
Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
1 - Einführung und Übersicht
6. Sprachen, Compiler und Theorie
6.1-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Literatur (1/3)
BücherMichael L. Scott : „Programming Language Pragmatics”, MKP 2000, ISBN 1-55860-578-9http://www.cs.rochester.edu/u/scott/pragmatics/Uwe Schöning: „Theoretische Informatik kurzgefaßt“, 2001, ISBN 3827410991 Rechenberg & Pomberger: „Informatik-Handbuch“, Hanser Verlag, ISBN 3-446-21842-4Drachenbuch
Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman:„Compilers - Principles, Techniques and Tools“.Addison-Wesley 1988, ISBN 0-201-10088-6 Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman: „Compilerbau.“Oldenbourg Verlag 1999, Teil 1: ISBN 3-486-25294-1, Teil 2: ISBN 3-486-25266-6Wikipedia: http://en.wikipedia.org/wiki/Compilers:_Principles,_Techniques_and_Tools
Einführung
6. Sprachen, Compiler und Theorie
6.1-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Literatur (2/3)
BücherKlassiker der Automatentheorie von Hopcroft/Ullman/Motwani
Hopcroft, Motwani, Ullman : „Introduction to Automata Theory, Languages, and Computation“, 2001, http://www-db.stanford.edu/~ullman/ialc.htmlHopcroft, Motwani, Ullman: „Einführung in die Automatentheorie, Formale Sprachen und Komplexitätstheorie“, Pearson Studium 2002, ISBN 3827370205
Asteroth, Baier: „Theoretische Informatik: Eine Einführung in Berechenbarkeit, Komplexität und formale Sprachen mit 101 Beispielen“, Pearson Studium 2002, ISBN 3-8273-7033-7 (insbesondere für Nebenfächler geeignet, da kaum Mathematikkenntnisse vorausgesetzt werden.)
Einführung
6. Sprachen, Compiler und Theorie
6.1-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Literatur (3/3)
Skripte Compilerbau-Skript von Prof. Dr. Goltz, Universität Braunschweighttp://www.cs.tu-bs.de/ips/ss04/cb/skript_cp.ps.gzInformatik-Skripte von Prof. Dr. Waack, Universität Göttingenhttp://www.num.math.uni-goettingen.de/waack/lehrmaterial/
FolienInformatik II - SS2003 Folien dienen als Grundlage und wurden übersetzt und ev. teilweise ergänzt. Es wird aber auch komplett neue Teile geben!!!http://user.informatik.uni-goettingen.de/~info2/SS2003/Übersetzerbau I – Prof. Dr. Goos, Universität Karlsruhehttp://www.info.uni-karlsruhe.de/lehre/2003WS/uebau1/
WWW: Wikipediahttp://en.wikipedia.org/wiki/Compilers:_Principles,_Techniques_and_Toolshttp://de.wikipedia.org/wiki/Compiler
Erfahrungsberichte von Studentenseite sind erwünschtEinführung

6. Sprachen, Compiler und Theorie
6.1-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Weitere Quellen
Katalog von Konstruktionswerkzeugen für Compiler http://www.first.gmd.de/cogent/catalog/
ANTLR, ANother Tool for Language Recognition: http:/www.antlr.org
Konferenzen und JournaleACM Transactions on Programming Languages and SystemsACM SIGPLAN Conference on Programming Language Design and ImplementationACM SIGPLAN Conference on Programming Language Principles
Einführung
6. Sprachen, Compiler und Theorie
6.1-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Einführung
InhalteGrundlegende Konzepte von ProgrammiersprachenOrganisation von Compilern für moderne ProgrammiersprachenEinführung in die Theorie von formalen Sprachen und Automaten
Als Grundlage dient das Buch “Programming Language Pragmatics” von Michael L. Smith
Einführung
6. Sprachen, Compiler und Theorie
6.1-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Abstraktionen...
Eliminiere Details welche unnötig zum Lösen eines speziellen Problems sind
Komplexität wird verstecktBaue oft auf anderen auf
Erlaubt das Lösen von zunehmend komplexeren Problemen (teile und herrsche, divide and conquer)
Komplexität moderner Software ist ohne Beispiel (Präzedenzfall)Abstraktion ist ein grundlegender Bestandteil zum Handhaben von diesen komplexen Problemen
Allokation von Ressourcen (Zeit, Speicher, etc.)Betriebssystem(Physikalische) Netzwerke, ProtokolleComputerkommunikation
MaschinenspracheAssemblerspracheDigitale LogikComputerarchitekturTransistorenDigitale LogikAbstraktumAbstraktion
Einführung
6. Sprachen, Compiler und Theorie
6.1-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Sprachen als Abstraktion
Die menschliche Sprache ist ein Werkzeug für die Abstraktion vonGedanken
„Wenn es mir warm ist, dann schalte ich den Ventilator ein.“Eine einfache Absicht wird mitgeteilt, wobei aber die kognitiven und neurologischen Bedingungen, durch welche die Absicht aufkam, höchst wahrscheinlich für jeden zu komplex sind um sie zu VerstehenDie Bedeutung dieser Aussage ist dem Verständnis des Individuumswelches es äußert und den Individuen die es hören überlassen
Programmiersprachen sind ein Werkzeug zum Abstrahieren von Berechnungen
if (temperatur() > 30.0) { schalte_ventilator_ein(); }Beinhaltet eine komplexe aber konkrete Sequenz von Aktionen:
lese Thermostat; konvertiere den Ablesewert zu einer IEEE Fliesskomazahl nach der Celsiusskala; Vergleiche den Wert mit 30.0; wenn größer dann sende ein Signal an eine PCI Karte, welche ein Signal an ein Relais sendet, welches den Ventilator einschaltet
Die Bedeutung dieses Ausdrucks ist festgelegt durch die formale Semantikder Programmiersprache und der Implementierung der Funktionen temperatur() und schalte_ventilator_ein().
Einführung

6. Sprachen, Compiler und Theorie
6.1-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie abstrahieren Programmiersprachen Berechnungen? (1/4)
1. Biete eine Notation für den Ausdruck von Algorithmen welche(meistens) unabhängig von der Maschine ist auf welcher der Algorithmus ausgeführt wird,Fähigkeiten (features) auf höchster Ebene bietet und die Aufmerksamkeit des Programmierers mehr auf den Algorithmus fokussiert und weniger auf
wie der Algorithmus in einer Maschinensprache implementiert wird,wie Hilfsalgorithmen, z.B. Hash-Tabellen, Listen, implementiert werden,
es dem Programmierer erlaubt seine eigene Abstraktion (Unterprogramme, Module, Bibliotheken, Klassen, etc.) zu bauen um die Weiterführung des Konzepts „Komplexitätsmanagement durch Schichtenbildung“ zu ermöglichen.
Einführung
6. Sprachen, Compiler und Theorie
6.1-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie abstrahieren Programmiersprachen Berechnungen? (2/4)
2. Verberge unterliegende (systemnahe) Details der ZielarchitekturBefehlsnamen der Assemblersprache, Registernamen, Argumentordnung, etc.Abbildung von Sprachelementen auf die Assemblersprache
Arithmetische Ausdrücke,Bedingungen,Konventionen für Prozeduraufrufe, etc.
if (a < b + 10) {do_1();
} else {do_2();
}
SPARC
MIPSaddi $t2,$t1,10bge $t0,$t2,L1call do_1b L2
L1: call do_2L2: …
add %l1,10,%l2cmp %l0,%l2bge .L1; nopcall do_1; nopba .L2; nop
.L1: call do_2; nop
.L2: …
SPA
RCM
IPS
Einführung
6. Sprachen, Compiler und Theorie
6.1-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie abstrahieren Programmiersprachen Berechnungen? (3/4)
3. Biete Grundbefehle (primitives), Unterprogramme und Laufzeitunterstützung für übliche (lästige) Programmierpflichten
Lesen und schreiben von DateienHandhabung von Zeichenfolgen (Vergleiche, Erkennung von Teilzeichenfolge, etc.)Dynamische Allokation von Speicher (new, malloc, etc.)Rückgewinnung von unbenutztem Speicher (garbage collection)Sortierenetc.
Einführung
6. Sprachen, Compiler und Theorie
6.1-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie abstrahieren Programmiersprachen Berechnungen? (4/4)
Biete Merkmale welche eine besondere Art von Algorithmus oder Softwareentwicklung unterstützen (encourage) oder durchsetzen (enforce)
Objekt-Orientierte ProgrammierungKlassenVererbungPolymorphismus
Strukturiertes ProgrammierenUnterprogrammeVerschachtelte (Nested ???) Variablenbereiche ( scopes??)SchleifenBeschränkte Formen des „goto“ Befehls (statement??)
Einführung

6. Sprachen, Compiler und Theorie
6.1-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kategorien von Programmiersprachen
Alle Sprachen fallen in eine der beiden folgenden Kategorien:Imperative Sprachen erfordern die schrittweise Beschreibung durch Programmierer wie ein Algorithmus seine Aufgabe erledigen soll.
Analogie aus der realen Welt: „Ein Rezept ist eine Art von imperativem Programm, welches einem Koch sagt wie ein Gericht zuzubereiten ist.“
Deklarative Sprachen erlauben die Beschreibung durch Programmierer was ein Algorithmus erledigen soll ohne exakt zu beschreiben wie es getan werden soll.
Analogie aus der realen Welt: „Das Pfandgesetz ist ein deklarativesProgramm welches Einzelhändlern mitteilt das sie ein Recyclingprogramm für Einwegflaschen und Dosen des eigenen Sortiments aufstellen müssen, ohne exakt mitzuteilen wie dies zu erfolgen hat.
Einführung
6. Sprachen, Compiler und Theorie
6.1-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Imperative Sprachen (1/2)
Die von Neumann Sprachenschließen Fortran, Pascal, Basic und C einstellen eine Reflektion der von Neumann Computerarchitektur dar, auf welcher die Programme laufenFühren Befehle aus welche den Zustand des Programms(Variablen/Speicher) ändern
Manchmal auch Berechnung durch Seiteneffekte genanntBeispiel: Aufsummieren der ersten n Ganzzahlen in C
for(sum=0,i=1;i<=n;i++) { sum += i; }
Einführung
6. Sprachen, Compiler und Theorie
6.1-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Imperative Sprachen (2/2)
Die objekt-orientierten Sprachenschließen Smalltalk, Eiffel, C++, Java und Sather einSind ähnlich der von Neumann Sprachen mit der Erweiterung von ObjektenObjekte
enthalten ihren eigenen internen Zustand (Klassenvariablen, membervariables) und Funktionen welche auf diesem Zustand operieren (Methoden)Berechnung ist organisiert als Interaktion zwischen Objekten (ein Objekt ruft die Methoden eines anderen Objektes auf)
Die meisten objekt-orientierten Sprachen bieten Konstrukte (facilities) basierend auf Objekten welche objekt-orientierte Programmierungfördern
Kapselung (encapsulation), Vererbung (inheritance) und Polymorphismus(polymorphism) Wir werden uns darüber später genauer unterhalten
Einführung
6. Sprachen, Compiler und Theorie
6.1-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Deklarative Sprachen (1/2)
Die funktionalen Sprachenschließen Lisp/Scheme, ML, Haskell (Gofer) einSind eine Reflektion von Church‘s Theorie der rekursiven Funktionen (lambda calculus)Berechnung werden ausgeführt als Rückgabewerte von Funktionen basierend auf der (möglicherweise rekursiven) evaluation von anderen Funktionen
Mechanismus ist als Reduktion bekanntKeine Seiteneffekte
Erlaubt gleichungsbasiertes Problemlösen (equational reasoning), einfachere formale Beweise von Programmkorrektheit, etc.
Beispiel: Aufsummieren der ersten n Ganzzahlen in SMLfun sum (n) = if n <= 1 then n else n + sum(n-1)
Einführung

6. Sprachen, Compiler und Theorie
6.1-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Deklarative Sprachen (2/2)
Die logischen Sprachenschließen Prolog, SQL und Microsoft Excel/OpenOffice OpenCalc einSind eine Reflektion von der Theorie der Aussagenlogik(propositional logic)Berechnung ist ein Versuch einen Wert zu finden welcher eine Menge von logischen Beziehungen erfüllt
Der meist verwendete Mechanismus um diesen Wert zu finden ist bekannt als Resolution (resolution) und Vereinheitlichung (unification)
Beispiel: Aufsummieren der ersten n Ganzzahlen in Prologsum(1,1). sum(N,S) :- N1 is N-1, sum(N1,S1), S is S1+N.
Einführung
6. Sprachen, Compiler und Theorie
6.1-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine historische Perspektive: Maschinensprachen
Die ersten Maschinen wurden direkt in einer Maschinensprache oder Maschinencode programmiertLangweilig, aber Maschinenzeit war teurer als Programmiererzeit
MIPS Maschinencode für ein Programm zum Berechnen des GGT von zwei Ganzzahlen
Einführung
6. Sprachen, Compiler und Theorie
6.1-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine historische Perspektive: Assemblersprachen (1/2)
Programme wurden immer Komplexerzu schwierig, zeitintensiv und teuer um Programme in Maschinencode zu schreiben
Assemblersprachen wurden entwickeltFür den Menschen lesbar ☺Ursprünglich wurde eine eins-zu-eins Beziehung zwischen Instruktionen der Maschinensprache und Instruktionen der Assemblersprache bereitgestelltSchließlich wurden „makro“ Einrichtungen hinzugefügt um Softwareentwicklung durch anbieten von primitiven Formen von Code-Wiederverwendung weiter zu beschleunigenDer Assembler war das Programm welches ein Assemblerprogramm in Maschinencode übersetzte mit welchem die Maschine laufen konnte
Einführung
6. Sprachen, Compiler und Theorie
6.1-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine historische Perspektive: Assemblersprachen (2/2)
Beispiel:
Assembler
Einführung

6. Sprachen, Compiler und Theorie
6.1-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine historische Perspektive: höhere Sprachen (1/2)
Programme wurden immer Komplexeres war zu schwierig, zeitintensiv und teuer um Programme in Assemblersprache zu schreibenes war zu schwierig von einer Maschine zu einer anderen zu wechseln, welche eine andere Assemblersprache hatte
Es wurden höhere Programmiersprachen entwickeltMitte der 1950er wurde Fortran entworfen und implementiert
es erlaubte numerische Berechnungen in einer Form ähnlich von mathematischen Formeln auszudrücken
Der Compiler war das Programm welches ein höheres Quellprogramm in ein Assemblerprogramm oder Maschinenprogramm übersetzte.
Ursprünglich konnten gute Programmierer schnellere Assemblerprogramme schreiben als der Compiler
Andere höhere Programmiersprachen folgen Fortran in den späten 50er und frühen 60er
Lisp: erste funktionale Sprache, basierte auf der Theorie der rekursiven FunktionenAlgol: erste block-strukturierte Sprache
Einführung
6. Sprachen, Compiler und Theorie
6.1-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine historische Perspektive: höhere Sprachen (2/2)
Beispiel:
int gcd (int i, int j) {while (i != j) {
if (i > j)i = i – j;
elsej = j – i;
}printf(“%d\n”,i);
}
Compiler
Einführung
6. Sprachen, Compiler und Theorie
6.1-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Ausführung von Programmen höherer Sprachen
KompilationProgramm wird in Assemblersprache oder direkt in Maschinensprache übersetztKompilierte Programme können so erstellt werden, dass sie relativ schnell in der Ausführung sindFortran, C, C++
InterpretationProgramm wird von einem anderem Programm gelesen und Elemente der Quellsprache werden einzeln ausgeführtIst langsamer als kompilierte ProgrammeInterpreter sind (normalerweise) einfacher zu implementieren alsCompiler, sind flexibler und können exzellent Fehlersuche (debugging) und Diagnose unterstützenJava, Pyhton, Perl, etc.
Einführung
6. Sprachen, Compiler und Theorie
6.1-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Entwurf eines Compilers
Compiler sind gut untersuchte, aber auch sehr komplexe Programme
Daher sollte man nicht davon ausgehen, dass Compiler immer fehlerfrei arbeiten!!!
Die Komplexität wird durch die Aufteilung der Compilerarbeiten in unabhängige Abschnitte oder Phasen bewältigtTypischerweise analysiert eine Phase eine Repräsentation von einem Programm und übersetzt diese Repräsentation in eine andere, welche für die nächste Phase besser geeignet istDas Design dieser Zwischenrepräsentationen eines Programms sind kritisch für die erfolgreiche Implementierung eines Compilers
Einführung

6. Sprachen, Compiler und Theorie
6.1-25Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Der Kompilationsprozess (-phasen)
Scanner (lexikalische Analyse)
Parser (syntaktische Analyse)
Semantische Analyse
Zwischencodegenerierung
Optimierung
Zielcodegenerierung
Optimierung Maschinenebene
Lese Programm und konvertiere Zeichenstrom in Marken (tokens).
Lese Tokenstrom und generiere Parserbaum (parse tree).
Traversiere Parserbaum, überprüfe nicht-syntaktische Regeln.
Traversiere Parserbaum noch mal, gebe Zwischencode aus.
Untersuche Zwischencode, versuche ihn zu verbessern.
Übersetze Zwischencode in Assembler-/Maschinencode
Untersuche Maschinencode, versuche ihn zu verbessern.
Einführung
6. Sprachen, Compiler und Theorie
6.1-26Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Eine Programmdatei ist nur eine Sequenz von ZeichenFalsche Detailebene für eine SyntaxanalyseDie lexikalische Analyse gruppiert Zeichensequenzen in TokensTokens sind die kleinste „Bedeutungseinheit“ (units of meaning) im Kompilationsprozess und sind die Grundlage (foundation) fürs Parsen (Syntaxanalyse)Die Compilerkomponente zum Ausführen der lexikalischen Analyse ist der Scanner, welcher oftmals ausgehend von höheren Spezifikationen automatisch generiert wird
Mehr über Scanner in der nächsten Vorlesung
Einführung
6. Sprachen, Compiler und Theorie
6.1-27Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Beispiel für lexikalische Analyse
int gcd (int i, int j) {while (i != j) {if (i > j)i = i – j;
elsej = j – i;
}printf(“%d\n”,i);
}
int gcd (int i ,int j ) { while (i != j) { if( i > j ) i= i –j ; elsej = j – i ;} printf (“%d\n” , I) ; }
Ein GGT Programm in C Token
Einführung
6. Sprachen, Compiler und Theorie
6.1-28Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Die lexikalische Analyse erzeugt einen Strom von TokensFalsche Detailebene für die semantische Analyse und CodegenerierungDie Syntaxanalyse gruppiert eine Zeichenfolge von Tokens in Parserbäume, was durch die kontextfreie Grammatik gelenkt wird, die die Syntax der zu kompilierenden Sprache spezifiziert
conditional -> if ( expr ) block else block
Parserbäume repräsentieren die Phrasenstruktur eines Programmes und sind die Grundlage für die semantische Analyse und CodegenerierungDie Compilerkomponente zum Ausführen der syntaktischen Analyse ist der Parser, welcher oftmals ausgehend von höheren Spezifikationen automatisch generiert wird
Mehr über kontextfreie Grammatiken und Parser später
Einführung

6. Sprachen, Compiler und Theorie
6.1-29Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Beispiel Syntaxanalyse
if ( i > j )i = i – j ;else j = j – i; }
Token conditional
if ( expr ) block else block
id comp id
i j>
statement
id = expr
i id op id
i j-
statement
id = expr
j id op id
j i-
Einführung
6. Sprachen, Compiler und Theorie
6.1-30Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Semantische Analyse
Bestimmt die Bedeutung eines Programms basierend auf der Repräsentation des ParserbaumesSetzt Regeln durch, welche nicht durch die Syntax der Programmiersprache verwaltet werden
Konsistente Verwendung von Typen, z.B.int a; char s[10]; s = s + a; illegal!
Jeder Bezeichner (identifier) muss vor der ersten Verwendung deklariert seinUnterprogrammaufrufe müssen die richtige Argumentanzahl und Argumenttyp habenetc.
Bringt die Symboltabelle auf den aktuellen Stand, welche neben anderen Dingen den Typ von Variablen, deren Größe und den Gültigkeitsbereich in welchen die Variablen erklärt wurden notiert
Einführung
6. Sprachen, Compiler und Theorie
6.1-31Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zwischencodegenerierung
Parserbäume sind die falsche Detailebene für die Optimierung undZwischencodegenerierungZwischencodegenerierung verwandelt den Parsebaum in eine Sequenz von Anweisungen (statements) der Zwischensprachewelche die Semantik des Quellprogramms verkörpertDie Zwischensprache ist genauso Mächtig, aber einfacher, wie diehöhere Sprache
z.B. die Zwischensprache könnte nur einen Schleifentyp (goto) haben, wogegen die Quellsprache mehrere haben könnte (for, while, do, etc.)
Eine einfache Zwischensprache macht es einfacher nachfolgende Compilerphasen zu implementieren
Einführung
6. Sprachen, Compiler und Theorie
6.1-32Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zielcodegenerierung
Das Endziel eines Compilerprozesses ist die Generierung eines Programms welches der Computer ausführen kann
Dies ist die Aufgabe der ZielcodegenerierungSchritt 1: durchlaufe (traverse) die Symboltabelle, weise Variablen einen Platz im Speicher zuSchritt 2: durchlaufe (traverse) den Parsebaum oder Programm in der Zwischensprache um arithmetische Operationen, Vergleiche, Sprünge und Unterprogrammaufrufe auszugeben, sowie Lasten und Vorräte von Variablenreferenzen
Einführung

6. Sprachen, Compiler und Theorie
6.1-33Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Optimierung
Zwischencode und Zielcode ist typischerweise nicht so effizient wie er sein könnte
Einschränkungen erlauben es dem Codegenerator sich auf die Codeerzeugung zu konzentrieren und nicht auf die Optimierung
Ein Optimierer kann aufgerufen werden um die Qualität des Zwischencodes und/oder Zielcodes nach jeder dieser Phasen zu verbessernDie Compilerkomponente zur Verbesserung der Qualität des generierten Codes wird Optimierer (optimizer) genannt.Optimierer sind die kompliziertesten Teile eines CompilersOptimierungsalgorithmen sind oftmals sehr ausgefeilt, benötigen erheblich viel Speicher und Zeit für die Ausführung und erzeugen nur kleine Verbesserungen der Programmgröße und/oder Leistung der LaufzeitZwei wichtige Optimierungen
Registerzuteilung – entscheide welche Programmvariablen zu einem bestimmten Zeitpunkt der Programmausführung in Registern gehalten werden könnenUnbenutzten Code eliminieren – entferne Funktionen, Blöcke, etc., welche niemals vom Programm ausgeführt würden
Einführung
6. Sprachen, Compiler und Theorie
6.1-34Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Warum Programmiersprachen und Compiler studieren?
Nach Aussage von Michael Scott (siehe Literaturangabe)Verstehe schwer verständliche SpracheigenschaftenWähle zwischen alternativen Wegen um etwas auszudrückenMache guten Gebrauch von Debuggern, Assemblern, Linkern und andere verwandte WerkzeugeSimuliere nützliche Eigenschaften (features) welche in einer Sprache fehlen
Nach Aussage von Kevin Scott (vorheriger Dozent)Compiler sind große und komplexe Programme: studieren dieser Programme hilft dir „große Software“ besser zu verstehenViele Programme enthalten „kleine Programmiersprachen“
Unix shells, Microsoft Office Anwendungen, etc.Es ist nützlich etwas über Sprachdesign und –implementierung zu wissen, so dass Sie kleine Sprachen in die eigene Software einbauen können
Einführung
6. Sprachen, Compiler und Theorie
6.1-35Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Weitere Fragen zum Nachdenken
Was macht eine Programmiersprache erfolgreicher als andere?Werden Programmiersprachen mit der Zeit besser?An welchen Eigenschaften (features) mangelt es deiner bevorzugten Sprache um Sie
mächtiger,zuverlässiger,einfacher in der Verwendung zu machen?
Einführung
6. Sprachen, Compiler und Theorie
6.1-36Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Plan für nächste Vorlesungen
Die nächsten Vorlesungen (Kapitel 2 vom Buch)lexikalische Analysesyntaktische AnalyseAutomatentheorie und automatische Generierung von Scannern und ParsernReguläre und kontextfreie Grammatiken
Nachfolgende 5 VorlesungenNamen, Geltungsbereiche und Binden (Kapitel 3)Kontrollfluss (Kapitel 6)Unterprogramme und Kontrolle über Abstraktion (Kapitel 8)Zusammenbauen eines lauffähigen Programms (Kapitel 9)Objekt-orientierte Programmierung (Kapitel 10)
Einführung

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
2 – Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Der Kompilationsprozess (-phasen)
Scanner (lexikalische Analyse)
Parser (syntaktische Analyse)
Semantische Analyse
Zwischencodegenerierung
Optimierung
Zielcodegenerierung
Optimierung Maschinenebene
Lese Programm und konvertiere Zeichenstrom in Marken (tokens).
Lese Tokenstrom und generiere Parserbaum (parse tree).
Traversiere Parserbaum, überprüfe nicht-syntaktische Regeln.
Traversiere Parserbaum noch mal, gebe Zwischencode aus.
Untersuche Zwischencode, versuche ihn zu verbessern.
Übersetze Zwischencode in Assembler-/Maschinencode
Untersuche Maschinencode, versuche ihn zu verbessern.
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Die lexikalische Analyse gruppiert Zeichensequenzen in Tokens(Marken) bzw. SymboleTokens sind die kleinste „Bedeutungseinheit“ (units of meaning) im Kompilationsprozess und sind die Grundlage (foundation) fürs Parsen (Syntaxanalyse)Die Compilerkomponente zum Ausführen der lexikalischen Analyse ist der Scanner, welcher oftmals ausgehend von höheren Spezifikationen automatisch generiert wird
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Beispiel für lexikalische Analyse
int gcd (int i, int j) {while (i != j) {if (i > j)i = i – j;
elsej = j – i;
}printf(“%d\n”,i);
}
int gcd (int i ,int j ) { while (i != j) { if( i > j ) i= i –j ; elsej = j – i ;} printf (“%d\n” , I) ; }
Ein GGT Programm in C Token
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
2 Fragen
Wie beschreiben wir die lexikalische Struktur einer Programmiersprache?
Mit anderen Worten, was sind die Tokens (Symbole)Wie implementieren wir den Scanner nachdem wir wissen was die Tokens sind?
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie beschreiben wir die lexikalische Struktur? (1/2)
1. Versuch: Liste aller Tokensif else long int short char ; , : ( ) { } …Aber was ist mit den Konstanten (Ganzzahlen, Fliesskommazahlen, Zeichenketten)?
Es können nicht alle aufgelistet werden, es gibt ~8 Milliarden 32-bit integer und floating-point Konstanten und eine unendliche Anzahl von ZeichenfolgenkonstantenDas gleiche Problem gilt für Bezeichner (Variablen, Funktionen und benutzerdefinierte Typnamen)Lösung: Wir brauchen einen Weg um kurz und prägnant Klassen von Tokens zu beschreiben, welche eine große Anzahl von verschiedenen Werten abdecken können
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Wie beschreiben wir die lexikalische Struktur? (2/2)
2. Versuch: Reguläre AusdrückeMuster (patterns) welche zum Auffinden von passendem Text verwendet werden könnenWerden mit folgenden Ausdrücken rekursiv ausgedrückt
Ein ZeichenDer leeren Zeichenfolge εDer Verkettung zweier regulärer Ausdrücke
r1.r2 ist der Wert von r1 gefolgt vom Wert von r2
Der Alternative zweier regulärer Ausdrücker1|r2 ist der Wert von r1 oder der Wert von r2
Der Kleenesche Hülle * (ode einfach Hülle oder Stern)r* ist kein oder mehrere Vorkommen des Wertes von r1
Runde Klammern können zum Gruppieren von regulären Ausdrücken verwendet werden, um Zweideutigkeiten bei Kombinationen auszuschließen
z.B. bedeutet r1.r2|r3 nun (r1.r2)|r3 oder r1.(r2|r3)???
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Abkürzungen von regulären Ausdrücken
Zeichenfolgenr=‘c1c2c3...cn‘ ist äquivalent zur=c1.c2.c3.....cn
Zeichenbereicher=[c1-cn] ist äquivalent zur=c1|c2|c3|...|cn für die aufeinander folgende Reihe von n Zeichen beginnend mit c1 und endend mit cnz.B. r=[a-d] ist äquivalent zu r=a|b|c|d
Kleenesche Hülle +r+ ist ein oder mehrere Vorkommen des Wertes von rFormal definiert als r+ = r.r*
Das Symbol . steht für jeden Charakter außer „newline“
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse: Reguläre Ausdrücke bei der Arbeit
digit=[0-9]letter=[a-z]|[A-Z]punct=\|%INT=‘int’WHILE=‘while’IF=‘if’ID=letter.(letter|digit)*LPAREN=(RPAREN=)COMMA=,SEMI=;LBRACE={RBRACE=}EQ==MINUS=-GT=>SC=“.(letter|digit|punct)*.”
INT ID:gcd LPARENINT ID:i COMMAINT ID:j RPARENLBRACE WHILE LPARENID:i NEQ ID:jRPAREN LBRACE IFLPAREN ID:i GTID:j RPAREN ID:iEQ ID:i MINUSID:j SEMI ELSEID:j EQ ID:jMINUS ID:i SEMIRBRACE ID:printf LPARENSC:“%d\n” COMMA ID:iRPAREN SEMI RBRACE
Tokens
int gcd (int i, int j) {while (i != j) {
if (i > j)i = i – j;
elsej = j – i;
}printf(“%d\n”,i);
}
Ein GGT Programm in CReguläre Ausdrücke
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Ein genauerer Blick auf die lexikalische Analyse
Wie behandelt der lexikalische Analysator Leerzeichen, Kommentare und Konflikte zwischen regulären Ausdrücken?
Leerzeichenint gcd (int i, int j) {
Kommentare einer Programmiersprache/* gcd */ int gcd (int i, int j) {
Konflikte zwischen regulären AusdrückenGegeben:
WHILE=‘while’ID=letter.(letter|digit)*
Beide reguläre Ausdrücke decken die Zeichenfolge „while“ ab. Welcher Ausdruck soll aber nun gewählt werden?
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Handhabung von Leerzeichen
Leerzeichen können als Token durch folgende Regel erkannt werden
WS=(\n|\r|\t|\s)*\n ist ein „escape“ Zeichen für „newline“ (neue Zeile)\r ist ein „escape“ Zeichen für „carriage return“ (Wagenrücklauf)\t ist ein „escape“ Zeichen für „tab“ (Tabulator)\s ist ein „escape“ Zeichen für „space“ (Leerzeichen)
Das Leerzeichentoken WS ist normalerweise unwichtig für die Syntax einer Programmiersprache, weshalb es einfach vom Tokenstrom gelöscht werden kann
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Handhabung von Kommentaren (1/2)
Alternative 1: PräprozessorenSpezielles Programm welches eine Datei einliest, Kommentare entfernt, andere Operationen wie Makro-Expansion ausführt und eine Ausgabedatei schreibt, welche vom lexikalischen Analysator gelesen wird.Quellprogramme können auch Steueranweisungen enthalten, die nicht zur Sprache gehören, z.B. Makro-Anweisungen. Der lexikalische Analysator behandelt die Steueranweisungen und entfernt sie aus dem Tokenstrom.Präprozessor-Anweisungen in C und C++
z.B. #include und #define
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Handhabung von Kommentaren (2/2)
Alternative 2: KommentartokenIn Abhängigkeit von der Komplexität von Kommentaren ist eine Beschreibung via regulärer Ausdrücke vielleicht möglich
Zeilenkommentare (single line comments) können mit regulären Ausdrücken gefunden werden
SLC=‘//’.*.$$ ist ein spezielles Symbol, welches das Ende einer Zeile bedeutet
Findet Texte wie// Dies ist ein Kommentar
Einige Kommentare sind zu kompliziert um durch reguläre Ausdrücke gefunden zu werden
Willkürlich verschachtelte Kommentare/* level 1 /* level 2 */ back to level 1 */
Wird Normalerweise vom Präprozessor behandelt
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Handhabung von Konflikten
Gegeben sind zwei reguläre Ausdrücke r1 und r2, welche eine Teileingabe p=‘c1..ck‘ finden. Welche soll nun ausgewählt werden?
Alternative 1: Längster FundNehme solange Eingabezeichen hinzu bis weder r1 noch r2 passen. Entferne ein Zeichen und entweder r1 oder r2 muss passen. Die Teileingabe p ist der längste Fund und wenn nur einer von r1 oder r2 passt, dann wähle ihn.Beispiel:
r1=‘while’r2=letter.(letter|digit)*Eingabe
int while48; …Wenn p=‘while’, beide, r1 und r2 passenWenn p=‘while48;’ weder r1 noch r2 passenWenn p=‘while48’ nur r2 passt, wähle r2 aus
Alternative 2: RegelprioritätWenn der längste Fund immer noch in einem Konflikt endet, dann wähle den erste regulären Ausdruck aus der lexikalischen Definition der Sprache
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Weitere spezielle Probleme
Reservierte SchlüsselwörterSchlüsselwörter dürfen nicht in Bezeichnern (Namen) verwendet werden
Groß-/Kleinschreibungintern nur eine Repräsentation verwenden, weshalb eine Anpassungnotwendig ist
TextendeDas Textende muss dem Syntaxanalysator mitgeteilt werden, weshalb ein eind-of-text Symbol (eot) eingefügt werden muss
Vorgriff (lookahead) um mehrere Zeichengelesene aber nicht verwendete Zeichen müssen für nächsten Test berücksichtigt werden
Lexikalische FehlerDie Verletzung der Syntax (z.B. falscher Wertebereich) wird gemeldet und trotzdem an den Syntaxanalysator weitergegeben
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Implementierung eines lexikalischen Analysators
Wie übertragen wir reguläre Ausdrücke in einen lexikalischen Analysator?
Konvertiere reguläre Ausdrücke zu einem deterministischen endlichen (finite) Automaten (DFA)
Warum??? DFAs sind einfacher zu simulieren als reguläre Ausdrücke
Schreibe ein Programm zum Simulieren eines DFAsDer DFA erkennt die Tokens im Eingabetext und wird der lexikalische AnalysatorWenn ein Token erkannt wurde, dann kann eine benutzerdefinierte Aktion ausgeführt werden
z.B. überprüfe, ob der Wert einer Ganzzahlkonstante in eine 32-bit integer passt
Die Konvertierung von regulären Ausdrücken zu DFAs und das Schreiben eines Programms zum Simulieren des DFA kann entweder von Hand vorgenommen werden oder von einem anderen Programm, welches lexikalischer Analysegenerator genannt wird.
RegularExpressions
+Actions
Lexical AnalyzerGenerator
Lexical analyzersource code
High-level languagecompiler
Lexical analyzer
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Endliche Automaten
Formal, ein endlicher Automat M ist ein Quintupel M=(Q,Σ,q,F,δ), wobei
Q ist eine endliche Menge von Symbolen genannt Zustände (states)Σ ist eine endliche Menge von Eingabesymbolen genannt Alphabetq ist der StartzustandF ist eine endliche Menge von finalen oder akzeptierenden Zuständen. F ist eine, möglicherweise leere, Teilmenge von Q.δ ist eine Übergangsfunktion
L(M), oder die Sprache von M, ist die Menge von endlichen Zeichenketten von Symbolen aus dem Alphabet Σ welche vom Automaten M akzeptiert werden
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Ein Beispiel eines endlichen Automaten
Q={q1,q2,q3,q4,q5}Σ={a,b}q=q1F={q4}δ=
{((q1,a),q2),((q1,b),q3),((q2,a),q4),((q2,b),q2),((q3,a),q4),((q3,b),q5),((q4,a),q5),((q4,b),q5),((q5,a),q5),((q5,b),q5)}
q1
q2
q3
q4 q5
a a
b
b a
b
a,b
a,b
Eingabe:
abba a
Welche Sprache akzeptiert M?
(ab*a)|ba
Nicht akzeptiert!
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zwei Arten von endlichen Automaten:Deterministisch und Nichtdeterministisch
Deterministische endliche AutomatenDie Übergangsfunktion ist formal definiert als
δ:Q x Σ -> QEin Eingabesymbol und ein Zustand ergeben den einzigen nächsten Zustand
Nichtdeterministische endliche Automaten (NFA)Die Übergangsfunktion ist formal definiert als
δ:Q x Σ -> φQ (Potenzmenge von Q)Ein Eingabesymbol und ein Zustand ergeben eine Menge vonmöglichen nächsten Zuständen. Die Menge kann auch leer sein.
Abgesehen von den Übergangsfunktionen sind DFAs und NFAsgleich
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Ein Beispiel eines nichtdeterministischen Automaten (NFA)
Q={q1,q2,q3,q4,q5}Σ={a,b}q=q1F={q4}δ=
{((q1,a),{q2,q3}),((q1,b),{q3}),((q2,a),{q4}),((q2,b),{q2}),((q3,a),{q4}),((q3,b),{q5}),((q4,a),{q5}),((q4,b),{q5}),((q5,a),{q5}),((q5,b),{q5})}
q1
q2
q3
q4 q5
a a
b
a,b a
b
a,b
a,b
Eingabe:
abba a
Welche Sprache akzeptiert M?
(ab*a)|ba
Gleiche wie zuvor beim DFA…
Nicht akzeptiert!
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine interessante Sache über endliche Automaten
Auch wenn es so aussieht als ob Nichtdeterminismus einem endlichen Automaten mehr Ausdruckskraft verleiht, sind NFAs und DFAs formal äquivalent
Jeder NFA kann in einen DFA umgewandelt werden und ungekehrtWarum machen wir dann aber die Unterscheidung?
Es ist einfacher reguläre Ausdrücke in NFAs umzuwandelnEs ist einfacher DFAs zu simulieren
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine Nebenbemerkung zu endlichen Automaten
Endliche Automaten sind auch für andere Dinge als lexikalische Analyse nützlich
Die meisten Systeme, welche Transaktionen zwischen einer endlichen Anzahl von Zuständen vornehmen, können mit endlichen Automaten modelliert werdenBeispiele
Beschreibung, Simulation, Überprüfung und Implementierung von ProtokollenBauen von schnellen, zustandsbasierten Schaltungen (siehe Kapitel 2)
0¢
25¢
50¢
75¢ vend
Vending machine automata
25 ¢
25 ¢
25 ¢
25 ¢
25 ¢50 ¢
50 ¢
50 ¢
50 ¢
MESI cache coherence protocol(Courtesy: John Morris, University of Western Australia)
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Bau des lexikalischen Analysators:Reguläre Ausdrücke nach NFA
Kleenesche Hülle: r*
Verkettung: r1.r2
Alternative: r1|r2
Leere Zeichenkette: є
Charakter: c
NFARegulärer Ausdruck
c
є
r1r2
є
є
є
є
r1 r2є
rє є
є є
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Beispiel: Reguläre Ausdrücke nach NFA
r=(‘ab’|’cd’)*Faktor:
r1=a.br2=c.dr3=r1|r2r=r3*
a
b
a bє
r1:
c
dc dє
r2:
a bє
c dє
є
є
є
єr3:
a bє
c dє
є
є
є
є
єєє
r4:
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-25Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Theoretische Ergebnisse 1Definitionen
Endliche Automaten akzeptieren oder erkennen SprachenReguläre Ausdrücke erzeugen SprachenL(M) ist die akzeptierte Sprache vom endlichen Automaten ML(R) ist die erzeugte Sprache vom regulären Ausdruck RL(R) and L(M) sind Mengen von endlichen Zeichenketten von Symbolen der Alphabete ΣR und ΣMLR ist die Menge { L(r):alle reguläre Ausdrücke r }LN ist die Menge { L(n):alle nichtdeterministische endliche Automaten n }
LR ist eine Untermenge von LNNichtdeterministische endliche Automaten akzeptieren alle von regulären Ausdrücken erzeugten SprachenWarum? Wir haben gezeigt wie beliebige reguläre Ausdrücke zu einem NFA konvertiert werden können
Beschreiben LR und LN die gleichen Mengen?Es stellt sich heraus, dass die Antwort ja istBeweis durch zeigen das LN eine Untermenge von LR ist oder das jeder nichtdeterministische endliche Automat in einen regulären Ausdruck umgewandelt werden kannSiehe jedes gute theoretische Informatik Buch für Details:
Introduction to Automata Theory, Languages, and Computation by Hopcroft and UllmanIntroduction to the Theory of Computation by Michael Sipser
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-26Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Bau des lexikalischen Analysators:NFA nach DFA
Regulärer Ausdruckr=(‘ab’|’cd’)*
Konvertiere NFA nach DFA unter Verwendung der Konstruktion von UntermengenBeschrifte jeden DFA Zustand als die vom vorherigen Zustand in einem Schritt erreichbare Menge von ZuständenWenn irgendein NFA Zustand in der Menge der erreichbaren Zustände ein Endzustand ist, dann ist der ganze DFA Zustand ein Endzustand
q4aq3 q6
bq5є
q8cq7 q10
dq9єq2є
єq11
є
єq12
єq1 єє
NFA
{q1,q2,q3,q7,q12}
{q4,q5}
{q8,q9}
a
c
{q2,q3,q6,q7,q11,q12}
{q2,q3,q7,q10,q11,q12}
a
a
b
d
c
c
DFA
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-27Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Theoretische Ergebnisse 2Definitionen
Erinnerung, LN ist die Menge { L(n):alle nichtdeterministische endliche Automaten n } LD ist die Menge { L(d): alle deterministischen endlichen Automaten d }
LN ist eine Untermenge von LD und LR ist eine Untermenge von LDDeterministische endliche Automaten akzeptieren alle Sprachen die auch von nichtdeterministischen endlichen Automaten akzeptiert werdenNeben Transitivität, akzeptieren DFAs auch alle durch reguläre Ausdrücke generierte SprachenWarum? Wir haben gezeigt wie jeder NFA zu einem DFA und jeder reguläre Ausdruck zu einem NFA konvertiert werden kann
Beschreiben LN und LD die gleichen Mengen?Es stellt sich heraus, dass die Antwort ja istBeweis durch zeigen das LD eine Untermenge von LN ist oder das jeder DFA in einen NFA umgewandelt werden kannNoch mal, siehe jedes gute theoretische Informatik Buch für Details
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-28Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Einige Bemerkungen zu DFAs
Ein DFA M gebaut unter Verwendung der Konstruktion von Untermengen kann nicht minimal sein
Mit anderen Worten, es könnte einen Automaten M‘ geben wobei L(M)=L(M‘) und M‘ hat weniger Zustände als M
Minimale DFAs sind besser geeignet für ImplementierungszweckeWeniger Zustände benötigen weniger Speicher und führen generell zu schnelleren Simulationen
Die meisten automatischen Werkzeuge zum Konvertieren von NFAsnach DFAs führen einen Optimierungsprozess aus um die Anzahl der DFA Zustände zu reduzieren
Das Finden eines minimalen DFAs ist ein sehr hartes Problem (auch NP-vollständig bezeichnet), weshalb Optimierer keinen minimalen DFA garantieren könnenPraktisch gesehen ist das Ok, obwohl weniger Zustände immer besser ist ☺
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-29Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Bau des lexikalischen Analysators: DFA zu Code
DFAs können effizient Simuliert werden indem ein tabellenbasierter Algorithmus verwendet wird
void dfa (char *in) {s = in;state = start_state;while(1) {c = *s++;state = table[state][c];if (final[state)]) {printf(“Accepted %s\n”,in);break;
}}
}
q1
q2
q4
a
c
q3
q5
a
a
b
d
c
c
q6q4q6q2q5
q6q6q6q6q6
q5q6q6q6q4
q6q4q6q2q3
q6q6q3q6q2
q6q4q6q2q1
dcba
Tabelle
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-30Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Bau des lexikalischen Analysators: Letzter Schritt
DFA Simulatorcode wird der Kern des lexikalischen AnalysatorsWenn der DFA in einem Endzustand ist
Führe mit dem letzten, passenden regulären Ausdruck, entsprechend dem längsten Fund und/oder der Regelpriorität, die verbundene, benutzerdefinierte Aktion ausMerke aktuelle Stelle im Eingabestrom und gebe Token an Tokenkonsument (parser) weiter
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-31Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Eine reale JLex lexikalische Spezifikation für einen Kalkulatorsprache
1 2 import java.io.IOException;3 4 %%5 6 %public7 %class Scanner8 9 %type void
10 %eofval{11 return;12 %eofval}13 %{ public static void main (String args []) {14 Scanner scanner = new Scanner(System.in);15 try {16 scanner.yylex();17 } catch (IOException e) { System.err.println(e); }18 }19 %}20 21 comment = ("#".*)22 space = [\ \t\b\015]+23 digit = [0-9]24 integer = {digit}+25 real = ({digit}+"."{digit}*|{digit}*"."{digit}+)26 IF = ("if")27 THEN = "then"28 ELSE = else29 30 %%31 32 {space} { System.out.println("space"); 33 break;34 }35 {comment} { System.out.println("comment"); 36 break;37 }38 {integer} { System.out.println("Integer CONSTANT\t" + yytext());39 break;
39 break;40 }41 {real} { System.out.println("REAL CONSTANT\t" + yytext());42 break;43 }44 {IF} { System.out.println("IF Token\t" + yytext());45 break;46 }47 {THEN} { System.out.println("THEN Token\t" + yytext());48 break;49 }50 {ELSE} { System.out.println("ELSE Token\t" + yytext());51 break;52 }53 \n { System.out.println("NL"); 54 break;55 }56 "+" { System.out.println("ADD"); 57 break;58 }59 "-" { System.out.println("SUB"); 60 break;61 }62 "*" { System.out.println("MUL"); 63 break;64 }65 "/" { System.out.println("DIV"); 66 break;67 }68 "%" { System.out.println("MOD"); 69 break;70 }71 "(" { System.out.println("LPAR"); 72 break;73 }74 ")" { System.out.println("RPAR"); 75 break;76 }77 . { System.out.println("error" + "+" + yytext() + "+");78 break;79 }
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-32Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Plan für nächste Vorlesungen
Die nächsten Vorlesungen (Kapitel 2 vom Buch)syntaktische AnalyseAutomatentheorie und automatische Generierung ParsernReguläre und kontextfreie Grammatiken
Nachfolgende 5 VorlesungenNamen, Geltungsbereiche und Binden (Kapitel 3)Kontrollfluss (Kapitel 6)Unterprogramme und Kontrolle über Abstraktion (Kapitel 8)Zusammenbauen eines lauffähigen Programms (Kapitel 9)Objekt-orientierte Programmierung (Kapitel 10)
Lexikalische Analyse

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
2a – Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-34Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Pumping Lemma für reguläre Sprachen (1/2)
Das Pumping Lemma ist eine Methode, um heraus zu finden, ob eine Sprache nichtregulär.
6. Sprachen, Compiler und Theorie
6.2-35Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Pumping Lemma für reguläre Sprachen (2)
Satz: Sei L eine reguläre Sprache. Dann gibt es eine Zahl (Konstante) n, derart dass alle Wörter (Zeichenreihen) w in L mit |w | ≥ n gilt, dass wir in w drei Wörter w = xyz zerlegen können, für die gilt:
|y | ≥ 1 (oder y ≠ ε)|xy | ≤ n,Für alle k ≥ 0 gilt, dass die Zeichenreihe xy kz auch in L enthalten ist.
6. Sprachen, Compiler und Theorie
6.2-36Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Beweis
Jede Zeichenreihe, deren Länge nicht kleiner ist als die Anzahl der Zustände, muss bewirken, dass ein Zustand zweimal durchlaufen wird (Schubfachschluss).

6. Sprachen, Compiler und Theorie
6.2-37Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Beispiele
Sind diese Sprachen (nicht) regulär?w = anbn
w= ab|c
Die Anwendung des Pumping Lemmas ist ein kreativer Vorgang, da es kein „mechanisches“ Vorgehen für den Einsatz gibt.
vergleiche Ableitungsregeln aus der Mathematik (Analysís)
6. Sprachen, Compiler und Theorie
6.2-38Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Rückblick
Reguläre Sprachen, reguläre Ausdrücke, (deterministische und nichtdeterministische) endliche AutomatenWichtige Algorithmen
Konvertierung von regulären Ausdrücken zu nichtdeterministischenendlichen Automaten (NFA) (inklusive Beweise)Konvertierung von nichtdeterministischen endlichen Automaten zu deterministischen endlichen Automaten (DFA)Tabellenbasierte Simulation von DFAs
Lexikalische Analyse und ScannerVerwenden reguläre Ausdrücke zur Definition der lexikalischen Struktur (Symbole/Token) einer SpracheVerwenden die Theorie der regulären Sprachen zur Erzeugung einesScanners ausgehend von der Beschreibung der lexikalischen Struktur einer Programmiersprache anhand von regulären Ausdrücken
6. Sprachen, Compiler und Theorie
6.2-39Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Ausdrücke (1/3)
Werden mit folgenden Ausdrücken rekursiv ausgedrückt:Ein Zeichen c aus dem Alphabet Σ, oderder leeren Zeichenfolge ε, oderder Verkettung zweier regulärer Ausdrücke, r1 . r2, oderder Alternative zweier regulärer Ausdrücke, r1 | r2, oderder Kleenesche Hülle * (ode einfach Hülle oder Stern), r1*.
Ein regulärer Ausdruck ist gedacht um Zeichenketten aus Zeichen aus einem Alphabet Σ zu erzeugenDie Menge aller durch einen regulären Ausdruck R erzeugte Zeichenketten wird die Sprache von R genannt und wird symbolisiert durch L(R)
6. Sprachen, Compiler und Theorie
6.2-40Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Ausdrücke (2/3)
Zeichenfolgenr=‘c1c2c3...cn‘ = c1.c2.c3.....cn
Zeichenbereicher=[c1-cn] = c1|c2|c3|...|cn Kleenesche Hülle +r+ = r.r*
Lexikalische Analyse

6. Sprachen, Compiler und Theorie
6.2-41Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Ausdrücke (3/3)
Alle Zeichenketten mit a’s, b’s und c’s, welche exakt drei a’s beinhalten.(b|c)*.a.(b|c)*.a.(b|c)*.a.(b|c)*
Alle Zeichenketten mit a’s, b’s und c’s, welche die Teilzeichenkette aba enthalten.(a|b|c)*.a.b.a.(a|b|c)*
Alle Zeichenketten mit a’s, b’s, und c’s, welche mit einem a beginnen und einem einzelnen a enden.
a.(a|b|c)*.(b|c).a
Alle Zeichenketten mit a’s, b’s und c’s, welche mit einem a beginnen und enden.a.(a|b|c)*.a
Die Zeichenketten if, then, or else.‘if’|’then’|’else’
Erzeugt…Reguläre Ausdrücke
6. Sprachen, Compiler und Theorie
6.2-42Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Endliche Automaten (1/5)
Formal, ein endlicher Automat M ist ein Quintupel M=(Q,Σ,q0,F,δ), wobei
Q ist eine endliche Menge von Symbolen genannt Zustände (states)Σ ist eine endliche Menge von Eingabesymbolen genannt Alphabetq0 ist der StartzustandF ist eine endliche Menge von finalen oder akzeptierenden Zuständen. F ist eine, möglicherweise leere, Teilmenge von Q.δ ist eine Übergangsfunktion
Ein endlicher Automat ist geeignet um Zeichenketten aus Zeichen aus dem Alphabet Σ zu akzeptierenL(M), oder die Sprache von M, ist die Menge von endlichen Zeichenketten von Symbolen aus dem Alphabet Σ welche vom Automaten M akzeptiert werden
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-43Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Endliche Automaten (2/5)
Deterministische endliche Automaten (DEA/DFA)Übergänge sind deterministisch
Übergang von einzelnem Zustand zu einzelnem ZustandδD:Q x Σ -> Q
Übergangsfunktionen können als eine Tabelle oder Zustandsübergangsdiagramm geschrieben werden
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-44Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Endliche Automaten (3/5)
Beispiel DFAQ={q1,q2,q3,q4,q5}Σ={a,b}q0=q1F={q4}δ=
{((q1,a),q2),((q1,b),q3),((q2,a),q4),((q2,b),q2),((q3,a),q4),((q3,b),q5),((q4,a),q5),((q4,b),q5),((q5,a),q5),((q5,b),q5)}
q1
q2
q3
q5
a a
b
b a
b
a,b
a,b
q4
q5q4q3q2q1
q5q5q5q5q5q4q2q4q3q2ba
Tabelle
Zustandsüber-gangsdiagramm

6. Sprachen, Compiler und Theorie
6.2-45Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Endliche Automaten (4/5)
Nichtdeterministische endliche Automaten (NEA/NFA)Übergänge sind nichtdeterministisch
Übergang von einzelnem Zustand zu einer Menge von möglichen ZuständenδD:Q x Σ -> P(Q) ( P(Q) Potenzmenge von Q )
Das Alphabet ist erweitert um Übergänge der leeren Zeichenkette є zu erlauben
Lexikalische Analyse
6. Sprachen, Compiler und Theorie
6.2-46Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Endliche Automaten (5/5)
Beispiel NFAQ={q1,q2,q3,q4,q5}Σ={a,b,є}q0=q1F={q4}δ={((q1,є),{q2,q3}),((q2,a),{q5}),((q2,b),{q2,q4}),((q3,a),{q4}),((q3,b),{q5}),((q4,a),{q5}),((q4,b),{q5}),((q5,a),{q5}),((q5,b),{q5})}
q1
q2
q3
q5
є b
b
є a
b
a,b
a,b
q4
{q5}{q5}{q5}{q5}
{q2,q3}є
q5q4q3q2q1
{q5}{q5}{q5}{q5}{q5}{q4}
{q2,q4}{q5}{q5}{q5}
ba
Zustandsüber-gangsdiagramm
Tabelle
a
6. Sprachen, Compiler und Theorie
6.2-47Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Sprachen
Eine Sprache L(X) ist Regulär wenn:Es gibt einen regulären Ausdruck R so dass gilt L(R) = L(X), oderEs gibt einen DFA MD so dass gilt L(MD) = L(X), oderEs gibt einen NFA MN so dass gilt L(MN) = L(X)
Die Sprachen der regulären Ausdrücke, DFA Sprachen und NFA Sprachen sind alle regulär
Gegeben ist beliebiger regulärer Ausdruck R und ein NFA MN, mit L(R)=L(MN)
Wir können jeden regulären Ausdruck in einen NFA konvertieren und umgekehrt
Gegeben ist ein beliebiger NFA MN und DFA MD, mit L(MN) = L(MD)Wir können jeden NFA in einen DFA konvertieren und umgekehrt
6. Sprachen, Compiler und Theorie
6.2-48Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Ausdrücke nach NFA (1/2)
Kleenesche Hülle: r*
Verkettung: r1.r2
Alternative: r1|r2
Leere Zeichenkette: є
Charakter: c
NFARegulärer Ausdruck
є є
r1 r2є
c
є
r1r2є є
rє є
є є

6. Sprachen, Compiler und Theorie
6.2-49Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
Reguläre Ausdrücke nach NFA (2/2)
r=‘ab’|’cd’Faktor:
r1=‘ab’r2=‘cd’r=r1.r2
b
a bє
r1:
c
dc dє
r2:
a bє
c dє
є
є
є
єr3:
6. Sprachen, Compiler und Theorie
6.2-50Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
NFAs nach DFAs (1/2)
Definition:є-FZ(s) ist die Menge aller Zustände, welche in s beinhaltet sind, plus aller von den Zuständen in s erreichbaren Zustände unter ausschließlicher Verwendung des є Überganges
Gegeben NFA M=(Q,Σ,q,F,δ) und DFA MD=(QD,Σ,qD,FD,δD)QD=P(Q), z.B., QD ist die Menge aller Untermengen von QFD = {S:∀S ∈QD wobei S∩F ≠ {} }qD= є-FZ (q)δD({q1,q2,…,qk},a) = є-FZ(δ(q1,a)∪ δ(q2,a)∪… ∪(δ(qk,a))
6. Sprachen, Compiler und Theorie
6.2-51Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Lexikalische Analyse
NFAs nach DFAs (2/2)
Schritt 1: Der StartzustandqD= є-FZ({q1}) = {q1,q2,q3}
Schritt 2: Zustand {q1,q2,q3}δD({q1,q2,q3},a) =є-FZ(δ(q1,a)∪δ(q2,a)∪δ(q3,a)) =є-FZ({q5}∪{q5}∪ {q4}) = {q4,q5}
δD({q1,q2,q3},b) =є-FZ(δ(q1,b)∪δ(q2,b)∪δ(q3,b)) =є-FZ({q2,q4}∪{q2,q4}∪ {q5}) = {q2,q4,q5}
Schritt 3: Zustand {q4,q5}…
Schritt 4: Zustand {q2,q4,q5}…
q1
q2
q3
q5
є b
b
є a
b
a,b
a,b
q4
NFAa
{q1,q2,q3}
b
a{q4,q5}
{q2,q4,q5}
{q5}a,b
a,b
a
b
DFA

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
3 – Syntaktische Analyse
6. Sprachen, Compiler und Theorie
6.3-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Der Kompilationsprozess (-phasen)
Scanner (lexikalische Analyse)
Parser (syntaktische Analyse)
Semantische Analyse
Zwischencodegenerierung
Optimierung
Zielcodegenerierung
Optimierung Maschinenebene
Lese Programm und konvertiere Zeichenstrom in Marken (tokens).
Lese Tokenstrom und generiere Parserbaum (parse tree).
Traversiere Parserbaum, überprüfe nicht-syntaktische Regeln.
Traversiere Parserbaum noch mal, gebe Zwischencode aus.
Untersuche Zwischencode, versuche ihn zu verbessern.
Übersetze Zwischencode in Assembler-/Maschinencode
Untersuche Maschinencode, versuche ihn zu verbessern.
6. Sprachen, Compiler und Theorie
6.3-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Lexikalische Analyse
Die lexikalische Analyse gruppiert Zeichensequenzen in Tokens(Marken) bzw. SymboleTokens sind die kleinste „Bedeutungseinheit“ (units of meaning) im Kompilationsprozess und sind die Grundlage (foundation) fürs Parsen (Syntaxanalyse)Die Compilerkomponente zum Ausführen der lexikalischen Analyse ist der Scanner, welcher oftmals ausgehend von höheren Spezifikationen automatisch generiert wird
6. Sprachen, Compiler und Theorie
6.3-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Der Kompilationsprozess (-phasen)
Scanner (lexikalische Analyse)
Parser (syntaktische Analyse)
Semantische Analyse
Zwischencodegenerierung
Optimierung
Zielcodegenerierung
Optimierung Maschinenebene
Lese Programm und konvertiere Zeichenstrom in Marken (tokens).
Lese Tokenstrom und generiere Ableitungsbaum (parse tree).
Traversiere Parserbaum, überprüfe nicht-syntaktische Regeln.
Traversiere Parserbaum noch mal, gebe Zwischencode aus.
Untersuche Zwischencode, versuche ihn zu verbessern.
Übersetze Zwischencode in Assembler-/Maschinencode
Untersuche Maschinencode, versuche ihn zu verbessern.

6. Sprachen, Compiler und Theorie
6.3-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaktische Analyse
Die lexikalische Analyse erzeugt einen Strom von Symbolen (Tokens)Falsche Detailebene für die semantische Analyse und CodegenerierungDie Syntaxanalyse gruppiert eine Zeichenfolge von Tokens in Ableitungsbäume (Struktur-/Parser-/Syntaxbäume), was durch die kontextfreie Grammatik gelenkt wird, die die Syntax der zu kompilierenden Sprache spezifiziert
conditional -> if ( expr ) block else blockAbleitungsbäume repräsentieren die Phrasenstruktur eines Programms und sind die Grundlage für die semantische Analyse und CodegenerierungDie Compilerkomponente zum Ausführen der syntaktischen Analyse ist der Parser, welcher oftmals ausgehend von höheren Spezifikationen automatisch generiert wird
6. Sprachen, Compiler und Theorie
6.3-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beispiel Syntaxanalyse
if ( i > j )i = i – j ;else j = j – i; }
Token conditional
if ( expr ) block else block
id comp id
i j>
statement
id = expr
i id op id
i j-
statement
id = expr
j id op id
j i-
6. Sprachen, Compiler und Theorie
6.3-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaxbeschreibung
Warum können wir nicht reguläre Ausdrücke zum Beschreiben der Syntax einer Programmiersprache verwenden? Betrachte die folgenden Beschreibungen:
Identitäten:digit=[0-9]letter=[a-z] id=letter.(letter|digit)*
Kann Identitäten von id durch Substitution entfernen:
id=[0-9].([a-z]|[0-9])*id ist ein regulärer Ausdruck
Identitäten:digits=[0-9]+sum=expr.’+’.exprexpr=(‘(‘.sum.’)’) | digits
Kann nicht Identitäten von exprdurch Substitution entfernen:
expr ist durch Rekursion definiertexpr ist kein regulärer Ausdruck
6. Sprachen, Compiler und Theorie
6.3-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kontextfreie Grammatiken (1/4)
Eine kontextfreie Grammatik (KFG/CFG) ist eine rekursive Definition einer Sprache mit:
Einem Alphabet Σ von Symbolen
Eine Menge von Produktionen (oder Regeln) der Formsymbol -> symbol symbol … symbol
Ein Startsymbol
Eine Menge von nicht-terminalen Symbolen aus dem Alphabet Σ, welche auf der linken oder rechten Seite einer Produktionsregel erscheinen darf (convention: written in all capital letters)
Eine Menge von terminalen Symbolen aus dem Alphabet Σ, welche nur auf der rechten Seite einer Produktionsregel erscheinen darf. (convention: written in all lower case letters)
Die Menge aller von einer CFG G erzeugten Strings wird die Sprache von Ggenannt und wird symbolisiert durch L(G)

6. Sprachen, Compiler und Theorie
6.3-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kontextfreie Grammatiken (2/4)
Kurzschreibweisen:Alternativen
s->a1..an|b1..bn|…|z1..zn =s->a1..ans->b1..bn…s->z1..zn
Kleenesche * Hülles->s1*s->s1’s1’->s1 s1’s1’->є
6. Sprachen, Compiler und Theorie
6.3-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kontextfreie Grammatiken (3/4)
Wenn eine CFG G zum Parsen von Programmiersprachen verwendet wird, dann gilt
L(G) ist die Menge von gültigen Quellprogrammen, unddie terminalen Symbole sind die Tokens, welche vom Scanner zurückgeliefert werdenKlammergrammatik
Beispiel:expr -> LPAREN sum RPARENexpr -> INTsum -> expr PLUS expr
Terminale: {PLUS,LPAREN,RPAREN,INT}Nichtterminale: {sum,expr}Startsymbol: {expr}Σ = Terminale ∪ Nichtterminale
6. Sprachen, Compiler und Theorie
6.3-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kontextfreie Grammatiken (4/4)
Eine CFG G erzeugt Zeichenketten durch:Beginne mit dem Startsymbol
s ⇒ s1 s2 … snErsetze ein nichtterminales Symbol sk auf der rechten Seite mit der rechten Seite dieses Nichtterminals
Gegeben: sk -> k1…kmDann: s ⇒ s1…sk…sn ⇒ s1…k1…km…sn
Wiederhole bis nur noch Terminal auf der linken Seite sindJeder Schritt in diesem Prozess wird Ableitung (derivation) genannt und jede Zeichenkette von Symbolen entlang dieses Weges wird Satzform genannt. Die abschließende Satzform, welche nur Terminalsymbole enthält, wird ein Satz (sentence) der Grammatik oder auch das Ergebnis (yield) des Ableitungsprozesses genannt
6. Sprachen, Compiler und Theorie
6.3-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen (1/4)
Grammatik:expr -> ( sum )expr -> INTsum -> expr + expr
Mögliche Ableitungen:expr ⇒ ( sum )⇒ ( expr + expr )⇒ ( INT + expr )⇒ (INT + ( sum ) )⇒ (INT + ( expr + expr ) )⇒ (INT + ( INT + expr ) )⇒ (INT + (INT + INT ) )

6. Sprachen, Compiler und Theorie
6.3-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen (2/4)
Rechtsseitige Ableitungen (rightmost derivations)Ersetze jeweils das äußerste rechte Nichtterminalsymbol in jedemAbleitungsschrittWird manchmal auch die kanonische Ableitung genannt
Linksseitige Ableitungen (leftmost derivations)Ersetze jeweils das äußerste linke Nichtterminalsymbol in jedem AbleitungsschrittSiehe vorherige Folie
Andere Ableitungsreihenfolgen sind möglich
Die meisten Parser suchen nach entweder einer rechtsseitigen oder linksseitigen Ableitung
6. Sprachen, Compiler und Theorie
6.3-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen (3/4)
Eine Ableitung (oder Herleitung) ist eine Operationenfolge von Ersetzungen, welche zeigen wie eine Zeichenkette von Terminalen(Tokens), ausgehend vom Startsymbol einer Grammatik, abgeleitet werden kann
Unter der Annahme es gibt eine Produktion X -> y, eine einzelne Ersatzoperation oder ein Ableitungsschritt, dann können diese beschrieben werden durch αXβ⇒αγβ, für beliebige Zeichenketten von Grammatiksymbolen α, β und γ
Kurzschreibweisen:α ⇒* β bedeutet β kann abgeleitet werden von α in 0 oder mehr Schrittenα ⇒+ β bedeutet β kann abgeleitet werden von α in 1 oder mehr Schrittenα ⇒n β bedeutet β kann abgeleitet werden von α in genau n Schritten
6. Sprachen, Compiler und Theorie
6.3-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen (4/4)
Linksseitige Ableitungen (leftmost derivations):Für jeden Ableitungsschritt αXβ⇒αγβ, muss X das äußerte linke Nichtterminal im String von Symbolen αXβ seinWird verwendet in LL(k) bzw. top-down parsen
Rechtsseitige Ableitungen (rightmost derivations):Für jeden Ableitungsschritt αXβ⇒αγβ, muss X das äußerte rechte Nichtterminal im String von Symbolen αXβ seinWird verwendet in LR(k) bzw. bottom-up parsenWird manchmal auch die kanonische Ableitung genannt
6. Sprachen, Compiler und Theorie
6.3-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beispiel Ableitungen
Grammatik:expr -> ( sum ) | INTsum -> expr + expr
Linksseitige Ableitung:expr ⇒ ( sum )⇒ ( expr + expr )⇒ ( INT + expr )⇒ (INT + ( sum ) )⇒ (INT + ( expr + expr ) )⇒ (INT + ( INT + expr ) )⇒ (INT + (INT + INT ) )
Rechtsseitige Ableitung:expr ⇒ ( sum )⇒ ( expr + expr )⇒ ( expr + ( sum ) )⇒ (expr + ( expr + expr) )⇒ (expr + ( expr + INT ) )⇒ (expr + ( INT + INT ) )⇒ (INT + (INT + INT ) )
Eingabe:(INT + (INT + INT))

6. Sprachen, Compiler und Theorie
6.3-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen und Ableitungsbäume (1/2)
Ein Ableitungsbaum ist eine graphische Repräsentation des Ableitungsprozesses
Blätter eines Ableitungsbaumes entsprechen den Terminalsymbolen (Token) der Grammatik
Innere Knoten von Ableitungsbäumen entsprechen den Nichtterminalsymbolen der Grammatik (Produktionen auf der linken Seite)
Die meisten Parser konstruieren einen Ableitungsbaum während des Ableitungsprozesses für eine spätere Analyse
6. Sprachen, Compiler und Theorie
6.3-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungen und Ableitungsbäume (2/2)
expr
⇒ ( sum)
⇒ ( expr + expr )
⇒ ( INT + expr )
⇒ (INT + ( sum ) )
⇒ (INT + ( expr + expr ) )
⇒ (INT + ( INT + expr ) )
⇒ (INT + (INT + INT ) )
expr
sum( )
expr + expr
INT
sum
expr + expr
( )
INT
INT
6. Sprachen, Compiler und Theorie
6.3-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Mehrdeutigkeiten (1/2)
Eine Grammatik gilt als Mehrdeutig, wenn ein Satz mit (mind.) zwei verschiedenen Ableitungsbäumen abgeleitet werden kannBeispiel – linksseitige versus rechtsseitige Ableitung:
Grammatik:expression -> identifier | number | - expression | ( expression ) |
expression operator expressionoperator -> + | - | * | /
Eingabe: slope * x + intercept
6. Sprachen, Compiler und Theorie
6.3-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Mehrdeutigkeiten (2/2)
Berühmteres Beispiel – “dangling else”Programmfragment: if a then if b then s1 else s2Kann interpretiert werden als:
1) if a then { if b then s1 else s2}2) if a then { if b then s1 } else s2
Mehrdeutigkeit kann manchmal durch die Auswahl eines akzeptierenden Ableitungsbaumes aus mehreren gehandhabt werden
Zum Beispiel, obige Interpretation #1 wird von den meisten Parsern für Sprachen die die „dangling else“ Mehrdeutigkeit haben ausgewählt
Generell ist Mehrdeutigkeit jedoch ein Zeichen dafür, dass die Grammatik „schlecht“ spezifiziert wurde und umgeschrieben werdensollte um Mehrdeutigkeiten zu beseitigen

6. Sprachen, Compiler und Theorie
6.3-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Grammatiken und Parser
Kontextfreie Grammatiken erzeugen durch den Ableitungsprozess Strings (oder Sätze)Die kontextfreien Sprachen sind definiert durch
LCF={L(G): Alle kontextfreien Grammatiken G}Mit anderen Worten: Die Menge aller Sprachen von allen kontextfreien Grammatiken
Ein Parser für eine kontextfreie Grammatik erkennt Strings in der GrammatikspracheParser können automatisch aus einer kontextfreien Grammatik generiert werdenParser zum Erkennen von allgemeinen kontextfreien Sprachen können langsam seinParser, die nur eine Untermenge von kontextfreien Sprachen erkennen können, können so gestaltet werden, dass sie schneller sind
6. Sprachen, Compiler und Theorie
6.3-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kellerautomat (1/4)
6. Sprachen, Compiler und Theorie
6.3-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kellerautomat (2/4)
Kontextfreie Grammatiken können von Kellerautomaten (Push Down Automata, PDA) erkannt werdenPDAs sind eine Erweiterung der endlichen Automaten um ein „einfaches“ Gedächtnis (Hilfsband)Eigenschaften eines Kellerautomaten:
Das Eingabeband kann sich nur in eine Richtung bewegen.Es existiert ein "Hilfsband", welches sich in beide Richtungen bewegen kann.Der Automat liest im ersten Schritt die jeweils erste Zelle beider Bänder.Als Reaktion des Automaten kann entweder das Hilfsband vorwärts bewegt und ein Zeichen in die nächste Zelle geschrieben werden oder das Symbol gelöscht und das Hilfsband eine Zelle zurück bewegt werden.
6. Sprachen, Compiler und Theorie
6.3-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kellerautomat (3/4)
Das Hilfsband heißt auch Kellerstapel oder einfach Stapel (engl.stack ).
Ein Element kann immer nur oben auf den Stapel gelegt (bzw. an das Ende des Bandes geschrieben) werden (= push ).Immer nur das oberste (letzte) Element kann wieder vom Stapel entfernt werden (= pop ).
Die erste Zelle des Hilfsbandes enthält eine spezielle Kennzeichnung, um anzuzeigen, wann der Stapel leer ist. Ein Kellerautomat kann bei leerem Stapel nicht weiterarbeiten.Kellerautomaten arbeiten eigentlich nicht-deterministisch, nichtdeterministische Kellerautomaten sind aber in deterministische überführbarε-Bewegungen sind erlaubtEine Eingabe wird genau dann erlaubt, wenn es möglich ist, eine Konfiguration zu erreichen, bei der die gesamte Eingabe gelesen wurde und der Stapel leer ist.

6. Sprachen, Compiler und Theorie
6.3-25Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Kellerautomat (4/4)
Ein Kellerautomat (=pushdown automaton, PDA) ist ein Septupel P = {Q, Σ, Γ, δ, q0, Z0, F } mit:
Q Zustandsmenge, |Q | < ∞Σ Eingabealphabet, |Σ| < ∞Γ Stackalphabet, |Γ| < ∞δ Übergangsfunktion (ZustandsÜF)
δ(q,a,X) mit q ∈ Q, a ∈ {Σ, ε}, X ∈ Γq0 AnfangszustandZ0 Startsymbol (für Stack)F Endzustände, F ⊆ Q
6. Sprachen, Compiler und Theorie
6.3-26Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
PDA-Übergangsfunktionen
Die Ausgabe von δ besteht aus einer endlichen Menge von Paaren (p, γ), wobei p für den neuen Zustand und γ für die Zeichenreihe der Stack-symbole steht, die X auf dem oberen Ende des Stacks ersetzt.
Wenn γ = ε, dann wird das oberste Stacksymbol wird gelöscht. (pop-Operation)Wenn γ = X, dann bleibt der Stack unverändert.Wenn γ = YZ, dann wird X durch Z ersetzt und Y zuoberst auf dem Stack abgelegt. (push-Operation)
Da PDAs nicht-deterministisch arbeiten, kann die Ausgabe von δ eine Menge an Paaren ergeben, z.B.
δ(q, a, X) = { (p, YZ), (r, ε) }Die Paare müssen dabei als Einheit betrachtet und behandelt werden.Wenn sich der PDA im Zustand q befindet, X das oberste Stacksymbolist und die Eingabe a gelesen wird, kann
in den Zustand p gewechselt und X durch YZ ersetzt werden, oderin den Zustand r gewechselt und X vom Stack entfernt werden.
6. Sprachen, Compiler und Theorie
6.3-27Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beispiel PDA: Palindrome
Formelle Beschreibung: P = ({q0,q1,q2},{0,1},{0,1,Z0}, δ, q0, Z0, {q2})
δ(q0, 0, Z0) = {(q0,0 Z0)} lesen und pushδ(q0, 1, Z0) = {(q0,1 Z0)}δ(q0, 0, 0) = {(q0,00)} lesen und pushδ(q0, 0, 1) = {(q0,01)}δ(q0, 1, 0) = {(q0,10)}δ(q0, 1, 1) = {(q0,11)}δ(q0, ε, Z0)= {(q1, Z0)} Wechsel nach q1, ohne Stackδ(q0, ε, 0) = {(q1, 0)} zu verändernδ(q0, ε, 1) = {(q1, 1)}δ(q1, 0, 0) = {(q1, ε)} lesen, vergleichen, popδ(q1, 1, 1) = {(q1, ε)}δ(q1, ε, Z0)= {(q2, Z0)} Z0 erreicht, akzeptiert
6. Sprachen, Compiler und Theorie
6.3-28Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Schreibkonventionen für PDAs
a, b, ... ∈ Σp, q, ... ∈ Qw, z, ... = Zeichenreihen aus Σ (Terminale)X, Y, ... = Γα, β, γ, ... = Zeichenreihen aus Γ (Nichtterminale)

6. Sprachen, Compiler und Theorie
6.3-29Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beschreibung der Konfiguration eines PDA (1/2)
Im Gegensatz zum endlichen Automaten, bei denen lediglich der Zustand (neben dem Eingabesymbol) für einen Übergang von Bedeutung ist, umfasst die Konfiguration eines PDA sowohl den Zustand als auch den Inhalt des Stacks.
Die Konfiguration wird daher durch das Tripel (q, w, γ) dargestellt, wobei
q für den Zustand,w für die verbleibende Eingabe,γ für den Inhalt des Stacks steht.
(Das obere Ende des Stacks steht am linken Ende von γ.)
6. Sprachen, Compiler und Theorie
6.3-30Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beschreibung der Konfiguration eines PDA (2/2)
Sei P = {Q, Σ, Γ, δ, q0, Z0, F } ein PDA.
Angenommen, δ(q, a, X) enthält (p, α).Dann gilt für alle Zeichenreihen w aus Σ* und β aus Γ*:
(q, aw, X β) ⊢ (p, w, αβ)
D.h., der Automat kann vom Zustand q in den Zustand p übergehen, indem er das Symbol a (das ε sein kann) aus der Eingabe einliest und X auf dem Stack durch α ersetzt. (Die restliche Eingabe w und der restliche Inhalt des Stacks β beeinflussen die Aktion des PDA nicht!)
6. Sprachen, Compiler und Theorie
6.3-31Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Akzeptanzzustände von PDAs
Es gibt zwei Ansätze, wann ein PDA eine Eingabe akzeptiert:Akzeptanz durch EndzustandAkzeptanz durch leeren Stack
Zwar unterscheiden sich die Sprachen, die die jeweiligen PDAsakzeptieren, aber sie sind jeweils ineinander überführbar.Akzeptanz durch Endzustand
Sei P = {Q, Σ, Γ, δ, q0, Z0, F } ein PDA.Dann ist die Sprache L(P ), die von P durch Endzustand akzeptiert wird,{w | (q0, w, Z0) ⊢ (q, ε, β) für einen Zustand q in F und eine Stackzeichenreihe α.
Akzeptanz durch leeren StackSei P = {Q, Σ, Γ, δ, q0, Z0, F } ein PDA.Dann ist die Sprache N(P ), die von P durch Endzustand akzeptiert wird,{w | (q0, w, Z0) ⊢ (q, ε, ε) für einen beliebigen Zustand q.N(P) ist die Menge der Eingabezeichenreihen w, die P einlesen kann und bei der er gleichzeitig den Stack leeren kann.
*p
*
6. Sprachen, Compiler und Theorie
6.3-32Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Klassen von Grammatiken und Parsern
LL(k) ParserEingabe wird von links-nach-rechts(1. L) abgearbeitetlinksseitige Ableitung (2. L)“top down” oder “prädiktive” (voraussagende) Parser genannt
LR(k) parsersEingabe wird von links-nach-rechts(1. L) abgearbeitetrechtsseitige Ableitung (2. R)“bottom up” oder “schiebe-reduziere“ (shift-reduce) Parser genannt
“k” steht für die Anzahl von Symbolen (token) für die in der Eingabe vorausgeschaut werden muss um eine Entscheidung treffen zu können
LL(k) – welche nächste Produktion auf der rechten Seite ist bei einer linksseitigen Ableitung zu wählenLR(k) – ob zu schieben oder reduzieren

6. Sprachen, Compiler und Theorie
6.3-33Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Top-down versus Bottom-up Syntaxanalyse (1/2)
Top-down oder LL-SyntaxanalyseBaue den Ableitungsbaum von der Wurzel aus bis hinunter zu den Blättern aufBerechne in jedem Schritt voraus welche Produktion zu verwenden ist um den aktuellen nichtterminalen Knoten des Ableitungsbaumes aufzuweiten (expand), indem die nächsten k Eingabesymbole betrachtet werden
Bottom-up oder LR-SyntaxanalyseBaue den Ableitungsbaum von den Blättern aus bis hinauf zu der Wurzel aufErmittle in jedem Schritt, ob eine Kollektion von Ableitungsbaumknoten zu einem einzelnen Vorgängerknoten zusammengefasst werden kann oder nicht
6. Sprachen, Compiler und Theorie
6.3-34Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Top-down versusBottom-up Syntaxanalyse (2/2)
Grammatik:
id_list -> id id_list_tailid_list_tail -> , id id_list_tailid_list_tail -> ;
Beispiel Strings:
A;A, B, C;
6. Sprachen, Compiler und Theorie
6.3-35Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaxanalyse durch rekursiven Abstieg (1/4)
Rekursiver Abstieg ist ein Weg um LL (top-down) Parser zu implementieren
Es ist einfach von Hand zu schreibenEs wird kein Parsergenerator benötigt
Jedes nichtterminale Symbol in der Grammatik hat einen Prozeduraufruf
Es muss im Stande sein die nächste, anzuwendende, linksseitige Ableitung zu bestimmen (predict), indem nur die nächsten k Symbole angeschaut werden
k ist üblicherweise 1
6. Sprachen, Compiler und Theorie
6.3-36Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaxanalyse durch rekursiven Abstieg (2/4)
Rekursiver Abstieg ist ein Weg um LL(1)-Parser zu implementieren:Erinnerung: LL(1)-Parser machen linksseitige Ableitungen, unter Verwendung von höchstens 1 Symbol in der Vorausschau, um zu entscheiden welche rechte Seite einer Produktion verwendet wird, um ein linksseitiges Nichtterminal in einer Satzform zu ersetzen.
LL(1)-Parser Beispiel:Grammatikfragment:
factor -> ( expr ) | [ sexpr ]Wenn die Satzform “n1 … nk factor sm … sn” lautet, dann sollte die nächste Satzform folgende sein:
“n1 … nk ( expr ) sm … sn” oder“n1 … nk [ sexpr ] sm … sn”

6. Sprachen, Compiler und Theorie
6.3-37Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaxanalyse durch rekursiven Abstieg (3/4)
Grammatik für eine Kalkulatorsprache
Beispieleingabe:read Aread Bsum := A + Bwrite sumwrite sum / 2
6. Sprachen, Compiler und Theorie
6.3-38Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Syntaxanalyse durch rekursiven Abstieg (4/4)
Ableitungsbaum für Beispieleingabe:
read Aread Bsum := A + Bwrite sumwrite sum / 2
6. Sprachen, Compiler und Theorie
6.3-39Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
LL-Syntaxanalyse
Finde zu einer Eingabe von Terminalsymbolen (tokens) passende Produktionen in einer Grammatik durch Herstellung von linksseitigen Ableitungen
Für eine gegebene Menge von Produktionen für ein Nichtterminal, X->y1|…|γn, und einen gegebenen, linksseitigen Ableitungsschritt αXβ⇒ αγiβ, müssen wir im Stande sein zu bestimmen welches γizu wählen ist indem nur die nächsten k Eingabesymbole angeschaut werden
Anmerkung:Für eine gegebene Menge von linksseitigen Ableitungsschritten, ausgehend vom Startsymbol S ⇒ αXβ, wird der String von Symbolen α nur aus Terminalen bestehen und repräsentiert den passenden Eingabeabschnitt zu den bisherigen Grammatikproduktionen
6. Sprachen, Compiler und Theorie
6.3-40Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Probleme mit der LL-Syntaxanalyse (1/4)
LinksrekursionProduktionen von der Form:
A -> AαA -> β
Wenn eine Grammatik linksrekursive Produktionen enthält, dann kann es dafür keinen LL Parser geben
LL Parser würden in eine Endlosschleife eintreten, wenn versucht wird eine linksseitige Ableitung in solch einer Grammatik vorzunehmen
Linksrekursion kann durch das Umschreiben der Grammatik ausgeschlossen werden
A -> βA’A’ -> αA’ | є

6. Sprachen, Compiler und Theorie
6.3-41Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Probleme mit der LL-Syntaxanalyse (2/4)
Originalgrammatik:A -> AαA -> β
Ableitungen:A ⇒ Aα ⇒ Aαα⇒ Aααα⇒*
βααα…
Umgeschriebene Grammatik:A -> βA’A’ -> αA’ | є
Ableitungen:A ⇒ βA’ ⇒ βαA’ ⇒ βααA’ ⇒*
βααα…
Linksrekursion: BeispielGrammatik:
id_list -> id_list_prefix ;id_list_prefix -> id_list_prefix , id | id
Linksrekursion kann durch das Umschreiben der Grammatik ausgeschlossen werden
id_list -> id id_list_tailid_list_tail -> , id id_list_tail | ;
Linksrekursion: Nicht formale Rechtfertigung
6. Sprachen, Compiler und Theorie
6.3-42Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Probleme mit der LL-Syntaxanalyse (3/4)
Gemeinsame PräfixeTritt auf wenn zwei verschiedene Produktionen mit der gleichen linken Seite mit den gleichen Symbolen anfangen
Produktionen der Form:A -> bαA -> bβ
LL(1) Parser kann nicht entscheiden welche Regel auszuwählen ist, wenn A in einem linksseitigen Ableitungsschritt zu ersetzen ist, weil beide rechten Seiten mit dem gleichen Terminalsymbol anfangen
Kann durch Faktorisierung ausgeschlossen werden:A -> bA’A’ -> α | β
6. Sprachen, Compiler und Theorie
6.3-43Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Probleme mit der LL-Syntaxanalyse (4/4)
Gemeinsame PräfixeBeispiel:
stmt -> id := exprstmt -> id ( argument_list )
Gemeinsame Präfixe können durch das Umschreiben der Grammatik ausgeschlossen werden
stmt -> id stmt_list_tailstmt_list_tail -> expr | ( argument_list )
Der Ausschluss von Linksrekursion und gemeinsame Präfixe garantiert nicht das eine Grammatik LL wirdWenn wir keinen LL Parser für eine Grammatik finden können, dannmüssen wir einen mächtigere Technik verwenden
z.B., LALR(1) – Grammatiken
6. Sprachen, Compiler und Theorie
6.3-44Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Bau eines Top-Down Parsers mit rekursivem Abstieg (1/2)
Für jedes Nichtterminal in einer Grammatik wird ein Unterprogramm erzeugt, welches einem einzelnen linksseitigen Ableitungsschrittentspricht, wenn es aufgerufen wird
Beispiel:factor -> ( expr )factor -> [ sexpr ]
Schwieriger Teil:Herausbekommen welches Token den ‚case‘ Arm vom switch Befehl benennt
void factor (void) {switch(next_token()) {
case ‘(‘: expr(); match(‘)’); break;
case ‘[‘:sexpr(); match(‘]’); break;
}}

6. Sprachen, Compiler und Theorie
6.3-45Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Bau eines Top-Down Parsers mit rekursivem Abstieg (2/2)
PREDICT-Mengen (Vorhersagemengen)PREDICT Mengen teilen uns mit, welche rechte Seite einer Produktion bei einer linken Ableitung auszuwählen ist, wenn mehrere zur Auswahl stehenPREDICT-Mengen dienen somit als Grundlage für Ableitungstabellen (Parse-Tabellen) bzw. sind eine andere Teildarstellungsform für die TabellenWird in Form von FIRST-, FOLLOW- und NULLABLE-Mengen definiert :
Sei A ein Nichtterminal und α beliebig, dann giltPREDICT(A->α) = FIRST(α) ∪ FOLLOW(A) wenn NULLABLE(α)PREDICT(A->α) = FIRST(α) wenn nicht NULLABLE(α)
NULLABLE-MengenSei X ein NichtterminalNULLABLE(X) ist wahr wenn gilt X ⇒* є (X kann den leeren String ableiten)
6. Sprachen, Compiler und Theorie
6.3-46Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
FIRST-Mengen
Sei α eine beliebige Folge von Grammatiksymbolen (Terminaleund Nichtterminale)
FIRST(α) ist die Menge aller Terminalsymbolen a mit denen ein aus α abgeleiteter String beginnen kann:
FIRST(α) ist { a: α⇒* aβ}
Gilt α⇒* є, dann ist auch є in FIRST(α)
6. Sprachen, Compiler und Theorie
6.3-47Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Berechnung von FIRST-Mengen (1/2)
Für alle Grammatiksymbole X wird FIRST(X) berechnet, indem die folgenden Regeln solange angewandt werden, bis zu keiner FIRST-Menge mehr ein neues Terminal oder є hinzukommt:
1. Wenn X ein Terminal ist, dann ist FIRST(X)={X}
2. Wenn eine Produktion ist, dann füge zu FIRST(X) hinzu
3. Wenn X Nichtterminal und eine Produktion ist, dann nehme a zu FIRST(X) hinzu, falls (a) a für irgendein i in FIRST(Yi) und (b) ein in allen FIRST(Y1), ..., FIRST(Yi-1) enthalten ist (Y1...Yi-1 sind alle
NULLABLE)
εX → ε
kYYYYX K321→
ε
6. Sprachen, Compiler und Theorie
6.3-48Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Berechnung von FIRST-Mengen (2/2)
Folglich gilt: Elemente aus FIRST(Y1) gehören immer auch zu FIRST(X)
Ist є nicht aus Y1 ableitbar (NICHT NULLABLE), dann brauch nichts mehr hinzugefügt werden
Ist є aus Y1 ableitbar (NULLABLE), dann muss auch FIRST(Y2) zu FIRST(X) hinzugefügt werden
Ist є aus Y2 ableitbar (NULLABLE), dann muss auch FIRST(Y3) zu FIRST(X) hinzugefügt werdenusw.
є wird nur zu FIRST(X) hinzugefügt, wenn es in allen Mengen FIRST(Y1), ... ,FIRST(Yk) enthalten ist
6. Sprachen, Compiler und Theorie
6.3-49Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
FOLLOW-Mengen
Sei A ein Nichtterminal
FOLLOW(A) ist die Menge aller Terminalsymbole a, die in einer Satzform direkt rechts neben A stehen können ( sei S Startregel; α, β beliebig):
FOLLOW(A) ist { a:S ⇒* αAaβ }
Achtung: Zwischen A und a können während der Ableitung Symbole gestanden haben, die aber verschwunden sind, weil aus Ihnen є abgeleitet wurde!
Gibt es eine Satzform, in der A das am weitesten rechts stehendeSymbol ist, dann gehört auch $ (die Endemarkierung) zu FOLLOW(A)
6. Sprachen, Compiler und Theorie
6.3-50Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Berechnung von FOLLOW-Mengen
Follow(A) wird für alle Nichtterminale A berechnet, indem die folgenden Regeln solange angewandt werden, bis keine Follow-Menge mehr vergrößert werden kann:
1. Sei S das Startsymbol und $ die Endemarkierung, dann nehme $ in FOLLOW(S) auf
2. Wenn es eine Produktion gibt, dann wird jedes Element von FIRST( ) mit Ausnahme von auch in FOLLOW(B) aufgenommen.
3. Wenn es Produktionen oder gibt und FIRST( ) enthält (d.h. β⇒* ), dann gehört jedes Element von FOLLOW(A) auch zu FOLLOW(B)
βαBA→β ε
BA α→ βαBA→ β εε
6. Sprachen, Compiler und Theorie
6.3-51Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Beispiel für NULLABLE-, FIRST- und FOLLOW-Mengen
A -> aB -> bS -> A B S A -> BB -> єS -> s$
FOLLOWFIRSTNULLABLE
{$}{s}FalseS{}{b, є}TrueB{}{a}FalseA
Schritt 1: i=0FOLLOWFIRSTNULLABLE
{$}{s,a}FalseS{s}{b, є}TrueB{b}{a,b,є}TrueA
Schritt 2: i=1
FOLLOWFIRSTNULLABLE
{$}{s,a,b}FalseS{s,a}{b, є}TrueB{b,s}{a,b,є}TrueA
Schritt 3: i=2FOLLOWFIRSTNULLABLE
{$}{s,a,b}FalseS{s,a,b}{b, є}TrueB{b,s,a}{a,b,є}TrueA
Schritt 4: i=3
6. Sprachen, Compiler und Theorie
6.3-52Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
FOLLOWFIRSTNULLABLE
{$}{s,a,b}FalseS{s,a,b}{b, є}TrueB{b,s,a}{a,b,є}TrueA
Beispiel für PREDICT-Mengen
{a,b,s}S->ABS
{b, є}B->b{a,b,s}B->є
PREDICT
{s}S->s$
{a}A->a{a,b,є,s}A->B PREDICT-Mengen zeigen uns welche
Menge von look-ahead Symbolen die rechte Seite einer Produktion selektiertDiese Grammatik ist NICHT LL(1), da es duplizierte Symbole in den PREDICT-Mengen für alle drei Nichtterminale gibt
Siehe Hervorhebungen (dick, rot)
A -> aB -> bS -> A B S A -> BB -> єS -> s$

6. Sprachen, Compiler und Theorie
6.3-53Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
LL(k) Eigenschaften
Satz: Jede kontextfreie Grammatik G ist genau dann LL(1), wenn für alle Alternativen A ⇒ α1| α2 | ... | αn gilt1. FIRST(α1), ..., First(αn) paarweise disjunkt,2. falls αi ⇒* є gilt, dann FIRST1(αj) ∩ FOLLOW1(A) = Ø für 1 ≤ j ≤ n, j ≠ i
In Worten:Aus α1, α2 , ... und αn sind jeweils keine Strings ableitbar, wo zwei mit dem gleichen Nichtterminal anfangenDer leere String є kann nicht sowohl aus αi und αj für i ≠ j abgeleitet werdenFalls αi ⇒* є gilt, dann beginnt kein aus αi ableitbarer String mit einem Terminal aus FOLLOW(A)
Satz: Sei G kontextfreie Grammatik, k ≥ 0. G ist genau dann LL(k), wenn gilt:Sind A ⇒ β, A ⇒ ζ verschiedene Produktionen, dann Firstk(βα) ∩ FIRSTk(ζα) = Ø für alle α, σ mit S ⇒* σ A α
6. Sprachen, Compiler und Theorie
6.3-54Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungsbäume und Parser mit rekursivem Abstieg (1/2)
Die Beispielparser auf die wir bisher geschaut haben sind nur Erkenner
Sie bestimmen, ob eine Eingabe syntaktisch korrekt ist, aber bauen keinen Ableitungsbaum
Wie konstruieren wir dann einen Ableitungsbaum?In Parser mit rekursivem Abstieg machen wir für jede nichtterminaleFunktion:
Konstruktion eines korrekten Ableitungsbaumknoten für sich selbst und Verbindungen zu seinen KindernGeben den konstruierten Ableitungsbaumknoten an den Aufrufer zurück
6. Sprachen, Compiler und Theorie
6.3-55Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ableitungsbäume und Parser mit rekursivem Abstieg (2/2)
Beispiel: Jedes nichtterminale Unterprogramm konstruiert einen Ableitungsbaumknoten
factor -> ( expr )factor -> [ sexpr ]
Nicht alle Symbole werden zu einem Ableitungsbaumknoten
Beispiele: ‘(‘, ‘)’, ‘[‘, ‘]’Diese Art von Ableitungsbaum wird „Abstrakter Syntaxbaum“ (abstract syntax tree, AST) genannt
node *factor (void) {switch(next_token()) {
case ‘(‘: node = factor_node(expr());match(‘)’); break;
case ‘[‘:node = factor_node(sexpr());match(‘]’); break;
}return node;
}
6. Sprachen, Compiler und Theorie
6.3-56Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Parsergeneratoren und Syntaxanalyse
Parsergeneratoren erzeugen ausgehend von der kontextfreien Grammatik einen ParserAn Produktionen dürfen semantische Aktionen angehängt sein
Wenn ein Parser eine Produktion erkannt hat, dann wird die semantische Aktion aufgerufenWird hauptsächlich dazu verwendet einen Ableitungsbaum explizit zu konstruieren
Die Ausgabe eines Parsergenerators ist ein Programm in einer Hochsprache (z.B. C, C++, oder Java) welches einen Symbolstrom (token stream) von einem Lexer (für die lexikalische Analyse) entgegen nimmt und welches einen Ableitungsbaum für die nachfolgenden Compilerphasen produziert
6. Sprachen, Compiler und Theorie
6.3-57Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
ANTLR als Beispiel eines Parsergenerators
ANTLR Grammatik-spezifikation
(parser.g)
ANTLR
(java antlr.Tool parser.g)
parser.javasymbols.java
javac parser.java
java parser.class
Eingabe10+(27-5);(44-2)-(1-10);
Ausgabe=32=51
lexikalischerAnalysator
(scanner.class)
6. Sprachen, Compiler und Theorie
6.3-58Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Rückblick
Kontextfreie Grammatiken (KFG) und Sprachen (KFS), KellerautomatWichtige Algorithmen:
Auflösung von Linksrekursion und gemeinsame PräfixeFIRST, FOLLOW, NULLABLE und PREDICT Mengen für kontextfreie Grammatiken
Syntaktische Analyse und ParserDie Syntax einer Programmiersprache wird mit KFGs spezifiziertKonstruktion eines Parsers mit rekursivem Abstieg anhand von KFGsAutomatische Generierung von Parsern anhand von KFGsParser erzeugen Ableitungsbäume für die Analyse und weitere Verarbeitung in den nachfolgenden Compilerphasen
6. Sprachen, Compiler und Theorie
6.3-59Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Syntaktische Analyse
Ausblick
Namen, Bindungen und Gültigkeitsbereiche (Kapitel 3)Objektlebenszeit und SpeichermanagementKontrollfluss (Kapitel 6)Zusammenführung (Bau eines ausführbaren Programms) (Kapitel 9)

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
4 – Namen, Bindungen und Gültigkeitsbereiche
6. Sprachen, Compiler und Theorie
6.4-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Namen, Bindungen und Gültigkeitsbereiche (1/3)
NamenEin mnemonischer Zeichenname wird verwendet um irgendetwas anderes zu repräsentieren oder zu benennen (Mnemonic ist die Bezeichnung für Ausdrücke deren Bedeutung vorwiegend durch die verwendete Buchstabenfolge leicht behalten werden kann.)
Normalerweise Bezeichner (identifier)Ist essentiell für Abstraktion
Erlaubt es Programmierern Werte zu bezeichnen damit die Notwendigkeit zur direkten Manipulation von Adressen, Registernamen, etc. vermieden wird
Beispiel: Es ist nicht notwendig zu wissen ob die Variable foo im Register $t0 oder an der Speicherstelle 10000 gespeichert wird
Erlaubt es Programmierern einen einfachen Namen für ein potenziell komplexes Programmstück stehen zu lassen
Beispiel: foo = a*a + b*b + c*c + d*d;Beide Fälle verringern die konzeptuelle Komplexität
6. Sprachen, Compiler und Theorie
6.4-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Namen, Bindungen und Gültigkeitsbereiche (2/3)
BindungenIst eine Assoziation zwischen zwei Dingen
Ein Variablenname zu einem WertEin Variablenname zu einer spezifischen SpeicherstelleEin Typ und seine Repräsentation oder Layout im Speicher
Die Bindezeit ist die Zeit zu der eine solche Assoziation gemacht wird
6. Sprachen, Compiler und Theorie
6.4-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Namen, Bindungen und Gültigkeitsbereiche (3/3)
Gültigkeitsbereiche (Scope)Ist der Textbereich eines Programms in welchem eine Bindung aktiv istJava Beispiel:
public void foo (int a) {int b;while(a < n) {
int c;c = a + a;b = a * c;a++;
}}
Verbessert die Abstraktion durch die Kontrolle über die Sichtbarkeit von Bindungen
Global Scope
Method Scope
Block Scope

6. Sprachen, Compiler und Theorie
6.4-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (1/8)
Wir unterscheiden 7 Zeitpunkte für die Entscheidung über eine Bindung
SpracheEntwurfImplementierung (mit Compilern)
ProgrammProgrammierung (Schreiben des Programms)KompilationLinkenLadenAusführen
6. Sprachen, Compiler und Theorie
6.4-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (2/8)
Zeitpunkt des Sprachentwurfs
Entscheidungen welche vom Designer der Programmiersprache gemacht wurden
Typische Beispiele:Binden von Kontrollstrukturen (Bedingungen, Schleifen, etc.) zu Ihrer abstrakten Bedeutung
„Befehle in einem while Schleifenblock werden ausgeführt bis die Bedingung nicht mehr länger wahr ist“
Binden von primitiven Datentypnamen (int, float, char, etc.) zu Ihrer geforderten Repräsentation
„Variablen vom Typ int beinhalten vorzeichenbehaftete Ganzzahlen“„Variablen vom Typ int beinhalten vorzeichenbehaftete 32-bit Werte“
6. Sprachen, Compiler und Theorie
6.4-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (3/8)
Zeitpunkt der Sprachimplementierung
Entscheidungen welche vom Compiler bzw. vom Compilerprogrammierer gemacht wurden
Mit anderen Worten, Angelegenheiten der Sprachimplementierung die nicht spezifisch während des Sprachentwurfs definiert wurden
Typische Beispiele:Binden von primitiven Datentypen zu deren Repräsentationsgenauigkeit (Anzahl der Bits)
„bytes sind 8-bits, shorts sind 16-bits, ints sind 32-bits, longs sind 64-bits“
Binden von Dateioperationen zur betriebssystemspezifischen Implementierung dieser Operationen
open() ist mit einem SYS_open Systemaufruf implementiert
6. Sprachen, Compiler und Theorie
6.4-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (4/8)
Zeitpunkt des ProgrammierensEntscheidungen des ProgrammierersTypische Beispiele:
Binden eines Algorithmus zu den Befehlen der Programmiersprache mit denen der Algorithmus implementiert istBinden von Namen zu Variablen, welche für einen Algorithmus erforderlich sindBinden von Datenstrukturen zu Sprachdatentypen
Zeitpunkt der KompilationEntscheidungen des CompilersTypische Beispiele:
Binden von höheren Konstrukten zu Maschinencode (Optimierung eingeschlossen)Binden von statisch definierten Datenstrukturen zu einem spezifischen SpeicherlayoutBinden von benutzerdefinierten Datentypen zu einem spezifischen Speicherlayout

6. Sprachen, Compiler und Theorie
6.4-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (5/8)
Zeitpunkt des Verbindens (linken)Entscheidungen des Linkers
Linker binden Programmmodule zusammenTypische Beispiele:
Binden von Objekten (Unterprogramme und Daten) zu einem spezifischen Platz in einer ausführbaren DateiBinden von Namen, welche Objekte in anderen Modulen referenzieren, zu deren tatsächlichen Ortsreferenz
Zeitpunkt des LadensEntscheidungen des Laders
Lader holen ausführbare Dateien in den SpeicherTypische Beispiele:
Binden von virtuellen Adressen in der ausführbaren Datei zu den physikalischen Speicheradressen
In modernen Betriebssystemen nicht mehr wirklich notwendig, da das Betriebssystem virtuelle Adresse zu physikalischen Adressen bindet in dem es virtuellen Speicher (einschließlich der notwendiger Hardware) verwendet
6. Sprachen, Compiler und Theorie
6.4-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (6/8)
Zeitpunkt der Programmausführung
Entscheidungen welche während der Programmausführung gemacht werden
Typische Beispiele:Binden von konkreten Werten zu Programmvariablen
„a = a + 1;“Binden von Referenzen von dynamisch zugeteilten Objekten zu SpeicheradressenBinden von Namen zu Objekten in Sprachen mit dynamischen Gültigkeitsbereichen
6. Sprachen, Compiler und Theorie
6.4-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (7/8)
Ähnliche Bindeentscheidungen können zu mehrerenBindezeitpunkten durchgeführt werden
Linkentscheidungen können zur Linkzeit, Ladezeit (ein Typ des dynamischen Linken) oder Laufzeit (ein anderer Typ des dynamischen Linkens) auftretenOptimierungsentscheidungen können zur Compilezeit, Linkzeit, Ladezeit und sogar zur Laufzeit (dynamische Optimierung) auftreten
Bindeentscheidungen können zu verschiedenen Bindezeitpunkten in verschiedenen Sprachen getroffen werden
C bindet Variablennamen an die referenzierten Objekte zur CompilezeitWenn wir in C sagen „foo=bar;“, dann wissen wir genau ob foo und bar global oder lokal sind oder nicht, von welchem Typ sie sind, ob ihre Typen für Zuweisungen kompatibel sind oder nicht, etc.
Perl (und gilt eigentlich für alle interpretierten Sprachen) bindet Variablennamen an die referenzierten Objekte zur Laufzeit
Wir können in Perl sagen „$foo=$bar;“, und wenn der Name $bar nicht schon an ein Objekt gebunden ist, dann wird eines erzeugt, und dann zu $foo zugewiesen
6. Sprachen, Compiler und Theorie
6.4-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Bindezeitpunkte (8/8)
Statisches Binden (static binding)Bezieht sich auf alle Bindeentscheidungen die vor der Laufzeit gemacht werden
Dynamisches Binden (dynamic binding)Bezieht sich auf alle Bindeentscheidungen die zur Laufzeit gemacht werden
Frühe BindezeitpunkteVerbunden mit größerer Effizienz
Kompilierte Sprachen laufen typischerweise viel schneller, weil die meisten Bindeentscheidungen zur Compilezeit getroffen wurdenIst eine Bindeentscheidung aber erst einmal getroffen worden, dann verlieren wir auch einiges an Flexibilität
Späte BindezeitpunkteVerbunden mit größerer Flexibilität
Interpretierte Sprachen erlauben es die meisten Bindeentscheidungen zur Laufzeit zu treffen, was eine größere Flexibilität erlaubt
Zum Beispiel, die meisten interpretierten Sprachen erlauben es einem Programm Fragmente eines anderen Programms dynamisch zu generieren und auszuführen
Da Bindeentscheidungen zur Laufzeit getroffen werden, können interpretierte Sprachen langsam sein

6. Sprachen, Compiler und Theorie
6.4-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Zusammenfassung Namen und Bindungen
NamenEin mnemonischer Zeichenname wird verwendet um irgendetwas anderes zu repräsentieren oder zu benennen
Beispiel: Variable foo kann die Speicherstelle 10000 referenzieren
BindungenIst eine Assoziation zwischen zwei Dingen
Ein Name und das was er referenziert
BindezeitDie Bindezeit ist die Zeit zu der die Entscheidung über eine solche Assoziation gemacht wird
Beispiel: Ist der Wert von foo in einem Register oder im Speicher? (Entscheidung wird zur Compilezeit gemacht)
6. Sprachen, Compiler und Theorie
6.4-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Gültigkeitsbereiche
Textueller Bereich eines Programms in welchem eine Bindung aktiv istEs gibt grundsätzlich zwei Varianten:
Statische Gültigkeitsbereiche (static scopes)Es kann zur Compilezeit genau festgestellt werden welcher Name welches Objekt an welchen Punkten im Programm referenziert
Dynamische Gültigkeitsbereiche (dynamic scopes)Bindungen zwischen Namen und Objekten hängen vom Programmfluss zur Laufzeit ab
Nähere AusführungDer Prozess durch den eine Menge von Bindungen aktiv wird wenn die Kontrolle in einen Gültigkeitsbereich eintritt
Zum Beispiel die Allokation von Speicher um Objekte darin zu halten
6. Sprachen, Compiler und Theorie
6.4-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Gültigkeitsbereiche
Referenzierende Umgebung (referencing environment)Die Menge von aktiven Bindungen zu einem gegebenen Zeitpunkt in der ProgrammausführungWird durch die Regeln für Gültigkeitsbereiche einer Programmiersprache festgelegt
Statische GültigkeitsbereicheBindungen zwischen Namen und Objekten könne zur Compilezeitfestgestellt werdenEinfache Varianten
Frühe Versionen von BASIC hatten einen, globalen GültigkeitsbereichKomplexe Varianten
Moderne Programmiersprachen erlauben verschachtelte Unterprogramme und Module weshalb kompliziertere Regeln für Gültigkeitsbereiche erforderlich sind
6. Sprachen, Compiler und Theorie
6.4-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Static scope: Verschachtelte Unterprogramme
Frage:Welches Objekt wird von X im Funktionsblock von F1 referenziert?
Regel über den nächsten Gültigkeitsbereich(closest nested scope )
Referenzen von Variablen referenzieren das Objekt im naheliegendsten Gültigkeitsbereich

6. Sprachen, Compiler und Theorie
6.4-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Ein Problem welches nicht von verschachtelten Unterprogrammen behandelt wird (1/2)
Geheimnisprinzip (information hiding) für komplexe abstrakte Datentypen (ADT)Für einfache ADTs könnten Funktionen mit statischen lokalen Variablen funktionieren
Siehe Beispiel auf nächster Folie:Die Variable name_nums behält seinen Wert über Aufrufe von gen_new_name beiDies ist zu einfach für ADTs mit mehreren Funktionen die sich einen globalen Zustand teilen müssen
6. Sprachen, Compiler und Theorie
6.4-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Ein Problem welches nicht von verschachtelten Unterprogrammen behandelt wird (2/2)
6. Sprachen, Compiler und Theorie
6.4-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Module
Ein Modul erlaubt es eine Sammlung von Objekten zu kapseln, so dass
Objekte innerhalb eines Moduls sich gegenseitig sehen könnenObjekte innerhalb des Moduls nach außen nicht sichtbar sind, es sei denn sie werden explizit exportiertObjekte von außerhalb nach innen nicht sichtbar sind, es sei denn sie werden explizit importiert
Module mit geschlossenem GültigkeitsbereichBetrifft Module in welche Namen explizit importiert werden müssen um innerhalb des Moduls sichtbar zu sein
Module mit offenem GültigkeitsbereichBetrifft Module für die es nicht explizit erforderlich ist Namen von außerhalb zu importieren um sichtbar zu sein
6. Sprachen, Compiler und Theorie
6.4-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Ein Modul Beispiel
Abstraktion eines Stacks in ModulaWir exportieren die push und pop FunktionenAußerhalb des Moduls nicht sichtbar
Top des Stackzeigers „top“Stack array „s“

6. Sprachen, Compiler und Theorie
6.4-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Dynamische Gültigkeitsbereiche
Bindungen zwischen Namen und Objekten hängen vom Programmfluss zur Laufzeit ab
Reihenfolge in welcher Unterprogramme aufgerufen werden ist wichtigDie Regeln für dynamische Gültigkeitsbereiche sind normalerweiseeinfach
Die aktuelle Bindung zwischen Name und Objekt ist diejenige die während der Ausführung als letzte angetroffen wurde (sprich diejenige die am kürzlichsten gesetzt wurde)
6. Sprachen, Compiler und Theorie
6.4-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Statische vs. dynamische Gültigkeitsbereiche
Statischer GültigkeitsbereichProgramm gibt 1 aus
Dynamischer GültigkeitsbereichProgramm gibt 1 oder 2 aus in Abhängigkeit des gelesenen Wertes in Zeile 8
Warum?Ist die Zuweisung zu „a“ in Zeile 3 eine Zuweisung zu dem globalen „a“ von Zeile 1 oder dem Lokalen „a“ von Zeile 5?
6. Sprachen, Compiler und Theorie
6.4-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Vorteile von dynamischen Gültigkeitsbereichen
Was sind die Vorteile von dynamischen Gültigkeitsbereichen?Es erleichtert die Anpassung von UnterprogrammenBeispiel:
begin --nested blockprint_base: integer := 16print_integer(n)
Die Variable print_base kontrolliert die Basis welche print_integer für die Ausgabe von Zahlen verwendet
print_integer kann früh in einem globalen Gültigkeitsbereich mit einem Standardwert belegt werden und kann temporär in einem globalen Gültigkeitsbereich auf eine andere Basis überschrieben werden
6. Sprachen, Compiler und Theorie
6.4-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Ein Problem von dynamischen Gültigkeitsbereichen
Problem: unvorhersagbare referenzierende Umgebungen
Globale Variable max_score wird verwendet von scaled_score()max_score wird umdefiniert in foo()scaled_score() wird von foo() aufgerufen Ahhhhh

6. Sprachen, Compiler und Theorie
6.4-25Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Vermischte Gültigkeitsbereiche (mixed scoping)
Perl unterstützt beide Arten, dynamische wie statische Gültigkeitsbereiche
$i = 1; sub f { local($i) = 2;return g();
} sub g { return $i; } print g(), f();
Dynamic Scoping
Ausgabe:1 2
$i = 1; sub f { my($i) = 2;return g();
} sub g { return $i; } print g(), f();
Static Scoping
Ausgabe:1 1
6. Sprachen, Compiler und Theorie
6.4-26Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Zusammenfassung für Gültigkeitsbereiche
Statische GültigkeitsbereicheWird von den meisten, kompilierten Hochsprachen verwendet
C, C++, Java, Modula, etc.Bindungen von Namen zu Variablen können zur Compilezeit festgestellt werdenEffizient
Dynamische GültigkeitsbereicheWird von vielen interpretierten Sprachen verwendet
Ursprüngliches LISP, APL, Snobol und PerlBindungen von Namen zu Variablen können eine Feststellung zur Laufzeit benötigenFlexibel
6. Sprachen, Compiler und Theorie
6.4-27Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Namen, Bindungen und Gültigkeitsbereiche
Ausblick
Namen, Gültigkeitsbereiche und Bindungen (Kapitel 3)Speichermanagement und ImplementierungKontrollfluss (Kapitel 6)Zusammenführung (Bau eines ausführbaren Programms) (Kapitel 9)

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
5 – Speichermanagement und Implementierung
6. Sprachen, Compiler und Theorie
6.5-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Inhalt
Lebensdauer von ObjektenSpeichermanagementWeiterführende Spracheigenschaften und Bindungen
Implementierung von statischen Gültigkeitsbereichen für verschachtelte UnterprogrammeImplementierung von Unterprogrammreferenzen
6. Sprachen, Compiler und Theorie
6.5-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Objektlebensdauer (1/3)
Schlüsselereignisse während der Lebensdauer eines ObjektesObjekt wird erzeugtBindungen zum Objekt werden erzeugtReferenzen zu den Variablen, Unterprogrammen und Typen werden durch Bindungen gemachtDeaktivierung und Reaktivierung von temporär nicht verwendbaren BindungenVernichtung von BindungenVernichtung des Objekts
Lebensdauer von Bindungen: Zeit zwischen Erzeugung und Vernichtung einer Bindung
Beispiel: Zeit während der eine Java Referenz ein Objekt im Speicher referenziert
Lebensdauer von Objekten: Zeit zwischen Erzeugung und Vernichtung eines Objekts
Beispiel: Zeit während der ein Objekt im Speicher „lebt“
6. Sprachen, Compiler und Theorie
6.5-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Objektlebensdauer (2/3)
Beispiel:
public void foo (void) {Bar b = new Bar();while(1) {
int b;b = b + 1; ...
}}
Anmerkung: Das durch foo() erzeugte Objekt Bar ist nicht unbedingt nach der Rückkehr aus dem Unterprogramm zerstört. Es kann nach der Rückkehr von foo() nicht länger referenziert werden, aber es wird wahrscheinlich erst bei der „garbage collection“ zu einem späteren Zeitpunkt in der Programmausführung zerstört werden.
Lebensdauerdes Objekts Bar
Binde Namen b an Objekt Bar
Reaktiviere Bindung von b zu Bar
Deaktiviere Bindung von b zu Bar

6. Sprachen, Compiler und Theorie
6.5-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Objektlebensdauer (3/3)
Die Lebenszeit eines Objekts korrespondiert mit einem von drei Hauptmechanismen der Speicherallokation
Statische AllokationObjekte werden zur Compilezeit oder Laufzeit zu festen Speicherplätzen allokiert
Stack AllokationObjekte werden zur Laufzeit wie benötigt allokiert, wobei eine last-in, first-outOrdnung gilt
Beispiel: Lokales
Heap AllokationObjekte werden zur Laufzeit in einer beliebigen Reihenfolge allokiert und freigegeben
Beispiel: dynamisch allokierte Objekte
6. Sprachen, Compiler und Theorie
6.5-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Statische Allokation
Was wird statisch allokiert?Globale Variablen
Beispiel: Statische KlassenvariablenKonstante Variablen welche während der Programmausführung sich nicht ändern sollten
Beispiel: “i=%d\n” ist konstant in printf(“i=%d\n”,i);Der Programmcode (Unterprogramme, etc.)
Ausnahme: dynamisch verbundene UnterprogrammeVom Compiler produzierte Informationen zum DebuggenFalls eine Sprache rekursive Unterprogrammaufrufe nicht untersützt, dann auch lokale Variablen, Unterprogrammargumente, Rückgabewerte, vom Compiler generierte temporäre Daten, etc.
6. Sprachen, Compiler und Theorie
6.5-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Beispiel: Statische Allokation von Lokalem
Keine Rekursionbedeutet das es zu einer Zeit nur eine aktive Instanz bzw. Aktivierung einer Instanz von jedem gegebenen Unterprogramm geben kann
Daher können wir für eine einzelne, mögliche Aktivierung für jedes Unterprogramm eines Programms den Speicher statisch reservieren
6. Sprachen, Compiler und Theorie
6.5-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Allokation über einen Stack (1/2)
Fall eine Sprache Rekursion erlaubt, dann kann jedes Unterprogramm mehrere simultane Aktivierungen habenBeispiel:public int foo (int n) {
int a, b, c;a = random(); b = random();if (n > 0) { c = foo(n-1); }c = c * (a + b);
}
Wir können n Aktivierungen von foo() haben und jede benötigt Speicherplatz um die eigenen Kopien von a, b, c, Übergabeargument n und jeden temporären, vom Compiler generierten Wert zu speichern

6. Sprachen, Compiler und Theorie
6.5-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Allokation über einen Stack (2/2)
Die Lösung für das Rekursionsproblem ist die Allokation über einen Stack (stack allocation)
„Push“ Stack um Platz für Lokales (locals) für Unterprogrammaufrufe zu reservieren
„Pop“ Stack um Platz für Lokales (locals) bei der Rückkehr von einem Unterprogramm wieder freizugeben
6. Sprachen, Compiler und Theorie
6.5-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Allokation über einen Heap
Wir wissen wie Code für Globales, Lokales, Konstanten, Temporäres, etc. allokiert wirdWas bleibt übrig:
Dynamisch allokierte ObjekteWarum können diese nicht statisch allokiert werden?
Weil sie dynamisch erzeugt werdenWarum können diese nicht auf einem Stack allokiert werden?
Ein Objekt, welches dynamisch von einem Unterprogramm erzeugt wurde, könnte die Aktivierung des Unterprogramms überleben
Beispiel: Objekt wird einem Globalen zugewiesen oder von dem Unterprogramm zurückgegeben
Heaps lösen dieses ProblemEin Heap ist eine Speicherregion in welcher Speicherblöcke jederzeit willkürlich allokiert und wieder freigegeben werden können
Wie sind Heaps implementiert?Wie handhaben wir Anfragen zur Allokation und Freigabe?
6. Sprachen, Compiler und Theorie
6.5-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Heap-Management (1/4)
Wir bekommen eine Allokationsanforderung für n Bytes vom SpeicherDer Heap hat verwendete (dunkle) und freie (helle) BereicheWie wählen wir einen freien Bereich um eine Allokationsanforderung zu befriedigen?Einfache Antwort:
Finde den ersten freien Bereich welcher groß genug ist der Allokation zu entsprechen (wird first fit genannt)Problem: interne Fragmentierung
Wenn wir n Bytes anfordern und der erste, verfügbare freie bereich hat n+kBytes, dann verschwenden wir k Bytes durch die Allokation im ersten Bereich
Heap
Allokationsanforderung
6. Sprachen, Compiler und Theorie
6.5-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Heap-Management (2/4)
Eine bessere Antwort (vielleicht):Finde den ersten Bereich, welcher von der Größe am nächsten zur Allokationsanforderung ist (wird best fit genannt)Problem: Zeitaufwendiger
Muss alle freie Blöcke finden um den Besten zu finden Es kann immer noch interne Fragmentierung geben, aber hoffentlich weniger als bei first fit
Heap
Allokationsanforderung

6. Sprachen, Compiler und Theorie
6.5-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Heap-Management (3/4)
Ein anderes Problem: externe FragmentierungWir bekommen eine Allokationsanforderung für n Bytes und der Heaphat mehr als n Bytes frei, aber
kein einzelner freier Bereich ist n Bytes groß oder größerWir haben genügend freien Speicher, aber wir können die Allokationsanforderung nicht befriedigen
Mögliche Lösungen:Vereinigung von Bereichen: wenn zwei benachbarte Bereiche mit j und k Bytes frei sind, dann vereinige diese zu einem einzelnen, freien Bereich mit j+k BytesIst eine Verbesserung, aber kann nicht alle externen Fragmentierungen eliminieren
Heap
Allokationsanforderung
6. Sprachen, Compiler und Theorie
6.5-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Heap-Management (4/4)
Wie handhaben wir die Freigabe?Explizit:
Der Programmierer muss dem Heap-Manager mitteilen dass ein Bereich nicht länger vom Programm verwendet wird
Beispiel: verwende in C free(p) um den Bereich freizugeben auf den p zeigt
Automatisch:Das Laufzeitsystem bestimmt welche Objekte auf dem Heap lebendig (sprich immer noch an Namen gebunden sind) oder tot (sprich nicht länger zu irgendeinem Namen gebunden sind) sind und gibt die toten Objekte automatisch freiWird Garbage Collection (Speicherbereinigung) genannt
Heap
Allokationsanforderung
6. Sprachen, Compiler und Theorie
6.5-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Speicherbereinigung (Garbage Collection) (1/2)
Warum verwenden wir Speicherbereinigung?Verhindert:
Speicherlöcher (memory leak): Programmierer können die Freigabe von dynamisch allokiertem Speicher vergessenDangling pointers: Programmierer können ein Objekt freigeben bevor alle Referenzen darauf zerstört sind
Reduzieren den Programmieraufwand und resultiert in zuverlässigeren Programmen
6. Sprachen, Compiler und Theorie
6.5-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Speicherbereinigung (Garbage Collection) (2/2)
Warum Speicherbereinigung nicht verwenden?Teuer: Festzustellen welche Objekte lebendig und welche tot sind kostet Zeit
Schlecht für Echtzeitsysteme: Können normalerweise nicht garantieren wann die Speicherbereinigung laufen wird und wie lange es dauern wird
Schwierig zu implementieren: Das Schreiben einer Speicherbereinigung ist schwierig und macht den Compiler und dieLaufzeit einer Sprache komplizierter
Sprachdesign: Einige Sprachen wurden nicht mit dem Gedanken an eine Speicherbereinigung entworfen, was es schwierig machte eineSpeicherbereinigung zuzufügen

6. Sprachen, Compiler und Theorie
6.5-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Weiterführende Spracheigenschaften und Bindungen
Wie implementieren wir statische Gültigkeitsbereiche in Sprachendie verschachtelte Unterprogramme erlauben?Wie implementieren wir Referenzen auf Unterprogramme?
6. Sprachen, Compiler und Theorie
6.5-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Implementierung von statischen Gültigkeitsbereichen (1/2)
Problem:Von c(), wie referenzieren wir nichtlokale Variablen in a() und b()?
void a (void) {int foo1;void b (void) {
int foo2;void c (void) {
int foo3 = foo1 + foo2;}void d (void) {}
}void e (void) {}
}
6. Sprachen, Compiler und Theorie
6.5-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Implementierung von statischen Gültigkeitsbereichen (2/2)
Lösung: statische LinksJede Aktivierung eines Unterprogramms speichert einen Zeiger zum nächsten, umgebenden Gültigkeitsbereich in seinem Stackrahmenc() bekommt seine eigenen Lokalen von seinem eigenen Stackrahmenc() bekommt die Nichtlokalen in b() durch die einmalige Dereferenzierung seines statischen Linksc() bekommt die Nichtlokalen in a() durch die Dereferenzierung seines statischen Links zu b() und dann b()‘s statischen Link zu a()
6. Sprachen, Compiler und Theorie
6.5-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Implementierung von Referenzen auf Unterprogramme - 1
Große Frage:Wie wenden wir Gültigkeitsbereichsregeln in Sprachen an wo Unterprogramme als Wert übergeben werden können?
Zwei Antworten:Flache Bindung (shallow binding):
Referenzierende Umgebung wird sofort festgestellt bevor das referenzierteUnterprogramm aufgerufen wirdIst normalerweise der Standard in Sprachen mit dynamischen Gültigkeitsbereichen
Tiefe Bindung (deep binding):Referenzierende Umgebung wird festgestellt wenn die Referenz auf das Unterprogramm erzeugt wird

6. Sprachen, Compiler und Theorie
6.5-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Tiefe vs. flache Bindung
Flache Bindung (shallow)Nötig für die line_lengthZuweisung in print_selected_records um das print_personUnterprogramm zu erreichen
Tiefe Bindung (deep)Nötig für die thresholdZuweisung im Hauptprogramm um das older_than Unterpogramm zu erreichen
6. Sprachen, Compiler und Theorie
6.5-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Implementierung von Referenzen auf Unterprogramme - 2
Zum AbschlussEin Zeiger auf den Code des Unterprogramms und ein Zeiger auf die referenzierende Umgebung des Unterprogramms
Warum benötigen wir einen Zeiger auf die referenzierendeUmgebung?
Wir müssen einen Weg für das Unterprogramm haben mit welcher es Zugriff auf seine nichtlokalen, nichtglobalen Variablen hat
Für Sprachen mit dynamischen Gültigkeitsbereichen schließt dies Variablen in den umschließenden, dynamisch verschachtelten Unterprogrammen ein (Unterprogramme die andere aufrufen)Für Sprachen mit statischen Gültigkeitsbereichen schließt dies Variablen in den umschließenden, statisch verschachtelten Unterprogrammen ein
6. Sprachen, Compiler und Theorie
6.5-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Zusammenfassung
Lebensdauer von ObjektenDie Zeitperiode während der ein Name an ein Objekt (Variable, Unterprogramm, etc.) gebunden ist
SpeichermanagementStatische Allokation, Stacks und Heaps
Weiterführende Spracheigenschaften und BindungenImplementierung von statischen Gültigkeitsbereichen für verschachtelte Unterprogramme
Links auf Stackrahmen ablegenImplementierung von Unterprogrammreferenzen
Ein Zeiger auf den Code des Unterprogramms und ein Zeiger auf die referenzierende Umgebung des Unterprogramms (flache und tiefe Bindung)
6. Sprachen, Compiler und Theorie
6.5-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Speichermanagement und Implementierung
Ausblick
Namen, Gültigkeitsbereiche und Bindungen (Kapitel 3)Speichermanagement und ImplementierungKontrollstrukturen (Kapitel 6)Zusammenführung (Bau eines ausführbaren Programms) (Kapitel 9)

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
6 – Kontrollstrukturen
6. Sprachen, Compiler und Theorie
6.6-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Rückblick
Lebensdauer von ObjektenSpeichermanagementWeiterführende Spracheigenschaften und Bindungen
Implementierung von statischen Gültigkeitsbereichen für verschachtelte UnterprogrammeImplementierung von Unterprogrammreferenzen
6. Sprachen, Compiler und Theorie
6.6-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Was fehlt uns noch?
KontrollflussSpezifikation der Reihenfolge in welcher Elemente einer höheren Programmiersprache ausgeführt werden
KontrollflussmechanismenAnweisungen (statements), Schleifen, Unterprogrammaufrufe, Rekursion, etc.Übersetzung zu ausführbarem Code
6. Sprachen, Compiler und Theorie
6.6-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Kontrollfluss (control flow)
Das Offensichtliche: Programme machen ihre Arbeit durch ausführen von Berechnungen
Kontrollfluss (control flow) spezifiziert die Reihenfolge in welcher Berechnungen ausgeführt werden
Sprachen stellen eine große Vielfalt von Kontrollflussmechanismen (control flow mechanism) bereit welche es dem Programmierer erlauben den Kontrollfluss zu spezifizieren

6. Sprachen, Compiler und Theorie
6.6-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Kontrollfluss und Kontrollflussmechanismen
Iterationen (Wiederholungen)Führt eine Gruppe von Berechnungen mehrmals aus (repeatedly)Eine von sieben Kategorien von Kontrollflussmechanismen
Wie implementieren Sprachen Iterationen?
for(i=0;i<N;i++) {do_something(i);
}
Schleifen: C, C++, Java
fun foo i N =if i < N then
do_something ifoo i + 1 N
foo 0 N
Einige Sprachen verwenden andere Mechanismen um das gleiche Ziel zu erreichen
Rekursion: ML
every do_something(0 to N-1)Iteratoren: Icon, CLU
6. Sprachen, Compiler und Theorie
6.6-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Wichtige Fragen
Wie lauten die Kategorien von KontrollflussmechanismenWelche Eigenschaften stellen Sprachen zur Verfügung um die Kontrollflussmechanismen einer gegebenen Kategorie zu implementieren?Wie übersetzen Compiler Kontrollflussmechanismen in ausführbaren Code?
6. Sprachen, Compiler und Theorie
6.6-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Kategorien von Kontrollflussmechanismen
Sequentialität (sequencing)Bestimmt für ein gegebenes Paar von Berechnungen welches zuerst ausgeführt wird
Auswahl (selection)Wähle, basierend auf einer Laufzeitbedingung, welche von mehreren Berechnungen ausgeführt werden soll
Iteration (iteration)Führt eine Gruppe von Berechnungen mehrmals aus
Rekursion (recursion)Erlaubt es Berechnungen durch sich selbst zu definieren (Allows computations to be defined in terms of themselves)
Prozedurale Abstraktion (procedural abstraction)Erlaubt es einer Gruppe von Berechnungen zu bennen, möglicherweise zu parametrisieren und auszuführen wann immer der Name referenziert wird
Nebenläufigkeit (concurrency)Erlaubt es Berechnungen „zur gleichen Zeit“ auszuführen
Keine Festlegung (Nondeterminancy)Reihenfolge zwischen Berechnungen wird unspezifiziert gelassen
6. Sprachen, Compiler und Theorie
6.6-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Sequentialität (sequencing)
Bestimmt für ein gegebenes Paar von Berechnungen welches zuerst ausgeführt wirdZwei Typen von Berechnungen für welche wir die Reihenfolge betrachten wollen
Ausdrücke (expressions)Berechnungen die einen Wert erzeugenBeispiel:
zweistellige Ausdrücke: foo + barEvaluieren wir zuerst die Unterausdrücke foo oder bar bevor wir die Addition ausführen?
Zuweisungen (assignments)Berechnungen welche die Werte von Variablen ändernBeispiel:
foo = bar + 1;bar = foo + 1;
Welche von diesen beiden Zuweisungen evaluieren wir zuerst?

6. Sprachen, Compiler und Theorie
6.6-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Was genau ist eine Ausdruck (expression)?
Berechnungen welche einen Wert erzeugenVariablenreferenzen
Holt den Wert der Variablen aus dem SpeicherKonstantenreferenzen
1, 2, 3, ‘a’, ‘b’, ‘c’, …Operatoren oder Funktionen angewandt auf eine Sammlung von Unterausdrücken
Funktionsaufrufefoo(a,b+10)
Arithmetische Operationenfoo + bar
6. Sprachen, Compiler und Theorie
6.6-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Evaluation von Ausdrücken und Seiteneffekte
Evaluation von Ausdrücken kann zusätzlich zu den Werten auch Seiteneffekte erzeugenBeispiele:
int foo (void) { a = 10; return a; }… foo() + 20 …Evaluation von „foo()+20“ ergibt den Wert 30 UND als einen Seiteneffekt die Zuweisung des Wertes 10 an die Globale a
Ausdrücke ohne Seiteneffekte werden „referentially transparent”genannt
Solche Ausdrücke können als mathematische Objekte behandelt werden und entsprechend durchdacht
6. Sprachen, Compiler und Theorie
6.6-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Priorität und Assoziativität
Zwei Wege um die Reihenfolge zu spezifizieren in welcher Unterausdrücke von komplexen Ausdrücken evaluiert werdenPrioritätsregel
Spezifiziert wie Operationen gruppieren wenn Klammern abwesend sindAssoziativität
Ähnlich dem mathematischen Konzept mit dem gleichen NamenSpezifiziert ob Operatoren von der gleichen Prioritätsgruppe zur Linken oder Rechten zuerst evaluieren
6. Sprachen, Compiler und Theorie
6.6-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Priorität (Precedence)
Beispiel:-a * cWie ist die Reihenfolge der Evaluierung?
(-a) * c oder –(a * c)???In C, -, unäre Negierung (unary negation), hat höhere Priorität als * (Multiplikation), weshalb die erste Klammerung korrekt ist
Prioritätsregeln variieren stark von Sprache zu Sprache
Frage: Wie wird in C int i = 0; int *ip = &i; ++*ip++; ausgewertet?++( ) auf den Wert von *ip++. Der Wert ist der Inhalt der Variablen, auf die ipverweist. Wenn ip abgerufen wurde, wird ip im nachhinein um eins erhöht (Zeigerarithmetik). Daher ist am Ende i = 1 und der Zeiger ip wurde auch um eins erhöht (und zeigt somit höchstwahrscheinlich ins Nirvana, da kein Bezug zu dieser Speicherstelle besteht)

6. Sprachen, Compiler und Theorie
6.6-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
6. Sprachen, Compiler und Theorie
6.6-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Assoziativität (Associativity)
Die Assoziativität ist in Sprachen einheitlicherElementare arithmetische Operatoren assoziieren von links nach rechts
Operatoren werden von links nach rechts gruppiert und evaluiertBeispiel (Subtraktion):
9 – 3 – 2 evaluiert eher zu (9 – 3) -2 als 9 - (3 - 2)Einige arithmetische Operatoren assoziieren aber von rechts nachlinks
Beispiel (Potenzieren):4**3**2 evaluiert eher zu 4**(3**2) als (4**3)**2
In Sprachen die Zuweisungen in Ausdrücken erlauben, assoziieren Zuweisungen von rechts nach links
Beispiel:a = b = a + c evaluiert zu a = (b = a + c)a + c wird berechnet und b zugewiesen, danach wird b zu a zugewiesen
6. Sprachen, Compiler und Theorie
6.6-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Arbeiten mit Prioritäten und Assoziativität
Regeln für Prioritäten und Assoziativität variieren stark von Sprache zu Sprache
In Pascal:„if A < B und C < D then ...“Könnte zu „if A < (B and C) < D then...“ evaluiert werdenUpps!
Leitfaden/Richtlinie:Im Zweifelsfall lieber Klammern verwenden, speziell wenn jemand oft zwischen verschiedenen Sprachen wechselt!
6. Sprachen, Compiler und Theorie
6.6-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Mehr zur Evaluierungsordnung von Ausdrücken (1/2)
Prioritäten und Assoziativität können nicht immer eine Evaluierungsreihenfolge festlegen
Beispiel:a – f(b) – c * dMit Prioritäten ergibt sich a – f(b) – (c * d) und weiter mit Assoziativität (a –f(b)) - (c * d)Aber welches wird zuerst ausgeführt: a-f(b) oder (c*d)?Warum kümmert uns das?
SeiteneffekteWenn f(b) die Variablen c oder d modifiziert, dann hängt der Wert des ganzen Ausdruckes davon ab, ob f(b) zuerst ausgeführt wird oder nicht
Verbesserung des CodesWir wollen (c*d) zu erst berechnen, so dass wir das berechnete Ergebnis nicht speichern und wiederherstellen müssen bevor und nachdem f(b) aufgerufen wird
Nochmals: Im Zweifelsfall Klammern setzen!

6. Sprachen, Compiler und Theorie
6.6-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Mehr zur Evaluierungsordnung von Ausdrücken (2/2)
Boolesche AusdrückeAusdrücke die eine logische Operation ausführen und entweder zu wahr (true) oder falsch (false) evaluierenBeispiele:
a < ba && b || c oder a & b | c
Die Evaluation von booleschen Ausdrücken kann durch die „shortcircuiting“ Technik optimiert werden
Beispiel:(a < b) && (c < d)Wenn (a < b) zu falsch evaluiert wird dann gibt es keinen Bedarf mehr (c <d ) auszuwertenSiehe Regel R1 aus Kapitel 2, Boolesche Algebra und Gatter
Dies wird wichtig bei Code nach folgendem Muster:if (unwahrscheinliche Bedingung && teure Funktion() ) ...Wir wollen die Auswertung einer teuren Funktion() verhindern, wenn eine unwahrscheinliche Bedingung zu falsch ausgewertet wird
6. Sprachen, Compiler und Theorie
6.6-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Zuweisungen
Berechnungen welche den Wert einer Variablen beeinflussenBeispiel: c = a + b
Weisst den Wert, der durch den Ausdruck „ a +b“ berechnet wird, der Variablen c zu
Zuweisungen sind der fundamentale Mechanismus um Seiteneffekte zu erzeugen
Werte die Variablen zugewiesen werden können zukünftige Berechnungen beeinflussen
Zuweisungen sind unerlässlich für das imperative Programmiermodel
6. Sprachen, Compiler und Theorie
6.6-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Was genau ist eine Variable? (1/2)
Die Interpretation eines Variablennamens hängt von dem Kontext ab in welchem er auftritt
Beispiele:d = a
Die Referenz zu der Variablen „a“ auf der „rechten Seite“ einer Zuweisung benötigt einen Wert
Wird ein r-value-context genannt und das „a“ wird r-value genannt
a = b + cDie Referenz zu der Variablen „a“ auf der „linken Seite“ einer Zuweisung bezieht sich auf a‘s Speicherort
Wird ein l-value-context genannt und das „a“ wird l-value genannt
6. Sprachen, Compiler und Theorie
6.6-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Was genau ist eine Variable? (2/2)
Zwei Wege um eine Variable zu behandelnWertemodell
Variablen sind benannte Container für WerteBeide Interpretationen als l-value und r-value von Variablen sind möglichModell wird verwendet von Pascal, Ada, C, etc.
ReferenzmodellVariablen sind benannte Referenzen für WerteNur die Interpretation als l-value ist möglich
Variablen in einem r-value-context müssen „dereferenziert“ werden um einen Wert zu erzeugen
Modell wird verwendet von Clu
Wertemodell Referenzmodell

6. Sprachen, Compiler und Theorie
6.6-21Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Zuweisungsfolgen
Zuweisungsfolgen (assignment sequencing ) ist in den meisten Sprachen einfach
Zuweisungen werden in der Reihenfolge ausgeführt in der sie im Programmtext auftreten
Beispiel:a = 10; b = a; Es wird zuerst die 10 dem a zugewiesen und danach wird a demb zugewiesen
AusnahmenZuweisungsausdrücke
Beispiel: a = b = a * cErinnere dich an die Auswertereihenfolge bei Ausdrücken: In den meisten Programmiersprachen gilt die Assiziation von rechts nach links
InitialisierungKombinationen mit dem Zuweisungsoperator
6. Sprachen, Compiler und Theorie
6.6-22Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Zuweisungsfolgen: Initialisierung (1/2)
Wie initialisieren oder wie weisen wir initiale Werte Variablen zu?
Verwende den Zuweisungsoperator um initiale Werte zur Laufzeit zuzuweisen
Probleme:Ineffizienz: Wenn wir den initialen Wert einer Variablen zur Compilezeitkennen, dann kann der Compiler diesen Wert dem Speicher zuweisen ohne eine Initialisierung zur Laufzeit zu benötigenProgrammierfehler: Wenn Variablen kein initialer Wert bei der Deklaration zugewiesen wird, dann könnte ein Programm eine Variable verwenden bevor sie irgendeinen (sinnvollen) Wert enthält
6. Sprachen, Compiler und Theorie
6.6-23Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Zuweisungsfolgen: Initialisierung (2/2)
Verwende den Zuweisungsoperator um initiale Werte zur Laufzeit zuzuweisen
Lösungen:Statische Initialisierung:
Beispiel für C: static char s[] = “foo”Der Compiler kann den Elementen des Arrays s die Werte zur Compilezeitzuweisen, was uns 4 Zuweisungen zur Laufzeit erspart (eine für jedes Zeichen plus dem NULL (String-)Terminator)siehe auch C++ Konstruktorinitialisierung
Defaultwerte (Standardwerte/Ausgangswerte/...)Sprachen können einen Defaultwert für jede Deklaration eines eingebauten(built-in) Typs spezifizieren
Dynamische WertkontrollenMache es zu einem Laufzeitfehler, wenn eine Variable verwendet wird bevor ihr ein Wert zugewiesen wurde
Statische WertkontrollenMache es zu einem Compilerfehler wenn eine Variable verwendet werden könntebevor ihr ein Wert zugewiesen wurde
6. Sprachen, Compiler und Theorie
6.6-24Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Zuweisungsfolgen: Kombinationen
Gibt es einen effizienteren Weg um komplexe Zuweisungen zu handhaben?
Beispiele:a = a + 1;b.c[3].d = b.c[3].d * e;
Probleme:Ist fehleranfällig und schwierig zu schreiben, da Text wiederholt wirdKann zu ineffizientem kompilierten Code führen
Lösungen: Kombinationen mit dem ZuweisungsoperatorBeispiele:
a += 1;b.c[3].d *= e;
Zuweisungen werden mit Operatoren für Ausdrücke kombiniertVermeidet sich wiederholenden CodeErlaubt es dem Compiler auf einfacherem Wege effizienteren Code zu generieren

6. Sprachen, Compiler und Theorie
6.6-25Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Sequentialität: Zusammenfassung
AusdrückePrioritäten und Assoziativität kontrollieren die ReihenfolgeEs müssen Seiteneffekte bei Unterausdrücken beachtet werdenLogische Ausdrücke können von der short-circuit Auswertung profitieren
ZuweisungenDie Folge des Auftretens im Programmtext bestimmt die ReihenfolgeZuweisungen zur Compilezeit erlauben die Vermeidung von Zuweisungen zur LaufzeitZusammengesetzte Zuweisungsoperatoren kombinieren Ausdrucksauswertung und Zuweisung um effizienter sein zu können
6. Sprachen, Compiler und Theorie
6.6-26Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Auswahl (selection) (1/4)
Wähle, basierend auf einer Laufzeitbedingung, welche von mehreren Berechnungen ausgeführt werden sollAm häufigsten Ausgeführt vom if..then..else Sprachkonstrukt
Beispiel:if ((a < b) && (c < d)) { do_something(); }Wenn beide bedingte Anweisungen „a<b“ und „c<d“ zu wahr ausgewertet werden, dann führe die Berechnung, welche durch das Unterprogramm do_something() referenziert wird, aus
6. Sprachen, Compiler und Theorie
6.6-27Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Auswahl (selection) (2/4)
Short circuitingZur Erinnerung: Kann verwendet werden um unnötige Ausdrucksauswertungen zu verhindenBeispiel:
if ( (a < b) && (c < d) ) { do_something(); }Wenn (a < b) falsch ist, dann kann do_something() nicht ausgeführt werden, egal was (c < d) ergibtSiehe Regel R1 aus Kapitel 2, Boolesche Algebra und GatterShort circuiting wird Code generieren der die Auswertung von (c < d) genauso ausläßt (skipped) wie die Ausführung von do_something(), wenn (a < b) falsch ist
6. Sprachen, Compiler und Theorie
6.6-28Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Auswahl (selection) (3/4)
Angenommen wir haben Code der ähnlich wie dieser aussieht:j := … (* something complicated *)IF j = 1 THEN
clause_AELSIF j IN 2, 7 THEN
clause_BELSIF j in 3..5 THEN
clause_CELSE
clause_DEND
Problem:Ist kompliziert zu schreiben

6. Sprachen, Compiler und Theorie
6.6-29Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Auswahl (selection) (4/4)
Lösung: case/switch Befehle
Beispiel:CASE …
1: clause_A| 2,7: clause_B| 3..5: clause_C
ELSE clause_DEND
Ist einfacher zu schreiben und zu verstehen
6. Sprachen, Compiler und Theorie
6.6-30Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Iteration
Führt eine Gruppe von Berechnungen mehrmals ausSprachen bieten für Iterationen Schleifenkonstrukte an
Aufzählungsgesteuerte SchleifenDie Schleife wird für jeden Wert aus einer endlichen Menge (Aufzählung) ausgeführt
Logikgesteuerte SchleifenDie Schleife wird solange ausgeführt bis sich eine boolesche Bedingung ändert
Anmerkung:Der imperative Stil der Programmierung favorisiert Schleifen gegenüber RekursionIteration und Rekursion können beide verwendet werden um eine Gruppe von Berechnungen wiederholt auszuführenAlle Arten von Schleifen können auf die beiden Konstrukte Selektion (if..then..end) und Sprung (goto) zurückgeführt werden. Wird oft in Zwischensprachen zur Codegenerierung verwendet.
6. Sprachen, Compiler und Theorie
6.6-31Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Aufzählungsgesteuerte Schleifen: Probleme (1/3)
Beispiel von FORTRAN I, II und IVdo 10 i = 1, 10, 2...10: continue
Die Variable i wird die Indexvariable genannt und nimmt hier die Werte 1, 3, 5, 7, 9 anDie Statements zwischen der ersten und letzte Zeile werden der Schleifenrumpf(loop body) genannt und wird hier für jeden der fünf Werte von i einmal ausgeführt
Probleme:Der Schleifenrumpf wird immer mindestens einmal ausgeführtStatements im Schleifenrumpf könnten i ändern und somit würde auch das Verhalten der Schleife verändert werdenGoto Statements können in oder aus der Schleife springen
Goto-Sprünge in die Schleife hinein, wobei i nicht vernünftig initialisiert wird, werden wahrscheinlich in einem Laufzeitfehler enden
Die Schleife wird beendet wenn der Wert von i die obere Grenze überschreitet. Dies könnte einen (unnötigen) arithmetischen Überlauf veranlassen, wenn die obere Grenze in der Nähe des größten, zulässigen Wertes von i liegt
6. Sprachen, Compiler und Theorie
6.6-32Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Aufzählungsgesteuerte Schleifen: Fragen (2/3)
Allgemeine Form von Schleifen:FOR j := first TO last BY step DO
…END
Fragen die zu dieser Schleifenart zu stellen sind:1. Kann j, first und/oder last im Schleifenrumpf verändert werden?
Wenn ja, welchen Einfluss hat dies auf die Steuerung?2. Was passiert wenn first größer als last ist?3. Welchen Wert hat j wenn die Schleife beendet wurde?4. Kann die Kontrolle von außerhalb in die Schleife hineinspringen?

6. Sprachen, Compiler und Theorie
6.6-33Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Aufzählungsgesteuerte Schleifen: Antworten (3/3)
Können der Schleifenindex oder die Grenzen verändert werden?Ist bei den meisten Sprachen verboten
Algol 68, Pascal, Ada, Fortran 77 und 90, Modula-3Was passiert wenn first größer als last ist?
Die meisten Sprachen werten first und last aus bevor die Schleife ausgeführt wirdFalls first größer als last ist, dann wird der Schleifenrumpf niemals ausgeführt
Welchen Wert hat der Schleifenindex j am Ende der Schleife?Ist in einigen Sprachen nicht definiert, z.B. Fortran IV oder PascalIn den meisten Sprachen gilt der zuletzt definierte WertEinige Sprachen machen die Indexvariable zu einer lokalen Variablen der Schleife, weswegen die Variable außerhalb des Gültigkeitsbereiches der Schleife nicht sichtbar ist
Kann die Kontrolle von außerhalb in die Schleife hineinspringen?Nein, für die meisten SprachenViele Sprachen erlauben aber den Sprung von innen nach außenViele Sprachen bieten Anweisungen (break; exit; last, etc,) an, die einen frühzeitige Abbruch der Schleife ohne expliziten Sprung erlauben
6. Sprachen, Compiler und Theorie
6.6-34Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Iteratoren
Alle bisher betrachteten Schleifen iterieren über eine arithmetische Folge (1,3,5,7)Aber wie iterieren wir über eine frei wählbare Menge von Objekten?Antwort: Iteratoren
Die “FOR j := first TO last BY step DO … END” Schleife kann auch geschrieben werden als “every j := first to last by step do { … }” in ICON
Beispiel:“every write (1 + upto(‘ ‘, s))” in ICON schreibt jede Position in den String s welcher ein Leerzeichen folgtupto(‘ ‘,s) erzeugt jede Position in s gefolgt von einem Leerzeichen
Iteratoren sind Ausdrücke die mehrere Werte generieren und welche Ihre enthaltende Ausdrücke und Statements bestimmen können um diese mehrmals auszuwerten oder auszuführenEin anderes Beispiel:
“write(10 + 1 to 20)” schreibt 10 + j für jedes j zwischen 1 und 201 bis 20 erzeugt die Folge 1 bis einschließlich 20
Siehe auch Standard Template Library (STL) von C++
6. Sprachen, Compiler und Theorie
6.6-35Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Logikgesteuerte Schleifen
Beispiele:Vorprüfende Schleife
„while Bedingung do Anweisung“Die C for-Schleife ist eine vorprüfende, logikgesteuerte Schleife und nicht eine aufzählungsgesteuerte Schleife!
for(Vor-Anweisung; Bedingung; Nach-Anweisung ) Block
Nachprüfende Schleife„repeat Anweisung until Bedingung“„do Anweisung while Bedingung“Diese Art von Schleife werden oft falsch verwendet und sollten daher vermieden werden (da mindest ein Durchlauf erfolgt!)
Prüfung in der Mitte einer Schleife„loop Anweisung when Bedingung exit Anweisung end“
6. Sprachen, Compiler und Theorie
6.6-36Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Rekursion
Erlaubt es Berechnungen durch sich selbst zu definierenMit anderen Worten, komplexe Berechnungen werden mit Begriffen von einfacheren Berechnungen ausgedrücktÄhnlich dem Prinzip der mathematischen Induktion
Ist die bevorzugte Methode der wiederholenden Programmausführung in funktionalen Sprachen
Eigentlich ist es die meiste Zeit der einzigste Weg um Berechnungen in funktionalen Sprachen wiederholt auszuführenWarum?
Weil für die Alternative, nämlich Iteration (Schleifen), die Ausführung von Anweisungen mit Seiteneffekten (wie Zuweisungen) verbunden ist, was in rein funktionalen Sprachen verboten ist
Dies ist nicht wirklich eine Einschränkung da Rekursion streng genommen genauso Mächtig ist wie Iteration und umgekehrt

6. Sprachen, Compiler und Theorie
6.6-37Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Rekursion und Iteration
Informell gesprochen, die Schleife“FOR j := first TO last BY step DO … END”wird durch Rekursion zu:
fun loop j step last = if j <= last then
…loop j + step step last
Es gibt mit der rekursiven Emulation von Iteration aber ein Problem:sie ist langsam!
6. Sprachen, Compiler und Theorie
6.6-38Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Verbesserte Durchführung von Rekursion
Gegebene Schleifefun loop j step last =
if j <= last then…loop j + step step last
Der rekursive Aufruf der Schleife „loop“ ist die letzte ausgeführte Berechnung der Funktion „loop“
Wird Endrekursion (tail recursion) genanntGeschickte Compiler werden Endrekursionen durch eine Schleife ersetzen
Argumente für den Aufruf der Endrekursion werden ausgewertet und in den entsprechenden Lokalen platziert und ein Sprung zurück zum Anfang der Funktion wird gemacht anstatt einen rekursiven Aufruf zu machenDies kann zu einer signifikanten Steigerung der Leistung führen
6. Sprachen, Compiler und Theorie
6.6-39Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Evaluationskonzepte von Funktionsargumenten
Wie werden Argumente für Funktionen ausgewertet?Die Argumente einer Funktion werden ausgewertet bevor die Funktion die Steuerung erhält?
Wird Applicative-Order Evaluation (eager evaluation, call-by-value) bezeichnetIst der Standard in den meisten Sprachen
Die Argumente einer Funktion werden nur dann ausgewertet, wenn sie auch benötigt werden?
Wird Normal-Order Evaluation (lazy evaluation‚ call by need, delayed evaluation) bezeichnetKann zu einer besseren Leistung führen wenn an eine Funktion übergebene Argumente manchmal nicht gebraucht werdenBeispiel:
void foo (int a, int b, int c) {if (a + b < N) { return c; } else { return a + b; }
foo(a,b,expensive_function())In einigen Fällen wird „c“ nicht benötigt, und der Wert von c könnte von einerteuer zu berechnenden Funktion bestimmt werden
6. Sprachen, Compiler und Theorie
6.6-40Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Kontrollstrukturen
Ausblick
Namen, Gültigkeitsbereiche und Bindungen (Kapitel 3)Speichermanagement und ImplementierungKontrollfluss (Kapitel 6)Zusammenführung (Bau eines ausführbaren Programms) (Kapitel 9)

Prof. Dr. Dieter HogrefeDipl.-Inform. Michael Ebner
Lehrstuhl für TelematikInstitut für Informatik
Informatik IIInformatik IISS 2004
Teil 6: Sprachen, Compiler und Theorie
7 – Zusammenführung
6. Sprachen, Compiler und Theorie
6.7-2Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Der Kompilationsprozess (-phasen)
Scanner (lexikalische Analyse)
Parser (syntaktische Analyse)
Semantische Analyse
Zwischencodegenerierung
Optimierung
Zielcodegenerierung
Optimierung Maschinenebene
Lese Programm und konvertiere Zeichenstrom in Marken (tokens). Theorie: Reguläre Ausdrücke, endlicher Automat
Lese Tokenstrom und generiere Ableitungsbaum (parse tree). Theorie: Kontextfreie Grammatiken, Kellerautomat
Traversiere Parserbaum, überprüfe nicht-syntaktische Regeln.
Traversiere Parserbaum noch mal, gebe Zwischencode aus.
Untersuche Zwischencode, versuche ihn zu verbessern.
Übersetze Zwischencode in Assembler-/Maschinencode
Untersuche Maschinencode, versuche ihn zu verbessern.
6. Sprachen, Compiler und Theorie
6.7-3Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Die Organisation eines typischen Compilers
FrontendFührt Operationen aus welche von der zu kompilierenden Sprache abhängen und nicht von der Zielmaschine
BackendFührt Operationen aus welche etwas Wissen über die Zielmaschine haben müssen
6. Sprachen, Compiler und Theorie
6.7-4Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Schreiben des Programms
Ein kleines Programm, geschrieben in Pascal, welches den größten gemeinsamen Teiler (ggT) von zwei Ganzzahlen berechnet
program gcd (input, output);var i, j : integer;begin
read(i,j);while i <> j do
if i > j then i := i – jelse j :- j – i;
writeln(i)end.
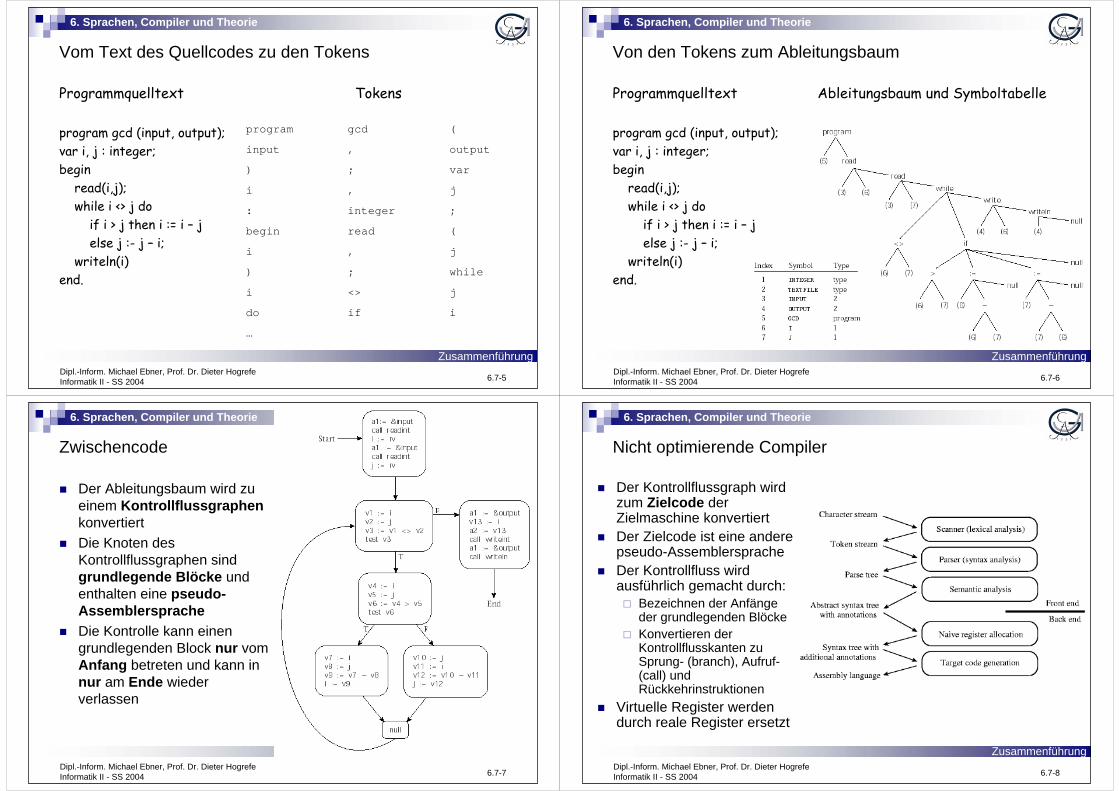
6. Sprachen, Compiler und Theorie
6.7-5Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Vom Text des Quellcodes zu den Tokens
Programmquelltext
program gcd (input, output);var i, j : integer;begin
read(i,j);while i <> j do
if i > j then i := i – jelse j :- j – i;
writeln(i)end.
program gcd (input , output) ; vari , j: integer ;begin read (i , j) ; whilei <> jdo if i…
Tokens
6. Sprachen, Compiler und Theorie
6.7-6Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Von den Tokens zum Ableitungsbaum
Ableitungsbaum und SymboltabelleProgrammquelltext
program gcd (input, output);var i, j : integer;begin
read(i,j);while i <> j do
if i > j then i := i – jelse j :- j – i;
writeln(i)end.
6. Sprachen, Compiler und Theorie
6.7-7Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Zwischencode
Der Ableitungsbaum wird zu einem KontrollflussgraphenkonvertiertDie Knoten des Kontrollflussgraphen sind grundlegende Blöcke und enthalten eine pseudo-AssemblerspracheDie Kontrolle kann einen grundlegenden Block nur vom Anfang betreten und kann in nur am Ende wieder verlassen
6. Sprachen, Compiler und Theorie
6.7-8Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Nicht optimierende Compiler
Der Kontrollflussgraph wird zum Zielcode der Zielmaschine konvertiertDer Zielcode ist eine andere pseudo-AssemblerspracheDer Kontrollfluss wird ausführlich gemacht durch:
Bezeichnen der Anfänge der grundlegenden BlöckeKonvertieren der Kontrollflusskanten zu Sprung- (branch), Aufruf-(call) und Rückkehrinstruktionen
Virtuelle Register werden durch reale Register ersetzt

6. Sprachen, Compiler und Theorie
6.7-9Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Zielcode
Der Zielcode ist beinahe Assemblercode
Der Kontrollfluss ist ausführlichDer Code referenziert nur reale RegisternamenAnweisungen zum Speicherreservieren sind vorhanden
Zielcode ist einfach zu Assemblercode zu übersetzen
6. Sprachen, Compiler und Theorie
6.7-10Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Vom Zielcode zum Assemblercode
Normalerweise einfach:r10 := r8 + r9 -> add $10, $8, $9r10 := r8 + 0x12 -> addi $10, $8, 0x12
Manchmal auch zu einer Folge von Instruktionen erweitert:r14 := 0x12345abc ->
lui $14, 0x1234ori $14, 0x5abc
6. Sprachen, Compiler und Theorie
6.7-11Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Binden (linking)
Beim Binden werden mehrere durch den Assembler erzeugte Objektdateien zu einer einzelnen, ausführbaren Datei kombiniert, welche durch ein Betriebssystem lauffähig ist
6. Sprachen, Compiler und Theorie
6.7-12Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Optimierende CompilerOptimierung ist ein komplexer ProzessVerbessert die Qualität des generierten Codes auf Kosten von zusätzlicher CompilezeitOptimierer sind schwierig zu schreiben und einige Optimierungen verbessern das fertige Programm vielleicht nicht
Praxistip: Die jeweilige Einstellung der Optimierungstiefe eines Compilers genau auf korrekte Funktion kontrollieren, da diese öfters fehleranfällig sind (lieber erstmal auf Optimierung verzichten und erst am Ende austesten!)

6. Sprachen, Compiler und Theorie
6.7-13Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Peephole-Optimierung
Sehe dir den Zielcode an, wenige Instruktionen gleichzeitig, undversuche einfache Verbesserungen zu machenVersucht kurze, sub-optimale Folgen von Instruktionen zu finden und ersetzt diese Sequenzen mit einer „besseren“ SequenzSub-Optimale Sequenzen werden durch Muster (patterns) spezifiziert
Meistens heuristische Methoden — Es gibt keinen Weg um zu überprüfen ob das Ersetzen eines sub-optimalen Musters tatsächlich das endgültige Programm verbessern wird
Einfach und ziemlich wirksam
6. Sprachen, Compiler und Theorie
6.7-14Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Peephole-Optimierungstypen (1/3)
Redundante load/store Instruktionen beseitigen
Konstantenfaltung (constant folding)
Entfernung gemeinsamer Teilausdrücke (common subexpression elimination)
r2 := r1 + 5i := r2r3 := ir4 := r3 x 3
r2 := 3 x 2
r2 := r1 x r5r2 := r2 + r3r3 := r1 x r5
r2 := r1 + 5i := r2r4 := r2 x 3
r2 := 6
r4 := r1 x r5r2 := r4 + r3r3 := r4
wird zu
wird zu
wird zu
6. Sprachen, Compiler und Theorie
6.7-15Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Peephole-Optimierungstypen (2/3)
Fortpflanzung von Konstanten (constant propagation)
und auch
Fortpflanzung von Zuweisungen (copy propagation)
r2 := 4r3 := r1 + r2r2 := …
wird zur2 := 4r3 := r1 + 4r2 := …
und r3 := r1 + 4r2 := …
r2 := 4r3 := r1 + r2r3 := *r3
wird zu r3 := r1 + 4r3 := *r3
undr3 := *(r1+4)
r2 := r1r3 := r1 + r2r2 := 5
wird zur2 := r1r3 := r1 + r1r2 := 5
und r3 := r1 + r1r2 := 5
6. Sprachen, Compiler und Theorie
6.7-16Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Peephole-Optimierungstypen (3/3)
Algebraische Vereinfachung (strength reduction)
Beseitigung von unnötigen Instruktionen
r1 := r2 x 2r1 := r2 / 2 wird zu
r1 := r2 + r2r1 := r2 >> 1 oder r1 := r2 << 1
r1 := r1 + 0r1 := r1 - 0r1 := r1 * 1
wird zu (wird komplett beseitigt)

6. Sprachen, Compiler und Theorie
6.7-17Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Komplexe Optimierungen
Es ist für den Optimierer erforderlich den Datenfluss zwischen Registern und Speicher zu „verstehen“
Wird durch Datenflussanalyse (data flow analysis) bestimmtBeispiel: Finde die Variablenmenge welche einen grundlegenden Block auf dem Weg zu einem anderen Block „durchfliesst“ und von diesem anderen Block verwendet wird (lebendige Variablen)
Ist wichtig für Optimierungen welche datenverändernde Instruktionen einfügen, löschen oder bewegenDer ursprüngliche Programmdatenfluss kann nicht geändert werden!
Es ist für den Optimierer erforderlich die Struktur des Kontrollflussgraphen (control flow graph) zu „verstehen“
Wird durch Kontrollflussanalyse bestimmtIst wichtig für die Leistungsoptimierung von Schleifen oder schleifenähnlichen Strukturen in dem Kontrollflussgraphen
6. Sprachen, Compiler und Theorie
6.7-18Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Beispiel für komplexe Optimierung
Schleifeninvarianter Code (Loop Invariant Code Motion)
Bewege Berechnungen, dessen Werte während allen Schleifeniterationen gleich bleiben (invariant sind), aus der Schleife raus
L1:r1 := *(sp + 100)r2 := *r1…r3 := r2 < 100if r3 goto L1
L1:r2 := *r1…r3 := r2 < 100if r3 goto L1
L0:r1 := *(sp + 100)
6. Sprachen, Compiler und Theorie
6.7-19Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Was haben Sie in diesem Kapitel gelernt?
Programmiersprachen sind Abstraktionsmechanismen, welche:ein Rahmenwerk zum Lösen von Problemen und erzeugen neuer Abstraktionen bietenSchirmen den Programmierer von niederen Detailebenen (low-leveldetails) der Zielmaschine (Assemblersprache, Verbinden (linken), etc.) ab
Compiler sind komplexe Programme welche eine höhere Programmiersprache in eine Assemblersprache umwandeln um danach ausgeführt zu werdenCompilerprogrammierer handhaben die Komplexität des Kompilationsprozesses durch:
aufteilen des Compilers in unterschiedliche Phasenverwenden, ausgehend von der Spezifikation, eine Theorie für den Bau von Compilerkomponenten
6. Sprachen, Compiler und Theorie
6.7-20Dipl.-Inform. Michael Ebner, Prof. Dr. Dieter HogrefeInformatik II - SS 2004
Zusammenführung
Ausblick
Betriebssysteme (Kapitel 5)
Maschinenorientierte Programmierung (Kapitel 4)
SpeicherZahlen und logische Schaltungen (Kapitel 2)
von-Neumann-Rechner (Kapitel 3)
von-Neumann-Rechner
Kommunikation (Kapitel 7)
Compilerbau (Kapitel 6)
Recommended

















