Embed Size (px)
Citation preview

Julius-Maximilians-Universität WürzburgInstitut für Informatik
Lehrstuhl für Künstliche Intelligenzund Angewandte Informatik
Bachelorarbeitim Studiengang Informatik
zur Erlangung des akademischen GradesBachelor of Science
Recherche, Anwendung und Evaluierung verschiedenerVerfahren zur Gesichtswiedererkennung
Autor: Alexander Hartelt <[email protected]>MatNr. 1949647
Abgabe: 18. Oktober 2016
1. Betreuer: Prof. Dr. Frank Puppe2. Betreuer: M. Sc. Christian Reul

2
AbstractIn dieser Bachelorarbeit wurde ein Programm entwickelt, das ein übergebenes Bild ei-ner Person vorverarbeitet und von diesem Merkmale des Gesichtes extrahiert. DieseMerkmale werden verwendet, um eine Klassifikation der Person durchzuführen. DieMerkmalsextraktion wurde mit der Local Binary Pattern Histogramm (LBPH) Im-plementierung von OpenCV und der Convolutional Neural Netzwerk Implementierungvon OpenFace getestet. Bei der Vorverarbeitung wird das übergebene Bild in ein Grau-stufenbild umgewandelt, das Gesicht aus dem Bild heraus geschnitten und eine Aus-richtung des Gesichts vorgenommen. Zusätzlich besteht die Möglichkeit, den Kontrastder Bilder durch einen Histogramm Ausgleich zu erhöhen. Die Evaluation erfolgte aufmehreren Datensets, von denen eines selbst erstellt wurde. Die Ergebnisse fielen, jenach Datenset sehr unterschiedlich aus. Auf dem eigens erstellten Datenset erreich-te das System mit der LBPH-Extraktion eine Erkennungsrate von bis zu 66%. DieConvolutional Neural Netzwerk Implementierung erzielte bei demselben Datenset eineErkennungsrate von ca. 93,9%. Zusätzlich wurde der Einfluss auf die Erkennungsratedurch die Anzahl der Trainingsdaten evaluiert. Bei einer Erhöhung der Trainingsbilderverbesserte sich bei beiden Systemen stets die Erkennungsrate. Vor allem die Verdopp-lung der Anzahl der Trainingsbilder von einem auf zwei Bildern erwies sich als sehreffektiv.Des weiteren wird vor der Konzipierung und Evaluation eine Zusammenfassung ver-
schiedener Herangehensweisen zur Gesichtswiedererkennung gegeben. Darunter befin-det sich eine Beschreibung der LBPH-, der Eigengesichter-, der Convolutional NeuralNetwork- und der Feature basierten Herangehensweise.

Inhaltsverzeichnis 3
Inhaltsverzeichnis
Abbildungsverzeichnis 5
Tabellenverzeichnis 6
1 Einleitung 7
2 Grundlagen für die Computer Vision 82.1 Computer Vision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Darstellung von Bildern in der Computer Vision . . . . . . . . . . . . . 82.3 RGB-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 Grundlage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.2 Umwandlung zum Graustufenbild . . . . . . . . . . . . . . . . . 10
2.4 Histogramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.4.1 Grundlage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.4.2 Histogramm Ausgleich . . . . . . . . . . . . . . . . . . . . . . . 12
2.5 Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Übersicht zur Gesichtswiedererkennung 163.1 Typischer Ablauf der Gesichtswiedererkennung . . . . . . . . . . . . . . 163.2 Mögliche Herangehensweisen zur Gesichtswiedererkennung . . . . . . . 173.3 Local Binary Pattern . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.1 Variationen am Radius und Anzahl der Punkte . . . . . . . . . 183.3.2 Uniforme Binary Patterns . . . . . . . . . . . . . . . . . . . . . 193.3.3 Anpassungen für die Gesichtswiedererkennung . . . . . . . . . . 19
3.4 Eigengesichter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.5 Fishergesichter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.6 Feature basierte Herangehensweise . . . . . . . . . . . . . . . . . . . . 253.7 Convolutional Neural Networks . . . . . . . . . . . . . . . . . . . . . . 27
3.7.1 Convolutional Layer . . . . . . . . . . . . . . . . . . . . . . . . 283.7.2 Max-Pooling Layer . . . . . . . . . . . . . . . . . . . . . . . . . 283.7.3 Fully Connected Layer . . . . . . . . . . . . . . . . . . . . . . . 293.7.4 Training des gefalteten Neuronalen Netzwerk . . . . . . . . . . . 30
3.8 Weitere State of the Art Methoden . . . . . . . . . . . . . . . . . . . . 313.8.1 High Dimensional LBP . . . . . . . . . . . . . . . . . . . . . . . 313.8.2 High Fidelity Pose and Expression Normalization . . . . . . . . 32
3.9 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.10 Probleme bei der Gesichtswiedererkennung . . . . . . . . . . . . . . . . 34
3.10.1 Variierende Beleuchtung . . . . . . . . . . . . . . . . . . . . . . 353.10.2 Pose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.10.3 Verdeckung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 Konzeption und Verwendete Materialien 374.1 Konzeption . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.2 Verwendete Computer Vision Bibliotheken . . . . . . . . . . . . . . . . 38
4.2.1 OpenCV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.2.2 Dlib . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2.3 Überblick über weitere Frameworks zur Gesichtswiedererkennung 39

Inhaltsverzeichnis 4
4.3 Datensets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.3.1 Face94 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.3.2 Fussball Datenset Deutschland . . . . . . . . . . . . . . . . . . . 41
5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 425.1 Gesichtserkennung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.1.1 Augenerkennung anhand Kaskaden . . . . . . . . . . . . . . . . 435.1.2 Augenerkennung mit Hilfe der Dlib Bibliothek . . . . . . . . . . 44
5.2 Anpassung der Intensität von Farben . . . . . . . . . . . . . . . . . . . 47
6 Evaluation 496.1 Durchführung der Evaluation . . . . . . . . . . . . . . . . . . . . . . . 49
6.1.1 Ergebnisse des Face94-Datenset . . . . . . . . . . . . . . . . . . 496.1.2 Ergebnisse des Face95-Datenset . . . . . . . . . . . . . . . . . . 506.1.3 Parameter des LBPH . . . . . . . . . . . . . . . . . . . . . . . . 516.1.4 Evaluation des Fussball-Datensets . . . . . . . . . . . . . . . . . 516.1.5 Der Einfluss der Anzahl der Trainingsbilder auf die Genauigkeit 52
6.2 Evaluation von OpenFace . . . . . . . . . . . . . . . . . . . . . . . . . 536.3 Erwähnenswerte Auffälligkeiten . . . . . . . . . . . . . . . . . . . . . . 55
7 Diskussion und Ausblick 577.1 Zusammenfassung der Ergebnisse . . . . . . . . . . . . . . . . . . . . . 577.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Literaturverzeichnis 59
Anhang 627.3 Einlesen der Trainingsbilder . . . . . . . . . . . . . . . . . . . . . . . . 627.4 Programm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7.4.1 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 637.4.2 Anwendung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
8 CD mit Ausarbeitung und Programmcode 66
Eidesstattliche Erklärung 66

Abbildungsverzeichnis 5
Abbildungsverzeichnis1 Mögliche Darstellung eines Graustufenbildes in der Computer-Vision . 82 Darstellung des RGB Farben Spektrums als drei Dimensionaler Würfel
[BB09] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103 Umwandlung des RGB Bildes zum Graustufenbild . . . . . . . . . . . . 114 Histogramm eines Graustufenbild . . . . . . . . . . . . . . . . . . . . . 125 Histogramm Ausgleich . . . . . . . . . . . . . . . . . . . . . . . . . . . 136 Funktionsweise eines Filter . . . . . . . . . . . . . . . . . . . . . . . . . 147 Nicht Lineare Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148 Phasen der Gesichtswiedererkennung . . . . . . . . . . . . . . . . . . . 179 LBP-Berechnung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1810 Unterschiedliche Radien bei der LBP-Erstellung . . . . . . . . . . . . . 1911 LBP Histogramm Gewichtung . . . . . . . . . . . . . . . . . . . . . . . 2012 Darstellung von Eigengesichtern . . . . . . . . . . . . . . . . . . . . . . 2313 Darstellung der genutzten Merkmale . . . . . . . . . . . . . . . . . . . 2514 Darstellung eines Integralbildes . . . . . . . . . . . . . . . . . . . . . . 2715 Beispiel eines Convolutional Neural Networks (CNN) . . . . . . . . . . 2816 Funktionsweise des Pooling Layers . . . . . . . . . . . . . . . . . . . . . 2917 Training des CNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3118 LBP Pyramide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3119 Ablauf der Hoch dimensionalen LBP Herangehensweise . . . . . . . . . 3220 Posen und Ausdruck Normierung . . . . . . . . . . . . . . . . . . . . . 3321 Evaluationen des LFW-Datenset . . . . . . . . . . . . . . . . . . . . . . 3422 Beleuchtungsproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3523 Posenproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3624 Ablaufdiagramm des Programms . . . . . . . . . . . . . . . . . . . . . 3825 Beispielbilder des Faces94 Datenset . . . . . . . . . . . . . . . . . . . . 4026 Beispielbilder des eigenem Datensets . . . . . . . . . . . . . . . . . . . 4127 Unbearbeitete Bilder . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4328 Augenerkennung mit Hilfe von openCV . . . . . . . . . . . . . . . . . . 4429 Dlib Landmark Positionen . . . . . . . . . . . . . . . . . . . . . . . . . 4530 Augenerkennung mit Hilfe von Dlib . . . . . . . . . . . . . . . . . . . . 4631 Resultat des Face Alignments . . . . . . . . . . . . . . . . . . . . . . . 4732 Ergebnis der Histogram Equalization . . . . . . . . . . . . . . . . . . . 4833 Trainingsbilder des face94-Datenset . . . . . . . . . . . . . . . . . . . . 5034 Trainingsbilder des face95-Datenset . . . . . . . . . . . . . . . . . . . . 5035 Einfluss auf die Erkennung, durch die Anzahl der Trainingsbilder pro
Person 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5136 Einfluss der Anzahl an Trainingsbildern pro Person auf die Erkennungsrate 5337 Falsch Klassifzierungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 5538 Auffälligkeiten bei der Evaluation . . . . . . . . . . . . . . . . . . . . . 5639 Vergleich eines modellierten Gesichtes mit einer Aufnahme . . . . . . . 56

Tabellenverzeichnis 6
Tabellenverzeichnis1 Gefundenen FaceRecogntion Projekte/Frameworks . . . . . . . . . . . . 392 Evaluation des LBPH . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523 Einfluss der Anzahl an Trainingsbildern pro Person auf die Erkennungsrate 534 Gegenüberstellung von OpenFace und OpenCV . . . . . . . . . . . . . 545 Einfluss der Anzahl an Vergleichsbilder auf die Erkennungsrate . . . . 55

1 Einleitung 7
1 EinleitungDas Automatische Wiedererkennen von Personen anhand biometrischer Daten mit Hil-fe eines Computers hat in den letzten Jahren zunehmend an Bedeutung gewonnen. Inder Kriminalistik werden heutzutage Fingerabdrücke genutzt um anhand dieser einePerson zu identifizieren. Jedoch hat die Identifizierung durch Fingerabdrücke den Nach-teil, dass eine Interaktion mit der zu identifizierenden Person nötig ist. Diese ist beider Wiedererkennung einer Person durch das Gesicht nicht nötig. Stattdessen werdenmit Hilfe von Kameras Bilder aufgenommen, anhand deren eine Identifizierung erfolgenkann. Dadurch ist die Gesichtswiedererkennung besonders bei Themen wie der Terro-rismusprävention heutzutage nicht mehr weg zu denken. Besonders der Einsatz solcherSysteme im Bereich der öffentlichen Verkehrsmitteln, z. B. an Flughäfen, Bahnhöfenoder in Zügen, ist derzeit ein heiß diskutiertes Thema.
Ziel dieser Arbeit ist es dem Leser einen Überblick über die Gesichtswiedererken-nung zu geben. Dazu werden sowohl Problematiken, als auch der Stand der Technikaufgezeigt. Im zweiten Teil der Arbeit soll ein Gesichtswiedererkennungs-Programmimplementiert werden. Für die Evaluation wird ein eigenes aus Fußballspielern beste-hendes Datenset erstellt. Evaluiert wird die Local Binary Pattern Histogramm Imple-mentierung von OpenCV und die Neuronale Netz Implementierung von OpenFace. Zuerwähnen ist hier, dass OpenFace bereits eine Vorverarbeitung der Bilder implemen-tiert hat. Die OpenCV Implementierung umfasst keine Vorverarbeitung und musstedahingehend zuerst erweitert werden.
Die Arbeit ist in acht Kapitel aufgeteilt und ist wie folgend strukturiert:In Kapitel 2 werden Grundlagen der Computer Vision, die für den Verlauf der Ar-
beit wichtig sind, aufgezeigt. Anschließend wird im Kapitel 3 ein Überblick über dengrundsätzlichen Ablauf der Gesichtswiedererkennung gegeben. Des Weiteren werdenHerangehensweisen zur Gesichtswiedererkennung, die teilweise in OpenCV implemen-tiert sind oder zum State of the Art gehören, aufgezeigt. In Kapitel 4 werden genutzteMaterialien, wie Bibliotheken oder Datensets beschrieben. Zusätzlich wird eine kurzeÜbersicht zum Konzept des implementierten Programms gegeben. Im 5 Kapitel wirddie Herangehensweise, die Probleme und die Erfolge der implementierten Vorverarbei-tung aufgezeigt. Die Ergebnisse zur Evaluation des Implementierten Programms undOpenFace finden sich in Kapitel 6 wieder. Die Arbeit wird mit einer Diskussion undeinem Ausblick über Erweiterungen des Programms, abgeschlossen.

2 Grundlagen für die Computer Vision 8
2 Grundlagen für die Computer VisionZiel dieses Kapitel ist es einen Überblick über wichtige Grundlagen für die ComputerVision und die Gesichtswiedererkennung zu geben. Aus diesem Grund ist dieses wiefolgt strukturiert: Zuerst wird der Begriff Computer Vision definiert. Anschließendwerden Hintergrundinformationen über das Abspeichern von Bildern in der ComputerVision gegeben. Dabei werden sowohl RGB als auch Graustufenbilder diskutiert, dadiese wichtig für die Gesichtswiedererkennung und Vorverarbeitung sind. Zusätzlichwird ein kurzer Überblick über Histogramme gegeben, die ebenfalls relevant für eineHerangehensweise der Gesichtswiedererkennung ist. Auch wird eine Beschreibung derverschiedene Herangehensweisen zur Gesichtserkennung gegeben.
2.1 Computer Vision
Die Computer Vision beschreibt den Bereich der Informatik, der sich mit Systemenoder Algorithmen beschäftigt, die dem menschlichen Sehen nachempfunden sind. Da-bei wird versucht Bilder auf Computerebene zu verstehen, um automatisiertes Arbeitenzu bewerkstelligen. Computer Vision umfasst dabei Bereiche wie Objektdetektion, Zei-chenerkennung und Lageerkennung.
2.2 Darstellung von Bildern in der Computer Vision
Um automatisiertes Arbeiten mit Bildern zu bewerkstelligen, müssen Bilder für denComputer so dargestellt werden, dass diese für ihn verständlich sind. In der ComputerVision werden Bilder häufig als Matrizen dargestellt. Jeder Eintrag in dieser Matrixrepräsentiert dabei ein Pixel im Bild. Ein Graustufenbild mit Breite x und Höhe y hatsomit xy viele Einträge. Beispielsweise hat die Repräsentation eines Graustufenbild mitPixelhöhe 80 und Pixelbreite 80 bereits 6400 Einträge.
P1,1 . . . . . P1,x
. . . . . . .
. . . . . . .
. . . . . . .
. . . . . . .
. . . . . . .Py,1 . . . . . Py,x
Abbildung 1: Mögliche Darstellung eines Graustufenbildes in der Computer-Vision
Anders als im geometrischen Koordinatensystem, ist der Nullpunkt in der Bildver-arbeitung im oberen linken Eck angesiedelt (siehe 1). Ausgehend davon nimmt derx-Wert nach rechts zu und der y-Wert wird nach unten hin größer.Die Repräsentation von RGB-Bildern in der Computer Vision basiert auf dem gleichen

2 Grundlagen für die Computer Vision 9
Ansatz. Da bei den RGB-Bildern jedoch drei Kanäle für die Farben Rot, Grün undBlau existieren, ist diese leicht erweitert worden. Diese Erweiterung für RGB-Bilderist auf zwei Wegen möglich: Eine der Varianten besteht darin, statt in jedem Eintragder Matrix nur einen Wert zu speichern, gleich drei Werte abzulegen. Statt nur denGrauwert in einem Eintrag zu speichern, wird in einem Eintrag der Rotwert, Grünwertund Blauwert gesichert.Die andere Möglichkeit besteht darin, für jeden Kanal des RGB eine eigene Repräsen-tation (Matrix) zu erstellen.
2.3 RGB-Modell
Im Folgendem Abschnitt wird eine Übersicht über das RGB-Modell und dessen Um-wandlung zum Graustufenbild gegeben.
2.3.1 Grundlage
Nach der Dreifarbentheorie lässt sich jede Farbe durch das Mischen der Primärfarbenerhalten. Das RGB-Modell basiert auf dieser Methode und nutzt die Farben Rot, Grünund Blau, um andere Farben auszudrücken. Der Farbanteil der Farben kann je nachGröße des Speicherplatzes, den sie beziehen unterschiedliche Werte einnehmen. In derRegel wird jedem Farbanteil ein Byte (8 Bit) zugewiesen, wodurch Werte zwischen 0und 255 möglich sind (28). Insgesamt existieren in der 1 Byte Darstellung ausreichendFarben (ca. 16 Millionen), um alle wichtigen Informationen zu repräsentieren. Da dasRGB Modell Farben addiert, um andere Farben zu erhalten (additive Farbmischung)startet jede Farbe mit der schwarzen Farbe. Erst mit dem Addieren einer Primärfarbeentstehen andere Farben [BB09].

2 Grundlagen für die Computer Vision 10
Abbildung 2: Darstellung des RGB Farben Spektrums als drei Dimensionaler Würfel[BB09]
2.3.2 Umwandlung zum Graustufenbild
Für die Gesichtswiedererkennung spielen Graustufenbilder eine wichtige Rolle, da mitdiesen schneller und einfacher zu arbeiten ist. Bilder von Gesichtern liegen oftmals inder Farbversion vor, weswegen diese erst in ein Graustufenbild umgewandelt werdenmüssen. Das RGB-Bild hat mit Rot, Grün und Blau drei Kanäle zu Verfügung, umFarben zu generieren. Das Graustufenbild besitzt dagegen nur einen Kanal, dement-sprechend kann ein Pixel des Graustufenbildes nur einen Grauwert annehmen. Je höherder Wert des Grauwertes desto heller erscheint der Pixel. Einer der einfachsten Algo-rithmen für das Umwandeln eines RGB-Bildes in ein Graustufenbild ist wahrscheinlichdas Bilden des Durchschnittes über alle drei Kanäle.
Grauwert = 13 ·R + 1
3 ·G+ 13 ·B (1)
Dadurch, dass das menschliche Auge Farben unterschiedlich stark wahrnimmt, wirdhäufig bei der Umwandlung des Bildes in der Computer Vision versucht dies zu be-rücksichtigen. Aus diesem Grund werden die einzelnen Farbkanäle unterschiedlich starkgewichtet. Die Farben Grün und Rot werden heller wahrgenommen als die blaue Farbe[BB09]. Daraus ergibt sich zur Umwandlung folgende Gleichung:
Grauwert = 0.299 ·R + 0.587 ·G+ 0.114 ·B (2)

2 Grundlagen für die Computer Vision 11
(a) RGB-Bild (b) Graustufenbild
Abbildung 3: Umwandlung des RGB Bildes zum Graustufenbild
2.4 Histogramme
Im Folgendem Abschnitt wird eine Übersicht über Histogramme gegeben.
2.4.1 Grundlage
Das Histogramm eines Bildes beschreibt das statistische Aufkommen bestimmter Far-ben. Bei einem 1 Byte großen Graustufenbild würde beispielsweise das Auftreten der256 Farben gezählt, indem die Farbe jedes Pixels betrachtet wird. Die Ausgabe einerHistogramm Erstellung ist ein Vektor. Oftmals wird dieser Vektor als Balkendiagrammvisualisiert, dessen X-Achse die Intensität der verschiedenen Pixel angibt und dessenY-Achse die Anzahl der Pixel mit genau dieser Intensität darstellt. Das Histogrammist so dargestellt, dass von links nach rechts die Intensität heller wird. In dem einfachenFall eines 8-Bit Graustufenbildes würde das Histogramm beispielsweise das Aufkom-men der 256 Graustufen festhalten. Dabei sind im linken Teil des Histogramms diedunklen Pixel des Bildes angesiedelt, die nach rechts hin immer heller werden. JederBalken im Histogramm ist dabei definiert als,
h(i) = die Anzahl der Pixel in einem Bild mit der Intensität i [BB09]. (3)
Die Verteilung der Pixel lässt sich aus dem Histogramm somit leicht ablesen. Da dasHistogramm das statistische Aufkommen bestimmt, gehen globale, räumliche Informa-tionen des Bildes verloren. Dementsprechend lässt sich aus einem Histogramm nichtmehr das ursprüngliche Bild rekonstruieren.Oftmals ist es auch nützlich zu wissen wie weit das Aufkommen der Farbwerte der Pi-xel von einer Gleichverteilung entfernt ist. Um dies ebenfalls leicht abzulesen, wird einkumulatives Histogramm erstellt, indem jedem Grauwert die Summe aller Aufkommenbis zu diesem Grauwert zugerechnet wird.
H(g) =∑
h(i) (4)

2 Grundlagen für die Computer Vision 12
(a) Graustufenbild (b) Histogramm
Abbildung 4: Histogramm eines Graustufenbild
Bei einer Gleichverteilung aller Grauwerte wäre die Darstellung des kumulativen Hi-stogramms eine monoton steigende Gerade.
Diese beiden Histogramme und die Informationen, die mit dem Bild extrahiert wer-den, können genutzt werden, um das Bild besser zu verstehen und eventuell nötige An-passungen vorzunehmen. Beispielsweise lässt sich damit herausfinden, ob Bilder über-oder unterbelichtet sind. Zusätzlich zur Helligkeit gibt ein Histogramm Auskunft überden Kontrast und die Intensitätsverteilung der Pixel in einem Bild. Dies ist unter an-derem in der Gesichtswiedererkennung sinnvoll, um Unregelmäßigkeiten gegebenenfallszu normieren.
2.4.2 Histogramm Ausgleich
Der Histogramm Ausgleich wird genutzt, um den Kontrast von Bilder zu verbessern.Oftmals ist es notwendig Bilder soweit anzupassen, dass ihre Intensitätsverteilung ähn-lich ist, um diese besser vergleichen und vereinheitlichen zu können [BB09]. Dies findetvor allem Verwendung bei über- oder unterbelichteten Bildern. Ziel des HistogrammAusgleichs ist es das Bild so anzupassen, dass das Histogramm dieses angepasstenBildes eine Gleichverteilung aufweisen würde. Dies wird bewerkstelligt, indem einePunktoperation auf jeden Pixelwert angewendet wird. Der Punktoperat wird aus demKumulativen Histogramm generiert. Dieser ist wie folgt für jeden Pixelwert definiert:
2 Grundlagen für die Computer Vision 13
feq(a) = H(a) · K − 1MN
(5)
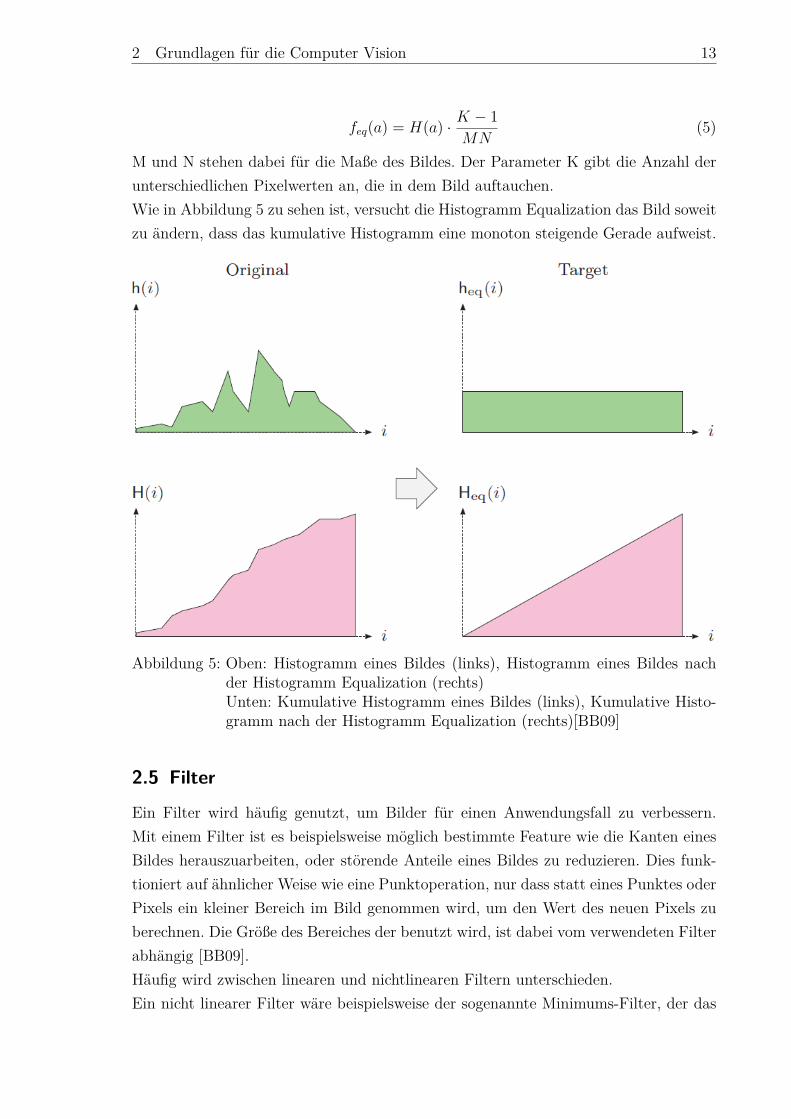
M und N stehen dabei für die Maße des Bildes. Der Parameter K gibt die Anzahl derunterschiedlichen Pixelwerten an, die in dem Bild auftauchen.Wie in Abbildung 5 zu sehen ist, versucht die Histogramm Equalization das Bild soweitzu ändern, dass das kumulative Histogramm eine monoton steigende Gerade aufweist.
Abbildung 5: Oben: Histogramm eines Bildes (links), Histogramm eines Bildes nachder Histogramm Equalization (rechts)Unten: Kumulative Histogramm eines Bildes (links), Kumulative Histo-gramm nach der Histogramm Equalization (rechts)[BB09]
2.5 Filter
Ein Filter wird häufig genutzt, um Bilder für einen Anwendungsfall zu verbessern.Mit einem Filter ist es beispielsweise möglich bestimmte Feature wie die Kanten einesBildes herauszuarbeiten, oder störende Anteile eines Bildes zu reduzieren. Dies funk-tioniert auf ähnlicher Weise wie eine Punktoperation, nur dass statt eines Punktes oderPixels ein kleiner Bereich im Bild genommen wird, um den Wert des neuen Pixels zuberechnen. Die Größe des Bereiches der benutzt wird, ist dabei vom verwendeten Filterabhängig [BB09].Häufig wird zwischen linearen und nichtlinearen Filtern unterschieden.Ein nicht linearer Filter wäre beispielsweise der sogenannte Minimums-Filter, der das
2 Grundlagen für die Computer Vision 14
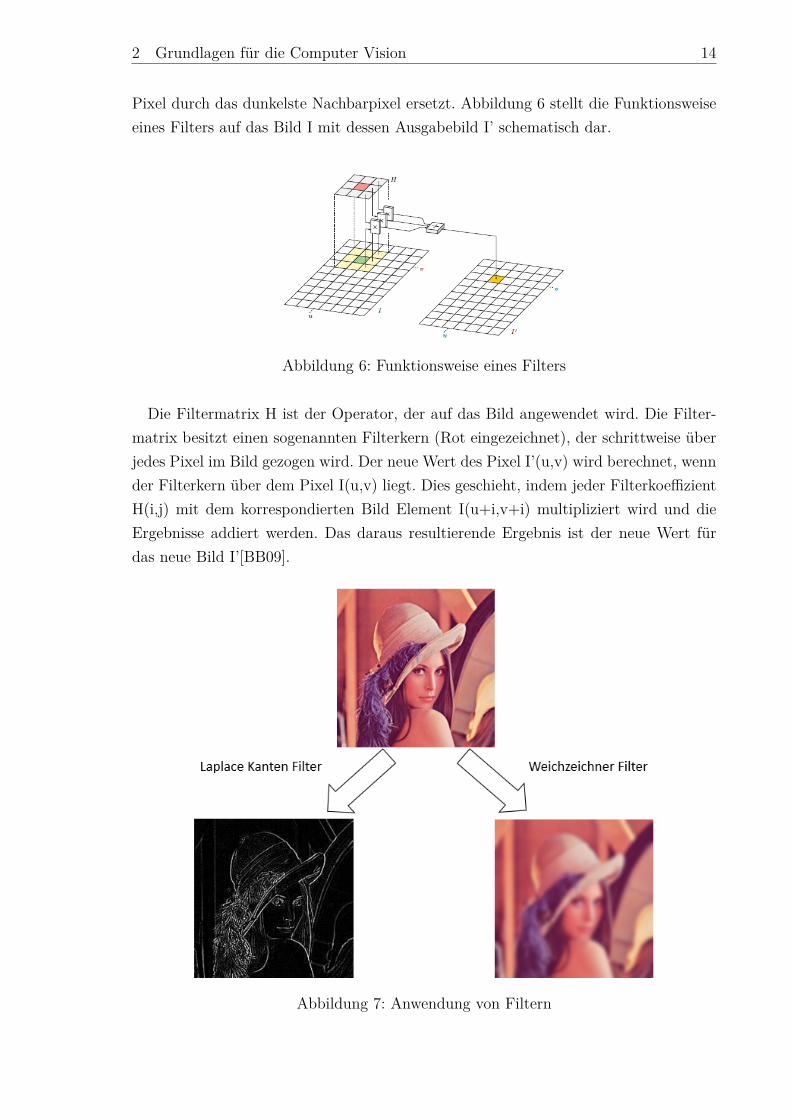
Pixel durch das dunkelste Nachbarpixel ersetzt. Abbildung 6 stellt die Funktionsweiseeines Filters auf das Bild I mit dessen Ausgabebild I’ schematisch dar.
Abbildung 6: Funktionsweise eines Filters
Die Filtermatrix H ist der Operator, der auf das Bild angewendet wird. Die Filter-matrix besitzt einen sogenannten Filterkern (Rot eingezeichnet), der schrittweise überjedes Pixel im Bild gezogen wird. Der neue Wert des Pixel I’(u,v) wird berechnet, wennder Filterkern über dem Pixel I(u,v) liegt. Dies geschieht, indem jeder FilterkoeffizientH(i,j) mit dem korrespondierten Bild Element I(u+i,v+i) multipliziert wird und dieErgebnisse addiert werden. Das daraus resultierende Ergebnis ist der neue Wert fürdas neue Bild I’[BB09].
Abbildung 7: Anwendung von Filtern

2 Grundlagen für die Computer Vision 15
In Abbildung 7 wird die Anwendung von zwei Filtern gezeigt. Das Weichzeichnenwird erzeugt, indem eine Filtermatrix verwendet wird, die die umliegenden Nachbar-pixel verwendet, um den Durchschnitt zu berechnen. Entgegengesetzt dazu wird beimLaplace-Kantenfilter der Unterschied zwischen den Pixel und dessen Nachbarn dazugenutzt, um Kanten im Bild zu berechnen.

3 Übersicht zur Gesichtswiedererkennung 16
3 Übersicht zur GesichtswiedererkennungDiese Kapitel gibt zuerst einen grundsätzlichen Überblick zum Ablauf der Gesichts-wiedererkennung. Nachfolgend werden zusätzlich die bekanntesten Methoden zur Ge-sichtswiedererkennung genauer erläutert.
3.1 Typischer Ablauf der Gesichtswiedererkennung
Die Gesichtswiedererkennung setzt sich aus mehreren Bereichen zusammen. Abbildung8 zeigt beispielsweise einen möglichen Ablauf der Gesichtswiedererkennung. Dieser kannin die Phasen Gesichtserkennung, eventuell benötigtes Vorbearbeiten der Daten, Ex-trahieren der Gesichtsmerkmale und anschließendes Wiedererkennen des Gesichtes un-terteilt werden. Teilweise kann auf die Phasen Gesichtserkennung und Vorbearbeitungder Daten verzichtet werden, falls die Testbilder und Trainingsbilder bereits vorbear-beitet vorliegen.Der folgende Abschnitt gibt einen kurzen Überblick über die einzelnen Phasen derGesichtswiedererkennung:
Gesichtserkennung: Obwohl die Face Detection ein eigenes Gebiet der Computer Vi-sion ist, ist dieses eng mit der Gesichtswiedererkennung verknüpft. Dies hat meh-rere Gründe: Liegen beispielsweise die Bilder der Gesichter unvorbereitet vor, somuss erst das Gesicht in diesem Bild gefunden und herausgeschnitten werden.Dies ist vor allem sinnvoll, wenn mehrere Gesichter in einem Bild vorkommen.Bei den meisten Methoden zur Wiedererkennung wird davon ausgegangen, dassbereits nur ein Gesicht auf dem übergebenen Bild zu sehen ist.
Preprocessing: Eng verbunden mit der Gesichtswiedererkennung ist das Vorbearbei-ten der Bilder, da die Gesichtserkennung genutzt werden kann, um sich auf denBereich des Bildes mit dem Gesichtes zu konzentrieren und weitere unwichtigeInformationen auf dem Bild zu verdecken. Zusätzlich wird in dieser Phase ver-sucht die einzelnen Bilder untereinander zu normieren. Die Idee dahinter ist, dassdie Gesichter insgesamt ähnlich bis gleich aufgebaut sind und somit Unregelmä-ßigkeiten wie Verschiebungen oder Rotation beseitigt werden. Neben besserenErgebnissen bei der Gesichtswiedererkennung führt dies zu einer besseren Per-formance, wodurch in späteren Phasen weniger Rechenleistung für die Wiederer-kennung nötig ist.
Feature Extraction: Diese Phase entzieht dem Bild die wichtigsten Informationen umdamit später Gesichter untereinander vergleichen zu können. Wie und welcheInformationen herausgezogen werden hängt von der Herangehensweise des ver-wendeten Algorithmus ab.

3 Übersicht zur Gesichtswiedererkennung 17
Face Recognition: Das eigentliche Wiedererkennen der Gesichter wird in der Litera-tur häufig einer eigenen Phase zugeschrieben. Hier werden die Merkmale, bzw.Informationen, die aus den Gesichtern herausgelesen wurden dazu genutzt, umdiese mit dem wiederzuerkennenden Gesicht zu vergleichen und bei einem Trefferdie ID der Wiedererkannten Person auszugeben.
Abbildung 8: Phasen der Gesichtswiedererkennung
3.2 Mögliche Herangehensweisen zur Gesichtswiedererkennung
Das Gebiet der Gesichtserkennung ist sehr beliebt. Jährlich entstehen hunderte neueArbeiten über diesen Bereich. Dementsprechend gibt es eine große Anzahl von verschie-denen Herangehensweisen, die sich dem Problem der Wiedererkennung von Gesichternwidmen. Diese Herangehensweisen unterscheiden sich teils stark von anderen, teils sinddiese aber nur kleine Anpassungen von bereits existierenden Algorithmen. Trotz diesergroßen Anzahl lassen sich diese Methoden in drei Unterkategorien einteilen:
Die Geometrische Feature basierte Herangehensweise nutzt lokale Merkmale, wieAugen, Nasen, Mund Position und Beziehungen wie Auge zu Auge Distanz um Gesich-ter wieder zu erkennen.
Die Holistische Herangehensweise nutzt anstelle von lokalen Merkmalen im Ge-sicht das komplette Gesicht oder auch Bild zur Gesichtswiederkennung. Diese Art derWiedererkennung nutzen oft die Diskriminanzanalyse oder Hauptkomponentenanalyseum die Feature Vektoren zu reduzieren. Hierunter zählen Methoden wie Fisherfacesoder Eigenfaces.

3 Übersicht zur Gesichtswiedererkennung 18
Die Hybride Herangehensweise wird genutzt, falls Methoden sich weder in dieGeometrische Feature basierte, beziehungsweise in die Holistische Herangehensweiseeingliedern lassen. Solche Methoden basieren oft auf Teilen beider Methoden um Ge-sichter wiederzuerkennen.
Nachfolgend werden verschiedene Methoden zur Merkmalsextraktion vorgestellt.
3.3 Local Binary Pattern
Local Binary Pattern (LBP) ist ein sehr beliebtes Thema in der Computer Vision, dadiese schnell und einfach zu verstehen sind. Ursprünglich wurden LBP zur Klassifizie-rung von Texturen genutzt. Inzwischen lassen sich durch Anpassungen diese auch zumWiedererkennen von Gesichtern nutzen.Die Grundidee von LBP ist es die lokale Struktur festzuhalten, indem jedem Pixelein Wert zugeordnet wird, der durch einen Vergleich der Intensität mit jedem Nach-bar Pixel erstellt wird. Ist die Intensität des zu vergleichenden Pixel höher so wirdeine 1 geschrieben, andernfalls eine 0. Das Ergebnis ist eine Binärsumme, die durchAblesen der erstellten Werte in eine Richtung entsteht. Aus den so entstehenden Bi-närsummen wird ein Histogramm erstellt, das genutzt werden kann um Texturen zuerkennen. Das Histogramm selbst hat dabei 256 (28) verschiedene Einträge, da jedesPixel acht Nachbarn hat und diese jeweils zwei Werte (0 oder 1) annehmen können.Durch dieses Vorgehen haben die Local Binary Patterns den Vorteil, robuster gegenLichteinstrahlung und Pose zu sein [Pie].
Abbildung 9: Beispielberechnung des Lokal Binary Pattern für ein Pixel [AHP06]
3.3.1 Variationen am Radius und Anzahl der Punkte
Um auch einen Deskriptor für Texturen unterschiedliche Größe zu erstellen, wurde derLBP Pattern dahingehend erweitert, dass auch unterschiedlich große Nachbarschaftengenutzt werden können [AHP06]. Die Nachbarschaft eines Pixel ist dabei eine Aus-wahl von Punkten, die sich mit einem bestimmten Radius um das Pixel befinden. DieSchreibweise ist definiert als :
(P,R) bei der P die Anzahl der Punkte auf dem Kreis ist und R der Radius ist. (6)

3 Übersicht zur Gesichtswiedererkennung 19
Falls sich die Punkte des Kreises nicht auf dem Zentrum eines Pixels befinden, wirdeine bilineare Interpolation benötigt um sich den nächsten Zentren anzunähern. Wiein 10 zu sehen ist, ist (8,1) ein Kreis mit Radius von 1, auf welchem 8 Punkte markiertsind.
Abbildung 10: Nachbarkeitbeispiele der Größe (8,1), (16,2) und (8,2)[AHP06]
3.3.2 Uniforme Binary Patterns
Um die Größe des Histogramm Vektors zu reduzieren wurden sogenannte Uniforme Lo-cal Binary Pattern eingeführt [OPM02]. Uniform Binary Pattern haben höchstens zweiBitübergänge im Patter. Dementsprechend wäre 00000000, 00011000 und 11110000 bei-spielsweise Uniform. Pattern mit vier Übergänge wie 11001100 oder mit sechs 10101100wären nicht mehr uniform. Der Unterschied befindet sich jedoch in der Erstellung desHistogramms aus den Binary Patterns. Während jeder unterschiedlicher Uniforme Pat-tern einen Eintrag im Histogramm bekommt, werden alle nicht uniformen Pattern demgleichen Eintrag zugeordnet [AHP06].Das Histogramm eines 1 Byte großen Graustufenbildes kann 256 Einträge (bins) auf-weisen, mit Hilfe der uniformen Pattern können die Einträge des Histogramms jedochauf 59 (58 uniforme Pattern + 1 Pattern für alle nicht uniforme) reduziert werden. Dieshat viel kleinere Vektoren zur folge, mit denen einfacher zu Arbeiten ist. Die meistenvorkommenden Pattern in einen Graustufenbild sind laut Matti Pietikäinen [AHP06]Uniform. So besteht ein 1 Byte großes Graustufenbild zu 90,6% aus uniformen Pattern(8,1). Mit der Größe des Radius des Kreises nimmt dies aber ab, bei (16,2) sind nurnoch 70% aller Pattern uniform.
3.3.3 Anpassungen für die Gesichtswiedererkennung
Das Problem der Local Binary Pattern für die Gesichtserkennung ist hierbei, dass dieglobalen Informationen des Gesichtes, wie der Aufbau eines Gesichtes, durch die Nut-zung des Histogramms verloren gehen. Aus diesem Grund wird das Bild in viele kleinereSegmente geteilt. Für jedes dieser kleineren Bildsegmente wird das Histogramm nach

3 Übersicht zur Gesichtswiedererkennung 20
obigem Schema berechnet. Aus den daraus resultierenden Histogrammen wird ein De-skriptor für das gesamte Bild erstellt, in dem die einzelnen Histogramme miteinanderkonkateniert werden. Der somit entstandene Deskriptor basiert somit auf drei verschie-denen Level der Lokalität[AHP06]Das erste Level ist das Vergleichen der einzelnen Pixel miteinander. Auf dem zweitenLevel werden die Binärsummen genutzt, um das Histogramm eines kleinen Bereicheszu erstellen. Letztendlich wird durch das konkatenieren dieser "lokalen" Histogrammeein globaler Deskriptor erstellt, der die Informationen des gesamten Bildes nutzt undder dazu genutzt werden kann, um Gesichter wieder zu erkennen. Zusätzlich werdendie einzelnen Segmente des Bildes unterschiedlich stark gewertet. So ist vor allem derAugenbereich für die Gesichtserkennung aussagekräftig, aber Bereichen wie Mund undSchläfen kommen ebenso mehr Bedeutung zu.
Abbildung 11: LBP Histogramm Gewichtung [AHP06]

3 Übersicht zur Gesichtswiedererkennung 21
3.4 Eigengesichter
Die Eigengesichter gehört dem holistischen Methodenbereich zur Gesichtswiedererken-nung an, die zudem auf der Hauptkomponentenanalyse basieren. Die Hauptkompo-nentenanalyse erstellt Hauptkomponenten (Linearkombinationen), um mit Hilfe diesergroße Matrizen vereinfacht darzustellen.
Auf diesem Grundgedanke baut die Eigengesichter Herangehensweise auf. Die Ma-trixrepräsentation (siehe 2.2) der Gesichtsbilder werden in Vektoren umgebaut, damitdiese Punkte im Raum repräsentieren. Dies geschieht, indem die Zeilen der Matrix derReihe nach hinten angehängt werden. Die Matrix aus Kapitel 2.2 könnte dann in etwaso aussehen:
vector = (p1,1, ., ., ., p1,x, ...., py,1, ., ., ., py,x) (7)
Die Vektoren der Gesichter bilden einen sogenannten Gesichtsraum. Die Idee ist, durchdas Messen der Distanz in dem Gesichtsraum, die Ähnlichkeit verschiedener Gesichterzu ermitteln. Liegt die Distanz in einem bestimmten Bereich so gilt das Gesicht alserkannt. Zusätzlich lässt sich anhand der Distanz erkennen, ob es sich bei dem Bild umein Gesicht handelt, indem ermittelt wird, ob das zu erkennende Gesicht im Bereichdes Gesichtsraumes liegt. Jedoch ist dieser Gesichtsraum selbst bei sehr kleinen Bildernsehr groß.Wird beispielsweise ein übliches Graustufenbild mit Länge und Breite 100 betrachtet,so besitzt der Vektor dieses Graustufenbildes bereits zehntausend Dimensionen. MitVektoren dieser Dimension Operationen auszuführen ist natürlich sehr rechenintensivund führt zu zusätzlichen Problemen bei der Gesichtsidentifizierung. Aus diesem Grundwerden diese Daten in einen kleiner dimensionierten Raum mit Hilfe der Hauptkompo-nentenanalyse versucht zu projizieren. Das Verfahren selbst wurde von Matthew Turkund Alex Pentland entwickelt [TP91] und gliedert sich in folgende Schritte:
Schritt 1: Aufgrund der Hauptkomponentenanalyse müssen die einzelnen Bilder normiertwerden. Aus diesem Grund wird bei der Eigengesichts Herangehensweise einDurchschnittsbild aus allen Gesichtern konstruiert, indem alle Gesichter addiertund durch deren Anzahl geteilt werden.
µ = 1n
n∑i=1
xi (8)
,wobei n die Gesamtanzahl aller Gesichterund x ein Gesicht aus dem Trainingsset ist.

3 Übersicht zur Gesichtswiedererkennung 22
Schritt 2: Das ermittelte Durchschnittsbild wird von jedem Bild abgezogen um die normier-ten Gesichter zu bekommen.
φi = xi − µ (9)
Schritt 3: Der nächste Schritt ist das Bauen der Kovarianz Matrix aus den normalisiertenGesichtern nach dem Schema:
C = 1n
n∑i=1
φiφTi = AAT (10)
Schritt 4: Aus der Kovarianz Matrix werden die Eigenwerte und Eigenvektoren berechnet.Der Vektor v ist dabei ein Eigenvektor der Matrix C, wenn dieser durch Mul-tiplikation mit C auf ein vielfaches von v abgebildet wird. Daraus ergibt sichfolgender Formel, bei der v der Eigenvektor und λ der Eigenwert ist.
Cv = λv (11)
Schritt 5: Nachdem die Eigenwerte berechnet wurden, werden die Eigenvektoren absteigendnach ihrem Eigenwert sortiert. Dabei bildet jeder Eigenvektor vi eine Spalte derMatrix V, der Eigenraum genannt wird.[WS00]
V = (v1, v2..., vn) (12)
Gesichtserkennung bei der Eigengesichtsmethode
Mit dem Eigenraum, der in Gleichung 12 erstellt wurde, ist es möglich die Gesichts-wiedererkennung durchzuführen.Bevor das wiederzuerkennende Gesicht wiedererkannt werden kann, müssen alle Trai-ningsbilder in den Gesichtsraum projiziert werden. Dies wird bewerkstelligt, indem dasSkalarprodukt vom Gesichtsraum mit jeden normalisierten Bild berechnet wird. Diedaraus resultierenden Vektoren sind die Eigengesichter - daher auch der Name dieserHerangehensweise. Jedes Trainingsbild lässt sich aus Addition der verschiedenen Ei-gengesichter rekonstruieren. Dabei werden die Eigengesichter für jedes Gesicht jedochunterschiedlich stark gewichtet.Abbildung 12 zeigt die ersten zehn Eigengesichter, die beim Training eines Datensetserstellt worden. Die Gesichter können dabei als globale Varianz über alle Gesichterwahrgenommen werden [ZT]. Durch die Sortierung der Eigenwerte stellen die vorders-ten Eigengesichter die größte Varianz dar. Die letzten Eigengesichter, die im Normalfalldie geringsten Varianz aufweisen, sind bei größeren Datensets oftmals nur noch ver-rauschte Bilder.

3 Übersicht zur Gesichtswiedererkennung 23
Um das zu klassifizierende Bild zu erkennen wird dieses ebenfalls in den Gesichts-raum projiziert. Davor muss dieses jedoch erst ebenfalls nach Schema 8 vereinheitlichtwerden. Ist dies geschehen muss lediglich der nächste Vektor im Gesichtsraum gefun-den werden um das Testbild zu klassifizieren. Da über die Distanz der Vektoren dieÄhnlichkeit der Gesichter zueinander bestimmt werden kann, kommt als Klassifikatordie Euklidische Distanz zum Einsatz. Diese sucht lediglich den nächsten Vektor imUnterraum um das Gesicht zu klassifizieren.
Abbildung 12: Darstellung von Eigengesichter des faces94 Datensets
3.5 Fishergesichter
Das Fishergesichtsverfahren ist genauso wie die Eigengesichtsherangehensweise eineholistische Methode zur Gesichtswiedererkennung. Beide Verfahren sind dabei ähnlichaufgebaut. Das Problem bei der Eigengesichtsmethode ist, dass bei Klassifizierung einesGesichtes, das sich in Mimik und Beleuchtung von den trainierten Gesichtern unter-scheidet, es zu einer falschen Klassifizierung kommen kann. Dies liegt daran, dass dieVariation in Mimik und Beleuchtung zu einer höheren Varianz, als der Unterschied zueinem Gesicht einer anderen Person führen kann. Um dies zu vermeiden werden beidem Fishergesichtsverfahren die Gesichter in Klassen aufgeteilt. Genauso wie bei demEigengesichtsverfahren werden die einzelnen Bilder in einen Unterraum projiziert. Beider Fishergesichtsmethode wird versucht die Varianz der Bilder von ähnlichen Personen(Klassen) zu minimieren und zugleich die Varianz der Bilder unterschiedlicher Perso-nen zu maximieren. Gesichter einer Person werden dadurch im projizierten Unterraumunabhängig von deren Unterschiede (bsp. durch Zeit, Licht hervorgerufen) nah bei-einander liegen, währenddessen die Gesichter anderer Personen weiter davon entferntsein werden. Insgesamt ist das Fishergesichter Verfahren dem Eigengesichtsverfahrenähnlich aufgebaut und gliedert sich in folgende Schritte:

3 Übersicht zur Gesichtswiedererkennung 24
Schritt 1: Ähnlich wie bei dem PCA basierten Verfahren wird auch hier ein Durchschnitts-gesicht aller Gesichter erstellt.
µ = 1n
n∑i=1
xi (13)
Da die einzelnen Gesichter einer Klasse angehören, wird zusätzlich ein Durch-schnittsgesicht jeder Klasse (Person) erstellt.
µk = 1nk
nk∑i=1
xi,k (14)
bei der nk die Anzahl aller Gesichter in einer Klasse,und xi,k ein Gesicht der Klasse k aus dem Trainingsset ist.
Schritt 2: Darauffolgend wird sowohl die Zerstreuungsmatriz für die Zerstreuung der Bilderin jeder Klasse berechnet
Sw =C∑
i=1
ni∑j=1
(xji −mj)(xji −mj)T (15)
als auch die Zerstreuung zwischen den einzelnen Klassen,
Sb =C∑
i=1ni(mi −m)(mi −m)T (16)
bei der ni die Anzahl der Bilder in der Klasse i,m das Durchschnittsgesicht aller Gesichter,und mj das Durchschnittsgesicht einer Klasse (Person) ist.
Schritt 3: Der Fisher Algorithmus versucht nun eine Projektion W zu finden, der die Klassenbestmöglich trennt [Faca]
Wopt = argmaxw|W TSBW ||W TSWW |
(17)
Schritt 4: Die Berechnung von W erfolgt auf dem selben Weg wie bei dem Eigengesichts-verfahren, indem das generelle Eigenproblem gelöst wird, [Faca]
SBvi = λiSwviw (18)
bei der v ein Eigenvektor und λ der dazugehörige Eigenwert ist.
Die Klassifizierung selbst erfolgt analog zur Eigengesichtsmethode.

3 Übersicht zur Gesichtswiedererkennung 25
3.6 Feature basierte Herangehensweise
Einer der ersten Versuche automatisch Gesichter zu klassifizieren lag darin, Positionenwichtiger Gesichtsparteien wie Augen und Mund zu extrahieren um damit einen Vektorzu konstruieren, der ein Gesicht beschreibt. Der Vektor wurde dabei aus 16 sogenannterFeatures konstruiert. Die erfolgreiche Klassifikation lag bei einem 20 Bilder Datensetbei 75%.[BP92]. Jedoch nahm die erfolgreiche Klassifizierung recht schnell bei der Hin-zunahme weitere neuen Personen ab.Später veröffentlichte R. Brunnelli eine erweiterte Form dieser Herangehensweise. DerUnterschied ist hierbei, dass der Vektor zur Klassifizierung eines Gesichtes aus Punktenbesteht, [BP92]
• die viele Informationen des Gesichtes festhalten,
• robust gegen Licht und Stimmung der Person sind
• und bei denen die Bestimmung der Punkte möglichst einfach ist.
Abbildung 13 zeigt ein Beispielgesicht mit Markierungen solcher verwendeter Features.
Abbildung 13: Verwendete Merkmale im Gesicht zur Vektorerstellung[BP92]
Insgesamt wurden 22 Features zur Vektorerstellung genutzt. Darunter befinden sich[BP92]
• die Position von Nase, Mund und Augen,
• die Dicke der Augenbrauen über der Pupille des Auges,

3 Übersicht zur Gesichtswiedererkennung 26
• die Gesamtbreite des Gesichtes und Informationen zur Breite und Höhe von wich-tigen Merkmalen,
• sowie eine Beschreibung der Form des Kinns durch mehrere Radien.
Sehr wichtig bei dieser Herangehensweise ist die Pose und Perspektive der Gesichter.Dies liegt unter anderem daran, dass beispielsweise Informationen wie die Höhe der Au-genbrauen zur Klassifizierung genutzt werden. Ist das trainierte Gesicht beispielsweisemehr rotiert als das zu klassifizierende Gesicht würde keine erfolgreiche Klassifizierungmehr stattfinden. Aus diesem Grund müssen die Gesichter vorher normiert werden,damit sie unabhängig von Rotation, Skalierung und Position sind.Die wichtigsten Schritte umfassen dabei[BP92]:Das Finden der Augenpositionen und Winkels, um mit Hilfe dieser die Skalierung an-zupassen, indem die Distanz zwischen den Augen gefunden wird und das Gesicht nacheinem Referenz Template skaliert wird.Zusätzlich wird die Helligkeit des Bildes angepasst, indem jeder Pixel durch die durch-schnittliche Pixelintensität der Nachbarschaft geteilt wird, um Helligkeitsschwankun-gen auszugleichen.
Um das Finden der Gesichtsmerkmale und Kanten zu vereinfachen, wird ein Inte-gralbild erstellt. Aber anstatt das Integralbild als Ganzes zu nutzten, wird es in zweiBereiche gegliedert. Zum einen in die Vertikale Integral Projektion
V (x) =y2∑
y=y1
I(x, y) (19)
und die Horizontale Projektion
H(x) =x2∑
y=x1
I(x, y) (20)
Diese Aufteilung hat den Vorteil, dass aus der Horizontalen Projektion leichter Infor-mationen wie die Breite des Gesichtes und der Nase abgelesen werden können.Aus der Vertikalen Projizierung können dagegen Informationen, wie Position von be-stimmten Merkmalen und Höheninformationen entnommen werden.[BP92].Die Klassifizierung erfolgte dann über den nächsten Nachbar Klassifizierer. Mit dieser
Herangehensweise wurden schon deutlich bessere Ergebnisse erzielt. So besitzt es beieinem 20 Klassen großen Datenset eine Genauigkeit von circa 85%. Jedoch weißt dieHerangehensweise auch eine relativ große abnehmende Genauigkeit bei der Hinzunahmeneuer Klassen auf. Zusätzlich ist diese sehr empfindlich gegenüber Verdeckungen undzeitlichen Änderungen.

3 Übersicht zur Gesichtswiedererkennung 27
Abbildung 14: Darstellung von einem Integralbild eines Gesichtes[BP92]
3.7 Convolutional Neural Networks
Convolutional oder auch gefaltete Neuronale Netzwerke (CNN) sind eine Art von Neu-ronalen Netzen, die vor allem Aufgaben im Bereich der Computer Vision automatisierensollen. Optische Zeichenerkennung, Gesicht oder Objekt Erkennung, aber auch Iden-tifizierung von Objekten und Personen, sind Bereiche der Computer Vision in denengefaltete Neuronale Netze bereits erfolgreich zum Einsatz kommen. In diesem Abschnittwird ein Überblick über gefaltete Neuronale Netze gegeben.Ein gefaltetes Neuronales Netztwerk kann aus vielen Layern bestehen. Die wichtigs-
ten Layer eines CNN können dabei von folgendem Typ sein:
• Convolutional Layer
• (Max)-pooling Layer
• Fully Connected Layer
Im folgendem wird über diese Layer ein Überblick gegeben. Abbildung 15 stellt denMöglichen Aufbau eines Convolutional Network dar.

3 Übersicht zur Gesichtswiedererkennung 28
Abbildung 15: Beispiel eines Convolutional Neural Networks [CNNa]
3.7.1 Convolutional Layer
Der Convolutional Layer ist der Kern des gefalteten Netzwerk. Die Hauptaufgabe die-ses Layers ist es Merkmale des Bildes zu extrahieren. Dieser Output wird berechnet,indem ein Filter/Kernel (siehe 2.5) über das Bild gelegt wird. Das Filterfenster wirdschrittweise über jedes Pixel im Bild gezogen, um den Wert für das Pixel des neuenBildes zu berechnen. Dieses neue Bild wird Feature Map genannt [CNNb][CNNa]. Zuerwähnen ist jedoch, dass jeder Convolutional Layer mehrere Filter besitzen kann. DerOutput des Convolution Layer kann dementsprechend eine unterschiedliche Tiefe auf-weisen.Aus der Sicht des neuronalen Netzwerkes ist der Filter die Gewichtung für alle Neuro-nen im Convolutional Layer. Als Eingabe dienen kleinere quadratischer Bereiche vonPixeln aus dem Bild, die durch ein über das Bild gleitendes Fenster bestimmt werden.
Rezeptive Felder: Ein weiterer Grund für das Aufteilen in mehrere kleinerer Be-reiche ist die Performance. Da der Rechenaufwand zu hoch wäre, um jedes Neuronmit jedem Pixel auf dem Bild zu verknüpfen werden sogenannte Rezeptive Felder er-stellt. Diese Felder sind immer eine bestimmte Breite und Höhe groß. Jedes Neuronist somit nur noch mit allen Pixeln in einem kleinen Bereich des Bildes verknüpft. EinNebeneffekt ist zusätzlich der Erhalt der lokalen Struktur des Bildes.
3.7.2 Max-Pooling Layer
In der Regel ist nach jedem Convolutional Layer ein Pooling Layer geschaltet. DieAufgabe des Pooling Layer ist es die Größe der Feature Maps, die aus dem Convolutio-nal Layer gewonnen werden zu reduzieren [CNNa]. Dies bewirkt unter anderem aucheine Reduzierung des Rechenaufwands für später folgende Layers. Der Pooling Layer

3 Übersicht zur Gesichtswiedererkennung 29
reduziert die Dimension der Feature Maps, indem er kleine Blöcke der Feature Mapnimmt und diese zusammenfasst. Abbildung 16 veranschaulicht die Funktionsweise desMax-Pooling Layers. Der obere Abschnitt des Bildes zeigt die Ausgabe des Convolu-tinal Layers bei dem 64 verschiedene Filter für das Eingabebild benutzt wurden. Nachdem Pooling Schritt verringert sich die Größe jeder Feature Maps von 224 x 224 auf112 x 112. Bei Max Pooling mit Filtergröße 2 x 2 wird in dem Filterbereich der größtevorkommende Wert als neuer Wert für die Reduzierte Feature Map gewählt (siehe Abb.16). Zudem wird durch das Wählen des stets größten Wertes die Robustheit gegen dieRotation bei der Erkennung verbessert.
Abbildung 16: Funktionsweise des Pooling Layers [CNNa]
3.7.3 Fully Connected Layer
Die Fully Connected Layers stehen meist am Ende des Neuronalen Netzes und kannaus mehreren Schichten bestehen. Diese verbinden die Neuronen des Layers mit allenAktivierungen der vorherigen Schicht. Der Fully Connected Layer nutzt die extrahier-ten Merkmale aus dem Convolutional Layer und dem Pooling Layer um das Bild zuklassifizieren. Oftmals wird in der Ausgabeschicht des Fully Connected Layers die Soft-

3 Übersicht zur Gesichtswiedererkennung 30
max Funktion genutzt, wodurch die Ausgabe des Neuronalen Netzes ein Vektor ist, dersummiert 1 ergibt.
3.7.4 Training des gefalteten Neuronalen Netzwerk
Um ein Aussagekräftiges Modell zu erhalten, muss dieses vorher trainiert werden. Ge-nauso wie bei herkömmlichen Neuronalen Netzen wird dazu Backpropagation genutzt.Das Training des Gefalteten Neuronalen Netzen lässt sich vereinfacht in folgendenSchritten ausdrücken:
Schritt 1: Das Neuronale Netzwerk wird mit zufälligen Werten initialisiert. Die Filter,die am Anfang des Neuronalen Netzes verwendet werden, sind somit mit zufäl-ligen Werten versehen. Wie bei einem herkömmlichen Feedforward NeuronalenNetz wird der Output des Netzes mit diesen Gewichtungen berechnet.
Schritt 2: Das Erwartete Ergebnis wird mit dem in Schritt 1 berechneten Ergebnisverglichen. Falls ein Unterschied vorliegt, wird dies als Fehler des NeuronalenNetzes angesehen.
Schritt 3: Wurde in Schritt 2 ein Fehler berechnet, so wird ausgehend von der Ausga-beschicht das Neuronale Netzwerk rückwärts durchgegangen. Dabei werden dieGewichtungen und damit die Filter soweit angepasst, dass bei erneuter Eingabeder gleichen Werte ein besserer Ergebnis resultieren würde.
Abbildung 17 visualisiert das gerade Genannte noch einmal. Eingabe ist ein Bild, aufdem ein Boot abgebildet ist. Das Gewünschte Ergebnis bei diesem Netzwerk ist, derFeature Vektor [0,0,1,0]. Da die Werte am Anfang zufällig initialisiert werden ist es sehrunwahrscheinlich diesen Vektor direkt als Ausgabe zu erhalten. Je nach Filter könnteder Ausgabe Vektor nach dem ersten Durchlauf beispielsweise den Vektor [0.1,0,5,0.2,0.2] annehmen. Das Neuronale Netzwerk wird deswegen rückwärts durchgegangen, umdie Werte so anzupassen, dass bei erneuter Eingabe der Ausgabe Vektor dem erwar-teten Vektor ähnlicher aussehen würde. Je mehr Trainingsbilder genommen werden,desto robuster ist das resultierende Modell. Zur Klassifizierung müssen die Gesichterlediglich in das Neuronale Netz eingespeist werden. Ausgabe ist entweder eine Matrix-Repräsentation, anhand deren ein Vergleich stattfinden kann oder ein Softmax-Vektor.

3 Übersicht zur Gesichtswiedererkennung 31
Abbildung 17: Training des Gefalteten Neuronalen Netzes [CNNb]
3.8 Weitere State of the Art Methoden
Dieser Abschnitt stellt ein paar aktuelle State of the Art Methoden kurz zusammen,die nicht auf Convolutional Neural Networks basieren.
3.8.1 High Dimensional LBP
Dieser Ansatz ist eine Erweiterung der in 3.3.2 vorgestellten Herangehensweise. An-statt die Local Binary Pattern für jedes Pixel im ganzem Bild zu berechnen, werdenhierbei ausschließlich fixe Bereiche wichtiger Punkte wie Augen, Nase und Mundpositi-on gewählt (Beispielsweise der 20 x 20 Bereich um das Auge). Dieser fixe Bereich wirdvon unterschiedlichen Skalierungen des Bildes genommen um den Feature Vektor zubauen[CCWS13]. Dies hat den Vorteil, dass der fixe Bereich der großen Skalierung diedetaillierte Erscheinung um den betrachteten Punkt beschreibt und der fixe Bereichder kleinen Skalierung beispielsweise die Form und Aufbau des Gesichtes festhält.
Abbildung 18: Mehrskalige Repräsentation [CCWS13]

3 Übersicht zur Gesichtswiedererkennung 32
Die so generierte Feature Vektoren können bis zu 100000 Dimensionen aufweisen,weshalb es nötig ist eine Reduzierung vorzunehmen. Die Reduzierung erfolgt, indem zu-erst mit Hilfe der Hauptkomponentenanalyse der Feature Vektor komprimiert wird[CCWS13].Auf diese komprimierten Feature Vektoren wird eine überwachte Unterraum Lernme-thode wie LDA oder Joint Bayesian angewendet, um für die Gesichtserkennung wichtigeInformationen zu extrahieren.
Nachdem diese Vorgehensweise für alle Bilder im Trainingsset angewendet wurde,kann eine Matrix konstruiert werden, mit der hoch dimensionierte Feature Vektorendirekt auf klein dimensionierte projiziert werden können.Mit Hilfe dieser können die zu testenden Bilder auf eine schnelle Weise in niedrig
dimensionierte Feature Vektoren umgewandelt werden, die mit den Feature Vektorendes Trainingssets auf Ähnlichkeiten verglichen werden kann. In Abbildung 20 ist derAblauf schematisch dargestellt.
Abbildung 19: Ablauf der Hochdimensionalen LBP Herangehensweise [CCWS13]
3.8.2 High Fidelity Pose and Expression Normalization
Viele Fehler bei der Wiedererkennung geschehen durch die unterschiedlichen Posen undAusdrucke der Personen. Diese Herangehensweise versucht diese Fehler zu reduzieren,

3 Übersicht zur Gesichtswiedererkennung 33
indem eine Normierung der Gesichtspartie vorgenommen wird. Anstatt der herkömmli-chen Vorverarbeitungspipeline, bei der die Gesichter lediglich gedreht werden und ver-schiedene Pixeloperationen durchgeführt werden, können hier beispielsweise gedrehteGesichter zu einem Frontalgesicht rekonstruiert werden und Ausdrücke des Gesichtesvereinheitlicht werden. Wie in Abbildung 20 zu sehen, besteht der erste Schritt deshalbdarin verschiedene Landmarks im Gesicht zu bestimmen, die mit einem 3D Face Mo-del gepaart werden, um damit die Pose des Gesichtes zu ermitteln und später leichterdie Gesichtstextur auf Pixel abzubilden [ZLY+15]. Mit Hilfe dieses Face Models ist esmöglich das Gesicht in eine frontale Position zu bringen. Zusätzlich wird versucht denAusdruck und die Stimmung des Gesichtes in einen neutralen Zustand zu bringen, derdann bei allen Gesichtern einheitlich ist. Die Stellen im Gesicht, die vorher im Gesichtdurch die Pose verdeckt waren, werden rekonstruiert, indem unter anderem durch dasSpiegeln des Gesichtes Informationen hinzugewonnen werden. Dieses erweiterte Vor-verarbeiten erhöhte die ohnehin gute Erkennungsrate bei den High Dimesional LocalBinary Pattern um circa 2% auf 95%.
Abbildung 20: Ablauf der erweiterten Vorverarbeitung [ZLY+15]
3.9 Ergebnisse
Für den Vergleich von Herangehensweisen zur Gesichtswiedererkennung ist ein Daten-set notwendig, das zum einen einheitlich ist und zum anderen sämtliche Herausfor-derungen des Alltags mit einschließt. Darunter zählt unter anderem die Problematikbei der Erkennung durch Mimik, Pose und der Beleuchtung. Da das „Labeld Faces inthe Wild (LFW)“[4] Datenset aus Bildern des öffentliche Lebens besteht, sind all dieseHerausforderung enthalten. Aus diesem Grund ist das LFW-Datenset häufig die ersteAnlaufstelle bei der Evaluation von neuen Algorithmen. Abbild 21 hält die Ergebnissevon verschiedenen State of the Art Methoden der Gesichtswiedererkennung fest.Auf der Y-Achse ist die Erkennungsrate der evaluierten Herangehensweisen zu findenund die X-Achse beschreibt die prozentuale Rate der falsch positiv wiedererkanntenGesichter. Die Evaluation zeigt, das mit der richtigen Vorverarbeitung Pipeline und
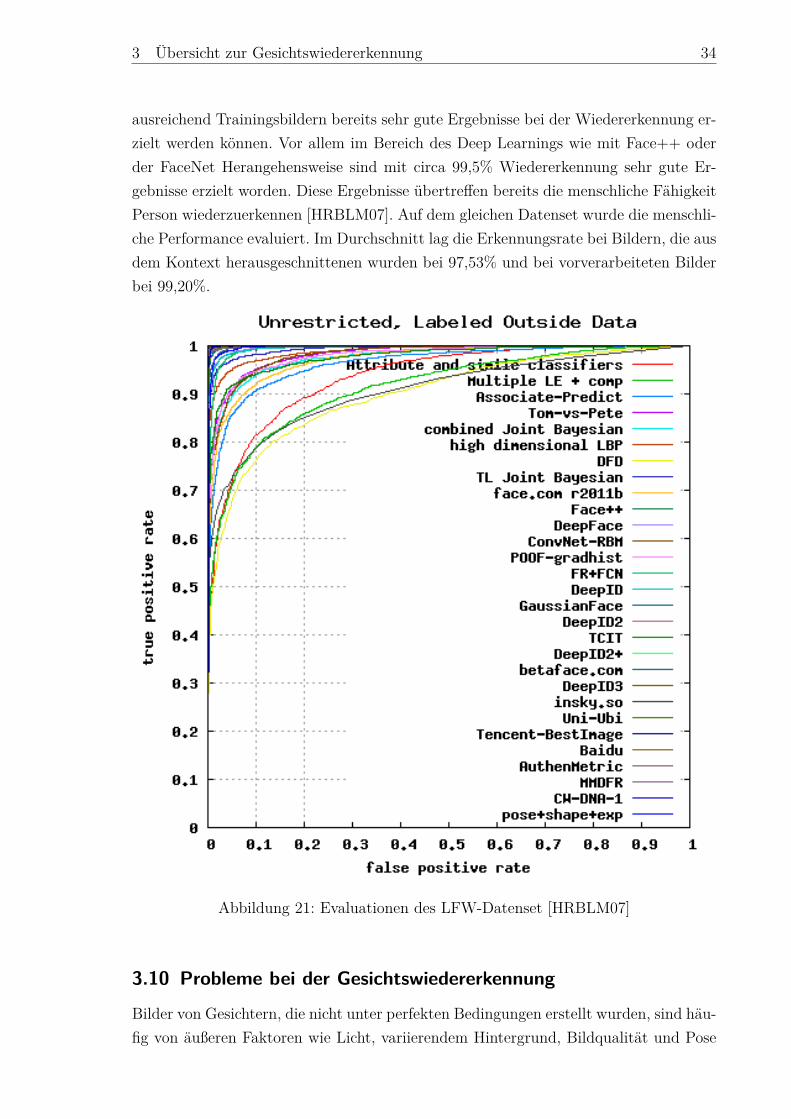
3 Übersicht zur Gesichtswiedererkennung 34
ausreichend Trainingsbildern bereits sehr gute Ergebnisse bei der Wiedererkennung er-zielt werden können. Vor allem im Bereich des Deep Learnings wie mit Face++ oderder FaceNet Herangehensweise sind mit circa 99,5% Wiedererkennung sehr gute Er-gebnisse erzielt worden. Diese Ergebnisse übertreffen bereits die menschliche FähigkeitPerson wiederzuerkennen [HRBLM07]. Auf dem gleichen Datenset wurde die menschli-che Performance evaluiert. Im Durchschnitt lag die Erkennungsrate bei Bildern, die ausdem Kontext herausgeschnittenen wurden bei 97,53% und bei vorverarbeiteten Bilderbei 99,20%.
Abbildung 21: Evaluationen des LFW-Datenset [HRBLM07]
3.10 Probleme bei der Gesichtswiedererkennung
Bilder von Gesichtern, die nicht unter perfekten Bedingungen erstellt wurden, sind häu-fig von äußeren Faktoren wie Licht, variierendem Hintergrund, Bildqualität und Pose

3 Übersicht zur Gesichtswiedererkennung 35
der Person beeinflusst. Während Probleme, wie der variierende Hintergrund behobenwerden können, indem diese durch Bildbearbeitungstechniken entfernt werden, stellenVariation in Licht und Pose ein größeres Problem dar. Im Folgenden werden Problemeder Gesichtswiedererkennung aufgezeigt.
3.10.1 Variierende Beleuchtung
Ungünstige Lichtverhältnisse oder Belichtungen kann die Klassifizierung des Gesichtsstark beeinflussen. Häufig ist ein anderer Aufnahmeort oder eine andere Uhrzeit derGrund für solch einen Unterschied in der Belichtung. Abbildung 22 zeigt Bilder von zweiPersonen, bei denen das automatische Wiedererkennen durch die unterschiedliche Be-lichtung der Gesichter erschwert wurde. Das Problem tritt vor allem bei Herangehens-weisen auf, die Bilder auf Pixelebene vergleichen. Dies liegt daran, dass der Unterschieddurch die Belichtung zweier Gesichter größer sein kann, als der Unterschied zwischenzwei verschiedenen Gesichtern [Facb]. Die Folge ist schließlich eine falsche Klassifizie-rung, da der Unterschied der zwei fremden Gesichtern kleiner ist, als der Unterschiedder unterschiedlich beleuchteten Gesicht derselben Person. Herangehensweisen, die von
Abbildung 22: Gesichter mit Variation in der Beleuchtung[Facb]
diesem Problem besonders betroffen sind, sind hollistische Methoden wie die Eigenge-sichter oder Fishergesichter.
3.10.2 Pose
Ein weiteres Problem stellt der Winkel des Gesichts auf dem Bild dar. Frontalaufnah-men eines Gesichts liefern die besten Ergebnisse. Während leichte Winkelvariationenvon den meisten Herangehensweisen verkraftet (vgl. ersten zwei Gesichter in Abbildung23) werden und die Erkennungsrate dabei nur minimal beeinflusst wird, kommt es beistarker Variation (viertes Gesicht 23) im Winkel oder Pose des Gesichts zu starker

3 Übersicht zur Gesichtswiedererkennung 36
Beeinträchtigung bei der Erkennung des Gesichtes. Dies liegt unter anderem daran,dass beim Training der Gesichtserkennung Gesichter genommen werden die vereinheit-licht (bsp. Augen sind im Bild oben, Kinn unten) wurden. In der Theorie ist es zwarmöglich die Klassifikatoren der jeweiligen Personen auf alle möglichen Gesichtsrotati-on zu trainieren, um eine Wiedererkennung zu ermöglichen. In der Praxis macht diesjedoch keinen Sinn, da zum einem zu viele Trainingsbilder benötigt werden, um soeinen Klassifikator zu trainieren, was die Performance verschlechtern würde, zum an-deren dies einen Verlust in der Genauigkeit mit sich bringen würde. Deswegen werdenin der Praxis oftmals vereinheitlichte Bilder mit kleiner Variationen in der Rotationgenommen ,um die Robustheit zu erhöhen. Die zweite Spalte in Abbildung 23 stellteine Kombination des Posen und Beleuchtung Problem dar.
Abbildung 23: Gesichter mit Variation in der Pose[Facb]
3.10.3 Verdeckung
Ursachen einer Verdeckung können beispielsweise Gegenstände, wie Brillen oder Schalesein die Teile der Gesichts verdecken. Aber auch ungünstige Aufnahmen, bei der sichbeispielsweise die Hand vor dem Gesicht befindet oder Aufnahmen bei denen mehrereJahre dazwischen liegen, können Ursache sein. Dies stellt vor allem ein Problem beiApplikationen dar, die anhand eines Bildes die Person wiedererkennen sollen. Bei derIdentifizierung durch einen Videostream ist es möglich nur die gut geeigneten Bilderfür die Wiedererkennung zu benutzten und andere Bilder zu verwerfen.

4 Konzeption und Verwendete Materialien 37
4 Konzeption und Verwendete MaterialienDieses Kapitel gibt zuerst eine Übersicht über den Ablauf des Implementierten Pro-gramms, mit dem die Evaluation durchgeführt wurde. Des weiteren werden Materialienwie Datensets und benutzte Bibliotheken vorgestellt.
4.1 Konzeption
In Abbildung 29 ist der grobe Ablauf des Programms als Ablaufdiagramm dargestellt.Das Programm kann dabei in zwei Teile aufgespalten werden. Der erste Teil bestehtaus dem Training des Gesichtswiedererkennungsmodell mit den Trainingsbildern. DieTrainingsbilder, die zum Training verwendet wurden, sind mit dem gleichen Vorverar-beitungsablauf, der für die Testbilder zum Einsatz kommt, vorverarbeitet worden. DieVorverarbeiten der Trainingsbilder findet jedoch außerhalb des eigentlichen Program-mablaufs statt, damit bei jeder Neuinitialisierung des Programms nicht alle Datenerneut vorverarbeitet werden müssen. Die Gesichtsmerkmale, die zum Vergleich dereinzelnen Personen verwendet werden, werden durch OpenCV im RAM abgelegt, umbei einer Klassifizierung schnell darauf zurückgreifen zu können.Die andere Hälfte des Programms versucht anhand der Merkmale der Trainingsdatendas Testbild zu klassifizieren. Dazu wird das Testbild auf die gleiche Weise, wie dieTrainingsbilder vorverarbeitet.Die wichtigsten Schritte sind unter anderem die Gesichtsausrichtung (Ausschneiden,Rotation, Skalierung), die Anpassung der Intensität der Farbe und die Umwandlungzum Graustufenbild. Daraufhin werden aus dem Bild die Gesichtsmerkmale extrahiert,die dann wiederum mit dem im RAM abgelegten Merkmalen der Trainingsdaten ver-glichen werden können, um eine Klassifizierung vorzunehmen.Zu erwähnen ist, dass über die Programm Parameter ebenfalls eine Evaluation desTrainingssets gestartet werden kann. Statt der weiteren Eingabe eines Testbildes, kon-struiert das Programm aus dem übergebenen Datenset eigenständig ein Test und Trai-ningsset, mit denen die Evaluation durchgeführt wird.

4 Konzeption und Verwendete Materialien 38
Abbildung 24: Ablauf des Programms
4.2 Verwendete Computer Vision Bibliotheken
Nachfolgend wird ein kurzer Überblick über die verwendeten Computer Vision Biblio-theken gegeben.
4.2.1 OpenCV
OpenCV ist eine im Jahre 2000 entstandene frei zugängliche Bibliothek für den Bereichder Computer Vision und Bildbearbeitung. Die Bibliothek selbst ist plattformunabhän-gig und ist in C und C++ geschrieben. Inzwischen ist Version 3.1 veröffentlicht worden.OpenCV zeichnet sich dabei durch ihre Geschwindigkeit und großen Umfang aus. DieBibliothek weist dabei über 2500 optimierte Algorithmen auf, die sowohl klassische alsauch State-of-the-Art Algorithmen umfassen [opeb].Durch die modular gehaltene Struktur von OpenCV müssen nur die Teile der Biblio-
thek geladen werden, die auch gebraucht werden. Wichtige Module neben dem KernModule, sind unter anderem diese Module:
imgproc, für Aktionen rund um die Bildbearbeitung
imgcodecs, zum Laden und Abspeichern von Bildern
objdetect, zur Detektion von Objekten mithilfe von Kaskaden
ml, für Algorithmen rund um das Thema Machine Learning
highgui, was eine GUI bereitstellt

4 Konzeption und Verwendete Materialien 39
Seit Version 3.0 sind Teile der Funktionen von OpenCV ausgelagert worden. Davonbetroffen sind vor allem neue Module, die entweder noch nicht genug getestet wurdenoder an denen noch weiter entwickelt wird. Diese sogenannte opencv_contrib Ergän-zung Bibliothek kann jedoch sehr einfach in OpenCV integriert werden.Des weiteren ist zu erwähnen, dass OpenCV die BSD Lizenzierung nutzt, wodurch
sich diese Bibliothek sowohl für die gewerbliche, als auch nicht gewerbliche Nutzungeignet.
4.2.2 Dlib
Dlib ist ein in C++ geschriebenes Toolkit für viele Algorithmen zum Bereich des Ma-schinellen Lernens und der Computer Vision. Dabei zeichnet sich dieses vor allemdurch die Implementierung von relativ neuen Algorithmen zur Computer Vision aus.Zusätzlich stellt Dlib durch das Bereitstellen einer aktuellen Dokumentation und vielenBeispielen einen schnellen Einstieg dar.Durch die Open Source Lizenzierung eignet sich Dlib sowohl für den privaten als auchgewerbliche Gebrauch.
4.2.3 Überblick über weitere Frameworks zur Gesichtswiedererkennung
Im Laufe dieser Arbeit wurde nach frei zugänglichen Bibliotheken zum Thema Ge-sichtswiedererkennung recherchiert. Neben mehreren Online APIs, die hauptsächlichauf Gefaltete Neuronale Netze basieren und meistens nur für eine kleinen Kontingentkostenlos nutzbar sind, sind vor allem die Frameworks OpenFace [ALS16]und OpenBr[Oped] gefunden worden. Beide Projekte besitzen eine eigene Vorverarbeitungspipeli-ne und sind Open Source lizenziert. OpenFace implementiert mit dem ConvolutionalNeural Network einen relativ neuen Ansatz zu Gesichtswiedererkennung. Dies ist eben-falls an der Erkennungsrate zu erkennen, bei der die Neuronale Netzwerk Implemen-tierung von OpenFace beide implementierten Verfahren von OpenBR schlägt [opec].
Projekt Algorihmus LFW ErkennungsrateOpenFace Convolutional Neural Networks 97,3%OpenBR 4SF 82,8%OpenBR Eigenfaces 64,8%
Tabelle 1: Gefundenen FaceRecogntion Projekte/Frameworks
4.3 Datensets
In diesem Abschnitt wird ein Überblick über existierende Gesicht-Datensets gegeben,die unter anderem für die spätere Evaluation nötig sind. Aufgrund des hohen Interessesan diesem Thema existiert eine hohe Anzahl an verschiedenen Datensets. Jedoch muss

4 Konzeption und Verwendete Materialien 40
beachtet werden, dass je nach Zweck und Herangehensweise Datensets unterschied-lich sinnvoll sind. Beispielsweise brauchen PCA oder LDA basierte Herangehensweisenmehrere Bilder pro Klasse und können deswegen schwer bei Datensets, die nur wenigeoder ein Bild pro Klasse beinhalten genutzt werden. Zusätzlich ist zu erwähnen, dassalle hier aufgeführten Datensets, bis auf das Fussball Datenset, frei zugänglich undonline einsehbar sind.
4.3.1 Face94
Hierbei handelt es sich um ein vom Schwierigkeitsgrad einfaches Datenset. Insgesamtsind 153 unterschiedliche Personen enthalten die sowohl Gesichter männlicher, als auchweiblicher Personen beinhalten. Jedes Bild ist eine Frontalaufnahme des Gesichtes mitder Auflösung von 180 auf 200 Pixel. Da alle Bilder in einer Aufnahme-Session gemachtwurden, sind die Bilder von keiner durch die Zeit veränderten Erscheinung betroffen.Der Hintergrund der Bilder ist mit der Farbe grün für alle Bilder derselbe. Viel Unter-schied bei den Bildern ist durch einen sich ändernden Ausdruck gegeben. Die Positionder Gesichter auf den Bildern besitzen lediglich leichte Variationen. Zusätzlich existie-ren durch die Aufnahme am denselben Ort keine Variationen in der Beleuchtung beiden verschiedenen Aufnahmen.
Abbildung 25: Beispielbilder des Faces94 Datenset [1]

4 Konzeption und Verwendete Materialien 41
4.3.2 Fussball Datenset Deutschland
Das für diese Arbeit konstruierte Datenset besteht aus 80 unterschiedlichen Spielernder ersten Fußball Bundesliga. In jedem Bild ist eine Frontalaufnahme des Gesich-tes eines Fußballers zu sehen. Als Frontalaufnahme wurden alle Gesichter gezählt, diehöchstens 10◦- 15◦Grad von einer Profilaufnahme abweichen. Dabei existiert keine ein-heitliche Auflösung der Bilder. Die Bilder weisen teilweise niedrigere Auflösungen von300 x 300 und Hohe, wie 1500 x 1500 auf. Es wurde lediglich darauf geachtet, dassBilder ausgesucht wurden, bei denen die Auflösung des Gesichtes auf dem Bild circa200 x 200 oder mehr beträgt. Die Grundlage der Bilder für das Datenset wurde ausder Internetseite kicker [3] extrahiert. Zusätzlich wurde das Datenset durch Bilder derGoogle-Bilder Suche erweitert. Unter anderem dadurch, dass die Bilder weitestgehendzufällig ausgewählt wurden, ergaben sich folgende Schwierigkeiten für die Gesichtser-kennung:
• Stark variierender Hintergrund
• Veränderungen des Gesichts (Bart, Narben)
• Häufig variierende Pose
• unterschiedliche Beleuchtung
Abbildung 26: Beispielbilder des Fußballdatenset. Alle hier aufgelisteten Bilder sindaus dem Online Kicker-Sportmagazin entommen [3]

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 42
5 Vorbearbeiten der Bilder zur Verbesserung derErkennungsraten
Bilder von Gesichtern, die nicht unter perfekten Bedingungen erstellt wurden, sindhäufig von äußeren Faktoren wie Licht, Bild Qualität und Pose der Person beeinflusst.Diese wirken sich häufig auf die Klassifikation des Gesichtes einer Personen negativaus. Um diesen Faktoren entgegenzuwirken werden Bilder häufig vorverarbeitet. Zieldieser Vorverarbeitung ist es zum einen die Erkennungsraten zu erhöhen, aber auchein leichteres Weiterverarbeiten der Bilder zu ermöglichen, womit eine Reduzierungder Verarbeitungszeit einhergeht. Je nach Herangehensweise der Wiedererkennung vonGesichtern in Bildern werden unterschiedliche Methoden zur Vorverarbeitung genutzt.Bei einigen holistischen Methoden ist es beispielsweise wichtig auf eine einheitlicheBeleuchtung der Gesichter in den Bildern zu achten. Dies wird bei den Local BinaryPattern nicht benötigt. Einzig das Umwandeln von Farbbildern in Graustufenbildernwird derzeit von den meisten State of the Art Methoden genutzt.
5.1 Gesichtserkennung
Wie bereits erwähnt, ist es hilfreich die Gesichter der Personen zu vereinheitlichen.Wichtig ist vor allem die Bilder bzw. Gesichter so zu drehen, dass die Augen in einerHorizontalen Ebene liegen. Bevor dies bewerkstelligt werden kann, müssen die Gesichterim Bild gefunden werden. Dies hat zusätzlich den Zweck unwichtige Informationenherauszuschneiden, die weder für das Face Alignment, noch für die Gesichtserkennungvon Bedeutung sind. Getestet wurde die Face Detektion sowohl mit Hilfe der Haar-Cascaden von OpenCV, als auch mit der Histogramm of Gradient Implementierungder Dlib Bibliothek. Bei Frontalgesichtern oder kaum verdeckten Gesichtern liefertedie Erkennung der Gesichter bei beide Methoden gute Ergebnisse. Jedoch wies dieImplementierung von OpenCV eine höhere False Positive Rate auf. Oftmals wurdenalso Gesichter erkannt, die keine Gesichter waren. Dies war jedoch für diese Arbeit keingrößeres Problem, da sowieso Bilder genommen wurden auf denen sich nur ein Gesichtbefindet und somit das Gesicht gewählt wurde, dass die höchste Wahrscheinlichkeitaufgewiesen hat. Abbildung 27 zeigt die Bilder auf, anhand deren die nächsten Schrittezum Face Alignment veranschaulicht werden.

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 43
Abbildung 27: Unbearbeitete Bilder Datenset:[2]
5.1.1 Augenerkennung anhand Kaskaden
Um das Gesicht richtig auszurichten werden die Postionen der Augen benötigt. DieAugenpostion wurde anfangs ebenfalls mit den Kaskaden der OpenCV Bibliothek be-stimmt. Dazu wurde das Erkannte und bereits ausgeschnittene Gesicht genutzt. Open-CV stellt zum Erkennen von Augen verschiedene Kaskaden zur Verfügung. Darunterbefinden sich:
• haarcascade_eye.xml
• haarcascade_mcs_lefteye.xml
• haarcascade_mcs_righteye.xml
Während erstere Kaskade sowohl auf das linke und das rechte Auge trainiert ist, sind diebeiden anderen jeweils auf ein Auge trainiert. Das haarcascade_eye.xml liefert jedochnur unter sehr günstigen Bedingungen akzeptable Ergebnisse. Weit bessere Ergebnisseliefern haarcascade_mcs_lefteye.xml und haarcascade_mcs_righteye.xml, die von derErweiterten OpenCV_Contribution Bibliothek mitgeliefert werden.Um die Erkennungsrate zu erhöhen und die Zeit zu reduzieren wurde zudem das er-kannte Gesicht in der Mitte geteilt und dem richtigen Kaskade zugeordnet.Sind die Augenpostionen bestimmt, können diese dazu verwendet werden eine Rotati-onsmatrix zu erstellen, anhand dessen das Bild gedreht wird. Dazu muss lediglich derWinkel zwischen den beiden Augen und der Punkt an der das Bild gedreht werden sollbestimmt werden.Abbildung 28 zeigt die Ergebnisse der Augenerkennung mithilfe der beiden Kaska-den an. Insgesamt wurden zehn Augen von möglichen 16 erkannt. Nur von vier deracht Personen wurden beide Augen erkannt, wodurch das Face Alignment möglich

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 44
war. Für den Fall, das nur ein oder kein Auge erkannt wird ist kein Face Alignmentnach beschriebener Methode möglich. Insgesamt gesehen liefern die Kaskaden unzu-
Abbildung 28: Augenerkennung mit Hilfe von OpenCV Kaskaden Datenset:[2]
verlässige Erkennungsraten. Wird diese ungenaue Bestimmung für das Preprocessingder Trainingsdaten benutzt, kann dadurch die Wiedererkennungsrate einer Personenverschlechtert werden.
5.1.2 Augenerkennung mit Hilfe der Dlib Bibliothek
Die Dlib Bibliothek verwendet einen anderen Weg um die Landmarks in einem Gesichtzu erkennen. Ziel der Landmark Erkennung ist es [KS14][ali] eine Form S zu erkennen,die der wirklichen Form des Gesichts am nächsten ist. Um dies zu bewerkstelligen, wirdeine Regression Funktion gelernt, die versucht extrahierte Gesichtsmerkmale auf eineForm abzubilden. Zum Extrahieren der Features kommen Methoden, wie die HOGFeatures oder der Pixelunterschied in dem Bereich des zu extrahierenden Merkmalszum Einsatz. Eine Gesichtsform ist dabei definiert als
S = [x1, y1, ...., xn, yn], (21)
bei der n die Anzahl der unterschiedlichen Landmarks ist.Die Landmark Erkennung läuft dabei in mehreren Schritten, sogenannten RegressionStages ab. Ähnlich wie bei der Gesichtserkennung von Viola und Jones, werden mehrereschwache Regressoren (R1, R2, ..., RT ) auf additive Weise zusammen gefasst (vgl. [ali])um die möglichst genaue Form des Gesichts zu ermitteln.
St = St−1 +Rt(I, St−1), t = 1, ...T (22)

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 45
Der Regressor Rt berechnet anhand eines Bildes I und der vorherigen Form St−1 einenInkrement, der zur vorherigen Form wiederum addiert wird um eine aktualisierte Formzu erhalten. Dies geschieht so lange bis alle T Regressoren benutzt wurden. Die Re-gressoren selbst werden gelernt, damit diese den Alignment Fehler
||S − Strue||2 (23)
minimieren. Es wird also versucht den Unterschied zwischen der vorhergesagten und dertatsächlichen Form des Gesichts zu minimalisieren. Die Regressoren werden sequentiellberechnet. Dementsprechend ergibt sich für den Rt Regressor folgende Formel:
Rt = argminR
N∑i=1||Si_true − (St−1
i +R(Ii, Sti − 1))|| (24)
bei der Ii das Bild mit dem Index i, Si_true die echte Form des I-ten Gesichts ist undSt−1
i die im Schritt vorher geschätzte Form des Gesichts ist [ali].
Die Implementierung von Dlib baut auf diesem Ansatz auf, erweitert diesen jedochanhand eines Regression Baumes[KS14].Insgesamt liefert der Landmark Detektor der Dlib Bibliothek die x und y Koordinatevon 68 Landmarks. Die Punkte beschränken sich dabei auf Stellen im Gesicht. DieLandmarks befinden unter anderem auf den Augenbrauen, den Augen, dem Gesichtund den Konturen des Gesichtes. Laut Vahid Kazemi and Josephine Sullivan liegt die
Abbildung 29: Positionen der Landmarks der Dlib Bibliothek
durchschnittliche Fehlerrate der Landmark Erkennung bei gerade mal 5%. Die Feh-lerrate gibt an, um wieviel Prozent der erkannte Landmark vom echten Landmarkentfernt ist. Bei dem sehr häufig genutzten Datenset LFPW zur Landmark Erkennungerzielte es gerade mal eine Fehlerrate von 3,4% und übertrifft damit die meisten ande-

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 46
ren Landmark Erkennungs-Algorithmen. Zu erwähnen ist, das die Erkennung ebenfallsnur einen Bruchteil vorheriger Landmark Erkennungs Algorithmen dauert.Abbildung 30 visualisiert dieses Ergebnis. Entgegen der Herangehensweise mit den
Abbildung 30: Landmark Erkennung mithilfe der Dlib Bibliothek Datenset:[2]
Kaskaden liefert dieser Ansatz eine verlässliche Erkennungsrate. Bei allen acht Bildernliefert Dlib die Koordinaten von 69 Landmarks, die mit der wirklichen Lage in denmeisten Fällen exakt übereinstimmen. Lediglich im ersten Gesicht werden die Konturenauf der linken Seite des Gesichtes nicht richtig erkannt. Die Position der Augen werdenbei allen Bildern exakt bestimmt, wodurch eine zuverlässige Gesicht Alignment möglichist. Zu erwähnen ist, das selbst die richtige Postion von verdeckten Landmarks oftrichtig erkannt wird. Dies ist vor allem in dritten Bild gut zu erkennen bei der beinahedie Hälfte des Gesichtes von Haaren bedeckt ist. Wie in 30 weist die Detektion einegute Robustheit gegen die Invarianz der Pose des Gesichts auf.Die Ergebnisse des Face Alignments werden in Abbildung 31 dargestellt. Zu sehen
ist, dass das Ziel des Face Alignment erfüllt wurde. Die Augen jedes Gesichtes befindensich in einer horizontalen Ebene, sind also von eventuellen Rotationen befreit.

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 47
Abbildung 31: Resultat des FaceAlignment mithilfe der Dlib Bibliothek Datenset:[2]
5.2 Anpassung der Intensität von Farben
Jedoch hat nicht nur die Pose und der Ausdruck Einfluss auf die Wiedererkennung desGesichtes. Die erfolgreiche Klassifizierung von Gesichtern hängt ebenfalls stark von derQualität des zu klassifizierenden Bildes ab. Wie in 3.10.1 bereits erwähnt stellen unter-oder überbelichtete Bilder bei der Gesichtswiederkennung ein Problem dar. Aus diesemGrund werden schon im vorhinein solche Bilder vorverarbeitet, um die entstehendenProbleme bei der Gesichtswiedererkennung zu reduzieren.
Diese Arbeit nutzt einen Histogramm Ausgleich, um die Bilder so zu bearbeiten, dassder Kontrast des Bildes verbessert wird, indem die Intensität der Pixel umverteilt wer-den. Ziel ist es das Aufkommen der Grauwerte so zu verteilen, dass diese möglichst dasgesamte Graustufen Spektrum umfassen.Abbildung 32 zeigt das Ergebnis der Bilder nach dem Histogramm Ausgleich.Besonders hervorzuheben sind sowohl das zweite, fünfte und letzte Bild, die durch denHistogramm Ausgleich deutlich an Kontrast hinzugewonnen haben.

5 Vorbearbeiten der Bilder zur Verbesserung der Erkennungsraten 48
Abbildung 32: Ergebnis der Beispielbilder nach der FaceAlignment mithilfe der dlibBibliothek Datenset:[2]
Insgesamt bietet sich ein Histogramm Ausgleich zum Vorverarbeiten bei Applikatio-nen an, die über den Tag verteilt Aufnahmen machen und wodurch die Bilder Schwan-kungen in der Helligkeit besitzen.

6 Evaluation 49
6 EvaluationIn diesem Kapitel wird die Local Binary Pattern Histogramm mit verschiedenen Para-metern und Einstellungen getestet. Zusätzlich wird die Neuronale Netz Implementie-rung von OpenFace evaluiert.
6.1 Durchführung der Evaluation
Um aussagekräftigere Ergebnisse bei der Evaluation zu erhalten, wurde das Test- undTraining-Datenset dynamisch aus dem Ursprungsdatenset erstellt. Dazu wurde vorjedem Durchgang ein zufälliger "Seed" erstellt, mit dem entschieden wurde, ob dasentsprechende Bild dem Trainings oder Test-Datenset hinzugefügt wird. Mit den soresultierenden Test- und Trainingssets wurde eine Evaluation durchgeführt, indem fürjedes Bild im Testset überprüft wurde, ob die richtige Person klassifiziert wurde. Insge-samt wurden für jede Parameter Einstellung zehn Evaluationen durchlaufen. Zusätzlichwurde für jedes falsch klassifizierte Testbild die Distanz zur richtigen Klassifikation er-mittelt.
6.1.1 Ergebnisse des Face94-Datenset
Die Evaluation mit diesem Datenset erzielte wie erwartet sehr gute Ergebnisse. Bereitsmit einem Trainingsbild lag die Erkennungsrate zwischen 98% und 99%. Die Hinzu-nahme neuere Trainingsbilder erbrachte keine nennenswerte Verbesserungen. Die gutenErgebnisse liegen unter anderem an dem sehr einfachen Datenset. Die Bilder jeder Per-son im Datenset sind sich sehr ähnlich. Abbildung 33 stellt jeweils sechs Bilder zweierPersonen dar. Wie dort zu sehen sind die Unterschiede der Bilder einer Person sehrgering, wodurch weniger Trainingsbilder für eine gute Erkennungsrate benötigt werden.Zusätzlich sind alle Bilder gleich aufgebaut, wodurch ebenfalls die Erkennungsrate ver-bessert wird. Jedoch zeigt dieses Trainingsset, wie wichtig eine gute Vorverarbeitungfür die Erkennungsrate ist.

6 Evaluation 50
Abbildung 33: Trainingsbilder des face94-Datenset
6.1.2 Ergebnisse des Face95-Datenset
Bei diesem Datenset konnte der Einfluss durch die Anzahl der Trainingsbilder auf dieErkennungsrate sehr gut getestet werden. Die Erkennungsrate bei der Nutzung vonlediglich einem Trainingsbild liegt bei 75%. Obwohl, dass face94- und face95-Datensetähnlich aufgebaut sind, ist die schlechtere Erkennungsrate zum einen auf die Bewegungin den Bildern, wodurch verschiedene Veränderungen hervor geworfen werden und dieschlechtere Qualität der Bilder zurückzuführen. Durch die Hinzunahme eines Trainings-bildes stieg die Erkennungsrate um 8%-9%. Die weitere Hinzunahme führte stets zueiner Verbesserung (siehe Abbildung 36. Bei der Nutzung von 10 Trainingsbildern wiesder LBPH eine Erkennungsrate von circa 99% auf. In Abbildung 34 sind Beispielbilderdas face95-Datensets zu sehen, die im Vergleich zum face94-Datenset schon deutlichgrößere Unterschiede aufweisen.
Abbildung 34: Trainingsbilder des face95-Datenset
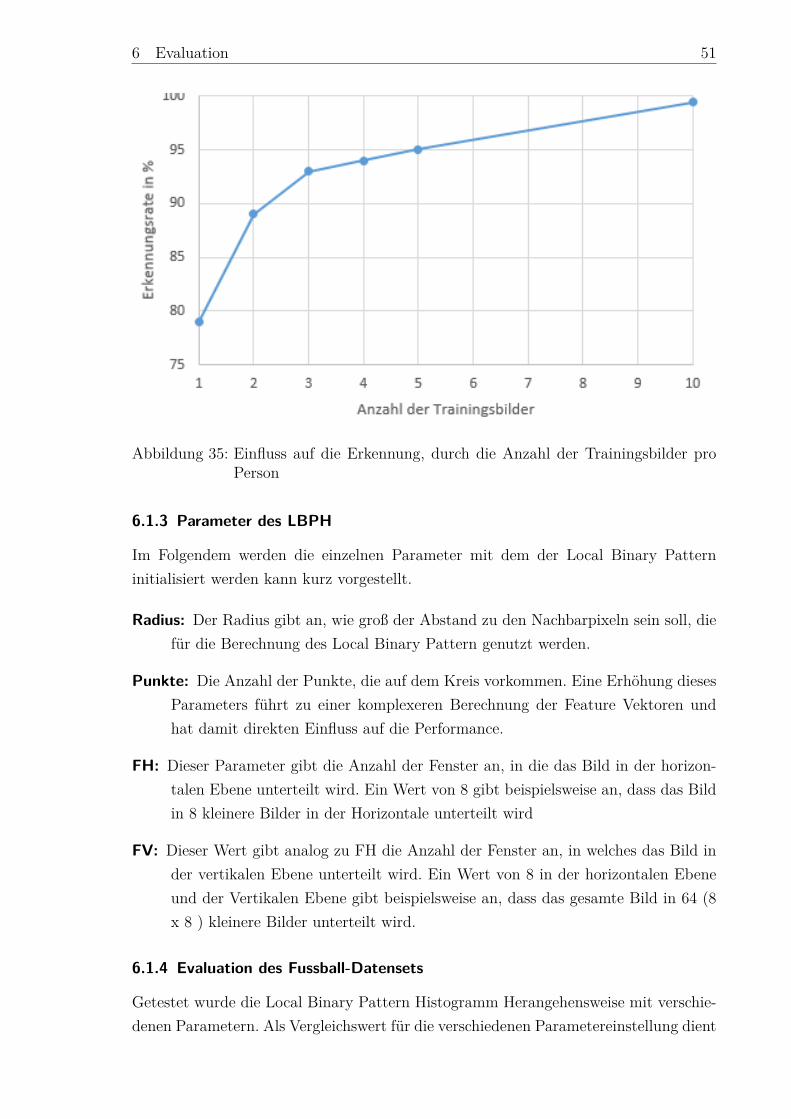
6 Evaluation 51
Abbildung 35: Einfluss auf die Erkennung, durch die Anzahl der Trainingsbilder proPerson
6.1.3 Parameter des LBPH
Im Folgendem werden die einzelnen Parameter mit dem der Local Binary Patterninitialisiert werden kann kurz vorgestellt.
Radius: Der Radius gibt an, wie groß der Abstand zu den Nachbarpixeln sein soll, diefür die Berechnung des Local Binary Pattern genutzt werden.
Punkte: Die Anzahl der Punkte, die auf dem Kreis vorkommen. Eine Erhöhung diesesParameters führt zu einer komplexeren Berechnung der Feature Vektoren undhat damit direkten Einfluss auf die Performance.
FH: Dieser Parameter gibt die Anzahl der Fenster an, in die das Bild in der horizon-talen Ebene unterteilt wird. Ein Wert von 8 gibt beispielsweise an, dass das Bildin 8 kleinere Bilder in der Horizontale unterteilt wird
FV: Dieser Wert gibt analog zu FH die Anzahl der Fenster an, in welches das Bild inder vertikalen Ebene unterteilt wird. Ein Wert von 8 in der horizontalen Ebeneund der Vertikalen Ebene gibt beispielsweise an, dass das gesamte Bild in 64 (8x 8 ) kleinere Bilder unterteilt wird.
6.1.4 Evaluation des Fussball-Datensets
Getestet wurde die Local Binary Pattern Histogramm Herangehensweise mit verschie-denen Parametern. Als Vergleichswert für die verschiedenen Parametereinstellung dient

6 Evaluation 52
Distanz/Parameter(R,P,X,Y)
1 2 3 4 5 >5
1_8_8_8 43% 6% 4% 3% 5% 39%2_8_8_8 48% 8% 5% 4% 4% 31%1_12_8_8 40% 10% 5% 4% 3% 38%1_12_12_12 48% 8% 5% 4% 3% 32%2_12_8_8 48% 9% 4% 3% 2% 34%2_12_16_16 61% 6% 4% 3% 3% 23%3_12_16_16 66% 9% 3% 3% 2% 17%
Tabelle 2: Evaluation des LBPH
die Einstellung 1,8,8,8 (Radius,Punkte/Nachbarn,FensterX, FensterY). Diese Einstel-lungen erzielte eine Genauigkeit von 43%. Mit dem Versuch, die Genauigkeit zu erhöhenwurde an den LBPH Parametern experimentiert. Dazu wurden einzeln die verschie-denen Parameter des Local Binary Pattern Histogramm justiert. Tabelle 2 gibt eineÜbersicht über die Einstellungen, mit denen das Datenset evaluiert wurde. Bereits dieErhöhung des Radius um den Wert 1 führt zu einer 5%-igen Verbesserung. Jedoch musshierbei beachtet werden, dass jedes Vorverarbeitete Gesicht auf die Größe 200 x 200skaliert wurde. Somit lässt sich nicht pauschal sagen, dass eine Erhöhung des Radiusbei den LBPH stets zu einer Verbesserung führt. Die Erhöhung der Punkte, die für dieBerechnung der Lokal Binary Pattern benötigt wird, führte in den Tests stets zu einerErhöhung der Erkennungsrate. Ausnahme ist hier die Erhöhung der Punkte von 8 auf12 bei einem Radius von 1. Da bei einem Radius von 1 höchstens acht Nachbarpixelexistieren, ist dies aber nachvollziehbar. Auch die Erhöhung des FH & FV Wertes wirk-te sich positiv auf die Erkennungsrate aus. Dies liegt daran, dass durch die Erhöhungdieses Parameters mehr Wert auf die lokale Struktur des Bildes gelegt wird. Das besteErgebnis wurde mit der Einstellung 3,12,16,16 mit einer Genauigkeit von 66% erzielt.In Tabelle 2 ist zusätzlich die Distanz zu der Richtigen Klassifikation angeben. DieSpalte mit dem Wert zwei gibt beispielsweise an, dass bei der Parametereinstellung3,12,16,16 9% der Bilder richtig erkannt wurden, nachdem das Bild mit der geringstenDistanz entfernt wurde. Dies ist die Wahrscheinlichkeit wie viel der falsch klassifiziertenBilder durch den LBPH Klassifikator als zweit Ähnlichstes eingestuft wird.Insgesamt besitzen lediglich 17% der Testbildern eine Distanz größer fünf.
6.1.5 Der Einfluss der Anzahl der Trainingsbilder auf die Genauigkeit
Im folgendem Abschnitt wird der Einfluss der Anzahl der Trainingsbilder auf die Er-kennungsrate evaluiert. Getestet wurde der LBPH mit einer unterschiedlichen großenAnzahl an Trainingsbilder pro Person und der Parametereinstellung (2,12,16,16), damit dieser die Evaluation deutlich schneller war und somit mehr getestet werden konnte.
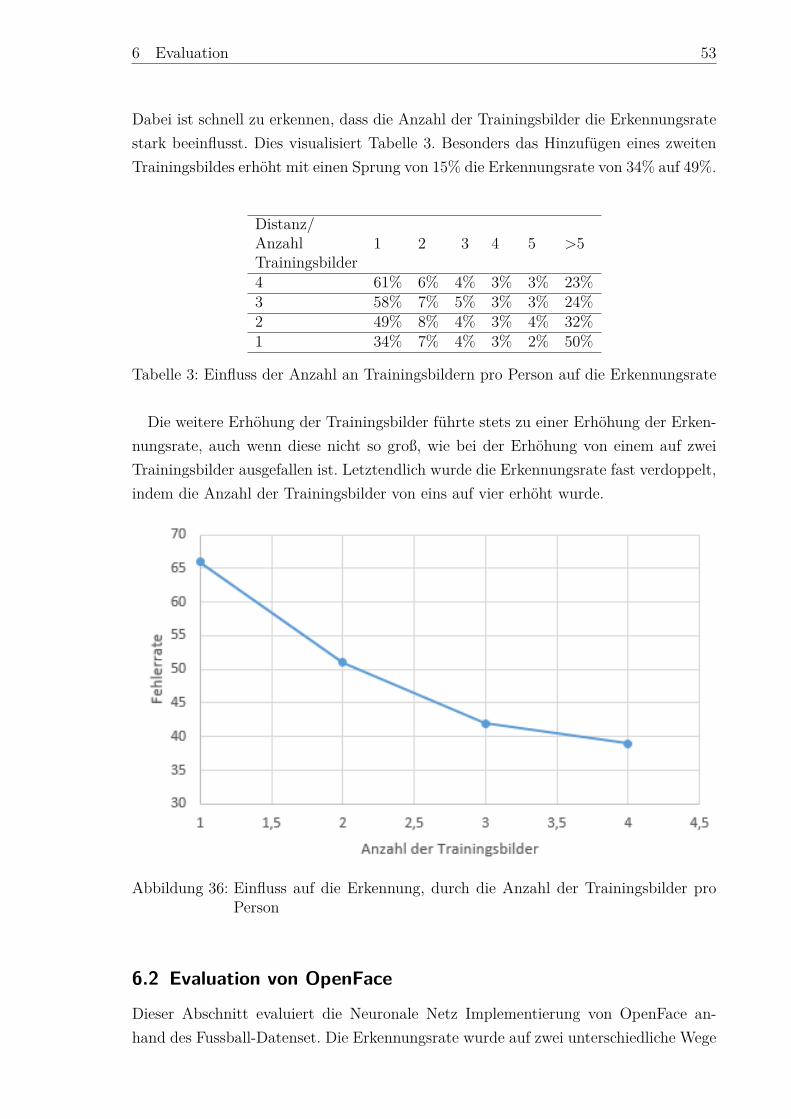
6 Evaluation 53
Dabei ist schnell zu erkennen, dass die Anzahl der Trainingsbilder die Erkennungsratestark beeinflusst. Dies visualisiert Tabelle 3. Besonders das Hinzufügen eines zweitenTrainingsbildes erhöht mit einen Sprung von 15% die Erkennungsrate von 34% auf 49%.
Distanz/AnzahlTrainingsbilder
1 2 3 4 5 >5
4 61% 6% 4% 3% 3% 23%3 58% 7% 5% 3% 3% 24%2 49% 8% 4% 3% 4% 32%1 34% 7% 4% 3% 2% 50%
Tabelle 3: Einfluss der Anzahl an Trainingsbildern pro Person auf die Erkennungsrate
Die weitere Erhöhung der Trainingsbilder führte stets zu einer Erhöhung der Erken-nungsrate, auch wenn diese nicht so groß, wie bei der Erhöhung von einem auf zweiTrainingsbilder ausgefallen ist. Letztendlich wurde die Erkennungsrate fast verdoppelt,indem die Anzahl der Trainingsbilder von eins auf vier erhöht wurde.
Abbildung 36: Einfluss auf die Erkennung, durch die Anzahl der Trainingsbilder proPerson
6.2 Evaluation von OpenFace
Dieser Abschnitt evaluiert die Neuronale Netz Implementierung von OpenFace an-hand des Fussball-Datenset. Die Erkennungsrate wurde auf zwei unterschiedliche Wege

6 Evaluation 54
ermittelt. Zum einen wurde die Erkennungsrate ermittelt, indem jeweils zwei Bilderim Datenset verglichen wurden. Beim Vergleich von zwei Bildern der gleichen Personmusste das System beispielsweise erkennen, dass es sich um die gleiche Person handelt.Genauso musste das System beim Vergleich von zwei unterschiedlichen Personen er-kennen, dass es sich um verschiedene Personen handelt. Die Erkennungsrate ergab sich,indem die Anzahl der Richtigen Erkennungen durch die Anzahl der gesamten Vergleichegeteilt wurde. Insgesamt wurde jedes Bild jeder Person mit jedem anderen Bild vergli-chen (Ausgenommen sind Vergleiche von denselben Bildern). Da für diese Evaluationdas Fußballdatenset gewählt wurde, wurden somit insgesamt ca. 160.000 ((80 Perso-nen * 5 Bilder pro Person)2) Vergleiche durchgeführt. Die Wiedererkennung erreichtehierbei eine Erkennungsrate von 99,3%. Der Vergleich wurde mit den vom NeuronalenNetz konstruierten Repräsentationen durchgeführt. Dementsprechend musste für jedesBild im Datenset die Repräsentation vorher abgespeichert werden.Zusätzlich wurde die Erkennungsrate auf dem gleichen Weg, wie bei der LBPH Eva-
luation ermittelt, um einen Vergleich beider Herangehensweisen darstellen zu können.Dementsprechend wurde das zu testende Bild im Datensatz mit jedem Bild im Daten-set verglichen, um das ähnlichste Bild zu erhalten. Für eine erfolgreiche Klassifizierungmusste die Person auf dem ähnlichsten Bild, mit der Person auf dem getesteten Bildübereinstimmen. Zusätzlich wurde für jede falsche Klassifizierung wieder ermittelt, obdas zweit, dritt, viert oder fünft ähnlichste Bild, der getesteten Person gleicht. Wiein Tabelle 4 zu sehen, liegt die Erkennungsrate nur noch bei 93,9%, statt den soeben99,3% genannten. Dies liegt daran, dass bei dieser Evaluation weniger Vergleiche ge-macht werden und somit eine falsch Klassifikation mehr Einfluss auf die Erkennungsratehatte. Insgesamt ist die Erkennungsrate trotzdem sehr gut, was durch den recht neuenAnsatz nicht verwunderlich ist. Vor allem ist zu erwähnen, das nur bei 1,1% der Bilderdie gesuchte Person sich nicht unter den ähnlichsten fünf befand. Tabelle 4 stellt dieErgebnisse von OpenFace und OpenCV mit vier Vergleichsbilder gegenüber.
Distanz/Projekt 1 2 3 4 5 >5OpenFace 93,9% 2,8% 1,5% 0,7% 0% 1,1%OpenCV 66% 9% 3% 3% 2% 17%
Tabelle 4: Gegenüberstellung von OpenFace und OpenCV
Des Weiteren wurde der Einfluss der Trainingsdaten auf Erkennungsrate ermittelt.Tabelle 5 präsentiert die Ergebnisse. Genauso wie bei der LBPH-Herangehensweiseführen mehr Vergleichsbilder zu einer höheren Genauigkeit bei der Erkennung.

6 Evaluation 55
Distanz/Anzahl der Vergleichsbilder 1 2 3 4 5 >54 93,9% 2,8% 1,5% 0,7% 0% 1,1%3 92,9% 3,5% 1,5% 0,8% 0,2% 1,1%2 90% 5,2% 1,8% 0,7% 0,7% 1,6%1 84% 7,5% 3,1% 1,4% 0,8% 3,1%
Tabelle 5: Einfluss der Anzahl an Vergleichsbilder auf die Erkennungsrate
Abbildung 37 zeigt vier Falsch Klassifizierungen. In den vier Sets, war das linke Bilddas zu testende Bild und das rechte Bild jeweils das ähnlichste Bild zum getestetenBild im ganzen Datenset.
Abbildung 37: Falsch Klassifzierungen, Bilderquelle:[6][3]
6.3 Erwähnenswerte Auffälligkeiten
Im Laufe der Evaluation mit OpenFace ist aufgefallen, dass dunkelhäutige Personen imDatenset tendenziell häufiger als hellhäutige inkorrekt klassifiziert wurden. Insgesamtwaren ca. 43% der falsch Klassifizierungen dunkelhäutig, bei einer 17,7% Vertretungdunkelhäutiger Personen im Datenset. Vor allem die mehrmalige Verwechslung der inder ersten Zeile in Abbildung 38 abgebildeten Personen ist verwunderlich, da diesesowohl eine komplett andere Kopfform, als auch eine anderen Hauttyp aufweisen. Diezweite Zeile im Bild stellt andere Vergleichsbilder von Ramos da, die eine geringereÄhnlichkeit, als das Bild von Kingsley aufgewiesen haben.

6 Evaluation 56
Abbildung 38: Auffälligkeiten bei der Evaluation, Bilderquelle:[6][3]
Ob diese Verhalten jedoch am trainierten Modell von OpenFace oder den verwen-deten Bildern liegt, kann aufgrund der kleinen Menge an Testbildern nicht endgültiggeklärt werden.Erwähnenswert ist auch der Vergleich eines mit dem Computer modellierten Gesich-
tes mit der wirklichen Aufnahme der Person. Interessanterweise wies dieses Modellbildbeim Vergleich mit einer Realaufnahme eine hohe Ähnlichkeit auf. Teilweise wies diesessogar eine höhere Ähnlichkeit als andere Vergleichsbilder der Person auf.
Abbildung 39: Vergleich eines mit dem Computer modellierten Gesichtes mit einer Auf-nahme, Bilderquellen:[5][3]

7 Diskussion und Ausblick 57
7 Diskussion und AusblickIm folgendem Kapitel werden die Ergebnisse zusammengefasst und mögliche Erweite-rungen des Programms vorgestellt, die die Erkennungsrate weiter verbessern könnten.
7.1 Zusammenfassung der Ergebnisse
Die Evaluation der Datensätze mit OpenFace und OpenCV, brachte schnell zum Vor-schein, dass eine Vorverarbeitung der Daten sehr wichtig für die Wiedererkennung ist.Bei dem face94 Datenset, bei dem die Bilder unter Laborbedingungen erstellt wurden,erreichte die LBPH Herangehensweise eine Erkennungsrate von über 99%. Anders ver-hielt es sich bei dem speziell für dieser Arbeit erstellten Fußball Datenset. Hierbei lagdie Wiedererkennungsrate bei gerade einmal 66%. Bei der Evaluation der einzelnenParametern wurde deutlich, dass vor allem die Erhöhung der Anzahl der interpoliertenPunkte und der Fenster zu einer Verbesserung der Erkennungsrate führten. OpenFaceerreichte eine Wiedererkennung von 93,3% auf diesem Datenset. Das Ausrichten desGesichtes wurde mit Hilfe antrainierter Kaskaden und eines Landmark Erkennung ge-testet. Hierbei wurde schnell deutlich, dass die Landmark Erkennung deutlich bessereErgebnisse liefert.
7.2 Ausblick
Vor allem beim Vorverarbeiten der Bilder kann noch einiges getestet und umgesetztwerden. Interessant wäre eine Evaluation, bei der alle Trainingsbilder und Testbildereinen einheitlichen Hintergrund besitzen. Um dies zu bewerkstelligen, könnten bei-spielsweise die Koordinaten der Landmark Erkennung von Dlib genutzt werden, umeine Maske zu konstruieren, mit der das Gesicht herausgeschnitten werden kann.
Des Weiteren könnte evaluiert werden, inwiefern ein verkleinerter Ausschnitt des Ge-sichtes Sinn macht und ob dies eine Verbesserung der Genauigkeit mit sich bringenwürde. In dieser Arbeit wurde beispielsweise der Ausschnitt des Gesichtes so gewählt,dass ein Großteil der Stirn ebenfalls auf den bearbeiteten Bildern zu sehen ist. Open-Face dagegen wählt den Bereich so, dass gerade noch die Augen im Bereich liegen.
Bei den LBPH Herangehensweise wurde gezeigt, dass bei einer falsch klassifizier-ten Person, die richtige Klassifikation oftmals unter den ähnlichsten fünf Personen ist.Dieses Wissen kann genutzt werden, um die Klassifikation dahingehend zu erweitern,dass vorher eine grobe Segmentierung der Personen stattfinden, um die Erkennungsratezu verbessern. Beispielsweise könnte eine vorherige Segmentierung stattfinden, indemanhand der Hautfarbe oder anhand verschiedener Beziehungen im Gesicht, wie dieDistanz oder das Verhältnis verschiedenen Landmarks zueinander, entschieden wird,

7 Diskussion und Ausblick 58
welche Personen vorab aussortiert werden.
Interessant wäre ebenfalls eine Evaluation über die gefundenen Bibliotheken, inwie-fern diese sich zur Geschlechtsbestimmung eignen. Dies könnte sehr einfach umgesetztwerden, indem beispielsweise nur Trainingsbilder eines Geschlechts genommen werden.Sind die resultierenden Ergebnisse sehr gut, so könnten diese als weitere Hilfsmittel beider Gesichtswiedererkennung dienen. Beispielsweise könnte so direkt am Anfang bereitsdie Anzahl, der zu überprüfenden Personen deutlich verringert werden. Dies ließe sichmit weiteren vorliegenden Information, wie beispielsweise dem Alter erweitern.
Eine weitere Verbesserung ist bei der Extraktion der Local Binary Pattern Histo-grammen vorstellbar. In der Arbeit wurden verschiedene Parametereinstellungen getes-tet. Dabei haben verschiedene Einstellungen teilweise unterschiedliche Personen wie-dererkannt. Somit ist es vorstellbar, dass eine Konkatenation von verschiedenen LBPHParametersätzen zu besseren Ergebnissen bei der Wiedererkennung führen könnte. Nor-malerweise werden die Histogramm Segmente erstellt, indem ein Paramtersatz (Bsp.(1,8) oder (2,16)) verwendet wird. Mit dem gerade genannten Ansatz könnten mehrereParametersätze verarbeitet werden, um die Histogramm Segmente zu erstellen.
Zum Abschluss ist festzuhalten, dass, wie im Ausblick dargestellt, weitere Erweite-rungen möglich sind, aber die Systeme dennoch gute Ergebnisse liefern.

Literaturverzeichnis 59
Literaturverzeichnis[AHP06] Ahonen, T. ; Hadid, A. ; Pietikainen, M.: Face Description with Local
Binary Patterns: Application to Face Recognition. In: IEEE Transactionson Pattern Analysis and Machine Intelligence 28 (2006), Dec, Nr. 12,S. 2037–2041. http://dx.doi.org/10.1109/TPAMI.2006.244. – DOI10.1109/TPAMI.2006.244. – ISSN 0162–8828
[ali] Face Alignment by Explicit Shape Regression. http://research.microsoft.com/en-us/um/people/jiansun/papers/CVPR12_FaceAlignRegression.pdf, Abruf: 15.09.2016
[ALS16] Amos, Brandon ; Ludwiczuk, Bartosz ; Satyanarayanan, Mahadev:OpenFace: A general-purpose face recognition library with mobile app-lications / CMU-CS-16-118, CMU School of Computer Science. 2016. –Forschungsbericht
[BB09] Burger, W. ; Burge, M. J.: Principles of Digital Image Processing,Fundamental Techniques. Springer, 2009
[boo] http://www.boost.org/doc/libs/1_55_0/doc/html/bbv2/installation.html, Abruf: 16.10.2016
[BP92] Brunelli, R ; Poggio, T: Face Recognition Through Geometrical Fea-tures. In: Proceedings of the Second European Conference on ComputerVision. London, UK, UK : Springer-Verlag, 1992 (ECCV ’92). – ISBN3–540–55426–2, 792–800
[CCWS13] Chen, D. ; Cao, X. ; Wen, F. ; Sun, J.: Blessing of Dimisionality: HighDimensional Feature and Its Efficient Compression for Face Verification.In: CVPR 2013, 2013
[CNNa] Convolutional Networks. http://cs231n.github.io/convolutional-networks/, Abruf: 15.09.2016
[CNNb] An Intuitive Explanation of Convolutional Neural Networks. https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/, Ab-ruf: 15.09.2016
[dli] http://dlib.net/compile.html, Abruf: 16.10.2016
[Faca] Face Recognition with OpenCV. http://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial.html, Abruf:15.09.2016
[Facb] Image-based Face Recognition: Issues and Methods. https://www.researchgate.net/publication/2850666_Image-based_Face_Recognition_Issues_and_Methods, Abruf: 15.09.2016
[HRBLM07] Huang, Gary B. ; Ramesh, Manu ; Berg, Tamara ; Learned-Miller,Erik: Labeled Faces in the Wild: A Database for Studying Face Reco-gnition in Unconstrained Environments / University of Massachusetts,Amherst. 2007 (07-49). – Forschungsbericht

Datensets 60
[KS14] Kazemi, V. ; Sullivan, J.: One millisecond face alignment with anensemble of regression trees. In: 2014 IEEE Conference on ComputerVision and Pattern Recognition, 2014. – ISSN 1063–6919, S. 1867–1874
[opea] http://docs.opencv.org/2.4/doc/tutorials/introduction/linux_install/linux_install.html, Abruf: 16.10.2016
[opeb] About OpenCV. http://opencv.org/about.html, Abruf: 15.09.2016
[opec] Accuracy on the LFW Benchmark with Openface. https://cmusatyalab.github.io/openface/models-and-accuracies/, Abruf:29.09.2016
[Oped] Open Source Biometric Recognition. http://openbiometrics.org/, Ab-ruf: 15.09.2016
[OPM02] Ojala, T. ; Pietikainen, M. ; Maenpaa, T.: Multiresolution gray-scaleand rotation invariant texture classification with local binary patterns.In: IEEE Transactions on Pattern Analysis and Machine Intelligence 24(2002), Jul, Nr. 7, S. 971–987. http://dx.doi.org/10.1109/TPAMI.2002.1017623. – DOI 10.1109/TPAMI.2002.1017623. – ISSN 0162–8828
[Pie] Pietikäinen, M.: Local Binary Patterns. http://www.scholarpedia.org/article/Local_Binary_Patterns, Abruf: 15.09.2016
[TP91] Turk, M. ; Pentland, A.: Eigenfaces for Recognition. In: J. CognitiveNeuroscience 3 (1991), Januar, Nr. 1, 71–86. http://dx.doi.org/10.1162/jocn.1991.3.1.71. – DOI 10.1162/jocn.1991.3.1.71. – ISSN 0898–929X
[WS00] Wendy S., Yambor: ANALYSIS OF PCA-BASED AND FISHERDISCRIMINANT-BASED IMAGE RECOGNITION ALGORITHMS.(2000). http://www.cs.colostate.edu/evalfacerec/papers/tr_00-103.pdf
[ZLY+15] Zhu, X. ; Lei, Z. ; Yan, J. ; Yi, D. ; Li, S. Z.: High-fidelity Pose andExpression Normalization for face recognition in the wild. In: 2015 IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2015.– ISSN 1063–6919, S. 787–796
[ZT] Zhang, S. ; Turk, M.: Eigenfaces. http://www.scholarpedia.org/article/Eigenfaces, Abruf: 15.09.2016
Datensets[1] Dr Libor Spacek. Collection of Facial Images ,
http://cswww.essex.ac.uk/mv/allfaces/ Abrufdatum: 13.09.2016
[2] L. Lenc and P. Král. Unconstrained Facial Images: Database for Face Recognitionunder Real-world Conditions, http://ufi.kiv.zcu.cz/ Abrufdatum 13.09.2016
[3] Fussball Sport Magazin, http://www.kicker.de/ Abrufdatum 13.09.2016

Bilderquellen 61
[4] G. B. Huang and M. Ramesh and T. Berg and E. Learned-Miller,Labeled Faces inthe Wild: A Database for Studying Face Recognition in Unconstrained Environ-ments, http://vis-www.cs.umass.edu/lfw/index.html Abrufdatum 13.09.2016
Bilderquellen[5] http://cdn.images.express.co.uk/img/dynamic/143/590x/secondary/fifa-16-
414574.jpg 13.10.2016
[6] Google-Bilder Suche 14.10.2016

Anhang 62
Anhang
7.3 Einlesen der Trainingsbilder
Da die Standard Bibliothek von C++ keine Möglichkeiten bietet über Ordnerstruk-turen zu iterieren musste zusätzlich eine Bibliothek eingebunden werden. Es ist zwardurchaus möglich mit OS spezifischen Bibliotheken ,wie bei POSIX Systemen mit GNU-C, diese Funktionen bereitzustellen. Dies würde jedoch die Einschränkung mit sichbringen, dass das Programm lediglich auf dem entwickelten Betriebssystem funktionie-ren würde.Aus diesem Grund wurde die Boost Bibliothek verwendet. Mit Hilfe dieser ist es mög-lich sowohl Unterstützung für Posix, als auch bei Windows Systemen zu gewährleisten.Folgender Baum zeigt die Ordnerstruktur an, die für das Lernen des Gesichtserken-ner von Nöten ist. Es wurde sich für diese Struktur entschieden, da viele Datensetsebenfalls diese Struktur verwenden und dementsprechend weniger Anpassungen für dieeigene Applikation von Nöten war.
Wie zu sehen besitzt die Struktur einen Überordner, welcher wiederum für jede Person
OrdnerMitTrainingsdatenNameDerErstenPerson
Bild1...Bildn
NameDerZweitenPersonBild1...Bildn
...NameDerXtenPerson
Bild1...Bildn
einen auf die Person zugeschnittenen Ordner aufweist. Die Name des Ordners sollte derwirkliche Name der Person sein. Dies ist notwendig um später anhand der Klassen ID,welcher von der Gesichtserkennung ausgegeben wurde den richtigen Namen zuordnenzu können. Jeder zugeschnittene Ordner enthält wiederum Bilder dieser Person. DieAnzahl der Bilder einer Person ist dabei keine Grenze gesetzt. In der Regel bedeuteteine höhere Anzahl der Bilder einer Person eine höhere Wahrscheinlichkeit diese Personbei einem anderen Bild wiederzuerkennen.

Anhang 63
7.4 Programm
In diesem Abschnitt wird die Installation des Programms beschrieben und ein Überblicküber die Benutzung gegeben.
7.4.1 Installation
Für die Installation des Programms sind folgende Pakete notwendig:
• wget
• tar
• unzip
Zuerst müssen die grundlegenden Pakete installiert werden. In Linux ist dies überdie Konsole mit folgenden Befehlen möglich[opea]:
1 [ compi le r ] sudo apt−get i n s t a l l bui ld−e s s e n t i a l2 [ r equ i r ed ] sudo apt−get i n s t a l l cmake g i t l i b g t k 2 .0−dev pkg−c o n f i g
l ibavcodec−dev l ibavformat−dev l i b s w s c a l e−dev3 [ op t i ona l ] sudo apt−get i n s t a l l python−dev python−numpy l ib tbb2 l ibtbb−
dev l i b j p e g−dev l ibpng−dev l i b t i f f −dev l i b j a s p e r−dev l ibdc1394−22−dev
OpenCV 3.1 wird über folgende Befehle heruntergeladen und installiert.1 cd ~/<my_working_directory>2 wget https : // github . com/opencv/opencv/ arch ive / 3 . 1 . 0 . ta r . gz3 wget https : // github . com/opencv/ opencv_contrib / arch ive / 3 . 1 . 0 . ta r . gz4 ta r −x f z opencv −3 . 1 . 0 . ta r . gz5 ta r −x f z opencv_contrib −3 . 1 . 0 . ta r . gz6 mkdir r e l e a s e7 cd r e l e a s e8 cmake −DOPENCV_EXTRA_MODULES_PATH=<opencv_contrib >/modules <
opencv_source_directory>9 make −j 5
10 sudo make i n s t a l l
Zusätzlich wird Dlib 19.1 benötigt. Die Installation ist über folgende Befehle möglich[dli]:
1 cd ~/~< i n s t a l l _ d i r e c t o r y >2 wget http :// d l i b . net / f i l e s / d l ib −19.1 . z ip3 unzip d l ib −19.1 . z ip4 cd dl ib −19.1/ examples5 mkdir bu i ld6 cd bu i ld7 cmake . .8 cmake −−bu i ld . −−c o n f i g Re lease
Die Installation ist entweder mit [boo]

Anhang 64
1 wget −O boost_1_55_0 . ta r . gz http :// s o u r c e f o r g e . net / p r o j e c t s / boost / f i l e s /boost /1 . 55 . 0/ boost_1_55_0 . ta r . gz/download
2 ta r xzvf boost_1_55_0 . ta r . gz3 cd boost_1_55_0/4 sudo apt−get update5 sudo apt−get i n s t a l l bui ld−e s s e n t i a l g++ python−dev autotoo l s−dev l i b i c u−
dev bui ld−e s s e n t i a l l ibbz2−dev l i bboo s t−a l l−dev6 . / boots t rap . sh −−p r e f i x=/usr / local7 . / b28 sudo . / b2 i n s t a l l
oder mit folgenden Befehlen installierbar:1 sudo apt−get i n s t a l l l i bboo s t−a l l−dev
Das auf dem Datenträger beigelegte Programm wird mit folgenden Befehlen kompiliert:1 cd ~/~<prgramm di r e c to ry >2 cmake .3 make

Anhang 65
7.4.2 AnwendungDas Programm ist in mehrere Module aufgebaut. Jedes dieser Module kann separatverwendet werden. Die Benutzung des Programms ist durch den Aufruf .\FaceReco-gnition [Parameter] möglich. Bei Aufruf von .\FaceRecognition -h erscheint folgendeAusgabe, die die Funktionalität des Programms aufzeigt:
A Toolkit for Face Recognitionfiles:
image files in format: JPG, PNG
Options:-h [ --help ] Print help messages-r [ --LBPH-Radius ] arg (=1) Radius-n [ --LBPH-Neighbors ] arg (=8) Number of Neighbors-x [ --LBPH-windowx ] arg (=8) Number of WindowX-y [ --LBPH-windowy ] arg (=8) Number of WindowY
Evaluation:-p [ --path ] arg Path to Evaluation Folder(Test and Trainset
will be automatically generated), Required!-t [ --trainingPicture ] arg Number of TrainingPictures for each class,
Required!-u [ --usedTrainingPictures ] arg Number, how many training pictures should be
used for training, Required-m [ --mode ] arg (=0) 0:Fast Evaluation/1:Evaluation with more
Details
Standard:-k [ --pathtest ] arg Path to testPicture, Required-l [ --pathtrain ] arg Path to trainingFolder,Required-a [ --algorithm ] arg (=1) 1:LBPH, 2:Eigenfaces, 3:Fisherfaces
Preprocess Traningdata:--path1 arg Path to training folder, Required!--path2 arg Path to output folder, Required!--preprocess_mode arg (=0) 1: Preprocessing with/ 0: without Histogramm
Equalization

Anhang 66
8 CD mit Ausarbeitung und ProgrammcodeDer Arbeit ist eine CD mit digitaler Fassung der Arbeit beigelegt. Desweiteren befindensich auf der CD der Programmcode und das erstellte Datenset.

Eidesstattliche ErklärungIch versichere, die von mir vorgelegte Arbeit selbstständig verfasst zu haben. Alle Stel-len, die wörtlich oder sinngemäß aus veröffentlichten oder nicht veröffentlichten Arbei-ten anderer entnommen sind, habe ich als entnommen kenntlich gemacht. SämtlicheQuellen und Hilfsmittel, die ich für die Arbeit benutzt habe, sind angegeben. Die Arbeithat mit gleichem Inhalt bzw. in wesentlichen Teilen noch keiner anderen Prüfungsbe-hörde vorgelegen.
Unterschrift : Ort,Datum :