
StoffsammlungTechnische Informatik II
von Stephan Senn, D-ITET
InhaltsverzeichnisDas Betriebsystem (BS)..................................................................................................... 3
Aufgaben.......................................................................................................................... 3Klassifizierung.................................................................................................................. 3
Batch Systems / Multiprogrammed Systems............................................................................................3Real-Time Systems...................................................................................................................................3Mainframe Systems..................................................................................................................................3Time-Sharing Systems.............................................................................................................................4Multiprocessor Systems............................................................................................................................4Clustered Systems....................................................................................................................................4Distributed Systems..................................................................................................................................4Handheld Systems....................................................................................................................................4
Parallelverarbeitung........................................................................................................... 5Möglichkeiten der Parallelisierung................................................................................... 5Klassifikation nach parallel arbeitenden Funktionseinheiten............................................5
Prozessverwaltung............................................................................................................. 6Terminologie.................................................................................................................... 6Prozesszustände.............................................................................................................. 6Process Control Block (PCB)........................................................................................... 6Process Scheduling......................................................................................................... 6Scheduling Algorithmen................................................................................................... 7
Waiting Time.............................................................................................................................................7Turnaround Time......................................................................................................................................7First Come, First Served (FCFS)..............................................................................................................7Shortest Job First (SJF)............................................................................................................................7Scheduling nach Prioritäten......................................................................................................................8Round-Robin Scheduling (RR).................................................................................................................8Die Rolle der Ankunftzeit..........................................................................................................................9Multilevel Queue Scheduling....................................................................................................................9Multilevel Feedback-Queue Scheduling.................................................................................................10Real-Time Scheduling.............................................................................................................................11Zusammensetzung der Reaktionszeit eines Schedulers........................................................................11
Synchronisation von Prozessen..................................................................................... 11Behandlung von kritischen Bereichen (critical sections)........................................................................11Semaphore.............................................................................................................................................13
Interprozesskommunikation........................................................................................... 14Shared Memory......................................................................................................................................14Message Passing....................................................................................................................................14Interprozesskommunikation in TOPSY...................................................................................................15
Speicherverwaltung......................................................................................................... 16Aufgabe.......................................................................................................................... 16Adressbindung............................................................................................................... 16Swapping....................................................................................................................... 16Algorithmen für die Speicherzuteilung........................................................................... 16Speicherfragmentierung................................................................................................. 17Physikalischer und virtueller Speicher........................................................................... 17Grundregel für die Adressierung.................................................................................... 18Paging............................................................................................................................ 18
Stephan Senn, D-ITET -1- 06.08.04

Adressumsetzung...................................................................................................................................18Translation Look-Aside Buffer (TLB)......................................................................................................18
Segmentation................................................................................................................. 19Adressumsetzung...................................................................................................................................19Protection and Sharing...........................................................................................................................20
Virtual Memory............................................................................................................... 20Logische Einteilung des virtuellen Speichers.........................................................................................20Potentielle Vorteile..................................................................................................................................21Demand Paging......................................................................................................................................21Page-Replacement.................................................................................................................................21
Verteilte Systeme............................................................................................................. 22Begriffe........................................................................................................................... 22Charakteristiken von Computernetzen........................................................................... 23OSI-Referenzmodell (Open Systems Interconnection).................................................. 23
Sicherungsprotokolle...................................................................................................... 24Paketübermittlung: Fragmentierung, Framing und Stuffing........................................... 24
Stuffing....................................................................................................................................................24COBS (Consistent Overhead Byte Stuffing)...........................................................................................25Datenrahmen..........................................................................................................................................25
Idle Repeat Request (IRQ) Protokoll.............................................................................. 25Continuous Repeat Request (CRQ) Protokoll................................................................ 25
Selektive Wiederübertragung.................................................................................................................26Go-Back-N-Verfahren.............................................................................................................................26
Fluss- und Verkehrssteuerung....................................................................................... 26X-ON/X-Off-Verfahren............................................................................................................................26Fenstermethode (Sliding Window Mechanism)......................................................................................26
Piggyback Acknowledge................................................................................................ 27Simplex-Duplex.............................................................................................................. 27
Device Drivers.................................................................................................................. 28Das Schreiben von Gerätetreibern................................................................................. 28A Teachable Operating System (TOPSY)...................................................................... 28Generische Treiber in TOPSY....................................................................................... 28Das Schreiben von Gerätetreiber in TOPSY.................................................................. 30
Quellenverzeichnis........................................................................................................... 30
Stephan Senn, D-ITET -2- 06.08.04

Das Betriebsystem (BS)
Aufgaben• Effiziente Verwaltung der gemeinsamen Betriebsmittel:➢ Prozessverwaltung
➢ Speicherverwaltung
➢ Verwaltung von IO-Geräten
➢ Verwaltung von Sekundärspeicher
➢ Verwaltung des File-Systems
➢ Kommunikation
• Vermittler zwischen Hardware und Benutzer
• Komfort für den Benutzer
• Grundaufgabe: Programme zur Ausführung bringen
• Schutzfunktion:➢ Betriebsmodi: User / System
➢ privilegierte Instruktionen
➢ Beschränkung des Zugriffs zu IO-Geräten
➢ Speicherschutz
➢ Schnittstelle für Benutzer: Zugriff auf Betriebsmittel mit Hilfe von System Calls
• Kooperation der Anwendungsprogramme mehrerer Benutzer: Interprozesskommunikation,gleichzeitiger Zugriff auf gemeinsame Betriebsmittel,...
Klassifizierung
Batch Systems / Multiprogrammed SystemsDie ersten Computersysteme waren Stapelverarbeitungsmaschinen. Jeder Job wurde mittelsLochkarten in den Hauptspeicher eingelesen. Compiler, Interpreter oder andereAnwendungsprogramme mussten zuerst mittels Lochkarten eingelesen werden. Mit der Zeit konnteman dann auch mehrere gleichzeitig in den Hauptspeicher laden (Multiprogramming,Mehrprozessbetrieb). Man spricht in diesem Zusammenhang auch von Multiprogrammed Systems.
Real-Time SystemsReal-Time Systems sind Echtzeit-Systeme. Sie werden zur Steuerung von technischen Prozesseneingesetzt, wo schnelle Reaktionszeiten gefordert werden. Deshalb werden sie vorwiegend ineingebetteten Systemen (embedded Systems) verwendet. Man unterscheidet:
• Hard Real-Time System: hohe Anforderungen bezüglich Reaktions- und Ausführungszeit, keinTime-Sharing
• Soft Real-Time System: zeitkritische Prozesse nur beschränkt möglich, Time-Sharing mitVerwendung von Prioritäten möglich
Mainframe SystemsMainframe Systems sind Grossrechnersysteme. Batch Systems / Multiprogrammed Systems warenGrossrechnersysteme.
Stephan Senn, D-ITET -3- 06.08.04

Time-Sharing SystemsIn Time-Sharing Systems sind mehrere Jobs gleichzeitig im Hauptspeicher. Die Abarbeitung erfolgtzu gewissen Zeitschritten, Time-Slices genannt. Das Betriebssystem wählt nach einem bestimmtenAlgorithmus fortlaufend einen der Jobs aus und beginnt ihn abzuarbeiten. Nach einer bestimmtenZeit wird der Job in Abarbeitung unterbrochen und ein neuer Job wird abgearbeitet. Das schnelleUmschalten (Switiching) zwischen den Jobs, erweckt beim Benutzer den Eindruck, als ob die Jobsparallel abgearbeitet würden.
Mehrere Benutzer können gleichzeitig auf dem Computer arbeiten.
Time-Sharing Systems unterstützen Virtual Memory und ein File-System.
Solche Systeme benötigen interaktive Computersysteme (z.B. Mouse, Tastatur, usw.).
Desktop Systems, meist PC-Systems genannt, sind Time-Sharing Systems.
Multiprocessor SystemsMehrprozessorsysteme besitzen, wie der Name sagt, mehrere Prozessoren. Sie zeichnen sich durchfolgende Merkmale aus:
• Die Prozessoren haben einen gemeinsamen Takt und einen gemeinsamen Bus. Auch derHauptspeicher und die Peripherie kann gemeinsam sein.
• höherer Durchsatz
• bessere Ausfallsicherheit
• tiefere Anschauffungskosten für gleiche Rechenleistung als Singleprocessor Systems
Beim Symmetric Multiprocessing (SMP) läuft auf jedem Prozessor ein Betriebssystem.
Bei Assymmetric Multiprocessing erfüllt jeder Prozessor eine spezielle Aufgabe.
Clustered SystemsMehrere Singleprozessor-Systeme können vernetzt werden. Damit entsteht ein Cluster.
Distributed SystemsDistributed Systems sind verteilte Systeme. Sie zeichnen sich dadurch aus, dass die Prozessorenörtlich getrennt sind und über eine Verbindungsleitung miteinander kommunizieren. Dies ist beiMultiprozessor-Systemen nicht der Fall. Dort sind die Prozessoren nahe beisammen undkommunizieren über einen Bus. Aber auch das File-System oder ganze Dienste können über einNetzwerk verteilt sein. Der Benutzer hat immer den Eindruck, als sitze er vor einem lokalenSystem. In Tat und Wahrheit aber nutzt er Dienste, Funktionen und Ressourcen, die über einNetzwerk verteilt sind. Man spricht in diesem Zusammenhang auch von Transparenz.
Handheld SystemsHandheld Systems sind portable Systeme (z.B. PDAs). Sie zeichnen sich durch folgende Merkmaleaus:
• wenig Speicherplatz
• kleiner Bildschirm
• geringer Leistungsverbrauch
Stephan Senn, D-ITET -4- 06.08.04

Parallelverarbeitung
Möglichkeiten der ParallelisierungEs gibt folgende Möglichkeiten:
• Verwendung von mehreren Prozessoren
• Multithreading: Gleichzeitige Ausführung von Benutzerprogrammen
• Pipelining: Überlappung der einzelnen Schritte bei der Abarbeitung einer Instruktion
• zeitliche Überlappung von Berechnung und IO-Funktionen
• Interrupts (Interrupt driven1): Prozessor, der mit einer Aufgabe beschäftigt ist, wird unterbrochenund mit einer neuen Aufgabe beschäftigt. Nach deren Abarbeitung wird die alte Aufgabe wiederan der unterbrochenen Stelle aufgegriffen und fortgesetzt.
Klassifikation nach parallel arbeitenden FunktionseinheitenDatenpfad
einfach vorhanden mehrfach vorhanden
Steuerpfad
einfachvorhanden
Single Instruction, Single Data(SISD)
Parallelisierung durch Pipelining
Single Instruction, MultipleData (SIMD)
Parallelisierung durchgleichzeitige Abarbeitung
mehrerer Datensätze(Vektorprozessor)
mehrfachvorhanden
Multiple Instruction, Single Data(MISD)
Parallelisierung durch dasgleichzeitige Ausführen mehrererProzesse des gleichen Programms
oder mehrerer Programme aufeinem Datensatz (Erhöhung der
Zuverlässigkeit)
Multiple Instruction, MultipleData (MIMD)
allgemeinster Fall; jedochschwierig einzusetzen
Bemerkung:
Der Speedup bei Mehrprozessorsystemen ist von der Architektur, dem parallel gelösten Problemund den Eigenschaften des Verbindungsnetzwerks (z.B. Übertragungsrate, Verzögerungszeit)abhängig.
Speedup=Ausführungszeit mit einem ProzessorAusführungszeit mit mehreren Prozessoren
1 im Gegensatz zu Polling!
Stephan Senn, D-ITET -5- 06.08.04

Prozessverwaltung
Terminologie• Prozess: Ein Programm in Ausführung ist ein Prozess. Man beachte, dass ein ausgeführtes
Programm mitunter aus mehreren Prozessen bestehen kann. Ein Prozess verfügt über eineneigenen Adressraum.
• Thread: Ein Programm in Ausführung mit einem gemeinsamen Adressraum bezeichnet manThread. Threads können, im Gegensatz zu Prozessen, miteinander in einem gemeinsamenAdressraum kommunizieren. Die CPU-Umschaltung von Threads ist viel effizienter als die vonProzessen. Moderne Betriebssysteme haben Threads im Kernel als auch auf Userrebene.
Prozesszustände• new: Die für einen Prozess notwendigen Datenstrukturen sind kreiert und im Betriebssystemkern
vermerkt worden. Das zugehörige Speicherbild ist im Speicher oder wird erst bei Bedarf geladen.
• swapped: Das Speicherbild eines Prozesses ist auf dem Sekundärspeicher (Harddisk)ausgelagert.
• ready / runnable: Der Prozess ist bereit zur Ausführung.
• waiting / blocked: Der Prozess wartet auf das Eintreten eines Ereigneisses (z.B. Abschluss einerIO-Operation, Synchronisierung mit einem anderen Prozess).
• running: Der Prozess ist in Ausführung.
• terminated: Der Prozess hat terminiert.
Process Control Block (PCB)Jeder Prozess wird im Betriebssystem als Process Control Block (PCB) repräsentiert. Der PCBentält folgende Einträge:
• Process state
• Program counter
• CPU register
• CPU-scheduling information
• Memory-management information
• Accounting information
• IO status information
Die PCBs sind meist in verketteten Listen angeordnet. Die Zustände der PCBs müssen bei derProzessumschaltung gesichert werden.
Process SchedulingDas Zuteilen eines Prozesses an die CPU aus einem Pool von Prozessen wird Process Schedulinggenannt. Es gibt grundsätzlich zwei Ausprägungen von Scheduling:
• Non-preemptive Scheduling:Der Scheduler wird bei folgenden Ereignissen aktiviert:
➢ Ein laufender Prozess führt eine Operation aus, die ihn in den Wartezustand bringt.
Stephan Senn, D-ITET -6- 06.08.04

➢ Ein Prozess terminiert.
➢ Ein laufender Prozess gibt den Zustand freiwillig ab und wechselt in den Zustand ready.
• Preemptive Scheduling: Der Scheduler wird zusätzlich bei den folgenden Ereignissen aktiviert:
➢ Ein laufender Prozess wird mittels Interupt in den Zustand ready versetzt.
➢ Ein wartender Prozess wird in den Zustand ready versetzt.
Scheduling Algorithmen
Waiting TimeDie aufsummierte Zeit bei der der Prozess lauffähig ist aber nicht läuft, wird Waiting Timebezeichnet.
Turnaround TimeDie Zeitspanne von der Ankunft eines Prozesses im Scheduler bis zu seiner Beendigung wirdTurnaround Time bezeichnet.
First Come, First Served (FCFS)Der Scheduler wählt denjenigen Prozess, der zuerst eine Anfrage an die CPU stellt. Jeder weitereProzess wird gemäss dem Zeitpunkt seiner Anfrage in eine FIFO-Warteschlange gestellt. Diesveranschaulicht das folgende Beispiel mit Hilfe des Gantt-Charts:
Process Arrival Time Burst Time2
P1 0 24
P2 10 4
P3 20 7
P4 25 10
Die totale Wartezeit beträgt: tw=0242835=87 Die mittlere Wartezeit beträgt: tw ,m=87/4
FCFS ist non-preemptive. Ein Prozess verweilt solange in der CPU bis er von sich aus die CPUwieder frei gibt. Das Betriebssystem hat keine Möglichkeit, den Prozess zu unterbrechen.
Shortest Job First (SJF)Derjenige Prozess mit der kleinsten CPU Zeit wird bevorzugt. Längere Prozesse werden also nachhinten geschoben. Dies zeigt das folgende Beispiel:
Process Arrival Time Burst TimeP1 0 24
P2 0 4
P3 0 7
P4 0 10
2 Die Burst Time ist die CPU Zeit, also die Zeit, die der Prozess zur Abarbeitung in der CPU benötigt.
Stephan Senn, D-ITET -7- 06.08.04
P1 P2 P3 P40 24 28 35 45

Die totale Wartezeit beträgt: tw=041121=36 Die mittlere Wartezeit beträgt: tw ,m=36 /4=9
Das Hauptproblem des SJF-Algorithmus besteht darin, die CPU Zeit eines Prozessesvorherzusagen. Dies gelingt mit Hilfe von folgender Formel:
n1=α⋅tn1−α⋅nα ist eine Konstante zwischen 0 und 1. tn ist die CPU Zeit des aktuellen Prozesses. τn beschreibt denexponentiellen Mittelwert der vergangenen Prozesse. Für den Initialwert τ0 kann der Mittelwert deraktuellen Prozesse genommen werden.
SJF kann als preemptive oder non-preemptive Algorithmus implementiert werden.
Scheduling nach PrioritätenJeder Prozess erhält eine Priorität. Normalerweise entsprechen kleine Prioritätszahlen eine hohePriorität und grosse Prioritätszahlen eine niedrige. Doch dies kann von System zu System variieren.Gemeinsam ist allen Systemen, dass Prozesse mit einer hohen Priorität bevorzugt werden. Dasfolgende Beispiel dient der Veranschaulichung:
Process Arrival Time Burst Time PriorityP1 0 24 2
P2 0 4 3
P3 0 7 1
P4 0 10 4
Die totale Wartezeit beträgt: tw=073135=73 Die mittlere Wartezeit beträgt: tw ,m=73/4
Damit verbunden ergibt sich ein generelles Problem: Wann kommt ein Prozess mit niedrigerPriorität zum Zug? - Bei reinem Prioritätsscheduling kommt es zum sogenannten Starvation-Effekt.Prozesse mit einer niedrigen Priorität verweilen unendlich lang im Scheduler und werden nieausgeführt. Eine Lösung dieses Problems heisst Aging. Die Priorität der Prozesse mit niedrigerPriorität wird nach einer gewissen Verweildauer laufend erhöht. Damit wird sichergestellt, dass alleProzesse zum Zug kommen.
Scheduling mit Prioritäten kann als preemptive oder non-preemptive Algorithmus implementiertwerden.
Round-Robin Scheduling (RR)Round-Robin arbeitet auf der Grundlange von FCFS-Scheduling. Die Prozesse werden in einerFCFS-Tabelle verwaltet. RR ist ein preemptive Algorithmus und besitzt deshalb eine bestimmteZeitspanne bis zum nächsten Unterbruch des Prozesses, Time Slice oder Time Quantum genannt.Läuft nun diese Zeit vor dem Beenden des Prozesses ab, dann wird der Prozess unterbrochen undder nächste Prozess wird gemäss der FCFS-Tabelle ausgeführt. Ist die Burst Time kleiner als die dieZeit des Time Slice, dann wird der Prozess normal beendet und kehrt zum Scheduler zurück, derden nächsten Prozess auswählt. Das folgende Beispiel soll dies veranschaulichen:
Stephan Senn, D-ITET -8- 06.08.04
P1P2 P3 P40 4 11 21 45
P1 P2P3 P40 7 31 35 45

Process Arrival Time Burst TimeP1 0 18
P2 0 4
P3 0 7
P4 0 10Das Time Quantum beträgt 3.
Für die totale Wartezeit gilt:
t P1=012741=22
t P2=39=12
t P3=976=20
t P4=12743=26
tw=t P1t P2t P3t P4=80
Für die mittlere Wartezeit gilt:
q sei die Zeit des Time Slice und n die Anzahl Prozesse. Jeder Prozess wartet dann nie mehr alstw≤q⋅n−1 . Für die totale Wartezeit eines Prozesses mit der Burst Time B gilt dann:
t tot≤tw⋅Bq=n−1⋅B
Zu beachten ist, dass wenn q sehr gross gewählt wird, RR sich wie der reine FCFS-Algorithmusverhält. Eine Faustformel besagt zudem, dass 80% der CPU Bursts kleiner als das Time Quantum qsein sollte.
Die Rolle der AnkunftzeitDie Ankunftzeit spielt bei allen Algorithmen eine Rolle. Denn die Auswahl des Schedulers in einerbestimmten Zeitspanne hängt von den anfragenden Prozessen ab. Andere Prozesse, die später dieCPU erbitten, werden dann noch nicht beachtet, obwohl sie vielleicht aufgrund ihrer Eigenschaftenvorzuziehen wären. Dies zeigt das folgende Beispiel eines Schedulers mit preemptive SJF:
Process Arrival Time Burst TimeP1 2 24
P2 4 4
P3 0 7
P4 6 10
Multilevel Queue SchedulingProzesse können in verschiedene Gruppen aufgteilt werden. Eine einfache Einteilung besteht darin,dass man die Prozesse in Vorder- und Hintergrundprozesse aufteilt. Für jede Prozessgruppe wirdeine Scheduling-Warteschlange, Queue genannt, gebildet, die mit einem bestimmten SchedulingAlgorithmus verknüpft ist. Dabei ist zu beachten, dass die Queues verschiedene Scheduling
Stephan Senn, D-ITET -9- 06.08.04
0 3 9 12 15 18 19 22 25 28 29 32 35 36 39 42P2P1 P3 P4 P1 P2 P3 P4 P1 P3 P4 P1 P4 P1 P1
tw ,m=t P1t P2t P3t P4
4=80
4=20
P1P2 P40 4 8 11 21 45
P3 P3

Algorithmen aufweisen können. Die Queues müssen nun auch verwaltet werden. Dies geschiehtwiederum mit einem Scheduling Algorithmus. Meistens wird dafür ein preemptive Scheduling nachPrioritäten verwendet. Eine andere Möglichkeit besteht darin Time Slices einzuführen. Jeder Queueerhält dann eine bestimmte CPU Zeit zugewiesen und wird nach Ablauf dieser Zeit unterbrochen.
Das folgende Beispiel zeigt ein Scheduling Verfahren für Vorder- und Hintergrundprozesse mitTime Slices:• FCFS-Scheduling für die Vordergrundprozesse
• SJF-Scheduling für die Hintergrundprozesse
• preemptive RR-Scheduling der Queues mit 2 Timeslots für die Vordergrundprozesse und 1 Timeslot für denHintergrundprozess
Für die Vordergrundprozesse gilt:
ForegroundProcess
ArrivalTime
Burst Time
F1 4 2
F2 0 7
F3 2 5
Für die Hintergrundprozesse gilt:
BackgroundProcess
ArrivalTime
Burst Time
B1 8 2
B2 1 1
B3 6 4
Damit gilt dann:
Bemerkung:Ist eine Queue leer, dann wird sie vom Scheduler übersprungen und der folgende Queue kommtzum Zug.
Multilevel Feedback-Queue SchedulingBei diesem Scheduling Verfahren können Prozesse zwischen Queues ausgetauscht werden. Diesfunktioniert im allgemeinen so, dass jeder Queue ein bestimmtes Time Quantum besitzt. EinProzess wird zuerst in das Queue mit dem kleinsten Time Quantum platziert. Ist dieses TimeQuantum zu kurz, dann wird nach Ablauf des Time Quantums der Prozess an die Queue mit demnächst grösseren Time Quantum verwiesen. Auf diese Weise werden Prozesse mit einer grossenBurst Time zur Queue mit dem grössten Time Quantum verwiesen. Jede Queue besitzt wie beimnormalen Multilevel Queue Scheduling einen eigenen Scheduling Algorithmus.
Stephan Senn, D-ITET -10- 06.08.04
F20 7 12 14
F3 F1
0 2 3 5 7 8 9 10 11 13 14 16 17 19 21F2 B2 F2 F2 B3 F2 F3 B1 F3 B1 F3 B3 F1 B3
B10 1 6 8 10 12
B3B2 B3

Real-Time Scheduling• Hard Real-Time Systems: Der Prozess wird entweder akzeptiert oder verworfen. Er wird dann
akzeptiert, wenn sichergestellt ist, dass der Prozess innerhalb einer bestimmten Zeit terminiert.
• Soft Real-Time Systems: Hier wird ein Scheduling-Verfahren mit Prioritäten angewendet, dadie Zeitanforderungen nicht so hoch sind wie bei Hard Real-Time Systems. Hard Real-TimeProzesse haben die höchste Priorität.
Zusammensetzung der Reaktionszeit eines SchedulersDie Reaktionszeit setzt sich zusammen aus:
• Interruptlatenzzeit: Zeit von der Auslösung des Interrupts (Eintritt des Ereignisses) einesProzesses bis zum Beginn der Aktivierung des neuen Prozesses
• Zeit bis zur Aktivierung des neuen Prozesses:
➢ Warten auf den Zugang zu den Ressourcen
➢ Starten des Prozesses
• Behandlung des Ereignisses: Scheduling-Tabellen nachführen, usw.
Synchronisation von ProzessenZwei Prozesse müssen dann synchronisiert werden, wenn sie über gemeinsame Betriebsmittel, auchRessourcen genannt, verfügen. Der Bereich des Codes, der auf solche Betriebsmittel zugreift, wirdkritischer Bereich genannt.
Behandlung von kritischen Bereichen (critical sections)Vor dem kritischen Bereich wird ein Eintrittsprotokoll definiert, das den Zugriff auf diegemeinsamen Betriebsmittel regelt. Nach dem kritischen Bereich wird ein Austrittsprotokolldefiniert, das den kritischen Bereich wieder freigibt und dafür sorgt, dass ein anderer Prozess in denkritischen Bereichen eintreten kann. Der Code eines Programmes, das auf gemeinsameBetriebsmittel zugreift, sieht dann wie folgt aus:init();while(not finished){<unkritischer Bereich><Eintrittsprotokoll><kritischer Bereich><Austrittsprotokoll><unkritischer Bereich>}An das Eintritts- und das Austrittsprotokoll werden folgende Anforderungen gestellt:
• Zu jeder Zeit soll höchstens ein Prozess in einem kritischen Bereich bezüglich ein und desselbenBetriebsmittels sein.
• Der Zutritt zu einem kritischen Bereich soll einem Prozess in endlicher Zeit gestattet werden.
• Es sollen keine vermeidbaren Behinderungen von Prozessen zugelassen werden.
Bei schlechten Implementierung dieser Protokolle treten folgende Probleme auf:
Stephan Senn, D-ITET -11- 06.08.04

• Deadlock: Die Prozesse fallen in eine Endlosschleife, aus der sie nicht mehr herausfinden, dadas gegenseitige Aufwecken (notify) nicht mehr gewährleistet ist. Ein anderer Deadlock, der oftauch Verklemmung genannt wird, tritt dann auf, wenn gemeinsame Betriebsmittel von beidenProzessen gleichzeitig benutzt werden. Das Verhalten des Systems ist von System zu Systemverschieden und meist nicht vorhersagbar.
• Livelock: Bei vollkommen gleichzeitiger Abarbeitung der Prozesse tritt ein Deadlock auf.
• Starvation: Ein Prozess wird nie bedient (Verhungern).
Mögliche Implementierungen für die Synchronisation von zwei Prozessen P1 und P2 sind:
• praktischer Ansatz:boolean besetzt1 = false;boolean besetzt2 = false;Prozess P1:while(not finished){<unkritischer Bereich>besetzt1 = true;while(besetzt2){
besetzt1 = false;wait(Random);besetzt1 = true;
}<kritischer Bereich>besetzt1 = false;}
Prozess P2:while(not finished){<unkritischer Bereich>besetzt2 = true;while(besetzt1){
besetzt2 = false;wait(Random);besetzt2 = true;
}<kritischer Bereich>besetzt2 = false;}
• Dekker-Algorithmus:boolean besetzt1 = false;boolean besetzt2 = false;int vortritt = 1;
Stephan Senn, D-ITET -12- 06.08.04

Prozess P1:while(not finished){<unkritischer Bereich>besetzt1 = true;while(besetzt2){
if(vortritt == 2){
besetzt1 = false;while(vortritt!=1){}besetzt1 = true;
}}<kritischer Bereich>besetzt1 = false;vortritt = 2;}
Prozess P2:while(not finished){<unkritischer Bereich>besetzt2 = true;while(besetzt1){
if(vortritt == 1){
besetzt2 = false;while(vortritt!=2){}besetzt2 = true;
}}<kritischer Bereich>besetzt2 = false;vortritt = 1;}
SemaphoreEin Semaphor v ist eine Datenstruktur, auf welcher die beiden Operationen signal(v) undwait(v) definiert sind. Er dient als Synchronisationselement wie der folgende Formalismus zeigt:semaphor v;signal(v);Dieser Semaphor schützt alle kritischen Bereiche bezöglich einesBetriebsmittels. Er ist allen Prozessen, welche diese Betriebsmittel verwendenzugänglich.Prozess P1:while(not finished){<unkritischer Bereich>wait(v);<kritischer Bereich>signal(v);<unkritischer Bereich>}
Prozess P2:while(not finished){<unkritischer Bereich>wait(v);<kritischer Bereich>signal(v);<unkritischer Bereich>}
Für die Implementierung des Semaphors gilt:r(v): Anzahl vollständig ausgeführte Wait-Operationen auf v seit Zeitbeginns(v): Anzahl vollständig ausgeführte Signal-Operationen auf v seit ZeitbeginnZum Zeitbeginn gilt: r v=s v =0 .
Stephan Senn, D-ITET -13- 06.08.04

Zu jeder Zeit gilt weiter:• 0≤r v ≤s v• s v −r v ≤max
Damit gilt:
wait(v){if(r(v) < s(v)) r(v) = r(v) + 1;else // r(v) = s(v) <aufrufender Prozess wird verzögert>}
Ein Prozess wird verzögert wenn gilt:r(v) ≥ s(v). Ein Prozess wird solange verzögert, biswieder r(v) < s(v) gilt.
signal(v){if(s(v) – r(v) == max)<Signalisiere Ausnahmebedingung>else{
s(v) = s(v) + 1;if(Prozess ist verzögert){
r(v) = r(v) + 1;<Prozess zur Ausführung bereit machen>
}}}
Bermerkung:
Die Variablen s(v) und r(v) können auch mit einer Variablen k(v) ausgedrückt werden. Es gilt dann:k v =s v −r v mit k v ≥0 .
Der Befehl signal(v) inkrementiert k(v); wait(v) dekrementiert. Ein Prozess wird dann in denWartezustand versetzt, wenn k v =0 ist.
Semaphore können auch zu Beginn eines Programms initialisiert werden. Eine AnweisungSemaphore v = 2; bedeutet beispielweise, dass zwei signal(v)-Anweisungen bereits ausgeführtsind. Es sind also 2 wait(v)-Anweisungen nötig, um einen Prozess in den Wartezustand zuversetzen.
Interprozesskommunikation
Shared MemoryDie Prozesse tauschen ihre Informationen über einen gemeinsamen Speicherbereich aus. Allerdingsmuss der Zugriff auf gemeinsame Ressourcen synchronisiert werden. Meist werden Threadsverwendet, da diese bereits über einen gemeinsamen Speicher verfügen.
Message PassingEin Prozess sendet über einen Kanal eine Nachricht an einen anderen Prozess. Dabei wird zwischenzwei Kommunikationsarten unterschieden:
• direkte Kommunikation: Der Sender schickt direkt an den Emfpänger eine Meldung (Punkt-zu-Punkt-Verbindung).
Stephan Senn, D-ITET -14- 06.08.04

• indirekte Kommunikation: Die Kommunikation erfolgt über eine Mailbox. Der Sender stelltdie Nachricht in die Mailbox und der Empfänger holt die Nachricht von der Mailbox ab.
Man unterscheidet weiter zwischen synchronem (blocked) und asynchronem (non-blocked) Sendenund Empfangen:
• synchrones Senden (blocked sending): Der Sender sendet eine Nachricht an den Empfängerund geht in den Wartezustand. Der Empfänger quittiert dem Sender den Empfang der Nachricht.Dieser wird nun aktiv und beginnt mit der Abarbeitung.
• asynchrones Senden (non-blocked sending): Der Sender muss nicht auf eineEmpfangsbestätigung des Empfängers warten. Er schickt die Nachricht an den Empfänger undsetzt die Abarbeitung des Programms fort. Der Kanal hat in diesem Fall einen Buffer. Es könnenalso auch dann Nachrichten gesendet werden, wenn der Empfänger nicht bereit ist. Allerdings istdie Kapazität beschränkt.
• synchrones Empfangen (blocked receiving): Der Empfänger wartet solange bis er eineNachricht vom Sender erhält. Nach Erhalt der Nachricht wird der Empfänger aktiv und beginntmit der Abarbeitung. Danach kehrt er wieder in den Wartezustand zurück und wartet auf denEmpfang der nächsten Nachricht.
• asynchrones Empfangen (non-blocked receiving): Der Empfänger muss nicht auf eineNachricht des Senders warten. Bei jedem Durchauf des Empfängerprogramms wird überprüft, obeine Nachricht anliegt. Diese Lösung benötigt daher einen Empfangsbuffer.
Interprozesskommunikation in TOPSYTOPSY verwendet Message Passing.
• Senden von Nachrichten:Das Senden einer Nachricht ist asynchron. SyscallError tmMsgSend(ThreadId to, Message* msg)Rückgabewerte: TM_MSGSENDFAILED, TM_MSGSENDOK
• Empfangen von Nachrichten:Der Empfang einer Nachricht ist synchron, wenn die Zeitüberwachung auf timeOut=INFINITYgestellt ist. Im anderen Fall ist das Empfangen asynchron. SyscallError tmMsgRecv(ThreadId* from, MessageId msgId, Message* msg, inttimeOut)Rückgabewerte: TM_MSGRECVFAILED, TM_MSGRECVOK
• Senden und Empfangen von Nachrichten im Kernel-Mode:int kSend(ThreadId to, Msg* msg)int kRecv(ThreadId* from, Msg* msg)Rückgabewerte: TM_OK
Für die Funktionsparameter gilt:
from, to Identifikation eines ProzessesANY: Empfangen einer Nachricht eines beliebigen Prozesses
msg Zeiger auf NachrichtmsgId Typ der Nachricht (anwendungsspezifisch)
ANYMSGTYPE: beliebiger Typ einer Nachricht akzeptieren
Stephan Senn, D-ITET -15- 06.08.04

timeOut maximale Wartezeit von tmMsgRecv()INFINITY: tmMsgRecv() wartet solange bis eine Meldung anliegt(synchrones Empfangen).
Speicherverwaltung
AufgabeDie Speicherverwaltung hat folgende Aufgaben:
• Verwaltung von Caches, Arbeitsspeicher und Hintergrundspeicher (Filesystem)
• Verwaltung mehrere Prozesse im Arbeitsspeicher
• Allokation von Speicher
AdressbindungEin Programm enthält meistens Speicheradressen. Oft sind diese Adressen erst an einem der dreiZeitpunkte bekannt:
• zur Compilezeit
• beim Ladevorgang
• bei der Ausführung
SwappingDer ursprüngliche Begriff Swapping bezeichnete das Ein- und Auslagern von Prozessen vomSpeicher in und aus dem Hintergrundspeicher (Sekundär- oder Tertiärspeicher). Swapping wirddann benötigt, wenn zur Ausführung von Prozessen zu wenig Arbeitsspeicher zur Verfügung steht.Das Ein- und Auslagern von Prozessen auf den Hintergrundspeicher ist sehr langsam und solltewenn möglich vermieden werden. Meistens werden Caches eingesetzt, um das Ein- und Auslagernzu beschleunigen.
Algorithmen für die Speicherzuteilung• First-Fit: Belege den ersten freien Speicherplatz, der gross genug ist, um die Anforderung zu
erfüllen.
• Rotating-First-Fit: Wie First-Fit, jedoch wird von der Position der vorherigen Platzierung (Endeder benutzten Lücke) ausgehend die nächste passende Lücke gesucht. Wird dabei dasSpeicherende erreicht, fängt das Verfahren wieder von vorne an.
• Best-Fit: Belege den kleinsten freien Speicherbereich, in den die Anforderung passt.
• Worst-Fit: Belege den grössten freien Speicherbereich, in den die Anforderung passt.
• Buddy: Der Speicherbereich wird solange durch 2 unterteilt, bis ein passender Block gefundenwurde. Blöcke können auch wieder miteinander verschmolzen werden. Dabei entsteht ein neuerBlock. Das folgende Beispiel zeigt diesen Algorithmus.
Stephan Senn, D-ITET -16- 06.08.04
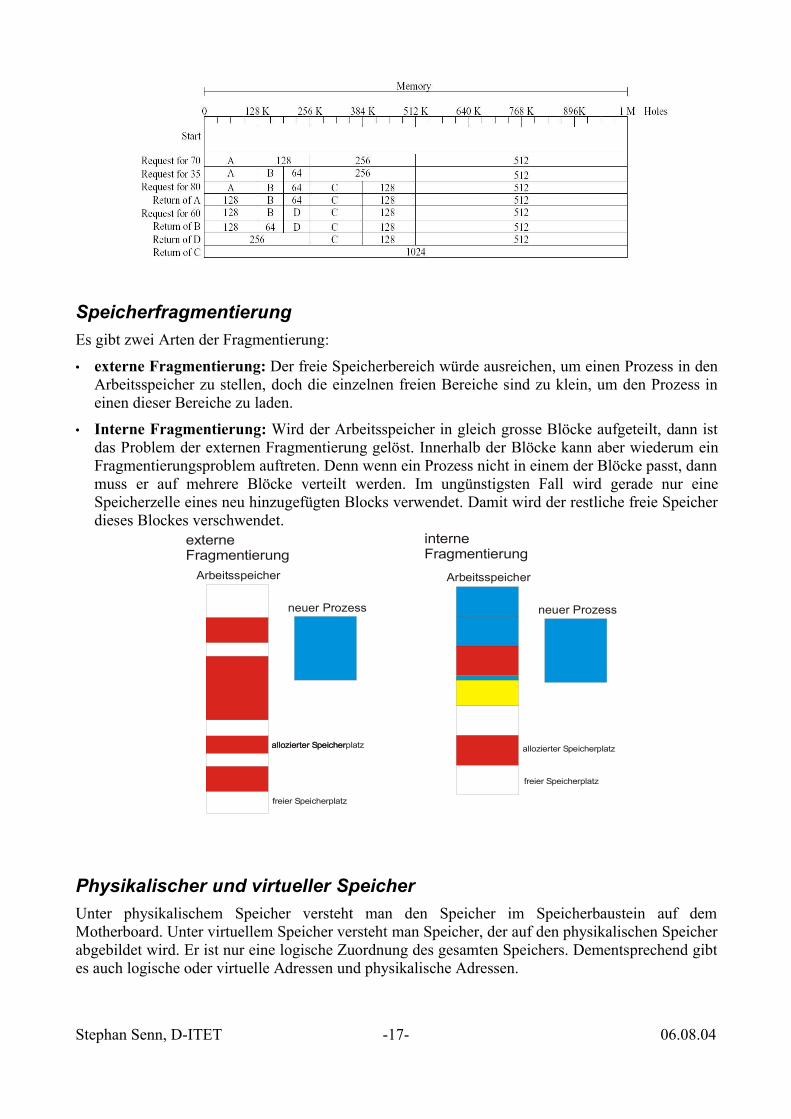
SpeicherfragmentierungEs gibt zwei Arten der Fragmentierung:
• externe Fragmentierung: Der freie Speicherbereich würde ausreichen, um einen Prozess in denArbeitsspeicher zu stellen, doch die einzelnen freien Bereiche sind zu klein, um den Prozess ineinen dieser Bereiche zu laden.
• Interne Fragmentierung: Wird der Arbeitsspeicher in gleich grosse Blöcke aufgeteilt, dann istdas Problem der externen Fragmentierung gelöst. Innerhalb der Blöcke kann aber wiederum einFragmentierungsproblem auftreten. Denn wenn ein Prozess nicht in einem der Blöcke passt, dannmuss er auf mehrere Blöcke verteilt werden. Im ungünstigsten Fall wird gerade nur eineSpeicherzelle eines neu hinzugefügten Blocks verwendet. Damit wird der restliche freie Speicherdieses Blockes verschwendet.
Physikalischer und virtueller SpeicherUnter physikalischem Speicher versteht man den Speicher im Speicherbaustein auf demMotherboard. Unter virtuellem Speicher versteht man Speicher, der auf den physikalischen Speicherabgebildet wird. Er ist nur eine logische Zuordnung des gesamten Speichers. Dementsprechend gibtes auch logische oder virtuelle Adressen und physikalische Adressen.
Stephan Senn, D-ITET -17- 06.08.04
neuer Prozess
Arbeitsspeicher
neuer Prozess
Arbeitsspeicher
externe Fragmentierung
interne Fragmentierung
allozierter Speicher allozierter Speicherplatzallozierter Speicherplatz
freier Speicherplatz
freier Speicherplatz

Grundregel für die AdressierungIm Normalfall gilt:
Eine Adresse zeigt jeweils auf einen Speicherplatz von 1 Byte.
PagingPaging ist ein Speicherverwaltungsschema. Der physikalische Speicher wird dabei inSpeicherblöcke, Frames genannt, aufgeteilt. Den logischen oder virtuellen Speicher teilt man inSeiten auf, die Pages genannt werden. Die Grösse einer Seite entspricht gerade derjenigen einesFrames. Jede virtuelle Adresse besteht aus einer Seitennummer (Page Number) und einemSeitenoffset (Page Offset). Die Zuordnung von virtueller zu physikalischer Adresse geschieht mitHilfe einer Zuordnungstabelle, die Page Table genannt wird. Aufgrund der Geschwindigkeit wirdPaging in Hardware realisiert.
Man beachte, dass Paging keine externe Fragmentierung besitzt; wohl aber eine interne. Zudemunterstützt Paging die Interprozesskommunikation mit Shared Memory.
AdressumsetzungDie physikalische Adresse wird nun mit Hilfe der Page Table-Zuordnungstabelle bestimmt. DieSeitennummer entspricht dem Zeilenindex dieser Tabelle. Der Eintrag in der entsprechenden Zeileist gerade die Basisadresse eines Frames. Mit Hilfe des Seitenoffsets ist nun die entsprechendephysikalische Adresse eindeutig bestimmt. Dies zeigen die folgenden Abbildungen:
Translation Look-Aside Buffer (TLB)Um Paging schnell und effizient zu gestalten, wird ein Cache eingeführt, den Translation Look-Aside Buffer (TLB). Der TLB-Cache besitzt zwei Einträge pro Zeile: die Seitennummer und dieBasisadresse des entsprechenden Frames. Wird nun die Seitennummer nicht im Cache gefunden, soresultiert ein Cache Miss und die zur Seitenummer entsprechende Basisadresse des Frames muss imPage Table nachgeschaut werden. Das Resultat wird dann in den Cache gestellt. Bei einem weiterenZugriff auf dieselbe Seitennummer resultiert ein Cache Hit und die Basisadresse des Frames kanndirekt übergeben werden. Dies zeigt die folgende Abbildung:
Stephan Senn, D-ITET -18- 06.08.04

Der Page Table enthält zudem noch ein Protection Bit, das den Zugriff auf ein Frame regelt: read –write / read only.
Für die durchschnittliche Zugriffszeit tav bei gegebener Hit-Rate h gilt:
t av=h⋅tTLB1−h⋅tMemh: Hit-Rate tTLB: TLB-Zugriffszeit tMem: Speicherzugriffszeit
SegmentationSegmentation ist ebenfalls ein Speicherverwaltungsschema wie Paging. Zwischen Paging undSegmentation gibt es aber grosse Unterschiede. Bei Paging arbeitet der Benutzer stets mit einerlogischen Adresse als wäre es eine physikalische Adresse. Die Aufteilung der Adresse inSeitennummer und Seitenoffset bleibt dem Benutzer verborgen. Anders sieht dies bei Segmentationaus. Hier sieht der Benutzer die Aufteilung der virtuellen Adresse in eine Segmentnummer(Segment Number) und einen Offset. Zudem wird der physikalische Speicher nich in fixe Blöckeaufgeteilt. Jedes Segment hat eine variable Länge und repräsentiert eine logische Einheit. Die Ideeentstammt unserer Vorstellung vom Speicherinhalt. Ein Programm besteht aus logischen Einheiten(z.B. Hauptprogramm, Unterprogramme, Module, Stack, usw.). Die Vorstellung vonSpeicherblöcken ist dem Menschen schwerer zugänglich.
Segmentation wird wie Paging vorwiegend in Hardware realisiert. Das Verfahren leidet an externerFragmentierung. Es besitzt aber umgekehrt keine interne Fragmentierung.
AdressumsetzungDie physikalische Adresse wird mit Hilfe einer Zuordnungstabelle bestimmt. Die Segmentnummerist der Zeilenindex des Segment Tables, der die Basisadresse des Segments (Segment Base) und dieDifferenz zur höchsten physikalischen Adresse im Segment (Segment Limit) beinhaltet. Ausgehendvon der Segementnummer wird nun die Basisadresse des Segments im physikalischen Speicherermittelt. Der Offset des Segments muss innerhalb des Segments liegen. Dies wird mit Hilfe desInhalts Segment Limit geprüft. Liegt die angeforderte Adresse nicht im Segment, so wird ein Trapausgelöst und ans Betriebssystem weitergereicht. Mit Hilfe des Offsets ist nun die physikalischeAdresse eindeutig bestimmt, wie die folgende Abbildung zeigt:
Stephan Senn, D-ITET -19- 06.08.04

Protection and SharingJedem Segement können Zugriffsrechte zugewiesen werden (read-only, read-write, usw.).Segmentation unterstützt auch Code und Data Sharing. Dies ist vorallem bei derInterprozesskommunikation mit Shared Memory von grosser Bedeutung, weil man damitInformationen zwischen Prozessen über einen gemeinsamen Speicher austauschen kann.
Virtual MemoryVirtual Memory ist ein Speicherkonzept, mit dem Prozesse ausgeführt werden können, die nur zumTeil im Arbeitsspeicher vorhanden sind. Programme können also grössser sein als derArbeitsspeicher. Virtual Memory geht aber noch einen Schritt weiter, indem die Gesamtheit derSpeicher zu einem riesigen Speicher zusammengefasst wird. Egal ob ein Prozess auf der Festplatte,im Arbeitsspeicher oder auf einem anderen Speichermedium abgespeichert wurde, für den Benutzergibt es nur einen Speicher. Dieser virtuelle Speicher mit einem virtuellen Speicherbereich mussnatürlich auf den richtigen physikalischen Speicher abgebildet werden. Dazu bedarf es einesgeeigneten Mappings.
Logische Einteilung des virtuellen SpeichersDie logische Einteilung des virtuellen Speichers zeigt die folgende Abbildung.
Virtuelle Speicheradresse StrukturHöchste Adresse Stack
↓freier Speicher
(z.B. für Shared Memory)↑
HeapDaten
0 Code
Stephan Senn, D-ITET -20- 06.08.04

Potentielle Vorteile• Es können Prozesse ausgeführt werden die grösser sind als der physikalische Arbeitsspeicher.
Damit können mehr Prozesse gleichzeitig ausgeführt werden.
• Da nicht der ganze Prozess, sondern nur ein Teil ausgelagert werden muss, werden weniger IO-Operationen benötigt.
• Interprozesskommunikation mit Shared Memory
Demand PagingVirtual Memory wird meist mit Paging realisiert. Virtual Memory lebt von der Idee, dass nicht dergesamte Prozess im Arbeitsspeicher verfügbar muss, damit der Prozess ausgeführt werden kann.Diese Eigenschaft lässt sich gezielt ausnutzen. Anstelle, dass der gesamte Prozess von der Festplattein den Arbeitsspeicher geladen wird, lädt ein Pager nur einzelne Seiten in den Arbeitsspeicher. Miteinem Flag-Bit im Page Table wird dem System mitgeteilt, ob sich die Seite im Arbeitsspeicheroder auf der Festplatte befindet. Ist die Seite nicht im Arbeitsspeicher, dann wird ein Page FaultTrap ausgelöst, der dazu führt, dass die entsprechende Seite in den Arbeitsspeicher geladen wird.Diesen Vorgang zeigt die folgende Abbildung:
1. Es wird auf eine virtuelle Adressezugegriffen. Dazu schaut das System im PageTable nach.
2. Das Flag-Bit ist auf invalid gesetzt. Die Seiteist nicht im Arbeitsspeicher. Es wird ein Trapausgelöst. Der Prozess wird unterbrochen.
3. Das Betriebssystem veranlasst, dass dieentsprechende Seite von der Festplattegeladen wird.
4. Es wird ein freies Frame bestimmt, in das derSpeicherinhalt geschrieben wird.
5. Der Page Table wird aktualisiert indem dasFlag-Bit auf valid gesetzt wird.
6. Der Prozess wird fortgesetzt. Dieunterbrochene Instruktion wird nochmalsausgeführt.
Page-ReplacementDa der Arbeitsspeicher nicht beliebig gross ist, kann er leicht überfüllt werden. In diesem Fall sindkeine Frames mehr frei verfügbar. Das System muss dann Frames wieder zurück auf die Festplatteauslagern. Dieser Vorgang wird Page Replacement genannt. Es gibt verschiedene Verfahren umimmer zu gewährleisten, dass genügend freie Frames im Arbeitsspeicher vorhanden sind. Diewichtigsten Verfahren sind:
• FIFO Page Replacement (First In First Out)Die Pages werden nach dem First In First Out-Schema ersetzt. Es wird also die Page ersetzt, diezuerst in den Speicher geladen wurde.
Stephan Senn, D-ITET -21- 06.08.04

• Optimal Page ReplacementErsetze diejenige Page, die am längsten nicht gebraucht wird. Dieses Verfahren ist schwer zuimplementieren, da das System die zukünftige Nutzungsdauer einer Page abschätzen muss. Eswird aber für theoretische Betrachtungen verwendet, um einen optimalen Algorithmusanzugeben. Andere Algorithmen können dann mit diesem verglichen werden.
• LRU Page Replacement (Least Recently Used)Es wird diejenige Page ersetzt, die am längsten nicht gebraucht wurde. Dazu wird der Zeitpunktdes letzten Zugriffs betrachtet.
• NRU Page Replacement (Not Recently Used)NRU ist sehr ähnlich wie LRU. Auch hier wird diejenige Page ersetzt, die am längsten nichtgebraucht wurde. Im Gegensatz zu LRU protokolliert NRU nicht den Zeitpunkt des letztenZugriffs, sondern setzt ein Reference Bit, wenn auf die Page zugegriffen wurde. Nach einerbestimmten Zeit wird das Bit wieder zurückgesetzt. Erst bei einem erneuten Zugriff auf die Page,wird das Bit wieder gesetzt.
• Second-Chance StrategieSecond-Chance basiert auf dem FIFO-Verfahren. Wenn das Reference Bit 0 ist, dann wird diePage ersetzt. Ist das Reference Bit 1, dann wird der Page eine zweite Chance gewährt und dasReference Bit auf 0 gesetzt; daher der Name. Das Verfahren geht nun, gemäss dem FIFO-Verfahren, durch die einzelnen zu ersetzenden Pages durch und wählt diejenige Page, derenReference Bit 0 ist. Die Implementierung erfolgt meistens in zirkularen Listen.
• LFU Strategie (Least Frequently Used)Es wird diejenige Page ersetzt, die am wenigsten gebraucht wurde. Dazu werden die Zugriffe aufdie Page gezählt und als Reference Count abgelegt. Diejenige Page mit der kleinsten AnzahlZugriffe wird ersetzt. Ein Problem besteht bei Prozessen, auf die zu Beginn sehr starkzugegriffen wurde, die aber später kaum referenziert wurden. Dies kann durch eine Art 'Zerfallder Zugriffszeit' gelöst werden.
• MFU Strategie (Most Frequently Used)MFU ist genau das Gegenstück zu LFU. Es wird die Page mit der grössten Anzahl an Zugriffenersetzt. Die Idee besteht darin, dass die Page mit einer kleinen Anzahl an Zugriffen gerade neugebildet wurde und deshalb gebraucht wird.
Verteilte Systeme
Begriffe• Rechnernetz, Computernetz: Eine Menge von autonomen Computern, die miteinander
Informationen austauschen können. Der Benutzer kann aber die einzelnen Computer voneinanderunterscheiden. Er sieht nicht ein Gesamtsystem. Diese Unterscheidung erstreckt sichbeispielsweise auf die Software oder auf den Speicher. Der Benutzer weiss, dass erAnwendungen auf einem bestimmten Computer ausführt oder dass er auf Daten von einembestimmten Computer zugreift.
• Verteiltes System: Eine Menge von geographisch verteilten, autonomen und miteinanderverbundenen Computern, die durch eine geeignete Kooperation einen Dienst erbringen. DerBenutzer sieht nur die Gesamtheit des Systems; aber nicht die Teile davon. Er hat das Gefühl, als
Stephan Senn, D-ITET -22- 06.08.04
ob er nur vor einem System sitzen würde. Man spricht in diesem Zusammenhang auch von derTransparenz der Verteiltheit. Einige Beispiele sind: E-Mail-System, Domain Name System(DNS) und andere Client-Server-Anwendungen.
• Verteilte Anwendung: Anwendung, die auf mehreren kooperierenden, geographisch verteiltenRechnern läuft und dem Benutzer einen spezifizierbaren Diesnt liefert. Eine verteilte Anwendungrealisiert eine bestimmte Ausprägung eines verteilten Systems.
Charakteristiken von Computernetzen• Adressierung
• Zuweisung / gemeinsame Nutzung von Betriebsmitteln
• Koordination des gleichzeitigen Zugriffs zu gemeinsamen Ressourcen
• Ausfallsicherheit
• Datenübertragung
• Behandlung von Übertragungsfehlern
• Zwischenspeicherung
• Routenwahl
• anfallende Kosten
OSI-Referenzmodell (Open Systems Interconnection)AnwendungsschichtApplication Layer
Benutzerprotokolle; Benutzeranwendungen (z.B. HTTP, E-Mail,Dateiübertragungen, usw.)
DarstellungsschichtPresentation Layer
gewährleistet den Austausch zwischen Computern mit unterschiedlichenDatendarstellungen; Standardkodierung; Syntax und Semantik derDaten
SitzungsschichtSession Layer
Aufbau von Sitzungen (Datenverbindungen) zwischen Benutzern
TransportschichtTransport Layer
Übernahme der Daten von der Sitzungsschicht; Zerlegung der Daten inkleinere Einheiten (Fragmentierung); Übergabe der Einheiten an dieVermittlungsschicht; Sicherstellung, dass die Daten richtig ankommen;Festlegung des Art des Dienstes (Punkt-zu-Punkt Verbindung,Broadcasting, usw.)
VermittlungsschichtNetwork Layer
Betrieb des Verbindungsnetzes; Routing vom Ursprungs- zumBestimmungsort; Qualitätsüberwachung der Verbindung
SicherungsschichtData Link Layer
reine Übertragungseinrichtung in eine Leitung verwandeln;Flusskontrolle und Fehlerbehebung; Framing und Stuffing
BitübertragungsschichtPhysical Layer
Übertragung von reinen Bits über einen Kommunikationskanal
Stephan Senn, D-ITET -23- 06.08.04

SicherungsprotokolleDie Sicherungsprotokolle sind die Protokolle der Sicherungsschicht im OSI-Referenzmodell. Diefolgenden Protokolle gehen von der Annahme aus, dass der Kanal mit Rauschen behaftet ist undnicht jeder gesendete Datenblock3 richtig angkommt.
Paketübermittlung: Fragmentierung, Framing und StuffingBei der Paketübermittlung werden die Daten in Pakete aufgeteilt und übermittelt. Die Aufteilungder Daten in Pakete wird Fragmentierung bezeichnet. Jedes Paket wird vor der Übermittlung ineinen Rahmen (Frame) gestellt. Diesen Vorgang nennt man Framing. Framing hat folgendeVorteile:
• ermöglicht Error und Flow Control
• Fariness beim Multiplexen (Lastausgleich)
StuffingFür das Framing werden Trennzeichen (Flagbyte) benötigt, die auch in den Daten vorkommenkönnen. Um diese Trennzeichen klar von den gleichen Zeichen im Datenfeld zu kennzeichnen, isteine besondere Markierung nötig, die man Stuffing nennt. Die Idee besteht nun darin, alleTrennzeichen, die in den Daten vorkommen speziell mit einem Sonderzeichen, dem StuffingCharacter (meist ESC), zu markieren. Wird also ein Trennzeichen in den Daten gefunden, so wirdvor das Trennzeichen ein Stuffing Character gesetzt. Kommt der Stuffing Character auch in denDaten vor, so wird er verdoppelt. Die Trennzeichen in den Daten und an den Frameendenunterscheiden sich somit. Je nach Datenformat gibt es unterschiedliche Stuffing-Arten:
• Character Stuffing: Die Daten liegen als ASCII-Zeichen vor. Das Stuffing-Zeichen ist einCharacter.
• Byte Stuffing: Die Daten liegen in Byteform vor. Das Stuffing-Zeichen ist 1Byte gross.
• Bit Stuffing: Die Daten liegen in Binärform vor. Für die Trennzeichen wird meist einebestimmte 8-Bitfolge gewählt (z.B. 011111102). Das Stuffing-Zeichen ist das 0-Bit. Nach z.B. 51-Bits wird ein 0-Bit gesetzt.
Die folgende Abbildung zeigt ein Beispiel des Character Stuffings.
3 Die Begriffe Datenblock und Datenrahmen werden hier gleichwertig verwendet.
Stephan Senn, D-ITET -24- 06.08.04

COBS (Consistent Overhead Byte Stuffing)Ein anderer Stuffing-Verfahren ist der COBS. Dieser Algorithmus hat sehr viel bessere Worst CaseEigenschaften als konventionelles Stuffing. Ein Datenpaket wird maximal um ein Zeichenverlängert. Es funktioniert wie folgt:
Wähle einen oft vorkommenden Charakter als Stuffing Charakter, merke wo er das erste malvorkommt, ersetze ihn dann jeweils durch die Anzahl der Zeichen bis dieser häufig vorkommendeCharakter das nächste mal vorkommt.
Es folgt ein Beispiel:Ich_habe_bei_dieser_Uebung_viel_gelernt4Ich5habe4bei7dieser7Uebung5viel0gelernt
DatenrahmenDer Datenrahmen ist wie folgt aufgebaut:
M T V B L D M
M: Rahmenmarken (Anfang/Ende) L: Länge der folgenden Nutzdaten
T: Typ des Blocks D: Nutzdaten
V: zugeordnete VerbindungB: Folgenummer der Bestätigung für die Gegenrichtung
Idle Repeat Request (IRQ) ProtokollJeder gesendete Datenblock muss mit dem Senden einer Bestätigung ACK (Acknowledge) bestätigtwerden. Der Sender sendet also einen Datenblock und wartet solange bis der Empfänger eine ACK-Meldung zurückschickt. Tifft nach einer bestimmten Zeit kein ACK beim Sender ein, so wird beimSender ein Timeout ausgelöst und der entsprechende Block wird erneut gesendet. Der Empfängerkann mit einer NACK-Meldung (Not Acknowledge) signalisieren, dass der Datenblock fehlerhaftangekommen ist. In diesem Fall wird der Sender die Daten erneut senden. Die Datenblöcke und dieACK- und NACK-Meldungen werden nummeriert, um Duplikate und Fehleinformationen zuvermeiden. Denn es muss davon ausgegangen werden, dass auch Meldungen verloren gehenkönnen. Dies kann zu einer asymmetrischen Information zwischen Sender und Empfänger führen.Der Sender glaubt, dass die Daten nicht angekommen sind, während der Empfänger schon auf neueDaten wartet.
Für den Durchsatz gilt:
B IRQ d =L
T SENDT ACK= L
2dLLACKB
mit T SEND=dLB , T ACK=d
LACKB
d: Kanalverzögerung L: Länge des Datenpakets LACK: Länge der ACK-Meldung
B: Bandbreite des Kanals
Continuous Repeat Request (CRQ) ProtokollUm die Kanalausnützung zu verbessern, wird dem Sender erlaubt, mehrere Datenblöcke zu senden.Damit sind immer mehrere Datenblöcke unbestätigt. Der Sender führt nun einen Sendepuffer,
Stephan Senn, D-ITET -25- 06.08.04

indem die nicht bestätigten Datenblöcke in einer FIFO-Warteschlange4 abgelegt werden. DerEmpfänger verfügt auch über einen Puffer, wo die ankommenden Datenblöcke abgelegt werden.Die Netzwerkschicht wird nun laufend aus dem Empfangspuffer die Daten entnehmen und an dieoberen Schichten des OSI-Modells weiterreichen. Auch hier kann eine Zeitüberwachung für jedeneinzelnen Datenblock eingeführt werden. Für die Bestätigung der Datenblöcke gibt es nun zweiVerfahren, die im folgenden vorgestellt werden.
Selektive WiederübertragungJeder Datenblock wird einzeln (selektiv) bestätigt. Datenblöcke und Meldungen werdennummeriert. Jeder bestätigte Datenblock wird aus dem Sendepuffer entfernt. Der Sender durchsuchtbei Erhalt einer ACK-Meldung seinen Puffer, beginnend mit dem ältesten darin verzeichnetenBlock, und wiederholt alle Datenblöcke, die älter sind als der soeben bestätigte. Weiter gilt zubeachten, dass die Empfangsreihenfolge nicht zwangsweise der Sendereihenfolge entsprechen muss.Der Empfänger muss also die Daten laufend sortieren. Wiederholte Datenblöcke werden aus demSendpuffer entfernt und wieder neue eingefürgt. Im allgemeinen leidet die selektive Übertragung anfolgenden Mängeln:
• Im allgemeinen sind grosse Puffer notwendig. Je nach Anpassung von Sender und Empfängerkann dieses Problem noch zusätzlich verschärft werden. Im schlimmsten Fall kommt praktischkeine Bestätigungsmeldung zurück. Der Sender ist dann für den Empfänger zu schnell.
• Die wiederholte Übertragung von Daten kann sehr kostspielig sein.
Go-Back-N-VerfahrenAuch das Go-Back-N-Verfahren benötigt Sende- und Empfangspuffer. Der Empfangspuffer hat nureine Kapazität von einem Datenblock. Datenblöcke und Bestätigungsmeldungen werdennummeriert. Die Bestätigungen mit ACK und NACK haben aber nun andere Bedeutungen:
• ACK(N): Alle Blöcke bis und mit Nummer N werden bestätigt.
• NACK(N): Alle Blöcke bis und mit Nummer N werden bestätigt. Zusätzlich wird dem Sendermitgeteilt, dass die Folgenummer der Blöcke ab dem Block N nicht mehr korrekt ist.
Der Empfänger akzeptiert nur Datenblöcke, die in der richtigen Reihenfolge eintreffen. BeiEmpfang von NACK(N) werden die Blöcke N+1, N+2, usw. erneut gesendet; daher der Name Go-Back-N. Für jedes N gibt es zudem nur eine NACK-Meldung. Somit wird ein mehrfachesRücksetzen verhindert.
Fluss- und Verkehrssteuerung
X-ON/X-Off-VerfahrenDer Empfänger teilt dem Sender einen drohenden Überlast vorzeitig mit und stoppt ihn durch dasSenden von X-OFF-Steuerzeichen. Durch das Senden von X-ON-Steuerzeichen wird der Senderwieder aktiviert.
Fenstermethode (Sliding Window Mechanism)Ein Fenster hat jeweils einen oberen und einen unteren Rand. Man definiert nun für den Sender undden Empfänger ein Fenster. Der Sender kann nur dann Datenblöcke senden, wenn sie imSendefenster liegen. Der Empfänger kann umgekehrt nur Datenblöcke empfangen, wenn sie in dasEmpfangsfenster passen. Die Fenstergrösse legt die Anzahl Folgenummern der Datenblöcke fest.Diese können dann mit Hilfe des Modulo-Operators berechnet werden. Ein Fenster der Grösse 16
4 First In, First Out-Warteschlange
Stephan Senn, D-ITET -26- 06.08.04

hat also die Folgenummern 0 bis 15 (Modulo 16).
Für das Sendefenster gilt:
n n+1 n+2 n+3 n+4 n+5 n+6 n+7 n+8L(W) ↑ V(S) ↑
gesendet und lückenlosbestätigt
gesendet aber nichtbestätigt
bisher nicht gesendet, dürfen aberjederzeit gesendet werden
dürfen gegenwärtig nichtgesendet werden
L(W): Die Variable L(W) beschreibt den unteren Rand des Sendefensters (Lower Window Edge). Der untere Rand desSendefensters zeigt auf den ältesten nicht bestätigten Datenblock.
V(S): Die Variable V(S) (Send State Variable) zeigt auf den nächsten zu sendenden Datenblock. Ausgehend von V(S)lässt sich der obere Rand des Fensters bestimmen.
Für das Empfangsfenster gilt:
n+1 n+2 n+3 n+4 n+5 n+6 n+7 n+8 n+9V(R) ↑
korrekt empfangen aktuellempf.
können emfpangen werden können nicht empfangen werden
V(R): Die Variable V(R) beschreibt den unteren Rand des Empfangsfensters und bezeichnet jeweils den aktuellempfangenen Datenblock. Ausgehend von V(R) lässt sich der obere Rand des Fensters bestimmen.
Man beachte, dass sich die Grösse des Empfangsfensters nicht ändert; diejenige des Sendefenstersjedoch schon. Beim Sendefenster bleibt der Offset von V(S) zum oberen Rand konstant.
Es ist nun klar, dass die Fenstermethode sich sehr gut in das Continuous Repeat Request (CRQ)Protokoll einbauen lässt. Für die Empfangsfenstergrösse gilt:
• bei Go-Back-N-Verfahren: Grösse 1
• beim Verfahren mit selektiver Wiederholung: Grösse > 1
Für die Grösse des Empfangsfensters ge, die Grösse des Sendefensters gs sowie für den Vorrat anFolgenummern nf gilt:
• Allgemein gilt: g s≤ge• Für das Go-Back-N-Verfahren gilt: n f≥g s1
• Für das Verfahren mit selektiver Wiederholung gilt: n f≥2 g s
Piggyback AcknowledgeAnstatt die Bstätigungsmeldungen separat zu verschicken, kann man sie auch einem Datenblockanhängen und so verschicken.
Simplex-Duplex• Simplex: Die Datenübertragung erfolgt nur in eine Richtung.
• Halb-Duplex (Half-Duplex): Die Datenübertragung erfolgt in beide Richtungen; jedoch nichtgleichzeitig.
• Voll-Duplex (Full-Duplex): Die Datenübertragung erfolgt gleichzeitig in beide Richtungen.
Stephan Senn, D-ITET -27- 06.08.04

Device DriversDamit das Betriebsystem eine IO-Komponente ansprechen kann, braucht es einen Gerätetreiber. DerGerätetreiber ist im wesentliche nichts anderes als ein Programm, das vom Betriebssystemaufgerufen wird und das Funktionen bereitstellt, um mit dem Gerät zu kommunizieren.
Das Schreiben von GerätetreibernDas Schreiben von Treibern ist stark mit dem Betriebsystem verbunden. Die Betriebsysteme sindmeist so konzipiert, dass sie einen generischen Treiber anbieten, von dem man seinen speziellenTreiber dann ableitet. Dies kann im wesentlichen auf folgende Art bewerkstelligt werden:
• Verwendung von Pointerlogik: Das Betriebssystem ruft einen Standardtreiber auf, dem manParameter übergeben kann. Man schreibt nun seinen Treiber und übergibt dem Standardtreiberdie Funktions- bzw. Startadressen seines Treibers. Damit wird via Funktionspointerlogik derStandardtreiber zum spezifizierten Treiber.
• Objektorientierter Ansatz: Das Betriebssystem bietet Inferfaces oder abstrakte Klassen an, dieman implementieren bzw. erweitern kann. Man schreibt nun eine neue Treiberklasse, die dasentsprechende Interface implementiert bzw. die entsprechende abstrakte Klasse erweitert. DasBetriebssystem ruft dann mit der gewünschten Instanz das Interface bzw. die abstrakte Klasseauf. Damit wird aber genau die neu implementierte Treibklasse aufgerufen.. Die allgemeinenFunktionen des Interfaces oder der abstrakten Klasse werden somit mit den spezifischenFunktionen der Treiberklasse ersetzt (Polymorphismus).
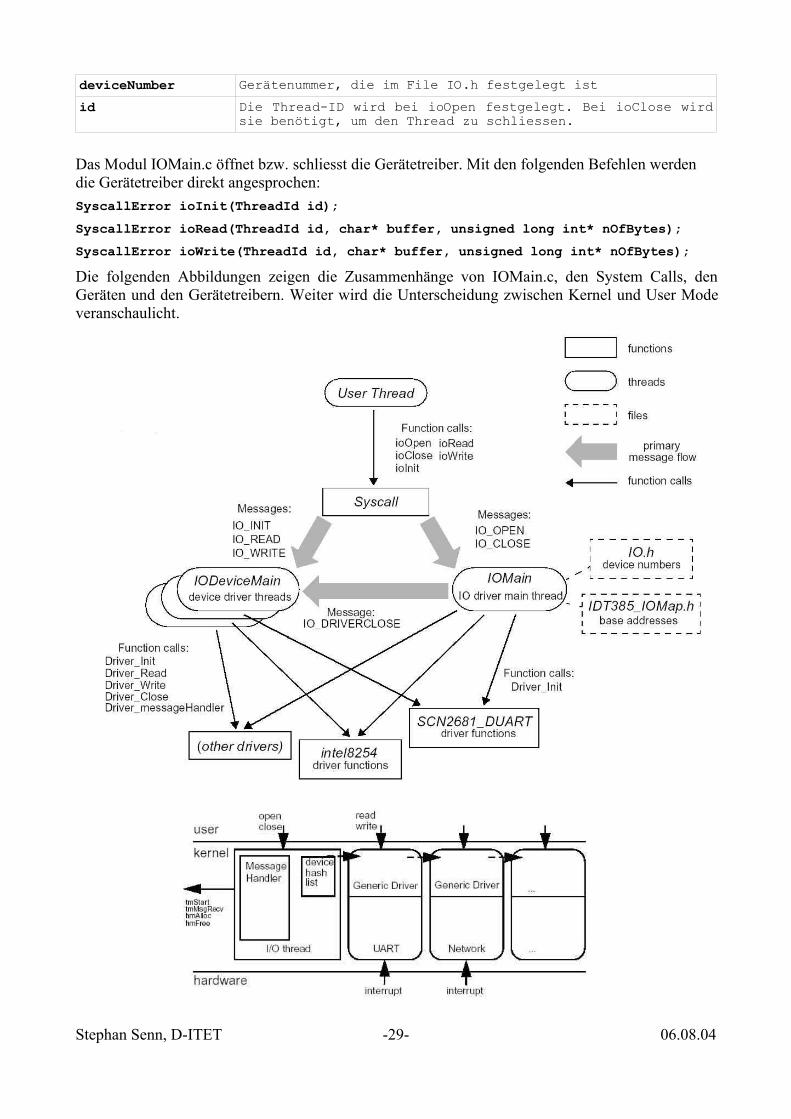
A Teachable Operating System (TOPSY)Die untere Abbildung zeigt den Aufbau des Betriebssystems TOPSY. Mehr dazu findet man imBenutzerhandbuch Topsy – A Techable Operating System.
Generische Treiber in TOPSYDas Modul IOMain.c wird als IO-Thread gestartet. Die System Calls ioOpen und ioClose öffnenbzw. schliessen den Gerätetreiber. Der Syntax der Befehle lautet:SyscallError ioOpen(int deviceNumber, ThreadId* id);SyscallError ioClose(ThreadId id);
Stephan Senn, D-ITET -28- 06.08.04
deviceNumber Gerätenummer, die im File IO.h festgelegt istid Die Thread-ID wird bei ioOpen festgelegt. Bei ioClose wird
sie benötigt, um den Thread zu schliessen.
Das Modul IOMain.c öffnet bzw. schliesst die Gerätetreiber. Mit den folgenden Befehlen werdendie Gerätetreiber direkt angesprochen:SyscallError ioInit(ThreadId id);SyscallError ioRead(ThreadId id, char* buffer, unsigned long int* nOfBytes);SyscallError ioWrite(ThreadId id, char* buffer, unsigned long int* nOfBytes);Die folgenden Abbildungen zeigen die Zusammenhänge von IOMain.c, den System Calls, denGeräten und den Gerätetreibern. Weiter wird die Unterscheidung zwischen Kernel und User Modeveranschaulicht.
Stephan Senn, D-ITET -29- 06.08.04

Das Schreiben von Gerätetreiber in TOPSY1. Eine neue Gerätenummer wird im File IO.h eingefügt. Die Konstante IO_DEVCOUNT wird um 1
erhöht.# define Mydevice 4
2. Im File IOMain.c wird die neue Gerätebeschreibung vom Typ IODeviceDesc imioDeviceTable eingetragen. Die Felder, die nicht benötigt werden, sind mit NULL zureferenzieren. Meist ist ein Typecast notwendig. Der Typ ioDeviceDesc ist ein Struct, der wiefolgt aufgebaut ist:
typedef struct IODeviceDesc_t {char* name;Address base;char* buffer;InterruptId interrupt;InterruptHandler interruptHandler;ReadFunction read;WriteFunction write;CloseFunction close;InitFunction init;MessageHandler handleMsg;Boolean isInitialised;void* extension;} IODeviceDesc;
3. Nun wird der eigene Gerätetreiber geschrieben. Dazu werden die nötigen Funktionen (z.B. readund write) implementiert. Weiter muss der Interrupthandler implementiert werden. EinMessagehandler ist optional.
Quellenverzeichnis• Vorlesungsskript 'Technische Informatik II' von Prof. B. Plattner
• Praktische Übungen 'Technische Infromatik II'
• TOPSY - A Teachable Operating System by Frankhauser, Conrad, Zitzler und Plattner
• Operating System Concepts (with Java), Sixth Edition
Silberschatz, Galvin, Gagne
John Wiley & Sons, Inc.
• Computernetzwerke, Andrew S. Tanenbaum, 4. überarbeitete Auflage, Prentice Hall
• http://www-itec.uni-klu.ac.at/~harald/bs2004/memorymanagment.pdf
Stephan Senn, D-ITET -30- 06.08.04
Recommended

















