-
Verwaltung sehr großer Datenmengenmit Sybase 15
Jürgen BittnerSQL GmbH
Deckblatt
-
DB-Stammtisch 06/2006, 2
Wie groß sind VLDB ? - 2005
-
DB-Stammtisch 06/2006, 3
•Performance & Effektivität•Skalierfähigkeit(Daten &
Anwender)
OLTP=einfache Query-verarbeitet 10s von Rows-1000s von Rows pro
Sekunde-einfache (½-Seite) SQL Statements
DSS=komplexe Query-verarbeitet M(B)ILLIONS von Rows-Millionen
von Rows pro Sekunde-komplexe (10-Seiten) SQL Statements
spaltenbasiertes IQ Multiplex(entworfen vor wenigen Jahren für
DSS)
zeilenbasiertes DBMS(entworfen vor +20 Jahren für OLTP) DB2,
Oracle, MS SQL, ASE, NCR etc.
2x-1000x
2x-1000x
DSS versus OLTP Workload
-
DB-Stammtisch 06/2006, 4
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 5
Der traditionelle RDBMS-Ansatz
Mon Einr Typ Land Prod Abs
0105 32 G SA Werne 12
0105 36 G MV Becks 9
0105 38 G SA Radeb 28
0105 41 K NS Jever 11
0105 43 G SA Radeb 9
0105 46 G BY Paula 3
0105 47 M NW Dortm 70
0105 49 K SA Lands 12
Berechne den durchschnittlichen Absatz von „Radeberger“in
Gastronomie-Einrichtungen in Sachsen je Monat
• Benutze einen Index wenn verfügbar- benötigt normalerweise
Table Scan
• Gehe zu den ausgewählten Datenseiten und addiere die Zahlen-
Zufällige Verteilung der Daten führt dazu, daß fast alle Seiten
gelesen werden müssen.
- Auf jeder Seite müssen alle - auch die irrelevanten - Daten
gelesen werden.
Traditioneller Ansatz:
SELECT AVG (Abs), SUM(Abs)/AnzGSA/36
FROM Absatz,
(SELECT COUNT(DISTINCT Einr) AS AnzGSA
FROM Absatz
WHERE Land = ‘SA‘ AND
Typ = ‘G‘)
WHERE Land = ‘SA‘ AND
Typ = ‘G‘ AND
Prod = ‘Radeb‘
-
DB-Stammtisch 06/2006, 6
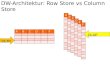
Sybase IQ: Es werden nur die relevanten Spalten gelesen
Vorteile:Ohne weitere Techniken kann IQ den Disk-I/O sehr stark
reduzieren
Vertikale Partitionierung
Mon Einr Typ Land Prod Abs
9805 32 G SA Werne 12
9805 36 G MV Becks 9
9805 38 G SA Radeb 28
9805 41 K NS Jever 11
9805 43 G SA Radeb 9
9805 46 G BY Paula 3
9805 47 M NW Dortm 70
9805 49 K SA Lands 12
Berechne den durchschnittlichen Absatz von Radebergerin
Gastronomie-Einrichtungen in Sachsen
-
DB-Stammtisch 06/2006, 7
Sybase IQ Advanced Bit-Mapped Indizes
25 Jahre bewährte Technologie (z.B. Model 204)Vor Sybase IQ nur
für Daten mit geringer Kardinalität(< 100 Werte) verwendbar
Sybase IQ erweitert diesen Wert auf > 1.000 Werte durch die
Kombination von Bitmaps und Komprimierung.Ohne weitere intelligente
Indizes allerdings von begrenztem Nutzen, da nur wenige Queries nur
Bitmaps brauchen
Bitmap Index für Land
row-id BY MV NS NW SA1 0 0 0 0 12 0 1 0 0 03 0 0 0 0 14 0 0 1 0
05 0 0 0 0 16 1 0 0 0 07 0 0 0 1 08 0 0 0 0 1
LandSAMVSANSSABYNWSA
-
DB-Stammtisch 06/2006, 8
“Wieviele Männer sind in Kalifornien nicht versichert?“
GeschlechtMMWMMW
800 Bytes/Satz
20MSätze
StaatCACANYCAMACT
RDBMSRDBMSVersichert
JNJNJN
800 Bytes x 20M 16K Seite = 1.000,000 I/Os
Verarbeitet grosse Mengen nicht benötigter DatenErfordert oft
“Full Table Scan”
M CA JM CA NW NY JM CA N
12
43
Geschlecht Staat Versichert
= 2+ +1101
0101
1101
20MBits
20M Bits x 3 Spalten / 816K Seite
= 470 I/Os
Dramatische I/O-Reduzierung
-
DB-Stammtisch 06/2006, 9
OLTP DBMS vs. IQ-Multiplex engine
1 2 3 4 ….. 100 Db page64KB-512KB 1 2 3 4 …. 100
IQ MultiplexSQL: Create table ABCyellow, blue, red..magenta
SQL:Select sum (red) from ABC
OLTP-centricDBMS
Db page2-32KB
Small size, random I/O gets less than 1MB/s-3MB/s from single
disk
IQM large, semi-sequential I/O gets 10MB/s-30MB/s from single
disk
1: Standard SQL language: (no patents, trivial migration and
retraining)2: Column structure ( patented, invisible to users )
-Designed for DW: Ad-Hoc/complex queries (no OLTP tradeoffs,
never FTS)- 90%-99% reduction in I/O compared with
traditional_DBMS-based DW-45,000 columns/table => enables
complexity AND flexibility, low RAM use
3: Indexing: Bit-wise, Word, Bitmap etc. (patented, invisible to
users )-Speed: designed for DSS=>2x-1,000x faster than
OLTP-centric DBMS-Data-driven (vs “one-size-fits-all”, I.e.
B-tree)-low-cost(=no index “explosion”): index every column (some
multiple times)
4: Data Compression ( patented, invisible to users )-Additional
reduction of DB size AND I/O by 30-80% (typ); improves security-IQM
DB size(fully indexed) : 75% of raw data (typ); IQM as an
ARCHIVE?-OLTP-centric DB size is 3x-10x of raw data size
=>4x-15x more disk than IQM-small IQM size & low
I/O=>fast/low_cost Backup/R, HA and Disaster Site site
5: IQ Multiplex-Shared-disk (non-partitioned data) with 97%
multi-node scalability-ZERO inter-node interference =>
Architecture with Built-in High Availability-Scalability and
Availability beyond MPP and pure-SMP+HA solutions
-
DB-Stammtisch 06/2006, 10
Administration der Indexstrukturen
Indexerstellung zur Designzeit
• Keine Datenspeicherung• Kardinalität• Datentyp
Keine Pflege der Indexstatistiken
Indextypen Sybase IQ
-
DB-Stammtisch 06/2006, 11
Index Advisor
• Vorschläge von Indextypen für
– Single Column Predicate (e.g. HG/LF, Date)– Join Column–
Subquery Predicate– Group By Column– Two Columns compared in Same
Table (CMP index)
• Erkennt ungeeignete Index-Definitionen
-
DB-Stammtisch 06/2006, 12
IQ Multiplex 12.5 (und davor)
IQ Main Store
Developer Tables
Base Tables
1 Sybase IQ Write Server N Sybase IQ Query Server
DBAs
Analysts
Developers
ETL Processes
WEB Access
Query Only UsersAnalyst Tables
-
DB-Stammtisch 06/2006, 13
IQ Multiplex 12.6 w/ Local Store
N Sybase IQQuery Only Server
Base Tables
1 Sybase IQ Write Server
DBAs
ETL Processes
WEB Access
Query Only Users
Analysts
Developers
IQ Main Store DeveloperTables
M Query Serverwith a
Local Store
Analysis Area
Local Store
-
DB-Stammtisch 06/2006, 14
IQ Multiplex – Local Store für Query Server
• Query Server ermöglichen einen 'Local IQ Store' , der es den
Benutzern erlaubt, permanente Objekte in der Datenbank
anzulegen
– Unterstützung für Benutzer wie Analysten und Entwickler, die
ihreeigenen Tabellen oder Prozeduren kreieren wollen
• Objekte, die im Local Store angelegt wurden, werden persistent
nacheinem Recycle des Query Servers
• Diese Objekte sind nur für die Benutzer sichtbar, die mit dem
Query Server verbunden sind, zu dem der Local IQ Store gehört
– Objekt-Zugriff gemäß Standard Rechten
• Ein Backup des IQ Main Store realisiert NICHT ein Backup im
Local IQ Stores
– Local Store backup muß separat ausgeführt werden– Gleiches
gilt für die Konsistenz-Prüfung der Daten im Local Store
-
DB-Stammtisch 06/2006, 15
SUN-Sybase Referenz DWH - Weltgrößtes DWH in Menlo Park Business
Case Telco
•2002
•179 Milliarden Zeilen
•48 TB Inputdaten
•Kompression der Inputdaten v. 48 TB auf 22 TB
•Ladezeit: 160 Millionen CDRs in < 1 h
•2004
•1 Billion Zeilen
•155 TB Inputdaten
•Kompression der Inputdaten v. 155 TB auf 55 TB
•Ladezeit: bis zu 1,8 Mrd. Datensätze pro Stunde
-
DB-Stammtisch 06/2006, 16
2005: World’s TopTenCompany DB size Input data(GB) DBMS Syst
Arch. DBMS vendor server storage
AT&T 26,269 94,305 Daytona SMP AT&T Sun SunAmazon.com
13,001 34,219 France Telecom 29,232 29,735 Health Insurance Review
Agency 11,942 29,299 IQ MPP/Cluster Sybase HP EMCBarclays Bank
6,408 24,756 Teradata MPP/Cluster Teradata NCR LSIFedEx Services
9,981 14,745 Teradata MPP/Cluster Teradata NCR EMCSamsung Card.
7,684 14,567 IQ MPP/Cluster Sybase HP HPKmart 12,592 13,874
Teradata MPP/Cluster Teradata NCR LSICho-Hung Bank 3,361 12,350 IQ
MPP/Cluster Sybase Sun HitachiLG Card 6,336 12,313 IQ MPP/Cluster
Sybase Sun EMC
Company Input data(GB) DB size DBMS Syst Arch. DBMS vendor
server storageFrance Telecom 29,735 29,232 SMP AT&T 94,305
26,269 Daytona SMP AT&T Sun SunSBC NULL 24,805 Teradata
MPP/Cluster Teradata NCR LSIAnonymous 8,591 16,191 DB2 MPP/Cluster
IBM IBM IBMAmazon.com 34,219 13,001 Oracle SMP Oracle HP HPKmart
13,874 12,592 Teradata MPP/Cluster Teradata NCR LSIClaria
Corporation 4,361 12,100 Oracle SMP Oracle Sun HitachiHealth
Insurance Review Agency 29,299 11,942 IQ MPP/Cluster Sybase HP
HitachiFedEx Services 14,745 9,981 Teradata MPP/Cluster Teradata
NCR EMCVodafone D2 GmbH NULL 9,108 Teradata MPP/Cluster Teradata
NCR LSI
Company rows (M) DBMS Syst Arch. DBMS vendor server
storageAT&T 496,041 Daytona SMP AT&T Sun Sun
Nielsen Media Research 380,000 IQ MPP/Cluster Sybase Sun
SunFrance Telecom 156,788 Oracle SMP Oracle HP HPSBC 144,417
Teradata MPP/Cluster Teradata NCR LSIKmart 133,079 Teradata
MPP/Cluster Teradata NCR LSIFedEx Services 89,343 Teradata
MPP/Cluster Teradata NCR EMCKroger 77,837 DB2 MPP/Cluster IBM IBM
IBMLG Card 74,703 IQ SMP Sybase Sun EMCHealth Insurance Review
Agency 72,093 IQ MPP/Cluster Sybase HP HitachiAT&T Wireless
Services 64,534 Teradata MPP/Cluster Teradata NCR NCR
Company input size GB rows (M) DBMS Syst Arch. DBMS vendor
server storageComScore Networks Inc. 14,464 61,361 IQ MPP/Cluster
Sybase HP EMCComScore Networks Inc. 19,604 44,195 IQ MPP/Cluster
Sybase Dell EMCComScore Networks Inc. 14,636 40,523 IQ MPP/Cluster
Sybase Dell EMCOrdina 6,402SQL Server SMP Microsoft IBM IBMArclight
Systems LLC 6,246SQL Server SMP Microsoft IBM EMCEdgars
Consolidated Stores 5,543SQL Server SMP Microsoft IBM IBMHewlett
Packard Company 3,704 Oracle SMP Oracle HP HPGomez 3,418SQL Server
SMP Microsoft HP otherDataQuick 3,273SQL Server SMP Microsoft Dell
EMCNAREX, Inc 3,228SQL Server SMP Microsoft Dell Dell
Company input size GB DB size DBMS Syst Arch. DBMS vendor server
storageComScore Networks Inc. 19,604 8,852 IQ MPP/Cluster Sybase HP
EMCComScore Networks Inc. 14,464 7,458 IQ MPP/Cluster Sybase Dell
EMCComScore Networks Inc. 14,636 7,336 IQ MPP/Cluster Sybase Dell
EMCHewlett Packard Company 2,165 Oracle SMP Oracle HP HPHewlett
Packard Company 1,755 Oracle SMP Oracle HP HPArclight Systems LLC
1,640SQL Server SMP Microsoft IBM IBM
(exploded) DB SIZE Windows
( Exploded ) DB Size, All Environments & UNIX
Input DATA Size, All Environments & UNIX
DB ROWS All Environments & UNIX
DB ROWS Windows
www.wintercorp.com
29 TB
15 TB
12 TB
380 B
74,7 B
72 B
China Telecom :134 B
IRS :15 B Citadel :83 B
61 B
SKCC :170 B
-
DB-Stammtisch 06/2006, 17
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 18
Neue Limits
ASE 15.0 very large storage system Vor ASE 15
Maximale device Anzahl = 231 (2 Billion) 256
Maximale device Größe = 4TB 32 GB
Datenbanken/Server = 32 767 (noch)
Das maximale Speichervolumen:
Datenbank-Größe:
231 pages * 16KB pg = 32 TB 256 * 32 GB = 8 TB
Theoretisches Speichervolumen eines Servers:
32,767 DB’s * 32 TB = 1 EB (exabyte) = 1,048,544 TB
-
DB-Stammtisch 06/2006, 19
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 20
Überblick zum Partitionieren
• Große Tabellen benötigen entsprechend großeRessourcen:
– Table Scans benötigen viele E/A– Verwaltungsaufgaben benötigen
viel Zeit – und viele Sperren– OLTP und DSS behindern sich
gegenseitig
• Durch die Partitionen werden die Tabellen in
Teilmengenzerlegt:
– Die Daten jeder Partition können unabhängig verarbeitet
werden– Die Bearbeitung kann parallel erfolgen– Administrative
Aufgaben können gezielt auf speziellen Partitionen
erfolgen
-
DB-Stammtisch 06/2006, 21
Vor ASE 15
• Partitionieren durch Segmente
• Nur die Tabellen (nicht die Indexe) sind partitioniert
• Primäre Ziele
• Reduzieren der last page Konflikte• Parallelisierte
query-Verarbeitung• Parallelisiertes dbcc checkstorage•
Parallelisiertes create index
-
DB-Stammtisch 06/2006, 22
ASE 15 Semantische Partitioinierung
• Partitionierte Tabellen und Indexe
– Partition types in ASE 15.x:• Range • List • Hash• Round-robin
(ersetzt Segment)
– Partition maintenance• Add oder Alter eine oder mehrere
partitions
• Globale und lokale Indexe auf partitions
– Clustered/non-clustered indexes
• Verbesserung der query-Verarbeitung
– Optimizer und execution support (Parallelisieren &
Eliminieren)
• Partition-basierte Wartung
– Update statistics auf einer oder allen partitions– Truncate,
reorg, dbcc, bcp (out) partition
-
DB-Stammtisch 06/2006, 23
Range Partition
• Es werden Grenzwerte für jede Partition festgelegt:
– Die Werte in den Datensätzen sind kleiner oder gleich
diesemGrenzwert
• Günstige Anwendung bei:
– Großen Tabellen in Anwendungen mit hohen Anforderungen an die
Performance.
• “ Gleitende Sichten” auf die Daten sind möglich.
– Datenmengen können ohne Auswirkungen auf andere
Partitionenhinzugefügt oder gelöscht werden.
• Die Balance der Partition hängt von den definierten
Grenzwerten ab.
-
DB-Stammtisch 06/2006, 24
Range Partition – Syntax und Beispiel
create table tablename(column definitions)
partition by range (columnlist)(partitionlabel values
-
DB-Stammtisch 06/2006, 25
Range Partition
seg1
1/3/051/3/051/4/051/5/051/5/051/5/05
q1
seg2
4/1/054/2/054/3/054/2/05
q2
seg3
7/5/057/5/057/6/057/7/057/8/057/8/05
q3
seg4
10/1/0510/2/0510/3/0510/4/0511/2/0512/2/05
q4sp_helpartition:
name type partition_type partitions partition_keys-----
---------- -------------- ----------- --------------sales base
table range 4 salesdatepartition_name partition_id pages
segment-------------- ------------ ----------- -------q1 1024003648
452 seg1q2 1040003705 331 seg2q3 1056003762 422 seg3q4 1072003819
628 seg4
-
DB-Stammtisch 06/2006, 26
List Partition
• Der Nutzer definiert Listen mit Werten für jede Partition:
– Mindestens ein Wert muss jeder Partition zugewiesen werden–
Jeder Wert darf nur einer Partition zugewiesen werden– Die Werte
sind in der Partition nicht sortiert
• Günstige Anwendung bei wenigen
unterschiedlichenSchlüsselwerten mit häufiger Wiederholung.
• Die Balance der Partition hängt von den zugeordnetenWerten
ab.
-
DB-Stammtisch 06/2006, 27
List Partition – Syntax und Beispiel
create table tablename(column definitions)
partition by list (column name)([partition label] values
(constant[,...])[on segmentname ]... )
create table customers
(cust_id char(10) not null,cust_name varchar(30) not null,state
char(2) not null,
phone char(10) not null)partition by list (state)(west values
('CA', 'OR', 'WA') on seg1,east values ('NY', 'NJ') on seg2
-
DB-Stammtisch 06/2006, 28
List Partition
sp_helpartition:
name type partition_type partitions partition_keys
---------- ---------- -------------- ----------
--------------
cust_table base table list 2 statepartition_name partition_id
pages segment
-------------- ------------ ----------- -------west 864003078 62
seg1east 880003135 41
seg2Partition_Conditions-------------------------VALUES ('CA',
'OR', 'WA')VALUES ('NY', 'NJ')
customers
NYNYNJNY
seg2seg1
CACAORWACAOR
west east
-
DB-Stammtisch 06/2006, 29
Hash Partition
• Adaptive Server verwendet eine Hash Funktion um
eineentsprechende Partition anzusteuern
– Basierend auf bis zu 31 Schlüsselspalten
• Günstige Anwendung bei:
– DSS Operationen– Große Tabellen mit vielen Partitionen–
Tabelle mit unsortierten Daten–
• Die Balance der Partitionen ist von der Anzahl derdoppelten
Schlüsselwerte abhängig.
-
DB-Stammtisch 06/2006, 30
Hash Partition – Syntax und Beispiel
create table lineitem
( l_orderkey int not null,l_partkey char(10) not null,l_suppkey
char(4) not null,
l_linenumber int not null,l_quantity int not null)
partition by hash (l_orderkey, l_linenumber)(litem_hash1 on
seg1,litem_hash2 on seg2,litem_hash3 on seg3)
create table tablename(column definitions)partition by hash
(column list){(partitionlabel [on segmentname] [,...])|
number_of_partitions [on (segmentname [,...])]}
-
DB-Stammtisch 06/2006, 31
Round Robin Partition
• Es sind keine Angaben zur Aufteilung notwendig
– Die Sätze werden den Partitions “rotierend” zugewiesen– Die
Sätze sind in den Partitionen unsortiert– Ermöglicht eine hohe
Parallelität bei mehreren Einfügepunkten
• Diese Methode ist annähernd vergleichbar mit derArbeitsweise
von 1 Partition/ Segment der älteren ASE Versionen
• Sichert die Kompatibilität mit älteren Versionen
• Die Partitionen sind automatisch in guter Balance (Löschen
?!)
-
DB-Stammtisch 06/2006, 32
Risiko Partition Key Update
create table t (status int, other_cols ... )partition by list
(status) (ptn1 values (1), ptn2 values (2), ptn3 values (3))
ptn1
ptn2
ptn3 3
1
2
update t set a = 1 where a = 3
select * from tErgebnis:- Nur Zeilen mit 2!- Zeilen mit 3 und 1
fehlen!
-
DB-Stammtisch 06/2006, 33
Partitionierung des Index
• Verbesserte Parallelität durch mehrere Eintrittspunkte•
Reduzierte root page contention
• Index size ergibt sich aus der Zeilenanzahl in jeder
Partition• Für kleinere Partitionen werden weniger index pages
durchsucht
bzw. traversiert
Vor ASE 15 nicht partitionierter Index Lokaler Index auf
partitionierter Tabelle
-
DB-Stammtisch 06/2006, 34
Globale Indizes
• Dieser Indextyp enthält die Daten aller Partitionen
derTabelle.
• Bei “range”, “hash” oder “list” Partitionierung muß derIndex
“nonclustered” sein.
• Bei “round robin” Partitionierung sind Clustered
oderNonclustered Indizes möglich.
-
DB-Stammtisch 06/2006, 35
Non-clustered Global Index
Create unique index ci_nkey_ckey on
customer(c_nationkey,c_custkey)on segment4
-
DB-Stammtisch 06/2006, 36
Lokale Indizes
• Jede Partition hat ihre eigene Indexstruktur
• Kann clustered oder nonclustered sein
• Bei einem lokalen “clustered index” sind die Daten innerhalb
der Partition sortiert.
• Wenn ein Index lokal, unique und clustered ist:
– müssen die Index- alle Partitionspalten enthalten– muß die
Reihenfolge der Index- der der Partitionspalten entsprechen
• Lokale Indizes mit den Eigenschaften “Unique clustered” sind
nichtmöglich bei Tabellen die “round robin” partitioniert sind (mit
mehr als einerPartition).
-
DB-Stammtisch 06/2006, 37
Non-clustered Local Index
Create unique index ci_nkey_ckey on
customer(c_nationkey,c_custkey)on segment4 local index
-
DB-Stammtisch 06/2006, 38
Clustered (Local) Index
• Customer-Tabelle ist range-partitioniert auf der Spalte
c_custkey
Create unique clustered index ci_nkey_ckey on
customer(c_custkey, c_nationkey)
-
DB-Stammtisch 06/2006, 39
Zugriffsplan - Beispiel
-
DB-Stammtisch 06/2006, 40
Geringerer Einfluß von Administrationsarbeiten
• Folgende Funktionen können auf einzelnen Partitionenausgeführt
werden:
– reorg rebuild– update statistics– truncate table– dbcc– bcp in
/ out
• Mit der richtigen Plazierung der Partitionen auf verschiedene
physische Device sind reduzierteWartungszeiten möglich.
-
DB-Stammtisch 06/2006, 41
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 42
Computed Column Index und Function Based Index
• Berechnete Spalten
– Tabellenspalte wird als Ausdruck definiert– Ausdrücke können
Spalten der gleichen Zeile referenzieren– Ausdrücke können
Funktionen, arithmetische Operatoren, case Ausdrücke,
Globale Variable, Java Objekte, Pfadnamen oder andere Ausdrücke
enthalten– Materialisiert oder nicht materialisiert (virtuelle
Spalte)– Determiniert oder nicht determiniert
create table [database.[owner].] table_name(column name
{datatype | {compute | as} expression[materialized | not
materialized]} ...
• Index auf berechneten Spalten
– Eine oder mehrere Spalten des Schlüssels sind berechnete
materialisierte Spalten
• Funktionsbasierter Index
– Ein Index mit einem oder mehreren determinierten Ausdrücken
anstelle von Spalten
create table rental_not_materialized(cust_id int, start_date as
getdate(), last_change_dt datetime )
Insert into rental_not_materialized (cust_id,
last_change_dt)Values (1,getdate())
Select * from rental_not_materialized
cust_id start_date last_change_dt-------- -------------------
--------------
1 Mar 30 2005 4:00PM Mar 16 2005 3:14PM
create table rental_materialized(cust_id int, start_date as
getdate()materialized, last_change_dt datetime)
Insert into rental_materialized (cust_id, last_change_dt)Values
(1,getdate())
Select * from rental_materialized
cust_id start_date last_change_dt-------- -------------------
--------------
1 Mar 16 2005 3:14PM Mar 16 2005 3:14PM
create [unique] [nonclustered] index index_nameon
[owner.]table_name(expression [asc | desc][,expression [asc | desc
]...
-
DB-Stammtisch 06/2006, 43
Function Based Index - Beispiel
– 100,000-Zeilen-Tabelle; Index auf (a*10)
select * from t3 where a*10 = 76543210
– Vor ASE 15: 2-3 Sekunden; 16,000 I/Os
– In ASE 15.0: < 50 Millisekunden; 3 I/Os
-
DB-Stammtisch 06/2006, 44
Computed Column Index und Function Based Index
• Index auf berechneten Spalten
• Funktionsbasierter Index
alter table ordersadd up11 as unit*price*1.1
materializedgocreate index up11_ix on orders (up11)go
create index ix1 on orders (unit*price*1.1)
select unit*price*1.1 from orders where up11 > 200
benutzt Index auf up11, nicht auf (unit*price*1.1)
select unit*price*1.1 from orders where unit*price*1.1 >
200
benutzt Index auf (unit*price*1.1), nicht auf up11
-
DB-Stammtisch 06/2006, 45
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 46
Weniger E/A für Arbeitstabellen
• Beispiel:
select count(*), type from titles group by typeorder by type
• Vor Adaptive Server 15.0:
– Die Arbeitstabelle wird physisch angelegt– 624 I/O auf der
Tabelle und 29 I/O auf der Arbeitstabelle
• Adaptive Server 15.0
– Die Arbeitstabelle wird logisch angelegt– 624 I/O auf der
Tabelle und 0 I/O auf der Arbeitstabelle
-
DB-Stammtisch 06/2006, 47
Weniger E/A bei Arbeitstabellen
• Beispiel:
select sum(total_sales), max(price), type, pub_idfrom
titlesgroup by type, pub_id
• Vor Adaptive Server 15.0:
– Eine Arbeitstabelle für group by und die Aggregate – 624 I/O
auf der Tabelle titles, 8056 I/O auf der Arbeitstabelle
• Adaptive Server 15.0 :
– Verwendung der “hash based” Gruppierung im Speicher– 624 I/O
auf der Tabelle und 0 I/O auf der Arbeitstabelle
-
DB-Stammtisch 06/2006, 48
Weniger E/A bei Arbeitstabellen
•Vor ASE 15.0:
STEP 1 The type of query is SELECT (into Worktable1). GROUP BY
FROM TABLE titles ...Table Scan ...TO TABLE Worktable1.
STEP 2 The type of query is SELECT.
FROM TABLE Worktable1 ...
Table: titles scan count 1, logical reads: (total=624) ...Table:
Worktable1 scan count 1, logical reads: (total=8056) ...
• ASE 15.0:
The type of query is SELECTROOT:EMIT Operator ...| Using
Worktable1 for internal storage. | |SCAN Operator | | FROM TABLE |
| titles | | Table Scan.
Table: titles scan count 1, logical reads: (total=624) physical
reads: (total=0)...
-
DB-Stammtisch 06/2006, 49
Verbesserungen bei der “distinct” - Klausel
• Beispiel:
– select distinct type from titles
• Vor Adaptive Server 15.0:
– Eine Arbeitstabelle für distinct– 624 I/O auf der Tabelle
titles, 5125 I/O auf der Arbeitstabelle
• Adaptive Server 15.0:
– Verwendung der “hash based” distinct Methode im Speicher– 624
I/O auf der Tabelle und 0 I/O auf der Arbeitstabelle
-
DB-Stammtisch 06/2006, 50
Verbesserungen bei der OR Klausel
• Beispiel:
select * from titles_idprwhere title_id between "BU" and "BW"OR
price between 2.99 and 4.99
• -- Indizes auf title_id und price
• Vor Adaptive Server 15.0:
– Der Optimierer verwendet die ODER Strategie– Es werden 255
logische I/O benötigt
• Adaptive Server 15.0:
– Verwendung der speicherbasierten “hash based union”Methode
– Es werden 123 logical I/O benötigt
-
DB-Stammtisch 06/2006, 51
Verbesserungen bei der Union - Klausel
• Beispiel:
select title_id, title,type from titleswhere title_id <
"T7"
union select title_id, title, price from titles
where price > $45.00-- Keine Indizes auf title_id oder
price
• Vor Adaptive Server 15.0:
– Zwei Tabellen - Scans und eine Arbeitstabelle für distinct– Es
werden 6770 I/O benötigt
• Adaptive Server 15.0:
– Verwendung der “hash based” union distinct Methode– Es werden
1248 I/O benötigt
-
DB-Stammtisch 06/2006, 52
Verbesserungen bei der Union - Klausel
Vor Adaptive Server 15.0:
STEP 1
... Table Scan ...
TO TABLE Worktable1.
STEP 1
The type of query is INSERT.
The update mode is direct.
FROM TABLE ...
STEP 1
The type of query is SELECT.
This step involves sorting.
FROM TABLE Worktable1.
Using GETSORTED ...
Adaptive Server 15.0:
...
|HASH UNION Operator has 2 children.
| |SCAN Operator
| | FROM TABLE
| | titles
| | Table Scan.
| | Forward Scan ...
| |SCAN Operator
| | FROM TABLE
| | titles
| | Table Scan. ...
-
DB-Stammtisch 06/2006, 53
Nicht übereinstimmende Datentypen
• Beispiel:
– select * from A, B where A.a=B.b
– A.a - float– B.b - int , indiziert– B ist eine große
Tabelle
• Vor Adaptive Server 15.0:
– Indexauswahl ist problematisch – der Optimierer kann den
Startpunkt im Index B nicht ermitteln, da A.a einen anderenDatentyp
hat
• Adaptive Server 15.0:
– Indexauswahl konvertiert die Werte automatisch– Index B wird
für entsprechende Werte in A.a verwendet
-
DB-Stammtisch 06/2006, 54
Nicht übereinstimmende Datentypen
1. set showplan on
2. Index auf die total_sales Spalte der Tabelle titles
anlegen
create index idx_ts on titles(total_sales)
3. Anfrage ausführen:
declare @x floatselect @x = 3000.00select title_id,
total_sales
from titles where total_sales = @x
The type of query is SELECT...
SCAN Operator | FROM TABLE | titles | Index : idx_ts ...
-
DB-Stammtisch 06/2006, 55
Datenverteilung
• Beispiel:
select * from authors, publishers where authors.state =
publishers.stateand authors.state = "CO“
• Vor Adaptive Server 15.0:
– Einzelne, häufig auftretende Werte führen zu einem
Ungleichgewicht– Dieses Ungleichgewicht führt dazu, daß der
Optimierer die Join –
Reihenfolge falsch berechnet– Geschätzte Kosten – 5400 I/O
• Adaptive Server 15.0:
– Joinhistogramme werden dynamisch angelegt und dadurch die
Zugriffskosten korrekter geschätzt
– Geschätzte Kosten – 360 I/O
-
DB-Stammtisch 06/2006, 56
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 57
Hash Join
select t1.c1, t2.c2, t2.c1, t2.c3 from t1, t2where t1.c2 =
t2.c3
t1c1 c2
2432114765
ABCXYZDEFGHIBCA
ZZYYXXWWVVTT
ABCBCADEFXYZABCDEF
887766554433
123456
c4c3c2c1
t2
-
DB-Stammtisch 06/2006, 58
Hash Join
Hash Tabellet2
c1 c2 c3 c4
1234567
887766554433…
ABCBCADEFXYZABCDEF
ZZYYXXWWVVTT
C6 1, ABC 2, BCA
CF 3, DEF
10B 4, XYZ
5, ABC
6, DEFABCXYZDEFGHIBCA
2432114765
c2c1
t1
24 ABC 1 ABC24 ABC 5 ABC…
t1.c1 t1.c2 t2.c1 t2.c3
-
DB-Stammtisch 06/2006, 59
Sehr große Datenmengen
• Beispiel:
– select count(*), count(T1.price) – from titles T1, titles T2–
where isnull(T1.price, 0) = isnull(T2.price, 0) – and
rtrim(T1.title_id) rtrim(T2.title_id)
• Kein Index, Join mit Ausdrücken und Ergebnis ist sehr groß
• Vor Adaptive Server 15.0:
– Der Optimierer wählt den nested loop– Benötigte Zeit 41,106
ms, ungefähr 3.1 Millionen I/O
• Adaptive Server 15.0:
– Der Optimierer wählt den Hash bzw. Merge Join– Beim Hash Join
benötigt die Anfrage 320 ms mit 1248 I/O
-
DB-Stammtisch 06/2006, 60
Verwaltung großer Datenmengen mit
• Adaptive Server IQ
– Neues zu IQ 12.6
• Adaptive Server Enterprise 15 – Konzepte und Funktionalitäten
für große Datenmengen
– Partitionen– Berechnete Spalten und Funktions-basierter Index–
Verbesserungen der Anfrage-Verarbeitung
• Arbeitstabellen• Hash-Join
– Optimierer-Steuerung
-
DB-Stammtisch 06/2006, 61
Einstellen der Optimierungsziele und Gültigkeit
allrows_oltp Zur schnellen Optimierung für OLTP wird nur
einebegrenzte Anzahl von Verfahren benutzt
e.g. nested loop join, keine Parallelisierung
allrows_mix (default) generiert Pläne für gemischte
Lastprofilehauptsächlich allrows_oltp + merge joins,
Parallelisierung
allrows_dss generiert optimale Pläne für hoch-komplexe
DSShauptsächlich allrows_mix + hash joins
Server: sp_configure "optimization goal", 0, "allrows_oltp“
Session: set plan optgoal allrows_dss
Query: select * from A order by A.aplan "(use optgoal
allrows_oltp)"
-
DB-Stammtisch 06/2006, 62
Optimierungsaufwand bei großer Join-Anzahl
select * from T1, T2, ... T50where T1.a = T2.a AND T2.a = T3.a
...AND T49.a = T50.a
• Vor Adaptive Server 15.0:die Optimierung der Join-Reihenfolge
kann einen wesentlichen Zeitanteil benötigen(~ TabAnz!, 12! =
479M)
set table count n
• Adaptive Server 15.0 ermöglicht die Kontrolle über den Anteil
der Optimierungszeit:
Server: sp_configure "optimization timeout limit", 10
Session: set plan opttimeoutlimit 10
Query: select * from A order by A.aplan "(use opttimeoutlimit
10)“
Prozentanteil der Gesamtbearbeitungszeit, die der Optimierer
zurErstellung des Planes verwenden darf (Standard: 10%)
-
DB-Stammtisch 06/2006, 63
Optimierer Kostenmodell ab ASE 15
• Kostenschätzung im Optimierer:
– Kostenschätzung vor ASE 15:• Logischer Zugriff: 2• Physischer
Zugriff: 18
– ASE 15: bessere Annäherung an die Realität:• Logischer Zugriff
: 2• Physischer Zugriff : 25• CPU - je Zeile, die gesucht oder
verglichen wird: 0.1
-
DB-Stammtisch 06/2006, 64
Optimierungsaufwand - Beispiel
• Zusätzlicher Optimierungsaufwand führt zu
besserenAusführungsplänen.
• Die Einsparungen bei der Ausführung sollten natürlich mit
demzusätzlichen Optimierungsaufwand abgewogen werden.
Optimization Timeout (%)
Parse/Compile CPU Time Execution Time
10 1600 ms 10 ms
50 22,800 ms 3 ms
select *from authors, titleauthor, titles_idpr, titles_pridtitl,
publishers, roysched, titles, salesdetail, sales, stores,
discounts, blurbswhere titles.title_id = roysched.title_idAND
titles.title_id = titles_idpr.title_idAND titles.title_id =
titles_pridtitl.title_idAND titles.pub_id = publishers.pub_idAND
blurbs.au_id = authors.au_idAND titleauthor.au_id =
authors.au_idAND titleauthor.title_id = titles.title_idAND
titles.title_id = salesdetail.title_idAND salesdetail.ord_num =
sales.ord_numAND salesdetail.stor_id = sales.stor_idAND
sales.stor_id = stores.stor_idAND stores.stor_id =
discounts.stor_id
Set option show brief
-
DB-Stammtisch 06/2006, 65
Automatisierung für Update Statistics
-
DB-Stammtisch 06/2006, 66
Archive Database Access (ADA)
– DBCC checks directly on database dumps (archives)• Ability to
run DBCC directly on database dumps without having
the database fully loaded.
– Object Level Recovery • Customers have long requested the
ability to retrieve data from
a dump that may have been accidentally deleted or corrupted.
• Current method used by customers: reload of the entire
database which is time consuming
-
DB-Stammtisch 06/2006, 67
Archive Database Access (ADA)
ASE
Archive Database
Real Database
Real Database
Real Database
Database Dump File(acts as a DB device)
Database Devices
-
DB-Stammtisch 06/2006, 68
ADA - Object Level Recovery
– Archive databases can be accessed with regular SQL, as any
other database
• SELECT * INTO FROM ..
• Cross-server: use CIS (proxy tables) and SELECT INTO
-
DB-Stammtisch 06/2006, 69
Erreichte Effekte
LaufzeitLaufzeit
Zugriffsanzahl
-
DB-Stammtisch 06/2006, 70
Query Processing – Die Änderungen
Transact-SQL via TDS(sprocs stored in text
in syscomments table)ParsingParse Step
Normalization Step
Parse Tree
Query Plan Generation Compile
Query Tree(“p-code”-like tree storedin sysprocedures table)
Data and other Internal Resources
ExecuteQuery Plan
( only resides in memory)
AccessMethods
Managers(buffer, lock, etc.)
TransactionManagementUtilities
Execution Engine New in 15.0!
New in 15.0!
New in 15.0!
New in 15.0!
Resolve NamesNormalize
Resolve Views, Aggregates & Subqueries
Protection Map
New in 15.0!
DeckblattWie groß sind VLDB ? - 2005DSS versus OLTP
WorkloadVerwaltung großer Datenmengen mit Der traditionelle
RDBMS-AnsatzVertikale PartitionierungSybase IQ Advanced Bit-Mapped
IndizesDramatische I/O-ReduzierungOLTP DBMS vs. IQ-Multiplex
engineAdministration der IndexstrukturenIndex AdvisorIQ Multiplex
12.5 (und davor)IQ Multiplex 12.6 w/ Local StoreIQ Multiplex –
Local Store für Query ServerSUN-Sybase Referenz DWH - Weltgrößtes
DWH in Menlo Park Business Case Telco�2005: World’s
TopTenVerwaltung großer Datenmengen mit Neue LimitsVerwaltung
großer Datenmengen mit Überblick zum PartitionierenVor ASE 15ASE 15
Semantische PartitioinierungRange PartitionRange Partition – Syntax
und BeispielRange PartitionList PartitionList Partition – Syntax
und BeispielList PartitionHash PartitionHash Partition – Syntax und
BeispielRound Robin PartitionRisiko Partition Key
UpdatePartitionierung des IndexGlobale IndizesNon-clustered Global
IndexLokale Indizes Non-clustered Local Index�Clustered (Local)
Index�Zugriffsplan - BeispielGeringerer Einfluß von
AdministrationsarbeitenVerwaltung großer Datenmengen mit Computed
Column Index und Function Based Index Function Based Index -
BeispielComputed Column Index und Function Based IndexVerwaltung
großer Datenmengen mit Weniger E/A für ArbeitstabellenWeniger E/A
bei ArbeitstabellenWeniger E/A bei ArbeitstabellenVerbesserungen
bei der “distinct” - KlauselVerbesserungen bei der OR
KlauselVerbesserungen bei der Union - KlauselVerbesserungen bei der
Union - KlauselNicht übereinstimmende DatentypenNicht
übereinstimmende DatentypenDatenverteilungVerwaltung großer
Datenmengen mit Hash JoinHash JoinSehr große DatenmengenVerwaltung
großer Datenmengen mit Einstellen der Optimierungsziele und
GültigkeitOptimierungsaufwand bei großer Join-Anzahl Optimierer
Kostenmodell ab ASE 15Optimierungsaufwand - BeispielAutomatisierung
für Update StatisticsArchive Database Access (ADA)Archive Database
Access (ADA)ADA - Object Level RecoveryErreichte EffekteQuery
Processing – Die Änderungen