Embed Size (px)
Citation preview

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE
© Fujitsu Technology Solutions 2011 Seite 1 (15)
WHITE PAPER FUJITSU PRIMERGY SERVER GRUNDLAGEN DISK-I/O-PERFORMANCE
Diese technische Dokumentation richtet sich an Personen, die sich mit der Disk-I/O-Performance von Fujitsu PRIMERGY Servern beschäftigen. Das Dokument soll helfen, Disk-I/O-Messmethodiken und Performance-Daten zu verstehen, um geeignete Rückschlüsse auf die kundenspezifische Dimensionierung und Konfigurierung interner Disk-Subsysteme an PRIMERGY Servern zu ziehen.
Version
1.0
2011-05-09
Inhalt
Dokumenthistorie ................................................... 2
Performance-Kennzahlen für Disk-Subsysteme .... 3
Performance-relevante Einflussgrößen ................. 3
Blockgrößen........................................................ 3
Parallele Zugriffe auf Disk-Subsysteme ............. 4
Betriebssystem und Anwendungen .................... 5
Controller ............................................................ 5
Speichermedien .................................................. 6
Disk-I/O-Performance-Messungen ........................ 7
Das Messwerkzeug Iometer ............................... 7
Benchmark-Umgebung ....................................... 8
Lastprofile ........................................................... 8
Messverlauf ........................................................ 9
Messergebnisse ............................................... 10
Analyse von Disk-Subsystemen .......................... 11
Planung ............................................................. 11
Analyse bei Performance-Problemen ............... 12
Literatur ................................................................ 15
Kontakt ................................................................. 15

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 2 (15) © Fujitsu Technology Solutions 2011
Dokumenthistorie
Version 1.0

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 3 (15)
Performance-Kennzahlen für Disk-Subsysteme
Festplatten und Solid State Drives sind als nichtflüchtige Speichermedien sowohl besonders sicherheitsrelevante als auch Performance-kritische Komponenten im Server-Umfeld. Da ein einzelnes solches Speichermedium im Vergleich zu Serverkomponenten wie Prozessor oder Hauptspeicher eine sehr hohe Zugriffszeit aufweist, kommt der Dimensionierung und Konfigurierung von Disk-Subsystemen eine besondere Bedeutung zu. Wegen der Fülle unterschiedlicher Anwendungsszenarien sind gerade die Konfigurierungsmöglichkeiten bei Disk-Subsystemen besonders groß. Daher können auch nicht alle Aspekte eines Disk-Subsystems mit einer einzelnen Performance-Kennzahl bewertet werden. Von besonderem Interesse sind
der Datendurchsatz die Menge an Daten, die in einem bestimmten Zeitintervall verarbeitet werden kann
die Anzahl der Aufträge (Transaktionen), die in einem bestimmten Zeitintervall bearbeitet werden kann
die durchschnittliche Antwortzeit die Zeit, die im Schnitt für die Bearbeitung eines einzelnen Auftrags benötigt wird
Performance-relevante Einflussgrößen
Die mannigfaltigen Performance-relevanten Einflussgrößen lassen sich in fünf unterschiedliche Themenbereiche ordnen:
Blockgrößen
Parallele Zugriffe auf Disk-Subsysteme
Betriebssystem und Anwendungen
Controller
Speichermedien
Blockgrößen
Die Datenübertragung geschieht bei Zugriff auf ein Disk-Subsystem immer blockweise. Die Größe der übermittelten Datenblöcke ist abhängig von Eigenschaften des Betriebssystems und/oder der Anwendung und kann durch den Benutzer nicht beeinflusst werden.
Wie in der linken oberen Grafik veranschaulicht, steigen bei wahlfreiem Zugriff Durchsatz und Antwortzeit (Latency) mit zunehmender Blockgröße annähernd linear an, während die Anzahl der Transaktionen annähernd linear sinkt. Im Allgemeinen wird hierbei der theoretische Maximaldurchsatz des Disk-Subsystems nicht erreicht. Bei sequentiellem Zugriff steigt lediglich die Antwortzeit mit zunehmender Blockgröße annähernd linear an, der Durchsatz jedoch nicht. Der theoretische Maximaldurchsatz des Disk-Subsystems wird hier bei einer Blockgröße von 64 KB erreicht. Welche Durchsatzraten erreichbar sind, hängt also sehr stark vom Zugriffsmuster ab, das eine Anwendung auf dem Disk-Subsystem generiert.
0 16 32 48 64 80 96 112 128
Block size [KB]
Throughput [MB/s]
Transactions [IO/s]
Latency [ms]
0 128 256 384 512 640 768 896 1024
Block size [KB]
Throughput [MB/s]
Transactions [IO/s]
Latency [ms]
Einfluss der Blockgröße bei wahlfreiem Zugriff Einfluss der Blockgröße bei sequentiellem Zugriff

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 4 (15) © Fujitsu Technology Solutions 2011
Beispiele für typische Zugriffsmuster unterschiedlicher Anwendungen zeigt die folgende Tabelle:
Anwendung Zugriffsmuster
Betriebssystem wahlfrei, 40% read, 60% write, Blöcke ≥ 4 KB
File-Copy (SMB) wahlfrei, 50% read, 50% write, 64 KB Blöcke
File-Server (SMB) wahlfrei, 67% read, 33% write, 64 KB Blöcke
Mail-Server wahlfrei, 67% read, 33% write, 8 KB
Datenbank (Transaktionsverarbeitung) wahlfrei, 67% read, 33% write, 8 KB
Web-Server wahlfrei, 100% read, 64 KB Blöcke
Datenbank (Log-File) sequentiell, 100% write, 64 KB Blöcke
Backup sequentiell, 100% read, 64 KB Blöcke
Restore sequentiell, 100% write, 64 KB Blöcke
Video Streaming sequentiell, 100% read, Blöcke ≥ 64 KB
Parallele Zugriffe auf Disk-Subsysteme
Normalerweise greifen auf einen Server viele Clients gleichzeitig zu. Darüber hinaus ist es auch möglich, dass ein Client mehrere Aufträge an einen Server absetzt, ohne zwischenzeitlich auf deren Beantwortung zu warten. Beides kann zu gleichzeitigen Zugriffen auf einen einzelnen Controller oder sogar einzelnen Datenträger führen. Die meisten Controller und Datenträger besitzen daher Queueing-Mechanismen, die bei Bearbeitung mehrerer paralleler Aufträge unter Umständen sogar eine höhere Performance gewährleisten als bei Bearbeitung weniger paralleler oder gar nur einzelner Aufträge. Dies geschieht jedoch immer um den Preis höherer Antwortzeiten. Wenn viele parallele Aufträge nur noch eine Erhöhung der Antwortzeit, aber nicht mehr des Durchsatzes zur Folge haben, ist das Disk-Subsystem überlastet.
Die beiden oben stehenden Grafiken zeigen exemplarisch die Performance bei wahlfreiem und sequentiellem Zugriff, jeweils bei konstanter Blockgröße und unterschiedlich starker Belastung von 1 bis 64 ausstehenden Aufträgen („Outstanding I/Os“). In den Grafiken ist die Anzahl Transaktionen deckungsgleich mit dem Durchsatz, da aufgrund der konstanten Blockgröße deren Verhältnis unabhängig von der Anzahl „Outstanding I/Os“ immer gleich ist. Im wahlfreien Szenario (linke Grafik) steigt mit zunehmender Anzahl „Outstanding I/Os“ der Durchsatz zunächst stark an, erreicht recht früh sein Maximum und hält diesen Wert dann nahezu. Im sequentiellen Szenario (rechte Grafik) wird unabhängig von der Anzahl „Outstanding I/Os“ immer ein Durchsatz nahe des maximal Möglichen erreicht. Sowohl im wahlfreien als auch im sequentiellen Szenario steigen die Antwortzeiten (Latency) mit zunehmender Anzahl paralleler Aufträge durchgehend linear an. Daher kann im sequentiellen Szenario durch Erweiterung des Disk-Subsystems gefahrlos eine Optimierung auf kurze Antwortzeiten erfolgen, während im wahlfreien Szenario die Durchsatzleistung im Auge behalten werden muss.
Liegt ein Anwendungsszenario vor, bei dem das Antwortverhalten des Servers nicht außer Acht gelassen werden kann, hat man zwischen Optimierung des Durchsatzes und Optimierung des Antwortverhaltens
0 8 16 24 32 40 48 56 64
# outstanding I/Os
Throughput [MB/s]
Latency [ms]
0 8 16 24 32 40 48 56 64
# outstanding I/Os
Transactions [IO/s]
Latency [ms]
Einfluss der Outstanding I/Os bei wahlfreiem Zugriff
Einfluss der Outstanding I/Os bei sequentiellem Zugriff

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 5 (15)
abzuwägen. Der Server ist dann so zu dimensionieren und konfigurieren, dass er die Bearbeitung paralleler Aufträge den individuellen Erfordernissen entsprechend bewältigen kann.
Betriebssystem und Anwendungen
Von erheblichem Einfluss auf die Performance eines Disk-Subsystems ist die Art, wie Anwendungen auf den Massenspeicher zugreifen. Eine Rolle spielen hierbei das verwendete Betriebssystem, eine evtl. eingesetzte Virtualisierungsschicht, die I/O-Scheduling-Technik, das Dateisystem, die File-Caches und die Organisation der Datenträger, beispielsweise durch Partitionierung oder Software-RAID.
Controller
Eine wichtige Rolle bezüglich der Durchsatzleistung spielt, sofern Datenträger nicht per Software-RAID organisiert werden, die Auswahl des Controllers. Neben auf dem Systemboard integrierten Controllern können unterschiedliche steckbare Controller für den Anschluss interner oder externer Datenträger eingesetzt werden. Zu beachten ist, dass Controller für den Anschluss einer begrenzten Anzahl von Datenträgern ausgelegt sind. Wird deren Anzahl überschritten, so wird der Controller zum Performance-begrenzenden Faktor.
RAID und JBOD
Festplatten gehören zu den fehleranfälligsten Komponenten eines Computersystems. Daher werden in Serversystemen RAID-Controller eingesetzt, um einem Datenverlust bei einem etwaigen Ausfall von Festplatten vorzubeugen. Dabei werden mehrere Datenträger zu einem „Redundant Array of Independent Disks“, kurz RAID, zusammengefasst. Die Daten werden über mehrere Datenträger derart verteilt, dass beim Ausfall einzelner Datenträger trotzdem alle Daten erhalten bleiben. Ausnahmen bilden JBOD („Just a Bunch of Disks“) und RAID 0. Bei diesen Organisationsformen werden lediglich Datenträger zusammengefasst, aber keine Redundanz erzeugt. Die gebräuchlichsten Arten um Datenträger in Verbänden zu organisieren sind JBOD, RAID 0, RAID 1, RAID 5, RAID 6, RAID 10, RAID 50 und RAID 60. Die gewählte Organisationsform und die Anzahl der zusammengefassten Datenträger beeinflussen in hohem Maße auch die Performance des Disk-Subsystems.
LUN
LUN steht für „Logical Unit Number“ und wurde ursprünglich zur Zuordnung von SCSI-Festplatten verwendet. Heute bezeichnet der Begriff gemeinhin aus Sicht eines Betriebssystems eine virtuelle Festplatte. Eine solche virtuelle Festplatte kann mit einer physikalischen Festplatte identisch oder ein Festplattenverband (JBOD oder RAID) sein.
Stripe size
Bei einem RAID-Array werden Daten als sogenannte „Chunks“, d.h. gestückelt, auf die zugehörigen Speichermedien verteilt. Ein „Stripe set“ setzt sich aus je einem Chunk pro Datenträger eines Arrays zusammen. Die „Stripe size“ gibt die Größe eines Stripe set ohne Paritäts-Chunks an. Diese Größe, die bei der Erstellung eines RAID-Arrays anzugeben ist, beeinflusst sowohl den Durchsatz als auch die Antwortzeit.
Cache
Einige Controller besitzen Caches, mit denen sie den Durchsatz beim Einsatz von Datenträgern auf dreierlei, meist separat einstellbare, Weise beeinflussen können:
durch Zwischenspeicherung von Schreibdaten. Diese werden dem Anwender sofort als erledigt quittiert, obwohl sie in Wirklichkeit noch gar nicht auf dem Datenträger vorhanden sind. Der tatsächliche Schreibvorgang erfolgt zu einem späteren Zeitpunkt en bloc. Diese Prozedur ermöglicht eine optimale Ausnutzung der Controller-Ressourcen, eine schnellere Abfolge der Schreibaufträge und damit einen höheren Durchsatz. Eventuelle Stromausfälle können durch eine optionale BBU überbrückt werden, um die Integrität der Daten sicherzustellen.
durch Zwischenspeicherung von Lesedaten in Anwendungsszenarien mit rein sequentiellen Lesezugriffen, bei einigen Controllern auch bei nur anteilig sequentiellen Lesezugriffen.
durch Einrichtung von Auftragswarteschlangen. Dies ermöglicht, durch Umsortierung der Auftragsreihenfolge die Bewegungen der Schreib-Leseköpfe einer Festplatte zu optimieren. Voraussetzung ist allerdings, dass der Controller mit genügend Aufträgen versorgt wird, damit sich eine Warteschlange bilden kann.

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 6 (15) © Fujitsu Technology Solutions 2011
Speichermedien
Von großer Bedeutung hinsichtlich Performance ist zunächst der Typ des Speichermediums an sich. Festplatten haben als rotierende magnetische Speichermedien völlig andere Eigenschaften als Solid State Drives, die auf Halbleiterspeicher aufbauend eine deutlich höhere Performance aufweisen. Solid State Drives verfügen über eine um ein Mehrfaches höhere Performance als Festplatten, haben jedoch eine geringere Lebensdauer und sind deutlich teurer. Anders als bei Festplatten existiert bei SSDs ein Performance-Unterschied zwischen dem Beschreiben einer leeren Speicherzelle und dem Überschreiben eines alten Speicherinhalts, da dieser vor dem Überschreiben erst gelöscht werden muss. Dies führt dazu, dass die Schreibgeschwindigkeit bei SSDs mit steigendem Füllungsgrad stark absinken kann. Im Allgemeinen ist eine SSD einer Festplatte hinsichtlich Performance aber auch dann noch überlegen.
Generell spielen das Übertragungsprotokoll und der Cache eine wichtige Rolle.
maximale Übertragungsgeschwindigkeit des Festplatten-Interfaces: SATA 3.0 GBit/s 286 MB/s effektiver Durchsatz pro Richtung SAS: 286 MB/s effektiver Durchsatz pro Richtung SAS II: 572 MB/s effektiver Durchsatz pro Richtung
Cache Der Einfluss des Caches auf die Performance wird durch zwei Faktoren bewirkt: durch Einrichtung von Auftragswarteschlangen. Dies ermöglicht der Festplattenlogik, durch
Umsortierung der Auftragsreihenfolge die Bewegungen des Schreib-Lesekopfes zu optimieren. Voraussetzung ist allerdings, dass der Festplatten-Cache eingeschaltet ist. Darüber hinaus muss die Festplatte mit genügend Aufträgen versorgt sein, damit sich eine Warteschlange bilden kann.
durch die Zwischenspeicherung von Daten: normalerweise wird bei einem Leseauftrag nicht nur der angeforderte Sektor gelesen, sondern weitere auf der gleichen Spur befindliche Sektoren. Diese werden im Cache auf Verdacht gepuffert. Darüber hinaus lohnt es auch, Schreibaufträge im Cache der Festplatte zwischenzuspeichern, da deren Bearbeitung im Allgemeinen nicht so zeitkritisch ist wie die von Leseaufträgen, auf die die anfordernde Anwendung wartet. Dies gilt analog auch für Solid State Drives.
Bei Festplatten beeinflussen auch die Umdrehungsgeschwindigkeit sowie – bei vorgegebener Datenbereichsgröße – die Kapazität die Performance:
Umdrehungsgeschwindigkeit: Je höher die Umdrehungsgeschwindigkeit, desto höher die Zugriffsrate des Schreib-/Lesekopfes. SATA-Festplatten existieren mit Umdrehungsgeschwindigkeiten von 5400 rpm und 7200 rpm. SAS-Festplatten weisen höhere Umdrehungsgeschwindigkeiten von 10000 rpm oder 15000 rpm auf.
Kapazität: Festplatten besitzen sowohl eine konstante Drehzahl als auch eine konstante Datendichte. Daraus folgt, dass die Datenmenge pro Spur von innen nach außen zunimmt und somit auch die Zugriffsra-ten am äußeren Rand der Festplatte am höchsten sind. Da sich ein Datenvolumen fester Größe auf Festplatten mit hoher Kapazität weiter außen positionieren lässt, hat die Kapazität einen nicht unerheblichen Einfluss auf die Performance.

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 7 (15)
Disk-I/O-Performance-Messungen
Bei Fujitsu werden im PRIMERGY Performance Lab für alle PRIMERGY Server Disk-I/O-Performance-Messungen durchgeführt. Im Unterschied zu Applikations-Benchmarks wird im Allgemeinen nicht die Performance eines gesamten Servers inklusive Disk-Subsystem, sondern lediglich die Performance des Disk-Subsystems, also der Speichermedien an sich als auch deren Controller, überprüft. Das Disk-Subsystem ist hierbei so dimensioniert, dass Serverkomponenten wie beispielsweise Prozessor oder Hauptspeicher bei den Messungen keinen Engpass bilden. Es ist zwar durchaus möglich, mit einem genügend großen Disk-Subsystem die maximale Durchsatzleistung einer gesamten Server-Konfiguration zu messen. Dies ist aber nicht das eigentliche Ziel der hier beschriebenen Disk-I/O-Performance-Messungen. Messergebnisse werden in den Performance Reports der PRIMERGY Server, zu finden auf http://de.fujitsu.com/products/standard_servers/primergy_bov.html, dokumentiert.
Das Messwerkzeug Iometer
Bei den im PRIMERGY Performance Lab durchgeführten Disk-I/O-Performance-Messungen wird das ursprünglich von der Firma Intel entwickelte Messwerkzeug Iometer genutzt. Seit Ende 2001 ist Iometer ein Projekt bei http://SourceForge.net und wird von einer Gruppe internationaler Entwickler auf verschiedene Plattformen portiert und weiterentwickelt. Iometer besteht aus einer grafischen Benutzeroberfläche für Windows-Systeme und dem so genannten „dynamo“, der für verschiedene Plattformen verfügbar ist. Diese beiden Komponenten können seit einigen Jahren unter „Intel Open Source License“ von http://www.iometer.org/ oder http://sourceforge.net/projects/iometer heruntergeladen werden.
Iometer ermöglicht es, das Verhalten realer Anwendungen bezüglich der Zugriffe auf Disk-Subsysteme nachzubilden und bietet dazu eine Vielzahl von Parametern. Zunächst wird ein Datenbereich definiert, auf den während der Messungen zugegriffen wird. Zur Erstellung des Datenbereichs werden die folgenden Iometer-Parameter verwendet:
Maximum Disk Size Starting Disk Size
Des Weiteren wird über die folgenden Iometer-Parameter ein detailliertes Zugriffsszenario definiert:
# of Worker Threads # of Outstanding I/Os Test Connection Rate Transfer Request Size (Blockgröße) Percent of Access Specification Percent Read/Write Distribution Percent Random/Sequential Distribution Transfer Delay Burst Length Align I/Os Reply Size
Auf diese Art lassen sich unterschiedlichste Anwendungsszenarien, sei es mit sequentiellem Lesen oder Schreiben, wahlfreiem Lesen oder Schreiben und auch Kombinationen davon bei Verwendung unterschiedlicher Blockgrößen sowie mit variabel einstellbarer Anzahl simultaner Zugriffe nachbilden.
Als Ergebnis liefert Iometer für das jeweilige Zugriffsmuster eine Textdatei mit durch Komma separierten Werten (.csv). Wesentliche Kenngrößen sind
Durchsatz pro Sekunde Transaktionen pro Sekunde durchschnittliche Antwortzeit
Auf diese Weise kann man die Leistungsfähigkeit verschiedener Disk-Subsysteme bei bestimmten Zugriffsmustern vergleichen. Iometer ist in der Lage, sowohl auf Disk-Subsysteme mit einem Dateisystem als auch auf Disk-Subsysteme ohne Dateisystem, so genannte Raw-Devices, zuzugreifen. In jedem Fall wird der File-Cache des Betriebssystems umgangen und blockweise auf einer einzelnen Testdatei operiert.
Standardmäßig verwendet das PRIMERGY Performance Lab bei Disk-I/O-Performance-Messungen die Windows-Version des „dynamo“ von Iometer mit einem definierten Datenbereich und Satz von in der Praxis vorkommenden Lastprofilen sowie einem festgelegten Messszenario. Diese Festlegungen bilden die Grundlage für eine Reproduzierbarkeit von Messergebnissen und ermöglichen einen objektiven Vergleich der Performance verschiedener Disk-Subsysteme.
WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 8 (15) © Fujitsu Technology Solutions 2011
Benchmark-Umgebung
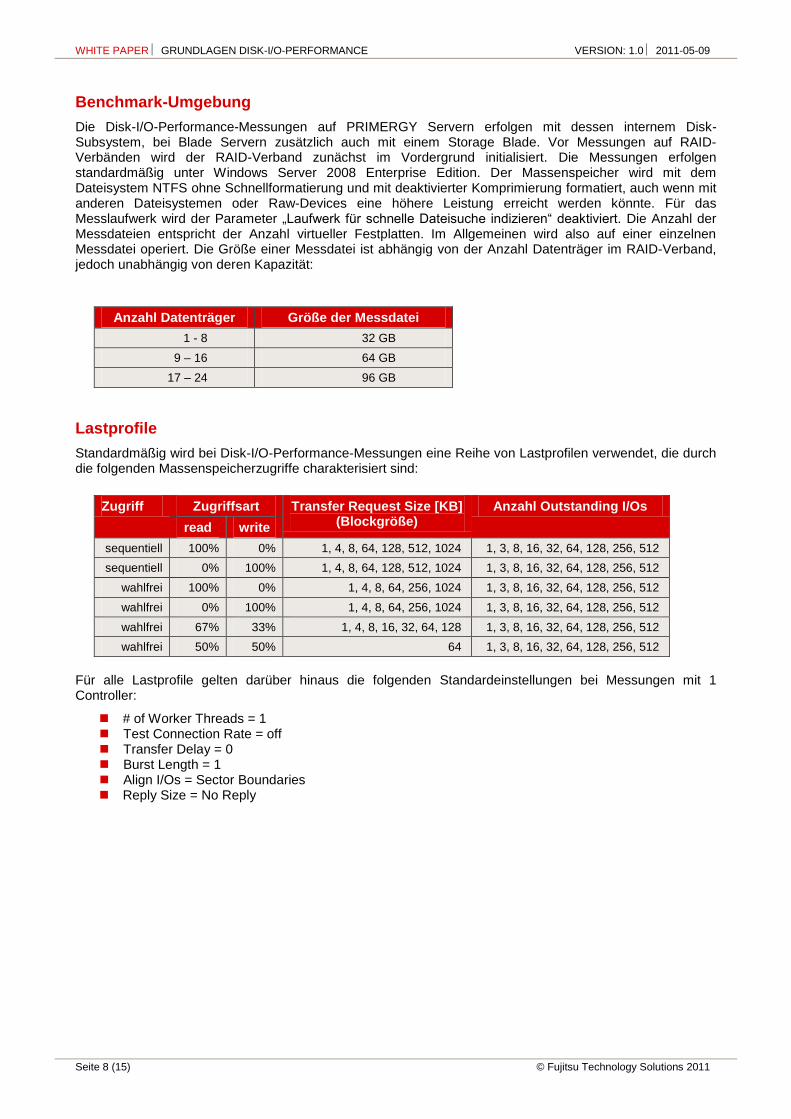
Die Disk-I/O-Performance-Messungen auf PRIMERGY Servern erfolgen mit dessen internem Disk-Subsystem, bei Blade Servern zusätzlich auch mit einem Storage Blade. Vor Messungen auf RAID-Verbänden wird der RAID-Verband zunächst im Vordergrund initialisiert. Die Messungen erfolgen standardmäßig unter Windows Server 2008 Enterprise Edition. Der Massenspeicher wird mit dem Dateisystem NTFS ohne Schnellformatierung und mit deaktivierter Komprimierung formatiert, auch wenn mit anderen Dateisystemen oder Raw-Devices eine höhere Leistung erreicht werden könnte. Für das Messlaufwerk wird der Parameter „Laufwerk für schnelle Dateisuche indizieren“ deaktiviert. Die Anzahl der Messdateien entspricht der Anzahl virtueller Festplatten. Im Allgemeinen wird also auf einer einzelnen Messdatei operiert. Die Größe einer Messdatei ist abhängig von der Anzahl Datenträger im RAID-Verband, jedoch unabhängig von deren Kapazität:
Anzahl Datenträger Größe der Messdatei
1 - 8 32 GB
9 – 16 64 GB
17 – 24 96 GB
Lastprofile
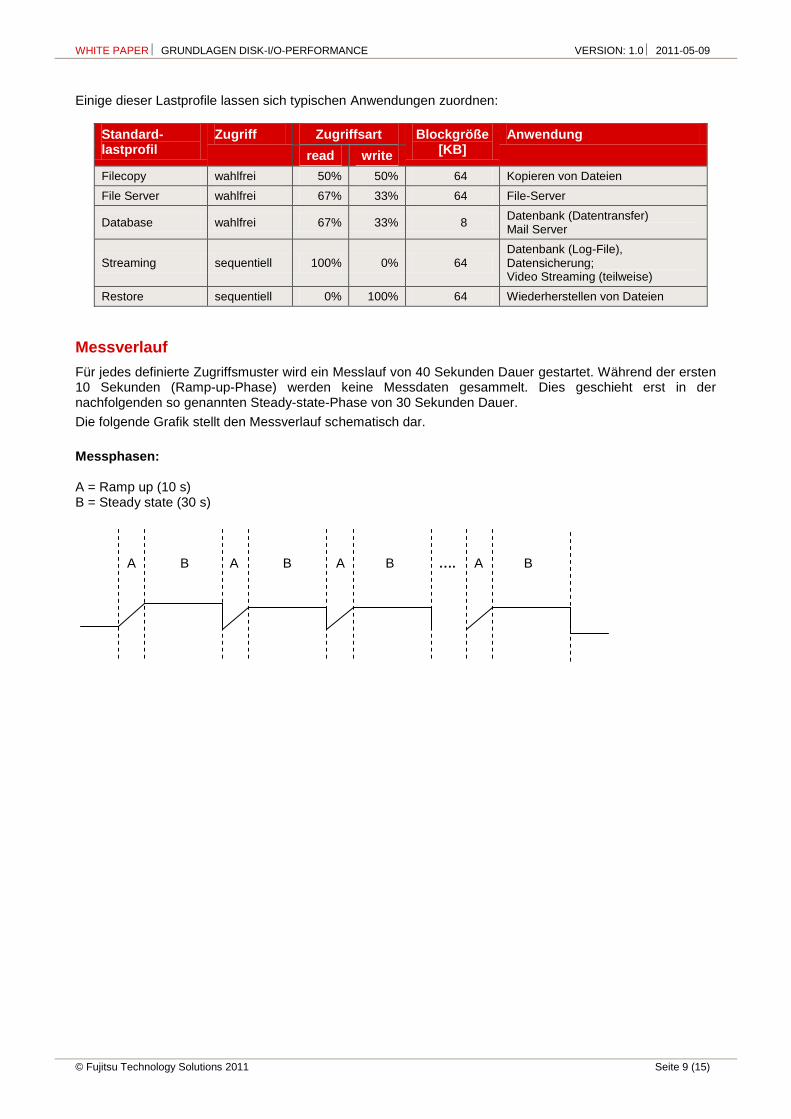
Standardmäßig wird bei Disk-I/O-Performance-Messungen eine Reihe von Lastprofilen verwendet, die durch die folgenden Massenspeicherzugriffe charakterisiert sind:
Zugriff Zugriffsart Transfer Request Size [KB] (Blockgröße)
Anzahl Outstanding I/Os
read write
sequentiell 100% 0% 1, 4, 8, 64, 128, 512, 1024 1, 3, 8, 16, 32, 64, 128, 256, 512
sequentiell 0% 100% 1, 4, 8, 64, 128, 512, 1024 1, 3, 8, 16, 32, 64, 128, 256, 512
wahlfrei 100% 0% 1, 4, 8, 64, 256, 1024 1, 3, 8, 16, 32, 64, 128, 256, 512
wahlfrei 0% 100% 1, 4, 8, 64, 256, 1024 1, 3, 8, 16, 32, 64, 128, 256, 512
wahlfrei 67% 33% 1, 4, 8, 16, 32, 64, 128 1, 3, 8, 16, 32, 64, 128, 256, 512
wahlfrei 50% 50% 64 1, 3, 8, 16, 32, 64, 128, 256, 512
Für alle Lastprofile gelten darüber hinaus die folgenden Standardeinstellungen bei Messungen mit 1 Controller:
# of Worker Threads = 1 Test Connection Rate = off Transfer Delay = 0 Burst Length = 1 Align I/Os = Sector Boundaries Reply Size = No Reply
WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 9 (15)
Einige dieser Lastprofile lassen sich typischen Anwendungen zuordnen:
Standard-lastprofil
Zugriff Zugriffsart Blockgröße [KB]
Anwendung
read write
Filecopy wahlfrei 50% 50% 64 Kopieren von Dateien
File Server wahlfrei 67% 33% 64 File-Server
Database wahlfrei 67% 33% 8 Datenbank (Datentransfer) Mail Server
Streaming sequentiell 100% 0% 64 Datenbank (Log-File), Datensicherung; Video Streaming (teilweise)
Restore sequentiell 0% 100% 64 Wiederherstellen von Dateien
Messverlauf
Für jedes definierte Zugriffsmuster wird ein Messlauf von 40 Sekunden Dauer gestartet. Während der ersten 10 Sekunden (Ramp-up-Phase) werden keine Messdaten gesammelt. Dies geschieht erst in der nachfolgenden so genannten Steady-state-Phase von 30 Sekunden Dauer.
Die folgende Grafik stellt den Messverlauf schematisch dar.
Messphasen: A = Ramp up (10 s) B = Steady state (30 s) A B A B A B …. A B

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 10 (15) © Fujitsu Technology Solutions 2011
Messergebnisse
Iometer liefert pro Lastprofil eine ganze Reihe von Kenngrößen. Von besonderem Interesse sind
Throughput [MB/s] Datendurchsatz in Megabytes pro Sekunde Transactions [IO/s] Transaktionsrate in I/O-Operationen pro Sekunde Latency [ms] mittlere Antwortzeit in ms
Datendurchsatz und Transaktionsrate sind direkt proportional zueinander und lassen sich nach der Formel
Datendurchsatz [MB/s] = Transaktionsrate [IO/s] × Blockgröße [MB]
Transaktionsrate [IO/s] = Datendurchsatz [MB/s] / Blockgröße [MB]
ineinander überführen.
Für sequentielle Lastprofile hat sich der Datendurchsatz als übliche Messgröße durchgesetzt, während bei den wahlfreien Lastprofilen mit ihren kleinen Blockgrößen meist die Messgröße „Transaktionsrate“ verwendet wird.
Darüber hinaus ist - unabhängig vom jeweiligen Lastprofil - die durchschnittliche Antwortzeit von Interesse. Deren Höhe ist abhängig von der Transaktionsrate und der Parallelität bei der Ausführung der Transaktionen. Sie lässt sich nach der Formel
mittlere Latenzzeit [ms] = 103 × Anzahl Worker Threads × parallele IOs / Transaktionsrate [IO/s]
berechnen.

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 11 (15)
Analyse von Disk-Subsystemen
Planung
Die Vielzahl von Einflussfaktoren, die die Durchsatzleistung eines Disk-Subsystems – teilweise gravierend – beeinflussen, erfordert detaillierte Informationen über das Anwendungsfeld, für das ein Disk-Subsystem dimensioniert und konfiguriert werden soll.
Von zentraler Bedeutung sind hierbei die folgenden Fragen:
Welches Zugriffsmuster liegt vor? Wie hoch sind die benötigten Transaktionsraten der Anwendung? Welche Kapazität (GB) wird benötigt? Wie groß ist das Zeitfenster für Backup? Kann die Datenmenge während dieses Zeitfensters komplett gesichert werden? Für wie lange darf der Datenbestand maximal wegen eines Restore nicht zur Verfügung stehen?
(Dabei ist zu beachten, dass dies gegebenenfalls die Restaurierung von einem Sicherungsmedium sowie das „replay“ von Transaktions-Logs beinhaltet.)
Erfahrungen aus der Praxis haben gezeigt, dass folgende Faustregeln bei der Auslegung eines Disk-Subsystems beachtet werden sollten, um spätere Performance-Probleme zu vermeiden:
Daten mit deutlich unterschiedlichem Zugriffsmuster sollten auf unterschiedliche RAID-Verbände gelegt werden. Beispielsweise würden auf ein und demselben Laufwerk die sequentiellen Zugriffe bei Transaktions-Logs zusammen mit den wahlfreien Zugriffen einer Datenbank zu Performance-Problemen führen. Die Ablage mehrerer Datenbanken auf einem Verband ist weniger kritisch, solange die benötigten Transaktionsraten geliefert werden können.
Bei großen Datenbanksystemen sind häufig unzureichende Transaktionsraten der Grund für Engpässe. Um die Anzahl möglicher I/Os pro Sekunde zu erhöhen, sollte man daher eher mehrere Datenträger mit geringer Kapazität als wenige mit hoher Kapazität verwenden.
Die RAID-Controller sollten optimal eingestellt sein. Hierbei hilft das für aktuelle Server mitgelieferte Dienstprogramm „ServerView RAID“ mit dem vordefinierten „Performance“-Modus, der statt des standardmäßig eingestellten Modus „Data Protection“ verwendet werden kann. Während diese beiden Konfigurationsvarianten gleich alle möglichen Parameter optimal aufeinander abstimmen, können die verschiedenen Einstellungen auch individuell vorgenommen werden. Bei Verwendung des Caches eines RAID-Controllers sollte eine Battery Backup Unit (BBU) zum Schutz vor Datenverlust bei einem Stromausfall verwendet werden.
Wenn möglich, sollten die Write-Caches der Datenträger eingeschaltet werden. Voraussetzung ist jedoch der Einsatz einer unterbrechungsfreien Stromversorgung (USV) zum Schutz vor Datenverlust bei einem Stromausfall.
WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 12 (15) © Fujitsu Technology Solutions 2011
Analyse bei Performance-Problemen
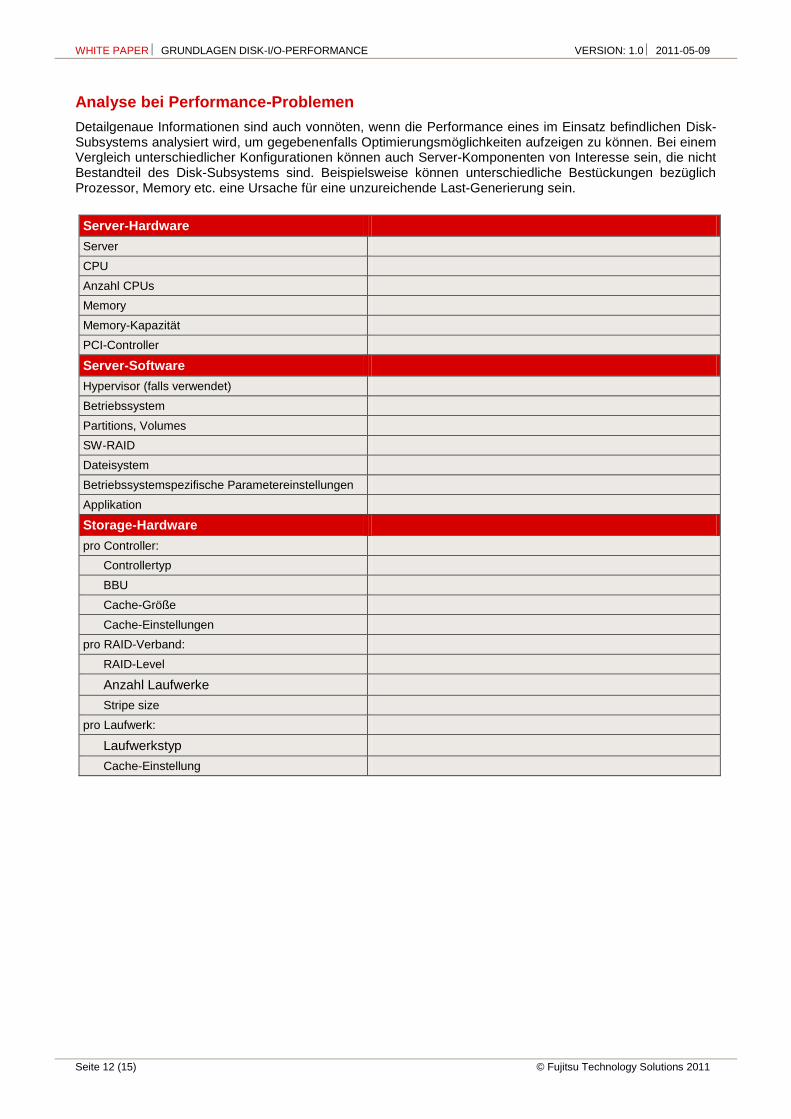
Detailgenaue Informationen sind auch vonnöten, wenn die Performance eines im Einsatz befindlichen Disk-Subsystems analysiert wird, um gegebenenfalls Optimierungsmöglichkeiten aufzeigen zu können. Bei einem Vergleich unterschiedlicher Konfigurationen können auch Server-Komponenten von Interesse sein, die nicht Bestandteil des Disk-Subsystems sind. Beispielsweise können unterschiedliche Bestückungen bezüglich Prozessor, Memory etc. eine Ursache für eine unzureichende Last-Generierung sein.
Server-Hardware
Server
CPU
Anzahl CPUs
Memory
Memory-Kapazität
PCI-Controller
Server-Software
Hypervisor (falls verwendet)
Betriebssystem
Partitions, Volumes
SW-RAID
Dateisystem
Betriebssystemspezifische Parametereinstellungen
Applikation
Storage-Hardware
pro Controller:
Controllertyp
BBU
Cache-Größe
Cache-Einstellungen
pro RAID-Verband:
RAID-Level
Anzahl Laufwerke
Stripe size
pro Laufwerk:
Laufwerkstyp
Cache-Einstellung

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 13 (15)
Tools
Neben Iometer gibt es eine Reihe unterschiedlicher Hilfsmittel zur Analyse der Leistungsfähigkeit von Speichersystemen. Hier eine kurze Zusammenfassung gebräuchlicher Tools:
LINUX sar zum Sammeln, Auswerten oder Sichern von Informationen zur Systemaktivität strace zum Protokollieren von Systemaufrufen und Signalen
Windows Performance-Monitor zum Aufzeichnen und Auswerten der in Windows-Systemen integrierten
Performance-Counter Process Monitor (von http://sysinternals.com) zur Anzeige und Analyse von File System
Aktivitäten
Externes Disk-Subsystem: Für einige externe Disk-Subsysteme gibt es Werkzeuge zur Analyse des I/O-Verhaltens.
Auf eine detaillierte Beschreibung der Tools wird an dieser Stelle verzichtet, da dies den Rahmen dieses Papiers sprengen würde. Vor dem Einsatz sollte man sich mit Hilfe der Online Hilfe oder Manuals mit der Nutzung vertraut machen.
Tipps
Wenn der Verdacht besteht, dass das Disk-Subsystem die Ursache für unzureichende Performance ist, sollte man das I/O-Verhalten der beteiligten Anwendung verstehen, um die für die Analyse verfügbaren Performance-Counter (z.B. aus dem Performance-Monitor von Windows) richtig interpretieren zu können. So ist, wenn im Server-Umfeld von Anwendung die Rede ist, in der Regel nicht ein für den Endanwender sichtbares Programm gemeint, sondern z.B. ein File-, ein Web-, ein SQL- oder ein Exchange-Server. Darüber hinaus muss man sich bewusst machen, dass in jeder Softwareschicht (z.B. ein Dateisystem mit seinen Caching Mechanismen, ein Volume Manager oder ein I/O Treiber) zwischen der Applikation und dem Disk-Subsystem Optimierungsstrategien implementiert sein können, die das Gesamtsystem nicht unbedingt in jeder Situation eine optimale Performance liefern lassen.
Den Durchsatz beeinflussende Faktoren wirken sich in einer realen Umgebung nicht konstant aus, sondern variieren - sowohl über die Zeit als auch über die verwendeten LUNs.
Wie man aus den Performance-Countern der Tools Nutzen für die Analyse von Performance-Problemen ziehen kann, sei hier anhand einiger Beispiele dargestellt:
Verhältnis von Read- zu Write-Aufträgen Um das Verhältnis von Lese- zu Schreibaufträgen zu erhalten, werden auf den betreffenden logischen Laufwerken mittels vom Betriebssystem (z.B. Performance-Monitor bei Windows oder „strace“ bei LINUX) oder dem Speichersystem bereitgestellter Tools die dort stattfindenden I/Os ermittelt. Diese Informationen können zusammen mit dem Wissen über die Applikation genutzt werden, um zu erkennen, ob sich das Speichersystem wie erwartet verhält. Wenn z.B. bei einem File-Server, der hauptsächlich für Datenabfragen genutzt wird, auf einem Volume schreibintensive Zugriffe zu verzeichnen sind, so macht dies deutlich, dass dort weitere Untersuchungen notwendig sind.
Blockgröße der durchgeführten Transaktionen Die Anzahl der Schreib-/Leseaufträge bestimmter Blockgrößen kann zur Aufdeckung von möglichen Performance-Problemen herangezogen werden. Wenn beispielsweise die eingesetzte Anwendung mit einer Blockgröße von 16 KB arbeitet, dann ist mit einem hohen Aufkommen von Aufträgen dieser Größe zu rechnen. Wenn dies nicht der Fall ist, dann sorgt eventuell ein Volume Manager oder ein I/O-Treiber für eine Zusammenfassung oder Auftrennung der Aufträge. Bei einer derartigen Untersuchung ist zu beachten, dass die z.B. vom Windows Performance-Monitor gelieferten Durchschnittswerte („Avg. Disk Bytes/Read“) nicht eine genaue Verteilung der Blockgröße wiedergeben. Hingegen ist es mit dem „Process Monitor“ möglich, die von der Anwendung an das Dateisystem übermittelten Aufträge zu protokollieren, ohne dabei allerdings die Aufträge beobachten zu können, die letztlich direkt an der Schnittstelle zum Disk-Subsystem auftreten. Weitere Analysemöglichkeiten kann auch ein Analyse-Tool auf dem externen Disk-Subsystem bieten.
Lokalität der Zugriffe Wenn die Zugriffe auf einen Datenbestand nicht über den gesamten Bestand verteilt sind, sondern teilweise innerhalb eines bestimmten Bereiches stattfinden, dann spricht man auch von einer Lokalität der Zugriffe. Diese Information kann man aus eventuell vorhandenen Statistiken über den

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
Seite 14 (15) © Fujitsu Technology Solutions 2011
Cache ableiten: hohe Trefferraten („hit rates“) im Cache lassen darauf schließen, dass wenigstens ein Teil der Zugriffe innerhalb eines bestimmten Datenbereiches stattfindet. Wenn man die Chance hat, mittels „Process Monitor“ oder „strace“ die verwendeten Bereiche innerhalb der bearbeiteten Dateien in Erfahrung zu bringen, kann man zusammen mit den gelesenen oder geschriebenen Byte-Anzahlen eine Vorstellung darüber entwickeln, ob die Zugriffe innerhalb einer z.B. 80 GB großen Datei vollkommen wahlfrei über die gesamten 80 GB verteilt sind oder ob während bestimmter Phasen immer nur einige Gigabyte bearbeitet werden. Nur wenn Zweiteres der Fall ist, macht die Aktivierung eventuell vorhandener Read Caches Sinn, da der Cache des Controllers ansonsten vergeblich nach Daten durchsucht würde.
Anzahl gleichzeitiger Aufträge an einem logischen Laufwerk Ein Maß für die Intensität der I/Os sind die an einem logischen Laufwerk anstehenden Aufträge („Avg. Disk Queue Length“) sowie unter Umständen auch die Auslastung („% Disk Time“) des Volumes. Durch das Erweitern eines logischen Laufwerks um weitere Datenträger kann die Parallelität auf den einzelnen Datenträgern beeinflusst und somit Transaktionsraten und Antwortzeiten optimiert werden. Dies erfordert jedoch in der Regel ein vollständiges Backup und Restore der betreffenden Datenbestände.
Antwortzeiten Die Antwortzeiten („Avg. Disk sec/Transfer“) eines logischen Laufwerks geben an, wie das Speichersystem auf die aufgebrachte Last reagiert. Hierbei ist zu beachten, dass die Antwortzeit nicht nur von der Anzahl und der Blockgröße der Aufträge abhängt, sondern auch davon, ob es sich um Schreib- oder Leseaufträge handelt und in welchem Mischungsverhältnis diese stehen.
Verteilung der I/Os auf die logischen Laufwerke und über die Zeit Wenn ein Disk-Subsystem unter hoher Belastung arbeitet, so ist darauf zu achten, dass die I/O-Intensität über alle LUNs möglichst gleichmäßig ist. In der Praxis ist dies allerdings nicht ganz einfach zu erreichen, da sowohl die I/O-Intensität als auch die Verteilung über die LUNs über die Zeit variiert. So sind z.B. die Belastungen zum Monats-, Quartals- oder Jahresende vollkommen anders als die normalen, durch die tägliche Arbeit entstehenden I/O-Lasten. Auch die regelmäßigen Backup-Zyklen oder große Datenbankabfragen können zu Engpass-Situationen führen. Auch das Anmelden der Benutzer oder deren Pausenzeiten kann Einfluss auf die I/O-Intensität und deren Verteilung über die Volumes haben. Wenn man die I/O-Belastungen der logischen Laufwerke analysiert und dabei die
I/O-Belastung zu kritischen Zeiten Laufwerke mit der höchsten Last niedrig belasteten Laufwerke
ermittelt, dann können diese Informationen bei der Entscheidung helfen, z.B. Daten von einem auf ein anderes logisches Laufwerk zu verlagern um eine gleichmäßigere Auslastung der Volumes zu erreichen. Es ist eventuell auch möglich, einige Engpässe durch die zeitliche Verschiebung von regelmäßigen Tätigkeiten, z.B. Backup zu eliminieren. Nach allen derartigen Veränderungen ist es aber notwendig, das Speichersystem weiter zu beobachten, um sicher zu stellen, dass die Beseitigung eines Engpasses an einer Stelle nicht zu einem neuen Engpass an anderer Stelle führt.
Optimaler RAID Level und Plattenanzahl Bei transaktionsintensiven Anwendungen wie z.B. Datenbanken kann es bei Engpässen sinnvoll sein, auf einen anderen RAID-Level oder auch auf eine größere Anzahl von Datenträgern umzurüsten. Derartige Änderungen erfordern meist ein vollständiges Backup und Restore der gespeicherten Datenbestände. Aktuelle RAID Controller bieten die Möglichkeit RAID-Verbände online zu erweitern („Online capacity expansion“). Dabei muss allerdings berücksichtigt werden, dass diese Erweiterung sehr zeitaufwändig ist, denn alle bereits gespeicherten Daten müssen reorganisiert, das heißt, neu über den erweiterten RAID-Verband verteilt werden.
Die oben aufgeführten Analysen können natürlich auch zu dem Ergebnis führen, dass nicht das Speichersubsystem selbst der Grund für eine unzureichende Performance ist, sondern dass die Gründe dafür in der Anwendung selbst oder mehr noch der Art der Nutzung des Speichersystems durch die Applikation liegen.

WHITE PAPER GRUNDLAGEN DISK-I/O-PERFORMANCE VERSION: 1.0 2011-05-09
© Fujitsu Technology Solutions 2011 Seite 15 (15)
Literatur
PRIMERGY Systeme
http://de.fujitsu.com/primergy
PRIMERGY Performance
http://de.fujitsu.com/products/standard_servers/primergy_bov.html
Informationen über Iometer
http://www.iometer.org
Kontakt
FUJITSU Technology Solutions
Website: http://de.fujitsu.com/
PRIMERGY Product Marketing
mailto:[email protected]
PRIMERGY Performance und Benchmarks
mailto:[email protected]
Alle Rechte vorbehalten, insbesondere gewerbliche Schutzrechte. Änderung von technischen Daten sowie Lieferbarkeit vorbehalten. Haftung oder Garantie für Vollständigkeit, Aktualität und Richtigkeit der angegebenen Daten und Abbildungen ausgeschlossen. Wiedergegebene Bezeichnungen können Marken und/oder Urheberrechte sein, deren Benutzung durch Dritte für eigene Zwecke die Rechte der Inhaber verletzen kann. Weitere Einzelheiten unter http://de.fujitsu.com/terms_of_use.html
2011-05-09 WW DE Copyright © Fujitsu Technology Solutions GmbH 2011





























