Embed Size (px)
Citation preview

Fachhochschule AachenCampus Jülich
Fachbereich 9Medizintechnik und Technomathematik
Vergleich von Segmentierungsansätzen fürNeonaten im Inkubator
Seminararbeitim Studiengang Angewandte Mathematik und Informatik
von
Kai SchröderMatr.-Nr.: 3193104
14. Dezember 2020
1. Prüfer: Prof. Dr. rer. nat. Alexander Voß2. Prüfer: M.Sc. Simon Lyra

Eidesstattliche Erklärung
Hiermit versichere ich, dass ich die Seminararbeit mit dem Thema Vergleich von Seg-mentierungsansätzen für Neonaten im Inkubator selbstständig verfasst und keine an-deren als die angegebenen Quellen und Hilfsmittel benutzt habe, alle Ausführungen, dieanderen Schriften wörtlich oder sinngemäß entnommen wurden, kenntlich gemacht sindund die Arbeit in gleicher oder ähnlicher Fassung noch nicht Bestandteil einer Studien-oder Prüfungsleistung war. Ich verpflichte mich, ein Exemplar der Seminararbeit fünf Jah-re aufzubewahren und auf Verlangen dem Prüfungsamt des Fachbereiches Medizintechnikund Technomathematik auszuhändigen.
Name: Kai Schröder
Aachen, den 14. Dezember 2020
Unterschrift der Studentin / des Studenten

Abstract
Vitalparameter, wie Herzschlag und Atmung, werden meistens über Kontaktsensoren ge-messen. Besonders für Frühgeborene sind diese Sensoren schädlich, da beim regelmä-ßigen Tausch die unterentwickelte Haut durch die verwendeten Klebstoffe beschädigtwerden kann. Deshalb wird aktiv an einer kamerabasierten Erfassung von Vitalparame-tern geforscht. Der erste Schritt in einer Verarbeitung der Bilddaten bildet meistens einesemantische Segmentierung. Dabei werden Pixel dieses Bildes in größere logische Ein-heiten eingeteilt. In dieser Arbeit werden diverse klassische Segmentierungsalgorithmenimplementiert, sowie deren Funktionsweisen erläutert und die Eigenschaften der resultie-renden Bilder analysiert. Dabei wurden Ansätze, die auf künstlicher Intelligenz basieren,bewusst ausgeschlossen. Die Algorithmen, sowie ein Graphical User Interface (GUI) zumTesten der Algorithmen, wurden implementiert. Folglich wurden die Segmentierungsan-sätze an mehreren Datensätzen von Frühgeborenen nach Echtzeitfähigkeit und Genauig-keit bewertet. Bei der Bewertung der Algorithmen stellt sich heraus, dass sich diese füreine Vorkonditionierung der Eingabe eignen, für eine komplexe semantische Segmentie-rung alleine allerdings nicht ausreichen.
iii

Inhaltsverzeichnis
Abkürzungsverzeichnis v
Abbildungsverzeichnis vi
Tabellenverzeichnis vii
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Gliederung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Segmentierung 32.1 Grundlegendes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Boolesche Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Kantenerkennung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Implementierung 143.1 Umgebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.3 Optimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.4 Erstellte Pipelines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Ergebnisse 234.1 Evaluation der Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . 264.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
Anhang 30
A Systemkontext 30
B Implementierung von einem Double Threshhold Filter als GLSL FragmentShader 31
Literatur 32
iv

Abkürzungsverzeichnis
KI Künstliche Intelligenz
GUI Graphical User Interface
ROI Region of Intrest
SLIC Simple Linear Iterative Clustering
WSI Window System Interface
v

Abbildungsverzeichnis
1.1 Hautschäden eines Neonaten mit scalded skin syndrome verusacht durchKontaktsensoren. [18] . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2.1 Normalisierter Absorptionsgrad menschlicher Zapfen in Nanometern (ap-proximiert). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Beispiel Anwendung eines 3×3 Kernels auf ein 5×5 Input in R. . . . . 52.3 Relative Intensitätskurven verschiedener Arten von Kanten. . . . . . . . . 62.4 Bekannte Kernel zum Berechnen des Gradienten eines Bildes [13]. . . . . 72.5 Anwendung eines Sobel Operators in Kombination mit einem Threshold
im Vergleich zum Canny Algorithmus. [6] . . . . . . . . . . . . . . . . . 82.6 K-Means verwendet für Color Quantization. . . . . . . . . . . . . . . . . 112.7 Auswirkungen von verschiedenen Parameter des SLIC-Superpixel Algo-
rithmus. Die konkrete Implementierung erzwingt kein Zusammenhängender Superpixel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1 Beispielcode, welcher eine Dear ImGui GUI (Abb. 3.2) erzeugt. . . . . . 153.2 Resultierende GUI aus dem ImGui Codebeispiel (Abb. 3.1). . . . . . . . 153.3 Screenshot entnommen aus der Segmentierungssoftware. Eine Pipeline
aus verschiedenen Filtern wird gezeigt, welche den Canny Algorithmusdarstellen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.4 Screenshots entnommen aus der Segmentierungssoftware, welche diverseFilter zeigen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.5 Der eindimensionale Gauss Kernel entsprechend einem 5×5 Gauss Kernel. 20
4.1 Anwendung der Pipelines aus Kapitel 3.4. Die Spalten korrespondieren zuden Patienten 1-4. Die erste Zeile zeigt die Originalbilder. Die folgendenZeilen zeigen chronologisch das Resultat der Pipelines 1-5. . . . . . . . . 24
4.2 Erstellte Binärmasken für Pipelines 1 und 2. . . . . . . . . . . . . . . . . 244.3 Erstellte Binärmasken für Pipelines 3 und 4. . . . . . . . . . . . . . . . . 24
vi

Tabellenverzeichnis
3.1 Übersicht der erstellten Pipelines . . . . . . . . . . . . . . . . . . . . . . 22
4.1 Zeitmessungen der Algorithmen auf zwei Testsystemen. . . . . . . . . . 254.2 Verhältniss der falsch erkannten Kanten zu allen erkannten Kanten. . . . . 254.3 Übereinstimmung der Binärmasken von Pipeline 3 - 4. . . . . . . . . . . 254.4 Vergleich von Kompaktheitsgraden. . . . . . . . . . . . . . . . . . . . . 26
vii

1 Einleitung
1.1 Motivation
Vitalparameter wie der Herzschlag, der Blutdruck, die Sauerstoffsättigung (SpO2) unddie Atemfrequenz, werden heutzutage über Kontaktsensoren gemessen. Die Sauerstoff-sättigung wird beispielsweise häufig über einen Fingerclip gemessen und der Blutdrucküber eine Manschette. Die Messung der Vitalparameter spielt eine essenzielle Rolle beider Überwachung von Patienten, um eine Aussage über deren Gesundheitsstatus zu tref-fen. Allerdings sind solche Kontaktsensoren in manchen Anwendungsfällen schädigend.So auch bei Frühgeborenen, wo solche Sensoren bekanntermaßen Hautschäden (vgl. Ab-bildung 1.1), sowie Infektionen verursachen können [10].
Abbildung 1.1: Hautschäden eines Neonaten mit scalded skin syndrome verusacht durchKontaktsensoren. [18]
Eine kontaktlose Erfassung der Vitalparameter ist daher zu bevorzugen. Neue Erkennt-nisse zeigen, dass eine Erfassung einiger Vitalparameter mit Hilfe von Kameras möglichist [12, 19]. Dies ist allerdings mit vielen Schwierigkeiten verbunden. Eine Kamera kannimmer nur einen Bereich des Patienten erfassen und man kann nicht davon ausgehen, dassimmer der gewünschte Bereich zu sehen ist. Außerdem werden durch die Umgebung vieleweitere Artefakte eingeführt. Zudem unterscheiden sich die Patienten in ihrem Aussehen.Wie in [1] gezeigt, hat diese Art der Datenerfassung oft Schwierigkeiten bei Patienten mitdunkleren Hauttönen, sowie in Räumen mit niedriger Beleuchtung.
1

1 Einleitung
In dieser Arbeit geht es um eine bestimmte Gruppe von Algorithmen, welche entstande-ne Bilddaten von Neonaten vorverarbeiten, um in späteren Schritten die Vitalparametermessen zu können. Spezifisch wird es um Segmentierungsverfahren gehen. Die Segmen-tierung eines Bildes bezeichnet in diesem Anwendungsfall das Aufteilen der Pixel in grö-ßere logische Einheiten. Für einen Algorithmus, welcher Vitalparameter aus Bilddatenextrahiert, ist eine Zuordnung von Pixeln zur Körperregion essenziell. Zurzeit werdenhäufig Modelle basierend auf einer KI genutzt, um die verschiedenen Regionen der Neo-naten zu extrahieren. Diese Ansätze liefern für eine Bildsegmentierung eine relativ hoheGenauigkeit bei einer relativ geringen Laufzeit, daher werden sie auch in vielen anderenKontexten genutzt [15, 3]. Aber auch bei diesen Ansätzen stellen sich Probleme heraus.So sind sie zum einen undurchsichtig - es ist manuell nur sehr schwer, einzelne Parameterzu ändern - zum anderen müssen die KIs trainiert werden, um gute Ergebnisse zu liefern.Dies erfordert große Datensätze, sowie eine Aufbereitung dieser. Solche sind nicht immervorhanden. Es wird in dieser Arbeit dargelegt, ob klassische Segmentierungsverfahrenähnliche Performance liefern. Zudem können sie auch als Vorkonditionierung der Datenfür die KIs dienen.
1.2 Ziel der Arbeit
Das Ziel dieser Arbeit ist es, nicht KI basierte Segmentierungsverfahren bezüglich derPerformance und Genauigkeit zu vergleichen. Daher soll eine Software in C++ entwi-ckelt werden, welche die Algorithmen implementiert und adäquat vergleichen kann. Aneinem kleinen Datensatz von Patienten soll dabei ein optimaler Segmentierungsalgorith-mus ermittelt werden.
1.3 Gliederung
In Kapitel 2 wird zunächst grundlegendes Wissen und über die Bildverarbeitung vermit-telt. Daraufhin werden einige Segmentierungs- und Bildverarbeitungsalgorithmen vorge-stellt.
In Kapitel 3 wird die Software, welche die Algorithmen implementiert und zum Verglei-chen programmiert wurde, vorgestellt. Weitere Optimierungen in einer konkreten Imple-mentierung der Algorithmen werden ebenfalls vorgestellt.
In Kapitel 4 werden im Anschluss die Ergebnisse der Algorithmen dargestellt und disku-tiert.
2
2 Segmentierung
In diesem Kapitel werden die untersuchten Bildverarbeitungs- und Segmentierungsal-gorithmen vorgestellt. Zum Verständnis ist grundlegendes Wissen über Bildverarbeitungnotwendig, welches im folgenden Unterkapitel vermittelt wird.
2.1 Grundlegendes
Es exisiteren verschiedene Möglichkeiten, ein Bild in eine digitale Form zu überführen.Welche Form gewählt wird, hängt von dem jeweiligen Anwendungsfall ab. Menschen sindtrichromatische Lebewesen. Stark vereinfacht gesagt haben sie drei verschiedene Artenvon Farbrezeptoren, welche von verschiedenen Wellenlängen des elektromagnetischenSpektrums angeregt werden [11].
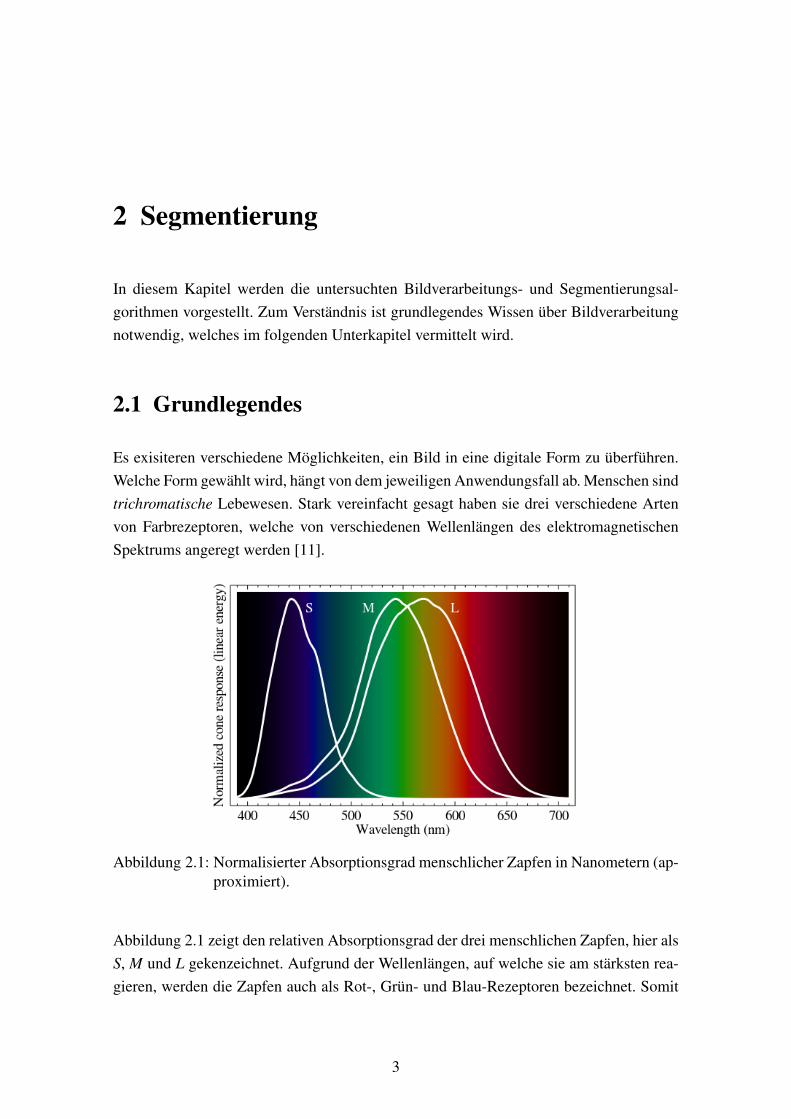
Abbildung 2.1: Normalisierter Absorptionsgrad menschlicher Zapfen in Nanometern (ap-proximiert).
Abbildung 2.1 zeigt den relativen Absorptionsgrad der drei menschlichen Zapfen, hier alsS, M und L gekenzeichnet. Aufgrund der Wellenlängen, auf welche sie am stärksten rea-gieren, werden die Zapfen auch als Rot-, Grün- und Blau-Rezeptoren bezeichnet. Somit
3

2 Segmentierung
ist naheliegend, wie ein Bild auf einem Monitor dargestellt wird. Ein klassischer Monitorbesteht aus Pixeln, welche jeweils aus einem roten, einem grünen und einem blauen Sub-pixel bestehen. Die Beleuchtungsstärke der Subpixel lässt sich digital einstellen. Durcheine Kombination verschiedener Beleuchtungsstärken ist es möglich, die meisten Farbendes sichtbaren Spektrums zu erzeugen. Eine Farbe lässt sich deshalb als einen Vektor imR3 darstellen, analog zu Formel 2.1. Die Komponenten modellieren dabei die Intensitätder Subpixel.
~C =
RGB
R,G,B ∈ [0;1] (2.1)
Eine 0-Komponente des Farbvektors entspricht dem Fall, dass dieses Subpixel kein Lichterzeugt, eine 1 bedeutet, dass dieses Subpixel mit seiner maximalen Stärke leuchtet. Beidieser Farbdarstellung spricht man vom normiertem RGB. In der Praxis werden die ein-zelnen RGB-Komponenten meist in einzelne Bytes gespeichert, wegen eines guten Ver-hältnisses zwischen Anzahl der darstellbaren Farben und Speicherbedarf.
Solch ein RGB-Vektor lässt sich in eine Beleuchtungsstärke umwandeln. Dies ist für Al-gorithmen notwendig, die einen einzelnen Wert pro Pixel benötigen. Die Konvertierungf : R3→R ist gegeben durch eine Berechnung des euklidischen Skalaproduktes mit demFarbvektor und einer Konstanten [4], wie Formel 2.2 zeigt.
f (~C) = < ~C,
0.21260.71520.7152
> (2.2)
Ein Bild lässt sich nun als zweidimensionale Matrix von Farbvektoren speichern. EineOperation oder ein Filter in diesem Kontext bezeichnet eine Funktion, welche auf denFarbvektoren eines Bildes agiert und ein neues Bild derselben Dimension ausgibt.
Für die Bildverarbeitung ist die Anwendung einer Nachbar-Operation eine wichtige Ope-ration. Die Idee dabei ist es, Informationen auf Basis von benachbarten Pixeln zu gene-rieren. Solche eine Operation wird in einigen Bildverarbeitungsalgorithmen verwendet,so etwa bei der Kantenerkennung oder bei der Glättung eines Bildes [17, S.117-118].Eine Nachbar-Operation braucht einen Operator, dieser ist hierbei eine Matrix, die auchKernel genannt wird.
4

2 Segmentierung
Abstrakt lässt sich eine Nachbar-Operation wie folgt definieren: Sei I eine Matrix derDimension N ×M mit Elementen in Z und K der Kernel, eine Matrix der DimensionA×B. Wenn gilt:
N ≥ A (2.3)
M ≥ B (2.4)
Ixy ·Ki j ∈ Z (2.5)
Lässt sich eine Operation fK : I → I definieren, wobei I die Eingabematrix ist, K derverwendete Kernel ist I die Ausgabematrix mit der Dimension N− (A−1)×M− (B−1)ist:
fK(I) = I (2.6)
Irc←A
∑i=0
B
∑j=0
Ki j · I(r+i),(c+ j) (2.7)
Anschaulich, legt man den Kernel als "Schablone" über jedes Element und berechnet dieSumme, wie Abbildung 2.2 veranschaulicht.
42 45 46 48 4738 44 47 50 5136 40 49 55 5632 42 53 58 6432 43 50 58 62
×0.1 0.2 0.10.2 0.5 0.20.1 0.2 0.1
=73.3 80.1 85.071.2 82.9 91.671.3 85.9 96.7
Abbildung 2.2: Beispiel Anwendung eines 3×3 Kernels auf ein 5×5 Input in R.
Beim Anwenden eines Kernels auf ein Bild müssen Randpixel gesondert betrachtet wer-den. Oftmals werden Werte für nicht exisiterende Randpixel angenommen. Hierfür gibtes verschiedene Strategien. Es können beispielsweise Null-Werte angenommen werdenoder der Wert der nächsten Kante übernommen werden.
Zudem ist es oft sinnvoll, dass bei der Anwendung eines Kernels die absolute Helligkeitunverändert bleibt. Dafür muss gelten, dass sich die Elemente des Kernels zu exakt 1aufsummieren.
5

2 Segmentierung
2.2 Boolesche Filter
Boolesche Filter sind Algorithmen, welche für jeden Pixel unabhängig eine Bedingungberechnen, auf Basis dessen wird dieser entweder akzeptiert oder verworfen.
Wichtige boolesche Filter sind Farbfilter, Schablonen und Schwellwert-Filter.
Farbfilter vergleichen die einzelnen Farbkomponenten mit Referenzfarben, um eine Ent-scheidung zu treffen. So können beispielsweise dunkle Pixel oder Pixel einer bestimmtenFarbrichtung gefiltert werden.
Schablonen agieren auf der Position der Pixel. Sie eignen sich, um statische Offsets zuentfernen und die Region of Intrest (ROI) einzugrenzen.
Ein Schwellwert-Filter weist jedem Pixel einen Wert zu und vergleicht diesen mit einemGrenzwert, dem Threshold. Basierend auf diesem Vergleich werden Pixel entweder ak-zeptiert oder entfernt.
2.3 Kantenerkennung
Kantenerkennung, im englischen als Edge-Detection bekannt, widmet sich der Extrahie-rung von Kanten, welche sich als kleine Regionen mit großem Intensitätsunterschied äu-ßern. Kantenerkennung ist weitesgehend erforscht, es existieren verschiedene, leicht ver-änderte Verfahren, die für verschiedene Arten von Kanten geeignet sind [7, 13, 14, 5].Kanten unterscheiden sich in der Art, wie sich die Intensität über die Pixel verändert.Abbildung 2.3 zeigt Intensitätskurven verschiedener Arten von Kanten.
(a) Step (b) Bar (c) Concave roof
Abbildung 2.3: Relative Intensitätskurven verschiedener Arten von Kanten.
Die meisten Kantenerkennungsalgorithmen basieren auf der Berechnung einer Art Ab-leitung des Bildes. Dazu werden meist zwei symmetrische Kernel, dessen Elemente sichinsgesamt auf 0 summieren, auf das Bild angewandt, welche einen zweidimensionalen
6

2 Segmentierung
Gradienten berechnen. Der Gradient stellt die Farb- / Intensitäts-Unterschiede dar. Be-kannte Kernel zum Berechnen dieser Ableitung beinhalten den Sobel Operator, PerwittOperator und Robert Cross Operator [5, 13] (siehe Abbildung 2.4).
Gx =
−1 0 1−2 0 2−1 0 1
Gy =−1 −2 −10 0 01 2 1
(a) Sobel Operator
Gx =
−1 0 1−1 0 1−1 0 1
Gy =−1 −1 −10 0 01 1 1
(b) Perwitt Operator
Gx =1 00 −1
Gy =0 −11 0
(c) Robert Cross Operator
Abbildung 2.4: Bekannte Kernel zum Berechnen des Gradienten eines Bildes [13].
Standardmäßig werden die Gradienten von den Beleuchtungsstärken des Bildes berech-net. Die Norm des errechneten Gradienten bestimmt die neue Intensität der Pixel. Nachdiesem Schritt ist die Anwendung eines Grenzwertes möglich, um eine rudimentäre Kan-tenerkennung zu erhalten (siehe Abbildung 2.5).
Mit diesen Schritten allein funktioniert Kantenerkennung im Allgemeinen allerdings nichtzuverlässlich, wie man in Abb. 2.5 sehen kann. Durch die feine Textur im Boden, sowiedie Lichteinstrahlung, werden viele unwichtige Kanten erkannt und einige wichtige, wieder Rücken des Löwen, übersehen; egal wie man den Grenzwert wählt. Erhöht man ihn,werden viele unwichtige erkannt. Senkt man ihn, werden viele wichtige Kanten überse-hen.
7

2 Segmentierung
(a) Original (b) Sobel Operator
(c) Sobel + Grenzwert Filter (d) Canny Edge Detection
Abbildung 2.5: Anwendung eines Sobel Operators in Kombination mit einem Thresholdim Vergleich zum Canny Algorithmus. [6]
Ein solcher Algorithmus lässt sich aber durch weitere Schritte verbessern. John Cannywidmete sich diesem Problem in seiner Publikation "A Computational Approach to EdgeDetection" im Jahre 1986 [2]. Er stellte drei Kriterien auf: Die Fehlerrate soll minimalsein, der Abstand zwischen den erkannten Kanten und den echten Kanten soll minimalsein und es soll keine Kante mehrfach erkannt werden. Basierend auf diesen Kriterienentstand der berühmte Canny Kantenerkennungs-Algorithmus. Dieser ist heute bekanntals der optimale Kantenerkennungs-Algorithmus [13]. Der Algorithmus besteht aus fol-genden Schritten: zuerst sollte das Bild glättet werden, um Artefakte zu reduzieren. Glät-ten bezeichnet hier die Anwendung einer Nachbar-Operation mit einem symmetrischen,positiven, monoton um den Ursprung fallenden Kernel. So werden die Pixel mit ihrenNachbarn mit einem bestimmten Faktor vermischt, was die Norm der Gradienten überallverkleinert. Dadurch werden Artefakte im Bild beseitigt, starke Kanten können dennocherkannt werden. Diese Operation wird im Englischen auch als Blur bezeichnet. Danachwird der Gradient des Bildes berechnet. Es folgt die Anwendung eines "Non-MaximumSuppression" Filters. Hier werden benachbarte Pixel in einer 3× 3 Umgebung, welchesich in der Gradienten-Richtung befinden, mit einer niedrigeren Intensität entfernt. Da-durch erscheinen die erkannten Kanten als Linien, welche die Breite eines Pixel haben.Der letzte Schritt des Canny Algorithmus ist die Hysteresis. Um die Hysteresis anzu-wenden, muss das Bild erst in schwache und starke Kanten unterteilt werden. Dies wirdmit Hilfe von zwei Schwellwerten getan. Pixel, welche eine niedrigere Intensität als denersten Schwellwert haben, werden verworfen. Pixel, welche eine niedrigere Intensität als
8

2 Segmentierung
den zweiten Schwellwert haben, werden als schwache Kanten markiert, die restlichen alsstarke Kanten. Die Hysteresis konviertiert nun alle schwache Kanten zu starken Kanten,wenn sie mindestens eine benachbarte starke Kante haben. Die am Ende übrig bleibendenstarken Kanten bilden das Ergebnis der Kantenerkennung.
In einer konkreten Implementierung des Algorithmus wird zum Glätten des Bildes häufigein Gaussian Blur oder manchmal ein Linear Blur angewandt. Eine diskrete Approxi-mation der zweidimensionalen Gauß Funktion (siehe Formel 2.8) wird hierbei als Kernelverwendet. Formel 2.9 zeigt einen diskreten 5× 5 Gauß Filter mit σ = 1. Formel 2.10zeigt den N×N Kernel, welcher bei einem linearen Blur verwendet wird. Diese Kerneländern die absolute Helligkeit nicht. In der Floating-Point Arithmetik sollte sichergestelltsein, dass die Elemente sich tatsächlich auf 1 summieren.
G(x,y) =1
2πσ2 · e− x2+y2
2σ2 (2.8)
Gk =1
256·
1 4 6 4 14 16 24 16 46 24 36 24 64 16 24 16 41 4 6 4 1
(2.9)
Lk =1
N2 ·
1 . . . 1... . . . 11 1 1
(2.10)
Für den Non-Maximum Supperession Schritt wird bei der Berechnung der Gradienten dieKantenrichtung mitberechnet als:
θ = arctan(
Gy
Gx
)(2.11)
Mit diesem Winkel lässt sich jedes Pixel in eine von vier verschiedenen Richtung eintei-len: In 0°, 45°, 90° und 135°. Damit lassen sich die Pixel in einer diskreten 3x3 Pixel-Umgebung nach der Kantenrichtung vergleichen und ggf. nach dem Non-Maximum Su-peressions Schritt entfernen.
Es existieren weitere Ansätze zur Kantenerkennung, welche keinen Gradienten zur Be-stimmung der Kanten brauchen, wie etwa der Boolean Edge Detector, welcher auf Binär-
9

2 Segmentierung
masken basiert [9, S.1510-1511]. Dieser liefert ähnliche Ergebnisse wie Cannys Algorith-mus, trotz der unterschiedlichen Funktionsweise [9, S.1519].
Der Nutzen einer Kantenerkennung ergibt sich durch den Anwendungsfall. Generell lässtsich sagen, dass eine Kantenerkennung Umrisse von Objekten erkennt. Dies könnte für ei-ne semantische Segmentierung genutzt werden, wenn die gesuchten Segmente sich deut-lich von der Umgebung unterscheiden. Gibt eine Kantenerkennung eine geschlosseneForm des Segmentes, könnte mit einem Forest Fire Algorithmus eine Binärmaske undsomit das Segment extrahiert werden. Dies funktioniert aufgrund von Artefakten, welchebeispielsweise durch Lichteinstrahlung oder detailreiche Texturen entstehen, ohne wei-tere Verarbeitung eher schlecht. Dies zeigt auch Abbildung 2.5, wo keine geschlosseneKurve um den Löwen entsteht.
2.4 Clustering
Clustering bezeichnet den Prozess, Daten basierend auf Ähnlichkeiten in Gruppen zu un-terteilen. In der Statistik sind diese Probleme unter Cluster Analysis zu finden [17, S.256-257]. Ein Clustering-Algorithmus ist das K-Means-Clustering. K-Means-Clustering istein iterativer Algorithmus, welcher versucht, ein Datenset in K Gruppen zu unterteilen,indem die euklidische Distanz zwischen Elementen der Gruppen minimiert wird [8]. ImAllgemeinen folgt der Algorithmus diesen Schritten:
1. Wähle für jedes Cluster K ein beliebiges Zentrum Ci.
2. Weise jedem Element x aus dem Datensatz X das Zentrum Ci zu, welches ||x−Ci||minimiert.
3. Berechne neue Zentren Ci als Ci =1N ·∑x∈Ci x mit N als Anzahl der Elemente die zu
Ci gehören.
4. Wiederhole ab Schritt zwei bis zur Konvergenz, bis keine der Zentren Ci durchSchritt drei verändert werden.
Dieses Verfahren lässt sich auch auf Bilder anwenden, um den Farbraum zu reduzieren,was im Englischen unter Color Quantization bekannt ist. Die Norm lässt sich dabei imRGB-Farbraum als die Norm im R3 der Farbkomponenten definieren mit:
∣∣∣∣∣∣~C∣∣∣∣∣∣=√r2 +g2 +b2 (2.12)
10

2 Segmentierung
Abbildung 2.6 zeigt solch eine Color Quantization. Bei diesem Beispiel könnte ein Clus-tering in wenige Farben als Segmentierungansatz verwendet werden. Wie Abbildung 2.6(c) zeigt, gehören die grünen Früchte dem selben grünen Zentrum an. Ein Clustering inviele Farben, wie etwa 32, kann für eine Datenkompression genutzt werden. Abb. 2.6 (e)lässt sich nur wenig von Abb. 2.6 (f) unterscheiden, obwohl nur ein kleiner Bruchteil derFarben in Abb. 2.6 (e) genutzt wurden. Möglicherweise stellen sich diese Eigenschaftenauch bei der Anwendung auf Bilder von Neonaten heraus.
(a) 2 Farben (b) 4 Farben (c) 8 Farben
(d) 16 Farben (e) 32 Farben (f) 16581375 Farben (Orig.)
Abbildung 2.6: K-Means verwendet für Color Quantization.
Weitere Segmentierungsansätze, die auf Clustering aufbauen, sind Superpixelansätze.Diese versuchen, Pixelgruppen in größere Superpixel zu unterteilen. Das Ziel ist dabei,Pixel, die zu einem Objekt gehören, lokal zusammenzufassen, ohne dabei die Form desObjektes zu verändern. Ein Algorithmus, welcher ein Bild in Superpixel unterteilt istder Simple Linear Iterative Clustering (SLIC) Algorithmus, welcher erstmals in der Pu-blikation von R. Achanta "SLIC Superpixels" im Jahre 2010 veröffentlicht wurde [16].Der Algorithmus teilt ein Bild mit N Pixeln in K ähnliche große Superpixel, mit ei-ner linearen Komplexität von O(N), auf. Die ungefähre Größe S jedes Superpixels istgegeben durch S = N/K. Der Algorithmus bildet die Superpixel im 5-dimensionalenRaum, jedes Element besteht aus drei Farbkomponenten und zwei Positionskomponen-ten. R. Achanta arbeitet im CIELAB Farbraum, ein Element (Pixel) ist also gegebendurch Ck = [lk,ak,bk,xk,yk]
T . Im RGB Farbraum funktioniert der Algorithmus ähnlich,der Einfachheit halber wird hier im RGB Farbraum weitergearbeitet. Die l, a und b Kom-ponenten werden dafür durch r, g und b Komponenten ersetzt. Nun definiert R. Achantaeine Distanz. Konvertiert in den RBG Farbraum ist die Distanz Ds gegeben als:
11

2 Segmentierung
drgb =
√(rk− ri)
2 +(gk−gi)2 +(bk−bi)
2 (2.13)
dxy =
√(xk− xi)
2 +(yk− yi)2 (2.14)
Ds = drgb +mS·dxy (2.15)
Die Distanz Ds ist in zwei Summanden aufgeteilt, einen Farbteil drgb und einen Abstands-teil dxy. Der Abstandsteil wird mit einem Faktor von m
S multipliziert, das m hierbei ist eineneu eingeführte Variable und ist der einzige Eingabeparameter. Dieser gibt Kontrolle überdas Verhältnis zwischen Farb- und Geometrischer-Distanz. Der Algorithmus läuft nunwie folgt ab:
1. Initialisiere die Zentren der Superpixel Ck = [rk,gk,bk,xk,yk]T in einem uniformen
Feld, sodass jeder Pixel N/K Einheiten von dem nächsten Zentrum entfernt ist.
2. Verschiebe jedes Zentrum in einer n×n Umgebung zur Position mit dem niedrigs-ten Gradienten.
3. Weise jedem Pixel ein Superpixel Zentrum Ck zu, welches die kleinste Distanz Ds
aufweist in einer 2S×2S Umgebung.
4. Berechne die Zentren neu nach K-Means sowie die Distanz Ds zwischen den neuenund alten Zentren.
5. Wiederhole ab Schritt drei bis zur Konvergenz der Zentren.
6. Erzwinge Zusammenhängen der Superpixel.
Die Zentren der Superpixel werden in Schritt zwei zum niedrigsten Gradienten verscho-ben, um zu vermeiden, dass ein Zentrum genau auf einer Kante liegt. Obwohl der Al-gorithmus ohne Schritt 6 keine zusammenhängende Pixel erzwingt, sind die Superpixelaufgrund des Abstandsteils in Ds trotzdem oftmals zusammenhängend. R. Achanta zeigtzudem, dass dieser Schritt weniger als 10% der Laufzeit benötigt mit einem O(N) Algo-rithmus [16, S. 6]. R. Achantas Untersuchungen, sowie die Untersuchungen, welche fürdiese Arbeit angestellt wurden, ergaben, dass der Algorithmus oftmals schon nach vierIterationen stark konvergiert.
Abbildung 2.7 zeigt mehrere Anwendungen des SLIC Algorithmus mit unterschiedlichenParametern. Es stellt sich eine höhere Genauigkeit bei mehr Iterationen heraus, dies istbesonders bei der Reflektionen im Apfel zu erkennen. Ein größeres m sorgt dafür, dass
12

2 Segmentierung
Abbildung 2.7: Auswirkungen von verschiedenen Parameter des SLIC-Superpixel Algo-rithmus. Die konkrete Implementierung erzwingt kein Zusammenhängender Superpixel.
einzelne Pixel geometrisch näher aneinander bleiben. So werden die Superpixel rechte-ckiger. Bei einer hohen Anzahl an Superpixeln ist kaum noch ein Unterschied zum Ori-ginal (siehe Abb. 2.6 (f)) zu erkennen, welches aus hundert mal so vielen Pixeln besteht.Auch sieht man hier, dass die Superpixel meistens zusammenhängen, obwohl diese Im-plementierung keine zusammenhängende Superpixel erzwingt. Das liegt am Distanzteildxy, welches in die Berechnung von Ds einfließt.
Da die Superpixel die Form der Objekte sehr gut beibehalten, können einzelne Superpixelmöglicherweise ein Segment in einer semantischen Segmentierung bieten. Im Falle vonNeonaten stellen sich möglicherweise einzelne Gliedmaßen, wie Arme und Beine, alswenige Superpixel heraus. Dazu reduzieren Superpixel kleinere Details, was für manchefolgenden Algorithmen von Vorteil sein könnte.
13

3 Implementierung
Zum Testen der Segmentierungsalgorithmen wurde eine Software in C++ entwickelt, wel-che eine interaktive Visualisierung der Algorithmen bietet. Diese Software wird in die-sem Kapitel vorgestellt. Mit ihr lassen sich mehrere Filter hintereinander auf ein Bildanwenden, um eine Pipeline zu bauen. Änderungen der Inputparameter werden direkt aufden Output angewandt. Die Laufzeit, welche einzelne Filter beansprucht haben, lässt sichmessen.
3.1 Umgebung
Bei dem Design der Software wurde der hohe Grad an Dynamik, welcher für diesen An-wendungsfall benötigt wird, festgestellt. Einzelne Filter / Algorithmen müssen dynamischerzeugt werden. Diese müssen wiederum dynamisch eigene UI-Elemente erzeugen, wel-che dynamisch die Parameter der Filter setzen. Daher wurde die Bibliothek Dear ImGui[Github] benutzt. Dear ImGui ist eine Open-Source C++ Bibliothek, welche in der La-ge ist, grafische Widgets zu erzeugen. Im Gegensatz zu anderen Grafikbibliotheken, wiez.B. QT, folgt Dear ImGui dem neueren Idiom der Immediate Mode GUI. Hier werdenMethoden bereitgestellt, die Widgets "direkt" erzeugen. Die Idee ist nun, diese Methodenin der Hauptschleife des Programmes aufzurufen. So wird für jedes neu generierte Bilddas User Interface ebenfalls erzeugt. Im Vergleich zu üblichen GUIs, die auf Interruptsbasieren, ist dieser Ansatz merklich ineffizienter. Allerdings bieten sich durch diese Artder Programmierung einige Vorteile, welche an folgendem Beispiel erläutert werden:
14

3 Implementierung
s t a t i c f l o a t v a l { 0 .776 f } ;
ImGui : : Begin ( "Window" ) ;
ImGui : : Tex t ( " The v a l u e i s %.2 f : Th i s v a l u e i s %s ! " , va l , v a l > 0 . 5 f ? " l a r g e " : " s m a l l " ) ;ImGui : : S l i d e r F l o a t ( " T r e s h o l d " , &va l , 0 . f , 1 . f ) ;
i f ( ImGui : : Bu t t on ( " R e s e t " ) ){
v a l = 0 . 3 3 f ;s t d : : c o u t << " Value was s e t t o 0 . 3 3 f " << ’ \ n ’ ;
}
ImGui : : End ( ) ;
Abbildung 3.1: Beispielcode, welcher eine Dear ImGui GUI (Abb. 3.2) erzeugt.
Abbildung 3.2: Resultierende GUI aus dem ImGui Codebeispiel (Abb. 3.1).
Input-Widgets, wie der Slider, setzen die Variable nicht über einen Callback, sondernüber einen Pointer. So werden Multithreading Probleme vermieden. Das mathematischeModel kann direkt verändert werden. Des Weiteren muss das Model nicht mit der GUIsynchronisiert werden, da die GUI jeden Frame neu erzeugt wird und deshalb den Wertneu lesen muss. Über if -Anweisungen lässt sich die erzeuge UI komplett verändern. Fürdie von Grund auf dynamische Art der Filter eignet sich Dear ImGui.
Dear ImGui ist lediglich in der Lage, grafische Widgets zu erstellen. Pixeloperationenan den Grafiktreiber zu senden oder mit dem Fenstersystem des Betriebsystem zu inter-agieren liegt außeralb von Dear ImGui’s Scope. Diese Teile können selbst geschriebenwerden und mit weiteren Bibliotheken, welche sich auf diese Bereiche spezialisieren, er-weitert werden. Für die Software wurde als Window System Interface (WSI) Bibliothek,GLFW genutzt, als Render-API OpenGL 4.x. Dies ermöglicht mit Hilfe von Shadern,nativ auf der Grafikkarte Algorithmen zu implementieren. Durch die hohen Parallelie-rungsmöglichkeiten der Grafikkarte ist eine wesentlich geringere Laufzeit zu erwarten.
3.2 Features
Die App ermöglicht es, mehrere Bilder zu laden. Auf die geladenen Bilder lässt sichnun eine selbst erstellte Pipeline anwenden. Eine Pipeline besteht hier aus diversen Fil-
15

3 Implementierung
tern, welche nacheinander angewandt werden. Jeder Filter der Pipeline öffnet ein eige-nes Fenster zum ändern der Parameter dieses Filters. Abbildung 3.3 zeigt eine Pipeline,welche dem Canny Algorithmus entspricht. Abbildung 3.4 zeigt weitere Screenshots mitdiversen einzelnen Filtern.
Alle der beschriebenen Filter aus Kapitel 2 wurden implementiert. Dazu gehören zumeinen die Clustering Algorithmen, der K-Means Algorithmus zur Color Quantization, so-wie der SLIC Superpixel Algorithmus, zum anderen die einzelnen Schritte des CannyEdge Detektors als einzelne Filter. Weitere boolesche und triviale Filter, wie ein RGBFarbfilter, Schablonen in Rechteck-, Kreis- und Ellipsen-Form, sowie ein Mix-Filter, wel-cher mehrere Pipelines zusammenführen kann, wurden ebenfalls implementiert. Das Pro-gramm kann die Laufzeit, welche die einzelnen Filter beansprucht haben, messen, wo-durch die verschieden Verfahren bezüglich der Performance verglichen werden können.Die Software benutzt explizit die GPU. Eine dedizierte GPU beschleunigt die Berechnun-gen daher signifikant.
Abbildung 3.3: Screenshot entnommen aus der Segmentierungssoftware. Eine Pipelineaus verschiedenen Filtern wird gezeigt, welche den Canny Algorithmusdarstellen.
16

3 Implementierung
(a) Anwendung eines Blur Filters (b) Anwendung eines Farbfilters
(c) SLIC Superpixels (d) K-Means Farbreduktion zu 15 Farben
Abbildung 3.4: Screenshots entnommen aus der Segmentierungssoftware, welche diverseFilter zeigen.
17

3 Implementierung
3.3 Optimierung
Die meisten Filter sind leicht oder sogar trivial parallelisierbar. In einigen Filtern wird aufjeden Pixel unabhängig eine Operation angewandt, so beispielsweise bei einem Thres-hold oder bei der Anwendung eines Kernels. Dazu kommt, dass es sich hier um Texturenhandelt, auf welche algebraische Operationen angewandt werden. Moderne Grafikkartensind auf diesen Anwendungsfall spezialisiert. In diesem Fall wurden die parallelisierbarenFilter in GLSL Shadern implementiert, genauer gesagt, in Fragment Shadern. FragmentShader sind im Kern Codestücke, welche für jeden Pixel einzeln und parallel auf der GPUausgeführt werden.
Die Asynchronität von Grafikarten ist ein weiterer Vorteil, der sich neben der hohen Par-allelität ergibt. Die CPU sendet Befehle an die GPU und setzt meistens sofort seine eineArbeit fort, ohne auf die GPU zu warten. So kann beispielsweise schon das nächste Bildder Kamera eingelesen und verarbeitet werden, während die GPU das Bild segmentiert.Die Haupt-Nachteile, die sich ergeben, sind zum einen der extra Overhead, welcher durchdie Synchronisation von GPU und CPU entsteht, zum anderen müssen die Daten zur GPUkopiert werden, was auch wieder Zeit in Anspruch nimmt.
Wie im vorherigen Kapitel erwähnt, kann die Software die Zeit der einzelnen Filter mes-sen. Allerdings funktionieren Zeitmessungen aufgrund der Asynchronität fundamentalanders, wenn die GPU beteiligt ist. So müssen explizite Synchronisierungs-Objekte aufdie GPU geladen werden, was wiederum zu Overhead führt. Deshalb werden die realenZeiten kürzer ausfallen.
Wenn es bei einem Filter möglich ist, aus der Farbe eines Pixels alleine den Output zudeduzieren, ohne dabei Kenntnisse über andere Pixel zu haben, lässt sich dieser Filtertrivial in einem Fragment Shader implementieren und bietet exzellente Performance. Zuden Filtern, welche sich so implementieren lassen, gehören beispielsweise Grenzwert-,Schablonen- und Farbfilter. Die dazugehörigen Shader lesen die Farbe ihres Pixels, be-kommen Parameter über uniform Variablen und implementieren den Algorithmus kom-plett im Shader selbst. Hier ist im Regelfall keine extra Synchronisation zwischen GPUund CPU notwendig, da die Daten nur auf der GPU Seite gebraucht werden. Ein BeispielShader befindet sich im Anhang.
Filter, die Kenntnisse über andere Pixel brauchen, aber keinen globalen akkumuliertenWert benötigen, können ohne weiteren Synchronisations-Overhead ebenfalls in einemFragment Shader implementiert werden. Hierzu gehören beispielsweise alle Filter, wel-che einen Kernel anwenden, wie z.B. ein Gaussian Blur. Die anderen Pixel können bei-spielsweise über texelFetchOffset gelesen werden. Allerdings bricht die Performance ein,
18

3 Implementierung
wenn pro Pixel zu viele andere eingelesen werden. Das ist besonders bei der Anwendungvon Kerneln ein Problem, da hier die Anzahl der Leseoperationen pro Pixel quadratischmit der Größe des Kernels wächst. Da auf jeden gelesenen Pixel eine Multiplikations-Operation angewandt wird, steigt hier auch die Anzahl der Multiplikationen quadratisch.Allerdings gibt es eine Optimierung, die man bei einigen Kerneln vornehmen kann, umdie Komplexität von O(N2) auf O(2N) zu reduzieren. Manche Kernel sind separierbar,d.h. sie lassen sich in einen horizontalen und vertikalen Kernel aufteilen, welche nachein-ander angewendet werden [17, S.122-123]. Ob das bei einem konkreten Kernel möglichist, verrät meist die analytische Form. Der Gaussian-Blur ist separierbar. Dies lässt sichdaran erkennen, dass sich die Gauß Funktion G(x,y) in die Form G(x) ·G(y) überführenlässt, wie die Formeln 3.1 - 3.3 zeigen.
G(x,y) =1
2πσ2 · e− x2+y2
2σ2 (3.1)
=1√
2πσ2· e−
x2
2σ2 · 1√2πσ2
· e−y2
2σ2 (3.2)
= G(x) ·G(y) (3.3)
Es wird nun die Funktion K(x,y) aufgestellt, welche den neuen Pixelwert an der Stelle(x,y) gibt, mit N als Kernelgröße −1 und C(x,y) als den ursprünglichen Pixelwert an derStelle (x,y).
K(x,y) =N
∑i=−N
N
∑j=−N
G(i, j) ·C(x,y) (3.4)
=N
∑i=−N
N
∑j=−N
G(i) ·G( j) ·C(x,y) (3.5)
=N
∑i=−N
G(i) ·N
∑j=−N
G( j) ·C(x,y) (3.6)
Diese Darstellung von K in Formel 3.6 impliziert, dass der vertikale Teil des Algorithmussich auf das Ergebnis vom horizontalen Teil anwenden lässt und dasselbe Ergbenis liefert.Deshalb lässt sich hier ein eindimensionaler Kernel zweimal hintereinander ausführen,einmal in X- und Y-Richtung [17, S.123]. Insgesamt werden so pro Durchlauf nur noch NMultiplikations-Operationen pro Pixel durchgeführt. Da zudem noch eine Symmetrie umden Ursprung exisitert, kann ein N×N Gauß Kernel berechnet werden, indem nur
⌈N2
⌉Gewichte gespeichert werden. Die folgende Abbildung 3.5 zeigt den eindimensionalen
19

3 Implementierung
Kernel, welcher einem 5× 5 Gauß Kernel, mit σ = 1, entspricht. Die zu speicherndenGewichte wären hier konkret 6
16 , 416 und 1
16 .
116 · 1 4 6 4 1
Abbildung 3.5: Der eindimensionale Gauss Kernel entsprechend einem 5×5 Gauss Ker-nel.
Für die Implementierung in einem Fragment Shader kann eine uniform Variable genutztwerden, um die Richtung des Filters anzugeben. Der Shader muss nun zweimal ausgeführtwerden, wobei der Output des ersten Durchlaufes in eine extra Textur geleitet werdenmuss, welche als Input des zweiten Durchlaufes dient. In OpenGL muss hierzu ein zweiterFramebuffer angelegt werden.
Der K-Means-, sowie der Superpixel-Algorithmus gestalten sich für die Implementierungin Shadern etwas komplizierter. Diese Algorithmen müssen nach einer Iteration alle Pixel,die zu einer bestimmten Gruppe gehören, akkumulieren, um einen Mittelwert zu bilden.K-Means lässt sich zwar sehr gut parallelisieren, da die einzelnen Pixel unabhängig zujedem Zentrum den Abstand bestimmen können, es ist in einem Fragment Shader alleineaber nicht möglich. Dazu muss es einen globalen, threadsicheren Zähler geben, der dieAnzahl der Pixel zu einem Zentrum zählt. Der SLIC Superpixel Algorithmus muss um-geschrieben werden, um parallelisierbar zu sein. Er operiert normalerweise über das Setder Zentren. Da ein Pixel zu N vielen Zentren gehören kann, würde es bei einer Paralle-lisierung hier zu Race-Conditions kommen. Der Algorithmus müsste so umgeschriebenwerden, dass jeder Pixel einzeln berechnet, zu welchen Zentren er theoretisch gehörenkönnte. In der Software wurde dies nicht gemacht, diese zwei Algorithmen wurden aufder CPU seriell implementiert.
3.4 Erstellte Pipelines
Für das Ziel, einen Patienten semantisch zu segmentieren, wurden nun fünf Pipelines er-stellt. Der Aufbau der Pipelines wird nun vorgestellt, die Ergebnisse werden im anschlie-ßenden Kapitel betrachtet. Die Pipelines dienen zur Evaluation der Bildverarbeitungsal-gorithmen, welche in Kapitel 2 beschrieben wurden.
Bis auf Pipeline 4 starten alle Ansätze mit zwei Schablonen, welche den irrelevanten Teildes Bildes entfernen. Die erste Schablone ist eine Elipse, deren Fokusse am Kopf undam Fuß des Patienten platziert sind. Die zweite Schablone ist ein Rechteck, welches dieElipse weiter einschränkt.
20

3 Implementierung
Die ersten zwei Pipelines fokussieren sich auf eine Kantenerkennung. Da bei dem vorhan-denen Datensatz die Umgebung sehr unterschiedlich ist, es wurde beispielsweise andereKleidung getragen oder Decken und Unterlagen hatten verschiedene Texturen, benutzt Pi-peline 1 einen sehr großen, linearen Blur mit einer Größe von 13×13, um die Details zueliminieren. Daraufhin wird der Robert Cross Operator angewandt mit einem maximalenWert von 0.1557. Da der große Blur die Ableitung stark reduziert, muss ein kleiner Maxi-malwert gewählt werden. Es folgt ein Double Threshold und eine Hysteresis nach Canny,mit Grenzwerten von 0.17 und 0.237. Pipeline 2 ist ein klassicherer Kantenerkennungal-gorithmus, er benutzt einen 3×3 Gauß Blur mit σ = 1.8, den Sobel Operator mit einemmaximalen Wert von 0.385 und auch wieder einen Double Threshold mit Hysteresis. Derschwache Grenzwert liegt bei 0.335 und der starke bei 0.515.
Pipeline 3 nutzt die Tatsache aus, dass die Hautfarbe der Patienten sich weitesgehend vonder Farbe der Umgebung unterscheidet. Sie benutzt einen Farbfilter, welcher den RGBVektor der Pixel normiert und ein Skalarprodukt mit der allgemeinen Hautfarbe bildet.Ist dieses Produkt größer als 0.25 wird dieser Pixel angenommen. Um ein möglichst zu-sammenhängendes Resultat zu erzielen, wird vorher ein 9× 9 Gauß Filter mit σ = 10angewandt.
Die Pipelines 4 und 5 benutzen Clustering Algorithmen. Pipeline 4 wendet direkt denSLIC Algorithmus an mit relativ großen Superpixeln, welche eine durschnittliche Grö-ße von 131× 131 Pixeln haben. Die Originalbilder haben eine Größe von 1920× 1200Pixeln. Es wurden große Superpixel gewählt, damit ganze Superpixel einen großen Teilvon einer Körperregion einnehmen können. Der Parameter m wurde auf 0.619 gesetzt. Eswerden 5 Iterationen berechnet. Eine Schablone wird hier nicht angewandt, da der SLICAlgorithmus nicht direkt Superpixel entfernen kann. Pipeline 5 wendet den K-Means Al-gorithmus mit 16 Farben und 10 Iterationen an. Die Werte der Zentren werden nicht zufäl-lig gewählt, es werden die Zentren des letzten Patienten als Initialwerte angenommen.
Tabelle 3.1 zeigt eine grobe Übersicht der Pipelines.
21

3 Implementierung
Pipe
line
1Pi
pelin
e2
Pipe
line
3Pi
pelin
e4
Pipe
line
5Sc
habl
one:
Elip
seSc
habl
one:
Elip
seSc
habl
one:
Elip
seSL
ICSu
perp
ixel
sSc
habl
one:
Elip
seSc
habl
one:
Rec
htec
kSc
habl
one:
Rec
htec
kSc
habl
one:
Rec
htec
k-
Scha
blon
e:R
echt
eck
Lin
earB
lur,
13×
13G
auß
Blu
r,3×
3,σ=
1.8
Gau
ßB
lur,
9×
9,σ=
10-
K-M
eans
16,1
0It
erat
ione
nC
ross
Ope
rato
rSo
belO
pera
tor
Farb
filte
r-
-D
oubl
eT
hres
hold
Dou
ble
Thr
esho
ld-
--
Hys
tere
sis
Hys
tere
sis
--
-
Tabe
lle3.
1:Ü
bers
icht
dere
rste
llten
Pipe
lines
22

4 Ergebnisse
In diesem Kapitel werden die Ergebnisse der Algorithmen präsentiert und evaluiert. Siewurden auf einen Datensatz von 4 Patienten angewandt. Abbildung 4.1 zeigt die Ergeb-nisse der Pipelines aus Kapitel 3.4. Tabelle 4.1 zeigt die Zeiten, welche einzelne Filterbeansprucht haben. Gemessen wurde auf zwei Testsystemen. Im Anhang ist die Hard-ware der Testsysteme zu finden. Die Algorithmen wurden direkt auf die Originalbilderangwandt, welche eine Auflösung von 1920× 1200 Pixeln haben. Gestartet wurden dieZeitmessungen nachdem sich die Texturen im Arbeitsspeicher befanden, gestoppt nach-dem sich die Textur darstellbar im RAM oder GPU Speicher befindet. Um den Vorteileiner Implentierung auf der GPU zu demonstrieren, wurden neben den selbst implemen-tierten Algorithmen noch weitere OpenCV Algorithmen gemessen. Das Testprogrammwurde mit den höchsten Kompiler-Optimierungen kompiliert.
Um die Ergebnisse zu quantifizieren, wurden per Hand Binärmasken erstellt und mit demOutput verglichen. Für die Pipelines, welche eine Kantenerkennung anwenden, wurde derUmriss der einzelnen Körperregionen der Neonaten markiert. Das Verhältniss zwischenden Kanten in der Maske und allen erkannten Kanten, wurde berechnet. Für Pipelines 3und 4 wurden Binärmasken erstellt, welche die einzelnen Körperregionen komplett abde-cken. Der Output aus Pipeline 3 wurde direkt mit dieser verglichen. Für Pipeline 4 wur-den die Superpixel, welche zu den jeweiligen Körperregionen gehören, zuvor per Handherausgefiltert. Da Pipeline 5 nur ein Clustering-Algorithmus anwendet, wird hier einKompaktheitsgrad berechnet, welcher den farblichen Abstand zum Original misst. Hier-für wird der Mittelwert der euklidischen Länge der Distanzvektoren berechnet, welchesich durch L =
∣∣∣∣∣∣~Corig−~Cout
∣∣∣∣∣∣ ergibt. Der Mittelwert K wird nun Kompaktheit gennant.
Die Abbildungen 4.2 und 4.3 zeigen die erstellten Masken für die Pipelines 1 - 4. Tabel-le 4.2 zeigt die Fehlerquoten der Pipelines 1 und 2, Tabelle 4.3 zeigt die Übereinstim-mung der Binärmasken, Tabelle 4.4 zeigt die Kompaktheitsgrade aus Pipeline 5, sowieeinige Vergleichswerte, welche von den geclusterten Bildern aus Kapitel 2.4 berechnetwurden.
23
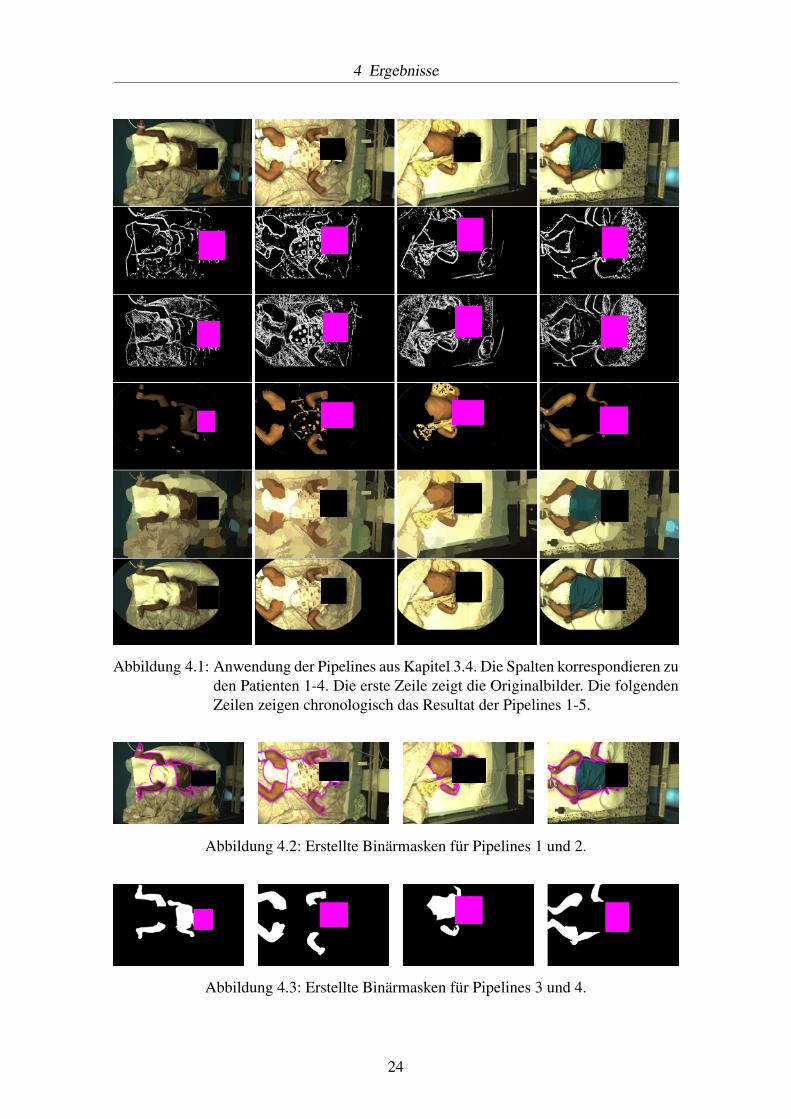
4 Ergebnisse
Abbildung 4.1: Anwendung der Pipelines aus Kapitel 3.4. Die Spalten korrespondieren zuden Patienten 1-4. Die erste Zeile zeigt die Originalbilder. Die folgendenZeilen zeigen chronologisch das Resultat der Pipelines 1-5.
Abbildung 4.2: Erstellte Binärmasken für Pipelines 1 und 2.
Abbildung 4.3: Erstellte Binärmasken für Pipelines 3 und 4.
24
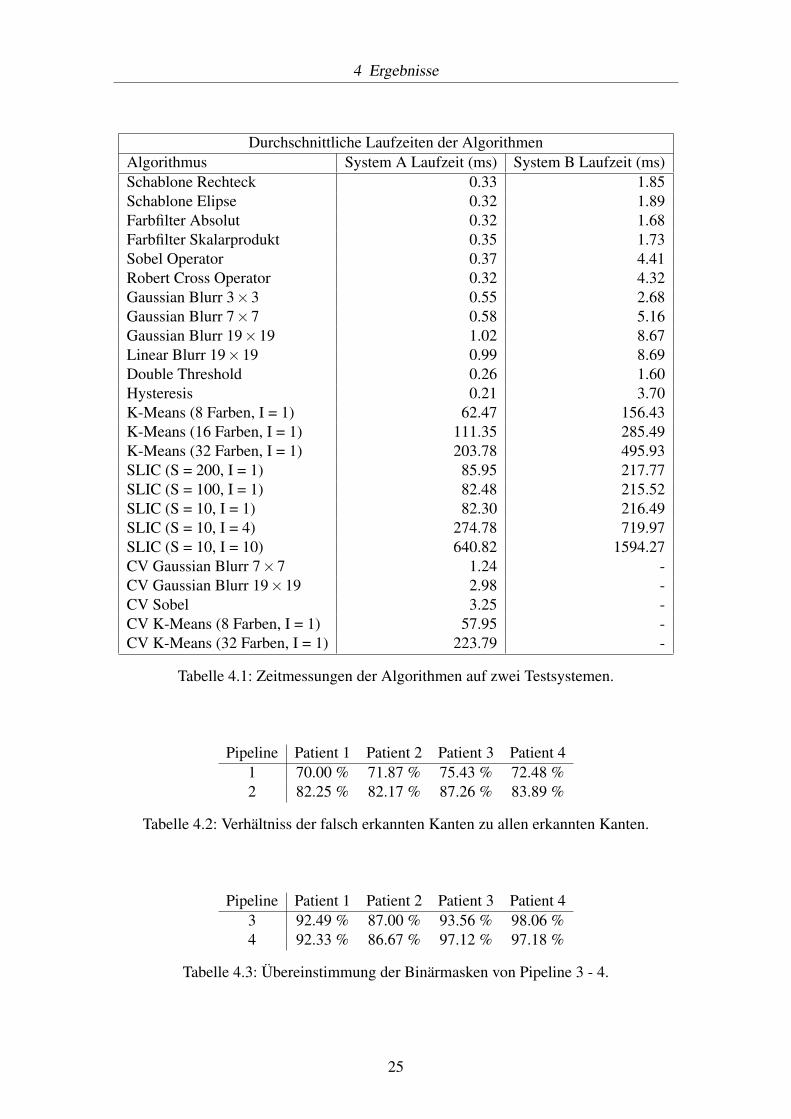
4 Ergebnisse
Durchschnittliche Laufzeiten der AlgorithmenAlgorithmus System A Laufzeit (ms) System B Laufzeit (ms)Schablone Rechteck 0.33 1.85Schablone Elipse 0.32 1.89Farbfilter Absolut 0.32 1.68Farbfilter Skalarprodukt 0.35 1.73Sobel Operator 0.37 4.41Robert Cross Operator 0.32 4.32Gaussian Blurr 3×3 0.55 2.68Gaussian Blurr 7×7 0.58 5.16Gaussian Blurr 19×19 1.02 8.67Linear Blurr 19×19 0.99 8.69Double Threshold 0.26 1.60Hysteresis 0.21 3.70K-Means (8 Farben, I = 1) 62.47 156.43K-Means (16 Farben, I = 1) 111.35 285.49K-Means (32 Farben, I = 1) 203.78 495.93SLIC (S = 200, I = 1) 85.95 217.77SLIC (S = 100, I = 1) 82.48 215.52SLIC (S = 10, I = 1) 82.30 216.49SLIC (S = 10, I = 4) 274.78 719.97SLIC (S = 10, I = 10) 640.82 1594.27CV Gaussian Blurr 7×7 1.24 -CV Gaussian Blurr 19×19 2.98 -CV Sobel 3.25 -CV K-Means (8 Farben, I = 1) 57.95 -CV K-Means (32 Farben, I = 1) 223.79 -
Tabelle 4.1: Zeitmessungen der Algorithmen auf zwei Testsystemen.
Pipeline Patient 1 Patient 2 Patient 3 Patient 41 70.00 % 71.87 % 75.43 % 72.48 %2 82.25 % 82.17 % 87.26 % 83.89 %
Tabelle 4.2: Verhältniss der falsch erkannten Kanten zu allen erkannten Kanten.
Pipeline Patient 1 Patient 2 Patient 3 Patient 43 92.49 % 87.00 % 93.56 % 98.06 %4 92.33 % 86.67 % 97.12 % 97.18 %
Tabelle 4.3: Übereinstimmung der Binärmasken von Pipeline 3 - 4.
25

4 Ergebnisse
Quelle Vergleich KPatient 1, Abb. 4.1 Pat 1. Pipeline 5, Abb. 4.1 13.537Patient 2, Abb. 4.1 Pat 2. Pipeline 5, Abb. 4.1 131.762Patient 3, Abb. 4.1 Pat 3. Pipeline 5, Abb. 4.1 178.668Patient 4, Abb. 4.1 Pat 4. Pipeline 5, Abb. 4.1 149.621
Früchte, Abb. 2.6 (f) K-Means 8, Abb. 2.6 (c) 23.738Früchte, Abb. 2.6 (f) K-Means 16, Abb. 2.6 (d) 17.103Früchte, Abb. 2.6 (f) K-Means 32, Abb. 2.6 (e) 13.362Früchte, Abb. 2.6 (f) SLIC S=10, Abb. 2.7 (i) 7.874Patient 1, Abb. 4.1 Pat 1. SLIC S=10 5.02
Tabelle 4.4: Vergleich von Kompaktheitsgraden.
4.1 Evaluation der Ergebnisse
Es folgt eine Analyse der Ergebnisse der Pipelines.
Die Kantenerkennungs-Pipelines 1 und 2 liefern mäßige Ergebnisse. Bei beiden Pipelinesergeben sich sehr hohe Fehlerquoten von über 70 %. Einige Ergebnisse zeigen sichtlichkeinen Mehrwert. Pipeline 1 übersieht beispielsweise bei Patient 1 viele wichtige Kanten,Pipeline 2 erkennt zu viele unwichtige. Pipeline 2 markiert große Teile der Umgebung alsKanten, wie bei Patient 2 und 3 zu sehen, was bei Patient 1 zu einem relativ unbrauchbarenErgebnis führt. Etwas bessere Ergebnisse entstehen durch Pipeline 1. Dies zeigen auch dieFehlerquoten, welche hier im Durchschnitt ca. 10% niedriger ausfallen. Es wurden zwarimmer noch viele Kanten markiert, welche nicht zu den Neonaten gehören, wie die Tisch-kante oder Bettdecke, allerdings ergibt sich bei Patient 3 und 4 eine geschlossene Kurveum die Patienten. Aber trotz der hohen Fehlerquote sind die Ergebnisse im Allgemeinennicht unbrauchbar. Die Fehlerquote bezieht sich nur auf die Masken, es kann sein, dassein Bild viele Kanten hat, diese aber leicht herauszufiltern sind, wie bei beispielsweisePatient 3.
Pipeline 3 filtert sichtlich alle hautfarbenden Pixel heraus. Dies führt allerdings nicht im-mer zu einer perfekten Überdeckung, da beispielsweise Haare, Augen oder überklebteKörperregionen entfernt wurden. Dazu kommen weitere Artefakte, welche wieder durchdie Umgebung zustande kommen. Die Kleidung von Patient 2 und 3 wird hier teilweiseerkannt. Generell bietet diese Pipeline eine gute Überdeckung von meistens über 90%.Patient 4 gibt das beste Ergebnis, mit einer Überdeckung von insgesammt 98.06 %.
Die SLIC Superpixel in Pipeline 4 erzielen eine ähnliche Überdeckung im Vergleich zuPipeline 3, trotz der relativ großen Größe der Superpixel. Aufgrund einiger Artefakte,welche lokal zwischen den Superpixel auftreten, wo keine der angrenzenden Pixel gutpassen, fällt sie nicht höher aus. Patient 3 zeigt beispielsweise, dass Teile der Kleidung
26

4 Ergebnisse
dem Superpixel des Armes zugewiesen wurden. Die Ergebnisse zeigen zudem, dass dieSuperpixel kleinere Details zusammenfassen können. Dies ist besonders bei Patient 1 zusehen, wo die überdeckten Regionen des Brustkorbes scheinbar verschwinden. Generellbehalten die Superpixel die Form der Neonaten größtenteils bei. Der Arm von Patient 4 istdurch zwei Superpixel fast eins zu eins abgebildet. Um dieses Verfahren in einer Segmen-tierung zu nutzen, müsste allerdings noch ein Algorithmus geschrieben werden, welcherdie dazugehörigen Superpixel selber herausfiltert. Ein Farbfilter, wie er in Pipeline 3 ge-nutzt wird, könnte dabei einen ersten Schritt bieten.
Pipeline 5 scheint zunächst eine gute Approximation zu liefern. Schaut man sich aller-dings die berechneten Werte in Tabelle 4.4 an, stellt sich ein doch relativ großer Farbun-terschied zu den Originalen fest. Bis auf Patient 1 liefert die Pipeline bei allen anderenPatienten eine Kompaktheit von über 100. Dies liegt vermutlich an den fehlenden Farbenfür die Details, welche bei den anderen Patienten zu sehen sind. Das Ergebnis von Patient3 enthält beispielsweise keinen rötlichen Ton für das Muster der Decke. Außerdem wur-de der K-Means Algorithmus hier nicht bis zur Konvergenz ausgeführt. Patient 1 liefertvermutlich so ein gutes Ergebnis, da die initialen Zentren gut gepasst haben und die weni-gen Farben ausreichen. Es ist zudem aufgefallen, dass der SLIC Algorithmus mit kleinenSuperpixeln eine deutlich geringere Kompaktheit aufweist. Der Farbraum bleibt bei denSuperpixeln zwar deutlich größer, allerdings ist eine bessere Approximation zu erwarten.Zudem ist eine originalgetreue Approximation für eine Segmentierung nicht umbedingtnotwendig, solange die relativen Unterschiede beibehalten werden.
Schaut man sich die Laufzeiten aus Tabelle 4.2 an, sieht man, dass die meisten der an-gewandten Algorithmen ohne Zeitprobleme in einem Echtzeitszenario berechnet werdenkönnen. Die Implementierung in Shadern zeigt auch große Wirkung, so lassen sich alldiese Filter auf ein Bild mit 1920×1200 Pixeln ohne Probleme in wenigen oder sogar inunter einer Millisekunde anwenden. Selbst der Gaussian Blur Filter, welcher einen 19×19Kernel anwendet, kann dank der Optimierung aus Kapitel 3.3 innerhalb weniger Millise-kunden berechnet werden. Der Vorteil einer GPU wird hier ebenfalls klar. CPU-Zeitenlassen sich zwar nicht eins zu eins mit GPU-Zeiten vergleichen, es stellt sich allerdingszwischen der OpenCV und GPU Blur-Implementierung ein Faktor von über 2.1 heraus.Bei den Sobel Implentierungen stellt sich sogar ein Faktor von fast 10 heraus.
Besonders die Hysteresis zeigt den Vorteil einer dedizierten GPU. System B enthält keinededizierte GPU, System A dagegen schon. Auf System A braucht die Hysteresis unge-fähr doppelt so lange wie der Double Threshold. Die Hysteresis bei System A ist dagegenschneller als der Double Threshold. Die Hardware ist auf die hier angewandten Operatio-nen besser optimiert. Außerdem können bei der Hysteresis weitere interne Optimierungen
27

4 Ergebnisse
vorgenommen werden, da keine uniform Variablen gebraucht werden, wodurch kein Spei-cher mit der CPU geteilt werden muss.
Die auf der CPU implementierten Filter, welche ohnehin aufwendiger sind, brauchendeutlich mehr Laufzeit. Vor allem der K-Means Algorithmus benötigt relativ viel Zeit.Die Laufzeit wächst hier linear mit der Anzahl der Farben. Bei vielen Farben könntenZeitprobleme auftreten, da im Regelfall mehr als eine Iteration ausgeführt werden muss.Eine Laufzeit von über 200 Millisekunden pro Iteration ist deshalb kritisch. Wie im vorhe-rigen Kapitel beschrieben, ließe sich der Algorithmus aber auf der GPU implementieren,was die Performance verbessern wird. Der SLIC Algorithmus ist mit unter einer halbenSekunde mit 4 Iterationen noch in einem akzeptablen Bereich. Interessant ist, dass dieAnzahl der Superpixel keine oder sogar eine kleine positive Auswirkung auf die Laufzeithat. Vermutlich handelt es sich hier aber nur um Schwankungen durch frühzeitige Ab-brüche im Algorithmus, wenn ein Pixel schon zu einem Zentrum gehört, woraufhin dieDistanz nicht nochmals ausgerechnet werden muss.
Die Laufzeit aller hier gemessenen Algorithmen wächst zudem linear mit der Anzahl derPixel. So könnte die Performance drastisch verbessert werden durch einen komprimiertenInput.
Im Allgemeinen ergibt sich, dass die behandelten Algorithmen zum Großteil echtzeitfä-hig sind, allerdings für eine gute semantische Segmentierung in diesem Anwendungsfallvermutlich nicht ausreichen, aufgrund der vielen Unterschiede zwischen den Patienten.
4.2 Ausblick
Insgesamt lässt sich sagen, dass die Qualität der Ergebnisse stark vom Umfeld abhängt.Es können viele Parameter einzeln eingestellt werden, wie beispielsweise die Grenzwerteoder die initialen Zentren von Clustern, wodurch die Ergebnisse eines bestimmten Fallesdeutlich verbessert werden können. Ein klassischer Algorithmus, welcher eine vollstän-dige semantische Segmentierung durchführt, wäre möglich. Damit er gut funktionierenkann, sollte sich aber auf eine einheitliche Umgebung geeinigt werden. Er könnte auf die-se spezielle Umgebung spezialisiert werden. Das Ergebnis könnte zudem immer durchOptimierungen der Algorithmen verbessert werden. Zudem könnten weitere Algorith-men untersucht werden. Im Allgemeinen eignen sich die behandelten Algorithmen aberweniger für eine semantische Segmentierung, sondern eher für eine Vorkonditionierung.Aufgrund der geringen Laufzeit könnte solch ein Algorithmus meistens auch nebenherberechnet werden, um weitere Informationen zu liefern.
28

4 Ergebnisse
Es könnte zudem untersucht werden, ob die Ergebnisse der Algorithmen als Input füreinen KI-basierenden Klassifikator dienen können, welche durch die reduzierten Detailsund mehr Informationen bessere Ergebnisse liefern könnten. Wie besonders der SLICAlgorithmus gezeigt hat, kann er kleinere Details zusammenfassen.
Da die behandelten Algorithmen nicht nur in diesem Bereich Anwendung finden, kanndie entwickelte Software ebenfalls als eigenes Produkt weiterentwickelt werden.
29
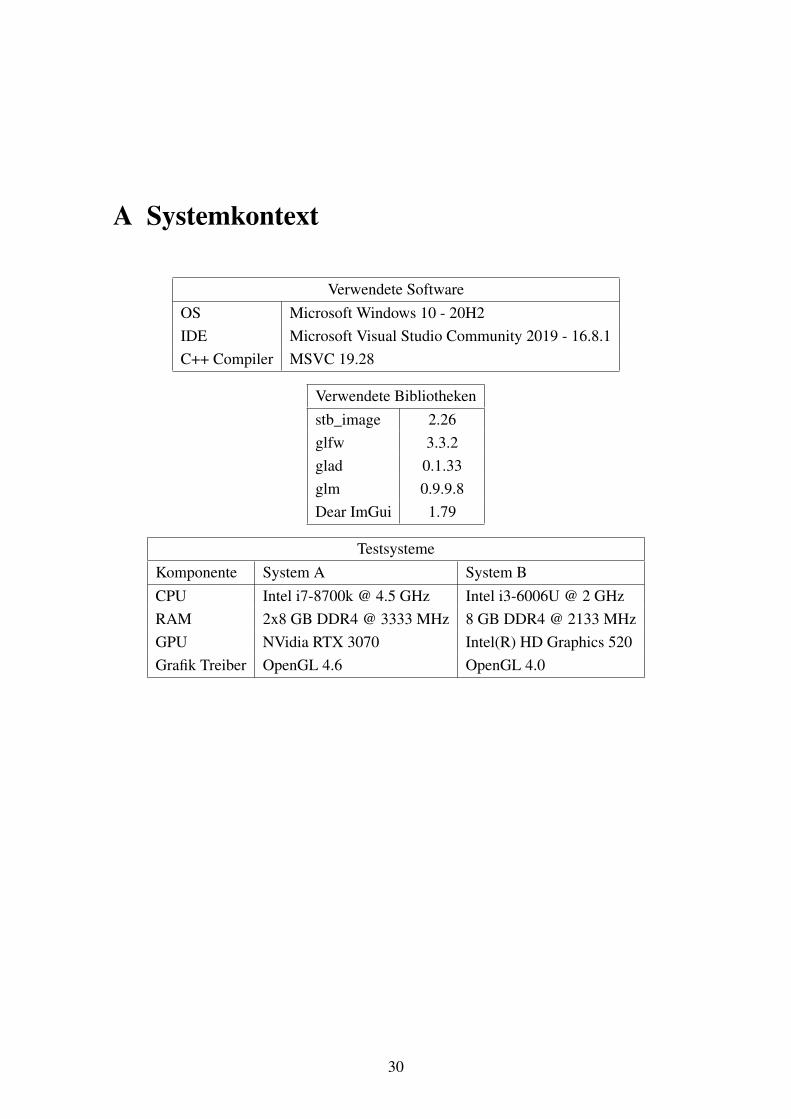
A Systemkontext
Verwendete SoftwareOS Microsoft Windows 10 - 20H2IDE Microsoft Visual Studio Community 2019 - 16.8.1C++ Compiler MSVC 19.28
Verwendete Bibliothekenstb_image 2.26glfw 3.3.2glad 0.1.33glm 0.9.9.8Dear ImGui 1.79
TestsystemeKomponente System A System BCPU Intel i7-8700k @ 4.5 GHz Intel i3-6006U @ 2 GHzRAM 2x8 GB DDR4 @ 3333 MHz 8 GB DDR4 @ 2133 MHzGPU NVidia RTX 3070 Intel(R) HD Graphics 520Grafik Treiber OpenGL 4.6 OpenGL 4.0
30

B Implementierung von einem DoubleThreshhold Filter als GLSL FragmentShader
# v e r s i o n 430
o u t vec4 o _ f r a g _ c o l o r ;
un i fo rm sampler2D t e x _ s c e n e ;
un i fo rm f l o a t l o w _ t h r e s h ;un i fo rm f l o a t h i g h _ t h r e s h ;
c o n s t vec4 p i x _ c o l o r = t e x e l F e t c h ( t e x _ s c e n e , i v e c 2 ( g l_FragCoord . xy ) , 0 ) . r gba ;
c o n s t vec3 lum = vec3 ( 0 . 2 1 2 6 , 0 . 7 1 5 2 , 0 . 7 1 5 2 ) ;f l o a t l uminance ( vec3 rgb ){
re turn d o t ( lum , rgb ) ;}
void main ( ){
i f ( p i x _ c o l o r . a < 0 . 5 ){
o _ f r a g _ c o l o r = p i x _ c o l o r ;re turn ;
}
c o n s t f l o a t I = luminance ( p i x _ c o l o r . rgb ) ;
i f ( I < l o w _ t h r e s h ){
o _ f r a g _ c o l o r = vec4 ( 0 , 0 , 0 , 1 ) ;}e l s e{
i f ( I > h i g h _ t h r e s h ){
o _ f r a g _ c o l o r = vec4 ( 1 ) ;}e l s e{
o _ f r a g _ c o l o r = vec4 ( 0 . 5 , 0 . 5 , 0 . 5 , 1 ) ;}
}}
31

Literatur
[1] Lonneke A.M. Aarts et al. „Non-contact heart rate monitoring utilizing came-ra photoplethysmography in the neonatal intensive care unit — A pilot study“.In: Early Human Development 89.12 (2013), S. 943–948. URL: http://www.sciencedirect.com/science/article/pii/S0378378213002375.
[2] John Canny. „A Computational Approach to Edge Detection“. In: IEEE PAMI-8.6(Nov. 1986).
[3] Yan Xu Zhipeng Jia Liang-Bo Wang Yuqing Ai Fang Zhang Maode Lai Eric I-ChaoChang. „Large scale tissue histopathology image classification, segmentation, andvisualization via deep convolutional activation features“. In: BMC Bioinformatics18.281 (2017).
[4] David Wolf. OpenGL 4 Shading Language Cookbook - Build high-quality, real-time 3D graphics with OpenGL 4.6, GLSL 4.6 and C++17. 3. Aufl. Birmingham:Packt, 2018.
[5] Salvatore Tabbone Djemel Ziou. Edge Detection Techniques - An Overview.
[6] Falense. Bild von einem Löwen. CC BY-SA 3.0<http://creativecommons.org/licenses/by-sa/3.0/>, via Wikimedia Commons,Zugriff: 2020-12-11. URL: https://commons.wikimedia.org/wiki/File:Okonjima_Lioness.jpg.
[7] Dr.C. Chandrasekar G.T. Shrivakshan. „A Comparison of various Edge DetectionTechniques used in Image Processing“. In: IJCSI International Journal of Compu-ter Science Issues 9.1 (Okt. 2012).
[8] J.T. Tou R.C. Gonzalez. Pattern Recognition Principles. 1974.
[9] Ehsan Nadernejad Sara Sharifzadeh Hamid Hassanpour. „Edge Detection Tech-niques: Evaluations and Comparisons“. In: Applied Mathamatical Sciences 2.31(2008).
[10] Mayank Kumar, Ashok Veeraraghavan und Ashutosh Sabharwal. „DistancePPG:Robust non-contact vital signs monitoring using a camera“. In: Biomed. Opt. Ex-
32

Literatur
press 6.5 (Mai 2015), S. 1565–1588. URL: http://www.osapublishing.org/boe/abstract.cfm?URI=boe-6-5-1565.
[11] Barry B. Lee. „The evolution of concepts of color vision“. In: Neurociencias 4.4(Mai 2008).
[12] M. Poh, D. J. McDuff und R. W. Picard. „Advancements in Noncontact, Multipa-rameter Physiological Measurements Using a Webcam“. In: IEEE Transactions onBiomedical Engineering 58.1 (2011), S. 7–11.
[13] Dr. Himanshu Aggarwal Raman Maini. „Study and Comparison of Various ImageEdge Detection Techniques“. In: IJIP International Journal of Image Processing3.1 (2009).
[14] Dr.V. Sankaranarayanan S. Lakashmi. „A study of Edge Detection Techniques forSegmentation Computing Approaches“. In: IJCA International Journal of Compu-ter Applications (2010).
[15] F. Shi J. Wang J. Shi Z. Wu Q. Wang Z. Tang K. He Y. Shi D. Shen. „Review ofArtificial Intelligence Techniques in Imaging Data Acquisition, Segmentation andDiagnosis for COVID-19“. In: IEEE Reviews in Biomedical Engineering (2020).
[16] Radhakrishna Achanta Appu Shaji Kevin Smith Aurelien Lucchi Pascal Fua SabineSüsstrunk. SLIC Superpixels. Techn. Ber. 149300. EPFL, Juni 2010.
[17] Richard Szelski. Computer Vision: Algorithms and Applications. 2. Aufl. Springer,Okt. 2020.
[18] Sonia Valero-Portero et al. „Staphylococcal scalded skin syndrome in an extreme-ly preterm newborn: management in a neonatal intensive care unit“. In: Archivesof Disease in Childhood - Fetal and Neonatal Edition 102.3 (2017), F224–F225.eprint: https://fn.bmj.com/content/102/3/F224.full.pdf. URL: https://fn.bmj.com/content/102/3/F224.
[19] Sun Yu et al. „Motion-compensated noncontact imaging photoplethysmography tomonitor cardiorespiratory status during exercise“. In: Journal of Biomedical Optics16.7 (2011), S. 1–10. URL: https://doi.org/10.1117/1.3602852.
33





























