachfolgezustand angesteuert wird, hängt nur vondem Zustand i ab, in dem sich die Markov-Kette befindet. Die Größe dieser Übergangs-Wahrscheinlichkeiten gibt die sogenannte Übergangsmatrix2 A an. Dort steht in der i-ten Zeileund der j-ten Spalte die Wahrscheinlichkeit dafür, dass die Kette aus Zustand i in den Zustandj übergeht. Wenn zum Beispiel auf einen Sonnentag mit 50%iger Wahrscheinlichkeit ein Son-nentag folgt, ist an dieser Stelle der Wert der Transitionsmatrix aso,so = 0, 5. Genauer gesagtist damit:
p(X(t + 1) = j |X(t) = i) = ai j.
Es stehen also in der i-ten Zeile der Übergangsmatrix die Wahrscheinlichkeiten für alle Nach-folgezustände von Zustand i. Damit die Wahrscheinlichkeiten zusammen 1 ergeben und so dieNormalisierungsbedingung einhalten, muss deswegen für alle Zeilen i gelten
M∑j=1
ai j = 1.
2Manchmal wird sie auch Transitionsmatrix genannt.
101

8. Klassifikation von Zeitreihen
Hier steht M für die Anzahl von Zuständen der Markov-Kette. Die Spalten hingegen summie-ren sich höchstens zufällig zu 1.
Zusammengefasst sind also drei Größen nötig, um eine Markov-Kette vollständig zu be-schreiben:
• eine Menge von Zuständen S (hier im Beispiel ist S = re, so, sn),
• die Übergangsmatrix, die in Gleichung 8.3 für das Wetter-Markov-Modell gezeigt wird,und schließlich
• ein Satz von initialen Wahrscheinlichkeiten Π = π1 . . . πM.
Definition Übergangsmatrix:
Allgemein A =
a11 a12 · · · a1M...
.... . .
...aM1 aM2 · · · aMM
Für das Wetter-Beispiel A =
aso,so aso,re aso,sn
are,so are,re are,sn
asn,so asn,re asn,sn
(8.3)
=
0, 5 0, 3 0, 20, 1 0, 8 0, 10, 3 0, 4 0, 3
→ M∑j=1
ai j = 1∀i
↓
M∑i=1
ai ji.A., 1
Eigenschaften von Markov-Ketten
8.3.1. Berechnung der Wahrscheinlichkeit von Zustandssequenzen
Um die Wahrscheinlichkeit einer Sequenz von T Zuständen (angefangen bei t = 1) zu erhalten,muss die initiale Wahrscheinlichkeit des ersten Zustandes mit den Wahrscheinlichkeiten allerZustandsübergänge multipliziert werden. Damit erhält man
P (i(1), i(2) . . . i(T )) = πi(1) · ai(1),i(2) · ai(2),i(3) · . . . ai(T−1),i(T )
= πi(1) ·
T−1∏t=1
ai(t),i(t+1) .
102

8. Klassifikation von Zeitreihen
8.3.2. Berechnung der durchschnittlichen Aufenthaltsdauer in einem Zustand
Die durchschnittliche Aufenthaltsdauer3 t im Zustand i beträgt 11−aii
, was folgendermaßen her-geleitet werden kann:
t = E(t)=
∑t
t · P(t)
= 1 · (1 − aii) + 2 · aii(1 − aii) + 3 · a2ii(1 − aii) . . .
= 1 − aii + 2aii − 2a2ii + 3a2
ii − 3a3ii . . .
= 1 + aii + a2ii + a3
ii . . .
=
∞∑n=0
anii.
Das ist die geometrische Reihe,4 also ist
t =1
1 − aii. (8.4)
Das heißt, dass Markov-Ketten auch die durchschnittliche Aufenthaltsdauer in einem Zustandmodellieren. Beispielsweise gilt für das oben gezeigte Wetter-Modell im Zustand „Regen“:are,re = 0, 8, sodass man mit der Gleichung (8.4) auf ein Mittel von fünf aufeinander folgendenRegentagen kommt.
8.4. HIDDEN MARKOV MODELLE
Bei Hidden Markov Modellen kann die Zustandssequenz nicht mehr direkt beobachtet wer-den. Stattdessen hat man nur noch Beobachtungen zur Verfügung, aus denen man indirektauf den Zustand des Prozesses schließen kann. Für dieses Beispiel kann man sich vorstellen,dass in einem fensterlosen Großraumbüro nur ein Funkthermometer steht, aus dessen Anzeigeman Rückschlüsse auf das Wetter draußen ziehen möchte. Deswegen ist, neben der Über-gangsmatrix A und den initialen Wahrscheinlichkeiten Π, zusätzlich eine Verteilungsdichteerforderlich, die beschreibt, mit welcher Wahrscheinlichkeit in einem bestimmten Zustandein bestimmter Beobachtungswert (also eine bestimmte Temperatur) erzeugt wird. Um die-se Wahrscheinlichkeiten zu beschreiben, ordnet man jedem Zustand i eine Verteilungsdichtebi(o) zu. Diese sagt dann, mit welcher Wahrscheinlichkeit in dem Zustand i eine bestimmteBeobachtung o auftritt. Abbildung 8.2 zeigt ein Beispiel, in dem ein gesamtes Hidden MarkovModell zu sehen ist.
3Das ist die Zeit, die die Markov-Kette durchschnittlich im Zustand i verbringt, nachdem sie hineingeraten ist.4Die geometrische Reihe ist die Summe
∑∞n=0 c · yn und konvergiert gegen c
1−y , falls |y| < 1.
103

8. Klassifikation von Zeitreihen
1/3
„2“
Regen
1/2
1/4
„3“
Schnee
„1“
Sonne
so =
1/4
sn
= 1/4
re
= 1/2
Beispiel-HMM
1/4
1/4
1/4
1/4
1/4
1/2
1/2
o
bre(o)
1 2 3 4
1/4
bsn(o)
o-1-2 0
1/8
1/4
bso(o)
o1 2 3 40-1
Abbildung 8.2.: Ein HMM besteht aus einer Menge von Zuständen, denen jeweils eine eige-ne Verteilungsdichte zugeordnet ist. Diese Verteilungsdichte beschreibt dieWahrscheinlichkeit, dass das Modell, wenn es sich im betreffenden Zustand ibefindet, einen bestimmten Beobachtungsvektor o erzeugt. Das heißt also inanderen Worten: bi(o) = p(O(t) = o|X(t) = i). In welchem Zustand ein HMMsich im ersten Zeitschritt befindet, ist auch dem Zufall überlassen, die Wahr-scheinlichkeiten für die einzelnen Zustände stehen im initialen Wahrschein-lichkeitsvektor π, der hier die Werte [0, 5 0, 25 0, 25] enthält. Schließlich er-folgt in jedem Zeitschritt ein Zustandsübergang, wobei die Wahrscheinlich-keiten für alle möglichen Übergänge in der Transitionsmatrix A stehen. Suchtman die Wahrscheinlichkeiten A2 für den Zustandswechsel nach zwei Über-gängen, findet man diese, indem man A quadriert, also A2 = A2 und auf diegleiche Art ergibt sich die Transitionswahrscheinlichkeit nach n ÜbergängenAn aus An = An.
Zur Beschreibung eines HMMs sind also insgesamt fünf Angaben erforderlich:
• die Übergangsmatrix A,
• ein Satz von initialen Wahrscheinlichkeiten Π = π1 . . . πM und
• eine Menge von Zuständen S = re, so, sn;
und als neue Merkmale gegenüber den Markov-Ketten:
• eine Menge von möglichen Beobachtungen O (hier im Beispiel ist O = N) und
• eine Menge von dazugehörigen Beobachtungsverteilungsdichten, eine für jeden Zu-stand: B = b1(o) . . . bM(o).
104

8. Klassifikation von Zeitreihen
Berechnung der Wahrscheinlichkeit von Zustands- undBeobachtungssequenzen
Genau wie für die Markov-Ketten kann man auch bei Hidden Markov Modellen die Wahr-scheinlichkeit einer bestimmten Sequenz von Zuständen durch
P(i(1), i(2) . . . i(T )) = πi(1) ·
T−1∏t=1
ai(t),i(t+1) (8.5)
berechnen. Interessiert man sich dagegen für die Wahrscheinlichkeit, dass das Modell die Zu-standsfolge i(1), i(2) . . . i(T ) durchläuft und dabei gleichzeitig die Folge von Beobachtungeno(1), o(2) . . . o(T ) produziert, muss man zusätzlich noch die Beobachtungswahrscheinlichkei-ten einbeziehen. Das ergibt zusammen die Wahrscheinlichkeit
P(i(1), o(1), i(2), o(2) . . . i(T ), o(T )) =
πi(1)bi(1)(o(1)) · ai(1),i(2)bi(2)(o(2)) · ai(2),i(3)bi(3)(o(3)) · . . . ai(T−1),i(T )bi(T )(o(T )) =
πi(1) · bi(1)(o(1))T−1∏t=1
ai(i),i(t+1)bi(t+1)(o(t + 1)) .
8.5. HIDDEN MARKOV MODELLE FÜR DIE SPRACHERKENNUNG
8.5.1. Ausgangsverteilungsdichten für die Spracherkennung
Die Beobachtungswahrscheinlichkeiten bi (o(t)) = P (o(t)|X(t) = i) geben an, mit welcherWahrscheinlichkeit im Zustand i die Beobachtung o(t) auftritt. Dazu werden primär zwei For-men von Verteilungsdichten eingesetzt:
• die Diskrete Verteilungsdichte und
• Gauß’sche Mischungsmodelle.
8.5.1.1. Diskrete Verteilungsdichte
Bei der diskreten Verteilungsdichte ist eine Menge möglicher Beobachtungen O = o1 . . . ok
gegeben, von denen jeder eine bestimmte Wahrscheinlichkeit P(on) zugeordnet ist. Das ent-spricht der Form einer Verteilungsfunktion, wie sie im Beispiel-HMM in Abbildung 8.2 zusehen ist. Für Spracherkenner, die mit vektorquantisierten Features arbeiten, ist die diskreteVerteilungsfunktion ebenfalls sinnvoll (wegen der diskreten Features, die jeweils einer Num-mer in einer Tabelle entsprechen). Als typische Codebuchgrößen werden 256 (eher für kleineVokabularien) bis 1.024 Einträge verwendet, sodass also aus einem hochdimensionalen Fea-turevektor jeweils eine 8-10 Bit große Binärzahl wird.
105

8. Klassifikation von Zeitreihen
8.5.1.2. Gauß’sche Mischungsmodelle
Wie es in Gleichung 3.2 definiert wurde, besteht ein Gauß’sches Mischungsmodell aus einergewichteten Summe von einzelnen Gaußglocken:
p(o) =
K∑i=1
γiN(o, µi, σi).
Dabei müssen sich die Mischungsgewichte γi zu 1 addieren, damit das Modell der Normalisie-rungsbedingung gehorcht. Wie es in [AS72] nachgewiesen wurde, lassen sich mit Gauß’schenMischungsmodellen beliebige Verteilungsdichtefunktionen mit beliebiger Genauigkeit appro-ximieren (wenn hinlänglich viele Mischungskomponenten, also hinreichend viele einzelneGaußglocken addiert werden). Wie viele Komponenten ein Mischungsmodell für eine erfolg-reiche Spracherkennung benötigt, hängt davon ab, wie groß die Variationen innerhalb der zuerkennenden Daten sind. Wenn beispielsweise nur ein Sprecher gelernt wird, und wenn al-le Daten unter ähnlichen Bedingungen aufgenommen sind, kann man unter Umständen mitnur einer Mischungskomponente akzeptable Ergebnisse erreichen. Wenn dagegen ein großesVokabular mit vielen Sprechern, Akzenten, Sprechercharakteristika und Aufnahmebedingun-gen trainiert wird, benötigt man viel mehr Flexibilität bei den Modellen, und wählt deshalbmehr Mischungskomponenten. Typische Werte für die Anzahlen der Mischungskomponentenliegen zwischen 5 und 30 Komponenten.
8.5.2. Hidden Markov Modell-Strukturen zur Spracherkennung
Die bisher gezeigten Beispiel-HMMs waren alle ergodisch, das heißt, dass sie für limt→∞ inein stationäres Verhalten übergehen. Damit eignen sie sich zum Beispiel für die Modellierungvon
• biologischen und
• physikalischen Prozessen oder auch
• Börsenkursen (falls sich neben einem Nachbau der Börse überhaupt etwas zur Model-lierung von Börsenkursen eignet)
und sind auch schon zu allen diesen Zwecken eingesetzt worden. Für die Spracherkennungallerdings sind Links-Rechts-Modelle und deren Varianten geeigneter. Dabei werden bei all-gemeinen Links-Rechts-Modellen Übergänge beliebiger Länge in eine Richtung zugelassen,bei linearen Modellen ist die Schrittweite auf einen und bei Bakis-Modellen auf zwei Schrit-te beschränkt. Abbildung 8.3 zeigt diese drei häufigen Arten von HMMs, zusammen mit derStruktur von ihren Transitionsmatrizen A (ein weiß gefärbtes Feld zeigt an, dass dieser EintragNull ist).
106

8. Klassifikation von Zeitreihen
a)
b)
c)
/ //l/ /f/ /t/
Lineares HMM
A:
Links-Rechts-HMM
A:
Bakis-Modell
A:
obere Dreiecksmatrix
Abbildung 8.3.: Links-Rechts-HMMs: a) Lineares HMM b) allgemeines Links-Rechts-Modell und c) Bakis-Modell.
8.5.3. Drei wichtige Probleme
Um HMMs erfolgreich für die Spracherkennung einsetzen zu können, müssen drei wichtigeProbleme gelöst werden.5
Um hierfür eine einfache Notation zu schaffen, sollen alle Parameter eines HMMs, also
• die Übergangsmatrix A = ai, j mit allen Einträgen,
• die Ausgangswahrscheinlichkeiten für alle Zustände B = bi(o) und
• die initialen Wahrscheinlichkeiten Π = πi
zu einem Parametersatz λ def= A, B,Π zusammengefasst werden, der das gesamte HMM be-
schreibt. Außerdem wird als Abkürzung für o(t) und i(t) bei Bedarf ot bzw. it geschrieben.
8.5.3.1. Problem 1: Berechnung der Wahrscheinlichkeit einer Beobachtungssequenz
Die Wahrscheinlichkeit einer Folge von Beobachtungsvektoren soll berechnet werden, wenndas HMM gegeben ist (d.h. es ist fertig trainiert und alle Parameter λ sind bekannt). Problem 1lautet also:
Finde P(o1, o2 . . . oT |λ).5Diese Gliederung und die komplette Beschreibung findet man ausführlich auch in [Rab89].
107

8. Klassifikation von Zeitreihen
Nützlich ist es an vielen Stellen, dieses Problem lösen zu können. Wichtig ist es für die Ein-zelworterkennung. Wenn man für jedes Wort, das man erkennen möchte, ein separates HMMhat, wie das in Abbildung 8.4 gezeigt ist, kann man (sobald das Problem 1 gelöst ist) für al-
„w“ „n“„ “
Modell-
parameter
1
„t“ „u “
„ “ „i:“„r“
2
3
Abbildung 8.4.: Drei stark vereinfachte Einzelwort-HMMs für die Worte „One“, „Two“ und„Three“.
le Modelle der verschiedenen Worte w = 1, 2, 3 die Wahrscheinlichkeiten P(o1, o2 . . . oT |λw)berechnen. Anschließend kann man dann mit
w = arg maxw
P(w|o1, o2 . . . oT )
≈ arg maxw
P(Wortmodell w|o1, o2 . . . oT )
= arg maxw
P(o1, o2 . . . oT |Wortmodell w)P(w)P(o1, o2 . . . oT )
= arg maxw
P(o1, o2 . . . oT |λw)P(w)
das gegeben die Beobachtung o1, o2 . . . oT wahrscheinlichste Wort w finden und als erkanntausgeben.
8.5.3.2. Problem 2: Finden der besten Zustandssequenz
Das zweite wichtige Problem ist die Suche nach der Sequenz, die das Modell am wahrschein-lichsten durchlaufen hat. Genauer gesagt, wird die Sequenz i = [i(1) . . . i(T )] gesucht, für diedie Wahrscheinlichkeit am größten ist, dass sie gleichzeitig mit den gemachten Beobachtun-gen auftritt. Problem 2 lautet also:
108

8. Klassifikation von Zeitreihen
Finde i∗ = arg maxi P(i, o|λ).
Diese wahrscheinlichste Sequenz wird effizient z. B. vom Viterbi-Algorithmus gesucht undgefunden. Sie ist wichtig, wenn ein Verbundworterkenner oder ein phonembasierter Erkennerfür kontinuierliche Sprache aufgebaut wird, denn somit kann man aus der wahrscheinlichstenZustandssequenz auf die wahrscheinlichsten Worte schließen, da die Zustände jeweils eindeu-tig einem Wort bzw. Phonem zugeordnet sind. Dazu konstruiert man zuerst ein Verbundwort-HMM, wie es in Abbildung 8.5 zu sehen ist. Wenn so ein Modell vorhanden ist, und wenn
1 32
4 5
6 87
„w“ „ “ „n“
„t“ „u:“
„r“ „i:“„ “
0
1/3
1/3
1/39
1
= „Glue State“, besitzt keine Beobachtungswahrscheinlichkeit
Abbildung 8.5.: Verbundwort-HMM für die Worte „One“, „Two“ und „Three“. Entsprechenddieses Modells dürfen die drei Worte in beliebig langen Ziffernketten ohneZwischenpause aufeinander folgen.
man außerdem in der Lage ist, die optimale Sequenz i∗ durch das Modell zu finden (wennalso Problem 2 gelöst ist), kann man, wie in Abbildung 8.6 gezeigt, für eine gegebene Zu-standssequenz den besten Pfad durch das Verbundwort-HMM ermitteln und daraus auf diegesprochenen Worte schließen. In dem hier gezeigten Modell korrespondiert die optimale Se-quenz i∗ = [4, 4, 5, 6, 7, 8] mit einem Durchlauf durch die Wortmodelle „two, three“, und damitwürden diese beiden Worte hier „erkannt“ werden.
109

8. Klassifikation von Zeitreihen
Beobachtung:
x*: 0, 4, 4, 5, 9,0, 6, 7, 8
Erkannte Worte: two three
o1 o2 o3 o4 o5 o6
Abbildung 8.6.: Beobachtungssequenz o und dazugehörige optimale Zustandssequenz i∗.
8.5.3.3. Problem 3: Lernen der Modellparameter
Das dritte wichtige Problem ist das Training von HMMs, genauer gesagt die Berechnung derbesten Modellparameter.
Dieses Problem löst man beispielsweise mit dem Baum-Welch-Algorithmus, der die Li-kelihood der Beobachtungen (der Trainingsdaten), gegeben die Modellparameter maximiert.Man sucht die Lösung zum Optimierungsproblem
λ = arg maxλ
P(o1, o2 . . . oT |λ)
und erhält damit die Modellparameter λ, die man später für die Erkennung entsprechend Ab-schnitt 8.5.3.1 oder 8.5.3.2 benötigt.
110

8. Klassifikation von Zeitreihen
8.5.4. Lösung für die Probleme 1 und 2
8.5.4.1. Lösung 1: Berechnung der Wahrscheinlichkeit einer Beobachtungssequenz
Die Berechnung der Wahrscheinlichkeit einer Sequenz gegeben das Modell P(o|λ) kann mangut in zwei Teile zerlegen. Zuerst berechnet man die Beobachtungswahrscheinlichkeit für einefeste Zustandssequenz, anschließend summiert man über alle möglichen Zustandssequenzen:
• Problem 1a: Berechne die Wahrscheinlichkeit der Beobachtungssequenz, wenn die Zu-standssequenz gegeben ist, finde also P(o1, o2 . . . oT |i1, i2 . . . iT , λ). Wenn die Abfolge derZustände bekannt ist, müssen nur die Beobachtungswahrscheinlichkeiten für die gege-benen Zustände und für alle Zeitpunkte miteinander multipliziert werden:
P(o1, o2 . . . oT |i1, i2 . . . iT , λ) = P(o1, o2 . . . oT |i, λ) =
T∏t=1
bit(ot) (8.6)
• Problem 1b: Berechne die Wahrscheinlichkeit der Beobachtungssequenz bei unbekann-ter Zustandssequenz. Wenn die Wahrscheinlichkeiten aus Problem 1a berechnet sind,kann man über alle möglichen Zustandssequenzen addieren:
P(o1, o2 . . . oT |λ) =∑
i
P(o1, o2 . . . oT |i, λ) P(i|λ). (8.7)
Nun benötigt man nur noch die Wahrscheinlichkeit der Zustandssequenz, also P(i|λ). Diesewar schon im Abschnitt über Markov-Ketten bestimmt worden, man erhält sie entsprechendGleichung (8.5) aus
P(i|λ) = πi1
T−1∏t=1
ait ,it+1 . (8.8)
Fügt man dann die Lösungen der beiden Teilprobleme zusammen, ergibt sich daraus die ge-samte Lösung für Problem 1 als
P(o1, o2 . . . oT |λ) =∑
i
T∏t=1
bit(ot) πi1
T−1∏t=1
ait ,it+1 . (8.9)
Bei direkter Berechnung dieser Summe ist der Rechenaufwand allerdings indiskutabel,rechnet man zuerst alle Sequenzen aus und ermittelt für jede einzelne von ihnen die Lösung,dann beträgt die Anzahl der benötigten Multiplikationen 2T NT (wobei N die Anzahl der Zu-stände und T die Anzahl der Beobachtungen bezeichnet), der Aufwand steigt also exponentiellmit der betrachteten Zeitdauer. Deswegen ist eine effiziente Implementierung an dieser Stellewichtig. Sehr viel effizienter kann man mit Hilfe von Methoden der dynamischen Program-mierung6 werden, speziell für diesen Fall gibt es den Forward-Algorithmus, der das exakte
6Das Verfahren der dynamischen Programmierung besteht darin, zuerst die optimalen Lösungen der kleinstenTeilprobleme zu berechnen, und diese dann geeignet zu einer Lösung eines nächstgrößeren Teilproblemszusammenzusetzen, und so weiter. Es gilt hier, bei der Lösung kostspielige Rekursionen durch Wiederver-wendung schon berechneter Zwischenlösungen zu vermeiden. Einmal berechnete Teilergebnisse werden ineiner Tabelle gespeichert, um später auf sie zurückgreifen zu können [MS08].
111

8. Klassifikation von Zeitreihen
Ergebnis mit linearem Aufwand (linear in T ) liefert. Insgesamt beträgt der Rechenaufwanddes Forward-Algorithmus in der Größenordnung O(T N2) Multiplikationen. Wenn beispiels-weise der Rechenaufwand für N = 5 Zustände und T = 100 Zeitpunkte für die direkte Summeentsprechend Gleichung (8.9) etwa 1072 Multiplikationen beträgt, liegt er für den Forward-Algorithmus mit T N2 + T N = 3.000 Multiplikationen durchaus im akzeptablen Bereich.
Forward-Algorithmus
Der „Forward-Algorithmus“ berechnet in jedem Zeitschritt t partielle Wahrscheinlichkeitenαt(i). Diese geben an, mit welcher Wahrscheinlichkeit die Beobachtungen o1 bis ot auftretenund das Modell außerdem zur Zeit t im Zustand i endet. Kurz gefasst, sind also die partiellenWahrscheinlichkeiten αt(i) definiert durch
αt(i)def= P(o1 . . . ot,Xt = i|λ). (8.10)
Aus diesen partiellen Wahrscheinlichkeiten für die Zeit t kann in einer Iteration die partielleWahrscheinlichkeit für den nächsten Zeitschritt t + 1 berechnet werden, sodass Rechnungennicht unnötig mehrfach ausgeführt werden. Dazu müssen, wie die Abbildung 8.7 zeigt, fol-gende Operationen ausgeführt werden:
Initialisierungα1(i) = πi · bi(o1)
IterationFür alle t ≤ T
Update
αt(i) =
N∑j=1
αt−1( j)a j,i
· bi(ot)
Terminierung
P(o1 . . . oT ) =
N∑i=1
αT (i)
Den Beweis zum Forward-Algorithmus im Anhang A.5 zu finden.
Skalierungsproblem
Bei der Berechnung des Forward-Algorithmus werden die benötigten Wahrscheinlichkeitenschnell sehr klein. Schon im gezeigten Beispiel, in dem weder das HMM noch die Dimen-sion der Beobachtungsvektoren besonders groß war, sind die Wahrscheinlichkeiten in denPromille-Bereich geraten, bei realistischen oder tatsächlichen HMMs kommt man schnell inden Bereich, der auch auf 32 Bit-Rechnern in der Fließkommadarstellung nicht mehr darstell-bar ist. Deswegen müssen die berechneten Werte umskaliert werden, wofür es prinzipiell zweiAnsätze gibt:
112

8. Klassifikation von Zeitreihenα1(i) α2(i)
14 ·
18 = 1
32
14 ·
13 = 1
12
0
14
12
14 [ 1
32 ·14 + 1
12 ·12 ] · 0 = 0
[ 132 ·
14 + 1
12 ·14 ] · 1
4 ≈ 7 · 10−3
[ 132 ·
12 + 1
12 ·14 ] · 1
4 ≈ 9 · 10−3
t = 1o(t) = 0
21
re
sn
so
Abbildung 8.7.: Dieses Lattice-Diagramm zeigt, welche Berechnungen in einem Schritt desForward-Algorithmus nötig sind. Dieser berechnet nach dem Prinzip der dy-namischen Programmierung die partiellen Wahrscheinlichkeiten αt(i) allerZustände i zum Zeitpunkt t aus den partiellen Wahrscheinlichkeiten αt−1 desvergangenen Zeitpunktes. Dafür muss zu jedem Zeitpunkt für jeden Zustand ides HMM bestimmt werden, wie groß die Wahrscheinlichkeit ist, dass dasModell aus einem beliebigen anderen Zustand in den betrachteten Zustand iübergeht und dann dort die Beobachtung ot macht. Hier wird die Initiali-sierung und der erste Update-Schritt für das HMM aus Abbildung 8.2 ge-zeigt, wenn die beobachtete Sequenz von Temperaturen [o1, o2] = [0, 1]lautet. Die Formel für den einzigen hier benötigten Update-Schritt heißt:α2(i) =
(∑Nj=1 α1( j) a j,i
)· bi(o2).
• Lineare Skalierung und
• Logarithmierte Rechnung.
Bei der linearen Skalierung werden zu jedem Zeitschritt t die partiellen Wahrscheinlichkeitenαt(i) aller Zustände i mit der gleichen Zahl multipliziert, um in einen vernünftigen Zahlenbe-reich zu kommen. Das sieht also folgendermaßen aus:
αt( j) =αt( j)∑Ni=1 αt(i)
. (8.11)
Statt diese Rechnung zu jedem Zeitpunkt durchzuführen, kann man sie alternativ auch nurnach Bedarf anwenden.
Bei der alternativen Lösung des Skalierungsproblems, der Logarithmierung, rechnet mannicht mit den Wahrscheinlichkeiten αt(i) = P(o1 . . . ot,Xt = i|λ) sondern mit ihren Logarith-men logαt(i) = log P(o1 . . . ot, Xt = i|λ). Mit dem Logarithmieren der Wahrscheinlichkeitenhandelt man sich allerdings auch noch ein weiteres Problem ein: Im Forward-Algorithmusbenötigt man in jedem Zeitschritt die Summe über die Wahrscheinlichkeiten
∑Ni=1 αt(i)ai, j.
Diese sind allerdings nicht ohne Weiteres zu berechnen, da man nicht die Wahrscheinlichkei-ten selbst, sondern nur ihre Logarithmen kennt. Die erste Lösung, die einem einfallen könnte,
113

8. Klassifikation von Zeitreihen
nämlich die „Ent-Logarithmierung“ zum Zweck der Summenbildung, ist auch nicht durch-führbar, da die „Ent-Logarithmierten“ Zahlen zu klein wären, um sie darzustellen.
So braucht man also eine Möglichkeit, den Logarithmus log(a + b), zu berechnen, wobeinur log(a) und log(b) aber nicht a oder b bekannt sind. Glücklicherweise haben schon andereüber dieses Problem nachgedacht. Gelöst wird es folgendermaßen:
log(a + b) = log[a(1 +
ba
)]= log(a) + log
(1 +
ba
)= log(a) + log
(1 + elog b−log a
). (8.12)
Diese letzte Formel (8.12) heißt auch „Kingsbury-Rayner-Formel“.
Anwendungen
So ist man also in der Lage, mit dynamischer Programmierung effizient die Wahrscheinlichkei-ten P(o1 . . . oT |λ) einer Beobachtung bei bekanntem HMM mit den Parametern λ zu berechnen.Verwendet wird diese Möglichkeit wenn man
• einen Einzelworterkenner realisieren möchte, in dem man durch Vergleich aller Wort-wahrscheinlichkeiten P(λWort1 |o),P(λWort2 |o) . . . P(λWortk |o) das wahrscheinlichste Wortals erkannt auswählen kann, oder
• wenn man HMMs trainieren möchte, wobei man dann neben dem Forward-Algorithmusauch noch eine Methode braucht, in der Zeit rückwärts zu rechnen, den analogen Back-ward-Algorithmus, der im Abschnitt zum HMM-Training genauer beschrieben wird.
8.5.4.2. Lösung 2: Berechnung des besten Pfades
Viterbi-Algorithmus
Das Problem der Wahrscheinlichkeitsberechnung, also der Bestimmung von P(o|λ), ist damitgelöst. Das zweite wichtige Problem, das mit und für HMMs gelöst werden sollte, ist die Suchenach der wahrscheinlichsten Sequenz von Zuständen, gegeben eine Beobachtungsfolge, also
i∗ = arg maxi
P(i|o, λ) = arg maxi
P(i, o|λ).
Wie man in Abbildung 8.8 sieht, besteht zwischen beiden Problemen eine strukturelle Ähn-lichkeit; während allerdings für Problem 1 die Summe über alle möglichen Pfade durch denZustandsraum gesucht wird, ist bei Problem 2 nur die Wahrscheinlichkeit des besten Pfadesvon Interesse. Deswegen kann man den Suchalgorithmus für den besten Pfad, den Viterbi-Algorithmus, aus dem Vorwärts-Algorithmus gewinnen, indem man statt einer Summenbil-dung eine Maximumsbildung über die partiellen Pfadwahrscheinlichkeiten vornimmt.
114

8. Klassifikation von Zeitreihen
Mit dieser Definition der partiellen Wahrscheinlichkeit,
φt(i) = max[i1...it−1]
P(o1 . . . ot,Xt = i|λ), (8.13)
kann man anfangen, den Viterbi-Algorithmus zu formulieren. Man braucht aber noch zusätz-lich eine Möglichkeit, sich den bisher besten Pfad zu merken. Das macht man in der VariablenΨt(i), in der der beste, direkte Vorgängerknoten des Knotens i zum Zeitpunkt t steht. Alleszusammengenommen, sieht der Viterbi-Algorithmus wie folgt aus:
Initialisierung
φ1(i) = α1(i) = πi · bi(o1)Ψ1(i) = 0
IterationFür alle t ≤ T
Update
φt( j) =
(maxi=1...N
φt−1(i)ai, j
)· b j(ot)
Ψt( j) = arg maxi=1...N
φt−1(i)ai, j
Terminierung
P∗(o1 . . . oT |λ) = maxi=1...N
φT (i)
i∗T = arg maxi=1...N
φT (i)
Backtrackingi∗t−1 = Ψt(i∗(t)).
Übrigens steht hier P∗(o1 . . . oT |λ) für die Wahrscheinlichkeit der wahrscheinlichsten Sequenz.
Diese gesamte Berechnung wird in Abbildung 8.9 an einem kurzen Beispiel gezeigt. Indiesem Beispiel ist dann der beste Zustand zum Zeitpunkt T = 3 gerade i∗(T ) = 3 und diebeste Zustandssequenz kann man durch Backtracking ermitteln:
i∗(T − 1) = i∗(2) = Ψ3(i∗(3)) = Ψ3(3) = 3i∗(1) = Ψ2(i∗(2)) = Ψ2(3) = 2i∗(0) = Ψ1(i∗(1)) = Ψ1(2) = 0.
Sie lautet also i∗ = [0, 2, 3, 3].
115
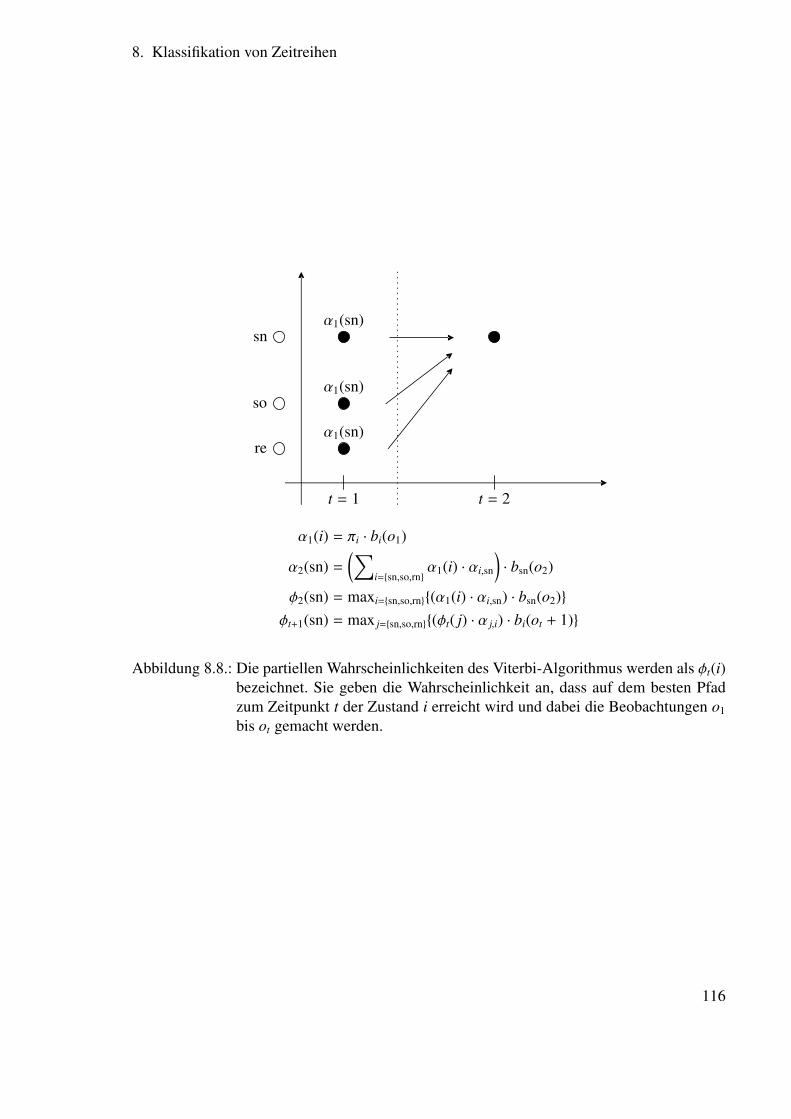
8. Klassifikation von Zeitreihen
sn
so
re
α1(sn)
α1(sn)
α1(sn)
t = 1 t = 2
α1(i) = πi · bi(o1)
α2(sn) =
(∑i=sn,so,rn
α1(i) · αi,sn
)· bsn(o2)
φ2(sn) = maxi=sn,so,rn(α1(i) · αi,sn) · bsn(o2)φt+1(sn) = max j=sn,so,rn(φt( j) · α j,i) · bi(ot + 1)
Abbildung 8.8.: Die partiellen Wahrscheinlichkeiten des Viterbi-Algorithmus werden als φt(i)bezeichnet. Sie geben die Wahrscheinlichkeit an, dass auf dem besten Pfadzum Zeitpunkt t der Zustand i erreicht wird und dabei die Beobachtungen o1
bis ot gemacht werden.
116

8. Klassifikation von Zeitreihen
t = 3t = 2t = 1
1 so
2 sn
3 re
φ1(i) φ3(i)φ2(i)Ψ1(i) Ψ3(i)Ψ2(i)
14·
18
=132
14·
13
=112
12· 0 = 0
112·
14·
14
0
112·
14·
14
112·
14·
14
0
112·
14·
14
0
0
0
2
2
2
1
1
3
Abbildung 8.9.: Beispiel für den Viterbi-Algorithmus, bei dem im Wetter-HMM (sieheAbb. 8.2 auf Seite 104) die beste Zustandssequenz für die Beobachtungsfolgeo = [0, 1, 2] gesucht wird.
117

8. Klassifikation von Zeitreihen
Logarithmierte Rechnung
Auch den Viterbi-Algorithmus kann man mit logarithmierten Wahrscheinlichkeiten arbeitenlassen. Das ist noch unproblematischer als der logarithmierte Forward-Algorithmus, da keineSummen auftreten und man auch das HMM gleich mit logarithmierten initialen Wahrschein-lichkeiten, Übergangsmatrizen und Ausgabewahrscheinlichkeiten speichern kann. Damit läuftder logarithmierte Viterbi-Algorithmus wie folgt ab:
Initialisierung
φ1(i) = log πi + log bi(o1)Ψ1(i) = 0
IterationFür alle t ≤ T
Update
φt( j) = maxi=1...N
(φt−1(i) + log ai, j
)+ log b j(ot)
Ψt( j) = arg maxi=1...N
(φt−1(i) + log ai, j
)Terminierung
log P∗(o1 . . . oT |λ) = maxi=1...N
φT (i)
i∗T = arg maxi=1...N
φT (i)
Backtrackingi∗t−1 = Ψt(i∗t ).
Einzelworterkennung mit dem Viterbi-Algorithmus
Um den Viterbi-Algorithmus in einem Einzelworterkenner einzusetzen, trainiert man einzelneWortmodelle, rechnet nach erfolgter Beobachtung die Wahrscheinlichkeiten des aufgenomme-nen Signals für alle Wortmodelle aus und gibt dann nach Anwendung des Satzes von Bayesdas wahrscheinlichste Wort (gegeben die Beobachtung) aus.
118

8. Klassifikation von Zeitreihen
•Wortmodelle als Links-Rechts-Modelle trainieren
• w∗ = arg maxw
p∗ (w|o)
= arg max
w
p∗ (o|w) p (w)
p (o)
• Für alle Wortmodelle
S (t) p∗ (o|λ1) . . . p∗ (o|λk)Viterbi
HMMs
o1 · · · oT
∀λi
one λone
two λtwo
⇒ HMMs
p(w): Wortwahrscheinlichkeitenw∗: gilt als erkannt
ExtractionFeature
Abbildung 8.10.: Strukturdiagramm und prinzipieller Ablauf der Einzelworterkennung mitHilfe des Viterbi-Algorithmus.
Verbundworterkennung mit dem Viterbi-Algorithmus
Für einen Verbundworterkenner erzeugt und trainiert man ein Verbundwortmodell, in dem ein-zelne Wortmodelle durch sogenannte „nichtemittierende Zustände“ verbunden werden kön-nen. Für die Verwendung nicht emittierender Zustände muss der Viterbi-Algorithmus ange-passt werden, sodass er in Zeiten, in denen nichtemittierende Zustände auftreten, jeweils zurErklärung der aktuellen Beobachtung einen weiteren, emittierenden, Zustand sucht. Schlei-fen von nicht emittierenden Zuständen führen zu Endlosschleifen in der Pfadsuche und sinddeswegen unzulässig.
119
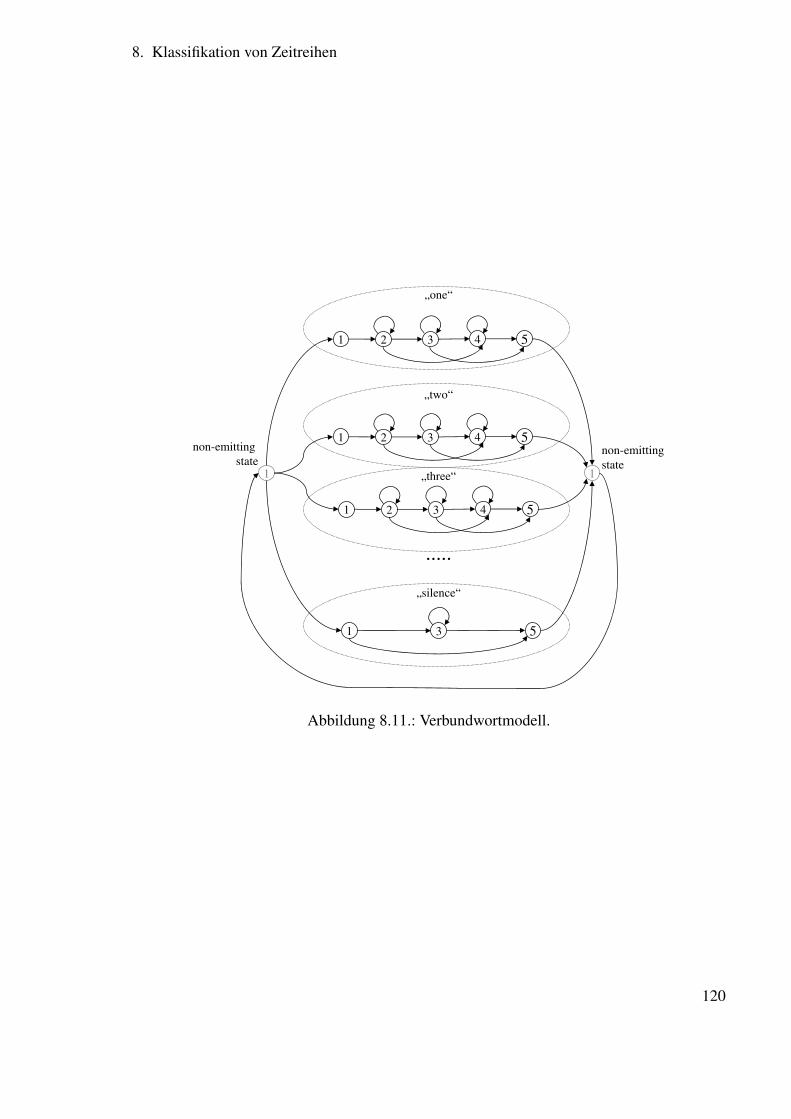
8. Klassifikation von Zeitreihen
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
.....
1
„one“
„two“
„three“ 1
non-emitting
state
1 3 5
„silence“
non-emitting
state
Abbildung 8.11.: Verbundwortmodell.
120

8. Klassifikation von Zeitreihen
8.6. TRAINING VON HIDDEN MARKOV MODELLE FÜR DIESPRACHERKENNUNG
8.6.1. Lösung für das Problem 3
8.6.1.1. Lösung 3: Berechnung der optimalen HMM-Parameter
Wie es in Abschnitt 8.5.3.3 beschrieben ist, besteht das dritte wichtige Problem bei der Ver-wendung von HMMs im Lernen von den dazugehörigen Parametern λ.
Dazu ist es üblich, eine Maximum-Likelihood-Strategie zu verfolgen, man wählt also dieParameter so, dass die Likelihood der Beobachtungen (der Trainingsdaten), gegeben die Mo-dellparameter, maximiert wird.7 Man sucht also die Lösung zum Optimierungsproblem
λ = arg maxλ
P(o1, o2 . . . oT |λ),
um die Modellparameter λ zu schätzen.Genauer gesagt, sind es folgende Parameter, die bestimmt werden müssen:
• die initialen Wahrscheinlichkeiten πi,
• alle Ausgangsverteilungsdichten b j(o) und
• die Übergangsmatrix A.
Bestimmung der initialen Wahrscheinlichkeiten
Am einfachsten ist die Wahl der initialen Wahrscheinlichkeiten, denn diese werden durchdie Struktur des Modells vorgegeben. Bei einem einzelnen Links-Rechts-Modell würde zumBeispiel nur ein einziger Knoten, nämlich der linkeste, eine initiale Wahrscheinlichkeit , 0erhalten und genauso würde auch in einem HMM mit einem Glue State8 der Vektor π am An-fang genau eine 1 und ansonsten Nullen enthalten. Diese Fälle sind in den Abbildungen 8.12und 8.13 zu sehen.
21 3 4
Einzelworterkenner:
Links-Rechts-Modell
=[1 0 0 0 ]
Abbildung 8.12.: Initiale Wahrscheinlichkeiten für einzelne Wortmodelle sind jeweils 1 fürden ersten Zustand eines Wortes.
7Eine interessante Alternative besteht darin, die Parameter so einzustellen, dass die Anzahl der Klassifikati-onsfehler auf den Trainingsdaten minimiert wird. Dieses sogenannte Minimum Classification Error (MCE)Training führt im Allgemeinen zu besseren Erkennungsraten, ist allerdings sowohl konzeptuell als auch vomRechenaufwand schwieriger umzusetzen.
8Glue States werden auf Deutsch konfluente Zustände genannt.
121
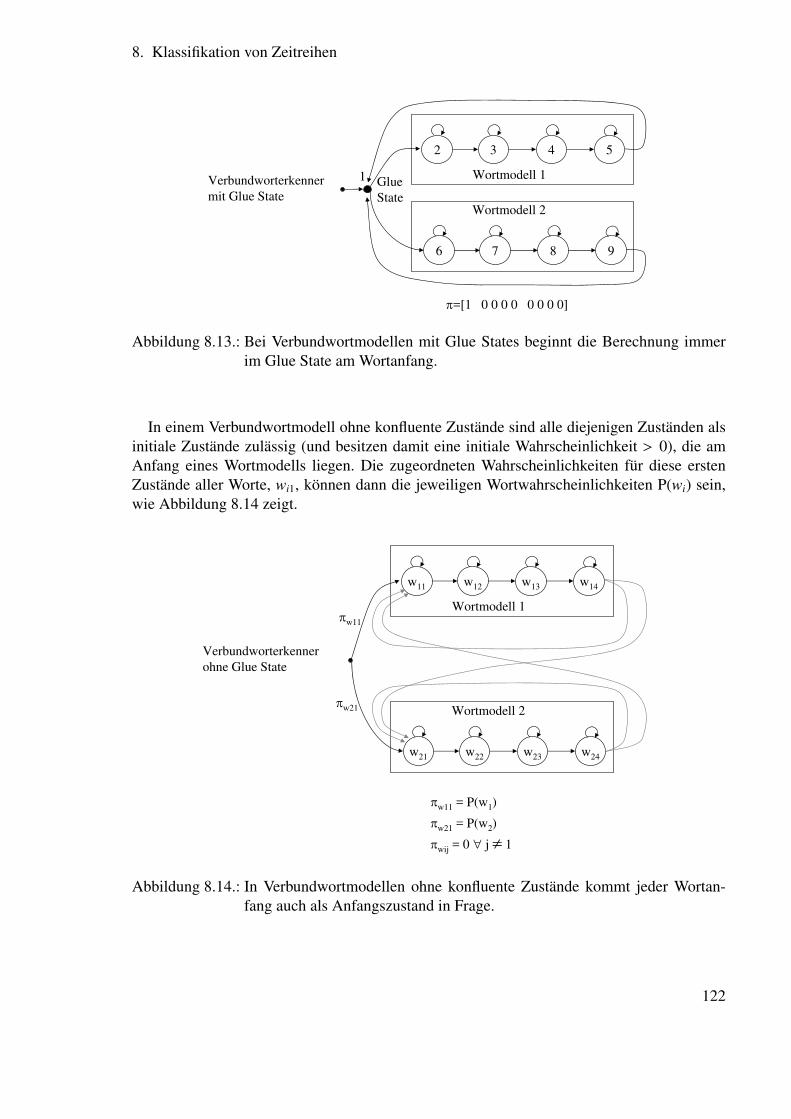
8. Klassifikation von Zeitreihen
Verbundworterkenner
mit Glue State
Glue
State
32 4 5
76 8 9
1
=[1 0 0 0 0 0 0 0 0]
Wortmodell 1
Wortmodell 2
Abbildung 8.13.: Bei Verbundwortmodellen mit Glue States beginnt die Berechnung immerim Glue State am Wortanfang.
In einem Verbundwortmodell ohne konfluente Zustände sind alle diejenigen Zuständen alsinitiale Zustände zulässig (und besitzen damit eine initiale Wahrscheinlichkeit > 0), die amAnfang eines Wortmodells liegen. Die zugeordneten Wahrscheinlichkeiten für diese erstenZustände aller Worte, wi1, können dann die jeweiligen Wortwahrscheinlichkeiten P(wi) sein,wie Abbildung 8.14 zeigt.
Verbundworterkenner
ohne Glue State
w12w11 w13 w14
w22w21 w23 w24
w21 = P(w2)
Wortmodell 1
Wortmodell 2
w11
wij = 0 j 1
w11 = P(w1)
w21
Abbildung 8.14.: In Verbundwortmodellen ohne konfluente Zustände kommt jeder Wortan-fang auch als Anfangszustand in Frage.
122

8. Klassifikation von Zeitreihen
Bestimmung der Parameter A und b
Die Werte der Übergangsmatrix A und der Wahrscheinlichkeitsverteilungen bi(o) sind schwie-riger zu bestimmen, sodass ein iteratives Vorgehen nötig wird. Dazu müssen zuerst initialeParameterwerte gefunden werden, die dann in mehreren Durchgängen sukzessive verfeinertwerden können. Dieser Ablauf ist in Abbildung 8.15 gezeigt.
Initialisierung der
Modellparameter
Reestimation der
Parameter
Konvergenztest
konvergiert
nic
ht konverg
iert
Abbildung 8.15.: Vorgehensweise zum Training der Modellparameter A und b.
8.6.1.2. Erste Phase: Initialisierung
Die Initialisierung eines HMM ist nicht ganz einfach - um Parameter zu bestimmen, bräuchteman ein initialisiertes HMM. Um dieses Henne-Ei-Problem zu lösen, kann man auf verschie-dene Weisen an ein initialisiertes HMM gelangen. Dafür ist es sinnvoll, zuerst eine HMM-Struktur festzulegen, und dann für dieses HMM die Trainingsdaten in Segmente aufzuteilen,für die man jeweils weiß, zu welchem Zustand des HMM sie gehören. Das kann man
• von Hand machen, was mühselig ist aber die besten Ergebnisse liefert,
• von einem bestehenden Spracherkenner passender Struktur durchführen lassen, was vor-aussetzt, dass man einen solchen hat oder
• man kann die Daten in ganze Worte zerlegen, die man dann in mehrere gleichlange Seg-mente aufteilt, wobei man genauso viele Segmente verwendet, wie das HMM Zuständebesitzt.
Diese drei Vorgehensweisen illustriert Abbildung 8.16.
123
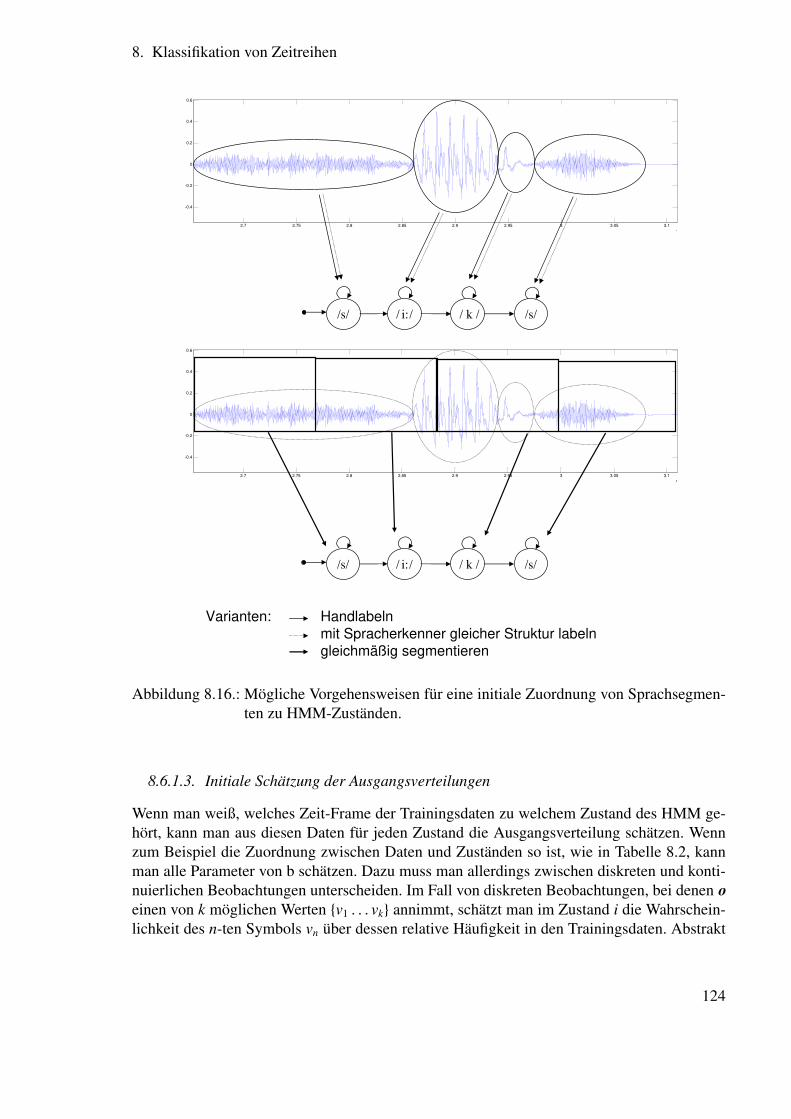
8. Klassifikation von Zeitreihen
2.7 2.75 2.8 2.85 2.9 2.95 3 3.05 3.1
4
-0.4
-0.2
0
0.2
0.4
0.6
/ /i:/s/ / k / /s/
Varianten: Handlabeln
mit Spracherkenner gleicher Struktur labeln
gleichmäßig segmentieren
2.7 2.75 2.8 2.85 2.9 2.95 3 3.05 3.14
-0.4
-0.2
0
0.2
0.4
0.6
/ /i:/s/ / k / /s/
Abbildung 8.16.: Mögliche Vorgehensweisen für eine initiale Zuordnung von Sprachsegmen-ten zu HMM-Zuständen.
8.6.1.3. Initiale Schätzung der Ausgangsverteilungen
Wenn man weiß, welches Zeit-Frame der Trainingsdaten zu welchem Zustand des HMM ge-hört, kann man aus diesen Daten für jeden Zustand die Ausgangsverteilung schätzen. Wennzum Beispiel die Zuordnung zwischen Daten und Zuständen so ist, wie in Tabelle 8.2, kannman alle Parameter von b schätzen. Dazu muss man allerdings zwischen diskreten und konti-nuierlichen Beobachtungen unterscheiden. Im Fall von diskreten Beobachtungen, bei denen oeinen von k möglichen Werten v1 . . . vk annimmt, schätzt man im Zustand i die Wahrschein-lichkeit des n-ten Symbols vn über dessen relative Häufigkeit in den Trainingsdaten. Abstrakt
124

8. Klassifikation von Zeitreihen
t 1 2 3 4 5 6 7 8o(t) 2 3 4 3 2 0 -1 1x(t) Re So Sn Re
Tabelle 8.2.: Beispiel für eine initiale Zuordnung zwischen Daten und HMM-Zuständen.
heißt das
bi(vn) =Anzahl der Beobachtungen vn in Zustand i
Anzahl der Frames in Zustand iund für das konkrete Beispiel und den Zusand Regen und die Temperatur 1 erhält man so
bRe(1) =14.
Für Gauß’sche Modelle kann man bei gegebener Zuordnung zwischen Beobachtungen undZuständen die Maximum Likelihood-Schätzung für Gaußverteilungen einsetzen und entspre-chend rechnen
µi =
∑t:Xt=i ot∑t:Xt=i 1
(8.14)
und
Σi =
∑t:Xt=i (ot − µi)(ot − µi)ᵀ∑
t:Xt=i 1. (8.15)
Die Summe∑
t:Xt=i 1 in (8.14) und (8.15) ist die Anzahl von Trainingsframes ni, die in derinitialen Segmentierung dem Zustand i zugeordnet worden sind.
8.6.1.4. Initiale Schätzung der Übergangswahrscheinlichkeiten
Auch die Übergangsmatrix bestimmt man aus den segmentierten Trainingsdaten. Dazu zähltman die Zustandsübergänge, die in den Trainingsdaten vorkommen, und schätzt die Wahr-scheinlichkeiten daraus. Wenn beispielsweise in den segmentierten Daten 1.000 Übergängeaus dem Zustand i erfolgen, davon 17 in den Zustand j, schätzt man die Übergangswahr-scheinlichkeit ai j auf den Wert 17
1.000 = 1, 7%. Allgemeiner sieht es folgendermaßen aus:
ai j =Anzahl der Übergänge aus Zustand i in Zustand j
Anzahl der Übergänge aus Zustand i
und für das konkrete Beispiel und den Zustand Regen erhält man so
aRe,Re =23.
8.6.1.5. Zusammenfassung der Initialen Parameterschätzung
125

8. Klassifikation von Zeitreihen
Benötigt: Initiale Segmentierung Xt ∀ 1 ≤ t ≤ T
Dann gilt: µi =
∑t:Xt=i ot
ni=
∑t:Xt=i ot∑t:Xt=i 1
ni: Anzahl von Frames, in denen der Zustand i vorkommt
Σi =
∑t:Xt=i (ot − µi)(ot − µi)ᵀ∑
t:Xt=i 1
ai j =
∑t:Xt=i&Xt+1= j 1∑
t:Xt=i,t<T 1
sind die Maximum-Likelihood-Schätzer für µ, Σ und a.
Abbildung 8.17.: Aus gelabelten Featurevektoren können mit den hier gezeigten Schätzglei-chungen initiale HMM-Parameter bestimmt werden. Die Schätzungen erge-ben sich in diesem Fall als Maximum-Likelihood-Schätzer aus den empiri-schen Mittelwerten und empirischen Varianzen der Beobachtungen.
8.6.2. Verbesserung der Parameterschätzung durch Viterbi-Reestimation
Bei dem sogenannten Viterbi-Training wird aus einer initialen Segmentierung die Initialisie-rung der HMM-Parameter vorgenommmen. Mit diesem ersten HMM lässt man den Viterbi-Algorithmus laufen, der die beste (bzw. wahrscheinlichste) Zustandssequenz findet. Diese Se-quenz betrachtet man als neue Segmentierung der Daten und schätzt damit neue Parameter,wobei man genauso vorgeht, wie schon mit der Zeit-Zustandszuordnung aus der initialen Seg-mentierung, nämlich entsprechend Abbildung 8.17. Der ganze Vorgang wird iteriert, bis dievom Viterbi-Algorithmus geschätzte Wahrscheinlichkeit der Beobachtungen P∗ pro Iterationnicht mehr genügend verbessert wird. Die gesamte Vorgehensweise zeigt Abbildung 8.18 imÜberblick.
8.6.3. Verbesserung der Parameterschätzung durch Baum-Welch-Reestimation
Während die Viterbi-Reestimation eine feste Zuordnung von Frames und Zuständen vor-nimmt, lässt der Baum-Welch-Algorithmus unscharfe Frame-State-Zuordnungen zu, das heißt,dass ein Frame zu zum Beispiel 50% für das Training des einen und zu 50% für das Trainingeines anderen Zustandes verwendet werden kann. Wie wichtig ein Frame t für das Trainingeines einzelnen Zustandes i sein soll, wird danach festgelegt, mit welcher Wahrscheinlich-keit das t-te Frame zum i-ten Zustand gehört, das heißt also, mit welcher WahrscheinlichkeitP(Xt = i) sich das HMM zu diesem Zeitpunkt t in diesem Zustand i befindet. Und überall,wo im Viterbi-Algorithmus eine harte Zuordnung benötigt wurde (also überall dort, wo inden Reestimationsgleichungen eine 1 für jedes t : Xt = i stand), wird stattdessen die genauereWahrscheinlichkeitsinformation P(Xt = i) verwendet. Und weil sie so oft vorkommt, bekommtsie einen neuen Namen: P(Xt = i) def
= γt(i).Genauso wird für die Schätzung der Übergangswahrscheinlichkeiten ai j auch eine Wahrschein-
126
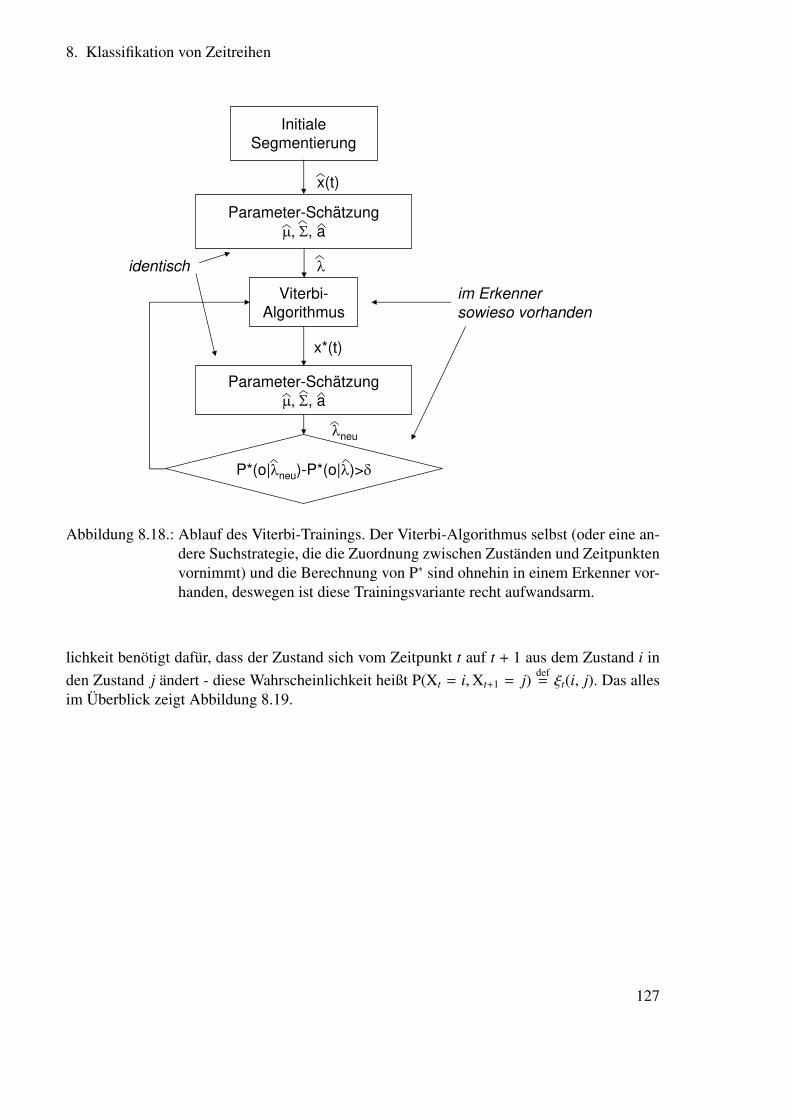
8. Klassifikation von Zeitreihen
Initiale
Segmentierung
Parameter-Schätzung
, a
Viterbi-
Algorithmus
im Erkenner
sowieso vorhanden
Parameter-Schätzung
, a
x*(t)
identisch
P*(o| neu)-P*(o| )>
neu
x(t)
Abbildung 8.18.: Ablauf des Viterbi-Trainings. Der Viterbi-Algorithmus selbst (oder eine an-dere Suchstrategie, die die Zuordnung zwischen Zuständen und Zeitpunktenvornimmt) und die Berechnung von P∗ sind ohnehin in einem Erkenner vor-handen, deswegen ist diese Trainingsvariante recht aufwandsarm.
lichkeit benötigt dafür, dass der Zustand sich vom Zeitpunkt t auf t + 1 aus dem Zustand i inden Zustand j ändert - diese Wahrscheinlichkeit heißt P(Xt = i,Xt+1 = j) def
= ξt(i, j). Das allesim Überblick zeigt Abbildung 8.19.
127

8. Klassifikation von Zeitreihen
Reestimationsgleichungen
µi =
∑t:Xt=i ot
ni=
∑t:Xt=i ot∑t:Xt=i 1
∑ᵀt=1 p (Xt = i) ot∑ᵀ
t=1 p (Xt = i)
ni: Anzahl von Frames, in denender Zustand i vorkommt
Σi =
∑t:Xt=i (ot − µi)(ot − µi)ᵀ∑
t:Xt=i 1
∑ᵀt=1 p (Xt = i) (ot − µi)(ot − µi)ᵀ∑ᵀ
t=1 p (Xt = i)
ai j =
∑t:Xt=i&Xt+1= j 1∑
t:Xt=i,t<T 1
∑T−1t=1 p (Xt = i,Xt+1 = j)∑T−1
t=1 p (Xt = i)
sind die Maximum-Likelihood-Schätzerfür µ, Σ und a.
Abbildung 8.19.: Die Neuschätzung der Parameter erfolgt beim Baum-Welch-Algorithmusmit einer weichen Zuordnung von Frames zu Zuständen, gewichtet jeweilsmit der Wahrscheinlichkeit, dass das betrachtete Frame zu dem jeweils neuzu schätzenden Zustand i gehört.
In Abbildung 8.20 sind die Reestimationsgleichungen nach Baum-Welch aufgelistet; dassind die selben Gleichungen wie in Abbildung 8.19, allerdings unter Verwendung von zweineuen Abkürzungen: γt(i) := p (Xt = i) und ξt(i, j) := p (Xt = i,Xt+1 = j).
Reestimationsgleichungen
µi =
∑ᵀt=1 γt(i)ot∑ᵀ
t=1 γt(i)
Σi =
∑ᵀt=1 γt(i)(ot − µi)(ot − µi)ᵀ∑ᵀ
t=1 γt(i)
ai j =
∑T−1t=1 ξt(i, j)∑T−1
t=1 γt(i)
Abbildung 8.20.: Reestimationsgleichungen, die selben wie oben, unter Verwendung derLikelihood-Werte γt(i) und ξt(i, j).
Es fehlen also zur Reestimation die beiden Likelihood-Werte
γt(i) = P(Xt = i|λ, o
)und
ξt(i, j) = P(Xt = i,Xt+1 = j|λ, o
).
128

8. Klassifikation von Zeitreihen
Um diese Werte berechnen zu können, benötigt man einerseits die Vorwärtswahrscheinlich-keiten
αt(i) = P(o1, o2 . . . ot,Xt = i|λ)
(die in der zweiten HMM-Vorlesung behandelt wurden und mit dem Vorwärtsalgorithmus be-stimmt werden) und andererseits die (noch zu definierenden) Rückwärtswahrscheinlichkeitenβ. Diese geben bei bekanntem Zustand Xt die Wahrscheinlichkeit an, dass alle folgenden Be-obachtungen auftreten werden, also:
βt(i) = P(ot+1, ot+2 . . . oT |Xt = i, λ). (8.16)
Die Rückwärtswahrscheinlichkeiten β werden mit einem Algorithmus der dynamischen Pro-grammierung berechnet, dessen Struktur der des Vorwärtsalgorithmus entspricht und der imAnhang A.6 genauer dargestellt ist.
Wenn dann sowohl die Vorwärts- als auch die Rückwärtswahrscheinlichkeiten bekannt sind,kann mit Hilfe des Satzes von Bayes die Likelihood γt(i) (für alle Zustände i und Zeiten t)berechnet werden:
γt(i) = P(Xt = i|λ, o)Bayes=
P(Xt = i, o|λ)P(o|λ)
. (8.17)
Der Nenner ist unproblematisch, denn P(o|λ) kann man mit Hilfe des Vorwärtsalgorithmusbestimmen, wie es in Abschnitt 8.5.4.1 beschrieben ist. Für den Zähler muss man mit derProduktregel9 weiterrechnen. So kann der Zähler aus Gleichung (8.17) folgendermaßen ge-schrieben werden:
P(Xt = i, o|λ) = P(ot+1 . . . oT︸ ︷︷ ︸A
, o1 . . . ot︸ ︷︷ ︸B
,Xt = i︸︷︷︸C
|λ)
Mit Bayes gilt also
P(Xt = i, o|λ) = P(ot+1 . . . oT︸ ︷︷ ︸A
| o1 . . . ot︸ ︷︷ ︸B
,Xt = i︸︷︷︸C
, λ) · P(o1 . . . ot︸ ︷︷ ︸B
,Xt = i︸︷︷︸C
|λ).
Der erste Term entspricht den neu definierten Rückwärtswahrscheinlichkeiten aus Gleichung (8.16):
P(ot+1 . . . oT︸ ︷︷ ︸A
| o1 . . . ot︸ ︷︷ ︸B
,Xt = i︸︷︷︸C
, λ) = βt(i)
und der zweite Term entspricht den bereits besser bekannten Vorwärtswahrscheinlichkeiten:
P(o1 . . . ot︸ ︷︷ ︸B
,Xt = i︸︷︷︸C
|λ) = αt(i).
9Die Produktregel P(A, B) = P(A)P(B|A) kann um beliebiges Vorwissen erweitert werden, es gilt also z. B. auchP(A, B|C) = P(A|C)P(B|A,C).
129

8. Klassifikation von Zeitreihen
So ist insgesamt der Zähler aus Gleichung (8.17) mit
P(Xt = i, o|λ) = αt(i) · βt(i)
relativ leicht zu bestimmen. Der Nenner aus Gleichung (8.17) ist auch nicht problematisch,denn wie in Abschnitt 8.5.4.1 beschrieben, ist die Wahrscheinlichkeit P(o|λ) gleich der Summeüber die Vorwärtswahrscheinlichkeiten, also
P(o|λ) =
N∑j=1
αT ( j).
So kann man schließlich aus Gleichung (8.17) die Wahrscheinlichkeiten γt(i) erhalten:
P(Xt = i|λ, o) =P(Xt = i, o|λ)
P(o|λ)
=αt(i) · βt(i)∑N
j=1 αT ( j).
Damit sind die γt(i) bestimmt. Die noch fehlenden Likelihoods der Zustandsübergängeξt(i, j) können auf die gleiche Art aus
P(Xt = i,Xt+1 = j|o1 . . . oT , λ) =P(Xt = i,Xt+1 = j, o1 . . . oT |λ)
P(o1 . . . oT |λ)
hergeleitet werden. Intuitiv gesprochen setzt sich die im Zähler benötigte Wahrscheinlichkeit,dass ein Übergang von i zur Zeit t nach j zum Zeitpunkt t + 1 erfolgt und dass gleichzeitig dieBeobachtungen o1 bis oT erfolgen, zusammen aus
1. der Wahrscheinlichkeit, dass die Beobachtungen o1 bis ot auftreten und der Zustand zurZeit t = i ist (also der Vorwärtswahrscheinlichkeit αt(i)),
2. der Wahrscheinlichkeit, dass dann ein Übergang in den Zustand j erfolgt (also ai j),
3. der Wahrscheinlichkeit, dass im Zustand j die Beobachtung o(t+1) auftritt, also b j(ot+1),
4. der Wahrscheinlichkeit, dass vom Zustand j zur Zeit t + 1 ausgehend alle folgendenBeobachtungen (ot+2 . . . oT ) auftreten (also der Rückwärtswahrscheinlichkeit βt+1( j)).
Nach einer ähnlichen Rechnung wie oben erhält man entsprechend die Wahrscheinlichkeitenξt(i, j) aus den Vorwärts- und Rückwärtswahrscheinlichkeiten:
ξt(i, j) =αt(t) · ai j · b j(ot+1) · βt+1( j)
P(o|λ).
Damit hat man alle Wahrscheinlichkeiten, die man für die Berechnung der Baum-Welch-Reestimationsgleichungen, entsprechend Abbildung 8.20, benötigt.
Die Herleitung des Vorwärts- und Rückwärtsalgorithmus, und die Reestimationsgleichun-gen sind im Anhang A.6, Anhang A.7 und Anhang A.8 zu finden.
130
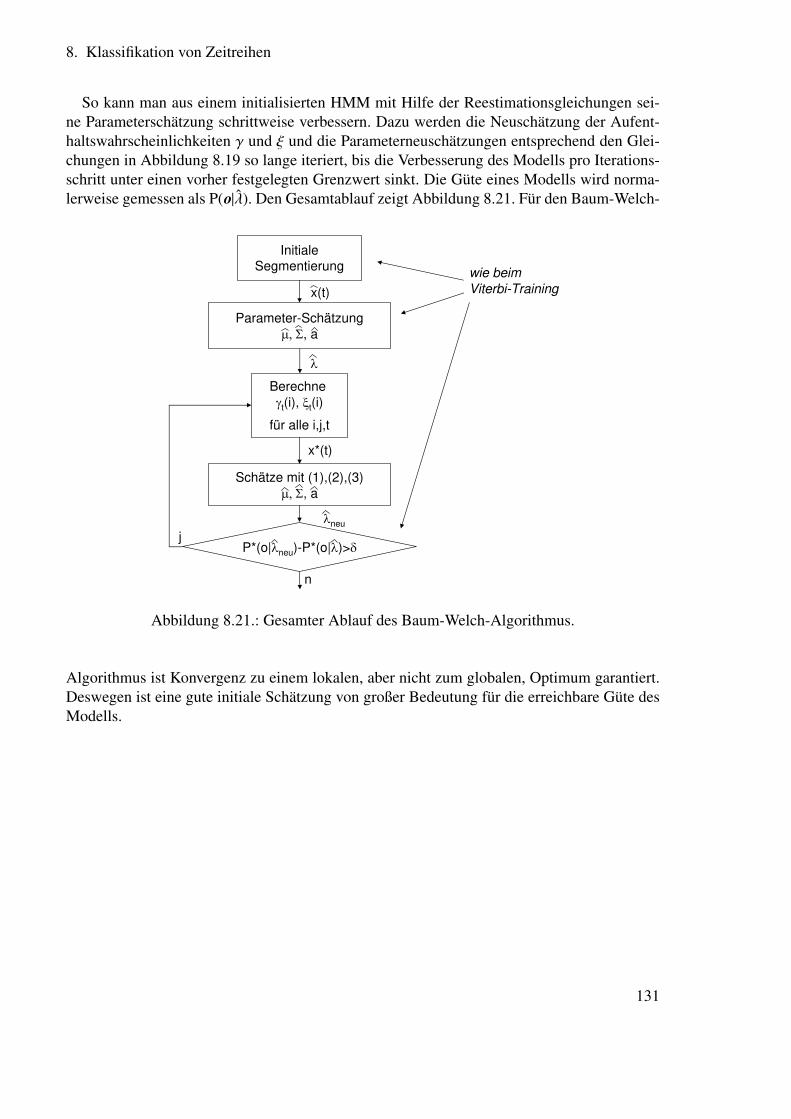
8. Klassifikation von Zeitreihen
So kann man aus einem initialisierten HMM mit Hilfe der Reestimationsgleichungen sei-ne Parameterschätzung schrittweise verbessern. Dazu werden die Neuschätzung der Aufent-haltswahrscheinlichkeiten γ und ξ und die Parameterneuschätzungen entsprechend den Glei-chungen in Abbildung 8.19 so lange iteriert, bis die Verbesserung des Modells pro Iterations-schritt unter einen vorher festgelegten Grenzwert sinkt. Die Güte eines Modells wird norma-lerweise gemessen als P(o|λ). Den Gesamtablauf zeigt Abbildung 8.21. Für den Baum-Welch-
Initiale
Segmentierung
Parameter-Schätzung
, a
Berechne
t(i), t(i)
für alle i,j,t
Schätze mit (1),(2),(3)
, a
x*(t)
P*(o| neu)-P*(o| )>
neu
x(t)
n
j
wie beim
Viterbi-Training
Abbildung 8.21.: Gesamter Ablauf des Baum-Welch-Algorithmus.
Algorithmus ist Konvergenz zu einem lokalen, aber nicht zum globalen, Optimum garantiert.Deswegen ist eine gute initiale Schätzung von großer Bedeutung für die erreichbare Güte desModells.
131

9. Gesamtstruktur vonSpracherkennern
Die bisher betrachtete Vorgehensweise zur Spracherkennung kann in zwei Klassen geteilt wer-den. Zum einen können reine Einzelworte erkannt werden, wie in Abbildung 9.1 gezeigt wird,zum anderen ist die Erkennung von fließend gesprochener Sprache möglich, was weiter untenausführlicher dargestellt wird.
Auf einer abstrakteren Ebene kann der Ablauf der Einzelworterkennung auch entsprechendBild 9.2 dargestellt werden.
Auch die Verbundworterkennung ist auf diesen beiden Abstraktionsebenen darstellbar. Ab-bildung 9.3 gibt den Überblick über die vorgestellte Methode zur Verbundworterkennung, wasin Abbildung 9.4 um eine Stufe allgemeiner dargestellt wird.
132
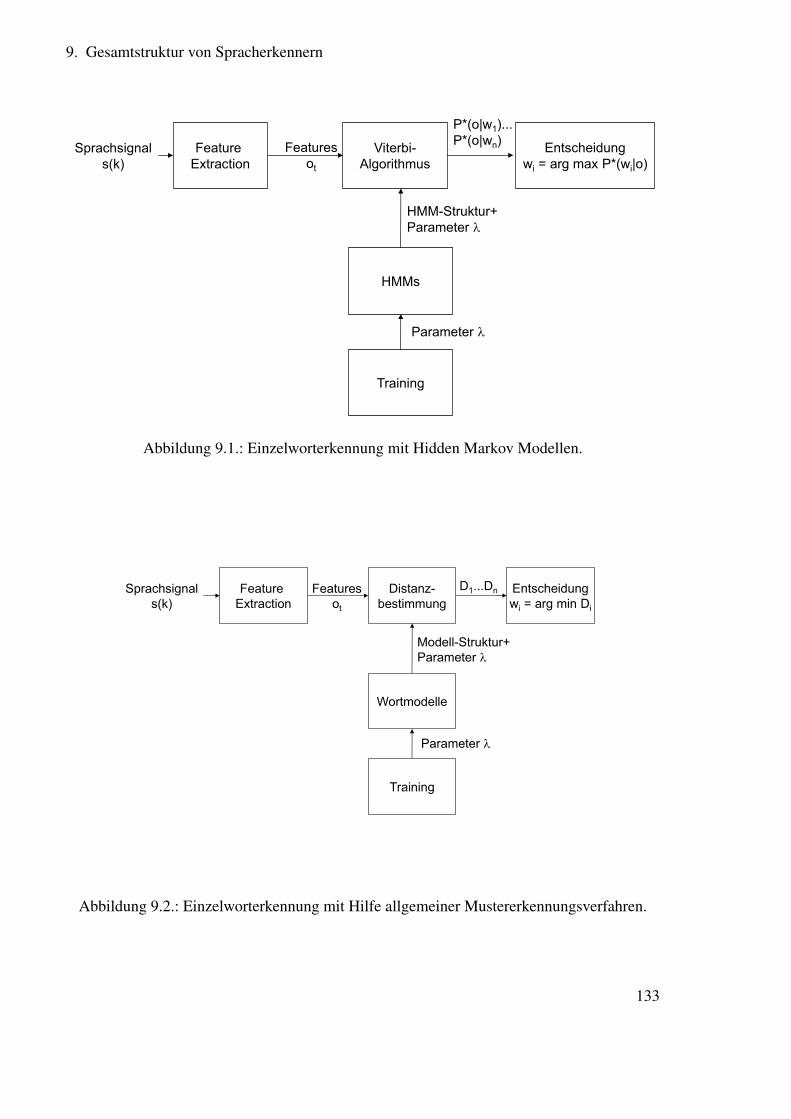
9. Gesamtstruktur von Spracherkennern
Feature
Extraction
HMM-Struktur+
Parameter l
Viterbi-
Algorithmus
HMMs
Parameter l
Training
Sprachsignal
s(k)
Features
ot
Entscheidung
wi = arg max P*(wi|o)
P*(o|w1)...
P*(o|wn)
Abbildung 9.1.: Einzelworterkennung mit Hidden Markov Modellen.
Feature
Extraction
Modell-Struktur+
Parameter l
Distanz-
bestimmung
Wortmodelle
Parameter l
Training
D1...DnSprachsignal
s(k)
Features
ot
Entscheidung
wi = arg min Di
Abbildung 9.2.: Einzelworterkennung mit Hilfe allgemeiner Mustererkennungsverfahren.
133
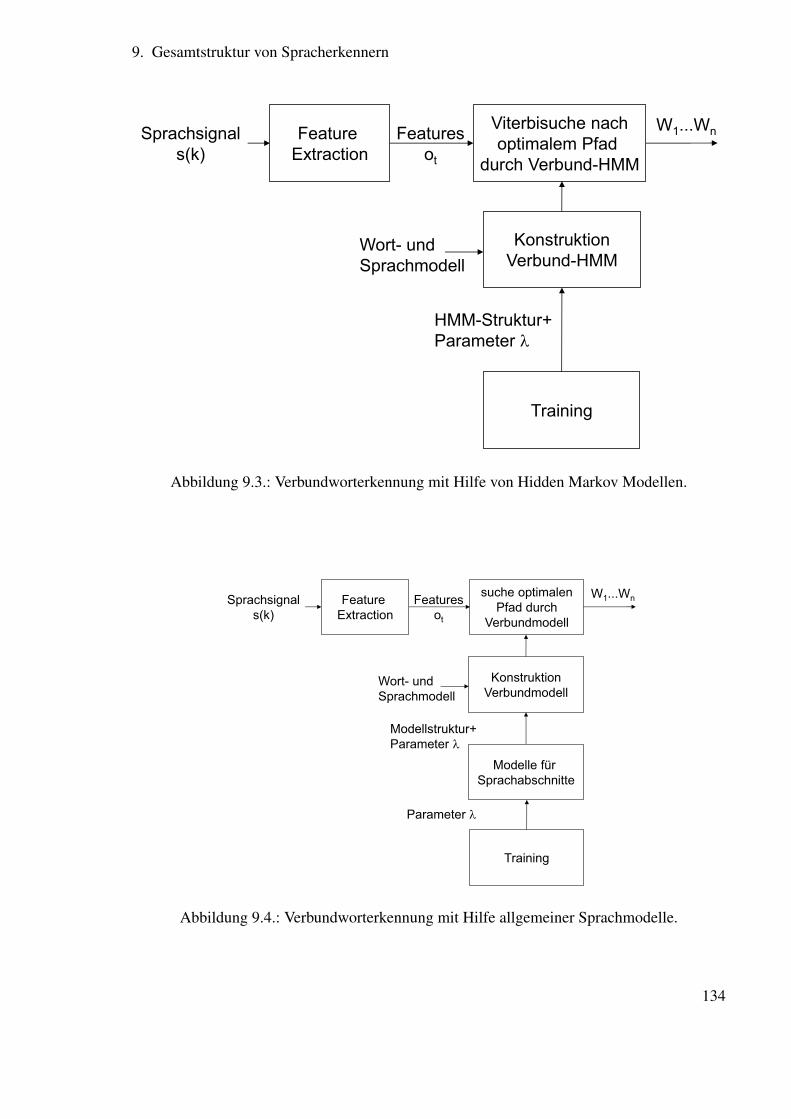
9. Gesamtstruktur von Spracherkennern
Feature
Extraction
HMM-Struktur+
Parameter l
Training
W1...WnSprachsignal
s(k)
Features
ot
Viterbisuche nach
optimalem Pfad
durch Verbund-HMM
Konstruktion
Verbund-HMMWort- und
Sprachmodell
Abbildung 9.3.: Verbundworterkennung mit Hilfe von Hidden Markov Modellen.
Feature
Extraction
Modellstruktur+
Parameter l
Modelle für
Sprachabschnitte
Parameter l
Training
W1...WnSprachsignal
s(k)
Features
ot
suche optimalen
Pfad durch
Verbundmodell
Konstruktion
VerbundmodellWort- und
Sprachmodell
Abbildung 9.4.: Verbundworterkennung mit Hilfe allgemeiner Sprachmodelle.
134

9. Gesamtstruktur von Spracherkennern
Um ein Sprachsignal zu erkennen, muss dieses also zunächst in einen geeigneten Merk-malsraum transformiert, und anschließend in diesem Merkmalsraum mit Modellen verglichenwerden. Dabei sind die Modelle nicht auf HMMs beschränkt, auch wenn diese zurzeit dieweitaus häufigste Variante darstellen. Alternativen bestehen aber auch in
• Templates, wie sie beim Dynamic Time Warping verwendet werden,
• Neuronalen Modellen, oder Hybridmodellen (aus Neuronalen und HMM-Anteilen) und
• allgemeineren Bayes’schen Netzen (auch als Graphical Models bezeichnet), die we-gen ihrer flexiblen Struktur zurzeit stark weiterentwickelt werden, bisher aber an einemgroßen Rechenaufwand leiden.
Egal aber welche Form die Modelle genau haben, in jedem Fall steht man neben der Wahlder Modellstruktur noch vor zwei weiteren Designentscheidungen. Zum einen muss festge-legt werden, welche Einheiten der Sprache modelliert werden sollen, zum anderen, welcheSatzstrukturen zulässig sind, und wie man diese beschreiben möchte. Diese beiden Bereichewerden in den folgenden Abschnitten 9.1 und 9.2 kurz vorgestellt.
9.1. PHONETISCHE SPRACHMODELLIERUNG
Die Struktur eines HMM-basierten Einzelworterkenners zeigt Abbildung 9.5 genauer. Wie zuerkennen ist, ist man hier also nicht darauf beschränkt, pro Wort ein HMM zu trainieren. Dieswäre insbesondere dann unpraktisch, wenn es auch möglich sein soll, Worte zu erkennen, fürdie keine Trainingsdaten vorliegen, und das ist der weitaus häufigere Fall. Stattdessen bestehtmeistens eine Trainingsdatenbasis aus einer Vielzahl phonetisch vielfältiger Worte, von denendie meisten recht selten vorkommen, und unter denen sich viele Worte nicht befinden.
Auch unter anderen Gesichtspunkten ist die Modellierung ganzer Worte nicht optimal:
• Selbst wenn unbegrenzte Ressourcen zur Verfügung stünden, wäre die Menge des be-nötigten Trainingsmaterials bei der Ganzwortmodellierung proportional zu dem Wort-schatz des Erkenners. Bei sprecherabhängigen Modellen müsste man die Geduld desNutzers in der Anlernphase deutlich überstrapazieren.
• Ganzwortmodelle machen es ungleich schwieriger, das Vokabular an neue Gegebenhei-ten anzupassen, da dann ein neues Training erforderlich wäre.
• Daten, die mehrfach genutzt werden könnten, werden nur einmal verwendet, wenn se-parate Wortmodelle für ähnliche Worte oder Worte mit dem gleichen Wortstamm undverschiedenen Endungen gelernt werden.
• Auch für leicht unterschiedliche Aussprachevarianten des selben Wortes müssen neueWortmodelle gelernt werden, was zu einer großen Menge an Modellen und einem ent-sprechend sinnlos großen Speicheraufwand führen würde.
135

9. Gesamtstruktur von Spracherkennern
Feature
Extraction
Modell-Struktur+
Parameter l
Pattern
Matching
Konstruktion der
Wort-HMMs
Parameter l
Training der
Subwort-HMMs
Sprachsignal
s(k)
Features
ot
phonetisches
Wörterbuch
P(w1)...
P(wn)
Entscheidung
wi = arg max P(wi)
Abbildung 9.5.: Einzelworterkennung mit Hilfe von Hidden Markov Modellen.
Deswegen ist es sinnvoll, HMMs zu trainieren, die einzelne Untereinheiten der Sprache mo-dellieren, und diese dann anhand eines phonetischen Wörterbuchs zu Gesamtwort-HMMs zu-sammenzusetzen.
Als phonetische Einheit bietet sich zunächst das Phonem selbst an, die kleinste bedeutungs-tragende Einheit der Sprache. Für eine solche phonembasierte Erkennung würde dann ent-sprechend Abbildung 9.5 ein HMM pro Phonem der benötigten Sprache trainiert werden, undanschließend würden für jedes Wort das erkannt werden soll Gesamtwort-HMMs konstruiert,wie das Abbildung 9.6 zeigt.
Aber während Phoneme insofern günstig erscheinen, als es relativ wenige von ihnen gibt,1
haben sie den großen Nachteil, sich je nach akustischen Kontext stark zu verändern.2
Alternativen zu Phonemmodellen sind vor allem:
• Diphone (Modelle für zwei Phoneme, die vom Zentrum des initialen bis zum Zentrumdes zweiten Phonems reichen),
• Triphone (Modelle für Phoneme, bei denen der linke und rechte akustische Kontext
1Die meisten Sprachen haben zwischen 10 und 80 Phoneme, zum Beispiel gibt es etwa 50 in der englischenund japanischen Sprache und ca. 35 im deutschen, wenn die Dialekte unberücksichtigt bleiben.
2Beispielsweise klingt eben das Phonem /x/ je nach dem vorausgehenden Vokal unterschiedlich, zu erkennenzum Beispiel in den Worten „Dach“ und „dich“.
136

9. Gesamtstruktur von Spracherkennern
Trainierte Phonem-HMMs Wörterbuch
...
FINAL f ay n l
FINAL'S f ay n l z
FINALE f ih n aa l iy
FINALE'S f ih n aa l iy z
FINALED f ay n l d
FINALED f ih n aa l iy d
FINALES f ih n aa l ih z
FINALIS f ay n ax l ih s
FINALISATION f ay n ax l ay z ey sh ax n
FINALISATIONS f ay n ax l ay z ey sh ax n z
FINALISED f ay n ax l ih s t
FINALISES f ay n ax l ih s ih z
FINALISING f ay n ax l ih s ih ng
FINALISM f ay n ax l ih z ax m
...
....
....
/f/
1-a44,f
/ay/
1-a44,ay
/n/
1-a44,n
/l/
1-a44,l
/l/
1-a44,l
/n/
1-a44,n
/ay/
1-a44,ay
/f/
1-a44,f
Final
Abbildung 9.6.: Konstruktion von Wort-HMMs aus Subwort-HMMs mit Hilfe eines Wörter-buches.
gleich ist),
• Halbsilben und
• Silben.
Allgemein gilt, dass eine feinere phonetische Modellierung mehr Trainingsmaterial erfor-derlich macht, aber auch zu einer besseren Erkennungsleistung führen kann, wenn genügendTrainingsmaterial vorhanden ist. So ist bei Anwendungen mit kleinem, festem Vokabular oftdie Wortmodellierung die beste Wahl, während sich in Erkennern mit mittleren und großenVokabularien der Flexibilität wegen; kleine, phonetisch orientierte Einheiten wie das Triphondurchgesetzt haben.
9.2. GRAMMATIKALISCHE SPRACHMODELLIERUNG
Wenn nicht nur einzelne Worte sondern ganze Sätze erkannt werden sollen, ist es notwen-dig, auch die gesamte zulässige Satzstruktur zu beschreiben. Einfach ist das für klar begrenzte
137
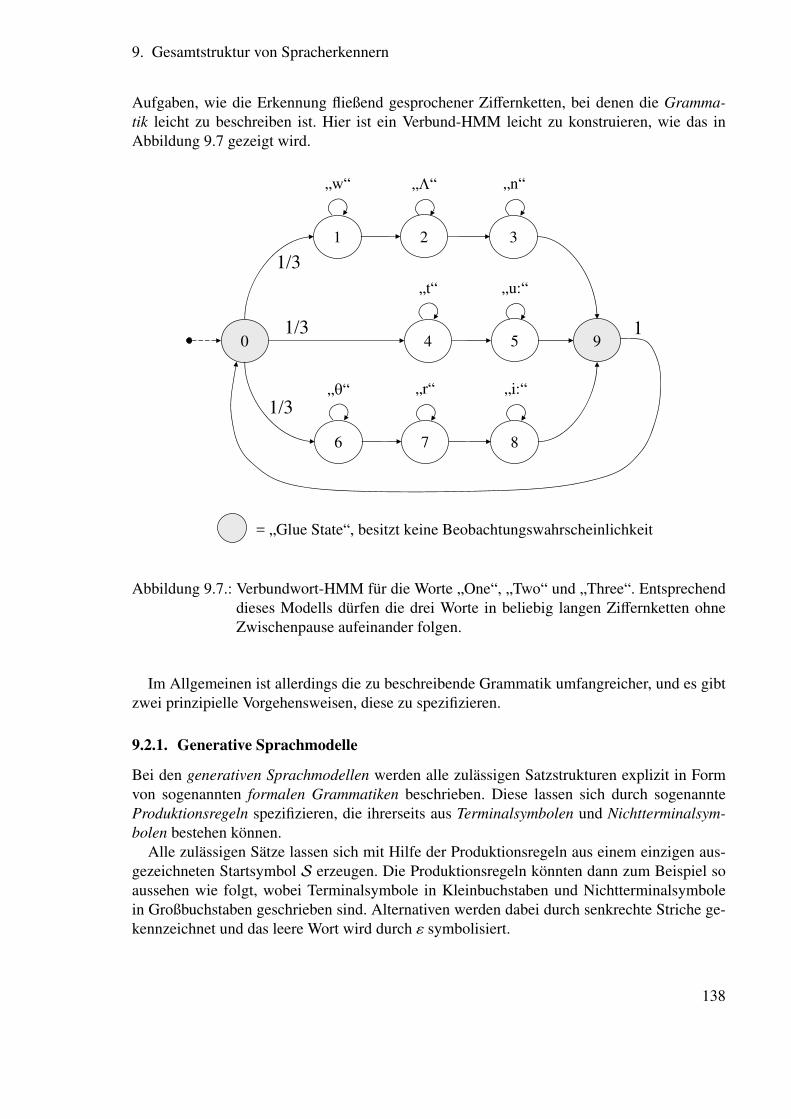
9. Gesamtstruktur von Spracherkennern
Aufgaben, wie die Erkennung fließend gesprochener Ziffernketten, bei denen die Gramma-tik leicht zu beschreiben ist. Hier ist ein Verbund-HMM leicht zu konstruieren, wie das inAbbildung 9.7 gezeigt wird.
1 32
4 5
6 87
„w“ „ “ „n“
„t“ „u:“
„r“ „i:“„ “
0
1/3
1/3
1/39
1
= „Glue State“, besitzt keine Beobachtungswahrscheinlichkeit
Abbildung 9.7.: Verbundwort-HMM für die Worte „One“, „Two“ und „Three“. Entsprechenddieses Modells dürfen die drei Worte in beliebig langen Ziffernketten ohneZwischenpause aufeinander folgen.
Im Allgemeinen ist allerdings die zu beschreibende Grammatik umfangreicher, und es gibtzwei prinzipielle Vorgehensweisen, diese zu spezifizieren.
9.2.1. Generative Sprachmodelle
Bei den generativen Sprachmodellen werden alle zulässigen Satzstrukturen explizit in Formvon sogenannten formalen Grammatiken beschrieben. Diese lassen sich durch sogenannteProduktionsregeln spezifizieren, die ihrerseits aus Terminalsymbolen und Nichtterminalsym-bolen bestehen können.
Alle zulässigen Sätze lassen sich mit Hilfe der Produktionsregeln aus einem einzigen aus-gezeichneten Startsymbol S erzeugen. Die Produktionsregeln könnten dann zum Beispiel soaussehen wie folgt, wobei Terminalsymbole in Kleinbuchstaben und Nichtterminalsymbolein Großbuchstaben geschrieben sind. Alternativen werden dabei durch senkrechte Striche ge-kennzeichnet und das leere Wort wird durch ε symbolisiert.
138

9. Gesamtstruktur von Spracherkennern
• S → SUBJECT VERB OBJECT
• SUBJECT→ she | a burglar | our dog
• VERB→ ate | hid | stole | brought | understood
• OBJECT→ the cake | my time | the portfolio | ε.
Mit dieser Grammatik könnte man also Sätze wie „Our dog ate the cake“, „She understood“und auch viel Sinnloses erzeugen.
Als weiteres Beispiel sind auch die Ziffernketten, bestehend aus bis zu sieben Ziffern, ausder TI-Digits-Datenbank leicht zu spezifizieren. Dies sähe dann folgendermaßen aus:
• S → N | N N | N N N | N N N N | N N N N N | N N N N N N | N N N N N N N
• N→ one | two | three | four
• N→ five | six | seven | eight
• N→ nine | oh | zero.
Eine solche generativen Grammatiken liefert eine überschaubare Struktur für mögliche Sät-ze, die dann bei der Erkennung zum Beispiel in der Erzeugung von den jeweils passendenVerbund-HMMs berücksichtigt werden kann.
Wenn Dialogsysteme spezifiziert werden müssen, kann je nach Kontext die Grammatik um-geschaltet werden. So kann beispielsweise bei der automatischen Buchung von Zugreisen zu-erst eine Grammatik für die Angabe des Zielortes, dann eine für die Klärung der Uhrzeit undzum Schluss eine für die Zahlungsabwicklung verwendet werden.
9.2.2. Probabilistische Sprachmodelle
Probabilistische Sprachmodelle beschreiben, mit welcher Wahrscheinlichkeit eine Wortkettein der gegebenen Sprache entstehen kann. Dazu kann man ganz allgemein die Wahrschein-lichkeit einer Wortkette aus N Worten W = W(1) . . .W(N) zerlegen in
P(W
)= P (W(1)) P (W(2)|W(1)) P (W(3)|W(2),W(1)) . . . P (W(N)|W(1) . . .W(N − 1)) . (9.1)
Natürlich ist es unrealistisch, statistische Modelle zu entwickeln für die Wahrscheinlichkeitenbeliebig langer Wortketten. Wenn beispielsweise ein Vokabular von 10000 Worten angestrebtist, wären es für 10 Worte lange Ketten schon 10.00010 = 1040 verschiedene Wortketten,deren relative Häufigkeiten man in einer Trainingsphase lernen müsste. Daher werden nurModelle für die statistische Häufigkeitsverteilung kürzerer Wortketten gelernt. Drei Variantensind häufig anzutreffen:
• Unigram-Modelle
• Bigram-Modelle und
139

9. Gesamtstruktur von Spracherkennern
• Trigram-Modelle.
Bei Unigram-Modellen modelliert man nur die Häufigkeit einzelner Worte, man ersetzt alsoden exakten Ausdruck 9.1 durch
P(W
)≈ P (W(1)) · P (W(2)) · P (W(3)) . . . · P (W(N)) .
Die Tatsache, dass die TI-Digits maximal 7 Worte lang sind, lässt sich hiermit also nichtbeschreiben, dafür wird die Grammatik leicht zu spezifizieren, denn alles was nötig ist, istdie Wortwahrscheinlichkeit für jedes Wort W1 . . .W11 aus dem Wortschatz. Die dazugehörigeUnigram-Grammatik wäre also:
P(W) =
N∏n=1
P (W(n))
und man wählt wegen der Gleichverteilung der Ziffern P(Wi) = 111 . Wenn entsprechend dieses
Sprachmodells ein Verbund-HMM konstruiert wird, erhält man das Modell, das in Abbil-dung 9.7 gezeigt wurde, erweitert auf alle 11 Ziffern der TI-Digits.
Im Gegensatz zu den Unigrammen wird bei den Bigrammen und den Trigrammen auch dieunmittelbare Vergangenheit berücksichtigt, deswegen benötigt ein Bigram-Modell die Wahr-scheinlichkeiten aller Wortpaare und ein Trigram-Modell braucht alle Tripel-Wahrscheinlich-keiten P(W(n)|W(n − 1),W(n − 2)).
Damit kann dann beispielsweise für Bigramme die Gleichung 9.1 durch
P(W
)≈ P (W(1)| < s >)·P (W(2)|W(1))·P (W(3)|W(2)) . . .·P (W(N)|W(N − 1)) P (< \s > |W(N))
vereinfacht werden, wobei < s > und < \s > als Symbole für Satzanfang und Satzende stehen,und vorne und hinten an den Wortstring W angehangen werden.
140

10. Ausblick auf weitere Themen
Die Struktur, die in den letzten Veranstaltungen für die Erkennung von Sprachsignalen vorge-stellt wurde, ist bereits oben in Abbildung 9.1 zu sehen. Verbesserungen dieser Grundstruktursind auf viele Arten möglich. Je nach Anwendung benötigt man effizientere Suchstrategien,optimierten Speicherplatzbedarf und Rechenaufwand oder robustere Erkennungsergebnisse.
10.1. EFFIZIENTE SUCHSTRATEGIEN
Um die Suche effizienter zu gestalten, kann man:
• mit Sprachmodellen wie oben beschrieben die mögliche Abfolge von Worten einschrän-ken,
• die Anzahl von Pfaden, die der Viterbi-Algorithmus sucht, einschränken, zum Beispielindem man alle Pfade kappt, deren Wahrscheinlichkeit unter einen bestimmten Wertgesunken ist (Pruning) oder
• statt des Viterbi-Algorithmus andere Suchverfahren, z. B. Token Passing oder andereVerfahren in Anlehnung an den A∗-Algorithmus, einsetzen.
10.2. RECHENZEIT- UND SPEICHERPLATZÜBERLEGUNGEN
Um gleichzeitig Rechenzeit und Speicherplatz zu sparen, ist Vektorquantisierung geeignet.Diese muss keine Auswertungen von Gaußfunktionen sondern stattdessen nur Tabellen-Look-ups durchführen. Alternativ oder zusätzlich ist es interessant, mit Hilfe einer Principal Com-ponent Analysis (PCA) oder der Linear Discriminant Analysis (LDA) die Dimension der Fea-tures nach der Feature Extraction zu reduzieren.
10.3. ROBUSTE SPRACHERKENNUNG
Für Ergebnisse, die auch gegenüber Störgeräuschen und Nachhall robust sind, gibt es fünfAnsätze, die auch in Abbildung 10.1 gezeigt sind:
• man kann eine Vorverarbeitung einsetzen, die beispielsweise aus einem Beamformer,einer Störsignalunterdrückung oder Independent Component Analysis (ICA) bestehenkann,
• man kann aus der Vorverarbeitung auch Informationen über den Grad der Sicherheitoder Unsicherheit bestimmter Features gewinnen, die dann zur sogenannten MissingFeature Erkennung verwendet werden kann,
141

10. Ausblick auf weitere Themen
• man kann besonders robuste Features zur Erkennung benutzen. Dazu haben sich in denletzten Jahren gehörorientierte Feature-Extraction-Stufen als nützlich erwiesen und diezusätzliche Einbeziehung von visuellen Merkmalen ist ein aktuelles Forschungsthema.
• man kann das Training mit möglichst vielen, unterschiedlich gestörten Sprachdatendurchführen (Multi-Condition-Training), und
• man kann die Erkennungsmodelle zur Laufzeit adaptieren. Dies ist besonders nützlich,wenn „ge-labelte“ Adaptionsdaten vorhanden sind, bei denen bekannt ist, welche Wortegesprochen wurden.
Robuste
Feature
Extraction
HMM-Struktur+
Parameter l
Robustes
Pattern
Matching
HMMs
Parameter l
Multi-
Condition
Training
W1...Wn
Sprach-
signal
s(k)
Features
ot
Vorver-
arbeitung
Referenz-
transkription
Adaption
Zusatzinfo:
Information über
Unsicherheit der
extrahierten Features
Abbildung 10.1.: Strategien zur robusten Spracherkennung.
142

A. Anhang
143

A. Anhang
A.1. HERLEITUNG DES MAXIMUM-LIKELIHOOD-KLASSIFIKATORS
Wenn als Risikofunktionci j =
1P(i)
(1 − δi j)
benutzt wird, ist der Erwartungswert der Kostenfunktion ci j
R j(x) = E(ci j)
=
N∑i=1
ci jP(i|x)
=
N∑i=1
1P(i)
(1 − δi j)P(i|x)
=
N∑i=1,i, j
P(i|x)P(i)
=
N∑i=1
P(i|x)P(i)
−P( j|x)P( j)
.
Dieser letzte Term kann mit dem Satz von Bayes umgeformt werden:
R j(x) =
N∑i=1
P(i|x)P(i)
−P( j|x)P( j)
=
N∑i=1
P(x|i)P(i)P(i)P(x)
−P(x| j)P( j)P( j)P(x)
=
N∑i=1
P(x|i)P(x)
−P(x| j)P(x)
=1
P(x)
N∑i=1
P(x|i) − P(x| j). (A.1)
Weil P(x) durch die Wahl der Klasse j nicht beeinflusst wird, kann man auch statt (A.1) gleich
R j(x) ∝N∑
i=1
P(x|i) − P(x| j)
optimieren. Und weil auch die ganze Summe∑N
i=1 P(x|i) von j unabhängig ist, wird die Risi-kofunktion R j minimal, wenn man
jopt = arg maxj
P(x| j)
wählt, was genau die Klassifikationsregel der Maximum-Likelihood-Methode ist.
144

A. Anhang
A.2. HERLEITUNG DES MAXIMUM-LIKELIHOOD-SCHÄTZERS FÜRMEHRERE BEOBACHTUNGEN
Im Normalfall werden nicht nur einer sondern mehrere Featurevektoren x1 . . . xN in die Maximum-Likelihood-Schätzung einbezogen. Die oben gezeigte Rechnung ist dann nicht mehr so leichtdurchzuführen, da die Likelihood-Funktion
p(x1, x2 . . . xN |µ) =
N∏i=1
N(xi, µ, σ)
=
N∏i=1
1√
2πσe−
(xi−µ)2
2σ2
nach µ abgeleitet werden müsste. Hier ist es einfacher, stattdessen die logarithmierte Like-lihood log p(x1, x2 . . . xN |µ) zu benutzen, denn es ganz allgemein gilt:
arg maxx
F(x) = arg maxx
log F(x)
(da der Logarithmus eine streng monoton steigende Funktion ist). Deswegen können die Pa-rameter auch geschätzt werden mit
µ = arg maxµ
p(x|µ)
= arg maxµ
log p(x|µ).
Nun ist
log p(x|µ) = logN∏
i=1
1√
2πσe−
(xi−µ)2
2σ2
= log(
1√
2πσ
)N
+ logN∏
i=1
e−(xi−µ)2
2σ2
= log(
1√
2πσ
)N
+
N∑i=1
log e−(xi−µ)2
2σ2
= N log1√
2πσ−
N∑i=1
(xi − µ)2
2σ2 . (A.2)
Um die Maximum-Likelihood-Schätzung µ zu finden, muss Gleichung A.2 nach µ abgeleitetund zu Null gesetzt werden. Die Ableitung ist
δ
δµlog p(x|µ) =
δ
δµ
N log1√
2πσ−
N∑i=1
(xi − µ)2
2σ2
=
δ
δµ
− N∑i=1
(xi − µ)2
2σ2
=
N∑i=1
xi − µ
σ2 . (A.3)
145

A. Anhang
Damit das Maximum erreicht wird, muss Gleichung A.3 zu Null werden, muss also
N∑i=1
xi − µ
σ2!= 0
gelten, weswegen
1σ2
N∑i=1
xi − µ = 0
N∑i=1
xi −
N∑i=1
µ = 0
⇒
N∑i=1
xi =
N∑i=1
µ
⇒
N∑i=1
xi = Nµ
auch gelten muss. Daraus erhält man schließlich für den Maximum-Likelihood-Schätzer
µ =
∑Ni=1 xi
N,
was der Mittelwert aller Datenpunkte ist. Auf die gleiche Art, allerdings aufwändiger, lässtsich auch der Maximum-Likelihood-Schätzer σ für die Varianz herleiten.
146

A. Anhang
A.3. HERLEITUNG DES SNR
Das SNR ist definiert als
SNRquant = 10 logσ2
x
σ2q
(A.4)
Die Störsignalvarianz σ2q erhält man als
σ2q = E
((sq − s)2)
wobei s das Sprachsignal und sq die quantisierte Version davon ist. Es gibt bei gleichmäßi-ger Mid-Rise Quantisierung 2B Quantisierungsstufen, die bei einer maximal quantisierbarenSignalamplitude smax die Breite
∆ =2smax
2B (A.5)
haben. Nimmt man an, dass der Fehler innerhalb einer Quantisierungsstufe gleichverteilt ist,dann erhält man als Varianz aus
σ2q = E
((sq − s)2) def
= E(e2)
=
∫ ∆/2
−∆/2e2p(e)de
=1∆
∫ ∆/2
−∆/2e2de
den Ausdruck
σ2q =
∆2
12.
Aus (A.5) ergibt sich also
σ2q =
s2max
3 · 22B
und deswegen ist entsprechend der Definition (A.4) das SNR
SNRquant = 10 log3 · 22Bσ2
x
s2max
≈ 4, 77 + 2B · 10 log 2 − 20 logsmax
σx
≈ 4, 77 + 6, 02B − 20 logsmax
σx.
147

A. Anhang
A.4. VERHÄLTNIS ZWISCHEN DFT UND DCT
A.4.1. Definition der DCT
Die DCT eines Signals x(t) ist definiert als
XDCT(k) =
1√
N
∑N−1m=0 x(m) für k = 0,√
2N
∑N−1m=0 x(m) cos (2m+1)kπ
2N für 1 ≤ k ≤ N − 1.
Eine andere Definition, bei der die Ergebnisse anders skaliert sind, sowohl absolut als auchrelativ zueinander, aber die gleichen Eigenschaften besitzen, wurde von Makhoul in [Mak80]beschrieben und eignet sich gut zur Herleitung der Frequenzbereichseigenschaften der Dis-kreten Kosinustransformation. Sie lautet:
XDCT(k) = 2N−1∑m=0
x(m) cos(2m + 1)kπ
2N. (A.6)
Hiermit analysiert man also die Zeitbereichssequenz x(m) und gelangt so in den Frequenz-bereich mit der diskreten Frequenzvariablen k.
A.4.2. Definition der erweiterten Sequenz
Um zu untersuchen, welche Eigenschaften diese Transformation hat, definiert man zuerst eineSequenz
x2(m) =
x(m) für m = 0, 1 . . .N − 1,x(2N − m − 1) für m = N,N + 1 . . . 2N − 1.
Diese Sequenz ist eine symmetrische Ergänzung von x um den Punkt x(N − 1/2), wie Abbil-dung A.1 zeigt.
A.4.3. DFT der symmetrischen Erweiterung
Die DFT eines Zeitsignals y(n) ist definiert als
YDFT(k) =
N−1∑m=0
y(n)e− j 2πnkN
(für die Herleitung, siehe Abschnitt 7.4.1).Wenn man hier die Sequenz x2(m) analysiert, die von m = 1 bis 2N − 1 läuft, dann erhält
man
X2,DFT(k) =
2N−1∑m=0
x2(m)e− j 2πmk2N .
Mit der DefinitionWA = e− j 2π
A (A.7)
148
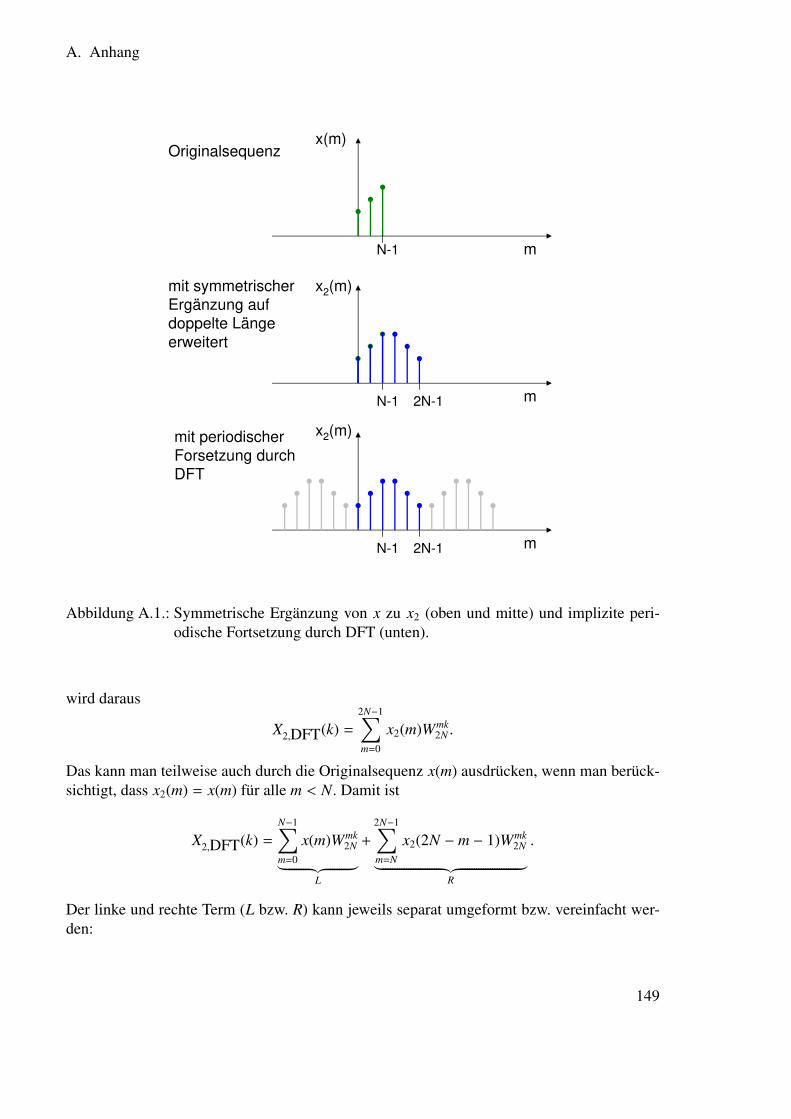
A. Anhang
x(m)
x2(m)
x2(m)mit periodischer
Forsetzung durch
DFT
Originalsequenz
mit symmetrischer
Ergänzung auf
doppelte Länge
erweitert
m
m
m
N-1
N-1 2N-1
N-1 2N-1
Abbildung A.1.: Symmetrische Ergänzung von x zu x2 (oben und mitte) und implizite peri-odische Fortsetzung durch DFT (unten).
wird daraus
X2,DFT(k) =
2N−1∑m=0
x2(m)Wmk2N .
Das kann man teilweise auch durch die Originalsequenz x(m) ausdrücken, wenn man berück-sichtigt, dass x2(m) = x(m) für alle m < N. Damit ist
X2,DFT(k) =
N−1∑m=0
x(m)Wmk2N︸ ︷︷ ︸
L
+
2N−1∑m=N
x2(2N − m − 1)Wmk2N︸ ︷︷ ︸
R
.
Der linke und rechte Term (L bzw. R) kann jeweils separat umgeformt bzw. vereinfacht wer-den:
149

A. Anhang
L =
N−1∑m=0
x(m)Wmk2N
=
N−1∑m=0
x(m)W−k/22N Wk/2
2N Wmk2N
= W−k/22N
N−1∑m=0
x(m)Wk/22N Wmk
2N .
Bei dem rechten Term kann man eine Substitution der Variablen vornehmen. Dazu definiertman
m = 2N − m − 1,
sodassm = 2N − m − 1.
Mit dieser neuen Variablen wird aus
R =
2N−1∑m=N
x2(2N − m − 1)Wmk2N
jetzt
R =
0∑m=N−1
x2(m)W (2N−m−1)k2N
=
N−1∑m=0
x2(m)W2Nk2N W−mk
2N W−k2N .
Wenn man berücksichtigt, dass W2Nk2N = e− j2πk = 1, wird daraus
R =
N−1∑m=0
x2(m)W−mk2N W−k
2N
=
N−1∑m=0
x2(m)W−k/22N W−mk
2N W−k2NWk/2
2N
= W−k/22N
N−1∑m=0
x2(m)W−mk2N W−k/2
2N .
Jetzt können die beiden Terme, L und R, zusammengefasst werden. Die Benennung der Lauf-variablen ist unwichtig, so kann man z. B. beide Summen auch über n laufen lassen:
X2,DFT(k) = L + R
= W−k/22N
N−1∑n=0
x(n)Wk/22N Wnk
2N + W−k/22N
N−1∑n=0
x2(n)W−nk2N W−k/2
2N .
150

A. Anhang
Weil in der rechten Summe der Index bis N − 1 läuft, gilt hier x2(n) = x(n), also ist
X2,DFT(k) = W−k/22N
N−1∑n=0
x(n)Wk/22N Wnk
2N + x(n)W−nk2N W−k/2
2N
= W−k/2
2N
N−1∑n=0
x(n)(Wk/2
2N Wnk2N + W−nk
2N W−k/22N
) .Wegen e jx + e− jx = 2 cos(x) und aufgrund der Definition von W in (A.7) ist das
X2,DFT(k) = W−k/22N
N−1∑n=0
x(n)(e−2 jπ
(k/22N
+nk2N
)+ e−2 jπ
(−k/22N
+−nk2N
))= W−k/2
2N
N−1∑n=0
x(n)(2 cos
(2πk4N
+2πnk2N
))= W−k/2
2N
N−1∑n=0
x(n)(2 cos
(kπ(2n + 1)
2N
)) .Der letzte Ausdruck entspricht der Kosinustransformation von der Ursprungssequenz x(n),wie sie in Gleichung A.6 definiert wurde, deswegen kann man auch schreiben
X2,DFT(k) = W−k/22N · XDCT(k)
= e( (2 jπk)/2
2N
)· XDCT(k)
oderXDCT(k) = e
(−
(2 jπk)/22N
)· X2,DFT(k).
Deswegen entspricht die DCT der Ursprungssequenz x(n) der DFT einer auf doppelte Längeerweiterten Sequenz x2(n), die zusätzlich noch um ein halbes Sample nach rechts verschobenist,1 sodass sie symmetrisch wird (wie man sich vorstellen kann, wenn man Abbildung A.1um ein halbes Sample nach rechts verschiebt) und sich so zur Darstellung mit symmetrischenBasisfunktionen anbietet.
1Die Multiplikation eines Signals mit e− jωT entspricht einer Zeitverschiebung um T nach rechts, bei den dis-kreten Systemen wird statt der kontinuierlichen Kreisfrequenz ω für das k-te Band die diskrete, normierteFrequenz 2πk
2N eingesetzt, mit 2N im Nenner wegen der verdoppelten Sequenzlänge.
151

A. Anhang
A.5. BEWEIS ZUM FORWARD-ALGORITHMUS
Der Forward-Algorithmus soll die Wahrscheinlichkeit einer Beobachtungssequenz berechnen,wenn das Modell mit allen Parametern λ bekannt ist. Gesucht wird also P(o1 . . . oT |λ), und zuzeigen ist hier, dass der Forward-Algorithmus dieses Ergebnis liefert.
Dafür werden die partiellen Wahrscheinlichkeiten αt(i) benötigt. Die sind definiert durch
αt(i)def= P(o1 . . . ot, xt = i|λ).
Darauf aufbauend arbeitet der Forward-Algortihmus wie folgt:
Initialisierungα1(i) = πi · bi(o1)
IterationFür alle t ≤ T
Update
αt(i) =
N∑j=1
αt−1( j)a j,i
· bi(ot)
Terminierung
P(o1 . . . oT ) =
N∑i=1
αT (i)
Zu zeigen sind dann drei Dinge:
• die Initialisierungsvorschrift muss α1(i) = P(o1, xt = i|λ) liefern,
• der Update muss korrekt sein, das heißt, wenn αt(i) = P(o1 . . . ot, xt = i|λ) bekannt ist,muss nach einem Update-Schritt als Ergebnis αt+1(i) = P(o1 . . . ot+1, xt+1 = i|λ) vorlie-gen, und
• die Terminierungsvorschrift muss das gewünschte Gesamtergebnis, P(o1 . . . oT |λ), lie-fern.
A.5.1. Kettenregel und Marginalisierung
Beide werden für alle folgenden Beweise benötigt.Die Kettenregel lautet
P(A, B) = P(A) · P(B|A).
Zusätzliches Vorwissen darf immer einbezogen werden, deswegen kann die Kettenregelauch geschrieben werden als
P(A, B|C) = P(A|C) · P(B|A,C).
152

A. Anhang
Bei der Marginalisierung wird der Satz von der totalen Wahrscheinlichkeit verwendet, also
P(A) =∑∀bi∈B
P(A|bi) · P(bi)
=∑∀bi∈B
P(A, bi).
Hier muss die Menge der bi eine Partitionierung des Ereignisraums in disjunkte Ereignissedarstellen.
A.5.2. Initialisierung
Die Initialisierungsvorschrift α1(i) = πi · bi(o1) liefert wie gewünscht P(o1, xt = i|λ), denn
P(o1, x1 = i|λ) = P(x1 = i|λ) · P(o1|x1 = i, λ) = πi · bi(o1).
A.5.3. Update
Es ist zu zeigen, dass ein Update-Schritt als Ergebnis αt+1(i) = P(o1 . . . ot+1, xt+1 = i|λ) lie-fert, wenn bisher αt( j) = P(o1 . . . ot, xt = j|λ) bekannt ist. Um das zu zeigen, wird das ge-wünschte Ergebnis αt(i) =
(∑Nj=1 αt−1( j) · a j,i
)· bi(ot) sukzessive umformuliert, bis sich die
Update-Vorschrift ergibt:
P(o1 . . . ot+1, xt+1 = i|λ) = P(o1 . . . ot, xt+1 = i|λ) · P(ot+1|o1 . . . ot, xt+1 = i, λ)= P(o1 . . . ot, xt+1 = i|λ) · P(ot+1|xt+1 = i, λ).
Aus dem Satz von der totalen Wahrscheinlichkeit folgt durch Summierung über alle möglichenN Zustände für den Zeitpunkt t
P(o1 . . . ot+1, xt+1 = i|λ) =
N∑j=1
P(o1 . . . ot, xt = j, xt+1 = i|λ)
P(ot+1|xt+1 = i, λ)
=
N∑j=1
P(o1 . . . ot, xt = j|λ) · P(xt+1 = i|o1 . . . ot, xt = j, λ)
P(ot+1|xt+1 = i, λ)
=
N∑j=1
αt( j) · P(xt+1 = i|xt = j, λ)
P(ot+1|xt+1 = i, λ)
=
N∑j=1
αt( j) · a j,i
bi(ot+1).
Das entspricht der Update-Vorschrift, sodass die Iterationen des Forward-Algorithmus eben-falls das gewünschte Ergebnis liefern.
153

A. Anhang
A.5.4. Terminierung
Gesucht ist P(o1 . . . oT |λ), der Forward-Algorithmus lieferte bisher αT (i) = P(o1 . . . oT , xT =
i|λ). Aus dem Satz von der totalen Wahrscheinlichkeit folgt:
P(o1 . . . oT |λ) =
N∑i=1
P(o1 . . . oT , xT = i|λ) =
N∑i=1
αT (i),
also die Terminierungsregel des Forward-Algorithmus. Damit ist gezeigt, dass alle Schrit-te des Algorithmus zusammen das gewünschte Ergebnis liefern, und dass
∑NxT =1 αT (xT ) =
P(o1 . . . oT |λ) ist.
154

A. Anhang
A.6. HERLEITUNG DES VORWÄRTSALGORITHMUS
Die Herleitung des Vorwärtsalgorithmus beruht auf der Definition der partiellen Wahrschein-lichkeiten αt(i). Diese lautet:
αt(i) = P(o1 . . . ot,Xt = i|λ).
Der Vorwärtsalgorithmus selbst lautet:
Initialisierungα1(i) = πi · bi(o1)
IterationFür alle t ≤ T
Update
αt(i) =
N∑j=1
αt−1( j)a j,i
· bi(ot)
Terminierung
P(o1 . . . oT ) =
N∑i=1
αT (i)
Zu zeigen ist die Korrektheit der Terminierungsgleichung
P(o1 . . . oT ) =
N∑i=1
αT (i). (A.8)
Dazu geht man in mehreren Schritten vor. Zuerst kann die Korrektheit der Initialisierung ge-zeigt werden. Zu zeigen ist dazu:
α1(i) = P(o1,X1 = i|λ) = πi · bi(o1).
Dafür kann man schreiben
P(o1,X1 = i|λ) = P(X1 = i|λ)P(o1|X1 = i, λ) = πi · bi(o1).
wobei der letzte Ausdruck aus der Definition des HMM folgt.Anschließend zeigt man, dass die Update-Gleichungen die Eigenschaft
αt(i) = P(o1 . . . ot,Xt = i|λ) beibehalten, wenn man einen Zeitschritt zu t + 1 weitergeht. Ge-sucht ist alsoP(o1 . . . ot, ot+1,Xt+1 = i|λ). Der Einfachheit halber wird „gegeben λ“ im Folgenden weggelas-sen, ist aber implizit ab jetzt in jeder Wahrscheinlichkeit dabei. Dann ist
αt+1(i) = P(o1 . . . ot, ot+1,Xt+1 = i) = P(o1 . . . ot,Xt+1 = i)︸ ︷︷ ︸1
·P(ot+1|o1 . . . ot,Xt+1 = i)︸ ︷︷ ︸2
. (A.9)
155

A. Anhang
Wegen P(A) =∑
ΩBP(A, B) gilt für Term 1:
P(o1 . . . ot,Xt+1 = i) =∑∀it
P(o1 . . . ot, it,Xt+1 = i),
wobei it die Rolle von B im Satz der totalen Wahrscheinlichkeit einnimmt. Das kann manfolgendermaßen vereinfachen:
P(o1 . . . ot,Xt+1 = i) =
N∑j=1
P(o1 . . . ot,Xt = j)P(Xt+1 = i|o1 . . . ot,Xt = j)
=
N∑j=1
αt( j)P(Xt+1 = i|Xt = j)
=
N∑j=1
αt( j)a j,i.
Der Term 2 aus Gleichung (A.9) kann auch vereinfacht werden wenn man beachtet, dass sichdie Wahrscheinlichkeit einer Beobachtung ohne Berücksichtigung der Vergangenheit nur ausdem aktuellen Zustand ergibt.2 Es ist
P(ot+1|o1 . . . ot,Xt+1 = i) = P(ot+1|Xt+1 = i) = bi(ot+1).
Diese beiden Terme können in (A.9) eingesetzt werden, so kommt man zu
P(o1 . . . ot, ot+1,Xt+1 = i) =
N∑j=1
αt( j)a j,i
· bi(ot+1),
was zu zeigen war.Schließlich bleibt zu zeigen, dass die Terminierungsberechnung zu dem korrekten Ergebnis
führt, dass also (A.8) gilt. Dazu kann man wegen des Satzes von der totalen Wahrscheinlichkeitrechnen
P(o1 . . . oT ) =
N∑i=1
P(o1 . . . oT ,Xt = i) =
N∑i=1
αT (i).
So ist zu erkennen, dass der Vorwärtsalgorithmus zum Schluss die Wahrscheinlichkeit derBeobachtungssequenz gegeben das Modell, P(o1 . . . oT |λ), berechnet, wie es sein sollte.
2Genau wie die Wahrscheinlichkeit von Xt+1 nur vom Zustand zur Zeit t abhängt, sodass oben P(Xt+1 =
i|o1 . . . ot,Xt = it) = P(Xt+1 = i|Xt = it) gerechnet werden konnte.
156

A. Anhang
A.7. HERLEITUNG DES RÜCKWÄRTSALGORITHMUS
Initialisierung: βT ( j) = 1
Rekursion: Gesucht βt−1( j) = 1 für t = T − 1 . . . 1
βT−1(i) βT (1)
βT (2)
βT (3)
1
2
3
T − 1 T
βT−1(i) = ai1b1(oT ) + ai2b2(oT ) + ai3b3(oT )
βt−1(i) = ai1b1(ot)βt(1) + . . .
βt−1(i) =∑N
j=1 ai jb j(ot)βt( j)
Abbildung A.2.: Der Rückwärtsalgorithmus berechnet mittels dynamischer Programmierungdie Wahrscheinlichkeiten βt(i) = P(ot+1, ot+2 . . . oT |Xt = i, λ).
157

A. Anhang
A.8. REESTIMATIONSGLEICHUNGEN FÜR MEHRERE SEQUENZEN
Unten zu sehen ist die Reestimationsgleichungen nach Baum-Welch, diesmal aber für dieSchätzung mit mehreren Trainingsfiles f = 1 . . . F (was den Normalfall darstellt).
Zusatzinfo:Reestimationsgleichungen für das Training mit mehrere Files f = 1 . . . F
der Länge T1 . . . TF:
µi =
∑Ff =1
∑T f
t=1 γ f ,t(i)o f ,t∑Ff =1
∑T f
t=1 γ f ,t(i)
Σi =
∑Ff =1
∑T f
t=1 γ f ,t(i)(o f ,t − µi)(o f ,t − µi)ᵀ∑Ff =1
∑T f
t=1 γ f ,t(i)
ai j =
∑Ff =1
∑T f
t=1 ξ f ,t(i, j)∑Ff =1
∑T f
t=1 γ f ,t(i)
wobei o f ,t die t-te Beobachtung im f -ten File ist und γ f ,t bzw. ξ f ,t für jedes File f separatberechnet werden.
158

A.9. LISTE DER ABKÜRZUNGEN
AKF Autokorrelationsfunktiona.s. almost surelyCMS Cepstral Mean SubtractionCRLB Cramer-Rao Lower BoundDC Direct CurrentDCT Discrete Cosine TransformDFT Discrete Fourier TransformDIN Deutsches Institut für NormungDNN Deep Neural NetworkDM Deutsche MarkEM Expectation-maximizationETSI European Telecommunications Standards InstituteFFT Fast Fourier TransformFIR Finite Impulse Responseg.d.w. genau dann, wennGSM Global System for Mobile CommunicationsHTK Hidden Markov Model ToolkitIBM International Business Machines CorporationICA Independent Component AnalysisIDFT Inverse Discrete Fourier TransformIIR Infinite Impulse ResponseIPA International Phonetic AlphabetIPA International Phonetic AssociationISO International Organization for Standardizationi.A. im AllgemeinenHMM Hidden Markov ModellLDA Linear Discriminant AnalysisLPC Linear Predictive CodingMAP Maximum-a-posterioriMAVE Minimum Absolute Value of ErrorMCE Minimum Classification ErrorMMSE Minimum Mean Square ErrorMOG Mixture of GaussiansNN Nearest NeighborNN Neural NetworkNTT Nippon Telegraph and Telephone CorporationPCA Principal Component AnalysisPr. in ProbabilityReLU Rectified Linear UnitSNR Signal to Noise RatioZDFT Zeitdiskrete Fouriertransformation

A.10. LISTE DER SYMBOLE
A Übergangsmatrix, TransitionsmatrixB Matrix der BeobachtungswahrscheinlichkeitenC Covarianzmatrixo BeobachtungsvektorR Autokorrelationsmatrixx Spaltenvektor, Featurevektor, ab Kapitel 8.2: Zustand eines Modellsxᵀ Zeilenvektor (transponierter Spaltenvektor)
ai, j Übergangswahrscheinlichkeit aus dem Zustand i in den Zustand jai, j Geschätzte Übergangswahrscheinlichkeitbi(o) Verteilungsdichte der Beobachtung o im Zustand iB Anzahl der Quantisierungsbits, Menge von BeobachtungsverteilungsdichtenE(k) Energie des k-ten FramesE(x) Erwartungswert der Zufallsvariablen xEges Summe aus dem Quantisierungsrauschen und dem ÜberlastungsfehlerEq QuantisierungsrauschenEu Überlastungsfehlerf(a) VerteilungsdichteF(a) Kumulative Verteilungsdichte: VerteilungsfunktionF0 Grundfrequenzfm Mittenfrequenzen auf der Mel-Skalaf ′m Nächstgelegene Frequenzstützstelle der FouriertransformationFmax Im Signal maximal vorkommende FrequenzFs Abtastfrequenz, Abtastrateh(t) ImpulsantwortI0 Bezugswert für die Schallintensitätspegel, Bessel-Funktion Nullter OrdnungLI SchallintensitätspegelLP Schalldruckpegelmn Mittelwert einer Zufallsvariablen nach n ExperimentenO Menge von Beobachtungenot, o(t) Beobachtung zum Zeitpunkt tp0 Referenzdruckp(a) Wahrscheinlichkeit einer kontinuierlichen Zufallsvariablen aP(a) Wahrscheinlichkeit einer diskreten Zufallsvariablen aP(A|B) Bedingte Wahrscheinlichkeit von A gegeben BP(A; B) Wahrscheinlichkeit von A mit Parameter Brss(τ) Autokorrelationsfunktion zur GrundfrequenzanalyseS Deterministische SequenzS Menge von Zuständensmax Maximal zu quantisierende Amplitudes(k) Abgetastetes Sprachsignal

A. Anhang
sq(k) Quantisierungskennlinies(t) Sprachsignal< s >, < \s > Symbole für Satzanfang und Satzende bei probabilistischen Sprachmodellent′ Verzögerungszeit im Zeitsignal, Quefrenzt Durchschnittliche Aufenthaltsdauer in einem ZustandT0 GrundperiodeTp Grundperiode eines SprachsignalsTs Abtastperiodexcep(t′) Cepstrum eines SignalsX( jω) Fouriertransformation des Signals x(t)XDCT(n) Discrete Cosine Transform (DCT) des Signals x(k)XDFT(n) Discrete Fourier Transform (DFT) des Signals x(k)Xzd( jω) Zeitdiskrete Fouriertransformation (ZDFT) des Signals x(k)w(t) FensterfunktionW( jω) Fouriertransformierte der FensterfunktionW Wortkette in probabilistischen Sprachmodellen
αt(i) Partielle Wahrscheinlichkeit, Vorwärtswahrscheinlichkeit des Vorwärtsalgorithmusβt(i) Rückwärtswahrscheinlichkeitγt(i) Zustanswahrscheinlichkeit der Baum-Welch-Reestimationδ(t) Einheitsimpuls, Impulsfolge∆xcep(t′) Ableitung des Cepstrums eines Signals∆∆xcep(t′) Zweite Ableitung des Cepstrums eines Signalsε Symbol für das leere Wort bei generativen Sprachmodellenη Lernrateθ Parametervektorλ Menge der Parameterµ Erwartungswert einer Zufallsvariablenµ Geschätzter Mittelwertξ1, ξ2 Parameter der Fensterfunktionenξt(i, j) Likelihood der Zustandsübergänge bei der Bauch-Welch-Reestimationπi Initiale Wahrscheinlichkeit des Zustands iΠ Matrix der initialen Wahrscheinlichkeitenσ,Σ Standardabweichung einer ZufallsvariablenΣ Geschätzte Kovarianzmatrixσ Standardabweichung einer Zufallsvariablenσ2 Varianz einer Zufallsvariablenσ2
q Quantisierungsrauschenergieσ2
x Nutzenergieτ Frame-Indexφt(i) Partielle Wahrscheinlichkeit des Viterbi-AlgorithmusΨt(i) Bester, direkter Vorgängerknoten des Knotens i zum Zeitpunkt tΩ Ereignisraum eines Zufallsexperiments, normierte Kreisfrequenz
161

A. Anhang
∀ Für alle∃ Es existiertO GrößenordnungN(x, µ, σ) Gaußverteilung einer Zufallsvariablen xN Menge der natürlichen ZahlenR Menge der reellen ZahlenS Startsymbol bei generativen Sprachmodellen
/a/ Notation für Phoneme[a] Notation für Phone
162

A. Anhang
A.11. LITERATURHINWEISE
[AS72] Alspach, D. ; Sorenson, H.: Nonlinear Bayesian estimation using Gaussian sumapproximations. In: IEEE Transactions on Automatic Control 17 (1972), Aug, Nr.4, S. 439–448. http://dx.doi.org/10.1109/TAC.1972.1100034. – DOI10.1109/TAC.1972.1100034. – ISSN 0018–9286
[ASWF16] Assael, Yannis M. ; Shillingford, Brendan ; Whiteson, Shimon ; Freitas, Nandode: LipNet: Sentence-level Lipreading. In: CoRR abs/1611.01599 (2016). http://arxiv.org/abs/1611.01599
[BM94] Bourlard, Herve A. ; Morgan, Nelson: Connectionist Speech Recognition: AHybrid Approach. Norwell, MA, USA : Kluwer Academic Publishers, 1994. –ISBN 0792393961
[DHS00] Duda, Richard O. ; Hart, Peter E. ; Stork, David G.: Pattern classification.Wiley, 2000 (Pattern Classification and Scene Analysis: Pattern Classification). –ISBN 9780471056690
[DPH93] Deller, John R. Jr. ; Proakis, John G. ; Hansen, John H.: Discrete Time Proces-sing of Speech Signals. 1st. Upper Saddle River, NJ, USA : Prentice Hall PTR,1993. – ISBN 0023283017
[EM84] Ephraim, Y. ; Malah, D.: Speech enhancement using a minimum-meansquare error short-time spectral amplitude estimator. In: IEEE Transacti-ons on Acoustics, Speech, and Signal Processing 32 (1984), Dec, Nr. 6, S.1109–1121. http://dx.doi.org/10.1109/TASSP.1984.1164453. – DOI10.1109/TASSP.1984.1164453. – ISSN 0096–3518
[ETS00] ETSI: Speech Processing, Transmission and Quality Aspects (STQ); Dis-tributed speech recognition; Front-end feature extraction algorithm; Com-pression algorithms / European Telecommunications Standards Institute.Version: 2000. http://www.etsi.org/deliver/etsi_es/201100_201199/201108/01.01.03_60/es_201108v010103p.pdf. 2000 (ETSI ES 201108). –Forschungsbericht
[FA82] Flickner, M. D. ; Ahmed, N.: A derivation for the discrete cosine transform. In:Proceedings of the IEEE 70 (1982), Sept, Nr. 9, S. 1132–1134. http://dx.doi.org/10.1109/PROC.1982.12439. – DOI 10.1109/PROC.1982.12439. – ISSN0018–9219
[FKS84] Fasold, W. ; Kraak, W. ; Schirmer, W.: Taschenbuch Akustik. VEB VerlagTechnik, 1984 https://books.google.de/books?id=RRI4PwAACAAJ
[GCSR03] Gelman, Andrew ; Carlin, John B. ; Stern, Hal S. ; Rubin, Donald B.: BayesianData Analysis, Second Edition. Taylor & Francis, 2003 (Chapman & Hall/CRCTexts in Statistical Science). – ISBN 9781420057294
163

A. Anhang
[JB03] Jaynes, E.T. ; Bretthorst, G.L.: Probability Theory: The Logic of Science.Cambridge University Press, 2003 https://books.google.de/books?id=tTN4HuUNXjgC. – ISBN 9780521592710
[JKUL] http://www.stochastik.jku.at/Kurs_Stochastik/
[JW69] Jenkins, G.M. ; Watts, D.G.: Spectral analysis and its applications. Holden-Day,1969 (Holden-Day series in time series analysis)
[Kay93] Kay, Steven M.: Fundamentals of Statistical Signal Processing Volume I: Esti-mation Theory. Upper Saddle River, NJ, USA : Prentice-Hall, Inc., 1993. – ISBN0133457117
[Köh05] Kohler, B.U.: Konzepte der statistischen Signalverarbeitung. Springer BerlinHeidelberg, 2005 https://books.google.de/books?id=j4kuBAAAQBAJ. –ISBN 9783540275091
[LPH90] Levitt, Harry ; Pickett, James H. ; Houde, Robert A.: Sensory Aids for theHearing Impaired. New York : IEEE Press, 1990 (IEEE Press Selected ReprintSeries)
[Mak80] Makhoul, J.: A fast cosine transform in one and two dimensions. In: IEEE Tran-sactions on Acoustics, Speech, and Signal Processing 28 (1980), February, Nr.1, S. 27–34. http://dx.doi.org/10.1109/TASSP.1980.1163351. – DOI10.1109/TASSP.1980.1163351. – ISSN 0096–3518
[MS08] Mehlhorn, Kurt ; Sanders, Peter: Algorithms and Data Structures: The Ba-sic Toolbox. 1. Springer Publishing Company, Incorporated, 2008. – ISBN9783540779773
[Nol67] Noll, A. M.: Cepstrum Pitch Determination. In: The Journal of the AcousticalSociety of America 41 (1967), 03, Nr. 2, 293-309. http://dx.doi.org/10.1121/1.1910339. – DOI 10.1121/1.1910339
[OS04] Oppenheim, A. V. ; Schafer, R. W.: From frequency to quefrency: a historyof the cepstrum. In: IEEE Signal Processing Magazine 21 (2004), Sept, Nr.5, S. 95–106. http://dx.doi.org/10.1109/MSP.2004.1328092. – DOI10.1109/MSP.2004.1328092. – ISSN 1053–5888
[Pap04] Papamichalis, Panos: Lecture Notes zu „Digital Speech Processing“.Version: 2004. http://engr.smu.edu/ee/8373/lectures09-11.pdf
[PHG00] Pearce, David ; Hirsch, Hans günter ; Gmbh, Ericsson Eurolab D.: The AuroraExperimental Framework for the Performance Evaluation of Speech RecognitionSystems under Noisy Conditions. In: in ISCA ITRW ASR2000, 2000, S. 29–32
164

A. Anhang
[Rab89] Rabiner, L. R.: A tutorial on hidden Markov models and selected applicationsin speech recognition. In: Proceedings of the IEEE 77 (1989), Feb, Nr. 2, S.257–286. http://dx.doi.org/10.1109/5.18626. – DOI 10.1109/5.18626.– ISSN 0018–9219
[Ros97] Ross, Sheldon M.: Introduction to Probability Models. Academic Press, 1997
[RS75] Rabiner, Lawrence R. ; Sambur, Marvin R.: An Algorithm for Determiningthe Endpoints of Isolated Utterances. In: Bell System Technical Journal 54(1975), Nr. 2, 297-315. http://dx.doi.org/10.1002/j.1538-7305.1975.tb02840.x. – DOI 10.1002/j.1538–7305.1975.tb02840.x. – ISSN 1538–7305
[Sch93] Schmidt, (Hrsg.) Robert F.: Neuro- und Sinnesphysiologie. Springer-Verlag, 1993
[TYRW14] Taigman, Y. ; Yang, M. ; Ranzato, M. ; Wolf, L.: DeepFace: Closing the Gap toHuman-Level Performance in Face Verification. In: 2014 IEEE Conference onComputer Vision and Pattern Recognition, 2014. – ISSN 1063–6919, S. 1701–1708
[UU04] Universitat Ulm, Abteilung S.: Vorlesungsskript: Wahrscheinlichkeitsrechnung.Version: 05 2004. http://www.mathematik.uni-ulm.de/stochastik/lehre/ws03_04/wr/skript/
[Vas96] Vaseghi, Saeed V.: Advanced signal processing and digital noise reduction. Teub-ner, 1996
[VHH98] Vary, Peter ; Heute, Ulrich ; Hess, Wolfgang: Digitale Sprachsignalverarbei-tung: mit 30 Tabellen. Teubner, 1998 https://books.google.de/books?id=Rmpp91y5ZEIC. – ISBN 9783519061656
[XDH+16] Xiong, Wayne ; Droppo, Jasha ; Huang, Xuedong ; Seide, Frank ; Seltzer, Mike; Stolcke, Andreas ; Yu, Dong ; Zweig, Geoffrey: Achieving Human Parity inConversational Speech Recognition. In: CoRR abs/1610.05256 (2016). http://arxiv.org/abs/1610.05256
[YEK+02] Young, Steve ; Evermann, Gunnar ; Kershaw, Dan ; Moore, Gareth ; Odell,Julian ; Ollason, Dave ; Povey, Dan ; Valtchev, Valtcho ; Woodland, Phil: TheHTK Book. 3.2. Cambridge University Engineering Department, 2002 http://htk.eng.cam.ac.uk/prot_docs/htk_book.shtml
[ZF99] Zwicker, Eberhard ; Fastl, Hugo: Psychoacoustics - Facts and Models. SpringerScience& Business Media, 1999
[ZHW93] Zeppenfeld, T. ; Houghton, R. ; Waibel, A.: Improving the MS-TDNN for wordspotting. In: 1993 IEEE International Conference on Acoustics, Speech, and Si-gnal Processing Bd. 2, 1993. – ISSN 1520–6149, S. 475–478 vol.2
165





























