Embed Size (px)
Citation preview

Algorithmentheorie
Skript zur Vorlesung
SS 2006
Fassung vom 21.03.2006
Martin Dietzfelbinger
Technische Universitat Ilmenau
Fakultat fur Informatik und Automatisierung
Fachgebiet Komplexitatsheorie und Effiziente Algorithmen

Inhaltsverzeichnis
Literaturverzeichnis 1
0 Vorbemerkungen 3
0.1 Fragestellung und Uberblick . . . . . . . . . . . . . . . . . . . . . . . . . . 3
0.2 Grundbegriffe: Alphabete, Sprachen und Probleme . . . . . . . . . . . . . . 6
0.3 Mathematische Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . 12
0.3.1 Abzahlbarkeit und Uberabzahlbarkeit . . . . . . . . . . . . . . . . . 12
1 Entscheidbarkeit und Berechenbarkeit 15
1.1 Registermaschinen, Turingmaschinen und Rekursivitat . . . . . . . . . . . 15
1.1.1 Registermaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.1.2 Turingmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
1.2 Programmiertechniken und Varianten von Turingmaschinen . . . . . . . . . 39
1.3 Nichtdeterministische Turingmaschinenund Chomsky-0-Grammatiken . . . 54
1.3.1 Nichtdeterministische Turingmaschinen . . . . . . . . . . . . . . . . 54
1.3.2 Turingmaschinen und Chomsky-0-Grammatiken . . . . . . . . . . . 66
1.3.3 Linear beschrankte Automaten undChomsky-1-Grammatiken . . . . 71
1.4 Struktur- und Abschlusseigenschaften . . . . . . . . . . . . . . . . . . . . . 76
1.5 Aquivalenz von Turingmaschinen und Registermaschinen . . . . . . . . . . 84
1.5.1 Simulation von Turingmaschinen auf Registermaschinen . . . . . . . 84
1.5.2 Simulation von Registermaschinen auf Turingmaschinen . . . . . . . 87
1.6 Zur Bezeichnung”Rekursive Funktionen“ und
”Rekursive Mengen“ . . . . . 92
1.7 Die Churchsche These . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
1.8 Universelle Turingmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . 100
1.9 Unentscheidbare Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
1.9.1 Existenz von unentscheidbaren Sprachen . . . . . . . . . . . . . . . 105
i

1.9.2 Eine unentscheidbare rekursiv aufzahlbare Sprache . . . . . . . . . 106
1.9.3 Die Unentscheidbarkeit des Halteproblems . . . . . . . . . . . . . . 108
1.9.4 Reduzierbarkeit und die Reduktionsmethode . . . . . . . . . . . . . 109
1.10 Unentscheidbarkeit semantischer Fragen . . . . . . . . . . . . . . . . . . . 116
1.10.1 Der Satz von Rice . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
1.10.2 Semantische Fragen uber Programme . . . . . . . . . . . . . . . . . 120
1.10.3 Unmoglichkeit von Zertifikaten fur Programme . . . . . . . . . . . . 121
1.11 Das Postsche Korrespondenzproblem . . . . . . . . . . . . . . . . . . . . . 125
1.12 Unentscheidbare Fragen bei Grammatiken . . . . . . . . . . . . . . . . . . 132
2 Die Theorie der NP-vollstandigen Probleme 139
2.1 Polynomiell zeitbeschrankte Turingmaschinen . . . . . . . . . . . . . . . . 141
2.2 Polynomiell zeitbeschrankte NTMn . . . . . . . . . . . . . . . . . . . . . . 144
2.3 Optimierungsprobleme und Sprachen in NP . . . . . . . . . . . . . . . . . 146
2.4 Polynomialzeitreduktionen und NP-Vollstandigkeit . . . . . . . . . . . . . 154
2.5 Der Satz von Cook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
2.6 Einige NP-vollstandige Probleme . . . . . . . . . . . . . . . . . . . . . . . 172
ii

Literaturverzeichnis
Lehrbucher zum Stoff der Vorlesung:
1. A. Asteroth, C. Baier: Theoretische Informatik. Eine Einfuhrung in Berechenbarkeit,Komplexitat und formale Sprachen mit 101 Beispielen, Pearson Studium, 2002.
2. N. Blum: Theoretische Informatik — Eine anwendungsorientierte Einfuhrung, 2.Auflage, Oldenbourg, 2001.
3. J. Hopcroft, R. Motwani, J. Ullman: Introduction to Automata Theory, Languages,and Computation, Second Edition, Addison-Wesley, 2001.
4. (Deutsche Fassung) J. Hopcroft, R. Motwani, J. Ullman: Einfuhrung in die Automa-tentheorie, Formale Sprachen und Komplexitatstheorie, 2., uberarbeitete Auflage,Pearson Studium, 2002.
5. U. Schoning: Theoretische Informatik — kurzgefasst, 4. Auflage, Spektrum Akade-mischer Verlag, 2001.
6. J. Hromkovic, Theoretische Informatik: Berechenbarkeit, Komplexitatstheorie, Algo-rithmik, Kryptographie. Eine Einfuhrung, 2. Auflage, Teubner, 2004.
7. G. Vossen, K.-U. Witt: Grundkurs Theoretische Informatik, 3., erweiterte Auflage,Vieweg, 2004.
8. K. Wagner: Theoretische Informatik: Eine kompakte Einfuhrung, 2. Auflage, Sprin-ger, 2003.
9. I. Wegener: Theoretische Informatik — eine algorithmische Einfuhrung, 2. Auflage,Teubner, 1999.
10. I. Wegener: Kompendium Theoretische Informatik — eine Ideensammlung, Teubner,1996.
1

Weiterfuhrende, erganzende Literatur:
1. T. H. Cormen, C. E. Leiserson, R. L. Rivest, C. Stein: Introduction to Algorithms,2nd Edition, MIT Press, 2001.
2. I. Wegener: Komplexitatstheorie. Grenzen der Effizienz von Algorithmen, Springer,2003.
3. C. Papadimitriou: Computational Complexity, Addison-Wesley, 1994.
2

Kapitel 0
Vorbemerkungen
0.1 Fragestellung und Uberblick
Wir skizzieren hier kurz den Stoff der Vorlesung”Algorithmentheorie“ (3. Semester) und
motivieren die behandelten Fragestellungen.
Die Vorlesung zerfallt in zwei große Teile: Berechenbarkeitstheorie und Theorie der NP-Vollstandigkeit. Im ersten Teil geht es um die Frage, welche Probleme man mit Rechnernprinzipiell losen kann und welche nicht. Man beschrankt sich der Einfachheit halber (aberohne Moglichkeiten fur eine tiefe Theorie auszuschließen) auf die Aufgabenstellungen,Funktionen zu berechnen und Entscheidungsprobleme zu losen. Eine typische, fur dieInformatik zentrale Art von Entscheidungsproblem ist es z. B., zu einer gegebenen ASCII-Datei prog.pas festzustellen, ob diese ein syntaktisch korrektes Pascal-Programm enthalt,das seinen Input aus einer oder mehreren Eingabedateien entnimmt. (Analoge Fragestel-lungen gibt es fur alle anderen Programmiersprachen.) Dies entspricht offenbar dem Pro-blem festzustellen, ob der Inhalt von prog.pas zu der Sprache LPascal aller syntaktischkorrekten Pascal-Programme gehort. Wir wissen, dass jeder Pascal-Compiler diese Auf-gabe lost (und noch viel mehr). Eine andere, ebenso interessante Fragestellung ware, obdas in prog.pas gespeicherte Programm syntaktisch korrekt ist und bei der Ausfuhrung,z. B. mit einer Textdatei daten.txt als externem Input, nach endlicher Zeit anhalt undeine Ausgabe liefert. (Diese Frage nennt man das Halteproblem fur Pascal-Programme.)Es ist klar, dass es wunschenswert ware, ein Programm zu haben, das mit prog.pas unddaten.txt als Inputdateien diese Frage beantwortet. Es ist ein Ziel der Vorlesung, nach-zuweisen, dass es kein solches Programm geben kann — man sagt, das Halteproblem furPascal-Programme sei unentscheidbar. Ebenso stellen sich andere wichtige Fragestellun-gen, die sich auf die Semantik von Programmen beziehen, als unentscheidbar heraus, zumBeispiel die Frage nach der Aquivalenz von Programmen (
”ist das Ein-/Ausgabeverhalten
der Programme in prog1.pas und prog2.pas identisch?“) oder nach der Redundanz vonFunktionsdefinitionen (
”fuhrt die Ausfuhrung des Programms in prog.pas zum Aufruf
der Funktion mit Namen f?“).
3

Zur Einstimmung geben wir eine Argumentation dafur, dass das Halteproblem fur Pascal-Programme nicht von Pascal-Programmen gelost werden kann. Dabei handelt es sichwohlgemerkt nicht um einen mathematisch sinnvollen Beweis, weil wir Eigenschaftenvon Pascal-Compilern, von Laufzeit- und Dateisystemen in einem gedachten Compu-ter(system) ziemlich freihandig benutzen, ohne sie zu formalisieren. Außerdem wissenwir (einstweilen) nicht, ob es nicht Algorithmen gibt, die nicht als Pascal-Programmeformuliert werden konnen.
Wir sagen, ein Pascal-Programm P”lost das Halteproblem fur Pascal-Programme“, wenn
P folgendes Ein-/Ausgabeverhalten hat: P erhalt zwei (read-only) Textdateien d1.txt
und d2.txt als Eingabe und liefert als einzige Ausgabe (auf der Standard-Ausgabe) denBuchstaben
”J“ (fur
”ja“), wenn d1.txt den Text eines korrekten Pascal-Programmes Q
enthalt, das mit d2.txt als einziger Eingabedatei irgendwann anhalt; P liefert als Ausgabeden Buchstaben
”N“ (fur
”nein“), wenn d1.txt kein korrektes Pascal-Programm enthalt
oder das in d1.txt gegebene Pascal-Programm mit d2.txt als Eingabe nie anhalt.
Behauptung: Es gibt kein Pascal-Programm, das das Halteproblem fur Pascal-Programmelost.
”Beweis“: Indirekt. Angenommen, P sei ein Pascal-Programm, das das Halteproblem fur
Pascal-Programme lost. (Wir mussen nun einen Widerspruch herleiten.) Wir stellen unsvor, P sei als Text gegeben, und bauen P ein wenig um, in 2 Schritten.
Im ersten Schritt erzeugen wir aus (dem Text von) P ein neues Pascal-Programm P′ mitfolgendem Verhalten: P′ erhalt eine Textdatei d.txt als Eingabe. Mit Hilfe von Standard-Lese- und Schreibfunktionen generiert P′ zwei Textdateien d1.txt und d2.txt, die beidedenselben Inhalt haben wie d.txt. Dann lauft das Programm P ab, mit Eingabedateiend1.txt und d2.txt.
(Ist es”sinnvoll“, in die beiden Eingabestellen von P, die ja eigentlich ein Programm und
einen Eingabetext erwarten, identische Texte einzugeben? Auf den ersten Blick nicht, aberes gibt Programme Q, bei denen ein solches Einsetzen sinnvoll ist — z. B. konnte d.txt
einen in Pascal geschriebenen Compiler Q enthalten, den man naturlich auch mit seinemeigenen Programmtext als Eingabe testen konnte. Unbestreitbar ist jedenfalls, dass manP′ leicht aus P gewinnen kann.)
Nun erzeugen wir aus P′ durch weiteren Umbau noch ein Programm P′′. Dieses verhalt sichso: P′′ erhalt eine Textdatei d.txt als Eingabe. Es rechnet wie P′, bis P′ einen Buchsta-ben auf die Standardausgabe schreibt. Diese Ausgabe wird nicht vorgenommen, sondern
”abgefangen“, und der geschriebene Buchstabe wird inspiziert. Nach Konstruktion von P′
und der Annahme uber das Verhalten von P muss dies immer passieren, und der Buch-stabe ist
”J“ oder
”N“.
Fall J: Die Ausgabe ist”J“. Dann geht P′′ in eine
”Endlosschleife“, d. h. ruft eine Prozedur
auf, deren Rumpf begin i:=0; while (i=0) do i:=0 end lautet. Dies hat naturlichden Effekt, dass P′′ nie halt.Fall N: Die Ausgabe ist
”N“. Dann halt P′′ an, ohne eine Ausgabe zu erzeugen.
Es sollte klar sein, dass man aus dem Programmtext fur P′ den fur P′′ leicht erhalten
4

kann.
Nun schreiben wir Kopien des Programmtextes von P′′ in die Dateien d1.txt und d2.txt
und starten (die lauffahige Version von) P mit diesen Dateien als Eingabe. Nach demangenommenen Verhalten von P gibt es zwei Falle:
1. Fall : Die Ausgabe ist”J“. Nach der Konstruktion von P′ heißt dies, dass P′ mit dem
Programmtext von P′′ in der Eingabedatei d.txt gestartet ebenfalls”J“ ausgibt. Dies
heißt, nach der Konstruktion von P′′, dass P′′ auf Eingabe d.txt (mit dem Text von P′′)in eine Endlosschleife gerat, also nicht halt. — In diesem Falle liefert P also nicht dieversprochene Ausgabe.
2. Fall : Die Ausgabe ist”N“. Dann gibt P′ mit dem Programmtext von P′′ in d.txt ge-
startet ebenfalls”N“ aus. Nach Konstruktion von P′′ halt P′′ mit Eingabe d.txt (mit dem
Text von P′′) ohne Ausgabe an. — Auch in diesem Falle liefert P nicht die versprocheneAusgabe.
Welcher Fall auch immer eintritt: P wird auf der beschriebenen Eingabe (zwei Kopienvon P′′) falsch antworten. Das ist der gewunschte Widerspruch: es kann kein ProgrammP geben, das das Halteproblem fur Pascal-Programme lost.
Diese Uberlegung sieht wohl gekunstelt und verwickelt aus, aber sie sitzt im Kern allerUnentscheidbarkeitsresultate der Berechenbarkeitstheorie, und ist es daher wert, genau-er angesehen zu werden. In diesem Zusammenhang wird auch empfohlen, im Abschnitt
”Mathematische Grundlagen“ die Anmerkungen zu
”Diagonalisierung“ zu studieren.1
Um eine Aussage der Art
”Fur das Entscheidungsproblem P gibt es keinen Algorithmus und kein Com-
puterprogamm“
mathematisch prazise formulieren und beweisen zu konnen, muss man das Konzept”Ent-
scheidungsproblem“ formalisieren (das ist nicht sehr schwer) und die Idee des”Algorith-
mus“ mathematisch prazise fassen — das ist etwas schwieriger, was man schon daran sehenkann, dass es einige beruhmte Mathematiker (Turing, Godel, Church, Kleene, Markoff)ziemlich lange beschaftigt hat — und schließlich die Beziehung dieses Algorithmusbegriffszu Computerprogrammen klaren.
Wir gehen dazu so vor: Wir besprechen einige mogliche Formalisierungen des Algorithmus-begriffs, manche naher an der Computerstruktur wie wir sie kennen (Registermaschine),manche weiter weg (Turingmaschine, µ-rekursive Funktionen), und stellen ihre Aquivalenzfest. Eine dieser Formalisierungen ist also so gut wie jede andere. Wir wahlen dann ei-ne, die technisch gut handhabbar ist, namlich die Turingmaschinen-Berechenbarkeit, undbeweisen mit ihr als technischer Grundlage die Unentscheidbarkeit des Halteproblems.
1Wenn man das Argument nochmals liest, stellt man fest, dass unser Vorgehen konstruktiv ist infolgendem Sinn: Fur jedes Pascal-Programm P, das zwei Textfiles als Input hat, konstruieren wir (durch
”Diagonalisierung“) ein Programm P′′, das ein Beleg dafur ist, dass P nicht das Halteproblem lost.
5

Mit Hilfe des Begriffs der Reduktion zwischen Berechnungsproblemen kann dann die Un-entscheidbarkeit vieler weiterer Probleme bewiesen werden, insbesondere aller Probleme,die die Semantik, oder kurz das Ein-/Ausgabeverhalten, von Programmen betreffen.
Nebenbei kann man mit Hilfe des Turingmaschinenmodells die Maschinenmodelle identi-fizieren, die den Stufen 0 und 1 der Chomsky-Hierarchie entspricht (Akzeptierung durchbeliebige Turingmaschinen bzw. durch nichtdeterministische Turingmaschinen mit linearbeschranktem Speicherplatz).
Das Turingmaschinenmodell ist auch eine gute Grundlage fur die Untersuchungen im zwei-ten Teil der Vorlesung. Beim Konzept der prinzipiellen Berechenbarkeit und Entscheidbar-keit spielt die Rechenzeit keine Rolle. Hier wollen wir untersuchen, ob wir Probleme, dieAlgorithmen mit
”vernunftigen“ Laufzeiten wie O(n), O(n log n) oder O(n2) haben (allge-
meiner:”polynomielle Laufzeit“), wie etwa das Sortierproblem, unterscheiden konnen von
Problemen, die solche Algorithmen nicht haben. Hierzu betrachtet man Entscheidungspro-bleme, die auf gewohnlichen Rechnern in polynomieller Rechenzeit gelost werden konnen.Wir diskutieren, wieso Turingmaschinen mit polynomieller Rechenzeit ein gutes abstrak-tes Modell fur alle solchen Verfahren sind. Das Konzept der NP-Vollstandigkeit von Ent-scheidungsproblemen, das wiederum auf der Basis des Turingmaschinenmodells definiertwerden kann, indem man Nichtdeterminismus hinzufugt, erlaubt es, eine sehr wichtigeKlasse von Entscheidungs- und Berechnungsproblemen zu identifizieren, die vermutlichnicht von gewohnlichen, deterministischen Polynomialzeit-Turingmaschinen gelost wer-den konnen, und daher vermutlich keinen effizienten Algorithmus haben. Hierzu gehorenviele Graphenprobleme (z. B. das in Kap. 0.2 beschriebene Hamiltonkreisproblem oderdas beruhmte Problem des Handlungsreisenden, auch als TSP-Problem bekannt), Proble-me aus dem Gebiet des Schaltungsentwurfs (z. B. das Aquivalenzproblem fur BoolescheSchaltungen), oder Probleme aus der Zahlentheorie (die Frage nach der Losbarkeit vonlinearen Ungleichungssystemen, wenn die Koeffizienten ganzzahlig sind und die Losun-gen aus naturlichen Zahlen bestehen sollen) und vielen anderen Gebieten der Informatikund der Anwendungsgebiete. Eine genauere Untersuchung der Welt der NP-vollstandigenProbleme wird in der Vorlesung
”Komplexitatstheorie“ vorgenommen.
0.2 Grundbegriffe: Alphabete, Sprachen und Proble-
me
0.2.1 Vereinbarung N = {0, 1, 2, . . .} bezeichnet die Menge der naturlichen Zahlen.
0.2.2 Definition Fur eine beliebige Menge A, A 6= ∅, bezeichnet Seq(A) die Mengeder endlichen Folgen oder
”Tupel“ in A, d. h. die Menge
{(a1, . . . , an) | n ≥ 0, a1, . . . , an ∈ A}.
6

Wenn zum Beispiel A = N ist, dann sind (0, 6, 4, 6), (3), und () (die leere Folge) Elementevon Seq(A). Beachte, dass AN = {(ai)i≥0 | ai ∈ A fur i ≥ 0} die Menge der unendlichenFolgen in A ist.
Wir werden uns insbesondere fur Tupel aus naturlichen Zahlen interessieren, also Seq(N).
Eines unserer Rechnermodelle (die Registermaschine) wird tatsachlich mit Zahlen undZahlenfolgen rechnen. Wenn man genau hinsieht, sieht man, dass reale Rechner dies garnicht tun. Vielmehr operieren sie auf Bitfolgen: der Inhalt des Hauptspeichers etwa isteine Bitfolge, ebenso Dateiinhalte. Will man mit Zahlen rechnen oder Zeiger benutzen,muss man diese binar kodieren. Auch wir werden andere Rechenmodelle betrachten (ins-besondere die Turingmaschine), die nur Zeichenreihen mit Zeichen aus einem endlichenZeichensatz bearbeiten konnen. Damit sind wir in der aus der Vorlesung
”Automaten und
Formale Sprachen“ bekannten Welt der Alphabete, Worter, Sprachen und der Funktio-nen, die Worter auf Worter abbilden. Die dort besprochenen Begriffe, die Worter undSprachen betreffen, setzen wir als bekannt voraus. Das wichtigste benennen wir hier kurz.
0.2.3 Definition Ein Alphabet Σ ist eine endliche nichtleere Menge.
0.2.4 Beispiel Die Menge {1} oder {|} heißt das unare Alphabet. Die Menge Σ = {0, 1}heißt das binare Alphabet. Die Menge {0, 1, #} ist das binare Alphabet mit Trennzeichen#. Der ASCII-Code gibt eine injektive Abbildung einer Menge von
”naturlichen“ Buch-
staben, Ziffern, und Symbolen (d. h. eines gewissen Alphabets) in {0, 1}8 an.
0.2.5 Definition Σ sei ein Alphabet. Fur n ∈ N bezeichnet Σn die Menge aller Folgenw = (a1, . . . , an) aus n Buchstaben aus Σ. Statt (a1, . . . , an) schreiben wir a1 · · · an, undnennen w ein Wort uber Σ (oder einen String uber Σ). Die Lange von w, bezeichnet mit|w|, ist n.
Σ∗ :=⋃
{Σn | n ∈ N} = Seq(Σ).
Ein besonderes Wort ist ε = (), das leere Wort mit Lange 0.
0.2.6 Definition Eine Menge L heißt eine Sprache, wenn es ein Alphabet Σ gibt, sodass L eine Teilmenge von Σ∗ ist. In diesem Fall sagt man auch, L sei eine Sprache uberΣ.
Sprachen interessieren uns in zweierlei Hinsicht: einerseits, wie in der Vorlesung”Auto-
maten und Formale Sprachen“ ausfuhrlich besprochen, als Grundkonzept der Theorie derformalen Sprachen; in dieser Vorlesung verwenden wir Sprachen aber viel mehr als Forma-lisierung des Begriffs eines
”Berechnungsproblems“ oder
”Entscheidungsproblems“. Wegen
ihrer fundamentalen Bedeutung wollen wir diese Konzepte noch genauer besprechen.
7

Berechnungsprobleme und Funktionen zwischen Wortmengen. Ein Berechnungs-problem wird beschrieben durch die Angabe zweier Mengen I (die Inputs) und O (diemoglichen Outputs) und einer Funktion f : I → O. Die Aufgabe besteht darin, eine Me-thode anzugeben, mit der man zu jedem x ∈ I den Funktionswert f(x) ∈ O findenkann.
Man sollte sorgfaltig unterscheiden zwischen dem durch die Funktion f : I → O gegebe-nen Berechnungsproblem und dem Einzel-
”Problem“, zu einem gegebenen Input x den
Wert f(x) zu finden. Das letzte bezeichnet man als”Instanz“ des Berechnungsproblems;
etwas abgekurzt nennt man dann gleich jedes x ∈ I eine Instanz des durch f gegebenenBerechnungsproblems.
Beispiele fur Berechnungsprobleme:
Großter gemeinsamer Teiler :
Input/Instanz: Ein Paar (a, b) von naturlichen Zahlen.
Output: 0, falls a = b = 0 und c = ggt(a, b) sonst.
Multiplikation von Zahlenfolgen:
Input/Instanz: Eine Folge (a1, . . . , an) von naturlichen Zahlen.
Output: Das Produkt a1 · . . . · an (wenn n = 0, ist das Produkt per Definition gleich 1).
Zusammenhangskomponenten von Graphen:
Input/Instanz: Ein ungerichteter Graph G = (V,E).
Output: Die Knotenmengen V1, . . . , Vr der Zusammenhangskomponenten von G.
Wie man an diesen Beispielen sieht, wird bei der Spezifikation von Berechnungsproblemenoft nur eine (allgemein formulierte) Instanz in mathematischer Notation angegeben undder zu findende Funktionswert informal beschrieben. Außerdem kann es passieren (wie imdritten Beispiel), dass die Ausgabe nicht eindeutig ist; die Reihenfolge der Komponentenin der Ausgabe ist nicht festgelegt.
Wir formalisieren Berechnungsprobleme mit Hilfe der Terminologie von Alphabeten undWortmengen.
Wenn Σ und ∆ Alphabete sind und A ⊆ Σ∗ und f : A → ∆∗ eine Funktion ist, so istdadurch naturlich ein Berechnungsproblem definiert (namlich das, einen Algorithmus zufinden, der f berechnet). Umgekehrt zeigt die Erfahrung, und eine etwas allgemeinere
8

Uberlegung, dass man jedes Berechnungsproblem als eine Funktion formulieren kann, dieWorter auf Worter abbildet. Um ein Problem
”rechnergerecht“ formulieren zu konnen,
muss man die Inputs in einem Format vorgeben, das von einem Rechner bearbeitet wer-den kann, also digital. (Beispiel fur Eingabeformate: eine Textdatei — das ist letztendlicheine Folge von ASCII-Zeichen, also ein Wort uber dem ASCII-Alphabet; eine beliebi-ge Datei mit Bilddaten oder intern dargestellten float-Zahlen ist letztendlich ein langesBinarwort; eine Folge von Tastendrucken oder Mausklicks wird ebenfalls binar kodiert.Auch jede Ausgabe, als Text oder als Graphik oder als Klang hat immer eine Zwischendar-stellung als (binarer) Text.) Also verlieren wir eigentlich nichts, wenn wir im wesentlichennur Berechnungsprobleme betrachten, deren Ein- und Ausgabemengen Wortmengen sind.Zwischendurch werden wir auch Berechnungsprobleme betrachten, deren Ein- und Aus-gabemengen Teilmengen von Seq(N) sind.
Entscheidungsprobleme und Sprachen. Entscheidungsprobleme sind spezielle Be-rechnungsprobleme. Bei Entscheidungsproblemen sind zu einem Input x nur die Ausgaben
”Ja“ oder
”Nein“ moglich; allerdings betrachtet man auch Algorithmen oder Rechenver-
fahren, die zu manchen Eingaben uberhaupt kein Resultat liefern.
Beispiele fur Entscheidungsprobleme:
Teilerfremdheit :
Input/Instanz: Ein Paar (a, b) von naturlichen Zahlen.
Output:”Ja“, falls a und b teilerfremd sind, und
”Nein“ sonst.
Primzahlproblem:
Input/Instanz: Eine naturliche Zahl n.
Output:”Ja“, falls n eine Primzahl ist, und
”Nein“ sonst.
Graphzusammenhang :
Input/Instanz: Ein ungerichteter Graph G = (V,E).
Output:”Ja“, falls G zusammenhangend ist, und
”Nein“ sonst.
Wenn L ⊆ Σ∗ eine Sprache ist, so gehort zu L in ganz naturlicher Weise ein Entschei-dungsproblem, namlich:
Wortproblem fur L: Input/Instanz: w ∈ Σ∗ Output:”Ja“, falls w ∈ L,
”Nein“ sonst.
Umgekehrt kann man normalerweise Entscheidungsprobleme als Wortprobleme uber pas-senden Sprachen formulieren. Wir geben dazu einige Beispiele.
9

0.2.7 Beispiel
(a) Das Problem zu entscheiden, ob eine vorgelegte naturliche Zahl n gerade ist odernicht, entspricht der Sprache Lgerade = {bin(n) | n ist gerade}.Das Problem zu entscheiden, ob eine vorgelegte naturliche Zahl n eine Primzahl istoder nicht, entspricht der Sprache Lprim = {bin(n) | n ist Primzahl}.
(b) Das Problem zu entscheiden, ob eine vorgelegte Folge a1, . . . , an von naturlichenZahlen aus paarweise teilerfremden Zahlen besteht, entspricht der SpracheLteilerfremd = {bin(a1)# · · ·#bin(an) |
n ∈ N, a1, . . . , an ∈ N,∀d > 1, i 6= j : d teilt ai ⇒ d teilt aj nicht}uber dem Alphabet {0, 1, #}.
Kodierung von Graphproblemen. Als Beispiel fur die Formulierung von zu berech-nenden Funktionen bzw. von Entscheidungsproblemen als Funktionen Σ∗ → ∆∗ fur Al-phabete Σ, ∆ bzw. als Wortprobleme fur Sprachen formulieren wir hier einige Graphpro-bleme in dieser Weise. Eine kleine technische Schwierigkeit, die aber mit etwas Gewohnungnicht schwer zu bewaltigen ist, ist die Wahl einer passenden Kodierung fur die Objektein der Ein- und Ausgabemenge. Die hier vorgeschlagene Art der Kodierung ist keineswegseindeutig, sondern willkurlich. Der Einfachheit halber nehmen wir hier und auch spaterimmer an, dass die Knoten unserer Graphen Zahlen sind.
Ein Graph ist also ein Paar (V,E), wo V ⊆ N endlich ist und E ⊆ V × V eine Mengevon Paaren ist. Wie in der Graphentheorie ublich, kann man ein solches Paar (V,E) alsgerichteten Graphen (kurz Digraphen, von
”directed graph“) auffassen, indem man ein
Paar (u, v) ∈ E als geordnetes Paar interpretiert, oder auch als (ungerichteten) Graphen,indem man das Paar (u, v) ∈ E als ungeordnetes Paar auffasst. Wir kodieren Knoten-namen durch ihre Binardarstellung. Eine einfache Methode, einen (Di-)Graphen G alsWort uber dem Alphabet {0, 1, #} darzustellen, besteht darin, alle Knoten und alle Kan-ten in Binardarstellung aufzulisten. Das heißt, wenn G = (V,E) mit V = {v1, . . . , vn},E = {e1, . . . , em}, wobei ej = (vij , wij) ∈ V × V ist, dann ist eine Darstellung von G alsWort uber {0, 1, #} durch
[G] = ###bin(v1)#bin(v2)# · · ·#bin(vn)##
bin(vi1)#bin(wi1)## · · ·##bin(vim)#bin(wim)###
gegeben. Ein Beispiel:
V = {4, 6, 9, 10}
E = {(4, 9), (6, 9), (6, 10)}
[G] = ###100#110#1001#1010##100#1001##110#1001##110#1010###,
ein Wort uber Σ = {0,1,#}. Auch seltsame Graphen lassen sich darstellen: Der GraphG = ({0, 3, 7}, ∅) mit drei Knoten und keiner Kante hat die Kodierung
###0#11#111#####.
10

Weil die Knoten- und Kantenordnung nicht vorgegeben ist, hat ein (Di-)Graph normaler-weise mehrere verschiedene Kodierungen. Man konnte die Kodierung eindeutig machen,indem man v1 < v2 < · · · < vn fordert und die Kanten lexikographisch anordnet. Wichtigbei dieser Kodierung (und in ahnlichen Situationen) ist der Umstand, dass aus dem Wort[G] der (Di-)Graph G leicht rekonstruiert werden kann und dass Worter w ∈ {0, 1, #}∗,die keinen (Di-)Graphen kodieren, leicht zu erkennen sind.
Wir geben nun beispielhaft einige Graphprobleme und ihre Formalisierung als Funktionenuber Wortern bzw. als Sprachen an.
(i) Das Graphzusammenhangsproblem (fur ungerichtete Graphen) wird durch die fol-gende Sprache uber {0, 1, #} dargestellt:
Lzush = {[G] | G ist zusammenhangend}.
(Das Wortproblem fur Lzush ist eine Formalisierung des Graphzusammenhangspro-blems.)
(ii) Ein (gerichteter) Hamiltonkreis in einem Digraphen G = (V,E) ist eine Anordungder Knoten v1, . . . , vn so dass zwischen in der Anordnung aufeinanderfolgenden Kno-ten eine Kante liegt und eine Kante vom letzten zum ersten Knoten fuhrt. Anord-nungen beschreibt man bequem durch Permutationen π von {1, . . . , n}: wenn π einesolche Permutation ist, ist vπ(1), . . . , vπ(n) eine Knotenanordnung; umgekehrt ist jedeKnotenanordnung durch eine Permutation darstellbar.(Beispiel: Die Permutation π mit π(1) = 3, π(2) = 4, π(3) = 2, π(4) = 1 gehort zuder Anordnung v3, v4, v2, v1.)Ein Hamiltonkreis in G = (V,E) ist also eine Permutation π derart dass (vπ(i), vπ(i+1))∈ E fur 1 ≤ i < n und (vπ(n), vπ(1)) ∈ E ist. Das Hamiltonkreisproblem ist folgendesEntscheidungsproblem:
Input/Instanz: Ein Digraph G = (V,E) mit V = {v1, . . . , vn}.
Output:”Ja“, falls G einen Hamiltonkreis besitzt, und
”Nein“ sonst.
Diesem Problem entspricht die Sprache
LHamilton = {[G] | G ist Digraph, G hat einen Hamiltonkreis}.
(iii) Kreisfreiheitsproblem: Die Sprache
Lazyklisch = {[G] | G ist Digraph, G hat keinen gerichteten Kreis}
formalisiert das Problem, zu einem gegebenen Digraphen zu entscheiden, ob dieserkreisfrei (synonym: azyklisch) ist.
11

(iv) Zusammenhangskomponentenproblem: Das Problem, zu einem (ungerichteten) Gra-phen G seine Zusammenhangskomponenten zu berechnen, kann man zum Beispielwie folgt als Funktion f : {0, 1, #}∗ → {0, 1, #}∗ kodieren:
f(w) =
0, falls w 6= [G] fur alle Graphen G ist;
###bin(v11)#bin(v12)# · · ·#bin(v1r1)##
bin(v21)# · · ·#bin(v2r2)## · · ·
bin(vs1)# · · ·#bin(vsrs)###,
wo {v11, . . . , v1r1}, . . . , {vs1, . . . , vsrs
} dieZusammenhangskomponenten von G sind, falls w = [G].
Um zu erzwingen, dass zu gegebenem w = [G] der Funktionswert f(w) eindeutigist, konnte man festlegen, dass in der Ausgabe die Knoten in jeder Zusammenhangs-komponente so wie in der Eingabe angeordnet sind und dass die Zusammenhangs-komponenten selber so angeordnet sind, dass die Reihenfolge der ersten Elementev11, . . . , vsrs
dieselbe wie in der Eingabe ist.
Man beachte, dass wir syntaktisch falschen Eingaben (Wortern w, die keinen Gra-phen kodieren) eine Ausgabe zugeordnet haben, die nicht als Liste missverstandenwerden kann. Diese Ausgabe ist als Fehlermeldung zu verstehen.
Bemerkung : Nach einer Weile wird es Routine, Entscheidungsprobleme als Sprachen aus-zudrucken und Berechnungsprobleme als Funktionen. Auch gewohnt man sich daran, dassalle mathematischen Strukturen irgendwie kodiert werden mussen, und an die Standard-verfahren fur diese Kodierungen. Der besseren Lesbarkeit halber notiert man dann Ent-scheidungsprobleme in der Input/Instanz–Output-Formulierung und verzichtet auf dieexplizite Angabe der Kodierung. So wird es auch in der Literatur gemacht. Zur Ubungwerden wir in der Vorlesung noch eine Weile die Formulierung von Problemen als Sprachenoder Funktionen mitfuhren.
0.3 Mathematische Grundbegriffe
0.3.1 Abzahlbarkeit und Uberabzahlbarkeit
Wir rekapitulieren hier kurz Begriffe aus den Mathematik-Grundvorlesungen (fur Informa-tiker). Alle, denen dies unbekannt vorkommt, mogen auch einfuhrende Mathematikbucherkonsultieren. Wir benutzen die Konzepte nur als
”Hintergrund“ fur Untersuchungen in
Kapitel 1.
0.3.1 Definition Eine Menge A heißt abzahlbar (oder abzahlbar unendlich), wenn eseine Bijektion f : N ↔ A gibt, das ist eine Aufzahlung (f(0), f(1), f(2), f(3), . . .) von Aohne Wiederholung. Ist A unendlich, aber nicht abzahlbar, so heißt A uberabzahlbar.
12

0.3.2 Bemerkung
(a) Falls f : N→ A surjektiv ist, so ist A endlich oder abzahlbar.
(b) Falls g : A→ N injektiv ist, ist A endlich oder abzahlbar.
(c) Ist A abzahlbar und A′ ⊆ A, so ist A′ endlich oder abzahlbar.
Die Beweise sind einfache (mathematische) Ubungsaufgaben.
0.3.3 Bemerkung Falls A abzahlbar ist, gilt:
(a) P(A) = {B | B ⊆ A} ist uberabzahlbar.
(b) {0, 1}A = {f | f : A → {0, 1}} ist uberabzahlbar. (Dasselbe gilt fur jede Funktio-nenmenge ΣA mit |Σ| ≥ 2.)
(c) Seq(A) = {(a1, . . . , an) | n ∈ N, a1, . . . , an ∈ A} ist abzahlbar.
(d) P<∞(A) = {B | B ⊆ A und A endlich} ist abzahlbar.
Beweis
(a) Wir zeigen mit dem”Cantorschen Diagonalverfahren“, dass es keine Bijektion N↔
P(A), also keine Aufzahlung aller Elemente von P(A) gibt. Es sei namlich a =(a0, a1, a2, . . .) eine Aufzahlung aller Elemente von A ohne Wiederholung, die nachVoraussetzung existiert, und F = (B0, B1, B2, . . .) eine Aufzahlung irgendwelcherElemente von P(A). Wir zeigen, dass F nicht ganz P(A) enthalten kann. Diesgeschieht durch Konstruktion einer
”Diagonalmenge“, die in F nicht vorkommt:
D := {ai | i ∈ N, ai /∈ Bi}.
Wir haben namlich fur alle i ∈ N:
ai ∈ Bi ⇔ ¬(ai /∈ Bi)⇔ ai /∈ D,
also ist Bi 6= D fur alle i ∈ N.
(b) Ganz ahnlich wie (a): Es sei a = (a0, a1, a2, . . .) eine Aufzahlung von A ohne Wieder-holung, und F = (f0, f1, f2, . . .) eine Folge irgendwelcher Funktionen fi : A→ {0, 1}.Wir definieren:
fD(ai) :=
{1, falls fi(ai) = 00, falls fi(ai) = 1
}
, fur i ∈ N.
Dann gilt fur jedes i ∈ N:
fD(ai) = 0 ⇔ fi(ai) = 1,
13

also jedenfalls fD 6= fi. (Ahnlich argumentiert man, wenn statt {0, 1} eine andereMenge Σ mit |Σ| ≥ 2 als Wertebereich der fi vorliegt.)
Um die Bezeichnung”Diagonalverfahren“ zu verstehen, stelle man sich die Werte-
verlaufe von f0, f1, f2, . . . als Zeilen einer (unendlichen) Matrix vor. Der Werteverlaufvon fD entsteht durch Kippen der Bits auf der Diagonalen. Dann kann fD naturlichmit keiner der Zeilen ubereinstimmen.
(c) Es genugt zu zeigen, dass Seq(N) abzahlbar ist. Wir betrachten die folgende Funk-tion Un. (
”Un“ steht fur
”Unardarstellung von Zahlentupeln“.)
Un: Seq(N) \ {()} → {0, 1}∗
(a1, . . . , an) 7→ 1a101a20 · · · 01an .
Beispielsweise ist Un((3, 0, 2, 0)) = 11100110 und Un((5)) = 11111. Man uberlegtsich leicht, dass Un bijektiv ist. Nach Korollar A.1.12 im AFS-Skript ist {0, 1}∗
abzahlbar; dies ubertragt sich via Un auch auf Seq(N).
(d) Die Abbildung
Seq(N)→ P<∞(N), (a1, . . . , an) 7→ {a1, . . . , an}
ist offenbar surjektiv. Nach (c) existiert also eine surjektive Abbildung N→ P<∞(N);nach Bemerkung 0.3.2(a) ist dann P<∞(N) abzahlbar.
�
0.3.4 Bemerkung Es gibt noch eine andere Darstellung des Cantorschen Diagonal-verfahrens, das ohne Indizes auskommt. Ein Argument dieser Art wurde in Abschnitt 0.1benutzt, um die Unentscheidbarkeit des Halteproblems fur Pascal-Programme zu demons-trieren. Hier geben wir dieses Beweisverfahren einmal in der puren, mengentheoretischenFormulierung an, um folgendes zu beweisen:Behauptung: Wenn A eine beliebige Menge ist und f : A→ P(A) = {B | B ⊆ A} eineFunktion, dann ist f nicht surjektiv. (Insbesondere kann es keine Bijektion zwischen Aund P(A) geben.)
Beweis : Sei f : A→ P(A) beliebig. Wir definieren:
D := {a ∈ A | a /∈ f(a)}.
Offenbar ist D eine Teilmenge von A, also D ∈ P(A). Fur jedes beliebige a ∈ A gilt nachder Definition von D:
a ∈ D ⇔ a /∈ f(a),
also ist f(a) 6= D. Das heißt, dass D nicht im Bild von f liegt, daher ist f nicht surjektiv.2
�
2Man beachte, dass dieser Beweis”konstruktiv“ ist in folgendem Sinne: Zu jedem f konstruieren wir
durch”Diagonalisierung“ einen
”Beleg“ D = Df dafur, dass f nicht surjektiv ist.
14

Kapitel 1
Entscheidbarkeit undBerechenbarkeit
1.1 Registermaschinen, Turingmaschinen und Rekur-
sivitat
In diesem Abschnitt stellen wir zwei fur das folgende grundlegende Maschinenmodellebereit: das Modell der Registermaschine (RAM — random access machine — Maschinemit wahlfreiem Speicherzugriff) und das Modell der Turingmaschine (TM, benannt nachAlan Turing, der diese Maschinen 1936 definierte).
Beide Modelle sind als Grundlage fur”echte“ Berechnungen ungeeignet; ihr Wert liegt in
ihrer einfachen Struktur, die allgemeine Untersuchungen zu Berechenbarkeits- und Kom-plexitatsfragen erleichtern.
Registermaschinen operieren auf naturlichen Zahlen bzw. endlichen Folgen von Zahlen;ihre Struktur stellt sie in die Nahe des von-Neumann-Rechenmodells. Sie haben Program-me mit Befehlen, die einem extrem reduzierten Befehlssatz eines gewohnlichen Rechnersentsprechen, und einen Speicher mit Speicherzellen, auf die mit direkter und indirek-ter Adressierung zugegriffen werden kann. Turingmaschinen dagegen verarbeiten Worterdurch Manipulation von Zeichenreihen, in Verallgemeinerung von endlichen Automatenund Kellerautomaten.
1.1.1 Registermaschinen
Eine Registermaschine (RAM) hat einerseits einen Speicher, der aus unendlich vielenSpeicherzellen R0, R1, R2, . . . besteht, die man traditionell Register nennt. Jedes Regis-ter kann eine naturliche Zahl speichern. 〈Ri〉 bezeichnet die in Ri gespeicherte Zahl. Wirinteressieren uns nur fur Speicherzustande, in denen alle bis auf endlich viele Registerden Inhalt 0 haben. Wie eine RAM arbeiten soll, wird durch ein Programm festgelegt,
15

das einem Maschinenprogramm in einer simplen Maschinensprache gleicht. Formal istdas Programm eine Folge B0, B1, . . . , Bl−1 von l Befehlen, die aus einem Befehlsvorratstammen, der Speicher- oder Kopierbefehle, arithmetische Befehle und bedingte und un-bedingte Sprungbefehle enthalt. Bk heißt
”die k-te Programmzeile“; man stellt sich die
Befehle also in l Zeilen angeordnet vor. Um die Arbeitsweise der RAM zu beschreiben, ge-ben wir ihr noch ein zusatzliches Register, den Befehlszahler BZ, das ebenfalls naturlicheZahlen speichern kann. Der Inhalt von BZ wird mit 〈BZ〉 bezeichnet.
Schema einer RAM:
6
5
4
3
2
0
1
0
2
0
4
0
5
3 R
R
R
R
R
mit Programm
und Befehlszähler
R
R
B
B
Bl −1:
BZ
B
SpeicherSteuereinheit
.
.4
2:1:0:
.
−1
0
1
2
l
RAMs mit verschiedenen Programmen werden als verschiedene Maschinen angesehen. Hatman eine RAM M (d. h. ein Programm) und stehen in BZ und R0, . . . , Rm irgendwelcheZahlen, und in Rm+1, Rm+2, . . . Nullen, kann M einen Schritt ausfuhren:
Falls 0 ≤ 〈BZ〉 < l, wird Befehl B〈BZ〉 ausgefuhrt (dies verandert 〈BZ〉 undeventuell den Inhalt eines Registers). Ist 〈BZ〉 ≥ l, passiert nichts: die RAMhalt.
Dieser Vorgang kann naturlich iteriert werden, bis moglicherweise schließlich ein Be-fehlszahlerinhalt ≥ l erreicht wird. Nun beschreiben wir, in der folgenden Tabelle, denBefehlssatz einer RAM. Es handelt sich um sogenannte Dreiadressbefehle: Operandenwerden aus zwei Registern geholt, das Resultat einer Operation in einem dritten Registergespeichert. Nicht-Sprungbefehle fuhren dazu, dass der Befehlszahler um 1 erhoht wird.In der Tabelle steht das Zeichen := fur eine Zuweisung wie in Pascal: Ri := p fur einenIndex i ∈ N und eine Zahl p ∈ N bewirkt, dass nachher das Register Ri die Zahl p enthalt.Analog sind Zuweisungen BZ := m zu interpretieren. Bei der Subtraktion werden negativeResultate durch 0 ersetzt; die Division ist die ganzzahlige Division ohne Rest. Divisiondurch 0 fuhrt zum Anhalten.
16
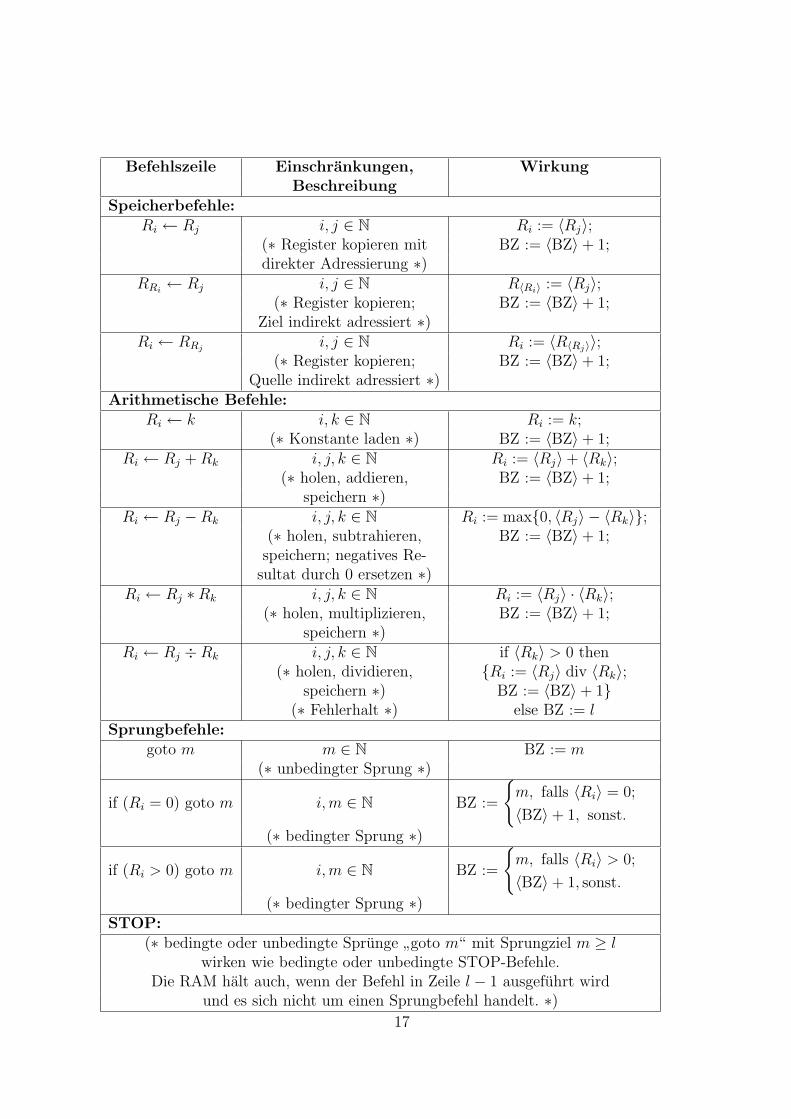
Befehlszeile Einschrankungen, WirkungBeschreibung
Speicherbefehle:Ri ← Rj i, j ∈ N Ri := 〈Rj〉;
(∗ Register kopieren mit BZ := 〈BZ〉+ 1;direkter Adressierung ∗)
RRi← Rj i, j ∈ N R〈Ri〉 := 〈Rj〉;
(∗ Register kopieren; BZ := 〈BZ〉+ 1;Ziel indirekt adressiert ∗)
Ri ← RRji, j ∈ N Ri := 〈R〈Rj〉〉;
(∗ Register kopieren; BZ := 〈BZ〉+ 1;Quelle indirekt adressiert ∗)
Arithmetische Befehle:Ri ← k i, k ∈ N Ri := k;
(∗ Konstante laden ∗) BZ := 〈BZ〉+ 1;Ri ← Rj + Rk i, j, k ∈ N Ri := 〈Rj〉+ 〈Rk〉;
(∗ holen, addieren, BZ := 〈BZ〉+ 1;speichern ∗)
Ri ← Rj −Rk i, j, k ∈ N Ri := max{0, 〈Rj〉 − 〈Rk〉};(∗ holen, subtrahieren, BZ := 〈BZ〉+ 1;speichern; negatives Re-
sultat durch 0 ersetzen ∗)Ri ← Rj ∗Rk i, j, k ∈ N Ri := 〈Rj〉 · 〈Rk〉;
(∗ holen, multiplizieren, BZ := 〈BZ〉+ 1;speichern ∗)
Ri ← Rj ÷Rk i, j, k ∈ N if 〈Rk〉 > 0 then(∗ holen, dividieren, {Ri := 〈Rj〉 div 〈Rk〉;
speichern ∗) BZ := 〈BZ〉+ 1}(∗ Fehlerhalt ∗) else BZ := l
Sprungbefehle:goto m m ∈ N BZ := m
(∗ unbedingter Sprung ∗)
if (Ri = 0) goto m i,m ∈ N BZ :=
{
m, falls 〈Ri〉 = 0;
〈BZ〉+ 1, sonst.
(∗ bedingter Sprung ∗)
if (Ri > 0) goto m i,m ∈ N BZ :=
{
m, falls 〈Ri〉 > 0;
〈BZ〉+ 1, sonst.
(∗ bedingter Sprung ∗)STOP:
(∗ bedingte oder unbedingte Sprunge”goto m“ mit Sprungziel m ≥ l
wirken wie bedingte oder unbedingte STOP-Befehle.Die RAM halt auch, wenn der Befehl in Zeile l − 1 ausgefuhrt wird
und es sich nicht um einen Sprungbefehl handelt. ∗)
17

Mitunter betrachtet man RAMs mit eingeschranktem Befehlsvorrat, z. B. {+,−}-RAMs,bei denen die ∗- und ÷-Befehle fehlen. Da man Multiplikation und Division durch Teil-programme ersetzen kann, die nur Addition und Subtraktion benutzen, bedeutet dieskeine prinzipielle Einschrankung; allerdings kann sich die Anzahl der fur eine Berechnungnotigen Schritte erhohen.
Ein-/Ausgabekonventionen: Fur die Eingabe benutzen wir folgende Konvention (an-dere sind moglich): Ist die Eingabe (a0, . . . , an−1) ∈ Nn, so wird anfangs
R0 auf nR1 auf a0
R3 auf a1...
R2i+1 auf ai, 0 ≤ i < n,
gesetzt, alle anderen Registerinhalte sind 0. (Damit hat man die Register R2, R4, . . . zurfreien Verfugung.) Zudem hat BZ den Inhalt 0. Fur die Ausgabe wird die entsprechende(umgekehrte) Konvention benutzt: als Resultat nach dem Anhalten gilt das Zahlentupel
(〈R1〉, 〈R3〉, . . . , 〈R2〈R0〉−1〉).
Nun konnen wir erklaren, wie eine vollstandige Rechnung von M auf einer Eingabe(a0, . . . , an−1) ∈ Seq(N) ablauft.
©1 man schreibt a0, . . . , an−1 gemaß der Eingabekonvention in die Register von M undsetzt BZ auf 0.
©2 while 0 ≤ 〈BZ〉 < l do
”fuhre Befehl B〈BZ〉 aus“
(mit der Wirkung wie in der Tabelle angegeben)
©3 falls und sobald in ©2 eine Situation mit 〈BZ〉 ≥ l erreicht wird, wird aus denRegisterinhalten gemaß der Ausgabekonvention das Resultat abgelesen.
1.1.1 Beispiel Wir wollen aus a0, . . . , an−1 die Summe a0 + · · ·+an−1 und das Produkta0 · · · an−1 berechnen. Die Register mit geraden Indizes werden verwendet wie folgt:In Register R2 wird von n nach 0 heruntergezahlt,in R4 wird die Summe und in R6 das Produkt akkumuliert,R8 enthalt den Index des nachsten zu verarbeitenden Inputregisters,in R10 wird der Inhalt dieses Registers zwischengespeichert,R12 enthalt die Konstante 1, R14 die Konstante 2.
18

Zeile Befehl Kommentar0 R12 ← 1 Konstante1 R14 ← 2 laden2 R2 ← R0 n ins Zahlregister3 R4 ← 0 Initialisiere Teilsumme4 R6 ← 1 und Teilprodukt5 R8 ← 1 Indexregister auf R1 stellen6 if (R2 = 0) goto 13 Schleife: Zeilen 6–127 R10 ← RR8
Operanden holen8 R4 ← R4 + R10 addieren9 R6 ← R6 ∗R10 multiplizieren10 R8 ← R8 + R14 Indexregister um 2 erhohen11 R2 ← R2 −R12 Zahler dekrementieren12 goto 6 zum Schleifentest13 R1 ← R4 Ausgabeformat14 R3 ← R6 herstellen:15 R0 ← 2 2 Ausgabewerte
1.1.2 Definition Fur eine RAM M definieren wir:
(a) HM := {(a0, . . . , an−1) ∈ Seq(N) | auf Eingabe (a0, . . . , an−1) angesetzt,halt M nach endlich vielen Schritten}
(b) Fur a = (a0, . . . , an−1) ∈ Seq(N) sei
fM(a) =
undefiniert, falls a /∈ HM ;
(b0, . . . , bm−1), falls M auf Eingabe (a0, . . . , an−1) beim
Anhalten die Ausgabe (b0, . . . , bm−1) erzeugt.
fM heißt die von M berechnete Funktion.
(c) Die Menge der RAM-berechenbaren Funktionen ist die Menge aller Funktionen f ,die sich als fM oder als die Einschrankung eines fM auf ein Nn, n fest, beschreibenlassen.
Bemerkung: (a) Im allgemeinen ist fM eine”partielle Funktion“ — die Menge Def(fM) =
{x ∈ Seq(N) | fM(x) ist definiert} = HM ist eine Teilmenge von Seq(N), oft verschiedenvon Seq(N). Z. B. ist es leicht, ein RAM-Programm M mit HM = ∅ anzugeben; in die-sem Falle ist fM fur keine Eingabe definiert. Es wird sich spater herausstellen, dass esbei einer systematischen Behandlung des Berechenbarkeitsbegriffs unvermeidlich ist, auchFunktionen zu betrachten, die nicht fur alle Eingaben definiert sind.(b) Oft sind Funktionen f von Interesse, die nur eine feste Anzahl von Inputzahlen haben,z. B. (a, b) 7→ ab oder (a, b) 7→ max{a, b}. Wenn f eine Funktion ist, deren Definitionsbe-reich eine Teilmenge von Nn ist, sagen wir, dass M f berechnet, wenn f die Einschrankungvon fM auf Nn ist, d. h. wenn fur alle a ∈ Nn gilt f(a) = fM(a).
19

1.1.3 Beispiel Berechnung von aa1
0 . Dabei ist nur das Verhalten auf zweistelligen Ein-gaben (a0, a1) interessant.
Idee: a1-faches Multiplizieren von a0 mit sich selbst. Realisiert wird dies durch eine Schlei-fe, in der R3 in Einerschritten von a1 bis 0 heruntergezahlt wird. Programm fur M :
Zeile Befehl Kommentar0 R2 ← 1 Konstante 11 R4 ← 1 a0
0
2 if (R3 = 0) goto 6 Zeilen 2–5:3 R4 ← R4 ∗R1 Schleife4 R3 ← R3 −R2
5 goto 26 R1 ← R4 Resultatformat7 R0 ← 1 herstellen
Auf der Eingabe (a0, a1) = (6, 3) lauft das Programm wie folgt ab. Die Zeile zu Schritt treprasentiert dabei den gesamten Zustand (die
”Konfiguration“ der RAM) nach Schritt
t = 0, 1, 2, . . .. Schritt 0 entspricht dem Anfangszustand, nach der Initialisierung.
Schritt-Nr. R0 R1 R2 R3 R4 〈BZ〉0 2 6 0 3 0 01 2 6 1 3 0 12 2 6 1 3 1 23 2 6 1 3 1 34 2 6 1 3 6 45 2 6 1 2 6 56 2 6 1 2 6 27 2 6 1 2 6 38 2 6 1 2 36 49 2 6 1 1 36 510 2 6 1 1 36 211 2 6 1 1 36 312 2 6 1 1 216 413 2 6 1 0 216 514 2 6 1 0 216 215 2 6 1 0 216 616 2 216 1 0 216 717 1 216 1 0 216 8
Wir wollen den Ablauf (des Programms) von M auf einer Eingabe a = (a0, . . . , an−1)die
”Berechnung von M auf a“ nennen. Als nachstes ordnen wir jeder solchen Berech-
nung”Kosten“ zu. Die eine Kostenfunktion zahlt einfach die Anzahl der ausgefuhrten
Rechenschritte, die andere versucht, die Anzahl der benotigten Bitoperationen genauerzu erfassen.
20

1.1.4 Definition
(a) Uniformes Kostenmaß/Schrittzahl cM,unif(a) oder cunif(a): Einem RAM-Schritt wer-den die Kosten 1 zugeordnet. Damit betragen die Kosten cM,unif(a) fur die gesamteRechnung von M auf Eingabe a = (a0, . . . , an−1)
{∞ , falls M auf a nicht halt;die Anzahl der Schritte, die M auf a ausfuhrt, falls a ∈ HM .
(b) Logarithmisches Kostenmaß oder Bitmaß1cM,logar(a) oder clogar(a) : Jede in einemausgefuhrten Befehl als Registerinhalt oder Operand vorkommende Zahl p tragt|bin(p)| = max{1, dlog2(p+1)e} (die Anzahl der Bits in der Binardarstellung bin(p))zu den Kosten bei, im Zusatz zu Grundkosten 1 fur jeden Befehl.(Die Ausfuhrung des Befehls Ri ← Rj hat Kosten 1 + |bin(〈Rj〉)|; die des BefehlsRRi
← Rj hat Kosten 1 + |bin(〈Rj〉)| + |bin(〈Ri〉)|; die des Befehls Ri ← RRj
hat Kosten 1 + |bin(〈Rj〉)| + |bin(〈R〈Rj〉〉)|. Der Ladebefehl Ri ← k hat Kosten1 + |bin(k)|; die anderen arithmetischen Befehle wie Ri ← Rj ∗ Rk haben Kosten1 + |bin(〈Rj〉)| + |bin(〈Rk〉)|. Der unbedingte Sprung hat Kosten 1; die bedingtenSprunge bezuglich Register Ri haben Kosten 1 + |bin(〈Ri〉)|.)
(Beispiel: Die Ausfuhrung des Befehls R3 ← RR8mit 〈R8〉 = 12, 〈R12〉 = 18 hat
logarithmische Kosten 1 + dlog 13e+ dlog 19e = 1 + 4 + 5 = 10.)
Die logarithmischen Kosten cM,logar(a) der Ausfuhrung eines Programms M aufEingabe a sind als Summe der Kosten der Einzelschritte definiert.
Das uniforme Kostenmaß ist das einfachere und fur eine ganze Reihe von Anwendungengeeignet, insbesondere dann, wenn die in der Berechnung als Zwischenergebnisse erzeug-ten Zahlen nicht sehr viel langere Binardarstellungen als die Eingabezahlen haben. Daslogarithmische Kostenmaß ist angemessen, wenn wahrend der Rechnung sehr lange Zah-len erzeugt werden. Der Zeitaufwand fur die Addition und die Subtraktion sehr langerZahlen in
”richtigen“ Rechnern mit fixer Operandenbreite in der CPU ist proportional zu
ihrer Bitlange, fur Multiplikation und Division noch etwas hoher.
1.1.5 Beispiel Die RAM aus Beispiel 1.1.3 hat Kosten cunif(a0, a1) = 5 + 4 · a1 imuniformen Kostenmaß. Zur Ermittlung des logarithmischen Kostenmaßes betrachten wirdie Zeilen einzeln und uberlegen, wie oft sie ausgefuhrt werden.
Zeile 0: einmal ausgefuhrt, Kosten 1 + dlog 2e = 2.
Zeile 1: einmal ausgefuhrt, Kosten 1 + dlog 2e = 2.
1Die Idee beim logarithmischen Kostenmaß ist, dass es 1 kostet, ein gespeichertes Bit zu lesen odersonst zu verwenden.
21

Zeile 2: a1-mal ausgefuhrt,Kosten jeweils ≤ 1 + dlog(a1 + 1)e.Gesamtkosten fur Zeile 2: ≤ a1 log a1 + O(a1).
Zeile 3: a1-mal ausgefuhrt,Kosten bei der i-ten Durchfuhrung:1 + dlog(ai−1
0 + 1)e+ dlog(a0 + 1)e = i · log a0 + O(1).Gesamtkosten fur Zeile 3:
∑a1
i=1(i · log a0 + O(1)) = O(a21 · log a0).
Zeile 4: a1-mal ausgefuhrt, Kosten jeweils ≤ 1 + dlog(a1 + 1)e+ dlog 2e.Gesamtkosten fur Zeile 4: ≤ a1 log a1 + O(a1), wie bei Zeile 2.
Zeile 5: a1-mal ausgefuhrt, Kosten a1.
Zeile 6: einmal ausgefuhrt, Kosten 1 + dlog(aa1
0 + 1)e = a1 · log a0 + O(1).
Zeile 7: einmal ausgefuhrt, Kosten 2.
Wenn wir die Kosten fur alle Zeilen aufsummieren, erhalten wir als KostenschrankecM,logar(a0, a1) = O(a2
1 log a0) + O(a1 log a1) + O(1) = O(a21 log a0). (Das ist auch intuitiv
naheliegend: in den letzten 12a1 Schleifendurchlaufen hat die Zahl in R4 eine Bitlange von
mindestens 12a1 · log a0. Allein die Manipulation dieser Zahlen kostet also schon 1
4a2
1 · log a0
im logarithmischen Kostenmaß.)
Ubungsaufgabe: Es gibt eine viel elegantere Moglichkeit, aa1
0 auf RAMs zu berechnen,namlich durch iteriertes Quadrieren. Die Idee ist durch die Rekursionsformel
x0 = 1;
xb = (xb div 2)2, fur gerade b > 0
xb = (xb div 2)2 · x, fur ungerade b
gegeben. Man setze diese Idee in ein iteratives RAM-Programm um und analysiere dieuniformen und logarithmischen Kosten. (Ideale Losung: uniform O(log a1), logarithmischO(log(aa1
0 )) = O(a1 · log(a0)).)
1.1.6 Beispiel Berechne max(a0, . . . , an−1).
Idee: Gehe die Zahlen der Reihe nach durch, speichere jeweiliges Maximum in ausgezeich-netem Register.
Der Einfachheit halber verwenden wir symbolische Namen fur die Programmzeilen; zudemschreiben wir
R”0“ fur R2 Konstante 0
R”1“ fur R4 Konstante 1
R”2“ fur R6 Konstante 2
Rmax fur R8 derzeitiges MaximumRakt fur R10 Zeiger im ArrayRhilf fur R12 Hilfsregister
22

Die”Ubersetzung“ in ein korrektes RAM-Programm ist Routine.
Marke Befehl KommentarR
”0“ ← 0 Initialisiere
R”1“ ← 1 Konstante
R”2“ ← 2
Rmax ← 0 max(∅) := 0Rakt ← R
”2“ ·R0 Zeiger auf
Rakt ← Rakt −R”1“ R2n−1 stellen
fertig?: if (Rakt = 0) goto fertig for-SchleifeRhilf ← RRakt
Rhilf ← Rhilf −Rmax
if (Rhilf = 0) goto gleich Rmax ≥ RRakt
Rmax ← RRakt
gleich: Rakt ← Rakt −R”2“
goto fertig?fertig: R1 ← Rmax Ausgabe-
R0 ← 1 format
Auf dieselbe Weise wie im vorhergehenden Beispiel uberlegt man sich, dass die Kostenim uniformen Kostenmaß durch 8 + 7 ·n beschrankt sind, im logarithmischen Kostenmaßhingegen durch O(n(log n + log(max{ai|0 ≤ i < n})).
1.1.7 Bemerkung Wir betrachten (idealisierte) Programme in einer Standard-Program-miersprache — der Eindeutigkeit halber nehmen wir etwa Pascal. Wir konnen uns alleZahltypen wie ganze Zahlen oder reelle Zahlen durch Tupel von naturlichen Zahlen re-prasentiert denken, Characters ebenfalls durch Zahlen, Zeiger durch Arrayindizes. Uber-setzen wir das Programm mittels eines Compilers in Maschinensprache, ergibt sich einProgramm, das relativ leicht in ein RAM-Programm zu transformieren ist. Wir stellendaher fest: mit Standard-Programmiersprachen berechenbare Funktionen sind auch aufeiner RAM berechenbar. — Umgekehrt kann man sich fragen, ob alle RAM-berechenbarenFunktionen von Pascal-Programmen berechnet werden konnen. Diese Frage ist dann zuverneinen, wenn man die Endlichkeit von Rechnern in Betracht zieht, die dazu fuhrt,dass fur jedes auf einer festen Maschine ausfuhrbare Pascal-Programm eine großte dar-stellbare Zahl und eine Maximalzahl von verwendbaren Registern gegeben ist. Betrachtetman
”idealisierte“ Programme und Computer ohne solche Einschrankungen, lasst sich
tatsachlich die Aquivalenz beweisen. Wir geben uns damit zufrieden, im RAM-Modelleine Abstraktion zu erkennen, die auf jeden Fall die Fahigkeiten konkreter Rechner undProgrammiersprachen umfasst.
23

1.1.2 Turingmaschinen
Wir wenden uns nun unserem zweiten Maschinenmodell zu, der Turingmaschine. DiesesModell ist noch primitiver als die Registermaschine, unterstutzt aber noch besser als diesedie prinzipiellen Untersuchungen in dieser Vorlesung. Wir werden (als Hauptergebnis vonKap. 1.5) feststellen, dass sich die Berechnungskraft von RAMs und TMs nicht wesentlichunterscheidet. Im Gegensatz zur Registermaschine, die mit Zahlen als elementaren Ob-jekten umgeht, bearbeiten Turingmaschinen Zeichenreihen, also Worter.2 Dabei stellensie eine Verallgemeinerung der aus der AFS-Vorlesung bekannten Modelle des endlichenAutomaten (DFAs und NFAs) und des deterministischen oder nichtdeterministischen Kel-lerautomaten dar. Der Hauptunterschied zum Kellerautomaten besteht darin, dass dieserimmer nur am oberen Ende des Kellerwortes lesen und andern darf, die Turingmaschinedagegen auch irgendwo in der Mitte des auf einem Speicherband geschriebenen Worteslesen und andern darf.
Wir beginnen mit der deterministischen 1-Band-Turingmaschine, die wir einstweilen kurzTuringmaschine (TM) nennen, und geben eine ausfuhrliche anschauliche Erklarung desAufbaus und der Funktion. Diese wird nachher in eine prazise mathematische Definitionubertragen. Eine TM M hat als Speicher ein zweiseitig unendliches Band, das in Zellenoder Bandfelder eingeteilt ist. (Wenn man will, darf man sich die Zellen mit i ∈ Z durch-numeriert vorstellen, das ist aber nicht Bestandteil der Definition.) Jede Zelle auf demBand enthalt genau einen Buchstaben eines endlichen Alphabetes Γ (des
”Bandalphabe-
tes“). Ein Buchstabe des Bandalphabetes ist als Blankbuchstabe ausgezeichnet. Meistensschreibt man dafur
”B“, mitunter auch
”0“ oder
”“.
”Sinnvolle“ Bandinschriften sind
nur solche, bei denen nur endlich viele Zellen von B verschiedene Buchstaben enthalten.Weiter hat die TM einen (Lese-Schreib-)Kopf, der immer auf einem Bandfeld positioniertist und der sich in einem
”Schritt“ immer nur (hochstens) zu einer Nachbarzelle bewe-
gen kann. Die Moglichkeit der direkten oder indirekten Adressierung von Zellen und des
”springenden“ Zugriffs auf Zellen existiert also nicht.
2Will man Zahlen bearbeiten, muss man sie als Zeichenreihen kodieren, z. B. durch ihre Binardarstel-lung.
24

Qδ
q
qm q
q
0
1
2
3q
Steuereinheit
B B B b a n d i n B B * # − s c h r i f t B B B B B B B ......
Bewegen um 1 BandfeldLese−Schreib−Kopf:
Schreiben Lesen
Übergangsfunktion
Zustandsmenge
gegenwärtiger Zustand
q
Abbildung 1.1: Bestandteile einer Turingmaschine M
Das Programm als die Vorschrift, wie sich die TM zu verhalten hat, sitzt in einer”Steuerein-
heit“3. Diese besteht aus einer endlichen Menge Q von Zustanden und einer Vorschrift,was die TM tun soll, wenn sie in einem Zustand q ist, und der Lese-Schreib-Kopf auf einerZelle steht, die den Buchstaben a ∈ Γ enthalt. Diese Vorschrift sagt
– welcher Buchstabe zu schreiben ist (in das eben besuchte Feld) (a′ ∈ Γ),
– was der neue Zustand ist (q′ ∈ Q);
– in welche Richtung sich der Kopf bewegen soll: D ∈ {L,R,N} (dabei bedeutet L
”links“, R
”rechts“ und N
”gar nicht“).
– oder ob eventuell gar nichts passieren soll, also die TM halten soll.
Ein”Schritt“ der TM besteht in folgendem:
– Lies das Symbol a ∈ Γ, das in der eben vom Lese-Schreib-Kopf besuchten Zellesteht;
– Entscheide aufgrund des gegenwartigen Zustands q und a, was
der neue Zustand q′,das neue Symbol a′,die Bewegungsrichtung D
sein soll, und fuhre die entsprechenden Ubergange aus.
3engl.:”control unit“. Bitte nicht mit
”Kontrolleinheit“ oder gar mit
”Kontrolle“ ubersetzen.
25

(Dann folgt der nachste Schritt. Einfachere Maschinenzyklen gibt es nicht, oder?)
Formal denken wir uns die oben erwahnte”Vorschrift“ als Ubergangsfunktion δ : Q×Γ→
Q× Γ× {L,R,N} gegeben. Wir behalten uns aber vor, dass fur manche Paare (q, a) dieMaschine keinen weiteren Schritt macht, formal, dass δ eine partielle Funktion ist, d. h.dass Def(δ) eine echte Teilmenge von Q × Γ ist. Weil man fruher δ als Tabelle (von 5-Tupeln (q, a, q′, a′, D) mit δ(q, a) = (q′, a′, D)) aufgefasst hat, wird δ oder eine Darstellungvon δ noch oft als Turingtafel bezeichnet.
Damit man mit TMn irgendetwas berechnen kann, mussen noch Ein- und Ausgabekonven-tionen festgelegt werden. Wir wollen entweder Funktionen berechnen, wobei Argumentewie Resultate als endliche Strings gegeben sind, oder Entscheidungsprobleme/Wortpro-bleme losen, d. h. es liegt eine Sprache L uber Σ vor, und zu x ∈ Σ∗ ist zu entscheiden, obx ∈ L oder nicht. (Vgl. dazu Abschnitt 0.2.) Die zulassigen Eingaben fur eine TM M sinddie Worter x ∈ Σ∗, wo Σ ⊆ Γ − {B} das Eingabealphabet ist. Die Eingabekonventionbesteht darin, dass eine Eingabe x = a1 · · · an ∈ Σ∗ so auf das Band geschrieben wird,dass ai in Zelle i steht, 1 ≤ i ≤ n, und dass der Kopf auf Zelle 1 steht; der Rest desBandes ist mit dem Blankbuchstaben
”B“ vorbesetzt:
BBBBBBBBBBB e i n g a b e B B B B B BBB
q0
B B... ...
Abbildung 1.2: Startkonfiguration fur Eingabe x = eingabe
(NB: x = ε⇔ anfangs liest der Kopf ein B.) Weiter soll ein Startzustand q0 ∈ Q festgelegtsein. Die TM fuhrt, startend in dieser Startkonfiguration, einen Schritt nach dem anderenaus, bis sie halt, d. h. bis eine Situation (q, a) auftritt, fur die δ(q, a) undefiniert ist.Moglicherweise halt die TM auch uberhaupt nicht. Wenn sie halt, wird die Ausgabe wiefolgt abgelesen:
(i) (Funktionen) Das Resultat ist das Wort, das in den Zellen von der gegenwartigenKopfposition (einschließlich) nach rechts bis zum ersten
”B“ (ausschließlich) auf
dem Band steht. Ein Beispiel enthalt die folgende Abbildung.
26

... B ...B B
q
r e s u l t a t i r r e l e vtnavelerri
Abbildung 1.3: TM M halt, wenn δ(q, r) undefiniert ist; Ausgabe: resultat
Steht der Kopf auf einer Zelle mit Buchstaben”B“, ist das Resultat das leere Wort.
(ii) (Entscheidungsprobleme) Es gibt eine vorher festgelegte Teilmenge F ⊆ Q, die
”akzeptierenden (End-)Zustande“.
Halt die TM im Zustand q, so gilt die Eingabe x als”akzeptiert“, falls q ∈ F ,
”verworfen“, falls q ∈ Q− F ist.
1.1.8 Beispiel Wir beschreiben eine Turingmaschine, die die Worter der Sprache L ={anbncn | n ≥ 0} akzeptiert.
Damit sehen wir schon, dass Turingmaschinen”mehr konnen“ als Kellerautomaten, da
wir wissen, dass L nicht kontextfrei ist und daher kein Kellerautomat L akzeptieren kann.
Die Idee fur das Verfahren ist, mit dem Lese-Schreibkopf mehrere Male uber den Bereichdes Eingabewortes zu fahren, dabei jedesmal zu uberprufen, in der Manier eines endlichenAutomaten, ob die jetzige Bandinschrift aus lauter X besteht (dann akzeptieren wir) oderin der durch den regularen Ausdruck X∗a(a+X)∗b(b+X)∗cc∗ beschriebenen Sprache liegt;dann ersetzen wir jeweils das erste gefundene a, das erste gefundene b und das erstegefundene c durch ein X und beginnen von vorn. Die Eingabe ist offenbar (!) 4 genaudann in L, wenn am Ende ein Wort aus L(X∗) auf dem Band steht.
Unsere TM M hat die Zustandsmenge Q = {A,C,D,E,H, Y }, der Startzustand istq0 = A. Das Eingabealphabet ist Σ = {a, b, c}; das Bandalphabet ist Γ = {a, b, c, X, B}mit dem Blankbuchstaben B. Die Zustande dienen folgenden Zwecken:Im Zustand A lesen wir kein, ein oder mehrere X bis zum ersten a. Dieses wird in X
umgewandelt und der Zustand wechselt nach C. Finden wir im Zustand A den BuchstabenB, ist das Ziel erreicht; wir wechseln in den Zustand Y .Im Zustand C lesen wir eine beliebige Anzahl von a’s und X’s bis zum ersten b. Dieseswird in X umgewandelt, wir wechseln in den Zustand D.Im Zustand D lesen wir eine beliebige Anzahl von b’s und X’s bis zum ersten c. Dieseswird in X umgewandelt, wir wechseln in den Zustand E.Im Zustand E lesen wir eine beliebige Anzahl von weiteren c’s bis zum ersten B, daseinen Wechsel in den Zustand H auslost. Im Zustand H schließlich fahrt der Kopf von
4Das Zeichen”(!)“ heißt, dass man sich die Begrundung selbst uberlegen sollte.
27

rechts nach links zuruck uber c’s, b’s, a’s und X’s bis zum ersten Feld der Eingabe, derdurch das erste gefundene B identifiziert wird; nun beginnt der Zyklus mit Zustand Avon vorn.
Der Zustand Y wird erreicht, wenn das Eingabewort erfolgreich in lauter X’s transformiertworden ist, bzw. von Anfang an das leere Wort ε gewesen ist; demnach ist F = {Y } zusetzen.
Die Ubergangsfunktion δ findet sich in der folgenden Tabelle. Wenn ein Ubergang δ(q, a)undefiniert ist (in der Tabelle gekennzeichnet durch
”-“) fur q 6= Y , bedeutet dies, dass
M anhalt, ohne zu akzeptieren.
aq a b c X BA (C, X, R) − − (A, X, R) (Y,B,N)C (C, a, R) (D, X, R) − (C, X, R) −D − (D, b, R) (E, X, R) (D, X, R) −E − − (E, c, R) − (H,B,L)H (H, a, L) (H, b, L) (H, c, L) (H, X, L) (A,B,R)Y − − − − −
Graphische Darstellung. Wie bei endlichen Automaten und bei Kellerautomatenkann man auch Turingmaschinen durch gerichtete Graphen mit Knoten- und Kanten-beschriftungen darstellen; dies ist oft ubersichtlicher als die Turingtafel. Der Graph GM
hat einen Knoten vq fur jeden Zustand q ∈ Q; dieser ist mit q beschriftet. Startzustand undakzeptierende Zustande werden wie bei Automaten bezeichnet. Wenn δ(q, a) = (q′, a′, D),gibt es eine Kante von vq nach vq′ mit Beschriftung a | a′, D. Wie ublich zieht man mehrereKanten von vq nach vq′ zu einer zusammen, mit mehreren Beschriftungen.
Die in Beispiel 1.1.8 beschriebene Turingmaschine hat die folgende Darstellung als be-schrifteter Graph.
28
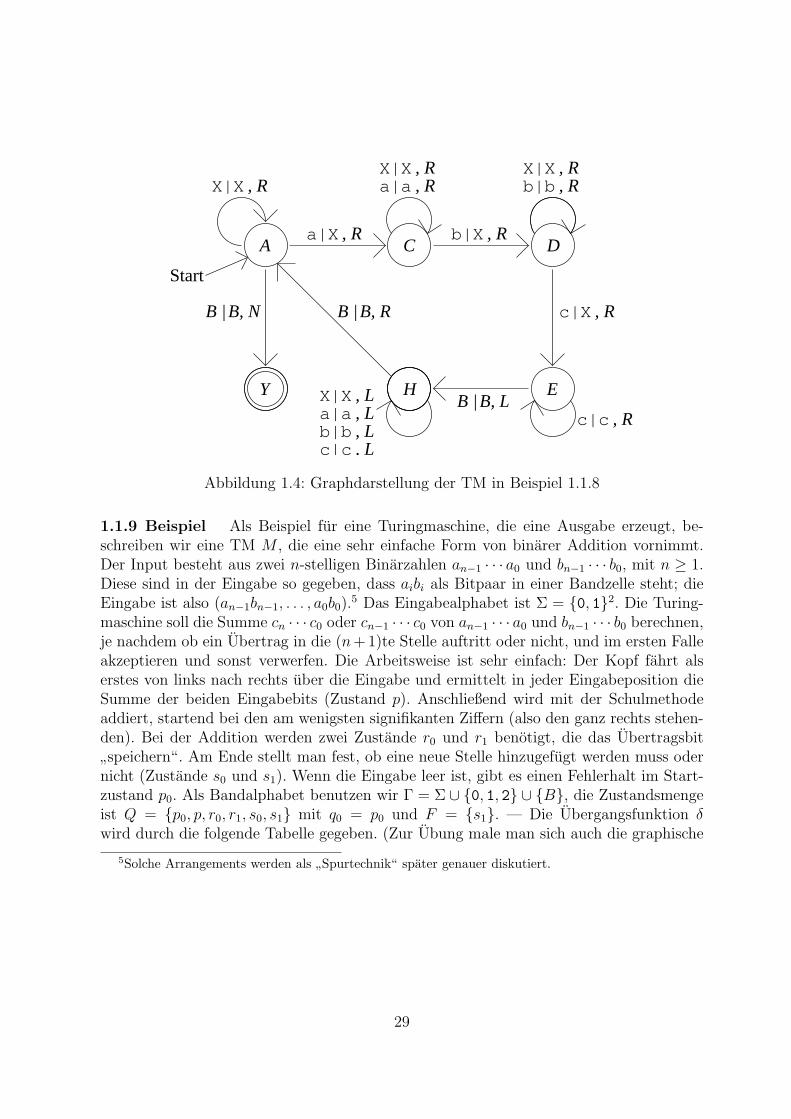
, RX|X
a|X , R , Rb|X
c|X , R
X|Xa|ab|b
, L, L, L, Lc|c
, Rc|cB | B, L
, Ra|a , Rb|b, RX|X , RX|X
B | B, N
Start
C D
HY
A
E
B | B, R
Abbildung 1.4: Graphdarstellung der TM in Beispiel 1.1.8
1.1.9 Beispiel Als Beispiel fur eine Turingmaschine, die eine Ausgabe erzeugt, be-schreiben wir eine TM M , die eine sehr einfache Form von binarer Addition vornimmt.Der Input besteht aus zwei n-stelligen Binarzahlen an−1 · · · a0 und bn−1 · · · b0, mit n ≥ 1.Diese sind in der Eingabe so gegeben, dass aibi als Bitpaar in einer Bandzelle steht; dieEingabe ist also (an−1bn−1, . . . , a0b0).
5 Das Eingabealphabet ist Σ = {0, 1}2. Die Turing-maschine soll die Summe cn · · · c0 oder cn−1 · · · c0 von an−1 · · · a0 und bn−1 · · · b0 berechnen,je nachdem ob ein Ubertrag in die (n+1)te Stelle auftritt oder nicht, und im ersten Falleakzeptieren und sonst verwerfen. Die Arbeitsweise ist sehr einfach: Der Kopf fahrt alserstes von links nach rechts uber die Eingabe und ermittelt in jeder Eingabeposition dieSumme der beiden Eingabebits (Zustand p). Anschließend wird mit der Schulmethodeaddiert, startend bei den am wenigsten signifikanten Ziffern (also den ganz rechts stehen-den). Bei der Addition werden zwei Zustande r0 und r1 benotigt, die das Ubertragsbit
”speichern“. Am Ende stellt man fest, ob eine neue Stelle hinzugefugt werden muss oder
nicht (Zustande s0 und s1). Wenn die Eingabe leer ist, gibt es einen Fehlerhalt im Start-zustand p0. Als Bandalphabet benutzen wir Γ = Σ ∪ {0, 1, 2} ∪ {B}, die Zustandsmengeist Q = {p0, p, r0, r1, s0, s1} mit q0 = p0 und F = {s1}. — Die Ubergangsfunktion δwird durch die folgende Tabelle gegeben. (Zur Ubung male man sich auch die graphische
5Solche Arrangements werden als”Spurtechnik“ spater genauer diskutiert.
29

Darstellung dieser TM auf.)
aq 00 01 10 11 0 1 2 Bp0 (p, 0, R) (p, 1, R) (p, 1, R) (p, 2, R) − − − −p (p, 0, R) (p, 1, R) (p, 1, R) (p, 2, R) − − − (r0, B, L)r0 − − − − (r0, 0, L) (r0, 1, L) (r1, 0, L) (s0, B,R)r1 − − − − (r0, 1, L) (r1, 0, L) (r1, 1, L) (s1, 1, N)
s0, s1 − − − − − − − −
Wir verfolgen die Arbeitsweise von M an einer konkreten Eingabe x = (10, 11, 00, 01, 11),entsprechend den zu addierenden Zahlen 11001 und 01011. Die Zeilen in der nachfolgen-den Tabelle entsprechen den Situationen nach jeweils einem Schritt. Ein Paar (q, a) ∈Q × Γ reprasentiert dabei die Bandzelle, auf der der Kopf steht, und den aktuellen Zu-stand.
B B (p0, 10) 11 00 01 11 B
B B 1 (p, 11) 00 01 11 B
B B 1 2 (p, 00) 01 11 B
B B 1 2 0 (p, 01) 11 B
B B 1 2 0 1 (p, 11) B
B B 1 2 0 1 2 (p,B)
B B 1 2 0 1 (r0, 2) B
B B 1 2 0 (r1, 1) 0 B
B B 1 2 (r1, 0) 0 0 B
B B 1 (r0, 2) 1 0 0 B
B B (r1, 1) 0 1 0 0 B
B (r1, B) 0 0 1 0 0 B
B (s1, 1) 0 0 1 0 0 B
Die Addition wird korrekt durchgefuhrt (wie man sieht), die Ausgabe lautet 100100, unddie Eingabe wird akzeptiert.
An dieser Stelle andern wir die Sichtweise. Haben wir bisher so getan, als ware durch einTuringmaschinenprogramm und eine Eingabe ein tatsachlich ablaufender Vorgang gege-ben, den man sich anschaulich vorstellt, geben wir nun mathematisch prazise Definitionenan, die den bisher informal eingefuhrten Konzepten entsprechen. Dadurch wird die voneiner TM M berechnete Funktion fM ein prazise definiertes Objekt, ebenso die Menge dervon M akzeptierten Worter. Damit legen wir die Basis fur die exakte Untersuchung der
30

Begriffe”Berechenbarkeit“ und
”Entscheidbarkeit“. Zudem ergibt sich die Gelegenheit,
den Ansatz der”operationalen Semantik“ kennenzulernen, einer wichtigen Methode, die
Semantik von Rechensystemen zu beschreiben.
1.1.10 Definition Eine Turingmaschine M besteht aus sieben Komponenten:Q, Σ, Γ, B, q0, F, δ (formal: M = (Q, Σ, Γ, B, q0, F, δ)), wobei gilt:
(a) Q 6= ∅ ist eine endliche Menge. (Q ist die Menge der Zustande.)
(b) Σ 6= ∅ ist eine endliche nichtleere Menge.(Σ ist das Eingabealphabet.)
(c) Γ ist eine endliche Menge mit Σ ⊆ Γ.(Γ ist das Bandalphabet.)Dabei ist B ∈ Γ− Σ. (B ist das Blanksymbol.)
(d) q0 ∈ Q. (q0 ist der Startzustand.)
(e) F ⊆ Q. (F ist die Menge der akzeptierenden Zustande.)
(f) δ : Q× Γ→ Q× Γ× {R,N,L} ∪ {−} ist die Ubergangsfunktion.(Wenn δ(q, a) = −, dann gilt δ(q, a) als undefiniert. δ ist also eine partielle Funkti-on.)
Die Funktionsweise, insbesondere das Ein-/Ausgabeverhalten, einer Turingmaschine Mwerden gemaß dem Konzept der
”operationalen Semantik“ beschrieben. Das heißt, wir
betrachten den Gesamtzustand, wie er durch Bandinhalt, Kopfposition und aktuellen Zu-stand gegeben ist, und beschreiben, welche Anderung dieser Zustand durch die Ausfuhrungeines Schrittes erfahrt. Das Wort
”Band“ kommt in diese Definition allerdings nicht vor,
sondern wir benutzen das Konfigurationskonzept wie schon in der Vorlesung”Automa-
ten und Formale Sprachen“ bei den Kellerautomaten. Obgleich das Band unendlich ist,konnen nach endlich vielen Schritten der TM nur endlich viele Bandzellen besucht wordensein, also nur endlich viele mit einem von B verschiedenen Buchstaben beschriftet sein.Daher lassen sich Konfigurationen als endliche Texte beschreiben. Bezuglich der Konfi-gurationsubergange sind die Verhaltnisse einstweilen einfach, da unsere Turingmaschinendeterministisch sind und in jeder Konfiguration maximal ein Schritt ausfuhrbar ist. DieNotation ist aber schon so gestaltet, dass sie leicht auf den spater zu besprechenden Fallder nichtdeterministischen Turingmaschinen zu verallgemeinern ist.
1.1.11 Definition Eine TM M = (Q, Σ, Γ, B, q0, F, δ) sei gegeben. Eine Konfigurationk (engl.
”instantaneous description“ (Momentaufnahme), technisch:
”snapshot“) von M
ist ein Wort α1(q, a)α2 mit q ∈ Q, a ∈ Γ, α1, α2 ∈ Γ∗, wobei α1 nicht mit B beginnt undα2 nicht mit B endet.(Fur Formelspezialisten: Die Menge KM aller Konfigurationen von M ist einfach (Γ∗ −{B}Γ∗)(Q×Γ)(Γ∗−Γ∗{B}).) Hieraus sieht man sofort, dass die Zahl der Konfigurationenabzahlbar unendlich ist.)
31

Eine Konfiguration k entspricht einem moglichen inneren Zustand der Turingmaschine Mwie folgt (vgl. Abb. 1.5).
... B ...B
q
aB B B α 1 2 B B BBBBBα
Abbildung 1.5: Veranschaulichung einer Konfiguration α1(q, a)α2
Die Bandinschrift ist α1aα2, umrahmt von mit B beschrifteten Feldern; der Zustand ist qund der Kopf steht auf dem Feld mit dem Buchstaben a. Fur die Anschauung ist es gunstig,sich das
”q“ nicht neben dem
”a“, sondern daruber oder darunter vorzustellen. Umgekehrt
entspricht jeder moglichen Kombination von Bandinhalt mit nur endlich vielen von Bverschiedenen Buchstaben, Kopfposition und Zustand der TM genau eine Konfiguration.6
1.1.12 Definition (Semantik von TM-Berechnungen)
Sei M = (Q, Σ, Γ, B, q0, F, δ) eine Turingmaschine.
(a) k = α1(q, a)α2 sei Konfiguration von M . Wenn δ(q, a) = − ist, hat k keine Nach-folgekonfiguration; k heißt dann eine Haltekonfiguration. Wenn δ(q, a) = (q′, a′, D) ∈Q × Γ × {L,R,N}, dann besitzt k genau eine Nachfolgekonfiguration k′. Wir schreibenk `M k′ oder k ` k′ und lesen
”k′ ist (die) direkte Nachfolgekonfiguration von k“. Wie k′
aussieht, ist durch eine langere Fallunterscheidung beschrieben. (Die meisten Falle kom-men durch die Sonderbehandlung von B am Rand der Bandinschrift zustande.)
1. Fall: D = R (∗ Kopfbewegung nach rechts ∗)Standardfall: α2 6= ε. — Wir schreiben α2 = bβ mit b ∈ Γ, β ∈ Γ∗. Dann ist
k = α1(q, a)bβ `M α1a′(q′, b)β, falls α1a
′ 6= B,
k = (q, a)bβ `M (q′, b)β, falls α1 = ε und a′ = B.
Sonderfall: α2 = ε. — Dann ist
k = α1(q, a) `M α1a′(q′, B), falls α1a
′ 6= B
k = (q, a) `M (q′, B), falls α1 = ε und a′ = B
6Die Regel, dass α1 nicht mit B beginnen darf und α2 nicht mit B enden darf, dient dazu, zu ver-hindern, dass einem inneren Zustand der TM viele
”aquivalente“ Konfigurationen entsprechen, die durch
Streichen oder Hinzufugen von Blanks an den Randern auseinander hervorgehen.
32

2. Fall: D = L (∗ Kopfbewegung nach links ∗)Standardfall: α1 6= ε. — Wir schreiben α1 = βb mit β ∈ Γ∗, b ∈ Γ. Dann ist
k = βb(q, a)α2 `M β(q′, b)a′α2, falls a′α2 6= B
k = βb(q, a) `M β(q′, b), falls a′ = B und α2 = ε
Sonderfall: α1 = ε. — Dann ist
k = (q, a)α2 `M (q′, B)a′α2, falls a′α2 6= B
k = (q, a) `M (q′, B), falls a′ = B und α2 = ε
3. Fall: D = N (∗ Keine Kopfbewegung ∗)Dann ist
k = α1(q, a)α2 `M α1(q′, a′)α2.
Elegante Alternative:Zur Verringerung der Anzahl der Falle kleben wir links und rechts an k jeweils ein Blank-symbol an: Schreibe Bα1 = γ1c und α2B = dγ2 fur passende c, d ∈ Γ und γ1, γ2 ∈ Γ∗.Dann beschreibt k = Bα1(q, a)α2B = γ1c(q, a)dγ2 dieselbe Situation von M wie k, nurmit zwei zusatzlichen Blankzeichen. Wir definieren
k′ :=
γ1(q′, c)a′dγ2 , falls D = L;
γ1ca′(q′, d)γ2 , falls D = R;
γ1c(q′, a′)dγ2 , falls D = N .
Die Nachfolgekonfiguration k′ entsteht aus k′ durch Streichen aller B’s am Beginn undam Ende von k′.
(Beispiel : In Beispiel 1.1.8 gilt
XXaX(C, b)bXcc ` XXaXX(D, b)Xcc und
XXaXXbX(D, c)c ` XXaXXbXX(E, c) , aber auch
cXcX(D, b) ` cXcXX(D,B),
obgleich die Konfigurationen in der letzten Zeile in keiner Berechnung von M auf irgend-einem Input vorkommen. Die Haltekonfiguration
XaXb(D, a)c
entsteht in der Berechnung mit Input aabbac und bedeutet das nicht-akzeptierende Endeder Berechnung. Die Haltekonfiguration
XXX(Y,B)
wird auf Input abc erreicht.)
33

(b) Fur i ∈ N wird die Relation (”indirekte Nachfolgerelation“) `i
M (oder `i) induktiverklart durch: k `0 k′, falls k = k′, und k `i k′, falls es eine Konfiguration k′′ gibt mitk `i−1 k′′ und k′′ ` k′, fur i ≥ 1. Anders ausgedruckt: k `i k′, falls i = 0 und k = k′ giltoder i ≥ 1 ist und es Konfigurationen k0, k1, . . . , ki gibt, mit k = k0 ` k1 ` k2 ` · · · `ki−1 ` ki = k′.
(c) k′ heißt (indirekte) Nachfolgekonfiguration von k, in Zeichen
k `∗M k′ oder k `∗ k′,
falls k `i k′ fur ein i ∈ N.
1.1.13 Bemerkung Etwas abstrakter betrachtet ist `∗ einfach die”reflexive und
transitive Hulle“ der Relation `. — Wenn R ⊆ A×A eine beliebige zweistellige Relationist, so ist die reflexive und transitive Hulle A∗ von A die durch die folgende induktiveDefinition gegebene Relation:
(i) Es gilt aR∗a fur jedes a ∈ A; und wenn aRa′ gilt, dann auch aR∗a′.
(ii) Wenn aR∗a′ und a′R∗a′′, dann ist auch a `∗ a′′.
(iii) Sonst stehen keine Paare (a, a′) in der Relation R∗.
R∗ ist die kleinste — bzgl. der Mengeninklusion — reflexive und transitive Relation uberA, die R enthalt.
1.1.14 Definition Sei M = (Q, Σ, Γ, B, q0, F, δ) eine TM, und k = α1(q, a)α2 eineKonfiguration von M .
(a) k heißt Haltekonfiguration von M , falls δ(q, a) = −.
(b) Ist k = α1(q, a)α2 Haltekonfiguration, so heißt k akzeptierend, falls q ∈ F , verwer-fend, falls q ∈ Q− F .
(c) Ist n ∈ N und x = a1 · · · an ∈ Σn ein Eingabewort fur M , so heißt
init(x) := initM(x) :=
{
(q0, a1)a2 · · · an falls n ≥ 1
(q0, B) falls n = 0
die Startkonfiguration fur x auf M .
1.1.15 Definition M = (Q, Σ, Γ, B, q0, F, δ) sei eine TM, x ∈ Σ∗ sei ein Eingabewort.
34

(a) Zur Startkonfiguration k0 = init(x) gehort eine (eindeutig bestimmte) Folge k0 `k1 ` · · · von Konfigurationen. Diese heißt die Berechnung von M auf x. Es gibtzwei einander ausschließende Moglichkeiten:
(i) Die Berechnung von M auf x ist endlich, d. h. init(x) `∗ k fur eine (eindeutigbestimmte) Haltekonfiguration k. In diesem Fall sagen wir, dass M auf x halt.Wenn k akzeptierend ist, sagen wir, dass M x akzeptiert ; wenn k verwerfendist, sagen wir, dass M x verwirft.
(ii) Die Berechnung von M auf x ist eine unendliche Folge von Konfigurationen.D. h. es gibt keine Haltekonfiguration k mit init(x) `∗ k. In diesem Fall sagenwir, dass M auf x nicht halt.
(b) LM := {x ∈ Σ∗ |M akzeptiert x}.
(c) HM := {x ∈ Σ∗ |M halt auf x}.
(d) Fur x ∈ Σ∗ ist die Ausgabe fM(x) von M auf x folgendermaßen definiert: Falls M aufx nicht halt, ist fM(x) undefiniert. Sonst sei k die (eindeutige) Haltekonfigurationmit init(x) `∗M k, und k = α1(q, b)α2, α1, α2 ∈ Γ∗, b ∈ Γ, q ∈ Q. Dann ist fM(x) daslangste Prafix von bα2, das den Blankbuchstaben B nicht enthalt.(Offenbar gilt fM(x) = ε⇔ b = B. Beachte: Fur die Bestimmung der Ausgabe vonM auf x ist es unerheblich, ob M x akzeptiert oder verwirft.)
1.1.16 Definition
(a) Eine Sprache L heißt rekursiv aufzahlbar (r. a.) (oder TM-akzeptierbar), falls es eineTuringmaschine M gibt, so dass L = LM ist.
(b) Eine Sprache L heißt rekursiv (rek.) (oder TM-entscheidbar), falls es eine Turingma-schine M = (Q, Σ, . . .) gibt, die auf allen Eingaben x ∈ Σ∗ halt und fur die L = LM
gilt. (Man beachte, dass in diesem Fall HM = Σ∗ und {x ∈ Σ∗ | M verwirft x} =Σ∗ − LM gilt.)
(c) Eine Funktion f : D → R heißt partiell rekursiv, falls es eine TM M = (Q, Σ, Γ, . . .)gibt derart dass D = HM , R ⊆ (Γ − {B})∗ und f = fM ist. (Andere Bezeichnung:
”partielle TM-berechenbare Funktion“.)7
(d) f heißt total rekursiv (”totale TM-berechenbare Funktion“) oder einfach rekursiv,
falls f partiell rekursiv und total ist, d. h. falls D = Def(f) = Σ∗ ist.
7Die Funktion ist partiell, d. h. sie muss nicht auf allen Inputs in Σ∗ definiert sein. Der Ausdruck
”partiell rekursiv“ ist grammatisch eine Fehlbezeichnung, denn eigentlich mussten solche Funktionen
”partiell, rekursiv“ heißen; die falsche Zusammenfugung hat sich aber eingeburgert.
35

1.1.17 Bemerkung Alle Bezeichnungen aus der vorigen Definition sollten einen Index
”TM“ tragen. Im Hinblick auf unsere spatere Feststellung, dass der Berechenbarkeitsbe-
griff vom Maschinenmodell unabhangig ist, und aus historischen Grunden, knupfen wirdie Standardbezeichnungen
”rekursiv aufzahlbare Menge/Sprache“ und
”rekursive Men-
ge/Sprache“ sowie”partiell rekursive Funktion“ und
”(total) rekursive Funktion“ an das
Turingmaschinenmodell.
Wir stellen noch fest, dass es fur die Definition der r. a. Sprachen keinen Unterschiedmacht, ob man LM oder HM betrachtet.
1.1.18 Lemma (a) Wenn M eine TM ist, dann gibt es TMn M ′ und M ′′ derart dassHM ′ = LM und LM ′′ = HM ist.(b) Eine Sprache L ist rekursiv aufzahlbar genau dann wenn es eine TM M mit L = HM
gibt.
Beweis (Konstruktion) Sei M = (Q, Σ, Γ, B, q0, F, δ).(a) Wir bauen M um zu einer TM M ′, die zunachst wie M rechnet, aber nicht anhalt,wenn M verwerfend halt. Hierzu mussen wir nur die Ubergangsfunktion leicht verandern.Also: M ′ = (Q, Σ, Γ, B, q0, F, δ′), wobei wir fur (q, a) ∈ Q× Γ definieren:
δ′(q, a) :=
δ(q, a), falls dies definiert ist,−, falls δ(q, a) = − und q ∈ F ,(q, a,N), falls δ(q, a) = − und q ∈ Q− F .
Die Form”δ′(q, a) = (q, a,N)“ bewirkt offenbar, dass M ′ bei Erreichen dieser Situation
endlos weiterlauft: dies realisiert eine”Endlosschleife“. — Ahnlich bauen wir M um zu
einer TM M ′′, die wie M rechnet, aber immer akzeptiert, wenn M halt. Dazu setzen wireinfach M ′′ = (Q, Σ, Γ, B, q0, F
′′, δ) mit F ′′ := Q.
(b) Dies folgt unmittelbar aus (a). �
Mit den Haltemengen HM werden wir uns im weiteren Verlauf der Vorlesung noch beschafti-gen.
Wir wollen Turingmaschinen fur zwei sehr verschiedene Zwecke benutzen. Zunachst sinddies Untersuchungen zur Leistungsfahigkeit des Modells im allgemeinen, zum Vergleichmit anderen Rechenmodellen, zur Konstruktion von
”universellen Maschinen“, zum Ob-
jekt struktureller Untersuchungen, zur Konstruktion nicht rekursiver Sprachen. Fur dieseZwecke kommt uns die primitive Struktur dieser Maschinen zupass. Drastisch ausgedrucktist es sehr angenehm, dass der Befehlssatz von Turingmaschinen so primitiv ist und dieUbergangsfunktion keine Struktur hat, um die wir uns kummern mussen. (Man moge sichim nachhinein Untersuchungen wie die im folgenden angestellten vor Augen halten, diemit einer Maschine hantieren, die auch nur 10 Maschinenbefehle hat, wie z. B. die RAM.Man wurde in Fallunterscheidungen
”ertrinken“.)
36

Andererseits kommen wir nicht darum herum, uns davon zu uberzeugen, dass gewisseFunktionen von einer TM berechnet werden konnen, bzw. dass gewisse Sprachen rekursivaufzahlbar oder rekursiv sind. D. h. wir mussen TMn angeben, die gewisse Rechnungenausfuhren, also TMn programmieren. Hierfur ist die primitive Struktur des Modells undder primitive Befehlssatz extrem ungunstig. Man moge in fruhere Texte zum Thema
”Berechenbarkeit“ schauen, um den Aufwand zu ermessen, den man treiben muss, um auf
dem TM-Modell eine einigermaßen handhabbare Programmiermethodik zu entwickeln.Wir werden diese Arbeit nicht durchfuhren, sondern stattdessen etwa wie folgt vorgehen.
Um eine TM anzugeben, die ein bestimmtes Problem lost, durfen wir den Mengen Q, Σund Γ eine ganz beliebige und bequeme Struktur geben, solange sie endlich sind. Wei-ter durfen wir die Ubergangsfunktion δ auf ganz beliebige Weise definieren, z. B. indemwir beschreiben, wie aus dem alten Zustand q und dem gelesenen Zeichen a das Tripel(q′, a′, D) = δ(q, a) berechnet werden kann. Die Funktion δ muss aber keineswegs in ir-gendeiner Weise effizient oder sonstwie
”berechenbar“ sein, sondern zur Spezifikation von δ
sind”alle Mittel erlaubt“. Ein extremer Fall einer solchen strukturierten TM-Steuereinheit
wird im folgenden beschrieben. Einfachere Konstruktionen finden sich im folgenden Ab-schnitt zu
”Programmiertechniken“.
1.1.19 Beispiel Γ = {0, 1}213
= {0, 1}8192 (die”Bandsymbole“ sind Blocks von
1 kByte), B = 08192 fungiert als Blank. Die Steuereinheit sieht so aus:
Band
... ...
Programm
Daten
Puffer
Richtung
Halt?
Akzeptiere?
Block
1kByte=1 Buchstabe
Flagregister
Befehlszähler
Abbildung 1.6: Strukturierte Steuereinheit
Das”Programm“ ist ein Programm in irgendeiner Programmiersprache.
”Daten“ ist ein
lokaler Speicher mit fester Kapazitat (in Bits) und vollig beliebiger Organisation. Insbe-sondere kann dieser Teil einen Befehlszahler fur das
”Programm“ enthalten. Ein Schritt
besteht aus folgendem:
• Kopiere den Bandblock aus der eben besuchten Zelle in den Puffer.
37

• Das”Programm“, startend am im Befehlszahler angegebenen Programmpunkt, be-
rechnet aus”Daten“ und
”Puffer“ einen neuen Block
”Daten′“ und einen neuen
Pufferinhalt”Puffer′“ sowie eine Richtung D ∈ {L,R,N} (die fur diese Berechnung
benotigte Zeit wird nicht in Betracht gezogen, sie gilt als”konstant“).
• Puffer′ wird aufs Band geschrieben, Lesekopf wird um einen Block auf dem Band inRichtung D bewegt.
• Eventuell wird ein Flag (”Halt?“ und/oder
”Akzeptiere?“) gesetzt.
• Wenn das Flag”Halt?“ gesetzt ist, erfolgt keine weiterer Schritt; das Flag
”Akzep-
tiere?“ bestimmt, ob die Eingabe akzeptiert werden soll.
Was ist jetzt Q?
Q = {w | w moglicher Inhalt von”Daten“,
”Befehlszahler“ und Flagregistern}
Z. B. konnte”Daten“ ein binarer Speicher der Kapazitat 64 kByte sein, in dem Flagre-
gister und Befehlszahler integriert sind. Dann ist Q = {0, 1}64·8·1024. Es ist aber nichtvorgeschrieben, dass die Steuereinheit einem digitalen Rechner gleichen muss. SowohlBandalphabet als auch Speicher konnen eine ganz beliebige Struktur haben.
Wir wollen kurz uberlegen, wie aus einer solchen Beschreibung die”unstrukturierte“ Be-
schreibung gemaß Definition 1.1.2 zu gewinnen ist, z. B. wie eine Wertetabelle fur δ zuerzeugen ware. Sei a ∈ Γ (also ein beliebiger wie auch immer strukturierter) Bandbuchsta-be. q sei einer der moglichen inneren Zustande der Steuereinheit. Wir schreiben a in denPuffer, setzen die internen Daten wie von q vorgeschrieben und lassen das
”Programm“
der Steuereinheit rechnen, bis es an eine Stelle kommt, wo der Puffer beschrieben wird.Fur diesen Pufferinhalt a′, den jetzigen internen Zustand q′, der Daten und Register, unddas Zeichen D aus dem Richtungsregister gilt δ(q, a) = (q′, a′, D). Auf diese (praktischsehr langwierige) Weise ließe sich eine Wertetabelle fur δ aufstellen.
Mit dem skizzierten Ansatz lassen sich TM recht leicht programmieren. Oft gehen wiraber noch weiter und begnugen uns damit, eine informale Beschreibung der Aktivitatender TM zu geben, und uns davon zu uberzeugen, dass im Prinzip eine Steuereinheit mitfixem Speicher diese Aktivitaten ausfuhren kann.
Wir mussen bei diesem Vorgehen nur folgendes beachten:
– Das Arbeitsbandalphabet ist eine endliche Menge; fur jede Turingmaschine ist einemaximale Zahl unterschiedlicher Zelleninhalte vorgegeben. Bei einer festen TM Mist es nicht moglich, in einer Bandzelle beliebig große naturliche Zahlen zu speichern.
– die Kapazitat des Speichers der Steuereinheit ist fest; er hangt nicht von der Langeder Eingabe ab.
– das Programm in der Steuereinheit ist fest, insbesondere von fester Lange.
38

Gravierende Programmierfehler bei TM, die in dieser Art spezifiziert sind, sind fol-gende:
• Die Steuereinheit enthalt Integervariable, deren Wertebereich nicht beschrankt ist.Allgemeiner: Datentypen mit unendlich vielen Instanzen kann man nicht in derSteuereinheit halten.
• Der Umfang der Daten, die in der Steuereinheit gehalten werden, hangt von derEingabe ab (z. B. verkettete Strukturen, deren Knotenzahl unbeschrankt ist). Eserfolgen rekursive Aufrufe mit unbeschrankter Tiefe, wobei der Laufzeitkeller in derSteuereinheit gehalten wird.
Zum Speichern solcher Daten muss man auf das Band ausweichen. Um naturliche Zah-len zu speichern, benutzt man Binardarstellung (konstante Zahl von Bits pro Zelle); umZeiger zu speichern, die Binardarstellung der Zahlenwerte; ein eventuell notiger Laufzeit-keller wird auf dem Band organisiert. Bemerkung: Strukturen mit Records / Verbunden /Satzen sollte man so anlegen, dass jedes Record eine eindeutige Nummer hat, die explizitangegeben ist.
1.2 Programmiertechniken und Varianten von Turing-
maschinen
In diesem Abschnitt besprechen wir eine Reihe von Methoden, wie man die Zustands-menge Q und das Bandalphabet Γ strukturieren kann, um die Programmierung von Tu-ringmaschinen ubersichtlicher zu gestalten oder unmittelbar einsichtig zu machen, dasseine TM eine bestimmte Berechnungsaufgabe erfullen kann. Zudem betrachten wir Mo-dellvarianten wie Turingmaschinen mit nur einem einseitig unendlichen Band oder solchemit mehreren Arbeitsbandern und weisen nach, dass solche Einschrankungen oder Er-weiterungen unseres ursprunglichen Maschinenmodells ebenso zu den partiell rekursivenFunktionen und den rekursiv aufzahlbaren Sprachen fuhren wie das Standardmodell.
1.2.1 Endlicher Speicher in der Steuereinheit Wir konnen uns vorstellen, dassdie Steuereinheit Speicherplatz fur eine beschrankte Anzahl von Bandsymbolen hat (oderObjekte aus einer beliebigen endlichen Menge, also eines Alphabets ∆). Hierzu benutztman eine Zustandsmenge Q, deren Elemente folgende Struktur aufweisen: (q, a1, . . . , ak),wobei q ein Zustand im eigentlichen Sinne ist, der der Ablaufsteuerung dient; a1, . . . , ak
sind die gespeicherten Buchstaben.
Als Beispiel betrachten wir die Sprache
L = {a1a2 · · · an−1an ∈ Σ∗ | n ≥ 2, a1a2 = an−1an}
39

der Worter uber Σ, bei denen die beiden Anfangsbuchstaben mit den beiden Endbuchsta-ben identisch sind.8 Die Idee fur eine TM M mit L = LM ist, die beiden ersten Buchstabenin der Steuereinheit zu speichern und nach einer Fahrt mit dem Kopf uber das Einga-bewort mit den beiden letzten Buchstaben zu vergleichen. Hierzu legen wir δ wie folgtfest:
δ(q0, a) = ((q1, a), a, R), fur a ∈ Σ
δ((q1, a), b) = ((q2, a, b), b, R), fur a, b ∈ Σ
δ((q2, a, b), c) = ((q2, a, b), c, R), fur a, b, c ∈ Σ
δ((q2, a, b), B) = ((q3, a, b), B, L), fur a, b, c ∈ Σ
δ((q3, a, b), b) = ((q4, a), b, L), fur a, b ∈ Σ
δ((q4, a), a) = (q5, a,N), fur a ∈ Σ
Wie ublich sind nicht erwahnte Ubergange undefiniert. Zustand q0 ist der Startzustand;in Zustand (q1, a) ist a gespeichert; in Zustand (q2, a, b) sind a und b gespeichert und derKopf fahrt zum Ende der Eingabe; in Zustand (q3, a, b) wird getestet, ob b gelesen wird(als letzter Eingabebuchstabe); in Zustand (q4, a) wird getestet, ob a gelesen wird (alsvorletzter Buchstabe); q5 schließlich ist der akzeptierende Endzustand.
Schließlich definieren wir
Q := {q0, q5} ∪ {(q1, a), (q4, a) | a ∈ Σ} ∪ {(q2, a, b), (q3, a, b) | a, b ∈ Σ}
und F := {q5}.
Man beachte, wie hier M in Abhangigkeit von Σ festgelegt wird, ohne dass wir Σ explizitkennen mussen. Weiter ist die Anzahl der in einem Zustand gespeicherten Buchstabenje nach Bedarf schwankend. Man darf nur nicht vorsehen, dass unbeschrankt viele Buch-staben in Zustanden gespeichert werden, weil sonst Q nicht mehr endlich ist. In Verall-gemeinerung des Speicherns von Buchstaben aus der Eingabe kann man in Zustandennach Bedarf auch Flagbits oder Register aus Flagbits anlegen, die es erlauben, vorhergesammelte Informationen aufzubewahren.
1.2.2 Spurtechnik Ist ∆ irgendein Alphabet und k ≥ 1, dann kann man sich vorstel-len, dass das TM-Band mit k Spuren versehen ist, deren jede in jeder Zelle ein Symbolaus ∆ aufnehmen kann.
Spur 12345
...
...
...
...
...
...
...
...
...
...
e i n s BB z w e i3 3 3 3 Bv i e r 4B B B B 5
8Naturlich ist L eine regulare Sprache, fur die man leicht einen DFA ohne weitere TM-Fahigkeitenangeben konnte.
40

Abbildung 1.7: Band mit funf Spuren
Wir realisieren dies dadurch, dass wir ein Bandalphabet Γ benutzen, das alle Elemen-te (a1, . . . , ak) von ∆k enthalt. (In Abb. 1.7 sind etwa (e, B, 3, v, B) und (B, i, B, 4, 5)Elemente von Γ.) Gelesen werden immer die Symbole in allen Spuren gleichzeitig. DieSteuereinheit kann fur die Verarbeitung einige Spuren ausblenden; dieses kann man z. B.uber Flagregister in der Steuereinheit steuern. Anschaulich kann man diese zusammenge-setzten Buchstaben auch als Spaltenvektoren schreiben:
Γ ⊇ ∆k =
{(a1...ak
)
: a1, . . . , ak ∈ ∆
}
.
Wenn man wahrend der Rechnung oder auf verschiedenen Bandabschnitten die Spuran-zahl wechseln will, benutzt man einfach Γ mit ∆∪∆2∪ · · ·∪∆k ⊆ Γ, fur ein festes k, undhat nach Belieben 1 bis k Spuren zur Verfugung. Allerdings ist es ein Programmierfehler,wenn die TM inputabhangig unbeschrankt viele Spuren anlegen soll, da dann die MengeΓ nicht mehr endlich ist.
Man kann sich die Spuren auch mit Symbolen verschiedener Spezialalphabete beschriftetdenken — das ist nutzlich, wenn man Bandzellen markieren will:
...
.........
B b a n d # # i n s c h r i f t* +* +
TextspurMarkierung
Abbildung 1.8: Markierungen auf zweiter Spur
Es ist erlaubt, eine feste Anzahl von Markierungen in einer Bandzelle zu halten, einProgrammierfehler ist es aber, wenn unbeschrankt viele Markierungen in einer Zelle vor-gesehen sind.
1.2.3 Programmiertechnik: Bandinhalt verschieben Mit der Mehrspurtechnikund der Technik des Speicherns von Buchstaben lasst sich die folgende wichtige Grund-aufgabe fur Turingmaschinen losen:Verschieben eines Teils des Bandinhaltes : Auf Spur 1 steht eine Inschrift uber dem Al-phabet ∆ (mit B /∈ ∆), auf Spur 2 stehen drei Markierungen: ein /c und (irgendwo rechtsdavon) ein $ sowie an beliebiger Stelle rechts vom /c ein �. Die Aufgabe ist es nun, dasTeilwort zwischen der mit /c und der mit $ markierten Stelle so nach rechts zu verschieben,dass der erste Buchstabe des Teilworts in der Bandzelle mit der Markierung � steht, undden entstehenden Platz mit B’s aufzufullen. Anfangs soll der Bandkopf irgendwo linksvon der Markierung /c stehen.
41

vorher:
Spur 1
Spur 2
nachher:
Spur 1
Spur 2
Hilfsspur
l i n k s r e c h t s u n d s o w e i t e r
c $
B B B
c $
l i n k s B B B B B B B B r e c h t s u n d s o w
r e c h t s u n d s o w
zu verschieben
Die einfache Idee ist, auf dem Band eine neue (Hilfs-)Spur anzulegen und auf dieserHilfsspur das zu verschiebende Teilwort so zu speichern, dass es bei der Markierung �beginnt. Eine Initialisierung der Hilfsspur ist uberflussig, wenn man vereinbart, dass einenicht vorhandene dritte Spur in einer Zelle so zu verstehen ist, dass die dritte Spur indieser Zelle ein B enthalt. Ein spezielles Markierungszeichen (z. B. +) wird benutzt, umschon kopierte Zeichen zu markieren. Das Teilwort wird wie folgt Zeichen fur Zeichenkopiert.
Zu Beginn fahrt der Kopf nach rechts bis zum /c. Diese Zelle enthalt das erste zu kopie-rende Zeichen.Zunachst wiederhole folgendes (1.–5.):
1. Speichere den Buchstaben a aus Spur 1 in der Steuereinheit; markiere die Zellemit +;
2. Fahre den Kopf nach rechts bis zur ersten Zelle nach dem � (einschließlich), dasin der Hilfsspur ein B enthalt; uberschreibe dieses B mit dem gespeicherten Buchstabena;
3. Fahre den Kopf nach links, bis eine mit + markierte Zelle erreicht wird;4. Wenn dies die $-Zelle ist, ist der Kopiervorgang beendet; gehe zu 6.5. Sonst bewege den Kopf um eine Zelle nach rechts und mache bei 1. weiter.
6. Fahre den Kopf nach links bis zur /c-Zelle;7. Fahre den Kopf nach rechts bis zur �-Zelle (ausschließlich), uberschreibe in jeder dabeibesuchten Zelle Spur 1 mit B;8. von der �-Zelle (einschließlich) nach rechts gehend kopiere die Buchstaben von Spur3 auf dasselbe Feld in Spur 1, losche dabei gleichzeitig Spur 3, bis zur ersten Zelle (aus-schließlich), die in Spur 3 ein B enthalt;9. fahre den Kopf nach links bis zur /c-Zelle.
Wenn l die Lange des zu verschiebenden Teilwortes ist und d die Distanz von /c nach �,so benotigt das Kopieren O(l · d) Schritte der TM. Wofur kann diese Prozedur dienen?
42

Da jedes Bandfeld nur endliche Kapazitat hat, kann es passieren, dass man an einerbestimmten Stelle des Bandes neue Felder
”einfugen“ mochte, um dort entstehende Daten
zu speichern. Die Verschiebeprozedur erlaubt dies, ohne dass man das Modell erweiternmuss. Ein typischer Fall sind binare Zahler, die in manchen Rechnungen benutzt werdenund deren Umfang (in Bits) mit dem Zahlerstand wachst. — Ebenso oft kommt es vor,dass Information, die sich an einer Stelle des Bandes befindet, an einer anderen Stellegebraucht wird.
1.2.4 Modelleinschrankung: Einseitig unbeschranktes Band Gegeben sei einebeliebige TM M = (Q, Σ, Γ, B, q0, F, δ). Wir behaupten, dass es eine andere TM M ′ gibt,die dasselbe Ein-/Ausgabeverhalten wie M hat, d. h.
LM = LM ′ , HM = HM ′ , und fM = fM ′
erfullt, und zusatzlich die Eigenschaft hat, dass der Kopf nie ein Feld links der ursprung-lichen Position betritt.
Turingmaschinen mit einseitig unbeschranktem Band sind als Unterprogramme nutzlich,wenn man fur die Durchfuhrung des Unterprogramms kein ganzes unbeschriebenes Bandverwenden kann, sondern nur ein
”halbes Band“ rechts von einer Bandinschrift, die nicht
zerstort werden darf.
verboten
i n p u t B B B B B B B ...
0 1 2 3 4 5
q0
b a n d + v o n + M + 2 s e i t i g B ...
-3 -2 -1 0 1 2 3 4 5
Band
von M’:n + M + 2 s e i t i g B B B B B B
* o v + d n a b B B B B B B B B B
...
...
-1 -2 -3
0 1 2 3 4 5
Die Idee ist, den Bandanteil links von der ursprunglichen Kopfposition”umzuklappen“
und in umgekehrter Reihenfolge auf einer zweiten Spur zu speichern. In Spur 2 des erstenBandfeldes (Kopfposition zu Beginn der Berechnung) wird eine Markierung
”∗“ ange-
bracht. Die Steuereinheit enthalt ein Flagregister, das anzeigt, ob momentan in der oberen
43

Spur (rechte Seite) oder der unteren Spur (linke Seite) gearbeitet wird. Die Steuereinheitder neuen Maschine M ′ sieht anschaulich so aus:
Steuer-
einheit
von M oben
ea Puffer
oben/unten?
Abbildung 1.9: Neue Steuereinheit
Formal konnen wir definieren: M ′ = (Q′, Σ, Γ′, B′, q′0, F′, δ′), wobei die Komponenten wie
folgt festgelegt sind.
Q′ = Q× {u, o} ∪ {q′0};
Γ′ = Γ× (Γ ∪ {∗}) ∪ Σ;
B′ = (B,B)
Um die Notation zu vereinfachen, soll das Lesen eines Zeichens a ∈ Σ in δ dasselbebewirken wie das Lesen von (a,B). Der neue Startzustand q′0 dient nur dem Anbringender ∗-Markierung. Die Ubergangsfunktion kann so festgelegt werden (wobei immer a, b, c ∈Γ, q, p ∈ Q,D ∈ {L,R,N}):
δ′(q′0, a) = ((q0, o), (a, ∗), N), fur a ∈ Σ;
δ′(q′0, (B,B)) = ((q0, o), (B, ∗), N), (falls der Input ε ist);
δ′((q, o), (a, c)) = ((p, o), (b, c), D), fur q ∈ Q, δ(q, a) = (p, b,D), c 6= ∗;
δ′((q, u), (c, a)) = ((p, u), (c, b), D), fur q ∈ Q, δ(q, a) = (p, b,D), a 6= ∗,
wobei R = L, L = R, N = N ;
δ′((q, u), (a, ∗))δ′((q, o), (a, ∗))
}
=
((p, u), (b, ∗), R), falls D = L,((p, o), (b, ∗), R), falls D = R,((p, o), (b, ∗), N), falls D = N ;
wobei immer δ(q, a) = (p, b,D).
Es sollte klar sein, dass M ′ die Aktionen von M Schritt fur Schritt simuliert. Damitgilt schon einmal HM = HM ′ . Um gleiches Akzeptierungsverhalten zu haben, mussenwir noch F ′ := F × {u, o} setzen. Um zu erreichen, dass fM = fM ′ , benotigt man eineNachverarbeitungsphase, in der nach dem Anhalten von M der Inhalt der beiden Spurenso verschoben wird, dass das Ausgabewort in der oberen Spur in der richtigen Reihenfolgeerscheint, und in der schließlich die Doppelbuchstaben durch einfache ersetzt werden. Diesist mit der in 1.2.3 dargestellten Technik moglich; wir lassen die Details aus.
44

1.2.5 Definition k-Band-Maschine. Wir betrachten Turingmaschinen mit k ≥ 2Bandern. Die Eingabe steht zu Beginn auf Band 1, jedes Band besitzt einen eigenenBandkopf.
B... ...B B B B B B B
B... ...B B B B B B BB B B B B B B
B... ...B B B B B B BB B B B B B B
e i n g a b e
Steuer-
einheit
Abbildung 1.10: 3-Band-Maschine
Die Ubergangsfunktion δ bildet nun (eine Teilmenge) von Q×Γk nach Q×Γk×{L,R,N}k
ab. Dabei bedeutet δ(q, a1, . . . , ak) = (q′, a′1, . . . , a
′k, D1, . . . , Dk), dass, falls im Zustand q
auf Band i Buchstabe ai gelesen wird, 1 ≤ i ≤ k, auf Band i Buchstabe a′i gedruckt wird
und sich der Kopf in Richtung Di bewegt, fur 1 ≤ i ≤ k.
Konfigurationen, Akzeptierungsbegriff, Ausgabe werden analog zu 1-Band-TMn definiert.Fur die Eingabe und die Ausgabe betrachtet man nur die Inschrift auf Band 1.
1.2.6 Satz Ist M eine k-Band-TM, so gibt es eine 1-Band-TM M ′, die dasselbe Ein-Ausgabe-Verhalten wie M hat, d. h. die LM = LM ′, HM ′ = HM und fM = fM ′ erfullt.
Beweis (Konstruktion) Sei M = (Q, Σ, Γ, B, q0, F, δ). Wir beschreiben, wie die 1-Band-TM M ′ aufgebaut ist und wie sie arbeitet. Das Band von M ′ ist mit 2k + 1 Spurenversehen. Dem iten Band von M entsprechen Spuren 2i − 1 und 2i von M ′. Spur 2i − 1tragt dabei die Bandinschrift von Band i, (Alphabet Γ), auf Spur 2i gibt es außer Blanksnur eine Markierung
”∗“, die die Position des Lese-Schreib-Kopfes von M auf Band i
markiert (Alphabet {∗, B}). Spur 2k + 1 enthalt Markierungen /c und $, die Anfang undEnde des bisher besuchten Abschnittes des Bandes von M ′ markieren.
45

...
...
...
...
...
...
...
Spur 1
Spur 2
Spur 3
Spur 4
Spur 5
Spur 6
Spur 7
...
...
...
...
...
...
...
B + + + 1 + B B B B B B B B B
B B B + + + + + 2 + + B B B B
*
*
B + + + + + + + + + 3 + + + B
*
$C
Steuer-
einheit
von M
-
aktueller
Zustand
Register
fur Symbole
bei "*"
Rich-
tungs-
register
+
L
N
L
Steuer-
einheit
von M’
i n s c h r i f t b a n d
i n s c h r i f t b a n d
b a n di n s c h r i f t
d
i
(3 Bänder)
M ′ simuliert jeden Schritt von M wie folgt:
(i) Zu Beginn steht der Kopf von M ′ auf der Zelle mit /c.
(ii) Die Steuereinheit von M ′ speichert den gegenwartigen Zustand q von M in einemZustandsregister.
(iii) Der Kopf von M ′ durchlauft das Band von /c nach $ und speichert dabei in k Γ-Registern in der Steuereinheit die Buchstaben a1, . . . , ak, die in den Spuren 1, 3, . . . , 2k−1 in den mit ∗ markierten Zellen stehen. Dann fahrt der Kopf zum /c zuruck.
(iv) M ′ bestimmt (in der Steuereinheit) δ(q, a1, . . . , ak) = (q′, a′1, . . . , a
′k, D1, . . . , Dk),
falls dies definiert ist. Damit sind die neuen zu schreibenden Bandsymbole a′1, . . . , a
′k,
die Richtungen D1, . . . , Dk ∈ {L,R,N} fur die Kopfbewegungen und der neue Zu-stand q′ von M gegeben. Wenn δ(q, a1, . . . , ak) undefiniert ist, endet die schrittweiseSimulation, man springt zur Nachbearbeitung (s. u.).
(v) Der Kopf fahrt erneut von /c nach $ und zuruck. Fur jedes i wird in derjenigen Zelle,die in Spur 2i die ∗-Markierung tragt, in Spur 2i − 1 das Zeichen a′
i eingetragen.Bei der Links-Rechts-Bewegung werden zudem die ∗-Markierungen in den Spuren
46

2i mit Di = R um eine Zelle nach rechts bewegt; bei der Rechts-Links-Bewegungentsprechend die mit Di = L um eine Zelle nach links. Wird ein ∗ in der /c-Zelle nachlinks verschoben, wird auch die /c-Markierung mit verschoben, entsprechend bei der$-Markierung rechts.
(vi) Schließlich steht Kopf von M ′ wieder auf der /c-Zelle. Beginne wieder mit (i).
Vorbearbeitung: Ganz zu Anfang enthalt das Band von M ′ die Eingabe x = a1 · · · an,ohne Spurstruktur. M ′ beschreibt die 2k+1 Spuren in einem Schritt mit (a1, ∗, B, ∗ . . . , B,∗, {/c, $}), bzw. mit (B, ∗, B, ∗ . . . , B, ∗, {/c, $}), wenn x = ε ist. Wenn wahrend der Simu-lation eine Zelle betreten wird, die nur einen Inputbuchstaben ai enthalt, wird diese sobehandelt, als enthielte sie die Inschrift (ai, B, . . . , B).
Ende der Rechnung: Falls in (iv) δ(q, a1, . . . , ak) undefiniert ist, muss M ′ noch etwasaufraumen. M ′ fahrt den Kopf bis zur ∗-Markierung in Spur 2 und von da zum ersten Bauf Spur 1 rechts davon, aber auch nicht weiter als bis zur $-Zelle.
vorher:
*
b b b b B i r r e l e v a n t ...
...
......
...
...
i r r e l e v a n t ......b b b b B
1 2 3 r
1 2 3 rnachher:
2k+1
Von dort fahrt der Kopf zuruck zum ∗ in Spur 2, uberschreibt dabei Bandzellen mit Eintragb ∈ Γ auf Spur 1 mit b (ohne Rucksicht auf die Spurstruktur). Sobald die ∗-Markierungerreicht ist, halt M ′ und akzeptiert/verwirft je nachdem ob q ∈ F oder q /∈ F .
Nach Konstruktion hat M ′ dasselbe Ein-/Ausgabeverhalten wie M .
Aus Satz 1.2.6 ziehen wir die Konsequenz, dass wir, wenn es bequem ist, auch Mehrband-Turingmaschinen benutzen konnen, wenn wir zeigen wollen, dass Sprachen rekursiv aufzahl-bar oder rekursiv oder Funktionen (partiell) rekursiv sind.
Wie bei Registermaschinen kann man TM-Berechnungen einen Zeitaufwand zuordnen,und zudem einen Platzverbrauch. Wir formulieren diese Konzepte gleich fur k-Band-TMn.
1.2.7 Definition (Zeit- bzw. Platzbedarf [”Zeit- bzw. Platzkomplexitat“] einer TM)
Sei M eine k-Band-TM, x ∈ Σ∗ fur das Eingabealphabet Σ von M . Wir definieren:
47

tM(x) := Zahl der Schritte, die M auf Eingabe x ausfuhrt ∈ N ∪ {∞}(d. h. das eindeutig bestimmte i mit initM(x) `i k fur eine Haltekonfigu-ration k von M bzw. ∞, falls M auf x nicht halt);
sM(x) := Anzahl der verschiedenen Zellen, auf die die Kopfe von M bei Eingabex schreibend zugreifen, auf allen Bandern zusammen ( ∈ N ∪ {∞}); 9
TM(n) := max{tM(x) | x ∈ Σn}(Zeitbedarf im schlechtesten Fall uber alle Eingaben der Lange n: worst-case-Zeitkomplexitat);
SM(n) := max{sM(x) | x ∈ Σn}.
Sei t : N → R+ eine Funktion. M heißt t(n)-zeitbeschrankt, falls TM(n) ≤ t(n) fur allen ∈ N gilt, d. h. falls tM(x) ≤ t(|x|) fur alle x ∈ Σ∗ gilt.Sei s : N → R+ eine Funktion. M heißt s(n)-platzbeschrankt, falls SM(n) ≤ s(n) fur allen ∈ N gilt, d. h. falls sM(x) ≤ s(|x|) fur alle x ∈ Σ∗ gilt.
Man kann z. B. sagen, eine TM M sei 10n2-zeitbeschrankt, wenn TM(n) ≤ 10n2 fur alle ngilt. Der entscheidende Vorteil dieser Sprechweise ist, dass die Funktion TM(n) oft einensehr unubersichtlichen Verlauf hat, sich eine einfache obere Schranke t(n) aber in vielenFallen angeben lasst. Man beachte, dass aus
”M ist t(n)-zeitbeschrankt“ und t(n) ≤ t′(n)
folgt, dass M auch t′(n)-zeitbeschrankt ist.
Zur Erinnerung: Fur Funktionen f, g : N → R+ schreiben wir g(n) = O(f(n)), wenn eseine Konstante c > 0 gibt, so dass g(n) ≤ c · f(n) gilt, fur alle n ∈ N.
Offenbar gilt fur jede k-Band-Turingmaschine M : wenn M t(n)-zeitbeschrankt ist, dannist M k · t(n)-platzbeschrankt; die in Satz 1.2.6 beschriebene 1-Band-TM M ′ zu M istsogar t(n)-platzbeschrankt.
1.2.8 Satz Sei eine t(n)-zeitbeschrankte und s(n)-platzbeschrankte k-Band-TM M ge-geben. M ′ sei die in Satz1.2.6 beschriebene 1-Band-TM. Dann gilt:(a) M ′ ist s(n)-platzbeschrankt.(b) M ′ ist O(s(n) · t(n))-zeitbeschrankt.(c) M ′ ist O(t(n)2)-zeitbeschrankt.
Beweis Sei die Eingabe x ∈ Σn. M ′ benutzt nicht mehr Zellen als M . Damit ist diePlatzschranke in (a) klar. Fur jeden Rechenschritt von M muss der bislang besuchte Teildes Bandes von M ′ viermal uberquert werden — das dauert O(s(n)) Schritte. Insgesamtbenotigt M ′ also hochstens t(n) · O(s(n)) = O(s(n)t(n)) Schritte. Damit ist (b) gezeigt.(c) folgt aus (b) und der Bemerkung vor dem Satz. �
9Wenn ein Kopf eine Zelle erstmals besucht, aber dieser Besuch in einer Haltekonfiguration stattfindet,gilt dies nicht als schreibender Zugriff und zahlt nicht zum Platzbedarf.
48

1.2.9 Definition (Zeitkomplexitatsklassen) Fur t : N→ R+ definieren wir:
DTIME(t(n)) := {LM |M ist k-Band-TM,
∃c > 0 : M ist c · t(n)-zeitbeschrankt} .
Die so definierten Sprachenmengen heißen Zeit-Komplexitatsklassen.10
1.2.10 Programmiertechnik: Unterprogramme Ist M eine TM, so konnen wir beider Programmierung einer beliebigen anderen TM M ′ die TM M als
”Unterprogramm“
nutzen. D. h., M ′ schreibt wahrend der Rechnung auf ein sonst leeres Band eine Eingabex fur M , startet M durch Umschalten auf den Startzustand von M , und erhalt vonM nach Beendigung der Rechnung eine Ja/Nein-Entscheidung, je nachdem ob x ∈ LM
oder nicht, oder auch den Funktionswert fM(x) geliefert. Mit diesem Ergebnis nimmt M ′
seine Berechnung wieder auf. M selbst kann auch mehrere Bander benutzen. Ist M wiein Beispiel 1.2.4, genugt auch ein einseitig leeres Band von M ′, dann benutzt man alsArbeitsbereich fur M einen Bandabschnitt rechts von allen beschrifteten Zellen.
Es kann sein, dass M von mehreren verschiedenen Programmstellen (Zustanden) von M ′
aus aufrufbar sein soll und mehrere Wiedereinstiegsstellen (Rucksprungadressen) moglichsein sollen. In diesem Falle ist es am einfachsten, die Version von M zu benutzen, die nurein einseitig unbeschranktes Band hat, und M ′ als Eingabe #q0
ruck#q1ruck#x zu ubergeben,
wo q0ruck und q1
ruck die Rucksprungadressen im Programm (d. h. der Turingtafel) von M ′
fur die Falle x ∈ LM oder x 6∈ LM sind. Statt zweier Rucksprungadressen kann manauch nur eine oder mehr als zwei angeben. Mit diesen Tricks ist es recht einfach, sogarrekursive Unterprogramme oder sich gegenseitig aufrufende rekursive Unterprogrammeauf Turingmaschinen zu realisieren. (Details werden in den Ubungen besprochen.)
10Platz-Komplexitatsklassen werden in der Vorlesung”Komplexitatstheorie“ behandelt.
49

Band von MB B a a a ... a B B B ......
...
... ...
...
Programm
von M’
ohne M
Beschreibung
von M
M’:
endliches
Objekt!
1 2 3 n
Bänder von M’
Abbildung 1.11: TM M als Unterprogramm von TM M ′
1.2.11 Programmiertechnik: Textsuche Eine haufig auftretende Teilaufgabe inTuringmaschinenberechnungen (die sich auch als Unterprogramm realisieren lasst) ist dieSuche nach einem Abschnitt einer Bandinschrift (Text) t = b1 · · · bm, der mit einem vor-gegebenen Muster (engl. pattern) p = a1 · · · an ubereinstimmt.
Ist z. B. p = 10010, t = 011010011001001010101, findet sich p in t beginnend bei Position9 und nochmals beginnend bei Position 12.
Wenn ∆ ein Alphabet ist, das # nicht enthalt, dann existiert eine 3-Band-TM M =(Q, Σ, Γ, . . .) , die folgendes tut:
Auf Eingabe a1 · · · an#b1 · · · bm ∈ ∆∗{#}∆∗ berechnet M (als Ausgabe auf Band 2) dasBinarwort bin(j), wo j minimal ist mit bjbj+1 · · · bj+n−1 = a1 · · · an, falls ein solches jexistiert. Zudem steht am Ende der Rechnung der Bandkopf von Band 1 auf der Zelle,die bj enthalt. Falls das Teilwort a1 · · · an nicht in b1 · · · bm vorkommt, halt M in einemverwerfenden Zustand.
50

bm
Band 2
Band 3
Band 1B a a ... a # b b B B ...
bin(j)
B a a ... a B ...
1 2 n 1 2
1 2 n
... ...
*
bj
Bandinhalt während der Rechnung :
Methode: Kopiere a1 · · · an auf Band 3. Initialisiere Band 2 mit 1. Markiere b1 auf Extra-Spur auf Band 1 mit ∗.
Wiederhole: Vergleiche den String auf Band 1, startend bei ∗, Zeichen fur Zeichen mita1 · · · an. Falls alle Zeichen gleich: fahre den Bandkopf auf Band 1 nach links zum ∗ undhalte. Falls a1 · · · an nicht vollstandig gelesen werden kann, halte verwerfend. Sonst rucke∗ um eine Zelle weiter nach rechts, erhohe die Binarzahl auf Band 2 um 1.
Anwendung: Falls ein Band eine Folge von Records enthalt, die durch einen Schlussel oderNamen identifiziert werden (
”identifier“), etwa der Form
... ...feld3 # identifier # feld1 # feld2 # feld3 # identifier
Binärzahl Binärzahl
so findet man den durch einen”Zeiger“ (auf einem anderen Band)
# identifier #0
bezeichneten Record via Textsuche.
1.2.12 Modelleinschrankung: Standardalphabete Σ = {0, 1}, Γ = {0, 1, B}.
Wie in der Vorlesung”Automaten und Formale Sprachen“ schon bemerkt, kann man jedes
Alphabet Σ mit |Σ| = b durch das”Normalalphabet“ {0, 1, . . . , b − 1} ersetzen. Ebenso
kann man sich immer vorstellen, die Zustandsmenge Q einer TM sei einfach {0, 1, . . . , |Q|−1}.
Mitunter ist es aber unbequem, Eingabealphabete und Bandalphabete beliebiger Kardi-nalitat zu haben. In diesen Fallen hilft der Ansatz, Bandsymbole binar zu kodieren.11
11Das ist naturlich ein in der Informatik alltagliches Vorgehen.
51

(a) Eingabealphabet. Sei Σ irgendein Alphabet, |Σ| ≥ 2. Betrachte eine beliebige, aberfeste Binarkodierung
ϕ : Σ1−1→ {0, 1}dlog2 |Σ|e
fur die Buchstaben.
Nun kodiert man Worter binar:
ϕ(a1 · · · an) := ϕ(a1) · · ·ϕ(an)︸ ︷︷ ︸
∈{0,1}∗
, fur n ∈ N, a1, . . . , an ∈ Σ.
Ebenso kann man dann die Binarkodierung von Sprachen definieren:
ϕ(L) = {ϕ(w) | w ∈ L} ⊆ {0, 1}∗, fur L ⊆ Σ∗.
Wenn beispielsweise ϕ : {a, b, c, d, #, $} → {0, 1}3 durch
a a b c d # $
ϕ(a) 000 001 010 011 110 111
gegeben ist, so istϕ(ab#dc) = 000001110011010
undϕ({ab#dc, a$d}) = {000001110011010, 000111011}.
Ahnlich definiert man die Binarkodierung einer Funktion f : D → Σ∗ mit D ⊆ Σ∗
als fϕ : φ(D)→ {0, 1}∗, ϕ(w) 7→ ϕ(f(w)).
Mit diesen Definitionen gilt:
(i) L ist rekursiv ⇔ ϕ(L) ist rekursiv;
(ii) L ist rekursiv aufzahlbar ⇔ ϕ(L) ist rekursiv aufzahlbar;
(iii) f ist partiell rekursiv ⇔ fϕ ist partiell rekursiv.
Beweisidee:”(i), (ii) ⇒“: Sei L = LM fur eine TM M (bei (i): M halt auf allen
Inputs). Eine neue TM M ′ mit Inputalphabet Σ′ = {0, 1} arbeitet wie folgt: EinInput w ∈ Σ′∗ wird in Blocken von jeweils l = dlog2 |Σ|e Bits gelesen und jederBlock wird mittels ϕ−1, das in der Steuereinheit gespeichert ist, in einen Buchstabena ∈ Σ umgewandelt und auf Band 2 geschrieben. Falls |w| nicht Vielfaches von l ist,wird die Eingabe verworfen. Danach wird M mit dem nun auf Band 2 stehendenEingabewort gestartet. — Die Umkehrung in (i) und (ii) zeigt man ahnlich, miteiner vorgeschalteten Ubersetzung von Σ∗ in {0, 1}∗. In (iii) muss man fur beideRichtungen ϕ und ϕ−1 verwenden.
52

(b) Bandalphabet. Ist M = (Q, Σ, Γ, B, q0, F, δ) mit Σ = {0, 1} eine Turingmaschine,so kann das Verhalten von M durch eine TM M ′ = (Q′, Σ, Γ′, . . .) mit BandalphabetΓ′ = {0, 1, B′} simuliert werden. Insbesondere gilt also: es existiert eine TM M ′ =(Q′, {0, 1, B′}, {0, 1}, B′, . . .) mit LM = LM ′ , HM = HM ′ und fM = fM ′ .
Konstruktionsidee: Das Band von M ′ ist in Blocke der Lange l = dlog2(|Γ| − 1)eunterteilt. Jeder Block entspricht einer Zelle von M . Die Buchstaben in Γ− {BM}werden durch Binarworter der Lange l kodiert, das Blanksymbol BM von M durchBl. M ′ hat in seiner Steuereinheit die Kodierungsfunktion ϕ und die Beschreibungder TM M gespeichert. Weiter hat die Steuereinheit l Bitregister und ein Register furden Zustand von M wahrend der Simulation. Um einen Schritt von M zu simulieren,liest und speichert M ′ alle l Zellen des Blocks, in dem gegenwartig der Kopf steht,und dekodiert das Gelesene mittels ϕ−1 zu einem Buchstaben a ∈ Γ. Gemaß demgegenwartigen Zustand q von M bestimmt M ′ nun δ(q, a) = (q′, a′, D), schreibt ϕ(a′)in den aktuellen Block, bewegt den Kopf um l Zellen in Richtung D, und stellt denneuen Zustand q′ ein. Die Sonderfalle, dass Bl gelesen wird oder der Ubergang nichtdefiniert ist, sind einfach zu beschreiben. Ebenso liegt die notige Vorbereitung zuBeginn der Rechnung (die Eingabe muss in das Blockformat umkodiert werden) unddie Nachbearbeitung am Ende der Berechnung (Herstellung der Ausgabe aus denBlocken) auf der Hand.
B B B B B B ... 0 1 0 1 1 1 0 0 0 1 1 0
code(B) code(a) code(b)
log (| |)2
Kopfbewegungen von M’:
Programm
von M
Decode
Code
Puffer:
a’
a ε Γ
Γ
M’:
�
53

1.3 Nichtdeterministische Turingmaschinen
und Chomsky-0-Grammatiken
1.3.1 Nichtdeterministische Turingmaschinen
Man bezeichnet ein Maschinenmodell (eine Turingmaschine oder ein anderes Maschinen-modell wie z. B. die Registermaschine) als deterministisch, wenn in jeder Konfigurationder nachste auszufuhrende Schritt und damit auch die Nachfolgekonfiguration eindeutigfestgelegt sind. In der Vorlesung
”Automaten und Formale Sprachen“ haben wir schon
die Modelle nichtdeterministischer endlicher Automat (NFA) und nichtdeterministischerKellerautomat (NPDA) kennengelernt, die die Moglichkeit hatten, in manchen Konfigu-rationen zwischen mehreren moglichen Zugen zu wahlen. In diesem Abschnitt beschafti-gen wir uns mit der Variante des Turingmaschinenmodells, die durch Hinzufugen dieserMoglichkeit entsteht. Wir sagen, eine solche Maschine akzeptiere eine Eingabe, wenn eseine legale Berechnung gibt, die zu einer akzeptierenden Konfiguration fuhrt. Zwei Bemer-kungen vorab:
• Nichtdeterministische TMn (oder andere Berechnungsmodelle) sind ausdrucklichnicht als Modelle fur realistische Rechner gedacht. Man sollte also nicht an derFrage verzweifeln, wie denn nun eigentlich so eine nichtdeterministische Maschine
”rechnet“, wo sie doch nicht
”weiß“, welcher Schritt als nachster auszufuhren ist.
Vielmehr sind nichtdeterministische TMn ein abstraktes Hilfsmittel. Oft erleichternsie die Programmierung von (gewohnlichen) Turingmaschinen. Andererseits erlau-ben sie es, nutzliche Konzepte wie die Klasse NP der auf nichtdeterministischenTMn in Polynomialzeit akzeptierbaren Sprachen zu definieren — die Grundlage furdie Theorie der NP-Vollstandigkeit im zweiten Teil der Vorlesung.
• Will man die Funktionsweise nichtdeterministischer Maschinen und den Akzeptie-rungsbegriff intuitiv verstehen, kann man sich etwa vorstellen, dass so eine Maschineeine akzeptierende Berechnung sucht, dabei aber die magische Fahigkeit hat, unter-wegs die richtigen Zuge, die zum Ziel fuhren, erraten zu konnen, wenn sie existieren.
1.3.1 Definition Eine nichtdeterministische (1-Band-)Turingmaschine (NTM) M be-steht aus sieben Komponenten:Q, Σ, Γ, B, q0, F (mit denselben Einschrankungen und Rollen wie in 1.1.2 angegeben) undδ, wobei
δ : Q× Γ→ P(Q× Γ× {R,N,L}).
(P(X) bezeichnet die Potenzmenge der Menge X.)
Intuitiv bedeutet diese Art von Ubergangsfunktion folgendes: In einer Situation, wo dieTM im Zustand q ist und auf dem Band das Zeichen a liest, kann sie einen der in der Mengeδ(q, a) ⊆ Q× Γ× {R,N,L} liegenden
”Zuge“ (q′, a′, D) ausfuhren. Ist also |δ(q, a)| ≥ 2,
besteht eine Auswahl.
54

1.3.2 Beispiel Wir betrachten folgendes Entscheidungsproblem:
Eingeschranktes Rucksackproblem – Exaktes Packen:
Input: Eine Folge (a1, . . . , an, b) von n + 1 naturlichen Zahlen, fur ein n ≥ 1.
Output:”Ja“, falls es eine Teilfolge (ai)i∈I gibt, so dass die Summe
∑
i∈I ai genau b ist,und
”Nein“ sonst.
(Informal stellt man sich vor, dass eine Menge von verformbaren Gegenstanden mit Vo-lumina a1, . . . , an gegeben ist und fragt, ob man mit einem Teil der Gegenstande einenRucksack vom Volumen b exakt fullen kann.)
Wir konnen dieses Problem als eine Sprache formalisieren:
LRucksack∗ := {bin(a1)# · · · #bin(an)#bin(b) | n ∈ N, a1, . . . , an, b ≥ 1
∃I ⊆ {1, . . . , n} :∑
i∈I
ai = b}.
Zum Beispiel gilt:
1010#101#1000#11#1101 ∈ LRucksack∗ ;
110#10#1010#110#1111 /∈ LRucksack∗ .
Wir beschreiben (in den deterministischen Teilen informal) eine NTM M = (Q, Σ, . . .)mit Σ = {0, 1, #}, die genau die Worter aus LRucksack∗ akzeptiert. Die NTM arbeitet indrei Phasen. Die erste Phase besteht in einer Syntaxprufung: gehort das Eingabewort zuder regularen Sprache, die zu dem regularen Ausdruck 1(0 + 1)∗(#1(0 + 1)∗)+ gehort? DieSyntaxprufung kann von einem DFA durchgefuhrt werden; die TM benotigt dazu nur daseinmalige Lesen des Inputs von links nach rechts. Ist die Eingabe nicht syntaktisch korrekt,halt M verwerfend, sonst wird der Kopf auf das erste Eingabezeichen zuruckgestellt, undes folgt Phase 2.
In Phase 2 werden einige der Eingabezahlen nichtdeterministisch ausgewahlt. Konkretgeschieht das dadurch, dass einige der #-Zeichen durch ∗ ersetzt werden, mit der Idee,dass in Phase 3 die Eingabezahlen ai, die mit · · · bin(ai)∗ · · · markiert wurden, gestrichenwerden. Phase 2 beginnt in Zustand q2, der Kopf steht auf dem ersten Eingabebit. In derTuringtafel sieht das nichtdeterministische Markieren so aus:
δ(q2, a) = {(q2, a, R)}, fur a ∈ Σ
δ(q2, #) = {(q2, ∗, R), (q2, #, R)}, fur a ∈ Σ
δ(q2, B) = {(q3, B, L)}.
In Phase 3 werden die in Phase 2 gewahlten Zahlen durch 0 · · · 0 ersetzt. Zustand q3 lasstdie Zeichen stehen, Zustand q∗3 loscht. Die letzte Binarzahl, also bin(b), bleibt auf jeden
55

Fall stehen. Am Ende der Phase steht der Kopf auf dem ersten Zeichen der Eingabe.
δ(q3, a) = {(q3, a, L)}, fur a ∈ Σ
δ(q∗3, a) = {(q∗3, 0, L)}, fur a ∈ Σ
δ(q3, #) = δ(q∗3, #) = {(q3, #, L)},
δ(q3, ∗) = δ(q∗3, ∗) = {(q∗3, #, L)},
δ(q3, B) = δ(q∗3, B) = {(q4, B,R)}.
In Phase 4 werden in der jetzigen Bandinschrift
w1# · · · #wn#wn+1
mit Binarzahlen w1, . . . , wn, die auch 0 · · · 0 sein durfen, alle außer der letzten Zahl addiert.Die resultierende Binarzahl u wird Bit fur Bit mit wn+1 verglichen. (Techniken fur dieAddition und den Vergleich von Wortern werden in der Ubung bereitgestellt.) Wennwn+1 = u, wird akzeptiert, sonst wird verworfen.
Wir beobachten die folgenden Eigenschaften der Berechnungen auf der NTM M : Wenn dieEingabe aus n + 1 Zahlen besteht, gibt es genau 2n verschiedene Berechnungen, entspre-chend den Moglichkeiten, aus den n #-Zeichen eine Teilmenge in ∗ umzuwandeln. Wenndie Eingabe in LRucksack∗ liegt, gibt es mindestens eine Berechnung, die zum akzeptieren-den Halten fuhrt. Wenn die Eingabe nicht in LRucksack∗ liegt, gibt es keine akzeptierendeBerechnung.12
Es erscheint sinnvoll festzulegen, zumindest in diesem Beispiel, dass M eine Eingabe xakzeptiert genau dann wenn es fur M auf x mindestens eine akzeptierende Berechnunggibt. (Von den vielen nichtakzeptierenden, in denen falsch geraten wurde, lasst man sichnicht storen.)
Nun mussen wir den eben angedeuteten Akzeptierungsbegriff formalisieren. Hierzu gehenwir ganz ahnlich wie in Definition 1.1.11 vor.
1.3.3 Definition Eine nichtdeterministische TM M = (Q, Σ, Γ, B, q0, F, δ) sei gegeben.
(a) Die Menge der Konfigurationen von M ist ebenso definiert wie im deterministischenFall (Def. 1.1.11), ebenso das Konzept der Startkonfiguration initM(x) von M zux ∈ Σ∗.
(b) (Vgl. Def. 1.1.12) k = α1(q, a)α2 sei Konfiguration von M . Sei nun (q′, a′, D) ∈δ(q, a). Dann gibt es zu (q′, a′, D) eine Nachfolgekonfiguration k′ von k, die imfolgenden beschrieben wird. Wir schreiben dafur k `M k′ oder k ` k′.
12Genauer gesagt entspricht jedem I ⊆ {1, . . . , n} mit∑
i∈I ai = b genau eine akzeptierende Berech-nung.
56

Schreibe Bα1 = γ1c und α2B = dγ2 fur passende c, d ∈ Γ und γ1, γ2 ∈ Γ∗. Dannbeschreibt k = Bα1(q, a)α2B = γ1c(q, a)dγ2 dieselbe Konfiguration wie k, nur mitzwei zusatzlichen Blankzeichen. Wir definieren
k′ :=
γ1(q′, c)a′dγ2 , falls D = L;
γ1ca′(q′, d)γ2 , falls D = R;
γ1c(q′, a′)dγ2 , falls D = N .
Die Nachfolgekonfiguration k′ von k fur den Zug (q′, a′, D) entsteht aus k′ durchStreichen aller B’s am Beginn und am Ende von k′.
Eine Konfiguration α1(q, a)α2 kann also keine, eine oder mehrere Nachfolgekonfiguratio-nen haben, hochstens jedoch |δ(q, a)| viele.
(c) Sind k, k′ Konfigurationen und ist i ∈ N, so schreiben wir k `iM k′ oder k `i k′,
falls i = 0 und k = k′ oder i ≥ 1 und es Konfigurationen k1, . . . , ki−1 gibt, so dassk ` k1 ` · · · ` ki−1 ` ki = k′ gilt.
(d) k′ heißt (indirekte) Nachfolgekonfiguration von k, in Zeichen
k `∗M k′ oder k `∗ k′,
falls k `iM k′ fur ein i ∈ N.
(e) k = α1(q, a)α2 heißt Haltekonfiguration von M , falls δ(q, a) = ∅ ist.
(f) Eine Folge initM(x) = k0 ` k1 ` · · · ` kt mit kt Haltekonfiguration heißt einehaltende Berechnung von M auf x; die Lange oder Schrittzahl dieser Berechnungist t; eine unendliche Folge initM(x) = k0 ` k1 ` k2 ` · · · ` kt ` · · · heißt einenicht-haltende Berechnung von M auf x; die Lange einer unendlichen Berechnungist ∞.
(g) Ist k = α1(q, a)α2 Haltekonfiguration, so heißt k akzeptierend, falls q ∈ F , verwer-fend sonst. Entsprechend heißen haltende Berechnungen, die in einer akzeptieren-den/verwerfenden Haltekonfiguration enden, selbst akzeptierend/verwerfend.
1.3.4 Definition M = (Q, Σ, Γ, B, q0, F, δ) sei eine nichtdeterministische TM, x ∈ Σ∗
sei ein Eingabewort. Wir sagen:
(a) M akzeptiert x, falls initM(x) `∗M k fur eine akzeptierende Haltekonfiguration k gilt,d. h. falls M fur x mindestens eine akzeptierende Berechnung besitzt.
(b) LM := {x ∈ Σ∗ |M akzeptiert x}.
57

Man beachte, dass in diesen Definitionen nichts weiter uber die Situation gesagt wird, woeine oder mehrere oder alle Berechnungen von M auf x in einer verwerfenden Haltekonfi-guration enden. Insbesondere fuhrt man den Begriff
”Die NTM M verwirft x“ nicht ein,
nur einzelne Berechnungen konnen verwerfend enden.
Alle Programmiertricks und Modellvarianten aus Abschnitt 1.2 kann man auch fur nicht-deterministische Turingmaschinen einsetzen. Hier sei erinnert an die Verwendung derSteuereinheit als endlicher Speicher, an die Spurtechnik, an ein einseitig unbeschrank-tes Band und an Unterprogramme.
Besonders erwahnt werden soll noch das k-Band-Modell. Ebenso wie im deterministi-schen Fall definiert man nichtdeterministische k-Band-TMn. Die Ubergangsfunktion δbildet Tupel (q, a1, . . . , ak) auf Teilmengen von Q × Γk × {L,R,N}k ab. Dabei bedeutet(q′, a′
1, . . . , a′k, D1, . . . , Dk) ∈ δ(q, a1, . . . , ak), dass M in der durch (q, a1, . . . , ak) beschrie-
benen Situation den durch (q′, a′1, . . . , a
′k, D1, . . . , Dk) gegebenen Zug ausfuhren kann. Wie-
der werden Konfigurationen und Akzeptierungsbegriff ebenso wie bei 1-Band-NTMn de-finiert. Dieselbe Konstruktion wie in Satz 1.2.6 (das war die Konstruktion mit den 2k + 1Spuren auf einem Band) und dieselbe Uberlegung wie in Satz 1.2.8 liefert folgendes.
1.3.5 Satz M sei eine nichtdeterministische Turingmaschine mit k Bandern. Danngilt:(a) Es gibt eine 1-Band-NTM M ′, die LM = LM ′ erfullt.(b) Wenn jede Berechnung von M auf Inputs x ∈ Σn nach hochstens t(n) Schrittenanhalt, so kann die NTM M ′ in (a) so konstruiert werden, dass jede Berechnung von M ′
auf Inputs x ∈ Σn nach hochstens O(t(n)2) Schritten anhalt.
Dieser Satz hat zur Folge, dass wir beim Entwurf von NTMn auch solche mit k Bandernbenutzen konnen. Als nachstes geben wir ein Beispiel an, bei dem zwei Bander sehrnutzlich sind.
1.3.6 Beispiel Definition: Ein Wort u = b1 · · · bm heißt Teilfolge eines Wortes x =a1 · · · an, wenn es eine Folge 1 ≤ i1 < · · · < im ≤ n gibt, so dass b1 · · · bm = ai1 · · · aim .Umgekehrt heißt x Oberfolge von u, wenn u Teilfolge von x ist. Zum Beispiel ist 001011001Oberfolge von 1000, nicht aber 001011101.
Wir betrachten das Oberfolgenproblem. Gegeben sei eine beliebige rekursiv aufzahlbareSprache L ⊆ Σ∗. Wir definieren dann
L′ := {x ∈ Σ∗ | ∃w ∈ L : x ist Oberfolge von w}.
Weil L rekursiv aufzahlbar ist, gibt es eine (deterministische) TM M mit L = LM . Wirentwerfen eine 2-Band-NTM fur L′. Die Berechnung verlauft in zwei Phasen:
Phase 1: Lese den Input x auf Band 1 von links nach rechts, wahle nichtdeterministischZeichen aus, die auf Band 2 kopiert werden. (Wir sagen:
”M ′ wahlt nichtdeterministisch
eine Teilfolge von x“ oder”M ′ rat eine Teilfolge von x“.) Wenn das Ende der Eingabe
erreicht ist, fahre den Kopf auf Band 2 zuruck zum Bandanfang.
58

Phase 2: Starte M mit Band 2 als seinem einzigen Arbeitsband. Wenn M akzeptiert,akzeptiert auch M ′.
Zur Illustration geben wir die Ubergangsfunktion fur die erste Phase von M ′ an. In Zu-stand q0 werden nichtdeterministisch einige Eingabezeichen kopiert. In Zustand q1 fahrtder Kopf auf Band 2 zuruck zum Beginn der Bandinschrift, der auf Band 1 tut nichts.Der Zustand qM
0 ist der Startzustand fur das Unterprogramm, das das Programm von Mauf Band 2 ablaufen lasst.
δ(q0, a, B) = {(q0, a, a, R,R), (q0, a, B,R,N)}, fur a ∈ Σ;
δ(q0, B,B) = {(q1, B,B,N, L)};
δ(q1, B, a) = {(q1, B, a,N, L)}, fur a ∈ Σ;
δ(q1, B,B) = {(qM0 , B,B,N,R)}.
In Phase 1 werden genau n nichtdeterministische Schritte mit jeweils 2 Alternativen durch-gefuhrt. Es ist klar, dass es dafur 2n verschiedene Ablaufe gibt. Nach dem Ende von Phase1 ist irgendeine der Konfigurationen (a1 · · · an(qM
0 , B), (qM0 , b1)b2 · · · bm) erreicht, fur eine
Teilfolge b1 · · · bm von x = a1 · · · an, oder (a1 · · · an(qM0 , B), (qM
0 , B)), wenn kein Zeichenausgewahlt wurde.13 Beispiel : Ist der Input x = abac, so ist jede Konfiguration mit einerInschrift auf Band 2 aus der folgenden Liste moglich:
abac, aba, abc, ab, aac, aa, ac, a, bac, ba, bc, b, ac, a, c, ε.
(In diesem Fall gibt es zwar 16 Ablaufe, aber nur 14 verschiedene mogliche Konfigurationennach Phase 1.)
Da in Phase 2 deterministisch gerechnet wird, besitzt M ′ auf a1 · · · an genau 2n vieleverschiedene Berechnungen. Es ist klar, dass genau diejenigen dieser Berechnungen ak-zeptierend halten, bei denen die Bandinschrift b1 · · · bm von Band 2 nach Phase 1 zu Lgehort. Daraus folgt: es gibt eine akzeptierende Berechnung auf a1 · · · an genau dann wenneine Teilfolge b1 · · · bm von a1 · · · an zu L gehort; mit anderen Worten: LM ′ = L′.
Aus den Beispielen sollte man ein Gefuhl dafur bekommen haben, was es bedeutet, dasseine NTM auf einem Input x mehrere oder viele verschiedene Berechnungen haben kann.Um dieses Nebeneinander mehrerer Berechnungen zu verdeutlichen und den Akzeptie-rungsmodus von NTMn zu veranschaulichen, fuhren wir das Konzept des Berechnungs-baums (zu M und einer Eingabe x) ein. Dieser Baum fasst alle moglichen Berechnungenvon M auf Eingabe x zusammen.
1.3.7 Definition Ist M eine nichtdeterministische TM, x ∈ Σ∗ Eingabe fur M , soist der Berechnungsbaum CT (M,x)14 definiert wie folgt. CT (M,x) ist ein endlicher oderunendlicher gerichteter Baum mit Wurzel, dessen Knoten mit Konfigurationen markiertsind, und zwar folgendermaßen:
13Wir notieren Konfigurationen von k-Band-Maschinen als k-Tupel von 1-Band-Konfigurationen. Esstort nicht weiter, dass dabei der Zustand q k-mal vorkommt.
14zu engl. computation tree
59
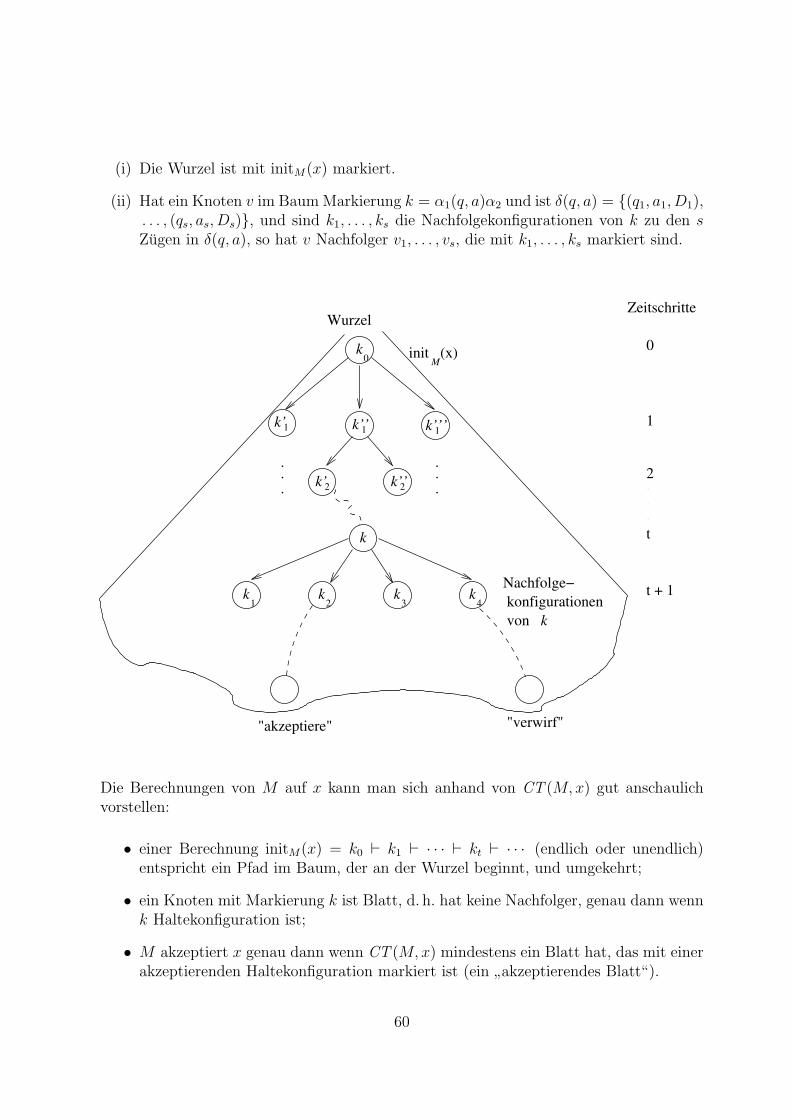
(i) Die Wurzel ist mit initM(x) markiert.
(ii) Hat ein Knoten v im Baum Markierung k = α1(q, a)α2 und ist δ(q, a) = {(q1, a1, D1),. . . , (qs, as, Ds)}, und sind k1, . . . , ks die Nachfolgekonfigurationen von k zu den sZugen in δ(q, a), so hat v Nachfolger v1, . . . , vs, die mit k1, . . . , ks markiert sind.
.
.
.
.
.
1k’’k’1
"akzeptiere"
Zeitschritte
0
1
2
t
"verwirf"
k
k
t + 1k1 konfigurationen
von
Nachfolge−
Minit (x)
.
.
.
.
.
.
k2
k3
k4
k
Wurzel
0
2k’’k’2
1k’’’
Die Berechnungen von M auf x kann man sich anhand von CT (M,x) gut anschaulichvorstellen:
• einer Berechnung initM(x) = k0 ` k1 ` · · · ` kt ` · · · (endlich oder unendlich)entspricht ein Pfad im Baum, der an der Wurzel beginnt, und umgekehrt;
• ein Knoten mit Markierung k ist Blatt, d. h. hat keine Nachfolger, genau dann wennk Haltekonfiguration ist;
• M akzeptiert x genau dann wenn CT (M,x) mindestens ein Blatt hat, das mit einerakzeptierenden Haltekonfiguration markiert ist (ein
”akzeptierendes Blatt“).
60

Interessant ist der Fall, dass CT (M,x) endlich ist, also endlich viele Knoten hat. Man kannsich uberlegen, dass ein unendlicher Berechnungsbaum eine nicht abbrechende Berechnungenthalten muss.
1.3.8 Bemerkung Es gilt:
CT(M,x) endlich ⇔ jede Berechnung von M auf x
endet nach endlich vielen Schritten.
Beweis :”⇒“ ist offensichtlich.
”⇐“: Wir nehmen an, dass CT (M,x) unendlich viele Knoten hat und konstruieren in-
duktiv einen unendlichen Weg in CT (M,x). Dieser entspricht einer nichthaltenden Be-rechnung von M auf x.Basis : Sei v0 die Wurzel. Nach der Annahme ist der Unterbaum mit Wurzel v0 unendlich.Ind.-Schritt : Seien Knoten v0, . . . , vn−1 schon konstruiert, so dass sie einen Weg in CT (M,x)bilden, und so dass der Unterbaum mit Wurzel vn−1 unendlich ist. Weil vn−1 nur endlichviele direkte Nachfolgeknoten hat, muss es einen geben, wir nennen ihn vn, so dass derUnterbaum mit Wurzel vn unendlich ist.Die so definierte Knotenfolge v0, v1, . . . bildet einen unendlichen Weg in CT (M,x). �
Wegen der vorangegangenen Bemerkung liegt es nahe, fur eine NTM M = (Q, Σ, . . .) zudefinieren:
HM := {x ∈ Σ∗ | CT(M,x) ist endlich }.
Es ist etwas komplizierter festzulegen, was es bedeuten soll, dass eine nichtdeterministischeTM eine Funktion berechnet. Wir definieren diesen Begriff hier nicht; die Bezeichnung fM
ist also fur eine nichtdeterministische TM M nicht definiert und darf nicht benutzt werden.
Wir wollen nun den Zusammenhang zwischen deterministischen und nichtdeterministi-schen TMn klaren. Die eine Richtung ist einfach.
1.3.9 Bemerkung Man kann deterministische TMn als Spezialfall nichtdeterministi-scher TMn auffassen: ist M = (Q, Σ, Γ, B, q0, F, δ) eine deterministische TM, so betrachteδ : Q× Γ→ P(Q× Γ× {L,R,N}), das folgendermaßen definiert ist:
δ(q, a) :=
{
{(q′, a′, D)}, falls δ(q, a) = (q′, a′, D);
∅, falls δ(q, a) undefiniert.
Es ist klar, dass fur die nichtdeterministische TM M = (Q, Σ, Γ, B, q0, F, δ) LM = LM
und HM = HM gilt. Fur jedes x ∈ Σ∗ ist CT (M,x) ein Pfad ohne Verzweigung.
Nun wollen wir umgekehrt zeigen, dass”Nichtdeterminismus“ die prinzipielle Berech-
nungskraft bei Turingmaschinen nicht erhoht. Die Grundidee hierbei ist, dass eine deter-ministische TM alle moglichen Berechnungen der nichtdeterministischen TM
”durchpro-
bieren“ kann. Wir brauchen dazu eine einfache Hilfs-TM, die zu einem Alphabet ∆ alleWorter uber ∆
”aufzahlt“, d. h., nacheinander erzeugt.
61

1.3.10 Lemma Sei ∆ ein Alphabet. Dann gibt es eine deterministische 1-Band-TM,die, wenn sie mit Eingabe ε gestartet wird, unendlich lange lauft und dabei nacheinanderdie Konfiguration (qfertig, B) und dann die Konfigurationen (qfertig, a1)a2 · · · an erreicht, furalle a1 · · · an ∈ ∆+; dabei ist qfertig ein Zustand, der sonst nie erreicht wird.
Beweis : (Siehe auch Ubung.) Schreibe ∆ = {c0, . . . , cd−1}. Die Idee ist, ci mit i zuidentifizieren, und dann geeignet im d-aren System zu zahlen, hierbei aber auch alleZahldarstellungen mit fuhrenden Nullen zu erzeugen. Der Einfachheit halber nehmen wir∆ = {0, 1, . . . , d− 1} an, fur d ≥ 1.15
Anfangs wird das leere Wort erzeugt:
δ(q0, B) = (qfertig, B,N);
dabei ist q0 der Startzustand. Wenn ein Wort erzeugt worden ist, wird es in der nachstenRunde um 1 inkrementiert (auf das Wort (d− 1)r folgt aber 0r+1). Hierzu fahrt der Kopfan das rechte Ende; auf dem Weg vom rechten zum linken Ende werden Ziffern d − 1in Nullen umgewandelt, bis zur ersten Ziffer < d − 1, die um 1 erhoht wird; der Restwird nicht verandert. Sollte das ganze Wort nur aus Ziffern d− 1 bestanden haben, wirdvorne eine 0 angefugt. Realisiert wird dies durch die folgende Ubergangsfunktion, wobeiQ = {q0, qfertig, qrechts, qincr, qlinks} die Zustandsmenge ist.
δ(qfertig, b) = (qrechts, b, N), fur b ∈ ∆ ∪ {B};
δ(qrechts, a) = (qrechts, a, R), fur a ∈ ∆;
δ(qrechts, B) = (qincr, B, L);
δ(qincr, a) = (qlinks, a + 1, L), fur a ∈ ∆− {d− 1};
δ(qlinks, a) = (qlinks, a, L), fur a ∈ ∆;
δ(qlinks, B) = (qfertig, B,R);
δ(qincr, d− 1) = (qincr, 0, L);
δ(qincr, B) = (qfertig, 0, N).
�
1.3.11 Satz Ist L = LM fur eine nichtdeterministische TM M , dann ist L rekursivaufzahlbar.
Beweis : Sei M = (Q, Σ, Γ, B, q0, F, δ). Wir beschreiben eine deterministische TM M ′ =(Q′, Σ, Γ′, B′, q′0, F
′, δ′) mit LM = LM ′ .
Die Menge Z := Q×Γ×{L,R,N} aller moglichen”Einzelzuge“ von M ist endlich. Jede
Berechnung k0 ` k1 ` k2 ` . . . (haltend oder nichthaltend) von M entspricht einer Folge
15Derselbe Ablauf ergibt sich, wenn man Σ = {1, . . . , d} setzt und in der d-adischen Zahldarstellungzahlt, die in Anhang A.1.2 des AFS-Skripts beschrieben ist.
62

(z1, z2, . . .) in Z (endlich oder unendlich), wobei beim Ubergang von kt−1 zu kt gerade Zugzt benutzt wird. Es gibt naturlich auch Zugfolgen, die keiner korrekten Berechnung vonM entsprechen.
Beispiel : In Beispiel 1.3.2 gibt es in Phase 2 die folgende (Teil-)Berechnung mit zugehorigerZugfolge:
Konfiguration Zug(q0, 1)1#11#1#100 (q0, 1, R)
. . . . . .(q2, 1)1#11#1#100 (q2, 1, R)1(q2, 1)#11#1#100 (q2, 1, R)11(q2, #)11#1#100 (q2, ∗, R)11 ∗ (q2, 1)1#1#10 (q2, 1, R)11 ∗ 1(q2, 1)#1#10 (q2, 1, R)11 ∗ 11(q2, #)1#10 (q2, #, R)11 ∗ 11#(q2, 1)#10 (q2, 1, R)
. . . . . .(q4, 0)0#11#1#100 . . .
. . . . . .
Wegen Satz 1.2.6 durfen wir uns vorstellen, dass M ′ drei Bander hat. Band 1 enthaltanfangs den Input x ∈ Σ∗; diese Inschrift wird nie verandert. Band 2 dient als Arbeitsbandvon M . Auf Band 3 werden nacheinander alle endlichen Zugfolgen (z1, z2, . . . , zr) ∈ Seq(Z)erzeugt. Die Technik hierfur wurde in Lemma 1.3.10 beschrieben; setze einfach ∆ = Z.Fur jede erzeugte Folge (z1, z2, . . . , zr) tut M ′ folgendes:
1. Kopiere x von Band 1 auf Band 2, stelle den Lese-/Schreibkopf auf Band 2 auf denersten Buchstaben von x.
2. Stelle den Bandkopf auf Band 3 auf z1.
3. Lasse den Anfang einer Berechnung von M auf Band 2 ablaufen, gesteuert vonder Zugfolge auf Band 3, wie folgt: Stelle M auf Zustand q0. Dann wiederhole diefolgenden Schritte: Wenn M in Zustand q ist und der Kopf auf Band 2 Buchstabea ∈ Γ liest, dann verfahre wie folgt.
– wenn δ(q, a) = ∅ ist und q ∈ F , dann halt M ′ akzeptierend; sonst:
– wenn der Kopf auf Band 3 den Zug z = (q′, a′, D)”sieht“, und (q′, a′, D) ∈
δ(q, a), fuhre Zug z = (q′, a′, D) aus und verschiebe den Kopf auf Band 3 um1 Feld nach rechts; sonst:
– bricht die Berechnung von M mit der gegenwartigen Zugfolge ab: erzeuge aufBand 3 die nachste Zugfolge, losche Band 2, und beginne wieder bei 1.
63

Man sieht leicht folgendes ein: Wenn M ′ akzeptierend halt, ist unmittelbar vorher eineakzeptierende Berechnung von M abgelaufen. Dann ist also x ∈ LM . Umgekehrt gilt: wennx ∈ LM ist, dann existiert eine akzeptierende Berechnung von M auf x. Eine Zugfolge(z1, z2, . . . , zr), die zu einer akzeptierenden Berechnung gehort16, wird irgendwann einmalerzeugt und fuhrt zur Entdeckung dieser akzeptierenden Berechnung, also akzeptiert M ′.�
Wenn CT (M,x) endlich ist, ist nach Bem. 1.3.8 die Menge aller Berechnungen von Mauf x endlich. Es ware gut, wenn auch die simulierende TM M ′ auf Input x anhalten undverwerfen wurde, wenn x 6∈ LM . Dies lasst sich durch eine leichte Modifikation von M ′
erreichen: Die TM M ′ beobachtet mit Hilfe eines Flagregisters in der Steuereinheit furjedes r, ob alle M -Berechnungen fur Zugfolgen (z1, . . . , zr) ∈ Zr vor oder mit Schritt r(nichtakzeptierend) enden. In diesem Fall kann dann auch M ′ (verwerfend) anhalten, weiles sicher keine einzige akzeptierende Berechnung von M auf x gibt. Wenn zudem bekanntist, dass fur x alle Berechnungen nach hochstens t ≥ |x| Schritten enden, dann ist derZeitbedarf fur einen Versuch mit r Schritten O(r + |x|), also insgesamt
∑
0≤r≤t
|Z|r ·O(|x|+ r) = O(|Z|t · (|x|+ t)) = O(|Z|t · t).
Fur alle t gilt |Z|t · t ≤ 2(log |Z|+1)t. — Diese Uberlegung liefert folgendes Resultat:
1.3.12 Korollar (a) Wenn L = LM fur eine NTM M ist, die die Eigenschaft hat, dassfur jedes x ∈ Σ∗ der Berechnungsbaum CT (M,x) endlich ist, dann ist LM rekursiv.(b) Wenn in der Situation von (a) t : N→ R+ eine Funktion ist derart dass fur jedes x ∈ Σ∗
jede Berechnung von M auf x hochstens t(|x|) Schritte macht, dann ist die simulierendeTuringmaschine M ′ aus Satz 1.3.11 O(2c·t(n))-zeitbeschrankt, fur c = 1 + log |Z|. �
Satz 1.3.11 und Korollar 1.3.12(a) haben die schone Konsequenz, dass wir nichtdetermi-nistische Turingmaschinen als eine Art Programmiertechnik einsetzen konnen, um leichterdie Rekursivitat oder rekursive Aufzahlbarkeit einer Sprache nachzuweisen. Wir demons-trieren dies an einigen Beispielen.
1.3.13 Beispiel (a) Die Sprache LRucksack∗ zum eingeschrankten Rucksackproblem istrekursiv. Die in Beispiel 1.3.2 angegebene NTM fur LRucksack∗ hat die Eigenschaft, dassalle Berechnungen auf einer Eingabe x anhalten; nach Bemerkung 1.3.8 ist CT (M,x)endlich fur alle x; nach Korollar 1.3.12 ist die Sprache LRucksack∗ rekursiv.
(b) Wenn L rekursiv aufzahlbar ist, und L′ = {x ∈ Σ∗ | ∃w ∈ L : x ist Oberfolge von w},dann ist L′ ebenfalls rekursiv aufzahlbar. (In Beispiel 1.3.6 wurde eine NTM M ′ fur L′
angegeben.)
(c) Wenn L rekursiv ist und L′ ist wie in (b) definiert, ist auch L′ rekursiv. Geht mannamlich in Beispiel 1.3.6 von einer TM M fur L aus, die fur jede Eingabe halt, dann ist fur
16Ganz genau: die erste, die in der in Lemma 1.3.10 beschriebenen Aufzahlung von Seq(Z) auftritt
64

jedes x ∈ Σn jede der 2n moglichen Berechnungen von M ′ auf x endlich, also CT (M,x)endlich. Nach Korollar 1.3.12 ist also L′ rekursiv.
Nichtdeterministische TMn sind besonders bequem beim Beweis von Abschlusseigenschaf-ten, wie in den folgenden Beispielen angegeben. Weitere Beispiele werden in den Ubungenbehandelt.
1.3.14 Beispiel (a) Wenn L1, L2 ⊆ Σ∗ rekursiv aufzahlbar sind, und # ist ein Zeichen,das nicht in Σ vorkommt, dann sind auch die Sprachen
L′ = {u#w | u ∈ L1 ∨ w ∈ L2} und L′′ = {u#w | u ∈ L1 ∧ w ∈ L2}
rekursiv aufzahlbar.
(b) Wenn L1, L2 aus (a) sogar rekursiv sind, sind L′ und L′′ ebenfalls rekursiv.
Beweis : (a) Wir gehen von (deterministischen) TMn M1 und M2 mit L1 = LM1bzw.
L2 = LM2aus. Eine NTM M ′ fur L′ arbeitet wie folgt: Eine Eingabe x ∈ (Σ ∪ {#})∗
wird zunachst darauf getestet, ob sie das Format u#w mit u, v ∈ Σ∗ hat. Falls dies nichtso ist, wird sofort verworfen. Sonst wird z. B. ein Zustand q′3 erreicht und ein einzigernichtdeterministischer Schritt
δ1(q′3, a) = {(q′1, a,N), (q′2, a,N)}, fur a ∈ Σ ∪ {#}
ausgefuhrt. Im Zustand q′1 wird #w geloscht und M1 auf u gestartet. Im Zustand q′2hingegen wird u# geloscht und M2 auf w gestartet. — Nach dem Akzeptierungsmodusbei nichtdeterministischen TMn wird x von M ′ akzeptiert genau dann wenn x = u#w mitu ∈ L1 oder w ∈ L2. Also ist LM ′ = L′; nach Satz 1.3.11 ist L′ rekursiv aufzahlbar.
Eine TM M ′′ fur L′′ arbeitet deterministisch: Sie uberpruft ihre Eingabe x zuerst, ob siedas Format u#w hat. Falls dies so ist, wird zuerst (als Unterprogramm, auf einem zweitenBand) M1 mit Eingabe u gestartet. Falls diese Berechnung verwirft, halt M ′′ und verwirft.Falls M1 u akzeptiert, wird M2 mit Eingabe w gestartet. Falls diese Berechnung ebenfallsakzeptiert, halt M ′′ und akzeptiert. — Es ist klar, dass M ′′ die Eingabe x genau dannakzeptiert, wenn x = u#w mit u ∈ L1 und w ∈ L2. Also ist LM ′ = L′. Man sollte nochbeachten, dass es moglich ist, dass M1 auf u uberhaupt nicht halt. Dann wird M2 auf wnicht gestartet und M ′′ auf x halt ebenfalls nicht. Dies ist aber in Ordnung, weil u 6∈ L1,also x 6∈ L′′.
(b) Wenn L1 und L2 rekursiv sind, gehen wir vor wie in (a), verwenden aber TMn M1
und M2, die fur alle Eingaben halten. Dann passiert folgendes: Alle BerechnungsbaumeCT (M ′, x) zur NTM M ′ sind endlich. Nach Korollar 1.3.12 ist dann L′ = LM ′ rekursiv. ImFalle von M ′′ halten alle Berechnungen der TM M ′′ an, demnach ist L′′ = LM ′′ rekursiv.
65

1.3.2 Turingmaschinen und Chomsky-0-Grammatiken
Man erinnere sich an die Definition von Chomsky-0- oder Typ-0-Grammatiken in der Vor-lesung
”Automaten und formale Sprachen“. Dies waren die
”uneingeschrankten“ Gram-
matiken G = (V, Σ, S, P ), wo die Menge P aus beliebigen Produktionen der Form
l→ r, l, r ∈ (V ∪ Σ)∗, |l| ≥ 1
bestand.
1.3.15 Beispiel Die Grammatik G = (V, Σ, S, P ) mit V = {S,X,B}, Σ = {a, b, c}und Produktionen
S → aXbc
X → aXB
X → ε
Bb → bB
Bc → bcc
ist eine Chomsky-0-Grammatik.
Die Sprache L(G) ist folgendermaßen definiert: Fur α, β ∈ (V ∪Σ)∗ schreiben wir α⇒ β,wenn α = γlδ und β = γrδ fur irgendwelche γ, δ ∈ (V ∪ Σ)∗ und eine Regel l → r in P .Dann bilden wir die reflexive und transitive Hulle von ⇒ und schreiben α ⇒∗ β, wennα = β oder es k ≥ 1 und α0 = α, α1, . . . , αk−1, αk = β gibt mit α0 ⇒ α1 ⇒ · · · ⇒ αk.Schließlich definieren wir L(G) := {w ∈ Σ∗ | S ⇒∗ w}.Eine Sprache L gehort zu der Klasse L0 der Chomsky-0-Sprachen oder Typ-0-Sprachen,wenn es eine Typ-0-Grammatik G gibt mit L = L(G).
Wenn G eine Typ-0-Grammatik ist, so gehort zu jedem Wort w ∈ L(G) eine (nichtnotwendig eindeutig bestimmte) Ableitung S = α0 ⇒ α1 ⇒ · · · ⇒ αk = w, die w aus S
”erzeugt“.
In Beispiel 1.3.15 sind folgendes Ableitungen fur das Wort aaabbbccc:
S ⇒ aXbc⇒ aaXBbc⇒ aaaXBBbc⇒ aaaBBbc
⇒ aaaBbBc⇒ aaabBBc⇒ aaabBbcc⇒ aaabbBcc⇒ aaabbbccc
und
S ⇒ aXbc⇒ aaXBbc⇒ aaXbBc⇒ aaXbbcc
⇒ aaaXBbbcc⇒ aaaXbBbcc⇒ aaaXbbBcc⇒ aaaXbbbccc⇒ aaabbbccc.
Ableitungen lassen sich auch sehr gut ruckwarts interpretieren. Wenn l→ r eine Produk-tion ist, sagen wir, dass man αrβ durch (Ruckwarts-)Anwendung der Regel l → r (oder
66

durch Anwendung der Reduktionsregel r ← l) zu αlβ reduzieren kann, und schreibenαrβ ⇐ αlβ. Dann bilden wir Reduktionsfolgen
α1 ⇐ α2 ⇐ · · · ⇐ αk.
Offenbar ist w ∈ L(G) genau dann wenn w ∈ Σ∗ und eine Reduktion w ⇐ · · · ⇐ Sexistiert. Folgendes ist eine Reduktionsfolge in der Grammatik G aus Beispiel 1.3.15:
aaabbbccc ⇐ aaaXbbbccc⇐ aaaXbbBcc⇐ aaaXbBbcc⇐ aaaXBbbcc
⇐ aaXbbcc⇐ aaXbBc⇐ aaXBbc⇐ aXbc⇐ S.
Der Reduktionsprozess erinnert etwas an die Arbeitsweise einer nichtdeterministischenTuringmaschine, die von einem Eingabewort x ∈ Σ∗ zu einer
”Normalform“, namlich dem
Startsymbol S, zu gelangen versucht. Tatsachlich gibt es einen engen Zusammenhang.Wir werden beweisen, dass die rekursiv aufzahlbaren Sprachen genau die Chomsky-0-Sprachen sind, indem wir zeigen, dass Reduktionsfolgen im wesentlichen dasselbe wieNTM-Berechnungen sind.
1.3.16 Satz Sei L ⊆ Σ∗ eine Sprache. Dann gilt:
L ist rekursiv aufzahlbar ⇔ L ist in L0.
Beweis : Wir fuhren zwei Konstruktionen durch.
”⇒“: Gegeben sei eine nichtdeterministische 1-Band-TM M = (Q, Σ, Γ, B, q0, F, δ) mit
L = LM . Wir konnen annehmen, dass M vor dem Akzeptieren immer das gesamte Ar-beitsband mit Blanks uberschreibt (
”das Band loscht“) und dass M nur einen einzigen
akzeptierenden Zustand q∗ besitzt, d. h. dass F = {q∗} gilt, und dass δ(q∗, B) = ∅. (Wenndies nicht so ist, konnen wir M so umbauen, dass die Bedingungen erfullt sind.) DieseAnnahmen fuhren dazu, dass M nur eine akzeptierende Haltekonfiguration hat, namlich(q∗, B). Wir konstruieren eine Typ-0-Grammatik G = GM mit LM = L(G). Die Grund-idee ist, dass eine Ableitung in G im wesentlichen eine Berechnung von M in umgekehrterReihenfolge sein sollte — das heißt, dass Berechnungen von M sich als Reduktionsfolgenvon G wiederfinden. Die Satzformen von G, d. h. die auf S reduzierbaren Worter uberV ∪ Σ, haben die Form
/cB · · ·BkB · · ·B$,
wobei k eine Konfiguration von M ist, von der aus man zur akzeptierenden Haltekon-figuration gelangen kann. Hinzu kommen einige spezielle Worter in der Teilableitung/c initM(w) $⇒∗ w.
G hat als Terminalzeichenalphabet das Eingabealphabet Σ von M , das Startsymbol S,die Variablenmenge V = (Γ−Σ)∪ (Q×Γ)∪{S, /c, $, #}, und die folgenden Produktionen:
Startregel:
S → /c(q∗, B)$.
67

Damit ist genau die akzeptierende Konfiguration von M ableitbar. In jeder Konfigurationwollen wir an den Randern beliebig Blankzeichen hinzufugen und streichen konnen:
Blankregeln:
/c → /cB,
/cB → /c,
$ → B$,
B$ → $.
Nun folgen Regeln, die es erlauben, die Schritte von M ruckwarts als Produktionen zubenutzen, d. h. die Schritte von M entsprechen Reduktionsschritten:
Schrittregeln:
a′(q′, c)→ (q, a)c , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, R) ∈ δ(q, a);
(q′, c)a′ → c(q, a) , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, L) ∈ δ(q, a);
(q′, a′)→ (q, a) , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, N) ∈ δ(q, a).
Man sieht ganz leicht ein (formal: durch einen Induktionsbeweis uber die Schrittzahl vonM bzw. die Lange einer Ableitung mittels der bisher angegebenen Produktionen), dassgilt:
S ⇒ /c(q∗, B)$⇒∗ α
mit den bisher angegebenen Produktionen genau dann wenn α = /cB · · ·BkB · · ·B$ fureine Konfiguration k von M mit k `∗M (q∗, B). Uns interessieren nur Startkonfigurationen,d. h. solche α = /c B · · ·BkB · · ·B $, bei denen k das Format (q0, B) oder (q0, a1)a2 · · · an
fur ein n ≥ 1 und a1, . . . , an ∈ Σ hat. Mit einigen Abschlussregeln sorgen wir dafur, dassgenau aus solchen α Worter uber Σ abgeleitet werden konnen. Die Idee ist, (q0, a) durcha zu ersetzen und damit die Anwendung weiterer Schrittregeln unmoglich zu machen,und dann das Spezialzeichen # von links nach rechts durch das Wort laufen zu lassenund dabei zu uberprufen, dass nur Terminalzeichen vorhanden sind, und schließlich beimAuftreffen des # auf das $-Zeichen am rechten Ende beide Zeichen verschwinden zu lassen.
Uberflussige Blankzeichen am rechten Ende kann man mit den Blankregeln entfernen.
Abschlussregeln:
/c(q0, B)$ → ε;
/c(q0, a) → a# , fur a ∈ Σ;
#a → a# , fur a ∈ Σ;
#$ → ε.
68

Wenn z. B. Σ = {a, b, c}, wird durch die Abschlussregeln die folgende Teilableitung er-moglicht:
/c(q0, a)bcaBB$⇒ a#bcaBB$⇒ ab#caBB$⇒ abc#aBB$⇒ abca#BB$.
Mit zwei Anwendungen von Blankregeln und der letzten Abschlussregel erhalt man:
abca#BB$⇒ abca#B$⇒ abca#$⇒ abca.
Man”sieht“, dass /c- und $-Zeichen nur verschwinden konnen, wenn das verbleibende Wort
nur aus Terminalzeichen besteht.
Damit ist die Grammatik G = GM vollstandig beschrieben. Wir mussen zeigen: LM =L(G).
”⊆“: Wenn w ∈ LM , dann gibt es eine Berechnung initM(w) ` · · · ` (q∗, B). Nach der
bisherigen Uberlegung gibt es eine Ableitung S ⇒∗ /cB · · ·B initM(w) B · · ·B$. Mitden Blankregeln erhalten wir S ⇒∗ /c initM(w) $. Wegen der Abschlussregeln gilt/c initM(w) $⇒∗ w, also ist w ∈ L(G).
”⊇“: Wenn w = a1 · · · an ∈ L(G), gibt es eine Ableitung S ⇒ /c(q∗, B)$ ⇒∗ w. Damit
das /c-Symbol verschwindet, muss einmal eine der”/c(q0, c)-Schlussregeln“ verwen-
det werden. Dies eliminiert den Zustandsbuchstaben (q0, c), also sind danach keineSchrittregeln mehr anwendbar, nur noch Abschlussregeln und die Blankregeln furden $. Wegen der Struktur der Abschlussregeln zerfallt die Ableitung in zwei Phasen:
S ⇒ /c (q∗, B) $⇒∗ /c (q0, c)a2 · · · anB · · ·B $
und/c (q0, c)a2 · · · anB · · ·B $⇒∗ w.
Dabei eliminiert der erste Schritt von Phase 2 das (q0, c); falls w = ε, ist c = B,sonst ist und c = a1. Die erste Phase liefert wegen der Gestalt der Schrittregeln undder Blankregeln, dass initM(w) `∗M (q∗, B), also w ∈ LM .
”⇐“: Gegeben sei eine Typ-0-Grammatik G = (Σ, V, S, P ). Wir beschreiben die Arbeits-
weise einer 1-Band-NTM M = (Q, Σ, Γ, B, q0, F, δ). Dabei ist Γ so gewahlt, dass das Bandeine Textspur hat, in der Zeichen aus V ∪ Σ ∪ {B} stehen konnen, sowie eine Spur furMarkierungen. M versucht, zu Eingabewort w = a1 · · · an eine Reduktion in G von wzu S zu finden. Die Menge P der Produktionen ist endlich, also konnen wir sie in derUbergangsfunktion δ verwenden.
Aus Zustand q0 wechselt M in den Zustand p0. Die Rechnung danach erfolgt in Runden.Zu Beginn einer Runde ist M immer in einer Konfiguration (p0, x1)x2 · · ·xm; dann setzenwir α := x1 · · ·xm ∈ (V ∪ Σ)+. Ausnahme: Zu Beginn der ersten Runde kann das Band
69

vollig leer sein, dann ist M in der Konfiguration (p0, B) und wir setzen α := ε. Spur 2 istzu Beginn einer Runde leer.
Eine Runde besteht aus folgenden Aktionen:1. Teste, ob α = S. Falls ja, halt M akzeptierend.2. Sonst markiere nichtdeterministisch Beginn und Ende eines Teilwortes xi · · ·xj, 1 ≤i, j ≤ m, i ≤ j + 1, von α;17 dann3. wahle nichtdeterministisch eine Produktion l → r aus P . Teste, ob r = xi · · ·xj. Fallsdies nicht erfullt ist, halte verwerfend; sonst4. ersetze auf dem Band das Teilwort xi · · ·xj durch l. (Falls |l| 6= |r|, ist hierzu eineVerschiebung des Teilwortes xj+1 · · ·xm um |l| − |r| Zellen nach rechts oder links notig.)5. Losche alle Markierungen, fahre den Kopf auf das erste Feld der Bandinschrift, gehe inZustand p0.
Nach der Beschreibung ist klar, dass M genau dann in einer Runde von Konfigurati-on (p0, x1)x2 · · ·xm in Konfiguration (p0, y1)y2, . . . , ys gelangen kann, wenn y1 · · · ys ⇒x1 · · · xm. Daraus folgt, dass M genau dann in einer Folge von Runden von (p0, a1)a2 · · · an
(bzw. (p0, B), fur w = ε) in die Konfiguration (p0, S) gelangen kann, die zum Akzeptierenfuhrt, wenn S ⇒∗ a1 · · · an. Das bedeutet, dass M die Eingabe w akzeptiert genau dannwenn x ∈ L(G). �
1.3.17 Bemerkung Satz 1.3.16 beinhaltet die auf den ersten Blick uberraschen-de Tatsache, dass das Konzept
”rekursiv aufzahlbare Sprache“ eine Charakterisierung
durch Grammatiken hat, also Regelsysteme zur Erzeugung von Wortmengen. Diese ha-ben auf den ersten Blick uberhaupt nichts mit Berechnungen zu tun. Erst der Blick ausder Perspektive der nichtdeterministischen Berechnungen auf TMn zeigt, dass zwischenTM-Berechnungen und Ableitungen bzw. Reduktionen in einer Grammatik gar kein sogroßer Unterschied besteht.
Wo sind hier die partiell rekursiven Funktionen und die rekursiven Sprachen einzuordnen?In der Ubung wird gezeigt, dass eine Funktion f : D → Σ∗ mit D ⊆ Σ∗ genau dann partiellrekursiv ist, wenn der
”Graph“ {x#f(x) | x ∈ D} eine rekursiv aufzahlbare Sprache uber
Σ ∪ {#} ist. Das heißt, dass auch die partiell rekursiven Funktionen ohne jeden Bezugauf eine Maschine oder Berechnung definiert werden konnen. — In Abschnitt 1.4 werdenwir sehen, dass L genau dann rekursiv ist, wenn L und L = Σ∗ − L rekursiv aufzahlbarsind. Dies fuhrt zu folgender Charakterisierung der rekursiven Sprachen ohne Bezug aufMaschinen, Programme oder Berechnungen:
L ist rekursiv ⇔ es gibt Typ-0-Grammatiken G und G′ mit L = L(G) und L = L(G′).
17Wenn i = j + 1, ist xi · · ·xj = ε.
70

1.3.3 Linear beschrankte Automaten undChomsky-1-Grammatiken
Mit den Methoden aus dem letzten Abschnitt konnen wir auch den Maschinentyp be-schreiben, der zu den Chomsky-1-Grammatiken gehort.
Zur Erinnerung: Eine Grammatik G = (V, Σ, S, P ) hieß vom Typ 1 oder eine Chomsky-1-Grammatik, falls alle ihre Produktionen
”kontextsensitiv“ waren, d. h. von der Form
αAγ → αβγ, wo A ∈ V , α, β, γ ∈ (Σ ∪ V )∗ und |β| ≥ 1;
die einzige Ausnahme ist die Produktion S → ε, die erlaubt ist, wenn S in keiner Pro-duktion auf der rechten Seite vorkommt.
Alternativ betrachtet man”(wortlangen)monotone“ Grammatiken, die nur
”monotone
Produktionen“ haben, das sind Produktionen
l→ r, wo l ∈ (Σ ∪ V )+, r ∈ (Σ ∪ V )∗ und |l| ≤ |r|;
bezuglich der Produktion S → ε gilt dieselbe Ausnahme wie bei den Typ-1-Grammatiken.
1.3.18 Beispiel Die Grammatik aus Beispiel 1.3.15 ist offenbar nicht monoton (wegender Produktion X → ε). Ebenso ist die im Beweis von Satz 1.3.16
”⇒“ konstruierte
Grammatik nicht monoton, insbesondere wegen der Blankregeln /cB → /c und B$ → $.Diese Regeln erlauben es, im Verlauf einer Ableitung fur x Satzformen α zu benutzen, dieviel langer sind als x.
Folgendes ist eine monotone Grammatik fur die Sprache {anbncn | n ≥ 0}: G = (V, Σ, S, P )mit V = {S,X,B}, Σ = {a, b, c} und Produktionen
S → ε
S → abc
S → aXbc
X → aXB
X → aB
Bb → bB
Bc → bcc
Eine Ableitung fur das Wort x = aaabbbccc in dieser Grammatik sieht so aus:
S ⇒ aXbc⇒ aaXBbc⇒ aaaBBbc
⇒ aaaBbBc⇒ aaabBBc⇒ aaabBbcc⇒ aaabbBcc⇒ aaabbbccc
Man bemerkt, dass naturlich in der Ableitung die Langen der Satzformen nicht abnehmen,d. h. jede Satzform hat ≤ |x| Buchstaben.
71

Schon in der Vorlesung”Automaten und Formale Sprachen“ hatten wir bemerkt, dass
monotone Grammatiken und kontextsensitive Grammatiken dieselben Sprachen erzeugen.
1.3.19 Lemma Fur eine Sprache L ⊆ Σ∗ sind aquivalent:(i) L = L(G) fur eine monotone Grammatik G.(ii) L = L(G′) fur eine Typ-1-Grammatik G′ (d. h. L liegt in L1).
Beweis : Die Implikation”(ii)⇒ (i)“ ist offensichtlich. Wir beweisen
”(i)⇒ (ii)“. Gegeben
ist also eine monotone Grammatik G = (V, Σ, S, P ). Wir bauen G zu einer kontextsensi-tiven Grammatik um. (Zur Vereinfachung nehmen wir an, dass P die Produktion S → εnicht enthalt. Anderenfalls wird diese Produktion beim Umbau unverandert gelassen.)
Schritt 1: Separierung. Fur jedes a ∈ Σ erfinde eine neue Variable Ca. Ersetze in allenProduktionen in P (auf linken und rechten Seiten) jedes Vorkommen von a ∈ Σ durchCa, und fuge zu P die neuen Produktionen Ca → a hinzu. Die neue Grammatik Gsep =(V ′, Σ, S, P ′) mit V ′ = V ∪ {Ca | a ∈ Σ} erzeugt offensichtlich dieselbe Sprache wie Gund ist separiert, d. h. jede Produktion hat die Form
A1 · · ·Ar → B1 · · ·Bs, 1 ≤ r ≤ s, A1, . . . , Ar, B1, . . . , Bs ∈ V ′;
A→ a, A ∈ V ′, a ∈ Σ.
Schritt 2: Wir starten mit einer separierten Grammatik G (benenne Gsep aus Schritt 1wieder in G um). Produktionen der Form A→ B1 · · ·Bs, s ≥ 1, bleiben unverandert; siesind schon kontextsensitiv. Fur eine Produktion
A1 · · ·Ar → B1 · · ·Bs
mit 2 ≤ r ≤ s fuhren wir r neue Variable Z1, . . . , Zr ein und ersetzen die Produktiondurch die folgende Folge von kontextsensitiven Produktionen:
A1A2 · · ·Ar → Z1A2 · · ·Ar,
Z1A2A3 · · ·Ar → Z1Z2A3 · · ·Ar,...
......
Z1 · · ·Zr−1Ar → Z1 · · ·Zr−1Zr;
Z1Z2 · · ·Zr → B1Z2 · · ·Zr;
B1Z2Z3 · · ·Zr → B1B2Z3 · · ·Zr;...
......
B1 · · ·Br−2Zr−1Zr → B1 · · ·Br−2Br−1Zr
B1 · · ·Br−1Zr → B1 · · ·Br−1Br · · ·Bs.
Man sieht sofort, dass man alle Ableitungen in der Grammatik G in der neuen GrammatikG′ nachbauen kann, d. h. dass L(G) ⊆ L(G′) ist. Weil die Anderung an den neuen Z-Variablen immer nur im vollen Kontext erfolgen kann, ist es auch nicht schwer einzusehen,
72

dass man aus einer G′-Ableitung fur w auch eine G-Ableitung fur w gewinnen kann, sodass also L(G′) ⊆ L(G) ist. �
Wir betrachten nun Turingmaschinen, deren Kopf nie die Felder verlasst, in denen ur-sprunglich die Eingabe steht. Um der TM die Chance zu geben, das Eingabeende zuerkennen, wird die Eingabekonvention leicht verandert: man
”markiert“ den letzten Ein-
gabebuchstaben.”Markierte“ Buchstaben erhalt man wie folgt. Zu Σ definiert man
Σ0 := {(a, 0) | a ∈ Σ} , Σ1 := {(a, 1) | a ∈ Σ} , Σ# := {(a, #) | a ∈ Σ} .
Dann schreibt man wieder a fur (a, 0) (unmarkierte Version), a fur (a, 1) und a# fur(a, #). (Die a-Buchstaben werden als Bandbuchstaben benutzt; die #-Buchstaben ineiner Grammatik im Beweis des folgenden Satzes.) Fur Eingabe x = a1 · · · an ist dieStartkonfiguration
init′M(x) =
(q0, B), falls x = ε;(q0, a), falls x = a ∈ Σ;(q0, a1)a2 · · · an−1an, falls x = a1 · · · an ∈ Σn, n ≥ 2.
Mit dieser Konvention kann die NTM sicher erkennen, wenn der Kopf die Zelle mit demletzten Eingabebuchstaben betritt.
Die Eingabe ε lasst sich leicht behandeln. Wir konnen annehmen, dass bei allen betrach-teten Maschinen δ(q0, B) = ∅ ist, dass bei beliebigen Inputs nach dem Start der Rechnungq0 nie mehr betreten wird, und dass q0 akzeptierend ist genau dann wenn ε akzeptiertwerden soll.
1.3.20 Definition Eine NTM M heisst linear bandbeschrankt (oder ein”linear be-
schrankter Automat“,”LBA“), wenn auf Eingabe a1 · · · an, n ≥ 1, d. h. mit Konfiguration
init′M(a1 · · · an) gestartet, der Kopf von M niemals ein Bandfeld außerhalb der n Einga-befelder betritt. (Auf Eingabe ε halt M an, ohne einen Schritt zu machen.)
Der folgende Satz entspricht in Aussage und Beweis Satz 1.3.16 zur Beziehung zwischennichtdeterministischen Turingmaschinen und Typ-0-Grammatiken. Im Beweis muss manzusatzlich die Monotonie der Grammatik und die Platzschranke der NTM berucksichtigen.
1.3.21 Satz Sei L ⊆ Σ∗ eine Sprache. Dann gilt:
L = LM fur einen LBA M ⇔ L ist in L1.
Beweis : Wir betrachten wieder zwei Richtungen.
”⇒“: Gegeben sei ein LBA M = (Q, Σ, Γ, B, q0, F, δ) mit L = LM . Wir konnen annehmen,
dass M (neben dem Sonderfall q0 im Falle ε ∈ LM) nur einen akzeptierenden Zustand q∗
besitzt, und dass M vor dem Ubergang nach q∗ das Feld, auf dem der Kopf stehenbleibt,mit B uberschreibt. Damit haben die akzeptierenden Konfigurationen von M die Gestaltα(q∗, B)β, fur Worter α, β ∈ Γ∗.
73

Wir geben eine monotone Grammatik fur L an. Diese ahnelt der aus Satz 1.3.16, wiederentsprechen also Turingmaschinenberechnungen den Reduktionsfolgen in G, jedoch mussman mit einem kleinen Trick dafur sorgen, dass nichtmonotone Produktionen vermiedenwerden.
G hat als Terminalzeichenalphabet das Eingabealphabet Σ von M , das Startsymbol S,die Variablenmenge V = (Γ − Σ) ∪ (Q × Γ) ∪ {a, a# | a ∈ Σ} ∪ {S}, und die folgendenProduktionen:
Startregeln:
S → (q∗, B);
(q∗, B) → X(q∗, B), fur X ∈ Γ,
(q∗, B) → (q∗, B)X, fur X ∈ Γ,
S → ε , falls ε ∈ LM .
Hiermit sind alle akzeptierenden Konfigurationen von M aus S ableitbar, sowie eventuellε.
Schrittregeln:
a′(q′, c)→ (q, a)c , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, R) ∈ δ(q, a);
(q′, c)a′ → c(q, a) , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, L) ∈ δ(q, a);
(q′, a′)→ (q, a) , fur q, q′ ∈ Q, a, a′, c ∈ Γ,
falls (q′, a′, N) ∈ δ(q, a).
Wieder ist klar, dass die Schrittregeln es erlauben, Berechnungen von M ruckwarts nach-zubilden. Nun mussen wir Abschlussregeln so formulieren, dass ein Terminalzeichenwortx ∈ Σ+ nur aus der Startkonfiguration init′M(x) ableitbar ist. Dabei durfen wir keineSonderzeichen benutzen, die die Wortlange verandern. Der simple Trick: Wir integrierenein Sonderzeichen in die Buchstaben. Hierzu benutzen wir die #-markierten Buchstabenvon oben.
Abschlussregeln:
(q0, a) → a , fur a ∈ Σ,
(q0, a) → a# , fur a ∈ Σ,
a#b → ab# , fur a, b ∈ Σ,
a#b → ab , fur a, b ∈ Σ.
Beispielsweise sieht eine Teilableitung init′M(abaa) ⇒∗ abca mit diesen Abschlussregelnfolgendermaßen aus:
(q0, a)bca⇒ a#bca⇒ ab#ca⇒ abc#a⇒ abca.
74

Die beschriebene Grammatik G ist offenbar monoton. Dass LM = L(G) ist, zeigt mananalog zu dem Argument im Beweis von Satz 1.3.16.
”⇐“: Wie in Satz 1.3.16, Beweisteil
”⇐“, benutzen wir eine 1-Band-NTM M mit zwei
Spuren, einer Textspur, in der im wesentlichen Zeichen aus V ∪Σ∪{a | a ∈ Σ} stehen, undeiner Spur fur Markierungen. Der Fall ε wird gesondert behandelt, wie oben beschrieben.Ausgehend von der Startkonfiguration (q0, a1)a2 · · · an−1an (bzw. (q0, a1) fur n = 1) fahrtder Kopf einmal hin und her uber den gesamten Input, um in die Markierungsspur untera1 ein /c-Zeichen zu schreiben und in der Zelle, die an enthalt, in die Textspur an und indie Markierungsspur ein $-Zeichen zu schreiben. Die /c- und die $-Markierung werden nieverandert. Ab jetzt arbeitet M genau wie die NTM in Satz 1.3.16, Beweisteil
”⇐“, mit den
folgenden Unterschieden: Der Kopf macht nie von der /c-Zelle aus eine L-Bewegung undnie von der $-Zelle aus eine R-Bewegung. In den Ersetzungsrunden, in denen ein Teilwortr der Inschrift in Spur 1 durch ein Teilwort l ersetzt wird, darf die Produktion S → εnicht benutzt werden. Weil G monoton ist, gilt fur alle anderen Produktionen l→ r, dass|l| ≤ |r| ist; daher tritt in den Ersetzungsrunden nie eine Verlangerung der Bandinschriftein. M halt und akzeptiert genau dann, wenn die Bandinschrift in der Textspur schließlichSB · · ·B ist. �
Man kann den Beweis des vorherigen Satzes etwas ausbauen, um das folgende Ergebniszu beweisen.
1.3.22 Satz Wenn L eine kontextsensitive Sprache ist, dann ist L rekursiv.
Beweisskizze: Gegeben sei eine monotone Grammatik G mit L = L(G). Man bemerkt,dass man wegen der Monotonie der Produktionen eine leicht zu berechnende Funktiong : N→ N findet, so dass jedes Wort x ∈ L eine Ableitung einer Lange ≤ g(|x|) hat. Nunkann die im vorherigen Beweis betrachtete NTM M bei ihrer Suche nach einer Ableitungfur ein Eingabewort x nach Runde g(|x|) abbrechen. Damit erhalten wir eine NTM fur L,die nur endliche Berechnungen hat. Aus den Ergebnissen von Abschnitt 1.3.1 folgt dann,dass L rekursiv ist. Die Details sind Gegenstand einer Ubungsaufgabe. �
1.3.23 Bemerkung: Die Chomsky-Hierarchie Mit den Erkenntnissen dieses Ka-pitels konnen wir die bisherigen Aussagen zur Chomsky-Hierarchie erweitern:
(a) L3 ( L2. (AFS-Vorlesung.)
(b) L2 ( L1. (AFS-Vorlesung.)
(c) L1 ⊆ {L | L ist rekursiv}. (Vorhergehender Satz.)
(d) {L | L ist rekursiv } ⊆ {L | L ist rekursiv aufzahlbar}.
(e) {L | L ist rekursiv aufzahlbar} = L0. (Satz 1.3.16.)
Die Frage, ob die Inklusionen in (c) und (d) echt sind, wird im weiteren Verlauf derVorlesung (mit
”ja“) beantwortet. Damit ergibt sich zusammenfassend:
75

Hauptsatz uber die Chomsky-Hierarchie:L3 ( L2 ( L1 ( L0 .
1.4 Struktur- und Abschlusseigenschaften
In diesem Abschnitt untersuchen wir, unter welchen Operationen die Sprachklassen derrekursiven und der rekursiv aufzahlbaren Sprachen abgeschlossen sind. Weiter diskutierenwir das Konzept eines
”Aufzahlers“ (eines deterministischen Erzeugungsverfahrens) fur re-
kursiv aufzahlbare Sprachen. Zu diesem Zweck fuhren wir weitere Programmiertechnikenfur Turingmaschinen ein, die dazu dienen, mit dem Problem nichthaltender Berechnungenumzugehen.
Im folgenden ist Σ immer ein Alphabet, das Eingabealphabet der vorkommenden TMn,und das den vorkommenden Sprachen zugrundeliegende Alphabet. Zu L ⊆ Σ∗ ist L =Σ∗ − L.
Bei den rekursiven Sprachen sind die Verhaltnisse einfach.
1.4.1 Satz Es seien L,L1, L2 ⊆ Σ∗. Dann gilt:
(a) L ist rekursiv ⇒ L ist rekursiv.
(b) L1, L2 sind rekursiv ⇒ L1 ∩ L2 und L1 ∪ L2 sind rekursiv.
(c) L ist rekursiv ⇔ cL ist rekursiv, wo
cL(x) =
{
1, falls x ∈ L
0, sonst
die charakteristische Funktion von L bedeutet.
(d) L1, L2 sind rekursiv ⇒ L1L2 ist rekursiv.
(e) L ist rekursiv ⇒ L∗ ist rekursiv.
Beweis : Alle Beweise bestehen darin, dass man gegebene TMn nimmt und in andereumbaut.
(a) Gegeben sei eine TM M = (Q, Σ, Γ, B, q0, F, δ) mit L = LM , die auf allen Inputshalt. Wir benotigen eine TM M mit L = LM , die ebenfalls auf allen Inputs halt.Dafur genugt es, in M die akzeptierenden und die verwerfenden Zustande zu ver-tauschen, d. h. man setzt M = (Q, Σ, Γ, B, q0, Q− F, δ).
76

(b) L1, L2 ⊆ Σ∗ seien rekursiv. M1 und M2 seien TMn mit L1 = LM1und L2 = LM2
,die auf allen Inputs halten. Eine neue Maschine M ′ geht vor wie folgt:
1. Kopiere Eingabe x ∈ Σ∗ auf ein zweites Band.
2. Lasse M1 auf Band 1 ablaufen. Dann lasse M2 auf Band 2 ablaufen.
3.”∩“: Falls M1 und M2 akzeptierend gehalten haben, akzeptiert M ′, sonst ver-
wirft M ′.
”∪“: Falls M1 oder M2 akzeptierend gehalten hat, akzeptiert M ′, sonst verwirft
M ′.
Offenbar gilt LM ′ = L1 ∩ L2 im”∩“-Fall und LM ′ = L1 ∪ L2 im
”∪“-Fall, und auch
M ′ halt auf allen Inputs.
(c)”⇒“: Sei L = LM fur eine TM M , die auf allen Eingaben halt. Die Ubergangs-
funktion δ von M wird leicht modifiziert, wie folgt: Ist δ(q, a) undefiniert (d. h. Mhalt), fuhrt die modifizierte TM M ′ noch zwei Schritte aus: Sie schreibt
”bB“ auf
das Band, b ∈ {0, 1}, und stellt den Kopf auf das b; dabei ist b = 1, falls q ∈ F , undb = 0, falls q /∈ F . Nach den Ausgabekonventionen fur TMn gilt dann: M ′ halt furjeden Input, und fM ′ = cL.
”⇐“: Umgekehrt kann aus einer TM M ′ mit fM ′ = cL leicht eine TM M konstruiert
werden, die mittels des Endzustandes akzeptiert/verwirft: Wenn M ′ halt, fuhrt Meinen weiteren Schritt aus und geht in einen akzeptierenden Zustand, wenn der Kopfeine 1 liest, und in einen verwerfenden, wenn der Kopf eine 0 liest.
(d) Ubungsaufgabe.
(e) Ubungsaufgabe. �
1.4.2 Satz Wenn L,L1, L2 ⊆ Σ∗ rekursiv aufzahlbare Sprachen sind, dann gilt:
(a) L1 ∩ L2 ist rekursiv aufzahlbar.
(b) L1 ∪ L2 ist rekursiv aufzahlbar.
(c) L1L2 ist rekursiv aufzahlbar.
(d) L∗ ist rekursiv aufzahlbar.
Beweis : Wieder werden aus gegebenen Turingmaschinen andere konstruiert. Fur (a), (b),(c) seien M1,M2 1-Band-TMn mit L1 = LM1
, L2 = LM2.
(a) Eine 2-Band-TM M mit LM = L1∩L2 arbeitet wie folgt: Der Input x wird auf Band2 kopiert. Dann wird M1 mit Eingabe x auf Band 1 gestartet. Wenn und sobald M1
akzeptierend halt, wird M2 mit Eingabe x auf Band 2 gestartet. Wenn auch dieseBerechnung akzeptierend halt, akzeptiert M . — Es ist klar, dass LM = L1 ∩ L2.Dies gilt, obwohl es passieren kann, dass M1 auf x nicht halt, und M2 auf x garnicht gestartet wird. Aber weil dann x /∈ L1 ∩ L2, ist dies unerheblich.
77

(b) Nun suchen wir eine TM M fur L1 ∪ L2. Der eben benutzte Ansatz, M1 und M2
nacheinander laufen zu lassen, funktioniert hier nicht, denn M muss x auch akzep-tieren, wenn M1 nicht halt, aber M2 akzeptiert. Stattdessen lassen wir M1 und M2
parallel ablaufen.
1) Vorbereitung: Kopiere Eingabe x ∈ Σ∗ auf das zweite Band.
... B B B e i n g a b e B B B ...
... B e i n g a b e B B B B B ...
M AKZ M1 2
Flagregister
2) Lasse M1 auf Band 1 und M2 auf Band 2 gleichzeitig laufen. Die TM M benutztdazu die Zustandsmenge Q1 ×Q2 und eine Ubergangsfunktion δ1 × δ2, wo Q1
und δ1 fur das erste Band und Q2 und δ2 fur das zweite Band zustandig sind.
3) Wenn und sobald eine der Teilmaschinen M1 oder M2 akzeptierend gehaltenhat, halt M in einem akzeptierenden Zustand.
Es ist offensichtlich, dass M eine Eingabe x genau dann akzeptiert, wenn x ∈ L1∪L2
ist.
(c) Seien M1,M2 1-Band-TMn mit L1 = LM1, L2 = LM2
. Eine 2-Band-NTM M furL1L2 = {x1x2 | x1 ∈ L1, x2 ∈ L2} arbeitet wie folgt: Auf Input x wird ein nichtde-terministisch gewahltes Suffix x2 von Band 1 geloscht und auf Band 2 geschrieben.Der Rest auf Band 1 heißt x1. Dann wird M1 auf x1 auf Band 1 gestartet; wenndiese Berechnung akzeptiert, wird M2 auf x2 auf Band 2 gestartet. Wenn auch dieseBerechnung akzeptiert, halt M akzeptierend. — Nach dem fur NTMn geltendenAkzeptierungsmodus ist klar, dass M x genau dann akzeptiert, wenn man x = x1x2
mit x1 ∈ L1 und x2 ∈ L2 schreiben kann. Nach Satz 1.3.11 ist damit L1L2 rekursivaufzahlbar.
(d) Sei M eine 1-Band-TM mit L = LM . Eine 2-Band-NTM M ′ fur L∗ arbeitet wiefolgt auf Input x, der anfanglich auf Band 1 steht:Solange die Inschrift auf Band 1 nicht ε ist, wird folgende Runde wiederholt:
1) Ein nichtdeterministisch gewahltes Prafix z 6= ε der Inschrift y auf Band 1 wirdvon Band 1 geloscht und auf Band 2 geschrieben.
78

2) M wird mit Input z auf Band 2 gestartet. Wenn diese Berechnung von Mverwerfend halt, halt auch M ′ verwerfend. Wenn M akzeptiert, beginnt eineneue Runde.
Sobald nach der Ausfuhrung von r ≥ 0 Runden die Inschrift auf Band 1 ε gewordenist, akzeptiert M ′. —Es ist klar, dass M ′ x genau dann akzeptiert, wenn man x als z1 · · · zr schreibenkann mit z1, . . . , zr ∈ LM = L, d. h. wenn x ∈ L∗ ist. Nach Satz 1.3.11 ist damit L∗
rekursiv aufzahlbar.
�
1.4.3 Bemerkung Eine andere Moglichkeit fur den Beweis von (b) ware die Benutzungeiner NTM, die sich im ersten Schritt nichtdeterministisch entscheidet, ob M1 oder M2 aufx gestartet wird (vgl. Beispiel 1.3.14). Wir haben direkt eine deterministische 2-Band-TMM ′ fur L1 ∪L2 beschrieben, da die Konstruktion gleich nochmals benotigt wird, in einemZusammenhang, in dem Nichtdeterminismus nichts nutzt.
1.4.4 Satz Fur jede Sprache L ⊆ Σ∗ gilt:
L ist rekursiv ⇔ L und L sind rekursiv aufzahlbar.
Beweis :”⇒“: Sei L rekursiv. Nach Satz 1.4.1(a) ist dann auch L rekursiv. Nach Defini-
tion 1.1.16 (a) und (b) sind L und L rekursiv aufzahlbar.
”⇐“: (Durch Konstruktion.) Seien M1,M2 Turingmaschinen mit L = LM1
, L = LM2.
Wir betrachten die Maschine M aus dem Beweis von Satz 1.4.2(b) (sie startet M1 undM2 gleichzeitig auf Eingabe x), nur mit anderem Akzeptierungsverhalten:
Sobald M1 halt und akzeptiert, halt und akzeptiert M .Sobald M2 halt und akzeptiert, halt und verwirft M .
Wir haben fur Eingaben x ∈ Σ∗:x ∈ L⇒M1 halt und akzeptiert ∧ M2 akzeptiert nicht ⇒M halt und akzeptiert.x ∈ Σ∗ − L⇒M1 akzeptiert nicht ∧ M2 halt und akzeptiert ⇒M halt und verwirft.
Also ist L = LM fur die TM M , die fur alle Eingaben halt; demnach ist L rekursiv. �
Wir wollen nun noch den Grund fur die eigenartige Bezeichnung”rekursiv aufzahlbar“
fur die von TMn akzeptierten Sprachen besprechen. Es zeigt sich, dass genau diejenigenSprachen rekursiv aufzahlbar sind, die von einem rekursiven (auf einer TM ablaufenden)Prozess aufgezahlt, deren Elemente also nacheinander erzeugt werden konnen.
79

1.4.5 Definition Eine Mehrband-TM N heißt ein Aufzahler fur L ⊆ Σ∗, falls N aufEingabe ε auf einem besonderen Ausgabeband eine Zeichenfolge
#x1#x2#x3# · · · , x1, x2, x3 . . . ∈ Σ∗, # 6∈ Σ,
schreibt, wobei L = {x1, x2, x3, . . .} ist. Im Normalfall halt N nicht an. Fur das Ausgabe-band gilt die Einschrankung, dass der Kopf sich nicht nach links bewegen darf und einmalgeschriebene Symbole a ∈ Σ ∪ {#} nicht mehr verandert werden durfen.
Intuitiv gesprochen stellt ein Aufzahler fur L einen Algorithmus zur systematischen Er-zeugung aller Worter in L dar. Im Gegensatz zu dem von einer Grammatik gegebenenErzeugungsprozess ist das Verfahren aber deterministisch.
1.4.6 Satz L ist rekursiv aufzahlbar ⇔ es gibt einen Aufzahler fur L.
Beweis : Der Beweis besteht aus zwei Konstruktionen. Ein Aufzahler N fur L wird in eineTM M mit LM = L umgebaut, und umgekehrt.
”⇐“: Sei N ein Aufzahler fur L. Wir konstruieren eine TM M mit LM = L. M enthalt N
mit seinen Bandern als Teilmaschine, und besitzt ein weiteres Band, auf dem die Eingabex steht (und nicht verandert wird).
N
.
:M
:
N
MB B B a a a a B B B
a r b e i t s b a n d + v o n +
... ...
# x # x # x #
1 2 3 n
1 2 3
Bänder von
Eingabe x für
N
Auf Eingabe x arbeitet M wie folgt: Lasse N auf der leeren Eingabe ε laufen. Jedesmalwenn N
”#“ druckt und damit die Ausgabe eines Wortes x′ ∈ L abschließt, wird die
Berechnung von N unterbrochen und die Eingabe x wird mit dem Wort x′ ∈ Σ∗ verglichen,das vor dem letzten
”#“ auf dem Ausgabeband von N steht. Falls x = x′, halt und
akzeptiert M , sonst wird die Berechnung von N an der Unterbrechungsstelle fortgesetzt.
Wir haben: M akzeptiert x ⇔ N zahlt x auf ⇔ x ∈ L. Also ist LM = L, und L istrekursiv aufzahlbar.
”⇒“: Die andere Richtung des Beweises ist etwas schwieriger. Gegeben ist eine TM
M = (Q, Σ, Γ, B, q0, F, δ) mit LM = L. Der naive Ansatz ware, alle Elemente von Σ∗
80

aufzuzahlen (etwa y0, y1, . . .), M nacheinander auf y0, y1, . . . zu starten und diejenigen yi
auf das Ausgabeband zu schreiben, die von M akzeptiert werden. Das funktioniert aberleider nicht, da M zum Beispiel auf y0 nicht halten konnte und dann die Berechnung aufy1 gar nicht beginnt, obwohl y1 ∈ LM ist. Wir mussen also vorsichtiger vorgehen und esvermeiden, die Berechnung von M auf einem Input y immer weiter laufen zu lassen.
Zu diesem Zweck fuhren wir zwei neue Programmiertechniken ein:”Uhr-kontrollierte Be-
rechnungen“ und”dovetailing“.
Programmiertechnik: Uhr-kontrollierte Berechnungen. (Engl.:”clocked compu-
tations“). M sei eine beliebige TM oder NTM. Wir beschreiben eine TM (bzw. NTM)M ′, die Berechnungen von M bis zu einer durch eine Binarzahl vorgegebene Schrittzahlausfuhrt. M ′ hat neben den Bandern fur M ein zusatzliches Band, das Schrittzahlband.M ′ erhalt Inputs vom Format x#w, wobei x ∈ Σ∗ der Input von M , w ∈ {1}{0, 1}∗ dieBinardarstellung einer Zeitschranke t = (w)2 und # /∈ Σ ∪ {0, 1} ein Trennzeichen ist.Mit dieser Eingabe arbeitet M ′ wie folgt: w wird auf das Schrittzahlband kopiert und #wwird aus der Eingabe geloscht. Dann fuhrt M ′ abwechselnd die folgenden Schritte durch:
1. Fuhre einen Schritt von M aus. Wenn M nun in einer Haltekonfiguration ist, haltauch M ′ (
”erfolgreiche Simulation“).
2. Reduziere die Binarzahl auf dem Schrittzahlband um 1. Falls dort nun 0 steht, haltM ′ an (
”erfolglose Simulation“).
1.4.7 Lemma Fur Eingabe x#w gilt:
(a) M ′ fuhrt min{tM(x), (w)2} Schritte von M aus.
(b) M ′ halt erfolgreich genau dann wenn tM(x) ≤ (w)2.
(c) Die Gesamtzahl der Schritte von M ′ wahrend der eigentlichen Simulation (ohne dasKopieren von w) ist O((w)2).
Beweis : (a) und (b) sind klar; der Beweis von (c) ist eine schone Ubungsaufgabe. �
Wir beziehen uns auf die Technik der Uhr-kontrollierten Berechnungen, indem wir sagen:M ′ simuliert die Berechnung von M auf x fur (w)2 Schritte. Statt einer binaren Uhr kannman naturlich auch eine unare oder eine d-are zu einer Basis d ≥ 3 benutzen.
Programmiertechnik:”Quasiparallele Ausfuhrung“. Hier geht es um eine Tech-
nik, die es gestattet, auf einer TM M ′ Berechnungen einer TM M auf einer endlichenMenge x1, . . . , xm von Inputs fur M durchzufuhren, auch wenn man nicht weiß, welchedieser Berechnungen anhalten. Dabei ist m zwar endlich, aber nicht beschrankt; daherkonnen wir nicht einfach M ′ mit m Bandern versehen und wie im Beweis von Satz 1.4.2(b)auf diesen Bandern parallel arbeiten. Stattdessen muss man zwischen den Berechnungenabwechseln und auf M ′ z. B. den folgenden Ablauf erzeugen:
81

fur t := 1, 2, 3, . . . tuefur j = 1, . . . ,m tue
simuliere M auf xj fur t Schritte.
Technisch lasst man die Eingaben x1, . . . , xm unverandert auf dem Eingabeband ste-hen, und erzeugt mit der Methode von Lemma 1.3.10 nacheinander die Binarworterw ∈ {1}{0, 1}∗. Fur jedes solche w startet man fur jedes j ∈ {1, . . . ,m} eine Uhr-kontrollierte Berechnung von M auf xj#w; nach jeder solchen Berechnung werden diedabei benutzten Bander wieder geloscht. Das Verhalten dieses Verfahrens ist klar: Wennxj ∈ HM , dann wird die Simulation von M auf xj fur (w)2 ≥ tM(xj) erfolgreich sein.Wenn es ein j mit xj /∈ HM gibt, halt die Prozedur nie an. Wenn M auf allen xj halt,kann auch das Verfahren schließlich halten.
Programmiertechnik:”Dovetailing“. Man kann die Idee der quasiparallelen Aus-
fuhrung noch weiter treiben und auf eine unendliche Folge x1, x2, . . . von Inputs anwenden.Das Ziel dabei ist, in einer unendlich lange laufenden Berechnung schließlich alle haltendenBerechnungen von M auf irgendwelchen xj zu finden — oder auch nur ein xj zu finden,auf dem M halt. Es ist klar, dass wir bei einem Berechnungsversuch M auf einem Inputxj nur fur eine vorgegebene Zahl t von Schritten laufen lassen. Wenn wir sicherstellen,dass fur jedes xj eine unbeschrankte Menge von Zeitschranken t probiert wird, gilt:
xj ∈ HM ⇒
{irgendwann wird die haltende Berechnungvon M auf xj gefunden.
Eine konkrete Methode, um dies zu erreichen, ware etwa der folgende Ablauf:
fur t := 1, 2, 3, . . . tuefur j = 1, . . . , t tue
simuliere M auf xj fur t Schritte.
Damit wird fur jedes j eine Simulation von M auf xj fur t = j, j + 1, j + 2, . . . Schrittedurchgefuhrt, also im Fall xj ∈ HM eine haltende Berechnung von M auf xj gefunden.
Dieses”verschrankte“ Ausprobieren mehrerer Rechnungen von M (quasi-)gleichzeitig auf
unendlich vielen Eingaben nennt man”dovetailing“. (Das englische Wort heißt wortlich
”Schwalbenschwanz“ und bezieht sich auf die Technik des Verschrankens mit Nut und
Feder bei Holzarbeiten.) Dies ist eine sehr wichtige und grundlegende Technik, um mitdem Problem des Nicht-Haltens von TM zurechtzukommen.
Wir wenden die Dovetailing-Technik an, um aus einer TM M = (Q, Σ, Γ, . . .) einenAufzahler N fur LM zu konstruieren. Das Zeichen # soll nicht in Σ ∪ {0, 1} vorkom-men. N hat zwei Bander zur Erzeugung von Wortern: Band 1 fur Binarworter, Band 2fur Worter aus Σ∗. Zudem hat N eine Teilmaschine, die Uhr-kontrollierte Berechnungenvon M ausfuhren kann, sowie ein Ausgabeband. N rechnet wie folgt. Auf Band 1 wird 0geschrieben, auf das Ausgabeband #. Dann wird folgendes wiederholt:
82

1. Erhohe den Binarzahler auf Band 1 um 1. Die jetzige Inschrift sei w.
2. Erzeuge auf Band 2 mit der Technik von Lemma 1.3.10, erweitert um einen Zahler,der von t = (w)2 nach unten zahlt, die ersten t Worter x1, . . . , xt in der Aufzahlungvon Σ∗.
3. Fur jedes Wort xj auf Band 2:Simuliere M auf xj fur t = (w)2 Schritte.Falls diese Berechnung akzeptierend halt,
fuge xj# an die Inschrift auf dem Ausgabeband an.
Zu zeigen bleibt:x ∈ L = LM ⇔ N schreibt irgendwann x#.
”⇐“: Wenn N das Wort x# schreibt, ist vorher eine akzeptierende Berechnung von M
auf x gefunden worden. Daher ist x ∈ LM = L.
”⇒“: Wenn x ∈ LM , akzeptiert M den Input x nach tM(x) Schritten. In jeder Runde der
Berechnung von N mit einem w, das (w)2 ≥ tM(x) erfullt, ist die Simulation vonM auf x erfolgreich, also wird x# geschrieben.
Damit ist der Beweis von Satz 1.4.6”⇒“ beendet. �
1.4.8 Bemerkung (a) Der Aufzahler N aus dem eben gefuhrten Beweis gibt jedesWort x ∈ L unendlich oft aus. Das ist fur manche Anwendungen eine erwunschte Erschei-nung.(b) Andererseits gilt: Wenn N irgendein Aufzahler fur L ist, konstruiert man folgender-maßen einen Aufzahler N ′ fur L, der jedes Wort x ∈ L genau einmal ausgibt: N ′ benutztN mitsamt den Bandern von N als Teilmaschine und hat ein zusatzliches Ausgabeband.Die von N erzeugte Ausgabe wird gefiltert. Der Kopf auf dem Ausgabeband von N kannauch nach links fahren und Geschriebenes nochmals lesen (aber nichts andern). Immerwenn N auf seinem Ausgabeband ein #-Zeichen schreibt, wird N unterbrochen. N ′ inspi-ziert das letzte Wort xi ∈ Σ∗ unmittelbar links vom #-Zeichen und pruft mit Textsuche(Beispiel 1.2.11) auf dem Ausgabeband von N , ob xi unter den vorher erzeugten Worternx1, . . . , xi−1 schon vorkommt. Nur wenn dies nicht so ist, wird xi an die Ausgabe von N ′
angefugt.
Man kann die Anforderungen an die Ausgabe von N nicht beliebig erhohen. Wenn wir furein Alphabet Σ = {0, 1, . . . , d−1} die kanonische Ordnung <kan auf Σ∗ wie folgt festlegen:
x <kan y :⇔ |x| < |y| oder (|x| = |y| ∧ (x)d < (y)d),
83

konnte man verlangen, dass die Elemente von L in aufsteigender Reihenfolge ausgegebenwerden. Dabei gilt jedoch:
L ist rekursiv ⇔
es existiert ein Aufzahler fur L,
der die Worter x ∈ L in der durch <kan
vorgeschriebenen Reihenfolge ausgibt.
(Der Beweis ist eine Ubungsaufgabe.) — Wir werden bald sehen, dass es rekursiv aufzahl-bare Sprachen gibt, die nicht rekursiv sind. Diese haben dann zwar einen Aufzahler, aberkeinen, der die Elemente in kanonischer Ordnung ausgibt.
1.5 Aquivalenz von Turingmaschinen und Register-
maschinen
In diesem Abschnitt wollen wir uns klarmachen, dass Turingmaschinen und Registerma-schinen dieselbe Berechnungskraft haben. Zunachst zeigen wir, dass man Turingmaschinen-Berechnungen auf Registermaschinen (und auf idealisierten Computern ohne Platz- undZeitbeschrankung) simulieren kann. Danach uberlegen wir, wie man die Berechnungenvon Registermaschinen auf Turingmaschinen simulieren kann. Da wir uns, zumindest in-formal, schon uberlegt haben, dass auf Registermaschinen alle Maschinenprogramme zurealen Computern ausgefuhrt werden konnen, ergibt sich die vielleicht uberraschende Kon-sequenz, dass Turingmaschinen im Prinzip alle Computerprogramme ausfuhren konnen.
1.5.1 Simulation von Turingmaschinen auf Registermaschinen
In diesem Abschnitt zeigen wir, dass alle von Turingmaschinen berechenbaren Funktionenauch auf Registermaschinen berechenbar sind. Analoges gilt fur Entscheidungsprobleme,also Sprachen.
Sei also M = (Q, Σ, Γ, B, q0, F, δ) eine Turingmaschine. Turingmaschinen verarbeitenWorter uber Alphabeten; Registermaschinen verarbeiten Zahlen. Um die TM-Berechnungauf einer RAM ausfuhren zu konnen, benennen wir die Elemente des Bandalphabets Γmit |Γ| = s so in Zahlen um, dass folgende Situation entsteht:
Γ = {0, . . . , s− 1}; Σ ⊆ {1, . . . , s− 1}; B = 0.
Nach den Konventionen aus Abschnitt 1.1 wird eine Eingabe x = a1 · · · an ∈ Σn bei derRegistermaschine anfangs in die Register R1, R3, R5, . . . , R2n−1 geschrieben; R0 enthalt n;die anderen Register sind mit 0 vorbesetzt. Als Ausgabe beim Anhalten der Registerma-schine gilt der Inhalt der Register R1, R3, R5, . . . , R2k−1, wobei k = 〈R0〉 ist.
Bezuglich der TM M nehmen wir an, dass M ein einseitig unbeschranktes Band hat (s.Beispiel 1.2.4), also nur Bandzellen 1, 2, . . . benutzt, und dass die Ausgabe schließlich in
84

den Bandzellen 1, 2, . . . , k steht. Dies lasst sich durch Umkopieren zum Ende der Rechnungstets erreichen. Eine Akzeptiere/Verwirf-Entscheidung der TM wird nicht uber F ⊆ Q,sondern durch den Ausgabewert reprasentiert (etwa
”1“ fur
”akzeptiere“ und
”2“ fur
”verwirf“, vgl. Satz 1.4.1(c)).
1.5.1 Satz M sei eine 1-Band-Turingmaschine. Dann gibt es eine RegistermaschineM ′ mit demselben Ein-Ausgabeverhalten wie M , d. h. fur jedes x = a1 · · · an ∈ Σ∗ gilt:
M halt auf x⇒M ′ halt auf x und die Ausgabe von M ′ auf x ist fM(x).
M halt nicht auf x⇒M ′ halt nicht auf x.
Die Zahl der Schritte von M ′ auf x ist O(tM(x)), falls M auf x halt. Die Kosten imlogarithmischen Kostenmaß sind O(tM(x) · log(tM(x))).
Beweis : M sei wie oben beschrieben. Eine Berechnung von M auf x soll, wie durch dieUbergangsfunktion δ gegeben, Schritt fur Schritt auf der RAM M ′ simuliert werden. DieRegister R1, R3, R5, . . . stellen das einseitig unbeschrankte Band dar. Die Eingabekonven-tionen sind so abgestimmt, dass die Eingabesymbole a1, . . . , an anfangs in den richtigenZellen stehen; die Vereinbarung B = 0 bewirkt, dass alle Zellen ausser den ersten n mitB initialisiert sind. Wir benotigen einige Hilfsregister, die aus R2, R4, R6, . . . ausgewahltwerden:
Rhead enthalt die gegenwartige Kopfposition
Rread enthalt den gerade gelesenen Buchstaben
R”a“ enthalt die konstante Zahl a ∈ Γ = {0, . . . , s− 1}.
Anstelle die Zeilen des RAM-Programms durchzunumerieren, verwenden wir im folgendenfur Sprungbefehle im RAM-Programm symbolische Marken. Das RAM-Programm bestehtaus:
– einem Initialisierungsteil, in dem die Hilfsregister R”a“ besetzt werden, und die Be-
fehle Rhead ← 1, Rread ← R1 und goto Block q0ausgefuhrt werden;
– einer Folge von Blocken Blockq, q ∈ Q, die gleich beschrieben werden; und
– einem Nachbearbeitungsteil, in dem die RAM M ′ in einer einfachen Schleife dasmaximale k mit 〈R1〉, 〈R3〉, . . . , 〈R2k−1〉 6= 0 sucht und k in R0 speichert; danachhalt M ′ an.
Fur q ∈ Q sieht Blockq folgendermaßen aus:
Blockq:Eine endliche Kaskade bedingter Sprunge,die folgenden Effekt hat:springe zu Bq,a fur a = 〈Rread〉 ∈ Γ.
85

Bq,0: · · ·
Bq,1: · · ·
Bq,s−1: · · ·
Dabei sieht der mit”Bq,a:“ markierte Teilblock je nach dem Wert δ(q, a) in der Turingtafel
verschieden aus:
1. Fall: δ(q, a) ist undefiniert. Dann
Bq,a: goto Nachbearbeitung
2. Fall: δ(q, a) = (q′, a′, D) ∈ Q× Γ× {L,R,N}. Dann
Bq,a:
RRhead← R
”a′“
falls D = R : Rhead ← Rhead + R”2“
falls D = L : Rhead ← Rhead −R”2“
falls D = N : −
Rread ← RRhead
goto Block q′
Es sollte klar sein, dass dieses RAM-Programm fur jeden beliebigen Input x ∈ Σ∗ dieSchritte der TM M auf x nacheinander simuliert und bezuglich Halten und Ausgabe dieim Satz angegebenen Eigenschaften hat.
Fur die Zeitanalyse nehmen wir der Einfachheit halber an, dass M die Eingabe vollstandigliest, also tM(x) ≥ |x| ist, und dass die Lange der Ausgabe nicht großer als tM(x) ist. DerInitialisierungsteil macht eine konstante Zahl von Schritten. Fur die Simulation eines TM-Schrittes wird nur eine konstante Zahl von Schritten der RAM benotigt. (Die Zahl derSchritte, die fur die Kaskade bedingter Sprunge zur Unterscheidung der verschiedenenBuchstaben notig sind, hangt von der Alphabetgroße s ab.) Der Nachbearbeitungsteilerfordert hochstens O(tM(x) + 1) Schritte. Also ist die Gesamtzahl der RAM-SchritteO(tM(x)). Fur das logarithmische Kostenmaß ist zusatzlich die Bitlange der Zahl in Rhead
zu berucksichtigen. Alle anderen vorkommenden Zahlen und Registerindizes sind durch ei-ne Konstante beschrankt, haben also Bitlange O(1). Weil der Kopf von M in tM(x) Schrit-ten keine Zelle jenseits der (tM(x)+1)-ten erreichen kann, gilt stets 〈Rhead〉 ≤ 2tM(x)+1.Also ist die Bitlange der Zahl in Rhead nicht großer als dlog2(2tM(x)+2)e = O(log(tM(x))),und die logarithmischen Kosten pro Schritt sind O(log(tM(x))), die Gesamtkosten alsoO(tM(x) · log(tM(x))). �
Man beachte noch, dass die Konstruktion des RAM-Programms aus der Beschreibung derTuringmaschine
”effektiv“ moglich ist, d. h. es gibt einen Algorithmus, der die Transforma-
tion fur beliebige gegebene TMn durchfuhren kann. Außerdem sollte klar sein, dass man
86

die beschriebene Methode auch benutzen kann, um Turingmaschinen mit Programmen inPascal, C oder Java zu simulieren.
1.5.2 Simulation von Registermaschinen auf Turingmaschinen
In Abschnitt 1.1 wurde das Registermaschinenmodell eingefuhrt und erklart, wie Regis-termaschinen Funktionen berechnen konnen. In diesem Abschnitt zeigen wir, dass jedeRAM-berechenbare Funktion auch von einer Turingmaschine berechnet werden kann. Re-gistermaschinen berechnen Zahlfunktionen, Turingmaschinen arbeiten auf Wortern. Alsomussen wir erst einmal erkaren, wie eine Turingmaschine eine Zahlfunktion berechnenkann. Naturlich geschieht dies uber Zahldarstellungen, zum Beispiel mittels der Binardar-stellung von naturlichen Zahlen.
1.5.2 Definition
(a) M = (Q, {0, 1, #}, Γ, B, q0, F, δ) sei eine deterministische Turingmaschine. Die vonM berechnete Zahlfunktion fM : DM → Seq(N) wird definiert, indem man die Wir-kung von M auf Kodierungen von Zahlenfolgen betrachtet. Der Definitionsbereichvon fM ist
DM := {(a1, . . . , an) ∈ Seq(N) | w = bin(a1)# · · ·#bin(an) ∈ HM ,
∃(b1, . . . , bm) ∈ Seq(N) : fM(w) = bin(b1)# · · ·#bin(bm)}.
Fur (a1, . . . , an) ∈ DM ist
fM(a1, . . . , an) = (b1, . . . , bm),
wenn fM(bin(a1)# · · ·#bin(an)) = bin(b1)# · · ·#bin(bm).
(Wenn z. B. fM(100#1101#1#0#11) = 10101#110100, dann ist fM(4, 13, 1, 0, 3) =(21, 52).)
(b) Eine Zahlfunktion f : D → Seq(N), fur ein D ⊆ Seq(N), heißt partiell rekursiv, wennes eine TM M mit f = fM gibt.
(c) Eine Menge A ⊆ Seq(N) heißt rekursiv aufzahlbar, wenn es eine TM M gibt mit
A = {(a1, . . . , an) ∈ Seq(N) | bin(a1)# · · ·#bin(an) ∈ LM}.
(d) Eine Menge A ⊆ Seq(N) heißt rekursiv, wenn es eine TM M gibt, die auf allenEingaben halt und
A = {(a1, . . . , an) ∈ Seq(N) | bin(a1)# · · ·#bin(an) ∈ LM}
erfullt.
87

1.5.3 Bemerkung Um das Verhalten der TMn auf den Inputs, die nicht das richti-ge Inputformat bin(a1)# · · ·#bin(an) fur Zahlen a1, . . . , an haben, sollte man sich keineSorgen machen. Die Menge der legalen Zahlkodierungen ist regular, daher kann eine Syn-taxprufung immer in linearer Zeit durchgefuhrt werden und ein passendes Verhalten derTM (Halten mit Output ε oder (0), Nichthalten, usw.) eingestellt werden. Man machtnichts falsch, wenn man annimmt, dass solche syntaktisch falschen Eingaben gar nichtvorkommen.
1.5.4 Notation: Ist a ∈ N, so ist
‖a‖ = |bin(a)| = max{1, dlog2(a + 1)e}.
Ist a = (a1, . . . , an) in Seq(N), so ist ‖a‖ =n∑
i=1
‖ai‖ die”Gesamtbitlange“ der Binardar-
stellung der Komponenten von a. (Zum Beispiel ist ‖(5, 9, 16)‖ = 12.)
1.5.5 Satz Es sei D ⊆ Seq(N) und f : D → Seq(N) eine Funktion. M sei eine RAM,die f berechnet. Dann gilt:
(a) Es existiert eine Turingmaschine M ′ mit f = fM ′.
(b) Bezeichnet cM,logar(a) die Kosten der Rechnung von M auf a = (a1, . . . , an) ∈ Dim logarithmischen Kostenmaß (vgl. Definition 1.1.4), so macht M ′ auf Input aO((cM,logar(a) + ‖a‖+ ‖b‖)3) Schritte, wenn b = fM(a) ist.
Beweis : (Durch Konstruktion einer TM M ′.) Die Registermaschine M sei durch ein Pro-gramm
0 : B0
1 : B1
...
l − 1 : Bl−1
mit l Programmzeilen aus dem Befehlsvorrat fur Registermaschinen gegeben. Die nahe-liegende Idee fur die Simulation ist, die Registerinhalte von M in Binardarstellung aufeinem Band von M ′ zu halten (zum Beispiel auf Band 1). Zur Identifizierung wird demRegisterinhalt der Registerindex in Binardarstellung vorangestellt. Die Darstellungen dereinzelnen Register werden mit
”##“ voneinander getrennt. Den Registerinhalten
〈Ri1〉 = b1, . . . , 〈Rim〉 = bm (alle anderen Registerinhalte sind 0)
entspricht also die Bandinschrift
· · ·BB ##bin(i1)#bin(b1)##bin(i2)#bin(b2)## . . . ##bin(im)#bin(bm)## BB · · ·
88

(Beispiel : Wenn 〈R0〉 = 5, 〈R4〉 = 12, 〈R7〉 = 3, und wenn alle anderen Register 0enthalten, ware folgendes eine legale Darstellung dieser Registerinhalte:
· · ·B ##100#1100##11#0##0#101##111#11##B · · ·
Man bemerkt, dass die Reihenfolge nicht vorgeschrieben ist und dass Register mit Inhalt0 explizit dargestellt sein konnen, aber nicht mussen.)
Die andere wichtige Information wahrend einer Berechnung von M ist der jeweilige Be-fehlszahlerstand. Dieser stammt aus dem endlichen Bereich {0, 1, . . . , l − 1}, wenn wirSprungziele ≥ l (die zum Anhalten von M fuhren) einstweilen ignorieren. Daher kannder Befehlszahlerstand in der Steuereinheit von M ′ gespeichert werden.
Naturlicherweise hat das Programm von M ′ drei Teile:
1. Initialisierung : Umbau der Eingabe auf das fur die Simulation benotigte Format;
2. Schritt-fur-Schritt-Simulation;
3. Nachbearbeitung : Umbau der Ausgabe auf das fur Turingmaschinen geforderte For-mat.
Initialisierung: Eine Eingabe (a1, . . . , an) ∈ Seq(N) fur M wird gemaß Definition 1.5.2der TM M ′ als Wort bin(a1)# · · ·#bin(an) auf Band 1 prasentiert. Dieser Eingabe ent-sprechen auf der RAM M die Registerinhalte 〈R2i−1〉 = ai, 1 ≤ i ≤ n, und 〈R0〉 = n; alleanderen Register stehen auf 0. Wir erzeugen eine diesen Registerinhalten entsprechendeBandinschrift, namlich
##bin(1)#bin(a1)##bin(3)#bin(a2)## · · ·##bin(2n−1)#bin(an)##bin(0)#bin(n)##
auf Band 1, wie folgt.
Wir benutzen zwei Hilfsbander (Band 2 und 3). Auf Band 3 wird ## geschrieben.Der Kopf auf Band 1 wird auf den Anfang der Inschrift (also zu bin(a1)) gestellt. AufBand 2 werden nun nacheinander die Binardarstellungen bin(0), bin(1), bin(2), . . . er-zeugt. (Vgl. Lemma 1.3.10 und Ubung.) Jedes zweite Element dieser Folge (also bin(2i−1))wird an die Inschrift auf Band 3 angefugt, gefolgt von dem Teilstring #bin(ai)##, wobeibin(ai) von Band 1 kopiert wird. Dies wird fortgefuhrt, bis der Kopf auf Band 1 das Endeder Bandinschrift erreicht hat. Die letzte benutzte Binarzahl auf Band 2 ist bin(2n− 1).Wir addieren 1 und streichen die letzte 0, um bin(n) zu erhalten, und schreiben schließlichnoch 0#bin(n)## auf Band 3. Schließlich wird Band 3 auf Band 1 kopiert, Bander 2 und3 mit Blanks uberschrieben.
Schritt-fur-Schritt-Simulation: Fur jede Zeile z : Bz, 0 ≤ z < l, des Programms vonM , mit einem Befehl Bz aus dem RAM-Befehlsvorrat, besitzt das Programm der TM M ′
ein Teilprogramm TPz, das einfach einem Block von Zeilen in der Turingtafel entspricht.
89

Wir zeigen an zwei Beispielen, wie Befehlszeilen in Teilprogramme umgesetzt werden.Wenn die Ausfuhrung von TPz begonnen wird, sind Bander 2 und 3 leer, der Kopf aufBand 1 steht auf dem ersten #.
10: Ri ← Rj ·Rk
Das Teilprogramm TP10 tut folgendes:
1. Suche auf Band 1 das Teilwort uj = ##bin(j)#. (Da j eine feste, von der Eingabeunabhangige Zahl ist, kann man uj in der Steuereinheit speichern.) Falls uj gefundenwird, steht es in einem Zusammenhang ##bin(j)#b1 · · · br## fur ein Binarwortb1 · · · br. Dann kopiere b1 · · · br auf Band 2. Wenn uj nicht gefunden wird, schreibe0 auf Band 2.
2. Suche auf Band 1 das Teilwort uk = ##bin(k)#. Falls uk gefunden wird, steht esin einem Zusammenhang ##bin(k)#c1 · · · ct##. Dann kopiere c1 · · · ct auf Band3. Wenn uk nicht gefunden wird, schreibe 0 auf Band 3.
3. Berechne die Binardarstellung d1 · · · ds des Produkts der Inhalte b1 · · · br von Band2 und c1 · · · ct von Band 3. Schreibe das Resultat auf Band 2.
4. Suche auf Band 1 das Teilwort ui = ##bin(i)#. Falls ui gefunden wird, steht es ineinem Zusammenhang ##bin(i)#e1 · · · em##. Kopiere die gesamte Bandinschrift##y rechts von e1 · · · em auf Band 3, uberschreibe e1 · · · em mit d1 · · · ds (von Band2), und kopiere ##y von Band 3 zuruck rechts von d1 · · · ds. — Falls ui auf Band1 nicht gefunden wird, erzeuge einen neuen Eintrag bin(i)#d1 · · · ds## rechts derexistierenden Bandinschrift auf Band 1.
5. Losche Bander 2 und 3, fahre Kopf auf Band 1 auf Ausgangsposition.
6. (Falls l ≥ 12:) Springe zum Teilprogramm TP11.(Falls l = 11, springe zur Nachbearbeitung.)
15: Ri ← RRj
Das Teilprogramm TP15 tut folgendes:
1. Suche auf Band 1 das Teilwort uj = ##bin(j)#. Falls uj gefunden wird, steht esin einem Zusammenhang ##bin(j)#b1 · · · br## fur ein Binarwort b1 · · · br. Dannkopiere b1 · · · br auf Band 3. Wenn uj nicht gefunden wird, schreibe 0 auf Band 3.
90

2. Suche ein Teilwort ##b1 · · · br# (Inschrift Band 3) auf Band 1. (Da die Lange r die-ses Teilwortes nicht durch eine nur von M abhangige Konstante zu beschranken ist,sondern inputabhangig beliebig groß sein kann, muss hierzu die Technik
”Textsuche“
aus Abschnitt 1.2.11 benutzt werden.) Falls ##b1 · · · br# gefunden wird, steht es ineinem Zusammenhang ##b1 · · · br#c1 · · · ct## fur ein Binarwort c1 · · · ct. Kopierec1 · · · ct auf Band 2. Wenn ##b1 · · · br# nicht gefunden wird, schreibe 0 auf Band2.
3. Wie 4. im vorherigen Beispiel.
4. Wie 5. im vorherigen Beispiel.
5. (Falls l ≥ 17:) Springe zum Teilprogramm TP16.(Falls l = 16, springe zur Nachbearbeitung.)
Wenn die Registermaschine M auf Input a anhalt, erhalt der Befehlszahler schließlicheinen Wert ≥ l. In den Teilprogrammen TPz schreibt man an eine solche Stelle einenSprung zum Beginn der Nachbearbeitung.
Die Umsetzung der anderen RAM-Befehle gemaß der Tabelle in Abschnitt 1.1.1 in Turing-maschinen-Teilprogramme seien dem Leser/der Leserin zur Ubung uberlassen.
Die Phase”Schritt-fur-Schritt-Simulation“ wird begonnen, indem man von der Initialisie-
rung zum Teilprogramm TP0 fur Programmzeile 0 springt.
Nachbearbeitung: Wenn M auf Input a anhalt, springt die TM M ′ nach Simulationdes letzten Schritts zur Nachbearbeitung. In diesem Teil mussen die Inhalte der auf Band1 in beliebiger Ordnung aufgefuhrten Register R1, R3, . . ., R2k−1, mit k = 〈R0〉 in dasAusgabewort
bin(〈R1〉)#bin(〈R3〉)# · · ·#bin(〈R2k−1〉)
umgeformt werden. Hierfur findet man zunachst die Darstellung von R0 und liest denInhalt k ab. Dann erzeugt man wie in der Initialisierungsphase alle Binarzahlen bin(2i−1),1 ≤ i ≤ k, und sucht mit Textsuche die Darstellungen der entsprechenden Register auf.Die Registerinhalte werden dann in der richtigen Reihenfolge hintereinandergefugt.
Beispiel : Aus der Bandinschrift
##11#101##10#1111##1001#11##110#11101##0#100##101#10##,
die den Registerinhalten 〈R3〉 = 5, 〈R2〉 = 15, 〈R9〉 = 3, 〈R6〉 = 29, 〈R0〉 = 4, 〈R5〉 = 2entspricht, erzeugt die Nachbearbeitung die Ausgabe-Bandinschrift
0#101#10#0,
entsprechend der RAM-Ausgabe (0, 5, 2, 0).
Wir schatzen nun die Anzahl der fur diese Simulation benotigte Anzahl von Schritten derTM M ′ ab.
91

Es sei s die maximal auftretende Lange der gesamten Inschrift auf Band 1, t sei die maxi-male Bitlange einer im Verlauf der gesamten Berechnung in einem Register gespeichertenZahl. Die Suche nach einem Teilwort ##c1 · · · cr# auf Band 1 kann so realisiert werden,dass die benotigte Schrittzahl O(s) ist. Die Simulation eines Schrittes erfordert hochstens3 solche Suchvorgange. Das Eintragen des Resultates auf Band 1 erfordert ebenfalls ZeitO(s). Die aufwendigsten arithmetischen Operationen sind Multiplikation und Division;sie erfordern hochstens O(t2) Schritte Die Anzahl der zu simulierenden RAM-Schritte istdurch c(a) := cM,logar(a) beschrankt. Daher sind die Gesamtkosten der Schritt-fur-Schritt-Simulation O(c(a) · (s + t2)).
Wie kann man s abschatzen? Mit der Initialisierung werden die n Eingabezahlen in adurch die Binardarstellung von n Registernummern erweitert, die alle < 2n sind; mansieht daraus, dass die resultierende Bandinschrift hochstens Lange ‖a‖ + O(n log n) =O(‖a‖ log ‖a‖) hat. Eine Verlangerung der Bandinschrift kommt nur durch die Ausfuhrungeines Befehls zustande, in dem Zahlen gelesen und verarbeitet werden. Nach der Definitionder logarithmischen Kosten ist die Anzahl der neuen Zeichen in der Bandinschrift durchdie logarithmischen Kosten fur den Schritt (multipliziert mit einer kleinen Konstanten)beschrankt. Durch Summation uber alle Schritte sieht man, dass s = O(‖a‖ log ‖a‖+c(a))ist. Mit t ist es einfacher: Offenbar ist t = O(‖a‖+ c(a)). — Damit ist die Gesamtzahl dervon M ′ in der Initialisierung und der Schritt-fur-Schritt-Simulation ausgefuhrten Schritte
O(c(a)) · (O(‖a‖ log ‖a‖+ c(a)) + O((‖a‖+ c(a))2) = O((‖a‖+ c(a))3).
Ist nun fM(a) = (b1, . . . , bl), so kann man die Kosten der Nachbearbeitung durch O((s +‖b‖)2) abschatzen. Die Gesamtkosten sind also O((‖a‖+ ‖b‖+ c(a))3). �
1.5.6 Bemerkung Fur eine polynomielle Laufzeitbeschrankung der simulierenden Tu-ringmaschine ist es notwendig, bei der RAM das logarithmische Kostenmaß zugrundezule-gen. Es ist namlich moglich, auf einer RAM in O(k) Schritten durch iteriertes Quadrierendie Zahl 22k
der Bitlange 2k zu erzeugen, deren Bearbeitung auf einer TM Zeit Θ(2k)erfordert.
1.6 Zur Bezeichnung”Rekursive Funktionen“ und
”Rekursive Mengen“
In den bisherigen Betrachtungen haben wir Rechenmodelle, namlich Registermaschinenund Turingmaschinen benutzt, um den Begriff
”berechenbare Funktion“ bzw.
”entscheid-
bare Sprache“ prazise zu fassen. Daneben gibt es noch eine ganze Reihe anderer Me-thoden, mit denen das Konzept
”intuitiv berechenbare Funktion“ prazise gefasst werden
kann (Stichworte: λ-Kalkul, Markov-Algorithmen, µ-rekursive Funktionen, Spezifikationin einem Logik-Kalkul, . . .). Eine solche nicht maschinenorientierte Methode wird hiernoch kurz skizziert, deren Struktur Anlass fur die Namensgebung
”rekursive Funktion“
92

bzw.”rekursive Menge“ gab. Wir arbeiten im Bereich der
”partiellen Zahlenfunktionen“,
der folgendermaßen erklart ist:
1.6.1 Definition Fur n ≥ 0 sei Fn := {F | F : D → N fur ein D ⊆ Nn}. Der Defi-nitionsbereich D von F wird mit DF = Def(F ) bezeichnet.18 Wenn DF = Nn, heißt Ftotal.
F :=⋃{Fn | n ≥ 0} ist die Gesamtheit aller partiellen Zahlenfunktionen.
Als Abkurzung fur (m1, . . . ,mn) ∈ Nn schreiben wir oft ~m. Die Stelligkeit muss dann ausdem Zusammenhang hervorgehen.
1.6.2 Definition Die folgenden (totalen) Funktionen heißen Basisfunktionen:
(a) Konstante Funktionen: Cn,k ∈ Fn, n, k ≥ 0, wobei Cn,k(~m) = k fur alle ~m ∈ Nn.
(b) Projektionen: Pn,i ∈ Fn, n ≥ 1, 1 ≤ i ≤ n, wobei Pn,i(m1, . . . ,mn) = mi fur alle(m1, . . . ,mn) ∈ Nn.
(c) Nachfolgerfunktion: S ∈ F1, wobei S(m) = m + 1, fur alle m ∈ N.
Es ist klar, dass jede Basisfunktion intuitiv berechenbar ist. (Man uberlege zur Ubung, wiePascal-Funktionsprozeduren oder RAM-Programme fur die Basisfunktionen aussehen.)
Nun betrachten wir drei Methoden (”Schemata“) zur Gewinnung neuer Funktionen aus
gegebenen.
1.6.3 Definition (Einsetzen)
Zu G ∈ Fr, H1, . . . , Hr ∈ Fn mit r ≥ 1, n ≥ 0, betrachte die Funktion F ∈ Fn, die wiefolgt definiert ist:
F (~m) = G(H1(~m), . . . , Hr(~m)),
fur alle ~m ∈ DF , wobei
DF = {~m ∈ Nn | ~m ∈ DH1∩ . . . ∩DHr
und (H1(~m), . . . , Hr(~m)) ∈ DG}.
Wir sagen, F entsteht aus G,H1, . . . , Hr durch Einsetzen, und schreiben E(G,H1, . . . , Hr)fur F . Wir bemerken: Wenn fur G und H1, . . . , Hr Berechnungsverfahren vorliegen, erhaltman auch leicht eines fur F .
18Man beachte den Sonderfall n = 0. Hier ist nur DF = {()} sinnvoll, F : {()} → N hat nur einen WertF (()) ∈ N, entspricht also einer Konstanten.
93

1.6.4 Definition (Primitive Rekursion)
Zu G ∈ Fn und H ∈ Fn+2 mit n ≥ 0, betrachte die Funktion F ∈ Fn+1, die wie folgtdefiniert ist:
F (0, ~m) = G(~m) (definiert falls ~m ∈ DG),F (i + 1, ~m) = H(i, F (i, ~m), ~m) (definiert falls F (i, ~m) definiert
und (i, F (i, ~m), ~m) ∈ DH).
Wir sagen, F entsteht aus G und H durch primitive Rekursion, und schreiben R(G,H)fur F . Wir bemerken, dass man aus Berechnungsverfahren fur G und H eines fur Fgewinnen kann, wie folgt. Angenommen, es soll F (j, ~m) berechnet werden. Falls j = 0,berechnen wir G fur die Eingabe ~m. Falls dies gelingt, ist G(~m) das Resultat. Falls j ≥ 1,berechnen wir (rekursiv) F (j−1, ~m). Falls dies gelingt, mit Resultat kj−1, berechnen wirH(j − 1, kj−1, ~m). – Man sollte auch bemerken, dass in diesem Verfahren die Rekursionleicht zu eliminieren ist und F auch einfach per Iteration berechnet werden kann. Hierfurgenugt eine for-Schleife, z.B. in Pascal-Notation:
(* Eingabe: j, m1,...,mn: integer *)
k := G(m1,...,mn);
for i := 1 to j do
k := H(i-1, k, m1,...,mn);
F := k;
(* Resultat: F *)
1.6.5 Definition (µ-Rekursion)
Sei G ∈ Fn+1 eine Funktion. Betrachte die Funktion F ∈ Fn, die wie folgt definiert ist:
F (~m) =
das (eindeutig bestimmte) k ≥ 0 mit(i, ~m) ∈ DG fur 0 ≤ i ≤ k undG(i, ~m) > 0 fur 0 ≤ i ≤ k undG(k, ~m) = 0, falls ein solches k existiert;
undefiniert, sonst.
Wir sagen, F entstehe aus G durch µ-Rekursion und schreiben (µG) fur F . Wiederbemerken wir, dass aus einem Berechnungsverfahren fur G eines fur F konstruiert werdenkann.
(* Eingabe: j, m1,...,mn: integer *)
i := 0;
while G(i, m1,...,mn) > 0 do i := i+1;
F := i;
(* Resultat: F *)
Es gibt zwei Moglichkeiten fur das Nicht-Terminieren dieses Algorithmus: wenn ein”auf-
gerufenes“ G(i, ~m) kein Resultat liefert oder wenn G(i, ~m) fur alle i zwar definiert ist,aber keiner dieser Werte 0 ist.
94

Wieso nennt man diese Regel µ-Rekursion?Man kann sich uberlegen, dass F (~m) = H(0, ~m), wo
H(i, ~m) =
i, falls (i, ~m) ∈ DG und G(i, ~m) = 0;H(i + 1, ~m), falls (i, ~m) ∈ DG und G(i, ~m) > 0;und H(i + 1, ~m) definiert;
undefiniert, sonst.
Diese Definition von H stellt eine Rekursion”in Aufwartsrichtung“ dar.
Nun kommen wir zur entscheidenden Definition.
1.6.6 Definition
(a) PR (die Klasse der primitiv rekursiven Funktionen) ist die kleinste Klasse von Funk-tionen in F , die die Basisfunktionen enthalt und unter Einsetzung und primitiverRekursion abgeschlossen ist, d.h.
(i) Die Basisfunktionen sind in PR.
(ii) Wenn G ∈ Fr, H1, . . . , Hr ∈ Fn alle in PR sind, so auch E(G,H1, . . . , Hr).
(iii) Wenn G ∈ Fn und H ∈ Fn+2 in PR sind, dann auch R(G,H).
(iv) Nichts sonst ist in PR.
(b) R (die Klasse der µ-rekursiven Funktionen) ist die kleinste Teilklasse von F , diedie Basisfunktionen enthalt und unter Einsetzung, primitiver Rekursion und µ-Rekursion abgeschlossen ist, d.h.
(i)–(iii) wie in (a) mit R statt PR
(iv) Wenn G ∈ Fn, n ≥ 1, in R, dann ist auch (µG) in R.
(v) Nichts sonst ist in R.
Die Beschreibung von R und PR ⊆ R durch induktive Definitionen hat auf den erstenBlick nichts mit Maschinen zu tun. Mit Konstruktionen wie oben angedeutet, kann manaber durch Induktion uber den Aufbau von R folgendes zeigen:
F ∈ R ⇒ es existiert ein (idealisiertes) Pascal-Programm, das F berechnet.
Mit analogen Methoden zeigt man:
F ∈ R ⇒ es existiert ein RAM-Programm, das F berechnet.
Andererseits kann man zeigen, dass alle RAM-berechenbaren Funktionen in R liegen.Nach unserer Definition und den Resultaten der Abschnitte 1.3 und 1.4 ist also
R = Menge der partiell rekursiven Zahlenfunktionen.
95

Die Moglichkeit, die Klasse der RAM- oder Turing-berechenbaren Funktionen mittels desRekursionsprinzips definieren zu konnen, hat zu der Namensgebung
”(partiell) rekursiv“
bzw.”(total) rekursiv“ fur die Funktionen dieser Klasse gefuhrt. Dieser Name ubertrug
sich dann auf die rekursiven Sprachen, das sind die Sprachen, deren charakteristischeFunktion (total) rekursiv ist.
Zu guter letzt geben wir noch einige Beispiele von Funktionen in PR an, um den Mecha-nismus der induktiven Definition zu illustrieren.
1.6.7 Beispiel
(a) Addition: A(i,m) = i + m. Diese Funktion lasst sich mittels primitiver Rekursionaus Basisfunktionen gewinnen, wie folgt:
A(0,m) = m = P1,1(m),
A(i + 1,m) = A(i,m) + 1 = S(A(i,m)).
Wenn wir H(k, l, r) = S(P3,2(k, l, r)) definieren, ist A(i + 1,m) = H(i, A(i,m),m).Also ist A = R(P1,1, E(S, P3,2)) primitiv rekursiv.
(b) Multiplikation: M(i,m) = i · m. Diese Funktion erhalten wir mittels primitiverRekursion aus A, wie folgt:
M(0,m) = 0 = C1,0(m),
M(i + 1,m) = M(i,m) + m = A(M(i,m),m).
Wenn wir H(k, l, r) = A(P3,2(k, l, r), P3,3(k, l, r)) setzen, ist M(i+1,m) = H(i,M(i,m),m).Also ist M = R(C1,0, E(A,P3,2, P3,3)) primitiv rekursiv.
(c) Vorgangerfunktion:
P (i) =
{0 falls i = 0i− 1 falls i ≥ 1.
Diese kann man wie folgt definieren:
P (0) = 0 = C0,0(()),
P (i + 1) = i = P2,1(i, P (i)), fur i ≥ 0.
Also ist P = R(C0,0, P2,1) primitiv rekursiv.
(d) (Abgeschnittene) Subtraktion:
Sub′(i,m) =
{0 falls i > mm− i sonst.
96

Diese Funktion erhalt man wie folgt:
Sub′(0,m) = m = P1,1(m),
Sub′(i + 1,m) = P (Sub′(i,m)).
Mit H(k, l, r) = P (P3,2(k, l, r)), also H = E(P, P3,2) ist also Sub′ = R(P1,1, E(P, P3,2))primitiv rekursiv.
Die gewohnliche Subtraktion Sub(m1,m2) = m1−m2 erhalt man als Sub′(P2,2(~m), P2,1(~m)),also Sub = E(Sub′, P2,2, P2,1).
(e) Signum-Funktion: Die durch
sgn(i) =
{0 falls i = 01 falls i ≥ 1
definierte Funktion ist wegen sgn(0) = 0, sgn(i + 1) = 1, also sgn = R(C0,0, C3,1)primitiv rekursiv. Analog ist auch
sgn(i) =
{1 falls i = 00 falls i ≥ 1
primitiv rekursiv, wegen sgn(i) = Sub(1, sgn(i)).
(f) ≤-Relation:
LE(m1,m2) =
{1 falls m1 ≤ m2
0 sonst.
Es ist klar, dass LE(m1,m2) = sgn(Sub(m1,m2)), d.h. LE = E(sgn, Sub), primitivrekursiv ist.
In dieser Art fortfahrend, kann man fur viele naturliche Funktionen zeigen, dass sie pri-mitiv rekursiv sind.
Beispiele:
Teilbarkeitsrelation:
DIV BLE(m1,m2) =
{1 falls ∃x ∈ N : xm1 = m2,0 sonst.
Primzahlen:
PRIM(m) =
{1 falls p ist Primzahl,0 sonst.
97

1.7 Die Churchsche These
Wir erinnern uns aus Abschnitt 0.2 an die Konzepte Berechnungsproblem und Entschei-dungsproblem, an die Formulierung von Berechnungsproblemen als Funktionen, die Worterauf Worter abbilden, und die Formulierung von Entscheidungsproblemen als Sprachen.
Sei f eine partielle Funktion, d. h. f : D → ∆∗ fur ein D ⊆ Σ∗. Wir sagen: f ist (imintuitiven Sinn) berechenbar, wenn es ein
”mechanisches, algorithmisches Verfahren“ gibt,
das zu jedem x ∈ D den Funktionswert f(x) bestimmt.
Eine Sprache L ⊆ Σ∗ heißt (im intuitiven Sinn) entscheidbar, wenn es ein solches Verfahrengibt, das zu jedem x ∈ Σ∗ eines der Resultate
”Ja“ und
”Nein“ berechnet, und zwar
”Ja“
genau fur die x ∈ L. Die Sprache L heißt unentscheidbar, wenn es kein solches Verfahrengibt.
Als Churchsche These bezeichnet man die Behauptung, dass das Konzept der partiellrekursiven Funktionen, wie in dieser Vorlesung auf der Basis von Turingmaschinen defi-niert, die
”richtige“ Formalisierung des informalen Konzeptes
”Berechenbare Funktionen“
ist und dass analog das Konzept der rekursiven Sprachen die”richtige“ Formalisierung
des Konzeptes”algorithmisch losbare Entscheidungsprobleme“ ist.
Churchsche These:Eine Funktion f : D → ∆∗, fur ein D ⊆ Σ∗, ist berechenbar genau dann wennf partiell rekursiv ist.
Das Wortproblem fur eine Sprache L ⊆ Σ∗ ist entscheidbar genau dann wennL rekursiv ist.
Der Mathematiker Alonzo Church hatte 1936 eine solche Feststellung formuliert. Sie istprinzipiell nicht beweisbar, denn sie behauptet die Aquivalenz eines intuitiven und nichtprazise fassbaren Konzeptes (
”algorithmisch berechenbar“) und einer mathematisch prazi-
sen Definition (”es gibt eine TM M mit f = fM“). Die Churchsche These ist aber als
Basis fur Uberlegungen zu allem, was mit Algorithmen zu tun hat, etabliert.
Welche Argumente gibt es dafur, die TM-Berechenbarkeit als Formalisierung der Ideeder
”algorithmischen Berechenbarkeit“ zu benutzen? In der fruhen Zeit der Entwicklung
der Theorie der Berechenbarkeit wurden viele Versuche unternommen, das Konzept”Be-
rechenbarkeit“ zu formalisieren. Man definierte µ-rekursive Funktionen, im λ-Kalkul be-schreibbare Funktionen, Markov-Algorithmen, spezifizierte Funktionen in Logik-Kalkulen,untersuchte Turingmaschinen, spater auch while-Programme und Registermaschinen. Da-neben untersuchte man allgemeine Grammatiken. Alle diese Formalismen versuchten, je-der mit einer anderen Terminologie, manche fur Wortfunktionen, manche fur Zahlenfunk-tionen, das Konzept
”algorithmische Berechenbarkeit“ zu formalisieren. Nun stellte sich
heraus, als mit mathematischen Methoden beweisbare Satze, dass alle diese Ansatze genau
98

dieselbe Klasse von Funktionen lieferten: namlich die partiell rekursiven Funktionen. AlsKlasse der entscheidbaren Sprachen ergab sich immer die Klasse der rekursiven Sprachen.Wir haben zwei Beispiele fur solche Aquivalenzbeweise gesehen: In Abschnitt 1.3 wurdegezeigt, dass der Grammatikformalismus zum Turingmaschinenformalismus aquivalent ist;in Abschnitt 1.5 haben wir gesehen, dass TM-Berechenbarkeit und RAM-Berechenbarkeitaquivalent sind, wenn man zwischen Zahlenmengen und -funktionen und Wortmengenund -funktionen passend ubersetzt.19 In spateren Jahren wurden dann sehr viele Program-miersprachen definiert, und damit viele neue Formalismen, mit denen sich Algorithmenals Programme prazise fassen ließen. Auch hier stellte sich heraus, dass man in jeder Pro-grammiersprache ohne kunstliche Einschrankungen, sei sie nun imperativ wie Pascal oderC, funktional wie Haskell, Lisp oder ML, oder logisch wie Prolog, bei der Annahme einigersimpler Idealisierungen (keine Zeit- und Speicherplatzbeschrankung) immer Programmegenau fur die partiell rekursiven Funktionen formulieren konnte. Die partiell rekursivenFunktionen sind also eine sehr naturliche Funktionenmenge, zu der alle bekannten Ansatzefuhren, das Algorithmenkonzept zu formalisieren.
Wir diskutieren nochmals kurz die beiden Richtungen der Churchschen These.
”⇒“: Wenn es fur ein Entscheidungsproblem, das als Wortproblem fur eine Sprache L
formuliert ist, ein algorithmisches Verfahren oder ein Computerprogramm gibt, soist L rekursiv; wenn eine Funktion f durch einen Algorithmus berechenbar ist, dannist f partiell rekursiv.
Diese Richtung der Churchschen These wird in zweifacher Weise angewendet:
(a) Man spezifiziert einen Algorithmus fur eine Funktion f in einem beliebigen Forma-lismus, einer Programmiersprache oder auch in informaler Weise und schließt (
”nach
der Churchschen These“), dass f partiell rekursiv ist. Bei Entscheidungsproblemenformuliert man ein Entscheidungsverfahren informal oder formal und schließt, dassdie entsprechende Sprache rekursiv ist. Damit erspart man sich die muhevolle Be-schreibung eines TM-Verfahrens. Meist ist es in diesen Fallen so, dass man sich dieUmsetzung des Algorithmus in ein TM-Programm im Prinzip vorstellen kann, mitHilfe der vielen Programmier- und Simulationstechniken, die wir inzwischen kennen.
(b) Wir betrachten Aussagen wie:
”L ist unentscheidbar, d. h. das Wortproblem fur L ist nicht algorithmisch losbar“
oder
”Die Funktion f ist nicht algorithmisch berechenbar“.
19Weitere Aquivalenzbeweise findet man auch im Buch von Schoning, z. B. zur Aquivalenz der Rekur-sivitat mit den Konzepten
”berechenbar mit while-Programmen“ und
”µ-rekursiv“.
99

Die prinzipielle Schwierigkeit hierbei ist, dass eine Feststellung uber alle Algorithmengemacht werden soll, das Konzept
”alle Algorithmen“ aber gar nicht formalisiert
ist, und tatsachlich zum Beispiel mit neuen Programmiersprachen andauernd neueArten entstehen, Algorithmen aufzuschreiben. Uber alle diese, gleichgultig ob schonausgedacht oder noch nicht, soll eine Aussage gemacht werden. Die ChurchscheThese sagt nun, dass es genugt, zu zeigen, dass L nicht rekursiv ist bzw. dass dieFunktion f nicht partiell rekursiv ist; dann kann man davon ausgehen, dass keinBerechnungsverfahren, das man algorithmisch nennen wurde, f berechnet oder Lentscheidet.
”⇐“: Alle partiell rekursiven Funktionen sind berechenbar; ist L rekursive Sprache, so ist
das Wortproblem fur L algorithmisch entscheidbar.
Diese Aussage ist ziemlich offensichtlich korrekt. Wenn M eine TM ist, so stellt das Pro-gramm von M zusammen mit unserer Erklarung der Arbeitsweise von Turingmaschinenaus Abschnitt 1.1.2 eine prazise algorithmische Anweisung dar, wie aus x der Wert fM(x)zu berechnen ist, fur beliebige x ∈ HM ; wenn M auf allen Inputs halt, stellt M einenAlgorithmus dar, um fur jedes x ∈ Σ∗ zu entscheiden, ob x ∈ LM ist oder nicht.
Eine kleine Warnung ist aber am Platz: Manchmal weiß man, dass eine Funktion rekursivist, d. h. dass eine TM existiert, die die Funktion f berechnet, aber man kann keine solcheTM explizit angeben, und man kann auch f(x) nicht ausrechnen. Ein Beispiel:
f(x) :=
{0, falls es unendlich viele Primzahlzwillinge gibt;1, sonst.
}
, fur x ∈ {0, 1}∗.
f ist konstant, also rekursiv (”. . . es gibt eine TM M mit f = fM . . .“), aber es ist ein
offenes mathematisches Problem, herauszufinden, ob f ≡ 0 oder f ≡ 1, also kennt bisheute auch kein Mensch eine Methode, mit der man zum Beispiel f(ε) bestimmen konnte.
1.8 Universelle Turingmaschinen
In unseren bisherigen Uberlegungen hatten wir”special purpose“-Turingmaschinen be-
trachtet: zu jeder Funktion f (bzw. zu jeder Sprache L) gab es eine eigene TM M mit f =fM (bzw. L = LM). Dies entspricht der Situation in der Fruhzeit der Computer, wo ganzeRechner zur Losung eines Problems gebaut wurden (Maschinen fur die Grundrechenar-ten, Maschinen zur Losung von Differentialgleichungen, Chiffrier-/Dechiffriermaschinenu. a.). Von einigen Ausnahmen abgesehen, sind reale Rechner schon seit langem
”general
purpose“-Maschinen. Man prasentiert dem Rechner ein Programm P in einer Program-miersprache und Eingabedaten. Nun wird P ubersetzt, in ein Maschinenprogramm P ′
oder ein interpretierbares Programm P ′ in einer Zwischensprache. Entweder die Hardwa-re oder ein Interpretierprogramm lasst dann P ′ auf den Daten D ablaufen. Pascal- oderJava-Ubersetzer und -Interpreter sind recht komplexe Programme.
100

In diesem Abschnitt werden wir feststellen, dass das Turingmaschinenmodell solche”gene-
ral purpose“-Maschinen schon umfasst. Es gibt also Turingmaschinen, die beliebige TM-Programme (durch M = (Q, Σ, Γ, B, q0, F, δ) gegeben) auf beliebigen Eingaben x ∈ Σ∗
ablaufen lassen konnen. Eigentlich sollten solche TM”programmierbar“ heissen; sie hei-
ßen jedoch aus historischen Grunden”universell“. Im Licht der Churchschen These ist die
Existenz solcher universeller Turingmaschinen keine Uberraschung: das in Abschnitt 1.1beschriebene Verfahren zur Abarbeitung eines TM-Programms auf einer Eingabe x istsicher ein Algorithmus; also gibt es nach der Churchschen These auch eine TM, die diesenAlgorithmus ausfuhrt. Wir werden aber sehen, dass man solche TM recht leicht direktbeschreiben kann.
Eine universelle Turingmaschine erhalt ihr”Programm“, d. h. die Beschreibung der TM,
die sie ablaufen lassen soll, als Teil des Eingabewortes. Daher ist es notig, Turingmaschinendurch einen Text uber einem festen Alphabet zu beschreiben. Wir wahlen eine einfachebinare Kodierung.
1.8.1 Definition
(a) Eine TM M = (Q, Σ, Γ, B, q0, F, δ) heißt normiert, falls gilt:Q = {0, 1, . . . , s−1} fur ein s ≥ 2, q0 = 0, F = {1}, Σ = {0, 1}, Γ = {0, 1, 2}, B = 2.
(Bemerkung : Jede TM M kann durch eine normierte TM M ′ simuliert werden. ZurReduzierung der Eingabe- und Bandalphabete siehe Abschnitt 1.2.12; die Namender Zustande q spielen fur die Arbeit der TM ohnehin keine Rolle; eine leichteModifikation erlaubt es, mit einem akzeptierenden Zustand auszukommen.)
Wir kodieren L,R,N durch 0, 1, 2.
(b) Eine normierte TM M = (Q, Σ, Γ, B, q0, F, δ) sei gegeben; move1, . . . , mover seiendie Elemente von {(q, a, q′, a′, D) | δ(q, a) = (q′, a′, D)} ⊆ Q×Γ×Q×Γ×{0, 1, 2},aufsteigend sortiert gemaß (q, a).
Wir kodieren jedes 5-Tupel wie folgt als Binarwort:
〈(q, a, q′, a′, D)〉 := 0q+1 1 0a+1 1 0q′+1 1 0a′+1 1 0D+1.
Schließlich definieren wir
〈M〉 := 111 0s+1 111 〈move1 〉 11 〈move2〉 11 · · · 11 〈mover〉 111.
〈M〉 heißt die Binarkodierung von M oder auch Godelnummer von M . (Der Mathe-matiker Kurt Godel hatte eine Kodierung von Formeln der Pradikatenlogik durchZahlen definiert, daher die Bezeichnung
”Nummer“. Auch unsere Binarkodierung
M 7→ 〈M〉 ordnet jeder normierten TM M eine”Nummer“ zu, namlich die Zahl
(〈M〉)2.)
101

1.8.2 Beispiel Wir betrachten eine normierte TM M mit Q = {q0, q1, q2, q3} und derfolgenden Turingtafel. Der Deutlichkeit halber schreiben wir qi statt i und B statt 2. (DieTM tut etwas einigermaßen Sinnvolles. Was?)
aq 0 1 Bq0 (q2, 1, R) (q0, 0, R) (q1, 1, N)q1 − − −q2 (q2, 0, R) (q2, 1, R) (q3, B, L)q3 − − −
Die TM hat sechs Zuge, namlich
(q0, 0, q2, 1, R), (q0, 1, q0, 0, R), (q0, B, q1, 1, N),(q2, 0, q2, 0, R), (q2, 1, q2, 1, R), (q2, B, q3, B, L)
mit den Kodierungen
0101000100100 , 01001010100 , 010001001001000 ,00010100010100 , 0001001000100100 , 000100010000100010 .
Damit erhalten wir folgenden Binarstring als Binarkodierung fur M . (Die Lucken dienennur der besseren Lesbarkeit.)
〈M〉 = 111 00000 111 0101000100100 11 01001010100 11 010001001001000 11
00010100010100 11 0001001000100100 11 000100010000100010 111 .
Der numerische Wert dieses Strings, als Binarzahl aufgefasst, liefert die Nummer von M .
1.8.3 Bemerkung (”Syntaxcheck“ fur TM-Codes)
Es ist leicht, einen Binarstring w darauf zu testen, ob er ein Prafix der Form 〈M〉 hat,also ob w = 〈M〉x fur eine normierte TM M und ein x ∈ {0, 1}∗. M und x sind danndurch w eindeutig bestimmt. Formal halten wir fest:
(a) Die Sprache LTM−Code = {〈M〉 |M normierte TM} ⊆ {0, 1}∗ ist rekursiv.
(b) Die Sprache D = {〈M〉x |M normierte TM, x ∈ {0, 1}∗} ⊆ {0, 1}∗ ist rekursiv.
(c) Die Funktion f : D 3 〈M〉x 7→ 〈M〉#x ist wohldefiniert und partiell rekursiv.
(d) Aus 〈M〉 kann (leicht) die Ubergangsfunktion δ und damit M rekonstruiert werden.
1.8.4 Definition Eine TM U heißt universell, wenn sie bei Eingabe 〈M〉x das Ein-/Ausgabeverhalten von M auf x simuliert, d. h. wenn fur alle TM-Codes 〈M〉 ∈ LTM−Code
und alle x ∈ {0, 1}∗ gilt:
102

(a) U halt auf 〈M〉x ⇔ M halt auf x;
(b) U
{akzeptiertverwirft
}
〈M〉x ⇔ M
{akzeptiertverwirft
}
x ;
(c) fU(〈M〉x) = fM(x).
(d) Auf Eingaben, die nicht die Form 〈M〉x haben, halt U nicht an.
1.8.5 Satz Es gibt eine universelle Turingmaschine U mit drei Bandern.
Beweis : Wir beschreiben die Arbeitsweise von U auf einer Eingabe w ∈ {0, 1}∗:
Im Gegensatz zu fruheren Simulationen zwischen Turingmaschinen verschiedenen Typsmuss hier auch der Zustand der simulierten Turingmaschine auf dem Band von U unter-gebracht werden, da U TMn mit beliebig großen Zustandsmengen simulieren soll und Unur eine feste Anzahl von Zustanden haben darf. Auf eine Kodierung des Bandalphabetsvon M kann man verzichten, weil M als normiert vorausgesetzt wird.
1 n
1 n
Konfiguration
Band-
w
Zustand symbol
U
von M
explizite
Band 2 ... B B B a ... a B B B B B ... Arbeitsband von M
Band 1... B B <M> a ... a B B B ... Programm
Band 3... B B 1 1 0 1 0 0 1 B B ... Zustand von M
Eingabe x für M
A. Initialisierung : Teste (nach Bem. 1.8.3(b)), ob w die Form 〈M〉x fur eine normierteTM M hat.Falls ja, kopiere x = a1 · · · an auf Band 2 und stelle den Kopf auf Band 2 auf a1,sonst geht U in eine Endlosschleife.Schreibe 1101 (entspricht q0) auf Band 3.
103

B. Wiederhole (Simulation eines Schrittes von M):
1. Schreibe 0a+11 rechts neben den String 110q+11 auf Band 3, wo a ∈ {0, 1, 2}der fur den Bandkopf von M auf Band 2 sichtbare Buchstabe ist.
2. Mit Textsuche (s. Beispiel 1.2.11) suche in 〈M〉 auf Band 1 das Teilwort u =110q+110a+11, das auf Band 3 steht.
Falls u nicht gefunden wird:Falls q = 1, halte und akzeptiere, sonst halte und verwirf.
Falls u gefunden wird:u ist Prafix eines Teilworts 110q+110a+110q′+110a′+110D+111 von 〈M〉 auf
Band 1. Uberschreibe Band 3 mit 110q′+11, schreibe a′ ∈ {0, 1, 2} auf Band 2,bewege Kopf auf Band 2 in Richtung D ∈ {0, 1, 2} = {L,R,N}. Gehe zu 1.
Aufgrund der Konstruktion sieht man, dass U die Aktionen von M auf Eingabe x Schrittfur Schritt nachahmt. Daher ergibt sich sofort, dass das E/A-Verhalten von U auf Eingabe〈M〉x dasselbe ist wie das von M auf x. Die Ausgabe fU(〈M〉x) = fM(x) ist auf Band 2abzulesen, wenn und sobald U auf 〈M〉x halt. �
1.8.6 Bemerkung
(a) Falls M auf x halt, gilt fur den Rechenzeit- und Speicherplatzbedarf von U :
tU(〈M〉x) = O(|〈M〉| · tM(x)) und
sU(〈M〉x) = O(|〈M〉|+ sM(x)).
(b) Ist M eine feste normierte TM, die s(n)-platzbeschrankt bzw. t(n)-zeitbeschranktist, so ist fur x ∈ {0, 1}n
tU(〈M〉x) = O(t(n)) und
sU(〈M〉x) = O(s(n)).
(Fur festes M wird |〈M〉| als konstant angesehen, fur festes k werden also Faktoren|〈M〉|k in O(. . .)
”geschluckt“.)
(c) Es gibt auch eine universelle TM U ′ mit einem Band, fur die die Aussage (b) zutrifft.
104

Beweis :
(a), (b) Die Simulation eines Schritts von M benotigt Zeit O(|〈M〉|). Die Abschatzung furden Platzbedarf ist klar.
(c) Die Details des Beweises dieser Behauptung lassen wir weg. Die Idee ist, 〈M〉 unddie Bandinschrift von M auf separaten Spuren des einen Bandes von U ′ zu halten,und wahrend der Simulation bei Kopfbewegungen von M (durch fortwahrendesVerschieben um eine Zelle) stets 〈M〉 so mitzufuhren, dass der erste Buchstabe von〈M〉 in der Zelle steht, auf der momentan der Kopf von M positioniert ist (vgl. dasfolgende Bild).
1 1 1 0 0 ... 0 1 1 1
B B
1 1 111 ... 11
BSpur 1
Spur 2
Spur 3
Spur 4
b a n d i n s c h r i t + v o n + M
Kopfposition
bei M
<M>
(q,a)
*
1 1 0 ... 0 1 0 0 1
Band von M
s<move >1
f
<move >
Abbildung 1.12: Die vier Bandspuren einer universellen 1-Band-TM
1.9 Unentscheidbare Probleme
In diesem Abschnitt lernen wir nichtrekursive Sprachen kennen, also Sprachen, die furunentscheidbare Probleme stehen. Im Zentrum steht dabei die Unentscheidbarkeit desHalteproblems fur Turingmaschinen. Aus dieser folgt dann die Unentscheidbarkeit vieleranderer Probleme.
1.9.1 Existenz von unentscheidbaren Sprachen
Wir zeigen zunachst, dass es Sprachen gibt, deren Wortproblem unentscheidbar ist.
1.9.1 Bemerkung Es gibt Sprachen L ⊆ {0, 1}∗ mit der Eigenschaft, dass weder Lnoch L rekursiv aufzahlbar sind.
105

Beweis : (Vgl. Abschnitt 0.3.1) Die Menge {〈M〉 | M ist normierte Turingmaschine} ⊆{0, 1}∗ ist abzahlbar. Da zu jeder rekursiv aufzahlbaren Menge L ⊆ {0, 1}∗ eine normierteTuringmaschine M mit L = LM gehort, ist auch {L ⊆ {0, 1}∗ | L rekursiv aufzahlbar}eine abzahlbare Menge; dasselbe gilt dann fur {L ⊆ {0, 1}∗ | L rekursiv aufzahlbar}. Alsoist die Vereinigung der beiden Mengen abzahlbar. Andererseits ist {L | L ⊆ {0, 1}∗},die Menge aller Sprachen, uberabzahlbar. Also ist {L | L r.a. oder L r.a.} ⊆
6{L | L ⊆
{0, 1}∗}. �
Leider genugt dieses abstrakte Argument nicht, um die Existenz von rekursiv aufzahlbarenMengen, die nicht rekursiv sind, nachzuweisen. (Wieso nicht?) Wie wir sehen werden, sindaber gerade diese Sprachen hochinteressant.
1.9.2 Eine unentscheidbare rekursiv aufzahlbare Sprache
1.9.2 Definition
(a) Erinnerung: Die Haltemenge fur eine TM M = (Q, Σ, Γ, . . .) ist folgende Sprache:
HM := {x ∈ Σ∗ |M auf x halt}.
(b) Die Haltesprache fur TMn ist
H := {〈M〉x |M auf x halt}.
Dies ist gleich HU fur die universelle Turingmaschine U , siehe Definition 1.8.4. DasWortproblem fur H ist eine Formalisierung des folgenden Entscheidungsproblems:
Das (allgemeine) Halteproblem fur Turingmaschinen:
Input: Eine normierte Turingmaschine M und ein x ∈ {0, 1}∗.
Output:”Ja“, falls M auf x halt,
”Nein“ sonst.
(c) Die Selbstanwendungssprache oder Diagonalsprache ist
K := {〈M〉 |M ist normierte TM und M halt auf Eingabe 〈M〉}.
Das Wortproblem fur K ist eine Formalisierung des folgenden Entscheidungspro-blems:
Das spezielle Halteproblem fur Turingmaschinen:
Input: x ∈ {0, 1}∗.
Output:”Ja“, falls x Binarkodierung einer normierten TM M ist und diese TM M
auf x halt,”Nein“ sonst.
106

1.9.3 Behauptung H und K sind rekursiv aufzahlbar.
Beweis : H ist rekursiv aufzahlbar, weil H = HU ist und nach Lemma 1.1.18 fur jede TMM die Haltemenge HM rekursiv aufzahlbar ist. — Fur K betrachte eine TM MK , die aufEingabe x folgendes tut:
1. Prufe ob x = 〈M〉 fur eine TM M . Falls nein, gehe in eine Endlosschleife.
2. Schreibe xx auf Band 1 und starte die TM U (als Unterprogramm) auf dieser Ein-gabe.
Nun gilt:MK halt auf Eingabe x ⇒ x = 〈M〉 fur eine TM M und U halt auf xx ⇒ x ∈ K;andererseits:x ∈ K ⇒ x = 〈M〉 fur eine TM M und M halt auf x⇒ U halt auf 〈M〉x = xx⇒MK halt auf Eingabe x.
Also ist HMK= K und K ist rekursiv aufzahlbar nach Lemma 1.1.18. �
1.9.4 Satz (a) K ist nicht rekursiv. (b) K ist nicht rekursiv aufzahlbar.
Beweis : (a) folgt sofort aus (b) (vgl. Satz 1.4.4). Wir mussen also nur (b) beweisen.Dazu zeigen wir, dass keine rekursiv aufzahlbare Sprache mit K ubereinstimmen kann.Sei dazu L ⊆ {0, 1}∗ eine beliebige rekursiv aufzahlbare Sprache. Nach Lemma 1.1.18und der Konstruktion in 1.2.12(b) gibt es eine normierte TM M mit L = HM . Nun giltfolgendes:
〈M〉 ∈ HM ⇔ M halt auf 〈M〉 ⇔(Def.v.K)
〈M〉 ∈ K ⇔ 〈M〉 6∈ K.
Also unterscheiden sich L = HM und K auf dem Element 〈M〉 ∈ {0, 1}∗, und es folgtL 6= K. �
Der formale Beweis ist damit beendet. Er ist kurz, aber vielleicht etwas unanschaulich.(Das Cantorsche Diagonalverfahren wird hier in ahnlich kompakter Weise wie in Bemer-kung 0.3.4 angewendet.) Wir beschreiben dieselbe Uberlegung nochmals etwas anschauli-cher, so dass die
”Diagonale“ direkt ins Auge fallt.
Wir numerieren die Worter in {0, 1}∗ in der bekannten Weise durch (kanonische Anord-nung, vgl. das Ende von Abschnitt 1.4):
{x1, x2, x3, x4, x5, . . .} = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, . . .}.
Nun stellen wir uns ein Schema in der Art einer unendlichen Matrix vor, deren Zeilen undSpalten Indizes 1, 2, 3, . . . haben. Der Spalte i ist xi als Eingabewort zugeordnet. Der Zeilej ist eine normierte TM Mj zugeordnet, wie folgt: Wenn xj = 〈M〉 fur eine normierte TM
107

M , dann ist Mj = M ; wenn xj keine TM-Kodierung ist, dann ist Mj = M∅ fur eine festeTM M∅, die auf keiner Eingabe halt. Offensichtlich gilt fur jede normierte TM M , dasses ein j mit M = Mj gibt.
x i
<M >=xj j
x r
<M >r
0 0 1 0
1 1 0 1
1 1 0 0
0 1 1 0
x x x x ... {0,1}1 2 3 4
*
# K??
K
...
<M >=x
<M >=x
<M >=x
<M >=x
x
1 1
2 2
3 3
4 4
i
0 sonst
j i
K=H?
M
EingabenTM-
Codes
1, falls M auf x hält
r
In das Schema werden wie folgt Nullen und Einsen eingetragen: der Eintrag in Zeile j,Spalte i ist 1, wenn Mj auf xi halt, und 0 sonst. Wir beobachten:
(i) Ist L rekursiv aufzahlbar, dann gibt es eine Zeile j mit L = HMj. In dieser Zeile j
steht die charakteristische Funktion von L.
(ii) In der Diagonale findet sich die charakteristische Funktion von K: xi ∈ K gilt genaudann, wenn der Eintrag in Zeile i, Spalte i gleich 1 ist.
(iii) Die charakteristische Funktion von K kann nicht als Zeile r vorkommen, denn derEintrag am Schnittpunkt einer solchen Zeile r mit der Diagonalen (der naturlich inSpalte r liegt) musste zu K passen (Zeile r) und gleichzeitig zu K (Diagonale).
Aus (i) und (iii) folgern wir, dass K nicht rekursiv aufzahlbar ist. �
1.9.3 Die Unentscheidbarkeit des Halteproblems
Nun konnen wir beweisen, dass das allgemeine Halteproblem fur Turingmaschinen unent-scheidbar ist.
1.9.5 Satz (a) H ist nicht rekursiv. (b) H ist nicht rekursiv aufzahlbar.
108

Beweis : Wie im vorigen Satz folgt (a) aus (b). Wir beweisen (b) indirekt.Annahme: H ist rekursiv aufzahlbar.Dann gibt es eine (normierte) TM M ′ mit H = LM ′ . Betrachte nun eine TM M ′′, die aufEingabe x folgendes tut:
1. Prufe, ob x Binarkodierung einer normierten TM M ist. Falls nicht, halte.
2. Andernfalls lasse M ′ auf Eingabe xx laufen.
Behauptung: HM ′′ = K.
Beweis der Behauptung:1.Fall : x ∈ {0, 1}∗ ist nicht Binarkodierung einer TM M . Dann ist x ∈ K nach derDefinition von K und x ∈ HM ′′ , nach der Konstruktion von M ′′.2.Fall : x = 〈M〉 fur eine TM M . Dann gilt:
x ∈ HM ′′ ⇔ M ′ halt auf 〈M〉x ⇔ 〈M〉x ∈ H
⇔ M halt nicht auf x ⇔ x 6∈ K ⇔ x ∈ K.
Die Behauptung ist damit bewiesen. Sie impliziert nach Lemma 1.1.18, dass K rekursivaufzahlbar ist, im Widerspruch zu Satz 1.9.4. Also ist die Annahme falsch, und H istnicht rekursiv aufzahlbar. �
Anmerkung : Der Beweis ist indirekt formuliert. Aber er kann in eine Konstruktion vonGegenbeispielen umgemunzt werden. Sei dazu M ′ eine beliebige TM. Wie im vorangegan-genen Beweis konstruiert man die TM M ′′. Aus dem Beweis von Satz 1.9.4 sieht man,dass sich K und HM ′′ im Verhalten auf dem Wort y = 〈M ′′〉 unterscheiden. Es gibt zweiFalle:1. Fall : y ∈ K ∧ y ∈ HM ′′ . — Dann ist yy ∈ H und M ′ halt auf yy.2. Fall : y /∈ K ∧ y /∈ HM ′′ . — Dann ist yy /∈ H und M ′ halt auf yy nicht.Also gilt: yy ∈ H ⇔ M ′ halt auf yy. Das Binarwort yy = 〈M ′′〉〈M ′′〉 ist also ein aus M ′
konstruierbarer Beleg dafur, dass HM ′ 6= H ist.
Wir merken uns als Hauptergebnis dieses Kapitels die informale Version des eben bewie-senen Satzes:
Das Halteproblem fur Turingmaschinen ist unentscheidbar.
1.9.4 Reduzierbarkeit und die Reduktionsmethode
Wir haben im letzten Beweis unser Wissen”K ist nicht rekursiv aufzahlbar“ benutzt,
um dasselbe uber H zu beweisen. Nun stellen wir eine allgemeine Methode bereit, umin durchsichtiger Weise nachzuweisen, dass weitere Sprachen nicht rekursiv bzw. nichtrekursiv aufzahlbar sind. Hierzu fuhren wir ein neues, wichtiges Konzept ein: die Reduktioneiner Sprache auf eine andere.
109

1.9.6 Definition Seien L ⊆ Σ∗ und L′ ⊆ ∆∗ Sprachen. Wir sagen:
L ist reduzierbar auf L′, in Zeichen L ≤ L′,
wenn es eine (totale) rekursive Funktion f : Σ∗ → ∆∗ gibt mit
∀x ∈ Σ∗ : x ∈ L⇔ f(x) ∈ L′.
Wenn diese Bedingung erfullt ist, schreibt man auch”L ≤ L′ mittels f“ oder
”L ≤ L′ via
f“.
Man kontrolliert anhand der Definitionen leicht nach, dass
L ≤ L′ mittels f ⇔ f−1(L′) = L.
Ist L reduzierbar auf L′, so ist das Wortproblem fur L′
”mindestens so schwer zu ent-
scheiden“ wie das fur L. Das”≤“-Symbol stellt also schwierigere Wortprobleme auf die
”großer“-Seite.
Warnung: (a) Viele Studierende haben mit dem Reduktionsbegriff zunachst Probleme.Der erste Schritt zum richtigen Verstandnis ist, sich die Definition genau einzupragen. Esist wichtig, dass f eine totale Funktion ist und dass die Aussage x ∈ L ⇔ f(x) ∈ L′ furalle x ∈ Σ∗ gilt, nicht etwa nur fur die x ∈ L. Weiter ist es nicht genug, zu verlangen,dass ∀x ∈ Σ∗ : x ∈ L ⇒ f(x) ∈ L′ gilt. (Das sieht man schon daran, dass L′ = ∆∗ dieseForderung fur jedes beliebige L erfullt.)(b) Fur die Benutzung des Reduktionsbegriffs genugt es nicht, die intuitive Erklarung
”mindestens so schwer zu entscheiden wie . . .“ zugrundezulegen. Vielmehr muss man direkt
mit der Definition arbeiten.
Wir notieren einige technische Eigenschaften der ≤-Relation.
1.9.7 Lemma
(a) (Reflexivitat) L ≤ L gilt fur jede Sprache L.
(b) (Transitivitat) Wenn L ≤ L′ und L′ ≤ L′′, dann gilt auch L ≤ L′′.
(c) L ≤ L′ mittels f ⇔ L ≤ L′ mittels f .
Beweis :
(a) Es gilt L ≤ L mittels der Identitatsfunktion id : x 7→ x.
(b) Ist L ≤ L′ mittels f : Σ∗ → ∆∗ und L′ ≤ L′′ mittels g : ∆∗ → Φ∗, so ist L ≤ L′′
mittels der Hintereinanderausfuhrung g ◦ f , denn fur jedes x ∈ Σ∗ gilt:
x ∈ L⇔ f(x) ∈ L′ ⇔ g(f(x)) ∈ L′′ ⇔ (g ◦ f)(x) ∈ L′′.
Da f und g rekursiv sind, ist auch g ◦ f rekursiv — wenn f = fM1und g = fM2
,rechnet man zu Input x zunachst mit M1 das Wort y = f(x) aus und dann mit M2
das Wort g(y) = (g ◦ f)(x).
110

(c) Offensichtlich gilt∀x ∈ Σ∗ : x ∈ L⇔ f(x) ∈ L′
genau dann wenn∀x ∈ Σ∗ : x 6∈ L⇔ f(x) 6∈ L′
gilt. Daraus folgt die Behauptung. �
Mit dem Reduktionskonzept werden Berechenbarkeitsaussagen zwischen Sprachen uber-tragen.
1.9.8 Lemma
(a) Wenn L′ rekursiv ist und L ≤ L′ gilt, dann ist L ebenfalls rekursiv.
(b) Wenn L′ rekursiv aufzahlbar ist und L ≤ L′ gilt, dann ist L ebenfalls rekursivaufzahlbar.
Beweis :
(a) Es gelte L ≤ L′ mittels f . Weil L′ rekursiv ist, gibt es eine TM M ′ mit L′ = LM ′ , diefur jeden Input halt. Weil f rekursiv ist, gibt es eine TM M ′′, die auf allen Eingabenhalt und f = fM ′′ erfullt. Wir konstruieren eine neue TM M , die auf Eingabe x wiefolgt rechnet: Lasse M ′′ auf x laufen; das Ergebnis sei y ∈ ∆∗. Nun lasse M ′ aufEingabe y laufen. Wenn M ′ akzeptierend halt, halt auch M akzeptierend; wenn M ′
verwerfend halt, verwirft auch M .
Offenbar gilt fur jedes x:
M akzeptiert x⇔M ′ akzeptiert y = f(x)⇔ f(x) ∈ LM ′ = L′ ⇔ x ∈ L.
(Die letzte Aquivalenz gilt nach der Definition von”≤“.) Also ist LM = L. Weiter
ist klar, dass M auf allen Eingaben halt.
(b) Die Konstruktion und der Beweis ist identisch zu Teil (a). Nur wird nicht verlangt,dass M ′ auf allen Eingaben halt; dann halt naturlich auch M nicht unbedingt aufallen Eingaben. �
Wir werden Lemma 1.9.8 praktisch nie benutzen, um zu beweisen, dass eine Sprache rekur-siv oder rekursiv aufzahlbar ist. Vielmehr benutzen wir die Kontraposition des Lemmas,um zu zeigen, dass Sprachen nicht rekursiv bzw. rekursiv aufzahlbar sind.
1.9.9 Korollar
(a) Wenn L nicht rekursiv ist und L ≤ L′ gilt, dann ist auch L′ nicht rekursiv.
(b) Wenn L nicht rekursiv aufzahlbar ist und L ≤ L′ gilt, dann ist auch L′ nicht rekursivaufzahlbar.
111

Rezept: Um zu zeigen, dass L′ nicht rekursiv [nicht rekursiv aufzahlbar] ist,wahle eine passende als nicht rekursiv [nicht rekursiv aufzahlbar]bekannte Sprache Lund definiere eine Funktion f , die L ≤ L′ mittels f erfullt.
Wir benutzen das Rezept zunachst mit K und K an der Stelle von L, um mit der Reduk-tionsmethode nochmals zu zeigen, dass H nicht rekursiv und H nicht rekursiv aufzahlbarist. Im weiteren Verlauf benutzen wir vorzugsweise H bzw. H an der Stelle von L. Jemehr Sprachen als nicht rekursiv bzw. nicht rekursiv aufzahlbar erkannt sind, desto mehrMoglichkeiten hat man bei der Wahl von L.
1.9.10 Beispiel Wir wollen zeigen, dass K ≤ H gilt. Dazu definieren wir eine Funktionf : {0, 1}∗ → {0, 1}∗ durch
f(x) :=
{xx, falls x = 〈M〉 fur eine TM Mε, fur alle anderen x ∈ {0, 1}∗.
Nach Bemerkung 1.8.3(a) ist f total rekursiv. Weiter gilt fur jedes x ∈ {0, 1}∗:
x ∈ K ⇒ es gibt eine TM M mit x = 〈M〉 und M halt auf x⇒ f(x) = xx ∈ H;
weil ε /∈ H ist, gilt umgekehrt
f(x) ∈ H ⇒ f(x) = xx, es gibt eine TM M mit x = 〈M〉 und M halt auf x⇒ x ∈ K.
Das bedeutet, dass K ≤ H mittels f gilt. — Mit Lemma 1.9.7(c) folgt, dass auch K ≤ Hgilt. Mit Korollar 1.9.9 folgern wir, dass H nicht rekursiv ist und dass H nicht rekursivaufzahlbar ist.
Das folgende Beispiel fur die Anwendung der Reduktionsmethode ist exemplarisch furviele ahnliche Konstruktionen. Zudem zeigen wir, wie man vorgeht, wenn die rekursiveAufzahlbarkeit von Teilmengen von {〈M〉 |M normierte TM} zu beweisen ist.
1.9.11 Beispiel Es sei Hε die Sprache, die das Halteproblem bei leerem Eingabebandreprasentiert:
Hε := {〈M〉 |M halt bei Eingabe ε}.
(Achtung : Hε ist eine unendliche Menge von Godelnummern und etwas ganz anderes alsLε = {ε}, eine Menge mit dem einzigen Element ε, das keine Godelnummer ist.)
Wir zeigen:
(i) Hε ist rekursiv aufzahlbar.
112

(ii) Hε ist nicht rekursiv aufzahlbar. (Daraus folgt: Hε ist nicht rekursiv.)
Zu (i): (Konstruktion.) Nach der Definition von H gilt
〈M〉 ∈ Hε ⇔ 〈M〉 = 〈M〉ε ∈ H = HU .
Dies benutzen wir, um eine TM Mε mit HMε = Hε zu konstruieren. Mε arbeitet aufEingabe x ∈ {0, 1}∗ folgendermaßen:
1. Teste, ob x eine TM-Kodierung 〈M〉 ist. Falls nein, gehe in eine Endlosschleife.
2. Falls ja, starte U als Unterprogramm auf Eingabe x = 〈M〉.
Nach dieser Beschreibung haben wir:Mε halt auf x ⇒ x = 〈M〉 fur eine TM M und U halt auf 〈M〉 = 〈M〉ε⇒ M halt auf ε ⇒ x ∈ Hε.
Umgekehrt gilt:x ∈ Hε ⇒ x = 〈M〉 fur eine TM M und M halt auf ε⇒ U halt auf 〈M〉ε = x ⇒ Mε halt auf x.
Zu (ii): Wir wollen das Rezept nach Korollar 1.9.9 mit L = H benutzen, also H ≤ Hε
zeigen, oder aquivalent H ≤ Hε. Wir brauchen also eine rekursive Funktion f : {0, 1}∗ →{0, 1}∗, die folgende Eigenschaft hat:
(∗) ∀y ∈ {0, 1}∗ : y ∈ H ⇔ f(y) ∈ Hε.
Einzig interessant sind Werte f(y), die TM-Kodierungen sind. Wir mussen also zu jedemy eine TM My und ihre Kodierung f(y) = 〈My〉 angeben, so dass
∀y ∈ {0, 1}∗ : y ∈ H ⇔ f(y) = 〈My〉 ∈ Hε
odery ∈ H ⇔ My halt auf Eingabe ε.
Wir beschreiben, wie sich My verhalt, wenn auf dem Band die Eingabe x steht:
(∗ Ignoriere den Input x vollig ∗)
1. Uberschreibe den Inhalt x des Bandes mit y(∗ dazu ist y in der Steuereinheit von My gespeichert; die Abhangigkeit von My vony ist also echt ∗)
2. Starte die universelle TM U mit der Bandinschrift y als Eingabe.
Wir mussen zwei Eigenschaften uberprufen:
113

(a) f mit f(y) = 〈My〉 fur y ∈ {0, 1}∗ ist rekursiv. Dazu uberlegen wir, dass die Kon-struktion von My aus y, auch im Formalismus der Godelnummern, bestimmt al-gorithmisch ausfuhrbar ist; nach der Churchschen These ist f rekursiv. (Es ist in-struktiv, sich einen Algorithmus zur Berechnung von 〈My〉 bis zu einem gewissenDetailliertheitsgrad auszudenken. Das Programm der TM My besteht aus einemVorspann, in dem die Eingabe x geloscht wird, dann |y| Schritten zum Schreibenvon y und |y| Schritten, um den Kopf auf die Startposition zuruckzufahren, und ausdem Programm von U . Nur der zweite Teil ist, in einfacher Weise, von y abhangig.)
(b) Fur y ∈ {0, 1}∗ gilt, nach der Definition von f(y) = 〈My〉:
y ∈ H ⇒ U halt auf y ⇒My halt auf allen x⇒My halt auf ε⇒ f(y) = 〈My〉 ∈ Hε,
undf(y) = 〈My〉 ∈ Hε ⇒My halt auf ε⇒ U halt auf y ⇒ y ∈ H.
Damit gilt H ≤ Hε mittels f , wie gewunscht. �
1.9.12 Bemerkung Wir bemerken, dass die Funktion f aus dem letzten Beispiel furviele andere Sprachen, die aus TM-Kodierungen bestehen, als Reduktionsfunktion dienenkann. Das liegt an der folgenden (offensichtlichen) Eigenschaft von f : fur alle y ∈ {0, 1}∗
gilt
y ∈ H ⇒ HMy = {0, 1}∗;
y /∈ H ⇒ HMy = ∅.
Beispielsweise sei w ∈ {0, 1}∗ ein beliebiges, festes Wort. Mit Hw bezeichnen wir die Mengeder Codes von Turingmaschinen M mit w ∈ HM :
Hw := {〈M〉 |M halt auf w}.
Ahnlich wie in Teil (i) des vorangegangenen Beispiels zeigt man, dass Hw rekursiv aufzahl-bar ist (Ubung).
Mit derselben Argumentation wie in Teil (ii) des Beispiels sieht man (Details: Ubung),dass f die folgende Eigenschaft hat:
∀y ∈ {0, 1}∗ : y ∈ H ⇔ f(y) = 〈My〉 ∈ Hw.
Daher ist H ≤ Hw, woraus folgt, dass Hw nicht rekursiv und Hw nicht rekursiv aufzahlbarist.
Es ist also gut, wenn man zunachst einmal mindestens diese eine Reduktionsfunktion inseinem Werkzeugkasten hat.
114

Am Ende dieses Abschnitts wollen wir noch diskutieren, was die bisherigen Resultate mitden Programmen zu tun hat, mit denen man als Informatiker(in) taglich zu tun hat. AlsBeispiel-Programmiersprache nehmen wir Pascal; dieselben Uberlegungen lassen sich aberfur alle anderen Programmiersprachen anstellen.
Wir definieren eine Sprache, die das Halteproblem fur Pascal-Programme formalisiert. Un-sere Programme lesen ihre Eingabe aus einer Eingabedatei, die ASCII-Zeichen enthalt.Ascii sei das Alphabet der 128 ASCII-Zeichen. Man erinnert sich, dass jedes Pascal-Programm mit
”end z .“ endet, wobei z eine beliebige Folge von Leerzeichen und Zei-
lenvorschuben ist, und dass diese Kombination nirgendwo anders im Programm vorkom-men kann. Daher ist bei einer Verkettung Px fur ein Pascal-Programm P und ein Wortx ∈ Ascii
∗ die Trennstelle zwischen P und x eindeutig zu identifizieren. Die Sprache
LPascal := {P ∈ Ascii∗ | P ist syntaktisch korrektes Pascal-Programm}
ist rekursiv. Sie ist zwar nicht kontextfrei, aber jeder Pascal-Compiler enthalt einen Teil,den Parser, der die Korrektheitsprufung durchfuhrt. Nun setzen wir
LPascal−Halt := {Px | P ∈ LPascal, x ∈ Ascii∗, P halt auf Input x}.
Unser Ziel ist es, zu zeigen, dass die Sprache LPascal−Halt unentscheidbar ist, dass es alsokeinen Algorithmus gibt, der zu einem Pascal-Programm P mit Input x feststellt, ob P aufx anhalt. Das heißt insbesondere, dass es heute und in Zukunft keinen Formalismus gebenkann, in dem ein Tool formulierbar ist, das zuverlassig die einfachste semantische Frageuber Pascal-Programme beantwortet, die man sich vorstellen kann: halt P mit Input xoder nicht?
Man erinnert sich, dass wir dieselbe Frage in der Einleitung bezuglich Pascal-Programmenals Prufverfahren schon behandelt haben. Mit der Churchschen These kommen wir zueiner viel starkeren, allgemeinen Aussage uber alle algorithmischen Verfahren. Weiterhinkonnen wir die Unentscheidbarkeit von LPascal−Halt nun mathematisch exakt formulieren.
1.9.13 Satz LPascal−Halt ist nicht rekursiv.
Beweis : In Abschnitt 1.5.1 haben wir gesehen, wie man beliebige Turingmaschinen auf Re-gistermaschinen simulieren kann. Mit ganz ahnlichen Methoden sieht man, dass es zu jederTM M mit Inputalphabet {0, 1} ein Pascal-Programm PM gibt, so dass die Ausfuhrungvon PM mit einer Eingabedatei, die das binare Wort x enthalt, genau dann halt wennM auf Eingabe x halt. (Ein Band wird als dynamisches, also langenveranderliches Ar-ray oder als doppelt verkettete Liste dargestellt. Die Ubergangsfunktion der TM wirdin die Struktur von PM ubersetzt. Naturlich muss man die ubliche Idealisierung vorneh-men: der Lange des Arrays bzw. der Liste, die das Band darstellt, sind keine Grenzengesetzt.) Wir verwenden diese Konstruktion nur fur eine einzige TM, namlich die uni-verselle TM U , und stellen fest, dass es ein Pascal-Programm PU ∈ Ascii
∗ gibt, das aufInput w ∈ {0, 1}∗ ⊆ Ascii
∗ genau dann halt wenn U auf w halt, d. h. genau dann wennw ∈ H ist. Das heißt:
w ∈ H ⇔ PU w ∈ LPascal−Halt .
115

Wenn wir also definieren:
f : {0, 1}∗ → Ascii∗ , f(w) = PU w ,
dann giltH ≤ LPascal−Halt mittels f ,
und der Satz ist bewiesen. �
Man sieht an diesem Beweis, dass dieselbe Unentscheidbarkeitsaussage fur alle Program-miersprachen gilt, in denen man einen Simulator fur die universelle Turingmaschine Uschreiben kann — und das geht in jeder vernunftigen allgemeinen Programmiersprache.Dass Simulatoren fur Turingmaschinen nicht unbedingt die Programme sind, die manjeden Tag schreibt, andert nichts an der Folgerung, dass es ein Tool zum Uberprufendes Haltens eines beliebigen Programms nicht geben kann. Die Konsequenz ist, dass derProgrammdesigner mit seinem Entwurf die Verantwortung dafur tragt, dass keine nicht-haltenden Berechnungen auftreten.
Ist denn die Unentscheidbarkeit des Halteproblems wirklich ein so großes Hindernis? Nie-mand will wirklich Programme schreiben, die fur manche Inputs nicht anhalten. Naturlichhindert einen die Unentscheidbarkeit von LPascal−Halt nicht daran, nur Programme zuschreiben, die fur beliebige Eingaben stets anhalten, und fur jedes Programm einen Ter-minierungsbeweis zu fuhren. Wir werden aber noch sehen, dass es keinen Algorithmus gibt,der fur jedes Programm, das auf allen Eingaben terminiert, einen solchen Terminierungs-beweis liefert. Hier ist also der findige Programmierer gefragt, der fur jedes Programmeinen spezifischen Terminierungsbeweis fuhrt. — Diese und andere Beobachtungen erge-ben sich im nachsten Abschnitt als Ergebnis weiterer Reduktionen.
1.10 Unentscheidbarkeit semantischer Fragen
In diesem Abschnitt stellen wir uns die Frage, inwieweit man einem als Text gegebenen(Pascal-)Programm semantische (das heißt sich auf das Ein-/Ausgabeverhalten beziehen-de) Eigenschaften ansehen kann. Zum Beispiel:
(i) Halt ein gegebenes Programm P auf allen Eingaben?(Oder: Halt P auf allen Eingaben aus L0? [Dabei ist L0 ⊆ Ascii
∗ beliebig.])
(ii) Halt ein gegebenes Programm P auf wenigstens einer Eingabe?(Oder: Halt P auf wenigstens 20 Eingaben? Oder: Halt P auf unendlich vielen Ein-gaben?)
(iii) Berechnen zwei gegebene Programme P1 und P2 dieselbe Funktion?(Oder: Berechnet ein gegebenes Programm P die Funktion g? [Dabei ist g einebeliebige partiell rekursive Funktion.])
116

(iv) Gegeben sei ein Programm P, das als Eingabe eine naturliche Zahl n erhalt, garan-tiert halt und die Ausgabe fP(n) schreibt. Gilt fP(1) < fP(2) < · · · ?
(v) Gegeben sei ein Programm P, das als Eingabe eine naturliche Zahl n erhalt, garan-tiert halt und die Ausgabe fP(n) ∈ {0, 1} schreibt. Gibt es ein n ∈ N mit fP(n) = 1?
1.10.1 Der Satz von Rice
Wir werden in diesem Abschnitt eine einheitliche Beweismethode bereitstellen, mit derman fur viele Fragen der eben genannten Art die Unentscheidbarkeit nachweisen kann.Wir formulieren unsere Ergebnisse zunachst in der TM-Terminologie. Die Anwendung aufPascal-Programme wird dann an Beispielen diskutiert.
Wir geben Sprachen an, deren Wortprobleme einigen der eben betrachteten semantischenFragen entsprechen. 〈M〉 steht immer fur die Kodierung einer normierten TM.
1.10.1 Beispiel
(i) {〈M〉 | HM = {0, 1}∗}. (Oder: {〈M〉 | L0 ⊆ HM}.)
(ii) {〈M〉 | |HM | ≥ 1}. (Oder: {〈M〉 | |HM | ≥ 20}. Oder: {〈M〉 | |HM | =∞}.)
(iii) {〈M1〉〈M2〉 | fM1= fM2
}. (Oder: {〈M〉 | fM = g}.)
(iv) {〈M〉 | HM = {bin(n) | n ∈ N} und ∀n ∈ N : (fM(bin(n)))2 < (fM(bin(n + 1)))2}.
(v) {〈M〉 | HM = {0, 1}∗ und ∃x ∈ {0, 1}∗ : fM(x) = 1}.
Anstatt nun die Methoden aus Abschnitt 1.9 auf jede dieser Sprachen anzuwenden, stellenwir einen allgemeinen Satz bereit, aus dem leicht folgt, dass alle diese Mengen nichtrekursiv sind.
Allen betrachteten Mengen ist folgendes gemeinsam: Es sind Mengen von TM-Kodierungen〈M〉 (oder im Fall (iii) von Paaren von TM-Kodierungen), wobei an 〈M〉 nur Bedingungengestellt werden, die sich auf die Menge HM oder die Funktion fM beziehen — semanti-sche Fragen eben. (Es kommt z. B. nicht die Anzahl der Schritte, die M auf einer Eingabemacht, oder die Anzahl der Zustande von M oder die Anzahl der Bits im Wort 〈M〉 vor.)Wir charakterisieren solche Bedingungen wie folgt:20
1.10.2 Definition
(a) Eine Eigenschaft von rekursiv aufzahlbaren Sprachen uber {0, 1} ist eine TeilmengeE von {L ⊆ {0, 1}∗ | L ist rekursiv aufzahlbar}.
(b) Eine Eigenschaft von partiell rekursiven Funktionen uber {0, 1} ist eine TeilmengeF von {f : {0, 1}∗ → {0, 1}∗ | f ist partiell rekursiv}.
20Hier wird ein in der Mathematik ublicher Trick benutzt: Eine Eigenschaft wird mit der Menge derObjekte identifiziert, die die Eigenschaft haben.
117

Hinter unseren Beispielen stecken folgende Eigenschaften:
1.10.3 Beispiel
(i) E = {Σ∗}.
(ii) E = {L | L rekursiv aufzahlbar und |L| ≥ 1}.(Oder: E = {L | L rekursiv aufzahlbar und |L| ≥ 20}.
Oder: E = {L | L rekursiv aufzahlbar und |L| =∞} ).
(iii) F = {g}.
(iv) F = {f | f ist partiell rekursiv und f ist fur alle bin(n), n ∈ N, definiertund (f(bin(n)))2 < (f(bin(n + 1)))2 fur alle n ∈ N}.
(v) F = {f | f : {0, 1}∗ → {0, 1} ist totale rekursive Funktion und ∃x ∈ {0, 1}∗ :f(x) = 1}.
Der Satz von Rice besagt, dass fur kein E und kein F anhand von 〈M〉 mit einer TMentschieden werden kann, ob HM Eigenschaft E bzw. F hat, außer in vollig trivialenFallen. Alle oben angegebenen Eigenschaften von Sprachen und Funktionen werden mitdiesem Satz erfasst. Mit der Churchschen These interpretiert man ihn so, dass es keinealgorithmische Methode gibt, eine TM M anhand ihrer Binarkodierung 〈M〉 darauf zutesten, ob HM die Eigenschaft E hat oder nicht; analog fur die Funktion fM und F . VonTMn ubertragt sich diese Aussage auf alle anderen Programmiersprachen: nichttrivialesemantische Eigenschaften von Programmen sind unentscheidbar.
1.10.4 Satz (Satz von Rice)
(a) Es sei E eine nichttriviale Eigenschaft von rekursiv aufzahlbaren Sprachen,d. h. ∅ 6= E ( {L ⊆ {0, 1}∗ | L ist rekursiv aufzahlbar}. Dann gilt:
LE := {〈M〉 | HM ∈ E} ist nicht rekursiv.
(b) Es sei F eine nichttriviale Eigenschaft von partiell rekursiven Funktionen, d. h.∅ 6= F ( {f : {0, 1}∗ → {0, 1}∗ | f ist partiell rekursiv}. Dann gilt:
LF := {〈M〉 | fM ∈ F} ist nicht rekursiv.
Beweis : (a) Wir nehmen zunachst an, dass ∅ /∈ E . Weil E nichttrivial ist, gibt es einerekursiv aufzahlbare Sprache L1 ∈ E , L1 6= ∅.
21
21Im folgenden benutzen wir ausschließlich, dass ∅ /∈ E und L1 ∈ E . Wie E sonst aussieht, ist irrelevant.
118

Wir reduzieren H auf LE . (Dann kann LE nicht rekursiv sein, nach Korollar 1.9.9.) Wirbenotigen also eine Reduktionsfunktion g, die ein beliebiges Wort y ∈ {0, 1}∗ in eineTM-Kodierung g(y) = 〈My〉 transformiert, so dass fur alle y gilt
y ∈ H ⇔ g(y) = 〈My〉 ∈ LE ;
d. h.y ∈ H ⇔ HMy ∈ E .
Weil ∅ /∈ E und L1 ∈ E , genugt es, folgendes zu erreichen:
(∗)
{y ∈ H ⇒ HMy = L1 ( ∈ E);y /∈ H ⇒ HMy = ∅ ( /∈ E).
Im Stil von Beispiel 1.9.11 beschreiben wir das Verhalten von My. Wir tun dabei so, alshatte My zwei Bander. Bevor man 〈My〉 bilden kann, muss man sich noch My in einenormierte 1-Band-TM umgebaut denken. Wir benutzen eine beliebige feste TM M1 mitHM1
= L1. — Die TM My tut folgendes, auf Eingabe x:
1. Schreibe y auf Band 2;(∗ Dazu ist y in der Steuereinheit von My gespeichert. ∗)
2. Starte U auf der Inschrift y von Band 2.(∗ falls y /∈ H, halt dies nicht; falls y ∈ H, wird 3. erreicht. ∗)
3. Starte M1 auf der Eingabe x (auf Band 1).(∗ Diese Berechnung halt genau dann, wenn x ∈ L1. ∗)
Es ist klar, dass man aus y die TM My und auch g(y) = 〈My〉 algorithmisch konstruierenkann, dass also g rekursiv ist (Churchsche These). Weiter gilt, nach der Beschreibung vonMy:
y /∈ H ⇒ My halt fur keine Eingabe
y ∈ H ⇒ My halt genau fur Eingaben x ∈ HM1= L1.
Damit ist (∗) erfullt; es folgt, dass H ≤ LE mittels g, und damit folgt, dass LE nichtrekursiv ist.
Schließlich ist der Fall zu betrachten, dass ∅ ∈ E . Dann wenden wir den obigen Beweisauf die ebenfalls nichttriviale Eigenschaft
E = {L | L rekursiv aufzahlbar, L /∈ E}
an und erhalten, dass LE nicht rekursiv ist. Weil LE = LE , ist LE ebenfalls nicht rekursiv.
(b) Der Beweis verlauft genauso wie der von Teil (a). Man betrachtet zunachst den Fall,dass die leere partielle Funktion f∅, berechnet von TMn, die auf keiner Eingabe halten,
119

nicht in F liegt. Weil F nichttrivial ist, gibt es eine partiell rekursive Funktion f1 in F .Wir wahlen eine TM M1 mit f1 = fM1
.
Die Reduktionsfunktion g wird wortlich so definiert wie in Teil 1. Man erhalt:
y ∈ H ⇒ fMy = f1 ( ∈ F);y /∈ H ⇒ fMy = f∅ ( /∈ F).
Daraus folgt wiederum, dass H ≤ LF mittels g, also dass LF nicht rekursiv ist.
Der Fall f∅ ∈ F wird ebenso wie in (a) durch Betrachten der Komplementeigenschaftbehandelt.
�
1.10.5 Beispiel Alle in Beispiel 1.10.1 angegebenen Mengen von TM-Kodierungensind nichtrekursiv; die zugehorigen Wortprobleme sind unentscheidbar. Dazu muss mannur beobachten, dass die in Beispiel 1.10.3 angegebenen Eigenschaften alle nichttrivialsind.
1.10.2 Semantische Fragen uber Programme
Was bedeutet der Satz von Rice fur den Informatiker oder die Informatikerin, der/diegerne die Korrektheit oder andere wichtige semantische Eigenschaften von Programmenin seiner/ihrer Lieblingsprogrammiersprache testen mochte, und das moglichst mit einemkommerziell verfugbaren Tool? Er bedeutet schlechte Aussichten: Man kann ein ProgrammP einer Programmiersprache nicht automatisch darauf testen,
(i) ob P auf allen Eingaben halt;
(ii) ob P auf mindestens einer Eingabe halt (oder: auf mindestens 20 Eingaben halt;oder: auf unendlich vielen Eingaben halt);
(iii) ob P eine vorgegebene (partiell rekursive) Funktion g berechnet;
(iv) ob fur die von P berechnete Zahlfunktion f : N → N gilt, dass f total ist undf(1) < f(2) < · · · gilt;
(v) ob P auf allen Eingaben halt und ein bestimmtes Unterprogramm C, das im Text vonP vorkommt, jemals aufgerufen wird (oder: jemals ein Zeichen der Eingabe gelesenwird; oder: die Eingabe komplett gelesen wird; oder: jemals ein Ausgabezeichenerzeugt wird).
Die im Beweis des Satzes von Rice verwendete Technik zusammen mit der Beobachtung,dass man in Programmen jeder Programmiersprache die universelle TM U simulieren
120

kann, liefert dies in ziemlich schematischer Weise. Fur eine beliebige Pascal-Prozedur Bbetrachten wir Pascal-Programme einer speziellen Bauart:
Jedem Wort y ∈ {0, 1}∗ wird ein Programm Py zugeordnet, das bei Eingabe x ∈ Ascii∗
folgendes tut:
1. Starte eine Simulation der universellen TM U auf y;2. wenn und sobald die Berechnung in 1. halt: fuhre B aus;3. halte an.
Py fuhrt B auf Eingabe x aus, wenn y ∈ H ist. Wenn y /∈ H, halt U auf y nie an unddamit auch Py auf x nicht; die Prozedur B wird nicht ausgefuhrt. Damit haben wir:
y ∈ H ⇒ ∀x ∈ Ascii∗ : Bei Aufruf von Py auf x wird B ausgefuhrt;
y /∈ H ⇒ ∀x ∈ Ascii∗ : Bei Aufruf von Py auf x wird B nicht ausgefuhrt.
Um in den eben genannten Beispielen die Nichtrekursivitat der Menge der entsprechendenPascal-Programme zu erhalten, mussen wir nur B passend wahlen:
(i) B tut nichts.
(ii) B tut nichts.
(iii) B berechnet g(x) und gibt dies aus.
(iv) P erhalt als Eingabe eine Zahl n. B gibt die Eingabe n aus.
(v) B besteht aus dem Aufruf von C (oder: B liest alle Zeichen der Eingabe ein; oder:B schreibt ein Ausgabezeichen).
Fur manche(n) Leser(in) ist diese Konstruktion vielleicht unbefriedigend, weil man in derReduktion direkt das Halteproblem einbaut, und explizit Pascal-Programme benutzt, dienicht halten. Vielleicht kann man semantische Eigenschaften von Programmen wenigstensdann algorithmisch testen, wenn man sich auf Programme konzentriert, die garantiertanhalten? Wir stellen im folgenden Abschnitt und in einer Ubungsaufgabe fest, dass auchdies leider nicht zutrifft.
1.10.3 Unmoglichkeit von Zertifikaten fur Programme
Es sei E bzw. F eine Eigenschaft wie im Abschnitt 1.10.1. Nach dem Satz von Rice kannman nicht algorithmisch entscheiden, ob HM ∈ E bzw. fM ∈ F , man kann also nichtmittels eines Algorithmus
”gute“ TM-Codes akzeptieren und
”schlechte“ ablehnen. Eine
bescheidenere Frage ist es, ob es fur E bzw. F ein”algorithmisches Zertifizierungsverfah-
ren“ gibt. Ein solches Verfahren erhalt eine TM-Kodierung 〈M〉 als Eingabe und liefert
”o.k.“, falls HM ∈ E bzw. fM ∈ F , und irgendeine andere oder gar keine Ausgabe sonst.
121

(Mit einem solchen Verfahren fur Pascal-Programme konnte man zumindest positiv nach-weisen, dass ein Programm P auf allen Eingaben halt oder eine bestimmte Funktion gberechnet.)
Formal ist ein solches Zertifizierungsverfahren eine partiell rekursive Funktion h : D →{0, 1}, D ⊆ {〈M〉 |M TM}, mit
h(〈M〉) ist
{1, falls HM ∈ E bzw. fM ∈ F6= 1 (evtl. auch undefiniert), sonst.
Nun kann man sich leicht klarmachen (!), dass E bzw. F ein solches Zertifizierungsver-fahren h genau dann besitzt, wenn LE bzw. LF rekursiv aufzahlbar ist.
Fur manche der in Abschnitt 1.10.1 betrachteten Eigenschaften E bzw. F ist LE bzw.LF tatsachlich rekursiv aufzahlbar (z. B. fur E = {L | L r. a., L 6= ∅} oder F = {f |f partiell rekursiv, f(x) = 0 fur alle x mit |x| ≤ 3}).
Es gibt aber Eigenschaften E , bei denen weder LE noch LE rekursiv aufzahlbar sind.Das heißt, dass weder die
”guten“ noch die
”schlechten“ TM-Programme zertifizierbar
sind. Wir betrachten ein typisches Beispiel: die Menge der Codes von TMn, die auf allenEingaben halten, hat kein Zertifizierungsverfahren, ebensowenig wie die Menge der Codesvon TMn, die nicht auf allen Eingaben halten.
1.10.6 Satz Fur die Sprache
L = {〈M〉 | HM = Σ∗}
gilt, dass weder L noch L rekursiv aufzahlbar ist.
Beweis : Nach dem Rezept aus Abschnitt 1.9.4 sollten wir H ≤ L und H ≤ L beweisen.Nach Lemma 1.9.7 lauft das darauf hinaus, H ≤ L und H ≤ L zu beweisen.
”H ≤ L“: Hier konnen wir die Reduktionsfunktion f : y 7→ 〈My〉 aus Beispiel 1.9.11
benutzen. Diese hat, wie in Bemerkung 1.9.12 beobachtet, die Eigenschaft
∀y ∈ {0, 1}∗ : y ∈ H ⇒ HMy = {0, 1}∗;
y /∈ H ⇒ HMy = ∅
und erfullt damit ∀y ∈ {0, 1}∗ : y ∈ H ⇔ f(y) = 〈My〉 ∈ L.
”H ≤ L“: Wir konstruieren eine Reduktionsfunktion g : y 7→ 〈M ′
y〉 mit folgender Eigen-schaft:
∀y ∈ {0, 1}∗ : y ∈ H ⇒ HM ′y
ist endlich;
y /∈ H ⇒ HM ′y
= {0, 1}∗.
Hierzu benutzen wir einen fur Reduktionen neuen Trick: Uhr-kontrollierte Berechnungen,siehe Abschnitt 1.4.
Zu y ∈ {0, 1}∗ betrachte die TM M ′y, die auf Eingabe x folgendes tut:
122

1. Schreibe y auf Band 2;(∗ Dazu ist y in der Steuereinheit von M ′
y gespeichert. ∗)
2. Lasse U auf y fur |x| Schritte laufen.(∗ Dies halt immer. ∗)
3. Falls die Berechnung in 2. erfolgreich beendet wurde, gehe in eine Endlosschleife;sonst halte an.
(∗ Diese Berechnung halt genau dann, wenn |x| < tU(y). ∗)
Man kann M ′y und 〈M ′
y〉 leicht aus y bestimmen; nach der Churchschen These ist g : {0, 1}∗ →{〈M〉 |M TM}, g(y) = 〈M ′
y〉, rekursiv. Weiter gilt:
∀y ∈ {0, 1}∗ : y ∈ H ⇒ HM ′y
= {x | |x| < tU(y)};
y /∈ H ⇒ HM ′y
= {0, 1}∗.
Damit gilt fur alle y:
y ∈ H ⇔ HM ′y
= {0, 1}∗ ⇔ g(y) ∈ L ,
wie gewunscht. �
Mit der Technik aus Abschnitt 1.10.2 kann man diesen Beweis so umbauen, dass sich er-gibt, dass die Menge der Pascal-Programme, die auf allen Eingaben halten, nicht rekursivaufzahlbar ist, also dass die Eigenschaft
”halt auf allen Eingaben“ von Pascal-Programmen
nicht zertifizierbar ist.
Mit derselben Technik wie im letzten Beweis kann man zeigen, dass man anhand vonTM-Kodierungen nicht auf den Verlauf der berechneten Funktionen schließen kann, sogarwenn man sich auf totale Funktionen beschrankt. Das heißt dann, dass man es mit un-entscheidbaren Semantikfragen auch dann zu tun bekommen kann, wenn man zuverlassignur Programme schreibt, die immer halten.
Wir betrachten zwei Eigenschaften von partiell rekursiven Funktionen:
F0 := {f | ∀x ∈ {0, 1}∗ : f(x) = 0};
F1 := {f | ∀x ∈ {0, 1}∗ : f(x) ∈ {0, 1} ∧ ∃x ∈ {0, 1}∗ : f(x) = 1}.
1.10.7 Satz Es gibt keine partiell rekursive Funktion d : D → {0, 1}∗ fur ein D ⊆{0, 1}∗, so dass fur alle normierten TMn M gilt:
(i) fM ∈ F0 ∪ F1 ⇒ 〈M〉 ∈ D;
(ii) fM ∈ F0 ⇒ d(〈M〉) = 0;
123

(iii) fM ∈ F1 ⇒ d(〈M〉) = 1.
(Das Verhalten von d auf Eingaben, die nicht zu {〈M〉 | fM ∈ F0∪F1} gehoren, ist volligbeliebig.)
Beweis : Indirekt. Annahme: Eine Funktion d wie beschrieben existiert. Wir benutzennun eine Reduktion ganz ahnlich der im letzten Beweis, mit dem Unterschied, dass alleTuringmaschinen My totale 0-1-wertige Funktionen berechnen, so dass 〈My〉 im Definiti-onsbereich von d liegt.
Zu y ∈ {0, 1}∗ betrachte die TM My, die auf Eingabe x folgendes tut:
1. Schreibe y auf Band 2;
2. Lasse U auf y fur |x| Schritte laufen.
3. Falls die Berechnung in 2. erfolgreich beendet wurde, halte mit Ausgabe 1, sonsthalte mit Ausgabe 0.
(∗ Diese Berechnung liefert 1 genau dann, wenn tU(y) ≤ |x|. ∗)
Es ist wieder klar, dass die Funktion h : y 7→ 〈My〉 rekursiv ist. Weiter gilt, dass fMy furjedes y eine totale 0-1-wertige Funktion ist, und:
∀y ∈ {0, 1}∗ : y /∈ H ⇒ fMy ≡ 0, d. h. fMy ∈ F0;
y ∈ H ⇒ fMy 6≡ 0, d. h. fMy ∈ F1.
Daraus folgt: Die Abbildungd ◦ h : y 7→ d(〈My〉)
ist total rekursiv und erfullt
y ∈ H ⇔ d ◦ h(y) = 1.
Das heißt, dass d◦h die charakteristische Funktion von H ist, ein Widerspruch zur Nicht-rekursivitat von H. �
In einer Ubungsaufgabe wird gezeigt, dass man in derselben Weise Unentscheidbarkeitsre-sultate fur Pascal-Programme erhalten kann, wobei ausschließlich Programme betrachtetwerden, die auf jeder Eingabe halten.
124

1.11 Das Postsche Korrespondenzproblem
In diesem Abschnitt wird ein unentscheidbares Problem vorgestellt, das nicht auf denersten Blick Fragen uber Turingmaschinen beinhaltet, wie in den bisher betrachteten Si-tuationen. Das Problem ist nach Emil Post benannt, der es 1946 formulierte. Es dientals Basis fur viele Unentscheidbarkeitsbeweise fur Entscheidungsprobleme in der Mathe-matik und in anderen Teilen der (theoretischen) Informatik. (Man lasse sich von der indieser Vorlesung geubten Zuruckhaltung nicht tauschen: es gibt sehr viele unentscheidbareProbleme, die mit Maschinen und formalen Sprachen nichts zu tun haben.)
1.11.1 Definition Das Postsche Korrespondenzproblem (PKP)22 ist folgendesEntscheidungsproblem:
Eingabe: Eine Folge s = ((x1, y1), (x2, y2), . . . , (xn, yn)) von Paaren von Wortern ubereinem Alphabet ∆.
Frage: Gibt es eine Folge i1, . . . , ir in {1, . . . , n} (Wiederholungen erlaubt!) mit r ≥ 1derart dass
xi1xi2 · · ·xir = yi1yi2 · · · yir ?
Eine Indexfolge, die dies erfullt, heißt Losungsfolge fur s.
Man kann sich die Eingabe als eine endliche Menge von zweizeiligen Puzzlesteinen vor-stellen, wobei der ite Stein in der oberen Zeile die Inschrift xi, in der unteren die Inschriftyi hat. Die Frage ist, ob man Kopien der Puzzlesteine so nebeneinander hinlegen kann,dass in der oberen Zeile und in der unteren Zeile dasselbe Wort entsteht.
Zur Verdeutlichung der Trennstellen zwischen Wortteilen benutzen wir in diesem Ab-schnitt oft das Zeichen ◦ fur die Konkatenation.
1.11.2 Beispiel Die Eingabe besteht aus sechs Paaren von Wortern uber dem Alphabet∆ = {a, b, c, d, r, !}, namlich:
i 1 2 3 4 5 6xi !a a ada a br c
yi ! rac d ra ab a
Diese Instanz des PKP hat verschiedene Losungsfolgen:
Die Indexfolge 1, 5, 4 liefert
x1x5x4 = !a ◦ br ◦ a = !abra = ! ◦ ab ◦ ra = y1y5y4.
22Das Wort”Korrespondenz“ wird hier im Sinn von
”Entsprechung“ gebraucht, eine Bedeutung, die
das englische”correspondence“ viel starker hat.
125

Die Indexfolge 1, 5, 2, 6, 3, 5, 4 liefert
!a ◦ br ◦ a ◦ c ◦ ada ◦ br ◦ a = !abracadabra = ! ◦ ab ◦ rac ◦ a ◦ d ◦ ab ◦ ra
1.11.3 Bemerkung Am Beispiel kann man sich einige andere offensichtliche Eigen-schaften des PKP klarmachen:
1. Da die endlichen Folgen von Wortpaaren nur endlich viele Buchstaben enthaltenkonnen, muss man das Alphabet ∆ eigentlich nicht explizit benennen; es kann ausder Folge von Paaren abgelesen werden.
2. Wenn i1, . . . , ir und j1, . . . , jt Losungsfolgen fur s sind, dann ist auch i1, . . . , ir, j1, . . . , jt
Losungsfolge. Im Beispiel sind etwa 1, 5, 4, 1, 5, 4 und 1, 5, 4, 1, 5, 2, 6, 3, 5, 4, 1, 5, 4weitere Losungsfolgen. Wenn es also eine Losungsfolge gibt, dann gibt es sogar un-endlich viele verschiedene.
1.11.4 Beispiel Betrachte folgende Eingabe, mit dem Alphabet {0, 1}:
i 1 2 3xi 10 011 101yi 101 11 011
Wir versuchen, eine Losungsfolge zu bauen. Offenbar mussen wir mit (x1, y1) anfangen.
Erzwungener Start:
10101
Nun hat die”y-Reihe“ einen Vorsprung von einer 1. Als nachste Elemente kommen nur
Paare 1 und 3 in Frage, wobei aber Paar 1 nicht”passt“. Erzwungene Fortsetzung also:
10 ◦ 101 = 10101101 ◦ 011 = 101011
Wieder hat die”y-Reihe“ einen Vorsprung von einer 1. Die einzig mogliche Fortsetzung
besteht darin, erneut das Paar (x3, y3) anzuhangen. Man sieht, dass dieser Vorgang des
”Anbauens“ nie zu einem Ende kommt; daher kann es keine Losungsfolge geben.
Wir uberlegen kurz, dass es genugt, das Standardalphabet {0, 1} zu betrachten. Gegebensei ein beliebiges Alphabet ∆. Wahle eine feste Binarkodierung fur die Buchstaben in ∆mit Codes fester Lange, d. h. eine injektive Funktion ϕ : ∆ → {0, 1}l, wo l ≥ dlog2(|∆|)efest gewahlt wird. Durch ϕ wird auch jedes Wort x = a1 · · · am uber ∆ binar kodiert,namlich durch ϕ(x) = ϕ(a1) · · ·ϕ(am). In Beispiel 1.11.2 konnte man die Kodierung
126

! a b c d r
000 001 010 011 100 101
wahlen und die folgende kodierte Eingabefolge s′ betrachten:
i 1 2 3 4 5 6x′
i 000001 001 001100001 001 010101 011y′
i 000 101001011 100 101001 001010 001
Man uberlegt sich leicht, dass wegen der Kodierung durch Blocke gleicher Lange fur dieEingabe
s = ((x1, y1), . . . , (xn, yn))
uber ∆ genau dann xi1 · · ·xir = yi1 · · · yir gilt, wenn fur die binar kodierte Eingabe
s′ = ((x′1, y
′1), . . . , (x
′n, y′
n)) = ((ϕ(x1), ϕ(y1)), . . . , (ϕ(xn), ϕ(yn)))
uber {0, 1} gilt, dass x′i1· · ·x′
ir= y′
i1· · · y′
ir. Die Menge der Losungsfolgen fur beide Ein-
gaben ist also identisch.
Wir benutzen diese Beobachtung so, dass wir großere Alphabete benutzen, wo es bequemist. Formal hat man sich aber immer die binar kodierten Versionen eingesetzt zu denken.— Nun konnen wir das PKP als Sprache definieren.
1.11.5 Definition
LPKP := {((x1, y1), . . . , (xn, yn)) | n ≥ 1, x1, y1, . . . , xn, yn ∈ {0, 1}∗,
∃r ≥ 1∃i1, . . . , ir ∈ {1, . . . , n} : xi1 · · · xir = yi1 · · · yir}
(Formal gesehen ist LPKP eine Sprache uber dem Alphabet {0, 1, (, ),”,“}, wobei das Kom-
ma”,“ auch als Buchstabe benutzt wird.)
Das Wortproblem der Sprache LPKP ist im wesentlichen das Postsche Korrespondenz-problem, bis auf einen trivialen Syntaxcheck, der Eingaben darauf uberpruft, ob sietatsachlich Wortfolgen in der vorgeschriebenen Beschreibung darstellen.
1.11.6 Satz LPKP ist rekursiv aufzahlbar, aber nicht rekursiv.
Damit hat LPKP bezuglich der Entscheidbarkeit denselben Status wie das Halteproblemfur Turingmaschinen. Jedoch erwahnt LPKP Turingmaschinen oder Berechnungen uber-haupt nicht.
Beweis :”Rekursive Aufzahlbarkeit“. Dass LPKP rekursiv aufzahlbar ist, ist leicht einzuse-
hen. Auf Eingabe w ist folgendes zu tun: Uberprufe, ob w das Format ((x1, y1), . . . , (xn, yn))hat. Falls nein, verwirf die Eingabe. Falls ja, erzeuge die Folgen bin(i1), . . . , bin(ir), r =
127

1, 2, 3, . . ., mit i1, . . . , ir ∈ {1, . . . , n}, nacheinander. Fur jede so erzeugte Folge prufe, obxi1 · · ·xir = yi1 · · · yir gilt. Wenn und sobald dies der Fall ist, halte und akzeptiere w.
Man beachte bei diesem Teil des Beweises, dass es keine Moglichkeit gibt, vorab festzu-stellen, wie groß das kleinste r ist, so dass eine Losungsfolge der Lange r existiert.
Fur den zweiten Teil des Beweises benutzen wir unser Rezept zum Nachweis von Nicht-rekursivitat und zeigen, dass
H ≤ LPKP
gilt, wo H die Haltesprache fur Turingmaschinen ist. Die Konstruktion dieser Reduktionist etwas komplizierter, und nimmt den ganzen Rest dieses Abschnittes ein.
Hinweis: Der folgende Beweis ist im Wintersemester 2004/05nicht prufungsrelevant.
Wir benotigen ein Hilfsproblem, das dadurch entsteht, dass man das PKP so modifiziert,dass nur Losungsfolgen zugelassen werden, die mit dem ersten Paar (x1, y1) beginnen.Dieses Problem heißt MPKP (
”modifiziertes PKP“):
Eingabe: Eine Folge s = ((x1, y1), (x2, y2), . . . , (xn, yn)) von Paaren von Wortern ubereinem Alphabet ∆.
Frage: Gibt es eine Folge i1 = 1, i2, . . . , ir in {1, . . . , n} mit r ≥ 1 derart dass
x1xi2 · · ·xir = y1yi2 · · · yir ?
Eine Indexfolge 1, i2, . . . , ir, die dies erfullt, heißt wieder Losungsfolge fur s.
Auch fur das MPKP gelten die Bemerkungen zur Binarkodierung, und wir konnen es alsSprache formulieren:
LMPKP := {((x1, y1), . . . , (xn, yn)) | n ≥ 1, x1, y1, . . . , xn, yn ∈ {0, 1}∗,
∃r ≥ 1∃i2, . . . , ir ∈ {1, . . . , n} : x1xi2 · · ·xir = y1yi2 · · · yir}
1.11.7 Lemma Das Problem MPKP ist auf PKP reduzierbar, formal:
LMPKP ≤ LPKP.
Wir schieben den Beweis von Lemma 1.11.7 noch einen Moment auf und notieren, dasswir nur noch
(1.1) H ≤ LMPKP
beweisen mussen, da dann mit dem Lemma 1.11.7 und der Transitivitat der ≤-Relationfolgt, dass H ≤ LPKP gilt.
Nach Behauptung 1.9.3 ist H rekursiv aufzahlbar. Daher genugt es, die folgende Behaup-tung zu beweisen.
128

1.11.8 Satz Fur jede r.a. Sprache L gilt L ≤ LMPKP.
Beweis : Sei L ⊆ Σ∗ eine beliebige rekursiv aufzahlbare Sprache. Nach Satz 1.3.16 gibtes eine Chomsky-0-Grammatik G = (V, Σ, S, P ) mit L = L(G). Die Idee der ReduktionL ≤ LMPKP ist folgende: Jedem w ∈ Σ∗ wird eine Folge sw = ((x1, y1), . . . , (xn, yn))von Wortpaaren zugeordnet, so dass eine Ableitung fur w in G eine Losungsfolge fur sw
induziert, und so dass man umgekehrt aus einer Losungsfolge fur sw relativ leicht eineAbleitungsfolge fur w in G ablesen kann. Diese Idee fuhren wir nun im Detail durch.
Fur sw benutzen wir das Alphabet
∆ = V ∪ Σ ∪ {#, $}
(genauer: eine Binarkodierung dieses Alphabets), wobei naturlich $ und # in V ∪Σ nichtvorkommen. Das erste Paar in sw ist das
”Startpaar“
(x1, y1) = (#w#, #),
die weiteren Paare, in beliebiger Reihenfolge, sind die”Produktions-Paare“
(l, r), wobei l→ r eine Produktion in P ist,
die”Kopier-Paare“
(X,X), fur X ∈ V ∪ Σ ∪ {#} ,
und das”Abschlusspaar“
($, S#$).
Wir mussen zeigen:w ∈ L = L(G) ⇔ sw ∈ LMPKP,
d.h.
w besitzt eine Ableitung in G ⇔ sw hat eine MPKP-Losungsfolge.
”⇒“: Es sei w ∈ L(G) und
S = α0 ⇒G α1 ⇒G · · · ⇒G αt−1 ⇒G αt = w
eine Ableitung von w in G. Die Losungsfolge i1 = 1, i2, . . . , ir wird nun so gewahlt, dassdas Losungswort z die Struktur
z = #w#αt−1#αt−2# · · ·#α1#S#$
hat, und zwar gegliedert als
auf der x-Seite: #w# ◦ αt−1# ◦ αt−2# ◦ · · · ◦ α1# ◦ S# ◦ $auf der y-Seite: # ◦ αt# ◦ αt−1# ◦ · · · ◦ α2# ◦ α1# ◦ S#$ .
129

Es ist klar, wo das Startpaar und das Abschlusspaar einzusetzen sind. Um zu sehen, dasseine solche Losungsfolge moglich ist, muss nur noch gezeigt werden, dass es fur jedes ueine Indexfolge j1, . . . , js gibt mit
αu−1# = xj1 · · ·xjsund αu# = yj1 · · · yjs
.
Das ist aber unter Benutzung der Kopier-Paare und der Produktions-Paare offensichtlichmoglich. Damit ist
”⇒“ bewiesen.
”⇐“: Es sei i1 = 1, i2, . . . , ir eine Losungsfolge fur sw, also
z = x1xi2 · · · xir = y1yi2 · · · yir .
Wir beobachten zunachst, dass das Startpaar (x1, y1) ein Ungleichgewicht der #-Zeichenerzeugt, das nur ausgeglichen werden kann, wenn irgendwo auch das Abschlusspaar ($, S#$)vorkommt. Es sei t minimal mit (xit , yit) = ($, S#$). Weil x1xi2 · · ·xit und y1yi2 · · · yit
Prafixe von z sind, und in beiden genau ein $-Zeichen vorkommt, namlich als letztes Zei-chen, gilt x1xi2 · · ·xit = y1yi2 · · · yit . Also ist schon i1 = 1, i2, . . . , it Losungsfolge, und wirkonnen o.B.d.A. t = r annehmen, d.h. dass in z das $-Zeichen genau einmal vorkommt,namlich als letztes Zeichen.
Nach dem bisher Gesagten kommt das #-Zeichen in xi2 · · · xir−1nur noch in Kopierpaaren
(#, #) vor. Wir sondern alle diese Kopierpaare fur # aus und konnen schreiben:
(1.2)x-Seite: z = #w# ◦ β1 ◦# ◦ β2 ◦# ◦ · · · ◦# ◦ βp ◦# ◦ $y-Seite: z = # ◦ γ1 ◦# ◦ γ2 ◦# ◦ · · · ◦# ◦ γp ◦# ◦ S#$ ,
wobei β1, . . . , βp, γ1, . . . , γp Worter uber V ∪Σ sind. Hierbei haben wir die #-Zeichen, diezu einem Kopier-Paar gehoren, untereinander plaziert.
Jedes Paar von Teilwortern βu und γu, 1 ≤ u ≤ p, entspricht einem zusammenhangendenSegment in xi2 · · ·xir−1
. Da diese Teilfolgen nur Kopier-Paare und Produktions-Paareenthalten, sieht man, dass γu aus βu dadurch entsteht, dass auf disjunkte Teilworter in γu
Produktionen l→ r angewendet werden. Indem wir diese Ableitungsschritte nacheinanderausfuhren, sehen wir, dass
(1.3) βu ⇒∗G γu , fur 1 ≤ u ≤ p.
Andererseits bilden beide Zeilen in (1.2) jeweils dasselbe Wort z. In diesem Wort mussendie vorkommenden #-Zeichen naturlich an denselben Stellen stehen. Dies liefert:
w = γ1; β1 = γ2; β2 = γ3; . . . ; βp−1 = γp; βp = S.
Wenn wir dies mit (1.3) kombinieren, erhalten wir
S = βp ⇒∗G γp = βp−1 ⇒
∗G γp−1 = βp−2 ⇒
∗G · · · ⇒
∗G γ2 = β1 ⇒
∗G γ1 = w.
Dies ist die gesuchte Ableitungsfolge fur w. Damit ist der Beweis von”⇐“ beendet. �
130

Es folgt der bisher aufgeschobene Beweis von Lemma 1.11.7. Wir benutzen das Al-phabet ∆ = {0, 1, /c, $, #} (genauer gesagt: Binarkodierungen fur die Buchstaben diesesAlphabets). Fur Worter z uber {0, 1} definieren wir Worter, die durch Einstreuen von#-Zeichen entstehen, wie folgt:
Wenn z = a1a2 · · · am, dann soll
#z = #a1#a2 · · ·#am und
z# = a1#a2# · · · am#
sein. (Beispiel: Fur z = 01101 ist #z = #0#1#1#0#1 und z# = 0#1#1#0#1#. Furz = ε ist #z = z# = ε.)
Sei s = ((x1, y1), . . . , (xn, yn)) (Eingabe fur MPKP) gegeben. Vorab betrachten wir denSonderfall, dass in s das Paar (ε, ε) vorkommt. Falls (x1, y1) = (ε, ε), ist offenbar (1) eineLosungsfolge bzgl. des MPKP, und wir wahlen mit s′ = ((ε, ε)) eine losbare Eingabe furdas PKP. Falls (x1, y1) 6= (ε, ε), dann lassen wir aus s alle Paare (ε, ε) weg — solche Paaretragen zur Losbarkeit der Eingabe s im Sinn von MPKP nichts bei. Ab hier konnen wiralso annehmen, dass die Folge s das Paar (ε, ε) nicht enthalt.
Wir bilden dann zu s die folgende Eingabe s′ fur PKP:
s′ = ((x#1 , #y1), . . . , (x
#n , #yn), (/c# ◦ x#
1 , /c ◦ #y1), ($, #$)),
und behaupten:
(1.4) s ∈ LMPKP ⇔ s′ ∈ LPKP.
(Damit ist die Funktion, die s auf s′ abbildet, eine Reduktionsfunktion.)
”⇒“: Sei 1, i2, . . . , ir eine Losungsfolge fur s, d. h. x1xi2 · · ·xir = y1yi2 · · · yir . Es ist dann
klar, dass/c# ◦ x#
1 ◦ x#i2◦ · · · ◦ x#
ir◦ $ = /c ◦ #y1 ◦
#yi2 ◦ · · ·#yir ◦#$.
Damit ist n + 1, i2, . . . , ir, n + 2 eine Losungsfolge fur s′.
”⇐“: Sei j1, j2, . . . , ju eine Losungsfolge fur s′. Das heißt:
z = x′j1
x′j2· · ·x′
ju= y′
j1y′
j2· · · y′
ju.
Man konnte nun zeigen, dass die Losungsfolge j1, j2, . . . , ju in disjunkte Blocke zerfallt,die jeweils mit n + 1 beginnen und mit n + 2 enden, aber im Inneren diese Indizes nichtenthalten, und die auf der x- und auf der y-Seite jeweils denselben Teilwortern von zentsprechen.23 Fur unsere Zwecke genugt es aber, nur einen solchen Block zu finden.
Weil s das Paar (ε, ε) nicht enthalt, ist z nicht das leere Wort. Wegen der Bauart derPaare in s′ enthalt z mindestens ein #-Zeichen.
23Eine Losungsfolge fur s ergibt sich aus j1, j2, . . . , ju, indem man die Vorkommen von n + 2 weglasstund n + 1 durch 1 ersetzt.
131

Behauptung 1: Der Index n + 2 kommt in j1, . . . , ju vor.
[Beweis indirekt. Annahme: n+2 kommt in j1, . . . , ju nicht vor. — Dann endet das Wortz = x′
j1· · ·x′
juauf # (weil x′
1, . . . , x′n+1 leer sind oder auf # enden), andererseits endet
das Wort z = y′j1· · · y′
junicht auf # (weil y′
1, . . . , y′n+1 leer sind oder auf einen Buchstaben
6= # enden). Dies ist der gewunschte Widerspruch.]
Es sei t der kleinste Index mit jt = n + 2, also (xjt, yjt
) = ($, #$). Dann enthaltenx′
j1· · ·x′
jtund y′
j1· · · y′
jtbeide genau ein $-Zeichen, und zwar als letztes Zeichen. Diese
beiden Worter sind Anfangsstucke von z, und daher muss das $-Zeichen in beiden Folgenan derselben Stelle in z stehen. Damit haben wir
x′j1· · ·x′
jt= y′
j1· · · y′
jt.
Behauptung 2: Der Index n + 1 kommt in j1, . . . , jt−1 vor.
[Beweis indirekt. Annahme: n + 1 kommt in j1, . . . , jt−1 nicht vor. — Wegen der Bauartder Worter in s′ beginnt das Wort x′
j1· · ·x′
jtmit einem Zeichen 6= #; dagegen beginnt
y′j1· · · y′
jtmit #. Das ist unmoglich.]
Es sei p der maximale Index < t mit jp = n + 1, also x′jp
= /c# ◦ x#1 und y′
jp= /c ◦ #y1.
Wie eben sieht man, dass im Wort z das /c-Zeichen aus x′jp
und das aus y′jp
an derselbenStelle stehen mussen. Daraus folgt, dass
x′n+1x
′jp+1· · ·x′
jt−1x′
n+2 = y′n+1y
′jp+1· · · y′
jt−1y′
n+2,
und dass jp+1, . . . , jt−1 ∈ {1, . . . , n}. Wegen der Bauart der Worter in s′ erhalt man
x1xjp+1· · ·xjt−1
= y1yjp+1· · · yjt−1
;
mit anderen Worten: 1, jp+1, . . . , jt−1 ist eine Losungsfolge fur s. Damit ist”⇐“ gezeigt,
und der Beweis von (1.4) beendet. �
1.12 Unentscheidbare Fragen bei Grammatiken
Hinweis: Die Beweise dieses Abschnittes sind im Wintersemes-ter 2004/05 nicht prufungsrelevant. Jedoch sollte man wissen,welche Fragen uber kontextfreie Grammatiken unentscheidbar sind.Diese sind aus den Satzen abzulesen.
In der AFS-Vorlesung wurden fur eine ganze Reihe von Fragen fur kontextfreie Spra-chen Algorithmen vorgestellt. Insbesondere ist es moglich, eine kontextfreie Grammatikin einen NPDA fur dieselbe Sprache umzubauen, und aus einem NPDA eine aquivalen-te kontextfreie Grammatik zu gewinnen. Es gibt Algorithmen fur das Wortproblem furkontextfreie Sprachen, fur das Leerheits- und fur das Unendlichkeitsproblem.
132

Fur eine Reihe von Problemen hingegen wurden keine Algorithmen angegeben. Zentralhierbei ist eigentlich das Aquivalenzproblem fur kontextfreie Sprachen:
Eingabe: Kontextfreie Grammatiken G1, G2.
Frage: Sind G1, G2 aquivalent, d.h. gilt L(G1) = L(G2)?
Wir werden in diesem Abschnitt sehen, dass dieses Problem unentscheidbar ist, es alsokeinen Algorithmus geben kann, der das Problem entscheidet. In ahnlicher Weise sind eineganze Reihe anderer Fragen, die zwei kontextfreie Sprachen betreffen, unentscheidbar.Aber auch Fragen zu einzelnen kontextfreien Grammatiken (
”Ist L(G) = Σ∗?“) stellen
sich als unentscheidbar heraus.
Technisch grundlegend ist das Problem”Nichtleerer Durchschnitt“:
Eingabe: Kontextfreie Grammatiken G1, G2.
Frage: Gilt L(G1) ∩ L(G2) 6= ∅?
Formal definieren wir:
Lnl := {(G1, G2) | G1, G2 kfG mit L(G1) ∩ L(G2) 6= ∅}.
(Naturlich muss man hierzu kontextfreie Grammatiken geeignet als Worter kodieren.) Esist eine nicht allzu schwierige Ubungsaufgabe zu zeigen, dass Lnl rekursiv aufzahlbar ist.Dass das Nichtleerheitsproblem unentscheidbar ist, folgt dann nach unserem Rezept furden Beweis von Nichtrekursivitat aus Satz 1.11.6 und dem folgenden Satz.
1.12.1 Satz LPKP ≤ Lnl.
Beweis : Wir konstruieren eine Reduktionsfunktion f , die jeder Eingabefolge s fur PKPein Paar f(s) = (Gs
1, Gs2) von kontextfreien Grammatiken zuordnet, derart dass
s ∈ LPKP ⇔ L(Gs1) ∩ L(Gs
2) 6= ∅.
Sei s = ((x1, y1), . . . , (xn, yn)) gegeben. Dann haben Gs1 und Gs
2 beide das Terminalzei-chenalphabet
Σ = {0, 1, $} ∪ {p1, p2, . . . , pn},
wobei p1, . . . , pn einfach n neue Zeichen sind. (Zum Beispiel konnte man Σ = {0, 1, 2, . . . , n+2} verwenden, wobei 2 die Rolle von $ spielt und 3, . . . , n+2 die Rolle von p1, . . . , pn spie-len.) Wie fruher bedeutet xR das Spiegelwort ak · · · a1 des Wortes x = a1 · · · ak.
Die Grammatik Gs1 hat Startsymbol S1, Variablenmenge V1 = {S1, A,B}, und Produk-
tionen
S1 → A $ B
A → p1 Ax1 | . . . | pn Axn
A → p1 x1 | . . . | pn xn
B → yR1 B p1 | . . . | y
Rn B pn
B → yR1 p1 | . . . | y
Rn pn
133

Man erkennt leicht, dass in L(Gs1) die Worter des folgenden Formats erzeugt werden
konnen:
(1.5) pir . . . pi1xi1 . . . xir $ yRjt
. . . yRj1
pj1 . . . pjt,
wo r ≥ 1, i1, . . . , ir ∈ {1, . . . , n} und t ≥ 1, j1, . . . , jt ∈ {1, . . . , n}. Man erkennt, dassrechts und links des $-Zeichens voneinander unabhangig Konkatenationen von x- undy-Komponenten von s gebildet werden, und dass die pi-und pj-Folgen dokumentieren,welche dieser Komponenten gewahlt worden sind.
Die Grammatik Gs2 hat Startsymbol S2, Variablenmenge V2 = {S2, T} und Produktionen
S2 → p1 S2 p1 | . . . | pn S2 pn | T
T → 0T0 | 1T1 | $
Die Sprache L(Gs2) enthalt die Worter des Formats
(1.6) uv $ vRuR , u ∈ {p1, . . . , pn}∗, v ∈ {0, 1}∗.
1.12.2 Bemerkung Man kann relativ leicht einsehen, dass sowohl L(Gs1) als auch
L(Gs2) von einem deterministischen Kellerautomaten akzeptiert werden. Das heißt, dass
L(Gs1) und L(Gs
2) deterministisch kontextfrei sind, und dass die KomplementsprachenL(Gs
1) und L(Gs2) ebenfalls (deterministisch) kontextfrei sind. Man kann dann sogar algo-
rithmisch kontextfreie Grammatiken Gs1′ und Gs
2′ konstruieren, die L(Gs
1′) = L(Gs
1) undL(Gs
2′) = L(Gs
2) erfullen.
Behauptung: s ∈ LPKP ⇔ L(Gs1) ∩ L(Gs
2) 6= ∅.
Beweis der Behauptung:”⇒“: Es sei i1, . . . , ir eine Losungsfolge fur s, d. h.
xi1 · · ·xir = yi1 · · · yir .
Dann erfullt das Wort
zs = pir . . . pi1xi1 . . . xir $ yRir
. . . yRi1pi1 . . . pir
die in (1.5) und die in (1.6) notierten Bedingungen. Also ist zs ∈ L(Gs1) ∩ L(Gs
2).
”⇐“: Es sei z ∈ L(Gs
1) ∩ L(Gs2). Wegen Bedingung (1.6) fur L(Gs
2) gibt es r ≥ 0 undpi1 , . . . , pir mit
z = pi1 . . . pirv$vRpir . . . pi1 ,
wobei v ∈ {0, 1}∗ gilt. Wegen Bedingung (1.5) muss weiter r ≥ 1 und
v = xir . . . xi1 und vR = yRi1
. . . yRir
gelten. Weil yRi1
. . . yRir
= (yir . . . yi1)R, heißt das, dass
xir . . . xi1 = yir . . . yi1 ,
also ist ir, . . . , i1 eine Losungsfolge fur s, und s ∈ LPKP.
Damit ist die Behauptung bewiesen und der Beweis von Satz 1.12.1 beendet. �
134

Wir definieren nun weitere Sprachen, die Entscheidungsproblemen zu Paaren von kon-textfreien Sprachen entsprechen.
Linfinite := {(G1, G2) | G1, G2 kfG mit |L(G1) ∩ L(G2)| =∞},
Lkfschnitt := {(G1, G2) | G1, G2 kfG mit L(G1) ∩ L(G2) kontextfrei},
Lsubset := {(G1, G2) | G1, G2 kfG mit L(G1) ⊆ L(G2)},
Lequiv := {(G1, G2) | G1, G2 kfG mit L(G1) = L(G2)}.
Wir zeigen, dass alle diese Sprachen nichtrekursiv, die entsprechenden Entscheidungspro-bleme also unentscheidbar sind.
1.12.3 Satz
(a) LPKP ≤ Linfinite.
(b) LPKP ≤ Lkfschnitt.
(c) LPKP ≤ Lsubset.
(d) Lsubset ≤ Lequiv.
Beweis : (a) Betrachte die Konstruktion im Beweis von Satz 1.12.1. Gegeben sei eineEingabe s fur PKP. Zu jeder Losungsfolge i1, . . . , ir fur s finden wir ein Wort zs in L(Gs
1)∩L(Gs
2), und alle diese Worter sind verschieden. Wir erinnern uns nun an Bemerkung 1.11.3,die besagte, dass es zu s entweder keine oder unendlich viele Losungsfolgen gibt. Das heißt:Wenn s /∈ LPKP, dann ist L(Gs
1)∩L(Gs2) = ∅; wenn s ∈ LPKP, dann ist |L(Gs
1)∩L(Gs2)| =
∞. Damit ist die Funktion s 7→ (Gs1, G
s2) auch eine Reduktionsfunktion von LPKP auf
Linfinite.
(b) Wir verwenden nochmals die Reduktionsfunktion s 7→ (Gs1, G
s2).
Falls s /∈ LPKP, ist L(Gs1) ∩ L(Gs
2) = ∅.
Sei nun s = ((x1, y1), . . . , (xn, yn)) ∈ LPKP. Zu zeigen ist, dass die Sprache L(Gs1) ∩
L(Gs2) nicht kontextfrei ist. Hierzu benutzen wir das Pumping-Lemma fur kontextfreie
Sprachen. (Fur die Erklarung des Pumping-Lemmas und das resultierende Muster vonNicht-Kontextfreiheits-Beweisen siehe die AFS-Vorlesung.)
Es sei N ≥ 1 beliebig gegeben. Nach Teil (a) ist L(Gs1) ∩ L(Gs
2) unendlich; wir konnenalso ein
z = uv$ vRuR, u ∈ {p1, . . . , pn}∗, v ∈ {0, 1}∗
in L(Gs1) ∩ L(Gs
2) wahlen, mit |u| ≥ N und |v| ≥ N . Dabei ist u = pir · · · pi1 undv = xi1 · · ·xir = yi1 · · · yir . Nun betrachte eine beliebige Zerlegung
z = z1z2z3z4z5
mit |z2z4| ≥ 1 und |z2z3z4| ≤ N . Wir unterscheiden einige Falle.
135

1. Fall : z2z4 enthalt das $-Zeichen aus z. — Dann ist z1z3z5 = z1z02z3z
04z5 /∈ L(Gs
1)∩L(Gs2).
Ab hier nehmen wir an, dass in z2z4 das $-Zeichen aus z nicht vorkommt. Alle Modifika-tionen z1z
i2z3z
i4z5, i ≥ 0, enthalten also genau ein $-Zeichen, so dass man die
”linke Seite“
und die”rechte Seite“ unterscheiden kann.
2. Fall : z2 enthalt ein Zeichen des u-Teils von z. — Dann kann z2z3z4 keinen Buchsta-ben aus dem uR-Teil enthalten. Es folgt, dass in z1z3z5 der erste Block aus Zeichen ausp1, . . . , pn nicht Spiegelbild des letzten Blocks, namlich uR, ist; damit ist z1z3z5 /∈ L(Gs
2).
2. Fall : z2 enthalt kein Zeichen des u-Teils, aber ein Zeichen des v-Teils von z. — Dannist in z1z3z5 der erste Block aus {0, 1}∗ nicht gemaß den in u festgehaltenen Indizes ausden Wortern x1, . . . , xn gebildet, also z1z3z5 /∈ L(Gs
1).
3. Fall : z2 enthalt kein Zeichen des uv-Teils von z. — Dann ist in z1z3z5 der Wortteilrechts des $-Zeichens nicht mehr das Spiegelbild des Wortteils links des $-Zeichens, alsoist z1z3z5 /∈ L(Gs
1).
In allen Fallen ist z1z3z5 /∈ L(Gs1) ∩ L(Gs
2). Damit ist die nach dem Pumping-Lemmageltende Bedingung verletzt, also kann L(Gs
1) ∩ L(Gs2) nicht kontextfrei sein.
(c) In Bemerkung 1.12.2 hatten wir festgestellt, dass L(Gs2) deterministisch kontextfrei ist
und dass man daher aus s auch eine kontextfreie Grammatik Gs2′ konstruieren kann, die
L(Gs2′) = L(Gs
2) erfullt. Damit gilt:
s ∈ LPKP ⇔ L(Gs1) ∩ L(Gs
2) 6= ∅ ⇔ L(Gs1) 6⊆ L(Gs
2) = L(Gs2′).
Daher ist die Funktion s 7→ (Gs1, G
s2′) eine Reduktionsfunktion von LPKP auf Lsubset.
(d) Zu gegebenen kontextfreien Grammatiken G und G′ konnen wir eine kontextfreieGrammatik G′′ bauen, die L(G′′) = L(G) ∪ L(G′) erfullt. Offensichtlich gilt:
L(G) ⊆ L(G′) ⇔ L(G) ∪ L(G′) = L(G′) ⇔ L(G′′) = L(G′).
Damit ist die Funktion (G,G′) 7→ (G′′, G′) eine Reduktionsfunktion von Lsubset auf Lequiv.�
Die Reduktionen in den Fallen (a)–(c) arbeiten ausschließlich mit deterministisch kon-textfreien Sprachen. Daher erhalten wir, dass die Entscheidungsprobleme
”leerer Durch-
schnitt“,”unendlicher Durchschnitt“ und
”Teilmenge“ schon fur deterministisch kontext-
freie Sprachen (gegeben durch entsprechende Kellerautomaten) unentscheidbar sind. ImBeweis von Teil (d) geht man uber die deterministisch kontextfreien Sprachen hinaus,das diese unter der Operation
”Vereinigung“ nicht abgeschlossen sind. Tatsachlich wurde
1997 von G. Senizergues bewiesen, dass das Aquivalenzproblem fur deterministisch
kontextfreie Sprachen entscheidbar ist.
Nun wollen wir noch weitere Probleme fur kontextfreie Sprachen betrachten, die sich alsunentscheidbar herausstellen. Fur die Definition der Begriffe siehe die AFS-Vorlesung.
(a) Totalitat :
136

Eingabe: Kontextfreie Grammatik G.
Frage: Ist L(G) = Σ∗?
(b) Komplement kontextfrei?
Eingabe: Kontextfreie Grammatik G.
Frage: Ist L(G) kontextfrei?
(c) Deterministisch kontextfrei?
Eingabe: Kontextfreie Grammatik G.
Frage: Ist L(G) deterministisch kontextfrei?
(d) Regularitat :
Eingabe: Kontextfreie Grammatik G.
Frage: Ist L(G) regular?
(e) Mehrdeutigkeit :
Eingabe: Kontextfreie Grammatik G.
Frage: Ist G mehrdeutig?
1.12.4 Satz Die in (a)–(e) genannten Entscheidungsprobleme zu kontextfreien Spra-chen sind unentscheidbar.
Beweis : Wir verzichten darauf, die Formulierungen als Sprachen vorzunehmen, und be-schreiben nur die wesentlichen Reduktionen. Wir wissen aus dem Beweis von Satz 1.12.3(b),dass wir aus einer Eingabe s fur PKP kontextfreie Grammatiken Gs
1 und Gs2 konstruieren
konnen derart, dass
(i) s /∈ LPKP ⇒ L(Gs1) ∩ L(Gs
2) = ∅
(ii) s ∈ LPKP ⇒ L(Gs1) ∩ L(Gs
2) ist nicht kontextfrei.
Weiter konnen wir nach Bemerkung 1.12.2 kontextfreie Grammatiken Gs1′ und Gs
2′ kon-
struieren derart dass L(Gs1′) = L(Gs
1) und L(Gs2′) = L(Gs
2). Damit konnen wir auch einekontextfreie Grammatik Gs
3 konstruieren mit
L(Gs3) = L(Gs
1′) ∪ L(Gs
2′) = L(Gs
1) ∩ L(Gs2).
Aufgrund von (i) und (ii) erhalten wir:
(i) s /∈ LPKP ⇒ L(Gs3) = Σ∗. In diesem Fall ist also L(Gs
3) auch kontextfrei,deterministisch kontextfrei, und sogar regular.
137

(ii) s ∈ LPKP ⇒ L(Gs3) ist nicht kontextfrei. In diesem Fall ist L(Gs
3) nicht determi-nistisch kontextfrei, und auch nicht regular.
Damit gilt fur die Funktion s 7→ Gs3:
s ∈ LPKP ⇔ L(Gs3) 6= Σ∗
s ∈ LPKP ⇔ L(Gs3) ist nicht kontextfrei
s ∈ LPKP ⇔ L(Gs3) ist nicht deterministisch kontextfrei
s ∈ LPKP ⇔ L(Gs3) ist nicht regular
Daraus folgt die Unentscheidbarkeit der Entscheidungsprobleme (a), (b), (c) und (d).
Zu (e): Betrachte nochmals die Grammatiken Gs1 und Gs
2 aus dem Beweis von Satz 1.12.1.Diese sind offensichtlich eindeutig, d. h. jedes Wort in L(Gs
i ) besitzt genau einen Ablei-tungsbaum, fur i = 1, 2. Wir bilden nun eine neue Grammatik Gs
4, indem wir die Variablenund die Produktionen von Gs
1 und Gs2 vereinigen, und eine neue Startvariable S sowie die
Produktionen S → S1 und S → S2 hinzufugen. Die Grammatik Gs4 erzeugt die Sprache
L(Gs1)∪L(Gs
2). Es ist leicht zu sehen, dass Worter in L(Gs1)−L(Gs
2) und in L(Gs2)−L(Gs
1)genau einen Ableitungsbaum besitzen, die Worter in L(Gs
1)∩L(Gs2) hingegen genau zwei
(einen fur eine Ableitung in Gs1 und einen fur eine Ableitung in Gs
2). Das heißt: Gs4 ist
mehrdeutig genau dann wenn L(Gs1) ∩ L(Gs
2) 6= ∅. Damit ergibt sich:
s ∈ LPKP ⇔ Gs4 ist mehrdeutig;
die Reduktion s 7→ Gs4 zeigt also, dass Problem (e) unentscheidbar ist. �
Erganzung: In der Vorlesung wurden noch einige weitere Probleme genannt, die sich alsunentscheidbar erwiesen haben:
• (Allgemein-)Gultigkeitsproblem fur Formeln der Pradikatenlogik
• Wahre aussagenlogische Formeln fur die Arithmetik(Naturliche Zahlen mit Addition und Multiplikation)
• Das”10. Hilbertsche Problem“: Existenz ganzzahliger Nullstellen bei (multivariaten)
Polynomen mit ganzzahligen Koeffizienten
Als schriftliche Unterlage fur diese Hinweise sei auf die Folien zur Vorlesung verwiesen.Eine genauere Beschreibung der Probleme und Skizzen der Unentscheidbarkeitsbeweisefindet man auch in dem Buch
”Theoretische Informatik kurzgefasst“ von Uwe Schoning.
138

Kapitel 2
Die Theorie der NP-vollstandigenProbleme
Haben wir im ersten Kapitel die Grenze zwischen algorithmisch behandelbaren (den re-kursiven) und denjenigen Problemen kennengelernt, die uberhaupt nicht algorithmisch zubehandeln sind, wenden wir uns hier der Frage zu, ob es Probleme gibt, die zwar prinzi-piell algorithmisch losbar sind, aber keinen effizienten Algorithmus besitzen, d. h. keinen,dessen Zeit- und Platzaufwand mit der Eingabelange
”ertraglich“ langsam wachst. Wir
greifen dazu aus dem Gebiet der Komplexitatstheorie ein Kapitel heraus, das auch fur diePraxis von großer Bedeutung ist: die NP-Vollstandigkeits-Theorie. (Die Thematik wirdim Hauptstudium in der Vorlesung
”Komplexitatstheorie“ genauer behandelt.)
Wie schon im Kapitel 1 kummern wir uns in erster Linie um Entscheidungsprobleme, diedurch Sprachen L ⊆ Σ∗ reprasentiert werden, und um Funktionsberechnungen, reprasen-tiert durch Funktionen f : Σ∗ → ∆∗. Fur solche Probleme sollen Algorithmen bereitge-stellt werden. Wann soll ein Algorithmus effizient heißen? Aus der Programmierungs-und der Graphentheorie-Vorlesung weiß man, dass
”effiziente“ Algorithmen Laufzeiten
O(n), O(n log n), O(n2), O(n3), . . . haben, und dass man Algorithmen mit exponentiellenLaufzeiten wie O(2n) oder O(n!) normalerweise nicht als effizient ansieht. Wir erklaren(informal): ein Algorithmus A zur Berechnung einer Funktion f heißt ein Polynomial-zeitalgorithmus, falls es ein Polynom p(n) gibt, so dass A auf Eingaben x der
”Große“ n
hochstens p(n) Schritte macht.
Beispiele fur Polynomialzeitalgorithmen:
(a) Fur das Sortieren von n Zahlen gibt es Algorithmen mit Schrittzahl O(n log n), alsoO(n2); z. B. Mergesort oder Heapsort.
(b) Die Zusammenhangskomponenten eines ungerichteten Graphen G = (V,E), |V | =n, |E| = m, gegeben in Adjazenzlistendarstellung, konnen in Zeit O(n + m) be-rechnet werden. Die entsprechenden Algorithmen lernt man unter der Bezeichnung
”Breitensuche“ oder
”Tiefensuche“ in der Vorlesung und den Buchern zum Gebiet
”Effiziente Algorithmen“ kennen.
139

(c) Ein maximaler Fluss in einem Flussnetzwerk mit n Knoten und m Kanten kann inZeit O(nm2) = O(n5) berechnet werden. (Siehe Vorlesung
”Graphentheorie“. Die
behauptete Laufzeit ergibt sich, wenn man den Ford-Fulkerson-Algorithmus dahinandert, dass immer flussvergroßernde Wege mit moglichst wenigen Kanten gesuchtwerden. Der resultierende Algorithmus heißt nach seinen Erfindern
”Edmonds-Karp-
Algorithmus“. Er ist bei weitem nicht der schnellste Flussalgorithmus, aber er hatjedenfalls polynomielle Laufzeit.)
Fur das weitere legen wir folgende Arbeitshypothese zugrunde:
(A) Nur Algorithmen mit polynomieller Laufzeit konnen effizient sein.
Wohlgemerkt heißt das nicht, dass wir behaupten, alle Algorithmen mit polynomiellerLaufzeit waren effizient — man denke an Laufzeiten wie O(n1000). Um Aussagen wie
”Problem P besitzt keinen Polynomialzeitalgorithmus“ sinnvoll formulieren zu konnen,
benotigen wir eine prazise Formulierung des informalen Konzepts”Polynomialzeitalgorith-
mus“. Hierfur benutzen wir wie in Kap. 1 das Turingmaschinenmodell.1 Betrachtet mandie Simulation zwischen RAMs und TMs (Abschnitt 1.5) genauer, so bemerkt man, dassdie Simulation von RAMs mit logarithmischem Kostenmaß, das polynomiell beschranktist, auf TMs nur polynomielle Zeit erfordert (Satz 1.5.5) und umgekehrt (Satz 1.5.1).Ahnlich verhalt es sich mit anderen Methoden, mit denen man Algorithmen spezifizierenund ihren Zeitbedarf messen kann. Eine gewisse Sorgfalt bei der Kodierung von Inputsist dabei notig; fur unsere Zwecke genugt die Faustregel, dass eine einfache Binarkodie-rung fur Zahlen und fur Graphen und andere Strukturen praktisch immer angemessen ist.Weiter muss man darauf achten, dass bei der Zeitmessung nicht allzu komplexe Opera-tionen, wie z. B. die Addition sehr langer Zahlen, mit Kosten 1 veranschlagt werden. Furunser weiteres Arbeiten legen wir die folgende effiziente Variante der Churchschen
These (vgl. Abschnitt 1.7) zugrunde:
(B) Eine Sprache L ⊆ Σ∗ (eine Funktion f : Σ∗ → ∆∗) kann genau dann von einem Poly-nomialzeitalgorithmus berechnet werden, wenn es eine polynomiell zeitbeschrankteTuringmaschine M mit L = LM (bzw. f = fM) gibt.
Unsere Aussagen (A) und (B) liefern zusammen ein notwendiges Kriterium fur Problememit effizienten Algorithmen:
(C) Wenn eine Sprache L ein effizientes Entscheidungsverfahren hat, dann ist L = LM
fur eine polynomiell zeitbeschrankte Turingmaschine.Und analog: Wenn eine Funktion f von einem effizienten Algorithmus berechnetwerden kann, dann kann f von einer TM mit polynomieller Zeitschranke berechnetwerden.
1In Abschnitt 2.1 wird genau erklart, wann eine TM polynomiell zeitbeschrankt heißt.
140

Man beachte wieder, dass nicht behauptet wird, alle polynomiell zeitbeschrankten Tu-ringmaschinen wurden effiziente Algorithmen darstellen. Aus (C) erhalt man durch Kon-traposition:
(D) Besitzt eine Sprache keine polynomiell zeitbeschrankte Turingmaschine, so ist Ldurch keinen effizienten Algorithmus entscheidbar.Analog: Wenn f nicht von einer polynomiell zeitbeschrankten Turingmaschine be-rechnet werden kann, dann besitzt f keinen effizienten Algorithmus.
Das Programm fur das vorliegende Kapitel sieht wie folgt aus: Wir untersuchen das Kon-zept der polynomiell zeitbeschrankten Turingmaschine. Weiter definieren wir die KlasseNP derjenigen Sprachen, die durch
”Nichtdeterministische Polynomiell zeitbeschrankte
TM“ entschieden werden konnen. Innerhalb von NP werden”NP-vollstandige“ Sprachen
als”die schwierigsten“ identifiziert. Wir sammeln Indizien dafur, dass es zu diesen NP-
vollstandigen Sprachen vermutlich keine polynomiell zeitbeschrankten Turingmaschinengibt, also, im Licht von (D), die entsprechenden Entscheidungsprobleme und verwandteBerechnungs- und Optimierungsprobleme keinen effizienten Algorithmus haben. Schließ-lich besprechen wir eine Reihe von Beispielen fur solche NP-vollstandigen Probleme.
2.1 Polynomiell zeitbeschrankte Turingmaschinen
Vereinbarung: Im Rest des Kapitels meinen wir mit”Turingmaschinen“ immer TMn
mit einer beliebigen festen Anzahl von Bandern. (Vgl. Satze 1.2.6 und 1.2.8.) Wir nehmenan, dass das Eingabealphabet die Form Σ = {0, . . . , k− 1} fur ein k ≥ 2 hat. Meist wirdhierbei k = 2 angenommen. (Fur die entsprechenden Simulationen siehe Abschnitt 1.2.12.)
Erinnerung: (Vergleiche Definition 1.2.7.) Eine Turingmaschine M (auch mit mehrerenBandern) heißt g(n)-zeitbeschrankt (fur eine Funktion g : N → R+), falls fur alle x ∈ Σ∗
gilt, dass M auf Eingabe x hochstens g(|x|) Schritte macht (formal: tM(x) ≤ g(|x|)).Eine TM M (auch mit mehreren Bandern) heißt polynomiell zeitbeschrankt , wennM p(n)-zeitbeschrankt fur ein Polynom p(n) ist.
Offenbar gilt fur jede g(n)-zeitbeschrankte TM M , dass M auf allen Eingaben halt; d. h.LM ist eine rekursive Sprache und fM ist eine rekursive Funktion.
2.1.1 Definition
(a) Fur eine Funktion t : N→ R+ definieren wir
DTIME(t(n)) := {LM | ∃c > 0: M ist c · t(n)-zeitbeschrankte TM}.
(Kommentar : Beachte, dass diese”Zeitkomplexitatsklassen“ keinen Unterschied bezuglich
konstanten Faktoren in den Zeitschranken machen. Fur die Frage, ob LM ∈ DTIME(n log n)ist, ist es also gleichgultig, ob M 10n log n-zeitbeschrankt oder 10000n log n-zeitbeschranktist.)
141

(b) P ist die Klasse der Sprachen, die von polynomiell zeitbeschrankten Turingmaschi-nen entschieden werden konnen, genauer:
P :=⋃
{DTIME(nk) | k ≥ 1}
= {LM | ∃c > 0, k ≥ 1: M ist c · nk-zeitbeschrankte TM}.
(c) Fur t : N→ R+ definieren wir:
FDTIME(t(n)) := {fM | ∃c > 0: M ist c · t(n)-zeitbeschrankte TM}.
(d) FP ist die Klasse der Funktionen, die von polynomiell zeitbeschrankten TM berech-net werden konnen:
FP :=⋃
{FDTIME(nk + 1) | k ≥ 1}
= {fM | ∃c > 0, k ≥ 1: M ist c · (nk + 1)-zeitbeschrankte TM}.
2.1.2 Bemerkung In der Definition von P und FP werden Zeitschranken der Formc · nk bzw. c · (nk + 1) benutzt. Diese spezielle Form spielt weiter keine Rolle. Es giltnamlich:
L ∈ P ⇔ es gibt eine TM M und ein Polynom p(n) mit ganzzahligen Koeffi-zienten, so dass M p(n)-zeitbeschrankt ist und LM = L gilt.
Beweis :”⇐“: Es sei L = LM fur eine TM M mit tM(x) ≤ p(|x|) fur alle x ∈ Σ∗. Zuerst
uberlegt man, dass man M so umbauen kann, dass M auf Eingabe ε keinen Schritt macht.(Wenn ε ∈ L, ist q0 akzeptierend, sonst verwerfend.) Wenn nun p(n) = akn
k +ak−1nk−1 +
· · ·+ a1n + a0, so ist fur c := |ak|+ |ak−1|+ · · ·+ |a1|+ |a0| stets p(n) ≤ cnk, falls n ≥ 1.Also ist tM(x) ≤ c|x|k fur alle x ∈ Σ∗, also ist L ∈ P.
”⇒“ ist trivial. �
Ahnlich zeigt man:
f ∈ FP ⇔ es gibt eine TM M und ein Polynom p(n) mit ganzzahligen Koef-fizienten, so dass M p(n)-zeitbeschrankt ist und fM = f gilt.
Wir haben schon festgestellt, dass jede Sprache in P rekursiv ist und jede Funktion in FP
rekursiv ist. Nebenbei sei gesagt, dass sehr viele rekursive Sprachen (Funktionen) nicht inP (bzw. in FP) liegen.
Fur die folgenden Beispiele brauchen wir eine Kodierung von Graphen als Worter ubereinem endlichen Alphabet. Hier gibt es mehrere Moglichkeiten. Eine haben wir in Ab-schnitt 0.2 vorgestellt. (Diesen Abschnitt sollte man rekapitulieren, bevor man weiter-liest.) Dabei konnten die Knotenmengen beliebige Mengen von naturlichen Zahlen sein.
142

Hier werden wir uns nur mit Graphen beschaftigen, die eine Knotenmenge V = {1, . . . ,m}fur ein m ∈ N haben. Fur diesen Fall gibt es noch einfachere Kodierungen, von denen wirzwei nennen wollen.
G = (V,E) sei ein (gerichteter oder ungerichteter) Graph mit V = {1, . . . ,m} und E ={(v1, w1), . . . , (ve, we)} mit v1, . . . , ve, w1, . . . , we ∈ V (geordnete oder ungeordnete Paare).
Adjazenzmatrixdarstellung : Die Adjazenzmatrix von G ist bekanntermaßen die Ma-trix AG = (aij)1≤i,j≤m mit aij = 1 falls (i, j) ∈ E und aij = 0 sonst. Wir konnen Gdarstellen, indem wir die Zeilen von AG nebeneinander hinschreiben:
〈G〉 := 0m1a11 · · · a1m · · · am1 · · · amm .
Diese Darstellung erfordert exakt m(m + 1) + 1 Bits, gleichgultig wie viele Kanten derGraph hat.
Darstellung durch Kantenliste: Man kann auch eine Liste aller Kanten benutzen, umden Graphen darzustellen. Setze l := dlog(m+1)e. Dann besitzt jede Zahl i ∈ {0, 1, . . . ,m}eine Darstellung binl(i) als Binarwort mit exakt l Bits (eventuell mit fuhrenden Nullen).Wir setzen
〈〈G〉〉 := 0m10e1binl(v1)binl(w1) · · · binl(ve)binl(we),
wo E = {(v1, w1), . . . , (ve, we)}. Fur diese Darstellung werden genau m+2+e(1+2l) Bitsbenotigt. Wenn der Graph nicht allzu viele Kanten hat (deutlich weniger als m2/2l viele),dann ist diese Darstellung etwas kompakter als die Adjazenzmatrixdarstellung. Um zuerzwingen, dass die Darstellung durch G eindeutig bestimmt ist, kann man verlangen, dassdie Kantenliste lexikographisch sortiert ist. Dies ist aber fur das folgende nicht wichtig.
Man sollte sich kurz klarmachen, dass es leicht ist, auch fur eine Turingmaschine in poly-nomieller Zeit, ein Binarwort darauf zu testen, ob es die Form 〈G〉 (oder 〈〈G〉〉) fur einenGraphen G hat. Wir werden immer annehmen (und nur manchmal erwahnen), dass TMn,die Graphdarstellungen als Input erwarten, einen solchen Syntaxcheck durchfuhren.
Es ist eine Ubungsaufgabe, sich zu uberlegen, dass es irrelevant ist, welche der beidenKodierungen man benutzt, wenn es um die Frage geht, ob eine Sprache von Graphkodie-rungen, die ein Graphproblem formalisiert, in P liegt oder nicht. Dabei benutzt man dieBeobachtung, dass |〈〈G〉〉| ≤ |〈G〉|2 und |〈G〉| = m+1+m2 < (m+1)2 ≤ |〈〈G〉〉|2, und dassdie beiden Kodierungen leicht ineinander umzurechnen sind. — Eine Verallgemeinerungdieser Kodierungen auf Graphen mit (ganzzahligen oder rationalen) Kantengewichtenliegt auf der Hand: Man schreibt diese Gewichte einfach in Binardarstellung auf.
2.1.3 Beispiel Die folgenden Sprachen sind in P:
(a) Lzush = {〈G〉 | G ist zusammenhangender ungerichteter Graph};
(b) Lstark−zush = {〈G〉 | G ist stark zusammenhangender gerichteter Graph}.(G heißt stark zusammenhangend, wenn fur jedes Knotenpaar (u, v) in G ein ge-richteter Weg von u nach v und ein gerichteter Weg von v nach u existiert.)
143

(c) LMaxGrad ≤d = {〈G〉 | G ist Graph, jeder Knoten in G hat ≤ d Nachbarn}.
(d) Lbipartit = {〈G〉 | G ist bipartiter Graph}.(G heißt bipartiter oder paarer Graph, wenn man die Knoten von G so mit 2 Farbenfarben kann, dass keine zwei benachbarten Knoten dieselbe Farbe haben.)
(e) LBaum = {〈G〉 | G ist zusammenhangend und kreisfrei}.
Die folgende Funktion ist in FP:
(f) fZush−Komp : {0, 1}∗ → {0, 1}∗, mit der Eigenschaft:fZush−Komp(〈G〉) = Liste der Zusammenhangskomponenten von G;fZush−Komp(w) = ε, falls w keinen ungerichteten Graphen kodiert.
Um TM-Verfahren zu konstruieren, die diese Sprachen bzw. Funktionen berechnen, kannman z. B. Versionen der aus der Graphentheorie-Vorlesung bekannten Algorithmen aufTuringmaschinen umschreiben. Dass dies im Prinzip moglich ist, ohne den Bereich poly-nomieller Laufzeiten zu verlassen, haben wir oben allgemein festgestellt.
2.2 Polynomiell zeitbeschrankte NTMn
In Abschnitt 1.3.1 haben wir uns ausfuhrlich mit nichtdeterministischen Turingmaschinenbeschaftigt. Wichtig ist es, sich an den Berechnungsbaum CT (M,x) zur NTM M und einerEingabe x zu erinnern, der alle moglichen Berechnungen von M auf Eingabe x enthalt.Die Anzahl tM(x) der Schritte von M auf x ist die Tiefe von CT (M,x), das heißt dieLange der langsten Berechnung von M auf x. Wieder konnen unsere TMn eine beliebigeAnzahl von Bandern haben.
2.2.1 Definition (Polynomiell zeitbeschrankte NTM)
(a) Eine nichtdeterministische TM M heißt t(n)-zeitbeschrankt , wenn fur jedes x ∈Σ∗ die langste Berechnung von M auf x maximal t(|x|) Schritte macht, d. h. wennCT (M,x) hochstens Tiefe t(|x|) hat.
(b) Eine nichtdeterministische TM M heißt polynomiell zeitbeschrankt , wenn Mp(n)-zeitbeschrankt fur ein Polynom p(n) ist.
Es folgt eine der wesentlichen Definitionen dieses Kapitels.
144

2.2.2 Definition
(a) Fur eine Funktion t : N→ R+ definieren wir
NTIME(t(n)) := {LM | ∃c > 0: M ist c · t(n)-zeitbeschrankte NTM}.
(b)
NP :=⋃
{NTIME(nk) | k ≥ 1}
= {LM | ∃c > 0, k ≥ 1: M ist c · nk-zeitbeschrankte NTM}.
(NP ist die Klasse der Sprachen zu Nichtdeterministischen Polynomiell zeitbe-schrankten TM.)
(c) co-NP := {L | L ∈ NP} (Komplemente von Sprachen in NP).
Wie in Bemerkung 2.1.2 sieht man, dass NP die Menge der Sprachen LM fur nichtde-terministische polynomiell zeitbeschrankte NTM M ist. Aus den Definitionen und derTatsache, dass deterministische TMn nur spezielle NTMn sind, folgt sofort P ⊆ NP.
Fur die ubersichtliche Konstruktion von nichtdeterministischen TMn stellen wir eine Hilfs-maschine bereit. Diese NTM ist nicht wegen ihres Akzeptierungsverhaltens interessant,sondern wegen des produzierten Bandinhalts.
2.2.3 Beispiel
(Nichtdeterministisches Schreiben eines Binarstrings:”Ratewort-TM“)
Die Ratewort-TM MRatewort ist eine NTM mit folgendem Verhalten:
Eingabe: 0n
Ausgabe: Ein Binarwort b1 · · · bn ∈ {0, 1}n. Dabei soll jedes solche Wort als Ausgabe
moglich sein, d. h. der Berechnungsbaum hat 2n Blatter.
Die Idee ist einfach: man lese das eingegebene Wort von links nach rechts (Zustand q0),wandle dabei jede 0 nichtdeterministisch in 0 oder 1 um, stelle den Kopf wieder zuruckauf die Ausgangsposition (Zustand q1) und halte (Zustand q2).
Formal: Q = {q0, q1, q2}, Σ = {0}, Γ = {0, 1, B}, δ wie folgt:
δ(q0, 0) = {(q0, 0, R), (q0, 1, R)}
δ(q0, B) = {(q1, B, L)}
δ(q1, a) = {(q1, a, L)} fur a ∈ {0, 1}
δ(q1, B) = {(q2, B, R)} .
Fur alle nicht explizit erwahnten Paare (q, a) gilt δ(q, a) = ∅.
Auf Eingabe 0n macht MRatewort offenbar 2n+1 Schritte, d. h. sie ist 2n+1-zeitbeschrankt.
Naturlich kann man nach demselben Prinzip fur jedes Alphabet Σ eine NTM erstellen,die auf Eingabe 0n nichtdeterministisch ein Wort b1 · · · bn ∈ Σn schreibt.
145

2.3 Optimierungsprobleme und Sprachen in NP
Viele Berechnungsaufgaben verlangen, dass man eine in einem bestimmten Sinn optimaleStruktur findet:
• einen kurzesten Weg von Knoten 1 zu Knoten n in einem Graphen G,
• einen maximalen Fluss in einem Flussnetzwerk
• ein VLSI-Layout fur einen Schaltkreis mit moglichst kleiner Flache
• eine Aufteilung von n Jobs mit Bearbeitungszeiten l1, . . . , ln auf m (gleichartige)Maschinen, so dass die maximale Bearbeitungszeit, uber alle Maschinen betrachtet,minimal ist.
Solche Optimierungsaufgaben fallen nicht direkt in unsere Kategorien”Entscheidungs-
probleme“ und”Funktionen“. Allerdings findet man meistens eng verwandte Entschei-
dungsprobleme und Funktionen, die mit unseren Mitteln klassifiziert werden konnen. Wirdemonstrieren dies am Beispiel des Cliquenproblems.
2.3.1 Beispiel
(a) Ist G = (V,E) ein ungerichteter Graph, so heißt V ′ ⊆ V eine Clique in G, fallsdie Knoten in V ′ einen vollstandigen Teilgraphen bilden, d. h. wenn gilt: ∀v, w ∈V ′, v 6= w : (v, w) ∈ E. Dabei heißt |V ′| die Große der Clique.
Beispiel : Im in Abb. 2.1 angegebenen Graphen
4
2 3
1
5
6 7
Abbildung 2.1: Ein Graph mit zwei maximal großen Cliquen
bilden die Knotenmengen V ′ = {1, 2, 3, 7} und V ′′ = {2, 3, 6, 7} jeweils eine Clique mitvier Knoten. Auch {1, 2} und {1, 2, 3} bilden Cliquen. Dagegen ist V ′′′ = V ′ ∪ V ′′ ={1, 2, 3, 6, 7} keine Clique; uberhaupt gibt es in G keine Clique mit funf oder mehr Knoten.
146

(b) Das Cliquenproblem ist die Aufgabe, in einem gegebenen Graphen eine moglichstgroße Clique zu finden. Es kann in verschiedenen Formulierungen auftreten. Wirbetrachten drei Varianten. (Ahnliche Varianten gibt es fur viele Optimierungspro-bleme.)
Variante 1: (Optimierungsproblem im eigentlichen Sinn; Suche nach einer optimalenStruktur)Gegeben sei ein Graph G = (V,E).Aufgabe: Finde eine Clique V ′ ⊆ V , so dass |V ′| ≥ |V ′′| fur jede Clique V ′′ in G.
Variante 2: (Parameteroptimierung)Gegeben sei ein Graph G = (V,E).Aufgabe: Bestimme das maximale k ∈ N, so dass G eine Clique der Große k hat.
Variante 3: (Entscheidungsproblem)Gegeben seien G = (V,E) und k ∈ N.Frage: Gibt es in G eine Clique V ′ der Große |V ′| ≥ k?
Man kann diese Varianten naturlich formalisieren. Dabei werden Parameteroptimierungs-probleme als Funktionen beschrieben, Entscheidungsprobleme als Sprachen. Optimie-rungsprobleme im eigentlichen Sinn erfordern eine neue Terminologie, hauptsachlich des-wegen, weil die Ausgabe durch die Eingabe nicht eindeutig bestimmt ist (zu G kann es javiele Cliquen maximaler Große geben).
Variante 2: Die Funktion fClique−Size ist folgendermaßen definiert:fClique−Size(〈G〉) = bin(kG), wo kG = max{|V ′| | V ′ ⊆ V ist Clique in G}, fur belie-bige Graphen G; falls w ∈ {0, 1}∗ keinen Graphen kodiert, ist fClique−Size(w) = ε.
Variante 3:
LClique := {〈G〉bin(k) | k ≥ 1, G Graph uber V = {1, . . . ,m},
G hat Clique der Große k}.
LClique ist also eine Sprache uber {0, 1}.
Variante 1: Um Knotenmengen V ′ ⊆ V = {1, . . . ,m} als Binarworter darzustellen,benutzen wir
”charakteristische Vektoren“: die Menge V ′ ⊆ V entspricht dem Wort
y = b1 · · · bm ∈ {0, 1}m mit bi = 1 ⇔ i ∈ V ′, fur 1 ≤ i ≤ m.
Zu einem Graphen G = (V,E) mit V = {1, . . . ,m} sei
Sol(〈G〉) := {b1 · · · bm ∈ {0, 1}m | V ′ = {i | bi = 1} ist Clique in G}.
(Die Menge der zulassigen Losungen (engl. admissible solution) zum Graphen G istdie Menge aller seiner Cliquen.) Zu b1 · · · bm ∈ Sol(〈G〉) sei
m(〈G〉, b1 · · · bm) :=∑
1≤i≤m
bi
147

die Große der durch b1 · · · bm dargestellten Clique.Berechnet werden soll nun eine Funktion f : {0, 1}∗ → {0, 1}∗, so dass fur alle Gra-phen G gilt: f(〈G〉) ∈ Sol(〈G〉) und
m(〈G〉, f(〈G〉)) ≥ m(〈G〉, y), fur alle y ∈ Sol(〈G〉).
(Falls w ∈ {0, 1}∗ keinen Graphen kodiert, ist f(w) = ε.)
Es ist nicht sinnvoll zu verlangen, dass von f alle Cliquen maximaler Große aus-gegeben werden, da dann normalerweise die (Bit-)Lange der Ausgabe nicht mehrpolynomiell in der Lange der Eingabe ware.
2.3.2 Bemerkung Man sieht sofort die folgenden Implikationen ein:
(i) Wenn es eine Funktion f mit den in Variante 1 verlangten Eigenschaften gibt, diedurch einen Polynomialzeitalgorithmus berechenbar ist, d. h. mit f ∈ FP, dann istauch fClique−Size in FP, d. h. die Große einer maximal großen Clique ist in Polyno-mialzeit berechenbar.(Man berechnet eine Clique maximaler Große und zahlt, wieviele Knoten sie hat.)
(ii) Wenn fClique−Size in FP ist, dann ist die Sprache LClique in P. (Auf Input w =〈G〉bin(k) berechnet man l = fClique−Size(〈G〉) und akzeptiert genau dann wennl ≥ k.)
(Es sei (ohne Beweis) angemerkt, dass auch die umgekehrte Implikation gilt:
(iii) Wenn LClique ∈ P ist, dann hat das eigentliche Optimierungsproblem aus Variante1 einen Polynomialzeitalgorithmus.)
Wir werden im weiteren Verlauf Indizien fur die Vermutung angeben, dass LClique nichtin P ist. Mit (ii) und (i) folgt aus dieser Vermutung, dass kein Polynomialzeitalgorithmusexistiert, der zu einem Graphen G eine maximal große Clique findet, oder der die maximalmogliche Cliquengroße berechnet.
Fur viele andere Optimierungsprobleme P geht man ahnlich vor: man findet ein ver-wandtes Entscheidungsproblem P ′ derart, dass aus jedem Polynomialzeitalgorithmus furP einer fur P ′ gewonnen werden kann. Wenn man Grund zu der Annahme hat, dass furP ′ kein solcher Algorithmus existiert, so folgt das auch fur (das eigentlich interessante)Optimierungsproblem P . Diese Situation ist der Grund dafur, dass wir in den folgendenAbschnitten anstelle der eigentlichen Optimierungsprobleme die verwandten Entschei-dungsprobleme betrachten.
148

2.3.3 Beispiel Wir zeigen nun, dass die Sprache LClique aus dem vorhergehenden Bei-spiel in NP liegt. Dazu geben wir eine polynomiell zeitbeschrankte, nichtdeterministischeNTM M mit LM = LClique an. Sie benutzt die NTM MRatewort aus Beispiel 2.2.3.Verfahren: Auf Eingabe w ∈ {0, 1}∗ tut M folgendes:
0. Prufe, ob w das Format 〈G〉bin(k) hat, wo G ein Graph mit m Knoten 1, . . . ,m ist,und 1 ≤ k ≤ m. Falls nicht, halte verwerfend. Sonst:
1. Ermittle m und schreibe 0m auf Band 2 (deterministisch);
2. Lasse MRatewort auf Band 2 ablaufen (nichtdeterministisch);
Das auf Band 2 erzeugte Wort sei b1 · · · bm ∈ {0, 1}m. Dieses Binarwort liefert eine
Knotenmenge V ′ = {i | 1 ≤ i ≤ m, bi = 1}.
3. Uberprufe (deterministisch):
(α) Die Anzahl der Einsen in b1 · · · bm ist ≥ k;(β) V ′ ist Clique in G.
Falls (α) und (β) zutreffen, halte akzeptierend, sonst halte verwerfend.
Die folgende Skizze gibt die Struktur des resultierenden BerechnungsbaumsCT (M, 〈G〉bin(k)) fur einen Graphen mit m Knoten wieder. Sie reprasentiert auch all-gemein die typische Struktur einer nichtdeterministischen Berechnung unter Verwendungvon MRatewort.
A V A V V A V V V A V V
...
...
... ... ...
m
Teil 1
Teil 2
Tiefe m
2 Blätter akzeptiere/verwerfe
Teil 3
149

Abbildung 2.2: Berechnungsbaum zu Beispiel 2.3.3
Wieso ist die von M akzeptierte Sprache genau LClique? Dies lasst sich gut durch einenBlick auf den Berechnungsbaum einsehen. Wir betrachten nur Eingaben mit Format〈G〉bin(k); die anderen werden durch den Syntaxcheck abgefangen.Wenn V ′ ⊆ V eine Clique der Große k in G ist, dann betrachte das Binarwort b1 · · · bm mitV ′ = {i | 1 ≤ i ≤ m, bi = 1}. Auf einem der 2m Berechnungswege im BerechnungsbaumCT (M, 〈G〉bin(k)) erzeugt die Ratewortmaschine genau diesen Binarstring. Die folgen-de deterministische Uberprufung (Teil 3) endet damit, dass M akzeptierend halt. Alsoenthalt CT (M, 〈G〉bin(k)) eine akzeptierende Berechnung; damit ist w ∈ LM .Wenn G keine Clique der Große k enthalt, dann auch keine irgendeiner Große ≥ k.Daraus folgt aber, dass fur jeden Binarstring b1 · · · bm die Uberprufung in Teil 3 der Be-rechnung von M liefert, dass dieser keine solche Clique beschreibt. Daher enden alle 2m
Berechnungswege in CT (M, 〈G〉bin(k)) an einem verwerfenden Blatt. Damit ist w /∈ LM .(Man kann sich uberlegen, dass die akzeptierenden Blatter/Wege in CT (M, 〈G〉bin(k))eineindeutig den Cliquen in G mit k oder mehr Knoten entsprechen.)
Rechenzeit: Teile 0 und 1: O(m2) Schritte genugen fur die Syntaxprufung und die Be-stimmung von m. Teil 2: 2m; Teil 3: O((m2)l) fur eine Konstante l. Also insgesamt O(|w|l),also polynomiell. Diese Zeitschranke gilt fur jede der 2m Berechnungen.
Die in Beispiel 2.3.3 konstruierte NTM fur die Sprache LClique ist polynomiell zeitbe-schrankt, also ist LClique ∈ NP.
Hinweis: Man mache sich am einfachen Beispiel dieser NTM die Struktur der Berech-nungen einer mit der Ratewortmaschine konstruierten NTM mit polynomieller Laufzeitfur eine Sprache in NP klar. Die Laufzeitschranke tM(x) ≤ c|x|l bezieht sich auf die Tiefedes Berechnungsbaums, also die Lange eines langsten Weges. Die Anzahl der Wege unddie Anzahl der Knoten im Berechnungsbaum ist hingegen exponentiell groß. Man hatalso nicht die Moglichkeit, in polynomieller Zeit
”alle Berechnungen der NTM durchzu-
probieren“, und eine solche NTM liefert keine Moglichkeit, irgendeine praktisch sinnvolleRechnung in polynomieller Zeit durchzufuhren. Vielmehr dient das kunstliche Modell derpolynomiell zeitbeschrankten NTMn nur dazu, die Klasse NP zu definieren.
2.3.4 Beispiel LRucksack: das Rucksackproblem
Informal besteht das Rucksackproblem in folgendem: Gegeben sind ein Rucksack mitVolumen b und m verformbare Gegenstande mit Volumina a1, . . . , am ∈ N sowie
”Nutzen-
werten“ c1, . . . , cm ∈ N. Man mochte einige der Gegenstande in den Rucksack packen unddabei den Gesamtnutzen maximieren, ohne die Volumenschranke zu uberschreiten.
Wir formulieren wieder drei Varianten. Mathematisch beschreibt man eine Auswahl derGegenstande durch eine Menge I ⊆ {1, . . . , n}. Die Gegenstande i mit i ∈ I werdeneingepackt, die anderen nicht. Die Volumenschranke ist eingehalten, falls
∑
i∈I ai ≤ b.Der Gesamtnutzen der durch I gegebenen Auswahl ist
∑
i∈I ci.
150

Variante 1: (Optimierungsproblem im eigentlichen Sinn; Suche nach optimaler Struk-tur)Gegeben seien b, a1, . . . , am c1, . . . , cm ∈ N.Aufgabe: Finde I ⊆ {1, . . . ,m} mit
∑
i∈I ai ≤ b, derart dass gilt:
∀J ⊆ {1, . . . ,m} :∑
i∈J
ai ≤ b ⇒∑
i∈J
ci ≤∑
i∈I
ci.
Variante 2: (Parameteroptimierung)Gegeben seien b, a1, . . . , am, c1, . . . , cm ∈ N. Bestimme
k = max{∑
i∈I
ci | I ⊆ {1, . . . ,m},∑
i∈I
ai ≤ b}
.
Variante 3: (Entscheidungsproblem)Gegeben seien b, a1, . . . , am, c1, . . . , cm ∈ N und k ∈ N.Frage: Gibt es I ⊆ {1, . . . ,m} mit
∑
i∈I ai ≤ b und∑
i∈I ci ≥ k?
Die Formalisierung dieser Varianten als Sprachen bzw. Funktionen wird analog zum Cli-quenproblem durchgefuhrt. Als Beispiel geben wir die Formalisierung des Entscheidungs-problems als Sprache an:
LRucksack :={
bin(a1)# · · ·# bin(am)##bin(c1)# · · ·#bin(cm)#bin(b)#bin(k)∣∣∣
m ≥ 1, a1, . . . , am, c1, . . . , cm ∈ N, b, k ∈ N,
∃I ⊆ {1, . . . ,m} :∑
i∈I
ai ≤ b ∧∑
i∈I
ci ≥ k}
.
Mit dieser Formulierung ist LRucksack eine Sprache uber {0, 1, #}. Wie ublich kann mandie drei Zeichen des Alphabets nochmals uber {0, 1} kodieren und so eine aquivalenteSprache uber {0, 1} erhalten.
Man sieht wieder sofort, dass aus jedem Polynomialzeitalgorithmus fur die Optimierungs-variante des Rucksackproblems einer fur das Entscheidungsproblem gewonnen werdenkonnte.
Schließlich stellen wir fest:
Behauptung : LRucksack ∈ NP.(Die entsprechende NTM benutzt die Ratewort-NTM in naheliegender Weise. Details:Ubung.)
151

2.3.5 Beispiel
(Das Problem des Handlungsreisenden — Traveling Salesperson Problem — TSP)
Anschaulich besteht das TSP-Problem in folgendem: Gegeben sind m Stadte, reprasentiertdurch die Knoten 1, . . . ,m des vollstandigen Graphen, und Entfernungen zwischen jeweilszwei Stadten, gegeben durch Zahlen aij ∈ N, 1 ≤ i < j ≤ m. (Hier und im folgenden wirdfur i > j immer aij := aji gesetzt.) Gesucht ist eine
”Rundreise“, die jede Stadt genau
einmal besucht, mit minimaler Gesamtweglange.
2.3.6 Beispiel Im in Abb. 2.3 angegebenen Graphen
10
12
9
5 9
9
85
610
1
54
32
Abbildung 2.3: Ein vollstandiger Graph mit Kantenkosten bzw. Kantenlangen
hat die Rundreise 1, 4, 3, 2, 5, 1 die Weglange (Kosten) 6+5+10+8+9 = 38, die Rundreise1, 2, 5, 3, 4, 1 hingegen die Weglange 5 + 8 + 12 + 5 + 6 = 36.
Einen Weg, der jeden Knoten genau einmal besucht, konnen wir durch eine Permutation πvon {1, . . . ,m} beschreiben. (Die Knoten werden in der Reihenfolge π(1), π(2), . . . , π(m), π(1)besucht.) Die Gesamtweglange ist
aπ(1)π(2) + · · ·+ aπ(m−1)π(m) + aπ(m)π(1) ;
gesucht ist eine Rundreise, die diese Weglange minimiert.
Wieder konnen wir drei Varianten formulieren:
Variante 1: (Optimierungsproblem im eigentlichen Sinn, Suche nach optimaler Struktur)
Gegeben sei eine Zahl m ≥ 1 und m(m−1)2
Zahlen aij ∈ N, 1 ≤ i < j ≤ m.Gesucht ist eine Permutation π von {1, . . . ,m}, die unter allen Permutationen diekleinste Summe aπ(1)π(2) + · · ·+ aπ(m−1)π(m) + aπ(m)π(1) liefert.
152

Variante 2: (Parameteroptimierung)Die Eingabe ist wie in Variante 1.Bestimme k = min{
∑
1≤i<m aπ(i)π(i+1) +aπ(m)π(1) | π Permutation von {1, . . . ,m} }.
Variante 3: (Entscheidungsproblem)
Gegeben sei eine Zahl m ≥ 1 und m(m−1)2
Zahlen aij ∈ N, 1 ≤ i < j ≤ m, sowie eineZahl k ∈ N.Entscheide, ob es eine Rundreise mit Gesamtlange ≤ k gibt, d. h. ob eine Permu-tation π von {1, . . . ,m} existiert, die aπ(1)π(2) + · · · + aπ(m−1)π(m) + aπ(m)π(1) ≤ kerfullt.
Wieder kann man die Problemvarianten formalisieren; wir geben die Formalisierung derEntscheidungsvariante als Sprache an:
LTSP :={
bin(m)#bin(a12)#bin(a13)# · · ·#bin(a1m)#bin(a23)# · · ·#bin(a2m)#
· · ·#bin(am−1,m)#bin(k)∣∣∣ m ≥ 1, aij ∈ N, 1 ≤ i < j ≤ m,
es existiert eine Permutation π von {1, . . . ,m}
mit∑
1≤i<m
aπ(i)π(i+1) + aπ(m)π(1) ≤ k}
.
Es ist klar, dass man aus einem Polynomialzeitalgorithmus fur die Optimierungsvarianteeinen Polynomialzeitalgorithmus fur die Sprache LTSP erhalten kann. Die umgekehrteRichtung (aus einem Polynomialzeitalgorithmus fur Variante 3 konnte man einen fur dasKonstruktionsproblem, Variante 1, gewinnen), trifft ebenfalls zu, ist hier aber keineswegsoffensichtlich.
Auch die Sprache LTSP liegt in NP. Dies zeigt man durch Angabe einer NTM, diedie Ratewort-NTM einsetzt, um nichtdeterministisch eine Permutation auf das Band zuschreiben. Technisch muss man etwas uberlegen, wie Permutationen geeignet binar zukodieren sind. (Details: Ubung.)
2.3.7 Bemerkung Bisher haben wir sehr sorgfaltig darauf geachtet, dass Elementevon Sprachen Worter sind und die betrachteten Strukturen (Graphen, Zahlenfolgen) alsZeichenfolgen kodiert. Wir werden uns oft erlauben, diese Kodierung in der Notation zuunterdrucken und zum Beispiel
anstelle von 〈G〉bin(k) einfach (G, k)
undanstelle von bin(a1)# · · ·#bin(am) einfach (a1, . . . , am)
schreiben. Nur wenn man im Detail TM-Programme beschreibt, die die Eingaben bear-beiten, muss man sich auf geeignete Kodierungen beziehen.
153

Wir beobachten noch, dass NP nur rekursive Sprachen enthalt; diese sind zudem deter-ministisch in Exponentialzeit berechenbar.
2.3.8 LemmaNP ⊆
⋃
{DTIME(2nl
) | l ∈ N}.
(Insbesondere sind alle Sprachen in NP rekursiv.)
Beweis Sei L ∈ NP. Nach der Definition existiert eine nichtdeterministische TM M =(Q, Σ, Γ, B, q0, F, δ) fur L und Konstanten d > 0 und k ∈ N, so dass fur x ∈ Σ∗ der Berech-nungsbaum CT (M,x) Tiefe hochstens d|x|k hat. Wir konnen annehmen (nach Satz 1.3.5und der Version von Satz1.2.8 fur NTMn), dass M nur ein Band benutzt. Weil jeder Kno-ten im Berechnungsbaum hochstens γ := 3|Q| · |Γ| Nachfolger haben kann, ist die Zahl derBerechnungswege durch γd|x|k+1 beschrankt. In Analogie zur Konstruktion aus 1.3.11 kannman diese Berechnungswege systematisch nacheinander durchprobieren, jedoch brauchtman nur eine einzige Zeitschranke d|x|k. Jeder Berechnungsversuch kostet Zeit O(d|x|k).Der Gesamtzeitbedarf ist also O(d|x|k · 2(log γ)|x|k) = O(2|x|
2k
). �
Die Frage, ob die im letzten Lemma angegebene drastische Laufzeiterhohung beim Uber-gang von NTMn zu deterministischen TMn wirklich notig ist, kann man knapp so fassen:Ist P = NP? Offenbar ist P ⊆ NP. Also heißt die Frage praziser:
P-NP-Problem: Gibt es fur jede Sprache L ∈ NP einen deterministischen polynomial-zeitbeschrankten Algorithmus? Oder aquivalent: Gilt P = NP?
Diese Frage ist ein — das wohl beruhmteste — offene Problem der (Theoretischen) In-formatik. Formuliert wurde es in moderner Sprache 1970 (von Edmonds), obgleich vorherschon vielen Forschern das Problem bewusst gewesen zu sein scheint (z. B. Godel 1936).Die meisten Experten glauben, dass P und NP verschieden sind. Wir diskutieren dieseVermutung ausfuhrlich in den nachsten Abschnitten.
2.4 Polynomialzeitreduktionen und NP-Vollstandig-
keit
Fur die folgende Definition vgl. Def. 1.9.6. Zum dortigen Reduktionskonzept fugen wirdie Polynomialzeitberechenbarkeit der Reduktionsfunktion hinzu.
2.4.1 Definition Eine Sprache L1 uber Σ1 heißt polynomialzeit-reduzierbar aufeine Sprache L2 uber Σ2, in Zeichen, L1 ≤p L2, wenn L1 ≤ L2 mittels eines f ∈ FP gilt,d. h. wenn es eine in polynomieller Zeit berechenbare Funktion f : Σ∗
1 → Σ∗2 gibt mit
∀x ∈ Σ∗1 : x ∈ L1 ⇔ f(x) ∈ L2.
154

Achtung: Wie bei den Reduktionsfunktionen im Kontext der Berechenbarkeitstheorie istes wichtig, dass f total ist und dass in der Bedingung an f die Aquivalenz x ∈ L1 ⇔f(x) ∈ L2 und nicht nur eine Implikation steht. Wichtig ist auch, darauf zu achten, dassdie TM, die ein solches f berechnet, deterministisch sein muss.
Bevor wir konkrete Reduktionen anschauen, halten wir einige grundlegende Eigenschaftendieses Begriffs fest.
2.4.2 Lemma ≤p ist reflexiv und transitiv, d. h.(a) L ≤p L fur beliebige Sprachen L, und(b) L1 ≤p L2 und L2 ≤p L3 impliziert L1 ≤p L3.
Beweis (a) Reflexivitat ist klar (die Identitatsfunktion x 7→ x ist polynomialzeitbere-chenbar).(b) Zur Transitivitat: Ist L1 ≤ L2 mittels f ∈ FP und L2 ≤ L3 mittels g ∈ FP, so istL1 ≤ L3 mittels g ◦ f , denn
x ∈ L1 ⇔ f(x) ∈ L2 ⇔ g(f(x)) = (g ◦ f)(x) ∈ L3,
fur beliebige Eingaben x. Zu zeigen bleibt also: g ◦ f ∈ FP. Angenommen, f = fM1und
g = fM2fur c(nk + 1)- bzw. d(nl + 1)-zeitbeschrankte deterministische TM M1 bzw. M2.
Eine neue TM M tut folgendes auf Eingabe x:
1. Lasse M1 auf x ablaufen; Resultat y;2. Lasse M2 auf y ablaufen; Resultat z;3. Gib z aus.
Offenbar gilt fM = g ◦ f . Die Rechenzeit von M wird abgeschatzt wie folgt. Entscheidendist dabei die Beobachtung, dass |y| = |f(x)| ≤ tM1
(x) ist.
tM(x) ≤ tM1(x) + tM2
(f(x))
≤ c(|x|k + 1) + d · ((c(|x|k + 1))l + 1) ≤ C · (|x|kl + 1),
fur eine passend gewahlte Konstante C. Also ist M C(nkl +1)-zeitbeschrankt, also g ◦f ∈FP. �
Anmerkung: Die Aussage der Transitivitat sieht unscheinbar aus, aber sie ist fur allesweitere extrem wichtig. Man sollte auch den Beweis gut verstanden haben und sich klar-machen, dass hinter ihm hauptsachlich die Eigenschaft steckt, dass das Einsetzen einesPolynoms in ein anderes wieder ein Polynom liefert.
Es gibt einfache und komplexe Polynomialzeitreduktionen. Zum Eingewohnen betrachtenwir zwei recht einfache Reduktionen. Dazu definieren wir zwei weitere Graphenprobleme,die sich als mit dem Cliquenproblem eng verwandt erweisen werden. Fur die Verfahrenkommt es auf die Kodierung nicht an; daher tun wir so, als waren die Elemente unsererSprachen mathematische Objekte wie Graphen oder Zahlen. Fur die Bearbeitung mitTuringmaschinen muss man die Dinge naturlich in geeigneter Weise binar kodieren.
155

2.4.3 Definition (a) G = (V,E) sei ein Graph. Ein Knoten v uberdeckt eine Kante(u,w) falls v ∈ {u,w}; eine Knotenmenge V ′ ist eine Knotenuberdeckung von (V,E), fallsjede Kante in E von einem Knoten in V ′ uberdeckt wird. Das Knotenuberdeckungspro-blem (
”vertex cover“) besteht darin, zu gegebenem Graphen G eine Knotenuberdeckung
mit moglichst wenigen Knoten zu finden.
Beispiel :
G=
Abbildung 2.4: Die schwarzen Knoten bilden eine Knotenuberdeckung minimaler Große
Die Entscheidungsvariante des Vertex-Cover-Problems lasst sich folgendermaßen als Spra-che formulieren:
LVC :={
(G, k) | G = (V,E) Graph, k ≥ 1; es gibt V ′ ⊆ V mit |V ′| ≤ k
und ∀(v, w) ∈ E : v ∈ V ′ ∨ w ∈ V ′}
.
(b) Wieder sei G = (V,E) ein Graph. Eine Teilmenge V ′ ⊆ V heißt unabhangig (oder
”stabil“, englisch
”independent“), wenn es zwischen Knoten von V ′ keine Kanten gibt.
Das Problem”Independent Set“ besteht darin, in G eine moglichst große unabhangige
Menge zu finden.
Beispiel:
G=
Abbildung 2.5: Die schwarzen Knoten bilden eine unabhangige Menge maximaler Kardi-nalitat
Die Entscheidungsvariante des Problems ist durch folgende Sprache gegeben:
156

LIS := {(G, k) | G = (V,E) Graph, k ≥ 1; es gibt V ′ ⊆ V mit |V ′| ≥ k
und ∀u, v ∈ V ′ : (u, v) 6∈ E}
(c) (Erinnerung)
LClique = {(G, k) | G = (V,E) Graph, k ≥ 1,
G hat Clique der Große ≥ k}.
Wir zeigen nun, dass es zwischen allen drei genannten Problemen ≤p-Reduktionen gibt.
2.4.4 Satz
(a) LClique ≤p LIS und LIS ≤p LClique.
(b) LIS ≤p LVC und LVC ≤p LIS.
Beweis (a) Zu G = (V,E) betrachte den Komplementgraphen G := (V, E), wo (v, w) ∈E ⇔ (v, w) 6∈ E, fur v, w ∈ V .
Beispiel:
G= G=
Abbildung 2.6: schwarz: Clique in G, unabhangige Menge in G
Setze: f((G, k)) := (G, k). Man sieht leicht, dass f in Polynomialzeit berechenbar ist,gleichgultig ob die Graphen per Adjazenzmatrix oder uber Kantenlisten dargestellt sind.Wir zeigen
LClique ≤p LIS mittels f und LIS ≤p LClique mittels f.
Zunachst macht man sich leicht folgende Hilfsbehauptung (HB1) klar: Fur V ′ ⊆ V gilt:
V ′ Clique in (V,E)⇔ V ′ unabhangig in (V, E).
Damit erhalt man:
157

(G, k) ∈ LCliqueDef.⇔ G hat Clique der Große k
(HB1)⇔ G hat unabhangige Menge der Große kDef.⇔ f((G, k)) = (G, k) ∈ LIS.
Damit ist gezeigt: LClique ≤p LIS mittels f .
Die andere Richtung (LIS ≤p LClique mittels f) zeigt man genauso.
(b) Wir benotigen folgende Hilfsbehauptung (HB2), die den engen Zusammenhang zwi-schen Knotenuberdeckungen und unabhangigen Mengen auf den Punkt bringt. Fur V ′ ⊆V gilt:
V ′ ist unabhangige Menge in (V,E) ⇔ V − V ′ ist Knotenuberdeckung in (V,E).
Beispiel:
Abbildung 2.7: schwarze Knoten: Knotenuberdeckung, weiße Knoten: unabhangige Menge
Man kann HB2 am einfachsten beweisen, indem man die Aussagen negiert:
Fur V ′ ⊆ V gilt:V ′ ist nicht unabhangig ⇔ V − V ′ ist keine Knotenuberdeckung.
Dies ist leicht zu sehen:
∃v, w ∈ V ′ : (v, w) ∈ E
⇔ ∃(v, w) ∈ E : v ∈ V ′ ∧ w ∈ V ′
⇔ ∃(v, w) ∈ E : v /∈ V − V ′ ∧ w /∈ V − V ′.
Setze g(((V,E), k)) := ((V,E), |V | − k). Es ist leicht zu sehen, dass g in Polynomialzeitberechenbar ist. Weiter erhalt man:
((V,E), k) ∈ LIS ⇔ (V,E) hat unabhangige Menge der Große ≥ k(HB2)⇔ (V,E) hat Knotenuberdeckung der Große ≤ |V | − k
⇔ g(((V,E), k)) = ((V,E), |V | − k) ∈ LVC.
Damit ist gezeigt: LIS ≤p LVC mittels g. Man zeigt genauso, dass LVC ≤p LIS mittels g.�
158

Diese Beispiele sollten gezeigt haben, dass manche Polynomialzeitreduktionen sehr einfachsind. Nun kommen wir zur wichtigsten Definition des ganzen Kapitels. Man zeichnet dieSprachen in NP aus, die bezuglich der Relation ≤p uber allen anderen stehen.
2.4.5 Definition
(a) Eine Sprache L heißt NP-vollstandig (engl.”NP-complete“), falls
(i) L ∈ NP
(ii) fur alle L′ ∈ NP gilt L′ ≤p L(hierfur sagt man: L ist NP-schwer [
”NP-hard“,
”NP-hart“]).
(b) NPC:= {L | L Sprache, L NP-vollstandig}.
Wir werden unten feststellen, dass die Sprachen LClique, LVC, LISNP-vollstandig sind. Dasgleiche gilt fur LRucksack und LTSP (siehe die Komplexitatstheorie-Vorlesung). Das folgendeLemma gibt einfache Beziehungen zwischen dem Reduktionsbegriff
”≤p“ und der Klasse
P an:
2.4.6 Lemma
(a) L ∈ P ∧ L′ ≤p L ⇒ L′ ∈ P.
(b) L ∈ P ∧ ∅ 6= L′ 6= Σ∗ ⇒ L ≤p L′.
Beweis (a) (Vergleiche Lemma 2.4.2(b).) Es sei L′ ≤p L mittels f ∈ FP. Man wahlteine TM M1 mit f = fM1
, die c(nk +1)-zeitbeschrankt ist, und eine TM M2 mit L = LM2,
die dnl-zeitbeschrankt ist. Eine neue TM M tut folgendes auf Eingabe x:
1. Lasse M1 auf x ablaufen; Resultat y;2. Lasse M2 auf y ablaufen; akzeptiere genau dann wenn M2 akzeptiert.
Offenbar gilt x ∈ LM ⇔ M2 akzeptiert f(x) fur alle x, also LM = L′. Genau wie imBeweis von Lemma 2.4.2(b) sieht man, dass M O(nkl)-zeitbeschrankt ist.
(b) Seien y0 ∈ Σ∗ − L′ und y1 ∈ L′ fest. (Solche Worter gibt es, weil ∅ 6= L′ 6= Σ∗.) DieAbbildung
f : x 7→
{
y0, falls x /∈ L
y1, falls x ∈ L
ist in FP, da es fur die Entscheidung, ob x ∈ L oder nicht, eine Polynomialzeit-TM gibtund weil y0 und y1 feste, von der Eingabe x nicht abhangige Worter sind. Offensichtlichgilt x ∈ L⇔ f(x) ∈ L′, fur alle x. �
Wir haben nun die Hilfsmittel gesammelt, die wir benotigen, um die zentrale strukturelleAussage uber die Klassen P, NP und NPC beweisen zu konnen.
159

2.4.7 SatzNPC ∩ P = ∅ ⇔ P 6= NP.
Beweis Wir beweisen die Aquivalenz der umgekehrten Aussagen, also:
NPC ∩ P 6= ∅ ⇔ P = NP.
”⇐“ ist ganz einfach: Wenn P = NP ist, dann betrachte irgendein L ∈ P, nur nicht ∅
und nicht Σ∗. Es gilt
(i) L ∈ P = NP (klar);
(ii) L′ ≤p L fur alle L′ ∈ P = NP (nach Lemma 2.4.6(b)).
Also ist L ∈ NPC ∩ P.(Man erkennt, dass man hier beweist, dass aus P = NP folgen wurde, dass alle Sprachenin P außer ∅ und Σ∗ NP-vollstandig sind.)
”⇒“: Sei L ∈ NPC ∩ P. Wir zeigen P = NP. Weil P ⊆ NP auf jeden Fall gilt, mussen
wir nur NP ⊆ P beweisen. Sei also L′ ∈ NP beliebig. Aus L ∈ NPC folgt nach Definition2.4.5, dass L′ ≤p L gilt; daraus und aus L ∈ P folgt mit Lemma 2.4.6(a), dass L′ ∈ P ist,wie gewunscht. �
Der Satz macht klar, dass die die Frage
”Gilt P 6= NP?“
der Komplexitatstheorie aquivalent ist zu der fur die Algorithmentheorie zentralen Frage
”Ist es richtig, dass kein NP-vollstandiges Problem einen Polynomialzeit-
Algorithmus, also einen Algorithmus mit vertretbarem Aufwand, hat?“
Leider ist es so, dass man heute nicht sagen kann, ob die Aussagen, deren Aquivalenz imSatz behauptet wird, beide zutreffen oder beide falsch sind. Die Frage, ob P 6= NP gilt, istdas beruhmteste offene Problem der Theoretischen Informatik. Es wurde in dieser Formum 1970 formuliert.
Fur das Arbeiten im Alltag des Informatikers/der Informatikerin kann man aber den Ex-perten (in Algorithmentheorie wie auch in der Komplexitatstheorie) folgen, die fast alleannehmen, dass P 6= NP ist. Wenn diese Vermutung stimmt, dann sind alle NP-schweren,insbesondere alle NP-vollstandigen Probleme algorithmisch schwer (
”intractable“) in dem
Sinn, dass sie keine polynomialzeitbeschrankten Algorithmen besitzen. Fur die Praxis be-deutet dies, dass man nicht versuchen sollte, fur ein als NP-vollstandig oder NP-schwererkanntes Problem einen effizienten Algorithmus zu finden, sondern dass man besser nachAusweichmoglichkeiten wie Approximationsalgorithmen oder Abschwachungen des Pro-blems suchen sollte. Man erkennt ein Problem als NP-schwer, indem man es in der langen
160

Liste von bekannten NP-vollstandigen und NP-schweren Problemen findet, oder indemman selbst, z. B. mit der bald zu besprechenden Reduktionsmethode, die NP-Vollstandig-keit beweist.
Folgendes kann als Indiz dafur gelten, dass vermutlich NPC ∩ P = ∅ ist: Ware P = NP,dann besaßen alle NP-vollstandigen Probleme Polynomialzeitalgorithmen. Jedoch wurdebisher noch kein einziges Problem in NPC∩P gefunden, trotz großter Anstrengungen vonvielen Forschern, die sich mit ganz verschiedenen NP-vollstandigen Problemen auseinan-dergesetzt haben.
Als Veranschaulichung fur die (vermutete) Situation mag folgendes Diagramm dienen:
P
NPC
NP
Sprachen, die
effiziente Algo-
rithmen haben
2.5 Der Satz von Cook
Wir haben nun schon genau diskutiert, was es bedeutet, dass eine Sprache L NP-vollstandigist. Auch wurden schon eine ganze Reihe von Kandidaten angegeben, die in diese Kate-gorie fallen. Allerdings fehlt noch der Beweis fur diese Behauptung.
Dreh- und Angelpunkt der Theorie der NP-vollstandigen Probleme ist das Erfullbarkeits-problem, das in diesem Abschnitt besprochen wird. In der Vorlesung wird die Definitionangegeben und der Satz von Cook formuliert, aber nicht bewiesen. Fur Neugierige enthaltdieser Abschnitt den vollstandigen Beweis. Wir kommen darauf in der Vorlesung
”Kom-
plexitatstheorie“ ausfuhrlich zuruck.
Obgleich die Terminologie etwas anders ist, ist es zum Verstandnis des Folgenden gunstig,sich an die Aussagenlogik zu erinnern. (Stichworte: Aussagevariablen A,B,C, . . . , Formelnwie A ∨ ¬A,A → B, (A → B) ↔ (¬B → ¬A), A → (B → C), . . . , Belegungen der Aus-sagevariablen mit Wahrheitswerten in {falsch,wahr}, {false, true}, oder {0, 1}, und dieAuswertung einer Formel unter einer Belegung oder unter allen Belegungen z. B. mittelsWahrheitstafeln oder rekursivem Vorgehen.) Eine Formel ϕ heißt eine Tautologie, wennsie unter jeder Belegung wahr ist. (Beispielsweise sind A ∨ ¬A und ((A→ B) ∧A)→ B)Tautologien.) Klar ist: ϕ ist Tautologie genau dann wenn ¬ϕ nicht erfullbar ist, d. h.wenn der Wert von ¬ϕ unter jeder Belegung falsch ist.
Das Tautologieproblem ist das Problem, zu einer vorgelegten aussagenlogischen Formel ϕzu entscheiden, ob ϕ eine Tautologie ist. Nach den eben gemachten Bemerkungen ist die
161

Frage, ob eine Formel erfullbar ist, dazu aquivalent.
Im Zentrum der Theorie der NP-Vollstandigkeit steht, wenn auch mit etwas andererTerminologie, eine spezielle Variante des Erfullbarkeitsproblems.
2.5.1 Definition Wir definieren die syntaktische Struktur von KNF-Formeln.
(a) Die Menge {X0, X1, X2, X3, . . .} heißt die Menge der Booleschen Variablen (≈ Aus-sagevariablen).
(b) Die Menge {X0, X0, X1, X1, X2, X2, . . .} heißt die Menge der Literale. (Xi, oder syn-onym ¬Xi, steht fur die Negation der Variablen Xi.)
(c) Sind l1, . . . , ls Literale, s ≥ 1, so heißt (l1 ∨ · · · ∨ ls) eine Klausel. (Eine Klausel isteine Disjunktion von Literalen.)
(d) Sind C1, . . . , Cr Klauseln, r ≥ 1, so heißt C1 ∧ · · · ∧ Cr eine Formel in konjunktiverNormalform (KNF-Formel).
Beispiele: X1 und X1 (bzw. ¬X1) sind Literale, nicht aber ¯X1 (bzw. ¬¬X1).(X1 ∨X3 ∨X1 ∨ X8) und (X2) sind Klauseln, nicht jedoch ((X1 ∧ X3) ∨ (X4)).(X0) ∧ (X1 ∨X3) ∧ (X0 ∨ X3) ist eine KNF-Formel.
Formeln sind Texte und als solche nur syntaktische Objekte. Eine Formel kann nicht wahroder falsch sein. Erst durch Belegungen erhalten Formeln Wahrheitswerte. Die Zahlen0 und 1 stehen fur die Wahrheitswerte falsch und wahr.
2.5.2 Definition (Belegungen, Wahrheitswerte von KNF-Formeln)
(a) Eine Belegung der Booleschen Variablen ist eine Abbildung
v : {X0, X1, X2, . . .} → {0, 1}.
Im folgenden beschreiben wir, wie eine gegebene Belegung v dazu benutzt wird, Literalen,Klauseln und KNF-Formeln Wahrheitswerte zuzuordnen. Diese werden als Erweiterungvon v angesehen; entsprechend schreibt man v(l), v(C), v(ϕ) fur diese Wahrheitswerte.
(b) Durch die Belegung v erhalt jede Boolesche Variable Xi den Wahrheitswert v(Xi),das entgegengesetzte Literal Xi den komplementaren Wahrheitswert v(Xi) := 1 −v(Xi) ∈ {0, 1}.
(c) Wenn v eine Belegung ist, definieren wir fur eine Klausel (l1 ∨ · · · ∨ ls):
v(l1 ∨ · · · ∨ ls) :=
{
1, falls es ein j mit v(lj) = 1 gibt,
0, sonst.
(Offenbar druckt dies die Semantik der”ODER“-Verknupfung aus: die Klausel wird
unter der Belegung v wahr genau dann wenn mindestens eines der Literale darinunter v wahr ist.)
162

(d) Wenn v eine Belegung ist, definieren wir fur eine KNF-Formel (C1 ∧ · · · ∧ Cr):
v(C1 ∧ · · · ∧ Cr) :=
{
1, falls v(Ci) = 1 fur alle i,
0, sonst.
(Offenbar druckt dies die Semantik des”UND“ aus: Die Formel wird wahr unter
der Belegung v, wenn alle Klauseln unter v wahr sind.)
2.5.3 Beispiel (X0), (X1∨X3), (X1∨X2∨ X5) sind Klauseln, ϕ = (X0)∧ (X1∨X3)∧(X1∨X2∨X5) ist KNF-Formel. Die Wahrheitswerte v(X0) = v(X1) = v(X2) = v(X5) = 0und v(X3) = 1 machen die erste Klausel falsch, die beiden anderen wahr, daher ist v(ϕ) =0: diese Belegung macht die Formel falsch. Die Wahrheitswerte v′(X0) = v′(X1) = 1 sorgendafur, dass jede Klausel ein wahres Literal enthalt, also wird damit v′(ϕ) = 1.
Es ist klar, dass fur den Wert v(ϕ) nur die Werte v(Xi) von Bedeutung sind, fur die Xi inϕ vorkommt. Wenn ϕ genau m Variable enthalt, dann gibt es genau 2m unterschiedlicheBelegungen fur diese Variablen.
2.5.4 Definition Eine KNF-Formel ϕ = C1 ∧ · · · ∧ Cr heißt erfullbar, falls es eineBelegung v gibt, so dass v(ϕ) = 1 ist.
2.5.5 Beispiel Die Formel (X1∨X2)∧(X1∨X2) ist erfullbar, weil v(X1) = 1, v(X2) = 0beide Klauseln wahr macht. Dagegen ist die Formel (X1) ∧ (X1 ∨ X2) ∧ (X1 ∨X2) nichterfullbar, was man z. B. einsieht, indem man alle vier moglichen Belegungen durchprobiert.Man kann auch die Formel (X0 ∨ X1) ∧ (X1 ∨ X2) ∧ (X2 ∨ X3) ∧ · · · (Xk−1 ∨ Xk) ∧ (Xk ∨X0)∧ (X0)∧ (Xk) betrachten. Die Unerfullbarkeit dieser Formel lasst sich (fur großere k)nicht mehr durch Einsetzen feststellen.
Wir definieren (informal):
SAT := {ϕ | ϕ KNF-Formel, ϕ erfullbar}.
Die Menge SAT charakterisiert das Erfullbarkeitsproblem, ist aber keine Sprache, weilkein endliches Alphabet zugrundeliegt, sondern die unendliche Menge {X0, X1, X2, X3, . . .}∪ {(, ),¬,∧,∨}. Hier hilft wieder einmal Kodierung.
2.5.6 Bemerkung (a) Man will Formeln uber dem Alphabet Σ = {[, ], (,), ∧, ∨, ¬,0, 1} kodieren. Dazu kodiert man z. B. Xi durch [bin(i)] und Xi durch ¬[bin(i)], fur i ∈ N.Die Formel ϕ = (X1 ∨X2) ∧ (X1 ∨ X2) liest sich dann wie folgt:
〈ϕ〉 = ([1] ∨ [10]) ∧ (¬[1] ∨ ¬[10]).
163

Wir benutzen folgende Konvention: Xi wird als alternative Notation fur [bin(i)] aufgefasst,Xi als Notation fur ¬[bin(i)]. Dann kann man die Kodierungsklammern weglassen.
Wir bemerken: Die Sprache
LKNF = {〈ϕ〉 | ϕ ist KNF-Formel}
uber Σ ist regular. Die Prufung eines Wortes x ∈ Σ∗ darauf, ob es eine syntaktisch korrekteKNF-Formel darstellt, kann also von einem endlichen Automaten durch einmaliges Lesenvon x durchgefuhrt werden. Wir werden im folgenden eine solche Syntaxuberprufung meistnicht erwahnen.
(b) Oft wird man wahrend der Konstruktion einer Formel die Variablen anders benennen(z. B. unten im Beweis des Satzes von Cook: Xt,p,a, Yt,q, Zt,p). Wenn eine solche Formelgegeben ist, ist es leicht, die verwendeten Variablen in X0, X1, X2, . . . umzubenennenund wie in (a) als Wort uber einem endlichen Alphabet zu schreiben. Eigenschaften wieErfullbarkeit andern sich durch solche Manipulationen nicht. — Wir werden im folgendenmeist keinen Unterschied mehr zwischen
”gewohnlichen“ Formeln und ihren Kodierungen
machen.
2.5.7 Definition (Das Erfullbarkeitsproblem fur KNF-Formeln)
LSAT := {ϕ | ϕ KNF-Formel , ϕ erfullbar }
(oder ganz formal: {〈ϕ〉 | ϕ KNF-Formel, ϕ erfullbar } ).
Aus technischen Grunden betrachtet man oft auch das Erfullbarkeitsproblem fur”3-
KNF-Formeln“ wie
(X2 ∨ X4 ∨X7) ∧ (X0 ∨X1 ∨X4) ∧ (X2 ∨ X1 ∨X6) ∧ (X1 ∨ X2 ∨X4),
in denen jede Klausel genau drei Literale besitzt. Das entsprechende Erfullbarkeitsproblemheißt 3-SAT.
2.5.8 Definition (Das Erfullbarkeitsproblem fur 3-KNF-Formeln)
L3−SAT := {ϕ ∈ LSAT | jede Klausel von ϕ hat genau 3 Literale }.
Das Erfullbarkeitsproblem ist von großer praktischer Relevanz; z. B. taucht bei der Kon-struktion logischer Schaltungen das Teilproblem auf zu entscheiden, ob eine vorgelegteBoolesche Formel, die Teil der Schaltung werden soll, ohnehin immer nur
”0“ ausgibt.
Daneben sind LSAT und L3−SAT aber auch ausgezeichnete NP-vollstandige Probleme. Dashat historische Grunde — LSAT war das erste nicht maschinennahe als NP-vollstandig er-kannte Problem (Cook, 1970) — und auch technische Grunde — LSAT und L3−SAT dientenund dienen als bequemer
”Anker“ fur NP-Vollstandigkeitsbeweise mittels der Redukti-
onsmethode, siehe den folgenden Abschnitt.
164

2.5.9 Satz von Cook LSAT ist NP-vollstandig.
Beweis :
Wir mussen die beiden Eigenschaften aus Definition 2.4.5 uberprufen: (i) LSAT ∈ NP,und (ii) LSAT ist NP-schwer, d. h. fur alle L′ ∈ NP gilt L′ ≤p LSAT.
(i)”LSAT ∈ NP“:
Wir beschreiben eine NTM M fur LSAT. M tut folgendes auf Input x:
(1) Prufe, ob x = ϕ (genauer: x = 〈ϕ〉) fur eine KNF-Formel ϕ. Falls nicht: halte undverwerfe. (Dies ist von einem endlichen Automaten durchfuhrbar.)
(2) Schreibe auf Band 2:#[bin(i1)]#[bin(i2)]# · · ·#[bin(im)], wobei [bin(i1)], . . . , [bin(im)] genau die in ϕvorkommenden Variablen (Kodierungen) sind, in beliebiger Reihenfolge, aber oh-ne Wiederholung. Hierzu schreibt man die Variablen von Band 1 ab und benutztTextsuche, um Wiederholungen zu erkennen.
(3) Schreibe 0m auf Band 3.
(4) Lasse MRatewort auf Band 3 ablaufen. Resultat: b1 · · · bm ∈ {0, 1}m.
(5) Andere Band 2 zu b1[bin(i1)]b2[bin(i2)] · · · bm[bin(im)].
(6) Ersetze auf Band 1 jedes Teilwort [bin(ir)] durch br · · · br und jedes Teilwort ¬[bin(ir)]durch br · · · br. (Hierzu wird wieder Textsuche verwendet.)
(7) Teste, ob auf Band 1 in jedem Paar von runden Klammern mindestens eine 1 vor-kommt. (Diese Aufgabe kann durch einen endlichen Automaten gelost werden.) Fallsja, akzeptiere, falls nein, verwerfe.
Man sieht leicht, dass fur jedes x gilt:x ∈ LSAT
⇔ x = ϕ fur eine erfullbare KNF-Formel ϕ⇔ es existiert eine Belegung v (interessant nur die m Werte fur die in ϕ vorkommendenVariablen) mit v(ϕ) = 1⇔ es gibt ein Binarwort b1 · · · bm, das in Schritten (5)–(7) dazu fuhrt, dass M akzeptiert⇔ es gibt eine akzeptierende Berechnung von M auf x.
(Dabei entspricht die in einer akzeptierenden Berechnung geschriebene Bitfolge b1 · · · bm
einer erfullenden Belegung fur die in x = ϕ vorkommenden Variablen.)
Außerdem: M hat polynomielle Laufzeit.
(ii)”LSAT ist NP-schwer“: Dies ist viel schwieriger als Teil (i).
Sei L ∈ NP beliebig, aber fest gewahlt. Wir wollen zeigen, dass L ≤p LSAT gilt. Dazugehen wir aus von einer polynomiell zeitbeschrankten NTM M ′ fur L und bauen gemaßSatz 1.2.8 und Beispiel 1.2.4 M ′ zu M = (Q, Σ, Γ, B, q0, F, δ) um mit:
165

• M hat ein Band
• M betritt nie Zellen links der Eingabe
• Anstatt zu halten, mit δ(q, a) = ∅, verharrt M in derselben Konfiguration, es giltalso δ(q, a) = {(q, a,N)}. Eine Konfiguration α1(q, a)α2 ist also eine akzeptierende
”Haltekonfiguration“ genau dann wenn δ(q, a) = {(q, a,N)} und q ∈ F .
• M hat polynomielle Laufzeit: tM(x) ≤ c|x|k fur alle x ∈ Σ∗, fur gewisse Konstantenc, k ∈ N, c, k ≥ 1.
Fur x ∈ Σ∗ gilt: x ∈ L = LM ⇔ es existiert eine Berechnung initM(x) = k0 ` k1 ` · · · ` kT
mit T = c|x|k, wobei kT einen Zustand q ∈ F enthalt.
Wenn wir uns die Bandzellen von M mit 1, 2, 3,. . . numeriert denken, ist klar, dass injeder Berechnung von M auf x, |x| = n, der Kopf keine Zelle mit einer Nummer > T + 1erreichen kann.
Im folgenden beschreiben wir eine Reduktionsfunktion Φ, so dass L ≤p LSAT mittels Φgilt. Es soll also gelten:
Φ : Σ∗ → {ϕ | ϕ KNF-Formel}, x 7→ ϕx
mit Φ ∈ FP, und
∀x ∈ Σ∗ : x ∈ L⇔ ϕx hat eine erfullende Belegung.
Dazu bauen wir ϕx so auf, dass gilt:
∃ akzeptierende Berechnung von M auf x ⇔ ∃v : v(ϕx) = 1.
Der Rest des Beweises ist nicht prufungsrelevant.
Als Bausteine fur ϕx fuhren wir drei Familien von Variablen ein.
(a) Xt,p,a mit 0 ≤ t ≤ T , 1 ≤ p ≤ T + 1 und a ∈ Γ.
Ein solches Xt,p,a symbolisiert die Aussage”nach Schritt t steht in Zelle p das Zeichen
a“.
(b) Yt,q mit 0 ≤ t ≤ T und q ∈ Q.
Ein solches Yt,q symbolisiert die Aussage”nach Schritt t ist M im Zustand q“.
(c) Zt,p mit 0 ≤ t ≤ T und 1 ≤ p ≤ T + 1.
Ein solches Zt,p symbolisiert die Aussage”nach Schritt t befindet sich der Kopf von
M in Zelle p“.
166

Eine Belegung v fur diese Variablen liefert dann Aussagen uber eine Berechnung von M .Z. B. wird v(X3,5,#) = 1 gelesen als
”nach Schritt 3 steht in Zelle 5 das Zeichen #“;
v(Y4,q) = 0 wird gelesen als”nach Schritt 4 ist M nicht in Zustand q“. Naturlich gibt es
jede Menge Belegungen, die zu widerspruchlichen Aussagen fuhren. (Zum Beispiel sprichteine Belegung v mit v(Z1,4) = 1 nie uber eine korrekte Berechnung von M , weil nachSchritt 1 der Kopf nicht in Zelle 4 sein kann.) Uns interessieren Belegungen, die korrekteakzeptierende Berechnungen von M beschreiben.
Die Formel ϕx ist als Konjunktion aus vielen Teilen aufgebaut, die folgendes erzwingensollen: v ist erfullende Belegung fur ϕx ⇔ v
”beschreibt“ eine korrekte akzeptierende
Berechnung von M .
Fur die Konstruktion von ϕx benutzen wir die folgenden Abkurzungen:
Sind C1, . . . , Cr Klauseln, so steht∧
1≤u≤r
Cu fur die KNF-Formel C1 ∧ · · · ∧ Cr.
Sind l1, . . . , ls Literale, so steht∨
1≤u≤s
lu fur die Klausel (l1 ∨ · · · ∨ ls).
Nun geben wir die acht Teilformeln von ϕx an:
(1) Genau ein Symbol pro Zelle und Schritt
ϕ1 =∧
0≤t≤T
∧
1≤p≤T+1
∨
a∈Γ
Xt,p,a ∧∧
a,a′∈Γa 6=a′
(Xt,p,a ∨ Xt,p,a′
)
Dabei sorgt der linke Ausdruck in der großen Klammer dafur, dass nur solche Bele-gungen ϕ1 erfullen konnen, bei denen mindestens ein Symbol a pro Zelle und Schrittvorhanden ist. Der rechte Ausdruck sorgt dafur, dass nicht mehrere Zeichen pro Zelleund Schritt vorhanden sein konnen.
Genauer macht man sich folgendes klar:v(ϕ1) = 1⇔ Fur jedes Paar (t, p) existiert genau ein a ∈ Γ mit v(Xt,p,a) = 1.
(2) Genau ein Zustand pro Schritt
ϕ2 =∧
0≤t≤T
(∨
q∈Q
Yt,q
)
∧∧
q,q′∈Q
q 6=q′
(Yt,q ∨ Yt,q′
)
Man uberlegt sich:v(ϕ2) = 1⇔ Fur jedes t existiert genau ein q ∈ Q mit v(Yt,q) = 1.
167

(3) Genau eine Kopfposition zu jedem Zeitpunkt
ϕ3 =∧
0≤t≤T
(∨
1≤p≤T+1
Zt,p
)
∧∧
1≤p,p′≤T+1p 6=p′
(Zt,p ∨ Zt,p′
)
Man uberlegt sich:v(ϕ3) = 1⇔ fur jedes t gibt es genau ein p, 1 ≤ p ≤ T + 1, mit v(Zt,p) = 1.
(4) Startkonfiguration
ϕ4 =∧
1≤p≤n
(X0,p,ap) ∧
∧
n+1≤p≤T
(X0,p,B) ∧ (Y0,q0) ∧ (Z0,1)
Man uberlegt sich: v(ϕ4) = 1⇔ die in v beschriebene Bandinschrift in Schritt 0 hatdie Form a1 · · · anB · · ·B; der Kopf steht auf Zelle 1; der Zustand ist q0.
(5) Endkonfiguration
ϕ5 =∨
q∈F
YT,q
Hier ist klar:v(ϕ5) = 1⇔ Es existiert ein q ∈ F mit v(YT,q) = 1.
(6) Wo der Kopf nicht ist, bleibt die alte Bandinschrift erhalten
ϕ6 =∧
1≤t≤T
∧
1≤p≤T+1
∧
a∈Γ
(Zt−1,p ∨ Xt−1,p,a ∨Xt,p,a
)
Klar: v(ϕ6) = 1 gilt genau dann wenn [v(Zt−1,p) = 0∧ v(Xt−1,p,a) = 1⇒ v(Xt,p,a) =1], fur alle t, p und a.
Fur (7) und (8) fuhren wir neue Hilfsvariablen ein:
Ut,q,a,q′,a′,D mit 1 ≤ t ≤ T,q, q′ ∈ Q,a, a′ ∈ Γ,D ∈ {L,R,N} und(q′, a′, D) ∈ δ(q, a)
Abkurzung: Ut,r fur r = (q, a, q′, a′, D).
Ein solches Ut,r symbolisiert die Aussage”in Schritt t wird die durch (q′, a′, D) ∈
δ(q, a) gegebene Regel benutzt“.
168

(7) Genau ein Ubergang
ϕ7 =∧
1≤t≤T
(∨
r Regel
Ut,r
)
∧∧
r,r Regelnr 6=r
(Ut,r ∨ Ut,r
)
Man zeigt:v(ϕ7) = 1 gilt genau dann wenn es fur jeden Schritt 1 ≤ t ≤ T genau eine Regel rgibt, fur die v(Ut,r) = 1 ist.
(8) Der in Schritt t benutzte Ubergang ist legal (bzgl. Konfiguration kt−1) undhat bzgl. Kopfposition, Zelleninhalt und Zustand den vorgeschriebenenEffekt.
ϕ8 =∧
1≤t≤T
∧
1≤p≤T+1
∧
r=(q,a,q′,a′,D)Regel
((Ut,r ∨ Zt−1,p ∨Xt−1,p,a
)∧
(Ut,r ∨ Yt−1,q
)∧
(Ut,r ∨ Zt−1,p ∨Xt,p,a′
)∧
(Ut,r ∨ Yt,q′
)∧
(Ut,r ∨ Zt−1,p ∨ Zt,p+d(D)
))
,
wobei d(D) =
−1 fur D = L0 fur D = N1 fur D = R
die Richtung der Kopfbewegung beschreibt.
ϕx ergibt sich nun zu: ϕx = ϕ1 ∧ ϕ2 ∧ · · · ∧ ϕ8.
Nun mussen wir nur noch die X-, Y -, Z- und U -Variablen in die Standard-Variablenmenge{X0, X1, . . .} ubersetzen. Hier arbeitet man am besten direkt mit den Binardarstellungender Indizes, z.B. durch
Xt,p,a = [100 bin(t) bin(p) bin(a)],Yt,q = [101 bin(t) bin(q)],Zt,p = [110 bin(t) bin(p)],
Ut,q,a,q′,a′,D = [111 bin(t) bin(q) bin(a) bin(q′) bin(a′) bin(d(D))].
Dabei werden bin(t), bin(p) mit dlog(T + 2)e Bits und die Elemente von Q, Γ und D miteiner festen Bitzahl dargestellt. Auf die Erfullbarkeit hat eine solche Umbenennung derVariablen keinen Einfluss.
169

Wir stellen fest:Durch Inspektion der acht Formelteile sieht man, dass jeder O(T 2) oder O(T 3) (Fall (3))Literale und Verknupfungszeichen enthalt. Jedes Literal hat O(log T ) = O(log n) Zeichen.Zudem ist T = O(|x|k), also log T = O(log |x|). Daraus folgt: |ϕx| = O(|x|3k+1). Weitersieht man leicht ein, dass ϕx aus x in Polynomialzeit berechenbar ist.
Zentrale Feststellung: x ∈ L⇔ ϕx ∈ LSAT, fur beliebiges x ∈ Σ∗.
Beweis:
”⇒“: Sei x ∈ L, |x| = n. Dann existiert eine akzeptierende Berechnung mit cnk Schritten
von M auf x.
Wir belegen die Variablen genau entsprechend dem Ablauf dieser Berechnung, wiefolgt:
v(Xt,p,a) =
{1 nach Schritt t steht in Zelle p Buchstabe a0 sonst.
v(Yt,q) =
{1 nach Schritt t ist M in Zustand q0 sonst.
v(Zt,p) =
{1 nach Schritt t steht der Kopf in Zelle p0 sonst.
v(Ut,r) =
{1 in Schritt t wird Regel r = (q, a, q′, a′, D) benutzt0 sonst.
Es ist nun eine langwierige, aber einfache Routineaufgabe, zu uberprufen, dass v dieFormel ϕx = ϕ1 ∧ ϕ2 ∧ · · · ∧ ϕ8 erfullt.
Wir betrachten als Beispiel ϕ8. Seien t, p und r = (q, a, q′, a′, D) beliebig. Wir be-trachten die funf Klauseln, die sich auf t, p, r beziehen.
1. Fall: In Schritt t wird nicht Regel r benutzt. Dann ist v(Ut,r) = 1, also enthaltenalle Klauseln ein wahres Literal.
2. Fall: In Schritt t wird Regel r benutzt. Dann ist M nach Schritt t − 1 in Zustandq und nach Schritt t in Zustand q′, also gilt v(Yt−1,q) = v(Yt,q′) = 1. Alsoenthalten die Klauseln 2 und 4 zu t, p, r je ein wahres Literal.
Fall 2a: Vor Schritt t ist der Kopf nicht in Zelle p. Dann ist v(Zt−1,p) = 1, alsoenthalten die Klauseln 1, 3 und 5 zu t, p, r je ein wahres Literal.
Fall 2b: Vor Schritt t ist der Kopf in Zelle p. Weil wir von einer korrekten Rech-nung ausgehen, steht vor Schritt t in Zelle p der Buchstabe a, nachherder Buchstabe a′, und nach Schritt t ist der Kopf bei Zelle p + d(D). Al-so v(Xt−1,p,a) = v(Xt,p,a′) = v(Zt,p+d(D)) = 1, und wieder enthalten dieKlauseln 1, 3 und 5 je ein wahres Literal.
170
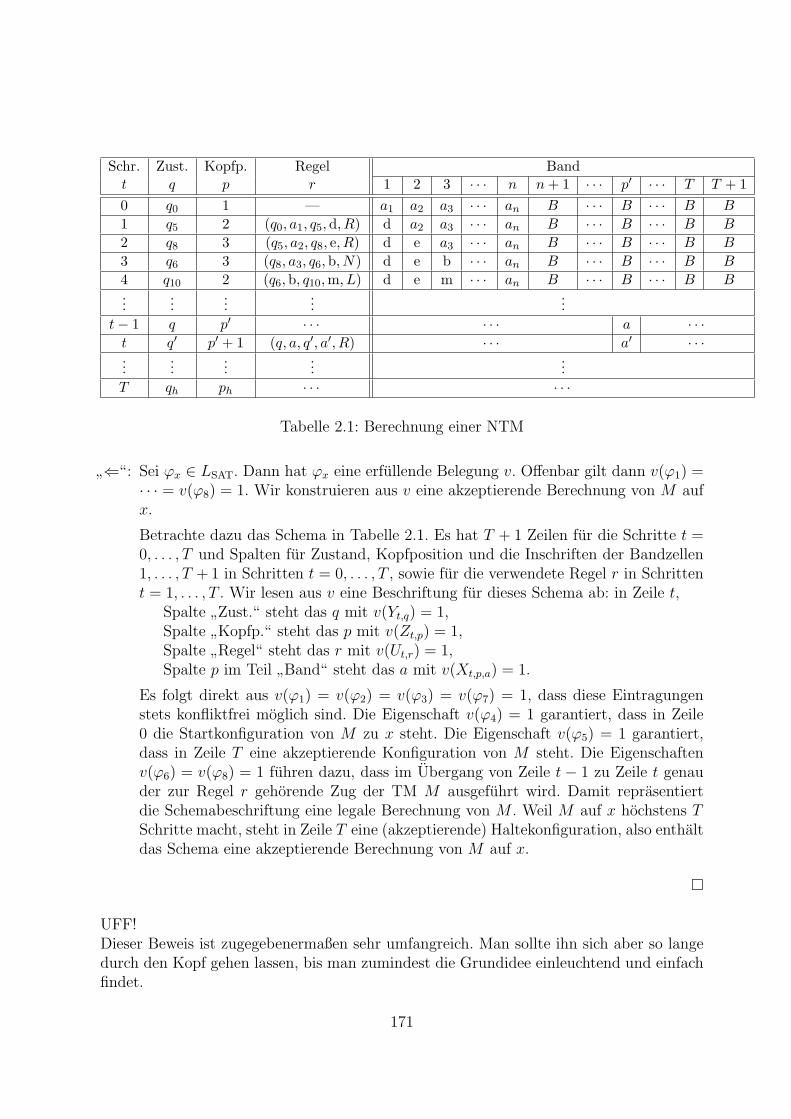
Schr. Zust. Kopfp. Regel Bandt q p r 1 2 3 · · · n n + 1 · · · p′ · · · T T + 1
0 q0 1 — a1 a2 a3 · · · an B · · · B · · · B B
1 q5 2 (q0, a1, q5, d, R) d a2 a3 · · · an B · · · B · · · B B
2 q8 3 (q5, a2, q8, e, R) d e a3 · · · an B · · · B · · · B B
3 q6 3 (q8, a3, q6, b, N) d e b · · · an B · · · B · · · B B
4 q10 2 (q6, b, q10, m, L) d e m · · · an B · · · B · · · B B...
......
......
t− 1 q p′ · · · · · · a · · ·
t q′ p′ + 1 (q, a, q′, a′, R) · · · a′ · · ·...
......
......
T qh ph · · · · · ·
Tabelle 2.1: Berechnung einer NTM
”⇐“: Sei ϕx ∈ LSAT. Dann hat ϕx eine erfullende Belegung v. Offenbar gilt dann v(ϕ1) =
· · · = v(ϕ8) = 1. Wir konstruieren aus v eine akzeptierende Berechnung von M aufx.
Betrachte dazu das Schema in Tabelle 2.1. Es hat T + 1 Zeilen fur die Schritte t =0, . . . , T und Spalten fur Zustand, Kopfposition und die Inschriften der Bandzellen1, . . . , T + 1 in Schritten t = 0, . . . , T , sowie fur die verwendete Regel r in Schrittent = 1, . . . , T . Wir lesen aus v eine Beschriftung fur dieses Schema ab: in Zeile t,
Spalte”Zust.“ steht das q mit v(Yt,q) = 1,
Spalte”Kopfp.“ steht das p mit v(Zt,p) = 1,
Spalte”Regel“ steht das r mit v(Ut,r) = 1,
Spalte p im Teil”Band“ steht das a mit v(Xt,p,a) = 1.
Es folgt direkt aus v(ϕ1) = v(ϕ2) = v(ϕ3) = v(ϕ7) = 1, dass diese Eintragungenstets konfliktfrei moglich sind. Die Eigenschaft v(ϕ4) = 1 garantiert, dass in Zeile0 die Startkonfiguration von M zu x steht. Die Eigenschaft v(ϕ5) = 1 garantiert,dass in Zeile T eine akzeptierende Konfiguration von M steht. Die Eigenschaftenv(ϕ6) = v(ϕ8) = 1 fuhren dazu, dass im Ubergang von Zeile t− 1 zu Zeile t genauder zur Regel r gehorende Zug der TM M ausgefuhrt wird. Damit reprasentiertdie Schemabeschriftung eine legale Berechnung von M . Weil M auf x hochstens TSchritte macht, steht in Zeile T eine (akzeptierende) Haltekonfiguration, also enthaltdas Schema eine akzeptierende Berechnung von M auf x.
�
UFF!Dieser Beweis ist zugegebenermaßen sehr umfangreich. Man sollte ihn sich aber so langedurch den Kopf gehen lassen, bis man zumindest die Grundidee einleuchtend und einfachfindet.
171

Mussen wir fur jeden NP-Vollstandigkeitsbeweis diesen Aufwand treiben? Nein, zumGluck hilft das Konzept der Polynomialzeitreduktion, von LSAT ausgehend viel einfachereBeweise zu fuhren.
2.6 Einige NP-vollstandige Probleme
Wir haben im letzten Abschnitt festgestellt, dass LSAT NP-vollstandig ist, durch direkteReduktion einer beliebigen NP-Sprache L auf LSAT. Wenn man immer, fur jedes SpracheL0, diese Reduktion ausfuhren musste, also Berechnungen von NTMn in das Problem L0
hineinkodieren, um zu zeigen dass L0 NP-vollstandig ist, ware wahrscheinlich der Theorieder NP-Vollstandigkeit kein solcher Erfolg beschieden gewesen wie er sich in den letzten 35Jahren eingestellt hat. Zum Gluck geht es viel einfacher, zumindest in den meisten Fallen.Die Schlusselmethode ist wieder Reduktion, wie bei den Unentscheidbarkeitsbeweisen. Siehat es ermoglicht, fur mehrere tausend Entscheidungsprobleme die NP-Vollstandigkeitnachzuweisen.
Aus Zeitgrunden konnen wir in dieser Vorlesung nur einige wenige Beispiele fur NP-Voll-standigkeits-Beweise mit der Reduktionsmethode behandeln. Herausragendes Beispiel istdabei das Cliquenproblem. Fur Beweise fur die NP-Vollstandigkeit anderer wichtiger Pro-bleme (insbesondere das TSP-Problem, das Rucksackproblem, Graphfarbbarkeitsproble-me, Hamilton-Kreis) sei auf die Vorlesung
”Komplexitatstheorie“ verwiesen.
2.6.1 Lemma (Reduktionsmethode)
Wenn fur eine Sprache L gilt:
(i) L ∈ NP und(ii)∗ L′ ≤p L fur ein L′ ∈ NPC,
dann ist L NP-vollstandig.
Beweis Wir mussen die Bedingungen (i) und (ii) der Definition 2.4.5 nachprufen. Offen-bar ist nur (ii) zu zeigen, d. h. dass L′′ ≤p L fur jedes L′′ ∈ NP. Weil nach Voraussetzung(ii)∗ L′ ∈ NPC ist, haben wir L′′ ≤p L′ fur jedes L′′ ∈ NP, weiter ist nach Voraussetzung(ii)∗ L′ ≤p L. Daraus folgt mit 2.4.2(b) (Transitivitat von ≤p), dass L′′ ≤p L fur jedesL′′ ∈ NP, was zu zeigen war. �
Wir wollen die Reduktionsmethode noch einmal als Handlungsanweisung formulieren:
172

Sei L eine Sprache.Um zu zeigen, dass L NP-vollstandig ist, gehe folgendermaßen vor:(i) Zeige, dass L ∈ NP ist.(ii) Wahle eine geeignete als NP-vollstandig bekannte Sprache L′
und zeige (durch Konstruktion der Reduktionsfunktion), dass L′ ≤p L.
Oft spielt LSAT oder auch L3−SAT die Rolle von L′. In der Praxis kann man auch einbeliebiges der vielen als NP-vollstandig bekannten Probleme aus der Literatur nehmenund die Rolle von L′ spielen lassen. Damit es gerechtfertigt ist, in solchen Beweisen L3−SAT
zu verwenden, das eine angenehmere Struktur als LSAT hat, benotigen wir folgenden Satz.
2.6.2 Satz L3−SAT ist NP-vollstandig.
Beweis Nach unserem Rezept zeigen wir zunachst L3−SAT ∈ NP. Hier konnen wir das-selbe Verfahren wie fur LSAT benutzen (Beweis von Satz 2.5.9), nur muss der Syntaxcheckhier prufen, ob die Eingabe eine 3-KNF-Formel ist.
Nun bleibt zu zeigen: LSAT ≤p L3−SAT.
Hierfur mussen wir eine Reduktionsfunktion definieren, die eine KNF-Formel ϕ in eine3-KNF-Formel ϕ∗ transformiert derart, dass
ϕ ist erfullbar ⇔ ϕ∗ ist erfullbar
gilt. Bei der Beschreibung der Reduktionsfunktion ignorieren wir Kodierungen und daseher nebensachliche Problem, dass Inputs eventuell keine KNF-Formeln darstellen. (Eineinfacher Syntaxcheck ermittelt solche Inputs und bildet sie auf eine 3-KNF-Formel ab,die nicht erfullbar ist.)
Sei eine KNF-Formel ϕ = C1 ∧ · · · ∧ Cr gegeben. Wir bilden zu jeder Klausel Cj eineFormel ϕ∗
j in 3-KNF-Form, um dann
ϕ∗ = ϕ∗1 ∧ · · · ∧ ϕ∗
r
zu definieren. Sei dazu vorlaufig j fest. Wie wird ϕ∗j aus Cj gebildet? Es gibt Literale
l1, . . . , ls mitCj = (l1 ∨ · · · ∨ ls).
1. Fall : s = 1. — Dann wahle zwei neue Variable Z1 und Z2, die sonst nirgends vorkommen(insbesondere nicht in anderen Teilformeln ϕ∗
j′ , j′ 6= j) und definiere
ϕ∗j = (l1 ∨ Z1 ∨ Z2) ∧ (l1 ∨ Z1 ∨ Z2) ∧ (l1 ∨ Z1 ∨ Z2) ∧ (l1 ∨ Z1 ∨ Z2).
173

2. Fall : s = 2. — Dann wahle eine neue Variable Z1 und definiere
ϕ∗j = (l1 ∨ l2 ∨ Z1) ∧ (l1 ∨ l2 ∨ Z1).
3. Fall : s = 3. — Dann definiere
ϕ∗j = (l1 ∨ l2 ∨ l3) = Cj.
4. Fall : s ≥ 4. — Dann wahle s− 3 neue Variable Z3, Z4, . . . , Zs−1 und definiere
ϕ∗j = (l1 ∨ l2 ∨ Z3)
∧ (Z3 ∨ l3 ∨ Z4)
∧ (Z4 ∨ l4 ∨ Z5)...
∧ (Zs−2 ∨ ls−2 ∨ Zs−1)
∧ (Zs−1 ∨ ls−1 ∨ ls) .
Beispielsweise ergibt sich aus der Klausel Cj = (X2 ∨ X4 ∨ X5 ∨ X7 ∨ X8 ∨ X10) dieTeilformel
ϕ∗j = (X2 ∨X4 ∨ Z3) ∧ (Z3 ∨ X5 ∨ Z4) ∧ (Z4 ∨ X7 ∨ Z5) ∧ (Z5 ∨X8 ∨ X10).
Wir stellen zunachst fest, dass die Transformation ϕ 7→ ϕ∗ so einfach ist, dass sie sicherin Polynomialzeit berechnet werden kann.
Zu zeigen bleibt:
Behauptung: ϕ ist erfullbar ⇔ ϕ∗ ist erfullbar.
Man beachte, dass ϕ∗ mehr Variablen enthalt als ϕ und daher die beiden Formeln nicht
”aquivalent“ sein konnen. Dennoch sind sie
”erfullungsaquivalent“.
Beweis der Behauptung:”⇒“: Eine Belegung v mit v(ϕ) = 1 sei gegeben. Wir definieren
eine Belegung v∗ fur die Variablen in ϕ∗, und prufen, dass durch v∗ alle Klauseln in ϕ∗
den Wert 1 bekommen, wie folgt. Zuerst setzen wir
v∗(Xi) = v(Xi)
fur alle Xi, die in ϕ vorkommen. Fur jedes j erhalten die neuen Variablen in ϕ∗j ihre
Belegung anhand der Falle fur die Definition von ϕ∗j aus Cj = (l1 ∨ · · · ∨ ls).
1. Fall : s = 1. Wenn Z1, Z2 die neuen Variablen in ϕ∗j sind, dann setze v∗(Z1) = v∗(Z2) = 0.
— Weil v(Cj) = 1, muss v(l1) = 1 sein. Damit gilt auch v∗(l1) = 1, und alle vier Klauselnin ϕ∗
j erhalten unter v∗ den Wahrheitswert 1.
2. Fall : s = 2. Wenn Z1 die neue Variable in ϕ∗j ist, dann setze v∗(Z1) = 0. — Weil
v(Cj) = 1, muss einer der Werte v(l1) oder v(l1) gleich 1 sein. Damit ist auch v∗(l1) = 1oder v∗(l2) = 1, und beide Klauseln in ϕ∗
j erhalten unter v∗ den Wahrheitswert 1.
174

3. Fall : s = 3. Dann ist ϕ∗j = Cj und v∗(ϕ∗
j) = v(Cj) = 1.
4. Fall : s ≥ 4. Wenn Z3, . . . , Zs−1 die neuen Variablen in ϕ∗j sind, dann verfahre wie folgt:
Weil v(ϕ) = 1, ist auch v(Cj) = 1, also gibt es ein k mit v(lk) = 1. Fur 3 ≤ h ≤ s − 1setze
v∗(Zh) =
{
1 , falls h ≤ k,
0 , falls h > k.
Dann erhalten unter v∗ alle Klauseln in ϕ∗j den Wert 1, was man wie folgt einsieht: Die
Klausel, die lk enthalt, hat unter v∗ den Wert 1, weil v∗(lk) = v(lk) = 1. Die vorangehendenKlauseln enthalten eine Variable Zh mit einem h ≤ k, und erhalten daher unter v∗ denWert 1; die darauffolgenden Klauseln enthalten ein Literal Zh mit einem h > k, underhalten daher unter v∗ ebenfalls den Wert 1.
”⇐“: Nun sei eine Belegung v∗ fur die Variablen in ϕ∗ gegeben, die v∗(ϕ∗) = 1 erfullt. Wir
wollen zeigen, dass auch v∗(ϕ) = 1 gilt. Dazu ist zu zeigen, dass alle Klauseln von ϕ unterv∗ den Wert 1 erhalten. Wir betrachten dazu eine beliebige Klausel Cj = (l1 ∨ · · · ∨ ls).Wir wissen, dass v∗(ϕ∗
j) = 1 ist.
1. Fall : s = 1. — Dann ist ϕ∗j = (l1∨Z1∨Z2)∧ (l1∨Z1∨ Z2)∧ (l1∨ Z1∨Z2)∧ (l1∨ Z1∨ Z2)
mit zwei neuen Variablen Z1, Z2. In einer der vier Klauseln haben beide Literale zu Z1
und Z2 den Wahrheitswert 0; daher muss v∗(l1) = 1 sein.
2. Fall : s = 2. — Dann ist ϕ∗j = (l1 ∨ l2 ∨ Z1) ∧ (l1 ∨ l2 ∨ Z1) fur eine neue Variable Z1.
In einer der beiden Klauseln erhalt das Z1-Literal unter v∗ den Wahrheitswert 0; dahermuss v∗(l1) = 1 oder v∗(l2) = 1 sein.
3. Fall : s = 3. — Dann ist ϕ∗j = Cj und daher v∗(Cj) = 1.
4. Fall : s ≥ 4. — Dann ist
ϕ∗j = (l1 ∨ l2 ∨ Z3) ∧ (Z3 ∨ l3 ∨ Z4) ∧ · · · ∧ (Zs−2 ∨ ls−2 ∨ Zs−1) ∧ (Zs−1 ∨ ls−1 ∨ ls)
mit s− 3 neuen Variablen Z3, . . . , Zs−1. Alle s− 2 Klauseln erhalten unter v∗ den Wahr-heitswert 1. Falls v∗(Z3) = 0 ist, muss v∗(l1 ∨ l2) = 1 sein und damit v∗(Cj) = 1. Fallsv∗(Zs−1) = 1 ist, muss v∗(ls−1 ∨ ls) = 1 sein und wieder v∗(Cj) = 1. Es bleibt der Fallv∗(Z3) = 1 und v∗(Zs−1) = 0. Das heißt: Die 0-1-Folge v∗(Z3), . . . , v
∗(Zs−1) beginnt mit1 und endet mit 0. Daher muss es ein k geben, 3 ≤ k ≤ s − 2, mit v∗(Zk) = 1 undv∗(Zk+1) = 0. Weil
v∗(Zk ∨ lk ∨ Zk+1) = 1,
folgt v∗(lk) = 1. Also enthalt Cj ein Literal, das unter v∗ den Wahrheitswert 1 erhalt, wiegewunscht. �
Bemerkung : Falls ϕ die Eigenschaft hat, dass keine Klausel ein Literal zweimal enthalt,dann gilt dies auch fur ϕ∗. Diese Eigenschaft ist fur manche Reduktionen wichtig, die vondem Problem 3-SAT ausgehen.
Exemplarisch zeigen wir nun, wie man mit der Reduktionsmethode beweist, dass LClique
NP-vollstandig ist.
175

2.6.3 Satz LClique ist NP-vollstandig.
2.6.4 Korollar LVC und LIS sind NP-vollstandig. �
Beweis von Korollar 2.6.4: Wir wenden die Reduktionsmethode an und verwenden alsbekannte Sprache aus NPC die Sprache LClique. (i) Dass LVC und LIS in NP sind, zeigtman analog zur Konstruktion in Beispiel 2.3.3. (ii) Mit Satz 2.4.4 und Lemma 2.4.2(b)folgt LClique ≤p LIS und LClique ≤p LVC. �
Beweis von Satz 2.6.3: Wieder wird die Reduktionsmethode angewendet.(i) Dass LClique ∈ NP ist, haben wir schon in Beispiel 2.3.3 gesehen.(ii) Wir zeigen:
L3−SAT ≤p LClique.
Wir mussen also eine Funktion f definieren, die eine Eingabe ϕ fur L3−SAT (also ϕ =C1 ∧ · · · ∧ Cr mit Cj Klausel mit 3 Literalen fur 1 ≤ j ≤ r) abbildet auf eine Eingabef(ϕ) = (Gϕ, kϕ) fur das Problem LClique. Dabei soll gelten:
• f ∈ FP, d. h. f ist polynomialzeitberechenbar, und
• Fur jede 3-KNF-Formel ϕ gilt: ϕ ∈ L3−SAT ⇔ f(ϕ) = (Gϕ, kϕ) ∈ LClique.
(Fur Puristen: damit f total ist, muss man noch z. B. f(x) := ε 6∈ LClique definieren furEingaben x fur L3−SAT, die nicht eine 3-KNF-Formel darstellen.)
Wir betrachten nun eine feste Eingabe
ϕ = C1 ∧ · · · ∧ Cr
fur L3−SAT, wobei Cj = (lj1 ∨ lj2 ∨ lj3), 1 ≤ j ≤ r, fur Literale ljs, 1 ≤ j ≤ r, 1 ≤ s ≤ 3,und definieren den ungerichteten Graphen Gϕ = (Vϕ, Eϕ) und die Zahl kϕ.
Der Graph Gϕ hat 3r Knoten vjs, 1 ≤ j ≤ r, 1 ≤ s ≤ 3. Jeder”Literalposition“ ljs
entspricht ein Knoten. Anschaulich kann man sich die Knoten in r Spalten zu je dreiKnoten angeordnet denken, eine Spalte fur jede Klausel. Auch kann man Knoten vjs mitljs beschriften, allerdings gibt es eventuell mehrere Knoten mit derselben Beschriftung.
Innerhalb einer Spalte gibt es keine Kanten. Andere Knoten sind genau dann miteinanderverbunden, wenn sie nicht zu entgegengesetzten Literalen Xi und Xi gehoren.
Formal:
Vϕ := {vjs | 1 ≤ j ≤ r, 1 ≤ s ≤ 3} und
Eϕ := {(vjs, vj′s′) | 1 ≤ j 6= j′ ≤ r, ljs, lj′s′ sind nicht entgegengesetzte Literale }.
Zuletzt definieren wir Gϕ := (Vϕ, Eϕ) und kϕ := r.
176

Beispiel : Eingabe fur L3−SAT:
ϕ = (X1 ∨ X2 ∨ X4) ∧ (X2 ∨X1 ∨X3) ∧ (X1 ∨ X2 ∨X4).
v
v
23
v
X
v
12
v
13
111
X1
X1
X2
X2
X3X4
X4
X2
v
31
v
32
v
33
v
21
22
Abbildung 2.8: Ein Graph Gϕ zu einer 3-KNF-Formel ϕ
Der Graph Gϕ hat neun Knoten v11, v12, v13, v21, v22, v23, v31, v32, v33. Die Kantenmengebesteht aus allen ungeordneten Paaren (vjs, vj′s′) mit j 6= j′ außer den Paaren (v11, v31),(v22, v31) (Literale X1 und X1), (v12, v21) (Literale X2 und X2), (v21, v32) (Literale X2 undX2), (v13, v33) (Literale X4 und X4).
Man sieht leicht ein, dass die Funktion f , die durch f(ϕ) := (Gϕ, kϕ) gegeben ist, polyno-mialzeitberechenbar ist. Wir mussen also noch zeigen: ϕ ∈ L3−SAT ⇔ f(ϕ) ∈ LClique, d. h.ϕ erfullbar ⇔ (Gϕ, kϕ) ∈ LClique, oder in Worten:
Es gibt eine Belegung v, so dass jede Klausel von ϕ ein wahres Literal enthalt⇔ Gϕ hat eine Clique der Große r.
Beweis dazu:”⇒“: Sei v eine Belegung, die in jeder Klausel Cj, 1 ≤ j ≤ r, ein Literal
wahr macht. Fur jedes j wahlen wir ein sj ∈ {1, 2, 3} mit v(lj,sj ) = 1. Dann ist die Menge
V ′ := {vj,sj| 1 ≤ j ≤ r}
eine Clique in Gϕ. Ist namlich j 6= j′, so kann es wegen v(lj,sj ) = v(lj′,sj′ ) = 1 nicht sein,
dass lj,sj und lj′,sj′ entgegengesetzte Literale sind. Also ist (vj,sj, vj′,sj′
) eine Kante in Gϕ.
— Dass |V ′| = r ist, ist offensichtlich.
”⇐“: Sei V ′ ⊆ Vϕ eine Clique in Gϕ mit r Knoten. Weil die Knoten, die zu einer Klausel
Cj gehoren, nicht miteinander verbunden sind, gehoren die r Knoten zu unterschiedlichen
177

Klauseln. Also gibt es fur jedes j, 1 ≤ j ≤ r, genau ein sj ∈ {1, 2, 3}, so dass V ′ = {vj,sj|
1 ≤ j ≤ r} ist.
Wir definieren eine Belegung v folgendermaßen:
v(Xi) :=
{
1 falls Xi = lj,sj fur ein j,
0 sonst.
Diese Belegung erfullt jede Klausel Cj, denn:1. Fall : lj,sj ist eine Variable Xi. — Dann gilt v(Xi) = 1 nach der Definition von v, alsoenthalt Cj ein wahres Literal.2. Fall : lj,sj ist eine negierte Variable Xi. — Weil V ′ eine Clique in Gϕ ist, kann kein
Literal lj′,sj′ , j′ 6= j, gleich Xi sein. Also ist v(Xi) = 0, nach der Definition von v; daraus
folgt v(Xi) = 1 und v(Cj) = 1. �
178





























