Embed Size (px)
Citation preview


3. XML Schema
1. Einführung 2. DTD 3. XML Schema 4. XPath 5. XSLT 6. XSL-FO 7. XQuery 8. Web Services 9. XML und Datenbanken

Inhalt des Moduls:
Grundlagen
Einfache Modelle
Inhaltsmodelle
Datentypen
Schlüssel und Schlüsselverweise

Grundlagen Das W3C XML Schema stellt eine W3C-Weiterführung der DTD dar.
Das XML Schema sollte bei neuen Anwendungen verwendet werden, in denen auf seine Vorteile wie Datentypvalidierung/-erstellung sowie die sehr umfangreichen Möglichkeiten der Ableitung von einfachen und komplexen, d.h. aus mehreren Elementen zusammen gesetzten Datentypen, Wert gelegt wird.
Insbesondere die Datentypen stellen ein wichtigen Pfeiler von XML Schema dar und sind in einem eigenen Standard spezifiziert, da sie auch in anderen XML-Technologien Verwendung finden.
XML Schema ist eine XML-Datei und kann daher auch mit XML-Techniken erstellt, bearbeitet, abgefragt und in andere Formate umgewandelt werden.
Folgende Ressourcen sind beim W3C verfügbar:
Einstiegsseite des W3C: http://www.w3c.org/XML/Schema
Einführung: http://www.w3c.org/TR/xmlschema-0/
Strukturen: http://www.w3c.org/TR/xmlschema-1/
Datentypen: http://www.w3c.org/TR/xmlschema-2/

Grundlagen
A-D E-N O-Z
all annotation any anyAttribute appinfo attribute attributeGroup choice complexContent complexType documentation
element extension (simpleContent) extension (complexContent) field group import include key keyref list notation
redefine restriction (simpleType) restriction (simpleContent) restriction (complexContent) schema selector sequence simpleContent simpleType union unique
Einen Überblick über die Namen der Elemente, die teilweise auch bereits ihre Funktion verraten, findet sich in nachfolgender Tabelle. Sie bieten eine Vielzahl an Vorgaben und Syntaxvarianten bei der Erstellung von Datenmodellen.

Fragen...

Inhalt des Moduls:
Grundlagen
Einfache Modelle
Inhaltsmodelle
Datentypen
Schlüssel und Schlüsselverweise

Einfache Modelle: Basis-Angaben
Einfache Inhaltsmodelle bestehen zunächst nur aus einigen Angaben, die
in jedem Regeldokument vorhanden sein müssen.
Identität: Welche Elemente erscheinen im Dokument? Wie heißen sie, und
welche Inhaltsmodelle haben sie wiederum?
Beziehungen: Zu welchen anderen Elementen stehen sie durch ihre
Inhaltsmodelle, d.h. durch den Aufruf anderer Elemente als Inhalt, in
Beziehung?
Kardinalität: Wie oft treten die einzelnen Elemente alleine oder im Verbund
bzw. in Gruppierungen auf? Sind sie obligatorisch, unbegrenzt oder optional zu
verwenden?
Reihenfolge: In welcher Reihenfolge treten die Elemente in ihrer jeweiligen
Dokumentebene auf? In welche Reihenfolgebeziehung stehen sie zu anderen
Elementen?
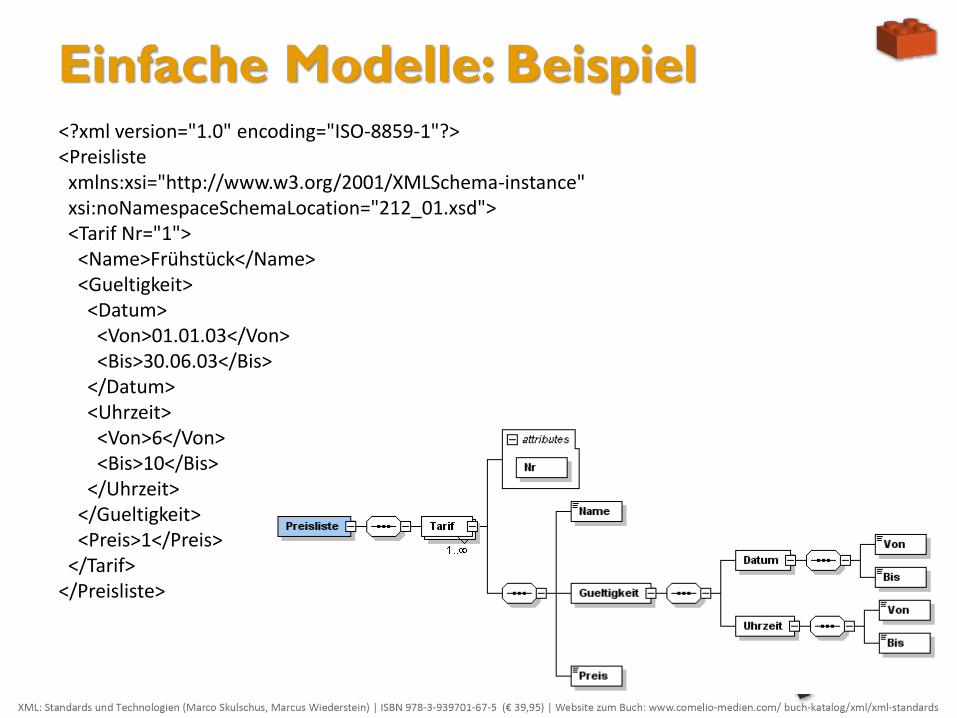
Einfache Modelle: Beispiel <?xml version="1.0" encoding="ISO-8859-1"?> <Preisliste xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="212_01.xsd"> <Tarif Nr="1"> <Name>Frühstück</Name> <Gueltigkeit> <Datum> <Von>01.01.03</Von> <Bis>30.06.03</Bis> </Datum> <Uhrzeit> <Von>6</Von> <Bis>10</Bis> </Uhrzeit> </Gueltigkeit> <Preis>1</Preis> </Tarif> </Preisliste>

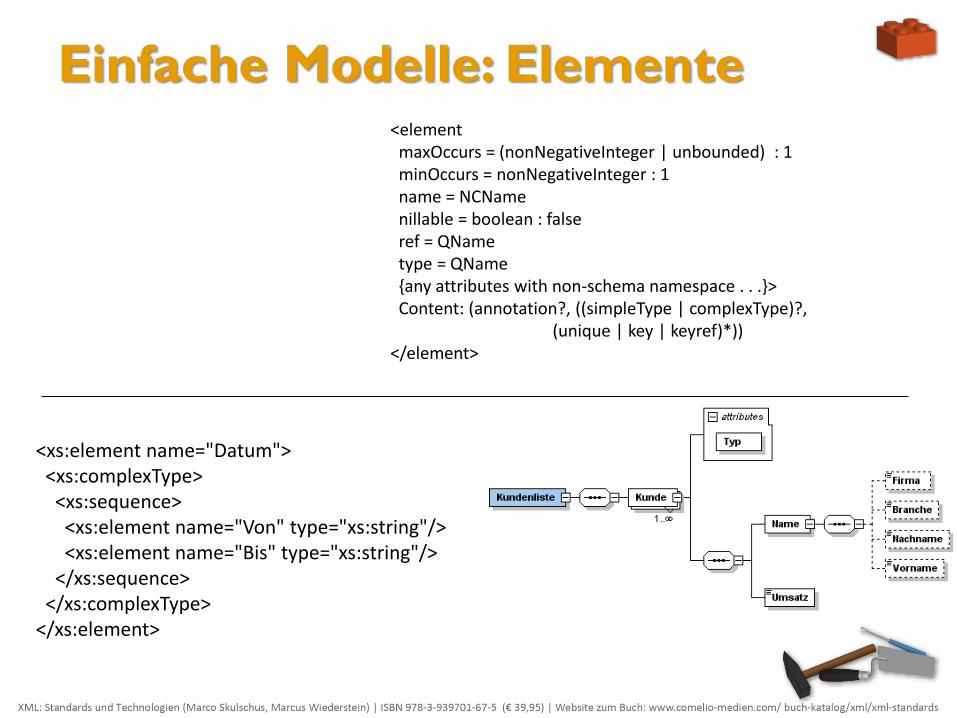
Einfache Modelle: Elemente Ein Element lässt sich mit dem Element element festlegen, wobei die Attributliste auf die für den Einsteiger
wesentlichen Elemente gekürzt wurde.
Der Name wird im name-Attribut angegeben, das einen gültigen XML-Namen ohen Namensraumpräfix erwartet.
Die Häufigkeit lässt sich – sofern das Element nicht genau einmal auftreten soll – über die beiden Attribute
minOccurs (minimales Auftreten) und maxOccurs (maximales Auftreten) festlegen, die jeweils eine nicht-negative
Ganzzahl, d.h. auch den Wert 0 erwarten. Jede beliebige Kombination ist möglich. Sofern ein Element beliebig oft
auftreten darf, ist der Standardwert unbounded zu verwenden.
Der Datentyp wird über die vordefinierten Namen der XML Schema-Datentypen oder über einen eigenen Namen
aus der Liste der selbst erstellten Datentypen (globale simpleType-Elemente für einfache und complexType-
Elemente für komplexe Strukturen mit Kind-Elementen und Attributen) im type-Attribut angegeben.
Eine Referenz auf ein so genanntes globales element-Element, das direktes Kind vom Wurzelement ist, wird im
ref-Attribut über seinen Namen eingerichtet.
Ob ein Element leer sein kann, wird über das Attribut nillable angegeben.
Der Inhalt eines Elements können innerhalb vom complexType-Kind andere Elemente, Attribute sein oder
Schlüssel- und Schlüsselverweiselemente sowie innerhalb vom simpleType-Kind genaue Datentypangaben,
welche das type-Attribut ersetzen.
Die Reihenfolgenbeziehung zu anderen Elementen wird nicht innerhalb des Elements
selbst angegeben, sondern ist abhängig von seinem direkten Elternelement.
Einfache Modelle: Elemente
<xs:element name="Datum"> <xs:complexType> <xs:sequence> <xs:element name="Von" type="xs:string"/> <xs:element name="Bis" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>
<element maxOccurs = (nonNegativeInteger | unbounded) : 1 minOccurs = nonNegativeInteger : 1 name = NCName nillable = boolean : false ref = QName type = QName {any attributes with non-schema namespace . . .}> Content: (annotation?, ((simpleType | complexType)?, (unique | key | keyref)*)) </element>

Einfache Modelle: Elemente Attribute befinden sich innerhalb des complexType-Kindelements innerhalb des element-Elements, gehören also zum komplexen Inhalt eines Elements, stehen aber außerhalb der Reihenfolgenangabe wie z.B. dem sequence-Element.
Der Name wird im name-Attribut angegeben, das einen gültigen XML-Namen ohen Namensraumpräfix erwartet.
Der Datentyp wird über die vordefinierten Namen der XML Schema-Datentypen oder über einen eigenen Namen aus der Liste der selbst erstellten Datentypen (globale simpleType-Elemente für einfache Typen) im type-Attribut angegeben.
Eine Referenz auf ein so genanntes globales attribute-Element, das direktes Kind vom Wurzelement ist, wird im ref-Attribut über seinen Namen eingerichtet.
Der Standardwert wird im default-Attribut mit einer Zeichenkette angegeben.
Der feste Wert wird im fixed-Attribut mit einer Zeichenkette angegeben.
Die Attributverwendung wird mit vorgegeben Werten im use-Attribut angegeben: optional (optional, kann vorkommen oder fehlen), prohibited (verboten, darf nicht auftreten, was nur sinnvoll bei der so genannten Ableitung ist) und required (verpflichtend, muss auftreten).
Der Inhalt eines attribute-Elements ist sinnvollerweise nur ein simpleType-Element, welches das type-Attribut ersetzt und genauere Datentypangaben enthält.
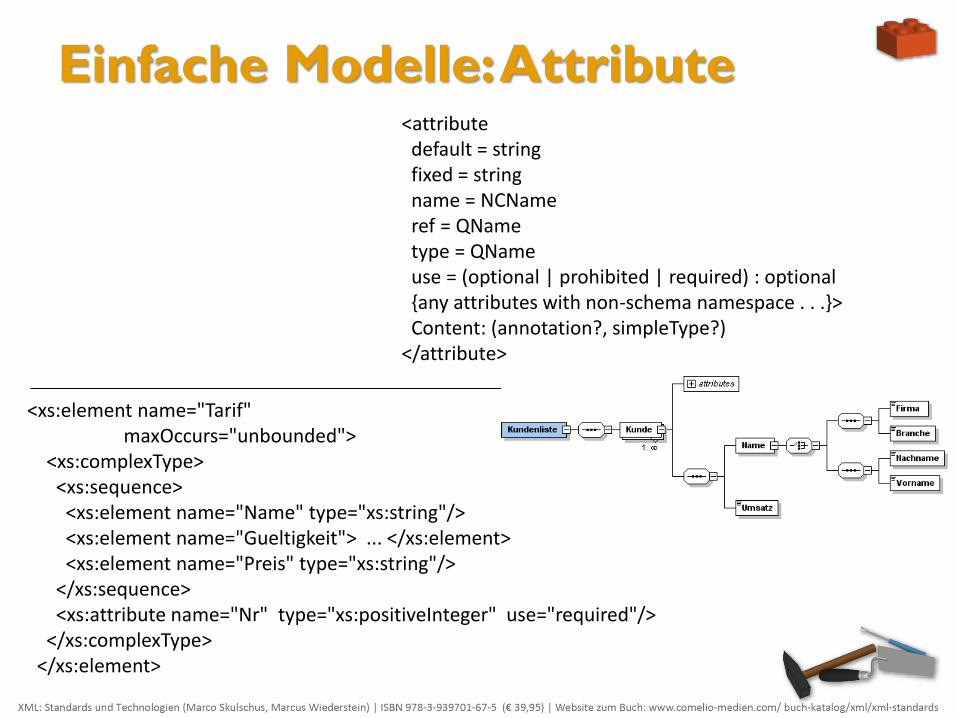
Einfache Modelle: Attribute
<xs:element name="Tarif" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="Name" type="xs:string"/> <xs:element name="Gueltigkeit"> ... </xs:element> <xs:element name="Preis" type="xs:string"/> </xs:sequence> <xs:attribute name="Nr" type="xs:positiveInteger" use="required"/> </xs:complexType> </xs:element>
<attribute default = string fixed = string name = NCName ref = QName type = QName use = (optional | prohibited | required) : optional {any attributes with non-schema namespace . . .}> Content: (annotation?, simpleType?) </attribute>

Einfache Modelle:
Lokale und globale Strukturen
XML Schema unterscheidet zwischen globalen und lokalen Strukturen:
Einfache und komplexe Datentypen
Elemente und Attribute
können einzeln oder auch als Gruppe (Element group für Elemente und Element attributeGroup für Attribute) global auftreten.
Das bedeutet, dass sie als direkte Kinder vom schema-Element erscheinen und im ref-Attribut von Elementen und Attributen global oder lokal aufgerufen werden können.
Dadurch hat man die Möglichkeit, Auslagerung und Wiederverwendung einzurichten und die angegeben Eigenschaften mehrfach im Dokument zu verwenden.

Einfache Modelle:
Lokale und globale Strukturen <xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"> <!-- Globale Elemente --> <xs:element name="Von" type="xs:string"/> <xs:element name="Bis" type="xs:string"/> <!-- Wurzelelement --> <xs:element name="Preisliste"> <xs:complexType> ... ... </xs:complexType> </xs:element> </xs:schema>
<xs:element name="Datum"> <xs:complexType> <xs:sequence> <xs:element ref="Von"/> <xs:element ref="Bis"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Uhrzeit"> <xs:complexType> <xs:sequence> <xs:element ref="Von"/> <xs:element ref="Bis"/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element>

Fragen...
Inhalt des Moduls:
Grundlagen
Einfache Modelle
Inhaltsmodelle
Datentypen
Schlüssel und Schlüsselverweise

Inhaltsmodelle: Beispiel
<?xml version="1.0" encoding="ISO-8859-1"?> <Kundenliste xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="32_08.xsd"> <Kunde Typ="g"> <Name> <Firma>Fleckner + Söhne GmbH + Co. KG</Firma> <Branche>Fördergurte Gummi Kunststoffe</Branche> </Name> <Umsatz>703.43</Umsatz> </Kunde> <Kunde Typ="p"> <Name> <Nachname>Erdle</Nachname> <Vorname>Johann</Vorname> </Name> <Umsatz>229,45</Umsatz> </Kunde> </Kundenliste>
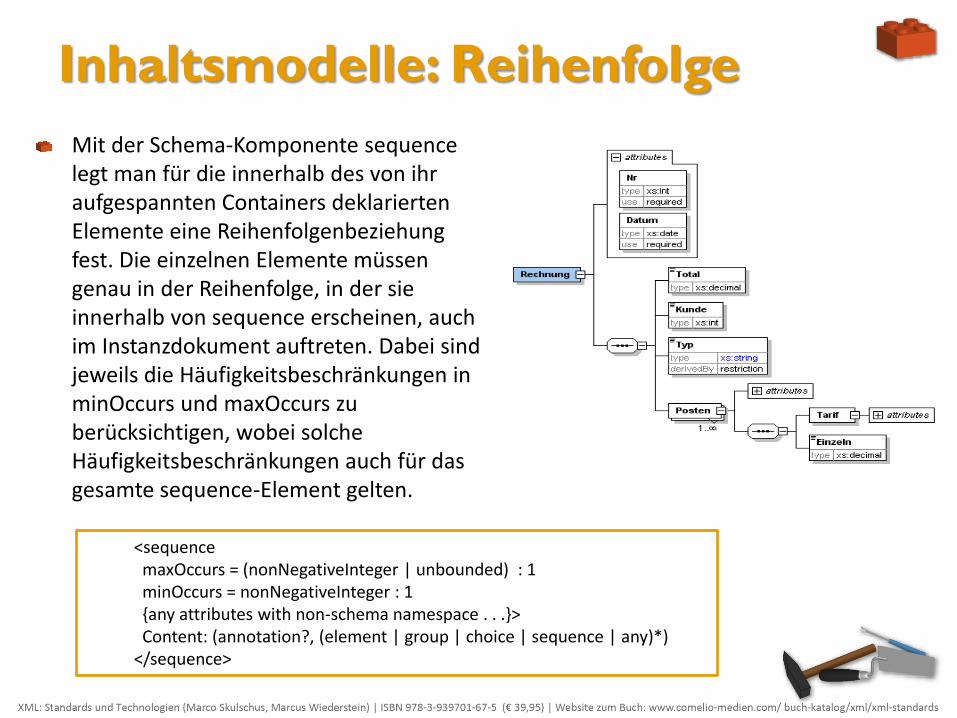
Inhaltsmodelle: Reihenfolge
Mit der Schema-Komponente sequence legt man für die innerhalb des von ihr aufgespannten Containers deklarierten Elemente eine Reihenfolgenbeziehung fest. Die einzelnen Elemente müssen genau in der Reihenfolge, in der sie innerhalb von sequence erscheinen, auch im Instanzdokument auftreten. Dabei sind jeweils die Häufigkeitsbeschränkungen in minOccurs und maxOccurs zu berücksichtigen, wobei solche Häufigkeitsbeschränkungen auch für das gesamte sequence-Element gelten.
<sequence maxOccurs = (nonNegativeInteger | unbounded) : 1 minOccurs = nonNegativeInteger : 1 {any attributes with non-schema namespace . . .}> Content: (annotation?, (element | group | choice | sequence | any)*) </sequence>
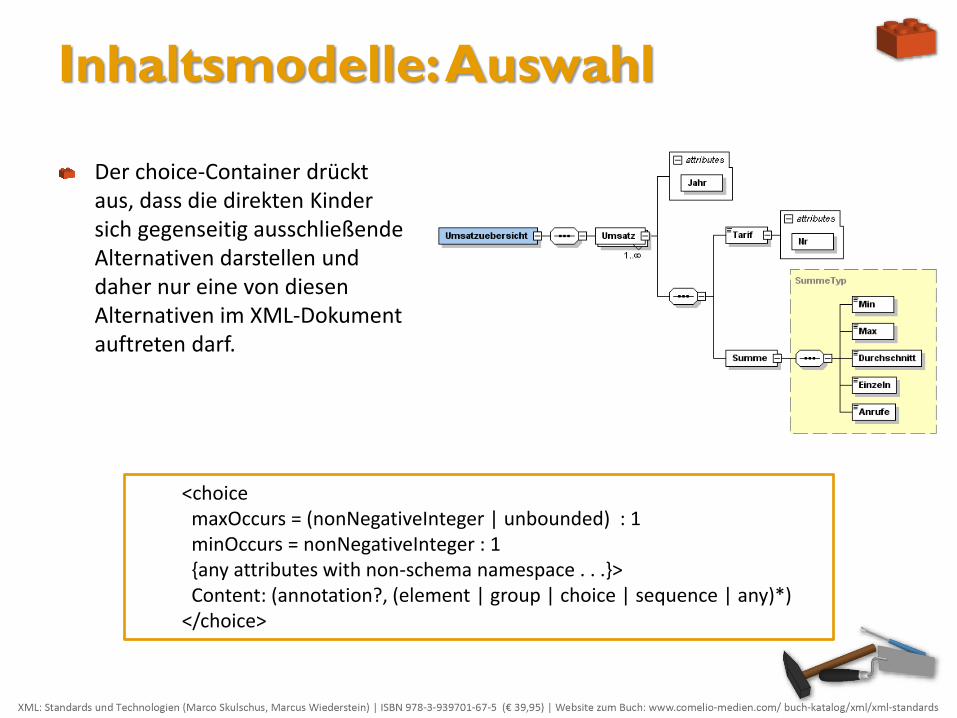
Inhaltsmodelle: Auswahl
Der choice-Container drückt aus, dass die direkten Kinder sich gegenseitig ausschließende Alternativen darstellen und daher nur eine von diesen Alternativen im XML-Dokument auftreten darf.
<choice maxOccurs = (nonNegativeInteger | unbounded) : 1 minOccurs = nonNegativeInteger : 1 {any attributes with non-schema namespace . . .}> Content: (annotation?, (element | group | choice | sequence | any)*) </choice>

Inhaltsmodelle: Freie Wahl
Der all-Container drückt aus, dass eine beliebige Reihenfolge der element-Kinder im XML-Dokument auftreten kann.
<all maxOccurs = 1 : 1 minOccurs = (0 | 1) : 1 {any attributes with non-schema namespace . . .}> Content: (annotation?, element*) </all>

Inhaltsmodelle: Ko-Abhängigkeiten
<?xml version="1.0" encoding="ISO-8859-1"?> <Kundenliste xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="32_08.xsd"> <Kunde Typ="g"> <Name> <Firma>Fleckner + Söhne GmbH + Co. KG</Firma> <Branche>Fördergurte Gummi Kunststoffe</Branche> </Name> <Umsatz>703.43</Umsatz> </Kunde> <Kunde Typ="p"> <Name> <Nachname>Erdle</Nachname> <Vorname>Johann</Vorname> </Name> <Umsatz>229,45</Umsatz> </Kunde> </Kundenliste>
Die so-genannte Ko-Abhängigkeit zwischen Attributwert und Elementen ist weder in XML Schema noch in der DTD abzubilden.

Fragen...

Inhalt des Moduls:
Grundlagen
Einfache Modelle
Inhaltsmodelle
Datentypen
Schlüssel und Schlüsselverweise

Datentypen: Typsystem
Das XML Schema zeichnet sich insbesondere durch die Integration einer überaus umfangreichen Datentypstruktur aus.
Mit ihr können für alle Programmiersprachen und Datenbanken Datentypangaben getroffen werden.
In Kombination mit eigenen Datentypen und weiteren Einschränkungen können genau die erforderlichen Angaben getroffen werden, die für den aktuellen Einsatz notwendig sind.
Die Datentypen sind in einem eigenen Standard beschrieben, da sie auch in anderen XML-Technologien vom W3C verwendet werden.
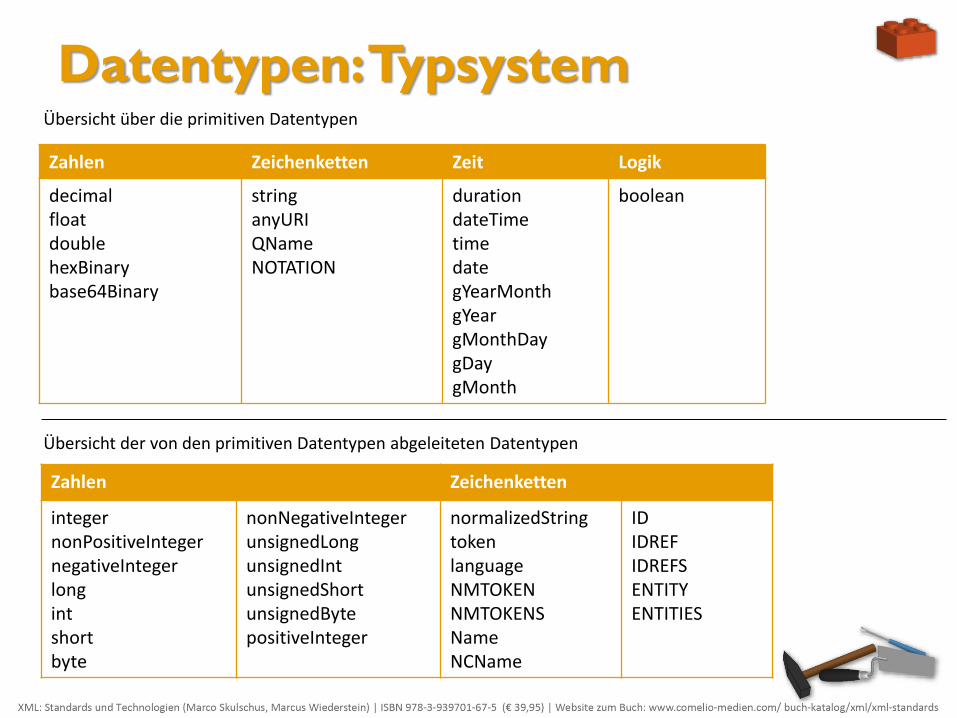
Datentypen: Typsystem
Zahlen Zeichenketten Zeit Logik
decimal float double hexBinary base64Binary
string anyURI QName NOTATION
duration dateTime time date gYearMonth gYear gMonthDay gDay gMonth
boolean
Zahlen Zeichenketten
integer nonPositiveInteger negativeInteger long int short byte
nonNegativeInteger unsignedLong unsignedInt unsignedShort unsignedByte positiveInteger
normalizedString token language NMTOKEN NMTOKENS Name NCName
ID IDREF IDREFS ENTITY ENTITIES
Übersicht der von den primitiven Datentypen abgeleiteten Datentypen
Übersicht über die primitiven Datentypen

Datentypen: Typsystem
Jahr Monat Tag Stunde Minute Sekunde
nY nM (*) nD (*) nH (*) nM (*) nS (*) (wahlweise auch Dezimalstellen für kleinere Unterteilungen)
Die Datums- und Zeittypen erfordern spezielle Formatierungen, die in Datenbanken teilweise nur mit Trigger oder eigenen CHECK-Bedingungen überprüft werden können. Sie sind daher für die DB-Entwicklung besonders interessant und nützlich.
Eine Dauer (duration) wird im Format PnYnMnDTnHnMnS, angegeben:
Datum und Uhrzeit (dateTime) werden in der Form CCYY-MM-DDThh:mm:ss mit dem Trennzeichnen T zwischen Tages- und Uhrzeitangabe angegeben:
Jahr Monat Tag Stunde Minute Sekunde
CCYY MM DD hh mm ss (wahlweise auch Dezimalstellen für kleinere Unterteilungen)

Datentypen: Typsystem
Analog zu diesen beiden Beispielen lauten die anderen Formate für den gregorianischen Kalender:
Zeit (time): hh:mm:ss.sss.
Datum (date): CCYY-MM-DD
Kombinationen und Felder wie Jahr/Monat (gYearMonth) CCYY-MM, Tag/Monat (gMonthDay) MM-DD, Jahr (gYear) CCYY, Monat (gMonth) MM und Tag (gDay) DD.
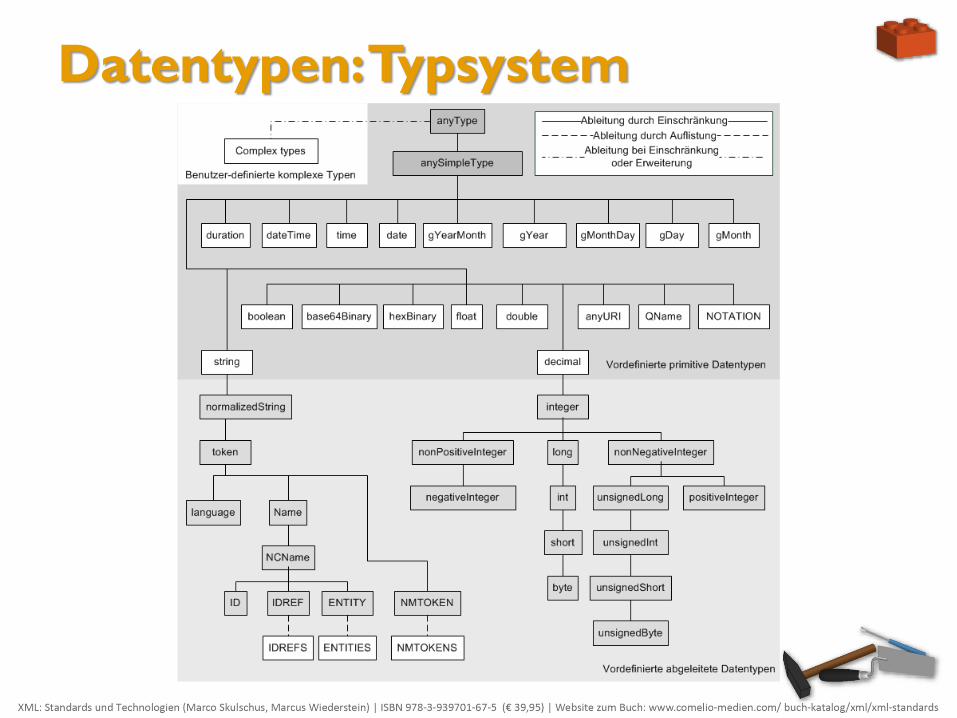
Datentypen: Typsystem

Datentypen:
Eigene einfache Datentypen
Sofern keine bereits vordefinierten Datentypen zum Einsatz kommen können, besteht die Möglichkeit, lokal weitere Einschränkungen zu treffen oder sogar global eigene benannte Datentypen zu erstellen.
Dabei kommen so genannte Fassetten zum Einsatz. Nicht jede Fassette ist für jeden Datentyp zulässig.
Sie geben typischerweise Längenbeschränkungen für Zeichen oder Grenzen für Zahlen sowie Dezimalaufteilungen an. Sollte dann komplexe Prüfungen notwendig werden, kann man sogar reguläre Ausdrücke verwenden.
Man unterscheidet zwischen grundlegenden und einschränkenden Fassetten, wobei die grundlegenden nicht beeinflusst werden können, sondern Datentypen allgemein charakterisieren. Die einschränkenden dagegen lassen sich über XML Schema-Elemente innerhalb vom simpleType-Element verwenden.

gleich
geordnet
beschränkt
Kardinalität
numerisch
length
minLength
maxLength
pattern
enumeration
whiteSpace
maxInclusive
maxExclusive
minInclusive
minExclusive
totalDigits
fractionDigits
Grundlegende Fassetten Einschränkende Fassetten
Fassetten
Datentypen:
Eigene einfache Datentypen

Datentypen: Komplexe Datentypen
Neben den einfachen Datentypen gibt es in XML Schema einen weiteren wesentlichen Pfeiler, der sowohl für einfache Auslagerung und Wiederverwendung nützlich ist als auch in erweiterten – oftmals als objektorientierten - Ableitungstechniken genutzt wird.
Dies betrifft die Möglichkeit, die complexType-Kinder von element-Elementen ebenfalls zu globalisieren und ihnen einen Namen zu geben, unter dem sie dann im type-Attribut genauso wie einfache Datentypen in einem element-Element aufgerufen werden können.
Diese Technik eröffnet Möglichkeiten, auch komplexe Strukturen mit verschachtelten Inhalten auszulagern und wieder zu verwenden als auch diese Strukturen abzuleiten, d.h. zu erweitern und zu verkleinern.
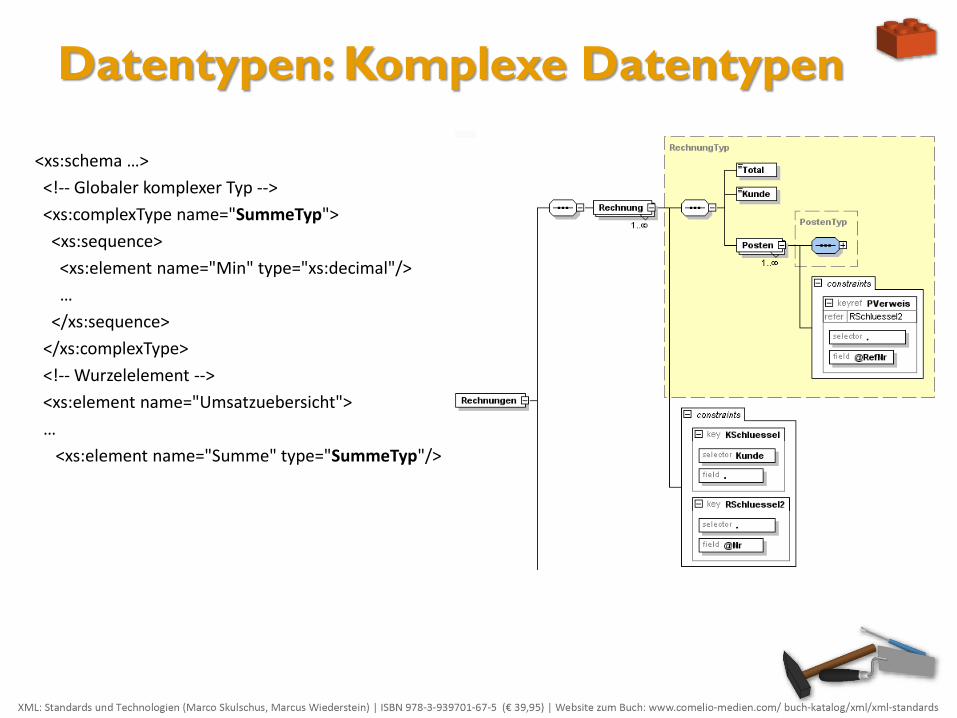
Datentypen: Komplexe Datentypen
<xs:schema …>
<!-- Globaler komplexer Typ -->
<xs:complexType name="SummeTyp">
<xs:sequence>
<xs:element name="Min" type="xs:decimal"/>
…
</xs:sequence>
</xs:complexType>
<!-- Wurzelelement -->
<xs:element name="Umsatzuebersicht">
…
<xs:element name="Summe" type="SummeTyp"/>

Datentypen: Komplexe Datentypen
Der nächste Schritt besteht in der Ableitung von globalen komplexen Strukturen, in dem
entweder weitere Einschränkungen durchgeführt werden (weniger Kind-Elemente
oder Attribute bzw. kleinerer Datenbereich) oder Erweiterungen stattfinden (Anhängen von Kindelementen oder Attributen).
Globale komplexe Typen eignen sich dazu, wieder verwendbare Komponenten in Form von benannten Bereichen als Kind-Elemente des schema-Elements zu erstellen, die später innerhalb der Definitionen anderer Elemente in ihrem type-Attribut aufgerufen werden.
Man überträgt dadurch die im globalen komplexen Typ definierten Eigenschaften in das gerade deklarierte Element und verzichtet dabei auf eine lokale Definition der jeweiligen Kind-Elemente.

Datentypen: Komplexe Datentypen
Ableitung durch Erweiterung:
Bei der Ableitung durch Erweiterung ergänzt man einen gegebenen globalen komplexen Typen um weitere Elemente oder Attribute.
Wichtig ist hier die Einschränkung, dass man also keine andere Reihenfolge wählen und nur weitere Elemente an die ohnehin schon bestehenden des globalen komplexen Typen anhängen kann.
Das gleiche Prinzip gilt auch für Attribute. Daher ist bei der Gestaltung des XML-Dokuments Vorsicht geboten, damit eine mögliche Ableitung und dadurch z.B. eine weitere Auslagerung von Komponenten oder eine Verkürzung von Quelltext überhaupt realisierbar wird.
Ableitung durch Einschränkung:
Die Ableitung durch Einschränkung fällt für globale komplexe Typen deutlich aus dem Rahmen der bisher vorgestellten Syntax und Konzeptionen.
Zwar lässt sich ein Basistyp definieren, aber man muss das gesamte Inhaltsmodell redefinieren.
Dabei verzichtet man dann einfach auf die nicht benötigten Elemente. Grundsätzlich kommt dies aber einer komplett neuen Definition gleich, wobei lediglich ein Bezug in Form einer syntaktisch deutlich verankerten Dokumentation oder Anmerkung auf die Existenz eines globalen komplexen Typs und damit einer ausgelagerten Komponente verweist.
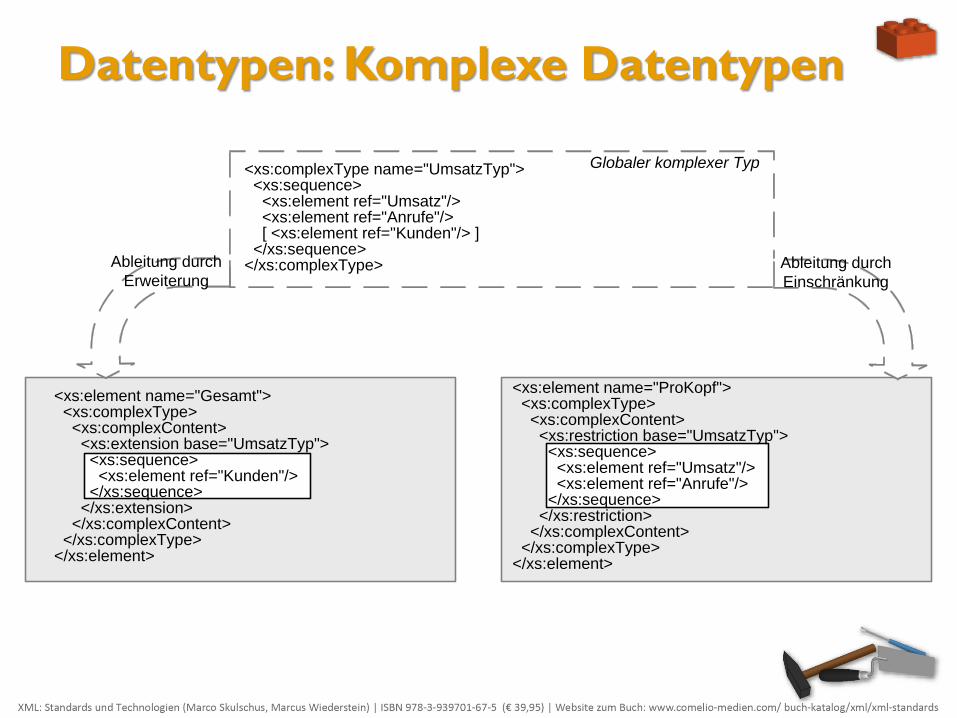
<xs:complexType name="UmsatzTyp"> <xs:sequence> <xs:element ref="Umsatz"/> <xs:element ref="Anrufe"/> [ <xs:element ref="Kunden"/> ] </xs:sequence> </xs:complexType>Ableitung durch
ErweiterungAbleitung durch
Einschränkung
Globaler komplexer Typ
<xs:element name="Gesamt"> <xs:complexType> <xs:complexContent> <xs:extension base="UmsatzTyp"> <xs:sequence> <xs:element ref="Kunden"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType></xs:element>
<xs:element name="ProKopf"> <xs:complexType> <xs:complexContent> <xs:restriction base="UmsatzTyp"> <xs:sequence> <xs:element ref="Umsatz"/> <xs:element ref="Anrufe"/> </xs:sequence> </xs:restriction> </xs:complexContent> </xs:complexType></xs:element>
Datentypen: Komplexe Datentypen

Fragen...
Inhalt des Moduls:
Grundlagen
Einfache Modelle
Inhaltsmodelle
Datentypen
Schlüssel und Schlüsselverweise

Schlüssel und Schlüsselverweise
Die Identitätsbeschränkungs-Komponenten dienen mit den
Elementen key, selector, field, keyref sowie unique dazu, eine
Verbindung zwischen einem qualifizierten Namen und einer
Schlüsselangabe herzustellen bzw. eine Referenz auf einen solchen
Schlüssel festzulegen.
Man setzt dabei XPath-Ausdrücke für die Bestimmung von
Lokalisierungspfaden zu den identitätsbeschränkten Selektoren und
ihren untergeordneten Feldern.
Als Syntax für den Schlüsselbezug, also die Referenz auf einen
gültigen Schlüssel, verwendet man dabei den qualifizierten Namen
des Schlüssels innerhalb des keyref-Elements für einen oder den
Namen des keyrefs-Elements für mehrere Schlüssel.

Schlüssel und Schlüsselverweise
In XML Schema gibt es zwei verschiedene Elemente zur Auswahl, mit denen Schlüssel und ein Element, mit dem Verweise angegeben werden können.
Definition eines eindeutigen Schlüssels mit Hilfe der Schema-Komponente unique, wobei die Existenz des Feldes (Attribut oder Element) nicht kontrolliert wird.
<unique
name = NCName
{any attributes with non-schema namespace . . .}>
Content: (annotation?, (selector, field+))
</unique
Definition eines eindeutigen Schlüssels und Kontrolle auf Existenz der als Schlüsselbestandteile angegebenen Feldes (Attribut oder Element) mit Hilfe der Schema-Komponente key.
<key
name = NCName
{any attributes with non-schema namespace . . .}>
Content: (annotation?, (selector, field+))
</key>

Schlüssel und Schlüsselverweise
Für die Definition von Verweisen wird nur ein Element benötigt.
Definition eines Schlüsselverweises mit Hilfe der Schema-Komponente keyref unter Angabe des Schlüsselnamens und des Feldes (Attribut oder Element), welches den referenzierenden Wert enthält.
<keyref
name = NCName
refer = QName
{any attributes with non-schema namespace . . .}>
Content: (annotation?, (selector, field+))
</keyref>
Schlüssel und Schlüsselverweise
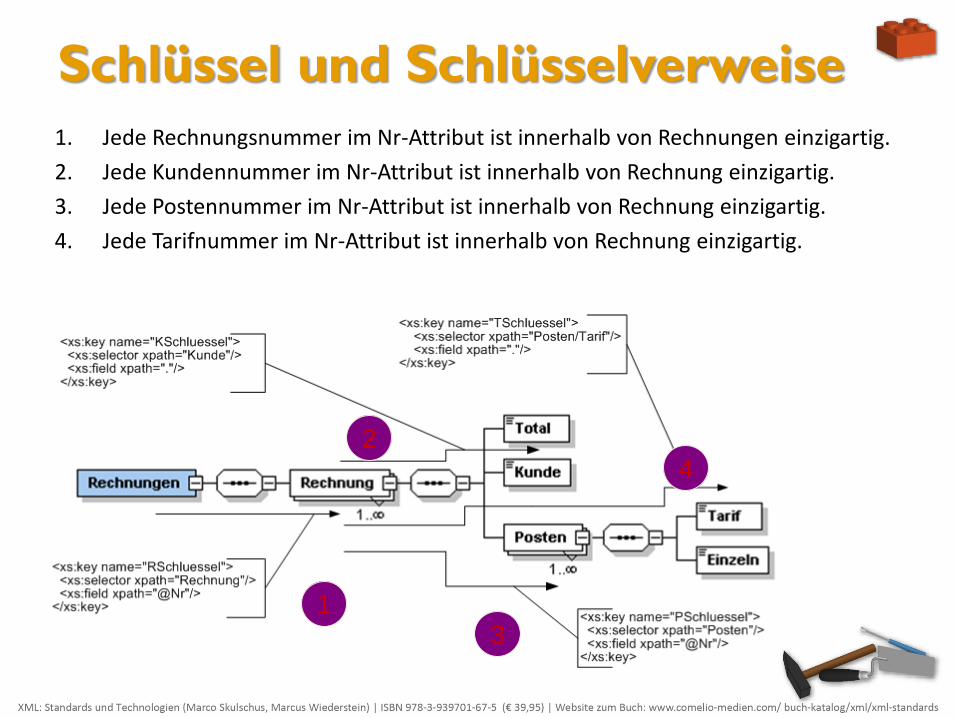
1. Jede Rechnungsnummer im Nr-Attribut ist innerhalb von Rechnungen einzigartig.
2. Jede Kundennummer im Nr-Attribut ist innerhalb von Rechnung einzigartig.
3. Jede Postennummer im Nr-Attribut ist innerhalb von Rechnung einzigartig.
4. Jede Tarifnummer im Nr-Attribut ist innerhalb von Rechnung einzigartig.
1
2
3
4
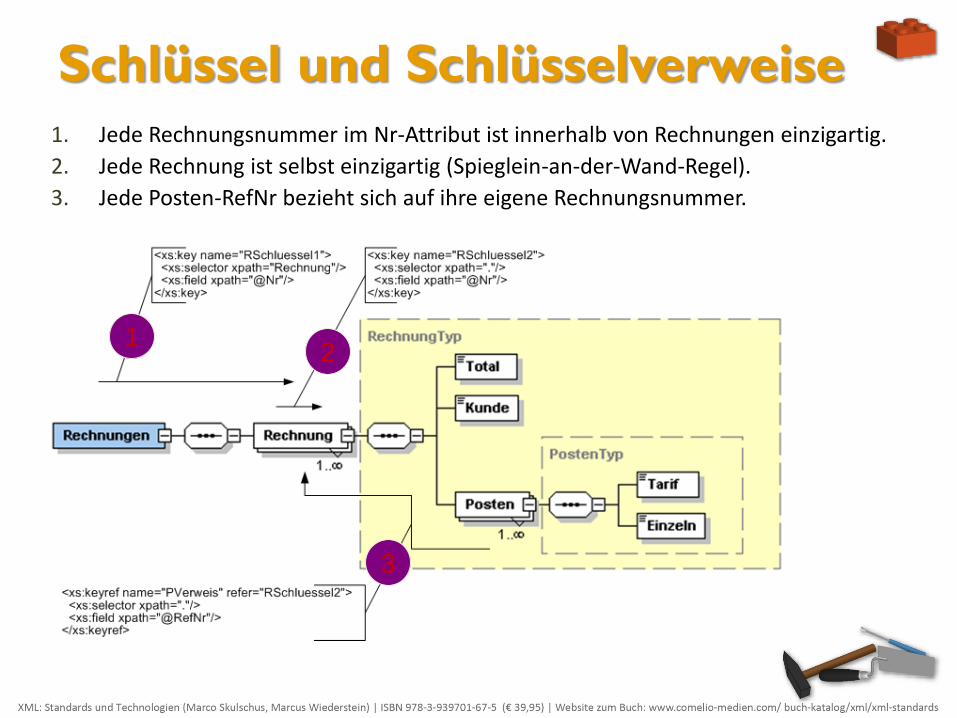
Schlüssel und Schlüsselverweise 1. Jede Rechnungsnummer im Nr-Attribut ist innerhalb von Rechnungen einzigartig.
2. Jede Rechnung ist selbst einzigartig (Spieglein-an-der-Wand-Regel).
3. Jede Posten-RefNr bezieht sich auf ihre eigene Rechnungsnummer.
1 2
3

Fragen...