Embed Size (px)
Citation preview

i
¸
XML Based Billing Agent
for Public WLANs
Diplomarbeit: DA Sna 02/4 6. September bis 28. Oktober 2002 Betreuender Dozent: Prof. Dr. Andreas Steffen Partnerfirma: futureLAB AG Diplomanden: Martin Heusser Rémy Schumm


iii
Zusammenfassung
Das Ziel dieser Diplomarbeit war es, für das CIPnG - basierende Public Wireless LAN, welches ehemalige Studenten der ZHW für die Firma futureLAB AG in Winterthur entwickelt hatten, ein XML – basiertes Billing-Modul zu spezifizieren und zu implementieren, das den De-facto-Standart von IPDR.org erfüllt. Das Public Wireless LAN benötigt eine Infrastruktur, welches ihm ermöglicht, die Benutzung der Ressourcen durch die Endbenutzer, aber auch die Verteilung des Verkehrs auf die verschiedenen Basisstationen aufzuschlüsseln. Auf diese Weise ist es dem Netzwerkbetreiber möglich, den Endbenutzern detaillierte Rechnungen zu stellen und den Betreibern der Basisstationen Rückvergütungen zu zahlen. Laut der Ausschreibung der Arbeit wären die Daten auf dem Linux Netfilter Modul des CIPnG Gateways schon vorhanden gewesen, woher man sie auch einfach hätte abholen können, um sie mit einem Java - basierendem XML – Agenten zu parsen, eine IPDR.org – konforme Billing Data Ausgabe zu produzieren und diese auf eine geeignete Art und Weise darzustellen. Leider bereitete uns das Linux Netfilter Modul des CIPnG - Gateways massive Probleme: die benötigten Daten waren nicht oder nur teilweise vorhanden, und sie liessen sich auch nicht einfach extrahieren. Wir mussten mehr als 50% unserer Ressourcen für diese Probleme aufwenden. Im Moment funktionieren nur Teile des neu entwickelten Netfilter Modules. Trotz allem konnten wir ein solches Billing System entwerfen und implementieren, das IPDR -konformen XML Output produziert. Wir benutzten dazu Java-, JDBC-, PostgreSQL- und XSLT- Technologien. Ausserdem haben wir neue IPDR Schemas entworfen – als Ersatz für die existierenden von IPDR.org, die noch nie benutzt wurden und nicht funktionierten. Wir haben auch neue, proprietäre XML Schemas zur Darstellung von Billing Daten spezifiziert, um diejenigen Anwendungsfälle abzudecken, für welche sich die IPDR Normen nicht eigneten.

iv

v
Abstract
The goal of this diploma thesis was to specify and implement an XML-based Billing Agent - fulfilling the de-facto standard specifications of IPDR.org - for the CIPnG-based Public Wireless LAN that had been implemented by former ZHW students for futureLAB Ltd. in Winterthur, Switzerland. The Public Wireless LAN needs a Billing Infrastructure to be able to track down the use of resources by the customers on the one hand and the distribution of the traffic to the different base stations on the other hand. So, the network operator is able to produce billings for his customers and pay reimbursements to the operators of the Base Stations. According to the posting of this thesis, the billing data should have been easily extracted out of the CIPnG-Gateway’s Linux Netfilter Module, from where a Java Based XML Agent should parse the data, produce Billing Data Output in accordance to IPDR.org and display it in a convenient way. Unfortunately, the CIPnG-Gateway’s Linux Netfilter Module caused overwhelming troubles for us: the needed data was not present in it, nor was it to be extracted easily. More than 50% of the resources had to be put in that issue. For the moment, just parts of the new designed Netfilter Modules do really work. Nevertheless, we could specify and implement such a Billing System that produces IPDR XML output, using Java-, JDBC-, PostgreSQL- and XSLT- technologies. In addition, we drafted new IPDR schemas for the existing ones that never had been used and did not work. We also specified some new, proprietary XML schemas for displaying Billing Data for those use cases that could not be satisfied by the IPDR specifications.


vii
Inhaltsverzeichnis
Zusammenfassung......................................................................................................3
Abstract......................................................................................................................5
Inhaltsverzeichnis......................................................................................................7
Abbildungsverzeichnis ............................................................................................13
Tabellenverzeichnis.................................................................................................14
1 Vorwort ...............................................................................................................1
2 Aufgabenstellung ................................................................................................3
3 Organisation der Dokumentation – UP..............................................................5
3.1 Frei nach Unified Process.................................................................................. 5
3.2 Abweichungen vom Unified Process................................................................ 6
4 Anforderungen....................................................................................................9
4.1 Geschäftsmodell................................................................................................. 9

viii
4.2 Anwendungsfälle............................................................................................... 10
4.2.1 Handhabung in der Praxis ......................................................................... 12
4.3 Das Problem der Aggregation des Netzverkehrs ............................................. 13
5 Analyse ............................................................................................................. 15
5.1 Architektur: Systemgrenzen und Akteure ....................................................... 15
5.2 Subsystem: CIPnG Netfilter-Modul ................................................................. 16
5.2.1 Beschreibung .............................................................................................. 16
5.2.2 Anwendungsfälle........................................................................................ 17
5.3 Subsystem: Java-Daemon auf Gateway ............................................................ 18
5.3.1 Beschreibung .............................................................................................. 18
5.3.2 Anwendungsfall ......................................................................................... 18
5.4 Subsystem: Datenbank ...................................................................................... 18
5.4.1 Beschreibung .............................................................................................. 18
5.4.2 Anwendungsfall ......................................................................................... 19
5.5 Subsystem: Billing Agent .................................................................................. 19
5.5.1 Beschreibung .............................................................................................. 19
5.5.2 Anwendungsfälle........................................................................................ 20
5.6 Subsystem: Darstellung ..................................................................................... 21
5.6.1 Beschreibung .............................................................................................. 21
5.6.2 Anwendungsfall ......................................................................................... 22
5.7 Zusätzliche Anforderung: Bemerkungen zur Sicherheit ................................ 22
6 IPDR.org: Der IP Data Record Standart .......................................................... 23
6.1 Die Organisation IPDR.org ............................................................................... 24
6.2 NDM – U............................................................................................................ 24

3.1: Frei nach Unified Process
ix
6.3 Das IPDRDoc und der IPDR............................................................................. 26
6.4 Was ein IPDR ist, und was nicht ...................................................................... 26
6.5 Die Service Specification „Internet Access Wireless“ WIA ............................ 27
6.5.1 Daten in SS – WIA ..................................................................................... 28
6.6 Schemas der SS – WIA ...................................................................................... 29
6.6.1 Das IPDR Schema....................................................................................... 29
6.6.2 Das WIA Schema........................................................................................ 33
6.7 Das Problem der Validierung oder: der Editor-in-Chief der IPRD.org........ 34
6.7.1 Neue Drafts für SS-IA und SS-WIA .......................................................... 35
7 Grundlagen Netfilter.........................................................................................37
7.1 Kernelmodule .................................................................................................... 37
7.2 Netfilter .............................................................................................................. 38
7.3 Proc File-System................................................................................................ 40
7.4 Implementierung ............................................................................................... 41
7.5 IPv4 Header ....................................................................................................... 42
7.6 IPv6 Header ....................................................................................................... 47
8 Design................................................................................................................51
8.1 Das CIPnG Netfiltermodul................................................................................ 51
8.1.1 Probleme bei der Datenerfassung.............................................................. 52
8.1.2 Ort der Datenerfassung .............................................................................. 54
8.1.3 Datenerfassung auf dem Gateway ............................................................. 56
8.2 Der Netfilter-Dämon und der Billing-Agent-Dämon...................................... 61
8.2.1 Der DaemonController .............................................................................. 62
8.2.2 Der NetfilterDatareaderDaemon ............................................................... 63

x
8.2.3 Der BillingAgentDaemon .......................................................................... 65
8.2.4 Gesamtdesign und Ablauf .......................................................................... 67
8.2.5 Lebenszyklus eines IP Data Records ......................................................... 72
8.3 Die Datenbank................................................................................................... 74
8.4 Sicherheit des Gesamtsystems .......................................................................... 76
8.4.1 Schutz vor Angriffen und Manipulationen............................................... 76
8.4.2 Fehlerbehandlung, Ausnahmefälle ........................................................... 77
8.5 Die Darstellung.................................................................................................. 77
8.5.1 Gesamtdesign.............................................................................................. 78
8.5.2 Neue XML Schemas ................................................................................... 78
8.5.3 Zuständigkeit .............................................................................................. 81
9 Implementierung.............................................................................................. 83
9.1 Das CIPnG Netfiltermodul................................................................................ 83
9.1.1 Andere Netfilter Module ........................................................................... 87
9.1.2 Kernel Netfiltermodul billing_bs: ............................................................. 87
9.1.3 Schwächen der billing_bs Implementierung............................................ 88
9.1.4 Kernel Netfiltermodul billing_gw:............................................................ 89
9.1.5 Linked List .................................................................................................. 90
9.1.6 Proc File System ......................................................................................... 95
9.1.7 Shell-Script ................................................................................................. 95
9.1.8 Java .............................................................................................................. 96
9.1.9 Schwächen der billing_gw Implementierung .......................................... 96
9.2 Das Subsystem der Java – Dämonen................................................................. 97
9.2.1 Starten der Java Subsysteme ...................................................................... 97
9.2.2 Das Properties – System der Java Subsysteme .......................................... 97
9.2.3 Das AlarmSystem der Java – Subsysteme.................................................. 99

3.1: Frei nach Unified Process
xi
9.3 Der Java NetfilterDatareaderDaemon............................................................... 102
9.3.1 Der Parser ................................................................................................... 103
9.3.2 Die Methode writeData(): Schnittstelle zur Datenbank. ......................... 105
9.4 Der Java BillingAgentDaemon.......................................................................... 106
9.4.1 Die Methode writeIPDR() ......................................................................... 106
9.5 Die Datenbank ................................................................................................... 111
9.5.1 Installation .................................................................................................. 112
9.5.2 Start ............................................................................................................. 112
9.5.3 Zugriff via PHP Tool phpPgAdmin........................................................... 113
9.5.4 Zugriff mit dem SQL Plugin von jEdit ...................................................... 114
9.5.5 Erstellen des ER – Schemas........................................................................ 115
9.5.6 JDBC............................................................................................................ 118
10 Test ..................................................................................................................119
11 Aussicht ...........................................................................................................121
12 Projektmanagement ........................................................................................123
12.1 Projektverlauf................................................................................................. 123
12.1.1 Einarbeitung und Beginn ........................................................................... 123
12.1.2 Ändern der Schwergewichte ..................................................................... 124
12.1.3 Anpassen der Ziele ..................................................................................... 124
12.1.4 Abschluss .................................................................................................... 125
12.2 Ressourcen...................................................................................................... 126
12.2.1 Aufteilung der Arbeit................................................................................. 126
12.2.2 Technische Ressourcen .............................................................................. 126
12.3 Probleme......................................................................................................... 127
12.3.1 IPDR............................................................................................................ 127
12.3.2 ZHW Netzwerk.......................................................................................... 127

xii
12.3.3 Bestehendes CIPnG System ....................................................................... 128
12.3.4 Datenerfassung auf dem CIPnG – Linux Kernel Programmierung ......... 128
12.3.5 Laptop – beziehungsweise WLAN und Linux .......................................... 129
12.4 Soll- und Ist- Plan .......................................................................................... 129
13 Glossar............................................................................................................. 133
14 Literaturverzeichnis ....................................................................................... 137
15 CD-Rom.......................................................................................................... 141

xiii
Abbildungsverzeichnis
Abbildung 1 Geschäftsmodell............................................................................................... 10
Abbildung 2: Geschäftmodell: Details.................................................................................. 12
Abbildung 3: Systemarchitektur .......................................................................................... 16
Abbildung 4: Das Logo der IPDR.org................................................................................... 23
Abbildung 5: NDM - U Refrenz Modell .............................................................................. 25
Abbildung 6: Die grundlegenden IPDR Elemente .............................................................. 26
Abbildung 7: Das IPDRDoc Schema .................................................................................... 31
Abbildung 8: Das IPDR Schema........................................................................................... 32
Abbildung 9: SE-WIA Schema ............................................................................................. 33
Abbildung 10: SC-WIA Schema........................................................................................... 33
Abbildung 11: UE-WIA Schema .......................................................................................... 34
Abbildung 12: Architektur Netfilter .................................................................................... 39
Abbildung 13: IPv4 Header .................................................................................................. 42
Abbildung 14: IPv6 Header .................................................................................................. 47
Abbildung 15: Probleme bei einer Abrechnung nach Volumen........................................ 52
Abbildung 16: Zusätzlicher IPv4 Billing Header Mobilehost Internet ......................... 58
Abbildung 17: Internet Basestation................................................................................. 59
Abbildung 18: Control Pakete Basestation Gateway...................................................... 60
Abbildung 19: Control Pakete Node Gateway................................................................ 60
Abbildung 20: Dämonen Klassendiagram............................................................................ 62
Abbildung 21: Netfilter Klassendiagram.............................................................................. 63
Abbildung 22: Billing Klassendiagramm.............................................................................. 66
Abbildung 23: Billing Sequenzdiagram................................................................................ 67
Abbildung 24: Hilfsklassen Diagramm................................................................................. 68

xiv
Abbildung 25: Hauptsequenzdiagramm Dämonen ............................................................. 71
Abbildung 26: Datenbank ER - Schema .............................................................................. 74
Abbildung 27: Schema zur Dispute Resolution................................................................... 79
Abbildung 28: Schema für Base Station Usage .................................................................... 80
Abbildung 29: Schema für Base Station Periode ................................................................. 81
Abbildung 30: Architektur Netfiltermodule ....................................................................... 84
Abbildung 31: Linked List und Hash ................................................................................... 91
Abbildung 32: Node Linked List .......................................................................................... 92
Abbildung 33: Funktion move_to_head .............................................................................. 93
Abbildung 34: Funktion addNode........................................................................................ 94
Abbildung 35: phpPgAdmin............................................................................................... 113
Abbildung 36: jEdit mit SQL Plugin .................................................................................. 114
Abbildung 37: Das ER - Schema......................................................................................... 115
Abbildung 38: Soll-Plan...................................................................................................... 131
Abbildung 39 : Ist-Plan....................................................................................................... 132
Tabellenverzeichnis
Tabelle 1: IPDR Attributsbelegung...................................................................................... 28
Tabelle 2: Ort der Datenerfassung ....................................................................................... 54

1
1 Vorwort
Diese Diplomarbeit war eine interessante, über viele Technologien breit gefächerte Arbeit mit verschiedenen unvorhergesehenen Überraschungen und Wendungen, die uns sehr herausforderten: Geplant als klassische Ingenieurarbeit mit Unified Process Elementen und objektorientierter Java Entwicklung, wurde es zum Abenteuer in den Tiefen des Linux Kernels und diversen alltäglichen Problemen der Informatikingenieurarbeit. So mussten wir unter anderem die Normen, die wir erfüllen sollten, zuerst selbst implementieren und mit undokumentierten Linux Kernel Sourcecode arbeiten. Sie gab uns Einblick, wie in der Industrie ein Problem angegangen wird, das Problem näher beschrieben wird, eine Lösung dafür gesucht wird und schliesslich dieses Lösung implementiert wird. Hierbei möchten wir uns bei Herrn Prof. Dr. Andreas Steffen und bei der Firma futureLAB AG für die Betreuung während der Diplomarbeit recht herzlich bedanken.
Winterthur, den 28. Oktober 2002
Martin Heusser Rémy Schumm

Kapitel 1: Vorwort
2

3
2 Aufgabenstellung
XML-based Billing Agent for Public WLANs
Arbeit Nummer: DA Sna 02/4
Fachgebiet: Kommunikation
Dozent(en): Andreas Steffen, Büro: E509, Tel.: 434
Studiengang: --/IT/KI
Anzahl Studenten: 2
Beschreibung:
In sogenannten "Hotspots" werden immer häufiger grossflächige Wireless LANs
installiert, die es jedermann erlaubt, sich mittels eines mit einer WLAN-Karte
ausgerüsteten Laptops oder PDAs in das Internet einzuklinken. Diese Dienstleistung ist
meist nicht gratis, da der WLAN Service Provider durch das Betreiben der WLAN
Infrastruktur natürlich Geld verdienen will. Heute wird der Zugang fast immer auf der
Basis einer Flat-Rate ermöglicht, d.h. durch Zahlung einer festen Gebühr kann zum
Beispiel das Netz 24 Stunden lang unbeschränkt benutzt werden.

Kapitel 2: Aufgabenstellung
4
In dieser Diplomarbeit soll ein volumenbasiertes Billing System konzipiert und realisiert
werden, das die über die WLAN-Funkstrecke ausgetauschten IP-Pakete nach Benutzern
aufschlüsselt und die statistischen Informationen in einem XML-Format codiert. Dabei
sollen die Empfehlungen von www.ipdr.org beachtet werden. Die Billing-Daten sollen
durch einen zentralen Managementprozess periodisch von allen WLAN-Gateways
abgerufen und in einer Datenbank abgelegt werden. Es soll auch eine Möglichkeit
bestehen, die Daten nach verschiedenen Kriterien aufgeschlüsselt als Webseite
darzustellen.
Als WLAN Infrastruktur wird "Cellular IP" auf der Basis von Linux Access Points
verwendet. Die für das Billing benötigten Rohdaten sind im WLAN Gateway schon
vorhanden, d.h. es muss nur noch ein in C, C++ oder Java programmierter Agent erstellt
werden, der die Rohdaten aufarbeitet und in eine XML-Struktur giesst.
Weiterführende Informationen: http://www.ipdr.org/
Voraussetzungen:
Die während des Studiums erworbenen Kenntnisse auf den Gebieten Datenbanken,
Netzwerkkommunikation und Linux-Betriebsystem werden vorausgesetzt.
XML-Grundkenntnisse
Gute C, C++ oder Java Programmierkenntnisse
Partnerfirma:
FutureLAB AG, Schwalmenackerstr. 4, 8400 Winterthur (http://www.futurelab.ch)

5
3 Organisation der Dokumentation – UP
3.1 Frei nach Unified Process
Die Dokumentation lehnt sich frei an den Unified Process an: wir halten uns an die
klassische Gliederung in Artefakte wie Anforderungen, Analyse, Design und
Implementierung.
Anforderungen
In den Anforderungen geht es darum zu Verstehen, was mit der Software überhaupt
erreicht werden soll, was ihr Umfeld ist und wie dieses funktioniert.
Analyse
In der Analyse schliesslich wird versucht, diese Anforderungen in Anwendungsfällen zu
verpacken: es wird beschrieben, was genau mit der Software passiert, wer was von ihr
will, was dabei rauskommt und so weiter.

Kapitel 3: Organisation der Dokumentation – UP
6
Es wird schliesslich zum ersten Mal eine Systemarchitektur entworfen, Grenzen des
Systems festgelegt und interne Subsysteme identifiziert.
Design
Im Design wird das System konkret modelliert: welche Softwaremodule haben welche
Aufgabe, was machen sie, wie interagieren sie, wie funktionieren sie.
Implementierung
In der Implementierung wird beschrieben, wie genau das System aufgrund des Designs
implementiert wurde. Wie funktionieren die Module, wie müssen sie initialisiert
werden, wie läuft die Fehlerbehandlung und so weiter.
3.2 Abweichungen vom Unified Process
Auf die bei UP mit grossen Projekten übliche Aufteilung in Iterationen haben wir
verzichtet, weil das Projekt mit 7 Wochen dafür eigentlich zu kurz ist.
Aus gleichem Grund ist auch die allgemeine Anzahl der Artefakte stark reduziert.
Kernelmodule
Da unser System in einem grossen Teil kein klassisches Objektorientiertes System ist,
konnten wir natürlich nicht die gesamte Entwicklung klassisch objektorientiert abbilden.
Wir haben aber dennoch versucht, die Kernelmodule in den UP einzubinden.
IPDR
Dem IPDR haben wir ein eigenständiges Kapitel gewidmet, da diese Norm zentral für die
Arbeit war und erklärt werden musste.

3.2: Abweichungen vom Unified Process
7
Varianten
Im Klassischen UP wird normalerweise Analyse, Design und Implementierung des
fertigen, funktionierenden Systems beschrieben. Wie man darauf gekommen ist,
interessiert dann normalerweise niemanden mehr.
Vor allem für die Kernelmodule aber mussten wir extrem viel Abklärungs- und
Einarbeitungsarbeit leisten. Es gehörte zentral zu unserer Diplomarbeit, diese
Abklärungen zu machen, auszuwerten, eine Lösung zu finden und zu Begründen, warum
wir diese Lösung gewählt haben. Darum haben wir im Design, vor allem für die
Kernelmodule, alle Varianten, deren Probleme und so weiter dokumentiert.


9
4 Anforderungen
4.1 Geschäftsmodell
In einem grösserem Gebiet sollen WLAN Access Points (Basestations) aufgestellt werden,
die vom Netzbetreiber betrieben werden: Registrierte Benutzer sollen mit diesem Netz
drahtlosen Zugang zum Internet bekommen. Sie bezahlen dafür in Abhängigkeit der
transferierten Bytes.
Zusätzlich werden dem Standortinhaber der Basestations gewisse Beträge gutgeschrieben
in Abhängigkeit des auf seiner Basestation generierten Verkehrs.

Kapitel 4: Anforderungen
10
Abbildung 1 Geschäftsmodell
4.2 Anwendungsfälle
Ein Benutzer authentisiert sich am Netz und surft eine gewisse Zeit lang darauf. Dabei
kann er uneingeschränkt oft die Basestations wechseln (Handovers).
Um ihm diese Leistung verrechnen zu können, muss der Billing Agent folgende sehr
groben Hauptanwendunsgfälle erfüllen können:
Verrechnung der Internet-Access-Leistung
Der Billing Agent gibt Auskunft über wie viel ein bestimmter Kunde in einer
bestimmten Zeitspanne den Internetanschluss in Anspruch genommen hat. Als Mass gilt
die Anzahl transferierte Bytes.
Im Falle einer Reklamation soll der Billing Agent aufschlüsseln können, über welche
Basestation der Kunde wie viel Transferiert hatte.
Konkret:
• Das System wird gefragt: wie viel hat der Benutzer X im Monat September
gesurft?

4.2: Anwendungsfälle
11
• Das System antwortet: Er hat 103'487kB downlink und 30'487kB uplink
transferiert.
Im Falle einer Reklamation:
• Benutzer X hat nicht soviel gesurft. Das System wird gefragt: Wo hat er wann
soviel heruntergeladen?
• Das System antwortet: Benutzer X war vom Zeitpunkt y bis Zeitpunkt z mit
Basestation N verbunden und hat k Kilobytes transferiert.
Rückvergütung für Standort einer Basestation
Der Billing Agent gibt Auskunft über den Verkehr, der über eine bestimmte Basestation
in einer bestimmten Zeitspanne generiert wurde.
• Wie viel Verkehr ging im Monat September über die Basestation 2 im
Stadtcasino Winterthur?
• Die Basestation 2 hat 502'234'987 Bytes aufs WLAN geschickt und 52'234'987
Bytes empfangen.
im Detail:
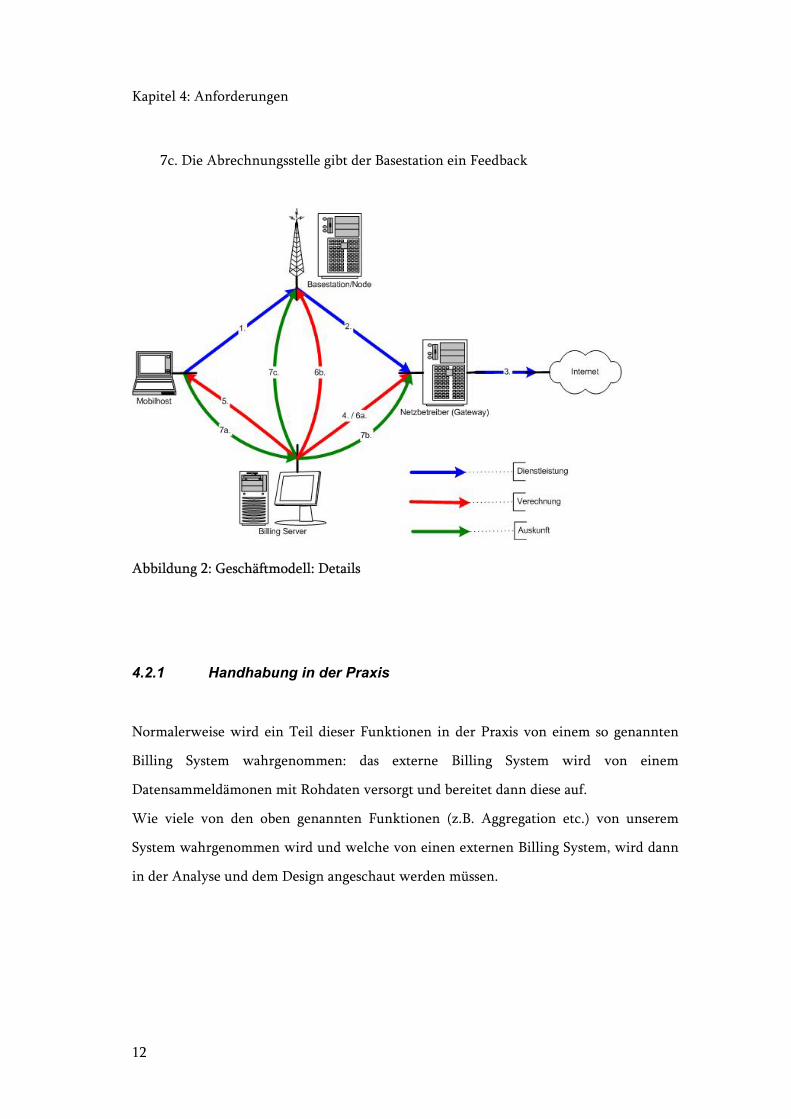
Erklärungen zum Bild Abbildung 2: Geschäftmodell: Details:
1. Der Benutzer bezieht eine Dienstleistung in Form eines Internet Access über
eine Basestation.
2. dito 1. + Weiterleitung des Verkehrs zum Gateway
3. dito 1. + Internetanschluss
4. Die Abrechnungsstelle erhält/verlangt die Benutzerdaten
5. Die Abrechnungsstelle stellt dem Benutzer eine Rechnung
6a. Die Abrechnungsstelle vergütet dem Netzbetreiber die Unkosten
6b. Die Abrechnungsstelle vergütet der Basestation die Unkosten
7a. Der Benutzer verlangt Auskunft über die Rechnung
7b. Die Abrechnungsstelle gibt dem Netzbetreiber ein Feedback
Kapitel 4: Anforderungen
12
7c. Die Abrechnungsstelle gibt der Basestation ein Feedback
Abbildung 2: Geschäftmodell: Details
4.2.1 Handhabung in der Praxis
Normalerweise wird ein Teil dieser Funktionen in der Praxis von einem so genannten
Billing System wahrgenommen: das externe Billing System wird von einem
Datensammeldämonen mit Rohdaten versorgt und bereitet dann diese auf.
Wie viele von den oben genannten Funktionen (z.B. Aggregation etc.) von unserem
System wahrgenommen wird und welche von einen externen Billing System, wird dann
in der Analyse und dem Design angeschaut werden müssen.

4.3: Das Problem der Aggregation des Netzverkehrs
13
4.3 Das Problem der Aggregation des Netzverkehrs
Die Benutzung des Internets soll laut Geschäftsmodell volumenabhängig abgerechnet
werden, jedoch soll gleichzeitig festgestellt werden können, wann wie viel transferiert
wurde.
Dabei stellt sich sofort das Problem, wie ein kontinuierlicher Vorgang wie dauernder
Netzverkehr zeitlich aufgeschlüsselt werden soll, und sich dabei die aufgezeichneten
Daten einigermassen in Grenzen halten.
Die zeitliche Aufschlüsselung interessiert in grossen Abständen (von ca. 1 Monat) für die
Abrechung, aber in kleineren Abständen für die Dispute Resolution. Allerdings braucht
es für letzteres keine kontinuierliche Aufzeichnung, sondern es genügt eine zeitliche
Auflösung von 10 Minuten oder 15 Minuten.
Die Daten müssen also in unserem System in einer Genauigkeit von 15 Minuten oder
ähnlich gespeichert werden. Dazu muss der kontinuierliche Datenverkehr irgendwo im
System aufsummiert (aggregiert, integriert) werden.


15
5 Analyse
Aufgrund der im letzten Kapitel gemachten Erkenntnisse soll nun das System genauer
analysiert werden: was sind seine Grenzen, seine Akteure, seine internen Strukturen.
5.1 Architektur: Systemgrenzen und Akteure
Das Billing Agent System ist sehr umfangreich, sodass wir es in 5 Subsysteme mit ihren
eigenen Systemgrenzen aufgeteilt haben: Siehe Abbildung 3: Systemarchitektur
Dieser modulare Aufbaue ermöglicht es uns, die Teile besser zu analysieren und auch die
Arbeiten aufzuteilen. Die Subsysteme sollen in sich möglichst kohärent und unter sich
möglichst offen gekoppelt sein, sodass Änderungen in den Subsystemen einfacher von
statten gehen können. Das wollen wir durch einfach Schnittstellen erreichen.
Das Gesamtsystem hat als Akteur im Prinzip nur den externen Billing Server bzw. unsere
Darstellungsschicht. Die Hauptanwendungsfälle des Gesamtsystems wurden schon in
den Anforderungen beschrieben: Verrechung von Zugangsleistungen auf zeitlicher Basis
und Rückvergütung für Benutzung der Basestations.
Im Folgenden analysieren wir deshalb die 5 Subsysteme:

Kapitel 5: Analyse
16
Abbildung 3: Systemarchitektur
5.2 Subsystem: CIPnG Netfilter-Modul
5.2.1 Beschreibung
Das Netfilter Modul lebt auf dem Gateway in der Kette der anderen CIPnG Module.
Seine Aufgabe ist es, den vorbeiströmenden Netzverkehr nach bestimmten Kriterien
aufzuschlüsseln, zu aggregieren und an einer bestimmten Schnittstelle für das nächste
Subsystem zur Verfügung zu stellen.

5.2: Subsystem: CIPnG Netfilter-Modul
17
Die Akteure für dieses Subsystem sind abstrakt und entsprechen etwa den folgenden
Schnittstellen: Der Netzverkehr, der die Daten liefert und der Java-Daemon auf dem
Gateway, der Daten abholt.
Voraussetzungen
Jedes IP Packet, das auf dem Gateway ankommt, muss eindeutig bestimmt sein, von
welcher Basisstation und von welchem Benutzer es kommt. Die erstere Information ist in
den IP Haeders des verpackten IP Packets schon implizit vorhanden (weil jeder Benutzer
eine eindeutige IP pro Gateway hat), die zweite muss durch Anpassung eines anderen
Netfilter-Modules herbeigeführt werden.
5.2.2 Anwendungsfälle
Hauptablauf
• Das Modul aggregiert für jeden Benutzer und für jede Basistation (diese beiden
stellen den Schlüssel einer solchen Dateneinheit) eine bestimmte Zeitlang die
Anzahl empfangenen und verschickten Bytes.
• Nach dieser Zeit schreibt das Modul die Informationen an einen geeigneten Ort
und vergisst sie wieder.
• Der Java-Daemon holt die Daten am besagten Ort ab und sorgt dafür, dass er
diese nur einmal holt.
Fehlabläufe
Wenn der Java-Daemon lange Zeit seine Daten nicht abholt, schreibt das Modul seine
Daten einfach weiter an den üblichen Ort. Es kommt nicht darauf an, wie lange der Java-
Daemon nicht vorbeikommt.

Kapitel 5: Analyse
18
5.3 Subsystem: Java-Daemon auf Gateway
5.3.1 Beschreibung
Dieses Subsystem ist sehr klein und hat fast keine Aufgaben: es ist ein Dienst zwischen
zwei Schnittstellen.
5.3.2 Anwendungsfall
Der Java-Daemon holt Daten vom Ort ab, an dem das Netfilter-Modul sie gespeichert
hat. Er sorgt dafür, dass er diese Daten nur einmal holt.
Diese Daten gibt der Daemon der Datenbank weiter. Er muss eventuell fehlende Daten
durch eine eigene Logik bzw. durch Datenbankabfragen ergänzen.
5.4 Subsystem: Datenbank
5.4.1 Beschreibung
Auch dieses Subsystem hat wenige Aufgaben, ist aber sehr wichtig. Es ist dafür zuständig,
die von den Dämonen gesammelten Daten aufzunehmen und zu speichern.
Ein Datenbank-Subsystem kann einen oder mehrere Dämonen bedienen: im Moment
beschränken wir uns aber darauf, dass dieses Subsystem fest mit einem Gateway
verbunden ist, und auch auf dieser Maschine lebt.

5.5: Subsystem: Billing Agent
19
Die Datenbank kann dafür sorgen, dass gewisse Gültigkeitsüberprüfungen der Daten
vorgenommen werden, und kann das Gesamtsystem darin unterstützen, die Daten richtig
zu verarbeiten (z.B. nur einmal auszuwerten).
Akteure für dieses Subsystem sind die beiden Subsysteme Java-Dämon und Biling-Agent.
5.4.2 Anwendungsfall
• Der Daemon schreibt seine Daten in die Datenbank.
• Der Billing-Agent holt die Daten in der Datenbank ab.
5.5 Subsystem: Billing Agent
5.5.1 Beschreibung
Dieses Subsystem ist der Kern des gesamten XML-Billing-Agents. Er erledigt die meiste
Arbeit.
Haupt-Akteure für dieses Subsystem sind der externe Billing-Server bzw. evtl. das
Darstellungs-Subsystem, welche sich die gewollten Daten vom Billing Agent holen.
Unterstützender Akteur ist das Subsystem Datenbank.
Der Billing Agent kann zentral oder auf einem Gateway sein. Im Moment soll jeder
Gateway seinen eigenen Billing Agenten haben.

Kapitel 5: Analyse
20
5.5.2 Anwendungsfälle
Verrechnung der Internet-Access-Leistung
• Ein Hauptakteur fragt auf einem Billing Agenten nach, um eine Liste des
gesamten Internetverkehrs aller Benützer seines Gateways innerhalb einer
bestimmten Zeitpanne (z.B. einem Monat) zu bekommen.
o Alternativ kann der Billing Agent auch Daten in einem bestimmten
Zeitrhythmus an einen Ort ablegen, von wo aus dann ein BSS die Daten
abholt.
• Der Billing Agent liefert Daten nach den IPDR-Spezifikationen, welche
aufschlüsseln, welcher Benutzer seines Gateways ungefähr wann wie viel
transferiert hat, und zwar auch über welche Basisstation. Die Granularität dieser
Zeitspannen ist ca. 10min. Es kann also sein, dass ein Benutzer innerhalb der
gleichen Zeitspanne auf zwei oder mehreren Basisstationen Verkehr verursacht
hat. Das genaue Format dieser Daten ist im Abschnitt 6.5 beschrieben, deren
genaue Inhalt im Design.
Rückvergütung für Standort einer Basestation
• Ein Hauptakteur frägt auf einem Billing Agenten nach, um eine Liste des
gesamten Internetverkehrs aller Basisstationen seines Gateway innerhalb einer
bestimmten Zeitpanne (z.B. einem Monat) zu bekommen.
o Alternativ kann der Billing Agent auch Daten in einem bestimmten
Zeitrhythmus an einen Ort ablegen, von wo aus dann ein BSS die Daten
abholt.
• Der Billing Agent liefert eine Liste nach den IPDR-Spezifikationen, welche
aufschlüsselt, welcher Basistation seines Gateways ungefähr wann wieviel
transferiert hat. Die Granularität dieser Zeitspannen ist ca. 10min.

5.6: Subsystem: Darstellung
21
• Das genaue Aussehen dieser Listen ist im Kapitel Datenpräsentation gemäss
IPDR.org beschrieben.
Der Billing Agent hat also sozusagen zwei Strategien, um seine Daten anzuzeigen.
Bemerkung:
Es bleibt im Kapitel 6 über IPDR abzuklären, ob diese Anforderungen mit IPDR
überhaupt erfüllt werden können, und ob diese Sinn machen. Je nachdem wird dies im
Design angepasst werden müssen.
5.6 Subsystem: Darstellung
5.6.1 Beschreibung
Dieses Subsystem dient Demonstrationszwecken bzw. der Präsentation der erzeugten
Daten des Billing Agenten. Akteure sind menschliche Anwender, die Daten ansehen
wollen, unterstützender Dienst ist der Billing Agent.
Die Darstellung kann via WebInterface (gewünscht) oder über ein beliebiges Interface
erfolgen.
Da es sich bei diesem Subsystem um ein Demo-Tool handelt, sollen keine
Berechtigungen überprüft noch sonstige Sicherheitsmechanismen eingebaut werden.

Kapitel 5: Analyse
22
5.6.2 Anwendungsfall
Der Akteur kann über die Darstellungs-Applikation eine Darstellung eines der beiden
Anwendungsfälle des Billing-Agenten anfordern. Er muss dafür erst einen Billing
Agenten bzw. dessen Gateway auswählen, ebenso die gewünschten Strategie zum
Erstellen der Daten.
Er bekommt dann eine übersichtliche Darstellung der Daten und kann sie wenn
gewünscht als XML abspeichern1.
5.7 Zusätzliche Anforderung: Bemerkungen zur
Sicherheit
Sieht man in der Systemarchitektur (Abbildung 3: Systemarchitektur) nach, sieht man
zwischen den einzelnen Subsystemen diverse Schnittstellen. Es muss dafür gesorgt
werden, dass diese Schnittstelle entweder nicht über öffentliche Netze führen bzw. dass
sie in diesem Falle verschlüsselt werden.
In Design soll festgelegt werden, wo genau welche Subsysteme residieren und wie sie
miteinander kommunizieren sollen.
1 Auch hier bleibt abzuklären, ob IPDR-XML solche Daten überhaupt darstellen kann.

23
6 IPDR.org: Der IP Data Record Standart
Für den Datentransfer zwischen unserem System und dem externen Billing System soll
ein Standart verwendet werden, der international anerkannt ist und von mehreren
Grossfirmen benutzt wird. Unser Auftraggeber futureLAB AG hat sich für die XML-
basierte Norm von IPDR.org entschieden.
Abbildung 4: Das Logo der IPDR.org

Kapitel 6: IPDR.org: Der IP Data Record Standart
24
6.1 Die Organisation IPDR.org
Die Organisation IPDR.org hat sich folgendes Ziel gesetzt:
"Implement de-facto open standards for IP-based support system interoperability, enabling
providers to profitably deploy next-generation services" - The IPDR.org Mission
Die Organisation hat Sitz in Pittstown (New Jersey, USA) und wird von diversen
grösseren Firmen getragen, u. a. von: ITU, HP, NEC, GBA (Global Billing Association).
Aus den Statements von IPDR.org:
IPDR delivers:
Standardization of a usage-record format and delivery protocol (NDMU). Representation of
the usage in state-of-the-art encapsulation techniques such as XML. The primary goal is to
define an open, extensible, flexible record that encapsulates the essential parameters for
any service transaction, including an extension mechanism so network elements and support
systems can exchange optional service metrics for a particular service.
6.2 NDM – U
IPDR.org definiert einen „Network Data Management – Usage“ Leitfaden. [NDM-U]
Darin beschreibt die Organisation auf Seite 16 ein Referenzmodell für IP-Data-Record-
Systeme: Für unser System sind dabei folgende Elemente interessant:

6.2: NDM – U
25
Abbildung 5: NDM - U Refrenz Modell
SC
Unser Service Consumer (SC) ist der Endverbraucher, der die Internetverbindung in
Anspruch nimmt.
SE
Service Element (SE) ist in unserem Fall die BaseStation.
IT
Ein IPDR Transmitter (IT) ist eine Dienst, der die D - Schnittstelle zu einem aussen
stehenden BSS zur Verfügung stellt; dies ist in unserem Fall der BillingAgent.
BSS
Ein Billing Support System ist ein externes Billing System, das die Daten (IPDRs)
aufnimmt und weiterverarbeitet, z.B. zu Monatsrechnungen für Endkunden.
Schnittstelle D
Die Schnittstelle D verbindet IT und BSS: Unser System soll im Prinzip gegen Aussen nur
die Schnittstelle D zum BBS zur Verfügung stellen. Alle anderen Schnittstellen A, B und
C sind innerhalb unserer Systemgrenzen und müssen nicht IPDR-konform
implementiert werden.

Kapitel 6: IPDR.org: Der IP Data Record Standart
26
6.3 Das IPDRDoc und der IPDR
IPDR definiert im gleichen Dokument [NDM-U]das Schema zur Codierung von IP-Data-
Records. Schemenhaft ist das in Abbildung Abbildung 6: Die grundlegenden IPDR
Elemente abgebildet:
Ein IPDR-Dokument (IPDRDoc) besteht neben diversen Meta-Informationen wie
Version und docId vor allem aus mehreren IPDR (IP Data Records). Im (optionalen und
von uns nicht implementierten) IPDRDoc.End wird beschrieben, wie viele davon im
Dokument sind. Alle IPRDs sind durchnumeriert und von einem Typ IPDRType. Der
Typ IPDR ist dabei Basis für alle weiteren IPDRTypes: sie sind je nach
Anwendungsbereich in den verschiedenen Service Spezifikationen beschrieben.
Abbildung 6: Die grundlegenden IPDR Elemente
6.4 Was ein IPDR ist, und was nicht
In einem IPDR eines bestimmten Typs wird ein atomischer „Network-Usage“ Vorgang
gespeichert: in unserem Fall zum Beispiel ein 15min Block einer Netzwerkbenützung
eines Kunden auf einer Basestation.
Ein IPDR beschreibt also die kleinste Einheit eines Network-Usages: z. B. ein Telefonat,
eine Dienstleistung u.a.

6.5: Die Service Specification „Internet Access Wireless“ WIA
27
Aus diesen Erkenntnissen wird auch klar, dass sich IPDR nicht eignet, um aggregierte
Daten darzustellen: in einem IPDRDoc können nicht Daten „intelligent“ nach Kriterien
zusammengefasst werden, sondern es eignet sich nur für eine normierte Darstellung von
Rohdaten aus einem Netzwerk-System.
Ein IPDR (IP Data Record) bildet genau ein „Usage“ (UsageEntry einer
ServiceSession) - genau eine Benutzung - einer Ressource (ein Telefonat, eine Session,
die Abfrage einer Telefonnummer etc.) ab. Ein IPDRDoc sammelt solche IPDR. IPDR eignet
sich deshalb nicht für Abbildungen von Auswertungen (Aggregationen, Zusammenfassungen
etc.) von solchen IPDR – Sammlungen. Diese Aufgabe wird von externen BSS
wahrgenommen.
Demzufolge können die in der Analyse beschriebenen Anwenungdsfälle des Billing
Agenten (siehe Abschnitt 5.5.2 auf Seite 20) nicht mehr unterschieden werden: der
Billing Agent liefert atomische Daten, aufgrund deren die beiden Anwendungsfälle
abgedeckt werden können. Anders ausgedrückt: ein IPDR liefert Daten für beide
Anwendugsfälle, die Daten können aber nicht weiter aufgeschlüsselt oder aggregiert
werden, weil sie einerseits atomisch sind und sich anderseits IPDR nicht zur Aggregation
eignet.
Im Folgenden ging es darum, eine brauchbare Service Spezifikation („von welchem Typ
sind die IPDRs“) für unsere Anwendung zu finden.
6.5 Die Service Specification „Internet Access Wireless“
WIA
Nach einigen Abklärungen wurde uns relativ schnell klar, dass für unsere Anwendung
die Service Specification „Internet Access Wireless“ [SS-IA] benutzt werden muss.
Kapitel 6: IPDR.org: Der IP Data Record Standart
28
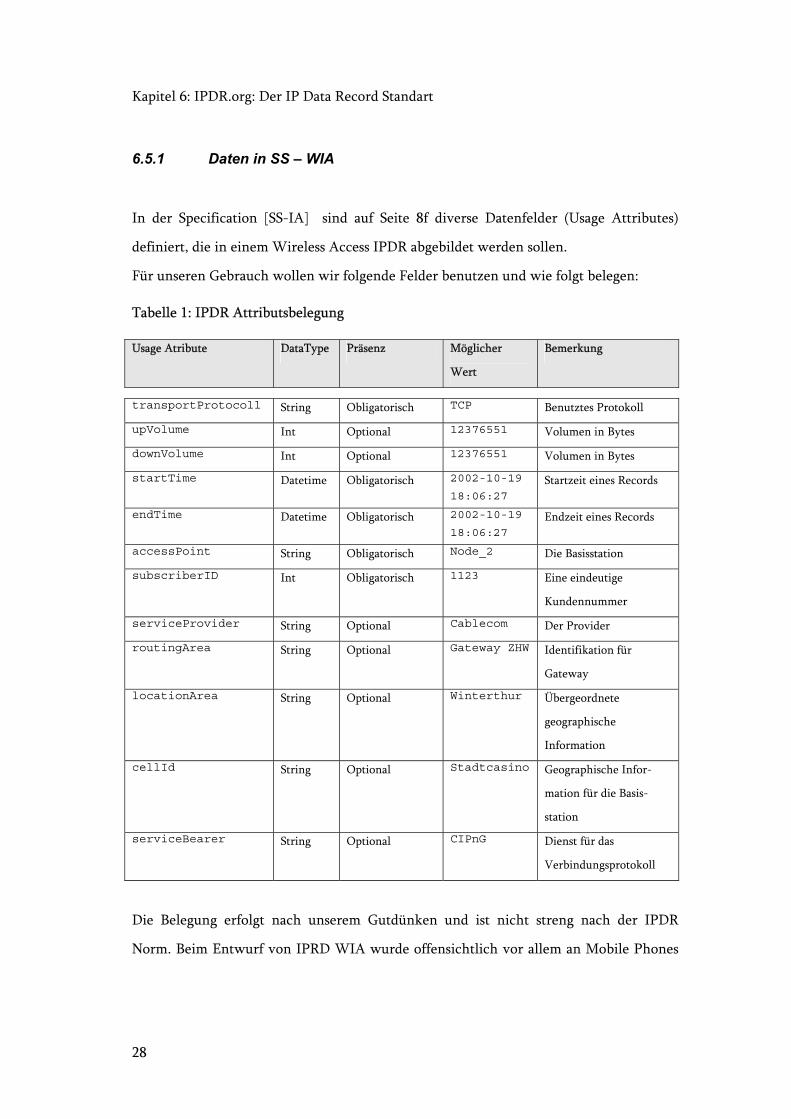
6.5.1 Daten in SS – WIA
In der Specification [SS-IA] sind auf Seite 8f diverse Datenfelder (Usage Attributes)
definiert, die in einem Wireless Access IPDR abgebildet werden sollen.
Für unseren Gebrauch wollen wir folgende Felder benutzen und wie folgt belegen:
Tabelle 1: IPDR Attributsbelegung
Usage Atribute DataType Präsenz Möglicher
Wert
Bemerkung
transportProtocoll String Obligatorisch TCP Benutztes Protokoll
upVolume Int Optional 12376551 Volumen in Bytes
downVolume Int Optional 12376551 Volumen in Bytes
startTime Datetime Obligatorisch 2002-10-19
18:06:27 Startzeit eines Records
endTime Datetime Obligatorisch 2002-10-19
18:06:27 Endzeit eines Records
accessPoint String Obligatorisch Node_2 Die Basisstation
subscriberID Int Obligatorisch 1123 Eine eindeutige
Kundennummer
serviceProvider String Optional Cablecom Der Provider
routingArea String Optional Gateway ZHW Identifikation für
Gateway
locationArea String Optional Winterthur Übergeordnete
geographische
Information
cellId String Optional Stadtcasino Geographische Infor-
mation für die Basis-
station
serviceBearer String Optional CIPnG Dienst für das
Verbindungsprotokoll
Die Belegung erfolgt nach unserem Gutdünken und ist nicht streng nach der IPDR
Norm. Beim Entwurf von IPRD WIA wurde offensichtlich vor allem an Mobile Phones

6.6: Schemas der SS – WIA
29
und ähnliches gedacht, sodass wir einige Felder sozusagen etwas nach unserem
Gutdünken umbelegen mussten, allerdings ohne die ursprüngliche Absichten allzu zu
verfälschen.
Vor allem die Verteilung von AccessPoint, CellId, routingArea und
locationArea ist etwas heikel: wir denken aber, dass dieser Verteilung so vertretbar
sei.
6.6 Schemas der SS – WIA
Für die Abbildung der IPDR schlägt IPDR.org unter anderem XML vor: unser
Auftraggeber futureLAB AG wünscht dann auch diese Darstellung.
IPDR hat zur Definition der Datentypen XML Schemas [SS-IA] erstellt, die wir erfüllen
müssen.
Das SS – WIA - Schema ist dreifach vererbt: Zuoberst ist das IPDR.xsd welches an
IA.xsd weitervererbt, zuunterst in der Hierarchie ist schliesslich WIA.xsd, welches
von IA.xsd erbt.
6.6.1 Das IPDR Schema
Ein IPDRDoc (IPDR Document) besteht aus mehreren IPDR (IP Data Records). (Siehe
Abbildung 7: Das IPDRDoc Schema) Ein IPDR seinerseits besteht wiederum aus
mehreren Elementen. (Siehe Abbildung 8: Das IPDR Schema.)2
Die gestrichelt eingezeichneten Elemente sind optional und werden von uns nicht
gebraucht.
Man kann also sagen, dass ein IPDR aus einer UE (UsageEntry) und aus einer SS
(ServiceSession) besteht, welche wiederum aus SC (ServiceConsumer) und und SE

Kapitel 6: IPDR.org: Der IP Data Record Standart
30
(ServiceElement) zusammengesetzt ist. Die Verteilung der Attribute von Tabelle 1: IPDR
Attributsbelegung auf die Unterelemente der IPDR ist von IPDR.org vorgegeben.
Erstellt man ein IPDRDoc mit einem IPDR, sieht das etwa folgendermassen aus:
<?xml version="1.0" encoding="UTF-8"?>
<IPDRDoc xmlns="http://www.ipdr.org/namespaces/ipdr" xmlns:xsi="http://www.w3.org/2001/XMLSchema-
instance" version="2.5-A.0.0.draft" docId="1_2002294_0">
<IPDRRec info="ZHW Billingagent" id="N10001"/>
<IPDR xmlns="" seqNum="1" time="2002-10-19 18:06:27.0" id="N10007">
<UE type="TimeSlot for User/Node/Protocoll">
<transportProtocol>UDP</transportProtocol>
<upVolume>604</upVolume>
<downVolume>276</downVolume>
<startTime>2002-10-19 18:06:27.0</startTime>
<endTime>2002-10-21 17:54:35.0</endTime>
<routingArea>Gateway ZHW</routingArea>
<locationArea>Winterthur</locationArea>
</UE>
<SS service="Internet Access" id="N10007">
<SC id="N10007">
<subscriberId>1</subscriberId>
<cellID>Phantasie</cellID>
</SC>
<SE id="N10007">
<accessPoint>DatenTest_Node</accessPoint>
<serviceProvider>ZHW Diplomarbeiten</serviceProvider>
<serviceBearer>ZHW CIPnG</serviceBearer>
</SE>
</SS>
</IPDR>
</IPDRDoc>
2 Die Vollständige Schemadokumentation ist auf der CD im Odner IPDRxsd mitgeliefert.
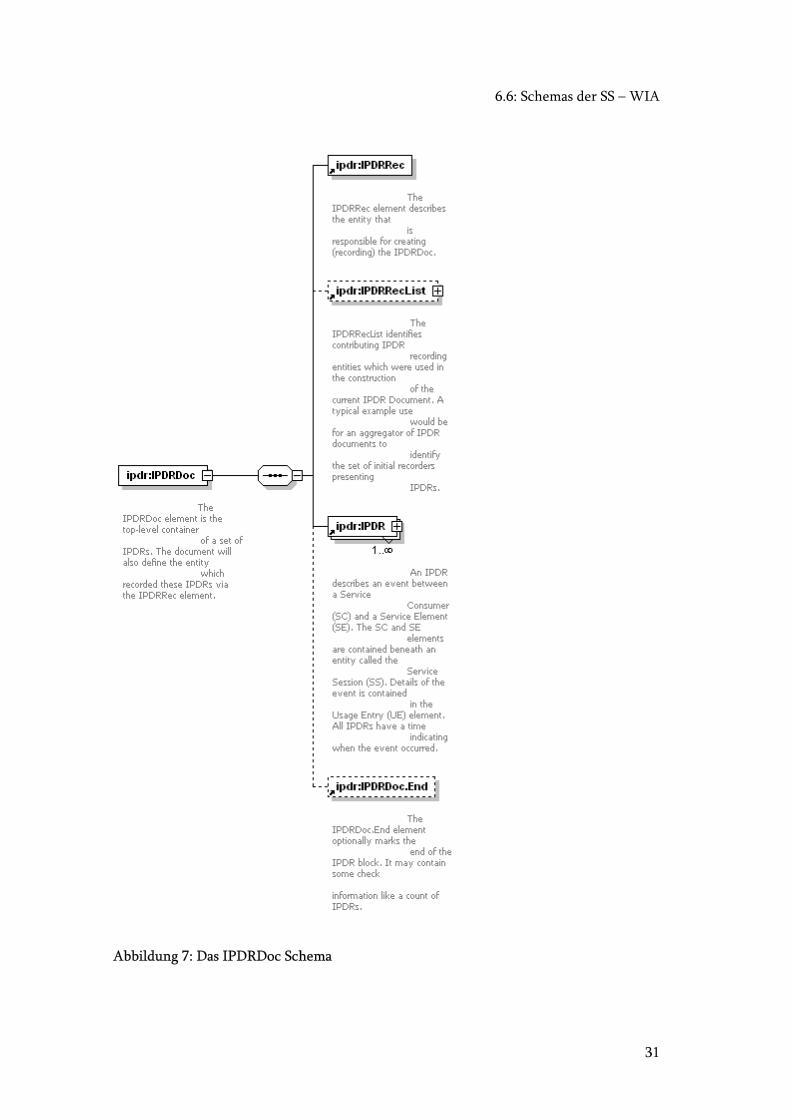
6.6: Schemas der SS – WIA
31
Abbildung 7: Das IPDRDoc Schema
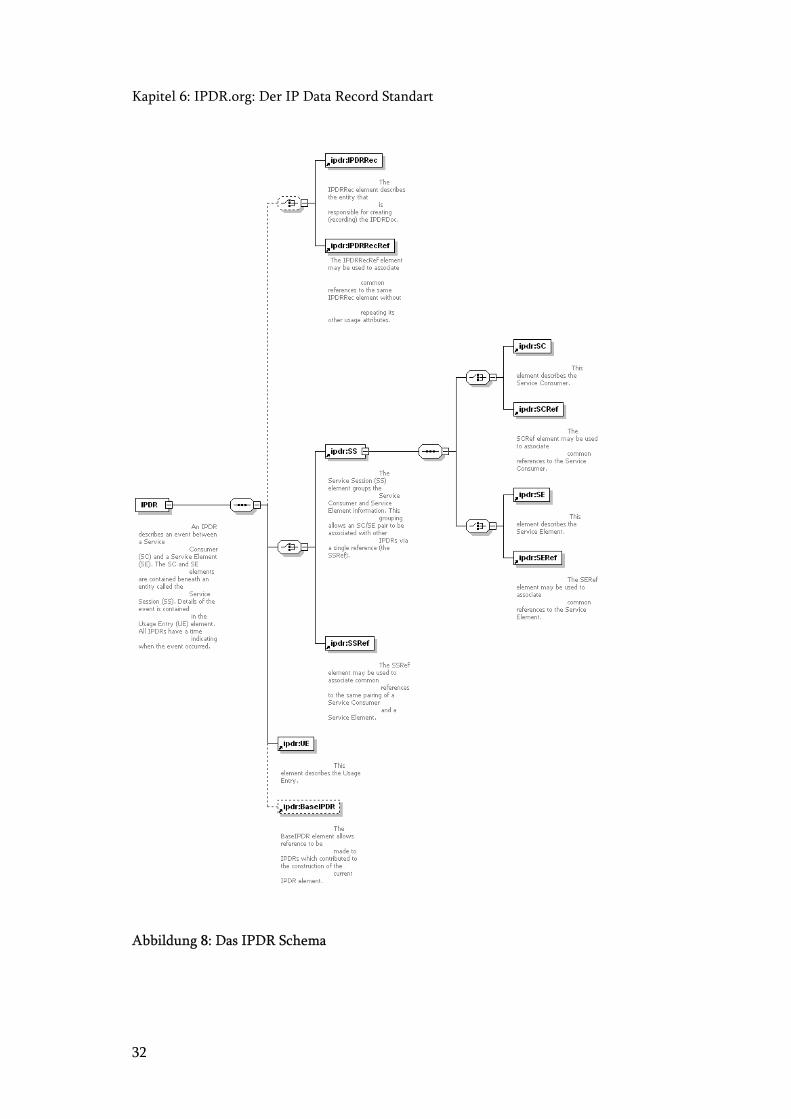
Kapitel 6: IPDR.org: Der IP Data Record Standart
32
Abbildung 8: Das IPDR Schema
6.6: Schemas der SS – WIA
33
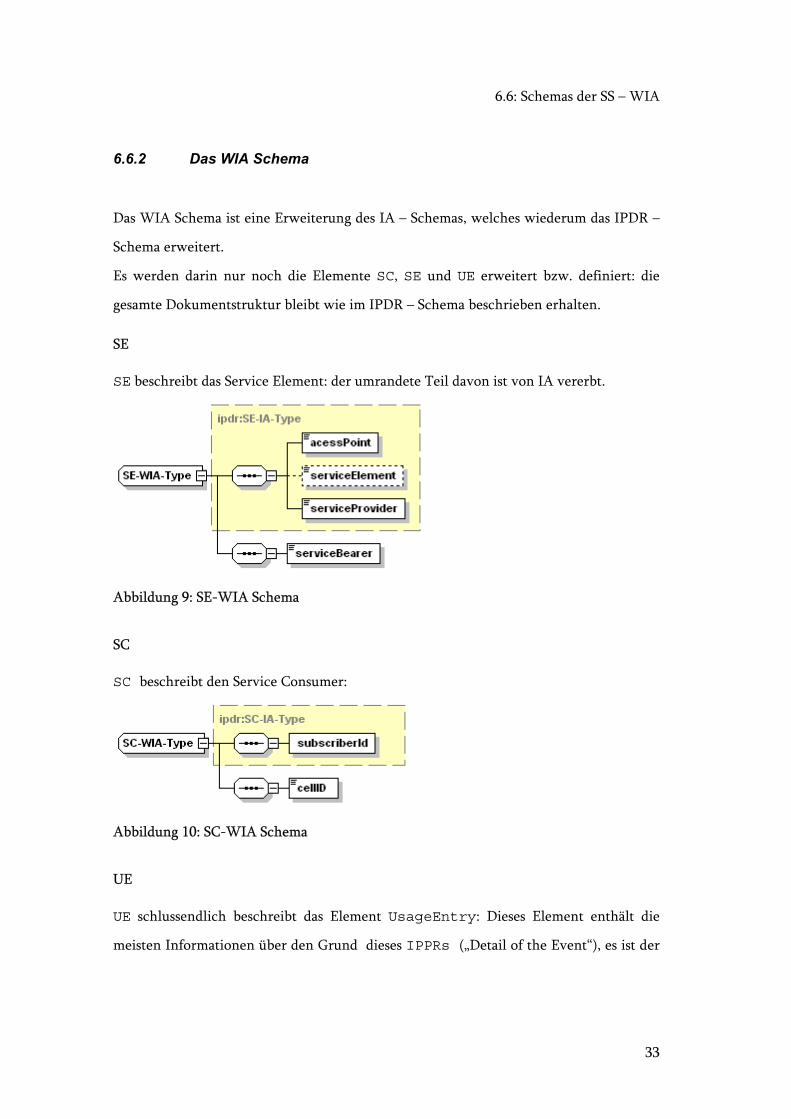
6.6.2 Das WIA Schema
Das WIA Schema ist eine Erweiterung des IA – Schemas, welches wiederum das IPDR –
Schema erweitert.
Es werden darin nur noch die Elemente SC, SE und UE erweitert bzw. definiert: die
gesamte Dokumentstruktur bleibt wie im IPDR – Schema beschrieben erhalten.
SE
SE beschreibt das Service Element: der umrandete Teil davon ist von IA vererbt.
Abbildung 9: SE-WIA Schema
SC
SC beschreibt den Service Consumer:
Abbildung 10: SC-WIA Schema
UE
UE schlussendlich beschreibt das Element UsageEntry: Dieses Element enthält die
meisten Informationen über den Grund dieses IPPRs („Detail of the Event“), es ist der

Kapitel 6: IPDR.org: Der IP Data Record Standart
34
„Benutzungs-Eintrag“ mit den Informationen, was genau für eine Internet Access
Ressource und wie viel davon benutzt wurde.
Abbildung 11: UE-WIA Schema
6.7 Das Problem der Validierung
oder: der Editor-in-Chief der IPRD.org
Zu Beginn unserer Arbeit hatten wir grosse Mühe, die Schemas der IPRD.org zu parsen
und zu verstehen, bis wir einmal herausgefunden haben, dass WIA auf IA basieren

6.7: Das Problem der Validierung
oder: der Editor-in-Chief der IPRD.org
35
müsste, wie im vorherigen Abschnitt beschrieben. Allerdings konnten wir beim besten
Willen bei IPDR.org kein Schema für IA finden.
Wir haben eine Kontaktperson bei IPDR.org kontaktiert, und wurden relativ schnell an
Steven Cotton, dem Editor in Chief von IPDR.org verwiesen.
Es stellte sich heraus, dass die Vererbungen in den Schemas falsch implementiert waren,
und – noch schlimmer – dass es überhaupt kein Schema für IA gibt. Steven Cotton
schreibt3 als Antwort auf unsere Bedenken: Von: Steven A. Cotton [mailto: [email protected]]
Gesendet: Di 01.10.2002 15:26
An: Schumm Rémy
Cc: Heusser Martin; 'Fabio Vena'; Steffen Andreas, sna; BR WG; IPDR Protocol WG
Betreff: RE: IPDR Confusions
Rémy and Martin:
Your observations make sense to me. There is one problem--the original
author of this specification is no longer active in IPDR.org. This is
the problem with the use of Service Specifications at level 1 of
development--they have never been qualified as applicable via such
things as an interoperability event or field deployment.
My suggestion is that you could draft an IA "parent" schema and forward
it to me. I would then sponsor it as a contribution to the Business
Requirements Working Group for consideration. An approach could be to
simply add the elements to the schema for WIA directly, rather than
creating a separate schema for a core IA set of elements.
Regards,
Steve Cotton
Editor-in Chief
IPDR.org (http://www.ipdr.org)
6.7.1 Neue Drafts für SS-IA und SS-WIA
Wir haben daraufhin unser eigenes Schema für IA und WIA implementiert und der
IPDR.org unentgeltlich zur Verfügung gestellt. Es ist bis zum Zeitpunkt dieses
3 Der gesamte e-Mail Verkehr ist auf der CD enthalten.

Kapitel 6: IPDR.org: Der IP Data Record Standart
36
Schreibens noch in Validation bei der IPDR Business Requirements Working Group –
und darum noch Draft.
Bei den im vorherigen Abschnitt beschriebenen Schemas handelt es sich um diese unsere
Draft - Vorschläge. Andere Schemas gibt es noch nicht.
Was mit all den anderen Firmen ist, die IPDR unterstützen, bzw. ob wohl noch niemand
diesen Standart verwendet hat, konnten wir leider nicht in Erfahrung bringen.

37
7 Grundlagen Netfilter
7.1 Kernelmodule
Kernelmodule sind Erweiterungen des Kernels: sie sind vorteilhaft, da sie währen der
Laufzeit zum Kernel hinzugelinkt werden können. Das heisst, dass jedes einzelne
Kernelmodul für sich selbst kompiliert werden kann, und nicht in den Kernel
hineinkompiliert werden muss. Die geladenen Kernelmodule lassen sich mit dem Befehl
lsmod anzeigen. Um die Abhängigkeiten zwischen den Modulen auszutauschen lohnt es
sich, vor dem Laden eines Kernelmodules depmod –a auszuführen. Zuvor muss das
Modul zum Beispiel an /lib/modules/’uname -r’/kernel/ kopiert werden. Das
Kernelmodul wird schliesslich mit dem Befehl insmod modulname oder modprobe
modulname geladen, wobei wir modprobe empfehlen. Ein Kernelmodul läuft im
Kernelspace, daher sollte der Computer während der Entwicklung über eine gut
zugängliche Reset-Taste verfügen.
Ein Kernelmodul hat folgenden Aufbau:

Kapitel 7: Grundlagen Netfilter
38
#include <linux/module.h>
int init_module(void){…..} // Initialisierung des Moduls
void cleanup_module(void){….} // Modul abmelden und Speicher etc. freigeben
Um ein Kernelmodul kompilieren zu können müssen dem Compiler einige Optionen
gesetzt werden. Siehe Literaturverzeichnis [LinSh], [MT], [LF]
Makefile für ein einfaches Kernelmodul
CC=gcc
MODCFLAGS := -Wall -DMODULE -D__KERNEL__ -DLINUX -DEXPORT_SYMTAB
CMPFLAGS := -I/lib/modules/`uname -r`/build/include
hallo_welt.o: hallo_welt.c
$(CC) $(CMPFLAGS) $(MODCFLAGS) -c -O2 hallo_welt.c
echo hallo welt ist bereit....
clean: rm *.o
all: touch *.c
make
7.2 Netfilter
Netfilter bietet die Möglichkeit, Pakete ausserhalb der „Berkeley Socket“ Schnittstelle auf
ihren Weg durch den Kernel zu verändern. Dazu werden fünf Punkte (Hooks)
vorgegeben, an denen man sich „registrieren„ kann und dort einen Zugriff auf die Pakete
erhält. Siehe Literaturverzeichnis [CIPnG], [NetF]
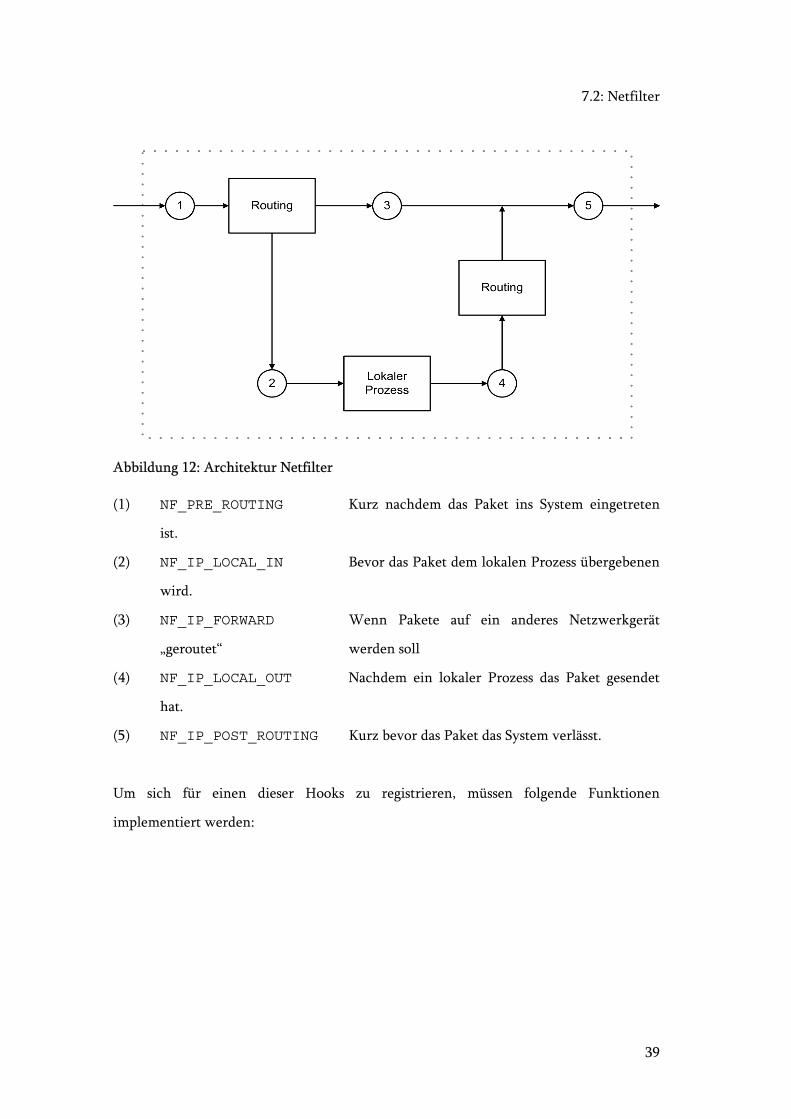
7.2: Netfilter
39
Abbildung 12: Architektur Netfilter
(1) NF_PRE_ROUTING Kurz nachdem das Paket ins System eingetreten
ist.
(2) NF_IP_LOCAL_IN Bevor das Paket dem lokalen Prozess übergebenen
wird.
(3) NF_IP_FORWARD Wenn Pakete auf ein anderes Netzwerkgerät
„geroutet“ werden soll
(4) NF_IP_LOCAL_OUT Nachdem ein lokaler Prozess das Paket gesendet
hat.
(5) NF_IP_POST_ROUTING Kurz bevor das Paket das System verlässt.
Um sich für einen dieser Hooks zu registrieren, müssen folgende Funktionen
implementiert werden:

Kapitel 7: Grundlagen Netfilter
40
#include <linux/kernel.h>
#include<linux/module.h>
#include <linux/skbuff.h>
#include <linux/netfilter.h>
/* funktionen um sich für einen hook zu registrieren ps.-1 bedeutet, dass dieses modul eine
höhere priorität hat als ein anderes modul mit 0*/
static struct nf_hook_ops hook_netfilter = {{NULL,NULL}, hook_handler,PF_INET,NF_IP_LOCAL_IN,-1};
static unsigned int hook_handler(unsigned int hook,
struct sk_buff **pskb,
const struct net_device * indev,
const struct net_device *outdev,
int (*okfn)(struct sk_buff *)){
// Paket Manipulationen….
}
int init_module(void){
/* meldet das modul für den netfilter an */
nf_register_hook(&hook_netfilter);
}
void cleanup_module(){
/* meldet das modul für den netfilter ab */
nf_unregister_hook(&hook_netfilter);
}
7.3 Proc File-System
Das Proc File System ist ein virtuelles Filesystem, welches eigentlich den Speicher des
Linux Betriebssystems abbildet. Man kann das Proc File System dazu verwenden,
während eines laufenden Betriebssystems mit dem Kernel zu kommunizieren,
beziehungsweise dessen Verhalten zu ändern. Es bildet also eine Schnittstelle zwischen
dem Userspace und dem Kernelspace. Siehe Literaturverzeichnis [CIPnG], [LF], [Proc],
[LinDD]
Die Funktion hallo_world_proc [siehe Codeblock] ist eine Callbackfunktion, das
heisst, wenn ich das File auslesen will, welches bei der Callbackfunktion „registriert“ ist,
wird die Funktion aufgerufen.
Bsp. cat /proc/proc_dir/hallo_welt liefert im unten stehenden Beispiel
„Hallo Proc File“ zurück. Um in einem Kernelmodul eine Schnittstelle zum Proc

7.4: Implementierung
41
File System bereitstellen zu können, müssen folgende Funktionen implementiert
werden.
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
static struct proc_dir_entry * proc_directory;
static struct proc_dir_entry * proc_file;
static int hallo_world_proc (char *buffer,
char **buffer_location,
off_t requested_offset,
int requested_len,
int *eof,
void *data){
MOD_INC_USE_COUNT;
len =sprintf(buffer,"Hallo Proc File \n");
MOD_DEC_USE_COUNT;
return len;
}
int init_module(void){
/* erzeugt einen Ordner im proc file system */
proc_directory = proc_mkdir("proc_dir",NULL);// NULL = /proc/...
proc_directory ->owner = THIS_MODULE;
/*erzeugt eine Datei im proc file system */
proc_file = create_proc_read_entry("hallo_welt",S_IFREG | S_IRUGO,proc_dir,proc_file,NULL);
proc_file->owner = THIS_MODULE;
}
void cleanup_module(){
/* löscht proc file und directory */
remove_proc_entry("proc_file",proc_directory);
remove_proc_entry("proc_directory ",NULL);
}
7.4 Implementierung
Auf eine vollständige Erklärung der einzelnen Fuktionen, welche in den
vorhergehenden drei Unterkapiteln erwähnt wurden, verzichten wir aus Platzgründen.
Vieles kann nicht einmal in Büchern nachgelesen werden, es bleibt nichts anders übrig,

Kapitel 7: Grundlagen Netfilter
42
als die Kernelsourcen zu studieren! Trotzdem lohnt es sich, sich die im
Literaturverzeichnis aufgeführte Literatur zu Gemühte zu führen.
7.5 IPv4 Header
Da wir im Rahmen unserer Diplomarbeit, insbesondere bei den Kernelmodulen, viel mit
dem IP Headern zu tun haben, möchten wir es nicht unterlassen, kurz in diesem
Unterkapitel auf den IPv4 Header und im nächsten Unterkapitel auf den IPv6 Header
einzugehen.
Abbildung 13: IPv4 Header
Version:
Das Versions-Feld enthält die Versionsnummer des IP-Protokolls. Durch die
Einbindung der Versionsnummer besteht die Möglichkeit, über eine längere Zeit mit
verschiedenen Versionen des IP Protokolls zu arbeiten. Die einten Hosts können mit der
alten und andere mit der neuen Version arbeiten. (4)

7.5: IPv4 Header
43
Length:
Das Feld Length (Internet Header Length - IHL) enthält die Länge des Protokollkopfs,
da diese nicht konstant ist. Die Länge wird in 32-Bit-Worten angegeben. Der kleinste
zulässige Wert ist 5 - das entspricht also 20 Byte; in diesem Fall sind im Header keine
Optionen gesetzt. Die Länge des Headers kann sich durch Anfügen von Optionen aber
bis auf 60 Byte erhöhen (der Maximalwert für das 4-Bit-Feld ist 15).
Type of Servive:
Über das Feld Type of Service kann IP angewiesen werden, Nachrichten nach
bestimmten Kriterien zu behandeln. Als Dienste sind hier verschiedene Kombinationen
aus Zuverlässigkeit und Geschwindigkeit möglich. In der Praxis wird dieses Feld aber
ignoriert, hat also den Wert 0.
Precedence (Bits 0-2) gibt die Priorität von 0 (normal) bis 7 (Steuerungspaket) an. Die
drei Flags (D,T,R) ermöglichen es dem Host anzugeben, worauf er bei der
Datenübertragung am meisten Wert legt: Verzögerung (Delay - D), Durchsatz
(Throughput - T), Zuverlässigkeit (Reliability - R). Die beiden anderen Bit-Felder sind
reserviert.
Total Length:
Enthält die gesamte Paketlänge, d.h. Header und Daten. Da es sich hierbei um ein 16-Bit-
Feld handelt, ist die Maximallänge eines Datengramms auf 65’535 Byte begrenzt. In der
Spezifikation von IP (RFC 791) ist festgelegt, dass jeder Host in der Lage sein muss,
Pakete bis zu einer Länge von 576 Bytes zu verarbeiten. In der Regel können von den
Host aber Pakete grösserer Länge verarbeitet werden.
Identification:
Über das Identifikationsfeld kann der Zielhost feststellen, zu welchem Datengramm ein
neu angekommenes Fragment gehört. Alle Fragmente eines Datengramms enthalten die
gleiche Identifikationsnummer, die vom Absender vergeben wird.

Kapitel 7: Grundlagen Netfilter
44
Flags:
Das Flags-Feld ist drei Bit lang. Die Flags bestehen aus zwei Bits namens DF - Don't
Fragment und MF - More Fragments. Das erste Bit des Flags-Feldes ist ungenutzt bzw.
reserviert. Die beiden Bits DF und MF steuern die Behandlung eines Pakets im Falle einer
Fragmentierung. Mit dem DF-Bit wird signalisiert, dass das Datengramm nicht
fragmentiert werden darf. Auch dann nicht, wenn das Paket dann evtl. nicht mehr
weiter transportiert werden kann und verworfen werden muss. Alle Hosts müssen, wie
schon gesagt, Fragemente bzw. Datengramme mit einer Grösse von 576 Bytes oder
weniger verarbeiten können. Mit dem MF-Bit wird angezeigt, ob einem IP-Paket weitere
Teilpakete nachfolgen. Dieses Bit ist bei allen Fragmenten ausser dem letzten gesetzt.
Fragment Offset:
Der Fragmentabstand bezeichnet, an welcher Stelle relativ zum Beginn des gesamten
Datengramms ein Fragment gehört. Mit Hilfe dieser Angabe kann der Zielhost das
Originalpaket wieder aus den Fragmenten zusammensetzen. Da dieses Feld nur 13 Bit
gross ist, können maximal 8192 Fragmente pro Datengramm erstellt werden. Alle
Fragmente, ausser dem letzten, müssen ein Vielfaches von 8 Byte sein. Dies ist die
elementare Fragmenteinheit.
Time to Live:
Das Feld Time to Live ist ein Zähler, mit dem die Lebensdauer von IP-Paketen
begrenzt wird. Im RFC 791 ist für dieses Feld als Einheit Sekunden spezifiziert. Zulässig
ist eine maximale Lebensdauer von 255 Sekunden (8 Bit). Der Zähler muss von jedem
Netzknoten, der durchlaufen wird, um mindestens 1 verringert werden. Bei einer
längeren Zwischenspeicherung in einem Router muss der Inhalt sogar mehrmals
verringert werden. Enthält das Feld den Wert 0, muss das Paket verworfen werden:
damit wird verhindert, dass ein Paket endlos in einem Netz umherwandert. Der
Absender wird in einem solchen Fall durch eine Warnmeldung in Form einer ICMP-
Nachricht informiert.

7.5: IPv4 Header
45
Protocol:
Enthält die Nummer des Transportprotokolls, an das das Paket weitergeleitet werden
muss. Die Numerierung von Protokollen ist im gesamten Internet einheitlich. Bisher
wurden die Protokollnummern im RFC 1700 definiert. Diese Aufgabe ist nun von der
Internet Assigned Numbers Authority (IANA)[http://www.iana.org] übernommen
worden.
Header Checksum:
Dieses Feld enthält die Prüfsumme der Felder im IP-Header. Die Nutzdaten des IP-
Datengramms werden aus Effiziengründen nicht mit geprüft. Diese Prüfung findet beim
Empfänger innerhalb des Transportprotokolls statt. Die Prüfsumme muss von jedem
Netzknoten, der durchlaufen wird, neu berechnet werden, da sich der IP-Header durch
das Feld Time-to-Live bei jeder Teilstrecke verändert. Aus diesem Grund ist auch eine
sehr effiziente Bildung der Prüfsumme wichtig. Als Prüfsumme wird das 1er-
Komplement der Summe aller 16-Bit-Halbwörter der zu überprüfenden Daten
verwendet. Zum Zweck dieses Algorithmus wird angenommen, dass die Prüfsumme zu
Beginn der Berechnung Null ist.
Source Address, Destination Address:
In diese Felder werden die 32-Bit langen Internet-Adressen eingetragen.
Options und Padding:
Das Feld Options wurde im Protokollkopf aufgenommen, um die Möglichkeit zu
bieten, das IP-Protokoll um weitere Informationen zu ergänzen, die im ursprünglichen
Design nicht berücksichtigt wurden. Das Optionsfeld hat eine variable Länge. Jede
Option beginnt mit einem Code von einem Byte, über den die Option identifiziert wird.
Manchen Optionen folgt ein weiteres Optionsfeld von 1 Byte und dann ein oder mehrere
Datenbytes für die Option. Das Feld Options wird über das Padding auf ein Vielfaches
von 4 Byte aufgefüllt. Derzeit sind die folgenden Optionen bekannt:

Kapitel 7: Grundlagen Netfilter
46
End of Option List
Kennzeichnet das Ende der Optionsliste.
No Option
Kann zum Auffüllen von Bits zwischen Optionen verwendet werden.
Security
Bezeichnet, wie geheim ein Datengramm ist. In der Praxis wird diese Option jedoch fast
immer ignoriert.
Loose Source-Routing, Strict Source-Routing
Diese Option enthält eine Liste von Internet-Adressen, die das Datagramm durchlaufen
soll. Auf diese Weise kann dem Datenpaket vorgeschrieben werden, eine bestimmte
Route durch das Internet zu nehmen. Beim Source-Routing wird zwischen Strict
Source and Record Route und Loose Source and Record Route
unterschieden. Im ersten Fall wird verlangt, dass das Paket diese Route genau einhalten
muss. Desweiteren wird die genommene Route aufgezeichnet. Die zweite Variante
schreibt vor, dass die angegebenen Router nicht umgangen werden dürfen. Auf dem
Weg können aber auch andere Router besucht werden.
Record Route
Die Knoten, die dieses Datengramm durchläuft, werden angewiesen, ihre IP-Adresse an
das Optionsfeld anzuhängen. Damit lässt sich ermitteln, welche Route ein Datengramm
genommen hat. Wie anfangs schon gesagt, ist die Grösse für das Optionsfeld auf 40 Byte
beschränkt. Deshalb kommt es heute auch oftmals zu Problemen mit dieser Option, da
weit mehr Router durchlaufen werden, als dies zu Beginn des ARPANET der Fall war.
Time Stamp
Diese Option ist mit der Option Record Route vergleichbar. Zusätzlich zur IP-Adresse
wird bei dieser Option die Uhrzeit des Durchlaufs durch den Knoten vermerkt. Auch
diese Option dient hauptsächlich zur Fehlerbehandlung, wobei zusätzlich z.B.
Verzögerungen auf den Netzstrecken erfasst werden können.
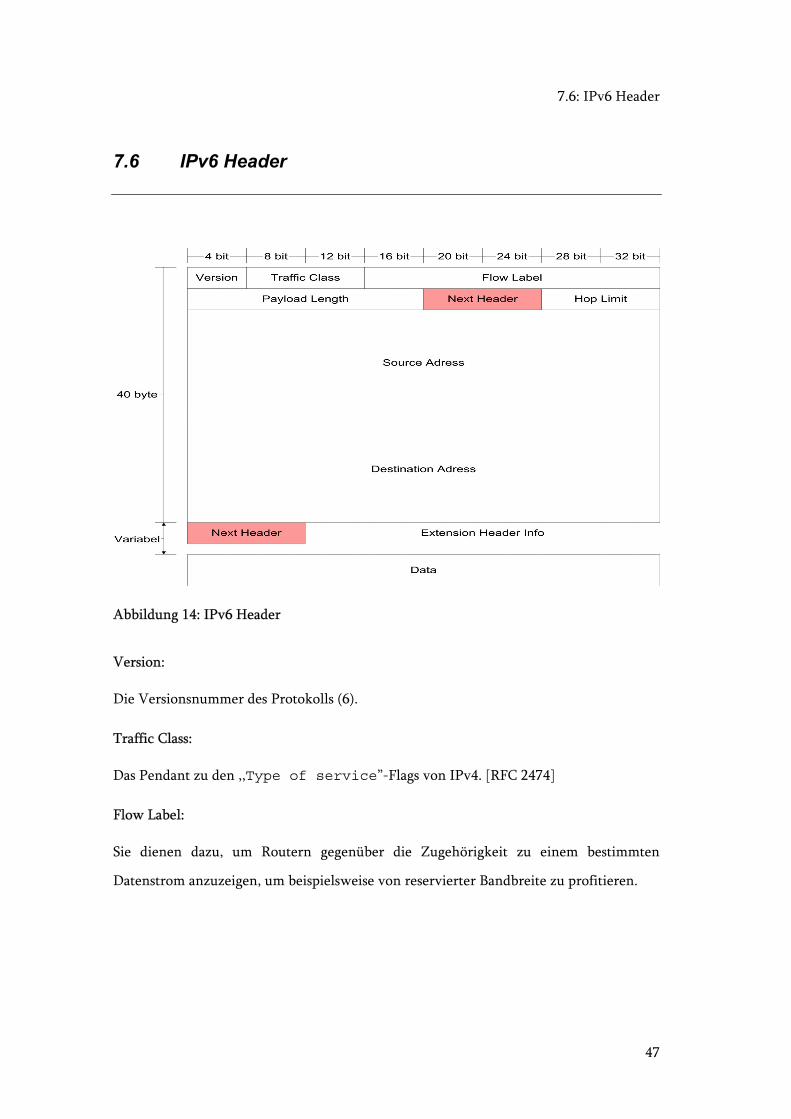
7.6: IPv6 Header
47
7.6 IPv6 Header
Abbildung 14: IPv6 Header
Version:
Die Versionsnummer des Protokolls (6).
Traffic Class:
Das Pendant zu den ,,Type of service”-Flags von IPv4. [RFC 2474]
Flow Label:
Sie dienen dazu, um Routern gegenüber die Zugehörigkeit zu einem bestimmten
Datenstrom anzuzeigen, um beispielsweise von reservierter Bandbreite zu profitieren.

Kapitel 7: Grundlagen Netfilter
48
Payload Length:
Die Länge der übertragenen Nutzdaten (in Bytes). Im Gegensatz zu IPv4 wird hier nicht
die Länge des gesamten Pakets (einschliesslich IP-Header) gespeichert.
Next Header:
Bestimmt das Format der Daten nach dem IP-Header.
Hop Limit:
Gibt die Zahl der Routingschritte (Hops) an, bevor das Paket verworfen wird. Dieses Feld
von jedem Router um eins dekrementiert.
Extension Headers
Weitere Optionen werden bei IPv6 mittels Extension Headers angegeben. Diese sind
durch das ,,Next Header-Feld miteinander verknüpft; das Feld des vorigen Headers gibt
den Typ des folgenden an (bzw. beim letzten Header die Art der übertragenen Daten,
z.B. TCP).
Sämtliche Extension Headers (mit Ausnahme des Hop-by-Hop Option Headers und des
Routing Headers) werden erst vom Empfänger des Pakets geparst. Die Reihenfolge der
Extension Header ist beliebig, nur der Hop-by-Hop Option Header muss - sofern
vorhanden - direkt dem IPv6-Header folgen. Auf diese Weise wird der Aufwand in den
Routern minimiert.
Die Länge der einzelnen Header ist jeweils ein Vielfaches von 64 Bit. Bei Headern mit
variabler Länge (z.B. Option Header) ist dies durch entsprechendes Padding
sicherzustellen.
Header mit variabler Länge enthalten ein Header-Length-Feld. Dieses gibt die Länge in
64 Bit-Einheiten an, wobei die ersten acht Bytes nicht mitgezählt werden. Ein Feldinhalt
von 0 entspricht also 8 Bytes Länge, ein Inhalt von 1 ergibt 16 Bytes Länge, etc. Einzige
Ausnahme sind die IPSec-Header; um Kompatiblität zu alten IPv4-Implementierungen

7.6: IPv6 Header
49
zu erreichen, wird hier die Länge in 32 Bit-Einheiten angegeben. Allerdings werden
auch hier die ersten 8 Bytes nicht mitgezählt.
Für IPsec ist von besonderem Interesse, welche Header während der Übertragung
verändert werden können, da diese beim Erstellen und beim Überprüfen einer digitalen
Signatur besonders behandelt werden müssen.


51
8 Design
In diesem Kapitel wollen wir das Design des Gesamtsystems und derjenigen Subsysteme
beschreiben, wie sie in der Analyse identifiziert wurden (siehe Abbildung 3:
Systemarchitektur auf Seite 16).
Das Zusammenwirken der Subsysteme ist aus obig genanntem Diagramm ersichtlich;
zudem wird in den Unterkapiteln der einzelnen Subsysteme jeweils die Schnittstelle
beschrieben.
8.1 Das CIPnG Netfiltermodul
Für das Design des CIPnG Netfiltermoduls mussten wir zuerst abklären, wie wir die
Anforderungen aus der Analyse umsetzen können. Da wir noch keine Ahnung von der
Linux Kernelprogrammierung hatten, vermischte sich das Design oft mit der
Implementierung. Gemäss Unified Process machten wir ständig kleine Iterationen:
Design eines Teilprogramms -> Konnte so nicht Implmentiert werden -> neues Design ->
…. Frei nach dem Motto „try and error“.

Kapitel 8: Design
52
8.1.1 Probleme bei der Datenerfassung
Die Datenerfassung nach Volumen stellt sich einiges schwieriger dar, als eine
Abrechnung nach Zeit. Bei einer Abrechnung nach Zeit müssen nur der Zeitpunkt der
Einwahl und der Zeitpunkt der Beendigung festgehalten werden. Bei einer
Volumenbasierten Abrechnung müssen einige Fälle mehr beachtet werden. Insgesamt
haben wir sieben Fälle [siehe Abbildung 15: Probleme bei einer Abrechnung nach
Volumen] eruiert, welche nach unserer Meinung beachtet werden müssen. Fall eins bis
Abbildung 15: Probleme bei einer Abrechnung nach Volumen

8.1: Das CIPnG Netfiltermodul
53
drei stellen den normalen Ablauf dar, Fall vier bis sieben problematische, fehlerhafte
Abläufe. Insbesondere aus den Fällen vier bis sieben stellt sich eine grundsätzliche Frage:
Wo werden die Daten erfasst? Auf der Basestation, auf dem Node oder auf dem Gateway?
Fall 1: Fall eins stellt den normalen Ablauf ohne Handover einer Session dar. Bei
diesem Ablauf können keine Abrechnungsfehler auftreten.
Fall 2: Fall zwei stellt den normalen Ablauf mit Handover einer Session dar. Bei
diesem Ablauf können keine Abrechnungsfehler auftreten.
Fall 3: Bei Fall drei gehen Daten ausserhalb des CIPnG Netzwerkes verloren. Da
ein Betreiber eines CIPnG Systems keine Garantie für ein fehlerfreies
Internet abgeben kann, bleibt es ein Risiko des CIPnG Benutzers.
Fall 4: Die Daten gehen beim Uplink, das heisst vom Mobilehost ins Internet,
irgendwo im CIPnG Netzwerk verloren.
Fall 5: Die Daten gehen beim Downlink, das heisst vom Internet zum
Mobilehost, irgendwo im CIPnG Netzwerk verloren.
Fall 6: Die Daten gehen beim Uplink, auf der Funkstrecke zwischen Mobilehost
und Basestation verloren.
Fall 7: Die Daten gehen beim Downlink, auf der Funkstrecke zwischen
Basestation und Mobilehost verloren.
Kapitel 8: Design
54
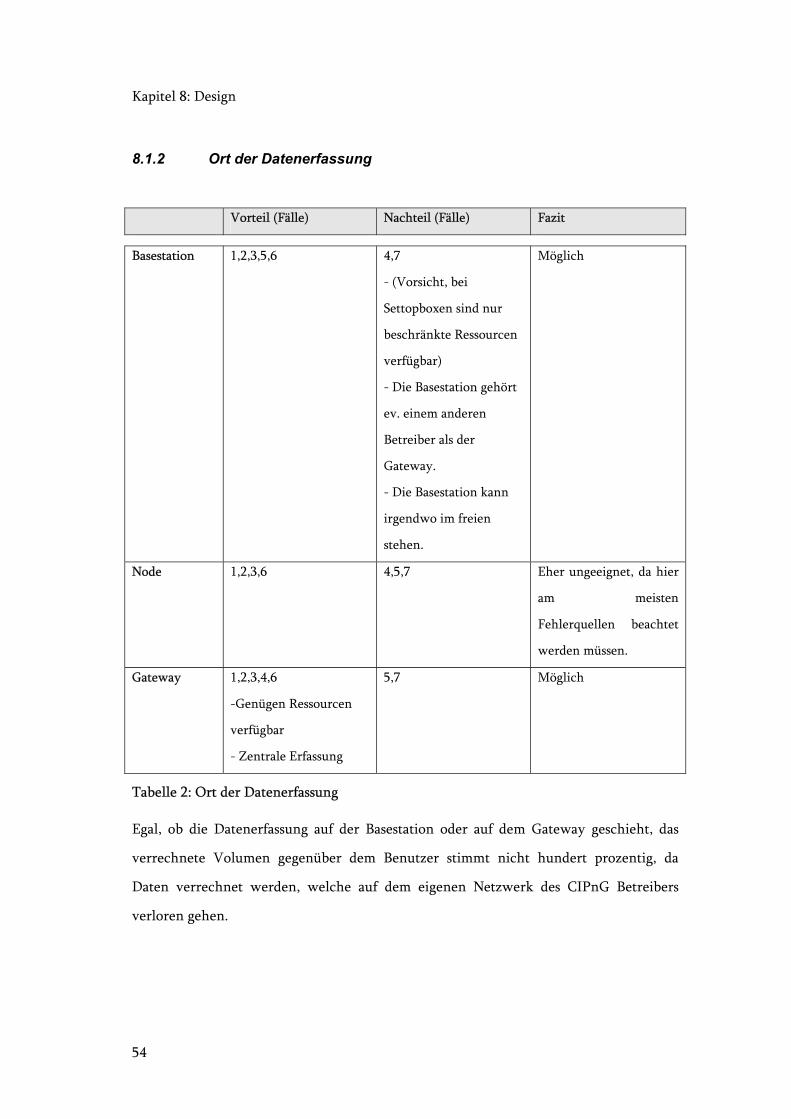
8.1.2 Ort der Datenerfassung
Vorteil (Fälle) Nachteil (Fälle) Fazit
Basestation 1,2,3,5,6 4,7
- (Vorsicht, bei
Settopboxen sind nur
beschränkte Ressourcen
verfügbar)
- Die Basestation gehört
ev. einem anderen
Betreiber als der
Gateway.
- Die Basestation kann
irgendwo im freien
stehen.
Möglich
Node 1,2,3,6 4,5,7 Eher ungeeignet, da hier
am meisten
Fehlerquellen beachtet
werden müssen.
Gateway 1,2,3,4,6
-Genügen Ressourcen
verfügbar
- Zentrale Erfassung
5,7 Möglich
Tabelle 2: Ort der Datenerfassung
Egal, ob die Datenerfassung auf der Basestation oder auf dem Gateway geschieht, das
verrechnete Volumen gegenüber dem Benutzer stimmt nicht hundert prozentig, da
Daten verrechnet werden, welche auf dem eigenen Netzwerk des CIPnG Betreibers
verloren gehen.

8.1: Das CIPnG Netfiltermodul
55
Die beste Lösung aus Sicht der korrekten Datenerfassung wäre, auf der Basestation den
Downlink zu verrechnen und auf dem Gateway den Uplink.
Da dies aber den Rahmen unserer Diplomarbeit sprengen würde, haben wir uns
entschieden, eine einfachere Variante zu wählen. Entweder erfassen wir die Daten
allesamt auf dem Gateway oder allesamt auf der Basestation. Besser eignet sich der
Gateway, da auf dem Gateway mehr Ressourcen zur Verfügung stehen (vor allem bei
einer späteren Verwendung von Settopboxen als Basestations). Ein zweiter Punkt ist,
dass ein Betreibers eines Gateway mehrere Betreiber von Basestations zusammenfassen
kann. Aus diesen beiden Tatsachen haben wir uns auf die vollständige Datenerfassung
auf dem Gateway entschieden.
Datenerfassung auf der Basestation
Dieses Unterkapitel zeigt nur eine Möglichkeit auf, wie Daten auf der Basestation erfasst
und zum Gateway übermittelt werden können. In unserer Diplomarbeit haben wir diese
Ideen nicht implementiert.
Der Downlink wird auf der Basestation mittels eines Netfilter-Kernel-Modules gezählt.
Die Basestation sendet periodisch, oder per Aufforderung des Gateways, die Billingdaten
zum Gateway. Dies geschieht am besten mittels eines eigens definierten Paket-Typs,
analog wie in der Diplomarbeit „Sichere Cellular IP Implementierung auf der Basis von
Linux Netfilter“ [CIPnG] auf Seite 65 bis 67 beschrieben wird. Das CIPnG System könnte
um folgende ASN.1 Notation ergänzt werden:

Kapitel 8: Design
56
MsgTypes :: = CHOICE {
.
.
billing BILLING
}
.
.
BILLING :: = [APPLICATION 20] IMPLICIT SEQUENZE {
bs_ip IPFORMAT
user_ip IPFORMAT
protocol INTEGER
up INTEGER
down INTEGER
time TIME
}
Durch diese Ergänzung müsste der „Message Paser“ des CIPnG angepasst werden. Man
kommt aber nicht darum herum, ein Netfiltermodul auf dem Gateway zu
programmieren, welches die Billing Pakete der Basestations entgegennimmt und der Java
Applikation zur Verfügung stellt. Die Synchronisation zwischen den Kernelmodulen auf
der Basestation beziehungsweise Gateways und der Java Applikation wurde in unseren
Überlegungen bis jetzt noch nicht berücksichtigt, dürfen aber nicht vergessen werden.
8.1.3 Datenerfassung auf dem Gateway
Identifikation der beteiligten Parteien und der Daten
Wie im Unterkapitel „Ort der Datenerfassung“ beschrieben, haben wir uns für die
Datenerfassung auf dem Gateway entschieden. Durch den Geschäftsfall, welcher eine
Dispute Resolution für alle beteiligten Parteien [siehe Kapitel 4 Anforderungen] verlangt,
und den Normen gemäss IPDR [siehe Kapitel 6 IPDR.org: Der IP Data Record Standart ],
muss ein Datenpaket den einzelnen Benutzer (Mobilehost und Basestation) zugewiesen
werden können.

8.1: Das CIPnG Netfiltermodul
57
Wir mussten uns auf etwas einigen, um die einzelnen Parteien bzw. die Datenpakete zu
identifizieren. Im bestehenden CIPnG System ist dafür nichts vorgesehen. Die einzige
Möglichkeit dazu, ohne grössere Eingriffen im bestehenden CIPnG System
vorzunehmen, ist, die IP Adresse des Mobilehosts und der Basestation zu verwenden. Es
ist uns bewusst, dass eine IP eigentlich keine eindeutige Zuweisung zulässt; die
Eindeutigkeit wird durch die Datenbank zum Zeitpunkt der Erstellung der IPDR
Rohdaten gewährleistet [siehe Kapitel 8.3 Die Datenbank und 8.2.2: Der
NetfilterDatareaderDaemon auf Seite 63]. Da der Gateway die Datenerfassung vornimmt,
muss man ihn nicht näher identifizieren.
Markierung eines IP-Paketes
Es wäre natürlich möglich, den vorhandenen CIPnG Header mit irgendwelchen Flags zu
markieren, dies währe aber ein sehr unsauberes Design und würde ein proprietäres
Netzwerk mit sich ziehen.
Jedem IP-Paket, welches auf der Basestation empfangen wird, wird ein zusätzlicher IP-
Header vorne angefügt. Im „Source-Adress“-Feld wird die IP-Adresse der
Basestation eingeführt. Durch den zusätzlichen IPv4- Header entsteht ein Overhead von
16 Byte (20 Byte IPv4 Header – 4 Byte IP-Adresse des Mobilehost). Damit das Paket
später einfach als „Billing“-Packet identifiziert werden, kann haben wir entschieden,
eine neue Protokollnummer einzuführen. Im CIPnG werden die Protokollnummern 150
und 151 verwendet. Wir haben uns auf die Protokollnummer 152 festgelegt, die ebenfalls
aus dem frei wählbaren Bereich der „Assigned Numbers RFC 1700; (freier Bereich 101
bis 254)“ stammt.
Da das ganze CIPnG System schon aus Netfiltermodulen besteht, haben wir uns
entschieden, zwei neue Netfiltermodule zu entwickeln, eines auf der Basestation welches
die Pakete „markiert“ und eines auf dem Gateway, welches die Pakete auswertet und den
zusätzlichen IP-Header entfernt.
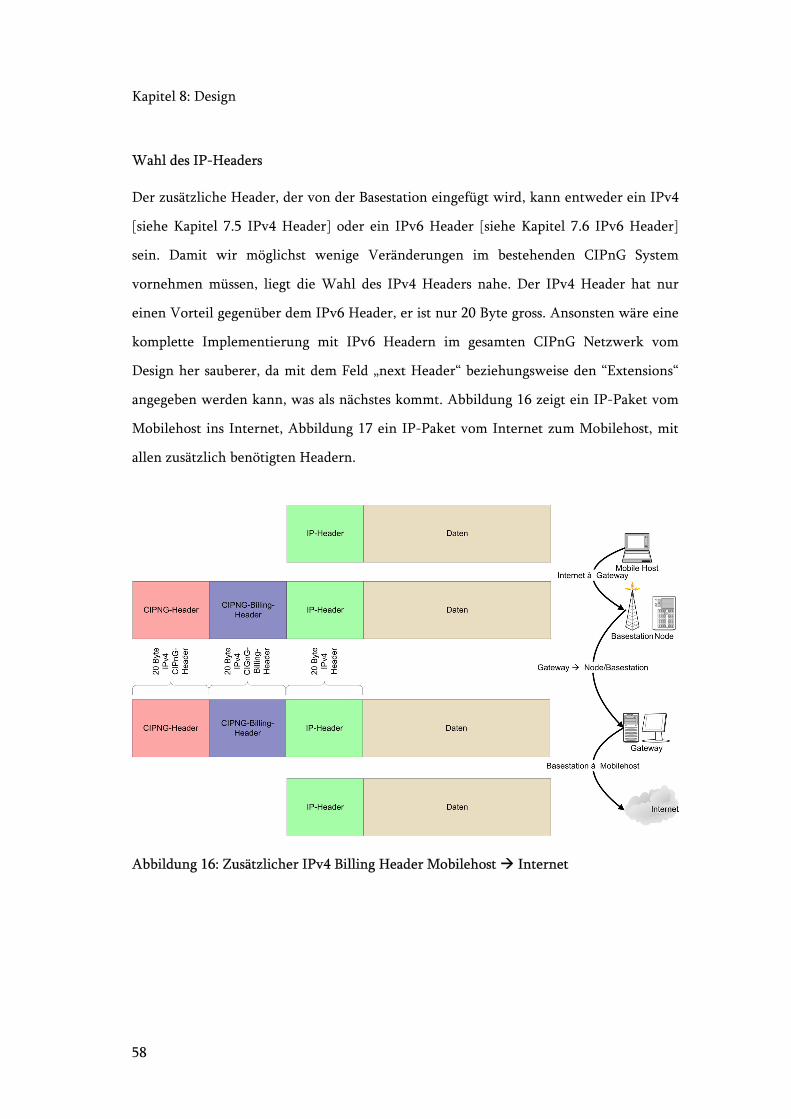
Kapitel 8: Design
58
Wahl des IP-Headers
Der zusätzliche Header, der von der Basestation eingefügt wird, kann entweder ein IPv4
[siehe Kapitel 7.5 IPv4 Header] oder ein IPv6 Header [siehe Kapitel 7.6 IPv6 Header]
sein. Damit wir möglichst wenige Veränderungen im bestehenden CIPnG System
vornehmen müssen, liegt die Wahl des IPv4 Headers nahe. Der IPv4 Header hat nur
einen Vorteil gegenüber dem IPv6 Header, er ist nur 20 Byte gross. Ansonsten wäre eine
komplette Implementierung mit IPv6 Headern im gesamten CIPnG Netzwerk vom
Design her sauberer, da mit dem Feld „next Header“ beziehungsweise den “Extensions“
angegeben werden kann, was als nächstes kommt. Abbildung 16 zeigt ein IP-Paket vom
Mobilehost ins Internet, Abbildung 17 ein IP-Paket vom Internet zum Mobilehost, mit
allen zusätzlich benötigten Headern.
Abbildung 16: Zusätzlicher IPv4 Billing Header Mobilehost Internet
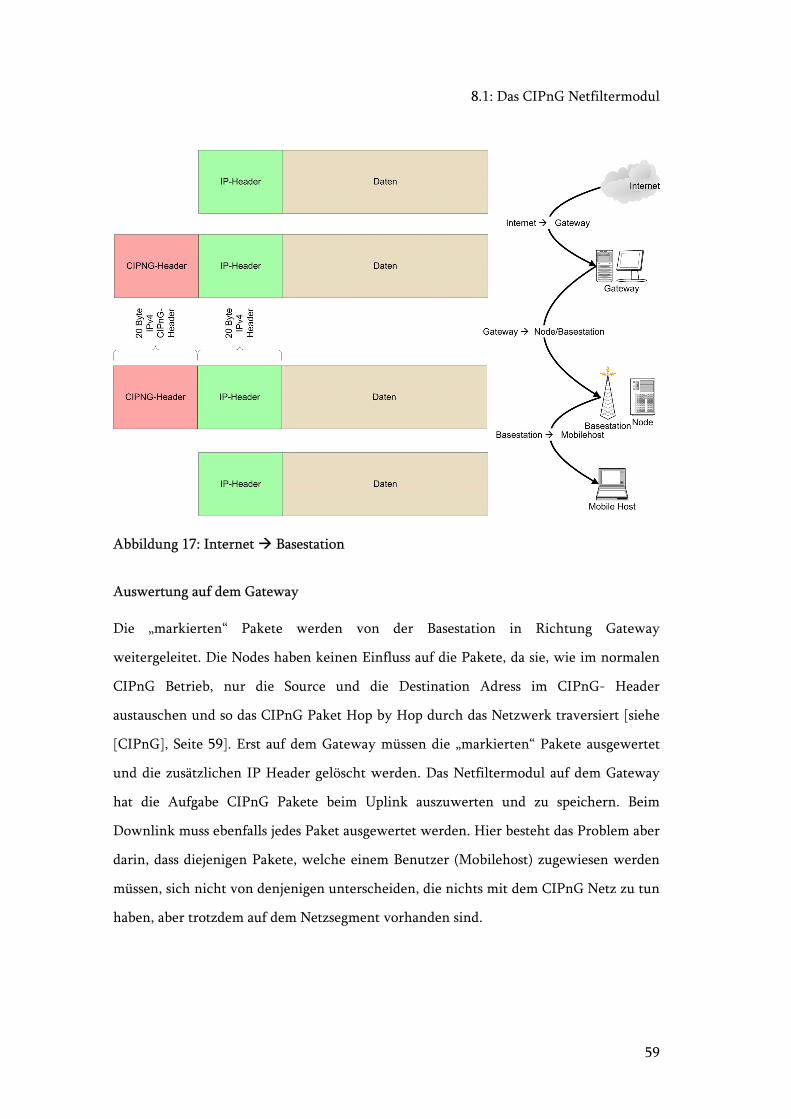
8.1: Das CIPnG Netfiltermodul
59
Abbildung 17: Internet Basestation
Auswertung auf dem Gateway
Die „markierten“ Pakete werden von der Basestation in Richtung Gateway
weitergeleitet. Die Nodes haben keinen Einfluss auf die Pakete, da sie, wie im normalen
CIPnG Betrieb, nur die Source und die Destination Adress im CIPnG- Header
austauschen und so das CIPnG Paket Hop by Hop durch das Netzwerk traversiert [siehe
[CIPnG], Seite 59]. Erst auf dem Gateway müssen die „markierten“ Pakete ausgewertet
und die zusätzlichen IP Header gelöscht werden. Das Netfiltermodul auf dem Gateway
hat die Aufgabe CIPnG Pakete beim Uplink auszuwerten und zu speichern. Beim
Downlink muss ebenfalls jedes Paket ausgewertet werden. Hier besteht das Problem aber
darin, dass diejenigen Pakete, welche einem Benutzer (Mobilehost) zugewiesen werden
müssen, sich nicht von denjenigen unterscheiden, die nichts mit dem CIPnG Netz zu tun
haben, aber trotzdem auf dem Netzsegment vorhanden sind.
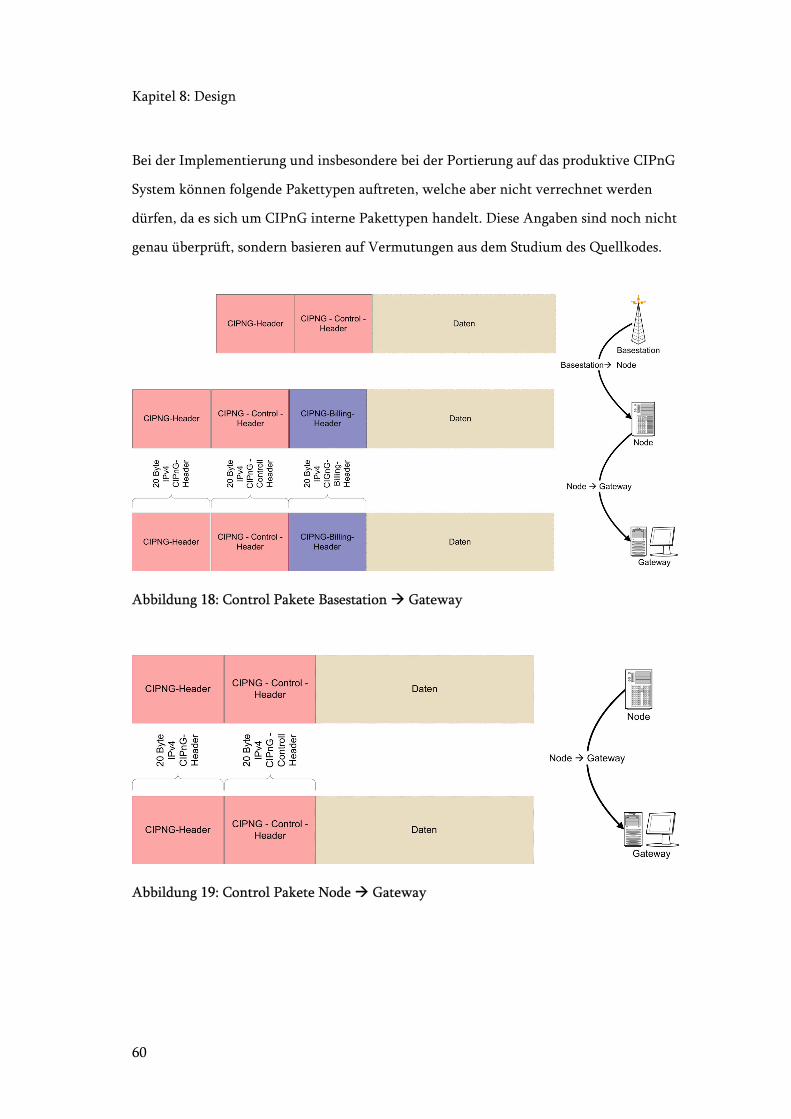
Kapitel 8: Design
60
Bei der Implementierung und insbesondere bei der Portierung auf das produktive CIPnG
System können folgende Pakettypen auftreten, welche aber nicht verrechnet werden
dürfen, da es sich um CIPnG interne Pakettypen handelt. Diese Angaben sind noch nicht
genau überprüft, sondern basieren auf Vermutungen aus dem Studium des Quellkodes.
Abbildung 18: Control Pakete Basestation Gateway
Abbildung 19: Control Pakete Node Gateway

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
61
8.2 Der Netfilter-Dämon und der Billing-Agent-Dämon
Die beiden Subsysteme Java Netfilter Dämon und Billing Agent Dämon, welche in der
Analyse gefunden wurden, sollen im Design in ein und demselben Kapitel behandelt
werden.
Der Grund dafür ist, dass beide Dienste Dämonen sind, die von einem gemeinsamen
DämonController kontrolliert werden sollen, und die auch gewisse Eigenschaften von
einem abstrakten Dämonen übernehmen sollen. Ausserdem sollen sie in der gleichen
Java-Architektur implementiert werden.
Die beiden Anwendungsfälle, die in der Analyse entworfen wurden (siehe Abschnitt
5.5.2 auf Seite 20), können aufgrund der Überlegungen über die Einschränkungen von
IPDR (siehe Abschnitt 6.4 auf Seite 26) nicht einzeln erfüllt werden. Stattdessen liefert
dieses Modul atomische Daten, mit denen beide Anwendungsfälle erfüllt werden
können.
Das Domänen-Modell
Die Übersicht über die Dämon-Domäne entnehme man dem Klassendiagramm4
Abbildung 20: Dämonen Klassendiagram.
4 Wir unterscheiden in dieser Dokumentation nicht zwischen Domänen- und Klassendiagrammen und
verwenden Klassendiagramme als Domänendiagramme.

Kapitel 8: Design
62
h舁t
kontrolliert
kontrolliert
startet
kennt
...netfilter.NetfilterDatareaderDaemon
parser:NetfilterParser-dc:DaemonController-start:String-end:String
+NetfilterDatareaderDaemon+process:void+writeData:void+shutdown:void
Daemon
#conn:Connection#alarm:AlarmSystem#p:Properties#lebt:boolean#fixgwid:int
+process:void+Daemon+shutdown:void
connection:Connection
Main
-dc:DaemonControlle
+main:void
interfacejava.sql.Connection
ThreadDaemonController
#conn:Connection#alarm:AlarmSystem#p:Properties-lebt:boolean-bad:BillingAgentDaemon-net:NetfilterDatareaderDaemon-lastrunfile:File-dateformat:DateFormat-now:Date
+DaemonController+run:void
lastrun:Date
...billing.BillingAgentDaemon
-outdir:FileletzteRunde:GregorianCalendarseq:IPDRFileSequence
+BillingAgentDaemon+process:void-writeIPDR:void+shutdown:void
ch.zhwin.billingagent Verbindung zurDatenbank
Abbildung 20: Dämonen Klassendiagram
Beschreibungen
Im Folgenden beschreiben wir den Controller, die einzelnen Dämonen und
schlussendlich, wenn alle Teilkomponenten beschrieben sind, den
Gesamtzusammenhang. (siehe u.a. Abbildung 25: Hauptsequenzdiagramm Dämonen)
8.2.1 Der DaemonController
Der DaemonController wird von der Main Klasse gestartet. Er selbst ist ein
Thread. Er erstellt die beiden Dämonen NetfilterDatareaderDaemon und
BillingAgentDaemon. In bestimmten Zeitabständen ruft er die process()
Methoden der beiden Daemonen auf, welche ihre Aufgaben ausführen. Er merkt sich
dabei persistent, in einem File, wann er zum letzten Mal gelaufen ist; damit weiss der
Controller auch noch nach einem Absturz, wann er zum letzten Mal gelaufen ist. Diese
Information ist in der BeanProperty lastrun verfügbar. Deshalb hat der

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
63
NetfilterDatareaderDaemon Sichtbarkeit auf den DaemonController, weil er
von diesem wissen muss, wann das System zum letzten Mal gelaufen ist.
8.2.2 Der NetfilterDatareaderDaemon
Der NetfilterDatareaderDaemon (welcher vom Dämoncontroller erstellt und
verwaltet wird) hat die Aufgabe, die Daten aus dem Subsystem Netfiltermodul zu holen.
Dafür steht ihm ein Parser zur Verfügung und zwei Hilfsklassen, welche die HEX
Darstellung der Internetadressen umrechnen und Protokolltypen nach RFC1700
aufschlüsseln können.
Über den Dämonkontroller hat die Klasse Zugriff auf das File lastrun, welches
speichert, wann der letzte Durchgang des Systems war.
kenntbetreibt
hat
kontrolliert
kennt...billingagent.util.IPAddressTool
+main:void+hexToDotDecString:String
DaemonNetfilterDatareaderDaemon
parser:NetfilterParser-dc:DaemonController-start:String-end:String
+NetfilterDatareaderDaemon+process:void+writeData:void+shutdown:void
...billingagent.util.IPProtocolTool
-instance:IPProtocolTool-prots:LinkedList-alarm:AlarmSystem
-IPProtocolTool-getInstance:IPProtocolTool+getProtocolString:String+getProtocolStringFromHex:String
NetfilterParser
-d:NetfilterDatareaderDaemon-procdatafile:File-alarm:AlarmSystem
+NetfilterParser#readData:void
java.lang.Objectjava.io.Serializable
java.lang.Comparablejava.io.File
Thread...DaemonController
#conn:Connection#alarm:AlarmSystem#p:Properties-lebt:boolean-bad:BillingAgentDaemon-net:NetfilterDatareaderDaemon-lastrunfile:File-dateformat:DateFormat-now:Date
+DaemonController+run:void
lastrun:Date
Hilfsklassen
Persistenz Filef・ letztenDurchgang
Abbildung 21: Netfilter Klassendiagram
Der NetfilterDaemon holt sich seine Informationen direkt aus dem Netfilter Modul. Sein
Parser hat (eventuell indirekt) Zugriff auf das Procfilesystem.

Kapitel 8: Design
64
Zeitstempel
Weil die Daten, die vom Netfiltermodul kommen, „zeitlos“ sind, d.h. keinen Zeitstempel
haben, muss dies der Netfilterdämon machen. Der Dämoncontroller weiss, wann das
System zum letzen Mal gelaufen ist. Wenn der Netfilterdämon Datensätze vom Netfilter
holt, ergänzt er diese mit dem Zeitpunkt des letzten Durchlaufs als Startpunkt und dem
jetzigen Zeitpunkt als Endpunkt. Dadurch kann die Zeitkomponente des Datensatzes
dynamisch berechnet werden, auch wenn das Abholen der Daten nicht ganz synchron
sein sollte. Je nach Aggregationsmodus und Einstellung in den Queues und Lists des
Netfiltermoduls kann auf diese Weise höchsten ein Fehler vom Ausmass der Auflösung
der Datenaquisition (10min- 15min) entstehen. Dies ist für die Zwecke, für welche wir
die Daten benötigen (Dispute Resolution) vollauf genügend.
Schreiben der Datenbank
Die Methode writeData() im Dämon schreibt die Daten in die Datenbank. Die
Rohdaten aus dem Netfiltermodul haben codierte Informationen über Benutzer und
Basisstation, nämlich deren momentane IP Adressen. Die Datenbank hat diese aktuellen
Daten gespeichert und kann sie einer Basisstation bzw. einem Endkunden zuweisen. Die
Methode writeData() implementiert diese Aufschlüsselung und schreibt die
eindeutigen Daten in die Datenbank. Auf diese Weise kann garantiert werden, dass –
auch wenn die besagten IP Adressen ändern – die Datensätze eindeutig einem Kunden
und einer Basisstation zugeordnet werden können – was aufgrund des Geschäftmodells
sehr wichtig ist.
Mehr Infos dazu im Gesamtüberblick am Schluss dieses Unterkapitels, im Design der
Datenbank und der Implementierung dieser Klasse.

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
65
8.2.3 Der BillingAgentDaemon
Der BillingAgentDaemon hat die Aufgabe, die gespeicherten Datensätze aus der
Datenbank wieder herauszuholen und diese als IPDR Dokumente dem externen BSS zur
Verfügung zu stellen.
Wenn der Dämon vom Controller die Nachricht process() bekommt, geht er in der
Datenbank schauen, welche Daten neu da sind, bzw. welche er noch nie gelesen hat.
Diese Daten schiebt dann der Dämon über die Klasse BATransformerThread einem
XSL Transformer zu, der über sein XSL Stylesheet IPDR konforme Files produziert.
Die Schnittstelle zum externen BSS
Der Output des Dämons sind IPDR konforme Files. Die Schnittstelle zum BSS (bei
IPDR.org „Schnittstelle D“ bezeichnet) ist denkbar einfach: der Dämon schreibt die
Dateien in ein Filesystem, von wo dann ein BSS diese Files wieder holen kann.
Die Files müssen eindeutig identifizierbar sein: wir haben folgendes Format gewählt: [gwID]_[Jahr][TagDesJahres]_[Sequenznummer].xml
also z.B. 1_2002294_0.xml
Die Hilfsklasse IPDRFileSequence produziert die eindeutigen Sequenznummern für
einen Gateway.
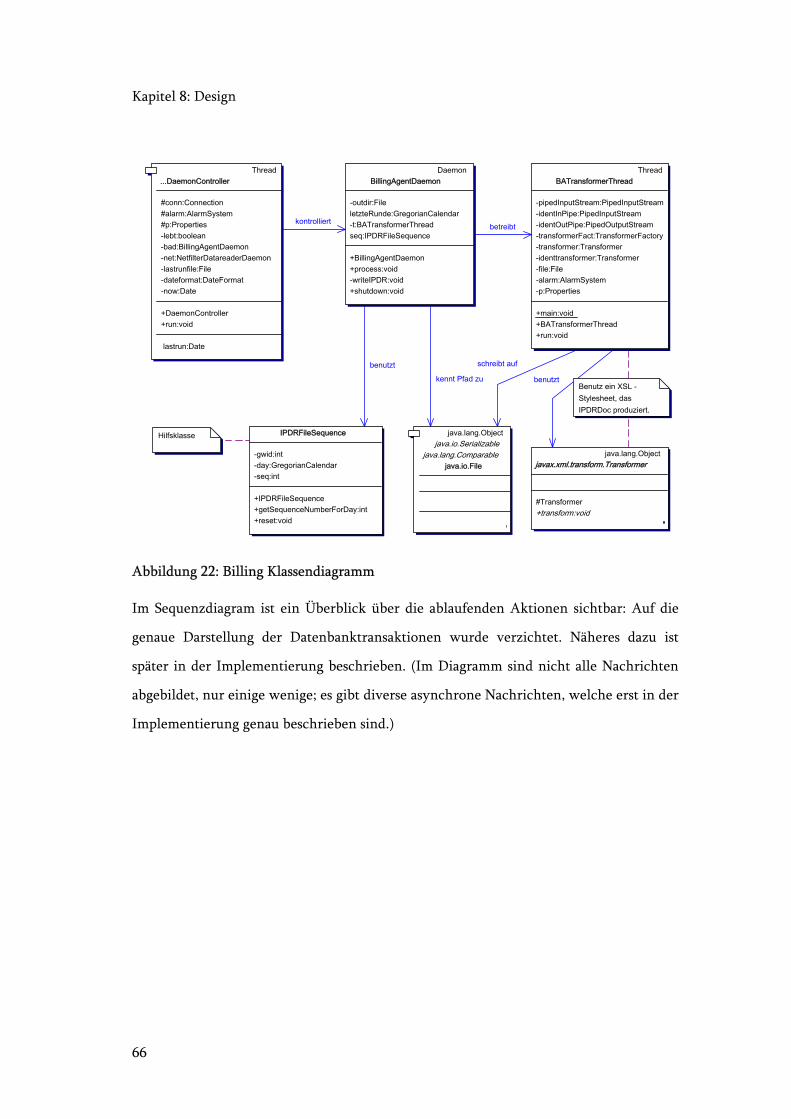
Kapitel 8: Design
66
benutzt
kennt Pfad zu
kontrolliert
schreibt auf
benutzt
betreibt
Thread...DaemonController
#conn:Connection#alarm:AlarmSystem#p:Properties-lebt:boolean-bad:BillingAgentDaemon-net:NetfilterDatareaderDaemon-lastrunfile:File-dateformat:DateFormat-now:Date
+DaemonController+run:void
lastrun:Date
ThreadBATransformerThread
-pipedInputStream:PipedInputStream-identInPipe:PipedInputStream-identOutPipe:PipedOutputStream-transformerFact:TransformerFactory-transformer:Transformer-identtransformer:Transformer-file:File-alarm:AlarmSystem-p:Properties
+main:void+BATransformerThread+run:void
DaemonBillingAgentDaemon
-outdir:FileletzteRunde:GregorianCalendar-t:BATransformerThreadseq:IPDRFileSequence
+BillingAgentDaemon+process:void-writeIPDR:void+shutdown:void
IPDRFileSequence
-gwid:int-day:GregorianCalendar-seq:int
+IPDRFileSequence+getSequenceNumberForDay:int+reset:void
java.lang.Objectjava.io.Serializable
java.lang.Comparablejava.io.File
java.lang.Objectjavax.xml.transform.Transformer
#Transformer+transform:void
Hilfsklasse
Benutz ein XSL -Stylesheet, dasIPDRDoc produziert.
Abbildung 22: Billing Klassendiagramm
Im Sequenzdiagram ist ein Überblick über die ablaufenden Aktionen sichtbar: Auf die
genaue Darstellung der Datenbanktransaktionen wurde verzichtet. Näheres dazu ist
später in der Implementierung beschrieben. (Im Diagramm sind nicht alle Nachrichten
abgebildet, nur einige wenige; es gibt diverse asynchrone Nachrichten, welche erst in der
Implementierung genau beschrieben sind.)

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
67
transformerTransformer
seqIPDRFileSequence
dcDaemonContr...
tBATransformerThread
badBillingAgentDaemon
1: process():void
1.1.3: start():void
1.1.2:
1.1.1: getSequenceNumberForDay(now):int
1.1: writeIPDR():void
1.1.3.1: transform(javax.xml.transform.Source,javax.xml.transform.Res...
1.1.2.1:
transformiertaufgrund desIPDR - XSL -Stylesheets
liest dieDatenbankaus: hiernichtdargestellt
schreibt dieFiles
schreibt asynchronin den Stream, dervom Transformderdirekt in IPDRumgewandelt wird.
Abbildung 23: Billing Sequenzdiagram
8.2.4 Gesamtdesign und Ablauf
Hilfsklassen
Das gesamte System hat Zugriff auf zwei Singleton-Klassen, die von überall her sichtbar
sind: eine zentrale Properties – Verwaltungsklasse und eine Alarmsystemklasse.
Properties
Die Properties sind in einem Property-File gespeichert, dessen Pfad auf der
Kommandozeile beim Start angegeben werden kann. Alle weiteren Voreinstellungen der
Applikation sind dann in diesem File im Standart Java Property-Format abgelegt. Das
kann zum Beispiel so aussehen: #Alarmsystem-Voreinstellungen.
alarmsystem.fromName=BillingAgent Daemon Alarm System

Kapitel 8: Design
68
alarmsystem.toName=Rémy Schumm;
alarmsystem.emailswitch=OFF
alarmsystem.smtp=smtp.zhwin.ch
alarmsystem.smtp.user=
alarmsystem.smtp.passwd=
Eine Property kann dann mit der statischen Methode der Singleton Klasse, public static String PropertyManager.getProperty(String key)
abgefragt werden.
Die genaue Implementierung der Properties und eine Auflistung aller Properties ist in
der Implementierung ersichtlich.
Alarmsystem
Ähnlich soll das Alarmsystem funktionieren: Es steht ein Sigleton-Konstrukt zur
Verfügung, das Systemweit aufgerufen werden kann, wenn etwas schief läuft. Optional
kann im Property-File eingestellt werden, dass das Alarmsystem ein Mail an eine
bestimmte Person verschickt, das diese auf ein Problem im System aufmerksam macht.
bietet an verschickt
<<Singleton>>PropertyManager
-instance:PropertyManager-props:Properties
-PropertyManager+getProperty:String+putProperty:void+getProperties:Properties+saveProperties:void
java.util.Hashtablejava.util.Properties
+getProperty:java.lang.String+getProperty:java.lang.String
<<Singleton>>AlarmSystem
-sprops:Properties-props:Properties-instance:AlarmSystem-message:MimeMessage
-AlarmSystem+getInstance:AlarmSystem+alarm:void
javax.mail.Messagejavax.mail.internet.MimePart
...mail.internet.MimeMessage
+RecipientType
Singleton, von・erall herzug舅glich
gepeichert improperties.props
verschicktauf Wunschein e-Mail
Abbildung 24: Hilfsklassen Diagramm

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
69
Gesamtablauf
Da nun alle beteiligten Klassen beschrieben sind, wollen wir den gesamten Ablauf bzw.
das Funktionieren der Dämonen beschreiben: Der gesamte Ablauf ist im Sequenzdiagram
(Abbildung 25: Hauptsequenzdiagramm Dämonen) abgebildet:
• Die Mainklasse erstellt und startet einen DaemonController (1.)5
• Der DaemonController seinerseits erstellt die beiden Dämonen bad und
net. (1.1, 1.2)
• Der DaemonController schickt zuerst dem Netfilterdämonen die Nachricht
process() (2.1.1), worauf dieser das Lesen der Daten im Procfilesystem des
Netfiltermoduls auslöst (2.1.1.2):
o Mit getLastRun() (2.1.1.1) findet der Dämon heraus, wann er zum
letzten Mal aktiv war.
o Der Netfilterdämon schickt die Nachricht readData() (2.1.1.2) an
seinen Parser, welcher die Daten holt: für jedem Datensatz (Zeile im
Procfile) ruft dieser writeData() (2.1.1.2.1) im Dämonen auf, welcher
dann die Daten in die Datenbank schreibt:
o Der Netfilterdämon schlüsselt bei jedem Aufruf von writeData() die
IP Adressen zu den entsprechenden Benutzer und Basistationen auf
speichert mit diesen Daten und den ermittelten Daten einen neuen
Datensatz in der Datenbank.
• Wenn die neuen Daten gelesen sind, merkt sich der Dämoncontroller den
jetzigen Zeitpunkt als „lastRun“ (2.1.2), damit aufgrund dessen beim nächsten
Durchlauf die Daten der neuen Datensätze berechnet werden können.
5 Die Nummern beziehen sich auf die Sequenznummern im Sequenzdiagramm.

Kapitel 8: Design
70
• Danach schickt der Dämoncontroller dem Billingdämonen die Nachricht
process() (2.1.3), welcher dann das Produzieren der IPDR Dokumente auslöst
(2.1.3.1) und diese am vorgesehenen Ort abspeichert.
• Jetzt schläft (2.1.4) der DaemonController für ca. 10min – 15min und wartet auf
den nächsten Einsatz.
Dieses Hauptvorgehen wird wie gesagt alle 15min (ca.) ausgelöst: der Dämoncontroller
hat in seiner run() (2.1) Methode eine Anweisung, in der er für die vorgesehene Zeit
wartet (2.1.4).
Datenintegrität
Durch die Abfolge der beiden process() Nachrichten im gleichen Thread können wir
garantieren, dass nie gleichzeitig Daten geschrieben und ausgewertet werden. Das
könnte nämlich zu Problemen führen, wenn die Datenbank neue Daten bekommt,
während der BillingAgentDämon am IPDR-Files schreiben ist: beim Abschluss der
Ausgabe würden die neuen Datensätze gerade auf read=true gesetzt, obwohl sie noch
gar nicht gelesen wurden.
Werden mehrere Gateway an die gleiche Datenbank gehängt, entstehen auch keine
Probleme, weil die Auswertung pro Gateway 6geschieht.
6 Allerdings ist in dieser Version das Verwalten von mehreren Gateways erst vorgesehen, aber noch nicht
geplant. Das Design ist so gewählt, dass spätere Abänderung in dieser Hinsicht keine zu grossen Probleme
verursachen.
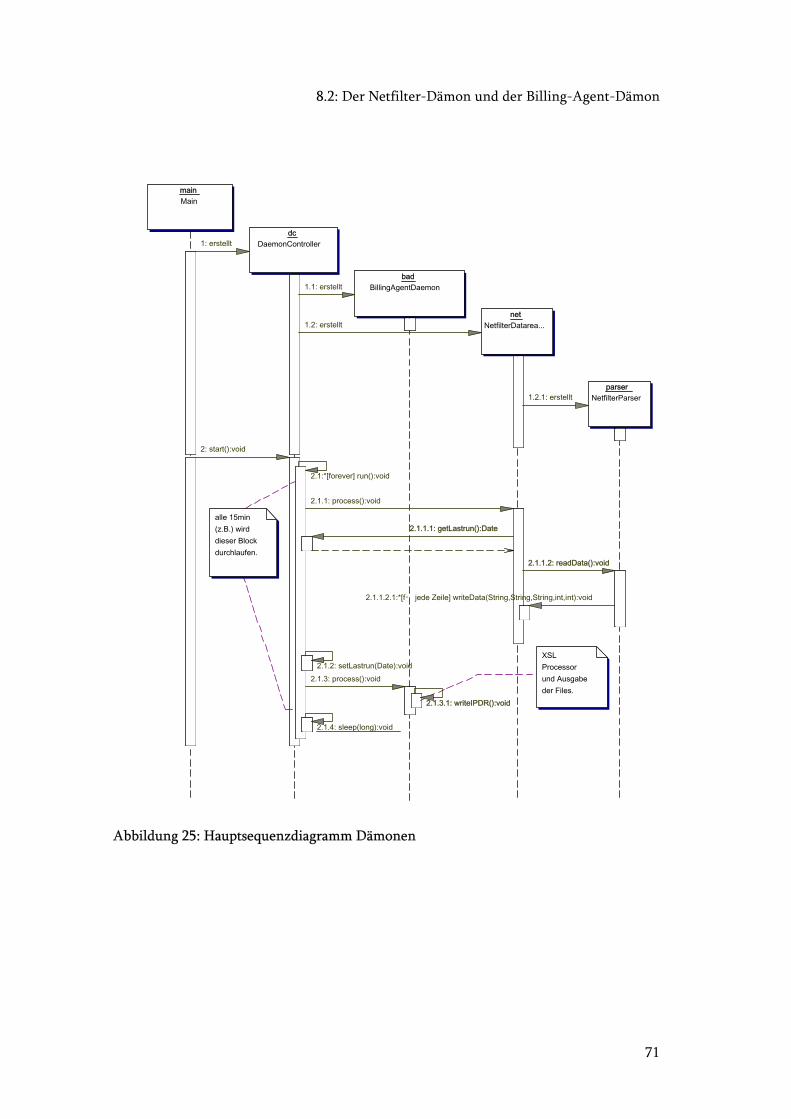
8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
71
badBillingAgentDaemon
netNetfilterDatarea...
parserNetfilterParser
mainMain
dcDaemonController
2.1.1.2.1:*[f・ jede Zeile] writeData(String,String,String,int,int):void
1.2.1: erstellt
2.1.3.1: writeIPDR():void
2.1.1.2: readData():void
2.1.3: process():void2.1.2: setLastrun(Date):void
2.1.1: process():void
2.1:*[forever] run():void
1.2: erstellt
1.1: erstellt
2: start():void
1: erstellt
2.1.1.1: getLastrun():Date
2.1.4: sleep(long):void
alle 15min(z.B.) wirddieser Blockdurchlaufen.
XSLProcessorund Ausgabeder Files.
Abbildung 25: Hauptsequenzdiagramm Dämonen
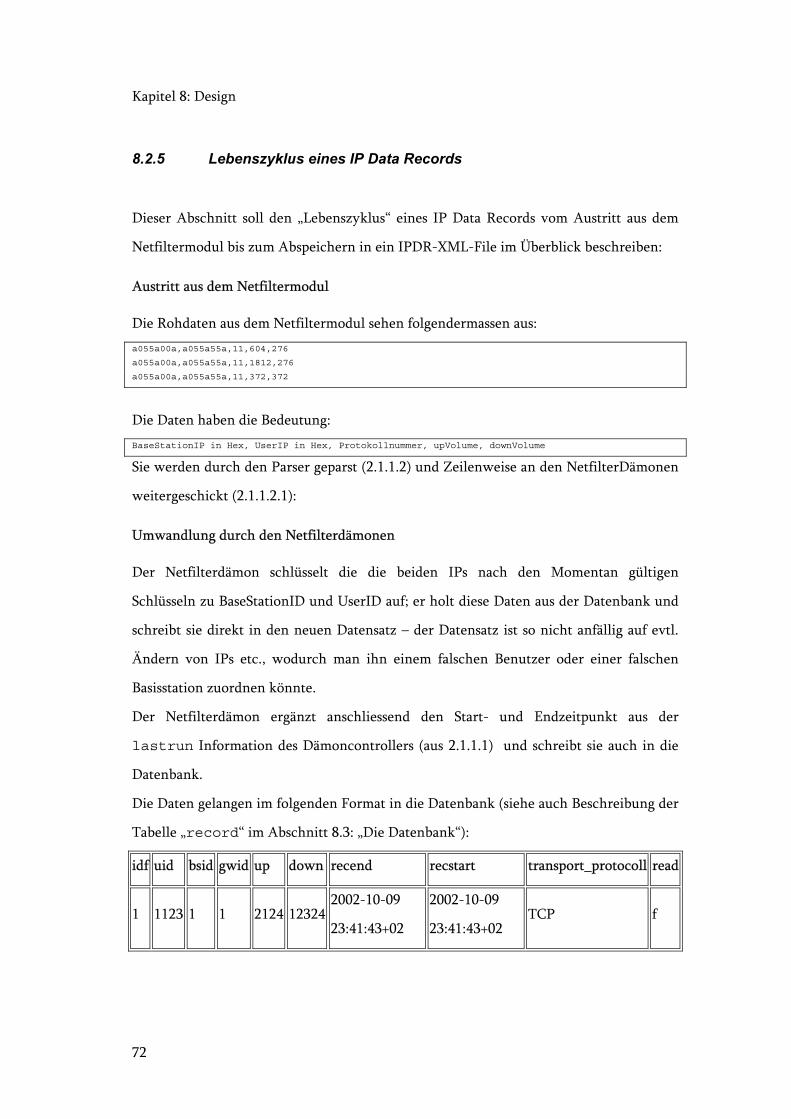
Kapitel 8: Design
72
8.2.5 Lebenszyklus eines IP Data Records
Dieser Abschnitt soll den „Lebenszyklus“ eines IP Data Records vom Austritt aus dem
Netfiltermodul bis zum Abspeichern in ein IPDR-XML-File im Überblick beschreiben:
Austritt aus dem Netfiltermodul
Die Rohdaten aus dem Netfiltermodul sehen folgendermassen aus: a055a00a,a055a55a,11,604,276
a055a00a,a055a55a,11,1812,276
a055a00a,a055a55a,11,372,372
Die Daten haben die Bedeutung: BaseStationIP in Hex, UserIP in Hex, Protokollnummer, upVolume, downVolume
Sie werden durch den Parser geparst (2.1.1.2) und Zeilenweise an den NetfilterDämonen
weitergeschickt (2.1.1.2.1):
Umwandlung durch den Netfilterdämonen
Der Netfilterdämon schlüsselt die die beiden IPs nach den Momentan gültigen
Schlüsseln zu BaseStationID und UserID auf; er holt diese Daten aus der Datenbank und
schreibt sie direkt in den neuen Datensatz – der Datensatz ist so nicht anfällig auf evtl.
Ändern von IPs etc., wodurch man ihn einem falschen Benutzer oder einer falschen
Basisstation zuordnen könnte.
Der Netfilterdämon ergänzt anschliessend den Start- und Endzeitpunkt aus der
lastrun Information des Dämoncontrollers (aus 2.1.1.1) und schreibt sie auch in die
Datenbank.
Die Daten gelangen im folgenden Format in die Datenbank (siehe auch Beschreibung der
Tabelle „record“ im Abschnitt 8.3: „Die Datenbank“):
idf uid bsid gwid up down recend recstart transport_protocoll read
1 1123 1 1 2124 12324 2002-10-09
23:41:43+02
2002-10-09
23:41:43+02 TCP f

8.2: Der Netfilter-Dämon und der Billing-Agent-Dämon
73
Der Record bekommt seine eindeutige ID (idf); BasestationID (bsid), GatewayID (gwid)
und UserID (uid)7 sind eindeutig aufgeschlüsselt, die Zeitpunkte sind eingetragen, das
Transportprotokoll (mithilfe der Klasse IPProtocolTool) aufgeschlüsselt; zusätzlich
hat der Datensatz ein Flag „read“ das auf „false“ gesetzt ist, weil der Datensatz neu ist und
noch nie ausgewertet wurde.
Auswertung durch den BillingAgentDaemon
Der Dämonencontroller wartet, bis der Netfilterdämon seine Arbeit abgeschlossen hat
und ruft dann erst den Billingagentdämonen zur Arbeit auf (2.1.3). Auf diese Weise kann
garantiert werden, dass der Netfilterdämon keine neuen Daten in die Datenbank
schreibt, während der Billingagentdämon die Daten auswertet.
Der Billingagentdämon liest nun alle Datensätze aus der Datenbank, die das Flag „read“
auf „false“ haben, diejenigen also, die noch nie angeschaut wurden. Er parst diese und
schreibt sie in einen internen XML-Strom welcher er der Klasse
BATransformerThread weiterschickt. Diese Klasse produziert aufgrund eines XSL
Stylesheets aus dem internen XML-Strom gültiges IPDR-XML und schreibt diese – mit
obig beschriebenen eindeutigen Filenamen – in das Output-Directory: auf diese Weise
kommen alle seit dem letzten Durchlauf erzeugten Datensätze in ein IPDR File.
Zum Schluss setzt der Dämon alle „read“ Flags dieser Datensätze auf „true“: so werden sie
durch den Billingdämonen nie mehr neu ausgewertet. Sie bleiben aber zur eventuellen
Weiterverwertung durch andere Systeme (z.B. durch die Präsentationsschicht) in der
Datenbank.
7 Diese IDs sind alle Fremdschlüssel auf ihre respektiven Entitäten.
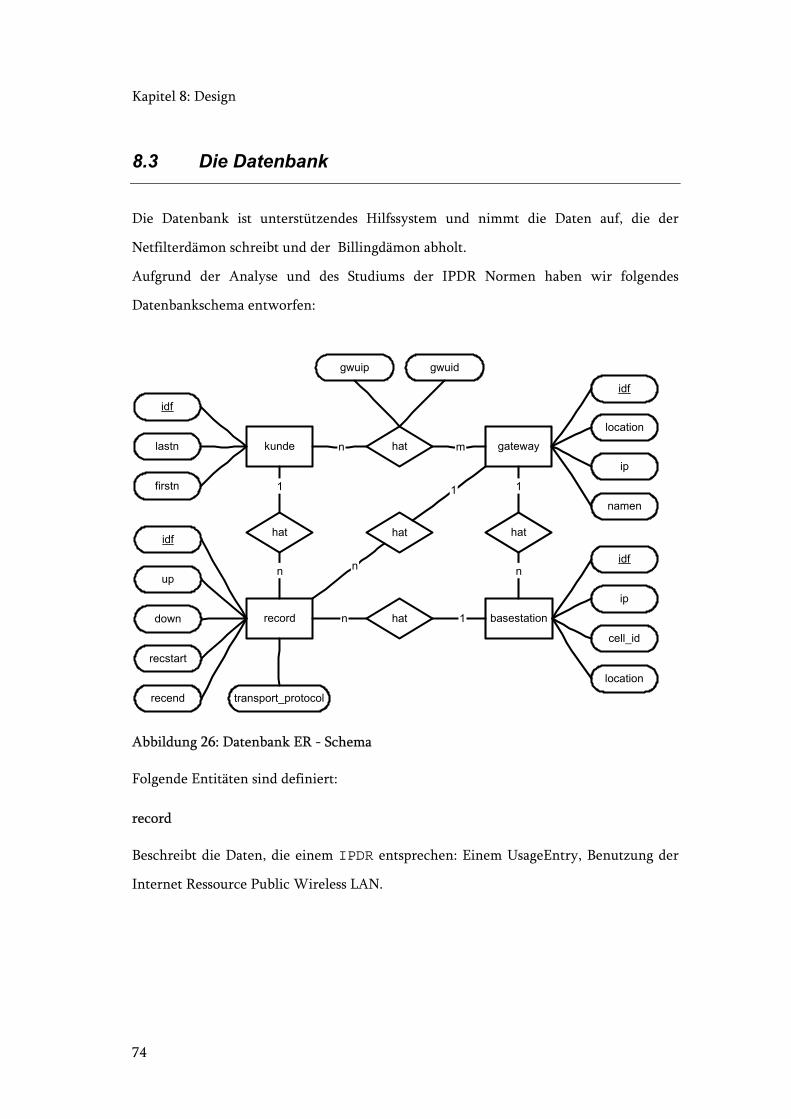
Kapitel 8: Design
74
8.3 Die Datenbank
Die Datenbank ist unterstützendes Hilfssystem und nimmt die Daten auf, die der
Netfilterdämon schreibt und der Billingdämon abholt.
Aufgrund der Analyse und des Studiums der IPDR Normen haben wir folgendes
Datenbankschema entworfen:
kunde
firstn
lastn
idf
gateway
ip
namen
hat
basestation
idf
cell_id
mn
record
recstart
recend
location
gwuip gwuid
down
up
transport_protocol
ip
idf hat
1
n
idf
location
hat
1
n
hat 1n
hat
1
n
Abbildung 26: Datenbank ER - Schema
Folgende Entitäten sind definiert:
record
Beschreibt die Daten, die einem IPDR entsprechen: Einem UsageEntry, Benutzung der
Internet Ressource Public Wireless LAN.

8.3: Die Datenbank
75
Ein Tupel beschreibt dabei einen atomischen Vorgang (wie im Kapitel über IPRD
beschrieben), in unserem Fall die Benutzung des Public WLAN Systems durch einen
Kunden auf einem Gateway während bestimmten 10min – 15min.
up und down sind dabei das transferierte Datenvolumen in beiden Richtungen.
Das read Flag wird benötigt, damit die Daten vom Billingdämonen nur einem
ausgewertet werden.
kunde
Ein Endkunde, eindeutig definiert. Jeder Kunde hat auf einem Gateway eine für den
Gateway eindeutige Signatur; die Tupel in dieser Entität sind aber global eindeutig.
Die Entität simuliert ein späteres CRM System, das dann z.B. durch ein LDAP Directory
implementiert werden könnte.
gateway
Beschreibt einen Gateway. Wird benötigt, weil z.B. jeder Kunde auf jedem Gateway eine
andere IP hat.
In unserem System gibt es momentan nur einen Gateway.
basestation
Beschreibt die Basisstation. Eine Basisstation gehört zu genau einem Gateway.
Relation <hat> zwischen kunde und gateway
Die Relation <hat> zwischen Kunde und Gateway hat die zwei Attribute gwuid und
gwuip: Sie entsprechen den Einträgen in /etc/cipng_accounts im Gateway-
System. gwuip ist die Momentante IP des Kunden auf dem Gateway.
Das Schema hat eine gewisse Redundanz, die etwas unschön ist. Dies ist jedoch gewollt.
Ein record gehört absichtlich zu kunde, basestation und gateway, obwohl diese
Relationen zum Teil über andere Relationen aufgeschlüsselt werden könnten. Es ist aber
so, dass z.B. die Zuordnung einer basestation zu einem gateway geändert werden

Kapitel 8: Design
76
kann: darum kann der gateway nicht über die basestation aufgeschlüsselt werden,
sondern jeder record muss wissen, zu welchem Tupel aller Entitäten er gehört, und
zwar zum Zeitpunkt seiner Entstehung. Die entsprechenden Relationen müssen in
record im Zeitpunkt seines Entstehens zugeordnet werden.
Das Datenbankmodell soll in einer Datenbank implementiert werden, die referentielle
Integrität unterstützt. Die Löschregeln werden in der Implementierung beschrieben.
8.4 Sicherheit des Gesamtsystems
Obwohl es sich bei unserem System um einen Prototypen handelt, wollen wir dennoch
Überlegungen über die Sicherheit machen:
8.4.1 Schutz vor Angriffen und Manipulationen
Wie schon in der Analyse bemerkt, hat unser System diverse interne Schnittstellen. Jede
dieser Schnittstellen ist potentielle Angriffsfläche für Angreifer, die die Daten
manipulieren könnten. Insbesondere wird es kritisch, wenn die einzelnen Subsysteme
auf verschiedene Maschinen verteilt werden.
In unserem Fall sollen aber alle Billing Agent Subsysteme auf dem Gateway selber laufen.
Daher entstehen bei der Kommunikation der einzelnen Module, welche über IP laufen
(JDBC etc.), keine Probleme, weil sie den local loop nicht verlassen.
Entscheidet man sich, das System verteilt zu machen, müssen die entsprechenden
Verbindungen z.B. durch ein VPN verschlüsselt werden.
Das externe BSS kann seine IPDR Files mit einer SSH Verbindung vom Gateway-
Filesystem holen.

8.5: Die Darstellung
77
8.4.2 Fehlerbehandlung, Ausnahmefälle
Wir haben uns aufgrund der unerwarteten Komplexität des Systems entschieden, eine
rudimentäre Fehlerbehandlung zu erstellen:
Passiert im BillingAgent etwas grobes, unvorhergesehenes, z.B. der Ausfall der
Datenbank, versucht das System weiterzuarbeiten. Es Informiert aber bei jedem Fehler
über das weiter oben beschriebene Alarmsystem via e-Mail einen Administrator sehr
ausführlich über Art des Fehlers, Lokalisierung im Modul etc. bis hin zum Stacktrace der
JavaVirtualMaschine.
Die gesamten internen Abläufe, wie weiter oben beschrieben, haben wir uns so
ausgedacht, dass sie auch funktionieren, wenn die Subsysteme nicht ganz synchron sind.
Es kann nicht passieren, dass unser System durch eine Verzögerung eines der Subsysteme
(hier ist nicht ein Ausfall gemeint) in einem unstabilen Zustand mit inkonsistenten
Daten gerät oder gar Daten verliert.
cron Job als Wächter
Das ganze Dämonensystem wird über die Main Klasse gestartet, als ein einziger Java-
Prozess auf einer Linux - Maschine.
Es ist denkbar, dass ein cron – Job diesen Prozess überwacht und bei Bedarf neu startet.
8.5 Die Darstellung
Wegen der im Kapitel Projektmanagement beschriebenen massiven Problemen mit dem
Netfiltermodul (und weitern, weiter unten beschriebenen Überlegungen) haben wir uns
nach Rücksprache mit unserem Betreuer Dr. A. Steffen dazu entschlossen, das
Darstellungs-Subsystem nicht zu erstellen. Es soll zu einem späteren Zeitpunkt als
Projektarbeit an unserer Schule ausgeschrieben und implementiert werden.

Kapitel 8: Design
78
Allerdings hatten wir uns schon einige Design - Überlegungen dazu gemacht, die hier
beschrieben werden sollen.
8.5.1 Gesamtdesign
Das Darstellungs-Subsystem soll eine Webapplikation sein, die auf die Daten der
Datenbank zugreifen kann und diese Daten auch nach gewissen Kriterien, wie in der
Analyse besprochen, darstellen kann.
So sollen z.B. angezeigt werden, wo ein Bestimmter Kunde in einer bestimmten Zeit wie
viel heruntergeladen hat. Oder: Wieviel Verkehr eine Basisstation in einer bestimmten
Zeit verursacht hat.
Als Technologie wurde vom Auftraggeber futureLAB AG eine Java Server Page
Anwendung (JSP) gewünscht, welche sich die Daten aus der Datenbank holt, in ein
IPDR umwandelt und dann mit XSLT transformiert auf der HTML Seite anzeigt. Man
könnte allerdings die Daten auch direkt aus der Datenbank holen und als HTML
darstellen: der Auftraggeber wollte aber ein XML - Zwischenformat, um zu zeigen, dass
diese (aggretierten) Daten in XML darstellbar sind. Vorteil einer XML Darstellung ist
zudem, dass diese Daten – wenn gewünscht – verschieden dargestellt werden können: als
HTML, als PDF in Rechnungen an den Kunden, u.a.
Aufgrund der Überlegungen in Abschnitt 6.4 auf Seite 26 ist allerdings IPDR dazu nicht
geeignet.
8.5.2 Neue XML Schemas
Wir haben deshalb eigene, proprietäre XML – Schemas definiert, die diese
Anwendungfälle abdecken8:
8 Die Vollständige Schemadokumentation ist auf der CD im Odner IPDRxsd mitgeliefert.

8.5: Die Darstellung
79
Dispute Resolution
Dies ist das Schema für den Anwendungsfall, bei dem man von einem Endkunden wissen
will, wo (welche Basestation) er wann wie viel gesurft ist. Ein Benutzer hat dann
mehrere BaseStationSessions, bei denen er einen gewissen Verkehr verursacht
hat. Wenn er innerhalb der gleichen 10min – 15min mit verschiedenen Basisstationen
verbunden war, kann es sein, dass er gleichzeitig mehrere BaseStationSessions
verursacht.
Abbildung 27: Schema zur Dispute Resolution
Base Station
Dies ist das Schema für den Anwendungsfall, bei dem man wissen will, wie viel Verkehr
eine Basisstation in einer bestimmten Zeit verursacht hat.
Das Schema ist selbsterklärend.
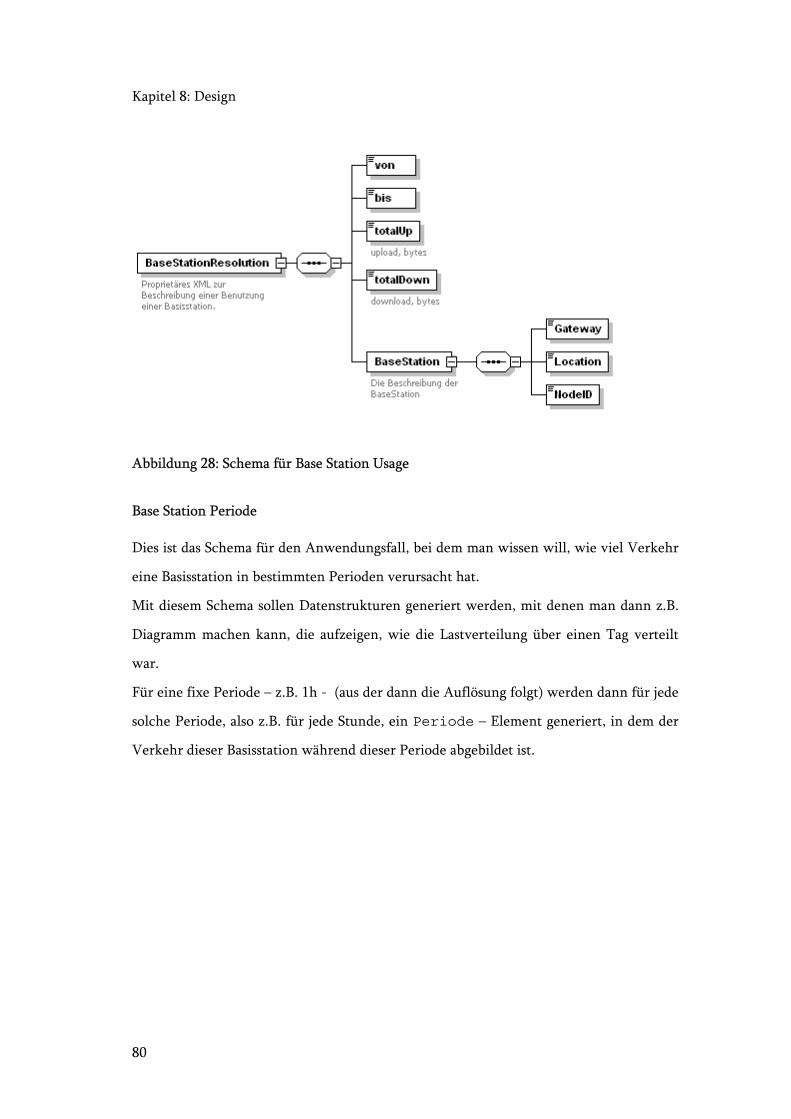
Kapitel 8: Design
80
Abbildung 28: Schema für Base Station Usage
Base Station Periode
Dies ist das Schema für den Anwendungsfall, bei dem man wissen will, wie viel Verkehr
eine Basisstation in bestimmten Perioden verursacht hat.
Mit diesem Schema sollen Datenstrukturen generiert werden, mit denen man dann z.B.
Diagramm machen kann, die aufzeigen, wie die Lastverteilung über einen Tag verteilt
war.
Für eine fixe Periode – z.B. 1h - (aus der dann die Auflösung folgt) werden dann für jede
solche Periode, also z.B. für jede Stunde, ein Periode – Element generiert, in dem der
Verkehr dieser Basisstation während dieser Periode abgebildet ist.
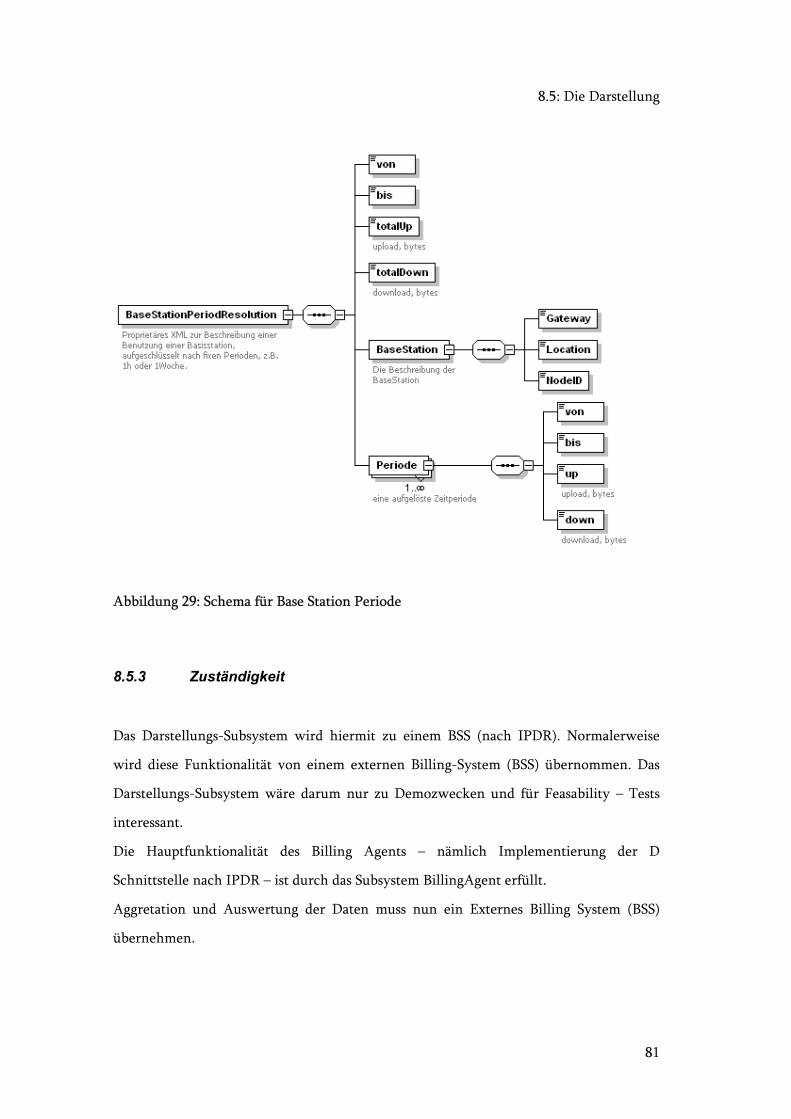
8.5: Die Darstellung
81
Abbildung 29: Schema für Base Station Periode
8.5.3 Zuständigkeit
Das Darstellungs-Subsystem wird hiermit zu einem BSS (nach IPDR). Normalerweise
wird diese Funktionalität von einem externen Billing-System (BSS) übernommen. Das
Darstellungs-Subsystem wäre darum nur zu Demozwecken und für Feasability – Tests
interessant.
Die Hauptfunktionalität des Billing Agents – nämlich Implementierung der D
Schnittstelle nach IPDR – ist durch das Subsystem BillingAgent erfüllt.
Aggretation und Auswertung der Daten muss nun ein Externes Billing System (BSS)
übernehmen.

Kapitel 8: Design
82

83
9 Implementierung
In diesem Kapitel beschreiben wir die Implementierung der einzelnen Subsysteme:
zuerst die Netfilter-Teile, dann die Java Teile.
9.1 Das CIPnG Netfiltermodul
Die gesamte Architektur der Implementierung des CIPnG Netfiltermodules kann am
besten anhand der Abbildung 30: Architektur Netfiltermodule erklärt werden. Wie ein
Modul geladen wird, ist im Kapitel 7 Grundlagen Netfilter kurz beschrieben.
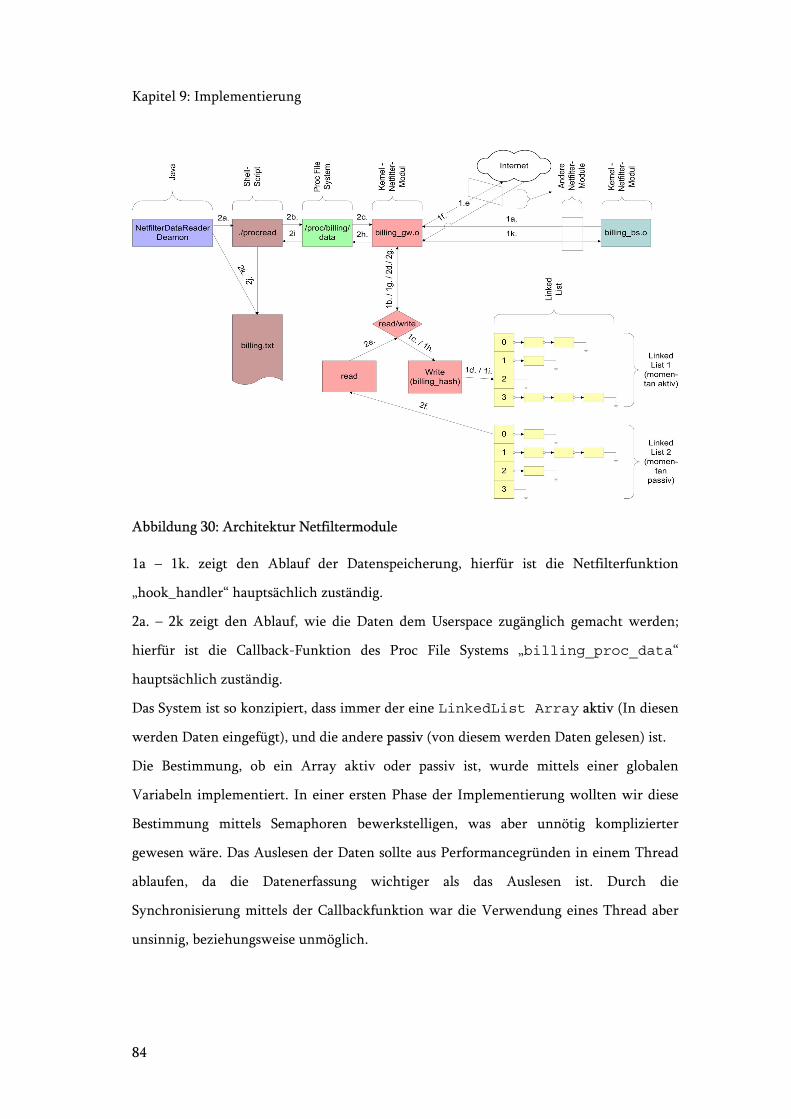
Kapitel 9: Implementierung
84
Abbildung 30: Architektur Netfiltermodule
1a – 1k. zeigt den Ablauf der Datenspeicherung, hierfür ist die Netfilterfunktion
„hook_handler“ hauptsächlich zuständig.
2a. – 2k zeigt den Ablauf, wie die Daten dem Userspace zugänglich gemacht werden;
hierfür ist die Callback-Funktion des Proc File Systems „billing_proc_data“
hauptsächlich zuständig.
Das System ist so konzipiert, dass immer der eine LinkedList Array aktiv (In diesen
werden Daten eingefügt), und die andere passiv (von diesem werden Daten gelesen) ist.
Die Bestimmung, ob ein Array aktiv oder passiv ist, wurde mittels einer globalen
Variabeln implementiert. In einer ersten Phase der Implementierung wollten wir diese
Bestimmung mittels Semaphoren bewerkstelligen, was aber unnötig komplizierter
gewesen wäre. Das Auslesen der Daten sollte aus Performancegründen in einem Thread
ablaufen, da die Datenerfassung wichtiger als das Auslesen ist. Durch die
Synchronisierung mittels der Callbackfunktion war die Verwendung eines Thread aber
unsinnig, beziehungsweise unmöglich.

9.1: Das CIPnG Netfiltermodul
85
Uplink: (Mobilehost Internet)
(1a) Das Netfiltermodul billing_bs fügt allen Paketen in
Uplinkrichtung einen zusätzlichen Billing-IP Header ein.
(1a / 1b) Das Netfiltermodul biling_gw liest die benötigten Daten aus
(IP der Basestation, IP des Mobilehost, Protokoll).
(1c / 1d) Die Daten werden in den aktiven Linked List Array
geschrieben. Den richtigen Index errechnet die Funktion
„billing_hash“ mittels der IP Adresse des Mobilehosts und
der Protokollnummer. Entweder wird zu einem bereits
vorhandener Node um das Uplinkvolumen hinzu addiert, oder es
wird ein neuer Node erzeugt.
(1e) Der Billing –IP Header wird gelöscht und das Packet an die
anderen CIPnG Netfiltermodule weitergegeben, so dass es
schliesslich ins Internet gelangt.
Downlink: (Internet Mobilehost)
(1f) Das Netfiltermodul „billing_gw“ nimmt alle Paket aus dem
Internet entgegen.
(1g / 1h / 1i / 1k) Das Netfiltermodul liest die benötigten Daten aus dem IP Paket
(Destination Adress und Protocol). Den richtigen Index errechnet
die Funktion „billing_hash“ mittels Destination Adress und
Protocol. Die Linked List des aktiven Linked List
Array wird in diesem Fall durchiteriert, bis ein Node gefunden
wird, bei welchem „user_ip“ und „protocol“ einer Nodes
der Destination Adress und Protocol entsprechen. Wenn ein
Node gefunden wird, wird das Downlinkvolumen der Node
hinzu addiert. Das Downlinkvolumen wird der ersten Node, die
gefunden wird hinzu addiert. Wenn der Mobilehost gerade einen

Kapitel 9: Implementierung
86
Handover vollzogen hat, wird daher das Downlinkvolumen der
falschen Basestation zugeschrieben. Wen der Mobilehost das
nächste Uplinkpaket (Bsp. Acknowledge) versendet, stimmt die
Zugehörigkeit der Basestation wieder. Wird kein Node gefunden,
wird das Packet an die anderen Netfiltermodule weitergereicht
und schliesslich zum Mobilehost versendet, oder falls nicht
vorhanden, ein ICMP Packet zurückgeschickt. Dieses
Downlinkpacket wird nicht erfasst. Bevor ein Downlinkpaket für
einen Mobilehost erfasst wird, muss also zuerst ein Uplinkpaket
vom Mobilehost zum Gateway gelangen, um einen Eintrag im
Linked List Array zu erzeugen.
Auslesen der Daten
(2a) Der „NetfilterDataReaderDeamon“ löst das Shell Script
„procread“ auf. Der NetfilterDataReaderDaaemon
synchronisiert somit das ganze Kernelmodul. Der Nachteil dieser
Synchronisierung besteht darin, dass es im Speicher zu einem
Überlauf kommen kann, wenn die Linked Lists nie gelöscht
werden. Dieser Überlauf sollte in einer Erweiterung des
Netfiltermodules „billing_gw“ abgefangen werden.
(2b / 2c) Die Callbackfunktion „billing_proc_data“ wird im
Netfiltermodul „billing_gw“ aufgerufen.
(2d/ 2e /2f /2g /2h /2i) Der passive Linked List Array wird komplett durchiteriert,
und der Inhalt jeder Node zeilenweise in das File „data“
geschrieben [siehe Abschnitt 8.2.5 Lebenszyklus eines IP Data
Records] Nachdem alles ausgelesen wurde, werden alle Nodes
gelöscht. Nun wird der passive Linked List Array auf aktiv

9.1: Das CIPnG Netfiltermodul
87
und der aktive Linked List Array auf passiv geschalten
(„switchLinkedList“).
(2j) Das Shell Script lenkt die ausgelesenen Daten in ein File namens
billing.txt um.
(2k) Der NetfilterDataReaderDaemon kann nun die Daten in
aller „Javagemütlichkeit“ aus dem File einlesen.
9.1.1 Andere Netfilter Module
Die anderen Netfiltermodule, welche im CIPnG Grundsystem implementiert sind, könne
unter [CIPnG] nachgeschlagen werden.
9.1.2 Kernel Netfiltermodul billing_bs:
Das Netfiltermodul billing_bs fügt allen Paketen einen zusätzlichen Header mit der
IP – Adresse der Basestation ein, dazu muss es als erstes Modul am Hook
NF_IP_PRE_ROUTING registriert sein, also vor jeden CIPnG Netfiltermodul (Priorität
0). Dies ist mittels einer Priorität (-1) fix einprogrammiert. [siehe Abschnitt: 7.2 Netfilter
Beispiel]
/* funktionen um sich für einen hook zu registrieren ps.-1 bedeutet, dass dieses modul eine
höhere priorität hat als ein anderes modul mit 0*/
static struct nf_hook_ops hook_opps = {{NULL,NULL}, hook_handler,PF_INET,NF_IP_LOCAL_IN,-1};

Kapitel 9: Implementierung
88
Das billing_bs Netfilermodul enthält folgende Funktionen: // setzt einen neuen IPv4 Header inklusive Checksumme
void set_billing_iphdr (void * data, //siehe sk_buff
__u16 protocol, //Protokoll
__u32 daddr, // Destination Adress
__u32 saddr, // Source Adress
__u16 tot_len) // Packetgrösse
// packt ein Datenpaket in ein Billing –Paket ein, falls es sich noch nicht um ein solches
handelt
int billing_encapsulation (struct sk_buff *skb, //
const struct net_device *_dev, //
__u32 saddr, //Source Adress
__u32 daddr) //Destination Adress
/*Gibt „1“ zurück, wenn es funktioniert hat, ansonsten „0“. */
// Funktion um einen Netfiltermodul an einen Hook anzubinden
unsigned int hook_handler(unsigned int hook, //
struct sk_buff **pskb, //
const struct net_device *indev, //
const struct net_device *outdev, //
int (*okfn)(struct sk_buff *)) //
// initialsierung des Moduls
int init_module(void); //
// aufräumen und abmelden des Moduls
void cleanup_module(void); //
9.1.3 Schwächen der billing_bs Implementierung
Das Netfiltermodul billing_bs hat noch einige Schwächen, die verbessert werden
sollten.
• Momentan werden alle Pakete eingekapselt. Dies ist nicht sehr effizient, da viele
Pakete an der Luftschnittstelle gar nicht für das CIPnG bestimmt sind. Daher
sollte eine Funktion eingebaut werden, die nur beim CIPnG angemeldete
Benutzer erfasst. Bedingung wäre aber, dass der Gateway den Basestations die
Benutzer beispielsweise über einen Broadcast mitteilt.
• Eine vollständige Implementierung mit IPv6 Header im CIPnG wäre vom Design
her besser.
• Das Modul ist noch zuwenig ausgetestet [siehe Kapitel 10 Test].

9.1: Das CIPnG Netfiltermodul
89
9.1.4 Kernel Netfiltermodul billing_gw:
Das Netfiltermodul billing_gw muss das erstes Netfiltermodul, welches am Hook
NF_IP_PRE_ROUTING registriert ist, sein; also vor jedem anderen CIPnG
Netfiltermodul (Priorität 0). Dies ist mittels einer Priorität (-1) fix einprogrammiert
[siehe 9.1.2Kernel Netfiltermodul billing_bs:].
Das billing_gw Netfilermodul enthält folgende Funktionen:
// initialisiert die beiden LinkedList Arrays
void initArray(int arraysize);
// löscht die Elemente eines LinkedList Arrays
void resetLinkedList(LinkedList array[]);
//managt und speichert die Billingdaten in der aktiven LinkedList Array
void billingAgent ( struct sk_buff * pskb, // sk_buff strukur
int up_down_link ); // B_UPLINK oder
// B_DOWNLINK
// schreibt die gesammelten Billingdaten des „passiven“ LinkedList Arrays ins Procfile
int _printElements ( LinkedList list[], //
char * buffer); // Buffer, in den geschrieben
//werden kann
// swechselt den status der beiden LinkedList Arrays aktiv passiv und umgekehrt
void switchLinkedList(void); //
// Funktion um einen Netfiltermodul an einen Hook anzubinden
static unsigned int hook_handler ( unsigned int hook, //
struct sk_buff **pskb, //
const struct net_device *indev, //
const struct net_device *outdev, //
int (*okfn)(struct sk_buff *)); //
// Callbackunktion -> wird aufgerufen, wenn das Profile gelesen wird, damit die Daten zur
Verfügung gestellt werden
static int billing_proc_data ( char *buffer, //
char **buffer_location, //
off_t requested_offset, //
int requested_len, //
int *eof, //
void *data); //
// initialsierung des Moduls
int init_module(void); //
// aufräumen und abmelden des Moduls
void cleanup_module(void); //

Kapitel 9: Implementierung
90
9.1.5 Linked List
Für die Speicherung der Daten haben wir uns für einen Array entschieden, der jeweils
eine Linked List enthält. Diese Implementierung hat einen entscheidenden Vorteil
gegenüber der Verwendung von einem „normalen“ Array, in dem die Daten gespeichert
werden: Sie ist dynamisch. Man muss also nicht von Anfang an einen grossen
Speicherplatz reservieren, damit alles abgespeichert werden kann.
Einzig die Grösse des Array, welcher die „Linked Lists“ enthält ist, in der jetzigen
Implementierung fix einprogrammiert, sollte aber in einer überarbeiteten Version beim
Laden des Netfiltermoduls gesetzt werden können (Bsp. modprobe billing_gw
ARRAYSIZE=10000). Die „ARRAYSIZE“ sollte genügend gross (je nach Anzahl der
Mobilehosts) gewählt werden, damit möglichst wenige Kollisionen nach dem „hashen“
auftreten.
Eine andere wichtige Funktion ist das „Hashing“, welche aufgrund der Wahl des Arrays
nötig ist. Der Hashfunktion wird die IP des Mobilehostes und die Protokollnummer
übergeben, und gibt einen Index zwischen 0 und ARRAYSIZE-1 zurück. Damit kann
die gesuchte Linked List im Array schnell gefunden werden. Die Implementierung ist in
der Headerdatei billing_hash.h ersichtlich. Der Algorithmus sollte noch verbessert
werden.
Die Hashfunktion hat folgende Signatur: int billing_hash ( __u32 user_ip, // IP des Mobilehostes
__u8 protocol, // Protokollnummer
int tablesize) // ARRAYSIZE
/* Gibt einen Index zwischen 0 und tablesize-1 zurück */
Anmerkung: In der ersten Phase der Implementierung wurde ein Hashwert mit der IP
der Basestation, der IP des Mobilehostes und der Protokollnummer berechnet. Diese
Funktion erlaubte es aber nicht, einen Arrayindex eines Downlink-Paketes (Internet
Mobilehost) zu berechnen, sondern nur eines Uplink-Paketes (Mobilehost Internet).

9.1: Das CIPnG Netfiltermodul
91
Abbildung 31: Linked List und Hash
In Abbildung 32 ist der Aufbau der Linked List ersichtlich. Die Implementierung kann in
der Headerdatei ll.h nachgelesen werden.
Eine Node ist mit folgender Struktur definiert: typedef struct _node {
__u32 bs_ip; // IP der Basestation
__u32 user_ip; // IP des Mobilehostes
__u8 protocol; // Protokollnummer
int up; // Uplink Volumen
int down; // Downlink Volumen
struct _node * nextNode; // Zeiger auf den nächsten Node
} NODE;
Die LinkedList ist mit folgender Struktur definiert: typedef struct _linkedlist {
NODE * headNode; // erster Node der LinkedList
int number_of_Elements; // anzahl der Nodes in der LinkedList
} LinkedList;

Kapitel 9: Implementierung
92
Abbildung 32: Node Linked List
move_to_head
Die Funktion move_to_head(…) sucht einen gewünschten Node in einer Linked List
anhand der IP Adresse der Basestation, der IP Adresse des Mobilehosts und der
Protokollnummer. Wenn ein Node gefunden wird, werden die Pointer neu verlinkt, so
dass der gefundene Node am Anfang der Linked List steht. Auf den ersten Node in der
Linked List kann mit LinkedListArray[index].headNode zugegriffen werden,
um die Up – und Down – Link -Zähler zu aktualisieren.
Die Funktion move_to_head hat folgende Signatur: int move_to_head ( LinkedList * list,
int bs_ip, // IP der Basestation
int user_ip, // IP des Mobilehost
int protocol) // Protokollnummer
/*Gibt „1“ zurück, wenn ein Node gefunden und an Anfang der Linked List verschoben wurde,
ansonsten „0“. */
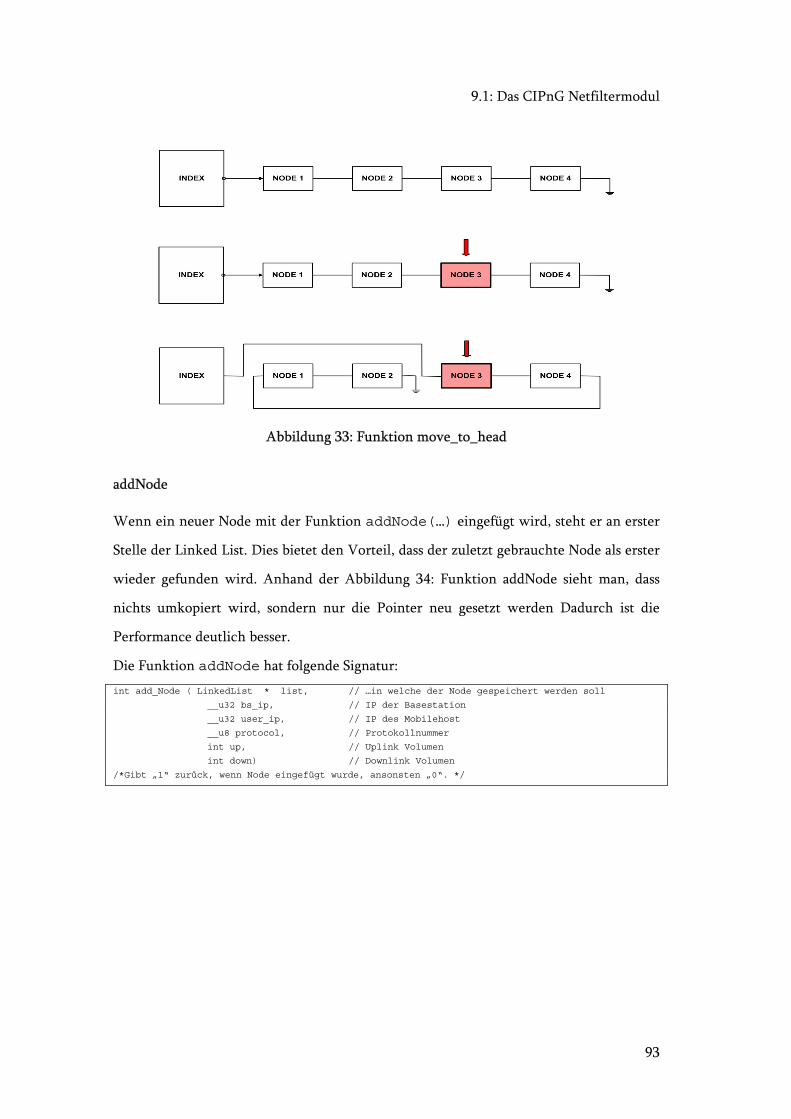
9.1: Das CIPnG Netfiltermodul
93
Abbildung 33: Funktion move_to_head
addNode
Wenn ein neuer Node mit der Funktion addNode(…) eingefügt wird, steht er an erster
Stelle der Linked List. Dies bietet den Vorteil, dass der zuletzt gebrauchte Node als erster
wieder gefunden wird. Anhand der Abbildung 34: Funktion addNode sieht man, dass
nichts umkopiert wird, sondern nur die Pointer neu gesetzt werden Dadurch ist die
Performance deutlich besser.
Die Funktion addNode hat folgende Signatur: int add_Node ( LinkedList * list, // …in welche der Node gespeichert werden soll
__u32 bs_ip, // IP der Basestation
__u32 user_ip, // IP des Mobilehost
__u8 protocol, // Protokollnummer
int up, // Uplink Volumen
int down) // Downlink Volumen
/*Gibt „1“ zurück, wenn Node eingefügt wurde, ansonsten „0“. */

Kapitel 9: Implementierung
94
Abbildung 34: Funktion addNode
Aus der Kombination der move_to_head und addNode Funktion ist folgende
„Pseudocode - Implementierung“ möglich: //Uplink
if (move_to_head(…)){
update UplinkVolumen;
}else{
addNode(….);
}
//Downlink
while(nextNode != NULL){
move_to_head(…);
update DownlinkVolumen;
}
remove_all_Nodes
Wenn Nodes hinzugefügt werden, müssen sie auch wieder gelöscht werden. Das
übernimmt die Funktion remove_all_Nodes. Nach dem Löschen aller Nodes und der
Speicherfreigabe, ist der „headNode“ mit NULL initialisiert.
Die Funktion addNode hat folgende Signatur: void remove_all_Nodes ( LinkedList * list)

9.1: Das CIPnG Netfiltermodul
95
9.1.6 Proc File System
Die gesammelten Daten werden über das Proc File System vom Kernelspace in den
Userspace transferiert. Wenn ein Programm auf ein File im Proc File System zugreift,
löst das die Callbackfunktion des betreffenden Files aus: Siehe [7.3 Proc File-System].
Durch diesen Mechanismus synchronisieren wir das gesamte Modul, das heisst, dass die
Daten des passiven Linked List Arrays ausgelesen und der Aussenwelt zur
Verfügung gestellt werden. Danach wird der passive LinkedList Array gelöscht,
beziehungsweise alle „headNodes“ der Linked List auf NULL gesetzt.
9.1.7 Shell-Script
Bei den Tests hat sich gezeigt, dass es aus Performancegründen besser ist, wenn ein Shell
Script die Daten vom Prof File System abholt und in ein File speichert. Bei einem Shell
Script hat man die Möglichkeit, die Daten direkt in ein File umzuleiten, was mit der Java
Applikation nicht „gleich gut“ geht. Das File heisst in unserem Beispiel „biling.txt“
wenn es einen anderen Namen haben soll, muss auch das File „properties.props“
des Subsystems Java Daemon angepasst werden. Es sollte „cat“ verwendet werden, da
sonst laut Newsgroupsartikeln Fehler auftreten können.
#!/bin/bash
cat /proc/cipng_billing/data > /pfad/zum/billing.txt

Kapitel 9: Implementierung
96
9.1.8 Java
Die Implementierung der Schnittstelle zum Java Dämonen Subsystem ist in der
Implementierung desselben beschrieben.
[Siehe Kapitel 9.3: Der Java NetfilterDatareaderDaemon]
9.1.9 Schwächen der billing_gw Implementierung
Das Netfiltermodul billing_gw hat noch einige Schwächen, die verbessert werden
sollten.
• Momentan sind die meisten Parameter „hardcodiert“, demzufolge ist das Modul
noch viel zu wenig flexibel.
• Wenn die Linked List nie gelöscht wird, das heisst, wenn die
Callbackfunktion des Proc File Systems nie aufgerufen wird, kann es zu einem
Überlauf kommen. Die beiden Zähler, welche das Up- und Down-Volumen
zählen, sind als Integerzahlen implementiert. Ein Zahler kann demnach ein
Volumen bis 231 Byte zählen, bis es zu einem Fehler führt. Bei einer
angenommenen Übertragungsrate von 10 MBit/s eines Mobilehost, würde dies
etwa 27 Minuten dauern. In der Praxis wird nur etwa 5 MBit/s über eine
Luftschnittstelle erreicht.
• Der Hash-Algorithmus sollte noch verbessert werden.
• Das Modul ist noch zuwenig ausgetestet [siehe Kapitel 10Test].
Im Folgenden werden die Java – Subsysteme beschrieben:

9.2: Das Subsystem der Java – Dämonen
97
9.2 Das Subsystem der Java – Dämonen
Vorerst beschreiben wir in diesem Abschnitt die Implementierung einiger gemeinsamer
Aspekte der Java Dämonen, um schliesslich die einzelnen Dämonen an sich zu
beschreiben:
9.2.1 Starten der Java Subsysteme
Wie im Design beschrieben, wird das gesamte Java Subsystem (die Dämonen) durch die
Klasse ch.zhwin.billingagent.Main gestartet. Diese Klasse ist sehr klein und
startet nur den DeamonController.
Damit das PropertySystem weiss, woher es sein PropertyFile holen muss, muss man der
Mainklasse den Pfad zum Property-File als SystemProperty mitgeben. Somit ist der
gesamte Aufruf zum Start der Dämonen: java ch.zhwin.billingagent.Main –Dch.zhwin.billingagent.propertyfile=pfad_zum_propertyfile
Wie im Design erwähnt, könnte man diesen Prozess auch mit einem Shellscript starten,
der sich seine PID (über ein PID-File) merkt.
Ein cron Job würde dann periodisch nachschauen, ob diese PID noch lebt, und wenn
nicht, das Shellscript neu starten. Wir haben jedoch diesen Mechanismus noch nicht
implementiert; vor allem weil wir das Gesamtsytem aus bekannten Gründen nicht in
seiner Gesamtheit in Betrieb nehmen konnten.
9.2.2 Das Properties – System der Java Subsysteme
Alle in Java implementierten Subsysteme (d.h. alle Dämonen) teilen sich ein
gemeinsames Property – System, wie es im Design beschrieben ist.
Darin lassen sich verschiedene Einstellungen bequem vornehmen.

Kapitel 9: Implementierung
98
Wir haben unten aufgeführte Properties implementiert: Deren Zweck ist grösstenteils
selbsterklärend; wo nicht, ist er direkt im File beschrieben.
Das PropertySystem selber ist als klassischer Singleton implementiert. Details dazu
entnehme man dem Sourcecode und der JavaDoc.
Insbesondere liest der Singleton – Konstruktor die SystemProperty (auf der
Kommandozeile anzugeben) ch.zhwin.billingagent.propertyfile aus, damit
er weiss, wo sein Property-File ist: /**
* Singleton - Konstruktor fuer das Objekt PropertyManager
*/
private PropertyManager() {
Properties sysprops = System.getProperties();
String file = sysprops.getProperty("ch.zhwin.billingagent.propertyfile");
this.props = new Properties();
try {
props.load(new FileInputStream(file));
} catch (java.io.IOException e) {
System.err.println("Fehler beim Erstellen des ProperyManagers: " + e.toString());
e.printStackTrace();
}
}

9.2: Das Subsystem der Java – Dämonen
99
Das gesamte Proptry-File properties.props:
#Alarmsystem-Voreinstellungen.
alarmsystem.fromName=BillingAgent Daemon Alarm System
alarmsystem.toName=Rémy Schumm;
alarmsystem.emailswitch=OFF
alarmsystem.smtp=smtp.zhwin.ch
alarmsystem.smtp.user=
alarmsystem.smtp.passwd=
#NetfilterDatareader
#Semaphore-File: unbenutzt
netfilter.semaphore=/proc/semaphore
#Pfad zum Procfile Datenfile: input des NetfilterParser
netfilter.datafile=billing.txt
#File mit den Protokolltypen nach RFC1700
netfilter.protocols=protocols.list
#File mit dem Lastrun-Timestamp
netfilter.lastrun=lastrun.timestamp
netfilter.triggerswitch=OFF
#Pfad zum Triggerscript
netfilter.triggerscript=readproc.sh
netfilter.triggerwait=30
#Datenbank
database.driver=org.postgresql.Driver
database.url=jdbc:postgresql://160.85.20.110/netfilterdb
database.user=billingdaemon
database.passwd=settop
#BillingAgent
billingagent.outputdir=ipdrout
#Diesen Switch braucht es für die DB, weil diese Multi-Gateway-fähig ist,
#Der BillingDaemon aber genau für ein Gateway zuständig ist.
billingagent.gatewayid=1
#15min bis zur nächsten Auswertung = 900s
billingagent.intervall=900
#Pfad zum XSL Stylesheet zur IPDR Produktion
billingagent.outxsl=rssimpleipdr.xsl
#Pfad zum XSL Stylesheet zum Einrücken von XML Output
billingagent.identxsl=ident.xsl
billingagent.identswitch=OFF
9.2.3 Das AlarmSystem der Java – Subsysteme
Alle in Java implementierten Subsysteme (d.h. alle Dämonen) teilen sich ein
gemeinsames Alarm – System, wie es im Design beschrieben ist.

Kapitel 9: Implementierung
100
Das Alarm – System ist als klassischer Singleton implementiert: es kann so von überall
her in der gesammten Applikation z.B. mit dem Befehl AlarmSystem.getInstance().alarm(„Meldung“, exception);
aufgerufen werden. Die Meisten Klassen haben eine Instanzvariable vom Typ
AlarmSystem, die mit AlarmSystem.getInstance(); abgefüllt wird.
Das Alarmsystem verschickt je nach Wunsch ein e-Mail an eine Person, je nachdem im
Property-File der Switch alarmsystem.mailswitch=ON oder =OFF gesetzt ist.
Das Alarmsystem extrahiert aus der mitgegebenen Exception den Stacktrace und schickt
diesen, neben der Meldung und dem Exception-String auch im Mail mit: if (e != null) {
es = e.toString();
StringWriter sw = new StringWriter();
e.printStackTrace( new PrintWriter( sw, true ) );
stacktrace = sw.toString();
} else {
es = "Keine Exception geworfen.";
}
Das Mail generiert das System mit JavaMail API Framework:

9.2: Das Subsystem der Java – Dämonen
101
Session session = Session.getDefaultInstance(props, null);
Transport transport = session.getTransport("smtp");
transport.connect(sprops.getProperty("mail.smtp.host"), "", "");
String from = props.getProperty("alarmsystem.from");
String fromName = props.getProperty("alarmsystem.fromName");
String to = props.getProperty("alarmsystem.to");
String toName = props.getProperty("alarmsystem.toName");
message = new MimeMessage(session);
message.setFrom(new InternetAddress(from, fromName, "iso-8859-1"));
message.addRecipient(Message.RecipientType.TO, new InternetAddress(to, toName, "iso-8859-1"));
message.setHeader("X-Mailer", "JavaMail / ch.zhwin.billingagent.AlarmSystem");
message.setSubject("ALARM: BillingAgent", "iso-8859-1");
String text = "" +
"Der BillingAgent hat einen Alarm geworfen: \n" +
"Das System k?nnte Daten verlieren oder unstabil werden.\n\n" +
"Meldung: " + meldung + "\n" +
"Exception: " + es + "\n\n" +
"Stack Trace: \n" +
"------------------------ \n\n\n "+
stacktrace;
//e.printStackTrace(new PrintStream());
message.setText(text, "iso-8859-1");
message.saveChanges();// implicit with send()
session.setDebug(false);
//Transport.send(message);
transport.sendMessage(message, message.getAllRecipients());
//Beende JavaMail
transport.close();
Auf jeden Fall gibt das Alarmsystem die Meldung zusätzlich auf System.err aus: //Gibt den Alarm zusätzlich local auf der System.err aus.
System.err.println("BillingAgent: Alarm: " + meldung + ": " + es + "\n");
if (e != null) e.printStackTrace();
Im System wird bei Problemen weitgehend nur das Alarmsystem aktiviert und dann
normal weitergearbeitet. Meistens wird dann das System versuchen, beim nächsten
Durchlauf die gleiche Operation nochmals zu machen. Im momentanen Stand der
Implementierung kann es daher vorkommen, dass das System nach einem Problem in
einem unvorhergesehenen Zustand gerät. Auf jeden Fall ist dann aber der Administrator
vorgewarnt. Diese Effekte tauchen aber nur bei wirklich schweren Fehlern auf wie
unerreichbare Datenbank, keine Schreibrechte auf dem Filesystem, fehlende Files etc.

Kapitel 9: Implementierung
102
Man könnte sich auch überlegen, das System bei solchen schweren Fehlern zu beenden
und durch den cron – Wächter neu starten zu lassen. Aber auch dies garantiert nicht,
dass das System nach dem Neustart einwandfrei funktioniert. Daher schien uns die
Benachrichtigung eines menschlichen Administrators via e-Mail am einfachsten und
effektivsten.
Andere Unregelmässigkeiten, z.B. kleine Verzögerungen im Systems, sollten das System
nicht stören, wie im Design weiter oben schon beschrieben.
Generiertes Mail
Ein Alarmmail sieht so aus:
Von: BillingAgent Daemon Alarm System <[email protected]> Datum: Mon, 14. Okt 2002 11:01:08 Europe/Zurich An: R•my Schumm; <[email protected]> Betreff: ALARM: BillingAgent X-Mailer: JavaMail / ch.zhwin.billingagent.AlarmSystem
Der BillingAgent hat einen Alarm geworfen:
Das System könnte Daten verlieren oder unstabil werden.
Meldung: Fehler beim Verbinden mit der Datenbank:
Exception: Verbindung verweigert. Prüfen Sie, daß der Server TCP/IP-Verbindungen annimmt.
Stack Trace:
------------------------
Verbindung verweigert. Prüfen Sie, daß der Server TCP/IP-Verbindungen annimmt.
at org.postgresql.Connection.openConnection(Unknown Source)
at org.postgresql.Driver.connect(Unknown Source)
at java.sql.DriverManager.getConnection(DriverManager.java:517)
at java.sql.DriverManager.getConnection(DriverManager.java:177)
at ch.zhwin.billingagent.Daemon.start(daemon.java:53)
at ch.zhwin.billingagent.BillingAgentDaemon.start(billingagentdaemon.java:41)
at ch.zhwin.billingagent.Main.main(main.java:102)
9.3 Der Java NetfilterDatareaderDaemon
Dieses Subsystem haben wir weitgehend implementiert, wie wir es im Design geplant
hatten.

9.3: Der Java NetfilterDatareaderDaemon
103
In diesem Kapitel beschreiben wir Implementierungsdetails; auf Klassendiagramme
verzichten wird, weil wir schon im Design anstatt Domänendiagrammen
Klassendiagramme verwendet haben. Die Klassendiagramme im Design entsprechen den
Klassendiagrammen, die in der Implementierung aufgeführt werden müssten9.
In diesem Kapitel sind also nur die zentralen, wichtigen Programmstellen beschrieben.
Für den Gesamtzusammenhang verweisen wir auf das Design; für Details verweisen wir
direkt in den Sourcecode, der stark kommentiert ist, oder auf die JavaDoc API der
Dämonen, in der wir jede Methode und Klasse detailliert beschrieben haben.
Sourcecodekommentare und JavaDoc API betrachten wir als vollwertigen Teil der
Implementierungsdokumentation.
Die JavaDoc API und der Sourcecode befinden sich auf der CD.
9.3.1 Der Parser
Der Parser wird vom Dämonen erstellt und bekommt eine Referenz auf das Procfile.
(Den Pfad dazu hat er aus dem Properties-System: netfilter.procfile.) Wenn im
Properties System der netfilter.triggerswitch=ON gesetzt ist, löst der Parser
zuerst ein Shellscript (netfilter.triggerscript) auf dem Gateway aus, das das
Profilesystem ausliest und das Ergebnis in ein File schreibt, dem procfile
(netfilter.procfile). Der Parser wartet eine Zeitlang
(netfilter.triggerwait), bis die Daten sicher im procfile sind, und beginnt
nachher das File auszulesen.
Ist der netfilter.triggerswicht=OFF liest der Parser direkt aus dem
Procfilesystem. Es hast sich aber gezeigt, dass Lesen im Procfilesystem direkt mit einer
Javaapplikation aus unbekannten Gründen sehr heikel ist. Darum haben wir das
9 Es ist uns bewusst, dass dies nicht ganz der Idee von UP entspricht; wir haben uns aber dennoch – wegen
der Natur des Projektes – dazu entschieden, hier so vorzugehen.

Kapitel 9: Implementierung
104
Triggerscript implementiert. Das Triggerscript selbst ist in der Netfiltermodul –
Implementierung beschrieben.
if (PropertyManager.getProperty("netfilter.triggerswitch").equals("ON")){
Runtime.getRuntime().exec(PropertyManager.getProperty("netfilter.triggerscript"));
try {
d.sleep(Long.parseLong(PropertyManager.getProperty("netfilter.triggerwait"))*1000);
} catch (java.text.ParseException e){
} catch (java.lang.InterruptedException e){
}
try {
eingang = new BufferedReader(new FileReader(procdatafile));
} catch (java.io.FileNotFoundException fn) {
alarm.alarm("Das Procfile Datenfile (netfilter.datafile) kann nicht gefunden werden:", fn);
return;
}
}
Der Parser parst anschliessend die Rohdaten, die er aus dem Netfiltermodul bekommt: a055a00a,a055a55a,11,604,276
a055a00a,a055a55a,11,1812,276
a055a00a,a055a55a,11,372,372
Er macht dies mit einem einfachen StringTokenizer. Der relevante Source Code ist
abgebildet: Man beachte die Umrechung von HEX in normale Darstellung durch die
Hilfsklasse: while ((zeile = eingang.readLine()) != null) {
st = new StringTokenizer(zeile, ",");
System.out.println(zeile);
if (! st.hasMoreTokens()) continue; //leere Zeilen (am Schluss) ignorieren.
bsip = IPAddressTool.hexToDotDecString(st.nextToken());
uip = IPAddressTool.hexToDotDecString(st.nextToken());
//prot = IPProtocolTool.getProtocolString(Integer.parseInt(st.nextToken()));
prot = IPProtocolTool.getProtocolStringFromHex(st.nextToken());
up = Integer.parseInt(st.nextToken());
down = Integer.parseInt(st.nextToken());
d.writeData(bsip, uip, prot, up, down);
}
Die Methode writeData() (2.1.1.2.1 im Sequenzdiagram) schickt die Daten dann
Zeilenweise zum NetfilterDatareaderDaemon, der sie in die Datenbank schreibt:

9.3: Der Java NetfilterDatareaderDaemon
105
9.3.2 Die Methode writeData(): Schnittstelle zur Datenbank.
Diese Methode bekommt vom Parser die Rohdaten (2.1.1.2.1 im Sequenzdiagram),
schlüsselt die IP Adressen aus der Datenbank auf und schreibt die Daten frisch in die
Datenbank: /**
* Wird vom Parser aufgerufen, um die neu gelesenen Daten in die Datenbank zu schreiben.<br>
* Diese Methode schlüsselt auch die IPs in die entprechenen PrimaryKeys der Datenbank auf
* damit die IP Data Records eindeutig werden. Ebenfalls schreibt sie die Zeitspannen der
* IP Data Records, berechnet aus den <code>lastrun</code> Methoden des Controllers, in die
* neuen Records herein. Neue Records haben automatisch das Flag <code>read = 'false'</code>.
*
*@param bsip Die BaseStationIP des IP Data Records (IP der "Antenne")
*@param uip Die UserIP des IP Data Records (IP des Mobile Hosts)
*@param prot Protokoll nach RFC1700 in Stringdarstellung
*@param up Hinaufgeladene Anzahl Bytes
*@param down Heruntergeladene Anzahl Bytes
*/
public void writeData(String bsip, String uip, String prot, int up, int down) {
//Wird vom Parser aufgerufen.
try {
//Bem.: später könnte man diese Aufschlüsselungen aus Performancegründen
//in einer Map cachen.
//Aufschlüsseln der UID
Statement stat = conn.createStatement();
ResultSet rset = stat.executeQuery(
"select uid from gw_user_relation " +
"where gwuip = '" + uip + "' " +
"and gwid = " + fixgwid + ";");
rset.next();
String uid = rset.getString("uid");
//Aufschlüsseln der BaseStation
stat = conn.createStatement();
rset = stat.executeQuery(
"select idf as bsid " +
"from basestation " +
"where ip = '" + bsip + "' " +
"and gwid = " + fixgwid + ";");
rset.next();
String bsid = rset.getString("bsid");
//Einfügen in die RECORD Tabelle:
stat = conn.createStatement();
stat.executeUpdate(
"insert into record (gwid, bsid, uid, transport_protocoll, up,
down, recstart, recend)" +
" values ('" + fixgwid + "', '" + bsid + "', '" + uid + "', '" +
prot + "', '" + up + "', '" + down + "', '" + start + "', '" + end + "'); "
);

Kapitel 9: Implementierung
106
} catch (SQLException e) {
alarm.alarm("Beim Einfügen neuer Daten in die Datenbank ist etwas schief
gelaufen: ", e);
}
}
Man beachte das Alarmsystem, das die Fehler abfängt und via alarm() Methode den
Admistrator mit einem Mail benachrichtigt.
9.4 Der Java BillingAgentDaemon
Auch diesen Dämon haben wir weitgehend wie im Design geplant implementiert.
Analog zum Netfilterdämon verweisen wir für Ablaufdetails auf das Design und für
Implementierungsdetails auf die Source bzw. die JavaDoc API.
Im Folgenden beschreiben wir zentrale Methoden, insbesondere Details der Datenbank
Auswertungen und der XML-Generierung.
9.4.1 Die Methode writeIPDR()
Diese Methode ist zuständig für das Generieren der IPDR Files und die Auswertung der
Datenbank. Wir wollen im Folgenden deren Funktion beschreiben und die darin
enthaltenen SQL Anweisungen erklären.
Wie im Sequenzdiagramm Abbildung 23: Billing Sequenzdiagram auf Seite 67
ersichtlich, betreibt der BillingAgentDaemon einen BATransformerThread, der
von Thread erbt, d.h. selbstständig läuft. Der BillingAgentDaemon Liest Daten aus der
Datenabank aus und schickt sie dem BATransformerThread, der diese gleichzeitig
weiterverarbeitet, d.h. zu IPDR XML transformiert.
Als erstes erstellt der Dämon ein PipedStream-Paar: das ist ein verpipetes Paar von
PipedOutputStream und PipedInputStream: was in den einen Stream
hineinkommt, kommt beim anderen wieder herraus.

9.4: Der Java BillingAgentDaemon
107
PipedOutputStream pipedOutputStream = new PipedOutputStream();
PipedInputStream pipedInputStream = new PipedInputStream(pipedOutputStream);
Dieses Paar kann später dazu verwendet werden, asynchron zu schreiben und lesen.
Anschliessend generiert der Dämon eine View auf die Datenbank, die nur die Daten
enthält, die ihn interssieren, … Statement stat = conn.createStatement();
String sql =
"create view legenda as " +
"select r.idf, r.read as READ, g.location as LOC, g.namen as ROU, b.cell_id as ACC,
b.location as CID, UID, UP, DOWN, TRANSPORT_PROTOCOLL, RECSTART, RECEND " +
"from record as r, gateway as g, basestation as b " +
"where g.idf = r.gwid and r.bsid = b.idf and r.read='false'; ";
stat.executeUpdate(sql);
… holt alle Daten aus der View herraus und merkt sich diese im ResultSet rset: //Daten aus dem View rausholen
stat = conn.createStatement();
sql =
"select * from legenda; ";
ResultSet rset = stat.executeQuery(sql);
Alle Daten im View sind nun gelesen10, sie müssen das Flag read = ‚true’ erhalten: //Alle Datensätze, die im View waren, auf gelesen=true setzen:
stat = conn.createStatement();
sql =
"update record " +
"set read='true' " +
"where idf in (select idf from legenda); ";
stat.executeUpdate(sql);
//View wieder löschen. Im Prinzip könnte man den view leben lassen,
//nur im Konstruktor generieren.
stat = conn.createStatement();
sql =
"drop view legenda; ";
stat.executeUpdate(sql);
Starten der Transformation
Nun kann die Transformation gestartet werden: Ihr input ist der gepipete Stream von
weiter oben:
10 Der View garantiert nicht, dass neue Datensätze eingefügt werden. Siehe dazu die Bemerkung im
Sourccode.

Kapitel 9: Implementierung
108
//Starte die Transformer-Thread mit dem gepipten Stream, indem
//wir nächsten reinschreiben:
t = new BATransformerThread(pipedInputStream, outfile);
t.start();
Der Stream ist bereit, es kann hineingeschrieben werden:
Der Dämon schreibt nun in den Stream ein primitives Flat-XML, das den Inhalt jeder
Zeile des ResultSets in einem <LINE>…</LINE> Element widerspiegelt: dieses
primitive XML landet über die PipedStreams direkt im Transformer. //Start des outputs in die Stream-Pipe:
ausgang.println("<?xml version=\"1.0\"?>\n<DATA>");
ausgang.println("\t<SEQNR>" + seqnr + "</SEQNR>");
/*
* an dieser Stelle könnte man mit rset.getMetaData() die Kolumnamen heraus-
* holen und das Flat-XML dynamisch generieren: daraufhin müsste man dann nur noch
* das XSL abändern.
*/
while (rset.next()) {
//Hier baue ich das Flat-XML auf:
ausgang.println("\t<LINE>");
String rou = rset.getString("ROU");
String loc = rset.getString("LOC");
String cid = rset.getString("CID");
String acc = rset.getString("ACC");
int uid = rset.getInt("UID");
int up = rset.getInt("UP");
int down = rset.getInt("DOWN");
String tpp = rset.getString("TRANSPORT_PROTOCOLL");
Timestamp start = rset.getTimestamp("RECSTART");
Timestamp end = rset.getTimestamp("RECEND");
ausgang.println("\t\t<NR>" + rset.getRow() + "</NR>");
ausgang.println("\t\t<ROU>" + rou + "</ROU>");
ausgang.println("\t\t<LOC>" + loc + "</LOC>");
ausgang.println("\t\t<CID>" + cid + "</CID>");
ausgang.println("\t\t<ACC>" + acc + "</ACC>");
ausgang.println("\t\t<UID>" + uid + "</UID>");
ausgang.println("\t\t<UP>" + up + "</UP>");
ausgang.println("\t\t<DOWN>" + down + "</DOWN>");
ausgang.println("\t\t<TRANSPORT_PROTOCOLL>" + tpp + "</TRANSPORT_PROTOCOLL>");
ausgang.println("\t\t<RECSTART>" + start + "</RECSTART>");
ausgang.println("\t\t<RECEND>" + end + "</RECEND>");
ausgang.println("\t</LINE>");
}
ausgang.println("</DATA>");
ausgang.close();
//Der Transformer-Thread beendet sich von alleine, wenn im gepipten
//Strema keine Daten mehr kommen.

9.4: Der Java BillingAgentDaemon
109
Der BATransfomerThread läuft unterdessen auf der anderen Seite und nimmt über
seinen PipedStream die Daten in seinen Transformer auf: transformer.transform(new StreamSource(pipedInputStream), new StreamResult(file));
Es entsteht ein IPDR-File.
Den Filenamen für dieses File hatte der Dämon mithilfe der Klasse
IPDRFileSequence schon vorher generiert: String seqnr = fixgwid + "_" +
now.get(GregorianCalendar.YEAR) +
now.get(GregorianCalendar.DAY_OF_YEAR) + "_" +
seq.getSequenceNumberForDay(now);
String filename = seqnr + ".xml";
File outfile = new File(outdir, filename);
Das IPDR XSL Stylesheet
Der Transformer generiert aus dem primitiven flat - XML und einem XSL Stylesheet
(welches er aus der Property billingagent.outxsl kennt) seine IPDR Dokumente.
Wir haben uns für diesen Ansatz entschieden, weil die Normen von IPDR noch nicht
abgesegnet sind und wir eine flexible Lösung wollten. Ändert der Output-Wunsch, muss
nur das XSL Stylesheet angepasst werden. Die Daten aus dem flat – XML, welche im
Prinzip nur die Zeilen der Datenbank widerspiegeln, können beliebig in das output –
XML verpackt werden. Der output muss demzufolge nicht IPDR sein, nicht einmal XML:
es kann jeder beliebige output produziert werden, den man mit XSLT produrieren
könnte.
Das Stylesheet haben wir folgendermassen implementiert:

Kapitel 9: Implementierung
110
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="DATA">
<IPDRDoc xmlns="http://www.ipdr.org/namespaces/ipdr"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" docId="{SEQNR}" version="2.5-A.0.0.draft">
<!-- xsi:schemaLocation="http://160.85.20.110/schemas/IAW2.5-A.0.1.xsd" -->
<IPDRRec id="{generate-id()}" info="ZHW Billingagent"/>
<xsl:apply-templates select="LINE"/>
<IPDRMta/>
</IPDRDoc>
</xsl:template>
<xsl:template match="LINE">
<IPDR id="{generate-id()}" time="{RECSTART}" seqNum="{NR}">
<UE type="TimeSlot for User/Node/Protocoll">
<transportProtocol>
<xsl:value-of select="TRANSPORT_PROTOCOLL"/>
</transportProtocol>
<upVolume>
<xsl:value-of select="UP"/>
</upVolume>
<downVolume>
<xsl:value-of select="DOWN"/>
</downVolume>
<startTime>
<xsl:value-of select="RECSTART"/>
</startTime>
<endTime>
<xsl:value-of select="RECEND"/>
</endTime>
<routingArea>
<xsl:value-of select="ROU"/>
</routingArea>
<locationArea>
<xsl:value-of select="LOC"/>
</locationArea>
</UE>
<SS id="{generate-id()}" service="Internet Access">
<SC id="{generate-id()}">
<subscriberId>
<xsl:value-of select="UID"/>
</subscriberId>
<cellID>
<xsl:value-of select="CID"/>
</cellID>
</SC>
<SE id="{generate-id()}">
<accessPoint>
<xsl:value-of select="ACC"/>
</accessPoint>
<serviceProvider>ZHW Diplomarbeiten</serviceProvider>
<serviceBearer>ZHW CIPnG</serviceBearer>
</SE>
</SS>
</IPDR>
</xsl:template>
</xsl:stylesheet>
Das File rssimpleipdr.xsl

9.5: Die Datenbank
111
Die ID Attribute werden automatisch durch die XSLT-Funktion generate-id()
generiert. Die Sequenznummer NR der IPDRs im IPDRDoc wird vom flat – XML
übernommen.
Ein generiertes IPDR File (hier mit nur einem IPDR – Element) könnte dann so
aussehen: <?xml version="1.0" encoding="UTF-8"?>
<IPDRDoc xmlns="http://www.ipdr.org/namespaces/ipdr" xmlns:xsi="http://www.w3.org/2001/XMLSchema-
instance" version="2.5-A.0.0.draft" docId="1_2002294_0">
<IPDRRec info="ZHW Billingagent" id="N10001"/>
<IPDR xmlns="" seqNum="1" time="2002-10-19 18:06:27.0" id="N10007">
<UE type="TimeSlot for User/Node/Protocoll">
<transportProtocol>UDP</transportProtocol>
<upVolume>604</upVolume>
<downVolume>276</downVolume>
<startTime>2002-10-19 18:06:27.0</startTime>
<endTime>2002-10-21 17:54:35.0</endTime>
<routingArea>Gateway ZHW</routingArea>
<locationArea>Winterthur</locationArea>
</UE>
<SS service="Internet Access" id="N10007">
<SC id="N10007">
<subscriberId>1</subscriberId>
<cellID>Phantasie</cellID>
</SC>
<SE id="N10007">
<accessPoint>DatenTest_Node</accessPoint>
<serviceProvider>ZHW Diplomarbeiten</serviceProvider>
<serviceBearer>ZHW CIPnG</serviceBearer>
</SE>
</SS>
</IPDR>
</IPDRDoc>
9.5 Die Datenbank
Auf Wunsch des Auftraggebers futureLAB AG haben wir zur Implementierung der
Datenbank das OpenSource RDBMS PostgreSQL verwendet.

Kapitel 9: Implementierung
112
9.5.1 Installation
PostgreSQL ist auf SuSE Linux mitgeliefert und darum auf dem Gateway schon
installiert.
Kein PostgreSQL Befehl darf als root ausgeführt werden – aus Sicherheitsgründen.
Meistens wird dafür der Benutzer postgres benützt.
Initialisiert wird das RDBMS durch den Befehl11: /usr/local/bin/initdb -D /var/lib/pgsql/data
wobei das letzte Argument der Pfad ist, an dem die Daten gespeichert werden sollen.
9.5.2 Start
Gestartet wird die Datenbank mit dem Befehl /usr/bin/pg_ctl –D /var/lib/pgsql/data –o –i start > postgres.log 2>&1
Die Option –i erlaubt es, dass externe Clients sich via IP (z.B. JDBC) mit der Datenbank
verbinden. Das > leitet den output in ein Logfile postgres.log, mit der Anweisung
2>&1 wir stderr in stdout umgeleitet, sodass auch Fehlermeldungen in das Logfile
geschrieben werden.
Gestoppt wird die Datenbank mit dem Befehl: /usr/bin/pg_ctl –D /var/lib/pgsql/data stop
Damit sich externe Clients mit der Datenbank verbinden können, müssen sie im File /var/lib/pgsql/data/pg_hba.conf
authentisiert werden.
11 Eine sehr gutes, kurzes HOWTO über PostgreSQL (für Mac OS X) ist auf der Site http://www.entropy.ch
zu haben; erstellt durch den futureLAB - Mitarbeiter Marc Liyanage. Dieses HOWTO hat zum Laufenlassen
der DB vollauf genügt. Ansonsten – für andere Probleme mit PostgreSQL – verweisen wir auf die online -
Dokumentation der Datenbank. Sie ist sehr übersichtlich, klar und vollständig.
9.5: Die Datenbank
113
Der Einfachheit halber haben wir für die benötigten Entwicklungs-Hosts die volle
Berechtigung eingestellt: # By default, allow anything over UNIX domain sockets and localhost.
local all trust
host all 127.0.0.1 255.255.255.255 trust
host all 160.85.134.36 255.255.255.255 trust
host all 217.162.28.203 255.255.255.255 trust
host all 160.85.162.62 255.255.255.255 trust
Die sonstigen Erklärungen in pg_hpb.conf sind selbsterklärend.
9.5.3 Zugriff via PHP Tool phpPgAdmin
Für einfachen Zugriff auf die Datenbank haben wir das OpenSource Tool phpPgAdmin
von sourceforge.net installiert. Es ist eine PHP Applikation, die in einem PHP Processor
mit PostgreSQL Support läuft. Der Standart PHP Processor von SuSE Linux hat diesen
Support hineinkompiliert.
Die Installation des Tools läuft mit den mitgelieferten Anleitungen problemlos.
Abbildung 35: phpPgAdmin
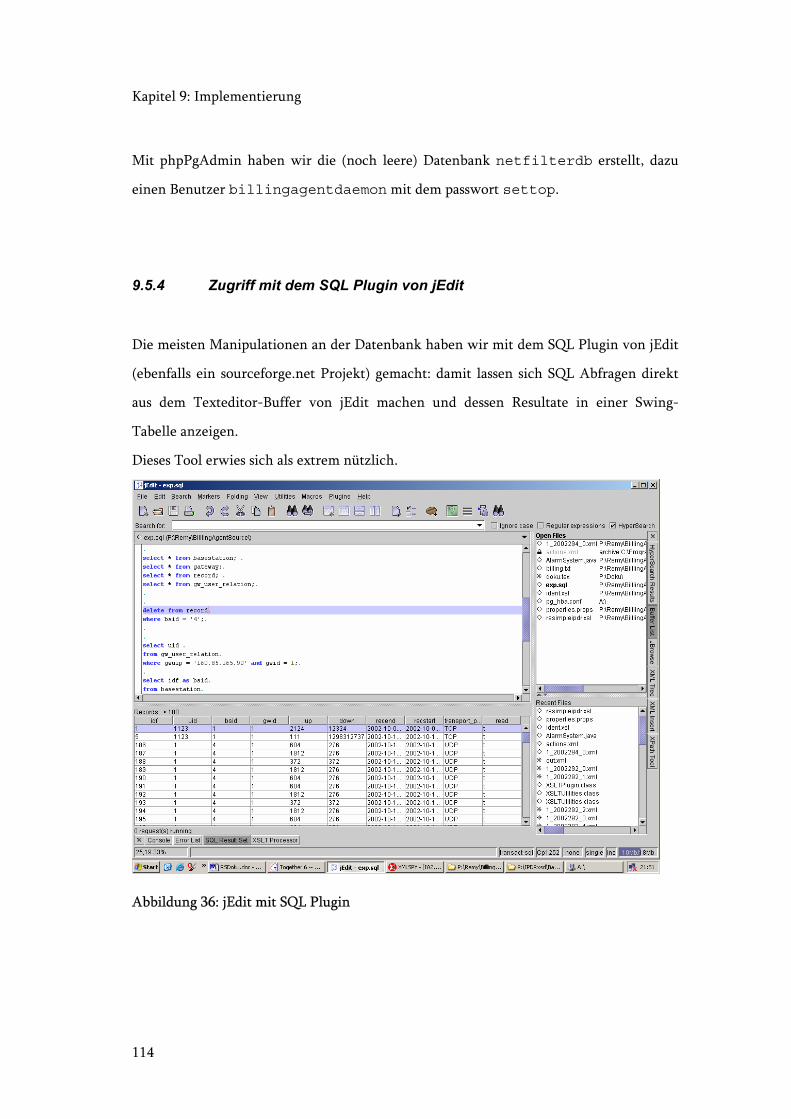
Kapitel 9: Implementierung
114
Mit phpPgAdmin haben wir die (noch leere) Datenbank netfilterdb erstellt, dazu
einen Benutzer billingagentdaemon mit dem passwort settop.
9.5.4 Zugriff mit dem SQL Plugin von jEdit
Die meisten Manipulationen an der Datenbank haben wir mit dem SQL Plugin von jEdit
(ebenfalls ein sourceforge.net Projekt) gemacht: damit lassen sich SQL Abfragen direkt
aus dem Texteditor-Buffer von jEdit machen und dessen Resultate in einer Swing-
Tabelle anzeigen.
Dieses Tool erwies sich als extrem nützlich.
Abbildung 36: jEdit mit SQL Plugin

9.5: Die Datenbank
115
9.5.5 Erstellen des ER – Schemas
Das ER-Schema haben wir wie im Design beschrieben implementiert.
Nachfolgend das graphische ER-Schema [Abbildung 37: Das ER - Schema] und das SQL-
Script [Seite 117] zur Generierung des Schemas.
„auto-increment“
Die Primärschlüssel werden alle – wenn leer – von der Datenbank automatisch mit einer
eindeutigen Sequenznummer gefüllt – z.B. beim Erstellen einer neuen Zeile in der
Datenbank. Dazu haben wir für jede Tabelle eine Sequenz definiert: CREATE SEQUENCE record_seq;
Der Primärschlüssel der entsprechenden Datei wird dann mit dem Default Wert aus
dieser Sequenz abgefüllt: IDF int8 PRIMARY KEY DEFAULT nextval('record_seq'),
idf lastn
kunde
firstn idf ip
gateway
namen
uid gwuid
gw_user_relation
gwuipgwid
idf ip
basestation
cell_id
idf transport_protocol
record
up down recendrecstart
location
uid
location
gwid
gwid
bsidread
Abbildung 37: Das ER - Schema

Kapitel 9: Implementierung
116
Referentielle Integrität
PostgreSQL untestützt referentielle Integrität, sodass wir alle Fremdschlüssel wie im
Diagramm eingezeichnet implementiert haben.
Für jeden Fremdschlüssel mussten wir uns eine DELETE Rolle überlegen:
• In basestation
o GWID int4 CONSTRAINT bs_gw_fk REFERENCES
GATEWAY(IDF) ON DELETE SET NULL,
Wird ein Gateway gelöscht, bekommt die Basestation die Null Referenz
auf den Gateway. Sie kann dann einem neuen Gateway zugeordnet
werden.
• In GW_USER_RELATION
o GWID int4 CONSTRAINT ur_gw_fk REFERENCES
GATEWAY(IDF) ON DELETE CASCADE,
Wird ein Gateway gelöscht, kann auch die Relation gelöscht werden. Sie
wird dann nicht mehr benötigt.
o UID int4 CONSTRAINT ur_ku_fk REFERENCES KUNDE(IDF)
ON DELETE SET NULL,
Wird ein Kunde gelöscht, bleibt die Relation bestehen und bekommt die
Referenz Null.
• In RECORD o BSID int4 CONSTRAINT re_bs_fk REFERENCES
BASESTATION(IDF) ON DELETE RESTRICT,
Wird versucht, eine Basestation zu löschen, zu der noch Records
vorhanden sind, wird das verboten. Es müssen erst alle Records
verarbeitet werden.
o GWID int4 CONSTRAINT re_gw_fk REFERENCES
GATEWAY(IDF) ON DELETE SET NULL,
Wird ein Gateway gelöscht, bekommt der Record die Null Referenz.
Die Zugehörigkeit zum Gateway ist nicht geschäftskritisch.
o UID int4 CONSTRAINT re_ku_fk REFERENCES KUNDE(IDF)
ON DELETE RESTRICT,

9.5: Die Datenbank
117
Wird versucht, ein Kunde zu löschen, für den noch Records vorhanden
sind, wird das verboten. Es müssen erst alle Records verarbeitet werden. CREATE SEQUENCE gateway_seq;
CREATE TABLE GATEWAY (
IDF int4 PRIMARY KEY DEFAULT nextval('gateway_seq'),
IP inet ,
LOCATION varchar ,
NAMEN varchar
);
CREATE SEQUENCE kunde_seq;
CREATE TABLE KUNDE (
FIRSTN varchar ,
IDF int4 PRIMARY KEY DEFAULT nextval('kunde_seq'),
LASTN varchar
);
CREATE SEQUENCE basestation_seq;
CREATE TABLE BASESTATION (
CELL_ID varchar ,
GWID int4 CONSTRAINT bs_gw_fk REFERENCES GATEWAY(IDF) ON DELETE SET NULL,
IDF int4 PRIMARY KEY DEFAULT nextval('basestation_seq'),
IP inet ,
LOCATION varchar
);
CREATE TABLE GW_USER_RELATION (
GWID int4 CONSTRAINT ur_gw_fk REFERENCES GATEWAY(IDF) ON DELETE CASCADE,
UID int4 CONSTRAINT ur_ku_fk REFERENCES KUNDE(IDF) ON DELETE SET NULL,
GWUID int4 ,
GWUIP inet ,
PRIMARY KEY (GWID , UID )
);
CREATE SEQUENCE record_seq;
CREATE TABLE RECORD (
BSID int4 CONSTRAINT re_bs_fk REFERENCES BASESTATION(IDF) ON DELETE RESTRICT,
DOWN int4 ,
GWID int4 CONSTRAINT re_gw_fk REFERENCES GATEWAY(IDF) ON DELETE SET NULL,
IDF int8 PRIMARY KEY DEFAULT nextval('record_seq'),
RECEND timestamp,
RECSTART timestamp,
TRANSPORT_PROTOCOLL varchar ,
UP int4 ,
UID int4 CONSTRAINT re_ku_fk REFERENCES KUNDE(IDF) ON DELETE RESTRICT
READ bool DEFAULT 'false'
);
Das Listing des SQL Scripts create.sql

Kapitel 9: Implementierung
118
9.5.6 JDBC
In der PostgreSQL Distribution ist der JDBC - Treiber mitgeliefert. Allerdings ist das
jar File auf der Postgres-JDBC Website in der Version zur Zeit dieses Schreibens
korrupt. Wir haben das File der Mac OS X Distribution von Marc Liyanage12 verwendet.
Es befindet sich auch auf der CD.
Die URL-Syntax für PostgreSQL lautet: jdbc:postgresql://160.85.20.110/netfilterdb
Die Treibersignatur lautet: org.postgresql.Driver
Einschränkungen
Es hat sich herausgestellt, dass JDBC Treiber verschiedener Versionen nicht mit
verschiedenen Versionen von PostgreSQL kompatibel sind.
Reverse Engineering von ER-Schemas mit DB-Tools wie DbVisualiser13 oder Apple
EOModeler14 funktionieren mit den aktuellen Versionen nicht.
12 www.entropy.ch
13 www.minq.se
14 www.apple.com/webobjects

119
10 Test
Aus Gründen, die wir im Kapitel Projektmanagement beschreiben, haben wir keine
systematischen Tests (Blackbox, Whitebox, Äquivalenzklassen etc.) der implementierten
Systeme durchgeführt. Uns fehlte dafür schlicht die Zeit.
Wir haben aber während der Implementierung laufend immer wieder Tests der
einzelnen Module, Klassen und Methoden durchgeführt und dabei sozusagen im Kopf
diejenigen Äquivalenzklassen überprüft, die uns eingefallen sind. So haben wir z.B. das
Netfiltermodul mit einem 70MB grossem File belastet um zu testen, ob es die Bytes
richtig zählt. Darum ist der Code nicht ungetestet – allerdings sind diese Tests nicht
unbedingt vollständig, noch systematisch und vor allem nicht dokumentiert. Hätten wir
mehr Zeit gehabt, hätten wir wohl den Java Code systematisch mit dem jUnit
Framework15 getestet, und für jede Operation einen Testfall geschrieben.
Im momentanen Zustand der Software können wir sagen, dass die implementierten
Subsysteme sicher in allen Gutfällen funktionieren und mindestens bei groben
Fehlerfällen so reagieren, dass man über die Fehler informiert wird.
15 www.junit.org

Kapitel 10: Test
120

121
11 Aussicht
Als Weiterführungspunkte am CIPnG Projekt können wir uns vorstellen:
Migration auf andere Kernelversionen
Da das CIPnG in der Testumgebung auf dem Kernel 2.4.14 läuft, wäre eine Migration auf
den neusten Kernel 2.4.19 wünschenswert, damit CIPnG in der Entwicklung nicht
stehen bleibt.
Für den Erfolg des CIPnG Netz müsste die Clientsoftware (Mobilhosts) wohl auf weitere
Betriebssysteme (Windows XP, Mac OS X) portiert werden.
Darstellungsschicht
Die IPDR Normen eignen sich nicht dazu, akkumulierte Records abzubilden, somit kann
die Dispute Resolution nicht mit einem IPDR-XML-File dargestellt werden. Einen
Lösungsansatz zu diesem Problem haben wir im Abschnitt 8.5: Die Darstellung
vorgeschlagen, welche als Projektarbeit an der ZHW an einem späteren Zeitpunkt
implementiert werden könnten.

Kapitel 11: Aussicht
122
IPDR
Unsere Drafts der nicht funktionierenden XML Schemas von IPDR.org sind von
IPDR.org noch nicht abgesegnet.
Diese müssen abgewartet werden, um dann evtl. die Stylesheets anzupassen.
Falls sie gutgeheissen werden, haben wir einen Beitrag zur Standardisierung dieser
Normen beigetragen.
Interaktion mit einem BSS
Um das System produktiv einsetzen zu können, muss ein BSS angeschafft werden, das
mit dem IPDR output unseres Billing Agenten zusammenarbeiten kann.
Benutzerverwaltung: LDAP / CRM
Die gesamte Benutzerverwaltung muss momentan an mehren Orten von Hand
administriert werden (/etc/cipng_accounts, in der Datenbank). Es wäre daher
sinnvoll, die gesamte Benutzerverwaltung z.B. über LDAP oder in einem CRM-Tool zu
organisieren.

123
12 Projektmanagement
12.1 Projektverlauf
12.1.1 Einarbeitung und Beginn
Am 6.September 2002 starteten wir unsere Projektarbeit „XML –based Billing Agent for
Public WLANs“. In der ersten Woche ging es primär darum, sich in das bestehende
CIPnG System und in Techniken, welche wir einsetzen wollten, einzuarbeiten. Als erstes
mussten wir jedoch das CIPnG System in Betrieb nehmen, was uns einige Mühe
bereitete. Als wir uns einigermassen einen Überblick verschafft hatten, erstellten wir
einen ersten, groben Projektplan, welchen wir später verfeinerten.
Jede Woche hatten wir eine Sitzung mit unserem betreuenden Dozenten Prof. Dr.
Andreas Steffen, damit auftretende Probleme oder generelle Fragen gelöst und
besprochen werden konnten. Grundlegende Designentscheide wurden mit Herrn Steffen
und Fabio Vena von der futureLAB AG jeweils besprochen.

Kapitel 12: Projektmanagement
124
12.1.2 Ändern der Schwergewichte
Relativ schnell merkten wir, dass die benötigten Daten nicht, wie in der
Diplomarbeitausschreibung vermerkt, im Netfilter Modul vorhanden waren, und dass es
grössere Eingriffe in die Architektur des CIPnG brauchte. Diese ist aber vollständig in C
geschrieben, schlecht dokumentiert – und wir kennen uns darin nicht aus.
Wir entschlossen uns daher, die beiden Hauptteile Linux und Java zu trennen, und das
Java System unter der Annahme zu bauen, das Linux System liefere die korrekten Daten.
Das war der Zeitpunkt, als Martin Heusser den Linux- und Rémy Schumm den Java-Teil
übernahm. Im Extremfall wollten wir aber sogar auf die Implementierung des Linux –
Teils verzichten, und nur den Java Teil übernehmen – aus Angst, mit dem Linux Teil
überfordert zu sein. Weil aber der Linux Teil für den Auftraggeber, laut dessen Aussage,
sehr zentral ist, entschieden wir uns, auf das Abenteuer Linux Netfilter dennoch
einzugehen und auf dieser Schiene weiterzufahren. Wir mussten in der Folge auf der
Java Seite Einbussen in der Architektur machen – aus Ressourcenmangel. (Geplant wären
eine strengere UP – Entwicklung gewesen, abstrakte Persistenzschicht –
Implementierung mit Java ER – OO Tools, Tests mit jUnit, u.a.)
Gleichzeitig wurden wir durch die Probleme mit der IPDR Implementierung verzögert,
als wir realisierten, dass IPDR so nicht funktionierte und nur teilweise für die geplanten
Anwendungsfälle geeignet war.
12.1.3 Anpassen der Ziele
Aufgrund dieser Probleme wurden wir massivst ausgebremst. Trotz Hilfe der Autoren
von [CIPnG] und Unterstützung von Herrn Steffen gelang es uns nicht, die Linux

12.1: Projektverlauf
125
Probleme in vernünftiger Zeit in den Griff zu bekommen. Trotzdem machten wir weiter
und verzichteten nicht auf den Abbruch des Linux Teils. Der Java Teil implementierten
wir mit halber Kraft weiter.
Herr Steffen kam uns in diesem Stadium entgegen, indem er uns von der
Implementierung einer Darstellungsschicht erlöste: einerseits wegen der eben
beschriebenen Probleme mit dem Linux Teil, andererseits weil klar wurde, dass sich
IPDR gar nicht für diese Anwendungsfälle eignete. Für dieses Entgegenkommen sind
wir Herrn Steffen dankbar.
12.1.4 Abschluss
Das ungeplante Abenteuer Linux Netfilter konnte nicht abgeschlossen werden: zu massiv
waren die Probleme. Es ist uns nicht gelungen, die Einzelteile zu integrieren und auf
dem CIPnG Referenzsystem zu testen. In der Schlussphase funktionierte (wegen eines
Filesystemcrashs) nicht einmal mehr dieses – und konnte Mithilfe von diversen Leuten,
inkl. futureLAB, nicht mehr zum Laufen gebracht werden. Wir werden versuchen, in
den verbleidenen zwei Wochen bis zur Präsentation diese Probleme noch in den Griff zu
bekommen.
Der Java Teil funktioniert in allen Gutfällen und den am meisten zu erwartenden
Fehlerfällen mit simulierten Daten tadellos – auch wenn das Design noch optimiert
werden könnte.

Kapitel 12: Projektmanagement
126
12.2 Ressourcen
12.2.1 Aufteilung der Arbeit
Das die Netfilter-Teile wie oben beschrieben massiv mehr Aufwand benötigten als
vorgesehen, hat sich Martin Heusser ausschliesslich um diese Linux Teile gekümmert,
während Rémy Schumm den ganzen Java- und XML- Teil übernommen hat.
Zentrale Design- und Implemetierungsentscheide haben wir immer zusammen gefällt.
12.2.2 Technische Ressourcen
Folgende Produkte haben wir eingesetzt:
Datenbank:
PostgreSQL 7.2 www.ch.postgresql.org
pgMyAdmin phppgadmin.sourceforge.net
DbVisualiser 3.1 www.minq.se
Software:
Windows XP ZHW Image mit zusätzlichen Programmen
SuSE Linux 7.1 und SuSE Linux
8.0 (Kernel 2.4.18)
www.suse.de
Ethereal Teil von SuSE
JBuilder 7.0 www.borland.com
Together Control Center 6.0 www.togethersoft.com
jEdit 4.0 jedit.sourceforge.net
XMLSpy 5.0 www.altova.com

12.3: Probleme
127
Hardware:
3 Schulrechner
CIPnG Netzwerk mit: einem Laptop, zwei Basestations und einem Gateway
12.3 Probleme
12.3.1 IPDR
Wie im Kapitel 6 beschrieben, waren die IPDR Schemas nicht funktionstüchtig, sodass
wir unsere eigenen Schemas erstellen und der IPDR.org zur Genehmigung vorlegen
mussten. Dieses Verfahren ist bis zum Zeitpunkt dieses Schreibens nicht abgeschlossen.
Ausserdem eigneten sich die IPDR Darstellungen nicht für die ursprünglich
vorgesehenen Anwendungfälle. Näheres dazu auch im besagten Kapitel.
12.3.2 ZHW Netzwerk
Die Verbindung zwischen den Arbeitsrechnern im EDU Subnetz der ZHW und dem
Produktivsystem im 128er Subnetz via KT-Router funktionierte lange nicht.
An dieser Stelle sei Herrn Kurt Hauser herzlich gedankt, der mit grosse Aufwand und
mithilfe der Assistenten, vor allem Herrn Andreas Schmid, das Netzwerk wieder zum
laufen brachte.

Kapitel 12: Projektmanagement
128
12.3.3 Bestehendes CIPnG System
Das bestehende CIPnG System ist teilweise undokumentiert, weil es nach Drucktermin
der Dokumentation noch erweitert wurde. Dies erschwert in manchen Teilen die
Nachvollziehbarkeit von Abläufen. Wegen der undokumentierten Weiterentwicklungen
ist es fast nicht möglich, innert vernünftiger Zeit das CIPnG System durch neue Module
zu ergänzen. Aus diesem Grund bleibt oft nur der mühsame Weg mit Ausprobieren, oder
in den tausenden Zeilen von C Code nachzusuchen, offen.
Die Inbetriebsetzung dauerte ein paar Tage, weil der Gateway teilweise, aus anfangs
unerklärlichen Gründen, abstürzte. Dieses Problem konnte gelöst werden, indem man
die Netzwerkkarten nach dem Booten nochmals von Hand startet (rcnetwork
restart) und einen manuellen Eintrag in der Routingtabelle vornimmt (route add
default gw 160.85.20.1).
12.3.4 Datenerfassung auf dem CIPnG – Linux Kernel Programmierung
Die Datenerfassung auf dem CIPnG System stellte sich masssiv schwieriger heraus als im
in der Diplomarbeitsausschreibung erwartet. Die Daten sind zwar auf dem Gateway
teilweise vorhanden, konnten aber nicht, wie in der Ausschreibung und vorgängiger
Besprechung vorgesehen, dort einfach abgeholt werden, sondern mussten zuerst mühsam
aus dem Kernel extrahiert werden. Wir stellten von Anfang an klar, dass für uns nur ein
in Java basierter Agent in Frage komme, da wir in etwa null Ahnung von C und auch
nicht allzu grosses Interesse daran hatten. Trotzdem versuchten wir zwei Netfilter
Kernel Module zu programmieren, was aber ein enormer Zeitaufwand mit sich zog.
Erstens mussten wir uns in C einarbeiten und zweitens, was sich als noch viel mühsamer
erwies, in die Kernelprogrammierung unter Linux. Viele Teile des Kernel sind schlecht
oder gar nicht dokumentiert. Oft fanden wir auch widersprüchliche Dokumentationen.

12.4: Soll- und Ist- Plan
129
Dadurch kamen wir unter Zeitdruck und konnten bis Ende der Diplomarbeit die
Realisierung der Netfiltermodule nicht hundertprozentig abschliessen.
Als erschwerend erwies sich auch, dass die gesamte Entwicklung im ungeschützten
Kernelmodus lief, sodass sich Fehler dauernd in Systemcrash und korrupten
Dateisystemen äusserten.
12.3.5 Laptop – beziehungsweise WLAN und Linux
Wie es sich für eine Diplomarbeit gehört, gab der Laptop drei Wochen vor Schluss
aufgrund eines File System Schadens den Geist auf. Als wir einen anderen Laptop für
Testzwecke aufsetzten wollten, liesst sich, aus bis jetzt ungeklärten Gründen, die WLAN
Karte nicht in Betrieb nehmen. Dies trotz Mithilfe von anderen Studenten, welche die
WLAN Karten auf einem gleichen Laptop in Betrieb nehmen konnten.
12.4 Soll- und Ist- Plan
Den Projektplan konnten wir zu Beginn trotz massiven Problemen relativ gut einhalten.
Grössere Verschiebungen gab es zuerst bei den Anwendungsfällen, als sich aufzeigte,
dass die IPDR Normen einige Anwendungsfälle nicht erfüllen konnten. Wir waren also
gezwungen, einzelne Anwendungsfälle neu zu definieren und teils vorhandenes Design
anzupassen.
Danach, durch die vielen Probleme bei der Entwicklung der Netfiltermodule, verloren
wir viel Zeit, sodass für die Dokumentation nur noch die letzte Woche übrig blieb,
anstatt während der letzten drei Wochen kontinuierlich daran zu arbeiten, wie es
geplant war. Aus unserer Sicht der wichtigste Punkt, den wir nicht einhalten konnten,

Kapitel 12: Projektmanagement
130
war das genaue Testen der einzelnen Subsysteme, sowie ein gesamter Systemtest mit der
Integration der einzelnen Subsysteme. Daher ist die Implementierung noch nicht
vollständig abgeschlossen.
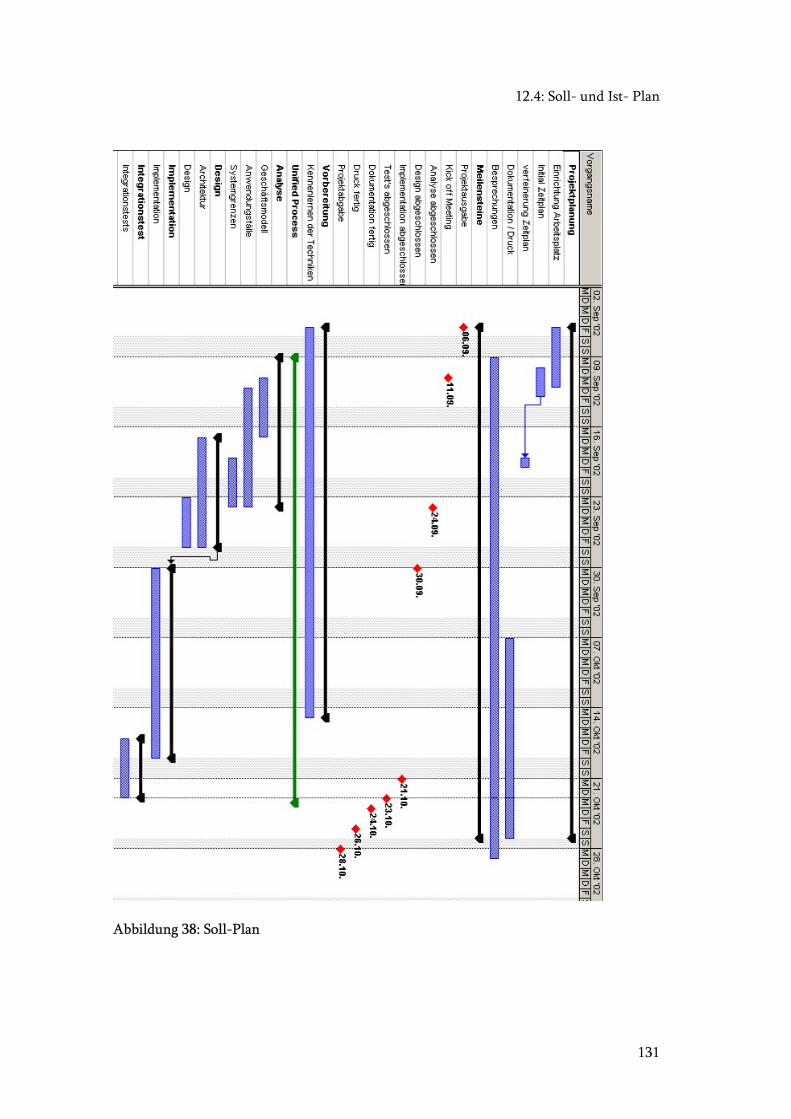
12.4: Soll- und Ist- Plan
131
Abbildung 38: Soll-Plan
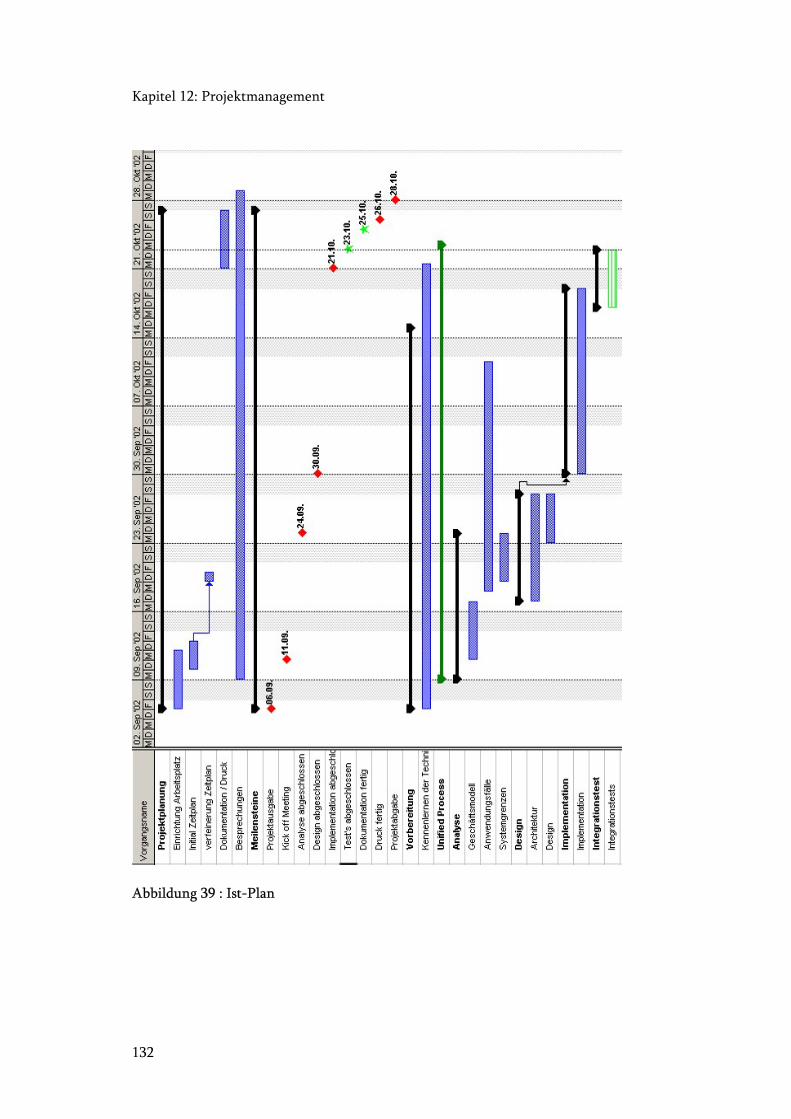
Kapitel 12: Projektmanagement
132
Abbildung 39 : Ist-Plan

133
13 Glossar
ASN.1 Abstract Syntax Notation 1
Basestation Eine Funk-Basisstation mit Antenne für das Public
WLAN. [CIPnG].
Billing Agent Agent, der Billing Daten sammelt; bzw. Subsystem zum
Produzieren von IPDR
Billing System, externes Siehe BSS
BSS Billing Support System nach [NDM-U]
CIPnG Cellular IP next Generation. Siehe [CIPnG]
Downlink Weg vom Internet zum Mobilehost
Entität Ein bestimmter Datentyp im Zusammenhang mit ER.
[Elmasri]
ER Entity Relationship: Paradigma, um Datenmodelle

Kapitel 13: Glossar
134
mittels Relationen zueinander darzustellen. [Elmasri]
Gateway Schnittstelle zwischen Internet und CIPnG. [CIPnG]
Gateway Verbindung des WLANs ins öffentliche Internet.
[CIPnG]
Hotspot Betrieb eines WLAN in einer kleinen Umgebung
IP Internet Protocol
IPDR IP Data Record: Aufzeichnung eines Internet-
Benutzungs-Ereignisses. [NDM-U]
IPv4 Internet Protocoll Version 4
IPv6 Internet Protocoll Version 6
JDBC Java Database Connectivity: Schnittstellenbeschrieb
von Java zu Datanbanken.
PDA Personal Digital Assistent
RDBMS Relational Database Management System: eine
Datenbank. [Elmasri]
Referentielle Integrität Garantiert, dass Daten in einer Datenbank in sich
konsistent sind. [Elmasri]
sk_buff Socket Buffer [CIPnG]
SQL Structured Query Language: Standartisierte Sprache zur
Datenbankabfrage. [Elmasri]

12.4: Soll- und Ist- Plan
135
Tupel Ein indiduelles Objekt einer Entität. [Elmasri]
UP Unified Process [UML]
Uplink Weg vom Mobilehost zum Internet
WLAN Wireless Local Area Network
XML Extensible Markup Language. SGML-basierendes
Datenformat zur hierarchichischen Darstellung von
Daten. [XMLSh]. IPDR benutzt zur Darstellung der
Daten XML
XSL Stylesheet Sprache für XSLT. [XMLSh]
XSLT Extensible Stylesheet Language Transformations:
Technologie zur Tranformation von XML Dokumenten.
[XMLSh]


137
14 Literaturverzeichnis
[C/C++] Kaiser, Ulrich: C/C++
Galileo Computing, Bonn, 2000
[CIPnG] Erinmez, Tanju; Chollet, Pascal: Sichere Cellular IP Implementierung auf
der Basis von Linux Netfilter
Zürcher Hochschule Winterthur, DA Sna 01/2, Winterthur, 2001
[Elmasri] Elmasri, Ramez; Navathe, Shamkant B.: Fundamentals of Database Systems.
Addison-Wesley, Reading USA, 2000
[Google] Div. Authoren: Suchergebnisse der Suchmaschine Google
www.google.ch
[IPv6] Schlott, Stefan: IPsec Implementierung in IPv6 fürLinux
Universität Ulm, Diplomarbeit 2000, Ulm, 2000
[JavaSh] Flanagan, David: Java in a Nutshell, 3rd Edition
O’Reilly, Sebastopol USA, 1999

Kapitel 14: Literaturverzeichnis
138
[LF] Ermer, Thomas; Meier, Michael: Die Linuxfiebel
Saxonia Systems AG, www.linuxfibel.de
[LinDD] Rubini, Alessandro; Corbet, Jonathan: LINUX Device Drivers, 2nd Edition
O’Reilly, Sebastopol USA, 2001
[LinKonf] Kofler, Michael: Linux Installation, Konfiguration, Anwendung
Addison-Wesley, München / S.u.S.E., Nürnberg, 2002
[LinSh] Siever, Ellen et al.: Linux in a Nutshell, 3. Deutsche Ausgabe
O’Reilly, Köln, 2001
[MAW] Weiss, Mark Allan: Data Structures & Problem Solving Using Java
Addison-Wesley, Reading USA, 1999
[MT] Thaler, Markus et al.: Einführung Module und Treiber
Zürcher Hochschule Winterthur,Vorlesungsscript, Winterthur, 2001
[MTC] Thaler, Markus: C für Java Programmierer
Zürcher Hochschule Winterthur, Vorlesungsscript, Winterthur, 2001
[NDM-U] ipdr.org: Network Data Management – Usage, Version 3.1, 15. 4. 2002
http://www.ipdr.org/public/
[NetF] Russel, Rusty: Linux Netfilter Hacking HOWTO
www.google.ch
[PG] PostgreSQL Global Development Group: PostgreSQL Interactive
Documentation
http://www.postgresql.org/idocs/
[Proc] Mouw, Erik: Linux Kernel Procfs Guide, Revision 1.0

12.4: Soll- und Ist- Plan
139
Delft University of Technology, Delft NL, 2001
[RFC1700] Network Working Group, J. Reynolds et al.:ASSIGNED NUMBERS www.ietf.org/rfc/rfc1700.txt
[RFC2474] Network Working Group, K. Nichols et al.: Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers www.ietf.org/rfc/rfc2474.txt
[RFC791] DARPA INTERNET PROGRAM, INTERNET PROTOCOL, PROTOCOL SPECIFICATION Defense Advanced Research Projects Agency, 1981 www.ietf.org/rfc/rfc791.txt
[SS-IA] ipdr.org: Service-Specification – Internet Access and Content, Including
Wireless, Version 2.5-A.0, 13. 4. 2002
http://www.ipdr.org/public/Service_Specifications/2.X/IA/
[UML] Larman, Craig: Applying UML and Patterns, Second Edition
Prentice Hall, Upper Saddle River USA, 2002
[XMLSh] Rusty Harold, Elliotte et al.: XML in a Nutshell, Deutsche Ausgabe
O’Reilly, Köln, 2001


141
15 CD-Rom





























