Embed Size (px)
Citation preview

1
Architecture of Parallel Computer Systems WS15/16 J.Simon 1
Topologie: Fetter Baum (Fat-Tree)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
• n Knoten, logkn Level• Schalter mit Grad 2k: je k Verbindung in Level i-1 und in Level i+1• Jeder Level mit n/k Schaltern
• Beispiel: k=2 Level
5
4
3
2
1
Architecture of Parallel Computer Systems WS15/16 J.Simon 2
Bewertung: Fat-Tree
• Fat-Tree/Clos– „Baum“ mit n Knoten und n/2 logkn Schaltern– Grad = 2k– Durchmesser = 2 logkn - 1– Kantenkonnektivität = k– Bisektionsbreite = n/2– Eigenschaften:
• Dynamisches Netzwerk, mehrstufig• Auch einstufige Variante mit logkn Durchläufen
möglich

2
Architecture of Parallel Computer Systems WS15/16 J.Simon 3
Topologie: Omega-Netzwerk
• Schalter <w,l> ist mit Schalter <wlcs,l+1> und <wlcsbf,l+1> verbunden, wobei wlcs durch left cyclic shift aus w entsteht und wlcsbf aus wlcs mit zusätzlichem bit flip des letzten Bits entsteht
• eindeutiger Pfad von jedem Eingang zu jedem Ausgang
0123456789101112131415
0123456789101112131415
<000,0> <000,1> <000,2> <000,3>
<001,3><001,2><001,1><001,0>
<111,3><111,2><111,1><111,0>
<010,2>
<011,2>
Architecture of Parallel Computer Systems WS15/16 J.Simon 4
Bewertung: Omega-Netzwerk
• Omega-Netzwerk– n Knoten, (n/2) log2n Crossbars– Grad = 2 (Crossbars mit Grad 4)– Durchmesser = log2n– Kantenkonnektivität = 2– Bisektionsbreite = n/2– Eigenschaften:
• Dynamisches Netzwerk, mehrstufig• Auch einstufige Variante mit log2n Durchläufen
möglich

3
Architecture of Parallel Computer Systems WS15/16 J.Simon 5
Topologie: Clos
• kleine Gruppen aus Knoten lokal vernetzbar mit kurzen Verbindungen
• gut im Raum platzierbar, wenige kreuzende Verbindungen
0123456789101112131415
0123456789101112131415
Architecture of Parallel Computer Systems WS15/16 J.Simon 6
Butterfly
Pro– konstanter Knotengrad (= 4)– logarithmischer Durchmesser
Cons– Erweiterbarkeit nur in bestimmten Größen (d 2d)
Butterfly der Dimension 3 - Bn(3)
0 1 2 3
2-nary 4-fly
4
Architecture of Parallel Computer Systems WS15/16 J.Simon 7
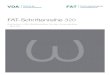
Zusammenfassung der EigenschaftenAnzahl Knoten
Anzahl Kanten
maximaler Knotengrad
Durch-messer
Bisektions-weite
Clique
Ring
GitterG(a1x a2...x ad)
TorusT(a1x a2...x ad)
Fat-Treelevel l, switch 2k
HypecubeHQ(d)
Omega(d)
CCC(d)
Butterfly Bn(d) 12
dd
ki
i
d
kk aa
1
)1(
2
)1( nn
d
kkad
1
d
kka
1d2
d
kka
1
)1(
d
kka
1d2
d
k
ka
12
d d1
2 d
dd
2
dd 2 1
23 d
d 22 dd
n 1n 1
n n 2 2n
4
)1( nn
2
k
d
k a1min
k
d
k a1min2
12
d
12
d
d2d
dd 2
dd 2 1
2 d
d dd
2
lk k21lk12 l
lkl
3
4
4
Architecture of Parallel Computer Systems WS15/16 J.Simon 8
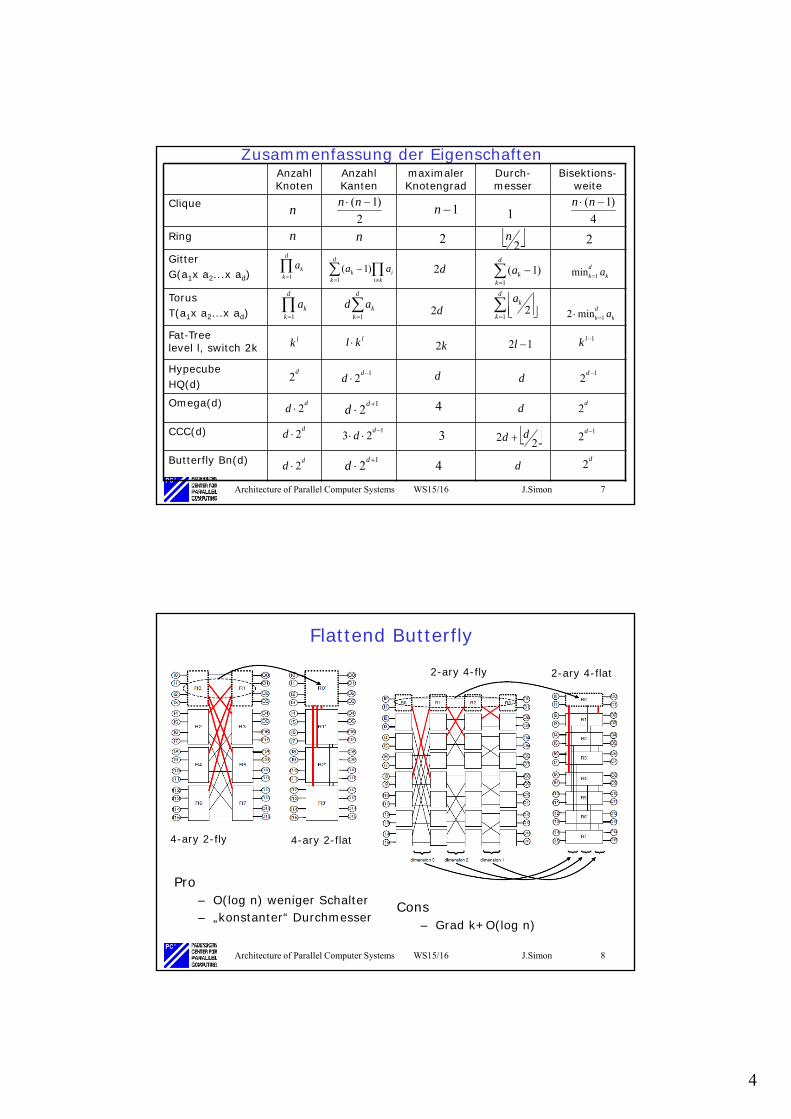
Flattend Butterfly
Pro– O(log n) weniger Schalter– „konstanter“ Durchmesser
4-ary 2-fly 4-ary 2-flat
2-ary 4-fly 2-ary 4-flat
Cons– Grad k+O(log n)
5
Architecture of Parallel Computer Systems WS15/16 J.Simon 9
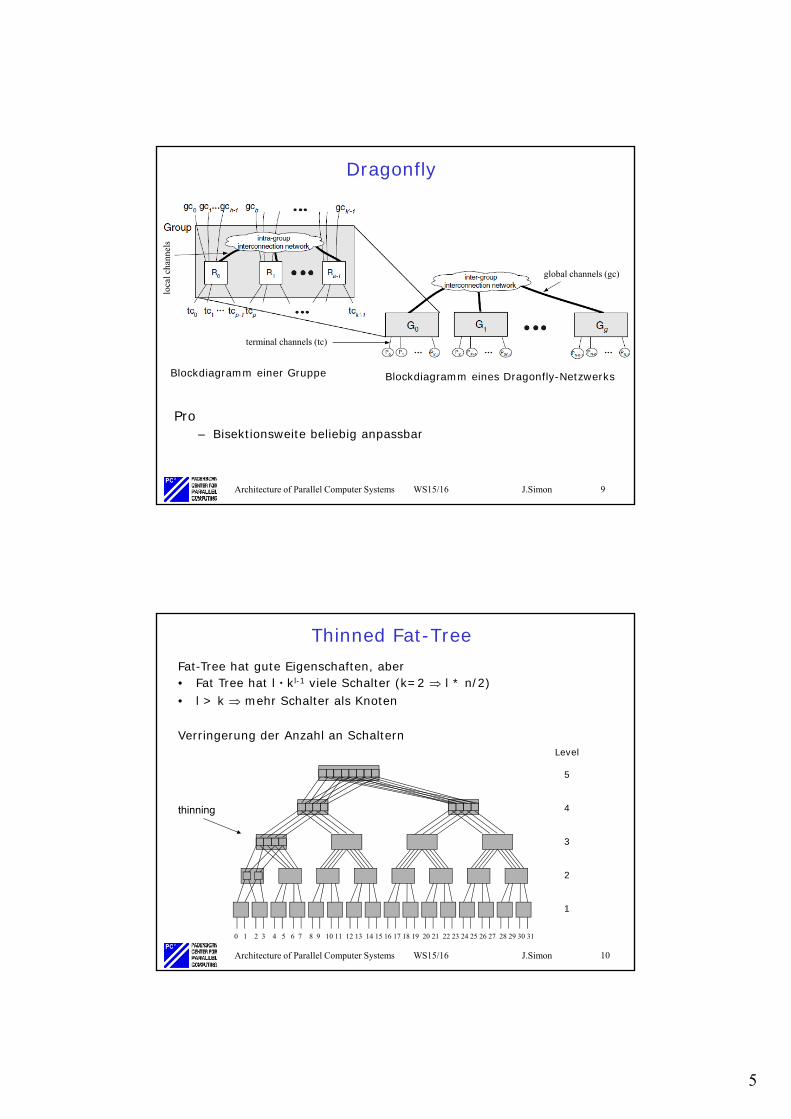
Dragonfly
Pro– Bisektionsweite beliebig anpassbar
Blockdiagramm einer Gruppe Blockdiagramm eines Dragonfly-Netzwerks
loca
lcha
nnel
s
terminal channels (tc)
global channels (gc)
Architecture of Parallel Computer Systems WS15/16 J.Simon 10
Thinned Fat-Tree
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Fat-Tree hat gute Eigenschaften, aber• Fat Tree hat l • kl-1 viele Schalter (k=2 l * n/2)• l > k mehr Schalter als Knoten
Verringerung der Anzahl an SchalternLevel
5
4
3
2
1
thinning

6
Architecture of Parallel Computer Systems WS15/16 J.Simon 11
Messbare Parameter von Netzwerken (1)
• Minimale Latenzzeit– Verzögerung einer Kommunikation– Zeit zwischen Absenden und Ankunft des Packet-Headers– Einheit: Zeit, meistens in µs – Vorgehen bei Messung:
• Ping-Pong Benchmark mit Austausch leerer Nachricht „0-Byte“
• Vorheriges „Warm-Up“ zugelassen• Für exakte Zeitmessung mehrere Iterationen durchführen• Latenzzeit = Ping-Pong-Zeit / Iter / 2
– Wenn mehr als ein Prozessorpaar gleichzeitig Ping-Pongdurchführen, dann steigt in Netzen mit kleiner Bisektionsbreitedie gemessene Latenz (network congestion).
Architecture of Parallel Computer Systems WS15/16 J.Simon 12
Messbare Parameter von Netzwerken (2)
• Maximale Bandbreite– Bestenfalls übertragbare Anzahl an Daten– Einheit: Byte pro Sekunde– Problem:
• Overhead nur bei Verwendung großer Datenpakete vernachlässigbar (O(MByte))
• Oftmals durch Protokoll bedingt nur kleine Datenpakete fester Größe möglich
– Vorgehen bei Messung:• Senden von großen Datenpaketen ohne dessen
Zurücksenden• Ping-Ping Benchmark mit Senden einer
Eingangsbestätigung– Bei mehreren Kommunikationspaaren gleichzeitig ist die
Bandbreite abhängig von der Bisektionsbreite

7
Architecture of Parallel Computer Systems WS15/16 J.Simon 13
Messbare Parameter von Netzwerken (3)
• Übertragungszeit– Übertragungszeit V ist abhängig von Größe der Nachricht– Einheit: Zeit, meistens in µs– Problem:
• Übertragungszeit nicht unbedingt proportional zu der Größe des Datenpakets
• Treppenfunktion, falls Pufferung und Fragmentierung der Nachrichten durchgeführt wird
– Vorgehen bei Messung:• Ping-Ping Benchmark mit Senden einer
Eingangsbestätigung• Verschiedene Größen an Datenpaketen messen
Architecture of Parallel Computer Systems WS15/16 J.Simon 14
Messbare Parameter von Netzwerken (4)
• Durchsatz– Bandbreite bei bestimmter Größe eines Datenpakets– Einheit: Byte pro Sekunde– Vorgehen bei Messung: siehe Übertragungszeit– Üblicherweise Diagramm (Durchsatz/Paketgröße) erstellen– „Half-Power-Point“: Bei welcher Paketgröße wird die Hälfte der
Bandbreite erreicht?

8
Architecture of Parallel Computer Systems WS15/16 J.Simon 15
Vermittlungstechnik
• Bestimmung eines Kommunikationspfades zwischen zwei Knoten, falls keine Punkt-zu-Punkt-Verbindung vorhanden
• Leitungsvermittlung (circuit switching) versus Paketvermittlung (paket switching)
• Begriffe– Routing = Wegebestimmung– Switching = Art und Weise des Datentransfers innerhalb eines
Vermittlungsknotens
Architecture of Parallel Computer Systems WS15/16 J.Simon 16
Leitungsvermittlung
• Zuerst werden Adressierungsdaten gesendet• Im Zuge der Adressdekodierung bauen die
Vermittlungsknoten einen Weg vom Sender zum Empfänderauf
• Wenn der Weg steht, dann folgen die Nutzdaten• Während der nachfolgenden Nutzdatenübertragung ist kein
weiterer Vermittlungs- oder Wegfindungsaufwand notwendig
• Expliziter Verbindungsabbau ist notwendig

9
Architecture of Parallel Computer Systems WS15/16 J.Simon 17
Paketvermittlung
• Nutzdaten werden in Pakete eingeteilt.• Jedes Paket wird mit Adressinformationen versehen
(Paketkopf) und separat verschickt• Verfahren berücksichtigt, dass Pakete verloren gehen oder
in veränderter Reihenfolge ankommen können
Architecture of Parallel Computer Systems WS15/16 J.Simon 18
Paketvermittlung: Store&Forward
• Paket wird vollständig im Vermittlungsknoten aufgenommen (store), dann analysiert, dann über den ausgewählten Ausgang weitergeleitet (forward)
• Paket ist zu einer Zeit auf höchstens zwei Knoten und eine Verbindungsleitung verteilt
• Blockierungsgefahr ist gering• Vermittlungsknoten benötigen ausreichende Pufferkapazität• Mittlere Übertragungszeit ist proportional zu Paketgröße und
Durchmesser des Netzwerks

10
Architecture of Parallel Computer Systems WS15/16 J.Simon 19
Paketvermittlung: Wormhole
• Sobald Paketkopf angekommen ist, wird entschieden, über welchen Ausgang das ganze Paket weitergegeben wird
• Ist Ausgang belegt, wird Paketrest nicht angenommen• Adresse (evtl. verkürzt/aktualisiert) verlässt ggf. den Switch
noch ehe der Paketrest empfangen worden ist• Paket ist ggf. über viele Knoten und Leitungen verteilt• In jedem Vermittlungsknoten fallen nur die kleinen Zeiten
für Adressdekodierung an• Übertragungszeit ist damit unbedeutend vom Durchmesser
des Netzwerks abhängig
Architecture of Parallel Computer Systems WS15/16 J.Simon 20
Blockierung beim Worm-Hole Routing
• Blaue Pfeile: Pakete die im Netz unterwegs sind
• Roter Pfeil: Paket kann nicht weiter vermittelt werden, weil Ausgang belegt ist

11
Architecture of Parallel Computer Systems WS15/16 J.Simon 21
Paketvermittlung: Virtual Cut-Through
• Im Unterschied zum Wormhole-Routing wird hierbei im Blockierungsfall der Paketrest empfangen und zwischengespeichert.
• Das führt tendenziell dazu, dass Blockierungen lokalen Charakter haben und sich wieder auflösen, statt zu Verklemmungen zu führen
Architecture of Parallel Computer Systems WS15/16 J.Simon 22
Paketvermittlung: Vergleich
…
…
…
…
…
…
…
…
…
…
…
…
Worm-Hole
Virtual-Cut-Through
12
Architecture of Parallel Computer Systems WS15/16 J.Simon 23
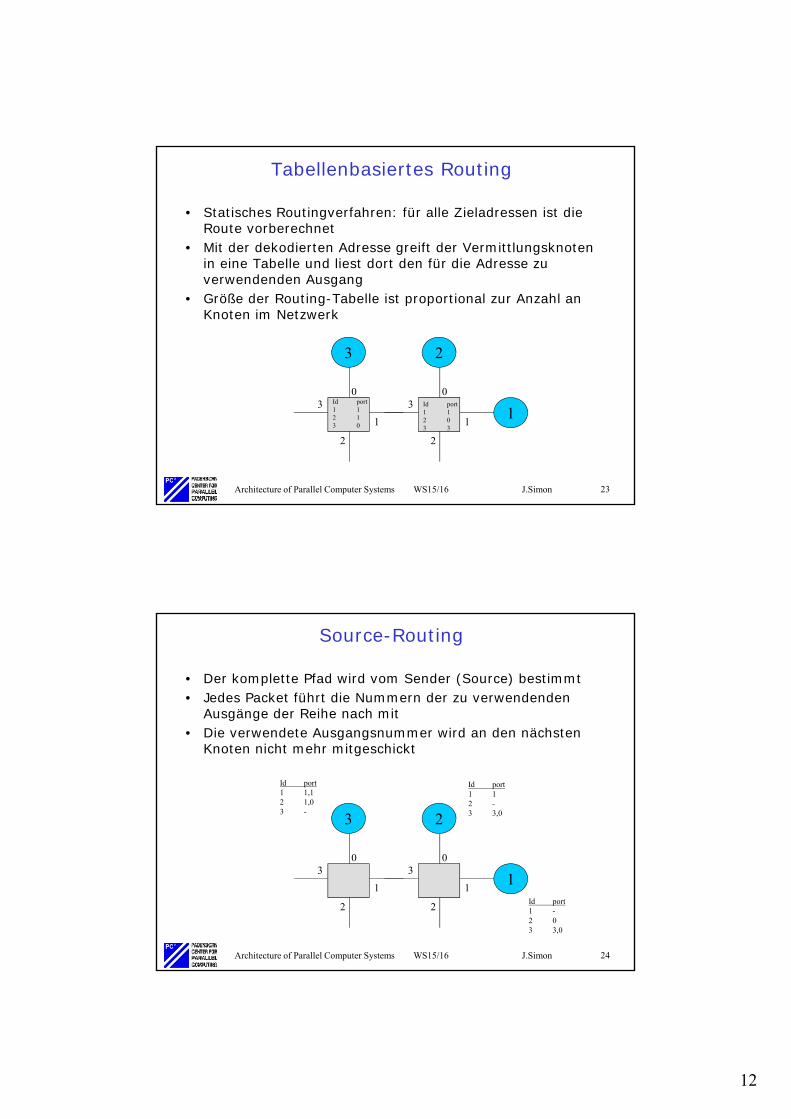
Tabellenbasiertes Routing
• Statisches Routingverfahren: für alle Zieladressen ist die Route vorberechnet
• Mit der dekodierten Adresse greift der Vermittlungsknoten in eine Tabelle und liest dort den für die Adresse zu verwendenden Ausgang
• Größe der Routing-Tabelle ist proportional zur Anzahl an Knoten im Netzwerk
0
2
1
30
2
1
31
23
Id port1 12 03 3
Id port1 12 13 0
Architecture of Parallel Computer Systems WS15/16 J.Simon 24
Source-Routing
• Der komplette Pfad wird vom Sender (Source) bestimmt• Jedes Packet führt die Nummern der zu verwendenden
Ausgänge der Reihe nach mit• Die verwendete Ausgangsnummer wird an den nächsten
Knoten nicht mehr mitgeschickt
0
2
1
30
2
1
31
23
Id port1 1,12 1,03 -
Id port1 12 -3 3,0
Id port1 -2 03 3,0

13
Architecture of Parallel Computer Systems WS15/16 J.Simon 25
Weitere Kriterien an Verbindungsnetzwerke
• Erweiterbarkeit– Netzwerk für beliebige Anzahl an Rechenknoten nutzbar– Pro Knoten beliebige Anzahl an Verbindungen ins Netzwerk
• Kosten– Annähernd konstante Kosten pro Rechenknoten, unabhängig
von der Anzahl an Knoten• Zuverlässigkeit
– Redundanz (Wege, Schalter, Interfaces)• Zusätzliche Funktionalitäten
– Verschiedene Nachrichtentransporte (Synchron, Asynchron)– Optimierungen für Gruppenkommunikation – Remote-Direct-Memory-Access (RDMA)– Dynamisch/adpative Wegewahl
Architecture of Parallel Computer Systems WS15/16 J.Simon 26
Generisches Verbindungsnetzwerk
Communication-Assistent (CA) initiiert Netzwerktransaktion
skalierbaresVerbindungsnetzwerk
CA
PMem
CA
PMem

14
Architecture of Parallel Computer Systems WS15/16 J.Simon 27
Komponenten eines Kommunikationsnetzwerks
• Netzwerkschnittstelle (Network Interface, NI)– an Prozessorknoten angeschlossen– treibt einen oder mehrere Ein-/Ausgabekanäle– einpacken und auspacken der Nachrichten in Pakete
• Verbindung (Links)– ein Bündel von Leitungen oder Fasern– Träger des physikalischen Signals
• Schalter (Switches)– Mehrere Anschlüsse für Ein- und Ausgabekanäle (Ports)– Anschluss von NICs und/oder weiteren Schaltern über Links
Architecture of Parallel Computer Systems WS15/16 J.Simon 28
Cluster-Kommunikationsnetzwerke

15
Architecture of Parallel Computer Systems WS15/16 J.Simon 29
Hochgeschwindigkeitsnetzwerk: MyriNet
• Hersteller: Myricom Inc.• PCI-x / PCI-e Netzwerkkarte mit Kommunikationsprozessor• Skalierbares Kommunikationsnetzwerk• Unterstützung von TCP/IP und MPI• Kommunikationssoftware ist Open Source• Kommunikationsleistung unter MPI
– MyriNet 2Gbit/s• Latenzzeit: 6 µs• bidir. Bandbreite: 489 MByte/s
– MyriNet 10Gbit/s• Latenzzeit: 2,67 µs• Bidirektionale Bandbreite: 2120 MByte/s
Architecture of Parallel Computer Systems WS15/16 J.Simon 30
MyriNet: Protokoll
• Wormhole Routing• Source-based Routing
– Neuberechung des CRC an jedem Knoten• Overhead
– 1 Byte Nachricht (10 Hops)=> Paketgröße 17 Byte
– 4 kByte Nachricht (10 Hops)=> Paketgröße 4112 Byte
• Flusskontrolle: STOP/GO• Bitübertragung (MyriNet 10G)
– 8bit / 10bit Kodierung– 1,25 GHz, IB4X-Kabel (8 Aderpaare)
• Keine atomare Operationen
16
Architecture of Parallel Computer Systems WS15/16 J.Simon 31
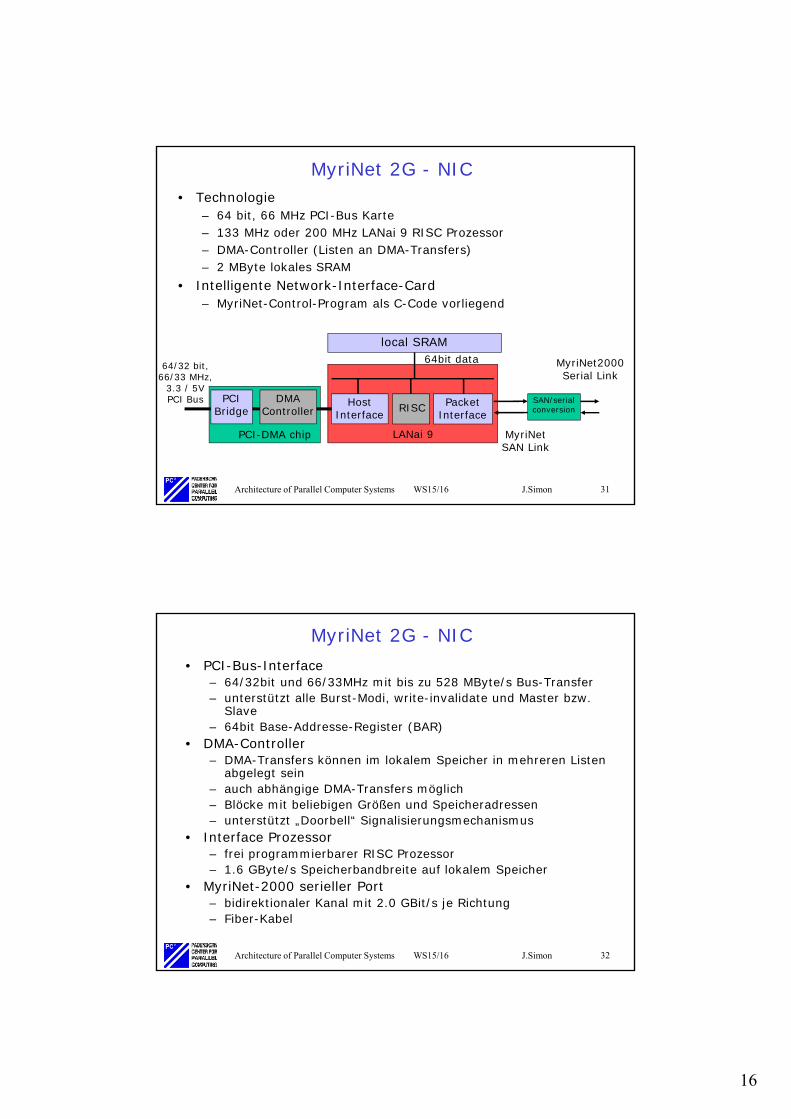
MyriNet 2G - NIC• Technologie
– 64 bit, 66 MHz PCI-Bus Karte– 133 MHz oder 200 MHz LANai 9 RISC Prozessor– DMA-Controller (Listen an DMA-Transfers)– 2 MByte lokales SRAM
• Intelligente Network-Interface-Card– MyriNet-Control-Program als C-Code vorliegend
local SRAM
LANai 9
HostInterface
PacketInterfaceRISC
PCIBridge
DMAController
SAN/serial conversion
64bit data64/32 bit,66/33 MHz,
3.3 / 5VPCI Bus
MyriNet2000Serial Link
PCI-DMA chip MyriNetSAN Link
Architecture of Parallel Computer Systems WS15/16 J.Simon 32
MyriNet 2G - NIC• PCI-Bus-Interface
– 64/32bit und 66/33MHz mit bis zu 528 MByte/s Bus-Transfer– unterstützt alle Burst-Modi, write-invalidate und Master bzw.
Slave– 64bit Base-Addresse-Register (BAR)
• DMA-Controller– DMA-Transfers können im lokalem Speicher in mehreren Listen
abgelegt sein– auch abhängige DMA-Transfers möglich– Blöcke mit beliebigen Größen und Speicheradressen– unterstützt „Doorbell“ Signalisierungsmechanismus
• Interface Prozessor– frei programmierbarer RISC Prozessor – 1.6 GByte/s Speicherbandbreite auf lokalem Speicher
• MyriNet-2000 serieller Port– bidirektionaler Kanal mit 2.0 GBit/s je Richtung– Fiber-Kabel
17
Architecture of Parallel Computer Systems WS15/16 J.Simon 33
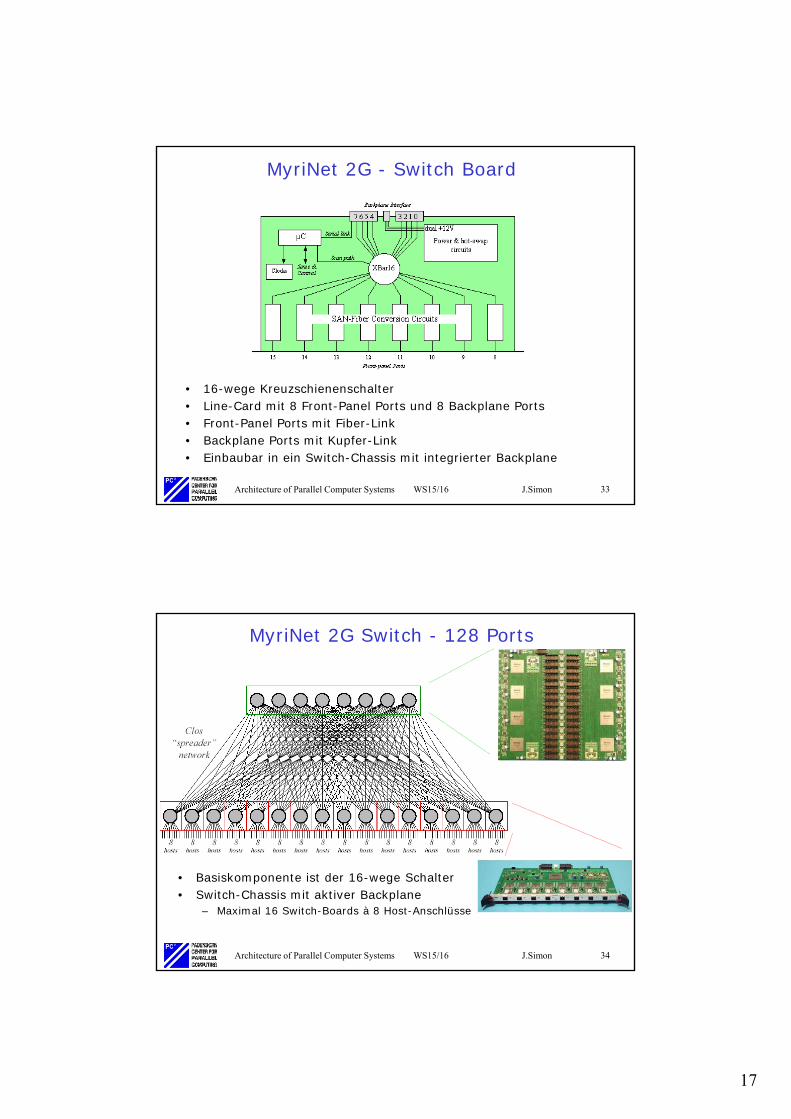
MyriNet 2G - Switch Board
• 16-wege Kreuzschienenschalter• Line-Card mit 8 Front-Panel Ports und 8 Backplane Ports• Front-Panel Ports mit Fiber-Link• Backplane Ports mit Kupfer-Link• Einbaubar in ein Switch-Chassis mit integrierter Backplane
Architecture of Parallel Computer Systems WS15/16 J.Simon 34
MyriNet 2G Switch - 128 Ports
• Basiskomponente ist der 16-wege Schalter• Switch-Chassis mit aktiver Backplane
– Maximal 16 Switch-Boards à 8 Host-Anschlüsse
18
Architecture of Parallel Computer Systems WS15/16 J.Simon 35
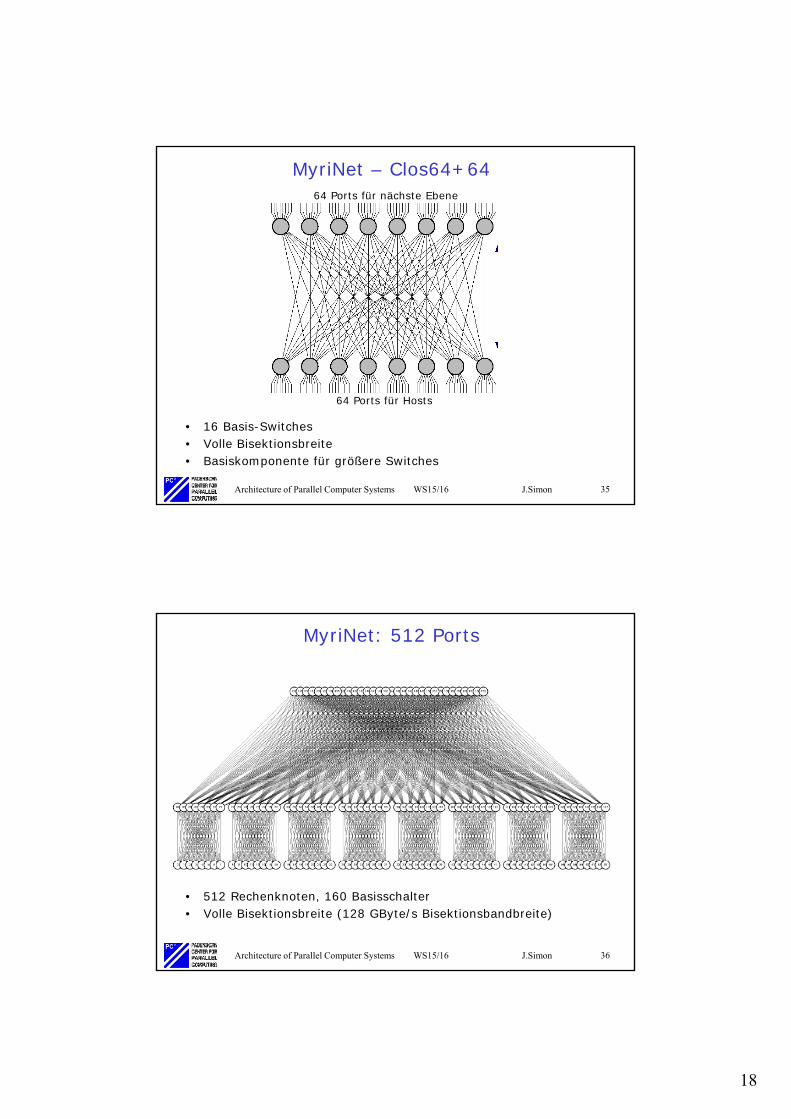
MyriNet – Clos64+64
• 16 Basis-Switches• Volle Bisektionsbreite• Basiskomponente für größere Switches
64 Ports für Hosts
64 Ports für nächste Ebene
Architecture of Parallel Computer Systems WS15/16 J.Simon 36
MyriNet: 512 Ports
• 512 Rechenknoten, 160 Basisschalter• Volle Bisektionsbreite (128 GByte/s Bisektionsbandbreite)

19
Architecture of Parallel Computer Systems WS15/16 J.Simon 37
MyriNet-10G
• PCIe Karte– 10 GBit/s Links
• X-Bar mit 32 Ports
Switches: 512 Ports, 256 Ports, 128 Ports
Architecture of Parallel Computer Systems WS15/16 J.Simon 38
Hochgeschwindigkeitsnetzwerk: QsNet
Network Adapter 128 way Switch Chassis
16 way Switch Card
Hersteller: Quadrics Ltd.

20
Architecture of Parallel Computer Systems WS15/16 J.Simon 39
Quadrics - NIC
• 100MHz IO processor• 8Kbytes on board cache• MMU with hardware
tablewalk and 16 entry TLB• DMA engine• 400Mhz byte wide LVDS link• 64 bit 66MHz PCI interface• 64Mbytes local ECC SDRAM• 0.5Mbytes flash memory
Architecture of Parallel Computer Systems WS15/16 J.Simon 40
Quadrics - Topologie
128 Rechenknoten, 80 BasisschalterVolle Bisektionsbreite

21
Architecture of Parallel Computer Systems WS15/16 J.Simon 41
QsNet III
NIC• 2 x 25 Gbit/s Links, PCIe 2.0• Kupfer oder Optik• 128 MByte lokaler Speicher
Switch-Fabric• X-Bar mit 32 Ports• 4 x 6.25 Gbit/s (2.5 GByte/s)
Fabric• Bis zu 512 Ports• Fat-Tree oder Gitter• Broadcast und Barrier
Unterstützung
Architecture of Parallel Computer Systems WS15/16 J.Simon 42
InfiniBand• NIC:
– InfiniBand 4x QDR• 40 GBit/s, PCIe2.0 8x
– InfiniBand 4x FDR• 56 Gbit/s, PCIe3 8x
– InfiniBand 4x, EDR• 100 Gbit/s, PCIe3 16x
• Switch Fabrics– X-Bar
• 36 Ports (QDR, FDR)– Virtual Cut Through mit Service-Levels und Virtual-Lanes– Table-based routing– Credit-based Flusskontrolle– Fabrics
• bis zu 864 Ports (QDR)• Multistage Clos-Netzwerk

22
Architecture of Parallel Computer Systems WS15/16 J.Simon 43
InfiniBand: Protokoll
• Paketformat– Local Route Header 8 Byte– Global Route Header 40 Byte [optional]– Base Transport Header 12 Byte– Payload: bis zu 4096 Byte– CRC: 4 Byte + 2 Byte
• Overhead– 1 Byte Nachricht => Paketgröße 27 Byte– 4 kByte Nachricht => Paketgröße 4122 Byte
• Übertragung– 8bit / 10bit Kodierung (SDR bis QDR), 64/66 encoding (FDR)– Basiert auf 1 Gbit/s Ethernet (802.3z), aber mit 2,5 Gbit/s
(SDR)
Architecture of Parallel Computer Systems WS15/16 J.Simon 44
InfiniBand: Paketformat
• Local Route Header 8 Byte– Virtual Lane: 4 bit– Link Version: 4 bit– Service Level: 4 bit– Reserved: 4 bit– LNH: 2 bit– LID: 16 bit– Reserved: 5 bit– Packet Length: 11 bit– SLID: 16 bit
• Base Transport Header– Opcode: 8 bit– Solicited Event: 1 bit– MigReq: 1bit– PCount: 2 bit– Transport Header: 4 bit– PKEY: 16
bit– Reserved: 8 bit– DQP: 24
bit– Acknowledge: 1 bit– Reserved: 7 bit– PSQ: 24
bit

23
Architecture of Parallel Computer Systems WS15/16 J.Simon 45
InfiniBand Eigenschaften
• RDMA-read und RDMA-write Operation• Atomare Operationen• Speicherzugriffsrechte durch Remote-Host geregelt
– nur Lesen– Lesen / Schreiben
• Umsetzung von virtuelle in physikalische Adressen• Zugriff auf das Netzwerk ohne Wechsel zwischen BS und
Benutzerkontext
Architecture of Parallel Computer Systems WS15/16 J.Simon 46
10 GBit/s Ethernet
• 10GE Standards– Glasfaserkabel (IEEE 802.3ae)
• Multimode-Fasern mit Reichenweiten bis 300m• Single-Mode Fasern und 1310nm Wellenlänge bis 10km
– Kupferkabel (IEEE 802.3ak und IEEE 802.3an)• Doppelt-twinaxiale Kupferkabel mit Reichenweiten bis 15m• Vier Twisten-Pair, bei CAT6a/7 bis 100m
• NICs– Derzeit noch relativ teuer, hauptsächlich in
zentralen Servern eingesetzt
• Switches– Switch ebenfalls noch teuer– Siehe auch MyriNet 10G
24
Architecture of Parallel Computer Systems WS15/16 J.Simon 47
Intel Omni-Path
• Communication Network integrated in– Xeon PHI KNL-F– Next Xeon Server Processors
• Also available as PCI-e Host Fabric Interface (HFI)
• Omni-Path Architecture (OPA)– OPA 100 with 100 Gbit/s– 25.8 Gbit/s per lane (4x lanes)– CRC with 14 bit– Enforcement of high priority messages– Link transfer layer 1.5 with Forward
Error Correction (16 flits)– 48 port switch chips
Architecture of Parallel Computer Systems WS15/16 J.Simon 48
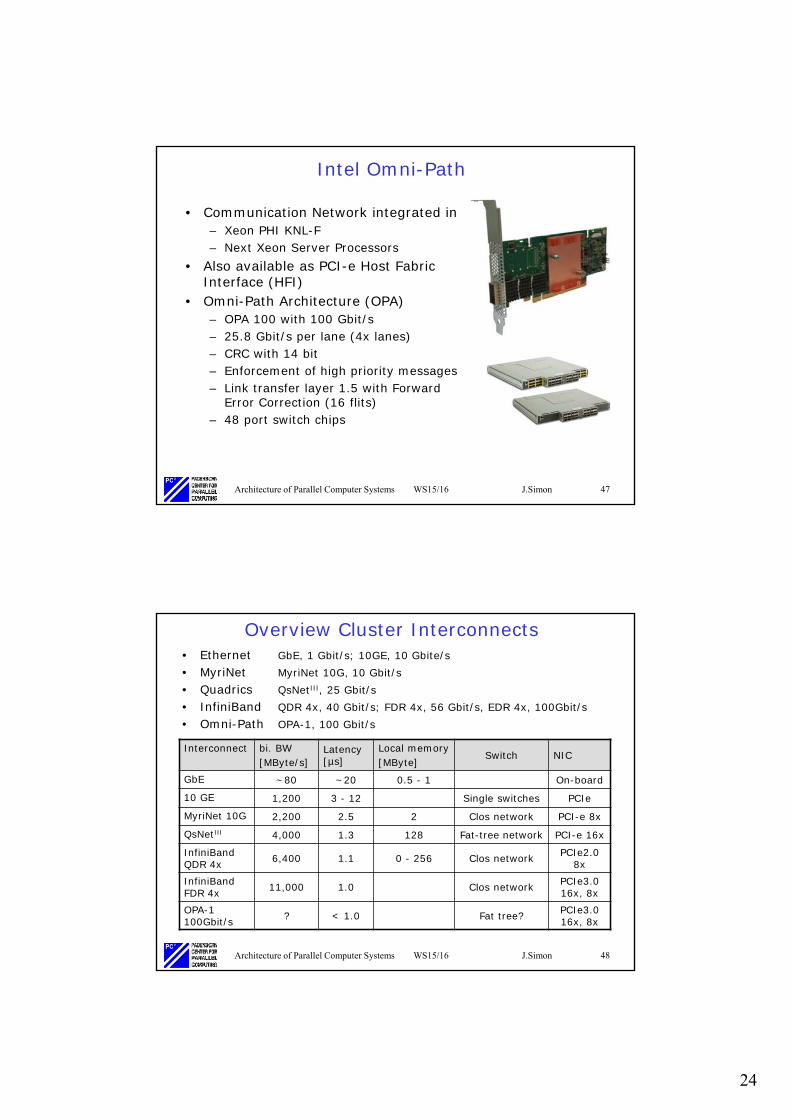
Overview Cluster Interconnects• Ethernet GbE, 1 Gbit/s; 10GE, 10 Gbite/s• MyriNet MyriNet 10G, 10 Gbit/s• Quadrics QsNetIII, 25 Gbit/s • InfiniBand QDR 4x, 40 Gbit/s; FDR 4x, 56 Gbit/s, EDR 4x, 100Gbit/s• Omni-Path OPA-1, 100 Gbit/s
Interconnect bi. BW[MByte/s]
Latency [µs]
Local memory[MByte]
Switch NIC
GbE ~80 ~20 0.5 - 1 On-board
10 GE 1,200 3 - 12 Single switches PCIe
MyriNet 10G 2,200 2.5 2 Clos network PCI-e 8x
QsNetIII 4,000 1.3 128 Fat-tree network PCI-e 16x
InfiniBandQDR 4x 6,400 1.1 0 - 256 Clos network PCIe2.0
8xInfiniBandFDR 4x 11,000 1.0 Clos network PCIe3.0
16x, 8xOPA-1 100Gbit/s ? < 1.0 Fat tree? PCIe3.0
16x, 8x

25
Architecture of Parallel Computer Systems WS15/16 J.Simon 49
Kommunikationsprotokolle
Architecture of Parallel Computer Systems WS15/16 J.Simon 50
Allgemeines über Protokolle
Protokolle sind formale Regeln zum Handeln (Funktionsvorschriften).
Protokolle koordinieren die Kommunikation zwischen Kommunikationspartnern.
Protokolle liefern– Adressierung des Kommunikationsendpunkts– Kontrolle des Datenflusses– Verlässlichkeit des Services (Datentransfer)
Kommunikation kennt zwei Arten an Protokollen1. verbindungsorientierte Leitungsvermittlung2. verbindungslose Paketvermittlung

26
Architecture of Parallel Computer Systems WS15/16 J.Simon 51
Protokolle
• verbindungsorientierte Leitungsvermittlung , z.B. öffentliches Telefonnetz:– Teilnehmer wird ein Übertragungskanal und dessen Bandbreite
zur alleinigen Nutzung zur Verfügung gestellt– Verbindungsaufbau, Datenübertragung, Verbindungsabbruch– Merkmale: kurze Verweilzeiten der Nachrichten im Netz,
ungenutzte Übertragungskapazitäten• verbindungslose Paketvermittlung, z.B. Internet:
– Nachrichtenzerlegung in individuell adressierte Paketen– Datenpakete werden in Netzknoten zwischen gespeichert
(store&forward) Verzögerungen möglich, aber eine bessere Ausnützung der Übertragungskanäle/ Netzzugänge
– Quittung an den Sender für jedes korrekt empfangene Paket
Applikation Applikation
idealisiertes Netzwerk
Architecture of Parallel Computer Systems WS15/16 J.Simon 52
Netzwerkmodelle
• im OSI-Modell ist ein Netz in sieben Schichten aufgeteilt• jede Schicht kommuniziert nur mit seiner oben und unten
benachbarten Schicht
application
presentation
session
transport
network
data link
physical
application
presentation
session
transport
network
data link
physical
OSI Referenzmodell
Anwendungsprotokoll
Bit-Übertragungsschicht
Sicherungsschicht
Vermittlungsschicht
Transportprotokoll
Kommunikationsprotokoll
Darstellungsprotokoll
physical medium

27
Architecture of Parallel Computer Systems WS15/16 J.Simon 53
Internet Referenzmodell
• UDP– verbindungsloser, ungesicherter Datentransport– Keine Garantie ob Daten in der richtigen Reihenfolge oder überhaupt
ankommen• TCP
– verbindungsorientierter, gesicherter Datentransport– Verbindungsaufbau, Sortierung und automatische Wiederholung bei
fehlerhafter Übertragung
application
transport
network
data link
application
transport
network
data link
physical layer
device driver, NIC
IP, ICMP, IGMP
TCP, UDP
telnet, HTTP, etc.
data link data link
physical layer physical layer
network
Rechner BRechner A
Router
Switch
Ethernet, ISDN,…
Architecture of Parallel Computer Systems WS15/16 J.Simon 54
TCP/IP-Protokoll
• TCP/IP ist eine Menge an Protokollen die kooperierenden Computern netzwerkweit existierende Ressourcen gemeinsam nutzbar machen
• Gesamtmenge an Protokollen wird als „Internet Protocol Suite“ bezeichnet
• TCP (Transmission Control Protocol) und IP (Internet Protocol) sind die bekanntesten Protokolle dieser Suite
• TCP/IP wurde durch eine Gruppe Wissenschaftlern für das ARPAnet entwickelt (ab 1973)
• IP mit Packetgrößen < 1500 byte bzw. < 9000 Byte (Jumbo Frames, limitiert durch 32-bit CRC)

28
Architecture of Parallel Computer Systems WS15/16 J.Simon 55
UNIX Netzwerk-Stack
Struktur des BSD Netzwerk-Stacks
process
socket layer
protocol layer(TCP, UDP, IP, …)
interface layer
protocolqueue
interfacequeues
socketqueue
system calls
function call
function callto start output
Architecture of Parallel Computer Systems WS15/16 J.Simon 56
IP-Packete
Erweiterungen
• Gigabit-Ethernet Jumbo-Frames:– Packetgrößen bis zu 9000 Bytes (limitiert durch 32-Bit CRC)
• IPv6– Destination-, Source-Adressen: je 16 Bytes
(Beispiel: 2001:0db8:85a3:08d3:1319:8a2e:0370:7344)
Preamble
Destination Source Frame Type
Data Checksum
8 Bytes 6 Bytes 6 Bytes 2 Bytes
46-1500 Bytes 4 Bytes
29
Architecture of Parallel Computer Systems WS15/16 J.Simon 57
IP Protokoll im Cluster
• Das Internet-Protokoll (IP) ist weltweit Standard für Netzwerke (best-effort Ansatz)
• Transmission Control Protocol (TCP) meistens eingesetzt
• Internet-Protokolle haben Nachteile für Cluster:• Overhead durch das Betriebssystem • Durch die Strukturierung des TCP/IP in mehrere Schichten
=> zwangsläufig mehrfaches kopieren im Speicher• Durch Schichtenstruktur schlechte Programmlokalität• Die Flusskontrollmechanismen des TCP
Architecture of Parallel Computer Systems WS15/16 J.Simon 58
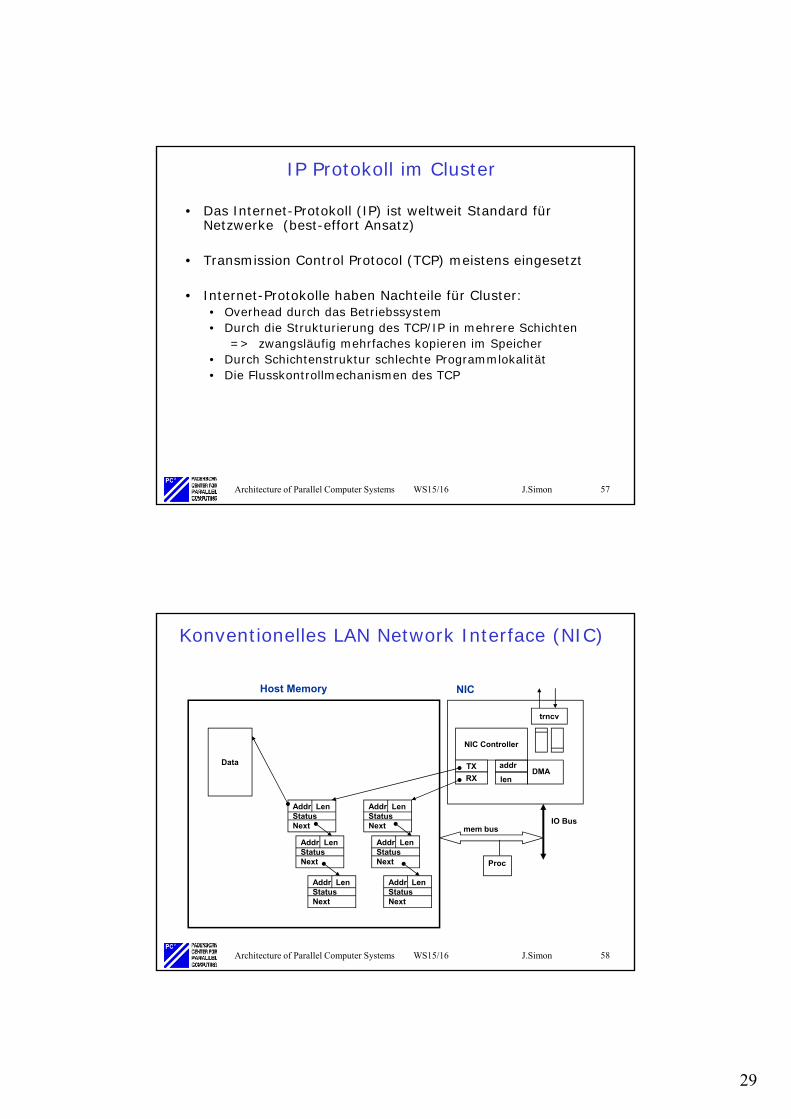
Konventionelles LAN Network Interface (NIC)
NIC Controller
DMAaddr
len
trncv
TX
RX
Addr LenStatusNext
Addr LenStatusNext
Addr LenStatusNext
Addr LenStatusNext
Addr LenStatusNext
Addr LenStatusNext
Data
Host Memory NIC
IO Busmem bus
Proc

30
Architecture of Parallel Computer Systems WS15/16 J.Simon 59
Kommunikationsprotokoll für Cluster
• Spezialisierung auf Message-Passing– Leichtgewichtige Kommunikationsprotokolle– Unterstützung großer Pakete– Schnelle Synchronisation– Gruppenkommunikationen
• Sichere Netzwerkübertragung– Fehlerbehandlungen ist absolute Ausnahme
• Einfache Switches– Optimierte Paketierung – Einfaches Routing (schnelle Wegewahl)– Keine Umsetzung zwischen Protokollen
• Mehr Unterstützung durch die Hardware im NIC– Beschleunigung der Protokollbearbeitung in den Komponenten
Netzwerkinterface (NIC) und Switch
Architecture of Parallel Computer Systems WS15/16 J.Simon 60
Nachrichtentransport ohne Hardwareunterstützung
• (dedizierter) Prozessor bearbeitet Nachrichtenausgabe auf Systemebene und interpretiert einkommende Nachrichten auf Systemebene
• User-Prozessor Msg-Prozessor (MP) via Shared-Memory• Msg-Prozessor Msg-Prozessor via Netzwerktransaktion
Netzwerk
° ° °
dest
Mem
P M P
NI
User System
Mem
P M P
NI
User System
31
Architecture of Parallel Computer Systems WS15/16 J.Simon 61
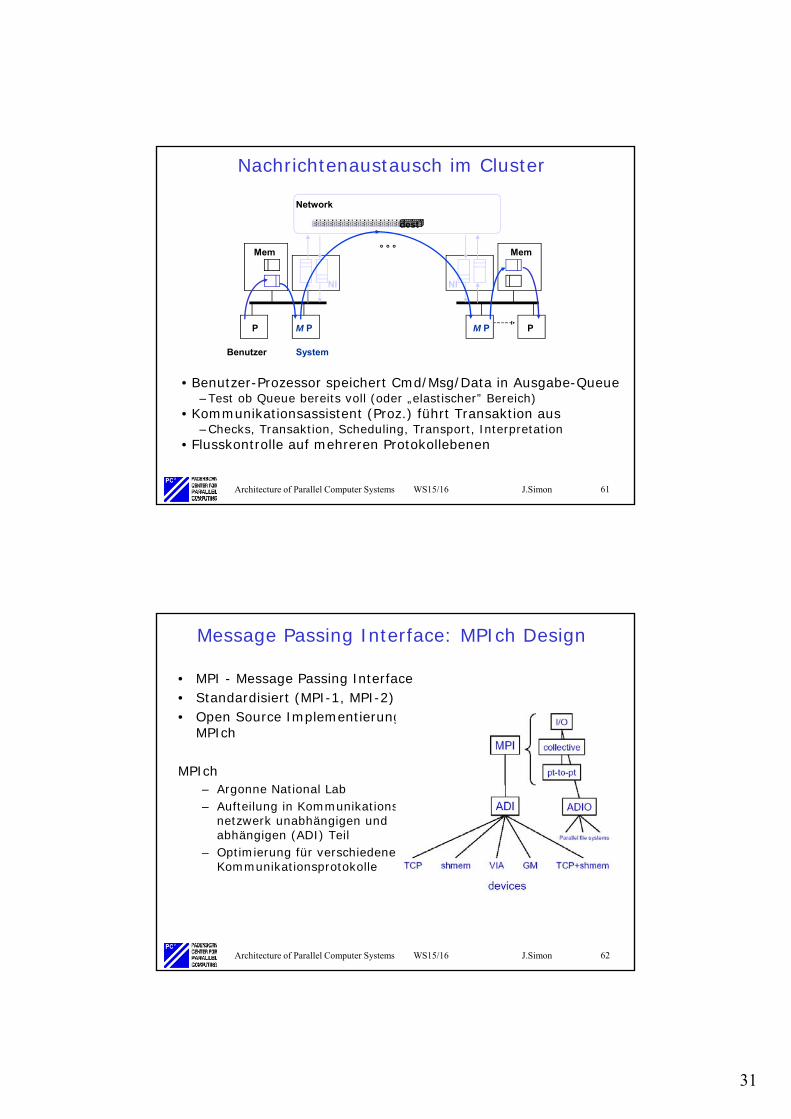
Nachrichtenaustausch im Cluster
• Benutzer-Prozessor speichert Cmd/Msg/Data in Ausgabe-Queue–Test ob Queue bereits voll (oder „elastischer” Bereich)
• Kommunikationsassistent (Proz.) führt Transaktion aus–Checks, Transaktion, Scheduling, Transport, Interpretation
• Flusskontrolle auf mehreren Protokollebenen
Network
° ° °
dest
Mem
P M P
NI
Benutzer System
Mem
PM P
NI
Architecture of Parallel Computer Systems WS15/16 J.Simon 62
Message Passing Interface: MPIch Design
• MPI - Message Passing Interface• Standardisiert (MPI-1, MPI-2)• Open Source Implementierung
MPIch
MPIch– Argonne National Lab– Aufteilung in Kommunikations-
netzwerk unabhängigen und abhängigen (ADI) Teil
– Optimierung für verschiedene Kommunikationsprotokolle

32
Architecture of Parallel Computer Systems WS15/16 J.Simon 63
Message-Passing vs. Shared-Memory
Quelle: Lenosky/Weber95
Zeit (µs) Message-Passing Shared-Memory
• OS Aufruf, Protection check, program DMA
DMA zum Netz
Latenz des Netzes
DMA vom Netz zum Systempuffer
OS Interrupt und Nachrichtendekodierung
OS Kopie vom Systempuffer in Benutzerpuffer
Re-Schedule des Benutzerprozesse
Benutzer liest Nachricht vom lokalen Speicher
0
5
10
15
• schreibt auf gemeinsamen Puffer und setzt Flagge
• Latenz des Netzes
• erkennt Flagge als gesetzt und liest Nachricht aus entfernten Speicher
Architecture of Parallel Computer Systems WS15/16 J.Simon 64
Techniken zur Beschleunigung
• Direct Memory Access (DMA)– Hardware unterstütztes Kopieren im lokalen Speicher
• OS-Bypass– Reduzierung der Anzahl an Prozesswechsel (Anwenderprozess,
Systemprozess, Anwenderprozess)– Verzicht auf teure Interrupt-Behandlung
• Zero-Copy Protokolle– Trotz Hardware-Unterstützung (DMA) teuer– Speicherbandbreite ist Engpass
• Remote DMA– Hardware unterstütztes Kopieren in entfernten Speicher
33
Architecture of Parallel Computer Systems WS15/16 J.Simon 65
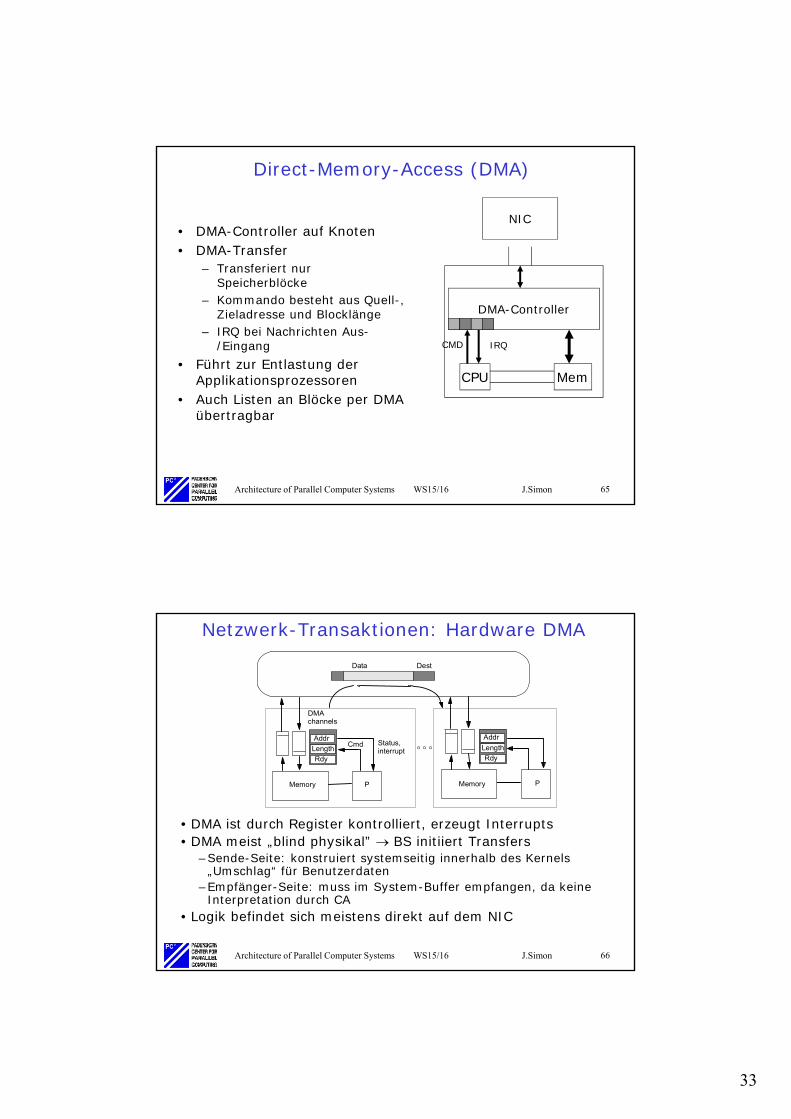
Direct-Memory-Access (DMA)
• DMA-Controller auf Knoten• DMA-Transfer
– Transferiert nur Speicherblöcke
– Kommando besteht aus Quell-, Zieladresse und Blocklänge
– IRQ bei Nachrichten Aus-/Eingang
• Führt zur Entlastung der Applikationsprozessoren
• Auch Listen an Blöcke per DMA übertragbar
CPU Mem
DMA-Controller
IRQCMD
NIC
Architecture of Parallel Computer Systems WS15/16 J.Simon 66
Netzwerk-Transaktionen: Hardware DMA
• DMA ist durch Register kontrolliert, erzeugt Interrupts• DMA meist „blind physikal” BS initiiert Transfers
–Sende-Seite: konstruiert systemseitig innerhalb des Kernels „Umschlag“ für Benutzerdaten
–Empfänger-Seite: muss im System-Buffer empfangen, da keine Interpretation durch CA
• Logik befindet sich meistens direkt auf dem NIC
PMemory
Cmd
DestData
Addr
Length
Rdy
PMemory
DMAchannels
Status,interrupt
Addr
Length
Rdy
34
Architecture of Parallel Computer Systems WS15/16 J.Simon 67
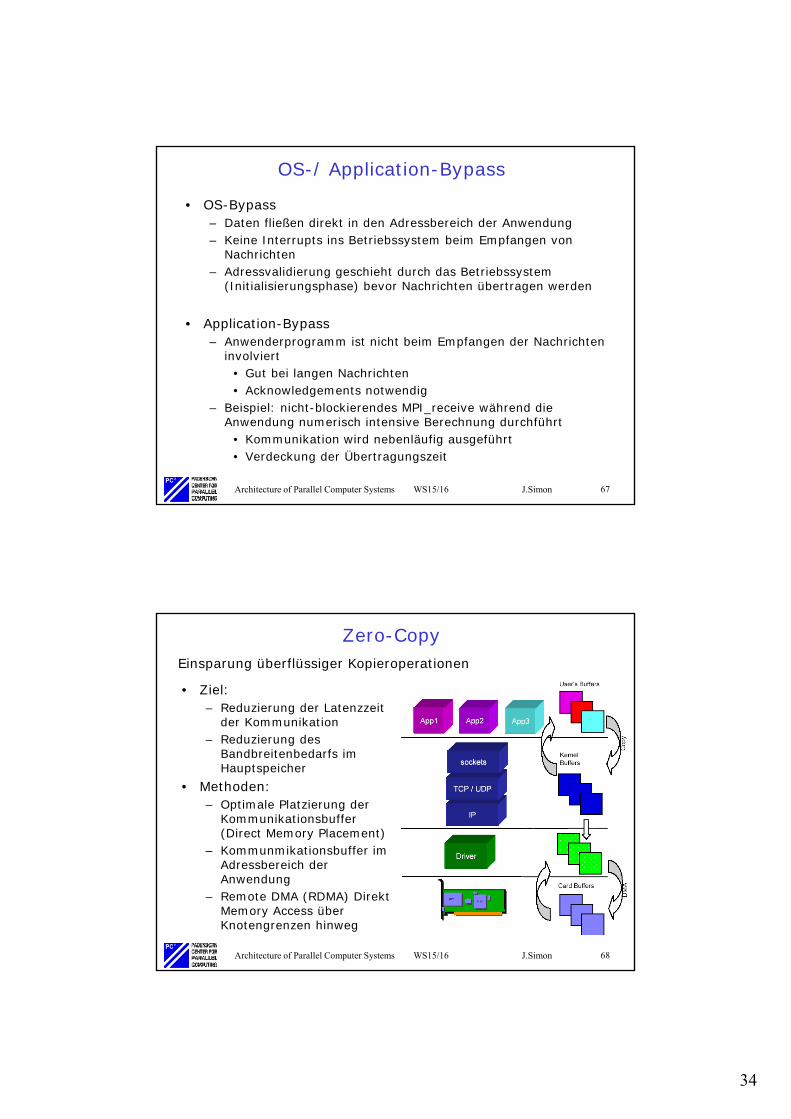
OS-/ Application-Bypass
• OS-Bypass– Daten fließen direkt in den Adressbereich der Anwendung– Keine Interrupts ins Betriebssystem beim Empfangen von
Nachrichten– Adressvalidierung geschieht durch das Betriebssystem
(Initialisierungsphase) bevor Nachrichten übertragen werden
• Application-Bypass– Anwenderprogramm ist nicht beim Empfangen der Nachrichten
involviert• Gut bei langen Nachrichten• Acknowledgements notwendig
– Beispiel: nicht-blockierendes MPI_receive während die Anwendung numerisch intensive Berechnung durchführt
• Kommunikation wird nebenläufig ausgeführt• Verdeckung der Übertragungszeit
Architecture of Parallel Computer Systems WS15/16 J.Simon 68
Zero-Copy
• Ziel:– Reduzierung der Latenzzeit
der Kommunikation– Reduzierung des
Bandbreitenbedarfs im Hauptspeicher
• Methoden:– Optimale Platzierung der
Kommunikationsbuffer(Direct Memory Placement)
– Kommunmikationsbuffer im Adressbereich der Anwendung
– Remote DMA (RDMA) Direkt Memory Access über Knotengrenzen hinweg
Einsparung überflüssiger Kopieroperationen

35
Architecture of Parallel Computer Systems WS15/16 J.Simon 69
Remote DMA (RDMA)
Registrierung von Puffern für Steering-Tags im NIC; Weiterleitung an Remote-Peer.
RDMA-Rahmen transportieren Direktiven und Steering-Tags im Datenstrom.
Direktiven und Steering-Tags steuern NIC Datenplatzierung.
Remote-Peer NIC
Architecture of Parallel Computer Systems WS15/16 J.Simon 70
Beispiel: MyriNet
• MyriNet ist auf Data-Link Ebene, (Ebene 2) des ISO Referenzmodells, definiert
• MyriNet beschreibt Paketformat und Flusskontrolle• Einfaches Packetvermittlungsverfahren• Mehrere Implementierungen der physikalischen Ebene• Source-Routing mit Header-Reduzierung
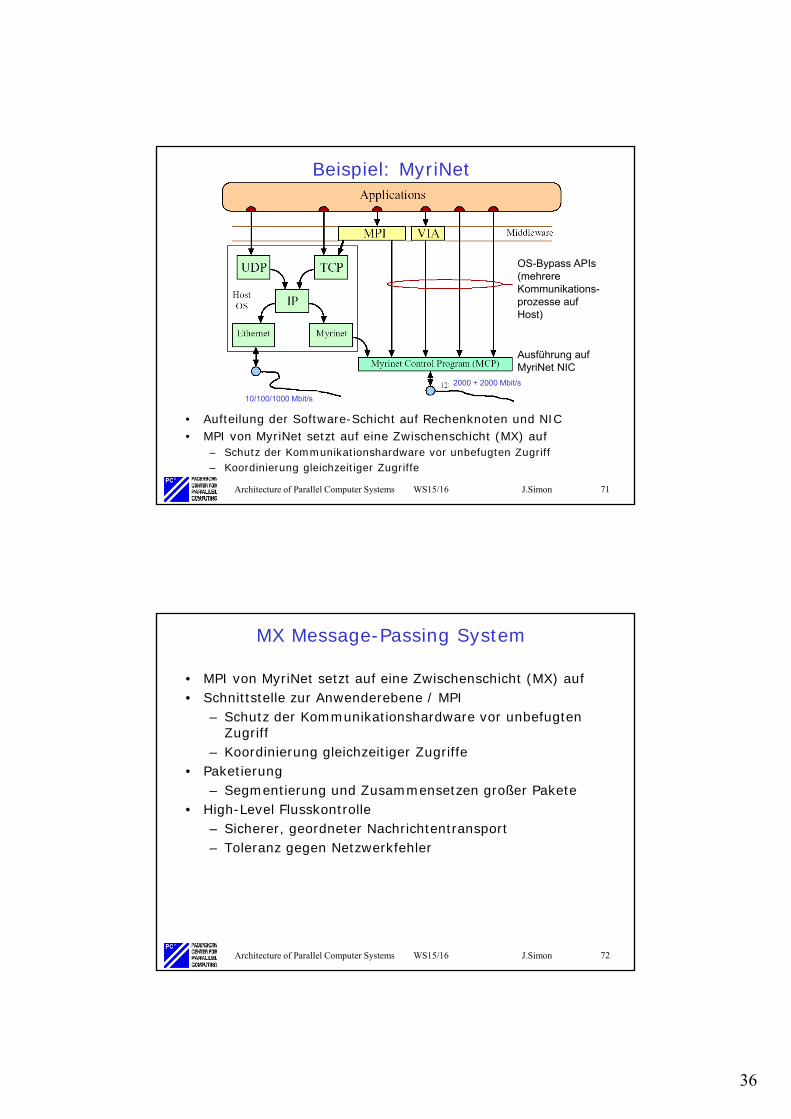
36
Architecture of Parallel Computer Systems WS15/16 J.Simon 71
Beispiel: MyriNet
• Aufteilung der Software-Schicht auf Rechenknoten und NIC• MPI von MyriNet setzt auf eine Zwischenschicht (MX) auf
– Schutz der Kommunikationshardware vor unbefugten Zugriff– Koordinierung gleichzeitiger Zugriffe
2000 + 2000 Mbit/s
10/100/1000 Mbit/s
Ausführung auf MyriNet NIC
OS-Bypass APIs (mehrere Kommunikations-prozesse auf Host)
Architecture of Parallel Computer Systems WS15/16 J.Simon 72
MX Message-Passing System
• MPI von MyriNet setzt auf eine Zwischenschicht (MX) auf• Schnittstelle zur Anwenderebene / MPI
– Schutz der Kommunikationshardware vor unbefugten Zugriff
– Koordinierung gleichzeitiger Zugriffe• Paketierung
– Segmentierung und Zusammensetzen großer Pakete• High-Level Flusskontrolle
– Sicherer, geordneter Nachrichtentransport– Toleranz gegen Netzwerkfehler
37
Architecture of Parallel Computer Systems WS15/16 J.Simon 73
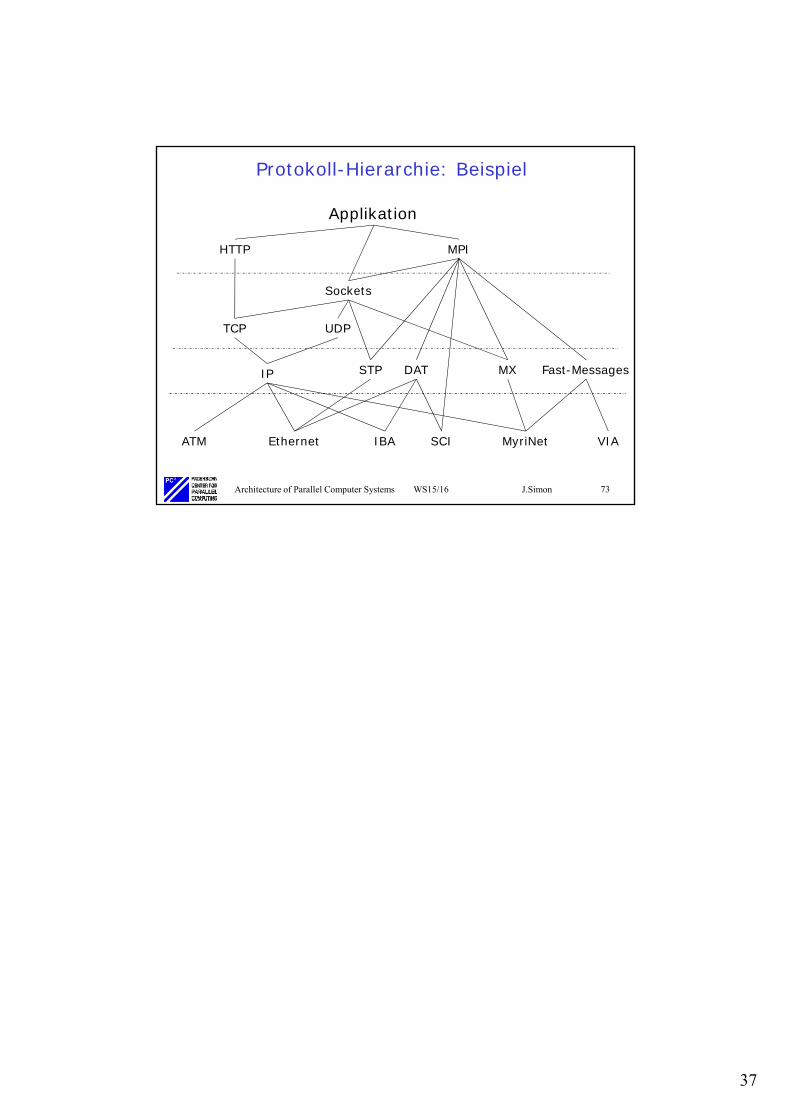
Protokoll-Hierarchie: Beispiel
Applikation
HTTP MPI
Sockets
TCP UDP
IP
ATM Ethernet MyriNet VIA
Fast-MessagesMXDAT
IBA SCI
STP