Embed Size (px)
Citation preview

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Dirk Fleischer GEOMAR Helmholtz-‐Zentrum für Ozeanforschung Kiel
Von der Datenentstehung bis zur PublikaOon
-‐ das Kieler Datenmanagement-‐Portal

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Programm
• Allgemeiner Stand - Entkoppelte AbschniQe im Lebenszyklus von Daten - VFU Kieler Datenmanagement Infrastruktur
• Provenienz - Was ist das -‐ im Kontext Forschungsdaten? - Datenerfassung zum Zeitpunkt ihrer Entstehung
• Ausblick - DatenlandschaYen - Int. DatenlandschaY – int. ForschungslandschaY
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
NATURE GEOSCIENCE | VOL 4 | SEPTEMBER 2011 | www.nature.com/naturegeoscience 575
commentary
A path to filled archivesDirk Fleischer and Kai Jannaschk
Reluctance to deposit data is rife among researchers, despite broad agreement on the principle of data sharing. More and better information will reach hitherto empty archives, if professional support is given during data creation, not in a project’s final phase.
Professionally managed, permanent data archives are essential to ensure the preservation and reusability
of data. !e idea of data deposition is supported by publishers and funding agencies around the world. Scientists, too, are generally in favour: they appreciate acknowledgement of (and future reference to) their hard-won data. Yet many repositories are almost empty1. Clearly, there are discrepancies between scientists’ attitudes to the principle of data sharing and their actions when it is time to deposit their data.
!ere are reasons for this gap1. When the time of deposition comes — usually either at the end of a project or on publication of the results — the data are o"en scattered between various storage media, not uniformly formatted, and insu#ciently tagged with metadata. As a result, deposition requires a substantial amount of e$ort, at a time when scientists really want to think about their next research question. Ongoing activities on data discovery and access that aim to innovate data reusability in the geosciences, such as the Data Observation Network for Earth project2, do not appropriately address the issue of capturing data.
We argue that most scientists view data deposition in remote archives as a burden3, because it is too far removed from their daily routine. Scientists need and want professional and locally supported systems to store their data in a structured%and reusable form. Support for scientists in this way, right at the beginning of the data life cycle, can avoid the discrepancy%between the principles and actions of data sharing. If raw data and their derivatives are recorded in a professional manner during collection and analysis, the task of data deposition can be automated. It will then need only a mouse click by the scientist to initiate formal deposition, and not the laborious work of days. In such an environment, local data
managers become%data navigators, rather than%curators.
Scaling upFrom the point of view of funding agencies and publishers — the main parties interested in data reusability and accessibility — data deposition at the end of the project or at the time of publication is su#cient. But data sharing is likely to evolve into a mandatory part of the research and publication process in the near future4,5.
If so, data pathways must be organized in a way that can be scaled up without a vast drain on resources. In the present system, projects and their data managers are focused on one dedicated data repository. As a result, data managers provide individual support to scientists who wish to deposit their data, for example, by converting scienti&c data &les into the format required by the chosen repository. !is kind of curation is
in'exible and very time consuming6, and it requires personal communication between the scientist, data manager and repository sta$ for quality assurance of the metadata.
!e human interaction in the data pathway creates unacceptable bottlenecks: only an automated process can turn around the full quantity of data that are generated and published. !e curation system simply will be overwhelmed if all data are to be%submitted.
The nagging problemAn analysis of data management requirements within the Cluster of Excellence: Future Ocean in Kiel7 revealed that researchers strongly desire reliable personal communication with local data curators3. !ey do not favour support by remote data managers: scientists like to be in charge of their data. (!ink about it: would you give your children to someone you barely know?) Our survey, con&rmed by an independent study3, included personal
WW
W.GLYNGOODW
IN.CO.UK
© 2011 Macmillan Publishers Limited. All rights reserved
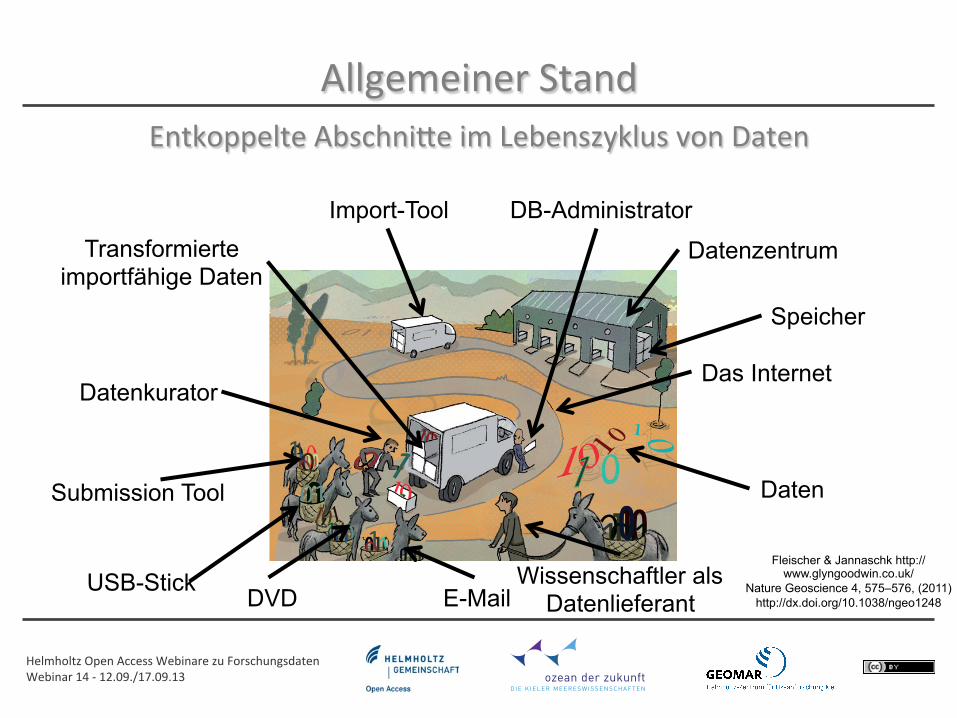
Import-Tool
Speicher
DB-Administrator
Datenzentrum
Das Internet
Wissenschaftler als Datenlieferant
Transformierte importfähige Daten
Daten
Datenkurator
USB-Stick E-Mail
Submission Tool
DVD
Allgemeiner Stand
Fleischer & Jannaschk http://www.glyngoodwin.co.uk/
Nature Geoscience 4, 575–576, (2011) http://dx.doi.org/10.1038/ngeo1248
Entkoppelte AbschniQe im Lebenszyklus von Daten
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
16
Anzahl an naturwissenschaftlichen Artikeln im SCI
0
200000
400000
600000
800000
1000000
1200000
1973
1975
1977
1979
1981
1983
1985
1987
1989
1991
1993
1995
1997
1999
2001
2003
Anz
ahl A
rtike
l wel
twei
t
0
20000
40000
60000
80000
100000
120000
Anz
ahl A
rtike
l Deu
tsch
land
International Deutschland
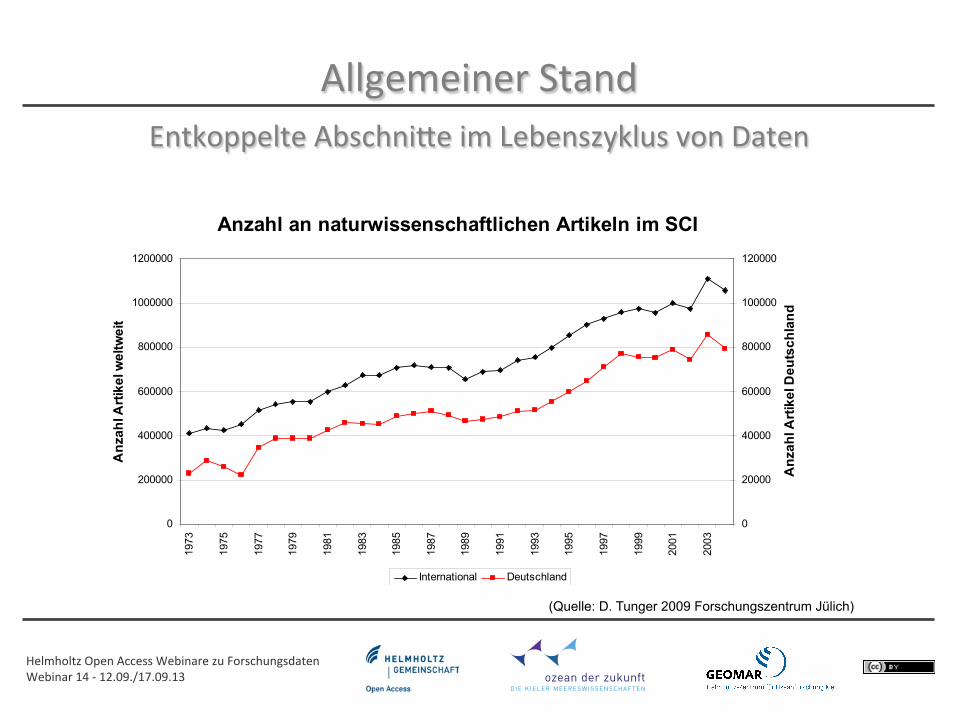
Abbildung 2: Anzahl wissenschaftlicher Artikel in der Datenbank Science Citation Index (SCI)
Die zentrale Frage in dieser Dissertation ist, ob durch die verbesserte Aufbereitung von bestehenden Daten und Informationsangeboten ein Trendbeobachtungssystem für die Naturwissenschaft entwickelt werden kann. Ziel dieses Systems soll die ver-besserte Informationsversorgung für wissenschaftliche Projekte sein, mit dem Ziel, möglichst frühzeitig neue wissenschaftliche Strömungen zu erkennen.
Menschliches Handeln ist grundsätzlich zukunftsgerichtet und auf bestimmte Ziele o-rientiert. An die Stelle sicheren Wissens über die Zukunft treten Erwartungen der ein-zelnen Individuen. Diese beruhen auf Informationen prognostischer Art (Rieser, 1980, S. 11).
Das Hauptaugenmerk dieser Dissertation liegt auf der bibliometrischen Untersu-chung der Entwicklung und Wahrnehmung von wissenschaftlichen Themen, aber auch auf der bibliometrischen Untersuchung von wissenschaftlichen Einrichtungen oder Wissenschaftlern selbst.
Eine Patentierbarkeit darf bei der Beurteilung von technologischer Entwicklung nicht darüber hinwegtäuschen, dass etwa 85 % aller Produkte oder Projekte mit Marktreife einen Fehlschlag erleiden (Schnabel, 2004, S. 1). Schnabel (2004) nennt folgendes Beispiel: Der Mikrowellenherd wurde bereits um das Jahr 1950 entwickelt und ging
Allgemeiner Stand
(Quelle: D. Tunger 2009 Forschungszentrum Jülich)
Entkoppelte AbschniQe im Lebenszyklus von Daten

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Allgemeiner Stand
Karte: GoogleEarth google.com
Entkoppelte AbschniQe im Lebenszyklus von Daten
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
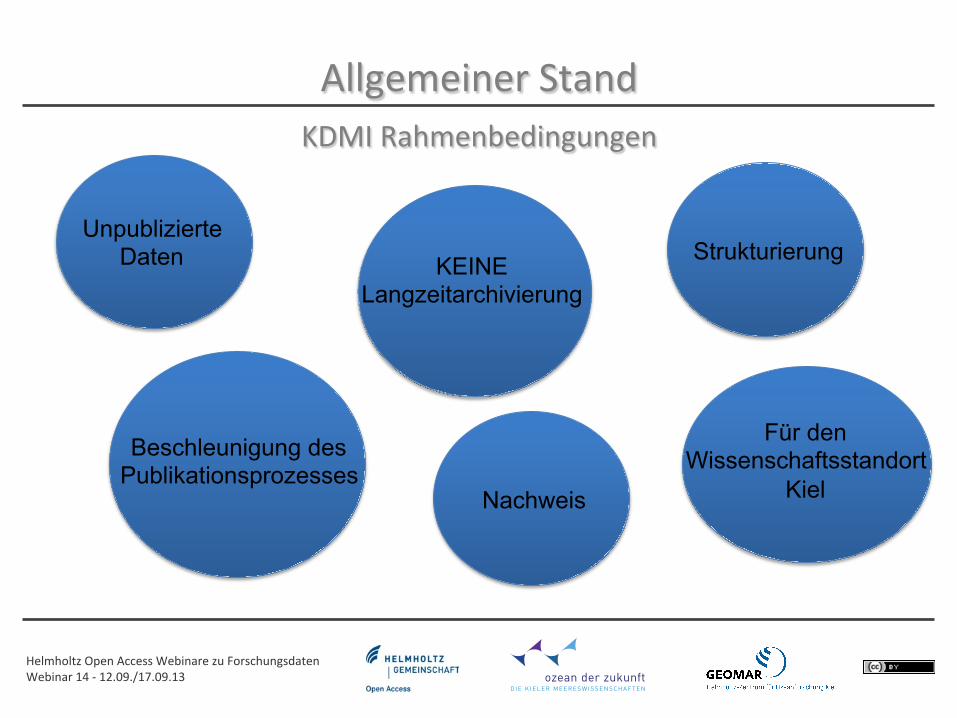
Allgemeiner Stand KDMI Rahmenbedingungen
Strukturierung
Beschleunigung des Publikationsprozesses
Unpublizierte Daten KEINE
Langzeitarchivierung
Nachweis
Für den Wissenschaftsstandort
Kiel
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Allgemeiner Stand
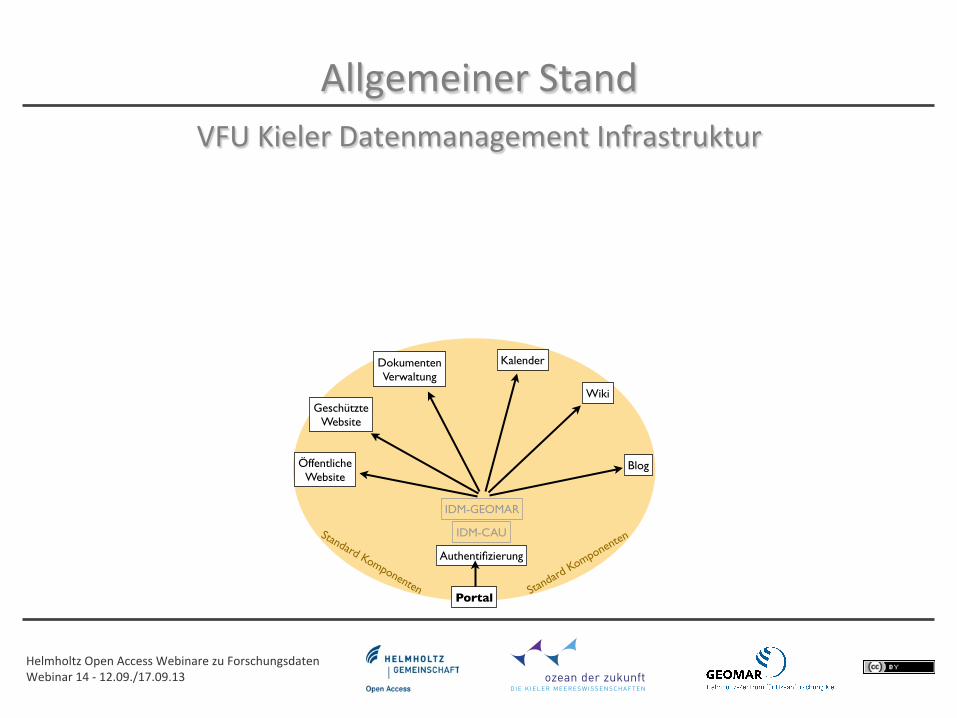
Portal
IDM-GEOMAR
IDM-CAU
GeschützteWebsite
Authentifizierung
Blog
Kalender
Standard
KomponentenStandard Komponenten
DokumentenVerwaltung
ÖffentlicheWebsite
Wiki
VFU Kieler Datenmanagement Infrastruktur
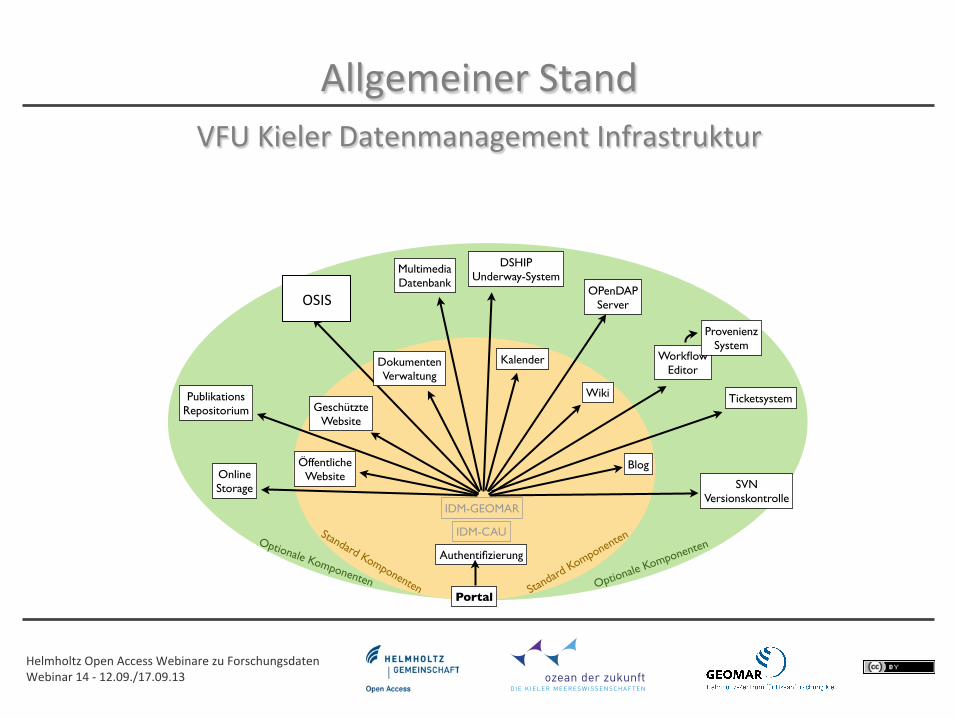
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Portal
IDM-GEOMAR
IDM-CAU
GeschützteWebsite
OnlineStorage
Authentifizierung
Blog
MultimediaDatenbank
FeldMetadaten
WorkflowEditor
ProvenienzSystem
PublikationsRepositorium
SVNVersionskontrolle
DSHIPUnderway-System
Ticketsystem
Kalender
OPenDAPServer
Standard
Komponenten
Optionale KomponentenStandard Komponenten
Optionale Komponenten
DokumentenVerwaltung
ÖffentlicheWebsite
Wiki
Allgemeiner Stand VFU Kieler Datenmanagement Infrastruktur
OSIS
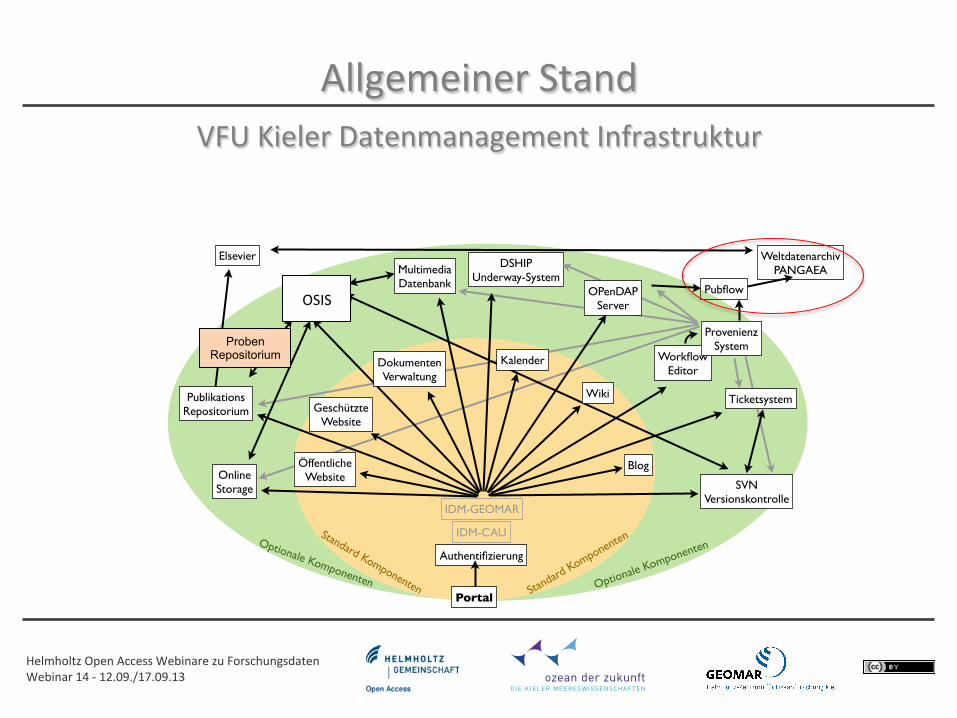
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Portal
IDM-GEOMAR
IDM-CAU
GeschützteWebsite
OnlineStorage
Authentifizierung
Blog
MultimediaDatenbank
FeldMetadaten
WorkflowEditor
ProvenienzSystem
PublikationsRepositorium
SVNVersionskontrolle
DSHIPUnderway-System
Ticketsystem
Kalender
OPenDAPServer
Standard
Komponenten
Optionale KomponentenStandard Komponenten
Optionale Komponenten
DokumentenVerwaltung
ÖffentlicheWebsite
Wiki
WeltdatenarchivPANGAEA
Pubflow
Elsevier
Allgemeiner Stand VFU Kieler Datenmanagement Infrastruktur
Proben Repositorium
OSIS

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Provenienz Was ist das – im Kontext Forschungsdaten?
• EDV -‐ InformaOk – ScienOfic Workflow - Workflow-‐Engine mit BEPL oder BPMN Workflowbeschreibung - Ausgangslage ist ein vorliegendes digitales Datenset - Endprodukt ist ein verändertes digitales Datenset - BEPL/BPMN Beschreibung + Engine Laufzeit = Provenienz
• Beobachtungsdaten - Beruhend auf realen Objekten (Proben) - Daten werden gemessen/erzeugt
- Wie wird das gemacht – Methode - Wie wurde die Methode ausgeführt
• Datenspeicherung als Humanprozess - Proben werden sequenziell bearbeitet - Menschen arbeiten sequenziell
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
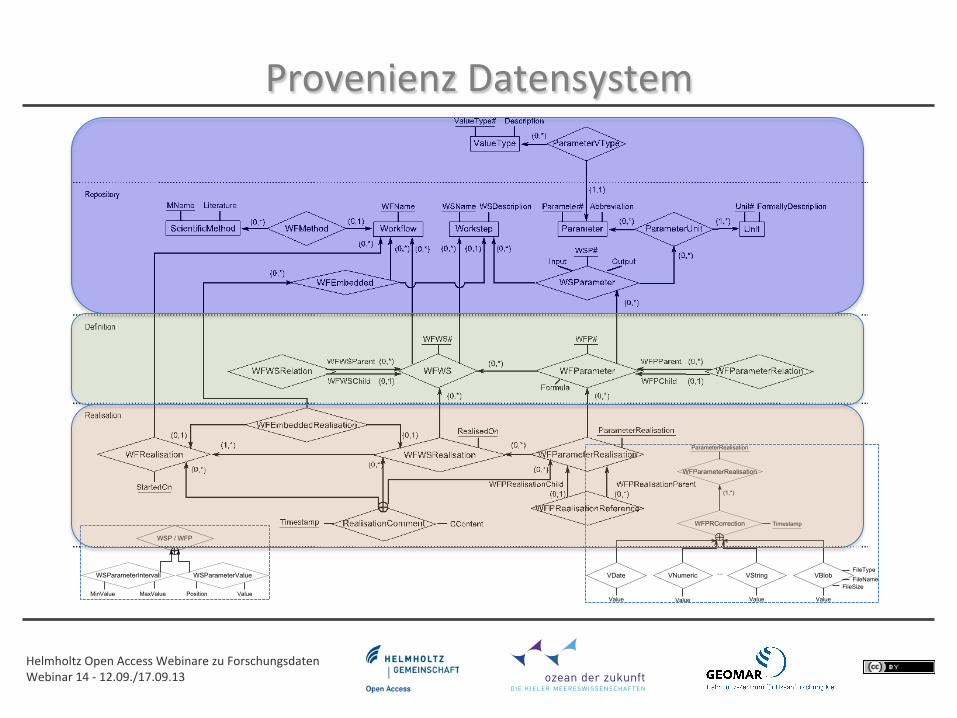
Provenienz Datensystem
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
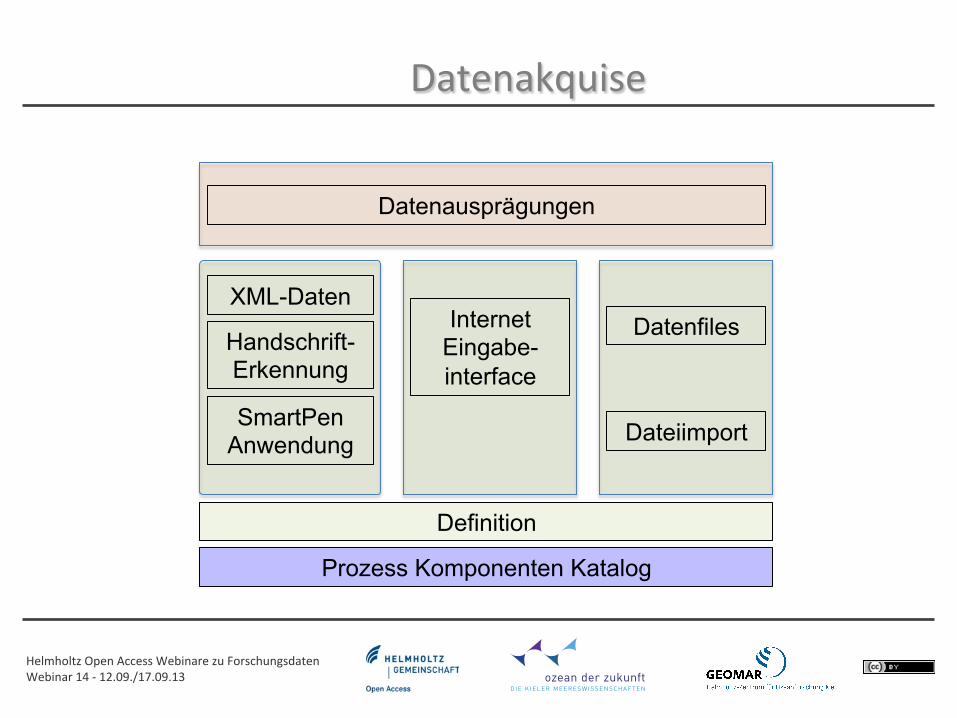
Definition
Dateiimport SmartPen Anwendung
XML-Daten
Datenausprägungen
Prozess Komponenten Katalog
Internet Eingabe-interface
Datenfiles
Datenakquise
Handschrift-Erkennung
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Leg Name
Event
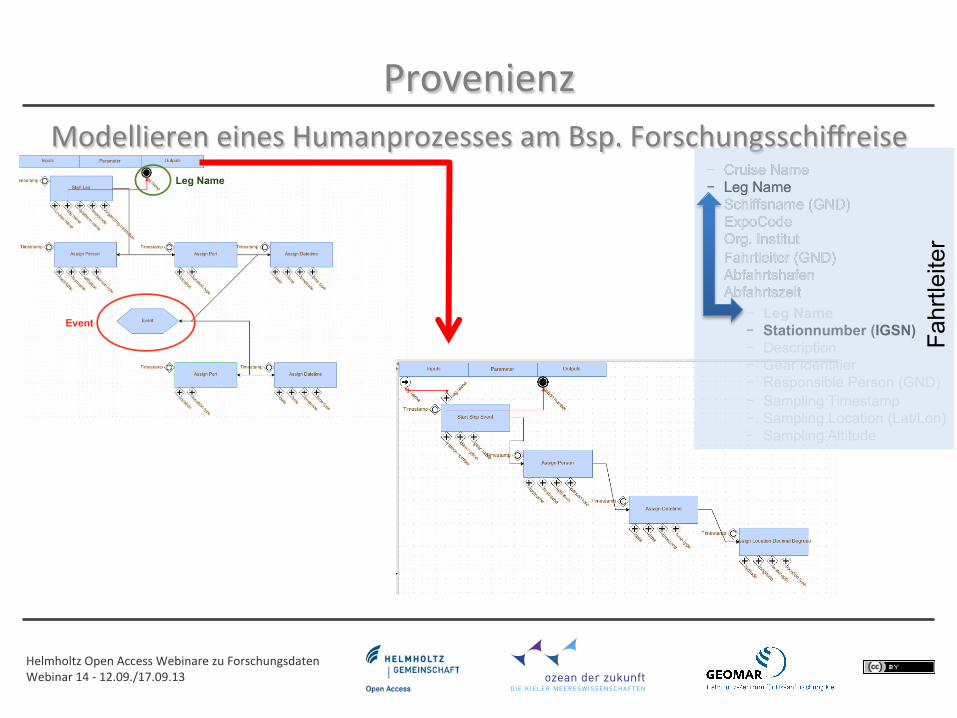
Provenienz Modellieren eines Humanprozesses am Bsp. Forschungsschiffreise
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Leg Name - Stationnumber (IGSN) - Description - Gear Identifier - Responsible Person (GND) - Sampling Timestamp - Sampling Location (Lat/Lon) - Sampling Altitude
Fahr
tleite
r
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
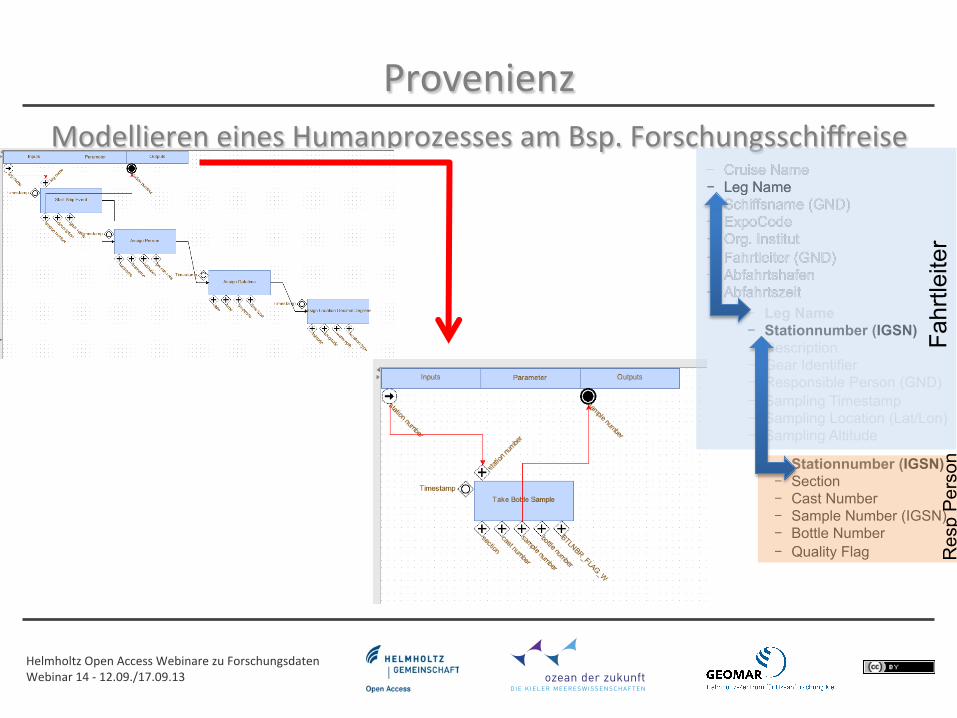
Provenienz Modellieren eines Humanprozesses am Bsp. Forschungsschiffreise
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Leg Name - Stationnumber (IGSN) - Description - Gear Identifier - Responsible Person (GND) - Sampling Timestamp - Sampling Location (Lat/Lon) - Sampling Altitude
- Stationnumber (IGSN) - Section - Cast Number - Sample Number (IGSN) - Bottle Number - Quality Flag
Fahr
tleite
r R
esp
Per
son
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
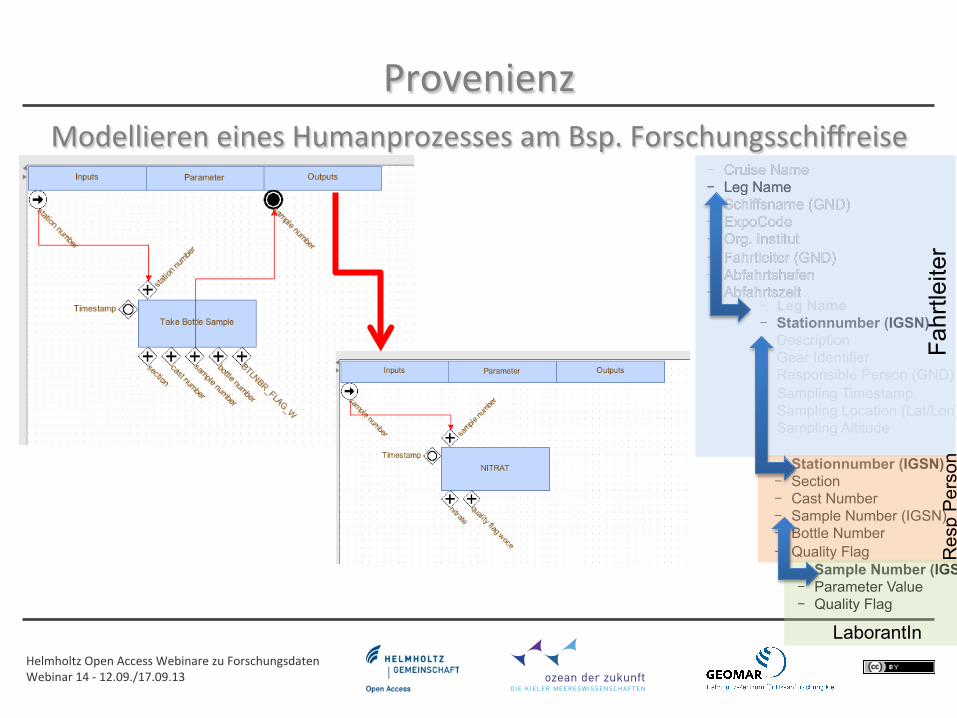
Provenienz Modellieren eines Humanprozesses am Bsp. Forschungsschiffreise
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Cruise Name - Leg Name - Schiffsname (GND) - ExpoCode - Org. Institut - Fahrtleiter (GND) - Abfahrtshafen - Abfahrtszeit
- Leg Name - Stationnumber (IGSN) - Description - Gear Identifier - Responsible Person (GND) - Sampling Timestamp - Sampling Location (Lat/Lon) - Sampling Altitude
- Stationnumber (IGSN) - Section - Cast Number - Sample Number (IGSN) - Bottle Number - Quality Flag
Fahr
tleite
r R
esp
Per
son
- Sample Number (IGSN) - Parameter Value - Quality Flag
LaborantIn

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Datenakquise Am Ort der Datenentstehung -‐ HandschriYen Erkennung

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Vittarica
chile-71 49 475
-39 23 570
07 03 2013
Go with Christian intothe field to search forthe second location.Problem with originalroad planning (closedgate to private propertygo to alternativeAltitude: 1380compass direction 244Start: 19:24 UTCStop: 20:11 UTC
Datenakquise SmartPen-‐Anwendung
XML-Daten für Datenbanken
Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
DatenlandschaY der ZukunY

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
DatenlandschaY der ZukunY

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Fazit Datenmanagement in jedem Haus
• AkOve Datenakquise und -‐management - Daten zum Zeitpunkt der Entstehung - Vorstrukturierung zur weiteren Verwendung - Datenmanager gleichberechOgte Partner in Projekten
- Teilprojekte um Datenmanagementmethoden innerhalb des Projektes zu erarbeiten - Projektplanung ebenfalls auf Basis der Datengrundlage
• Archivierung und Verteilung - DatenpublikaOonen stärker technisch unterstützen - Weltdatenarchive nutzen
- KooperaOonen mit wiss. Verlagen - Weltweiter Metadaten-‐Austausch bereits etabliert
• Provenienz als mulOdimensionales Qualitätsmerkmal - Einzelne Quality Flags sind subjekOv - DokumentaOon der Entstehung von Daten ist ein Qualitätsmerkmal

Helmholtz Open Access Webinare zu Forschungsdaten Webinar 14 -‐ 12.09./17.09.13
Danke für Ihre Aufmerksamkeit
Danke an meine Kollegen - Andreas Czerniak - Hela Mehrtens - Carsten Schirnick - Pina Springer






![NASE VORN mit der Energiefamilie IDM [systemtechnik] FORUM Alois Duregger IDM Vertriebsleiter](https://img.pdfslide.org/doc/110x75/55204d8149795902118d4bb0/nase-vorn-mit-der-energiefamilie-idm-systemtechnik-forum-alois-duregger-idm-vertriebsleiter.jpg)






















